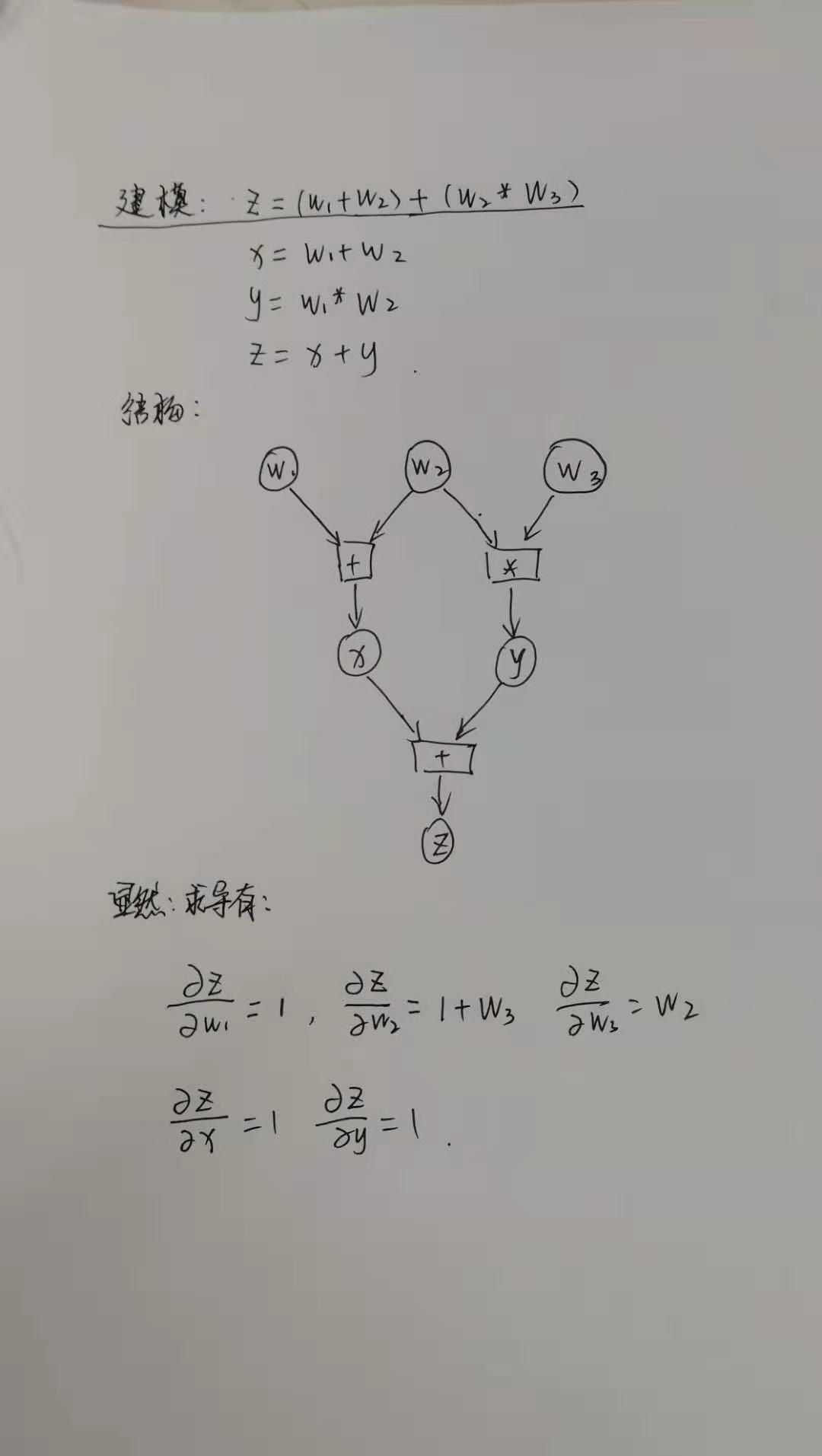
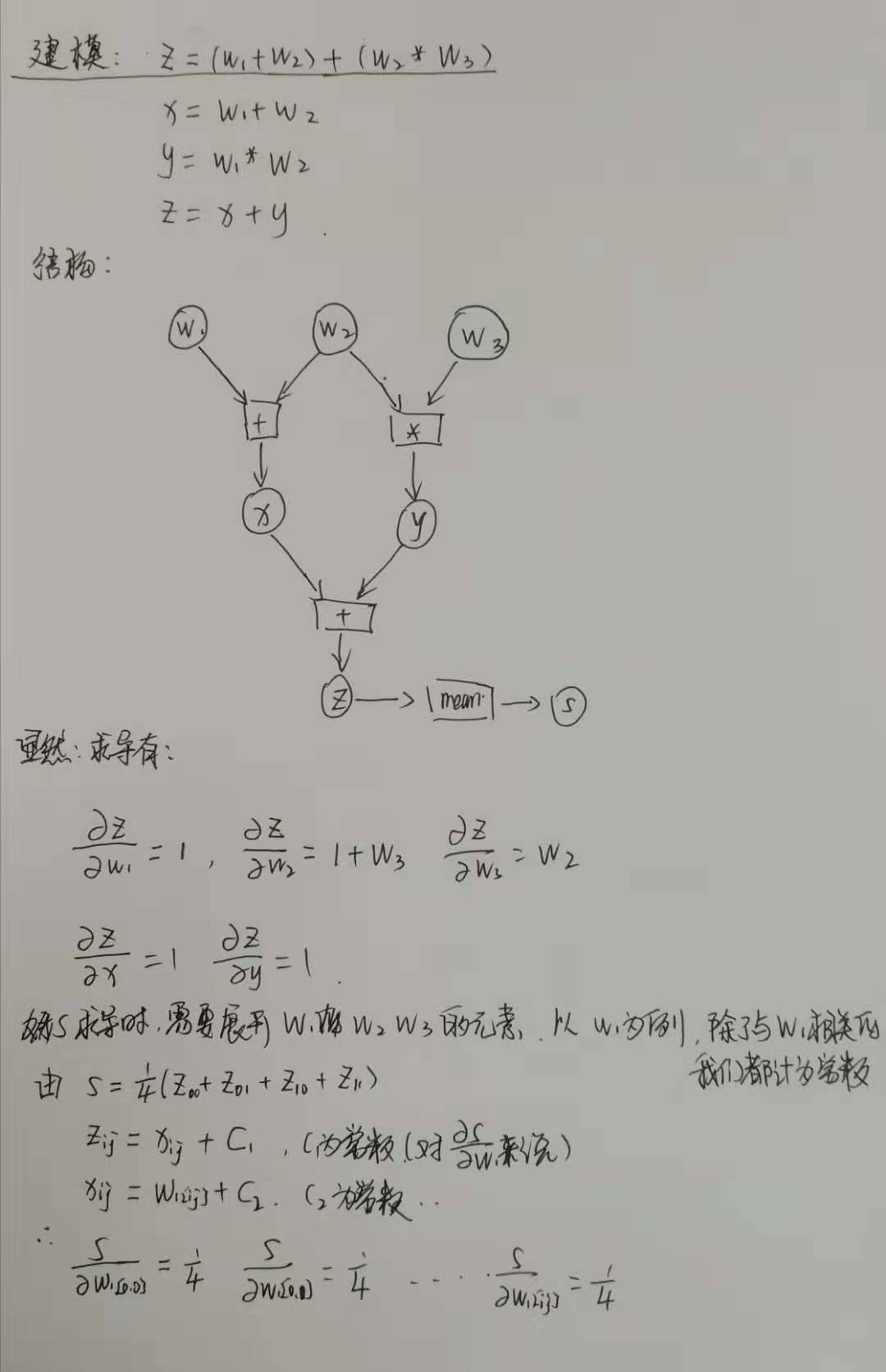
整体说明
- 在 PyTorch 里,张量的
layout属性主要用于表明内存的组织形式(tensor.layout属性可查看张量当前的布局类型) - 张量的存储主要分为稀疏布局(Sparse Layout)和稠密布局(Dense Layout)两种
- 稠密布局适合进行常规的张量运算
- 稀疏布局在处理大规模稀疏数据时,能够显著减少内存占用和计算量
- 在使用稀疏张量进行计算时,需要注意:
- 并非所有的 PyTorch 操作都支持稀疏张量,部分操作在执行前可能需要先将稀疏张量转换为稠密张量
稠密布局(torch.strided)
torch.strided是标准的多维数组布局,采用连续的内存存储方式torch.strided在每一个维度都具备步长(stride)属性,借助该属性可以计算出内存中的偏移量- 在 PyTorch 1.13 及后续版本中,很多张量创建函数(如
torch.ones等)的参数的默认值是都是torch.strided - 稠密布局示例:
1
2x = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(x.layout) # 输出:torch.strided
稀疏 CSR 布局(torch.sparse_csr)
torch.sparse_csr布局适用于存储稀疏矩阵,能有效节省内存torch.sparse_csr运用压缩稀疏行(Compressed Sparse Row)格式,借助三个张量来表示:crow_indices:记录每行在col_indices和values中的起始位置col_indices:存储非零元素所在的列索引values:存放非零元素的值
- 稀疏 CSR 布局示例:
1
2
3
4
5crow_indices = torch.tensor([0, 2, 3])
col_indices = torch.tensor([0, 1, 2])
values = torch.tensor([1, 2, 3])
sparse_tensor = torch.sparse_csr_tensor(crow_indices, col_indices, values, (2, 3))
print(sparse_tensor.layout) # 输出:torch.sparse_csr
其他稀疏布局
- PyTorch 还支持多种稀疏布局,以满足不同的访问和计算需求
- 稀疏 COO(
torch.sparse_coo)布局 - 稀疏 CSC(
torch.sparse_csc)布局
布局转换方法示例
- 可以使用以下方法在不同布局之间进行转换:
1
2
3
4
5
6
7
8
9# 从稠密布局转换为稀疏 COO 布局
dense_tensor = torch.tensor([[0, 1], [2, 0]])
sparse_coo = dense_tensor.to_sparse() # 默认为 COO 格式
# 从稀疏 COO 布局转换回稠密布局
dense_tensor = sparse_coo.to_dense()
# 稀疏布局之间的转换
sparse_csr = sparse_coo.to_sparse_csr()