本文主要汇总开源大模型核心结构,持续更新
- 参考链接:
- LLM开源大模型汇总- 假如给我一只AI的文章 - 知乎
- 各种模型框架展示:LLM Architecture Gallery
- 这个网站的 MetaData GitHub 地址:github.com/rasbt/llm-architecture-gallery
参考链接特殊说明
- Live Gallery 网址:LLM Architecture Gallery
- GitHub 地址:github.com/rasbt/llm-architecture-gallery
- 几乎包含了所有的开源模型结构
- 图片示例:

整体说明
- 现有开源大模型都是对传统 Transformer 的改进,传统的 Transformer 结构可参考DL——Transformer
- 借用 Decoder-Only Transformers: The Workhorse of Generative LLMs 中给出了 Decoder-Only Transformer 的核心结构图:
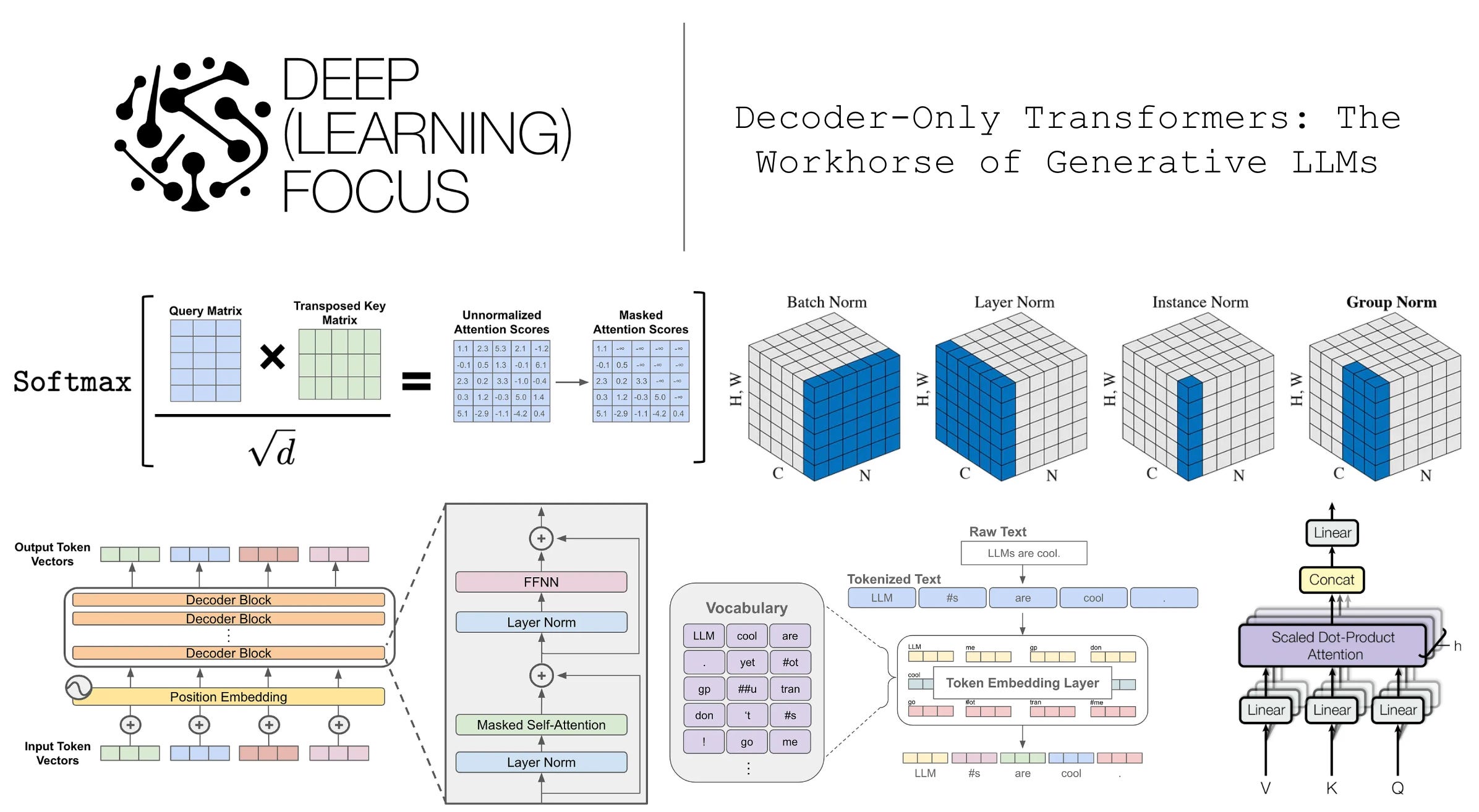
- 一些细节说明:
- 图中的 FFNN 是 Typo,应该是 FFN(Feed Forward Network)
- FNN是一个 \(n \times d \rightarrow n \times h_{ffn} \rightarrow n \times d\) 的过程,原始 Transformer 论文中使用的是 \(h_{ffn} = 4d\)(与这里一致)
- CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Benchmarking on HumanEval-X, KDD 2024, THU & Huawei中也给出了一个更为详细的 Transformer Decoder Layer 的结构图:
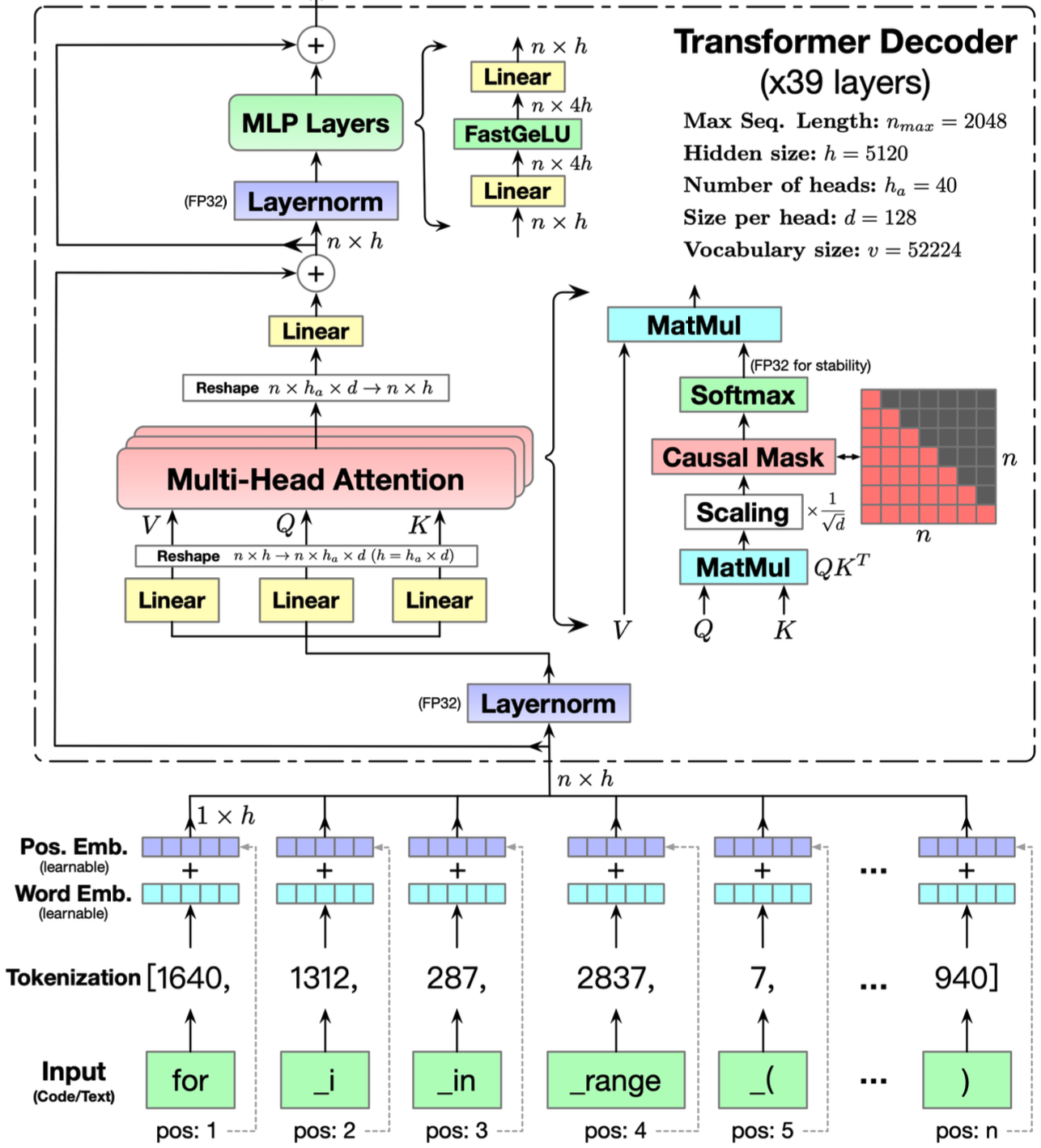
- 上图不是原始的 Transformer 参数配置,比如:
- 原始 Transformer 的 FFN 层激活函数是 ReLU,这里使用的是 FastGeLU (MLP Layers 层)
- 原始 Transformer 是 6 层,这里是 39 层
- 原始 Transformer 多头是 8,这里是 40
- 原始 Transformer d_model 是 512,这里是 5120
- 常见LLM结构梳理(一)- LLama、Llama2、Llama3 - mingming的文章 - 知乎 提供了另一个不错的 GPT 基本框架图(Decoder-Only 架构):
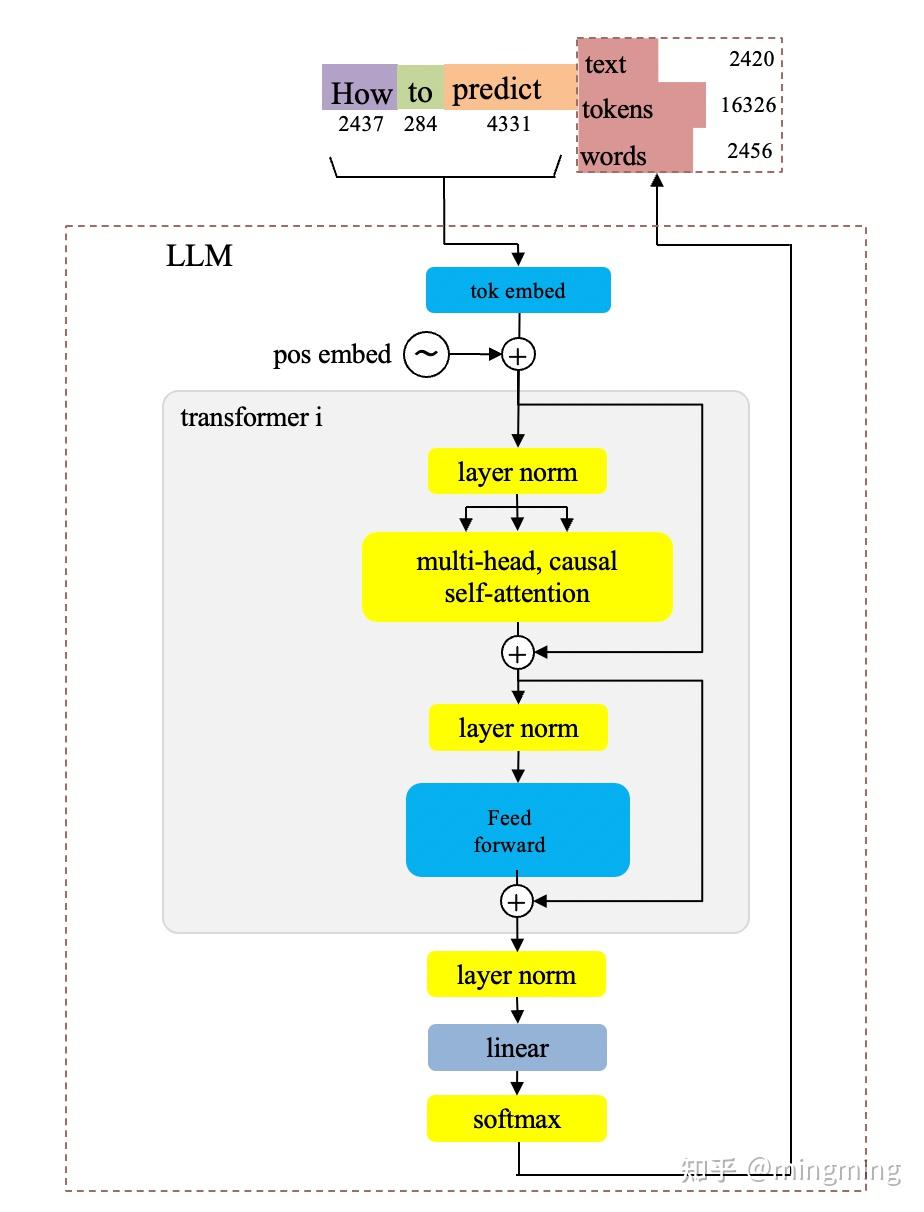
- 注:图中 multi-head attention 中还分别包含着 Attention 前(QKV变换) 和 后(多头合并后) 各一个 Linear Layer,作者未显式画出:
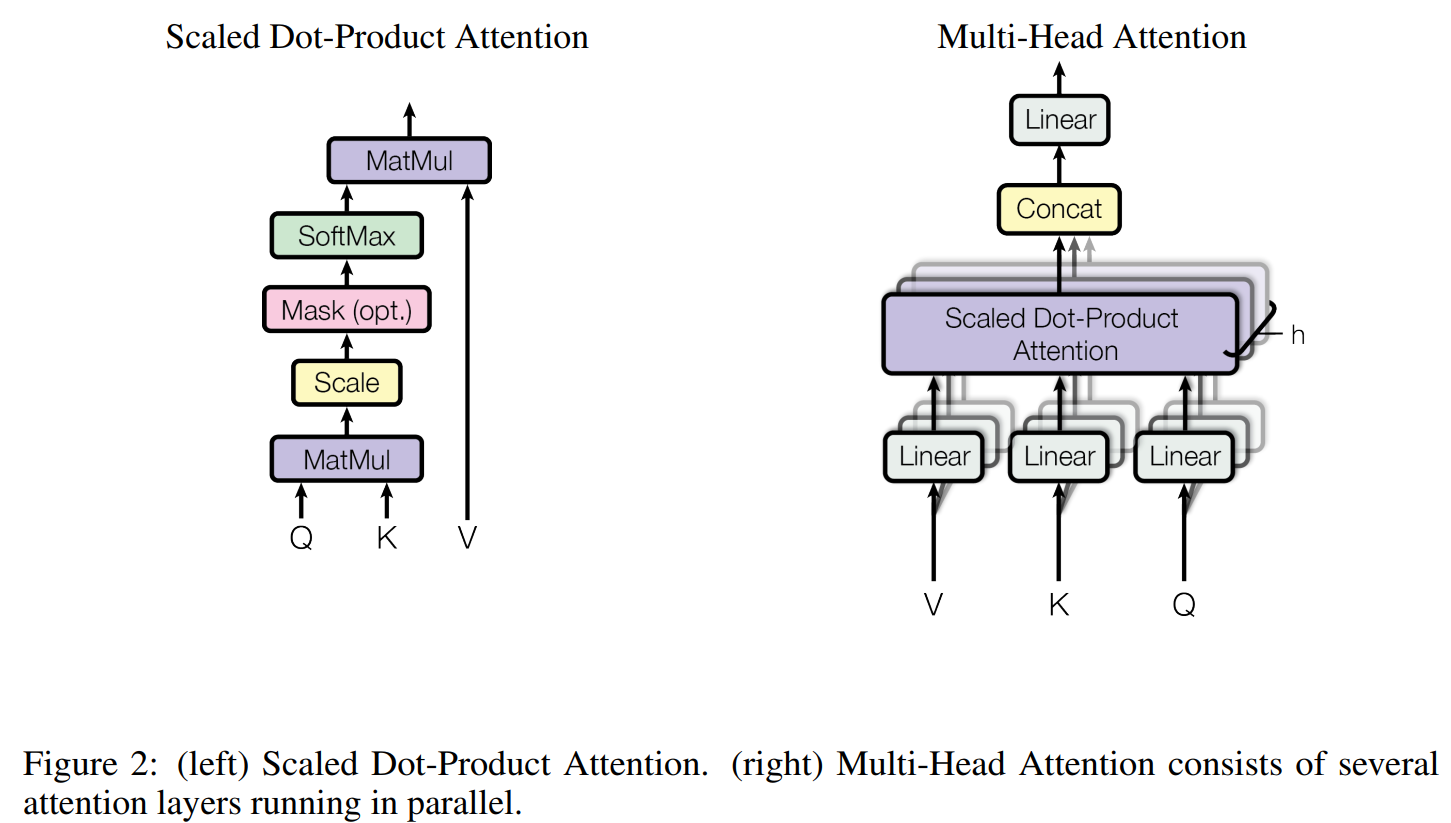
- 特别补充:连夜读完了Qwen3的2000行代码,我画出了Qwen3的结构图 中有非常清晰的 Transformer 实现图,但是针对 Qwen3 的
- 其他说明:
- 归一化位置 :传统 Transformer 中归一化是在 Attention 层和 FFN 层之后(Post-Norm),目前的大部分模型都会将 归一化层放到 Attention 层和 FFN 层之前(Pre-Norm)
- Pre-Norm在深层Transformer中容易训练(容易训练不代表效果好,Pre-Norm的拟合能力一般不如Post-Norm),目前很多模型还是会使用Pre-Norm,因为它更稳定
- Decoder和Encoder选择 :自从 ChatGPT 问世以来,大部分模型都开始朝 Decoder-Only的方向迭代了
- Tie Embedding :传统 Transformer 中,嵌入层(Embedding Layer)和输出投影层(Unembedding Layer / Output Projection Layer)是绑定,优势是节约存储、训练稳定;缺点是表达能力受限、梯度冲突可能严重(比如输入和输入的词分布差异大),所以后来的一些模型会选择不绑定
- 归一化位置 :传统 Transformer 中归一化是在 Attention 层和 FFN 层之后(Post-Norm),目前的大部分模型都会将 归一化层放到 Attention 层和 FFN 层之前(Pre-Norm)
Llama 系列(Meta)
- LLaMA Github链接:meta-llama/llama(分支
llama_v1,llama_v2分别表示不同版本),以及meta-llama/llama3 - LLaMA HuggingFace链接:meta-llama
LLama
- 参考链接:(LLaMA1 官方文档)LLaMA: Open and Efficient Foundation Language Models.pdf
- LLama 发布时间是 2023年2月,包含 Llama-7B,Llama-13B,Llama-30B,Llama-65B 四个版本
- 整体结构图:
")
- 接下来主要介绍 Llama在原始 Transformer 上的改进
- 改动点一:使用 RMSNorm 替代 LayerNorm
- 改动点二:使用 RoPE 替代 Sinusoidal 位置编码
- 改动点三:使用 SwiGLU 激活函数 替换 FFN 层的 ReLU 激活函数
- ReLU 激活函数对应的 FFN:
$$ FFN(\mathbf{X}) = ReLU(\mathbf{X}\mathbf{W}^U)\mathbf{W}^D $$ - SwiGLU 激活函数对应的 FFN:
$$
\begin{align}
FFN(\mathbf{X}) &= SwiGLU(\mathbf{X}\mathbf{W}^U)\mathbf{W}^D \\
&= (Swish_1(\mathbf{X}\mathbf{W}_1^U) \odot \mathbf{X}\mathbf{W}_2^U )\mathbf{W}^D
\end{align}
$$- 其中 \(\mathbf{W}_1,\mathbf{W}_2\)都是两个矩阵的乘积(两个矩阵相乘还是矩阵,可以合并)
- SwiGLU 激活函数的公式为:
$$
\begin{align}
SwiGLU(x, W, V, b, c, \beta) &= Swish_\beta(xW + b) \odot (xV + c) \\
&= Swish_\beta(xW’) \odot (xV’)
\end{align}
$$ - 由于 \(Swish_1(\mathbf{X}\mathbf{W}_1^U)\) 部分是一个门控结构,所以很多地方也称 \(\mathbf{X}\mathbf{W}_1^U\) 为 Gate 或 \(\mathbf{X}\) 的 gate projection
- ReLU 激活函数对应的 FFN:
- 改动点四:使用 Pre-normalization 替换 Post-normalization
- 传统 Transformer 中,归一化操作通常是在 Attention 层和 FFN 层之后(Post-normalization(后归一化))
- Llama系列使用 Pre-normalization,把归一化操作移到了 Attention 层和 FFN 层之前,能提升训练稳定性 ,并加快收敛速度
- Post-normalization :
- MHA:\( \text{Output}_{attn} = \text{LayerNorm}( \text{MultiHeadAttention}(x) + x) \)
- FFN:\( \text{Output}_{ffn} = \text{LayerNorm}( \text{FeedForward}( \text{Output}_{attn}) + \text{Output}_{attn}) \)
- Pre-normalization :
- MHA:\( \text{Output}_{attn} = \text{MultiHeadAttention}(\text{LayerNorm}(x)) + x \)
- FFN:\( \text{Output}_{ffn} = \text{FeedForward}(\text{LayerNorm}( \text{Output}_{attn})) + \text{Output}_{attn} \)
- 提升训练稳定性 :在训练过程里,随着网络层数的增加,梯度可能会出现不稳定的状况,例如梯度消失或者梯度爆炸。Pre-normalization可以让梯度在反向传播时更加稳定,从而避免这些问题,让模型能够更平稳地收敛
- 加快收敛速度 :由于梯度更加稳定,模型在训练时可以使用更大的学习率,这样就能够加快收敛速度,减少训练所需的时间
- 改动点五:使用 AdamW 替代 Adam 优化器
- 改动点六:嵌入层(Embedding Layer)和输出投影层(Unembedding Layer / Output Projection Layer)参数解绑(原始 Transformer 中是绑定的)
- Llama 上下文长度为 2048 tokens
- 训练预料约 1.4T tokens
- 详细模型版本参数和训练时长如下:
params dimension \(n\) heads \(n\) layers learning rate batch size \(n\) tokens GPU Type GPU - hours 6.7B 4096 32 32 \(3.0e^{-4}\) 4M 1.0T A100-80GB 82,432 13.0B 5120 40 40 \(3.0e^{-4}\) 4M 1.0T A100-80GB 135,168 32.5B 6656 52 60 \(1.5e^{-4}\) 4M 1.4T A100-80GB 530,432 65.2B 8192 64 80 \(1.5e^{-4}\) 4M 1.4T A100-80GB 1,022,362 - 耗时与模型参数大小成正比,与训练token量成正比
- 简单换算一下可知,训练 6.7B 的模型,训练 1.0T 的数据,在 1,000 块 A100-80G上,训练时间大约是 \(82432/1000/24 \approx 3.43\) 天
Llama2
- 参考链接:万字长文超详细解读LLama2模型,值得收藏!
- LLama2 发布时间是 2023年7月,包含 Llama-7B,Llama-13B,Llama-34B,Llama-70B 四个版本
- LLama2 不同参数量版本的模型结构不完全一致
- Llama2-7B 和 Llama2-13B 结构和 Llama 基本一致
- Llama2-34B 和 Llama2-70B 结构在 Llama 结构的基础上增加使用了 GQA 结构
- Grouped-Query Attention(GQA):Q拆开成多个头,K,V按照组分组,每个头的Q不同,同一组头K,V相同,不同组头之间K,V不同
- Llama2将上下文扩展至 4096 tokens
- 训练语料 2.0T tokens
Llama3
- 参考链接:(LLaMA3 官方文档)Introducing Meta Llama 3: The most capable openly available LLM to date 以及 LLaMA3 其他文档:测试一下Llama3,并探讨一下不用MoE的原因
- Llama3 发布时间是 2024年4月,发布了包含 Llama3-8B 和 Llama3-70B 两个版本
- 上下文是 8k(8192)tokens
- Llama-3 使用 GQA
- Llama-3 采用更高效的分词器:使用 Tiktoken 分词器 替换了之前的 SentencePiece
- 部分社区开发者也将 Llama3的长度最长扩展到了几十万甚至上百万 tokens
- 训练预料 15T tokens
Llama3.x
- Llama3.1 模型分批发布,发布时间为:
- 2024 年 7 月发布的 Llama-3.1 包含 8B、70B 和 405B 四个版本
- 2024 年 11 月发布的 Llama-3.2 包括 1B、3B、11B 和 90B 四个版本(其中 11B 和 90B 是支持视觉的多模态模型)
- 2024 年 12 月发布的 Llama-3.3 包含 70B 参数版本
- Llama3.x 模型结构和 Llama3结构一致,但 Llama3.1、Llama3.2和Llama3.3 的上下文都扩展到了 128k tokens
Llama4
- 参考链接:(LLaMA4 官方文档)The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
- Llama4 发布于 2025年4月5日 包含了多个版本,均采用 MoE 架构(注:这是Llama系列首次采用 MoE 架构),且均是多模态模型
- Llama 4 Scout:总参数量 109B,激活参数 17B,专家数 16(每次激活一个) + 共享专家 1,上下文长度为 1000万 tokens,可 INT4 量化后部署到单 NVIDIA H100 GPU 上

- Llama 4 Maverick:总参数量 400B,激活参数 17B,专家数 128(每次激活一个) + 共享专家 1,上下文长度为 100万 tokens

- Llama 4 Behemoth(仍在训练中,尚未发布):总参数量 2,000B,激活参数 288B,专家数 16(每次激活一个)+ 共享专家 1,目前主要用于内部蒸馏使用

- Llama 4 Scout:总参数量 109B,激活参数 17B,专家数 16(每次激活一个) + 共享专家 1,上下文长度为 1000万 tokens,可 INT4 量化后部署到单 NVIDIA H100 GPU 上
- 多模态的支持使用了早期融合(Early fusion)技术:
- Early fusion 发生在特征提取的早期阶段,将原始数据或初步处理后的数据直接合并,然后共同进行特征提取
- 举例:在多模态学习中,将图像像素和文本词嵌入直接拼接后送入网络;
Qwen 系列(Alibaba)
- Qwen系列参考链接:Qwen官方博客
Qwen
- 参考链接:Qwen Technical Report 和 (官方)谁是Qwen?通义千问开源模型技术解析
- Qwen 发布时间是 2023年8月,开源了Qwen-1.8B、Qwen-7B、Qwen-14B 和 Qwen-72B多个版本模型
- Qwen发布了一系列模型各个模型之间的关系是:

- 接下来主要介绍 Qwen 在原始 Transformer 上的改进(实际上 Llama 使用到的优化点,Qwen 都使用到了)
- 改动点一:使用 RMSNorm 替代 LayerNorm
- 改动点二:使用 RoPE 替代 Sinusoidal 位置编码
- 改动点三:使用 SwiGLU 激活函数 替换 FFN 层的 ReLU 激活函数
- 改动点四:使用 Pre-normalization 替换 Post-normalization
- 改动点五:使用 AdamW 替代 Adam 优化器
- 改动点六:为了稳定性而移除了 Bias 参数, 但为了保证 RoPE外推性,在Attention 的 QKV Layer 中保留了 Bias
- 移除 Bias的做法参考了 PaLM: Scaling language modeling with pathways, 2022, Google:
No biases - were used in any of the dense kernels or layer norms. We found this to result in increased training stability for large models.
- 移除 Bias的做法参考了 PaLM: Scaling language modeling with pathways, 2022, Google:
- 改动点七:嵌入层(Embedding Layer)和输出投影层(Unembedding Layer / Output Projection Layer)参数解绑
- 训练数据量:2-3T tokens
- Qwen 上下文长度为 32K tokens
Qwen1.5
- Qwen1.5 分批发布:
- 2024年2月6日 发布了 0.5B、1.8B、4B、7B、14B、72B 模型,(官方)Qwen1.5来了,开源LLM增加到6款,支持多平台调用
- 2024年3月29日 发布了MoE模型 Qwen1.5-MoE-A2.7B,(官方)通义千问开源首个MoE模型
- 2024年4月7日 发布了 32B 模型,通义千问开源320亿参数模型
- 2024年4月16日 发布了 CodeQwen1.5-7B 模型,通义千问开源320亿参数模型
- 2024年4月25日 发布了 110B 模型,通义千问开源千亿级参数大模型
- 在 Qwen 的基础上进行改动
- 在 32B 和 110B 模型上使用了 GQA (所以发布较晚)
- Qwen1.5 上下文仍然是 32K tokens
Qwen2
- 参考链接:(官方)Hello Qwen2
- Qwen2 发布于 2024年6月7日
- 包括 Qwen2-0.5B, 1.5B, 7B, 57B-A14B, 和 72B 模型
- Qwen2所有模型都使用 GQA 注意力机制
- Qwen2中 0.5B 和 1.5B 使用了 Tie Embedding,其他模型都使用 Embedding 解耦方案
- Qwen2 最大上下文长度是 128K tokens
- Qwen2 模型详细配置:

Qwen2-Math
Qwen2-Audio
Qwen2-VL
Qwen2.5
- 参考链接:Qwen2.5 Technical Report
- Qwen2.5 发布了很多版本,时间线也很长,其中最早发布时间是 24年9月,也是模型发布最多的一次
- 发布于 2024年9月((官方)Qwen2.5-LLM:扩展大型语言模型的边界 和(官方)Qwen2.5:基础模型大派对!),包括以下模型:
- Qwen2.5:0.5B,1.5B,3B,7B,14B,32B,以及72B;
- Qwen2.5-Coder:1.5B,7B,32B(即将推出,事实上24年9月-11月才逐步发布);
- Qwen2.5-Math: 1.5B,7B,72B
- 以上模型均为 Dense 模型,详细参数为:

- 上下文为 32K 或 128K tokens,生成长度均为 8K tokens
Qwen2.5-1M
- 2025年1月25日 发布了 Qwen2.5-7B-Instruct-1M 和 Qwen2.5-14B-Instruct-1M,将上下文长度扩充到 100W tokens,(官方)上新!支持100万Tokens上下文的Qwen2.5-1M 开源模型来了
- Qwen2.5-7B-Instruct-1M、Qwen2.5-14B-Instruct-1M Context Length: Full 1,010,000 tokens and generation 8192 tokens
- 注:大部分模型都有输出长度限制,包括 DeepSeek-V3 和 DeepSeek-R1 等,可能是训练时为针对超长文本进行优化,输出太长效果不佳?
- 上下文训练:

Qwen2.5-VL
- 参考链接:Qwen2.5-VL Technical Report
- 2025年1月26日发布了 Qwen2.5-VL-3B,Qwen2.5-VL-7B,Qwen2.5-VL-72B 三个多模态模型,(官方)Qwen2.5-VL!Qwen2.5-VL!!Qwen2.5-VL!!!
- Qwen2.5-VL 架构如下:
 architecture, incorporating advanced components such as FFN with SwiGLU activation, RMSNorm for normalization, and window-based attention mechanisms to enhance performance and efficiency.")
- Qwen2.5-VL-72B 模型效果评估如下:

- Qwen2.5-VL-72B 的视觉能力跟 GPT-40-0513 和 Claude-3.5-Sonnet-0620 在不同 Benchmark 表现各异,但整体有来有回;Qwen2.5-VL-72B 的文本能力全面超越 Llama-3.1-70B,且在部分指标上超过 Qwen2.5-72B
Qwen2.5-Coder
- 参考链接:Qwen2.5-Coder Technical Report
- Qwen2.5-Coder 发布于 2024年9月20日,开源了 1.5B、7B 两个尺寸 (官方)Qwen2.5-Coder: 码无止境,学无止境!
- 2024年11月12日 正式开源 0.5B、3B、14B、32B 四个尺寸 (官方)Qwen2.5-Coder全系列来咯!强大、多样、实用
- Qwen2.5-Coder 训练策略如下:

- Qwen2.5-Coder-32B 模型效果评估如下:

- Qwen2.5-Coder-32B 与 GPT-4o-20240806 基本持平,全面优于其他(DeepSeek-Coder-V2-Instruct等)模型
Qwen2.5-Math
- 参考链接:Qwen2.5-Math Technical Report: Toward mathematical expert model via self-improvement 和 Qwen2.5-Math: The world’s leading open-sourced mathematical LLMs
- Qwen2.5-Math 开发 Pipeline 如下:

Qwen2.5-Max
- Qwen2.5-Max 发布于 2025年1月29日 (官方)Qwen2.5-Max 发布,探索大规模 MoE 模型的智能
- Qwen2.5-Max 是超大规模 MoE 模型,使用了超过 20T tokens 预训练,同时还经过了 SFT 和 RLHF 进行后训练
- 是闭源模型,仅支持API调用,模型大小未知
- 仿照 DeepSeek-R1 训练?
Qwen2.5-Omni
- 参考链接:Qwen2.5-Omni Technical Report
- Qwen2.5-Omni 是基于 Qwen2.5 的端到端模型,支持文本、音频、图像、视频和自然语音交互
End-to-End Omni (text, audio, image, video, and natural speech interaction) model based Qwen2.5
- Qwen2.5-Omni 发布于 2025年 包含 Qwen2.5-Omni-3B 和 Qwen2.5-Omni-7B
- Omni 源自拉丁语([ˈɒmni]),意为“全部”或“所有”,在英语中通常作为前缀使用,表示“全面的、无所不包的”
- Qwen2.5-Omni 介绍如下:

- Qwen2.5-Omni 架构 Overview 如下:

QwQ
- 参考链接:QwQ-32B: Embracing the Power of Reinforcement Learning
- QwQ 发布于 2024年11月28日,(官方)新成员QwQ,邀你一起思忖未知之界
- 发布版本为 QwQ-32B-Preview,是实验性研究模型,专注于增强 AI 推理能力
- 24年 Qwen 开源时间线:

QVQ
- QVQ 发布于 2024年12月25日,(官方)刚刚,多模态推理模型QVQ全新开源
- 发布版本为 QVQ-72B-Preview,是一个基于 Qwen2-VL-72B 构建的开源多模态推理模型
- QVQ-Max:2025年3月发布的新模型,是 QVQ-72B-Preview 的迭代版本,参考QVQ-Max: Think with Evidence
Qwen3
- 参考链接:Qwen3_Technical_Report, 0513开放
- Qwen3 发布于 2025年4月29日 (官方)Qwen3:思深,行速,英文版本:Qwen3: Think Deeper, Act Faster
- 截止到2025年5月的开源 No.1!
- 本次开源包含 2 个 MoE 模型(Qwen3-235B-A22B 和 Qwen3-30B-A3B)和 6 个 Dense 模型(包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B),详细配置如下:
Models Layers Heads (Q / KV) Tie Embedding Experts (Total/Activated) Context Length Qwen3–0.6B 28 16 / 8 Yes - 32K Qwen3–1.7B 28 16 / 8 Yes - 32K Qwen3–4B 36 32 / 8 Yes - 32K Qwen3–8B 36 32 / 8 No - 128K Qwen3–14B 40 40 / 8 No - 128K Qwen3–32B 64 64 / 8 No - 128K Qwen3–30B–A3B 48 32 / 4 - 128 / 8 128K Qwen3–235B–A22B 94 64 / 4 - 128 / 8 128K - Qwen3 训练流程:

- Qwen3 的一个核心亮点引入了一个新的能力,可开关慢思考(即打开或关闭思考模式):这种方式的实现是通过修改对话模板
chat_template,在模型输出内容中(注意:和直接修改Prompt的结果不一样)插入<think>\n\n</think>来实现,详情见:Qwen3是如何实现混合推理(快慢思考)的? - Xode的文章 - 知乎 - Qwen3 训练数据量是 36T tokens
- Qwen3-0.6B Context Length: 32,768
- Qwen3-8B、Qwen3-32B、Qwen3-30B-A3B Context Length: 32,768 natively and 131,072 tokens with YaRN,
- Qwen3-235B-A22B Context Length: 32,768 natively and 131,072 tokens with YaRN
Qwen3-Turbo(未开源)
- 首次上线(快照版):2025年4月28日(阿里云百炼平台上架
qwen-turbo-2025-04-28) - Qwen3-Turbo(正式版):2025年6月23日(原
qwen-turbo-latest正式升级为 Qwen3 架构)
Qwen3-Plus(未开源)
- 首次上线(快照版)2025年4月28日(阿里云百炼平台上架
qwen-plus-2025-04-28) - Qwen3-Plus(正式版):2025年6月23日(原
qwen-plus-latest正式升级为 Qwen3 架构)
Qwen3-Max(未开源)
Qwen3-Max-Preview
- 上新!超万亿参数的Qwen3-Max-Preview来了, 20250906
- 20250906 凌晨发布 Qwen3-Max-Preview (Instruct),这是阿里迄今为止最大的模型,参数量超 1 万亿!
Qwen3-Max-Preview 在多项主流权威基准测试中展现出全球领先的性能。在通用知识(SuperGPQA)、数学推理(AIME25)、编程(LiveCodeBench v6)、人类偏好对齐(Arena-Hard v2)以及综合性能力评估(LiveBench)评测中,Qwen3-Max-Preview 超越了 Claude-Opus 4(Non-Thinking),以及 Kimi-K2、DeepSeek-V3.1 和我们此前的开源最佳 Qwen3-235B-A22B-Instruct-2507
在我们的内部测试和早期用户测评中,Qwen3-Max-Preview 的确表现出更强的智能水平,更广的知识面,更优秀的对话能力,在Agent任务与指令遵循等方面拥有更强劲的性能
这证明了,规模化扩展(Scaling)仍然有效,更大的模型拥有更强的性能
目前,Qwen3-Max-Preview 已正式上线阿里云百炼平台,可通过API直接调用。同时,Qwen Chat 也同步上线新模型,支持免费使用
欢迎大家体验我们的新模型,也敬请期待正式版Qwen3-Max的发布!
🔗体验地址:Qwen Chat: https://chat.qwen.ai/
Qwen3-Max-Instruct
- 发布于 2025年10月15日
Qwen3-Max-Thinking
- 发布于 2026年1月26日(最强推理版本)
Qwen3-Next
- HugggingFace:
- huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
- huggingface.co/Qwen/Qwen3-Next-80B-A3B-Thinking
- 其他还包括:Qwen3-Next-80B-A3B-Instruct-FP8 和 Qwen3-Next-80B-A3B-Thinking-FP8 等
- 博客链接:(官方)Qwen3-Next:迈向更极致的训练推理性价比
- Qwen3-Next 中认为 Context Length Scaling 和 Total Parameter Scaling 是未来大模型发展的两大趋势,所以提出了 Qwen3-Next 的模型结构,使用了 混合注意力机制、高稀疏度 MoE 结构
- Qwen3-Next 的模型结构为(3x Gated DeltaNet + 1x Gated Attention):

Gated-Attention Layer
- Gated-Attention 解决了 Attention Sink 现象
- Attention Sink 现象是指:初始 token(如序列第一个 token)占据过度集中的注意力权重 的现象
- 标准 softmax 注意力的 Attention Sink 本质是 “非负归一化导致的冗余注意力累积”
- 初始 token 的注意力分数会因 softmax 的行归一化(权重总和为 1),在后续 token 的注意力计算中不断累积,形成 “越早期 token 权重越重” 的循环
- Attention Sink 可能影响模型关注其他更重要的语义 Token 的能力,最终导致模型效果不佳、训练不稳定、以及限制模型长上下文能力等
- 稀疏门控在 SDPA 输出后直接对注意力权重进行 “动态裁剪”,即使 softmax 生成了初始 token 的高分数,门控也会将其与 Query 无关的部分抑制(因为这里的 Gate 是与 Query 有关的),避免冗余分数进入后续层的 residual 流
- 以输入依赖的稀疏门控为核心,结合头部特异性设计,既直接削弱初始 token 的过度权重,又避免全局偏置导致的冗余累积,最终打破标准 softmax 注意力中 “初始 token 主导注意力分配” 的循环
- Attention Sink 现象是指:初始 token(如序列第一个 token)占据过度集中的注意力权重 的现象
- 门控机制增强注意力层 (Augmenting Attention Layer with Gating Mechanisms),图中 \(G_1, \cdots, G_5\) 是五选一的关系,不是都使用了
")
- 门控机制形式化定义为:
$$Y^{\prime}=g(Y,X,W_{\theta},\sigma)=Y\odot\sigma(XW_{\theta}),$$- \(Y\) 是待调制(Modulate)的输入,在上图的 \(G_1\) 中(论文最终选择的节点),使用的是注意力加权后的 Value
- \(X\) 是用于计算门控分数的另一个输入,在上图的 \(G_1\) 中,使用的是 Query 的 Hidden State
- \(W_{\theta}\) 指门的可学习参数
- \(\sigma\) 是一个激活函数(例如 sigmoid)
- \(Y^{\prime}\) 是门控后的输出
- 门控分数 \(\sigma(XW_{\theta})\) 有效地充当了一个动态过滤器,通过选择性地保留或擦除其特征来控制来自 \(Y\) 的信息流
- Gated-Attention Layer 的探索集中在五个关键方面:
- (1) 位置 (Positions) :作者研究了在不同位置应用门控的效果,如图 1 所示:
- (a) 在 \(Q, K, V\) 投影之后,对应图 1 中的位置 \(G_{2}, G_{3}, G_{4}\)
- (b) 在 SDPA(Scaled Dot-Product Attention)输出之后 (\(G_{1}\))
- (c) 在最终拼接后的多头注意力输出之后 (\(G_{5}\))
- 注:从图中可以看出,在 SDPA 输出之后 (\(G_{1}\)) 的效果是最好的
- (2) 粒度 (Granularity) :作者研究了门控分数的两个粒度级别:
- (a) 逐头(Headwise):单个标量门控分数调制整个注意力头的输出
- (b) 逐元素(Elementwise) :门控分数是与 \(Y\) 维度相同的向量,支持细粒度的、逐维度的 Modulate
- 注:Elementwise 和 Headwise 均优效果提升 ,且两者各有优劣
- elementwise 门控在核心指标上表现更优,不过 headwise 门控在参数效率上更具优势
- 文章建议根据使用场景选择需要的方式:
- 若追求极致性能(如高精度语言建模、复杂任务推理):选择elementwise 门控,细粒度调制能最大化模型的表达能力和任务适配性,尤其在 3.5T 大 token 量训练后,性能优势更明显
- 若追求参数效率(如轻量化部署、低算力训练):选择headwise 门控,其以极小的参数增量实现接近 elementwise 门控的效果,同时仍能保留门控机制的核心优势(如提升训练稳定性、缓解 attention sink)
- (3) 头特定或头共享 (Head Specific or Shared) :考虑到注意力的多头性质,作者进一步考虑:
- (a) Head Specific :每个注意力头有其特定的门控分数,支持对每个头进行独立调制
- (b) Head Shared:\(W_{\theta}\) 和门控分数在头之间共享
- 注:Head Specific 效果最好
- (4) 乘性或加性 (Multiplicative or additive) :对于将门控分数应用于 \(Y\),论文考虑
- (a) 乘性门控(Multiplicative) :门控输出 \(Y^{\prime}\) 计算为:\(Y^{\prime}=Y\cdot\sigma(X\theta)\)
- (b) 加性门控(Additive):\(Y^{\prime}=Y+\sigma(X\theta)\)
- 注:Multiplicative 效果最好
- (5) 激活函数 (Activation Function) :论文主要考虑两种常见的激活函数:SiLU (2020) 和 sigmoid
- 由于 SiLU 的无界输出范围,论文仅将其用于加性门控,而 sigmoid 仅给出 \([0,1]\) 范围内的分数
- 此外,为了进一步剖析门控有效性的机制,论文还考虑了恒等映射或 RMSNorm (2019)
- 注:sigmoid 效果最好
- (1) 位置 (Positions) :作者研究了在不同位置应用门控的效果,如图 1 所示:
- 最终,论文采用 \(G_1\) 位置 ,Head Specific、乘性门控 ,并使用 sigmoid 激活函数 (\(\sigma(x)=\frac{1}{1+e^{-x} }\))
- 注:Elementwise 和 Headwise 均优效果提升 ,且两者各有优劣,要根据场景来选择
Gated DeltaNet(GDN)
- GDN 是一种与 Mamba2 类似的架构,采用了粗糙的 head-wise 遗忘门
附录:关于 Qwen3-Next 的缺点
- 根据博客 Qwen3-Next 首测!Qwen3.5的预览版?但为什么我的测试一塌糊涂? 的测评对比发现:
- 推理效率上,Qwen3-Next-80B-A3B-Instruct 的推理时间是 Qwen3-32B 的 39%
- 在 BABILong 任务上测试(注:一个简单的检索任务)上效果不如 Qwen3-32B
- Qwen3-32B 的效果在 2k 后开始低于 100,但性能保持到 32k 开始逐步降低(开始低于 80),256k 时跌为 0
- Qwen3-Next-80B-A3B-Instruct 从最开始的 0K 开始就有跌幅,且 4k 后的表现为 0
- 进一步分析原因是:Qwen3-Next-80B-A3B-Instruct 循环输出 “!”,直到结束,且 Qwen3-Next-80B-A3B-Thinking 也有类似情况
Qwen3.5
- 官方博客:Qwen3.5:迈向原生多模态智能体
- Qwen3.5 发布于 20260216,发布了两款模型:
- Qwen3.5-397B-A17B
- Qwen3.5-397B-A17B-FP8
- 补充:20260225,再发布了多款小模型(均是多模态的):
- Qwen3.5-122B-A10B
- Qwen3.5-35B-A3B
- Qwen3.5-35B-A3B-Base
- Qwen3.5-27B
- 再补充:20260303,再再发布了多款跟小的 Mini 模型及其一些 Base 模型(均是多模态的):
- Qwen3.5-0.8B
- Qwen3.5-0.8B-Base
- Qwen3.5-2B
- Qwen3.5-2B-Base
- Qwen3.5-4B
- Qwen3.5-4B-Base
- Qwen3.5-9B
- Qwen3.5-9B-Base
- 最大卖点:原生多模态(原生视觉-语言模型)
- 模型结合了线性注意力(Gated Delta Networks)与 MoE,
- 评估结果:
- 与当前 SOTA 模型比较,在 IFBench, BrowseComp 和 OmmiDocBench v1.5 等指标上处于领先地位

- 与当前 SOTA 模型比较,在 IFBench, BrowseComp 和 OmmiDocBench v1.5 等指标上处于领先地位
- RL Infra:
- API 使用注意:
- 模型名:”qwen3.5-plus”
- 开启推理、联网搜索与 Code Interpreter 等高级能力,只需在
extra_body字段传入以下参数:enable_thinking:开启推理模式(链式思考)enable_search:开启联网搜索与 Code Interpreter
- 博客 Qwen3.5:迈向原生多模态智能体 中演示的能力包括:
- 网页开发
- OpenClaw 接入
- 将 Qwen3.5 作为底层模型接入 Qwen Code 支持 Vibe Coding
- GUI 智能体
- 视觉编程:
Qwen3.5 能将手绘界面草图转化为结构清晰的前端代码,对简单游戏视频进行逻辑还原,或将长视频内容自动提炼为结构化网页或可视化图表
- 空间智能:物体计数、相对位置判断、空间关系描述等任务
- 带图推理:可根据迷宫图片找到最短路径
- 视觉推理:如给出多张相似图片,找出图片中不同的一个
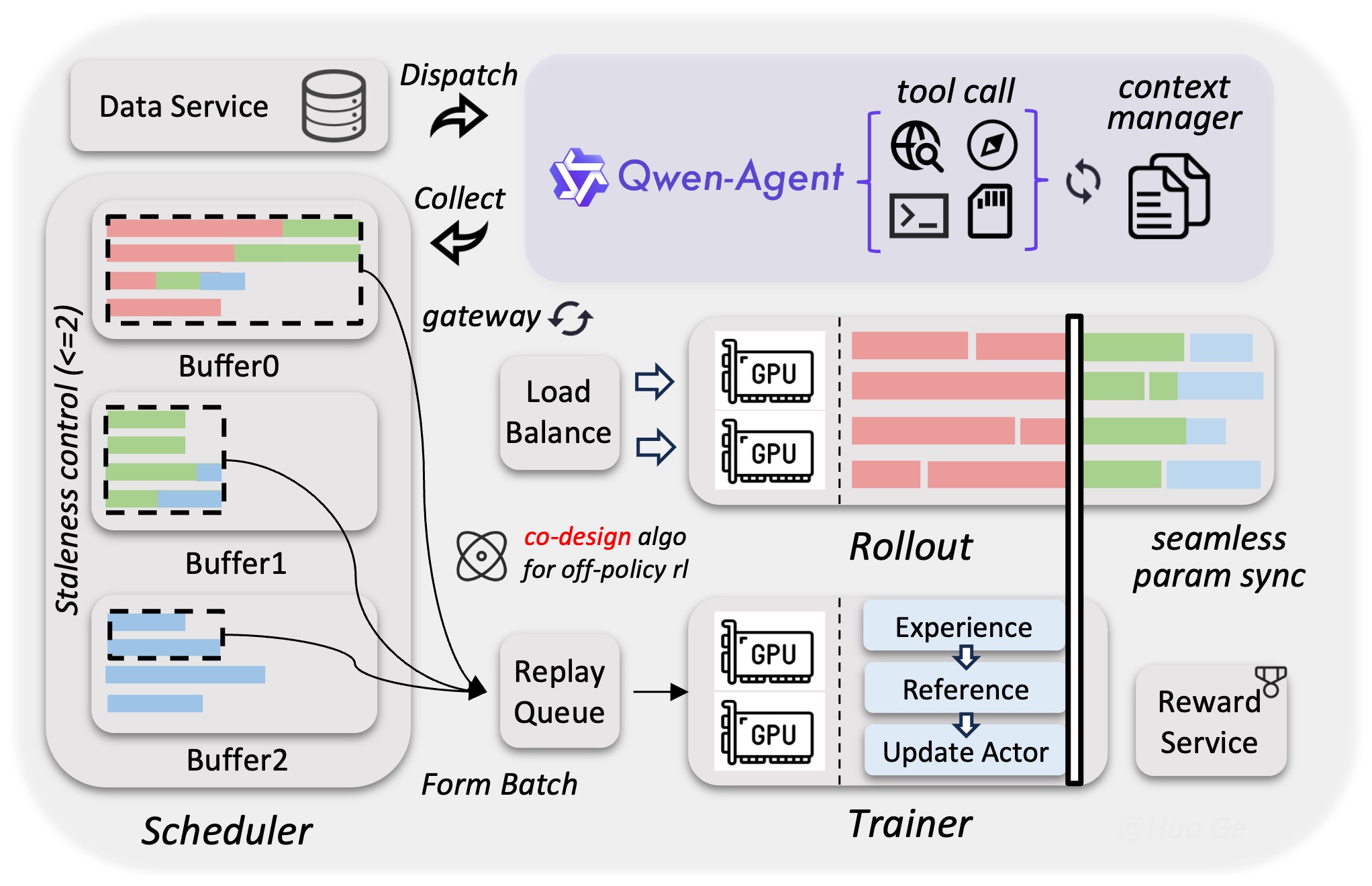
DeepSeek 系列(幻方量化)
DeepSeek-V1
- 跟已经开源的 Llama 结构基本差不多,无确定结构说明(DeepSeek-V2中提到有有Dense 67B 版本)
- 训练数据量约 2T tokens
DeepSeek-MoE
- 原始论文:DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- 有时候也将这个模型归为 DeepSeek-V1
- DeepSeekMoE 开源了 deepseek-moe-16b-base 和 deepseek-moe-16b-chat 两个模型
- 采用了 MoE 结构
DeepSeek-Math
DeepSeek-V2
- 参考链接:DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- DeepSeek-V2 发布于 2024年5月,开源 DeepSeek-V2(MoE-236B)参数
- 在DeepSeek-MoE 的基础上,沿着 MoE负载均衡继续做了3个优化
- 提出并使用了 Multi-head Latent Attention(MLA)
- 训练数据量约 8T tokens
- 上下文长度为 128K tokens
DeepSeek-V3
- 参考链接:DeepSeek-V3 Technical Report
- 发布时间为:2024年12月26日,
- 训练数据量约 14T tokens
- 引入了 Multi-Token Prediction(MTP)技术,训练时可作为辅助损失提升模型效果,推理时仅使用多一个 token 预测
- DeepSeek-V3 和 DeepSeek-V3-Base,都是 671B-A37B,上下文长度 128K
- 新发布版本 DeepSeek-V3-0324
DeepSeek-R1-Zero
- 在 DeepSeek-V3 上直接使用 强化学习方法(GRPO)得到的模型(注意不需要使用 SFT)
DeepSeek-R1
- 参考链接:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeepSeek-R1 训练过程:
- 注意:根据 DeepSeek-V3 辅助材料给出的结论,下图中存在问题(已补充),DeepSeek-R1 和 DeepSeek-R1-Zero 均是从 DeepSeek-V3-Base 训练而来,图中给的是 DeepSeek-V3 (这是 DeepSeek-V3-Base 的微调版本);部分训练数据(监督微调数据中的非推理类数据)确实来源于 DeepSeek-V3

- 注意:根据 DeepSeek-V3 辅助材料给出的结论,下图中存在问题(已补充),DeepSeek-R1 和 DeepSeek-R1-Zero 均是从 DeepSeek-V3-Base 训练而来,图中给的是 DeepSeek-V3 (这是 DeepSeek-V3-Base 的微调版本);部分训练数据(监督微调数据中的非推理类数据)确实来源于 DeepSeek-V3
- DeepSeek-R1 发布时间为 2025年1月20日,并同步开源模型权重(注:2024年11月20日,DeepSeek-R1-Lite 预览版正式上线网页端)
DeepSeek-V3.2-Exp
- 原始论文:DeepSeek-V3.2-Exp: Boosting Long-Context Efficiency with DeepSeek Sparse Attention, 20250929, DeepSeek-AI
- HuggingFace:huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp
- vLLM: DeepSeek-V3.2-Exp Usage Guide
- DeepSeek-V3.2-Exp 是一个实验性的稀疏注意力模型,通过持续训练,在 DeepSeek-V3.1-Terminus 的基础上增加了 DeepSeek 稀疏注意力 (DeepSeek Sparse Attention, DSA)
- DSA 是一种由 lightning 索引器(lightning indexer)驱动(powered by)的细粒度稀疏注意力机制(fine-grained sparse attention mechanism) ,借助 DSA,DeepSeek-V3.2-Exp 在训练和推理效率上均取得了显著提升,尤其是在长上下文场景中
- 模型检查点可在 huggingface.co/deepseek-ai/DeepSeek-V3.2-Exp 获取
DeepSeekMath-V2
- 发布时间:20251127
- GitHub:github.com/deepseek-ai/DeepSeek-Math-V2
- HuggingFace:huggingface.co/deepseek-ai/DeepSeek-Math-V2
- 参考博客:DeepSeek开源世界首个奥数金牌AI,正面硬刚谷歌
- 基于 DeepSeek-V3.2-Exp-Base 开发
- 特别在 IMO-ProofBench 指标上处于第一梯队
DeepSeekMath-V2 文档介绍
- LLM 在数学推理领域取得了显著进展(该领域不仅是 AI 的重要测试基准,若进一步突破,更可能对科学研究产生深远影响)
- 当前方案:通过 RL 对推理过程进行 scaling,并以正确的最终答案为奖励信号,LLMs 在一年内实现了性能飞跃:
- 从最初的表现不佳,到如今在AIME(美国数学邀请赛)、HMMT(哈佛-麻省理工数学竞赛)等定量推理竞赛中达到性能饱和(saturating)状态
- 问题提出:但以上这种方法存在根本性局限:
- 追求更高的最终答案准确率,无法解决一个核心问题:正确答案并不意味着正确的推理过程
- 此外,定理证明(theorem proving)等诸多数学任务,要求严格的分步推导(step-by-step derivation)而非仅输出数值结果,这使得“以最终答案为奖励”的机制完全不适用
- 为突破深度推理的极限,作者认为有必要对数学推理的完整性(comprehensiveness)与严谨性(rigor) 进行验证
- 自验证(self-verification)对于缩放测试时计算量(test-time compute)尤为重要,尤其是在处理无已知解的开放问题(open problems)时
- 针对可自验证数学推理这一目标,作者开展了以下研究:
- 1)验证器(verifier):训练一个 LLM-based 精准且可信(accurate and faithful)verifier,用于定理证明任务
- 2)证明生成器(proof generator):以该验证器作为奖励模型(reward model),训练一个 proof generator
- 并激励生成器在最终定稿前,自主识别并解决其证明过程中的尽可能多的问题;
- 3)为避免生成器性能提升后出现“生成-验证差距(generation-verification gap)”,作者提出通过 scale verification compute,自动标注新的“难验证证明(hard-to-verify proofs)”,并以此构建训练数据,进一步迭代优化 verifier
- 理解:这里的生成-验证差距是什么?
- 最终模型 DeepSeekMath-V2 展现出强大的定理证明能力:
- 在 2025 年国际数学奥林匹克(IMO 2025)和 2024 年中国数学奥林匹克(CMO 2024)中斩获金牌级分数(gold-level scores);
- With scaled test-time compute,在 2024 年普特南数学竞赛(Putnam 2024)中取得 118/120 的近乎满分成绩
- 尽管仍有大量工作亟待推进,但这些结果表明:可自验证数学推理是一条可行的研究方向 ,有望助力开发更具能力的数学 AI 系统
DeepSeek-V3.2
- 20251201日,同时发布 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale
- HuggingFace:
- DeepSeek-V3.2
- 目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用 Agent 任务场景
- 在公开的推理类 Benchmark 测试中,DeepSeek-V3.2 达到了 GPT-5 的水平,略低于 Gemini-3.0-Pro;
- 相比 Kimi-K2-Thinking,V3.2 的输出长度大幅降低,显著减少了计算开销与用户等待时间
- DeepSeek-V3.2-Speciale
- 目标是将极致性能,a model that harmonizes high computational efficiency with superior reasoning and agent performance
- V3.2-Speciale 是 DeepSeek-V3.2 的长思考增强版,同时结合了 DeepSeek-Math-V2 的定理证明能力
- V3.2-Speciale 模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美 Gemini-3.0-Pro
Kimi 系列(月之暗面)
Kimi-VL
- 原始论文:Kimi-VL Technical Report, Kimi Team, 20250410-20250623
- 2506 增加了一个模型:Kimi-VL-Thinking-2506
- Kimi-VL 包含一个 Native-resolution Vision Encoder(原生分辨率视觉编码器) MoonViT
- Native-resolution Vision Encoder 是一种能直接处理原始分辨率与宽高比图像、无需先统一缩放 / 裁剪的视觉编码模块,核心是基于 ViT 架构,用动态 token 与适配性位置编码(如 2D RoPE)保留细节并适配任意尺寸输入, Qwen2-VL 也使用了 Native-resolution Vision Encoder 实现
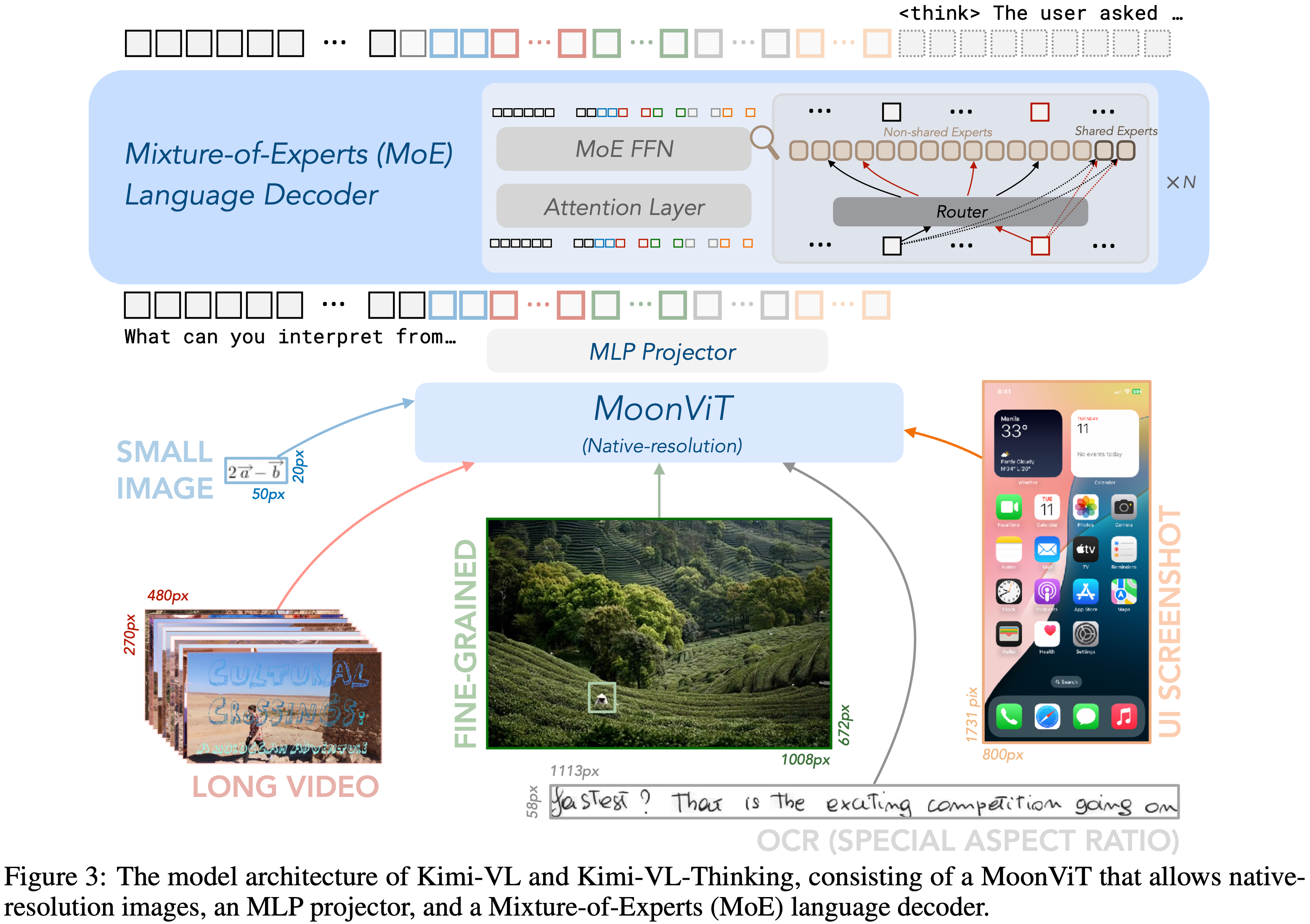
- Native-resolution Vision Encoder 是一种能直接处理原始分辨率与宽高比图像、无需先统一缩放 / 裁剪的视觉编码模块,核心是基于 ViT 架构,用动态 token 与适配性位置编码(如 2D RoPE)保留细节并适配任意尺寸输入, Qwen2-VL 也使用了 Native-resolution Vision Encoder 实现
Step 系列(阶跃星辰, StepFun)
Step1X-3D
- 参考链接:
- 发布时间:20250514日
- 最强开源:开源全链路代码和部分高质量数据(约800K高质量 3D 数据)
- 能力:可生成 3D 内容
Step 3.5 Flash
- 参考链接:Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters, 20260211 & 20260223, StepFun
- 开源时间:2026 年 2 月 2 日
GLM 系列(智谱AI)
GLM
- 参考链接:GLM: General Language Model Pretraining with Autoregressive Blank Infilling
- 是Prefix LM(前缀语言模型),也称为 Prefix Decoder,前缀之间可以互相看到,但后续生成的token也只能看到历史,是 Encoder-Decoder 和 Causal Decoder 的一个折中方案
GLM2
GLM3
GLM4
GLM4.5
- 开源时间:20250728日,同时还开源了 GLM 4.5 Air 版本
- 截止到发布时间,号称 “全球第三、国产第一、开源第一”
- 全球前两位是:GPT-o3 和 Grok4
- 原始论文:GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models, Zhipu AI & Tsinghua University, 20250808
- 训练方式:
- 性能评估:

- 后训练使用了一个智谱 AI 自己开发的后训练框架 slime,开源地址是:github.com/THUDM/slime
- 数据量 23T,参数量 335B-A32B
GLM 4.6
GLM 4.7
GLM 5
- HuggingFace: huggingface.co/zai-org/GLM-5
- 技术博客:GLM-5: From Vibe Coding to Agentic Engineering
- GLM-5 发布于 20260212,发布即国内 LMArena SOTA
- 数据量 28.5T,参数量 744B-A40B
- for 长文:使用了 DSA(DeepSeek Sparse Attention)
- 同样基于 GLM 子集的 RL 开源框架 slime 进行训练
MiniMax 系列(上海稀宇科技)
MiniMax-Text-01
MiniMax-M1
- 开源时间:2025 年 6 月 17 日发布
- MiniMax-M1 是全球首个开源的大规模混合架构推理模型,采用混合门控专家架构(MOE)与 Lightning Attention 注意力机制相结合的创新设计,支持 100 万 token 的上下文输入和 8万 token 的推理输出能力,与谷歌 Gemini 2.5 Pro 的长文本处理能力持平
- 总参数量为 456B,单次激活45.9B,开源版本包括具有 40K 和 80K COT长度的两个版本
- 在 SWE-bench 代码验证基准测试中,MiniMax-M1-40k 和 MiniMax-M1-80k 分别取得 55.6% 和 56.0% 的成绩,略逊于 DeepSeek-R1-0528 的 57.6%,但显著超越其他开源权重模型
- 在长上下文理解任务中,MiniMax-M1 全面超越所有开源权重模型,甚至超越 OpenAI o3 和 Claude 4 Opus,全球排名第二,仅以微弱差距落后于 Gemini 2.5 Pro
- 在代理工具使用场景(TAU-bench)中,MiniMax-M1-40k 领跑所有开源权重模型,并战胜 Gemini-2.5 Pro
- MiniMax-M1 API 定价采用阶梯式策略:
- 0-32k 输入长度时,输入 0.8元/百万token,输出 8元/百万token;
- 32k-128k 输入长度时,输入 1.2元/百万 token,输出 16元/百万token;
- 128k-1M 输入长度时,输入 2.4元/百万token,输出24元/百万token
- MiniMax App 与 Web 端保持不限量免费使用
MiniMax-M2
- 开源时间:2025 年 10 月 27 日发布并开源
- 基于 MIT 开源许可证,采用 230B 参数的 MoE 架构,单次推理时激活约 10B 参数
- 在全球权威测评榜单 Artificial Analysis中,MiniMax-M2 总分位列全球前五、开源第一,跻身全球第一梯队
- 其在推理与代码生成任务中的表现超过了谷歌的 Gemini 2.5 Pro,API 使用成本约为 Anthropic Claude Sonnet 4.5 的 8%,推理速度快了接近一倍
- MiniMax-M2 专为端到端开发工作流打造,在编码、指令遵循和 Agent 等核心任务上表现卓越
- 可以准确规划并稳定执行复杂长链条工具调用任务,协同调用Shell、Browser、Python代码执行器和各种MCP工具
- 其综合成本 API 价格定在每百万 Token 输入 0.3 美元(2.1 元人民币),输出 1.2 美元(8.4 元人民币),同时在线上提供 TPS(每秒输出 Token数)在 100 左右的推理服务
- MiniMax M2 通过 MiniMax API 向全球开发者免费开放,试用期至 2025 年 11 月 7 日,并兼容 Hugging Face 与 vLLM 等主流框架
- MiniMax-M2 使用的是 Full-Attention,许多人在质疑开倒车,但预训练负责人站出来发了博客进行讨论(核心观点:目前实现的系数注意力都是有损的,团队实践经验发现了问题才使用的 Full-Attention)
- MiniMax-M2 未放出详细的技术报告
- MiniMax-M2 在代码方面的能力很强, 已经被 AnyCoder 作为默认模型了
- 最新进展:默认模型已经是 DeepSeek-V3.2
MiniMax-M2.1
- 发布时间:20251223
- HuggingFace:huggingface.co/MiniMaxAI/MiniMax-M2.1
MiniMax-M2.5
- 发布时间:20260212
- HuggingFace:huggingface.co/MiniMaxAI/MiniMax-M2.5
- 从 2025 年 10 月底到 2026 年 2 月,仅 3 个半月, 完成 M2 -> M2.1 -> M2.5 三代迭代,SWE-Bench Verified 成绩从 69.4% 提升至 80.2%
OLMo 系列(AI2)
- OLMo 系列是艾伦人工智能研究所(AI2, Allen Institute for AI)推出的完全开源大模型家族
- OLMo 是 Open Language Model 的缩写
- 优点:其开源不仅公开模型权重,还会披露训练数据、代码、中间检查点等全套资源
OLMo 初代系列
- 技术报告:OLMo: Accelerating the Science of Language Models, AI2(Allen Institute for AI), 20240201 & 20240607
- 开源时间 2024年2月 ,此次开源包含 1 个 1B 参数模型和 4 个不同配置的 7B 参数模型(如 OLMo 7B、OLMo 7B (not annealed)等),所有模型均经过至少 2T token 训练
- 同时开源的还有 3T token 的预训练语料库、完整训练代码、训练日志、超 500 个训练检查点以及评估工具套件,且均采用 Apache 2.0 许可证,支持免费商用
OLMoE
- 开源时间 2024年9月 ,这是系列内首个专家混合模型
- 核心型号为 OLMoE-1B-7B(总参数 7B 但每个输入 token 仅激活 1B 参数)
- 还同步推出了指令微调版本 OLMoE-1B-7B-INSTRUCT
- 该模型在 5T token 上完成预训练,在同算力成本模型中性能领先,甚至能与 Llama2-13B 等更大规模模型竞争
- 此次开源同样披露了模型、数据、代码和训练日志等全套资源
OLMo 2 系列
- 开源时间:2024年底-2025年初
- 包含 7B 和 13B 两个参数版本,训练数据量高达 5T token
- 该系列模型在英文学术基准测试中,性能比肩甚至优于同规模开源模型,且能与 Llama 3.1 等开源权重模型一较高下
- 同时推出了指令微调版本OLMo 2-Instruct
- 此次开源延续全公开策略,除模型权重外,还公开了训练数据、代码、中间检查点、日志及超参数选择等
- 2025年10月 ,OLMo 系列迎来参数升级,推出OLMo 2-32B模型
- 这一 32B 参数的模型仅用三分之一的计算量就达到了与 Qwen-2.5-32B相近的性能,且在多技能学术基准测试中超越 GPT-3.5-Turbo 和 GPT-4o- mini
- 同期 AI2 还补充开源了 OLMo-7B/13B/34B 等型号,依旧公开了训练数据来源、清洗流程和评估指标等全部核心资源,适配学术研究与商用场景的多样化需求
OLMo 3系列
- 开源日期 2025年11月20日
- 包含 7B 和 32B 两个规模,共四个核心变体
- 基础预训练版 OLMo-3-Base
- 推理增强版 OLMo-3-Think
- 指令跟随版 OLMo-3-Instruct
- RL 对齐研究专用的 OLMo-3-RL-Zero
- 优点1:该系列上下文长度提升至 65K,且延续极致开源策略,完整披露训练数据集、数据处理流程、训练代码等全部技术细节
- 优点2:32B 参数的 OLMo-3-Think 模型,在仅用六分之一训练数据量的情况下,性能接近同规模的 Qwen3-32B 模型
Gemma
Gemma 4
- 开源时间 20260402
- Gemma 4 模型系列共包含四种型号,移动端设备 and 高性能工作站
- E2B 和 E4B 这两个型号专为手机等边缘设备设计,追求极致的计算和内存效率,可在设备上实现离线、低延迟运行
- 26B MoE / 31B Dense 为高性能型号
- Gemma 4 E2B (Effective 2B)
- 参数量: 有效参数约 2.3B,总参数 5.1B
- 上下文窗口: 128K tokens
- 核心特点: 作为系列中最轻量的模型,它在保持多模态能力的同时,将内存占用优化至极低水平,部分设备可低于1.5GB
- 原生支持音频输入,可用于语音识别和翻译等场景
- Gemma 4 E4B (Effective 4B)
- 参数量: 有效参数约 4.5B,总参数 8B
- 上下文窗口: 128K tokens
- 核心特点: 在 E2B 的基础上提供了更强的性能,同样为端侧设备优化,并原生支持音频输入
- Gemma 4 26B-A4B (MoE)
- 参数量: 总参数 25.2B,激活 3.8B
- 上下文窗口: 256K tokens
- Gemma 4 31B (Dense)
- 参数量: 30.7B
- 上下文窗口: 256K tokens
- 核心特点: Gemma 4 系列中性能最强的型号,在权威评测中表现优异,位列全球开源模型前三(截止到 0402 日,总榜 27,超越 Gemini-2.5-Pro)
其他开源和闭源系列总结
- 开源模型:Mistrial(法国 Mistral AI), MiniMax(上海稀宇科技),Gemma(Google DeepMind),BELLE(贝壳网),Bloom(BigScience 研究小组)
- BELLE 基于 Bloomz-7b1-mt 和 LLAMA-7b 等为基础,针对中文进行了优化
- Bloom 由 BigScience 研究小组主导开发,该项目是一个开放的研究合作项目,由 Hugging Face 主导并协调,代码和模型均开源
- 闭源模型:GPT系列(OpenAI),Claude(美国 Anthropic),文心一言(百度),Doubao(字节)
- 先开源后闭源的一些模型系列:
- Baichuan系列(百川智能)Baichuan,Baichuan2是开源的,Baichuan3是闭源的
- Mistral(法国 Mistral AI)初始是开源的,微软投资后新发布的 Mistral Large 是闭源的
- GLM(智谱AI)初始发布的3个版本是开源的,今年1月发布的GLM-4走向了闭源,7月底发布的 GLM4.5 又开源了
- 先闭源后开源的一些模型系列:
- MiniMax(上海稀宇科技)最早是闭源的,25年1月发布了 MiniMax-01 系列开源模型,2025年5月发布的 MiniMax-Speech-02 是闭源
- Qwen 也有闭源模型,20250906 凌晨发布 Qwen3-Max-Preview (Instruct) 是闭源的模型;此外,Qwen 还发布了 Qwen3-Turbo 和 Qwen3-Plus 等闭源模型
一些闭源系列的简单介绍
Doubao 系列(字节)
Doubao-1.5-pro
- 参考连接:Doubao-1.5-pro
模型使用 MoE 架构,并通过训练-推理一体化设计,探索模型性能和推理性能之间的极致平衡。Doubao-1.5-pro 仅用较小激活参数,即可超过一流超大稠密预训练模型的性能,并在多个评测基准上取得优异成绩
- Doubao-1.5-pro 模型评估结果如下:

- 从图上看,截至到Doubao发布时,效果还是不错的
- Doubao-1.5-pro亮点 :
- 高性能推理系统 :高度稀疏的 MoE 模型,针对 Prefill/Decode 与 Attention/FFN 构成的四个计算象限采用异构硬件结合不同的低精度优化策略,在确保低延迟的同时大幅提升吞吐量,在降低总成本的同时兼顾 TTFT 和 TPOT 的最优化目标
- 扎实数据标注,坚持不走捷径 :
在 PostTraining 阶段,我们精心构建了一套高度自主的数据生产体系,该体系通过高效标注团队与模型自提升技术的深度融合,持续且精准地优化数据质量,严格遵循内部标准,坚持不走捷径,不使用任何其他模型的数据,确保数据来源的独立性和可靠性
SFT 阶段,开发了一套算法驱动的训练数据优化系统,涵盖训练数据多样性优化以及精确人题匹配功能,并结合模型自演进(Self-evolve)技术,提升数据标注的多样性和难度,形成了模型性能提升的良性循环
Reward Model 部分,我们建立了包含 prompt 分布优化、response 筛选、多轮迭代和 active learning 的完整数据生产 pipeline。通过融合同等规模的合成与挖掘数据,有效规避了数据冲突和 pattern hacking 问题;设计了多阶段 Reward Model 训练框架,实现了模型在各类数据分布上的稳定判断能力;基于梯度筛选和迭代过滤技术,用 25% 的数据达到近似全量的训练效果,提高迭代效率;实现了 Verifier 和 Reward Model 的深度融合,构建了统一的 Reward 框架,实现了模型在数学、编程、知识、对话等多维度能力的均衡提升;提出了不同于传统判别式 RM 的生成式 RM 建模方法,在 OOD 泛化性能和 reward hacking 防御上取得显著提升
RL 阶段,基于 veRL 打造了高并行化的多角色训练推理一体框架,兼容不同类型的数据和奖励方式;通过自适应数据分布调节机制,解决了多任务训练中的冲突问题;攻克了价值函数训练难点,实现 token-wise 稳定建模,收敛速度提升 4 倍,在高难度任务上的性能提升超过 10 个绝对点;通过对比学习方法,有效提升了 LLM 的表现并显著缓解了 reward hacking 问题。在数据、算法、模型层面全面实现了 Scaling,完成算力到智力的有效转换
此外,依托字节在推荐、搜索和广告领域的 AB Test 经验,研发了基于用户反馈的高效 PostTraining 全流程,基于豆包的大规模用户反馈,我们构建了从问题发现、数据挖掘、人机结合标注到快速迭代的闭环优化系统,通过用户数据飞轮持续提升模型的实际使用体验 - 多模态
- 深度思考模式
- 据说 Doubao-1.5-pro 的参数量是 200B-A20B(参考自 阿里通义千问 Qwen3 系列模型正式发布,该模型有哪些技术亮点? - 橘鸦的回答 - 知乎)
Doubao-1.6
- 发布日期:20250611
- Doubao-1.6 系列包含3个版本,都支持256K上下文
- Doubao-seed-1.6
- Doubao-seed-1.6-thinking,在推理能力和指令执行测评中超越DeepSeek-R1-0528
- Doubao-seed-1.6-flash,低延迟
开源预告
- 预告:20250820日,网络爆出字节 Seed 将开源一个 36B 模型,详情见 PR github.com/huggingface/transformers/pull/40272 及其
- 具体参数在:
src/transformers/models/seed_oss/configuration_seed_oss.py文件中
- 具体参数在:
Claude 系列(Anthropic)
- Claude 1.3 :2023年3月推出的初代模型
- Claude 2 :2023年7月11日发布,性能有所提升,支持更长文本响应,编程、数学、推理能力增强
- Claude 2.1 :2023年11月21日发布,上下文窗口提升至200K
- Claude 3系列 :2024年3月4日发布,包括
- Claude 3 Haiku
- Claude 3 Sonnet
- Claude 3 Opus
- 以上三个子模型,在上下文理解、多模态处理能力以及整体性能方面表现出色,首次实现多模态能力,能处理图像和视频帧输入
- Claude 3.5 :于2024年6月推出Sonnet版本
- 在推理、知识和编程能力上达到行业新标准,在理解微妙语义、幽默和复杂指令方面表现突出,能输出更自然、高质量文本,视觉推理上可精确转录图像中文本并生成洞察
- Claude 4 的猜测:据说 Claude 4 是划时代的
Claude 3 有趣的命名
- Claude 3系列模型命名含义如下
- Haiku:含义是 日本的“俳句”,因为俳句简短,暗示该模型是轻量级的,是响应速度最快、成本最低的选项,适用于简单日常工作流
- Sonnet:含义是 英文的“十四行诗”,暗示模型就像十四行诗在文学体裁中具有一定的复杂性和表现力,该模型推理能力不错,能处理中等复杂度任务,是性价比之选
- Opus:含义是 音乐“巨作”,表明它是性能顶配的模型,具有强大的推理、数学和编码能力,适用于处理高度复杂的任务
Gemini(Google)
- Gemini 2.5 Pro:2025年3月25日发布(号称地表最强推理模型),2025年6月18日进入稳定阶段,可稳定支持生产级应用开发
Grok(xAI)
- 参考链接:Grok 4在两大测试中全面刷新记录,直接屠榜
- 发布时间:2025年7月10日
- Grok 4 在多个基准上取得最好成绩,在 AIME2025 上取得满分,在 HLE 上最高可拿到 50% 的分数:
- 原始的 Grok 4(不使用任何工具)
- HLE: 26.9% (TEXT ONLY)
- HLE: 25.4% (FULL HLE)
- 调用“工具”的 Grok 4(搜索引擎、计算器、编程语言)
- HLE: 41% (TEXT ONLY)
- HLE: 38.6% (FULL HLE)
- 多个 Agent 组合的 Grok 4(“parallel testing agents”或者“multiple agents”)
- HLE: 50% (TEXT ONLY)
- HLE: 44.4% (FULL HLE)
- 原始的 Grok 4(不使用任何工具)
- Grok 4 定价:输入 $3/100万 token,输出 $15/100万 token
- Sonnet 4:输入 $3/100万 token,输出 $15/100万 token
- Claude Opus 3:输入 $2/100万 token,输出 $8/100万 token
- GPT-4.1:输入 $2/100万 token,输出 $8/100万 token
OpenAI(GPT系列)
- ChatGPT :是一款主打聊天功能的模型,发布于 2022年11月30日,基于 OpenAI 的 GPT-3.5 架构
- GPT-4 :发布于 2023年3月14日,是大型多模态模型 ,可接受文本或图像输入并输出文本,具有更广泛的常识和先进的推理能力,能更准确地解决难题
- DALL·E 3 :2023年11月发布,是 OpenAI 的图像生成模型,通过图像API提供服务,支持根据自然语言描述创建逼真图像和艺术作品,还能创建特定大小的新图像
- GPT-4o :发布于 2024年5月13日,“o”代表“omni” ,意为“全能”,是多模态模型,接受文本或图像输入并输出文本。它具有与GPT-4 Turbo相同的高智能,但效率更高,生成文本速度提高2倍,成本降低50%
- GPT-4o mini :2024年7月18日 发布,是 OpenAI 当时最强大且成本效益最高的小型模型,在学术基准测试中超越GPT-3.5 Turbo等小型模型,在文本智能和多模态推理方面表现出色
- o1-preview :2024年9月 发布,是旨在解决跨领域难题的推理模型
- o3 :发布于 2025年4月,是 OpenAI 当时最强大的推理模型,在编程、数学、科学、视觉感知等多个维度的基准测试中刷新纪录,在分析图像等视觉任务中表现突出
- o4-mini :2025年4月 发布,是专为快速、经济高效的推理而优化的小模型,在非STEM任务以及数据科学领域超过了前代的o3-mini
- GPT-OSS系列 :2025年8月5日 发布,包含 120B 与 20B 双版本,采用 MoE架构,Apache2.0许可,支持免费商用
- 支持 MXFP4 量化
- 单卡 80GB GPU 能够支持 120B 规模的模型
- 20B 模型可在消费级 16GB 显存硬件上流畅推理,实现低成本本地化部署
- GPT-5 :2025年8月7日 发布,由多个子模型组成,可根据问题复杂程度自动切换模型。其上下文窗口提升至256K tokens,推理能力大幅增强,在编程、数学等领域表现出色,语音交互更稳定流畅
- GPT-5 mini :2025年8月7日 随 GPT-5 一同发布,是 GPT-5 的精简版本,当免费用户使用GPT-5达到次数限制后会切换为该模型
- GPT-5 Nano :2025年8月7日 发布,具体细节未详细披露,与GPT-5、GPT-5 mini共同构成了GPT-5系列,应是针对特定场景或资源受限环境设计的更轻量化模型
附录:LLM 名称前后缀及其含义
- -Base :通常是指未经特定任务微调的基础预训练模型,可用于进一步的微调,以适应特定任务或应用场景
- 包含大量通用知识,但未对特定任务进行优化
- -Chat :针对对话系统设计和优化的模型,用于生成自然语言对话,能够理解上下文并生成连贯且有意义的回复,可应用到聊天机器人、智能助理等
- 经过大量对话数据微调,具备更好的上下文理解能力和对话生成能力
- -Instruct :旨在遵循指令或完成特定任务而设计和优化的模型,用于执行具体指令,如回答问题、生成文本、翻译等任务
- 经过指令数据集微调,能够更好地理解和执行用户提供的指令
- -4bit(或-Int4) :表示该模型是基于4位量化技术的版本
- 量化是一种将模型参数表示为较低精度数据类型的技术,4bit量化可以显著减少模型的存储空间和计算量
- -AWQ :表示采用了激活值感知的权重量化(Activation-aware Weight Quantization)方法
- 这种方法通过统计激活值的绝对值均值,保留1%的关键权重通道为FP16精度,其余通道量化为4位整数(INT4),并通过缩放因子降低量化误差
- -GPTQ-Int4 :表示采用了生成式预训练变压器量化(Generative Pretrained Transformer Quantization)方法
- 将模型权重量化为4位整数(Int4),以减少模型存储空间和计算量,提高推理效率
- -GPTQ-Int8 :与 -GPTQ-Int4 类似的 Int8 版本
- -GGUF :表明该模型采用的是 GPT-Generated Unified Format 格式存储,这是一种专为大语言模型设计的二进制文件格式
- 这种存储旨在实现模型的快速加载和保存,同时易于读取,支持动态量化与混合精度配置,适用于不同硬件资源场景
.gguf采用紧凑的二进制编码格式和优化的数据结构来保存模型参数,兼顾存储效率、加载速度、兼容性和扩展性- 以
codeqwen-1_5-7b-chat-q5_k_m.gguf为例,q5_k_m是 GGUF 格式中关于模型量化的标识,其中q5表示模型的主量化精度为 5 比特;k代表量化过程中采用的是 k-quant 算法;m表示混合精度优化级别为中等,即中等混合,更多块使用高精度,以平衡速度和精度
- Code :表示专门为Code任务微调的模型
- -1M :表是上下文长度是 100W tokens(名字出自 Qwen2.5-7B-Instruct-1M和Qwen2.5-14B-Instruct-1M)
- -AxxB :表示 MoE 模型的激活参数,比如 Qwen2-57B-A14B 表示总参数量 57B,每次激活参数量 14B
- [None] :特别地,如果没有任何后缀,则有可能是 Pretraining 的基础版本(-Base版本),也可能是经过 Pretraining+Post-training 的版本,详细信息可以从 Model Card 中查看,比如:
- Qwen/Qwen2.5-32B : Training Stage: Pretraining
- Qwen/Qwen3-32B : Training Stage: Pretraining & Post-training
- -turbo :表示原模型的增强版,OpenAI 常用
- -mini :表示原模型缩小尺寸的版本,OpenAI 常用
- -nano :表示比 mini 还小的更小尺寸模型,OpenAI 常用
- -oss :OSS 代表 “Open-Source Series”,一般是闭源公司的 “开源系列” 模型, 比如 OpenAI 的 gpt-oss-120b 和 gpt-oss-20b
- -omni :“omni”(/ˈɑmni/) 常用来表示全模态,像 GPT-4o 中的 “o” 代表 “omni”,意味着全能的,”omni” 也常用于科技、学术、哲学等领域来表示全范围、全功能等概念
- Anthropic 专属:(注:Anthropic 为其 Claude 系列模型选取的这几个名字,全部源自文学或艺术领域的术语,核心逻辑是用“作品形式的规模与复杂度”来隐喻“模型的智能水平”)
- Haiku (俳句): /ˈhaɪkuː/ 指日本的一种超短诗(三行,5-7-5音节)
- 最轻量、最快、最便宜的模型
- Sonnet (十四行诗):/ˈsɒnɪt/ 指欧洲经典的十四行诗体(如莎士比亚的十四行诗)
- 中等规模、平衡型的模型
- Opus (巨作/乐章):/ˈəʊpəs/ 拉丁语原意为“作品”,常指音乐或文学中宏大、完整的杰作(如交响曲)
- 旗舰级、最强大、最智能的模型
- Mythos (神话):/ˈmaɪθɒs/ 希腊语意为“神话”或“叙事”
- 能力在 Opus 之上,隐喻比“巨作”更宏大、更深邃的叙事体系,可能代表超长上下文、多模态深度融合或更高阶的推理架构(但目前尚未有官方确认的正式产品)
- Haiku (俳句): /ˈhaɪkuː/ 指日本的一种超短诗(三行,5-7-5音节)