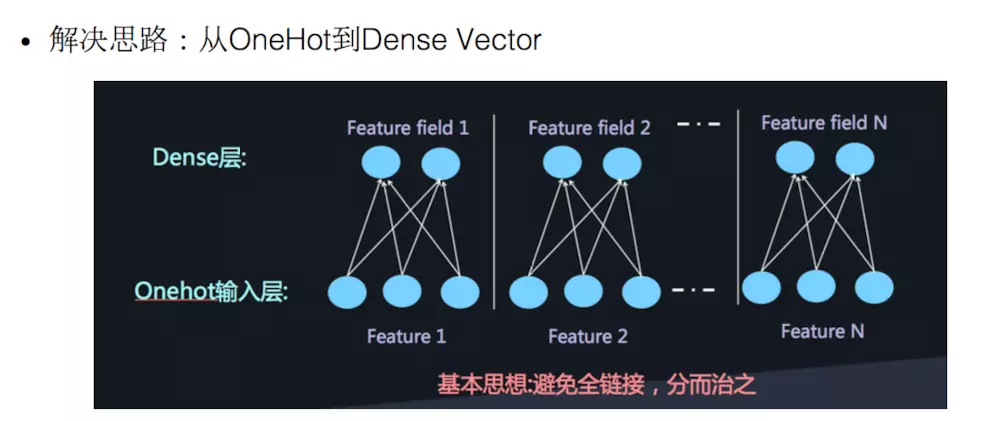
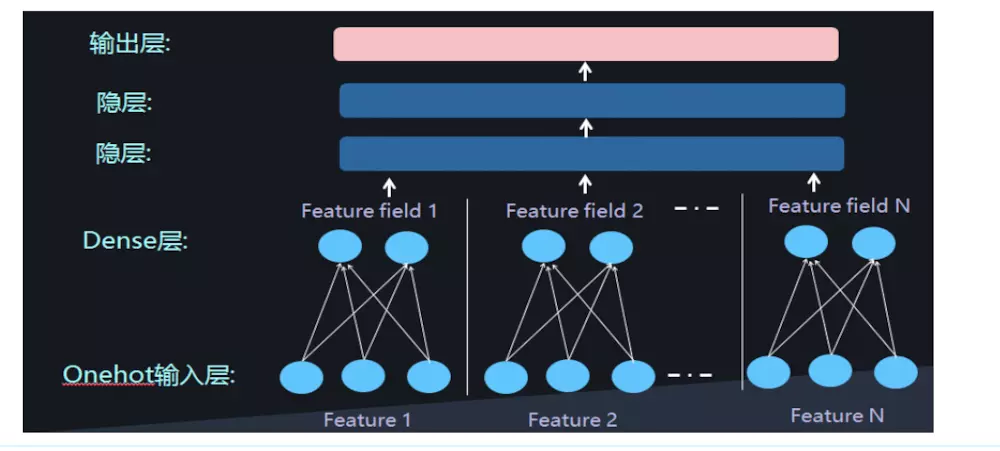
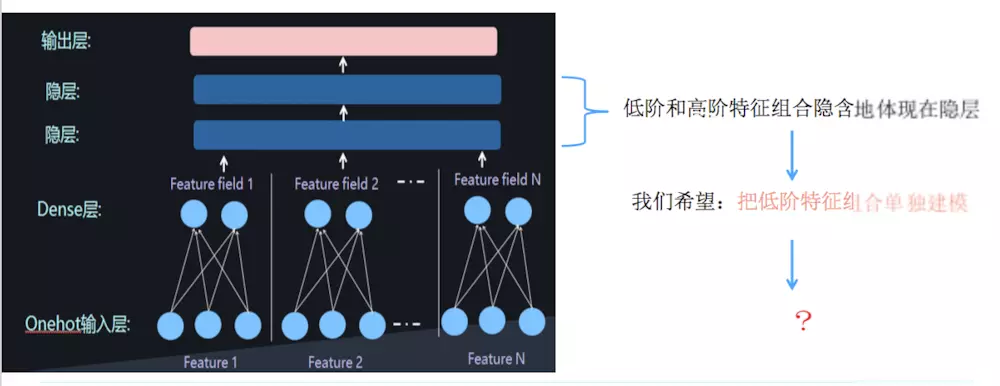
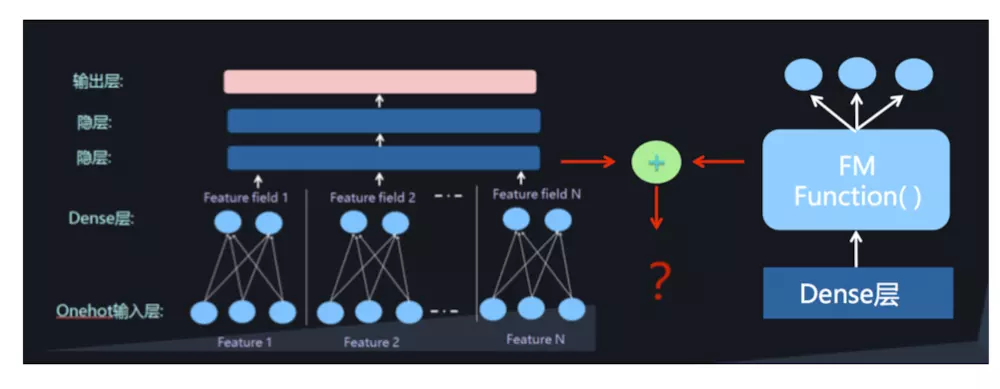
本文介绍AUC和GAUC
参考链接
编程实现
- AUC计算的3种实现方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75# encoding=utf8
from sklearn.metrics import roc_auc_score
## 实现1:O(Nlog(N))
def calculate_auc1(labels, predictions):
# 将预测结果和真实标签按照预测结果从大到小的顺序进行排序
sorted_predictions = [l for _, l in sorted(zip(predictions, labels), reverse=True)]
print(sorted_predictions)
# 统计正样本和负样本的数量
positive_count = sum(labels)
negative_count = len(labels) - positive_count
neg_found_count = 0
pos_gt_neg_count = 0
# 计算正样本大于负样本的数量之和
for label in sorted_predictions:
if label == 1:
pos_gt_neg_count += negative_count - neg_found_count
else:
neg_found_count += 1
# 计算AUC
auc = 1.0 * pos_gt_neg_count / (positive_count * negative_count)
return auc
## 实现2:O(N^2)
def calculate_auc2(labels, predictions):
pos_indexes = [i for i in range(len(labels)) if labels[i] == 1]
neg_indexes = [i for i in range(len(labels)) if labels[i] == 0]
p = len(pos_indexes)
n = len(neg_indexes)
pos_gt_neg_count = 0
for i in pos_indexes:
for j in neg_indexes:
if predictions[i] > predictions[j]:
pos_gt_neg_count += 1
elif predictions[i] == predictions[j]:
pos_gt_neg_count += 0.5
return pos_gt_neg_count/(p*n)
## 实现3:O(Nlog(N))
def calculate_auc3(labels, predictions):
# 将预测结果和真实标签按照预测结果从小到大的顺序进行排序,注意:排序是从小到大
sorted_predictions = [[p,l] for p, l in sorted(zip(predictions, labels))]
print(sorted_predictions)
# 统计正样本和负样本的数量
positive_count = sum(labels)
negative_count = len(labels) - positive_count
# 统计正样本的序号和,注意:序号从1开始
positive_count_indexes_sum = sum([i+1 for i in range(len(sorted_predictions)) if sorted_predictions[i][1] == 1])
return (positive_count_indexes_sum - 0.5*positive_count*(positive_count+1))/(positive_count*negative_count)
pass
# 真实标签
labels = [1, 1, 0, 0, 1, 1]
# 预测结果
predictions = [0.2, 0.8, 0.3, 0.4, 0.5, 0.6]
# 计算AUC
auc1 = calculate_auc1(labels, predictions)
print("AUC1:", auc1)
# 计算AUC
auc2 = calculate_auc2(labels, predictions)
print("AUC2:", auc2)
# 计算AUC
auc3 = calculate_auc3(labels, predictions)
print("AUC3:", auc3)
# 调用官方库计算AUC
auc = roc_auc_score(labels, predictions)
print("AUC:", auc)
SQL实现
详情见:深入理解AUC
推导思路:
- 统计每个正样本大于负样本的概率(排在该正样本后面的负样本数/总的负样本数)
- 对所有正样本的概率求均值
整体推导流程:
$$
\begin{align}
AUC &= \frac{1}{N_+} \sum_{j=1}^{N_+}\frac{(r_j - j)}{N_-} \\
&= \frac{\sum_{j=1}^{N_+}r_j - N_+(N_+ + 1)/2}{N_+N_-} \\
&= \frac{\sum_{j =1}^{N_+} r_j - N_+(N_+ + 1)/2}{N_+ N_-}
\end{align}
$$- 注意:以上公式是在按照预估值从大到小排序后的基础上计算的,实际应用上述公式时需要先排序
- 公式符号说明:对于第 \(j\) 个正样本 ,假定其排序定义为 \(r_j\),则在这个正样本之前共有 \((r_j-1)\) 个样本,其中有 \((j - 1)\) 个正样本,\((r_j-j)\) 个负样本,此时该正样本的预估值大于负样本的概率为:\(\frac{(r_j - j)}{N_-}\)
SQL实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15select
(ry - 0.5*n1*(n1+1))/n0/n1 as auc
from(
select
sum(if(y=0, 1, 0)) as n0,
sum(if(y=1, 1, 0)) as n1,
sum(if(y=1, r, 0)) as ry
from(
select y, row_number() over(order by score asc) as r
from(
select y, score
from some.table
)A
)B
)CSQL实现(分场景+pcoc实现)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21select
scene,
(ry - 0.5*n1*(n1+1))/n0/n1 as auc,
n1/(n1+n0) as ctr,
pctr,
pctr/(n1/(n1+n0)) as pcoc,
from(
select
scene,
sum(if(y=0, 1, 0)) as n0,
sum(if(y=1, 1, 0)) as n1,
sum(if(y=1, r, 0)) as ry,
avg(score) as pctr
from(
select scene, score, y, row_number() over(partition by scene order by score asc) as r
from(
select scene, y, score
from some.table
)A
)B
)C