注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- MiMo-V2-Flash 核心创新:
- 混合滑动窗口注意力架构 (Hybrid Sliding Window Attention architecture)
- 轻量级多 Token 预测 (Lightweight Multi-Token Prediction)
- MOPD 后训练范式
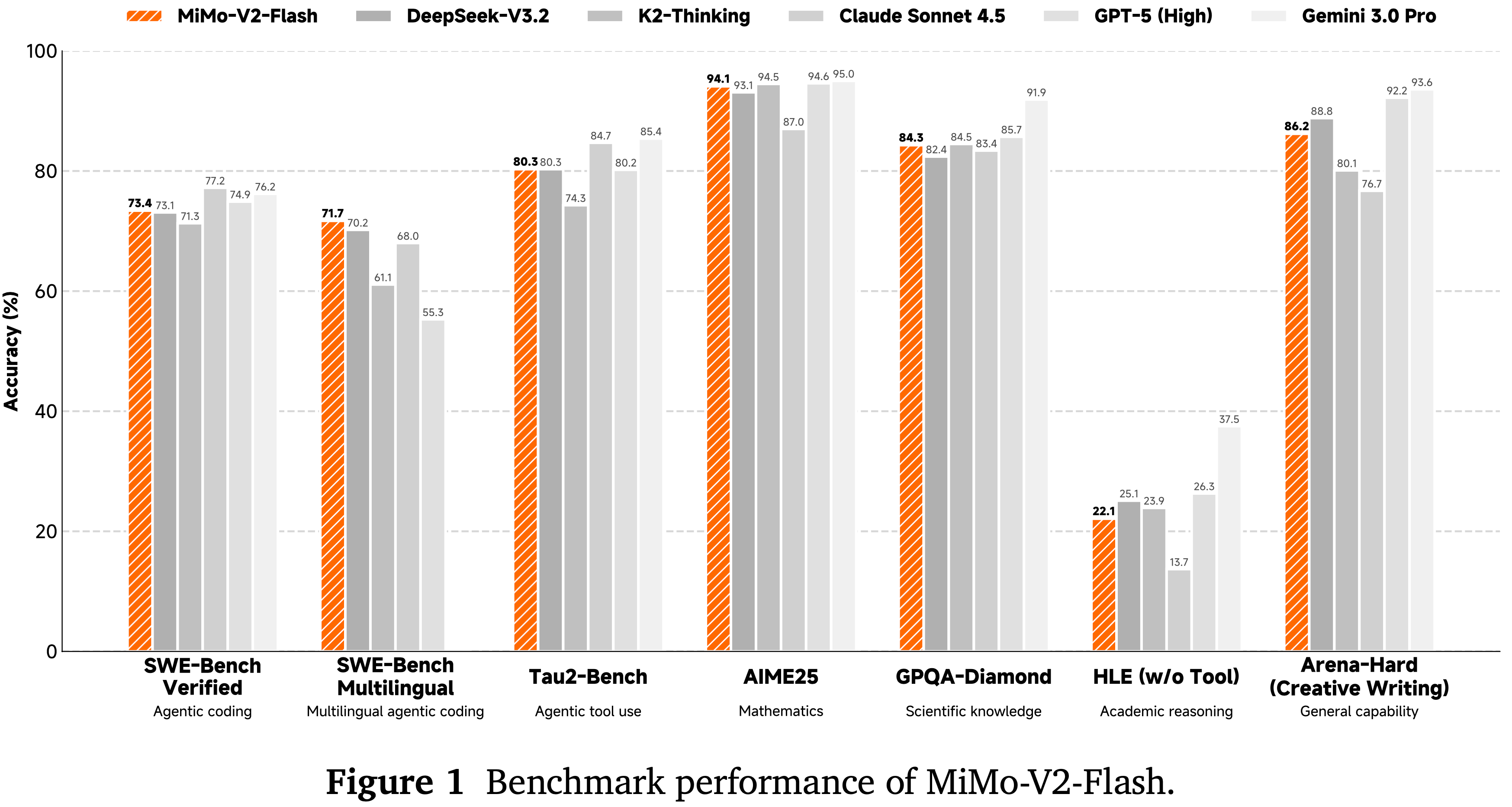
- 从论文中看:MiMo-V2-Flash 可与 DeepSeek-V3.2 和 Kimi-K2 等更大的开放权重模型相媲美
- MiMo-V2-Flash 核心创新:
- 完整训练流程:
- Pre-Training -> Mid-Training -> Context Extension -> SFT -> Non-Agentic RL -> Agentic RL -> MOPD (Multi-Teacher On-Policy Distillation)
- 学生模型:学生起点 = Stage 1 SFT 后的模型(注:论文未明确说明,但报告中表 7(Benchmark results of MOPD)显示了一列 “Student Before MOPD”,其数值与 SFT 后的性能吻合)
- 教师模型:从 SFT 模型或 Base 模型出发,经过独立的领域 RL/SFT 训练得到,在 MOPD 阶段固定
- 数学教师:SFT 模型 -> 强化学习(数学推理数据,程序化验证器作为奖励)
- 代码生成教师:SFT 模型 -> 强化学习(代码生成数据,代码执行结果作为奖励)
- 代码 Agent 教师:SFT 模型 -> 强化学习(GitHub issue环境,单元测试作为奖励,约12万环境)
- Terminal Agent教师:SFT 模型 -> 强化学习(Stack Overflow转化来的终端任务,Docker环境+测试用例)
- Web 开发 Agent 教师:SFT 模型 -> 强化学习(合成网页开发任务,Playwright+多模态视觉判别器作为奖励)
- 搜索 Agent 教师:SFT 模型 -> 仅监督微调(BrowseComp数据,无强化学习)
- 注意:搜索 Agent 目前仅是 SFT 得到的结果
- 函数调用/工具使用教师:SFT模型 -> 强化学习(合成工具调用环境,数据依赖+逻辑依赖构建任务)
- 通用知识教师:无专门训练 -> MOPD 阶段学生以自身为教师(Self),主要依赖结果奖励模型
- 注意:这里是 MOPD 的学生模型自身也作为教师,算是一个正则
- 注:在进行 MOPD 时,MiMo-V2 还加入了 ORM 结果奖励
- MiMo-V2-Flash 是一个 MoE 模型(309B-A15B),旨在实现快速、强大的推理和智能体能力
- MiMo-V2-Flash 采用了一种混合注意力架构
- 将滑动窗口注意力(Sliding Window Attention,SWA)与全局注意力(Global Attention, GA)以 5:1 的混合比例交错排列,滑动窗口大小为 128 个 token
- MiMo-V2-Flash 使用 Multi-Token Prediction(MTP) 在 27T Token 上进行预训练,拥有原生的 32k 上下文长度并随后扩展到 256k
- 为了高效扩展训练后计算,MiMo-V2-Flash 引入了一种新颖的多教师 On-policy 蒸馏范式
- 在此框架中,领域专业化的教师模型(例如,通过大规模强化学习训练)提供密集的、Token-level 奖励,使学生模型能够完美掌握教师的专业知识
- MiMo-V2-Flash 能够媲美 DeepSeek-V3.2 和 Kimi-K2 等顶级开源模型,尽管其总参数量仅分别为后者的 1/2 和 1/3
- 在推理过程中,通过将 MTP 重新用作推测解码的草稿模型,MiMo-V2-Flash 在使用三层 MTP 时实现了最高 3.6 的接受长度和 2.6 倍的解码加速
- 论文开源了模型权重和三层 MTP 权重,以促进开放研究和社区协作
- 本次解读重点关注后训练阶段,其他部分暂不深入
Introduction and Discussion
- 人工智能通用智能的最新进展越来越受到两个前沿领域的推动:
- 先进的推理链和基于大规模强化学习的自主智能体工作流 (Google DeepMind, 2025; Kimi Team, 2025b; 2025)
- 但构建可扩展的推理器和智能体面临一个共同的关键瓶颈:长上下文建模必须同时具备快速和强大的能力
- 论文介绍了 MiMo-V2-Flash,这是一个高效且经济实惠的 LLM,能够提供强大的推理和智能体性能
- 为了缓解完全注意力的二次复杂度,MiMo-V2-Flash 采用了一种混合注意力机制,交错排列局部滑动窗口注意力和全局注意力
- 滑动窗口大小为 128 Token,混合局部:全局比例为 5:1,对于长上下文,KV 缓存存储和注意力计算减少了近 \(6\times\)
- 借助可学习的注意力 Sink 偏置 (2025) 的帮助,即使采用了激进的滑动窗口大小和混合比例,该混合架构在长上下文场景中也能保持强大的建模能力
- MiMo-V2-Flash 还集成了 Multi-Token Prediction 以增强训练性能并加速推理解码
- 特别是,MTP 在提升 RL rollout 速度方面具有巨大潜力,这有助于将 LLMs 扩展到更强大的智能水平
- 通过轻量级的密集前馈网络和滑动窗口注意力,论文的 MTP 模块在实践中以高接受率提供了显著的解码加速
- MiMo-V2-Flash 的预训练方案在很大程度上遵循了 MiMo-7B (2025),并进行了若干改进
- 训练使用 FP8 混合精度进行,能够在 27T Token 上实现高效的大规模训练
- 模型最初以原生 32K 上下文进行预训练,随后扩展到 256K
- 得到的预训练模型 MiMo-V2-Flash-Base 已针对 Kimi-K2-Base (Kimi Team, 2025c) 和 DeepSeek-V3.2-Exp-Base (2025) 等领先的开源基础模型进行了评估
- MiMo-V2-Flash-Base 在通用基准测试中取得了有竞争力的性能,并在侧重于推理的任务上超越了同类模型
- 对于长上下文检索,论文的混合注意力架构在从 32K 到 256K 的上下文长度上实现了接近 \(100%\) 的成功率
- 在极端长上下文推理基准 GSM-Infinite (2025) 上,MiMo-V2-Flash 在从 16K 扩展到 128K 时表现出稳健的性能,性能下降最小
- 在训练后阶段,论文专注于高效扩展 RL 计算,以改进推理和智能体能力
- 为此,MiMo-V2-Flash 引入了一种称为多教师 On-policy 蒸馏的新训练后范式。该框架通过三阶段过程解决了能力不平衡和学习效率低下的问题:
- (1) 通用监督微调;
- (2) 专业化的 RL/SFT 用于训练领域特定的教师模型;
- (3) MOPD,其中学生模型从两个互补的信号中学习:来自在不同领域训练的特定教师的密集的、Token-level 奖励,以及一个可验证的、基于结果的奖励
- 通过以这种方式整合多样化的专家知识,MiMo-V2-Flash 同时掌握了领域教师的顶峰能力,并受益于稳定高效的学习动态
- 为此,MiMo-V2-Flash 引入了一种称为多教师 On-policy 蒸馏的新训练后范式。该框架通过三阶段过程解决了能力不平衡和学习效率低下的问题:
- MiMo-V2-Flash 在大多数推理基准测试中取得了与 Kimi-K2-Thinking 和 DeepSeek-V3.2-Thinking 相媲美的性能
- 在 LongBench V2 和 MRCR 等长上下文评估中,MiMo-V2-Flash 持续超越更大的全注意力模型,证实了其混合 SWA 架构的鲁棒性
- 值得注意的是,该模型在 SWE-Bench Verified 上达到了 \(73.4%\),在 SWE-Bench Multilingual 上达到了 \(71.7%\),使其成为软件工程任务中最领先的开源模型
