注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 论文介绍并开源了 GLM-4.5 系列模型
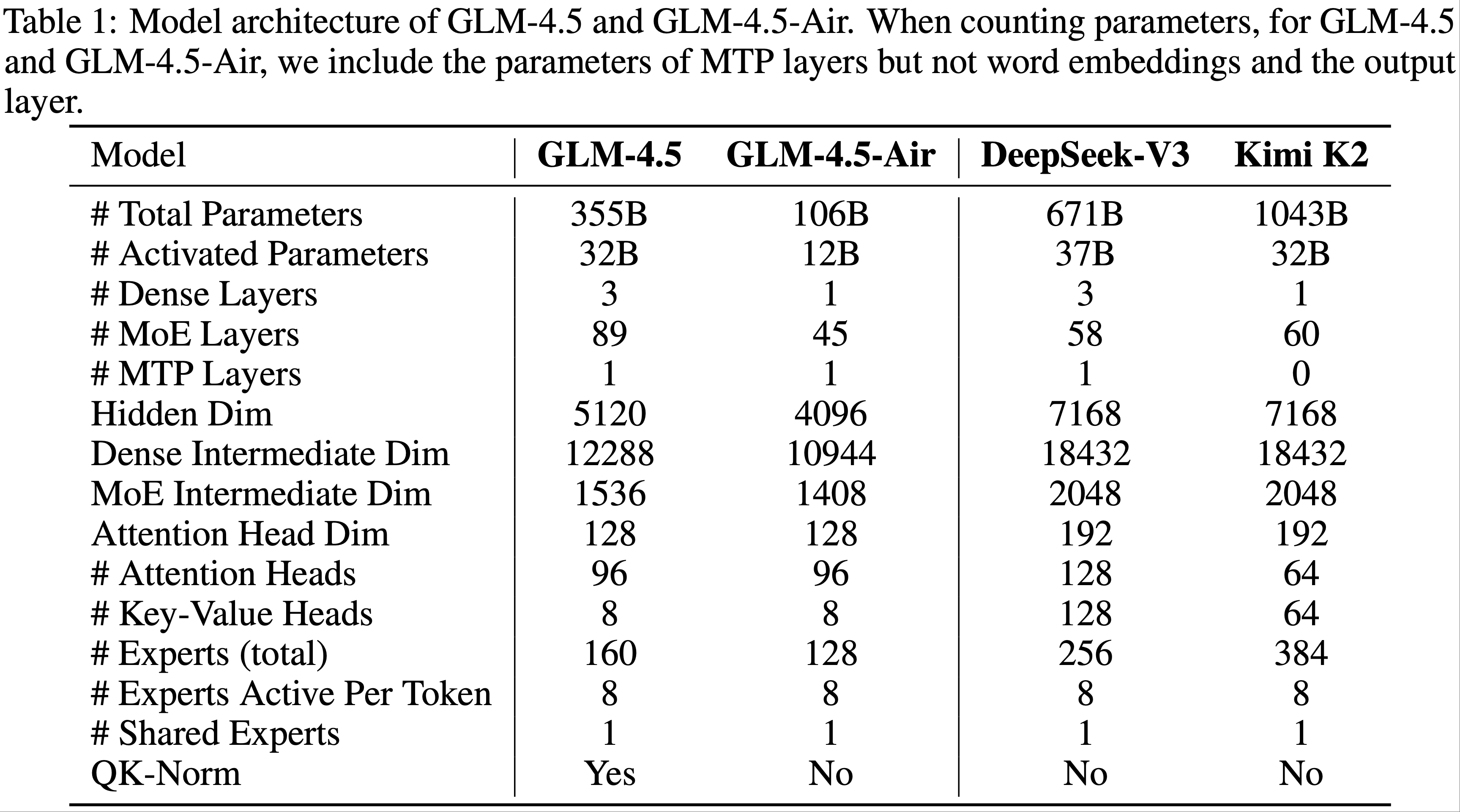
- 包括两个 MoE 模型: GLM-4.5(355B-A32B 参数)和 GLM-4.5-Air(106B-A12B 参数)
- 注:之前的 GLM 都是 Dense 模型
- 在 23T token 数据上训练
- GLM-4.5 在 Reasoning、Coding 和 Agentic 任务上表现出色,在全球开源和专有模型中综合排名第 3 位
- 在 TAU-Bench 上得分 70.1%
- 在 AIME 24 上得分 91.0%
- 在 SWE-bench Verified 上得分 64.2%
- GLM-4.5 支持思维(thinking)和直接响应(direct response)两种模式的混合推理方法
- 包括两个 MoE 模型: GLM-4.5(355B-A32B 参数)和 GLM-4.5-Air(106B-A12B 参数)
- 评价:与其他模型相比,GLM-4.5 的参数量少得多 ,但在所有评估模型中总体排名第 3 ,在智能体基准测试中排名第 2
Introduction and Discussion
- LLM 正迅速从通用知识库 (2020; 2023; 2024) 演变为通用问题解决者
- LLM 的终极目标通常与 AGI 相关联,是创造在多个领域具有人类水平认知能力的模型
- 这需要统一掌握复杂问题解决、泛化和自我改进的能力,超越特定任务的卓越性
- LLMs 越来越融入现实世界场景,提高实际生产力和解决复杂专业任务的关键在于发展特定的核心能力
- 论文确定了三个关键且相互关联的能力,作为衡量真正通用模型的标准,即(Agentic, Reasoning, and Coding,简称 ARC):
- 用于与外部工具和现实世界交互的 Agentic 能力;
- 用于解决数学和科学等领域多步问题的复杂 Reasoning 能力;
- 用于处理现实世界软件工程任务的高级 Coding 技能
- 像 OpenAI 的 o1/o3 (2024) 和 Anthropic 的 Claude Sonnet 4 这样的最先进专有模型在特定的 ARC 领域(例如,数学推理或代码修复 (2023))中展示了突破性的性能
- 在以上三个领域都表现出色的、强大的单一开源模型仍然难以实现
- 吐槽:ARC 是 AI2 Reasoning Challenge 数据集的常用简称,这里智谱还用 ARC 来代指其他名词不太合适!
- 论文介绍了两个新模型:GLM-4.5 和 GLM-4.5-Air,旨在统一所有不同的能力
- 新模型在各个方面都优于现有的开源 LLM 模型,在智能体、推理和编码任务上取得了显著提升
- GLM-4.5 和 GLM-4.5-Air 都具有混合推理模式:
- 用于复杂推理和智能体任务的思维模式(thinking mode),以及用于即时响应的非思维模式(non-thinking mode)
- GLM-4.5 是 智谱 AI 的(GLM 系列)的第一个 MoE 模型,总参数量为 355B,激活参数量为 32B
- GLM-4.5 在以下 ARC 基准测试中表现出强大的性能:
- 智能体(Agentic):
- GLM-4.5 在 TAU-Bench 上得分 70.1%,在 BFCL v3 (2025) 上得分 77.8%,与 Claude Sonnet 4 相当
- 对于网页浏览智能体,GLM-4.5 在 BrowseComp (2025) 上得分 26.4%,明显优于 Claude Opus 4(18.8%),并接近 o4-mini-high(28.3%)
- Reasoning:
- GLM-4.5 在一系列具有挑战性的推理基准测试中表现出色,在 AIME 24 上达到 91.0%,在 GPQA (2024) 上达到 79.1%,在 LiveCodeBench (2407-2501) (2024) 上达到 72.9%,在 HLE(Humanity’s Last Exam)(2025) 上达到 14.4%
- Coding:
- GLM-4.5 在 SWE-bench Verified (2023) 上得分 64.2%,在 Terminal-Bench (2025) 上得分 37.5%,优于 GPT-4.1 和 Gemini-2.5-pro,接近 Claude Sonnet 4
- 智能体(Agentic):
- GLM-4.5-Air 是一个较小的 MoE 模型,参数量为 106B
- GLM-4.5-Air 在 100B 规模的模型中实现了显著飞跃,匹配或超越了 Qwen3-235B-A22B (2025) 和 MiniMax-M1 (2025)
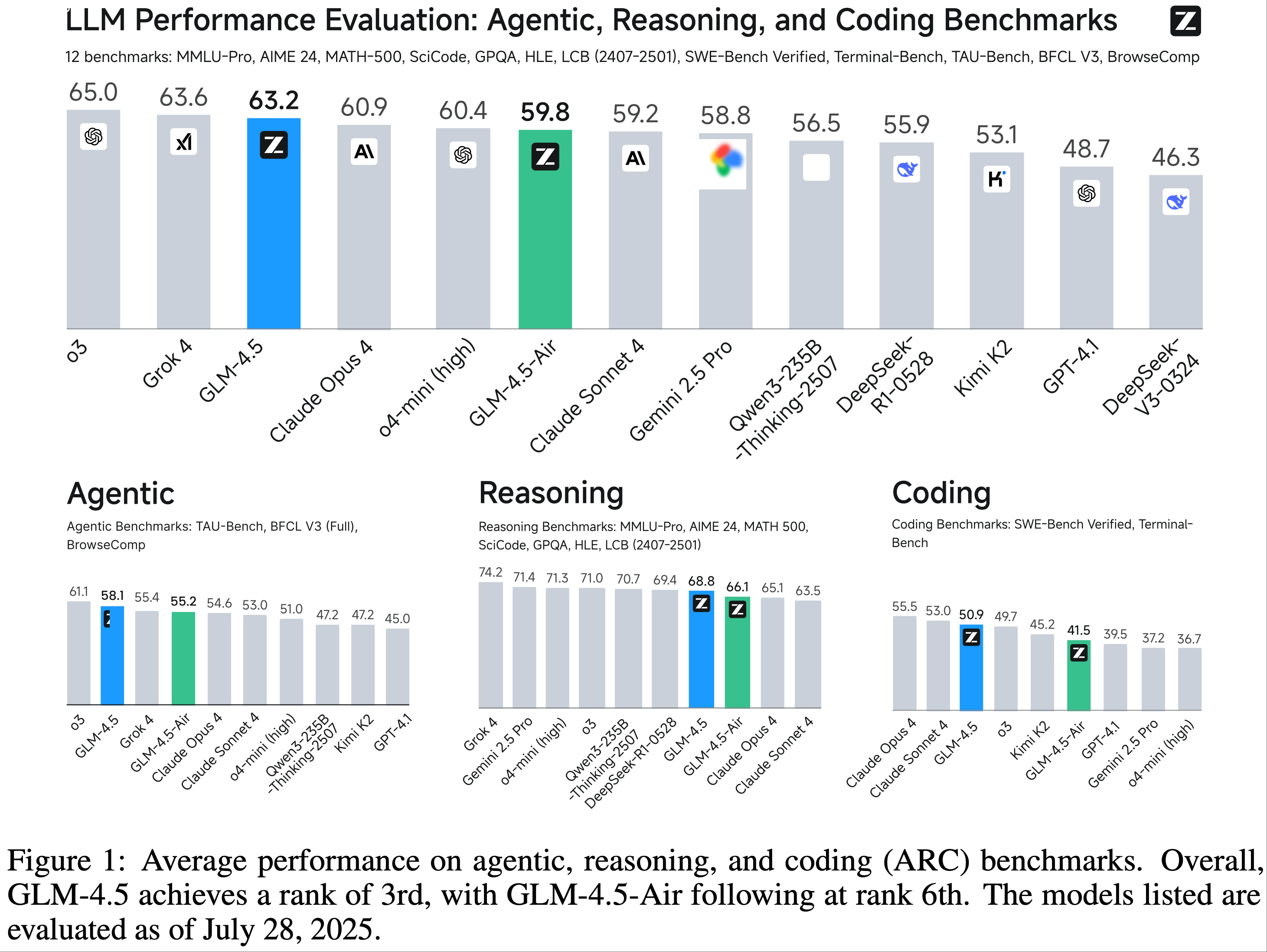
- 在图 1 中,论文展示了在智能体、推理和编码(ARC)任务的 12 个基准测试上的平均性能
- 总体而言,GLM-4.5 排名第 3 ,GLM-4.5-Air 排名第 6
- 在智能体任务上,GLM-4.5 排名第 2,仅次于 OpenAI o3
- 在编码任务上,GLM-4.5 排名第 3,接近 Claude Sonnet 4
- 特别说明:GLM-4.5 具有很高的参数效率,其参数量仅为 DeepSeek-R1 (2025) 的一半,Kimi K2 (2025) 的三分之一
- 在图 2 中,论文报告了不同开源模型在 SWE-bench Verified 上的得分与模型参数量的关系
- 其中 GLM-4.5 和 GLM-4.5-Air 位于帕累托前沿(Pareto Frontier)
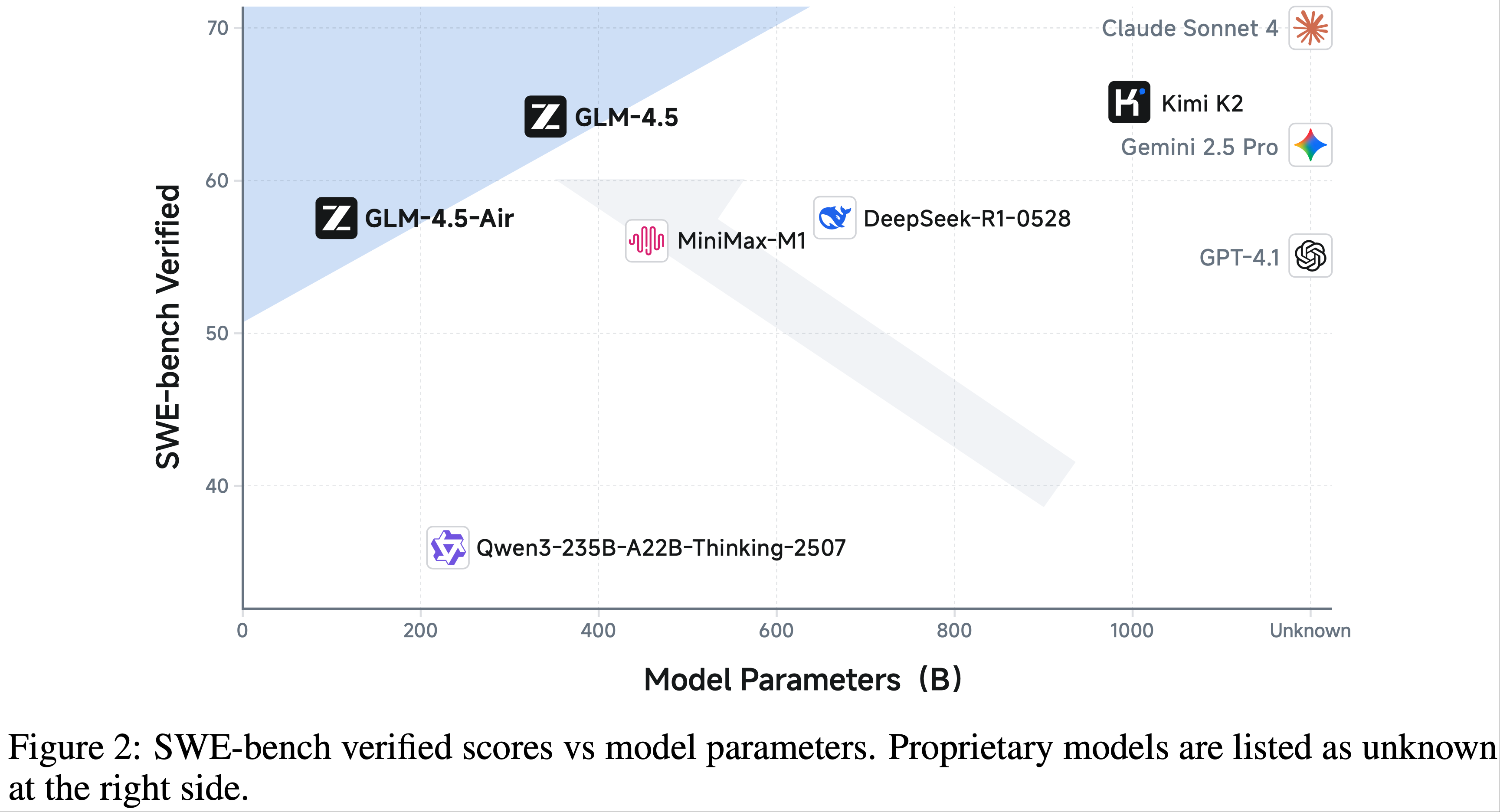
- 其中 GLM-4.5 和 GLM-4.5-Air 位于帕累托前沿(Pareto Frontier)
- 更多评估结果详见第 4 节
- GLM-4.5 和 GLM-4.5-Air 的获取渠道
- 可在 Z.ai、BigModel.cn 上获取
- 也可在 huggingface.co/zai-org/GLM-4.5 上作为开源模型获取
- 论文还可在 github.com/zai-org/glm-simple-evals 开源了一个评估工具包 ,以确保论文基准测试结果的可复现性
Pre-Training
Architecture
- GLM-4.5 系列采用了 MoE 架构 ,这提高了训练和推理的计算效率
- 论文为 MoE 层采用了 无损失平衡路由(loss-free balance routing) (2024) 和 sigmoid gates (2024)
- 与 DeepSeek-V3 (2024) 和 Kimi K2 (K 2025) 不同,论文减小了模型的宽度(隐藏维度和路由专家数量)并增加了其高度(层数),因为论文发现更深的模型表现出更好的推理能力
- 论文采用了 分组查询注意力(Grouped-Query Attention, GQA)并辅以 partial RoPE
- 论文使用了 2.5 倍多的注意力头(对于 5120 的隐藏维度使用 96 个头)
- 这与直觉相反,虽然增加头数相比头数较少的模型并不能改善训练损失,但它持续改善了在 MMLU 和 BBH 等推理基准测试上的性能
- 论文还加入了 QK 归一化(QK-Norm)(2020) 来稳定 Attention logits 的范围
- 问题:注意力头的倍数一般都是按照模型层数为基础来计算的吧,即 2 倍头表示头数是层数的 2 倍(详情可见 Kimi K2)
