注:本文包含 AI 辅助创作
参考链接:
注:暂时仅关注 Post-training 部分
Paper Summary
- 评价:
- ERNIE 5.0 26年1月刚线上线时,LMArena 排名位于国内第一,最高曾至第 6 名(截止到 20260210 日本文写作时位于 11 名),在用户体验方面是做的很好的
- 补充:在 20260212 日被 GLM-5 超过
- ERNIE 5.0 没有开源模型权重,只有本次的技术报告
- 模型大小是 万亿参数
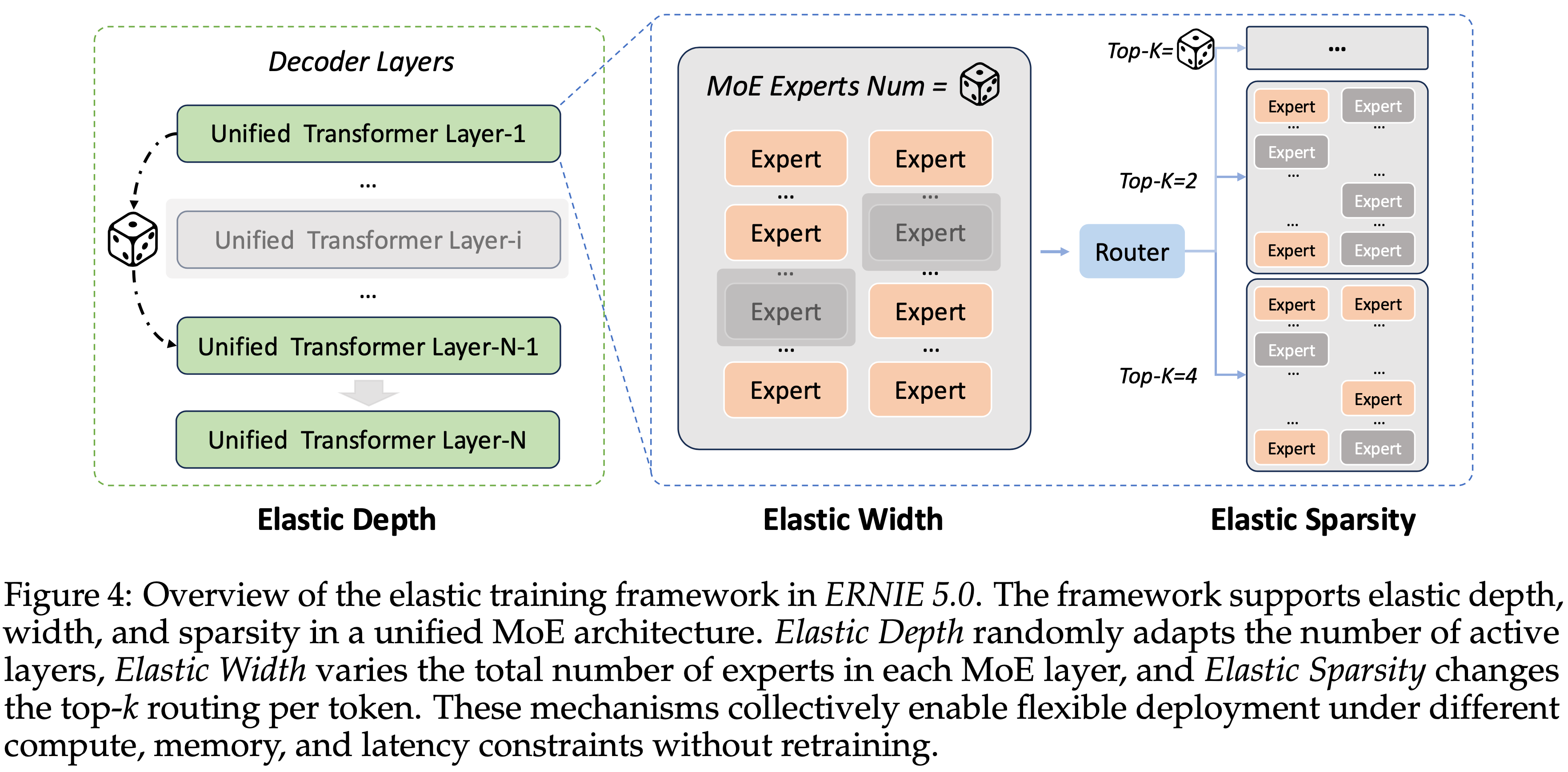
- 架构创新:Elastic Training,包含 Elastic Depth,Elastic Width 和 Elastic Sparsity 等
- 新补充:ERNIE-5.1 博客中介绍,这个方案将 ERNIE-5.0 压缩到 ERNIE-5.1(1/3 总参数,1/2 激活)
- ERNIE 5.0 26年1月刚线上线时,LMArena 排名位于国内第一,最高曾至第 6 名(截止到 20260210 日本文写作时位于 11 名),在用户体验方面是做的很好的
Elastic Training
- 弹性深度: 训练时随机跳过部分 Transformer 层,使不同深度的子模型共享权重,从而自适应地学习深层与浅层表征的平衡
- 弹性宽度: 弹性调控 MoE 层实际参与计算的专家池规模,通过随机动态屏蔽部分专家,迫使剩余专家承担更多样化的任务,从而提升专家利用效率
- 弹性稀疏度: 通过可变的 Top‑k 路由机制,灵活调整模型激活的专家数量
- 当激活专家较少时,可降低推理成本
- 当激活专家较多时,则能增强模型能力,实现推理开销与性能之间的动态权衡
Post-training(原文第4节)
- 经过多模态统一预训练后,采用与 ERNIE 4.5 相同的训练后流程来获得最终的 ERNIE 5.0
- 该流程包括两个阶段:SFT 和 RL
- SFT:
- 高质量指令对集合
- 基础的指令遵循能力
- 长链思维推理的能力
- RL:
- 统一多模态 RL
- 推理、智能体、指令遵循等各种任务的训练在一个多阶段 RL 流程中
- 扩展了统一验证器系统,使其能够为广泛多模态场景中的模型 Response 生成准确且一致的奖励信号
- RL 训练面临几个挑战
- First,RL 训练计算成本高昂,ERNIE 5.0 的大规模进一步加剧了这一点(似乎没有说模型的参数量是多少?)
- Second,超稀疏 MoE 架构加剧了训练-推理差异并破坏了稳定性
- Third,与独立的 RLVR 任务相比,训练一个同时支持多种场景和模态的模型引入了更高的复杂性
- 本文主要以解决以上几个问题为主旨
Enhancing Rollout Efficiency with Unbiased Replay Buffer
- Rollout 生成在 RL 训练中占据了超过 \(90%\) 的总时间,效率往往受限于 Rollout Response 长度的长尾分布
- 少数异常长的 Response 会阻塞整个批次,导致 GPU 空闲且利用率不足
- 最近如 APRIL (2025)等试图通过超额供应 Rollout 请求来缓解长尾低效问题
