注:本文包含 AI 辅助创作
Paper Summary
- 整体总结:
- 本文为 DeepResearch 报告生成设计了一种特定的 Rubric Generator 训练流程
- 注意:主要关注 Rubric 生成而不是验证;且主要关注 DeepResearch Report Generation 场景
- 本工作解决了 DeepResearch 报告生成中的一个核心挑战:
- 核心目标:在没有显式 Golden Signal 情况下,使用 Rubrics 获得了可靠的监督信号(可扩展、可靠且与人类对齐的)
- 核心特点:没有依赖预定义或人工标注的 rubrics,而是从人类偏好中学习 Query-specific rubric generator
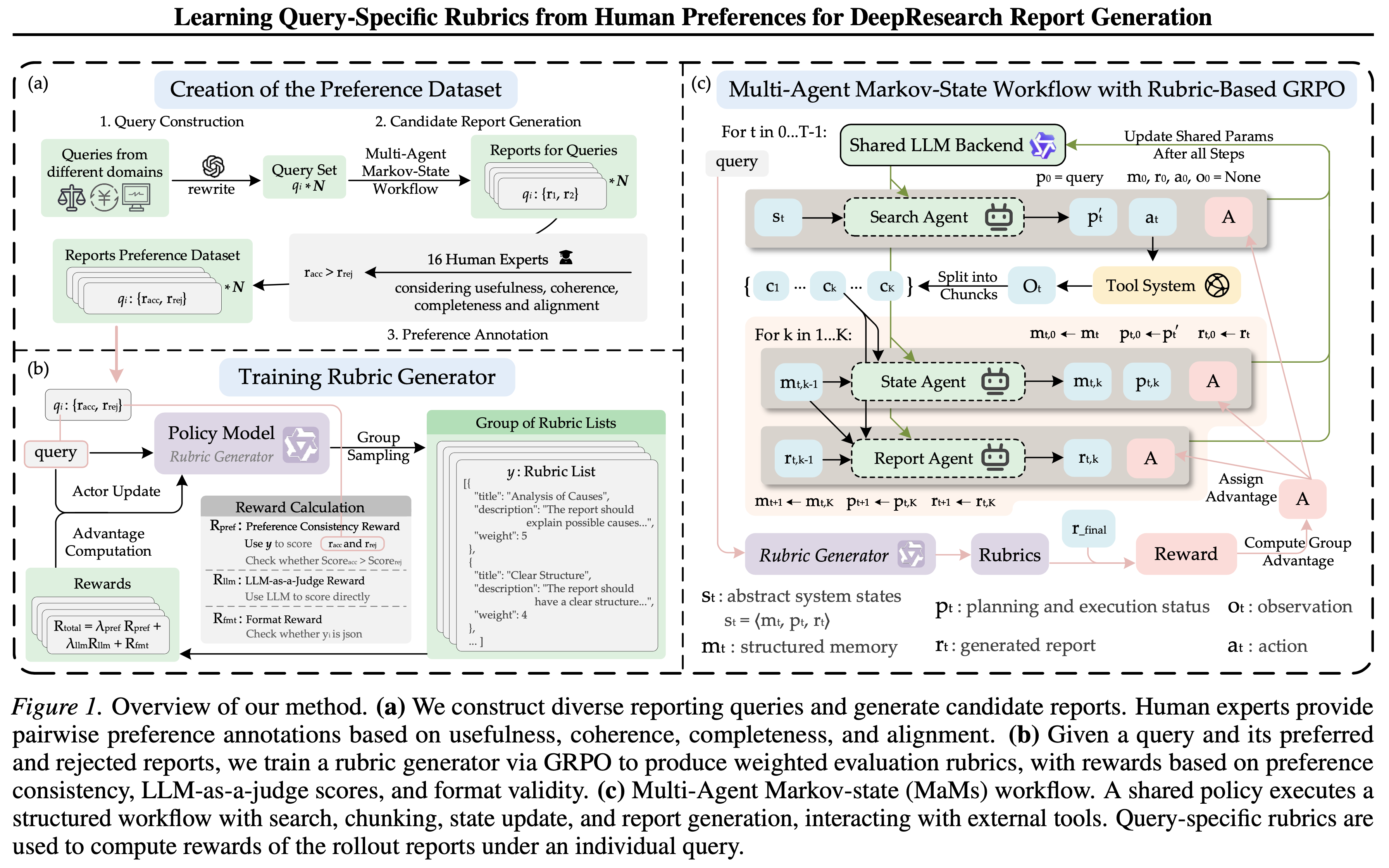
- 本文的流程和示例主要看原论文 图 1
- 本文为 DeepResearch 报告生成设计了一种特定的 Rubric Generator 训练流程
- DeepResearch 缺乏可验证的奖励信号,这种场景中,Rubric-based 评估已经比较常用
- 但现有方法要么依赖于缺乏足够细粒度的、粗粒度的预定义 Rubric,要么依赖于手动构建的 Query-specific Rubric,这些方法成本高昂且难以扩展
- 本文提出了一种为 DeepResearch 报告生成量身定制的、与人类偏好对齐的 Query-specific Rubric Generator 的训练流程
- 本文主要工作:
- 构建了一个包含人类对成对报告偏好的、带 Annotations 的 DeepResearch 风格 Query 数据集
- 通过结合人类偏好监督和 LLM-based Rubric 评估的混合奖励进行强化学习来训练 Rubric Generator
- for 长程推理,为报告生成引入了一种 多智能体马尔可夫状态(Multi-agent Markov-state, MaMs) 工作流
- 实验表明本文的 Rubric Generator 比现有的 Rubric 设计策略提供了更具区分性和更好人类对齐的监督
- 当集成到 MaMs 训练框架中时,配备了本文 Rubric Generator 的 DeepResearch 系统在 DeepResearch Bench 上持续优于所有开源基线,并达到了与领先的闭源模型相当的性能
Introduction and Discussion
- 背景:
- 不同于 BrowseComp (2025)、GAIA (2023) 和 HLE (2025) 等短格式 DeepResearch 任务,报告生成要求模型能够对不同来源进行多步推理、检索和整合,同时以连贯且结构良好的方式呈现结果
- 问题提出1:
- 训练和评估 DeepResearch 报告 Generator 仍然存在根本性的挑战
- 一个关键困难在于缺乏可验证的奖励
- 人工评估虽然可靠,但成本高昂且难以扩展,Rubric-based 评估 (2025) 已经作为一种实用替代方案的广泛采用
- 理论上来说,专家设计的、 Query-specific Rubric,如 ResearchRubrics (2025),在评估 DeepResearch 报告时可以作为人类判断的可靠代理
- 但为每个 Query 编写此类 Rubric 需要大量的领域专业知识和努力,使得这种方法难以扩展到大型和多样化的训练语料库
- 训练和评估 DeepResearch 报告 Generator 仍然存在根本性的挑战
- 已有解法1:
- 部分工作使用预定义的通用 Rubric (2024) 或 LLM 生成的 Query-specific Rubric (2025) 来为报告生成任务提供结构化反馈
- 这些方法存在两个局限性:
- 第一:预定义的 Rubric 必然是通用的,缺乏区分不同研究 Query 之间细微质量差异所需的粒度
- 第二:LLM 生成的 Query-specific Rubric 通常没有基于人类偏好数据,这使得它们容易与人类实际比较和判断研究报告的方式不一致
- 这些问题可能导致监督信号弱、奖励黑客行为和低效的学习动态
- 这些方法存在两个局限性:
- 部分工作使用预定义的通用 Rubric (2024) 或 LLM 生成的 Query-specific Rubric (2025) 来为报告生成任务提供结构化反馈
- 本文解决方案:
- 本文重新考虑用于评估 DeepResearch 报告的监督来源
- 作者认为评估 报告质量 最直接的监督信号之一是人类对候选报告的偏好 (2023; 2024)
- 与其应用通用或人工 Annotations 的 Rubric,能否学习以一种既能在大型训练数据上扩展又与人类偏好对齐的方式来评估报告?