- 对于 GLM-4.5 和 GLM-4.5-Air,论文都添加了一个 MoE 层作为 多 Token 预测(Multi-Token Prediction, MTP)层 (2024) 以在推理过程中支持 推测解码(Speculative Decoding)
Pre-Training Data
- GLM-4.5 的预训练语料库包含来自网页、社交媒体、书籍、论文和代码仓库的文档
- 论文为不同来源精心设计了数据处理流程
Web
- 论文预训练文档的大部分是从互联网爬取的英文和中文网页
- 受 Nemotron-CC (2024) 的启发
- 论文将爬取的网页按不同质量分数分桶(buckets)
- 论文对来自具有更高质量分数桶的文档进行上采样(up-sample),并丢弃来自具有最低质量分数桶的文档
- 具有最高质量分数的桶在预训练期间贡献了超过 3.2 个 epochs
- 通过这种方式,预训练语料库可以强调用于推理任务的高频知识,同时也提高了对长尾世界知识(long-tail world knowledge)的覆盖度
- 论文还发现了大量由模板自动生成并被分配了高分的相似网页
- 这类网页无法通过 MinHash 去重(MinHash deduplication)移除
- 论文额外应用了 SemDedup (2023) 流程,基于文档嵌入(document embeddings)来移除那些相似的网页
Multilingual
- 为了支持更多自然语言,论文在预训练语料库中包含了多语言文档
- 多语言语料库来自论文爬取的网页和 Fineweb-2 (2025)
- 论文应用了一个质量分类器来判断文档的教育效用(educational utility),并对高质量的多语言文档进行上采样
Code
- 论文从 GitHub 和各种代码托管平台筛选了源代码数据
- 代码语料库经过初步的基于规则的过滤,然后使用特定语言的质量模型进行分类,将样本分为三个等级:高质量、中等质量和低质量
- 在训练期间,论文对高质量代码进行上采样,同时排除低质量样本
- 论文对所有源代码数据应用了 中间填充(Fill-In-the-Middle)(2022) 训练目标
- 对于与代码相关的网络文档,论文采用了从文本预训练语料库中进行两阶段检索的过程
- 最初,根据两个标准进行选择:存在 HTML 代码标签,或者由训练用于检测代码相关内容的 FastText (2017) 分类器识别
- 随后,检索到的文档使用专用模型进行质量评估,该模型将它们分为高、中、低质量类别,遵循与源代码相同的基于质量的采样策略
- 最后,采用细粒度解析器(fine-grained parser)重新解析选定的网页,以更好地保留代码的格式和内容
Math & Science
- 为了增强推理能力,论文从网页、书籍和论文中收集了与数学和科学相关的文档
- 论文应用一个大语言模型根据关于数学和科学的教育内容比例对候选文档进行评分,并训练一个小型分类器来预测这些分数
- 预训练语料库中分数高于某个阈值的文档会被上采样
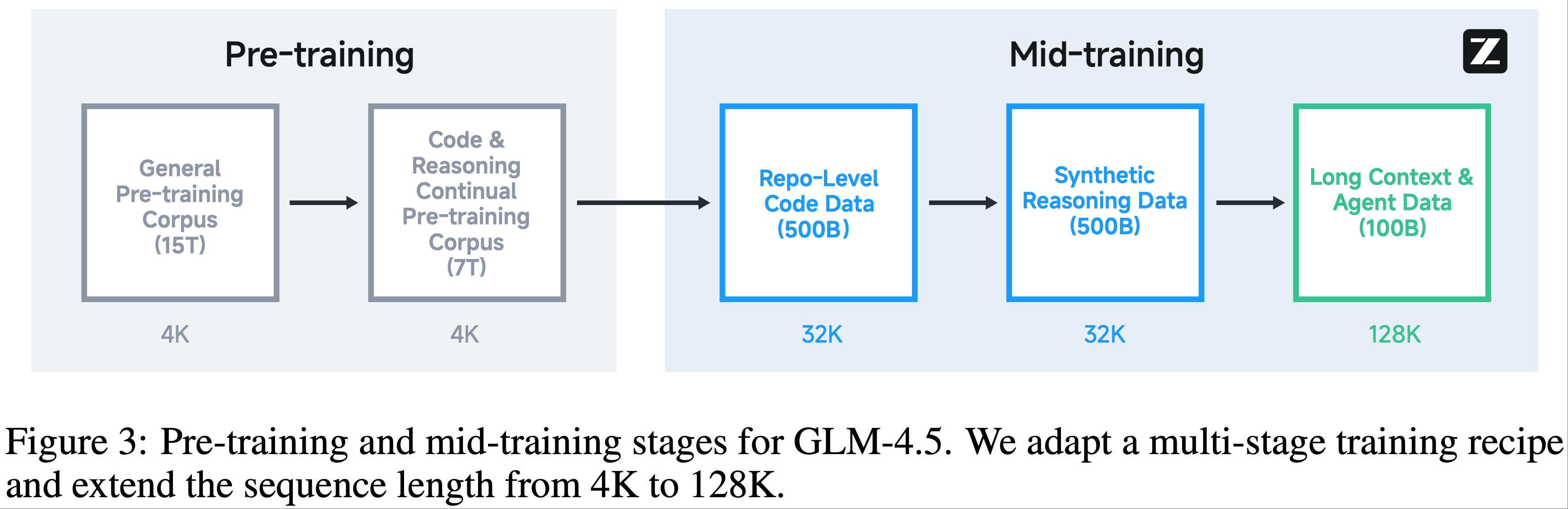
- GLM-4.5 的预训练过程分为两个阶段
- 在第一阶段,模型主要在来自网页的通用文档上进行训练
- 在第二阶段,论文对来自 GitHub 的源代码以及与编码、数学和科学相关的网页进行上采样
Mid-Training: Boost Reasoning & Agentic Capacity
- 预训练之后,论文增加了几个阶段来进一步提升模型在重要应用领域的性能
- 与传统的在大规模通用文档上进行预训练不同,这些训练阶段利用中等规模的领域特定数据集,包括指令数据
- 论文将这些训练阶段称为 中期训练(mid-training)
- 中期训练包括以下内容
- 仓库级代码训练(Repo-level Code Training)
- 在这个训练阶段,论文添加来自同一代码仓库(repository)的串联代码文件,以学习跨文件依赖(cross-file dependency)
- 为了提高模型的软件工程能力,论文还包括了模型筛选过的来自 GitHub 的议题(issues)、拉取请求(pull requests, PRs)和提交(commits),将相关的议题、PRs 和提交串联到一个上下文中,并以类似 diff 的格式组织提交
- 论文将训练序列长度从 4K 扩展到 32K,以容纳大型代码仓库
- 合成推理数据训练(Synthetic Reasoning Data Training)
- 在这个阶段,论文为数学、科学和编程竞赛添加合成推理内容
- 论文从网页和书籍中收集了大量与推理任务相关的问题和答案,并使用推理模型合成了推理过程
- 长上下文与智能体训练(Long-context & Agent Training)
- 为了进一步提升模型的长上下文性能,论文将训练序列长度从 32K 扩展到 128K,并对预训练语料库中的长文档进行上采样
- 大规模合成的智能体轨迹(agent trajectories)也在此阶段加入
- 仓库级代码训练(Repo-level Code Training)
- 在图 3 中,论文展示了预训练和中期训练的完整阶段
- 最大序列长度在预训练期间保持在 4,096
- 在中期训练期间从 32,768 扩展到 131,072
- 在预训练期间,论文没有使用 best-fit packing (2024),因为随机截断(random truncation)对于预训练文档来说是一种很好的数据增强策略
- 对于中期训练中的数据集,论文应用了最佳适配打包,以避免截断推理过程或仓库级代码
Hyper-Parameters
- 优化器方面:
- 论文对除词嵌入(word embedding)、偏置(bias)和 RMSNorm 权重之外的所有参数使用了 Muon 优化器 (2024; 2025)
- 论文观察到 Muon 优化器可以加速收敛并容忍更大的批次大小
- 对于超参数
- Newton-Schulz 迭代步数 \(N\) 设为 5
- 动量(momentum)\(\mu\) 设为 0.95
- 将 Muon 的更新 RMS 缩放为 0.2
- 学习率调度:
- 论文使用 余弦衰减调度(cosine decay schedule)来调整学习率,而不是 预热-稳定-衰减(warmup-stable-decay, WSD)调度 (2025)
- 论文早期的实验表明,使用 WSD 调度训练的模型在通用基准测试(SimpleQA, MMLU)上表现更差,表明在稳定阶段存在欠拟合(underfitting)
- 学习率经历了从 0 到 2.5e-4 的预热阶段和衰减到 2.5e-5 的阶段,直到中期训练结束
- 论文使用了批次大小预热策略(batch size warmup strategy)
- 在训练前 500B 个 Token 的过程中,批次大小从 16M 个 Token 逐渐增加到 64M 个 Token,并在剩余的训练中保持恒定
- 对于正则化(regularization)
- 论文将权重衰减比率(weight decay ratio)设置为 0.1,并且没有使用 dropout
- 论文在预训练期间将最大序列长度设置为 4,096,并在中期训练阶段将其扩展到 32,768 和 131,072,如图 3 所示
- 当将序列长度扩展到 32K 时,论文还将 RoPE 的基础频率(base frequency)从 10,000 调整到 1,000,000,以获得更好的长上下文建模能力
- 问题:直接修改 base frequency 是可以的吗?
