注:本文包含 AI 辅助创作
Paper Summary
- 背景 & 问题:LLM 虽然强大,但缺乏动态调整其权重以应对新任务、知识或示例的机制
- 论文提出了 自适应大语言模型(SEAL, Self-Adapting LLMs) 框架,通过生成自身的微调数据和更新指令,使 LLM 能够自我调整
- 给定新输入时,模型会 produces a self-edit
- a generation,可能以不同方式重组信息、指定优化超参数,或调用工具进行数据增强和基于梯度的更新
Given a new input, the model produces a self-edit—a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates
- a generation,可能以不同方式重组信息、指定优化超参数,或调用工具进行数据增强和基于梯度的更新
- 通过 SFT ,这些 self-edit 会带来持久的权重更新,从而实现长期适应(lasting adaptation)
- 为了训练模型生成有效的 self-edit,论文使用强化学习循环(loop) ,将更新后模型在下游任务中的表现作为奖励信号
- 与依赖独立适应模块或辅助网络的现有方法不同,SEAL 直接利用模型的生成能力参数化并控制其自身的适应过程
- 给定新输入时,模型会 produces a self-edit
- 在知识整合和 Few-shot 泛化的实验中,SEAL 展现了语言模型在新数据下实现自我导向适应的潜力
Introduction and Discussion
- 在大规模文本语料库上预训练的 LLM 在语言理解和生成方面表现出卓越能力(2020; 2023; 2024; 2025)
- 但将这些强大模型适配到特定任务(2020)、整合新信息(2020)或掌握新推理技能(2025)仍然具有挑战性,主要由于任务特定数据的稀缺性
- 论文探讨了一个有趣的假设:LLM 能否通过转换或生成自身的训练数据和学习过程来实现自我适应?(can an LLM self-adapt by transforming or generating its own training data and learning procedure?)
- 以人类学生学习为例,学生通常通过整理笔记来备考,这些笔记是对原始内容的重新解读和增强 :这种将外部知识转化为更易理解形式的能力是人类学习的普遍特征
- 但当前 LLM 的训练和部署方式与人类学习形成鲜明对比:面对新任务时,LLM 只能通过微调或上下文学习(ICL, In-Context Learning)(2022; 2024; 2023)直接利用原始数据
- 这些数据可能并非最优格式(或数量),且现有方法无法让模型开发定制化的数据转换和学习策略
- 为实现语言模型的高效适应,论文提出赋予 LLM 生成自身训练数据和微调指令的能力
- 具体而言,论文引入了一种强化学习算法,训练 LLM 生成 self-edit(即指定数据和优化超参数的自然语言指令(如图1 所示)
- 论文将此类模型称为 自适应大语言模型(Self-Adapting LLMs,SEAL)

- 论文在两个应用中评估 SEAL
- 首先,测试其在整合新事实知识任务中的表现:模型通过生成合成数据而非直接微调原文
- 在无上下文版本的 SQuAD(2016)问答任务中,准确率从 33.5% 提升至 47.0%
- 值得注意的是,SEAL 自生成的数据表现优于 GPT-4.1 生成的合成数据
- 其次,论文在简化版 ARC-AGI 基准(2025)上评估 Few-shot 学习能力,模型通过调用工具自主选择数据增强和优化超参数(如学习率、训练轮次等)
- 实验表明,SEAL 自动配置工具的能力显著优于标准上下文学习和未经强化学习训练的 self-edit 方法
- 这些结果共同证明,SEAL 是实现语言模型自我适应的通用框架
- 首先,测试其在整合新事实知识任务中的表现:模型通过生成合成数据而非直接微调原文
Methods
- 论文提出了 自适应性大语言模型(Self-Adapting LLMs, SEAL) ,这是一种框架,使语言模型能够通过生成自己的合成数据和优化参数(即“自我编辑”)来改进自身
- 模型通过 Token 生成直接产生这些自我编辑,生成过程以模型上下文中的数据为基础
- 自我编辑的生成通过 RL 进行训练,模型的奖励信号来源于应用自我编辑后模型在目标任务上的性能提升
- 因此,SEAL 可以视为一种包含两个嵌套循环的算法:
- 外部强化学习循环优化自我编辑的生成
- 内部更新循环利用生成的自我编辑通过梯度下降更新模型
- 论文的方法可以看作是一种元学习(meta-learning)实例,其目标是学习如何生成有效的自我编辑
General Framework
- 设 \(\theta\) 表示语言模型 \(\text{LM}_{\theta}\) 的参数,SEAL 在单个任务实例 \((C, \tau)\) 上运行,其中 \(C\) 是包含任务相关信息的上下文,\(\tau\) 是用于评估模型适应能力的下游任务
- 在知识整合任务中,\(C\) 是需要整合到模型内部知识中的段落,\(\tau\) 是关于该段落的一组问题和答案;
- 在 Few-shot 学习中,\(C\) 包含新任务的少量示例,\(\tau\) 是查询输入和真实输出
- 给定 \(C\),模型生成一个自我编辑(SE),其形式因领域而异(见原论文 3.2 节),并通过 SFT 更新参数:
$$\theta’ \leftarrow \text{SFT}(\theta, \text{SE})$$- 问题:SE 是什么,如何理解 SE?