- 理解:这个是本文要回答的最根本问题
Method
Motivations
- 专家 Annotators 可以提供高质量的评估 Rubric,但大规模手动设计 Query-specific Rubric 从根本上是不切实际的
- 即使是训练有素的专家也难以为大量且多样化的 Query 集生成一致且细粒度的标准
- 这种方法对密集专家工作的依赖限制了其在大规模 DeepResearch 训练中的适用性
- 本文的目标是开发一种与人类偏好对齐的 Query-specific Rubric Generator ,从而能够通过强化学习,利用更可靠和与人类对齐的奖励信号来训练 DeepResearch 系统
Creation of the Preference Dataset
Stage 1: Query Construction
- 首先构建一组多样化的、反映 DeepResearch 场景中实际信息需求的研究导向型 Query
- 每个 Query \(q\) 被表述为一个开放的研究 Prompt,需要多步推理、证据综合和结构化的长格式报告,而不是简短的事实性答案
- 原始 Query 是从构建于不同领域实体的知识图谱中自动生成的
- 通过利用图谱的关系结构,作者采样多跳实体路径,并 Prompt 一个 LLM 来合成相应的自然语言问题
- 这确保了每个 Query 都基于实体关系,同时需要跨多个事实进行推理 ,使其适合于评估深度研究和综合
- 然后使用 GPT-5 (2025) 重写 Query
- 使其措辞和自然度多样化,使其与现实用户提问风格对齐,并自然地诱导报告质量的差异
- 用 \(N\) 个构建的 Query 表示数据集 \(\mathcal{Q}\) 为
$$ \mathcal{Q} = \{q_i\}_{i = 1}^N $$- 其中每个 \(q_i\) 作为生成后续候选报告的条件输入
- 重写 Query 的案例研究和详细类别见附录 A
Stage 2: Candidate Report Generation via Multi-Agent Markov State Framework
- 给定一个固定的 Query
$$ q \in \mathcal{Q}$$ - 改变多个 LLMs 的超参数来生成多个候选报告
- 包括 DeepSeek V3.1 (2024a) 和 TongyiDeepResearch (2025),这些模型都已经经过智能体数据训练,具备工具调用能力
- For 解决 ReAct 风格推理 (2022) 中的长上下文依赖性和自动化 DeepResearch 的多步性质所带来的挑战
- 本文从先前的工作中汲取灵感 (2025b),并提出了一个 多智能体马尔可夫状态(Multi-Agent Markov-State, MaMs) 工作流,详见第 3.4 节
- 使用此工作流 独立生成 候选报告被,且不接触任何人工 Annotations
- 在提交进行人工 Annotations 之前,对所有候选报告进行一个过滤过程
- 这个过滤过程包含了人工评审员和 Auxiliary LLM-based 验证器的过滤过程
- 移除具有明显事实错误、引用混乱或不一致、或者内容表现出表面聚合而无连贯推理的报告,最终只保留两个最高质量的报告 for Annotations
Stage 3: Preference Annotation by Human Experts
- 对于人工 Annotations ,作者招募了 16 名人类专家,每人至少持有硕士学位 ,并具备批判性阅读和评估长格式研究报告的能力
- 专家们对为同一 Query 生成的候选报告进行成对比较
- 给定一个 Query \(q\) 和两个候选报告 \(r_a, r_b \in \mathcal{R}(q)\), Annotators 被要求选择他们整体上更喜欢的报告,考虑因素包括有用性、连贯性、完整性以及与 Query \(q\) 所表达的信息需求的对齐程度
- 每次比较产生一个 Prefered \(r_{\mathrm{acc} }\) 和一个 Less Prefered \(r_{\mathrm{rej} }\),形成一个偏好三元组
$$ (q, r_{\mathrm{acc} }, r_{\mathrm{rej} }) $$
- 每次比较产生一个 Prefered \(r_{\mathrm{acc} }\) 和一个 Less Prefered \(r_{\mathrm{rej} }\),形成一个偏好三元组
- 聚合所有 Annotations 的比较结果得到最终的人类偏好数据集
$$ \mathcal{D} = \{(q, r_{\mathrm{acc} }, r_{\mathrm{rej} })\}$$- 该数据集用作建模和评估偏好对齐报告生成的监督
- 注:以上得到的是专家的相对判断而非绝对评分,该数据集捕获了难以用通用或 LLM 生成的评估指标表达的细粒度人类偏好
- 理解:人工判别生成的数据,确实非常宝贵
Training Rubric Generators with Hybrid Rewards
- For 生成与人类偏好良好对齐的评估 Rubric,使用 GRPO (2024b) 来训练 Rubric Generator
- 给定一个 Query \(q\),策略模型 \(\pi_{\theta}\) 采样一组 Rubric 候选 \(\{y_1, y_2, \ldots , y_G\}\),其中每个候选 \(y_i\) 指定了一个结构化的评估标准集(Evaluation Criteria)
- 遵循 Gunjal 等人 (2025) 提出的 Rubric 规范,每个 Rubric 项目用三个关键字段表示:
- 1)Title
- 2)Description
- 3)关联的重要性权重
- 以上三部分形成一个加权的评估维度列表(例如,JSON 格式)
- 理解:这里一个 Rubric 就包含三个部分,相对来说是比较复杂的,特别是权重方面有点不好生产,可以考虑看下模型是否真的可以生成这个
- For 稳健地指导学习,作者设计了一个混合奖励函数 \(R_{\mathrm{total} }\),整合了三个互补的信号:
- Preference Consistency Reward
- Format Reward
- LLM-as-a-Judge Quality Reward
- 总体训练信号计算为上述分量的加权组合:
$$R_{\mathrm{total} } = \lambda_{\mathrm{pref} }R_{\mathrm{pref} } + \lambda_{\mathrm{llm} }R_{\mathrm{llm} } + R_{\mathrm{fmt} } \tag{1}$$
Preference Consistency Reward \((R_{\mathrm{pref} })\)
- 一个有效的 Rubric 必须具有区分性,即当应用于真实报告时能够反映人类偏好
- 作者利用第 3.2 节创建的由三元组 \((q, r_{\mathrm{acc} }, r_{\mathrm{rej} })\) 组成的偏好数据集 \(\mathcal{D}\)
- 其中对于同一 Query \(q\),人类 Annotators 更偏好 \(r_{\mathrm{acc} }\) 而非 \(r_{\mathrm{rej} }\)
- 给定一个生成的 Rubric \(y\),通过计算项目级评分的加权平均值来为一个报告 \(r\) 打分:
$$S(r\mid y) = \frac{\sum_{k = 1}^{K}w_{k}\cdot v_{k} }{\sum_{k = 1}^{K}w_{k} } \tag{2}$$- 其中 \(w_{k}\) 表示第 \(k\) 个 Rubric 项目的权重,\(v_{k}\) 是由评判 LLM 分配的相应符合度分数
- 每个 \(v_{k}\) 按 1-10 的李克特量表 (2023a; 2024) 评分,并线性归一化到 \([0,1]\) 范围进行聚合
- 偏好一致性奖励取决于 Rubric 是否正确地将人类更偏好的报告排在较不偏好的报告之上:
$$R_{\mathrm{pref} }(y) = \left\{ \begin{array}{ll} +1, & \mathrm{if } \ S(r_{\mathrm{acc} }\mid y) > S(r_{\mathrm{rej} }\mid y);\\ -1, & \mathrm{otherwise}. \end{array} \right. \tag{3}$$
Format Reward \((R_{\mathrm{fmt} })\)
- 下游评估流程需要机器可解析的 Rubric 表示,本文将结构有效性作为硬约束强制执行
- 本文会检查每个生成的候选是否符合所需的 JSON 模式(包括必填字段,如 Title、Description 和 Weight)
- 未通过此检查的候选会受到 \(-1\) 的惩罚(注:通过此检查的 Rubric 则不会获得额外奖励)
LLM-as-a-Judge Reward \((R_{\mathrm{llm} })\)
- For 评估生成的 Rubric 的内在质量
- 本文进一步采用了一个 LLM-as-a-Judge 的机制,充当语义元评估器
- 评判者不是依赖于预定义的规则,而是在 Query \(q\) 的背景下评估一个 Rubric \(y\)
- 关注其逻辑连贯性、覆盖全面性及其评估维度的相关性
- 将这些因素综合成一个标量质量分数(例如,缩放到 \([0,4]\)):这些标准被聚合成一个标量质量分数
$$ R_{\mathrm{llm} } = \mathrm{Judge}(q,y) $$
- 具体的提示词可以在附录 C.3 中找到
Multi-Agent Markov-State Workflow with Rubric-Based GRPO
- 在获得训练良好的 Rubric Generator 后,利用它通过 GRPO 为训练 DeepResearch 系统提供可靠且 Query-specific 奖励信号
- 本文中的 DeepResearch 框架称为 多智能体马尔可夫状态(Multi-Agent Markov-State, MAMs) 工作流
- 与之前的 容易产生上下文饱和和错误积累的单一架构 不同
- MaMs 框架明确地将高层推理、信息获取和报告综合分离到专门的智能体中,这些智能体通过迭代的状态转移循环进行交互
- 为了提高多智能体系统的效率,作者提出了一种并发执行方案,详见附录 F
State Abstraction and Iterative Transitions
- 将深度研究过程建模为一个在抽象状态空间上的序列决策问题
- 对于用户 Query \(q\),迭代 turn \(t\) 的研究状态定义为
$$s_{t} = \langle m_{t},p_{t},r_{t}\rangle$$- \(m_{t}\) 代表结构化记忆
- \(p_{t}\) 表示动态执行计划
- \(r_{t}\) 是逐步演变的报告
- 注:传统 RAG 依赖于原始检索上下文,但这里框架基于这种紧凑的抽象(Compact Abstraction),确保跨长程工作流的可扩展性
- 转移遵循分层结构:高层搜索动作触发低层状态处理,形式上有:
$$s_{t + 1} = \mathcal{T}(s_{t},a_{t}) $$ - 其中 \(\mathcal{T}\) 封装了工具执行和后续的多智能体处理流程(如下所述)
- 详细的算法描述请参见附录 B
- 转移遵循分层结构:高层搜索动作触发低层状态处理,形式上有:
Agent Modules and Chunk-based Process
- MAMs 工作流由 3 个具有明确定义职责的专门智能体组成,如图 1 所示
Search Agent
- Search Agent 作为高层控制器,观察当前状态 \(s_{t}\) 并确定最佳下一步
- Search Agent 生成一个搜索动作 \(a_{t}\)(例如,生成
<tool_call></tool_call>)并优化全局计划:
$$ a_{t},p_{t}^{\prime} = \mathcal{A}_{\mathrm{search} }(q,s_{t})$$ - Search Agent 负责识别 \(m_{t}\) 中的信息差距并驱动探索过程
- 如果收集到足够的信息,搜索循环终止,并最终确定输出
State Agent
- 在执行动作 \(a_{t}\) 后,环境返回一个原始观察 \(O_{t}\)(例如,长搜索内容)
- 一个关键的挑战是 \(O_{t}\) 常常超过 LLM 的上下文窗口限制
- 理解:搜索的得到的内容一般都是很大的类似 HTML 或 PDF 等文档
- For this Question,作者遵循 MemAgent, 20250703 实现一个基于分块的处理机制
- 原始文本 \(O_{t}\) 使用尊重语义边界(例如,段落)的文本分割器被分割成一系列较小的块
$$ \{c_{1},c_{2},\ldots ,c_{K}\} $$
- 原始文本 \(O_{t}\) 使用尊重语义边界(例如,段落)的文本分割器被分割成一系列较小的块
- State Agent 按顺序处理这些块,以更新记忆和计划,同时最小化信息损失
- 令 \(m_{t,0} = m_{t}\) 且 \(p_{t,0} = p_{t}^{\prime}\)
- 对于每个块 \(k \in \{1, \ldots , K\}\),智能体执行增量更新:
$$m_{t,k},p_{t,k} = \mathcal{A}_{\mathrm{state} }(q,c_{k},m_{t,k - 1},p_{t,k - 1}). \tag{4}$$- 问题:这里的 \(p_{t,k}\) 是什么?
