注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:(Nemotron-Cascade-2 Technical Report) Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation, 20260319-20260322, NVIDIA
- HuggingFace: huggingface.co/nvidia/Nemotron-Cascade-2-30B-A3B
- 补充前一篇文章:(Nemotron-Cascade Technical Report) Nemotron-Cascade: Scaling Cascaded Reinforcement Learning for General-Purpose Reasoning Models, 20251215-20260327, NVIDIA
Paper Summary
- 整体介绍
- 本文包含了非常详细的训练细节,值得一读
- 英伟达开源了 Nemotron-Cascade-2-30B-A3B(基于 Nemotron-3-Nano-30B-A3B-Base 进行后训练得到)
- 主推核心能力:Reasoning 和 Agentic 能力,小尺寸但其数学和编码 Reasoning 性能接近前沿的开放模型
- 是继 DeepSeek-V3.2-Speciale-671B-A37B 之后,第二个在 2025 年国际数学奥林匹克竞赛 (IMO)、国际信息学奥林匹克竞赛 (IOI) 和 ICPC 世界总决赛中达到金牌水平的开源权重 LLM
- 特点:显著更高的智能密度,参数减少了 20 倍
- 与 Nemotron-Cascade 1 相比,关键的技术进步如下
- 在经过精心策划的数据集上进行 SFT 之后,大幅扩展了 Cascade RL,使其覆盖更广泛的 Reasoning 和 Agentic 领域
- 在整个 Cascade RL 过程中为每个领域引入了来自最强中间教师模型的 MOPD (Multi-Domain On-Policy Distillation)
- 有效地恢复基准测试的退化,持续保持强大的性能提升
- Nemotron-Cascade-2 训练流程:SFT -> IF-RL -> Multi-domain RL -> MOPD -> RLHF -> Long-context RL -> Code RL -> SWE RL
- PS:Nemotron-Cascade 训练流程是 SFT -> RLHF -> IF RL -> Math RL -> Code RL -> SWE RL
- 注:本文还发布了训练数据(在 HuggingFace 上均可下载)
- Nemotron-Cascade-2-SFT-Data:用于 Nemotron-Cascade-2 的 SFT 数据集
- Nemotron-Cascade-2-RL-Data:用于 Nemotron-Cascade-2 的 RL 数据集
Introduction and Discussion
- Reasoning 和 Agentic 任务上,RL 的主要挑战在于成功整合更广泛的 RL 环境和非常多样化的 Reasoning 与 Agentic 任务
- 扩展 RL 以涵盖多方面的现实世界应用,需要能够处理各种奖励信号 和复杂环境反馈 , 且不破坏训练过程 的鲁棒框架
- 本文作者之前的工作 Nemotron-Cascade 1 (2025) 引入了 Cascade RL
- Cascade RL 是一个跨专业任务领域协调顺序的、领域特定的 RL 训练的框架
- Cascade RL 的多个阶段:SFT -> RLHF -> IF RL -> Math RL -> Code RL -> SWE RL
- Cascade RL 显著简化了与多领域 RL 相关的工程复杂性,同时在广泛的基准测试上实现了最先进的性能
- Cascade RL 的优势有三点
- 第一:特定领域的 RL 阶段对灾难性遗忘具有显著的抵抗力
- Cascade RL 很少会降低在早期领域获得的基准性能,甚至可能提高它
- 第二:Cascade RL 允许为每个特定领域精心定制 RL 超参数和训练课程
- 从而实现优化的学习动态和改进的最终性能
- 第三:每个 RL 阶段内的任务同质性也带来算力节省
- 因为在一个领域内,Response 长度和验证挂钟时间比在联合训练的多个领域中更一致
- 第一:特定领域的 RL 阶段对灾难性遗忘具有显著的抵抗力
- Cascade RL 是一个跨专业任务领域协调顺序的、领域特定的 RL 训练的框架
- 本文介绍了 Nemotron-Cascade 2,与其前身类似,Nemotron-Cascade 2 进一步在高优先级领域上扩展了 Cascade RL,以保留领域特定训练的好处,能够将关键领域的 Reasoning 性能极限推向最先进水平
- 本文将 On-Policy Distillation (2026; 2026) 融入到 Cascade RL 训练阶段
- 通过在 Cascade RL 期间从每个特定领域内表现最佳的中间教师模型中蒸馏知识,这种机制有效地恢复了在日益复杂的 RL 环境中训练时可能发生的任何基准测试性能退化
- 将多领域 RL 集成到 Cascade RL 中,用于具有相似 Response 格式和可比验证成本的任务组,允许它们联合训练,以扩展到更多的 RL 环境,并在跨任务干扰最小时提高训练效率
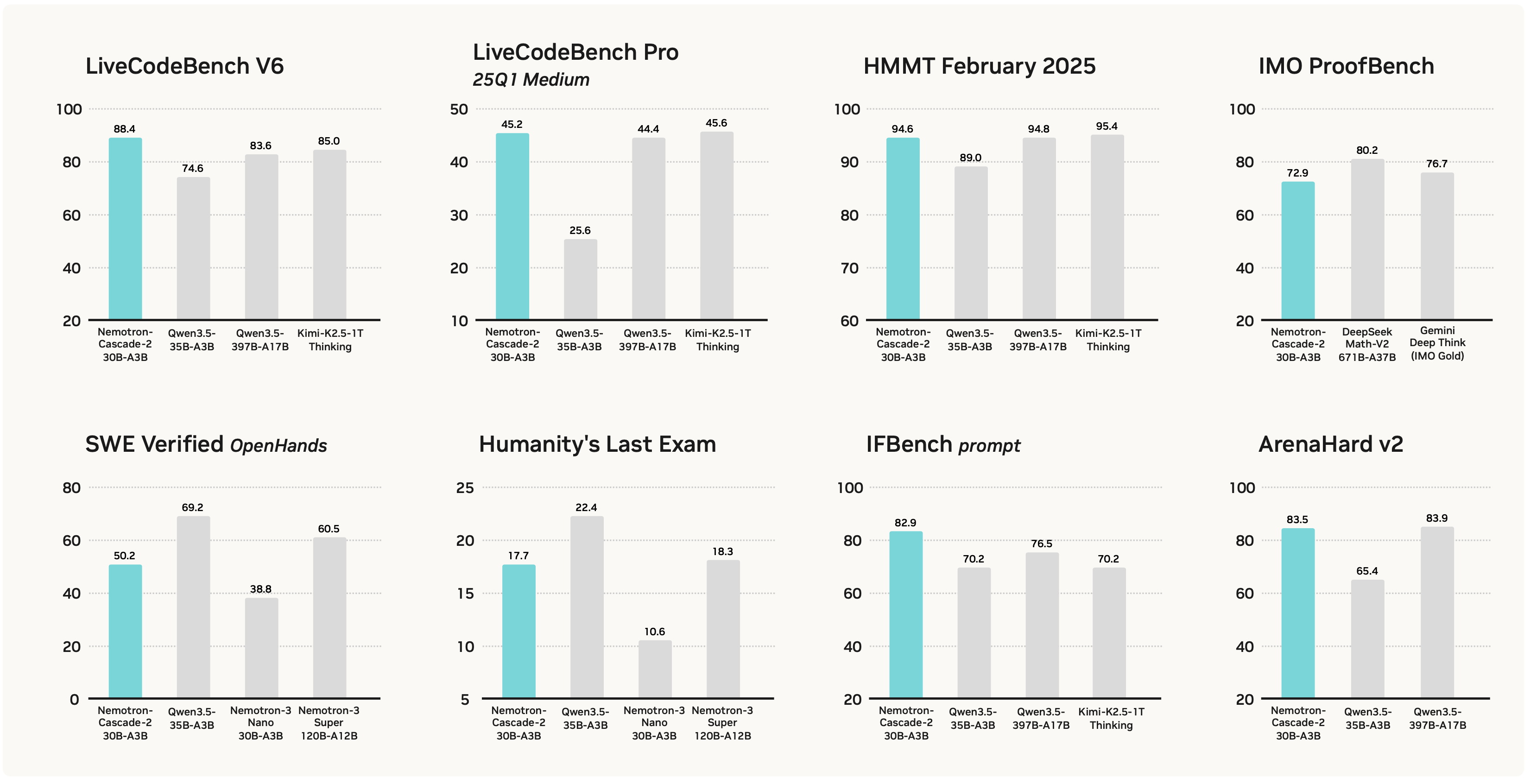
- 本文的 Nemotron-Cascade-2-30B-A3B 在数学和编码 Reasoning 方面实现了突破性的性能
- 仅 30B 的 MoE 模型,但在 2025 年国际数学奥林匹克竞赛 (IMO) 和国际信息学奥林匹克竞赛 (IOI) 中都获得了金牌成绩,同时在广泛的基准测试中提供了最佳性能,包括 Alignment、Instruction-Following、Long Context(例如,1M 上下文窗口)和 Agentic 任务
- 完整结果见表 1
- 注:本文完全开源了模型权重、训练数据和方法细节,使研究社区能够复现、分析和扩展所提出的 Cascade RL 训练范式
- 这一点特别重要,文章中包含许多训练细节和超参数等
Main Results
- 在涵盖数学和编码 Reasoning 、知识与 STEM、 Alignment 与 指令跟随 、长上下文理解与上下文学习 (In-Context Learning)、多语言能力和 Agentic 任务的全面基准套件上评估了 Nemotron-Cascade 2
- 主要结果显示在表 1 中,基准测试和详细的评估设置见附录 A
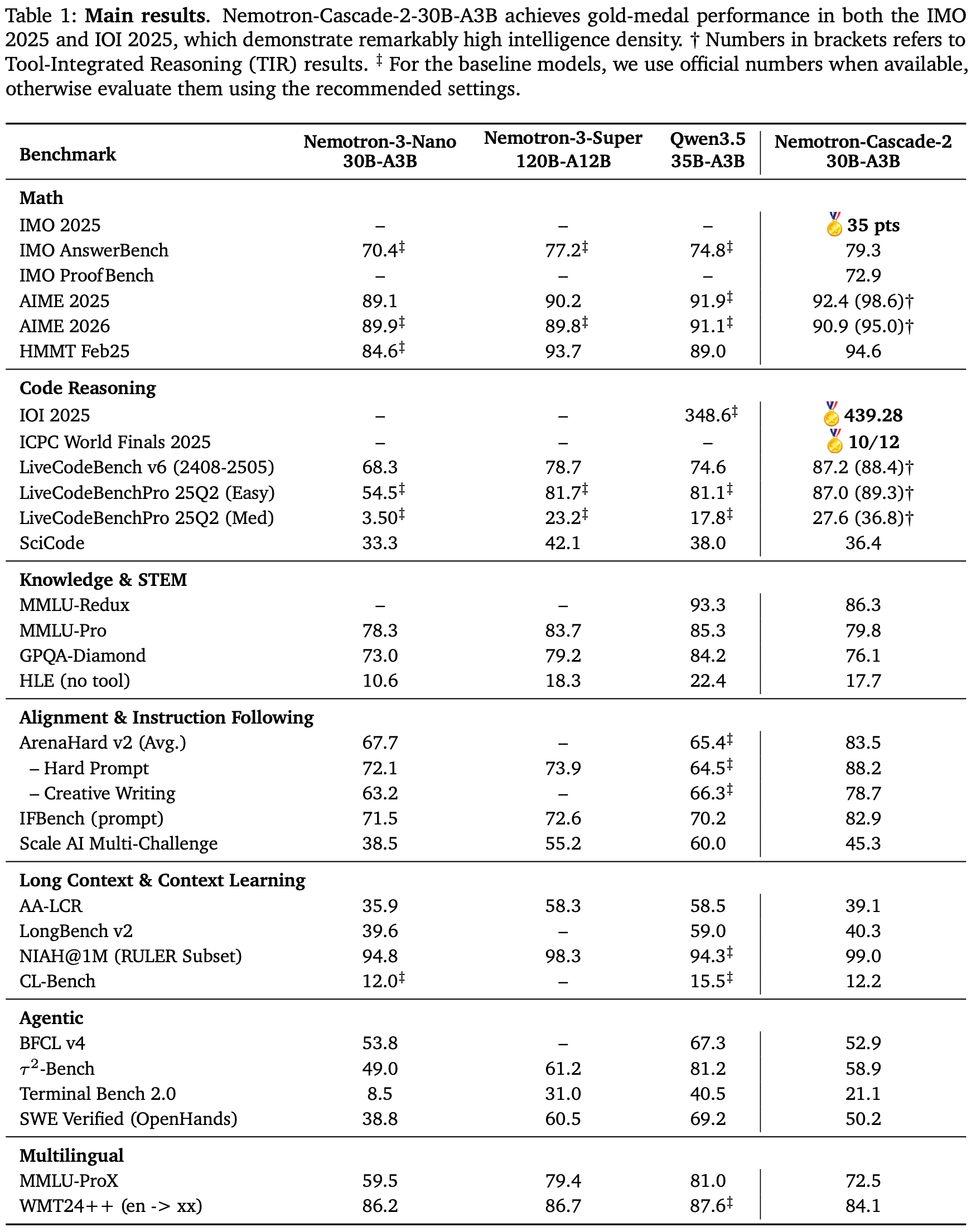
- 表 1:主要结果
- Nemotron-Cascade-2-30B-A3B 在 IMO 2025 和 IOI 2025 中均实现了金牌性能,展示了显著的高智能密度
- 方括号中的数字指的是工具集成推理 (Tool-Integrated Reasoning, TIR) 结果
- 对于基线模型,使用可用的官方数值,否则使用推荐的设置进行评估
- 从表 1 可以看出,Nemotron-Cascade-2-30B-A3B 不仅优于最新发布的 Qwen3.5-35B-A3B (2026-02-24) (Qwen Team, 2026),也优于更大的 Nemotron-3-Super-120B-A12B (2026-03-11) (2025),并在数学、代码 Reasoning 、通用 Alignment 和 指令跟随 的基准测试中实现了同类最佳性能
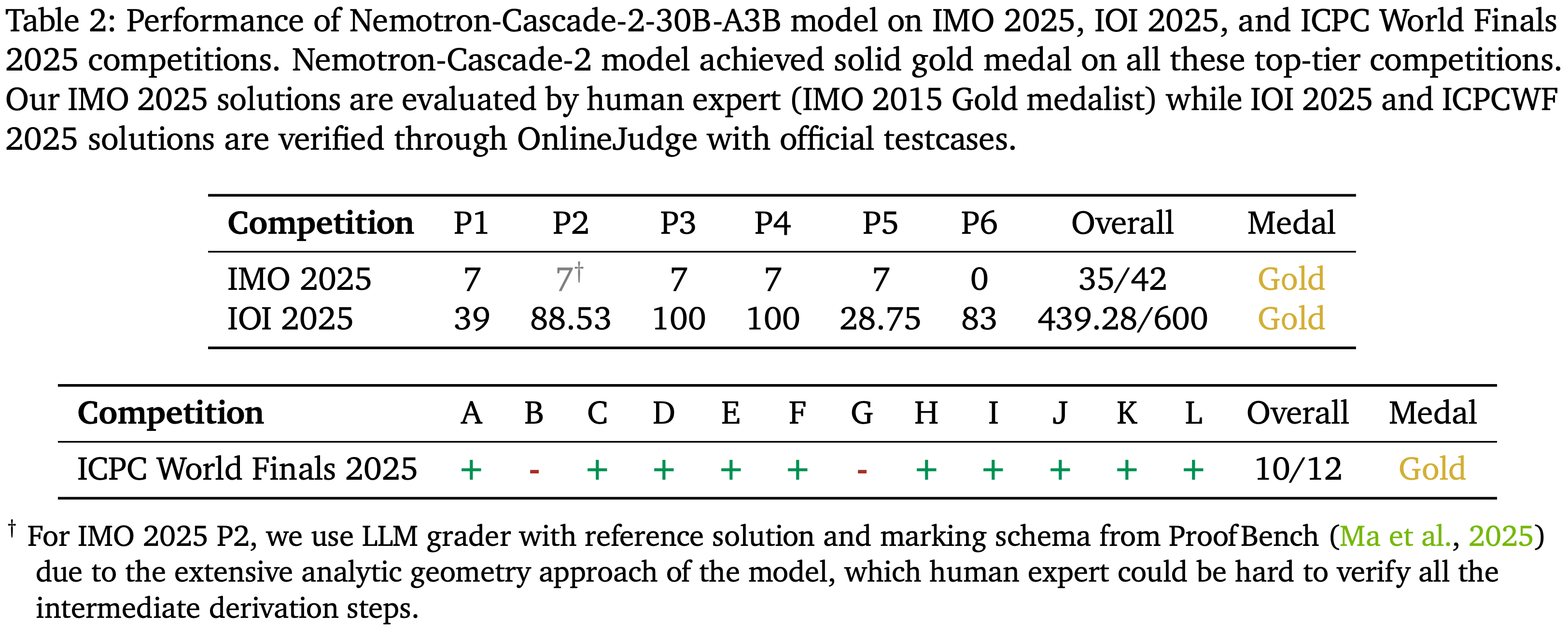
- 表 2:
- 对于 IMO 2025 P2,由于模型采用了广泛的分析几何方法,人类专家可能难以验证所有中间推导步骤
- 本文使用来自 ProofBench (2025) 的参考解决方案和评分方案的 LLM 评分器
- 本文使用来自 ProofBench (2025) 的参考解决方案和评分方案的 LLM 评分器
