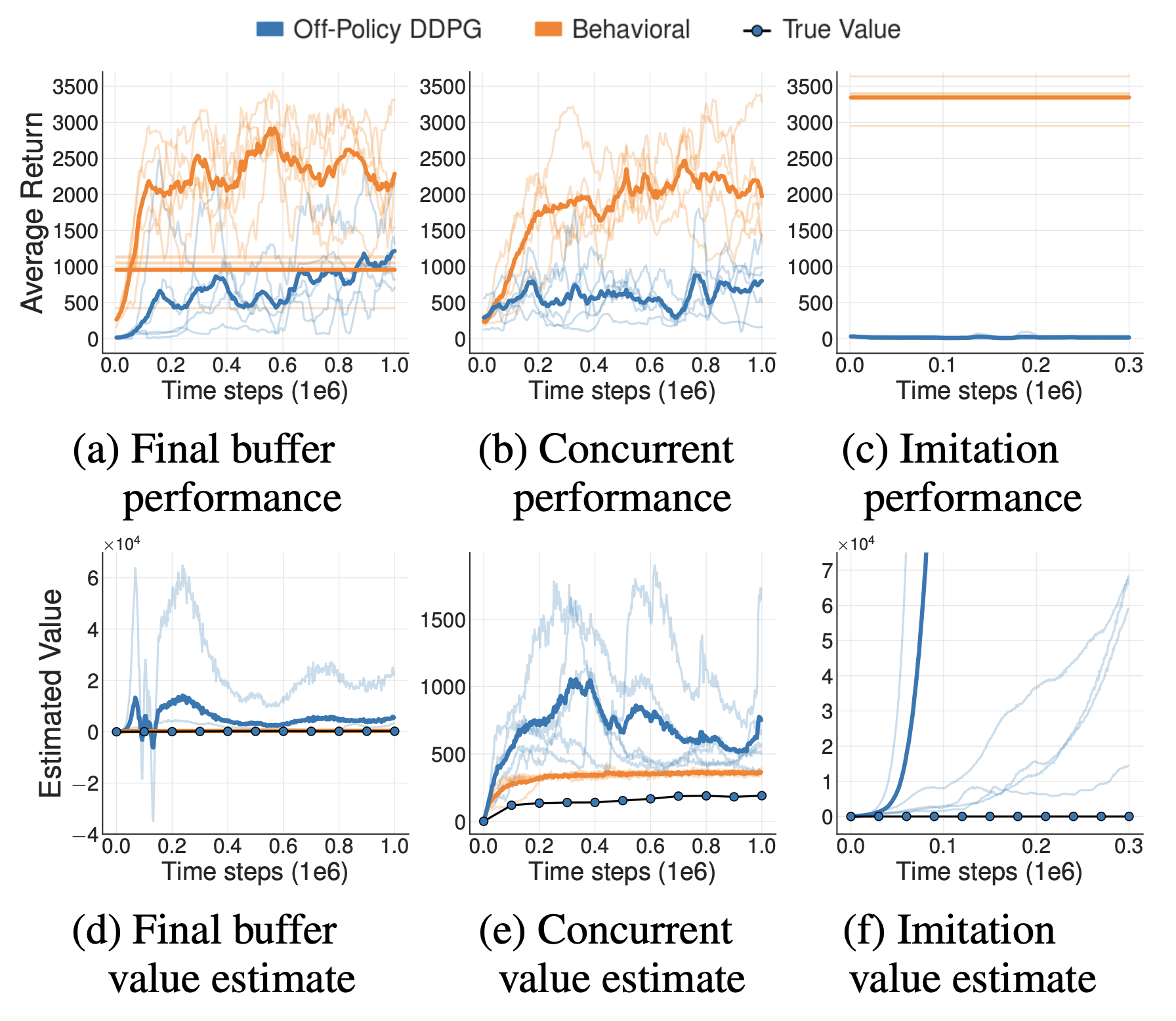
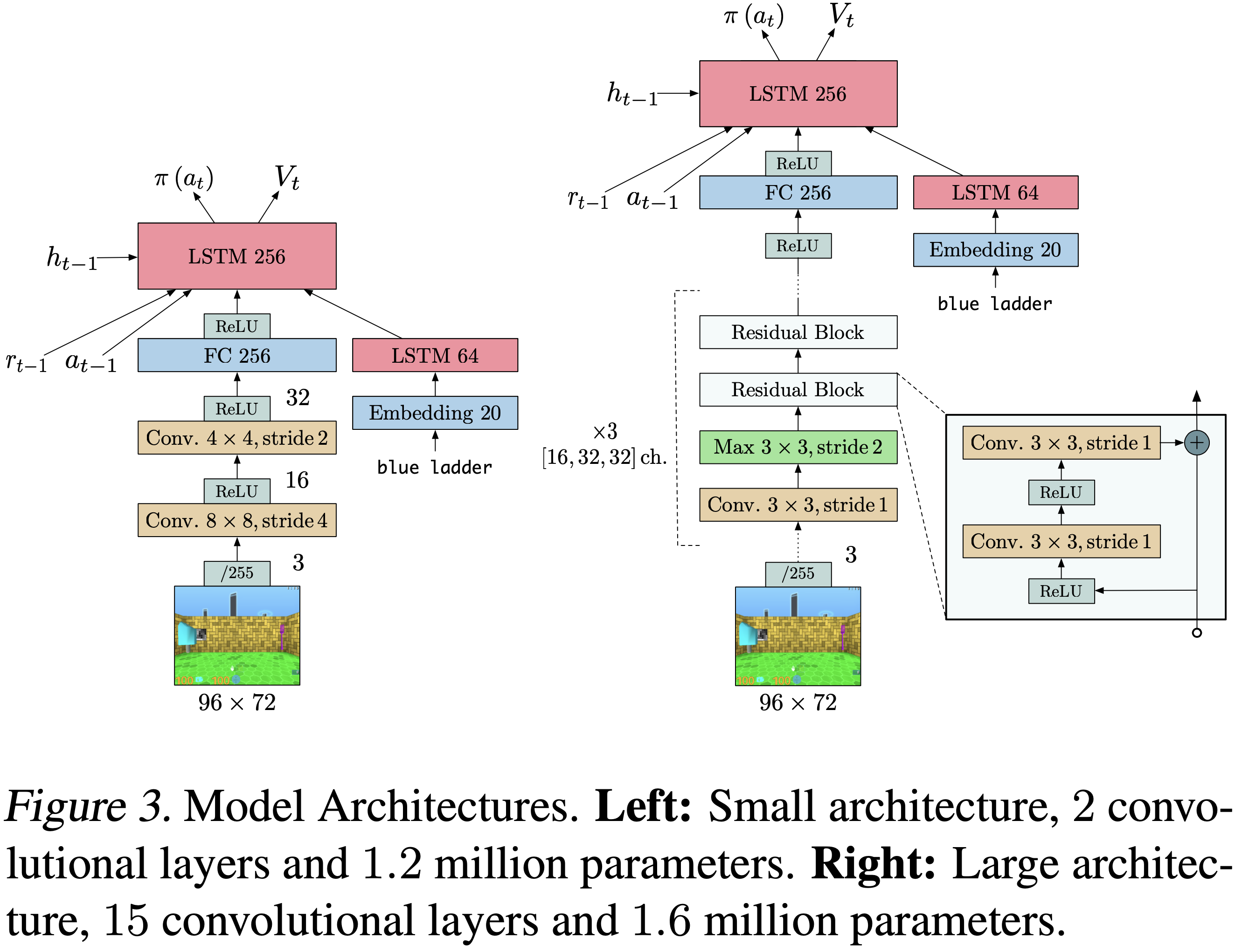
AlphaGo整体说明
- AlphaGo是强化学习的阶段性集大成者,其核心思想值得细细推敲
AlphaGo棋局介绍
- AlphaGo 的目标是解决围棋对弈问题 ,即在标准的 19×19 围棋棋盘上(共381维),通过观察棋盘情况选择最优的落子动作,击败对手
- 输入 :当前棋盘状态(包括棋子分布和历史信息)
- 输出 :下一步落子的最优位置(或概率分布)
- 挑战 :
- 围棋的状态空间复杂度高达 \(3^{361}\)(约\(10^{172}\)量级),无法暴力搜索
- 围棋的决策步长约100+步,决策需要结合长期策略收益
- 围棋的评估函数难以设计(难以量化当前局面是否有“局面优势”)
ALphaGo问题建模
- 状态空间:\(19 \times 19 \times N\),这里的N在不同版本不一样,比如17=16+1时,16是用于记录最近 8 步的状态(相当于记录了窗口),1则表示该哪一方下棋,其他还有一些需要理解围棋规则才能解释
- 动作空间:离散动作空间,362个动作可选(361位置 + 1 Pass)
- 奖励函数:对局结束时,胜利方奖励+1,失败方-1,平局为0(围棋通常无平局)
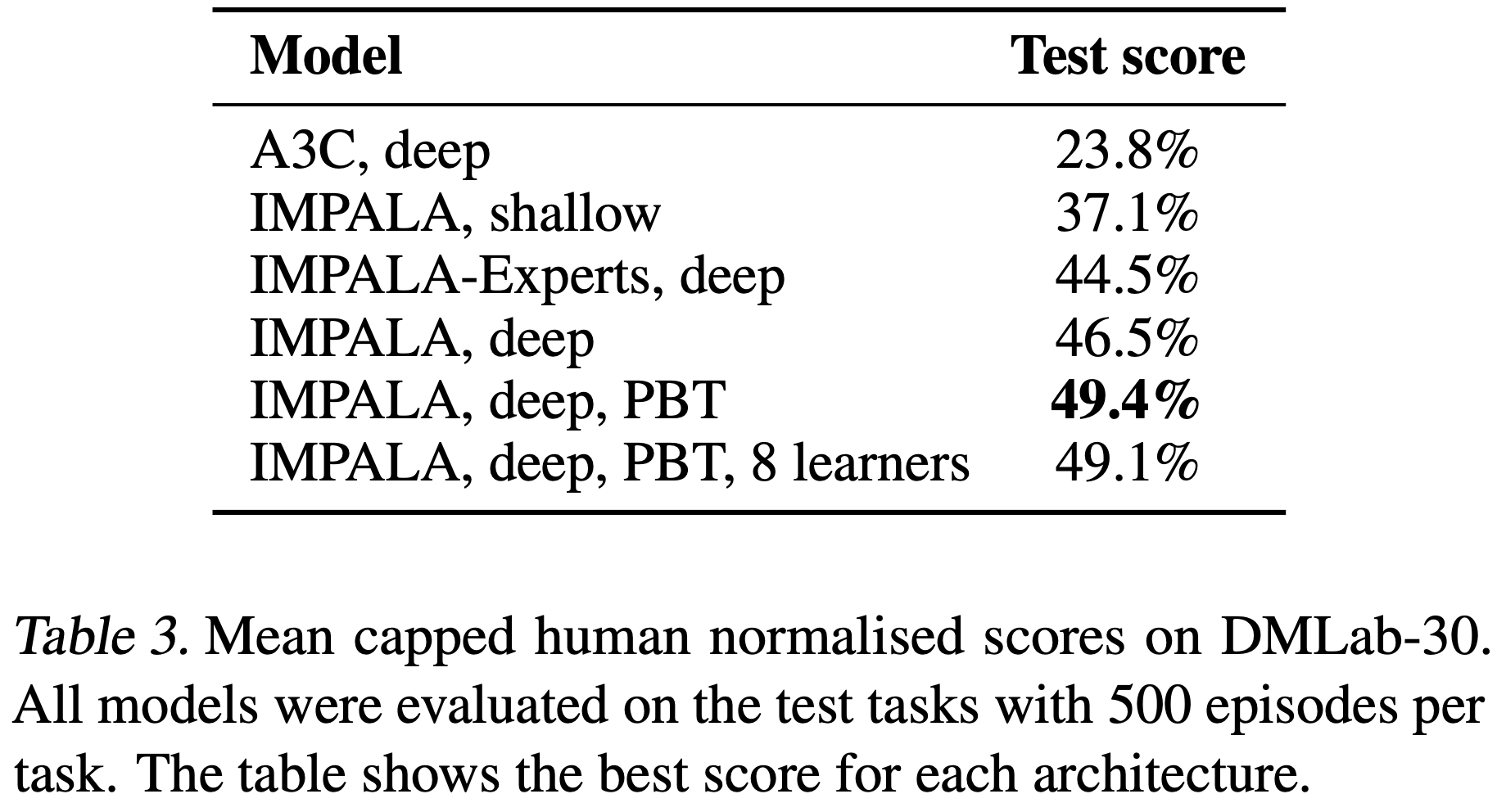
AlphaGo 训练过程(分三个阶段)
第一阶段:行为克隆(监督学习模仿人类专家)
- 基于 KGS 围棋平台上的 3000 万局人类对弈棋谱,学习人类专家的落子的模式
- 通过监督学习训练一个策略网络(Policy Network) ,输入棋盘状态,输出人类选手的落子概率分布
- 网络结构:13 层卷积神经网络(CNN)
- 准确率:57%(预测人类下一步动作)
第二阶段:强化学习(自我对弈优化,策略梯度优化)
- 通过策略梯度法,进一步优化策略网络,超越人类水平
- 自我对弈 :使用初始策略网络生成大量自我对局数据
- 策略梯度 :通过胜负结果优化策略网络(即强化学习策略网络),使其更倾向于获胜的走法
- 回报函数 :对局结束时获胜方获得 +1 奖励,失败方获得 -1
第三阶段:价值网络学习(局面评估)
- 价值网络学习阶段的目标是训练一个价值网络(Value Network) ,预测当前局面的胜率(替代蒙特卡洛rollout的耗时评估)
- 通过自我对弈生成 3000 万组棋盘状态及最终胜负结果,学习一个标量值(-1 到 +1),表示当前玩家获胜的概率
AlphaGo 决策过程
- AlphaGo 的实时决策基于蒙特卡洛树搜索(MCTS) ,结合神经网络的输出:
- 选择(Selection) :从根节点(当前棋盘状态)出发,通过树策略(如UCT算法)选择子节点,平衡探索与利用,使用策略网络优先选择高概率的落子分支
- 扩展(Expansion) :当遇到未探索的节点时,用策略网络生成可能的落子概率,扩展树结构
- Evaluation 对价值网络评估胜率,和策略网络模拟rollout到终局得到的奖励两者做加权结合
- 回溯(Backup) :将叶子节点的评估结果反向传播更新路径上的节点统计量(访问次数、平均胜率)
- 最终决策(Decision) :搜索结束后,选择访问次数最多的节点对应的落子动作
AlphaGo 相关思考
- 以模仿学习作为强化学习策略的冷启动是个不错的想法
- 使用MCTS来决策有助于提升模型决策能力,在MCTS下,随着围棋的进行,搜索空间变小,AlphaGo相对人类的优势会越来越明显
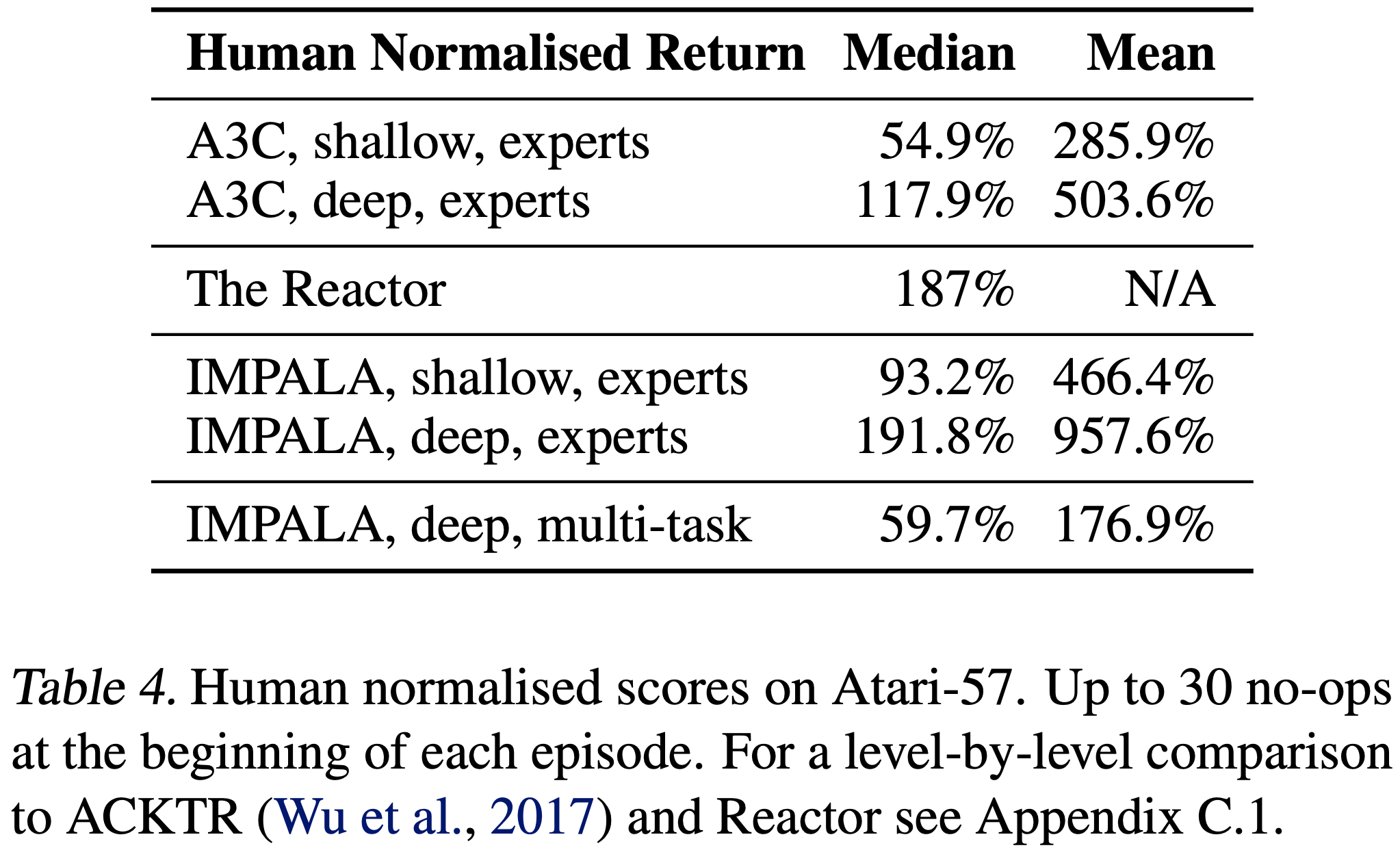
附录:AlphaGo 的迭代版本
| 版本 | 发版时间 | 训练数据 | 核心算法 | 计算需求 | 棋力提升 |
|---|---|---|---|---|---|
| AlphaGo Fan | 2015年10月 | 人类棋谱(监督学习) | SL + MCTS | 中等(分布式计算) | 首次击败职业棋手(樊麾) |
| AlphaGo Lee | 2016年3月 | 人类棋谱 + 自我对弈 | SL + RL + MCTS + 价值网络 | 高(1202 CPU + 176 GPU) | 超越人类顶尖(李世石) |
| AlphaGo Master | 2017年1月(Master) 2017年5月(正式对战柯洁) |
纯自我对弈 | 纯RL + 深度网络 | 低(单机) | 完胜人类第一柯洁 |
| AlphaGo Zero | 2017年10月 | 从零开始自我对弈 | 纯RL + ResNet + MCTS | 极低(4 TPU) | 100:0击败AlphaGo Lee |
| AlphaZero | 2017年12月 | 多棋类自我对弈 | 通用RL + 高效搜索 | 低(单机) | 8小时超越AlphaGo Zero |