- 回答:SE 是一些指令,给定一个新输入(如一段文本或少量示例),模型会生成一组数据或优化参数(即 self-edit),这些输出 SE 会被用于更新模型自身参数,从而提升模型
- 论文使用强化学习优化自我编辑的生成过程:模型采取动作(生成 SE),根据 \(\text{LM}_{\theta’}\) 在 \(\tau\) 上的表现获得奖励 \(r\),并更新其策略以最大化期望奖励:
$$
\mathcal{L}_{\text{RL} }(\theta_t) := -\mathbb{E}_{(C,\tau)\sim\mathcal{D} } \left[ \mathbb{E}_{\text{SE}\sim\text{LM}_{\theta_t}(:C)} \left[ r(\text{SE}, \tau, \theta_t) \right] \right]. \tag{1}
$$- 与标准强化学习设置不同,论文的奖励取决于模型参数 \(\theta\)(因为 \(\theta\) 会更新为 \(\theta’\) 并随后被评估)
- 因此,强化学习的状态必须包含策略的参数,即 \((C, \theta)\),尽管策略的观察仅限于 \(C\)(将 \(\theta\) 直接放入上下文不可行)
- 这意味着从旧模型 \(\theta_{\text{old} }\) 收集的(状态、动作、奖励)三元组可能与当前模型 \(\theta_{\text{current} }\) 不匹配
- 为此,论文采用同策略(on-policy)方法,即自我编辑从当前模型中采样,并且奖励也基于当前模型计算
- 论文尝试了多种同策略方法,如 GRPO 和近端策略优化(PPO),但发现训练不稳定
- 最终,论文采用了 ReST\(^{EM}\)(2023),这是一种基于过滤行为克隆的简化方法,也称为“拒绝采样 + SFT”
- ReST\(^{EM}\) 可以视为一种期望最大化(EM)过程:
- E 步 :从当前策略中采样候选输出;
- M 步 :仅对获得正奖励的样本进行监督微调
- 这种方法在二元奖励下优化了目标函数(1)的近似:
$$
r(\text{SE}, \tau, \theta_t) = \begin{cases}
1 & \text{If on } \tau \text{ adaptation using SE improves } \text{LM}_{\theta_t} \text{‘s performance}, \\
0 & \text{Otherwise}.
\end{cases} \tag{2}
$$- 具体来说,在优化(1)时,论文需要计算梯度 \(\nabla_{\theta_t} \mathcal{L}_{\text{RL} }\)
- 但由于奖励项 \(r(\text{SE}, \tau, \theta_t)\) 依赖于 \(\theta_t\) 且不可微,论文将其视为固定值
- 在这种近似下,对于包含 \(N\) 个上下文和每个上下文 \(M\) 个采样自我编辑的小批量,蒙特卡洛估计为:
$$
\nabla_{\theta_t} \mathcal{L}_{\text{RL} } \approx -\frac{1}{NM} \sum_{i=1}^{N} \sum_{j=1}^{M} r_{ij} \nabla_{\theta_t} \log p_{\theta_t}(\text{SE}_{ij} \mid C_i), \tag{3}
$$- 其中 \(p_{\theta_t}\) 表示模型的自回归分布
- \(y_s^{(i,j)}\) 是自我编辑 \(\text{SE}_{ij}\) 的第 \(s\) 个 Token
- 由于 \(r=0\) 的序列可以忽略,因此 ReST\(^{EM}\) 通过简单的“对优质自我编辑进行 SFT”优化了目标(1)
- SEAL 的训练流程总结在算法1 中

- 此外,尽管论文使用单一模型同时生成自我编辑和学习这些编辑,但也可以将这两个角色解耦
- 在这种“教师-学生”框架中,学生模型通过教师模型提出的编辑进行更新,而教师模型则通过强化学习训练,以生成能最大化学生改进的编辑
Domain Instantiations
- 论文在两个领域实现了 SEAL 框架:知识整合(Knowledge Incorporation)和 Few-shot 学习。这两个领域展示了模型适应的两种互补形式:
- 1)将新信息整合到模型权重中,使其无需依赖上下文即可回忆(通过无上下文 SQuAD 评估);
- 2)在少量示例后泛化到新任务(通过 ARC 评估)
Knowledge Incorporation
- 论文的目标是高效地将段落中的信息整合到模型权重中
- 一种有前景的方法是让语言模型生成基于段落的内容,然后对原始段落和生成内容进行微调(2022; 2023; 2024)
- 论文采用典型格式:段落的逻辑推论
- 这种方法将上下文 \(C\) 转换为一组推论 \(\text{SE} = \{s_1, s_2, \ldots, s_n\}\),并通过 Prompt 模型“列出从内容中衍生的几条推论”实现
- 输出可能包括原始段落的推论、逻辑结果或重述
- 在 附录C 中,论文还探索了其他 Prompt ,如“以不同方式重写段落”或“以问答格式重写”,并发现无论基础 Prompt 如何,论文的方法都能带来相似的性能提升
- 这些自我生成的语句构成 SFT 的训练数据:论文对每个序列 \(s_i\) 计算标准因果语言建模损失,并更新模型参数,得到 \(\theta’\)
- 由于每次更新的数据量较小且总更新次数较多,论文使用低秩适配器(LoRA)进行高效轻量级微调
- 最后,适应后的模型 \(\text{LM}_{\theta’}\) 在任务 \(\tau\) 上评估。这一过程如图2 所示

- 在强化学习训练中,适应模型在 \(\tau\) 上的准确率定义了奖励 \(r\),驱动外部强化学习优化。这训练模型以最适合微调的方式重组段落
Few-Shot Learning
- 抽象与推理语料库(Abstraction and Reasoning Corpus,ARC)是一个测试抽象推理和从极少示例中泛化的基准
- 每个任务包括少量输入-输出示例和一个需要预测正确输出的保留测试输入
- 论文采用测试时训练(TTT)协议,其中少量示例的增强用于执行基于梯度的适应。论文训练 SEAL 学习这些决策,而不是依赖手动调整的启发式方法。为此,论文定义了一组工具 ,每个工具是预定义的函数,用于转换数据或指定训练参数,包括:
- 数据增强(Data augmentations) :旋转、翻转、反射、转置、调整大小操作(如更改网格分辨率)以及链式或重复变换
- 优化参数(Optimization parameters) :学习率、训练周期数以及损失是否计算所有 Token 或仅输出 Token
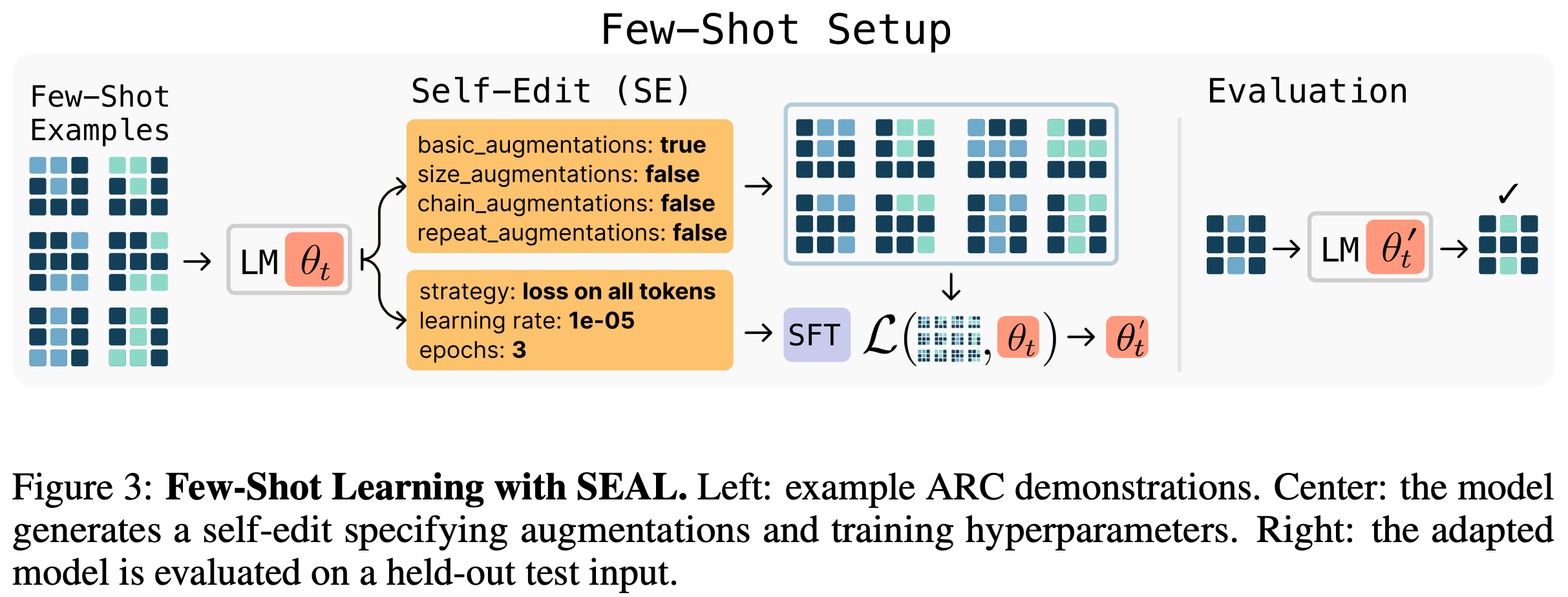
- 模型通过任务的少量示例 Prompt 生成自我编辑(即指定调用哪些工具及如何配置的指令),如图3 所示
- 然后通过基于 LoRA 的微调应用这些自我编辑来适应模型
- 适应后的模型在保留测试输入上评估,结果决定训练自我编辑生成策略的奖励
Results
- 本节论文通过两个适应领域实证评估 SEAL: Few-shot 学习和知识整合。完整的训练、超参数和评估细节见 附录A 和 附录B
Few-Shot Learning
- 论文使用 Llama-3.2-1B-Instruct(2023)进行实验,这是一个未针对 ARC 进行预训练的小型开源模型
- 由于大多数 ARC 任务对未经预训练的模型具有挑战性,论文从 ARC 训练集和评估集中分别筛选了 11 个和 8 个任务,确保它们在最优 TTT 配置下可解
- 模型通过 ReST\(^{EM}\) 训练,每个训练任务采样 15 个自我编辑
- 每个自我编辑独立生成 15 个更新模型,随后在对应的保留测试示例上评估
- 论文仅强化那些导致模型正确适应的自我编辑(即适应后能正确输出测试输入的模型)
- 训练后,论文通过为每个保留评估任务生成 5 个自我编辑并独立应用它们来评估模型
- 然后报告导致正确输出的自我编辑百分比,反映学习到的自我编辑生成策略的质量
- 论文对比了以下基线:
- 1)ICL(上下文学习) :Llama-3.2-1B-Instruct 直接通过少量示例 Prompt 并查询测试输入
- 2)TTT + 自我编辑(无 RL 预训练) :模型使用少量示例和合成增强进行测试时训练,但未通过 RL 优化增强或训练配置
- 3)Oracle TTT :模型使用人工设计的最优配置进行测试时训练,作为方法的上限
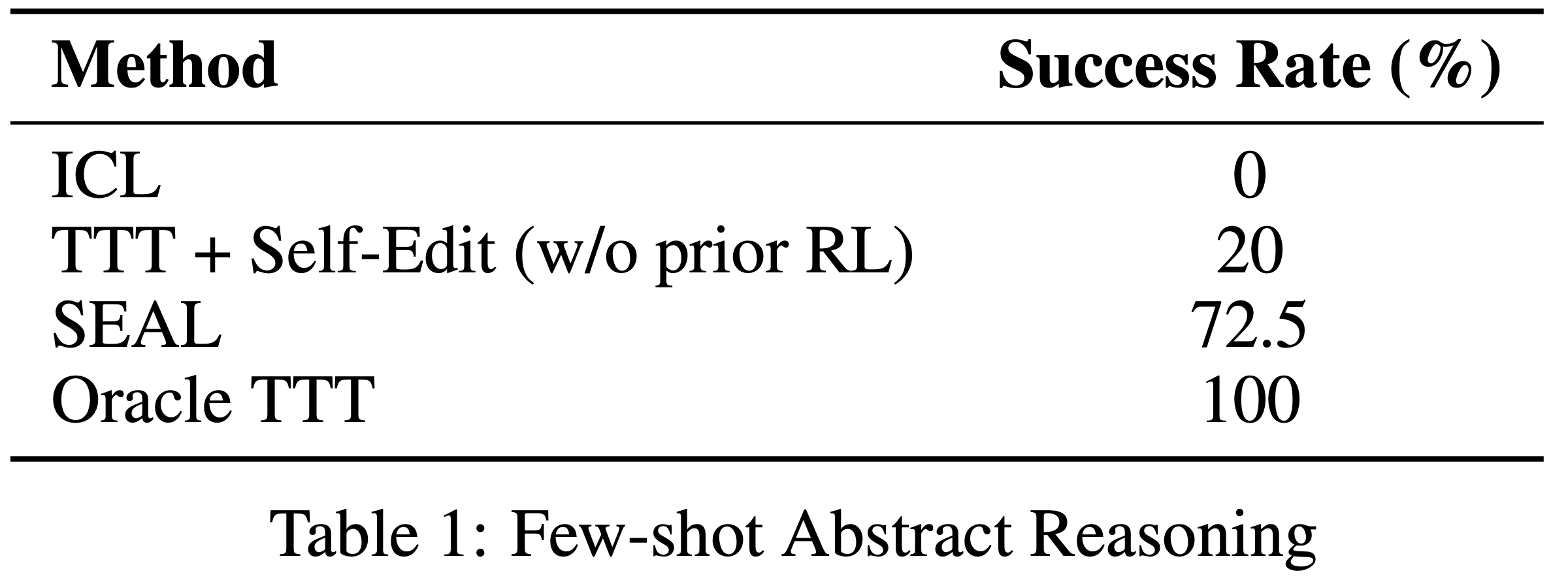
- 结果如表1 所示
- SEAL 显著提高了适应成功率:72.5% vs. 20%(无 RL 训练的自我编辑)和 0%(无适应),但性能仍低于 Oracle TTT,表明还有改进空间
- SEAL 显著提高了适应成功率:72.5% vs. 20%(无 RL 训练的自我编辑)和 0%(无适应),但性能仍低于 Oracle TTT,表明还有改进空间
Knowledge Incorporation
- 论文在 Quen2.5-7B 上实验,整合来自 SQuAD 段落的新事实内容
- 论文进行了两轮 ReST\(^{EM}\) 训练,每轮包含 50 个上下文(详见 附录B)。论文对比了以下基线方法:
- 1)基础模型 :未经适应的预训练模型,无法访问段落
