注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体介绍:
- 论文提出了关于 Pre-training,Mid-training 和 Post-training 如何共同决定语言模型推理能力的受控研究
- 论文仔细分离每个阶段的贡献,尝试阐明 RL 增强或未能增强推理泛化的因果机制
- 论文的方法采用具有明确原子操作(atomic operations)、可解析的逐步推理轨迹以及对训练分布进行系统性操控的合成推理任务
- 利用完全可控的合成推理任务和过程级评估,论文证明了:
- 通过 Post-training 实现的真正的推理改进,只有在 Pre-training 阶段建立起关键的推理原始技能时才会出现
- 评价:很实在的文章,对理解 LLM 的 各个训练阶段有较强的参考意义
- 背景 & 问题提出:
- RL 显著提升了语言模型的推理能力,但尚不清楚 Post-training 是否真正扩展了模型在 Pre-training 之外获得的推理能力
- 一个核心挑战在于现代训练流程缺乏控制:
- 大规模 Pre-training 语料库不透明, Mid-training 往往被忽视,而 RL 目标与未知的先验知识以复杂的方式相互作用
- 本文的工作:
- 为了澄清这一问题,论文建立了一个完全受控的实验框架,以分离 Pre-training 、 Mid-training 和 RL-based 的 Post Training 的因果贡献
- 论文沿两个轴评估模型:
- 向更复杂组合的外推泛化 (extrapolative generalization)
- 跨越不同表面上下文的上下文泛化 (contextual generalization)
- 利用此框架,论文调和了关于 RL 有效性的对立观点,研究表明:
- 1)RL 仅在 Pre-training 留有足够提升空间且 RL 数据针对模型的能力边缘 (edge of competence)
- 那些困难但尚未超出解决范围的任务边界时,才能产生真正的(genuine)能力提升 (
pass@128)
- 那些困难但尚未超出解决范围的任务边界时,才能产生真正的(genuine)能力提升 (
- 2)上下文泛化需要最小但充分的 Pre-training Exposure ,之后 RL 可以可靠地实现迁移
- 3)在固定计算量下, Mid-training 显著提升了性能,证明了其在训练流程中核心但未被充分探索的作用
- 4)过程级奖励减少了 Reward Hacking 并提高了推理的保真度
- 1)RL 仅在 Pre-training 留有足够提升空间且 RL 数据针对模型的能力边缘 (edge of competence)
- 图 1:大语言模型推理中 Pre-training 、 Mid-training 与 Post-training 阶段的相互作用
- 左图:RL 仅在任务难度略超出 Pre-training 数据范围时,才能带来真正的外推性能提升;当任务已被 Pre-training 数据覆盖,或完全超出 Pre-training 数据分布(分布外程度过高)时,性能提升会消失(在参数校准良好的情况下,
pass@128最高可提升 42%)- 理解:从图中可以看出,在适当 OOD(OOD-mid)的任务上才出现了很好的性能提升,完全分布内(within Pre-training range)或者过于 OOD(OOD-hard)的任务上均不会带来提升
- 中图:实现上下文泛化,需要模型在 Pre-training 阶段对长尾上下文具备最低限度但足够的接触量
- 若 Pre-training 对长尾上下文的接触量接近零, RL 无法发挥作用;
- 但只要存在稀疏接触(接触量 \(\ge 1%\)), RL 就能实现稳健的泛化,
pass@128最高可提升 60% - 理解:从图中可以看出,接触 10% 和接触 1% 的效果差距远远不如想象的大
- 右图:在 Pre-training 与 RL 之间加入一个 “Mid-training” 阶段,能在计算资源固定的情况下显著提升 OOD 推理性能
- 在困难分布外任务上,“Mid-training + RL” 的组合比单独使用 RL 的性能高出 10.8%
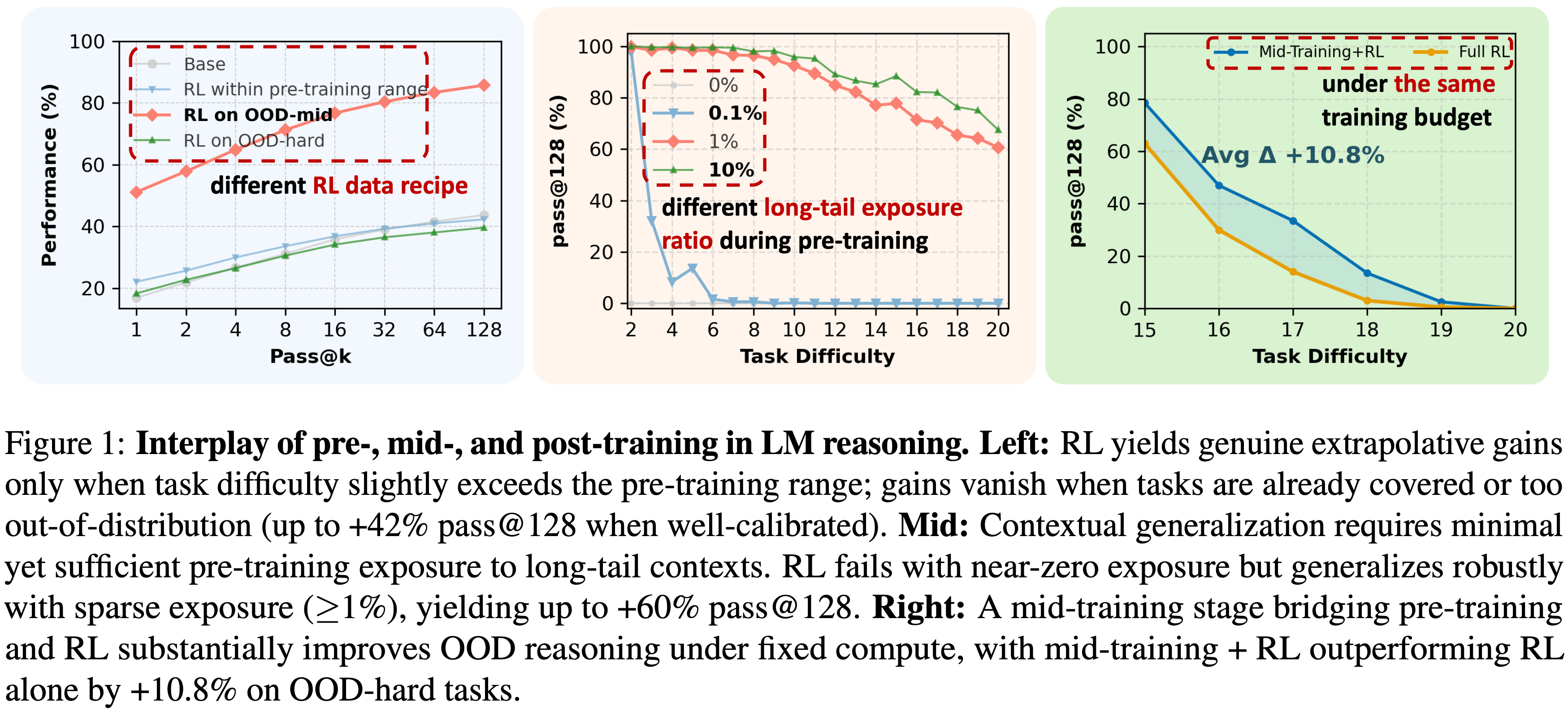
- 在困难分布外任务上,“Mid-training + RL” 的组合比单独使用 RL 的性能高出 10.8%
- 左图:RL 仅在任务难度略超出 Pre-training 数据范围时,才能带来真正的外推性能提升;当任务已被 Pre-training 数据覆盖,或完全超出 Pre-training 数据分布(分布外程度过高)时,性能提升会消失(在参数校准良好的情况下,
Introduction and Discussion
- 最近的 RL 进展显著提升了语言模型的推理能力 (2025, 2025)
- 但一个基本概念问题仍未解决:Post-training 是否真正扩展了模型在 Pre-training 之外获得的推理能力?