- 对于 IMO 2025 P2,由于模型采用了广泛的分析几何方法,人类专家可能难以验证所有中间推导步骤
- 特别说明:Nemotron-Cascade 2(30B 的 MoE 模型)在 IMO 2025、IOI 2025 和 ICPC World Finals 2025 上取得了金牌性能
- 这一结果以前被认为只有前沿的专有模型 (Gemini Team, 2025)(即 Gemini Deep Think)和前沿规模的开源模型 (2025)(即 DeepSeek-V3.2-Speciale-671B-A37B)才能达到
- 本文模型的详细性能在表 2 中报告
- 对于 IMO 2025,模型生成的解决方案以及人类专家的评审和分数见附录 E
- Nemotron-Cascade-2-30B-A3B 在几乎所有基准测试上也优于 Nemotron-3-Nano-30B-A3B
- 注:这两个模型都是从相同的预训练模型 Nemotron-3-Nano-30B-A3B-Base (NVIIDA, 2025) 进行后训练的
- 这一结果进一步证明了本文的 Cascade RL 加 MOPD 训练流程的有效性
- 注:Nemotron-Cascade-2-30B-A3B 在知识密集型和 Agentic 基准测试上表现不如 Qwen3.5-35B-A3B
- 未来工作重点:进行更强的知识密集型预训练和 Agentic RL
SFT
- 本节描述 SFT 训练框架和数据管理过程,这是作者后训练流程的第一阶段。此阶段为模型配备了基础能力,包括 Reasoning 、对话能力、 指令跟随 以及 Agentic 和软件工程技能
Training Framework
Overview
- 本文的 SFT 数据涵盖包括
- 数学、编码、科学、工具使用、Agentic 任务和软件工程
- 通用领域:如多轮对话、知识密集型问答、创意写作、角色扮演、安全性和 指令跟随
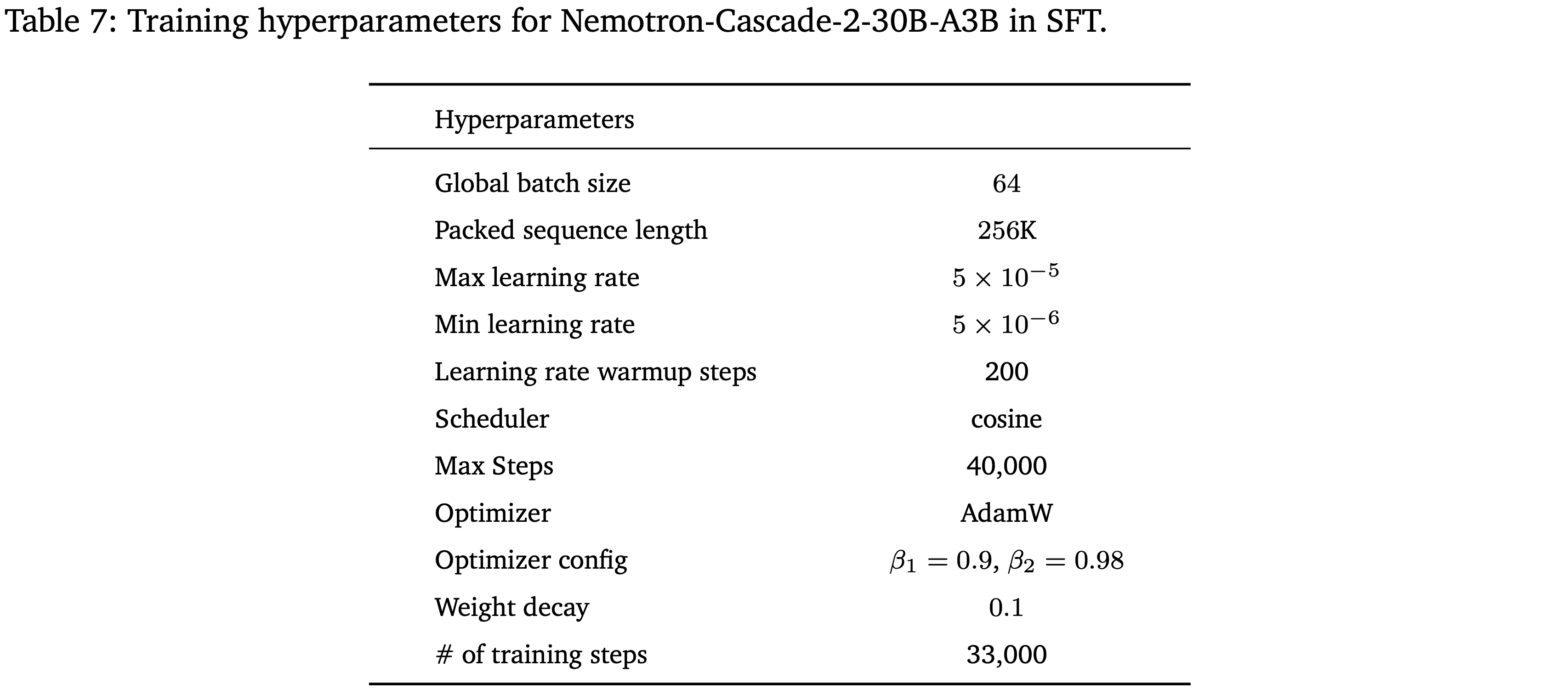
- 本文将所有 SFT 样本打包进长达 256K Token 的序列中,并在单个阶段训练模型
- 经验发现:SFT 模型在大约 1.5 个 Epoch 后达到最佳性能
- SFT 训练超参数见附录 B(表 7)
Chat Template
- 聊天模板如图 1 所示
- 与 Nemotron-Cascade (2025) (解读见:NLP——技术报告解读-Nemotron-Cascade)相比,聊天模板有两个变化
- 第一:为了简化,移除了
/think和/no_think标签 - 第二:预先添加一个空的
<think></think>块以激活非思考模式
- 第一:为了简化,移除了
- 对于工具调用任务,在系统 Prompt 中的
<tools>和</tools>标签内指定所有可用工具
- 与 Nemotron-Cascade (2025) (解读见:NLP——技术报告解读-Nemotron-Cascade)相比,聊天模板有两个变化
SFT Data Curation
Math
- 非证明数学 Prompt 主要来源于 Nemotron-Cascade (2025) 和 Nemotron-Math-v2 (2025)
- 从中收集了 1.8M 个工具调用(即 Python)样本和 190 万个非工具样本
- 其 Response 分别由 DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale (2025) 生成
- 从 Nemotron-3-Nano (2025) 的生成-选择类别中收集了 676K 个样本
- 其 Response 由 GPT-OSS-120B (2025) 生成
- 竞赛数学 SFT 包括 1.8M 个工具调用样本和 2.6M 个不使用工具的样本
- 对于数学自然语言证明,从 Nemotron-Math-Proofs-v1 (2025) 的 AOPS 分割中收集了 98K 个数学证明问题
- 为每个问题生成多个样本以涵盖两种能力:
- 证明生成 (410K ) 和证明验证 (400K )
- 使用 DeepSeek-V3.2-Speciale (2025),总共产生 816K 个样本
- 为每个问题生成多个样本以涵盖两种能力:
Code Reasoning
- 基于 Nemotron-Cascade 1 (2025),从几个开源数据集中管理了大约 165K 个 Unique 编码 Prompt
- 包括 OpenCode-Stage2 (2024)、OpenCodeReasoning (2025) 和 HardTests (2025)
- 这些 Prompt 最初来源于竞争性编程平台,如 Codeforces、AtCoder、AIZU 和 CodeChef
- 为鼓励 Prompt 多样性并减少 SFT 训练集中的冗余,使用两种方法应用了严格的去重:
- (1) 样本 I/O 指纹识别
- (2) 基于 n-gram 的文本分析
- 以上过程移除了大约 24.2% 的自我重复编码 Prompt
- 选择 GPT-OSS-120B (2025) 作为本文 SFT 教师模型
- 因为它具有强大的代码 Reasoning 能力
- 对于每个具有可验证测试用例的编码 Prompt,对教师的 Reasoning 轨迹应用正确性过滤,只保留那些生成正确代码的轨迹
- 对于没有可验证测试用例的 Prompt,通常选择更长的 Reasoning 轨迹,假设它们反映了更彻底的问题分析
- 此流程最终产生了一个数据集,包含 1.9M 条 Python Reasoning 轨迹、1M 条 C++14 Reasoning 轨迹和 1.3M 条用于竞争性编程的 Python 工具调用 Reasoning 轨迹
Scientific Coding
- 本文进一步收集了跨越生物学、材料科学、物理学、化学和数学领域的科学研究编码 Prompt
- 对这些 Prompt 的 Response 由 GPT-OSS-120B (2025) 生成,总共产生 1.1M 个 SFT 样本
Science
- 收集的科学 Prompt 跨越物理、化学和生物学
- 使用了来自 Nemotron-Cascade (2025) 的 1.4M 个科学 SFT 样本,以及来自 Nemotron-3-Nano (2025) 的另外 1.3M 个样本
- 两个数据集中的 Response 均由 GPT-OSS-120B (2025) 生成
Long Context
- 采用来自 Nemotron-3-Nano (2025) 的 160K 条长上下文 SFT 数据,其平均序列长度为 128K Token
- 此外还从 ChatQA-2 (2024) 收集了另外 74K 条长上下文 SFT,其平均长度为 29K Token
General Chat
- 从 Nemotron-Cascade 1 (2025) 获取 Prompt,并构建了 4.9M 个 Reasoning-on 和 372K 个 Reasoning-off 的样本
- Reasoning-on 样本的 Response 由 GPT-OSS-120B (2025) 生成
- Reasoning-off 样本中:
- 300K 个 Response 取自数据集本身内的高质量注释短答案
- 另外 330K 个由 DeepSeek-V3-0324 (2024) 生成以提高 Response 质量
- 为了增强多轮对话能力,使用两个 GPT-OSS-120B (2025) 实例在角色扮演设置中合成了大约 700K 个多轮对话样本,其中一个实例扮演用户,另一个扮演助手
- 用户端模型可以随时终止对话以防止重复交流
- 本文还从 Nemotron-3-Nano (2025) 中引入了 4.6M 个 Reasoning-on 聊天样本,其 Prompt 来源于 LMSYS (2023) 和 WildChat (2024)
- Response 由 GPT-OSS-120B (2025)、Qwen3-235B-A22B-Thinking-2507 和 Qwen3-235B-A22B-Instruct-2507 (2025) 生成
- 问题:是一个 Prompt 生成多个模型的 Response,同时使用吗?
Instruction Following
- 从 Nemotron-Cascade 1 (2025) 获取 Prompt
- 使用 GPT-OSS-120B (2025) 生成了大约 230K 个 Reasoning-on Response
- 使用 DeepSeek-V3-0324 (2024) 生成了 64K 个 Reasoning-off Response
- 此外从 Nemotron-3-Nano (2025) 引入了 497K 个 指令跟随 样本,包括 457K 个 Reasoning-on 和 40K 个 Reasoning-off Response
- 这些 Response 由 GPT-OSS-120B (2025)、Qwen3-235B-A22B-Thinking-2507 和 Qwen3-235B-A22B-Instruct-2507 (2025) 生成
Safety
- 从 Nemotron-3-Nano (2025) 收集了 4000 个安全性 SFT 样本,以使模型在遇到不安全输入时能够表现出适当的拒绝行为
- SFT Prompt 主要来源于 Nemotron Content Safety v2 (2025)、Gretel Safety Alignment v1 (2024)、Harmful Tasks (2024) 和 Red-Team-2K (2024)
Conversational Agent
- 除了用于数学和代码 Reasoning 的 Python 工具使用数据外,还在多轮对话设置中收集了工具使用样本
- 其中多个工具可用,助手必须确定调用哪些工具以及如何有效地使用它们
- 本文从 Nemotron3-Nano (2025) 收集了 822K 个对话式工具使用样本
- 其 Response 由 Qwen3-235B-A22B-Thinking-2507、Qwen3-32B、Qwen3-235B-A22B-Instruct-2507 (2025) 和 GPT-OSS-120B (2025) 生成
Software Engineering Agent
- 使用各种 Agentic Scaffold(包括 OpenHands (2025)、SWE-Agent (2024)、Mini-SWE-Agent 以及 Wei 等 (2025) 提出的无 Agent Scaffold)来管理软件工程数据,以增强模型的 Agentic 软件工程能力
- 第一:利用来自 Nemotron 3 Nano (2025) 和 Super (2025) 的数据
- 这些数据包括使用 Qwen3-Coder-480B-A35B-Instruct (2025) 生成的 SWE Agentic 轨迹
- 问题实例来自 SWE-Gym (Pan*2025)、SWE-rebench (2025) 和 R2E-Subset (2025)
- 第二:采用来自 Nemotron-Cascade 1 (2025) 的 SWE 无 Agent 数据,其中包括三个主要任务:
- (1) 错误代码定位
- (2) 代码修复
- (3) 测试用例生成
- 遵循 Wang 等 (2025) 中既定的程序,使用 DeepSeek-V3.2 (2025) 重构了代码修复数据
- 第一:利用来自 Nemotron 3 Nano (2025) 和 Super (2025) 的数据
- 本文初步研究表明,整合 SWE 无 Agent 数据可以提高模型在 SWE Agentic 任务上的有效性
- 例如
- 仅在 Agentic 数据上进行微调,在 SWE-bench Verified 上使用 OpenHands 的 Pass@1 为 48.9,Pass@4 为 62.8
- 在 Agentic 和无 Agent 数据组合上进行微调则分别将性能提高到 Pass@1 的 49.9 和 Pass@4 的 65.2
- 基于这一观察,本文将 125K 个 Agentic 样本和 389K 个无 Agent 样本组合起来,作为 SWE 任务的 SFT 数据
- 本文的模型在 SWE Agentic 数据上以非思考模式 训练,在 SWE 无 Agent 数据上以思考模式 训练
- 例如
Terminal Agent
- 为增强终端使用的 Agentic 能力,本文采用 Terminal-Task-Gen 方法 (2026) 来管理作者的训练任务
- 该框架包括
- (1) 将静态数据转换为交互式终端格式的数据集适配器
- (2) 从不同的种子 Prompt 和一个结构化的终端技能分类法中生成的合成任务
- 使用这个框架,总共 curate 了 490K 个样本
- 首先从现有的高质量来源 (2025) 适配了 162K 个数学、32K 个代码和 32K 个 SWE 特定样本,这建立了广泛的基础覆盖
- 为了进一步提高针对性技能的完善,合成了 120K 个基于种子和 140K 个基于技能的任务
- 对于轨迹构建,利用上述任务,并采用 DeepSeek-V3.2 作为核心引擎 ,通过在隔离的 Docker 环境中的执行-反馈循环来生成逐步的解决方案轨迹
- 注:Terminus 2 Agent 框架 (2026) 作为底层的 Scaffold 和工具使用协议,使模型能够与终端交互并完成复杂任务
Cascade RL and Multi-Domain On-Policy Distillation,Cascade RL 和 MOPD
- 遵循与 Nemotron-Cascade 1 (2025) 类似的方法,本文 Cascade RL 作为后训练流程
- 特别地,在 Cascade RL 流程中集成了多领域 On-Policy 蒸馏 (Multi-Domain On-Policy Distillation,简称 MOPD)
Training Framework
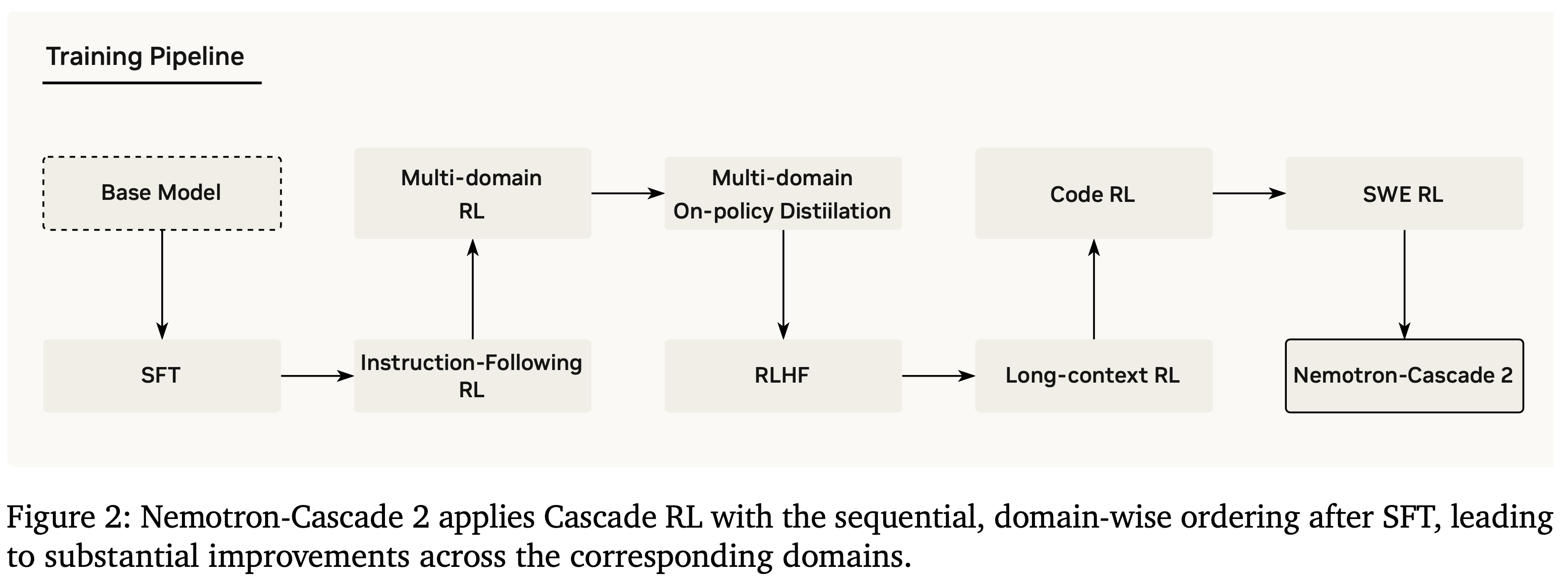
- 图 2 中展示了训练过程
- 第一步:从 IF-RL (§4.2) 开始 Cascade RL 流程
- 建立基础的指令遵循能力
- 第二步:进行多领域 RL (§4.3)
- 增强模型的工具调用能力、STEM 推理能力和 Response 格式遵循能力
- 第三步:过渡到 MOPD (§4.4)
- 将专门领域的专业知识统一到一个连贯的 Policy 中,以缓解性能下降
- 第四步;使用 RLHF (§4.5) 进行人类对齐
- 第五步:使用长上下文 RL (§4.6) 增强对长输入序列的推理能力
- 第六步:使用 Code RL (§4.7) 处理竞争性编程问题
- 第七步:使用 SWE RL (§4.8) 掌握 Agentic 软件交互
- 第一步:从 IF-RL (§4.2) 开始 Cascade RL 流程
What determines the ordering of Cascade RL,Cascade RL 的顺序
- Cascade RL 流程中各阶段的最优顺序并非一个通用常数
- 它是模型潜在行为和学习轨迹的动态函数
- 与原始的 Nemotron Cascade (2025) 相比
- 当前的工作 Nemotron-Cascade 2 在 SFT 数据质量上引入了显著改进,并大幅扩展了 RL 环境和任务的复杂性
- 这些进步从根本上改变了模型的行为动态,这使得需要采用不同的顺序,以更好地适应 LLM 不断发展的能力
Rule of thumb: Mitigating Inter-Domain Interference,经验法则:减少域内干扰
- 这种顺序的基本原理主要是为了缓解模型与日益多样化的环境交互时可能发生的灾难性遗忘
- Cascade RL 提供了一个精细的视角,通过它可以观察特定领域如何竞争或冲突
- 例如 IF-RL 中严格的指令遵循与 RLHF 中的人类偏好对齐
- 本文核心设计原则是确定一个能最小化领域间负面干扰的顺序,同时彻底优化最高优先级的领域
- 通过识别哪些任务是基础先验,哪些是专门的细化,我们可以减轻领域间干扰
Scaling via Multi-Domain Integration,通过多领域集成扩展
- 遵循这一原则,当特定领域被发现与整体性能不冲突或有益时,Cascade RL 流程可以包含多领域 RL 阶段
- 这种集成方法在 RL 环境和数据集复杂性增加时尤其有效,同时确保模型在 §4.3 中详述的各种基准测试中保持广泛的性能
Stabilization through On-policy Distillation,通过 OPD 稳定
- 发现:MOPD (§4.4) 在此顺序中充当了一个关键的稳定点
- MOPD 能够有效地恢复在 Cascade RL 早期、更专业化的阶段可能出现的基准性能下降,从而产生更平衡、更稳健的最终 Policy 模型
RL Training Configuration
- 在整个 Cascade RL 过程中,遵循 Nemotron Cascade (2025) 的做法
- 使用具有严格 On-Policy 训练的 GRPO 算法 (2024)
- 采用 On-Policy 训练以提高稳定性和准确性
- 使用 Nemo-RL 代码库 (NVIDIA, 2025) 进行训练
- 注:之前 Cascade RL 使用的是 VeRL
- 在每次迭代中,从当前 Policy \(\pi_{\theta}\) 生成一组 \(G\) 个 Rollout,然后执行一次梯度更新
- 这确保了用于数据收集的 Policy 始终与被更新的 Policy 匹配,使得重要性采样比率恰好为 1
- 这种 On-Policy 设置有助于稳定的 RL 训练并减轻熵崩溃
- 本文完全移除了 KL 散度项,这将 GRPO 目标简化为标准的 REINFORCE 目标 (1992),该目标具有组归一化奖励和 Token-level 损失 (2025):
$$\mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{(q,a)\sim \mathcal{D},\{o_i\}_{i = 1}^G\sim \pi_\theta (\cdot |q)}\left[\frac{1}{\sum_{i = 1}^G|o_i|}\sum_{i = 1}^G\sum_{t = 1}^{|o_i|}\hat{A}_{i,t}\right],\quad \text{ where }\hat{A}_{i,t} = \frac{r_i - \text{mean}(\{r_i\}_{i = 1}^G)}{\text{std}(\{r_i\}_{i = 1}^G)} \text{ for all } t \tag {1}$$- \(\{r_i\}_{i = 1}^G\) 表示分配给从数据集 \(\mathcal{D}\) 中抽取的给定问题 \(q\) 的采样 Response \(\{o_i\}_{i = 1}^G\) 的一组 \(\mathbf{G}\) 奖励
- 对于 RLVR,根据真实答案 \(a\) 进行验证
- 对于 RLHF,\(r_i\) 是来自生成式奖励模型 (generative reward model) 的,针对 Response \(o_i\) 和问题 \(q\) 的聚合奖励分数
- 不同领域的奖励函数细节将在相应的小节中提供
- 理解:上面是目标有点问题,应该还需要加个概率分布函数
$$
\mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^{G} \sim \pi_{\theta}(\cdot|q)} \left[ \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} \hat{A}_{i,t} \color{red}{\cdot \pi_\theta(o_{i,t}|q,o_{i, < t})} \right], \quad \text{Where } \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{r_i\}_{i=1}^{G})}{\text{std}(\{r_i\}_{i=1}^{G})} \text{ for all } t,
$$- 因为梯度应该是:
$$
\nabla \mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^{G} \sim \pi_{\theta}(\cdot|q)} \left[ \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} \hat{A}_{i,t} \color{red}{\nabla \pi_\theta(o_{i,t}|q,o_{i, < t})} \right], \quad \text{Where } \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{r_i\}_{i=1}^{G})}{\text{std}(\{r_i\}_{i=1}^{G})} \text{ for all } t,
$$
- 因为梯度应该是:
- \(\{r_i\}_{i = 1}^G\) 表示分配给从数据集 \(\mathcal{D}\) 中抽取的给定问题 \(q\) 的采样 Response \(\{o_i\}_{i = 1}^G\) 的一组 \(\mathbf{G}\) 奖励
IF-RL:Instruction-Following Reinforcement Learning
- Cascade RL 第一阶段是 IF-RL 方法
- 本文证明了应用可验证的 IF-RL 能显著提高指令遵循能力,在 IFBench (2025) 上达到了 \(83.13%\) 的最先进准确率
Dataset
- 使用与 NVIDIA Nano-v3 后训练 (2025) 相同的指令遵循训练数据
- 该数据集中的指令设计为客观可验证的,例如,要求 Response 字数少于 200 字
- 这使得该数据集非常适合训练和评估模型在严格遵循指令方面的能力
- 鉴于数据的基线质量很高,数据整理过程主要解决某些指令类型(例如,
count_increment_word)中关键字参数的格式不一致问题
Training recipe
- 遵循 (2025) 的方法,应用了动态过滤 (dynamic filtering) (2025)
- 该技术会过滤掉那些所有 Rollout 都完全正确或完全错误的样本
- 通过确保批次中的每个 Prompt 都能提供有效的梯度,动态过滤稳定了 IF-RL 训练并提高了模型性能的上限
- 过长的 IF-RL 训练可能导致 Token 使用过多,这对于满足一般聊天领域的特定约束通常是不必要的
- 为了缓解这个问题,应用 Oerlong penalty,即对那些未能在最大序列长度内完成生成的样本给予零奖励
- 与 Nemotron Cascade (2025) 的不同点
- 本文将 IF-RL 作为 Cascade RL 训练的第一阶段,主要有两个原因:
- (i) IF-RL 可能会对人类对齐能力(例如,ArenaHard)产生负面影响,而后续基于生成式奖励模型的 RLHF 对指令遵循分数的影响可以忽略不计
- 通过优先考虑指令遵循,可以专注于最大化指令遵循性能,然后利用后续阶段来恢复和完善人类偏好对齐
- (ii) 早期的 IF-RL 阶段会产生一个具有卓越指令遵循能力的模型,该模型可作为后续多领域 On-Policy 蒸馏的强大教师
- (i) IF-RL 可能会对人类对齐能力(例如,ArenaHard)产生负面影响,而后续基于生成式奖励模型的 RLHF 对指令遵循分数的影响可以忽略不计
- 与 Nemotron Cascade (2025) 的另一个不同之处:
- IF-RL 完全在“思考模式 (thinking mode)”下训练,没有结合奖励模型
- 理解:不训练 Non-thinking 模式,且仅使用 RLVR 奖励
- 由于后续的 RL 阶段会恢复 IF-RL 期间引入的人类偏好对齐的任何退化,我们可以完全专注于最大化指令遵循,而无需承担辅助奖励模型的计算开销
- IF-RL 完全在“思考模式 (thinking mode)”下训练,没有结合奖励模型
- 本文将 IF-RL 作为 Cascade RL 训练的第一阶段,主要有两个原因:
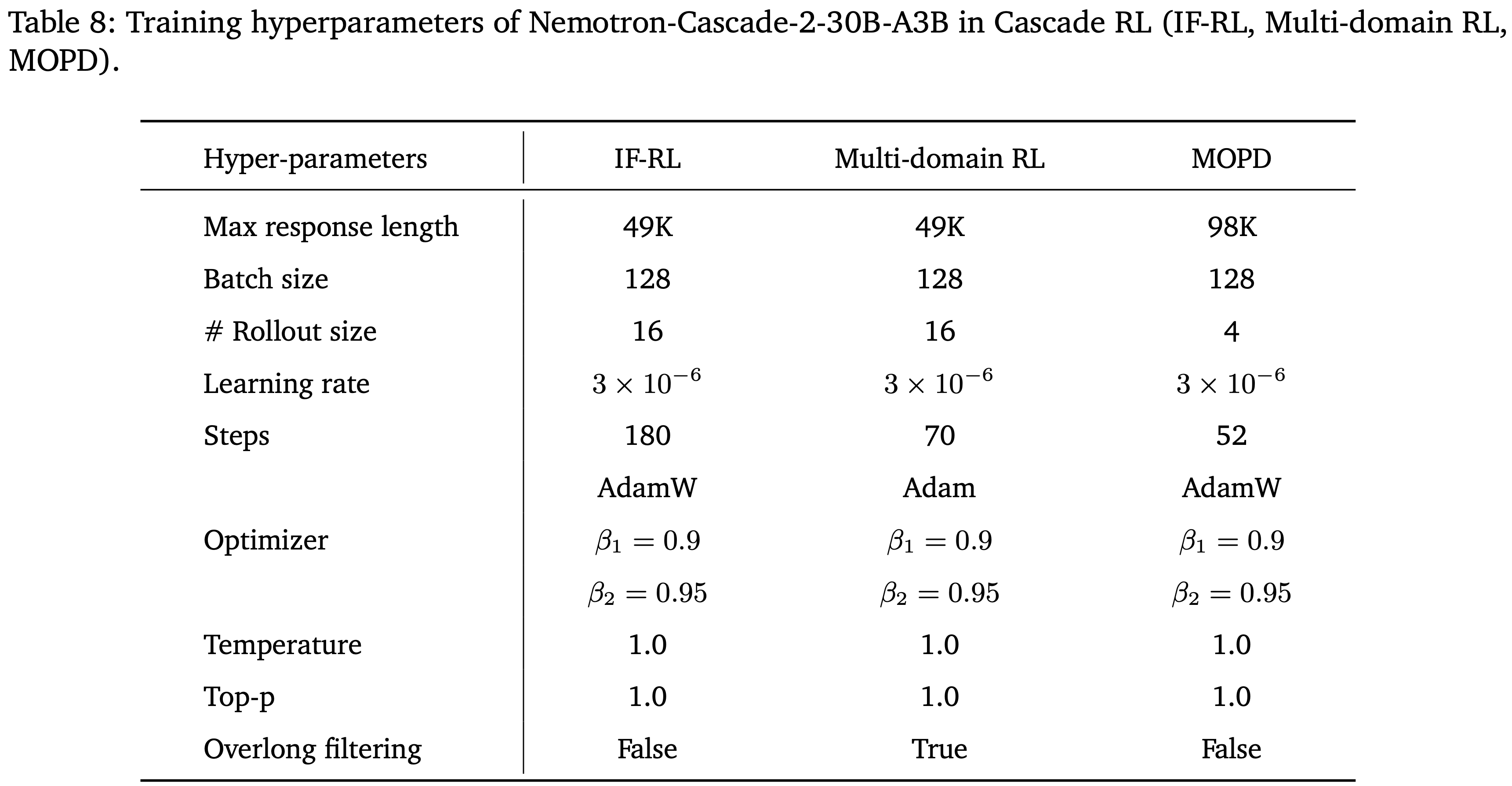
- 超参数:
- 使用 128 的 Batch Size ,每个 Prompt 采样 16 个 Response,温度为 1.0,Top-p 为 1.0
- 采用 AdamW 优化器,学习率为 3e-6,并将熵损失系数和 KL 损失系数均设为 0
- 带有动态过滤的 IF-RL 大约需要 180 步
- 完整的超参数集见附录 B(表 8)
Multi-domain RL
- 在 IF-RL 之后,进行了另一阶段的多领域 RL,涵盖了三种能力:
- STEM 领域的多项选择问答 (multiple-choice question answering,简称 MCQA)
- Agentic 工具调用
- 指令遵循的结构化输出
- 数据集取自 NVIDIA Nano-v3 RL 训练混合物 (2025)
- 数据混合比例大约为:
- \(55%\) 的 MCQA
- \(30%\) 的使用 Workplace Assistant 设置的 Agentic 工具调用 (2025)
- \(15%\) 的结构化输出
- 数据混合比例大约为:
- 本文将这些领域组合成一个单一的多领域 RL 阶段,主要有两个原因
- 第一:在混合领域上训练时,没有观察到评估基准上的性能下降
- 模型在包括 MMLU-Pro、\(\tau^2\)-Bench 和 IF-Bench 的基准测试中表现出持续改进
- 第二:这些数据集的 Response 长度和验证时间相似,这最大限度地减少了因等待更长的生成或较慢的环境验证而导致的训练效率低下
- 第一:在混合领域上训练时,没有观察到评估基准上的性能下降
- 超参数:
- 使用 128 的 Batch Size ,每个 Prompt 采样 16 个 Response,温度为 1.0,Top-p 为 1.0(见附录 B)
- 采用 AdamW 优化器,学习率为 \(3 \times 10^{-6}\),并将熵损失系数和 KL 损失系数均设为 0
- 此多领域 RL 阶段运行大约 70 个训练步
- 其他超参数与 IF-RL 一致,详情见附录 B(表 8)
MOPD:Multi-domain On-Policy Distillation
- 虽然精心设计的 Cascade RL 与任意顺序的普通顺序 RL 相比,大大减少了灾难性遗忘
- 但随着训练环境数量的增加,它并不能完全消除能力漂移(Capability Drift)
- 实践观察:整个训练过程中跟踪的不同基准类别存在明显波动,且主要的权衡因阶段而异
- 例如:
- 某些 RLVR 训练通常会降低模型熵并缩短推理轨迹,因此可能对数学推理性能产生负面影响
- 以 RLHF 为导向的优化可能会部分地与指令遵循行为进行权衡
- 这些观察结果促使我们在 Cascade RL 流程中增加一个额外的训练阶段来重新平衡能力
- 本文采用 MOPD (2024; 2024; 2025; 2026; 2025; 2026) 作为补充的后训练阶段
- 例如:
- 在本文 Setting 中,MOPD 由于三个原因而特别有吸引力
- 第一:教师 Checkpoint 可以直接从 Cascade RL 流程中选择,为每个基准类别选择最强的验证 Checkpoint,这使得组装一个能力多样的教师池变得容易,而无需引入外部模型系列
- 第二:由于这些教师都源自相同的 SFT 初始化,它们与 Student 共享相同的 Tokenizer 和词汇表,从而减少了分布偏移并避免了额外的对齐问题
- 第三,MOPD 提供了密集的 Token-level 训练优势,与稀疏的 Outcome Reward 相比尤其有用
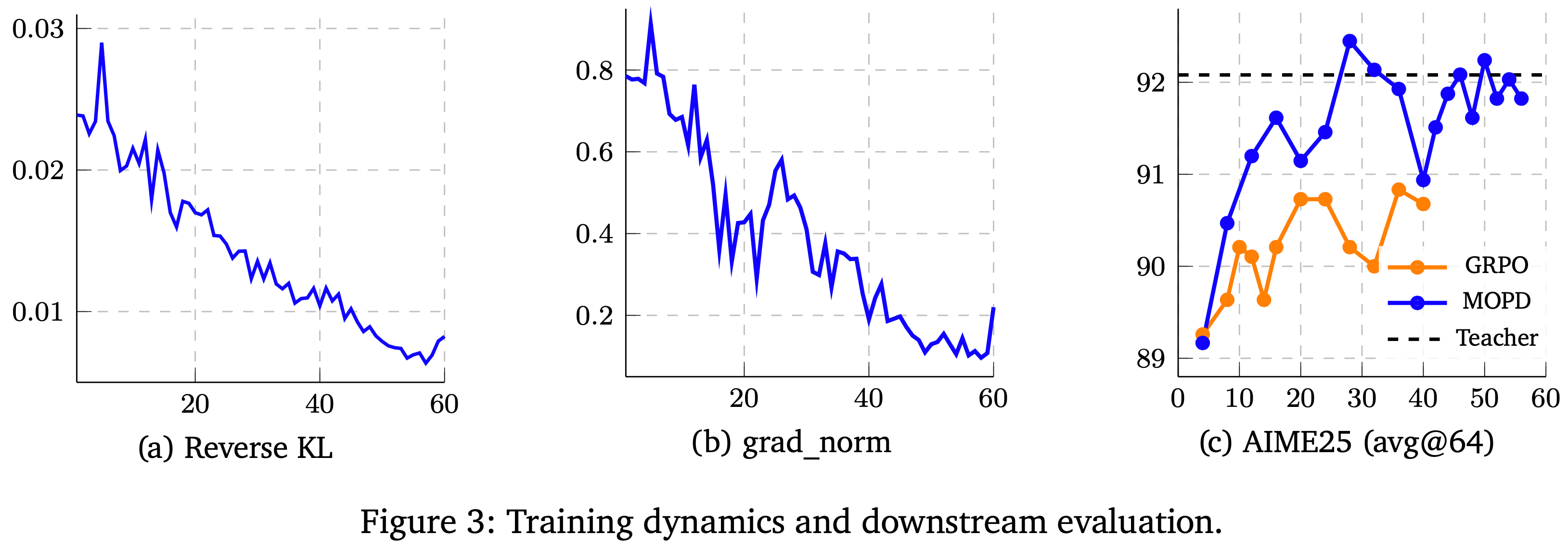
- 在图 3(c) 中,本文展示了其与 GRPO 相比的训练效率优势
- 在图 3(c) 中,本文展示了其与 GRPO 相比的训练效率优势
MOPD objective
- 令 \(\pi^{\text{inf} }\) 表示用于推理引擎中 Response 生成的 Student Policy
- 令 \(\pi^{\text{train} }\) 表示由训练引擎优化的 Student Policy
- 对于每个 Prompt \(x\)
- 采样一个 Response
$$ y = (y_1, \ldots , y_T) \sim \pi^{\text{inf} }(\cdot |x) $$ - 为该训练示例选择一个领域教师 \(\pi^{\text{domain}_i}\)
- 其中领域 \(i\) 表示与所选教师关联的能力领域(理解:根据提前约定的样本领域选择教师)
- 将 \(s_t = (x,y_{< t})\) 写为时间步 \(t\) 的解码状态,使用 Reverse-KL 定义 Token-level 蒸馏优势 (distillation advantage) 为
$$a_t^{\text{MOPD} } = \log \pi^{\text{domain}_i}(y_t |s_t) - \log \pi^{\text{train} }(y_t |s_t) \tag {2}$$- 当领域教师分配给采样 Token 的概率高于当前训练 Policy 时,此项为正
- 因此在训练期间作为密集的 Token-level 蒸馏优势收敛到 0(教师和学生概率相同时优势为 0)
- 对数概率差仅在 Student 采样的 Token 上计算,而不是在整个词汇表上计算
- 当领域教师分配给采样 Token 的概率高于当前训练 Policy 时,此项为正
- 采样一个 Response
- 由于 Response 是在 \(\pi^{\text{inf} }\) 下采样但在 \(\pi^{\text{train} }\) 下优化,应用截断重要性权重 (truncated importance weighting) 来解决训练-推理不匹配问题:
$$r_t = \frac{\pi^{\text{train} }(y_t |s_t)}{\pi^{\text{train} }(y_t |s_t)},\quad w_t = \text{sg}[r_t]\mathbf{1}[\epsilon_{\text{low} }\leq r_t\leq \epsilon_{\text{high} }] \tag {3}$$- 其中 \(\text{sg}[\cdot ]\) 表示停止梯度 (stop-gradient)
- 理解:当训推不一致差异过大时,即 \(r_t\) 不在指定范围内,则将权重置为 0(即 Mask 掉这个 Token)
- 最终的优化代理目标为:
$$\mathcal{L}_{\text{MOPD} } = -\mathbb{E}_{x\sim \mathcal{D},y\sim \pi^{\text{inf} }(\cdot |x)}\left[\frac{1}{|\mathcal{V}(y)|}\sum_{t\in \mathcal{V}(y)}w_t \cdot \text{sg}[a_t^{\text{MOPD} }]\log \pi^{\text{train} }(y_t |s_t)\right] \tag {4}$$- 其中 \(\mathcal{V}(y)\) 是由 Token 掩码保留的有效 Response Token 的集合
Hyperparameters(Of MOPD)
- Unless otherwise specified
- 本文使用 4 的 Rollout 大小和每次更新 128 个 Prompt,得到 512 个 Response 的有效 Batch Size
- 后来实验发现使用 512 个 Prompt 和 1 的 Rollout 大小产生的优化略稳定,同时产生相似的最终结果
- 本文使用 \(2 \times 10^{-6}\) 的学习率,并在前 30 个优化步中进行线性预热
- 从 \(2 \times 10^{-7}\) 开始
- 训练通常在 40-50 个优化步内收敛(图 3(a))(吐槽:也没多训练一会儿,目前根本没看到收敛!)
- 发现:预热阶段对稳定性很重要
- 梯度范数在训练开始时显著较大,并在预热阶段后迅速减小(图 3(b))
- 对于截断重要性权重
- 设置 \(\epsilon_{\text{low} } = 0.5\) 和 \(\epsilon_{\text{high} } = 2.0\)
- 主要实验使用了三个领域教师,分别对应数学、RLHF 和多领域
- 数学教师是初始的 SFT Checkpoint,在精心整理的 SFT 数据集下训练,SFT 后的模型已经表现出强大的数学推理能力
- RLHF 教师是一个通过 RLHF 从初始 SFT Checkpoint 优化的 Checkpoint
- 多领域教师是从先前 IF-RL + 多领域 RL 阶段之后的 Checkpoint 中选择的
- 理解:刚开始训练时,也就是说多领域教师与 MOPD 训练的目标策略是同一个模型,但也可能 多领域教师模型是之前步骤的最优 Checkpoint
- 数据采样方式:
- 相应地从 RL 训练数据池(RLHF、IF-RL 和多领域)以及 AceReason-Math (2025) 中对数学 Prompt 进行采样
- 问题:数据采样的百分比是?
Training efficiency advantage,训练效率优势
- MOPD 提供了密集的 Token-level 蒸馏优势(而 GRPO 依赖于稀疏的序列级别 Outcome Reward,该 Reward 在所有生成的 Token 之间共享)
- MOPD 在实践中更具样本效率和步效率
- 从相同的初始 Checkpoint 开始,MOPD 能够在更少的优化步内持续达到更强的性能
- 在 AIME25 上(图 3(c))
- 在仅数学训练下
- GRPO 在 25 步后从 89.9 提升到 91.0,而 MOPD 在 30 步内达到 92.0 并恢复到教师级别的性能
- 问题:89.9 到 91 分,怎么感觉像是波动
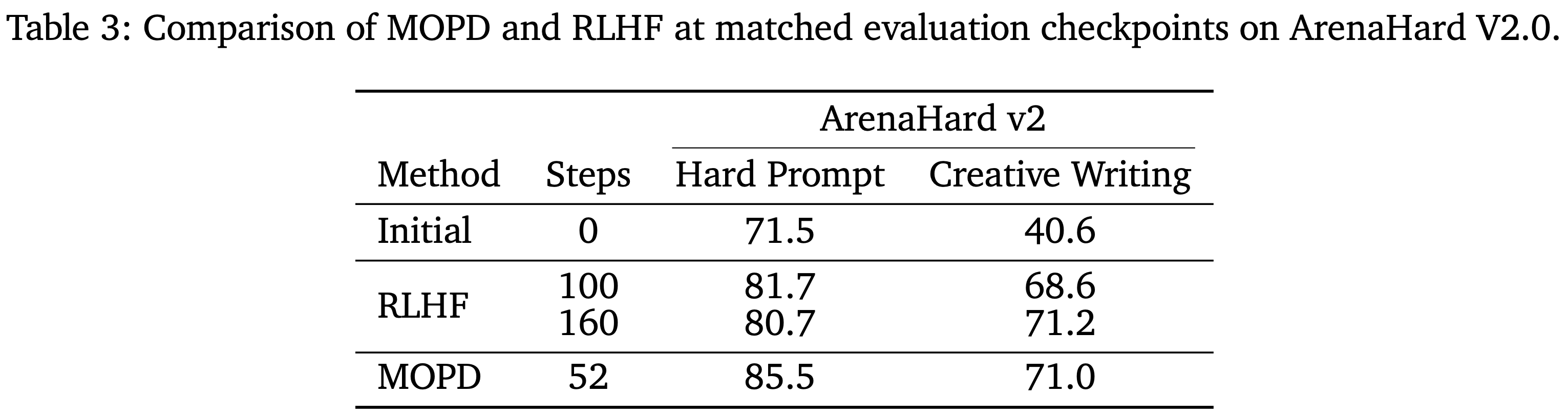
- 在 ArenaHard v2 上也出现了类似的趋势(表 3)
- 在 52 步后,MOPD 将 Hard Prompt 从 71.5 提升到 85.5,将 Creative Writing 从 40.6 提升到 71.0
- RLHF 训练则需要 160 步才能达到 Hard Prompt 的 80.7 和 Creative Writing 的 71.2
- 以上这些结果表明,On-Policy 蒸馏中的密集 Token-level 优势带来更快的训练收敛
- 在仅数学训练下
RLHF:Reinforcement Learning from Human Feedback
- 在 MOPD 的基础上,RLHF 方法侧重于人类偏好学习
- 此过程进一步增强了创造性写作以及在编码和数学中不可验证的问题解决能力(通过 ArenaHard v2 (2024) 衡量),同时保持其他领域的性能不下降
Dataset
- 采用了来自 NVIDIA Nano-v3 (2025) 的 RLHF 训练数据集
- 其中包括 HelpSteer3 (2025)、arena-human-preference-140k 数据集 (2024) 的一个商业友好子集,以及一个合成的安全混合集 (2025)
- 遵循 NVIDIA Nano-v3 (2025) 的做法,利用 Qwen3-235B-A22B-Thinking-2507 (2025) 作为生成式奖励模型 (generative reward model,简称 GenRM)
- 该模型通过 HelpSteer3 框架 (2025) 进行训练
- GenRM 的输入输出:
- 给定对话历史、用户请求和两个候选 Response,GenRM 首先推理每个 Response 的优缺点,然后生成各自的帮助性分数和最终的比较排名
Training recipe
- 遵循与 NVIDIA Nano-v3 (2025) 相似的训练方案,使用 GenRM 进行 RLHF
- 理解:看起来这里不再使用 BT RM 了
- 为确保训练信号的质量,采用 Pair-wise comparisons 来比较每个 Prompt 的所有 Rollout 对
- 以与 NVIDIA Nano-v3 RLHF 训练相同的方式聚合奖励分数,并应用相同的长度归一化奖励调整 (length-normalized reward adjustment) 和基于质量的门控简洁奖励 (quality-gated conciseness bonus) (2025)
- 这些机制鼓励更短的 Response 而不牺牲质量,从而有效缓解推理 Token 使用量的快速增长
- 与 Nemotron Cascade (2025) 不同,仅在思考模式下训练 RLHF
- 虽然同时结合思考模式和非思考模式可以提高训练收敛性并在评估基准上带来微小提升,但指令遵循性能显著下降(由此产生的下降幅度足够大,以至于早期 RLVR 阶段获得的收益无法完全恢复)
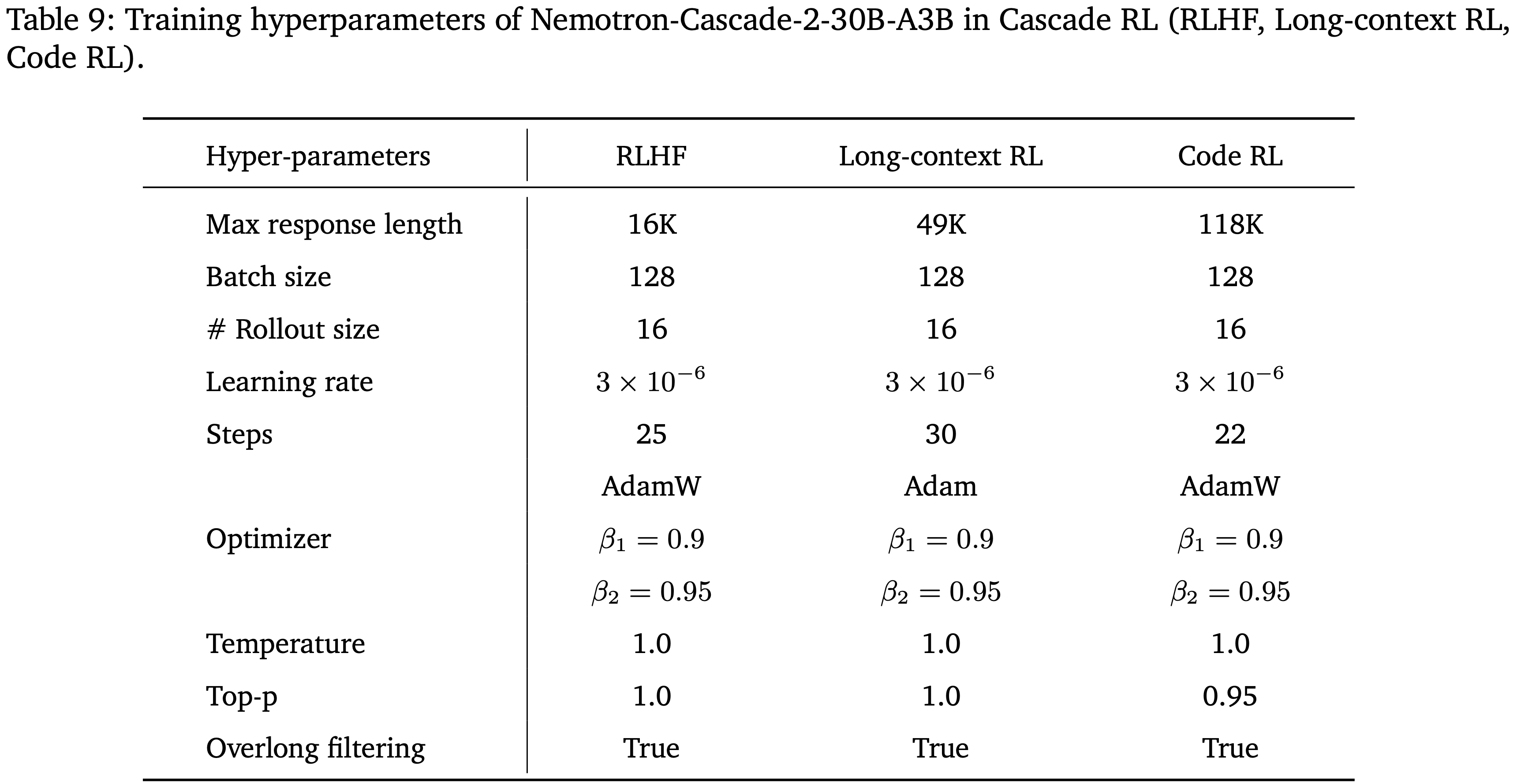
Hyper-parameters
- 使用 128 的 Batch Size ,每个 Prompt 生成 16 个 Rollout,温度为 1.0,Top-p 值为 1.0
- 使用 16K 的最大 Response 长度,不应用过长过滤
- 采用 AdamW 优化器,学习率为 \(3\times 10^{-6}\)
- 将熵损失系数设为 0,KL 损失系数设为 0.03,以保持模型在其他领域的能力
- 训练大约需要 30 步
- 更多参数见 表 9
Long-context RL
- 在 RLHF 之后进行一个阶段的长上下文 RL,以进一步增强模型的长上下文理解和推理能力
- 使用 NVIDIA Nano-v3 RL 数据混合集 (2025),但此阶段仅限于长上下文数据集
- 在本文实验中,在长上下文 RL 期间纳入其他领域会对不相关的基准测试产生负面影响,这证明了这种特定领域训练设置的合理性
- 采用 Nemo-Gym RL 环境 (NVIDIA, 2025),并使用 Qwen3-235B-A22B-Instruct-2507 作为 LLM Judge 来评估模型在问答任务上的 Rollout
- 在训练期间,输入序列限制为 32K Token,最大序列长度设置为 49K Token,不应用过长过滤
- 使用 128 的 Batch Size 进行训练,每个 Prompt 生成 16 个 Rollout,温度为 1.0,Top-p 为 1.0
- 使用 AdamW 优化器,学习率为 \(3\times 10^{-6}\),同时熵和 KL 损失系数均设为零
- 训练大约运行 30 步
- 因为观察到在此之后生成的 Token 数量会迅速增加
- 其他更多超参与 RLHF 相同,详情见表 9
Code RL
Data Curation
- 从 Nemotron-Cascade 编码语料库 (2025) 构建了 Code RL 训练集
- 其中包含来自现代竞争性编程平台(如 AtCoder、Codeforces 和 AIZU)的编码 Prompt,这些 Prompt 带有用于奖励验证的可靠测试用例
- 为了提高训练效率和加强深度推理,积极过滤掉那些 GPT-OSS-120B 在全部 8 次 Rollout 中都能正确解决的 Prompt ,最终得到一个仅包含 3.5K 个样本的紧凑集合
- 问题:为什么不使用自己当前的模型来 Rollout?万一 GPT-OSS-120B 能解决但当前不能解决的题目被过滤掉呢?
- 发现:高难度的 Prompt 与强大的测试用例相结合,对于进一步提升模型性能至关重要
Training Details
- 使用 128 的 Batch Size 和 AdamW 优化器进行 Code RL,学习率为 \(3\times 10^{-6}\)
- 与 Nemotron-Cascade 相比,
- 将 RL 期间的最大 Response 长度增加到 118K Token,并将每个样本的 Rollout 数量增加到 16,这使得 Policy 能够更好地捕捉那些需要长推理轨迹的极难问题上的稀疏奖励信号
- 采用严格的二元奖励函数来避免潜在的 Reward hacking,并保持整个训练过程的 On-Policy 性质以保持稳定性
- 为了支持由此产生的每个 RL 步 \(128\times 16 = 2,048\) 次代码执行的验证吞吐量,部署了一个异步奖励验证服务器,该服务器在 384 个 CPU 核心上,每批次完成时间为 427.2 秒
- 其他更多超参与 RLHF 相同,详情见表 9
SWE RL:Software Engineering Reinforcement Learning
Agentless RL
Training Details and Hyperparameters
- 为了增强模型的代码修复能力,本文采用与 Wang 等 (2025) 相同的数据源进行无智能体代码修复强化学习训练
- 由于大多数实例不提供可执行的 Docker 环境,本文采用 GPT-OSS-120B 作为奖励模型来评估模型生成的代码修复质量
- 遵循 Wang 等 (2025) 的方法
- 对于每个实例:使用 Golden localization 和排名前 5 的检索定位来构建 Prompt,并过滤掉相对容易的样本
- 进行无智能体 SWE RL 时
- Batch Size 为 \(128\times 16 = 2,048\)(128 个 Prompt,每个 Prompt 有 16 个 Rollout),最大序列长度为 98,304
- 使用 AdamW 优化器,学习率为 \(3\times 10^{-6}\)
- 以温度 1.0 和 Top-p 1.0 采样 Response
- 在训练期间,Mask 那些没有一个 Rollout 获得大于 0.5 奖励的 Prompt 的损失
- 本文观察到这些困难的 Prompt 会降低无智能体 SWE RL 训练的稳定性和有效性
- 本文的无智能体 RL 训练通常在 40-50 步内收敛
Can Agentless RL Training Helps Agentic Tasks?
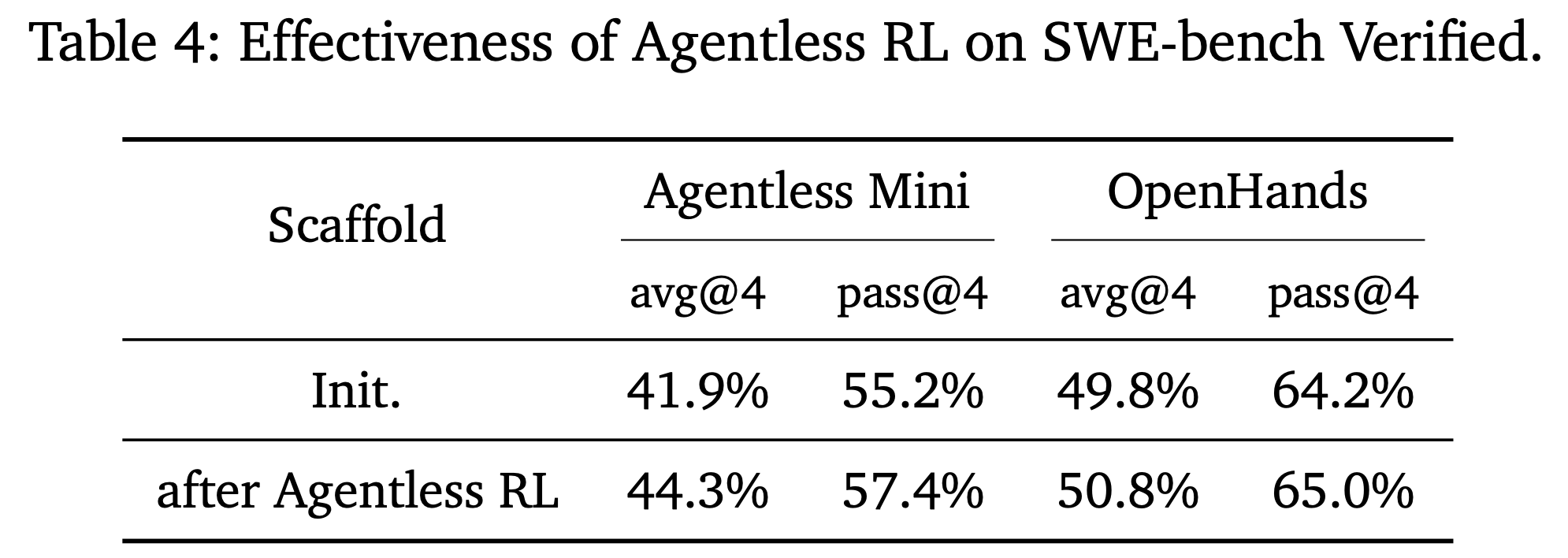
- 表 4 显示,无智能体 RL 训练不仅提高了模型在无智能体框架内的性能,还增强了模型在 Agentic 设置中解决 SWE 任务的能力
- 对于无智能体 Mini 评估,采用了一个代码 Embedding 模型 NV-Embed-Code (2025) 来检索 5 个候选文件,这些文件的代码内容在语义上与问题上下文相似
- 这一结果表明,仅提高模型的代码修复能力就可以泛化到不同的 Scaffold 上,这与 Yang 等 (2026) 的观察结果一致
Execution-based RL for Agentic SWE Scaffold,面向 Agentic SWE Scaffold 的基于执行的 RL
- 现代软件工程 Agent 依赖于协调仓库交互、工具调用、代码编辑和测试执行的 Scaffolding 框架
- 训练 Agent 在这些环境中有效运作,不仅需要优化单个模型输出,还需要优化整个问题解决轨迹
- 为了解决这个问题,本文直接在 Agentic SWE Scaffold 中应用 RLVR,从而实现完整 Agent 工作流的端到端优化
- 本文训练环境集成了已建立的 OpenHands 框架 (2025),该框架提供了结构化的工具使用、仓库交互和迭代 Patch 生成
- 本文在完全可执行的软件环境中使用基于执行的强化学习来训练 Agent,其中每个 Episode 对应于解决来自 SWE-bench 等基准测试的一个软件问题实例
- Agent 在一个仪器化的仓库内操作,该仓库公开了用于文件检查、搜索、代码编辑和测试执行的工具
- Agent 生成的候选 Patch 在环境内执行,该环境从编译结果和单元测试结果中返回可验证的信号,从而无需人工注释即可实现自动奖励计算
- 通过 OpenHands Scaffolding 框架,Agent 迭代地定位缺陷、提出 Patch,并通过测试执行对其进行验证
- 环境反馈:包括编译错误、失败的测试或成功的测试通过,提供了直接反映功能正确性的确定性奖励
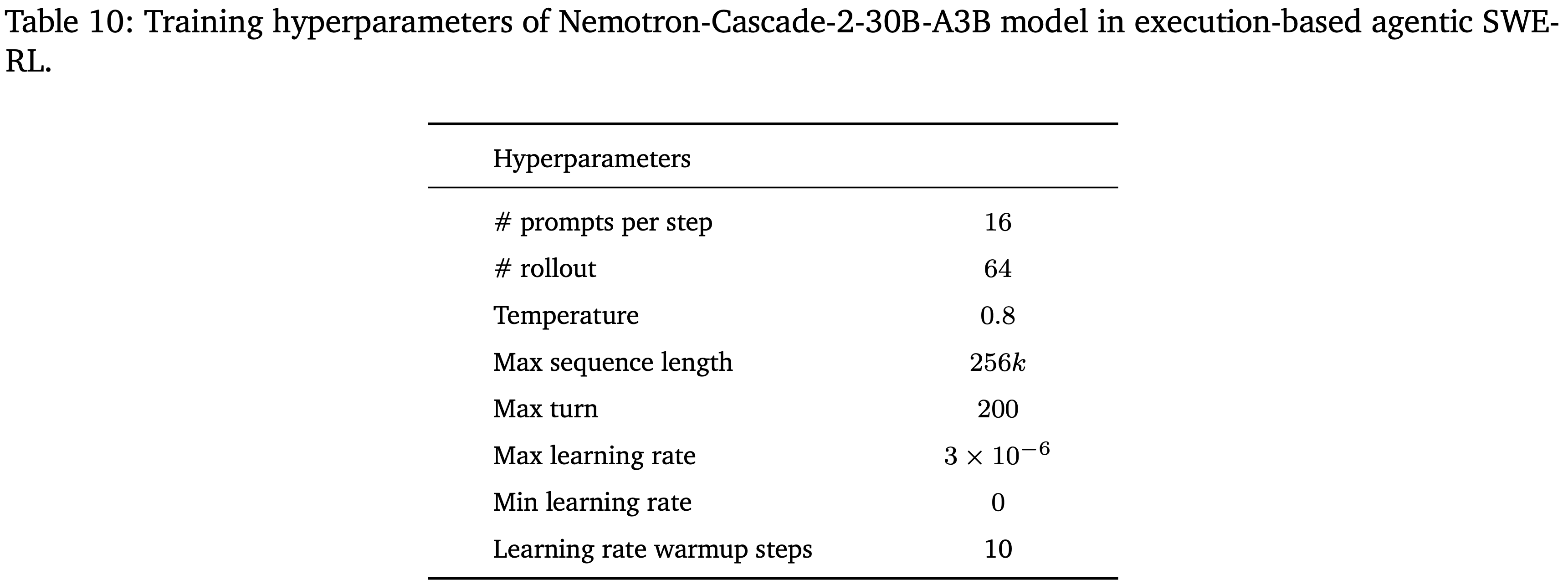
- 进行基于执行的 Agentic 强化学习时的超参
- Batch Size 为 1024,对应于 16 个 Prompt,每个 Prompt 有 64 个 Rollout
- 最大上下文长度设置为 256K Token,Agent 最多允许 200 个交互轮次(在 Agentic 编码问题解决期间提供更大的推理 Token 预算)
- 训练数据来自 SWE-Gym (Pan*2025) 和 R2E-Subset (2025)
- 使用中间模型为每个实例生成 16 个 Rollout,并使用验证流程进行评估
- 所有 Rollout 都通过验证(100% 准确率)的实例(表明问题过于简单)将从数据集中移除
- 对于没有 Rollout 通过验证(0% 准确率)的实例(表明问题极其困难),随机丢弃 90% 的此类案例,以减少它们在训练数据中的比例
- 更多超参数见附录 B(表 10)
IMO:International Mathematical Olympiad
IMO 2025
- 在表 2 中,本文使用一个自我改进的测试时扩展框架 (2025) 在 IMO 2025 问题集上评估了 Nemotron-Cascade-2-30B-A3B
- 在该框架中,模型迭代生成候选解决方案,对其进行验证,并根据其自身的反馈进行细化
- 尽管其规模相对较小(30B-A3B),该模型仍成功解决了前五个问题
- 本文在附录 E 中提供了完整的模型解决方案,以及人类专家的评论
- 这些结果尤其令人鼓舞,因为它们表明,当与有效的推理时扩展相结合时,一个相对紧凑的模型也能产生强大的奥林匹克级数学推理能力
- 仍有几个有希望的改进方向:
- 专家评审表明,一些证明比必要的要长,包括多余的中间步骤或定义,偶尔会暴露中间推理的痕迹,并且有时包含轻微的排版问题
- 对于问题 2,该模型采用了解析解策略,类似于 OpenAI 的方法,而不是像 Gemini Deep Think (IMO Gold) 使用的那种更具几何性的方法
IMO-ProofBench
- 如表 5 所示,Nemotron-Cascade-2-30B-A3B 在使用生成-验证-细化测试时扩展的情况下,在 IMO-ProofBench 上达到了 72.9 分
- 其使用的激活参数少了 \(10\times\),但与 DeepSeek-Math-V2-671B-A37B 的差距在 8 分以内
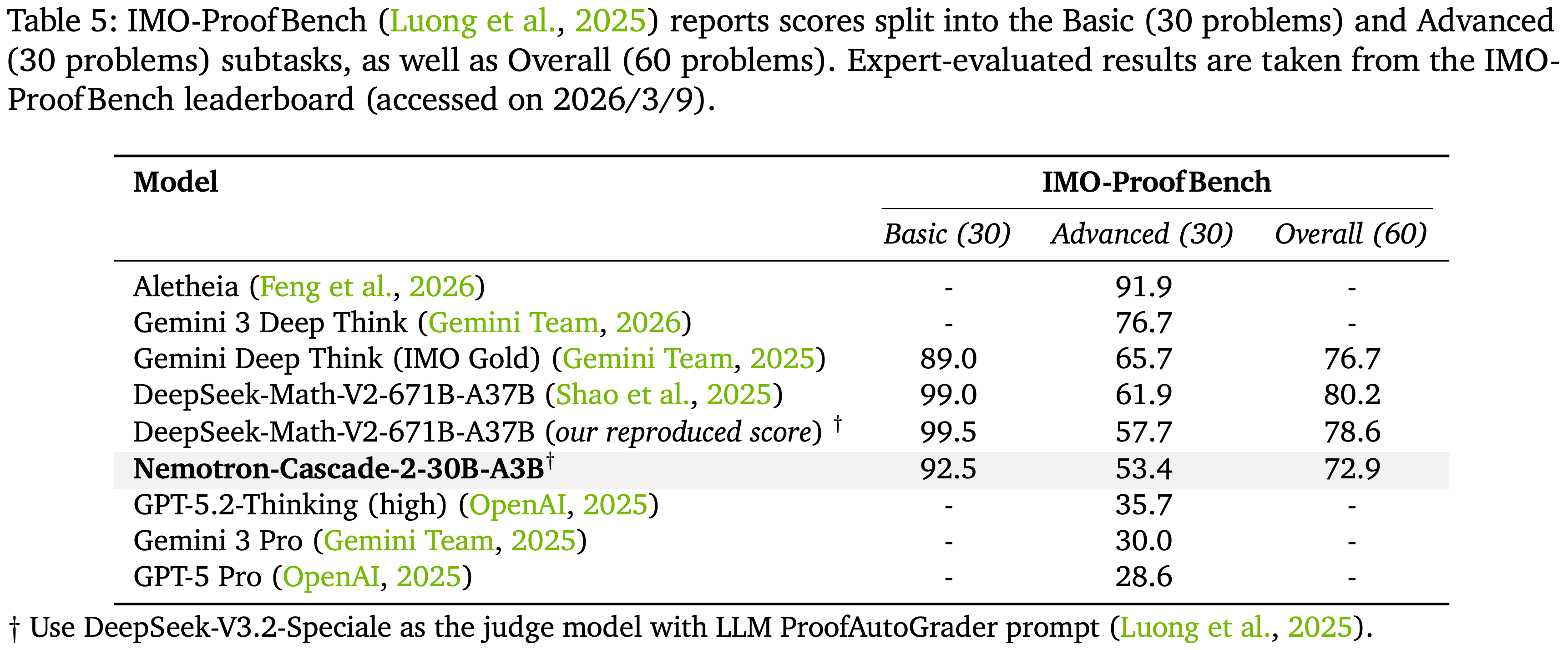
- 其使用的激活参数少了 \(10\times\),但与 DeepSeek-Math-V2-671B-A37B 的差距在 8 分以内
- 在 Basic 分集上达到 \(90+\) 分,并超过了 QED-Nano-4B (54.0) (LM-2026) 18 分
- 由于评判模型不同,后者不能直接比较
- 在本文 LLM 评判设置下重新评估提供的 DeepSeek-Math-V2 证明,得到的分数与报告的人类评分相差 4 分以内
- 这表明本文协议没有实质性地高估性能(更多细节见附录 A.1.2)
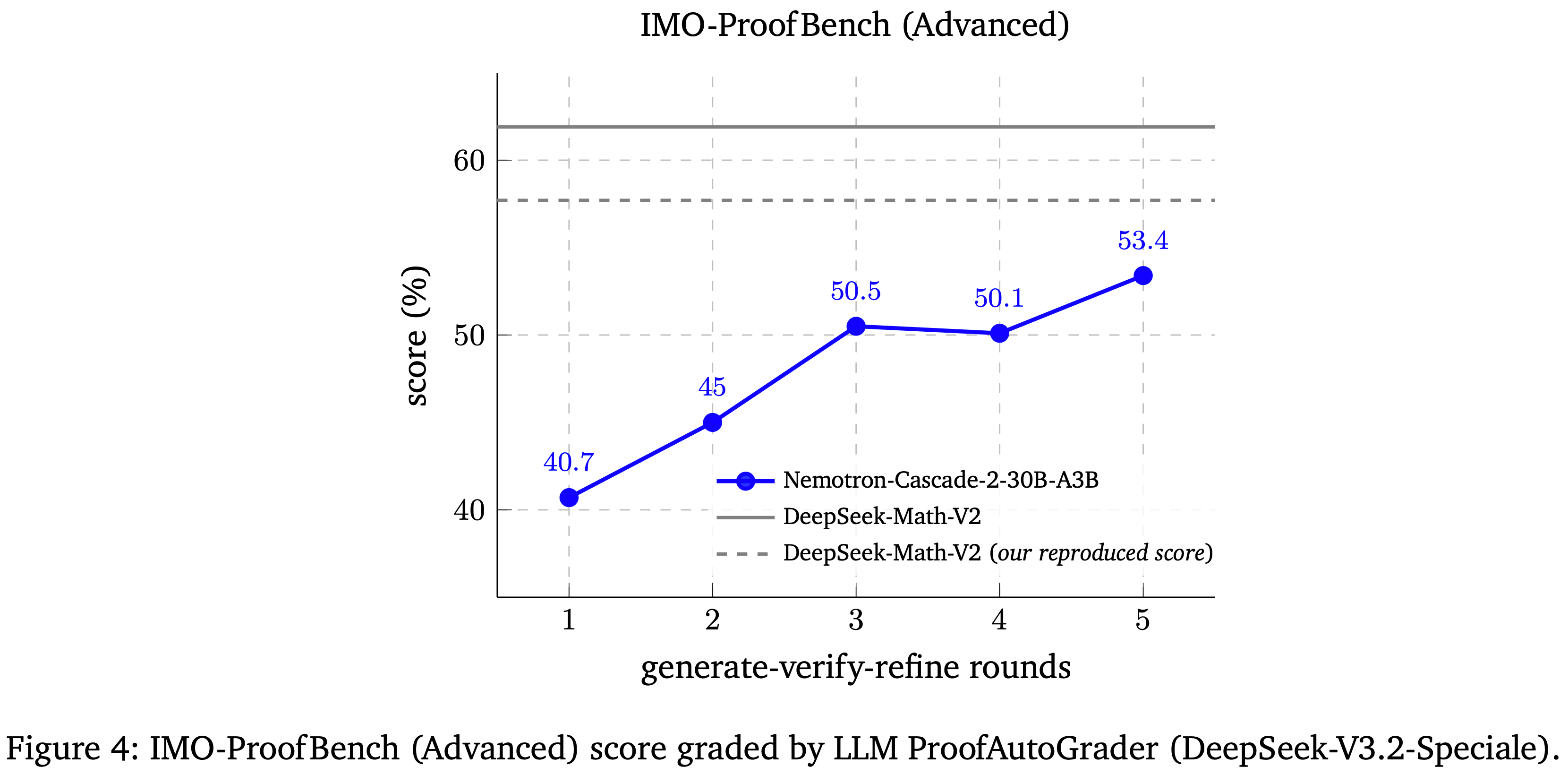
- 图 4 展示了增加测试时计算量可以提高 Nemotron-Cascade-2-30B-A3B 在 IMO-ProofBench (Advanced) 上的表现,将其分数从第 1 轮的 40.7 提升到第 5 轮的 53.4,并在相同评判下缩小了与 DeepSeek-Math-V2 的差距
Competitive Coding
IOI 2025 and ICPC World Finals 2025
- 对于 IOI 2025,采用了 Nemotron-Cascade (2025) 的 IOI 测试时扩展流程,该流程可视为一个多轮生成-选择-提交框架,利用了模型在 IOI 官方规则下的推理能力
- 每个子任务最多分配 50 轮
- 在每一轮中,提示模型生成 40 个候选解决方案,并结合了
- (1) 来自前几轮的带有官方评判结果的提交历史
- (2) 来自同一主任务中高分或完全解决的子任务的共享见解
- 完整的聊天模板见附录 C.1
- 在每一轮中,提示模型生成 40 个候选解决方案,并结合了
- 使用这种方法,在问题 3 和 4 上获得了满分,在至多 \(40 \times 50 = 2000\) 次模型生成内获得了 439.28 分的金牌分数,而在 5000 次生成内可获得 507.66 分
- 在需要设计和优化启发式算法的问题 2 上,本文流程仅在 5 轮内(至多 200 次模型生成)就获得了超过 86 分,证明了自我优化和跨子任务见解的有效性
- 每个子任务最多分配 50 轮
- 对于 ICPC 世界总决赛 2025
- 为每个问题生成最多 1000 个解决方案,并在初步筛选后提交给官方评估
- 本文成功解决了 12 个问题中的 10 个,获得了 #4 金牌名次,其中 8 个问题(除问题 A 和 I 外)仅在 100 次提交内就得到解决
Competitive Coding Benchmark Results
- 在各种竞争性编码基准上评估了 Nemotron-Cascade-2-30B-A3B 模型
- 包括 LiveCodeBench v6 (2024) 和 LiveCodeBench Pro (2025) 的 25Q1 和 25Q2 分集
- 还通过在 2501 至 2507 年间举办的 40 场 Div.1/Div.2 Codeforces 轮次中的模拟参与来估算 Codeforces ELO 分数
- 在 128K token 的思考预算、1.0 的采样温度和 0.95 的 top_p 下报告作者的 avg@8 结果
- 对于工具集成推理 (Tool-Integrated Reasoning, TIR) 结果,允许模型调用最多 100 次有状态的 Python 执行器
- 对于基线模型评估,遵循其推荐的推理配置,确保至少 128K token 到最多 256K token 的思考预算
- 更多评估细节可以在附录 A 和附录 D 中找到
- 如表 6 所示
- Nemotron-Cascade-2-30B-A3B 在 Pass@1 准确率和 ELO 评分方面取得了卓越的成绩
- 即使与总参数超过 100B 的前沿开源模型(如 Nemotron-3-Super-120B-A12B、GPT-OSS-120B 和 Qwen-3.5-122B-A10B)相比也是如此
- 通过工具集成推理 (TIR),模型的性能可以进一步提高,尤其是在难题上,并匹配了总参数超过 300B 的最强开源模型,如 Kimi-K2.5-1T-Thinking、Qwen-3.5-397B-A17B 和 DeepSeek-v3.2-Speciale,这些模型要么缺乏对深度推理的 TIR 支持,要么在使用 Python TIR 时表现不佳
- Nemotron-Cascade-2-30B-A3B 在 8 次尝试内在 LiveCodeBench Pro 的困难分集上实现了高于 0% 的准确率
- 展示了在即使对人类来说也极其困难的问题上的强大推理能力
- Nemotron-Cascade-2-30B-A3B 在 Pass@1 准确率和 ELO 评分方面取得了卓越的成绩
附录 A:Benchmarks and Evaluation Setups
A.1. Math
A.1.1. Non-proof Math
- 详情见原文
A.1.2. Math Proof
- 详情见原文
A.2. Code Reasoning
- 详情见原文
A.3. Knowledge and STEM
- 对于在 thinking 模式下评估 MMLU-Redux、MMLU-Pro、GPQA-Diamond 和 HLE 的 Nemotron-Cascade-2-30B-A3B
- 使用温度 1.0,top-p 值 0.95,以及 128K Token 的 thinking 预算(最大 Response 长度)
- 对于 HLE,使用默认的系统 Prompt
- 在每个问题后附加“请将最终答案放在 \boxed{} 中”
- 使用 GPT-OSS-120B 作为 LLM Judge
- 使用附录 C.2 中的 Prompt 进行答案提取和正确性验证
- 与官方的 HLE Response 格式(要求解释、答案和置信度分数)相比,此框式答案 Prompt 通过更好地与作者的数学 SFT 数据中使用的答案格式对齐,将准确率提高了 6-7 分,主要是在数学子集上
A.4. Alignment and Instruction-Following
- 在非 thinking 模式下评估 IFEval
- 在 thinking 模式下评估 IFBench 和 ArenaHard 的 Nemotron-Cascade 模型
- 使用温度 0.6,top-p 值 0.95,以及最大 Response 长度 32K Token
- 对于基线模型,尽可能使用官方报告的结果;如果没有这样的结果,将使用其推荐的推理配置或与作者的设置相同的设置进行评估
A.5. Long Context and Context Learning
- 对于长上下文和上下文学习任务,本文包括:
- AA-LCR (2025) 包含 100 个具有挑战性的基于文本的问题,需要对多个长的现实世界文档(包括公司报告、政府咨询、法律文件和学术论文)进行推理
- 每个样本包含一个平均约 100K Token 的文档集
- 这些问题的设计使得答案无法直接从文档中检索,而是需要跨多个信息源进行推理
- 本文报告 thinking 模式下的 pass@1 准确率,平均 16 次生成 (avg@16)
- LongBench v2 (2025) 包含 503 个具有挑战性的多项选择题,上下文长度范围从 8K 到 2M 个词
- 该基准涵盖六个任务类别:单文档 QA、多文档 QA、长上下文学习、长对话历史理解、代码库理解和长结构化数据理解
- 这些问题设计得很难;即使是配备文档搜索工具的人类专家也可能需要大量时间才能正确回答
- 本文在 thinking 模式下评估模型,并报告平均四次生成 (avg@4) 的 pass@1 准确率
- NIAH@1M (Ruler 子集) 指的是来自 RULER 基准 (2024) 的“大海捞针”(NIAH) 任务
- NIAH 测试 (Kamradt, 2023) 评估 LLM 检索嵌入在长干扰文本(“大海”)中的特定信息(“针”)的长上下文能力
- RULER 基准定义了此任务的四个变体:单针 (Single NIAH)、多键针 (Multi-keys NIAH)、多值针 (Multi-values NIAH) 和多查询针 (Multi-queries NIAH)
- 遵循 Blakeman 等人 (2025),本文使用 1M Token 上下文设置评估每个类别的 100 个实例
- 模型在 Reasoning-off 模式下评估,报告单次生成 (avg@1) 的 pass@1 准确率
- 遵循 Blakeman 等人 (2025),本文使用 1M Token 上下文设置评估每个类别的 100 个实例
- CL-Bench (2026) 评估 LLM 从提供的上下文中学习并将获得的知识应用于解决任务的能力,这一过程称为上下文学习
- 该基准包含 1,899 个测试样本,涵盖 500 个复杂上下文和 31,607 个验证 rubrics,全部由经验丰富的领域专家开发
- 完成这些任务所需的知识大部分超出了现有模型在预训练期间通常学习的内容,要求模型直接从提供的上下文中学习
- 模型在 thinking 模式下评估,报告单次生成 (avg@1) 的 pass@1 准确率
A.6. Agentic Tasks
- BFCL v4 (2025) 为 LLM 提供了一个全面的 Agentic 评估框架,涵盖诸如网络搜索、内存读写以及跨多种编程语言的函数调用等任务
- 遵循官方的 BFCL v4 评估协议,并报告跨 Agentic、多轮 (multi-turn)、实时 (live) 和非实时 (non-live) 类别的分数
- 模型在 thinking 模式下评估,报告基于单次生成 (avg@1) 的 pass@1 准确率
- SWE-bench Verified (OpenAI, 2024) 是来自 SWE-bench (2023) 原始测试集的一个子集,包含 500 个经人工标注员验证为无问题的样本
- 在非 thinking 模式下评估模型,并报告 pass@1 准确率,每个 Prompt 平均 4 次生成 (avg@4)
- \(\tau^2\)-Bench (2025) 在具有明确策略、工具使用和共享世界状态更新的环境中评估多轮客户服务 Agent
- 在三个官方子集上评估:航空 (airline,50 个示例)、零售 (retail,114 个示例) 和电信 (telecom,114 个示例)
- 为了将标准误差控制在 1.5 以内,在航空子集上报告 avg@16,在零售和电信子集上报告 avg@8
- Terminal Bench 2.0 (2026) 用于评估基于终端的环境中的 Agent,包含 89 个人工验证的任务,涵盖科学计算、机器学习和系统管理等专业领域
- 超越简单的代码生成,该基准专注于端到端的工作流,要求 Agent 展示在整体操作(如模型训练、系统配置和软件调试)中的熟练程度,而不仅仅是生成孤立的函数
- 本文使用默认的 Terminus-2 框架 (scaffolding) 评估模型,报告 avg@5 任务成功率
- 更多细节见原文
A.7. Multilingual
- MMLU-ProX (2025) 将具有挑战性的 MMLU-Pro 基准扩展到包括 29 种语言
- 遵循 Blakeman 等人 (2025),选择六种语言进行评估:英语 (en)、德语 (de)、西班牙语 (es)、法语 (fr)、意大利语 (it) 和日语 (ja)
- 模型在 thinking 模式下评估,报告单次生成 (avg@1) 的 pass@1 准确率
- WMT24++ (2025) 将 WMT24 机器翻译基准扩展到覆盖 55 种语言
- 遵循 Blakeman 等人 (2025),作者在五个翻译对上进行评估:英语到德语 (en \(\rightarrow\) de)、英语到西班牙语 (en \(\rightarrow\) es)、英语到法语 (en \(\rightarrow\) fr)、英语到意大利语 (en \(\rightarrow\) it) 和英语到日语 (en \(\rightarrow\) ja)
- 使用 XCOMET-XXL (2024) 作为评估指标来评估翻译质量
- 模型在 thinking 模式下评估,报告单次生成 (avg@1) 的 pass@1 准确率
附录 B:Training Hyperparameters
- 表 7、8、9、10 中列出了 Nemotron-Cascade-2-30B-A3B 在所有阶段的训练超参数
附录 C:Prompt Templates
C.1. Prompt Templates for Test-Time Scaling on IOI 2025
- 详情见原文
C.2. HLE Judge Prompt
英文原文
1
2
3
4
5
6
7
8
9
10Judge whether the following [response] to [question] is correct or not based on the precise and unambiguous [correct_answer] below.
[question]: {question}
[response]: {response}
Your judgement must be in the format and criteria specified below:
extracted_final_answer: The final exact answer extracted from the [response]. Put the extracted answer as ’None’ if there is no exact, final answer to extract from the response.
[correct_answer]: {correct_answer}
reasoning: Explain why the extracted_final_answer is correct or incorrect based on [correct_answer], focusing only on if there are meaningful differences between [correct_answer] and the extracted_final_answer.
Do not comment on any background to the problem, do not attempt to solve the problem, do not argue for any answer different than [correct_answer], focus only on whether the answers match.
correct: Answer ’yes’ if extracted_final_answer matches the [correct_answer] given above, or is within a small margin of error for numerical problems. Answer ’no’ otherwise, i.e. if there if there is any inconsistency, ambiguity, non-equivalency, or if the extracted answer is incorrect.
confidence: The extracted confidence score between 0|%| and 100|%| from [response]. Put 100 if there is no confidence score available.- 中文版:
1
2
3
4
5
6
7
8
9
10
11根据下面精确且明确的 [correct_answer],判断以下对 [question] 的 [response] 是否正确
[question]: \\{question\\}
[response]: \\{response\\}
你的判断必须符合以下指定格式和标准:
extracted_final_answer: 从 [response] 中提取的最终确切答案。如果 response 中没有要提取的确切最终答案,则将提取的答案设为 'None'
[correct_answer]: \\{correct_answer\\}
reasoning: 基于 [correct_answer] 解释 extracted_final_answer 正确或错误的原因,仅关注 [correct_answer] 和提取出的最终答案之间是否存在有意义的差异。不要评论问题的任何背景,不要试图解决问题,不要为除 [correct_answer] 之外的任何答案辩护,只关注答案是否匹配
correct: 如果 extracted_final_answer 与上面给出的 [correct_answer] 匹配,或者对于数值问题在小的误差范围内,则回答 'yes'。否则,即如果存在任何不一致、歧义、不等价,或者提取的答案不正确,则回答 'no'
confidence: 从 [response] 中提取的置信度分数,介于 \\(0\%\\) 和 \\(100\%\\) 之间。如果没有可用的置信度分数,则填入 100
- 中文版: