注:本文包含 AI 辅助创作
Paper Summary
- 整体说明:
- 本文对 On-policy distillation(OPD) 进行了系统分析,OPD 的成功需要满足两个条件:
- 思维模式一致性 (thinking-pattern consistency)
- 理解:学生和教师应共享兼容的思维模式(thinking pattern)
- 存在超越学生训练所见范围的真正新知识 (genuinely new knowledge)
- 理解:即使思维模式一致且得分更高,教师也还必须提供学生在其训练中未曾见过的真正新能力
- 思维模式一致性 (thinking-pattern consistency)
- 当上述条件不满足时可以有一些补救措施:
- Off-policy 冷启动
- 注:附录 C.1 中证明了:SFT 冷启动导致了 student 和 teacher 之间更好、更稳定的匹配
- 教师对齐的 Prompt 选择 (Teacher-aligned prompt selection)
- 注意:这里的 Prompt 不是数据(Query),是 Prompt 模板
- 从实验看,这里的 Prompt Template 对 OPD 的影响不小,详情见 6.2
- Off-policy 冷启动
- 其他:OPD 在长轨迹上会发生奖励退化现象
- 本文观点:OPD 中看似免费的密集 Token-level 奖励是有代价的,OPD 在长轨迹上会消失
- 理解:教师遇到学生的长文时,是懵的,因为他自己不一定会生成这个前缀(没人考核他的这个能力),所以教师此时的信号对学生的可参考性不高,继续训练可能导致模型崩溃
- 举例:学生做数学题时,如果已经写了很多错误的步骤了,老师可能也看不懂了,不知道怎么教导学生了
- 注:这在长 CoT 和 多步 Agentic 场景中要尤为注意
- Agentic 中的一个改进思路:
- 推测:如果教师具备从错误步骤中恢复的能力(即不管从哪里续写都可以成功的教师),那么这种教师应该不太会受这种情况影响
- 训练教师时就给教师一些从错误中恢复的能力,这样可以避免遇到错误的步骤,教师不知道怎么办
- 本文的有趣实验:
- 从弱到强的反向蒸馏实验:
- 从学生视角看,同家族的 1.5B 和 7B 教师在分布上是不可区分的
- 从 Token 层面看,成功的 OPD 的特点是在学生访问的状态上,高概率 Token 的渐进对齐,以及一个集中的共享 Token 集,该集合集中了绝大部分(97%-99%)的概率质量
- 从弱到强的反向蒸馏实验:
- 本文对 On-policy distillation(OPD) 进行了系统分析,OPD 的成功需要满足两个条件:
- 个人思考:
- 可以考虑提出一种新的方法,针对不同长度的 Token 使用不同的 Advantage,比如前面的 Token 使用 OPD 的损失,后面的 Token 使用传统的 GRPO Advantage?
Introduction and Discussion
- Qwen3 (2025)、MiMo (2026) 和 GLM-5 (2026) 等都在其后训练流程中采用了 OPD
- Thinking Machines Lab (2025) 以极小的 RL 计算成本复现了 Qwen3 OPD 的配方,独立证实了同策略、密集的监督是一种实用高效的替代方案
- OPD 的一个失败模式:
- 一个更强的教师可能反而无法改进学生
- 注:很少有研究探讨为什么教师的 Token-level 信号能将学生分布导向期望的方向,或者它失败的条件

Phenomenology,现象学
- 本文第三节识别了 OPD 成功的关键因素:
- (i) 思维模式一致性(thinking-pattern consistency) :
- 学生和教师应共享一致的思维模式(例如,它们在 Top-\(k\) Token 分布上有更高的重叠率)
- 即使教师获得了更高的基准分数,不匹配的思维模式会产生较低的重叠率,且训练无法完全恢复
- (ii) 更高的分数 不等于 新知识 :
- 即使思维模式一致且基准分数更高,教师也应提供学生尚未获得的知识
- 当两个模型在相同的数据和配方上训练 时,它们会收敛到各自规模下的相似分布 ,导致 教师几乎没有可迁移的信号
- 只有当教师拥有学生未曾见过的知识时,OPD 才能产生显著的收益
- (i) 思维模式一致性(thinking-pattern consistency) :
- 本文通过反向蒸馏实验验证了这两个条件
- 说明 OPD 学习的是思维模式,而不仅仅是受益于模式一致性,并且训练动态可以完全与基准分数解耦
Mechanism
- 本文第四节进行了 Token-level 机制研究
- 成功的 OPD 都表现出一个一致的特征(在所有研究的设置中):
- 在学生访问的状态上,学生和教师的分布变得越来越相似
- 高概率 Token 越来越多地重合(重叠率从 \(72%\) 上升到 \(91%\)),两个分布之间的熵差距缩小,且共享的 Top-\(k\) Token 集中了 \(97 - 99%\) 的组合概率质量
- 成功模式的表现总结:重叠率稳步上升, Token-level 优势改善,熵差距缩小
- 失败的运行从一开始就表现出停滞的重叠率和持续的熵不匹配
- 将监督限制在重叠 Token 上就能匹配完整的 Top-\(k\) 性能,证实了重叠集是 OPD 梯度信号的主要作用点
Recipe
- 第五节提出了两种互补的策略,可以在原本失败的配置中恢复 OPD:
- (i) Off-policy 冷启动(off-policy cold start)
- 在 OPD 之前,在教师生成的 Rollout 上进行一个预热 SFT 阶段,通过提高初始重叠率来弥合思维模式差距
- 附录 C.1 中证明了:SFT 冷启动导致了 student 和 teacher 之间更好、更稳定的匹配
- (ii) 与教师对齐的 Prompt 选择(teacher-aligned prompt selection)
- 使用来自教师 Post-training 数据的 Prompt,以锐化高概率 Token 上的对齐
- 注:但代价是学生熵显著降低,需要与分布外的 Prompt 混合使用
- 在这两种情况下,恢复后的运行都表现出与 第四节 中自然成功的运行相同的动态特征:重叠率稳步上升, Token-level 优势改善,熵差距缩小
- (i) Off-policy 冷启动(off-policy cold start)
OPD 密集监督的代价
- 奖励质量随着轨迹深度系统地下降,并且不稳定性起源于较后的 Token,然后反向传播到整个轨迹
- 即使是失败的教师也能提供与 Rollout 正确性全局相关的奖励 ,这表明失败的原因不在于信号质量,而在于局部优化几何
- 一个较大的教师可能诱导出一个在学生策略周围局部平坦的奖励景观,使得 Token-level 梯度无效(尽管存在一个信息丰富的全局信号)
- 这些发现揭示了监督密度和监督可靠性之间的基本矛盾,并指出了当前 OPD 在长时程推理和 Agentic 设置中的局限性
Preliminaries
Notation
- 令:
- \(x = (x_{1},\ldots ,x_{n})\) 表示一个输入 Prompt
- \(y = (y_{1},\ldots ,y_{m})\) 表示一个 Response
- 将 \(y_{< t}\) 记为到第 \(t\) 步为止的前缀:
$$ y_{< t}\triangleq (y_{1},\ldots ,y_{t - 1}) $$ - 考虑两个 LLM:学生 \(\pi_{\theta}\) 和教师 \(\pi_{T}\)
- 每个都定义了一个在词表 \(\mathcal{V}\) 上的下一个 Token 分布 \(\pi (\cdot \mid x,y_{< t})\)
- 将 \(y\sim \pi_{\theta}(\cdot \mid x)\) 记为从学生自回归采样得到的一个 Response
- \(\mathcal{D}\) 为 一个固定的,包含教师生成的输出的 Prompt-Response 对数据集 :
$$\mathcal{D} = \{(x^{(i)},y^{(i)})\}_{i = 1}^{N}$$- 理解:\(y^{(i)}\) 是教师生成的
- \(\mathcal{D}_x\) 为对应的 Prompt 集合:
$$ \mathcal{D}_x\triangleq \{x^{(i)}\}_{i = 1}^{N} $$
- \(\mathcal{D}\) 为 一个固定的,包含教师生成的输出的 Prompt-Response 对数据集 :
- 知识蒸馏(knowledge distillation,KD)通过最小化两个分布之间的散度来将知识从 \(\pi_{T}\) 转移到 \(\pi_{\theta}\)
- 一个标准的选择是 Kullback-Leibler(KL)散度,对于 \(\mathcal{V}\) 上的两个分布 \(P\) 和 \(Q\),定义为
$$ D_{\text{KL} }(P| Q) = \sum_{v\in \mathcal{V} }P(v)\log \frac{P(v)}{Q(v)} $$
- 一个标准的选择是 Kullback-Leibler(KL)散度,对于 \(\mathcal{V}\) 上的两个分布 \(P\) 和 \(Q\),定义为
On-Policy Distillation
- OPD 在当前学生 \(\pi_{\theta}\) 采样的轨迹上计算监督
- 给定一个 Prompt
$$ x\sim \mathcal{D}_x$$ - 学生采样一个 Response
$$ \hat{y} = (\hat{y}_1,\ldots ,\hat{y}_T)\sim \pi_{\theta}(\cdot \mid x)$$- 其中 \(T\triangleq |\hat{y} |\) 表示 Rollout 长度
- 然后在学生生成的前缀 \(\hat{y}_{< t}\) 上评估两个模型,在每个步骤 \(t\) 产生两个下一个 Token 分布:对于 \(\nu \in \mathcal{V}\),有
$$
p_t(\nu)\triangleq \pi_{\theta}(\nu \mid x,\hat{y}_{< t})\\
q_t(\nu)\triangleq \pi_T(\nu \mid x,\hat{y}_{< t})
$$ - 一个标准的公式是在学生生成的轨迹上最小化序列级别的反向 KL:
$$\mathcal{L}_{\text{OPD} }(\theta) = \mathbb{E}_{x\sim \mathcal{D}_x}\left[D_{\text{KL} }(\pi_{\theta}(\cdot \mid x)\parallel \pi_T(\cdot \mid x))\right] \tag {1}$$ - 利用自回归分解,这个序列级别的目标允许精确的 Token-level 分解:
$$\mathcal{L}_{\text{OPD} }(\theta) = \mathbb{E}_{x\sim \mathcal{D}_x,\hat{y}\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{T}D_{\text{KL} }(p_t| q_t)\right] \tag {2}$$ - 实践中不同的实现在如何计算这个精确的 Per-Token 反向 KL 上有所不同:
- 全词表(Full-vocabulary) OPD 直接优化公式 (2)
- Sampled-token OPD 使用 Per-Token-level KL 项的无偏蒙特卡洛估计
- Top-\(k\) OPD 则用基于子集的近似替换全词表 KL
Sampled-Token OPD
- 最轻量级的变体仅评估学生采样的 Token,也是先前同策略蒸馏工作中最常见的实现 (2025; 2026; 2026b)
- 给定 \(\hat{y}_t\sim p_t\), Per-Token 的损失是
$$ \ell_t^{\text{sample} }\triangleq \log p_t(\hat{y}_t) - \log q_t(\hat{y}_t)$$ - 聚合为:
$$\mathcal{L}_{\text{OPD} }^{\text{sample} }(\theta) = \mathbb{E}_{x\sim \mathcal{D}_x,\hat{y}\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{T}\ell_t^{\text{sample} }\right] \tag {3} $$ - 此时每个 \(\ell_t^{\text{sample} }\) 都是 Token-level 反向 KL 的一个无偏单样本估计量
- 证明:
$$ \mathbb{E}_{\hat{y}\sim p_t}[\ell_t^{\text{sample} }] = D_{\text{KL} }(p_t| q_t)$$- 注:这里的 \(p_t\) 就对应上述的 Student 模型 \(\pi_\theta(\cdot|x)\)
- 证明:
Full-Vocabulary OPD
- Full-Vocabulary 在每个前缀上计算整个词表上的散度:
$$\mathcal{L}_{\text{OPD} }^{\text{full} }(\theta) = \mathbb{E}_{x\sim \mathcal{D}_x,\hat{y}\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{T}D_{\text{KL} }(p_t| q_t)\right] \tag {4} $$- 与 Sampled-Token OPD 相比,这产生了更密集的梯度,但代价是对于批次大小 \(B\)、序列长度 \(T\) 和词表大小 \(M = |\mathcal{V}|\),需要 \(O(BTM)\) 的内存
Top-\(k\) OPD
- Top-\(k\) OPD 通过在子集 \(S_t\subseteq \mathcal{V}\) 上限制散度计算,提供了 Sampled-Token 和全词表 OPD 之间的中间设计
- 这里关注学生 Top-\(k\) 变体,选择在学生下概率最高的 \(k\) 个 Token,即
$$ S_t = \text{TopK}(p_t,k)$$- 注:(Revisiting-OPD)Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes, 20260326, CASIA(解读博客见:NLP——LLM对齐微调-Revisiting-OPD)中还消融了其他版本,最终结论是各有优劣:
- Teacher top-K 具有竞争力
- Student top-K 在几个单独的数据集上表现强劲(平均值优于 Teacher Top-K)
- Teacher top-K 加上 Sampled-token 在比较中取得了最佳平均分
- 注:(Revisiting-OPD)Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes, 20260326, CASIA(解读博客见:NLP——LLM对齐微调-Revisiting-OPD)中还消融了其他版本,最终结论是各有优劣:
- 定义在 \(S_t\) 上重新归一化的学生和教师分布为:
$$\bar{p}_t^{(S_t)}(\nu) = \frac{p_t(\nu)\mathbf{1}[\nu\in S_t]}{\sum_{u\in S_t}p_t(u)},\qquad \bar{q}_t^{(S_t)}(\nu) = \frac{q_t(\nu)\mathbf{1}[\nu\in S_t]}{\sum_{u\in S_t}q_t(u)}。$$ - 然后通过最小化子集 KL 散度 \(D_{\text{KL} }(\bar{p}_t^{(S_t)}| \bar{q}_t^{(S_t)})\) 来进行蒸馏,得到轨迹级别的目标:
$$\mathcal{L}_{\text{OPD} }^{\text{top - k} }(\theta) = \mathbb{E}_{x\sim \mathcal{D}_x,\hat{y}\sim \pi_{\theta}(\cdot |x)}\left[\sum_{t = 1}^{T}D_{\text{KL} }(\bar{p}_t^{(S_t)}| \bar{q}_t^{(S_t)})\right] \tag {5} $$- 这个公式丢弃了 \(S_t\) 之外的质量,因此仍然是全词表反向 KL 的一个近似,但它显著降低了教师查询成本,同时保留了学生高概率区域上的多 Token 监督
Dynamic Metrics
- 在第 \(t\) 步将学生和教师的 Top-\(k\) 集定义为 \(S_t^{(p)} = \text{TopK}(p_t,k)\) 和 \(S_t^{(q)} = \text{TopK}(q_t,k)\)
- 在后续实验中将在整个 OPD 训练过程中监控以下指标
- 重叠率(Overlap Ratio)
- 量化学生和教师候选空间之间的对齐程度,定义为同时出现在学生和教师 Top-\(k\) 集中的 Token 的平均比例:
$$\mathcal{M}_{\text{overlap} }\triangleq \mathbb{E}_t\left[\frac{|S_t^{(p)}\cap S_t^{(q)}|}{k}\right] \tag {6} $$ - 低重叠率表明学生的概率质量集中在与教师不相交的 Token 集上,表明显著的政策差异或“模式不匹配”
- 接近 1.0 的比率意味着学生已成功定位到教师支持的 Region
- 量化学生和教师候选空间之间的对齐程度,定义为同时出现在学生和教师 Top-\(k\) 集中的 Token 的平均比例:
- 重叠 Token 优势(Overlap-Token Advantage)
- 为衡量重叠 Token 内的分布一致性,定义
$$ A_{t}(\nu) \triangleq \bar{p}_{t}(\nu) (\log \bar{q}_{t}(\nu) - \log \bar{p}_{t}(\nu))$$- 其中 \(\bar{p}_{t}, \bar{q}_{t}\) 是在 \(S_{t}^{(p)} \cap S_{t}^{(q)}\) 上重新归一化的学生和教师分布
- 该指标平均了这个量:
$$\mathcal{M}_{\text{adv} }\triangleq \mathbb{E}_{t}\left[\frac{1}{|S_{t}^{(p)}\cap S_{t}^{(q)}|}\sum_{\nu \in S_{t}^{(p)}\cap S_{t}^{(q)} }A_{t}(\nu)\right] \tag {7} $$ - 接近零的值表示高质量的对齐,即学生以适当的置信度将质量放在教师偏好的 Token 上
- 大的负值表示在交集内,与教师相比学生过于自信(高 \(p_{t}\) 但较低的 \(q_{t}\))
- 为衡量重叠 Token 内的分布一致性,定义
- Entropy and Entropy Gap
- 为监控策略的分布特性,追踪学生的熵 \(H(p_{t})\) 和教师的熵 \(H(q_{t})\) 在学生 Rollout 上的情况,并定义熵差距为:
$$\Delta H_{t} = |H(q_{t}) - H(p_{t})| \tag {8} $$ - \(\Delta H_{t}\) 是模式对齐的一个特定状态指标
- 大的差距表明在相同访问状态上,学生和教师在置信度和多样性方面存在显著的不匹配,而收敛到零表明学生已经匹配了其生成轨迹上教师的不确定性剖面
- 为监控策略的分布特性,追踪学生的熵 \(H(p_{t})\) 和教师的熵 \(H(q_{t})\) 在学生 Rollout 上的情况,并定义熵差距为:
- 重叠率(Overlap Ratio)
Phenomenology of On-Policy Distillation,OPD 的现象学
- 在调查 OPD 的 Token-level 机制之前,本文首先提出一个更广泛的问题:
- 什么条件决定了 OPD 的有效性?