- 模型权重(包含 3 层 MTP 权重)可在 github.com/XiaomiMiMo/MiMo-V2-Flash 获取
MiMo-V2-Flash Model Architecture
Overall Architecture
- 如图 2 所示,MiMo-V2-Flash 遵循标准的 Transformer (2017) 主干,并增强了 MoE (2017) 和混合注意力 (2020; Gemma Team, 2024, 2025; Kimi Team, 2025a; 2025; Qwen Team, 2025)
- MiMo-V2-Flash 主要由重复的混合块组成,这些块交错排列局部滑动窗口注意力和全局注意力
- 它堆叠了 \(M = 8\) 个混合块,每个块的结构为 \(N = 5\) 个连续的 SWA 块后接一个 GA 块
- 唯一的例外是第一个 Transformer 块,它使用全局注意力和密集的前馈网络以稳定早期的表示学习
- MiMo-V2-Flash 中使用的滑动窗口大小 \(W\) 为 128
- SWA 块和 GA 块都使用稀疏的 MoE FFN。每个 MoE 层总共包含 256 个专家,每 Token 激活 8 个,并且不包含共享专家
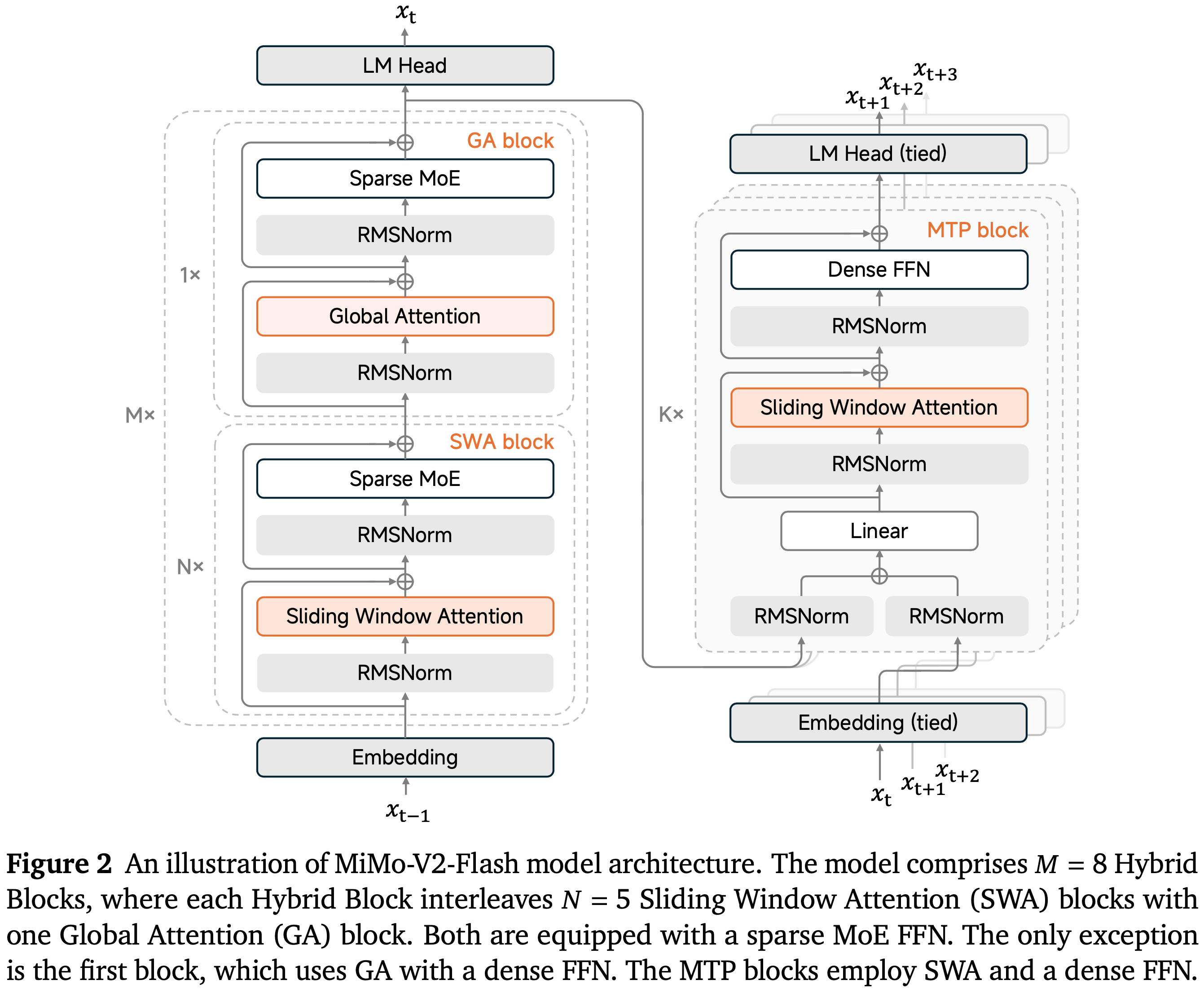
- MiMo-V2-Flash 还集成了 MTP (2024; 2024; 2025) 以提高模型性能(包括质量和效率)
- MTP 块使用 Dense FFN 而非 MoE,并采用 SWA 而非 GA,使其在推测解码中保持轻量级
- 每个 MTP 块的参数量仅为 0.33B
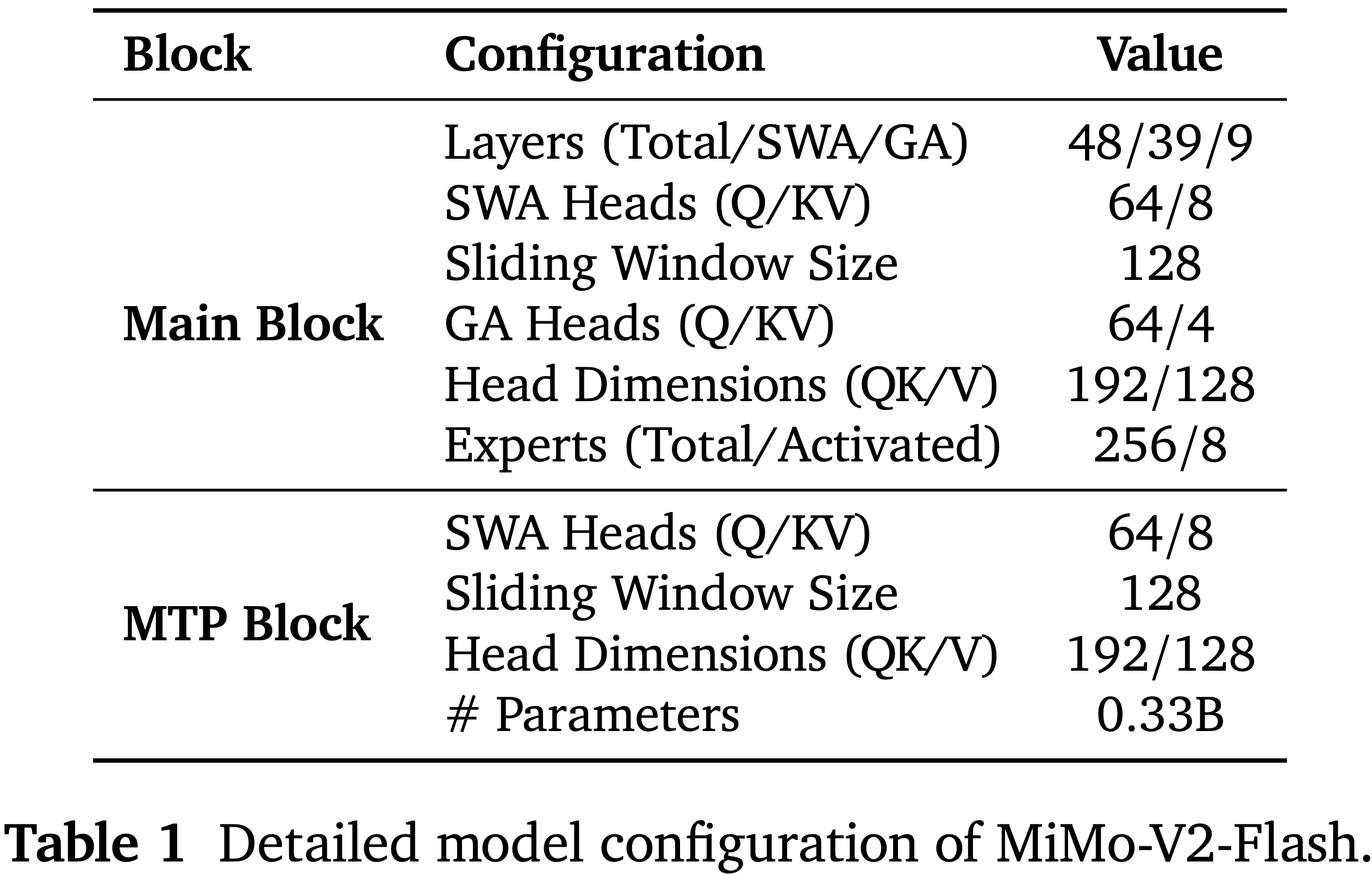
- 表 1 总结了 MiMo-V2-Flash 的详细配置
- 模型包含 39 个 SWA 层和 9 个 GA 层
- SWA 和 GA 都使用分组 Query 注意力 (2023)
- SWA 有 64 个 Query 头和 8 个键值头,GA 有 64 个 Query 头和 4 个键值头
- SWA 和 GA 的每个头的维度相同( Query 和键为 192,值为 128)
- 旋转位置嵌入部分应用于 Query 和键的前 64 个维度
- 遵循最近的最佳实践,论文采用了类似于 DeepSeek-V3 (2024) 的 FP8 混合精度框架
- 论文为注意力输出投影,以及嵌入和输出头参数保留 BF16 精度,同时为 MoE 路由器参数保持 FP32 精度
- 这种混合精度配置提高了数值稳定性,而不会对训练效率或内存占用产生实质性影响
- 这种混合精度配置提高了数值稳定性,而不会对训练效率或内存占用产生实质性影响
Hybrid Sliding Window Attention Architecture
- 滑动窗口注意力 (2020) 将每个 Token 的注意力范围限制在局部窗口而非整个序列,从而显著降低计算和内存复杂度
- 这自然激发了混合滑动窗口注意力架构的出现
- 但先前的工作表明,过度激进的 SWA 使用,如非常小的滑动窗口大小或高 SWA:GA 比例,可能导致模型性能显著下降 (Gemma Team, 2025),尤其是在长上下文任务中
- 最近,可学习的注意力 Sink 偏置的引入显著增强了基于 SWA 架构的建模能力 (2025),该机制允许模型在需要时将很少或没有注意力分配给某些 Token
- 尽管注意力 Sink 机制的确切理论基础仍是一个活跃的研究领域 (2024b; 2025; 2024; 2023),但论文通过实验观察到,可学习的注意力 Sink 偏置显著提升了混合 SWA 模型的性能,匹配甚至超过了使用完全 GA 层的基线
- 在 MiMo-V2-Flash 中,论文的实现遵循了 gpt-oss (2025) 中使用的设计,其中每个注意力头的 softmax 分母应用一个可学习的注意力 Sink 偏置 \(sink \in \mathbb{R}\)
- 令单个注意力头中 Token \(i\) 和 \(j\) 之间的注意力 logits 为:
$$a_{ij} = \frac{q_ik_j^\top}{\sqrt{d} }, \tag{1}$$- 其中 \(q_{i}\) 和 \(k_{j}\) 分别表示 Token \(i\) 的 Query 和 Token \(j\) 的键,\(d\) 是头的维度
- 注意力权重由下式给出:
$$
\begin{align}
s_{ij} &= \frac{\exp\left(a_{ij} - m_i\right)}{\exp\left(\text{sink} - m_i\right) + \sum_{j’}\exp\left(a_{ij’} - m_i\right)} \tag{2} \\
m_{i} &= \max \left\{\max_{j}a_{ij},\text{sink}\right\} \tag{3}
\end{align}
$$
- 令单个注意力头中 Token \(i\) 和 \(j\) 之间的注意力 logits 为:
- 最后, Query \(i\) 的注意力输出通过对值进行加权和获得:
$$o_{i} = \sum_{j = 1}^{n}s_{ij}\nu_{j}. \tag{4}$$
Model Architecture Experiments
- 了验证论文设计选择的有效性,论文在一个 32B Dense 模型上进行了探索性和实证研究,保持了与上述描述一致的 Query -键维度和旋转嵌入配置
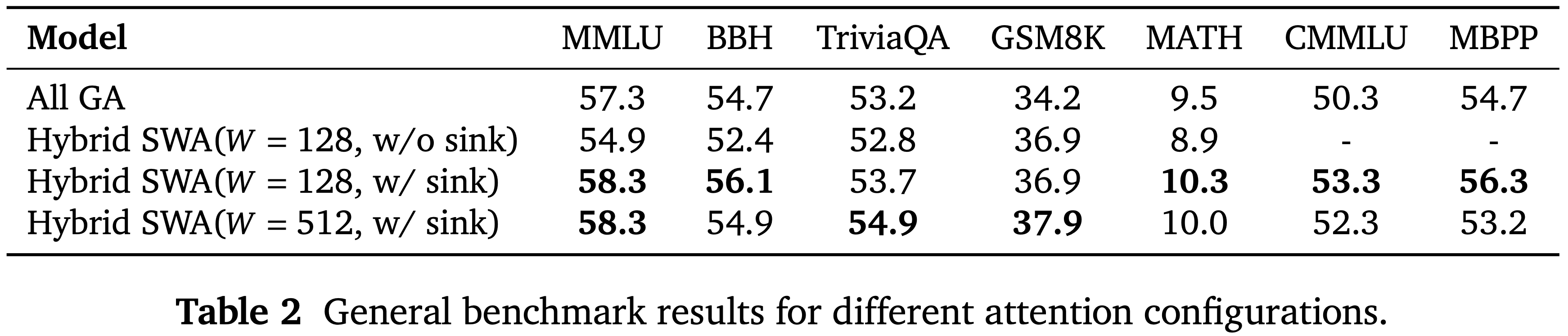
- 表 2:不同注意力配置的通用基准结果
- 表 3:不同注意力配置的长上下文基准结果
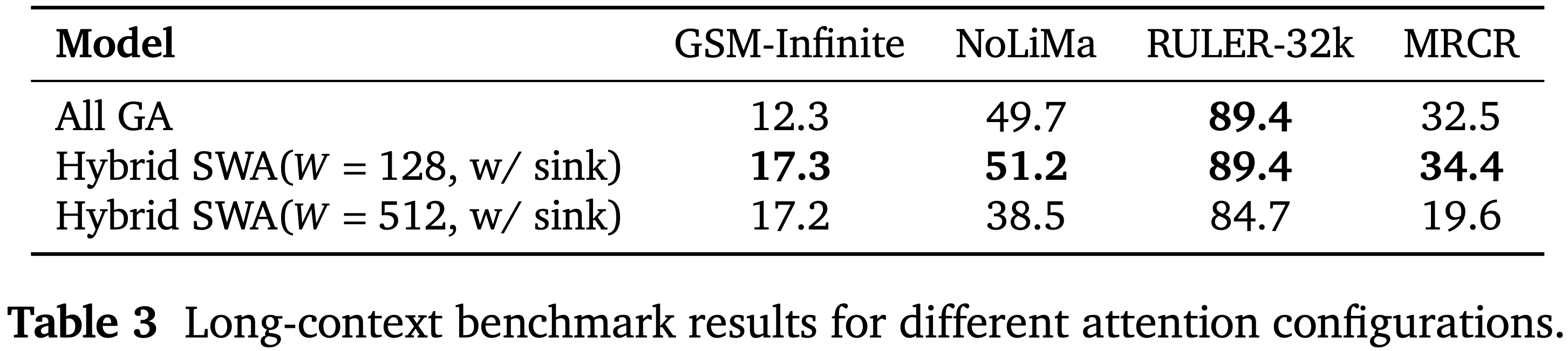
- 表 4:不同注意力配置的复杂推理基准结果

基线及基准测试
- 论文在比较环境中评估了四种模型架构变体,包括:
- 一个全全局注意力基线
- 一个不带注意力 Sink 偏置的 128 Token 窗口混合 SWA 模型
- 两个分别使用 128 和 512 窗口大小并增强了注意力 Sink 偏置的混合 SWA 模型
- 所有变体共享相同的训练流程:在 250B Token 上进行 8,192 序列长度的预训练,然后在额外的 40B Token 上长上下文扩展到 32,768,接着进行带有思维链监督的长上下文 SFT 和推理 SFT
- 论文评估模型变体在涵盖通用能力、长上下文理解和复杂推理的基准测试上的表现
- 通用领域结果(表 2)来自未经长上下文扩展的预训练基础模型,评估了在 MMLU (2021a), BBH (2023), TriviaQA (2017), GSM8K (2021), MATH (2021b), CMMLU (2023) 和 MBPP (2021) 上的通用知识和推理
- 长上下文结果(表 3)评估了长上下文扩展后的基础模型在 GSM-Infinite (2025), NoLiMa (2025) 和 RULER-32k (2024) 上的表现,以及长上下文 SFT 模型在 MRCR (2024) 上的表现
- 对于 GSM-Infinite 和 Nolima,论文构建了内部的 few-shot 基准来评估基础模型在受控的长上下文设置下的表现
- 复杂推理结果(表 4)评估了推理 SFT 模型在 AIME24&25 (MAA, 2024), LiveCodeBench (2024) 和 GPQA-Diamond (2024) 上的表现
- 论文关键的实证发现:
- 注意力 Sink 偏置消融实验 如表 2 所示,混合 SWA (\(W = 128\) ,w/o Sink ) 在通用基准测试中遭受了明显的性能下降,而引入注意力 Sink 偏置相对于全 GA 基线一致地恢复或提升了性能
- 因此,在进一步的实验中,论文默认假设应用了注意力 Sink 偏置
- 滑动窗口注意力大小 混合 SWA (\(W = 128\)) 和混合 SWA (\(W = 512\)) 在通用基准测试上表现相似(表 2)
