EGA: End-to-end Generative Advertising
- 参考链接:
整体说明
- 传统在线广告系统的多级级联架构(multi-stage cascaded architectures)存在低效问题 :
- 会过早过滤掉高潜力候选内容
- 并将业务决策逻辑分散到独立模块中
- 生成式推荐提供了端到端解决方案,但它们未能满足实际广告需求:
- 缺乏对出价、创意选择、分配机制和支付计算(bidding, creative selection, allocation mechanism, and payment computation)等关键要素的显式建模
- 论文提出了端到端生成广告(End-to-end Generative Advertising,EGA):
- 第一个统一的广告生成框架,将用户兴趣建模、POI(兴趣点)与创意生成、位置分配和支付优化无缝集成在单一模型中
- 利用 hierarchical tokenization 和 multitoken prediction 联合生成候选 POI 和创意内容
- 通过排列感知(permutation-aware)奖励模型和 token-level bidding 策略确保与用户体验和广告商业务目标的一致性
- 此外,论文通过专用的 POI-level 支付网络和可微分事后遗憾最小化(differentiable ex-post regret minimization)实现分配与支付的解耦,近似保证激励相容性(, guaranteeing incentive compatibility approximately)
- 在真实广告系统上进行的大规模离线和在线实验证明了 EGA 相比传统级联架构的有效性和实践优势,凸显其作为行业领先端到端生成广告解决方案的潜力
一些讨论
- 在线广告已成为主要互联网平台的关键收入引擎,每个用户请求会触发一个复杂的决策过程,平台需选择、排序并展示广告与自然内容的混合列表
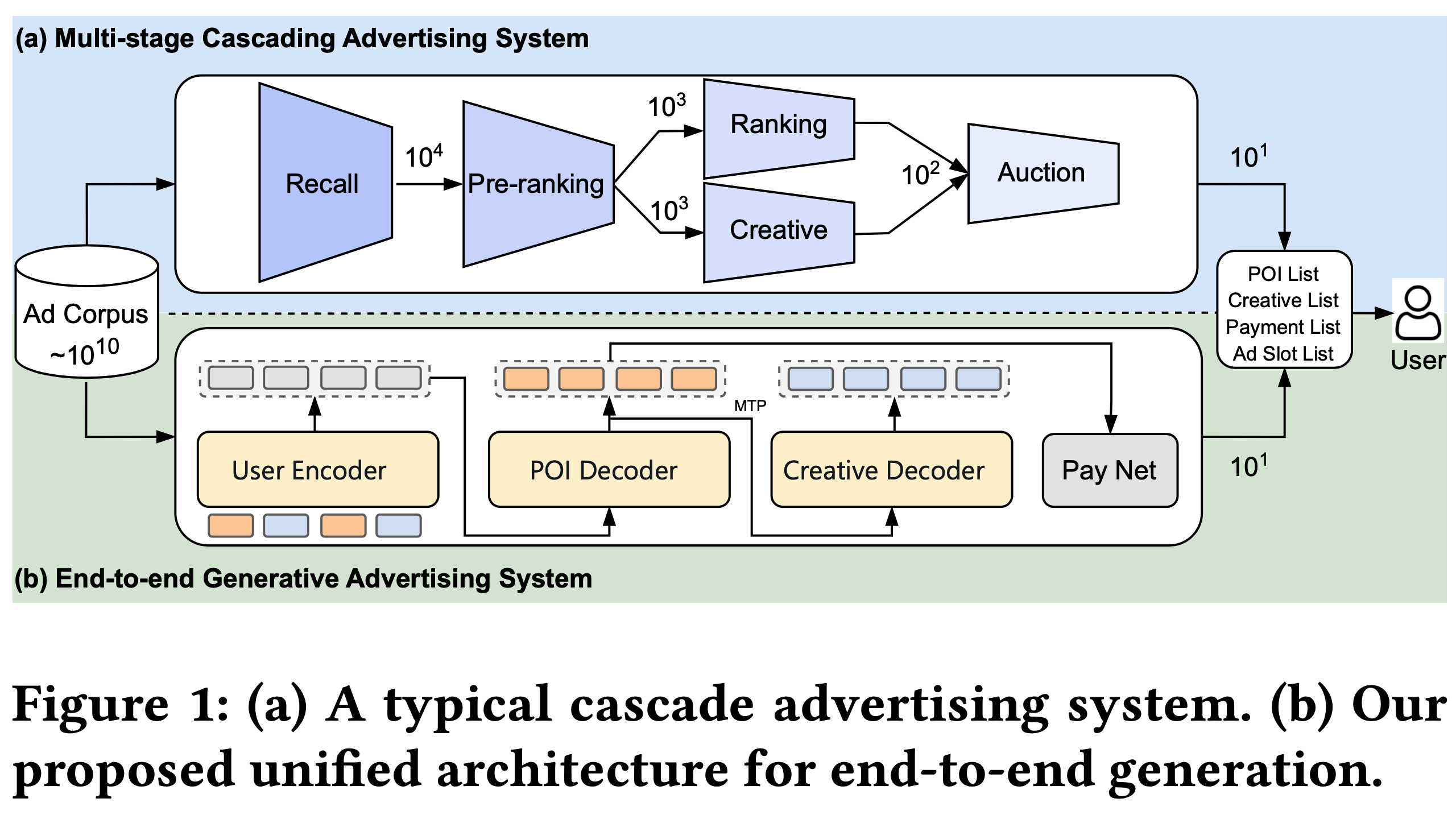
- 传统在线广告系统依赖多级级联架构,通常结构为:召回、预排序、排序、创意选择和拍卖(如图1(a)所示)
- 具体做法:每个阶段从其输入中选择前 \(k\) 个候选内容并传递给后续阶段。这种范式通过逐步缩小候选内容集,在严格延迟约束下有效平衡了性能与效率
- 级联架构存在固有局限:级联中的早期阶段本质上限制了下游模块的性能上限
- 例如,在上游召回或排序阶段被过滤的广告即使最终分配中极具价值也无法恢复,导致平台收入降低并无法实现全局最优
- 尽管已有多种努力通过促进排序模块间交互来提升整体推荐性能,但这些方法仍局限于传统级联排序框架
- 生成式推荐框架的出现为这些长期挑战提供了新视角
- 近期研究表明:Transformer-based 序列模型可以端到端统一检索、排序和生成,提供个性化内容并捕捉深层次 user-item 依赖关系
- 尽管此类方法在自然推荐场景中表现出显著潜力,广告系统的复杂性带来了一系列独特障碍
- 广告系统必须满足严格的业务约束,包括 bidding、创意选择、广告位分配和支付规则,同时优化用户与平台目标
- 这些需求引入了复杂依赖关系和实际挑战,直接应用现有生成式推荐模型无法完全解决
- 为解决上述挑战,论文提出 EGA,一种将决策阶段统一到单一模型中的新型生成框架:
- 整体来说:EGA 弥合了生成建模与工业广告实际需求之间的鸿沟,直接端到端输出最终广告序列及对应创意、位置和支付
- 第一:受生成式推荐技术启发,论文利用 RQ-VAE 将用户行为和物品特征编码为分层语义 token ,并采用带 multi-token prediction 的 Encoder-Decoder 架构联合生成候选广告序列和创意内容
- 第二:论文提出 token-level bidding 和生成式分配机制 ,通过排列感知奖励建模增强(enhanced by permutation-aware reward modeling)
- 该策略将分配与支付解耦,使模型在生成过程中有效反映业务目标,同时通过可微分支付网络近似保持激励相容性(IC)
- 第三:论文引入多阶段训练范式 :
- 预训练阶段 :从包含广告和自然内容的实际曝光序列中学习用户兴趣;
- 后训练阶段 :基于拍卖的后训练用于微调模型以适应广告特定约束,根据拍卖信号和平台目标动态优化广告分配
- 论文的贡献如下:
- 提出 EGA,通过统一单生成模型超越传统多级级联架构(首个广告端到端模型)
- 提出包含兴趣预训练和拍卖后训练的新颖多阶段训练策略
- 该设计有效平衡用户兴趣建模与广告特定约束,利用训练中的多样化数据源,并使模型输出与最终平台目标对齐
- 离线实验 + 在线A/B实验
相关工作(直译)
- 为实现工业广告的端到端优化,统一用户行为建模、拍卖机制和广告分配策略至关重要。基于此整合动机,本节回顾各领域的最新进展
生成式推荐
- 近年来,将生成范式应用于推荐系统的兴趣日益增长。一个特别有前景的方向是将推荐建模为序列生成任务,使用 Transformer-based 自回归架构捕捉 user-item 交互
- 这些方法旨在深度捕获用户行为上下文并以端到端方式生成个性化物品序列
- Tiger是开创性方法,引入RQ-VAE将物品内容编码为分层语义ID,实现语义相似物品间的知识共享
- 在此基础上,COBRA提出两阶段生成框架,首先生成稀疏ID再细化为稠密向量,实现从粗到细的检索过程
- 另一研究方向探索通用生成式推荐器
- HSTU 将推荐重构为序列转导任务,设计专为高基数非平稳流数据定制的 Transformer 架构
- OneRec 进一步推进这一方向,在单一 Encoder-Decoder 框架内统一检索、排序和生成,同时结合 session-level 生成和偏好对齐策略提升输出质量
- 此外,多种方法专注于增强语义 tokenization 和 representation
- LC-Rec 通过辅助目标将语义ID与协同过滤信号对齐
- IDGenRec 利用大语言模型生成稠密文本标识符,在零样本场景中展现强大泛化能力
- SEATER 引入通过对比和多任务目标训练的树结构 token 空间以确保一致性
- ColaRec 为更好对齐搭建内容与交互空间的桥梁
- 尽管这些工作展示了强大的通用推荐性能,但它们不足以满足在线广告系统的需求,后者需要对 bidding、支付和分配约束进行额外建模,而这些在纯用户兴趣建模中未被捕获
拍卖机制
- 传统拍卖机制如 GSP 及其变体(如uGSP)因简单性、可解释性和强收入保证而广泛应用于在线广告。然而,它们基于广告间独立的假设运作,未能考虑外部性(即其他广告的影响)
- 为解决此问题,计算能力的进步推动了基于学习的拍卖框架发展。例如:
- DeepGSP 和 DNA 通过将在线反馈纳入端到端学习流水线扩展经典拍卖
- DNA存在”排序前评估”困境,即必须在知晓最终序列前预测排序分数,限制了其建模集合级外部性的能力
- 其他尝试将最优性融入拍卖设计
- NMA 通过穷举枚举所有可能分配确保全局最优性,但其计算成本使其难以实时应用
- CGA 通过自回归分配模型和激励相容性的梯度友好重构,显式建模排列级外部性,克服传统和学习型广告拍卖的局限,实现分配与支付的端到端优化
广告分配
- 平台最初为广告和自然内容分配固定位置,但动态广告分配策略因优化整体页面级性能的潜力而受到关注
- CrossDQN 引入 DQN 架构将排列信号融入分配模型而不改变广告相对排序
- HCA2E提出具有理想博弈论特性和计算效率的分层约束自适应广告曝光
- MIAA提出深度自动化机制,集成广告拍卖与分配,同时决定广告的排序、支付和展示位置
前置基础知识