- 一个自然的假设是更强的教师应该总是产生更好的蒸馏结果,然而本文观察到一些配置中情况并非如此
- Takeaways
- 思维模式一致性
- 学生和教师应共享兼容的思维模式
- 即使教师获得了更高的基准分数,大的不匹配也会削弱 Token-level 蒸馏信号(第 3.1 节)
- 更高的分数 不等于 新知识
- 教师应提供学生在训练中未见过的知识
- 即使思维模式一致且分数更高,教师也可能没有提供真正的新知识,使得 OPD 缺乏驱动信号(第 3.2 节)
- 思维模式一致性
Thinking-Pattern Consistency
- 本节研究 OPD 是否要求学生和教师之间具有兼容的思维模式
- 更强的教师并不能保证更好的蒸馏:推理模式上的巨大不匹配会削弱蒸馏信号,无论教师的基准优势如何
Setup
- 使用 Qwen3-1.7B-Base (2025) 作为学生,并比较两个教师:
- Qwen3-4B(Non-thinking) (2025)
- GRPO 教师:Qwen3-4B-Base-GRPO (这是通过对 Qwen3-4B-Base 应用 Zero-RL(使用 GRPO (2024))获得的(详细的训练设置在附录 A.1 中提供)
- 问题:这里所说的 Qwen3-1.7B-Base 和 Qwen3-4B-Base-GRPO 都是 Thinking 模型吗?推测不是使用 Thinking 模式?
- 由于学生也是一个 Base 模型,这里期望其思维模式更接近经过 GRPO 训练的教师
- 使用 DAPO-Math-17K 数据集 (2025) 进行了两个 OPD 实验,仅在教师模型的选择上有所不同
- 所有实验都使用附录 A.2 中描述的默认超参数(另有不同的点会指明),并在 AIME 2024 (2024)、AIME 2025 (2025) 和 AMC 2023 (2024) 上进行评估
- 每个问题采样 16 个 Rollout
- 温度为 0.7
- Top-\(p\) 为 0.95
- 最大验证 Response 长度为 31,744 个 Token
- 本文报告 16 个样本的平均准确率(
avg@16)作为主要评估指标
Results
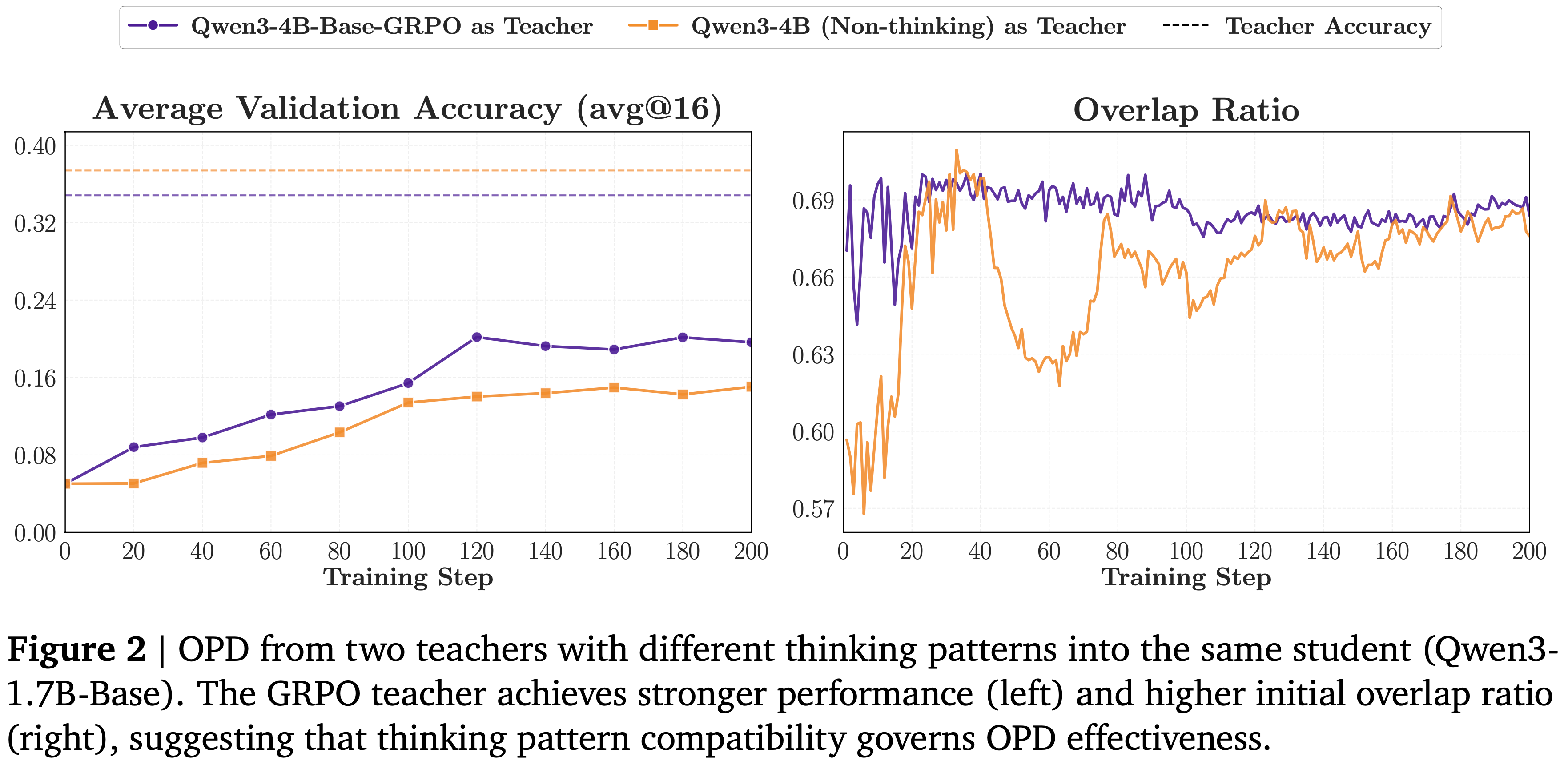
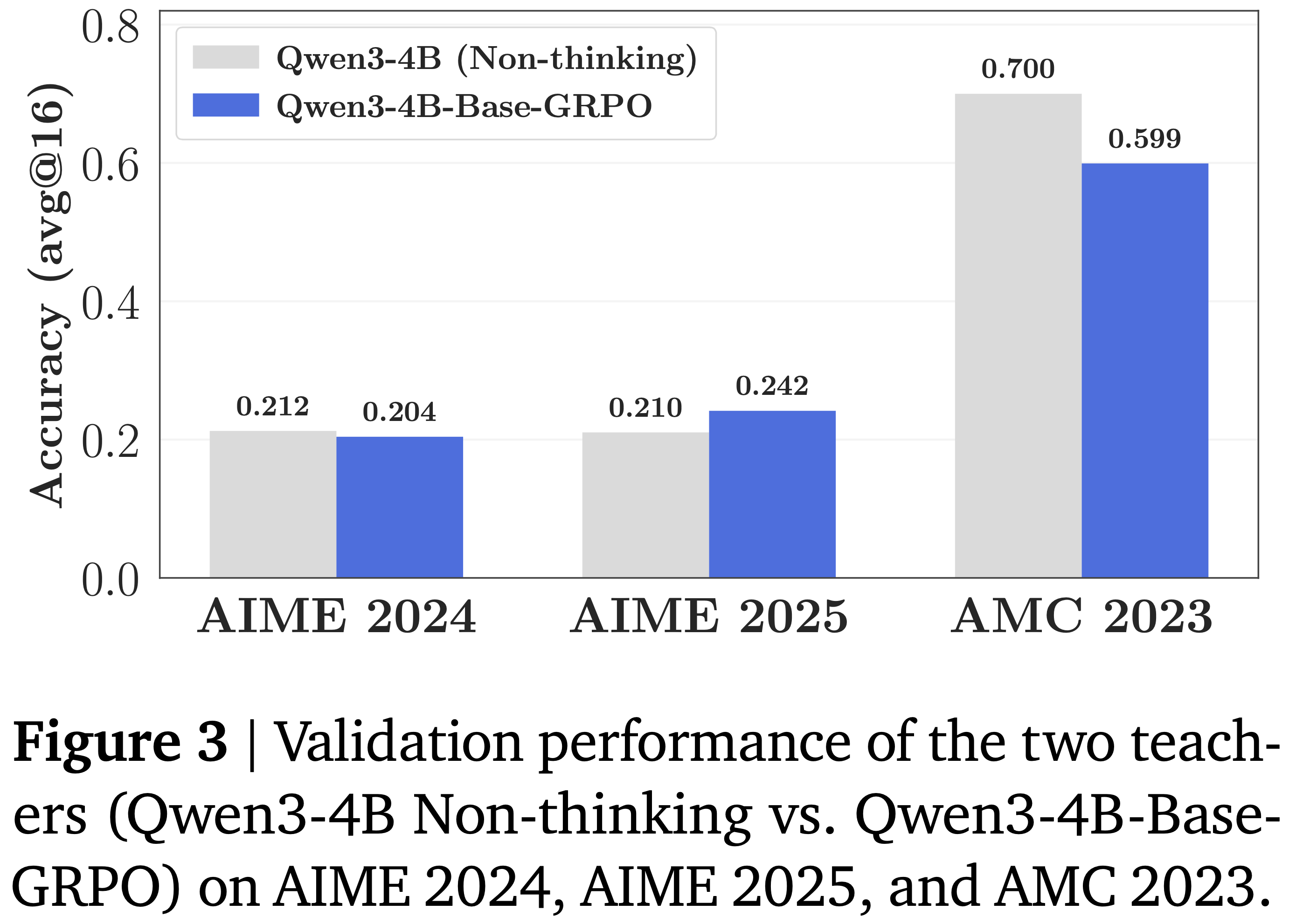
- 如图 2 所示,来自 Qwen3-4B-Base-GRPO 的蒸馏始终优于来自 Qwen3-4B(Non-thinking)的蒸馏
- 注:Qwen3-4B(Non-thinking)自身的 Accuracy 是高于 Qwen3-4B-Base-GRPO 的(图 2 左)
- GRPO 教师在基准测试中表现不佳(图 2 左),但 GRPO 教师表现出更高的初始重叠率(图 2 右)
- 表明 GRPO 教师 思维模式与学生更一致
- 问题:这里 GRPO 教师思维模式与学生更一致的原因是两者都是 Base 模型吗?Qwen3-4B 是 Instruct 模型
- 两个重叠曲线在训练后期趋于收敛(重叠率差异几乎消失),但性能差距持续存在
- 表明早期思维模式的不匹配导致了蒸馏效益的损失,且无法在后期恢复
- 表明早期思维模式的不匹配导致了蒸馏效益的损失,且无法在后期恢复
- 附录 A.3 中分别报告了每个基准的验证准确率,相同的总体趋势在所有数据集中都成立
New Knowledge, Not Just Scale
- 仅凭思维模式一致性并不能解释所有的观察结果
- 即使教师得分更高且与学生共享一致的思维模式,OPD 仍然可能失败
Setup
- 在不同模型家族中构建了两个受控比较
- 在 DeepSeek 家族中,使用 DeepSeek-R1-Distill-Qwen-1.5B(R1-Distill-1.5B) (2025) 作为学生,并比较两个教师:
- DeepSeek-R1-Distill-Qwen-7B(R1-Distill-7B) (2025)
- Skywork-OR1-Math-7B (2025b)(通过对 R1-Distill-7B 应用 RL 后训练获得的)
- 在 Qwen 家族中,使用 Qwen3-1.7B(Non-thinking) (2025) 作为学生,并比较两个教师:
- Qwen3-4B(Non-thinking)
- Qwen3-4B-Non-Thinking-RL-Math (2026b)(通过在 DeepMath (2025c) 的 57K 子集上对 Qwen3-4B(Non-thinking)应用 RL 获得的)
- 在 DeepSeek 家族中,使用 DeepSeek-R1-Distill-Qwen-1.5B(R1-Distill-1.5B) (2025) 作为学生,并比较两个教师:
- 在这两种设置中,关键对比在于来自相同训练流程的教师与通过进一步 RL 获得了额外能力的教师之间
- 所有运行都使用与之前相同的数据集和训练配方
Results
- 如图 4 所示,两个家族都表现出一致的模式
- 相同流程的教师带来的改进有限, Post-trained 教师在所有基准测试中都产生了显著更强的收益
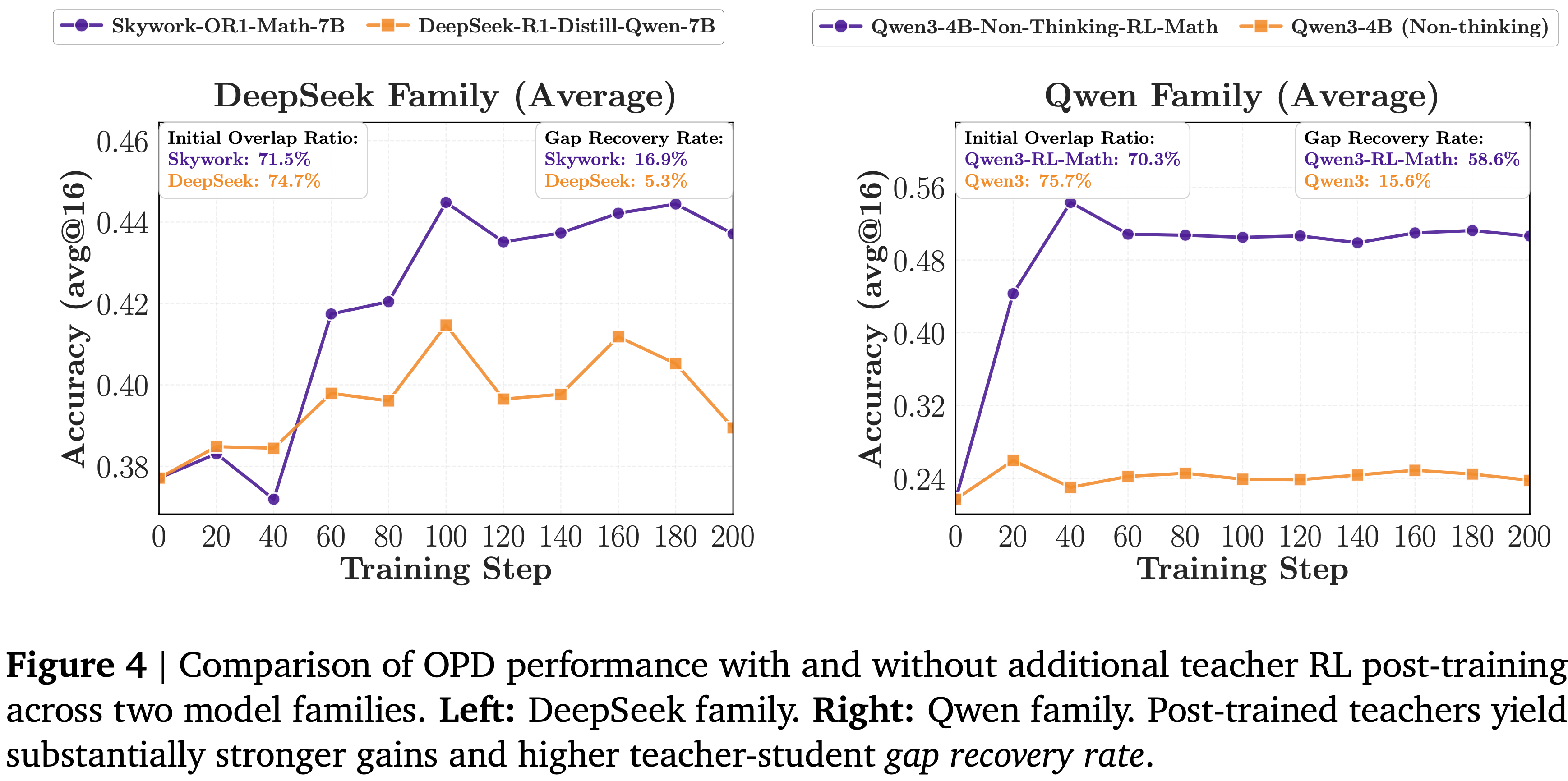
- 相同流程的教师带来的改进有限, Post-trained 教师在所有基准测试中都产生了显著更强的收益
- Post-trained 教师不仅取得了更高的绝对性能,而且通过差距恢复率衡量,恢复了更大比例的师生差距,其中差距恢复率定义如下:
$$ (\text{Acc}_{\text{after OPD} } - \text{Acc}_{\text{before OPD} })/(\text{Acc}_{\text{teacher} } - \text{Acc}_{\text{before OPD} }) $$ - 这表明:
- 这些教师获得的额外能力通过 OPD 实现了迁移
- 注:由于 Post-trained 教师源自相同的基础检查点,它们的思维模式仍然大致对齐(这也通过重叠率动态观察到),从而让学生学习到了教师通过 RL 获得的新能力
Validation via Reverse Distillation
- 本文设计了一个反向蒸馏(reverse-distillation)实验作为同时验证这两个条件的比较,并揭示了对 OPD 本质的更深入见解
Setup
- JustRL-DeepSeek-1.5B(JustRL-1.5B) (2025a) 是通过对 R1-Distill-1.5B 应用 RL 获得的
- 本文现在反转这个方向,使用 JustRL-1.5B 作为学生,并从 R1-Distill-1.5B(其自身的 RL 前检查点)进行蒸馏
- 理解:R1-Distill-1.5B 作为教师,JustRL-1.5B 作为学生,JustRL-1.5B 是 基于 R1-Distill-1.5B 训练的
- 比较组:使用 R1-Distill-7B 作为教师进行比较
- 注:R1-Distill-7B 的基准分数略高于 JustRL-1.5B,而 R1-Distill-1.5B 则明显更弱
- 本文现在反转这个方向,使用 JustRL-1.5B 作为学生,并从 R1-Distill-1.5B(其自身的 RL 前检查点)进行蒸馏
Results
- 图 5 揭示了两个惊人的现象
- 第一:将 JustRL-1.5B 向其自身的 RL 前检查点 R1-Distill-1.5B 蒸馏,导致学生几乎完全回归到其 RL 前的性能,消除了通过 RL 获得的所有收益
- 第二:当用 R1-Distill-7B(一个来自同一家族的规模明显更大甚至略强的模型)替换教师时,训练轨迹几乎无法区分:
- 在基准测试中得分高于 JustRL-1.5B,但 R1-Distill-7B 却将学生驱动到与较弱的 1.5B 教师相同的回归水平
- 注:从图 5 中可以看到,R1-Distill-7B 本身的性能非常高,(特别是在 AIME 2025 上比 JustRL-1.5B 还高,但是 JustRL-1.5B 无法从 R1-Distill-7B 上通过 OPD 学到知识)
- 理解:我的推测是有两种情况:
- 可能一:这里应该是短期内出现的坍缩现象,由于学生模型和教师模型差异过大,导致训练中途时,模型短期内被拉到了一个既不像学生,又不像教师的中间地带,只要学生的分布是不断接近教师的,继续训练下去,分数会逐渐回来(后续有资源可以考虑继续实验)
- 可能二:学生模型在当前评测的这些指标上过拟合了,让他学习教师模型反而导致短期内的下降
- 理解:我的推测是有两种情况:
- 由于 OPD 在学生生成的轨迹上最小化反向 KL 散度,这种收敛意味着这两个教师在学生访问的状态上诱导出几乎相同的局部目标分布,尽管它们的规模不同
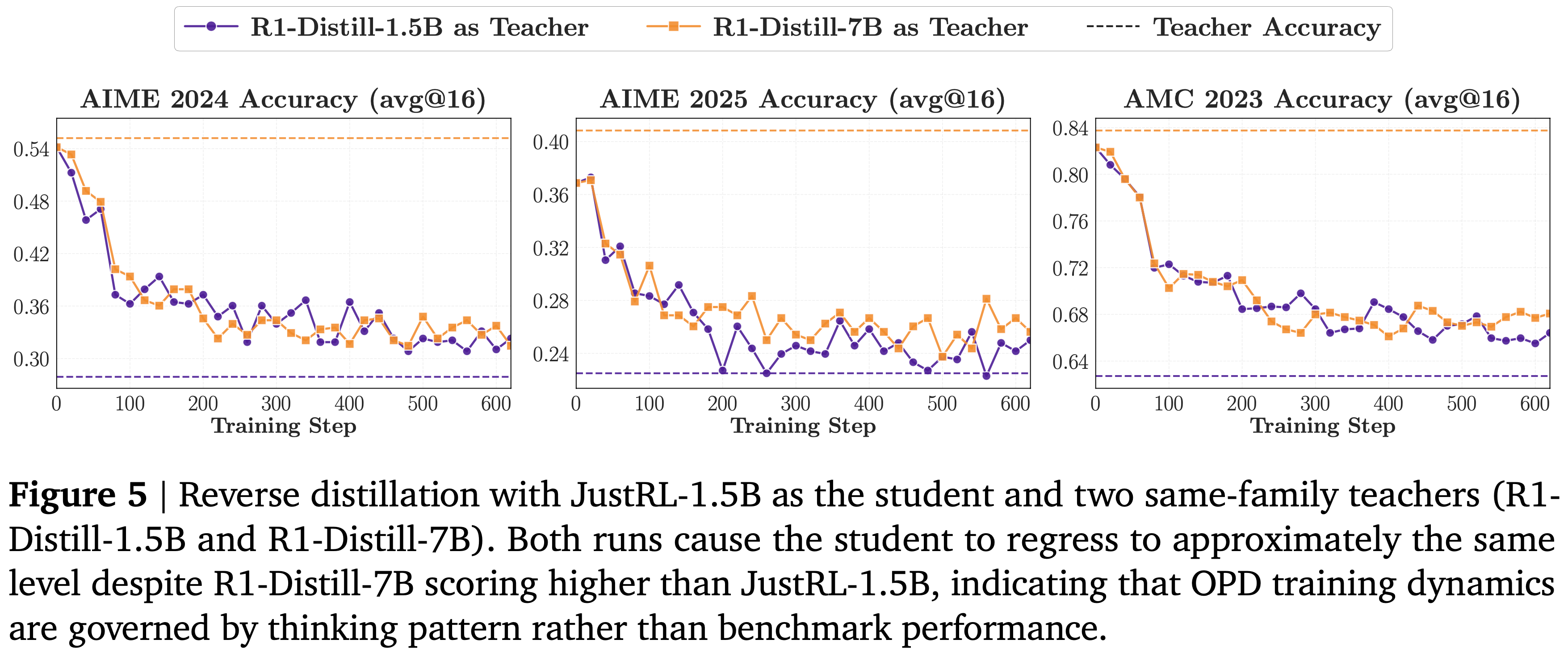
- 这些结果得出几个结论:
- 思维模式很重要,并且 OPD 从根本上学习思维模式
- 从 R1-Distill-1.5B 蒸馏到 JustRL-1.5B 导致 JustRL-1.5B 回归到其 RL 前的性能
- 这表明 OPD 主动获取教师的思维模式并覆盖学生自身的模式
- 这正是思维模式一致性重要的原因:如果差距太大,学生可能无法有效学习
- 问题:这里有点不好理解,只能说明 从 R1-Distill-1.5B 蒸馏到 JustRL-1.5B 导致 JustRL-1.5B 回归到其 RL 前的性能,并不能说明思维模式很重要啊!这里的思维模式定义是什么?应该是两者的 top-k Token 重叠率这样的指标吧
- 基准性能不能预测 OPD 的结果
- R1-Distill-7B 得分高于 JustRL-1.5B,但蒸馏没有产生改进,反而导致回归
- 这表明 OPD 的训练动态可以完全独立于教师的基准性能,甚至可能向相反方向移动
- 理解:这里可以理解为,如果教师和学生的思维模式(覆盖度)相差过大,那么朴素而鲁莽的把学生往教师的分布上拉动,收益可能是负的(学生会走到既不像自己,又不像教师的尴尬境地,至少在短时间内,学生没有完全学到教师的分布之前,下游评测分数应该是下降的)
- 问题:这里 In-Domain 的分数应该是上涨的吧,OOD 的分数倒是应该是下降的?
- 更高的分数并不意味着 OPD 的新知识
- R1-Distill-7B 和 R1-Distill-1.5B 属于同一模型家族,仅在规模上有所不同
- 这两个模型对学生产生无法区分的影响已经证实了:
- (i) 更高的分数(R1-Distill-7B)可能仅仅反映了对相同数据的不同程度的拟合,而不是真正新颖的能力
- 为了使 OPD 产生收益,教师应该拥有学生在其训练中尚未见过的知识
- 问题:这里应该是因为 R1-Distill-7B 跟 学生 JustRL-1.5B 的思考模式差异过大?所以 没法用 R1-Distill-7B 作为教师教授学生 JustRL-1.5B
- (ii) 规模不同,R1-Distill-7B 和 R1-Distill-1.5B 表现出相同的思维模式
- (i) 更高的分数(R1-Distill-7B)可能仅仅反映了对相同数据的不同程度的拟合,而不是真正新颖的能力
- 吐槽:这个结论 基准性能不能预测 OPD 的结果 的结论类似,都是想表明 R1-Distill-7B 的指标不错,但无法蒸馏到 JustRL-1.5B 上
- 思维模式很重要,并且 OPD 从根本上学习思维模式
- 反向蒸馏实验以及第 3.1 和 3.2 节中的正向比较巩固了这两个条件
- 思维模式一致性与更高的初始重叠率和更强的 OPD 结果相关
- 新知识(例如来自进一步的后训练)即使在重叠率已经很高时也能实现更大的可迁移收益
Mechanism of On-Policy Distillation
- 第 3 节确定了两个条件,即思维模式一致性和超出相同模型家族的新知识,它们决定了 OPD 的有效性
- 本节研究在训练过程中这些条件得以体现的 Token-level 机制
- 通过比较成功和失败的 OPD 运行,本文表明有效的蒸馏 是由高概率 Token 上的渐进对齐 驱动的
- Takeaways
- 渐进对齐 (Progressive alignment)
- 在学生访问的状态下,学生和教师的高概率 top-\(k\) Token 之间的重叠在整个训练过程中稳步增加
- 失败的运行从一开始就表现出停滞的重叠
- 重叠充分性 (Overlap sufficiency)
- 几乎所有优化的效果 都集中在共享的 top-\(k\) Token 上
- 仅优化这些重叠 Token 就足以匹配标准的 OPD(即:非重叠 Token 的贡献很小)
- 渐进对齐 (Progressive alignment)
Progressive Alignment of High-Probability Tokens,高概率 Token 的渐进对齐
- 比较在相同设置下,从两个不同教师蒸馏同一个学生的动态,一个产生了明显的改进,而另一个没有产生任何改进
- 发现:成功的 OPD 本质上是由学习学生和教师之间共享的高概率 Token 驱动的
Setup
- 选择 R1-Distill-1.5B 作为学生,并比较两个教师:
- JustRL-1.5B(在 R1-Distill-1.5B 进一步训练的模型)
- R1-Distill-7B
- 注:这两个教师表现出相当的数学性能,R1-Distill-7B 略强一些
- 使用与之前相同的 DAPO-Math-17K 数据集和训练设置,并在训练期间监控三个动态指标
Results
- 图 6 显示了截然不同的结果
- 从 JustRL-1.5B 蒸馏带来了持续的收益,最终学生恢复了超过 \(80%\) 的与教师的性能差距
- 从 R1-Distill-7B 蒸馏则未能带来任何改进(尽管教师整体上更强)
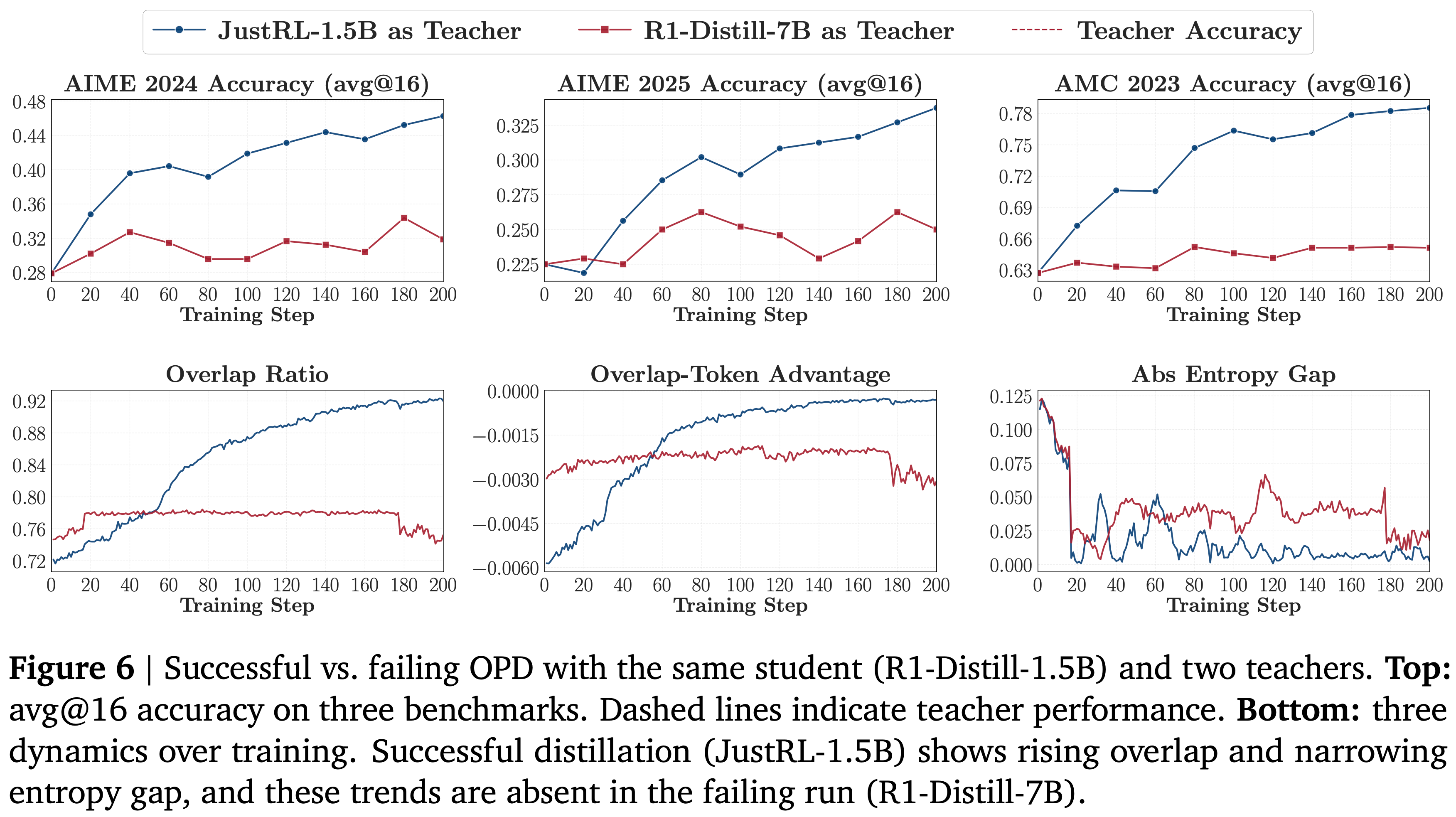
- 训练动态(图 6,底部)揭示了潜在的差异
- 在成功的运行中,重叠率稳步上升,重叠 Token 优势向零改善,熵差距缩小
- 表明学生逐渐定位了教师的高概率区域,在该区域内校准其质量,并匹配了教师的局部置信度
- 在失败的运行中,所有三个指标都停滞不前
- 个人补充:熵差距还是缩小了一些的,但是会波动
- 在成功的运行中,重叠率稳步上升,重叠 Token 优势向零改善,熵差距缩小
- 有两个观察值得强调
- 第一:在整个训练过程中,重叠 Token 承载了两种模型总概率质量的 \(97% - 99%\)(见附录 B.1)
- 因此不断上升的重叠反映了概率上占主导地位的 Token 上的对齐,而不仅仅是集合层面的重合
- 第二:重叠 Token 优势的改善表明 OPD 的主要优化信号在于在重叠区域内重新分配概率,而不是在区域外的 Token 上
- 第一:在整个训练过程中,重叠 Token 承载了两种模型总概率质量的 \(97% - 99%\)(见附录 B.1)
- 附录 B.2 中报告了辅助优化指标(策略损失、梯度范数和极端优势 Token 概率差异),这些指标显示了一致的次要模式:
- 成功的运行表现出递减的损失和持续的梯度幅度
- 失败的运行则显示出微弱的梯度和持续的概率差异
- 附录 B.3 中进一步验证了这些发现在不同的模型对之间具有普遍性
- 使用 R1-Distill-7B 作为学生,在相同设置下使用两个不同的教师
Optimizing Shared Tokens Alone Suffice,仅优化共享 Token 就够
- 上述分析表明,高概率 Token 对齐与 OPD 成功相关
- 本节进一步研究这种相关性是否具有因果性:
- 重叠区域是否不仅是对齐出现的地方,而且是驱动优化的区域
- 本文设计了一个有针对性的消融实验,将 top-\(k\) 支持分解为其重叠和非重叠部分,并单独对每个部分进行训练
