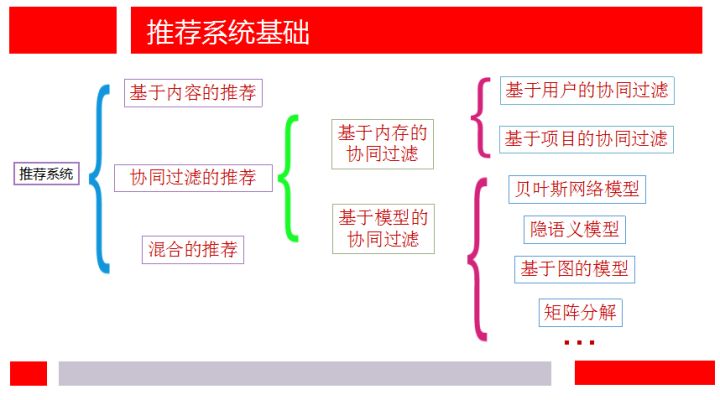
- 参考链接:
样本不均衡问题描述
- 问题描述:机器学习中的样本不均衡问题,是指在分类任务中不同类别的训练样例数量存在显著差异的情况
- 场景:包括金融欺诈检测、医疗诊断、网络入侵检测等领域
样本不均衡的影响
- 模型偏向性 :模型倾向于预测label为多数类,因为这样做可以最大化准确率,即使对少数类的预测几乎总是错误的
- 过拟合风险 :由于少数类样本数量少,模型容易过拟合这些样本,导致模型在新数据上泛化性差
- 总结:样本不均衡带来的根本影响是模型会学习到训练集中样本比例的这种先验性信息,以致于实际预测时就会对多数类别有侧重(可能导致多数类精度更好,而少数类比较差)通过解决样本不均衡,可以减少模型学习样本比例的先验信息,以获得能学习到辨别好坏本质特征的模型
哪些情况下需要解决样本不均衡问题
评估指标
- 不能使用:准确率(Accuracy)
- 建议使用:F1分数、精确率(Precision)、召回率(Recall)和AUC等
解决样本不均衡的方法
数据层面的方法
- 过采样(Over-sampling) :通过增加少数类样本的数量来缓解不均衡问题。常见的方法包括:
- 随机过采样 :简单地复制少数类样本,容易导致过拟合
- 数据增强(Data Augmentation) :通过变换现有样本生成新的样本,适用于图像(翻转,拉伸等)、文本等数据类型
- SMOTE(Synthetic Minority Over-sampling Technique) :通过在少数类样本间插值生成新的合成样本,一定程度上可以避免过拟合,但生成的数据置信度也存在问题
- ADASYN(Adaptive Synthetic Sampling) :通过生成少数类别样本改善不均衡问题,与传统的过采样技术(如SMOTE)相比,ADASYN更注重类间距离和局部密度,尤其是对于少数类中的困难样本或噪声敏感区域,它可以更加精细地调整采样策略,详情可参考:不平衡学习的自适应合成采样方法ADASYN(Matlab代码实现)
- 欠采样(Under-sampling) :通过减少多数类样本的数量来达到平衡。常用的方法有:
- 随机欠采样 :随机删除多数类样本,但可能丢失重要信息
- Tomek Links :移除位于类别边界附近的样本对,有助于清理噪声
- ENN(Edited Nearest Neighbors Rule) :移除与最近邻居类别不同的样本
- NearMiss :选择与少数类样本最接近的多数类样本
- 组合采样 :结合过采样和欠采样的方法
模型层面的方法
- 成本敏感学习(Cost-sensitive Learning) :为不同类别的错误分配不同的固定权重,使模型更加关注少数类的预测
- 集成学习(Ensemble Learning) :使用集成学习的方法降低过拟合问题(比如多个模型进行投票或加权平均)
损失函数层面
- 损失函数优化 :比如使用Focal Loss等
异常检测
- 异常检测(Anomaly Detection) :将少数类视为异常点(特别是少数类样本非常稀少的情况),使用异常检测算法进行识别,常见的异常检测算法通常包括统计方法、距离检测(K近邻方法)、聚类方法(K-Means)、分类模型(one-class SVM)、自编码器、孤立森林等
- 其中K近邻方法可以用于回归或者分类场景,还可以直接用于异常检测(距离过大的点认为是异常)
- K-Means方法作异常检测时,原理聚类中心的样本视为异常值
- 自编码器方法:通过训练一个自编码器来重建数据,重建误差大的数据点被视为异常点
- 孤立森林(Isolation Forest):通过随机挑选特征、随机挑选分割点构建多棵孤立树,在所有孤立树中的平均路径长度的数据点被视为异常点(孤立森林的核心思想是异常点通常更容易被孤立,即在随机分割数据空间时,异常点往往比正常点更快地被单独分隔出来)
实践建议
- 评估指标的选择 :在不均衡数据集上,不能使用准确率(Accuracy),建议使用均衡指标(F1-Score,AUC等)
- 模型选择 :选择对不均衡数据的适应性较好的模型,如决策树和随机森林等,可以多使用一些简单的模型,再进行Bagging来减少过拟合
- 具体情况具体分析,很多时候不需要特别的进行处理,另外如果真的进行采样,会导致预估均值有偏差,在CTR等对预估绝对值有要求的场景中,还需要校准