注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:(MAI-Thinking-1 Technical Report)MAI-Thinking-1: Building a Hill-Climbing Machine, 20260602
- 名称理解:微软 AI,Microsoft AI,MAI
- 原始论文:(MAI-Thinking-1 Technical Report)MAI-Thinking-1: Building a Hill-Climbing Machine, 20260602
Paper Summary
- 技术报告核心内容:
- 评价:本技术报告可读性极高,因为包含非常详细的流程
- 训练过程:Based on the technical report, the training process for MAI-Thinking-1 is: Pre-training → Mid-training (context extension) → RL (STEM, Agentic, and Helpfulness/Safety climbs) → Consolidation SFT → Consolidation RL
- 后训练说明:
- 三个专家模型独立训练完成后,再通过 SFT 蒸馏合并(consolidation SFT) 和 轻量级 consolidation RL 整合成最终的 MAI-Thinking-1 模型,详情见图 12
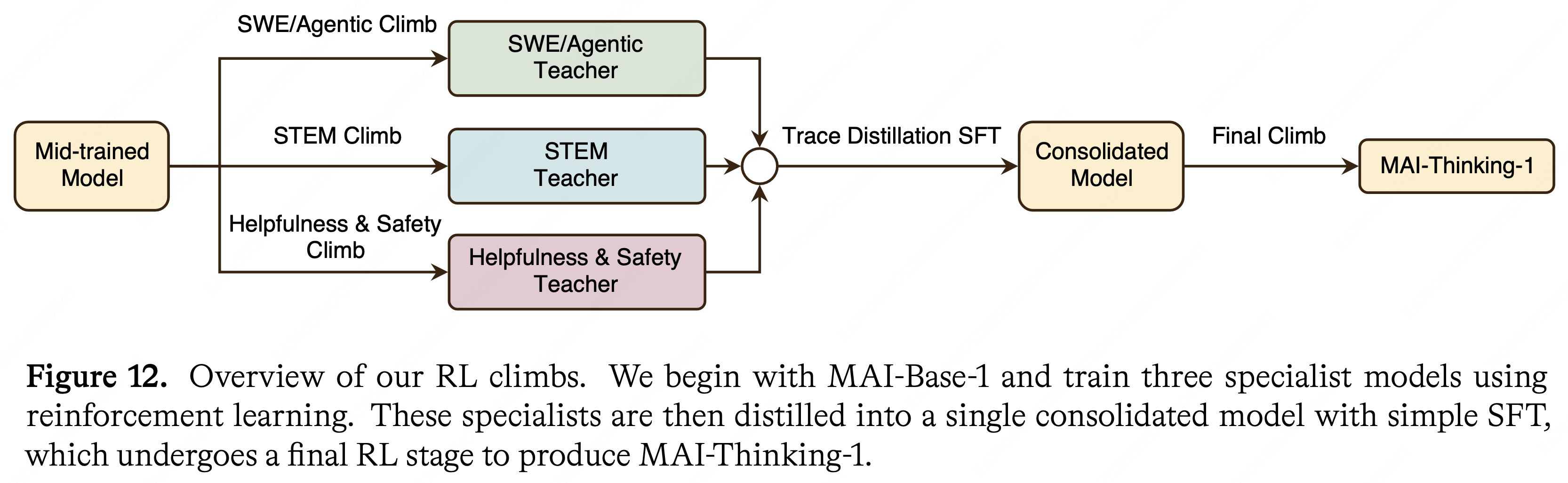
- 三个专家模型独立训练完成后,再通过 SFT 蒸馏合并(consolidation SFT) 和 轻量级 consolidation RL 整合成最终的 MAI-Thinking-1 模型,详情见图 12
- 后训练说明:
- 本文作者认为,AI 进步的核心是持续改进模型的状态,本将模型开发当做一个系统级的优化问题
- 这个优化问题的解决方案称是:构建一个能够快速改进的爬山机器 (hill-climbing machine)
- 本文流程包括:
- 一个面向预训练建模决策、以扩展为中心的框架
- 一个能够支持长期、对数线性性能提升的稳健 RL 流程和使用指南
- 本流程开发的第一个模型是 MAI-Thinking-1(1T-A35B)
- 核心特点:在 STEM 推理和编码任务上,它在相似规模的模型中表现突出
- MAI-Thinking-1 是从头开始训练的,完全使用干净的企业级数据,没有通过蒸馏从第三方模型获取能力
Introduction and Discussion
- Pre-training 专注于一个简单的扩展方法,该方法强调对架构和数据进行经验驱动的迭代改进
- RL 框架针对在数千步中持续的对数线性增长进行了优化(图 1:MAI-Thinking-1 在 RL 过程中的性能表现)
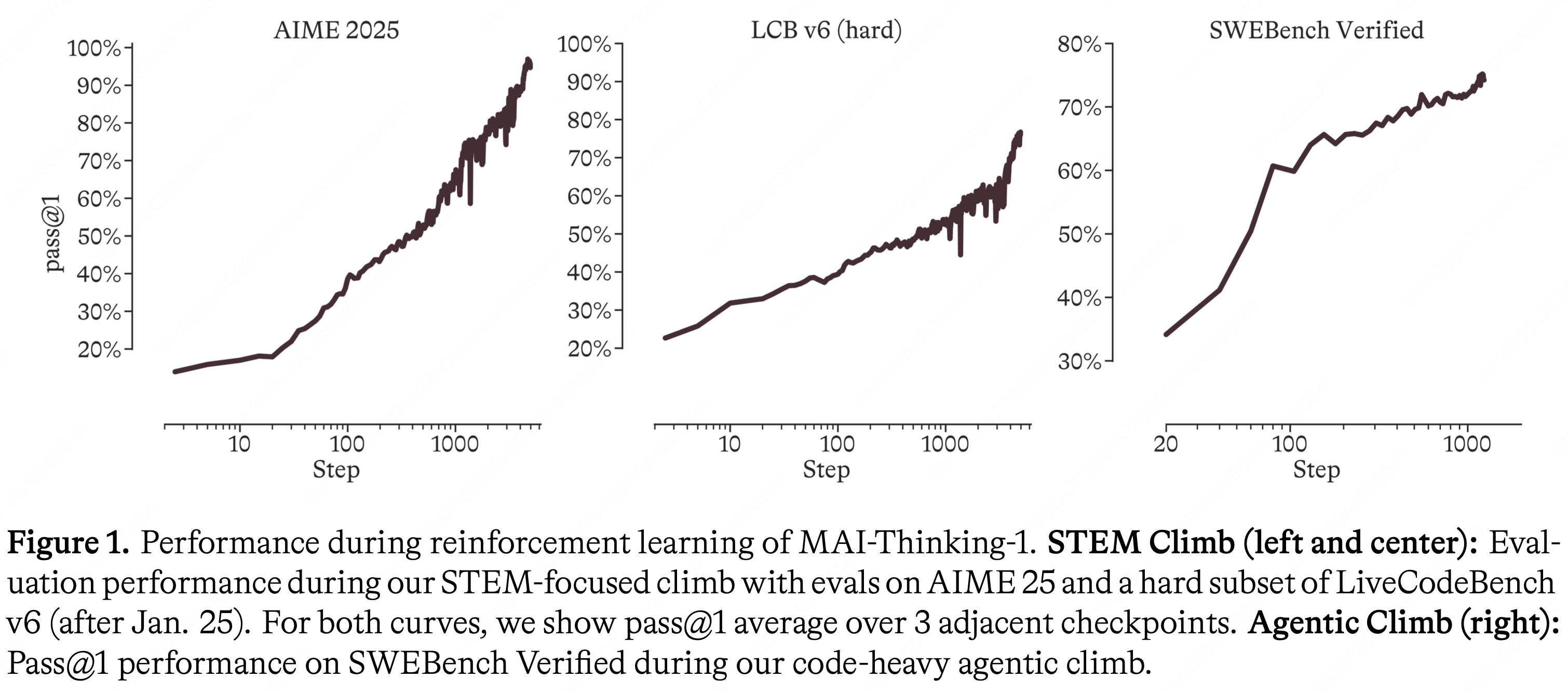
- 本文作者遵循三个主要设计原则来开发模型:
- 第一:能力应该是习得的,而非继承的
- 尽管通过蒸馏可以更快地获得智能,但它缺乏对漫长、持久的爬升至关重要的可操纵性 (steerability) 和稳健性 (robustness)
- 第二:简洁性 (simplicity) 是可持续的,作者倾向于
- 简单的、可扩展的流程
- 干净的、可信的数据
- 透明的、共同支持从头开始爬升的 Infrastructure
- 第三:科学严谨性 (scientific rigor) 可以避免走捷径
- 每一个决策都必须通过数据驱动的梯子 (ladder)、消融实验 (ablation) 和评估来检验,这些方法能够揭示通往顶峰的可靠路径
- 第一:能力应该是习得的,而非继承的
- MAI-Thinking-1 在 30T 个 Token 上进行了 Pre-training
- 这些 Token 来自一个混合了公开可用和许可的人类生成数据的混合物,涵盖了网络数据、公共 GitHub 代码、书籍、学术论文、新闻、多语言文本以及特定领域材料
- 这些来源中的每一个都是从头到尾在内部处理的
- 作者选择在预训练期间不使用任何由语言模型生成的合成数据 ,并努力避免和移除收集到的数据源中的 AI 生成内容
- 对于预训练,不使用任何开源训练数据集,并从训练数据中净化了常见的机器学习数据库
- 在 Mid-training 中,进一步强调 STEM、数学和编码能力,为 Reasoning RL climb 建立坚实的基础
- 在 Mid-training 之后,MAI-Thinking-1 实现了 256K 的最大上下文长度
- Pre-training 和 Mid-training 为基础模型提供了广泛的预测能力和知识,但它们并未指定模型应如何行为、如何解决长时程任务或如何分配推理时的计算资源
- 在 RL climb 过程中,教模型进行推理和响应
- 模型学习利用 CoTs 来应对特定任务的反馈,使用外部工具与环境交互,并遵循人类偏好和安全信号
- RL climb 是从零开始的,在没有任何先前推理痕迹 (Reasoning traces) 暴露的情况下学习推理
- 一个稳健的 RL recipe、自蒸馏以及 Infrastructure 的改进,使作者能够将 RL 运行维持数千步
- 使用这个流程,作者训练了三个特定领域的专家模型:
- 一个用于 STEM 推理
- 一个用于 Agentic 编码和工具使用
- 一个用于帮助性和安全性
- 开发 MAI-Thinking-1 时的一个关键技术挑战是在安全性(要求模型拒绝用户请求)和帮助性(要求模型遵从请求)之间取得平衡
- 一个安全的模型需要提供有帮助的响应,同时保持符合安全策略和标准
- 作者开发了内部安全基准来夯实我们的进展,并将帮助性和安全性训练纳入 RL climb 中
- 作为负责任的部署的一部分,在整个模型开发过程中持续进行红队测试 (red-team),以便在发布前发现并修复漏洞
- MAI-Thinking-1 是使用我们的爬山机器 (hill-climbing machine) 开发的第一个模型:
- 这是一个集成的过程,包括构建数据 Pipeline 、训练 Infrastructure 、 RL 环境和奖励、评估套件以及安全测试,将模型开发转变为在特定领域上的实证优化循环
Pre-training(简述)
- MAI-Base-1(1T-A35B)的预训练过程
- MAI-Base-1 从零开始训练,未使用任何蒸馏数据 ,训练数据完全由内部构建(包含公开及授权数据),在 8K 张 GB200 GPU 上完成了 30T 主预训练 Token 和 3.55T Mid-training Token
模型架构
- MAI-Base-1 采用 Decoder-only Transformer,具有以下特点:
- 交替使用局部注意力(5层,滑动窗口大小为 512)和全局注意力(1层,无位置编码),采用 GQA(8个 KV 头)
- 交替使用稀疏 MoE 层和密集 FFN 层,MoE 层采用 LatentMoE 设计,将 512 个专家中的 8 个激活于压缩潜在空间
- 使用 SwiGLU 激活函数、RMSNorm、无偏置、输入输出嵌入绑定
- 采用全局批负载均衡损失,并实现了无丢弃(dropless)MoE 变体以支持可变消息大小
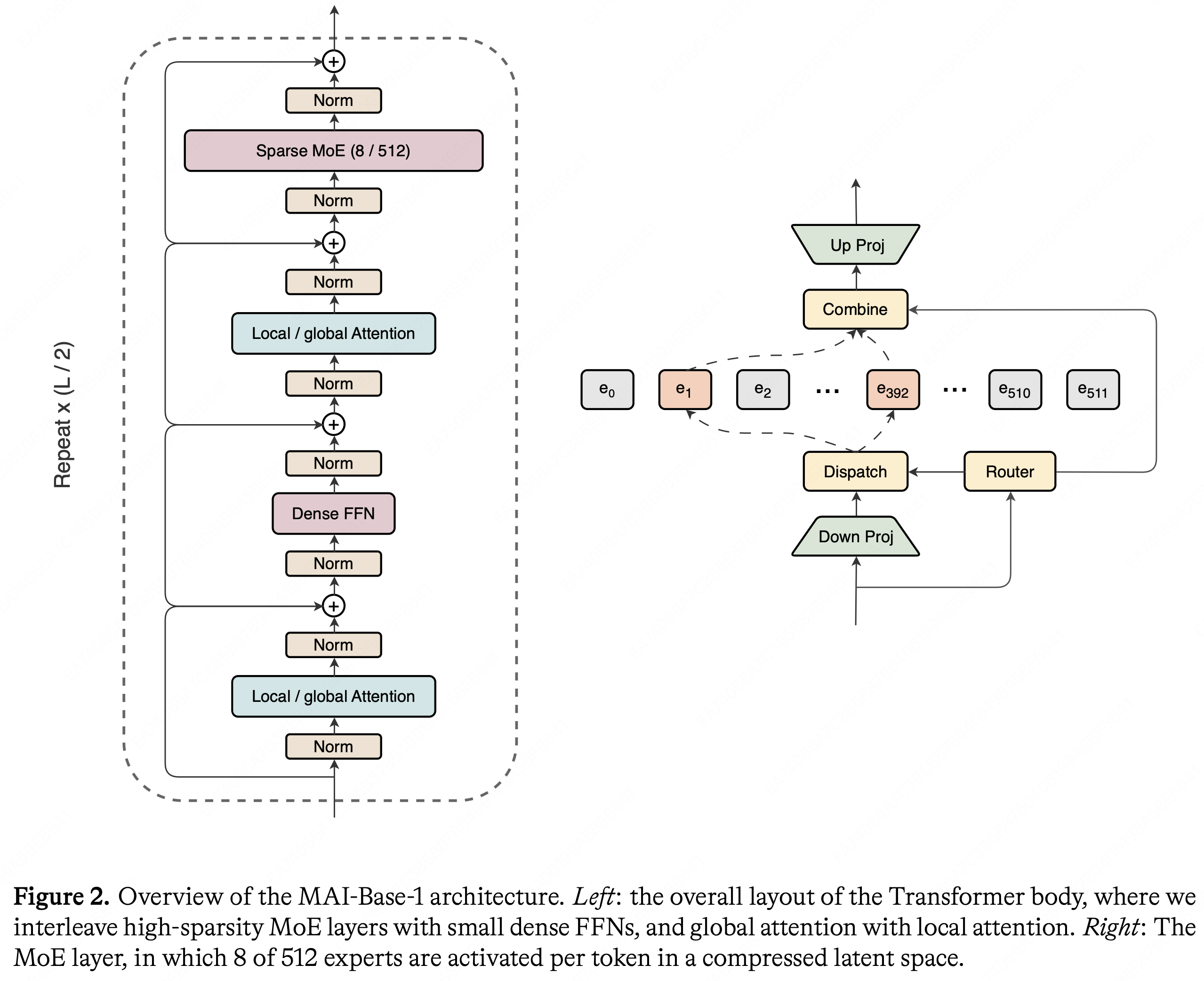
模型消融方法
- 为了评估设计决策,作者引入了缩放阶梯(Scaling Ladder)和效率增益(Efficiency Gain, EG) 的概念
- 缩放阶梯 :在不同模型大小下,以恒定的每激活参数 Token 数(TPP)训练模型,比较缩放曲线
- 效率增益 :衡量候选模型相对于基线模型达到相同评估损失所需的额外成本倍数,EG 的计算公式为:
$$
\text{EG} = \frac{f^{-1}(L’)}{C’}
$$- 其中 \(L’\) 是候选模型的损失,\(C’\) 是其成本,\(f\) 是基线模型的缩放定律 \(L = f(C)\)
- 两个消融示例表明:
- MoE-每层布局在 FLOPs 上 EG 较高,但在考虑实际时间的 \(\text{EG}_{\text{Time} }\) 上劣于交替布局
- 且随着专家数从 256 增加到 1024,模型架构保持了稳定的效率增益
评估方法
- 预训练阶段主要使用负对数似然(NLL) 评估而非准确率,原因包括:
- NLL 评估效率更高,成本更低
- 对格式干扰等混杂因素更鲁棒
- 构建成本更低
- 评估基准分为 Code、STEM、Math、General Knowledge、Multilingual 五类,并按加权公式聚合:
$$
\text{Target} = 0.5\times \text{Coding} + 0.175\times \text{STEM} + 0.175\times \text{Math} + 0.1\times \text{General~knowledge} + 0.05\times \text{Multilingual}
$$
预训练数据
- 数据完全内部处理,来源包括 Web HTML、Web PDF、书籍期刊、公共 GitHub 代码,不使用开源训练集或 LLM 生成数据,且尽力去除 AI 生成内容
- 知识截止日期为 2025 年 9 月至 2026 年 3 月
- 数据处理流程包括:
- HTML 提取 :针对不同领域使用结构化解析器、手工提取器甚至 LLM 处理
- 去重 :多级去重策略(精确去重、MinHash LSH 模糊去重、模板页面去重、语义去重)
- 过滤与分类 :利用元数据、启发式规则、学习分类器、Prompted LLM 进行过滤,并将数据分类到质量等级、语言、主题等“桶”中
选择训练数据混合(Data Mixture)
- 作者将数据混合选择视为优化问题,目标是最小化上述加权 NLL 目标
- 挑战 :效用定义、巨大搜索空间、尺度依赖效应、跨数据交互、多周期效应、计算成本高
- 方法 :先基于预测的方法训练数千个小模型(760M-4B),观察发现混合质量的排序并非尺度不变(rank non-invariance)
- 例如,在小规模上表现更好的 STEM-heavy 混合,在 23B 规模下反而被 Code-heavy 混合超越
- 作者推测:前者中两个高 STEM 但低多样性的数据源在大规模下效用下降
- 最终混合 :采用层次化局部+全局搜索,限制单数据重复最多 8 次
- 最终混合中,Coding 数据占 16.4T(~2 epoch),Math 数据约 300B 但重复 5.28 次,Web 和 PDF 数据平均小于 1 epoch
- Mid-training :从预训练数据中筛选更高质量子集,进一步偏向 STEM、Math、Code(STEM/Math 35%,Code 55%),并引入长上下文 NLL 评估
训练 Recipe
- 多阶段训练 :
- 主预训练 30T Token(上下文 16K) → Mid-training 1:3.4T(上下文 65K) → Mid-training 2:150B(上下文 262K)
- 超参数 :
- AdamW(\(\beta_1=0.95, \beta_2=0.925\))
- 峰值学习率 \(2\times10^{-4}\) 余弦衰减至 \(2\times10^{-5}\)(最终/峰值比 0.1),Dropout 0.15,全局批大小 134M Token
- 初始化技巧 :
- 将注意力输出初始化为零(设置 RMSNorm 增益为 0),避免初期 Attention 输出坍缩为均值池化,从而减少 MoE 路由不平衡
- 数值精度 :
- 默认 BF16,GEMM 使用 FP8(E4M3/E5M2),敏感位置(如 Attention 分数、MoE 路由器 logits、残差流)使用 FP32
与同期模型比较
- 在与 DeepSeek-V3.2、Kimi-K2、Gemma4-31B 等 Base 模型的 Bits-per-Byte (BPB) 对比中,MAI-Base-1 在四个内部 NLL 任务上均优于激活参数相似的模型
YOLO:大规模分布式训练框架
- YOLO 是微软内部的大规模训练框架,与硬件和模型架构协同设计
- 并行策略 :支持数据并行(自定义 ZeRO-1/2/3)、张量并行、上下文并行(Ulysses 风格)、专家并行
- MoE 优化 :支持 dropless 模式,使用自定义 Grouped GEMM 和 CuTe DSL 通信内核
- 确定性与容错 :
- 强制 bit-wise 确定性(禁用 SHARP、使用稳定排序、确定性累积)
- 采用分布式检查点(DCP)和异步检查点
- 通过 Ray Actor 热备实现快速作业恢复
- Model Architecture 和 Infrastructure 协同演化 :
- 从 v2 到 v5 版本,虽然每次架构改进(如专家数从 192 到 512、Top-4 到 Top-8、引入 LatentMoE)初期会降低 MFU
- 但通过 20+ 项系统优化(如 FlashAttention-4、ZeRO-2 回退、激活 Offload),最终使 1T-A35B 模型在 8K GB200 上保持了约 20% 的 MFU
The RL Climb
- 预训练和 Mid-training 为 MAI-Base-1 赋予了广泛的预测能力和知识
- 但它们并未规定模型应如何表现、如何解决长时程任务,或如何分配推理时的计算资源
- RL climb 通过针对特定任务的反馈来优化模型,解决了这一问题,使模型能够在给出回答前生成思维链 CoT,使用外部工具,与环境交互,并遵循偏好和安全性信号
- MAI-Thinking-1 是首个内部 Reasoning 模型,RL Climb 从一个未曾接触过任何 Reasoning traces 的检查点开始
- 模型必须从零开始发展其推理能力,这使得长期训练稳定性成为一个核心挑战
- 本文通过三种机制来实现这一点:
- (i) 对 Group Relative Policy Optimization (GRPO) (2024) 进行两项简单但关键的调整
- (ii) 在 RL Climb 崩溃或基础策略更新后,使用自蒸馏 (self-distillation) 来恢复 (Sec. 3.1)
- 新颖的 IDEA
- (iii) 消除训练与推理间数值不匹配的 Infrastructure 改进 (Sec. 3.6)
- 为了实现并行开发 (问题:仅仅是为了实现并行开发吗?),本文训练了三个特定领域的专家模型:
- 一个用于 STEM 和竞争性代码的模型 (Sec. 3.2)
- 一个用于 Agentic 编码和工具使用的模型 (Sec. 3.3)
- 一个用于帮助性和安全性的模型 (Sec. 3.4)
- 所有专家模型的 RL Climb 都遵循相同的 Recipe,但在 Prompt 的分布和模型因何获得奖励方面有所不同
- 超参数也一样吗?
- 如图 12 所示,这些专家模型随后通过 SFT 被蒸馏到一个单一的合并模型中
- 最后一轮轻量级 RL 将这个合并模型转化为 MAI-Thinking-1
- 注:MAI-Thinking-1 是一个在所有领域都表现强劲的模型 (Sec. 3.5)
- 图 12. RL Climb 的概览
- 从 MAI-Base-1 开始,使用 RL 训练三个专家模型
- 然后,这些专家模型通过简单的 SFT 被蒸馏到一个单一的合并模型中,该模型随后经历一个最终的 RL 阶段,以产生 MAI-Thinking-1
RL Recipe
RL Objective
- RL Climb 从一个 Policy \(\pi_{\theta}\) (例如 Mid-training 模型) 开始
- 对于一个 Prompt \(q\),Rollout 策略采样一组 \(G\) 个 Responses \(y_{1:G}\),每个 Response \(y_{i}\) 获得一个标量奖励 (Reward):
$$R_{i} = R(q,y_{i}) \tag {4}$$ - 奖励函数 \(R\) 是领域相关的
- 通常,它要么基于代码执行,要么来自 Prompted AI Judge 或已训练好的奖励模型的反馈
- 对于一个 Prompt \(q\),Rollout 策略采样一组 \(G\) 个 Responses \(y_{1:G}\),每个 Response \(y_{i}\) 获得一个标量奖励 (Reward):
- 本文从 GRPO (2024) 推导出训练目标,并结合了 Token 级别的策略梯度 (2025):
$$\mathcal{I}(\theta) = \mathbb{E}_{q\sim P(Q),y_{1:G}\sim \pi_{\text{old} } }\left[\frac{1}{\sum_{i = 1}^{G}|y_{i}|}\sum_{i = 1}^{G}\sum_{t = 1}^{|y_{i}|}\min \left(r_{i,t}(\theta)A_{i},\text{clip}\left(r_{i,t}(\theta),1 - \epsilon ,1 + \epsilon\right)A_{i}\right)\right] \tag {5}$$- \(P(Q)\) 是所有 Prompts 上的分布
- \(\pi_{\text{old} }\) 表示用于生成 Rollouts 的策略
- 在实践中,归一化是在全局训练批次 (across all data-parallel ranks) 上计算的,这样无论 Response 长度如何,每个 Token 的贡献都是平等的
- 对于 Response \(y_{i}\) 和 Token 位置 \(t\),重要性采样比为
$$r_{i,t}(\theta) = \frac{\pi_{\theta}(y_{i,t}\mid q,y_{i,< t})}{\pi_{\text{old} }(y_{i,t}\mid q,y_{i,< t})} \tag {6}$$ - Response 级别的优势 \(A_{i} = \left(R_{i} - \text{mean}(R_{1:G})\right) / \text{std}(R_{1:G})\) 在 Response \(y_{i}\) 的所有 Tokens 中共享
- 对于 Response \(y_{i}\) 和 Token 位置 \(t\),重要性采样比为
- 本文对此目标应用了两个修改:
- 自适应熵控制 (adaptive entropy control):动态调整上限裁剪范围以维持目标策略熵
- 一个外部比例裁剪 (outer ratio clip):限制了目标函数中未被裁剪的分支,以防止梯度范数爆炸
Adaptive entropy control
- 类似于 Yu 等 (2025) 和 Mistral-AI 等 (2025),本文使用独立的下限和上限裁剪范围
- 使用单个基础超参数 \(\epsilon\) (它控制基础信任区域宽度) 以及一个依赖于熵的松弛度 \(k\) (用于裁剪上限) 来参数化这些范围:
$$r_{i,t}^{\text{tr} }(\theta) = \text{clip}\left(r_{i,t}(\theta),1 - \epsilon ,(1 - \epsilon)^{-1} + \color{red}{k}\right)$$- 理解:这里的上界使用的是 \(\frac{1}{1-\epsilon}\),不是常规的固定值
- 作者发现:上限需要仔细调整,以避免当它太大时导致熵爆炸(注:观点可能错误) ,或当它太小时导致熵崩溃 (另见 2025; 2025)
- 理解:当上界太大时,容易导致熵爆炸可能是错误的观点,这里从原论文给到的 两篇参考文章都没有提到过这个观点 !!!
- 文章1:(Clip-Cov & KL-Cov)The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models, 20250528, Shanghai AI Lab & THU
- 文章2:BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMsvia Balanced Policy Optimization with Adaptive Clipping, 20251021, Fudan
- 通过调整 clip 上下界控制正负样本的贡献度,实现对熵的控制
- 观点:低概率正样本未被裁剪时,会增大协方差,进而提升熵,BAPO 动态提升 clip 上界,可纳入更多此类样本,避免熵坍缩
- 理解:当上界太大时,容易导致熵爆炸可能是错误的观点,这里从原论文给到的 两篇参考文章都没有提到过这个观点 !!!
- 理解:上述的公式中,k 通过控制 clip 的上界来控制熵的生成
- 为了解决这个问题,使用一个简单的积分 Controller ,基于当前策略的熵来动态调整 \(k\)
- 在每个训练步骤,通过一个重要性加权的估计器来估计目标策略的每个 Token 的熵:
$$\hat{H} (\pi_{\theta}) = \frac{1}{|\mathcal{T}|}\sum_{(i,t)\in \mathcal{T}} - \log \pi_{\theta}(y_{i,t}\mid q,y_{i,< t})\cdot r_{i,t}(\theta) \tag {7}$$- \(\mathcal{T}\) 表示当前训练批次中所有 (Response 索引, Token 索引) 对的集合
- 理解:这里是 token 粒度的上,但是带了 \(r_{i,t}(\theta)\) 权重,因为在旧/Rollout 策略上采样的,所以熵的计算使用了这个重要性采样来修正当前步的熵(注意是每个训练步骤都重新计算,所以策略不一定等于 Rollout 策略)
- 在每个训练步骤,通过一个重要性加权的估计器来估计目标策略的每个 Token 的熵:
- 给定一个目标熵 \(H^{\star}\), Controller 在每个步骤后以步长 \(\delta \in \mathbb{R}^{+}\) 更新 \(k\):
$$k\leftarrow \text{clip}\left(k + \delta \cdot \text{sign}\left(H^{\star} - \hat{H} (\pi_{\theta})\right),0,k_{\text{max} }\right) \tag {8}$$- 理解:类似 PID,但更简单,每次按照符号超某个方向更新一定步长,整体有上下界控制
- 直观理解:
- 当熵过低时,增加 \(k\) 会扩大上限裁剪范围,允许策略更激进地增加替代 Token 的概率
- 当熵足够高时,减小 \(k\) 以收紧信任区域
- 如图 13 所示,这种机制充当了一个自动熵正则化器,而无需在损失中显式添加熵奖励项,作者发现后者的效果不如自适应熵机制
- 本文初始化 \(k = 0\),使得裁剪范围 \(1 - \epsilon\) 和 \((1 - \epsilon)^{- 1}\) 互为乘法逆元,从而使初始裁剪区间在对数比空间 (log-ratio space) 中是对称的,然后根据上述熵 Controller 在线更新 \(k\)
- 图 13. 训练过程中的自适应熵控制
- 上图:在 RL Climb 的 800 个步骤中,目标熵为 \(H^{\star} = 0.3\) 时观察到的熵 \(\hat{H} (\pi_{\theta})\)
- 理解:上面的图有点反常,初始熵太低了,之前看到的大部分熵的初始值几乎也会在 0.4 以上(初始熵跟模型和数据集差异太大,不一定准确)
- 注意:图中甚至出现了熵增加到 0.3 的情况(之后一直持平,确实很优雅)
- 下图:对应的 \(k\) 值,其中 \(k_{\text{max} } = 1.0\):
- 当观察到的熵超过目标时减小 \(k\),反之则增加
- 调整 \(k\) 是调节策略熵的有效机制

- 上图:在 RL Climb 的 800 个步骤中,目标熵为 \(H^{\star} = 0.3\) 时观察到的熵 \(\hat{H} (\pi_{\theta})\)
Outer ratio clip, 外部比例裁剪
- GRPO 目标故意留下两种未裁剪的情况:
- (a) 优势为负且新策略赋予的概率高于旧策略 (即 \(A_{i}< 0\) 和 \(r_{i,t} > 1\))
- (b) 优势为正且新策略赋予的概率较低 ( \(A_{i} > 0\) 和 \(r_{i,t}< 1\) )
- 最初的动机 (2017) 是当策略在正确的方向上自我修正时不对其进行限制,只限制利用优势估计的移动
- 然而,在实践中,作者发现这些未裁剪的分支有时会导致灾难性的梯度范数峰值
- 本文通过添加一个应用于所有分支的硬性外部裁剪来解决这个问题:
$$r_{i,t}^{\text{out} }(\theta) = \text{clip}\big(r_{i,t}(\theta),r_{\text{min} },r_{\text{max} }\big) \tag {9}$$- 其中 \(r_{\text{max} }\) 被设置为一个较大的值,而 \(r_{\text{min} }\) 可以不加限制
- 这在精神上类似于 Ye 等 (2020) 提出的双裁剪 PPO (dual-clip PPO) 目标
- 理解:这里未裁剪出现梯度范数峰值大部分应该是 A < 0 时,不控制 \(r_{i,t}\) 的上界导致的梯度爆炸
- 这个做法的缺点是可能导致部分已经偏离 old 很远的策略回不来(但是实践上肯定是梯度范数稳定的)
- 补充理解:本节最后的超参数配置中提到,设置 \(r_{\text{max} } = 50\),并保持 \(r_{\text{min} } = 0\) 不受约束,所以其实还好,我们一般使用的是 \(r_{\text{max} } = 10\),本文中已经比较放宽了
- 本文通过添加一个应用于所有分支的硬性外部裁剪来解决这个问题:
- 这种两级策略丢弃了新旧概率之间存在极端差异的情况,同时为标准范围内的比例保留了标准的信任区域行为
- 根据经验,作者发现这会带来更少的梯度范数峰值和更稳定的 Climb
Reward Design
- 虽然本文的特定任务组件在特定领域的 RL Climb 中有所不同,但使用了相同的奖励分解方式:
$$R(q,y_{i}) = R_{\text{task} }(q,y_{i}) + w_{\text{lang} }\cdot R_{\text{lang} }(y_{i}) - w_{\text{len} }\cdot R_{\text{len} }(y_{i}) \tag {10}$$- \(R_{\text{task} }\) 表示特定任务的奖励
- \(R_{\text{lang} }\) 是语言一致性奖励
- \(R_{\text{len} }\) 是长度惩罚
- 系数 \(w_{\text{lang} }\) 和 \(w_{\text{len} }\) 是标量超参数
Language consistency reward,语言一致性
- 随着 RL 中上下文长度的增加,本文观察到模型开始在它们的 CoT 中生成外语 Token
- 这些混合语言的 CoT 与训练和推理策略之间的对数概率差异峰值相关,最终会破坏训练的稳定性
- 本文使用了一个类似于 Guo 等 (2025) 的语言一致性奖励 \(R_{\text{lang} }(y_i)\)
- 由于英语在训练分布中占主导地位,定义语言一致性时以英语为标准:
$$R_{\text{lang} }(y_i) = \max \left(1 - \alpha \cdot n_{\text{non-english} }(y_i),0\right) \tag {11}$$- \(n_{\text{non-english} }(y_i)\) 是 Response \(y_i\) 的 CoT 中非英语单词的数量
- 问题:是不是使用非英语单词的比例会更好些?使用绝对数量是不是有点对长样本不太公平,但因为这里使用了 \(\max(\cdot,0)\) ,所以还好,对于很长的文本也不会无限制的惩罚,但个人觉得还是使用相对比例会更好些
- 推测:作者应该是在非常长的本文下,需要保证几乎不要出现其他语言,所以直接使用绝对值来进行惩罚,可以防止太长的文本下输出一两个其他语言而没有收到惩罚的现象
- \(\alpha\) 是每个单词的惩罚
- 在实践中的发现:top-\(p\) 采样在防止单个低概率外语 Token 方面同样有效
- \(n_{\text{non-english} }(y_i)\) 是 Response \(y_i\) 的 CoT 中非英语单词的数量
Length penalty
- 遵循 Xiang 等 (2025),作者将长度惩罚定义为:
$$R_{\text{len} }(y_i) = \rho_q\cdot \frac{|y_i|}{\ell_{\text{max} } }\tag{12}$$- \(\rho_{q}\) 是问题 \(q\) 的 Pass Rate
- \(\ell_{\text{max} }\) 是最大 Rollout 长度
- 该惩罚同时依赖于 Response 长度和问题难度
- Pass Rate 低的高难度问题 会获得较弱的惩罚,允许模型探索更长的推理轨迹
- 简单问题则会受到更强的惩罚,通过消除冗余循环和规避行为 (hedging behavior) 来鼓励简洁且成本效益高的推理
Sampling Strategy
- 本文采用了几种采样策略来提高 RL Climb 的效率和稳定性
- 这些策略在两个层面运作:
- 选择哪些问题进行训练
- 控制如何为这些问题生成 Rollouts
- 这些策略在两个层面运作:
Problem sampling
- 对于训练集中的每个问题 \(q\),从当前的推理模型生成一组 Rollouts
- 为了降低推理成本,使用一个提前退出策略(early exit):
- 首先采样 \(G_{\text{early} }< G\) 个 Responses,并计算它们的经验 Pass Rate ,即获得正奖励的 Response 的比例
- 如果提前退出 Pass Rate 在一个可接受的范围内,就采样完整的 \(G\) 个 Responses;否则,丢弃该问题
$$ [\rho_{\text{min} }^{\text{early} }, \rho_{\text{max} }^{\text{early} }] $$
- 在生成全部 \(G\) 个 Responses 后,对完整组应用第二个 Pass Rate 过滤器
$$ [\rho_{\text{min} }, \rho_{\text{max} }]$$- 只有完整 Pass Rate 落在此范围内的问题才用于训练
- 这第二个过滤器的主要动机是移除低方差组:
- 如果几乎所有的 Responses 都是正确的或错误的,那么该组提供的相对学习信号就很少
- 理解:这样两阶段实现时,\([\rho_{\text{min} }^{\text{early} }, \rho_{\text{max} }^{\text{early} }]\) 的范围应该是更加宽泛的,即应该是 \([\rho_{\text{min} }^{\text{early} }, \rho_{\text{max} }^{\text{early} }] \subset [\rho_{\text{min} }, \rho_{\text{max} }] \)
- 一开始,先少量采样,然后用很宽的阈值剔除极端的 Query,降低成本
- 吐槽:微软也这么缺钱?
- 补充:后文给出了超参数:
- 设置总 Rollout 数为 \(G = 128\)
- 早期 Rollout 数为 \(G_{\text{early} } = 16\),\([\rho_{\text{min} }^{\text{early} },\rho_{\text{max} }^{\text{early} }] = [0.05,0.8]\)
- Pass Rate 过滤使用 \([\rho_{\text{min} },\rho_{\text{max} }] = [0.1,0.8]\)
- 为了降低推理成本,使用一个提前退出策略(early exit):
Rollout sampling
- 采用 top-p 采样 (2019) 使用 \(\pi_{\text{old} }\) 来采样 Rollouts \(y_{1:G}\)
- 发现:继续对采样核 (nucleus) 外 Token 对应的 logits 进行反向传播会导致灾难性的 off-policy 失配(即发生训推不一致),在几个训练步骤内就会引起发散
- 为了防止这种情况,在训练期间排除了这些 Token
- 方法是复用来自 Rollout 采样的 top-p 截断掩码 :在 softmax 计算之前将所有被排除 Token 的 logits 设置为 \(- \infty\),遵循 DeepSeek-V3.2 (2025b) 的方法
- 发现:top-p 掩码显著降低了 RL 训练期间的策略发散,代价是增加了掩码存储和重放的额外开销
- 理解:这里的 top-p mask 本质和 DeepSeek-V3.2 中提到的方法一样
- mask 的方式是:
- 在推理时记录采样时(计算 Softmax 前)被 drop 掉的 token
- 在训练引擎上,计算概率时 mask 掉这部分 token(mask 方式也是在计算 Softmax 前进行 mask,将 atten_score 置为 负无穷)
- 对 mask 的理解:
- 本质是防止训推不一致问题
- 梯度视角的理解: 这部分 token 推理时不参与决策,训练时就不要回传梯度
- 对部分 token 在计算 Softmax 前进行 mask 的本质是这部分 token 在 Softmax 处的梯度为 0,其 hidden_states 在 Softmax 这里不会被梯度影响(实际梯度接近 0)
- mask 的方式是:
- 为了防止这种情况,在训练期间排除了这些 Token
- 为了提高 Climb 早期阶段的训练效率,最初将最大 Rollout 长度限制在 8k Tokens
- 随着训练的进行,以 2 的幂次增加这个限制,直到达到最终的 128k Tokens 输出长度
- 这种长度扩展课程 (length extension curriculum) 显著降低了低性能阶段的推理成本,因为那时很少需要长推理轨迹,同时仍然允许模型随着其能力的提高逐渐适应更长的上下文
Self-Distillation
从 Mid-training 检查点实现强劲的性能需要经过大量的 RL 步骤训练
- 利用自蒸馏 (2022; 2022; 2023; 2026) 使这种长时间运行的 Climb 更加实用
对于自蒸馏:
- 收集 RL 期间生成的 Rollouts,并在一个 Mid-training 检查点上使用这些 Rollouts 进行 SFT
- 得到的模型作为继续 RL Climb 的起点,同时保留了在先前 RL 阶段发现的能力
使用自蒸馏有以下几个目的:
对于初始 Climb ,使用领域或任务特定的 Prompts 来引出目标行为
例如,图 14 显示了用于 STEM Climb 的初始原始文本 Prompt
- Figure 14. Prompt template used for reasoning prior to the first round of self-distillation with {QUERY} being a placeholder for the actual user query (from Guo et al. (2025)).
1
2
3
4
5A conversation between User and Assistant. The user asks a question, and the assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e.,
<think> reasoning process here </think>
<answer> answer here </answer>.
User: {QUERY}
Assistant: <think>
- Figure 14. Prompt template used for reasoning prior to the first round of self-distillation with {QUERY} being a placeholder for the actual user query (from Guo et al. (2025)).
自蒸馏允许通过简单地更新 SFT 数据的格式,从 Prompt 转换到使用自定义的原生聊天格式
另一个主要用途是从偶发的运行失败中恢复
- 在 RL 栈开发的早期,以及在引入 Sec. 3.6.4 中描述稳定性改进之前,训练和推理之间微小的数值差异有时会在训练过程中累积,导致 Climb 发散
- 在这种情况下,自蒸馏提供了一种简单有效的方法,可以将一次 RL Climb 的进展延续到下一次
- 从崩溃前的检查点恢复的替代方案通常不可行 ,因为一些不稳定性在实际崩溃发生之前的许多步骤就已经嵌入到模型参数中
随着新的预训练和 Mid-training 检查点可用,自蒸馏允许我们将先前 Climb 的进展延续到下一代模型
- 在自蒸馏过程中,可以应用过滤器来拒绝任何展示出不良 reward hacking 形式的样本
图 15 说明了自蒸馏在 STEM Climb 中如何被用来从数值不稳定性中恢复以及更新基础策略
- STEM Climb 期间在 AIME 2025 (左) 和 LiveCodeBench v6 的困难子集 (右) 上的性能
- 自蒸馏通过 \(\star\) 标记表示;不同的预训练和 Mid-training 模型版本以不同颜色显示
- 整个训练过程中的最大输出长度在底部标出
- 自蒸馏是在崩溃后(表现为性能突然下降)重置数值和在运行期间更改基础策略的有效方法
- 随着作者在整个 Climb 过程中对 Infrastructure 和算法进行改进,因运行崩溃而进行自蒸馏的情况变得不那么频繁
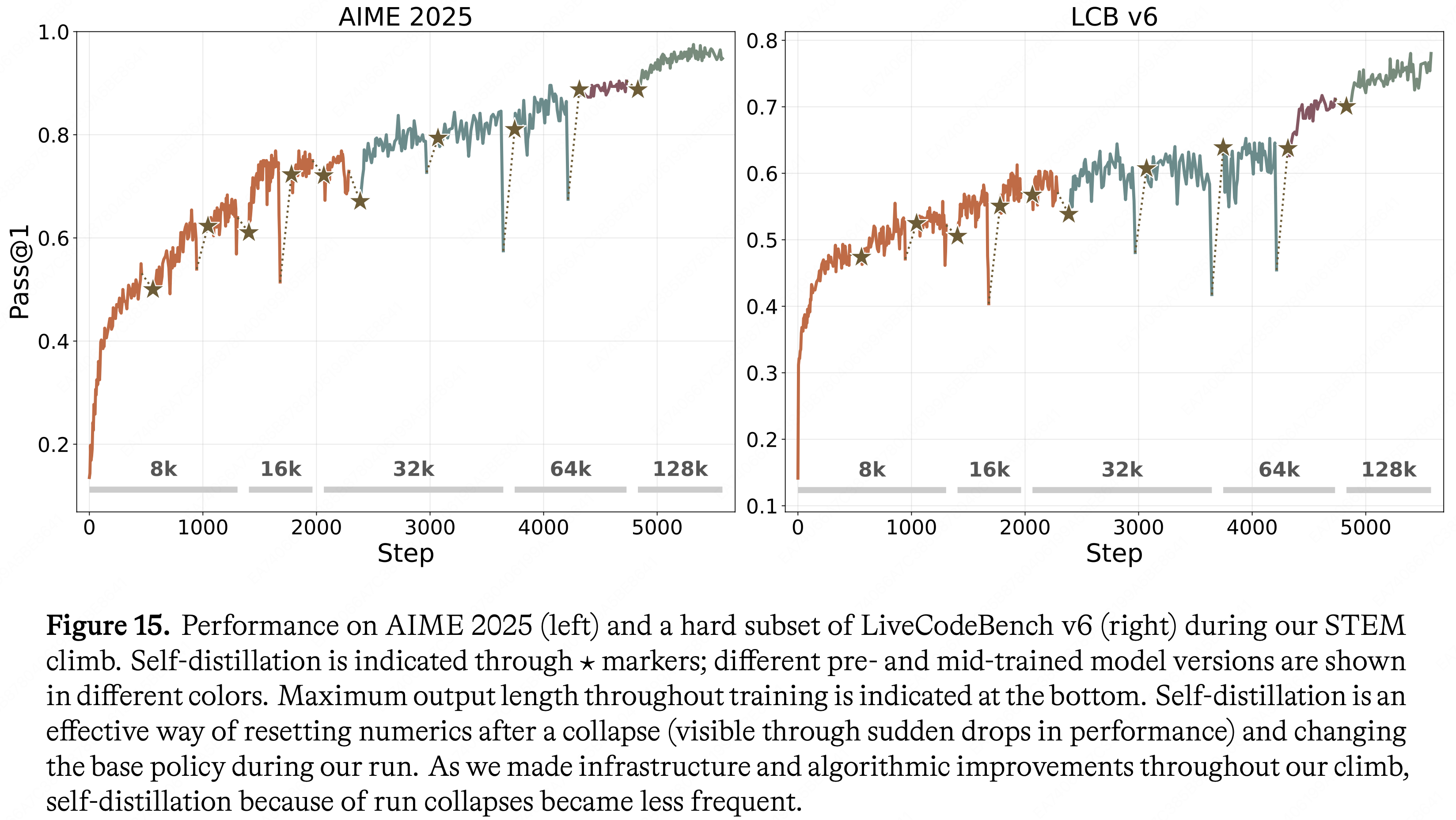
Key findings and best practices
- 作者进行了广泛的消融实验,以了解如何在实践中最好地执行自蒸馏,作者的主要发现是:
- \(\mathcal{O}(1M)\) 个推理轨迹足以匹配教师模型的性能,同时保留 SFT 的稳定性优势
- 使用显著更大的数据集会带来递减的收益,并有过度约束策略的风险,从而缩小其输出分布,并在恢复 RL 时留下很小的探索空间 (2024; 2025)
- 在包括那些导致最终答案错误的轨迹上进行训练,其效果与仅在成功轨迹上训练相似 (2025)
- 由于本文的 RL 运行通常产生远超 \(\mathcal{O}(1M)\) 的成功轨迹,本文最终将训练限制在成功的轨迹上
- 使用来自 Climb 后期阶段的轨迹很重要
- 包含来自非常早期检查点的轨迹会导致明显的性能下降,并需要许多后续的 RL 步骤才能恢复
- 仅从最终 RL 检查点生成轨迹会导致恢复 RL 后的性能较弱
- 一个可能的解释是,跨越一系列强大检查点收集的轨迹比从单个最终策略生成的轨迹提供了更大的多样性 ,从而在 RL 期间实现更好的探索
- 复用 RL 期间已生成的轨迹也避免了重新采样所需的额外计算和时间
- 对于固定的 Token 预算,增加 Prompt 的多样性比增加每个 Prompt 的轨迹数量更有价值
- 作者发现:简单的随机采样优于几种有偏选择策略,包括最短轨迹采样和类似于 Yang 等 (2025) 探索的启发式过滤方法
- 在自蒸馏期间,模型可能会遗忘从 Mid-training 学到的长上下文行为,尤其是在推理轨迹是从使用较短最大长度训练的早期 RL 运行中收集的情况下
- 为了缓解这个问题,在长度扩展之前的自蒸馏过程 中,将 Mid-training 数据与推理轨迹混合在一起
- \(\mathcal{O}(1M)\) 个推理轨迹足以匹配教师模型的性能,同时保留 SFT 的稳定性优势
Hyperparameters
- 下面报告了通常用于三个特定领域模型的主要 RL Climb 以及自蒸馏运行的超参数
RL climb
- 使用 AdamW 进行训练,其中 \(\beta_{1} = \beta_{2} = 0.95\), \(\epsilon = 10^{-15}\),且不使用权重衰减
- 问题:\(\beta_{2} = 0.95\) 说明确实比较稳了,否则 \(\beta_{2} = 0.999\) 会好些
- 使用恒定的学习率 \(\eta = 10^{-6}\),没有预热或衰减
- 全局批次大小为 7040 (打包后),未打包序列的最大数量上限为 12000
- 这个 Batch Size 明显大于当前大多 RL 训练的,无论是 12000 或是 7040 都大多了
- 而且这里对样本进行了打包,理论效率是更优的
- 因为本文的 RL 栈是完全异步的,随着作者增加生成长度,Rollouts 的延迟会增加,而训练步骤时间由于许多短生成的存在不会成比例增加
- 这意味着更长的 Rollouts (通常是最困难的问题) 的 off-policiness 会增加
- 为了应对这一点,作者选择在更长的长度上将学习率降低到 \(9\times 10^{- 7}\),以减少 off-policiness 并增加稳定性
- 理解:这同时也会导致学习这种长难样本的效率变低吧
- 最大生成长度为 128k,但首先在 8k, 16k, 32k 和 64k 上进行训练
- 对于带有自适应熵控制的 GRPO:
- 设置 \(\epsilon = 0.6\), \(k_{\text{max} } = 2.5\),步长 \(\delta = 0.25\),目标熵 \(H^{\star} = 0.3\)
- 理解:\(\epsilon\) 是 clip 的裁剪范围 \([1-\epsilon, (1-\epsilon)^-1]\) 的超参,0.6 这个值也太大了吧?
- 设置 \(\epsilon = 0.6\), \(k_{\text{max} } = 2.5\),步长 \(\delta = 0.25\),目标熵 \(H^{\star} = 0.3\)
- 对于外部裁剪
- 设置 \(r_{\text{max} } = 50\),并保持 \(r_{\text{min} } = 0\) 不受约束
- 对于语言一致性奖励,设置 \(w_{\text{lang} } = 0.5\),每个单词的惩罚 \(\alpha = 0.005\)
- 对于长度惩罚,在达到 64k 长度扩展阶段之前固定 \(w_{\text{len} } = 0.25\)
- 由于惩罚被 \(\ell_{\text{max} }\) 归一化,随着最大长度的增加,有效惩罚自然会减弱,允许模型在更大的 Token 预算下探索更长的推理轨迹
- 在 128k 扩展阶段,本文移除了长度惩罚 \((w_{\text{len} } = 0)\)
- 对于问题采样
- 设置总 Rollout 数为 \(G = 128\)
- 早期 Rollout 数为 \(G_{\text{early} } = 16\),\([\rho_{\text{min} }^{\text{early} },\rho_{\text{max} }^{\text{early} }] = [0.05,0.8]\)
- Pass Rate 过滤使用 \([\rho_{\text{min} },\rho_{\text{max} }] = [0.1,0.8]\)
- 对于 top-\(p\) 采样
- 使用 \(p = 0.97\)
- 较大的核值可以改善探索,但会增加传输采样掩码的 Infrastructure 开销
- 发现: \(p = 0.97\) 在探索和训练效率之间提供了良好的平衡
- 在推理模型更新之间执行 5 个梯度步骤,并丢弃任何生成策略比 8 次推理更新更陈旧 (即落后 40 个梯度步骤) 的 Rollout
- 这稍微放宽了对 on-policy 新鲜度的要求,以换取显著更高的吞吐量
- 使用 dropless MoE 训练,并将全局 MoE 负载均衡系数设置为 \(1\cdot 10^{- 5}\)
- 注:本文是开着负载均衡的
- 注:Dropless MoE(无丢弃混合专家模型)核心定义是:在 Token 路由和计算过程中,绝对不丢弃任何 Token,保证所有输入数据都能得到完整的计算
- 在传统的 MoE(如 GShard、Switch Transformer)中,可能丢弃数据
- 输入的一串 Token 会通过一个“路由器”分发给不同的专家进行处理,GPU 非常擅长处理形状固定的矩阵运算
- 如果每个专家分到的 Token 数量忽多忽少,GPU 就必须频繁面对动态形状,导致计算效率极低
- 传统解决方案——专家容量(Expert Capacity): 为了迎合 GPU,传统的做法是给每个专家设定一个“最大容纳上限”,超出部分的 Token 就会被直接丢弃(Dropped),跳过专家层(或者直接通过残差连接复制过去)
- 在传统的 MoE(如 GShard、Switch Transformer)中,可能丢弃数据
Self-distillation
- 对于自蒸馏 SFT,使用打包序列,全局批次大小为 2,048,序列长度为 128k Tokens
- 优化使用 AdamW,权重衰减为 0.001,以及余弦学习率调度
- 最大学习率设置为 \(1.7\cdot 10^{-5}\),最小学习率设置为 \(5.2\cdot 10^{-6}\),学习率预热比例为 \(2%\)
- 理解:这么精细的学习率,确实让人没想到,这是做过眼镜的消融得到的最优超参数?
- 在自蒸馏期间仔细调整了两个超参数:dropout (2014) 和 MoE 负载均衡损失系数
- 本文作者使用了相对较高的 dropout 率 0.15,这增加了熵并有助于防止模型崩溃,从而在后续的 RL 阶段提高了性能
- 由于特定领域 RL 中的数据分布比预训练和 Mid-training 期间使用的混合物窄得多,RL 期间的专家选择可能会变得高度不平衡
- 然而,在 RL 期间使用大的负载均衡系数也会损害稳定的性能提升
- 为了解决这个问题,在自蒸馏期间使用了相对较大的负载均衡系数 \(1 \cdot 10^{-2}\),而在 RL 期间使用了小得多的系数 \(1 \cdot 10^{- 5}\)
- 由于自蒸馏上下文是从 RL 运行本身生成的,因此遵循相似的分布,自蒸馏期间引发的专家平衡效应在 RL 期间得以保留
STEM Climb
- STEM Climb 是三个特定领域 RL 训练运行中持续时间最长的,旨在加强模型在单轮问题解决环境中的核心推理能力
- STEM Climb 涵盖了广泛的 STEM 领域,包括数学、物理、化学和竞争性编程
- 作者也见证了 Climb 过程中 Rollouts 中反映的模型行为演变,在附录 C.1 中有更详细的描述
- 由于数据质量是这次 Climb 成功的关键,作者专注于训练数据以及为构建、验证和过滤这些数据而建立的 Pipeline
- 整个 STEM Climb 都在可验证的数据对 (pairs of verifiable data) 上运行:
- 为了产生特定任务的奖励 \(R_{\text{task} }(q, y_i)\),从 \(y_i\) 中提取模型的最终答案,并将其与使用形式验证器 (如 SymPy (2017))、AI Judge 或 (对于竞争性编程) 针对一套特定问题的测试用例运行模型生成的代码片段的真实答案进行比较
- 因此,每个 RL 数据实例要么包含一个查询和真实答案的对 \((q, a)\),要么包含一个查询和 \(n\) 个测试用例的对 \((q, \{t_1, \ldots , t_n\})\)
- 在设计获取此类对的 Pipeline 时,考虑了三个主要标准:高质量、适当的难度和主题多样性
- 使用本文 STEM 数据 Pipeline ,处理了数百万份文档,生成了包含超过 500 万个样本的 STEM Mix 数据集,用于本文的 STEM Climb
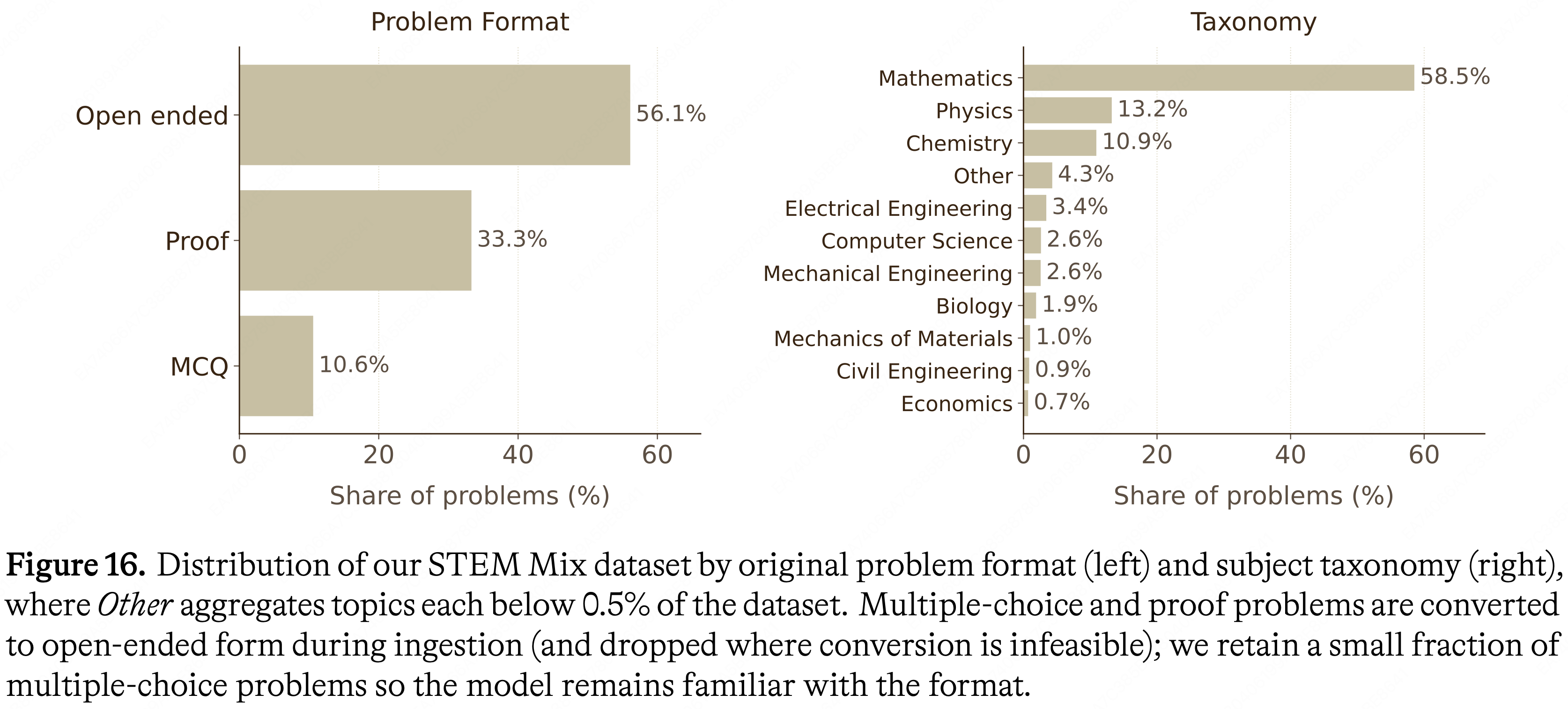
- 该混合数据集中最具挑战性的部分包含超过 55 万个 \((q, a)\) 对,该数据集的一些特性如图 16 所示
- 图 16. STEM Mix 数据集的分布,按原始问题格式 (左) 和主题分类 (右) 划分,其中 “Other” 汇总了每个占比低于 \(0.5%\) 的主题
- 补充:图中的问题类型说明
- Open Ended(开放式问题)
- MCQ(Multiple Choice Question,多项选择题)
- Proof(证明题)
- 理解:MCQ 考察的是识别、记忆和理解,Open Ended 考察的是综合表达与发散思维,而 Proof 考察的是严密的逻辑演绎能力
- 多项选择和证明题在收录过程中被转换为开放式形式 (如果转换不可行则被丢弃)
- 作者保留了一小部分多项选择题,以便模型保持对该格式的熟悉度
- 补充:图中的问题类型说明
Data Pipeline
- 本文的 STEM 数据 Pipeline 将异构的原始来源转换为 \((q,a)\) 对的数据集:
- 来源包括:教科书、学术 PDF、论坛讨论、竞赛档案以及从各种供应商处获得的问题
- 该 Pipeline 围绕一个可组合的、基于阶段 (stage-based) 的架构构建:
- 每个处理步骤都实现为一个独立的异步阶段
- Pipeline 特定于源的实例化会根据需要选择和组合这些阶段的子集
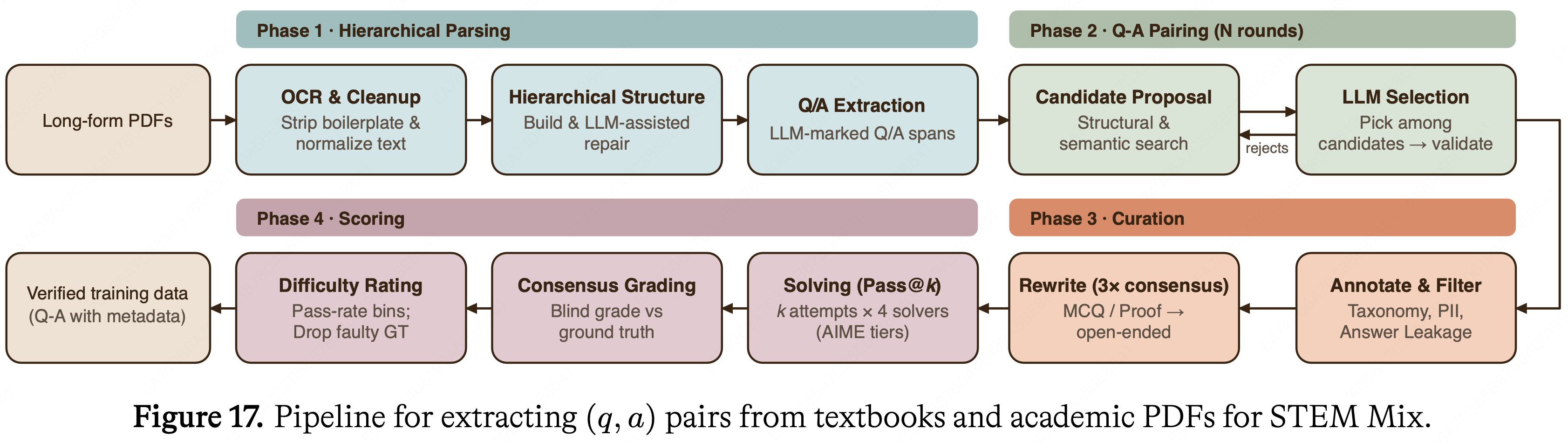
- 作者在下面描述几个 Pipeline 阶段,按照图 17 中所示的从长篇教科书和学术 PDF 中提取 \((q,a)\) 对的示例,将它们分组为四个阶段
- 对噪声或幻觉敏感的阶段会多次运行并通过共识投票
- 对噪声或幻觉敏感的阶段会多次运行并通过共识投票
Hierarchical parsing,分层解析
- 该阶段包括将原始文档转换为初始 \((q,a)\) 对的步骤。根据文档类型,使用视觉语言模型或 OCR 服务执行 OCR。文档被分块,没有 STEM 内容的页面被丢弃,并移除样板文本 (boilerplate)。一个独立的阶段使用 OCR 输出中的结构线索构建分层表示,并修复破损的交叉引用、错位的编号以及跨页分割的伪影。最后,在问答 (QA) 提取阶段,一个 LLM 在清理后的文档结构中标记问题和答案的范围,产生候选的 \((q,a)\) 对
QA pairing
- 对于问题和答案出现在不同位置的来源 (例如,章节末尾的练习,附录中的答案键),一个多轮配对阶段将每个问题与其对应的答案进行匹配。首先使用结构信号和语义相似性将问题与候选答案进行匹配;在检索到的候选中,一个 LLM 选择最匹配的答案并验证该配对
Curation
- curation 阶段的步骤用于标注、过滤和重写 \((q,a)\) 对,以确保质量和格式一致性
- 其中几个步骤是基于 LLM 的分类:
- 验证 (Verification): 将 Item 分类为可验证或不可验证;不可验证的 Item (例如,没有可检查答案的开放式论坛讨论) 被丢弃
- 问题类型 (Question type): 区分问题类型,包括开放式问题、多项选择题和证明题
- 分类法 (Taxonomy): 一个分层主题分类器分配细粒度的 STEM 主题,涵盖数学、物理、化学、生物学、计算机科学和工程学
- PII 检测 (PII detection): 一个专用的分类器标记个人身份信息;被标记的 Item 被丢弃
- 问题:这里的专用分类器也是 GRM 吧
- 答案泄漏 (Answer leakage): 检测并丢弃 \(a\) 被琐碎地包含在 \(q\) 中的 \((q,a)\) 对
- 另外两个 curation 阶段将问题转换为更有利于 RL Climb 的形式
- Conversion 阶段: 将多项选择和证明风格的问题重写为开放式形式
- 多项选择题通常可以通过猜测来解决,提供不可靠的奖励信号,而证明很难在不依赖更强 AI Judge 的情况下直接验证
- 此阶段运行三次,然后是一个共识阶段
- 未达成共识的 Item 被视为无法可靠转换并被丢弃
- Cleanup 阶段: 移除与问题无关的额外非数学文本和外部引用
- Conversion 阶段: 将多项选择和证明风格的问题重写为开放式形式
Scoring
- 这个最后阶段量化问题难度,并过滤其真实答案可能错误的 Item
- 在 “solving” 阶段,每个问题由四个模型层级 (其 AIME 2025 性能作为能力代理) 分别求解 \(k\) 次
- Pass Rate 用于将 Item 分组到难度等级
- “盲审 (blind-grading)” 阶段用于防范错误的真实答案
- 对于最强层级 Pass Rate 较低的 Item ,以随机顺序将该模型的共识答案(consensus answer)和真实答案呈现给一个 Judge
- 如果 Judge 偏爱共识答案,则因真实答案可疑而丢弃该 Item
- 如果 Judge 偏爱真实答案,将其保留为一个真正困难的问题(因为这里的答案都是 Pass Rate 较低的 Item)
- 理解:这里是要求真实答案本身的指令很高
- 对于最强层级 Pass Rate 较低的 Item ,以随机顺序将该模型的共识答案(consensus answer)和真实答案呈现给一个 Judge
Competitive Coding Data
- 对竞争性编程数据使用了一个专用的 Pipeline ,该 Pipeline 与本文主要的 STEM Pipeline 不同
- 这是因为对于竞争性编程问题,需要为每个 Prompt 提供一组测试用例 \(t_1, \ldots , t_n\)
- 包含全面测试用例的 Prompt 不太可能在非结构化来源 (如 PDF 文档) 中找到
- 因此,依赖于有针对性的来源和供应商获取的数据 ,这省去了 STEM 数据 Pipeline 中使用的许多提取和过滤步骤
- 理解:相当于这部分 Code 数据是买的
- 对于每个问题,获取参考解决方案并验证它们能通过所有相关的测试用例
- 总的来说,从多个来源收集了 16 万个问题,涵盖了多样化的主题,包括分治、动态规划、图和树算法以及搜索算法
- 除了测试用例,每个问题还包括运行时和内存限制
- 最终数据集支持 17 种编程语言,包括 Python、\(\mathbb{C} + +\)、\(\mathbb{C}\#\)、Java、JavaScript、Rust 和 TypeScript
Deduplication and Decontamination,去重+去污放到一个阶段
- STEM Mix 数据集和竞争性编程数据集都进行了自我去重,并根据 Sec. G 中报告的基准测试以及内部跟踪的内部奥林匹克和研究生级别的 STEM 评估进行了去污处理
- 本文使用一个三阶段 Pipeline 进行去重:
- 1)第一步:精确去重 (Exact deduplication).
- 使用 SHA-256 问题哈希识别精确重复项
- 2)第二步:词法模糊去重 (Lexical fuzzy deduplication).
- 使用字符级别的 \(n\)-gram 切片 (shingling),然后进行 MinHash 局部敏感哈希 (locality-sensitive hashing) 来识别近似重复的问题
- Jaccard 相似度高于给定阈值的问题对被标记为重复
- 3)第三步:向量去重 (Vector deduplication).
- 使用一个轻量级嵌入模型对问题进行嵌入
- 余弦相似度高于给定阈值的问题对被标记为重复
- 1)第一步:精确去重 (Exact deduplication).
- 仔细调整每个阶段的超参数,以在确保严格排除任何基准泄漏的同时,尽可能多地保留数据
Agentic Climb
- Agentic Climb 训练 MAI-Thinking-1 去解决需要与外部环境交互的任务(而不是单次文本响应)
- 在这种设置下,模型必须分解用户请求,选择工具或代码动作,观察结果,并在必要时跨多个步骤和轮次调整其计划
- 训练信号结合了可验证的奖励,例如在软件环境中通过测试或数据库达到目标状态,以及用于行为方面 (如任务解释、帮助性和轨迹质量) 难以精确指定的 AI 反馈奖励
- 本文专注于两个 Agentic 领域:
- (i) Software Engineering(SWE) (Sec. 3.3.1),涉及从真实仓库构建的可执行软件工程环境
- (ii) General Tool Use (Sec. 3.3.2),涉及在多步骤任务中调用结构化工具
- 实践中混合了 Agentic 和以推理为重点的 STEM 任务 (包括竞争性编程混合物) 上联合 Climb
- 发现:
- 包含 STEM 任务有助于稳定 RL Climb ,并对多步骤软件工程和工具调用性能显示出正迁移
- Agentic 任务对 STEM 相关的单次传递性能既没有正迁移也没有负迁移
- 与 STEM Climb 类似,在整个 Climb 过程中观察到模型行为的演变,附录 C.2 中有示例
- Agentic 设置与 STEM 设置的不同之处在于使用了多步骤 Rollouts 和容器化环境,如下节所述
- 发现:
Multi-step RL framework
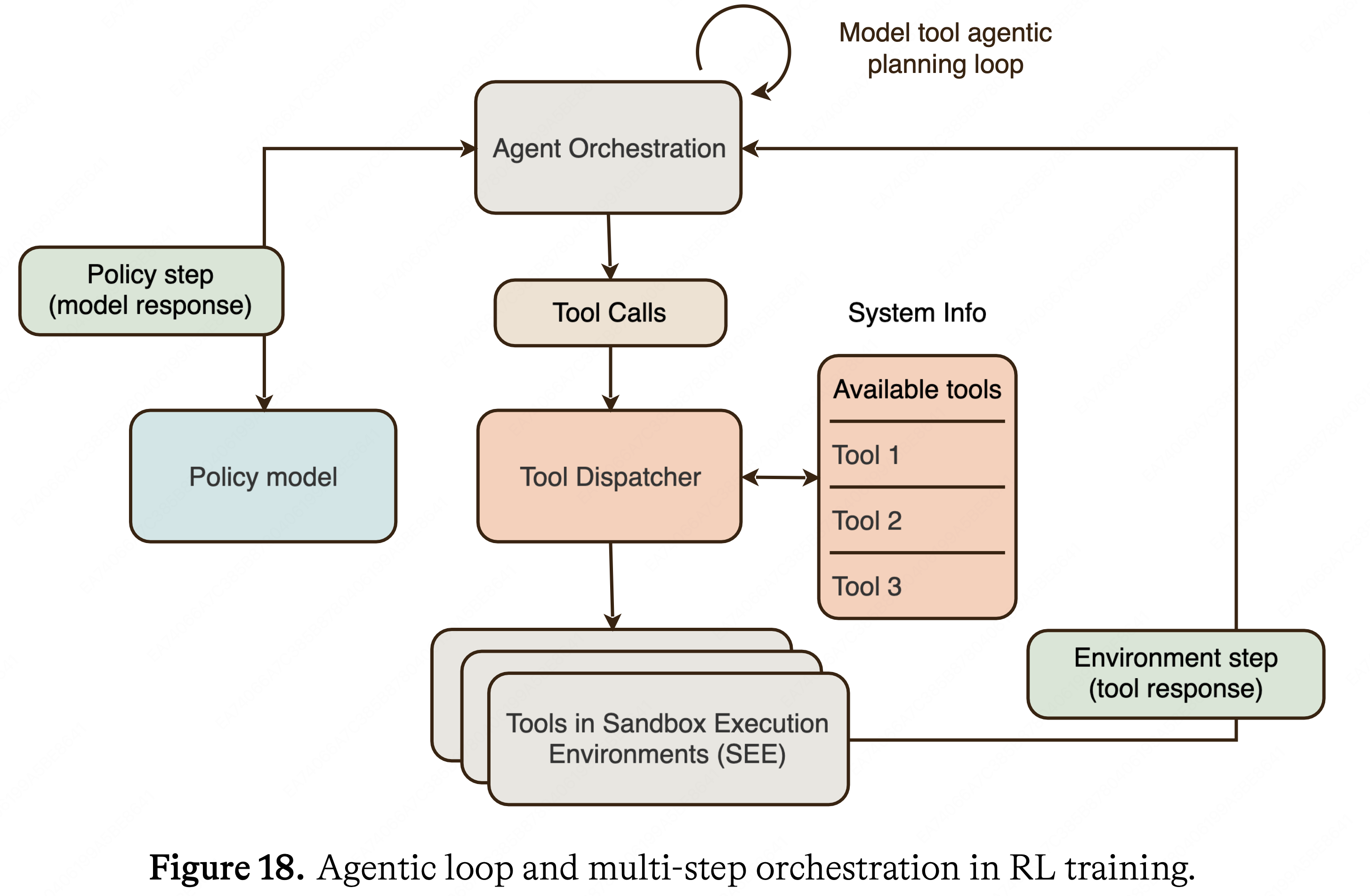
- Agentic 多步 RL 使用与 Sec. 3.1 中单步推理 RL 方案相同的核心目标,但将 Rollouts 从单个采样 Response 扩展到策略步骤和环境步骤 (观测) 的轨迹
- 每个 RL 环境包括:
- 一个任务规范
- 一个用于执行工具的沙箱执行环境 (Sandbox Execution Environment, SEE) 会话
- 一组用于评估任务完成情况的可验证或判断的奖励,同时跟踪环境状态
- 在每个策略步骤,模型可以发出工具调用或生成最终答案
- 工具调用在 SEE 会话内部执行,其输出在下一个策略步骤之前被附加到上下文中
- 然后对整个轨迹进行正确性评分,并可选择性地给予 AI 反馈,之后对所有策略步骤中的所有 Token 统一应用信用分配
- 编排框架是一个 ReAct 风格的循环 (2023):
- 解析模型的推理和动作,将工具调用分派给 SEE,将返回的观测值附加到上下文,并将控制权返回给策略以进行下一个动作
- 所有先前步骤的 Tokens 都保留在上下文中,并且它们是后续步骤的严格前缀
- 同一个循环支持软件工程和通用工具使用的工作负载
- 在 SWE 中,动作在特定于问题的容器镜像内部读取和编辑文件、运行 shell 命令以及检查仓库状态
- 在通用工具使用中,动作调用由可变任务状态 (例如,种子数据集) 支持的结构化工具,并将工具输出作为下一个模型动作的观测值返回
- 当模型不发出工具调用,或当 Rollout 超出步骤、上下文长度或时间预算时,循环终止
- Rollout 及其对应的 SEE 被发送给评分器 (graders)
- 评分器结合了格式检查、基于规则的检查、可执行测试、可验证状态比较和 AI Judge
- 图 18 概述了 Agentic RL 框架
- RL 环境来自两个主要领域:软件工程 (Sec. 3.3.1) 和通用工具使用 (Sec. 3.3.2)
- RL 环境来自两个主要领域:软件工程 (Sec. 3.3.1) 和通用工具使用 (Sec. 3.3.2)
- 解析模型的推理和动作,将工具调用分派给 SEE,将返回的观测值附加到上下文,并将控制权返回给策略以进行下一个动作
Sandbox execution environment (SEE) ,沙箱执行环境
- 沙箱执行环境按需提供大规模、隔离的容器环境
- SEE 在 RL 期间用于为模型训练环境提供高度并行、低延迟的容器
- SEE 每个 Agentic 任务提供一个全新的容器,并在任务完成后销毁它
- 这确保了可重复性,实现了安全探索,并防止了任务间的状态泄漏
- 容器默认是网络隔离的,确保训练 episodes 是确定性的,且不受外部副作用 (如速率限制或瞬时故障) 的影响
- 当环境确实需要网络访问时 (例如,安装包),流量通过缓存代理和域白名单进行中介,以平衡环境保真度、训练可重复性和安全性的需求
Software Engineering
- 训练一个前沿模型执行 SWE 任务,需要模型在真实的开发环境内部与真实的代码库进行交互
- 大量高质量的编码环境对于训练一个强大的编码模型至关重要
- 为了实现这一点,本文从对真实代码库的贡献中获取自然产生的数据
- 为了构造 RL 环境仓库,依赖以下原语:
- 一个大型的代码仓库数据集 (例如,公共 GitHub 代码),一个从真实世界的开源开发者拉取请求创建可执行软件工程问题的 Pipeline
- 用于执行的沙箱容器服务 SEE
- 为了构造 RL 环境仓库,依赖以下原语:
SWE RL environments, tasks, and tools
- 每个 SWE RL 问题被打包为一个自包含的容器镜像,其中包括在特定提交状态下检出并预安装了所有依赖的仓库、一个问题陈述以及用于评分的单元测试
- 因为镜像捕获了仓库的所有依赖,环境是确定性的,并且可以在 Rollout 开始时立即使用,无需任何设置
- 在 Rollout 期间,模型通过工具调用与容器交互:读取和编辑文件、运行 shell 命令以及浏览仓库
- 当模型发出完成信号或达到轮次限制时,一个评分器在同一个容器内部执行测试,并将结果与预期输出进行比较,产生一个可验证的奖励信号
- 模型可以使用两个常用工具:
- Bash:执行 bash 命令并返回标准输出和错误流的工具
- String replace editor:允许模型通过精确字符串替换来编辑文件的工具
- 注:String replace editor 避免了字符串操作时使用不符合人体工程学的 bash 工具 (Anthropic, 2025)
- 完整的工具描述和参数模式在附录 D 中提供
In-house scalable SWE environment building,内部可扩展的 SWE 环境构建
- 现有工作 (2024; 2026b; 2026) 探索了将来自互联网的原始代码仓库转换为 RL 环境
- 本文使用公共 GitHub 仓库的 Issues 和拉取请求作为原始数据的来源
- 并开发了一个可扩展的 Pipeline ,用于摄取真实世界的可验证 SWE 问题,其灵感来自 SWE-ReBench (2026a,b)
- 为了构建高质量的 RL 环境,本文确保问题陈述为 Agent 正确实现解决方案提供足够的信息,而不会过度指定任务
- 本文还确保评分器提供足够的覆盖率,同时避免过于具体的评估标准
- 该 Pipeline 由以下阶段组成,额外的 Infrastructure 细节在附录 F 中提供:
- 1) Public GitHub PR and issue collection Pipeline 从 102M 个公共 GitHub PR 开始
- 第一步:过滤 PR 以获得适合环境构建的子集
- 要包含在内,PR 必须已合并到其仓库的主分支,并且修改少于 15 个文件
- 每个 PR 还必须包含代码和测试更改,以便评分器可以利用测试更改作为隐藏测试来评估模型修复问题的能力
- 测试和代码更改根据补丁中的文件内容进行拆分
- 第二步:进一步基于 Issues 链接过滤 PR,保留与 GitHub、Jira、Bugzilla、YouTrack、Phabricator、Launchpad 或 Linear Issues 关联的 PR
- 在此阶段之后,获得了大约 4.87M 个带有链接 Issues 的 PR
- 第一步:过滤 PR 以获得适合环境构建的子集
- 2) Automatic agentic environment building
- 使用一个 LLM Agent 将选定的 PR 转换为可训练的环境,该 Agent 读取仓库状态并创建 Docker 文件以构建可执行的容器镜像
- 通过执行测试套件来验证每个镜像,并丢弃存在依赖或环境错误的构建
- 3) Reference grading signal extraction
- 对于每个候选问题,通过针对基础提交在两个阶段执行仓库测试套件来推导参考测试结果:
- 首先仅应用测试差异 (修复前)
- 然后同时应用测试和代码差异 (修复后)
- 从失败变为通过的测试 (fail-to-pass, F2P) 构成了问题解决信号,要求模型补丁翻转 (flip) 这些测试才能获得解决该问题的信用
- 在两个阶段都保持通过的测试 (pass-to-pass, P2P) 构成了回归信号,确保生成的补丁不会破坏现有功能
- 注:没有存活 F2P 测试的问题被丢弃
- 对于每个候选问题,通过针对基础提交在两个阶段执行仓库测试套件来推导参考测试结果:
- 4) Environment and grader verification
- 在获得可执行环境、测试和代码更改、测试执行脚本以及预期的修复前和修复后结果后,在 RL 训练期间使用的相同 SEE 训练 Infrastructure 内重新验证这些环境
- 这是针对环境构建沙箱和训练沙箱之间潜在差异的最终合理性检查
- 验证一个空代码补丁无法通过评分器,而 Golden 解决方案补丁能够成功,每次验证都进行多次试验
- 尽管上游补丁已知是正确的,但由于集群差异 (如网络出口策略、CPU/内存限制、执行超时),重新验证仍可能失败
- 本文进一步过滤 在重复执行中表现出非确定性测试行为的环境,以减少奖励噪声
- 5) Quality filtering and SWE environment rewriting
- 仅靠正确执行和无懈可击的测试是不够的,因为许多环境仍然包含低质量或未充分陈述的问题
- 例如,本文经常观察到简短模糊的错误描述、不完整的规范,或诸如 “修复问题” 之类的陈述,其中预期行为仅被隐式编码在隐藏测试中
- 如果问题陈述与评分器运行的最终测试期望之间存在巨大差距,那么模型就必须猜测测试的要求
- 1) Public GitHub PR and issue collection Pipeline 从 102M 个公共 GitHub PR 开始
- 为了改善环境质量,本文在同一个环境内部署一个 Agent 来检查问题陈述、仓库和测试,并根据规范清晰度、测试质量、泄漏风险和可行性对任务进行评分
- 对于低质量的环境,Agent 会重写问题陈述,以更好地与测试要求对齐,同时避免不必要的信息泄漏或过度规范
- 在最初的 4.87M 个候选问题中
- 有 2.08M 个 (42.8%) 成功通过了自动 Agentic 环境构建
- 745,452 个 (15.3%) 通过了参考评分信号提取
- 265,617 个 (5.5%) 存活的环境和评分器验证
- 注:这在 94,044 个唯一仓库中
Synthetic data
- 虽然环境构建 Pipeline 生成的许多环境未能通过验证,但其中很大一部分仍然是有效的可执行环境
- 在大多数情况下,失败是由于低质量的问题陈述或测试覆盖率不足,而不是无效的执行环境
- 为了重用这些可执行环境,本文采用了受 BugPilot (2025)、SWE-Smith (2026) 和 SWE-Mirror (2025a) 启发的方法,从与成功构建但未能通过质量检查的 PR 相关联的环境中生成新的合成问题和相应的测试
Preventing reward hacking during RL training
- 即使 SWE 环境使用可验证的、可执行的测试用例进行评分,它们仍然容易受到 Reward Hacking 的影响
- 使用一个 LLM 监视器来审查 Rollouts,并对标记的示例进行人工审查
- 这识别出三种主要的 Reward Hacking 类型:
- 互联网搜索 (Internet search).
- 由于 RL 环境源自 GitHub 上的公共仓库,PR (以及因此 Golden 解决方案) 通常可以通过搜索找到并检索
- 本文通过对沙箱执行环境实施网络访问控制来防止这种情况,要么在问题自包含时禁用互联网,要么只允许问题所需的最基本网络访问
- 本地 Git 历史搜索 (Local git history search).
- Git 是软件仓库的组成部分
- 有时 Agent 会搜索所有 Git 提交和日志,试图找到隐藏在本地 Git 数据库中的解决方案提交
- 移除所有 Git 提交也是不可行的,因为 Git 是一项宝贵的技能,可以为解决问题提供必要的合法信息
- 本文通过清除在问题基础提交之后发生的提交、引用和分支来完全清理环境,以创建仓库回到原始状态的“时间旅行”版本
- 篡改测试 (Tampering with tests).
- 遵循 SWE-Bench (2024) 中使用的评估协议,本文在评分前重置 Agent 修改过的所有测试文件,以防止 Agent 篡改测试用例使其通过评分
- 本文还进一步在推理期间对 Agent 隐藏测试更改,并仅在评分时应用它们,以减少作弊的机会
- 但仍然存在作弊的途径,例如,通过 monkey-patching 测试框架或修改等价行为,这些不能轻易地通过简单地重置测试文件或引入隐藏测试来防止
- 本文使用 LLM 监视 Agent 行为,并不断加强测试文件检测、测试文件重置和其他反篡改启发式方法
- 互联网搜索 (Internet search).
General Tool Use
- 与 SWE RL 环境相比,通用工具使用 RL 环境在可用工具和应用领域方面表现出更大的多样性
- 它们涵盖了广泛的通用工具调用任务 (例如,库存管理、日程安排平台、报告创建、客户支持以及其他面向企业的场景),强调与外部系统的可靠和有状态的交互
Tool-use RL environments
- 每个工具使用 RL 问题被实例化为一个交互式的、有状态的环境,并由模拟真实 API 或 MCP (Model Context Protocol, 2026) 行为的模拟后端支持
- 具体来说,每个问题由以下几个部分组成
- 一个 Query
- 一组带有模式的可用工具
- 一个初始环境状态
- 一个评分器
- SWE 通常只涉及少量工具的,工具使用环境模拟了丰富的真实世界服务交互,在单个环境中通常包含超过 50 个工具
- 这种设置训练模型高效地选择适当的工具,并提高在多样化工具使用场景中的泛化能力
- 本文模型在人工策划的环境和工具调用任务生成框架生成的合成环境上进行训练,如下所述
- Synthetic environment,合成环境
- 为了增加训练数据的规模和多样性,综合生成了自包含的封闭世界环境,其中包含种子数据库、工具定义和可验证的任务
- 本文 Pipeline 只需要用简单的英语描述所需环境,就能端到端地生成完整的工具使用环境
- 这种方法遵循了先前关于自动生成工具使用环境的工作 (2025; 2026; 2026; 2026),特别是 FunReason-MT Pipeline (2025b; 2025)
- 总的来说,本文的目标是复制常见的企业和消费者工具使用场景,例如旅行预订和库存管理
- 本文的 Pipeline 包含三个主要阶段:
- (i) 环境引导 (environment bootstrapping),生成工具描述、实现函数并用相关实体填充种子数据库
- (ii) 任务创建,采样可能的工具调用轨迹,创建与交互链相关的实体,并制定用户请求
- (iii) 验证和改进,执行前一阶段生成的动作,并移除过于相似的任务
- 每个阶段都涉及多次 LLM 调用,用于诸如实体生成和函数实现等任务
- 本文还采用迭代的批判和改进循环来改进每个阶段的输出 (2023; 2023)
- 本文生成特定环境的角色 (personas) (2024) 以进一步多样化任务
- 为了减轻过度 eager 的工具调用行为,还增加了包含工具描述但不需要工具使用的任务
- 总的来说,本文的 Pipeline 合成了超过 150 个环境和 130,000 个任务
- 为了增加训练数据的规模和多样性,综合生成了自包含的封闭世界环境,其中包含种子数据库、工具定义和可验证的任务
- Reward design
- 在训练期间混合使用特定于环境的评分器和跨环境的评分器
- 特定于环境的评分器基于最终环境状态、工具使用模式和最终答案来分配奖励
- 对于合成环境,使用一个 LLM Judge 将任务分解为多个子任务,并独立对每个子任务进行评分
- 本文还采用跨环境的评分器来鼓励高效的工具使用,包括在可能的情况下进行并行工具调用、避免重复调用以及使用有效参数类型和实参正确调用工具
Helpfulness and Safety Climb
- 帮助性和安全性 RL Climb 根据人类偏好、指令遵循、可引导性 (steerability)、安全性、诚实性和风格来优化 MAI-Thinking-1 的通用帮助性 (2022; 2019; 2024a)
- 这次 Climb 与其他 Climb 的不同之处在于,它侧重于那些性能不是客观定义且机器可验证的任务
- 本文通过首先描述 RL Climb 期间使用的所有奖励信号 (Sec. 3.4.1),然后介绍每个领域的具体数据方案和奖励设计来组织本节
Rewards
- 与其他 Climb 相比,帮助性和安全性 Climb 结合了更多样化的奖励类型来指导模型行为的主观方面
- 结合使用了在人类偏好数据上训练的 Reward Model (2025)、AI Judge 反馈 (通常基于 Rubric) (2024) 以及额外的可验证奖励 (2025; 2026) 来形成聚合奖励信号 (2024; 2024c)
Reward model
- 奖励模型基于 MAI-Base-1 的后训练版本,对其进行微调以预测表示为文本 Token 的人类偏好
- 完全在来自多个供应商的人类标注员收集的人类偏好数据上进行训练
- 采用 RRM (RRM: Robust Reward Model Training Mitigates Reward Hacking, 20240920, ICLR 2025, Google DeepMind) 中描述的鲁棒 Reward Hacking 缓解 Pipeline 来对抗训练数据中的相关偏见
- Training
- 对于一个上下文 \(c\) 和 \(k\) 路并排 (side-by-side) 响应 \(y_{1}, \ldots , y_{k}\),以及相应的分数 \(s_{1}, \ldots , s_{k} \in [1; 5]\),奖励模型的输入是
$$c< |\text{im_sep}| > y_{1}< |\text{im_sep}| > y_{2}< |\text{im_sep}| > \ldots < |\text{im_sep}| > y_{k}< |\text{im_sep}| >$$- 其中,training 目标是序列 \(s_1\ldots s_k\),通过 SFT 进行训练
- 问题:这里的训练数据如何构造?
- 理解,这里相当于是个 GRM 的形式,每次预测训练目标是对应的分数序列
- 对于一个上下文 \(c\) 和 \(k\) 路并排 (side-by-side) 响应 \(y_{1}, \ldots , y_{k}\),以及相应的分数 \(s_{1}, \ldots , s_{k} \in [1; 5]\),奖励模型的输入是
- Inference
- 将多个候选响应包含到单个奖励模型上下文中,可以更好地校准跨响应的点式质量分数
- 但由于奖励模型的自回归特性,这也会增加分数 \(y_{i,i > 1}\) 的噪声
- 为了应对这一点,本文循环应用奖励模型:
- 对于给定的上下文 \(c\) 和 \(k\) 个响应 \(y_{1},\ldots ,y_{k}\),在响应排列 \((y_{1},\ldots ,y_{k})\), \((y_{2},\ldots ,y_{k},y_{1}),\ldots ,(y_{k},y_{1},\ldots ,y_{k - 1})\) 上提示奖励模型 \(k\) 次
- 对于这 \(k\) 次推理调用中的每一次,仅解码第一个 Token ,并查看该 Token 的完整概率分布(理解:这个概率分布应该是 打分分布(比如在 [1,2,3,4,5] 词表上的分布))
- 对于第 \(i\) 次调用,它对应于第 \(i\) 个候选响应的奖励分数 \(s_i\)
- 理解:这里相当于是为了消除位置偏差,仅仅将第一个 token 作为识别第一个相应的概率
- 奖励信号 \(R_{\text{RM} }(c,y_i)\) 则被设置为 \(y_{i}\) 被评为最高质量 \((s_i = 5)\) 的概率
- 对于给定的上下文 \(c\) 和 \(k\) 个响应 \(y_{1},\ldots ,y_{k}\),在响应排列 \((y_{1},\ldots ,y_{k})\), \((y_{2},\ldots ,y_{k},y_{1}),\ldots ,(y_{k},y_{1},\ldots ,y_{k - 1})\) 上提示奖励模型 \(k\) 次
- 发现:这比本文考虑的其他替代方案提供了更稳定的 Climb 信号
- 将多个候选响应包含到单个奖励模型上下文中,可以更好地校准跨响应的点式质量分数
- Evaluation.
- 使用由标注员评级的实际训练 Rollouts 和奖励模型训练数据的验证集来评估奖励模型
AI Judge
- 除了微调奖励模型提供的人类偏好信号外,还采用 AI Judge (2024; 2025) 来获得可以快速调整并针对任何给定上下文进行定制的反馈
- 特别是,AI 反馈提供了一个快速杠杆,可以以有针对性的方式塑造模型的行为,而无需因奖励模型数据收集和重新训练而导致的延迟
Verifiable rewards
- 使用可验证奖励来提高在指令遵循等领域的能力,这些领域的约束遵守情况可以直接检查
- 例如,对于要求“用一个段落回答”或“使用少于 10 个词”的上下文,会包含可验证奖励
- 与不可验证奖励相比,可验证奖励更不容易受到 Reward Hacking (2025b; 2024) 的影响,对多轮次 (multi-epoching) 不那么敏感,并且通常对稳定训练有用
- 可验证奖励也用于减轻不可验证奖励中的偏见
- 例如,AI 反馈 Rubric 往往会对长度和风格元素产生向上压力 ,通过使用奖励模型和可验证奖励来减轻这种压力
- 具体来说,对于长度,离线识别每个上下文可接受的 Response 长度分布 ,并对落在预定义分位数范围之外的 Response 进行惩罚
- 这可以在训练过程中稳定 Response 长度,而不会过度约束响应或引入一个可以通过将 Response 压缩得过于简洁而被破解的奖励
Combining rewards
- 在为帮助性和安全性 Climb 优化这些奖励时,会出现两个挑战 (2024c)
- 首先,不同类型的奖励处于不同的尺度,不能直接比较
- 其次,奖励分布本身依赖于上下文,对于某些 Prompts 来说很窄,对另一些来说很宽
- 简单地求和这些奖励会导致幅度最大的信号主导一切,而不管其重要性如何
- 此外,虽然我们希望联合优化奖励,但某些标准是无可争议的:
- 例如,一个写得好但不安全的响应仍然是不可接受的,无论其质量如何
- 此外,虽然我们希望联合优化奖励,但某些标准是无可争议的:
- 本文通过两种互补的策略来解决这些挑战,并根据上下文选择性地应用它们
- 词典奖励塑造 (Lexicographic reward shaping).
- 对于一组上下文,只有当 Rollout 组中的所有响应在更高优先级的奖励上得分相同时,较低优先级的奖励才会被激活
- 这引入了一个严格的优先级排序,其中只有当主要奖励在 Rollout 组内持平时,次要奖励才会影响梯度 (2022)
- 因为它是基于组内相对比较进行操作的,所以这种形式也对每个奖励的绝对尺度保持不变
- 门控奖励应用 (Gated reward application).
- 对于其他上下文,更高优先级的奖励必须满足最低性能水平后,才能应用较低优先级的奖励 (2017)
- 安全性是典型情况:一个不安全的 Response 会获得最低奖励,并且永远不会在响应质量上进行评分
- 词典奖励塑造 (Lexicographic reward shaping).
Instruction Following and Steerability,指令遵循和可引导性
- 指令遵循 (Instruction Following, IF) 是 LLM 的一项核心能力:
- 模型应遵守用户在对话中直接指定的约束、API 用户通过开发者指令指定的约束,以及平台所有者通过特权系统指令指定的约束
- 模型应根据预定义的优先级,能够跨这些格式和行为约束进行引导 (steerable) (2024)
- 为了构建强大的指令遵循能力,本文构建了一个数据集,涵盖了一系列约束、场景和复杂程度,这些数据来自合成数据和专家人工标注
Data
- 使用两个不同的数据来源:专家编写的上下文和合成数据
- 发现:专家编写的 Prompt 中的复杂约束有助于引导能力的启动,而合成数据则能实现最大覆盖
- Synthetic data generation
- 受先前工作 (2025a; 2025) 的启发,本文构建了一个灵活的多阶段 Pipeline ,用于生成具有评估 Rubric 的真实指令和场景
- 补充:
- 参考工作1:(Evol-Instruct)WizardLM: Empowering large pre-trained language models to follow complex instructions, Microsoft & PKU, arXiv 20230424, 20230610, 20250527
- 参考工作2:(AutoIF)Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models, ICLR 2025, Qwen Team
- 首先使用 LLM 生成 Prompt 指令和模型规范,该 LLM 受到人工整理的约束分类法 (详见 Sec. E) 和一组多样化的种子的指导
- 随后是生成场景
- 这些场景是多语言的,涵盖短对话和扩展对话,包括包含系统、开发者和用户消息的情况,并跨越包括编码、写作、分析和旅行规划在内的 40 多个领域
- 此外,还包括具有冲突的系统、开发者和用户指令的对抗性案例 ,以训练模型尊重指令层次结构
- 最后一步是批判和重写,根据自然性、Rubric 对齐和 groundedness 来评估和更新每个场景
- 补充:
- 受先前工作 (2025a; 2025) 的启发,本文构建了一个灵活的多阶段 Pipeline ,用于生成具有评估 Rubric 的真实指令和场景
- Data filtering
- 通过多轮过滤、结合各种质量启发式方法、复杂度过滤和拒绝采样来保持高质量数据
- 特别是,Rubrics 会根据其自洽性、明确性以及与既定约束的一致性进行验证,同时根据作者的安全策略筛选 Prompts\
- 遵循 POLARIS: A POst-training recipe for scaling reinforcement Learning on Advanced ReasonIng modelS, 2025, UHK & ByteDance & Fudan,本文还通过 Pass Rate 分析来控制难度级别
- 只保留那些对作者的模型来说具有挑战性但可解决的例子
- Reward design
- 为了在 RL 期间防止退化的响应和 Reward Hacking ,使用了混合奖励信号
- 对于具有确定性验证器的约束,使用基于规则的检查
- 这提供了快速、确定性和良好校准的奖励信号
- 另外用一个 LLM Judge (Sec. 3.4.1) 独立评估原子 Rubrics ,每个 Rubric 产生一个二元判断
- 为了鲁棒性,对多次判断传递的结果进行平均
- 用训练好的奖励模型评估通用响应质量,以补充特定于约束的 IF Judge
- 对于具有确定性验证器的约束,使用基于规则的检查
- 奖励使用 Sec. 3.4.1 中的词典评分聚合方案进行组合,其中特定于 IF 的奖励作为主要信号
- 理解:即 词典奖励塑造 (Lexicographic reward shaping) 方案,只有在更高优先级的奖励上得分相同时,较低优先级奖励才会被激活
- 为了在 RL 期间防止退化的响应和 Reward Hacking ,使用了混合奖励信号
Safety
- 根据对支持人类自主性的承诺,将安全性定义为模型提供符合政策的帮助性响应的能力 (Microsoft, 2022)
- Data
- 为了使训练与这一目标保持一致,为数据策划开发了一个分类法
- 安全数据针对两种互补的失败模式:
- 不安全遵从 (unsafe compliance),即模型满足了一个它应该拒绝的请求
- 过度拒绝 (over-refusal),即不必要地拒绝了一个合法请求
- 每个候选示例都根据政策分类法进行标注,并被分配到两个 Prompt 类别之一:
- 有害 Prompts (Harmful prompts): 政策部分或完全禁止协助的请求
- 响应策略是完全拒绝或部分拒绝 (拒绝不安全部分,同时提供安全替代方案)
- 所属不清的 Prompts (Borderline prompts): 涉及敏感领域但仍在政策范围内可以回答的请求
- 响应策略是不拒绝:提供有边界的、有帮助的答案,而不是回避或拒绝
- 有害 Prompts (Harmful prompts): 政策部分或完全禁止协助的请求
- Data sources
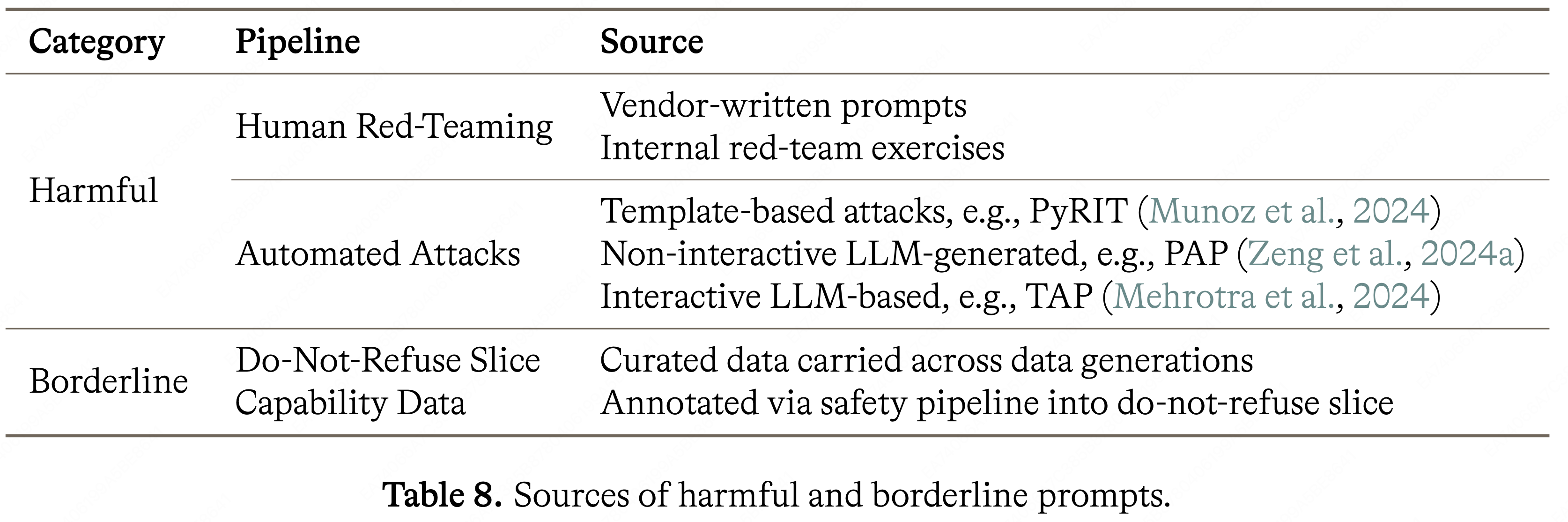
- 表 8 总结了每个类别中 Prompts 的来源
- 有害 Prompt 通过人工红队测试和自动对抗生成来收集
- Borderline Prompt 来自跨数据世代延续的现有 “不拒绝” 切片,以及通过安全标注 Pipeline 路由并被选入 “不拒绝” 切片的能力数据,使模型接触应在政策范围内可回答的请求
- 表 8 总结了每个类别中 Prompts 的来源
- Reward design
- 每个模型响应由安全 Judge 沿着三个维度进行评分:
- 政策合规性 (Policy compliance) 衡量响应是否违反了作者的安全政策
- 响应参与度 (Response engagement) 将响应的参与度水平与预期目标 (拒绝、部分拒绝或不拒绝) 进行比较,惩罚过度拒绝和对严重请求的遵从
- 响应风格 (Response style) 衡量响应是否遵循预期的语气和指导原则,例如,对于敏感的自我伤害请求,承认困难而不进行道德说教或向用户复述创伤性事件
- Judge 的分数与奖励模型的奖励信号以及 (根据数据源) 额外的 AI Judge 信号相结合
- 简单的加权平均是不够的:标量奖励在不符合政策的响应上可能仍然保持正值
- 因此本文使用了一个安全门控聚合器:政策合规性字段按照 Sec. 3.4.1 中的描述对奖励进行门控
- 如果安全 Judge 标记一个响应为不合规,则该 Rollout 无论其他分数如何都获得最低奖励;否则,使用正常的加权混合
- 每个模型响应由安全 Judge 沿着三个维度进行评分:
Honesty
- 本文将诚实性定义 为模型在知道答案时产生正确响应,并在不知道时适当规避 的能力
- 同时,模型不应过度规避,因为仅最小化事实错误可能会简单地促使模型做出更少的断言 (2023)
- 因此,目标必须平衡事实精确性与信息量
- Data
- 本文整理了一组多样化的数据,包括来自供应商的人工策划数据、经过 PII 过滤的消费者 Copilot 日志以及合成生成的数据
- 受先前工作 (2024; 2024b,c) 的启发,本文的数据涵盖了一个难度范围:
- (a) 已建立的事实查询,包括短格式和长格式,其响应可以对照参考答案进行精确验证
- (b) 具有挑战性的事实查询,针对长尾或晦涩主题,预计模型覆盖率不一致,且参考标签通过搜索增强验证生成
- (c) 错误前提查询,其中问题包含一个错误预设,并且不存在正确的肯定答案
- 覆盖这些边界情况促使模型保持事实完整性,并且仅在缺乏知识时才进行规避
- Reward design
- 对于事实性评分,每个 RL 示例的参考标签通过检索增强生成和验证离线生成
- 然后,每个模型响应由一个 LLM Judge 沿着两个维度 (事实性和置信度) 进行评分,产生五个类别之一:
- CONFIDENT_CORRECT, UNCONFIDENT_CORRECT, NOT_ATTEMPTED, UNCONFIDENT_INCORRECT 和 CONFIDENT_INCORRECT
- 这些通过加权求和组合成一个标量奖励:
- 自信正确的响应获得最高奖励,自信的幻觉受到最严厉的惩罚,弃权获得中性奖励,而不自信但正确的响应获得较低的奖励以阻止过度规避
Style
- 本文定义了一个风格指南,规定了好的输出是什么样的:
- 热情而不谄媚,易于浏览的结构,以及根据上下文校准的语气,而不是简单地模仿用户
- 风格指南还涵盖了何时以及如何使用表情符号、正式程度、数学和代码的表示法,以及一般的文本密度
- 表 9 给出了训练模型遵循的指导原则的高级示例

- Data
- 风格是在一套广泛的、经过 PII 过滤的 Microsoft 消费者 Copilot 日志、供应商编写的上下文 (包括静态和交互式) 以及 Arena 对话上进行评分的
- 这些数据涵盖了低到中等难度的 Prompts,排除了复杂的指令遵循、编码、数学和 STEM
- Prompts 根据用户意图进行分类 (例如,创意写作、实用指导、信息寻找和闲聊),并积极收集模型表现薄弱的领域的 Prompts
- 理解:这说明这里的风格是来自真实人类的倾向的,如果在 ChatBot 中添加一些真实反馈渠道,收集更多的反馈信号会更好
- Reward design
- 除了 Sec. 3.4.1 中介绍的奖励模型外,本文还使用 Prompted LLM Judge 沿着特定轴对输出进行评分,并惩罚不良行为
- 这些 Prompted Judge 以 0、1 或 2 的整数尺度对响应进行评分,表示主要、次要或没有风格问题
- 发现:粗粒度评分器优于更细粒度的评分器或特定于 Prompt 的 Rubric,因为它们给予 LLM Judge 更多的灵活性来为给定的 Prompt 和 Response 适当地解释 Rubric,使得模型更难 Hack 评分器
- 风格评分器仅在可验证奖励和安全约束得到满足后应用,并根据领域与其他评分器一起加权
- 除了 Sec. 3.4.1 中介绍的奖励模型外,本文还使用 Prompted LLM Judge 沿着特定轴对输出进行评分,并惩罚不良行为
Consolidating Capabilities into a Single Model,将能力整合到单一模型中
- 前面的部分描述了三个教师模型:
- STEM 和竞争性编码 (Sec. 3.2)
- Agentic 能力 (Sec. 3.3)
- 帮助性和安全性 (Sec. 3.4) 独立训练
- 本文分两个阶段将它们整合到一个单一模型中,如图 12 所示
- SFT 阶段重用了 Sec. 3.1.4 中的自蒸馏 Pipeline ,并将其应用于每个专家教师,尽管三个教师需要不同的过滤和拒绝采样策略
- 对于 STEM 和 Agentic 教师:
- 按照 Sec. 3.1.4 中的多样性发现,对每次 Climb 的多个检查点进行 Rollout 采样,优先考虑较晚的检查点
- 本文为每个上下文保留多个正确的 Rollouts,并仅应用轻量级过滤来移除退化的 CoT
- 对于帮助性和安全性教师:
- 使用 LLM Judge 和启发式过滤器,除了正确性之外,还对轨迹的风格、结构和已知缺陷进行评分
- 使用 LLM Judge 和启发式过滤器,除了正确性之外,还对轨迹的风格、结构和已知缺陷进行评分
- 对于 STEM 和 Agentic 教师:
- SFT 阶段重用了 Sec. 3.1.4 中的自蒸馏 Pipeline ,并将其应用于每个专家教师,尽管三个教师需要不同的过滤和拒绝采样策略
Consolidation SFT,整合 SFT
- SFT 阶段将三个教师蒸馏到一个单一模型中
- 本文迭代了数据混合和超参数,以平衡推理、Agentic 和通用帮助性能力,并在公共基准、内部基准和人工评估上进行评估
- 表 10 报告了按样本和 Token 权重划分的最终混合结果

- 表 10 报告了按样本和 Token 权重划分的最终混合结果
- 发现:按样本权重平衡混合非常重要
- Token 分布相应地由 STEM 和编码主导,这是由于它们的轨迹较长,在实践中这不会损害帮助性和安全性能力
- 与本文的标准自蒸馏方案不同,整合 SFT 进行了 4 个轮次,从最大值 \(1\cdot 10^{- 5}\) 开始将学习率衰减 \(2\times\)
Consolidation RL,整合 RL
- 最后一阶段的轻量级 RL 进一步提高了安全性、过度拒绝和风格
- 该方案基于帮助性和安全性 Climb (Sec. 3.4),但进行了一些更改以保持推理性能
- 以 128k Tokens 的最大序列长度进行训练,并在 RL 混合中保留一小部分 STEM 和编码数据
- 发现:两者都很重要,因为否则复杂任务的推理性能会在 Climb 过程中缓慢下降
RL Infrastructure (Reinforcement Learning Infrastructure)
- RL Climb 依赖于 Rocket
- Rocket 是一个用于大规模异步分布式 RL 的内部框架,为 learner 使用 YOLO (Sec. 2.8),为模型推理使用 SGLang (2024)
- 构建 Rocket 是因为需要在 MAI-Thinking-1 所需的数千个 GPU 规模上支持异步 RL 的能力,是现有的开源 RL 框架 (2020; 2024; 2024) 无法满足的
- Rocket 的核心 RL 数据流围绕一个单一的 Controller、一个问题 Worker (problem worker) 和 Rollout Worker 池,以及产生模型生成的路由器 (router) 和推理服务器 (inference server) 进行组织
- Controller 、问题 Worker 和 Rollout Worker 各自实现为单个 Python 进程 / Ray Actor,而路由和推理由基于 SGLang 的服务栈提供
- Rocket 架构的概览如图 19 所示
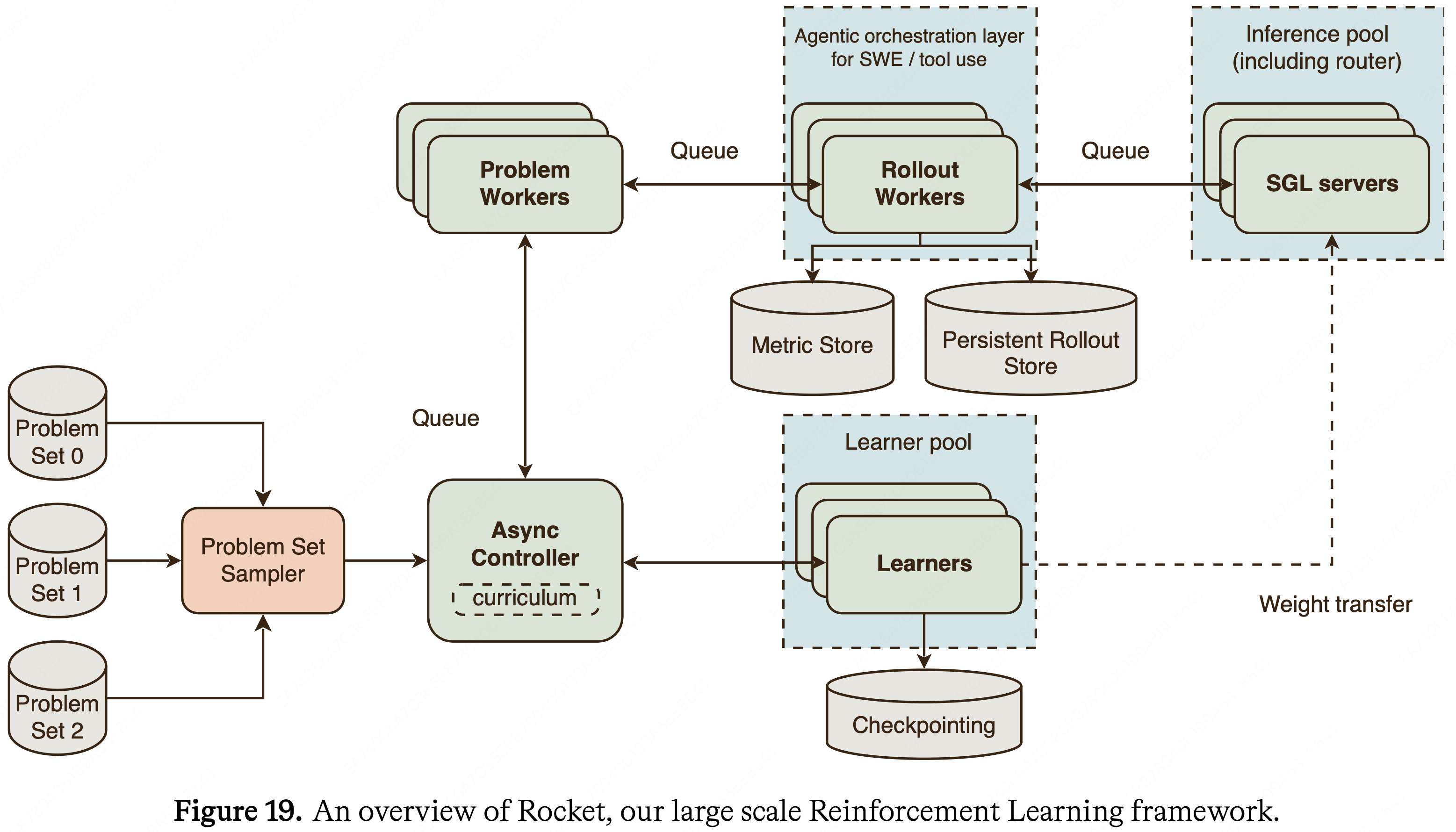
Controller
- Controller 加载 RL 任务并将它们发送给问题 Worker 进行处理
- 对于每个任务, Controller 接收一组已完成的 Rollouts 以及相关的评分元数据 (通过/失败决策、奖励、归一化优势等)
- Controller 过滤已完成的 Rollouts,并将它们作为批次发送给 Learner
- Controller 的抽象允许 Rocket 在 on-policy 和 off-policy RL 之间切换不同的 Controller 实现
- 在实践中,主要将 off-policy RL 用于大型运行 ,并将 on-policy RL 保留用于较小的实验和调试
Problem Worker
- 当问题 Worker 从 Controller 接收到一个 RL 任务时,它会生成一组 Rollouts,为每个 Rollout 计算归一化优势,并将结果发送回 Controller
- 问题 Worker 本身不处理 Rollout 生成,它向 Rollout Worker 发送一组请求(每个 Rollout 一个)
- 问题 Worker 为大规模异步 RL 实现了容错,例如,如果 Rollout Worker 失败,则重试某个任务的 Rollouts
- 对问题 Worker 的单个请求的典型流程是:
- 1)提前退出 Rollouts (Early-exit rollouts).
- 遵循 Sec. 3.1.3 中描述的提前退出策略,问题 Worker 从 Controller 接收一个 RL 任务,并向 Rollout Worker 发送 16 个请求,根据需要重试失败的请求
- 每个 Rollout 都被评分,并将此信息聚合成任务的总体 Pass Rate
- 如果总体 Pass Rate 在预定区间内,问题 Worker 继续进行完整 Rollout 阶段
- 否则,RL 任务被中止
- 2)完整 Rollouts (Full rollouts).
- 问题 Worker 向 Rollout Worker 发送额外的 128 个请求,再次根据需要重试失败的请求
- 每个 Rollout 都被评分,并将此信息聚合成任务的总体 Pass Rate
- 如果总体 Pass Rate 在预定区间内,问题 Worker 继续进行后处理
- 否则,RL 任务被中止
- 3)后处理 (Postprocessing).
- 问题 Worker 为每个 Rollout 计算归一化优势,以用于 RL 目标 (Sec. 3.1.1)
- 根据具体问题,此步骤可能包括对长 Rollouts 应用长度惩罚、应用 GRPO 奖励归一化或其他启发式方法
- 1)提前退出 Rollouts (Early-exit rollouts).
Rollout Worker (Rollout Worker)
- 当 Rollout Worker 从问题 Worker 收到请求时,它会生成单个 Rollout,可选择对其进行评分,然后将结果发送回调用者
- 在典型流程中,Rollout Worker 首先生成一个初始模型 Prompt,并将其发送给模型推理服务器
- 当响应返回时,Rollout Worker 解析它,执行任何工具调用,并将结果合并到对推理服务器的后续请求中
- 此过程一直持续,直到模型停止发出工具调用并输出最终答案,或者超过某些预先确定的步骤数或 Rollout 时间限制
- Rollout 完成后,下一步是对模型的输出进行评分
- 评分器的输出包含一个数值奖励和一个可选的通过/失败判定
- 根据问题的不同,评分可以在 Rollout Worker 或问题 Worker 上进行
- 如果可以孤立地评估单个 Rollouts,则评分由 Rollout Worker 执行
- 例如,在一个数学问题上,如果模型的输出在数学上等价于问题的真实答案,评分器可能输出 (1, pass),否则输出 (0, fail)
- 一些评分器需要同时查看多个 Rollouts 的答案,例如,以便它们可以要求一个 LLM 对不同的模型答案进行成对比较
- 在这种情况下,评分发生在问题 Worker 上
- 单个问题可以有多个评分,在这种情况下,用户定义的策略将各个评分聚合为一个单一的总体奖励
- 如果可以孤立地评估单个 Rollouts,则评分由 Rollout Worker 执行
Router and Inference
- 推理是系统中最重要的组件之一:根据作业的规模和特性,推理 GPU 与 Learner GPU 的比例可高达 5:1
- 在使用 4864 块 GB300 芯片的最大 RL 作业中,4096 块芯片专用于推理,而其余 768 块芯片专用于 Learner
- 因此,推理性能和系统稳定性是首要关注点
- Learner 和推理引擎之间的数值差异对于控制 RL 训练稳定性至关重要
Inference setup
- 本文的 RL 推理栈构建在 SGLang 和 SGLang 路由器之上 (2024)
- 选择 SGLang 是因为它满足本文对丰富 RL 服务功能集、针对开源模型的快速实验能力以及强大的生态系统发展速度的需求
- 在单个 SGLang Worker 之上,使用 SGLang 路由器来处理负载均衡、流量控制和前缀缓存
Inference performance,推理性能
- 由于作业的大部分 GPU 使用来自推理,因此优化推理吞吐量对于高效的 RL 至关重要
- 注:最小化请求延迟对于控制陈旧度 (staleness) 也至关重要
- 根据 Rollouts 是在单轮还是多轮中进行来专门化优化
- 对于单轮工作负载,Prompts 通常很短,但生成 (包括思考) 可能长达 128k Tokens,因此主要瓶颈是 KV 缓存内存
- 通过注意力机制的专家并行和数据并行来减少 KV 缓存和权重的占用
- 禁用前缀缓存,以便在长生成期间可以完全驱逐滑动窗口注意力 Token (本文的模型架构 heavily relies on sliding window attention)
- 本文进一步通过 MLP 层上的数据并行、DeepEP (Deep-EveryParallel) (2025a) 和 EPLB (Expert Parallelism Load Balancer) (DeepSeek-AI, 2025) 来减少通信开销
- 对于多轮工作负载,Prompts 可能会变得非常长,而生成通常很短,这使得这些工作负载主要是预填充 (prefill) 密集型
- 在这里,heavily rely on 前缀缓存:在生产 RL 运行中,前缀缓存命中率达到 \(97 - 98%\)
- 对于单轮工作负载,Prompts 通常很短,但生成 (包括思考) 可能长达 128k Tokens,因此主要瓶颈是 KV 缓存内存
Inference system stability,推理稳定性
- 在用于训练 MAI-Thinking-1 的拥有数千个推理芯片的 RL 规模下,单个副本 (replicas) 崩溃、挂起、变慢或因节点故障而失败是常态
- 推理层必须能够优雅地降级和重启,而不是在发生这种情况时导致整个作业失败
- 本文依赖三个层面的纵深防御
- 在副本级别,每个 SGLang 服务器运行一个自我监控器 (self-watchdog),探测自己的生成端点和监控调度器内存
- 一个不健康的副本会触发自身的优雅重启,以便编排器可以启动一个干净的替换
- 在路由器级别,SGLang 路由器充当中断器 (circuit breaker):
- 当后端副本变得不健康时,它停止接收新请求,在重新开放之前运行多阶段探测,并定期重新发现从其活动集中悄然掉落的副本
- 每个副本的流控制 (per-replica flow control) 可防止慢副本积累会降低整个池性能的积压
- 在作业级别,一个存活监控器 (liveness monitor) 跟踪每个类别 (推理副本、路由器、Rollout Worker 、 Learner ranks) 中活跃 Actor 的数量
- 如果任何类别低于其允许的阈值,则使作业失败以进行干净重启
- 一个正交的步骤进展监控器 (step-progress watchdog) 捕获更难处理的情况,即一切似乎都在运行但训练已停止进展
- 在副本级别,每个 SGLang 服务器运行一个自我监控器 (self-watchdog),探测自己的生成端点和监控调度器内存
- 当 Rollout Worker 向推理服务器的请求在半途中失败时,将针对另一个副本进行重试,因此单个副本的失败会降低池的吞吐量,但不会丢失 Rollouts
Numerics gap between inference and learner, 训推差异
- RL 的一个关键方面是推理引擎和 Learner 之间的数值差异
- YOLO ( Learner ) 和 SGLang (推理引擎) 使用不同的内核、调度和并行策略
- 即使是很小的每 Token logprob 差异也会在长 Rollouts 中累积,并可能破坏 off-policy RL 中的重要性采样校正
- 为了缓解这些问题,本文在 RL 运行中对 Learner 和推理引擎都使用 bf16
- 这产生比本文评估的低精度替代方案小得多的数值差距和更稳定的训练
- 在 bf16 之上,应用 MoE 路由重放 (2025) 和 top-\(p\) 掩码重放 (Sec. 3.1.3)
Weight Transfer,权重传输
- 从同步 RL 转向异步 RL 将权重传输变成了一个重复出现的分布式同步问题:
- 每 \(k\) 步,新鲜的 Learner 权重必须到达推理集群,而传输时间会带来推理空闲和额外的陈旧度
- 核心困难在于 Learner 和推理分配以不同的方式对相同的张量进行分片:
- 每一方可能使用不同的组合或程度的 FSDP、流水线并行、数据并行注意力以及张量布局,同时参数在精度、量化状态或矩阵布局上也可能不同
- 因此,每次传输都必须同时重新分片字节并执行每张量变换
- 传输计划 (Transfer plan).
- 本文将重新分片、数据移动和每张量变换编译成一个单一的传输计划,在作业启动时计算一次,之后重复使用
- 对于每个参数,规划器计算 Learner 和推理服务器分片布局的交集,并为每个非空的子分片重叠发出一个条目,记录源 rank、目标 rank、字节范围以及所需操作 (如 dtype 转换或布局排列)
- 重新分片隐含在这个交集中
- 每个 Learner rank 只发送其配对的推理 rank 需要的切片,从而消除了单独实现完整张量的需要
- 变换在成本最小化的一侧运行,运行时通过流水线处理打包、传输和解包,使得连续的 sub-shards 在时间上重叠
- 为了使规划与集群规模解耦,该计划针对一个理想化的拓扑 (一个 Learner 和一个推理服务器)
- 在运行时,每个源-目标对扩展为一个覆盖目标 rank 所有活动副本的传输组,因此当副本加入、离开或被替换时,该计划仍然有效
- 因为数据并行复制而不是分片参数,所以一个 DP 组已经拥有每个模型参数:计划不需要征用所有 \(D\) 个 Learner ranks
- 本文将其限制在一个 DP 组的子集中,每个子集与一个不相交的推理副本切片配对,并独立运行
- 一个 36 服务器的集群分成四组,并行执行 4 次 9 服务器传输,从而在提高吞吐量的同时控制故障爆炸半径
Evaluations
Benchmark Evaluations
- 本文将 MAI-Thinking-1 的性能与各种开源和闭源的前沿模型在公共基准和人类并排评估上进行比较
- 这些评估涵盖了广泛的领域,突显了模型在不同领域的多功能性:STEM、Agentic 编码、知识、指令遵循、长上下文、安全、健康、诚实和工具调用
- 除非另有说明,MAI-Thinking-1 的所有基准评估结果均报告为 4 次运行的平均值,使用统一的推理设置,温度为 \(T = 1\),top-\(p\) 采样为 \(p = 0.97\)
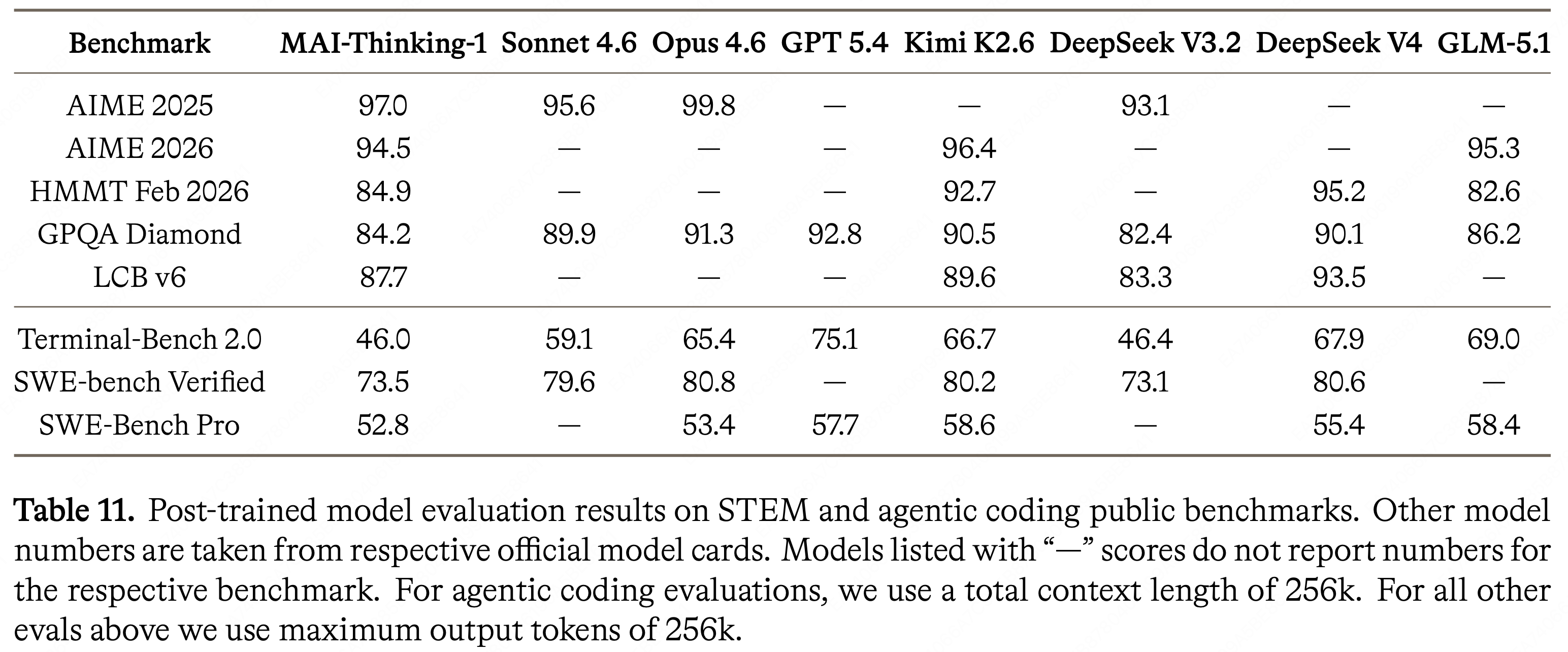
- 表 11 报告了作者在 STEM 和 Agentic 编码基准上的结果
- 注:参考了其他模型的官方模型卡和发布公告中的数据
- 综合来看,这些结果将 MAI-Thinking-1 置于其他流行 LLM 的竞争范围内:它并不领先,但在广泛的基准类别中提供了持续强劲的性能
- 注意:MAI-Thinking-1 在 AIME 2025 上超过了 Claude Sonnet 4.6,并且在 SWE-Bench Pro 上的性能接近 Claude Opus 4.6
- 此外,所有的 SWE Agentic 训练数据仅使用 bash 和字符串替换作为工具,不包括针对性的终端交互环境
- 因此,模型当前的 Terminal-Bench 性能反映了从更广泛的 Agentic 训练中的泛化能力,而不是在类似 Terminal-Bench 的环境上的直接训练
Math, science, and competitive coding
- 对于数学,在 2025 年和 2026 年的 AIME,以及 MathArena (2026) 的 2026 年 2 月 HMMT 基准上评估 MAI-Thinking-1
- 对于科学,在 Graduate-Level Google-Proof Q&A benchmark (GPQA) (2023) 上进行评估,该基准包含知识密集型、研究生和研究级别的问题,主要来自 STEM 领域
- 对于竞争性编码,在 LiveCodeBench v6 (LCB v6) (2024) 上进行评估,该基准包含最新的竞争性编码问题。更多评估细节见附录 G
Agentic coding and tool calling
- 对于 Agentic 编码,在 SWE-bench Verified (2024)、SWE-Bench Pro (2025) 和 Terminal-Bench 2.0 (2026) 上评估 MAI-Thinking-1
- 对于工具调用,在 BFCL v3 (2025) 上评估 MAI-Thinking-1
- 与 STEM 评估不同,这些评估是多轮的,需要模型与环境交互
- 对于所有三个基准,使用一个非常简单的 ReAct 风格 (2023) 循环来评估模型(理解:消息附加到图 18 所示的 Agent 循环中)
- 对于 SWE-bench Verified 和 SWE-Bench Pro,启用了 bash 和字符串替换工具
- 对于 Terminal-Bench 2.0,仅启用 bash 工具以模拟最基本的终端界面
- 为了消除推理速度和 Infrastructure 混杂因素 (Segato, 2026),忽略了 Terminal-Bench 2.0 的预定义超时
- 更多关于评估设置的细节在附录 H 中
General capabilities
- 在表 12 中,报告了在涵盖知识、指令遵循、长上下文、安全、诚实、健康和工具调用的基准上的结果
- 在这些领域的基准测试中,作者发现并非所有实验室都在模型卡或模型公告中报告官方结果
- 为了提供一个与 MAI-Thinking-1 比较的基线,使用最大推理努力和最大序列长度在这些基准上评估了 Sonnet 4.6,并将这些结果也报告在表 12 中
- 在大多数基准测试中,本文模型与 Sonnet 4.6 相当
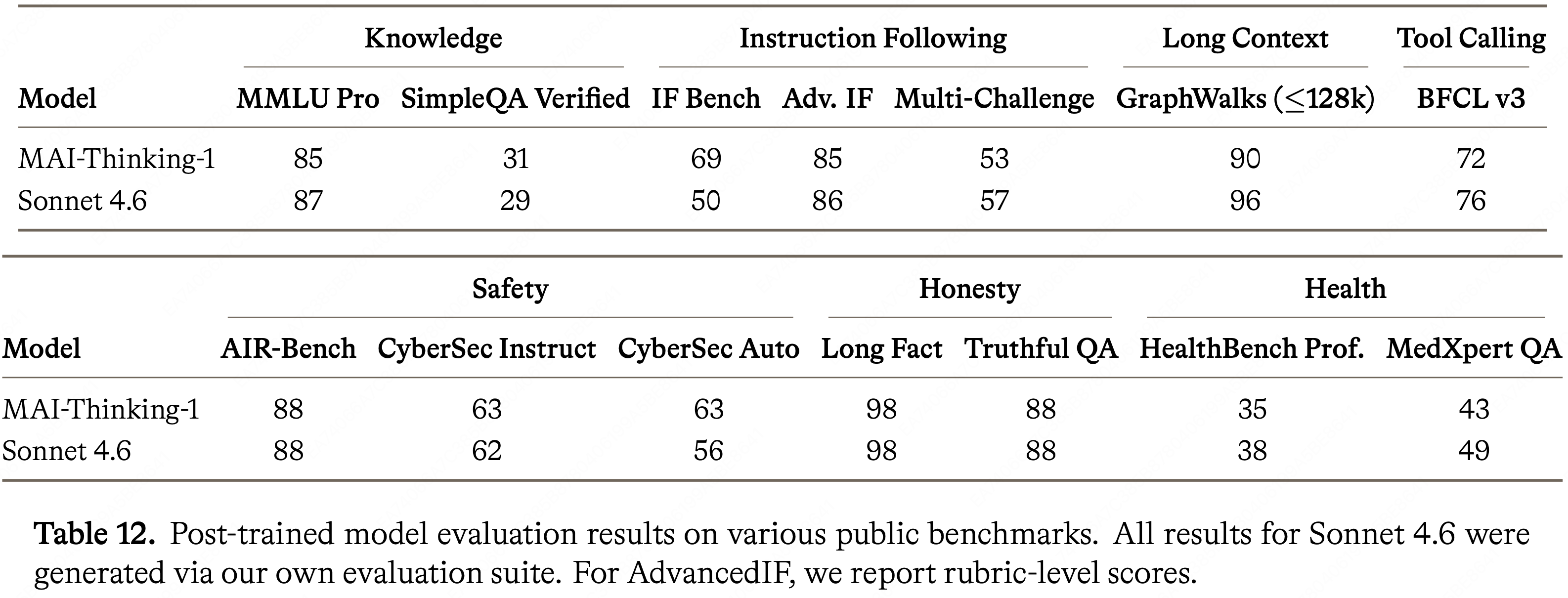
- 报告了以下部分:
- 知识推理能力的 SimpleQA Verified (2026) 和 MMLU-Pro (2024b)
- 指令遵循的 IFBench (2026)、AdvancedIF (2025) 和 MultiChallenge (2025)
- 长上下文能力的 GraphWalks
- 安全的 AIR-Bench (2024b) 和 CyberSecEval 4 (2024; 2024)
- 诚实的 TruthfulQA (2022) 和 LongFact (2024c)
- 健康知识任务的 HealthBench (2025) 和 MedXpertQA (2025)
- 关于每个评估设置的描述,请参见附录 J
Human Side-by-Side Evaluations,人类并排评估
- 为了补充上述以能力为中心的公共基准(这些基准侧重于狭窄且客观定义的质量标准),本文对各种真实世界任务进行了人工评估
- 这些评估并排比较两个模型,整体上关注整体帮助性
- 并排评估有助于发现单独审查响应时不明显的质量差异
Evaluation task selection
- 评估任务来源于互补的来源,以确保全面覆盖真实的用户需求,并对比较模型具有强大的区分能力
- 最终集合包含 1276 个任务,全部为英文,其中 \(30%\) 是多轮的
- 有关任务分布的详细信息,请参见表 13
- 任务的来源:
- 第一个来源是专家撰写的 Prompt,遵循一个结构化的分类法,涵盖不同复杂度的真实用例,包括单轮和多轮对话
- 第二个来源是来自微软消费者 Copilot 产品的日志,经过仔细过滤,排除了包含个人身份信息(PII)的 Prompt、不完整或缺乏必要对话上下文的 Prompt、对抗性 Prompt 以及需要自定义配置(如编码环境、图像生成能力或访问外部工具)的 Prompt
- 本文使用分层抽样来确保用例覆盖,并在特定性和约束多样性等维度上平衡难度
Rater pool and evaluation process,评估人员池和评估过程
- 为了进行这些模型评估,本文作者与信誉良好的数据标注供应商 Surge AI 管理的评估人员合作
- 这些评估人员是来自不同通才和专业背景的英语母语者
- 评估人员通过一个多阶段的资格筛选过程,该过程评估他们评估核心 LLM 能力和失败模式的能力,包括事实核查、阅读理解和指令遵循
- 培训材料包括评级说明和常见失败模式的示例
- 对于每个 Prompt,评估人员首先被要求仔细评估 MAI 和其他模型的响应,分别在几个维度上:
- 指令遵循(显式和隐式)
- 事实性(使用搜索引擎帮助事实核查)
- 简洁性
- 相关性
- 完整性
- 风格和语调
- 对于每个维度,评估人员确定响应是否存在无、轻微或重大问题
- 作为最后一步,评估人员在 7 点 Likert 量表上决定两个响应之间的总体偏好评级,范围从“远差于”(-1.5) 到“远优于”(1.5)
- 观察:评估人员之间具有很强的一致性,验证了评级在可接受的噪声阈值内是一致的且可重复的
Results
- 表 14 显示了在 \([- 1.5,1.5]\) 尺度上的总体成对偏好以及在 \([- 1,1]\) 尺度上的各个质量维度的差异的人工评估结果
- 发现:评估人员更喜欢 MAI-Thinking-1 而不是 Sonnet 4.6,但更喜欢 Opus 4.6 而不是 MAI-Thinking-1
- 与 Sonnet 4.6 相比,MAI-Thinking-1 在 \(49%\) 的比较中获胜,在 \(6%\) 中平局,在 \(45%\) 中失败
- 与 Opus 4.6 相比,MAI-Thinking-1 在 \(43%\) 的比较中获胜,在 \(5%\) 中平局,在 \(52%\) 中失败
- 在目标维度上,评估人员发现 MAI-Thinking-1 在简洁性和相关性以及风格和语调方面优于 Sonnet 4.6,在指令遵循、事实性和完整性方面大致相当(在噪声范围内)
Internal Safety Evaluation,内部安全评估
安全与过度拒绝 (Safety and over-refusal).
- 本文构建了一个内部基准来测量在模型应该回答的低风险请求 Prompt 上的过度拒绝率
- 然后,一个拒绝判断 (refusal judge) 根据规定的策略对每个响应进行评分,标记拒绝、回避或不合理的部分拒绝
- 过度拒绝率是响应未能遵守的 Prompt 比例,帮助性报告为 1 减去该比率
- 与高风险项上的安全 Pass Rate (判断安全得分 \(>3\),基于 1-5 Likert 量表)配对,这揭示了理想模型行为:
- 在高风险、有害请求上更安全,在低风险、良性请求上更有帮助
- 有关评估方法和数据集构建的详细解释,请参见附录 I
- 图 20 绘制了 MAI-Thinking-1 与 Sonnet 4.6 的这种安全-帮助性平衡
- 在八个类别中的五个中,MAI-Thinking-1 位于 Sonnet 4.6 的右上方,表明性能积极,其中在化学、生物、放射性和核 (CBRN)、自残 (Self Harm) 以及选举与政治 (Elections & Politics) 方面的增益最大
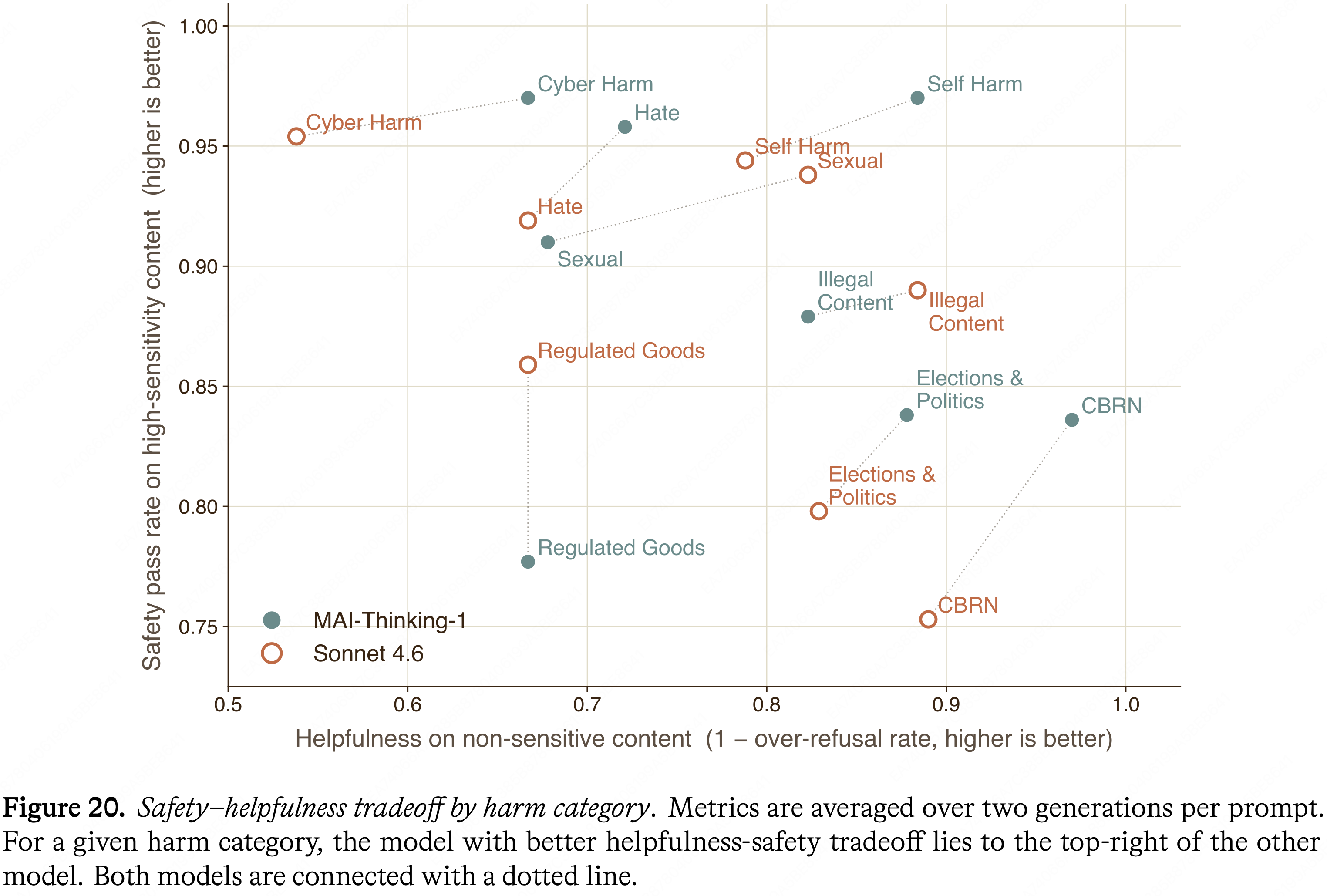
- 在八个类别中的五个中,MAI-Thinking-1 位于 Sonnet 4.6 的右上方,表明性能积极,其中在化学、生物、放射性和核 (CBRN)、自残 (Self Harm) 以及选举与政治 (Elections & Politics) 方面的增益最大
Jailbreaks,越狱
- 本文作者从供应商、内部红队和开源基准(包括 HarmBench (2024) 和 StrongREJECT (2024))中获取 2.5K 个独特的种子场景,构建了一个内部越狱评估套件
- 本文扩充了源 Prompt,生成了大约 9.5K 个越狱 Prompt 的最终评估集
- 根据转换程度和攻击者自适应性将这些 Prompt 分为三组:基础 (Foundational)、组合 (Compositional) 和自适应 (Adaptive) 技术(定义见图 21)
- 基础技术是通过简单的修改(如越狱包装器或 Prompt 模板)来保持有害意图的单步转换
- 组合技术结合了多次转换或结构化重写,包括基于模板的攻击,如 PyRIT (2024)、PAP 风格转换 (2024a) 以及非英语或混合语言变体
- 自适应技术引入了交互、搜索或多轮结构,包括 TAP (2024) 和多轮攻击 (2024)
- 图 21 报告了这三个类别的攻击成功率(ASR);值越低表示安全性越强
- 在这些 Prompt 转换类型中,MAI-Thinking-1 实现了与 Sonnet 4.6 和 Opus 4.6 相当的低 ASR
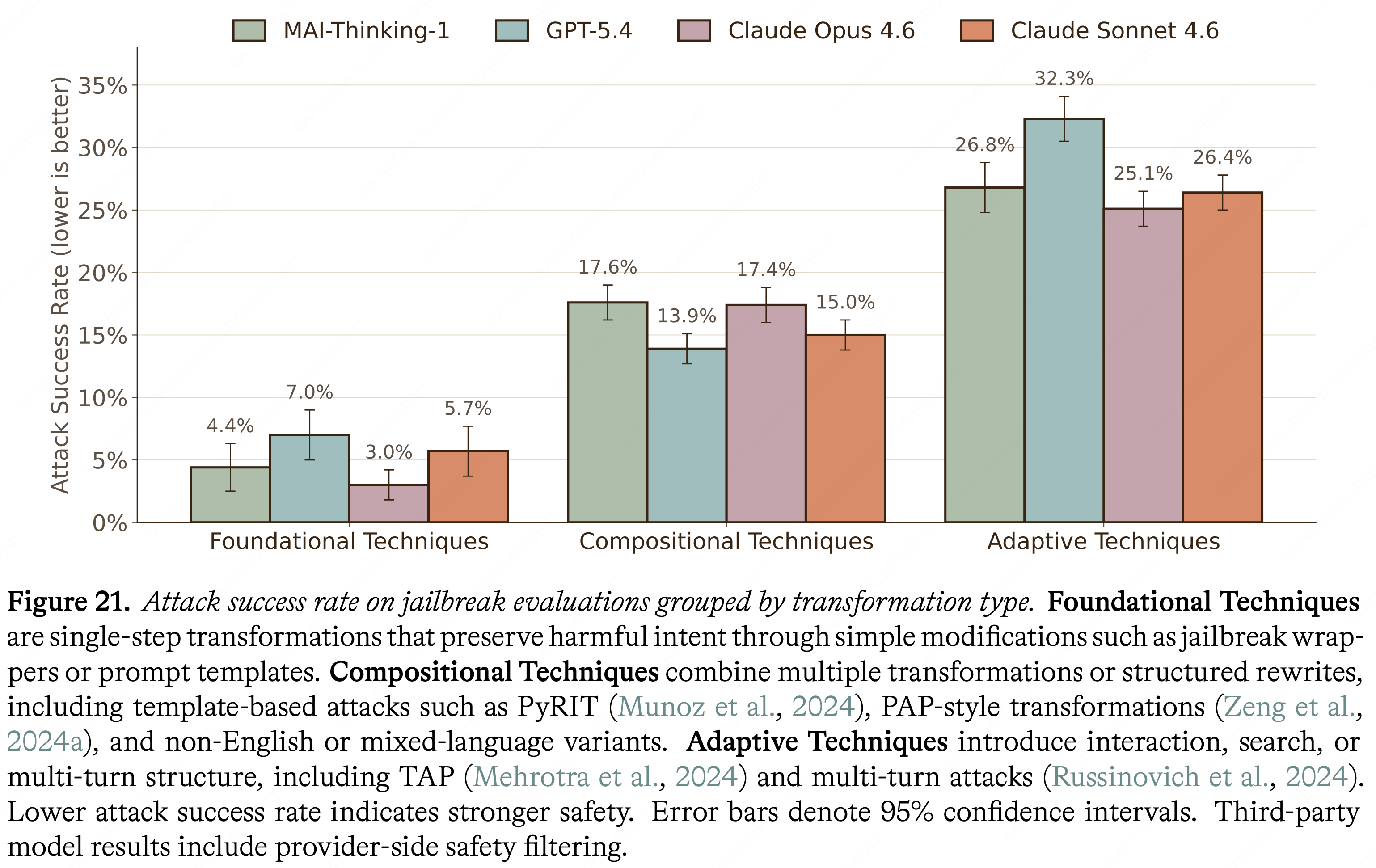
- 在这些 Prompt 转换类型中,MAI-Thinking-1 实现了与 Sonnet 4.6 和 Opus 4.6 相当的低 ASR
Safety Red Teaming,安全红队测试
- 详情见原文
Cluster Environment
- 详情见原文
Conclusion and Future Directions
- 本文介绍了 hill-climbing machine,一种模型开发方法,它优化了 Pipeline 的每个组成部分,从数据和 Infrastructure 到 RL 配方的评估
- MAI-Thinking-1 是这个机器生产的第一个模型:1T-A35B MoE,训练过程中完全未经第三方模型蒸馏
- MAI-Thinking-1 在其重量级别中,在 STEM 推理和软件工程任务上属于最强模型之列
- MAI-Thinking-1 是一个起点,而非终点
- 未来作者计划将 Climb 扩展到更多的模态、更大的规模和更精细的能力
- AI 的进步不是任何单一模型的产物;它是可以可靠改进的 Pipeline 的产物
附录 A:Pre‐training Data Pipeline Details
- 详情见原文