Setup
- 使用第 4.1 节中成功的 OPD 设置 (JustRL-1.5B \(\rightarrow\) R1-Distill-1.5B),本文比较了三种变体,它们的区别仅在于蒸馏损失覆盖哪些 Token:
- (i) Student Top-\(k\):在完整的 student top-\(k\) 支持 \(S_{t}^{(p)}\) 上进行优化
- (ii) Overlap Top-\(k\):将优化限制在 student 和 teacher top-\(k\) 集合的交集 \(S_{t}^{(p)}\cap S_{t}^{(q)}\) 上
- (iii) Non-Overlap Top-\(k\):将优化限制在它们的对称差集 \(S_{t}^{(p)}\Delta S_{t}^{(q)}\) 上(即 学生独有支持集)
- 补充:将默认的 \(k\) 设置为 16
Results
- 如图 7 所示,仅优化重叠区域就足以在所有三个基准测试上恢复标准 Student Top-\(k\) OPD 的几乎全部收益,而 Non-Overlap Top-\(k\) 则始终较弱
- 这表明 OPD 的主要收益来自于共享高概率区域上的梯度,而不是非重叠 Token
- 这也解释了为什么 Student Top-\(k\) 和 Overlap Top-\(k\) 表现得如此相似
- 学生独有支持中的额外 Token 携带的概率质量非常少
- Student Top-\(k\) 和 Overlap Top-\(k\) 的重叠 Token 优势曲线几乎无法区分,Non-Overlap Top-\(k\) 的幅度则小得多
- 表明在重叠 Token 上的有效梯度要弱得多(更正错误:这里是 非重叠 Token 吧)
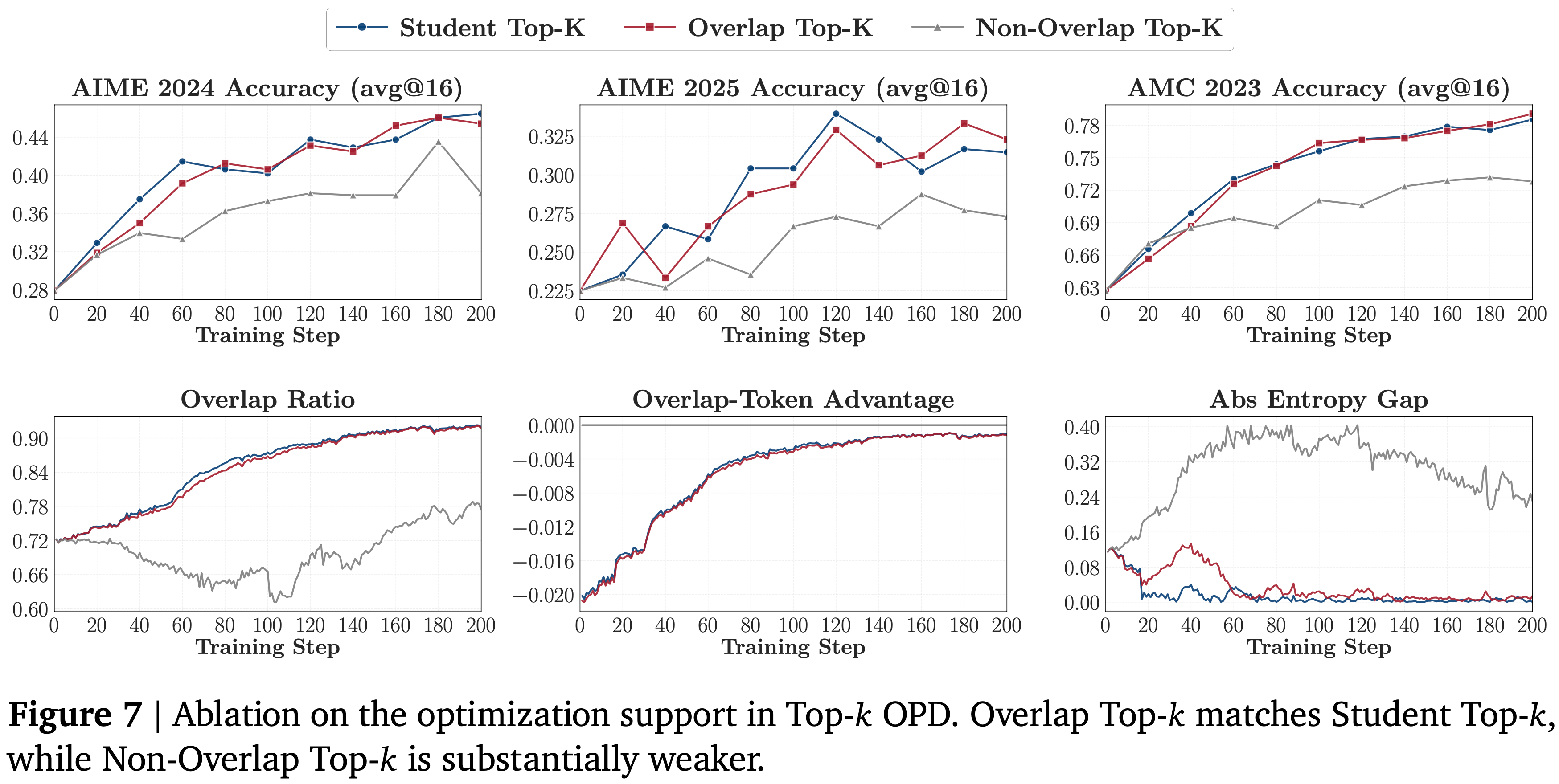
- 表明在重叠 Token 上的有效梯度要弱得多(更正错误:这里是 非重叠 Token 吧)
- 重叠优化是自我强化的 (self-reinforcing)
- Student Top-\(k\) 和 Overlap Top-\(k\) 都将重叠率从约 \(72%\) 稳步提高到 \(91%\) 以上
- Non-Overlap Top-\(k\) 先下降,然后仅部分恢复(图 7,左下)
- 这揭示了一种自我强化的动态:
- 一旦一个 Token 进入共享的高概率区域并受到教师青睐,reverse-KL 更新就会将更多的质量集中在它上面,逐渐将竞争性的非重叠 Token 推出学生的 top-\(k\) 集合
- 因此,重叠区域的扩大并非与优化过程相悖,反而正是优化所导致,由此形成一个良性循环,在整个训练过程中持续维持对齐。
- Student Top-\(k\) 和 Overlap Top-\(k\) 都将重叠率从约 \(72%\) 稳步提高到 \(91%\) 以上
- 这些结果支持了 OPD 的一个统一机制:
- OPD 主要效果是在学生访问的状态下,逐步优化学生在教师支持的高概率 Token 上的分布
- 这种对齐既是 OPD 成功的标志,也是其操作的核心所在,其中仅优化重叠 Token 就足够了,而非重叠 Token 贡献很小
- 当满足第 3 节中确定的条件时,这种自我强化的动态驱动着稳定的改进
- 当不满足时,重叠停滞,训练无法取得进展
Practical Recipe
- 第 3 节确定了成功进行 OPD 的两个条件
- 拥有新知识是教师的内在属性,但教师和学生之间的思维模式差距可以通过训练设计来缩小
- 本节提出了两种互补的策略,通过改善重叠动态来恢复在其他情况下会失败的 OPD 配置
- Takeaways
- Off-policy 冷启动
- 在 OPD 之前,对学生在教师生成的 Rollout 上进行微调,可以弥合初始的思维模式差距,从而从一开始就获得更高的重叠率和持续更强的最终性能
- 教师对齐的提示
- 使用来自教师后训练数据的 Prompt 可以加强在高概率 Token 上的对齐
- 注:单独使用教师后代价是学生熵显著降低,需要将此类 Prompt 应与分布外的 Prompt 混合使用,以防止熵崩溃
- 使用来自教师后训练数据的 Prompt 可以加强在高概率 Token 上的对齐
- Off-policy 冷启动
Off-Policy Distillation from Teacher Rollouts as Cold Start
- 当学生和教师具有显著不同的思维模式时,纯粹的 OPD 可能无效,因为教师提供的 Token-level 监督信号难以被学生从其初始策略中利用
- 为了减轻这种不匹配,本文提出可考虑一个两阶段框架:
- 第一阶段:通过 SFT 学生在教师生成的 Rollout 上来进行 off-policy 蒸馏,使其更接近教师的思维模式
- 第二阶段:使用标准 OPD 继续训练
Setup
- 模型选择:使用 Qwen3-1.7B-Base 作为学生,Qwen3-4B (Non-thinking) 作为教师
- 数据选择:使用 OpenThoughts3-1.2M (2025) 的数学领域子集作为 SFT 的 Prompt 来源
- 具体做法:
- 教师在此数据集的一个子集上生成 200K 个 Response,使用这些教师 Rollout 对学生进行 SFT 作为冷启动,得到 Qwen3-1.7B-SFT
- 从该 SFT 初始化开始,使用在排除 SFT Prompt 子集 后剩余的 OpenThoughts Prompt(约 30K 个 Prompt)继续进行 OPD 训练
- 对照组:一个纯 OPD 基线,该基线直接从 Qwen3-1.7B-Base 开始,使用相同的教师和 OPD Prompt 集,但在 OPD 之前不进行冷启动蒸馏
- 详细的离线 Rollout 和 SFT 配置在附录 C.1 中提供
Results
- 如图 8 所示,两阶段方法显著优于纯 OPD
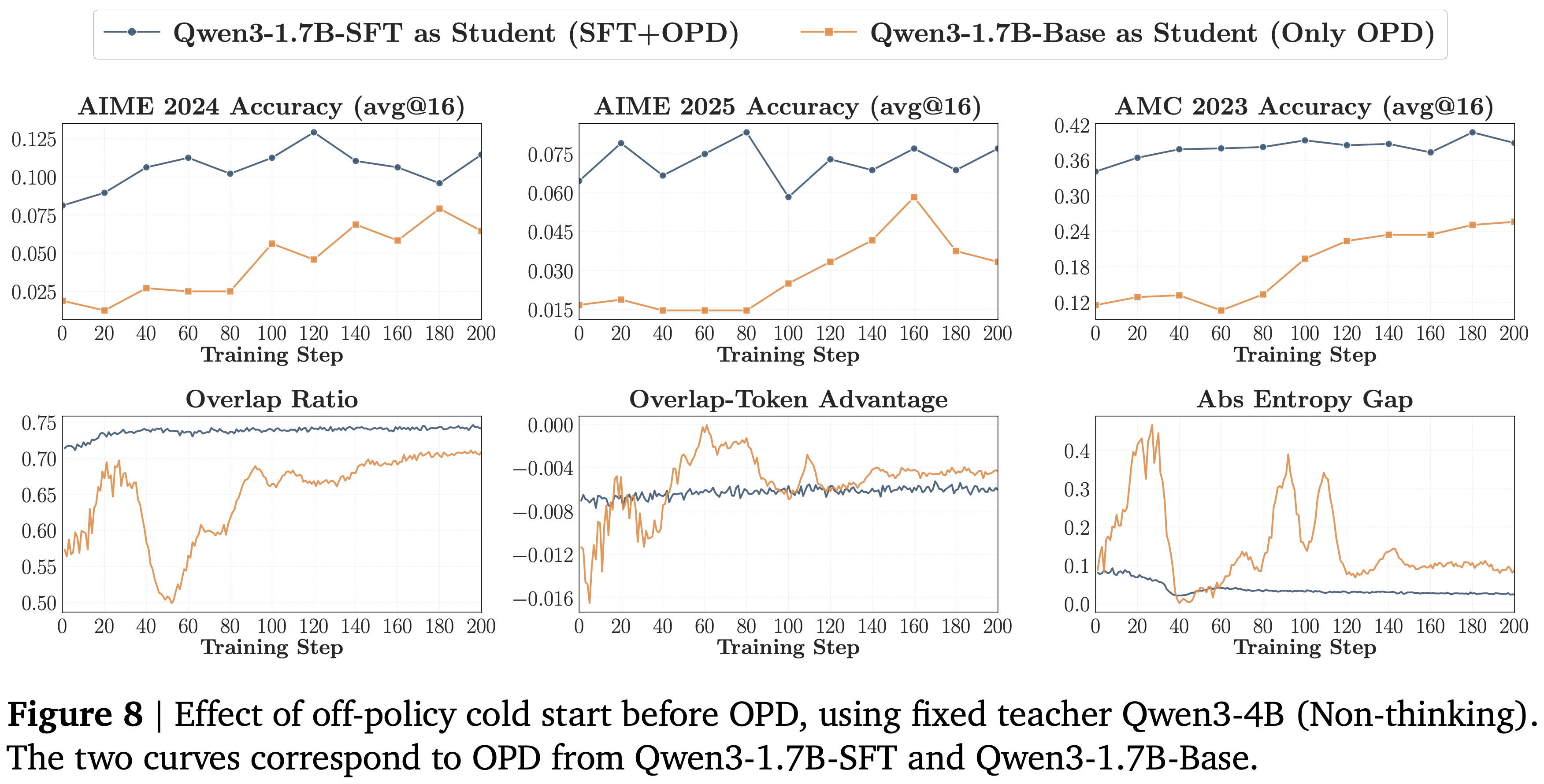
- 从 Qwen3-1.7B-SFT 开始始终比直接从 Qwen3-1.7B-Base 开始产生更好的验证性能
- 性能差距在整个训练过程中持续存在,表明 off-policy 冷启动不仅改善了早期的优化,还提高了后续 OPD 的最终性能上限
- 问题:
- 看着图 8 中,各种指标都是 SFT 带来的,SFT 的样本太多了吧,导致整体效果其实在 SFT 后就收敛到 Teacher 上了,表现在 Overlap Ratio 其实一直处于收敛的情况(也就是说 Student 已经被 SFT 大幅拉倒 OPD 上了)
- 而且 SFT 看到的数据,纯 OPD 看不到,也不够公平
- 问题:
- 重叠动态支持了相同的结论:
- SFT-initialized 学生开始时具有高得多的重叠率,并保持平滑、稳定的轨迹,而基础初始化的学生起点较低,并在逐渐恢复之前表现出明显的不稳定性
- SFT-initialized 学生的熵差距也小得多
- 表明从一开始 SFT-initialized 学生就与教师的置信度分布更匹配
- 结论:
- off-policy 蒸馏减少了初始的模式不匹配,使得一旦 OPD 开始,教师的 Token-level 监督信号就可以立即被利用
- 附录 C.2 中对重叠质量动态进行了更详细的分析
Leveraging Teacher Post-Training Prompts
- 由于教师的策略受到后训练期间所见 Prompt 的影响,在 OPD 期间使用与教师对齐的 Prompt 可以产生更有效的监督
Setup
- 本文在两个粒度上进行实验:
- 匹配 Prompt 模板是否重要
- 匹配 Prompt 内容是否重要
Prompt template
教师是 JustRL-1.5B,学生是 R1-Distill-1.5B
Prompt 集是 DAPO-Math-17K,仅 Prompt 模板不同
原始模板是之前所有实验中使用的标准 DAPO 格式(除非另有说明),而与教师对齐的模板则与 JustRL 后训练期间使用的格式相匹配:
Original DAPO Template:
1
2
3
4Solve the following math problem step by step. The last line of your response should be of the form Answer:
$Answer (without quotes) where $Answer is the answer to the problem.
{Question}
Remember to put your answer on its own line after “Answer:”Teacher-Aligned Template
1
{Question} Please reason step by step, and put your final answer within \boxed{}.
两次运行(消融 Prompt 模板)包含相同的数学问题,但任务呈现给模型的方式不同
- 这种设计隔离了 Prompt 模板与教师对齐的影响,同时保持底层问题内容不变
Prompt Content
- 教师是第 3.1 节中介绍的 Qwen3-4B-Base-GRPO,学生是 Qwen3-1.7B-Base
- 比较两个大小匹配的 Prompt 集:
- DAPO-Math-17K(与教师的 RL 训练数据集对齐)
- DeepMath 的一个子集(该子集与 DAPO-Math-17K 去重(见附录 C.3))
- 此设计测试了 OPD 是否受益于使用与教师后训练数据完全相同的 Prompt,而不仅仅是领域内的 Prompt
Results
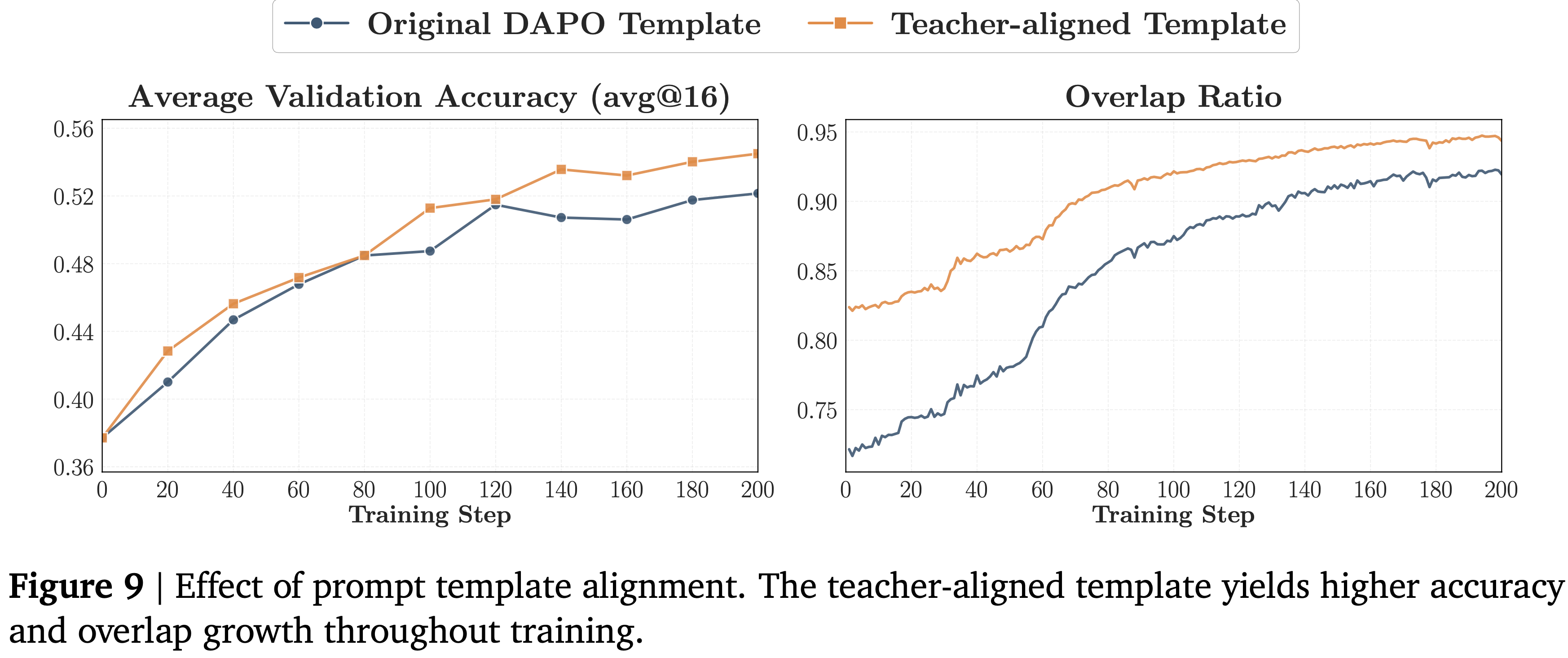
- 图 9 中的 Prompt 模板设置显示,仅仅切换到与教师对齐的模板就能提高在所有三个基准测试上的验证性能
- 重叠动态支持了这一结果:
- 与教师对齐的模板运行开始时具有更高的重叠率,并收敛到更高的水平
- 这表明即使是 Prompt 模板的微小变化,也能通过使学生生成的状态与教师更兼容,从而显著影响 OPD
- 附录 C.4 中的基准测试详细分解显示了相同的趋势
- 图 10 中的 Prompt 内容设置显示了类似的 downstream 优势,但有一个细微差别:
- 与教师对齐的 Prompt 在整个训练过程中产生的重叠率较低
- 但学生在重叠 Token 上的累积概率质量显著更高,表明学生将其质量集中在更少但共享程度更高的 Token 上
- 即使重叠集更小,高概率 Token 上的有效对齐也更强
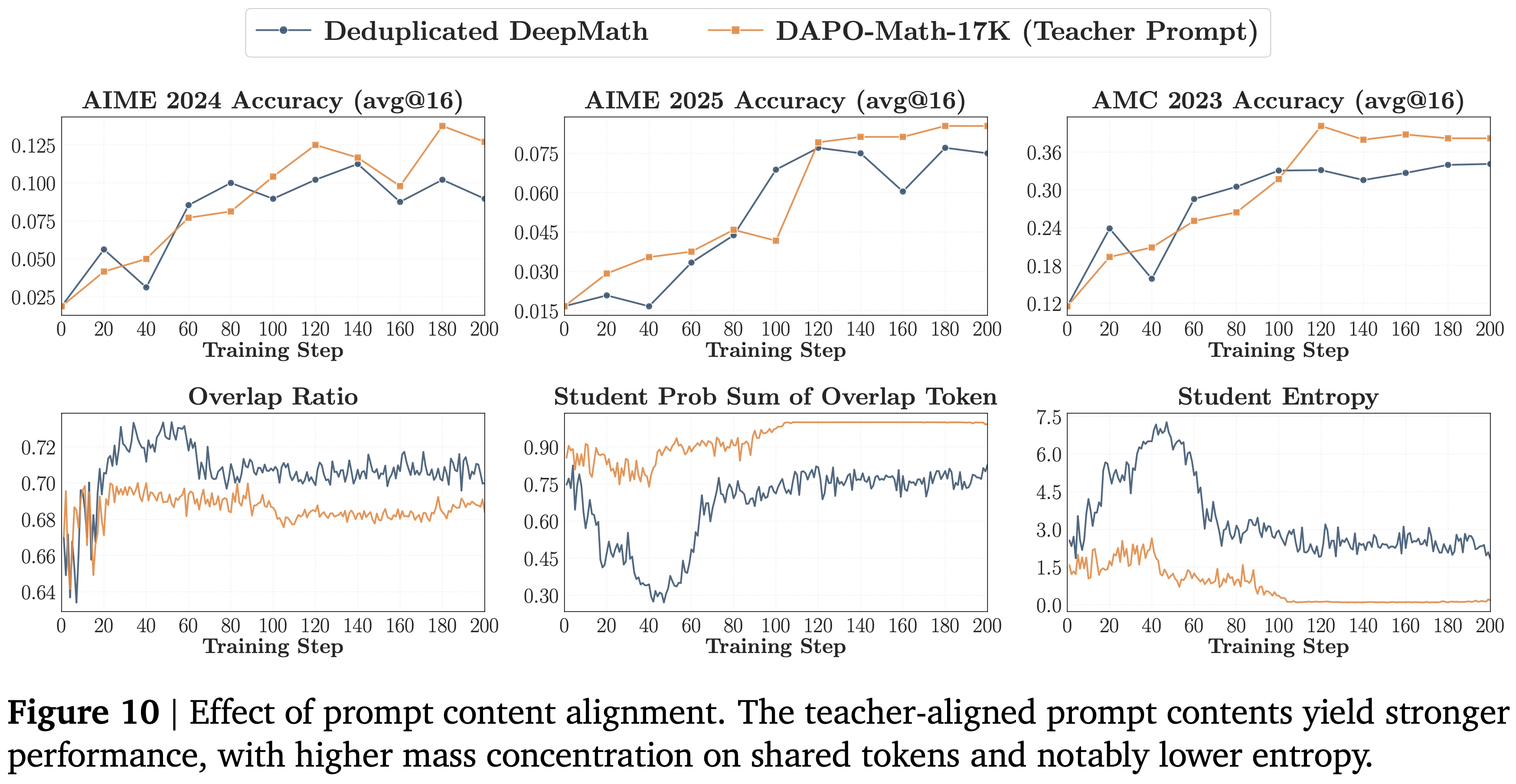
- 观察:使用与教师对齐的 Prompt 会导致训练期间学生的熵显著降低
- 这表明,仅在教师后训练期间见过的 Prompt 上进行 OPD 可能并不总是理想的,因为它会过度降低策略熵
- 在实践中,一个更稳健的策略可能是将与教师对齐的 Prompt 与教师后训练数据之外的 Prompt 混合,以保持策略熵并维持学生的探索能力
- 这些结果表明 OPD 不仅受益于合适的教师,还受益于匹配良好的 Prompt 集
- 更接近教师后训练数据的 Prompt 可以提高下游性能,并加强在最重要的共享 Token 上的对齐,但应谨慎使用,以避免过度抑制学生的熵
Discussion
- OPD 的吸引力在于其密集的监督信号,即 Per-Token 都从教师那里获得一个奖励信号
- 这与 RL 中使用的稀疏的 Outcome-level 奖励形成对比
- 但这种增加的监督密度是有代价的
- 上述所有章节都隐含地依赖于教师在学生访问的状态下的 Token-level 奖励是可靠的,但本文已经看到这个假设可能会失效
- 本节研究奖励信号本身,并考察其属性和局限性
Reward Quality Degrades with Trajectory Depth,奖励质量随轨迹深度退化
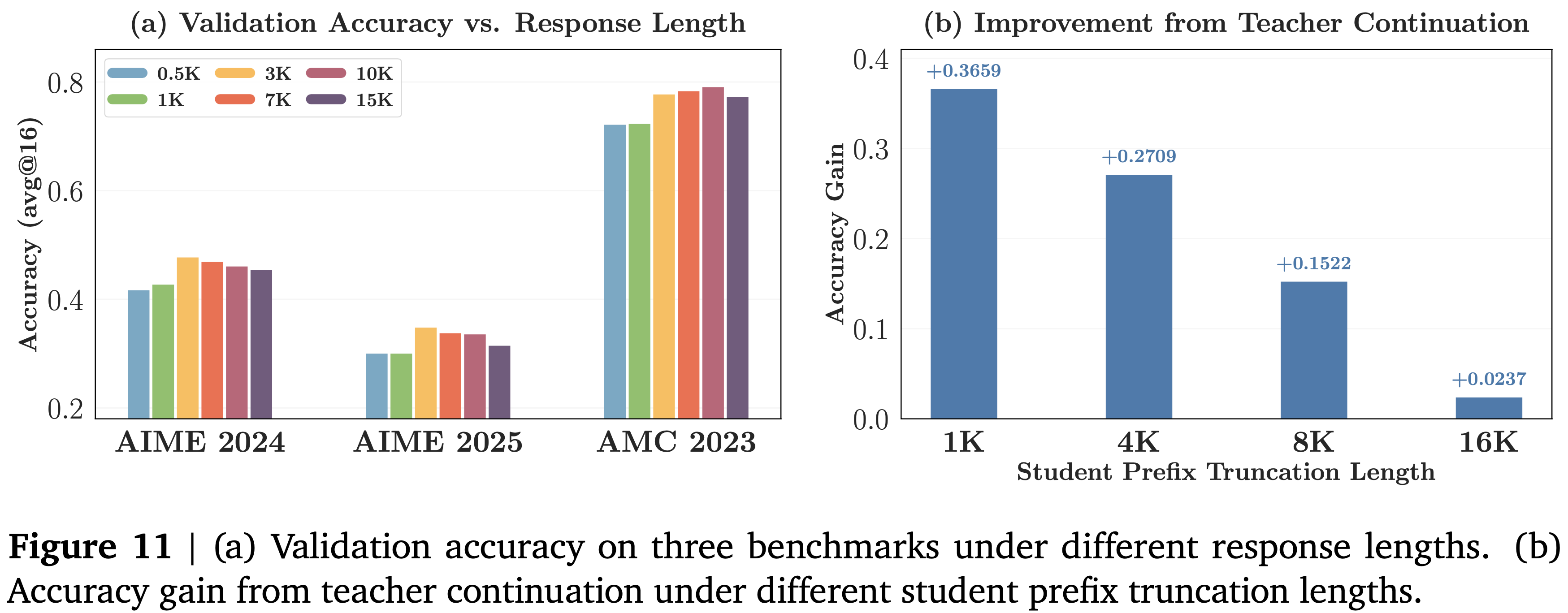
- 本节研究教师的奖励质量如何随响应长度变化
响应长度存在一个最佳区间 (sweet spot)
- 位置 \(t\) 的监督依赖于教师在学生生成的 Prefix \(y_{< t}\) 下的条件概率 \(\pi_{T}(y_{t} \mid x, y_{< t})\)
- 而该 Prefix 可能会偏离教师自然产生的轨迹
- 本文在六种最大响应长度下,针对 JustRL-1.5B 训练 R1-Distill-1.5B 200 步
- 如图 11(a) 所示
- 非常短的响应 (0.5K 和 1K) 提供的监督 Token 太少,无法进行样本高效的学习,而中等长度 (3K 和 7K) 产生了最强的结果
- 超出此范围 (10K 和 15K),性能趋于平稳或下降
- 图 12 中的训练动态证实
- 中等长度产生平滑的重叠率增长,而 10K 和 15K 则表现出后期崩溃,重叠率急剧下降,同时伴随着学生熵和梯度范数的峰值
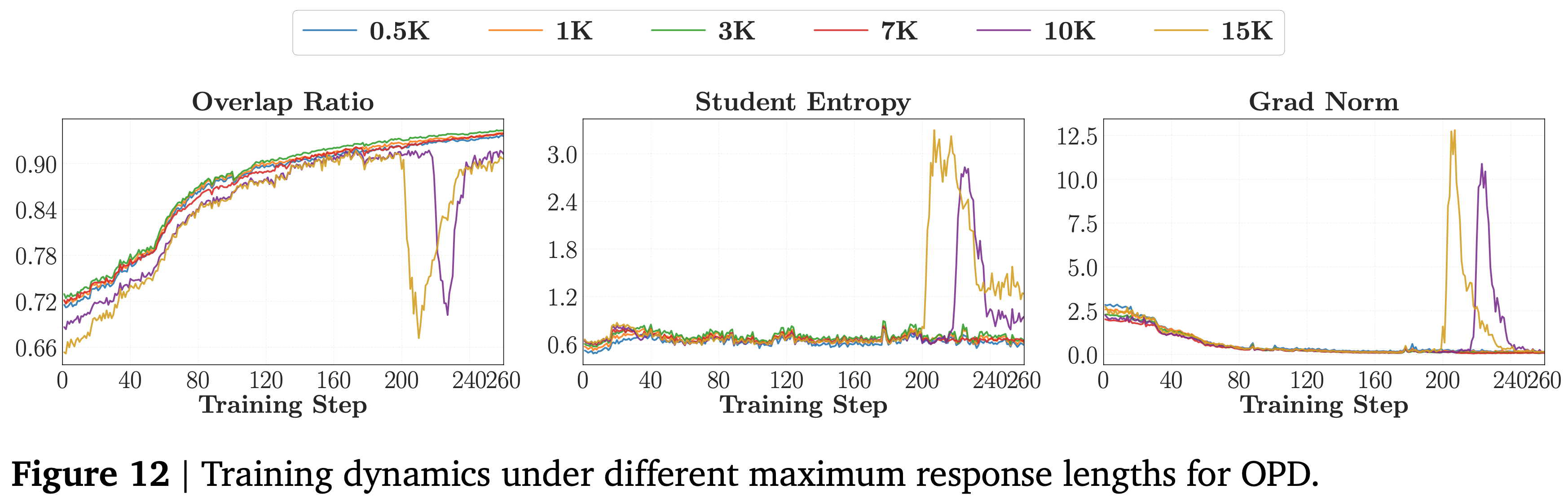
- 中等长度产生平滑的重叠率增长,而 10K 和 15K 则表现出后期崩溃,重叠率急剧下降,同时伴随着学生熵和梯度范数的峰值
不稳定性源于较后的 Token (later tokens)
- 这种崩溃从何开始?在 15K 设置中,分析整个训练步骤中作为输出位置函数的学生熵,揭示了一个清晰的从后向前的模式:
- 如图 13 所示,高熵首先出现在响应的末端,并在训练过程中逐渐向前面的 Token 传播
- 教师熵表现出类似的从后缀到前缀的趋势 (见附录 D.1)
- 这与教师在较后位置遇到越来越不熟悉的 Prefix 并使产生的奖励噪声更大 ,进而破坏学生的稳定性 这一观点一致
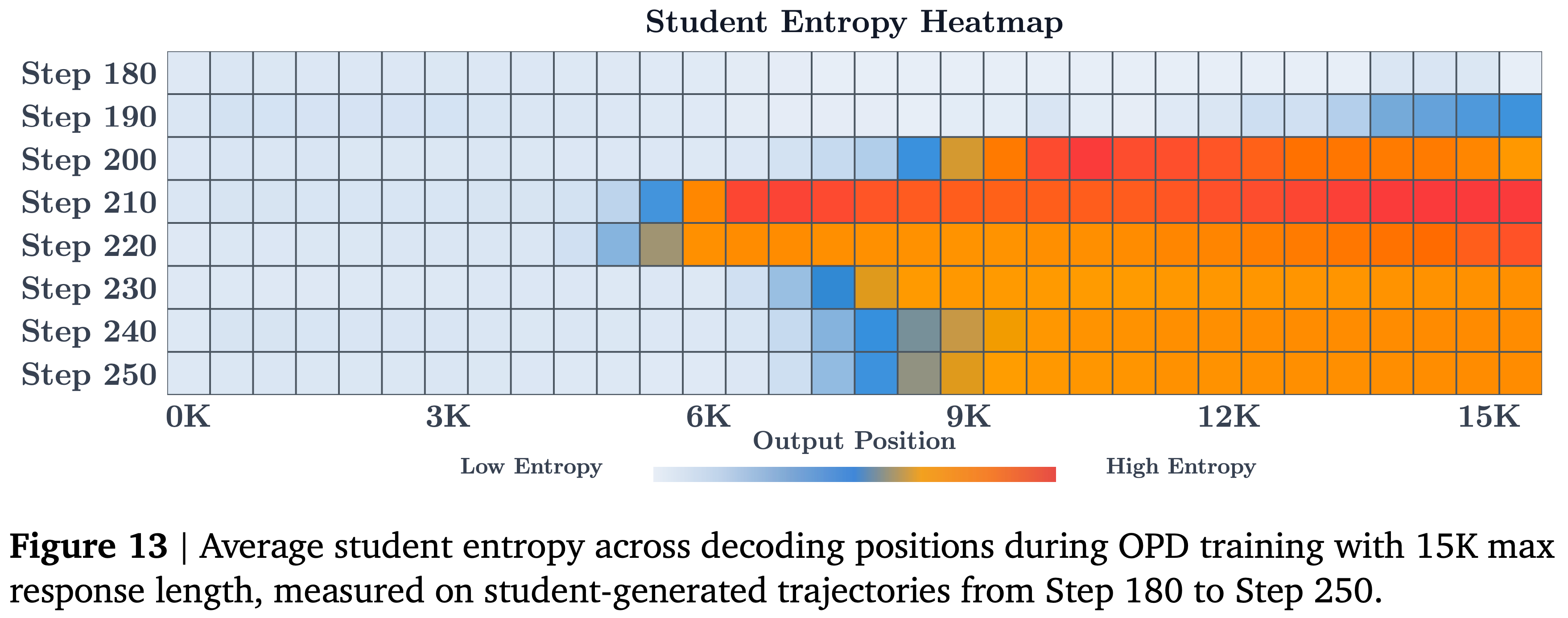
- 这与教师在较后位置遇到越来越不熟悉的 Prefix 并使产生的奖励噪声更大 ,进而破坏学生的稳定性 这一观点一致
教师延续 (teacher continuation) 能力随 Prefix 深度增加而下降
- 本文通过测试当从学生生成的 Prefix 开始时,教师是否仍然能够改进学生的延续来进一步探究这一点
- 从 DAPO-Math-17K 中采样 2K 个 Prompt,生成完整的学生 Rollout,并选择那些超过 16K Token 的 Rollout
- 然后在多个位置截断每个 Rollout,并让教师从生成的 Prefix 继续生成
- 图 11(b) 显示,教师的准确率优势单调下降,从 1K Prefix 处的 \(+0.37\) 下降到 16K Prefix 处的仅 \(+0.02\)
- 这些结果揭示了 OPD 的 Token-level 监督中的一个基本权衡
- 密集奖励在中等长度的推理轨迹上有效,但其可靠性随深度增加而下降,因为学生 Prefix 会进一步偏离教师熟悉的 States
- 这表明 OPD 可能无法干净地扩展到更长 Horizon 的设置,例如扩展的 Chain-of-Thought 或 Agentic 多轮交互
- 理解:教师遇到学生的长文时,是懵的,因为他自己不一定会生成这个前缀(没人考核他的这个能力),所以教师此时的信号对学生的可参考性不高,继续训练可能导致模型崩溃
- 举例:学生做数学题时,如果已经写了很多错误的步骤了,老师可能也看不懂了,不知道怎么教导学生了
Globally Informative Reward Does Not Guarantee Local Exploitability,全局信息性奖励不能保证局部可利用性
- 上一小节表明奖励质量随轨迹深度而下降
- 一个自然的问题是:在失败的 OPD 配置中,奖励信号是根本无信息量的,还是失败的原因在于其他地方?
Setup
- 重新审视第 4.1 节中的控制比较,以 R1-Distill-1.5B 为学生,两个教师:
- JustRL-1.5B (成功 OPD)
- R1-Distill-7B (失败 OPD)
- 对于每个学生 Rollout \(y\),计算序列平均奖励 (基于 Sampled-Token OPD )
$$\begin{array}{r}\bar{r} (y) = \frac{1}{T}\sum_{t = 1}^{T}\left[\log \pi_{T}(y_t\mid x,y_{< t}) - \log \pi_{\theta}(y_t\mid x,y_{< t})\right] \end{array}$$- 接下来比较正确和错误 Rollout 之间 \(\bar{r} (y)\) 的分布
- 注:上述序列平均奖励仅仅是用来统计了对比的,不是损失函数
Global reward structure is preserved in both settings,全局奖励结构在两种设置中都得以保留
- 图 14 显示
- 对于两个教师,正确的 Rollout 始终获得比错误 Rollout 更高的序列平均奖励,具有可比的 AUROC 值 (JustRL-1.5B 为 0.73,R1-Distill-7B 为 0.75)
- 理解:这说明对于两个教师,均有教师在正确 Rollout 上的输出概率比学生更高(符合预期)
- 失败的 7B 教师并未产生更弱的全局信号,该信号与 Rollout 正确性的相关性同样高
- 理解:
- 这里的相关性是指:即使在失败的 7B 教师上,也能看到其在正确 Rollout 上的输出概率比学生更高
- 这里的 全局信号是使用上述 Sequence 平均奖励来评估的
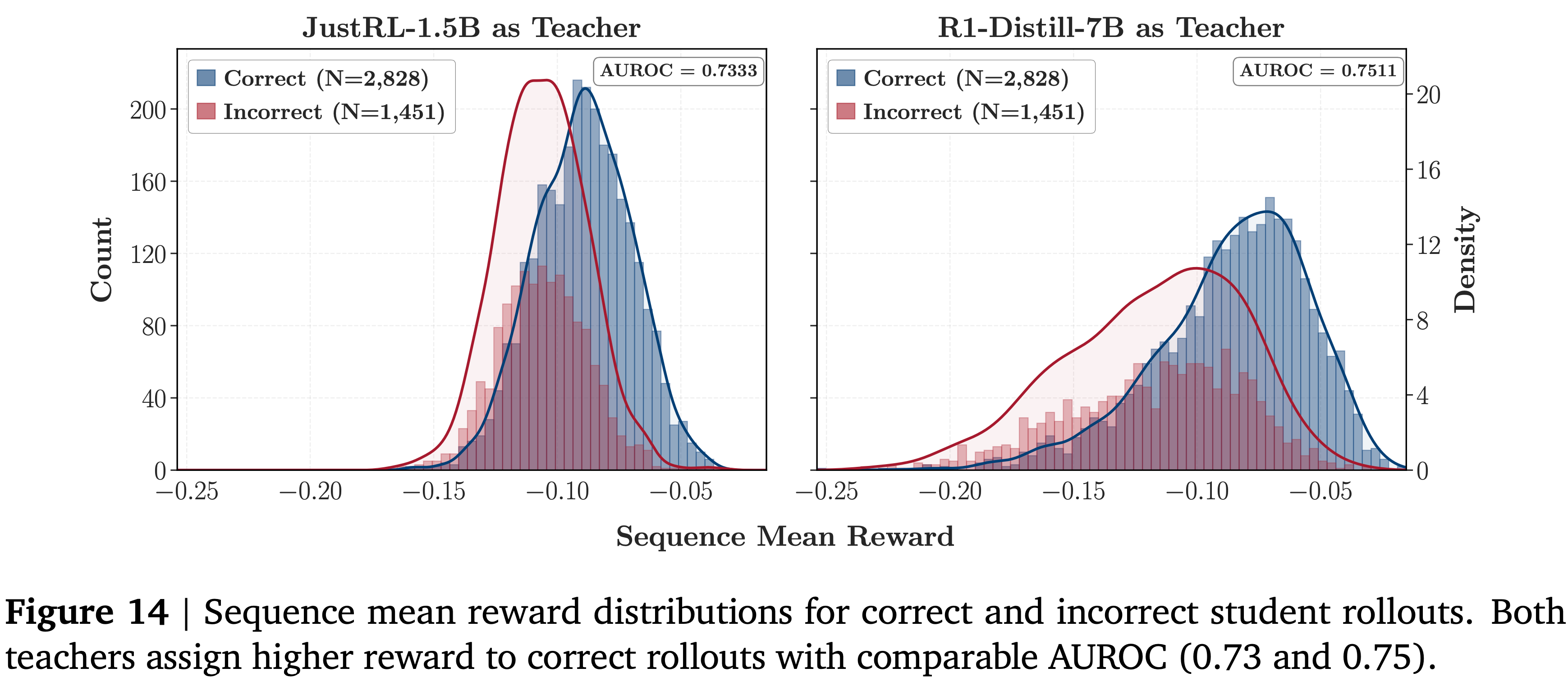
- 理解:
- 对于两个教师,正确的 Rollout 始终获得比错误 Rollout 更高的序列平均奖励,具有可比的 AUROC 值 (JustRL-1.5B 为 0.73,R1-Distill-7B 为 0.75)
A hypothesis on local optimization geometry,关于局部优化几何的假设
- 如果奖励在两种情况下都是全局信息性的,那么为什么 OPD 在 7B 教师时会失败?
- 第 4.1 节的训练动态提供了一个线索
- 如图 6 所示
- 当 R1-Distill-7B 作为教师时,在训练的后期阶段,Overlap-Token Advantage 的幅度比 JustRL 教师时的更大,然而梯度范数仍然持续较小 (见附录 B.2)
- 理解:图 6 中第二行第二列的图所示,这里的 幅度是偏离 0 的程度,看着图中是负的,所以深红色的线幅度更大

- 理解:图 6 中第二行第二列的图所示,这里的 幅度是偏离 0 的程度,看着图中是负的,所以深红色的线幅度更大
- 当 R1-Distill-7B 作为教师时,在训练的后期阶段,Overlap-Token Advantage 的幅度比 JustRL 教师时的更大,然而梯度范数仍然持续较小 (见附录 B.2)
- 一种可能的解释是:
- 7B 教师 的 Per-Token 优势虽然个体较大,但在每个序列内的不同位置之间是各向异性的 (anisotropic)
- 当这些异质信号聚合成一个梯度更新时,它们会部分抵消,导致尽管 Per-Token 的奖励很大,但有效的梯度却很小
- 理解:说明部分 Token 被鼓励,部分 Token 被打压,且针对同一个参数也有不同的反馈信号,导致参数的有效梯度信号变小
- 与学生具有兼容思维模式的 JustRL-1.5B ,可能将其优势集中在更连贯的 Token 子集上
- 由此产生的梯度,虽然由更小的 Per-Token 信号组成,但指向一个一致的方向,反向 KL 可以通过其 Mode-seeking 行为放大该方向
- 理解:比如一个序列上的每个 Token 都被鼓励,从而整体梯度方向也在提升,导致有效梯度信号相对较大
- 7B 教师 的 Per-Token 优势虽然个体较大,但在每个序列内的不同位置之间是各向异性的 (anisotropic)
- 注:本文尚未直接验证这个各向异性假设,这样做需要分析 Per-Token 梯度的方向结构,本文作者将这个问题留给未来的工作
- 高 Per-Token 优势 与低梯度范数 同时出现是暗示性的,并指出了一个重要的区别:
- 全局信息性奖励并不能保证局部可利用的奖励
- 理解 OPD 奖励 landscape 的几何结构,以及开发能够利用各向异性奖励结构的目标函数,仍然是一个悬而未决的问题
- 高 Per-Token 优势 与低梯度范数 同时出现是暗示性的,并指出了一个重要的区别:
Sampled-Token Reward Is Already Sufficient,Sampled-Token Reward 已经足够
- 关于 OPD 的奖励,一个自然的问题是每个位置需要多少个 Token 来计算有用的梯度
- Top-\(k\) OPD 将每个位置上 \(k\) 个最高概率 Token 的奖励聚合起来,人们可能期望更大的支持集总能带来更好或更稳定的学习
- 通过改变 \(k\) 并将其与更简单的 Sampled-Token OPD 进行比较来研究这一点
- 注:Sampled-Token OPD 在每个位置仅使用从学生分布中抽取的单个 Token
Setup
- 本文使用 R1-Distill-1.5B 作为学生,JustRL-1.5B 作为教师,并将 Top-\(k\) OPD (\(k \in \{1, 4, 16, 64\}\)) 与 Sampled-Token OPD 进行比较,保持所有其他超参数固定
Results
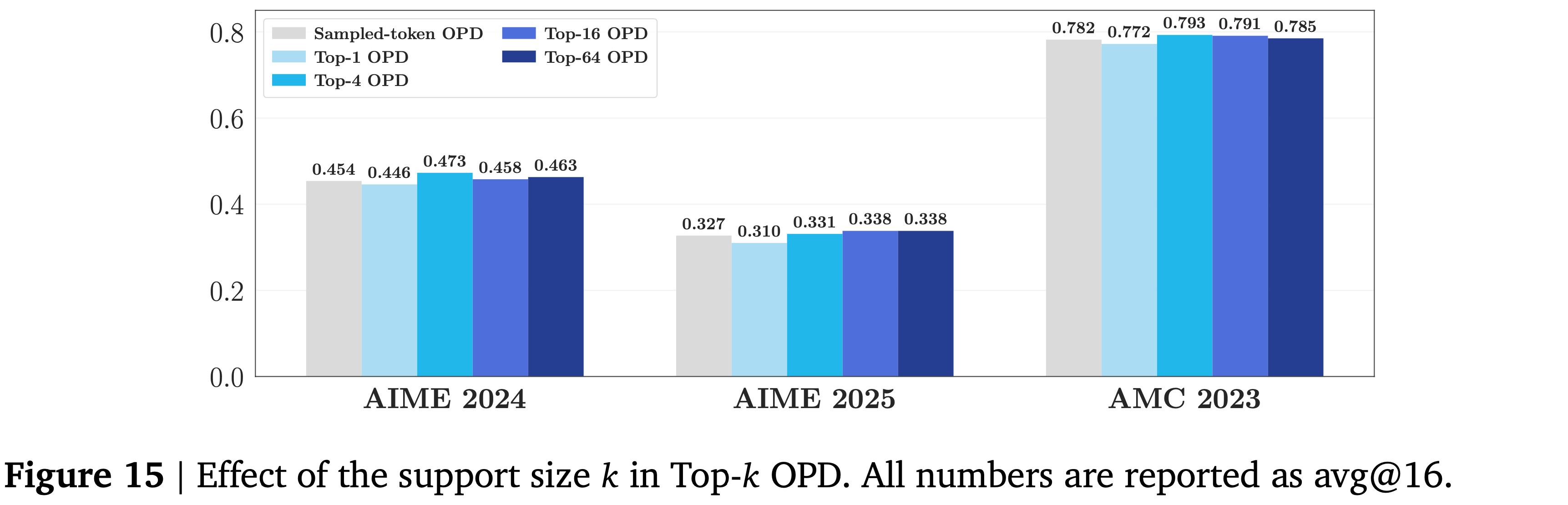
- 图 15 显示,在三个基准测试的平均值上, Sampled-Token OPD 实现了与 Top-\(k\) 设置相当的性能
- 唯一明显更差的配置是 Top-1,其表现始终不佳
- 将 \(k\) 增大到超过 4 会带来可忽略不计的额外收益,同时导致更大的计算开销
- 理解:这里说的超过 4 是指,Top-8 和 Top-16 相对 Top-4 收益几乎可忽略(甚至微降)
- 结论:Top-4 就够了
- 图 16 显示了训练动态,并揭示了差异产生的地方
- Top-1 表现出不稳定的重叠增长,伴随着熵和梯度范数的急剧峰值
- Top-4 明显更稳定,但仍显示出后期下降
- Top-16 和 Top-64 在整个过程中保持平滑
- 结论:Top-K 的 K 越大,训练越稳定,上和梯度都没有峰值(注意:梯度范数和熵的 spike 趋势是一致的)
- 思考:正因为 OPD 的 Advantages 均值倾向于小于 0,所以 Student 的熵一般不会降低,甚至会上涨(许多高概率 Token 降低自身概率带来的是熵增),少数 Token 会被提升概率,带来熵减
- OPD 的 Advantages 均值倾向于小于 0 见本文 图 7 和 图 8 中
- 注:这一点也可以见 NLP——LLM对齐微调-Revisiting-OPD
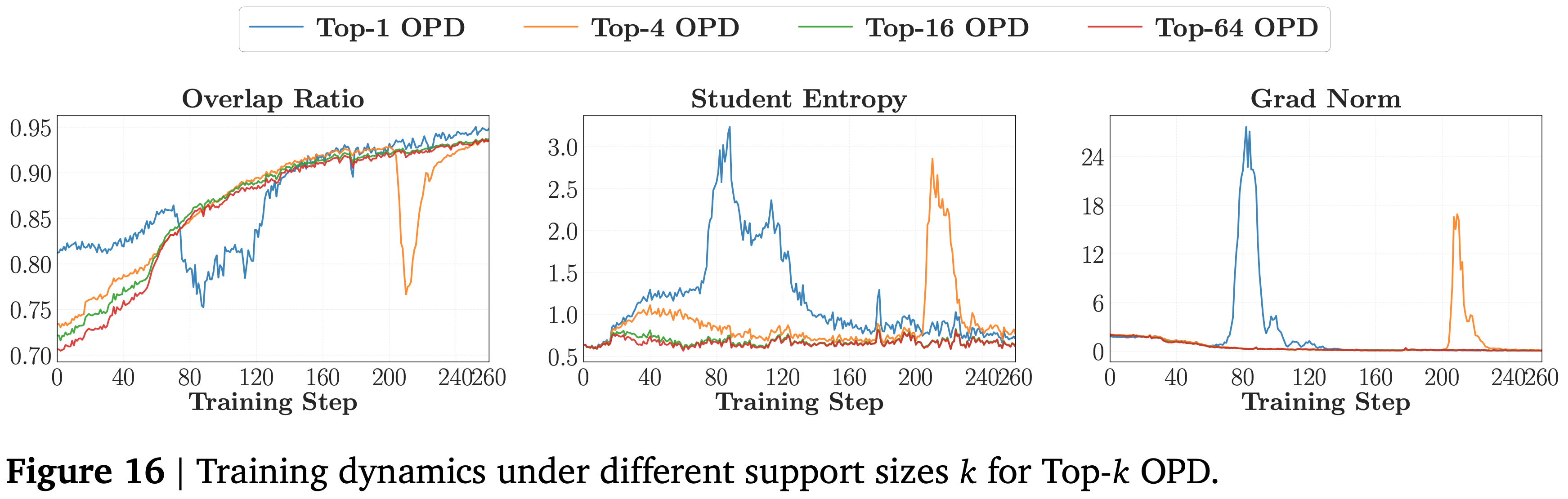
- 这些结果表明,只要避免退化的 Top-1 设置,支持集大小可能不是 OPD 的关键设计选择
- Sampled-Token OPD 之所以效果良好,尽管每个位置只使用一个 Token,是因为它按比例于学生自身的分布在每一步抽取一个不同的 Token,从而在训练过程中为高概率区域提供无偏覆盖
- Top-1 则相反,它总是选择 ArgMax Token,从而将奖励集中在一个单一模式上
- 小的策略变化可能会翻转哪个 Token 占据第一名(理解:比如第一第二名 Token 概率相近时),从而创建一个不稳定的奖励信号,该信号在训练过程中不会平均化
- 理解:但这里的理解只是相对 Top-K 而言的,相对 Sampled-Token 而言,更多是下面的原因(Top-1 选择本身是有偏的估计,而 Sampled-Token 本身是无偏的估计)
- Top-1 的失败不在于使用太少的 Token,而在于使用了一个有偏的、集中于单一模式的选择规则
Related Work
Knowledge Distillation
- 知识蒸馏 (KD) (2015) 通过训练学生网络学习教师的软输出分布,将知识从大模型转移到小模型
- 对于自回归序列模型,Kim 和 Rush (2016) 将其扩展到序列级蒸馏,通过在教师生成的输出上训练学生,建立了主导的 Off-policy 蒸馏基线 (2020;2019;2020)
- SFT 已被直接应用于提高各种下游任务的性能 (2024;2021;2021)
- 所有 Off-policy 方法共有的一个基本限制是训练-推理分布不匹配
- 学生在教师生成或参考序列上被优化,但在推理时必须从其自身的分布生成,这是暴露偏差 (exposure bias) (2015) 的一个实例,会在长生成过程中累积错误
- 这种不匹配促使将蒸馏转移到学生自己的 On-policy 分布上,这正是 On-policy 蒸馏的核心思想
On-Policy Distillation
- MiniLLM (2023) 首次在反向 KL 目标下为 LLM 形式化了 OPD,该目标通过策略梯度进行优化,认为反向 KL 的 Mode-seeking 行为可以防止学生将概率质量分散到教师认为不太可能的区域
- GKD (2024) 引入了一个统一框架,在多种散度上对 On-policy 和 Off-policy 数据进行插值,展示了相对于其他 KD 基线的一致改进
- Yang 等 (2026b) 后来在理论上将 OPD 形式化为密集 KL 约束 RL 的一个特例,表明教师的 Per-Token 对数比率构成了一个隐式奖励,并且将此奖励扩展到其标准权重之外可以推动学生超越教师的性能边界
- OPD 此后已被工业界采纳用于 Post-training 流程 (2026;2026;2026;2026;2025;2026;2025,2026b;2026),并扩展到可扩展的自蒸馏 (Ding,2026;2026;2026;2026;2026;2026;2026;2026a;2026a;2026a),其中单个模型通过以特权信息 (如 Ground-truth 解决方案或执行反馈) 为条件,充当自己的教师
- 尽管这方面的工作越来越多,但现有研究主要集中在展示 OPD 的前景,例如密集奖励和缓解的暴露偏差,在不同的目标、任务和师生对上,而没有系统地分析 OPD 何时或为何失败
Capacity Gap and Distillability
- 在知识蒸馏中,一个反复出现的观察是,较大的师生能力差距会降低甚至逆转蒸馏的益处
- Cho 和 Hariharan (2019) 证明,当教师能力显著更强时,蒸馏可能会损害学生表现,Mirzadeh 等 (2020) 提出了一个中等规模的教师助手 (teacher assistant) 来弥合差距
- Busbridge 等 (2025) 通过蒸馏缩放定律 (distillation scaling laws) 提供了定量处理,表明学生损失作为教师质量、学生规模和数据量的幂律函数,识别出一个 U 型能力区域,其中教师能力过强会降低蒸馏效率
- 对于 LLM 推理,Li 等 (2025) 记录了一个“可学习性差距”,表明在来自强推理教师的长 Chain-of-Thought 轨迹上训练小模型始终不如更简单的方法,这表明教师输出的推理复杂性必须与学生能力相匹配。这些发现提醒人们对蒸馏的普适性持谨慎态度
- 然而,现有的分析主要集中在 Off-policy 知识蒸馏上。特别是,能力差距和可蒸馏性在 OPD 中的问题仍未得到充分探索
Future Work
Beyond Mathematical Reasoning
- 注:本工作的所有实验都是在数学基准上进行的
- 后续开放问题:OPD 的相同条件和 Token-level 机制是否在代码和开放式设置等其他领域中也适用?
Impact of Pre-Training
- “新知识”条件隐含地依赖于预训练语料库的差异,但隔离这个因素具有挑战性
- 当前的研究主要依赖于跨家族蒸馏 (例如,Qwen \(\rightarrow\) LLaMA),这混淆了数据差异与 Tokenizer 不匹配和架构差异,而受控的预训练消融研究仍然代价高昂
- 衡量预训练数据对 OPD 的影响仍然是一个悬而未决的问题
Self-Distillation Dynamics
- 最近的工作越来越多地采用自蒸馏,其中单个模型在给定特权信息的情况下充当自己的教师
- 将这些见解扩展到自蒸馏机制 (思维模式一致性得到保证,但知识新颖性源于特权访问而非单独的教师) 是顺理成章的下一步
Long-Horizon and Agentic Settings
- 第 6 节提到的轨迹长度上限激励了混合方法,该方法将短段上的密集 Token-level 监督与更长 Horizon 的稀疏 Outcome-level 奖励相结合,以及在训练过程中逐步扩展监督 Horizon 的课程学习策略
附录 A:Details for Section 3
A.1. GRPO Training Details
Base Model :Qwen3-4B-Base
Training Dataset :使用处理后的 DAPO-Math-17K 数据集进行 GRPO 训练
- 具体来说,每个问题都添加了以下指令:
- GRPO dataset template
1
{Question} Please reason step by step, and put your final answer within \boxed{}.
- GRPO dataset template
- 具体来说,每个问题都添加了以下指令:
Training and Evaluation Settings
- 使用 GRPO 训练教师模型
- 在训练期间,为每个 prompt 采样 \(n = 8\) 个 responses
- 最大 prompt 长度和最大 response 长度分别设置为 1,024 和 7,168 个 tokens
- 训练在 8 张 A800 80G GPU 上进行一个 epoch
- 学习率为 \(1 \times 10^{- 6}\)
- 将 student 采样温度和 teacher 温度都设置为 1.0
- 重复惩罚设为 1.0
- 禁用 KL 正则化
- 采用 token-mean 损失聚合。主要超参数总结在表 1 中
A.2. Experimental Setup
- 所有实验均使用表 2 中列出的默认 OPD 超参数(特殊说明除外)
A.3. Benchmark-wise breakdown of thinking-pattern compatibility,思维模式兼容性的基准逐项分解
- 图 2 展示的是平均结果,这里图 17 展示了基准逐项的分解
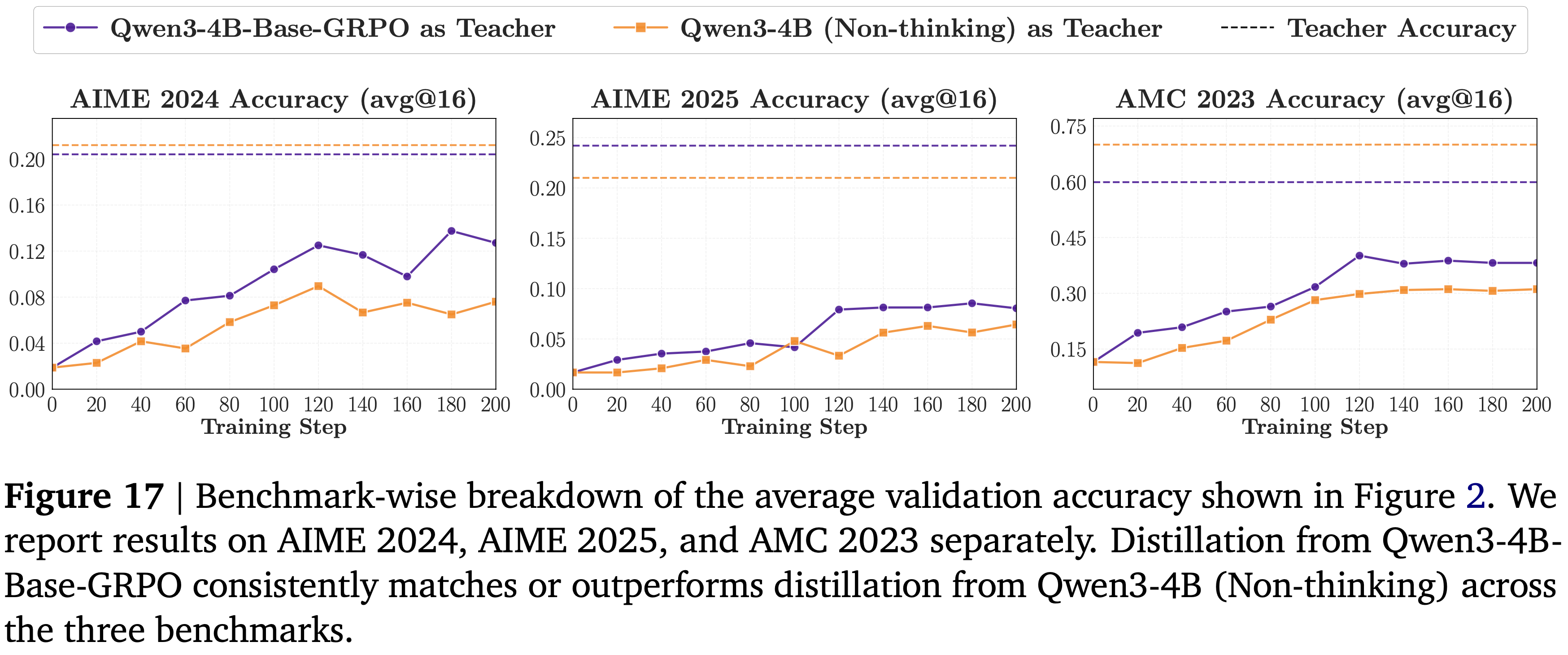
- 从 Qwen3-4B-Base-GRPO 进行蒸馏的优势在各个数据集上普遍存在(不是由单个基准驱动)
- 在 AMC 2023 和 AIME 2024 上差距更明显,在 AIME 2025 上差距较小但仍普遍存在
- 这种按基准划分的视图支持了以下解释:
- 更好的早期思维模式兼容性会导致更好的下游蒸馏性能,而早期不匹配造成的损失在训练后期无法完全恢复
附录 B:Details for Section 4
B.1. Additional Analysis of Token Overlap Mass
- 为量化每个模型分配给重叠 top-\(k\) 区域的概率质量,本文定义 \(\mathcal{M}_{\text{overlap-mass} }^{(p)}\) 为:
$$\mathcal{M}_{\text{overlap-mass} }^{(p)} = \mathbb{E}_t\left[\sum_{\nu \in S_t^{(p)}\cap S_t^{(q)} }p_t(\nu)\right] \tag {9}$$ - 定义 \(\mathcal{M}_{\text{overlap-mass} }^{(q)}\) 为:
$$\mathcal{M}_{\text{overlap-mass} }^{(q)} = \mathbb{E}_t\left[\sum_{\nu \in S_t^{(p)}\cap S_t^{(q)} }q_t(\nu)\right] \tag {10}$$ - 这衡量了 student 和 teacher 分别分配给其 top-\(k\) 集合中共享 token 的总概率质量的分数
- 在本文实验中,如图 18 所示,在整个训练过程中,重叠 token 为两个模型承载了 \(97% -99%\) 的总概率质量
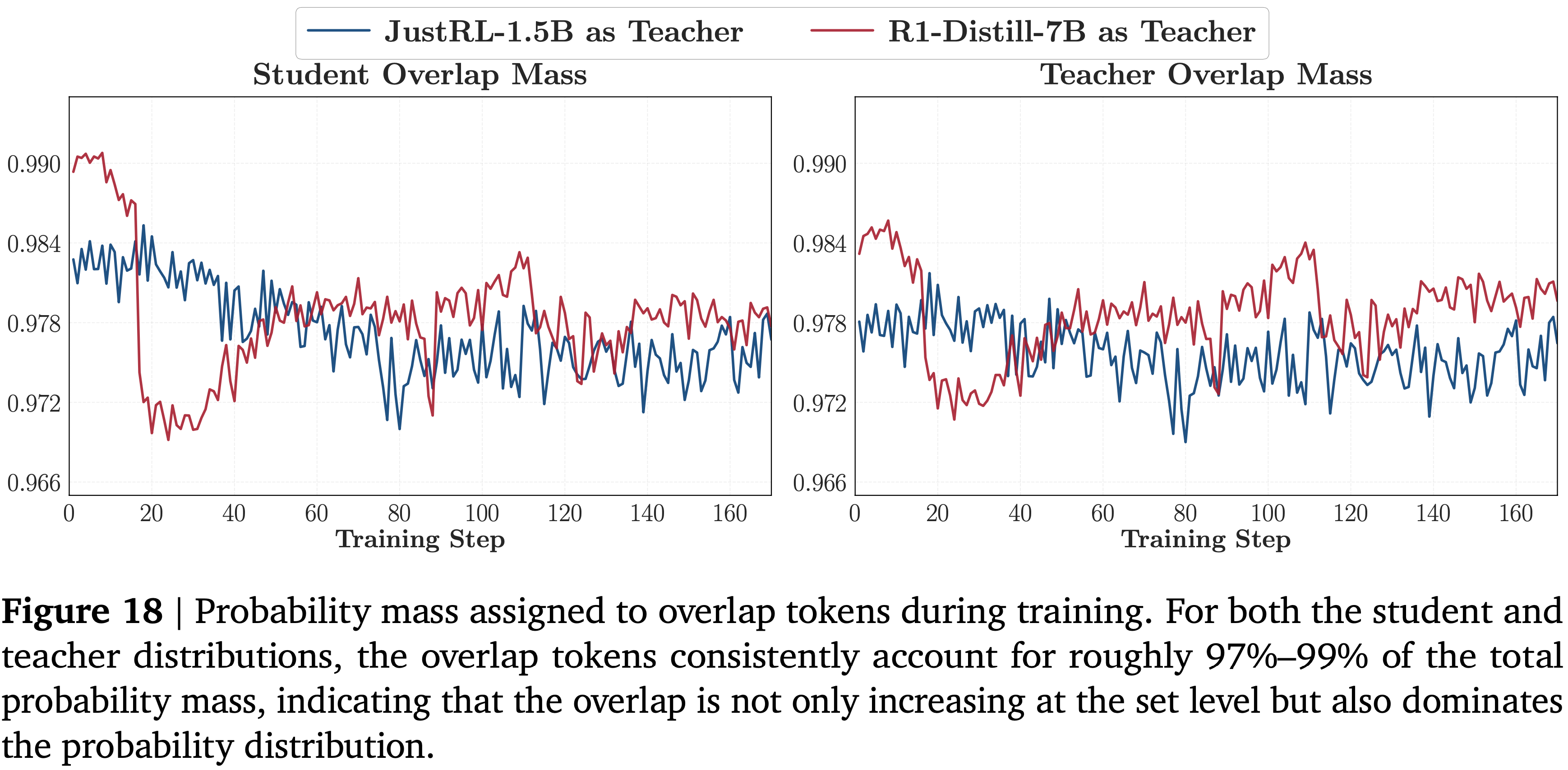
- 在本文实验中,如图 18 所示,在整个训练过程中,重叠 token 为两个模型承载了 \(97% -99%\) 的总概率质量
B.2. Auxiliary Optimization Dynamics,辅助优化动态
- 本节补充第 4.1 节的分析,针对相同的对比设置报告了几个额外的优化诊断指标
- 固定 student 为 R1-Distill-1.5B,并在相同的 Student Top-\(k\) OPD 训练方案下比较两个 teachers:
- JustRL-1.5B(产生成功的运行)
- R1-Distill-7B(在其它匹配条件下产生失败的运行)
- 这些诊断指标并非主要证据,它们提供了关于成功和失败的 OPD 之间优化信号差异的补充视图
Diagnostics,诊断
- 监测三个额外的量
- 第一个是批次平均的 OPD 训练损失,在图 19 中表示为 PG Loss
- 第二个是梯度范数,它衡量到达 student 的更新信号的整体幅度
- 第三个是具有最大绝对优势的 token 上的概率差 \(p_t(v) - q_t(v)\)
- 跟踪 student 是否能够减少在携带最强优化信号的 token 上与 teacher 最显著的局部不一致
- 跟踪 student 是否能够减少在携带最强优化信号的 token 上与 teacher 最显著的局部不一致
- 这些指标有助于区分成功和失败的 OPD:
- 在成功 OPD 中,student 接收到可用的信号并逐步减少不匹配
- 在失败 OPD 中,信号太弱或对齐太差,无法推动实质性改进
Results
- 图 19 中的趋势与第 4.1 节的主要结论一致
- 损失视角:
- 成功 OPD:使用 JustRL-1.5B 的成功运行显示出训练损失在优化过程中显著减少
- 从一个更大的初始不匹配开始,损失在训练的大部分时间里稳步下降,然后稳定在一个较低的值
- 失败 OPD:使用 R1-Distill-7B 的失败运行开始时损失小得多,之后变化不大
- 这种模式表明,失败运行中较小的损失并不表示优化更好
- 较小的 损失反映了从一开始 teacher 诱导的训练信号就较弱,该信号仍然太小,无法推动显著的政策改进
- 成功 OPD:使用 JustRL-1.5B 的成功运行显示出训练损失在优化过程中显著减少
- 梯度范数视角:(梯度范数显示了两个运行之间更清晰的分离)
- 成功 OPD:梯度范数初始很大,并在训练的很大一部分时间里保持较大
- 表明 student 持续接收到有意义的修正信号
- 失败 OPD:梯度范数始终小得多,随时间变化也有限
- 即使在相同算法和训练预算下进行优化,针对 R1-Distill-7B 训练的 student 经历的更新信号要弱得多
- 这一观察结果与以下发现一致:
- 失败与高概率 token 上的对齐性差有关
- 当 student 没有实质性地进入 teacher 支持的区域时,产生的梯度仍然很弱
- 成功 OPD:梯度范数初始很大,并在训练的很大一部分时间里保持较大
- 最大绝对优势的 Token 概率视角:
- 成功 OPD:成功的运行稳步减少了具有最大绝对优势的 token 上的概率差异
- 说明:当 OPD 成功时,student 逐步纠正了在 teacher 诱导的优势信号下最重要的局部错误
- 失败 OPD:失败的运行在整个训练过程中保持了明显更大的差距
- 说明:当 OPD 失败时,这些高优势的差异持续存在而未能解决
- 这再次与以下解释一致:
- OPD 中的决定性信号位于一小部分高概率、高优势的 token 上,当 student 无法有效利用该信号时就会发生失败
- 成功 OPD:成功的运行稳步减少了具有最大绝对优势的 token 上的概率差异
- 以上这些辅助动态强化了第 4.1 节中提出的解释
- 成功的 OPD 不仅以高概率 token 上的重叠增加为特征,而且还以训练机制为特征
- 在该机制中,student 接收到足够幅度的梯度,以减少最重要的局部分布不匹配
- 失败的 OPD 伴随着弱梯度、有限的损失减少以及在具有最强优势信号的 token 上持续存在的分歧