- 然而,经过长上下文扩展和长上下文 SFT 后,混合 SWA (\(W = 128\)) 超越了全 GA 基线,而 SWA (\(W = 512\)) 则经历了显著的性能下降(表 3)
- 推理能力 如表 4 所示,混合 SWA (\(W = 128\)) 在不同的挑战性推理基准测试上超越了全 GA 基线,在复杂推理能力上显示出清晰的改进
- 注意力 Sink 偏置消融实验 如表 2 所示,混合 SWA (\(W = 128\) ,w/o Sink ) 在通用基准测试中遭受了明显的性能下降,而引入注意力 Sink 偏置相对于全 GA 基线一致地恢复或提升了性能
Summary and Discussion
- 论文的实验表明,混合 SWA (\(W = 128\)) 不仅优于混合 SWA (\(W = 512\)),而且可以 超越全 GA 基线 ,这可能看起来违反直觉
- 论文推断这是由于更好的正则化和有效的稀疏性相结合的结果
- 较小的窗口迫使模型专注于局部上下文,作为一种归纳偏置,减轻了对虚假模式的过拟合
- 此外,更紧的窗口 (\(W = 128\)) 迫使 SWA 对局部信息建模,同时将长程依赖委托给全局注意力层,导致更清晰的分工和更准确高效的学习
- 相比之下,更大的窗口 (\(W = 512\)) 可能会模糊这种区别,导致 SWA 部分地自行处理长程依赖,这稀释了局部和全局信息之间的分离,并导致次优性能
- 论文这些观察和发现是实证性的,源于论文特定的实验设置,包括模型规模、数据集和训练过程
- 尽管如此,作者希望这些观察能为正在进行的关于推理和智能体 AI 模型时代高效注意力架构的讨论贡献一个额外的视角,并激励社区更广泛地研究高效架构
Lightweight Multi-Token Prediction
Motivation of using MTP
- 先前的工作表明,MTP 是一种强大的训练目标,可以增强训练效率和模型质量 (2024; 2024; 2025)
- 除了这些训练上的好处,论文更强调将 MTP 作为本机草稿模型用于自推测解码,以实现实际部署的加速
- 论文从两个角度详细阐述 MTP 如何加速推理:通用 LLM 解码加速和 RL 训练加速
Accelerating LLM Decoding
- 由于算术强度低,LLM 解码本质上是内存受限的
- MTP 加速特别适用于 RL 训练 (RadixArk Team, 2025),其中 rollout 阶段由于推理和解码成本始终是主要的瓶颈
- MTP 解决了 RL 训练中的两个关键挑战:
- 它使得小批次的 RL 高效且有效:当前的 RL 训练依赖于大批次、 Off-policy 算法来最大化吞吐量 (2025; 2017; 2025)
- 但实际上,On-policy 训练通常更稳定和有效,但其小批次无法充分利用 GPU 资源
- MTP 通过扩展 Token 级并行而不是批次大小来缓解这一限制,使得小批次、 On-policy RL 训练更加实用
- 它减轻了由长尾滞后项引起的 GPU 空闲
- 随着 rollout 阶段进行,处理长序列且批次大小较小(通常接近 1)的长尾滞后项会导致显著的 GPU 空闲 (2025; 2025)
- 在此类场景中,MTP 提高了注意力和 FFN 的计算效率,显著减少了总体延迟
- 理解:这里说的是当 Batch 较小时,MTP 可以提升并行度?还是说单纯的提升了整体解码速度?
- 它使得小批次的 RL 高效且有效:当前的 RL 训练依赖于大批次、 Off-policy 算法来最大化吞吐量 (2025; 2017; 2025)
Lightweight MTP Design in MiMo-V2-Flash
- 在 MiMo-V2-Flash 中,MTP 块被刻意保持轻量级,以防止其成为新的推理瓶颈
- 论文使用小型 Dense FFN 而不是 MoE 来限制参数数量,并采用 SWA 而不是全局注意力来减少 KV 缓存和注意力计算成本
- 在预训练期间,模型仅附加一个 MTP 头以避免额外的训练开销
- 在训练后阶段,该头被复制 \(K\) 次以形成 \(K\) 步 MTP 模块,并且所有头联合训练以进行多步预测
- 每个头接收主模型的隐藏状态和 Token 嵌入作为输入,提供更丰富的预测信息
- 尽管设计轻量,MTP 模块仍然非常有效,并实现了高接受率
- 详细结果见第 5 节
Pre-Training
- MiMo-V2-Flash 的预训练语料库包含来自多样化高质量来源的 27T Token,包括公共网络内容、书籍、学术论文、代码、数学和更广泛的 STEM 材料
- 论文的数据处理流程在很大程度上遵循了 MiMo-7B (2025),并有意转向展现长程依赖的数据
- 特别是,论文强调长格式的网络文档和精心整理的代码语料库,如仓库级代码、拉取请求、问题和提交历史,以增强模型捕获扩展上下文关系和执行复杂多步推理的能力
Data Scheduler
- MiMo-V2-Flash 的预训练组织为三个连续的阶段:
- 阶段 1 :在多样化的高质量通用语料库上使用 32K Token 的上下文长度进行训练,以建立强大的基础语言能力
- 阶段 2 :通过上采样以代码为中心的数据并纳入约 \(5%\) 的合成推理数据来修改数据混合,以进一步增强逻辑推理和程序合成能力
- 阶段 3 :遵循第 2 阶段的数据分布,将模型的上下文窗口扩展到 256K Token,并对具有长程依赖的数据进行上采样,实现对扩展上下文和长视野推理的更有效建模
Hyper-Parameters
模型超参数
- 论文将 MiMo-V2-Flash 配置为 48 个 Transformer 层,包括 39 个滑动窗口注意力层和 9 个全局注意力层。隐藏维度设置为 4096。除第一层外,所有层都配备了稀疏 MoE。每个 MoE 层包含 256 个路由专家,每 Token 激活 8 个专家,每个专家的中间隐藏维度为 2048。密集层 FFN 的中间隐藏维度设置为 16384。所有可学习参数均以 0.006 的标准差随机初始化。模型在预训练期间使用单层 MTP。总体而言,MiMo-V2-Flash 总参数量为 309B,其中激活参数量为 15B
训练超参数
- 论文采用 AdamW 优化器,其中 \(\beta_{1} = 0.9\) , \(\beta_{2} = 0.95\) ,权重衰减为 0.1。梯度裁剪的最大范数为 1.0。学习率调度分两个阶段运行。在阶段 1,学习率在前 50B Token 从 0 线性预热到 \(3.2 \times 10^{- 4}\),然后在 \(3.2 \times 10^{- 4}\) 保持 12T Token,最后在 10T Token 上以余弦衰减到 \(1.0 \times 10^{- 4}\)。阶段 2 从 \(1.0 \times 10^{- 4}\) 开始,并在 4T Token 上以余弦衰减到 \(3.0 \times 10^{- 5}\)。批次大小在前 500B Token 线性预热到 2,048,并在两个阶段的剩余时间保持恒定。关于辅助损失,所有阶段的 MoE 序列辅助损失系数设置为 \(1.0 \times 10^{- 5}\)。专家偏置更新因子在阶段 1 和阶段 2 设置为 0.001。MTP 损失权重在阶段 1 设置为 0.3,在阶段 2 和 3 设置为 0.1
长上下文扩展
- 在阶段 1,论文将预训练序列长度设置为 32,768,GA 的 RoPE 基础频率为 640,000,SWA 为 10,000。在阶段 3,序列长度扩展到 262,144,GA 的 RoPE 基础频率调整为 5,000,000。阶段 3 的学习率从 \(3.0 \times 10^{- 5}\) 以余弦调度衰减到 \(1.0 \times 10^{- 5}\),批次大小固定为 256。专家偏置更新因子在阶段 3 减少到 \(1.0 \times 10^{- 5}\)
Evaluations
Evaluation Setup
- 论文在涵盖各种能力的一系列基准测试上评估 MiMo-V2-Flash-Base:
- (1) 通用语言理解和推理,包括 BBH (2023), MMLU (2021a), MMLU-Redux (2024), MMLU-Pro (2024), DROP (2019), ARC (2018), HellaSwag (2019), WinoGrande (2020), TriviaQA (2017), GPQA-Diamond (2024), SuperGPQA (2025) 和 SimpleQA (OpenAI, 2024)
- (2) 数学推理: GSM8K (2021), MATH (2021b) 和 AIME (MAA, 2024) (2024 & 2025)
- (3) 代码: HumanEval+ (2023), MBPP+ (2023), CRUXEval (2024a), MultiPL-E (2022), BigCodeBench (2024), LiveCodeBench-v6 (2024) 和 SWE-Bench (2024a) (few-shot Agentless Repair (2024))
- (4) 中文理解: C-Eval (2023), CMMLU (2023) 和 C-SimpleQA (2025)
- (5) 多语言理解: GlobalMMLU (2025) 和 INCLUDE (2024)
- (6) 长上下文: NIAH-Multi (2024), GSM-Infinite (2025) (5-shot, Hard Ops-{2,4,6,8,10})
Evaluation Results
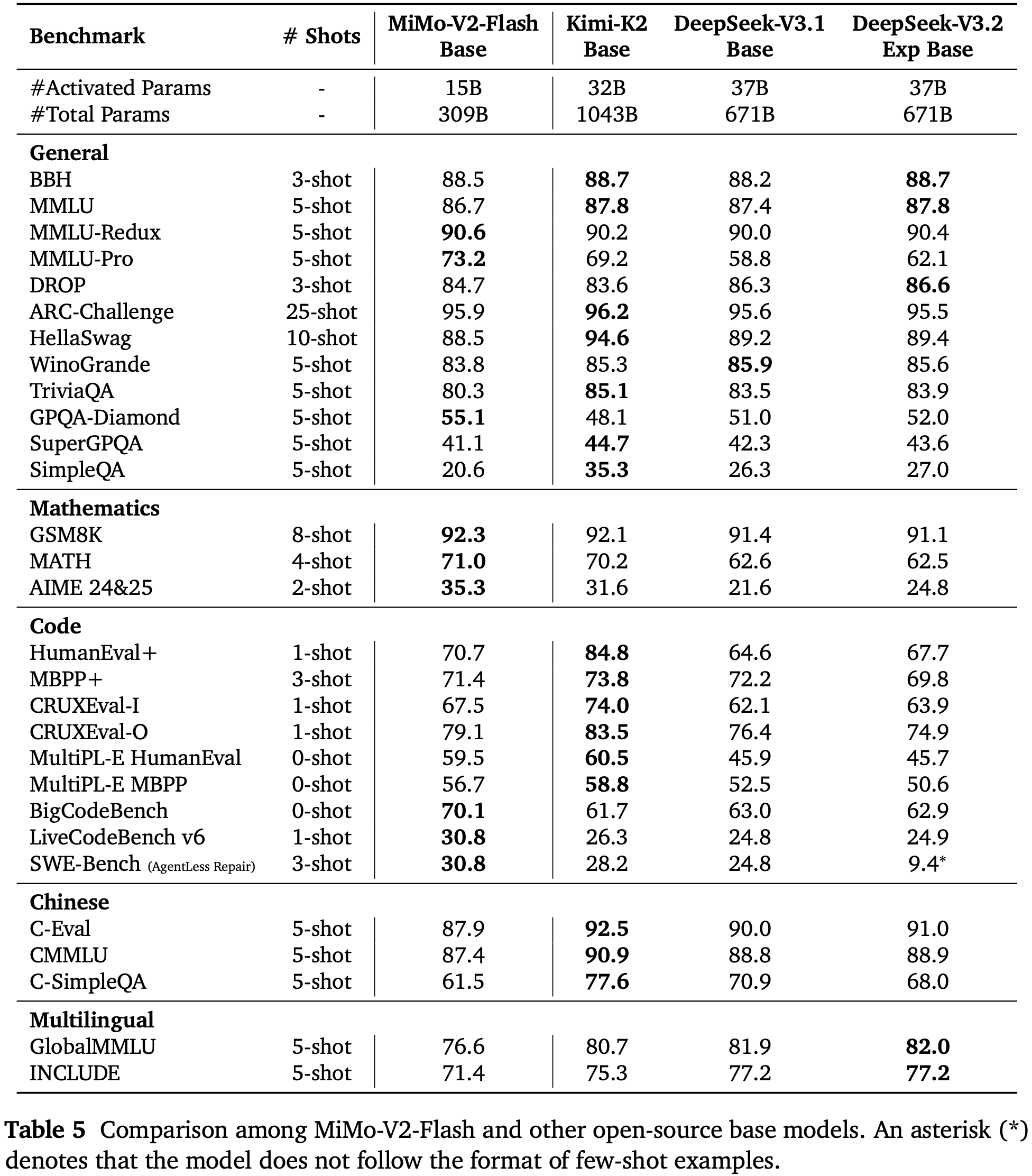
- 表 5 展示了 MiMo-V2-Flash-Base 与领先的开源基础模型 (Kimi Team, 2025c; 2024) 的全面比较
- MiMo-V2-Flash-Base 在大多数基准测试中提供了有竞争力的性能,并在推理任务上持续超越同行
- 在 SWE-Bench 上,它甚至超越了参数量大得多的 Kimi-K2-Base,同时使用了不到三分之一的参数,突显了论文方法在实际代码-智能体任务上的优势
- 受限于其有限的参数量,论文观察到与更大的模型相比,MiMo-V2-Flash 表现出较低的知识能力,这反映在 SimpleQA 上
- 论文在表 6 中说明了每个模型的长上下文能力
- 对于长上下文检索,论文的模型架构从 32K 到 256K 实现了接近 \(100%\) 的成功率
- 在极端压力长上下文推理基准 GSM-Infinite 上,MiMo-V2-Flash 也显示出强大的性能,从 16K 到 128K 性能下降最小
- 相比之下,DeepSeek-V3.2-Exp 是一个稀疏注意力 LLM,在 32K 以下获得了最高分,但在 64K 和 128K 时显著下降,表明其在带噪输入的长上下文推理中存在固有劣势
- 这些结果有力地证明了论文的混合 SWA 架构、原生 32K 预训练和上下文扩展训练的有效性和可扩展性
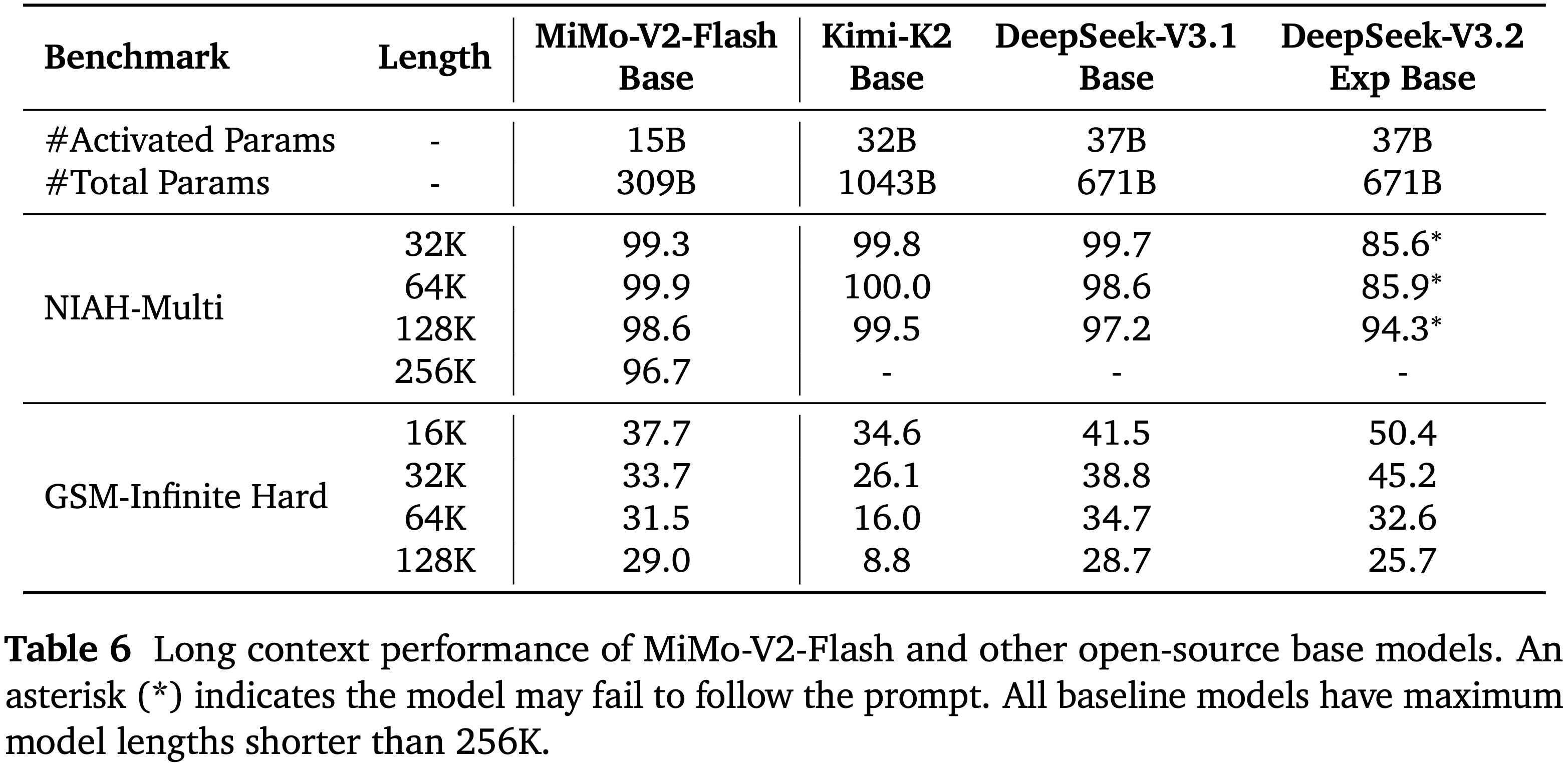
- 这些结果有力地证明了论文的混合 SWA 架构、原生 32K 预训练和上下文扩展训练的有效性和可扩展性
- 对于长上下文检索,论文的模型架构从 32K 到 256K 实现了接近 \(100%\) 的成功率
Post-Training
MOPD:多教师 On-policy 蒸馏 (Multi-Teacher On-Policy Distillation (MOPD): A New Post-Training Paradigm)
- 现代语言模型越来越依赖广泛的后训练来增强其智能和能力,当前的后训练流程面临两个根本性挑战:
- 能力不平衡 (capability imbalance) :提升某一技能会导致其他技能的退化(“跷跷板”效应);
- 学习效率低下 (learning inefficiency) : 现有方法在整合来自多个专业模型的知识时未能充分利用训练信号
- 论文提出多教师 On-policy 蒸馏 (Multi-Teacher On-Policy Distillation, MOPD),这是一个统一的后训练范式,通过一个三阶段的框架来解决这些挑战,如图 3 所示:
- Stage 1:SFT
- 论文通过在高质量指令-响应对上进行监督学习,建立基础的理解并遵循指令的能力,使模型能够理解并执行跨不同领域的用户请求
- Stage 2:Domain-Specialized Training
- 论文通过针对特定任务的独立 RL 优化来训练一系列领域专业化教师模型,这些任务包括:智能体能力(搜索、编码、通用工具使用)和非智能体任务(数学推理、通用推理、安全对齐)。每位教师通过针对其特定领域的奖励信号进行优化,在各自领域达到卓越性能
- Stage 3:Multi-Teacher On-Policy Distillation(MOPD)
- 与合并模型参数或从专家模型中生成静态离线数据集不同,论文将多教师知识集成(multi-teacher knowledge integration)制定为一个 On-policy RL 过程
- 学生模型从其自身不断演化的分布中进行采样,并通过 KL Divergence rewards (2023;2024;2025) 接收来自领域特定教师的 Token-level 监督,从而有效地结合了多种专业能力,而无需承受传统的权衡取舍(见表 7)
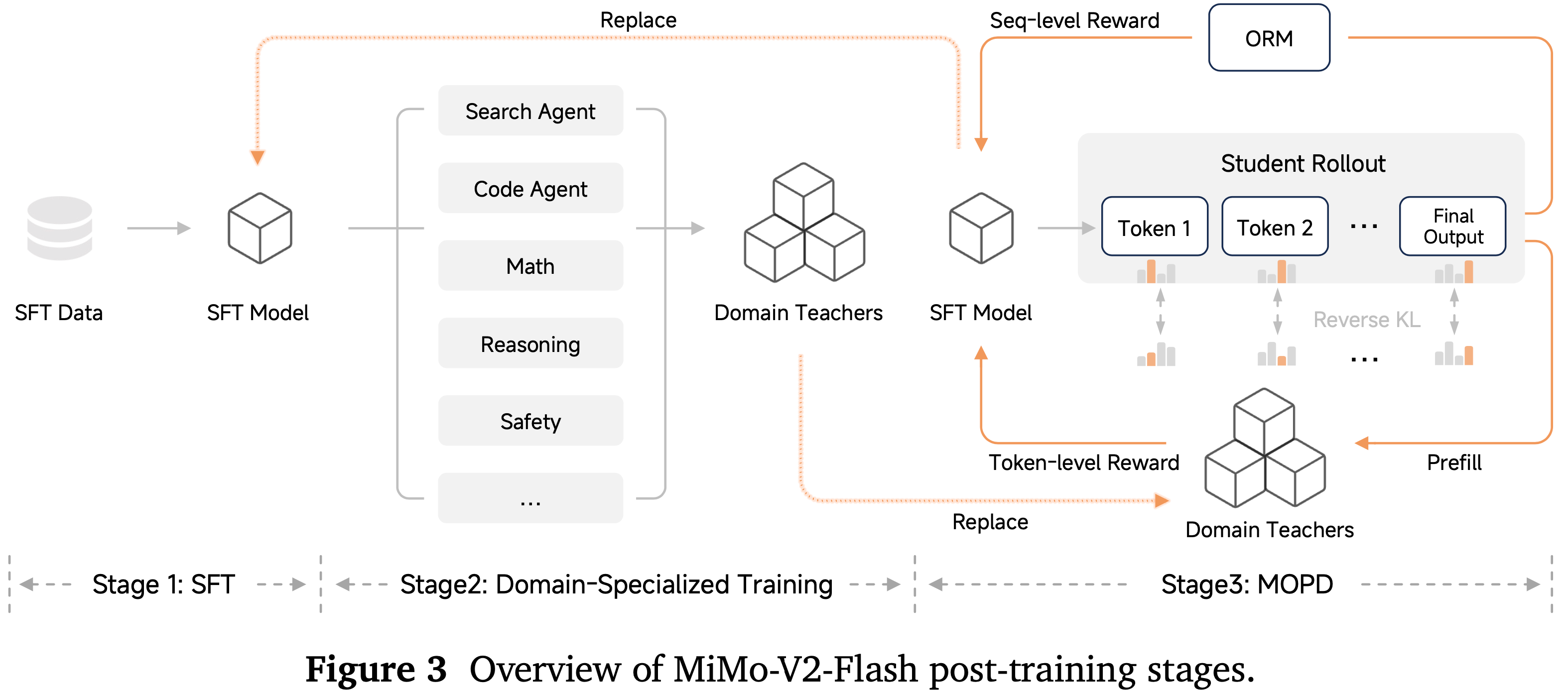
- Stage 1:SFT
- 这种统一的框架相较于传统的后训练方法具有几个关键优势:
- Effective and Efficient
- 与常常需要权衡能力取舍的参数合并(parameter merging)或顺序训练不同,MOPD 保留了最强教师在所有领域中的峰值性能(peak performance)
- 此外,利用来自教师 logits 的 Dense Token-level 奖励进行 On-policy 蒸馏,确保了稳定的信用分配(credit assignment)和快速收敛
- 通过从其自身分布中学习,学生模型避免了在基于静态数据集训练的离线方法中常见的暴露偏差(exposure bias)和分布失配(distribution mismatch)
- 模块化与可扩展性(Modular and Scalable)
- 教师模型的选择非常灵活:可以是具备强大能力的专门化 RL 衍生模型、一个不同的 SFT 模型,甚至可以是学生模型自身
- 这种解耦设计使得能够轻松集成新的教师模型,而无需重构整个流程
- 此外,该框架能与现有的结果奖励模型(Outcome Reward Models, ORMs) 无缝协作,并且对于复杂的智能体任务尤为有利,因为为这些任务搭建独立的训练流程通常非常繁琐
- 迭代协同进化(Iterative Co-Evolution)
- MOPD 天然支持师生协同进化循环
- 经过蒸馏的学生模型可以重新进入专门的 RL 阶段,以产生更强的教师模型;这些更强的教师模型反过来又能为下一代学生提供更高质量的监督,从而形成一个自我强化的改进循环,实现能力的持续扩展
- Effective and Efficient
SFT
- SFT 阶段是论文后训练流程的基础,它将基础模型转变为一个有帮助的助手,能够遵循指令并在各种任务中有效响应
- 这一阶段对于激活 模型在预训练期间获得的潜在能力,并将其输出与期望的格式和风格对齐至关重要
- 论文精心整理了数百万个涵盖广泛领域的训练样本,包括通用对话、推理、编码和智能体任务
- 这些样本覆盖了 Thinking 和 Non-thinking ,其中的回答由论文内部的领域专业化模型检查点生成
- 这种多样化的训练混合确保了模型在其预期用例中能力的全面激活
- 通过初步实验,论文为 MoE SFT 训练确定了一个关键稳定性指标:梯度为零的参数数量(number of parameters with zero gradients,num-zeros)
- 该指标为训练不稳定性提供了早期预警信号:
- num-zeros 增加 表明专家间的负载平衡正在恶化
- num-zeros 减少 则表明模型正在严重 Overfitting 训练数据
- 问题:为什么梯度为零的参数数量跟 是否过拟合有关?
- 因此,在整个训练过程中保持稳定的 num-zeros 对于成功的 SFT 至关重要
- 此外,这种稳定性对于确保后续 RL 阶段的稳健性和收敛性也至关重要
- 该指标为训练不稳定性提供了早期预警信号:
- 论文的实验表明,num-zeros 的稳定性关键取决于两个超参数:专家偏置更新率(expert bias update rate) 和 AdamW 优化器中的 \(\epsilon\) 参数
- 采用余弦衰减学习率调度器,从 \(5.0 \times 10^{-5}\) 衰减到 \(5.0 \times 10^{-6}\)
- 批次大小为 128
- AdamW 的 \(\epsilon\) 设置为 \(1.0 \times 10^{-8}\)
- MoE 专家偏置更新率设置为 \(1.0 \times 10^{-4}\)
- 序列辅助损失系数(sequence auxiliary loss coefficient)设置为 \(1.0 \times 10^{-6}\)
Scaling Reinforcement Learning
- 强化学习将模型能力提升到仅靠监督微调所无法达到的水平
- 根据任务是否涉及智能体行为,论文采用不同的 RL 策略,同时缩放非智能体和智能体 RL 训练,以最大化不同领域的性能
Non-Agentic RL Training
- 非智能体 RL 训练侧重于提升模型在单轮任务上的性能,此类任务中模型无需交互反馈或多步执行即可生成完整响应
- 其主要目标是在可验证领域(如数学、编码、逻辑)提升模型的推理准确性,同时在开放式对话中使其输出对齐于帮助性和安全性
- 论文生成奖励信号的方法因任务特征而异
- 对于有可验证结果的领域 :
- 论文采用结合程序化工具和 LLM Judge 的混合验证系统 ,以根据整理的 problem-solution pairs 自动评估正确性
- 对于主观特性,如帮助性和安全性 :
- 论文实施 基于评分细则 (rubrics) 的框架 ,由高级 LLM Judge 根据 详细的 rubrics 和参考答案 评估响应,产生细粒度的奖励信号,引导模型朝向期望的行为
- 问题:各个领域都没有使用 BT RM 吗?
- 对于有可验证结果的领域 :
Agentic RL Training
- 非智能体 RL 侧重于单轮推理和生成,而智能体 RL 则训练模型在需要规划、执行行动并根据反馈进行调整的交互式、多轮环境中运行
- 论文沿着两个关键维度来扩展智能体 RL:环境多样性和计算资源
- 扩展智能体环境多样性(Scaling Agentic Environment Diversity)
- 论文构建了一套多样化的智能体训练环境,涵盖代码调试、终端操作、Web 开发和通用工具使用,每个环境都针对不同的能力方向,同时均需满足多步推理与执行这一共同要求
Code Agent
- 论文在源自真实世界 GitHub 问题的大规模代码智能体任务上进行训练
- 模型在智能体循环中运行,读取和编辑文件、执行命令,并根据可验证的单元测试获得奖励
- 论文的关键 Insight 是: 持续扩展可用任务能推动代码智能的持续提升
- 为了在超过 10 万个代码任务上实现高效的 RL 训练,论文开发了两个基础设施组件
- 首先,论文构建了自动化环境设置流水线
- 该流水线从仓库快照中配置开发环境并将其打包成容器化镜像
- 在 8 种编程语言上达到 \(70%\) 的成功率,并由运行超过 1 万个并发 pod 的大规模 Kubernetes 集群支持
- 其次,论文实现了一个轻量级智能体 scaffold
- 可与 Kubernetes、Docker 或本地后端无缝集成,暴露了三个原子工具(bash、str_replace、finish),仅通过 shell 命令与执行后端交互
- 这种设计消除了基于服务器的工具实现,并采用最小的系统提示词,没有预定义的工作流,允许模型在训练中发现最佳实践
- 首先,论文构建了自动化环境设置流水线
Terminal Agent
- 除了 GitHub 问题,论文还利用来自 Stack Overflow 和 Stack Exchange 的任务来强化基于终端的解决问题能力
- 主要强调的是
- 论文选取需要高级技术专长的材料,并将其转化为具有相应 Query 、Dockerfile 和测试用例的计算任务
- 在验证环境安装并按难度和可靠性过滤后,论文获得了大约 3 万个带有已验证执行环境的 Query
- 基于通过率的额外过滤移除了那些正确性判断不可靠或复杂度不足以进行有效 RL 训练的任务
Web Development Agent
- 为了提升 Web 开发代码生成能力,论文构建了一个基于真实世界的合成数据集,并配有多模态验证器
- 论文收集高质量用户编写的网页,使用 Playwright 执行生成的代码以获得渲染视频,并应用多模态视觉判别器以仅保留高质量样本,其中基于视频的评估相较于静态截图减少了视觉幻觉
- 论文从整理的页面逆向工程用户 Query 作为种子提示词,合成大规模 RL 数据,涵盖与真实世界使用密切匹配的八个 Web 类别
- 论文的基于视觉的验证器根据录制的视频对 rollout 执行进行评分,联合评估视觉质量、功能正确性和可执行性,确保奖励反映外观和行为
General Agent
- 论文开发了两种通用智能体能力
- 搜索智能体(Search Agent):
- 采用一个提供三个核心工具(search、open、find)的脚手架,用于自主网页探索
- 论文通过从种子实体递归扩展事实图来构建 Query ,其中难度随关系链深度和细节混淆而增加,从而实现具有可验证答案的具有挑战性的搜索问题的自动生成
- 函数调用智能体(Function-Calling Agent)
- 在具有自定义工具集的合成应用环境中训练,这些工具集通过基于显式数据依赖(直接的输入-输出关系)和隐式逻辑依赖(关于隐藏系统状态的推理)生成工具调用图来构建,要求具备数据传播和状态推断能力
Scaling Agentic Compute
- 在之前多样化的智能体环境集上训练(表 8),论文发现扩展智能体 RL 计算不仅能提升代码智能体性能,还能有效地泛化到其他任务类型
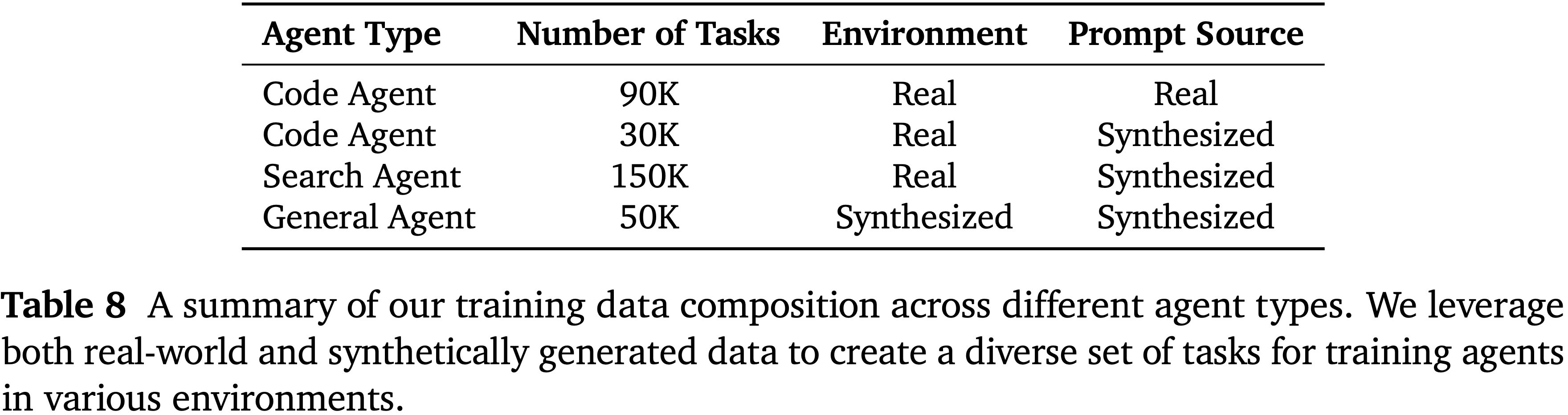
- 图 4 显示了论文代码智能体的 RL 训练曲线,模型在大约 12 万个环境中执行了 On-policy rollouts 和更新
- 这种扩展显著提升了 SFT 基础模型在 SWE-Bench-Verified 和 SWE-Bench-Multilingual 上的性能
- 这种扩展显著提升了 SFT 基础模型在 SWE-Bench-Verified 和 SWE-Bench-Multilingual 上的性能
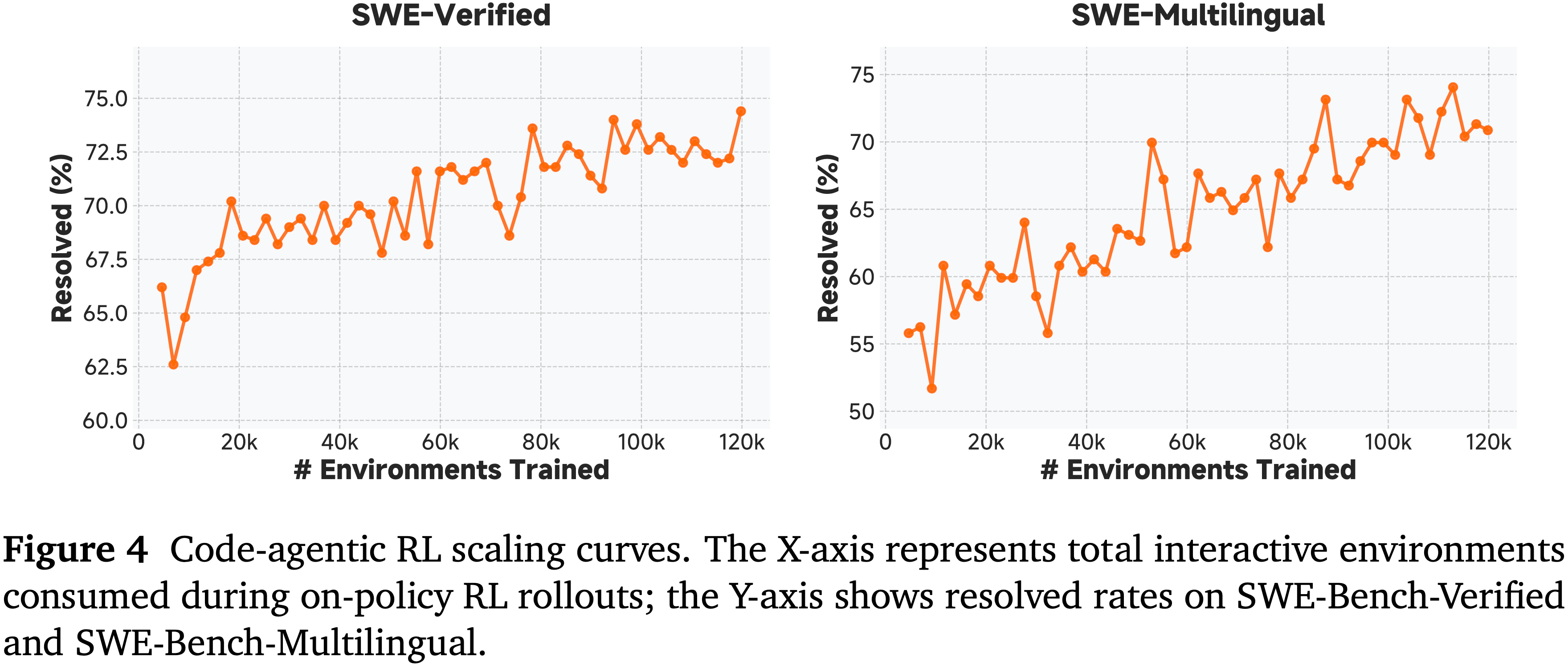
- 图 5 表明,大规模的代码智能体 RL 训练能有效地泛化到其他智能体任务,以及数学、代码和通用推理基准测试,这表明智能体训练培养了广泛可迁移的问题解决能力
Technical Formulation of MOPD
- 通过 SFT 奠定基础并训练了领域专业化教师后,论文现在将整合这些专业化能力到统一学生模型的多教师 On-policy 蒸馏机制形式化
- 具体地,论文将多教师蒸馏视为一个 On-policy 强化学习目标
- 令 \(\pi_{\theta}\) 表示训练引擎中优化的目标学生策略,\(\mu_{\theta}\) 表示推理引擎中采用的学生采样策略,\(\pi_{\mathrm{domain}_x}\) 表示从分布 \(\mathcal{D}\) 中采样的提示词 \(x\) 所在领域的专业化教师策略
- 理解:每个 Prompt 都有自己所对一个的 教师模型,每个 Prompt 对应仅使用自身的 Teacher,单个 Prompt 不涉及到多个 Teacher 的 融合
- 令 \(\mathrm{sg}[\cdot ]\) 表示停止梯度算子
- 学生与教师之间的反向 KL 散度损失(Reverse KL Divergence Loss)定义为:
$$\mathcal{L}_{\mathrm{reverse - KL} }(\theta) = -\mathbb{E}_{x\sim \mathcal{D},y_{t}\sim \pi_{\theta}(\cdot |x,y_{< t})}\log \frac{\pi_{\mathrm{domain}_x}(y_t|x,y_{< t})}{\pi_{\theta}(y_t|x,y_{< t})}. \tag{5}$$ - 注:这个式子看起来不像是 KL 散度,因为采样分布和分子分布不同,实际上经过转换后,即消除负号后,本身就是 Reverse-KL 散度,详情见附录 和 博客 On-Policy Distillation, Thinking Machines Lab, 20251027
- 其梯度为:
$$\nabla_{\theta}\mathcal{L}_{\mathrm{reverse - KL} }(\theta) = -\mathbb{E}_{x\sim \mathcal{D},y_{t}\sim \pi_{\theta}(\cdot |x,y_{< t})}\left[\log \frac{\pi_{\mathrm{domain}_x}(y_t|x,y_{< t})}{\pi_{\theta}(y_t|x,y_{< t})}\nabla_{\theta}\log \pi_{\theta}(y_t|x,y_{< t})\right]. \tag{6}$$ - 遵循 Zhao 等人的工作 (2025),论文应用训练-推理重要性采样,并舍弃表现出大差异的 Token,然后论文定义 MOPD 的替代损失为:
$$\mathcal{L}_{\mathrm{MOPD} }(\theta) = -\mathbb{E}_{x\sim \mathcal{D},y\sim \mu_{\theta}(\cdot |x)}\left[\frac{1}{|y|}\sum_{t = 1}^{|y|}w_{t}\hat{A}_{\mathrm{MOPD},t}\log \pi_{\theta}(y_t|x,y_{< t})\right], \tag{7}$$ - 其中
$$w_{t}(\theta) = \left\{ \begin{array}{ll}\mathrm{sg}\left[\frac{\pi_{\theta}(y_{t}|x,y_{< t})}{\mu_{\theta}(y_{t}|x,y_{< t})}\right], & \epsilon_{\mathrm{low} }\leq \frac{\pi_{\theta}(y_{t}|x,y_{< t})}{\mu_{\theta}(y_{t}|x,y_{< t})}\leq \epsilon_{\mathrm{high} },\\ 0, & \mathrm{otherwise}, \end{array} \right.\quad \hat{A}_{\mathrm{MOPD},t} = \mathrm{sg}\left[\log \frac{\pi_{\mathrm{domain}_x}(y_t|x,y_{< t})}{\pi_{\theta}(y_t|x,y_{< t})}\right]. \tag{8}$$- 其中 \(w_{t}(\theta)\) 是训推重要性采样
- 注意:这里的 Advantage 看似和 ThinkingMachines 提出的 OPD 实现是反的,实际上是一样的,因为 OPD 是先是先计算 Reverse-KL 散度的公式,然后再加个 负号的,这里相当于没有这个负号了
- 理解:最终含义:最大化 Advantage,等于最小化 Reverse-KL 散度
- 默认情况下,论文将 MOPD 的优势与其他类型的优势相结合,例如使用结果奖励模型 (Outcome Reward Models, ORMs) 计算的优势,包括 GRPO (2024)
- 令 \(\hat{A}_{\mathrm{ORM} }\) 表示由 ORMs 计算的优势;最终优势由下式给出:
$$\hat{A}_{\mathrm{MOPD},t} = \mathrm{sg}\left[\log \frac{\pi_{\mathrm{domain}_x}(y_t|x,y_{< t})}{\pi_{\theta}(y_t|x,y_{< t})}\right] + \alpha \hat{A}_{\mathrm{ORM} }. \tag{9}$$ - 图 6 展示了 MOPD 相较于传统后训练方法的有效性
- 在数学推理 (AIME 2025) 和编码 (LiveCodeBench) 基准测试上,MOPD 成功保留并整合了来自多位教师的专业化能力,在大多数领域达到或超过了最强教师的性能
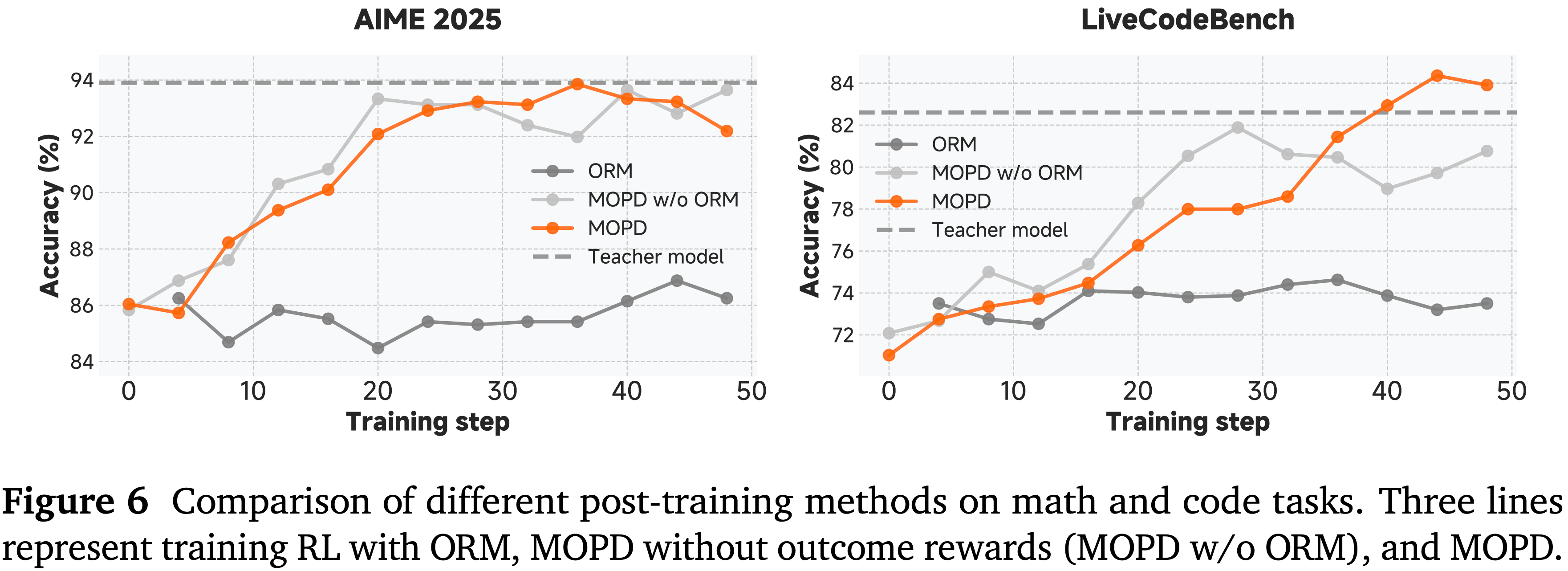
- 在数学推理 (AIME 2025) 和编码 (LiveCodeBench) 基准测试上,MOPD 成功保留并整合了来自多位教师的专业化能力,在大多数领域达到或超过了最强教师的性能
Evaluations
Evaluation Setup
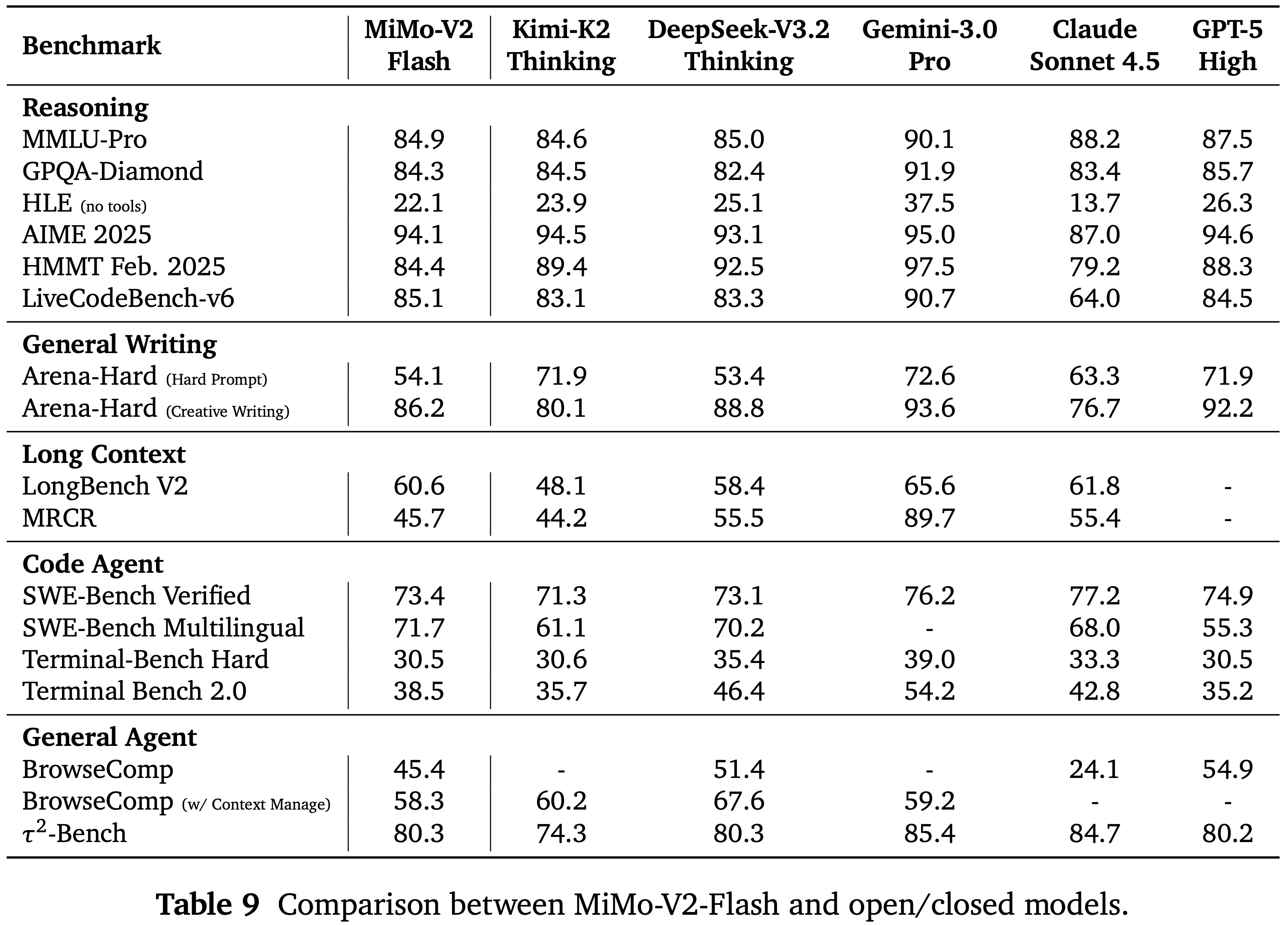
- 论文在 MMLU-Pro (2024)、GPQA-Diamond (2024)、HLE Text-only (2025)、AIME 2025 (MAA, 2024)、LiveCodeBench (2024.08-2025.04) (2024)、HMMT Feb. 2025 (Balunović2025)、Arena-Hard (2024)、LongBench V2 (2025)、MRCR (2024)({2,4,8}-needles,最大 128K)、SWE-Bench Verified (2024b)、SWE-Bench Multilingual (2025)、Terminal-Bench、BrowseComp (2025)、\(\tau^2\)-Bench (2025) 上评估 MiMo-V2-Flash
Evaluation Results
- 论文在表 9 中展示了评估结果
- MiMo-V2-Flash 在大多数推理基准测试上达到了与 Kimi-K2-Thinking 和 DeepSeek-V3.2-Thinking 相当的性能
- MiMo-V2-Flash 模型还保持了有竞争力的通用写作能力,使其能够在开放式任务上生成高质量响应
- 在长上下文评估中,论文的模型超越了规模大得多的全全局注意力 LLM Kimi-K2-Thinking,突显了论文混合 SWA 架构强大的长上下文能力
- MiMo-V2-Flash 在 SWE-Bench Verified 上达到了 \(73.4%\),超越了所有开源竞争对手,并接近 GPT-5-High 的性能
- 在 SWE-Bench Multilingual 上,论文的模型解决了 \(71.7%\) 的问题,确立了其作为软件工程任务中最强大的开源 LLM 的地位
- 这些结果强调了论文超大规模智能体 RL 训练的有效性
- 在 Terminal Bench 上,该模型也取得了有竞争力的分数
- 在搜索智能体评估中,MiMo-V2-Flash 在 BrowseComp 上得分为 45.4,应用附录 C 概述的上下文管理方法后进一步提升至 58.3
- 对于在 \(\tau^2\)-Bench 上的通用工具使用,论文使用 DeepSeek-V3.2 作为用户代理,获得了 95.3(电信)、79.5(零售)、66.0(航空)的类别分数
- 对于在 \(\tau^2\)-Bench 上的通用工具使用,论文使用 DeepSeek-V3.2 作为用户代理,获得了 95.3(电信)、79.5(零售)、66.0(航空)的类别分数
- 综上所述,这些结果验证了论文在 MOPD 后训练范式内超大规模 RL 训练的有效性,并突出了该模型在现实世界编码、推理和智能体工作流中的强大潜力
RL Infrastructures
- 论文的 RL(和 MOPD)基础设施使用 SGLang (2024) 作为推理引擎,使用 Megatron-LM (2019) 作为训练引擎
- 论文采用 FP8 进行训练和推理
- 为了实现稳定、高效且灵活的 RL 训练,论文实现了三个扩展模块:
- Rollout Routing Replay (R3) (2025)(第 4.6.1 节)、数据调度器 (Data Scheduler)(第 4.6.2 节)以及与 Toolbox 结合的 Tool Manager(第 4.6.3 节)
通过 Rollout Routing Replay (R3) 稳定训练 (Stablized Training via Rollout Routing Replay (R3))
- MoE 模型由于数值精度问题 (2025; 2025),在 rollout 和训练过程中会出现专家路由不一致的问题
- 论文提出 Rollout Routing Replay (R3) (2025) 来使用与 rollout 相同的路由专家进行 RL 训练,通过优化的数据类型和通信重叠使其开销可忽略不计
- 对于多轮智能体训练,论文在 rollout 期间采用请求级别的前缀缓存
- 此缓存存储先前轮次的 KVCache 和 MoE 路由专家,允许它们在同一请求的后续生成步骤中重复使用
- 与当前推理引擎中常用的基数缓存 (radix cache) 不同,论文的请求级别前缀缓存避免了重新预填充或请求间输出缓存共享 ,确保了路由专家的采样一致性
Data Scheduler
- 对于 MiMo-V2-Flash,论文扩展了 Seamless Rollout Engine (2025) 并实现了一个数据调度器 (Data Scheduler),以无缝调度细粒度的序列而非微批次,解决分布式 MoE 训练中的 GPU 闲置问题
- 在动态采样中,当序列返回进行奖励计算时,论文参考历史通过率,并在必要时将新的提示词分配给 GPU 以实现负载均衡
- 论文整合部分 rollout (partial rollout) (2025; Kimi Team, 2025b) 将过长的轨迹跨步骤分区,同时限制陈旧性以及每个批次中部分样本的比例
- 通过对部分 rollout 采用陈旧性感知的截断重要性采样,论文在不牺牲模型质量的前提下显著加速了 RL 训练
- 数据调度器支持特定数据源的配置(采样配额、调度优先级、长度限制、温度)并根据配置的比例拟合通过率来接受样本
- 基于优先级的调度在不同时间模式的数据源之间重叠奖励计算和推理,确保了高 GPU 利用率
Toolbox and Tool Manager
- 论文实现了 Toolbox 和 Tool Manager 来解决 RL 智能体训练中的全局资源争用和局部低效问题
- 这些模块利用 Ray (2018) 进行高效调度
- Toolbox 作为集中式资源分配器,对跨并发任务的工具强制执行资源配额和 QPS 限制
- 它采用容错的 Ray Actor 池,消除了冷启动延迟
- 与 rollout 引擎集成后,Tool Manager 与 Toolbox 协调,通过环境预预热和序列级异步奖励计算来加速训练
- 它通过超时恢复和实时监控来保持训练稳定性
- 通过将工具管理和 rollout 工作流解耦,Toolbox 将特定于任务的逻辑与系统范围策略隔离开来,实现了模块化可扩展性而不损害稳定性
MTP Speedup
MTP Acceptance Length
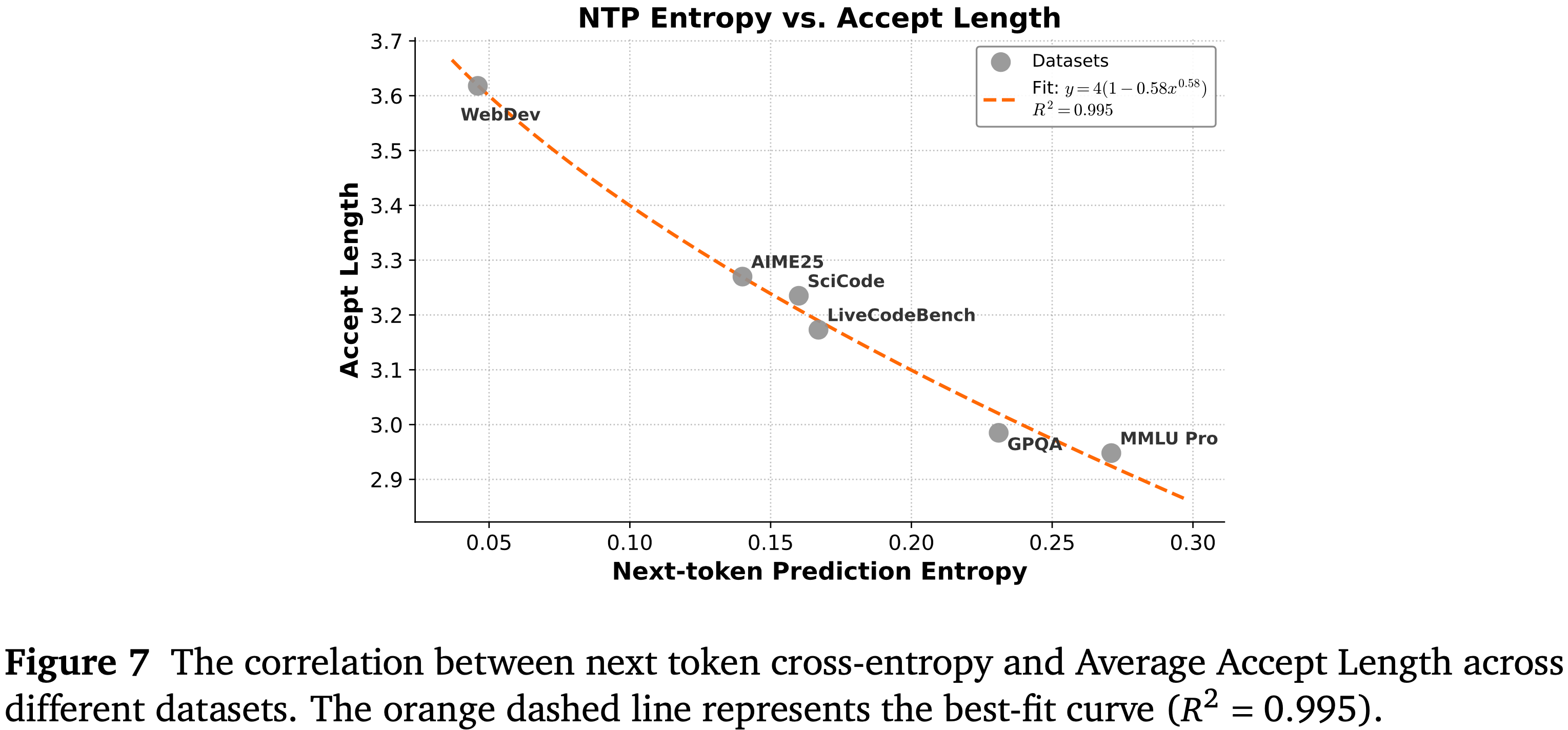
- 论文分析了模型通过下一 Token 交叉熵 (cross-entropy) 衡量的预测不确定性与多 Token 预测 (MTP) 模块效率之间的关系
- 如图 7 所示,论文在涵盖代码生成 (例如 WebDev, LiveCodeBench) 到复杂推理任务 (例如 AIME25, MMLU Pro) 的多样化基准测试中,评估了使用 3 层 MTP 时的平均接受长度
- 结果显示出强烈的负相关性:熵值较低的上下文 (如 WebDev) 允许显著更长的接受序列,达到约 3.6 个 Token
- 相反,内在不确定性较高的任务 (例如 MMLU Pro) 由于预测分歧增加,表现出较短的接受长度
- 这种行为可以通过一个对数变换拟合曲线 \((y = 4(1 - 0.58x^{0.58}))\) 精确建模,其 \(R^2\) 为 0.995,这表明下一 Token 交叉熵是 MTP 吞吐量的主要决定因素
MTP Inference Speedup
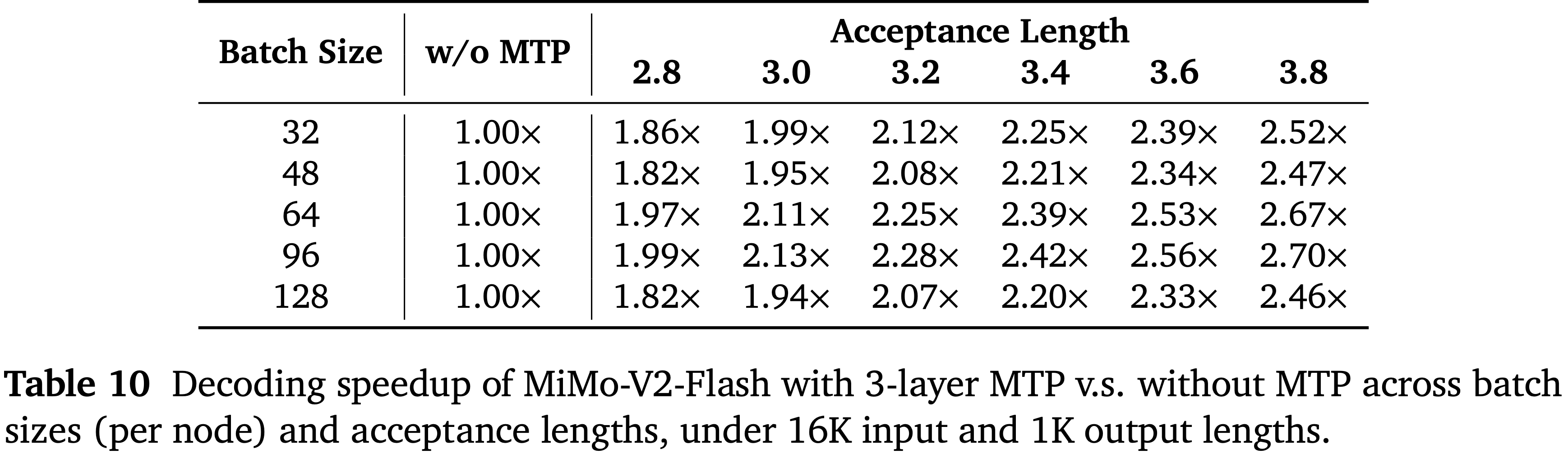
- 论文测量了 MiMo-V2-Flash 在使用 3 层 MTP 时,在不同批次大小 (每节点) 和接受长度下的解码加速情况,输入长度为 16K,输出长度为 1K
- 表 10 中的结果表明,在无需额外硬件成本的情况下,MTP 始终优于不使用 MTP 的基线
- 加速比随接受长度线性缩放
- 在不同的批次大小下,MTP 表现出不同的加速效果,这取决于相应的计算和 I/O 需求以及内核效率
- 在实践中,研究人员和工程师应根据硬件屋顶线模型 (hardware roofline models) 来调整批次大小和 MTP 层数,以优化速度-成本权衡
Limitation, and Future Work
- 与最强大的闭源权重模型相比,仍存在明显差距,论文计划通过扩大模型规模和训练计算量来缩小这一差距
- 论文目前的架构探索仍然是初步的,对设计权衡的分析有限
- 未来的工作将侧重于设计更鲁棒、更高效、面向智能体的模型架构
- 论文计划扩展 MOPD 中教师与学生迭代协同进化所需的计算量,以充分释放其潜力
附录 B:Reward Hacking 与 SWE-Bench**
- 与 SWE-Bench 社区近期的发现一致,论文同样识别出了官方 SWE-Bench 镜像中的一个漏洞:未正确删除用于验证的 ground truth 提交记录
- 在 RL 训练期间,这可能导致 Reward Hacking 和评估分数虚高,模型倾向于通过窥探未来提交记录(peeking at future commits) 来获得奖励,如图 8 所示
- 为解决此问题,论文在评估中已更新至最新的 SWE-Bench 镜像
- 对于论文自行构建的训练镜像,论文也遵循了官方 SWE-Bench 关于 git 黑客攻击的解决方案,并反复确认论文的模型未表现出任何奖励黑客攻击行为
- 图 8 论文的 Qwen3-32B 实验在未经处理的镜像中进行 RL 训练时表现出的奖励黑客攻击倾向
- 论文通过统计模型 rollout 轨迹中一组关键词(如 “git log –all”)的数量来量化模型的 git 黑客攻击尝试
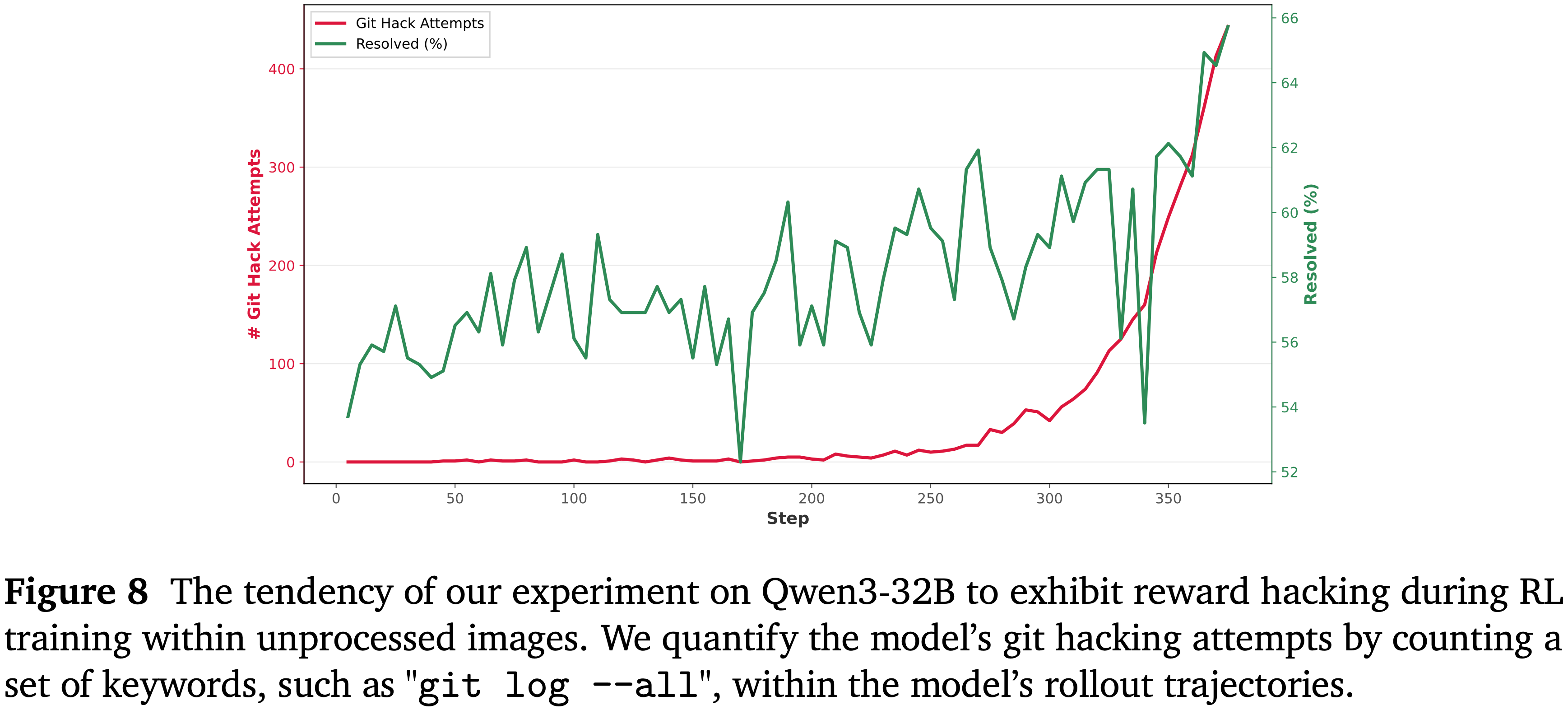
- 论文通过统计模型 rollout 轨迹中一组关键词(如 “git log –all”)的数量来量化模型的 git 黑客攻击尝试
附录 C:Context Management
- 虽然 Fine-tuning 和 RL 优化的是模型参数 \(\theta\),但上下文管理(Context Management)则是策略性地优化条件上下文 \(C\)(conditioning context),即影响 \(P(y \mid C, \theta)\)
- 论文的方法旨在解决两个互补的挑战
- 对于上下文增强(Context Augmentation)
- 论文采用了类 Unix 的抽象方法:工具(tools)、文档(documents)和数据库(databases)被统一视作文件(files)来暴露,使得模型能够利用其天然的代码生成能力,通过 Bash 命令来检索信息
- 对于上下文整合(Context Consolidation)
- 论文通过强制实施激进的内存压缩(aggressive memory compression)来对抗迷失在中间(”Lost in the Middle”) 现象
- 当上下文使用率超过一个阈值(可低至 30%)时,系统会提示模型进行总结(summarize),将完整的历史记录存档至一个可检索的记忆文件(retrievable memory file)中,并用摘要替换活跃上下文
- 对于上下文增强(Context Augmentation)
- Empirically,这在 Deep Research tasks 上能带来 5-10% 的准确率提升
- 论文的结果与 DeepSeek V3 的发现一致:
- 丢弃工具调用历史(discarding tool-call history)优于保留策略;
- 通过复现其激进的重置协议(aggressive reset protocol),论文在可比的基准测试中取得了 58.3 分
- 核心见解反直觉但有力:更少但策略性管理(strategically managed)的上下文,能产生更专注和更准确的生成结果
附录:MOPD 的详细理解
- 本报告中提出的 Multi-Teacher On-Policy Distillation(MOPD) 是一种新颖的后训练范式,旨在解决传统后训练中存在的“能力不平衡”和“学习效率低”问题
- 核心思想是通过多教师、基于当前策略的蒸馏 ,将不同领域的专家知识高效地集成到一个统一的学生模型中
MOPD 的核心思想与流程回顾
- MOPD 分为三个阶段:
- 阶段1:Supervised Fine-Tuning (SFT) :在高质量指令-响应对上进行监督微调,建立基础指令遵循能力
- 阶段2:Domain-Specialized Training :通过强化学习训练多个领域专家教师模型,如代码生成、数学推理、工具使用等
- 阶段3:Multi-Teacher On-Policy Distillation :学生模型基于自身当前策略进行采样,同时接收来自多个教师的 token 级别监督信号,进行策略优化
MOPD 的数学建模
- 基本符号定义:
- \( \pi_\theta \):学生模型的策略(训练引擎中优化)
- \( \mu_\theta \):学生模型的采样策略(推断引擎中使用)
- \( \pi_{\text{domain}_x} \):针对输入 \( x \) 对应领域的教师策略
- \( \mathcal{D} \):训练数据分布
- \( \text{sg}[\cdot] \):停止梯度操作(stop-gradient)
Reverse-KL Divergence Loss
- MOPD 使用 反向 KL 散度 作为教师对学生模型的监督信号:
$$
\mathcal{L}_{\text{reverse-KL} }(\theta) = -\mathbb{E}_{x \sim \mathcal{D}, y_t \sim \pi_\theta(\cdot|x, y_{ < t})} \log \frac{\pi_{\text{domain}_x}(y_t | x, y_{ < t})}{\pi_\theta(y_t | x, y_{ < t})}
$$- 注意:反向 KL 散度的详细介绍见后文
- 其梯度为:
$$
\nabla_\theta \mathcal{L}_{\text{reverse-KL} }(\theta) = -\mathbb{E}_{x \sim \mathcal{D}, y_t \sim \pi_\theta(\cdot|x, y_{ < t})} \left[ \log \frac{\pi_{\text{domain}_x}(y_t | x, y_{ < t})}{\pi_\theta(y_t | x, y_{ < t})} \cdot \nabla_\theta \log \pi_\theta(y_t | x, y_{ < t}) \right]
$$
训练-推理重要性采样与截断(解决训练-推理不一致问题)
- 为了稳定训练,引入重要性权重 \( w_t(\theta) \) 来筛选高置信度 token:
$$
w_t(\theta) =
\begin{cases}
\text{sg}\left[ \frac{\pi_\theta(y_t | x, y_{ < t})}{\mu_\theta(y_t | x, y_{ < t})} \right], & \epsilon_{\text{low} } \leq \frac{\pi_\theta(y_t | x, y_{ < t})}{\mu_\theta(y_t | x, y_{ < t})} \leq \epsilon_{\text{high} } \\
0, & \text{otherwise}
\end{cases}
$$
MOPD 优势函数定义
- MOPD 的优势函数由教师策略的对数似然比构成:
$$
\hat{A}_{\text{MOPD},t} = \text{sg}\left[ \log \frac{\pi_{\text{domain}_x}(y_t | x, y_{ < t})}{\pi_\theta(y_t | x, y_{ < t})} \right]
$$
MOPD 最终损失函数
- MOPD 的代理损失函数为:
$$
\mathcal{L}_{\text{MOPD} }(\theta) = -\mathbb{E}_{x \sim \mathcal{D}, y \sim \mu_\theta(\cdot|x)} \left[ \frac{1}{|y|} \sum_{t=1}^{|y|} w_t(\theta) \cdot \hat{A}_{\text{MOPD},t} \cdot \log \pi_\theta(y_t | x, y_{ < t}) \right]
$$
结合其他奖励信号(实际应用中的 MOPD)
- MOPD 可以与基于结果的奖励模型(如 GRPO)结合,形成混合优势函数:
$$
\hat{A}_{\text{final},t} = \hat{A}_{\text{MOPD},t} + \alpha \cdot \hat{A}_{\text{ORM} }
$$- 其中 \( \hat{A}_{\text{ORM} } \) 是由结果奖励模型计算的优势
MOPD 的核心逻辑与优势
- 逻辑流程总结:
- 1)采样阶段 :学生模型使用当前策略 \( \mu_\theta \) 生成响应序列
- 2)教师监督 :每个 token 对应领域的教师模型给出 token 级别概率分布
- 3)优势计算 :计算教师与学生策略的对数似然比作为优势信号
- 4)策略更新 :使用带重要性采样的策略梯度更新学生模型参数
- 关键优势总结:
- Token 级别监督 :教师提供密集的 token 级别反馈,而非仅序列级别奖励
- 多教师集成 :不同领域的教师并行监督,避免能力退化(跷跷板效应)
- On-Policy 学习 :学生基于自身当前策略采样,避免离线数据分布不匹配
- 可扩展性 :可与 ORM、GRPO 等外部奖励模型结合,形成混合训练目标
附录:Reverse KL Divergence vs Forward KL Divergence
两种 KL 散度的定义
- KL 散度(Kullback–Leibler Divergence)衡量两个概率分布 \( P \) 和 \( Q \) 之间的差异(非对称):
Forward KL
- Forward KL 从 真实分布 \(P\) 中采样,惩罚 \(Q\) 给 \(P\) 的高概率事件分配低概率(即“覆盖模式(Mode-covering)”)
$$
D_{KL}(P | Q) = \mathbb{E}_{x \sim P} \left[ \log \frac{P(x)}{Q(x)} \right]
$$
Reverse KL
- Reverse KL 从 近似分布 \(Q\) 中采样,惩罚 \(Q\) 给自身的样本分配高概率,而 \(P\) 却认为这些样本概率很低(即“避免零概率陷阱”或“模式寻求”)
$$
D_{KL}(Q | P) = \mathbb{E}_{x \sim Q} \left[ \log \frac{Q(x)}{P(x)} \right]
$$
两者的区别
- 假设真实分布 \(P\) 是一个双峰分布(两个分离的高峰),而论文的模型分布 \(Q\) 是一个单峰分布(如高斯分布)
- 最小化前向 KL 散度 \(D_{KL}(P | Q)\)
- 优化目标是让 \(Q\) 覆盖 \(P\) 的所有高概率区域
- \(Q\) 会尝试覆盖两个峰,变成一个宽而平的分布 ,覆盖两个模式,但无法精确匹配任何一个(均值覆盖,模糊拟合)
- 核心是 避免遗漏(avoid missing modes)
- 最小化反向 KL 散度 \(D_{KL}(Q | P)\)
- 优化目标是让 \(Q\) 只放在 \(P\) 的某一个高概率区域 ,并尽量让 \(Q\) 自身的概率集中
- \(Q\) 会选择其中一个峰 ,并紧密拟合它,完全忽略另一个峰(模式寻求(Mode-seeking),尖锐拟合)
- 核心 避免生成低概率样本(avoid generating low-probability samples)
在策略蒸馏中的具体含义
- 在 MOPD 中:
- \(P\) = 教师策略 \(\pi_{\text{teacher} }\)
- \(Q\) = 学生策略 \(\pi_{\theta}\)
如果在 MOPD 中使用前向 KL 散度(教师采样):
- 损失函数为:
$$
\mathcal{L}_{\text{forward-KL} } = \mathbb{E}_{x \sim \text{data}, y_t \sim \pi_{\text{teacher} } } \left[ \log \frac{\pi_{\text{teacher} }(y_t)}{\pi_{\theta}(y_t)} \right]
$$- 教师策略生成样本
- 学生被要求匹配教师实际生成的所有行为
- 教师可能有多种正确方式(多峰),学生被迫学习所有方式,可能导致 平均化、保守的输出
- 注意:从另一个角度讲,教师策略来生成样本就不应该叫做 On-policy 了
在 MOPD 中使用反向 KL 散度(学生采样):
- 损失函数为:
$$
\mathcal{L}_{\text{reverse-KL} } = \mathbb{E}_{x \sim \text{data}, y_t \sim \pi_{\theta} } \left[ \log \frac{\pi_{\theta}(y_t)}{\pi_{\text{teacher} }(y_t)} \right]
$$- 学生自己采样 ,检查教师对这些样本的评价
- 如果学生生成了一个教师认为很差的 token(\(\pi_{\text{teacher} }\) 很小),则受到强烈惩罚
- 如果学生生成了一个教师认可的 token,则鼓励学生 保持自信(增加该 token 的概率)
- 结果:学生学会避免生成教师不认可的 token ,并在教师认可的路径上强化自身策略
MOPD 选择反向 KL 的优势
- 模式寻求(Mode-seeking)而非模式覆盖(Mode-covering) :
- 在多个教师场景下,每个教师可能代表一种“正确风格”
- 反向 KL 让学生 专注于学习某一个教师的风格(选择一个模式深入学习),而不是在所有教师风格间取平均
- 问题:这个理解有时候也觉得不太对,因为如果每个教师对应一个峰值,那其实使用前向 KL 拟合多峰才是应该的?
- 回答:同一个样本只对应一个领域教师模型,每个教师是单独教授模型的,对于任意的 Query,学习的并不是多个教师的峰,本质还是在学习(固定 Query 下)某个教师的风格
- 这有助于形成 更确定、更一致 的生成行为
- 与 On-Policy RL 自然结合 :
- RL 中的策略梯度是
$$ \mathbb{E}_{y \sim \pi_{\theta} } [\text{reward} \cdot \nabla \log \pi_{\theta}]$$ - 反向 KL 的梯度形式与其完全一致:
$$ \mathbb{E}_{y \sim \pi_{\theta} } [\log(\frac{\pi_{\text{teacher} }}{\pi_{\theta}}) \cdot \nabla \log \pi_{\theta}]$$- 注意这里的采样策略是学生模型,不是教师模型,若是教师模型,这里是不可以的
- 这使得蒸馏信号可以直接作为 优势函数(advantage) 融入 RL 更新
- RL 中的策略梯度是
- 避免教师次优行为 :
- 教师策略可能有不完美的行为(噪声、次优选择)
- 即使教师偶尔生成了教师的低概率行为,反向 KL 也能让学生 避开 教师得这些低概率的行为(前向 KL 可能会让学生模仿这些次优行为)
- 稳定训练 :
- 反向 KL 鼓励学生分布 \(Q\) 避免探索教师分布的低概率区域,这在训练早期尤其稳定
MOPD 公式的微妙之处
- 注意 MiMo-V2-Flash 技术报告的公式 (5) 中的符号:
$$\mathcal{L}_{\mathrm{reverse - KL} }(\theta) = -\mathbb{E}_{x\sim \mathcal{D},y_{t}\sim \pi_{\theta}(\cdot |x,y_{< t})}\log \frac{\pi_{\mathrm{domain}_x}(y_t|x,y_{< t})}{\pi_{\theta}(y_t|x,y_{< t})}. \tag{5}$$- 这个式子看起来不像是 KL 散度,因为采样分布和分子分布不同,实际上经过转换(消除负号后)本身就是 Reverse-KL 散度
- 这实际上是 最大化教师对学生似然比的对数期望 ,等价于最小化:
$$\mathcal{L}_{\mathrm{reverse - KL} }(\theta) = \mathbb{E}_{x\sim \mathcal{D},y_{t}\sim \pi_{\theta}(\cdot |x,y_{< t})}\log \frac{\pi_{\theta}(y_t|x,y_{< t})}{\pi_{\mathrm{domain}_x}(y_t|x,y_{< t})} $$- 这就是 Reverse-KL 散度的表达是,OPD 的训练目标就是最小化这个 Reverse-KL 散度,最小化这个 KL 散度就是让两个分布足够接近
- 所以优化方向是让 \(\pi_{\theta}\) 在自身样本上得到教师的认可
- MOPD 使用反向KL,是因为它本质上是一个 “基于当前策略的强化学习” 过程:
- 学生作为 actor 生成行为(token)
- 教师作为 critic 给出每个 token 的“优势值”(\(\log \frac{\pi_{\text{teacher} } }{\pi_{\theta} }\))
- 学生更新策略以增加高优势 token 的概率,减少低优势 token 的概率