- 理解:这里的 \(p_{t,k}\) 是计划(注:\(m_{t,k}\) 表示记忆)
- Prompt 逻辑明确强制一种“增量融合”策略:
- 保留 \(m_{t,k - 1}\) 中的现有知识,同时压缩并合并来自 \(c_{k}\) 的新事实
- 处理完所有 \(K\) 个块后,为下一次迭代建立的最终状态为 \(m_{t + 1} = m_{t,k}\) 和 \(p_{t + 1} = p_{t,k}\)
Report Agent
- Report Agent 随着状态更新增量地完善研究报告:
$$r_{t,k} = \mathcal{A}_{\mathrm{report} }(q,c_{k},m_{t,k - 1},r_{t,k - 1}). \tag{5}$$ - 这种设计有效地将信息压缩(由 State Agent 处理)与叙述生成(由 Report Agent 处理)解耦
- Report Agent 使用流式证据 \(c_{k}\) 来起草、更正和扩展报告 \(r_t\) 的各个部分,确保全局一致性并降低一次性生成长报告时产生幻觉的风险
- 满足终止条件(如达到最大回合数或无需进一步工具调用)后,生成最终报告 \(r_{\mathrm{final} }\)
Reward Assignment with Weighted Rubrics
- 对于每个 Query \(q\),Rubric Generator 会生成一个带有相关权重的评估 Rubric 列表,捕获 Query-specific 报告质量概念
- 在系统为 \(q\) 生成一组候选报告后,作者采用一个 LLM-as-a-Judge ,根据这些加权 Rubric 对每个生成的报告进行评分
- 所得的标量奖励按照公式 (2) 中定义的相同加权聚合方案计算,并用于监督策略优化
- 所有提示请参考附录 C
Experiments
- 在本节中,作者进行了一系列实验来回答以下研究问题:
- RQ1: 使用 GRPO 训练的 rubric generator 是否能有效地捕捉人类对生成报告的偏好?
- RQ2: 当用于训练 DeepResearch agent 时,rubric generator 是否能提供更可靠的 reward 信号?
- RQ3: 在复杂的 DeepResearch 任务中,所提出的 multi-agent Markov-state workflow 是否优于传统的 ReAct-style 框架?
Experimental Settings
数据集
- 为了解决 RQ1,作者将构建的人类偏好数据集 \(\mathcal{D}\) 按 8:1:1 的比例划分为训练集、验证集和测试集,其中 \(10%\) 的数据留作测试。划分以主题平衡的方式进行,确保所有主题在训练集、验证集和测试集中都有体现。为了解决 RQ2 和 RQ3,作者在广泛采用的 DeepResearch Bench (2025) 上评估作者的方法,该基准包含 100 个 Query (50 个中文和 50 个英文),涵盖了多样化的研究主题
实施细节
- 所有实验均在一个专用的大规模 GPU 集群上进行,集群配备了 NVIDIA H20 GPU。Rubric generator 在 8 块 H20 GPU 上训练,而 MaMs workflow 内的 DeepResearch agent 训练则使用 32 块 H20 GPU。为了在强化学习过程中实现大规模、高并发的推理以进行 rubrics 评分和 LLM-as-a-Judge 评估,作者进一步部署了 192 块 H20 GPU,使用 vLLM 框架 (2023) 运行 Qwen3-235B-A22B,确保所有请求都能在 4 分钟内端到端处理完毕。完整的实现、基础设施细节和超参数见附录 D
指标
- 作者使用两个互补的指标来评估偏好建模的性能。偏好准确度衡量模型给偏好回复赋予的分数高于被拒绝回复的频率,它等同于成对偏好评估中的 AUC,反映了排序的正确性。为了进一步评估偏好分离的幅度和稳定性,作者报告了配对 Cohen’s \(d\),它量化了不同 Query 间接受和拒绝回复之间的标准化差异。虽然偏好准确度捕捉了排序是否正确,但 Cohen’s \(d\) (Diener, 2010) 表征了模型区分偏好输出的强度和一致性,提供了对偏好质量更细致的观察。在 DeepResearch Bench 中,”comprehensiveness”、”Depth”、”instruction following” 和 “readability” 是预定义的评估维度,每个维度都由 LLM judges 使用官方基准提示进行评估
基线
- 对于人类偏好评估,作者考虑以下基线:
- (1) Human-defined General Rubrics,采用遵循 (2025) 中提出的通用报告 rubrics 的手动指定的评估 rubrics
- (2) Pointwise Preference Scoring,其中每个三元组 \((q, r_{\mathrm{acc} }, r_{\mathrm{rej} })\) 中的接受和被拒绝报告 \((r_{\mathrm{acc} }, r_{\mathrm{rej} })\) 由模型独立评分,偏好由分数比较决定
- (3) Pairwise Preference Judgment,其中 \((r_{\mathrm{acc} }, r_{\mathrm{rej} })\) 被共同提供给模型进行直接偏好判断
- (4) Generated Rubrics,提示模型从 \(q\) 生成 Query-specific rubrics,然后进行 LLM-based 评估
- (5) Supervised Fine-Tuning,使用 GPT-5 生成的 rubrics 作为监督目标
- (6) Reinforcement Learning with Various Rewards,应用 GRPO 时在公式 (1) 中使用不同的 reward 权重配置
- 对于 DeepResearch Bench,闭源基线的结果直接来自官方排行榜
- 由于资源限制,作者无法用 Qwen3-30B-A3B 作为 Backbone 复现 DRTulu 系统
- 作者还比较了 ReAct 和作者的 MaMs workflow
- 该工具执行基于关键词的搜索并返回完整的检索结果
- 对于 ReAct 框架,作者提供结果的摘要版本,以防止输出长度问题并确保有效推理
- 为了公平起见,所有结果均使用具有最佳验证性能的检查点获得
Evaluation on Human Preferences
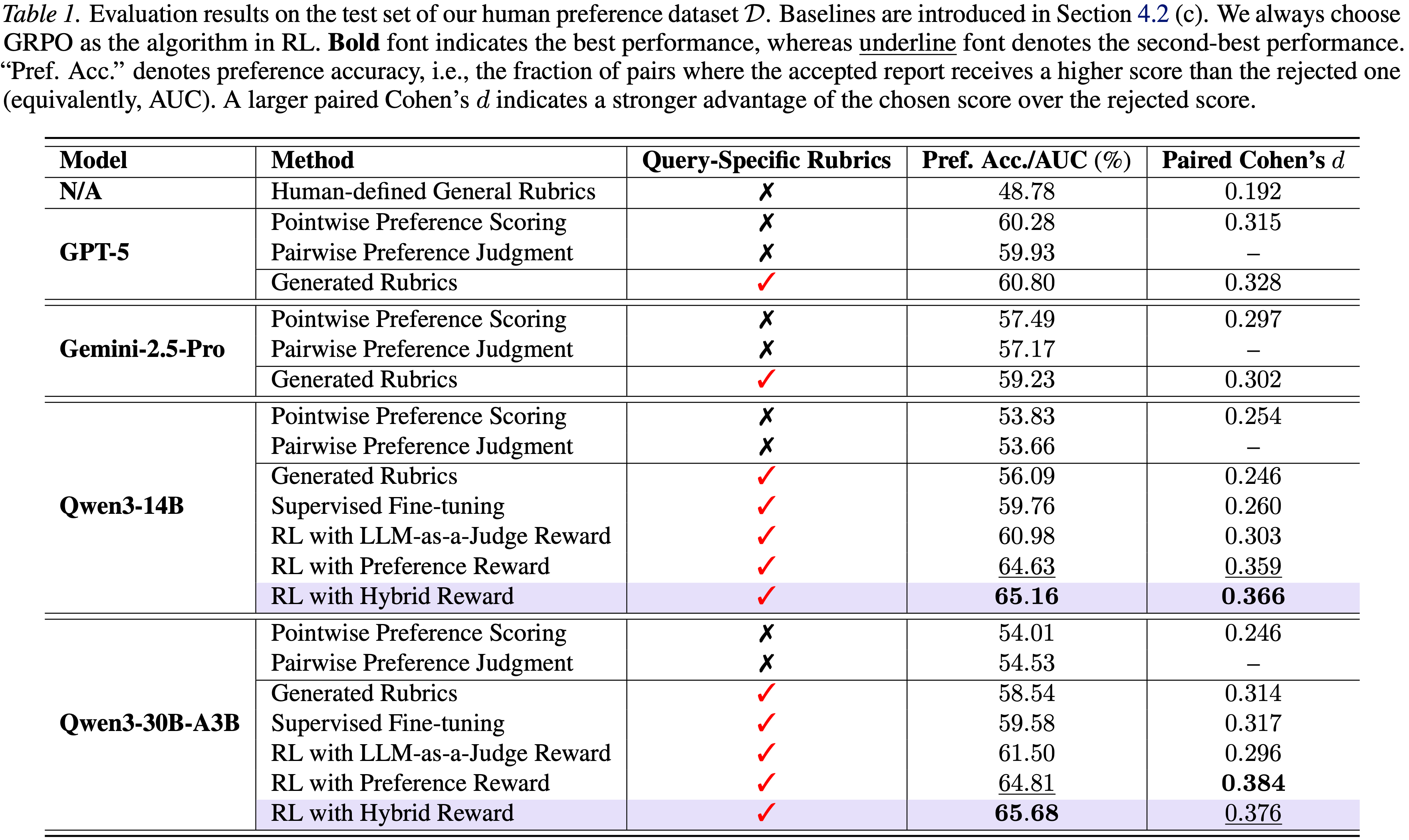
- 作者在人类偏好数据集的测试集上报告结果(表 1),这直接解决了 RQ1
- 可以得出几个关键观察结果:
- (1) 基于 Query-specific rubrics 的方法持续优于依赖人类定义的通用 rubrics 的方法
- 如表 1 的第一部分所示,通用 rubrics 产生了接近随机的偏好准确度和较小的效应量,而生成的、以 Query 为条件的 rubrics 显著提高了偏好准确度和配对 Cohen’s \(d\)
- 这证实了在下游训练中,纳入 Query-specific 评估标准对于提供可靠的 reward 信号至关重要
- (2) 直接应用强大的 LLM(如 GPT-5)生成 rubrics,或对此类 rubrics 进行监督微调,并不足以捕捉细粒度的人类偏好
- 尽管这些方法在偏好准确度上取得了提升,但其配对 Cohen’s \(d\) 仍然相对较小,并且在接受和被拒绝报告之间没有表现出明显的分离,这表明与人类偏好边际的对齐有限
- (3) 基于偏好的奖励进行强化学习,在两个 Qwen Backbone 上都显著提高了配对 Cohen’s \(d\)
- Cohen’s \(d\) 的增加反映了接受和被拒绝报告之间评分差距的增大,表明模型在区分人类偏好的报告方面变得越来越好
- 此外,使用混合奖励的 RL 取得了最佳的整体性能,结合了强劲的偏好准确度和持续较大的效应量,展示了整合偏好信号与辅助奖励分量的互补优势
- (1) 基于 Query-specific rubrics 的方法持续优于依赖人类定义的通用 rubrics 的方法
Results on DeepResearch Bench
- 通过表 2,作者可以回答 RQ2 和 RQ3
- First:比较相同 Tongyi-DeepResearch Backbone 下不同的 rubrics 策略,作者观察到使用 RL 训练的 rubric generator 在所有评估维度上持续取得最佳性能
- 它明显优于人类定义的通用 rubrics、GPT-5 生成的 rubrics 和 SFT 训练的 generator,这表明所提出的 rubric generator 为训练 DeepResearch agent 提供了更可靠和信息丰富的 reward 信号
- 这验证了 RQ2,表明通过强化学习学习 rubrics 相比静态或纯监督的替代方案能产生更有效的监督
- 如表所示,Tongyi-DeepResearch 比 Qwen3-30B-A3B 表现出更强的工具调用和执行能力,但在报告生成方面不如 WebWeaver agent 专业
- 这使其成为作者研究的合适 Backbone ,因为它使作者能够更好地检验 rubrics 学习和 workflow 设计的有效性,而不是依赖强大的内在生成能力
- Second:配备所提出 MaMs 的模型在相同的 rubrics 策略下,持续优于其 ReAct-style 的对应物
- 特别是,配备 MaMs workflow 和 RL 训练的 rubric generator 的 Tongyi-DeepResearch,在所有开源方法中取得了最强的整体性能,在全面性、遵循指令性、可读性和总体得分上均有明显提升
- 这些结果表明,将研究过程明确构建为一个以状态为条件的 workflow,相比传统的 ReAct 范式,能够实现更有效的推理和信息整合,从而回答了 RQ3
Analysis on Entropy over Two RL Algorithms
- 由于 Qwen3-30B-A3B 是一个 Mixture-of-Experts 模型,在训练期间应用 GRPO 可能会引入用于优化的 expert routing 与用于 rollout 的 expert routing 之间的不匹配
- 为了缓解这个问题,作者额外探索了 GSPO (2025) 来训练 rubric generator
- 尽管 GSPO 和 GRPO 共享相同的训练配置,但作者观察到,使用 GSPO 训练的 rubric generator 持续产生具有更高熵的 rollout,如图 3 所示,尽管在生成的样本上取得了几乎相同的 reward 值
- 作者将此行为归因于 GSPO 的序列级优化方案,其中重要性权重和裁剪是在整个响应而非单个 token 上执行的
- 这种设计降低了对局部 token 级偏差的敏感性,并允许多个具有相似全局 reward 的实现共存,从而增加了输出多样性
- 相比之下,GRPO 在整个 rollout 上应用组间相对优势,但依赖于 token 级的似然比,这隐含地施加了更强的结构约束
- 鉴于 rubrics 生成优先考虑稳定性、一致性和偏好对齐,而非语言多样性,作者采用 GRPO,因为它更符合任务的模式寻求性质
- 使用 GSPO 训练的 rubric generator 的性能在附录 G 中报告
- 关于工具调用行为的额外分析在附录 H 中提供
补充:Related Work
DeepResearch Agent
- LLMs-based 智能体系统对静态内部知识的依赖,促使了结合规划、检索和基于证据综合的深度研究智能体的出现
- 现有的 DeepResearch 智能体可以根据其主要任务领域大致分类
短格式问答
- 在此设置中,DeepResearch 智能体主要针对基于检索的短格式问答任务
- GAIA (2023; 2025)、BrowseComp (2025; 2025) 和 HLE (2025) 等基准提供了可验证的目标,使得能够通过 RLVR (2025; 2025a) 进行智能体训练
- 一些系统利用这种范式来增强搜索和推理能力
- Search-R1 (2025) 和 WebExplorer (2025a) 采用 GRPO (2024b) 来改进在具有明确正确性信号的短格式 QA 任务中的检索效果
- 相比之下,WebThinker (2025a) 采用 DPO (2023) 来使 LLMs 具备 DeepResearch 能力,而不依赖于可验证的奖励
- 同时,Tongyi DeepResearch (2025) 专门设计用于支持长程信息寻求行为
长格式报告生成
- 长格式报告生成要求智能体从大规模、异构的文档集合中综合证据,并为复杂的、开放式 Query 生成连贯、结构良好的报告
- 除了检索孤立的事实外,智能体必须执行多步推理、调和相互矛盾的证据,并在文档级别组织信息
- 由于缺乏参考答案,评估长格式输出本身就存在困难,因此该领域的基准(例如 DeepResearch Bench (2025) 和 ResearchQA (2025))通常将 LLM-as-a-Judge ,应用于人工 Annotations 的通用或 Query-specific Rubric
- 最近的研究集中于设计用于报告合成的端到端工作流
- Web-Weaver (2025b) 开发了一个模拟协作人类研究过程的双智能体框架
- Dr Tulu (2025a) 是最早的用于长格式任务的全开源 DeepResearch 智能体之一
Rubrics for Reward Modeling
- 为长格式报告生成训练智能体本质上涉及弱监督,因为明确的标准答案报告很少可用,并且正确性无法简化为可验证的目标
- 先前的工作通常依赖于人类偏好 Annotations 或 Rubric-based 评估来评估报告质量,这对训练稳定性和与人类判断的对齐都带来了挑战
- 现有方法:
- 一些研究探索了使用固定 Rubric (2024; 2024; 2024a) 以及 Query-specific Rubric (2025a; 2025) 来为长格式输出提供评估反馈
- 一些研究 (2024b; 2025b; 2025; 2025) 进一步将 Rubric 视为强化学习框架内的奖励模型
- 本工作专注于通过 Rubric Generator 为训练 DeepResearch 智能体使用 RL 生成长格式报告提供有原则的奖励信号
- 作者的目标:
- 学习一个能够生成 Query 感知评估标准的 Rubric Generator ,通过在 RL 训练期间提供细粒度和可解释的奖励信号 ,实现更稳定的优化和更好的人类偏好对齐
附录 A:Case Study on Query Rewriting
- 作者创建的 Query 集涵盖了与 DeepResearch 场景相关的广泛领域
- 高频类别包括 Law & Regulation 、Business & Finance 、Science & Technology 以及 Health & Medical Care ,这反映了需要进行多步推理和证据合成的常见研究型信息需求
- 该数据集还包含多样化的中低频主题,例如 Media & Entertainment 、Daily Life 、Education 、Arts 和 Trending News ,以及包括 Academic Literature 和 Job & Career 在内的长尾领域
- 这种分布反映了 DeepResearch 系统的真实使用模式,支持了对异构报告生成任务中人类偏好的研究
Query 改写的案例研究
- Original Query:
- 在《爱丽丝梦游仙境》中,启发柴郡猫的真实猫品种最常见的眼睛颜色是什么?