- 2)仅训练段落 :模型直接对段落进行标准语言建模损失微调,无合成数据
- 3)训练段落 + 合成数据 :模型训练段落及自我生成的推论,与 SEAL 相同但无 RL 训练
- 4)训练段落 + GPT-4.1 合成数据 :模型训练段落及通过 OpenAI API 从 GPT-4.1 生成的推论
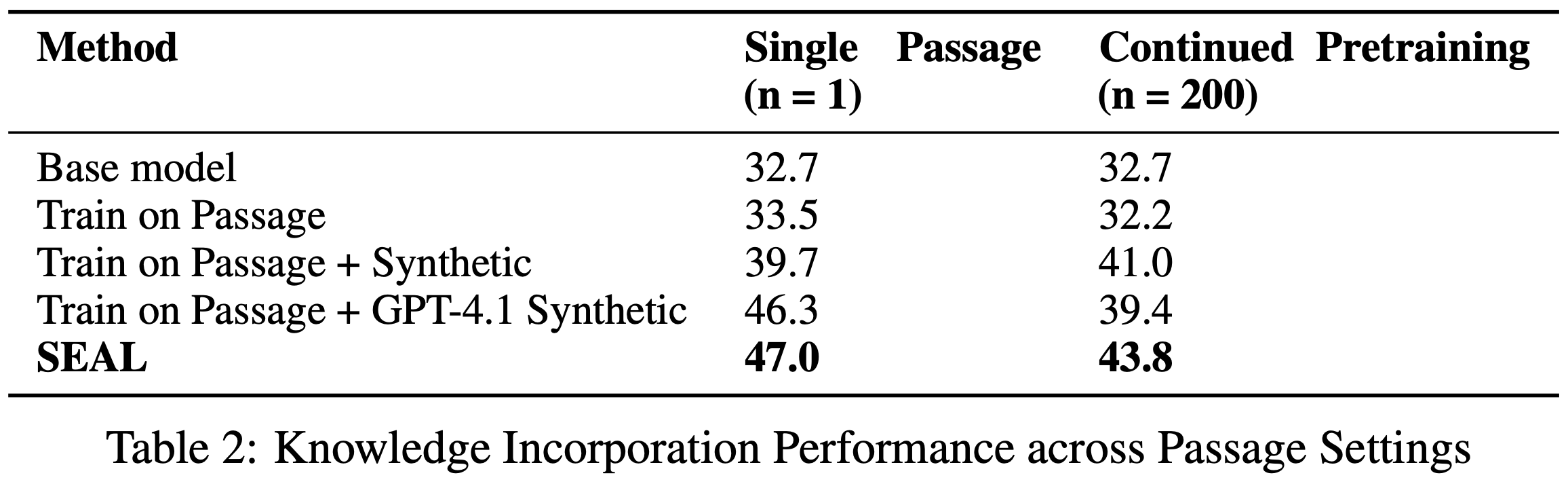
- 表2 报告了两种设置下的平均无上下文 SQuAD 准确率:单段落(\(n=1\))和持续预训练(CPT, \(n=200\))
- 在单段落设置中,直接微调段落仅比冻结基础模型略优(33.5% vs. 32.7%),表明原始数据不足
- 使用 GPT-4.1 生成的合成数据将准确率提升至 46.3%,比仅段落基线高 12.8 个百分点
- 使用 Quen-2.5-7B 生成的合成数据达到 39.7%,提高 6.2 个百分点
- 经过强化学习后,SEAL 进一步将准确率提升至 47.0% ,显著优于 GPT-4.1 的合成数据,尽管模型规模小得多
- 在 CPT 设置中,模型在一次持续预训练中整合了 \(n=200\) 个段落的信息,随后在所有 974 个对应问题上评估
- SEAL 再次超越所有基线,达到 43.8% 准确率。尽管绝对性能低于单段落设置(可能由于梯度干扰增加),但相对改进一致,表明 SEAL 的编辑策略能够泛化到原始 RL 设置之外
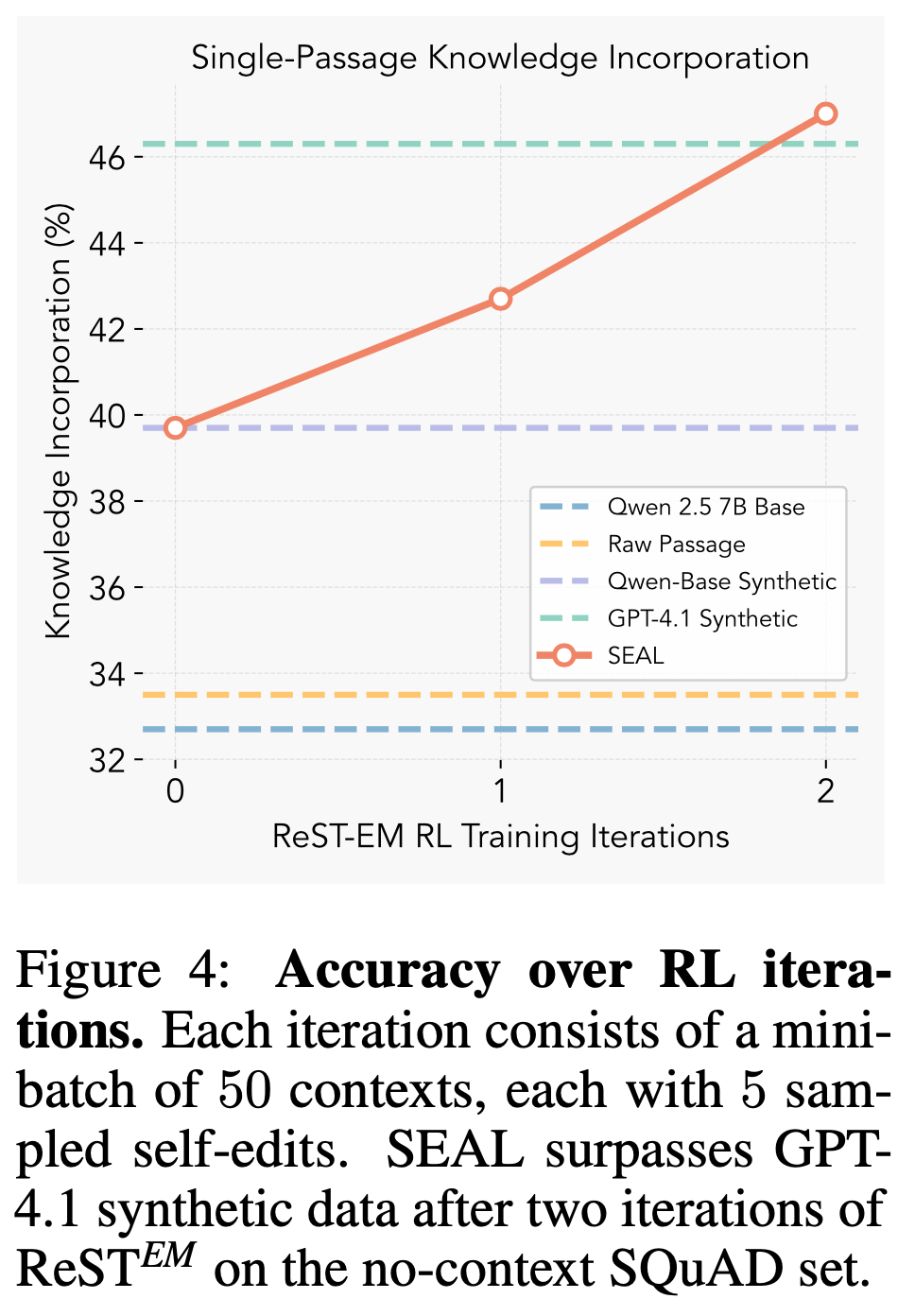
- 图4 跟踪了每轮 RL 迭代后的准确率。两轮迭代后 SEAL 即超越 GPT-4.1 数据;后续迭代收益递减,表明策略快速收敛为将段落提炼为易学习的原子事实(定性示例见图5)。所有结果均使用调优超参数(见附录B)

Limitations
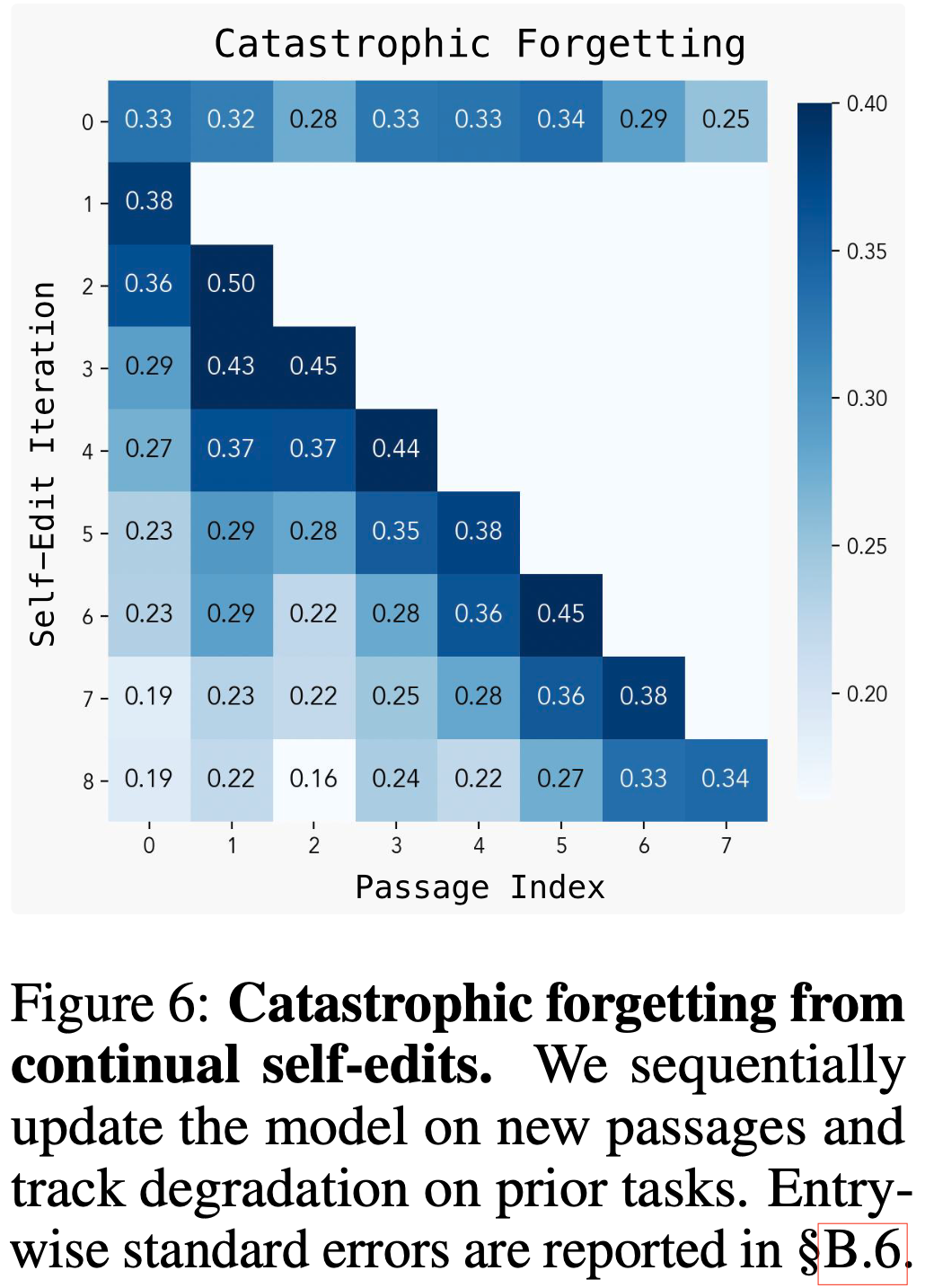
Catastrophic Forgetting
- 论文提出 self-edit 语言模型(SEAL)的一个关键动机是实现持续学习(Continual Learning)的终极目标——让模型能够随着时间的推移不断整合新信息,无论是通过与环境的主动交互还是通过标准训练
- 虽然之前的实验评估了 SEAL 在独立编辑场景下的适应能力,但更雄心勃勃的目标是支持连续的编辑序列 :模型能否在保留已有知识的同时,反复适应新信息?
- 这一问题直接关联到灾难性遗忘(2014, 2015)的挑战,即新更新会破坏过去的学习成果
- 当前的训练设置并未显式优化知识保留,但论文旨在建立一个基线,评估SEAL在没有专门机制的情况下处理连续 self-edit 的能力
- 为了测试这一点,论文在知识整合领域模拟了一个持续学习场景:模型接收一系列测试段落,每个段落触发一次新的 self-edit
- 每次更新后,论文重新评估模型在所有已见任务上的表现,以衡量其知识保留能力
- 如图6所示,随着编辑次数的增加,模型在早期任务上的表现逐渐下降,这表明SEAL仍然容易受到灾难性遗忘的影响
- 尽管如此,它能够在多次更新后避免完全崩溃,这表明未来仍有改进空间
- 未来的工作可以通过奖励塑形(2020, 2024)来增强这一能力,例如惩罚对早期任务的回归,或整合持续学习策略,如零空间约束编辑(2025)或表示叠加(2019)
Computational overhead
- TTT(Test-Time Training)奖励循环的计算成本显著高于其他用于 LLM 的 RL 方法
- 例如,基于人类偏好的奖励信号通常只需要一次模型前向传播,而基于验证解的奖励可能仅依赖简单的模式匹配(如正则表达式)
- 相比之下,论文的方法需要对整个模型进行微调和评估以计算奖励——每次 self-edit 评估大约需要30-45秒,带来了显著的开销(详见附录B.5)
Context-dependent evaluation
- 当前的实例化假设每个上下文都配有一个明确的下游任务:Few-shot 示例附带一个保留的查询对,每个段落捆绑了参考问答
- 这种耦合简化了奖励计算,但阻碍了 SEAL 的 RL 训练扩展到未标注语料库
- 一个潜在的解决方案是让模型不仅生成 self-edit,还为每个段落生成自己的评估问题(例如草拟问答项或合成测试用例),同时保留原始内容在上下文中
- 这些模型编写的查询可以提供强化学习所需的即时监督,从而将适用性扩展到缺乏外部问答集的通用训练领域
Related Work
- 合成数据生成(Synthetic Data Generation) :
- 合成数据在训练中的应用日益广泛,从大规模预训练数据集(2023; 2024; 2024)到任务特定的数据增强(2023; 2024)和指令微调集(2023; 2023)
- Yang 等人(2025)通过基于图的 Prompt 生成合成数据
- SEAL 在此基础上,利用强化学习训练生成策略,直接最大化合成数据在梯度更新中的下游效用,而非依赖手动调整的静态启发式方法
- 知识更新(Knowledge Updating) :
- 近期研究尝试通过权重更新修改或注入事实知识
- 部分方法直接定位与特定事实相关的参数(2022; 2022; 2023)
- 另一些则利用上下文信息生成额外的微调数据(2024; 2024; 2025; 2025)
- 论文采用后者,参考 Akyurek 等人(2024)提出的逻辑蕴涵生成和 Lampinen 等人(2025)展示的蕴涵微调优于上下文学习的结果
- SEAL 通过强化学习训练模型生成更优的微调数据,进一步扩展了这些方法
- Park 等人(2025)表明,直接生成问答对(QA)的 Prompt 优于蕴涵式 Prompt
- 由于 SEAL 框架对 self-edit 数据的格式无关,它同样可以训练生成 QA 对或其他输出格式
- 测试时训练(TTT, Test-Time Training) :
- 测试时训练基于输入临时调整模型权重(2020; 2022; 2024)。Akyurek 等人(2025)表明,TTT 与上下文学习结合可在 Few-shot 设置中超越标准 ICL
- SEAL 在内部优化中整合了 TTT,利用其高效性执行多次更新,并奖励带来最大性能提升的数据生成策略
- LLM 的强化学习(Reinforcement Learning for LLMs) :
- 强化学习在改进 LLM 行为中发挥核心作用,最初通过 RLHF(2022)实现
- 近期研究利用可验证奖励直接优化任务成功率(2022; 2024; 2025)
- SEAL 将强化学习应用于优化 self-edit 数据的生成,而非最终答案或推理轨迹的修订
- 元学习与自修改系统(Meta-Learning and Self-Modifying Systems) :
- SEAL 通过外部优化循环学习适应策略(即如何生成有效的 self-edit),体现了元学习原则(2001; 2017; 2025),其目标是学习如何高效地从任务上下文中学习
- 元学习同样已应用于强化学习领域在该领域中,模型通过元目标进行训练,以快速适应新任务
- 这类工作的一个自然延伸是自指网络(self-referential networks),即模型自行修改自身参数(1992; 2022)
- 在大型语言模型领域,近期的研究已将元学习原则应用于改进 LLM 的适应性[2024;2023]
- 值得注意的是,Hu等人(2023)训练了一个较小的模型,使其在对语料库进行微调时输出特定于标记的权重,以解决与我们类似的知识整合任务
- 然而,SEAL 通过利用模型现有的生成能力来参数化更新,从而在跨领域场景中展现出更强的通用性
- 自我改进(Self-Improvement) :
- 近期研究涵盖自我改进或自训练的多种方法
- RLAIF(2022; 2024)和自我奖励语言模型(2024; 2025)利用模型自身提供奖励信号,基于判断输出比生成更容易的观察(2025)
