注:本文包含 AI 辅助创作
整体总结
- 核心卖点:DeepSeek-V4 系列 实现了 1M Token 上下文 的高效支持 ,主要技术为:
- 混合压缩注意力(CSA/HCA)
- 流形约束超连接(mHC)
- Muon优化器
- 大量工程优化
- DeepSeek-V4 流程梳理:
- Pre-Trianing(Student 起点) -> Post-Training(训练各个 Teacher,包含 SFT 和 RL)-> OPD
- Pre-Training (32T/33T tokens, 4K→1M context)
- Post-Training: Specialist Training (Base -> Domain SFT -> Domain RL for Math/Code/Agent/Writing/White-Collar, plus SFT-only for Search)
- 注意:跟 MiMo-V2-Flash 技术报告一样,这里针对 Search Agent 场景,仅使用了 SFT-only 训练,没有走 RL 过程
- On-Policy Distillation (OPD, multi-teacher reverse KL distillation into unified student model)
- Pre-Trianing(Student 起点) -> Post-Training(训练各个 Teacher,包含 SFT 和 RL)-> OPD
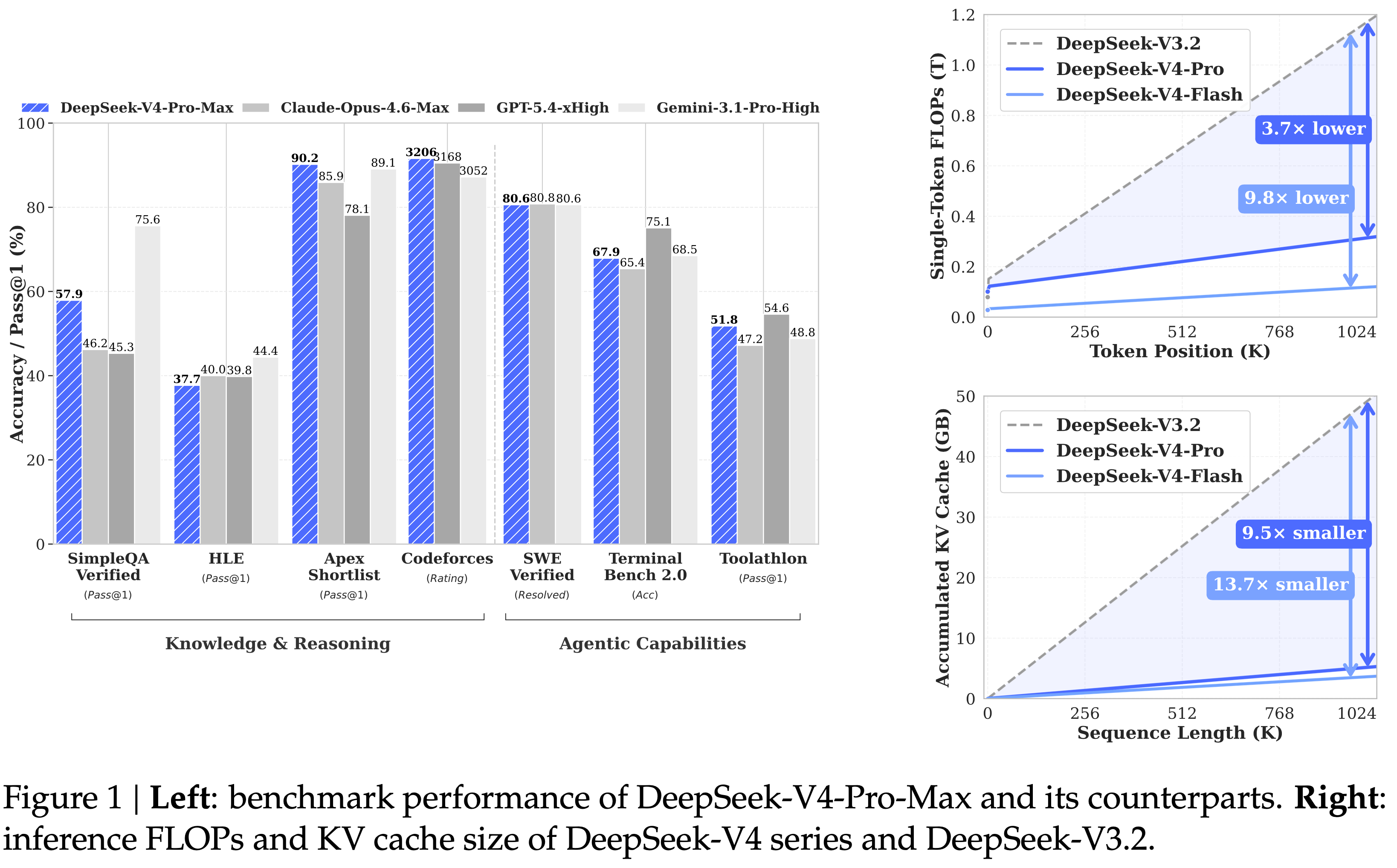
- V4-Pro-Max 在知识、推理、长上下文、Agent 等任务上全面超越现有开源模型 ,并显著缩小了与闭源前沿模型的差距
- V4-Flash 以更少激活参数达到接近的推理能力,极具成本效益
- 核心宣传点:打破超长上下文(1M Token 级别)处理中的效率瓶颈,实现高效推理与训练,并有利于测试时扩展和 long-horizon 任务提效
- 本次开源两版模型
- DeepSeek-V4-Pro :1.6T-A49B
- DeepSeek-V4-Flash :284B-A13B
- 两者均支持 1M Token 上下文 ,并在长上下文中大幅降低计算和显存开销
架构创新
- 继承 DeepSeek-V3 的 DeepSeekMoE 和 MTP
- 引入三项关键改进:
- mHC
- 混合注意力机制(CSA + HCA)
- Muon 优化器
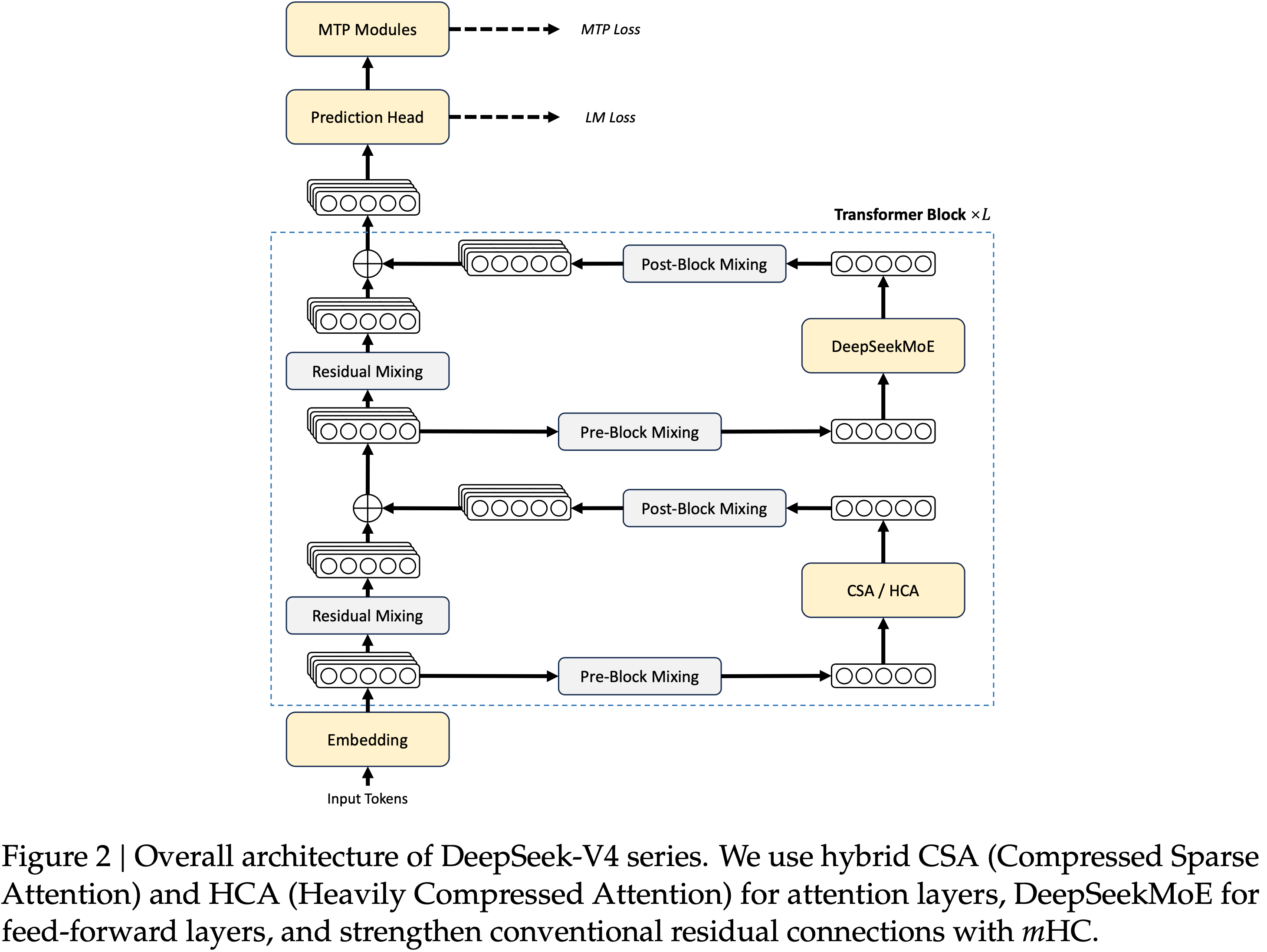
Manifold-Constrained Hyper-Connections (mHC)
- 出自之前 DeepSeek 发的文章
- 增强残差连接,通过将映射矩阵约束为双随机矩阵(Birkhoff 多面体),使谱范数 ≤1,提升信号传播稳定性
- 动态生成输入、残差、输出映射,并用 Sinkhorn-Knopp 算法实现双随机约束
混合注意力机制(CSA + HCA)
- 为应对超长上下文,设计了两种高效注意力架构:Compressed Sparse Attention(CSA)和 Heavily Compressed Attention (HCA)
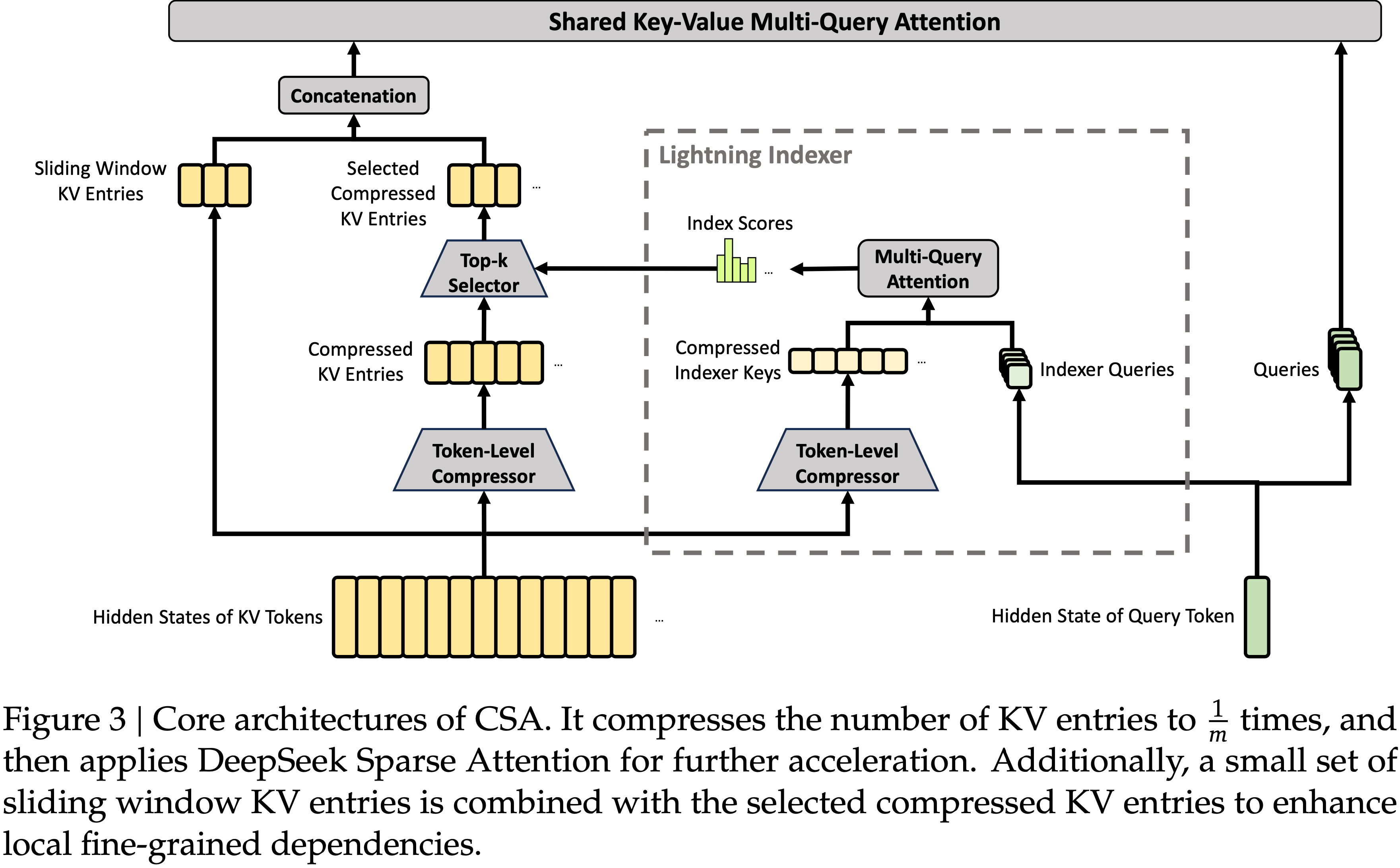
Compressed Sparse Attention (CSA)
- 将每
m个 Token 压缩为一个KV条目(压缩率 m=4) - 使用轻量索引器(Lightning Indexer)选择 top-k 压缩KV条目
- 多查询注意力(MQA)+ 分组输出投影
- 结合滑动窗口注意力(窗口大小 128)增强局部依赖
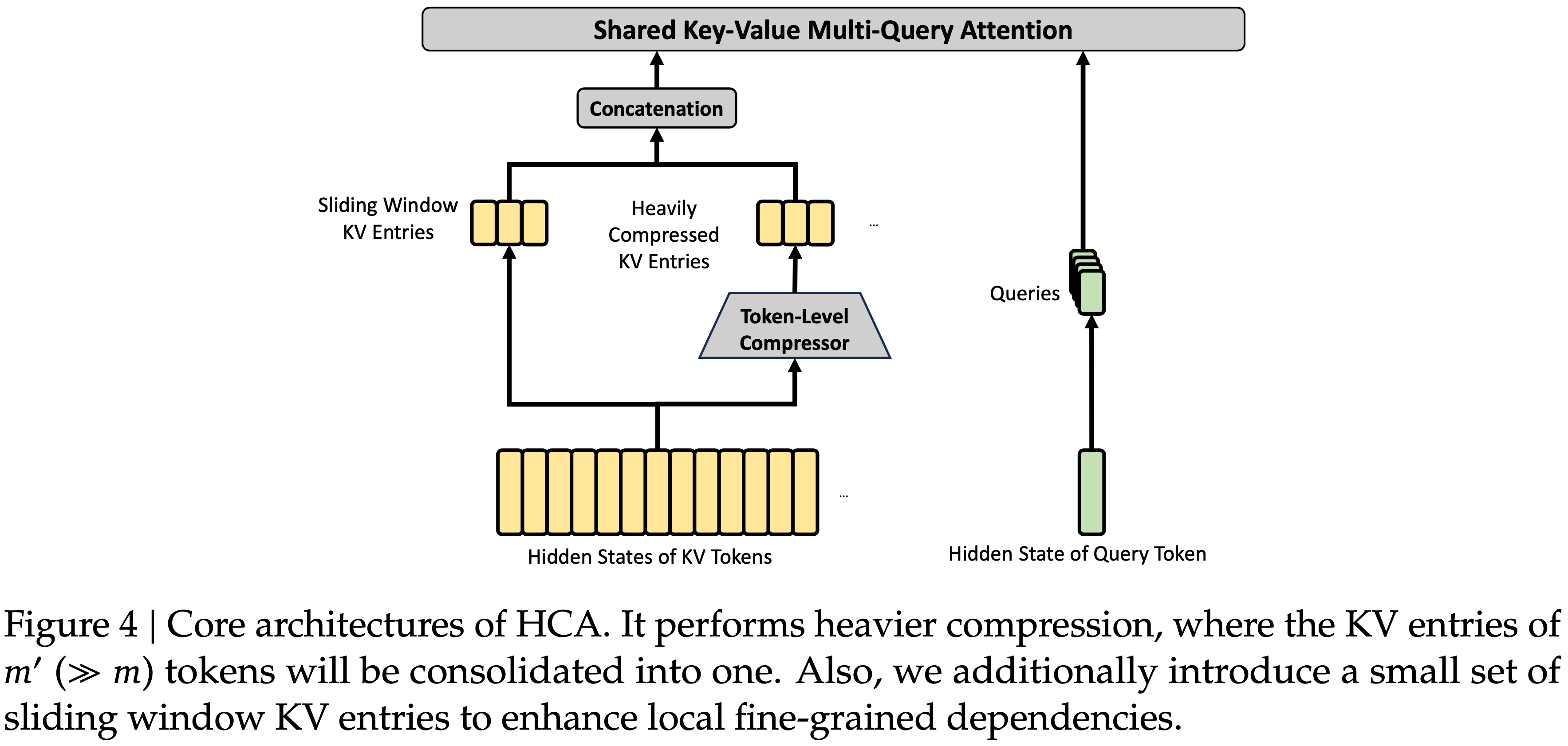
Heavily Compressed Attention (HCA)
- 更大压缩率(m’=128),无稀疏选择
- 同样采用 MQA 和分组投影
其他实现细节
- 查询/KV 归一化(RMSNorm)
- Partial RoPE 位置编码(仅后 64 维)
- Attention Sink 机制(可学习 logits)调整注意力总和
- 滑动窗口分支保证因果性和局部性
- sigmoid 激活改为 sqrt softplus 激活(Sqrt(Softplus(·))) 激活
- sqrt softplus 的值域范围更广,但实测 loss 效果有限
Muon优化器
- 替代大部分模块的 AdamW,提供更快收敛和更稳定训练
- 使用混合 Newton-Schulz 迭代进行正交化
- 嵌入层、预测头、RMSNorm 等仍保留 AdamW
工程与基础设施优化
专家并行(EP)中的细粒度通信-计算重叠
- 将专家划分为“波”(waves),实现通信与计算流水化
- 可容忍更低互联带宽,提升推理和 RL rollout 效率
- 开源 MegaMoE 内核(基于 CUDA)
TileLang DSL 加速内核开发
- 支持主机代码生成(Host Codegen),降低调用开销
- 集成 Z3 SMT 求解器进行整数分析,优化向量化、内存访问等
- 支持确定性、批无关(batch-invariant)和可重现的数值计算
FP4量化感知训练(QAT)
- 对 MoE 专家权重和 CSA 索引器的 QK 路径进行 FP4 量化
- 前向:FP4 -> FP8(无损),反向:STE 更新 FP32 主权重
- 注:STE 是 Straight-Through Estimator 的缩写,中文常译为直通估计器
- 量化存在的问题:量化过程通常包含一个不可微分的操作,例如四舍五入、取整、截断等
- STE 的做法:在前向传播中使用真实的量化函数(不可微),但在反向传播时,假装这个函数是恒等映射或简单的阶梯函数,直接将梯度“直通”过去
- 推理和 RL rollout 中直接使用 FP4 权重,减少显存和加速
训练框架增强
- Muon + ZeRO混合策略 :对稠密参数限制 ZeRO 并行度,对 MoE 专家独立优化
- mHC优化 :重计算 + 融合 kernel + 流水线调度,额外开销仅 6.7%
- 上下文并行(CP) :两阶段通信处理压缩 KV 的跨 rank 边界
- 张量级激活重计算 :基于 TorchFX 的细粒度控制,减少显存
推理框架
- 异构 KV 缓存管理 :区分 CSA/HCA 压缩 KV、SWA 状态缓存、未压缩尾部 Token
- 磁盘 KV 缓存 :支持共享前缀复用,针对 SWA 实现三种缓存策略(全缓存、周期检查点、无缓存)
Pre-training
Pre-Training 数据与策略
- 训练数据 >32T Token ,涵盖网页、数学、代码、长文档、多语言等
- 采用 Token 切分、填充中间(FIM)、样本级注意力掩码
- 序列长度从 4K 逐步扩展至 1M;先用密集注意力 warmup,后引入稀疏注意力
模型配置
- 两版模型参数详情:
参数 V4-Flash V4-Pro 层数 43 61 隐藏维度 4096 7168 CSA压缩率 m 4 4 HCA压缩率 m’ 128 128 激活专家数 6 6 总/激活参数 284B / 13B 1.6T / 49B
训练稳定性
- Anticipatory Routing :使用历史参数计算路由索引 ,打破路由与主干网络的同步更新,避免 loss 尖峰
- SwiGLU Clamping :将线性部分限制在
[-10, 10],门控部分上限为 10,消除异常值
预训练结果
- V4-Flash-Base :参数远少于 V3.2-Base,但在多数基准上超越后者,尤其在长上下文和知识任务
- V4-Pro-Base :全面超越 V3.2-Base 和 V4-Flash-Base,成为 DeepSeek 系列最强基础模型
Post-Training
两阶段流程
- 阶段 1)专家训练(Specialist Training) :
- 对数学、代码、Agent、指令跟随等域分别进行 SFT + RL(GRPO)
- 支持三种推理模式:Non-think、Think High、Think Max(最大推理 Effort )
- 引入生成式奖励模型(GRM)替代标量奖励模型
- 新增工具调用 schema(XML 格式)和
<think>标签
- 阶段 2)同策略蒸馏(On-Policy Distillation, OPD) :
- 多个教师模型(> 10个专家)蒸馏为一个统一学生模型
- 使用全词汇 KL 散度而非 Token 级估计,提高稳定性
- 教师模型权重存储在分布式存储,按需加载,减少显存
工程支持
- FP4 量化加速 Rollout 和推理
- 全词汇 OPD:缓存教师最后一层 Hidden State,动态计算 logits
- 可抢占、容错的 rollout 服务( Token 级 WAL)
- 百万 Token RL 优化:轻量元数据 + 共享内存数据加载
- DSec 沙箱平台 :支持函数、容器、microVM、fullVM 四种执行环境,用于 Agent 训练和评估
评估结果(部分内容)
知识
- V4-Pro-Max 在 SimpleQA、Chinese-SimpleQA 上大幅领先所有开源模型,但仍落后于 Gemini-3.1-Pro
- MMLU-Pro、GPQA、HLE 等教育与推理任务上,V4-Pro-Max 略优于 Kimi、GLM,但落后于闭源前沿模型
推理
- V4-Pro-Max 在推理基准上优于 GPT-5.2 和 Gemini-3.0-Pro,但略逊于 GPT-5.4 和 Gemini-3.1-Pro(约落后 3~6 个月)
- V4-Flash-Max 在更大思考预算下可达类似推理性能,成本更低
长上下文(1M Token )
- V4-Pro 在 MRCR 任务上优于 Gemini-3.1-Pro,接近 Claude Opus 4.6
- 128K 以内检索性能稳定,1M 时仍显著强于竞品
Agent 能力
- 在Terminal Bench、SWE-Verified 等基准上,V4-Pro-Max 与领先开源模型持平,略差于闭源模型
- 内部评估中,V4-Pro-Max 超越 Claude Sonnet 4.5,接近 Opus 4.5
- 研发编码任务(内部 30 道题):Pass rate 76%,接近 Opus 4.5(77%),优于 Sonnet 4.5(67%)
真实任务
- 中文写作 :功能写作胜率 62.7% vs Gemini 34.1%;创意写作质量胜率 77.5%
- 搜索 :Agentic Search 显著优于 RAG,成本略高
- 白领任务(White-Collar Task)(分析/生成/编辑):V4-Pro-Max vs Opus-4.6-Max,non-loss rate 63%,任务完成度和内容质量领先
- 理解:non-loss rate 是胜率+平收率,即模型不输给对手的比例
局限与未来方向
- 架构复杂度高 :保留了较多验证过的技巧,未来希望简化
- 训练稳定性机制 :Anticipatory Routing 和 SwiGLU Clamping 虽有效,但原理尚不清晰
- 未来计划 :
- 更稀疏的嵌入模块
- 更低延迟的长上下文部署
- 多模态能力
- 更好的数据合成策略
- 更深入的长时Agent任务研究
Post-Training(原文详解)
Post-Training Pipeline
- 训练流程很大程度上与 DeepSeek-V3.2 相似,仅做了一个关键的范式替换:
- 混合 RL 阶段完全被 On-Policy Distillation (OPD) 取代
Specialist Training
- 调整 DeepSeek-V3.2 的训练流程开发 领域专家
- 每个模型都通过初始微调阶段和后续由领域特定 prompts 和 reward 信号引导的 RL 进行顺序优化
- 在 RL 阶段,实现了 Group Relative Policy Optimization (GRPO) 算法,保持与先前研究密切相关的超参数 (2024; 2025)
Reasoning Efforts
- 众所周知:模型在推理任务上的表现从根本上受限于所投入的计算 Effort
- 本文作者在不同的 RL 配置下训练了不同的专家模型,以促进针对不同推理能力优化的模型的开发
- 如表 2 所示:
- DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 都支持三种特定的推理 Effort 模式
- 对于每种模式,在 RL 训练期间应用不同的长度惩罚和上下文窗口,使得不同模式在推理时输出 Token 长度不同
- 利用由
<think>和</think>Token 分隔的专用响应格式(整合不同的推理 Effort 模式)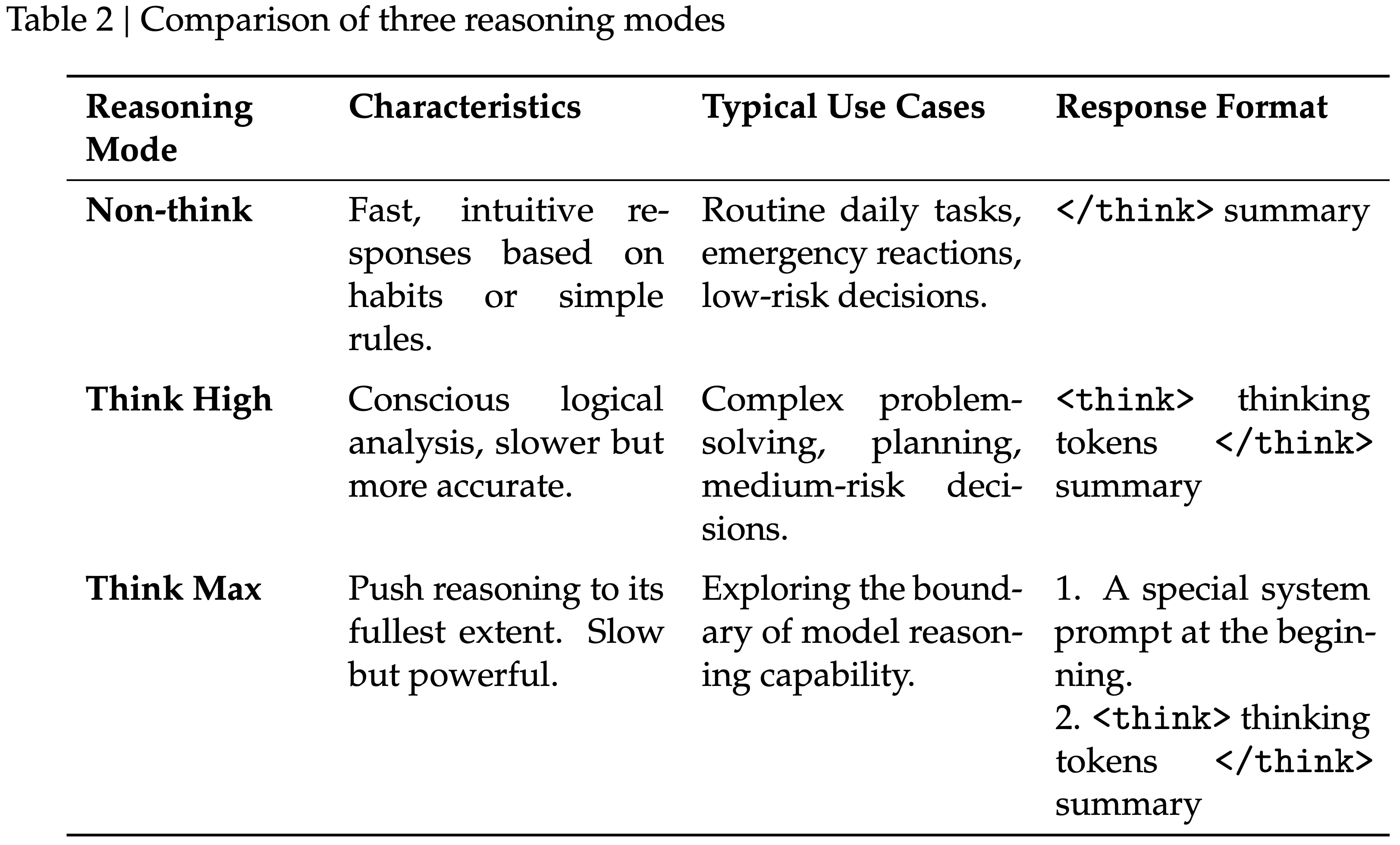
- 对于 “Think Max” 模式,在系统提示的开头添加一个特定的指令来引导模型的推理过程,如表 3 所示
- Reasoning Efforts 理解:
- Non-think :
</think> summary- 即输入
[Query]</think>,然后让模型续写
- 即输入
- Think High :
<think> thinking tokens </think> summary- 即输入
[Query]<think>,然后让模型续写,模型会自动完成 Thinking 过程
- 即输入
- Think Max :[special system prompt] +
<think> thinking tokens </think> summary- 即输入
[special system prompt][Query]<think>,然后让模型续写,模型会自动完成 Thinking 过程
- 即输入
- Non-think :
- Table 3 | Instruction injected into the system prompt for the “Think Max” mode
1
2
3Reasoning Effort: Absolute maximum with no shortcuts permitted.
You MUST be very thorough in your thinking and comprehensively decompose the problem to resolve the root cause, rigorously stress-testing your logic against all potential paths, edge cases, and adversarial scenarios.
Explicitly write out your entire deliberation process, documenting every intermediate step, considered alternative, and rejected hypothesis to ensure absolutely no assumption is left unchecked.
Generative Reward Model
- 传统:RM 跟任务可验证性有关
- 易于验证的任务:可以使用简单的基于规则的验证器或测试用例进行有效优化
- 难以验证的任务:传统上依赖于 RLHF(需要大量的人工标注来训练一个标量奖励模型)
- 在 DeepSeek-V4 系列的后训练阶段,
- 完全摒弃了这些传统的基于标量的奖励模型
- 为了解决难以验证的任务,使用了基于评分细则 (rubric-guided) 的 RL 数据 ,并采用生成式奖励模型 (GRM) 来评估策略轨迹
- 关键:直接将 RL 优化应用于 GRM 本身
- 在这个范式中,Actor 网络本身作为 GRM ,使得模型的评估(判断)能力与其标准生成能力能够联合优化
- 通过统一这些角色,模型的内在推理能力被固有地融合到其评估过程中,从而产生高度鲁棒的评分
- 这种方法仅需最少量的多样化人工标注就能实现卓越的性能,因为模型利用其自身的逻辑来泛化复杂的任务
- 理解:训练 RL 的流程是:
- 1)提前准备好 Query 和 Rubrics
- 2)训练时使用 Actor 作为 Verifier(GRM)
Tool-call Schema and Special Token
- 与之前的版本一致,使用专用的
<think></think>标签来划分推理路径 - 在 DeepSeek-V4 系列中,引入一种新的工具调用模式
- 该模式使用一个特殊的 “|DSML|” Token ,并采用基于 XML 的格式进行工具调用 ,如表 4 所示
- 实验表明,XML 格式有效缓解了转义失败并减少了工具调用错误,为模型-工具交互提供了更鲁棒的接口
- Table 4 | Tool-call schema for DeepSeek-V4 series
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17## Tools
You have access to a set of tools to help answer the user’s question. You can invoke tools by writing a "<|DSML|tool_calls>" block like the following:
<|DSML|tool_calls>
<|DSML|invoke name="$TOOL_NAME">
<|DSML|parameter name="$PARAMETER_NAME" string="true|false">$PARAMETER_VALUE</|DSML|parameter>
...
</|DSML|invoke>
<|DSML|invoke name="$TOOL_NAME2">
...
</|DSML|invoke>
</|DSML|tool_calls>
String parameters should be specified as is and set ‘string="true"‘. For all other types (numbers, booleans, arrays, objects), pass the value in JSON format and set ‘string="false"‘.
If thinking_mode is enabled (triggered by <think>), you MUST output your complete reasoning inside <think>...</think> BEFORE any tool calls or final response.
Otherwise, output directly after </think> with tool calls or final response.
### Available Tool Schemas
{Tool Definition...}
You MUST strictly follow the above defined tool name and parameter schemas to invoke tool calls.
Interleaved Thinking
- DeepSeek-V3.2 (2025) 引入了一种上下文管理策略,该策略在工具结果轮次之间保留推理轨迹,但在新的用户消息到达时丢弃它们
- 这种方式有效,但这在复杂的 Agentic 工作流中仍然导致了不必要的 Token 浪费
- 每个新的用户轮次都会清除所有累积的推理内容,迫使模型从头重建其问题解决状态
- 这种方式有效,但这在复杂的 Agentic 工作流中仍然导致了不必要的 Token 浪费
- 利用 DeepSeek-V4 系列扩展的 1M Token 上下文窗口,本文进一步完善了这一机制,以最大化交错式思维在 Agentic 环境中的有效性:
- Tool-Calling
- 如图 7(a) 所示,所有推理内容在整个对话过程中被完全保留
- 与 DeepSeek-V3.2 在每个新用户轮次丢弃思维轨迹不同,DeepSeek-V4 系列保留了跨所有轮次的完整推理历史,包括跨用户消息边界
- 这允许模型在长时程 Agent 任务上维持连贯、累积的思维链
- General Conversational,通用对话场景
- 如图 7(b) 所示,原始策略得以保留:
- 当新的用户消息到达时,先前轮次的推理内容被丢弃,从而使上下文在持久推理轨迹益处有限的环境中保持简洁
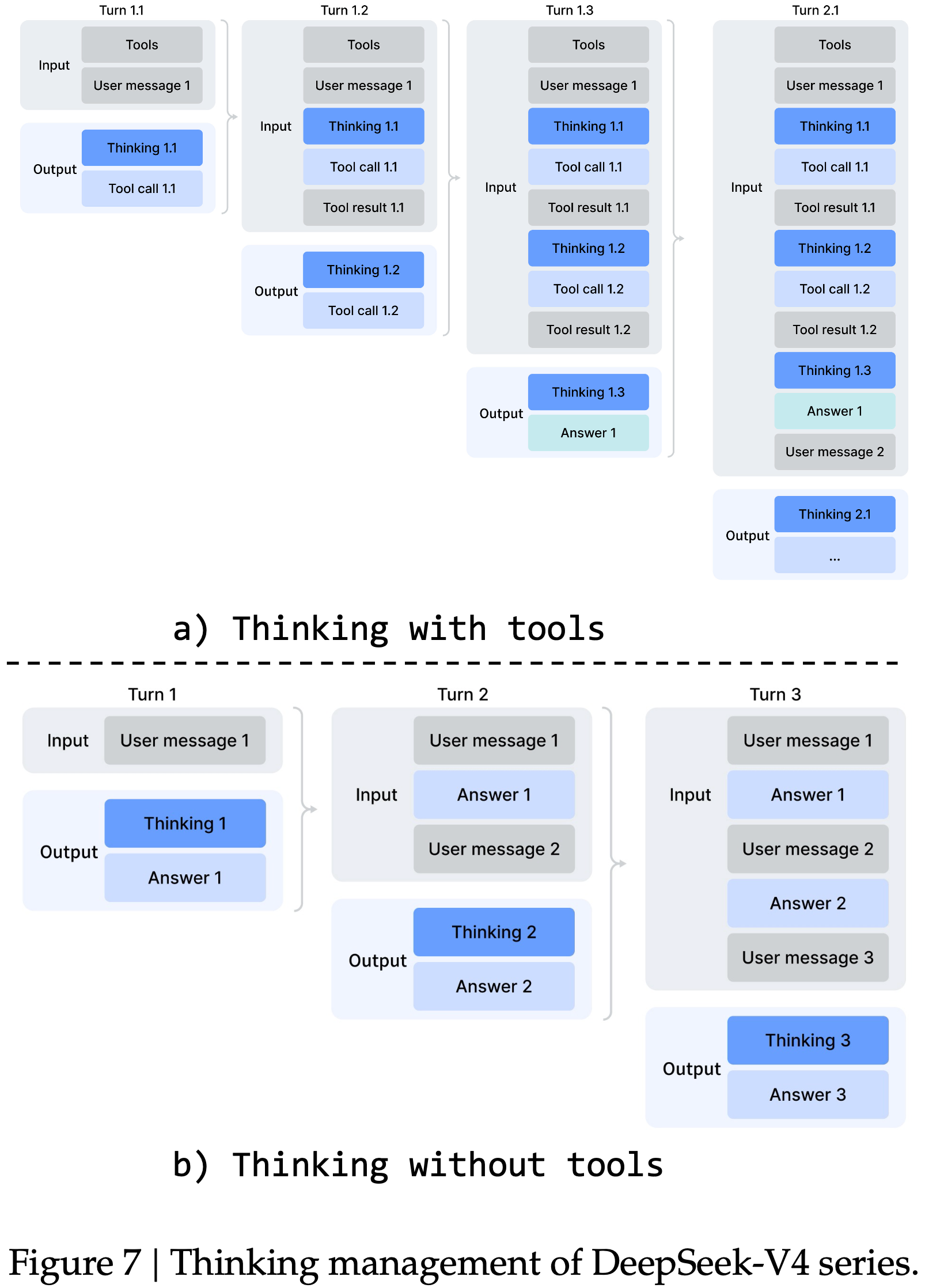
- 当新的用户消息到达时,先前轮次的推理内容被丢弃,从而使上下文在持久推理轨迹益处有限的环境中保持简洁
- 如图 7(b) 所示,原始策略得以保留:
- Tool-Calling
- 与 DeepSeek-V3.2 一样,通过用户消息模拟工具交互的 Agent 框架(例如 Terminus)可能不会触发工具调用上下文路径,因此可能无法从增强的推理持久性中受益
- 继续推荐在此类架构中使用非思维 (non-think) 模型
Quick Instruction,快速指令
- 在聊天场景中,许多 辅助任务(例如,确定是否触发网络搜索、意图识别等)必须在生成响应之前执行
- 传统上,这些任务由一个单独的小模型处理
- 由于无法重用现有的 KV 缓存,需要冗余的预过滤
- 理解:如何理解这里的无法重用现有的 KV 缓存?
- 为了克服这个限制,本文作者引入了快速指令 (Quick Instruction)
- 将一组专用的特殊 Token 直接附加到输入序列中,每个 Token 对应一个特定的辅助任务
- 通过直接重用已计算好的 KV 缓存,这种机制完全避免了冗余的预过滤,并允许某些任务(例如,生成搜索查询、确定权威性和领域)并行执行
- 这种方法显著减少了用户感知的到首个 Token 的时间 (time-to-first-token, TTFT),并消除了维护和迭代额外小模型的工程开销
- 表 5 总结了支持的快速指令 Token

On-Policy Distillation (OPD)
- 在通过专门的微调和强化学习训练了多个领域特定的专家之后,作者采用多教师 On-Policy Distillation (OPD) 作为将专家能力合并到最终模型的主要技术
- OPD 已经成为一种有效的后训练范式
- 用于将领域专家的知识和能力高效地转移到一个统一的模型中
- 注:OPD 通过让学生模型在其自身生成的轨迹上学习教师模型的输出分布来实现的
- 形式上,给定一组 \(N\) 个专家模型 \(\{\pi_{E_1}, \pi_{E_2}, \ldots, \pi_{E_N}\}\),OPD 目标函数定义为:
$$
\mathcal{L}_{\text{OPD} }(\theta) = \sum_{i=1}^{N} w_i \cdot D_{\text{KL} }\left( \pi_{\theta} |\ \pi_{E_i} \right).
\tag{29}
$$- \(w_i\) 表示为每个专家分配的权重,通常由专家的相对重要性决定
- 问题:不应该是不同领域的数据使用不同的专家吗? MiMo-V2-Flash 技术报告中提到的就是指定领域的数据上使用该领域的教师模型
- 理解:这里可以理解为更数学的表达,当 \(w_i\) 是取值为 \(\{0,1\}\) 时,即与 MiMo 的设计一致
- 计算反向 KL 散度 \(D_{\text{KL} }(\pi_{\theta} |\ \pi_{E_i})\) 需要从学生模型 \(\pi_{\theta}\) 中采样训练轨迹以保持 On-Policy 学习
- 其内在逻辑是确保统一策略 \(\pi_{\theta}\) 能够根据当前任务上下文选择性地从相关专家那里学习
- 例如:为数学推理任务与数学专家对齐,为编程任务与编码专家对齐
- 通过这种机制,来自物理上不同的专家权重的知识通过 logits 级别的对齐被整合到一个统一的参数空间中,实际上规避了传统权重合并或混合 RL 技术中经常遇到的性能下降
- 注:这里没有强调,但本质就是 MOPD 方法
- 在此阶段,使用覆盖多个领域的十多个教师模型来蒸馏一个学生模型
- 本文的特别选择:
- 之前工作通常将全词汇表 KL 损失简化为每个 Token 位置上的 Token 级 KL 估计,并通过在策略损失计算中将 下面的比例作为每个 Token 的优势估计来重用 RL 框架:
$$ \text{sg}\left(\log \frac{\pi_{E_i}(y_t | x, y_{ < t})}{\pi_{\theta}(y_t | x, y_{ < t})}\right) $$- 其中 \(\text{sg}\) 表示停止梯度操作
- 虽然这种方法资源高效,但梯度估计存在高方差,经常引起训练不稳定
- 本文在 OPD 中采用全词汇表 logit 蒸馏 ,保留完整的 logit 分布来计算反向 KL 损失能产生更稳定的梯度估计,并确保教师知识的忠实蒸馏
- 之前工作通常将全词汇表 KL 损失简化为每个 Token 位置上的 Token 级 KL 估计,并通过在策略损失计算中将 下面的比例作为每个 Token 的优势估计来重用 RL 框架:
- 注:下一小节中,将描述使大规模全词汇表 OPD 成为可能的工程努力
RL and OPD Infrastructures
- 后训练基础设施建立在为 DeepSeek-V3.2 开发的可扩展框架之上
- 集成了原论文第 3.5 节中描述的相同分布式训练栈,以及之前介绍的用于高效自回归采样的 Rollout 引擎
- 本文在次基础上引入了以下主要的增强功能
- 注:这些设计能够高效执行涉及十个以上不同教师模型的超长上下文 RL 和 OPD 合并任务,从而显著加快模型发布的迭代周期
FP4 Quantization Integration,FP4 量化集成
- 应用 FP4 (MXFP4) 量化来加速 Rollout 和所有仅推理的前向传播,包括教师模型和参考模型的,从而减少内存流量和采样延迟
- 如原论文第 3.4 节所述
- 在 Rollout 和推理阶段直接使用原生的 FP4 权重
- 对于训练步骤,通过无损的 FP4 到 FP8 反量化步骤来模拟 FP4 量化,允许无缝重用现有的 FP8 混合精度框架和 FP32 主权重,并且不需要修改反向传播流程
Efficient Teacher Scheduling for Full-Vocabulary OPD,面向全词汇表 OPD 的高效教师调度
- 本文框架支持全词汇表 OPD,可以使用数量不受限制的教师模型,每个教师模型可能包含数万亿参数
- 所有教师权重都被卸载到集中式分布式存储中,并在教师前向传播期间按需加载,同时采用类似 ZeRO 的参数分片来减轻 I/O 和 DRAM 压力
- 即使将 logits 卸载到磁盘(spooled to disk),在词汇量大小 \(|V| > 100k\) 的所有教师中直接实现 logits 也是不可行的
- 本文通过在前向传播期间仅将最后一层的教师隐藏状态缓存在集中式缓冲区中 来解决这个问题
- 在训练时,这些缓存的状态被检索,并通过相应的预测头模块传递,以即时重建完整的 logits
- 这种设计产生了可忽略的重计算开销,同时完全规避了与显式 logits 实现相关的内存负担
- 为了减轻教师预测头的 GPU 内存占用,在数据分发期间按教师索引对训练样本进行排序
- 这种安排确保每个不同的教师头在每个 mini-batch 中只被加载一次,并且在任何给定时间,设备内存中最多驻留一个教师头
- 所有参数和隐藏状态的加载/卸载操作都在后台异步进行,不会阻塞关键路径上的计算
- 本文通过在前向传播期间仅将最后一层的教师隐藏状态缓存在集中式缓冲区中 来解决这个问题
- 教师和学生 logits 之间的精确 KL 散度使用专门的 TileLang 内核计算
- 加速计算并减少了动态内存分配
Preemptible and Fault-Tolerant Rollout Service,可抢占和容错的 Rollout 服务
- 为最大化 GPU 资源利用率,同时为高优先级任务实现快速的硬件配置,GPU 集群采用了一个集群范围的可抢占任务调度器,其中任何正在运行的任务都可能随时被抢占
- 硬件故障在大规模 GPU 集群中普遍存在,所以为 RL/OPD Rollout 实现了一个可抢占且容错的 LLM 生成服务
- 具体做法:
- 为每个生成请求实现了一个 Token 粒度的预写日志 (token-granular Write-Ahead Log,WAL)
- 每当为一个请求生成一个新 Token 时,立即将其附加到该请求的 WAL 中
- 在抢占期间,暂停推理引擎并保存未完成请求的 KV 缓存
- 恢复后,使用持久化的 WAL 和保存的 KV 缓存继续解码
- 即使发生致命的硬件错误,也可以使用 WAL 中持久化的 Token 重新运行预填充阶段来重建 KV 缓存
- 为每个生成请求实现了一个 Token 粒度的预写日志 (token-granular Write-Ahead Log,WAL)
- 特别说明:
- 从头开始重新生成未完成的请求在数学上是不正确的,因为这引入了长度偏差
- 因为较短的响应更有可能在中断中幸存下来,所以每当发生中断时从头开始重新生成 这种做法会使模型更倾向于产生更短的序列
- 理解:这里应该是指每次中断后都对已经完整生成的序列进行训练这种方式本身是有长度偏好的
- 如果推理栈是批次不变 (batch-invariant) 和确定性的,这个正确性问题也可以通过使用采样器中伪随机数生成器的一致种子进行重新生成来解决
- 问题:这里所说的方法是确保训练使用 的样本是随机挑选的 ,而不是有长度偏好的?【重新随机采样能去除中断导致的长度偏好】
- 但这种方法仍然会产生重新运行解码阶段的额外成本,使其效率远低于本文 Token 粒度 WAL 方法
- 从头开始重新生成未完成的请求在数学上是不正确的,因为这引入了长度偏差
Scaling RL Framework for Million-Token Context
- 本文引入了针对百万 Token 序列上高效 RL 和 OPD 的定向优化
- 在 Rollout 阶段,采用了第 5.2.3 节中详述的可抢占和容错 Rollout 服务
- 对于推理和训练阶段,将 Rollout 数据格式分解为 lightweight 元数据和 heavy Per-Token 字段
- 在数据分发期间,可以加载整个 Rollout 数据的元数据以执行全局 shuffle 和打包布局计算
- heavy Per-Token 字段通过共享内存数据加载器加载,以消除节点内的数据冗余,并在 mini-batch 粒度上消费后立即释放,从而大大减少了 CPU 和 GPU 的内存压力
- 设备上 mini-batch 的数量根据工作负载动态确定,允许在计算吞吐量和 I/O 重叠之间进行有效的权衡
Sandbox Infrastructure for Agentic AI, 面向 Agentic AI 的沙箱基础设施
- 为满足后训练和评估期间 Agentic AI 的多样化执行需求,本文作者构建了一个生产级沙箱平台,DeepSeek Elastic Compute (DSec)
- DSec 由三个 Rust 组件组成
- API 网关 (Apiserver)
- Per-host Agent (Edge)
- 集群监视器 (Watcher)
- 以上三个组件通过自定义 RPC 协议互连,并在 3FS 分布式文件系统 (2025) 之上水平扩展
- 在生产环境中,单个 DSec 集群管理着数十万个并发的沙箱实例
- DSec 的设计基于四个观察结果:
- (1) Agentic 工作负载高度异构,范围从 lightweight 函数调用到具有不同操作系统和安全要求的完整软件工程流程
- (2) 环境镜像数量众多且体积庞大,但必须快速加载并支持迭代定制
- (3) 高密度部署要求高效的 CPU 和内存利用率
- (4) 沙箱生命周期必须与 GPU 训练计划协调,包括抢占和基于检查点的恢复。基于这些观察,作者逐一详细阐述 DSec 的四个核心设计
Four Execution Substrates Behind One Unified Interface,一个统一接口背后的四个执行底层
- DSec 公开了一个统一的 Python SDK (libdsec),它抽象了四个执行底层
- Function Call :将无状态调用分派到预热的容器池中,消除了冷启动开销
- Container :完全兼容 Docker,并利用 EROFS (2019) 按需加载以实现高效的镜像组装
- microVM :构建在 Firecracker (2020) 之上,为安全敏感、高密度的部署增加了 VM 级别的隔离
- fullVM :构建在 QEMU (2005) 之上,支持任意客户操作系统
- 这四个底层共享一个通用的 API 接口——命令执行、文件传输和 TTY 访问(在它们之间切换只需要更改一个参数)
Fast Image Loading via Layered Storage,通过分层存储实现快速镜像加载
- DSec 通过分层按需加载来协调快速启动与庞大且不断增长的镜像库
- 对于容器,基础镜像和文件系统提交作为 3FS 支持的只读 EROFS 层存储,直接挂载到 overlay lowerdirs 中
- 在挂载时将文件元数据保留在本地磁盘上
- 数据块在请求时从 3FS 获取
- 对于 microVM,DSec 使用 overlaydb (2020) 磁盘格式:
- 只读基础层位于 3FS 上以跨实例共享,而写入则转到本地的写时复制层
- 这种快照是可链接的,有助于高效的版本控制和毫秒级的恢复
- 对于容器,基础镜像和文件系统提交作为 3FS 支持的只读 EROFS 层存储,直接挂载到 overlay lowerdirs 中
Density Optimizations Under Massive Concurrency,大规模并发下的密度优化
- 为容纳每个集群数十万个沙箱,DSec 解决了两个资源瓶颈
- 第一:DSec 减轻了虚拟化环境中重复的页面缓存占用,并应用内存回收以实现安全的超额订阅
- 第二:减轻了容器运行时中的自旋锁争用,从而降低了每个沙箱的 CPU 开销,显著提高了每主机的打包密度
Trajectory Logging and Preemption-Safe Resumption,轨迹记录和可安全抢占的恢复
- DSec 为每个沙箱维护一个全局有序的轨迹日志,持久记录每个命令调用及其结果
- 该轨迹有三个目的:
- (1) 客户端快进 (client fast-forwarding)
- 当一个训练任务被抢占时,沙箱资源仍然保留
- 恢复后,DSec 为先前完成的命令重放缓存的结果 ,加速任务恢复,同时防止因重新执行非幂等操作而导致的错误
- (2) 细粒度的来源追踪 (fine-grained provenance)
- 每个状态变化的来源和相应结果都是可追溯的
- (3) 确定性重放 (deterministic replay)
- 任何历史会话都可以从其轨迹忠实地重现
- (1) 客户端快进 (client fast-forwarding)
Standard Benchmark Evaluation
Evaluation Setup
Knowledge and Reasoning,知识和推理
- 知识和推理数据集包括 MMLU-Pro (2024b)、GPQA (2023)、Human Last Exam (2025)、Simple-QA Verified (2025)、Chinese-SimpleQA (2024)、LiveCodeBench-v6 (2024)、CodeForces (内部基准)、HMMT 2026 Feb、Apex (2025)、Apex Shortlist (2025)、IMOAnswerBench (2025) 和 PutnamBench (2024)
- 对于代码
- 本文在 LiveCodeBench-v6 和一个内部的 Codeforces 基准上评估 DeepSeek-V4 系列
- 对于 Codeforces
- 收集了 14 场 Codeforces Division 1 比赛,包含 114 个问题(2025 年 5 月 - 2025 年 11 月)
- Elo 评分计算如下
- 对于每场比赛,为每个问题生成 32 个候选解决方案
- 对于每个问题,独立地无放回地采样 10 个解决方案,并将它们随机排序以形成提交序列
- 每个提交都根据由领域专家构建的测试套件进行评判
- 一个已解决问题的得分遵循 OpenAI (2025) 的惩罚方案:
- 模型获得解决了同一问题且先前失败尝试次数相同的人类参与者的中位数得分
- 这为每个采样的提交序列产生一个比赛总分,然后通过标准的 Codeforces 评分系统将其转换为比赛排名,随后转换为估计的评分
- 模型获得解决了同一问题且先前失败尝试次数相同的人类参与者的中位数得分
- 比赛级别的预期评分定义为在所有可能的 10 个提交的随机选择和排序上,该估计评分的期望值
- 模型的总体评分是所有 14 场比赛中这些上下文级别预期评分的平均值
- 对于推理和知识任务
- 温度设置为 1.0
- 上下文窗口分别设置为 8K、128K 和 384K Token ,对应 Non-think、 High 和 Max 模式
- 对于数学任务(例如 HMMT、IMOAnswerBench、Apex 和 HLE)
- 使用以下模板进行评估:
- “{question}\nPlease reason step by step, and put your final answer within \boxed{}. ”
- 对于 DeepSeek-V4-Pro-Max 在数学任务上,使用以下模板来引出更深入的推理:
- “Solve the following problem. The problem may ask you to prove a statement, or ask for an answer. If finding an answer is required, you should come up with the answer, and your final solution should also be a rigorous proof of that answer being valid.\n\n{question}”
- 使用以下模板进行评估:
- 对于形式化数学任务
- 在 Lean v4.28.0-rcl (2021) 上的 Agentic 环境中进行评估,可以访问 Lean 编译器和语义策略搜索引擎,最多运行 500 次工具调用,并采用最大推理 Effort
- 本文评估了一个计算量更大的流程,其中首先生成候选的自然语言解决方案,并通过自验证 (2025) 进行过滤,然后将保留的解决方案作为指导提供给形式化 Agent,以证明相应的 Lean 陈述
- 该设计使用非形式化推理来改进探索,同时通过形式化验证保持严格的正确性
- 只有当严格的验证器 Comparator 在两种设置下都接受时,提交才被计为正确
- 本文为 K2.6 和 GLM-5.1 留了一些空白,因为它们的 API 过于繁忙,无法返回对本文查询的响应
- 问题:这些模型开源了,可以自己部署了测试一下吧
1M-Token Context
- DeepSeek-V4 系列支持 1M Token 上下文,本文通过选择 OpenAI MRCR (2024b) 和 CorpusQA (2026) 作为基准来评估长上下文场景下的模型性能
- 本文在这些任务上重新评估了 Claude Opus 4.6 和 Gemini 3.1 Pro,目标是标准化所有模型的配置
- 本文没有评估 GPT-5.4,因为其 API 未能对本文的大部分查询做出响应
Agent
- Agent 数据集包括 Terminal Bench 2.0 (2026)、SWE-Verified (2024e)、SWE Multilingual (2025)、SWE-Pro (2025)、BrowseComp (2025)、MCPAtlas 的公共评估集 (2026)、GDPval-AA (AA, 2025; 2025) 和 Tool-Decathlon (2025)
- 对于代码 Agent 任务 (SWE-Verified, Terminal-Bench, SWE-Pro, SWE Multilingual)
- 使用内部开发的评估框架评估 DeepSeek-V4 系列
- 该框架提供了一组最小工具(一个 bash 工具和一个文件编辑工具)
- 最大交互步数设置为 500,最大上下文长度设置为 512K Token
- 关于 Terminal-Bench 2.0,作者承认 GLM-5.1 指出的环境相关问题
- 注:这个是在 GLM-5 的 TR 里面提到的(不是 GLM-5.1),Terminal-Bench 2.0 版本上有些模糊指令的修复
- 尽管如此,为了保持一致性,文章还是报告了在原始 Terminal-Bench 2.0 数据集上的性能
- 在 Terminal-Bench 2.0 Verified 子集上,DeepSeek-V4-Pro 的得分约为 72.0
- 使用内部开发的评估框架评估 DeepSeek-V4 系列
- 对于搜索 Agent 任务 (BrowseComp, HLE w/ tool)
- 也使用带有网络搜索和 Python 工具的内部测试工具,并将最大交互步数设置为 500,最大上下文长度设置为 512K Token
- 对于 BrowseComp,本文使用与 DeepSeek-V3.2 (2025) 相同的丢弃所有上下文管理策略
Evaluation Results
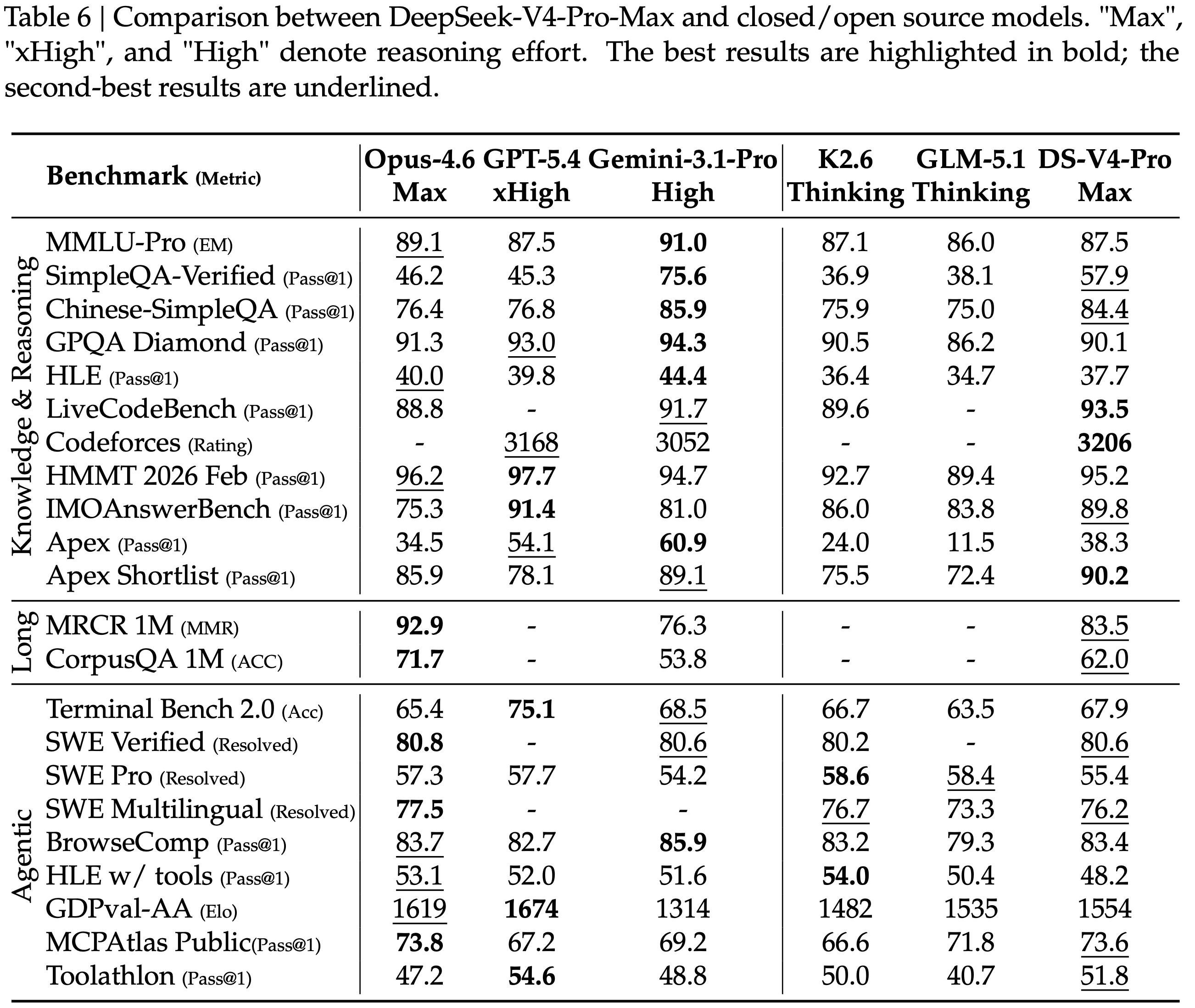
- 表 6 展示了 DeepSeek-V4-Pro-Max 与其他闭源/开源模型的比较
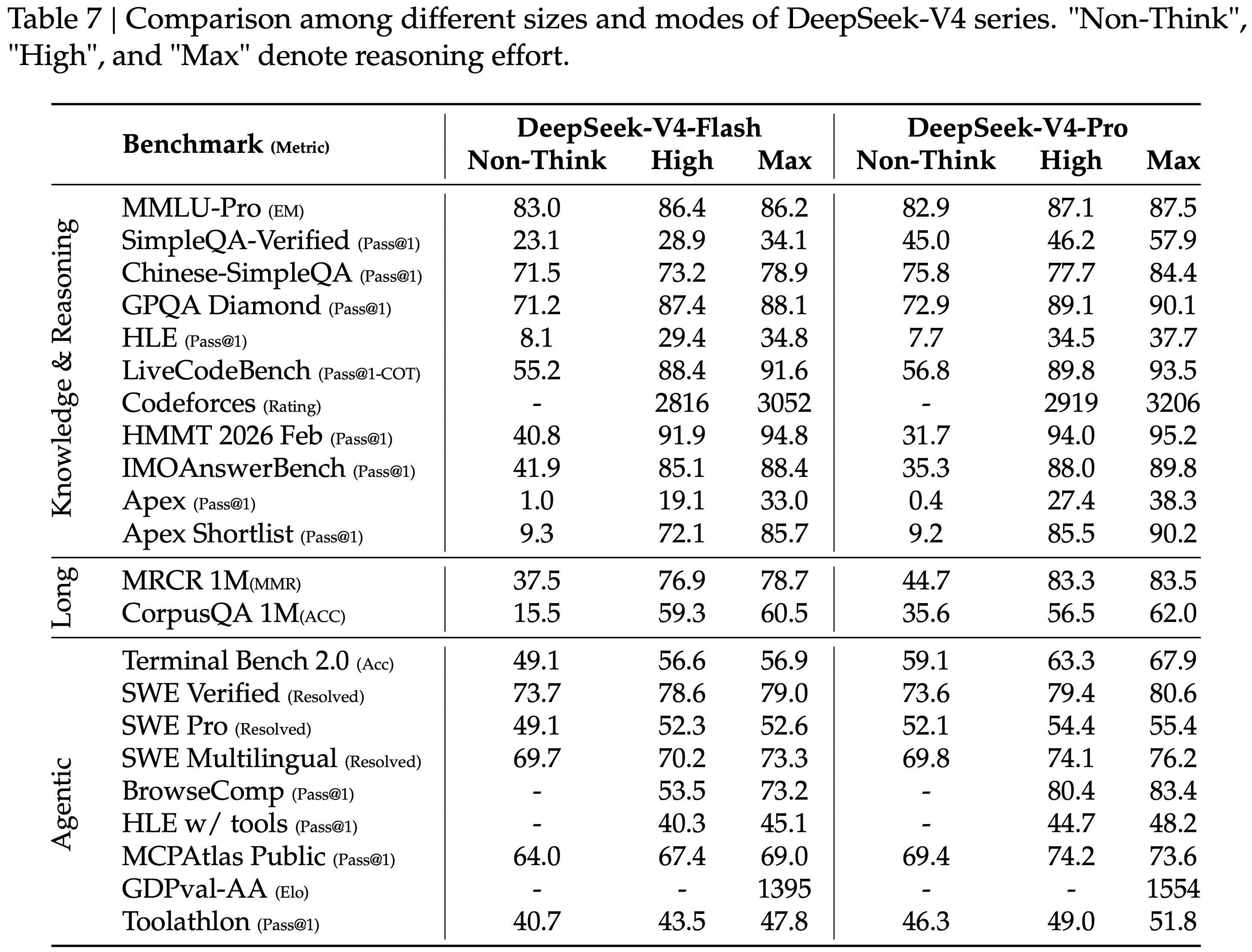
- 表 7 展示了 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 的不同模式
Knowledge
- 在通用世界知识的评估中,DeepSeek-V4-Pro-Max(DeepSeek-V4-Pro 的最大推理 Effort 模式)在开源大语言模型中建立了新的最高水平
- 如 SimpleQA-Verified 所示,DeepSeek-V4-Pro-Max 显著优于所有现有的开源基线,高出 20 个绝对百分点,但仍落后于 Gemini-3.1-Pro
- 在教育知识和推理领域,DeepSeek-V4-Pro-Max 在 MMLU-Pro、GPQA 和 HLE 基准上略微优于 Kimi 和 GLM,落后于领先的专有模型
- 在基于知识的任务上,DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 之间存在显著的性能差距
- 这是意料之中的,因为更大的参数数量有助于在预训练期间保留更多知识
- 当分配更高的推理 Effort 时,两个模型在知识基准上都表现出改进的结果
1M-Token Context
- DeepSeek-V4-Pro 在 MRCR 任务上优于 Gemini-3.1-Pro,该任务衡量上下文检索能力,但仍落后于 Claude Opus 4.6
- 如图 9 所示,在 128K 上下文窗口内,检索性能保持高度稳定
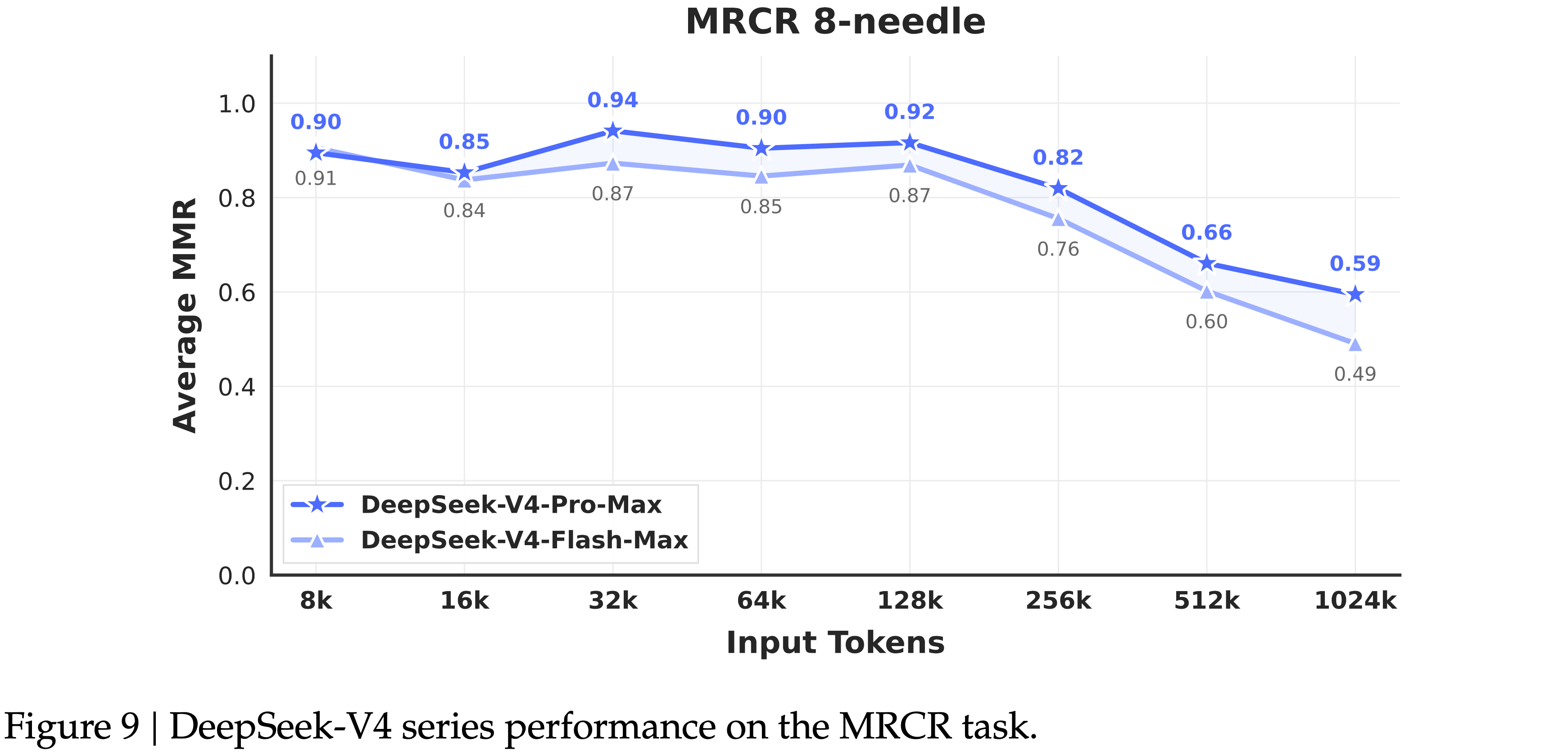
- 虽然在 128K Token 之后性能下降变得可见,但该模型在 1M Token 处的检索能力与专有和开源同行相比仍然非常强大
- 与 MRCR 不同,CorpusQA 更类似于真实场景
- 评估结果表明 DeepSeek-V4-Pro 优于 Gemini-3.1-Pro
Reasoning Effort
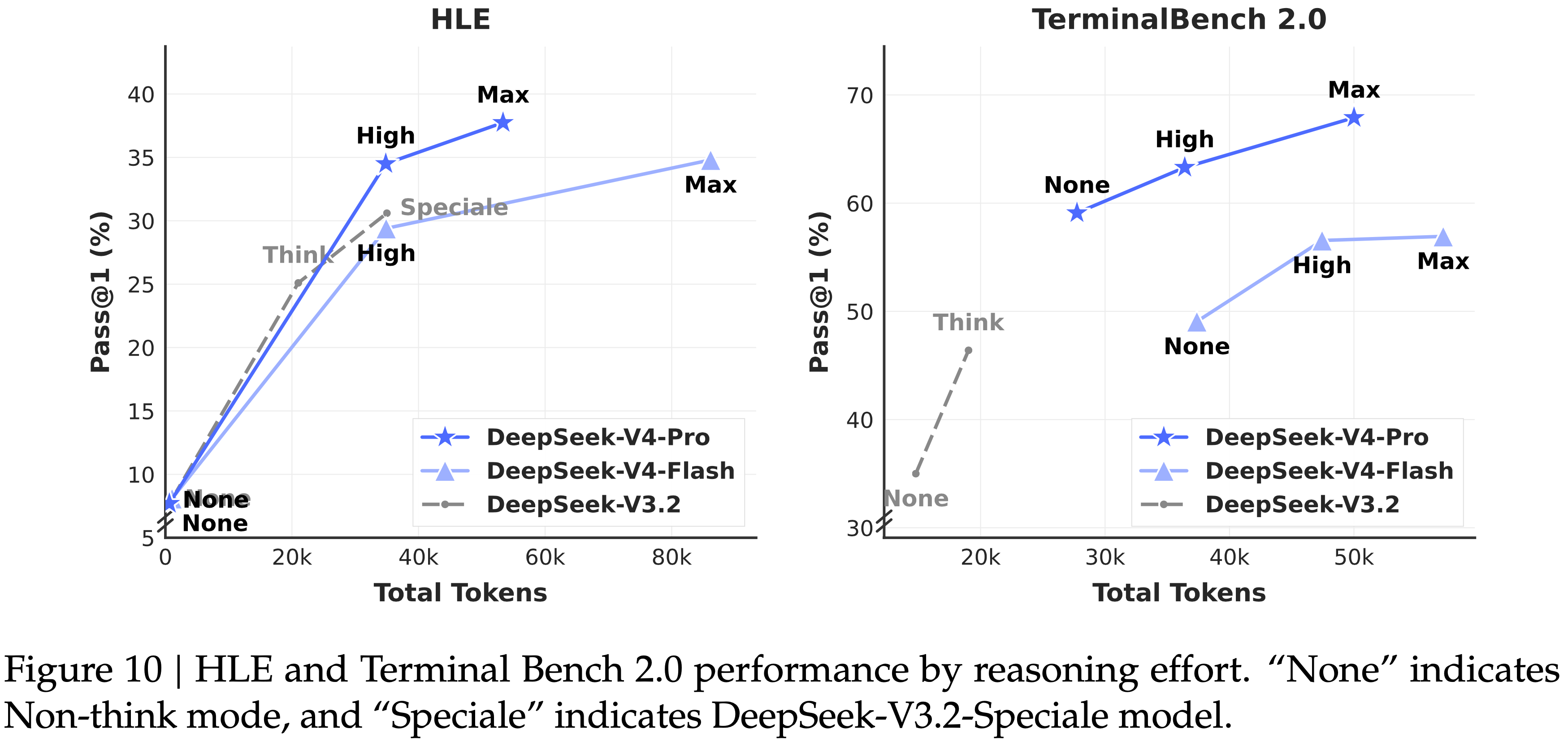
- 如表 7 所示,Max 模式(在 RL 中采用更长的上下文和减少的长度惩罚)在最具挑战性的任务上优于 High 模式
- 图 10 展示了 DeepSeek-V4-Pro、DeepSeek-V4-Flash 和 DeepSeek-V3.2 在代表性推理和 Agentic 任务上的性能和成本比较
- 通过扩展测试时计算,DeepSeek-V4 系列相比其前身取得了显著的改进
- 在像 HLE 这样的推理任务上,DeepSeek-V4-Pro 显示出比 DeepSeek-V3.2 更高的 Token 效率
Performance on Real-World Tasks
- 标准化基准测试通常难以捕捉多样化真实世界任务的复杂性,从而在测试结果和实际用户体验之间产生差距
- 为了弥合这一差距,本文作者特别开发了专有的内部指标,优先考虑真实世界的使用模式而非传统基准
- 这种方法确保本文的优化转化为实实在在的好处
- 本文的评估框架特别针对 DeepSeek API 和 Chatbot 的主要用例,使模型性能与实际需求保持一致
Chinese Writing(中文写作)
- DeepSeek 的主要用例之一是中文写作,对功能性写作和创意写作进行了严格的评估
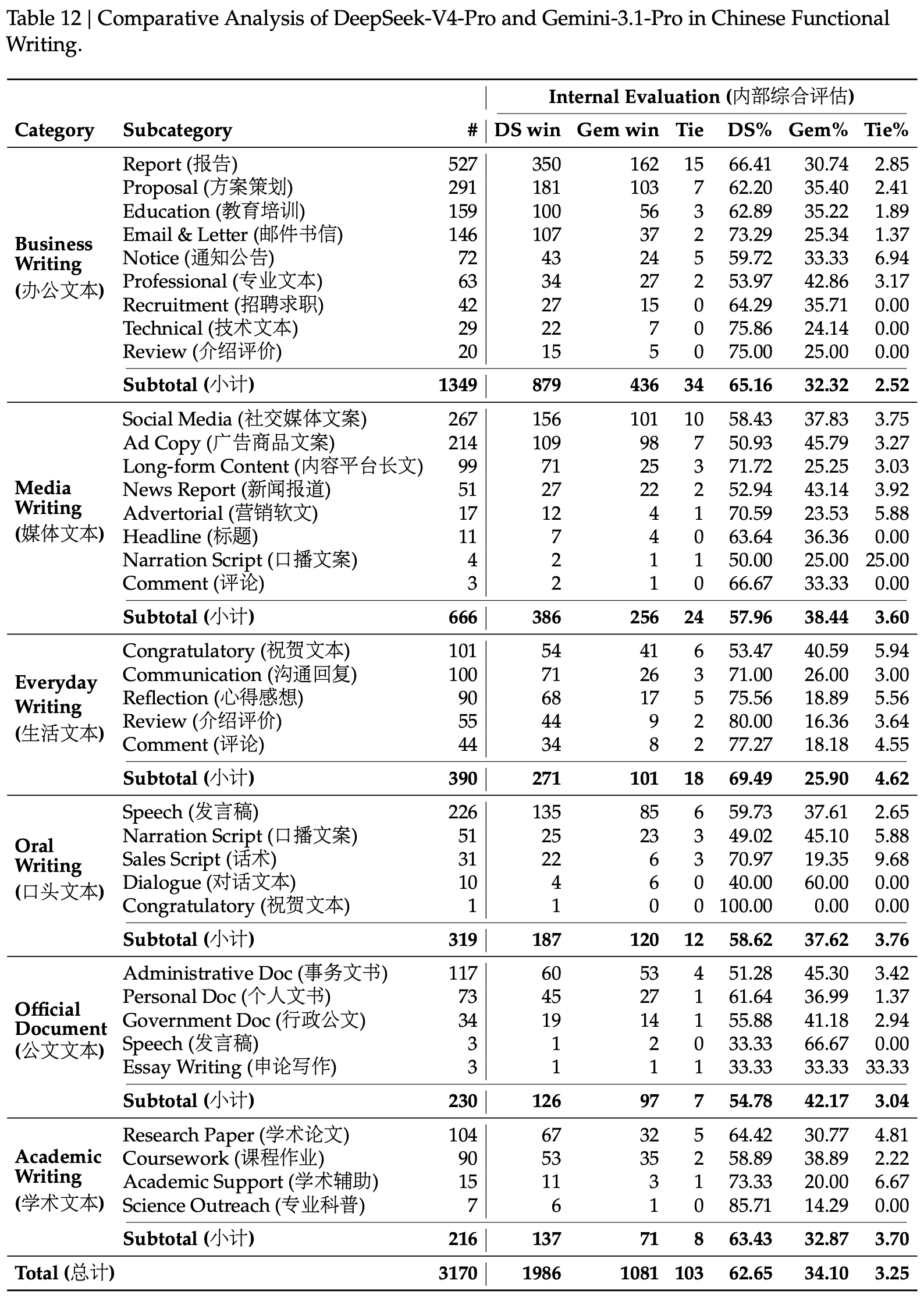
- 表 12 展示了 DeepSeek-V4-Pro 和 Gemini-3.1-Pro 在功能性写作任务上的 Pairwise 比较
- 这些任务包括日常写作查询,其中 prompts 通常简洁明了
- Gemini-3.1-Pro 被选为基线是因为它在评估中是中文写作方面表现最佳的外部模型
- 结果表明,DeepSeek-V4-Pro 以 \(62.7%\) 对比 \(34.1%\) 的总体胜率优于基线
- 这主要是因为 Gemini 在中文写作场景中偶尔会允许其固有的风格偏好覆盖用户的明确要求
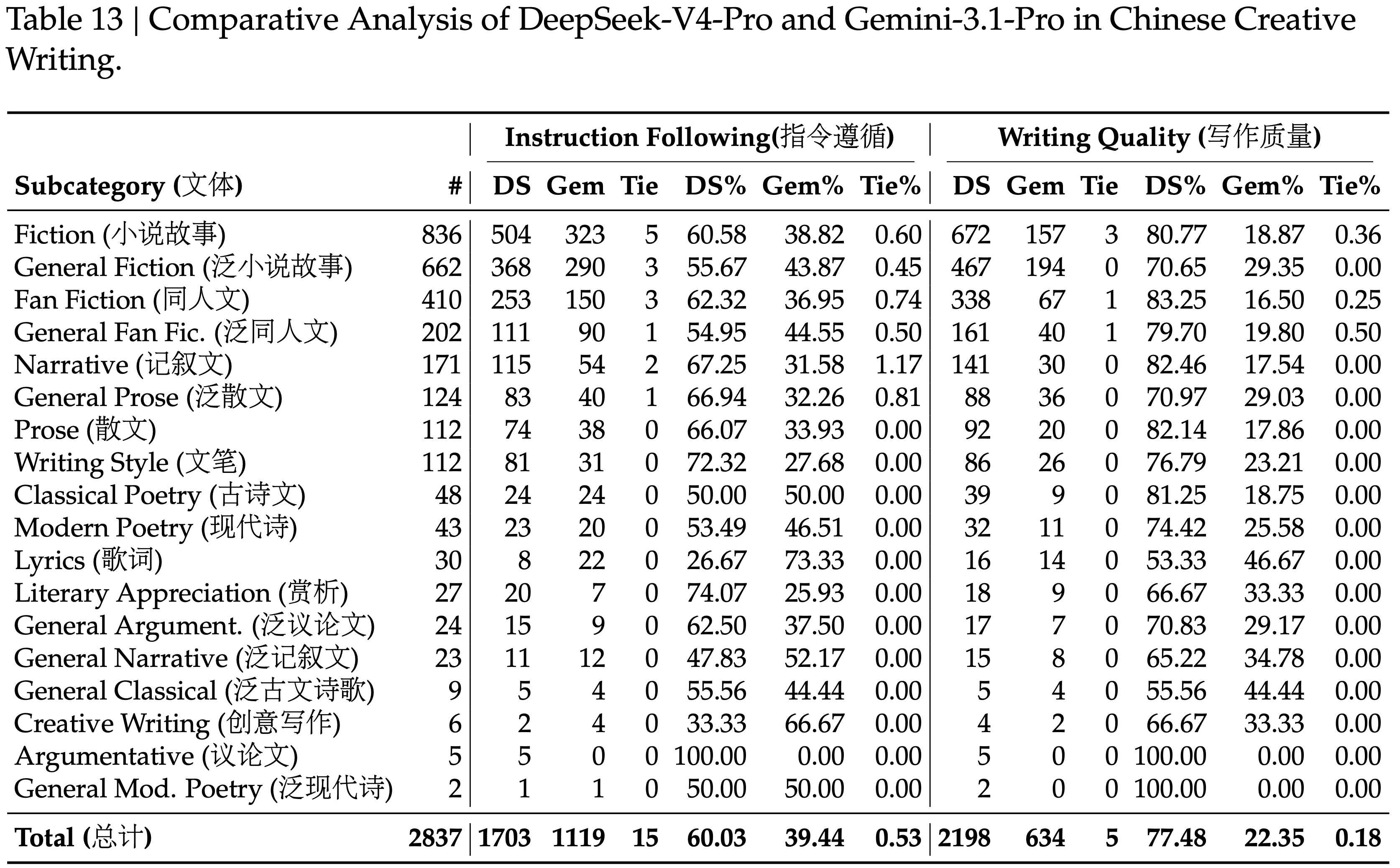
- 表 13 展示了创意写作比较,该比较沿着两个轴进行评估:
- 指令遵循和写作质量
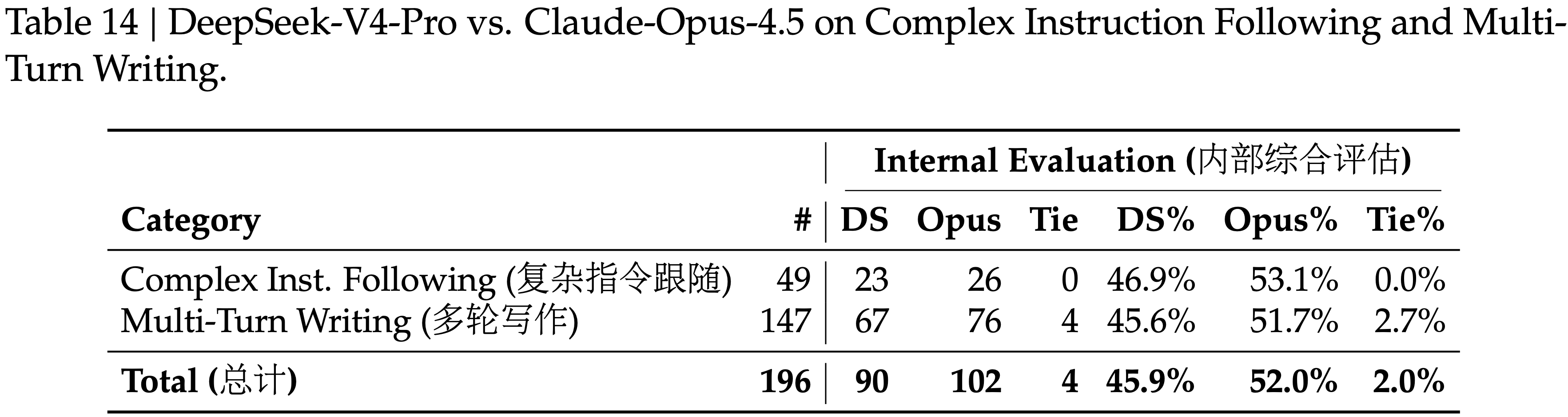
- 与 Gemini-3.1-Pro 相比,DeepSeek-V4-Pro 在指令遵循方面达到了 \(60.0%\) 的胜率,在写作质量方面达到了 \(77.5%\) 的胜率,表明指令遵循方面略有改进,而写作质量方面有显著提升
- DeepSeek-V4-Pro 在汇总的用户案例分析中产生了更优的结果,但仅限于最具挑战性的 prompts(特别是那些涉及高复杂性约束或多轮场景的 prompts)的评估显示,Claude Opus 4.5 相对于 DeepSeek-V4-Pro 保持了性能优势
- 如表 14 所示,Claude Opus 4.5 实现了 \(52.0%\) 的胜率,而 DeepSeek-V4-Pro 为 \(45.9%\)
Search
- 搜索增强的问答是 DeepSeek 聊天机器人的核心能力
- 在 DeepSeek 网页和应用上,“non-think” 模式采用 RAG,而“thinking” 模式利用 Agentic 搜索
- 理解:所以平时我们没有打开 Thinking 模式时,搜索问答都是 RAG 模式的吗?
Retrieval Augmented Search(RAG)
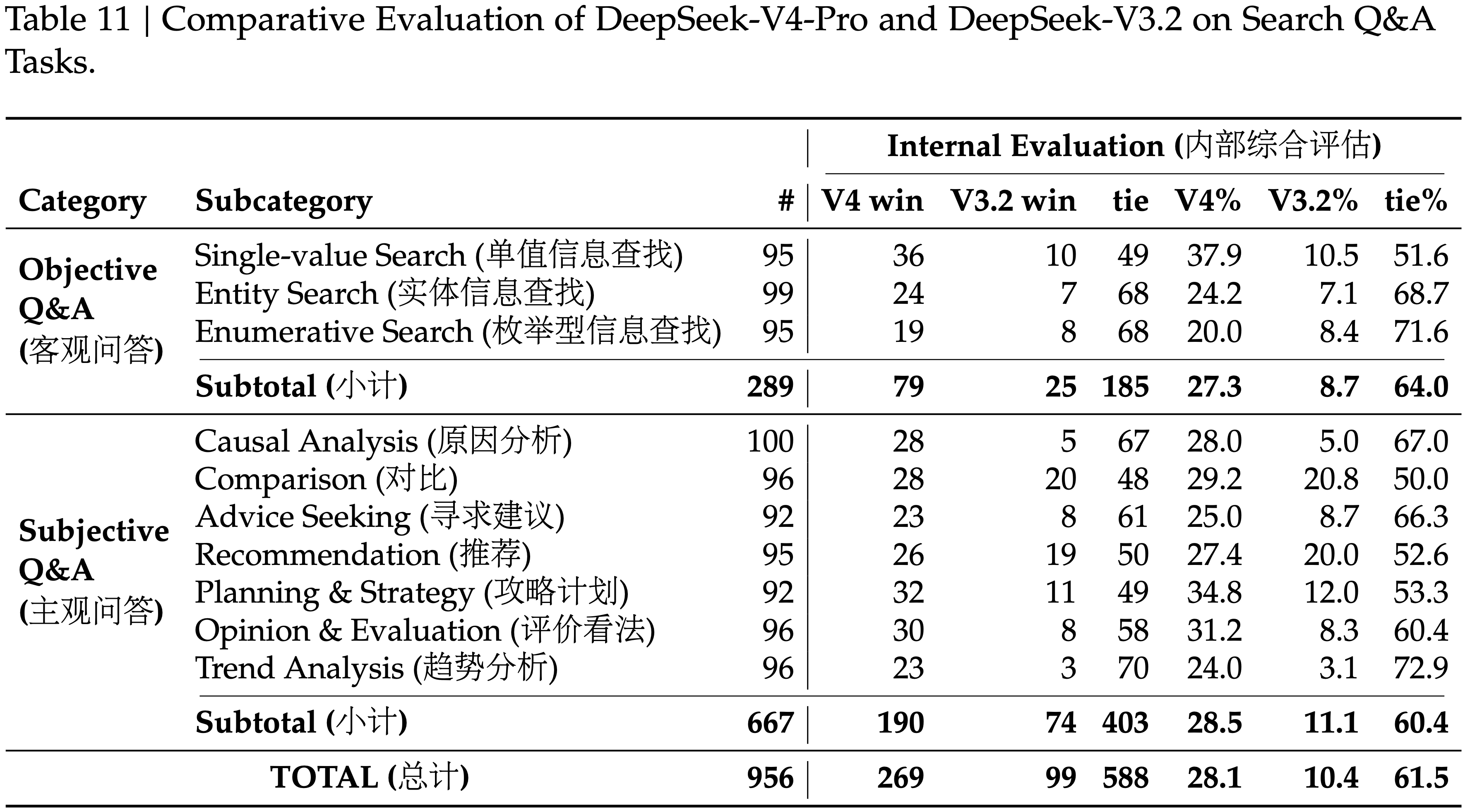
- 进行了一项 Pairwise 评估,比较 DeepSeek-V4-Pro 和 DeepSeek-V3.2 在客观和主观问答类别上的表现
- 如表 11 所示,DeepSeek-V4-Pro 以显著的幅度优于 DeepSeek-V3.2,在两个类别上都显示出一致的优势
- 最显著的提升出现在单值搜索和规划与策略任务中,表明 DeepSeek-V4-Pro 擅长定位精确的事实答案并从检索到的上下文中合成结构化计划
- 但 DeepSeek-V3.2 在比较和推荐任务上仍然具有相对竞争力,表明 DeepSeek-V4-Pro 在需要对搜索结果进行平衡、多角度推理的场景中仍有改进空间
Agentic Search
- 与标准 RAG 不同,Agentic 搜索使模型能够针对每个查询迭代调用搜索和获取工具,从而显著提高整体搜索性能
- 对于 DeepSeek-Chat 中的思维模式,本文优化了 Agentic 搜索功能,以在预定义的“思维预算”内最大化响应准确性
- 如表 9 所示,Agentic 搜索在复杂任务上始终优于 RAG
- 而且其成本仍然非常高效,Agentic 搜索仅比标准 RAG 略贵(见表 10)
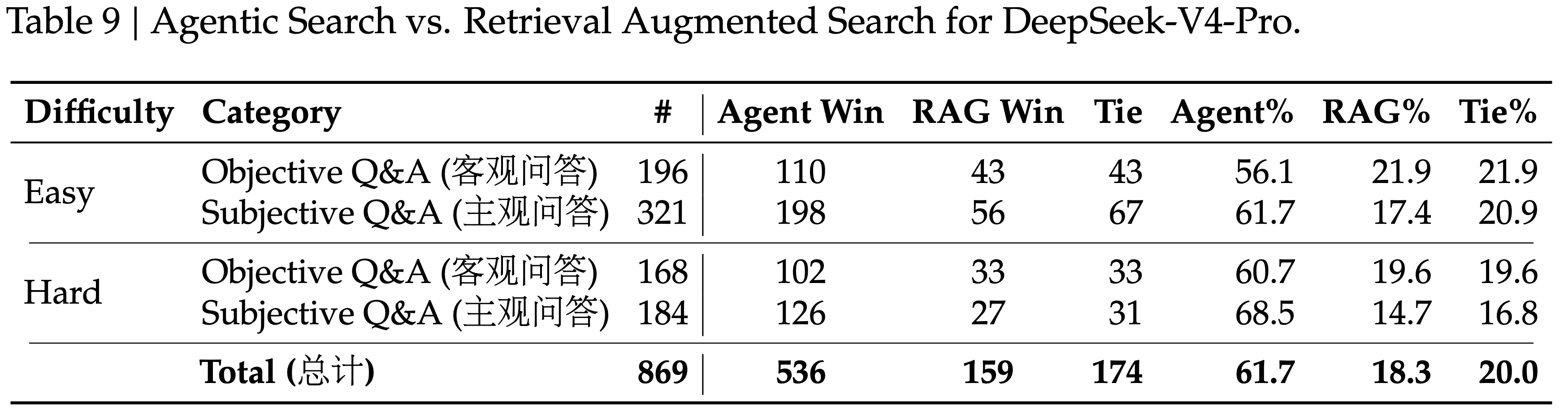

- 而且其成本仍然非常高效,Agentic 搜索仅比标准 RAG 略贵(见表 10)
White-Collar Task,白领任务
- 为了严格评估模型在复杂企业生产力场景中的效用,本文作者构建了一套包含 30 个高级中文专业任务的综合套件
- 这些工作流程有意包含了高层次的认知需求,包括深入的信息分析、全面的文档生成和细致的文档编辑,涵盖了 13 个关键行业(例如,金融、教育、法律和技术)的多样化领域
- 评估在一个配备了基本工具(包括 Bash 和网络搜索)的内部 Agent 工具架中进行
- 鉴于这些任务的开放性,自动化指标通常无法捕捉高质量响应的细微差别
- 本文进行了人工评估,比较 DeepSeek-V4-Pro-Max 和 Opus-4.6-Max 的性能
- 标注者盲目评估了模型输出的四个维度:
- 任务完成度 (Task Completion) :核心问题是否成功解决
- 指令遵循 (Instruction Following) :对特定约束和指令的遵守情况
- 内容质量 (Content Quality) :事实准确性、逻辑连贯性和专业语气
- 格式美观度 (Formatting Aesthetics) :布局可读性和视觉呈现
- 如图 11 所示
- DeepSeek-V4-Pro-Max 在多样化的中文白领任务上优于 Opus-4.6-Max,实现了 \(63%\) 的不败率,并在分析、生成和编辑任务中展现出一致的优势
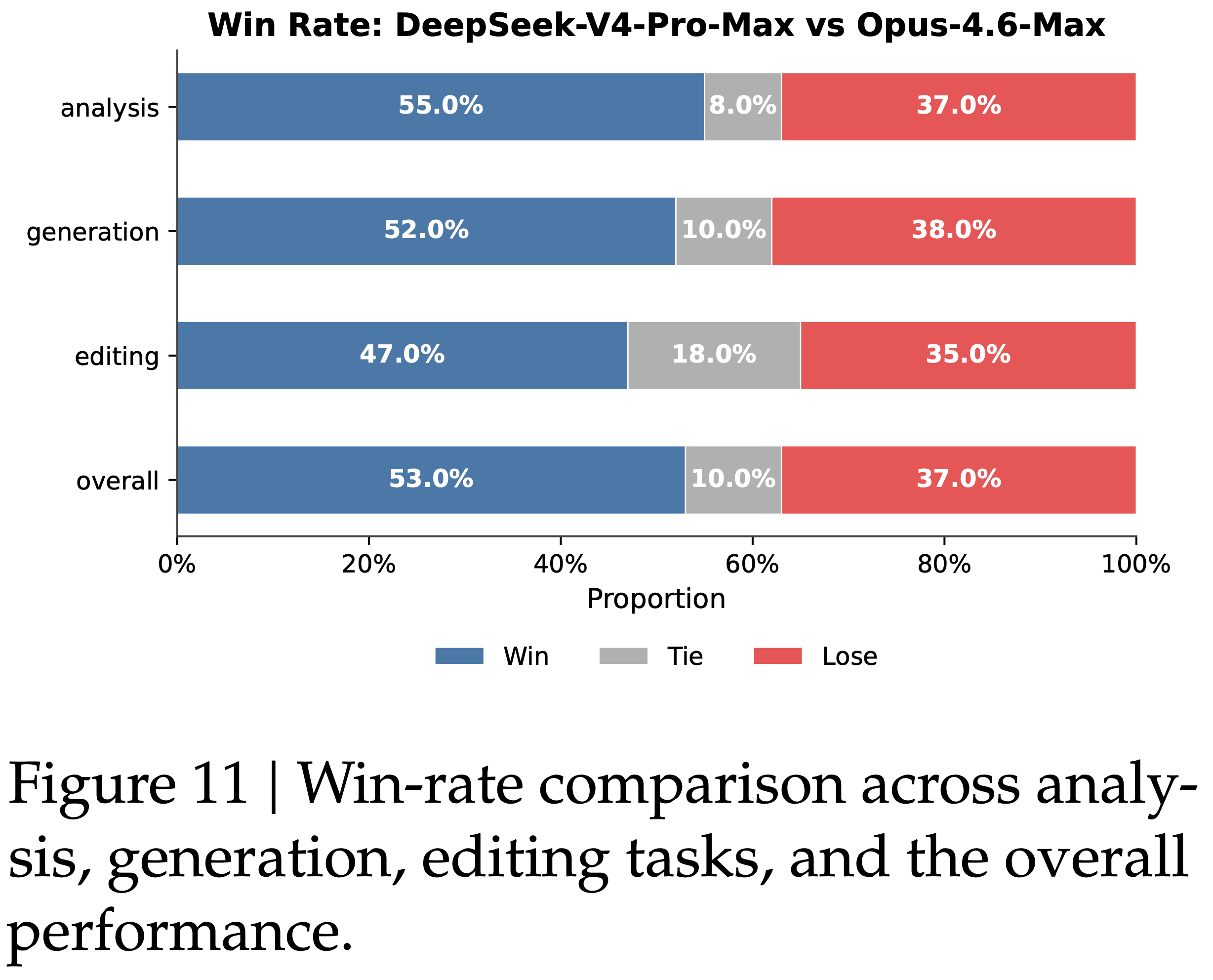
- DeepSeek-V4-Pro-Max 在多样化的中文白领任务上优于 Opus-4.6-Max,实现了 \(63%\) 的不败率,并在分析、生成和编辑任务中展现出一致的优势
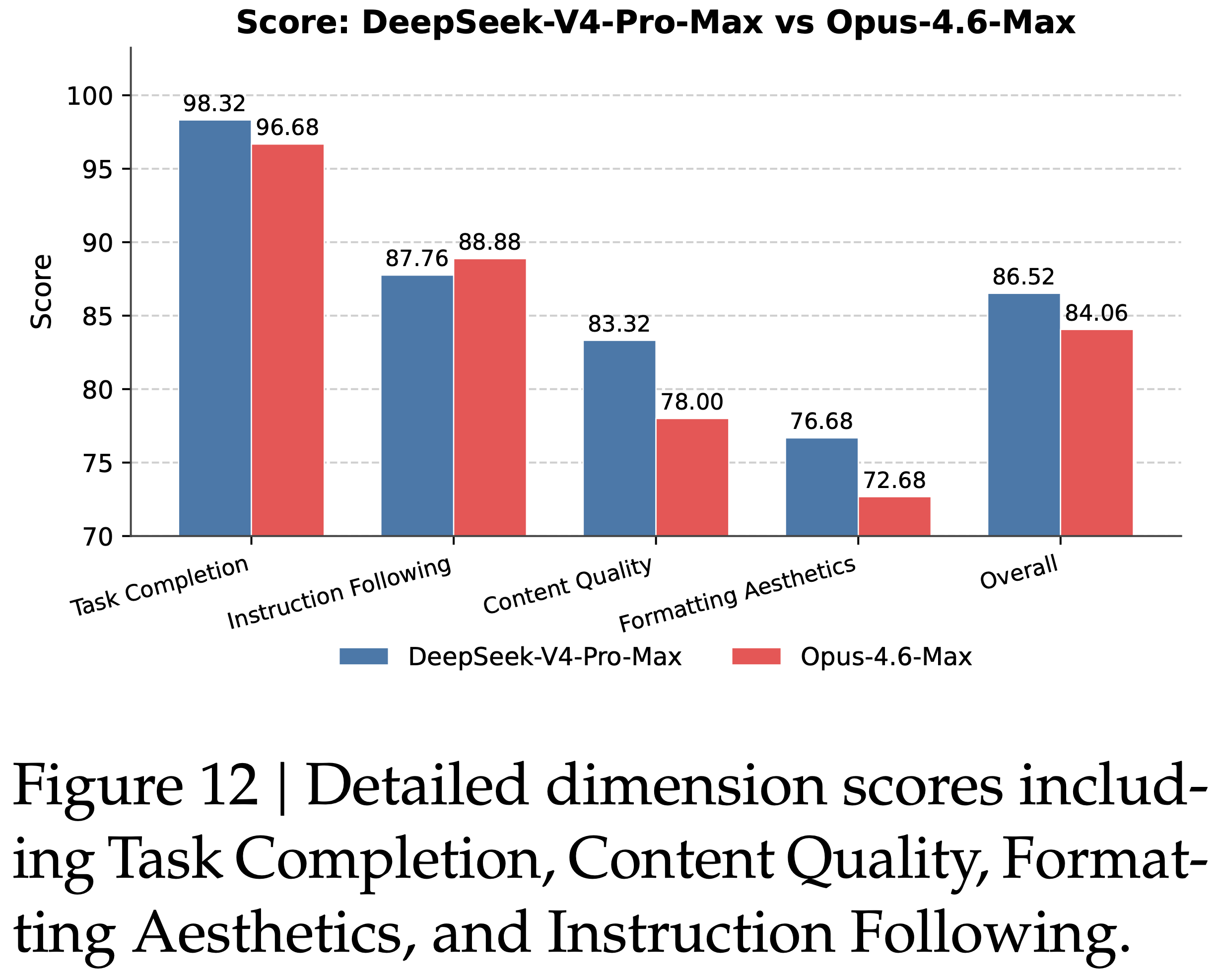
- 图 12 中显示的详细维度分数突出了模型在任务完成度和内容质量方面的主要优势
- DeepSeek-V4-Pro-Max 通过经常提供补充见解和自我验证步骤,主动预测用户的隐性意图
- DeepSeek-V4-Pro-Max 还在长文本生成方面表现出色,提供深入、连贯的叙述,而不是依赖 Opus-4.6-Max 经常产生的过于简单的要点
- 且该模型严格遵守正式的专业惯例,例如标准化的中文层次编号
- 弱势项:
- 在指令遵循方面,DeepSeek-V4-Pro-Max 偶尔会忽略特定的格式约束,略微落后于 Opus
- DeepSeek-V4-Pro-Max 将大量文本输入压缩为简洁摘要的能力较差
- DeepSeek-V4-Pro-Max 格式美观度在演示幻灯片的整体视觉设计方面仍有很大的改进空间
- 图 13、14 和 15 展示了几个测试用例(注:由于某些输出的长度过长,仅显示部分页面)


- 图 13、14 和 15 展示了几个测试用例(注:由于某些输出的长度过长,仅显示部分页面)
Code Agent
- For 代码 Agent 能力,本文从真实的内部研发工作负载中整理了任务
- 从 \(50+\) 名内部工程师那里收集了 \(\sim 200\) 个具有挑战性的任务
- 涵盖功能开发、错误修复、重构和诊断,涉及多种技术栈,包括 PyTorch、CUDA、Rust 和 C++
- 问题:DeepSeek 内部的工作主要是 Python,Rust 和 C++ 等
- 每个任务都附有其原始仓库、相应的执行环境以及人工标注的评分细则
- 经过严格的质量过滤后,保留了 30 个任务作为评估集
- 涵盖功能开发、错误修复、重构和诊断,涉及多种技术栈,包括 PyTorch、CUDA、Rust 和 C++
- 如表 8 所示,DeepSeek-V4-Pro 显著优于 Claude Sonnet 4.5,并接近 Claude Opus 4.5 的水平

- 在一项针对 DeepSeek 内部(在日常工作中使用 DeepSeek-V4-Pro 进行 Agentic 编码的经验)开发者和研究人员 \((N = 85)\) 的调查中
- 询问与其他前沿模型相比,DeepSeek-V4-Pro 是否已准备好作为他们的默认和主要编码模型:
- \(52%\) 的人回答“是”,\(39%\) 的人“倾向于是”,只有不到 \(9%\) 的人回答“否”
- 受访者发现 DeepSeek-V4-Pro 在大多数任务上都能提供令人满意的结果
- 但存在琐碎的错误、对模糊 prompts 的误解以及偶尔的过度思考
- 询问与其他前沿模型相比,DeepSeek-V4-Pro 是否已准备好作为他们的默认和主要编码模型: