注:本文包含 AI 辅助创作
Paper Summary
- Kimi K2 是截止到其发表时最强大的开源大语言模型 ,基于 MoE 架构(1T-A32B)(没看错,是1万亿!)
- 注:截止到发布,效果也是开源中最顶尖的
- 强调 Agentic 能力
- 论文同时还提出了 MuonClip 优化器(Muon + 新引入的 QK-clip 技术),解决了训练不稳定的问题,同时保留了 Muon 的高效 Token 利用率
- 亮点:基于 MuonClip,K2 在 15.5T Token 的预训练过程中实现了零损失峰值
- 后训练过程包含多个阶段
- 重点:包括大规模的具身数据合成流程和联合 RL 阶段,模型通过与真实和合成环境的交互进一步提升能力
- 特别地:Moonshot AI 团队公开了基模型和后训练模型的检查点 ,使社区能够探索、改进和规模化部署 Agentic 智能,以促进 Agentic 智能的未来研究和应用

Introduction and Discussion
- LLM 的发展正在经历一场深刻的范式转变(即朝着 Agentic 智能(Agentic Intelligence) 的方向演进)
- Agentic 智能是指模型能够在复杂动态环境中自主感知、规划、推理和行动(autonomously perceive, plan, reason, and act)
- 注:Agentic 智能不是具身智能(Embodied Intelligence),但这里的定义与具身智能很相似?
- 这一转变标志着模型从静态模仿学习转向通过交互主动学习 ,使其能够超越训练数据的限制,and adapt behavior through experiences (2025)
- 目前普遍认为,这种方法可以让 AI 智能体突破静态人类生成数据的局限,通过自身的探索和利用获得超人类能力
- Agentic 智能正迅速成为下一代基础模型的核心能力,对工具使用、软件开发和现实世界自主性等领域具有广泛影响
- Agentic 智能是指模型能够在复杂动态环境中自主感知、规划、推理和行动(autonomously perceive, plan, reason, and act)
- 实现 Agentic 智能在预训练和后训练阶段均面临挑战
- 预训练需要在高质量数据有限的约束下,为模型赋予广泛的通用先验知识 ,因此 Token Efficiency(learning signal per Token,即每个 Token 对模型性能提升的贡献)成为关键扩展系数
- 后训练需要将这些先验知识转化为可操作的行为,但多步推理、长期规划和工具使用等具身能力在自然数据中罕见且难以扩展
- 所以结构化、高质量具身轨迹的可扩展合成,结合能够整合偏好和自我批评的通用强化学习技术,是弥合这一差距的关键
- 论文介绍了 Kimi K2,专为解决核心挑战并推动具身能力边界而设计。论文的贡献涵盖预训练和后训练的前沿领域:
- MuonClip :一种新颖的优化器,将高效的 Muon 算法与增强稳定性的 QK-Clip 机制相结合
- 使用 MuonClip 在 15.5T Token 上预训练了 Kimi K2,未出现任何损失峰值
- 注:裁剪的 Idea 在之前的文献中就出现过,GPipe 论文中也是用了在 Softmax 操作前进行 Clip 的方案,缓解较深的网络容易出现尖锐激活(sharp activations)的问题
- 大规模具身数据合成流程(a large-scale agentic data synthesis pipeline) :通过模拟和真实环境系统性地生成工具使用示范
- 该系统构建了多样化的工具、智能体、任务和轨迹,以规模化生成高保真且可验证正确的具身交互数据
- 通用强化学习框架(a general reinforcement learning framework) :结合 RLVR 和自我批评评分奖励机制(self-critique rubric reward mechanism)
- 模型不仅从外部定义的任务中学习,还通过评估自身输出来扩展对齐能力,从静态领域延伸到开放领域
- MuonClip :一种新颖的优化器,将高效的 Muon 算法与增强稳定性的 QK-Clip 机制相结合
- Kimi K2 在广泛的具身和前沿基准测试中表现出色:
- Agentic 智能方面,超越了大多数开源和闭源基线模型(非思考设定下),缩小了与 Claude 4 Opus 和 Sonnet 的差距:
- 在 Tau2-Bench 上得分为 66.1,在 ACEBench(英文版)上得分为 76.5
- 在 SWE-Bench Verified 上得分为 65.8
- 在 SWE-Bench Multilingual 上得分为 47.3
- 编码、数学和推理任务中表现优异,进一步凸显了其在通用任务中的能力
- 在 LiveCodeBench v6 上得分为 53.7
- 在 AIME 2025 上得分为 49.5
- 在 GPQA-Diamond 上得分为 75.1
- 在 OJBench 上得分为 27.1
- Agentic 智能方面,超越了大多数开源和闭源基线模型(非思考设定下),缩小了与 Claude 4 Opus 和 Sonnet 的差距:
- 在 LMSYS Arena 排行榜(20250717)中,基于 3,000+ user votes,Kimi K2 位列开源模型第一名和总排名第五名
Pre-training
- Kimi K2 的基础模型是一个拥有 1T 参数的 MoE Transformer 模型 (2017),预训练数据规模为 15.5T 高质量 Token
- 最大化 Token Efficiency :高质量人类数据的可用性日益受限,Token Efficiency 正成为 LLM 扩展的关键系数,论文引入了一系列专门设计的预训练技术,旨在最大化 Token Efficiency
- 论文采用了 token-efficient Muon 优化器 (2024) 并通过 QK-Clip 技术缓解其训练不稳定性
- 论文还结合了合成数据生成技术,以进一步从有限的高质量 Token 中提取更多智能信号
- K2 模型架构采用超稀疏 MoE 设计 ,配备多头潜在注意力(Multi-head Latent Attention, MLA)机制(类似于 DeepSeek-V3 (2024))
- 其设计基于经验性的扩展定律分析
- AI Infra:底层基础设施的构建同时优化了训练效率和研发效率
MuonClip:通过权重裁剪实现稳定训练(MuonClip: Stable Training with Weight Clipping)
- Kimi K2 训练使用 token-efficient Muon 优化器 (2024),并结合了权重衰减(weight decay)和一致的更新 RMS 缩放技术 (consistent update RMS scaling)(2025)
- 注:这里的 consistent update RMS scaling 是指 在分布式训练过程中,更新 RMS 时,通过节点间通信同步数据,确保更新的缩放因子在所有设备上完全一致
- 在论文先前的工作 Moonlight (2025) 中的实验表明,在相同的计算预算和模型规模(即相同的训练数据量)下,Muon 显著优于 AdamW (2015, 2019) ,因此成为提升大语言模型训练 Token Efficiency 的有效选择
Training instability when scaling Muon
- 作者发现在扩展训练规模时,由于注意力 logits 爆炸导致的训练不稳定性
- 这一问题在 Muon 训练中更为常见,而在 AdamW 中较少出现
- 现有的缓解策略效果有限:
- logit soft cap (2024) 直接裁剪注意力 logits,但在裁剪应用之前, Query 和 Key 的点积仍可能过度增长
- Query-Key Normalization(QK-Norm)(2023) 不适用于多头潜在注意力(MLA),因为其 Key 矩阵在推理时并未完全实例化
Taming Muon with QK-Clip(通过 QK-Clip 驯服 Muon)
- 为了解决上述问题,论文提出了权重裁剪机制 QK-Clip(可显式约束注意力 logits)
- QK-Clip 的工作原理是在更新后重新缩放 Query 和 Key 的投影权重 ,以限制注意力 logits 的增长
- 设 Transformer 层的输入表示为 \(\mathbf{X}\)。对于每个注意力头 \(h\),其 Query、Key 和 Value 投影计算如下:
$$
\mathbf{Q}^{h} = \mathbf{X}\mathbf{W}_{q}^{h}, \quad \mathbf{K}^{h} = \mathbf{X}\mathbf{W}_{k}^{h}, \quad \mathbf{V}^{h} = \mathbf{X}\mathbf{W}_{v}^{h},
$$- 其中 \(\mathbf{W}_{q}, \mathbf{W}_{k}, \mathbf{W}_{v}\) 是模型参数
- 注意力输出为:
$$
\mathbf{O}^{h} = \text{softmax}\left(\frac{1}{\sqrt{d} }\mathbf{Q}^{h}\mathbf{K}^{h^{\top} }\right)\mathbf{V}^{h}.
$$
- 论文定义最大 logit(每头标量)为该批次 \(B\) 中 softmax 输入的最大值:
$$
S_{\text{max} }^{h} = \frac{1}{\sqrt{d} }\max_{\mathbf{X}\in B}\max_{i,j}\mathbf{Q}_{i}^{h}\mathbf{K}_{j}^{h^{\top} },
$$- 其中 \(i,j\) 是训练样本 \(\mathbf{X}\) 中不同 Token 的索引
- QK-Clip 的核心思想是当 \(S_{\text{max} }^{h}\) 超过目标阈值 \(\tau\) 时,重新缩放 \(\mathbf{W}_{k}\) 和 \(\mathbf{W}_{q}\)
- 特别说明:这一操作不会改变当前步骤的前向/反向计算(使用最大 logit 作为指导信号来控制权重的增长强度)
- 一种简单的实现是对所有头同时裁剪:
$$
\mathbf{W}_{q}^{h} \leftarrow \gamma^{\alpha}\mathbf{W}_{q}^{h}, \quad \mathbf{W}_{k}^{h} \leftarrow \gamma^{1-\alpha}\mathbf{W}_{k}^{h},
$$- 其中 \(\gamma = \min(1, \tau/S_{\text{max} })\),\(S_{\text{max} } = \max_{h}S_{\text{max} }^{h}\),\(\alpha\) 是平衡参数,通常设为 0.5,表示对 Query 和 Key 应用相同的缩放比例
- 问题:为什么 Query 和 Key 要分别设计成 \(\gamma^{\alpha}\) 和 \(\gamma^{1-\alpha}\) 呢?