- 文献中存在相互矛盾的观点:
- 一些工作将 RL 描述为 capability refiner (2025, 2025, 2025, 2025)
- 另一些则提供了超越 Pre-training 的实质性推理增益的证据 (2025, 2025, 2025)
- 文献中存在相互矛盾的观点:
- 这种差异的主要来源在于先前的分析依赖于不受控的 (uncontrolled) 训练环境
- 现代语言模型在大规模、不透明的互联网语料库上进行 Pre-training ,其构成本质上是未知的
- As a result,论文无法确定 Base Model 已经内化了哪些推理原语 (reasoning primitives)
- 这种控制的缺乏使得分离 Post Training 的因果效应以及理解 Pre-training 和 Post Training 如何共同塑造推理行为变得具有挑战性
- Meanwhile,一个额外的阶段 Mid-training 最近已成为现代语言模型训练流程的关键组成部分 (2025, 2025)
- 在一些文献中,Mid-training 阶段也被称为继续 Pre-training (Continued Pre-Training, CPT)
- Mid-training 在广泛的 Pre-training 语料库和专门的 Post Training 目标之间充当了中间分布桥梁,扩展了模型的原子操作覆盖范围,并将其内部表征 (internal representations) 与 RL 阶段强调的任务对齐
- As a result, Mid-training 在辩论中变得越来越核心:它可能解释了为什么 RL 有时能产生显著的泛化改进,而在其他设置中却失败 (2025)
- 这激发了论文工作的核心问题:Pre-training 、 Mid-training 和 RL 在塑造语言模型的推理能力方面是如何相互作用的?
- 本工作的目标是以受控的方式令人信服地回答这个问题,遵循该领域的先前工作 (2025, 2025, 2025)
- Specifically,论文通过受控实验来厘清 Pre-training 、 Mid-training 和 RL-based 的 Post Training 如何单独及共同影响推理泛化
- 为此,论文建立了一个完全受控的框架,以分离每个训练阶段的贡献。论文的设计基于三个原则:
- (i) 完全可控的合成推理任务 (fully controllable synthetic reasoning tasks) ,具有明确的原子操作和由有向无环图定义的(DAG-defined)依赖结构;
- (ii) 可观测、可解析的推理过程 (observable, parseable reasoning processes) ,支持过程级评估并减少奖励或评估欺骗 (reward/evaluation hacking);
- (iii) 对 Pre-training / Mid-training / Post Training 分布的系统性操控 (systematic manipulation) ,以将因果效应归因于每个阶段
- 论文沿两个关键维度评估推理:
- 1)外推 (深度) 泛化 (Extrapolative (Depth) generalization) 评估模型是否能通过以更深的结构组合已学习的原语,解决比 Pre-training 中遇到的更复杂的问题
- 2)上下文 (广度) 泛化 (Contextual (Breadth) generalization) 评估模型是否能在具有相同底层逻辑但 surface forms 不同的新颖上下文中迁移 (transfer) 其推理技能
- 这两个轴共同捕捉了与现实世界语言模型相关的广泛的组合和迁移推理能力
- 利用论文的受控框架,论文揭示了关于三个训练阶段如何相互作用的若干 insights:
- Firstly ,关于 RL 是否真正改善 Base Model 推理能力的两种对立观点并不真正冲突
- RL 仅在两个条件成立时才能产生真正的能力增益:
- (i) 该任务在 Pre-training 期间未被大量覆盖,为 RL 探索留下了足够的提升空间
- (ii) RL 数据被校准到模型的能力边缘 (edge of competence) ,既不太简单(in-domain)也不太困难(out-of-domain, OOD)
- 当任一条件被违反时,RL 倾向于锐化(sharpen)现有能力而非真正改进
- RL 仅在两个条件成立时才能产生真正的能力增益:
- Secondly ,RL 激励上下文泛化仅当相关的原子操作或基础技能已存在于 Base Model 中
- 如果对新的上下文没有最少的 Pre-training Exposure ,RL 无法产生迁移(induce transfer)
- 但即使非常稀疏的覆盖率(例如,\(\ge 1%\))也能提供一个足够的“种子”,RL 随后可以稳固地强化它,产生强大的跨上下文泛化
- Thirdly ,引入一个连接 Pre-training 和 Post Training 分布的 Mid-training 阶段,能在固定计算预算下显著增强分布内和分布外的性能,凸显了 Mid-training 作为训练设计中一个未被充分探索但强大的杠杆作用
- Fourthly ,过程奖励 (process rewards) 减轻了 Reward Hacking 并提高了推理保真度
