在Linux系统有多个用户时,我们可能需要从一个用户界面打开终端登录另一个用户,从而使用该用户的环境和软件
多用户打开各自软件问题
问题描述
- 在一个用户登录图形界面后,需要以另一个用户的身份打开一个图形化软件,此时直接打开图形化软件可能遇到如下错误
No protocol specified
问题发生原因
- 因为Xserver默认情况下禁止别的用户图形程序运行在当前用户图形界面上
解决方案
- 在当前用户下执行命令
1
xhost +
你真的认识URL了吗?
#字符#在URL中与服务器无关,也就是说正常访问服务器的URL不包含##仅仅与本地浏览器对网页的定位相关#由于不影响对远程服务器的访问,自然也不会存在于软件包的下载连接中参考博客:https://blog.csdn.net/qq_25384945/article/details/81219075
Python
1 | http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+ |
JavaScript
1 | /((([A-Za-z]{3,9}:(?:\/\/)?)(?:[\-;:&=\+\$,\w]+@)?[A-Za-z0-9\.\-]+|(?:www\.|[\-;:&=\+\$,\w]+@)[A-Za-z0-9\.\-]+)((?:\/[\+~%\/\.\w\-_]*)?\??(?:[\-\+=&;%@\.\w_]*)#?(?:[\.\!\/\\\w]*))?)/ |
Java
1 | ^(https?|ftp|file)://[-a-zA-Z0-9+&@#/%?=~_|!:,.;]*[-a-zA-Z0-9+&@#/%=~_|] |
Python
使用clamscan命令搜索所有文件, clamav详情见我之前的博客clamav安装与杀毒
1 | nohup clamscan / -r --infected -l clamscan.log > clamscan.out & |
查看扫描结果
1 | cat clamscan.log | grep FOUND |
/var/lib/docker/overlay/bdd049c71596d743907224a8dd6fdb3fb4ca76e3af8dfd6eee2d034de2be45a1/merged/tmp/kdevtmpfsi: Multios.Coinminer.Miner-6781728-2 FOUND
/var/lib/docker/overlay/bdd049c71596d743907224a8dd6fdb3fb4ca76e3af8dfd6eee2d034de2be45a1/merged/tmp/red2.so: Unix.Trojan.Gafgyt-6981174-0 FOUND
/var/lib/docker/overlay/bdd049c71596d743907224a8dd6fdb3fb4ca76e3af8dfd6eee2d034de2be45a1/upper/tmp/kdevtmpfsi: Multios.Coinminer.Miner-6781728-2 FOUND
/var/lib/docker/overlay/bdd049c71596d743907224a8dd6fdb3fb4ca76e3af8dfd6eee2d034de2be45a1/upper/tmp/red2.so: Unix.Trojan.Gafgyt-6981174-0 FOUND
删除这四个文件,这里直接到相关目录下查看发现../tmp目录下往往都是病毒文件(与kinsing相关,全部删除)
top查看CPU信息确定挖矿进程kdevtmpfsi的进程号[pid]
确定启动信息中启动命令,并删除(在这里查到的信息是文件已经被删除了)
1 | ls /proc/[pid] -ali |
查找父进程进程号
1 | systemctl status [pid] |
● docker-be9fcab033e6158f8ff7d6ac07d28cfd918375178c27e016aa800cbeef985161.scope - libcontainer container be9fcab033e6158f8ff7d6ac07d28cfd918375178c27e016aa800cbeef985161
Loaded: loaded (/run/systemd/system/docker-be9fcab033e6158f8ff7d6ac07d28cfd918375178c27e016aa800cbeef985161.scope; static; vendor preset: disabled)
Drop-In: /run/systemd/system/docker-be9fcab033e6158f8ff7d6ac07d28cfd918375178c27e016aa800cbeef985161.scope.d
└─50-BlockIOAccounting.conf, 50-CPUAccounting.conf, 50-DefaultDependencies.conf, 50-Delegate.conf, 50-Description.conf, 50-MemoryAccounting.conf, 50-Slice.conf
Active: active (running) since Mon 2019-11-11 11:24:17 UTC; 1 months 27 days ago
Tasks: 38
Memory: 2.3G
CGroup: /system.slice/docker-be9fcab033e6158f8ff7d6ac07d28cfd918375178c27e016aa800cbeef985161.scope
├─ 4475 redis-server *:6379
├─ 8528 sh -c /tmp/.ICEd-unix/vJhOU
├─ 8529 /tmp/.ICEd-unix/vJhOU
└─22822 /tmp/kdevtmpfsi
Warning: Journal has been rotated since unit was started. Log output is incomplete or unavailable.