- 回答:因为目标是让 Query 和 Key 的乘积缩小为 \(\gamma\) 倍,而 \(\gamma^{\alpha} * \gamma^{1-\alpha} = \gamma\)
- 但论文的实现是分不同头分别放缩的
- 原因:论文观察到在实践中,只有一小部分头会出现 logits 爆炸,为了最小化对模型训练的干预,论文为每个头确定一个独立的缩放因子,并选择对每个头单独应用 QK-Clip
$$ \gamma_{h} = \min(1, \tau/S_{\text{max} }^{h}) $$ - 这种裁剪对于常规的多头注意力(Multi-head Attention, MHA)是直接的
- 对于 MLA,论文仅对非共享的注意力头组件进行裁剪:
- \(\mathbf{q}^{C}\) 和 \(\mathbf{k}^{C}\)(head-specific components):分别缩放 \(\sqrt{\gamma_{h} }\);
- \(\mathbf{q}^{R}\)(head-specific rotary):缩放 \(\gamma_{h}\);
- \(\mathbf{k}^{R}\)(shared rotary):保持不变以避免跨头影响
- 原因:论文观察到在实践中,只有一小部分头会出现 logits 爆炸,为了最小化对模型训练的干预,论文为每个头确定一个独立的缩放因子,并选择对每个头单独应用 QK-Clip
MuonClip: The New Optimizer
- 作者将 Muon + 权重衰减 + 一致的 RMS 匹配(consistent RMS matching) + QK-Clip 整合为一个优化器,称为 MuonClip(参见算法 1)

- 论文从多项扩展实验中验证了 MuonClip 的有效性:
- 第一步:论文使用原始 Muon 训练了一个中等规模的模型(激活参数 9B,总参数 53B)
- 如图 2(左)所示,最大注意力 logits 迅速超过 1000,表明在这一规模下 Muon 训练中已经出现了明显的注意力 logits 爆炸现象
- 这一水平的最大 logits 通常会导致训练不稳定,包括显著的损失尖峰(loss spike)且偶尔导致发散(divergence)
- 第二步:论文证明了 QK-Clip 不会降低模型性能,并确认 MuonClip 优化器保留了 Muon 的优化特性,且不会对损失轨迹产生负面影响
- 实验设计和发现的详细讨论见附录 D
- 第三步:论文使用 MuonClip(\(\tau = 100\))训练了 Kimi K2 这一大规模 MoE 模型,并在整个训练过程中监控最大注意力 logits(图 2(右))
- 初始阶段,由于 QK-Clip 的作用,logits 被限制在 100 以内
- 随着训练的进行,最大 logits 逐渐衰减至不出所料的操作范围(typical operating rang),无需调整 \(\tau\)
- 重点:训练损失保持平滑稳定,未出现可观测的尖峰(如图 3 所示),验证了 MuonClip 在大规模语言模型训练中对注意力动态的稳健且可扩展的控制能力
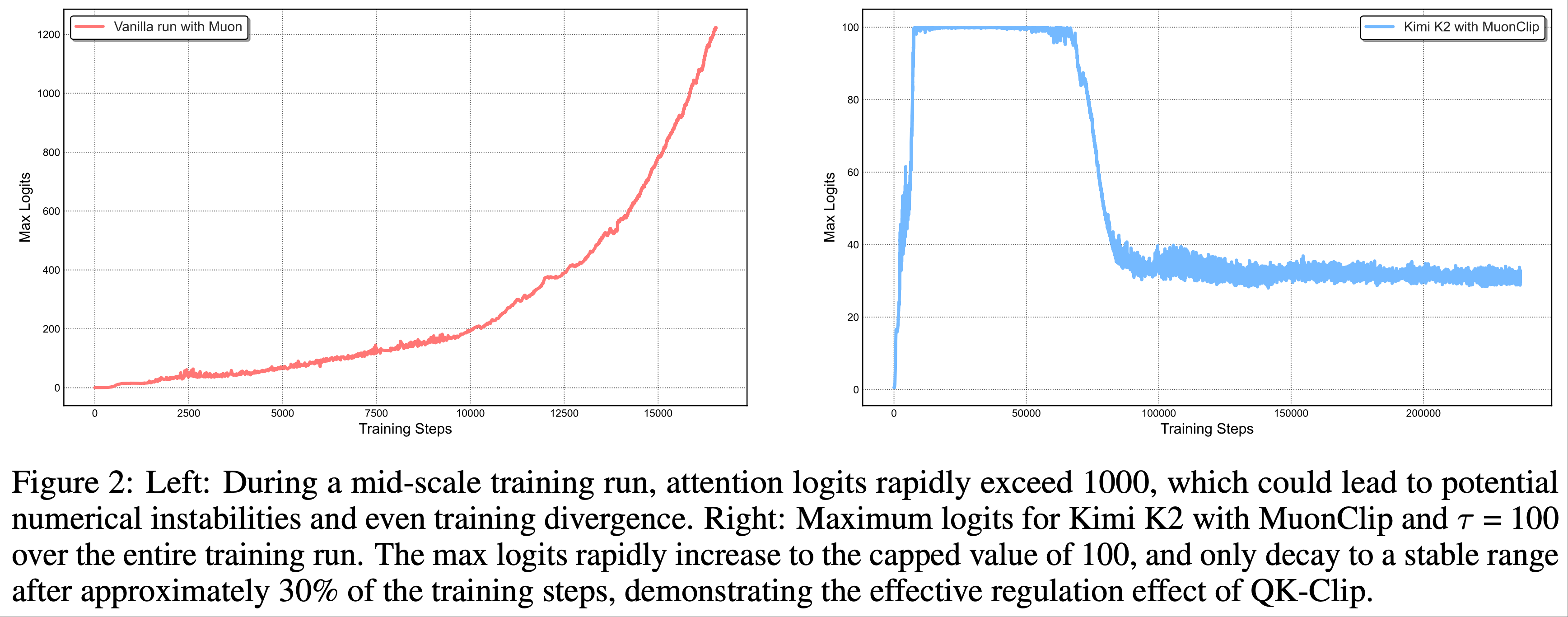
- 第一步:论文使用原始 Muon 训练了一个中等规模的模型(激活参数 9B,总参数 53B)
Pre-training Data: Improving Token Utility with Rephrasing
- 预训练中的 Token Efficiency 是指训练过程中每个消耗的 Token 对模型性能提升的贡献程度
- 提升 Token Utility(即每个 Token 提供的有效学习信号)可以直接改善 Token Efficiency(尤其是在高质量 Token 供应有限的情况下)
- 一种简单提升 Token Utility 的方法是重复 exposure 相同的 Token,但这可能导致过拟合并降低泛化能力
- Kimi K2 预训练数据相较于 Kimi K1.5 的一个关键进步是引入了合成数据生成策略以提升 Token Utility
- 论文采用了一种精心设计的重述流水线(Rephrasing Pipeline),在不引发显著过拟合的情况下扩增高质量 Token 的数量
- 本报告描述了两类针对特定领域(分别为知识领域和数学领域)的重述(Rephrasing)技术,实现了这种受控的数据增强
Knowledge Data Rephrasing
- 在自然、知识密集型文本上的预训练面临一个权衡:单轮训练不足以实现全面的知识吸收,而多轮重复则会导致收益递减并增加过拟合风险
- 为了提升高质量知识 Token 的效用,论文提出了一个合成重述框架,包含以下关键组件:
- 风格和视角多样化的提示(Style- and perspective-diverse promptin) :为了在保持事实完整性的同时增强语言多样性 ,论文应用了一系列精心设计的提示
- 这些提示指导 LLM 以多样化的风格和视角生成对原文的忠实重述
- 分块自回归生成(Chunk-wise autoregressive generation) :为了保留长文档的全局连贯性并避免信息丢失 ,论文采用了基于分块的自回归重写策略
- 文本被分割为多个段落,分别重述后再拼接为完整的篇章
- 这种方法缓解了 LLM 通常存在的隐式输出长度限制
- 该流水线的概述如图 4 所示
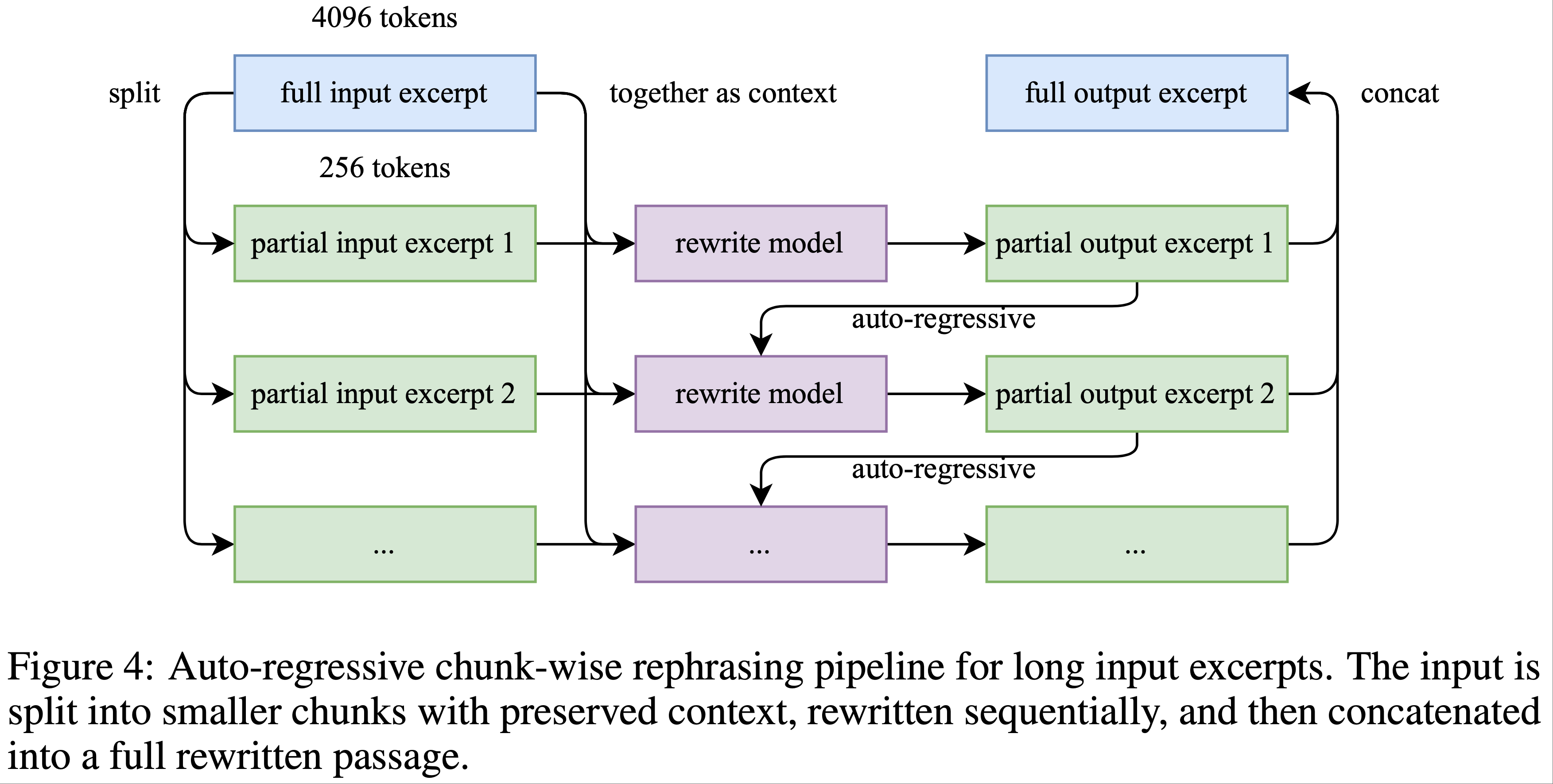
- 保真度验证(Fidelity verification) :为了确保原始内容与重述内容的一致性 ,论文对每段重述内容进行语义对齐检查 ,作为训练前的初步质量控制步骤
- 风格和视角多样化的提示(Style- and perspective-diverse promptin) :为了在保持事实完整性的同时增强语言多样性 ,论文应用了一系列精心设计的提示
- 论文通过测试 SimpleQA 的准确率,比较了数据重述与多轮重复的效果
- 实验使用 K2 的早期检查点,评估了三种训练策略:
- (1) 原始数据集重复 10 轮;
- (2) 数据重述一次后重复 10 轮;
- (3) 数据重述 10 次后单轮训练
- 如表 1 所示,准确率在这些策略中持续提升,证明了基于重述的增强方法的有效性
- 论文将此方法扩展到其他大规模知识语料库,并观察到类似的积极结果,每个语料库最多重述两次

- 实验使用 K2 的早期检查点,评估了三种训练策略:
Mathematics Data Rephrasing
- 为了增强数学推理能力,论文遵循 SwallowMath (2025) 引入的方法,将高质量的数学文档重写为“学习笔记(learning-note)”风格
- 作者还通过将其他语言的高质量数学材料翻译为英语,进一步提升了数据的多样性
- 对数据子集的初步重述实验显示了有希望的结果,但将合成数据作为持续扩展的策略仍是一个活跃的研究领域,关键挑战包括:
- 在不损害事实准确性的情况下将该方法推广到多样化的源领域
- 最小化幻觉和意外的毒性
- 确保其在大规模数据集上的可扩展性
Pre-training Data Overall
- Kimi K2 的预训练语料库包含 15.5T 亿 Token 的精选高质量数据,涵盖四个主要领域:网络文本、代码、数学和知识(Web Text, Code, Mathematics, and Knowledge)
- 大多数数据处理流水线遵循 Kimi K1.5 (2025) 中概述的方法
- TODO:待补充
- 对于每个领域,论文进行了严格的正确性和质量验证 ,并设计了针对性的数据实验,以确保最终数据集兼具高多样性和高效性
Model Architecture
- Kimi K2 是一个拥有 1.04T 参数的 MoE Transformer 模型,激活参数为 32B
- 架构设计与 DeepSeek-V3 (2024) 类似,采用多头潜在注意力(MLA)(2024) 作为注意力机制
- 模型隐藏维度为 7168,MoE 专家隐藏维度为 2048
- 专家数 384,激活专家数 8
- 论文的扩展定律分析表明,持续增加稀疏性可以显著提升性能 ,这促使论文将专家数量增加到 384(DeepSeek-V3 为 256)
- 注意力头数为 64
- 为了减少推理时的计算开销,论文将注意力头数削减至 64(DeepSeek-V3 为 128)
- 表 2 详细对比了 Kimi K2 与 DeepSeek-V3 的架构参数

Sparsity Scaling Law
- 论文为 MoE 模型家族开发了一条基于 Muon 的稀疏性扩展定律
- 稀疏性定义为专家总数与激活专家数的比值
- 通过精心控制的小规模实验,论文观察到:在固定激活参数数量(即恒定 FLOPs)的情况下,增加专家总数(即提高稀疏性)能够持续降低训练和验证损失,从而提升整体模型性能(图 5)
- 在计算最优的稀疏性扩展定律下,要达到相同的验证损失 1.5,稀疏性 48 相比稀疏性 8、16 和 32 分别减少了 1.69 倍、1.39 倍和 1.15 倍的 FLOPs
- 尽管增加稀疏性会带来性能提升,但这一增益伴随着基础设施复杂度的上升
- 为了平衡模型性能与成本,论文为 Kimi K2 选择了稀疏性 48,即每次前向传播激活 384 个专家中的 8 个
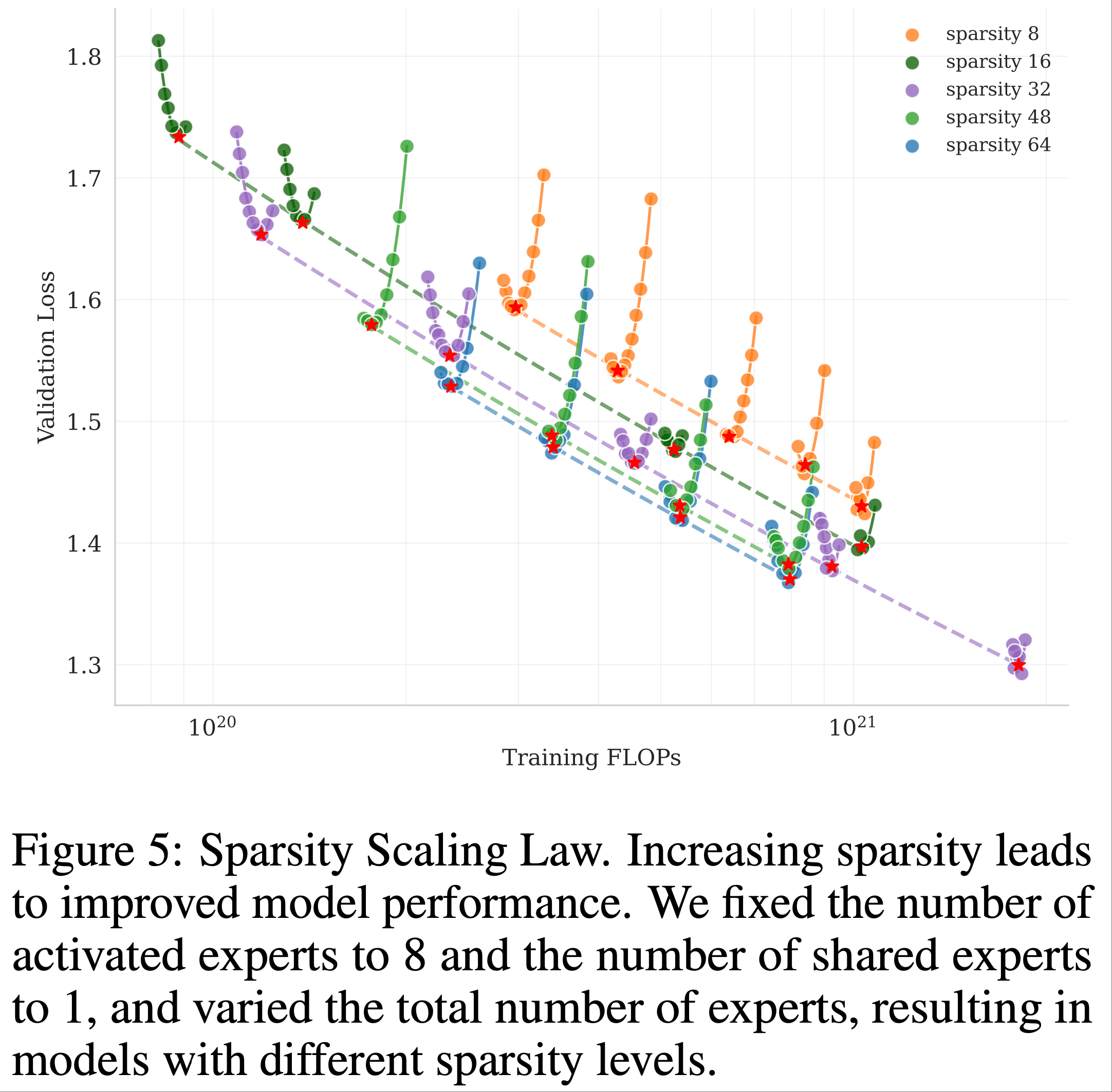
- 问题:为什么图 5 中显示,对于相同的稀疏性,随着训练 FLOPs 的增大,Loss 是先降低后上升的?
- 补充问题:图 5 是在固定激活参数数量(即恒定 FLOPs)的情况下得到的,增大训练的 FLOPs,本质是在修改哪个参数导致的 FLOPs 增加而 激活函数数量不变呢?
Number of Attention Heads
- DeepSeek-V3 (2024) 将注意力头数设置为模型层数的约两倍 ,以更好地利用内存带宽并提升计算效率
- 但是,随着上下文长度的增加,双倍注意力头数(即头数是层数的两倍)会导致显著的推理开销,降低长序列处理的效率
- 因为 Softmax 等操作是每个头都需要做一份的,整体复杂度为 \(O(n^2h)\)(\(n\)是序列长度);此外,太大的头会导致太小的 Attention Embedding 维度,从而不利于显存分块存储和读取?
- 由于代理应用(agentic applications)中常常涉及长上下文处理,所以长序列处理的低效已经成为一个主要限制,下面给出一个例子和实验:
- 在序列长度为 128k 时,将注意力头数从 64 增加到 128(同时保持专家总数 384 不变)会导致推理 FLOPs 增加 83%
- 论文进行了对照实验,比较了在相同 Token 训练条件下,注意力头数等于层数与双倍头数的配置在不同计算预算下的表现
- 结果显示:双倍注意力头数仅带来验证损失的微小改善(约 0.5% 至 1.2%)(图 6)
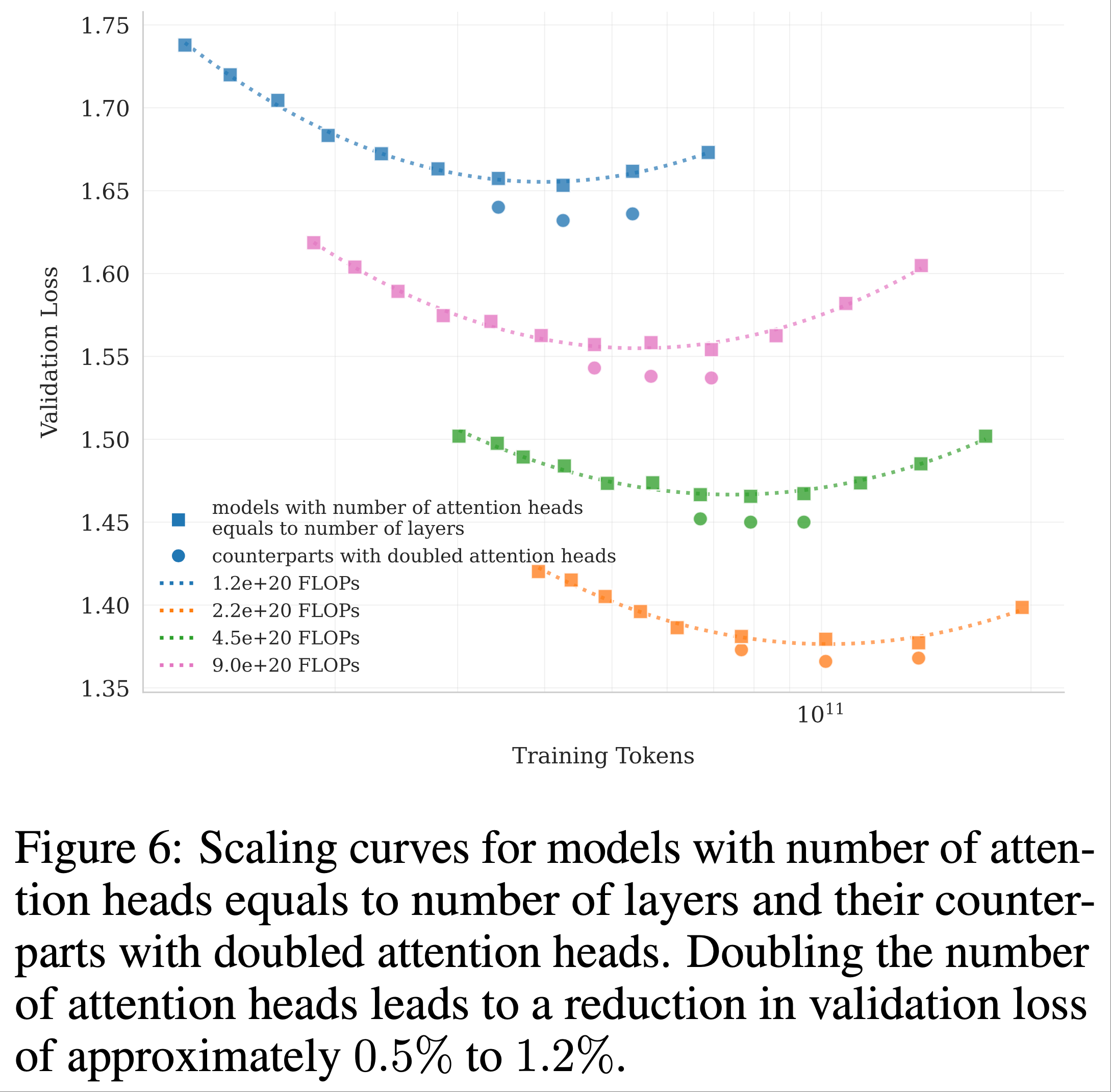
- 鉴于稀疏性 48(sparsity 48) 已经提供了强劲的性能,双倍注意力头数带来的边际增益无法证明其推理成本的合理性,因此论文选择 64 个注意力头
- 问题:sparsity 48 是什么?
- 回答:是上一小节提到的概念,sparsity = 总头数 / 激活头数
Sparsity is defined as the ratio of the total number of experts to the number of activated experts
- 问题:为什么图 6 中显示,对于相同的 FLOPs,随着训练 Token 的增大,Loss 是先降低后上升的?
- 补充问题:是因为训练 Token 提升时,为了保证 FLOPs 不变,需要减少模型参数吗?具体减少的是什么参数呢?
- 问题:为什么图 6 中显示,对于相同的 FLOPs,随着训练 Token 的增大,Loss 是先降低后上升的?
Training Infrastructure
Compute Cluster
- Kimi K2 在配备 NVIDIA H800 GPU 的集群上进行训练
- 每个 H800 集群节点包含 2TB RAM 和 8 个通过 NVLink 和 NVSwitch 连接的 GPU
- NVSwitch 是什么?
- 节点间通过 8 条 400 Gbps RoCE 互连实现通信
Parallelism for Model Scaling
- LLM 的训练通常在动态资源可用性的情况下进行
- 论文采用了一种灵活的策略,使得 Kimi K2 可以在任意 32 的整数倍节点数上训练
- 论文的策略结合了 16 路流水线并行(Pipeline Parallelism, PP)与 Virtual Stages (2023;)、16 路专家并行(Expert Parallelism, EP)(2020) 以及 ZeRO-1 数据并行 (2020)
- 问题:Virtual Stages 是什么?
- 在此设置下
- 以 BF16 存储模型参数并以 FP32 存储梯度累积缓冲区,大约需要 6TB 的 GPU 内存,分布在 256 个 GPU 的模型并行组中
- 优化器状态的放置取决于训练配置
- 当训练节点总数较大时,优化器状态被分布式存储,从而将每个设备的存储占用降至可忽略的水平
- 当训练节点总数较小(例如 32)时,可以将部分优化器状态卸载到 CPU
- 这种方法允许论文在小规模和大规模实验中复用相同的并行配置,同时让每个 GPU 保留约 30 GB 的 GPU 内存用于存储所有状态
- 剩余的 GPU 内存用于存储激活值,如第 2.4.3 节所述
- 这种一致的设计提高了研发效率(简化了系统并显著加快了实验迭代速度)
- EP 通信与交错 IF1B 的重叠(EP communication overlap with interleaved 1F1B)
- 通过增加预热微批次的数量,我们可以在标准的交错 IF1B 调度 (2023, 2023) 下将 EP 的 all-to-all 通信与计算重叠
- 相比之下,DualPipe (2024) 会使参数和梯度的内存需求翻倍,需要通过增加并行度来补偿
- 增加 PP 会引入更多气泡,而增加 EP(如下所述)会带来更高的开销
- 这些额外成本对于训练一个拥有超过 1T 参数的大型模型来说过高,因此论文选择不使用 DualPipe
- 问题:1F1B 调度是什么?
- 但交错 IF1B 将模型分割为更多阶段,引入了显著的 PP 通信开销
- 为了缓解这一成本,论文将权重梯度计算从每个微批次的反向传播中解耦,并将其与相应的 PP 通信并行执行
- 因此,除了预热阶段外,所有 PP 通信都可以有效重叠
- 通过增加预热微批次的数量,我们可以在标准的交错 IF1B 调度 (2023, 2023) 下将 EP 的 all-to-all 通信与计算重叠
- 更小的 EP 规模(Smaller EP size)
- 为了确保在 IF1B 阶段实现完全的计算-通信重叠,K2 中减少的注意力计算时间(与 DeepSeek-V3 的 128 头相比,K2 为 64 头)需要最小化 EP 操作的时间
- 这是通过采用最小的可行 EP 并行化策略(具体为 EP = 16)实现的
- 使用更小的 EP 组还放宽了专家平衡约束,无需进一步调优即可实现接近最优的速度
Activation Reduction
- 在保留参数、梯度缓冲区和优化器状态的空间后,每个设备上剩余的 GPU 内存不足以保存完整的 MoE 激活值
- 为了确保激活内存适应约束条件,特别是对于在 IF1B 预热阶段累积最大激活值的初始流水线阶段,论文采用了以下技术
- 选择性重计算(Selective recomputation)
- 重计算应用于成本低但占用空间大的阶段,包括 LayerNorm、SwiGLU 和 MLA 上投影 (2024)
- 此外,MoE 下投影在训练期间被重计算以进一步减少激活内存(可选的)
- 这种重计算保持了足够的 GPU 内存,防止了早期训练阶段因专家不平衡导致的崩溃
- 对不敏感激活值的 FP8 存储(FP8 storage for insensitive activations)
- MoE 上投影和 SwiGLU 的输入被压缩为 FP8-E4M3,以 1×128 块为单位,并带有 FP32 缩放因子
- 小规模实验显示没有可测量的损失增加
- 由于在初步研究中观察到的性能下降风险,论文没有在计算中应用 FP8
- 激活值 CPU 卸载(Activation CPU offload)
- 所有剩余的激活值被卸载到 CPU RAM
- 一个复制引擎负责流式传输卸载和加载,与计算和通信内核重叠
- 在 IF1B 阶段,论文在预取下一个微批次的反向激活值的同时卸载前一个微批次的前向激活值
- 预热和冷却阶段的处理方式类似,整体模式如图 7 所示
- 尽管卸载可能因 PCIe 流量拥塞略微影响 EP 通信,但论文的测试表明 EP 通信仍能完全重叠
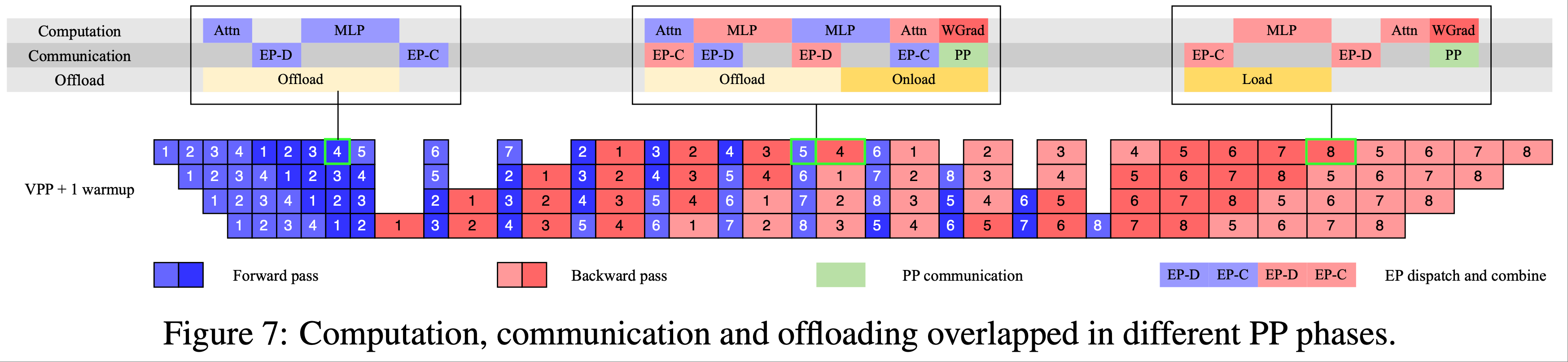
Training recipe
- 论文使用 MuonClip 优化器(算法 2)和 WSD 学习率调度 (2024) 对模型进行了预训练,上下文窗口为 4096 Token,共处理了 15.5T Token
- 前 10T Token 以恒定学习率 2e-4 训练(500 步预热),随后 5.5T Token 以从 2e-4 到 2e-5 的余弦衰减学习率训练
- 权重衰减始终设置为 0.1,全局批次大小保持在 67M Token
- 整体训练曲线如图 3 所示
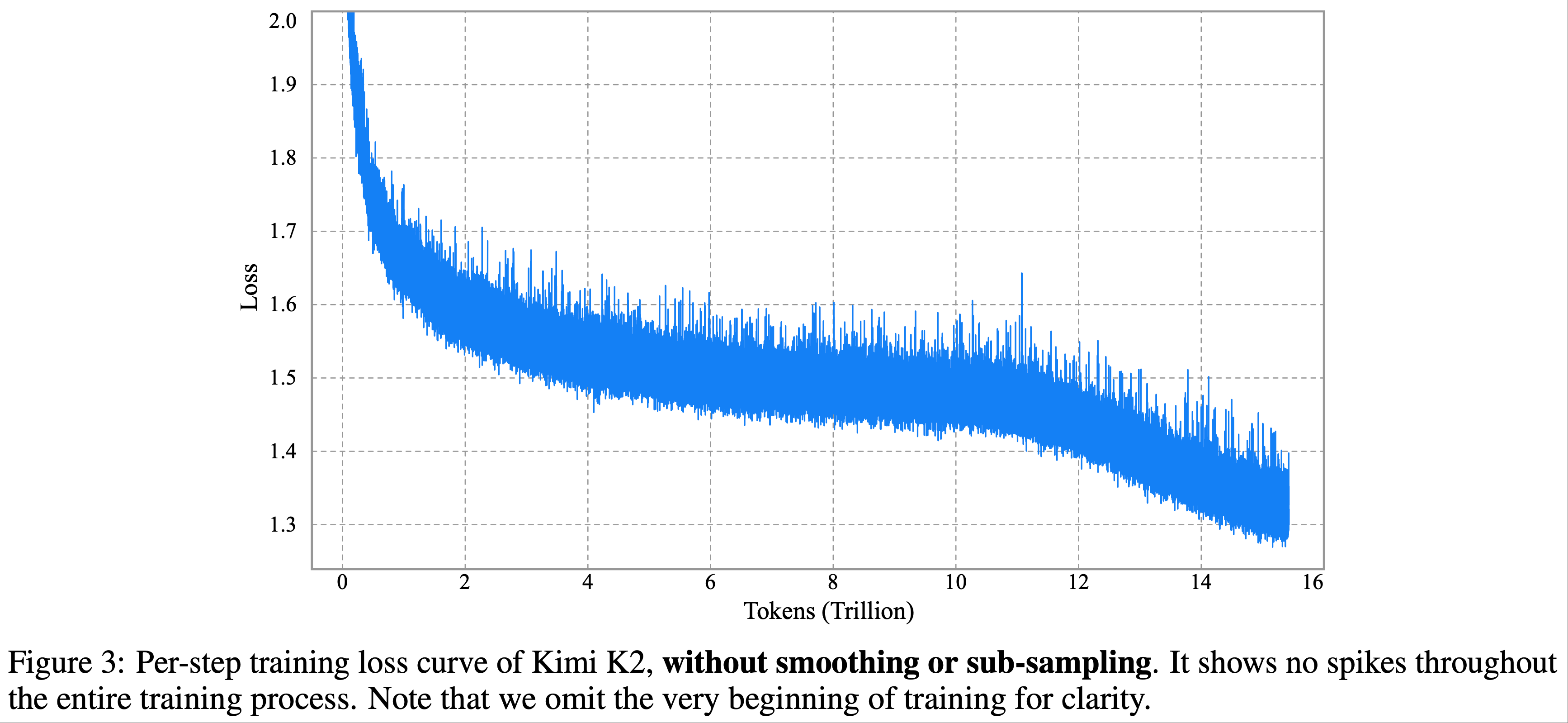
- 在预训练接近结束时,论文进行了退火阶段,随后是长上下文激活阶段
- 批次大小保持在 67M Token,学习率从 2e-5 衰减至 7e-6
- 在此阶段,模型在 400B Token 上以 4k 序列长度训练,随后在 60B Token 上以 32k 序列长度训练
- 论文采用了 YaRN 方法 (2023) 将上下文窗口扩展到 128k
Post-training
SFT
- 在 后训练 阶段,论文采用 Muon 优化器(2015)并推荐将其用于 K2 的微调
- 这一选择基于论文先前工作(2025)的结论:使用 Muon 预训练的检查点在 Muon 微调下表现最佳
- 论文构建了一个涵盖多样化领域的大规模指令微调数据集,其设计遵循两大核心原则 :最大化提示多样性(prompt diversity)和确保高质量响应
- 论文开发了一套针对不同任务领域的数据生成流程,每个流程结合了人工标注、提示工程和验证过程
- 论文采用 K1.5(2025)和其他内部领域专家模型为各类任务生成候选响应,随后通过 LLM 或人工评审进行自动化质量评估与过滤
- 对于智能体(agentic)数据,论文创建了一个数据合成流程,通过多步骤交互式推理教授模型工具使用能力
Large-Scale Agentic Data Synthesis for Tool Use Learning
- 现代 LLM 智能体的一项关键能力是自主使用陌生工具、与外部环境交互,并通过推理、执行和纠错迭代优化其行为
- 智能体工具使用能力对于解决需要与现实系统动态交互的复杂多步骤任务至关重要
- 近期基准测试如
- ACEBench(2025)和 \(\tau\)-bench(2025)强调了全面评估工具使用的重要性
- ToolLLM(2023)和 ACEBench(2025)等框架展示了让模型有效使用数千种工具的潜力
- 但大规模训练此类能力面临显著挑战:尽管真实环境提供丰富且真实的交互信号,但由于成本、复杂性、隐私和可访问性限制,通常难以大规模构建
- 近期合成数据生成的研究(AgentInstruct 2024;Self-Instruct 2022;StableToolBench 2025;ZeroSearch 2025)在不依赖真实交互的情况下创建大规模数据已取得成果
- 基于这些进展并受 ACEBench(2025)综合数据合成框架的启发,论文开发了一个流程,可大规模模拟真实世界工具使用场景,生成数万种多样且高质量的训练样本
- 论文的数据合成流程包含三个阶段(如图 8 所示):
- 第一步:工具规范生成(Tool spec generation) :从真实工具和 LLM 合成工具中构建大型工具库;
- 第二步:智能体与任务生成(Agent and task generation) :从工具库中采样工具,并为每组工具生成一个使用该工具集的智能体及其对应任务;
- 第三步:轨迹生成(Trajectory generation) :为每个智能体和任务生成轨迹,其中智能体通过调用工具完成任务
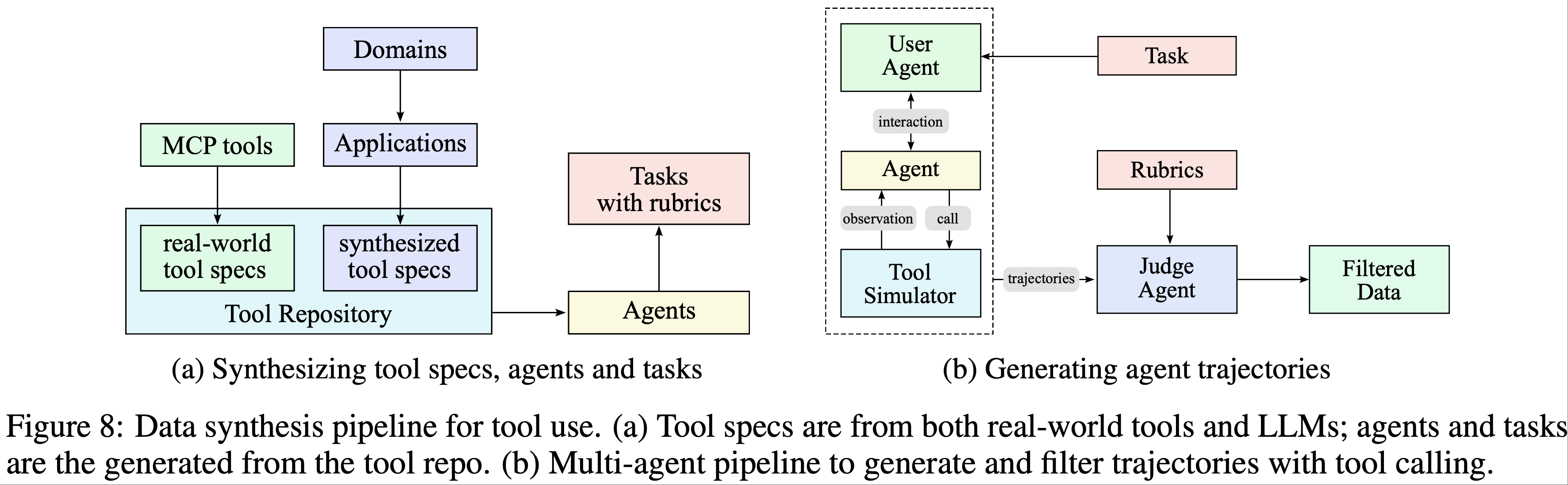
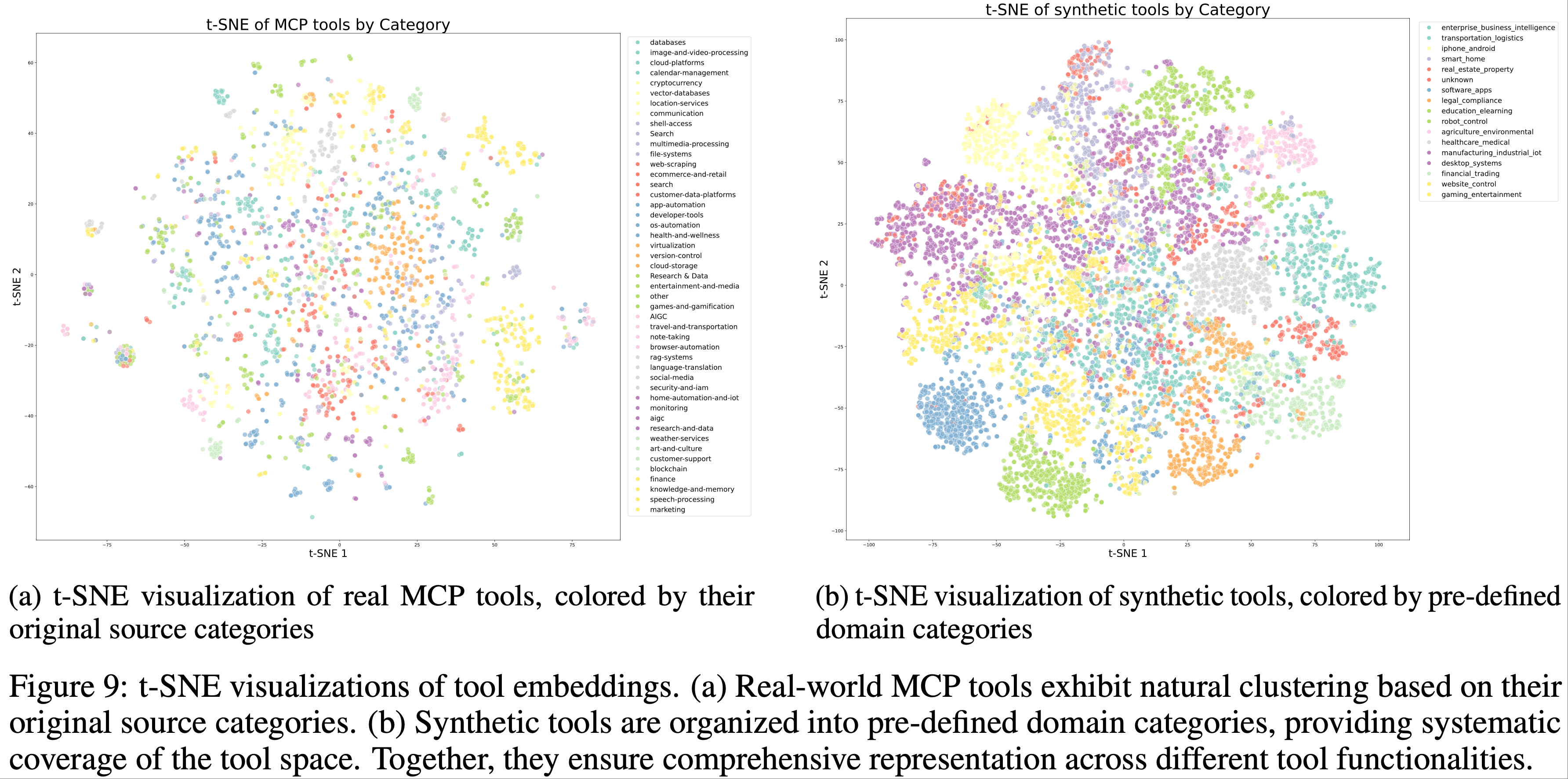
- 领域演化与工具生成(Domain Evolution and Tool Generation) :论文通过两种互补方法构建全面的工具库
- 第一步:直接从 GitHub 仓库获取 3000+ 真实 MCP(Model Context Protocol)工具,利用现有高质量工具规范
- 第二步:通过分层领域生成过程,系统地演化(2025)合成工具:
- 从关键类别(如金融交易、软件应用、机器人控制)开始
- 在每个类别内演化多个具体应用领域
- 随后为每个领域合成专用工具,明确接口、描述和操作语义
- 此过程生成超过 20,000 种合成工具
- 图 9 通过 t-SNE 嵌入可视化工具集的多样性,显示 MCP 和合成工具覆盖了工具空间的互补区域
- 智能体多样化(Agent Diversification)
- 通过合成多样化系统提示并为智能体配备工具库中的不同工具组合,论文生成数千种独特智能体
- 这创造了能力、专业领域和行为模式各异的智能体群体,确保广泛覆盖潜在用例
- 基于准则的任务生成(Rubric-Based Task Generation)
- 为每种智能体配置生成从简单到复杂操作的任务
- 每个任务配有明确准则,指定成功标准、预期工具使用模式及评估检查点
- 这种基于准则的方法确保对智能体性能的一致且客观的评估
- 多轮次轨迹生成(Multi-turn Trajectory Generation) ,通过以下组件模拟真实工具使用场景:
- 用户模拟(User Simulation) :LLM 生成的具有不同沟通风格和偏好的用户角色与智能体进行多轮对话,形成自然交互模式;
- 工具执行环境(Tool Execution Environment) :功能等效于世界模型的复杂工具模拟器执行工具调用并提供真实反馈
- 模拟器在每次工具执行后维护和更新状态,支持具有持久效果的复杂多步骤交互,并引入受控随机性以产生包括成功、部分失败和边缘情况在内的多样化结果
- 质量评估与过滤(Quality Evaluation and Filtering)
- LLM-based 评审员(LLM-based judge)根据任务准则评估每条轨迹
- 仅保留满足成功标准的轨迹用于训练 ,确保高质量数据的同时允许任务完成策略的自然变化
- 结合真实执行环境的混合方法(Hybrid Approach with Real Execution Environments)
- 模拟提供了可扩展性,但模拟保真度(simulation fidelity)仍存在固有局限
- 论文在真实性至关重要的场景(特别是编码和软件工程任务)中补充真实执行沙盒
- 这些沙盒执行实际代码,与真实开发环境交互,并通过 test suite 通过率等客观指标提供真实反馈
- 这种组合确保模型从模拟场景的多样性和真实执行的真实性中学习,显著增强实际智能体能力
- 结合可扩展模拟与针对性真实执行的混合流程,论文生成多样化、高质量的工具使用演示,平衡了覆盖范围与真实性
- 合成数据生成的规模化和自动化,加上真实执行环境的 grounding,通过质量过滤流程有效实现了大规模拒绝采样(2022;2025)
- 这种高质量合成数据用于监督微调时,显著提升了模型在广泛实际应用中的工具使用能力
Reinforcement Learning
- RL 被认为比 SFT 具有更好的 Token Efficiency 和泛化性
- 基于 K1.5(2025)的工作,论文在 K2 中继续扩大 RL 的任务多样性和训练 FLOPs
- 论文开发了一个类似 Gym 的可扩展框架 ,支持跨多种场景的 RL
- 论文通过大量可验证奖励任务扩展该框架
- 对于依赖主观偏好(subjective preferences)的任务(如创意写作和开放式问答),引入自评奖励机制(self-critic reward),模型通过成对比较判断自身输出
- 这种方法使得来自不同领域的任务都能受益于 RL 范式
Verifiable Rewards Gym
- 数学、STEM 与逻辑任务(Math, STEM and Logical Tasks) :对于数学、STEM 和逻辑推理领域,论文的 RL 数据准备遵循两大原则:多样化覆盖(diverse coverage)和适度难度(moderate difficulty)
- 多样化覆盖 :对于数学和 STEM 任务,论文结合专家标注、内部 QA 提取流程和公开数据集(2025;2024)收集高质量问答对
- 在收集过程中,利用标签系统刻意增加低覆盖领域的样本
- 对于逻辑任务,数据集包含多种格式,包括结构化数据任务(如多跳表格推理、跨表聚合)和逻辑谜题(如 24 点游戏、数独、谜语、密码算术和摩尔斯电码解码)
- 适度难度 :RL 提示集应既不太简单也不太困难,两者都可能产生较少信号并降低学习效率
- 论文使用 SFT 模型的 pass@k 准确率评估每个问题的难度 ,仅选择中等难度的问题
- 多样化覆盖 :对于数学和 STEM 任务,论文结合专家标注、内部 QA 提取流程和公开数据集(2025;2024)收集高质量问答对
- 复杂指令跟随(Complex Instruction Following) :有效的指令跟随不仅需要理解显式约束 ,还需处理隐式需求、边缘案例和保持长对话一致性;论文通过结合自动化验证与对抗检测的混合验证框架,以及可扩展的课程生成流程应对这些挑战;具体采用双路径系统确保精确性和鲁棒性:
- 混合规则验证(Hybrid Rule Verification) :实现两种验证机制:
- (1) 通过代码解释器对可验证输出的指令(如长度、风格约束)进行确定性评估;
- (2) 对需要细微理解约束的指令使用 LLM 作为评审员
- 为解决模型可能虚假声称满足指令的对抗行为,额外加入专门检测此类欺骗性声明的 hack-check 层
- 多源指令生成(Multi-Source Instruction Generation) :采用三种生成策略确保全面覆盖:
- (1) 数据团队开发的专家编写的复杂条件提示和说明(rubrics);
- (2) 受 AutoIF(2024)启发的智能体指令增强;
- (3) 针对生成探测特定故障模式或边缘案例指令的微调模型
- 这种多管齐下的方法确保指令覆盖的广度和深度
- 混合规则验证(Hybrid Rule Verification) :实现两种验证机制:
- 忠实性(Faithfulness) 对于多轮工具使用、自生成推理链和开放环境交互等场景,忠实性至关重要
- 受 FACTS Grounding(2025)评估框架启发,论文训练了一个句子级忠实性评审模型进行自动化验证
- 该评审模型能有效检测上下文中无证据支持的 factual claim ,将该评审模型作为奖励模型以提升整体忠实性表现
- 问题:为什么是上下文中无证据支持的?不应该是有证据支持的才是事实句子吗?
- 回答:这里应该是表达检测出申明为事实,但实际无证据支撑的(作为负奖励)
- Coding & Software Engineering
- Coding :为增强解决竞赛级编程问题的能力,论文从开源数据集(2023;2025)和合成来源收集问题及其评审器(problems and their judges)
- 为确保合成数据的多样性和奖励信号的正确性,论文整合了从预训练数据中检索的高质量人工编写单元测试
- Software Engineering :对于软件工程任务,论文从 GitHub 收集大量拉取请求和问题,构建包含用户提示/问题和可执行单元测试的软件开发环境
- 该环境基于强大的沙盒基础设施,由 Kubernetes 提供可扩展性和安全性支持,可稳定运行 10,000+ 并发沙盒实例,非常适合竞赛编程和软件工程任务
- Coding :为增强解决竞赛级编程问题的能力,论文从开源数据集(2023;2025)和合成来源收集问题及其评审器(problems and their judges)
- 安全性(Safety) :论文通过人工策划的种子提示集开始安全性增强工作,手动设计涵盖暴力、欺诈和歧视等主流风险类别
- 为模拟复杂越狱尝试(如角色扮演、文学叙事和学术讨论),论文采用包含三个关键组件的自动化提示演化流程:
- 攻击模型(Attack Model) :迭代生成旨在从目标 LLM 引发不安全响应的对抗提示;
- 目标模型(Target Model) :生成对这些提示的响应,模拟潜在漏洞;
- 评审模型(Judge Model) :评估交互以判断对抗提示是否成功绕过安全机制
- 每次交互使用任务特定准则评估,使评审模型能提供二元成功/失败标签
- 为模拟复杂越狱尝试(如角色扮演、文学叙事和学术讨论),论文采用包含三个关键组件的自动化提示演化流程:
Beyond Verification: Self-Critique Rubric Reward
- 为将模型对齐扩展至无可验证奖励的任务,论文引入了一个基于自评反馈的通用强化学习框架
- 该方法旨在通过将从可验证场景学到的能力扩展至更广泛的主观任务,使 LLM 与人类偏好(如帮助性、创造性、推理深度、事实性和安全性)对齐
- 框架通过自评准则奖励(Self-Critique Rubric Reward)机制运行,模型通过评估自身输出来生成偏好信号
- 为引导 K2 成为合格评审员,论文在 SFT 阶段混合开源和内部偏好数据集初始化其评审能力
- 自评策略优化(Self-Critiqued Policy Optimization)
- 在学习循环的第一核心过程中
- K2 Actor 为覆盖广泛用例的通用提示生成响应;
- K2 Critic 随后通过成对评估结合以下指标对所有结果排序:
- 核心准则(Appendix. F.1)(代表 Kimi 珍视的 AI 助手核心价值)
- 规定性准则(Appendix. F.2)(旨在消除奖励黑客行为)
- 人工标注准则(数据团队为特定指令上下文设计)
- 尽管某些准则可设为强制,K2 仍保留根据内部先验权衡的灵活性
- 这种能力确保模型响应在适应特定指令的同时,与其核心身份保持一致
- 在学习循环的第一核心过程中
- 闭环评审优化与对齐(Closed-Loop Critic Refinement and Alignment)
- 在 RL 训练期间,评审模型通过可验证信号优化:从可验证奖励提示生成的 on-policy rollouts 用于持续更新评审者 ,这一关键步骤将 RLVR 的客观性能信号蒸馏至评估模型中
- 这种迁移学习过程将其对缺乏显式奖励信号的复杂任务的主观判断 grounded 于可验证数据,使得从可验证任务获得的性能提升能增强评审者对复杂任务的判断力
- 这一闭环流程确保评审者随策略演化同步重新校准评估标准
- 通过将主观评估建立在可验证数据上,该框架实现了与(复杂且不可验证的)人类目标对齐 ,而且这个对齐过程是稳健且可扩展的
- 这种整体对齐在用户意图理解、创意写作、复杂推理和细微语言理解等广泛领域带来全面性能提升
user intent understanding, creative writing, complex reasoning, and nuanced language comprehension
RL Algorithm
- 论文采用 K1.5(2025)引入的策略优化算法作为 K2 的基础
- 对于每个问题 \(x\),论文从旧策略 \(\pi_{\text{old} }\) 采样 \(K\) 个响应 \(\{y_1, \ldots, y_k\}\),并针对以下目标优化模型 \(\pi_\theta\):
$$
L_{\text{RL} }(\theta) = \mathbb{E}_{x\sim\mathcal{D} } \left[ \frac{1}{K} \sum_{i=1}^K \left( r(x,y_i) - \bar{r}(x) - \tau \log \frac{\pi_\theta(y_i|x)}{\pi_{\text{old} }(y_i|x)} \right)^2 \right],
$$- \(\bar{r}(x) = \frac{1}{k} \sum_{i=1}^k r(x,y_i)\) 是采样响应的平均奖励
- \(\tau > 0\) 是促进稳定学习的正则化参数
- 与 SFT 相同,论文采用 Muon 优化器(2015)最小化该目标
- K2 中将 RL 训练扩展至更广泛任务领域,并在RL 算法中引入多项改进,目标是实现所有领域实现一致的性能提升
- 改进一:预算控制(Budget Control)
- RL 常导致模型生成响应长度大幅增加(2025;2019)
- 一般来说,更长响应使模型能利用额外测试时计算提升复杂推理任务性能
- 但在非推理领域,难以证明其推理成本带来的收益
- 为鼓励模型合理分配推理预算,论文在 RL 训练中强制实施基于任务类型的每样本最大 Token 预算(per-sample maximum token budget)
- 超出该预算的响应将被截断并受到惩罚,激励模型在指定限制内生成解决方案
- 实证表明,该方法显著提升模型的 Token Efficiency,鼓励所有领域生成简洁而有效的解决方案
- RL 常导致模型生成响应长度大幅增加(2025;2019)
- 改进二:PTX 损失(PTX Loss)
- 论文精选包含人工筛选高质量样本的数据集,并通过辅助 PTX 损失(2022)将其整合至 RL 目标
- PTX Loss 通常指的是把 Pre-Training 的 Loss 加入到 RLHF 阶段,最早提出于 Training language models to follow instructions with human feedback, 2022, OpenAI
- PTX Loss 用于防止联合 RL 训练期间遗忘有价值的高质量数据
- 该策略不仅利用高质量数据优势,还缓解对训练机制中显式存在的有限任务集过拟合的风险
- 这一增强显著提升模型在更广泛领域的泛化能力
- 论文精选包含人工筛选高质量样本的数据集,并通过辅助 PTX 损失(2022)将其整合至 RL 目标
- 温度衰减(Temperature Decay)
- 对于创意写作和复杂推理等任务,论文发现初始训练阶段通过高采样温度促进探索至关重要
- 高温允许模型生成多样化和创新性响应,从而促进有效策略的发现并降低过早收敛至次优解的风险
- 但在训练后期或评估阶段保持高温可能有害,因其引入过多随机性并损害模型输出的可靠性和一致性
- 论文采用温度衰减计划,在训练过程中从探索逐渐转向利用
- 该策略确保模型在最有裨益时利用探索,最终收敛于稳定且高质量的输出
- 对于创意写作和复杂推理等任务,论文发现初始训练阶段通过高采样温度促进探索至关重要
RL Infrastructure
Colocated Architecture
- 与 K1.5(2025)类似,论文为同步 RL 训练采用混合共置架构(hybrid colocated architecture),其中训练和推理引擎位于相同 worker 上
- 当一个引擎活跃工作时,另一个引擎释放或卸载其 GPU 资源以适配
- 在每次 RL 训练迭代中,中央控制器首先调用推理引擎生成新训练数据,随后通知训练引擎在新数据上训练,并将更新后的参数发送至推理引擎用于下一迭代
- 每个引擎均针对吞吐量高度优化。此外,随着模型规模扩展至 K2 级别,引擎切换和故障恢复的延迟变得显著。论文在这些方面的系统设计考量如下
Efficient Engine Switching
- 在 rollout 期间,训练引擎的参数被卸载至 DRAM。因此启动训练引擎仅是简单的 H2D 传输步骤。然而,启动推理引擎挑战更大,因其需从训练引擎获取采用不同分片范式的更新参数
- 鉴于 K2 的规模和涉及的大量设备,使用网络文件系统进行重新分片和广播参数不切实际,保持低开销所需的聚合带宽达每秒数 PB。为解决该挑战,论文开发了位于训练节点上的分布式检查点引擎以管理参数状态
- 执行参数更新时
- 每个检查点引擎 worker 从训练引擎获取参数的本地副本
- 随后跨所有检查点引擎 worker 广播完整参数集
- 接着推理引擎仅从检查点引擎检索所需参数分片
- 该流程如图 10 所示。为实现 1T 模型的该操作,更新以流水线方式逐参数执行,最小化内存占用(见 Appendix G)
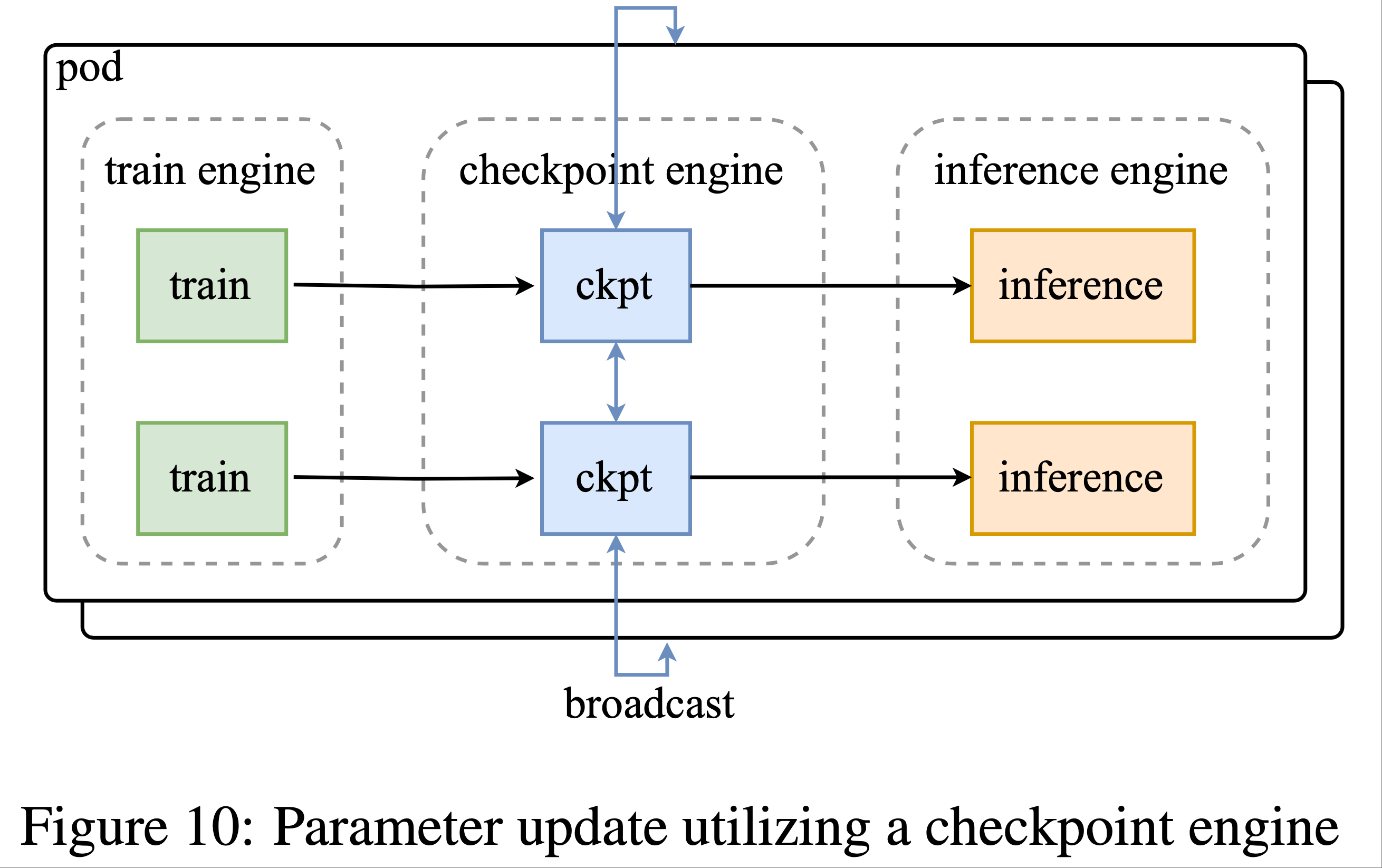
- 执行参数更新时
- 论文选择跨整个集群广播完整参数集,无论各推理 worker 的特定分片方案如何。尽管这比理论最优方法传输多倍数据,但其提供了更简单的系统设计,对训练和推理引擎的侵入性更低。论文选择以这一微小开销为代价,完全解耦训练引擎与推理引擎,显著简化维护和测试
- 值得注意的是,该方法优于“按需传输”方法,因其降低同步开销并提高网络带宽利用率。论文的系统可在不到 30 秒内完成 Kimi K2 的完整参数更新,对于典型 RL 训练迭代可忽略不计
Efficient System Startup
- 由于大规模训练易受系统故障影响,对 Kimi K2 等大型模型优化启动时间至关重要
- 启动训练引擎时,论文让每个训练 worker 选择性地从磁盘读取部分或无参数,并向其对等节点广播必要参数。设计目标是确保所有 worker 集体仅读取检查点一次,最小化昂贵磁盘 IO
- 由于推理引擎是独立副本,作者希望避免引入额外同步屏障。因此,论文选择重用检查点引擎启动:让检查点引擎集体从磁盘读取检查点,类似训练引擎启动方式。随后使用前一节介绍的方法更新未初始化推理引擎的状态。通过利用专用检查点引擎,系统还对单点故障具有鲁棒性,因为推理副本可无需与其他副本通信而重启
Agentic Rollout
- 论文的 RL 基础设施支持长视野、多轮智能体任务的训练。在 rollout 期间,这些任务呈现独特挑战,如复杂环境交互和延长 rollout 持续时间。以下介绍缓解这些问题的优化
- 由于环境多样性,某些交互可能因等待环境反馈(如虚拟机或代码解释器)而阻塞,导致 GPU 闲置。论文采用两种策略最大化 GPU 利用率:
- (i) 将重型环境部署为可更易扩展的专用服务;
- (ii) 使用大量并发 rollouts 分摊某些昂贵交互引发的延迟
- 智能体 rollout 的另一挑战是单个 rollout 轨迹可能极长
- 为防止长尾轨迹阻塞整个 rollout 流程,论文采用 部分 rollout(2025)技术(partial rollout technique)
- 该策略允许暂停未完成的长期任务,并在下一 RL 迭代中恢复
- 为提高研究效率,论文还设计了受 OpenAI Gym 框架(2025)启发的统一接口,以简化新环境的集成
- 作者希望未来将 RL 基础设施扩展至更多样化的交互环境
Evaluations
- 本节首先对 Kimi-K2-Instruct 进行后训练评估,随后简要概述 Kimi-K2-Base 的能力,最后进行全面的安全性评估
Post-training Evaluations
Evaluation Settings
- Benchmarks :在多个领域评估 Kimi-K2-Instruct 的表现
- 编码任务(Coding) :采用 LiveCodeBench v6(2024 年 8 月至 2025 年 5 月的题目)、OJBench、MultiPL-E、SWE-bench Verified、TerminalBench、Multi-SWE-bench、SWE-Lancer、PaperBench 和 Aider-Polyglot
- 工具使用任务(Tool Use Tasks) :评估多轮工具调用能力,重点关注 \(\tau^2\)-Bench 和 ACEBench
- 推理任务(Reasoning) :涵盖数学、科学和逻辑任务,包括 AIME 2024/2025、MATH-500、HMMT 2025、CNMO 2024、PolyMath-en、ZebraLogic、AutoLogi、GPQA-Diamond、SuperGPQA 和 Humanity’s Last Exam(仅文本)
- 长上下文能力(Long-context Capabilities) :评估 MRCR4(长上下文检索)、DROP、FRAMES 和 LongBench v2(长上下文推理)
- 事实性(Factuality) :使用 FACTS Grounding、Vectara Hallucination Leaderboard 和 FaithJudge 评估
- 通用能力(General Capabilities) :通过 MMLU、MMLU-Redux、MMLU-Pro、IFEval、Multi-Challenge、SimpleQA 和 LiveBench(截至 2024-11-25)评估
- Baselines :对比了开源和专有前沿模型,确保所有候选模型在非思考模式下评估,以消除测试时计算带来的额外增益
- 开源基线 :DeepSeek-V3-0324 和 Qwen3-235B-A22B(后者在无思考模式下运行)
- 专有基线 :Claude Sonnet 4、Claude Opus 4、GPT-4.1 和 Gemini 2.5 Flash Preview(2025-05-20),均通过官方 API 在统一温度和 top-p 设置下调用
- 评估配置(Evaluation Configurations)
- 所有模型在非思考模式下运行,输出长度上限为 8192 个 Token(SWE-bench Verified 除外,上限为 16384)
- 对于高方差基准测试,论文采用重复采样 \(k\) 次并取平均值(记为 Avg@\(k\))
- 长上下文任务的上下文窗口设置为 128K Token,超出部分截断
Evaluation Results
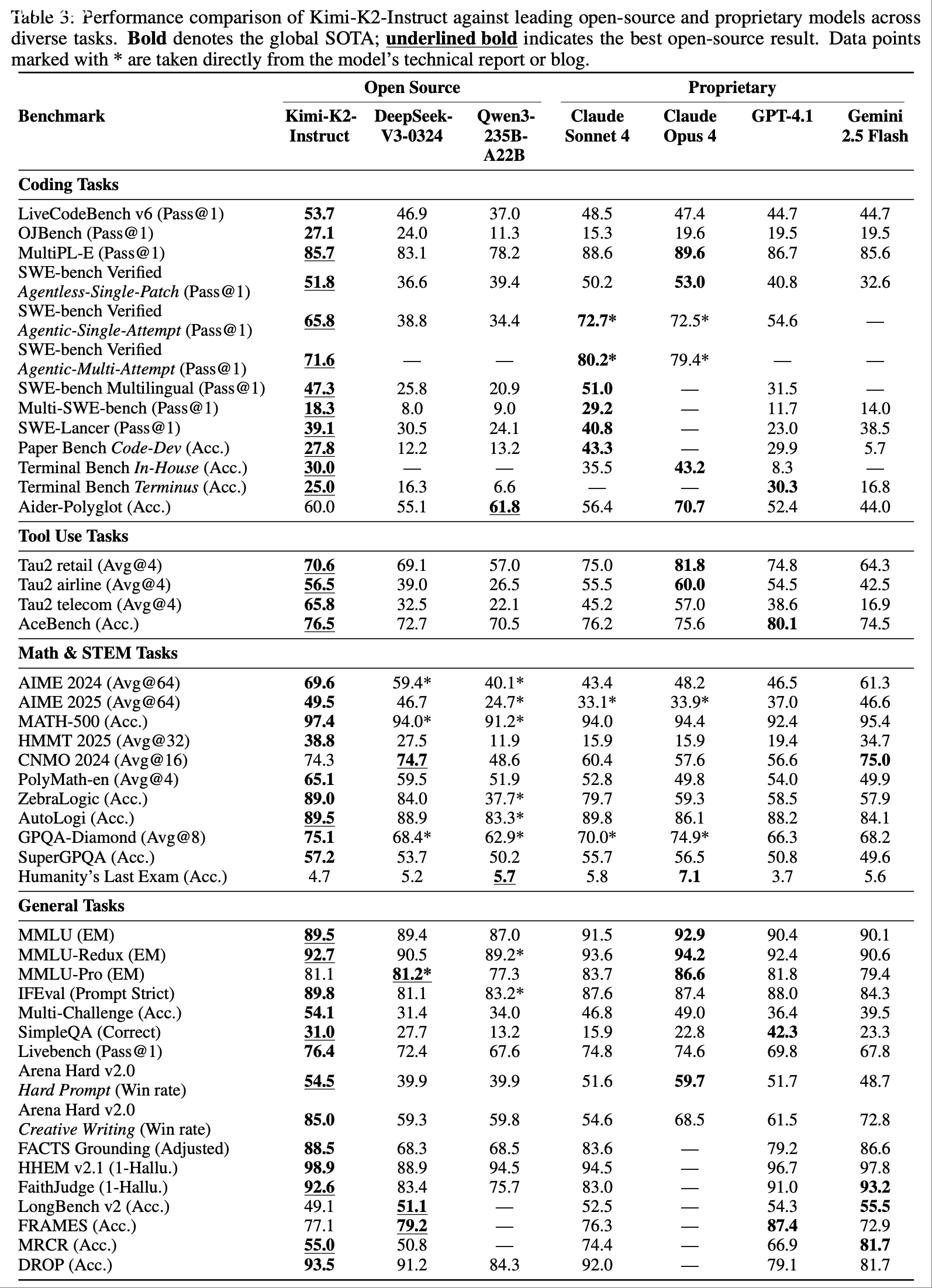
- 表 3 展示了 Kimi-K2-Instruct 的综合评估结果,详细解释见附录 C
- 以下是四个核心领域的重点结果:
- 代理式与竞技编码(Agentic and Competitive Coding) :Kimi-K2-Instruct 在真实世界软件工程任务中表现优异:
- SWE-bench Verified:65.8%(单次尝试),71.6%(多次尝试)
- SWE-bench Multilingual:47.3%
- SWE-lancer:39.1%
- 在竞技编码基准测试(如 LiveCodeBench v6 53.7%、OJBench 27.1%)中,Kimi-K2-Instruct 同样领先
- 代理式工具使用(Agentic Tool Use) :在多轮工具使用基准测试中,Kimi-K2-Instruct 表现卓越:
- \(\tau^2\)-Bench:66.1 Pass@1
- ACEBench:76.5
- 这些结果验证了其在多领域工具调用中的优势
- 通用能力(General Capabilities) :Kimi-K2-Instruct 在通用知识、数学、指令遵循和长上下文任务中表现均衡:
- SimpleQA:31.0%
- MMLU:89.5%
- MMLU-Redux:92.7%
- 在数学和 STEM 任务中,其得分同样领先(AIME 2024:69.6%,GPQA-Diamond:75.1%)
- 开放式评估(Open-Ended Evaluation)
- 在 LMSYS Arena 排行榜(2025 年 7 月 17 日)中,Kimi-K2-Instruct 以 3000 多张用户投票成为排名第一的开源模型 ,总排名第五
Pre-training Evaluations
Evaluation Settings
- Benchmarks :评估 Kimi-K2-Base 在多个领域的能力:
- 通用能力 :MMLU、MMLU-Pro、MMLU-Redux、BBH、TriviaQA、SuperGPQA、SimpleQA、HellaSwag、AGIEval、GPQA-Diamond、ARC-Challenge 和 WinoGrande
- 编码能力 :EvalPlus(平均 HumanEval、MBPP、HumanEval+ 和 MBPP+)、LiveCodeBench v6 和 CRUXEval
- 数学推理 :GSM8K、GSM8K-Platinum、MATH 和 CMATH
- 中文能力 :C-Eval、CMMLU 和 CSimpleQA
- Baselines :对比的开源基础模型包括 DeepSeek-V3-Base、Qwen2.5-72B-Base 和 Llama 4-Maverick
- 评估配置(Evaluation Configurations)
- 基于困惑度的评估:MMLU、MMLU-Redux、GPQA-Diamond、HellaSwag、ARC-Challenge、C-Eval 和 CMMLU
- 基于生成的评估:MMLU-Pro、SuperGPQA、TriviaQA、BBH、CSimpleQA、MATH、CMATH、GSM8K、GSM8K-Platinum、CRUXEval、LiveCodeBench 和 EvalPlus
Evaluation Results
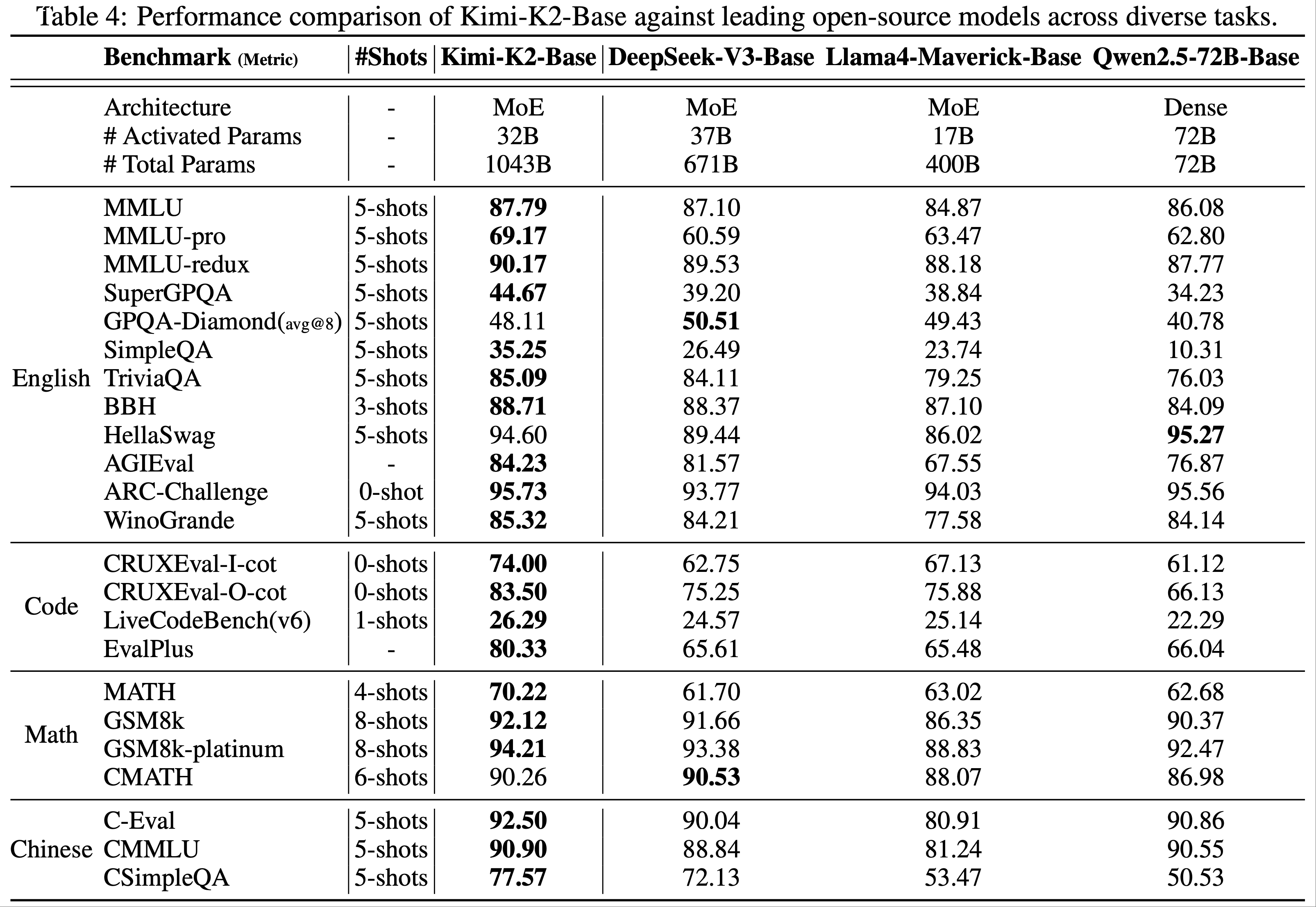
- 表 4 展示了 Kimi-K2-Base 与领先开源模型的对比结果:
- 通用语言理解 :在 12 项英语基准测试中,10 项表现最佳(如 MMLU 87.79%,MMLU-Pro 69.17%)
- 编码能力 :CRUXEval-I-cot 74.00%,LiveCodeBench v6 26.29%
- 数学推理 :MATH 70.22%,GSM8K 92.12%
- 中文理解 :C-Eval 92.50%,CMMLU 90.90%
Safety Evaluation
Experiment Settings
- 论文对 Kimi K2 与其他开源 LLM 进行了红队评估(red-teaming evaluations)
- 该评估涵盖了一系列攻击场景,包括有害内容、隐私内容、安全内容,以及不同的攻击策略,如提示注入(prompt injection)和迭代越狱(iterative jailbreak)
- 论文使用 Promptfoo 生成对抗性提示并分析响应
- 模型选择(Model Selection) :对比模型包括 Kimi K2、DeepSeek-V3、DeepSeek-R1 和 Qwen3
- Promptfoo Settings :表 5 列出了所评估的插件(plugins)和策略(strategies),每个插件都与所有策略配对以评估其性能

- 测试用例数量(Test Case Count) :每个插件策略组合生成 3 条攻击提示,支持双语的情况下生成 6 条
- 提示语言设置(Prompt Language Settings) :对每个插件-策略组合的语言兼容性进行了预测试
- 有些插件同时支持英文和中文,而其他插件仅支持英文
- 对于同时支持两种语言的组合,我们每种语言生成 3 个提示,因此每个组合共生成 6 个提示
- 人工审核(Manual Review) :通过多轮审核确保评估一致性
Safety Evaluation Results
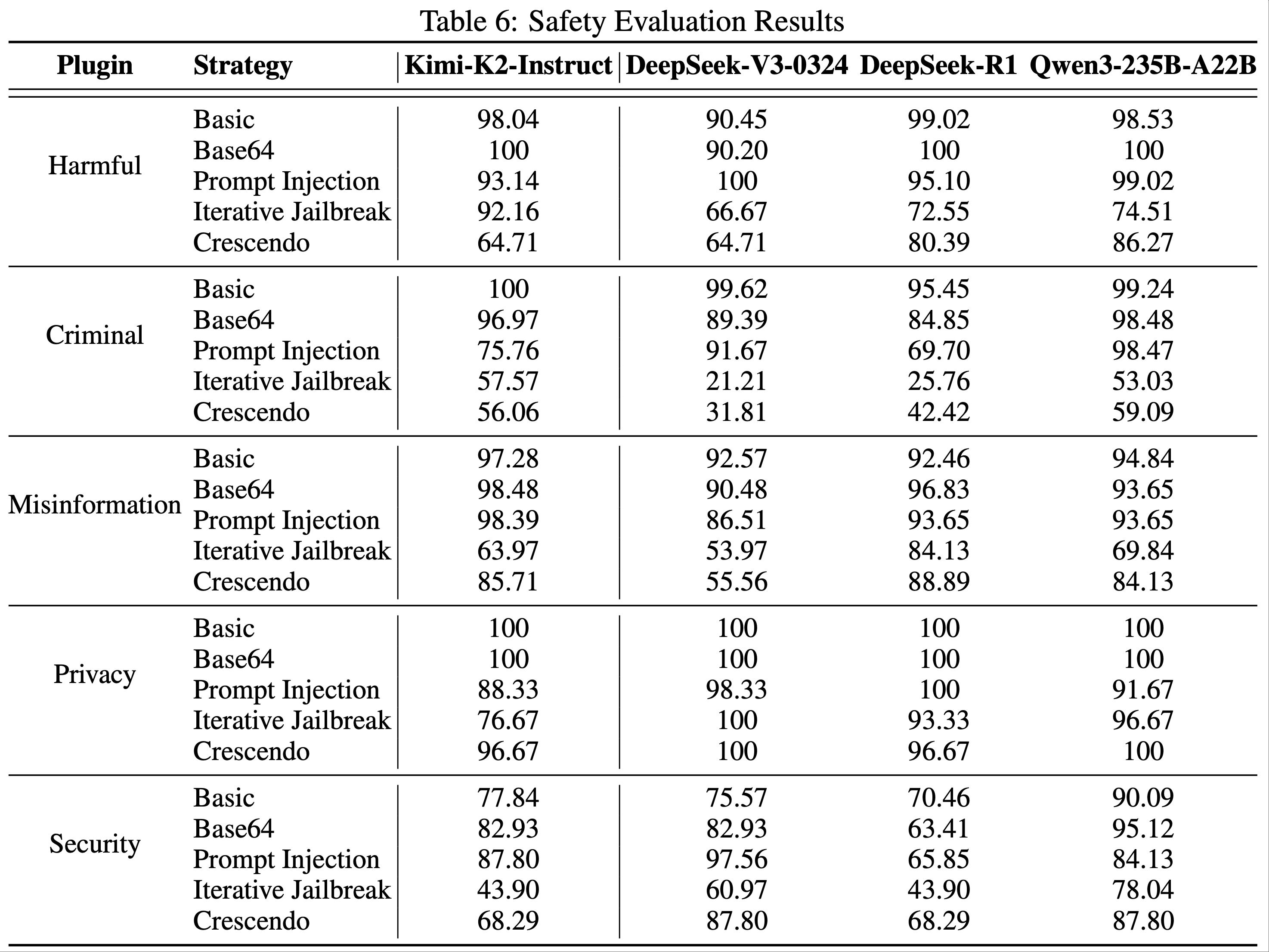
- 表 6 展示了不同模型在插件策略组合下的通过率:
- 有害内容(Harmful) :Kimi-K2-Instruct 在基础策略下通过率 98.04%,迭代越狱策略下 92.16%
- 犯罪内容(Criminal) :基础策略通过率 100%,迭代越狱策略下 57.57%
- 错误信息(Misinformation) :基础策略通过率 97.28%
- 隐私(Privacy) :所有策略通过率均高于 88%
- 安全(Security) :基础策略通过率 77.84%,迭代越狱策略下 43.90%
- 自动化红队测试局限性(Automated Red-teaming Limitations)
- 由于涉及人工审核,结果存在主观性。部分插件类型(如 API 滥用)更适合评估具备工具调用能力的代理模型
Limitations
- 在内部测试中,论文发现 Kimi K2 存在以下局限性:
- 处理复杂推理任务或模糊工具定义时 ,可能生成过多 Token ,导致输出截断或不完整工具调用
- 某些任务中,不必要的工具启用可能导致性能下降
- 一次性提示构建完整软件项目的成功率低于代理式编码框架
附录 B:Token Template of Tool Calling
工具调用的 Token 结构包含三个部分:
- 工具声明消息(Tool declaration message) :定义可用工具列表及其参数模式;
- 助手消息中的工具调用部分(Tool invoking section in assistant message) :编码模型调用工具的请求;
- 工具结果消息(Tool result message) :封装被调用工具的执行结果
工具声明消息的原始 Token 格式如下:
1
2
3
4
5
6<|im_begin|>
tool_declare
<|im_middle|>
# Tools
{ { tool declaration content } }
<|im_end|>- 蓝色高亮标记
{ { tool declaration content } }代表特殊 Token - 绿色部分(
<|im_begin|>等)是工具声明内容
- 蓝色高亮标记
论文使用 TypeScript 表达工具声明内容
- TypeScript 是一种简洁的语言,具有全面的类型系统,能够用简短的文本表达工具参数的类型和约束
- 代码 1 展示了两个简单工具的 JSON 格式定义(兼容 OpenAI 的聊天补全 API)
- 代码 2 用 TypeScript 定义了相同的两个工具,看起来更加简短
为提高兼容性,部分训练数据也使用 JSON 作为工具声明语言,以便第三方框架无需额外开发即可支持论文的工具调用方案
代码 1 :OpenAI 兼容 API 中的 JSON 工具定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37[{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for a location and date",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Beijing, China"
},
"date": {
"type": "string",
"description": "Date to query, format in '%Y-%m-%d'"
}
},
"required": ["location"]
}
}
},
{
"type": "function",
"function": {
"name": "Calculator",
"description": "Simple calculator",
"parameters": {
"properties": {
"expr": {
"type": "string",
"description": "Arithmetic expression in javascript"
}
},
"type": "object"
}
}
}]代码 2 :TypeScript 工具定义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16namespace functions {
// Get weather for a location and date
type get_weather = {
.: {
// City and country e.g. Beijing, China
location: string,
// Date to query, format in '%Y-%m-%d'
date?: string
}) => any;
// Simple calculator
type Calculator = {
.: {
// Arithmetic expression in javascript
expr?: string
}) => any;
}模型响应消息中工具调用部分的 Token 模板如下:
1
2
3
4
5
6
7
8
9
10
11<tool_call_section_begin|>
<|tool_call_begin|>
// call_id part
functions.{ {tool name} }:{ {counter} }
<|tool_arguments_begin|>
{ { json serialized call arguments } }
<|tool_call_end|>
<|tool_call_begin|>
// more tool calls
<|tool_call_end|>
<|tool_call_section_end|>如模板所示,论文通过将多个工具调用放在单个响应轮次中来支持并行工具调用
每个工具调用具有唯一的调用 ID,格式为
functions.{ {tool name} }:{ {counter} },其中工具名称是工具的名称,计数器是对话中所有工具调用的自增计数器(从 0 开始)在推理过程中,模型偶尔会生成意外的 Token,导致解析工具调用时出现格式错误
- 为解决此问题,论文开发了一个名为 enforcer 的约束解码模块,灵感来自 lm-format-enforcer (2023)
- 当生成
<tool_call_section_begin|>Token 时,它会确保接下来的工具相关 Token 遵循预定义的模板 ,并且 JSON 参数字符串符合声明的模式
工具结果消息是一个简单的文本消息,编码了工具的调用 ID 和相应的结果:
1
2
3
4
5
6<im_begin|>
tool
<im_middle|>
## Results of { {call_id} }
{ { execution result content } }
<im_end|>
附录 C:Evaluation Details
Coding Tasks
- 论文在竞争性编码基准 LiveCodeBench 和 OJBench 上评估模型能力
- Kimi-K2-Instruct 分别以 53.7% 和 27.1% 的分数表现出色
- 这一优势涵盖了中等难度编码挑战(如 LeetCode 和 AtCoder)以及高难度竞赛(如 NOI 和 ICPC),超越了领先的开源和专有模型
- 对于多语言编程能力,论文使用 MultiPL-E,涵盖 C++、C#、Java、JavaScript、PHP 和 Go 等语言
- Kimi-K2-Instruct 以 85.7% 的准确率超越顶级开源模型(DeepSeek-V3-0324 为 83.1%,Qwen3-235B-A22B 为 78.2%)
- 在软件工程任务中
- Kimi-K2-Instruct 在 SWE-bench Verified(Python)、SWE-lancer(Python)、SWE-bench Multilingual 和 Multi-SWE-bench 数据集上表现出色
- 它在解决真实代码仓库问题方面显著优于开源模型,并大幅缩小了与专有模型的性能差距,例如:
- SWE-bench Verified(多次尝试):71.6%(Kimi-K2-Instruct) vs. 80.2%(Claude 4 Sonnet)
- SWE-bench Multilingual:47.3%(Kimi-K2-Instruct) vs. 51.0%(Claude 4 Sonnet)
- SWE-lancer:39.1%(Kimi-K2-Instruct) vs. 40.8%(Claude 4 Sonnet)
- 在 PaperBench 上
- Kimi-K2-Instruct 达到 27.8% 的准确率,与 GPT-4.1 接近,并大幅领先 DeepSeek-V3-0324(12.2%)和 Qwen3-235B-A22B(8.2%)
- 在 TerminalBench 测量的终端交互任务中
- Kimi-K2-Instruct 使用默认 Terminus 框架达到 25.0%,在 Moonshot 内部代理框架中提升至 30%,突显了其在真实代理编程场景中的能力
- 在 Aider-Polyglot 基准测试中
- Kimi-K2-Instruct 在严格去污染程序下达到 60.0% 的准确率,进一步展示了其在不同编码环境中的优势和可靠性
Tool Use Tasks
- 论文通过两个互补的测试套件评估多轮工具使用能力:\(\tau^{2}\)-Bench 和 ACEBench
- \(\tau^{2}\)-Bench 将原始 \(\tau\)-bench 的单控制设置扩展为双控制环境,其中代理和模拟用户的 LLM 在共享状态上具有受限的工具能力,新增了 Telecom 故障排除领域,并支持协调与纯推理的分析
- ACEBench 是一个大型双语(英/中)API 基准测试(跨 8 个领域的 4.5K API;2K 标注评估项),分为 NORMAL(基础/个性化/原子)、SPECIAL(不完美或超出范围的输入)和 AGENT(场景驱动的多轮、多步骤沙盒)赛道,支持调用和结果的自动评分
- 实验配置:
- 所有模型以非思考模式运行;
- 设置温度为 0.0,使用确定性工具适配器,在 4 次种子下评分 \(\tau^{2}\) Airline/Retail/Telecom 的 Pass@1/4,并报告 ACEBench 英语的总体结果
- 结果:
- 在 \(\tau^{2}\) 上,Kimi-K2-Instruct 平均达到 66.1% 的微 Pass@1(DeepSeek-V3-0324 为 48.8%,Qwen3-235B-A22B 为 37.3%)
- 在 ACEBench Overall 中,Kimi-K2-Instruct 得分为 76.5,DeepSeek 为 72.7,Qwen 为 70.5,与 GPT-4.1(80.1)保持竞争
Math & STEM & Logical Tasks
- 在数学任务中,Kimi-K2-Instruct 表现稳定,平均超过 Geimini-2.5-Flash 5.3 个百分点,超过 DeepSeek-V3-0324 5.5 个百分点,超过 GPT4.1 15.8 个百分点,例如:
- 在 AIME 2024 上,Kimi-K2-Instruct 得分为 69.6%,大幅领先其他两个顶级开源模型(DeepSeek-V3-0324 高 10.2 分,Qwen3-235B-A22B 高 29.5 分)
- 在 STEM 评估中,Kimi-K2-Instruct 在 GPQA-Diamond 上达到 75.1%,领先 DeepSeek-V3-0324(68.4%)和其他非思考基线至少 5 个百分点
- 在 SuperGPQA 上,它也超过之前最佳开源模型 DeepSeek-V3-0324 3.5 分。Kimi-K2-Instruct 在逻辑推理上也优于其他两个领先模型,在 ZebralLogic 上达到 89.0%,在 AutoLogi 上达到 89.5%,显著超过 Qwen3-235B-A22B(37.7%,83.3%)
General Tasks
- Kimi-K2-Instruct 在 MMLU 和 MMLU-Pro 上与 DeepSeek-V3-0324 持平,在 MMLU-Redux 上以 92.7 EM 分数领先——略高于 GPT-4.1(92.4),仅落后 Claude-Opus-4 1.5 分
- 在简答题 SimpleQA 上,Kimi-K2-Instruct 达到 31.0% 的准确率,比 DeepSeek-V3-0324 高 3.3 分,是 Qwen3-235B-A22B 的两倍多,但仍低于 GPT-4.1(42.3%)
- 在对抗性自由回答 LiveBench(2024-11-25 快照)中,它达到 76.4%,超过 Claude-Sonnet 4(74.8%),领先 Gemini 2.5 Flash Preview 8.6 分。在这一衡量世界知识广度、深度和鲁棒性的挑战性三项中,Kimi-K2-Instruct 稳居开源模型前列
- 论文通过 IFEval 和 Multi-Challenge 评估指令遵循能力
- 在 IFEval 上,Kimi-K2-Instruct 得分为 89.8%,高于 DeepSeek-V3-0324(81.1%)和 GPT-4.1(88.0%)
- 在 Multi-Challenge 上(涉及多轮冲突指令对话),它达到 54.1%,优于 DeepSeek-V3-0324(31.4%)、GPT-4.1(36.4%)和 Claude-Opus-4(49.0%)
- 这些结果表明,Kimi-K2-Instruct 将强大的事实知识与单轮和多轮场景下一致的指令遵循相结合,支持稳健可靠的现实部署
Long Context and Factuality Tasks
- 为评估 Kimi-K2-Instruct 的事实性,论文使用三个基准:FACTS Grounding(通过专有模型 GPT-4o、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 衡量对提供文档的遵循)、HHEM(通过开源 HHEM-2.1-Open 评估器评估摘要质量)和 FaithJudge(以 o3-mini 为评估器分析 RAG 任务中的忠实性)
- 在 FACTS Grounding 上,Kimi-K2-Instruct 得分为 88.5,大幅超越所有开源竞争对手,甚至超过闭源 Gemini 2.5 Flash
- 在 HHEM-2.1-Open 上,Kimi-K2-Instruct 幻觉率为 1.1%(表中报告为 1 减幻觉率,即 98.9)
- 在 FaithJudge 的 RAG 任务中,Kimi-K2-Instruct 幻觉率为 7.4%(表中为 92.6)
- 在长上下文能力任务 DROP 上,Kimi-K2-Instruct(93.5%)优于所有开源和专有模型
- 在检索任务 MRCR(55.0% vs. 50.8%)上超过 DeepSeek-V3-0324
- 对于长上下文推理任务 FRAMES 和 LongBench v2,Kimi-K2-Instruct(77.1%,49.1%)略低于 DeepSeek-V3-0324 约 2%
Open-Ended Evaluation
- 除静态封闭式基准外,论文还评估模型在更贴近真实使用的开放式、细致任务上的表现
- 对于英语场景,论文利用 Arena-Hard-Auto v2.0 基准,通过 LLM 作为评估器的协议评估多样化开放式提示的生成质量 (2024)
- 这些评估涵盖高难度提示,在研究社区中广受认可
- 在 Arena-Hard-Auto v2.0 上,Kimi-K2-Instruct 在硬提示(54.5%)和创意写作任务(85.0%)上均达到最优胜率,超越所有开源模型,并与 GPT-4.1 和 Claude Sonnet 等顶级专有系统匹敌
- 这些结果突显了模型在复杂推理和多样化无约束场景下的细致生成能力
- Arena-Hard-Auto 对中文特定任务的覆盖有限
- 为此,论文开发了一个基于真实用户 Query 的内部保留基准
- 为保障评估完整性,基准数据受访问限制,杜绝过拟合风险
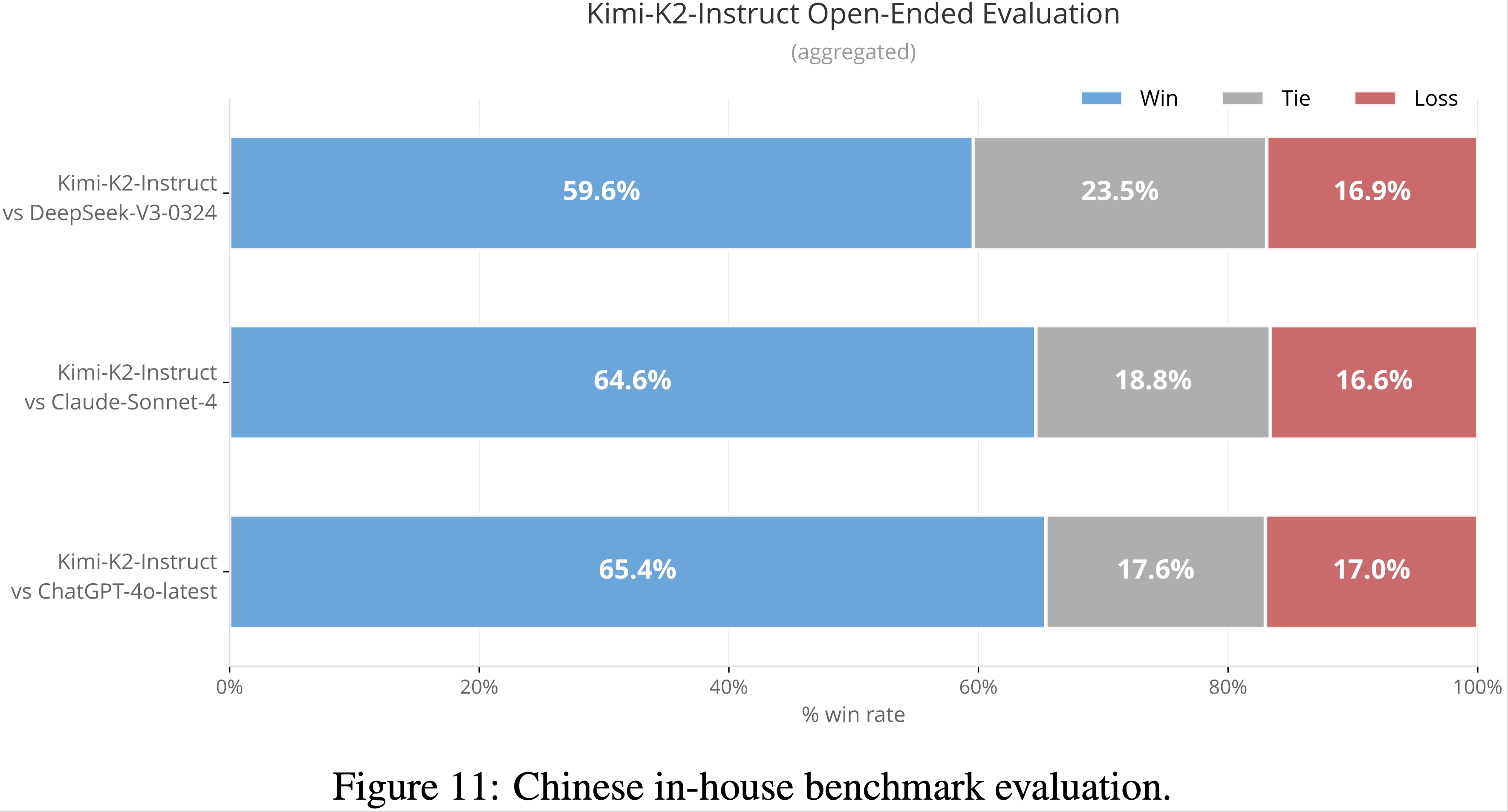
- 如图 11 所示,Kimi-K2-Instruct 在中文内部基准的所有比较中表现强劲:
- 以 65.4% 胜率超过 ChatGPT-4o-latest,64.6% 胜率超过 Claude Sonnet 4,59.6% 胜率超过 DeepSeek-V3-0324
- 所有情况下败率均较低(约 17%),表明 Kimi-K2-Instruct 极少落后
- 高胜率和稳定优势展示了其在开放式中文任务上的强大能力
- 除受控评估外,论文还通过公众人类评估考虑真实用户偏好
- 截至 2025 年 7 月 17 日,基于 3000 多份真实用户的盲投,Kimi-K2-Instruct 在 LMSYS Arena 排行榜上位列开源模型第一、总榜第五
- 该排行榜反映了用户提交的多样化提示上的直接人类偏好,为实际模型性能提供了补充视角
- Arena-Hard-Auto、内部基准和 LMSYS Arena 投票的结果共同展示了 Kimi-K2-Instruct 在开放式能力上的全面表现,证明其是英中双语真实用户体验中备受青睐的模型
附录 D:Appendix D: QK-Clip Does Not Impair Model Quality(QK-Clip 不会损害模型质量)
- QK-Clip 设计遵循最小干预原则 :仅在必要时激活,训练稳定后自动停用
- 实证证据和分析均表明 QK-Clip 对模型质量的影响可忽略不计
Small-Scale Ablations
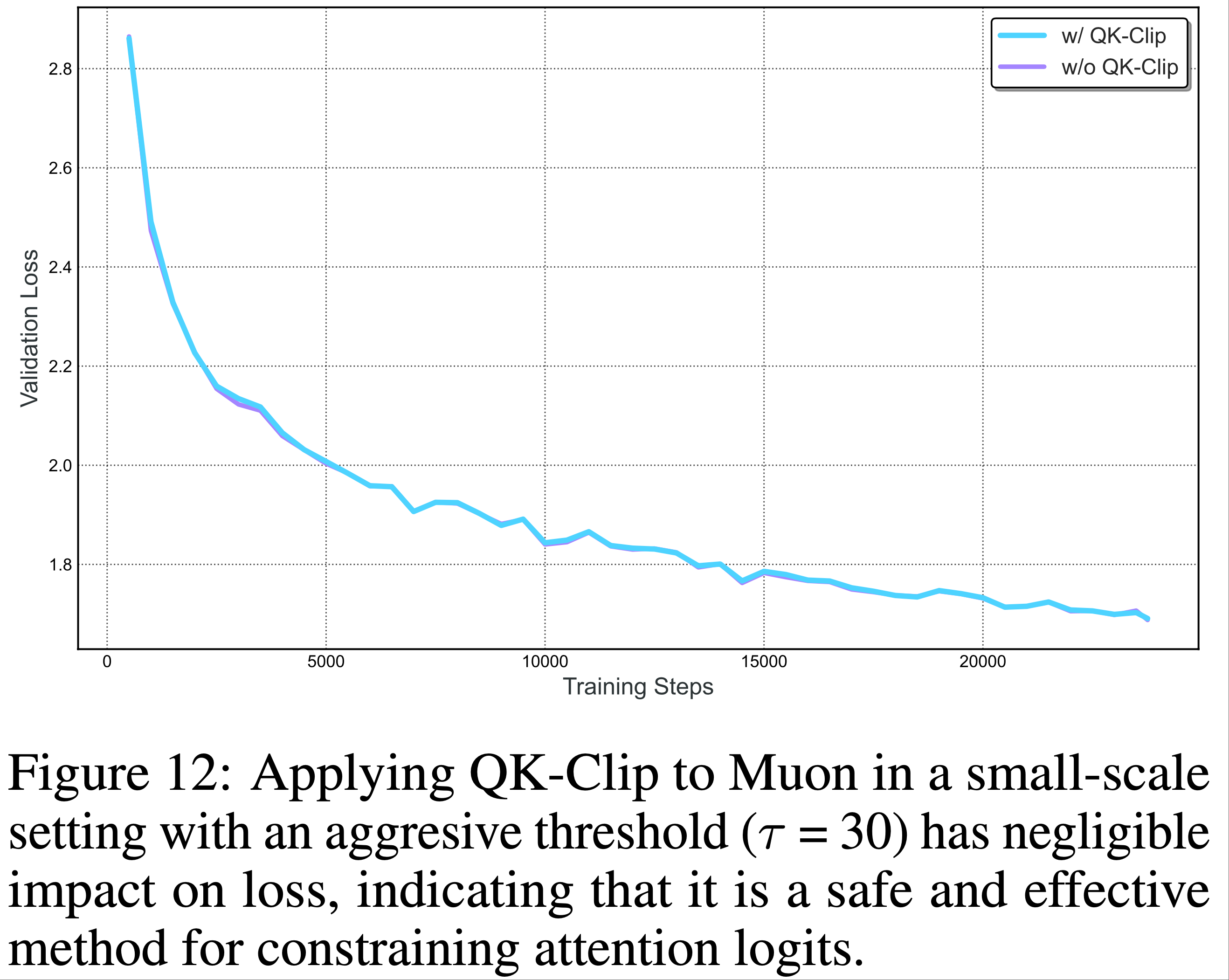
- 论文训练了两个小规模 MoE 模型(激活参数 0.5B,总参数 3B),一个使用原始 Muon,另一个使用 MuonClip(低裁剪阈值 \(\tau=30\))
- 如图 12 所示,应用 MuonClip 对损失曲线影响极小,表明即使激进裁剪也不会损害收敛或训练动态
- 下游任务评估也未显示性能退化
- 下游任务评估也未显示性能退化
- 这些结果共同证明 MuonClip 是一种安全有效的方法,可在不牺牲模型质量的前提下约束注意力对数
Self-deactivation
- 在 Kimi K2 中,QK-Clip 仅短暂激活:
- 初始 70000 步 :12.7% 的注意力头至少触发一次 QK-Clip,将 \(S_{\max}\) 限制为 100
- 70000 步后 :所有头的 \(S_{\max}\) 均降至 100 以下,QK-Clip 完全停用
- QK-Clip 激活时按头(而非按层)应用,以最小化对其他头的潜在过正则化。训练稳定后,QK-Clip 完全失效
附录 E:Why Muon is More Prone to Logit Explosion(为什么 Muon 更容易出现对数爆炸)
- 对数爆炸发生在训练期间最大预 softmax 注意力分数无界增长时:
$$ S_{\max} = \max_{i,j}(q_{i} \cdot k_{j}) $$ - 由于
$$ |q_{i} \cdot k_{j}| \leq |q_{i}||k_{j}| \leq |x_{i}||x_{j}||\mathbf{W}_{q}||\mathbf{W}_{k}|, $$ - 且
- RMS-Norm 保持 \(|x_{i}||x_{j}|\) 有界,该现象主要由 \(\mathbf{W}_{q}\) 或 \(\mathbf{W}_{k}\) 的谱范数增长驱动
- 实证发现 Muon 更易出现对数爆炸,假设如下:
- 更新结构差异(Structural difference in updates)
- Muon 的权重更新来自 msign 操作,其更新矩阵的所有奇异值均相同——有效秩为满秩。而 Adam 的典型更新矩阵呈现偏斜谱:少数大奇异值主导,有效秩较低。这一低秩假设并非新发现,高阶 mulP 同样基于此
- 在 16B Moonlight 模型上验证,Muon 训练的权重比 Adam 具有更高的奇异值熵(即更高有效秩),支持理论直觉
- SVD 公式化(SVD formulation)
- 设步骤 \(t-1\) 的参数矩阵奇异值分解为
$$ \mathbf{W}_{t-1} = \sum_{i}\sigma_{i} u_{i}v_{i}^{\top} $$ - 更新矩阵写作
$$ \Delta\mathbf{W}_{t} = \sum_{j}\bar{\sigma} \bar{u}_{j}\bar{v}_{j}^{\top} $$ - 则下一步参数更新为
$$ \mathbf{W}_{t} \leftarrow \sum_{i}\sigma_{i}u_{i}v_{i}^{\top} + \sum_{j}\bar{\sigma} \bar{u}_{j}\bar{v}_{j}^{\top} $$ - Muon 中权重和更新的有效秩均高于 Adam,假设奇异向量对 \(u_{i}v_{i}^{\top}\) 与 \(\bar{u}_{j}\bar{v}_{j}^{\top}\) 对齐概率更高,可能导致 \(\mathbf{W}_{t}\) 对应奇异值加性增长
- 设步骤 \(t-1\) 的参数矩阵奇异值分解为
- 注意力特异性放大(Attention-specific amplification)
- 注意力对数通过双线性形式计算
$$ q_{t} \cdot k_{j} = (x_{i}\mathbf{W}_{q}) \cdot (x_{j}\mathbf{W}_{k}). $$ - 乘积 \(\mathbf{W}_{q}\mathbf{W}_{k}^{\top}\) 将谱范数平方化,因此任一矩阵的奇异值增长会被复合放大
- Muon 增大奇异值的倾向从而转化为更高的对数爆炸风险
- 注意力对数通过双线性形式计算
附录 F:K2 Critic Rubrics for General RL
Core Rubrics
- 清晰性与相关性(Clarity and Relevance) :评估响应是否简洁且完全符合用户意图
- 重点是消除不必要的细节,保持与核心问题的一致性,并使用高效的格式(如简短段落或紧凑列表)
- 除非特别要求,否则应避免冗长的列举
- 当需要选择时,响应应明确提供单一、清晰的答案
- 对话流畅性与参与度(Conversational Fluency and Engagement) :评估响应是否促进自然流畅的对话,超越简单的问答
- 包括保持连贯性、展现对话题的适当参与、提供相关见解或观察、在适当时引导对话、谨慎使用后续问题、优雅处理假设或个人类比 Query ,以及有效调整语气以适应对话上下文(如共情、正式或随意)
- 客观与 grounded 互动(Objective and Grounded Interaction) :评估响应是否保持客观和 grounded 的语气,专注于用户请求的实质内容
- 重点避免元评论(分析 Query 结构、主题组合、感知的异常或互动本身的性质)以及对用户或输入的不必要赞美
- 优秀响应应尊重但中立,优先提供直接、任务导向的帮助,而非评论对话动态或通过赞美讨好用户
- 注:这里的 grounded 翻译为 有根据的 或 有充分理由的 更合适?
Prescriptive Rubrics
- 初始赞美(Initial Praise) :响应不得以对用户或问题的赞美开头(例如“这是个很棒的问题”“问得好!”)
- 显式理由(Explicit Justification) :显示理由包括任何解释响应为什么优秀或如何成功满足用户请求的句子或从句(这与单纯描述内容不同)
Limitations
- 该评估框架的一个潜在副作用是,它可能偏向于在涉及模糊性或主观性的上下文中仍表现出自信和果断的响应。这源于当前准则的两项关键限制:
- 避免自我修饰(Avoidance of Self-Qualification) :
- 规范性准则禁止自我评估、显式免责声明或模糊语言(例如“这可能不准确”“我可能错了”)
- 尽管这些短语可能反映认知谦逊,但它们通常被视为非信息性或表演性而被惩罚
- 偏好清晰与单一性(Preference for Clarity and Singularity) :
- 准则奖励在用户要求推荐或解释时提供直接、明确的答案
- 在复杂或开放式场景中,这可能会抑制适当谨慎或多视角的响应
- 避免自我修饰(Avoidance of Self-Qualification) :
- 因此,模型可能偶尔在需要模糊性、细微差别或认知谦逊的场景中过度表达确定性
- 未来框架迭代可能会纳入更精细的校准不确定性处理机制
附录 G:Engine Switching Pipeline for RL Training
- 检查点引擎(checkpoint engine) :在每个 GPU 上管理三个等大小的设备缓冲区:
- 一个用于加载卸载模型参数的 H2D 缓冲区
- 两个用于 GPU 间广播的 IPC 缓冲区
- IPC 缓冲区与推理引擎共享,允许其直接访问相同的物理内存
- 这三个缓冲区使论文能够将三个步骤安排为流水线
- 理论上的三阶段流水线(Theoretical three-stage pipeline) :如图 13a 所示,引入了一个三阶段流水线:
- 1)H2D :将最新权重的一个分片异步复制到 H2D 缓冲区
- 2)广播(Broadcast) :复制完成后,该分片将被复制到一个 IPC 缓冲区并广播到所有设备
- 3)重载(Reload) :推理引擎同时从另一个 IPC 缓冲区加载参数
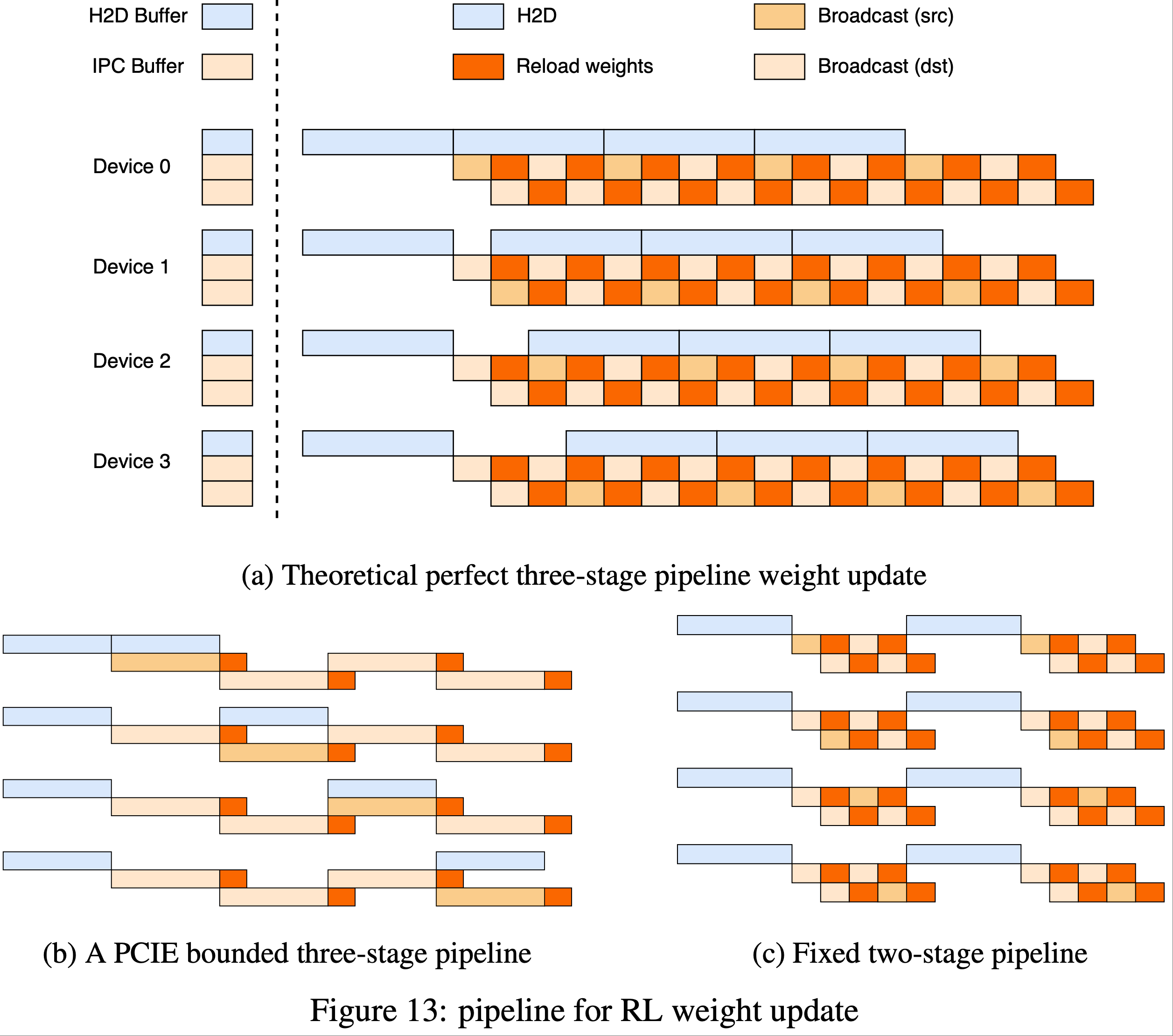
- 由于 PCIe 饱和的两阶段流水线(Two-stage pipeline due to PCIe saturation) :
- 在 NVIDIA H800 集群上,并发的 H2D 和广播会饱和共享的 PCIe 结构,将三阶段流程压缩为顺序过程(图 13b)。因此,论文采用更简单的两阶段方案(图 13c):
- 1)所有设备执行一次同步的 H2D 传输
- 2)广播和重载并行进行
- 在 NVIDIA H800 集群上,并发的 H2D 和广播会饱和共享的 PCIe 结构,将三阶段流程压缩为顺序过程(图 13b)。因此,论文采用更简单的两阶段方案(图 13c):
- 两阶段流水线会受到多次同步 H2D 复制操作的限制
- 但在大规模设备中,模型会被分割为小分片,整个参数集可通过一次传输装入 H2D 缓冲区,此时开销将消失
- 通过重叠 H2D、广播和重载权重,我们可以实现从训练引擎到所有推理引擎的高带宽权重分片重分配
附录:Kimi-K2-Thinking
- Kimi-K2-Thinking 于 20251106 晚间开源发布
- 截止到 20251107,Kimi-K2-Thinking 仅发布了模型权重和 博客,没有技术报告
- HuggingFace:huggingface.co/moonshotai/Kimi-K2-Thinking
- 技术博客:Introducing Kimi K2 Thinking, 20251106
- 核心特点:
- 各项指标都非常高,甚至可以跟闭源模型比较(比较的基线都是 GPT-5,Claude Sonnet 4.5(Thinking),DeepSeek-V3.2 和 Grok-4 等)
- 为了加速训练,训练时使用了 INT4 量化,Quantization-Aware Training (QAT)
- 这缓解了 Thinking 模型输出长,量化后模型效果容易降低的问题
- 博客中给了许多让人眼前一亮的示例
- 整体指标情况
Benchmark Intro K2 Thinking (K2 0905) GPT-5 Claude Sonnet 4.5 DeepSeek-V3.2 Grok-4 Reasoning Tasks HLE(Text-only)-no tools 23.9 26.3 19.8* 7.9 19.8 25.4 HLE(Text-only)-w/ tools 44.9 41.7 32.0* 21.7 20.3* 41.0 HLE(Text-only)-heavy 51.0 42.0 — — — 50.7 AIME 2025-no tools 94.5 94.6 87.0 51.0 89.3 91.7 AIME 2025-w/ python 99.1 99.6 100.0 75.2 58.1* 98.8 AIME 2025 - heavy 100.0 100.0 — — — 100.0 HMMT 2025-no tools 89.4 93.3 74.6* 38.8 83.6 90.0 HMMT 2025-w/ python 95.1 96.7 88.8* 70.4 49.5* 93.9 HMMT 2025 - heavy 97.5 100.0 — — — 96.7 IMO-AnswerBench-no tools 78.6 76.0* 65.9* 45.8 76.0* 73.1 GPQA-Diamond-no tools 84.5 85.7 83.4 74.2 79.9 87.5 General Tasks MMLU-Pro-no tools 84.6 87.1 87.5 81.9 85.0 — MMLU-Redux-no tools 94.4 95.3 95.6 92.7 93.7 — Longform Writing-no tools 73.8 71.4 79.8 62.8 72.5 — HealthBench-no tools 58.0 67.2 44.2 43.8 46.9 — Agentic Search Tasks BrowseComp-w/ tools 60.2 54.9 24.1 7.4 40.1 — BrowseComp-ZH-w/ tools 62.3 63.0* 42.4* 22.2 47.9 — Seal-0-w/ tools 56.3 51.4* 53.4* 25.2 38.5* — FinSearchComp-T3-w/ tools 47.4 48.5* 44.0* 10.4 27.0* — Frames-w/ tools 87.0 86.0* 85.0* 58.1 80.2* — Coding Tasks SWE-bench Verified-w/ tools 71.3 74.9 77.2 69.2 67.8 — SWE-bench Multilingual-w/ tools 61.1 55.3* 68.0 55.9 57.9 — Multi-SWE-bench-w/ tools 41.9 39.3* 44.3 33.5 30.6 — SciCode-no tools 44.8 42.9 44.7 30.7 37.7 — LiveCodeBench v6-no tools 83.1 87.0* 64.0* 56.1* 74.1 — OJ-Bench(cpp)-no tools 48.7 56.2* 30.4* 25.5* 38.2* — Terminal-Bench-w/ simulated tools (JSON) 47.1 43.8 51.0 44.5 37.7 —
附录:关于 heavy 模式
- 原文:
Heavy Mode: K2 Thinking Heavy Mode employs an efficient parallel strategy: it first rolls out eight trajectories simultaneously, then reflectively aggregates all outputs to generate the final result. Heavy mode for GPT-5 denotes the official GPT-5 Pro score.
- 说明:Heavy Mode 是一种通用的提升模型推理能力的方法,其方式为:
- 第一步:并行采样多个 Trajectories
- 第二步:结合第一步生成的结果放入模型,让模型解决问题
- 这种方式也称为 Deep Thinking 模式,在一些场合下 Deep Thinking 模式 等价于 Heavy Mode
- Heavy Mode:强调资源消耗和计算强度(Heavy=重型/高负载)
- Deep Thinking/Deep Think:强调思维深度和推理过程