注:本文包含 AI 辅助创作
Paper Summary
- 整体评价:
- RDPO(Reward-Decorrelated Policy Optimization) 的目标是解决 LLM RL 中多任务和混合奖励的不稳定性问题
- 注:不稳定性来源:异质的奖励分布和相关的(correlated)奖励维度 会破坏标量优势的稳定性
- RDPO 设计围绕以下目标进行(个人理解):
- Decorrelation:希望各个维度之间的信号不要互相影响
- 等幅度假设:希望 Prompt 之间的更新权重(幅度)不要有偏(不要太偏向某个 Prompt 的 Rollout)
- 希望极端值不敏感
- 其他:希望各个维度奖励之间的信号权重不要有偏(不要过于偏向于某个维度)
- RDPO 结合了两个创新以稳定混合奖励的 RL:
- prompt 级别的幅度感知分位数归一化( MAQ 归一化,Magnitude-Aware Quantile normalization)
- 使得 Prompt 之间等幅度
- 马氏白化 (Mahalanobis whitening)
- Decorrelation:实现各个维度之间的信号不要互相影响(使得不同维度奖励相互独立)
- prompt 级别的幅度感知分位数归一化( MAQ 归一化,Magnitude-Aware Quantile normalization)
- 实验:在 LongCat-Flash 模型上进行
- 特别提到在后训练中提升了指令遵循、写作和 ArenaHard v2 的表现,同时在推理和代码评估上取得了广泛有竞争力的结果
- RDPO(Reward-Decorrelated Policy Optimization) 的目标是解决 LLM RL 中多任务和混合奖励的不稳定性问题
- RDPO 创新点:
- 利用幅度感知分位数 (MAQ) 归一化 来稳定跨二元、分数和连续奖励的 prompt 级优势分配
- 在每个活跃奖励子空间内应用 Mahalanobis whitening 来在聚合之前减轻相关性冗余
Introduction and Discussion
- 本文展示了针对 LongCat-Flash 的 RDPO 后训练实验
- 考虑一个标准但具有挑战性的强化学习设定:
- 一次训练运行包含多种任务类型
- 每个任务提供一组不同的奖励信号,例如正确性、指令跟随、评分标准满足度、偏好模型分数以及 Response 长度
- 将这些异质信号聚合为单个标量优势常常会导致训练不稳定
- 这种不稳定性源于这些奖励表现出不同的尺度、多样的分布形状以及非平凡的相关性
- RDPO 通过一个轻量级的两步奖励处理流程来缓解这一挑战
- 第一步:幅度感知分位数 (MAQ) 归一化 使 prompt 级优势对二元奖励、平局、偏态分布和异常值更加鲁棒
- 第二步:Mahalanobis whitening 减少了在给定任务内共同出现的奖励维度之间的冗余方差
Method
Background
- 实际部署中,LLM 必须同时优化多个目标,例如计算效率 (2025; 2025)、与人类偏好对齐 (2017) 以及 prompt 特定约束 (2025a)
- 这种内在复杂性推动了近期在多任务和混合奖励设置中 RL 的进展 (2026; 2025; 2025b),其中单次 Rollout 可以产生多样、异质的奖励信号
- 常用的方法有两种
GRPO
- 对于给定的 prompt \(i\) 及其 \(G\) 个 Rollout,设第 \(j\) 个 Rollout 接收 \(n\) 个奖励,记为
$$ r^{(i,j)} = (r_{1}^{(i,j)},\ldots ,r_{n}^{(i,j)})^{T}$$ - GRPO (2024) 通过对原始奖励求和来聚合混合奖励反馈,然后在进行组级别归一化:
$$ r_{\text{sum} }^{(i,j)} = \sum_{k = 1}^{n}r_{k}^{(i,j)} $$- 虽然当奖励尺度可比较时,这种直接策略是有效的,但当各个奖励维度的尺度和潜在分布不同时,它可能掩盖单个奖励维度的贡献
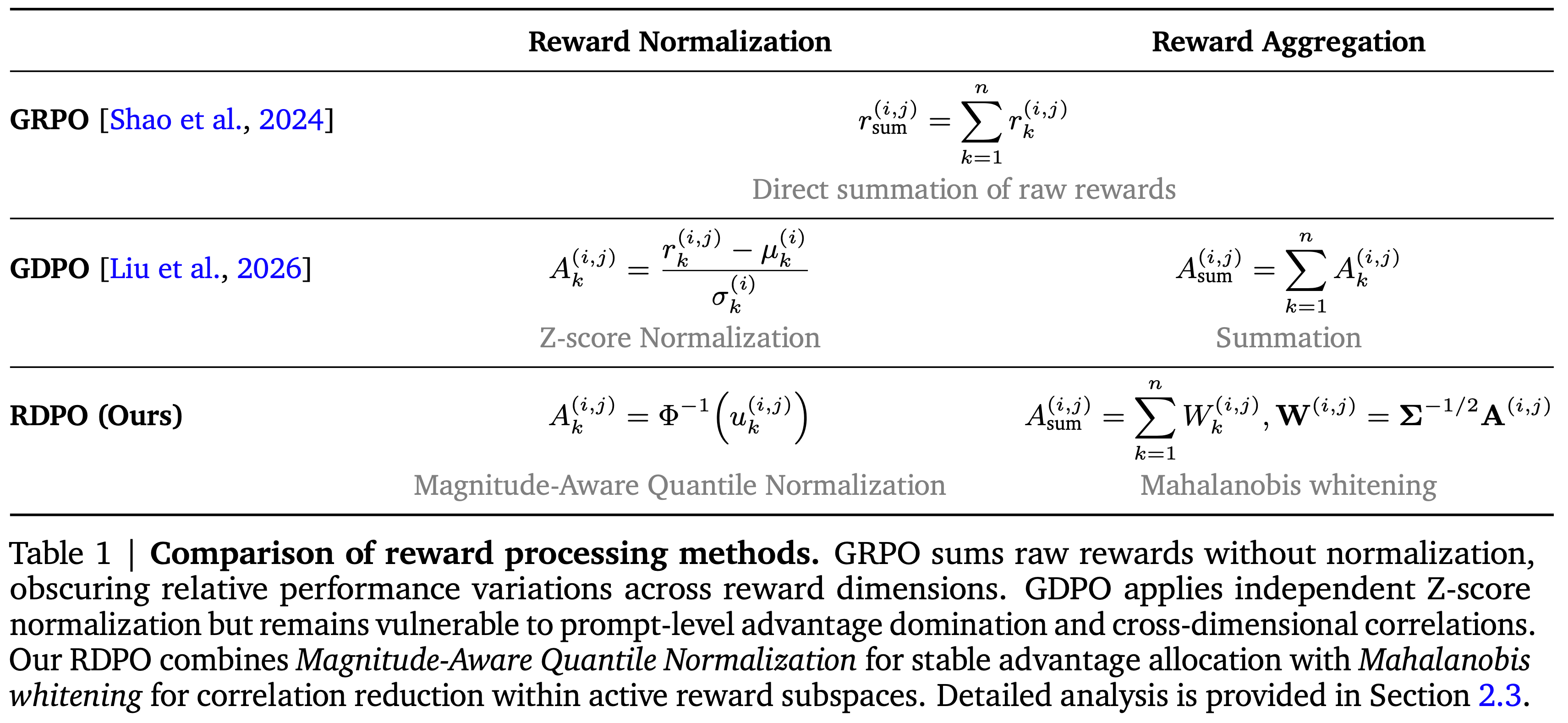
- 表 1 奖励处理方法的比较
- GRPO 直接对原始奖励求和而不进行归一化,掩盖了跨奖励维度的相对性能变化
- GDPO 应用独立的 Z-分数归一化,但仍然容易受到 prompt 级优势主导和跨维度相关性的影响
- RDPO 结合了用于稳定优势分配的幅度感知分位数归一化 (MAQ Normalization) 和用于在活跃奖励子空间内减少相关性的马氏白化 (Mahalanobis whitening)
- 详细分析见第 2.3 节
GDPO
- GDPO (2026) 通过在聚合之前独立地对每个奖励维度进行归一化来解决这种异质性问题,如表 1 所总结
- 对于第 \(k\) 个奖励维度,它使用维度级别的 Z-分数归一化来计算优势
- 然后通过对这些归一化的维度求和并应用 batch 级别的归一化来获得最终的标量优势
- 尽管这种解耦方法相比原始求和有所改进,但它仍然独立处理每个奖励,使得该方法对非高斯奖励分布和奖励间相关性敏感
Effective Information Efficiency,有效信息效率
- 本文引入有效信息效率 \((\eta_{\text{eff} })\) 作为一个诊断指标来评估混合奖励聚合
- 该指标捕捉了混合标量优势的两个互补方面:
- 聚合是否平衡了各个奖励维度的权重
- 聚合后的奖励是否包含由相关奖励维度引起的冗余变异
- 形式上,将其分解如下:
$$\eta_{\text{eff} } = \eta_{\text{proj} }\times \eta_{\text{corr} }.$$- 注:这个分解遵循了有用混合奖励优势的两个基本期望
- 第一:每个活跃奖励维度应在可比较的标准化尺度上做出贡献
- 第二:求和后的信号不应重复计算相同的潜在变异
- 所以 \(\eta_{\text{eff} }\) 可作为聚合质量的方法无关诊断指标
- 注:这个分解遵循了有用混合奖励优势的两个基本期望
- 该指标捕捉了混合标量优势的两个互补方面:
- 第一项 \(\eta_{\text{proj} }\) 衡量聚合方向与标准化奖励空间中等权重投影的接近程度
- 对于任意聚合权重向量 \(\mathbf{w}\) ,定义:
$$\eta_{\text{proj} }(\mathbf{w}) = \cos^2 (\mathbf{w},\mathbf{1}) = \frac{(\mathbf{w}^T\mathbf{1})^2}{n\cdot|\mathbf{w}|^2}.$$- \(\mathbf{1}\) 为全 1 向量
- 理解:\(\eta_{\text{proj} }\) 衡量实际聚合方向 \(\mathbf{w}\) 与等权重方向 \(\mathbf{1}\) 的一致性
- 取值范围:\([0, 1]\)
- \(\eta_{\text{proj} } = 1\) 当且仅当 \(\mathbf{w} \propto \mathbf{1}\),即各 Reward 维度权重相等
- \(\eta_{\text{proj} } \to 0\) 当 \(\mathbf{w}\) 与 \(\mathbf{1}\) 正交或某些维度权重极大、其他极小
- 注:这一点可通过求极限得出
- 取值范围:\([0, 1]\)
- 理解:为什么等权重方向是理想的?