杀死不需要的相关进程,如上面的4475,8528, 8529, 22822
查看是否还有需要杀死的进程,如果有,则杀死该进程
1 | ps -ef | grep kinsing |
top确定挖矿进程已经被杀死
加上正则项的FTL
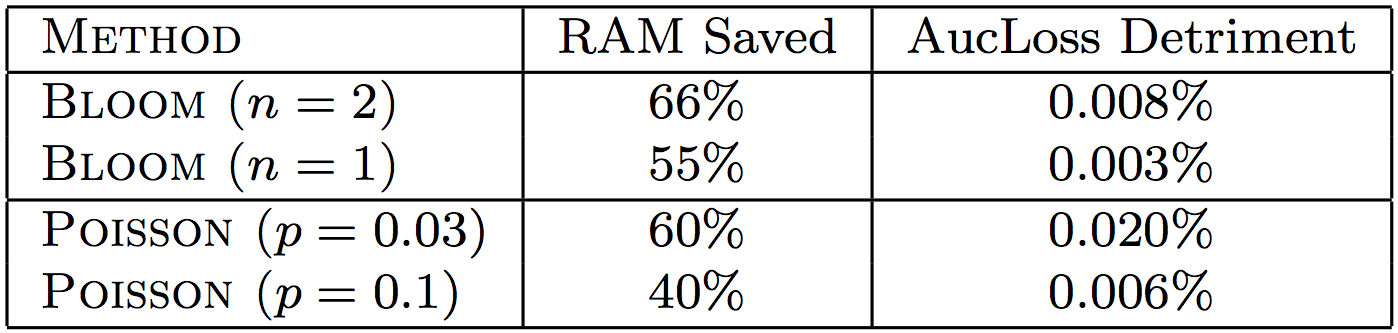
本节记录google的一些失败的尝试方向(有些可能会让人很惊讶),这些方向模型没有明显收益
关于特征哈希(Feature Hashing)的相关知识可参考Feature-Hashing
search.xml 文件:加载 search.xml 时错误为404search.xml 检查时错误为304修改最外层配置文件./_config.yml,添加以下语句(实测这一步非必须)
1 | search: |
安装搜索插件
1 | npm install hexo-generator-searchdb --save |
search.xml 文件链接,然后查看文件解析异常出现在哪个地方,然后删除特殊字符即可哈希函数定义(参考自博客:https://blog.csdn.net/qjf42/article/details/82387559)
1 | def feature_hashing(features, m): |
与词表法比较:
idx值可能相等)上(1, 0), 女(0, 1)这样的,所以如果二者映射到同一个维度上,那么这两个特征丢失了原本的表达能力| Package client | Language | Package format | Description |
|---|---|---|---|
| npm | JavaScript | package.json | Node package manager |
| gem | Ruby | Gemfile | RubyGems package manager |
| mvn | Java | pom.xml | Apache Maven project management and comprehension tool |
| gradle | Java | build.gradle or build.gradle.kts | Gradle build automation tool for Java |
| docker | N/A | Dockerfile | Docker container management platform |
| nuget | .NET | nupkg | NuGet package management for .NET |
| pip | Python | requirements.txt | use pip install -r requirements.txt |
| 软件管理方式 | 线下安装命令 | 线上安装命令 | distribution 操作系统 |
|---|---|---|---|
| RPM | rpm, rpmbuild | yum | Red Hat/Fedora |
| DPKG | dpkg | apt, apt-get | Debian/Ubuntu |
| 操作描述 | rpm | dpkg |
|---|---|---|
| 安装指定套件 | rpm -i pkgfile.rpm | dpkg -i pkgfile.deb |
| 显示所有已安装的套件名称 | rpm -qa | dpkg -l |
| 显示套件包含的所有档案 | rpm -ql [softwarename] | dpkg -L [softwarename] |
| 显示特定档案所属套件名称 | rpm -qf [/path/to/file] | dpkg -S [/path/to/file] |
| 显示制定套件是否安装 | rpm -q [softwarename] | dpkg -l [softwarename], -s或-p显示详细咨询, -l只列出简洁咨询 |
| 移除指定套件 | rpm -e [softwarename] | dpkg -r softwarename, -r 留下套件设定, -P完全移除 |
| 操作描述 | yum | apt |
|---|---|---|
| 软件源配置文件路径 | /etc/yum.conf | /etc/apt/sources.list |
| 安装软件包 | yum install [package] | apt-get install [package] |
| 删除软件包 | yum uninstall [package] | apt-get remove [package] |
| 删除有依赖关系的软件包和配置文件 | yum uninstall [package] | apt-get autoremove [package] –purge |
| 查看安装包信息 | yum info [package] | apt-cache show [package] |
| 更新软件包列表 | yum update | apt-get update |
| 清空缓存 | yum clean | apt-get clean |
| 搜索包名 | yum | apt-cahce search |
列出所有可用包名
1 | apt-cache pkgnames |
通过描述列出包名
1 | apt-cache search [keys] |
指定包的版本号
1 | apt-get install [package]=[version] |
搜索包的可用版本
1 | yum --showduplicates list [package] | expand |
expand命令用于将文件的制表符tab转换成空格符spacetab对应8个space-), 则expand会从标准输入读取数据unexpand命令与expand相反安装时指定包的版本号
1 | yum install [package]-[version] |
-y: 指定在询问是否安装时均选择yes-q: quiet,安装途中不打印log信息clam是一款Linux上免费的杀毒软件
命令行安装clamav会自动创建clamav用户和clamav组
Centos
在Centos7亲测*
1 | yum install –y clamav clamav-update |
ubuntu
在Ubuntu16.04上亲测*
1 | apt-get install clamav |
如果因为某些原因无法从命令行安装,可以尝试用源码安装,此时需要首先手动创建相关组和用户
创建clamav组
1 | groupadd clamav |
创建用户并添加到clamav组
1 | useradd -g clamav clamav |
下载
1 | wget http://www.clamav.net/downloads/production/clamav-0.102.0.tar.gz |
安装
解压
1 | tar -xf clamav-0.102.0.tar.gz |
切换目录
1 | cd clamav-0.102.0 |
安装依赖
1 | yum/apt install gcc openssl openssl-devel |
升级命令
命令行安装后更新命令
1 | freshclam |
源码安装后更新命令, 也可以建立软连接后直接使用上面的命令行启动
1 | /usr/local/clamav/bin/freshclam |
建立链接指令
1 | ln -s [source path] [target path] |
常用命令
1 | nohup clamscan / -r --infected -l clamscan.log > clamscan.out & |
-r 指明递归查杀--infected 表示仅仅输出被感染的部分文件, 否则没有被感染的文件会输出文件名: OK这样无用的信息-l 指明日志文件路径/ 是查找的目标目录,如果是整个机器查找则使用/nohupclamscan.out和clamscan.log分别存储输出和日志列出被感染文件
1 | cat clamscan.out | grep FOUND |