本文主要记录Neo4j使用过程中的遇到的问题和解决方案等
安装与启动
安装
- 安装Neo4j前,一般需要安装Java环境, Ubuntu自带的版本不行的话需要重新下载安装新的版本并设置环境变量
自动安装
- Ubuntu上安装和卸载命令
1
2sudo apt-get install neo4j
sudo apt-get remove neo4j
手动安装
- 下载neo4j已经编译好的文件, 官网为http://www.neo4j.com/
- 不要直接点download neo4j, 从官网选中products->neo4j database->拉到最下面选择Community Edition_>选择对应的release版本(.tar文件)下载即可
- 将下载到的.tar文件解压到安装目录中(一般选择/usr/local/neo4j/)
- 现已经安装成功,直接进入安装目录即可使用
./bin/neo4j console启动neo4j数据库 - 初始的账户和密码都是neo4j, 第一次登录需要重新设置密码
启动
使用console启动
1
./bin/neo4j console
- terminal将输出实时运行log信息,关闭terminal,neo4j数据库随之关闭
- 此时用其他电脑不能访问,只能本地电脑localhost:7474/browser访问
查看启动状态
1
./bin/neo4j status
启动
1
./bin/neo4j start
停止
1
./bin/neo4j stop
默认访问端口: 7474, 比如本地访问网址为: localhost:7474/browser
Neo4J导入Turtle文件
Turtle简介
参考博客: https://blog.csdn.net/u011801161/article/details/78833958
- Turtle是最常用的RDF序列化方式, 比RDF/XML更紧凑, 可读性比N-Triples更好
- 其他序列化方式包括:
- RDF/XML: 用XML格式来表示RDF数据
- N-Triples: 用多个三元组来表示RDF数据集合,是最直观的表示方法,每一行表示一个三元组,方便机器解析和处理,DBpedia 是按照这个方式来发布数据的
- RDFa: (The Resource Description Framework in Attributes)
- JSON-LD
安装neosemantics插件
注意,这里要求neo4j安装方式是手动安装的,(自动安装的neo4j本人找不到
下载插件release版本, 项目地址: https://github.com/neo4j-labs/neosemantics
- 注意,下载时一定要查看版本与已经安装的neo4j数据库是否兼容,否则可能造成运行时异常,或者找不到方法名等
按照项目中的README.md安装插件
复制release版本到
/plugins目录下 修改
/conf/neo4j.conf文件,添加一行 1
dbms.unmanaged_extension_classes=semantics.extension=/rdf
重启neo4j服务器
使用
call dbms.procedures()测试是否安装成功
导入Turtle文件
导入云端文件
1
CALL semantics.importRDF("https://raw.githubusercontent.com/jbarrasa/neosemantics/3.5/docs/rdf/nsmntx.ttl","Turtle")
导入本地文件
1
CALL semantics.importRDF("file:///home/jiahong/neosemantics/3.5/docs/rdf/nsmntx.ttl","Turtle")
彻底清空Neo4J数据库
参考链接: https://blog.csdn.net/u012485480/article/details/83088818
使用Cypher语句
- 直接使用下面的Cypher语句即可
1
match (n) detach delete n
特点
- 无需操作文件
- 无需停止和启动服务
- 对于数据量大的情况下删除很慢(需要先查询再删除,内存可能会溢出)
删除数据库文件
停止neo4j服务
1
sudo ./bin/neo4j stop
删除
./data/databases/graph.db目录1
sudo rm -rf ./data/database/graph.db
启动neo4j服务
1
sudo ./bin/neo4j start
特点
- 需要删除文件操作
- 需要停止和启动服务
- 对于数据量大的情况下删除速度也非常快速
Neo4j约束
查看当前数据库中的所有约束
- Cypher查询语句CQL
1
:schema
创建约束
1 | create constraint on (p:Person) assert p.name is unique |
删除约束
1 | drop constraint on (p:Person) assert p.name is unique |
节点的唯一性约束
为某个标签在某个属性上创建唯一性约束
1
create constraint on (p:Person) assert p.name is unique
- 创建唯一性约束后会自动为该标签对应的属性创建索引Index
- 这里的索引为
ON :Person(name) ONLINE (for uniqueness constraint) - 理解,因为要确保唯一性,所以需要索引加快每次插入节点前检索的效率
- 手动创建索引(为了加快某个标签的某个属性的检索效率)的方法为:
1
create index on :Person(name)
唯一性约束设置后,当写入重复的数据时,会报错
Neo.ClientError.Schema.ConstraintValidationFailed
Node(19718935) already exists with labelPersonand propertyname= ‘Joe’
节点操作
创建节点
创建结点方式如下,其中p
1
create (p:Person{name:'Joe'})
上面的句子创建了一个结点
结点标签为: Person
- 如果之前没有Person标签则新建Person标签
- 如果没有添加索引,那么这个标签在所有Person标签的节点都被删除后也会自动消失
- 如果添加了索引,则删除所有结点和相关索引后该标签会自动消失
结点名称为: p
- p本质上在这里是一个变量
- 如果当前执行语句中对当前结点没有更多操作, 甚至可以省略节点名称p
1
create (:Person{name: 'Joe'})
结点属性
name的值为: ‘Joe’- 这个属性很有用, 可以在显示结点的时候直接在结点中显示出来”Joe”, 方便查看
- 测试: 换成其他属性,比如属性
a后, 在Neo4j可视化结点时是不显示的 name本身也可以省略1
create (:Person)
删除结点
- 删除标签为Person且名字为”Joe”的所有结点
1
match (p:Person{name:'Joe'}) delete p
标签操作
- Neo4j中一般为节点创建一个标签即可,通常一些标准的知识图谱还会为同一个节点创建多个标签,说明这个节点属于多个标签
- 节点的标签数量可以为0个,1个或多个
- 没有标签的结点可通过id获取到
1
match (n) where id(n)=<node-id> return n
直接创建标签
单个标签创建
1
create (<node-name>:<label-name>)
多个标签创建
1
create (<node-name>:<label-name1>:<label-name2>:...:<label-nameN>)
- 从很多知识图谱的例子来看,标签之间并不是完全的从属关系
- 从属关系: Person:Student
- 并列关系: Man:Student
给已有的节点添加标签
- 使用
set关键字添加标签标签1
match (p:Person{name:'Joe'}) set p:Student
移除已有结点的标签
- 使用
remove关键字删除标签1
match (p:Person{name:'Joe'}) remove p:Student
属性操作
- 属性操作与标签操作类似, 使用的也是
REMOVE和SET指令
直接创建属性
- 使用
CREATE指令1
create (p:Person{name:'Joe'})
添加属性
- 使用
SET指令1
match (p:Person{name:"Joe"}) set p.sex="male"
移除属性
- 使用
REMOVE指令1
match (p:Person{name:"Joe"}) remove p.sex
各种操作命令总结
DELETE和CREATE指令用于删除节点和关联关系REMOVE和SET指令用于删除标签和属性
Neo4j同时创建多个数据库
- Neo4j中无法同时创建多个数据库,但是我们可以通过硬性和软性的方法分别实现等价功能
硬件上实现多个数据库
- Neo4j的数据库文件为
./data/databases/graph.db- 我们可以手动修改该文件的名称,然后重新创建文件实现
- Neo4j的数据库配置文件为
./conf/neo4j.conf- 可以修改
#dbms.active_database=graph.db - 修改方法为将注释取消并且修改数据库为对应的数据库名称
- 可以修改
软件上实现多个数据库
- 为不同数据库的每个结点分别指定同一个数据库名称对应的标签
- 比如”Docker”和”School”分别对应Docker知识图谱和学校知识图谱
Py2neo中结点如何被图识别?
- 每个Python结点对象都有个唯一的标识符ID
- 对应属性为
identity - 对于从Graph中读出的结点,该属性为一个唯一的数值,与图数据库中结点的数值一致
- 对于Python直接初始化的结点对象,该属性是
None
- 对应属性为
- 只要
identity属性指定了,其他属性与数据库中的结点不同也可以的- 使用
Graph.push(local_node)可以把本地结点更新到远处数据库中
- 使用
Neo4j和JVM版本兼容问题
报错:
1 | sudo ./bin/neo4j start |
ERROR! Neo4j cannot be started using java version 1.8.0_222.
- Please use Oracle(R) Java(TM) 11, OpenJDK(TM) 11 to run Neo4j.
- Please see https://neo4j.com/docs/ for Neo4j installation instructions.
解决方案
安装对应版本的Java虚拟机(这里不会修改操作系统中原来的JAVA_HOME)
1
2sudo yum search jdk
sudo yum install java-11-openjdk将对应的JAVA_HONE配置到Neo4j中(不修改原来系统中的JAVA_HOME)
1
sudo vim ./conf/neo4j.conf
在文件最后一行添加
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.5.10-0.el7_7.x86_64
重新启动neo4j
1
sudo ./bin/neo4j start
注意: 以上方法都不会影响系统的JAVA_HOME和JAVA环境
Neo4j服务器配置远程访问功能
打开配置文件
1
sudo vim ./conf/neo4j.conf
将下面的语句注释取消
dbms.connectors.default_listen_address=0.0.0.0
- 注意: 如果是服务器有防火墙,则需要把以下端口打开
- 7474: http
- 7687: bolt
Neo4j dump数据
- 参考链接:https://www.jianshu.com/p/8c501b49adb7
- dump原始数据库为
.dump文件bin/neo4j-admin dump --database graph.db --to [dir]- 将数据库graph.db中的数据dump为
.dump文件,文件名字自动生成为对应的数据库名称.dump
- 将数据库graph.db中的数据dump为
- 将
.dump文件导入到库中,(库需要停掉,并且库名不能有相同的名字)bin/neo4j-admin load --from graph.db.dump- 相当于是dump的逆向操作,数据库文件名称自动生成为前缀(注意不能与已经存在的数据库产生冲突)
- 当不同版本库相互倒数据时需要把该参数开启,在conf/neo4j.conf中
dbms.allow_format_migration=true - 这个dump命令只有在3.2.0才有的
Neo4j 4.0.0以后
- 数据库文件夹变化了,不能像之前一样修改文件夹名为
graph.db来更改数据库
使用Cypher查询数据库时的效率问题
- 应该把Cypher语句和MySQL的查询语句联系起来看
- Cypher从第一句开始匹配,然后依次匹配相关的每一句
- 如果存在两条匹配过程的路径,而又需要把这两个路径联系起来,那么需要使用
WHERE子句WHERE语句非常有用,能避免很多不必要的问题,还能加入与或非的逻辑
- 但是一定要注意,
WHERE语句使用方便,但是容易造成检索慢的问题
举例
尽量不要写出如下语句
1
2
3
4MATCH (image:Image), (base_image:BaseImage)
WHERE image.name = "ubuntu:latest" and
(image)-[:hasBaseImage]->(base_image)
RETURN base_image- 上述语句将匹配所有的Image对象
- 然后匹配所有BaseImage对象
- 接着执行WHERE子句过滤
- 最后再返回
上面的句子可以换成如下语句
1
2MATCH (image:Image{name:"ubuntu:latest"), (image)-[:hasBaseImage]->(base_image)
RETURN base_image- 上面的句子直接找到名称为”ubuntu:latest“的镜像
- 然后直接从改对象开始搜索相关关系的BaseImage
- 最后返回
实验表明:后面一句比前一句速度快很多
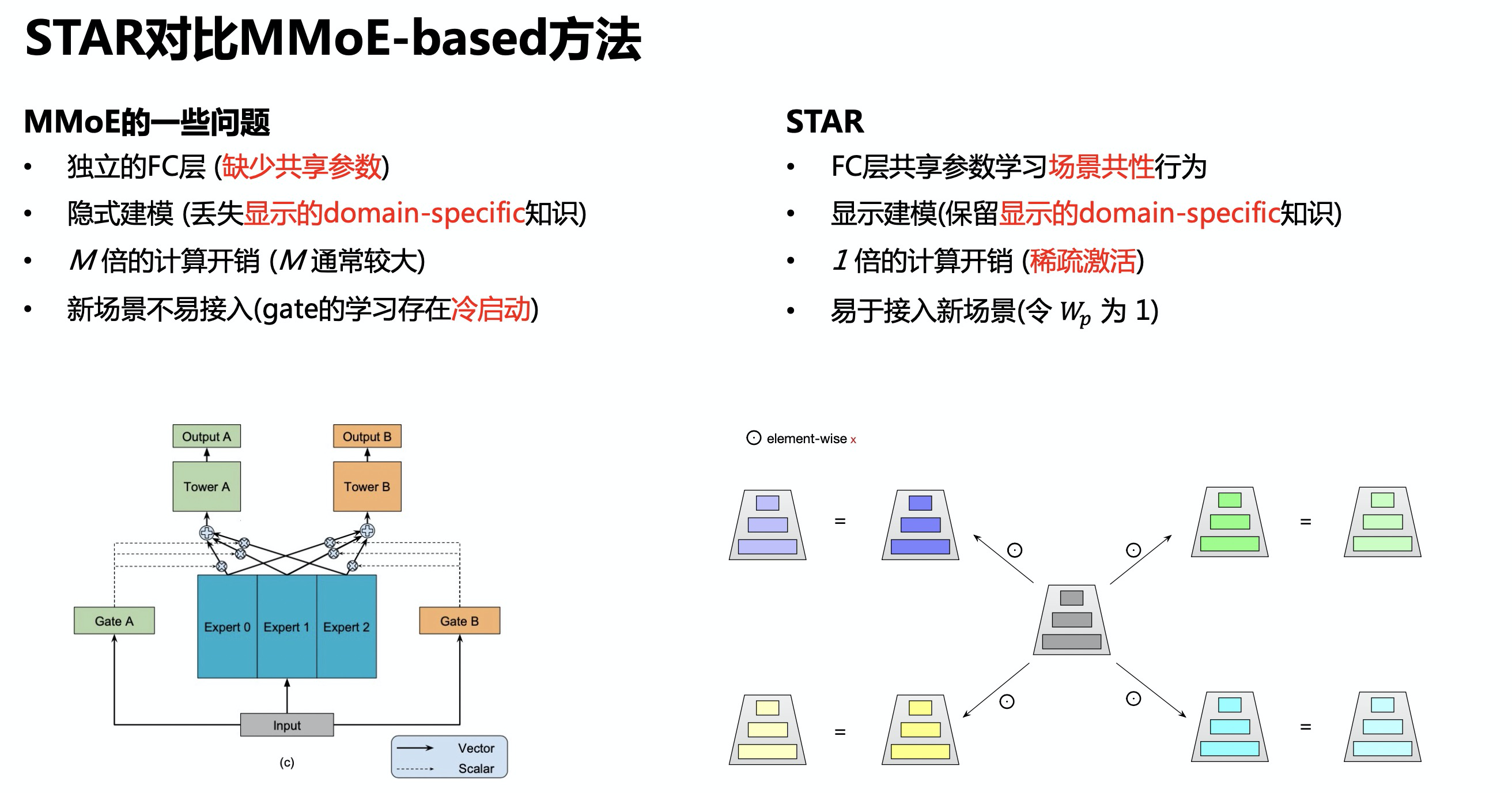
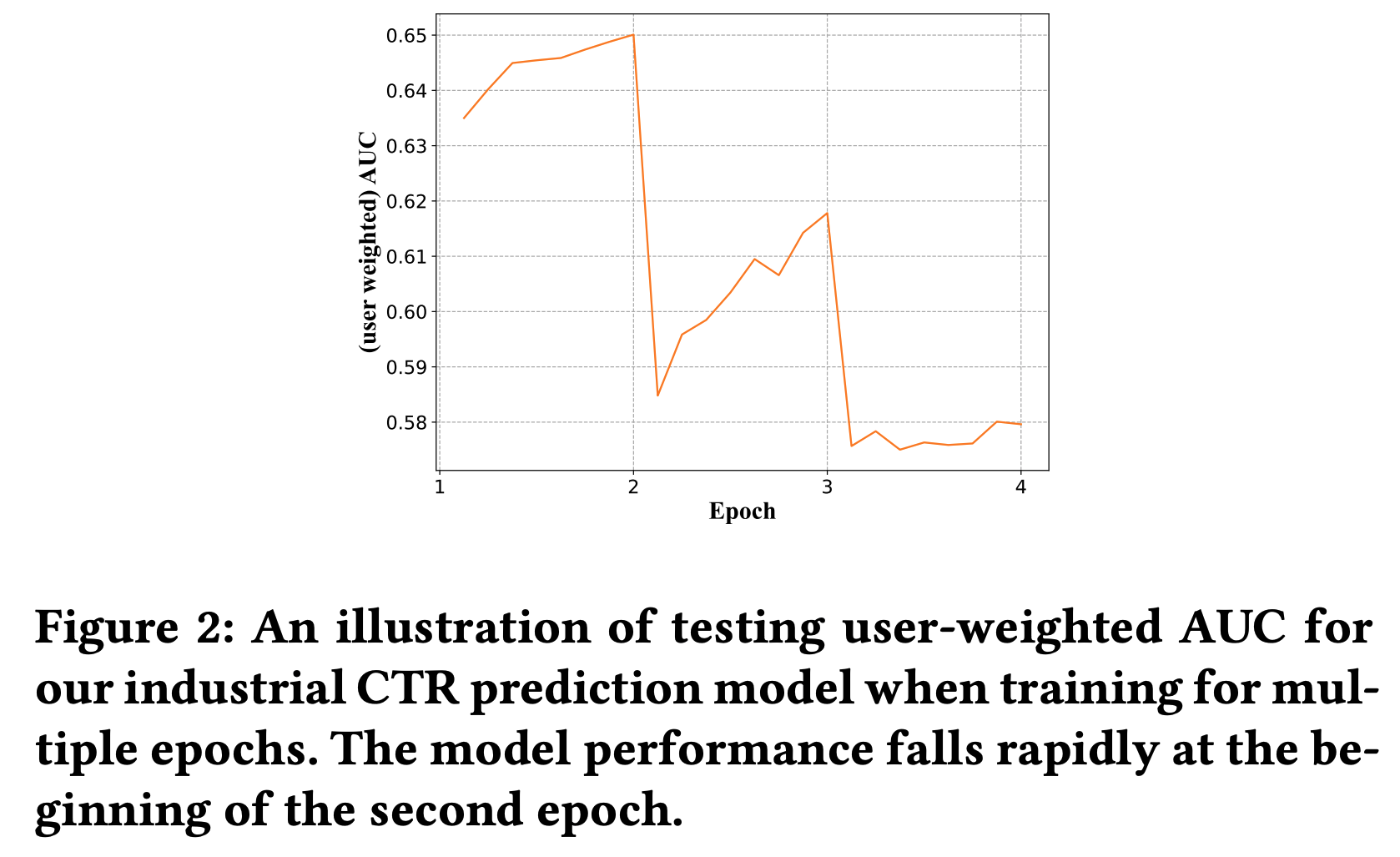

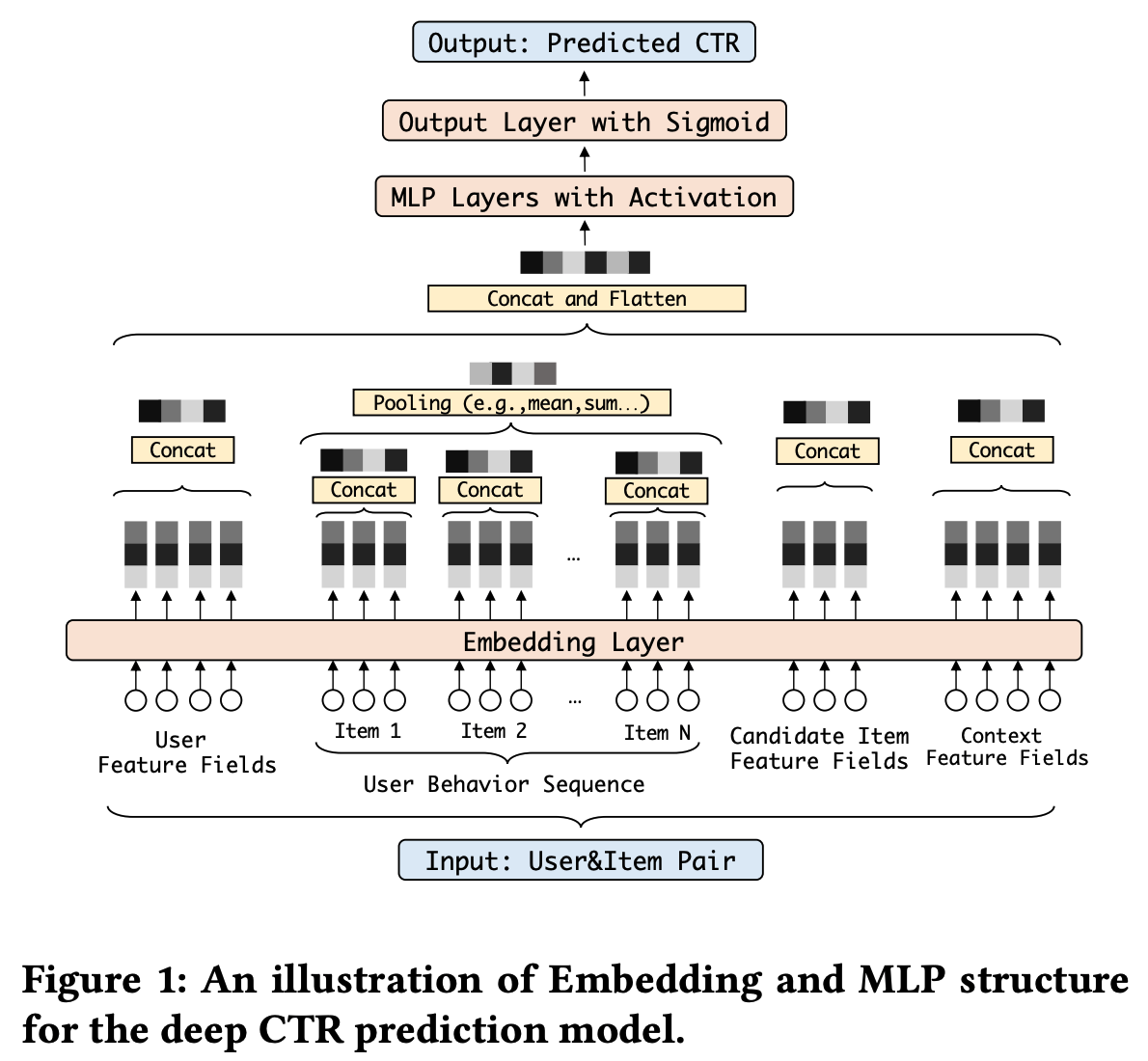
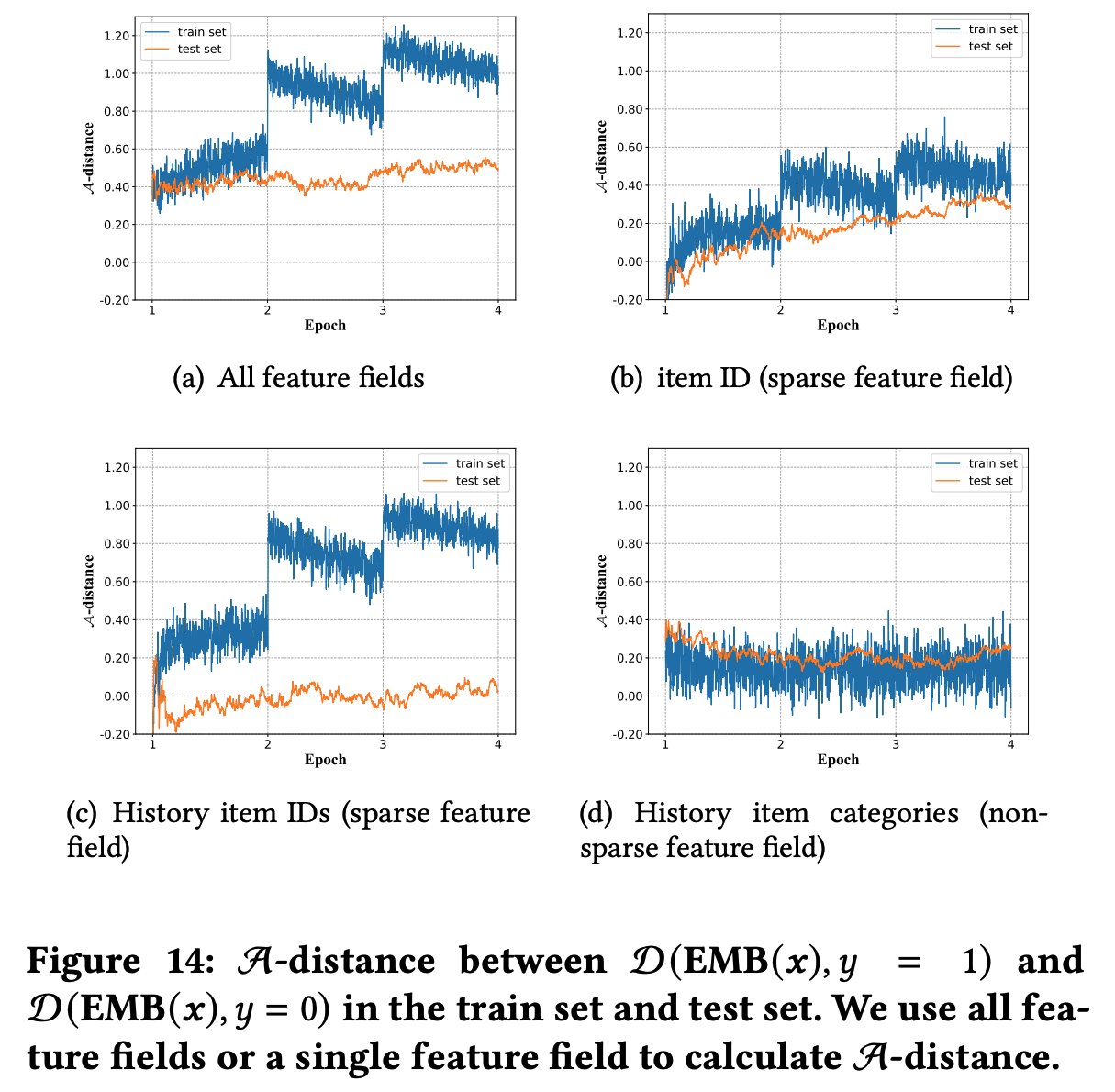
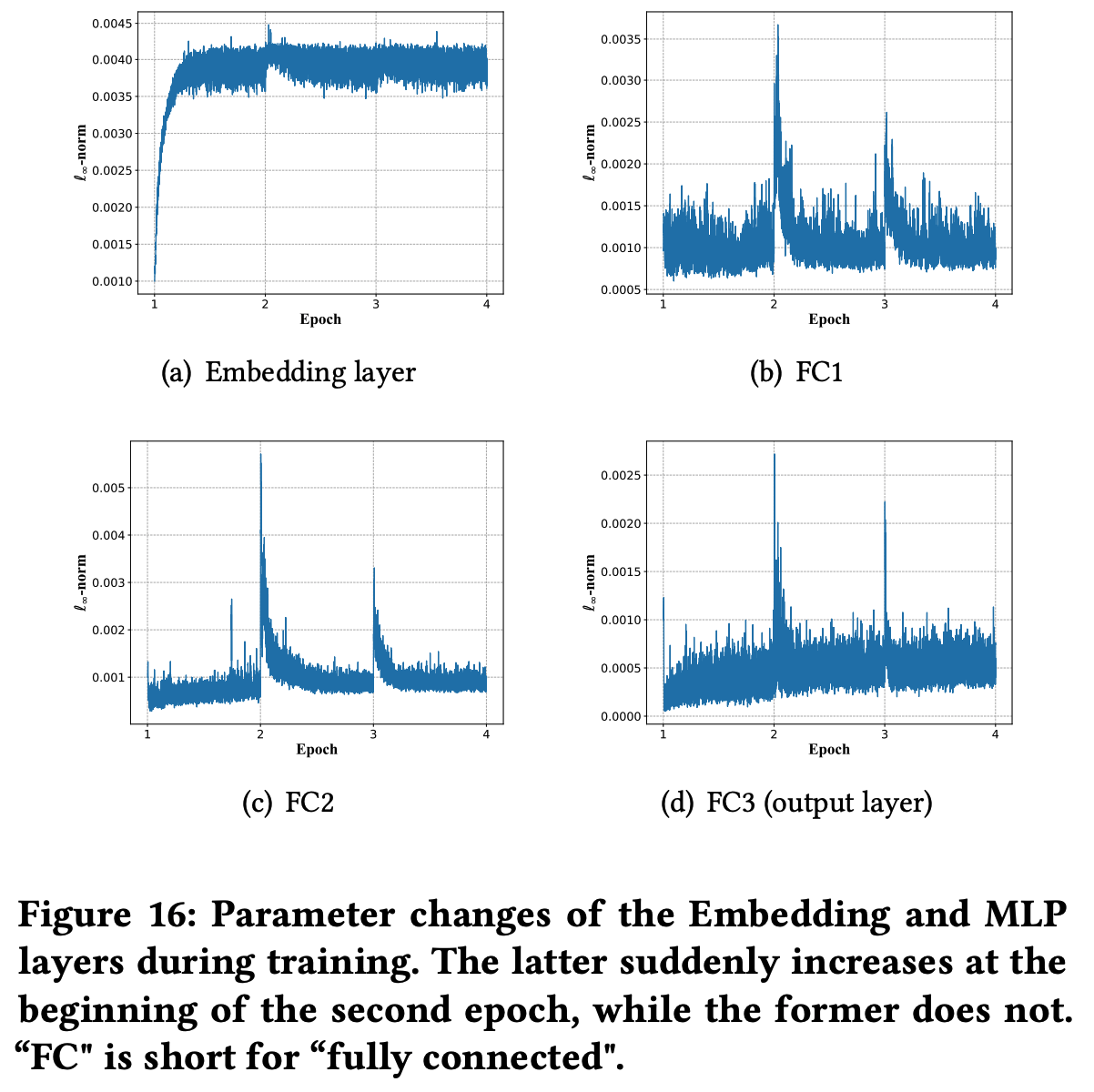
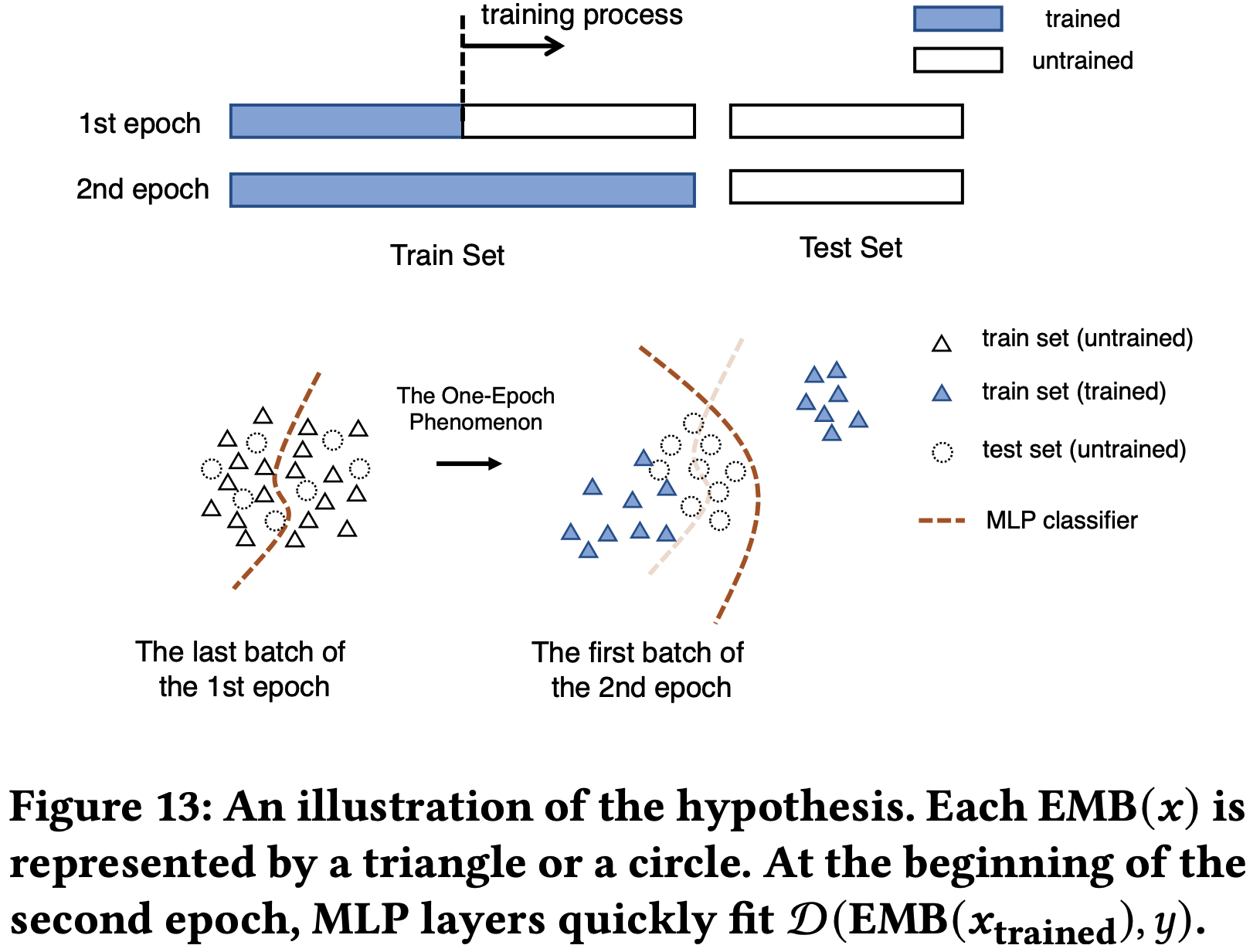
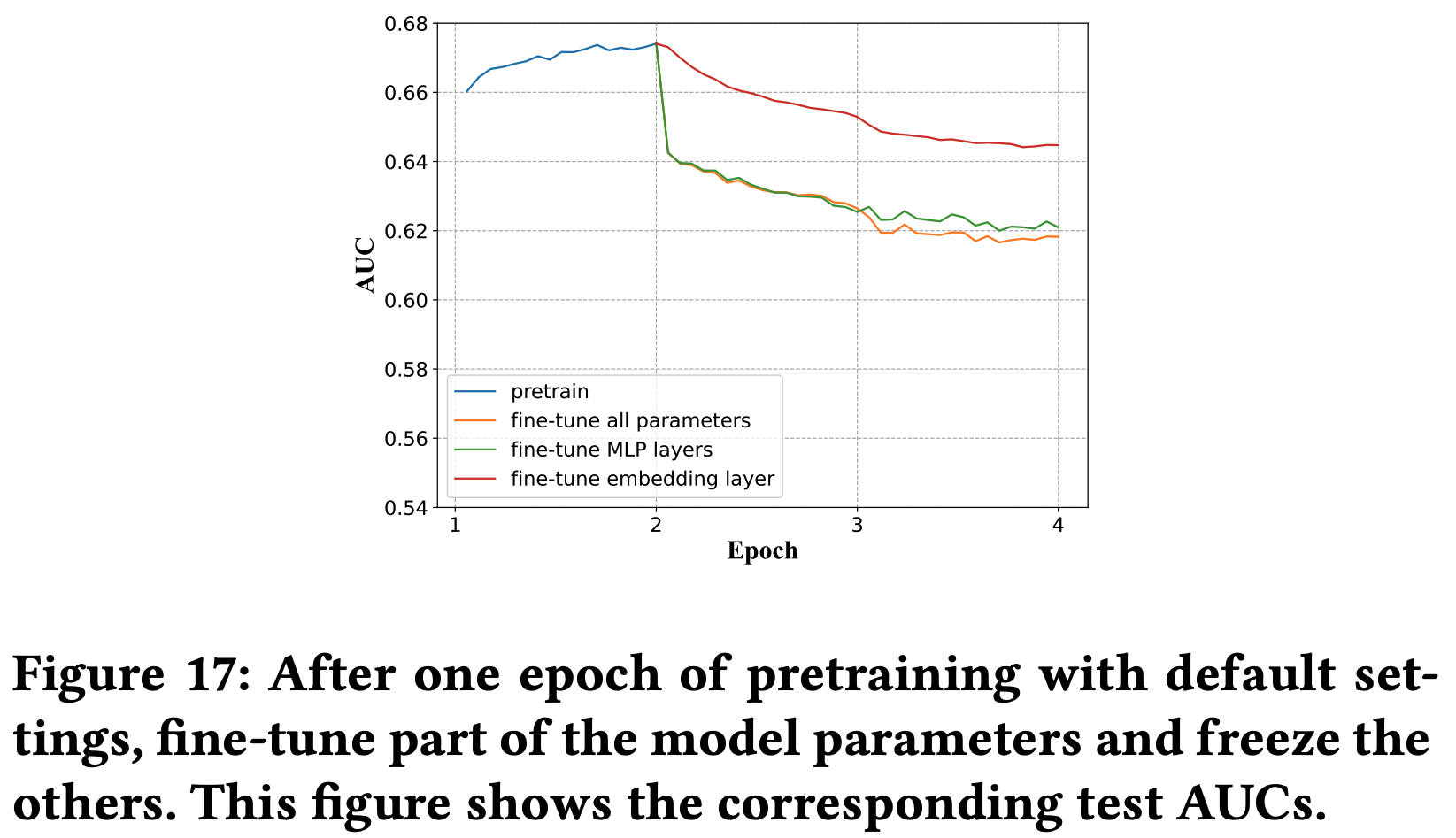
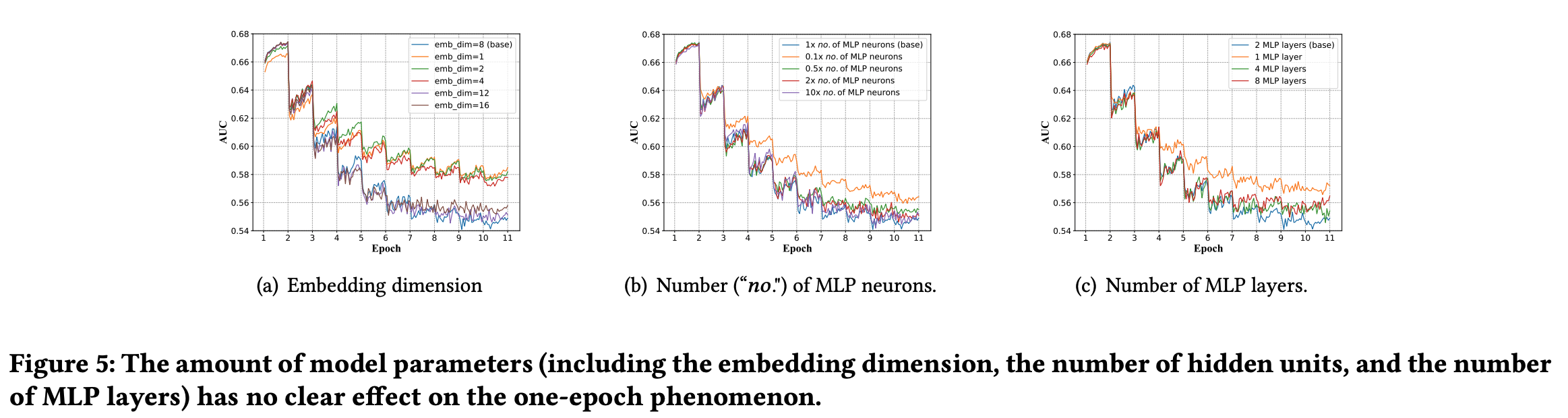
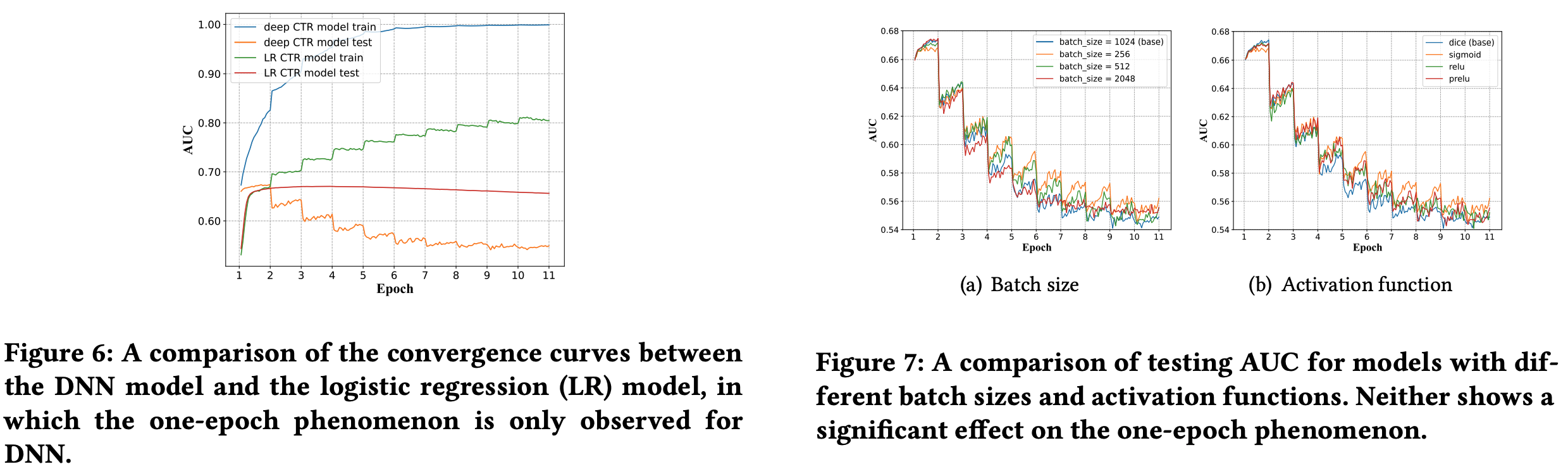
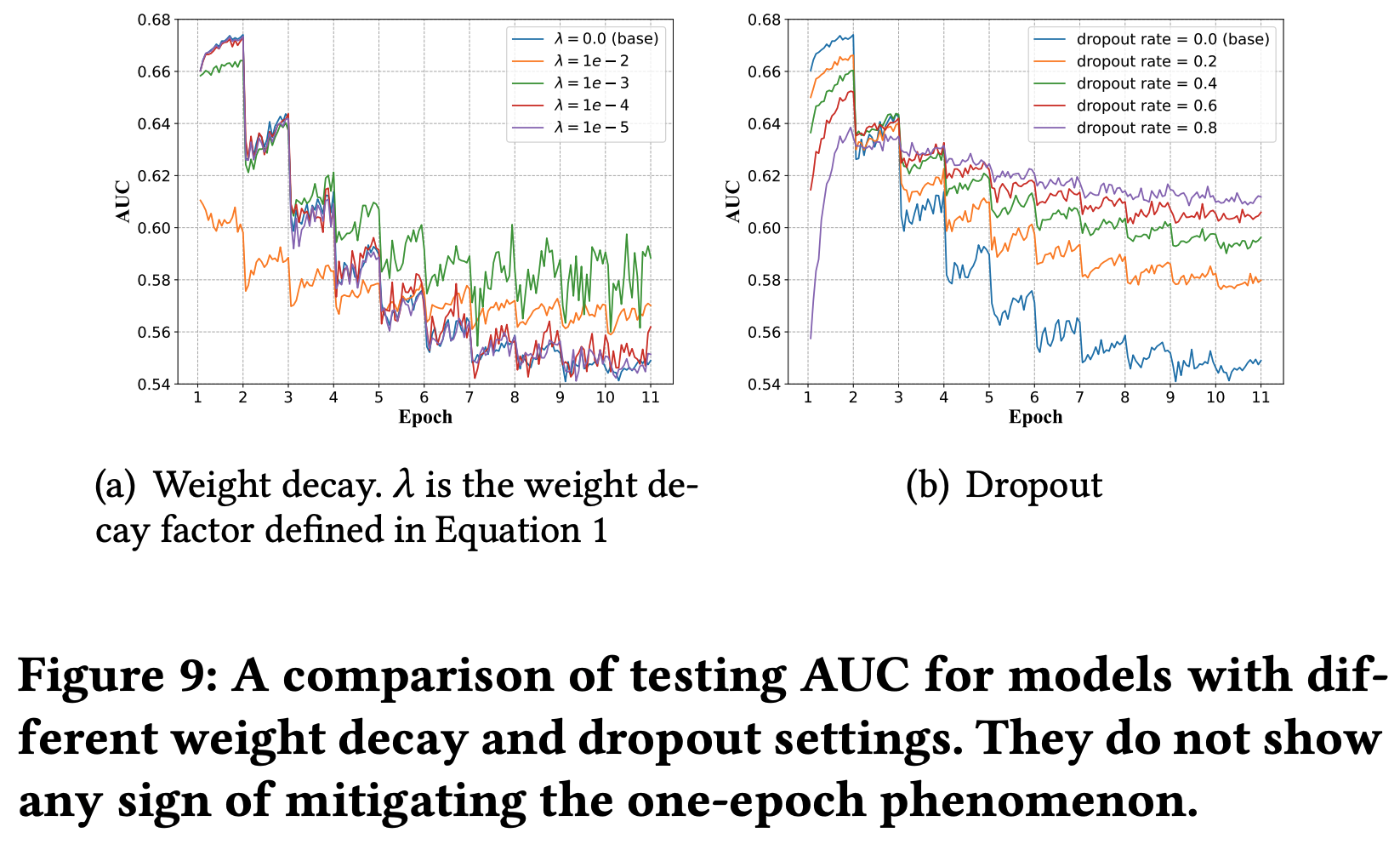
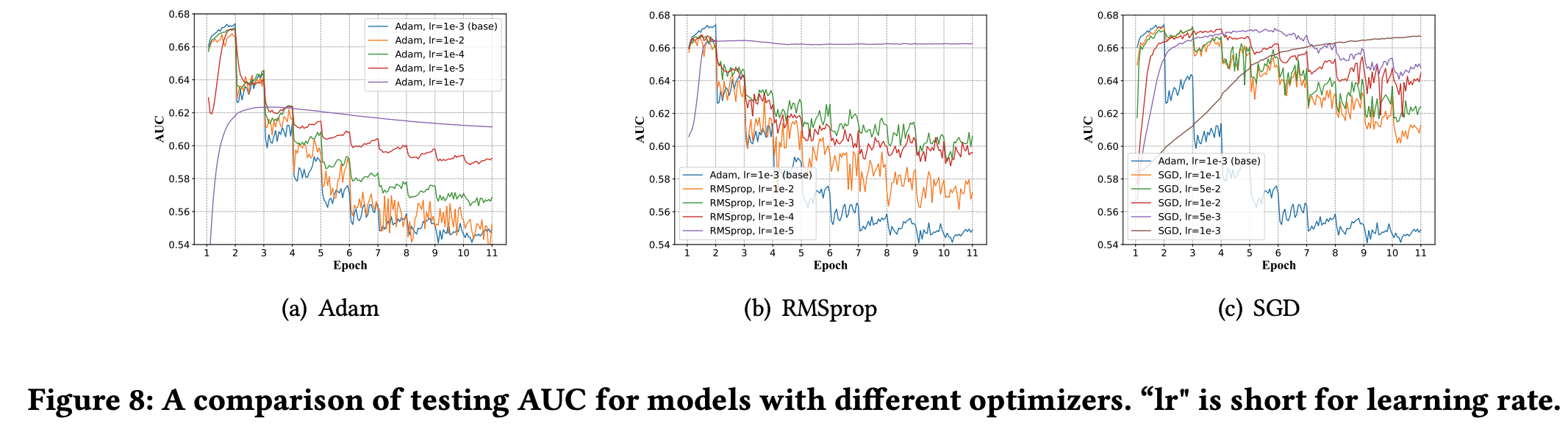
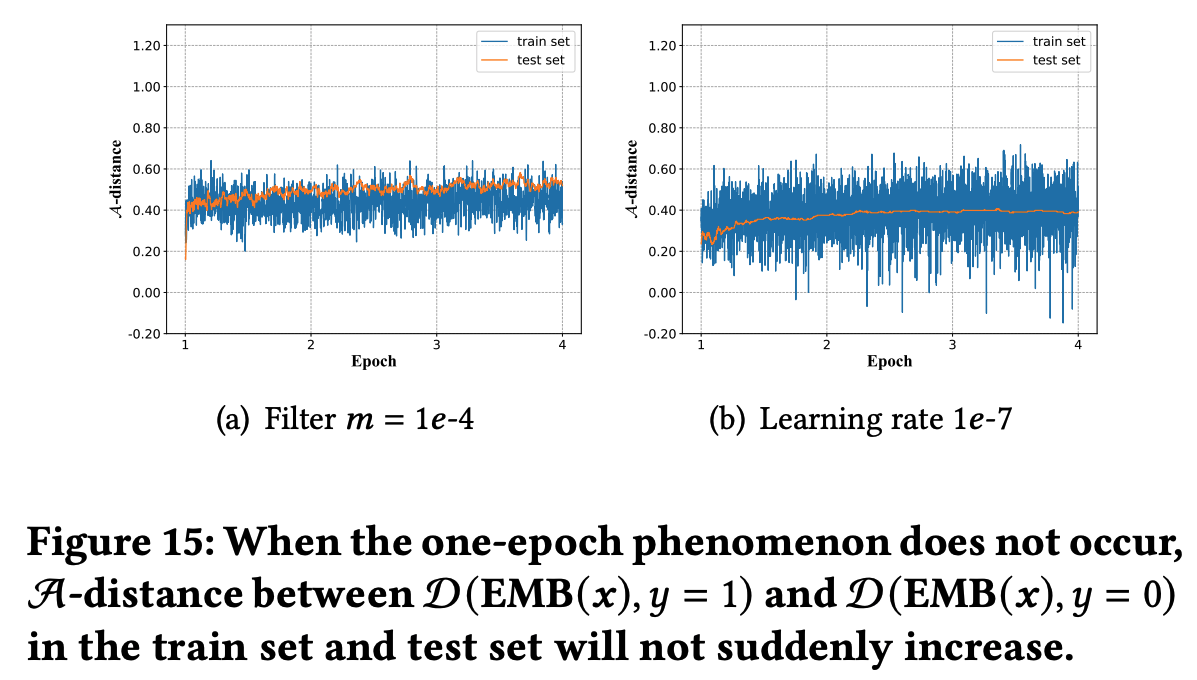 * 问题:为什么稀疏反而收敛快?甚至一个 epoch 就能收敛
* 回答:文章没有给出详细解释,但个人理解为稀疏和收敛快不一定是严格矛盾的,可能是 Embedding 层参数更容易学习,但从文章给的实验结果看,一个 epoch 后 Embedding 层参数分布确实几乎收敛了
* 问题:为什么稀疏反而收敛快?甚至一个 epoch 就能收敛
* 回答:文章没有给出详细解释,但个人理解为稀疏和收敛快不一定是严格矛盾的,可能是 Embedding 层参数更容易学习,但从文章给的实验结果看,一个 epoch 后 Embedding 层参数分布确实几乎收敛了