- 本节主要符号如表1所示:

任务定义
- 形式化定义在线广告系统中联合广告生成与分配的任务 :给定用户 \(u\) 的页面浏览(PV)请求,系统有 \(N\) 个候选广告和 \(M\) 个候选自然内容,假设自然内容序列 \(O\) 已根据预估 GMV 由上游模块预排序(This reflects common platform design constraints where organic content is ranked independently and must preserve user experience),其内部顺序将保持不变 \(^1\),系统最终选择 \(K\) 个 item 的排序列表( \(K \ll (N+M)\) )进行展示:
$$
\boldsymbol{\mathcal{Y} } = \{y_1, y_2, \ldots, y_K\}, \quad y_i \in X \cup O,
$$- 其中输出列表 \(\boldsymbol{\mathcal{Y} }\) 的生成需要在用户参与度和商业约束下联合做出以下决策:
- 广告排序 :从 \(X\) 中决定所选广告的排列顺序;
- 创意选择 :为每个选中的广告生成最合适的创意图片;
- 支付 :根据广告的出价 \(b_i\) 和分配位置,计算每个展示广告的支付价格 \(p_i\) ;
- 广告位 :在与自然内容竞争时,确定每个广告的最佳展示位置
- 其中输出列表 \(\boldsymbol{\mathcal{Y} }\) 的生成需要在用户参与度和商业约束下联合做出以下决策:
- 每个广告主 \(i\) 提交与其私有点击价值 \(v_i\) 对应的出价 \(b_i\) 。论文的目标是通过序列 \(\boldsymbol{\mathcal{Y} }\) 最大化平台预期收入:
$$
\max_{\theta} \mathbb{E}_{\boldsymbol{\mathcal{Y} } } \left[\textrm{Rev}\right] = \max_{\theta} \mathbb{E}_{\boldsymbol{\mathcal{Y} } } \left(\sum_{i=1}^K p_i \cdot \textrm{pCTR}_i\right).
$$
拍卖机制设计
拍卖约束(Auction Constraints)
- 与传统推荐系统不同,广告平台不仅需要优化平台收入,还需确保广告主效用。给定拍卖机制 \(\mathcal{M}(\mathcal{A}, \mathcal{P})\),其中分配规则为 \(\mathcal{A}\),支付规则为 \(\mathcal{P}\),广告主 \(i\) 的预期效用 \(u_i\) 定义为:
$$
u_i(v_i;b) = (v_i - p_i) \cdot \textrm{pCTR}_i.
$$ - 拍卖机制必须满足两个关键经济约束:激励相容性(IC)和个体合理性(IR)。IC要求真实出价能最大化广告主效用。对于广告 \(x_i\),需满足:
$$
u_i(v_i;v_i,b_{-i}) \geq u_i(v_i;b_i,b_{-i}), \quad \forall v_i, b_i \in \mathbb{R}^+.
$$ - IR要求广告主的支付不超过其出价,即:
$$
p_i \leq b_i, \quad \forall i \in [N].
$$
基于学习的拍卖(Learning-based Auction)
- 为了在模型中确保激励相容性(IC),论文采用事后遗憾(ex-post regret)的概念来量化广告主通过虚假报价可能获得的潜在收益。这种形式化方法使论文能够以可微分的方式强制执行IC约束,适用于端到端优化
- 形式上,给定生成的序列 \(\boldsymbol{\mathcal{Y} }\),广告 \(x_i \in \boldsymbol{\mathcal{Y} }\) 的真实估值 \(v_i\) 和上下文用户输入 \(u\),事后遗憾定义为:
$$
\operatorname{rgt}_i(v_i, \boldsymbol{\mathcal{Y} }, u) = \max_{b’_i} \left\{u_i(v_i;b’_i, \boldsymbol{b}_{-i}, \boldsymbol{\mathcal{Y} }, u) - u_i(v_i;b_i, \boldsymbol{b}_{-i}, \boldsymbol{\mathcal{Y} }, u)\right\},
$$- \(b_i\) 为真实 bidding
- \(b’_i\) 为潜在虚假报价
- \(\boldsymbol{b}_{-i}\) 表示除 \(x_i\) 外的其他广告 bidding
- 当且仅当所有广告主的 \(\operatorname{rgt}_i = 0\) 时,IC约束被满足
- 实践中,论文通过从分布 \(\mathbb{F}\) 中采样 \(N_0\) 个估值来近似计算广告 \(x_i\) 的经验事后遗憾:
$$
\widehat{\operatorname{rgt} }_i = \frac{1}{N_0} \sum_{j=1}^{N_0} \operatorname{rgt}_i(v^j_i, \boldsymbol{\mathcal{Y} }, u).
$$
- 随后,论文将拍卖设计问题形式化为在经验事后遗憾为零的约束下最小化预期负收入:
$$
\min_{\mathbf{w} } -\mathbb{E}_{\boldsymbol{v}\sim \mathbb{F} } \left[\operatorname{Rev}^{\mathcal{M} }\right], \quad \text{s.t.} \quad \widehat{\operatorname{rgt} }_i = 0, \ \forall i \in [N].
$$
EGA 方法介绍
基于兴趣的预训练(Interest-based Pre-training)
- 预训练阶段的目标是根据用户的历史行为(包括广告和自然内容)捕捉用户兴趣,这一阶段为学习反映用户兴趣的统一表征奠定了基础
- 数学上,预训练模型 \(\mathcal{F}\) 的目标是在给定输入用户行为序列 \(\mathcal{S}^u\) 的条件下,生成一个兴趣感知的输出序列 \(\boldsymbol{\mathcal{Y} }\):
$$
\boldsymbol{\mathcal{Y} } := \mathcal{F}(\mathcal{S}^u).
$$
特征表示(Feature Representations)
- 论文使用 \(\mathcal{S}^u = \{y_1, y_2, \ldots, y_B\}\) 表示用户上下文,其中每个 \(y_i\) 是用户之前交互过的 item (如点击、购买、喜欢), \(B\) 是序列长度。目标标签 \(\boldsymbol{\mathcal{Y} } = \{y_1, y_2, \ldots, y_K\}\) 对应于当前PV会话中实际曝光的高价值 item 。每个候选 item \(y_i\) 通过多模态表征描述,包括兴趣点( POI )特征嵌入 \(\boldsymbol{e}_i^{poi}\) (如稀疏ID特征和密集特征)以及从视觉内容中提取的创意图像嵌入 \(\boldsymbol{e}_i^{img}\)。最终输入可以表示为:
$$
\mathcal{S}^u = \{(\boldsymbol{e}_1^{poi}, e_1^{img}), (e_2^{poi}, e_2^{img}), \ldots, (e_B^{poi}, e_B^{img})\}.
$$
Vector Tokenization
- 受现有生成式推荐模型的启发,论文采用残差量化变分自 Encoder (RQ-VAE)将密集嵌入编码为语义 token 。历史序列中的每个用户行为表示为 POI-creative(创意)对:
$$
\mathcal{S}^u = \{(\boldsymbol{a}_1^{poi}, a_1^{img}), (a_2^{poi}, a_2^{img}), \ldots, (a_B^{poi}, a_B^{img})\},
$$ - 预测目标是一个结构类似的序列:
$$
\boldsymbol{\mathcal{Y} } = \{(\boldsymbol{a}_1^{poi}, a_1^{img}), (a_2^{poi}, a_2^{img}), \ldots, (a_K^{poi}, a_K^{img})\}.
$$ - 每对 token \((\boldsymbol{a}_i^{poi}, a_i^{img})\) 结合了高层类别意图和细粒度视觉语义
- 为简化,论文假设 POI 和创意图像均用单层 token \(\boldsymbol{a}\) 表示,但框架可扩展为分层 token 表示
- 例如,给定由 \(C\) 层(每层大小为 \(K\) )组成的 codebooks \(\mathcal{V}\), token \(\boldsymbol{a}_i\) 表示为:
$$
\boldsymbol{a}_i = (a_i^1, a_i^2, \ldots, a_i^C), \quad a_i^j \in \{\boldsymbol{V}_{j,1}, \boldsymbol{V}_{j,2}, \ldots, \boldsymbol{V}_{j,K}\}. \tag{12}
$$
- 例如,给定由 \(C\) 层(每层大小为 \(K\) )组成的 codebooks \(\mathcal{V}\), token \(\boldsymbol{a}_i\) 表示为:
Probabilistic Decomposition
- 目标 item 的概率分布建模分为两个阶段,利用 POI-level 和 creative-level 表征的互补优势。 EGA 首先预测 POI \(\boldsymbol{a}_{t+1}^{poi}\),再确定创意图像 \(\boldsymbol{a}_{t+1}^{img}\):
$$
P(\boldsymbol{a}_{t+1}^{poi}, \boldsymbol{a}_{t+1}^{img} \mid \mathcal{S}_{1:t}^u) = P(\boldsymbol{a}_{t+1}^{poi} \mid \mathcal{S}_{1:t}^u) \cdot P(\boldsymbol{a}_{t+1}^{img} \mid \boldsymbol{a}_{t+1}^{poi}, \mathcal{S}_{1:t}^u),
$$- \(P(\boldsymbol{a}_{t+1}^{poi} \mid \mathcal{S}_{1:t}^u)\) 表示基于历史序列生成下一个 POI 的概率,捕捉 item 的类别身份;
- \(P(\boldsymbol{a}_{t+1}^{img} \mid \boldsymbol{a}_{t+1}^{poi}, \mathcal{S}_{1:t}^u)\) 表示在给定 POI 和历史条件下生成创意图像的概率,捕捉 item 的细粒度多模态细节
Encoder-Decoder
- 整体生成架构遵循 Encoder-Decoder 设计,如图2所示
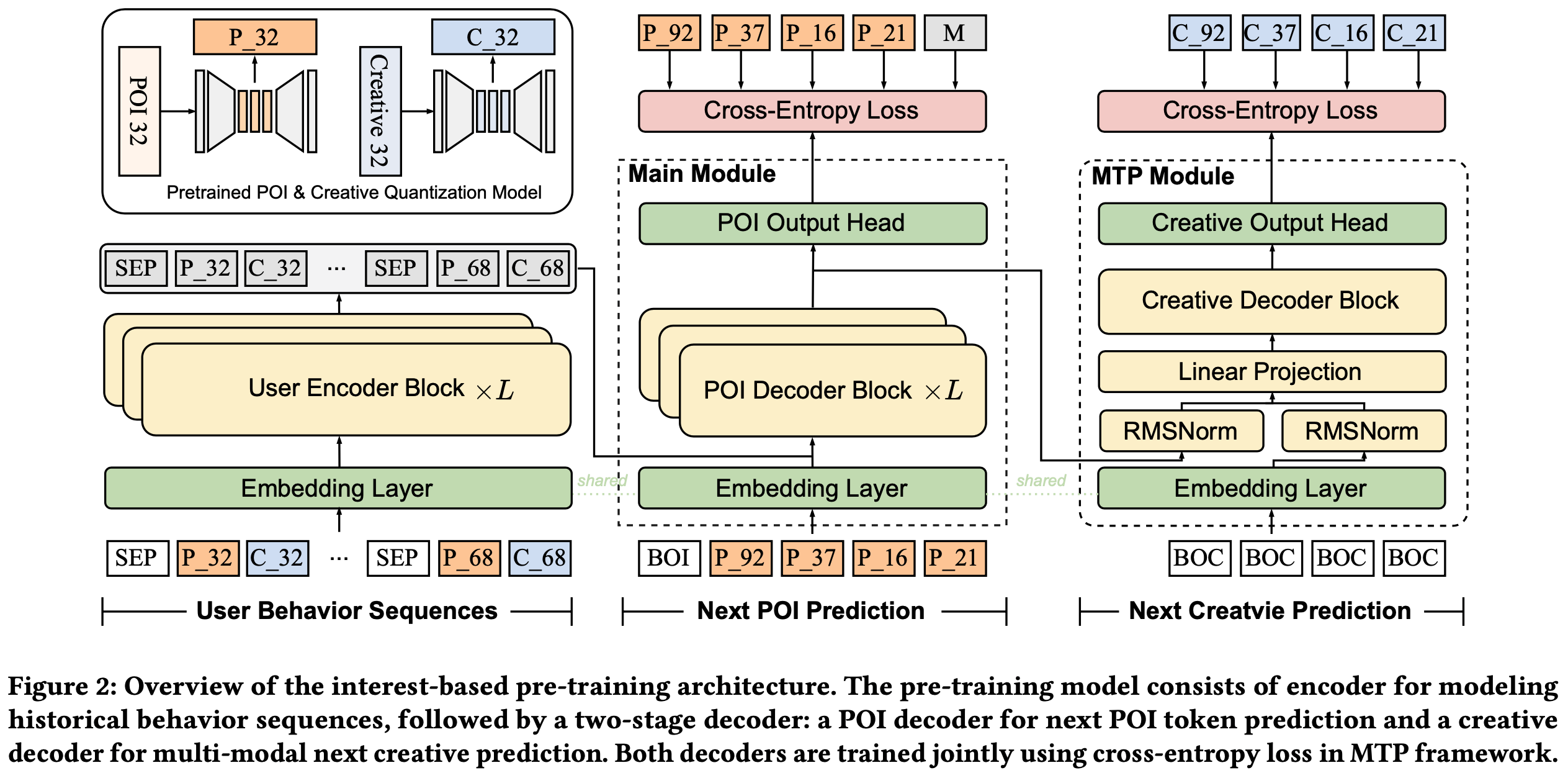
- Encoder 模块首先使用堆叠的自注意力和前馈层编码用户交互序列:
$$
\mathcal{S}^e = \text{Encoder}(\mathcal{S}^u),
$$- 其中 \(\mathcal{S}^e\) 表示用户兴趣的潜在上下文嵌入
- Decoder 以自回归方式生成目标序列 \(\boldsymbol{\mathcal{Y} }\),条件为编码的用户上下文 \(\mathcal{S}^e\)
- 每个解码步骤 \(t\) 包含两个子阶段: POI token 生成和创意 token 生成
- 为实现联合学习,论文引入 multi-token prediction (MTP)模块,通过交叉熵损失同时监督 POI 和创意预测
- 所有模块共享相同的 token Embedding 空间和量化 backbone,促进高效训练和一致的生成质量
- 问题:所有模块的 Embedding 空间是共享的,如何理解量化 backbone 也共享?
- 回答:这里是指量化相关的 codebook 和参数等共享吧
- 在步骤 \(t+1\), POI Decoder 基于先前生成的 token 和编码的历史序列预测下一个 POI token:
$$
\boldsymbol{a}_{t+1}^{poi} = \text{ POI -Decoder}(\boldsymbol{\mathcal{Y} }_{1:t}, \mathcal{S}^e).
$$- 注:从图2看,没有明确指出这里 POI Token \(\boldsymbol{a}_{t+1}^{poi}\) 的生成依赖 创意 Token \(\boldsymbol{a}_{t+1}^{img}\),但个人理解其实是应该包含的(不同创意对用户的感知是有影响的,应该包含在上下文中),公式里面也是包含的
- 随后,创意 Decoder 通过关注 POI 预测和编码上下文预测对应的创意 token:
$$
\boldsymbol{a}_{t+1}^{img} = \text{Creative-Decoder}(\boldsymbol{\mathcal{Y} }_{1:t}, \boldsymbol{a}_{t+1}^{poi}, \mathcal{S}^e).
$$- 注:图中的 MTP token 不太标准,真实的 MTP 是生成后续的多个 token,本质还是 Casual Model,在论文图2的建模下已经不是 Casual Model 了,但是给出的公式又是 Casual Model,比较迷惑,需要解答
- 整个目标序列 \(\boldsymbol{\mathcal{Y} }\) 的生成建模为条件概率的乘积:
$$
P(\boldsymbol{\mathcal{Y} } \mid \mathcal{S}^u) = \prod_{t=1}^T P(\boldsymbol{a}_t^{poi} \mid \boldsymbol{\mathcal{Y} }_{1:t-1}, \mathcal{S}^e) \cdot P(\boldsymbol{a}_t^{img} \mid \boldsymbol{\mathcal{Y} }_{1:t-1}, \boldsymbol{a}_t^{poi}, \mathcal{S}^e).
$$
排列感知的奖励模型(Permutation-aware Reward Model)
- 为确保生成的广告序列与真实用户兴趣对齐,论文引入排列感知的奖励模型(RM)指导迭代优化
- 广告领域的兴趣信号通常来自用户交互(如点击和转化),比人工标注更准确
- 设 \(R(\boldsymbol{\mathcal{Y} })\) 为奖励模型,估计候选目标 item \(\boldsymbol{\mathcal{Y} } = \{\boldsymbol{a}_1, \boldsymbol{a}_2, \ldots, \boldsymbol{a}_K\}\) 的奖励信号。每个 token \(\boldsymbol{a}_i\) 不一定对应唯一 item ,这增加了奖励模型中监督信号分配的复杂性。为此,论文通过拼接原始 item 嵌入 \(\boldsymbol{e}_i^{poi}\) 丰富每个 token 表示:
$$
\boldsymbol{h}_i = [\boldsymbol{a}_i; \boldsymbol{e}_i^{poi}],
$$- 其中 \([;]\) 表示拼接。目标 item 变为 \(\boldsymbol{h} = \{\boldsymbol{h}_1, \boldsymbol{h}_2, \ldots, \boldsymbol{h}_K\}\)
- 目标 item \(\boldsymbol{h}\) 通过自注意力层处理,捕捉上下文依赖并聚合序列中的相关信息:
$$
\boldsymbol{h}_f = \text{SelfAttention}(\boldsymbol{h}W^Q, \boldsymbol{h}W^K, \boldsymbol{h}W^V).
$$ - 为进行细粒度预测(如 POI 和创意图像的pCTR、pCVR),论文为奖励模型增加多任务特定塔:
$$
\hat{r}^{\text{pctr} } = \text{Tower}^{\text{pctr} } \left( \sum \boldsymbol{h}_f \right), \quad \hat{r}^{\text{pcvr} } = \text{Tower}^{\text{pcvr} } \left( \sum \boldsymbol{h}_f \right), \tag{20}
$$- 其中 \(\text{Tower}(\cdot) = \text{Sigmoid}(\text{MLP}(\cdot))\)
- 获得估计奖励 \(\hat{r}^{\text{pcvr} }\) 和对应真实标签 \(y^{\text{pcvr} }\) 后,通过最小化二元交叉熵损失训练奖励模型。详细训练过程见原文4.4节
基于拍卖的偏好对齐(Auction-based Preference Alignment)
- 在工业广告场景中,生成式推荐模型需同时满足用户兴趣和关键业务约束。具体需满足两大业务约束:
- i) 广告主对有效曝光、bidding 兼容性和支付一致性的需求;
- ii) 平台对平衡收入和用户体验的约束(如控制广告曝光比例)
- 为此,论文提出集成的生成式分配和支付策略进行偏好对齐,包括基于 token-level bidding 的分配模块和分离的 POI-level 支付网络。整体结构如图3所示
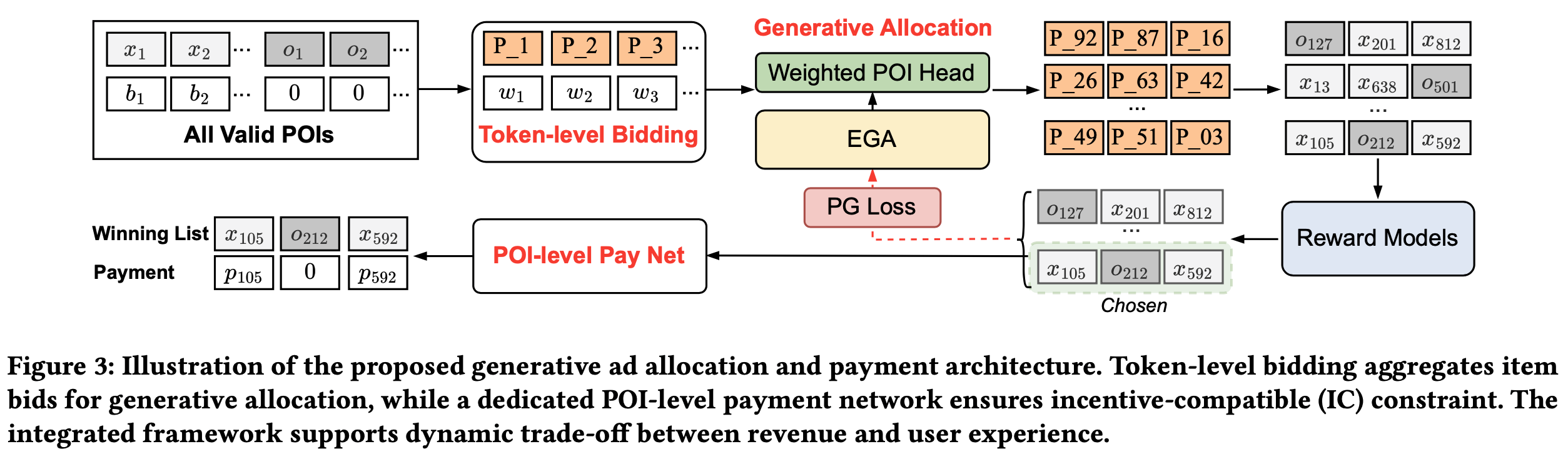
token-level Bidding
- 通过 RQ-VAE 进行 item tokenization 后,原始 item-level bids 不再直接与 token 空间对齐,因 item 和潜在 token 之间存在多对多映射
- 受 Google token-level bidding 理论启发,论文引入 token-level 分配机制,聚合与每个 token 关联的 item 的 bidding
- 如式(12)所述,每个 token \(\boldsymbol{a}_i = (a_i^1, a_i^2, \ldots, a_i^C)\) 。为保持不同 token 间 bidding 的区分度, token \(a_i^j\) 的出价 \(b(a_i^j) = \max(b_1, b_2, \ldots, b_{N_i})\),其中 \(N_i\) 为与 token \(a_i^j\) 关联的 item 数。形式上, token \(a_i^j\) 的聚合 bidding 权重定义为:
$$
w(a_i^j) = [b(a_i^j)]^\alpha + \beta = [\max(b_1, b_2, \ldots, b_{N_i})]^\alpha + \beta,
$$- 其中 \(\alpha\) 和 \(\beta\) 为超参数
- 调整 \(\alpha\) 可灵活控制 bidding 对分配过程的影响;
- 动态调整 \(\beta\) 可有效平衡生成结果中广告与自然内容的比例
生成式分配(Generative Allocation)
- 生成式分配中选择 token \(a_i^j\) 的概率通过 softmax 归一化:
$$
z(a_i^j) = \frac{w(a_i^j) \cdot e^{a_i^j} }{\sum_{k=1}^W [w(a^{j,k}) \cdot e^{a^{j,k} }]}, \tag{22}
$$- 其中 \(a^{j,k}\) 为第 \(j\) 层的第 \(k\) 个码
- 基于生成概率 \(z \in \mathbb{R}^{C \times W}\) ( \(C\) 为码本层数, \(W\) 为每层码本大小)
- 应用 Beam Search 生成 \(N_S\) 个长度为 \(K\) 的候选序列,确保分配的多样性和高质量选择:
$$
\mathcal{S}^{(1)}, \mathcal{S}^{(2)}, \ldots, \mathcal{S}^{(N_S)} = \text{BeamSearch}(z, N_S),
$$- 其中 \(\mathcal{S}^{(j)}\) 表示第 \(j\) 个生成的候选 token 序列, \(N_S\) 为束宽度和生成候选序列数。使用奖励模型 \(\mathcal{R}\) 评估每个序列的预期业务价值,输出第 \(j\) 个序列的奖励 \(\hat{r}_j\):
$$
\hat{r}_j = \mathcal{R}(\mathcal{S}^{(j)}).
$$
- 其中 \(\mathcal{S}^{(j)}\) 表示第 \(j\) 个生成的候选 token 序列, \(N_S\) 为束宽度和生成候选序列数。使用奖励模型 \(\mathcal{R}\) 评估每个序列的预期业务价值,输出第 \(j\) 个序列的奖励 \(\hat{r}_j\):
- 最终输出为奖励最高的序列 \(\mathcal{S}^*\)
- 奖励模型提供灵活接口,支持平台所需的多样化奖励信号组合
POI-level 支付网络
- 分配在 token-level 操作,而支付在 item 或 POI-level 计算,更符合传统广告主预期和业务逻辑。分离的支付网络专门设计以满足IC和IR约束,基于 item 表征计算支付
- 形式上,支付网络输入包括 item 表征 \(\mathcal{S}^* = \{y_1, y_2, \ldots, y_K\} \in \mathbb{R}^{K \times d}\)、自排除 bidding 配置 \(\mathcal{B}^- = \{\boldsymbol{b}_{-1}, \boldsymbol{b}_{-2}, \ldots, \boldsymbol{b}_{-K}\} \in \mathbb{R}^{K \times (K-1)}\) 和期望价值配置 \(\mathcal{Z} \cdot \Theta \in \mathbb{R}^{K \times 1}\),其中 \(\mathcal{Z} = \{z_1, z_2, \ldots, z_K\}\) 为式(22)定义的分配概率, \(\Theta = \{\hat{r}_1^{\text{pctr} }, \hat{r}_2^{\text{pctr} }, \ldots, \hat{r}_K^{\text{pctr} }\}\) 为式(20)中奖励模型估计的排列感知pCTR
- 支付率定义为:
$$
\hat{p} = \sigma(\text{MLP}(\mathcal{S}^*; \mathcal{B}^-; \mathcal{Z} \cdot \Theta)) \in [0, 1]^K,
$$- 其中 \(\sigma\) 为sigmoid激活函数以满足IR约束,最终 POI-level 支付 \(p\) 计算为:
$$
p = \hat{p} \odot b.
$$
- 其中 \(\sigma\) 为sigmoid激活函数以满足IR约束,最终 POI-level 支付 \(p\) 计算为:
- 注:若 \(y_i \in X\) 则支付仅针对广告计算;若 \(y_i \in O\) 则自然内容支付为零
优化与训练(Optimization and Training)
- 整体训练流程如图4所示,每个步骤的详细描述在后面小节:
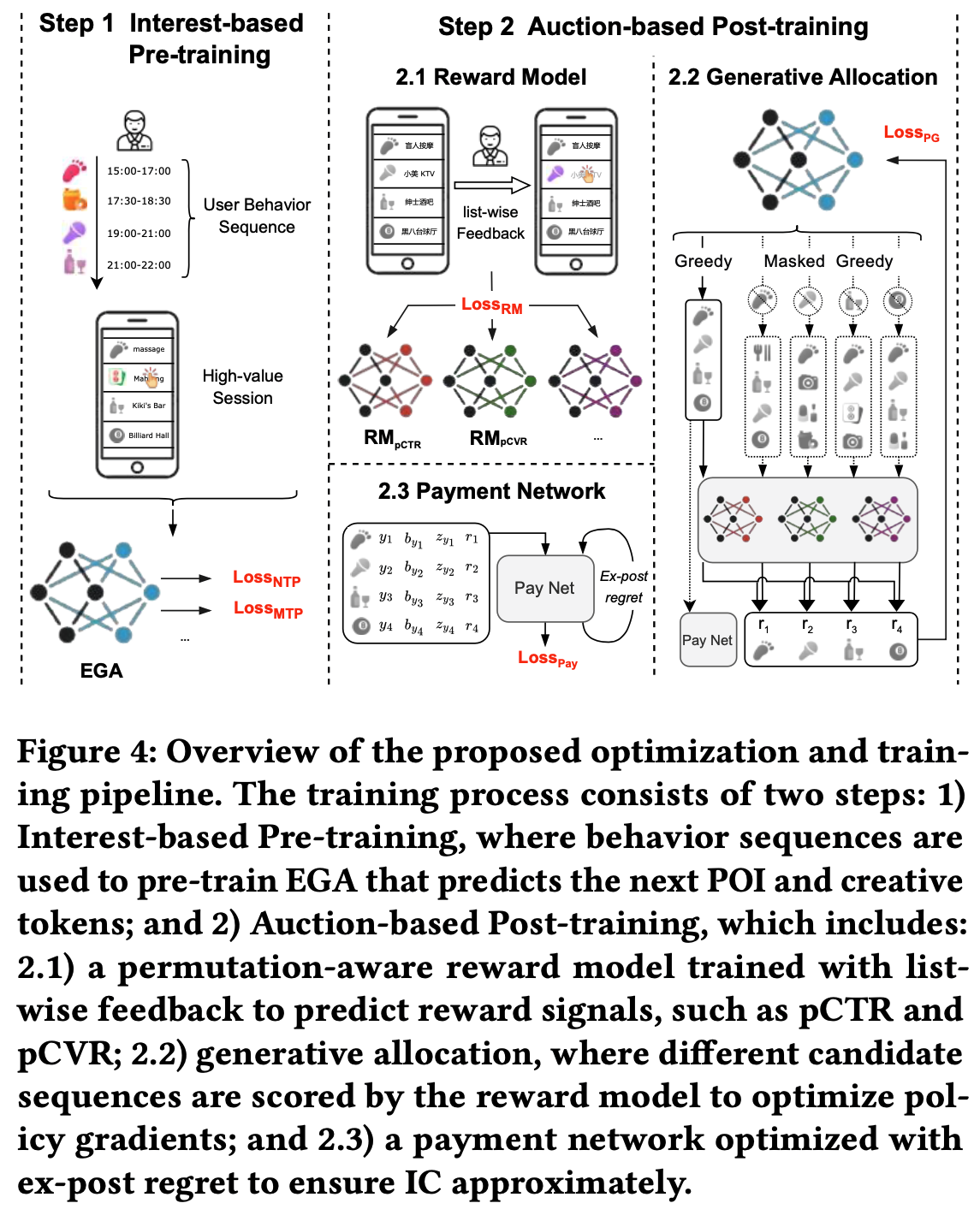
基于兴趣的预训练(Interest-based Pre-training)
- 预训练阶段首先训练生成 backbone 以从历史交互行为中捕捉用户兴趣。具体优化两个独立的交叉熵损失:主模块的下一个 POI 预测损失 \(\mathcal{L}_{\text{NTP} }\) 和MTP模块的下一个创意预测损失 \(\mathcal{L}_{\text{MTP} }\) 。形式上,根据式(17):
$$
\mathcal{L}_{\text{NTP} } = -\frac{1}{K} \sum_{i=1}^K \log P(\boldsymbol{a}_i^{poi} \mid \boldsymbol{\mathcal{Y} }_{1:i-1}, \mathcal{S}^e), \tag{27}
$$
$$
\mathcal{L}_{\text{MTP} } = -\frac{1}{K} \sum_{i=2}^{K+1} \log P(\boldsymbol{a}_{i-1}^{img} \mid \boldsymbol{\mathcal{Y} }_{1:i-1}, \boldsymbol{a}_i^{poi}, \mathcal{S}^e). \tag{28}
$$
- 总预训练损失定义为:
$$
\mathcal{L}_{\text{pre-train} } = \mathcal{L}_{\text{NTP} } + \mathcal{L}_{\text{MTP} }.
$$
基于拍卖的后训练(Auction-based Post-training)
- 预训练阶段后,论文冻结其参数,通过基于拍卖的后训练阶段在拍卖约束下优化生成式广告模型。此阶段将生成输出与平台收入目标和广告主需求对齐,包括两部分:
- i) 奖励模型训练,
- ii) 基于策略梯度的生成式分配训练,
- iii) 基于拉格朗日方法的支付网络优化
- 奖励模型训练 :使用用户真实反馈信号(如点击和转化)训练独立奖励模型(RM)。RM通过最小化二元交叉熵损失优化:
$$
\mathcal{L}_{\text{RM} }^{\text{pctr} } = -\frac{1}{|\mathcal{D}|} \sum_{d \in \mathcal{D} } \sum_{i=1}^K \left( y^{\text{pctr} } \log \hat{r}^{\text{pctr} } + (1 - y^{\text{pctr} }) \log(1 - \hat{r}^{\text{pctr} }) \right),
$$- \(y^{\text{pctr} }\) 为真实用户交互的标签
- \(\hat{r}^{\text{pctr} }\) 为式(20)中奖励模型的预测概率
- \(\mathcal{D}\) 为训练数据集
- 生成式分配训练 :奖励模型收敛后,采用基于非自回归策略梯度的方法
- 给定生成的获胜广告序列 \(\mathcal{S}^* = \{y_1, y_2, \ldots, y_K\}\),定义每个 item \(y_i\) 对平台收入的边际贡献为:
$$
r_{y_i} = \sum_{y_j \in \mathcal{S}^*} b_j r_j^{\text{pctr} } - \sum_{y_j \in \mathcal{S}_{-i}^*} b_j r_j^{\text{pctr} },
$$- 其中 \(\mathcal{S}_{-i}^*\) 为排除 \(y_i\) 的最佳替代广告序列
- 应用策略梯度目标最大化预期奖励:
$$
\mathcal{L}_{\text{PG} } = -\frac{1}{|\mathcal{D}|} \sum_{d \in \mathcal{D} } \sum_{y_i \in \mathcal{S}^*} r_{y_i} \log z_{y_i},
$$- 其中 \(z_{y_i}\) 为式(22)中 item \(y_i\) 的分配概率。此设计鼓励生成器产生更高总收入的序列,使用固定奖励模型参数
- 给定生成的获胜广告序列 \(\mathcal{S}^* = \{y_1, y_2, \ldots, y_K\}\),定义每个 item \(y_i\) 对平台收入的边际贡献为:
- 支付网络优化 :支付网络通过拉格朗日对偶形式优化式(8),平衡收入最大化和IC约束,损失函数整合总平台支付和事后遗憾最小化,给定选定序列 \(\mathcal{Y}\),支付损失 \(\mathcal{L}_{\text{Pay} }\) 定义为:
$$
\mathcal{L}_{\text{Pay} } = -\frac{1}{|\mathcal{D}|} \sum_{d \in \mathcal{D} } \left( \sum_{y_i \in \mathcal{S}^*} p_i \hat{r}_i^{\text{pctr} } - \sum_{y_i \in \mathcal{S}^*} \lambda_i \widehat{\text{rgt} }_i - \frac{\rho}{2} \sum_{y_i \in \mathcal{S}^*} (\widehat{\text{rgt} }_i)^2 \right),
$$- \(\widehat{\text{rgt} }_i\) 为广告 \(y_i\) 的事后遗憾
- \(p_i\) 为支付网络的预测支付
- \(\lambda_i\) 为拉格朗日乘子
- \(\rho > 0\) 为 IC 惩罚项超参数
- 通过迭代拉格朗日方法联合优化支付网络,具体步骤如下:
- 支付网络更新 :固定乘子,最小化拉格朗日目标优化支付网络参数 \(\theta_{\text{Pay} }\):
$$
\theta_{\text{Pay} }^{\text{new} } = \arg \min_{\theta_{\text{Pay} } } \mathcal{L}_{\text{Pay} }(\theta_{\text{Pay} }^{\text{old} }, \boldsymbol{\lambda}^{\text{old} }).
$$ - 乘子更新 :基于观测的事后遗憾调整拉格朗日乘子:
$$
\boldsymbol{\lambda}^{\text{new} } = \boldsymbol{\lambda}^{\text{old} } + \rho \cdot \widehat{\text{rgt} }(\theta_{\text{Pay} }^{\text{new} }).
$$
- 支付网络更新 :固定乘子,最小化拉格朗日目标优化支付网络参数 \(\theta_{\text{Pay} }\):
- 尽管整体目标非凸,但实证结果表明此优化策略能有效最小化遗憾,同时在现实场景中保持接近最优的收入
相关实验
- 本节在工业数据集上评估所提出的模型,旨在回答以下研究问题:
- RQ1 :与 SOTA 广告模型相比,论文的 EGA 模型表现如何?
- RQ2 :EGA 的设计(如MTP模块、token-level bidding、支付网络和多阶段训练)对其性能有何影响?
- RQ3 :EGA 模型的可扩展性如何?
- RQ4 :EGA 在真实工业广告场景中的表现如何?
Experiment Setup
数据集
- 实验使用的工业数据集来自大规模基于位置的服务(LBS)平台,时间跨度为 2024年9月至2025年4月
- 数据集包含2亿次请求,覆盖超过200万用户和近1000万条独立广告
- 前200天的数据用于预训练,并随机抽取10%用于偏好对齐
- 最后14天的数据用于测试
评估指标
- 离线实验中,采用以下指标全面评估平台收入、用户体验和广告主的后验遗憾:
- 千次展示收入(RPM) :
$$
\text{RPM} = \frac{\sum \text{click} \times \text{payment} }{\sum \text{impression} } \times 1000
$$ - 点击率(CTR) :
$$
\text{CTR} = \frac{\sum \text{click} }{\sum \text{impression} }
$$ - 激励相容性指标( \(\Psi\) ) :
$$
\Psi = \frac{1}{|\mathcal{D}|} \sum_{d \in \mathcal{D} } \sum_{i \in k} \frac{\widehat{\text{rgt} }_{i}^{d} }{u_{i}(v_{i}^{d}, b_{i}^{d})}
$$- \(\widehat{\text{rgt} }_{i}^{d}\) 表示广告主 \(i\) 在会话数据 \(d\) 中的经验后验遗憾(定义见公式(7))
- \(u_{i}\) 为实际效用
- 该指标通过反事实扰动测试激励相容性(IC):对每个广告主,将出价 \(b_{i}\) 替换为 \(\gamma \times b_{i}\),其中 \(\gamma \in \{0.2 \times j \mid j=1,2,\ldots,10\}\)
- 离线实验中,评估指标基于奖励模型的预测值计算
基线模型
- 评估 EGA 与以下两种工业常用架构的对比:
- MCA :多阶段级联架构(MCA)是工业在线广告的标准范式,包含五个关键阶段:召回、排序、创意选择、拍卖和广告分配
- 为实现强基线,采用以下方法实现 MCA:Tiger[20]用于召回,HSTU[34]用于排序,Peri-CR[32]用于创意选择,CGA[41]用于拍卖,CrossDQN[16]用于广告分配
- GR :生成式推荐(GR)将推荐任务建模为序列生成问题,使用 Transformer-based 自回归架构建模 user-item 交互
- 为适应在线广告场景,该基线整合了 OneRec[4](用于推荐)、Peri-CR[32](用于创意选择)和 GSP[8](用于支付)
- MCA :多阶段级联架构(MCA)是工业在线广告的标准范式,包含五个关键阶段:召回、排序、创意选择、拍卖和广告分配
实现细节
- EGA 使用 Adam 优化器训练,初始学习率为 0.0024,批量大小为 128
- 模型训练和优化在 80G 内存的 NVIDIA A100 GPU 上进行
- 通过网格搜索选择最优超参数:
- 兴趣预训练阶段:
- Encoder 和 Decoder 的块数 \(L=3\), codebook 层数 \(C=3\),每层 codebook 大小 \(W=1024\) ;
- 目标会话物品数 \(K=10\),历史行为序列长度 \(B=256\)
- 偏好对齐阶段:
- token-level bidding 的超参数 \(\alpha=1.2\), \(\beta=2\) ;每个请求通过 Beam Search 生成 \(N_{\mathcal{S} }=64\) 个候选序列。奖励模型和支付网络的MLP隐藏层维度为128、32和10
- 兴趣预训练阶段:
离线性能(RQ1)
- 表2展示了离线表现
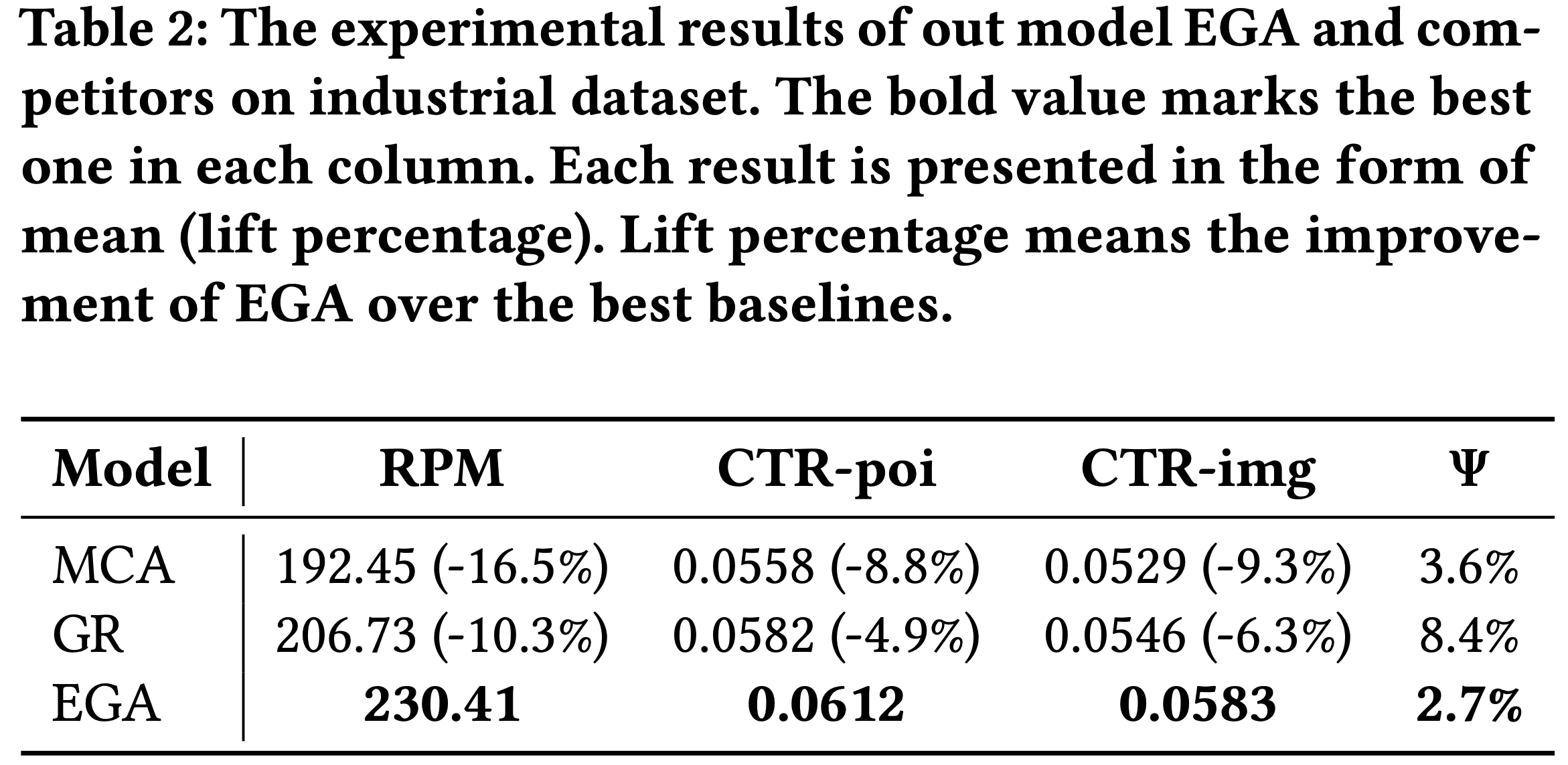
- 如表2所示,关键观察如下:
- 1)多阶段级联架构(MCA)存在早期过滤问题:高潜力广告常在初始阶段被淘汰,导致整体性能次优,表现为RPM和CTR指标较低
- 2)生成式推荐基线(GR)虽能改进序列建模和个性化,但因无法满足实际业务约束(如IC保证、动态广告分配和曝光率控制),在广告场景中表现有限,IC遗憾高达8.4%
- EGA 通过端到端生成、排列感知奖励建模、token-level bidding 和专用支付网络,实现了最佳综合性能:显著提升收入(RPM)、POI 和创意CTR,并以最低IC遗憾(2.7%)展现经济鲁棒性
- 这表明,解决早期候选丢失和业务约束对广告系统至关重要
消融研究(RQ2)
- 通过简化 EGA 设计验证各组件有效性:
- EGA-mtp :移除多令牌预测(MTP)模块,改用标准单令牌预测(NTP),独立预测 POI 和创意
- EGA-end :禁用多阶段训练,改为单阶段端到端训练
- EGA-bid :将 token-level bidding 的最大聚合改为平均值 \(b(a_{i}^{j})=\text{avg}(b_{1},…,b_{N_{i} })\)
- EGA-gsp :移除支付网络,改用标准GSP支付计算
- 结果如表3所示,完整 EGA 在所有指标上均优于变体
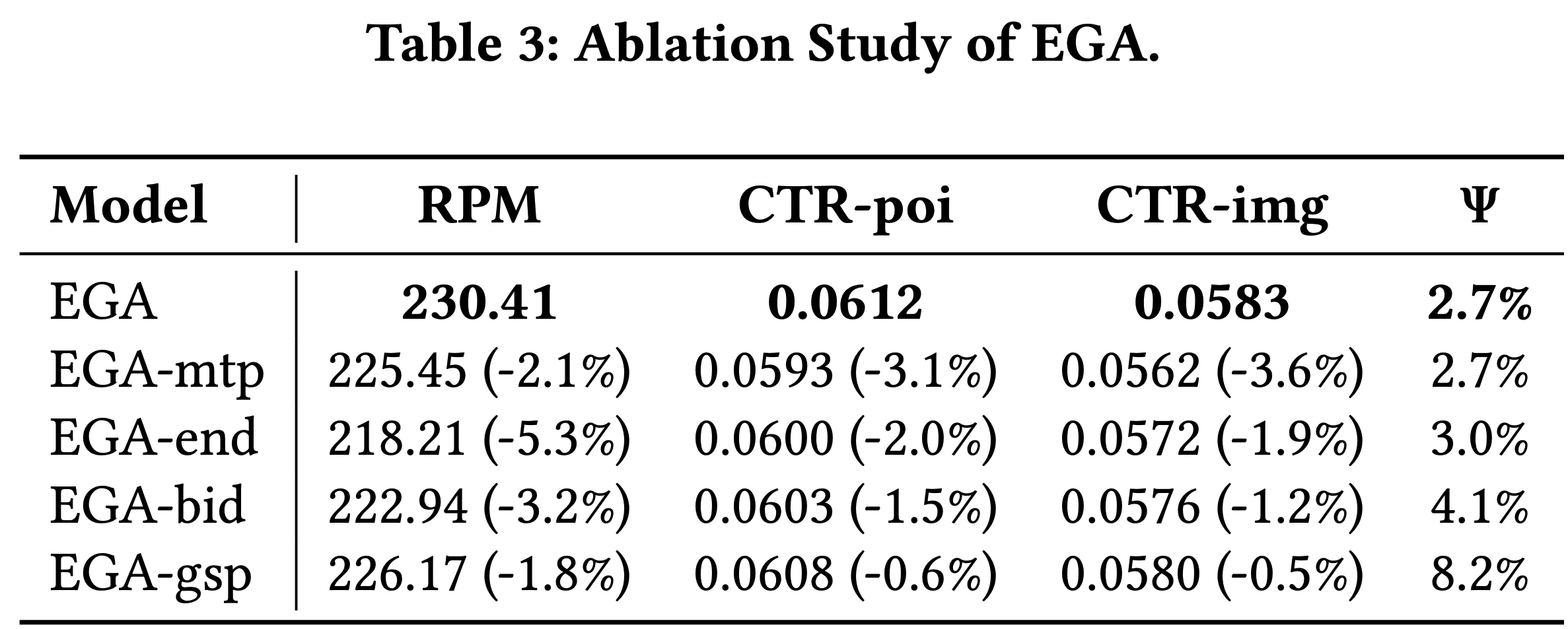
- 具体来说,结果如下:
- 1)EGA-mtp 导致 RPM、CTR-poi和CTR-img下降(-2.1%、-3.1%、-3.6%),表明联合建模的重要性
- 2)EGA-end 的 RPM 下降5.3%,凸显多阶段训练对对齐用户兴趣和业务目标的优势
- 3)EGA-bid 的 IC 遗憾升至4.1%,说明最大聚合对激励相容性的必要性
- 4)EGA-gsp 的 IC 遗憾高达8.2%,验证支付网络对近似IC的关键作用
模型可扩展性(RQ3)
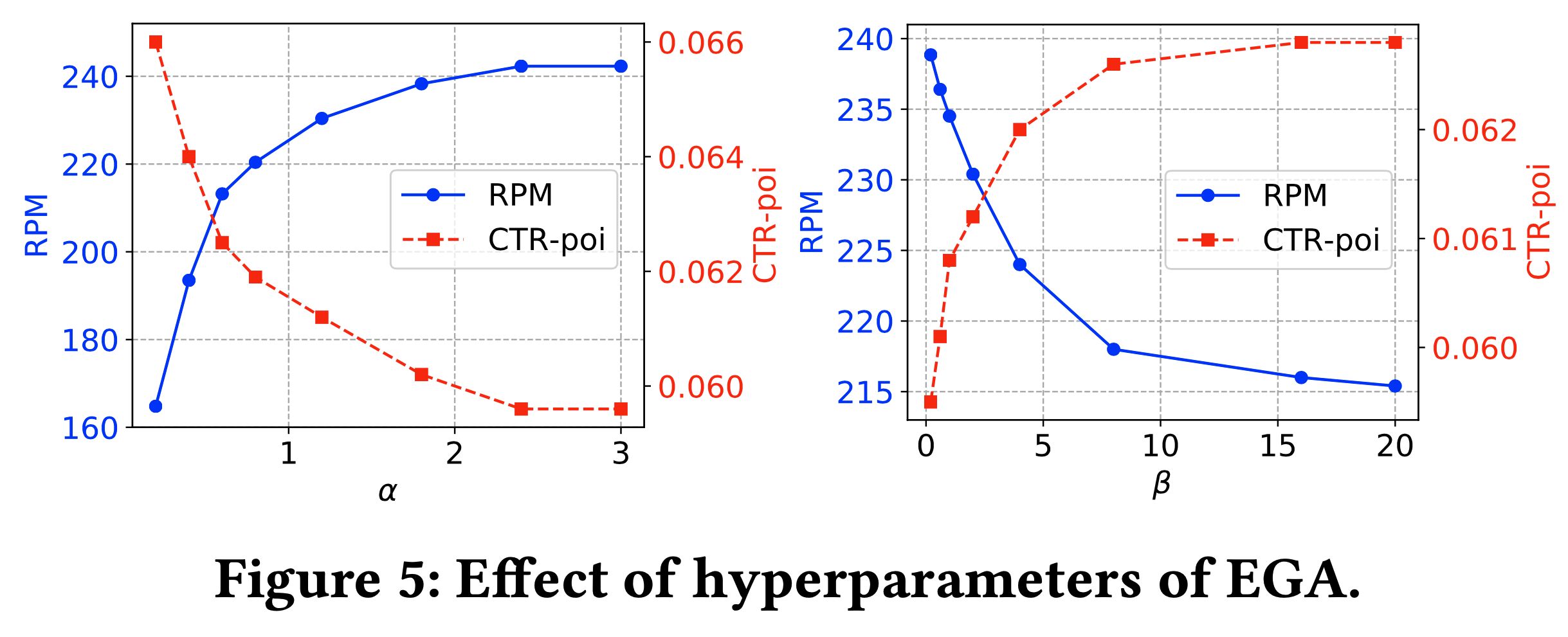
- 研究 EGA 对超参数和模型规模的敏感性
- 图5显示:bidding 参数 \(\alpha\) 提升RPM但降低CTR-poi,\(\beta\) 则相反,需权衡收入与用户体验
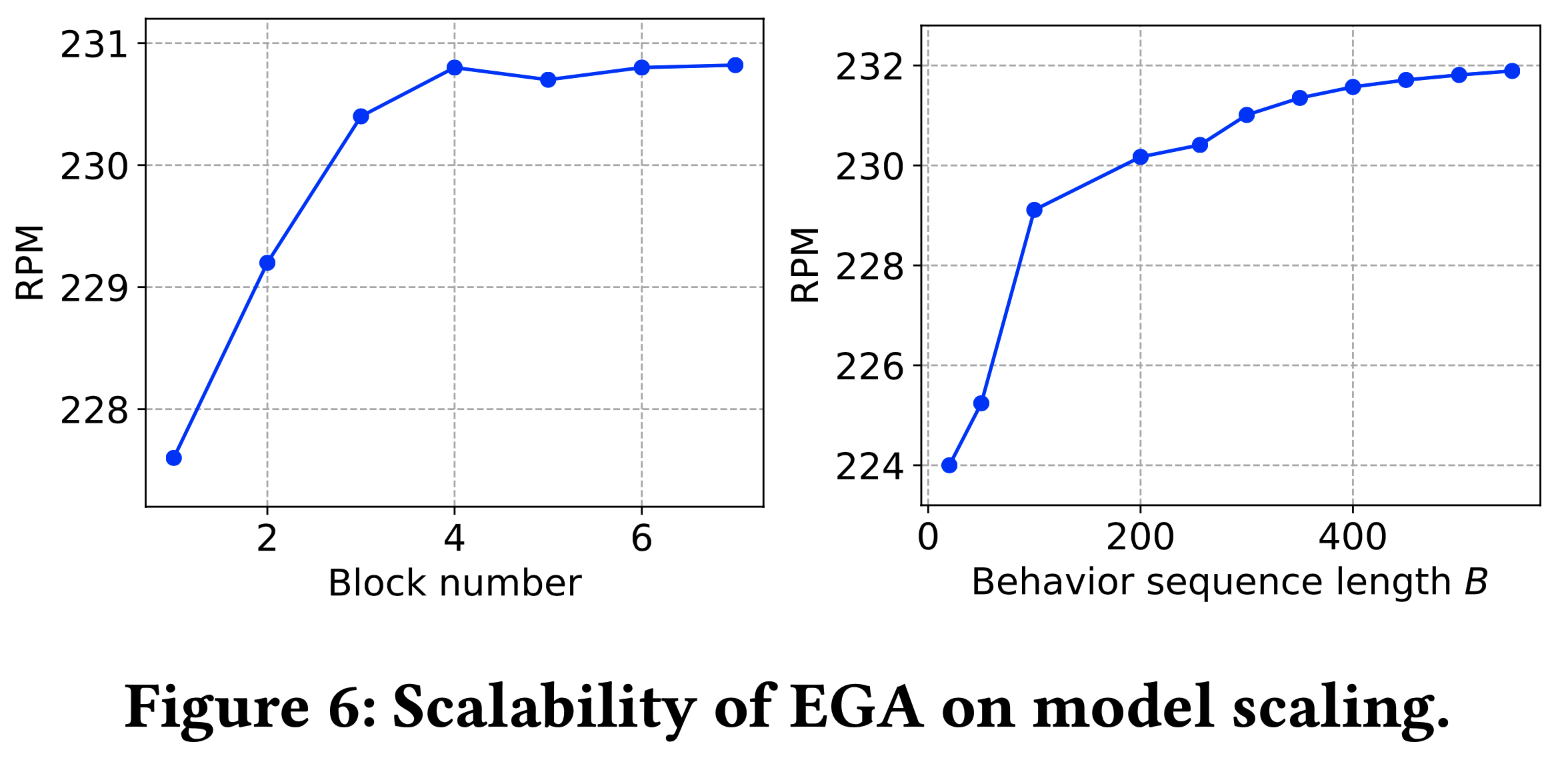
- 图6表明:增加 Encoder / Decoder 块数或用户行为长度可提升RPM,但边际效益递减
在线A/B测试(RQ4)
- 2025年4月2日至8日,在 2% 生产流量上对比 EGA 与MCA
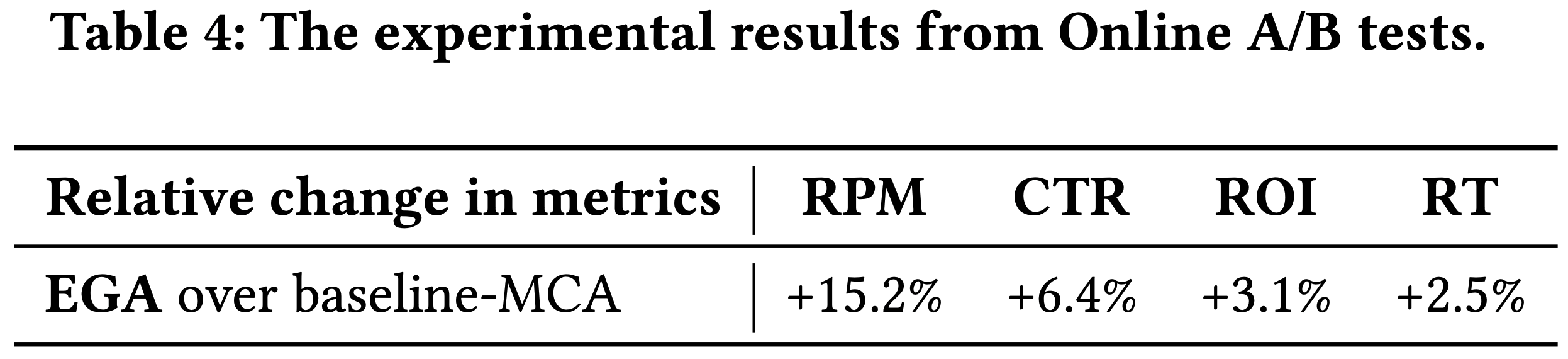
- 如表4所示,EGA 实现RPM提升15.2%、CTR 提升 6.4%、广告主投资回报率(ROI)提升 3.1%,且单请求响应时间仅增加7毫秒(2.5%),验证了其工业场景有效性
结论
- 在本研究中,论文提出了端到端生成式广告(EGA),这是一种新颖的框架,将排序、创意选择、广告分配和支付计算统一到一个生成式模型中,用于广告系统
- 通过利用分层语义 tokenization、排列感知的奖励建模以及基于 token 的 bidding 和分配机制, EGA 弥合了用户兴趣建模与业务关键拍卖约束(如激励兼容性(IC)和个体理性(IR))之间的差距
- 论文提出的多阶段训练范式,包括基于兴趣的预训练和基于拍卖的后训练,确保 EGA 在复杂的现实条件下能够同时捕捉用户兴趣和广告主效用
- 在工业数据集上进行的大量离线实验和大规模在线A/B测试表明,EGA 在多阶段级联架构和最新的生成式推荐基线中均实现了显著改进,包括平台收入、用户体验和广告主投资回报率的提升,同时仅带来极小的延迟开销
- 论文的消融研究验证了每个设计组件的有效性,并突出了所提出框架的灵活性和可扩展性
- 展望未来,作者认为 EGA 为生成式建模与经济机制设计在在线广告中的融合开辟了新的方向
- 未来的工作将进一步探索扩展规律并增强业务可解释性