- 收集到目标数量的 Response 立即终止生成;未完成的 Response 会被回收并在后续步骤中继续生成
- 但 APRIL 存在问题:
- 倾向于使用推理步骤较短的轨迹来更新模型参数 ,这些轨迹通常对应于较容易的 Query
- 更长步数的样本被推迟,导致数据难度分布不稳定
- 数据难度的周期性变化可能阻碍收敛并最终降低模型性能
U-RB:Unbiased Replay Buffer Generation
- U-RB 是 APRIL 的一种无偏扩展,旨在加速 RL 中的 Rollout 生成
- 如图 5 所示,U-RB 引入了一种数据排序约束,在此约束下,只有初始化时分配给当前迭代的数据组才被允许参与后续训练过程
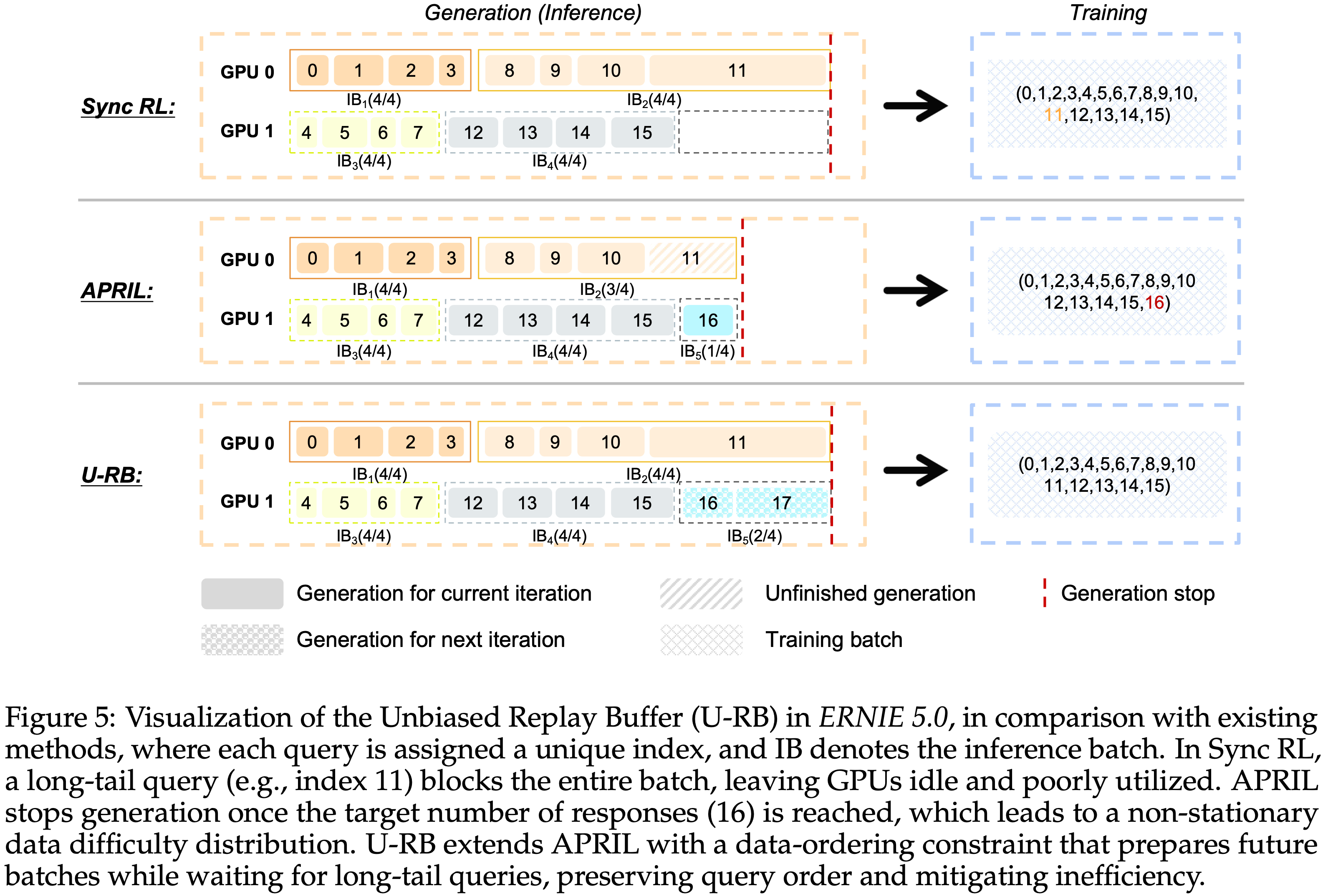
- 上图中的一些解释:
- IB 表示 Inference Batch
- 同步方式:被长尾拖住,浪费资源
- APRIL:足够了就停,对长难样本不友好
- U-RB:既不浪费资源,又等待长尾样本完成
- U-RB 构建了两个模块
- 第一个模块:高吞吐量推理池 \(\mathcal{P}_\text{infer}\),容量为
$$ \Omega_{RBS} = \Omega_{BS} * N$$- 其中 \(\Omega_{BS}\) 是训练批次大小,\(N\) 是缓冲区大小
- 第二个模块:训练池 \(\mathcal{P}_\text{train}\),用于收集已完成的轨迹以进行 RL 训练,容量为:
$$ \Omega_{BS} $$
- 第一个模块:高吞吐量推理池 \(\mathcal{P}_\text{infer}\),容量为
- 在迭代 \(t\) 时,推理引擎 \(\pi_{infer;\theta_t}\) 通过并行生成 Rollout 来填充推理池
- 推理持续进行,直到达到分配给迭代 \(t\) 的数据组 \(\mathcal{D}_t\) 中最长 Rollout 的终止状态
- 此时,与 \(\mathcal{D}_t\) 相关的 Rollout 将从 \(\mathcal{P}_\text{infer}\) 移动到训练池 \(\mathcal{P}_\text{train}\),使训练引擎 \(\pi_{train;\theta_t}\) 能够更新模型参数
- 这些 Rollout 可能包括从早期推理运行中恢复的轨迹
- 通过动态划分 Rollout 生成,U-RB 防止了因单个长 Rollout 导致的计算闲置,同时保持了无偏的数据分布
Stabilizing Training with Mitigated Entropy Collapse
- 多模态模型中快速熵崩溃的现象表现为 RL 早期阶段策略熵的急剧增加或减少
- 在集成文本、视觉和音频信息的多模态决策任务中,这种崩溃会逐渐削弱模型融合跨模态信息以进行灵活推理的能力,并显示出明显的模态偏向
- 近期研究将熵崩溃主要归因于两个因素
- First,大多数当代 RL 框架依赖独立的引擎进行训练和推理,这引入了数值计算的不一致性,并最终破坏了策略优化的稳定性