- 将过程验证 (process verification) 纳入奖励函数,使强化信号与有效的推理行为对齐,从而在复杂的组合设置下带来准确性和泛化性的可衡量改进
- Firstly ,关于 RL 是否真正改善 Base Model 推理能力的两种对立观点并不真正冲突
Preliminaries
- 本节介绍以下三个部分:
- (a) 基于依赖图 (dependency graphs) 和上下文渲染 (contextual rendering) 的合成数据生成框架 (data generation framework) ,该框架指定了推理过程
- (b) 用于外推和上下文泛化的任务设置 (task setup)
- (c) 过程验证评估 (process-verified evaluation) 框架,该框架评估推理过程和最终答案的准确性
- 这些组件共同使论文能够分离 Pre-training 、 Mid-training 和 Post Training 对推理泛化的不同影响
Controllable Synthetic Reasoning Dataset
- 论文基于 GSM-Infinite (2025) 数据生成框架创建了一个测试平台,能够精确控制推理结构、复杂性和上下文
- 图2:数据生成框架、任务设置和过程验证评估概览
- 图2 描述了依赖图 \(\mathcal{G}\) 和上下文模板 \(\tau\),用于外推和上下文泛化的任务设置,以及检查推理步骤正确性的过程验证评估框架
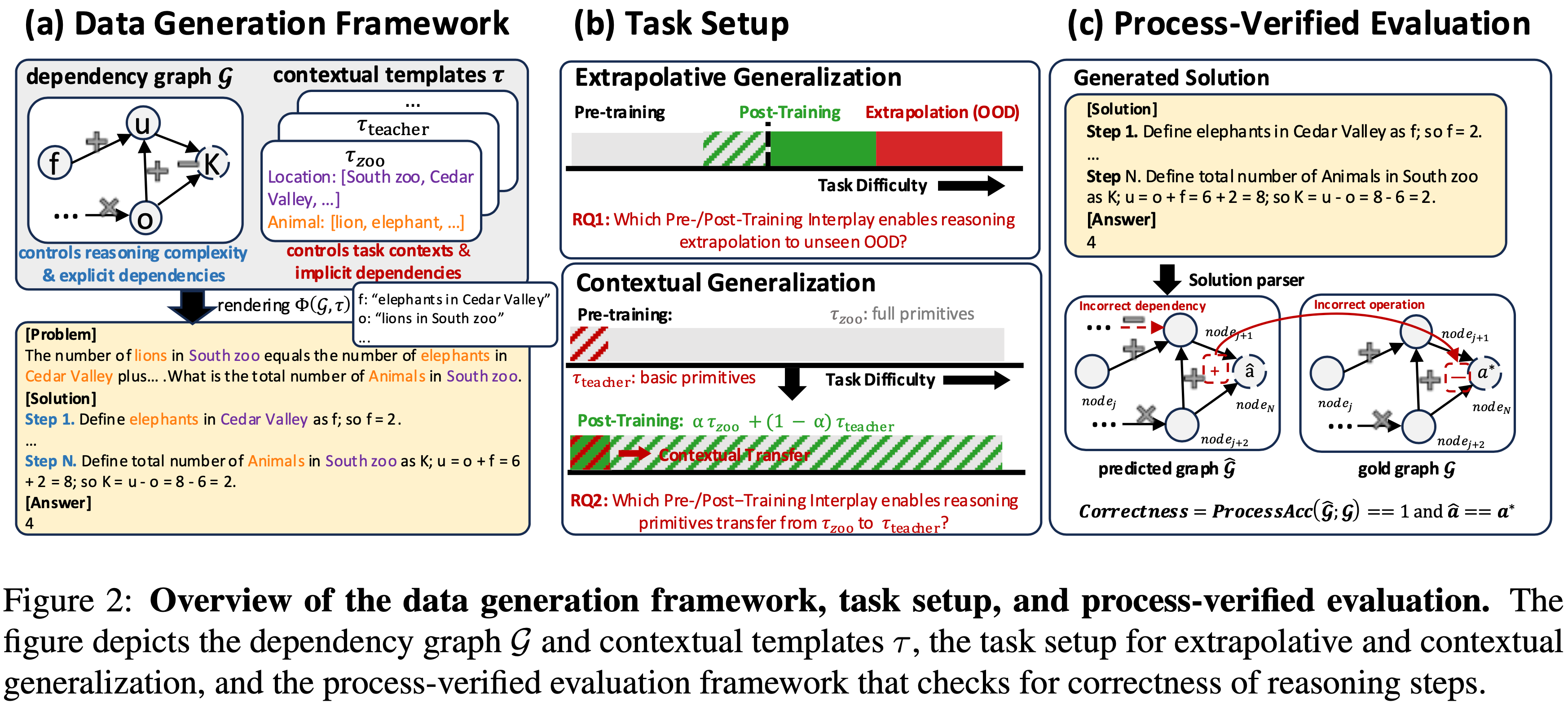
- 图2 描述了依赖图 \(\mathcal{G}\) 和上下文模板 \(\tau\),用于外推和上下文泛化的任务设置,以及检查推理步骤正确性的过程验证评估框架
- 图2:数据生成框架、任务设置和过程验证评估概览
- Specifically,数据生成流水线(图2(a))涉及三个关键组件:
- 依赖图 (Dependency Graphs).
- 每个推理问题由一个有向无环图 (DAG) \(\mathcal{G}=(\mathcal{V},\mathcal{E})\) 表示,其中节点 \(v\in\mathcal{V}\) 对应变量,有向边 \(e\in\mathcal{E}\) 表示它们之间的依赖关系
- 理解:每条边对应一次算数运算
- 该图最终汇聚到一个指定的答案节点 \(v^{*}\),该节点产生最终答案 \(a^{*}\)
- 每个推理问题由一个有向无环图 (DAG) \(\mathcal{G}=(\mathcal{V},\mathcal{E})\) 表示,其中节点 \(v\in\mathcal{V}\) 对应变量,有向边 \(e\in\mathcal{E}\) 表示它们之间的依赖关系
- 推理复杂性控制 (Reasoning Complexity Control).
- 论文通过算术运算的数量来量化图的复杂度:
$$
\text{op}(\mathcal{G})=|\mathcal{E}|,
$$ - 这控制了从基础算术到复杂多步推理的任务难度
- 论文通过算术运算的数量来量化图的复杂度:
- 上下文渲染 (Contextual Rendering).
- 给定一个预定义的上下文模板 \(\tau\)(例如,animals-zoo、teachers-school)及自然语言描述,论文将依赖图 \(\mathcal{G}\) 渲染成一个完整的数学问题
- Finally,论文通过抽样不同的图 \(\mathcal{G}\) 和模板 \(\tau\),并将它们渲染为文本来生成多样化的数学问题
- 依赖图 (Dependency Graphs).
- 论文采用此框架的动机在于三个主要优点:
- 1)对训练阶段无污染的控制 (Contamination-free control over training phases)
- 论文为 Pre-training 、 Mid-training 和 Post Training 指定了独立的数据分布以避免重叠
- 2)对结构和上下文进行因子化控制 (Factorized control over structure and context)
- 每个问题都从一个 DAG 生成,该图编码了推理结构和依赖关系,并在其上实例化了数值和上下文
- 3)过程级验证 (Process-level verification)
- 真实的 DAG 可作为验证中间步骤和防止错误推理的参考
- 作者在附录 A.1 中提供了详细的公式和解释
- 1)对训练阶段无污染的控制 (Contamination-free control over training phases)
Task Setup
- 在现实世界部署中,语言模型通常需要沿两个互补的轴(complementary axes)进行推理泛化:
- 外推 (深度) 泛化 (extrapolative (depth-wise) generalization)
- 上下文 (广度) 泛化 (contextual (breadth-wise) generalization) (2025, 2025, 2025)
- 论文的受控实验揭示了这两个维度(图2(b)),从而能够精确检验 Pre-training 、 Mid-training 和Post Training 如何影响每种类型的泛化
- 外推 (深度) 泛化 (Extrapolative (Depth) Generalization).
- 该维度评估模型在推理深度 \(\text{op}(\mathcal{G})\) 增加时保持正确性的能力 (2025)
- 如果模型能够解决其操作链长度超出 Mid-training 遇到的问题,则表现出强大的外推泛化能力
- 上下文 (广度) 泛化 (Contextual (Breadth) Generalization).
- 该维度衡量模型是否能够将其推理原语(Reasoning primitives)迁移到 surface forms不同但具有相似底层推理结构(similar underlying reasoning structure)的新领域
- 当模型的性能在模板或 surface forms 发生变化,底层计算图保持不变时 ,保持稳定,则认为该模型在上下文上实现了泛化
- 理解:底层计算图不变则认为其底层推理结构没有变化,此时能够泛化则说明训练跳脱了具体的模版或 surface forms
- 形式化符号、数据集构建以及泛化轴的完整定义见附录 A.2
Evaluation Protocol
- 论文按照过程验证评估 (process-verified evaluation) 方案(图2(c))报告所有结果
- 对于每个具有真实依赖图 \((\mathcal{G},a^{*})\) 的实例,模型生成一个自由形式的解决方案,作者将其解析为预测的依赖图 \(\hat{\mathcal{G} }\) 和最终答案 \(\hat{a}\)
- 在每个真实节点 \(v\in\mathcal{V}\) 的 Step-level 进行过程评估
- 通过比较预测节点与真实节点、它们的依赖关系以及数值 check 准确性
- 过程准确率 (process accuracy) 定义为所有真实节点的平均 Step-level 准确率
- 只有当推理步骤和最终答案都匹配时,预测才被视为完全正确
- 所有 \(
pass@k\) 指标(例如,\(pass@1\),\(pass@128\))均相对于此严格标准报告 - 详细的实现和解析方法见附录 A.4
Training Setup
- 论文使用 GSM-Infinite 框架生成的大规模合成推理数据集,训练了具有 100M 参数的 Decoder-only Qwen2.5-style (2025) 模型
- 整个语料库包含 30B 个 token,涵盖了多个操作范围和上下文模板,并被划分为互不相交的 Pre-training 、 Mid-training 和 Post Training 子集,以避免分布污染
Pre-training
- Pre-training 让模型接触多样化语料库以获取通用知识
- 在论文的受控推理任务中,它侧重于使模型掌握论文合成数据集中算术运算的基础推理技能和规则
- 重点是掌握基本推理原语,而非广泛的知识
- Following Chinchilla Scaling (2022) and trends in data-rich regimes (2025),论文在 10B 个 token(参数的 100 倍)上 Pre-training 论文的 100M 参数模型
- 数据集由跨模板的 op=2-10 操作组成,使模型能够掌握推理,同时为复杂任务保留提升空间
- 模型在分布内任务上达到了接近饱和的
pass@128准确率,确保在更深任务上的改进反映了真正的泛化- 理解:这里为什么要确保在 In-domain 任务上达到接近饱和才能在更深的任务上反应真正的泛化?
Mid-training
- Mid-training 是 Pre-training 和 Post Training 之间的中间阶段,因其在改进下游微调和 RL 性能方面的作用而受到关注 (2025, 2025, 2025)
- Mid-training 通常涉及使用更高质量或指令格式的数据,采用 Next-token prediction 或 SFT 目标
- Mid-training 通过提供结构化的推理监督来稳定优化并促进 RL 扩展 ,弥合了广泛 Pre-training 语料库和面向奖励的 RL 数据之间的差距
- 论文实现了精简版的 Mid-training ,保持与 Pre-training 相同的目标,但收窄数据分布使其与 RL 类似,此时模型展现出新兴(emerging)但不完整的能力(incomplete competence)
- 通过将监督集中在此边界,目标加强 RL 可以放大的更高级别推理先验
- 注:Mid-training 仅在 Section 5 中应用
Post Training
- Post Training 在 Pre-training 之后,使用特定任务的数据或目标来精炼模型在特定任务上的性能
- 通常涉及两种策略:
- 1)SFT :在带标签的数据集或特定任务指令上进行训练;
- 2)RL :模型通过接收其动作的奖励来进行优化
- 由于论文的 Pre-training 数据已经是结构化且特定于任务的,所以主要关注 RL 进行 Post Training
- 精心策划的 subset 上使用 GRPO (2025) 进行训练,这些 subset 旨在探究在更深操作范围和新颖模板中的泛化能力
When Does Post-Training Incentivize Reasoning Beyond the Base Model?(何时 Post Training 能激励超越 Base Model 的推理?)
- 为了厘清 Pre-training 和 Post Training 对推理能力的贡献,论文分离了 RL 的具体影响
- 提问:RL 是否以及何时能扩展 Base Model 在 Pre-training 之外获得的推理能力?
- 通过固定 Pre-training 阶段并改变 Post Training 数据的难度和覆盖范围,论文确定了 RL 驱动真正的组合泛化而非仅仅放大现有技能的具体机制
Task Setting
- 论文专注于外推泛化(在附录 A.6 中检查 Post Training 对上下文迁移的影响),根据操作计数定义三类问题(论文在附录 A.3.4 中说明了这种性能阶梯):
- 分布内 (In-Distribution, ID) 问题(Pre-training 范围内,op=2-10);
- 分布外-边缘 (OOD-edge) 问题(刚刚超出此范围,op=11-14), Base Model 在此保留非零的
pass@128准确率; - 分布外-困难 (OOD-hard) 问题(显著超出 Pre-training 分布,op=15-20), Base Model 在此表现出接近零的准确率
- 解决 OOD-hard 问题需要以新颖的方式组合从 ID 数据中学到的原子操作,以适应增加的推理深度
- 实验设置如下:
- Pre-training:
- Base Model 在由 ID 问题组成的 10B 个 token 上进行 Pre-training
- Post Training:
- 论文应用 GRPO,使用来自四个不同难度范围的共 200K 个样本:op=7-10(ID)、op=9-12(混合)、op=11-14(边缘)和 op=17-20(困难)
- Pre-training:
- 关于 Training Dynamics 和 Data Recipe 的更多信息,请参见 A.5 和 A.9
Summary 1
Observation 1
- 如图 3 所示, Post Training 的效果对 Pre-training 和 Post Training 数据机制高度敏感:
- (i) 对于 ID 任务(op=2-10),无论 RL 数据机制如何,在
pass@1上有明显的性能提升,但在pass@128上没有改进,这表明 RL 只是锐化了现有能力而没有扩展它们 - (ii) 然而,对于 OOD 任务(op=11-14 和 op=15-20),当应用于能力边缘 (edge of competence) 数据(op=11-14)时,RL 总是能提高
pass@128性能,证明了超越 Pre-training 的真正的能力增益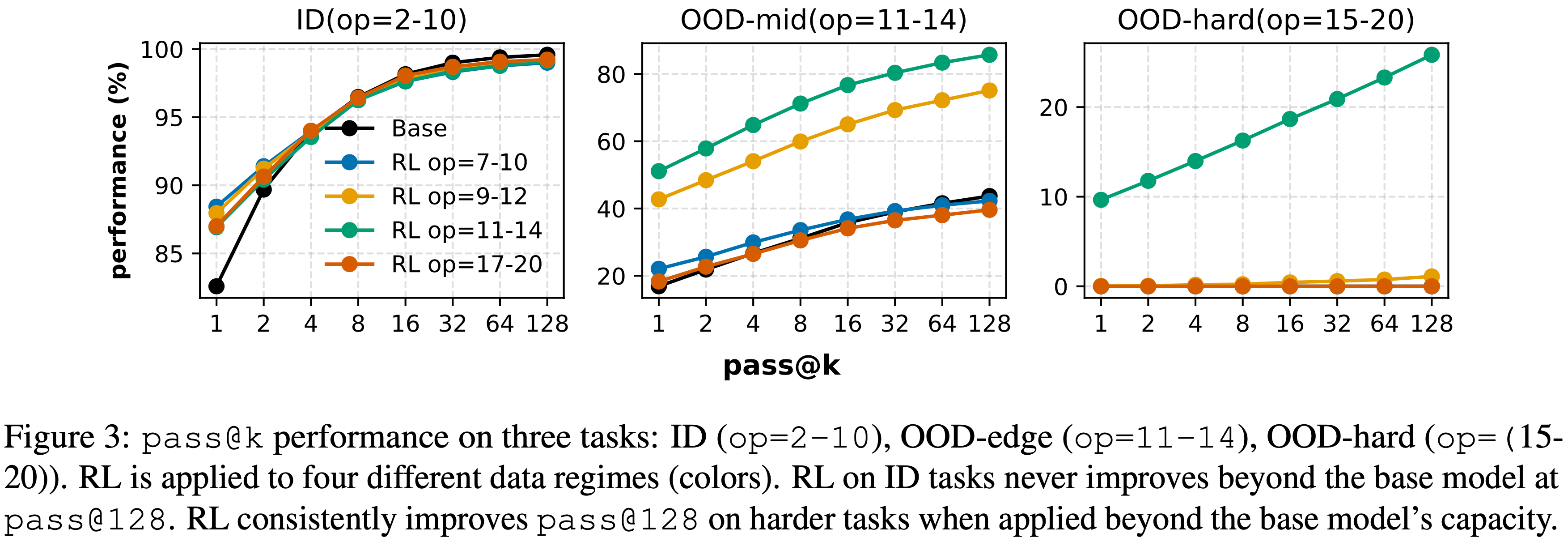
- (i) 对于 ID 任务(op=2-10),无论 RL 数据机制如何,在
- 理解:图 3 展示了,如果使用太 OOD 的数据(op=17-20)来进行 RL 时,模型其实无法提升其在 OOD-hard(op=15-20)任务上的表现
Takeaway 1
- RL 仅在两个条件成立时,才能在 Base Model 之外产生真正的能力增益 (
pass@128):- (i) 该任务在 Pre-training 期间未被大量覆盖,为探索留有足够的提升空间;
- (ii) RL 数据被校准到模型的能力边缘 (edge of competence) ,既不太简单(分布内)也不太困难(分布外)
Discussion 1
- 与近期工作的关联 最近的研究关于 RL 是否能增强 Base Model 的推理能力报告了看似矛盾的结论
- On the one hand,Zhao 等人 (2025),Yue 等人 (2025) 认为,当在数学和编码等 Pre-training 已充分覆盖的标准任务上评估时,RL* 并未* 改善
pass@128准确率 - On the other hand,在 Pre-training 覆盖率极低的合成任务上的研究 (2025, 2025, 2025) 报告了实质性的 Post Training 增益
- On the one hand,Zhao 等人 (2025),Yue 等人 (2025) 认为,当在数学和编码等 Pre-training 已充分覆盖的标准任务上评估时,RL* 并未* 改善
- 论文的受控设置通过表明这些结论源于Post Training 难度谱的不同区域而调和了这些发现
- 对于 Base Model 已经解决的分布内任务,随着
pass@k的增加性能趋于饱和,RL 没有优势 - In contrast,当 RL 针对 Base Model 失败的真正分布外任务时,论文观察到清晰的外推改进(前提是 RL 数据位于模型的“能力边缘”附近)
- 对于 Base Model 已经解决的分布内任务,随着
Practical Guidance 1
- 围绕模型的能力边缘 (edge of competence)设计 RL 数据
- 作者建议过滤 RL 数据集以针对那些模型在
pass@1上失败但在pass@k上成功的任务 - 此策略避免了在高
pass@1任务上的冗余,同时防止了在pass@k为 0 任务上的奖励稀疏
- 作者建议过滤 RL 数据集以针对那些模型在
- 这个过程也可以是迭代的:我们可以定期重新评估“能力边缘”任务池;
- 随着模型变得更强,先前分布外的任务将漂移到可解区间,从而创建一个自然的、自定进度的课程
How Does Pre-training Exposure Shape Post-Training Generalization?(问题:Pre-training Exposure 如何塑造 Post Training 泛化?)
- 在确定了 Post Training 激励泛化的条件之后,论文转向一个基础性问题:Pre-training Exposure 如何塑造 Post Training 泛化?
- 作者假设,Pre-training Exposure 基础推理原语对于有效的 Post Training 泛化至关重要
- 为了探讨这个问题,在固定的 RL Data Recipe 和设置下,论文改变 Pre-training 数据的分布,并检查其对 Post Training 泛化的影响
Task Setting
- 论文专注于上下文泛化,即向长尾 (long-tailed) 的 Context B 泛化
- 在 Pre-training 期间,作者操控模型接触包含原子推理原语(op=2 的示例)的长尾 Context B 的比例(关于简单上下文泛化和外推的实验分别在附录 A.6.1 和 A.7 中提供)
- 论文的实验设置结构如下:
- Pre-training : Base Model 在 10B 个 token 上进行 Pre-training
- 这些 token 由 op=2-20 的 Context A 和 op=2 的长尾Context B 示例组成
- 理解:这里的 Context A 和 Context B 分别表示不同领域的任务
- 其中论文变化原子 op=2 示例相对于长尾 Context B 接触的比例
- 这些 token 由 op=2-20 的 Context A 和 op=2 的长尾Context B 示例组成
- Post Training: 应用 RL 于 200K 个样本,这些样本由 50% Context A 和 50% Context B 组成,覆盖 op=2-20 的范围
- Pre-training : Base Model 在 10B 个 token 上进行 Pre-training
- 关于 Training Dynamics 和 Data Recipe 的更多细节,请参见附录 A.8 和 A.9
Summary 2
Observation 2
- 如图 4 所示, Pre-training Exposure 长尾上下文对 Post Training 泛化的影响是巨大的:
- (i) 当 Pre-training 排除 Context B 或提供零(0%)或极少接触(0.1%)时,RL 无法迁移到 Context B
- (ii) 在 Pre-training 中引入即使是 1% 的 Context B 数据,也能显著增强 Post Training 泛化,甚至对于 op=20 的最困难任务也是如此
- 这一观察强调,虽然 RL 在泛化中扮演着关键角色,但其有效性高度依赖于 Pre-training 数据的覆盖范围,特别是长尾上下文的包含
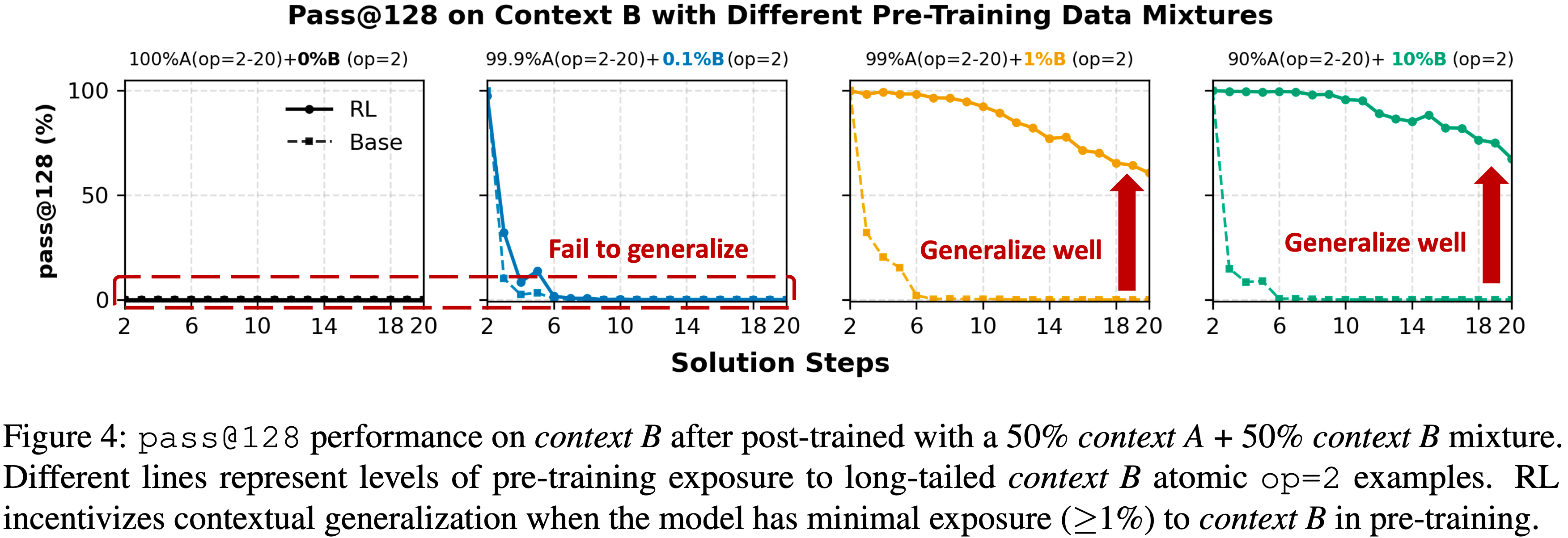
Takeaway 2
- 仅当 Base Model 已包含必要的原子操作时,RL 激励上下文泛化(RL incentivizes contextual generalization only when the base model already contains the necessary primitives)
- 如果没有对新上下文的最少 Pre-training Exposure ,RL 无法产生迁移
- However,即使是稀疏的接触(例如,\(\ge 1%\))也提供了一个足够的“种子”,RL 可以在 Post Training 期间强化它,从而产生鲁棒的跨上下文泛化
Discussion 2
- 复制还是创造(Replication or Creation)?
- 论文在图 5 中检查了生成的正确 Context B 图与来自 Context A 的真实拓扑之间的拓扑相似性分布
- 高相似性表明模型主要复制了现有的 Context A 推理模式,而低相似性则表明出现了与 Context A 不同的新颖推理结构

- 论文观察到任务难度与 Pre-training Exposure 之间的效应:
- 1)对于较简单的组合(op=2-10),模型倾向于复制来自 Context A 的现有模式
- 2)随着任务复杂度增加(op=11-20),模型生成更多新颖结构,特别是在 Pre-training 期间充分接触 Context B 时
Practical Guidance 2
- 在 Pre-training 中植入长尾原子操作以释放 RL 潜力(Seed long-tail primitives in pre-training to unlock RL potential)
- RL 无法从虚无中合成能力;它需要潜在的“种子”来放大
- However,这些种子不需要很复杂
- 论文的结果表明,只要原子推理原语 (atomic reasoning primitives) 存在于 Pre-training 中,RL 就能成功外推到困难任务
- 实践者应优先考虑广泛覆盖基本领域知识、规则和技能(大约 1% 的密度) ,而不是追求复杂的数据样本
- 一旦这些基本原语建立起来,RL 就有效地充当了组合器,将它们组合起来解决复杂的分布外问题
How Does Mid-Training Interact with Post-Training?(Mid-training 与 Post-training 交互?)
- 尽管 RL 能有效提升外推泛化能力,但其成功往往依赖于 Pre-training 阶段建立的表征先验
- 近期工作 (2025a; 2025) 提出了 Mid-training 作为 Pre-training 和 Post-training 之间的中间阶段,旨在弥合数据分布并在下游适应前加强推理先验
- 这引出了一个关键问题:在固定的计算预算下, Mid-training 和 RL 如何交互,以及两者之间怎样的平衡能带来最大的泛化收益?
- 本节研究 Mid-training 与 Post-training 之间的协同作用,试图界定它们的交互如何驱动推理泛化
- 计算预算公式化(Compute Budget Formulation)
- 为公平比较,论文根据浮点运算将两个阶段的训练归一化为等效的训练 Token 数
- 对于 Mid-training ,消耗量 \(T_{\text{mid} }\) 是处理的有监督 Token 数量
- 对于 RL ,其 Token 等效成本近似为:
$$
T_{\text{RL} } \approx \frac{5}{3} N \cdot r \cdot L_{\text{total} },
$$- \(N\) 是 RL 样本数
- \(r=6\) 是轨迹生成次数
- \(L_{\text{total} } = 2048\) 是总 Token 长度
- 更多细节:Detailed budget derivation are provided in Appendix A.10.1
- 论文系统地改变 RL 分配比例 \(\beta \in [0,1]\),以在总预算 \(T\) 的两个阶段之间进行分配:
$$
T_{\text{mid} } = (1 - \beta) \cdot T, \quad T_{\text{RL} } = \beta \cdot T.
$$
Task Setting
- 在本节中,论文使用在 10B 个 op=2-10 数据上 Pre-training 的相同 Base Model ,探索五种训练配置的性能:
- 在 op=11-14 范围内的1B有监督 Token 上进行 完全 Mid-training
- 在同一 op=11-14 范围内以批大小1024进行100步的完全 RL
- 三种混合策略
- Light RL(\(\beta=0.2\))
- Medium-RL(\(\beta=0.5\))
- 重度 RL(\(\beta=0.8\))
- 这些策略在等效计算预算下平衡 Mid-training 和 RL
- 第5节中的计算预算公式允许直接比较数据混合策略
Summary 3
Observation 3
- 如图6所示,计算分配在整个泛化谱上引起了质的不同行为
- (1) 在OOD-edge任务上,配置为完全 Mid-training 和 Light RL 的性能优于重度或完全 RL ,其中 Light RL 获得了最佳的
pass@1性能 - (2) 对于OOD-hard任务,将更多预算重新分配给重度 RL,可以显著提高在最难实例上的
pass@1和pass@128性能 - 图6:在外推任务上,不同中期和 Post-training 混合比例下的
pass@1和pass@128性能- 用于中期和 Post-training 的数据应用于 OOD-edge 范围
- 不同的线表示计算分配策略
- 重度 RL 总是改进未见过的OOD-hard任务,而 Light RL 在OOD-edge任务上获得最佳的
pass@1性能")
- (1) 在OOD-edge任务上,配置为完全 Mid-training 和 Light RL 的性能优于重度或完全 RL ,其中 Light RL 获得了最佳的
- 这些趋势表明,驱动探索的 RL 对于泛化到更难的任务是不可或缺的,但大量的 Mid-training 分配对于灌输 RL 可以有效利用的先验仍然至关重要
- 论文进一步分析了不同计算预算的影响(附录A.10)
Takeaway 3
- 引入一个连接 Pre-training 和 Post-training 分布的 Mid-training 阶段,在固定计算预算下能显著增强泛化能力
- 这突显了 Mid-training 作为训练设计中未被充分探索但强大的杠杆
- 计算分配应以任务感知的方式进行:
- (i) 当优先考虑分布内性能时,将更多预算分配给 Mid-training ,仅辅以 Light RL
- (ii) 为了获得分布外泛化能力,预留适中的计算部分用于 Mid-training 以建立必要先验,并将剩余预算投入到更重的 RL 探索中
Discussion 3
- The Role of Mid-Training
- 近期工作 (2025; 2025) 指出,像 Qwen (2025) 这样的模型对 RL 的响应远比对 LLaMA (2023) 等架构更有效
- 一个趋同的解释是存在一个 Mid-training 阶段,该阶段的监督与 Post-training 分布更紧密地对齐
- 面向推理的 Mid-training 已被证明能大幅提高模型的 RL 准备度
- Wang等人 (2025) 发现,在结构化推理数据上进行 Mid-training 的 LLaMA 模型,其 RL 性能可与更强的 Qwen Base Model 相媲美,这表明 Mid-training 在很大程度上决定了下游 RL 的响应能力
- Complementarily,Liu等人 (2025a) 表明, Mid-training 充当了分布桥梁,通过缩小 Pre-training 任务和 RL 任务之间的差距来减少遗忘并缓解适应
- 这一视角进一步与Akter等人 (2025) 的预加载原则一致:更早地注入结构化推理监督提供了支架,后续训练阶段(包括 RL)可以有效地放大这个支架
- Together,这些工作指向一个统一的结论:
- Mid-training 是一个 strategically important component,它能使模型为稳定且样本高效的 RL 做好准备,从而实现超越仅仅是锐化现有能力的改进
mid-training is a strategically important component that conditions models for stable and sample-efficient RL, enabling improvements that go beyond merely sharpening existing abilities.
- Mid-training 是一个 strategically important component,它能使模型为稳定且样本高效的 RL 做好准备,从而实现超越仅仅是锐化现有能力的改进
Practical Guidance 3
- 围绕互补优势平衡 Mid-training 和 Post-training (Balance mid-training and post-training around complementary strengths)
- 通过将 Mid-training 视为安装先验(installing priors)的阶段、将 RL 视为扩展探索(scaling exploration)的阶段来设计训练流程
- 对于 Mid-training ,策划位于模型“能力边缘(edge of competence)”的数据集,这能稳定 RL 所需的原始技能
- 从业者应根据部署目标调整计算预算:
- (1) 为了在类似任务(OOD-edge)上获得可靠性(reliability) ,将大部分计算分配给 Mid-training ,并使用 Light RL
- (2) 为了在复杂任务(OOD-hard)上进行探索(exploration) ,为 Mid-training 分配适中的预算(仅足以建立先验),并将大量计算投入到 RL 探索中
Mitigating Reward Hacking via Process Supervision in Outcome Rewards(结果奖励中的过程监督减轻 Reward Hacking)
- 使用基于结果的奖励进行 Post-training 已被证明能有效提高推理性能,但它仍然容易受到 Reward Hacking(a failure mode where 模型通过利用虚假捷径或通过无效推理链产生正确答案来实现高最终准确率)
- Earlier,作者引入了过程验证(process verification)作为评估标准,只有当中间步骤和最终结果都正确时才奖励模型
- 论文将这一原则扩展到奖励设计本身,并回答:过程感知的监督能否在保持泛化性能的同时减轻 Reward Hacking ?