- 虽然这些诊断指标是支持性的而非核心,但它们提供了一个优化层面的视图,该视图与以下观点完全一致:
- OPD 有用的学习信号集中在 student 访问状态下的高概率 token 上,当该信号太弱或对齐太差而无法驱动有效更新时,训练就会退化
- 虽然这些诊断指标是支持性的而非核心,但它们提供了一个优化层面的视图,该视图与以下观点完全一致:
- 成功的 OPD 不仅以高概率 token 上的重叠增加为特征,而且还以训练机制为特征
B.3. Cross-Model Validation of High-Probability-Token Alignment,高概率 Token 对齐的跨模型验证
- 本节测试第 4.1 节中的现象是否能推广到另一对模型
- 将 student 模型固定为 R1-Distill-7B,并选择 Skywork-OR1-Math-7B 和 DeepSeek-R1-Distill-Qwen-14B (R1-Distill-14B) 作为 teachers,使用与第 4.1 节相同的训练和评估设置
Results
- 图 20 显示了与图 6 相同的模式
- 以 Skywork-OR1-Math-7B 为 teacher,蒸馏提高了 student 的性能,并伴随着重叠率的稳步增加、重叠 token 优势趋近于零以及较小的熵差
- 以 R1-Distill-14B 为 teacher,训练几乎没有改进,对齐指标仍然较差或不稳定
- 这提供了额外的证据,表明成功的 OPD 始终与 student 访问状态下高概率 token 对齐的出现相吻合
- 理解:图 20 中,成功的运行再次伴随着高概率 token 对齐的增加,而停滞的运行则没有
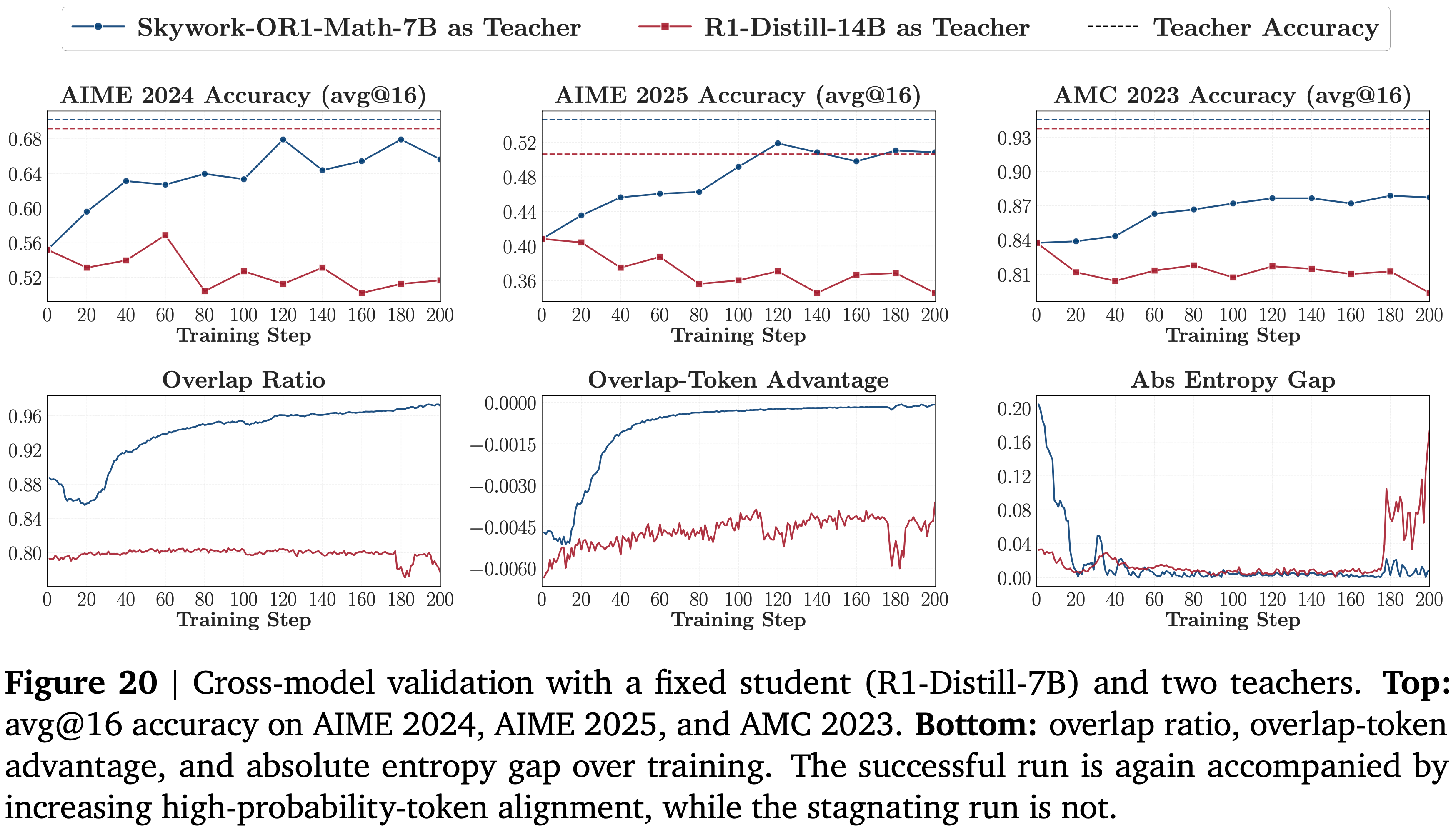
- 理解:图 20 中,成功的运行再次伴随着高概率 token 对齐的增加,而停滞的运行则没有
附录 C:Details for Section 5
C.1. Cold-Start Distillation Details
Offline teacher rollout
为了构建冷启动 SFT 数据,本文从 OpenThoughts3-1.2M (2025) 的数学子集中采样了 20 万个数学 prompts,并使用 Qwen3-4B (Non-thinking) 为每个 prompt 生成一个离线 response
对于每个 prompt,作者使用以下模板:
- Teacher rollout template
1
{Question} Please reason step by step, and put your final answer within \boxed{boxed{} }
- Teacher rollout template
解码超参:温度 0.7、top-\(p = 0.95\)、top-\(k = - 1\) 和最大生成长度 12,288 个 tokens 进行解码
生成后,过滤掉不完整的 responses(例如,未正确完成的截断输出)和退化的重复 responses
- 剩余的 prompt-response 对用作监督蒸馏语料库来训练 student
Student SFT
- 从 Qwen3-1.7B-Base 开始,使用 LLaMA-Factory 框架 (2024) 在过滤后的 20 万个 teacher 生成的样本上进行全参数 SFT,产生 Qwen3-1.7B-SFT
- 将详细的超参数总结在表 3 中
C.2. Additional Analysis of Overlap Mass,重叠质量的额外分析
- 为了更好地理解为什么基础初始化的 student 有时会表现出相当甚至稍好的重叠 token 优势 (Overlap-Token Advantage),但整体表现仍不佳,本文进一步从 student 和 teacher 两方面检查重叠集覆盖的概率质量
- 如图 21 所示
- SFT-initialized student 在整个训练过程中始终保持 student 重叠质量和 teacher 重叠质量在较高水平
- 这表明重叠 token 覆盖了 student 和 teacher 分布的大部分高概率区域,表明从 OPD 开始就存在强烈且稳定的对齐
- 而基础初始化的 student 表现出显著较低且更不稳定的重叠质量,尤其是在训练早期阶段
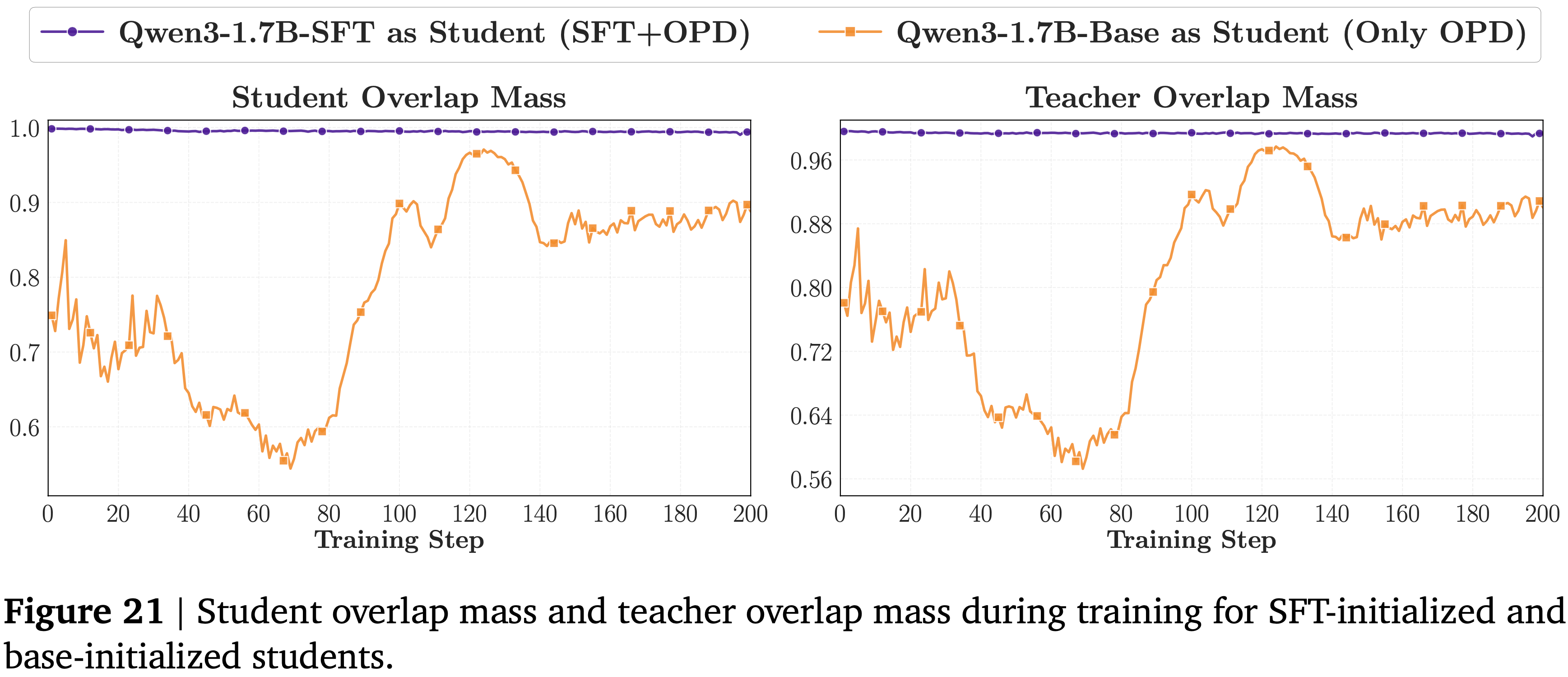
- SFT-initialized student 在整个训练过程中始终保持 student 重叠质量和 teacher 重叠质量在较高水平
- 这种分析有助于解释为什么重叠 token 优势 (Overlap-Token Advantage) 有时可能具有误导性
- 由于它仅在重叠 token 上平均,即使重叠集本身缺失了相当一部分 teacher 的高概率 token,它也可能看起来相对有利
- 重叠质量通过揭示共享支持是否真正覆盖了两个分布最重要的部分来补充这一观点
- 从这个角度来看,SFT 冷启动导致了 student 和 teacher 之间更好、更稳定的匹配
C.3. Deduplication Details for the DeepMath Subset,DeepMath 子集的去重细节
- 对于跨规模设置,构建了一个与 DAPO-Math-17K 去重后的 DeepMath 子集,以便比较与 teacher 的 RL 后训练数据对齐的 prompts 和仅在领域内的 prompts
- 本文的去重分两个阶段执行:精确匹配去重和语义去重
Question extraction
- 对于 DAPO-Math-17K 和 DeepMath,提取问题内容并移除 prompt 中的指令后缀,以便仅基于问题文本进行去重
Stage 1: Exact-match deduplication
- 将所有提取的 DAPO-Math-17K 问题收集到一个集合中,并移除其提取的问题与该 DAPO 问题精确匹配的任何 DeepMath 样本
Stage 2: Semantic deduplication
- Stage 2 进一步移除近似重复的 prompts
- 使用句子嵌入模型 all-mpnet-base-v2 (Reimers and Gurevych, 2019) 对 DAPO-Math-17K 和 DeepMath 的问题进行编码
- 对嵌入进行 L2 归一化,并在 DAPO 嵌入上构建一个 FAISS 内积索引,使得内积对应于余弦相似度
- 对于每个 DeepMath 问题
- 在 DAPO-Math-17K 中检索其最接近的邻居
- 如果与最近 DAPO 问题的余弦相似度至少为 0.6,将该 DeepMath 样本标记为语义重复并将其移除
Final retained subset
- 移除任何被精确匹配或语义去重标记的 DeepMath 样本
- 得到的子集在领域内,但与 DAPO-Math-17K 去重
- 能够在与 teacher 后训练数据重叠的 prompts 和仅在领域内的 prompts 之间进行受控比较
C.4. Benchmark-wise breakdown of prompt-template alignment,Prompt 模板对齐的基准逐项分解
- 图 9 中展示的是平均结果,图 22 展示了基准逐项的分解
- teacher 对齐的模板在各个数据集上产生了一致的改进,在两个 AIME 集上增益更大,在 AMC 2023 上影响较小但仍是正向的
- 使用 teacher 对齐的模板在三个基准上始终匹配或优于原始 DAPO 模板
- *使用 teacher 对齐的模板 *还允许 student 恢复 teacher 性能的更大一部分,从大约 \(80%\) 增加到大约 \(85%\)
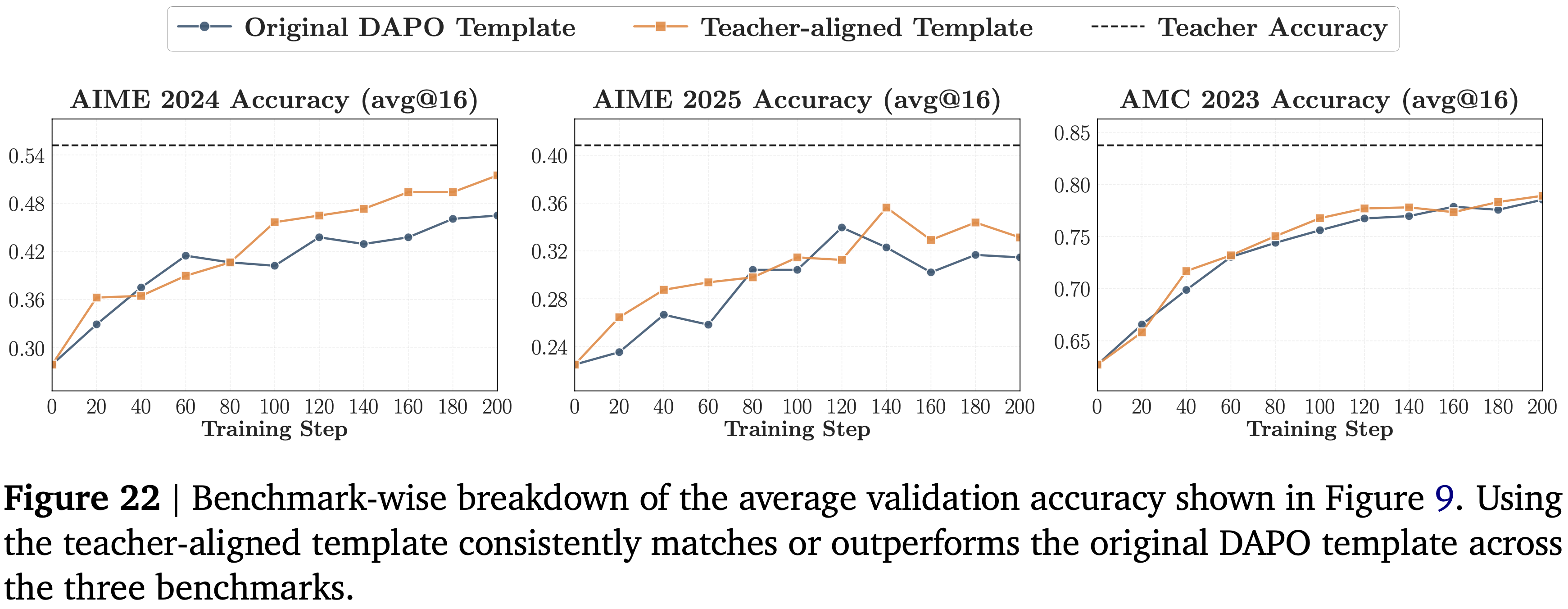
- teacher 对齐的模板在各个数据集上产生了一致的改进,在两个 AIME 集上增益更大,在 AMC 2023 上影响较小但仍是正向的
- 结合第 5.2 节中的重叠率结果,这表明 prompt 模板对齐通过使 student 生成的状态与 teacher 更兼容来改进 OPD
附录 D:Details for Section 6
D.1. Teacher entropy by output position,按输出位置划分的 Teacher 熵
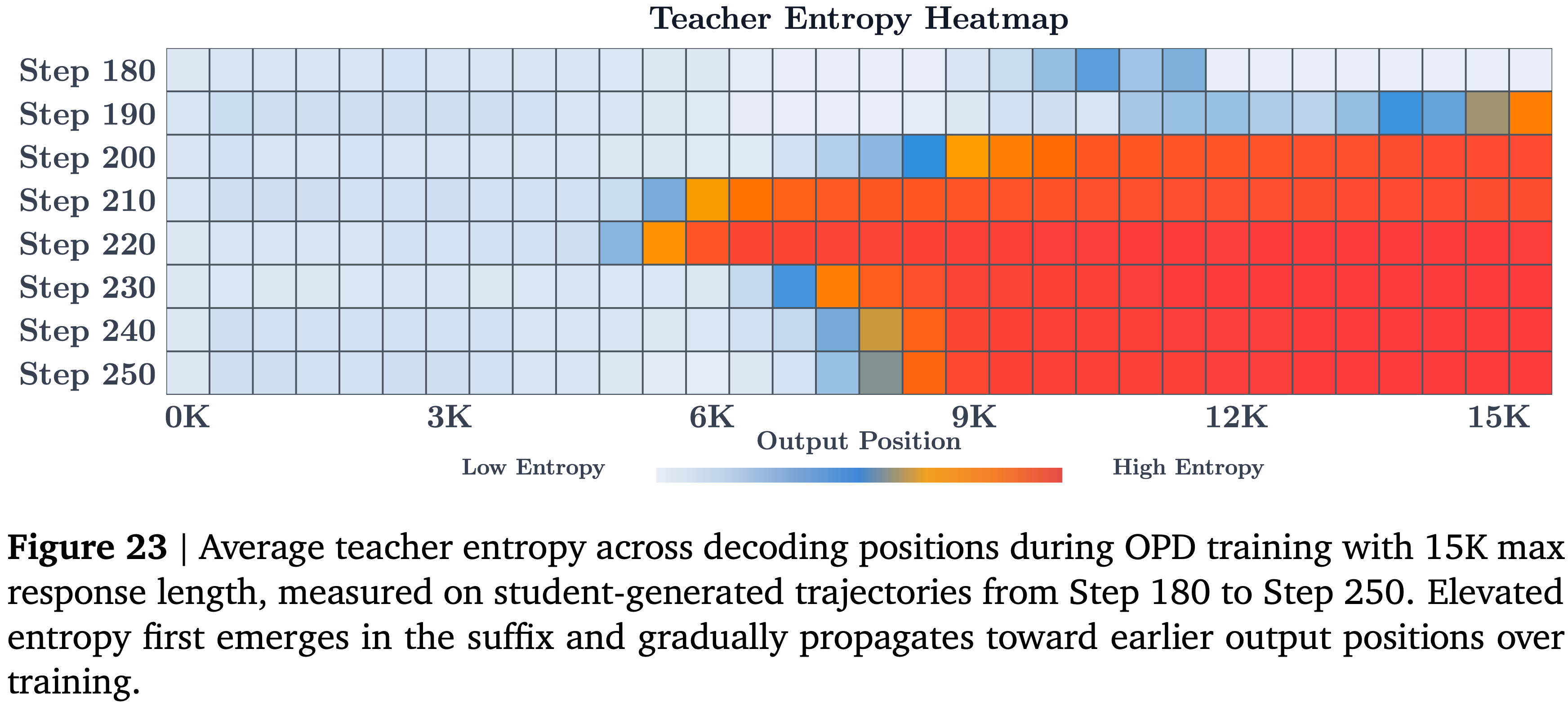
- 为补充第 6.1 节中的 student 熵分析,本节可视化了在最大 response 长度为 \(15K\) 的设置下,训练步骤中作为输出位置函数的 teacher 熵(见图 23)
- 与 student 类似,teacher 熵首先在较后的解码位置增加,然后随着训练的进行逐渐向前面的 token 传播
- 理解:升高的熵首先出现在后缀部分,然后随着训练的进行逐渐向前面的输出位置传播,说明是后面的 Token 先出现问题(教师信号不置信,逐步引起前面的 Token 崩溃)