HLLM : Hierarchical Large Language Model
整体说明
- 大语言模型(LLMs)在推荐系统的应用中,有三个关键问题尚未得到充分探讨:
- 第一 :LLMs 预训练权重通常被认为蕴含了世界知识,但其实际价值未得到验证;
- 第二 :针对推荐任务进行微调的必要性;
- 第三 :LLMs 在推荐系统中是否能展现出与其他领域相同的可扩展性优势(scalability benefits)
- 理解:也就是 LLM 在 推荐系统中的 Scaling Law 需要探索(问题:Meta-GRs 已经探索过了吧)
- 论文提出了分层大语言模型(Hierarchical Large Language Model,HLLM)架构来增强序列推荐系统
- 论文的方法采用双层模型:
- 第一层的 Item LLM 从 item 的详细文本描述中提取丰富的特征,输入是 item 的文本特征,输出是 item 的 Embedding
- 第二层的 User LLM 利用这些特征,基于用户的历史交互预测其未来兴趣,输入和输出都是 item 的 Embedding
- 一些其他细节:
- 论文的方法有效利用了开源 LLMs 的预训练能力,进一步的微调显著提升了性能
- HLLM 展现出优秀的可扩展性,在最大配置下,item 特征提取和用户兴趣建模中均使用了 7B 参数
- HLLM 具有高效的训练和服务效率,使其在实际应用中具有实用性
- 离线+在线实验+开源
- 离线:在两个大规模数据集(PixelRec 和 Amazon Reviews)上的评估显示,HLLM 显著优于传统的 ID-based Model
- 在线A/B测试中,HLLM 表现出显著的增益
- 特别地:代码已开源:https://github.com/bytedance/HLLM
一些讨论
- 推荐算法问题是:通过理解用户兴趣来预测其在各种 item 上的未来行为,有效推荐的关键在于准确建模 item 和用户特征
- 目前推荐系统的主流方法:
- 主流方法主要基于 ID:将 item 和用户转换为 ID 并创建相应的 Embedding 表进行编码
- 序列建模方法:可捕捉多样且随时间变化的用户兴趣,并在序列推荐中取得了显著成功
- 以上方法通常以 Embedding 参数为主,模型规模相对较小,导致两大缺陷:
- 缺陷一 :对 ID 特征的依赖性强,在冷启动场景中表现不佳;
- 缺陷二 :以及较浅的神经网络难以建模复杂多样的用户兴趣
- 将 LLMs 整合到推荐系统中探索可分为三类 :
- (1) 利用 LLMs 为推荐系统提供精炼或补充信息,例如用户行为摘要和 item 信息扩展;
- (2) 将推荐系统数据转化为对话形式以适应 LLMs ;
- (3) 修改 LLMs 以处理超越文本输入输出的推荐任务,包括将ID特征输入 LLMs,以及直接用 LLMs 替代现有模型并优化 CTR 等目标
- 将 LLMs 与推荐系统整合仍面临复杂性和有效性方面的显著挑战:
- 复杂性(效率低)方面 :将用户行为历史作为文本输入 LLMs 会导致输入序列非常长,导致LLMs 需要更长的序列来表示相同时间跨度的用户行为
- LLMs 中自注意力模块的复杂度随序列长度呈二次方增长;
- 推荐单个 item 需要生成多个文本 token(RQ-VAE的方法),导致多次前向传播,效率较低
- 有效性方面 :现有基于LLM的方法相比传统方法的性能提升并不显著 ,这引发了对 LLMs 潜力是否被充分挖掘的疑问
- 复杂性(效率低)方面 :将用户行为历史作为文本输入 LLMs 会导致输入序列非常长,导致LLMs 需要更长的序列来表示相同时间跨度的用户行为
- 此外,一些关键问题仍未得到充分探讨:
- 第一:LLMs 预训练权重通常被认为蕴含了世界知识,但其实际价值未得到验证
- 第二:针对推荐任务进行微调的必要性存疑
- 第三:LLMs 的 Scaling Law 在其他领域已被证明,但在推荐系统中的表现仍需验证
- 注:尽管一些研究在推荐领域验证了 Scaling Law [Shin 等, 2023; Zhai 等, 2024],但这些模型的参数量远小于 LLMs。参数量超过10亿的模型在推荐领域是否具有良好的可扩展性仍是一个开放问题
- 为解决这些挑战,论文提出了分层大语言模型(HLLM)架构
- 先使用 Item LLM 提取 item 特征:在每个 item 的文本描述末尾添加一个特殊 token [ITEM],并将增强后的描述输入 Item LLM ,将特殊 token 对应的输出作为 item 特征
- 再使用 User LLM 建模用户兴趣并预测未来行为:User LLM 的输入是 Item LLM 输出的 item 特征,通过将长文本描述转换为简洁的 Embedding,行为序列的长度被缩减至与 ID-based Model 相当,显著降低了计算复杂度
- 验证效率 :论文还验证了 HLLM 在训练效率上的优势,仅需少量训练数据即可超越 ID-based Model
- 预训练的价值探讨 :通过大量实验,论文探讨了预训练的价值
- HLLM 未以标准 LLMs 的文本交互方式使用(Item LLM 被设计为特征提取器;User LLM 的输入输出均为 item Embedding),但预训练权重对两类 LLM 均有益 ,这表明 LLMs 中蕴含的世界知识确实对推荐任务有价值
- 针对推荐目标进行微调的必要性 :实验表明这种微调对超越传统方法至关重要
- 可扩展性验证 :(离线验证)参数量达 7B 的模型仍能随规模扩大持续提升性能
- 论文的主要贡献总结如下:
- 提出了分层LLM(HLLM)框架用于序列推荐(实现优秀的训练和推理效率,拿到离线+在线收益)
- HLLM 有效将 LLM 预训练阶段编码的世界知识迁移至推荐模型,涵盖 item 特征提取和用户兴趣建模,并证明针对推荐目标的特定任务微调仍是必要的
- HLLM 展现出优秀的可扩展性,性能随数据量和模型参数增加持续提升
相关工作(直译)
传统推荐系统
- 传统推荐系统主要依赖基于ID的 Embedding,主要有以下迭代方向
- 特征交叉
- DeepFM通过FM建模低阶特征交互,通过DNN建模高阶特征交互
- DCN通过显式特征交叉建模更高阶交互
- 用户行为建模
- DIN和DIEN引入注意力机制捕捉用户多样化兴趣
- SASRec[Kang and McAuley, 2018]将自注意力机制应用于序列推荐
- CLUE[Shin 等, 2023]和HSTU[Zhai 等, 2024]表明参数量在数亿内的模型遵循扩展定律
- 特征交叉
- 一些工作还将内容特征(content features)引入推荐模型,展现出一定的泛化优势[Baltescu 等, 2022; Li 等, 2023b; Cheng 等, 2024]
基于语言模型的推荐
- LLMs 在推荐系统中应用的探索可分为三类:
- 首先,LLMs 被用于总结或补充用户或 item 信息[Zhang 等, 2024a; Ren 等, 2024; Xi 等, 2023]
- RLMRec[Ren 等, 2024]开发了一种由LLM支持的 user/item 画像范式,并通过跨视图对齐框架将 LLMs 的语义空间与协作关系信号的表示空间对齐
- LLMs 还被用于生成冷启动 item 的增强训练信号[Wang 等, 2024]
- 其次,一些工作将推荐领域数据适配为对话格式[Bao 等, 2023; Friedman 等, 2023; Zhang 等, 2023; Yang 等, 2023]
- 部分方法将推荐任务视为一种特殊的指令跟随任务 ,将用户历史行为以文本形式输入 LLM 以预测后续行为[Zhang 等, 2023]
- 最后,还有一些工作对 LLMs 进行适配以处理超越文本形式的推荐任务
- LLaRA[Liao 等, 2024]提出了一种混合提示方法,将基于ID的 item Embedding 与文本 item 特征结合
- LEARN[Li 等, 2023a]利用预训练 LLMs 提取 item 特征
- 首先,LLMs 被用于总结或补充用户或 item 信息[Zhang 等, 2024a; Ren 等, 2024; Xi 等, 2023]
- 其他方面,LLMs 还被适配为多分类或回归任务用于评分预测[Kang 等, 2023]
- 然而,以上这些方法相比传统推荐模型的改进有限
HLLM 方法介绍
问题定义
- 论文将序列推荐任务定义为:给定用户 \( u \in \mathcal{U} \) 及其 按时间顺序排列的历史交互序列 \( U = \{I_1, I_2, \ldots, I_n\} \),预测 next item \( I_{n+1} \)
- 其中 \( n \) 为序列长度
- 每个 item \( I \)(\( I \in \mathcal{I} \))包含对应的 ID 和文本信息(如标题、标签等),但论文方法仅使用文本信息
分层大语言模型架构
- 现有方法的性能问题 :许多 LLM-based 推荐模型将用户历史行为扁平化为纯文本输入,导致输入序列过长,这种设计会带来巨大计算负担(因为 LLM 中自注意力模块的复杂度与序列长度呈平方关系)
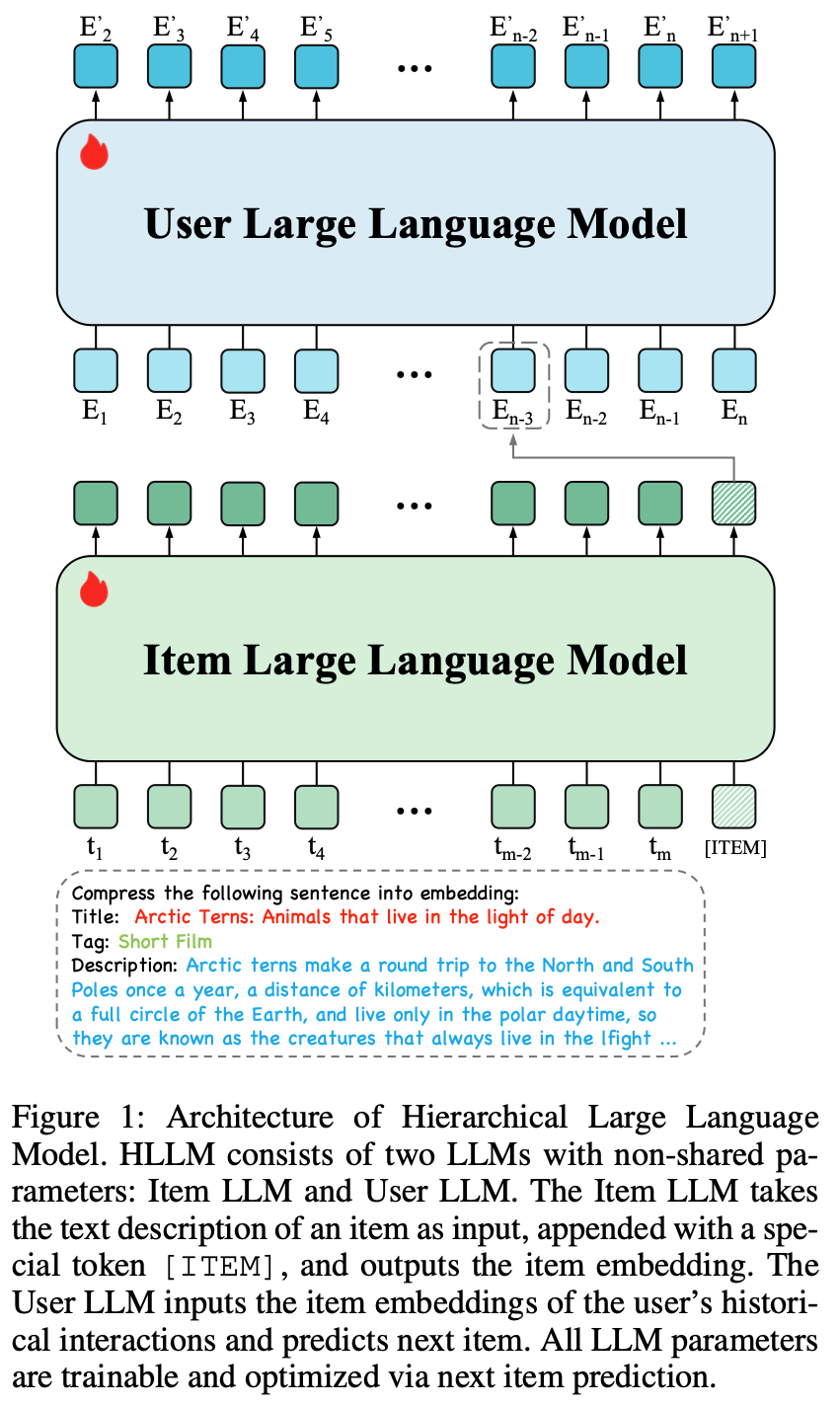
- 为减轻用户序列建模的负担 ,论文采用分层建模方法,称为分层大语言模型(HLLM) ,将 item 建模与用户建模解耦,如图1所示
- 首先通过 Item LLM 提取 item 特征,将复杂文本描述压缩为 Embedding 表示;
- 随后基于这些特征通过 User LLM 建模用户画像
- 此外,为确保与预训练LLM的兼容性并提升可扩展性,论文仅引入最小结构调整,并设计简单高效的训练目标
Item LLM:
- Item LLM 用于提取 item 特征,其输入为 item 的文本描述,输出为 Embedding 表示
- LLM在文本理解方面表现出色,但其应用多限于文本生成场景,鲜少作为特征提取器。受前人工作[5, 21]启发,论文在 item 文本描述末尾添加特殊 token \(\lceil \text{ITEM} \rceil\) 以提取特征
- 如图1所示,对于 item \( I \),首先将其文本属性拼接为句子 \( T \),并在开头添加固定提示词。通过 LLM 分词器处理后,额外在末尾添加特殊 token \(\lceil \text{ITEM} \rceil\),因此 Item LLM 的输入 token 序列可表示为 \(\{t_1, t_2, \ldots, t_m, \lceil \text{ITEM} \rceil\}\),其中 \( m \) 为文本 token 长度。最后一层对应 \(\lceil \text{ITEM} \rceil\) token 的隐藏状态即为 item Embedding
User LLM
- User LLM用于建模用户兴趣
- 原始用户历史序列 \( U = \{I_1, I_2, \ldots, I_n\} \) 可通过 Item LLM 转换为特征序列 \(\{E_1, E_2, \ldots, E_n\}\),其中 \( E_i \) 表示 \( I_i \) 的 item Embedding。User LLM 以该特征序列为输入,基于历史交互预测 next item 的 Embedding
- 如图1所示,User LLM 对 \( E_i \) 的 输出为 \( E’_{i+1} \) ,期望其为 \( I_{i+1} \) 的 Embedding
- 与传统 LLM 的 “text-in and text-out” 格式不同,此处 User LLM 的输入和输出均为 item Embedding。因此,论文舍弃预训练 LLM 的词 Embedding 层 ,但保留其余预训练权重。实验表明,这些预训练权重对推理用户兴趣非常有效
- 问题:模型的 Embedding 都变了,不会出现问题吗?
面向推荐目标的训练
- 现有 LLM 均基于通用自然语料库预训练,虽具备丰富的世界知识和强大推理能力,但其能力与推荐系统的需求仍存在显著差距。遵循其他工作的最佳实践[Zhou 等, 2024; Touvron 等, 2023],论文在预训练 LLM 基础上进行监督微调
- 推荐系统可分为生成式和判别式两类,HLLM 架构对两者均适用,仅需调整训练目标即可。以下分别介绍两类任务的训练目标
生成式推荐
- Meta-GRs 提出了成功的生成式推荐方案,涵盖检索和排序。论文的方法与其主要差异在于:模型架构升级为带预训练权重的大语言模型,输入特征从 ID 改为 LLM 的文本特征。这些差异对训练和服务策略影响较小,因此论文基本遵循 Meta-GRs 的方法
- 生成式推荐的训练目标采用 next item 预测,即根据用户历史 item Embedding 生成 next item 的 Embedding。具体采用 InfoNCE 损失[Oord 等, 2018]。对于 User LLM 输出序列中的每个预测 \( E’_i \),正样本为 \( E_i \),负样本从数据集中随机采样(排除当前用户序列)。损失函数如下:
$$
\mathcal{L}_{gen} = -\sum_{j=1}^{b} \sum_{i=2}^{n} \log \frac{e^{s(E’_{j,i}, E_{j,i})} }{e^{s(E’_{j,i}, E_{j,i})} + \sum_{k}^{N} e^{s(E’_{j,i}, E_{j,i,k})} }
$$- \( s \) 为带可学习温度参数的相似度函数
- \( E_{j,i} \) 表示第 \( j \) 个用户历史交互中第 \( i \) 个 item 的 Item LLM Embedding
- \( E’_{j,i} \) 表示 User LLM 为第 \( j \) 个用户预测的第 \( i \) 个 item Embedding
- \( N \) 为负样本数量,\( E_{j,i,k} \) 表示 \( E’_{j,i} \) 的第 \( k \) 个负样本 Embedding
- \( b \) 为批次内用户总数
- \( n \) 为用户历史交互长度
判别式推荐
- 由于判别式推荐模型在工业中仍占主导地位,论文亦提出 HLLM 在判别式模型下的应用方案
- 判别式模型的优化目标是:给定用户序列 \( U \) 和目标 item \( I_{tgt} \),判断用户是否对目标 item 感兴趣(如点击、喜欢、购买等)
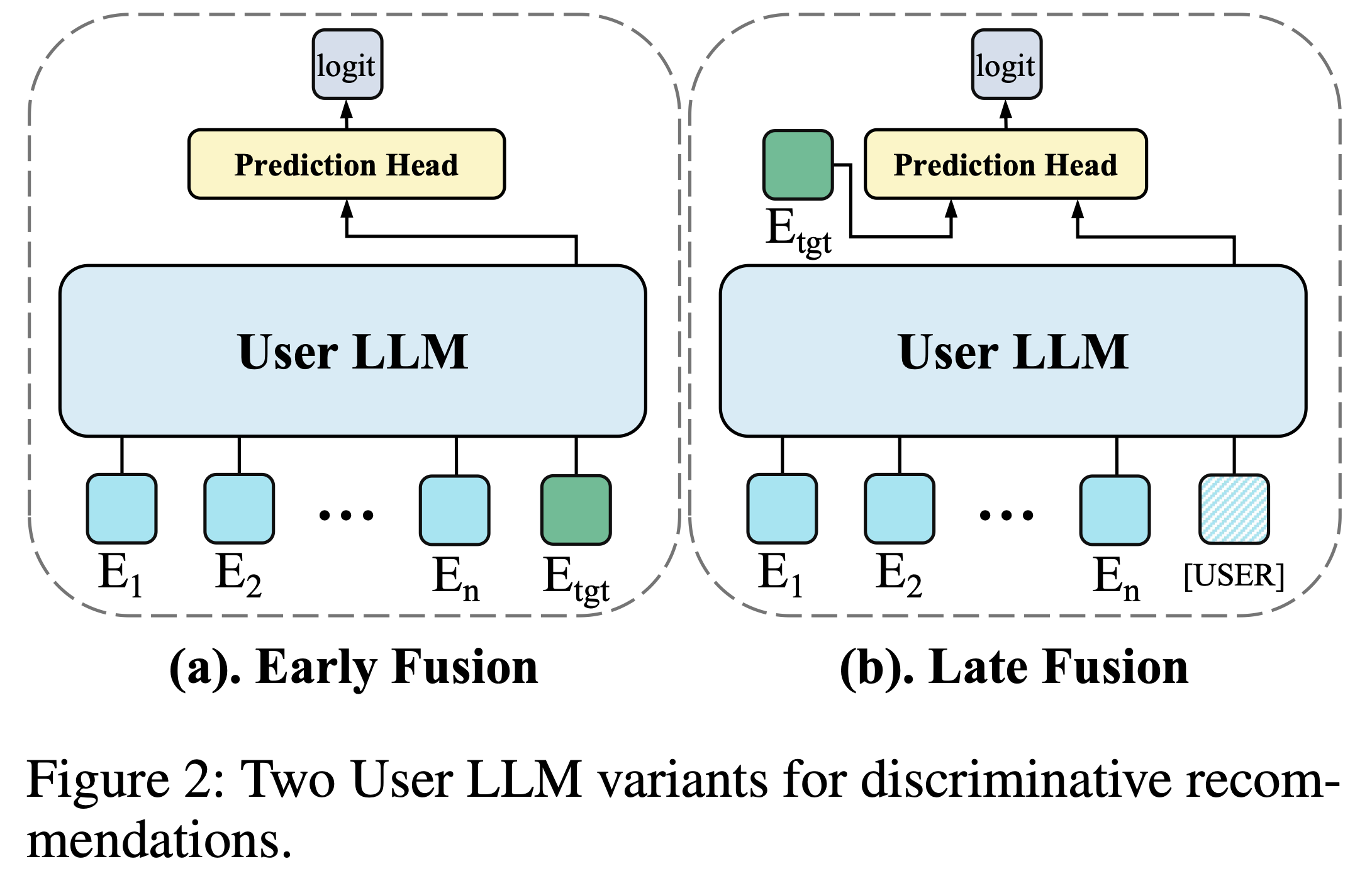
- 如图2所示,判别式推荐有两种 User LLM 变体,Item LLM 保持不变
- 早期融合(Early fusion) :将目标 item 的 Embedding \( E_{tgt} \) 追加到用户历史序列末尾,通过 User LLM 生成高阶交叉特征,最后将该特征输入预测头生成最终 logits
- 晚期融合(Late fusion) :则先通过 User LLM 提取与目标 item 无关的用户特征(类似 Item LLM 的特征提取方式),在用户序列末尾添加特殊 token \(\lfloor \text{USER} \rfloor\) 以提取用户表示,再将用户 Embedding 与目标 item Embedding 一同输入预测头生成 logits
- 对比来看:
- 早期融合因深度融合用户兴趣与目标 item ,效果更优但难以同时应用于多候选 item;
- 晚期融合因不同候选共享同一用户特征 ,效率更高但效果通常略低
- 判别式推荐的训练目标通常为分类任务(如预测用户是否点击等)。以二分类为例,训练损失如下:
$$
\mathcal{L}_{cls} = -\left( y \cdot \log(x) + (1 - y) \cdot \log(1 - x) \right)
$$- 其中 \( y \) 为样本标签,\( x \) 为预测 logit
- 实验表明,next item 预测亦可作为判别式模型的辅助损失以进一步提升性能。因此,最终损失为:
$$
\mathcal{L}_{dis} = \lambda \mathcal{L}_{gen} + \mathcal{L}_{cls}
$$- 其中 \( \lambda \) 控制辅助损失权重
实验设计及结论
- 论文的实验主要回答以下研究问题:
- RQ1 :LLM 的通用预训练和针对推荐目标的微调是否能提升最终的推荐性能?
- RQ2 :HLLM 是否具有良好的可扩展性?
- RQ3 :与其他模型相比,HLLM 的优势是否显著?
- RQ4 :HLLM 的训练和服务效率与 ID-based Model 相比如何?
数据集与评估设置
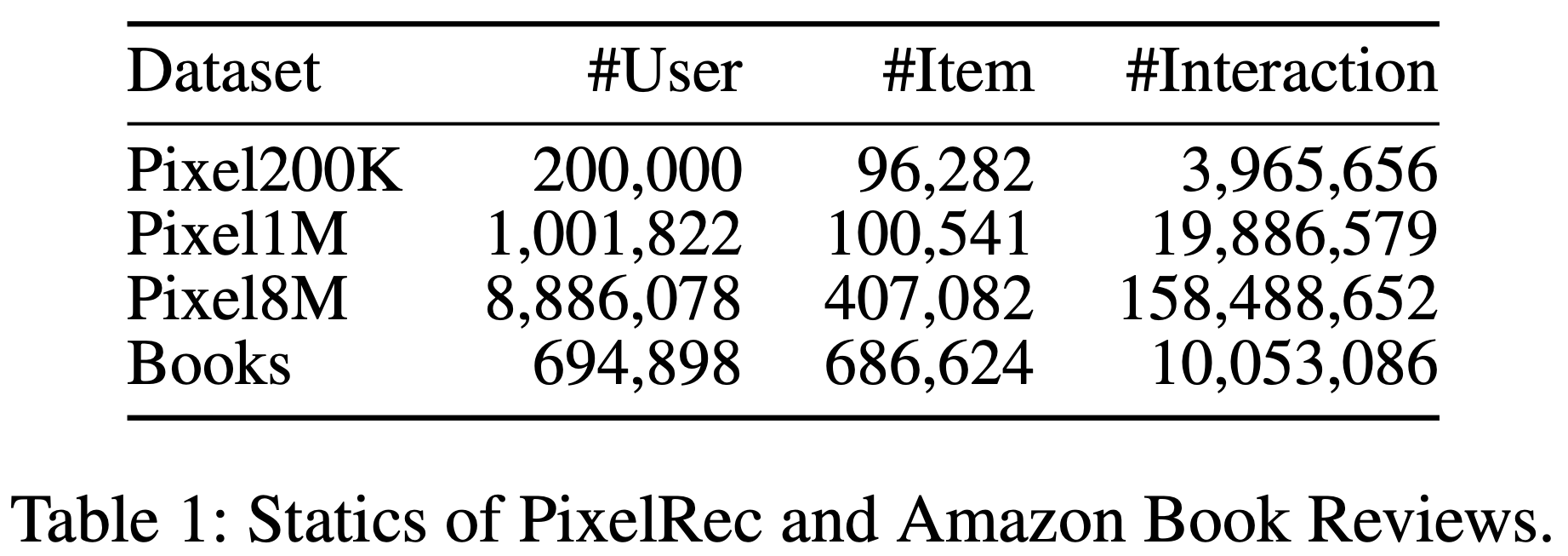
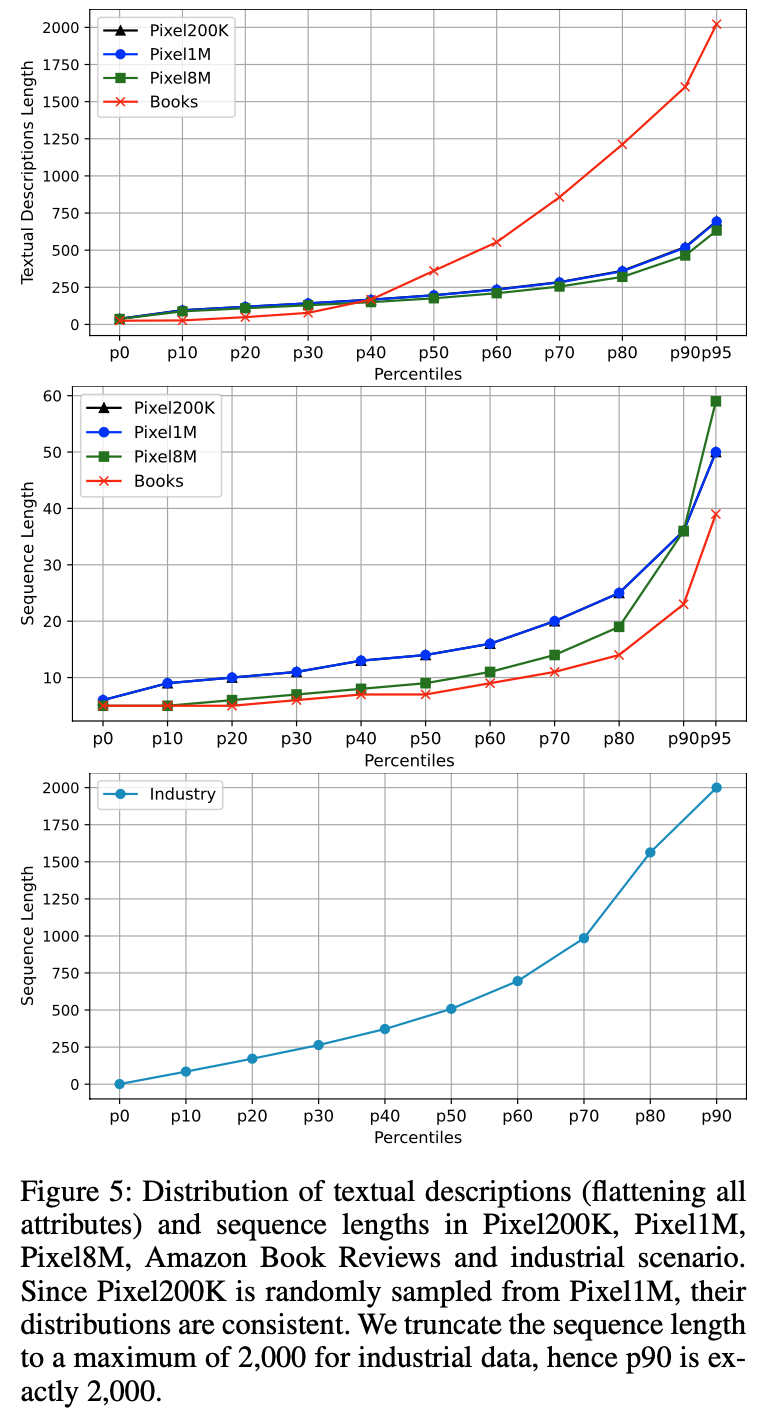
- 在离线实验中,论文在两个大规模数据集上评估 HLLM:PixelRec(包含三个子集:200K、1M和8M)[5]和Amazon Book Reviews(Books)[13]。与先前工作[5,19]一致,论文采用相同的数据预处理和评估协议以确保公平比较。表1和图5展示了预处理后数据集的详细分析
- 论文使用留一法(leave-one-out approach)将数据划分为训练集、验证集和测试集,性能指标采用Recall@K(R@K)和NDCG@K(N@K)。所有开源数据集仅用于离线实验的训练和评估
基线模型与训练设置
- 基线模型包括两种基于 ID 的序列推荐模型 SASRec[15] 和 HSTU[19],它们均面向工业应用并自称(boast)具有 SOTA 性能
- 离线实验采用生成式推荐以与其他方法保持一致,而在在线A/B测试中采用判别式推荐以更好地与在线系统对齐(注意,关于数据集:Experiments demonstrated that most conclusions drawn from the academic dataset still hold true on large-scale industrial benchmarks.)
- 在 HLLM-1B 中,论文使用 TinyLlama-1.1B[19] 作为 Item LLM 和 User LLM 的模型;
- 在 HLLM-7B 中,则采用 Baichuan2-7B[2]
- 由于资源限制,HLLM 在 PixelRec 和 Amazon Reviews 上仅训练 5 轮,而其他模型分别训练 50 轮和 200 轮
- 学习率设为 1e-4
- 每个 item 的文本长度截断为最多256
- 在PixelRec上,遵循PixelNet[5],论文使用批量大小为512,最大序列长度为10,正负样本比例为1:5632
- 在Books上,批量大小为128,最大序列长度为50,负样本数量为512
- 为公平比较,论文还实现了 SASRec-1B(将其网络结构替换为TinyLlama-1.1B)和 HSTU-1B(隐藏层大小和层数与 TinyLlama-1.1B 相同,但因移除了传统 FFN,参数量仅为 462M)
预训练与微调(RQ1)
- 从 表2 可以明显看出,预训练权重对 HLLM 有益,包括 item 特征提取和用户兴趣建模两方面
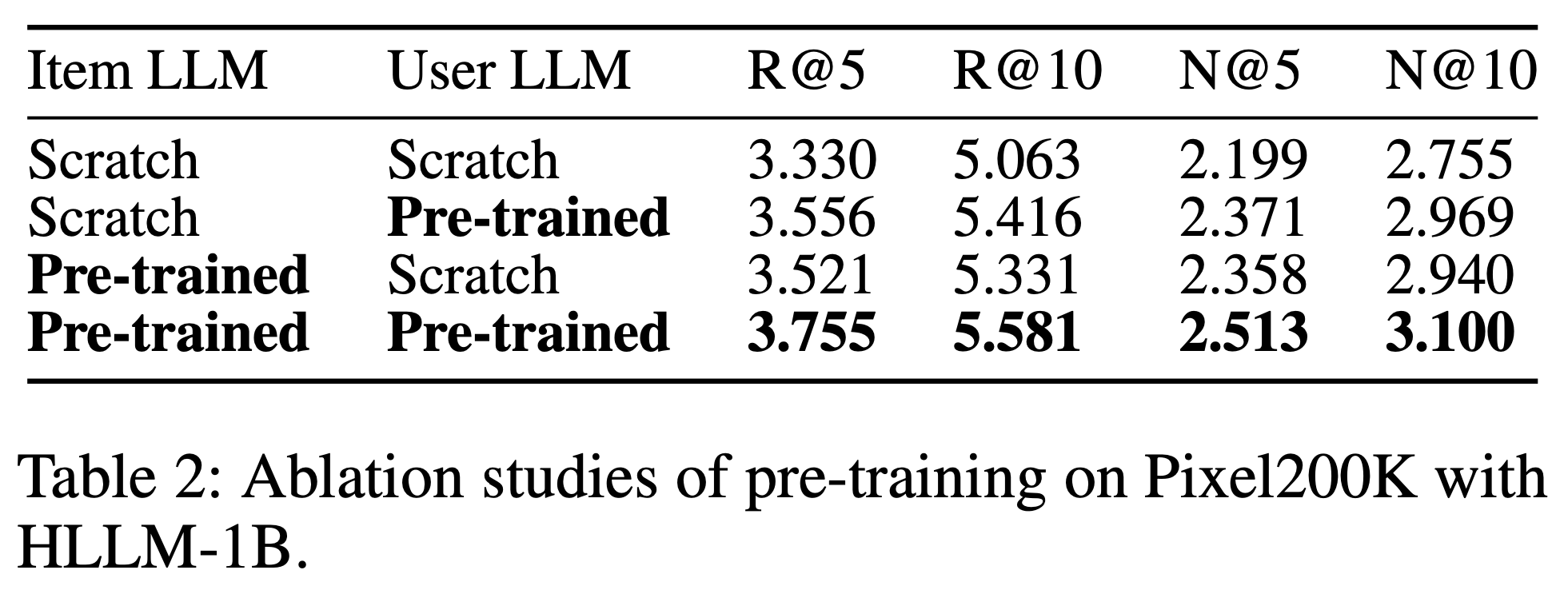
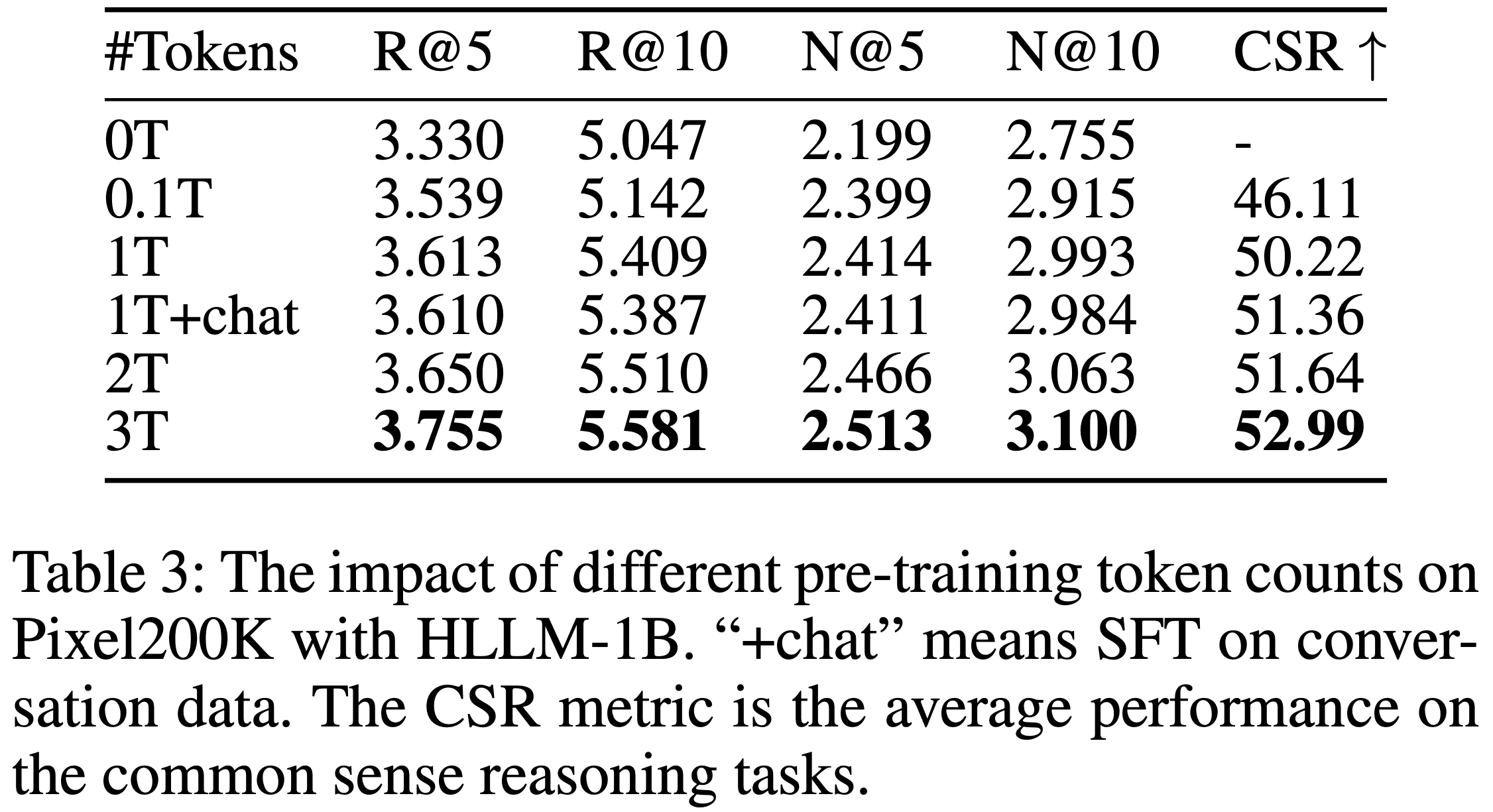
- 表3 显示性能与预训练 token 数量呈正相关,表明预训练权重的质量对推荐任务也有影响
- 然而,在对话数据上进行 SFT 可能带来轻微的负面影响 ,这可能是因为世界知识主要在预训练阶段获得,而 SFT 主要提升指令跟随能力,对推荐任务帮助有限[19]
- 理解:这里的 +chat 是指使用 chat 版本作为基座 ,再在 推荐系统上进行 SFT
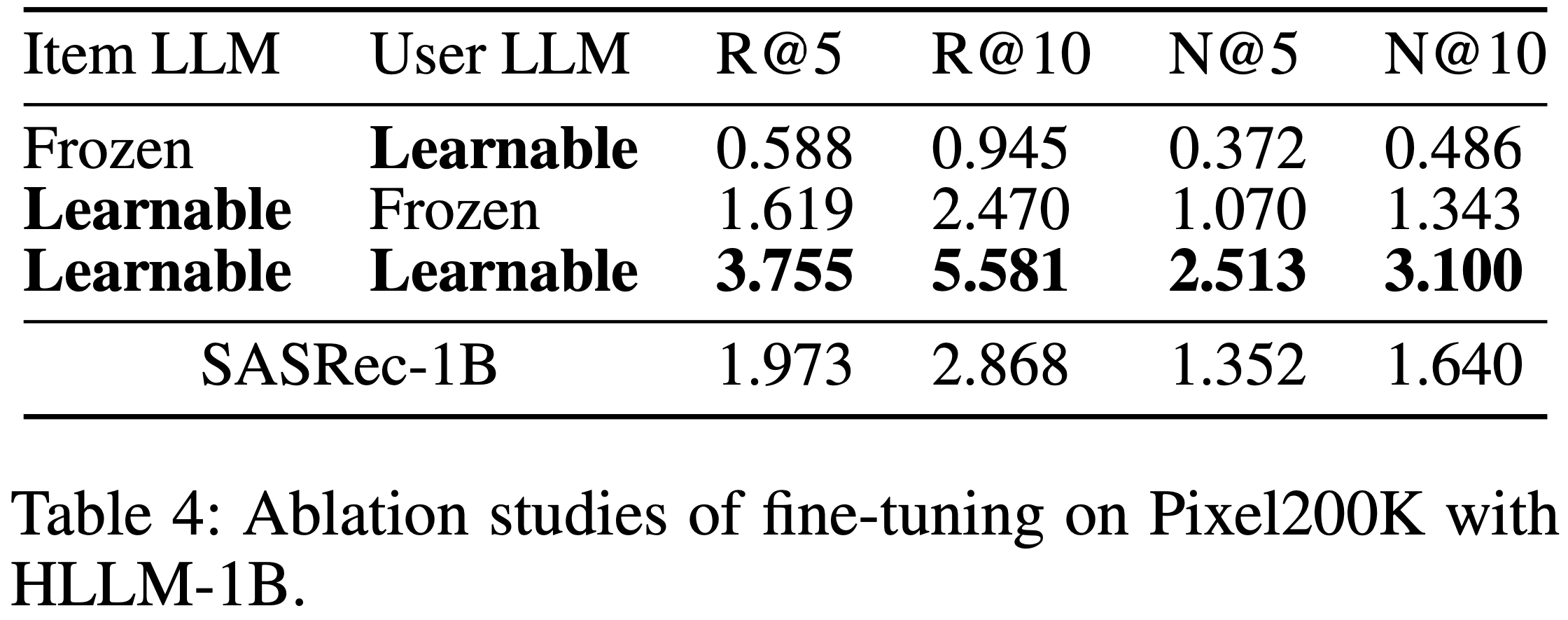
- 表4 的消融实验表明,微调 Item LLM 和 User LLM 对超越 ID-based Model 至关重要
- 若冻结 Item LLM 仅微调 User LLM,并使用 TinyLlama-1.1B 最后一层所有 token 输出的均值作为 item 特征,性能极差,表明训练用于预测 next token 的 LLM 并不适合直接作为特征提取器(理解:Item LLM 中输入文本内容变成了 item 的描述了,确实可能效果不好; User LLM 中则词表都变了,不微调效果会更差)
- 类似地,若使用在 Pixel200K 上微调的 Item LLM 并冻结预训练的 User LLM,性能仍然极低
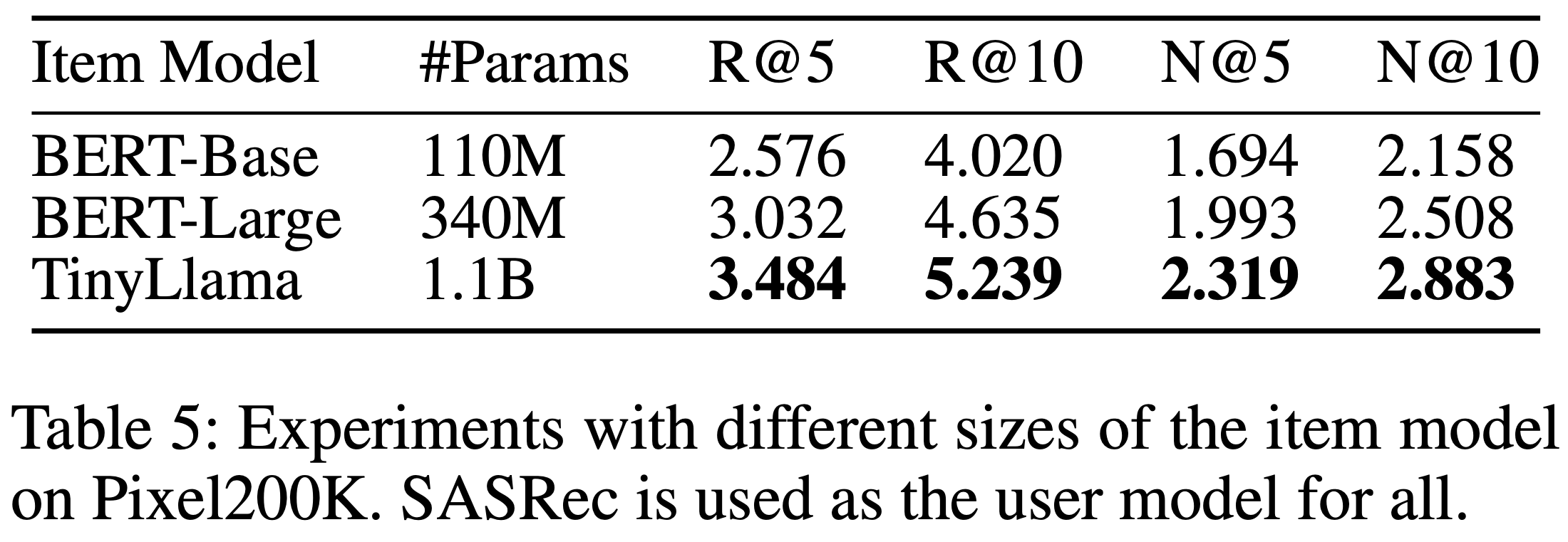
模型扩展(RQ2)
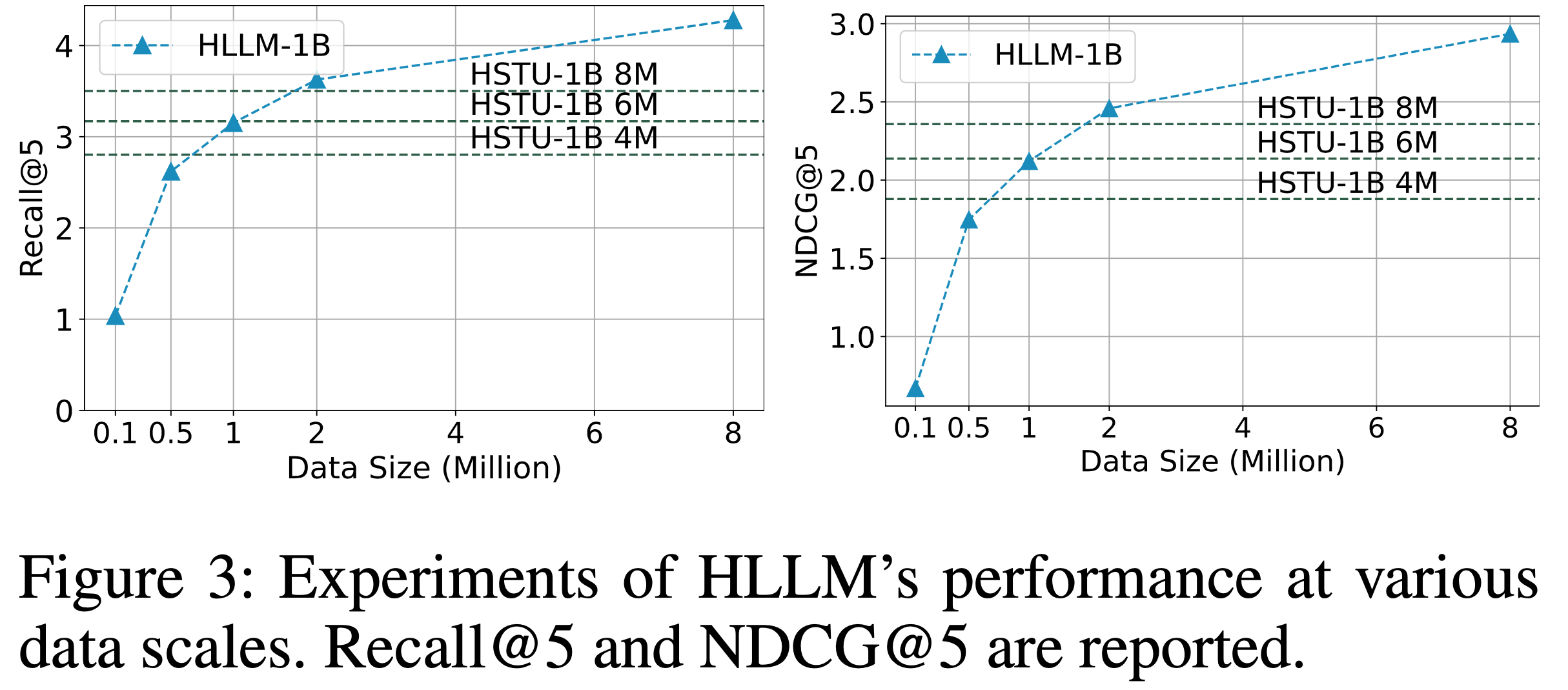
- 表5 和 表6 展示了模型参数量增加的实验结果。可以看出,Item LLM 和 User LLM 的参数增长均能持续提升性能。最终,在 Amazon Books 上将 Item LLM 和 User LLM 的参数量从 10亿 扩展到 70亿,如 表7 所示,进一步提升了性能,证明 HLLM 具有出色的可扩展性
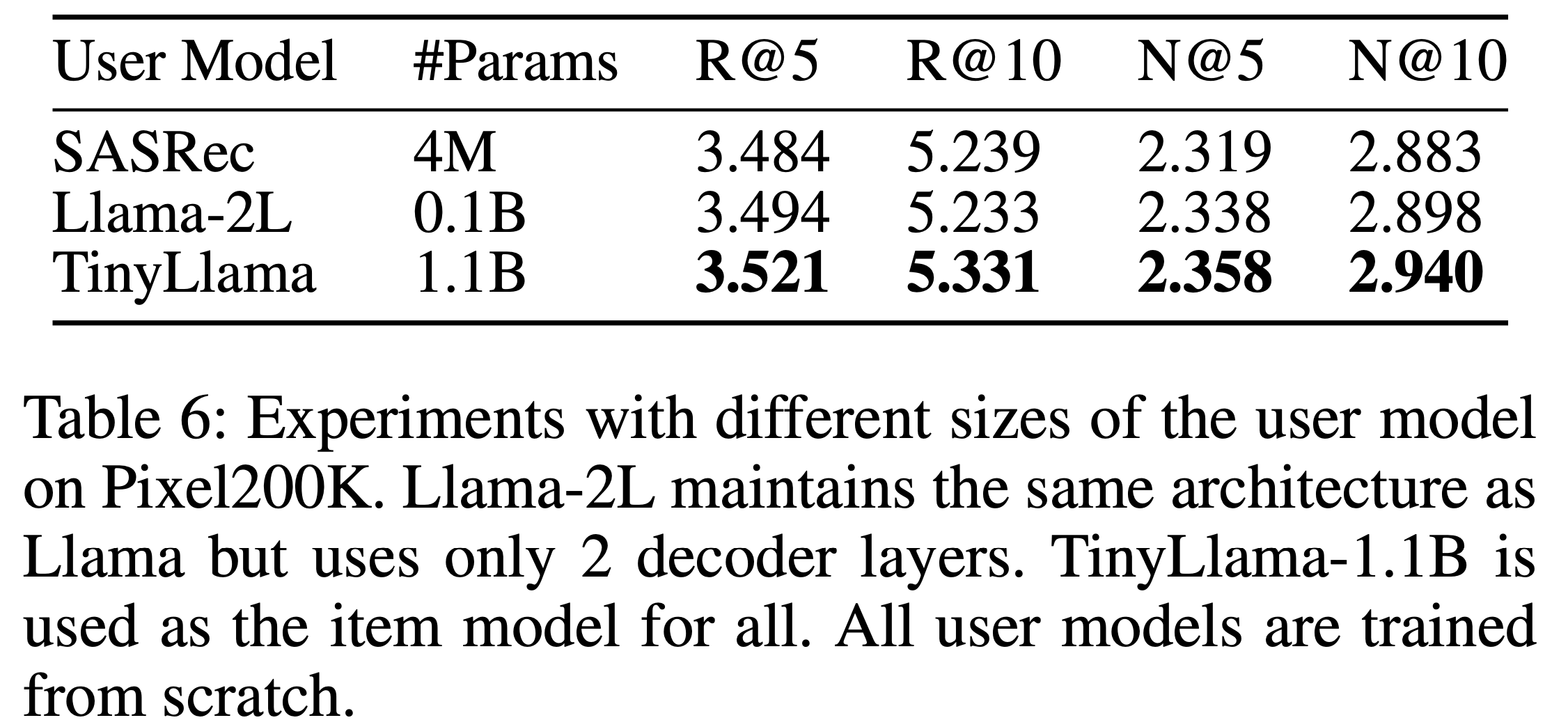
- 为探索数据量的可扩展性,论文从 Pixel8M 中采样了不同规模的数据进行训练,范围从 0.1M 到 8M。图3 显示,HLLM 在不同数据量下均表现出显著的可扩展性。随着数据量增加,性能显著提升,且在当前数据规模下未观察到性能瓶颈
- 论文还针对工业推荐数据集进行了更全面的扩展实验,详细结果见附录
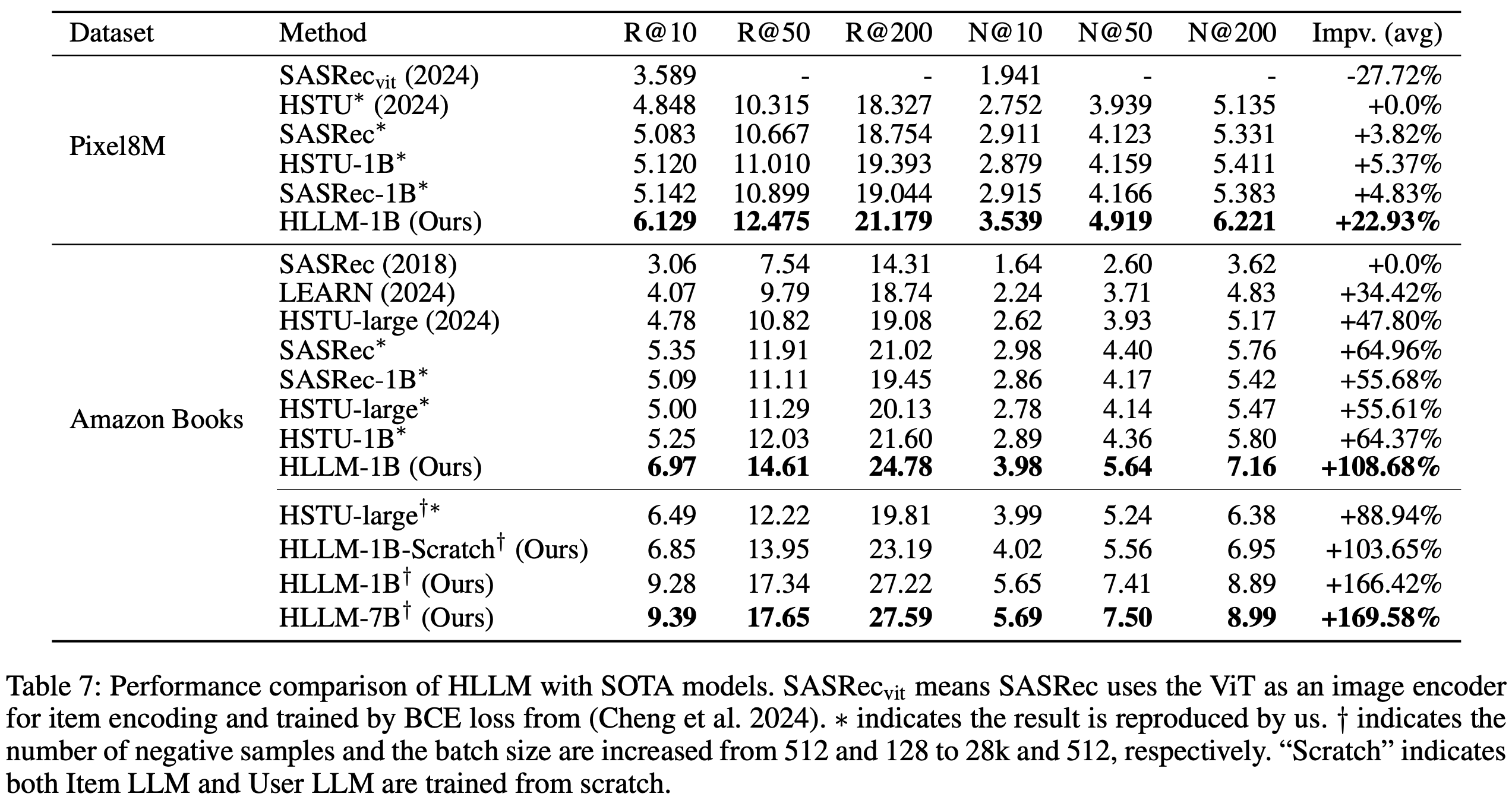
HLLM 与最先进模型的对比(RQ3)
- 表7 比较了 HLLM 与当前最先进模型的性能,包括 ID-based Model (如SASRec[15]和HSTU[24])以及基于文本的模型 LEARN[17]。在所有数据集和指标上,HLLM 均显著优于其他模型。在相同实验设置下,HLLM-1B 在 Pixel8M 上平均提升22.93%,在 Books 上平均提升108.68%。而 ID-based Model 在 Pixel8M 上最大仅提升5.37%,在 Books 上最大提升64.96%
- 重点 :当 ID-based Model 增加负样本数量和批量大小时,性能提升相对有限(如 HSTU-large 在 R@200 上仅提升 0.76,而 HLLM-1B 在相同设置下提升 2.44)。进一步增加模型参数后,HLLM-7B相比基线实现了169.58%的显著提升
- 表7 还显示,即使 ID-based Model 完全收敛,增加参数带来的增益也较小。例如,在Pixel8M上,SASRec-1B和HSTU-1B的性能提升有限;而在Books上,SASRec-1B的所有指标甚至下降。相比之下,HLLM 从1B扩展到7B仍能持续提升推荐任务性能,凸显了 HLLM 架构的优越性
训练与服务效率(RQ4)
- HLLM 展现出比 ID-based Model 更高的训练数据效率。如图3所示,HLLM 仅需 1/6 到 1/4 的数据量即可达到与基于 ID 方法相当的性能
- 先前实验表明,完全微调整个 HLLM 能显著提升性能,但推理时需要实时编码所有 item,效率较低。得益于 HLLM 中 item 与用户编码的解耦,我们可以通过预缓存 item Embedding 降低计算复杂度
- 为验证 item 缓存的可行性,论文在 Pixel8M 数据集上预训练 HLLM (序列长度截断为 10 以避免数据泄露,覆盖 300万 用户),随后冻结 Item LLM 并仅在 Pixel8M 上微调 User LLM。表8 结果显示,尽管冻结 Item LLM 会导致部分指标下降,但性能仍超越 ID-based Model,证明 item 缓存是有效的
- 考虑到工业场景中用户行为数量远多于 item 数量,HLLM 的训练和服务成本可与 ID-based Model 相当。值得注意的是,论文的预训练数据不到 Pixel8M 的一半,且部分 item 未出现在预训练数据中,但仍取得了可观的性能。工业数据实验表明,随着预训练数据量增加,item 缓存与完全微调之间的差距会显著缩小
在线A/B测试
- 除离线实验外,HLLM 还成功应用于实际工业场景。为简化流程、提升灵活性并与在线系统更好对齐,论文采用 HLLM-1B,使用判别式推荐的“后期融合”变体进行优化。训练过程分为以下三个阶段:
- 阶段I :端到端训练所有 HLLM 参数(包括 Item LLM 和 User LLM),采用判别式损失。用户历史序列长度截断为 150 以加速训练
- 阶段II :使用 阶段I 训练的 Item LLM 编码并存储推荐系统中所有 item 的 Embedding,随后仅训练 User LLM(从存储中检索所需 item Embedding)。此阶段仅训练 User LLM,显著降低训练需求,并将用户序列长度从 150 扩展到 1000,进一步提升 User LLM 的效果
- 阶段III :在前两阶段大量数据训练后,HLLM 模型参数不再更新。论文提取所有用户的特征,与 Item LLM Embedding 及其他现有特征结合,输入在线推荐模型进行训练
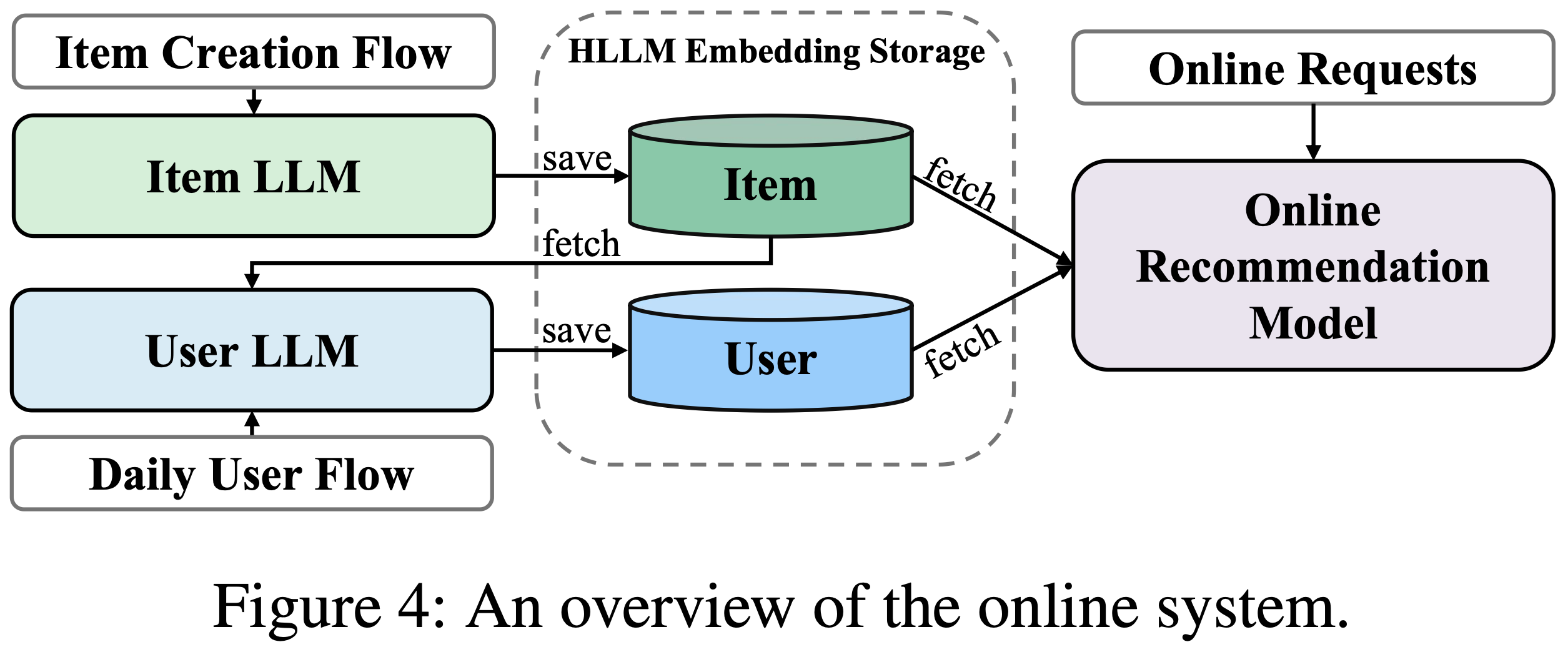
- 在服务阶段(如图4所示),item Embedding 在创建时即被提取,用户 Embedding 仅针对前一天活跃的用户每日更新一次。item 与用户的 Embedding 存储后供在线模型训练和服务使用。此方案下,在线推荐系统的推理时间几乎不变
- 最终,论文在排序任务的在线A/B测试中验证 HLLM,关键指标显著提升0.705%
附录A:学术数据集上的更多实验
文本输入长度与Item LLM的丰富性
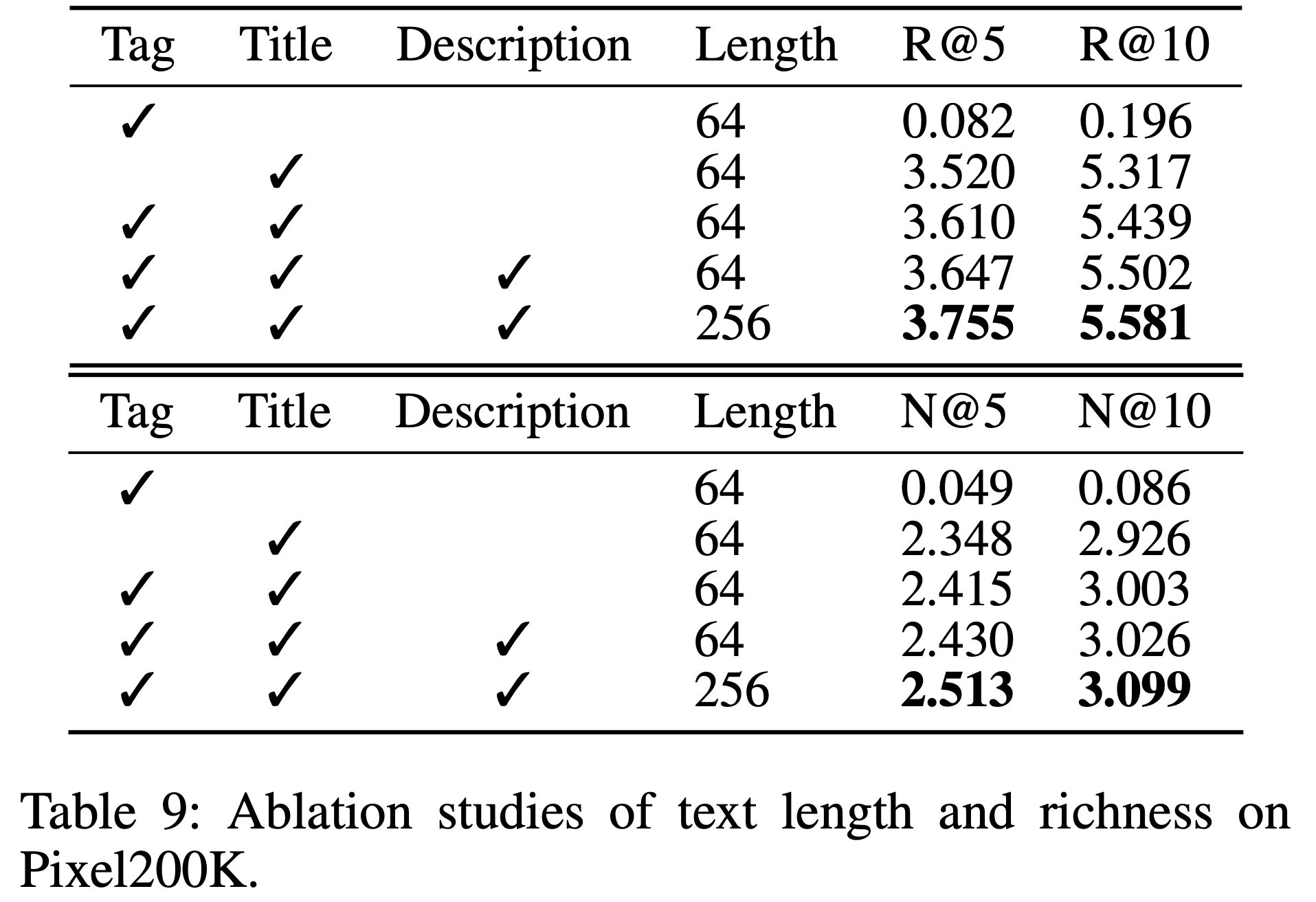
- 默认情况下,论文输入所有类型的文本信息,长度为256。此处论文对文本长度和丰富性进行消融实验。表9 显示,文本内容对最终性能有显著影响。更丰富的文本内容和更长的文本长度使得 Item LLM 能够提取更详细的 item 特征,更好地区分 item,并更有效地帮助 User LLM 建模用户兴趣
Item LLM特征提取方法
- 为了使训练在 next token prediction 任务上的 LLM 具备特征提取能力,论文在文本输入末尾添加了一个特殊 token [ITEM]。另一种可行的特征提取方法是取 LLM 最后一层隐藏状态的平均值来表示整个句子的特征
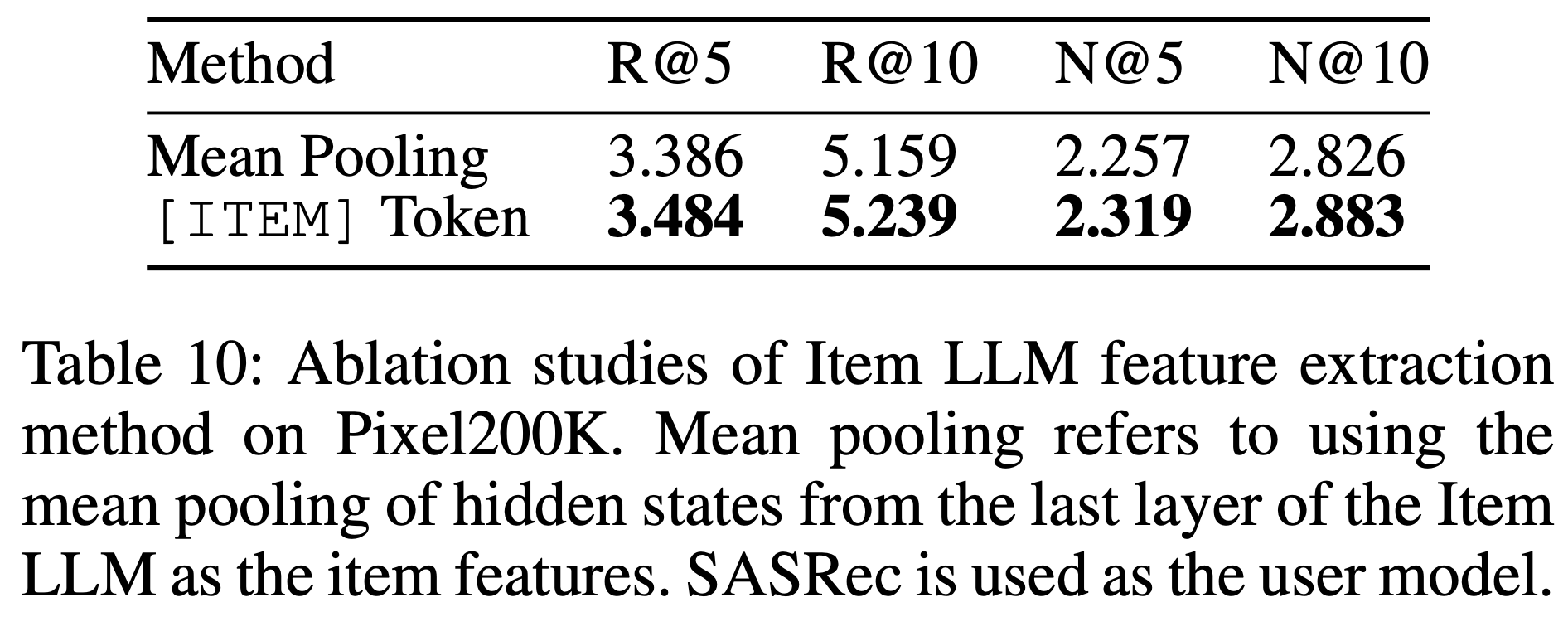
- 表10 展示了这两种方法的对比结果。可以看出,使用 [ITEM] token 比均值池化效果更好
- 问题:这个原因是什么呢?理论上两者都能捕捉到句子的整体信息
- 理解:猜测是自回归模型带来的 next token 含义对未来动作意图的信息优势
User LLM的序列长度
- 表11探讨了 User LLM 输入序列长度对 HLLM 推荐性能的影响。与其他序列推荐模型类似,HLLM 也能从扩展输入序列长度中受益
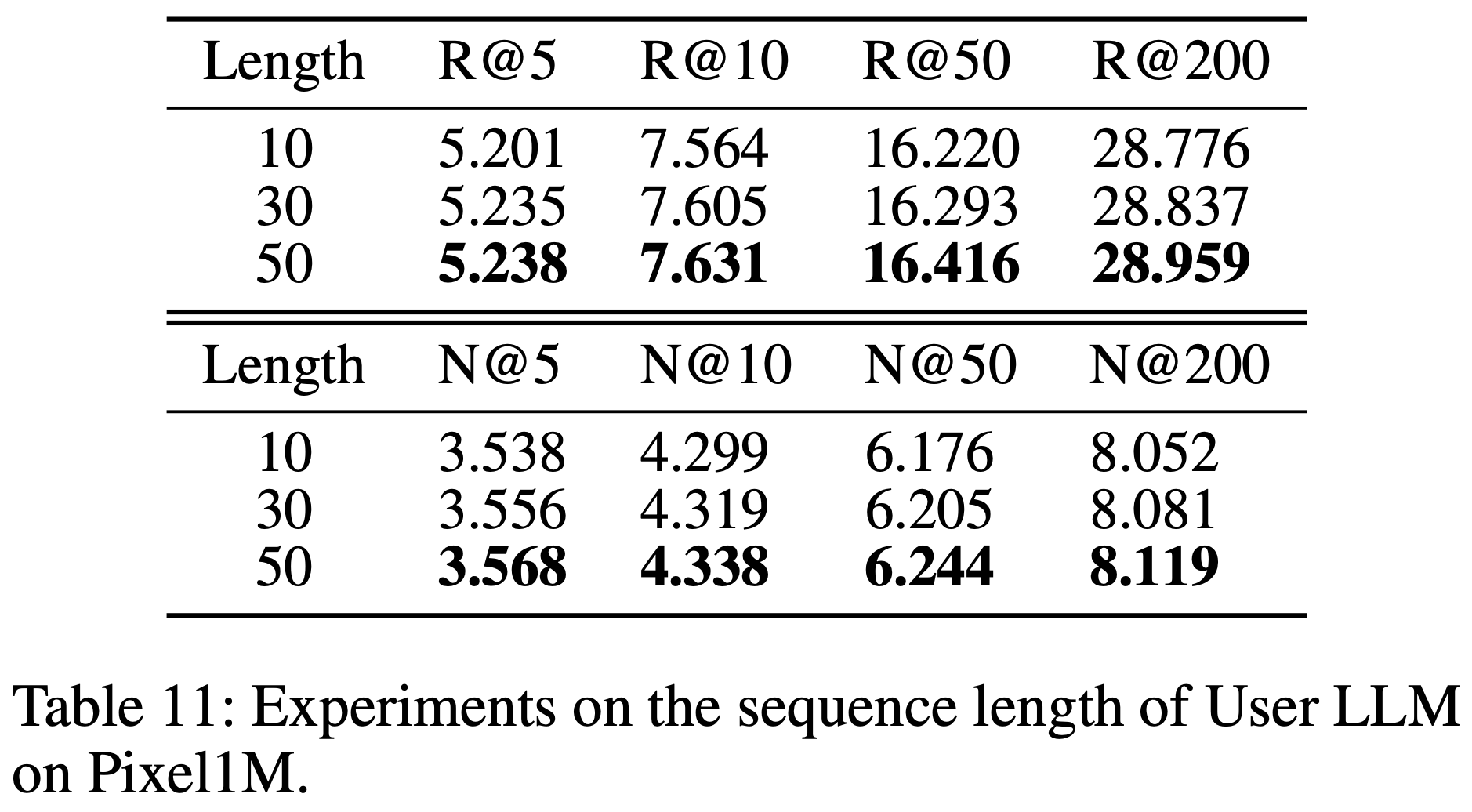
- 尽管表中显示随着序列长度的增加性能提升有限,但论文推测这可能是因为学术数据集中用户序列长度普遍较短,如图5所示。如 附录B 所示,在真实工业场景中,用户行为序列通常非常长,扩展序列长度可以让 HLLM 实现稳定的性能提升
与ID特征的兼容性
- 在前文中,论文主要基于 item 的文本描述建模 item 和用户特征。然而,当前大多数推荐系统仍依赖 ID 特征,不仅包括 item ID,还包括行为、时间戳和 item 类别等 ID 形式的特征。此处论文提出一种将 HLLM 与 ID 特征结合的兼容方案,并证明互补的 ID 特征与 item 描述结合能为 HLLM 带来显著提升,进一步凸显其在工业环境中的应用价值
- 论文选择原始 item ID 和时间戳作为 ID 特征进行验证
- item ID 通过 Embedding 查找表转换为 ID Embedding
- 行为的时间戳首先拆分为具体的年、月、日、时、分和秒组件,其 Embedding 表示如算法1所示(见附录)
- 在输入 User LLM 之前,论文将 ID 特征与 Item LLM 提取的 Embedding 进行求和池化
- 训练时的预测目标仍然是 Item LLM 提取的 item Embedding,实验结果如 表12 所示
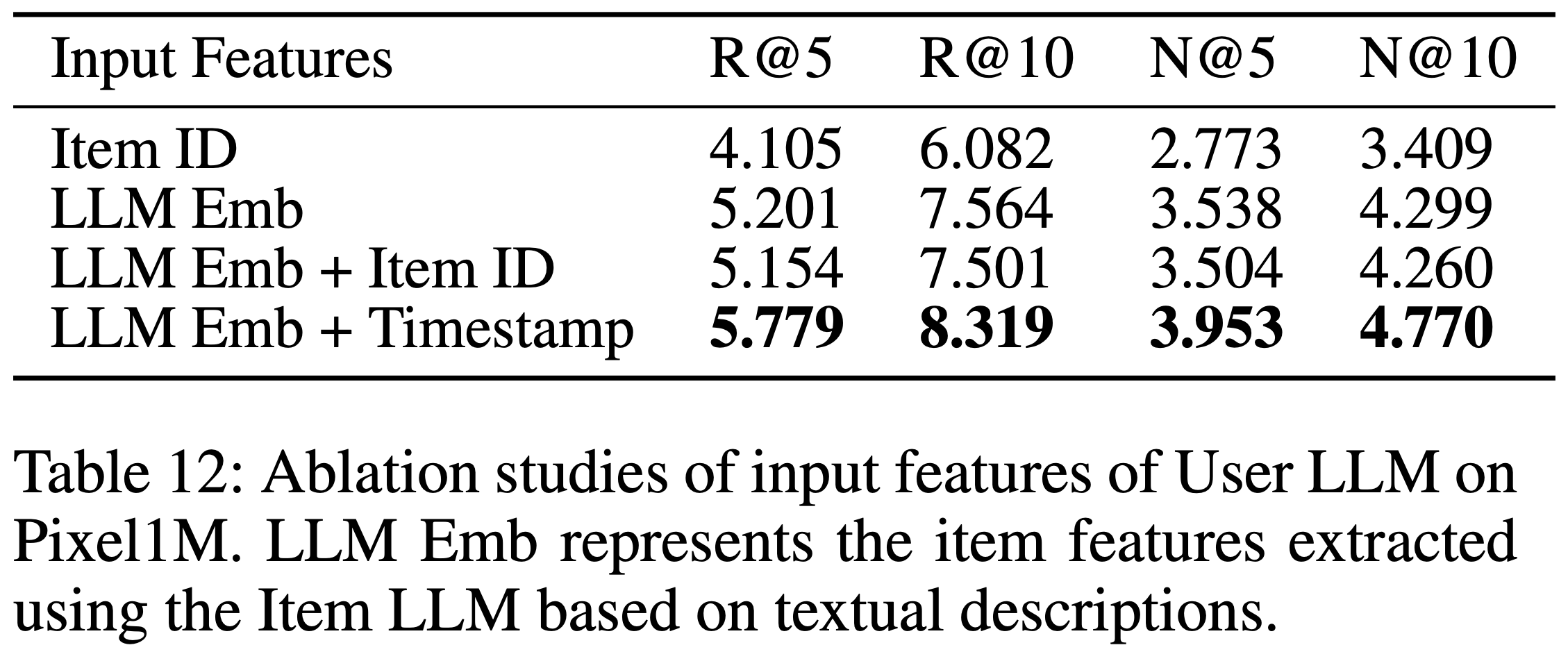
- 实验结论:
- 引入 item ID 实际上会导致性能轻微下降 ,可能是因为 item ID 未能提供超出文本描述之外的增量信息,而文本描述已全面覆盖 item 特征并被 Item LLM 充分提取
- 然而,引入时间戳带来的提升非常显著 ,因为时间戳是对文本描述的补充。这也表明论文的方法能够兼容ID特征
- 理解:这里时间戳能拿到收益相当于加入了对 token 加入了绝对位置编码信息,比如 8 月份买裙子和 12 月份买裙子的动作是不等价的
附录B:工业数据集上 HLLM 的扩展实验
- 论文在大型工业数据集上进行了更广泛的实验,以评估 HLLM 的可扩展性
- 抖音拥有海量用户和推荐候选 item,以及丰富的用户行为记录。论文从过去 3 年的日志中构建了一个包含 3000万 样本的数据集。每个样本仅包括用户的历史点击序列、目标 item 以及一个表示是否点击的标签。论文在判别式推荐系统中验证 HLLM 的有效性,使用 AUC 作为评估指标,并从两个方面验证可扩展性:User LLM 的序列长度,以及 Item LLM 和 User LLM 的参数规模
User LLM的序列长度
- 工业数据集中用户行为序列的长度如图5所示。表13 展示了用户序列长度的影响,随着序列长度的增加,HLLM 的性能稳步提升。这表明 HLLM 在建模长序列用户方面具有巨大潜力
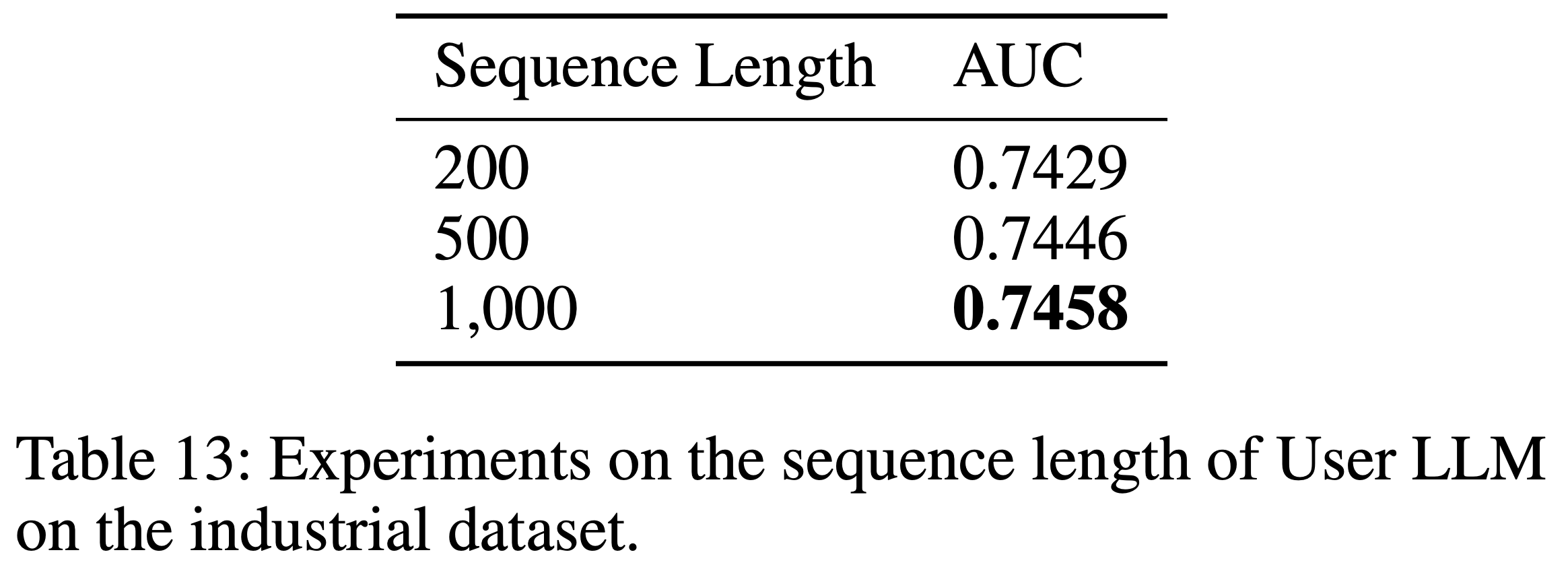
Item LLM和User LLM的参数规模
- 表14展示了工业场景中 HLLM 参数规模的影响。对于 Item LLM 和 User LLM,AUC 均随着参数数量的增加而持续提升
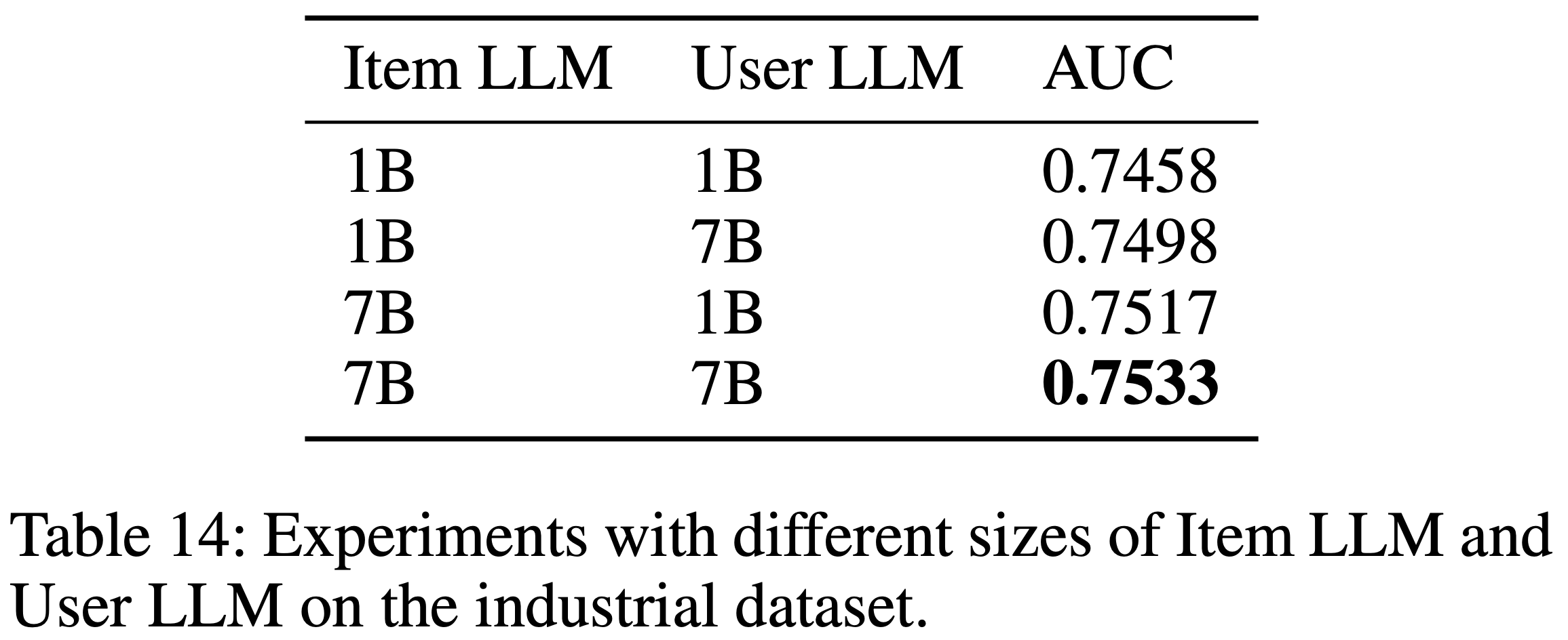
- 问题:有超过线上现在的 CTR 模型吗?
附录-算法1:timestamp processing 的伪代码
- Algorithm 1: Pseudo code of timestamp processing in a PyTorch-like style:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class TSEmbedding(nn.Module):
def__init__(self, time_num=6, time_dim=512, user_dim=2048):
super().__init__()
# 控制时间精度,例如4表示到小时,6表示到秒
self.time_num = time_num
self.time_embeddings = nn.ModuleList(nn.Embedding(x, time_dim) for x in [2100, 13, 32, 24, 60, 60])
# 从time_dim投影到user_dim
self.merge_time = MLP(time_dim * time_num, user_dim)
def split_time(self, timestamps: List) -> List:
# 将时间戳拆分为具体组件(年月日等)
# (seq) -> (seq, 6)
split_time = []
for time in timestamps:
dt = datetime.datetime.fromtimestamp(time)
split_time.append((dt.year, dt.month, dt.day, dt.hour, dt.minute, dt.second))
return split_time
def forward(self, timestamps: List) -> torch.tensor:
# 输入:时间戳列表,格式为(bs, seq)
# (bs, seq) -> (bs, seq, 6)
time_seq = torch.tensor([self.split_time(x) for x in timestamps])
# (bs, seq, 6) -> [(bs, seq, time_dim)] * time_num
time_emb = [self.time_embeddings[i](time_seq[..., i]) for i in range(self.time_num)]
# [(bs, seq, time_dim)] * time_num -> (bs, seq, time_dim * time_num)
time_emb = torch.cat(time_emb, dim=-1)
# (bs, seq, time_dim * time_num) -> (bs, seq, user_dim)
time_emb = self.merge_time(time_emb)
return time_emb