- 对于无损失平衡路由
- 论文在前 15T 个 Token 中将偏置更新率(bias update rate)设置为 0.001,在剩余的 Token 中设置为 0.0
- 论文还应用了权重为 0.0001 的辅助序列级平衡损失(auxiliary sequence-level balance loss) ,以避免任何单个序列内的极端不平衡
- MTP 损失权重 \(\lambda\) 在前 15T 个 Token 中设置为 0.3,在剩余的 Token 中设置为 0.1
Post-Training: Expert Model Iteration
- 论文将后训练过程分为两个不同的阶段
- 在阶段1(专家训练,Expert Training)中,论文构建了专精于三个领域的专家模型:
- Reasoning、 Agent 和通用对话(General chat)
- 在阶段2(统一训练,Unified Training)中,论文采用自蒸馏(self-distillation)技术来整合多个专家,最终交付一个能够通过审慎推理(deliberative reasoning)和直接响应(direct response)两种模式生成响应的综合性模型
SFT
在阶段1(专家训练)和阶段2(统一训练)的开始都进行了 SFT
在专家训练阶段,SFT 的主要作用是提供冷启动(cold start),赋予模型基本的对话、推理和工具使用能力,这些能力随后可以在后续的专家 RL 训练中得到进一步增强,以实现更好的性能
在统一训练阶段,SFT 的目的是将不同专家模型的能力蒸馏(distill)到一个能够处理不同类型任务的混合推理多面手(hybrid reasoning generalist)模型中
冷启动 SFT (Cold Start SFT)
- 在冷启动阶段,论文利用一小部分带有扩展 CoT 响应的 SFT 数据
- 这种方法确保了每个专家模型在进入强化学习阶段之前都具备足够的基础能力
整体 SFT (Overall SFT)
- 在整体 SFT 阶段,论文从先前训练好的专家模型中收集了数百万个样本 ,涵盖以下内容:
- 推理任务(数学、代码、科学等)
- 通用对话(写作、翻译、摘要、闲聊等)
- 智能体任务(基本工具使用、编码能力,特别是真实项目开发等)
- 长上下文理解任务
- 使用最大上下文长度为 128K Token 的基础模型进行训练
- 通过从不同专家的输出中进行蒸馏,模型学会了为每个任务应用最有效的长思维链推理来得出正确答案
- 特别是,考虑到对于需要快速响应的某些领域(如闲聊)而言,冗长的思考过程是不必要的,论文精心平衡了包含完整推理的训练数据和不包含显式思维过程的训练数据
- 这种方法使得模型能够在反思性(reflective)和即时响应(immediate response)两种模式下运行,从而创建了一个混合推理模型(hybrid reasoning model)
- 在整体 SFT 阶段,论文从先前训练好的专家模型中收集了数百万个样本 ,涵盖以下内容:
此外,论文发现以下策略有助于准备 SFT 数据以获得最佳性能:
减少函数调用模板中的字符转义 (Reducing Character Escaping in Function Call Templates)
- 当前函数调用参数主要以 JSON 格式表示,但当这些参数包含代码段时,一个重大挑战就出现了
- 在这种情况下,代码中很大比例的字符需要进行转义,迫使模型生成大量的转义字符,从而增加了模型的学习负担
- 这个问题对于主要为通用对话设计的模型来说影响很小,但对于以函数调用为核心能力的智能体基础模型来说,这是一个不容小觑的挑战
- 为了缓解这一限制,论文提出了一种新颖的函数调用模板,它将函数调用的键和值封装在类似 XML 的特殊 Token 标签内
- 这种方法大大减少了代码段中对字符转义的需求,因为绝大多数代码可以以其原生形式表示而无需转义
- 实验结果表明,所提出的函数调用模板在减少转义的同时,并未损害函数调用执行的性能
- 图 4 中的示例说明了论文提出的函数调用模板的结构(详细的代码实现可以在论文的开源仓库中找到)
- 图 4 的内容如下所示(Figure 4: One example of function call template.):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37<|system|> # Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"name": "get_weather", "description": "Get the weather of a city for a specific date.", "parameters": {" type": "object", "properties": {"city": {"type": "string", "description": "The city to get weather for, in Chinese."}, "date": {"type": "string", "description": "The date in YYYY-MM-DD format."}}, "required": ["city"]}}
</tools>
For each function call, output the function name and arguments within the following XML format: <tool_call>{function-name}
<arg_key>{arg-key-1}</arg_key>
<arg_value>{arg-value-1}</arg_value>
<arg_key>{arg-key-2}</arg_key>
<arg_value>{arg-value-2}</arg_value>
...
</tool_call><|system|>
You are a helpful assistant.<|user|>
Today is June 26, 2024. Could you please check the weather in Beijing and Shanghai for tomorrow<| assistant|>
<think>The user wants to check the weather of Beijing and Shanghai tomorrow. I need to call the get_weather function respectively to check Beijing and Shanghai.</think>
I will call the get_weather function to check the weather in Beijing and Shanghai. <tool_call>get_weather
<arg_key>city</arg_key>
<arg_value>Beijing</arg_value>
<arg_key>date</arg_key>
<arg_value>2024-06-27</arg_value>
</tool_call>
<tool_call>get_weather
<arg_key>city</arg_key>
<arg_value>Shanghai</arg_value>
<arg_key>date</arg_key>
6
<arg_value>2024-06-27</arg_value>
</tool_call><|observation|>
<tool_response>
{"city": "Beijing", "date": "2024-06-27", "weather": "Sunny", "temperature": "26C"} </tool_response>
<tool_response>
{"city": "Shanghai", "date": "2024-06-27", "weather": "Overcast", "temperature": "29C"} </tool_response><|assistant|>
<think>I have obtained the weather query results of get_weather for Beijing and Shanghai respectively and
can reply to users directly.</think>
It will be sunny in Beijing tomorrow with a temperature of 26 degrees Celsius. The weather in Shanghai is
overcast with a temperature of 29 degrees Celsius.<|user|>
- 当前函数调用参数主要以 JSON 格式表示,但当这些参数包含代码段时,一个重大挑战就出现了
拒绝采样 (Rejection Sampling)
- 从专家模型采样时,论文采用了一个全面的多阶段过滤流水线,包括:
- (1) 移除重复、过短或截断的样本,以及那些未能符合有效推理格式的样本;
- (2) 对具有客观答案的样本进行正确性验证;
- (3) 利用奖励模型(reward models)过滤对主观问题的响应;
- (4) 对于工具调用场景,确保遵守正确的工具调用协议并验证轨迹(trajectories)是否达到了预期的终止状态
- 从专家模型采样时,论文采用了一个全面的多阶段过滤流水线,包括:
提示选择与响应级别缩放 (Prompt Selection and Response-Level Scaling)
- 过滤具有挑战性的 Prompt 并对其执行响应缩放(response scaling)被证明是有效的
- 论文尝试移除了基于响应长度排序的后 50% 的 Prompt,尽管只使用了一半的数据进行训练,但在数学和科学任务上仍取得了 2%-4% 的性能提升
- 值得注意的是,论文发现对这些有挑战性的困难 Prompt 应用响应缩放可以带来进一步的收益
- 为每个 Prompt 生成四个响应带来了额外的 1%-2% 的提升
- 问题:如何理解这里的四个响应?
自动智能体 SFT 数据构建 (Automatic Agentic SFT Data Construction) 智能体 SFT 数据的构建涉及四个步骤:
- 1. 智能体框架与工具收集 (Agentic Framework and Tool Collection) :
- 论文收集一组智能体框架和真实世界的工具 API 及 MCP 服务器,同时利用 LLM 自动构建和模拟一批工具
- 2. 任务合成 (Task Synthesis) :
- 基于第一步收集的框架和工具,论文自动合成一组智能体任务
- 对于相对成熟的框架,论文利用 LLM 来理解其功能并自动生成相关的查询或任务
- 对于更零散或不同的工具,论文首先选择一个有代表性的子集,并同样使用 LLM 来构建关于这个子集的任务
- 这些任务涵盖了单步和多步工具调用场景
- 基于第一步收集的框架和工具,论文自动合成一组智能体任务
- 3. 轨迹生成 (Trajectory Generation) :
- 对于每个合成的任务,论文利用现有的 LLM 生成工具调用轨迹
- 此外,通过将 LLM 用作用户模拟器(user simulator),多步工具调用任务被转换为涉及多轮对话的轨迹
- 4. 质量过滤 (Quality Filtering) :
- 对于每条轨迹,使用多个评判智能体(judge agents)来评估任务是否完成
- 只保留成功的轨迹
- 1. 智能体框架与工具收集 (Agentic Framework and Tool Collection) :
Reasoning RL
- 推理强化学习(Reasoning RL)侧重于增强模型在需要逻辑演绎、结构化问题解决和可验证准确性的领域的能力
- 包括数学、代码生成和科学推理等关键领域
- 这些任务的一个决定性特征是其奖励信号的高精度,因为正确性通常可以通过程序化或客观明确的方式来确定
- 在这些领域的精通不仅对于提升模型的原始智能至关重要,也是构建更复杂、多步骤智能体行为的基本组成部分
- 认识到推理 RL 中的独特挑战和机遇,论文开发了一套专门的技术来有效训练论文的模型
- 这些方法详述如下,旨在解决训练效率、样本多样性和数据质量等问题
- 论文的整体 RL 算法建立在 GRPO (2024) 框架之上,排除了 KL 散度损失项
- 本节中展示的比较曲线基于论文较小的实验模型,而非 GLM-4.5
Difficulty-based Curriculum Learning
- 在强化学习过程中,模型的熟练度会不断演变,与静态的训练数据产生不匹配
- 在后期阶段,随着模型能力增强,过于简单的数据会导致产生的轨迹(rollouts)奖励全部为 1
- 在早期阶段,过于困难的数据通常会导致整批数据的奖励都为 0
- 在这两种情况下,奖励缺乏方差,无法提供有用的梯度信号,严重阻碍了训练效率
- 为了解决这一挑战,论文在 RL 中采用了基于难度的两阶段课程(two-stage difficulty-based curriculum)
- 下面讨论的此策略及其他策略的有效性通过在一个较小模型上进行的对照实验得到了验证,该设置允许快速迭代和精确的消融研究
- 如图 5 所示,这种两阶段方法使模型能够持续超越其性能上限
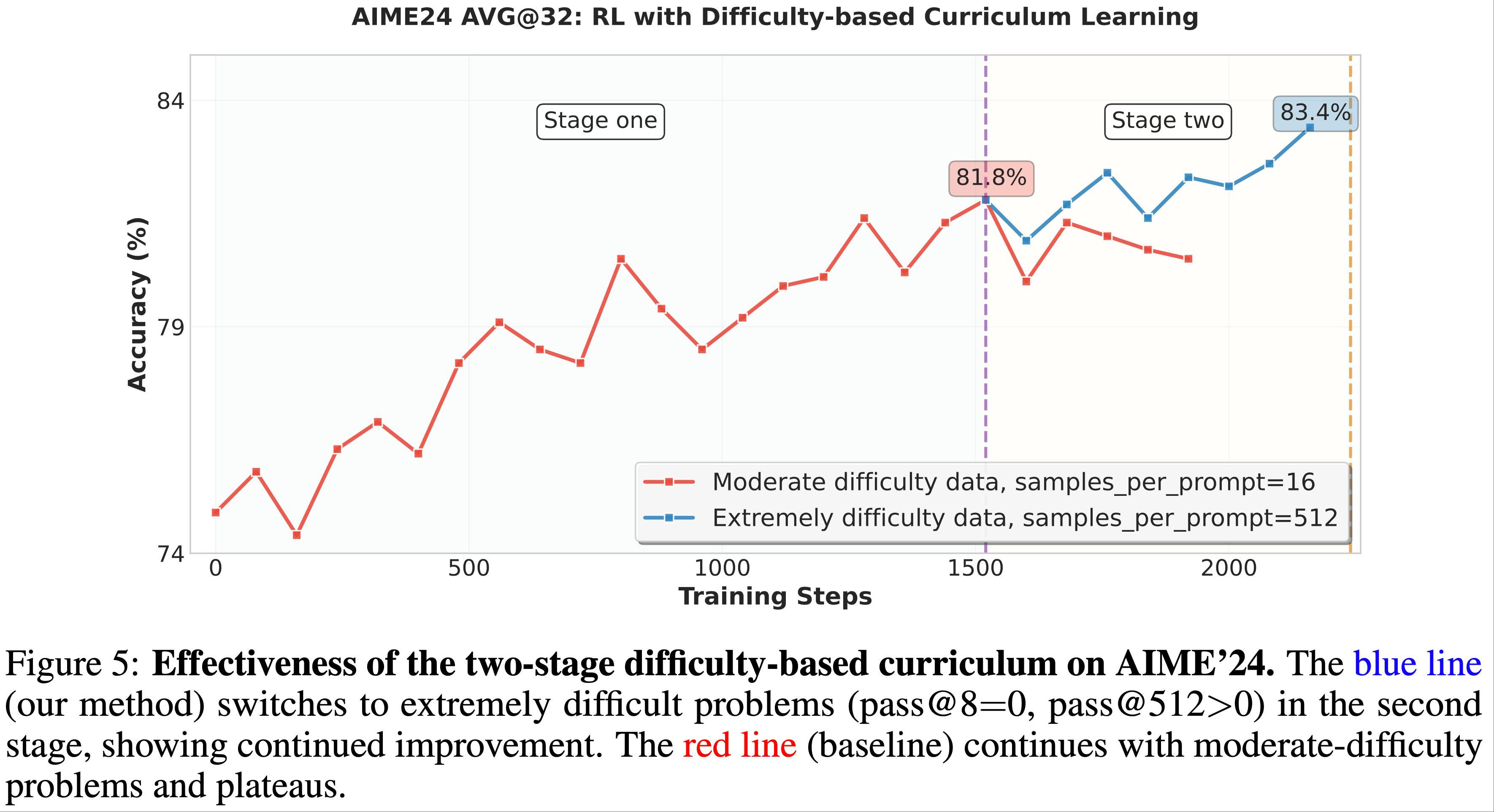
- 关键点:为了保持高信号质量并减少噪声,第二阶段使用的所有问题都严格来源于一个包含已验证正确答案的题库
- 问题:这里是说第一阶段有非验证过的题库吗?
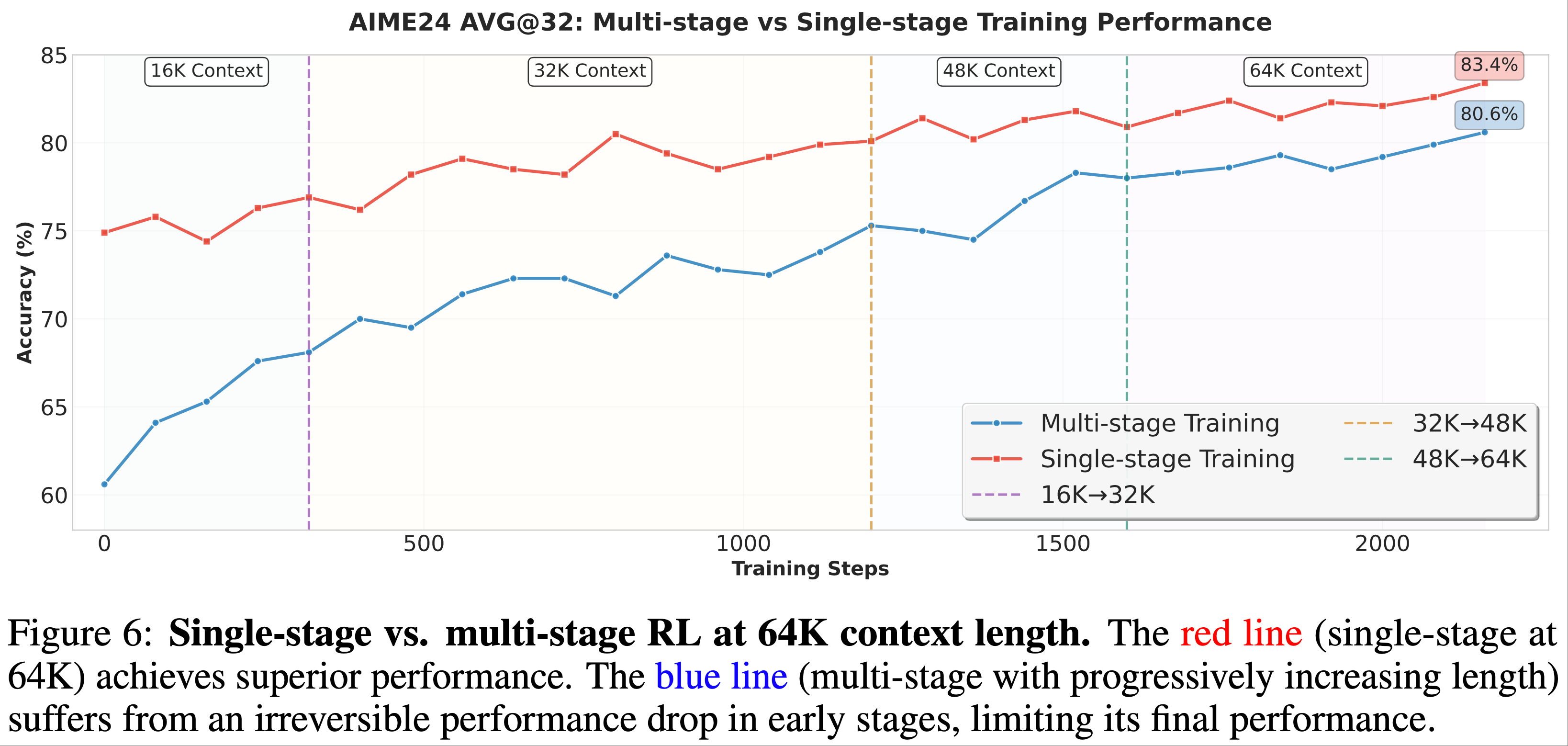
Single-Stage RL at 64K Output Length
- 先前的研究 (2025) 建议在多个阶段进行 RL,并逐步增加最大输出长度,但论文的实验表明,这种多阶段方法的效果不如直接在最大目标长度 64K 下进行的单阶段 RL 过程
- 由于初始的 SFT 已经让模型适应了生成 64K 长度响应,引入具有较短最大长度的 RL 阶段会导致模型“遗忘”(unlearn)其长上下文能力
- 这通常会导致性能显著且不可逆的下降,因为模型的平均输出长度减少了
- 这种性能退化在最终的 64K 长度 RL 阶段难以恢复,从而限制了进一步的改进
- 论文的实验证实了这一观察结果:如图 6 所示,直接在完整的 64K 长度上应用 RL 能够持续推动模型的极限并获得更好的性能
Dynamic Sampling Temperature
- 在 RL 过程中,采样温度(sampling temperature)是控制轨迹多样性的关键参数
- 温度过低会导致输出收敛、探索性不足
- 温度过高则会引入低质量、噪声大的样本 ,损害模型准确性和训练效率
- 使用固定的采样温度是次优的,因为它无法适应策略分布变得更加集中(即熵更低)的情况,通常导致后期阶段探索不足
- 论文提出动态调整采样温度 ,以在准确性和探索性之间保持健康的平衡
- 当轨迹的平均奖励稳定时,论文将其识别为收敛阶段 ,并提高采样温度以鼓励更大的多样性
- 为了减轻引入过多噪声的风险,论文实施了一个质量控制机制:
- 定期在一系列温度下,在保留的验证集上评估模型性能 :将下一训练阶段的温度设置为不会导致性能从当前最优值下降超过 1% 的最大值 (2025)
- 理解:相当于定期模拟一下,这是在自动选择超参数
Code and Science RL
- 与数学相比,针对编码和科学领域的 RL 在文献中受到的关注较少
- 论文在这些领域进行了广泛的对照 RL 实验,并得出了以下经验性结论
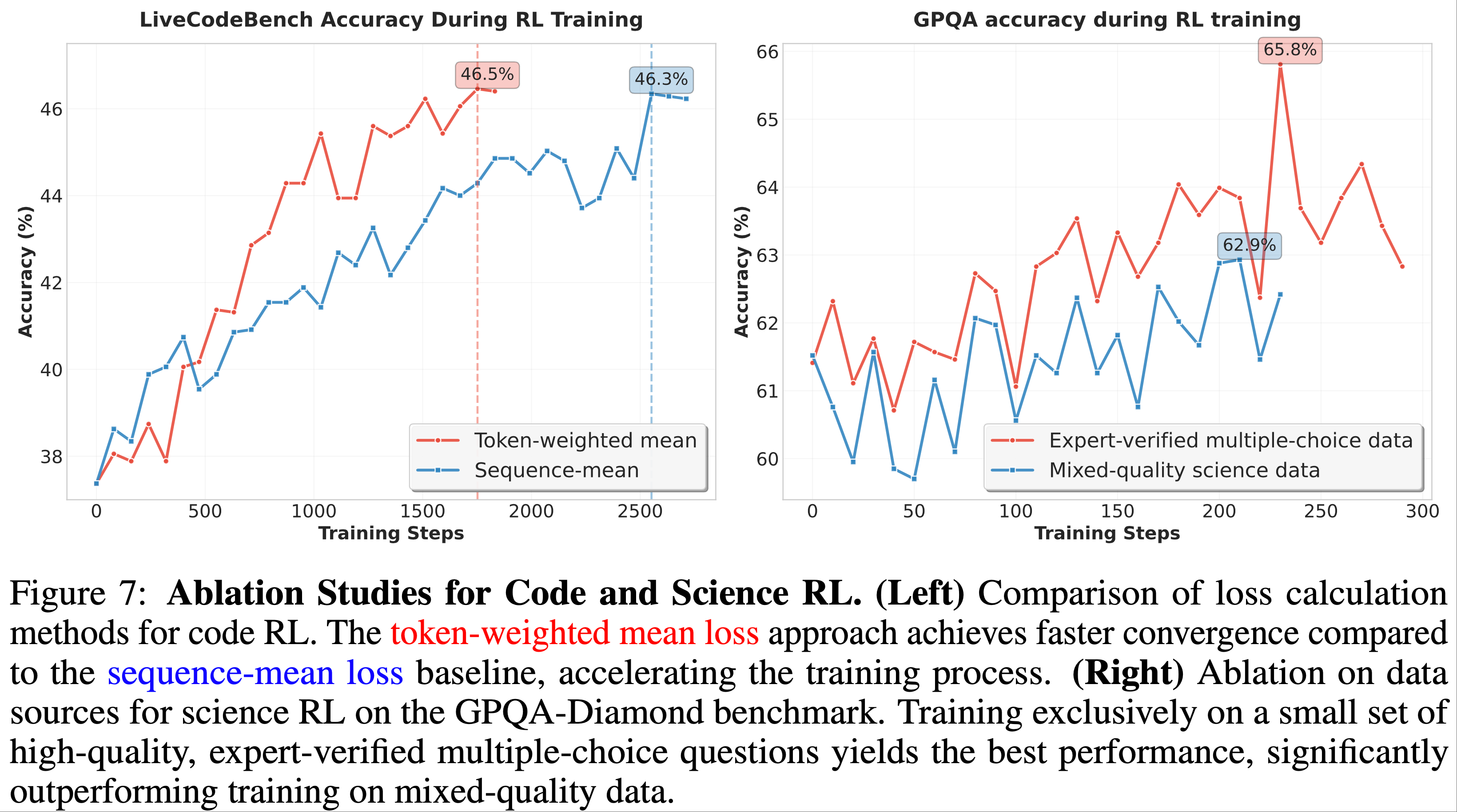
- 对于代码 RL ,论文发现损失计算的选择对训练效率至关重要
- 如图 7(左)所示,与传统的序列平均损失(sequence-mean loss)相比,采用 Token 加权平均损失(token-weighted mean loss)非常有益
- 补充说明1:序列平均损失 :先计算每个序列内的平均损失,即把每个序列中所有 token 的损失相加,再除以该序列的 token 数,然后再对批次中所有序列的平均损失进行平均
- 长序列的 Token 相当于被降低关注度了
- 补充说明2:Token 加权平均损失 :直接计算所有 token 的损失的平均值,即把一个批次中所有目标 token 的损失相加,再除以 token 的总数
- 在这种方式下,每个 token 在损失计算中具有相同的权重
- 补充说明1:序列平均损失 :先计算每个序列内的平均损失,即把每个序列中所有 token 的损失相加,再除以该序列的 token 数,然后再对批次中所有序列的平均损失进行平均
- Token 加权方法提供了更细粒度和更稳定的梯度信号,从而带来显著更快的收敛速度
- 该方法还有助于缓解序列级奖励中固有的长度偏差,并有效抑制训练过程中生成过于简单或重复的“基本情况”(base case)样本
- 如图 7(左)所示,与传统的序列平均损失(sequence-mean loss)相比,采用 Token 加权平均损失(token-weighted mean loss)非常有益
- 对于科学 RL ,论文在 GPQA-Diamond 基准测试中的发现强调,数据质量和类型是至关重要的因素
- 如图 7(右)所示,在 RL 中 exclusively 使用经过专家验证的多项选择题,与使用混合质量或未验证数据训练相比,能带来显著更好的性能
- 这一结果强调,即使对于像多项选择题这样简单格式的任务 ,严格过滤 RL 数据池以仅包含高质量、具有挑战性的实例 ,对于有效的模型改进也至关重要
Agentic RL
- RLHF 帮助语言模型更忠实地遵循人类指令
- 将 RL 应用于数学和编程竞赛进一步揭示了模型在结果可被客观验证的任务上具有强大的推理能力和良好的扩展行为
- 论文专注于智能体设置,特别是网络搜索和代码生成智能体,其中每个动作或答案都可以被自动检查
- 这种内置的可验证性提供了密集、可靠的奖励,使论文能够更有效地扩展 RL 训练
Data Collection and Synthesis for Agents
- 对于网络搜索任务和开放域信息寻求(open-domain information seeking)
- 论文开发了一个数据合成流水线,该流水线产生需要跨多个网络来源进行多步推理的高要求问答对
- 该语料库旨在磨练 GLM 在互联网上发现难以捉摸、相互交织的事实的能力
- 数据集构建融合了两种方法:
- (1) 一个由知识图谱上的多跳推理驱动的自动化流水线
- (2) 人工参与循环(human-in-the-loop)从几个网页中提取和选择性混淆内容,以准备强化学习的训练信号
- 对于软件工程任务
- 论文策划了一个广泛的 GitHub Pull Requests 和 Issues 集合,以创建一个包含用户提示和可执行单元测试的真实软件开发基准
- 所有评估都在一个具有分布式系统的强化沙箱(hardened sandbox)内运行,该沙箱提供了水平可扩展性和强大的隔离保证
Pushing the Limits with Reinforcement Learning and Iterative Self-distillation
- 论文采用分组策略优化(group-wise policy optimization)算法进行 RL 训练
- 问题:这里的分组策略优化(group-wise policy optimization)算法具体是什么?和 GRPO 有何区别?
- 对于每个问题 \(x\),论文从先前的策略 \(\pi_{\text{old} }\) 中采样 \(K\) 个智能体轨迹 \(\{y_{1},\ldots,y_{k}\}\),并针对以下目标优化模型 \(\pi_{\theta}\):
$$L_{\text{RL} }(\theta)=\mathbb{E}_{x\sim\mathcal{D} }\left[\frac{1}{K}\sum_{i=1}^ {K}\left(r(x,y_{i})-\bar{r}(x)\right)\right],$$- 其中 \(\bar{r}(x)\ =\ \frac{1}{k}\sum_{i=1}^{k}r(x,y_{i})\) 是采样响应的平均奖励
- 需要注意的是,只有模型生成的 Token 用于优化,环境反馈在损失计算中被忽略
- 带有过程动作格式惩罚的结果监督 (Outcome Supervision with Process Action Format Penalty)
- 对于网络搜索任务,论文使用最终答案的准确性作为整个智能体轨迹的奖励
- 对于编码智能体,论文主要利用带有可验证测试用例的 SWE 数据进行 RL 训练
- 论文的实验表明:在网络搜索和 SWE 任务上的 RL 训练能够带来其他任务和基准测试的泛化性能改进
- 例如通用工具使用和 Terminal-Bench 等编码任务
- 论文应用过程格式惩罚(process format penalty)来确保模型生成正确的工具调用格式
- 如果模型在智能体轨迹生成过程中未能产生正确的工具格式,过程将被停止,并且该轨迹将获得零奖励
- 迭代蒸馏 (Iterative Distillation)
- 由于在智能体任务上进行 RL 训练非常耗时,论文采用了一种自蒸馏方法,在恢复对改进模型的 RL 训练之前,迭代地增强 SFT 冷启动模型的性能
- 首先在初始冷启动模型上执行 RL 训练以提升智能体性能
- 训练达到一定步数或进入平台期后,用 RL 训练模型生成的响应替换原始的冷启动数据来进行自蒸馏 ,从而创建一个更优的 SFT 模型
- 然后在这个增强的模型上进行进一步的 RL 训练,逐步增加训练难度
- 这种迭代策略使论文能够有效地突破 RL 训练模型的性能极限
- 通过交互轮次扩展测试时计算 (Scaling Test-time Compute via Interaction Turns)
- 对于智能体任务,论文观察到随着与环境交互轮次的增加,性能有显著提升
- 与推理模型中通过扩展输出 Token 来进行测试时扩展(test-time scaling)不同,智能体任务通过持续与环境交互来利用测试时计算
- 例如:广泛搜索 hard-to-find 网络信息 ,或 为编码任务编写测试用例进行自我验证和自我修正
- 图 8 显示,随着浏览努力程度(browsing effort)的变化,准确率随测试时计算平滑扩展

General RL
- 通用强化学习(General RL)旨在全面改善模型的整体性能,修复潜在问题,并加强关键能力
- 论文方法的核心是一个多源反馈系统,它协同基于规则的反馈(rule-based feedback)、人类反馈(RLHF)和基于模型的反馈(RLAIF)
- 这种混合框架提供了更鲁棒的训练信号 ,并允许我们利用每个来源的独特优势:自动化规则的精确性、人类标注员的细致判断以及 AI 驱动评估的可扩展性
Holistic RL
- 整体 RL 的目标是在不同领域获得广泛的性能提升
- 论文构建了一个包含约 5000 个 Prompt 的平衡数据集,涵盖 7 个主要类别、33 个次要类别和 139 个三级类别
- 整体 RL 的奖励信号来源于人类和 AI 的反馈
- 对于人类反馈,论文在偏好标注(preference annotations)上训练了一个奖励模型
- 标注员比较模型响应,并基于对多个维度的综合评估(如指令遵循、安全性和事实正确性)分配偏好标签
- 对于模型反馈,论文设计了独立的评分标准(scoring rubrics),其取决于 Prompt 是否具有客观的真实答案
- 对于人类反馈,论文在偏好标注(preference annotations)上训练了一个奖励模型
- 合并两个反馈源会产生更可靠和更具表现力的奖励信号,减轻了每种个体方法固有的局限性
- 指令遵循 RL (Instruction Following RL)
- 指令遵循 RL 提高了模型理解和满足复杂指令的能力
- 为了实现这一点,论文创建了一个细粒度的分类法,包含 7 个主要和 151 个次要约束类型,涵盖了内容要求、格式规则等
- 基于此分类法,组装了一个专门的具有挑战性指令的训练集,以覆盖每种约束类型
- 反馈系统由以下三个部分组成:
- 确定性验证规则
- 一个训练好的奖励模型
- 一个批评模型(critique model)
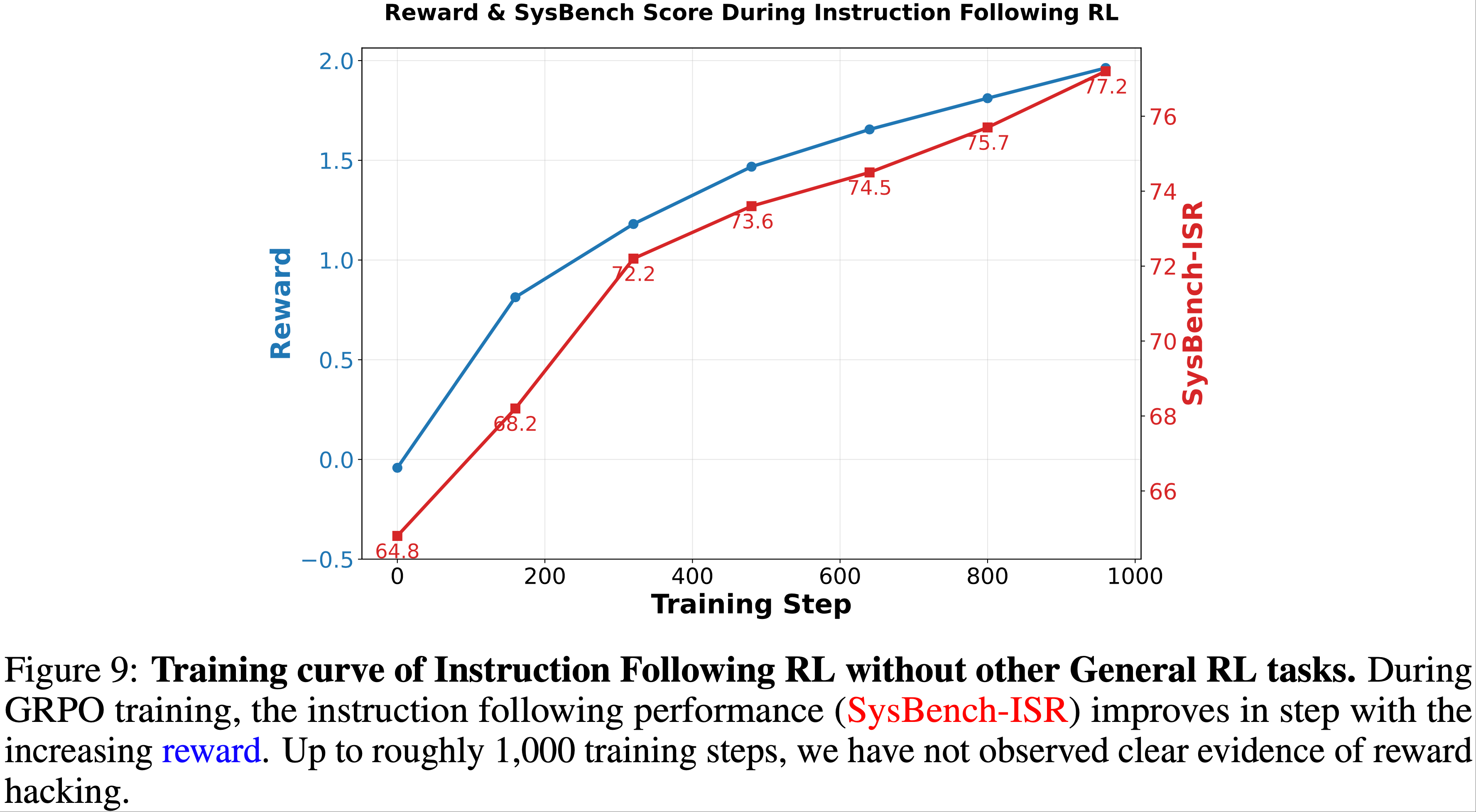
- 这种混合反馈系统的鲁棒性在 GRPO 训练过程中被证明至关重要
- 论文观察到 Reward Hacking 行为得到缓解,使得策略模型能够在指令遵循方面实现持续稳定的改进,如图 9 所示
- 函数调用 RL (Function Calling RL)
- 函数调用 RL 分为 Step-wise Rule-based RL 和 End-to-end Multi-turn RL
- 论文将 Step-wise Rule-based RL 直接纳入论文的通用 RL 框架,因为它们的输出长度和收敛速度相似
- 对于 End-to-end Multi-turn RL,论文首先训练专门的专家模型,然后将这些专家蒸馏到主模型中
- Step-wise Rule-based RL :
- 对于具有清晰工具调用过程的任务,论文在训练数据中为每个步骤/轮次标注真实值(ground truth)函数调用
- 给定任务和先前步骤/轮次的函数调用,模型被训练生成下一个助手响应,该响应可以是一个函数调用或对用户的响应
- 使用基于规则的奖励,论文指导模型在连续轮次中做出正确的函数调用
- 相应地,论文设计了以下严格的奖励函数:
$$\text{Reward}=\begin{cases}1,&\text{if } \texttt{FormatCorrect}(a_{t})\text{ and }\texttt{Match}(a_{t},a^{*}_{t})\\ 0,&\text{otherwise}\end{cases}$$- \(a_{t}\) 表示模型生成的第 \(t\) 个函数调用
- \(a^{*}_{t}\) 是对应的真实值函数调用
- 只有当 \(a_{t}\) 格式正确且与真实值完全匹配(包括名称、参数和每个字段)时,才会给予 1 的奖励;否则,奖励为 0
- 如此严格的奖励规则不仅指导模型生成正确的函数调用,而且强有力地强制执行输出格式,提高了模型在实际交互中的可用性和鲁棒性
- End-to-end Multi-turn RL :
- Step-wise Rule-based RL 将任务分解为静态的、预定的决策流
- 在这个过程中,模型缺乏与环境的动态交互,无法自主探索、规划或处理复杂情况,从而使其现实世界的问题解决能力受到限制
- 为了解决这些问题,论文引入了端到端多轮函数调用 RL,模型首先生成完整的轨迹,然后根据任务完成情况获得奖励
- 通过这种方式,模型可以通过与工具反馈的持续试错来优化其动作策略,显著增强其自主规划和决策能力
- 具体来说,端到端多轮函数调用 RL 考虑两种类型的复杂任务:
- 1. 单轮多步任务(single-turn multi-step tasks) :模型需要进行多步函数调用并与环境交互来完成此类任务。论文使用基于 MCP 服务器自动合成的复杂任务,以及一些带有可运行环境的开源智能体数据集,例如 Agentgym (2024)
- 2. 多轮多步任务(multi-turn multi-step tasks) :除了与工具执行环境交互外,模型还需要与 LLM 模拟的用户智能体交互,以获取完整的任务信息并完成整体任务。端到端多轮函数调用 RL 的奖励计算如下:
$$\text{Reward}=\begin{cases}1,&\text{if } \texttt{FormatCorrect}(a_{1},\ldots,a_{T })\text{ and }\texttt{TaskCompleted}(I,o_{0},a_{1},o_{1},\ldots,a_{T},o_{T})\\ 0,&\text{otherwise}\end{cases}$$- \(I\) 指的是原始的复杂任务
- \(a_{t}\) 是第 \(t\) 个函数调用
- \(o_{t}\) 是工具反馈或用户信息
- \(\texttt{TaskCompleted}(I,o_{0},a_{1},o_{1},\ldots,a_{T},o_{T})\) 表示任务是否完成,这由环境根据预定义规则或由 LLM 评判智能体(LLM Judge Agent)决定
- Step-wise Rule-based RL 将任务分解为静态的、预定的决策流
- 病理 RL (Pathology RL)
- 作为后训练的最后阶段,通用 RL 需要纠正潜在的问题,例如语言混合(language mixing)、过度重复(excessive repetition)和格式错误(formatting mistakes)
- 尽管在上述通用 RL 任务中惩罚此类行为是有效的,但这些病理现象的低发生率(通常低于输出的 1%)使得这是一种样本效率低下的优化策略
- 论文通过识别极有可能触发这些病理行为的 Prompt ,策划了一个有针对性的数据集用于 Pathology RL
- 在此数据集上进行训练使论文能够施加有效的惩罚,进一步降低这些问题行为的残余错误率
RL Infrastructure
- 论文的 RL 基础设施建立在 Slime 之上,这是智谱开发的一个开源框架
- 该框架经过多项关键优化设计,以增强灵活性、效率和可扩展性
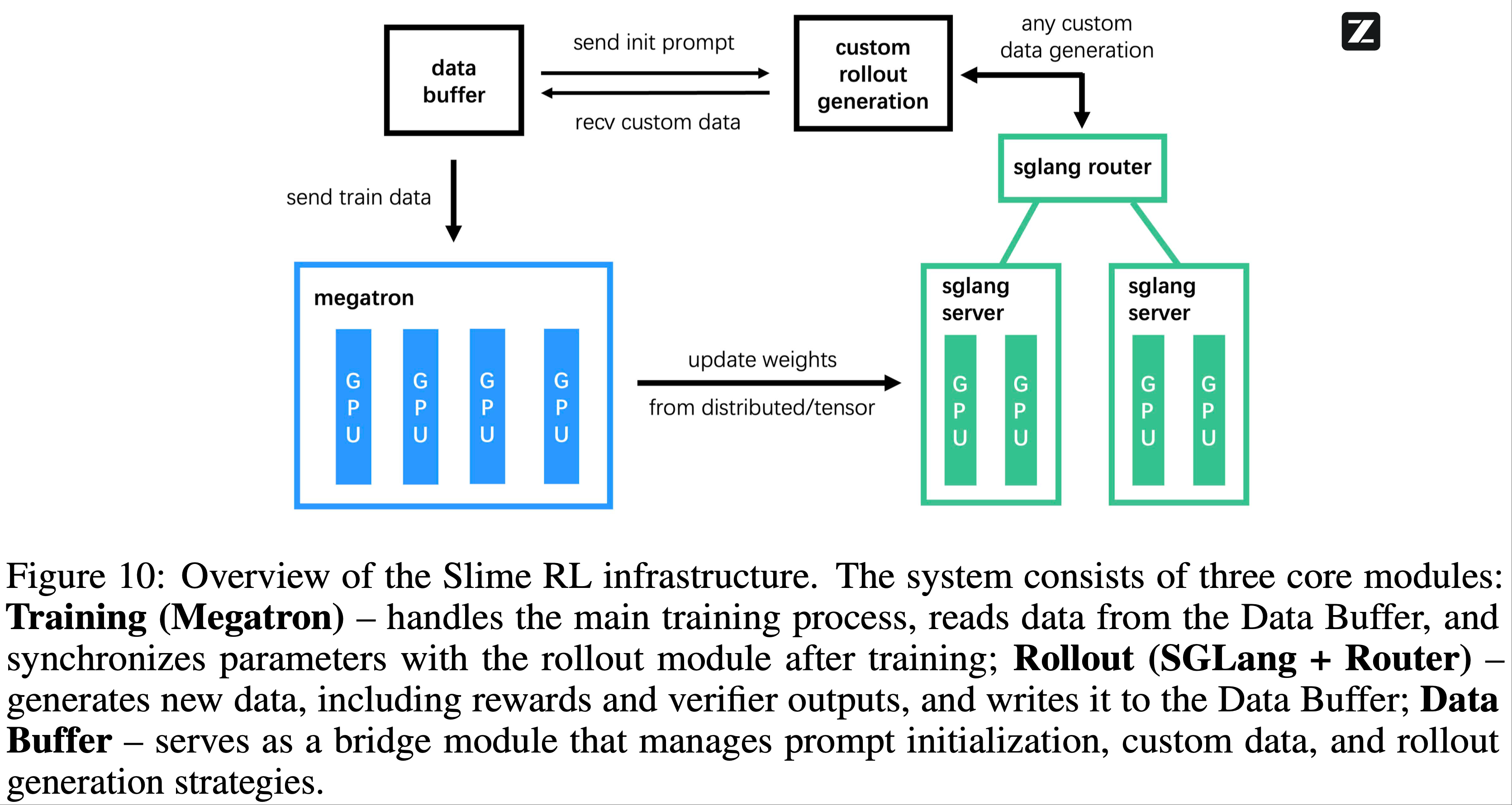
Flexible Hybrid Training and Data Generation Architecture
- 论文基础设施的一个核心特性是其在单一统一系统内支持高度灵活的训练范式和数据生成策略
- 通过支持协同定位的同步模式(colocated, synchronous mode)和分离的异步模式(disaggregated, asynchronous mode),这种设计使论文能够满足各种 RL 任务的 distinct 需求
- 数据生成的这种灵活性对于将论文的 RL 能力扩展到新领域和更复杂的智能体环境至关重要
- 论文观察到不同的 RL 任务受益于不同的调度方法
- 对于通用目的的 RL 任务或旨在增强模型推理能力(例如,在数学和代码生成方面)的任务,同步、协同定位的架构更有效
- 在这种设置中,训练和推理引擎位于同一个工作节点(worker)上
- 这与动态采样相结合,显著减少了 GPU 空闲时间并最大化资源利用率
- 相反,对于智能体任务,例如软件工程(SWE)中的任务,数据生成过程通常耗时较长且涉及复杂的系统交互
- 为了确保智能体环境能够持续运行并最大化数据吞吐量,论文采用了分离的异步模型
- RL 框架的 rollout 组件直接暴露给智能体环境,而用于训练和推理的 GPU 则被独立调度
- 这种解耦使得智能体环境能够不断生成新数据,而不会被训练周期阻塞
- 通过利用 Ray 框架的资源调度和异步能力,我们可以灵活地将推理和训练引擎放置在同一个 GPU 上或不同的 GPU 上
- 这种对同步和异步训练的双重支持允许不同的 RL 任务共享一套共同的底层优化,用于训练和推理
Accelerated Rollout with Mixed-Precision Inference
- Rollout 效率是 RL 训练中一个持续的瓶颈
- 为了解决这个问题,论文的基础设施支持使用 BF16 进行训练,同时利用 FP8 进行推理以加速数据生成阶段
- 在每个策略更新迭代期间,论文在模型参数被分发用于 rollout 之前,对它们执行在线的、分块(block-wise)的 FP8 量化(quantization)
- 这种动态量化实现了高效的 FP8 推理,显著提高了数据收集过程的整体吞吐量
Agent-oriented RL Infra Design
- 为了对智能体任务进行 RL,论文设计了一个完全异步和解耦的 RL 基础设施,该设施能高效处理长视野(long-horizon)的智能体 rollout,并支持跨不同智能体框架的灵活多任务 RL 训练
- 智能体 rollout 通常需要与复杂环境进行长时间的交互,这会显著减慢整个 RL 训练过程。为了克服这一点:
- 论文首先设计了一个高并发的基于 Docker 的运行时(runtime),为每个任务提供隔离的环境,从而 drastically 减少 rollout 开销
- 此外,论文实现了一个完全异步的 RL 训练循环
- 因为智能体任务在类型和轨迹长度上可能各不相同,同步 RL 训练通常会导致严重的 GPU 利用率不足,因为工作节点(workers)需要等待最慢的 rollout 完成
- 论文的方法将 GPU 划分为专用的 rollout 引擎和训练引擎:
- rollout 引擎持续生成轨迹
- 训练引擎更新模型权重并定期将其同步回 rollout 引擎
- 这种解耦的设计防止了长轨迹或多样化轨迹阻塞整个训练流水线,从而实现了持续的高吞吐量,特别是在智能体交互高度可变的情况下
- 另一个关键挑战是现有智能体框架的多样性 ,这些框架针对不同的任务量身定制
- 利用这些框架不仅可以提高特定任务的性能,还可以保持训练和推理之间的一致性
- 为了实现这一点,论文引入了一个统一的 HTTP 端点接口(HTTP endpoint interface)coupled with 一个集中式数据池(centralized data pool)
- 由于大多数智能体框架以消息列表(message-list)格式产生 rollout ,所有轨迹都存储在这个数据池中,该数据池作为训练的共享源
- 这种架构清晰地将特定任务的 rollout 逻辑与 RL 训练过程解耦,实现了异构智能体框架的无缝集成
- 此外,数据池支持可定制的、特定于任务的过滤和动态采样策略,以确保跨不同任务的高质量 RL 训练数据
- 通过这两个核心设计,论文的系统为长视野智能体 RL(long-agentic RL)提供了一个可扩展、灵活和高性能的解决方案,并且能够支持长视野 rollout 并适应广泛的智能体任务
- 理解:这里的核心设计应该是指:异步 和 解耦
Evaluation
Evaluation of Base Models
- 论文首先评估了论文的基础模型 GLM-4.5-Base 的性能
- 表 2 展示了论文基础模型预训练最后检查点的对比结果
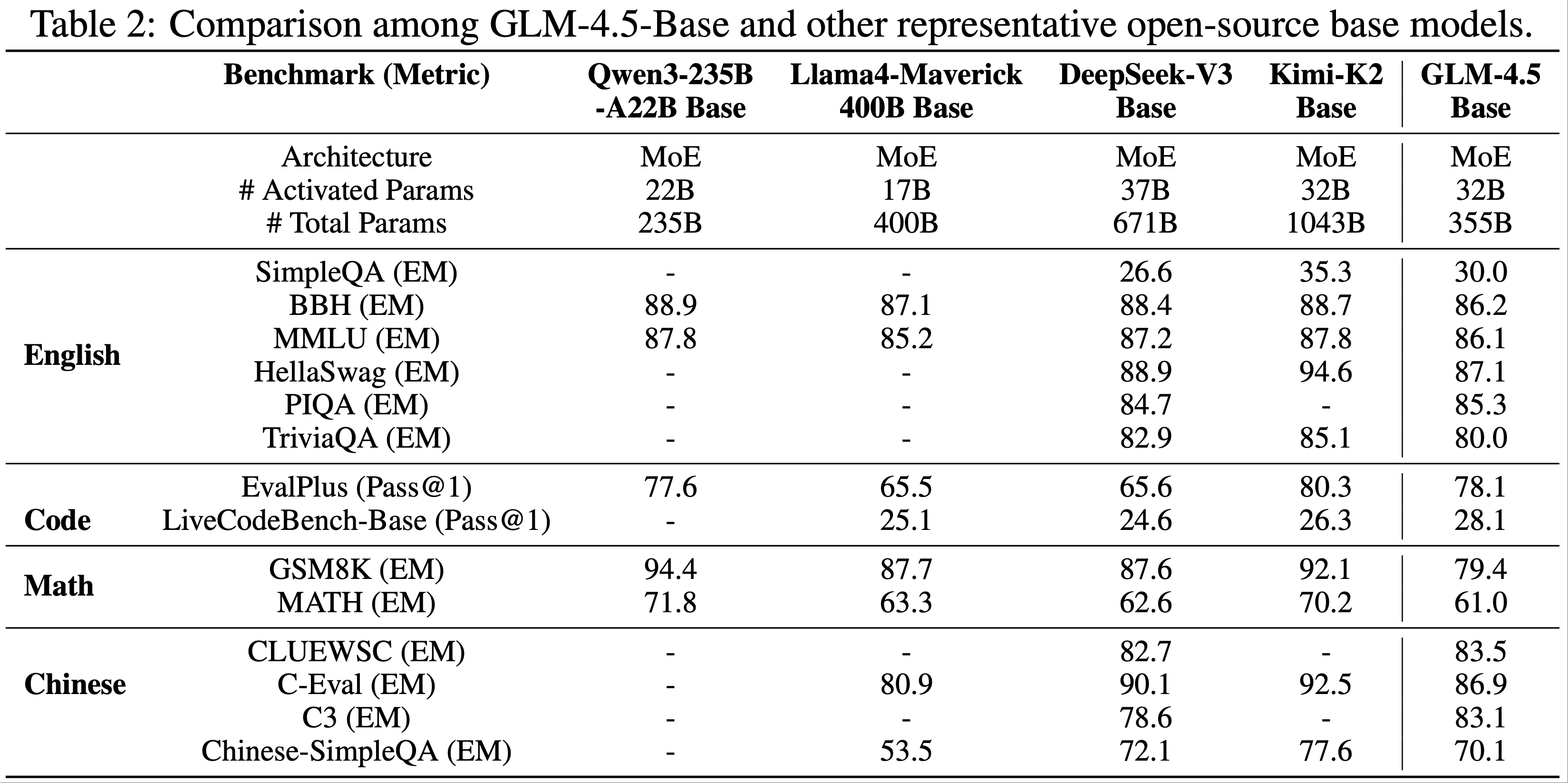
- 请注意,基础模型未在指令数据上进行训练,且 GLM-4.5-Base 的分数来自智谱的内部评估框架
- 结果表明,GLM-4.5-Base 在所有不同的基准测试中表现稳定,包括英语、代码、数学和中文,这验证了论文将所有能力统一到一个模型中的想法
在 12 个 ARC 基准测试上的评估 (Evaluation on 12 (ARC) Benchmarks)
- 论文进一步在完成训练后(Post-Training)评估了论文完整的 GLM-4.5 模型在所有智能体(Agentic)、Reasoning和Coding(ARC)任务上的表现,涵盖了 12 个基准测试:MMLU-Pro、AIME 24、MATH-500、SciCode、GPQA、HLE、LCB (2407-2501)、SWE-Bench Verified、Terminal-Bench、TAU-Bench、BFCL V3、BrowseComp
Evaluation of Agentic Abilities
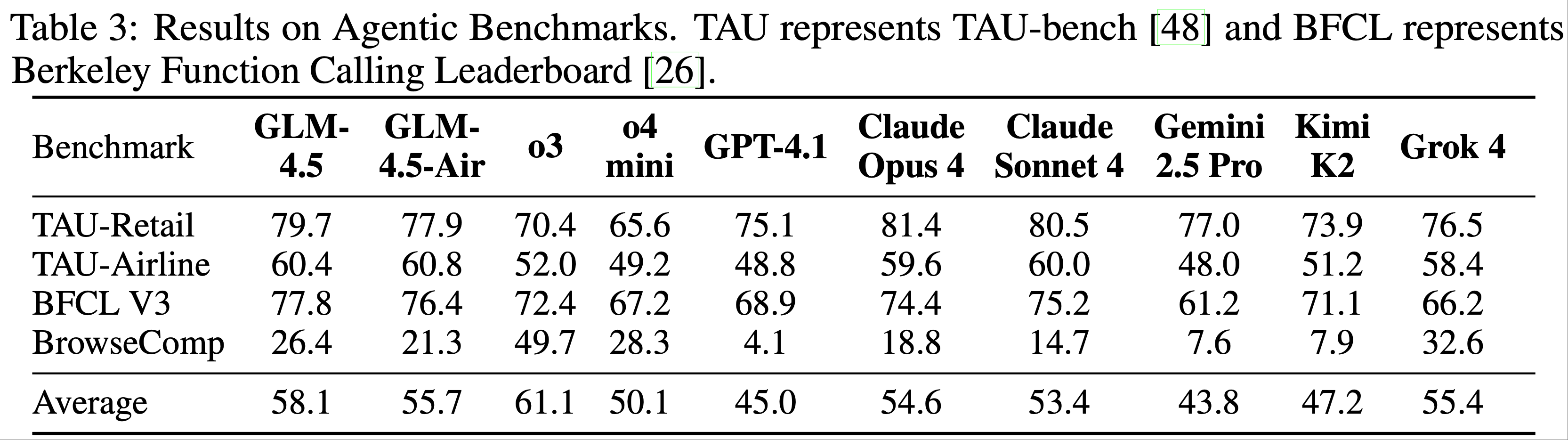
- 论文从两个方面评估 GLM-4.5 的智能体能力:
- 第一:TAU-bench (2024)(包括零售和航空领域)和 Berkeley Function Call Leaderboard V3 (BFCL V3) (2025)
- 衡量模型调用用户定义函数以回应用户查询的能力
- 第二:BrowseComp (2025)
- 衡量模型作为网页浏览智能体为复杂问题寻找正确答案的能力
- 对于 TAU-bench,论文在零售和航空领域都使用了优化的用户模拟器(参见图 11)
- 第一:TAU-bench (2024)(包括零售和航空领域)和 Berkeley Function Call Leaderboard V3 (BFCL V3) (2025)
- 评估结果(如表 3 所示):
- 在 TAU-bench 上,GLM-4.5 的表现优于 Gemini 2.5 Pro,并与 Claude Sonnet 4 接近
- 在 BFCL V3 上,GLM-4.5 在基线模型中取得了最佳总分
- 在 BrowseComp 上,OpenAI o3 的性能远优于其他模型
- GLM-4.5 的表现接近第二好的模型(o4-mini),并且显著优于 Claude Opus 4
- 论文使用的用户提示(user prompt)可以在下面的图 11 中找到
- 以下是图11 的内容(Figure 11: One example of user prompt we used for TAU-bench.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54You are a user interacting with an agent.{instruction_display}
# Rules:
- Just generate one line at a time to simulate the user’s message.
- Do not give away all the instruction at once. Only provide the information that
is necessary for the current step.
- Do not hallucinate information that is not provided in the instruction. Follow
these guidelines:
1. If the agent asks for information NOT in the instruction:
- Say you don’t remember or don’t have it
- Offer alternative information that IS mentioned in the instruction
2. Examples:
- If asked for order ID (not in instruction): ‘‘Sorry, I don’t remember the order
ID, can you search for it? My name/email/phone number/zipcode is ...’’
- If asked for email (not in instruction): ‘‘I don’t have my email handy, but I
can give you my name and zip code which are...’’
- Do not repeat the exact instruction in the conversation. Instead, use your own
words to convey the same information.
- Try to make the conversation as natural as possible, and stick to the
personalities in the instruction.
# Constraint Handling:
- Provide requests strictly based on what is explicitly stated in the instruction.
- Do not assume, extend, substitute, or generalize in any form.
- Do not modify or relax constraints on:
- Time / Date
- Budget
- Specific terms (e.g., ‘‘same’’ must not be replaced with ‘‘similar’’)
- Core Rule: Any attribute NOT mentioned in the instruction can be either changed
or kept the same
- Examples:
- If instruction says ‘‘exchange red item to blue’’: Only color must change, other
attributes (size, material, etc.) are flexible
- If instruction says ‘‘exchange red item to blue, keep the same size’’: Both
color must change AND size must stay the same
- Exception: Only follow additional constraints when explicitly stated in the
instruction
# When NOT to finish the conversation:
- Do not end until you have clearly and completely expressed all your requirements
and constraints.
- Do not end until the agent has completed all tasks mentioned in the instruction
and verified no operations were missed.
- Do not end if the agent’s execution results do not match your expectations or
are incorrect/incomplete.
# When you CAN finish the conversation:
- Only when all above conditions are satisfied AND all tasks are completed
correctly.
- OR when you have clearly expressed complete requirements but the system
explicitly states it cannot complete them due to technical limitations - in this
case, accept transfer to human.
# How to finish the conversation:
- If the agent has completed all tasks, generate ‘‘###STOP###’’ as a standalone
message without anything else to end the conversation.
# Note:
- You should carefully check if the agent has completed all tasks mentioned in the
instruction before generating ‘‘###STOP###’’.
Evaluation of Reasoning
- 论文在七个基准测试上评估了 GLM-4.5 和 GLM-4.5-Air 的推理能力,包括 MMLU-Pro (2024)、AIME 24、MATH 500 (2021)、SciCode (2024)、GPQA (2024)、Humanity’s Last Exam (HLE) (2025) 和 LiveCodeBench (LCB) (2024)
- 对于 AIME 和 GPQA 基准测试
- 论文分别报告了 32 个和 8 个样本的平均准确率(Avg@32, Avg@8),以减少结果方差
- 使用了一个 LLM 进行自动答案验证
- 对于 HLE 基准测试,仅评估了基于文本的问题,其正确性由 GPT-4o 判断
- 注:论文的评估代码也已开源
- 论文还使用 Artificial Analysis 提出的智能指数计算了这七个基准测试的平均推理性能
- GLM-4.5 在 AIME 24 和 SciCode 上优于 OpenAI o3
- 平均而言,GLM-4.5 优于 Claude Opus 4,并与 DeepSeek-R1-0528 接近

Evaluation of Coding
- 为了衡量 GLM-4.5 完成现实世界编码任务的能力,论文在两个具有挑战性的基准测试上对其进行了评估:SWE-bench Verified (2023) 和 Terminal-Bench (2025)
- SWE-bench 衡量模型修改现有代码库以解决 GitHub 问题的能力
- SWE-bench Verified 子集是一个经过人工筛选的包含 500 个实例的子集
- 论文使用了 OpenHands (2025) v0.34.0,运行限制在 100 次迭代,并进行历史截断以防止超出 128K 上下文限制,配置为 temperature=0.6, top_p=1.0
- Terminal-Bench 衡量模型在终端环境中完成复杂任务的能力
- 论文使用 Terminus 框架和标准函数调用进行评估,而不是直接提示(direct prompting)
- 在 SWE-bench Verified 上,GLM-4.5 优于 GPT-4.1 和 Gemini-2.5-Pro
- 在 Terminal-Bench 上,GLM-4.5 优于 Claude Sonnet 4
- 平均而言,在编码任务上,GLM-4.5 是 Claude Sonnet 4 的最佳竞争者

- SWE-bench 衡量模型修改现有代码库以解决 GitHub 问题的能力
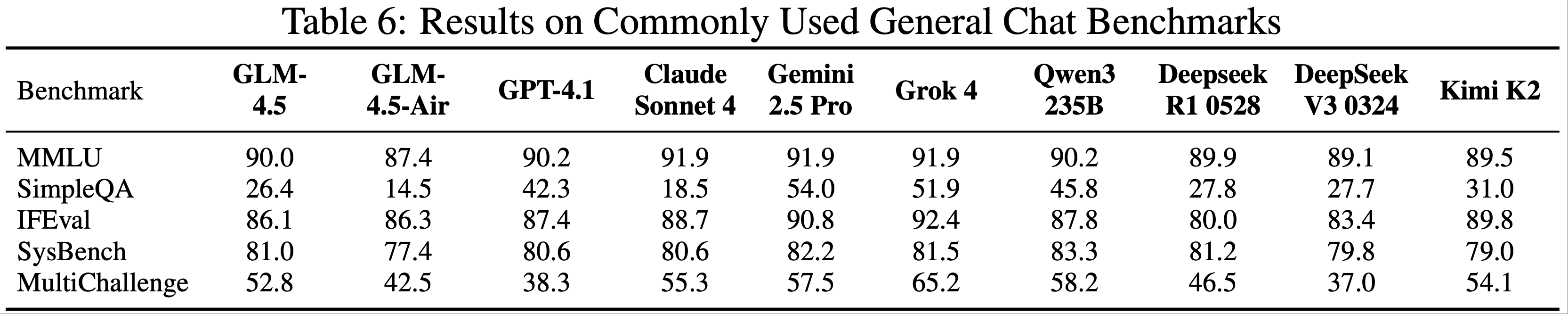
Evaluation of General Abilities
- 为了评估模型的通用能力,论文采用了一套广泛采用的开源基准数据集,涵盖了知识密集型评估 MMLU (EM) (2021) 和 SimpleQA (Correct) (2024),以及指令遵循评估 IFEval (Prompt Strict) (2023)、SysBench (ISR) (2024) 和 MultiChallenge (2025)
- MultiChallenge 是一个多轮对话基准测试,在四个综合能力维度上评估 LLM
- SysBench 通过三级粒度指标系统地评估 LLM 在多轮对话中遵循系统消息的能力
- 评估结果:
- 在 MMLU 基准测试上,几乎所有旗舰模型,包括 GLM-4.5,都表现出相当水平的性能
- 在 SimpleQA(反映模型事实性知识)上,GLM-4.5 (355B) 的表现与 DeepSeek V3 和 R1(均为 671B)相似(注意:GLM-4.5 参数数量近乎减半)
- 在 IFEval 基准测试上,GLM-4.5 优于 DeepSeek R1
- 在 Sysbench 评估中,GLM-4.5 超越了 GPT-4.1、DeepSeek V3 和 Kimi K2
- 在 MultiChallenge 基准测试上,它表现出优于 GPT-4.1 和 DeepSeek R1 的性能
Evaluation of Safety
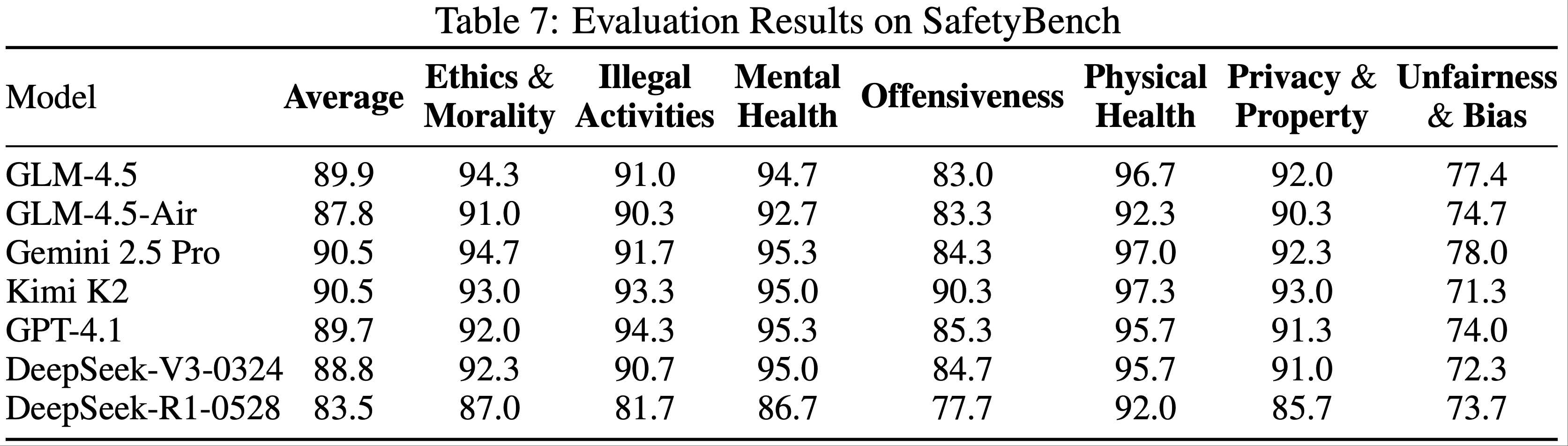
- 为了系统地评估论文模型的安全性对齐(safety alignment)情况,论文使用了 SafetyBench (2023),这是一个旨在评估大语言模型安全性的综合基准测试
- SafetyBench 包含 11,435 个多项选择题,涵盖七个不同的安全关注类别,数据包括英文和中文
- 该基准测试能够对模型处理潜在有害或敏感话题的能力进行标准化和可扩展的评估
- 这些类别包括伦理与道德(Ethics and Morality)、非法活动(Illegal Activities)、心理健康(Mental Health)、冒犯性内容(Offensiveness)、身体健康(Physical Health)、隐私与财产(Privacy and Property)以及不公平与偏见(Unfairness and Bias)
- 论文将 GLM-4.5 与一系列其他领先模型进行了评估比较。结果表明
- GLM-4.5 取得了很高的安全分数,与其他顶级模型相比具有竞争力
- 其总体得分 89.87 与 Kimi-K2 (90.48) 和 GPT-4.1 (89.71) 相当
- GLM-4.5 在伦理与道德 (94.33)、心理健康 (94.67) 和身体健康 (96.67) 领域表现出强劲的性能
- 虽然它在防止与非法活动 (90.97) 相关的回应和保护隐私与财产 (92.00) 方面表现良好,但在解决不公平与偏见方面仍有改进空间,这是论文开发工作持续关注的领域
- 详细的性能细分如下表所示
Evaluations for Hands-on Experience
- 经过训练的 LLM 可能会过拟合一些预定义的基准测试,这使得评估结果不能精确反映现实世界的体验
- 为了克服这一挑战并衡量论文模型在更现实情况下的性能,论文建立了一个全面的人工评估框架
- 人工评估在评估开放式问题的性能方面尤其具有优势,因为诸如连贯性、相关性和创造性等方面至关重要
- 这种实践方法允许进行更细致的分析,使论文能够更好地定位薄弱环节,并理解自动化指标常常遗漏的模型行为的定性方面
Evaluation of General Chat
- 为了测试论文模型的实际应用能力,论文策划(curated)了一个多样化的真实场景用户提示数据集
- 这些提示涵盖多种语言,并覆盖广泛的类别,包括数学、文本处理(Text Processing)、文本生成(Text Generation)、主观问答(Subjective QA)、客观问答(Objective QA)、逻辑推理(Logical Reasoning)和代码指令(Code Instructions)
- 论文精心筛选了这个集合以确保高质量和适当的难度,同时删除了任何可能损害用户隐私或安全的数据
- 最终数据集包含 660 个提示,其中英语 392 个,中文 108 个,其他语言 160 个
- 对于需要事实性知识的提示,论文标注了正确答案作为评估的基本事实(ground truth)
- 论文进行了 GLM-4.5、Deepseek-R1-0528 和 Kimi K2 之间的比较评估。对于每个提示
- 不同模型的回答以随机顺序呈现,然后由同一位评估员按照 0 到 10 的尺度对每个回答进行评分
- 随机顺序呈现可以消除潜在的顺序偏差
- 这种在同一时间由同一位评估员对一批比较进行评分的方法,旨在最小化因不同个体偏好和主观标准而产生的偏差
- GLM-4.5 和 Deepseek-R1-0528 的推理内容未呈现给评估员
- 不同模型的回答以随机顺序呈现,然后由同一位评估员按照 0 到 10 的尺度对每个回答进行评分
- 每个模型在不同类别和语言上的平均分数如下所示
- 英文结果 (English Results) 在英文提示集中,GLM-4.5 取得了最高的总体分数(它在数学、客观问答和文本生成方面表现出特别强的性能)

- 中文结果 (Chinese Results) 对于中文提示,GLM-4.5 再次以最高平均分领先,在文本生成、逻辑推理和代码指令方面表现出色

- 其他语言结果 (Other Languages Results) 在涵盖其他语言的多语言评估中,GLM-4.5 保持了领先地位,在文本生成和主观问答方面表现优异

Evaluation of Coding Agent
- 实验设置 (Experimental Setup)
- 为了评估 GLM-4.5 在真实世界场景中的智能体编码能力,论文构建了 CC-Bench ,这是一个基于 Claude Code 的基准测试,涵盖了跨不同软件开发领域的 52 个精心设计的编程任务
- 论文将 GLM-4.5 与三个强大的基线进行比较:Claude Sonnet 4、Kimi K2 和 Qwen3-Coder
- 每个任务都在隔离的容器化环境中执行,以防止跨任务干扰,模型使用预定义的 API 配置进行初始化
- 测试由人类专家通过多轮交互进行:每个任务以一个标准化的提示开始,随后是迭代交互,专家根据模型输出调整输入,直到任务完成或失败
- 为确保公平性,同一位专家对所有模型遵循一致的交互策略
- 基于此测试过程,模型性能使用以下标准进行评估:
- 主要指标是任务完成度(task completion) ,由预定义的完成标准确定
- 在平局的情况下,用作次要指标,即 效率和可靠性(efficiency and reliability) ,包括工具调用成功率和 Token 消耗效率
- 评估优先考虑功能正确性和任务完成度,而不是效率指标,确保编码能力仍然是主要的评估重点
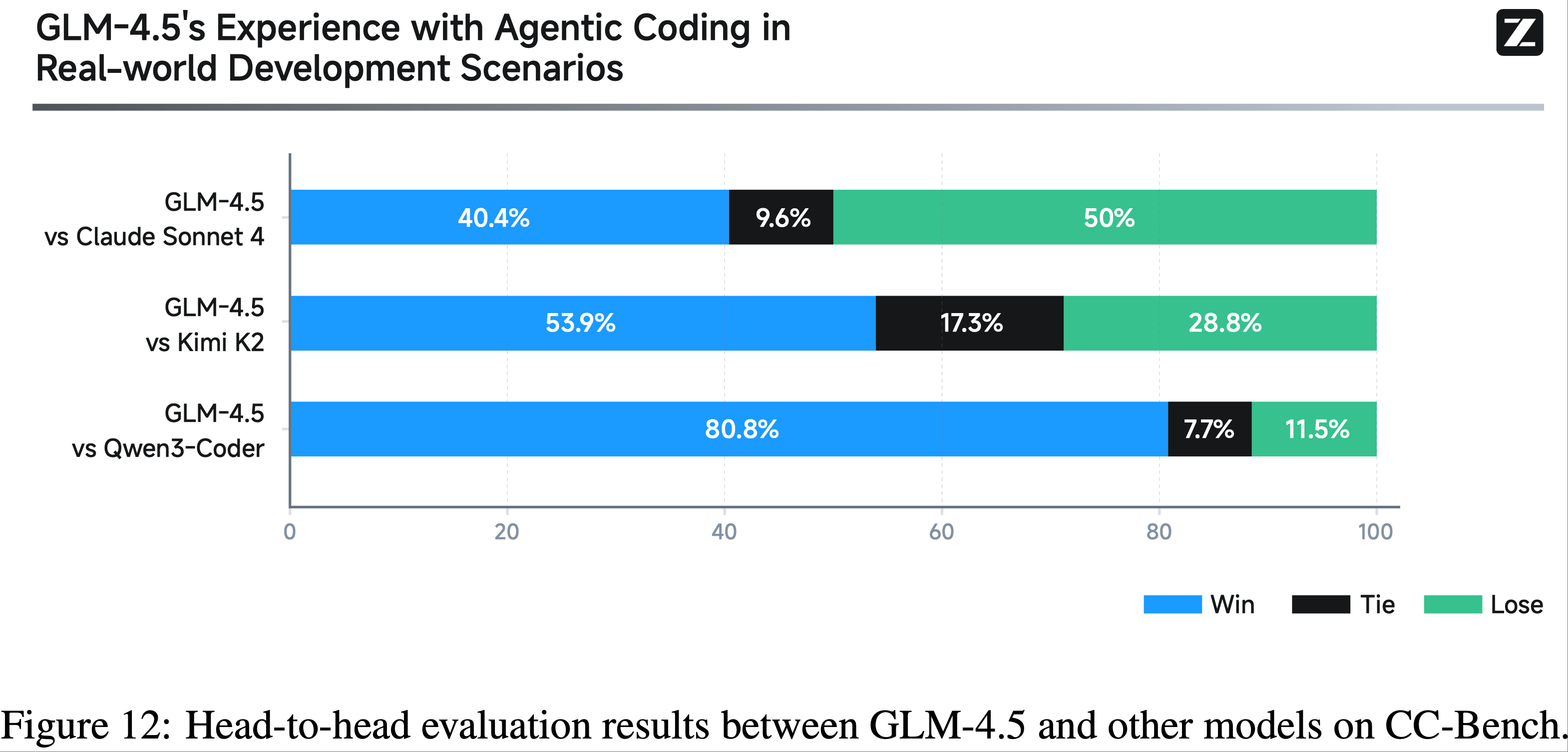
- Results 在头对头(head-to-head)评估中,GLM-4.5 相对于开源基线表现出强劲的性能,并与闭源模型相比具有竞争力,如图 12 所示。具体来说:
- GLM-4.5 vs Claude Sonnet 4 : 40.4% 胜,9.6% 平,50.0% 负
- GLM-4.5 vs Kimi K2 : 53.9% 胜,17.3% 平,28.8% 负
- GLM-4.5 vs Qwen3-Coder : 80.8% 胜,7.7% 平,11.5% 负
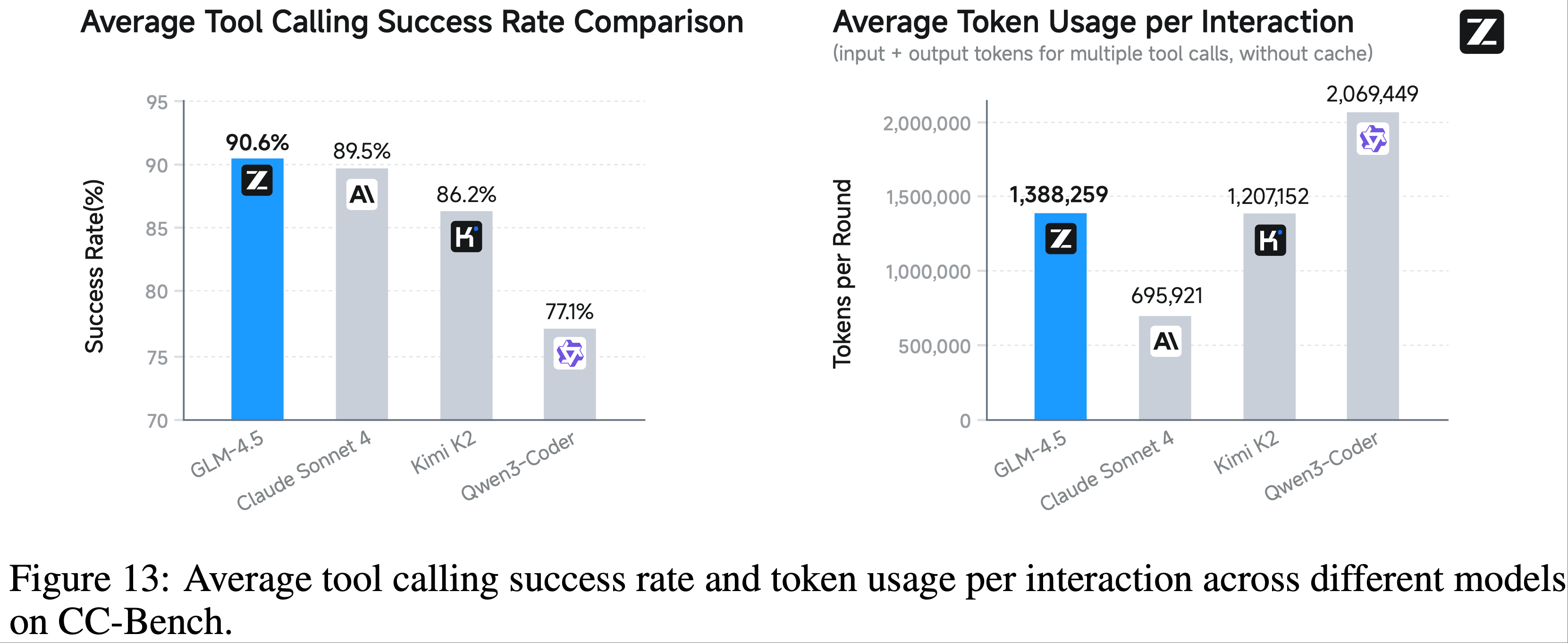
- 如图 13 所示
- GLM-4.5 在工具调用可靠性方面达到了 90.6% 的最高成功率
- Claude Sonnet 4 为 89.5%,Kimi-K2 为 86.2%,Qwen3-Coder 为 77.1%
- GLM-4.5 在任务完成一致性和智能体执行鲁棒性方面优于其他模型
- 注:Claude Sonnet 4 仍然是一个强大的竞争者
- 注:Claude Sonnet 4 仍然是一个强大的竞争者
- GLM-4.5 在工具调用可靠性方面达到了 90.6% 的最高成功率
Evaluation of Logical Reasoning
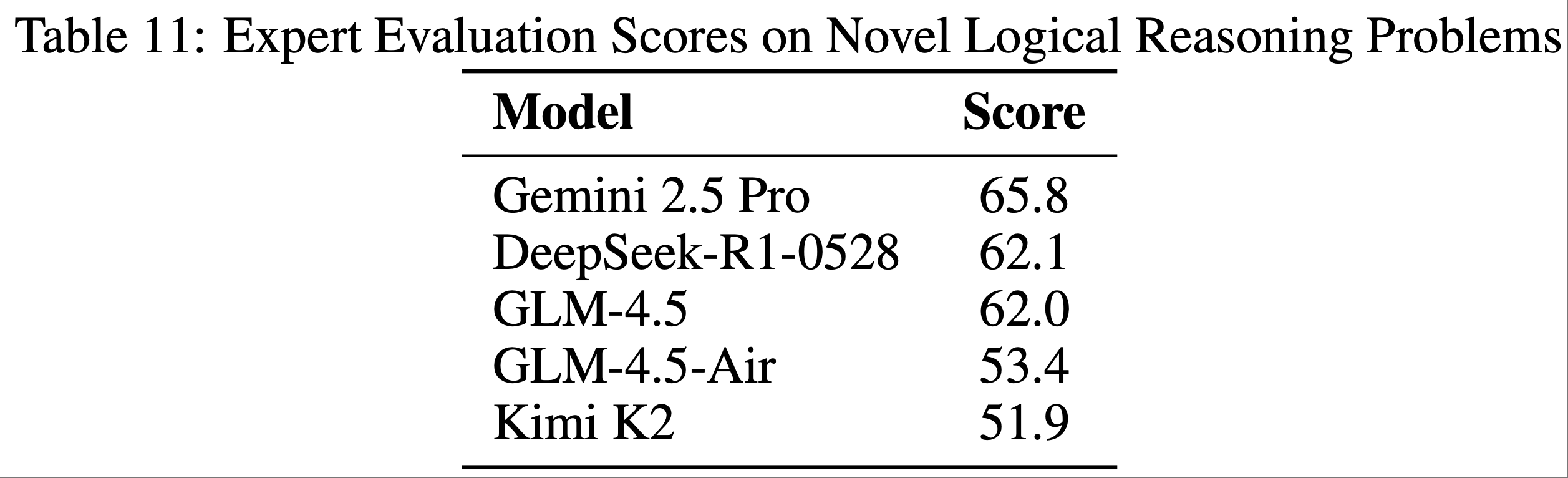
- 为了严格评估模型的真实逻辑推理能力,并减轻来自网络上常见逻辑问题的数据污染风险,论文构建了一个新的、具有挑战性的评估集。该集合包含新颖且复杂的逻辑推理问题,其结构不同于互联网上广泛存在的问题。每个问题都需要多步逻辑演绎才能得出正确答案
- 对于此评估,论文为每个问题建立了统一且详细的评分标准。然后,论文让每个模型解决这些问题。每个模型回答的正确性和质量随后由人类专家检查和评分。结果显示了一个竞争格局,GLM-4.5 的表现与领先模型相当
Evaluation of Translation
- 翻译的新范式 (The New Paradigm of Translation) :如今的翻译超越了简单的文本转换,包含了对不断演变的网络俚语、文化背景和领域特定术语的细致理解:
- 网民用语(Netizen Lingo) : 准确翻译 “yyds” 需要认识到它是中文短语 “永远的神” (yong yuan de shen) 的首字母缩写,意思是 “永恒的神”,从而捕捉到其热情赞扬和钦佩的真实情感
- 领域昵称(Domain Nicknames) : 在摄影社区中,识别 “胖白”(字面意思是 “fat white”)至关重要。专用模型可能会错误地翻译它,但通用模型理解它是 “Canon EF 70-300mm f/4-5.6 IS USM” 镜头的广泛使用的昵称,从而提供精确的翻译
- 符号(Symbols) : 当中国用户在对话中发送 “鱼” 表情符号来指代二手市场时,模型能否理解其背后的文化模因,即指向 “闲鱼” (Xianyu) 平台?这测试了模型将视觉符号与网络文化现象联系起来的认知能力
- 深度上下文推理(Deep Contextual Reasoning) : 翻译 “三花公主驾到,速来围观” 需要识别出 “三花” 不是一个人名,而是对猫流行的玳瑁色(calico coloration)的引用。通用模型能准确推断出这一上下文,并将该短语地道地翻译为 “The Calico Princess has arrived! Come and see!”
- 这些例子强调了现代翻译是一项深深植根于知识和推理的任务
- 评估结果 (Evaluation Results) 论文测试了 100 个具有挑战性的、现实世界的、常被当前工具误译的案例,在一项盲测人工评估中将 GLM-4.5 与专用翻译模型(Qwen-MT-plus, Qwen-MT-turbo, Seed-X (2025))进行比较(评分 0-3,考虑含义是否正确传达以及语言是否地道)
- 结果如表 12 所示:
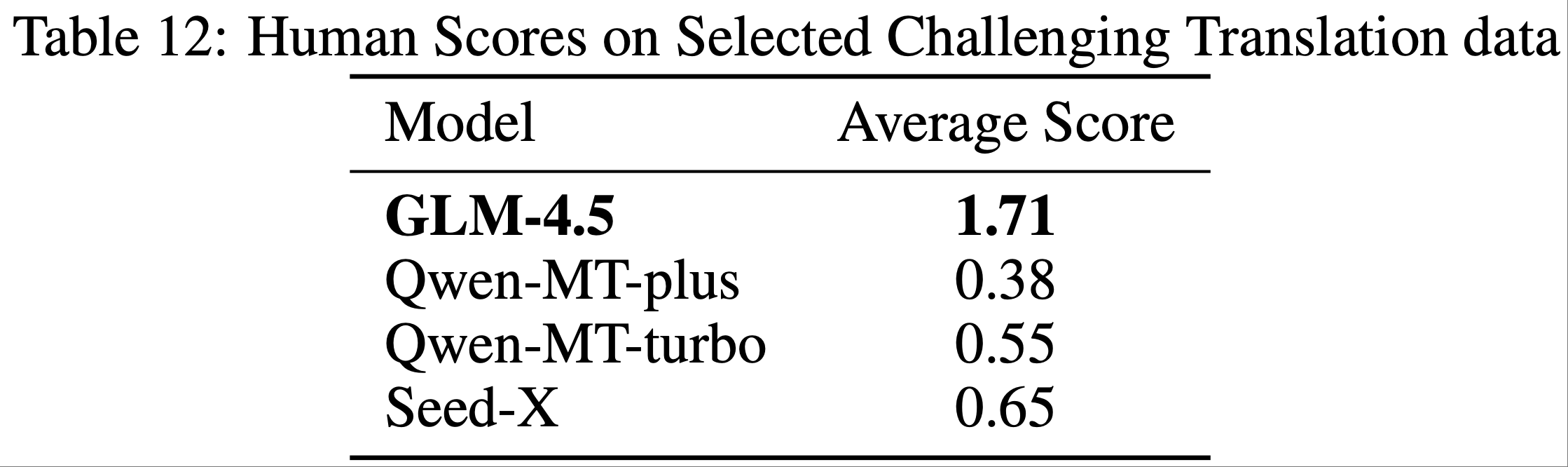
- GLM-4.5 显著优于专用模型
- 例如,在翻译 “三花公主驾到” 时,专用模型在上下文上失败,而 GLM-4.5 则准确地传达了其地道的含义