- 对于 MoE 模型,这个问题变得更加严重,因为动态路由进一步放大了数值不匹配问题
- Second,策略模型通常在训练早期阶段过拟合于简单 Query
- 这种行为加速了熵崩溃并限制了模型探索的能力
- First,大多数当代 RL 框架依赖独立的引擎进行训练和推理,这引入了数值计算的不一致性,并最终破坏了策略优化的稳定性
- 解决方案:引入 Multi-granularity Importance Sampling Clipping 和 Well-learned Positive Sample Mask ,在大规模 RL 训练中稳定训练
MISC:Multi-granularity Importance Sampling Clipping
- IcePop 通过对 GRPO 进行双端掩码校准来抑制训练-推理不匹配:
$$
\begin{align}
\mathcal{I}_\text{IcePop}^\text{GRPO}(\theta) &= \mathbb{E}_{x\sim D,(y_i)_{i = 1}^G\sim \pi_\text{infer}(\cdot |x;\theta_\text{old})}\\
&\frac{1}{G}\sum_{i = 1}^G\frac{1}{|y_i|}\sum_{j = 1}^{|y_i|} \mathcal{M}\left(\frac{\pi_\text{train}(y_{ij}|x,y_{i,j};\theta_\text{old})}{\pi_\text{infer}(y_{ij}|x,y_{i,j};\theta_\text{old})};\alpha ,\beta\right) \cdot \min (r_{ij}\hat{A}_{ij},clip(r_{ij},1 - \epsilon ,1 + \epsilon)\hat{A}_{ij})\\
r_{ij} &= \frac{\pi_\text{train}(y_{ij}|x,y_{i,j};\theta)}{\pi_\text{train}(y_{ij}|x,y_{i,j};\theta_\text{old})} \\
\mathcal{M}(k) &= \begin{cases}
k & \text{if } k\in [\alpha ,\beta ]\\
0 & \text{otherwise}
\end{cases}
\end{align} \tag{1}
$$- 其中 \(\alpha ,\beta\) 控制下限和上限
- 作者将 IcePop 的掩码技术应用于 GSPO:
$$
\begin{align}
\mathcal{I}_\text{IcePop}^\text{GSPO}(\theta) &= \mathbb{E}_{x\sim D,(y_i)_{i = 1}^G\sim \pi_\text{infer}(\cdot |x;\theta_\text{old})}\\
&\frac{1}{G}\sum_{i = 1}^G[\mathcal{M}\left(\frac{\pi_\text{train}(y_i|x,\theta_\text{old})}{\pi_\text{infer}(y_i|x,\theta_\text{old})}\right)^{\frac{1}{|y_i|} };\alpha ,\beta)\cdot \min (s_i(\theta)\hat{A}_i,clip(s_i(\theta),1 - \epsilon ,1 + \epsilon)\hat{A}_i)\\
s_i(\theta) &= \left(\frac{\pi_\text{train}(y_i|x;\theta)}{\pi_\text{train}(y_i|x;\theta_\text{old})}\right)^{\frac{1}{|y_i|} } = \exp \left(\frac{1}{|y_i|}\sum_{j = 1}^{|y_i|}\log \frac{\pi_\text{train}(y_{ij}|x,y_{i,j};\theta)}{\pi_\text{train}(y_{ij}|x,y_{i,j};\theta_\text{old})}\right)\\
\mathcal{M}(k) &= \begin{cases}
k & \text{if } k\in [\alpha ,\beta ]\\
0 & \text{otherwise}
\end{cases}
\end{align} \tag{2}
$$ - 注意:作者的实验表明,直接将 \(\mathcal{I}_\text{IcePop}^\text{GSPO}\) 应用于 ERNIE 5.0 的 RL 训练会导致快速熵崩溃,如图 6 中的浅蓝色线所示
- 这种现象是由序列级截断重要性采样引起的,由于训练-推理不匹配,修剪了大量低熵 Response
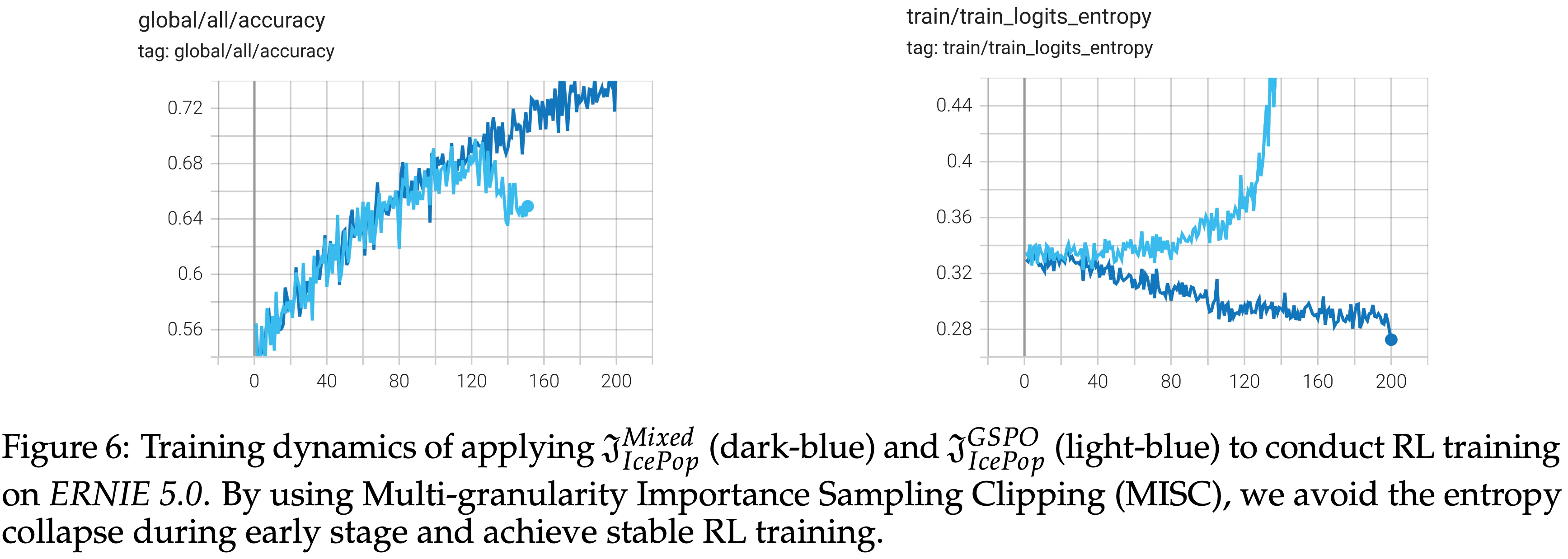
- 这种现象是由序列级截断重要性采样引起的,由于训练-推理不匹配,修剪了大量低熵 Response
- 为了解决这个问题,作者将 \(\Im_\text{IcePop}^\text{GSPO}\) 修改为 \(\Im_\text{IcePop}^\text{Mixed}\)
$$\begin{align}
\Im_\text{IcePop}^{Mixed}(\theta) &= \mathbb{E}_{x\sim D,[y_i]_{i = 1}^{C}\sim \pi_\text{infer}(\cdot |x;\theta_\text{old})}\\
&\frac{1}{G}\sum_{i = 1}^{G}[\mathcal{M}_{i\in [1,y_i]}] (\frac{\pi_\text{train}(y_{i,j}|x,y_{i,j};\theta_\text{old})}{\pi_\text{infer}(y_{i,j}|x,y_{i,j};\theta_\text{old})};\alpha ,\beta)\cdot \min(s_i(\theta)\hat{A}_i,clip(s_i(\theta),1 - \epsilon ,1 + \epsilon)\hat{A}_i)\\
s_i(\theta) &= \left(\frac{\pi_\text{train}(y_i|x;\theta)}{\pi_\text{train}(y_i|x;\theta_\text{old})}\right)^{\frac{1}{|\theta_i|} } = \exp\left(\frac{1}{|y_i|}\sum_{j = 1}^{|y_i|}\log \frac{\pi_\text{train}(y_{i,j}|x,y_{i,j};\theta)}{\pi_\text{train}(y_{i,j}|x,y_{i,j};\theta_\text{old})}\right)\\
\mathcal{M}(k) &= \begin{cases}
k& \text{if } k\in [\alpha ,\beta ]\\
0& \text{otherwise}
\end{cases}
\end{align} \tag{3}
$$ - 通过根据模态敏感性调整信任区域,作者实现了更平衡的探索-利用权衡
- 该机制避免了在复杂的多场景设置中过早收敛到“安全”但次优的策略,并保持了跨不同输入的灵活性
WPSM:Well-learned Positive Sample Mask
- 为防止模型对已经掌握的 Query 进行过优化,作者引入了一种样本掩码策略
- 注:其中熟练程度通过维护每个 Query 的成功率来跟踪
- 对于一个给定的 Query \(x\) 及其 Rollout 组 \(\mathcal{Y}^x = \{y_1^x,y_2^x,\dots,y_G^x\}\),其中 \(G\) 是组大小
- 如果迭代 \(t\) 中的平均准确率 \(acc_i^x\) 超过阈值 \(\tau\),并且其 策略熵 \(\mathcal{H}_{y_i^x}(\pi_\theta)\) 低于稳定边界 \(\eta\)
- 则标记 \(\mathcal{Y}^x\) 中的 Rollout \(y_i^x\) 为“已习得(Well-learned)” Response
- 在训练期间,“已习得”的 Response 被掩码如下:
$$
\begin{align}
\mathcal{I}(\theta) &= \mathbb{E}_{x\sim D,[y_i]_{i = 1}^{C}\sim \pi_{\theta_\text{old} }(\cdot |x)\left[\frac{1}{G}\sum_{i = 1}^{G}[1 - \mathbf{M}_{mask}^i ]min(s_i(\theta))\hat{A}_i,clip(s_i(\theta),1 - \epsilon ,1 + \epsilon)\hat{A}_i\right]}\\
\mathbf{M}_{mask}^i &= \begin{cases}
&\alpha & \mathcal{H}_{y_i^x}(\pi_\theta) < \eta \text{ and } \text{acc}_i^x >\tau \\
&0 & \text{otherwise}
\end{cases}
\end{align} \tag{4}
$$- \(s_i(\theta)\) 表示重要性比率
- \(\alpha \in [0,1]\) 控制应用于“已习得” Response 的补充学习程度
- 在此设计下,梯度预算被转移到更困难的样本上,例如那些奖励稀疏或推理路径多样的样本
- 通过掩码冗余的正信号,WPSM 缓解了因过拟合于简单 Query 而引起的熵崩溃问题,并鼓励模型提升具有挑战性的、低表现任务的性能
- 问题:相当于直接直接在线过滤样本了?
Boosting Sample Efficiency with Hint-based Learning
- 近期研究表明:
- RL 方法通过强化高奖励完成来提升 pass@1 指标,但它们在基础模型表现不佳的挑战性任务上表现出明显的局限性
- 具体来说,当所有 Rollout 都获得零奖励时,GRPO 框架无法为策略优化提供有效的梯度信号
- 在这种情况下,困难 Query 上的 RL 训练往往会进展得更慢,因为稀疏奖励和有限的样本效率阻碍了学习
- 为了应对这一挑战,作者提出了 Prompt-based 自适应强化学习,一种缓解困难 Query 上稀疏奖励问题的方法
- 如图 7 所示,Prompt-based 自适应强化学习引入了部分提示,将复杂问题分解为中间步骤,并逐步提高训练模型的性能

- 如图 7 所示,Prompt-based 自适应强化学习引入了部分提示,将复杂问题分解为中间步骤,并逐步提高训练模型的性能
AHRL:Adaptive Hint-based Reinforcement Learning
- Prompt-based 自适应 RL 旨在 RL 训练期间将部分思维提纲注入到 Query 中
- Prompt-based 自适应 RL 增加了基础模型生成正确 Response 的倾向,并提高了样本效率
- 因此,模型被驱动去掌握最困难的问题,从而加速了 RL 训练过程
- 对于一个给定的 Query \(x\),其 Response 由思维轨迹和最终解决方案组成,表示为 \(y = (\text{think, solution})\)
- Prompt-based 自适应强化学习通过将 think 的前 \(p_\text{hint}\) 个 token 附加到原始 Query ,将 \(x\) 增强为 \(\bar{x}^{(p)}\)
- \(p_\text{hint}\) 表示被揭示的思维比例,允许对 Query 难度进行细粒度控制
- Prompt-based 自适应强化学习通过将 think 的前 \(p_\text{hint}\) 个 token 附加到原始 Query ,将 \(x\) 增强为 \(\bar{x}^{(p)}\)
- 具体来说,概率 \(p_\text{hint}\) 遵循退火计划:
$$p_\text{hint}(x^t) = p_\text{initial}\cdot \exp (-\gamma \cdot t\cdot \text{pass}_\text{initial}^x) \tag{5}$$- \(t\) 是训练迭代次数
- \(\gamma\) 是衰减率
- \(pass_\text{initial}^x\) 是在监督微调模型上评估的 Query \(x\) 的 pass@k 分数
- 问题:\(x^t\) 表示迭代 \(t\) 中的 Query \(x\) 吗?
- 理解:
- \(t\) 越大,最终使用的比例 \(p_\text{hint}(x^t)\) 越小
- \(\text{pass}_\text{initial}^x\) 越大,最终使用的比例 \(p_\text{hint}(x^t)\) 越小
- 随着训练的进行和模型性能的提高,揭示的提示比例逐渐减少,使模型过渡到完全的自我探索
- 该机制提供了必要的“脚手架”以弥合初始探索和成功完成任务之间的差距
- 它防止了在复杂任务中训练停滞,在这些任务中有效的推理路径在统计上是罕见的,并确保了跨模态的性能持续改进
Scalable and Disaggregated RL Infrastructure
- 将 RL 扩展到具有万亿参数的统一多模态模型,在多个方面提出了独特的挑战:
- 计算一致性 (computational consistency)
- 数据分布偏差 (data distribution bias)
- 异构资源利用 (heterogeneous resource utilization)
- 解决方案:引入了 ERNIE 5.0 RL Infrastructure,一个解耦的系统,旨在编排大规模异步训练
- 优先考虑高吞吐量执行和计算确定性 (computation determinism),系统确保了稳定且高效的 RL 训练
- The key architectural components are summarized as follows:
- Disaggregated Control Plane for Asynchronous RL
- 一个完全解耦的控制平面,围绕一个集中式 RL 控制器 (RL controller) 构建,以最大化系统吞吐量
- 该控制器以异步方式协调训练、推理、环境交互和奖励评估
- 这些子系统之间的逻辑解耦实现了灵活的扩展和高效的流水线管理,为大规模异步多模态 RL 奠定了基础
- FP8 栈 (Unified FP8 Stack for Consistent Training and Inference).
- 精度分歧 (Precision divergence) 是低比特 RL 训练中的常见问题
- 为了缓解这种情况,作者构建了一个统一的 FP8 执行引擎 (execution engine)
- 通过在训练和推理 (rollout) 阶段采用相同的高性能算子,并整合 Rollout Router Replay (2025b) 策略,该引擎最大限度地减少了数值不匹配,并确保了低精度设置下的稳定收敛
- Replay Buffer for Sequence-Length Bias Mitigation
- RL 中的异步 rollout 可能会引入序列长度偏差 (sequence-length bias),即较短的 Response 更早进入训练,从而扭曲数据分布
- 作者设计了一个无偏回放缓冲区 (unbiased replay buffer),与第 4.1 节描述的算法协同工作,保留了原始数据顺序,确保数据一致到达,并减轻了异步完成引起的偏差
- Heterogeneous Resource Optimization with Elastic CPU Pooling
- 为解决在以 GPU 为主的 AI 集群中常见的 CPU 资源利用不足问题,作者使用了弹性 CPU 池策略
- 该弹性机制从集群中隔离并虚拟化空闲的 CPU 容量,以支持计算密集型的任务,例如密集的 RL 环境交互和结果验证
- 有效地放大了可用于环境 rollouts 的计算资源,实现了大规模的并行模拟
- 减少了训练迭代的 wall-clock time,同时显著提高了底层硬件的总体拥有成本 (Total Cost of Ownership, TCO) 效率
- 为解决在以 GPU 为主的 AI 集群中常见的 CPU 资源利用不足问题,作者使用了弹性 CPU 池策略
- Disaggregated Control Plane for Asynchronous RL
附录:ERNIE-5.1
- 原始博客链接:文心 5.1 正式发布!多榜登顶,模型”写得好更懂你”
- 核心总结:
- 参数缩小:相对 5.0 参数反而降低了至约 1/3(激活压缩至约 1/2)
- 手段:通过针对 ERNIE-5.0 模型提取最优子结构得到
- 号称:仅使用业界同规模模型约 6% 的预训练成本,实现同级别模型基础效果领先
- 截止 20260509,Arena 搜索榜全球第四、国内第一
- 参数缩小:相对 5.0 参数反而降低了至约 1/3(激活压缩至约 1/2)
最优子结构搜索
- 通过针对 ERNIE-5.0 模型提取最优子结构得到 ERNIE-5.1
- 弹性深度: 训练时随机跳过部分 Transformer 层,使不同深度的子模型共享权重,从而自适应地学习深层与浅层表征的平衡
- 弹性宽度: 弹性调控 MoE 层实际参与计算的专家池规模,通过随机动态屏蔽部分专家,迫使剩余专家承担更多样化的任务,从而提升专家利用效率
- 弹性稀疏度: 通过可变的 Top‑k 路由机制,灵活调整模型激活的专家数量
- 当激活专家较少时,可降低推理成本
- 当激活专家较多时,则能增强模型能力,实现推理开销与性能之间的动态权衡
四阶段后训练过程
- 四阶段整体过程概览图
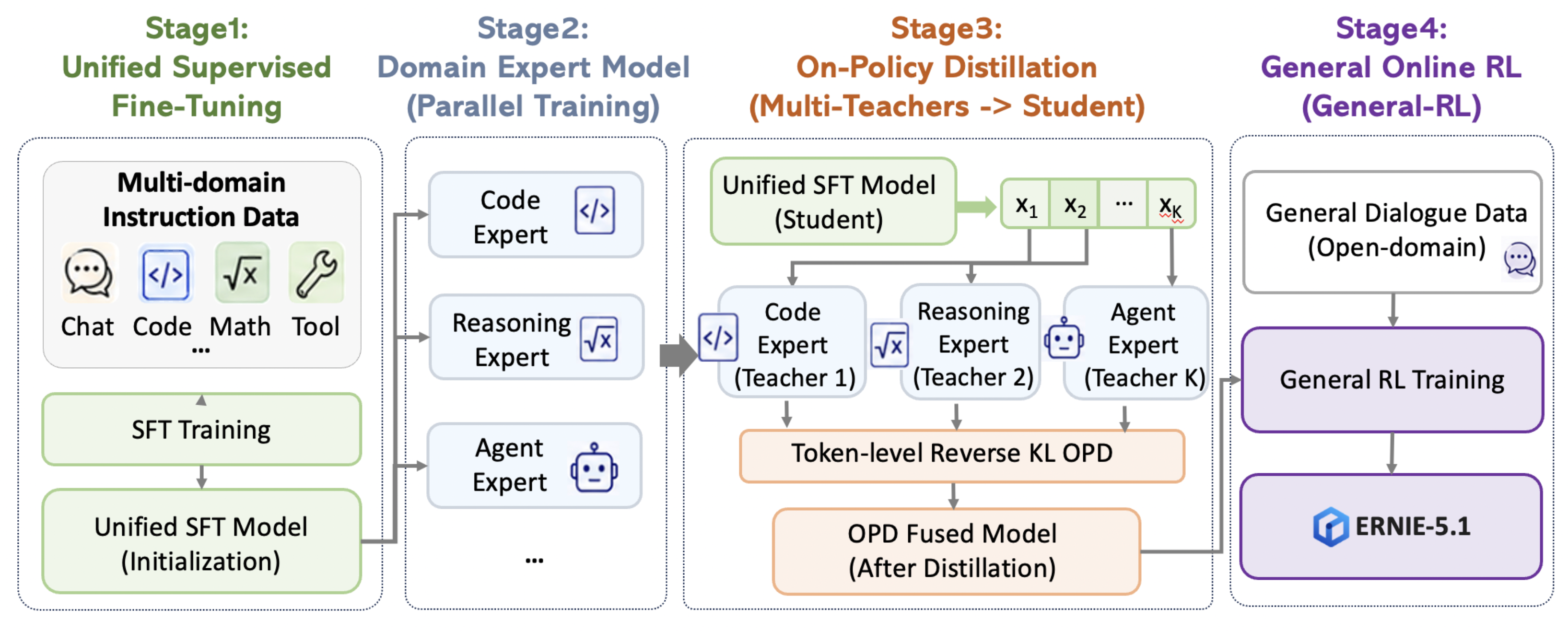
- 阶段一:统一监督微调(SFT)
- 使用高质量的多领域指令数据进行微调,为模型奠定指令遵循和工具调用的基础能力,作为后续能力扩展的初始化起点
- 阶段二:领域专家模型训练
- 并行训练多个领域的专家模型(如代码、推理、智能体)
- 每个方向独立定制专属的奖励信号和训练算法,从根本上避免了不同任务间的相互影响
- 阶段三:在线策略蒸馏(OPD)
- 以统一 SFT 模型为学生,多个领域专家模型为教师
- 学生基于自身策略分布采样,通过 Token-level reverse KL 同时学习多个教师能力,将不同专家的能力高效融合至统一的参数空间
- 阶段四:通用在线强化学习(General-RL)
- 在初次 OPD 阶段之后,作者专门引入了一个面向通用对话场景的在线强化学习
- 作者通过实验发现:并非所有任务都适合采用 Token-level KL 进行 OPD 能力融合
- 具有高熵分布为特征的任务,例如开放式聊天或创意写作,往往会导致蒸馏效率低下,并可能会使输出概率过度平滑
- 为解决这一问题,作者放弃了对该领域的蒸馏,转而在 OPD 训练后的模型上进行在线强化学习
- 该阶段确保了模型的指令遵循能力、生成多样性并更好地对齐了人类偏好 ,显著提升了模型的通用能力,同时也保留了专家模型的能力