注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 本文对 LLM 强化学习中的 Credit Assignment 进行了专门的综述,追溯了从 Reasoning RL 到 Agentic RL 的演变,并讨论了驱动方法论创新的根本挑战
- 针对 LLM 的 RL 越来越依赖稀疏的、结果层面的奖励
- 确定长轨迹中的哪些行为导致了该结果非常困难
- 这个信用分配(Credit Assignment, CA)问题体现在两种情形中:
- Reasoning RL(reasoning RL):信用必须分配到单个思维链生成(500-30K+ token)中的 token 和步骤上
- Agentic RL(agentic RL):多轮环境交互引入了随机转移、部分可观测性以及 100+ 轮(100K-1M token)的时域
- 使得 Episode 层面的信用越来越缺乏信息量
- 本文调研了 47 种信用分配方法(41 种核心方法,6 种相邻使能方法),这些方法发表于 2024 年至 2026 年初
- 作者按两个维度的分类法对它们进行了组织:
- 分配粒度(token、segment、step、turn、multi-agent)
- 方法论(Monte Carlo、时序差分、基于模型、博弈论、信息论)
- 除了调研本身,作者还贡献了三个可复用的资源:
- (1)一个结构化的、机器可读的论文清单,其中包含分类标签、基线族和证据等级
- (2)一个针对未来 CA 论文的报告清单,该清单根据已审文献进行了验证,以识别系统性的方法论空白
- (3)一个基准测试协议规范,包含任务族、元数据需求和受控分岔任务,并附带一个方法选择决策树
- 作者按两个维度的分类法对它们进行了组织:
- 从推理到 Agentic RL 的转变使得信用分配问题更加复杂并重塑了其格局:
- 推理 CA 正围绕过程奖励模型(Process Reward Model, PRM)
- 无 critic 的组比较方法趋于成熟,而 Agentic CA 则催生了真正的新方法
- 事后反事实分析(hindsight counterfactual analysis)
- 特权非对称 critic(privileged asymmetric critic)
- Turn-level MDP 重构
- 这些方法在 Reasoning RL 中没有直接先例
- 五个关键要点(用 Evidence-level 注释:[SE] = 强经验性,[LS] = 有限但具有启发性,[AS] = 作者综合):
- 1)Credit Assignment 是 LLM RL 的核心挑战 [SE]
- 而且 Credit Assignment 的重要性随着从推理环境转向 Agentic 环境而增长
- 从单次生成轨迹 ( \(\sim 1\text{K} - 30\text{K}\) 个 Token) 到多轮 Agent 交互 ( \(\sim 100\text{K} - 1\text{M}\) 个 Token) 的转变,将 Credit Assignment 从优化便利性转变为训练必要性
- 2)在 Reasoning RL 中,Credit Assignment 正在成熟 [SE]
- Token-level (VinePPO)、Segment-level (SPO, SCAR) 和 Step-level (PURE, HICRA, SPRO) 方法在转移是确定性的、轨迹是单次生成且结果可验证时提供了有效的解决方案
- PRM 范式和无需 Critic 的组比较代表了鲁棒、可扩展的方法
- 3)在 Agentic RL 中,Credit Assignment 尚处起步阶段 [LS]
- 质量上更困难挑战需要新的方法
- 挑战包括:随机环境、部分可观测性、异质 Action、超长时域和不可验证的中间状态
- 事后/反事实方法 (HCAPO, C3, CCPO) 和分层架构 (ArCHer, CARL) 代表了社区的新兴回应,但仍有许多工作要做
- 质量上更困难挑战需要新的方法
- 4)LLM-as-Critic 似乎是一个独特的范式 [LS]
- 在经典 RL 中没有直接镜像
- 使用 LLM 对中间状态进行语义评估的能力 (CAPO, SWEET-RL, LaRe, HCAPO, CriticSearch) 开辟了一个似乎是 LLM 时代特有的方法论轴心
- 这种方法是否会被证明比传统的基于价值的方法更有效,仍然需要继续探索
- 5)该领域正在加速发展 [AS——文献计量学观察]
- 仅 2026 年 3 月一周内就出现了三篇关于反事实 Credit Assignment 的独立论文,本文的分类法包含了仅两年(2024–2026 年)内发表的 47 种方法(41 种核心 CA,6 种辅助使能技术)
- 多 Agent Credit Assignment(现在作者的清单中有 6 篇专门论文)已从一个新兴领域发展成为一个活跃的研究前沿
- 1)Credit Assignment 是 LLM RL 的核心挑战 [SE]
- 随着 LLM 从推理引擎演变为在真实环境中运行的自主 Agent
- Credit Assignment 的问题从 “哪个推理步骤是正确的?” 转变为 “哪个 Action 以正确的方式改变了世界?”
- 本 Survey 的核心论点
- 作者认为,从 Reasoning RL 到 Agentic RL 的转变不仅仅是将现有方法扩展到更困难的任务
- 这个转变实质性地重塑了 Credit Assignment 问题
- 推理 CA 在一个相对温和的环境中运作(确定性转移、可验证步骤、较短的时域)
- Agentic CA 在一个更具挑战性的环境中运作(随机环境、不可验证状态、\(100+\) 轮时域)
- 这种质的转变正在产生真正的新方法:
- 事后反事实分析、特权非对称 Critic、基于熵的关键 Action 识别以及 Turn-level MDP 重构
- 作者预计 2026–2027 年该领域的活动将不断增加
- 作者认为,从 Reasoning RL 到 Agentic RL 的转变不仅仅是将现有方法扩展到更困难的任务
Introduction and Discussion
- LLM 强化学习的两波浪潮
- 第一波浪潮:Reasoning RL
- 展示了 RL 可以显著提升 LLM 解决数学问题、编写代码以及执行逻辑推理的能力(2025;2024)
- 像 DeepSeek-R1 和 OpenAI 的 o1 这样的模型表明,使用结果层面的奖励(“最终答案是否正确?”)进行训练可以激发复杂的思维链推理
- 第二波浪潮:Agentic RL
- 此范式扩展到多轮交互式任务:浏览网页(2024a)、使用工具(2024)、编写和调试代码以及与其他 Agent 协作的 LLM Agent
- 从推理到 Agentic(agency)的转变代表了 RL 问题复杂性的一次质的飞跃
- 这两波浪潮的核心是一个共同的瓶颈:信用分配
- 当唯一的反馈是一个稀疏的终端奖励(“问题解决”或“任务完成”)时,如何确定中间行为(哪些 token、哪些推理步骤、哪些工具调用)如何影响了结果呢
- 第一波浪潮:Reasoning RL
- 信用分配问题是核心瓶颈,且信用分配问题的严重性随轨迹复杂度而增大:
- 在 Reasoning RL 中,一条典型轨迹是单个 LLM 生成
- 范围从 \(\sim 500\) 个 token(GSM8K 级别的问题)到硬性竞赛数学题的 10,000-30,000+ 个 token
- 例如,在 AIME 2025 上,DeepSeek-R1 平均约 \(\sim 23\text{K}\) 个 token(2025)
- 这种情况下,信用必须分配到 token 和推理段上
- 像 GRPO(2024)和 REINFORCE 这样的 Episode-level 方法将相同的优势分配给每个 token(这种粗略的近似对于较短的轨迹有效)
- 范围从 \(\sim 500\) 个 token(GSM8K 级别的问题)到硬性竞赛数学题的 10,000-30,000+ 个 token
- 在 Agentic RL 中,轨迹跨越 10-100+ 轮,每轮都涉及一次 LLM 调用加上环境交互
- 总 token 数通常达到 100K-500K+
- 例如,在一个报告的 SWE-bench 设置中,Agent 平均约 \(64\) 轮,消耗约 \(131\text{K}\) 个 token(2025d)
- Episode-level 信用变得越来越没有信息量:
- 在第 3 轮的一个错误工具调用会与几十个正确的后续行为受到相同的惩罚
- 总 token 数通常达到 100K-500K+
- 在 Reasoning RL 中,一条典型轨迹是单个 LLM 生成
- 在 2024 年至 2026 年初期间,47 篇论文(41 篇提出核心 CA 方法,6 篇贡献 CA 相关的使能方法)提出了各种方法,从 Monte Carlo Token-level 价值估计(2025)到基于 Shapley 值的奖励分解(2025;2026b),从过程奖励模型(2025;2025)到事后反事实分析(2026;2026;2026c)
- 仅在 2026 年 3 月的一周内,出现了三篇关于反事实/事后信用分配的独立论文,这表明学术界对这个问题越来越感兴趣
Scope and inclusion criteria
- 本文核心纳入的文章是主要贡献是为 LLM RL 提供新颖信用分配机制 的方法
- 核心 CA 方法(core CA methods):提出跨行为分配信用的新算法(例如,VinePPO、HCAPO、CARL)
- CA 相关使能方法(CA-adjacent enablers):解决相关问题(训练基础设施、奖励 shaping、Agent 框架),其中信用分配是几个组成部分之一(例如,Agent Lightning、RAGEN、PRS)
- 以上这两类都会被回顾,但在本文比较表和论文计数中会标记其区别
- 当引用“47 种方法”时,指的是这两类的并集
- 参见后面第 1.1 节了解完整的搜索和筛选方案
Scope and narrative
- 与将信用分配视为子主题(2025a)或关注经典 RL(2023)的现有工作不同,本文以信用分配为中心视角来审视 LLM RL
- 本文的叙述脉络是:
- 经典 RL(Classical RL)\(\rightarrow\) Reasoning RL(Reasoning RL)\(\rightarrow\) Agentic RL(Agentic RL)\(\rightarrow\) 未来:多 Agent 系统(Future: Multi-Agent Systems)
- 在每个阶段,信用分配问题都变得更加困难,并且出现新的方法来应对挑战
Contributions
- 本文做出了三种不同类型的贡献:
I. Survey with taxonomy,带分类法的调研
- 1)专门分析:本文提供了一个专注于 LLM RL 中信用分配的专门调研,涵盖了推理和 Agentic 两种设置(第 3 节和第 5 节)
- 2)二维分类法:本文按粒度 \(\times\) 方法论组织了 47 种方法,揭示了系统性的模式和空白(第 2.4 节)
- 3)推理 \(\rightarrow\) Agentic 分析:本文明确刻画了为什么 Agentic RL 使信用分配在质量上更加困难,以及这需要哪些新技术(第 4 节)
- 4)系统比较:本文在计算成本、辅助模型需求、适用场景和实证性能方面比较了各种方法,包括一个结构化的 GRPO 系列元比较(第 7 节)
II. Reusable structured artifact,可复用结构化 Artifact
- 5)机器可读清单:提供了所有 47 种方法的结构化清单,包含分类标签、基线族、证据等级和主要基准测试(第 B 节),设计用于直接复
- 所有结构化数据将在发表后以可下载的 CSV/JSON 格式发布(见第 9.5 节)
III. Standardization proposals,标准化 Proposal
- 6)报告清单:为未来的 CA 论文提出了一个具体的报告清单,并根据现有文献进行了验证,以识别最常见的方法论空白(第 C 节)
- 7)基准测试协议:概述了信用分配评估套件的最低规格,包括任务族、所需元数据和受控分岔任务(第 9 节)
- 8)研究路线图:识别了前沿的开放问题——多 Agent 信用、超长时域、探索-信用 interplay——并将 Agentic RL 视为未来创新的可能驱动力(第 9 节)
Relation to existing work
- A Survey of Temporal Credit Assignment in Deep Reinforcement Learning, 2023, University College London & Google DeepMind 对经典深度 RL 中的时域信用分配进行了极好的回顾(56 页,2023),但完全早于 LLM 时代
- The Landscape of Agentic Reinforcement Learning for LLMs: A Survey, 20250902-20260417, Oxford & Shanghai AI Lab & NUS提供了针对 LLM 的 Agentic RL 的全面概述(100 页,500+ 篇论文),但仅将信用分配作为众多子主题之一处理,缺乏深度
- 几篇关于 Reasoning RL 的工作(2025b)广泛涵盖了 RL 算法,但未聚焦于信用分配
- 现有工作没有系统地审视跨推理和 Agentic LLM RL 的信用分配问题
Paper organization
- 第 2 节介绍背景、问题表述和分类法
- 第 3 节回顾 Reasoning RL 的信用分配方法
- 第 4 节刻画为什么 Agentic RL 使信用分配问题复杂化并重塑其格局
- 第 5 节回顾针对 Agentic 的信用分配方法
- 第 6 节涵盖多 Agent 信用分配
- 第 7 节提供系统比较
- 第 8 节将信用定位置于更广泛的 Agentic RL 训练流程中
- 第 9 节讨论开放问题和未来方向
- 第 10 节总结
How to use this survey
- 本文旨在以不同方式服务不同读者:
- 为特定任务选择 CA 方法的从业者:从决策树(图 4)和推荐表(表 8)开始,然后阅读相关方法章节获取详细信息
- 寻求开放问题的研究人员:阅读第 4 节了解核心挑战,然后阅读第 9 节了解研究路线图
- 基准测试协议(第 9 节)和报告清单(第 C 节)可能有助于设计实验
- 评审者和元研究人员:结构化清单(第 B 节)提供了所有 47 种方法的机器可读元数据
- 清单验证(第 C 节)记录了当前的报告空白
- LLM RL 信用分配的新入门者:阅读第 2 节了解基础知识,然后跟随第 3 节和第 5 节的叙述脉络
1.1 Literature Coverage, 文献覆盖范围
- 本文涵盖了 2024 年 1 月至 2026 年 4 月期间发表的针对 LLM RL 的信用分配方法
- 通过在 arXiv、Semantic Scholar 和 Google Scholar 上进行关键词搜索来识别论文,将信用分配术语(“credit assignment”,“process reward”,“reward decomposition”,“turn-level reward”)与 LLM/RL 术语相结合
- 通过从基础工作(VinePPO、ArCHer、GRPO、DeepSeek-R1)向前/向后追溯引用,以及系统性地监控主要会议(NeurIPS、ICML、ICLR、ACL 2025)和 HuggingFace Daily Papers 来补充这些搜索
- 本文纳入那些主要贡献是新颖信用分配机制的方法,并区分核心 CA 方法(41 篇论文)和 CA 相关使能方法(6 篇论文)
- CA 相关使能方法中的信用分配是多个组成部分之一
- 如果一篇论文的主要算法贡献是一种将稀疏奖励分配到行为上的新方法,则将其归类为“核心”
- “相关”论文为 CA 生态系统(基础设施、奖励 shaping、Agent 框架)做出贡献,但没有提出新的分解算法
- 边界情况(例如,跨越推理/Agentic 设置的方法)在第 9.4 节中讨论
- 所有 47 篇论文的完整清单及其分类标签在第 B 节中提供
- 包括详细搜索查询和筛选决策在内的补充材料将在发表后发布(第 9.5 节)
- 作者承认,作为单人调研,本文的覆盖范围可能存在空白
- 详见第 9.4 节的讨论
Background and Problem Formulation
From Reasoning RL to Agentic RL: A Brief History
- RL 在 LLM 上的应用经历了几个不同的阶段,每个阶段都引入了新的信用分配挑战
阶段 1:RLHF(2022-2023)
- InstructGPT(2022)提出了 RLHF(基于 PPO)
- 这个场景中,轨迹是中等长度(\(\sim 500\) 个 token)的单轮响应,奖励模型为整个响应提供一个密集的标量信号
- 此时的信用分配是隐式的:
- PPO 学习到的价值函数提供 Token-level 基线,尽管这些基线在高维 LLM 行为空间中的质量仍有争议
阶段 2:Reasoning RL(2023-2025)
- 一个突破:使用可验证的结果奖励(没有任何奖励模型)通过 RL 训练 LLM 可以激发复杂的推理行为
- DeepSeek-R1(2025)证明,在数学问题上使用带有二元正确性奖励的 GRPO 可以产生能够进行扩展思维链推理的模型
- OpenAI 的 o1 和 o3 模型展示了类似的能力
- 这个场景下,轨迹是单次生成,范围从 \(\sim 500\) 个 token(简单数学)到 30,000+ 个 token(困难竞赛题;在 AIME 上,DeepSeek-R1 平均约 \(\sim 23\text{K}\) 个 token(2025))
- 奖励纯粹是终端奖励(正确或错误)
- 此时信用分配是:
- 单个结果奖励应如何分配到数千个推理 token 上?
- 这个问题催生了第一波针对 LLM 的 CA 方法,包括过程奖励模型(2024;2024)、 Token-level 价值估计(2025)和步骤级优势计算(2025)
- 图 1:用于 LLM 的 RL 的演化及相应的信用分配挑战
- 每个阶段都引入了更长的轨迹、更复杂的环境和更困难的信用分配问题
- 从推理到 Agentic RL 的转变代表了 CA 难度的一次质的飞跃
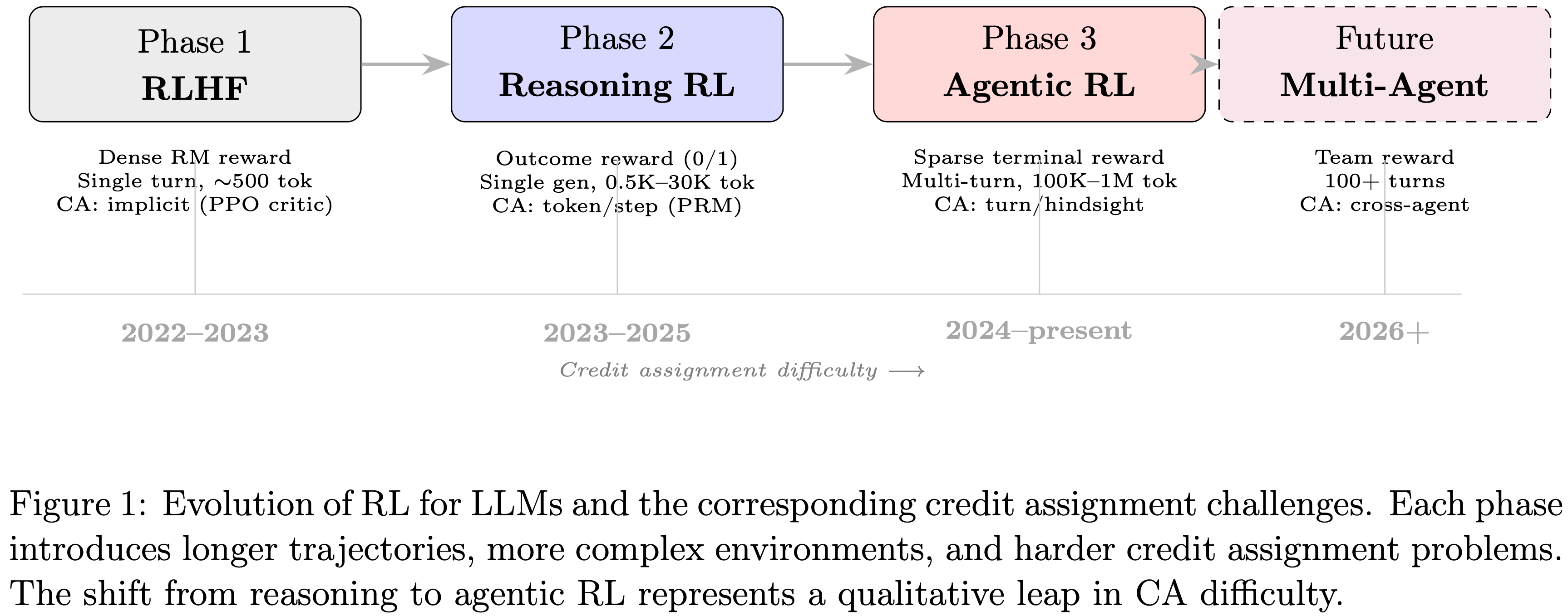
阶段 3:Agentic RL(2024-至今)
- Agentic RL 阶段将 RL 扩展到多轮、环境交互的 Setting 中
- ArCHer(2024c)在 2024 年初开创了用于 LLM Agent 的分层多轮 RL
- 2025 年,Agentic RL 爆炸式增长:
- 系统训练了用于网页导航(2024a)、软件工程(SWE-bench)、科学实验和多 Agent 协作的 Agent
- 在这个场景中,轨迹跨越 10-100+ 轮,每轮之间有环境交互,总 token 数达到 \(10^{5} - 10^{6}\),奖励保持稀疏和终端
- 信用分配问题现在在质量上更加困难(见第 4 节),这推动了第二波创新浪潮:
- 专注于 Turn-level 和基于 hindsight 的方法(2026;2026;2026c;2025;2025;2025b)
Problem Formulation: Two MDP Abstractions
Reasoning RL as a token-level MDP
- 在 Reasoning RL 中,模型针对一个 Prompt \(x\) 生成单个响应 \(y = (y_{1}, y_{2}, \ldots , y_{L})\)
- 这可以建模为一个 MDP,其中:
- 状态 \(s_{t} = (x, y_{1}, \ldots , y_{t - 1})\) 是提示加上迄今为止生成的 token
- 行为 \(a_{t} = y_{t}\) 是下一个 token
- 转移是确定性 的(自回归生成)
- 奖励 \(R\) 仅在终端状态给出(例如,答案正确性)
- 这里的信用分配意味着:推理链中的哪些 token(或 token 组)促成了正确答案?
Agentic RL as a turn-level POMDP
- 在 Agentic RL 中,模型与环境在 \(T\) 轮中进行交互:
- 状态 \(s_{t}\) 包括对话历史、环境状态(部分可观测)和检索到的上下文
- 行为 \(a_{t}\) 是模型在第 \(t\) 轮的完整响应(其本身包含许多 token)
- 转移是随机 的:环境响应取决于工具执行、网页状态等
- 奖励 \(R\) 是稀疏且终端的(任务成功/失败)
- 这种场景下,信用分配是双重分层的:
- (1) 哪一轮是关键?
- (2) 在该轮中,哪些 token 重要?
- 表 1:本文使用的主要符号总结

- The multi-granularity action hierarchy
- 此时是 多粒度行为层次结构
$$\tau_{\text{Episode} } = \underbrace{[\text{Turn}_{1},\ldots,\text{Turn}_{T}]}_{\text{Turn level} } = \underbrace{[\text{Seg}_{1,1},\ldots]}_{\text{Segment level} } = \underbrace{[a_{1,1,1},\ldots]}_{\text{Token level} } \tag {1}$$
- 此时是 多粒度行为层次结构
Why GRPO’s Episode-Level Credit is Insufficient,Why Episode-level 信用不够
- GRPO 估计器(2024)计算一个组优势:
$$\hat{A}_i^{\text{GRPO} } = R(\tau_i) - \frac{1}{G}\sum_{j = 1}^{G}R(\tau_j) \tag {2}$$- \(\tau_{i}\) 中的每个 token 都收到相同的优势 \(\hat{A}_i^{\text{GRPO} }\)
- 对于一个长度为 \(L\) 的轨迹:
- Reasoning RL(\(L \sim 10^{3} - 10^{4}\) 个 token,1 轮): Episode-level 方法(GRPO,REINFORCE)工作得相当好,因为“关键决策”的数量相对于总 token 数较少,且信噪比保持在可控范围内
- Agentic RL(\(L \sim 10^{5} - 10^{6}\) 个 token,10-100+ 轮): Episode-level 方法将一个关键的“选择正确的 API”行为和一个琐碎的“格式化输出”行为分配相同的信用
- 信噪比崩溃
- 问题:如何理解这里的信噪比?
- 理解:信噪比(Signal-to-Noise Ratio, SNR)是一个从通信和信号处理领域借用的概念,主要用来衡量模型在处理信息或进行训练时,“有用的目标信息(信号)”与“无用的干扰信息(噪声)”之间的比例
- 实证上,Zhou 等人(2024c)表明
- 使用 Episode-level 奖励的标准 PPO 未能学习有效的多轮策略
- 使用分层信用的方法成功了
- Wang 等人(2025d)报告了类似的发现,将其失败归因于他们所谓的“回声陷阱”(echo trap)
- 更正式地,在带有基线 \(b\) 的 REINFORCE 估计器中,单个行为 \(a_{t}\) 的策略梯度方差与 \((R(\tau) - b)^{2}\) 成比例
- 当相同的基线应用于所有 \(T\) 个行为时,总梯度方差按 \(\mathcal{O}(T \cdot \text{Var}[R])\) 缩放
- GRPO 和其他 Episode-level 方法通过组归一化部分缓解了这个问题,但根本问题仍然存在:
- 对于 \(T = 100\) 轮和二元奖励,每个行为的信噪比大约比单轮推理设置差 \(100\) 倍
- 实证上,Wang 等人(2025d)通过“回声陷阱”现象证明了这一点:
- 在 Episode-level 信用下,Agentic 模型收敛到重复行为,因为梯度信号太嘈杂,无法区分有成效的行为和冗余的行为
Taxonomy Overview
- 本文沿着两个正交轴组织方法(图 2):
- 1)粒度轴(Granularity axis):信用在哪个级别分配?
- Token-level (Token-level):生成过程中的单个 token
- Segment-level (Segment-level):语义上有意义的跨度(例如,一个推理步骤)
- 步骤/ Turn-level (Step/Turn-level):一个完整的 LLM 响应或工具调用周期
- 多 Agent 级(Multi-agent level):跨协作 Agent 的信用分解
- 2)方法论轴(Methodology axis):信用如何计算?
- Monte Carlo (MC):从中间状态进行 Rollout
- 时序差分(Temporal Difference, TD):学习到的价值函数与自举
- 基于模型 / LLM 作为 Critic(Model-based / LLM-as-Critic):LLM 评估中间状态
- 博弈论(Game-theoretic):Shapley 值,反事实基线
- 信息论(Information-theoretic):信息增益,基于熵的度量

- 1)粒度轴(Granularity axis):信用在哪个级别分配?
Classical Credit Assignment: A Brief Primer,经典信用分配简要入门
- 在 LLM 时代之前,深度 RL 为信用分配开发了丰富的工具包,许多针对 LLM 的方法直接建立在这些基础之上
Temporal Difference learning and value baselines
- 最广泛使用的方法估计一个状态价值函数 \(V(s)\) 并使用优势 \(A(s,a) = Q(s,a) - V(s)\) 来分配信用
- GAE(Generalized Advantage Estimation)(2016)通过参数 \(\lambda\) 在高偏差(TD(0))和高方差(MC)估计之间插值:
$$\hat{A}_t^{\text{GAE}(\gamma ,\lambda)} = \sum_{l = 0}^{\infty}(\gamma \lambda)^l\delta_{t + l},\quad \delta_t = r_t + \gamma V(s_{t + 1}) - V(s_t) \tag {3}$$ - 在 LLM 设置中,AgentPRM(2025)直接应用 TD+GAE 来学习 Agent 的 Turn-level 价值函数,而 ArCHe(2024c)使用带有 TD 更新的 off-policy critic
Return decomposition,Return 分解
- RUDDER(2019)通过训练一个序列模型从部分轨迹预测回报,将 episodic 回报分解为每个步骤的贡献
- 步骤 \(t\) 的贡献是预测回报的变化:
$$c_{t} = \hat{R} (s_{0:t}) - \hat{R} (s_{0:t - 1})$$ - 这个想法直接启发了 LLM 方法,如 RED(2024a)( Token-level 再分配)、SPA-RL(2025b)(基于 MLP 的进度估计)和 IGPO(2025a)(信息增益作为信用)
Hindsight credit assignment
- HCA(2019)根据观察到的结果重新加权过去的行为,利用“知道未来会改变作者对哪些过去行为重要的估计”这一见解
- 这种“向后看”的原则是 HCAPO(2026)的核心,它通过生成式验证将事后信用扩展到 LLM Agent
Counterfactual baselines, 反事实
- 差异奖励通过将实际结果与反事实基线进行比较来评估一个行为的贡献:
- “如果这个行为被默认行为替换,会发生什么?” 这需要环境重新执行或基于模型的近似
- 在 LLM 设置中,C3(2026)和 CCPO(2026c)通过对 Agent 轮次进行留一分析来实现反事实信用,而 SCAR(2025)使用 Shapley 值——反事实基线的博弈论泛化
Key mapping to LLM RL
- 经典范式映射到特定于 LLM 的方法如下:
- TD/GAE \(\rightarrow\) 学习到的 critic(ArCHer, AgentPRM)
- 回报分解 \(\rightarrow\) 奖励再分配(RED, SPA-RL)
- 事后(hindsight)\(\rightarrow\) 回顾性分析(HCAPO)
- 反事实(counterfactual)\(\rightarrow\) 留一和 Shapley(C3, SCAR)
- LLM Setting 引入了一个经典 RL 中不存在的独特能力:
- LLM 本身可以作为 critic,提供对中间状态的自然语言评估(2025;2025;2025)
- 这种 LLM-as-Critic 范式没有直接对应的经典类比,并代表了信用分配方法论的一个独特轴
- 图 3:本调研中回顾的所有 47 种信用分配方法的分层分类法
- 方法按设置(Reasoning / Agentic / Multi-Agent)组织,然后按方法论族组织
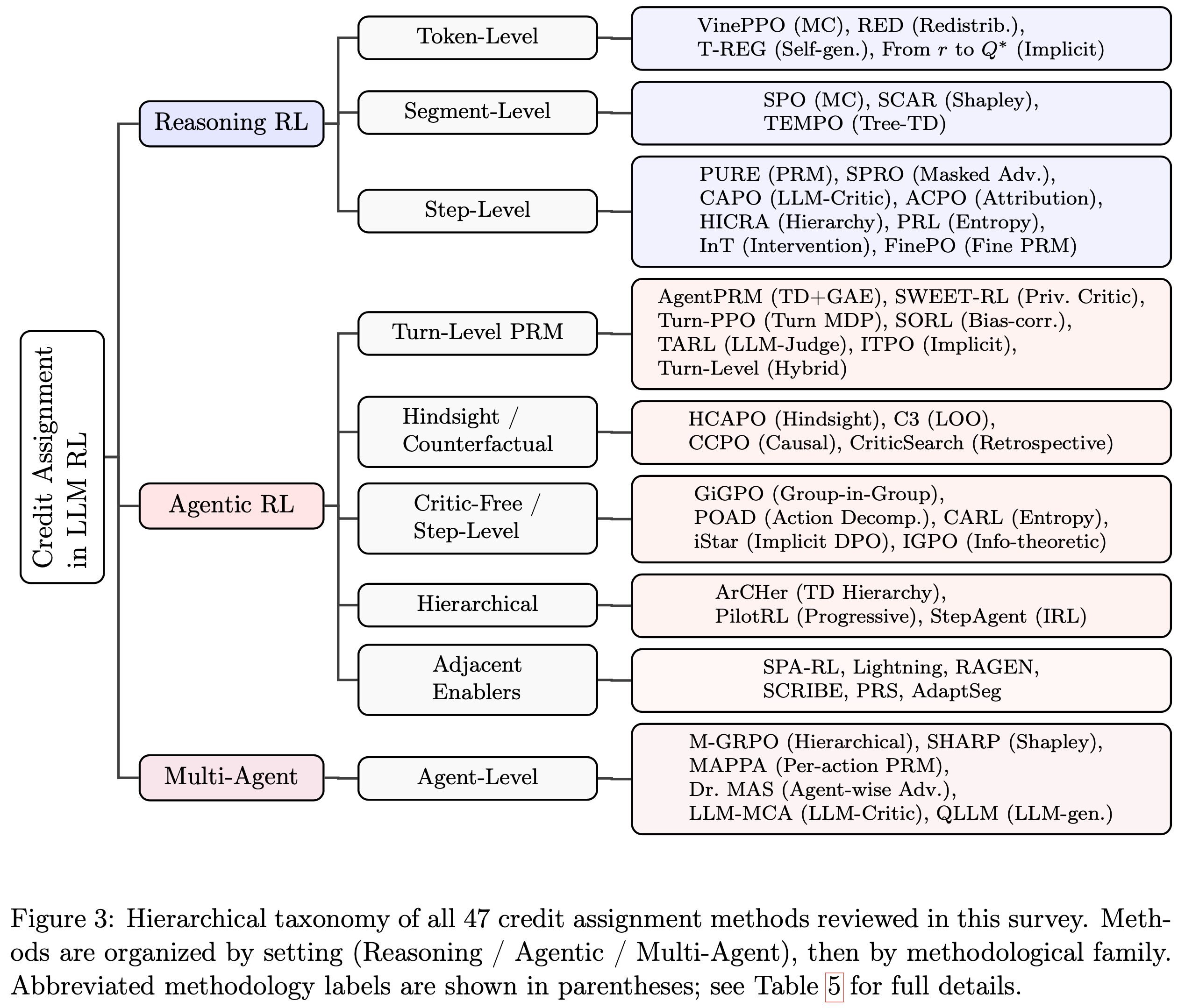
- 方法按设置(Reasoning / Agentic / Multi-Agent)组织,然后按方法论族组织
- 缩写的方法论标签显示在括号中
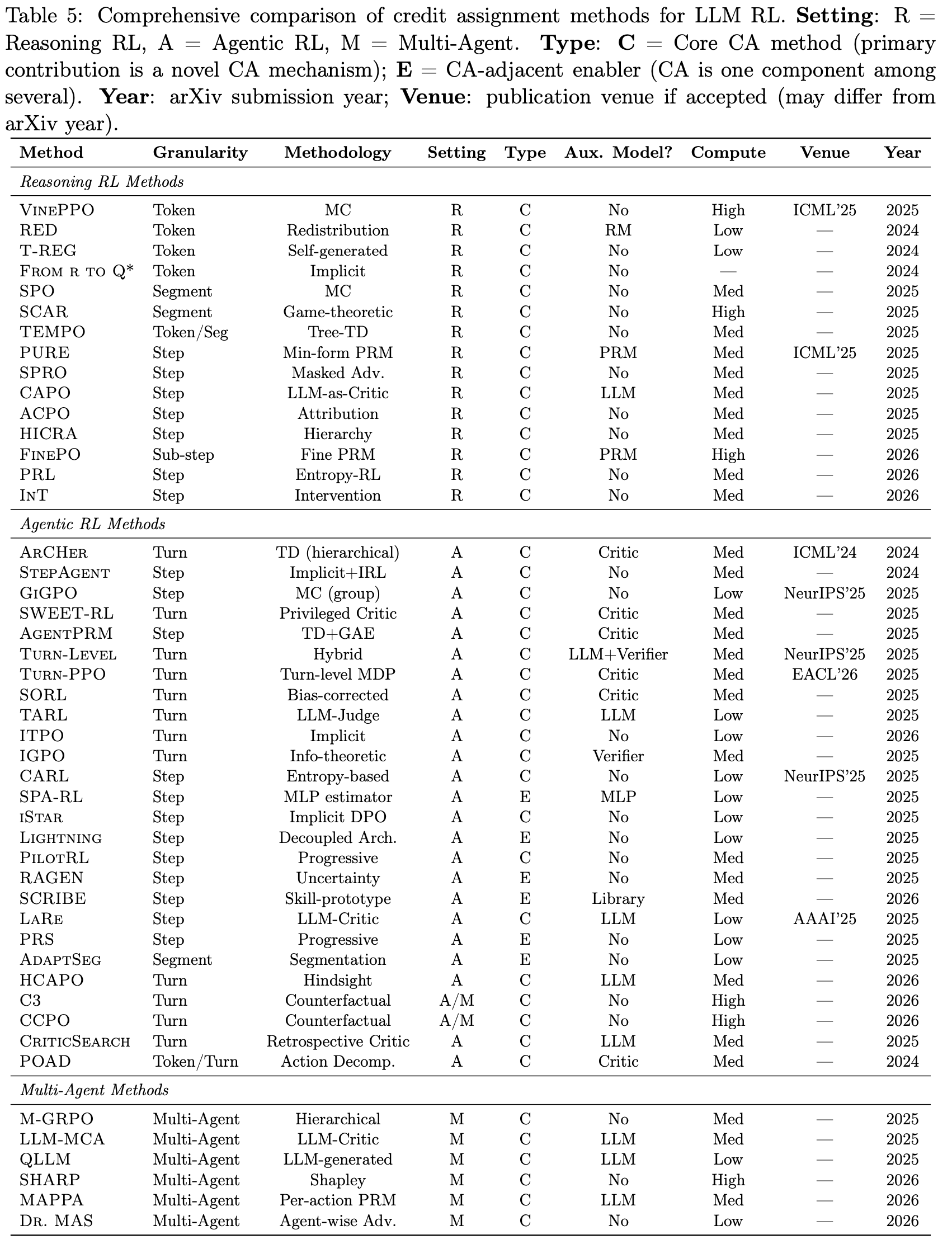
- 详情见表 5
- 详情见表 5
- Process Reward Models Are Credit Assignment
- 一个关键的概念澄清:过程奖励模型(Process Reward Models, PRMs)不仅仅是一种奖励建模技术
- PRMs 从根本上说是一种信用分配机制:一个为每个推理步骤 \(i\) 打分 \(r_i\) 的 PRM 正在对终端奖励 \(R(\tau)\) 执行步骤级的信用分解
- 因此,PRM 文献(Math-Shepherd, OmegaPRM, PURE)和 CA 文献(VinePPO, SPRO, SCAR)是同一潜在问题的两个视角
- 在本文采用 CA 视角,将 PRM 视为分配信用的几种方法论之一
- 一个关键的概念澄清:过程奖励模型(Process Reward Models, PRMs)不仅仅是一种奖励建模技术
RL Algorithms for LLMs: A Brief Overview
- 信用分配方法不是孤立运作的
- 信用分配是更广泛 RL 算法内部的组成部分
- 本节简要回顾用于 LLM 训练的主要 RL 算法,重点说明每个算法与信用分配的关系
PPO
- PPO 是 RLHF 的主力,用于 InstructGPT、ChatGPT 和 Claude
- PPO 训练一个学习到的价值函数 \(V_{\phi}(s)\) 作为基线,通过 GAE 计算 Token-level 优势
- 价值函数本身就是一个信用分配机制(其质量直接决定了训练效率)
- 问题:为 LLM 规模的状态空间训练一个准确的价值函数是出了名的困难:
- 价值网络必须处理数千个 token 的序列并产生可靠的标量估计,这一挑战催生了无 critic 的替代方案
REINFORCE and REINFORCE with baseline
- 最简单的策略梯度方法,REINFORCE 计算
$$ \nabla_{\theta}J = \mathbb{E}[\sum_{t}\nabla_{\theta}\log \pi_{\theta}(a_{t}|s_{t})\cdot R(\tau)]$$- 将完整回报作为信用分配给每个行为
- 添加一个基线 \(b\)(例如,平均回报)可以减少方差,但不能提供每个行为的信用区分
- 因为这类方法实现简单,带有学习到基线的 REINFORCE 被用于最近的一些 LLM RL 系统中,尽管它的信用分配是所有方法中最粗糙的
GRPO
- GRPO(2024)与 DeepSeek-R1 一起推出,用组比较基线取代了学习到的价值函数:
- 对于来自同一提示的一批 \(G\) 条轨迹,优势为
$$\hat{A}_{i} = R(\tau_{i}) - \frac{1}{G}\sum_{j}R(\tau_{j})$$ - 这完全消除了对 critic 网络的需求,使 GRPO 在计算上很有吸引力
- 对于来自同一提示的一批 \(G\) 条轨迹,优势为
- 但 GRPO 仅提供 Episode-level 信用(一条轨迹中的每个 token 都收到相同的优势)
- 这是本文中提到的大多数方法旨在改进的信用分配限制
DPO
- DPO(2023)通过直接从偏好对优化策略来绕过显式的奖励建模
- 正如 “From \(r\) to \(Q^{*}\)”(2024)所示,DPO 隐式地学习了 Token-level Q 值,提供了一种隐式的信用分配形式
- 像 iStar(2025)和 ITPO(2026)这样的方法利用这一见解,从经过 DPO 训练的模型中提取步骤级的信用,而无需显式的奖励计算
The credit assignment perspective on RL algorithms,RL 算法上的信用分配视角
- 从 CA 的角度来看,这些算法形成了一个谱系:
- REINFORCE/GRPO 提供 Episode-level 信用(最粗糙)
- PPO 通过学习到的 critic 提供 Token-level 信用(更精细但近似)
- DPO 提供隐式的 Token-level 信用(理论优雅但难以提取)
- 本文调研的方法可以看作是对这些基础算法的信用分配质量的增强,例如:
- VinePPO 用 MC 估计取代了 PPO 的学习到的 critic
- HCAPO 在 GRPO 之上增加了事后分析
- CARL 在任何基础算法中选择性地应用信用
Other related algorithms
- 在 LLM 训练中使用的其他几种 RL 和自我改进算法没有被深入覆盖,因为它们的信用分配特性属于上述范围之内
- RLOO(REINFORCE Leave-One-Out)使用留一基线
$$ b_{i} = \frac{1}{G - 1}\sum_{j\neq i}R(\tau_{j})$$- 这是一种与 GRPO 的组基线密切相关的方差 reduction 技术
- 从 CA 的角度来看,它仍然是 Episode-level
- REINFORCE++ 向 REINFORCE 添加了一个 Token-level KL 惩罚
- 介于 REINFORCE 和 PPO 之间,但没有引入新的信用分解机制
- Online DPO、IPO 和 KTO 是偏好优化变体,它们共享 DPO 的隐式信用结构
- 它们的 CA 属性继承自上述的“From \(r\) to \(Q^{*}\)”分析
- ReST、Expert Iteration 和 STaR 是迭代式的自我改进方法,它们基于结果质量过滤或精炼训练数据
- 它们间接地与信用分配交互(通过策划要从中学习的轨迹),但不会分解轨迹内的信用
- 本文关注 PPO、GRPO、REINFORCE 和 DPO
- 它们涵盖了信用分配方法设计空间的核心部分
Credit Assignment in Reasoning RL
- 在 Reasoning RL 中
- LLM 生成单条思维链响应
- 轨迹是一次生成中的 token 序列
- 这里的 credit assignment 方法在 Token-level 和 segment/ Step-level 上运作,将结果奖励分配到整个推理链中
Token-Level Methods
Monte Carlo Token-Level Estimation
- VinePPO
- VinePPO (ICML 2025) 将 PPO 中学习到的价值网络替换为 Token-level 无偏蒙特卡洛价值估计
- 关键 Insight:对于自回归 LLM,从任何中间前缀生成 rollout 都非常便宜(只需从模型中继续采样即可)
- 在每个 token 位置 \(t\),VinePPO 分叉出 \(K\) 条独立的延续(“藤蔓”),根据结果奖励评估每条延续,并估计
$$ V(s_t) \approx \frac{1}{K} \sum_{k = 1}^{K} R(\tau_k^{(k)})$$ - Token-level 优势为
$$\hat{A}_t = R(\tau) - V(s_t)$$- 这提供了无偏的优势,没有学习到的 critic 的函数近似误差
- 在 GSM8K 和 MATH 上,VinePPO 显著优于使用学习到的价值函数的标准 PPO,证明了 credit assignment 质量(而非策略优化)是主要的瓶颈
- 主要的限制是计算成本:每个训练轨迹需要 \(\mathcal{O}(K \cdot L)\) 次额外的前向传播,其中 \(L\) 是序列长度
Reward Redistribution
- RED
- RED(Reward Redistribution to Token Level)采用了一种务实的方法:
- 给定一个为 RLHF 训练的现成 RM,它通过线性回归探测 RM 的内部表示来估计 Token-level 奖励贡献
- 具体做法:训练一个轻量级探针(问题:似乎不需要重新训练吧,即使训练也没有中间标记的样本啊),利用 RM 的隐藏状态来预测每个 token 对整体奖励分数的边际贡献
- 设生成序列长度为 \( T \),\( \mathcal{R}_{\phi}(x, y_{\leq t}) \) 为奖励模型对前 \( t \) 个 token 的输出分数,定义 token 级别的奖励为:
$$
\tilde{r}_t^{RM} = \mathcal{R}_{\phi}(x, y_{\leq t}) - \mathcal{R}_{\phi}(x, y_{\leq t-1}), \quad \text{for } 0 \leq t \leq T
$$- 其中令 \( \mathcal{R}_{\phi}(x, y_{\leq -1}) = 0 \),则有:
$$
\sum_{t=0}^{T} \tilde{r}_t^{RM} = \mathcal{R}_{\phi}(x, y_{\leq T})
$$- 即所有 token 奖励之和等于原序列的整体奖励
- 其中令 \( \mathcal{R}_{\phi}(x, y_{\leq -1}) = 0 \),则有:
- RED 方法可与 PPO、RLOO 等 RL 算法无缝集成,最终每个 token 的奖励为:
$$
r_t^{\text{final} } = \tilde{r}_t^{RM} - \beta \cdot r_t^{KL}
$$
- 注:不需要额外的 RL 训练(再分配完全是事后进行的)
- RED 提供了一种 surprisingly effective 的 Token-level 信号,相比均匀 credit assignment 能改善 PPO 训练,这表明预训练的奖励模型已经编码了丰富的、未被充分利用的 credit assignment 信息
- RED(Reward Redistribution to Token Level)采用了一种务实的方法:
- T-REG
- T-REG(Token-Level Reward Regularization)在没有任何外部模型的情况下生成 Token-level 奖励信号
- T-REG 使用一种对比性自提示策略:
- 对于一个给定的问题,模型生成正确和不正确的解决方案,然后比较 Token-level 对数概率差异,以识别哪些 token 最具区分性
- 在正确和错误解决方案之间差异最大的 token 获得更高的 credit
- 这种自监督方法非常简洁,不需要奖励模型、critic 或额外的 rollout
Implicit Token-Level Credit,隐式 Token-level Credit
- From \(r\) to \(Q^*\)
- 这项工作为偏好训练模型中的隐式 credit assignment 提供了理论基础
- 文章表明:DPO 隐式地学习了一个 Token-level Q 函数:
- 在训练模型和参考模型之间,每个 token 位置的对数概率比率对应于贝尔曼方程下的 soft Q 值
$$
Q^{*}(s_t, a_t) = \beta \log \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\text{ref} }(a_t | s_t)} + \beta \log Z(s_t)
$$- \(\beta\) 是 DPO 温度参数,\(Z\) 是一个归一化配分函数
- 在训练模型和参考模型之间,每个 token 位置的对数概率比率对应于贝尔曼方程下的 soft Q 值
- 这一 Insight 意味着
- 任何经过偏好训练的 LLM 已经内在地编码了 credit assignment 信息,而提取这种隐式 credit 可能比学习显式的奖励模型更高效
- 注:这个 Insight 的实际意义是深远的:credit assignment 可能是对齐训练的一个“免费”副产品
Segment-Level Methods
- SPO
- SPO(Segment Policy Optimization)在 Token-level 和 Episode-level credit 之间找到了一个实用的中间地带
- SPO 将推理链在“切割点”处划分为语义上有意义的 segments(即按照一些转义 Token 等来划分)
- 这些 Segment 划分边界位置是推理在不同子问题或方法之间过渡的地方(例如,在建立方程和解方程之间)
- 对于每个 segment,SPO 通过比较共享该 segment 之前相同前缀的轨迹的结果来计算 MC 优势
- 这种 segment 级别的粒度自然地与数学推理的结构对齐,其中每个“步骤”是一个连贯的单元,同时避免了 Token-level MC 估计的过高成本
- TEMPO
- TEMPO(Tree-Structured Credit Assignment)将推理的线性链结构推广到树
- 在模型本可以采取不同路径的决策点
- TEMPO 将轨迹分支成一棵树,每个分支代表一个备选延续
- 然后应用分支门控 TD 校正:
- 叶节点(完成的轨迹)上的 MC 估计通过使用 TD 风格的自举在内部节点向上传播
- 这种混合方法结合了叶节点的 MC 无偏性和内部节点的 TD 方差减少
- 注:TEMPO 是无 critic 的
- TEMPO 不需要学习价值函数,而是使用树结构本身来提供多分辨率 credit 信号
- SCAR
- SCAR(Shapley Credit Assignment Rewards)将合作博弈论引入 credit assignment
- SCAR 将推理链视为一个联盟博弈,Shapley Value 的解释见:Math——博弈论-Shapley-Value
- 其中每个 segment 是一个“玩家”,结果奖励是博弈的价值
- 每个 segment 的 credit 是其 Shapley 值
- 即在所有可能的 segments 排序中,其平均边际贡献
- Shapley 值是唯一满足效率(credits 总和等于总奖励)、对称性(平等贡献者获得平等 credit)和虚拟玩家属性(非贡献者获得零 credit)的归因方法
- 主要挑战是计算量:对于 \(n\) 个 segments,精确的 Shapley 值需要评估 \(2^{n}\) 个联盟
- SCAR 使用基于抽样的近似,用精确性换取可处理性
- SCAR 提供了一个理论上严谨的 credit assignment,可以作为评估更便宜的启发式方法的黄金标准参考
Step-Level Methods in Reasoning
- 这些方法将每个“推理步骤”(例如,一行数学推导)视为 credit 的单位
Process Reward Models, PRMs
Background: Math-Shepherd and OmegaPRM
- 过程奖励模型 (PRM) 范式最初是为推理验证引入的,为 Step-level credit assignment 提供了一个自然的框架
- Math-Shepherd (2024) 开创了自动化的 Step-level 标注:对于每个推理步骤,它对多个 continuations 进行采样,如果有足够比例的 continuations 能到达正确答案,则将该步骤标记为“正确”
- OmegaPRM (2024) 使用分治策略扩展了这种方法,该策略有效地探索了可能的延续树
- 这些 PRM 基础为下游 CA 方法构建所依赖的 Step-level 监督提供了基础,并且它们基于 MC 的标注策略直接与经典的回报分解范式相关联
PURE
- 原始论文:(PURE)Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning (ICML 2025)
- PURE 对基于 PRM 的 credit 做出了一个微妙但重要的理论贡献
- 标准 PRM 将 Step-level 价值分配为未来奖励的期望总和:
$$ V(s_{t}) = \mathbb{E}[\sum_{t^{\prime} = t}^{T}r_{t^{\prime} }]$$- 理解:状态价值等于未来奖励的总和的期望
- PURE 认为这种“求和形式”的 credit 容易受到 Reward Hacking 的影响
- 模型可以学习产生“安全”的中间步骤来增加期望总和,而实际上并不对正确性做出贡献
- PURE 提出了最小形式 credit:
$$ V(s_{t}) = \mathbb{E}[\min_{t^{\prime} \geq t} r_{t^{\prime} }]$$- 含义:状态的价值由最差的未来步骤决定
- 问题:比如未来如果有一步会导致得到 0 分,那么前面的状态价值就是 0 分
- 问题:这改变了 RL 最大化未来累计奖励的目标
- 这可以防止模型将错误“隐藏”在高分步骤之后,并提供更稳健的 Step-level credit 信号
- 含义:状态的价值由最差的未来步骤决定
- 理论分析表明,最小形式 credit 能导致更好校准的过程奖励并减少过度优化
SPRO
- 原始论文:(SPRO)Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning, 20250703, Terminus Group & HKUST
- SPRO(Self-Guided Process Reward)引入了一种自监督的 Step-level credit 方法,不需要外部 PRM 或奖励模型
- SPRO 核心机制是掩码步骤优势:
- 在解决方案中,对于每个步骤 \(i\),SPRO 掩码(移除)该步骤并重新评估解决方案达到正确答案的可能性
- 步骤 \(i\) 的 credit 是其移除导致的性能下降:
$$ c_{i} = P(\text{correct}|\text{full solution}) - P(\text{correct}|\text{solution without step } i)$$ - 这种留一法方法提供了对每个步骤必要性的直观衡量
- SPRO 报告称,与标准 GRPO 相比,训练效率提高了 \(3.4 \times\),表明即使是简单的自监督 credit 信号也能极大地加速学习
FinePO
- FinePO (2026) 是用于图表理解的 SketchVL 框架的一部分
- FinePO 证明了 PRM 范式可以在特定领域设置中被推到子步骤粒度
- 在一个视觉推理流程中,FinePO 对每个推理步骤中 的单个操作 进行评分,提供了比标准 Step-level PRM 更精细的 credit 信号
- FinePO 是为特定领域(图表和图示理解,而非一般数学推理)开发的,但其 credit assignment 机制(将 Step-level 奖励分解为子步骤贡献 )说明了一个可能推广到其他推理步骤具有内部结构的设置的方向
PRL
- PRL(Process Reward Learning, 2026)在过程奖励与最优策略的结构之间提供了一个理论上优雅的联系
- PRL 从熵正则化 RL 目标的分解中推导出 Step-level 过程奖励,表明在熵正则化最优策略下,每个步骤的最优过程奖励等于优势函数
- 这种理论依据意味着 PRL 的 credit 信号不是启发式的,而是在特定假设下被证明是最优的,为 Step-level credit assignment 提供了一个有原则的基础
InT
- InT(自我提出干预,Self-Proposed Interventions, 2026)在推理 credit assignment 中采用了一种独特的方法:
- 模型自己提出干预:
- 对特定推理步骤的反事实修改,并评估这些干预是否会改变结果
- 给分:
- 那些改变结果的步骤获得高 credit
- 那些无关紧要的步骤获得低 credit
- 理解:这里指的 Credit 不是奖励,而是造成当前结果的影响权重(所以 高 credit 不意味着高 Reward,也可能是更置信的 低 Reward 结果)
- 这种自我提出的干预机制提供了一种有原则的、模型内在的步骤重要性度量,无需外部奖励模型
- 模型自己提出干预:
Attribution-Based and Curriculum Methods,基于归因和课程的方法
ACPO
- ACPO(Attribution-based Credit for RLVR,2025)将 credit assignment 与课程学习相结合
- ACPO 使用归因方法(例如,基于梯度的显著性)计算分解的层次化奖励,将结果奖励分解为步骤贡献,然后使用这些 Step-level 信号构建一个难度感知的训练课程
- credit 集中在少数步骤上(清晰的分叉点)的问题在训练早期被优先考虑,而 credit 分散的问题(许多步骤贡献相等)在后期引入
- credit assignment 和数据选择之间的这种协同作用体现了一个更广泛的趋势:
- CA 不仅仅是关于奖励再分配,而是关于使整个训练流程更高效
LLM-as-Critic for Reasoning
CAPO
- CAPO(Credit Assignment Policy Optimization, 2025)利用了 LLM 设置中独有的能力:
- 模型可以作为自己的 critic
- CAPO 使用 LLM 作为生成式 PRM (GenPRM)
- 给定一个推理轨迹,同一个 LLM(或其 Prompted 版本)会生成对每个步骤的自然语言批判,评估其正确性、相关性和对最终答案的贡献
- 这些批判被转换为标量的 Step-level 奖励,用于驱动策略优化
- 主要优势是自包含:
- 不需要单独的奖励模型、critic 网络或 MC rollouts
- 主要风险是:
- 自我评估偏差(模型可能系统地高估自己的步骤)
- 注:CAPO 通过校准技术来缓解这一点
Hierarchy-Aware Methods in Reasoning
HICRA
- HICRA(层次感知 Credit Assignment,2025)研究了 RL 如何在 LLM 中发展层次化推理
- HICRA 识别出一个两阶段的学习动态:
- 模型首先获得 procedural 技能(常规计算),然后发展出 Strategic Planning(高层次的问题分解)
- HICRA 建议将 credit 集中在高影响力的规划 token 上,而不是均匀地分布学习信号,表明这种层次感知的方法显著优于平坦的 credit assignment
- HICRA 是在 Reasoning RL 背景下开发的,但其 Insight 与 Agentic Setting 高度相关(见第 5.4 节),Agentic Setting 中战略决策和常规执行之间的区别甚至更为明显
- Insight 内容:Token 的不同功能角色(planning vs. procedural)应该得到不同的 credit 处理
Discussion: The State of Credit Assignment in Reasoning RL
- 本节回顾的方法揭示了一个成熟的格局,具有清晰的权衡:
- Token-level 方法(VinePPO,RED,T-REG)提供了最精细的 credit 粒度,但面临计算挑战
- VinePPO 的 MC 方法在理论上严谨但代价高昂
- RED 和 T-REG 提供了更便宜的替代方案,但代价是信用信号的严谨性较低
- Segment/ Step-level 方法代表了当前的主流
- PRM(PURE,SPRO)和层次感知方法(HICRA)在 credit 质量和计算成本之间提供了实用的平衡
- FinePO (2026) 这样的特定领域扩展表明,在结构化领域中,子步骤粒度是可行的
- LLM 作为 Critic 范式(CAPO)正在成为一种独特的、LLM 原生的方法,在经典 RL 中没有直接的类似物
- Token-level 方法(VinePPO,RED,T-REG)提供了最精细的 credit 粒度,但面临计算挑战
- 一个关键的观察是,所有 Reasoning RL credit assignment 方法都隐式地依赖于三个假设:
- 1)确定性转移 :从前缀生成下一个 token 总是产生相同的状态,这使得廉价的 MC 估计成为可能
- 否则随机性比较高的 Setting ,方差较大,需要采样更多的样本才能做较为准确的 MC 估计
- 2)单次生成轨迹 :整个轨迹是一次自回归生成,没有环境交互
- 3)可验证的结果 :最终答案(以及通常的中间步骤)可以根据 ground truth 进行检查
- 1)确定性转移 :从前缀生成下一个 token 总是产生相同的状态,这使得廉价的 MC 估计成为可能
- 当这些假设中的任何一个被违反时(就像在 Agentic RL 中那样),上述方法就会面临根本性的限制:
- VinePPO 的藤蔓扩展需要重新执行环境交互
- PRM 需要步骤级验证,但 Agentic 任务很少能提供这种验证
- 理解:更多是需要最后才知道是否成功
- Reasoning RL 中 credit assignment 的成功提出了一个自然的问题:
- 问题:当 LLM 与现实环境交互时,同样的方法能否工作?
- 回答:回答基本上是否定的,Agentic RL 引入了质的不同挑战,需要不同的方法
Why Agentic RL Fundamentally Reshapes Credit Assignment,Agentic RL 重塑 Credit Assignment
- 本节回答是什么使得 Agentic RL 中的 credit assignment 与 Reasoning RL 有质的不同
Challenge 1: Stochastic Environment Transitions
- 在 Reasoning RL 中,转移函数是确定性的:
- 给定一个前缀 \((x,y_{1},\ldots ,y_{t - 1})\),生成 token \(y_{t}\) 后的下一个状态就是 \((x,y_{1},\ldots ,y_{t})\)
- 这种确定性是 credit assignment 的强大推动因素
- 像 VinePPO (2025) 这样的方法可以通过从任何前缀分叉多条延续来廉价地估计 \(V(s_{t})\),因为知道“环境”(LLM 自身的生成)是完全可控和确定性的
- 在 Agentic RL 中,这个假设从根本上被打破了
- 在 Agent 发出一个动作(例如,工具调用、网络请求、代码执行命令)后,环境的响应是随机的:
- API 调用可能失败、超时或返回限流响应
- 自上次访问以来,网页可能已经更改,或者由于 A/B 测试而加载不同
- 代码执行可能产生非确定性输出(例如,浮点变化、竞态条件)
- 在对话设置中,用户的响应本质上是不可预测的
- 在 Agent 发出一个动作(例如,工具调用、网络请求、代码执行命令)后,环境的响应是随机的:
- 这种随机性对 credit assignment 有直接的影响
- 基于 MC 的方法需要从中间状态重新执行环境交互,这通常是昂贵的(需要沙盒环境)或不可能的(环境状态可能无法被 checkpoint)
- 个人补充:随机也会导致方差变大,从而需要采样更多样本用于 MC 估计才合适?
- 基于 TD 的方法必须应对 TD 误差中更高的方差
$$ \delta_{t} = r_{t} + \gamma V(s_{t + 1}) - V(s_{t})$$- 因为 \(s_{t + 1}\) 现在是一个随机变量
- 基于 MC 的方法需要从中间状态重新执行环境交互,这通常是昂贵的(需要沙盒环境)或不可能的(环境状态可能无法被 checkpoint)
- 这就是为什么 Agentic CA 方法越来越青睐事后分析(hindsight)方法 (2026)
- 在收集完轨迹后进行分析,而不是需要反事实重新执行
Challenge 2: Partial Observability,部分可观测性
- Reasoning RL 在一个完全可观测的 MDP 中运行:
- 状态(提示 + 到目前为止生成的 token)对模型是完全可见的
- Agentic RL 本质上是一个部分可观测的 MDP (POMDP)
- Agent 通过一个通常是损失性的文本观测函数 \(o_{t} = \mathcal{O}(s_{t})\) 来感知环境:
- 数据库的完整状态是不可见的(Agent 只看到查询结果)
- 文件系统内容只能通过显式的
ls或cat命令来观测 - 在多 Agent 设置中,其他 Agent 的内部状态和推理是隐藏的
- 网页状态包括不可见元素(JavaScript 状态、会话数据、服务器端逻辑)
- Agent 通过一个通常是损失性的文本观测函数 \(o_{t} = \mathcal{O}(s_{t})\) 来感知环境:
- 部分可观测性从根本上使 credit assignment 复杂化,因为它在决策质量和信息可用性之间引入了模糊性
- 一个事后看来“糟糕”的动作(例如,调用了错误的 API)可能基于 Agent 当时的信息是最优的
- 一个正确的 credit assignment 系统必须区分:
- 1)决策错误 :Agent 拥有足够的信息但做出了糟糕的选择
- 2)信息差距 :Agent 缺乏关键信息,并且没有可用的行动可以弥补这一差距
- 3)探索性动作 :Agent 正确地选择了收集信息,即使即时的结果是负面的
- 大多数当前的 CA 方法没有明确地处理这种区分,而是根据结果而不是相对于可用信息的决策质量来分配 credit
- 解决这个差距是一个重要的开放问题(见第 9 节)
Challenge 3: Vastly Longer Horizons,更长的视野
- Reasoning RL 和 Agentic RL 之间在轨迹长度上的定量差异是巨大的:
- 表 2:推理和 Agentic RL 设置中的轨迹复杂性
- Agentic 任务涉及更多的 turns、tokens 和决策点,为 credit assignment 带来了质的变化
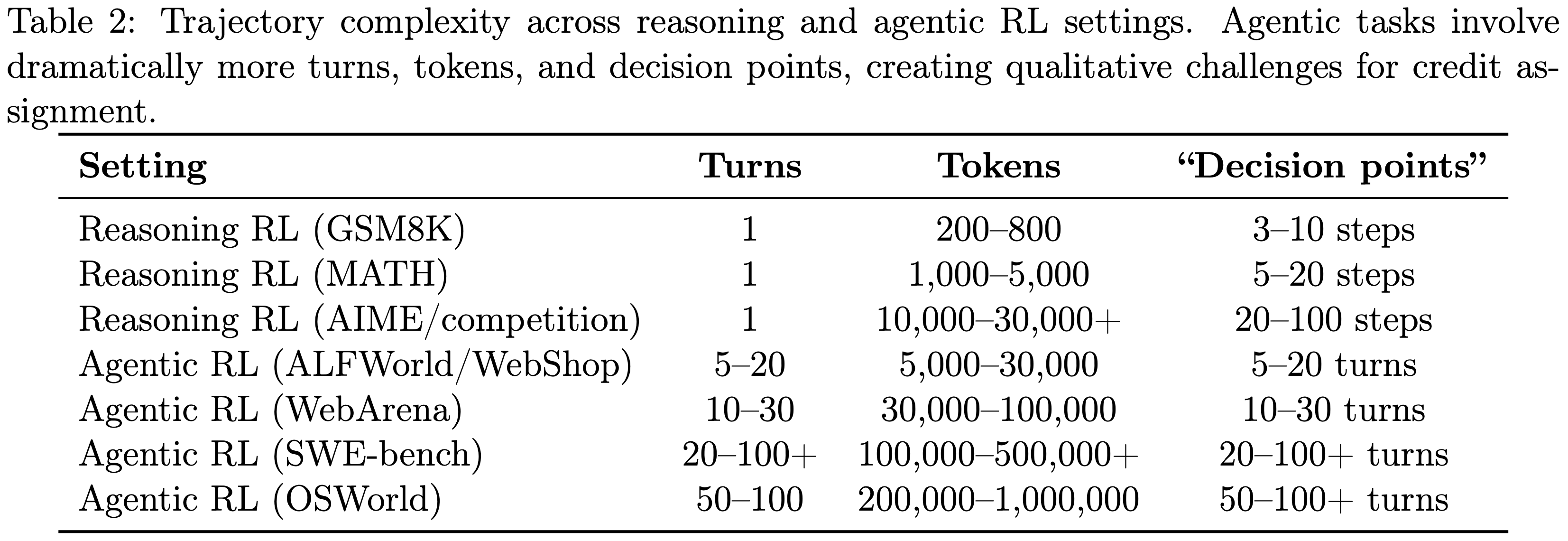
- Agentic 任务涉及更多的 turns、tokens 和决策点,为 credit assignment 带来了质的变化
- 这不仅仅是一个数量上的差异:这为 credit assignment 创造了一个质的障碍
- 具有常数基线的 REINFORCE 估计器的方差缩放为
$$ \mathcal{O}(T\cdot \text{Var}[R]) $$- \(T\) 是决策点的数量
- 从 \(T = 10\)(简单推理)到 \(T = 100\)(复杂 Agentic,例如 SWE-bench)会使梯度方差增加 \(10 \times\),需要成比例更多的 rollouts 才能达到相同的梯度质量
- 在实践中,这表现为训练不稳定、 Reward Hacking 和 Echo Trap (2025d),即 Agent 收敛到重复的安全行为
- 具有常数基线的 REINFORCE 估计器的方差缩放为
- 此外,长视野创造了一个时间距离问题:
- 早期决策(例如,在第 1 轮选择问题解决策略)的影响在许多轮之后才会显现
- 动作和结果之间的因果链变得越来越间接,使得 MC 和 TD 方法都效率降低
Challenge 4: Heterogeneous Action Types,异构动作类型
- 在 Reasoning RL 中,动作是同质的:
- 每个动作都是“生成下一个 token”或“产生下一个推理步骤”
- 动作的 credit 分布相对均匀(每个步骤都对解决方案做出增量贡献)
- Agentic RL 引入了根本性的动作异质性,在单个轨迹中,一个 Agent 可能执行:
- 规划动作 :制定高层次策略(“我应该先搜索 API 文档,然后编写测试,然后实现函数”)
- 工具选择 :选择调用哪个工具(搜索 vs. 计算器 vs. 代码执行)
- 工具参数化 :决定如何调用工具(搜索什么查询,运行什么代码)
- 通信 :向用户或其他 Agent 发送消息
- 错误恢复 :检测失败并决定如何重试或转向
- 记录性动作 :格式化输出、更新内部状态、记录进度
- 这些动作类型具有截然不同的“credit 分布”
- 在关键时刻选错工具可能是灾难性的(导致完全错误的解决路径),而次优的输出格式则是微不足道的
- 注:之前的 Episode-level credit 对两者赋予相同的权重
- 这种异质性催生了一些新的方法:
- CARL (2025) 这样的方法,使用动作熵 来识别高影响力的决策点并将 credit 集中于此
- HICRA (2025c),它在推理设置中区分了“Planning tokens”和“Procedural tokens”
- 在关键时刻选错工具可能是灾难性的(导致完全错误的解决路径),而次优的输出格式则是微不足道的
Challenge 5: Non-Verifiable Intermediate States,不可验证的中间状态
- Reasoning RL 中 credit assignment 的一个关键推动因素是步骤级别的可验证性
- 在数学推理中,每个中间步骤通常可以被检查:
- “这个代数操作正确吗?”
- “这个方程是从前一个推导出来的吗?”这种可验证性支撑着整个过程奖励模型 (PRM) 范式 (2024;2024;2025),
- 步骤级别的标签 \((+ / - )\) 为 credit assignment 提供了密集的监督
- 在数学推理中,每个中间步骤通常可以被检查:
- 在 Agentic RL 中,中间验证几乎是不可能的:
- 工具调用 :“search(‘Python web scraping’)” 是一个好动作吗?这完全取决于搜索返回什么,这在执行前是未知的
- 代码生成 :生成的代码正确吗?只有在执行后才能验证,即使那样,部分正确性也难以量化
- 导航 :点击链接 X 是否有效?取决于它指向哪里
- 通信 :“向用户寻求澄清”有帮助吗?主观且依赖于上下文
- 缺乏中间可验证性意味着在 Reasoning RL 中最成熟的 PRM 风格方法无法直接迁移到 Agentic 设置
- 这种差距推动了替代方法的发展:
- 基于事后分析的 credit (2026)(在结果出现后评估动作)、通过 DPO 的隐式 credit (2025)(完全避免显式的步骤级评估)以及特权 critic (2025)(使用仅在训练时可用的信息来提供步骤级信号)
- 这种差距推动了替代方法的发展:
- 个人理解:这里的挑战其实两者都有,且 Agentic 中也有类似可以验证的中间步骤,比如最经典的问题 “带领阿根廷获的 2022 年世界杯冠军的队长,其出生年份中国的 GDP 是多少?”
- 中间奖励可以是:是否定位到这个队长是梅西;是否定位到 1987
Challenge 6: The Bifurcation Point Problem,分叉点问题
- Reasoning RL 中,分叉点是中等频率的(Moderate frequency)
- Agentic RL 中,分叉点是稀有的,但往往是决定性的(Rare but decisive)
- 将分叉点 定义为一个状态,其中 Agent 的动作对轨迹结果产生超大的影响
- 一个“道路的岔路口”,不同的选择会导致截然不同的结果
- 在 Agentic RL 中,分叉点具有独特的特征:
- 稀有性 :Agentic 轨迹中的大多数动作都是“常规的”
- 遵循明显的后续步骤、格式化输出、进行标准的 API 调用
- CARL (2025) 中的实证分析表明,分叉点可能只发生在决策点的一小部分
- 决定性 :尽管稀有,但分叉点可能占结果方差的绝大部分
- 选择正确的调试策略、为任务选择正确的工具或制定有效的搜索查询,通常是区分成功与失败的动作
- 非显而易见性 :分叉点通常无法提前识别
- 分叉点的重要性只有在事后回顾轨迹如何展开时才变得清晰
- 稀有性 :Agentic 轨迹中的大多数动作都是“常规的”
- Episode-level credit (GRPO) 对分叉点是盲目的:
- GRPO 对关键的工具选择和琐碎的格式化动作赋予相同的 credit
- 这激发了两种互补的策略:
- (1) 识别分叉点并将 credit 集中于此
- CARL (2025) 使用动作熵作为代理
- HICRA (2025c) 区分 Planning 动作和 Procedural 动作
- (2) 事后评估分叉点
- HCAPO (2026) 使用事后分析
- C3 (2026) 使用反事实比较
- (1) 识别分叉点并将 credit 集中于此
Summary: The Agentic Credit Assignment Gap,Agentic Credit Assignment 差距
- 表 3:Credit assignment 挑战: Reasoning RL vs. Agentic RL

- 理解:
- 中间状态验证(Intermediate verification)部分,其实部分场景的 Agentic RL,如 Search Agent 中也可以通过只是图谱等方式拆解出来一些中间验证步骤
- 分叉点(Bifurcation points)部分,Reasoning RL 中应该也有,但是不清晰(比如类似 But,So 等连词)
Credit Assignment in Agentic RL
- 本节总结专门为 Agentic RL 设计或适用于 Agentic RL 的方法,其中多轮环境交互是核心
- Agentic RL 方法总结:

Turn-Level Process Reward Models
AgentPRM
- AgentPRM (2025) 通过用 \(TD + GAE\) 值的估计取代基于 MC 的步骤标记(labeling),将 PRM 范式从推理适应到 Agentic 设置
- AgentPRM 的关键洞察在于,MC 标记在 Agentic 设置中代价非常高
- 因为它需要重新执行环境交互(启动沙盒环境、发起真实 API 调用等)
- 注:这里 MC 标记指的是从每个步骤采样 continuations 以估计步骤正确性
- AgentPRM 使用时序差分学习来训练一个步骤级 Critic:
$$ V(s_t) \leftarrow V(s_t) + \alpha [r_t + \gamma V(s_{t + 1}) - V(s_t)]$$- 并使用 GAE 进行优势估计
- AgentPRM 应用于工具使用、代码生成和网页导航任务,AgentPRM 报告称与基于 MC 的 PRM 训练相比,样本效率提高了 \(8 \times\)
- 这项工作表明,当环境重执行代价高昂时,TD 范式(尽管通过 bootstrapping 引入了偏差)在实践中是必需的
SWEET-RL
- SWEET-RL(Meta/FAIR,2025)引入了特权(非对称)Critic 的概念,用于多轮 LLM Agent 训练
- 特权 Critic:Privileged Critic
- SWEET-RL 的核心思想利用了训练/推理的不对称性:
- 在训练时,可以访问 Agent 在推理时没有的信息
- 信息包括:ground truth 答案、完整的未来轨迹,以及可能的环境状态变量
- SWEET-RL 训练一个以这些特权信息为条件的 Critic,以提供高质量的 Turn-level 奖励信号,然后这些信号被用于 Actor 的 DPO 风格优化(Actor 仅能看到标准观测)
- 这种方法巧妙地规避了不可验证性的挑战(第 4.5 节):
- 即使中间状态无法从 Agent 的视角进行验证,特权 Critic 也可以使用仅在训练时可用的信息来评估它们
- 非对称设计确保了:
- Actor 的策略针对实际的(部分可观测)Setting 进行优化(所以训练完不需要 Privileged 信息就能使用)
- credit 信号则受益于训练期间可用的完整信息
Turn-Level Reward Design
- Turn-Level Reward Design (NeurIPS 2025)提出了一种混合奖励设计,将奖励类型与动作类型相匹配
- 对于输出可验证的轮次(例如,代码执行结果、数据库查询输出、数学计算),Turn-Level Reward Design 使用自动验证来提供精确的 Turn-level 奖励
- 对于输出主观或难以验证的轮次(例如,规划、信息综合、通信),Turn-Level Reward Design 采用 LLM-as-Judge 来提供近似的 Turn-level 分数
- Turn-Level Reward Design 框架将多轮 Agent 训练形式化为一个具有异构奖励源的 MDP
- 结果表名:这种混合方法显著优于纯基于验证的和纯基于 LLM-judge 的奖励 ,因为每种奖励类型都应用在它 Most Reliable 地方
Turn-PPO
- Turn-PPO(2025 & EACL 2026)将多轮 Agent RL 重新表述为一个 Turn-level MDP
- 其中每一轮(完整的 LLM 响应 + 环境反馈)被视为单个宏动作
- 在这个表述下,Turn-PPO 使用 Turn-level 值函数计算 Turn-level 优势估计,用 Turn-level 重要性比率取代了标准的 Token-level 重要性采样
- 这种重新表述消除了在多轮间由 Token-level credit 引入的巨大方差
- 在 WebShop 和 Sokoban 上的评估表明
- Turn-PPO 比标准 PPO 具有更好的稳定性和最终性能,证实了轮次是多轮 Agent credit 的自然原子单元
SORL
- SORL(Stabilizing Off-Policy RL for Long-Horizon Agent Training,2025)解决了多轮 Agent RL 中由两个来源引起的不稳定性:
- (1) Token-level 优化与轮次结构化交互之间的粒度不匹配
- (2) 来自 off-policy 采样的高方差梯度更新
- SORL 提出了 Turn-level 重要性采样结合裁剪触发归一化,以两种算法实例化(SO-PPO 和 SO-GRPO),使策略优化与多轮交互的结构对齐,并自适应地抑制不可靠的 off-policy 更新
- 在多轮搜索基准上的评估表明,SORL 为 “为什么 Turn-level CA 需要专门构建的优化算法而不是简单地应用标准 PPO 或 GRPO” 提供了理论基础
TARL
- TARL(Turn-level Adjudicated Reinforcement Learning,Turn-level 裁决 RL, 2025)为交互式多模态工具使用 Agent 提出了一个过程监督的 RL 框架
- TARL 核心机制采用 LLM as a Judge 在训练期间提供 Turn-level 评估,解决了长时域 Agentic 任务中的 credit 分配挑战
- 实验:结合一个混合任务训练课程(该课程整合了数学推理问题),TARL 报告称:
- 在 \(\tau\)-bench 基准测试上,与强 RL 基线相比,任务通过率提高了 \(6% +\),证明了 Turn-level 过程监督对多模态 Agent 的价值
ITPO
- 原始论文:(ITPO)Implicit Turn-Wise Policy Optimization for Proactive User-LLM Interaction, Meta AI, 20260321
- ITPO(Implicit Turn-Level Process Rewards,隐式 Turn-level 过程奖励,202603)从稀疏的结果信号中推导出隐式 Turn-level 过程奖励,无需训练单独奖励模型
- 基于 “From \(r\) to \(Q^{*}\)” 的洞察 (2024),ITPO 从模型自身在各轮次间的对数概率变化中提取 Turn-level 奖励,将策略本身视为一个隐式 Critic
- 实验:应用于主动式多轮交互设置(辅导、推荐),ITPO 表明:
- 隐式 Turn-level credit 与显式训练的 Turn-level Critic 相比具有竞争力,而计算成本仅为其一小部分
Hindsight and Counterfactual Methods,事后和反事实方法
- 这些方法利用了事后分析的一个关键优势:轨迹完成后,可以回溯并思考哪些因素是重要的
HCAPO
- HCAPO(Hindsight Credit Assignment for Policy Optimization,用于策略优化的事后 Credit 分配,202603)通过回顾性分析直接解决了 Agentic RL 的不可验证性挑战
- 在收集到一条轨迹后,HCAPO 使用一个 LLM Critic,在知晓完整轨迹结果的情况下 评估每一轮的贡献
- 该 Critic 执行生成式验证:
- 对于每一轮 \(t\),它生成反事实的 continuations(“如果这一轮的动作不同了会发生什么?”)并比较预期的结果
- 这种事后方法对于 Agentic RL 尤其强大,因为它不需要环境重执行(反事实分析完全在 LLM 的“想象”中执行)
- 关键 Insight:事后 credit 比前向 credit 提供更多信息:
- 知道结果使得 Critic 能够区分偶然成功的动作(尽管次优但碰巧有效)和真正好的动作(有决定性因果关系地促成了成功)
- 该 Critic 执行生成式验证:
C3
- C3(Contextual Counterfactual Credit Assignment,上下文反事实 Credit 分配,202603)
- 通过一个留一法框架形式化了 credit 分配
- 对于一条有 \(T\) 轮的轨迹,轮次 \(t\) 的 credit 被估计为实际结果与将轮次 \(t\) 的动作替换为“默认”动作后期望结果之间的差值:
$$ c_{t} = R(\tau) - R(\tau_{t})$$- 其中 \(\tau_{t}\) 表示反事实轨迹
- 由于为每个反事实重新执行环境代价高昂,C3 使用基于模型的近似:
- 一个 LLM 通过推理 “如果没有轮次 \(t\) 的特定动作轨迹将如何展开” 来估计 \(R(\tau_{t})\)
- C3 最初为多 Agent LLM 协作开发,其框架自然扩展到将轮次视为合作博弈中“玩家”的单 Agent 设置
CCPO
- CCPO(Counterfactual Credit Policy Optimization,反事实 Credit 策略优化,202603)为 Agentic credit 分配提供了一个正式的结构因果模型视角
- CCPO 将轨迹建模为一个结构因果模型(SCM),其中每一轮的动作是处理变量,结果是效应
- Turn-level credit 则是每个动作的平均处理效应(ATE),通过 do-演算(do-calculus)或实际近似来估计
- CCPO 的形式化框架在特定的因果假设下(轨迹内没有未观测的混杂因素,当完整对话历史可用时这是合理的)提供了 credit 准确性的理论保证
- 原文讨论:在 2026 年 3 月的一周内同时出现三篇独立的事后/反事实论文(HCAPO, C3, CCPO)是社区趋同的一个显著信号:
- 该领域已共同将回顾性反事实分析确定为 Agentic credit 分配的自然范式
CriticSearch
- CriticSearch(2025)将回顾性 credit 分配专门应用于搜索 Agent
- 即发出搜索查询、处理结果并迭代优化其答案的 LLM
- 冻结的、非对称的 critique LLM 使用特权信息(完整轨迹和 golden 答案)回顾性地评估每个搜索轮次,将这些评估转换为密集的、 Turn-level 奖励
- 这与 SWEET-RL 的特权 Critic 设计(第 5.1 节)密切相关,但专门针对每个轮次涉及独特查询-结果周期的搜索领域
- CriticSearch 报告称,在多跳推理基准测试上提高了收敛速度和稳定性,证明了回顾性 Critic 即使在以信息检索为中心的 Agent 任务中也是有效的
Critic-Free Step-Level Methods
GiGPO
- GiGPO(组中组策略优化,NeurIPS 2025)以一种优雅的、无需 Critic 的方式,将 GRPO 的组比较原则从 Episode-level 扩展到了步级
- GiGPO 引入了一个两层的优势估计:
- 在外层,轨迹像标准 GRPO 一样被分组和比较
- 在内层,单条轨迹内的步骤通过锚定状态分组进行比较
- 共享相似前缀(锚定状态)的步骤被分到同一组,每个步骤的优势相对于其组均值计算
- 这种“组中组”结构在不需学习值函数的情况下提供了步级 credit
- 在 Agentic 基准测试(ALFWorld, WebShop)上的评估表明,GiGPO 相比 GRPO 分别取得了超过 12% 和 9% 的提升,证实了无需 Critic 的步级 credit 能够显著改善多轮 Agent 训练
POAD
- POAD(Policy Optimization with Action Decomposition,带动作分解的策略优化,2024)解决了 Agentic RL 中一个细微的问题:
- 动作级和 Token-level 优化之间的差异
- 在 Agentic Setting 中,每个“动作”(例如,一个工具调用或响应)是一个可变长度的 Token 序列,然而标准 RL 将其视为原子操作
- 动作级和 Token-level 优化之间的差异
- POAD 推导了带动作分解的 Bellman Backup,它将 credit 分配在两个层面上进行整合:
- 动作内部(将 credit 分配到单个动作内的各个 Token)
- 动作之间(将 credit 分配到序列化的动作之间)
- 这种分解在 PPO 内部实现,增强了学习效率和泛化能力
- POAD 是早期(2024 年 5 月)形式化 LLM Agent 的动作到 Token credit 分解问题的方法之一,值得关注
Hierarchical Methods
- Agentic 任务具有自然的层级结构(计划 \(\rightarrow\) 执行 \(\rightarrow\) 验证),这些方法利用了这一结构
ArCHer
- ArCHer(ICML 2024)是用于多轮 LLM Agent 的层级 credit 分配的开创性工作
- ArCher 引入了一个明确的两层架构:
- 一个高层的 off-policy Critic,学习一个 Turn-level Q-函数
$$ Q^{H}(s_{t},a_{t})$$- 其中 \(a_{t}\) 是第 \(t\) 轮的完整 LLM 响应
- 一个低层的 on-policy Actor,它优化每一轮内的 Token-level 策略
$$\pi_{\theta}(y|s_{t})$$- 高层 Critic 通过 off-policy TD 更新进行训练,能够从过往轨迹的回放缓冲区中高效学习
- 低层 Actor 使用高层 Q-值作为 Turn-level 奖励进行 on-policy 优化
- 这种解耦架构直接解决了双重层级的 credit 分配挑战:
- 高层 Critic 处理哪些轮次是重要的,而低层 Actor 处理这些轮次中的哪些 Token 是重要的
- ArCHer 是第一个正式认识到多轮 LLM RL 需要与单轮 Reasoning RL 根本不同的 credit 分配的方法
- 一个高层的 off-policy Critic,学习一个 Turn-level Q-函数
- 注:在第 3 节中回顾的 HICRA (2025c),为层级感知的 credit 分配提供了 Reasoning RL 的基础,这直接为本节的 Agentic 方法提供了信息
- 其对 Planning Token 和 Procedural Token 的区分为理解 Agentic 轨迹中的功能角色提供了概念基础
PilotRL
- PilotRL (Global Planning-Guided Progressive RL, 2025) 将分层原则扩展为一个三阶段渐进式框架:
- (1) plan-level RL,即 credit 被分配给高层级的 plan 组件
- (2) step-level RL,即 credit 在每个 plan 组件内部进行细化
- (3) token-level RL,即 credit 进一步级联到单个 Token
- credit 在各个阶段之间从粗粒度流向细粒度,每个阶段为下一阶段提供 reward 信号
- 这种级联方法专为在执行任务前明确制定 plan 的 Agent 而设计(例如:“步骤 1:搜索相关文件;步骤 2:理解代码库;步骤 3:实现修复”)
CARL
- CARL (NeurIPS 2025) 针对异构动作问题(第 4.4 节)提出了一种非常简洁的解决方案
- CARL 与为每个动作分配细粒度 credit 不同,CARL 识别出关键动作(即 Agent 的决策对结果产生巨大影响的分叉点)
- 并仅在这些点上进行 RL 更新
- 其识别机制基于动作熵:
- 在每个决策点,CARL 测量策略动作分布的熵 ( H(\pi(\cdot|s_t)) )
- 高熵状态是“关键的”(模型不确定,因此选择很重要)
- 低熵状态是“常规的”(模型很确信,因此任何一个合理动作都足够)
- 在每个决策点,CARL 测量策略动作分布的熵 ( H(\pi(\cdot|s_t)) )
- 通过将梯度更新限制在熵最高的少数动作上,CARL 实现了减少 72% 的梯度更新且性能无下降(如作者所述)
- 这一结果表明,绝大多数 Agentic 动作可能具有可忽略的 credit,优化它们会浪费计算资源
Information-Theoretic Methods
- IGPO(信息增益策略优化,Information Gain Policy Optimization, 2025)采用信息论的方法进行 Turn 级信用分配
- 对于每个 Turn \( t \),IGPO 将信用定义为关于任务成功的信息增益:
$$c_t = \log P(\text{success}|h_{1:t}) - \log P(\text{success}|h_{1:t-1}) \quad (4)$$- \( h_{1:t} \) 表示到 Turn \( t \) 为止的历史
- 直觉解释:如果一个 Turn 能够显著提高任务成功的概率(即它提供了朝向目标的“有用信息”),那么它就会获得高信用
- 这种公式化方法天然适用于 Agentic 环境,其中每个 Turn 都会逐步揭示关于任务状态的信息(例如,一个搜索查询揭示了相关文档,一次代码执行揭示了 Bug)
- 概率 \( P(\text{success}|h) \) 由一个学习到的验证器或 LLM 本身来估计
- 对于每个 Turn \( t \),IGPO 将信用定义为关于任务成功的信息增益:
- IGPO 的主要局限性:
- 它要求在每个 Turn 都有一个可靠的 Success 概率估计器 ,而这对于所有 Agentic 任务来说可能并不都可用
Implicit and DPO-Based Methods
- iStar(Implicit Step Rewards, 2025)解决了在不存在中间验证器的 Agentic 环境中提供 Step-level 信用的挑战
- iStar 利用轨迹级的 DPO:
- 给定成对的轨迹(一条成功,一条不成功),iStar 通过比较每个 Turn 的对数概率比来提取隐式的 Step-level Reward
- 基于 “From \( r \) to \( Q^* \)” 的 Insight (2024)
- Turn \( t \) 的隐式 Advantage 是从模型自身的概率评估中推导出来的
- iStar 进一步引入了多级 Advantage 融合,通过加权聚合的方式结合了 Turn 级和 Token 级的隐式信号
- iStar 主要优势在于 iStar 不需要显式的 Reward 模型、Critic 或环境重执行,使其适用于所有其他信用分配机制都过于昂贵的 Agentic 任务
StepAgent
- StepAgent (2024) 将隐式 RL 与逆强化学习(Inverse RL)相结合,用于 Agentic 环境中的 Step-level 反馈
- 给定专家演示(成功的轨迹),它使用逆强化学习来推断专家隐式优化的 Step-level Reward ,然后使用这些推断出的 Reward 来训练 Agent
- 随着 Agent Step-level 表现的提高,一个从新手到专家的课程逐渐增加任务的难度
- 这种方法特别适用于那些有专家演示可用(例如,记录的人类与工具或网站的交互)但显式 Reward 函数难以定义的 Agentic 任务
Infrastructure and Practical Methods
Agent Lightning
- Agent Lightning(Microsoft Research)为基于 RL 的 LLM Agent 训练引入了一种解耦的训练架构
- Agent Lightning 的核心贡献是 LightningRL 算法
- LightningRL 算法将 Agent 轨迹分解为带有专用信用分配模块的训练 Transition
- Agent Lightning 框架将 Agent 执行与训练完全解耦,支持与流行的 Agent 框架(LangChain, AutoGen)集成,而无需修改 Agent 的推理代码
- 在 Text-to-SQL、检索增强生成和数学工具使用任务上的评估表明
- 将“信用分配到哪里”的问题与“如何生成轨迹”的问题分离开 可能与信用分配算法本身同样重要
- 问题:如何理解这里这句话?
RAGEN/StarPO
- RAGEN(2025) 引入了 StarPO(Star 策略优化,Star Policy Optimization)框架来训练推理 Agent,并提供了关于为何 Episode-level 信用在 Agentic 环境中会失败的最详细的实证分析之一
- RAGEN 核心贡献是识别出了“回声陷阱”(echo trap):
- 当使用 GRPO 训练时,Agent 会收敛到重复的 Action 序列(例如,使用相同参数反复调用同一个工具),因为嘈杂的 Episode-level 梯度无法区分高效的探索与冗余的重复
- StarPO 通过基于不确定性的过滤来解决这个问题:
- 在其信用估计中具有高不确定性的 Action 在策略更新期间会被降低权重,从而防止噪声信号破坏训练的稳定性
- RAGEN 还提供了开源的基准测试和训练框架,后续几个 Agentic CA 论文都基于此构建
SPA-RL
- SPA-RL(Stepwise 进度归因,Stepwise Progress Attribution, 2025)训练一个轻量级的 MLP 进度估计器,它将中间状态映射到一个标量的“进度”分数
$$ p_t \in [0, 1] $$ - 然后 Step-level 信用就是进度增量:
$$ c_t = p_t - p_{t-1} $$ - 这种方法受到 RUDDER 的 Return 分解 (2019) 的启发,但针对 LLM Agent 进行了调整
- MLP 与策略一起进行端到端训练,终端 Reward 提供监督信号 \( (p_T = R(\tau)) \)
- SPA-RL 的主要优势是极高的计算效率:
- 与 LLM-as-Critic 方法相比,一个小型 MLP 增加的开销可以忽略不计,使其适用于大规模训练,在这种训练中每一次浮点运算都很宝贵
SCRIBE
- SCRIBE(2026)通过结构化的中级监督(structured mid-level supervision)来提供信用
- SCRIBE 维护一个“技能原型”(skill prototypes)库
- 常见 Agentic 子任务(例如,“搜索并提取信息”、“编写和测试代码”、“格式化并提交输出”)的模板,每个模板都关联着预期的 Reward 特征
- 当 Agent 执行一个 Action 时,SCRIBE 将其与最近的技能原型进行匹配,并根据该 Action 在多大程度上满足原型的预期行为来分配信用
- 这种方法在单个 Token 和完整轨迹之间的语义层级上提供信用,将信用信号建立在关于“良好”Agent 行为看起来是什么样的结构化知识之上
LaRe
- LaRe(AAAI 2025)通过使用 LLM 生成自然语言的信用解释来桥接 LLM 推理和信用分配
- 对于轨迹中的每一步,LaRe 会提示一个 LLM 来解释该 Step 为何是有帮助或有害的,产生一个文本的理由,然后将其转换为标量 Reward
- LaRe 的方法最初是为符号化 RL 任务(例如,网格世界、简单游戏)开发的,它在概念上适用于任何 Action 具有 LLM 可以评估的语义含义的 Agentic 环境
- 自然语言解释也提供了可解释性,使从业者能够理解为什么某些 Action 会获得高或低的信用,这对于调试 Agent 行为非常有价值
PRS + VSPO
- PRS(Progressive Reward Shaping, 2025)通过课程式的 Reward 演化来解决信用问题
- 在训练初期,密集的 Reward 关注格式正确性
- 在后期阶段,Reward 转向任务准确性
- VSPO(Value-based Sampling Policy Optimization)通过优先训练那些信用信号信息量最大的轨迹来补充 PRS
- PRS 是一种 Reward 塑形方法而非纯粹的信用分配算法,但 PRS 渐进的 Reward 密集化过程在训练过程中有效地执行了从粗到细的信用分配
Adaptive Segment-Level Reward
- Adaptive Segment-Level Reward(2024) 使用语义分割来将轨迹划分为长度均衡的 Segment ,而不管其长度如何 ,从而确保 Reward 粒度的一致性
- 自适应分割防止了病理情况 ,即长轨迹获得实际上均匀的信用 ,而短轨迹获得过于嘈杂的信用
Discussion: Emerging Patterns in Agentic CA
- Agentic 信用分配的格局揭示了几种将其与 Reasoning RL 区分开来的独特模式:
- 1)Hindsight 正成为一种突出的方法
- 三种最新的方法(HCAPO、C3、CCPO)都使用了事后回顾分析
- 这种趋同性表明,在 Agentic RL 中,后向分析(“鉴于所发生的事情,这个 Action 有多重要?”)可能比前向预测(“这个状态有多大的价值?”)更实用,后者由于随机转移和部分可观测性而不可靠
- 2)LLM-as-Critic 显得特别强大
- 与经典 RL 不同(其中 Critic 是学习得到的、推理能力有限的神经网络),LLM Agent 可以利用 LLM 本身(或另一个 LLM)来对中间状态执行复杂的语义评估
- CAPO、SWEET-RL、HCAPO、CriticSearch 和 LaRe 都利用了这种能力
- LLM-as-Critic 范式在经典 RL 中没有直接的对等物,它代表了一个似乎是 LLM 时代所特有的方法论轴
- 与经典 RL 不同(其中 Critic 是学习得到的、推理能力有限的神经网络),LLM Agent 可以利用 LLM 本身(或另一个 LLM)来对中间状态执行复杂的语义评估
- 3)层级结构至关重要
- ArCHer、PilotRL 和 CARL 都表明,尊重 Agentic 任务的层级结构(规划 \( \rightarrow \) 执行 \( \rightarrow \) 验证)能够改善信用分配
- HICRA(2025)虽然是为 Reasoning RL 开发的,但提供了为这些 Agentic 方法提供信息的基础性 Insight
- 将所有 Action 一视同仁的扁平化方法会遗漏重要的结构信息
- 4)关键 Action 识别优于均匀信用分配
- CARL 中有一个发现:将信用集中在高熵 Action 上可以在远少于全信用分配所需的更新次数下达到匹配的性能
- 这表明 Agentic CA 的目标不必是为每个 Action 分配完美的信用,而是要识别并关注那些重要的 Action
- 这种“稀疏信用”的视角比密集信用分配更高效,也可能更鲁棒
- CARL 中有一个发现:将信用集中在高熵 Action 上可以在远少于全信用分配所需的更新次数下达到匹配的性能
- 5)实际考虑因素占主导地位
- Agent Lightning、SPA-RL 和 RAGEN 表明,在生产环境中,简单高效的方法 (解耦的训练架构、基于 MLP 的进度估计、基于不确定性的过滤)可能与复杂的信用算法同等重要
- 信用质量与计算成本之间的权衡是 Agentic CA 的一级设计考量
- 1)Hindsight 正成为一种突出的方法
Multi-Agent Credit Assignment
- 随着 LLM 系统向多 Agent 架构演进(编排器 + 专家 Agent、辩论框架、协作推理),credit 除需在时间维度上分解外,还必须在 Agent 之间进行分解
Multi-Agent Methods
M-GRPO
- M-GRPO(Multi-Agent GRPO, 2025)将 GRPO 框架扩展到多 Agent LLM 系统
- 在一个具有一个主 Agent 和 \(K\) 个子 Agent 的系统中,M-GRPO 引入了一个两层的 credit 分解:
- (1)Agent 间 credit:一个元级优势,用于确定每个 Agent 对团队结果的总体贡献,通过比较不同团队组成下的结果来计算
- (2)Agent 内 credit:每个 Agent 轨迹内部的标准 GRPO 风格优势
- M-GRPO 支持解耦训练:
- Agent 可以使用它们的 Agent 间 credit 作为奖励信号独立更新,避免了联合优化的协调开销
LLM-MCA
- LLM-MCA(2025)用一个基于 LLM 的集中式 Critic 取代了传统的多 Agent credit 分配机制(QMIX, VDN, COMA 混合网络)
- 给定所有 Agent 的完整交互历史,LLM Critic 阅读对话,识别每个 Agent 的贡献,并生成关于每个 Agent credit 的自然语言评估
- 然后将这些评估转换为标量奖励用于策略更新
- 关键优势在于语义理解:
- LLM Critic 能够以纯数值混合函数无法做到的方式,推理 Agent 角色、通信质量和战略贡献
QLLM
- QLLM(2025)采用了一种 Meta-level 方法:
- QLLM 不让 LLM 评估 credit,而是让 LLM 生成 credit 分配函数本身
- 给定一个任务描述和示例轨迹,QLLM 提示一个 LLM 编写一个 Python 函数,该函数计算每个 Agent 的 credit 分数
- 这个生成的函数随后以零边际成本应用于所有训练轨迹
- QLLM 方法无需训练且高度灵活,尽管其质量取决于 LLM 生成正确 credit 函数的能力
- 理解:QLLM 方法本身很有想法,相当于允许 LLM 去通过调用或编写脚本来判断 Critic,但这可能导致得到的结果不太符合预期,对 LLM 的代码能力要求很高
SHARP
- SHARP(Shapley Credit-based Optimization,基于 Shapley Credit 的优化,202602)将原则性的 Shapley 值分解引入多 Agent LLM 系统
- 对比之前的方法 SCAR:
- SCAR(第 3.2 节)将 Shapley 值应用于推理段
- SHARP 将其应用于 Agent 之间
- 对比之前的方法 SCAR:
- SHARP 框架将奖励分解为三个部分:
- (1)用于整体任务完成的全局 broadcast-accuracy 奖励
- (2)通过 coalition 分析计算每个 Agent 特定贡献的、基于 Shapley 的边际 credit 奖励
- (3)用于执行效率的工具过程奖励
- 通过对轨迹组进行 Agent 特定优势的归一化来稳定训练
- SHARP 报告称,相比单 Agent 基线平均提高了 23.7%,相比多 Agent 基线提高了 14.1%,为迄今为止基于 Shapley 的 credit 能改善多 Agent LLM 训练提供了最强有力的实证证据
MAPPA
- MAPPA(Multiagent Per-Action Process Awards,多 Agent 每个动作的过程奖励,202601)通过提供来自 AI 反馈的每个动作的过程奖励,解决多 Agent 微调中的 credit 分配和样本效率问题
- MAPPA 不等待终端任务结果,而是使用一个 AI Judge 单独评估每个 Agent 的动作 ,从每次 rollout 中提取最大的训练信号
- MAPPA 在数学竞赛中表现:
- 在 AIME 上达到了 \(+5.0 - 17.5\) 个百分点
- 在 AMC 上达到了 \(+7.8 - 17.2\) 个百分点的提升
- 在数据分析任务上 MAPPA 成功率提高了 \(+16.7\) 个百分点
- 这些是多 Agent CA 方法中报告的最大增益之一,证明了每个动作的粒度对于多 Agent 系统至关重要
Dr.MAS
- Dr.MAS(202602)识别出将 GRPO 扩展到多 Agent 系统时的一个特定失败模式:
- 全局归一化基线偏离了异构 Agent 的奖励分布,造成梯度不稳定
- 解决方案是 Agent 级别的优势归一化
- 每个 Agent 的优势使用该 Agent 自身的奖励统计量 而非全局统计量进行归一化
- 这使得梯度规模在不同 Agent(例如,一个代码专家 vs. 一个搜索专家)之间得到校准 ,减少了梯度尖峰
- Dr.MAS 报告称在数学任务上获得了 \(+5.6%\) 的平均@16 性能,同时实现了稳定的收敛,而标准的多 Agent GRPO 则会发散
C3(再次讨论) (2026). C3 的反事实框架自然扩展到多 Agent credit:Agent \(k\) 的 credit 为 \(c_{k} = R(\tau) - R(\tau_{k})\),其中 \(\tau_{k}\) 是没有 Agent \(k\) 的反事实轨迹。这种留一法方法提供了满足自然公平属性的清晰分解
Discussion: Multi-Agent CA as an Emerging Frontier, 多 Agent CA 作为一个新兴前沿领域
- 多 Agent credit 分配已从一个新兴领域发展为一个快速发展的领域,在本文的盘点中有 6 篇专门论文(M-GRPO, LLM-MCA, QLLM, SHARP, MAPPA, Dr. MAS),加上 C3 的跨场景框架
- 目前,Multi-Agent CA 关键的开放问题包括:
- 通信 credit: Agent 是否应该因发送有用消息而获得 credit?
- 当前方法仅将 credit 分配给与任务相关的动作,忽略了 Agent 间的通信价值
- 异构架构: 当 Agent 具有不同的能力时(例如,一个代码专家和一个搜索专家),应如何公平地分解 credit?
- 可扩展性: 对于 \(K\) 个 Agent,留一法方法需要 \(K\) 次反事实评估
- 对于拥有数十个 Agent 的系统,需要可扩展的近似方法
- 与经典 MARL 的联系: 经典的多 Agent RL 拥有丰富的 credit 分配文献(QMIX, COMA, MAPPO),但这些都假设动作空间是固定维度的
- 将它们适应于可变长度的文本动作并非易事
- 通信 credit: Agent 是否应该因发送有用消息而获得 credit?
- 随着多 Agent 系统在生产环境中的快速部署,面向 LLM 的多 Agent credit 分配将在 2026-2027 年成为一个重要的增长领域
Systematic Comparison
Unified Comparison Table
- 注:原文这里确少内容
Benchmark Landscape
Reasoning RL benchmarks
- Reasoning RL 的 Credit Assignment 方法受益于完善的基准测试:
- GSM8K(小学数学,8.5K 个测试问题)
- MATH(竞赛数学,5 个难度级别的 5K 个问题)
- AIME(美国 Invitational 数学考试)
- CodeContests(编程竞赛)
- 这些基准测试提供了可验证的真实结果,使得能够直接比较 CA 方法
- 几篇论文 (VinePPO, PURE, SPRO) 在重叠的子集上报告了结果,尽管基础模型、训练数据和超参数的差异使得完美比较变得困难
Agentic RL benchmarks
- Agentic CA 的基准测试格局明显更加碎片化:
- 网页导航:WebArena (2024a), Mind2Web, WebShop
- 工具使用:ToolBench, API-Bank, Gorilla
- 交互式编码:SWE-bench, HumanEval+, MBPP+
- 具身/模拟:ALFWorld, ScienceWorld, Minecraft
- 多 Agent (Multi-Agent):ChatDev, MetaGPT 评估套件
- 很少有 Agentic CA 论文使用相同的基准测试,这使得系统比较几乎不可能
- 这种碎片化本身就是进步的主要障碍:没有共享的评估,社区就无法确定哪些 CA 方法真正更好,而哪些只是受益于有利的基准测试选择
- 理解:主要还是 Agentic RL 场景太多,大家都更多只关注自己的领域吧,而且像 SWE-Bench 等其实已经比较广泛被关注和使用了,应该是会覆盖到的?
Quantitative Performance Comparison,定量性能比较
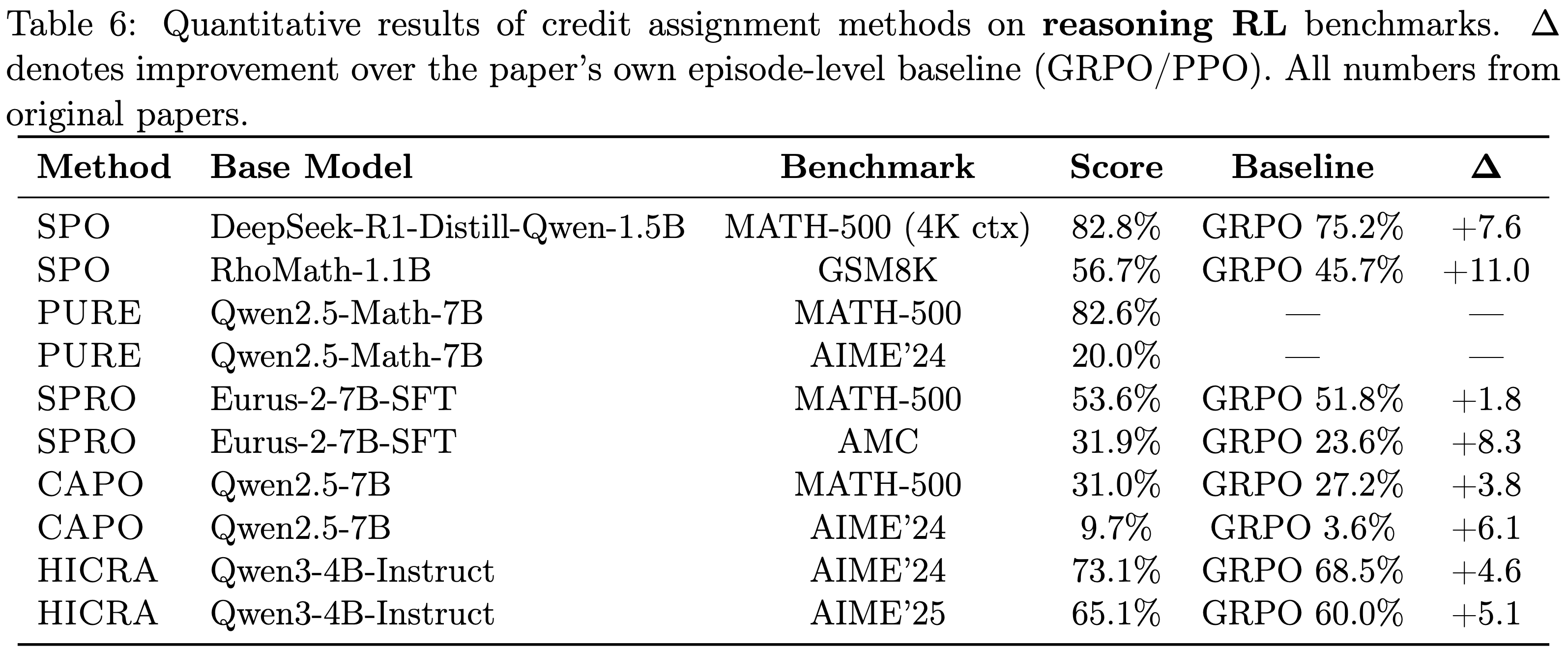
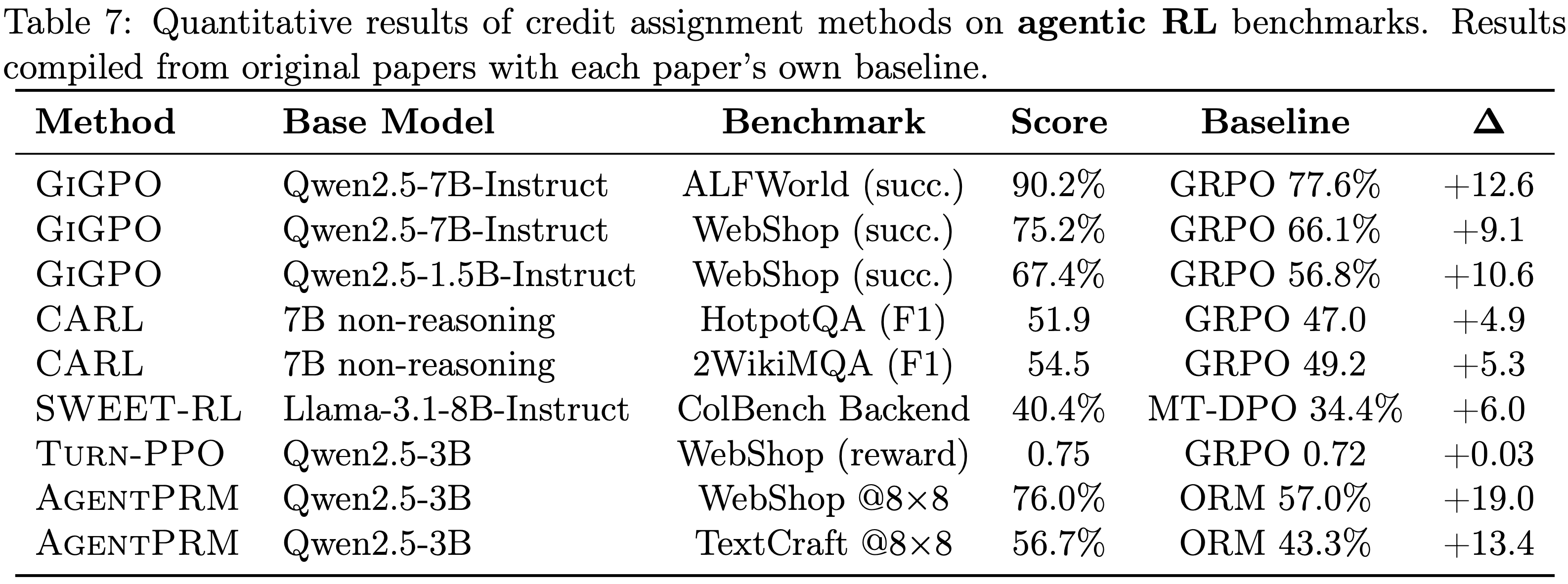
- 尽管基础模型和训练配置存在差异,本文仍整理了可用的定量结果,以提供 CA 方法所实现收益的具体情况
- 表 6 和表 7 总结了原始论文中报告的结果
- 注意:不同基础模型的结果不能直接比较;相对于每篇论文自身基线(通常是 GRPO 或 PPO)的增益是最有意义的比较
- 注意:不同基础模型的结果不能直接比较;相对于每篇论文自身基线(通常是 GRPO 或 PPO)的增益是最有意义的比较
- Descriptive Pattern: CA Improvements and Trajectory Length,描述性模式:CA 改进与轨迹长度
- Evidence-level:有限但具有启发性 (Agentic RL 方向有 6 中方法,跨 6 种方法,异质条件)
- 在基于 GRPO 基线的方法中,Agentic 子集显示出比推理子集更高的平均 \(\Delta\)
- Agentic:\(+8.5\), \(n = 5\), 2 种方法
- Reasoning:\(+6.0\), \(n = 8\), 4 种方法
- 该现象对单一异常值剔除是稳健的
- 修正后的差距: \(+7.5\) vs. \(+4.5\)
- 这与理论预期一致,尽管并非证明,即 Episode-level Credit 随着轨迹长度的增加而更严重地退化
- 其他关键混淆因素:
- (1) 不同的基础模型
- (2) 推理基准测试可能具有较低的提高空间
- (3) Agentic 子集由 GiGPO 主导 (3/5 个数据点)
- 本文仅将此作为对本文叙述性主张的粗略压力测试,而不是单独作为充分的证据
- AgentPRM 的 \(+19.0%\) (相对于 ORM 基线) 和 SWEET-RL 的 \(+6.0%\) (相对于 DPO 基线) 被排除在外,但与该模式一致
Key Trade-offs Across the Spectrum,整个范围内的关键权衡
- 本文的分析揭示了四个基本权衡,它们构成了 CA 方法的设计空间
- 本文用 Evidence-level 注释每一点:
- [SE] = 强经验性(Strong Empirical),[LS] = 有限但具有启发性(Limited but Suggestive),[AS] = 作者合成(Authors’ Synthesis)
- 本文的标准:
- [SE] 需要来自 \(\geq 3\) 篇独立论文的趋同发现,或 \(\geq 2\) 篇具有多基准评估和明确消融研究的论文
- [LS] 表示 1-2 篇论文、狭窄的基准测试或实质性的混淆因素
- [AS] 表示未经比较性证据直接建立的概念性综合
Granularity vs. computational cost [SE]
- 粒度 vs. 计算成本
- 更细的 Credit 粒度(Token-level)提供更精确的训练信号,但计算成本更高
- VinePPO 需要 \(\mathcal{O}(K\cdot L)\) 次额外的 Forward Pass
- SCAR 需要指数级的联盟评估
- Turn-level 方法 (CARL, SWEET-RL) 为 Agentic RL 提供了一个实用的最佳平衡点
- Episode-level 方法 (GRPO) 最便宜但信息量最少
Forward estimation vs. hindsight analysis [AS]
- 前向估计 vs. 事后分析
- 前向方法 (PRM, VinePPO, AgentPRM) 从当前状态估计价值,需要环境重新执行或学习到的近似
- 事后方法 (HCAPO, C3, CCPO) 在轨迹收集后分析 Credit
- 事后方法具有严格的信息优势,但引入了延迟,并可能遭受事后偏差
Auxiliary model requirements [SE]
- Auxiliary model requirements 方法涵盖了一个广泛的范围:
- 有些不需要辅助模型 (CARL, iStar, GiGPO)
- 有些需要轻量级辅助模型 (SPA-RL 的 MLP)
- 有些需要单独 Critic 或 PRM (ArCHer, AgentPRM, PURE)
- 还有一些需要 LLM 规模的评估 (CAPO, HCAPO, LLM-MCA)
- 辅助模型需求直接影响可扩展性
Reasoning-specific vs. agent-general [LS]
- 在 Reasoning RL 背景下开发的方法 (VinePPO, PURE, HICRA) 利用了在 Agentic 环境下会失效的假设(确定性转移、可验证步骤)
- 为 Agentic RL 开发的方法 (HCAPO, SWEET-RL, CARL, GiGPO) 做出的此类假设较少
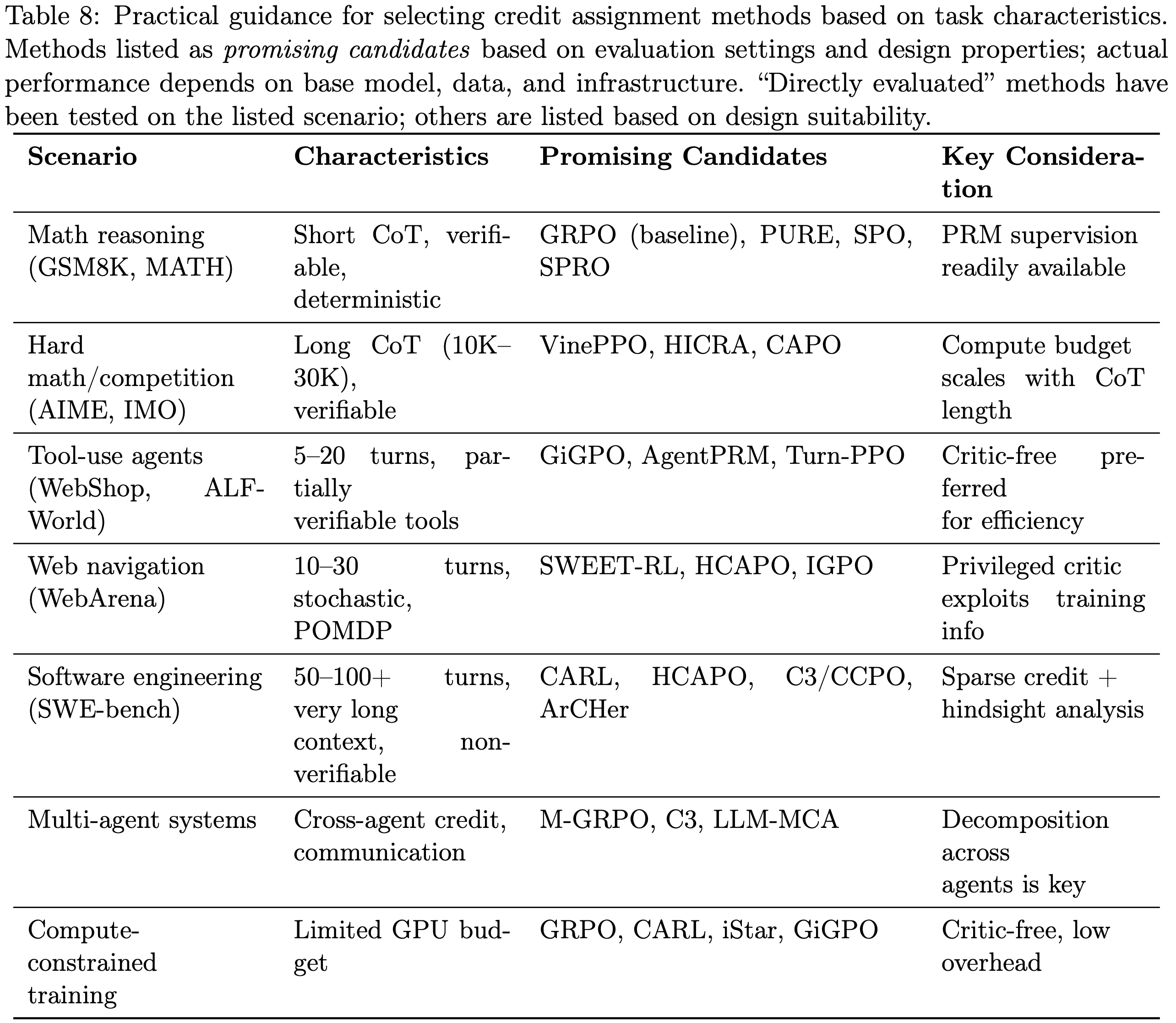
Practical Guidance: Matching Methods to Scenarios,实践指导:根据场景匹配方法
- 表 8 提供了一个基于任务特征选择 CA 方法的实用指南
- 这些建议反映了本文作者对文献的综合,实际性能可能因基础模型、数据分布和训练基础设施而异
- 这些建议反映了本文作者对文献的综合,实际性能可能因基础模型、数据分布和训练基础设施而异
- 图 4 提供了一个补充的决策树,将表 8 操作化为一个逐步选择过程
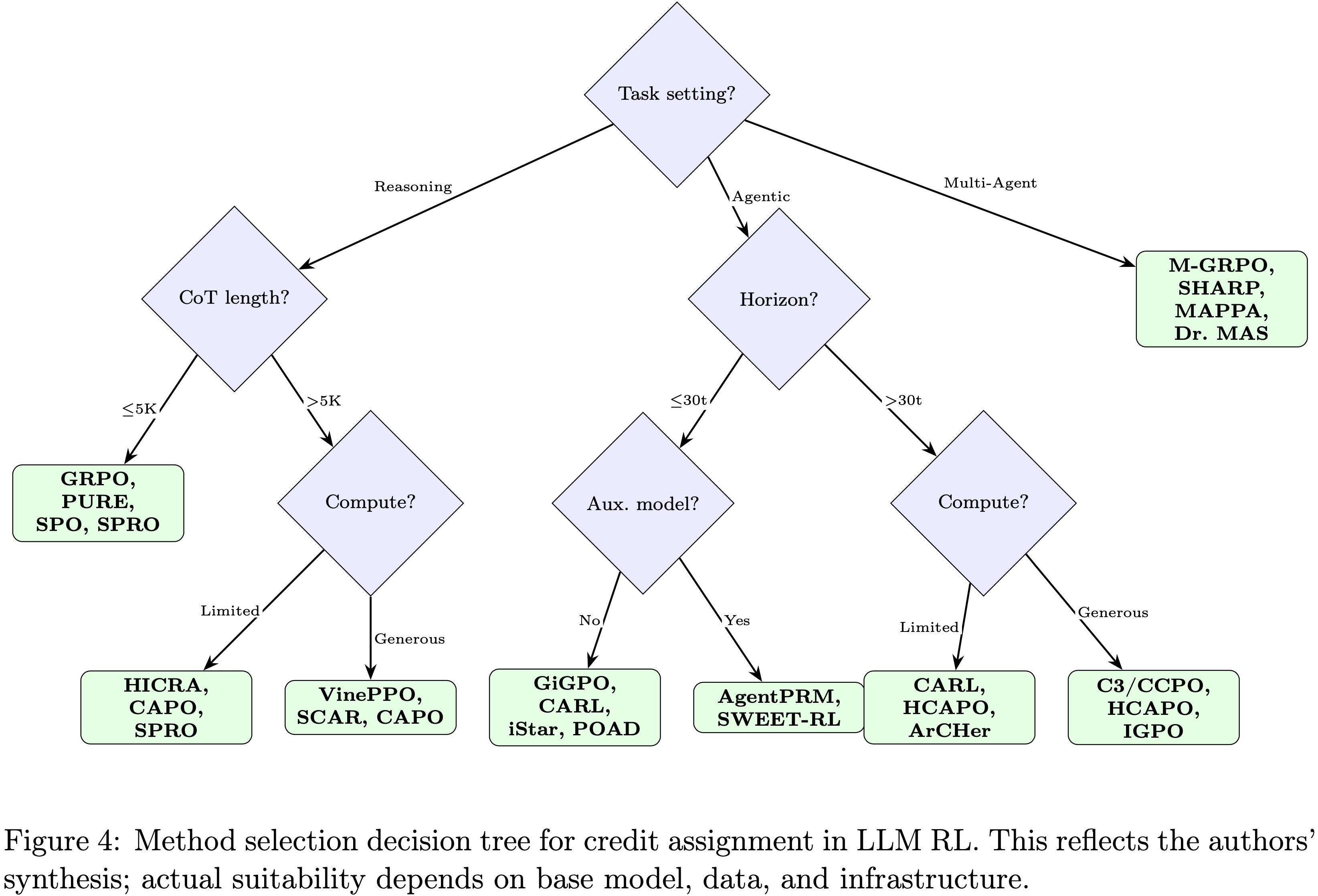
Retrospective validation,回顾性验证
- 本文作者追踪了 6 个已知的(任务,方法)对通过决策树:
- SPO 在 GSM8K 上
- HICRA 在 AIME’24 上
- VinePPO 在 MATH 上
- GiGPO 在 ALFWorld 上
- SWEET-RL 在 ColBench 上
- HCAPO 在长时域 Agentic 任务上
- 所有 6 个都被成功回溯 (6/6)
- 这验证了内部一致性
Credit Assignment in the Agentic RL Training Pipeline
- Credit Assignment 不是孤立运作的
- Credit Assignment 是一个五阶段流程中的一个组件:
- (1) 环境构建(沙盒执行)
- (2) Rollout 生成(多轮 Agent-环境交互)
- (3) 奖励计算(Terminal 任务成功)
- (4) Credit Assignment(本文的重点)
- (5) 策略更新 (PPO/GRPO/DPO)
- Credit Assignment 是一个五阶段流程中的一个组件:
- 本节关注 CA 与其他阶段之间的交互,这些交互经常被忽视
Interactions Between Credit Assignment and Other Pipeline Components
CA × Rollout efficiency,效率
- 更好的 Credit Assignment 会减少有效学习所需的 Rollout 数量
- CARL (2025) 直接证明了这一点:
- 通过将 Credit 集中在关键 Action 上,以 \(72%\) 更少的梯度更新实现了等效性能,这转化为比例更少的 Rollout
- CARL (2025) 直接证明了这一点:
- 更广泛地说,细粒度的 Credit 降低了梯度方差,使得更小的批量大小和更快的收敛成为可能
- 这创造了一个良性循环:
- 将计算投入更好的 CA(例如,运行 VinePPO 的 Vine 扩展)可以通过减少 Rollout 需求来回收
- 在 “更多 Rollout 配合粗糙 Credit” 和 “更少 Rollout 配合精确 Credit” 之间计算的最佳分配是一个关键的空缺问题(见第 9 节)
- 理解:即把时间/算力更多分配给 Rollout 还是 Credit 是一个需要谈的问题
- 这创造了一个良性循环:
CA × Reward Design
- Credit Assignment 方法有时会隐含地重新定义奖励函数
- PRS (2025) 明确地用渐进式密集奖励替换了 Terminal 奖励
- IGPO (2025a) 将二元成功信号转换为信息增益增量
- 这模糊了“奖励设计”和“Credit Assignment”之间的界限
- 两者都是为策略优化器提供有用训练信号的机制
- 本文作者观点:CA 不应被视为对固定奖励的后处理步骤,CA 应被视为奖励工程的一个组成部分
CA × Exploration
- Credit 信号原则上可以指导探索:
- Agent 应优先探索 Credit Assignment 不确定(Credit 估计的高方差)的状态,因为这些状态是需要更多信息来改进策略的状态
- IGPO (2025a) 通过信息论的术语定义 Credit,朝这个方向做出了示意,但目前没有方法明确使用 CA 不确定性来驱动探索
- 这是一个重大的错失机会
Infrastructure Challenges Specific to Agentic RL
- Agentic RL 训练面临 Reasoning RL 中不存在的、直接影响 Credit Assignment 的基础设施挑战:
- 环境重置成本 (Environment reset cost)
- 重置一个沙盒环境(启动 Docker 容器、初始化浏览器会话、加载代码库)可能需要数秒到数分钟
- 重置一个沙盒环境 比“重置”一个推理任务(加载一个新的 Prompt)的可忽略成本高出几个数量级
- 后果:基于 MC 的 CA 方法(需要从中间状态重新执行环境)尤其昂贵
- 不可微的转移 (Non-differentiable transitions)
- 环境交互(API 调用、代码执行)中断了计算图,阻止了基于梯度的 Credit 归因
- 所有 CA 方法必须与黑盒环境转移一起工作,依赖价值估计、事后分析或基于 LLM 的评估,而不是梯度流
- 理解:在 Agentic RL 中,不可微分的外部操作(如 API 调用、代码执行、用户交互)切断了从最终成败结果反向追溯到具体 Action 参数的自动微分路径
- 导致:不能用简单的反向传播训练:因为梯度传不回来,所以不能像训练神经网络那样直接训练 Agent 做决策,必须使用 RL 的 Credit 分配
- 训练期间的安全性 (Safety during training)
- Agentic RL Rollout 可能有现实世界的影响:发送实际的 API 请求、修改文件、发布到网络
- 训练 Rollout 期间的安全约束可能与探索要求冲突,并且对于“安全但次优”与“有风险但信息丰富”的 Action 的 Credit Assignment 是一个未被充分探索的挑战
- 异步训练 (Asynchronous training)
- 现代 Agentic RL 系统 (AReaL, Laminar) 使用异步 Rollout 生成和策略更新来最大化 GPU 利用率
- 异步训练引入了策略滞后:
- 当 Credit 被计算时,策略可能已经改变
- CA 方法必须对这种陈旧性具有鲁棒性,偏爱 Off-policy 兼容的方法 (ArCHer 的 Off-policy Critic,重要性采样校正)
- 环境重置成本 (Environment reset cost)
Open Problems and Future Directions
The Agentic Frontier: Where Credit Assignment Must Go, Agentic 前沿:CA 的未来
Ultra-Long Horizon Agents,超长时域 Agent
- 当前的 Credit Assignment 方法已在 5-30 轮的轨迹上进行了评估
- 现实世界的 Agent 会更多,比如处理 SWE-bench 问题的软件工程助手通常会执行 50-100+ 轮,消耗 100K-500K 个 Token (2025d; 2025),自主研究 Agent 进行多天实验,桌面自动化 Agent 需要 50-100 步及大量上下文
- 在这些规模下,即使是 Turn-level Credit Assignment 也可能不足:
- 轮数之多使得每轮 Credit 估计计算量巨大且统计上不可靠
- 本文作者推测分层方法 (ArCHer, HICRA, PilotRL) 代表了最有前途的方向,但当前的层次太浅(通常为 2 层)
- 超长时域 Agent 可能需要更深、更灵活的层次结构,能够动态适应任务复杂性
- 或许可以 Mirroring Agent 自身使用的分层规划结构
Open-World Agents Without Verifiable Rewards,没有可验证奖励的开放世界 Agent
- 大多数 Credit Assignment 方法假设可以访问二元或标量的 Terminal 奖励(任务成功/失败)
- 这个假设对于定义良好的任务(数学、编码、具有明确目标的网页导航)成立,但对于开放世界 Agent 则失效:
- 个人助手(“用户满意吗?”)
- 创意写作 Agent(“这个故事好吗?”)
- 研究助手(“这个实验有信息量吗?”)
- 在这些设置中,Terminal “奖励”本身是不确定的、主观的,或无限期延迟
- 在奖励模型本身具有显著不确定性的情况下进行 Credit Assignment 基本上仍未解决
- 一个有希望的方向是将 CA 方法与 RLHF 奖励模型连接起来,使用奖励模型的置信度作为 Credit 信号的加权因子
Multi-Agent Systems at Scale
- 如第 6.2 节所讨论的,多 Agent Credit Assignment 尚处起步阶段
- 随着 LLM 系统扩展到数十个具有不同专长的协作 Agent,Credit 分解问题呈指数级增长
- 三个具体挑战尤为突出:
- (1) 可扩展分解:基于 LOO 的方法 (C3) 需要 \(K\) 次反事实评估来处理 \(K\) 个 Agent;需要亚线性近似
- (2) 沟通的 Credit:当前方法仅对任务 Action 进行 Credit 归因,忽略了 Agent 间消息的价值
- (3) 部分团队可观测性下的 Credit:每个 Agent 仅看到自己的交互,使得在分散部署中进行集中式 Credit 计算具有挑战性
Theoretical Frontiers
Credit Assignment Meets Exploration
- 更好的 Credit Assignment 应该能够实现更有针对性的探索,然而当前的方法将 CA 和探索视为独立的问题
- 这种联系是自然的:
- Credit Assignment 最不确定的状态正是 Agent 应该探索的状态,因为需要更多信息来解决模糊性
- IGPO (2025a) 通过信息论的术语定义 Credit 提供了一个起点,但目前没有方法明确使用 Credit 不确定性来驱动探索
- 本文作者认为这是最有前途的研究方向之一,因为它可以同时提高样本效率和 Credit 质量
Formal Guarantees,形式化保证
- 大多数用于 LLM RL 的 Credit Assignment 方法缺乏形式化的收敛保证
- VinePPO (2025) 证明了其 MC 估计是无偏的
- PURE (2025) 分析了在特定条件下 Min-form Credit 的最优性
- CCPO (2026c) 在因果假设下提供了保证
- 但大多数方法(特别是 LLM-as-Critic 方法 (CAPO, HCAPO, LaRe))只有经验验证
- 在基于 LLM 策略的 POMDP 中发展 Credit Assignment 质量的理论分析是一个完全开放的挑战
- 关键问题包括:
- 在什么条件下,近似的 Credit Assignment 能收敛的策略优化?
- 从 imperfect Credit 信号中学习的样本复杂度是多少?
- 关键问题包括:
The Computation-Signal Trade-off,计算-信号权衡
- 一个基本问题贯穿整个领域:
- 给定固定的计算预算,下面那个选项更好:
- (a) 生成更多 Rollout 配合粗糙的 Episode-level Credit (GRPO)
- (b) 生成更少 Rollout 配合精确的细粒度 Credit (VinePPO, HCAPO)
- 这就是“CA 效率前沿”,类似于改变了监督学习的计算最优 Scaling Laws
- 没有论文提供系统的答案
- 给定固定的计算预算,下面那个选项更好:
- 本文作者推测,随着轨迹长度的增加,最优分配会向细粒度 Credit 转移:
- 对于短推理任务,更多 Rollout 可能更有效
- 对于长 Agentic 任务,更好的 Credit 可能值得其成本
Practical Frontiers
Unified Benchmarks for Credit Assignment
- 缺乏评估 CA 方法的标准基准测试是进步的主要障碍
- 论文使用不同的任务、基础模型、训练配方和评估指标,使得比较几乎不可能
- 本文作者呼吁建立一个统一的 CA 基准测试套件,涵盖:
- (1) 具有已知真实步骤 Credit 的推理任务(通过穷举 MC 评估)
- (2) 具有受控分叉点的 Agentic 任务(可计算“正确” Credit 的合成环境)
- (3) 具有设计好的 Credit 结构的多 Agent 任务
- 这样的基准测试将能够实现同类比较并加速方法论进展
Credit Assignment and Memory
- 长上下文 Agent 越来越多地使用记忆机制(显式检索、草稿本、长期数据库)
- 应如何对与记忆相关的 Action(存储信息、检索过去上下文、更新摘要)进行 Credit Assignment?
- 一个在第 5 轮看似无用的检索 Action 可能在第 25 轮当存储的信息变得相关时被证明至关重要
- 这种记忆 Credit 的时间跨度远远超过了当前 CA 方法的典型前瞻范围,需要全新的方法
- 可能借鉴经典 RL 中的资格迹,并将其扩展到 LLM Agent 的语义记忆
From Reasoning to Agentic: Transfer and Adaptation
- 推理 CA 方法能否有效地适配到 Agentic 环境?
- VinePPO 的 Vine 扩展可以应用于 Agentic 轮次(在轮边界而非 Token 位置分支),但需要环境检查点
- PURE 的 Min-form Credit 可以扩展到用于 Agent 的 Turn-level PRM
- HICRA 的规划-程序性区分可以应用于 Agentic 轨迹,其中功能区分更加显著
- 系统地研究哪些推理 CA 技术可以迁移到 Agentic 环境(以及需要什么修改)将是一个有价值的贡献,连接起本文分类法的两半
Threats to Validity
- 对本 Survey 结论有效性的几个威胁:
- 预印本波动性 (Preprint volatility)
- 所审查的论文大多数是尚未经过同行评审的 arXiv 预印本
- 它们的方法、结果甚至标题都可能改变
- 本文将分析快照定格在 2026 年 4 月
- Selection bias
- 尽管采用了系统的搜索协议(第 1.1 节),但可能遗漏了非索引场所、行业报告或作者截止日期后的并发预印本中的相关工作
- Non-comparability of results,不可比结果
- 定量表格汇集了来自不同基础模型、基准测试和训练配置的结果
- 跨论文比较是说明性的,而非受控实验
- Taxonomy boundary ambiguity,分类方法边界模糊
- 本文将方法分类为推理 vs. Agentic RL,以及核心 vs. 辅助,涉及判断
- 一些方法跨越边界
- Single-coder limitation
- 所有的筛选、分类和 Evidence-level 编码均由单一作者完成?【真厉害】
- 预印本波动性 (Preprint volatility)
Supplementary Material Release
- 为了最大化本 Survey 的复用价值,作者承诺在发布时提供以下补充材料:
- 结构化清单 (CSV 和 JSON) :包含所有 47 篇论文的完整清单,包含所有分类法标签、基线系列、 Evidence-level 、主要基准测试和 arXiv 标识符,采用机器可读格式,适用于程序化分析、筛选和扩展
- 筛选日志 (Screening log) :来自作者搜索协议(第 1.1 节)的候选论文完整列表,包含包含/排除的决定和理由,使得能够验证和扩展作者的覆盖范围
- 分类法标签 (Taxonomy labels) :每种方法的粒度 \(\times\) 方法论分类,采用允许自动生成分类法网格(图 2)和比较表(表 5)的格式
- 报告检查表模板 (Reporting checklist template) :一个独立的 PDF/LaTeX 模板的报告检查表(表 11),作者可以在论文投稿中作为补充自查包含
- 基准测试协议模式 (Benchmark protocol schema) :用于提议的基准测试元数据格式(第 9 节)的 JSON schema 文件,使得 CA 评估结果的标准化报告成为可能
- 注:所有材料将托管在一个公共 GitHub 仓库上
附录 A:方法快速参考索引
- 表 9 提供了本文回顾的所有方法的字母顺序索引,包含全名、arXiv 标识符(如有)以及章节参考,方便快速查阅
缩写 全名 参考文献 章节 ACPO Attribution-based Credit for RLVR Yin 等 (2025) §3.3 AgentPRM Process Reward Model for LLM Agents Xi 等 (2025) §5.1 ArCHer Actor-Critic with Hierarchical Evaluation Zhou 等 (2024c) §5.4 C3 Contextual Counterfactual Credit Chen 等 (2026) §5.2 CAPO Credit Assignment Policy Optimization Xie 等 (2025) §3.3 CARL Critical Action Reinforcement Learning Shen 等 (2025) §5.4 CCPO Counterfactual Credit Policy Optimization Li 等 (2026c) §5.2 CriticSearch Retrospective Critic for Search Agents Zhang 等 (2025c) §5.2 Dr. MAS Stable RL for Multi-Agent LLMs Feng 等 (2026) §6 FinePO Fine-Grained Process Reward (SketchVL) Huang 等 (2026) §3.3 From r to Q* Implicit Token-Level Credit via DPO Rafailov 等 (2024) §3.1 GiGPO Group-in-Group Policy Optimization Feng 等 (2025) §5.3 HCAPO Hindsight Credit Assignment PO Tan 等 (2026) §5.2 HICRA Hierarchy-Aware Credit Assignment Wang 等 (2025c) §3.3 IGPO Information Gain Policy Optimization Wang 等 (2025a) §5.5 InT Self-Proposed Interventions for CA Yang 等 (2026) §3.3 iStar Implicit Step Rewards Liu 等 (2025) §5.6 ITPO Implicit Turn-Level Process Rewards Wang 等 (2026) §5.1 LaRe Latent Reward Qu 等 (2025) §5.7 Lightning Agent Lightning / LightningRL Luo 等 (2025) §5.7 LLM-MCA LLM-based Multi-Agent CA Nagpal 等 (2025) §6 M-GRPO Multi-Agent GRPO Hong 等 (2025) §6 MAPPA Multiagent Per-Action Process Awards Li 等 (2026a) §6 PilotRL Global Planning-Guided Progressive RL Lu 等 (2025) §5.4 POAD Policy Optimization with Action Decomposition Wen 等 (2024) §5.3 PRL Process Reward Learning Yao 等 (2026) §3.3 PURE Min-Form Process Reward Cheng 等 (2025) §3.3 QLLM LLM-Generated Credit Functions Li 等 (2025c) §6 RAGEN/StarPO Star Policy Optimization Wang 等 (2025d) §5.7 RED Reward Redistribution to Token Level Li 等 (2024a) §3.1 SCAR Shapley Credit Assignment Rewards Cao 等 (2025) §3.2 SHARP Shapley Credit-based Multi-Agent Optimization Li 等 (2026b) §6 SCRIBE Structured Mid-Level Supervision Jiang and Ferraro (2026) §5.7 SPA-RL Stepwise Progress Attribution Wang 等 (2025b) §5.7 SPO Segment Policy Optimization Guo 等 (2025) §3.2 SPRO Self-Guided Process Reward Fei 等 (2025) §3.3 SORL Stabilizing Off-Policy RL (SO-PPO/SO-GRPO) Li 等 (2025a) §5.1 StepAgent Step-Wise IRL Agent Deng 等 (2024) §5.6 SWEET-RL Privileged Critic for Multi-Turn Agents Zhou 等 (2025) §5.1 TARL Turn-Level Adjudicated RL Tan 等 (2025) §5.1 TEMPO Tree-Structured Credit Assignment Tran 等 (2025) §3.2 T-REG Token-Level Reward Regularization Zhou 等 (2024b) §3.1 Turn-PPO Turn-Level Optimized PPO Li 等 (2025b) §5.1 VinePPO Monte Carlo Token-Level PPO Kazemnejad 等 (2025) §3.1
附录 B:完整论文清单
- 表 10 提供了本 Survey 回顾的所有 47 篇论文的完整清单,并附有分类标签和结构化元数据
- 类型: C = 核心 CA 方法, E = CA- 相关辅助方法
- Setting: R = Reasoning RL, A = Agentic RL, M = 多 Agent
- BL (Baseline Family): G = GRPO, P = PPO, D = DPO, O = ORM, T = TD
- Ev. (Evidence Level): S = 强实证, L = 有限但有启发性, A = 主要为分析性
- 分类说明: 回顾的 47 篇论文包括 41 篇核心 CA 方法(#1-35, #42-47)和 6 篇 CA 相关辅助方法(#36-41)
- 分类编码由本文作者完成
- 本文作者在第 9.4 节中承认这是一个局限性,并且这个分类不是唯一有效的
- 基础性论文(Math-Shepherd, OmegaPRM, GRPO, DeepSeek-R1)在背景章节中讨论,但不计入 47 种回顾方法中
- Complete paper inventory with taxonomy labels (41 core + 6 adjacent = 47 total)
# 方法 类型 Setting Gran. 方法论 BL Ev. 主要 Benchmarks Reasoning RL — 核心 CA 方法 (15) 1 VinePPO C R Token MC P S GSM8K, MATH 2 RED C R Token Redistribution P L MATH 3 T-REG C R Token Self-generated P L GSM8K, MATH 4 From r to Q* C R Token Implicit D A 理论分析 5 SPO C R Segment MC G S MATH-500, GSM8K 6 SCAR C R Segment Game-theoretic G L MATH 7 TEMPO C R Token/Segment Tree-TD P L MATH, GSM8K 8 PURE C R Step Min-form PRM G S MATH-500, AIME’24 9 SPRO C R Step Masked Adv. G S MATH-500, AMC 10 CAPO C R Step LLM-as-Critic G S MATH-500, AIME’24 11 ACPO C R Step Attribution G L MATH 12 HICRA C R Step Hierarchy G S AIME’24, AIME’25 13 PRL C R Step Entropy-RL G L MATH, GSM8K 14 InT C R Step Intervention G L MATH 15 FinePO C R Sub-step Fine PRM — L 特定领域 (visual) Agentic RL — 核心 CA 方法 (20) 16 ArCHer C A Turn TD (hierarchical) T S 多轮对话 17 StepAgent C A Step Implicit+IRL G L 工具使用任务 18 POAD C A Token/Turn Action Decomp. P S 交互式任务 19 GiGPO C A Step MC (group) G S ALFWorld, WebShop 20 SWEET-RL C A Turn Privileged Critic D S ColBench Backend 21 AgentPRM C A Step TD+GAE O S WebShop, TextCraft 22 Turn-Level C A Turn Hybrid G L Web 导航 23 Turn-PPO C A Turn Turn-level MDP G S WebShop 24 SORL C A Turn Bias-corrected G L 多轮搜索 25 TARL C A Turn LLM-Judge G S τ-bench 26 ITPO C A Turn Implicit D L 对话任务 27 IGPO C A Turn Info-theoretic G L Agentic 任务 28 CARL C A Step Entropy-based G S HotpotQA, 2WikiMQA 29 iStar C A Step Implicit DPO D L 轨迹对 30 PilotRL C A Step Progressive G L Agentic 规划 31 LaRe C A Step LLM-Critic G L 符号 + Agentic 32 HCAPO C A Turn Hindsight G S Agentic 任务 33 C3 C A/M Turn Counterfactual G L 多 Agent + Agentic 34 CCPO C A/M Turn Counterfactual G L Agentic 任务 35 CriticSearch C A Turn Retrospective Critic G S 多跳 QA Agentic RL — CA-相关辅助方法 (6) 36 SPA-RL E A Step MLP estimator G L Agentic 任务 37 Lightning E A Step Decoupled Arch. G L 多轮 Agent 38 RAGEN E A Step Uncertainty G S Benchmark 套件 39 SCRIBE E A Step Skill-prototype G L Agentic 任务 40 PRS E A Step Progressive G S 渐进式任务 41 AdaptSeg E A Segment Segmentation G L Agentic 任务 多 Agent — 核心 CA 方法 (6) 42 M-GRPO C M Multi-Agent Hierarchical G L 多 Agent 任务 43 LLM-MCA C M Multi-Agent LLM-Critic G L 多 Agent 评估 44 QLLM C M Multi-Agent LLM-generated G L 多 Agent 任务 45 SHARP C M Multi-Agent Shapley G S 多 Agent 任务 46 MAPPA C M Multi-Agent Per-action PRM G S AIME, AMC 47 Dr. MAS C M Multi-Agent Agent-wise Adv. G S 数学任务 背景 / 基础性 (不计入 47 种方法) Math-Shepherd — R Step MC labeling — S GSM8K, MATH OmegaPRM — R Step MC labeling — S MATH GRPO — R Episode Group baseline — S 数学, 代码 DeepSeek-R1 — R Episode GRPO — S AIME, 数学, 代码
附录 C:未来 Credit Assignment 论文的报告清单
- 注:详情见原文