Decision-Transformer,简称DT,使用序列预估的思想去实现决策问题
- 参考链接:
HER 技术
- 在 Decision Transformer 之前,HER(Hindsight Experience Replay)方法已经有这种事后的思想,HER 过将想要达到的目标状态添加到策略网络的输入端,实现在给定目标的情况下,进行决策
Decision Transformer
returns-to-go轨迹变换
- 原始的轨迹: \( \tau = (s_1,a_1,r_1,s_2,a_2,r_2,\cdots,s_T,a_T,r_T) \)
- returns-to-go对应的轨迹: \( \tau = (\hat{R}_1,s_1,a_1,\hat{R}_2,s_2,a_2,\cdots,\hat{R}_T,s_T,a_T) \)
- \(\hat{R}_t = \sum_{t’=t}^T r_{t’}\) 被称为return-to-go(与state、action等一样的粒度),表示复数或者泛指时,也是用returns-to-go
- 注意, \(\hat{R}_t\) 没有使用discount ratio,是无折扣的奖励,方便后续实现中减去已获得的奖励实现目标值变换
建模方式
- 整体架构
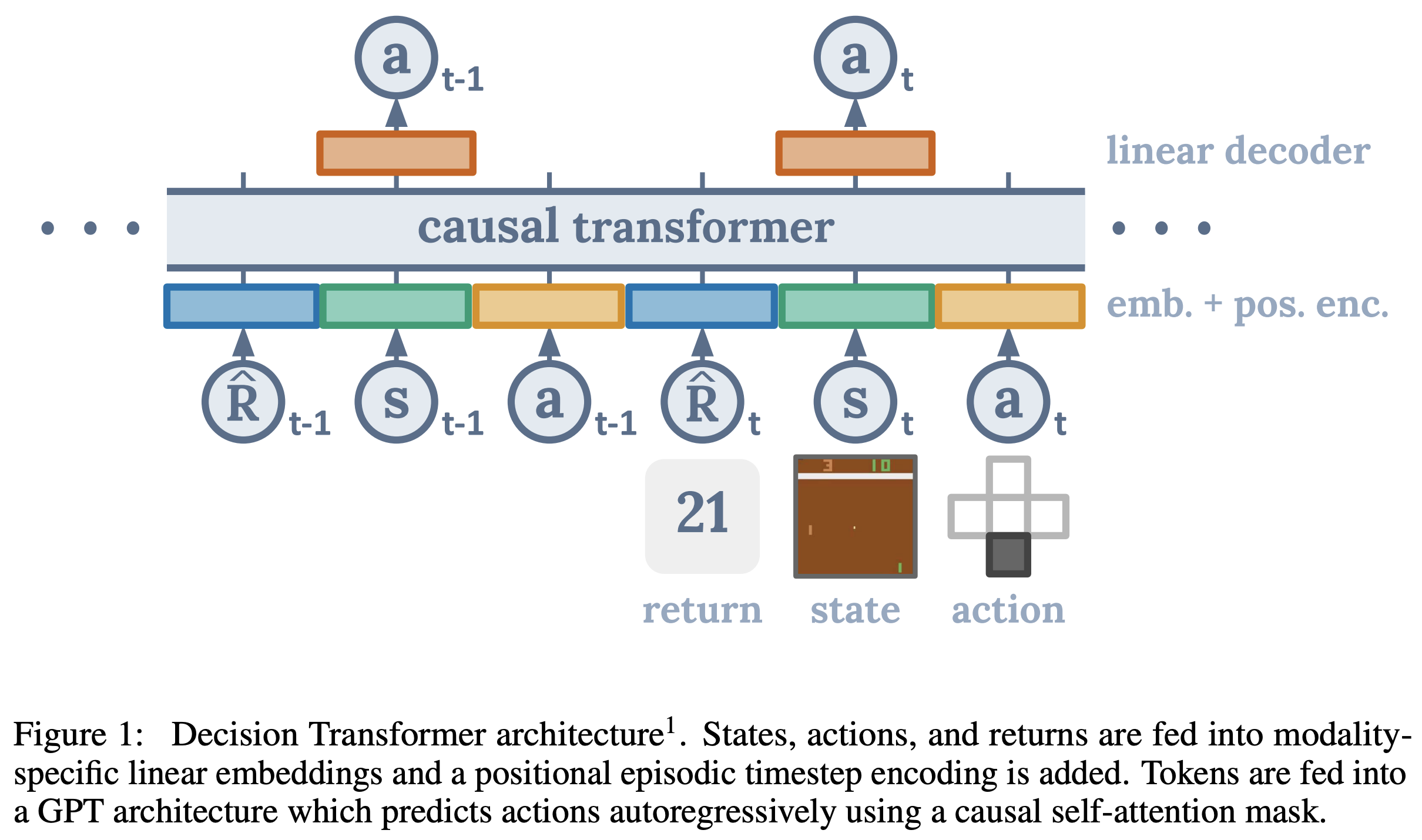
- demo
伪代码
在原始 Transformer 的基础上,DT 算法的实现非常简单,DT 算法的整体伪代码如下(连续版本):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# R, s, a, t: returns -to -go, states, actions, or timesteps
# K: context length (length of each input to DecisionTransformer)
# transformer: transformer with causal masking (GPT)
# embed_s, embed_a, embed_R: linear embedding layers
# embed_t: learned episode positional embedding
# pred_a: linear action prediction layer
# main model
def DecisionTransformer(R, s, a, t):
# compute embeddings for tokens
pos_embedding = embed_t(t) # per -timestep (note: not per -token)
a_embedding = embed_a(a) + pos_embedding
s_embedding = embed_s(s) + pos_embedding
R_embedding = embed_R(R) + pos_embedding
# interleave tokens as (R_1, s_1, a_1, ..., R_K, s_K)
input_embeds = stack(R_embedding, s_embedding, a_embedding)
# use transformer to get hidden states
hidden_states = transformer(input_embeds=input_embeds)
# select hidden states for action prediction tokens
a_hidden = unstack(hidden_states).actions
# predict action
return pred_a(a_hidden)
# training loop
for (R, s, a, t) in dataloader: # dims: (batch_size, K, dim)
a_preds = DecisionTransformer(R, s, a, t)
loss = mean((a_preds - a) ** 2) # L2 loss for continuous actions
optimizer.zero_grad()
loss.backward()
optimizer.step()
# evaluation loop
target_return = 1 # for instance, expert -level return
R, s, a, t, done = [target_return], [env.reset()], [], [1], False
while not done: # autoregressive generation/sampling
# sample next action
action = DecisionTransformer(R, s, a, t)[-1] # for cts actions
new_s, r, done, _ = env.step(action)
# append new tokens to sequence
R = R + [R[-1] - r] # decrement returns -to -go with reward
s, a, t = s + [new_s], a + [action], t + [len(R)]
R, s, a, t = R[-K:], s[-K:], a[-K:], t[-K:] # only keep context length of K伪代码讲解:
- token:包含三种模态的token,分别为return-to-go、state和action
- 位置编码:虽然是三个token,但是同一个时间片的return-to-go、state和action,对应的位置编码相同
- 模型的输入:过去 \(K-1\) 个时间片的(return-to-go,state,action)完整信息和当前时间片的(return-to-go,state),共 \((K-1)*3+2\) 个tokens
- 输出:仅在输入是state token对应的位置上,输出action token为决策目标
- 损失函数:伪代码中使用的是MSE损失函数(对应连续动作场景),实际上对于离散动作场景, 可以使用交叉熵损失函数(策略网络输出Softmax后的多个头)
- 训练时:
- 每个样本仅保留最近的 \(K\) 个步骤,模型输入是 \(K*\) 个样本
- 时间步 \(t\) 是一直累计的,与 \(K\) 无关
- 推断时的自回归:
- 初始化时先指定初始状态 \(s_0\) 和最终目标target_return \(R_0\)
- 通过DT模型决策得到动作 \(a_t\)
- 与环境交互执行动作 \(a_t\) 并得到reward \(r_{t}\),并跳转到状态 \(s_{t+1}\)
- 通过reward \(r_t\) 计算下个时间步的return-to-go \(R_{t+1} = R_t - r_t\)
- 将 \((a_t, s_{t+1}, R_{t+1})\) 分别加入到各自token列表中
- 截断到 \(K\) 个时间步,注意动作是保留 \(K-1\) 个,不足 \(K\) 个时间步时,会自动paddding(直接调用Transformer)即可,此时也需要保证模型输入action比return-to-go和state少一个
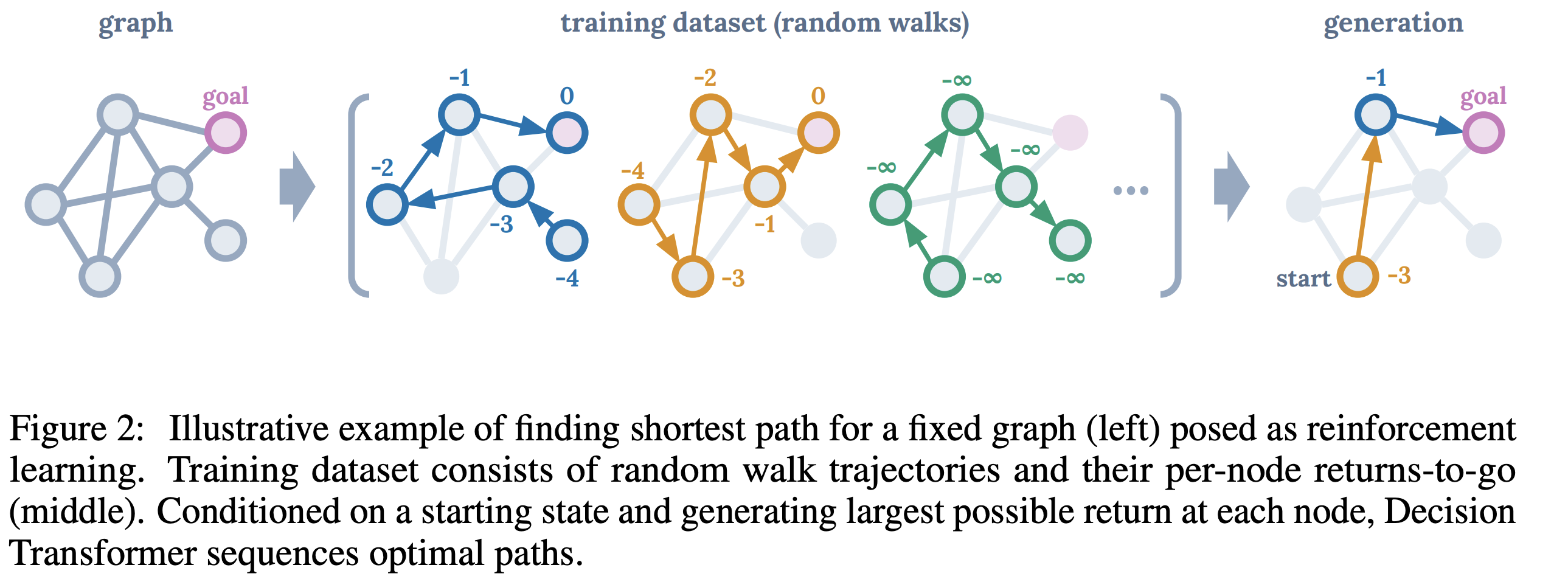
预测时如何指定Reward目标?
可以使用离线采样样本中Reward最大值作为目标,论文原始表述如下

个人理解:这个目标不一定要是最优目标,也不需要与离线目标完全相等,但是比较难设置:
- 如果太小,但是生成的不一定是最优的路径
- 如果太大,理论上,可以生成最优解,但是因为模型没有见过该目标值(模型做不到,因为训练时也收集不到这样的样本),可能会发生意想不到情况
实验结果
Atari上收集的实验数据集训练的实验结果见如下图:
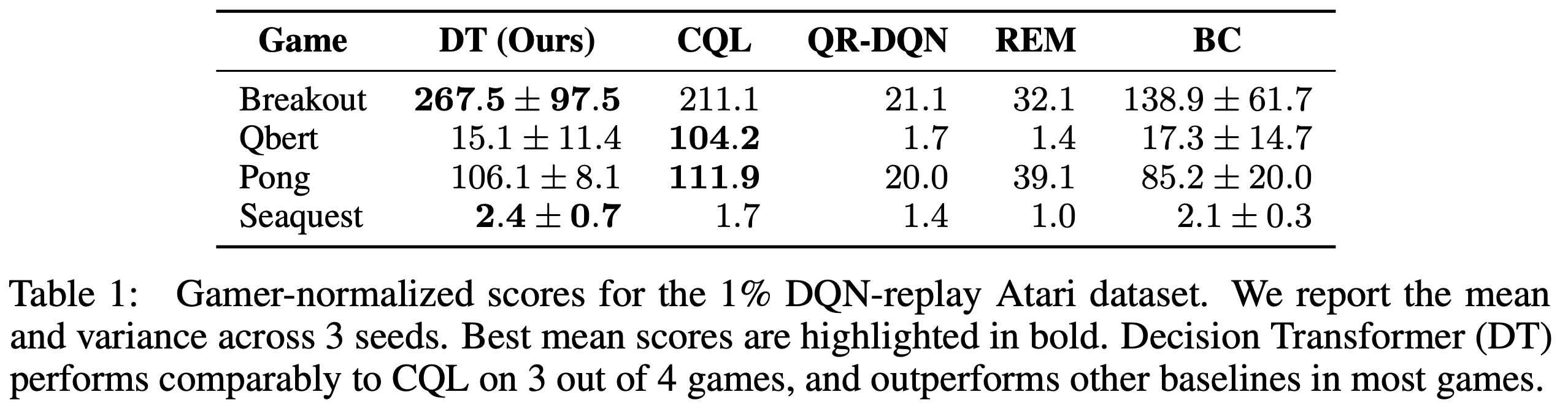
- 在部分场景上,CQL效果更好
D4RL以及OpenAI-Gym上收集的数据集上的实验结果如下图(注意,补充了一些):
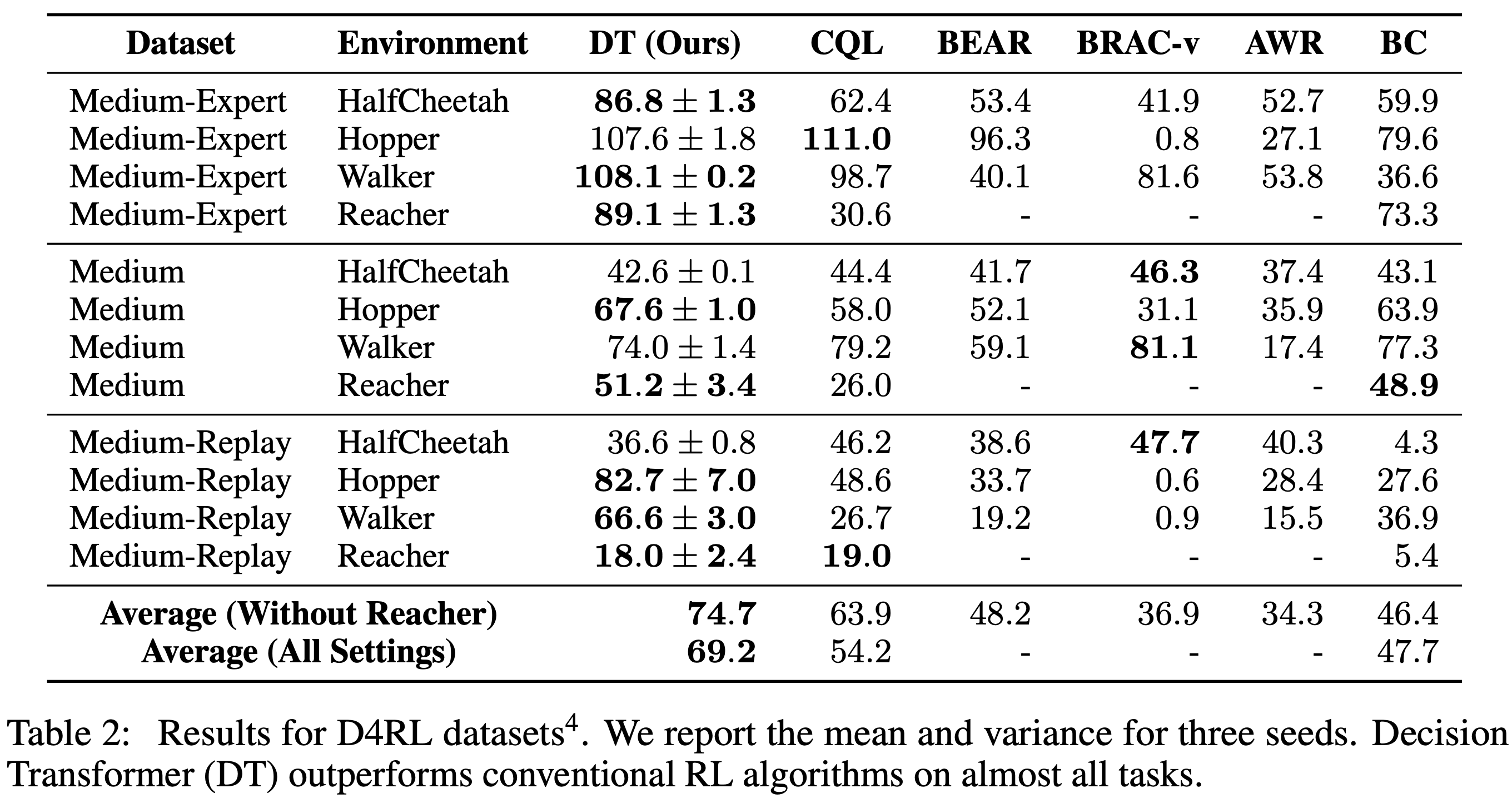
- 补充了一些D4RL中没有的数据集(Medium是指直接用Medium Agent与环境交互生成的样本;Medium-Replay是指训练一个Medium Agent时收集的Replay Buffer;Medium-Expert是Medium Agent和Expert Agent两种策略收集到的数据集的混合)

- 补充了一些D4RL中没有的数据集(Medium是指直接用Medium Agent与环境交互生成的样本;Medium-Replay是指训练一个Medium Agent时收集的Replay Buffer;Medium-Expert是Medium Agent和Expert Agent两种策略收集到的数据集的混合)