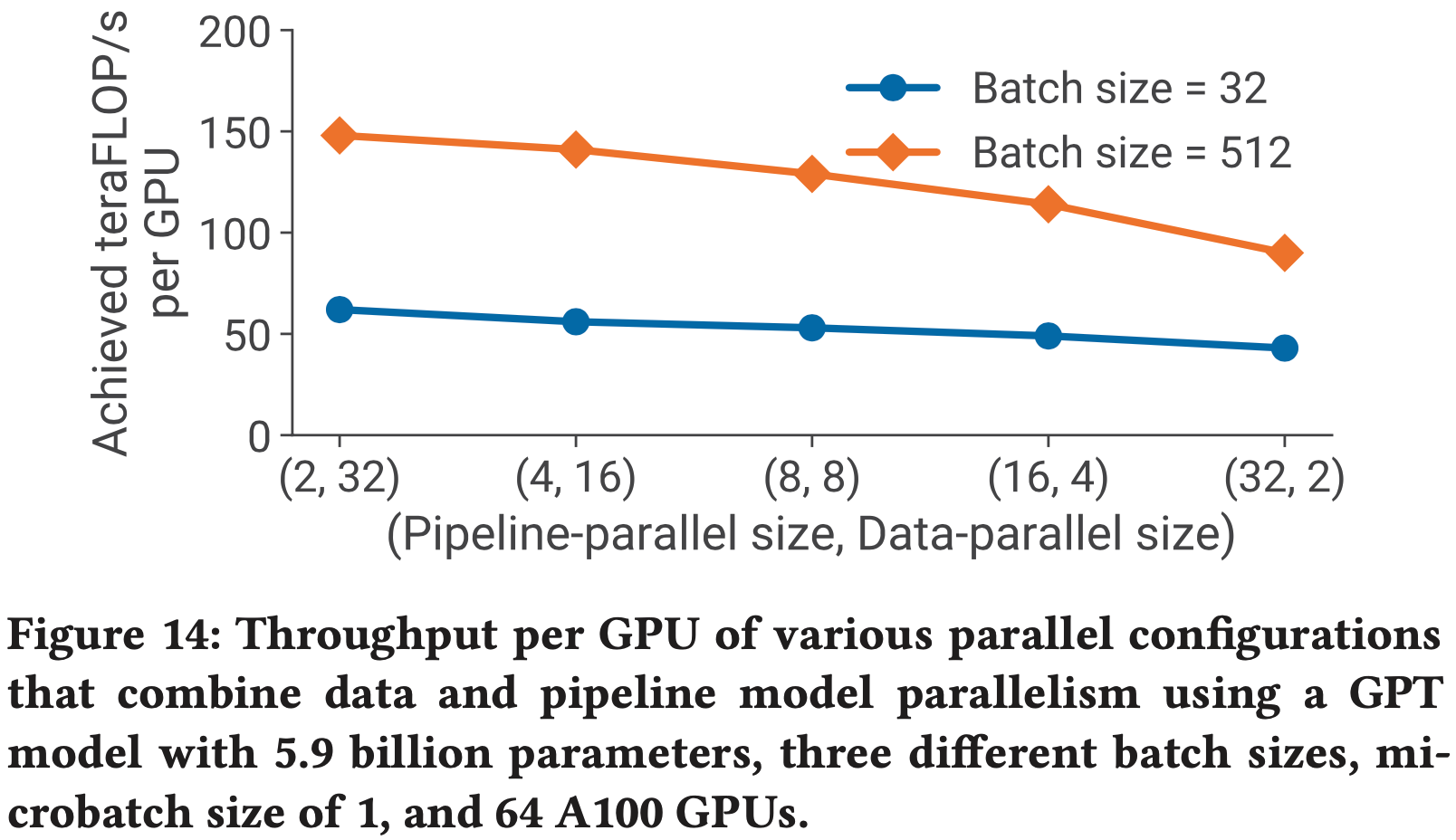
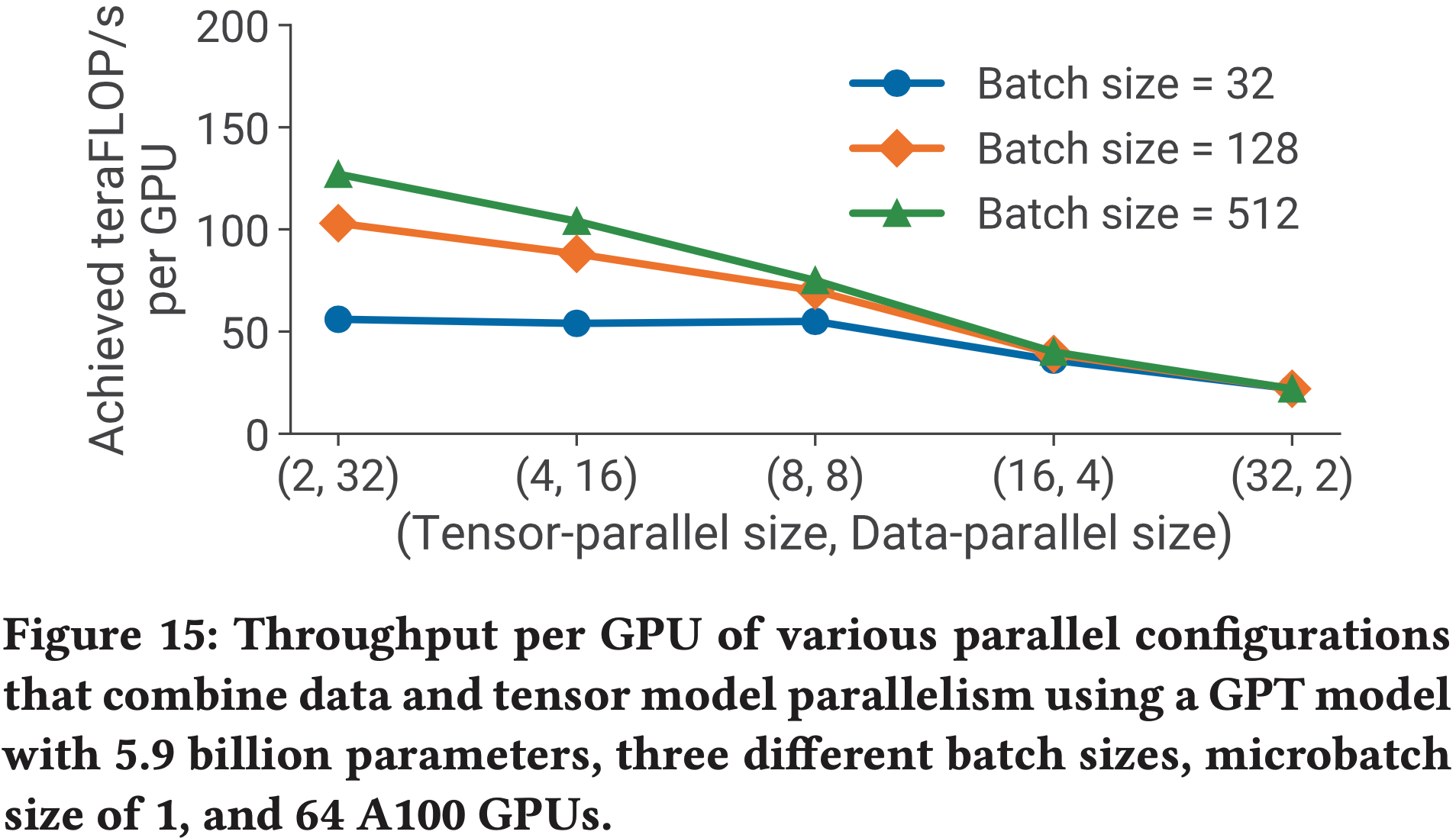
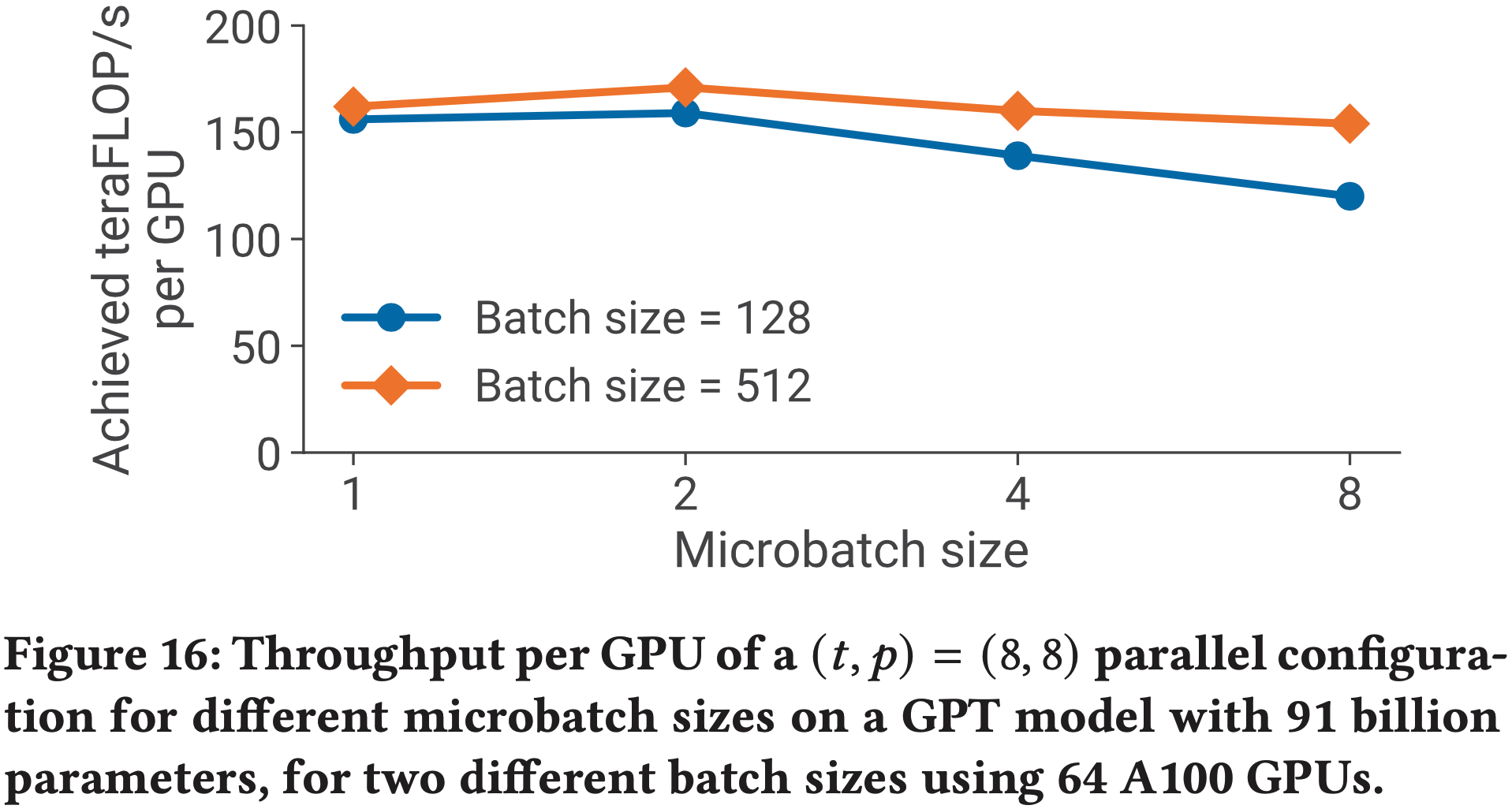
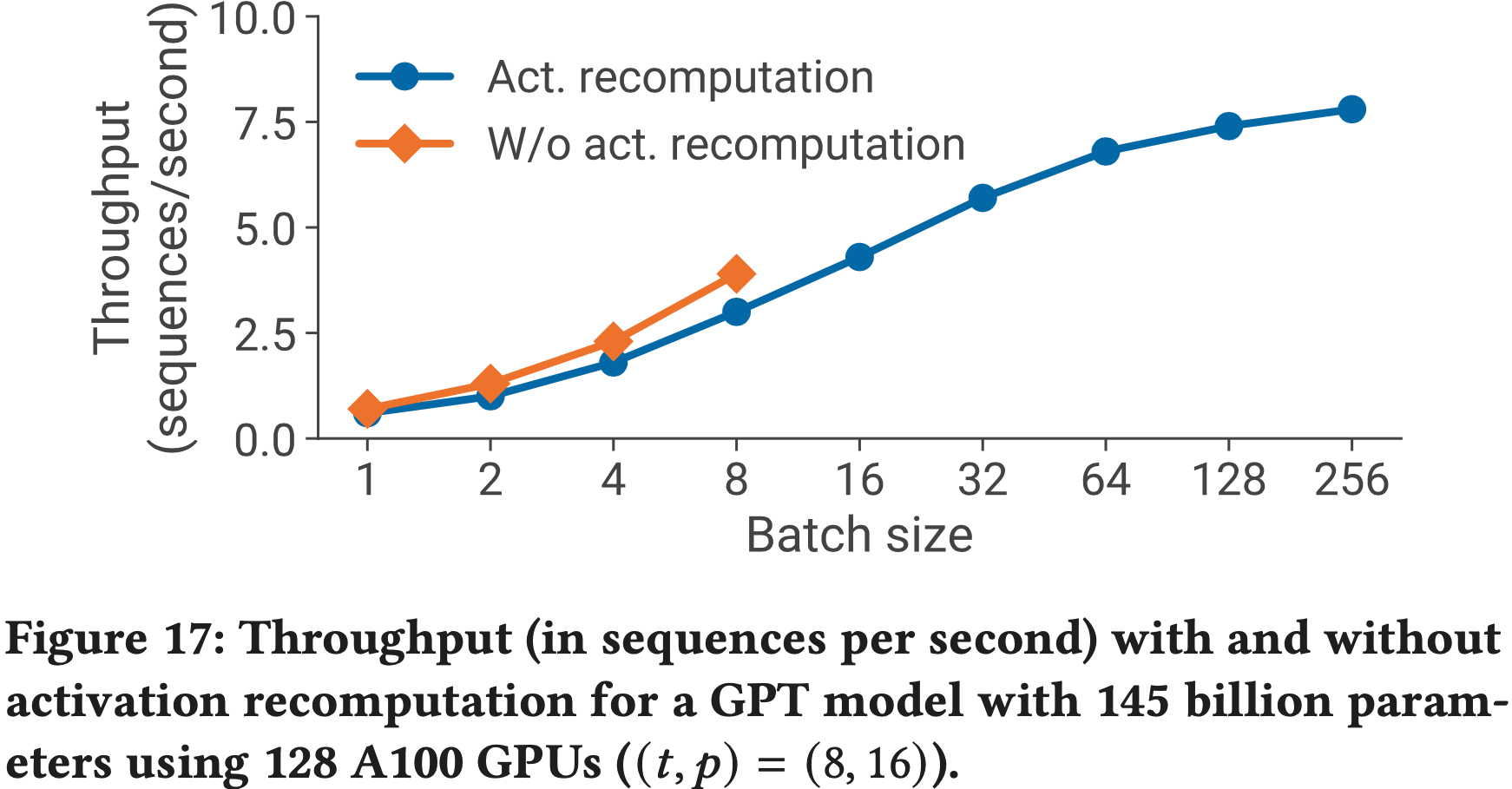
Qwen
- Qwen API 申请:获取API Key
- Qwen API 调用文档:Qwen-API Doc
- 吐槽:Qwen 的文档和申请链接写的很差,阿里云东西太多,需要翻来翻去找
- Qwen API 调用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def qwen_api():
import requests
url = "https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions"
headers = {
"Authorization": "Bearer $API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "qwen-plus",
"messages": [
{"role": "user", "content": "你好,请介绍一下你自己"}
],
"max_tokens": 50,
"temperature": 0.0, # 贪心采样示例
"top": 0.2, # 贪心采样示例
"logprobs": True, # 可以打开 logprobs 看每个 token 的 logprobs,使用 e^logprob 即可得到最终概率
"top_logprobs": 2,
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
if __name__ == "__main__":
qwen_api()
LongCat
LongCat 文档:LongCat API开放平台快速开始
文档写的清晰明了,Qwen 应该学习一下
LongCat API 调用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def longcat_api():
import requests
url = "https://api.longcat.chat/openai/v1/chat/completions"
headers = {
"Authorization": "Bearer $API_KEY",
"Content-Type": "application/json"
}
data = {
"model": "LongCat-Flash-Chat",
"messages": [
{"role": "user", "content": "你好,请介绍一下自己"}
],
"max_tokens": 1000,
"temperature": 0.7,
# "logprobs": True, # 打开这个参数会报错
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
if __name__ == "__main__":
longcat_api()- 特别强调:目前 LongCat 不支持返回 logprobs 信息
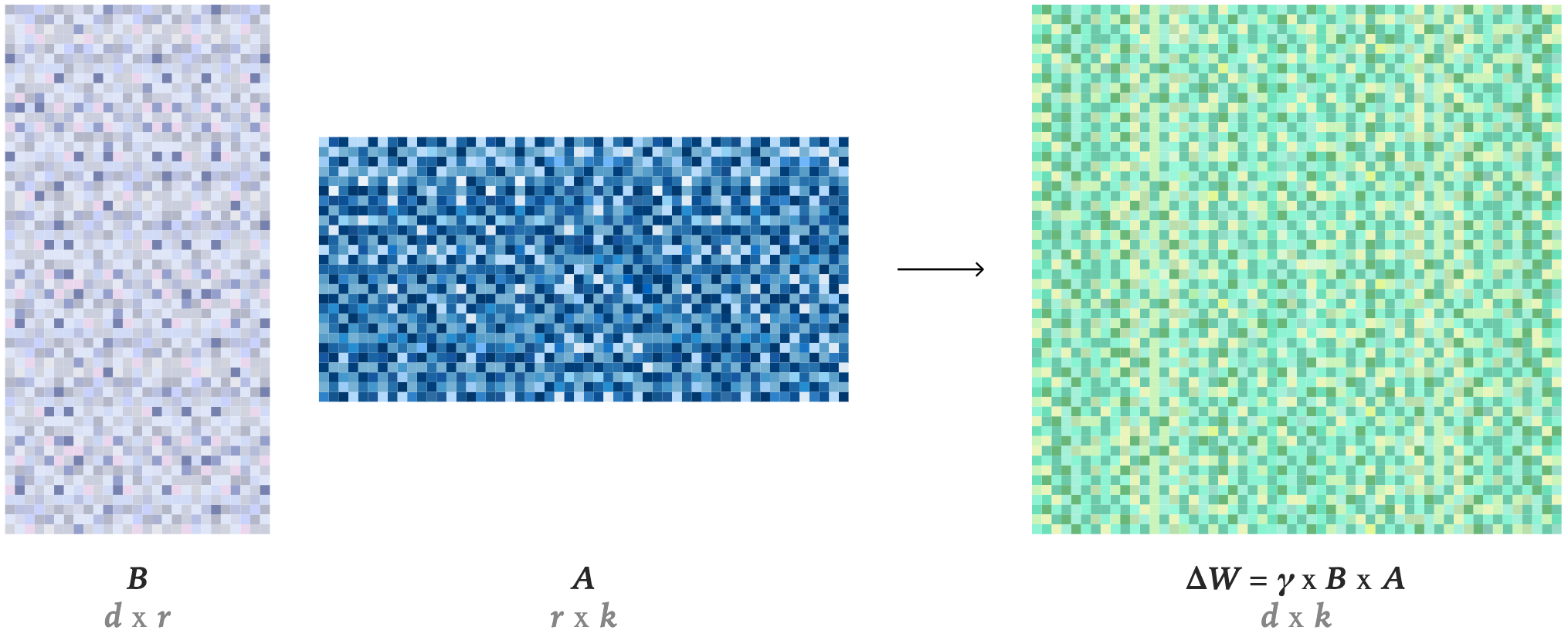
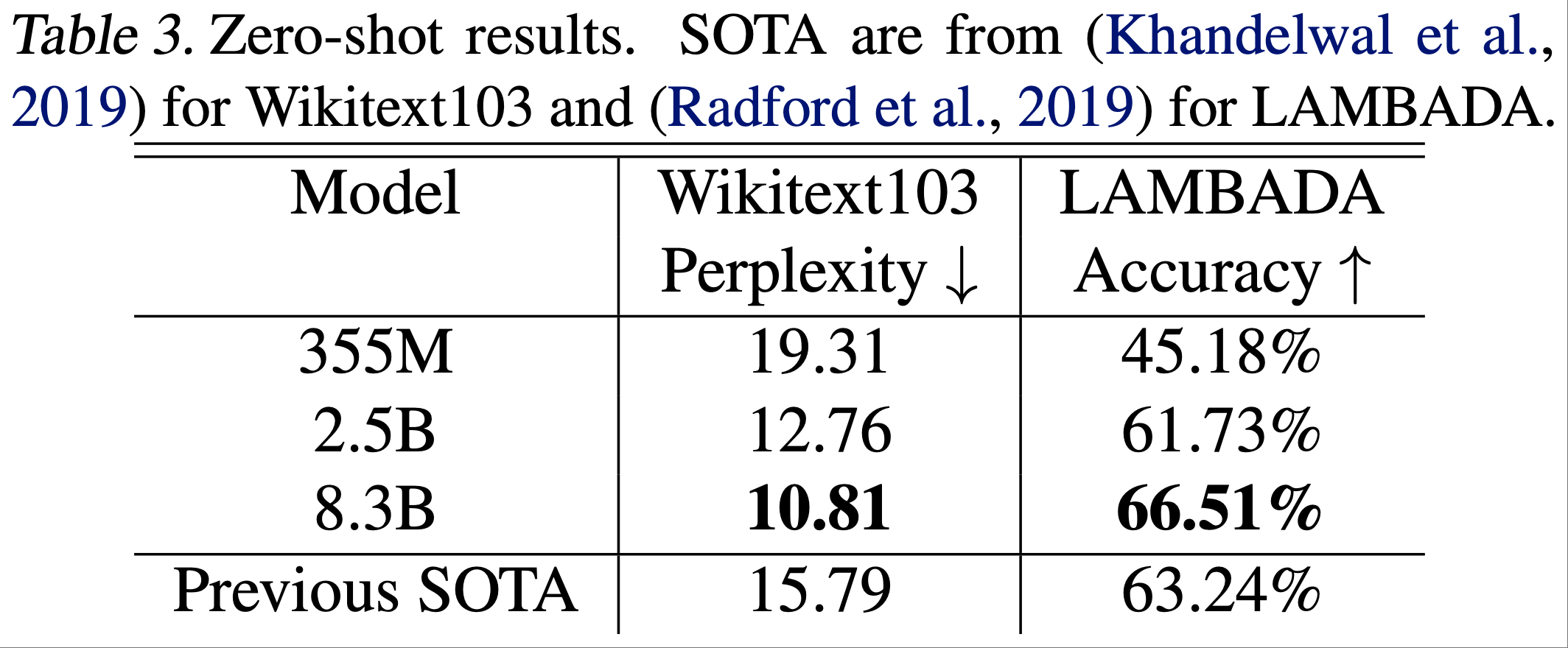
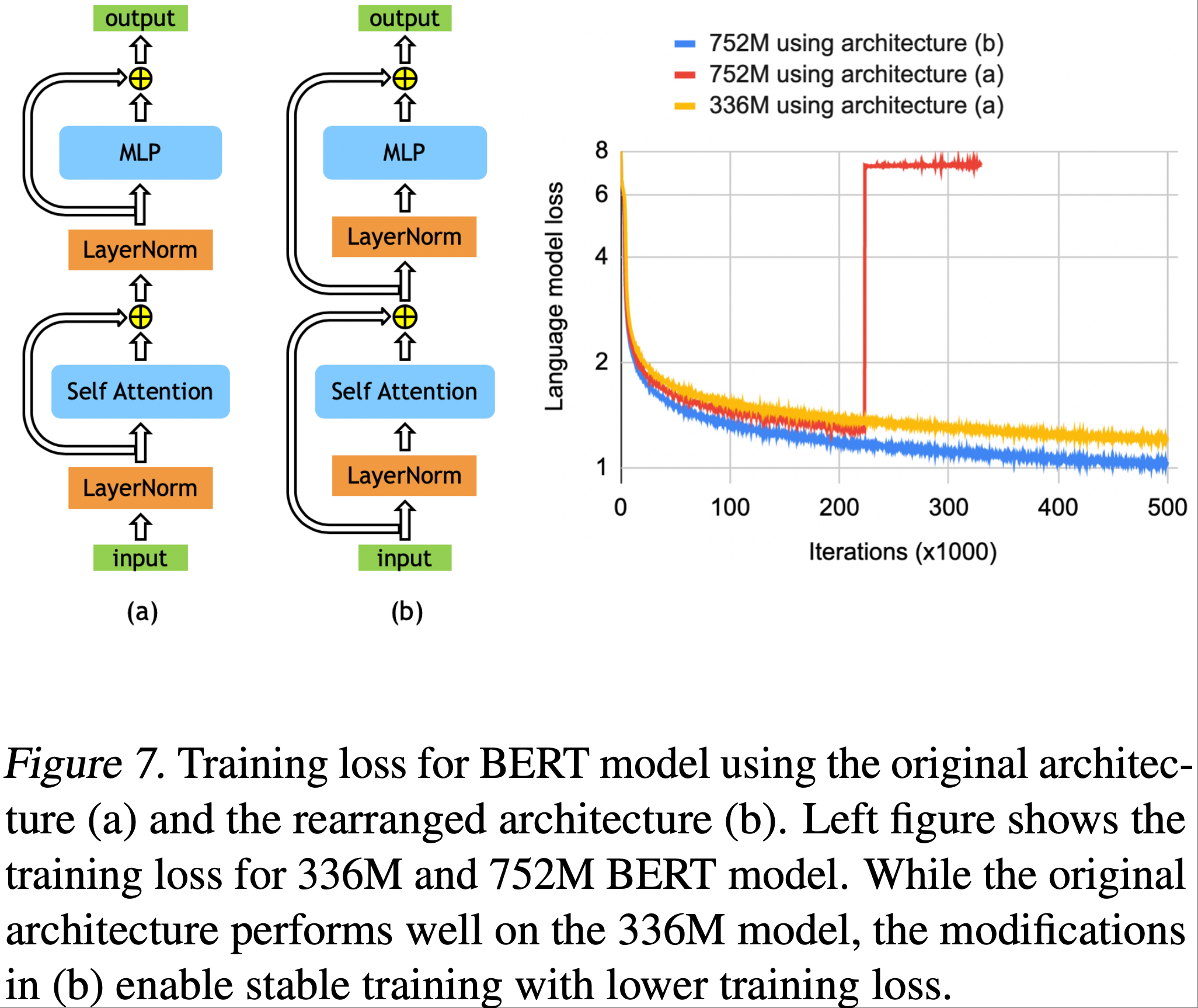
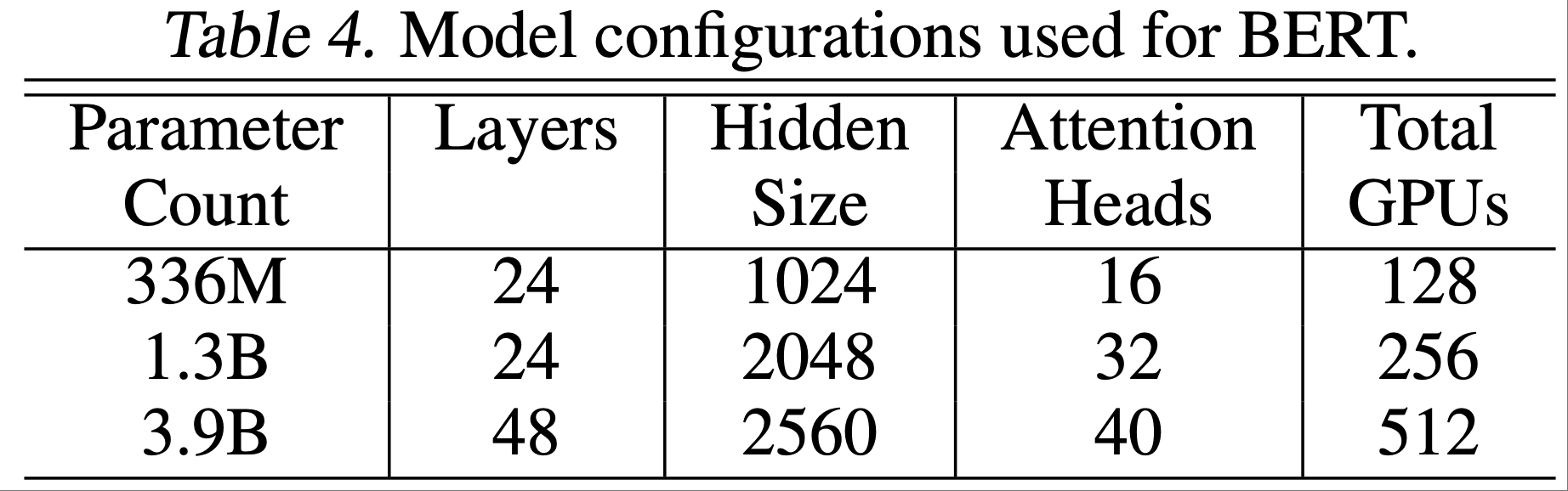
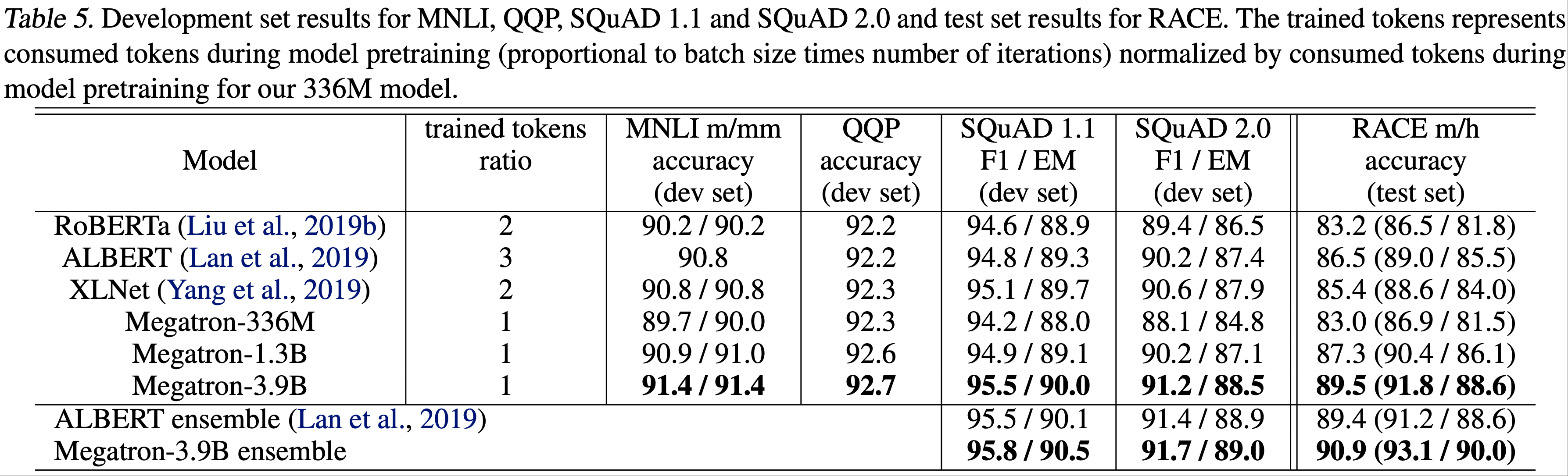
中,高 Rank LoRA 在一个数据集上的性能优于 FullFT,在另一个数据集上则表现较差;由于 Training Dynamics 或泛化行为的差异,LoRA 在不同数据集上的性能可能存在一定的随机波动")

与 FullFT(实线)之间存在持续的差距;右图:最终损失随批量大小变化的曲线显示,LoRA 因批量大小增加而产生的损失 penalty 更大")
的性能显著低于仅应用于 MLP 层的 LoRA(MLP-Only LoRA),且在 MLP 层应用 LoRA 的基础上再增加注意力层的 LoRA,也无法进一步提升性能;这种现象在 Dense 模型(Llama-3.1-8B)和稀疏 MoE 模型(Qwen3-30B-A3B-Base)中均存在")

和 MATH(右图)数据集上的学习率与最终奖励(准确率)关系图")

上的基准分数;右图展示了训练过程中思维链(CoT)长度的变化,这可以作为模型学习推理能力的一个指标")
的学习曲线差异;左图为学习曲线,右图为 Rank 16 和 Rank 256 对应的学习曲线差异(随时间增大);奇怪的是,在最初几步,该差异为负值(尽管数值很小),因此图中未显示这部分曲线")