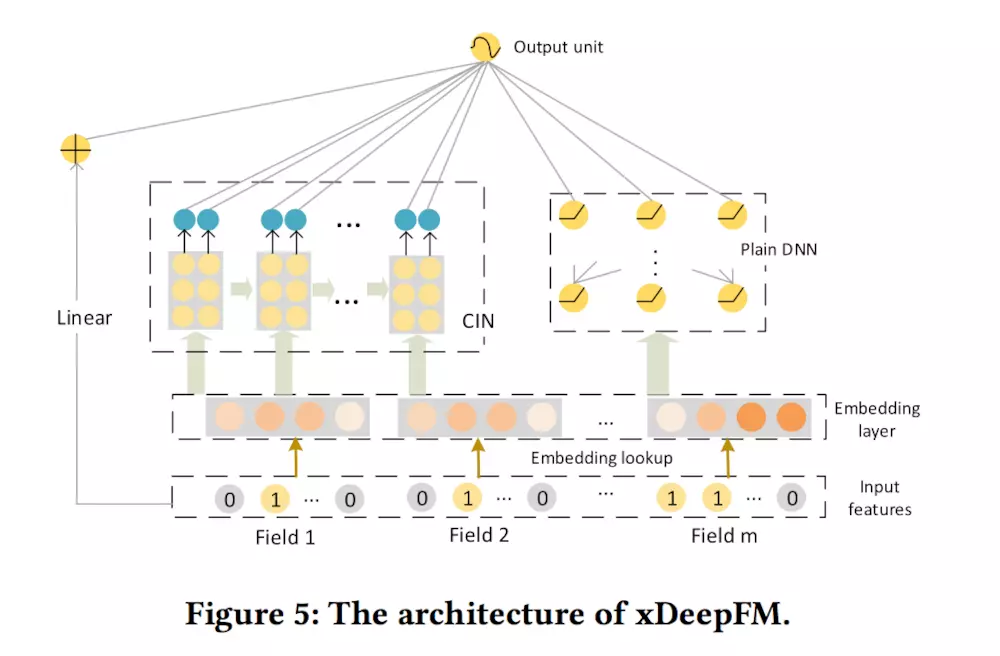
文本介绍随机微分方程(SDE)视角下的Diffusion的相关知识
- 参考链接:
- 原始论文1:(NCSN)Generative Modeling by Estimating Gradients of the Data Distribution, Stanford, 2020 ,Score-based 模型NCSN
- 原始论文2:Score-based generative modeling through stochastic differential equations, Stanford & Google, 2021:随机微分方程的视角,将DDPM,SDE,ODE,Score-based模型等概念串起来
- 其他参考1:深度学习(生成式模型)——score-based generative modeling through stochastic differential equations
- 其他参考2:生成扩散模型漫谈(五):一般框架之SDE篇,苏剑林,2022
- 其他参考3:论文学习笔记SDE:从EBM到Score-Matching,随机微分方程视角下的Diffusion大一统
写在前面
- 论文Score-based generative modeling through stochastic differential equations, Stanford & Google, 2021发表于2021年,这篇文章将DDPM,SDE,ODE等概念串起来了,论文在苏神博客生成扩散模型漫谈(五):一般框架之SDE篇,苏剑林,2022的基础上,以这篇论文为主分析SDE视角下的DDPM
ODE的定义
- 常微分长程(Ordinary Differential Equation,ODE),其典型的形式表达如下:
$$ dy = f(x,y) dx $$- 一种更常见的表达为: \(\frac{dy}{dx} = f(x,y)\)
- 理解:导数 \(\frac{dy}{dx}\) 可以表示因变量 \(y\) 关于 \(x\) 的变化率
- 常微分方程的离散形式:
$$ y(x + \Delta x) = y(x) + f(x, y(x)) \Delta x $$- 理解:即在任意一点 \((x_0,y_0)\) 处,有: \(y(x_0 + \Delta x) = y(x_0) + f(x_0, y_0) \Delta x \),即当 \(x\) 增加 \(\Delta x\) 时, \(y\) 增加大约 \(f(x_0,y_0)\Delta x\)
- 常微分方程一般可以直接求解,解析解是一系列差值为常数的函数,在给定某个点函数初始值的情况下,也可以使用欧拉(Euler)方法等方法迭代求解数值解
SDE的定义
- 随机微分方程(Stochastic Differential Equation, SDE)是数学中的一个分支,它描述了含有随机过程的系统随时间变化的行为。与普通的微分方程不同,SDE中除了包含确定性的微分项外,还包含了随机项,这些随机项通常由布朗运动(Brownian motion,也称为Wiener过程,一种连续时间随机过程)或其他类型的随机过程表示
SDE基本形式
- 一个典型的随机微分方程可以表示为:
$$ dX_t = \mu(X_t,t)dt + \sigma(X_t,t)dW_t $$ - 对SDE方程的理解:
- \(X_t\) 是随机过程
- \(\mu(X_t,t)\) 是漂移系数 ,表示了过程的平均变化率,类似于常微分方程里面的一阶导数 \(\frac{dX_t}{dt}\) 。漂移项 \(\mu(X_t,t)dt\) 描述了在没有随机影响的情况下, \(X_t\) 随时间的变化趋势
- \(dW_t\) 是布朗运动的增量,代表了随机扰动
- \(\sigma(X_t,t)\) 是扩散系数,表示了过程的波动程度。扩散项 \(\sigma(X_t,t)dW_t\) 描述了随机因素对 \(X_t\) 的影响。其中 \(dW_t\) 代表了布朗运动的一个小增量,它可以看做是一个均值为0,方差为 \(dt\) 的正态分布随机变量。 \(\sigma(X_t,t)dW_t\) 整体表示
参考自:《随机过程》布朗运动基本假设与实验结果不符 - 高宏的文章 - 知乎
《随机过程》布朗运动理论是描述和揭示质点随机运动现象及规律的科学理论,其基本假设(公理)是:布朗粒子在 \(t\) 时刻的位移 \(x_t\) 服从 \(\mathcal{N}(0, \sigma^2 t)\) 的正态分布
但是,实际布朗粒子位移观测实验结果表明:布朗粒子位移不服从正态分布,实验证明《随机过程》布朗运动基本假设不成立
- 与ODE的对比 :相对ODE方程 \(dy = f(x,y) dx\) 形式(对应 \(dX_t = \mu(X_t,t)dt \) ),SDE增加了一项随机项 \(dX_t = \mu(X_t,t)dt + \color{red}{\sigma(X_t,t)dW_t}\)
- SDE的离散形式:
$$ X_{t+\Delta} - X_t = \mu(X_t,t)\Delta t + \sigma(X_t,t)\sqrt{\Delta t} \epsilon, \ \epsilon \sim \mathcal{N}(0,1) $$- 在这里,原始形式中的 \(dW_t\) 可表示成服从均值为0,方差为 \(\Delta t\) 的高斯分布的随机变量 \(\epsilon’ \sim \mathcal{N}(0, \Delta t)\) 。同理, \(\sigma(X_t,t)dW_t\) 则可表示成一个服从均值为0,方差为 \(\sigma^2(X_t,t)\Delta t\) 的高斯分布的随机变量 \(\epsilon’ \sim \mathcal{N}(0, \sigma^2(X_t,t)\Delta t)\)
- 理解:在任意点 \((t_0,X_{t_0})\) 处,有:
$$ X_{t_0+\Delta} = X_{t_0} + \mu(X_{t_0},t_0)\Delta t + \sigma(X_{t_0},t_0)\sqrt{\Delta t} \epsilon, \ \epsilon \sim \mathcal{N}(0,1) $$- 在任意点 \((t_0,X_{t_0})\) 处, \(X_{t_0+\Delta}\) 约等于 服从均值为 \(X_{t_0} + \mu(X_{t_0},t_0)\Delta t\),方差为 \(\sigma^2(X_{t_0},t_0)\Delta t\) 的正太分布,写成分布采样形式有:
$$ X_{t_0+\Delta} \sim \mathcal{N}(X_{t_0} + \mu(X_{t_0},t_0)\Delta t, \sigma^2(X_{t_0},t_0)\Delta t) $$
- 在任意点 \((t_0,X_{t_0})\) 处, \(X_{t_0+\Delta}\) 约等于 服从均值为 \(X_{t_0} + \mu(X_{t_0},t_0)\Delta t\),方差为 \(\sigma^2(X_{t_0},t_0)\Delta t\) 的正太分布,写成分布采样形式有:
- 注:更一般的SDE,随机项不一定是服从正态分布,比如跳-扩散过程(Jump-Diffusion Process)模型: \(dX_t = \mu X_t dt + \sigma X_t dW_t + \color{red}{dJ_t} \) 中可以是包含其他随机项 \(dJ_t\) 表示复合泊松过程,代表价格中的突然跳跃
SDE求解方法
- 求解随机微分方程的方法包括解析方法和数值方法。由于大多数SDE没有闭式解,因此数值方法如Euler-Maruyama方法(类似于ODE中的欧拉(Euler)方法)
EBM
- 基于能量的生成模型(Energy-Based Model,EBM),是一种独立于GANs(Generative Adversarial Networks),VAEs(Variational Autoencoders),Diffusion之外的生成模型基于能量的生成模型。EBMs不直接建模概率密度函数,而是通过能量函数间接地表示数据分布,相关论文可见:Implicit Generation and Modeling with Energy Based Models, OpenAI, NeurIPS 2019
- 假设真实样本服从分布 \(x \sim p_{\text{data}}(x)\),一般的生成模型,比如GAN或者VAE都使用一个神经网络取拟合一个分布 \(p_\theta(x)\) 来逼近真实分布,而EBM不直接拟合真实分布,而是使用玻尔兹曼分布来建模原始分布,并使用神经网络取拟合能量函数 \(E_\theta(x)\),即:
$$ p_\theta(x) = \frac{1}{Z(\theta)}e^{-E_\theta(x)} $$ - 此时如果使用极大似然法优化 \(p_\theta(x)\),则需要最小化以下负对数似然目标:
$$ L_\text{ML}(\theta) = \mathbb{E}_{x \sim p_{D}}[-\log p_\theta(x)] = \mathbb{E}_{x \sim p_{D}}[E_\theta(x) - \log Z(\theta)]$$ - 由于 \(Z(\theta)\) 很难求解,所以我们一般不使用极大似然法,幸运的是,生成模型的最终目标是生成一个 \(x\),之前的研究给出了一种通过Langevin dynamics采样来近似得到 \(x_T\) 的方案,该方案重复使用下面的迭代来采样:
$$ x_t = x_{t-1} - \frac{\lambda}{2}\nabla_x E_\theta(x_{t-1}) + \sqrt{\lambda} \varepsilon, \ \epsilon \sim \mathcal{N}(0, 1) $$- 如果将这种建模方式可以假设为对应分布 \(q_\theta(x)\),可以证明,当 \(T \rightarrow +\infty\) 时,有 \(q_\theta(x) \approx p_\theta(x)\),也就是说,迭代的次数够多就能生成接近于真实分布的样本 \(x\)
- 虽然得到了采样的方式,但是,学习 \( E_\theta(x) \) 的参数依然需要使用到极大似然法,此时仍然要面对无法求解的 \(Z(\theta)\),幸运的是,为了避开 \(Z(\theta)\),可以进一步使用下面的方式来近似梯度:
$$ \nabla_\theta L_\text{ML} \approx \mathbb{E}_{x^+\sim p_{D}}[\nabla_\theta E_\theta(x^+)] - \mathbb{E}_{x^-\sim q_\theta(x)}[\nabla_\theta E_\theta(x^-)] $$- \(x^+ \sim p_D(x)\)
- \(x^- \sim q_\theta(x)\) 是按照Langevin dynamics采样过程中得到的中间样本
- 详细训练流程如下(其中 \(\Omega(\cdot)\) 表示停止梯度回传):

- 注:EBM的效果比较一般
Score-Matching
- 本节许多推导参考自:有没有谁通俗的讲一下Denoising score matching? - kkkkkkk的回答 - 知乎
- Score-Matching方法也把生成样本对应的分布建模为玻尔兹曼分布,但不同于EBM使用近似梯度来避开求解 \(Z(\theta)\),Score-Matching使用Score-based方法
- Score-based方法中,我们考虑 \(Z(\theta)\) 与 \(x\) 无关,于是我们考虑先对 \(x\) 求导,于是我们可以定义得分函数 \(s(x;\theta)\) 如下:
$$ s(x;\theta) = \nabla_x \log p_\theta(x) = - \nabla_x E_\theta(x) $$ - 得分函数 \(s(x;\theta)\) 的本质是对数概率函数关于 \(x\) 的梯度,如果我们能让 \(s(x;\theta)\) 尽量接近真实对数概率关于 \(x\) 的梯度,即可实现和极大似然法相似的效果,即最大化已知数据出现的概率,真实的对数概率关于 \(x\) 的梯度 \(s_\text{real}(x)\) 可以定义为:
$$ s_\text{real}(x) = \nabla_x \log p_\text{real}(x) = - \nabla_x E_\text{real}(x) $$ - Score-Matching的过程就是 \(s(x;\theta)\) 和 \(s_\text{real}(x)\) 匹配的过程,也就是最小化下面的目标函数 \(J(\theta)\):
$$
\begin{align}
J(\theta) &= \mathbb{E}_{x\sim p_\text{real}} [\Vert s(x;\theta) - s_\text{real}(x) \Vert^2] \\
&= \int_{x\in \mathbb{R}^n} p_\text{real}(x) \Vert s(x;\theta) - s_\text{real}(x) \Vert^2 dx
\end{align}
$$- 当两个得分函数相同时,他们的积分值会相差一个常数
- 至此,我们还不知道 \(s_\text{real}(x)\),为了求解上面的式子,我们进一步展开 \(\Vert s(x;\theta) - s_\text{real}(x) \Vert^2\) 并去除与参数 \(\theta\) 无关的部分,于是有(接下来的推导中,为了方便,我们先把 \(x\) 当做一维的情况来推导):
$$
\begin{align}
\mathop{\arg\max}_\theta J(\theta) &= \mathop{\arg\max}_\theta \int_{x\in \mathbb{R}^n} p_\text{real}(x) \Vert s(x;\theta) - s_\text{real}(x) \Vert^2 dx \\
&= \mathop{\arg\max}_\theta \int_{x\in \mathbb{R}^n} p_\text{real}(x) \Big( (s(x;\theta))^2 - 2 s(x;\theta) s_\text{real}(x)+ (s_\text{real}(x))^2 \Big) dx \\
&= \mathop{\arg\max}_\theta \int_{x\in \mathbb{R}^n} p_\text{real}(x) \Big( (s(x;\theta))^2 - 2 s(x;\theta) s_\text{real}(x) \Big) dx \\
\end{align}
$$- 其中 \( (s_\text{real}(x))^2\) 与 \(\theta\) 无关,可以丢掉
- 可以进一步消掉 \(s(x;\theta) s_\text{real}(x)\) 中的 \(s_\text{real}(x)\):
$$
\begin{align}
\int_{x\in \mathbb{R}^n} p_\text{real}(x) s(x;\theta) s_\text{real}(x) dx &= \int_{x\in \mathbb{R}^n} p_\text{real}(x) s(x;\theta) \nabla_x p_\text{real}(x) dx \\
&= \int_{x\in \mathbb{R}^n} p_\text{real}(x) s(x;\theta) \nabla_x \log p_\text{real}(x) dx \\
&= \int_{x\in \mathbb{R}^n} p_\text{real}(x) s(x;\theta) \frac{\nabla_x p_\text{real}(x)}{p_\text{real}(x)} dx \\
&= \int_{x\in \mathbb{R}^n} s(x;\theta) \nabla_x p_\text{real}(x) dx \\
&= s(x;\theta) p_\text{real}(x) - \int_{x\in \mathbb{R}^n} p_\text{real}(x) \nabla_x s(x;\theta) dx \\
\end{align}
$$- 其中用到了分部积分:\(\int u(x) dv(x) = u(x)v(x) - \int v(x) du(x)\) 的展开形式 \(\int u(x) v’(x) dx = u(x)v(x) - \int v(x)u’(x) dx\)
- 接下来,Estimation of Non-Normalized Statistical Models by Score Matching-Theorem 1, 2005文章做了一些假设,这些假设下,可以得到下面的结论(问题:为什么在 \(x \to \infty\) 时等于0就可以继续证明?):
$$ \lim_{x \to \infty }s(x;\theta) p_\text{real}(x) = 0$$ - 于是有 \(\int_{x\in \mathbb{R}^n} p_\text{real}(x) s(x;\theta) s_\text{real}(x) dx = - \int_{x\in \mathbb{R}^n} p_\text{real}(x) \nabla_x s(x;\theta) dx\),带入原始目标函数变成如下:
$$
\begin{align}
\mathop{\arg\max}_\theta J(\theta) &= \mathop{\arg\max}_\theta \int_{x\in \mathbb{R}^n} p_\text{real}(x) (s(x;\theta))^2 + 2 \nabla_x s(x;\theta) dx \\
&= \mathop{\arg\max}_\theta \mathbb{E}_{x \sim p_\text{real}(x)} [(s(x;\theta))^2 + 2 \nabla_x s(x;\theta)] \\
&= \mathop{\arg\max}_\theta \mathbb{E}_{x \sim p_\text{real}(x)} [\nabla_x s(x;\theta) + \frac{1}{2}(s(x;\theta))^2 ] \\
\end{align}
$$ - 上面的表达中,先把 \(x\) 当做一维的情况来推导只是为了推导方便,实际上,\(x\) 是多维的,因此 \(\nabla_x s(x;\theta)\) 是一个向量,此时需要使用如下将所有维度的梯度值的和的形式(原始论文中就是这样):
$$
\begin{align}
\mathop{\arg\max}_\theta J(\theta) &= \mathop{\arg\max}_\theta \mathbb{E}_{x \sim p_\text{real}(x)}[\sum_{i=1}^k(\nabla_{x_i} s(x;\theta) + \frac{1}{2}(s(x;\theta))^2)] \\
\end{align}
$$ - 至此,已经消掉了 \(s_\text{real}(x)\),上面的形式就是我们常见的Score-Matching形式
DDPM中的SDE
- SDE形式:
$$\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\end{equation}$$ - 写成离散形式:
$$\begin{equation}\boldsymbol{x}_{t+\Delta t} - \boldsymbol{x}_t = \boldsymbol{f}_t(\boldsymbol{x}_t) \Delta t + g_t \sqrt{\Delta t}\boldsymbol{\varepsilon},\quad \boldsymbol{\varepsilon}\sim \mathcal{N}(\boldsymbol{0}, \boldsymbol{I})\end{equation}$$ - 进一步移项可得:
$$\boldsymbol{x}_{t+\Delta t} = \boldsymbol{x}_t + \boldsymbol{f}_t(\boldsymbol{x}_t) \Delta t + g_t \sqrt{\Delta t}\boldsymbol{\varepsilon},\quad \boldsymbol{\varepsilon}\sim \mathcal{N}(\boldsymbol{0}, \boldsymbol{I})$$ - 变换成高斯分布采样形式:
$$\boldsymbol{x}_{t+\Delta t} \sim \mathcal{N} (\boldsymbol{x}_t + \boldsymbol{f}_t(\boldsymbol{x}_t) \Delta t, g_t^2 \Delta t) $$ - 前向过程条件概率的微分形式可以表示为:
$$\begin{equation}\begin{aligned}
p(\boldsymbol{x}_{t+\Delta t}|\boldsymbol{x}_t) =&\ \mathcal{N}\left(\boldsymbol{x}_{t+\Delta t};\boldsymbol{x}_t + \boldsymbol{f}_t(\boldsymbol{x}_t) \Delta t, g_t^2\Delta t \boldsymbol{I}\right)\\
\propto&\ \exp\left(-\frac{\Vert\boldsymbol{x}_{t+\Delta t} - \boldsymbol{x}_t - \boldsymbol{f}_t(\boldsymbol{x}_t) \Delta t\Vert^2}{2 g_t^2\Delta t}\right)
\end{aligned}\end{equation}$$ - 经过一系列推导(参见:生成扩散模型漫谈(五):一般框架之SDE篇,苏剑林,2022),可以得到反向过程的微分方程形式如下:
$$\begin{equation}\begin{aligned}
p(\boldsymbol{x}_t|\boldsymbol{x}_{t+\Delta t}) \propto&\ \exp\left(-\frac{\Vert\boldsymbol{x}_{t+\Delta t} - \boldsymbol{x}_t - \left[\boldsymbol{f}_t(\boldsymbol{x}_t) - g_t^2\nabla_{\boldsymbol{x}_t}\log p(\boldsymbol{x}_t) \right]\Delta t\Vert^2}{2 g_t^2\Delta t}\right) \\
\approx&\exp\left(-\frac{\Vert \boldsymbol{x}_t - \boldsymbol{x}_{t+\Delta t} + \left[\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t}) - g_{t+\Delta t}^2\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t}) \right]\Delta t\Vert^2}{2 g_{t+\Delta t}^2\Delta t}\right)
\end{aligned}\end{equation}
$$- 上面的 \(\approx\) 是一种近似,下面是苏神的回答:
本就不是严格的推导,“随意”是必然的。这里约等号的原因是 \(\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t})\Delta t
\) 与 \(\boldsymbol{f}_t(\boldsymbol{x}_t)\Delta t\) 具有相同的一阶近似精度
- 上面的 \(\approx\) 是一种近似,下面是苏神的回答:
- 最终可得到反向过程 \(p(\boldsymbol{x}_t|\boldsymbol{x}_{t+\Delta t})\) 近似一个均值为 \(\boldsymbol{x}_{t+\Delta t} - \left[\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t}) - g_{t+\Delta t}^2\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t}) \right]\Delta t\),协方差为 \(g_{t+\Delta t}^2\Delta t\ \boldsymbol{I}\) 的正太分布,即:
$$ p(\boldsymbol{x}_t|\boldsymbol{x}_{t+\Delta t}) = \mathcal{N}(p(\boldsymbol{x}_t|\boldsymbol{x}_{t+\Delta t}); \underbrace{\boldsymbol{x}_{t+\Delta t} - \left[\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t}) - g_{t+\Delta t}^2\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t}) \right]\Delta t}_{\mu}, \underbrace{g_{t+\Delta t}^2\Delta t\ \boldsymbol{I}}_{\Sigma}) $$ - 采样形式是:
$$
\begin{align}
\boldsymbol{x}_t &= \boldsymbol{x}_{t+\Delta t} - \left[\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t}) - g_{t+\Delta t}^2\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t}) \right]\Delta t - g_{t+\Delta t} \sqrt{\Delta t}\boldsymbol{\varepsilon},\quad \boldsymbol{\varepsilon}\sim \mathcal{N}(\boldsymbol{0}, \boldsymbol{I})
\end{align}
$$ - 变换一下形式可得:
$$
\begin{align}
\boldsymbol{x}_{t+\Delta t} - \boldsymbol{x}_t &= \left[\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t}) - g_{t+\Delta t}^2\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t}) \right]\Delta t + g_{t+\Delta t} \sqrt{\Delta t}\boldsymbol{\varepsilon},\quad \boldsymbol{\varepsilon}\sim \mathcal{N}(\boldsymbol{0}, \boldsymbol{I}) \\
\end{align}
$$ - 写成SDE的形式为(注意:\(d\boldsymbol{x} = \boldsymbol{x}_{t+\Delta t} - \boldsymbol{x}_t\)):
$$\begin{equation}d\boldsymbol{x} = \left[\boldsymbol{f}_t(\boldsymbol{x}) - g_t^2\nabla_{\boldsymbol{x}}\log p_t(\boldsymbol{x}) \right] dt + g_t d\boldsymbol{w}\end{equation}$$- \(\log p_t(\boldsymbol{x})\) 中带着下标 \(t\),表示是 \(t\) 时刻的分布,这里虽然SDE形式一样,但是不同时刻的分布是不同的
Score-Matching Loss
- 回顾DDPM反向过程的SDE形式:
$$\begin{equation}d\boldsymbol{x} = \left[\boldsymbol{f}_t(\boldsymbol{x}) - g_t^2\nabla_{\boldsymbol{x}}\log p_t(\boldsymbol{x}) \right] dt + g_t d\boldsymbol{w}\end{equation}$$ - 由于前向过程是已知的,所以 \(\boldsymbol{f}_t(\boldsymbol{x})\) 和 \(g_t\) 都是已知项。所以在反向过程SDE形式中,唯一的未知项是 \(\nabla_x \log p_\theta(x)\),即得分函数(按照得分函数的定义 : \(s(x;\theta) = \nabla_x \log p_\theta(x)\) 可知)
- 我们使用神经网络 \(s_\theta(x_t,t)\) 去拟合 \(t\) 时刻的得分函数 \(s(t) = \nabla_{x_t} \log p(x_t)\),DDPM对应的Score-Matching应该是(最小化 \(s_\theta(x_t,t)\) 和 \(s(t)\) 之间的距离):
$$
\begin{align}
J(\theta) &= \int_{x_t} p(x_t) \Vert s_\theta(x_t,t) - \nabla_{x_t} \log p(x_t)\Vert^2 dx_t \\
&= \mathbb{E}_{x_t \sim p(x_t)} [\Vert s_\theta(x_t,t) - \nabla_{x_t} \log p(x_t)\Vert^2] \\
\end{align}
$$ - 接下来的任务是求解 \(\nabla_x \log p(x)\),此时我们,在实际场景中,我们已知的数据是 \(x_0\),基于前向过程扩散可以得到任意时刻的数据 \(x_t\),所以前向过程中 \(x_t\) 也是已知的(或者说 \(p(\boldsymbol{x_t}|\boldsymbol{x_0})\) 是有解析解的):
$$ \begin{equation}p(\boldsymbol{x}_t) = \int p(\boldsymbol{x}_t|\boldsymbol{x}_0)\tilde{p}(\boldsymbol{x}_0)d\boldsymbol{x}_0=\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]\end{equation} $$- 其中 \(\tilde{p}(x_0) = p_\text{D}(x_0) = p_\text{real}(x_0)\),表示 \(x_0\) 的真实分布
- 按照对数概率求导的方法,于是有:
$$ \begin{equation}\nabla_{\boldsymbol{x}_t}\log p(\boldsymbol{x}_t) = \frac{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[\nabla_{\boldsymbol{x}_t} p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]}{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]} = \frac{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]}{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]}\end{equation} $$ - 经过推导可以得到最小化目标函数等价于最小化下面的形式:
$$
\begin{align}
\mathbb{E}_{x_t \sim p(x_t)} [\Vert s_\theta(x_t,t) - \nabla_{x_t} \log p(x_t)\Vert^2] &= \mathop{\arg\min}_\theta \left\Vert \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \frac{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]}{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]}\right\Vert^2 \\
&= \mathop{\arg\min}_\theta \frac{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\left\Vert \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right\Vert^2\right]}{\mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right]} \\
&= \mathop{\arg\min}_\theta \mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\left\Vert \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right\Vert^2\right]
\end{align}
$$- 上面的第二个等号可以通过推导证明 \(\forall \boldsymbol{f}(\boldsymbol{x}), g(\boldsymbol{x}), \quad \mathop{\arg\min}_\boldsymbol{\mu} \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \cdot \left\Vert
\boldsymbol{\mu} - \boldsymbol{f}(\boldsymbol{x})
\right\Vert^2 \right] = \frac { \mathbb{E}_{\boldsymbol{x}}[g(\boldsymbol{x}) \cdot \boldsymbol{f}(\boldsymbol{x})] }{ \mathbb{E}_{\boldsymbol{x}}[g(\boldsymbol{x})] } \) 得到,详细证明见附录:证明加权均方误差形式 - 第三个等号是因为上式的分母与参数 \(\theta\) 无关,可以消掉
- 上面的第二个等号可以通过推导证明 \(\forall \boldsymbol{f}(\boldsymbol{x}), g(\boldsymbol{x}), \quad \mathop{\arg\min}_\boldsymbol{\mu} \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \cdot \left\Vert
- 进一步对 \(x_t\) 进行积分(相当于对每个 \(x_t\) 都做最小化),最终可以得到下面的结论:
$$
\begin{align}
J(\theta)&= \int_{\boldsymbol{x}_t} \mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0)}\left[p(\boldsymbol{x}_t|\boldsymbol{x}_0)\left\Vert \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right\Vert^2\right] d\boldsymbol{x}_t \\
&=\ \mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0),\boldsymbol{x}_t \sim p(\boldsymbol{x}_t|\boldsymbol{x}_0)}\left[\left\Vert \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right\Vert^2\right]
\end{align}
$$
DDPM和Score-based模型的关系
扩散模型的一般流程总结
- 第一步:前向过程,定义如下的SDE:
$$\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\end{equation}$$ - 第二步:求解得到 \(p(x_t|x_0)\) 的表达式
$$ p(\boldsymbol{x}_{t+\Delta t}|\boldsymbol{x}_t) =\ \mathcal{N}\left(\boldsymbol{x}_{t+\Delta t};\boldsymbol{x}_t + \boldsymbol{f}_t(\boldsymbol{x}_t) \Delta t, g_t^2\Delta t \boldsymbol{I}\right)$$ - 第三步:Score-Matching,使用下面的损失函数训练得分函数模型 \(s_\theta(x_t, t)\)
$$ J(\theta) =\ \mathbb{E}_{\boldsymbol{x}_0 \sim \tilde{p}(x_0),\boldsymbol{x}_t \sim p(\boldsymbol{x}_t|\boldsymbol{x}_0)}\left[\left\Vert \boldsymbol{s}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t) - \nabla_{\boldsymbol{x}_t} \log p(\boldsymbol{x}_t|\boldsymbol{x}_0)\right\Vert^2\right] $$ - 第四步:将 \(s_\theta(x_t, t)\) 作为 \(\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t})\) 的近似值带入下面的式子采样生成样本 $$ p(\boldsymbol{x}_t|\boldsymbol{x}_{t+\Delta t}) = \mathcal{N}(p(\boldsymbol{x}_t|\boldsymbol{x}_{t+\Delta t}); \underbrace{\boldsymbol{x}_{t+\Delta t} - \left[\boldsymbol{f}_{t+\Delta t}(\boldsymbol{x}_{t+\Delta t}) - g_{t+\Delta t}^2\nabla_{\boldsymbol{x}_{t+\Delta t}}\log p(\boldsymbol{x}_{t+\Delta t}) \right]\Delta t}_{\mu}, \underbrace{g_{t+\Delta t}^2\Delta t\ \boldsymbol{I}}_{\Sigma}) $$
- 在DDPM中,有 \(t+\Delta t = t+1\),即 \(x_{t+\Delta t} = x_{t+1}\)
DDPM损失函数与Score-Based损失函数的区别
- 正太分布 \(\mathbf{x} \sim \mathcal{N}(\mathbf{\mu}, \sigma^2 \boldsymbol{I})\) 的梯度计算如下:
$$\nabla_{\mathbf{x}}\log p(\mathbf{x}) = \nabla_{\mathbf{x}} \Big(-\frac{1}{2\sigma^2}(\mathbf{x} - \boldsymbol{\mu})^2 \Big) = - \frac{\mathbf{x} - \boldsymbol{\mu}}{\sigma^2} = - \frac{\boldsymbol{\epsilon}}{\sigma}$$ - 结合 \(q(\mathbf{x}_t \vert \mathbf{x}_0) \sim \mathcal{N}(\sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t)\boldsymbol{I})\),可得:
$$
\mathbf{s}_\theta(\mathbf{x}_t, t)
\approx \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t)
= \mathbb{E}_{q(\mathbf{x}_0)} [\nabla_{\mathbf{x}_t} q(\mathbf{x}_t \vert \mathbf{x}_0)]
= \mathbb{E}_{q(\mathbf{x}_0)} \Big[ - \frac{\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{1 - \bar{\alpha}_t}} \Big]
= - \frac{\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{1 - \bar{\alpha}_t}}
$$ - Score-based模型中用神经网络建模并学习 \(\mathbf{s}_\theta(\mathbf{x}_t, t) \),DDPM中神经网络建模并学习 \(\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\)
附录:玻尔兹曼分布
- 玻尔兹曼分布(Boltzmann distribution),也称为吉布斯分布(Gibbs distribution),是统计力学中的一个核心概念,它描述了在热力学平衡状态下,一个系统处于各种可能状态的概率。该分布给出了粒子占据某个量子态的概率与该状态的能量以及系统的温度之间的关系
- 玻尔兹曼分布可以表示为:
$$ p_i \propto e^{-\frac{\varepsilon_i}{kT}} $$- \( p_i \) 是系统处于状态 \( i \) 的概率
- \( \varepsilon_i \) 是状态 \( i \) 的能量
- \( k \) 是玻尔兹曼常数
- \( T \) 是系统的绝对温度(热力学温度)
- 符号 \( \propto \) 表示正比例关系
- 实际使用中概率可以定义为: \(p_i = \frac{1}{Q}e^{-\frac{\varepsilon_i}{kT}}\),其中\(Q\)是归一化因子,用于确保概率和为1
- 这意味着,在较高的温度下,不同能量状态之间的概率差异会减小;而在较低的温度下,低能量状态将比高能量状态更有可能被占用
- 更一般的情况下,我们所说的玻尔兹曼分布,形式上有所变化,更像是Softmax形式,比如假定能量函数为 \(\{E_i\}_{i=1}^N\),玻尔兹曼分布可以定义为 \(p_i \propto e^{\frac{1}{\beta} E_i}\):
$$ p_i = \frac{e^{\frac{1}{\beta} E_i}}{\sum_i e^{\frac{1}{\beta} E_i}} $$- \(\frac{1}{\beta}\) 是温度系数
附录:Langevin dynamics方法
- Langevin dynamics 是一种用于模拟分子系统中粒子运动的方法,它结合了经典力学和随机过程。这种方法得名于法国物理学家保罗·朗之万(Paul Langevin),他提出了描述布朗运动的方程
附录:证明加权均方误差形式
注:以下证明参考自生成扩散模型漫谈(五):一般框架之SDE篇,shyoshyo评论
- 目标是证明:
$$ \begin{aligned}
\forall \boldsymbol{f}(\boldsymbol{x}), g(\boldsymbol{x}), \quad \mathop{\arg\min}_\boldsymbol{\mu} \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \cdot \left\Vert
\boldsymbol{\mu} - \boldsymbol{f}(\boldsymbol{x})
\right\Vert^2 \right] = \frac { \mathbb{E}_{\boldsymbol{x}}[g(\boldsymbol{x}) \cdot \boldsymbol{f}(\boldsymbol{x})] }{ \mathbb{E}_{\boldsymbol{x}}[g(\boldsymbol{x})] }
\end{aligned}
$$ - 证明过程:
$$\begin{aligned}
\mathop{\arg\min}_\boldsymbol{\mu} \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \cdot \left\Vert
\boldsymbol{\mu} - \boldsymbol{f}(\boldsymbol{x})
\right\Vert^2 \right] = & \mathop{\arg\min}_\boldsymbol{\mu} \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \cdot \left( \left\Vert
\boldsymbol{\mu} \right\Vert^2 - 2 \boldsymbol{\mu} \cdot \boldsymbol{f}(\boldsymbol{x}) + \left\Vert
\boldsymbol{ \boldsymbol{f}(\boldsymbol{x})} \right\Vert^2 \right) \right] \\
= & \mathop{\arg\min}_\boldsymbol{\mu} \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \cdot \left( \left\Vert
\boldsymbol{\mu} \right\Vert^2 - 2 \boldsymbol{\mu} \cdot \boldsymbol{f}(\boldsymbol{x}) \right) \right] \\
= & \mathop{\arg\min}_\boldsymbol{\mu} \left( \left\Vert
\boldsymbol{\mu} \right\Vert^2 \cdot \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \right] - 2 \boldsymbol{\mu} \cdot \mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x})\cdot\boldsymbol{f}(\boldsymbol{x}) \right] \right) \\
= & \mathop{\arg\min}_\boldsymbol{\mu} \left( \left\Vert
\boldsymbol{\mu} \right\Vert^2 - 2 \boldsymbol{\mu} \cdot \frac{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x})\cdot\boldsymbol{f}(\boldsymbol{x}) \right]}{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \right]} \right) \\
= & \mathop{\arg\min}_\boldsymbol{\mu} \left( \left\Vert
\boldsymbol{\mu} \right\Vert^2 - 2 \boldsymbol{\mu} \cdot \frac{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x})\cdot\boldsymbol{f}(\boldsymbol{x}) \right]}{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \right]} +
\left\Vert \frac{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x})\cdot\boldsymbol{f}(\boldsymbol{x}) \right]}{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \right]}\right\Vert^2 \right) \\
= & \mathop{\arg\min}_\boldsymbol{\mu} \left\Vert
\boldsymbol{\mu} - \frac{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x})\cdot\boldsymbol{f}(\boldsymbol{x}) \right]}{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \right]}\right\Vert^2 \\
= & \frac{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x})\cdot\boldsymbol{f}(\boldsymbol{x}) \right]}{\mathbb{E}_{\boldsymbol{x}}\left[ g(\boldsymbol{x}) \right]}
\end{aligned}
$$