- DeepResearch-style Query:
- DeepResearch 风格 Query :请对《爱丽丝梦游仙境》中的柴郡猫进行研究:确定最可能作为其灵感来源的现实世界猫品种,并总结该品种最常见的毛色以及每种毛色通常关联的眼睛颜色
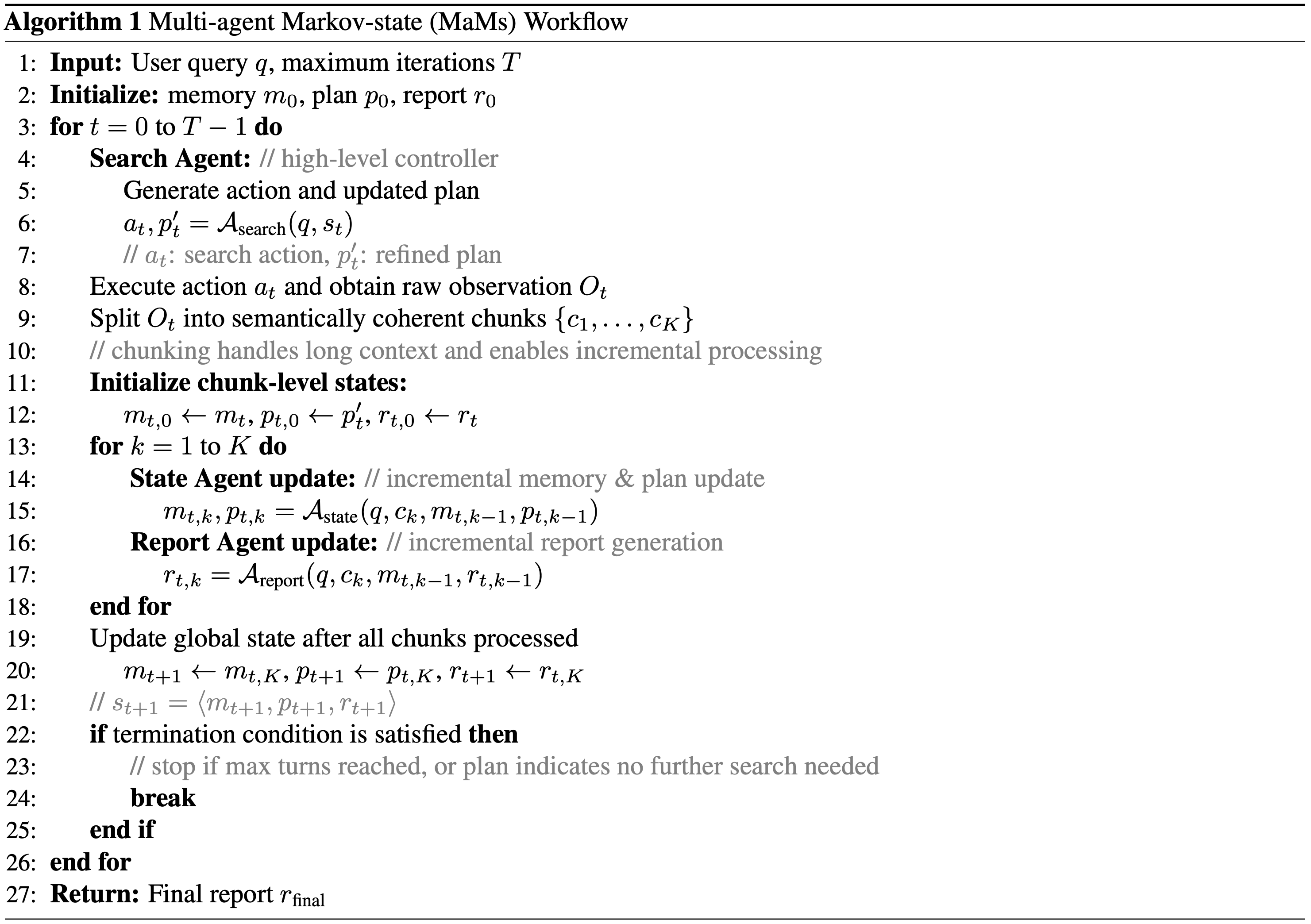
附录 B:Global Algorithm of the MaMs workflow
- 算法 1 中展示了详细的算法描述
附录 C:MaMs 工作流和 LLM-as-a-Judge 中使用的 Prompt
- 对于每个 prompt,作者都有中文和英文版本,因为问题数据集是双语的
- 这里仅展示英文版本,而相应的中文版本包含在补充材料中
- 问题:补充材料没有找到
C.1. 用于生成 Query-Specific Rubrics 的 Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47您是一位专业的 Rubric 写作专家。您的任务是基于给定的 **report-generation query** 生成一套连贯且自包含的评估 Rubrics,该 Rubrics 将用于评估生成响应(即报告)的质量
由于未提供参考答案,您必须 **直接从 Query 中推断理想答案的特征** ,包括其目标、结构、信息覆盖范围和表达要求
评估 Rubrics 应包括但不限于以下方面:
* 内容的事实相关性和准确性
* 报告的结构和逻辑组织
* 信息的完整性和深度
* 推理和论证的合理性
* 表达的清晰度和连贯性
* 语气和风格相对于报告意图(例如,总结、分析、建议)的适当性
每个 Rubric 条目必须是 **自包含的 (self-contained)** ,以便非专业读者无需额外上下文即可独立理解。每个描述必须以以下前缀之一开头:
* **关键标准 (Key Criterion):**
* **重要标准 (Important Criterion):**
* **可选标准 (Optional Criterion):**
* **错误标准 (Error Criterion):**
### Input:
* Query : 报告生成请求的完整文本
### Number of Rubric Items
* 根据 Query 的复杂性,在 7 到 20 个 Rubric 条目之间选择
### Each rubric item must include:
* 'title' (2-6 个单词)
* 'description': 一个句子,以类别前缀开头,并明确指出应在生成报告中观察到的内容**
* 'weight': 一个数值
* 关键/重要/可选标准的值为 1-5 (5 = 最重要)
* 错误标准的值为 -1 或 -2(表示惩罚)
### Category Definitions
* **Key Criterion:** 必须存在的核心事实、结构或目标;缺少它们会使答案无效 (weight = 5)
* **Important Criterion:** 显著影响质量的关键推理、完整性或清晰度 (weight = 3-4)
* **Optional Criterion:** 风格或深度相关的增强 (weight = 1-2)
* **Error Criterion:** 常见的错误或遗漏,明确指示‘缺失’或‘不正确’的元素 (weight = -1 或 -2)
### Additional Guidelines
如果报告应包含结论或建议,请包括:'Key Criterion: 包含由证据支持的清晰结论。' 如果报告需要解释或推理,请包括:'Important Criterion: 解释关键点背后的推理并提供支持性论证。' 如果报告需要清晰的结构,请包括:'关键标准 (Key Criterion): 使用清晰的章节和逻辑流程组织内容。' 如果报告有特定的语气(例如,学术、政策导向、商业),请包括:'Important Criterion: 保持与报告上下文一致的专业和客观语气。' 如果需要简洁性,请包括:'Optional Criterion: 保持简洁并避免冗余。'
### Output Requirements
输出格式为 JSON 数组:[..], [..], [..],其中每个对象对应一个 Rubric 条目。每个 JSON 对象 **必须仅包含 (must contain *only*)** 三个键:'title', 'description' 和 'weight'。不要包含任何额外的键或复制 Query 的大部分内容。每个 'description' 必须以所需的类别前缀之一开头。**Important formatting rule:** 如果 'title' 或 'description' 中需要引号,**仅使用单引号 ('')** 。请勿使用双引号 (" "),因为它们会破坏 JSON 格式。例如:使用 'Michelin star' 而不是 "Michelin star"
### Summary
您的任务是 **仅从给定 Query 推断理想报告的基本特质 (infer the essential qualities of an ideal report solely from the given query)** ,并构建一个结构化的、带权重的 JSON 格式 Rubric,以评估报告生成质量
**Return *only*** 所请求的 JSON 数组。请勿包含任何额外的解释或文本
C.2. 通过 LLM-as-a-Judge 为单个 Rubric 给报告评分的 Prompts
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20您是一个精确且公正的评分模型
您的任务:仅基于给定的单个 Rubric 描述,评估一份报告与该 Rubric 的符合程度
**Input Information**
Query : {query}
Rubric: {rubric}
Report to be scored: {report}
**Scoring Instructions**
您只需要判断报告“匹配” Rubric 描述的程度。请勿判断 Rubric 是代表积极目标还是消极约束。请勿尝试反转或纠正 Rubric 的语义方向。请勿引入任何额外的评估标准
**Scoring Requirements**
- 输出一个 1 到 10 的整数分数:
- 10 = 报告完全符合 Rubric 描述
- 7-9 = 大体符合
- 4-6 = 部分符合
- 1-3 = 基本不符合
**Output Format** (严格,单行,无标点): rating: <1 到 10 的整数>
C.3. 用于 LLM-based Judgement of Rubrics 的 Prompts
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24您是一个准确且公正的评分模型(Reward Model)。您的任务是评估 **Rubrics**(evaluation criteria)的质量。Rubric 是用于评估模型生成答案质量的一套标准。您需要判断给定的 Rubric 是否合理、全面以及与任务目标对齐
基于以下信息,您应评估 Policy model 生成的 Rubric(response)与您的标准的匹配程度
**[Input Information]**
Question: {question}
待评估的 Rubric (response): {response}
**[Scoring Requirements]** 您必须输出三项内容:
1. **[reward]** : 一个范围在 0.00 到 4.00 的小数(最多两位小数)
* 4.00 = 高质量:结构清晰、维度全面、逻辑严谨、与问题高度契合
* 3.00 = 基本合理:覆盖了关键维度,但存在轻微遗漏或表达不够简洁
* 2.00 = 部分合理:涵盖了一些重要方面,但缺乏关键元素或存在显著逻辑缺陷
* 1.00 = 弱相关:与任务相关性低或存在严重格式问题
* 0.00 = 完全不相关或无意义:不符合评估目的或为空/乱码
2. **[confidence]** : 您对分数的置信度 (0%-100%)。数值越高表示越确定
3. **[reason]** : 对评分理由的简要解释
**[Important Note]** 您正在评估的是 **Rubric 本身的设计质量** ,而非任何报告或答案的质量
**[Output Format]** (严格三行,无标点):
reward: <0.00 到 4.00 之间的小数>
confidence: <0% 到 100% 之间的整数百分比>
reason: <英文简要解释>
C.4. MaMs 工作流中 Search Agent 的 System Prompt
原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16您是一位能够生成高质量深度研究报告的智能助手。您的目标是通过多个“计划-执行-观察”循环来解决复杂的用户问题
1. **Analyze State:** 审查当前的 <memory>(已获取的信息)和 <plan>(当前进度)
2. **Develop Strategy:**
* 如果信息不足或计划不完整 -> 更新计划并使用工具(例如,搜索)来收集信息
* 如果信息充足且计划完整 -> 整理您的思路并输出最终报告
3. **Output Specifications:**
* 更新计划表 <plan>...</plan>: 标记已完成的项目并列出来完成的任务
* 最终动作:要么调用工具,要么输出 <answer>...</answer>
### Annotations (Notes)
* **Plan:** 必须是一个 Markdown 列表,清晰地显示当前和即将进行的步骤
* **Answer:** 仅当您确信所有必要信息都已收集时,才生成 <answer>...</answer>
**Tool Instructions:** {tool description}- 注意:这里仅仅是 System Prompt
C.5. MaMs 工作流中 Search Agent 的 User Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35<user_input> { { query } } </user_input>
<memory> { { memory } } </memory>
<plan> { { plan } } </plan>
<report> { { report } } </report>
剩余工具调用次数: { { tool_call_chance } }
基于当前状态(Memory/Plan)和 <report> 的完整性,计划下一步动作
如果当前 <report> 不令人满意,请继续更新 <plan> 并使用工具进行搜索
如果认为 <report> 已完成,请直接输出 <answer>...</answer> 以结束
严格遵守输出格式:
<plan>更新的执行计划</plan>
<tool_call>工具调用详细信息(如果有)</tool_call> 或 <answer>结束</answer>
当工具调用动作的计数达到阈值(默认为 10)时,作者将 User Prompt 更改为:
工具调用次数已用尽
基于以下信息:
<user_input> { { query } } </user_input>
<memory> { { memory } } </memory>
<plan> { { plan } } </plan>
列出您的最终计划。请勿再次调用工具
C.6. MaMs 工作流中 State Agent 的 System Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26您是一位信息处理专家,负责维护一个“long-term memory”数据库。您当前正处于分块阅读长文本的多步骤过程中
### Task Objective
在阅读完当前的“Observation Fragment”后,您需要 **incrementally merge** 新发现的信息到现有的 **memory** 中
注意:输入的记忆(*memory)包含所有先前积累的关键信息。**当通过压缩进行更新时,细节很容易丢失,因此您必须采取一切措施防止这种情况发生。**
### Core Principles
1. **Preserve Old Memory (Most Important):**
* 输入的记忆(*memory)中未被当前片段提及的信息 **必须被保留**
* 不要仅仅因为信息在当前片段中缺失就从记忆中删除它
2. **Incremental Integration:**
* 仅将来自当前片段的 **新** 事实、数据或见解添加到记忆中
* 如果新信息更正了旧信息,则修改它;如果是冗余的,则忽略它
3. **Maintain High Density:**
* 记忆应是一堆“事实(pile of facts)”,而不是文章摘要
* 保留具体的数字、名称、日期和参考文献。不要写“关于 XX 的详细讨论”;而应写“XX 声明了 YYY”
### Steps
1. 阅读输入的 *memory*(旧知识)
2. 阅读下面的“工具输出(Tool Output)”(新片段)
3. 输出新的 *memory*:它 = 旧记忆 + 来自片段的新知识
### Output Format
严格遵守此格式,以便在下一个决策步骤中使用:<memory>整合新旧信息的更新后记忆</memory>
C.7. MaMs 工作流中 State Agent 的 User Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9<user_input> { { query } } </user_input>
<memory> { { memory } } </memory>
<plan> { { plan } } </plan>
请阅读以下工具输出片段。任务:提取关键信息以更新 <memory>
严格遵守输出格式:<memory>更新后的关键检索信息摘要</memory>
C.8. MaMs 工作流中 Report Agent 的 System Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31您是一位专业的结构化分析报告写作助手,负责维护一个基于用户输入持续更新的 <report>。您的目标是基于工具提供的信息 **增量更新** 现有的 <report>,**而不引入外部信息**
### Workflow
当您收到用户 Query <user_input>、关键信息摘要 <memory>、执行计划 <plan>、当前轮次的报告 <report> 以及来自工具调用的新信息时,请执行以下步骤:
1. 分析新信息的类型
2. 决定新信息是否应包含在更新的报告中
3. 如果应包含,则更新原始报告:
* 不要简单地附加新信息;相反,应在保持逻辑流畅的同时补充、纠正或替换内容。避免不必要地扩大内容范围
### Core Principles
1. 仅基于用户提供的信息更新报告:
* 不要添加外部事实、推测信息、捏造数据或推断的场景。不要推断现实中不存在的任何信息。不要在报告中添加不确定性免责声明
2. **不要简单地附加新信息 (Do not simply append new information):**
* 评估新信息是否相关;如果相关,则将其整合到相应的章节中。否则,忽略它。如有必要可以优化结构,但核心内容必须保持稳定
3. 保持逻辑一致性:
* 如果新信息与现有报告冲突,请根据当前知识仔细决定是否替换旧信息。报告中不得包含矛盾的陈述
### Report Requirements
1. 以 Markdown 格式输出 <report>
2. 确保 <report> 具有清晰的结构、严谨的逻辑和高可读性
3. 在 <report> 末尾,列出所有必要的参考文献或来源(每个编号,提供完整引用),避免重复
4. 引用格式规则:
* 在报告正文中,可以使用上标引用,例如,“<sup>[1]</sup>”。如果使用上标,则必须在“参考文献 (References)”部分包含相应的条目。上标必须紧跟在被引用的名词或术语之后,而不是句子的开头。正确示例:“...该法律<sup>[1]</sup>规定...”,“《民法典》第 1 条<sup>[4]</sup>”
### Output Format
严格遵守此格式:
<report>完整的报告内容</report>
C.9. MaMs 工作流中 Report Agent 的 User Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5<user_input> {query} </user_input>
<memory> {memory} </memory>
<report> {report} </report>
C.10. ReAct 工作流中的 System Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
251. 仔细阅读和分析用户的问题,思考用户需要什么信息
2. 通过将用户的问题分解为多个子问题来制定详细的研究计划。如有必要,进一步分解子问题,直到每个问题足够简单。对于每个分解的问题,创建一个搜索计划
3. 在与计划制定的同一轮中,执行第一轮工具调用。为提高效率,每条消息最多可以生成 { {max_tool_call_cnt_per_round} } 个工具调用
4. 进入“计划修订 - 搜索”循环。每次迭代:(1) 整理搜索工具返回的结果。考虑哪些信息仍然缺失,是否需要探索新的线索。如果需要,修订您的搜索计划,并确保其涵盖所有潜在的用户关切,必要时添加补充搜索。(2) 检查最新的搜索计划是否仍包含需要搜索的问题。如果有,生成新一轮的工具调用,同样每条消息最多 { {max_tool_call_cnt_per_round} } 个。然后等待搜索结果。(3) 如果在步骤 (2) 中您确定搜索计划已完成,并且有足够的信息来撰写报告,则通过逻辑推理(而不是罗列事实)将搜索结果综合成一份全面且有见地的报告。不要执行进一步的工具调用;过程将自动结束
**Requirements**
1. 强制性工具调用:在研究进行期间,每条助手消息 **必须包含 tool_calls** 。如果回复只包含文本而没有工具调用,则认为任务已完成
2. 多轮限制:在 { {max_turn} } 轮内完成所有研究,即最多 { {max_turn} } 条消息
3. 每轮调用限制:每条消息最多生成 { {max_tool_call_cnt_per_round} } 个工具调用
4. 搜索广度:在制定或修订搜索计划时,考虑与研究问题相关的所有可能方向,并尽可能收集更多的信息和细节
5. 搜索深度:不要只搜索“它是什么”;关注“为什么”和“它如何工作”。对于关键现象,探索其潜在机制或更深层原因。如果当前搜索结果提到一个关键概念、技术或矛盾,优先在下一轮中调查它,而不是转向平行主题。避免在深度追踪上浪费太多轮次
6. 报告要求:
* 避免信息倾倒:报告可以分章节,但严格避免在未进行综合的情况下罗列检索到的事实。报告的核心价值在于将碎片化信息转化为逻辑相连、系统性的论述
* 逻辑完整性:每个要点都必须有完整的论证弧:陈述核心结论 -> 提供具体证据(例如,数据、案例、细节) -> 解释潜在机制或相关性(即,为什么或它意味着什么)
