注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 本文包含了非常详细的训练细节,值得一读
- 本文主要解决的问题:
- RL 构建通用推理模型时显著的跨领域异质性,包括推理时 Response 长度和验证延迟的巨大差异
- 这种可变性使 RL 基础设施复杂化,拖慢训练速度,并使训练课程(例如,Response 长度扩展)和超参数选择变得具有挑战性
- 本文的解法是 Cascade RL 方法
- Cascade RL 的多个阶段:SFT -> RLHF -> IF RL -> Math RL -> Code RL -> SWE RL
- 本文基于 Cascade RL 开发模型 Nemotron-Cascade
- 8B 和 14B
- Unified(Thinking & Non-Thinking) 和 Thinking 模型
- 注:Cascade RL 与传统方法对比:
- 传统方法:混合来自不同领域的异构 Prompt
- Cascade RL:按顺序编排领域特定的 RL,降低了工程复杂性(注:号称在广泛的基准测试中提供了 SOTA 性能)
- 注:本文的训练和数据方案透明(点赞!)
Introduction and Discussion
- 使用 RL 训练通用推理模型 的问题(不同领域的显著异质性):
- 异质性包括 Response 长度和奖励信号计算等,不同任务特点不同:
- 数学推理任务采用快速的基于符号规则的验证
- 代码生成和软件打补丁采用缓慢的基于执行的验证
- 对齐和创造性写作则计算基于 RM 的分数
- 这种领域特定的异质性使 RL 基础设施复杂化,拖慢了训练速度,并使训练课程(例如,最大 Response 长度扩展)和超参数选择更具挑战性
- 异质性包括 Response 长度和奖励信号计算等,不同任务特点不同:
- 传统方法:混合来自不同领域的异构 Prompt
- 在本文作者之前的解法 (2025):以级联方式在数学和代码领域进行 RL
- 具体方法:首先在纯数学 Prompt 上训练,然后在纯代码 Prompt 上训练
- 这种级联范式有几个优点:
- a)基于规则的数学验证可以快速执行,比代码验证快几个数量级,使得模型能够立即更新,无需等待代码 Prompt 所需的更长验证周期
- b)数学 RL 提升了数学基准测试的性能,并且也提升了代码基准测试的性能(注:奇怪的表现)
- c)代码 RL 显著提升了代码基准测试的性能,而不会降低数学结果(注:第二奇怪)
- 本文 的核心创新:
- 在之前研究基础上,进一步将级联跨领域 RL 范式扩展到更广泛的领域 ,以构建通用推理模型
- 关于 Thinking 和 Non-Thinking 模型之争
- 自从 OpenAI o1 (2024) 推出以来,LLM 社区的模型发布通常分为两类:
- 思维模型(thinking models)
- 在给出答案前生成大量推理 Token(例如,DeepSeek-R1 (2025),OpenAI o3 和 o4-mini (2025),Kimi-K2-Thinking (2025))
- 指令(instruct)或非思维模型(non-thinking models)
- 直接给出答案(例如,DeepSeek-V3 (2024),GPT-4.5 (2025),Kimi-K2-Instruct (2025))
- 思维模型(thinking models)
- 构建一个统一的推理模型,能够在非思维和思维两种模式下运行,并将所有能力集成到单一模型中,将是理想的选择,好处包括:
- i)极大地简化模型发布和生产流程
- ii)更接近通用人工智能的最终目标
- 注:当前大量工作已经投入到开发一个统一的模型 (2025; 2025; 2025) 上
- 自从 OpenAI o1 (2024) 推出以来,LLM 社区的模型发布通常分为两类:
- 在整合 Thinking 和 Non-Thinking 模型的工作中(2025),已认识到某些技术挑战
- 包括:统一模型在 Thinking 模式下运行时,其推理基准测试性能相较于专用思维模型会有所下降
- 特别说明:
- Qwen3 系列 (2025) 最初是作为一组统一推理模型发布的,但后来它又被恢复为分开的思维和指令变体,专用的思维模型 (2025) 在 Thinking 模式下的性能显著优于统一模型
- GPT-5 的发布探索了两个专用模型之间的路由,其中一个标准指令模型和一个专用思维模型一起使用
- 最终目标仍然是将它们集成到一个单一模型中 (2025)
- DeepSeek-V3.1 (2025) 是一个统一模型(统一 Thinking 和 Non-Thinking 模式)
- 它在推理基准测试上达到了与早期专用推理模型 DeepSeek-R1-0528 相当的 Thinking 模式性能
- 除了 DeepSeek-V3.1 和 DeepSeek-R1-0528 基于不同的基座模型,并且可能使用不同的数据混合进行训练之外,其他技术细节尚未公开
- 本文工作:
- 开发一个开放的 Post-Training 方案,使用预训练的 Qwen3-8B-Base 和 Qwen3-14B-Base (2025) 作为起点,以支持透明的比较并促进社区内的知识共享
- 本文扩展了 Cascade RL 框架来开发 Nemotron-Cascade 模型,在多个领域取得了新的 SOTA 结果
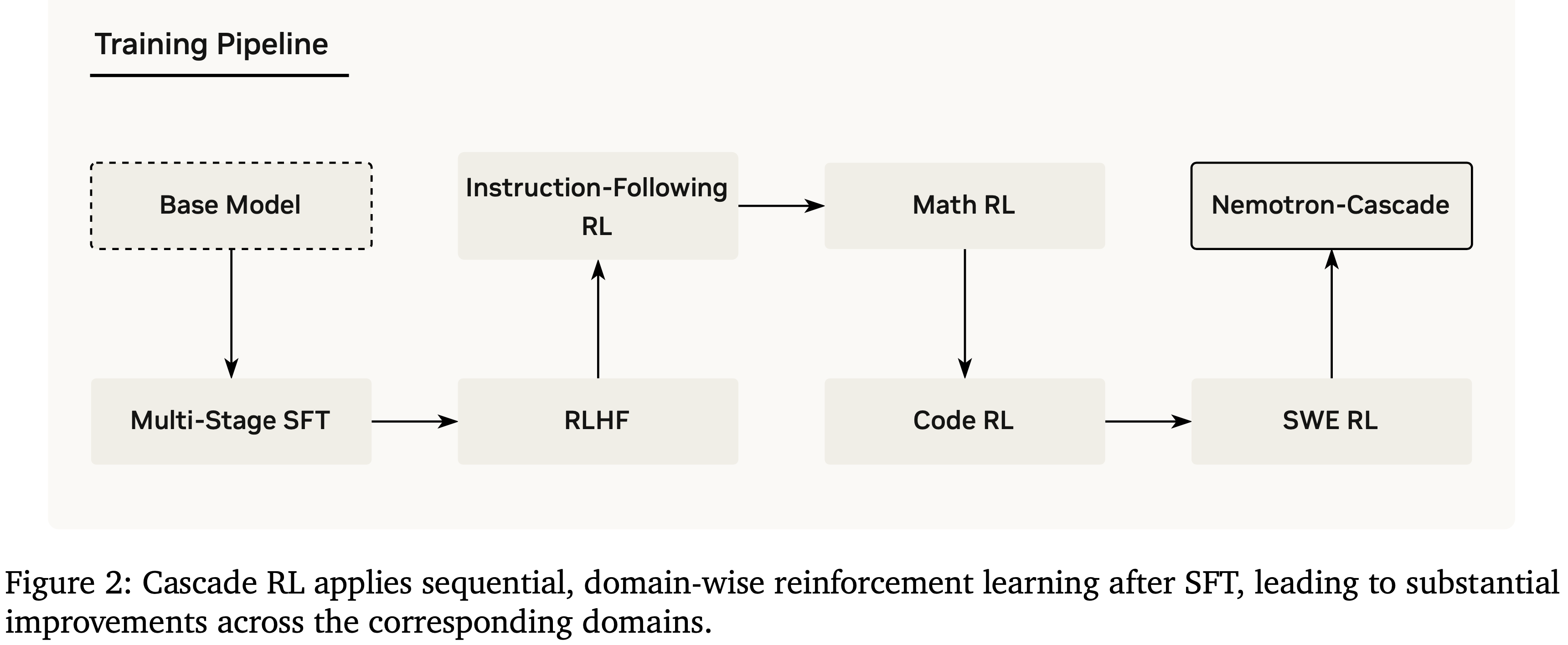
- 训练流程概览如图 2 所示
- Cascade RL 按顺序跨领域训练模型
- 与诸如 DeepSeek-R1 (2025) 和 Qwen3 (2025) 等方法形成不同,他们混合了来自所有(推理)领域的多样化 Prompt 分布进行联合 RL 训练
- 本文展示了一个统一的推理模型可以有效地在思维和 Non-Thinking 模式下运行,缩小了与专用思维模型的推理差距,同时通过开放的数据和训练方案确保透明度
- 本文工作的贡献包括:
- 本文将级联强化学习(Cascade Reinforcement Learning,Cascade RL)扩展到广泛的领域,包括人类反馈对齐、严格的指令遵循、数学推理、竞争性编程和软件工程
- Cascade RL 框架提供了显著的优势:
- i)RLHF 显著提升了整体的 Response 质量(例如,减少冗余),从而增强了推理性能
- ii)后续的领域特定 RL 阶段很少会降低前置领域所取得的基准性能,甚至可能提升它
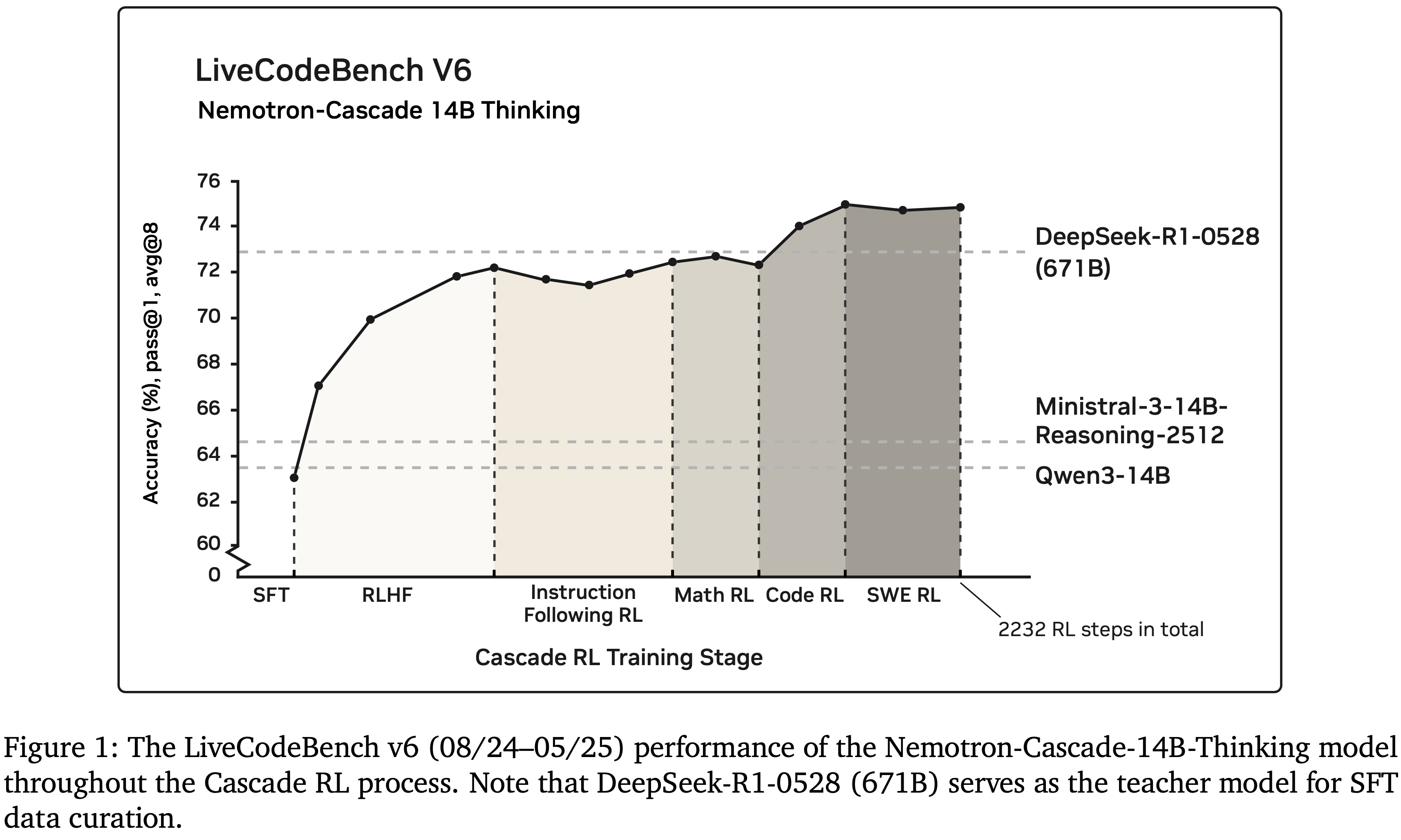
- 因为 RL 对灾难性遗忘具有抵抗力(见图 1 的演示和 §4.1.1 节的深入讨论)
- iii)RL 超参数和训练课程可以针对每个特定领域进行定制,以实现最优性能
- Cascade RL 框架提供了显著的优势:
- 本文开发了 Nemotron-Cascade-8B 统一推理模型,使用户能够在每个对话轮次控制思维和非思维/指令模式
- 本文挑战了 LLM,特别是较小的 LLM,缺乏从非思维和思维数据中有效学习能力的假设
- 本文展示了 8B 统一模型在 Thinking 模式下的推理性能差距与专用的 8B-Thinking 模型可以被缩小,即使两个模型都在相同的思维/推理数据上训练,而统一模型还额外在非思维数据上进行了训练
- 这一结果背后的关键技术是:
- (1) 针对相同的 Prompt,以并行方式在思维和指令模式下生成 Response 的 SFT 数据
- (2) 在每批数据中为每种模式分配相等数量的采样 Prompt 来融合这两种模式的 RLHF 训练
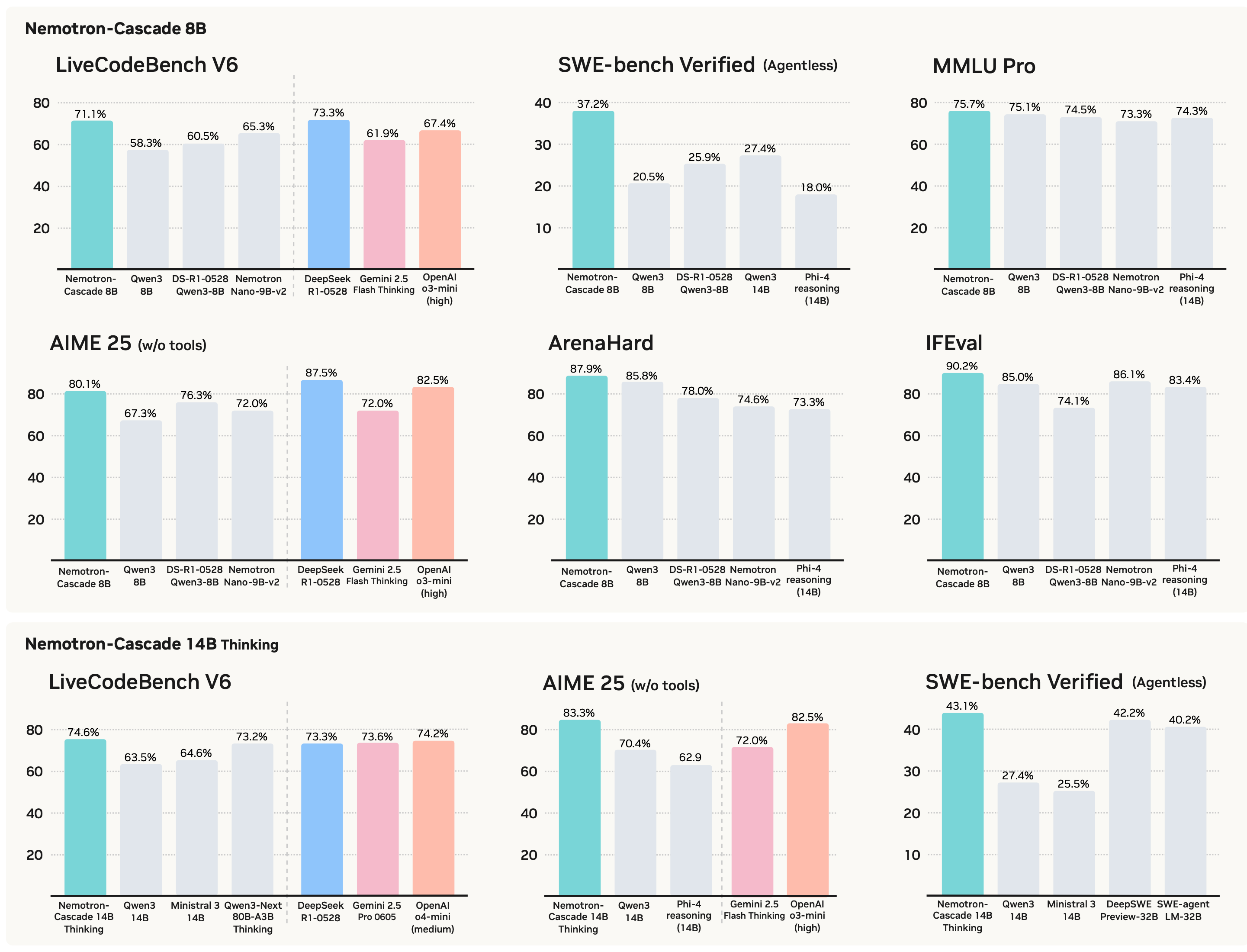
- 本文使用 Cascade RL 方法训练的 8B/14B 模型在涵盖所有这些领域的广泛基准测试中取得了 SOTA 、同级别最佳的(best-in-class)性能
- 本文 14B 专用思维模型(Dedicated Thinking model),在 64K Token 的推理预算下,在 LiveCodeBench v5/v6 (2024) 上优于 Gemini-2.5-Pro-06-05、o4-mini (medium)、Qwen3-235B-A22B( Thinking 模式)和 DeepSeek-R1-0528(其 SFT 教师模型)(见图 1 )
- 还在 2025 年国际信息学奥林匹克竞赛(IOI)上获得了银牌级别的表现
- 本文开源数据集和模型
- 本文将级联强化学习(Cascade Reinforcement Learning,Cascade RL)扩展到广泛的领域,包括人类反馈对齐、严格的指令遵循、数学推理、竞争性编程和软件工程
Main Results
- 对于基线模型,尽可能使用官方报告的结果
- 对于 Nemotron-Cascade 模型,将最大生成长度设置为 64K Token,temperature 设置为 0.6,top-p 设置为 0.95 用于推理任务
- 注:详情见附录 B 中详细描述
- 主要结果如表 1 所示
- 所有结果均报告为 pass@1,平均每个 Prompt 生成 k 次(avg@k),其中 k 根据测试集大小适当选择(通常在 4 到 64 之间)
- 统一推理模型 Nemotron-Cascade-8B,以及专用思维模型 Nemotron-Cascade-14B-Thinking,在几乎所有基准测试中都取得了同类别最佳的性能
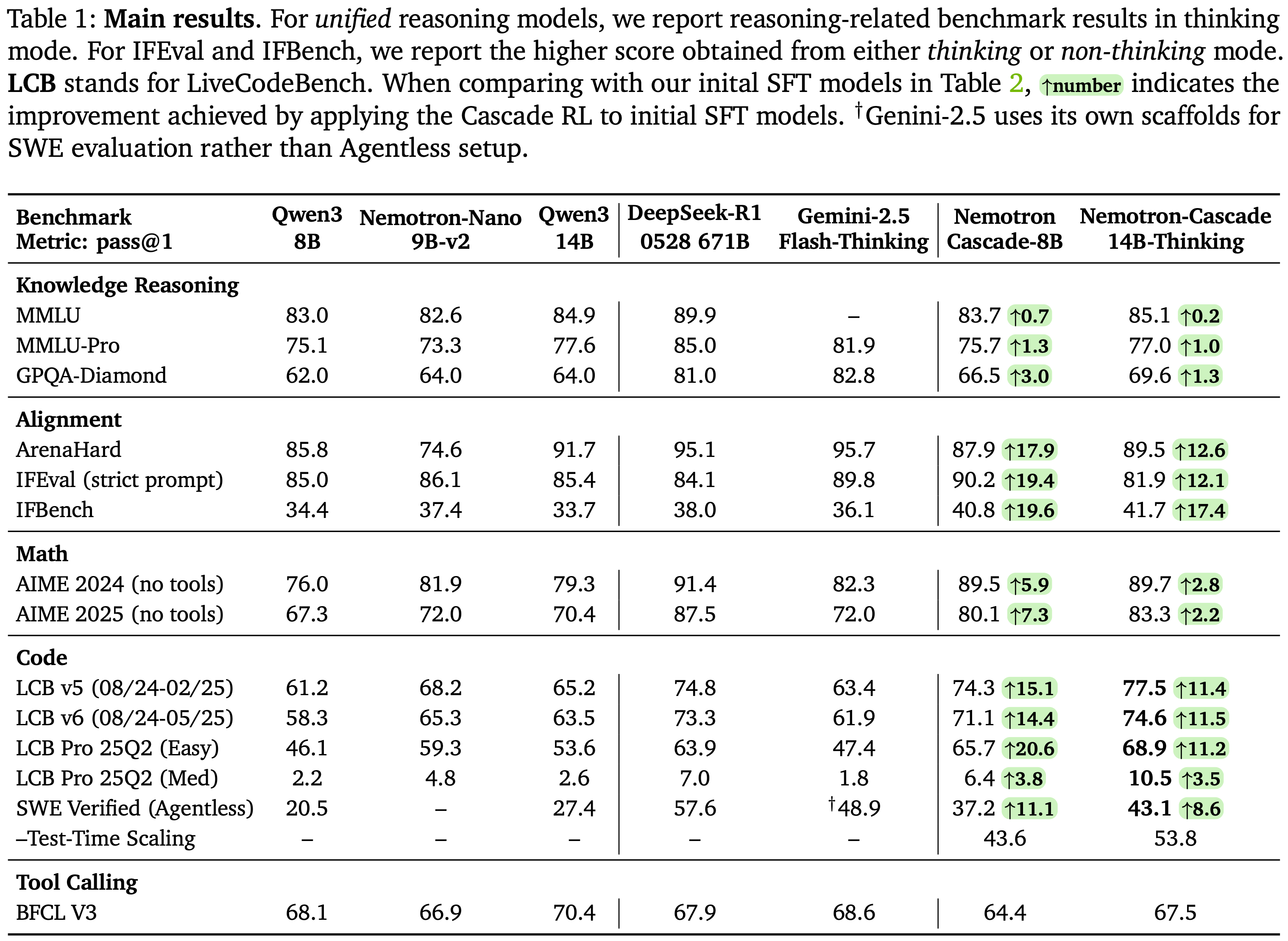
- 特别地,一些指标分析:
- 在 LiveCodeBench (LCB) 和 LCB Pro 上观察到了显著的进步,Nemotron-Cascade-8B 在 LCB v5 上达到 74.3,在 LCB v6 上达到 71.1
- DeepSeek-R1-0528 (671B) 在 SFT 期间担任教师模型,生成了 SFT 数据整理中使用的所有代码 Prompt 的 Response(见第 §3.2.3 节)
- 本文的 Nemotron-Cascade-14B-Thinking 模型在 LCB 和 LCB Pro 基准测试的所有划分中都显著超越了 DeepSeek-R1-0528
- Cascade RL 框架在增强推理能力方面是有效的
- 对于 SWE-bench Verified,最好的通用型开放 8B 和 14B LLM 在这个具有挑战性的基准测试上表现不佳
- 专用模型 DeepSWE-32B (2025),基于 Qwen3-32B 并为 SWE 任务专用,达到了 \(42.2%\) 的 pass@1 准确率
- 本文通用型 8B 和 14B 模型分别达到了 \(37.2%\) 和 \(43.1%\)
- 在 LiveCodeBench (LCB) 和 LCB Pro 上观察到了显著的进步,Nemotron-Cascade-8B 在 LCB v5 上达到 74.3,在 LCB v6 上达到 71.1
Supervised Fine-Tuning
- 本节描述了 SFT 的训练框架和数据整理,这是作者后训练管线的第一阶段
- 此阶段使模型具备了基础技能和能力,然后在后续阶段通过级联强化学习 (Cascade RL) 显著增强这些能力
Training Framework
Multi-Stage SFT
- SFT 课程包含两个阶段,涵盖了广泛的领域,包括数学、编码、科学、工具使用和软件工程,以及通用领域,如多轮对话、知识密集型问答、创意写作、角色扮演、安全性、安全性和指令遵循
- 这些领域的数据整理细节在第 §3.2 节中提供
- SFT 课程的概述如下:
- 阶段 1 (16K,一个 epoch) :
- 包括:
- 通用领域数据:每个 prompt 包含思考和思考及非思考模式的并行 responses
- 数学、科学和代码推理数据:仅包含思考模式的 responses
- 包括:
- 阶段 2 (32K,一个 epoch) :
- 目标:进一步增强模型的推理能力,并使其具备工具使用和软件工程技能
- 重新组合了:
- 通用领域数据:每个 prompt 包含思考和思考及非思考模式的并行 responses
- 新的阶段 2 数学、科学和代码推理数据:仅包含思考模式的 responses
- 工具使用和软件工程数据集:仅包含思考模式的 responses
- 阶段 1 (16K,一个 epoch) :
Chat Template
- 本文定义了模型的交互模式,这对于支持思考和思考及非思考生成模式的统一推理模型尤为重要
- 采用标准的 ChatML 模板 (OpenAI),并在 User Prompt 中引入了两个控制标志,
/think和/no_think,用于明确指示模型以相应模式生成 responses
- 采用标准的 ChatML 模板 (OpenAI),并在 User Prompt 中引入了两个控制标志,
- 先前的工作 (2025; 2025) 采用了类似的控制标志机制,本文引入了一些简化和增强,以实现对模型生成行为更精确和灵活的控制
- 与 Bakouch 等 (2025) 将
/think和/no_think标志放在 System Prompt 中从而全局控制整个对话不同- 将这些标志附加到每个单独的 User Prompt 上
- 这种设计同时支持全局和局部控制:
- 在每个用户轮次中附加相同的标志可以强制执行一致的全局行为
- 在多轮对话中改变标志则可以在单个对话中实现动态切换
- 与 Qwen3 推理模型 (2025) 相比,本文方法进一步简化了模式控制
- Qwen3 采用了一种冗余机制,可以通过两种方式切换模式:
- 显式标志(理解:应该是
no_think这样的显示标志?) - 隐式决定:通过 enable_thinking 参数修改模板(该参数隐式地决定模式)
- 显式标志(理解:应该是
- 默认为思考模式,同时会预先添加一个空的
<think> </think>块来激活非思考模式- 早期实验表明,显式标志比基于模板的提示能产生更可靠的模式转换
- 仅用标志的设计覆盖了所有用例,且没有任何性能下降
- 专门采用了基于标志的方法
- 通过这种简化,非思考模式中不再需要空的
<think> </think>块
- 对于工具调用任务,作者在 System Prompt 中的
<tools>和</tools>标签内指定所有可用的工具,如图 3 右侧所示- 本文进一步指示模型在
<tool_call>和</tool_call>标签内执行工具调用
- 本文进一步指示模型在
- Qwen3 采用了一种冗余机制,可以通过两种方式切换模式:
SFT Data Curation
General-Domain Data
- 本文整理了一个包含 2.8M 样本的综合语料库,包含来自不同通用领域数据集的 3.2T tokens,以使模型具备基础技能和强大的对话能力
- 该语料库涵盖了广泛的任务,包括下面几个部分:
- 日常对话、问答 (2023; 2024)
- 创意写作 (2025; 2024)
- 安全性 (2025)
- 指令遵循 (2024)
- 角色扮演 (2024)
- 该语料库涵盖了广泛的任务,包括下面几个部分:
- 对于涵盖通用领域的知识密集型任务 (2024; 2021; 2024):
- 从公开数据集中收集问题 (2020; 2023)
- 并进一步用来自专业法律和伦理等挑战性领域的领域特定问题进行增强,最终得到 1.2M 个样本,包含 1.5T tokens
- 直接组合这些语料库会带来三个显著的挑战
- 第一:许多 responses 过于简短(例如,单个词或最少句子的输出),因此缺乏足够的细节和阐述
- 第二:response 质量参差不齐,一些数据集包含不准确或次优的答案
- 第三:由于这些数据集的不同来源和标注惯例,直接在这些数据集上训练会导致模型生成的风格不一致
- 为了解决这些问题,对于每个 prompt,分别使用两个模型分别生成思考和非思考的数据(最大序列长度为 16K):
- 思考数据: DeepSeek-R1-0528
- 非思考数据: DeepSeek-V3-0324
- 确保风格和质量的一致性
- 为了进一步提高训练数据质量,应用了几个后处理步骤
- 对于具有高质量注释的样本,保留其原始 responses 以保持多样性
- 问题:如何理解这里的高质量注释?
- 对于具有可验证 ground-truth 答案的 prompts(例如,多项选择题),丢弃偏离 ground-truth 的 responses 来提高生成准确性
- 对于没有 ground-truth 答案的样本,使用辅助模型 (Qwen2.5-32B-Instruct (2024)) 交叉验证生成的 responses,以过滤掉可能低质量的生成
- 为了解决指令遵循和创意写作等领域的数据稀缺问题:
- 为每个 prompt 使用不同的随机种子生成多个 responses,从而丰富多样性并提高生成质量
- 为了进一步增强多轮对话能力,以两种方式手动增强多轮样本
- 第一:对于创意写作领域的单轮样本,添加第二轮 ,指示模型根据特定要求重写或编辑其先前的 response
- 第二:将单轮样本随机连接起来构建多轮对话,模拟真实的聊天机器人交互
- 对于具有高质量注释的样本,保留其原始 responses 以保持多样性
Math Reasoning Data
- 阶段 1 数学 SFT 数据集:
- 将 AceReason-Nemotron-1.1 (2025) 中的数学推理 SFT prompts 用于阶段 1 SFT 训练
- 这些 prompts 包含多种数据源,包括 AceMath (2024)、NuminaMath (2024) 和 OpenMathReasoning (2025)
- 相应的 responses 由 DeepSeek-R1 (2025) 生成
- 将最大上下文长度设置为 16,384 tokens (16K),并过滤掉超过此限制的样本以防止 response 截断,遵循 AceReason-Nemotron-1.1 中的 SFT 配置
- 总共收集了 353K 个唯一去重 prompts,并为每个 prompt 生成了多个 responses ,得到 2.77M 样本,平均每个 prompt 有 7.8 个 responses
- 通过移除任何与标准数学 benchmark 测试样本有 9-gram 重叠的样本来执行数据去污
- 阶段 2 数学 SFT 数据集:
- 为了进一步增强模型的推理能力,使用 DeepSeek-R1-0528 生成 responses 并构建阶段 2 数学 SFT 数据集
- 理解:阶段 2 数学 SFT 数据集的 Prompt 和阶段 1 是一样的,但会过滤掉相对简单的问题
- 具体来说是那些 DeepSeek-R1 responses 包含少于 2K tokens 的问题
- 注:与原始的 DeepSeek-R1 相比,更新的 DeepSeek-R1-0528 产生更长、更详细的推理轨迹,从而在具有挑战性的问题上提高了性能
- 理解:阶段 2 数学 SFT 数据集的 Prompt 和阶段 1 是一样的,但会过滤掉相对简单的问题
- 将最大上下文长度设置为 32,768 tokens (32K),为模型提供更大的推理 token 预算
- 总共获得了 163K 个 prompts 并生成了 1.88M 个样本,平均每个 prompt 有 11.5 个 responses
- 为了进一步增强模型的推理能力,使用 DeepSeek-R1-0528 生成 responses 并构建阶段 2 数学 SFT 数据集
- 阶段 1 和阶段 2 SFT 中的所有数学推理数据均采用思考模式格式化
Code Reasoning Data
- 遵循与数学推理数据构建类似的过程,采用了 AceReason-Nemotron-1.1 (2025) 中的代码推理 SFT prompts
- 其中包括了来自 TACO (2023)、APPs (2021)、OpenCoder-Stage-2 (2024) 和 OpenCodeReasoning (2025) 的数据
- 执行数据集去重以确保所有 prompts 都是唯一的,得到 172K 个不同的 prompts
- 阶段 1 SFT 数据:
- 使用 DeepSeek-R1 (2025),为阶段 1 SFT 生成了 1.42M 个样本,平均每个 prompt 有 8.3 个 responses,最大上下文长度为 16,384 tokens (16K)
- 去污:过滤掉任何与编码 benchmark 的任何测试样本有 9-gram 重叠的样本
- 问题 代码这种样本,很容易重复吧,9-gram 似乎是和容易重复的?
- 阶段 2 SFT 数据:
- 阶段 2 利用 OpenCodeReasoning (2025) 和 OpenCoder-Stage2 (2024) 中的 prompts
- OpenCodeReasoning 提供了多样且具有挑战性的编码 prompts 集合
- OpenCoder-Stage2 涵盖了带有起始代码入口点的编码任务
- 与阶段 2 数学 SFT 数据集类似,将最大上下文长度设置为 32,768 tokens (32K)
- 阶段 2 构建了 79K 个唯一去重 prompts,并使用 DeepSeek-R1-0528 生成 1.39M 个样本,平均每个 prompt 有 17.6 个 responses
- 阶段 2 利用 OpenCodeReasoning (2025) 和 OpenCoder-Stage2 (2024) 中的 prompts
- 阶段 1 和阶段 2 SFT 中的所有代码推理数据均采用思考模式格式化
Science Reasoning Data
- 从 S1K (2025) 以及 Llama-Nemotron (2025; 2025) 中使用的后训练数据集中整理出与科学相关的 prompts
- 注:这些来源中的许多 prompts 是多项选择题
- 本文排除了模型侧重于分析每个选项而不是直接解决问题并确定正确答案的样本
- 本文保留了那些需要强大科学知识并涉及大量推理或复杂计算的问题
- For 用较少见和更多样化的问题类型丰富数据集
- 利用 DeepSeek-R1-0528 从每个给定的 prompt 生成更罕见的问题,遵循 Liu 等 (2024) 中使用的合成问题生成策略
- 数据去污:移除任何与科学 benchmark 的任何测试样本有 9-gram 重叠的样本
- 总共收集了 226K 个科学 prompts
- 使用 DeepSeek-R1 为阶段 1 SFT 生成了 289K 个样本(最多 16K tokens)
- 使用 DeepSeek-R1-0528 为阶段 2 SFT 生成了 345K 个样本(最多 32K tokens)
- 所有科学推理数据均采用思考模式格式化,并为选定的高质量 prompts 生成多个 responses
- 阶段 2 科学推理数据在被混合到阶段 2 SFT 数据集之前被上采样了 \(2\times\)
Tool Calling Data
- 使用了 Llama-Nemotron (2025) 中的工具调用数据集,该数据集专门设计用于训练模型处理涉及外部工具使用(例如函数调用)的场景
- 该数据集非常全面,包含单轮、多轮和多步交互
- 一些 prompts 要求模型提出澄清问题以收集足够的信息进行工具调用
- 一些 prompts 可能涉及使用多个工具甚至在达到最终答案之前执行多轮工具调用
- 还包括模型在提供的工具列表中找不到合适工具的情况
- 对于每个对话,所有可用的工具都包含在 System Prompt 中(遵循 Qwen3 (2025) 中使用的设置)
- 平均每个对话包含 4.4 个可用工具
- 该数据集非常全面,包含单轮、多轮和多步交互
- 此工具调用 SFT 数据集用于阶段 2 SFT 训练,responses 由 Qwen3-235B-A22B (2025) 生成
- 注:所有工具调用数据均采用思考模式格式化
- 总计收集了 310K 个对话,包含 1.41M User-Assistant 轮次
Software Engineering Task
- 软件工程已成为 LLM 最重要的应用之一 (Anthropic, 2025)
- SWE-bench Verified (2023) (软件工程 benchmark) 包含与其相应代码库和描述配对的真实世界 GitHub 问题,其目标是生成能够成功解决所述问题的修复补丁
Agentless Framework
- 为了评估自动化的软件工程能力,本文采用 Agentless (2024)
- 注:Agentless 框架是 LLM 应用中的一种 “无智能体” 框架,核心是不依赖复杂的自主规划、工具调用与多轮反思,而是用预设的分层流程 + 固定模板调用 LLM来完成任务,主打极简、稳定、低成本、可解释
- Agentless 框架将整个任务分解为三个阶段(即,定位、修复和补丁验证)
- 对比:Agent 框架需要 LLM 本身规划动作序列或操作外部工具, Agentless 框架则不需要
- 本文采用一个类似于 Agentless Mini (2025) 的简化 Agentless 框架,该框架简化了定位过程,专注于仅识别相关的 issue 文件
- 这种方法与原始的 Agentless 工作流程不同
- 原始 Agentless 采用三阶段分层定位策略,从文件级别到类/函数级别,再到行级别识别,然后才进行修复和补丁验证阶段
- 通过简化定位过程,LLM 可以将更多的推理能力用于修复任务本身,而强化学习则被整合到一个直接优化修复补丁生成的重点目标中
- 这种方法与原始的 Agentless 工作流程不同
- 对于代码修复阶段,主要目标是生成有效的候选补丁,以解决已识别的仓库级别问题
- 通过早期阶段定位了相关文件后,就会提示 LLM 生成仅修改代码库必要部分的修复编辑
- For 最大化上下文理解,将多个定位的文件及其周围的代码片段(例如,导入、类定义和依赖函数)连接成一个统一的 prompt,使模型能够推理更广泛的仓库级别依赖关系
- 模型被引导生成有针对性的、diff 风格的补丁,而不是重写整个修复文件,这些补丁保留不相关的代码结构以减少幻觉和语法错误
- 对于补丁验证阶段,框架通过三个阶段运行: 回归、复现和多数投票
- 回归阶段:
- 每个候选补丁先通过仓库现有的回归测试进行评估,以确保兼容性
- 此步骤过滤掉引入失败或破坏先前正确功能的补丁,确保后续评估仅关注稳定且语法有效的候选者
- 复现阶段:
- 为每个 issue 实例生成 10 个复现测试,以在未修改的仓库上复制原始 bug 行为,并在应用补丁后验证功能正确性
- 未能触发原始 bug 的复现测试被丢弃,以保持高诊断精度,然后对每个候选补丁执行幸存的测试,允许系统识别哪些补丁成功消除了报告的问题
- 多数投票阶段:
- 聚合多个采样生成的结果以选择最可靠的补丁
- 在得分最高的候选者 中,先优先考虑在测试时样本中最常生成的补丁 (For 模型修复推理能力的共识)
- 问题:这里的得分是谁来打的?
- 在平局的情况下,倾向于生成序列更短或编辑距离最小的补丁(For 简洁性和可解释性)
- 这个多阶段验证框架确保最终选定的补丁在功能上正确且对仓库级别依赖关系具有鲁棒性,在精度和效率之间取得平衡
- 回归阶段:
- 可参考附录 C.2 了解每个阶段使用的 prompts
- 第 §7 节中详细介绍了本工作中使用的改进技术,包括增强的代码文件定位和补丁验证,与先前研究相比
Data Curation
数据源
- 用于软件工程任务的训练数据由以下开源数据集组成:
- SWE-Bench-Train (2023) :通过与 SWE-Bench 评估集相同流程生成但未经人工验证的训练集划分
- SWE-Fixer-Train (2025) :包含超过 100 个 pull requests 的 Python 仓库,在应用启发式过滤规则后产生 115K 个实例
- SWE-reBench (2025) :一个包含超过 21K 个交互式基于 Python 的 SWE 任务的公共数据集,通过一个新颖、自动化且可扩展的流程构建
- SWE-Smith (2025) :一个合成数据集,包含来自 128 个 GitHub 仓库的 50K 个实例,通过自动将 bug 注入代码库生成
- 为防止评估数据污染,针对 SWE-bench Verified (2023) 实施了一个全面的去重过程
- 具体做法:
- 排除所有源自评估数据集中存在的仓库的实例
- 对来自不同来源的训练数据执行去重,以消除重复实例
注:此去重过程依赖于匹配仓库名称和基础提交标识符,以确保移除相同的实例
- 具体做法:
Response generation
- 为 Agentless 框架中的三个子任务构建 SFT 数据集:
- 1)代码定位 (Code localization) :给定一个问题陈述和相应的 GitHub 仓库结构,模型识别并列出可能包含 bug 的代码文件
- 2)代码修复 (Code repair) :给定一个问题陈述以及一个或多个有 bug 的代码文件的内容,模型生成修订后的代码补丁,以解决问题陈述中描述的问题
- 3)测试代码生成 (Test code generation) :给定一个问题陈述、代码定位和修复补丁,模型生成验证所生成代码补丁的测试代码
- For 构建 SFT 数据集
- 使用 DeepSeek-R1-0528 为数据源中列出的四个数据集生成多个 responses
- 为 SWE-Bench-Train、SWE-reBench 和 SWE-Smith 的每个 prompt 生成 8 个 responses
- 为更大规模的 SWE-Fixer-Train 数据集生成 4 个 responses
- 输入的 prompts 被构建为包含任务规范、问题陈述、用于修复任务的代码文件内容以及期望的输出格式
- 注:有关模板的详细信息,请参见附录 C.2
- 模型被指示输出完整的推理链和解决方案
- 对于代码定位,解决方案包含一个优先级的潜在有 bug 的代码文件名列表,按从最可能到最不可能包含 bug 的顺序排列
- 对于代码修复,解决方案包含要替换的代码块以及用于替换的代码补丁
- 对于测试代码生成,解决方案包含一组单元测试和复现测试,旨在验证 bug 复现和补丁正确性
- 使用 DeepSeek-R1-0528 为数据源中列出的四个数据集生成多个 responses
Data filtering and splitting for SFT and RL
- 为确保高质量的训练数据,根据 ground-truth 注释验证所有生成的 responses
- 问题:RL 数据也需要验证 Response 吗?而且从本文后面的第 4 节也明确提到了,RL Prompt 和 SFT Prompt 是严格不想交的
- 过滤策略因三个任务而异
- 对于定位任务,仅保留那些包含解决该问题所需的所有有 bug 的代码文件的样本(即,召回率等于 1.0)
- 对于修复任务,使用 Unidiff(一个用于解析和与统一 diff 数据交互的轻量级 Python 库)
- 遵循 Wei 等 (2025) 的方法,衡量生成补丁与 ground-truth 补丁之间的相似度
- 采用分层方法:对于 SWE-Bench-Train、SWE-reBench 和 SWE-Smith,展示出一致解决方案质量(定义为在 8 个采样响应中至少有 4 个超过 0.5 相似度阈值)的实例被包含在 SFT 数据集中
- 更具挑战性的实例:定义为在 8 个采样响应中至少有 1 个达到非零相似度(排除 SFT 样本)
- 被保留用于第 §4.7 节中描述的 SWE RL 训练
- 考虑到 SWE-Fixer-Train 数据集的规模和多样性,将所有超过 0.5 相似度阈值的 prompt-response 对包含进来
- 对于测试代码生成,仅保留那些可以成功解析并作为复现测试执行而无任何语法错误的轨迹
Dataset composition summary,数据集组成总结
- 最终的代码修复数据集包含 127K 个实例,分布如下:
- 来自 SWE-Bench-Train 的 17K
- 来自 SWE-reBench 的 17K
- 来自 SWE-Smith 的 18K
- 来自 SWE-Fixer-Train 的 77K
- 注:这种组成确保了在保持高数据质量标准的同时,全面覆盖各种编码场景
- 用于定位和测试用例生成的最终数据集分别包含 92K 和 31K 个样本
- 所有 SWE 数据集在被纳入阶段 2 SFT 数据混合之前都上采样了 \(3\times\)
- 问题:阶段 1 不包含 SWE 数据吗?从文章看起来似乎是不包含
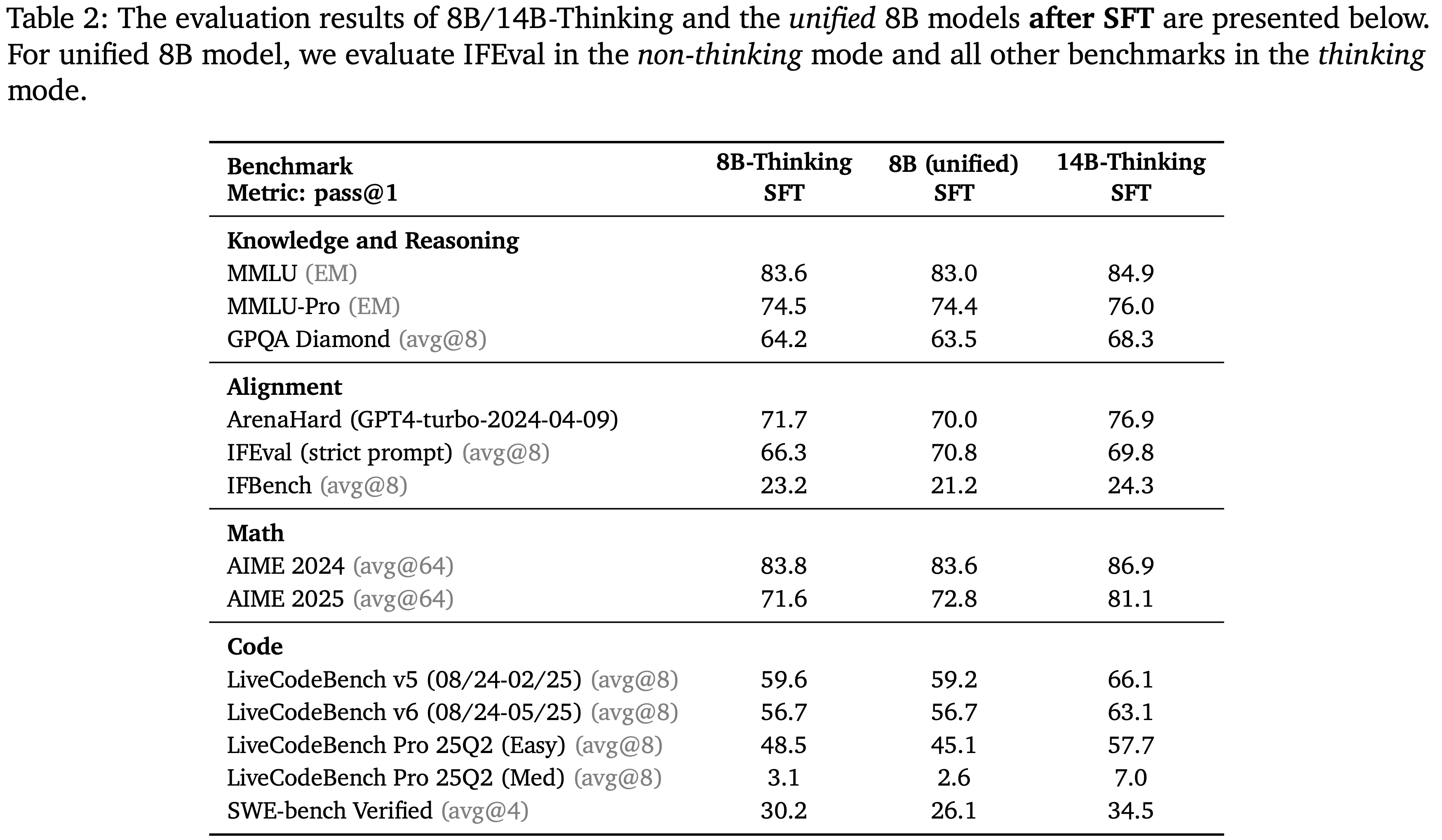
Results after SFT,SFT 后的结果
- 在多阶段 SFT 过程之后,8B 统一模型以及 8B/14B 思考模型的结果总结在表 2 中
- 注:Qwen3-8B 原始分数见表 1 第一列:
- 8B 统一模型的表现 vs 专用的 8B 思考模型(两个模型都在相同的 SFT 思考数据上进行了训练,统一模型进一步整合了非思考数据)
- 在所有与推理相关的 benchmarks 上
- 8B 统一模型的表现与专用的 8B 思考模型相当
- 在与指令遵循(更适合 instruct 模式的任务)相关的 IFEval benchmark 上
- 8B 统一模型的表现超越了专用的 8B 思考模型
- 注:其实也没有,IFBench 上 Unified 模型就不如 Thinking 模型
- 在所有与推理相关的 benchmarks 上
- 由于资源限制,本文只训练了一个 14B 思考模型,并提供了比 8B 模型更强的结果
- 本文接下来的核心:将检查所有 RL 阶段的结果,突出 Cascade RL 框架的鲁棒性和整体有效性
补充:两阶段 SFT 训练超参
- 8B 和 14B训练超参(注:两者有两个区别)
- 区别1:第二阶段的最大学习率上是 14B 偏大(\(5e^{-5} \text{ vs } 2^{e-5}\))
- 区别2:第一第二阶段 14B 模型的训练 Step 都要大一些(问题:14B 模型有更多数据?)

Cascade RL
- 本节介绍了 Cascade RL 方法
- 在整理 RL 数据时,确保 SFT 和 RL 数据集在 Prompt 方面是严格不相交的
- 这样模型在 RL 训练期间就不能利用对给定 Prompt 的记忆答案
Training Framework
- 如图 2 所示,Cascade RL 过程首先对 § 4.3 中描述的 SFT 模型应用通用领域的 RLHF,然后进行 RLVR
- 首先应用 RLHF,然后再应用 RLVR(例如 Math RL)
- 因为 RLHF 通过减少冗余和重复来显著提高生成响应的质量,从而在受限的 Response 长度(例如 64K Token)内提升推理性能
- 首先应用 RLHF,然后再应用 RLVR(例如 Math RL)
- 在 Cascade RL 中,依次应用以下流程:
- RLHF(§ 4.3)
- Instruction-Following RL(§ 4.4)
- Math RL(§ 4.5)
- Code RL(§ 4.6)
- 软件工程 RL(SWE RL,§ 4.7)
- 基本思路:逐步从更通用的领域过渡到更专门的领域
Why Cascade RL for LLMs Is Resistant to Catastrophic Forgetting,Why Cascade RL 能够抵抗灾难性遗忘
- 当一个模型在多个领域上顺序训练时,可能会在学习新知识的同时覆盖掉先前学到的知识,这种情况被称为灾难性遗忘
- 这是监督学习中的一个常见问题,其中不相交的训练数据集会导致更新将模型推向新的数据分布
- Cascaded Cross-Domain RL 在几个结构方面有所不同,从而缓解了这个问题:
- i)在 RL 中,训练数据分布是依赖于当前策略的(即 LLM 生成自身的经验,实际上就是 On-Policy)
- 当引入新的目标或任务时,LLM 仍然会在各种状态中进行探索,这意味着如果旧的行为仍然有用或能获得高奖励,它们就会被持续采样
- 这与监督学习(例如 SFT)形成对比,在 SFT 中,先前领域的样本除非被明确地重放,否则就会消失
- ii)RL 优化的是期望的累积奖励,而不是针对每个输入的确切目标
- 更新侧重于改善长期结果,而不是显式地拟合新的 Token-level 分布
- 那些仍然与奖励相关的旧知识会自然地持续存在
- 当新任务与旧任务共享结构时,更新倾向于泛化而不是覆盖
- iii)当一个新领域的奖励与先前领域的奖励发生剧烈冲突时(例如,优化简洁的 Response 与详细的、逐步的推理),灾难性遗忘仍可能发生,特别是当来自不同领域的 Prompt 在语义上相似时
- 但 RLHF 和 RLVR 的奖励结构在各个领域(如数学、代码、推理和指令遵循)之间存在大量重叠,因为它们都旨在使输出更好、更准确,并且更符合人类偏好或验证信号
- 例如:减少冗余或幻觉通常对所有领域都有益
- 但 RLHF 和 RLVR 的奖励结构在各个领域(如数学、代码、推理和指令遵循)之间存在大量重叠,因为它们都旨在使输出更好、更准确,并且更符合人类偏好或验证信号
- iv)在本文的 Cascade RL 框架中,由于各个领域的 Prompt 通常已经各不相同,本文进一步最大限度地减少了 Prompt 的重叠
- 例如:从 RLHF 阶段移除了所有与数学和竞技编程相关的 Prompt,以减少跨领域干扰
- 领域级的 RL 安排是从更通用的领域(例如 RLHF,指令遵循)到更专门的领域(例如数学、代码、SWE),从而防止专门的能力被通用行为所覆盖
- i)在 RL 中,训练数据分布是依赖于当前策略的(即 LLM 生成自身的经验,实际上就是 On-Policy)
- 个人总结:核心思路是,借助 RL 本身的 On-policy 优势(泛化能力),同时逐步从更通用的领域过渡到更专门的领域,从而防止专门的能力被通用行为所覆盖
- 注:这和我们平时的做法有些不同,平时常常是先训练数学和推理,再训练 General RL(通用能力, RLHF)
RL Training Configuration
- 在整个 Cascade RL 过程中,使用 GRPO 算法 (2024),并遵循 AceReason-Nemotron (2025) 的严格 On-policy 训练方式(采用 On-policy 训练可提高稳定性和准确性)
- RL Infra:使用 VeRL 代码库 (2025) 进行训练
- 在每次迭代中,从当前策略 \( \pi_\theta \) 生成一组 \( G \) 个 Rollout,然后执行一次梯度更新
- 这确保了用于数据收集的策略总是与正在更新的策略相匹配,使得重要性采样比率恰好为 1
- 这种 On-policy 设置有助于稳定的 RL 训练并减轻熵崩溃
- 注:完全移除了 KL 散度项,从而将 GRPO 目标简化为标准的 REINFORCE 目标 (1992),并带有组归一化奖励和 Token-level 损失 (2025):
$$
\mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^{G} \sim \pi_{\theta}(\cdot|q)} \left[ \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} \hat{A}_{i,t} \right], \quad \text{Where } \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{r_i\}_{i=1}^{G})}{\text{std}(\{r_i\}_{i=1}^{G})} \text{ for all } t,
$$- \( \{r_i\}_{i=1}^{G} \) 表示分配给针对数据集 \( \mathcal{D} \) 中给定问题 \( q \) 所采样 Response \( \{o\}_{i=1}^{G} \) 的一组 G 个奖励,并在
- RLVR 中 \( r_i \) 根据真实答案 \( a \) 进行验证
- 对于 RLHF,\( r_i \) 是奖励模型针对 Response \( o_i \) 和问题 \( q \) 输出的标量
- 注:不同领域的奖励函数细节将在相应的子章节中提供
- 理解:上面是目标有点问题,应该还需要加个概率分布函数
$$
\mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^{G} \sim \pi_{\theta}(\cdot|q)} \left[ \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} \hat{A}_{i,t} \color{red}{\cdot \pi_\theta(o_{i,t}|q,o_{i, < t})} \right], \quad \text{Where } \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{r_i\}_{i=1}^{G})}{\text{std}(\{r_i\}_{i=1}^{G})} \text{ for all } t,
$$- 因为梯度应该是:
$$
\nabla \mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{(q,a) \sim \mathcal{D}, \{o_i\}_{i=1}^{G} \sim \pi_{\theta}(\cdot|q)} \left[ \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} \hat{A}_{i,t} \color{red}{\nabla \pi_\theta(o_{i,t}|q,o_{i, < t})} \right], \quad \text{Where } \hat{A}_{i,t} = \frac{r_i - \text{mean}(\{r_i\}_{i=1}^{G})}{\text{std}(\{r_i\}_{i=1}^{G})} \text{ for all } t,
$$
- 因为梯度应该是:
- \( \{r_i\}_{i=1}^{G} \) 表示分配给针对数据集 \( \mathcal{D} \) 中给定问题 \( q \) 所采样 Response \( \{o\}_{i=1}^{G} \) 的一组 G 个奖励,并在
Reward Modeling
- 本节描述 RLHF 阶段的 RM 的构建过程
Data Curation
- 奖励建模偏好数据集混合了开源数据和内部数据,总共包含 82K 个偏好对(使用了以下开源数据):
- HelpSteer2 (2024)
- 一个包含 10K 个高质量、人工标注的偏好数据集,涵盖了帮助性、正确性、连贯性、复杂性和冗长度等多个方面的标注
- HelpSteer3 (2025)
- 一个包含 40K 个偏好对的数据集,涵盖多个领域,包括通用领域、STEM、代码和多语言
- 每个样本(Response 对)都标注有一个偏好分数,范围从 –3(Response 1 远好于 Response 2)到 3(Response 2 远好于 Response 1)
- 本文过滤掉了分数为 0(Response 1 与 Response 2 相似)的样本,剩余 36K 个样本
- HelpSteer2 (2024)
- 受先前工作 (2024) 的启发,本文生成了额外的数据以改进最终的偏好数据混合
- 核心思想是构建偏好对,其中较差的 Response 来自较强的 LLM,而较好的 Response 来自较弱的 LLM
- 注意:诱导较强的 LLM 生成较差的 Response 对于使数据有效至关重要
- 否则,偏好对对于奖励模型来说将太容易区分
- 问题:为什么一定要用 用弱模型生成正样本,二用强模型生成负样本?
- 看似反直觉,实则是整个 Off-topic Response Method 设计中的核心技巧,目的是刻意制造一种“高质量外表下的错误回答”,从而有效对抗 Judge Model 的偏倚
- 这种方法的核心逻辑:
- 利用 LLM 生成与原始指令 \( I \) 相似但不同的指令 \( I’ \)
- 弱模型(参考回答)生成 \( I \) 的正确回答 \( R_g \)
- 强模型生成 \( I’ \) 的候选回答 \( R_b \)
- \( R_b \) 表面具体、合理,但实际与 \( I \) 无关,\(R_g\) 则不一定表面很好,但是很贴合原始问题 \(I\)
- 一种具体的方法是:
- 生成一个略微偏离主题的 Prompt,并用它来从较强的模型获得一个较差的 Response
- 本文使用 DeepSeek-V3 通过重写原始 Prompt 来生成这些偏离主题的 Prompt,并且通过人工检查和基于 LLM 作为评判者的自动评估验证了重写后的质量很高
- 注:有关详细 Prompt,请参考附录 §C.1
- 本文探索了不同 LLM 作为弱模型和强模型的组合,并最终选择了 DeepSeek-V3-0324 和 DeepSeek-V3 分别作为强模型和弱模型
- 注:本文也尝试过明确指示强 LLM 对给定 Prompt 生成有细微错误的答案
- 但这种方法并未成功
Training Recipe
- 使用 Bradley-Terry 目标 (1952) 在成对的人类偏好数据上训练一个标量输出的奖励模型(RM):
$$
P_{\text{BT} }(y^+ \succ y^- | x) = \frac{\exp(r_\theta(x, y^+))}{\exp(r_\theta(x, y^+)) + \exp(r_\theta(x, y^-))}
$$- \( y^+ \) 是 Chosen(preferred),\( y^- \) 是 Rejected(dispreferred)
- 奖励模型使用 Qwen2.5-72B-Instruct (2024) 进行初始化,在其最后一个隐藏层之上添加了一个线性预测器,并通过最大化人类偏好的对数似然来进行训练:
$$
\mathcal{L}(\theta) = \mathbb{E}_{(x,y^+,y^-)\sim \mathcal{D} }\left[\log P_{\text{BT} }(y^+\succ y^-\mid x)\right]
$$
- 对于每个 Prompt,会比较两个 Response
- 使 RM 能够学习给 Chosen Response 分配更高的标量分数,给 Rejected Response 分配更低的分数
- 将这个标量分数视为模型 Response “质量” 的代理指标
- 训练超参数如下:
- Batch Size 256,学习率 2e-6,AdamW 优化器 (2017),训练 1 个 Epoch
- 注:也尝试了更长的训练计划,但发现一个 Epoch 能产生最佳结果
RM 评估
- 主要使用 RewardBench (2024) 来评估和选择用于 RLHF 过程的 RM
- 观察:RewardBench 分数低的奖励模型通常会导致 RLHF 后的策略对齐效果较差,但 RewardBench 分数最高的 RM 并不一定能产生最佳对齐的策略模型(即通过对齐基准测试来衡量),因为 RewardBench 可能是识别 RLHF 最佳奖励模型的不完美代理,而且 RLHF 过程本身也会引入额外的方差
- 正在进行研究,以建立能够作为更可靠代理指标的 Robust RM 基准,用于识别可能产生最佳最终对齐效果的奖励模型
- 对于使用哪个标准基准,目前还没有普遍的共识
关于 RM 的消融研究
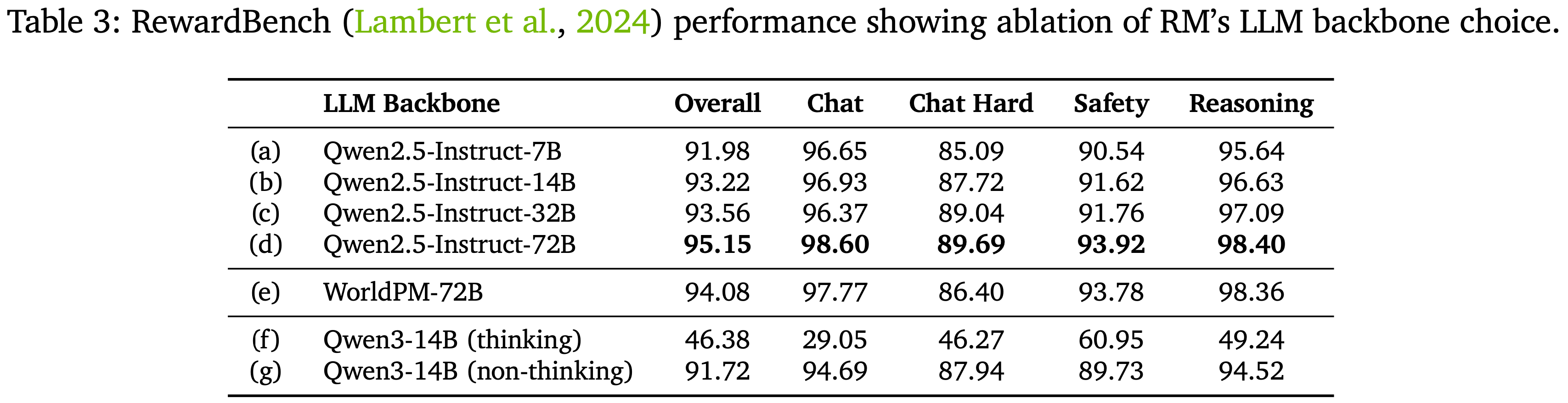
- 本文进行了消融研究以确定骨干 LLM 的选择,主要发现如下:
- 模型大小 :
- 使用 Qwen2.5-Instruct 系列(7B、14B、32B 和 72B)训练了不同大小的奖励模型,并观察到性能随模型大小正向扩展,确认了缩放定律 (2020) 在奖励模型训练中也成立
- 参见表 3 中的 (a)-(d)
- 较大的 LLM 对偏好数据中的风格伪影表现出更强的鲁棒性,而较小的模型则倾向于更关注 Response 的风格而非其整体质量
- 当将在 RLHF 中应用这些奖励模型时,无论是在有风格控制还是没有风格控制的情况下,这一观察都得到了 Arena-Hard 分数 (2024) 的进一步验证:
- 与较大的模型相比,较小的模型在受风格控制的评估下表现出更大的性能下降,详见 § 6.2 的讨论
- 使用 Qwen2.5-Instruct 系列(7B、14B、32B 和 72B)训练了不同大小的奖励模型,并观察到性能随模型大小正向扩展,确认了缩放定律 (2020) 在奖励模型训练中也成立
- 有无大规模偏好预训练 :
- 先前工作 (2025) 发布了 WorldPM 检查点,这是一个在 1500 万规模多样化偏好数据上进一步预训练的 Qwen2.5-72B 模型,可以作为奖励模型训练的强大初始化
- 实验中,从 WorldPM 初始化的模型在训练的早期阶段表现更好,但随着训练的延长,从原始 Qwen2.5-72B-Instruct 初始化的模型最终在 RewardBench (2024) 上赶上并略微超过了它们
- 参见表 3 中的 (d) vs (e)
- 推理模型 vs. 指令模型 :
- 在开发后训练流程的过程中,Qwen3 统一推理模型发布 (2025),促使本文也探索了 Qwen3 8B 和 14B 检查点
- 发现:当用作使用 BT 损失训练的奖励模型的骨干时,Qwen3 推理模型的性能始终低于相同大小的 Qwen2.5 指令/非思维模型
- 参见表 3 中的 (b) vs (f)
- 一开始作者怀疑这是由于偏好数据不太适合以 Thinking 模式运行的 Qwen3 模型,因此在启用 Non-Thinking 模式的情况下进行了额外的实验
- 尽管性能有了显著提高,但处于 Non-Thinking 模式的 Qwen3 模型仍然未能超越 Qwen2.5-Instruct
- Qwen2.5-Instruct 是非思维对应模型(参见表 3 中的 (b) vs (g))
- 作者推测这是因为 Qwen3 推理模型主要针对以推理为中心的任务(例如数学和代码)进行了优化,而不是通用的人类偏好对齐
- 模型大小 :
RLHF
- RLHF 是 Cascade RL 过程的第一阶段
- 发现:奖励模型的泛化能力对于确保稳定的 RLHF 训练起着至关重要的作用,并且较大的奖励模型(例如 72B RM)对策略 LLM 生成 OOD 样本更具鲁棒性
Data Curation
- 发现:将奖励模型的 OOD Prompt 引入 RLHF 阶段通常会导致不稳定甚至训练崩溃
- 原因是奖励信号不准确或具有误导性
- 理解:这里 RM 使用的 Prompt 数量是 82K 个偏好对,也就是说只能在这里面挑选 RLHF 的样本(有点偏少了)
- 思考:为了类似的 RM OOD Query 加入 RLHF,是否应该花时间针对这部分数据好好做一下正负样本对打标和 RM 训练,从而保证 RLHF 中,RM 不会遇到 OOD 的样本?
- 在 RLHF 阶段,使用来自 § 4.2 中描述的奖励模型偏好数据集的 Prompt 子集
- 问题:奖励模型的数据
- 此外,在 RLHF 中还排除了与数学和竞技编程相关的 Prompt
- 因为奖励模型可能无法提供像后续 Math RL 和 Code RL 阶段中使用的基于规则或基于执行的验证器那样可靠的奖励信号
- 在早期的实验中观察到:在 RLHF 期间未能排除与数学相关的 Prompt 导致 AIME25 基准测试的性能下降了 2%
- 本文的 RLHF 数据集主要侧重于提高帮助性、无害性以及与人类偏好的一致性,同时与将在后续 Cascade RL 阶段中增强的领域保持不相交
raining Recipe
- RLHF 帮助 LLM 更好地遵循用户意图并与人类偏好对齐
- 观察:
- 尽管本文 RLHF 数据集中不包含数学或代码相关的 Prompt,但 RLHF 提高了整体的生成质量
- 有趣的是,还增强了数学和代码基准测试上的推理性能
- RLHF 倾向于减少重复和冗长,从而压缩简单问题的思维 Token 数量
- 这反过来又提高了后续 Math RL 和 Code RL 阶段的推理效率和训练稳定性
- 尽管本文 RLHF 数据集中不包含数学或代码相关的 Prompt,但 RLHF 提高了整体的生成质量
- 基于上述观察,本文将 Cascade RL 流程设计为从 RLHF 阶段开始
- 本文 RLHF 训练从 SFT 检查点初始化,采用 GRPO 算法,并遵循 § 4.1.2 中的统一 RL 训练配置(例如, On-policy 、 Token-level 损失、无 KL 散度)
- 对于专用的思维模型,在 Thinking 模式下执行 RLHF
- 对于统一模型,在 Non-Thinking 模式和 Thinking 模式下都进行 RLHF 训练,在每个批次中平均分配 Prompt 给每种模式
- 注:在 § 6.1 中提供了进一步的研究
Reward Function
- RLHF 训练使用 RM 产生的奖励分数作为奖励函数
- 具体做法:提取模型的答案,将其与相应的问题连接起来,应用奖励模型的聊天模板,并将格式化后的输入送入奖励模型以获得一个点式奖励分数
- 对以 Non-Thinking 模式和 Thinking 模式运行的 LLM 采用不同的答案提取方式:
- 对于 Non-Thinking 模式,直接提取助手角色之后的模型答案
- 对于 Thinking 模式,排除推理轨迹,只提取思维过程之后的最终总结(即模型在
</think>Token 之后生成的内容)- 如果思维过程未能正确终止(即缺少
</think>Token),会将整个未完成的 Response 发送给奖励模型- 这种不完整的生成通常会获得较低的奖励分数,因为奖励模型没有针对未完成或未见过的推理轨迹进行训练,从而有效地惩罚了冗长或不完整的思维过程
- 如果思维过程未能正确终止(即缺少
- 在训练中,在 RLHF 中对 8B 和 14B 模型都使用 12K 的最大 Response 长度,不应用过长过滤,这鼓励了更简洁的生成
- 为了防止生成中的语言混合,当 Prompt 完全是英文,但生成的 Response(包括推理轨迹和总结)包含非英文 Token 时,会应用额外的惩罚
- 注:由于来自奖励模型的奖励分数是无界的,本文自适应地将混合语言生成的奖励分配为本批次中最低分减 10 ,确保它们在 GRPO 算法下获得最低的相对分数,从而对 Code-Switching 行为施加强烈的惩罚
- 不应用额外的 Reward Shaping 技术,因为 72B 奖励模型提供的奖励信号已经具有高质量
Hyperparameters
- 对于本文 8B 和 14B 模型,在 RLHF 期间使用 12K 的最大 Response 长度,不应用过长过滤
- 鼓励更简洁的生成
- 使用 128 的 Batch Size,为每个 Prompt 生成 8 个 Rollout,温度为 0.6,top-p 值为 0.95
- 采用学习率为 2e-6 的 AdamW (2014),并将熵损失系数和 KL 损失系数都设为 0
- 训练大约需要 800 步
- 注:更多训练超参数的详细信息参见附录 D(表 15)
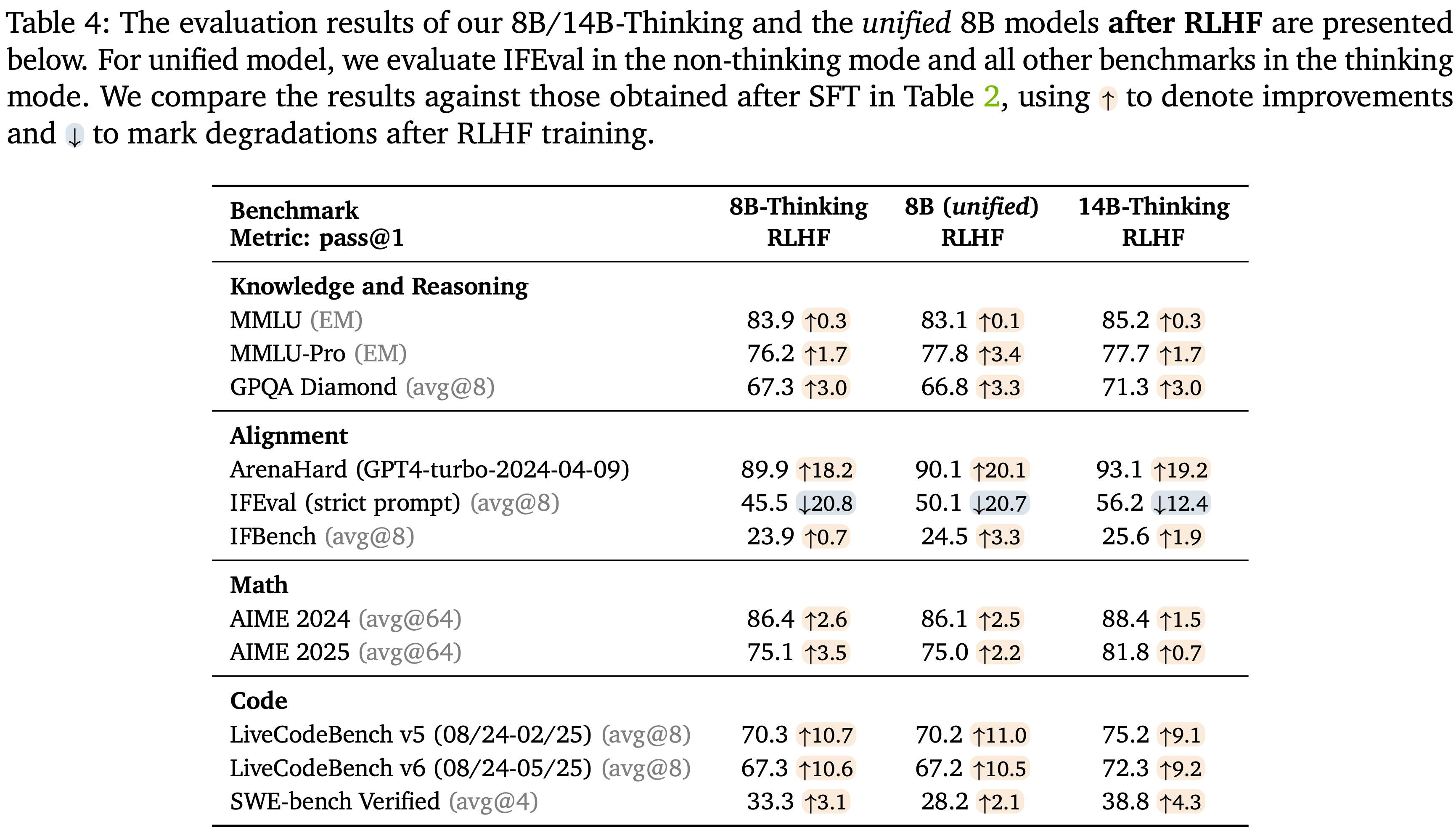
Results after RLHF
- RLHF 之后,8B 和 14B 模型的结果如表 4 所示
- 可以观察到,除了 IFEval 之外,几乎所有基准测试都有显著提升
- 主要原因是 RLHF 过程通过惩罚过长、冗长和重复的生成(尤其是 Thinking 模式)显著提高了 Response 质量
- 对于 IFEval 性能下降,主要原因是
- 1)RLHF 训练期间使用的 Prompt 与 IFEval 中的测试 Prompt 之间存在不可避免的语义重叠
- 2)RLHF 中使用的奖励模型鼓励了人类偏好的 Response 质量,这可能与验证器评估的严格指令遵循约束相冲突
- 作者相信,通过训练一个更强大的奖励模型(例如,一个大型生成式 RM (2025)),能够处理严格的指令遵循约束,可以缓解这个问题
- 这里将此留作未来的工作
- 理解:其实常用的方案是,同时训练 IFEval 方向的 Prompt(使用 RLVR 加强指令遵循能力) 和 General 的 Prompt
- 本文将在下一小节中重新讨论这一点
IF-RL: Instruction-Following Reinforcement Learning
- IF-RL 是确保 LLM 能够精确遵循人类指令的关键方面
- 本文的 SFT 数据混合已经包含了指令遵循数据,这里应用带有可验证奖励的 IF-RL 进一步提高了指令遵循的准确性
Data Curation
- 使用来自 Llama-Nemotron (2025) 的指令遵循数据集,该数据集由综合生成的 Prompt 组成,包含从 IFEval 分类法 (2023) 衍生出的一到十个详细的指令约束
- 但是,由于其合成性质,该数据集存在噪声
- 为了提高整体质量
- 本文进行了广泛的预处理和过滤,将 56K 个样本减少到 40K 个高质量样本
- 还额外整理了 60K 个自定义数据样本,以增强数据混合的多样性
- 使用了 LMSYS-Chat-1M (2023) 中的用户 Prompt,并结合了 IFEval 分类法中的各种指令约束
- 整合了来自先前工作 (2025) 的 IF-RLVR 训练数据,该数据旨在增强对未见约束分类法的鲁棒性
- 该数据集包含 Prompt 配对,这些指令约束要么来自 IFEval 分类法,要么来自 IF-Bench-Train 分类法 (2025),基础 Prompt 采样自 Tulu-3-SFT (2025)
Training Recipe
- IF-RL 训练分两个阶段进行,每个阶段使用不同的数据混合,难度逐渐增加
- 第一阶段专注于来自 IFEval 分类法的指令约束
- 第二阶段专注于来自 IF-Bench-Train 分类法的约束
- 发现:动态过滤 (2025) 在很大程度上稳定了 IF-RL 训练,并通过确保批次中的所有 Prompt 都具有有效的梯度,提高了两个阶段的结果
- IF-RL 阶段的主要挑战之一是 IF-RL 可能对 RLHF 阶段获得的人类对齐能力(例如,通过 ArenaHard 衡量)产生负面影响
- 在早期的实验中,使用基于规则的 IF 验证器作为奖励函数会降低人类对齐的结果
- 这是因为基于规则的 IF 验证器只关注 Response 是否遵循了指令指定的约束,而不考虑整体的 Response 质量
- 例如,一个写得不好的回答,只要其字数低于 300,仍然可以获得满分奖励(理解:这就是纯规则 IF RL 容易发生的问题)
- 在早期的实验中,使用基于规则的 IF 验证器作为奖励函数会降低人类对齐的结果
- 理解:上面提到了早期只使用 基于 规则的 IF 验证器容易发生 Reward Hacking,所以后期真实训练时(见下文),IF-RL 的训练都是使用的 RLVR + RLHF(RM) 的方式
Unified models: IF-RL in the non-thinking mode
- 对于统一推理模型,一个有效的策略是:
- 首先在 Thinking 模式和 Non-Thinking 模式下进行 RLHF,然后仅在 Non-Thinking 模式下应用 IF-RL
- 这种方法最大限度地减少了 RLHF 和 IF-RL 之间的负面相互干扰 ,同时仍然在模型的 Thinking 模式指令遵循能力上取得了显著提升(即 8B 统一模型在 Thinking 模式下达到了 85.3 的 IFEval 分数)
- 问题:为什么这种方式可以减少 干扰?
- 不是很容易解释,更多可能是因为在 Thinking 模式下,使用 IF-RL 容易出现 Reward Hacking(出现的原因或许与当前模型的 Thinking 模式训练有关,也不一定是通用的 Insight)
- 理解:虽然没有明确说明,但这里可以从上下文推测得到,训练时肯定是 RLVR + RLHF(RM) 的(详情见 Thinking Model 的奖励函数设计)
- 本文作者推测:
- 将 IF-RL 应用于经过 RLHF 训练的模型的 Non-Thinking 模式,比应用于 Thinking 模式产生低质量 Response 的可能性要小得多
- 因此更不容易对基于规则的 IF 验证器进行 Reward Hacking
- 理解:IF-RL 在 Thinking 模式上容易生成低质量的 Response,从而发生 Reward Hacking,但这个 Insight 不一定是通用的(可能仅仅在这个场景下能看到)
- 将 IF-RL 应用于经过 RLHF 训练的模型的 Non-Thinking 模式,比应用于 Thinking 模式产生低质量 Response 的可能性要小得多
- 本文也尝试过颠倒 RLHF 和 IF-RL 的顺序,但观察到的结果要差得多
- 在第一阶段和第二阶段 IF-RL 训练中,将最大 Response 长度设置为 8K Token,并且不对统一推理模型应用过长过滤
- 理解:不应用过长过滤的意思是,长的样本也会有梯度更新(往往是错误的样本,得到的是负分)
Thinking model: IF-RL with combined reward function
- 另一种方法是在 IF-RL 中设计一个奖励函数,同时考虑人类偏好和精确的指令遵循能力
- 对于专用的思维模型,这对于减轻 IF-RL 对 ArenaHard (2024) 等基准测试的负面影响至关重要
- 结合来自基于规则的指令遵循验证器和人类偏好奖励模型的信号,实现了两全其美
- 对于给定的 Prompt \( q \) 和一组生成的 Response \( \{o_i\}_{i=1}^{G} \),每个 Response \( o_i \) 的奖励定义如下:
$$
r_i = \begin{cases}
R_{\text{IF} }(o_i) + \text{sigmoid}(\hat{R}_{\text{RM} }(o_i)), & \text{if } R_{\text{IF} }(o_i) = 1 \\
0, & \text{otherwise}
\end{cases}, \quad \text{Where } \hat{R}_{\text{RM} }(o_i) = \frac{R_{\text{RM} }(o_i) - \text{mean}(\{R_{\text{RM} }(o_i)\}_{i=1}^{G})}{\text{std}(\{R_{\text{RM} }(o_i)\}_{i=1}^{G})}
$$- \( R_{\text{IF} }(o_i) \in \{0, 1\} \) 是指令遵循验证器的二元奖励(理解:基于规则的验证器)
- \( \hat{R}_{\text{RM} }(o_i) \) 是来自 RLHF 阶段使用的相同奖励模型的组归一化奖励(均值为 0,标准差为 1)
- 在归一化以后,再对 \( \hat{R}_{\text{RM} } \) 应用 Sigmoid 函数将其值缩放到 (0, 1) 范围,确保在聚合之前它与 \( R_{\text{IF} } \) 处于同一尺度
- 使用结合后的奖励,按照 § 4.1.2 中描述的 GRPO 目标进行 IF-RL
- 对于专用的思维模型:
- 在第一阶段 IF-RL 训练中将最大 Response 长度设置为 8K Token 并应用过长过滤
- 在第二阶段将其增加到 16K Token 并应用过长过滤(适应 Thinking 模式下困难 Prompt 所需的更长推理)
- 对于专用的思维模型:
Hyperparameters
- 对于 8B 和 14B 模型
- 使用 128 的 Batch Size ,为每个 Prompt 采样 8 个 Response,温度为 0.6,top-p 为 0.95,top-k 为 20
- 采用学习率为 2e-6 的 AdamW (2014),并将熵损失系数和 KL 损失系数都设为 0
- 对于 Non-Thinking 模式的 IF-RL
- 第一阶段训练大约需要 2000 步,第二阶段训练需要 1000 步
- 对于 Thinking 模式的 IF-RL
- 第一阶段训练大约需要 500 步,第二阶段训练需要大约 300 步
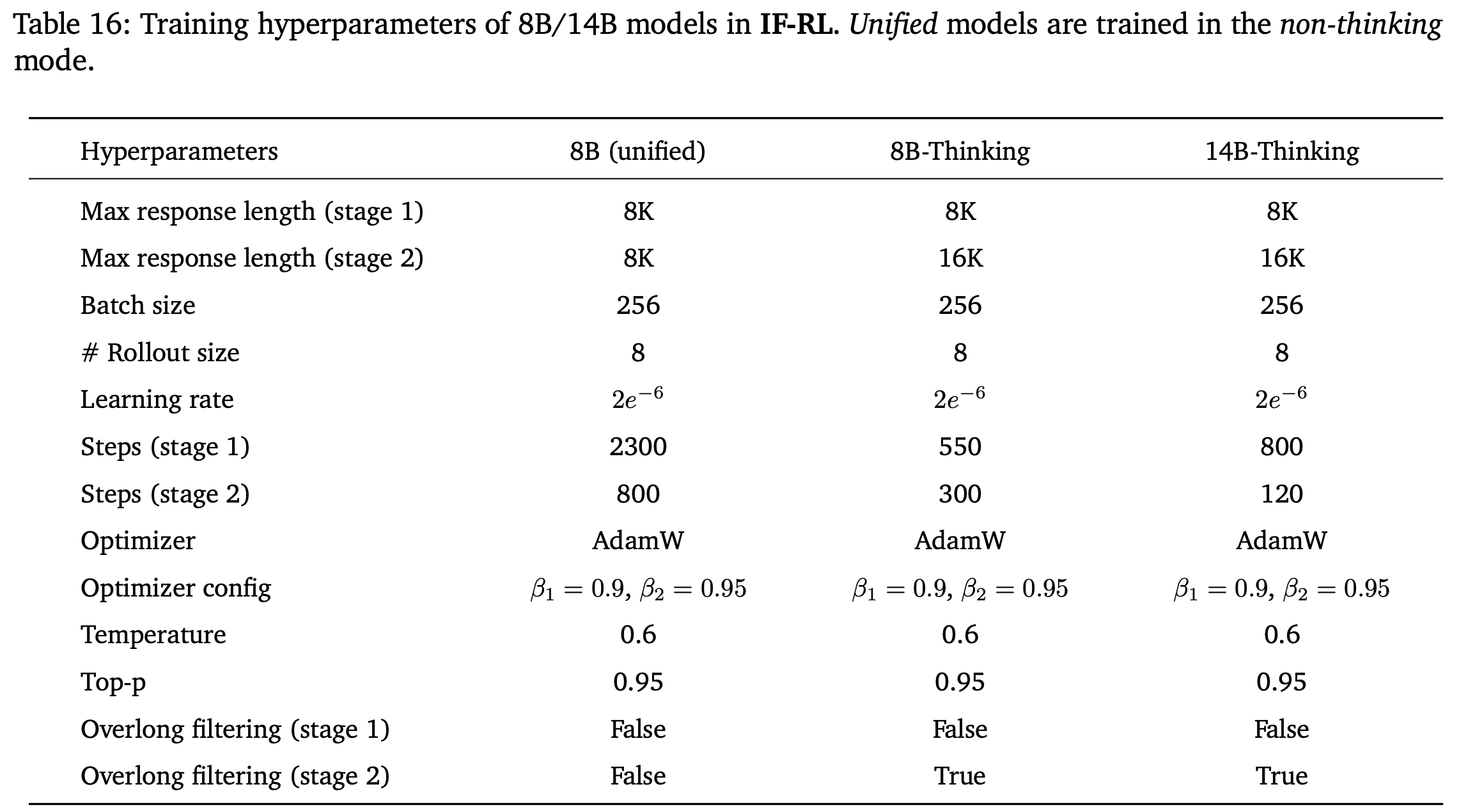
- 更多训练超参数的详细信息请参见附录 D(表 16)
- unified 模型始终不打开 Overlong Filtering,Thinking 模型的 2 阶段打开 Overlong Filtering
- 理解:在不开启 Overlong Filtering 时,一般是直接截断(得到的奖励会偏低),此时倾向于惩罚长文本,开启 Overlong Filtering 时,意味着对模型输出的长文本没有鼓励也没有惩罚,处于中立状态
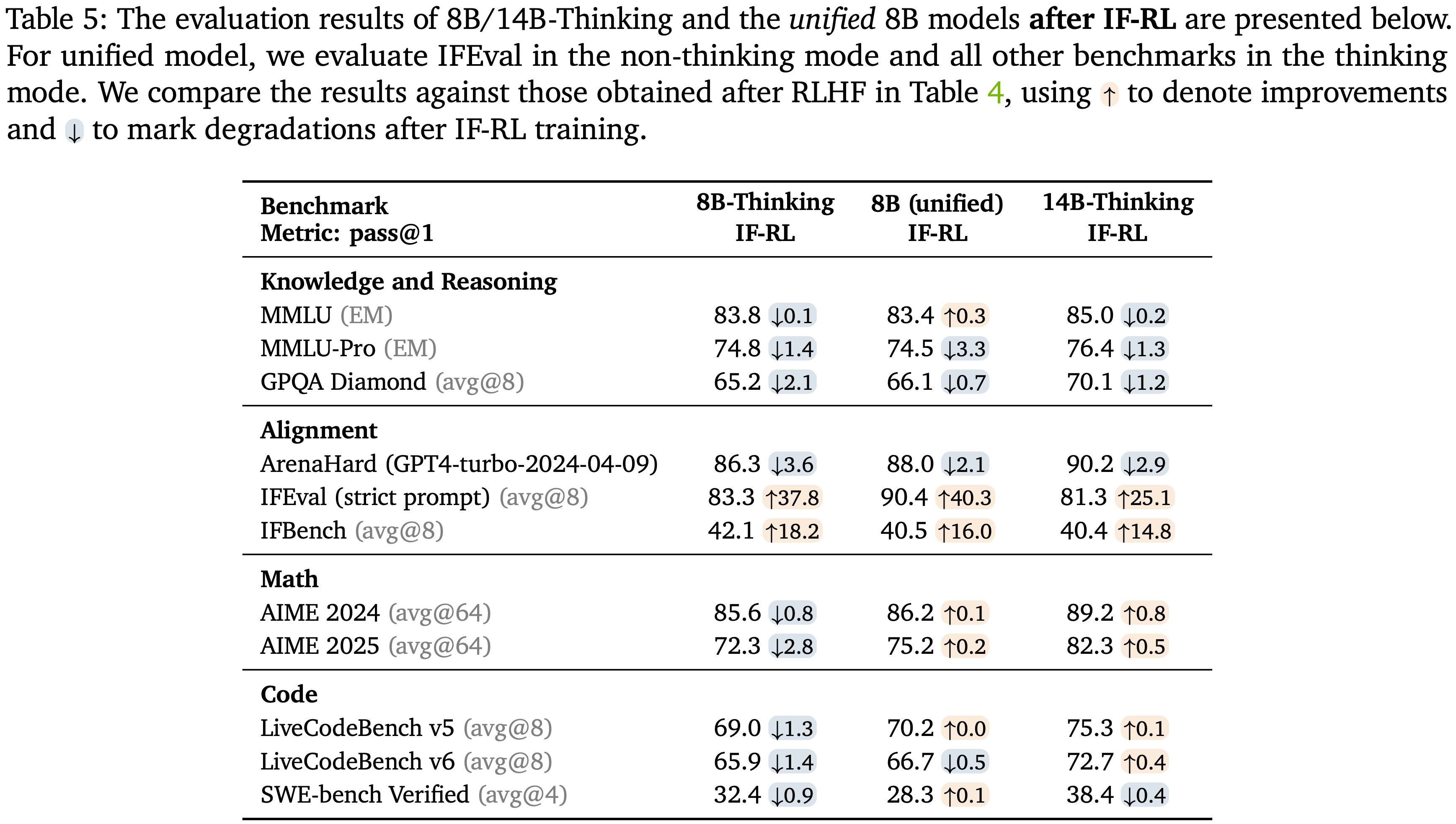
Results after IF-RL
- IF-RL 后的结果如表 5 所示
- 在对统一模型和专用思维模型应用改进技术后,IFEval 和 IFBench 有显著提升,而 ArenaHard 上的下降得到了控制
- IF-RL 通常会降低模型熵并缩短推理 Token 的平均长度(参见图 8 的示例)
- 负面影响:
- IF-RL 确实在推理基准测试上引入了轻微的下降,尽管其中大部分(除了 ArenaHard)在随后的 Math RL、Code RL 和 SWE RL 阶段后都可以完全恢复
- 积极影响:
- IF-RL 压缩了推理轨迹并提高了 Token 效率
- 总体来说:统一推理模型实现了比专用思维模型更强的平衡,在 ArenaHard 和 IFEval 上都提供了 Robust 的性能
Math RL
- Math RL 阶段重点是通过强化学习来增强模型的数学推理和问题解决能力
- 本文最终决定:将 Math RL 应用在 IF-RL 阶段之后
- 注:将 Math RL 直接应用于 RLHF 检查点也产生了非常相似的结果(理解:这里的相似应该是指跟直接应用于 IF-RL 之后的检查点一样)
Data Curation
- 主要使用 AceReason-Math 数据集(2025)并过滤掉过于简单的问题,保留了 18K 个高质量的数学问题用于 RL 训练
- AceReason-Math 数据集融合了 DeepScaleR 组合(2024;2025;2024)和 NuminaMath(2024),涵盖了代数、几何、组合数学和数论等主题
- 本文应用 9-gram 过滤来防止与常见数学基准(如 AIME 2024/2025 和 MATH (2021))的数据污染
- 排除不适合使用基于符号规则验证进行 RL 的问题
- 例如多项选择或判断题(答案容易被猜出)、证明题(难以验证正确性)、包含多个子问题的问题、非英语问题(会增加语言混合)以及引用图表的问题
- 噪声数据去除:
- NuminaMath 包含 OCR 和解析错误,每个问题都由 DeepSeek-R1 模型通过最多八次尝试进行验证
- 基于规则的验证器仅保留那些通过多数投票得到正确答案的问题,而模棱两可或带有噪声的数据项则被丢弃
- 移除简单问题:
- 移除了那些 AceReason-Nemotron-7B(2025)在 16 次生成中能以 \(\geq 75%\) 的成功率解决的过于简单的问题
- 数据集从原来的 49K 个问题减少到 14K 个问题
Training Recipe
- 本节的目标是开发一个通用的数学 RL 配方,该配方可应用于不同的基础模型,并能高效地扩展到大规模的 RL 训练
- 基于 AceReason-Nemotron(2025)的训练策略
- 该策略在 GRPO 目标下严格遵守 on-policy 训练,完全移除 KL 正则化,并结合了长度扩展训练(length extension training)和动态过滤(dynamic filtering)来稳定优化
- 从经过 RLHF 训练的模型初始化 Math RL 对于获得更好的性能起着至关重要的作用
- 在整个开发周期中,本文将此训练配方应用于五个不同的 8B 检查点,并在 500 个 RL 步骤内始终在 AIME24 上达到约 \(90%\) 的准确率,证明了该方法在不同训练动态的模型中的鲁棒性
Initialization from models that have undergone RLHF,从经过 RLHF 训练的模型初始化
- 作者早期探索了一种先应用 Math RL 和 Code RL,然后再应用 RLHF 和 IF-RL 的方法
- 发现:从经过 RLHF 训练的模型初始化 Math RL 是非常有益的,因为
- (i) 与 SFT 检查点相比,它提供了更强的初始数学推理能力
- 在 RLHF 之后,响应质量得到显著提升,推理变得更加 Token 高效(例如,冗长和重复更少)
- (ii) 它显著减少了数学 RL 训练所需的步骤数
- (i) 与 SFT 检查点相比,它提供了更强的初始数学推理能力
- 发现:从经过 RLHF 训练的模型初始化 Math RL 是非常有益的,因为
- 实践:在 RLHF 和 Math RL 之间插入了 IF-RL,因为 IF-RL 会降低模型熵并缩短推理轨迹 ,这可能会暂时损害与推理相关的基准性能
- 在 IF-RL 之后应用高温度的 Math RL 和 Code RL 可以将模型熵恢复到正常水平
- 理解:如果 IF-RL 放到 Math RL 和 Code RL 后面,可能不太合适,会导致推理有关的能力受损(熵降低严重)
Reward function
- 奖励严格基于答案的正确性来分配,正确性通过提取跟在
<think>token 之后的 Boxed 答案(\boxed{})中- 使用 AceMath(2024)的基于规则的验证器进行验证(正确为 1,错误为 0)来确定
- 语言混合惩罚:
- 为了防止在推理过程中出现语言混合,每当在推理链中检测到与原始提示语言(例如英语)不同的语言(例如中文)的 token 时,应用一个 code-switching penalty ,分配一个 \(-1\) 的奖励
- 理解:这里为什么叫做 code-switching 惩罚?推测这里的 Code 是语言?或者这里是指切换代码来计算惩罚?
- anyway,这里可以确定的是多语言混杂时,直接给负分
Response length extension training,长度扩展训练
- 性能提升的关键驱动力在于模型能够更深入地思考并生成更长的推理链
- 本文采用了一个分阶段的响应长度扩展课程,配置为 \((24\text{K}\rightarrow 32\text{K}\rightarrow 40\text{K})\)
- 其中每个阶段分别扮演着不同的角色:
- 24K:压缩过长的推理
- 32K:稳定推理长度
- 40K:最终扩展更长的推理链
- 其中每个阶段分别扮演着不同的角色:
- 从压缩阶段(即 24K)开始的一个关键好处是,可以将不同的初始模型带入一个一致的推理长度范围(在整个训练集上约为 16K),这使得后续的训练阶段能够在各种初始模型上有效工作,而无需 extensive 的超参数调整
- 24K(压缩阶段 Compression Stage)
- 首先使用 24K token 的预算进行训练,以解决在中小型 SFT 检查点中观察到的关键问题:
- 这些模型倾向于生成过长的推理链,导致在 32K token 预算下,AIME 基准测试上的不完整比例(incomplete ratio)达到 \(15-20%\)
- 这种过度生成浪费了 token,并且常常使解决方案不完整
- 通过从较短的 24K 预算开始,鼓励模型压缩和完善其推理
- 在此阶段,模型最初通常表现出非常高的不完整比例(\(30-50%\)),但在大约 100 步训练后,该比例在训练集上下降到约 \(15%\)
- 特意应用了超长过滤(overlong filtering) (即,跳过超过 24K token 的生成,而不是分配 0 奖励),因为这样做可能会过度惩罚困难问题上的长推理,导致压缩期间性能急剧下降(2025),并在高不完整比例的情况下,由于奖励噪声而导致训练不稳定
- 首先使用 24K token 的预算进行训练,以解决在中小型 SFT 检查点中观察到的关键问题:
- 32K(扩展阶段 Extension Stage)
- 推理链在 24K 上稳定下来后,将 token 预算扩展到 32K
- 从 24K 阶段出来的检查点在 token 使用效率方面差异很大:
- 有些以低至 \(5%\) 的不完整比例开始 32K 阶段,另一些则在 \(10%\) 左右徘徊
- 理解:存在部分超过 32K 的样本
- 这种可变性促使我们将 32K 阶段视为一个受控的扩展阶段
- 在此阶段,不应用超长过滤来将推理长度正则化以适应 32K 上下文(即为超长生成分配 0 奖励)
- 随着训练的进行,模型不仅适应了更大的预算,而且开始超越其初始准确率,反映了长度和正确性之间的平衡权衡
- 理解:惩罚超过 32K 的样本
- 40K(长推理阶段 Long Reasoning Stage)
- 在 32K 训练之后,模型在 AIME24/25 上的简单和中等问题的准确率几乎饱和(分别达到 \(99%\) 和 \(85%\)),但困难问题仍然具有挑战性,准确率停滞在 \(30%\) 以下
- 注:本文评估是在 64K token 预算下进行的,即使使用 YARN 长度扩展(因子为 2),模型也没有充分利用可用的上下文
- 为了解决这个差距,进一步将模型推进到最终的 40K 训练阶段
- 这种扩展明确地激励模型在推理过程中利用更多的 token
- 结果,困难 AIME 问题的性能从 30% 显著提高到 \(40%\),而其他问题的性能则保持在较高水平
- 24K(压缩阶段 Compression Stage)
Dynamic filtering
- 本文在所有数学 RL 实验中固定了一个种子数据集(For 简化开发)
- 由于模型能力各不相同,当使用组归一化优势函数时,过于简单或无法解决的问题无法提供有效的策略梯度信号
- 在每个 epoch 之后,根据该 epoch RL 训练的验证结果,过滤掉那些达到 \(100%\) 或 \(0%\) 准确率的问题
- 被过滤掉的困难问题会以 \(10%\) 的概率重新采样回数据集中 ,因为策略可能在同一个 epoch 内的后续更新中学会解决这些问题
- 被过滤掉的简单问题会以 \(1%\) 的概率重新采样回数据集中以稳定训练 ,因为策略可能会在一个 epoch 内忘记如何解决它们
- Dynamic Filtering 确保了大约 \(90%\) 的训练样本提供有意义的学习信号,并显著稳定了训练期间的模型准确率,尤其是在更多问题被 \(100%\) 解决的后期训练阶段
- 注:这种基于 epoch 的动态过滤可以被视为 基于批次的动态采样 (2025;2025)的一种更高效的替代方案
- 因为 基于批次的动态采样 需要大量的 rollouts 来构建一个没有过于简单或无法解决的 prompts 的固定大小的批次
- 理解:这种做法下,批次内部是不做样本过滤的,如果 epoch 过大,可能会导致同一个 epoch 内部训练到后面问题都非常容易解决了,且跟数据集和模型表现有非常大的关系
- 例如:如果 Rollout Batch Size 为 256 时
- 常规的 Batch 粒度 Dynamic Filtering 会采样 2-3 倍的 Prompt 来做 Rollout,避免过滤后样本不够 256
- 但本文的基于 Epoch 粒度的 Dynamic Filtering 可能会直接采样 256 个 Prompt,若 50% 以上都是简单题(100% 做对),那么真实有梯度的 Prompt 不到 128,波动会比较大吧
- 建议:Batch 粒度 Dynamic Filtering + Epoch 粒度的 Dynamic Filtering 结合使用!更好的解决问题
- 例如:如果 Rollout Batch Size 为 256 时
Hyperparameters
- 使用 128 的 batch size,每个 prompt 采样 8 个 rollouts,Temperature 为 1,top-p 为 0.95
- 采用学习率为 \(2 \text{或} 2.5 \times 10^{- 6}\) 的 AdamW(Kingma,2014)优化器,并将熵损失系数和 KL 损失系数都设置为 0
- 每个训练阶段大约需要 100 到 200 步,具体取决于 clip-ratio 达到 \(10%\) 的速度
- 理解:这里的 Clip-ratio 应该是指训练长度?
- 对于 8B 模型,采用了三个阶段的训练
- 长度从 \(24 \text{K} \rightarrow 32 \text{K} \rightarrow 40 \text{K}\) 扩展
- 对于 14B 模型,由于初始策略已经达到了高准确率,以 28K 的最大 token 长度开始,以避免在第一阶段出现准确率下降,然后直接扩展到 40K
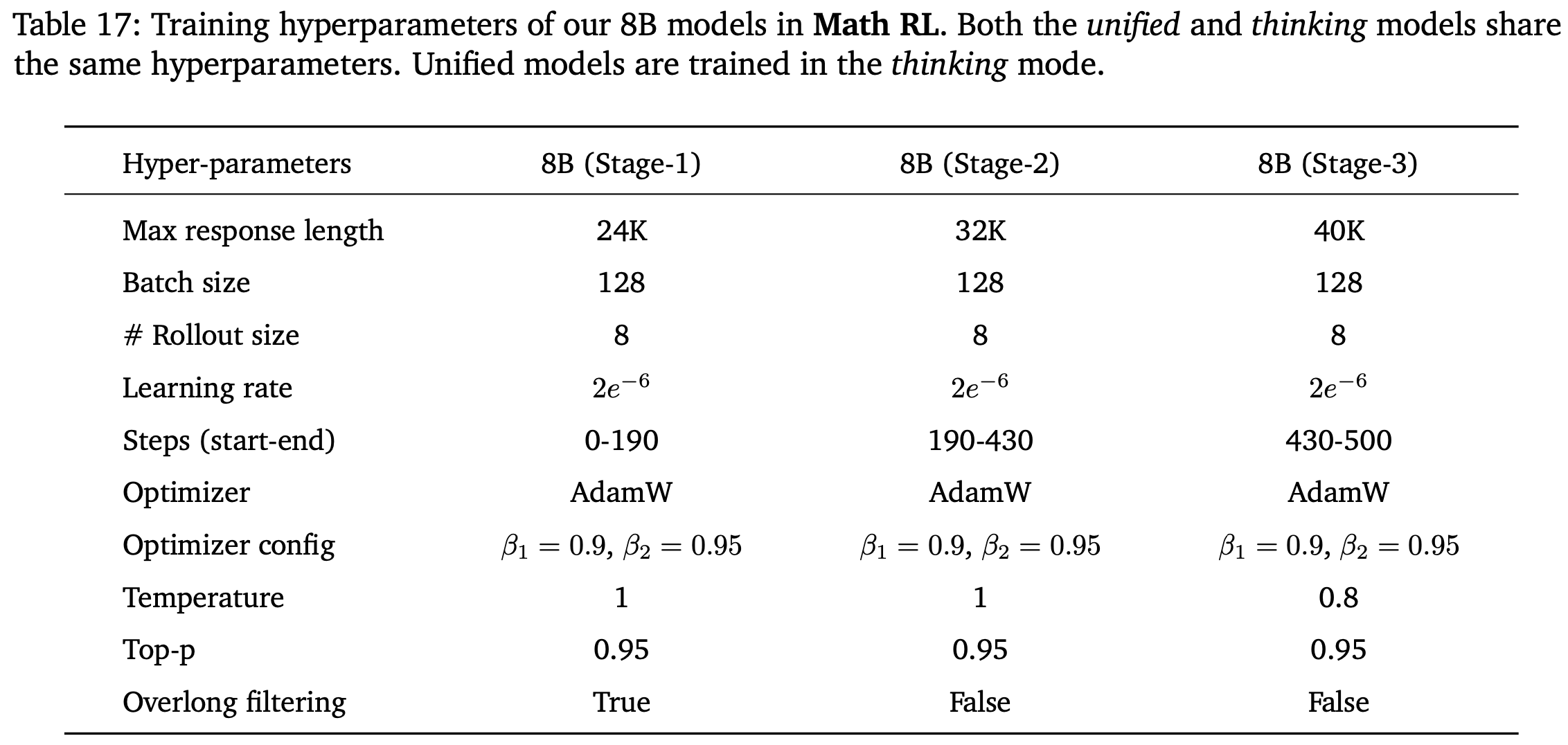
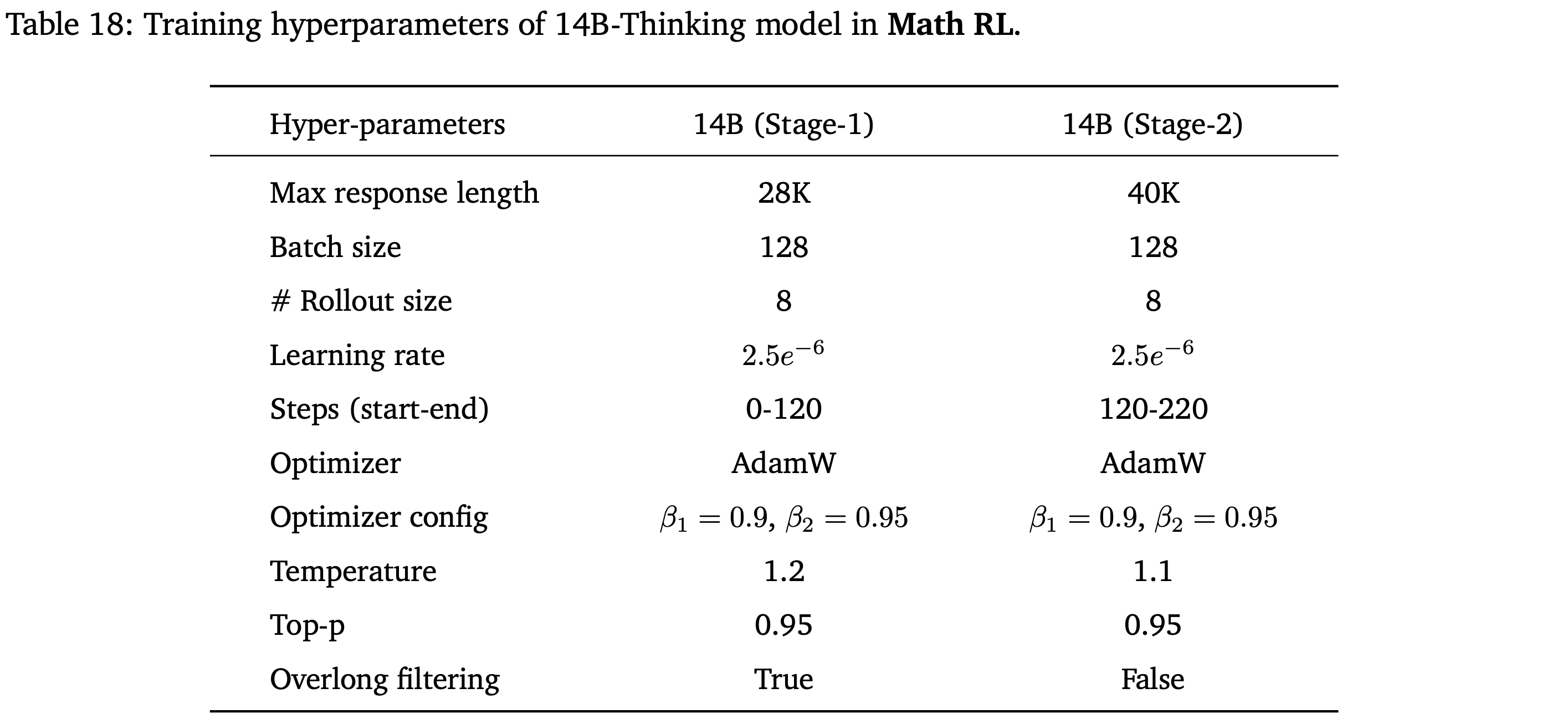
- 更多训练超参数的详细信息见附录 D(表 17 和 表 18)
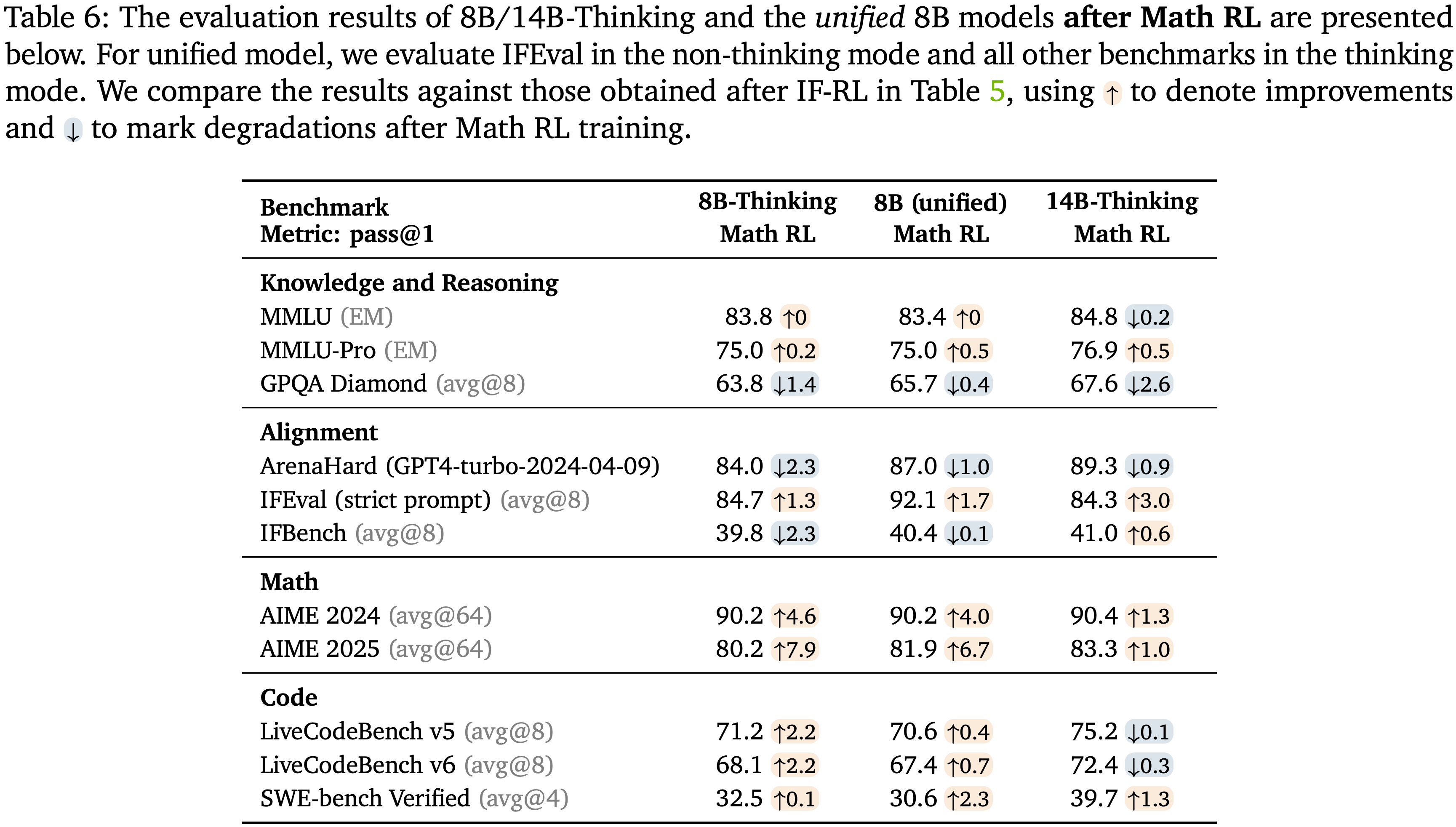
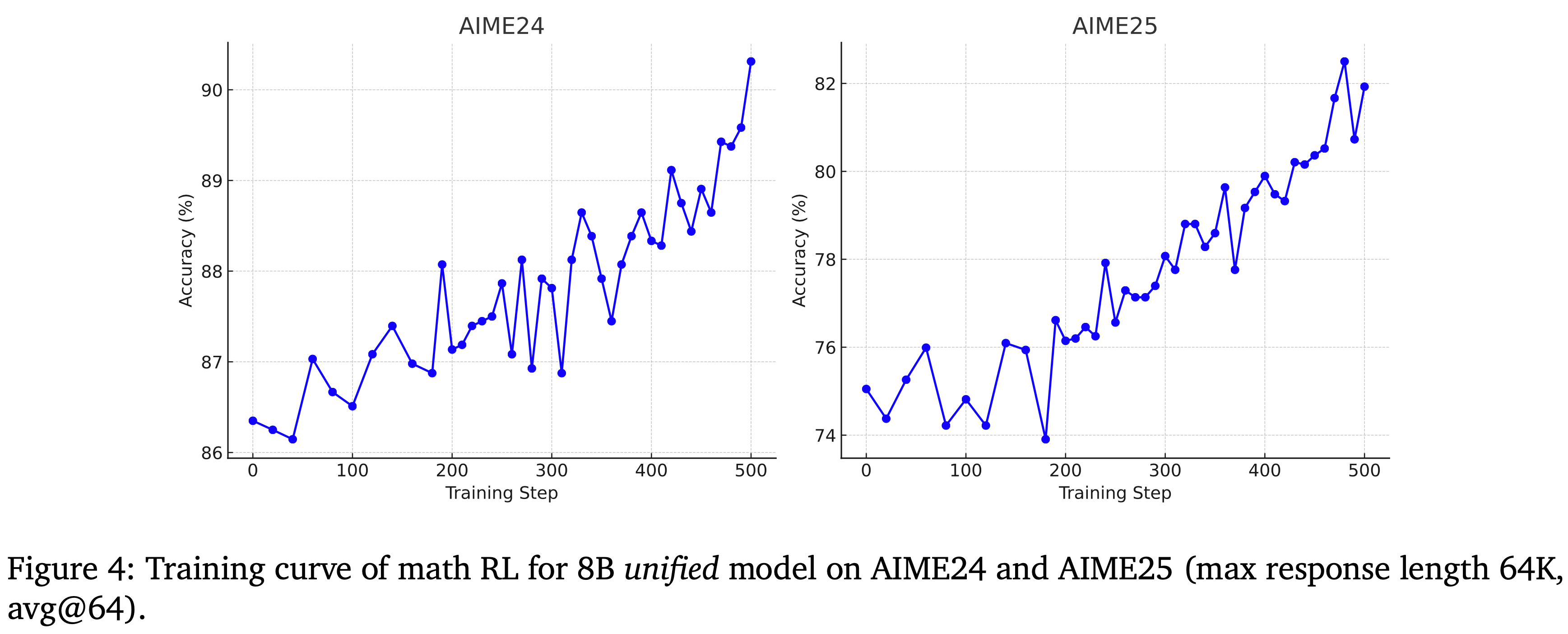
Results after Math RL
- 者通过追踪 8B 统一模型在 AIME24 和 AIME25 上的性能来监控其 Math RL 的训练动态,如图 4 所示
- Math RL 之后的结果呈现在表 6 中
- 在 AIME 2024 和 2025 上有了显著的提升
- Math RL 对知识推理和对齐基准的影响最小
- 观察到的大部分差异可归因于评估方差和检查点选择
- Math RL 改进了包括 LiveCodeBench 和 SWE 在内的编码基准
- 注:尽管提升幅度不如 AceReason-Nemotron(2025)中报告的那样显著,但这很大程度上是因为本文起始模型在 Math RL 之前已经表现出了强大的通用推理能力
- Math RL 对知识推理和对齐基准的影响最小
Code RL
- Code RL 的重点是通过强化学习来提高模型在竞争性编程(competitive programming)方面的性能
- 本文将 Code RL 应用于 Math RL 之后获得的模型检查点
Data Curation
- 基于 AceReason-Nemotron 编程语料库(2025)构建 Code RL 训练数据集
- 该语料库主要从包含单元测试的开源数据集中筛选而来,包括 TACO(2023)、APPS(2021)、DeepCoder(2025)等
- 这些问题涵盖了现代竞争性编程中常见的广泛算法主题
- 应用严格的过滤规则,排除与标准输出比较不兼容的问题(例如,交互式格式或需要特殊评测机的问题),以及单元测试对边界和边缘情况覆盖不足的问题
- 此过滤过程显著减少了训练期间已知会降低 Code RL 性能的假阳性和假阴性奖励信号(2025)
- 重复 & 污染:
- 使用 9-gram 过滤和原始问题 URL 匹配
- 校准问题难度
- 简单问题排除:采用 AceReason-Nemotron-7B(NVIDIA,2025)排除 Trivial 问题(在 8 次 rollouts 中全部解决)
- 复杂问题排除:使用 DeepSeek-R1-0528(DeepSeek-AI,2025)过滤掉难以处理或过于困难的问题(在 8 次 rollouts 中均未解决)
- 最终得到 9.8K 个样本的训练集
Training Recipe
- 在 Math RL 之后进行 Code RL,因为 Math RL 阶段可以作为有效的预热,稳定未来的 RL 训练并增强模型的通用推理能力(2025)
- 遵循 AceReason-Nemotron 的配方,从最终的 Math-RL 模型检查点初始化,执行单阶段、on-policy 的 Code RL(无 KL 正则化,使用第 4.1.2 节中描述的 Token-level 损失)
- 在训练期间,最大响应长度设置在 44K-48K 范围内,不应用超长过滤
Reward function
- Code RL 采用严格的基于规则的二元奖励函数
- 只有当生成的代码通过给定问题的所有测试用例时,才分配 1 的奖励 ;否则,分配 0 的奖励
- 采用 AceReason Evaluation Toolkit 中的并行代码验证器来验证模型生成代码的正确性(进行高效且鲁棒的评估)
- 在 VeRL(2024)中应用异步奖励计算 ,因为代码验证会产生显著的开销
- 异步计算大大减少了每个批次的平均代码验证时间
- 例如,在 8 个 DGX H100 节点上训练 Code RL,batch size 为 128,rollout 为 8 时,验证时间从 1172.4 秒下降到 416.2 秒
- 与 Math RL 类似,也应用 Code-Switching 惩罚
- 只要在推理轨迹中检测到与原始提示语言不同的语言的 token,就分配 0 的奖励(注:Math RL 中使用的 -1 奖励)
- 注:与 Math RL 不同的是,对 Code-Switching 分配 \(-1\) 的奖励会对编程性能产生负面影响
- 作者推测:可能是因为当组中所有 rollouts 要么不正确,要么包含语言混合时,额外的惩罚会促使模型在 GRPO 训练中产生没有 Code-Switching 的错误答案
- 问题:有没有可能是信号检测不准确,比如中文注释 + 英文代码被错误检测为有问题?
Hyperparameter
- batch size 设置为 128,使用 AdamW 优化器,学习率为 \(4\times 10^{- 6}\),每个训练 prompt 使用 8 个 rollouts
- 将采样温度设置为 1.0,top_p 设置为 0.95,注:(Code RL 对温度配置很敏感)
- 详细的超参数见附录 D(表 19)

Results after Code RL
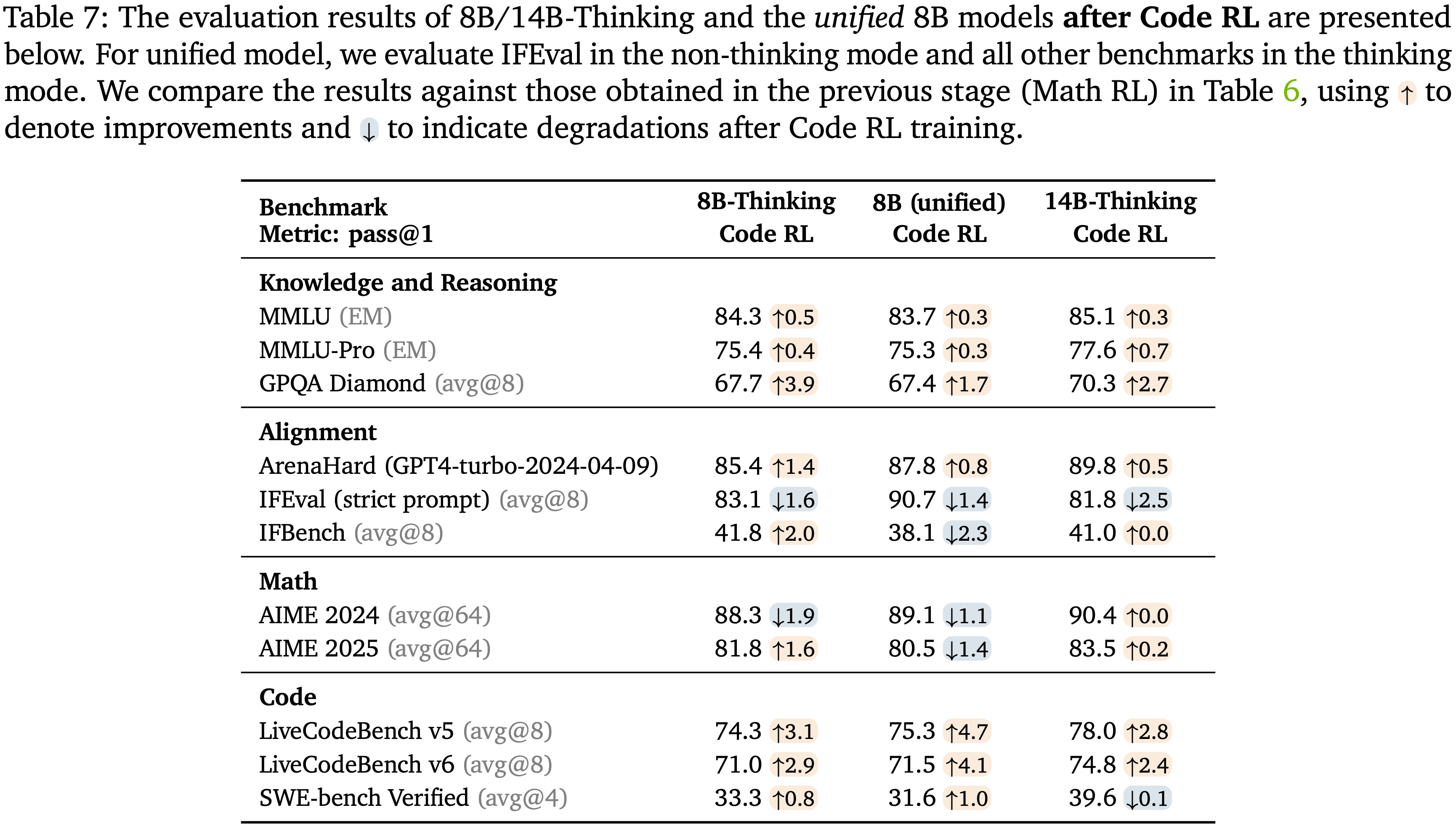
- Code RL 之后的结果呈现在表 7 中
- 在 LiveCodeBench (LCB) 上取得了显著的提升
- 统一 8B 模型在 LCB v5 上达到 75.3,在 LCB v6 上达到 71.5,与 DeepSeek-R1-0528 (671B) 的性能(分别为 74.8 和 73.3)相当
- 14B-Thinking 模型在 LCB v5 上达到 78.0,在 LCB v6 上达到 74.8,以明显的优势超过了 DeepSeek-R1-0528
- 注:DeepSeek-R1-0528 (671B) 是在 SFT 期间使用的教师模型,这些结果突显了 Cascade RL 在增强代码推理能力方面的显著效果
- 且即使对于小型的 8B 和 14B 模型也是如此
- 除了正常的检查点和评估方差外,Code RL 对其他领域的基准测试影响很小
- 注:对于 IFBench 和 IFEval 的影响还是不小的
- 注:Nemotron-Cascade 模型卓越的编程能力将在第 5 节中进一步检验
SWE RL
- 3.3.2 节中构建 SWE SFT 数据时,采用了 Agentless 框架来处理 SWE-bench(2023),将 SWE 任务分解为三个子任务:
- 定位(localization)、修复(repair)和补丁验证(patch validation)
- 然后分别为每个子任务构建了 SFT 数据
- 在以上这些子任务中,代码修复是最关键的,需要最高水平的推理和模型能力来生成修正错误并解决根本问题的修订代码补丁
- 本节 SWE RL 主要目标是提高代码修复的准确性
Data Curation
- 如第 3.3.2 节所述,用于代码修复的 RL 数据集由比 SFT 阶段更具挑战性的实例组成
- 具体做法:
- 保留有难度,但不是无法解决的
- 在八个采样响应中少于四个响应超过 0.5 相似度阈值
- 问题:这里的相似度是与 参考代码修复片段 的相似度?为什么不是直接验证修复的准确性
- 回答:后面 Reward function 小节会提到,作者做的是不需要 Docker 验证器的训练,Reward 是相似度而不是执行结果,这样可大幅提升训练效率
- 吐槽:应该就是 Docker 环境太难搞了
- 同时至少有一个来自 DeepSeek-R1-0528(DeepSeek-AI,2025)的响应获得非零相似度(表明该 prompt 不是太难或无法解决)的 prompts
- 在八个采样响应中少于四个响应超过 0.5 相似度阈值
- 保留有难度,但不是无法解决的
- 在 SFT 阶段
- 模型使用最大总序列长度为 32K 进行微调
- 构建的 prompts 仅包含真实定位文件(ground-truth localization files),作为代码修复的参考
- 即包含错误或需要进行修改以解决问题的所有文件
- 但当在 Agentless 框架下评估模型性能时,向模型提供从定位阶段检索到的文件内容作为代码修复的输入
- 这种设置在 SFT 训练和最终评估之间引入了差异
- 为了确保真实定位文件被包含在修复 prompts 中,整合了 top-\(k\) \((k \geq 4)\) 个定位文件,并使用 YaRN 缩放因子 3 将最大 prompt 长度扩展到 60K
- 这种设计给 SFT 模型带来了两种 OOD 的上下文:
- (i) 代码修复期间的总输入长度超过了 SFT 中使用的最大序列长度
- (ii) 包含 top-\(k\) 个定位文件可能会引入不相关的文件,使得代码修复任务比 SFT 期间更具挑战性
- 为了解决这个问题,为 RL 训练构建并组合了两个长 prompts(最长 \(l\) 个 token)的子集:
- 1)仅真实数据(Ground-truth only) :与 SFT 类似,使用仅包含真实定位文件的 prompts 进行构建
- 2)混合定位(Mixed localization) :使用 DeepSeek-R1-0528 定位的文件和真实定位文件共同构建增强的 prompts
- 总共包含最多五个文件,并确保所有真实文件都存在
- 具体做法:
- 初始 prompt 仅包含真实文件
- 然后逐个添加噪声文件,直到总 prompt 长度会超过 \(l\)
- 如果在添加任何噪声文件之前就超过限制,则丢弃该实例
- 为了增强鲁棒性,随机化每个 prompt 中文件的顺序
- 为了进一步提高训练效率,对于这两个子集,都丢弃总长度短于 8K token 的 prompts
- 在第 7.3 节中,将对不同 \(l\) 下的 RL 训练效果进行消融实验
Training Recipe
- SWE RL 是 Cascade RL 的最后阶段,因为它与通用领域相比是一个更专门的任务
- 从 Code RL 之后获得的检查点开始,使用 GRPO 算法进行 on-policy RL,采用 Token-level 损失,同时移除了 KL 正则化(详细配置见第 4.1.2 节)
Reward function
- 先前其他工作(2025;2025)通过在执行模型生成的代码补丁在 Docker 环境中来获取奖励
- 运行和管理大量的 Docker 实例显著限制了可扩展性,限制了先前工作在约 10K 个独特实例的训练数据集上
- 为了克服这个限制,本文作者设计了一个 Execution-free Verifier 作为奖励模型,使得代码修复生成的规模化 RL 训练成为可能
- 将奖励 \(r\) 定义为生成的补丁 \(\hat{p}\) 与人工标注的真实补丁 \(p^*\) 之间的相似度:
$$r(\hat{p},p^*) = \begin{cases}1, & \text{if } s_{\text{lex} }(\hat{p},p^*) = 1,\\ 0, & \hat{p}\text{ is identical to the original code snippet }\\ -1, & \text{if } \hat{p}\text{ cannot be parsed },\\ s_{\text{sem} }(\hat{p},p^*), & \text{ otherwise }, \end{cases} \tag {2}$$- \(s_{\text{lex} }(\hat{p},p^{*})\) 表示使用 Unidiff 库(遵循 Wei 等人 (2025) 的方法)计算的词汇相似度(lexical similarity)
- \(s_{\text{sem} }(\hat{p},p^{*})\) 表示由 LLM 生成的语义相似度(semantic similarity)分数
- 具体做法:
- 使用一个是/否问题来提示 Kimi-Dev-72B 模型(Kimi-2025),以评估生成的补丁与 golden 补丁之间的语义相似度(见附录 C.2 中的奖励建模 prompt)
- 分配给 “YES” token 的概率直接用作奖励分数
- 当生成的补丁与 golden patch 完全相同时,给 1 奖励
- 当模型生成的补丁无法解析时,分配 \(-1\) 的奖励
- 当生成的补丁与原始代码片段完全相同时,分配 0 的奖励
- 问题:为什么完全相同分配时,分配的是 0 奖励?应该是 1 奖励吧?
- 理解:这里与原始代码相同,是指没有进行任何修改,此时给 0 奖励
- 关于奖励函数的消融研究,请参阅第 7.2 节
- 将奖励 \(r\) 定义为生成的补丁 \(\hat{p}\) 与人工标注的真实补丁 \(p^*\) 之间的相似度:
Multi-stage RL training for input context extension
- 初步实验研究表明,输入上下文长度与 SWE 任务性能之间存在强烈的正相关关系
- 具体内容:包含更多用于分析的检索文件可以带来显著的性能提升
- 以上这一发现激发了本文训练策略的设计
- 该策略通过受控的上下文扩展来利用这种关系
- 为在保持训练稳定性的同时优化扩展上下文的利用,本文实施了一个精心设计的两阶段课程,将输入上下文长度从 16K 逐步扩展到 24K token,同时保持 16K token 的恒定输出长度
- 这种方法确保了鲁棒的学习,并避免了立即进行长上下文训练所观察到的性能下降效应,这对于较小的模型尤其有效,因为较小的模型的长上下文能力有限
- 16K 上下文初始化(热身阶段 Warmup Stage)
- 训练过程从保守的 16K 输入 token 预算开始,这作为一个重要的热身阶段
- 注:直接用 24K 上下文长度初始化训练会导致次优的收敛和最终性能下降
- 作者将此现象归因于模型最初难以在扩展的序列上进行信息关注和整合
- 问题:这里的上下文不是指生成, 而是指输入吧?
- 在此阶段,模型学习基本的长上下文利用技能,并在一个可管理的上下文窗口内为多文件分析开发稳定的注意力机制
- 24K 上下文扩展(24K Context Extension)
- 16K 设置达到奖励平台期后(即在连续迭代中几乎没有改进时),将上下文扩展到 24K token
- 这个转换的时机很重要:模型已经在 16K 上建立了强大的多文件分析技能,为扩展到更长上下文形成了坚实的基础
- 在扩展阶段,长上下文理解的稳定提升,包括更高级的跨文件推理和跨检索文件信息合成的改进
- 该模型展现出越来越熟练地利用扩展上下文窗口的能力,有效地使用额外的检索文件来产生更准确的解决方案
Hyperparameters
- 设置 batch size 为 128,使用 AdamW 优化器,学习率为 \(2.5 \times 10^{- 6}\)
- 对于每个 prompt,生成 16 个 rollouts,采样 Temperature 为 1,并设置最大响应长度为 16K
- 对达到最大响应长度的轨迹应用超长过滤
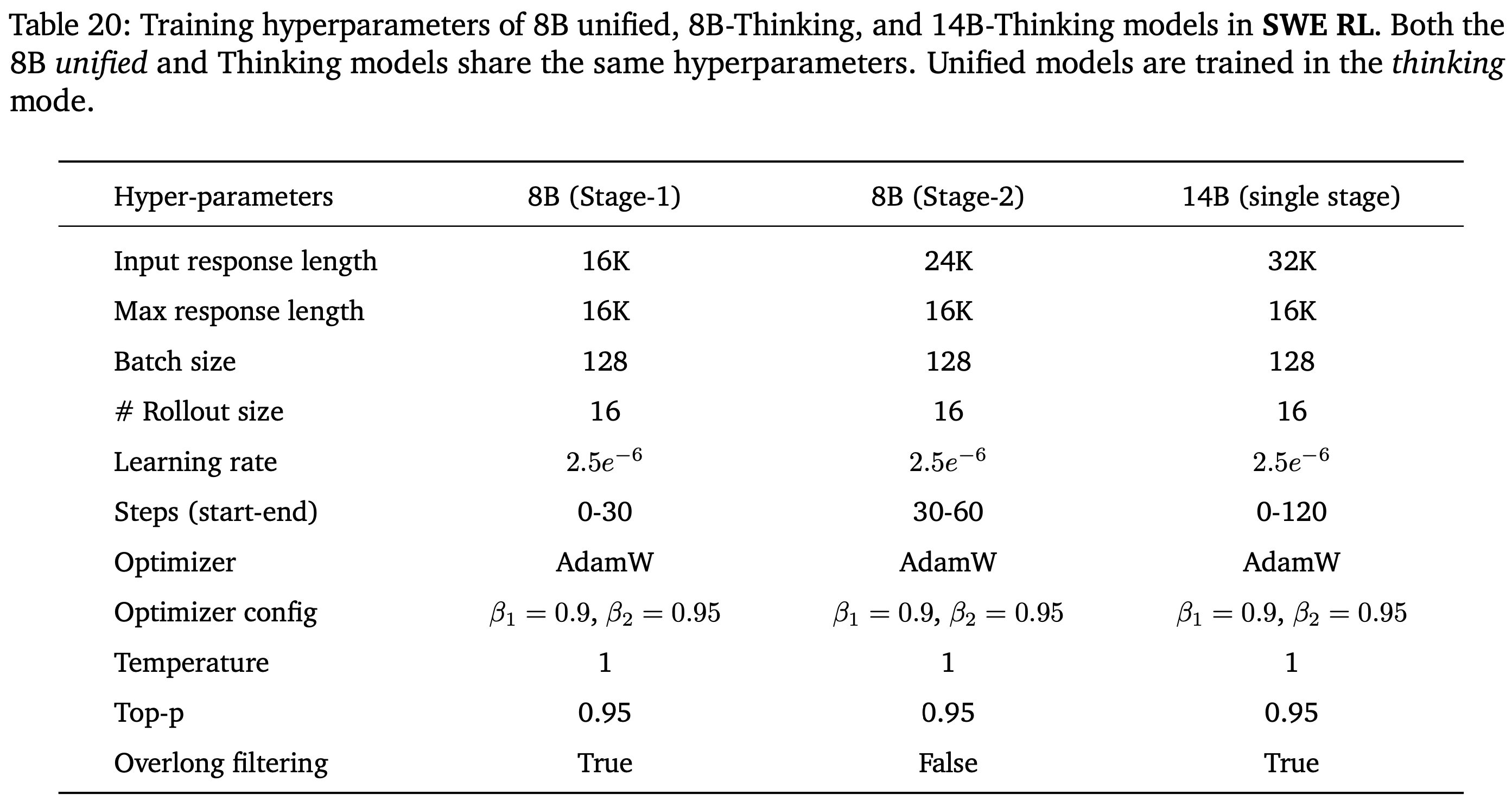
- 详细的超参数见附录 D(表 20)
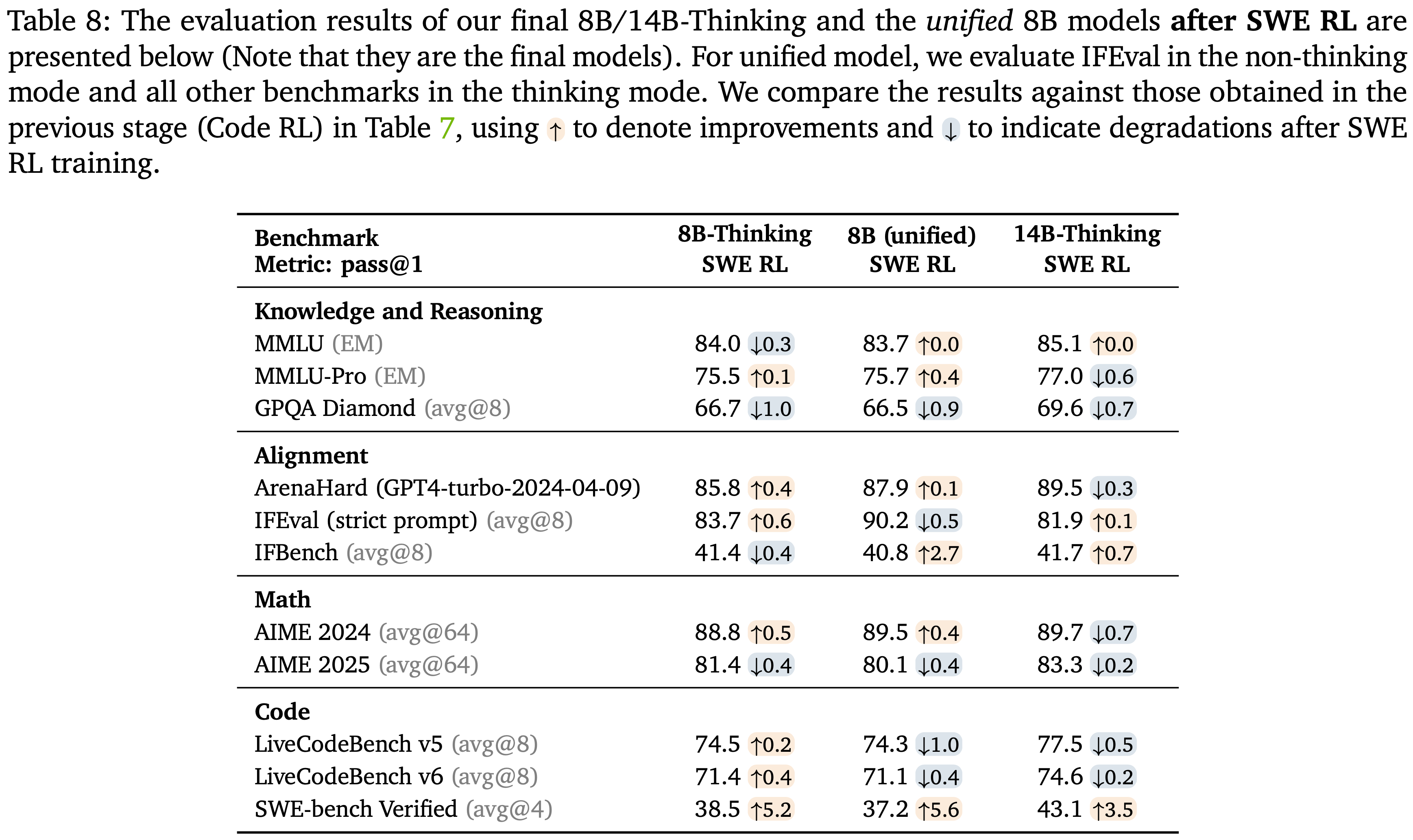
Results after SWE RL
- 应用 SWE RL 后的结果显示在表 8 中
- SWE RL 在 SWE-bench Verified 上带来了显著的提升,同时它对其他领域基准的正面或负面影响很小
- 在完整的 Cascade RL 过程之后,专用的 8B thinking SFT 模型和 8B 统一 SFT 模型之间在 SWE-bench Verified 上的性能差距
- 表 2(SFT)中的 30.2 对比 26.1 在很大程度上得到了缓解(38.5 对比 37.2)
- 统一的 Nemotron-Cascade-8B 在所有与推理相关的任务上表现与 Nemotron-Cascade-8B-Thinking 相当,同时在指令跟随任务上表现明显更好
- 理解:
- 这个差距在 RLHF 后进一步放大
- 主要 Gap 在 IF-RL、 Math RL、Code RL 阶段和 SWE RL 阶段 均有不同程度的缩小,特别是 Math RL 阶段缩小很多
Deep Dive on Competitive Coding
- 在具有挑战性的竞争性编程基准测试上评估了本文的 Nemotron-Cascade 模型的性能,包括
- LiveCodeBench (2024),其中包含近期发布的 AtCoder 和 LeetCode 问题
- LiveCodeBench Pro (2025),其中包含新发布的 Codeforces 问题
- 为避免基准测试污染,仅报告训练数据截止日期(2024 年 8 月)之后发布的问题的准确率
- 对于 LiveCodeBench,在子集 v5(2024 年 8 月 - 2025 年 2 月,279 个问题)和 v6(2024 年 8 月 - 2025 年 5 月,454 个问题)上进行评估
- 对于 LiveCodeBench Pro,使用两个最新的子集:2025Q1(2025 年 1 月 - 2025 年 4 月,166 个问题)和 2025Q2(2025 年 4 月 - 2025 年 7 月,167 个问题)
- 在 avg@8 设置下进行评估,思考预算为 64K tokens
- 另外,还根据 LiveCodeBenchPro (2025Q1, 2025Q2) 拆分中的 51 轮 Codeforces 比赛评估了模型 ELO 分数
- 关于 ELO 评级计算的更多细节和分析见附录 E
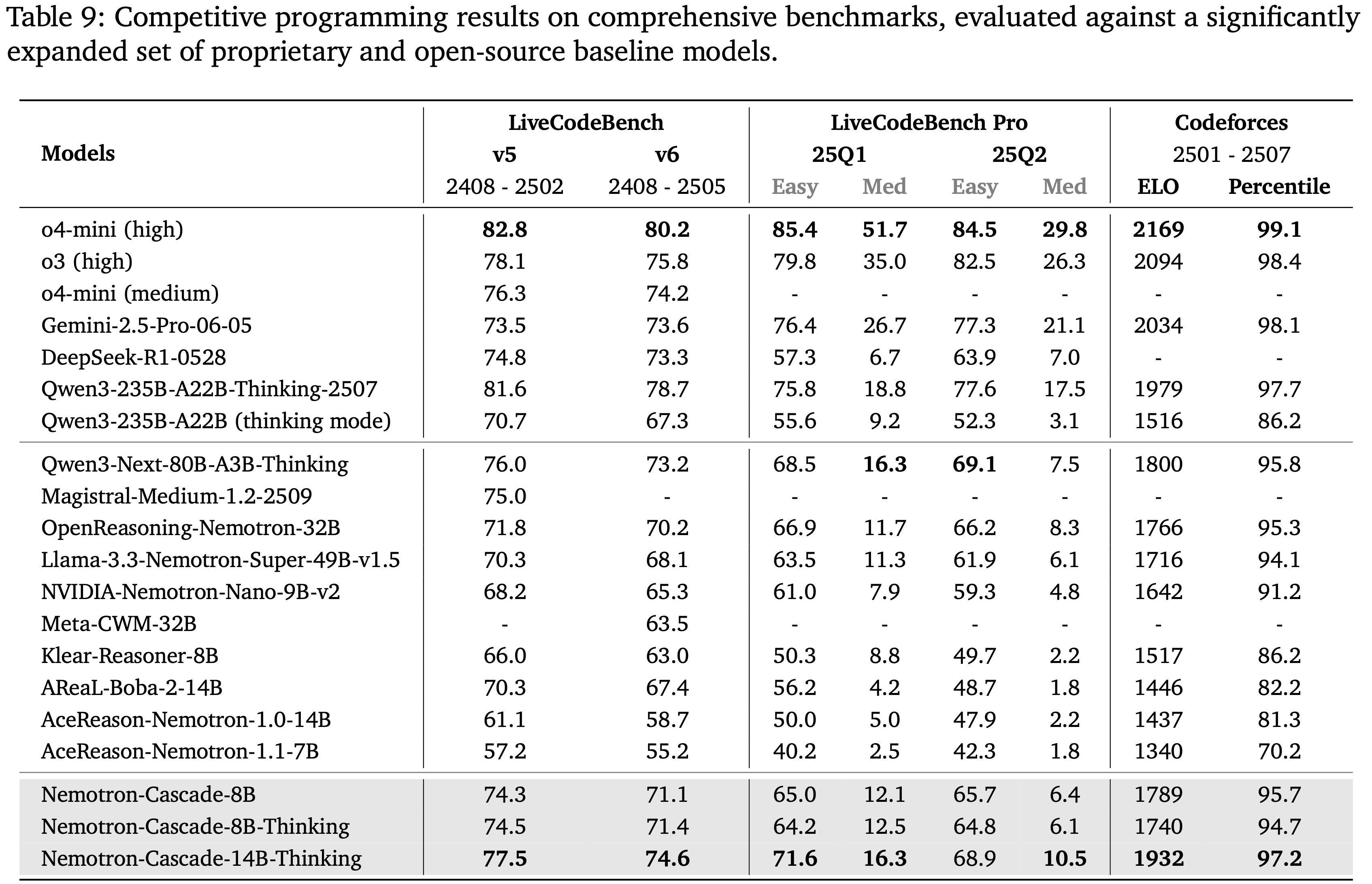
- 如表 9 所示
- Nemotron-Cascade 模型在多个竞争性编程基准测试中展现出强劲的性能,包括最新的 LiveCodeBench 和 LiveCodeBench-Pro 拆分
- Nemotron-Cascade-8B 显著优于几乎所有近期发布的、规模相当的理由 LLM,并达到了与先前 SOTA 蒸馏模型 OpenReasoning-Nemotron-32B (2025) 相当的性能,尽管其参数量要少得多
- Nemotron-Cascade-14B-Thinking 模型在所有竞争性编程基准测试中甚至优于其 SFT 教师模型 DeepSeek-R1-0528、Qwen3-235B-A22B 和 Qwen3-Next-80B-A3B-Thinking,展示了 Cascade RL 的卓越有效性
Test-Time Scaling in Practice: IOI 2025,TTS 实践测试
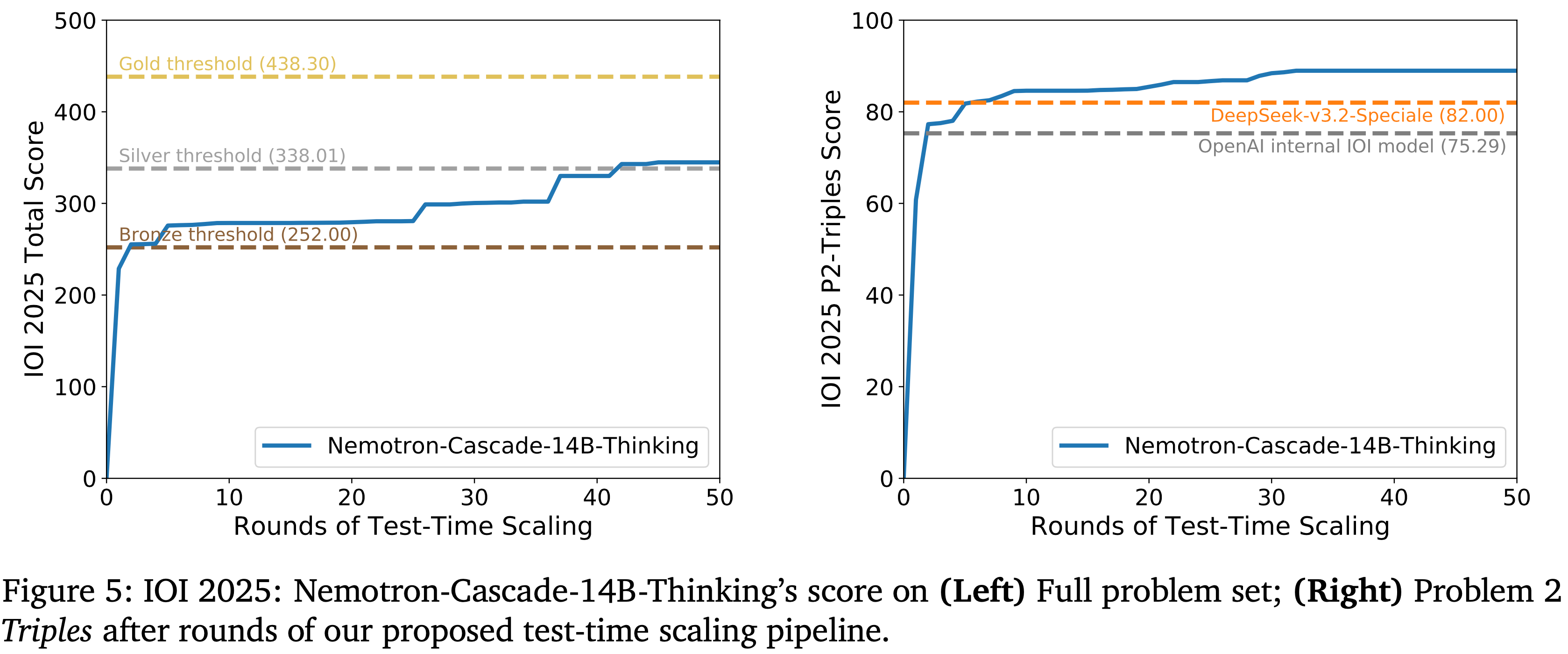
- 最具挑战性的竞争性编程竞赛之一:国际信息学奥林匹克竞赛 (IOI) 2025 上进行了评估
- IOI 对每个问题最多允许 50 次提交,每次提交都有官方评判反馈,但没有明确限制用于构建这些提交的模型生成次数
- 为了充分利用最强的 Nemotron-Cascade 模型的推理能力,部署了 Nemotron-Cascade-14B-Thinking,总思考预算为 128K tokens,并提出了一个反馈驱动的、测试时扩展流程如下
- 整个流程可视为一个多轮 生成-选择-提交 的过程,每个问题最多进行 50 轮(每轮对应一次提交)
- 在每一轮中,对于每个问题的每个子任务
- 模型会使用不同的随机种子生成 20 个候选 Response
- 然后过滤掉
- (i) 不包含代码的不完整 Response
- (ii) 生成的代码无法通过提供的示例测试用例(如果有的话)
- 对于每个子任务剩余候选中,应用 Fu 等 (2025) 的 Tail-10 选择启发式方法来获得最终的高质量 Response,并将此 Response 提交给官方评判以获得判定结果和(对于部分得分任务的)分数
- 每轮之后,更新每个子任务的生成 Prompt,加入来自官方评判的新反馈,以便后续的生成能够基于失败提交的历史记录
- 具体方法:对于经典问题中的每个未解决子任务,将最多 5 个针对此子任务的最近提交代码及其对应的官方判定附加到下一轮的 Prompt 中
- 将此历史缓存大小有意限制为 5,以避免过度拟合早期的失败尝试,同时仍鼓励模型分析并改进过去的错误尝试
- 对于部分得分问题,则附加最多 3 个得分最高的先前提交,并鼓励模型持续改进得分
- 在每一轮中,对于每个问题的每个子任务
- 除了提交历史,还引入跨子任务洞察:
- 一旦一个子任务被解决,其正确的解决方案代码将作为洞察附加到 Prompt 中,用于提示模型解决同一问题的其他具有不同约束的未解决子任务
- 这鼓励模型推理约束之间的关系,并在子任务之间传递有效的洞察
- 完整的 Prompt 模板见附录 C.3
- 凭借这种有效且显式自我改进的测试时扩展策略
- 14B-Thinking 模型在 IOI 2025 上取得了 343.37 的总分,对应一枚银牌,每个问题的生成次数最多为 1000 次(20 代 × 50 轮),且每个问题的官方提交不超过 50 次
- 在 IOI 2025 问题 2 Triples 上,该问题包含一个需要提出并迭代优化构造算法的构造性子任务,本文流程取得了 90.37 分,超过了 OpenAI 的内部 IOI-gold 模型 (75.29 分) 和 DeepSeek-V3.2-Speciale (82 分) (2025)
- 这个实验在真实的、高风险的竞争性编程问题上证明了作者反馈驱动的、自我进化的测试时扩展方法的有效性
- 图 5 中展示了本文轮次进展
The Role of Training Temperature in Code RL,训练温度在 Code RL 中的作用
- 为了确定 Code RL 训练的最合适温度,在 8B 统一模型上使用 0.6、0.8 和 1.0 的温度进行了消融实验(RL 曲线如图 6 所示)
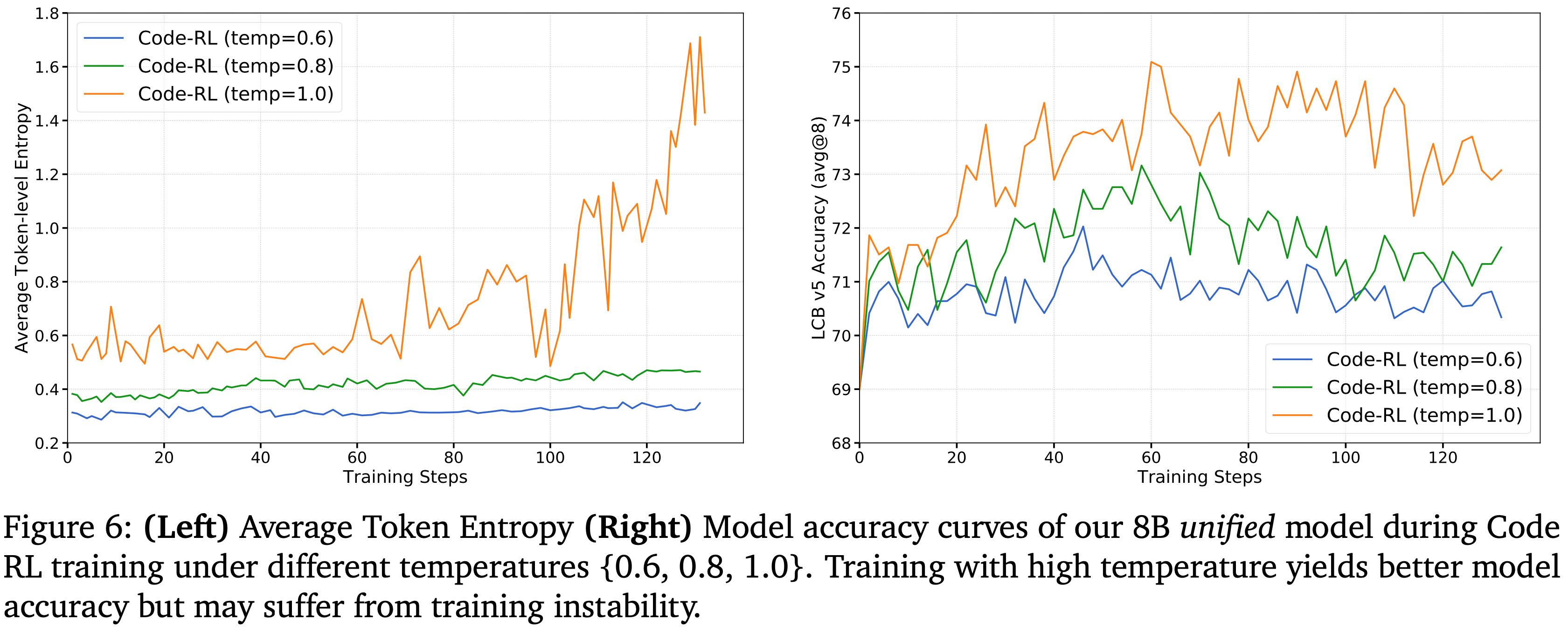
- 虽然较低的温度产生更稳定的熵曲线,但与较高温度设置相比,它们导致代码推理性能下降
- 这种模式表明,在诸如代码生成这样的大规模、有噪声的采样空间中,较高的温度在有限的 Rollout 预算下鼓励探索并提高样本效率
- 注:高温也可能导致训练不稳定,引发熵爆炸
- 设计能够保留高温采样优势同时确保熵稳定性的训练框架是一个有前景的未来工作方向
How Cascade RL Improves Code Reasoning,Cascade RL 如何改进代码推理
- 为评估 Cascade RL 流程的逐步有效性,分析了在连续的级联 RL 阶段(SFT、RLHF、IF-RL、Math RL 和 Code RL)之后,统一 8B 模型在 LiveCodeBench v6 的每个难度划分上的平均推理 Token 使用量和模型准确率(图 8)
- 初始的 RLHF 阶段提供了坚实的基础:
- 显著提高了推理 Token 效率,并通过大幅减少推理 Token 数量以及在所有难度划分上显著提高准确率,缓解了 SFT 模型的冗长问题
- 随后的 IF-RL 阶段进一步鼓励简洁性,使得 Token 使用量额外减少了 \(20%\),而准确率仅出现可忽略的下降 \((0.5%)\)
- 在初始阶段之后,简单问题的性能趋于饱和(\(>99%\)),从而将改进空间转移到中等和困难划分上
- Math RL 通过增加 Token 使用量来增强推理能力,提高了中等问题的准确率
- Code-RL 则通过大幅扩展推理轨迹,在中等和困难问题上都提供了最终的性能提升
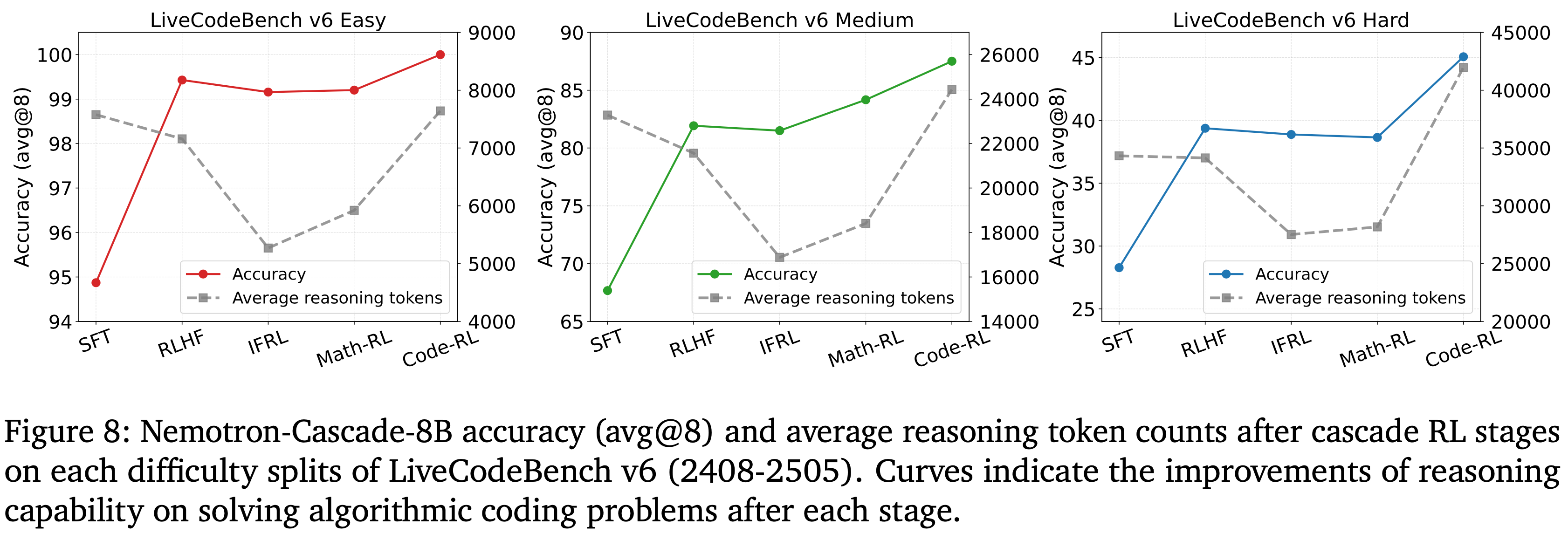
- 初始的 RLHF 阶段提供了坚实的基础:
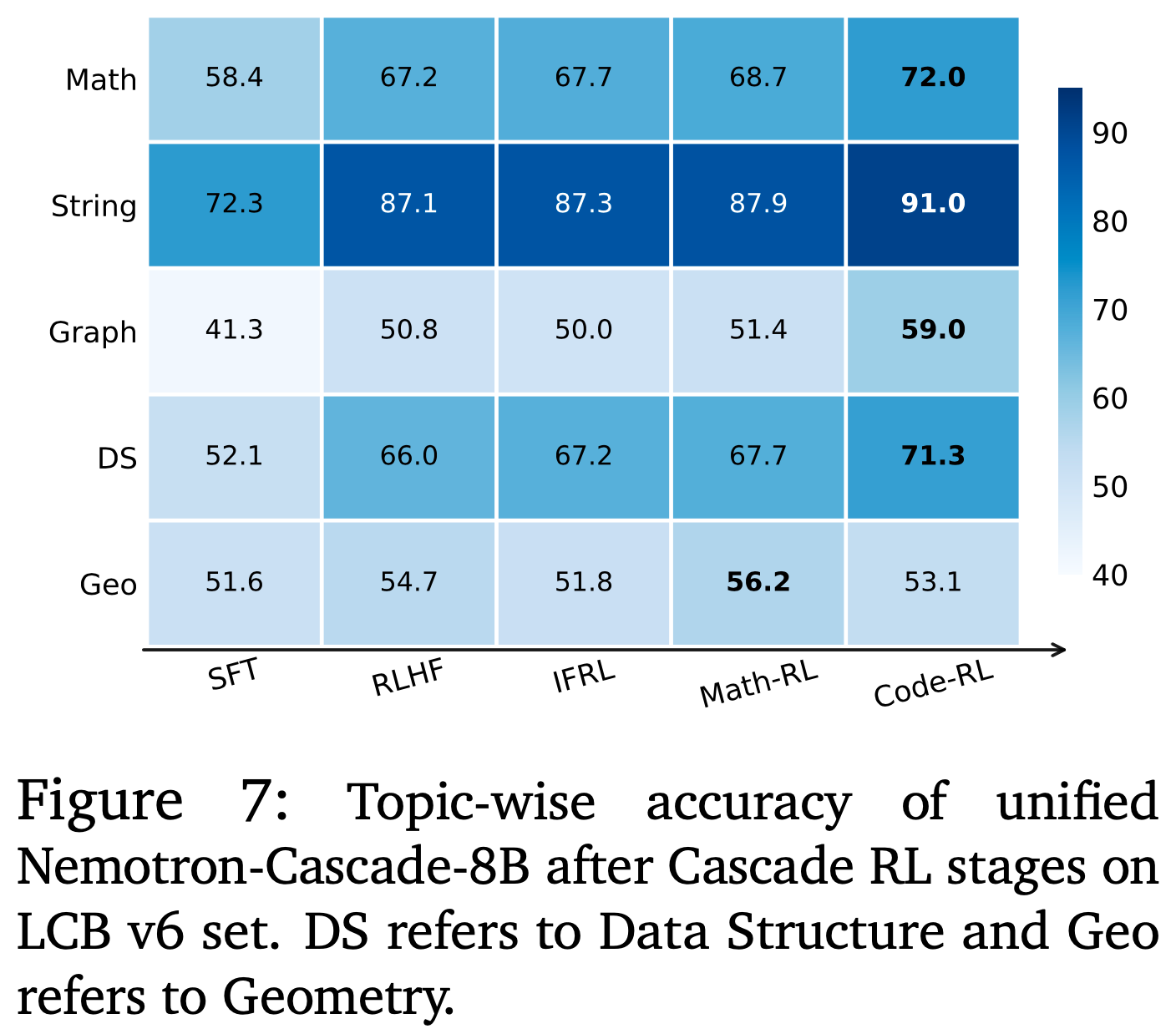
- 消融实验:分析 Cascade RL 如何在主题层面提升编码能力
- 用五个子类别(数学、字符串、图、数据结构、几何)对 LiveCodeBench v6 的问题进行了标注,并在图 7 中报告了作者的统一 8B 模型在每个 Cascade RL 阶段后的主题准确率
- RLHF 在所有子类别上都提供了强劲的初始增益
- Math RL 主要有利于与数学相关的主题(数学、图、几何),Math RL 在更多面向计算机科学的主题(字符串、数据结构)上提升有限
- Code RL 提供了最大的准确率提升,几乎所有主题的性能都得到了改善
Deep Dive on RLHF
- 本节展示了关于选择有效奖励模型和设计稳健 RLHF 方法的研究发现
- 发现1:使用最大奖励模型训练的 RLHF 在 ArenaHard 基准测试上产生了最强的性能,特别是在风格控制 (style control) (2024) 下,这有助于在 LLM Response 中区分实质内容和风格偏好
- 发现2:
- 较小的奖励模型倾向于产生噪声更大的奖励信号,需要额外的技术如 Reward Shaping 和 KL 正则化来保持训练稳定性
- 对于较大的奖励模型,这些技术是不必要的:它们的奖励信号本身就足够准确和一致,能够实现稳定的 RLHF 训练并在其他任务上取得更好的性能
RLHF Training Strategies for Unified Models,面向统一模型的 RLHF 训练策略
- 统一模型可以用思考模式和非思考模式进行响应,一个自然的研究问题出现了:
- 应该使用哪种模式进行 RLHF 训练,尤其是在许多基准测试偏向思考模式的情况下?
- 为了研究这一点,将 RLHF 应用于本文 8B 统一 SFT 模型(性能报告在表 2),使用与第 4.3.2 节描述相同的训练方法,但改变训练模式
- 具体方法:
- “Non-thinking” 设置在 RLHF 期间仅使用非思考模式
- “Thinking” 设置仅使用思考模式
- “Half-Half” 设置在每批中将 Prompt 平均分配给这两种模式
- 如图 9 所示,揭示了一个明显的趋势:
- ArenaHard、AIME 和 LiveCodeBench 都是在思考模式下评估的,但 “Half-Half” 训练设置提供了最强的整体性能,产生了最高的 ArenaHard 分数以及改进的数学和代码基准测试性能
- 这表明:在 RLHF 期间包含非思考模式的样本可以改善跨模式迁移和对齐,从而在推理和非推理场景中都能获得更强的通用能力

Impact of Reward Model Size on RLHF Performance,奖励模型大小对 RLHF 性能的影响
- 本文训练了一系列从 7B 到 72B 的奖励模型,并将第 4.3.2 节中描述的相同 RLHF 方法应用于 AceReason-Nemotron-1.0-7B 策略模型 (2025)
- 图 10 中报告了 ArenaHard 分数以及在数学和代码基准测试上的性能
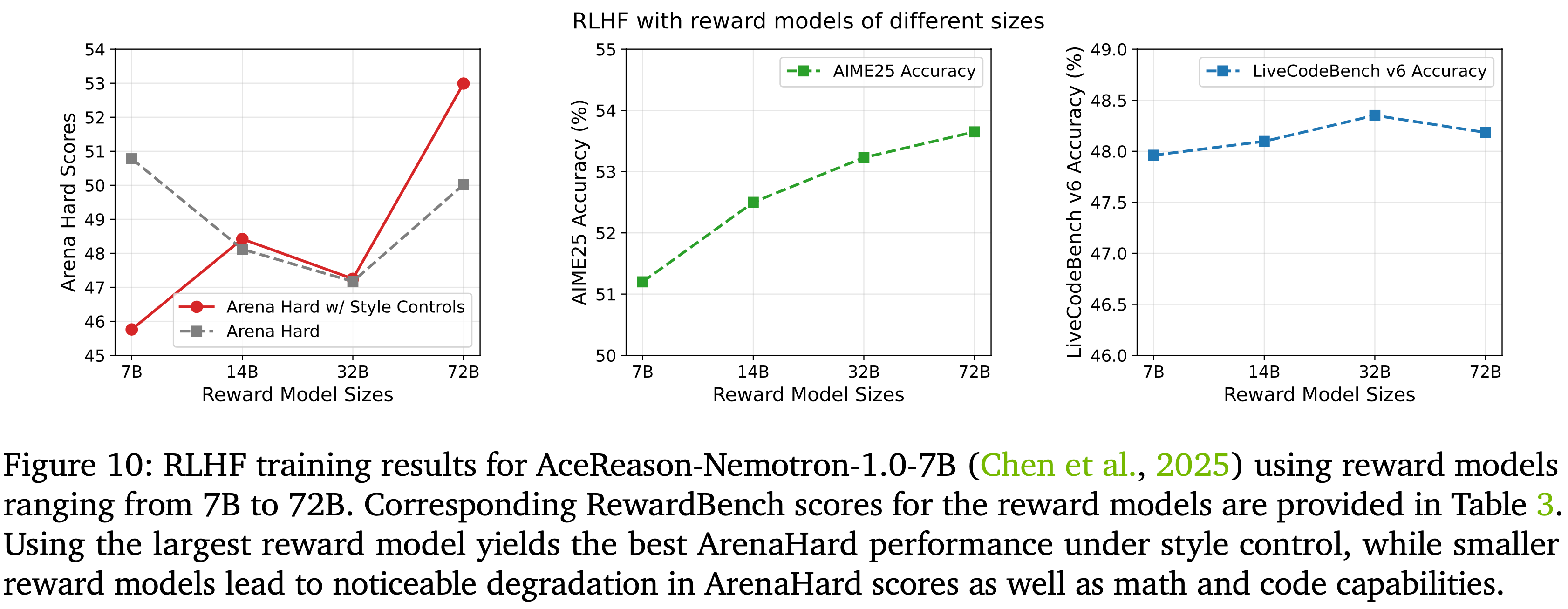
- 主要发现总结如下:
- 1)更大的奖励模型产生更强的 ArenaHard 性能
- 使用最大奖励模型训练的 RLHF 在风格控制 (2024) 下取得了最高的 ArenaHard 分数,该控制有助于在 ArenaHard 排行榜上区分实质内容和风格
- 但 7B 奖励模型在是否启用风格控制时存在巨大差距
- 这表明 7B 奖励模型容易出现 Reward Hacking ,例如,主要通过增加 Response 长度来提高 ArenaHard 分数
- 检查了 RLHF 训练曲线结果:
- 使用 7B 奖励模型的 RLHF 倾向于通过生成更长的输出以提高奖励分数,而使用 72B 奖励模型的训练则产生更稳定的 Response 长度
- 注意:Arena Hard without style control 的分数不能直接参考,因为模型可能是通过输出很长的文本来获取高分的(比如 7B 奖励模型就输出很长的 Response 来实现)
- 忽略 灰色线,看红色线(with Style Control)的话,整体趋势还是越大的 RM 越好
- 14B 提升到 32B 过程中出现了不同,推测是因为 RL 不稳定,容易发生 Reward Hacking 等导致波动
- 2)RewardBench 是一个有用的代理指标,但并不总能预测 RLHF 质量
- 虽然 RewardBench 分数总体上与奖励模型质量相关,但更高的 RewardBench 性能并不一定转化为更好的 ArenaHard 分数
- 作者推测 RewardBench 相对饱和(通常高于 90),因此超出该水平的边际收益不会有意义地改善下游的有用性
- 模型特定行为,例如对 Reward Hacking 的脆弱性,在决定 RLHF 有效性方面起着更决定性的作用
- 3)更大的奖励模型也能提升其他任务(如数学)的性能
- 使用 72B 奖励模型训练的 RLHF 比使用 7B 奖励模型训练的 AIME25 准确率高出约 \(3%\)
- 对于代码基准测试,奖励模型的选择影响很小,性能差异在 \(1%\) 以内
- 1)更大的奖励模型产生更强的 ArenaHard 性能
Bag of Tricks for Stabilizing RLHF Training,稳定 RLHF 训练的技巧集
- RL 算法对于实现长链式思维推理至关重要,但 RL 训练可能不稳定且容易早期崩溃
- 在 RLHF 中,这个问题被进一步放大,因为训练依赖于可能有噪声或 OOD 的基于模型的奖励
- 本节总结了一组能有效稳定 RLHF 训练的技术(“技巧集” “bag of tricks”):
- 1)KL penalty loss :KL 惩罚损失约束 On-policy 与冻结的参考策略之间的散度,确保策略不会偏离初始模型太远
- 当 RLHF 训练早期崩溃时,引入这个 KL 项是保持训练稳定性的有效方法
- 2)策略梯度损失聚合 (Policy gradient loss aggregation) :标准 GRPO 使用 Sequence-level loss,即先对每个样本内的 Token-level 损失求平均,然后在整个批次上聚合
- 对于长 CoT RL,通常推荐使用 Token-level 损失,即直接对批次中所有 Token 损失求平均
- 特别注意:这里聊的是损失的归一化方式,不是 Advantage 的方式
- 当 RLHF 出现早期崩溃迹象时,从 Token-level 损失切换到序列级损失有助于抑制 Response 长度的显著增加,并稳定训练
- 理解:Sequence-level 平均的 Loss 在鼓励短的正样本和唱的负样本
- 对于长 CoT RL,通常推荐使用 Token-level 损失,即直接对批次中所有 Token 损失求平均
- 3)Reward Shaping :
- 由于本文奖励模型是使用 Bradley-Terry 目标训练的,其原始奖励信号是无界的
- 当使用无界奖励训练 RLHF 时,有噪声或离群的奖励可能导致训练不稳定
- 需要使用 Reward Shaping 机制:
- 对于每组奖励,计算平均值和标准差,然后通过减去平均值并除以标准差来归一化每个奖励,生成一个中心化和缩放后的奖励(理解:这个是 GRPO 自己的结果吧)
- 最后应用 tanh 变换:将有形状的奖励限制在 \([-1,1]\) 范围内,有效减轻了组内离群值和噪声奖励信号的影响,从而带来更稳定的 RLHF 更新
- 1)KL penalty loss :KL 惩罚损失约束 On-policy 与冻结的参考策略之间的散度,确保策略不会偏离初始模型太远
- 在早期使用 7B 奖励模型的 RLHF 实验中,应用这些“技巧集”技术显著提高了训练稳定性,将稳定 RL 步数从 350 步延长到 950 步,并获得了更好的 ArenaHard 分数(表 10)
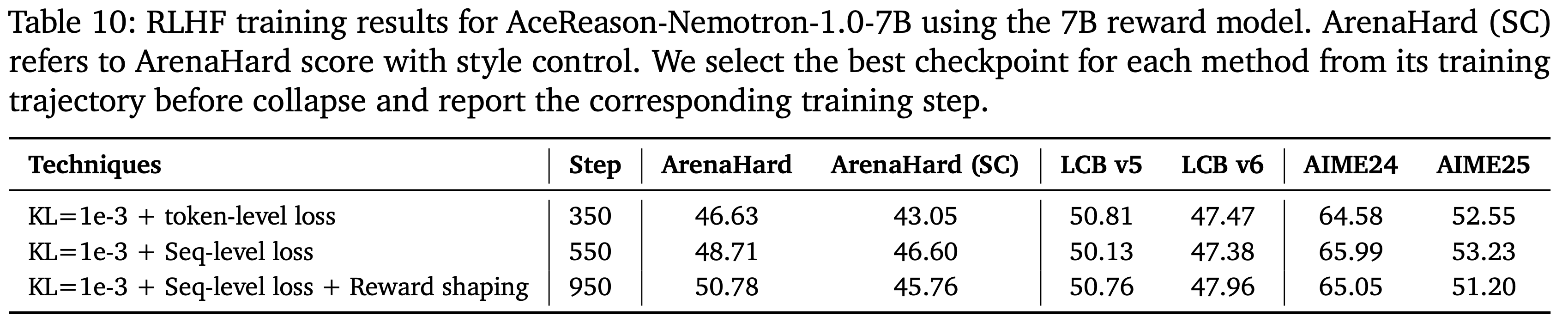
- 但当使用更强的奖励模型(例如 72B 奖励模型)时,RLHF 训练已经稳定,省略这些技术所带来的下游性能与使用它们相当,在某些情况下甚至略好,如表 11 所示
- 本文的结论是,这些技术应被视为一个工具箱,仅在训练显示出不稳定迹象时部署
- 否则,第 4.3.2 节中描述的 RLHF 方法就足够了
Deep Dive on SWE
- 本节介绍针对 SWE 任务的改进技术,并提供相应的消融实验结果
Generation-Retrieval Approach for Code Localization,用于代码定位的生成-检索方法
- 对于文件定位阶段,本文采用一种结合基于生成和基于检索方法的双重方法
- 在基于生成的方法中,模型根据问题描述和仓库结构被引导去推断可能存在 bug 的文件,如附录 C.2 所示
- 为了进一步增强此方法,聚合了多个 Rollout 的结果,并根据候选文件出现的频率对其进行排序,频率越高的文件排名越靠前 (2023)
- 问题:这种基于生成的方法只能访问仓库结构(即文件夹和文件名),而无法访问代码内容
- 为了弥补这一点,本文采用了一个代码 Embedding 模型 NV-Embed-Code (2025),用于检索那些代码内容在语义上与问题上下文相似的候选文件
- 然后通过使用倒数排名融合方法 (reciprocal rank fusion) (2009)(超参数 \(k\) 设为 0)聚合来自这两种方法的结果,确定最终的相关文件集,这有效地整合了两种定位信号的互补优势
- 为了评估代码定位性能,本文测量了不同截断点(top-\(k\))的召回率
- 具体方法:对于一个实例,如果所有需要进行修复的真实文件都出现在 top-\(k\) 个检索到的候选文件中,则定位被认为是成功的(召回率 \(=1\));否则,该实例的召回率定义为 0
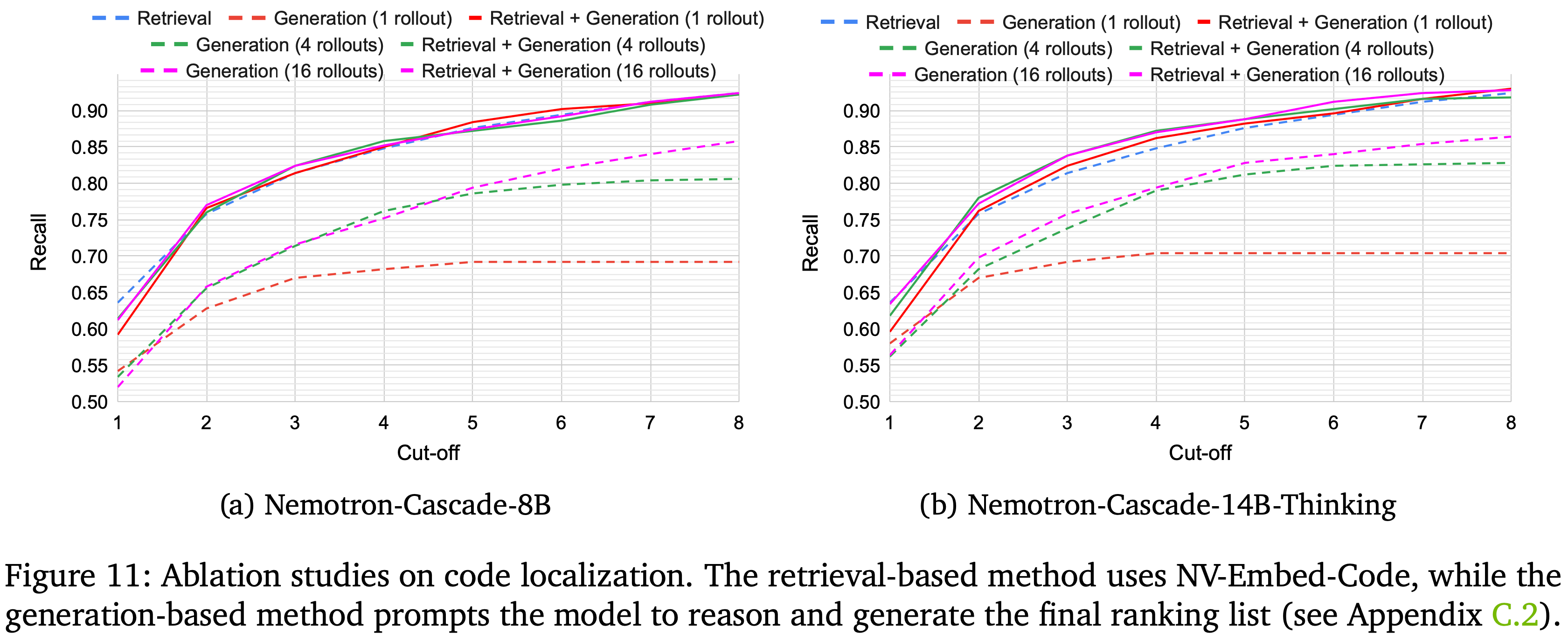
- 图 11 展示了不同方法在 SWE-bench 上的代码定位性能
- 基于检索的方法优于基于生成的方法
- 这种改进可能是因为基于检索的方法编码了每个仓库的完整源代码内容,而基于生成的方法在识别潜在相关文件时仅依赖于仓库结构
- 当来自多个 Rollout 的结果被聚合时,基于生成的方法在 top 排名和更高排名上都表现出一致的提升
- 这表明聚合不仅提高了 top 排名的准确性,还促进了代码定位中的排名多样性
- 使用倒数排名融合将基于生成和基于检索的方法结合起来,会带来轻微的额外改进,尤其是在 cutoff 低于 5 的时候
- 在所有的实验中,直接使用来自生成(16 个 Rollout)和基于检索的方法的倒数排名融合作为默认方法
- 在所有的实验中,直接使用来自生成(16 个 Rollout)和基于检索的方法的倒数排名融合作为默认方法
- 基于检索的方法优于基于生成的方法
Execution-Free Reward Model for SWE RL
- 如 \(\S 4.7.2\) 所述,在代码修复 RL 训练中使用了一个由公式 (2) 定义的无执行奖励
- 也就是说,给定一个人工编写的 Golden Patch,使用词汇相似度(使用 Unidiff 库计算 (2025))或由 Kimi-Dev-72B 模型生成的语义相似度分数,来计算其与模型生成的 Patch 之间的相似度
- 在消融研究中比较了这两种计算相似度的方法
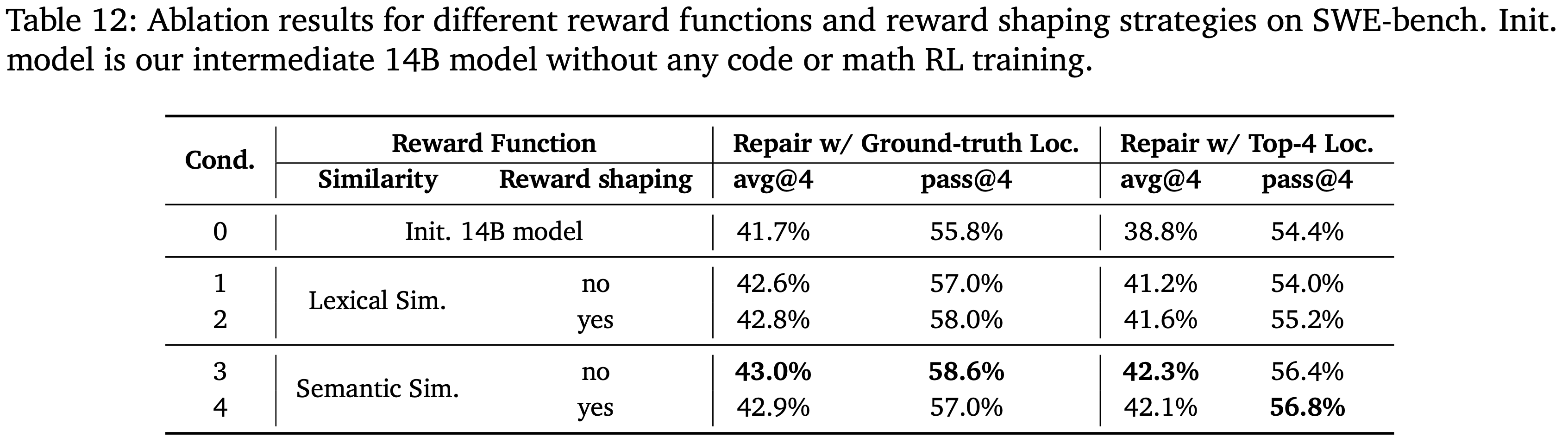
- 从一个尚未进行数学和代码 RL 训练的中间 14B 模型(表 12 中的条件 0)开始,并使用不同的相似度分数作为奖励函数进行代码修复的 RL 训练
- 遵循 \(\S 4.7.2\) 中的超参数设置,但将 Rollout 数量设置为 8,并且在奖励模型的消融实验中,使用最大 Prompt 长度为 24K 的训练数据
- 在两种设置下评估训练后的模型:
- i)当 Prompt 中提供了真实的定位文件时
- ii)当通过生成-检索方法获得 top-4 个定位文件时
- 对于基于语义相似度的奖励模型,直接应用公式 (2) 中定义的原始奖励函数
- 对于词汇相似度,在此奖励函数中用 \(s_{\text{lex} }(\hat{p},p^{*})\) 替换 \(s_{\text{rem} }(\hat{p},p^{*})\)
- 表 12 报告了在采样温度设为 0.6 的情况下,四次运行的平均解决率,以及 pass@4(如果一个实例在四次生成中至少有一次被成功修复,则认为该实例已被解决)
- RL 训练通常能提高模型在代码修复上的有效性,并且使用语义相似度作为奖励模型比使用词汇相似度能获得更好的效果(条件 4 与 2 对比)
- 对两个奖励模型都应用 Reward Shaping ,当奖励低于 0.5 时将其设置为 0
- 这种调整提高了词汇相似度奖励模型的有效性(条件 2 与 1 对比),表明 Reward Shaping 有助于过滤掉噪声监督信号
- 当词汇相似度低于 0.5 时,奖励往往为模型训练提供不可靠的指导
- 当将 Reward Shaping 应用于语义相似度时,没有观察到同样的效果(条件 4 与 3 对比),这表明即使在代码相似度较低时,语义相似度仍能提供有意义的训练信号
- 因此,将默认的奖励函数设置(表 12 中的条件 3)用于 SWE RL 训练
- 因此,将默认的奖励函数设置(表 12 中的条件 3)用于 SWE RL 训练
- 总的来说,本文证明了使用基于 LLM 的无执行奖励模型是扩展 SWE RL 训练规模的一个有前景的方向
- 注:奖励模型训练的探索留作未来的工作
Improving Long-Context Analysis,改进长上下文分析
- 为确保 Prompt 包含所有有错误的代码 Patch,本文用来自多个检索文件的代码内容构成长 Prompt
- 但初步研究表明,当输入 Prompt 长度超过 24K,同时 Response 长度为 16K 时,代码解决率会显著下降
- 作者推测次优的代码解决率是由于 SFT 阶段使用的最大序列长度为 32K
- 这是继承自 Qwen3-8B/14B-Base 模型的 32K 上下文窗口
- 因此,在 RL 阶段,通过混合模型检索到的噪声文件和真实文件来创建具有更长 Prompt 的训练数据
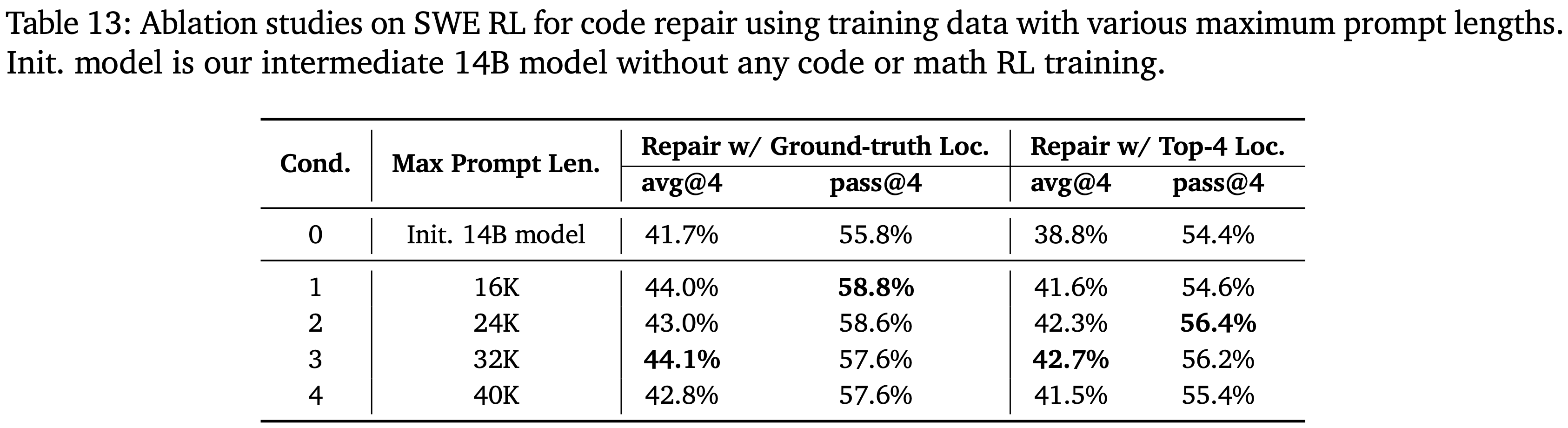
- 表 13 消融了使用不同最大 Prompt 长度创建的数据进行训练的效果(更多细节见 \(\S 4.7.1\))
- 从 16K 到 32K,使用更长的 Prompt 进行训练有助于提高模型的修复能力
- 本文将这种改进归因于模型处理更长上下文 Prompt 的能力,这在修复任务中尤其重要,因为在修复过程中,模型需要从所有检索到的代码内容中识别并修复有错误的代码 Patch
- 但当将最大 Prompt 长度扩展到 40K 时,训练效果变差
- 作者推测模型在这样的长 Prompt 下表现较差,导致采样的 Trajectory 包含更多 RL 训练的噪声,或者预训练的 Qwen3-14B-Base 在 32K 上下文外的长上下文能力有限
- 因此训练数据,将最终 8B 和 14B 模型的最大 Prompt 长度分别设置为 24K 和 32K
- 从 16K 到 32K,使用更长的 Prompt 进行训练有助于提高模型的修复能力
Test-Time Scaling and Patch Validation,TTS 与 Patch 验证
- 为进一步提高代码修复的准确性,本文采用了一种测试时扩展 (TTS) 策略,通过在推理过程中聚合和筛选多个候选 Patch 来增强模型性能
- 如第 \(\S 3.3.1\) 节所述
- 模型使用基于温度和 top-\(p\) 的解码生成一组多样化的候选修复 Patch 和复现测试
- 然后每个候选 Patch 通过一个 Patch 验证阶段进行评估,该阶段应用回归测试和复现测试来识别最可靠的修复
- 对于 SWE-bench Verified 基准测试
- 本文的 TTS 流水线为每个实例生成 \(k\) 个候选修复 Patch 以及 40 个复现测试
- 然后通过首先评估每个 Patch 通过了多少现有的回归测试
- 接着执行一组精心挑选的生成的复现测试来识别最有希望的修复 (理解:这里的复现测试是基于代码的测试用例?),从而对这些候选 Patch 进行筛选和排序
- 最终选择综合通过率最高的 Patch,如果出现平局,则首先通过多数投票解决,然后选择解决方案长度最短的。作者将这种排序和选择过程称为 best@k。这种方法拓宽了解决方案的搜索空间,通过探索多个推理 Trajectory 增强了鲁棒性,并显著增加了产生正确修复的可能性
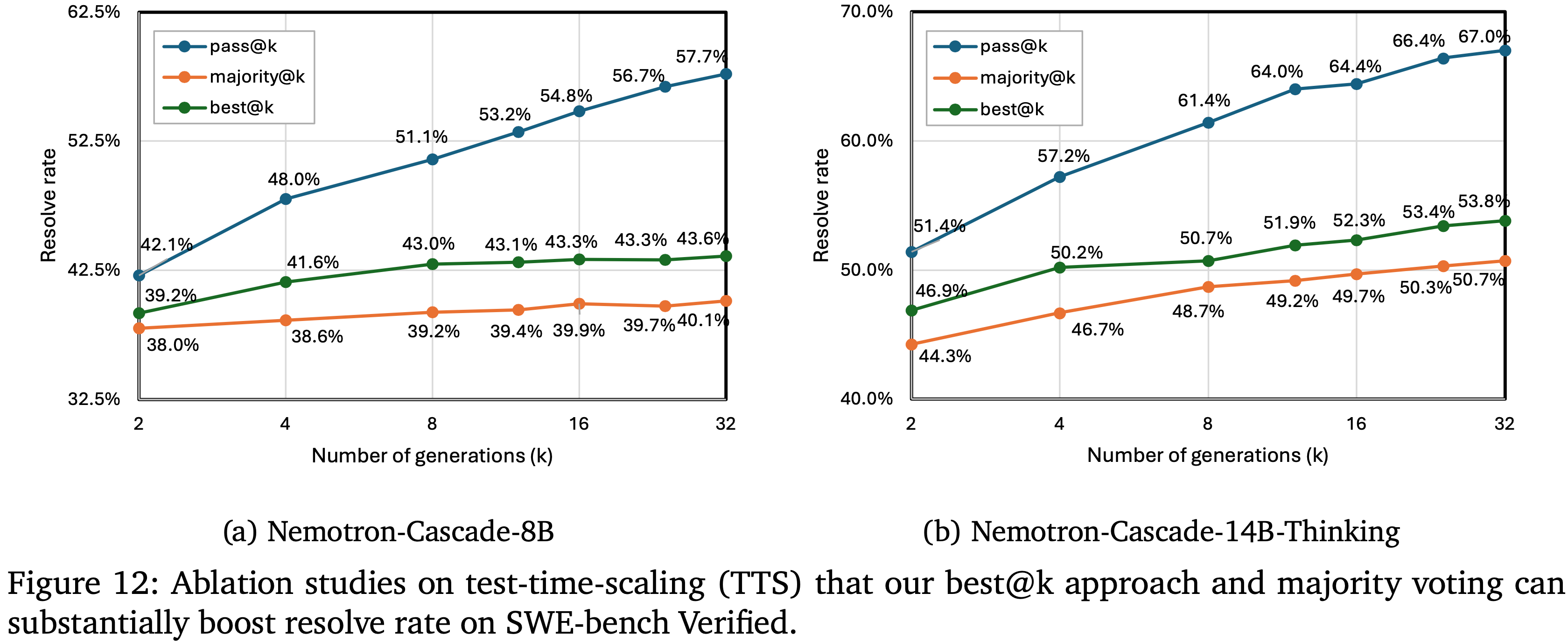
- 图 12 展示了 (a) Nemotron-Cascade-8B 和 (b) Nemotron-Cascade-14B-Thinking 在 SWE-bench Verified 上使用 TTS 结合本文 Patch 验证流水线的评估结果
- 图 12 绘制了 pass@k, majority@k 和 best@k 在 \(k \in 2, 4, 8, 12, 16, 24, 32\) 上的结果
- Pass@k 随着 \(k\) 的增加单调提升,而多数投票增长较慢且较早饱和
- Best@k 始终以显著优势优于 majority@k,证明了本文 Patch 验证流水线的有效性
- 对于 Nemotron-Cascade-14B-Thinking,所有指标的改进更为显著,反映了更强的推理能力和生成的修复 Patch 的更大多样性
- 总结:Nemotron-Cascade-8B 和 Nemotron-Cascade-14B-Thinking 都从 TTS 策略中受益匪浅,14B 模型取得了与更大的开放权重模型(如 DeepSWE (2025))竞争的结果(解决率:通过使用基于执行的验证器执行 TTS 达到 \(52.4%\))
- 这些增益表明,下游的筛选和验证仍然是提升 Patch 修复性能的强大机制,而无需修改模型权重
- 图 12 绘制了 pass@k, majority@k 和 best@k 在 \(k \in 2, 4, 8, 12, 16, 24, 32\) 上的结果
- 如图 12(a) 所示
- Nemotron-Cascade-8B 在 \(k = 32\) 时达到了 \(43.6%\) 的 best@32 解决率,从 \(k = 2\) 时的 \(39.2%\) 逐步提升
- 通过 TTS 和 Patch 验证,Nemotron-Cascade-8B 在 \(k = 32\) 时达到了 \(57.7%\) 的 pass@k 分数,表明存在 15.6 个百分点的差距,这反映了朝着 best@32 还有额外的改进空间
- 多数投票提供了一个更简单的替代方案,但在 39-40% 左右趋于平稳,随着 \(k\) 的增加仅显示出边际收益
- 这些结果表明,即使是对于较小的模型,结构化的测试时扩展与验证相结合也能显著提高修复准确性
- 如图 12(b) 所示
- Nemotron-Cascade-14B-Thinking 的整体指标提升更为显著
- Nemotron-Cascade-14B-Thinking 的 majority@k 解决率起始为 \(50.7%\),已经超过了 8B 变体的 best@32 分数 \(43.6%\)
- 在 TTS 策略下,best@k 提供了进一步的提升,在 \(53.8%\) 左右趋于平稳
- pass@k 曲线随着 \(k\) 的增加而继续上升,突显了为 14B 模型开发更有效的 TTS 策略的巨大潜力
补充:Related Work
Reinforcement Learning for LLMs
- 与需要高质量且昂贵标注的 SFT 中的教师强制训练相比,RLHF 提供了一种更具成本效益和泛化能力的方法来捕捉人类意图的细微差别和语言表达的微妙之处
- RLVR 采用客观且确定性的标准(例如,用于数学推理的基于符号规则的验证)来提供奖励信号
- 已有使用公开数据集的开放 RLVR 配方被开发出来,例如 AceReason-Nemotron (2025; 2025), DeepScaleR (2025), DeepCoder (2025), DAPO (2025) 和 Skywork-OR1 (2025)
- 但这类开放配方的模型主要关注数学和代码推理,与通用前沿模型不同
- 通用 DeepSeek-R1 和 Qwen3 的 RL 训练遵循两个阶段的过程:
- 初始的面向推理的 RL 阶段,随后是覆盖所有域的第二阶段
- 在每个阶段,都会使用多样化的 Prompt 进行联合训练
- 但由于任务之间的巨大异质性,这种设计使 RL 基础设施、训练课程和超参数调整变得复杂,最终导致性能次优
- 本文提出了 Cascade RL 框架,并发布了用于开发通用 LLM 的开放训练配方和数据集,这些 LLM 在包括数学、编码、科学、指令遵循、软件工程和通用领域在内的不同领域都具有强大的推理能力
- 特别地,系统地研究了 RLHF 和 RLVR 之间的相互作用(这是现有文献中尚未充分探索的一个主题)
Supervised Fine-Tuning and Distillation
- 本文还研究了 SFT 和 RL 之间的协同作用
- 发现:在精心设计的 RL 过程中,只要在探索和利用之间达到适当的平衡,初始 SFT 模型之间的性能差距会显著缩小
- 理解:开始的 SFT 可能有差异,经过 RL 后可能能补齐(比如 Unified 8B 和 Thinking 8B 模型)
Unified Reasoning Models
- 过去的一年中,许多专用的思考模型 (thinking models) 已经发布,包括 OpenAI 的 o1 (OpenAI, 2024), o3, o4-mini (OpenAI, 2025), DeepSeek-R1 (2025), Qwen3-Thinking (QwenTeam, 2025), MiniMax-M1 (2025), gpt-oss (2025) 和 Kimi-K2-Thinking (KimicTeam, 2025)
- 这些模型强调通过生成长 CoT 进行深度推理 (2025),涉及问题分析、构思草图、列举替代解决策略,以及验证和修正答案
- 近的几项工作旨在将指令模型 (instruct models) 和思考模型统一到一个模型中
- Llama-Nemotron (2025) 通过系统 Prompt 实现对思考或指令模式的全局控制
- Qwen3 (2025), GLM-4.5 (GLM-4.5-2025) 和 DeepSeek-V3.1 提供了更灵活的用户控制,允许在每个对话轮次中在思考和指令模式之间切换
- GPT-5 (OpenAI, 2025) 采用了一种自动路由机制,绕过了而非解决了这一挑战
附录 B:Benchmarks and Evaluation Setups
- 详情见原文附录
附录 C:Prompt Templates
C.1. Unpreferrable Response Generation for RM data,为 RM 数据生成 Unpreferrable Response
Step 1: Generate offtopic prompts
1
2
3
4
5
6
7
8Given an user input (called "given input"), please generate a new user input (called "generated input") such that:
(1) The generated input is highly relevant to but different from the given input.
(2) The correct response to the generated input superficially resembles the correct response to the given input as much as possible.
(3) But actually, the correct response to the generated input should not be a correct response to the
given input.
Given input:
{instruction}
Generated input:- 步骤 1:生成偏离主题的 Prompt
1
2
3
4
5
6
7
8
9给定一个用户输入(称为“给定输入”),请生成一个新的用户输入(称为“生成输入”),使得:
(1) 生成的输入与给定输入高度相关但又有所不同
(2) 对生成输入的正确 Response 应尽可能在外观上类似于对给定输入的正确 Response
(3) 但实际上,对生成输入的正确 Response 不应对给定输入也是正确的 Response
给定输入:{instruction}
生成的输入:
- 步骤 1:生成偏离主题的 Prompt
步骤 2:判断偏离主题的 Prompt 是否确实与原始 Prompt 不同 (Judge if the offopic prompts are really different to the original)
1
2
3有两个指令,指令 A 和指令 B。这两个指令是否在询问相同的事情?请用‘YES’或‘NO’回答
指令 A:{instruction A}
指令 B:{instruction B}
C.2. Prompts and Templates for SWE Task
代码定位 (Code Localization)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17请查看给定的 GitHub 问题和仓库结构,并提供为了解决问题需要编辑或查看的文件列表
### GitHub 问题描述 ###
{problem_statement}
###
### 仓库结构 ###
{structure}
###
以下是一些代码片段,每个来自一个相关文件。这些文件中可能有一个或多个包含错误。仅提供完整路径并最多返回 n 个文件。返回的文件应按重要性从高到低排序,用换行分隔,并用 \`\`\` 包裹。例如:
\`\`\`
most/important/file1.xx
less/important/file2.yy
least/important/file3.zz代码修复 (Code Repair)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32我们正在解决仓库中的以下问题。这是问题文本:
BEGIN ISSUE
{problem_statement}
END ISSUE
以下是一些代码片段,每个来自一个相关文件。这些文件中可能有一个或多个包含错误
BEGIN FILE
{content}
END FILE
请首先根据问题陈述定位错误,然后生成 SEARCH/REPLACE 编辑来修复问题
每个 SEARCH/REPLACE 编辑必须使用以下格式:
1. 以 '''diff\n 开始表示一个 diff 块,并以 ''' 结束整个块
2. 文件路径
3. 搜索块的开始:<<<< SEARCH
4. 要在现有源代码中搜索的连续行块
5. 分隔线:======
6. 要替换到源代码中的行
7. 替换块的结束:>>>> REPLACE
这是一个例子:
'''diff
###### mathweb/flask/app.py
<<<<<< SEARCH
from flask import Flask
======
import math
from flask import Flask
>>>>>>> REPLACE
'''
请注意,SEARCH/REPLACE 编辑需要正确的缩进。如果您想添加行‘print(x)’,您必须完整写出,包括代码前的所有空格!将每个 SEARCH/REPLACE 编辑像上面例子中那样包装在一个代码块中。如果您有多个 SEARCH/REPLACE 编辑,请为每个编辑使用单独的代码块。输出格式要求:请将您的推理 Token 放在一个单独的代码块中,以 <think> 开始,以 </think> 结束,并将 Solution 令牌放在一个单独的代码块中,以 <solution> 开始,以 </solution> 结束测试代码生成 (Test Code Generation)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48作者正在解决仓库中的以下问题。这是问题文本:
BEGIN ISSUE
{problem_statement}
END ISSUE
已经生成了几个候选修复补丁来解决这个问题。您必须仔细检查它们,并在创建测试时选择与问题描述最匹配的那个,以便专门验证应用补丁前后的行为:
BEGIN PATCH
{model_patch}
END PATCH
以下是一些代码片段,每个来自一个相关文件。这些文件中可能有一个或多个包含错误。
BEGIN FILE
{content}
END FILE
请生成一个完整的测试,可用于复现该问题
完整的测试应包含以下内容:
1. 包含所有必要的 imports
2. 在应用补丁之前复现问题描述中的问题
3. 测试修复补丁中修改的确切函数、类或行
4. 包含断言或检查,以确认在没有补丁的情况下问题可以复现
5. 包含断言或检查,以确认在应用补丁后问题已解决
6. 使用与补丁更改相关联的有意义的断言(例如,预期输出、引发的异常或更改的返回值)
7. 如果结果显示问题已复现,打印“Issue reproduced”
8. 如果结果显示问题已成功解决,打印“Issue resolved”
9. 如果结果显示源代码存在其他问题,打印“Other issues”
测试不应该是通用的;它必须直接验证补丁的正确性
这是一个例子:
'''python
from sqlfluff import lint
def test__rules__std_L060_raised() -> None:
try:
sql = "SELECT IFNULL(NULL, 100), NVL(NULL,100);"
result = lint(sql, rules=["L060"])
assert len(result) == 2
except:
print("Other issues")
return
try:
assert result[0]["description"] == "Use ’COALESCE’ instead of ’IFNULL’."
assert result[1]["description"] == "Use ’COALESCE’ instead of ’NVL’."
print("Issue resolved")
except AssertionError:
print("Issue reproduced")
return
return
test_rules_std_L060_raised()
'''奖励建模 (Reward Modeling)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34**系统 Prompt (System Prompt)**
您是一个评估 AI 助手交互的专家 Judge。您的任务是给定一个参考的 Golden Solution,判断 Assistant 是否成功解决了用户的请求
关键评估标准:
1. Assistant 是否完成了用户请求的主要任务?
2. 最终 Solution 中是否存在任何错误或问题?
仅用 "<judgement>YES</judgement>" 或 "<judgement>NO</judgement>" 回应
**用户 Prompt (User Prompt)**
作者正在解决仓库中的以下问题。这是问题文本:
— BEGIN ISSUE —
{problem_statement}
— END ISSUE —
以下是一些代码片段,每个来自一个相关文件。这些文件中可能有一个或多个包含错误
— BEGIN FILE —
{content}
— END FILE —
请首先根据问题陈述定位错误,然后生成 SEARCH/REPLACE 编辑来修复问题
1. 以 "diff\n" 开始表示一个 diff 块,并以 "" 结束整个块
2. 文件路径
3. 搜索块的开始:<<< SEARCH
4. 要在现有源代码中搜索的连续行块
5. 分隔线:=====
6. 要替换到源代码中的行
7. 替换块的结束:>>> REPLACE
这是参考的 Golden git diff Solution:
{golden_patch}
这是 Assistant 的 Solution:
{model_patch}
请比较 Assistant 的 Solution 和参考的 Golden git diff Solution,并判断 Assistant 的 Solution 是否成功解决了问题。请注意,Solution 不需要与参考的 Golden Solution 完全相同。运用你自己的知识来判断 Assistant 的 Solution 是否成功解决了问题。用 "<judgement>YES</judgement>" 或 "<judgement>NO</judgement>" 回应
C.3. Prompt Templates for Test-Time Scaling on IOI 2025,IOI 2025 上 TTS 的 Prompt 模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Write Python code to solve the problem. Please place the solution code in the following format:
“‘python
# Your solution code here
“‘
{problem_statement}
Below you are provided the accepted correct solutions but with different input constraints. You may use
them as a reference for your insights.
=======================
## Different Constraints (for reference only):
{subtask_constraints}
### Accepted Code:
[CODE]
=======================
## Different Constraints (for reference only):
...
=======================
From here, you are also given your submission history containing **incorrect** code and their corresponding official judgement verdicts as reference – Official judgement verdicts and problem statement/-
conditions are 100% reliable. You should make improvements from them if they could help:
=======================
### Incorrect Code
[CODE]
Judgement Verdict: [VERDICT], Score: [SCORE]
=======================
### Incorrect Code
...
=======================
附录 D:Training Hyperparameters
D.1. Multi-Stage SFT
- 表 14 中列出了 8B 和 14B 模型多阶段 SFT 的超参数
D.2. RLHF
- 表 15 中展示了 8B 和 14B 模型的 RLHF 超参数
D.3. IF-RL
- 8B 和 14B 模型在 IF-RL 训练中的超参数在表 16 中
D.4. Math RL
- 用于 Math RL 训练的 8B 和 14B 模型的超参数分别列于表 17 和表 18 中
D.5. Code RL
- 8B-Thinking、8B unified 和 14B-Thinking 模型在 Code RL 中的超参数在表 19 中
<img src=”/Notes/NLP/LLM-Technical-Reports/NLP——技术报告解读-Nemotron-Cascade/Nemotron-Cascade-Table19.png” title=”” height=”90%” width=”90%”
D.6. SWE RL
- 用于 SWE RL 训练的 8B unified、8B-Thinking 和 14B-Thinking 模型的超参数列于表 20 中
附录 E:ELO Rating Analysis
- 本节详细介绍了 Nemotron-Cascade-8B 和 Nemotron-Cascade-14B-Thinking 模型报告的 Codeforces Elo 评级,该评级基于 2501-2507 年间举行的 51 场近期 Codeforces 竞赛
- 问题和评估由 LiveCodeBench Pro (2025) 提供
- 对于每场竞赛,通过允许模型对每个问题最多进行 \(N\) 次独立提交(\(N\) 默认设置为 8)来模拟参赛,并使用温度为 0.6、top-p 为 0.95 以及最大 Token 预算为 128K 来生成模型的 Response
- 设 \(k\) 表示这 \(N\) 次尝试中正确提交的次数,\(N - k\) 表示错误提交的次数(\(0 \leq k \leq N\))
- 在实际竞赛中,提交是按顺序进行的,罚时提交次数由第一次正确提交之前的错误提交次数定义
- 为了估算提交惩罚,假设 \(k\) 次正确和 \(N - k\) 次错误提交的顺序在 \(\binom{N}{k}\) 种排列上均匀分布,预期的惩罚次数可以推导为:
$$\mathbb{E}[\# \text{ of penalties}] = \frac{N - k}{k + 1}$$
- 采用标准的 Codeforces 竞赛规则:
- 对于常规的 Codeforces 轮次,对每次预期的惩罚应用 50 分的分数惩罚
- 对于 ICPC 风格的轮次(例如 Educational 轮次,Div.3 轮次),每次错误提交增加 10 分钟的时间惩罚
- 未解决问题的惩罚将不予考虑
- 根据最终得分,将模型的竞赛表现与 \(n\) 个真实人类参赛者进行排名,得到名次 \(m\)(\(1 \leq m \leq n + 1\)),并按照标准 Elo 评级定义 (2025) 通过求解下式计算隐含的表现评级 \(R_{\text{model} }\):
$$m = \sum_{i = 1}^{n}\frac{1}{1 + 10^{(R_{\text{model} } - R_i) / 400} }$$- 其中 \(R_{i}\) 指每场竞赛前人类参赛者 \(i\) 的 Elo 评级
- 本文报告在 51 个 Codeforces 轮次上的平均表现评级作为作者的最终 Elo 分数,并在表 21 和表 22 中分别展示了作者的 Nemotron-Cascade-8B 和 Nemotron-Cascade-14B-Thinking 模型的性能细节
- 模型在不同竞赛中的估计表现评级存在很大差异
- 例如,Nemotron-Cascade-14B-Thinking 模型在 Codeforces Round 1015 上达到了 2600 以上的估计表现评级,但在 Round 1024 Div.1 上未能解决任何问题(即使尝试了 8 次),获得的 Elo 评级低于 1000
- 编码问题解决行为的不一致性:
- 虽然模型有时能够解决非常困难的问题,但它也可能在相对简单的问题上卡住,甚至在同一场竞赛中也是如此
- 此外,该模型在可通过标准技术、大量实现或直接直觉解决的问题上表现良好,但通常在需要通过小规模数据探索或特定想法(Ad Hoc Ideas)(例如构造性(Constructive)或交互式(Interactive)问题)进行假设驱动探索的问题上遇到困难
- 这可能是未来理解和改进此类推理能力的一个有趣方向
- 模型在不同竞赛中的估计表现评级存在很大差异
- 注:表 21 和 表 22 详情见原始论文