- 在标准化空间(\(z_k\) 均值为 0、方差为 1)中:
- 每个 Reward 维度在数值上已经具有可比性
- 如果某维度被赋予更大的权重,意味着该维度的微小变化会对 Advantage 产生不成比例的影响
- 理想情况下,我们希望每个 Reward 维度的改善对最终优化的贡献大致相等 ,除非有明确的先验偏好
- 因此,\(\eta_{\text{proj} }\) 反映了聚合方法是否尊重了标准化后的等重要性原则
- 在标准化空间(\(z_k\) 均值为 0、方差为 1)中:
- 对于任意聚合权重向量 \(\mathbf{w}\) ,定义:
- 第二项 \(\eta_{\text{corr} }\) 量化了在求和相关的标准化奖励后保留的独立信息量
- 正相关和负相关都意味着奖励维度之间的依赖性
- 因此,使用逐元素绝对相关矩阵 \(|\Sigma_{z}|\) 来计算这一项:
$$\eta_{\text{corr} } = \frac{n}{\mathbf{1}^T|\Sigma_z|\mathbf{1} }.$$- 理解:\(|\Sigma_z|\) 不是协方差矩阵的行列式,而是 元素级别的绝对相关系数矩阵 , \(\mathbf{1}^T |\Sigma_z| \mathbf{1}\) 是 \(\Sigma_z\) 矩阵的绝对值的元素和
- 给定:
- \(\mathbf{z} = (z_1, z_2, \dots, z_n)^T\) 是标准化后的 Reward 向量
$$ z_{k} = \frac{r_{k} - \mu_{k}}{\sigma_{k}} $$- 每个 \(z_k\) 的均值为 0,方差为 1
- \(\Sigma_z = \text{Cov}(\mathbf{z})\) 是 \(n \times n\) 的相关系数矩阵(因为方差为 1,协方差矩阵等于相关系数矩阵)
- \(\mathbf{z} = (z_1, z_2, \dots, z_n)^T\) 是标准化后的 Reward 向量
- 则 \(\Sigma_z\) 为:
$$
|\Sigma_z| = \big( |\rho_{ij}| \big)_{i,j=1}^{n}
$$ - \(|\Sigma_z|\) 就是将 \(\Sigma_z\) 中的每个元素替换为其绝对值后得到的新矩阵
$$
|\Sigma_z|_{ij} = |\rho_{ij}| = \left| \frac{\text{Cov}(z_i, z_j)}{\sqrt{\text{Var}(z_i)\text{Var}(z_j)} } \right| = |\text{Corr}(z_i, z_j)|
$$ - 进一步,有 \(\mathbf{1}^T |\Sigma_z| \mathbf{1}\) 如下:
$$
\mathbf{1}^T |\Sigma_z| \mathbf{1} = \sum_{i=1}^n \sum_{j=1}^n |\rho_{ij}|
$$- 分析:
- 对角线项:\(|\rho_{ii}| = |1| = 1\),共 \(n\) 项
- 非对角线项:\(|\rho_{ij}|\) 对于 \(i \neq j\),共 \(n(n-1)\) 项
- 因此有最终结果:
$$
\mathbf{1}^T |\Sigma_z| \mathbf{1} = n + \sum_{i \neq j} |\rho_{ij}|
$$
- 分析:
- 给定:
- 理解:对于具有皮尔逊相关系数 \(\rho\) 的两个奖励情况
- \(|\Sigma_z|\) 为:
$$
|\Sigma_z| = \begin{pmatrix} 1 & |\rho| \\ |\rho| & 1 \end{pmatrix}
$$ - 进一步有:
$$
\mathbf{1}^T |\Sigma_z| \mathbf{1} = 1 + |\rho| + |\rho| + 1 = 2 + 2|\rho|
$$ - 最终,有:
$$\eta_{\text{corr} } = \frac{2}{2 + 2|\rho|} = \frac{1}{1 + |\rho|}.$$
- \(|\Sigma_z|\) 为:
- 任何强的线性依赖性,无论是正还是负,都会减少求和的优势中存在的有效独立信息量
- 理解:针对 皮尔逊相关系数 \(\rho\) 取了绝对值,所以负相关也会被累加
- 理解:\(|\Sigma_z|\) 不是协方差矩阵的行列式,而是 元素级别的绝对相关系数矩阵 , \(\mathbf{1}^T |\Sigma_z| \mathbf{1}\) 是 \(\Sigma_z\) 矩阵的绝对值的元素和
- 现在应用这个指标来分析各种奖励处理策略
- 在 GRPO 的情况下,可以将每个原始奖励表示为 \(r_k = \mu_k + \sigma_k z_k\),直接奖励求和得到:
$$\sum_{k = 1}^{n}r_k = \sum_{k = 1}^{n}\mu_k + \sum_{k = 1}^{n}\sigma_kz_k.$$- 常数项 \(\sum_{k}\mu_{k}\) 被组级别优势归一化移除
- 因此,标准化奖励空间中的有效聚合方向完全由 \(z_{k}\) 的系数决定
- 因此,GRPO 隐式地依赖于权重向量 \(\mathbf{w}_{\text{GRPO} } = (\sigma_1,\sigma_2,\ldots ,\sigma_n)^T\)
- 这给具有较高原始方差的奖励维度分配了不成比例的大有效权重
- 将这个权重向量代入 \(\eta_{\text{proj} }\) 得到:
$$\eta_{\text{proj} }(\mathbf{w}_{\text{GRPO} }) = \frac{(\sum_{k = 1}^{n}\sigma_k)^2}{n\sum_{k = 1}^{n}\sigma_k^2}.$$- 这个公式突出了奖励尺度的不平衡如何削弱某些维度的有效贡献
- 理解:如果每个方差都相等 \(\sigma_k = c\),则 \(\eta_{\text{proj}}\) 的结果为 1
$$
\frac{(n c)^2}{n \cdot (n c^2)} = \frac{n^2 c^2}{n^2 c^2} = 1
$$
- GDPO 首先将每个奖励维度归一化为 ,然后再求和
$$ A_{k} = (r_{k} - \mu_{k}) / \sigma_{k} = z_{k} $$- GDPO 聚合方向因此是
$$ \mathbf{w}_{\text{GDPO} } = \mathbf{1}$$- 这与等权重参考方向完美对齐,并消除了 \(\eta_{\text{proj} }\) 在奖励维度层面捕捉到的方差缩放损失
- 本质上,GDPO 做的不仅仅是重新缩放奖励,GDPO 恢复了实际优化方向与预期偏好方向之间的几何一致性
- 这是其在混合奖励景观中有效性的基础
- 然而,Z-分数归一化在 prompt 级别仍然可能不稳定
- 当一个 prompt 级 Rollout 组包含偏态奖励、二元结果、平局或异常值时,GDPO Batch-level 归一化的优势质量可能会集中在一个 Rollout 上,而其余的 Rollout 获得接近零或被抑制的优势
- 在这种情况下,策略更新实际上是由少数样本驱动的,即使在每个奖励标准化之后,等贡献的假设也变得不太可靠
- GDPO 还假设奖励维度可以独立聚合,因此无法解决 \(\eta_{\text{corr} }\) 所捕捉的相关性损失
- GDPO 聚合方向因此是
- 在 GRPO 的情况下,可以将每个原始奖励表示为 \(r_k = \mu_k + \sigma_k z_k\),直接奖励求和得到:
- RDPO 旨在解决 \(\eta_{\text{eff} }\) 所测量的两种失效模式:
- 幅度感知分位数 (Magnitude-Aware Quantile, MAQ) 使 prompt 级归一化优势对异质奖励尺度和异常值不那么敏感
- 马氏白化 (Mahalanobis whitening) 减少了每个活跃奖励子空间中共同出现的奖励维度之间的冗余变异
- 注:关于此机制的更多细节将在下一节提供
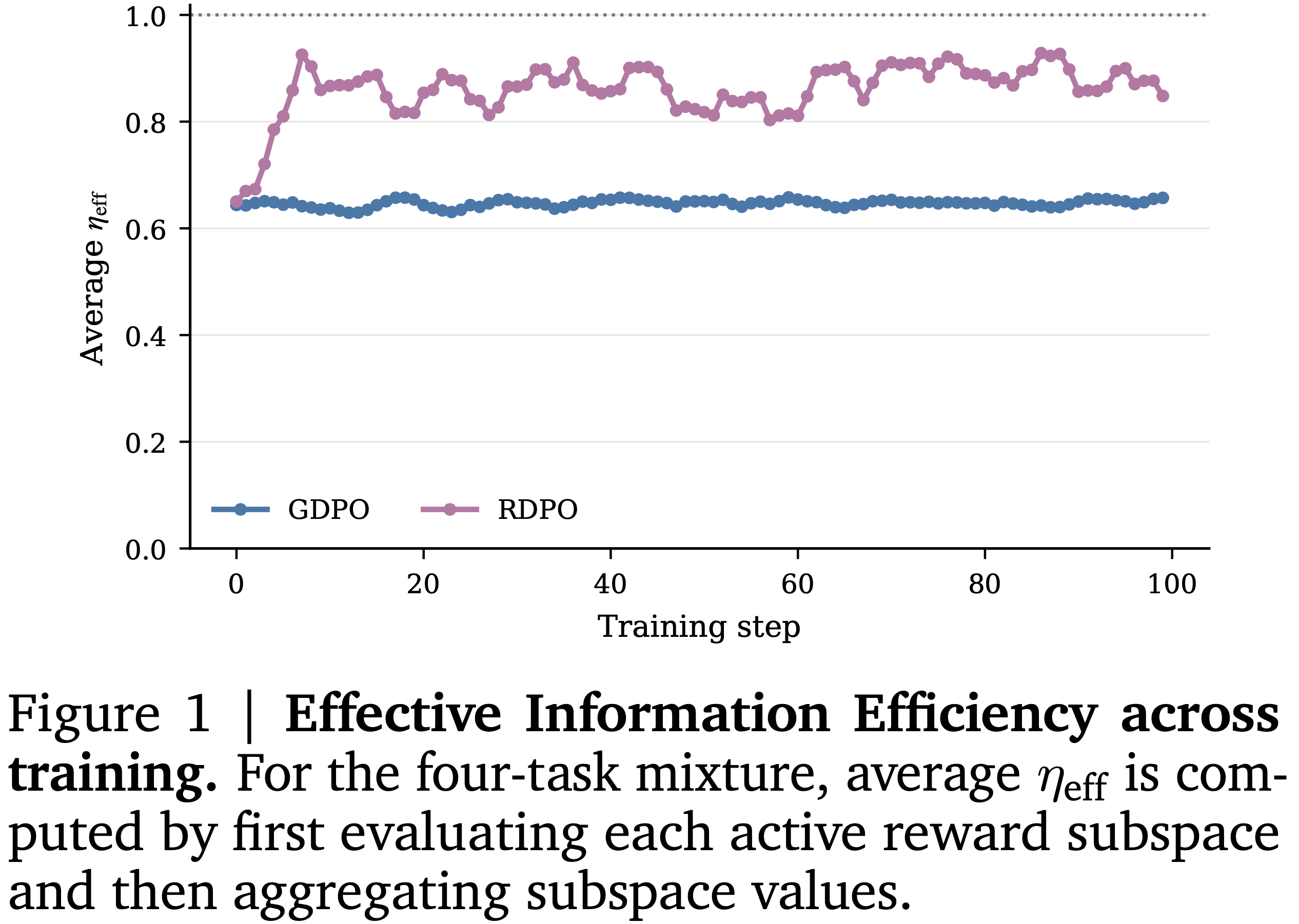
- 图 1 报告了跨活跃任务子空间的平均 \(\eta_{\text{eff} }\)
- 如图 1 所示,与 GDPO 归一化基线相比,RDPO 在整个训练过程中保持了更高的有效信息效率
- 根据上述绝对相关定义,效率值为 1.0 作为独立奖励参考基线,更强的依赖性会单调地降低 \(\eta_{\text{corr} }\)
- 图 1 中,对于四任务混合,首先评估每个活跃奖励子空间,然后聚合子空间值来计算平均 \(\eta_{\text{eff} }\)
RDPO:Reward-Decorrelated Policy Optimization,奖励 Decorrelated 策略优化
- Decorrelated 表示 Decorrelated 含义
- 本文首先为实验选择了四个代表性任务:
- 指令跟随、通用写作、数学推理和代码生成
- 注:所有这些任务都在一个统一的后训练运行中进行
- 每个任务包含两到三个奖励
- 这种配置使 RDPO 暴露于包含两个和三个奖励的子空间,以及二元、离散和连续奖励分布的混合
- 指令跟随、通用写作、数学推理和代码生成
MAQ:Magnitude-Aware Quantile Normalization,幅度感知分位数归一化
The Problem
- 投影项 \(\eta_{\text{proj} }\) 假设活跃奖励维度在聚合之前在可比较的标准化尺度上做出贡献
- GDPO 尝试通过对每个奖励应用 per-reward Z-分数归一化来满足这一要求
- 但这种线性变换仍然对每个 prompt 级 Rollout 组的分布形状高度敏感
- 为了评估每个 prompt 内优势分配的稳定性,本文计算 prompt 级统计量并报告每个任务子空间的平均值
- 对于归一化后的 Rollout 优势 \(\{A_{j}\}_{j = 1}^{G}\) ,使用 \(p_j\) 来衡量每个 Rollout 在 prompt 级绝对优势质量中的份额
$$ p_{j} = \frac{|A_{j}|}{\sum_{\ell = 1}^{G}|A_{\ell}|} $$- 这给出了两个互补的诊断指标:
- 优势主导度 \(\max_{j}p_{j}\) 衡量单个 Rollout 是否获得大部分更新信号
- 有效 Rollout 参与度 \(\frac{1}{G\sum_{j}p_{j}^{2}}\) 衡量优势质量在 \(G\) 个 Rollout 之间的分布均匀程度
- 这种方法突出了典型的 prompt 行为,而不是依赖于可能被少数极端组严重扭曲的汇集分布
- 这给出了两个互补的诊断指标:
- 由于本文设置中的潜在奖励可以是二元、分数或连续的,因此即使在 Z-分数归一化之后,诸如偏态分布、平局和异常值等现象也可能将大部分归一化优势质量集中到单个 Rollout 上
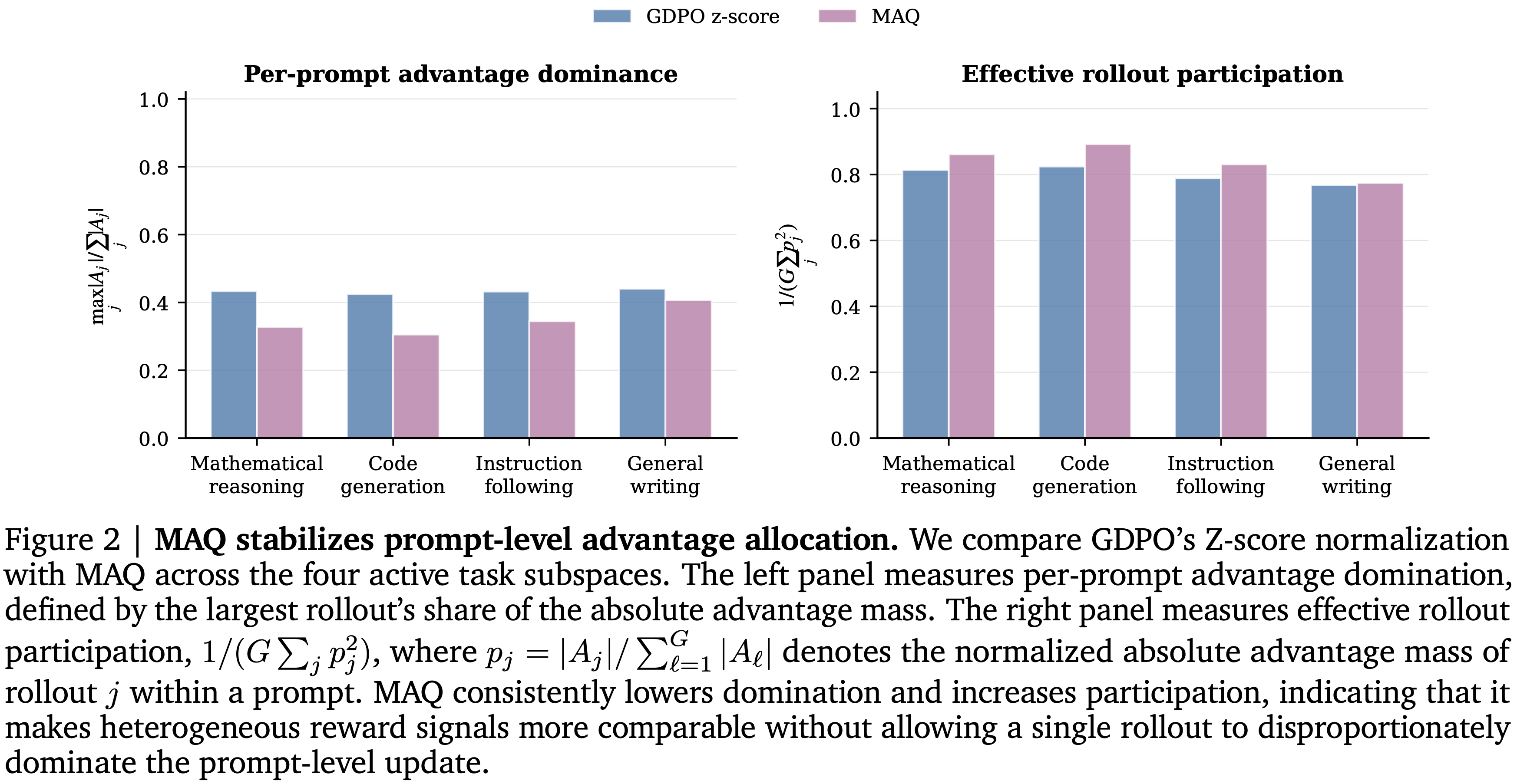
- 注:图 2 说明了这种失效模式:
- GDPO 频繁表现出高 per-prompt 优势集中度和较低的有效 Rollout 参与度,表明策略更新可能由一小部分 Rollout 驱动,而不是稳定的组级别比较
- 注:图 2 中,作者比较了 GDPO 的 Z-分数归一化与跨四个活跃任务子空间的 MAQ
- 左图衡量每个 prompt 的优势主导度,定义为最大 Rollout 在绝对优势质量中所占的份额
- 右图衡量有效 Rollout 参与度 \(\frac{1}{(G\sum_{j}p_{j}^{2})}\) ,其中 \(p_{j} \) 表示 prompt 内 Rollout \(j\) 的归一化绝对优势质量
- MAQ 持续降低主导度并增加参与度,表明它使得异质奖励信号更具可比性,而不会让单个 Rollout 不成比例地主导 prompt 级更新
- 对于归一化后的 Rollout 优势 \(\{A_{j}\}_{j = 1}^{G}\) ,使用 \(p_j\) 来衡量每个 Rollout 在 prompt 级绝对优势质量中的份额
The Solution
- 为了更好地满足非高斯奖励组下 \(\eta_{\text{proj} }\) 所依据的等贡献假设,本文提出了幅度感知分位数 (Magnitude-Aware Quantile, MAQ) 归一化
- 当 prompt 级奖励统计量可靠时,Z-分数归一化提供了实现等尺度投影的最清晰的线性途径,但对于二元、平局、偏态或易于出现异常值的奖励,这一假设变得脆弱
- MAQ 可以看作是一种鲁棒的替代方案
- MAQ 将每个奖励维度映射到一个共同的有界正态得分尺度,从而使得到的优势在不同维度之间保持大致可比,同时对病态的组统计量不那么敏感
- 与纯秩变换不同,MAQ 结合了幅度感知的间隙,以保留同一 prompt 内 Rollout 之间有意义的局部定量差异
- 此外,与标准的 Z-分数归一化不同,它压缩了极端间隙,从而防止单个异常值主导 prompt 级优势分配
- 对于每个 prompt \(i\) 和奖励 \(k\)
- 给定一组排序后 的 \(G\) 个 Rollout 分数
$$ r_1 \leq r_2 \leq \dots \leq r_G $$ - 1)对数压缩 Gap (Log-compressed gaps) :计算相邻 Rollout 之间的间距:
$$g a p_{j} = \log \left(1 + \frac{|r_{j + 1} - r_{j}|}{\beta\cdot\sigma_\text{global} }\right) \tag{1}$$- 其中 \(j = 1,\ldots ,G - 1\)
- 特别注意:这里是有序的结果下计算的,不是随机顺序下计算
- 这里,\(\sigma_\text{global}\) 是全局 batch 中奖励 \(k\) 的四分位距 (IQR,Inter-Quartile Range),作为一个鲁棒的尺度基准,\(\beta >0\) 控制压缩强度
- 理解:这里用奖励的四分位距(一组数据的四分位距是: \(Q_3 - Q_1\),75 分位点 - 25 分位点),是在整个 Batch(而非单个 Prompt)内,针对同一个 Reward 维度(如 Math Reward、Length Reward),计算所有 Rollout 在该维度上分数的 IQR
- 理解:相对标准差来说,IQR 是一个稳健的尺度估计量,不会因为少数 Outlier Rollout 而被拉偏
- 这种对数压缩是鲁棒性的关键:它自然地限制了极端异常值的影响,同时对于小的、密集的间隙保持近似线性,以保留细微的组内差异
- 其中 \(j = 1,\ldots ,G - 1\)
- 2)CDF 分配 (CDF Allocation) :
- 首先归一化 Gap
$$ \text{norm_gap}_{j} = \frac{\text{gap}_{j}}{\sum_{j = 1}^{G - 1}\text{gap}_{j}} $$ - 然后,将累积分布函数 (CDF) 位置 \(u_{(j)}\) 系统地按比例分配给这些归一化的间隙
- 理解:即累积得到 CDF 位置:
$$
u_{(1)} = 0, \quad u_{(j+1)} = u_{(j)} + \text{norm_gap}_j, \quad u_{(G)} = 1
$$ - 理解:\(\{u_{(j)}\}_{j=1}^{G}\) 本质是一个从 [0-1] 的有序数组,共 G 个元素,其中间隔是第一步归一化过的 Gap,这里得到的结果是对 奖励 \(\{r_j\}_{j=1}^{G}\) 的 Outlier 不敏感的,且保原始奖励序的
- 首先归一化 Gap
- 3)逆正态映射 (Inverse Normal Mapping) :最后,通过逆 CDF 将这些值映射到标准正态分布:
$$A_{(j)} = \Phi^{-1}(u_{(j)}) \tag{2}$$- 理解:一般情况下,\(A_{(j)}\) 只是近似服从标准正态分布(不是严格服从),特别地,当 \(u_{(j)}\) 服从均匀分布时,\(A_{(j)}\) 服从标准正态分布
- 理解:这里的 \(\Phi^{-1}\) 是标准真该分布 CDF 函数的反函数(CDF 的反函数也称为 (Percent Point Function,百分位点函数))
- 设 \(Z\) 服从标准正态分布 \(N(0,1)\),其 CDF 为:
$$
\Phi(z) = P(Z \le z) = \int_{-\infty}^{z} \frac{1}{\sqrt{2\pi} } e^{-t^2/2} dt
$$- CDF 是 从数值到概率 的映射:给定一个 Advantage 值 \(z\),输出在这个值左侧的累积概率(从负无穷到 \(z\) 的面积)
- PPF 是 从概率到数值 的映射:给定一个累积概率 \(u \in [0,1]\),输出一个临界值 \(z\),使得累积概率恰好为 \(u\)
- 数学关系:
$$
\Phi(z) = u \quad \Longleftrightarrow \quad z = \Phi^{-1}(u)
$$ - 直观例子(考试排名),假设某次考试成绩服从标准正态分布:
- 考了 \(z=0\) 分,超过多少人:函数 CDF \(\Phi(0)\),比如 超过 50% 的人
- 想超过 95% 的人,需要考多少分:函数 PPF \(\Phi^{-1}(0.95)\),比如 需要考 1.645 分
- 在 MAQ 中,\(u\) 就是“想达到的排名位置” ,PPF 告诉我们应该分配多大的 Advantage \(A\) 给这个 Rollout
- 设 \(Z\) 服从标准正态分布 \(N(0,1)\),其 CDF 为:
- 给定一组排序后 的 \(G\) 个 Rollout 分数
- 如图 2 所示,MAQ 减少了跨四个任务子空间的 prompt 级优势主导度,并在归一化后保持了高有效 Rollout 参与度
- 因此,MAQ 的作用不是直接 Decorrelate 奖励维度,而是在聚合之前产生一组更稳定、更具可比性的 per-reward 优势
- 这支持了由 \(\eta_{\text{proj} }\) 捕捉的投影效率目标,同时将剩余的相关性冗余留给白化阶段
Mahalanobis Whitening,马氏白化
The Problem
- 尽管 MAQ 在 prompt 级别稳定了单个奖励维度,但它本身并不能使不同的奖励维度相互独立
- 这个限制正是 \(\eta_{\text{corr} }\) 所衡量的:
- 如果两个共同出现的奖励包含重叠的信息,对它们求和可能会重复计算相同的变异
- 如果它们负相关,求和可能会抵消有用的变异
- 在本文的四个任务混合中,这种依赖性自然地在活跃奖励子空间内产生
- 例如,数学奖励或代码奖励可能与长度奖励相关,ifeval 奖励可能与评分标准 (rubrics) 奖励相关,而 RM 奖励可能与评分标准奖励和长度奖励都相关
- 更多细节在第 3.1 节中提供
- 图 3 显示,在 GDPO 下,这些相关性是不可忽略的,特别是在代码生成、通用写作和数学推理子空间中
- 图 3 展示了活跃任务子空间内的奖励相关性 (Reward correlation)
- 每个面板对应一个任务条件下的奖励子空间
- 本文报告了训练过程中共同出现的奖励维度之间的平均绝对皮尔逊相关系数
- 与 GDPO 相比,RDPO 通过在 MAQ 归一化后应用马氏白化来降低子空间内的奖励相关性,有助于减少四任务训练混合中由 \(\eta_{\text{corr} }\) 捕捉的冗余
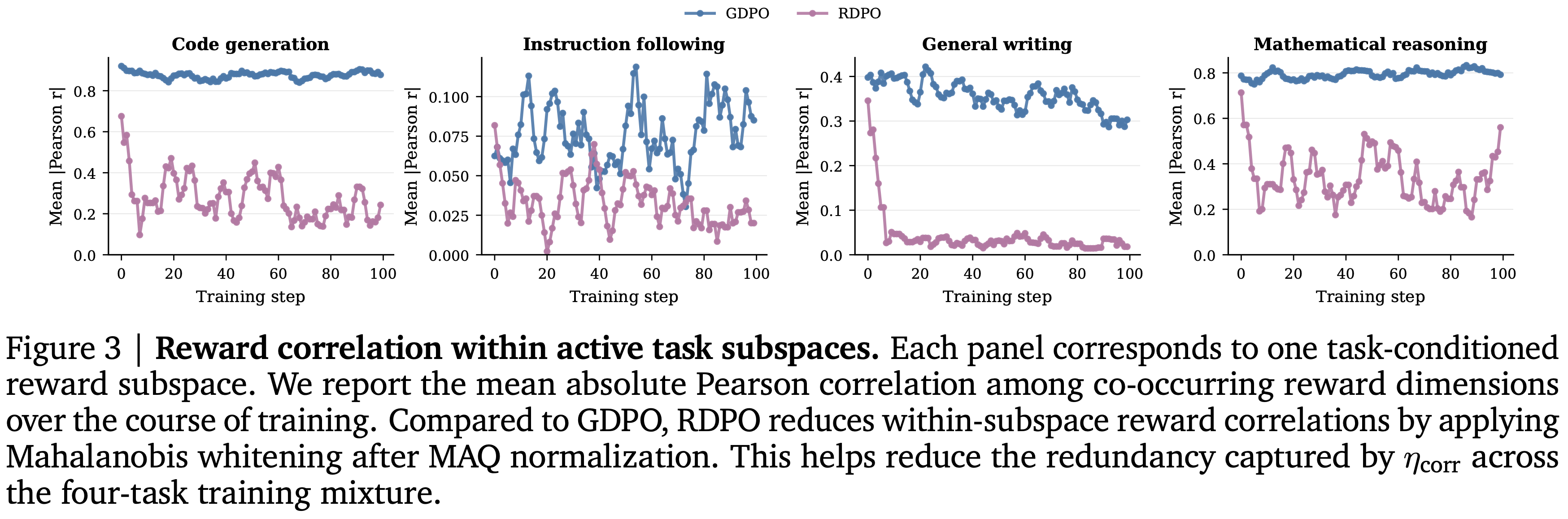
- 图 3 展示了活跃任务子空间内的奖励相关性 (Reward correlation)
The Solution
- 为了减轻奖励间相关性引起的冗余,RDPO 在 MAQ 归一化之后应用马氏白化
- 在 MAQ 之后,每个 Rollout \((i,j)\) 由优势向量表示为:
$$ \mathbf{A}^{(i,j)} = (A_{1}^{(i,j)},A_{2}^{(i,j)},\ldots ,A_{n}^{(i,j)})^{T}\in \mathbb{R}^{n}$$- 理解:\(\mathbf{A}^{(i,j)}\) 表示第 \(i\) 个 Prompt 的第 \(j\) 个 Rollout(response) 的所有奖励类别维度向量(\(n\) 代表奖励类型/维度数量),后续的马氏变换都是对这个向量的处理,最终结果是一个标量,即每个 Rollout \((i,j)\) 都有一个最终的结果
- 马氏白化变换将其映射到一个 Decorrelated 向量:
$$\mathbf{W}^{(i,j)} = \hat{\mathbf{\Sigma} }_{t}^{-1 / 2}\mathbf{A}^{(i,j)} \tag{3}$$- 其中 \(\hat{\mathbf{\Sigma} }_{t}^{- 1 / 2} = \mathbf{U}\mathbf{A}^{- 1 / 2}\mathbf{U}^{T}\) 通过运行协方差估计 \(\hat{\mathbf{\Sigma} }_{t} = \mathbf{U}\mathbf{A}\mathbf{U}^{T}\) 的特征分解计算
- 给定一个准确的协方差估计,这个变换的目标是 \(\text{Cov}(\mathbf{W})\approx \mathbf{I}_{n}\) ,使活跃奖励维度趋向于不相关、单位方差的信号
- 理解:对比 马氏白化和 Z-Score 标准化
- Z-Score 标准化:减去均值,除以标准差,只消除了各维度的量纲差异
- 马氏白化:减去均值,除以协方差矩阵的逆平方根,进一步消除了维度之间的线性依赖关系
- 马氏白化的详细描述见附录:
- 本文使用的不是原始的马氏白化(因为本文没有减去均值,仅仅除了协方差矩阵的逆平方根),原始的马氏白化是减去均值,除以协方差矩阵的逆平方根
- Running Covariance Estimation,运行协方差估计
- 在在线 RL 训练期间,真实的奖励协方差 \(\pmb{\Sigma}\) 是未知的,并且随着策略的演变而不断变化
- 本文使用训练步骤上的指数移动平均 (Exponential Moving Average, EMA) 来维持一个稳定的估计:
$$\hat{\mathbf{\Sigma} }_{t} = (1 - \alpha)\hat{\mathbf{\Sigma} }_{t - 1} + \alpha \hat{\mathbf{\Sigma} }_{\text{batch} } \tag{4}$$- \(\hat{\Sigma}_{\text{batch} }\) 是从当前 mini-batch 的 MAQ 归一化优势计算的样本协方差
- \(\alpha \in (0,1)\) 是 EMA 衰减率
- EMA 平滑了 batch 级别的噪声,并使白化矩阵能够跟踪缓慢演变的奖励相关结构
- 为了在应用变换之前确保可靠的协方差估计,白化只在 \(T_{\text{warm} }\) 步的预热阶段之后才开始
- 在本文的实现中,本文使用前五个训练步骤进行此预热
- Subspace Whitening for Heterogeneous Tasks,针对异构任务的子空间白化
- 在多任务设置中,单次 Rollout 很少能同时观察到所有 \(n\) 个奖励维度
- 注:\(n\) 是指整个训练任务中所有可能的 reward 类型的总数
- 当前的训练混合由四个活跃奖励子空间组成:{math, length},{code, length},{ifeval, rubrics} 和 {length, rm, rubrics}
- 理解:接下来的归一化是分别在子空间上做的,对每个子空间分别进行马氏白化,所以虽然有求逆矩阵的过程,复杂度其实不会太高
- 理解:对于每个子空间,每个奖励维度都有一个向量/变量,这个向量是所有这个子空间下,当前 Batch 的所有 Rollout 构成的,于是接下来才可以求不同维度之间的协方差,协方差矩阵的维度数就是 该子空间下的奖励维度数
- 为了适应这种异构性,我们仅在观测到的子空间上应用白化:
- 对于具有活跃奖励集 \(\mathcal{S}\) 的 Rollout
$$\mathcal{S}\subseteq \{1,\ldots ,n\} $$- \(n\) 是指整个训练任务中所有可能的 reward 类型的总数
- \(m\) 当前 rollout 实际观测到的 active reward 维度数
- 提取主子矩阵
$$\hat{\Sigma}_{\mathcal{S} }\in \mathbb{R}^{|\mathcal{S}|\times |\mathcal{S}|}$$ - 并独立计算
$$\hat{\Sigma}_{\mathcal{S} }^{- 1 / 2}$$ - 这种方法确保仅当奖励维度在同一个任务内共同出现时才应用 Decorrelation,避免了从从未重叠的维度之间引入人为的协方差估计
- 对于具有活跃奖励集 \(\mathcal{S}\) 的 Rollout
- 在多任务设置中,单次 Rollout 很少能同时观察到所有 \(n\) 个奖励维度
- Final Advantage
- 用于 PPO/GRPO 策略梯度更新的标量优势通过对白化后的维度求和获得:
$$A_{\text{sum} }^{(i,j)} = \sum_{k = 1}^{n}W_{k}^{(i,j)} = \mathbf{1}^{T}\mathbf{W}^{(i,j)} = \mathbf{1}^{T}\hat{\Sigma}_{t}^{-1 / 2}\mathbf{A}^{(i,j)} \tag{5}$$
- 用于 PPO/GRPO 策略梯度更新的标量优势通过对白化后的维度求和获得:
- 在理想的协方差估计下,其中 \(\text{Cov}(\mathbf{W}) = \mathbf{I}_n\) ,这个投影会捕捉到更少的跨维度冗余信息
- 由于协方差是通过 EMA 在线估计并在特定的观测任务子空间内应用的,因此这个白化过程是减少相关性冗余的实用机制,而不是完美 Decorrelated 严格数学保证
- 图 3 中的经验曲线显示,与 GDPO 相比,该机制在作者的训练混合中降低了平均绝对奖励相关性
- 结合 MAQ,这种方法将聚合优势推向具有更高有效信息效率的、较少冗余的奖励机制
- 与 GDPO 一样,本文随后应用 batch 级别的归一化以获得最终的优势估计
Training
Training Setup
- 本文在 LongCat-Flash 的后训练阶段应用 RDPO
- 策略在包含数学推理、代码生成、指令遵循和通用写作 prompt 的四个任务混合体上进行优化
- 对于每个 prompt,模型采样一组 rollouts,接收为该任务定义的特定奖励信号子集,并从活跃奖励维度构建一个标量优势
- 主模型采用完整的 RDPO 流程
- 首先独立地对每个奖励维度应用 MAQ 归一化,以稳定 prompt 级别的优势分配
- 然后在观察到的奖励子空间上执行马氏白化以减少相关冗余
- 最后将得到的白化优势求和,并在策略梯度更新前进行批归一化
- 这四个任务类别激活了不同的奖励子空间:
- 数学推理样本使用 math+length
- 代码生成样本使用 code+length
- 指令遵循样本使用 ifeval+rubrics
- 通用写作样本使用 length+rm+rubrics
- 注:每个奖励的详细描述在下一节中提供
- 这种异构设置代表了 RDPO 的预期用例
- 由于不同的任务会暴露不同的奖励子集,活跃奖励在尺度、分布形状和相关性结构上可能存在显著差异
Reward Design
Rubrics Reward
- 对于每个采样的 response,使用一个生成式奖励模型对其相关联的 rubric 集进行细粒度验证
- 每个 rubric 的评估结果记录为一个二值变量,使用预定义的 rubric 权重计算加权平均值以获得最终的 rubric 奖励
- 如果一个 response 未能满足任何标记为必要的标准,则总 rubric 奖励严格设置为 0
- 否则,计算所有有效 rubric 上的归一化加权和,并将结果裁剪到 \([0,1]\) 区间
- 这种设计确保了奖励既能覆盖明确的写作要求的广度,也能满足严格的关键约束
IFEval Reward
- IFEval 奖励衡量 response 是否遵守明确的指令约束
- 对于每个 response,作者调用与参考注释关联的基于规则的验证器,以评估格式、内容或行为要求
- 标准的 IFEval 注释产生严格的通过/失败信号
- 某些扩展数据集提供连续的分数
- 在这两种情况下,此奖励为指令遵循能力提供直接监督,并主要反映对硬性任务约束的遵守情况
Math Reward
- 数学奖励评估数学推理的正确性
- 对于具有可验证最终答案的问题,评分器提取生成的答案,并使用精确匹配或特定任务的等价性检查将其与参考解决方案进行比较
- 该指标为数学样本提供了主要的正确性信号,而 length 奖励则施加了补充性的压力以鼓励简洁推理
Code Reward
- 代码奖励评估生成程序的功能正确性
- 对于编码任务,评分器使用参考评估协议(例如,基于执行的检查或可用的特定任务验证器)评估生成的解决方案
- 此奖励与 length 奖励配对,以确保面向代码的强化学习同时优化正确性和响应效率
RM Reward
- RM 奖励由一个独立的奖励模型生成,以捕捉整体的 response 质量
- 将 prompt 和 response 连接成一个完整的对话,并将其输入奖励模型以获得原始标量分数
- 由于这些原始输出可能范围很广,将分数线性缩放到 \([0,1]\),以保持与其他奖励组件的数值一致性
- 与基于规则的指标(如 rubrics 和 IFEval)不同,RM 奖励为流畅性、完整性、连贯性和主观质量提供了一个软偏好信号
- RM Reward 作为补充信号而非硬性任务约束的替代
Length Reward
- 长度奖励鼓励在不牺牲任务满意度的情况下生成简洁的 response
- 对于每个 response,将生成的长度与参考统计数据进行比对:
- 对于给定 Query,从基础模型的多次采样中,成功完成任务的平均长度
- 该指标反映了基础模型的内在能力,并为后续训练建立了稳健的基线
- 奖励设计:
- 长度低于此阈值的 response 获得奖励 1
- 长度超过阈值时,奖励会根据二次惩罚衰减,并被裁剪到 \([0,1]\) 区间
- 这种表述避免了过度惩罚轻微的超长,同时对明显冗长的生成施加更严格的惩罚
Conditional Reward Handling
- 在组合多个奖励之前,应用一个条件处理机制,以防止辅助信号补偿核心要求的失败
- RM 奖励受 rubric 奖励约束:
- 如果 rubric 奖励低于 0.5,RM 奖励被截断为 \(\min(r_{\text{rubric} },r_{\text{rm} })\)
- 这确保了高的整体偏好分数不能掩盖对必要 rubrics 的违反
- 对 length 奖励应用类似的门控规则
- 对于指令遵循样本
- 仅当满足 IFEval 约束时,length 奖励才被视为有效
- 如果 IFEval 分数降至 0.5 以下,length 奖励会相应减少
- 对于数学、代码和基于 rubric 的写作样本,当主要任务奖励低于 0.5 时,length 奖励也会被类似地截断
- 对于指令遵循样本
- 理解:只有当 response 已经满足基本任务要求时,长度控制和整体偏好才能作为辅助优化信号
- RM 奖励受 rubric 奖励约束:
Evaluation
Evaluation Setup
- 为了评估在训练任务类别上的表现,本文选择了一组多样化的挑战性基准,并将它们组织成四个评估集群:
- 1)Instruction Following :此集群包括 IFEval (2023)、GuideBench (2025) 和 SOP-Maze (2025)
- 2)Math and Knowledge Reasoning :此集群包括 AIME24、AIME25、GPQA (2024) 和 MATH500 (2023)
- 3)Writing and Arena Evaluation :此集群包括 WritingBench (2025) 和 ArenaHard v2 (2024)
- 对于 ArenaHard v2,报告两个互补的子集:AH-Hard 和 AH-Creative
- 4)Coding :此集群包括 FullStackBench (2024)、HumanEval+ (2021)、MBPP+ (2021) 和 LiveCodeBench v6 (2024)
Small-Scale Validation on a Same-Family Smaller Model,在同系列小型模型上的小规模验证
- 在将 RDPO 扩展到更大的 LongCat-Flash 后训练运行之前,本文首先在来自同一系列的一个较小的内部模型上验证该方法
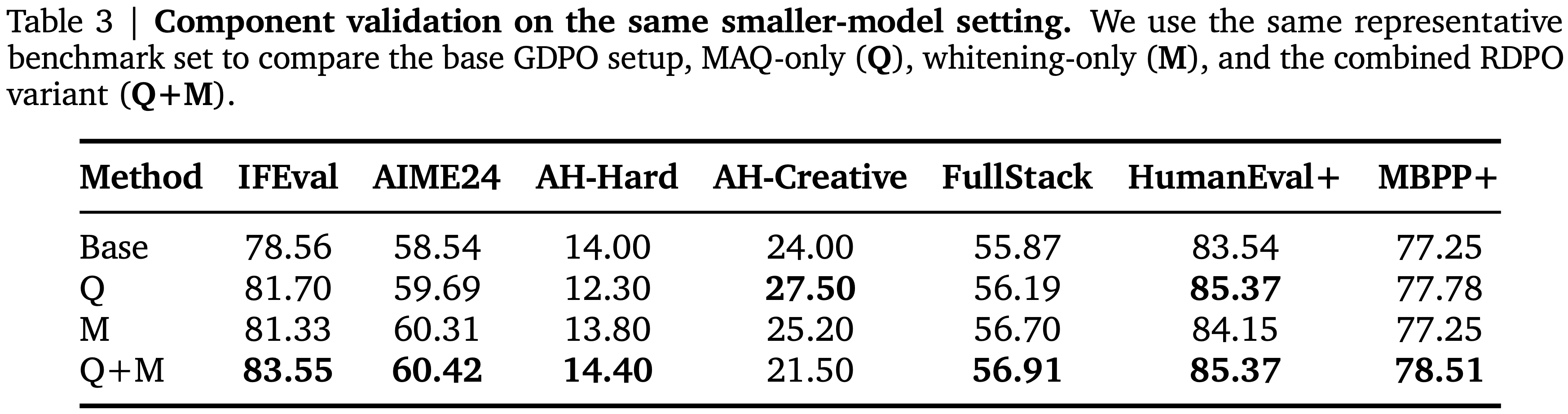
- 这个初步阶段有两个主要目的:评估完整的奖励解耦流程是否在相关基线上有所改进,并分离其两个核心组件(MAQ 归一化和马氏白化)的贡献
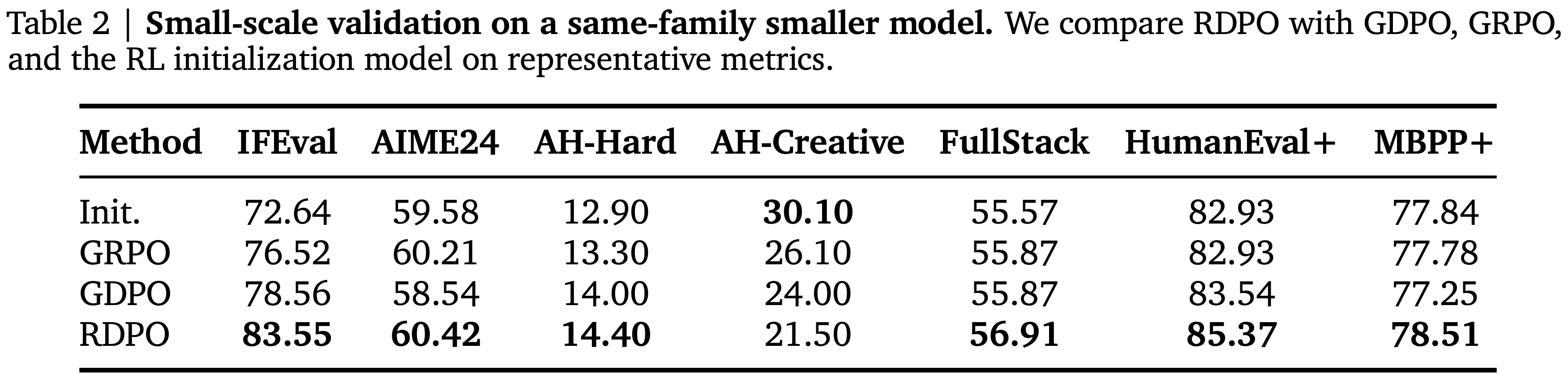
- 表 2 和表 3 显示了初步性能,支持了更大规模的 LongCat-Flash 试验
- 完整的流程在 IFEval、AIME24、AH-Hard、FullStackBench、HumanEval+ 和 MBPP+ 上相比 GDPO 基线有所改进
- 此外,组件级别的分析表明,MAQ 和白化提供了互补的优势:
- MAQ 在几个对分布敏感的指标(包括 AH-Creative)上表现强劲,而白化在相关性敏感的设定中有所帮助
- 这些实证结果激发了为 LongCat-Flash 后训练运行采用完整 RDPO 方案
- 表 2:在同系列小型模型上的小规模验证,在代表性指标上将 RDPO 与 GDPO、GRPO 以及 RL 初始化模型进行比较
- 表 3:在相同小型模型设定下的组件验证,使用相同的代表性基准集来比较基础的 GDPO 设定、仅 MAQ (Q)、仅白化 (M) 以及组合的 RDPO 变体 \((Q + M)\)
Scaled LongCat-Flash Post-Training Results,扩展训练结果
- 在小规模验证阶段之后,本文将完整的 RDPO 流程扩展到 LongCat-Flash
- 本文的 LongCat-Flash 评估侧重于端到端的可扩展性
- 本文研究了完整的奖励解耦优势构建在更大的后训练机制中是如何表现的
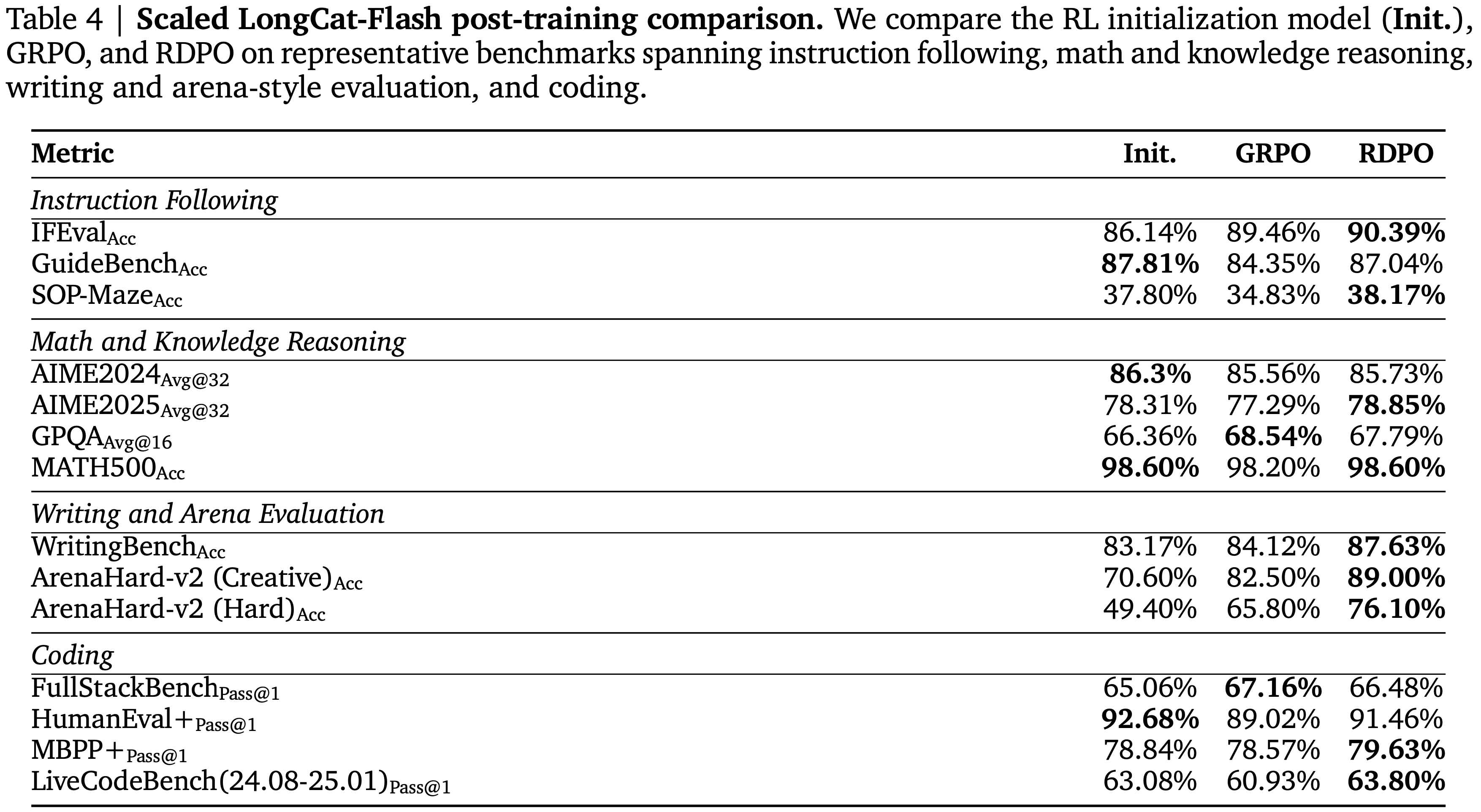
- 如表 4 所示,LongCat-Flash RDPO 模型主要在与混合奖励训练目标一致的能力上取得了提升
- 在评估的三个模型中,RDPO 在 IFEval 和 SOP-Maze 上获得了最高分,同时在 WritingBench 以及报告的两个 ArenaHard v2 子集(AH-Creative 和 AH-Hard)上也取得了显著的提升
- 这些结果与前文的小规模验证一致:稳定 prompt 级别的优势分配和减少奖励冗余似乎对指令遵循以及开放式、偏好敏感的评估很有用
- 在其余的推理和代码评估上,比较结果好坏参半但表现稳定
- RDPO 在 MATH500 上达到了最高分,并在 AIME2025 和 GPQA 上保持竞争力
- Init. 或 GRPO 在个别指标上可能仍然更强
- 代码结果遵循类似的模式:
- RDPO 在 MBPP\(^+\) 和 LiveCodeBench v6 上领先
- GRPO 或 Init. 在 FullStackBench 和 HumanEval\(^+\) 上仍然更强
- Scaled LongCat-Flash 实验表明,完整的 RDPO 方案可以从较小的模型验证中迁移过来,并在推理和代码结果上广泛保持稳定
- 表 4:本文在涵盖指令遵循、数学与知识推理、写作与竞技场式评估以及代码的代表性基准上比较了 RL 初始化模型 (Init.)、GRPO 和 RDPO
附录:常见分布的 CDF 介绍
标准正态分布的 CDF
- \(\Phi(z)\) 专门表示标准正态分布的 CDF :
$$
\Phi(z) = \int_{-\infty}^{z} \frac{1}{\sqrt{2\pi} } e^{-t^2/2} dt
$$- 均值为 0
- 方差为 1
- 记作 \(N(0,1)\)
- 这是统计学和机器学习论文中的通用约定
非标准正态分布的 CDF 表示方法
- 对于一般正态分布 \(N(\mu, \sigma^2)\),CDF 通常用以下几种方式表示:
方法一:用 \(\Phi\) 标准化后表示
- 比如:
$$
F_{X}(x) = \Phi\left(\frac{x - \mu}{\sigma}\right)
$$- 这是最常见、最简洁的写法
- 例如:
- \(X \sim N(\mu, \sigma^2)\)
- \(F_X(x) = P(X \le x) = \Phi\left(\frac{x - \mu}{\sigma}\right)\)
方法二:用 \(F\) 加下标
- 比如:
$$
F_{N(\mu, \sigma^2)}(x) \quad \text{或} \quad F_X(x)
$$- 然后用文字说明 “where \(X \sim N(\mu, \sigma^2)\)”
方法三:用不同字母区分
- 具体方式对比:
分布 CDF 符号 示例 标准正态 \(N(0,1)\) \(\Phi(z)\) \(\Phi(1.96) \approx 0.975\) 一般正态 \(N(\mu, \sigma^2)\) \(\Phi_{\mu,\sigma}(x)\) 或 \(F(x;\mu,\sigma)\) 不常用 任意分布 \(F_X(x)\) 通用符号
补充:其他常见分布的 CDF 符号
- 常见分布的 CDF 表示
分布 CDF 符号 PPF 符号 标准正态 \(N(0,1)\) \(\Phi(z)\) \(\Phi^{-1}(u)\) 均匀分布 \(U(0,1)\) \(F(x) = x\) 或 \(U(x)\) \(U^{-1}(u) = u\) 指数分布 \(\text{Exp}(\lambda)\) \(F(x) = 1 - e^{-\lambda x}\) \(F^{-1}(u) = -\frac{\ln(1-u)}{\lambda}\) 任意分布 \(F_X(x)\) \(F_X^{-1}(u)\)
附录:马氏白化与 Z-Score 归一化的区别
- 从纯粹的数学视角来看:
- Z-Score 标准化只消除了各维度的量纲差异
- 马氏白化(Mahalanobis Whitening)进一步消除了维度之间的线性依赖关系
- 总结对照表
性质 Z-Score 标准化 马氏白化 变换后均值 零向量 零向量 变换后各维度方差 1 1 变换后各维度相关性 保留原相关矩阵 \(\mathbf{P}\) 完全消除,变为 0 变换后的协方差矩阵 \(\mathbf{P}\)(相关矩阵) \(\mathbf{I}\)(单位阵) 几何效果 各轴独立缩放,不旋转 旋转 + 缩放,得到球体 旋转不变性 否 是 对异常值敏感性 中等 高 计算复杂度 \(O(d)\) \(O(d^3)\) 需要估计的参数 \(d\) 个均值,\(d\) 个方差 \(d\) 个均值,\(d(d+1)/2\) 个协方差
数学定义
- 设原始随机向量为
$$\mathbf{x} = (x_1, x_2, \ldots, x_d)^T \in \mathbb{R}^d$$- 均值为 \(\boldsymbol{\mu}\)
- 协方差矩阵为 \(\boldsymbol{\Sigma}\)
- Z-Score 标准归一化 :
- 对每个分量独立操作:
$$
x_i’ = \frac{x_i - \mu_i}{\sigma_i}
$$- 其中 \(\sigma_i = \sqrt{\boldsymbol{\Sigma}_{ii} }\)
- 写成向量形式:
$$
\mathbf{x}’ = \mathbf{D}^{-1/2} (\mathbf{x} - \boldsymbol{\mu})
$$- 这里 \(\mathbf{D}\) 是对角矩阵
$$ \mathbf{D} = \text{diag}(\boldsymbol{\Sigma}_{11}, \boldsymbol{\Sigma}_{22}, \ldots, \boldsymbol{\Sigma}_{dd})$$
- 这里 \(\mathbf{D}\) 是对角矩阵
- 对每个分量独立操作:
- 马氏白化 :
- 利用完整的协方差矩阵:
$$
\mathbf{z} = \boldsymbol{\Sigma}^{-1/2} (\mathbf{x} - \boldsymbol{\mu})
$$- 其中 \(\boldsymbol{\Sigma}^{-1/2}\) 是协方差矩阵的逆平方根
- 计算方式:
- 通常先对 \(\boldsymbol{\Sigma}\) 进行特征分解
$$ \boldsymbol{\Sigma} = \mathbf{U} \boldsymbol{\Lambda} \mathbf{U}^T$$ - 然后再计算:
$$
\boldsymbol{\Sigma}^{-1/2} = \mathbf{U} \boldsymbol{\Lambda}^{-1/2} \mathbf{U}^T
$$
- 通常先对 \(\boldsymbol{\Sigma}\) 进行特征分解
- 利用完整的协方差矩阵:
变换后的协方差结构
- Z-Score 标准化后 :
$$
\text{Cov}(\mathbf{x}’) = \mathbf{D}^{-1/2} \boldsymbol{\Sigma} \mathbf{D}^{-1/2} = \mathbf{P}
$$- 其中 \(\mathbf{P}\) 是相关矩阵 ,其对角线元素均为 1,但非对角线元素 \(\rho_{ij} = \frac{\boldsymbol{\Sigma}_{ij} }{\sqrt{\boldsymbol{\Sigma}_{ii}\boldsymbol{\Sigma}_{jj} } }\) 一般不为零
- 即:各分量方差变为 1,但相关性依然保留
- 马氏白化后 :
$$
\text{Cov}(\mathbf{z}) = \boldsymbol{\Sigma}^{-1/2} \boldsymbol{\Sigma} \boldsymbol{\Sigma}^{-1/2} = \mathbf{I}
$$- 即变换后的向量各分量方差为 1,且协方差(相关性)为零 ,达到完全去相关
几何解释
- 将 \(\mathbf{x}\) 视为高维空间中的一个数据点云,其分布呈椭球状
- Z-Score 标准化 :将椭球的每个轴独立缩放至单位长度,但不旋转坐标轴
- 结果是一个各轴长度相等但轴方向仍与原坐标轴平行的椭球
- 如果原数据有倾斜的相关结构(即椭球主轴不与坐标轴对齐),标准化后的椭球仍然是倾斜的
- 马氏白化 :
- 先旋转坐标轴使其与椭球的主轴对齐(通过 \(\mathbf{U}^T\))
- 再对各主轴缩放至单位长度(通过 \(\boldsymbol{\Lambda}^{-1/2}\))
- 最后再旋转回原坐标系(通过 \(\mathbf{U}\))。结果是数据点云变成一个各向同性的球体 ,即所有方向上的方差相等且无相关性
对线性变换的敏感性
- Z-Score 标准化 :对每个维度独立进行,因此在数据的正交变换(旋转)下不能保持形式不变
- 如果对 \(\mathbf{x}\) 施加一个旋转矩阵 \(\mathbf{R}\),先旋转再标准化,与先标准化再旋转,结果不同
- 马氏白化 :具有旋转不变性
- 对 \(\mathbf{x}\) 施加任意可逆线性变换 \(\mathbf{A}\) 后再进行马氏白化,等价于先马氏白化再施加同一变换的某种规范化形式
- 本质上,马氏距离 \(\sqrt{(\mathbf{x} - \boldsymbol{\mu})^T \boldsymbol{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu})}\) 本身是旋转不变的,而白化是该距离的线性实现
对异常值的鲁棒性
- Z-Score 标准化 :均值和标准差对异常值敏感
- 一个极端 outlier 会拉大 \(\sigma_i\),导致正常数据被过度压缩到接近零的区域
- 马氏白化 :更加敏感
- 因为协方差矩阵 \(\boldsymbol{\Sigma}\) 对异常值极其敏感(异常值会产生大的协方差项),同时 \(\boldsymbol{\Sigma}^{-1/2}\) 的计算依赖特征分解,异常值可能严重扭曲特征空间
- 因此,马氏白化通常要求数据已经经过预处理以去除明显异常值(本文中就是经过预处理的)
计算复杂度
- Z-Score 标准化 :\(O(d)\) 时间和空间复杂度,仅需计算每个维度的均值和方差
- 马氏白化 :\(O(d^3)\) 时间复杂度(特征分解)和 \(O(d^2)\) 空间复杂度(协方差矩阵存储)
- 对于高维数据(如 \(d \gg 10^4\)),计算代价极高,甚至不可行