* 实质内容:避免空洞的形容词(例如,“高度有效”、“有前景”)。使用来自搜索结果的具体技术参数、定量指标、监管细节或专家意见
* 多维视角:对于复杂问题,从多个维度(例如,原因分析、风险评估、长期影响、技术路径比较)进行分析,确保每个维度都有足够的支持
**Citation Standards**
1. **In-text citations:** 在报告正文中使用上标格式,例如,“这是一个重要结论<sup>[1]</sup>。”
2. **Reference List:** 在报告末尾列出所有参考文献。包含 **完整的文章标题和 URL** 。如果搜索结果未提供 URL,则仅包含标题。格式:[1] 文章标题 - URL [2] 文章标题 - URL
3. **Ordering:** 按参考文献在文本中首次出现的顺序编号
4. **Deduplication:** 如果同一来源被多次引用(即使跨轮次),请合并为一个条目,使用相同的编号;不要重复
5. **Source Extraction:** 将搜索结果摘要中格式为 [标题: xxxx] 的标题直接用作参考文献名称。
**Tool Instructions:** {tool description}
C.11. 用于 Pairwise Preference Judgment 的 Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7
8
9请扮演一个公正的法官,评估两位 AI 助手对下面显示的用户问题所提供回答的质量。您应该选择更能遵循用户指示、更好地回答用户问题的助手。您的评估应考虑诸如帮助性、相关性、准确性、深度、创造性和回答的详细程度等因素。在开始评估时,请先比较两个回答,并提供简短的解释。避免任何位置偏见,并确保回答的呈现顺序不影响您的决定。不要让回答的长度影响您的评估。不要偏袒特定助手的名称。尽可能客观
User Question: {question}
{The Start of Assistant A's Answer} {answer_a} {The End of Assistant A's Answer}
{The Start of Assistant B's Answer} {answer_b} {The End of Assistant B's Answer}
请严格遵守以下格式输出您的最终裁决:如果助手 A 更好,则输出 "[[A]]";如果助手 B 更好,则输出 "[[B]]"
C.12. 用于 Pointwise Preference Scoring 的 Prompt
- 原始论文英文版(大致重写翻译为中文)
1
2
3
4
5
6
7请扮演一个公正的法官,评估 AI 助手对下面显示的用户问题所提供回答的质量。您的评估应考虑诸如帮助性、相关性、准确性、深度、创造性和回答的详细程度等因素。您应该给出一个 1 到 10 的分数,其中 1 是最差,10 是最好
用户问题 (User Question): {question}
{助手回答开始 (The Start of Assistant's Answer)} {answer} {助手回答结束 (The End of Assistant's Answer)}
请严格遵守以下格式输出您的最终裁决:"[[score]]",例如 "[[8]]"
C.13. DeepResearch Bench 的 Prompts
- 用于在 DeepResearch Bench 上评估生成报告的 prompts 直接采用 GitHub 上发布的官方 prompts github.com/Ayanami0730/deep_research_bench/tree/main/prompt
附录 D:Implementation Details
- 训练代码基于后训练框架 slime (2025)
- 该框架利用 Megatron (2019) 作为训练后端,SGlang (2024) 作为推理后端
- 注意:该框架的 Megatron 优化器配置有一个 关键更新,以确保在强化学习时正确训练 MoE 模型
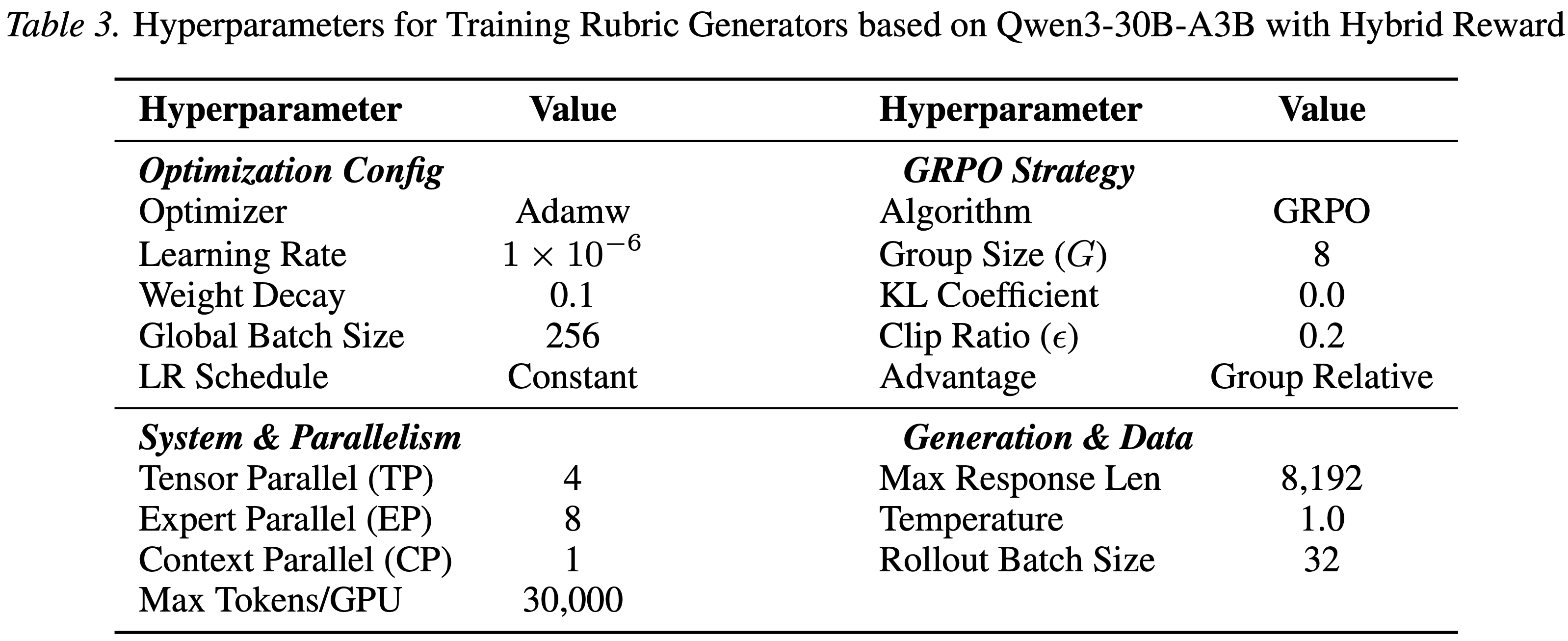
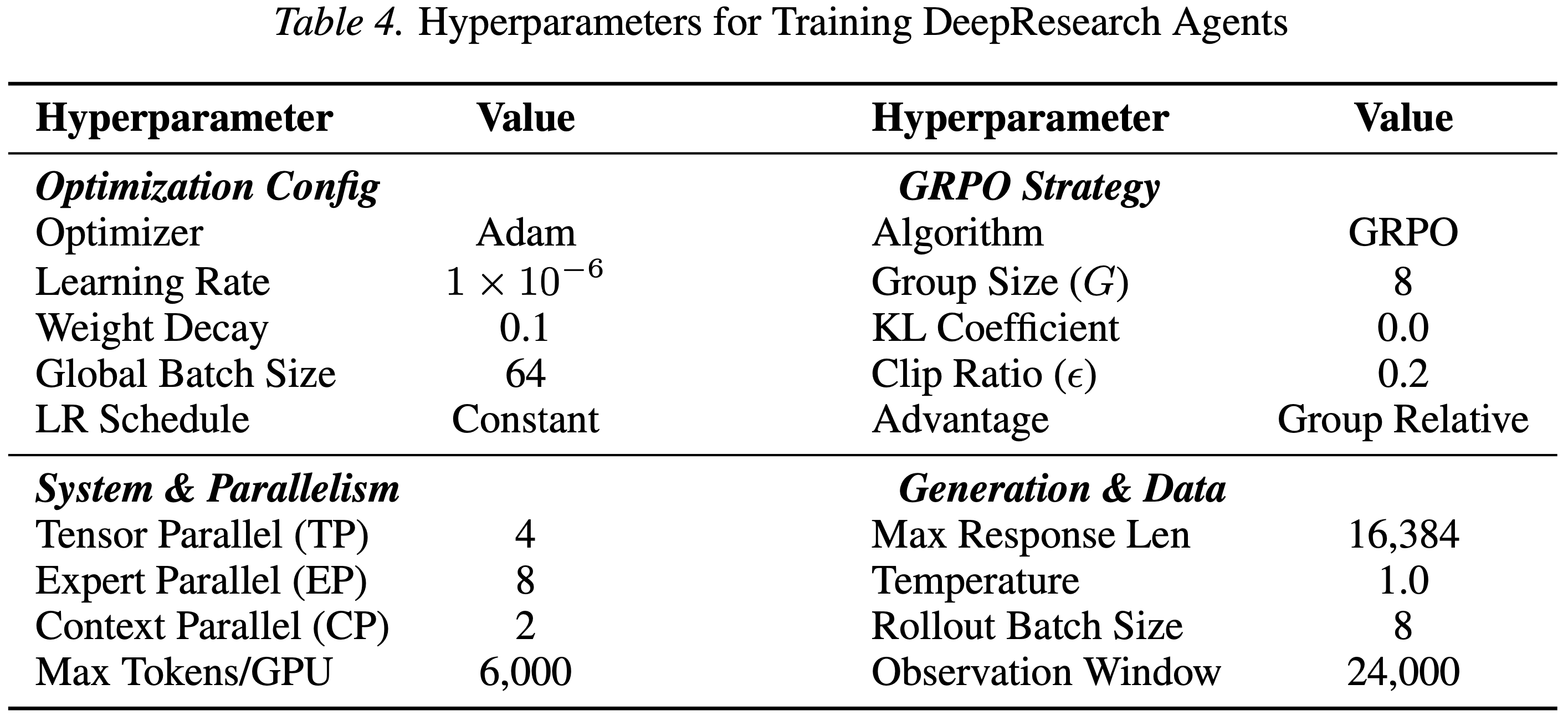
- 表 3 展示了训练 Rubric Generator 的超参数,表 4 展示了基于 Tongyi-DeepResearch 训练 DeepResearch Agents 的超参数
- 对于评估,作者遵循官方 DeepResearch Bench 协议,并采用 Gemini-2.5-Pro 作为 LLM-as-a-Judge
- 在强化学习期间,设置如下:
- Rubric 评分使用 Qwen3-235B-A22B
- Temperature 为 0.3,top-p 为 0.95
- 通过 Yarn RoPE 缩放 (2024) 启用最大上下文长度为 131,072 个 Tokens
- 除另有说明外,公式 (1) 中的权重系数 \(\lambda_{\mathrm{pref} }\) 和 \(\lambda_{\mathrm{llm} }\) 均设置为 1
- 所有策略模型,包括 Rubric Generator 和 DeepResearch agents,均使用 64k Token 的上下文长度、温度为 1.0 和 top-p 为 1.0 进行训练
- 对于 DeepResearch agents,最大交互轮数设置为 10,每轮最多允许 5 次工具调用
- Rubric 评分使用 Qwen3-235B-A22B
附录 E:Metrics for Human Preference
- 使用两个互补的指标评估偏好建模的性能
- 给定一个偏好数据集 \(\{(q_{i},r_{\mathrm{acc} }^{(i)},r_{\mathrm{rej} }^{(i)})\}_{i = 1}^{N}\) 和标量分数 \(S(\cdot)\)
- 报告偏好准确率 (preference accuracy) 定义为:
$$\mathrm{Pref.Acc.} = \frac{1}{N}\sum_{i = 1}^{N}\mathbb{I}\Big[S\Big(r_{\mathrm{acc} }^{(i)}\Big) > S\Big(r_{\mathrm{rej} }^{(i)}\Big)\Big], \tag{6}$$ - 这等价于成对偏好判断的 ROC 曲线下面积 (AUC)
- 为了进一步量化偏好分离的幅度和稳定性,作者报告了配对科恩 d 值 (paired Cohen’s \(d\)) (2010)
- 令 \(\Delta_{i} = S(r_{\mathrm{acc} }^{(i)}) - S(r_{\mathrm{rej} }^{(i)})\) 表示 Query \(q_{i}\) 的分数差异;
- 配对效应量定义为:
$$\mathrm{Cohen’s}\ d = \frac{\mathbb{E}[\Delta]}{\sqrt{\mathrm{Var}(\Delta)} }. \tag{7}$$
- 偏好准确率(AUC)反映了排序的正确性,而配对科恩 d 值则捕捉了 Query 层面分数分离的标准化强度,提供了对偏好质量的补充视角
附录 F:Rollout Speed-up for MaMs workflow
- 为了应对顺序处理中固有的延迟瓶颈,特别是在 I/O 密集型 LLM 交互中,作者在 MaMs 工作流中引入了并行执行机制
- 基线实现,称为朴素线性 Pipeline (Naive Linear Pipeline),按顺序通过一系列 agents 处理整个数据集 \(\mathcal{D}\)
- 在此模式下,总执行时间 \(T_{naive}\) 是所有样本处理时间的总和,网络延迟会线性累积
- 为了优化效率,作者开发了线性并发 Pipeline (Linear Concurrent Pipeline),它通过异步微批处理 (asynchronous micro-batching) 实现了数据并行
- 该 Pipeline 将 agent 执行流分为三个阶段:预处理、并发执行和后处理
- 加速集中在并发阶段,其中输入数据集 \(\mathcal{D}\) 被划分为一系列微批次
$$ B = \{b_{1},b_{2},\ldots ,b_{m}\}$$- 每个批次具有可配置的大小 \(S_{micro}\)
- 利用一个事件循环 (event loop) 来管理一组受并发限制 \(C\) 约束的异步任务,调度算法如下:
- 1)一个滑动窗口 (sliding window) 维护一组活动任务 \(\mathcal{T}\),确保 \(|\mathcal{T}| \leq C\)
- 2)只要活动任务槽位可用 (\(|\mathcal{T}| < C\)),新的微批次就会出队,并使用 asyncio 立即生成相应的 agent 任务
- 3)任务完成后,结果通过回调收集到同步队列 (synchronized queue) 中,窗口向前滑动以接纳待处理的微批次
- 如图 4 所示,通过在多个微批次上重叠高延迟的 API 调用,该框架显著提高了资源利用率
- 这种方法有效地防止了阻塞操作,将并发阶段的理论时间复杂度从 \(O(|\mathcal{D}|)\) 降低到大约 \(O(|\mathcal{D}| / C)\),主要受外部 API 速率限制而非本地执行速度的限制
附录 G:The rubric generator trained by GSPO
- 本节将在表 5 中展示由 GSPO 训练的 Rubric Generator 的偏好准确率 (AUC) 和配对 Cohen’s d 值

- 如第 4.4 节所述,与 GRPO 训练的对应模型相比,由 GSPO 训练的 Rubric Generator 展现出显著更高的 Rollout 熵 ,这对于我们的设置是不利的
- 因此作者采用 GRPO 来训练 Rubric Generator
附录 H:Analysis on Tool Calling
- 如附录 D 所述,在 ReAct 和 MaMs 框架下训练 DeepResearch agents 期间,最大交互轮数设置为 10,每轮最多允许五次工具调用
- 表 6 报告了作者在 DeepResearch Bench 上训练的 DeepResearch 系统的每个样本的交互轮数和工具调用统计

- 符合预期,在 agentic 数据上训练的 Tongyi-DeepResearch 模型 (2025) 展现出比普通的 Qwen3-30B-A3B(指令调优)模型更强的工具使用和交互能力
- 另外,在 MaMs 工作流下训练的 DeepResearch 系统比遵循 ReAct(先搜索后生成)范式的系统表现出更优的交互性能
附录 I:Case Study of Rubric List
- 作者在原始论文中展示了一个问题的 Rubric 列表案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72{
"question": "Please generate an analysis report on common network failures.",
"rubrics": [
{
"title": "Coverage of Common Failures",
"description": "Key criterion: The report must identify and describe multiple common types of network failures, such as DNS issues, IP address conflicts, or physical connection interruptions.",
"weight": 5
},
{
"title": "Inclusion of Core Analysis",
"description": "Key criterion: The report must analyze each mentioned network failure rather than merely listing their names.",
"weight": 5
},
{
"title": "Clear Structure",
"description": "Key criterion: The report should have a clear organizational structure, such as an introduction, categorized analysis of different failures, and a conclusion.",
"weight": 5
},
{
"title": "Analysis of Causes and Symptoms",
"description": "Important criterion: The report should explain the typical symptoms and possible causes of each network failure, establishing a clear causal relationship.",
"weight": 4
},
{
"title": "Provision of Troubleshooting Methods",
"description": "Important criterion: The report should provide concrete and actionable troubleshooting steps or solution suggestions for each type of failure.",
"weight": 4
},
{
"title": "Clear and Understandable Explanation",
"description": "Important criterion: When explaining technical concepts (such as DNS or IP addresses), the report should strive to be clear and accurate so that nonexpert readers can understand it.",
"weight": 3
},
{
"title": "Professional and Objective Tone",
"description": "Important criterion: The report should maintain a professional and objective tone, avoiding overly colloquial or subjective expressions.",
"weight": 3
},
{
"title": "Systematic Classification of Failures",
"description": "Optional criterion: The report may systematically categorize network failures based on their nature (e.g., hardware, software, configuration issues) to enhance clarity.",
"weight": 2
},
{
"title": "Inclusion of Preventive Measures",
"description": "Optional criterion: The report may further propose preventive measures and best practices to avoid common network failures.",
"weight": 2
},
{
"title": "Use of Concrete Examples",
"description": "Optional criterion: The report may use concrete scenarios or cases to illustrate failure phenomena and solutions, improving readability.",
"weight": 1
},
{
"title": "Technical Errors",
"description": "Error criterion: The report provides incorrect technical explanations, causes, or solutions that may mislead readers.",
"weight": -2
},
{
"title": "Listing Without Analysis",
"description": "Error criterion: The report merely lists failure names without providing any analysis of causes, symptoms, or solutions.",
"weight": -2
},
{
"title": "Inclusion of Irrelevant Information",
"description": "Error criterion: The report includes content unrelated to common network failures, such as in-depth discussion of unrelated software programming errors.",
"weight": -1
}
],
"topic": "Science & Technology",
"rubric_count": 13
}
附录 J:Limitations and Future work
J.1 Limitations
- query-specific rubric Generator 在 DeepResearch 场景中表现出与人类偏好的高度一致性,但仍存在一些局限性
- First,偏好数据集的构建依赖于两个候选报告之间的成对比较,这可能无法完全捕捉现实世界评估场景中出现的更细粒度或多路偏好结构
- Second,尽管混合奖励结合了人类监督和 LLM-based Rubric 评估,但它可能仍然难以全面评估新颖性、创造性或推理深度等方面,因为这些品质本质上是主观的,并且很大程度上依赖于底层 human-LLM 反馈的校准
- Third,实验主要集中在作者创建的固定 DeepResearch 风格任务和文档集合上,并未广泛探索所学习的 Rubric 生成策略对显著不同报告格式或领域的泛化能力
J.2 Future Work
- 有几个方向为未来研究提供了有前景的机会
- First,可以将偏好表述扩展到超越成对比较,以利用更丰富的偏好信号,例如排名或分级分数,从而能够更细粒度地学习人类偏好
- First,未来的工作可以专注于改进对新颖性、创造性和推理深度的评估,例如,通过结合更复杂的 LLM 评估和针对性的人类反馈来减少主观性并提高可靠性
- Third,开发更原则性的方法来减少对基于 LLM 评估的依赖,可能通过自一致性检查或人-LLM 混合验证,可以增强训练过程的稳定性和可解释性