- 其他工作通过多数投票或模型置信度作为强化学习奖励,在无真实标签的情况下提升数学任务性能(2023; 2024; 2025; 2025)
- 然而,这些方法受限于模型的当前评估能力和自一致性,相比之下,SEAL 通过与外部数据的交互实现自我改进,为更具扩展性的路径提供了可能
Discussion and Conclusion
- Villalobos等人(2024)预测,到2028年,前沿 LLM 将完成对所有公开人类生成文本的训练
- 作者认为,这一迫近的“数据墙”将迫使人们采用合成数据增强 ,一旦网络规模的语料库耗尽,进展将取决于模型自主生成高效用训练信号的能力
- 自然的下一步是元训练一个专用的 SEAL 合成数据生成模型,生成新的预训练语料库,使未来模型能够在无需额外人类文本的情况下扩展并实现更高的数据效率
- 我们可以设想一个未来场景:大语言模型能够消化新数据(如学术论文),并利用上下文中的数据和已有知识生成大量解释和推论
- 这种自我表达和自我优化的迭代循环可能使模型即使在缺乏外部监督的情况下,也能在罕见或代表性不足的主题上持续改进
- 此外,尽管现代推理模型通常通过强化学习生成思维链(CoT)轨迹,但 SEAL 可以提供一种互补机制,让模型学习何时以及如何更新自身权重
- 这两种方法可以协同作用:模型可能在推理过程中选择更新权重以引导当前轨迹,或在完成推理后将关键见解提炼到参数中——通过内部化学习提升未来推理能力
- 这种持续优化的循环对于构建代理系统(Agentic Systems)也很有前景——这些模型在长期交互中运行,并动态适应不断变化的目标
- 代理模型必须逐步获取和保留知识
- 论文的方法通过支持结构化的自我修改来实现这种行为:在交互后,代理可以合成一个 self-edit,触发权重更新
- 这可能使代理能够随时间发展,使其行为与先验经验对齐,并减少对重复监督的依赖
- SEAL 证明了大语言模型在预训练后不必保持静态:通过学习生成自己的合成 self-edit 数据并通过轻量级权重更新应用这些数据,它们可以自主整合新知识并适应新任务
- 展望未来,作者计划将 SEAL 框架扩展到预训练、持续学习和代理模型中,最终使语言模型能够在数据受限的世界中自我学习和扩展
附录A 实验细节:Few-shot 学习(Experimental Details: Few-shot Learning)
- 模型与设置 :论文使用Llama-3.2-1B-Instruct(2024)作为基础语言模型。由于该模型未针对ARC进行专门训练,其解决ARC任务的能力有限。为了进行受控评估,论文从训练集和评估集中筛选了一小部分可通过最优TTT超参数解决的 ARC 问题
- 训练集 :从训练集中选择了11个ARC任务作为RL优化的环境
- 评估集 :从评估集中选择了8个不同的ARC问题用于衡量泛化性能。这8个问题明确筛选为适合TTT的场景
- 这些集合的选择是为了隔离 self-edit 学习的效果,而非通用ARC能力
- 训练流程 :论文在11个训练问题上使用单轮强化学习训练SEAL。对于每个问题,模型生成15个 self-edit 配置,包括:
- 数据增强策略 :控制是否包含基本示例、基于尺寸的增强、链式推理和重复输入
- 优化配置 :指定学习率、训练轮数和损失函数类型(例如是否对所有 Token 或仅最终输出 Token 计算损失)
- 每个配置通过测试时训练(TTT)评估,并分配二元奖励:如果适应后的模型生成正确解则为1,否则为0
- 评估细节 :对于8个保留的评估任务,模型生成5个 self-edit 配置,共40个配置。成功率衡量为适应后生成正确输出的配置百分比
附录B 实验细节:知识整合(Experimental Details: Knowledge Incorporation)
- 模型与设置 :论文在知识整合实验中使用Quen-2.5-7B基础模型(2025)。论文将SQuAD数据集v1.1(2016)重新用于无上下文段落的问答任务
- RL训练流程 :论文运行2轮 ReST\(^{EM}\) 训练(2025)
- 每轮从 SQuAD 训练集中抽取 50 个 上下文-问题-答案 三元组。对于每个上下文,采样 5 个 self-edit 生成(温度=1),并通过 3 个随机种子评估每个生成
- 合成数据生成与微调细节 :在所有模型中,论文通过 Prompt 生成段落的推论来生成合成数据
- 评估细节 :论文在 SQuAD 评估集的 200 个段落子集上评估,共974个问题
- 使用 GPT-4.1(2025)通过 OpenAI API 进行自动评分
- 计算资源 :所有实验在 2×H100 或 2×H200 上运行
- 使用 DeepSpeed ZeRO-3(2020)进行 ReST\(^{EM}\) 训练的 SFT,使用 vLLM(2023)进行高效推理
附录C Prompting
- 近期研究表明,强化学习基线和结果对 Prompt 高度敏感。论文在知识整合设置中测试了 4 种额外的 self-edit Prompt;五种 Prompt 如下:
- 1)推论(Implications)
- 2)长推论(Implications-long)
- 3)超长推论(Implications-very-long)
- 4)重写(Rewrite)
- 5)自问答(Self-QA)
- 结果显示,尽管通过 Prompt 生成长响应可以提高性能,但以这些 Prompt 为基础的 RL 训练能带来更大的改进
- 在所有情况下,ReST\(^{EM}\)将性能提升了约 6 到 11 个百分点