Task Setting**
- 为了鼓励模型不仅生成正确的最终答案,还要生成有效的中间推理步骤,论文使用过程级验证来增强结果奖励
- 论文定义一个复合奖励函数:
$$
R = \alpha R_{\text{out} } + (1 - \alpha) R_{\text{pv} }.
$$- \(R_{\text{out} }\) 表示传统的结果奖励(最终答案正确为1,否则为0),\(R_{\text{out} }\) 可能是稀疏的且容易受到结果 Reward Hacking
- \(R_{\text{pv} }\) 表示由A.2节中定义的过程级准确率标准确定的过程验证奖励,\(R_{\text{pv} }\) 是一个反映每个推理步骤正确性的密集奖励
- \(\alpha \in [0,1]\) 控制结果准确性和过程保真度之间的平衡
- 论文还考虑一个更严格的公式:
$$
R =
\begin{cases}
R_{\text{out} }, & \text{If } R_{\text{pv} } = 1, \\
0, & \text{Otherwise}.
\end{cases}
$$- 该公式仅在完整推理过程被验证为正确时才给予结果奖励
- 此设置提供了过程级监督以减少 Reward Hacking
- 在此奖励设置下,论文使用不同的奖励组合在 op=11-14 上进行 Post-training ,以评估不同程度的过程监督如何影响推理泛化
Summary 4
Observation 4
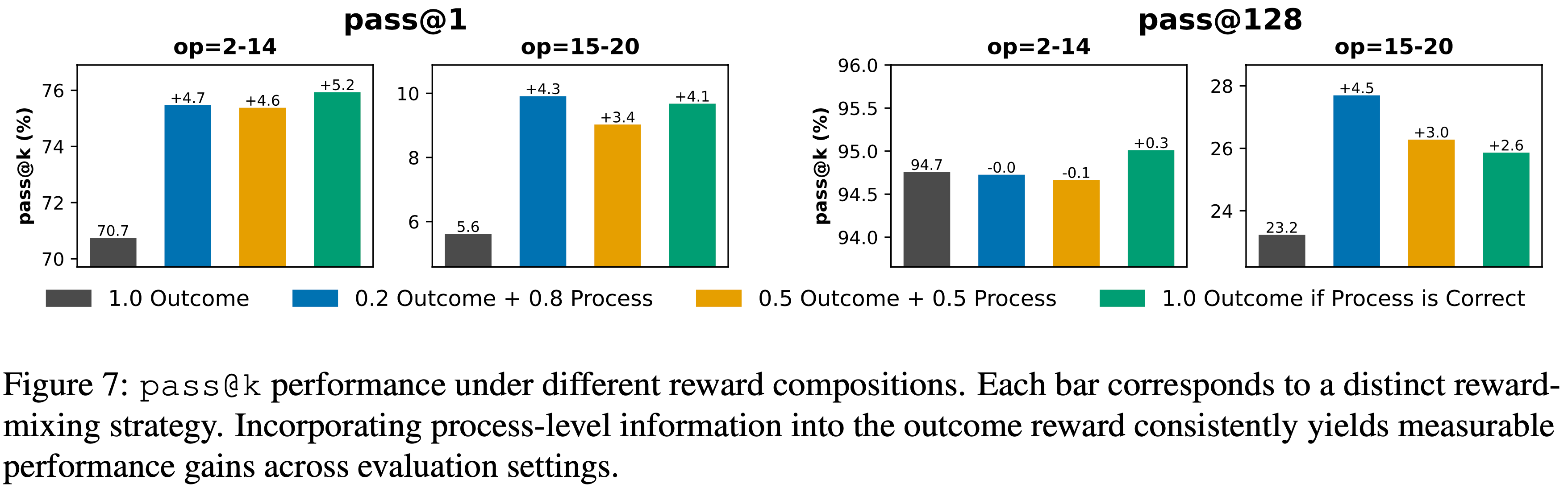
- 如图7所示,整合过程验证显著提高了跨外推(op=15-20)设置的
pass@1性能,提升了4-5%- 适度的奖励混合(\(0.2 R_{\text{out} } + 0.8 R_{\text{pv} }\))在结果准确性和推理一致性之间实现了最佳平衡
- 严格的奖励(仅当 \(R_{\text{pv} }=1\) 时给予 \(R_{\text{out} }\))则进一步带来了显著的改进
- 这些结果证实,过程级监督能有效减轻 Reward Hacking ,并鼓励忠实的推理行为
- 图7:不同奖励组合下的
pass@k性能- 每个条形对应一种不同的奖励混合策略
- 将过程级信息整合到结果奖励中,在各个评估 Setting 中都带来了可衡量的性能提升
Related Work
推理大语言模型的 RL 泛化(RL Generalization of Reasoning LMs
- RL 在 Deriving 大语言模型泛化中的作用一直是广泛讨论的主题
- 近期工作对于 RL 是否能将推理能力扩展到 Base Model 能力之外提出了不同的看法,文献中出现了相互对立的观点
- On the one hand,多项研究警告不要高估 RL 推动 Base Model 边界的能力
- Yue 等人 (2025) 认为,虽然经过 RL 训练的模型在较小的
pass@k值(例如 k=1)上可能优于 Base Model ,但随着 k 增加(例如 k=128),性能优势会减弱- 他们的覆盖率和困惑度分析表明,经过 RL 训练的模型的推理能力最终仍受限于 Base Model 的表征能力
- Additionally,Wu等人 (2025) 提供了一个理论框架,断言 RL 无法超越 Base Model 固有的局限性,从而挑战了 RL 能够实现新的、可泛化的推理技能的观点
- Yue 等人 (2025) 认为,虽然经过 RL 训练的模型在较小的
- On the other hand,也有强有力的论据支持 RL 能够实现泛化,尤其是在 Base Model 表现不佳的任务上
- Liu 等人 (2025b) 强调了 ProRL 在提高合成推理任务性能方面的成功,在这些任务中 Base Model 表现出显著的局限性
- Sun 等人 (2025a, 2025b) 进一步支持了这一观点,提供了明确的证据表明 RL 有潜力为复杂的任务族引入新的策略
- Yuan 等人 (2025) 提出了一个合成函数组合任务,证明经过 RL 训练的模型可以泛化到 Base Model 无法处理的未见过的函数组合
- 论文通过提供实证证据表明这两种观点并不相互排斥,从而为这场持续的辩论做出了贡献
- Instead,论文表明, RL 能够驱动泛化的条件是微妙且复杂的,它取决于 Base Model 的推理原始技能以及 RL 微调中使用的 Post-training 数据的性质
Understanding LMs via Controlled Experiments
- 几项先前工作 (2025; 2025b; 2025a) 强调了受控实验在理解大语言模型能力方面的重要性
- However,这类工作主要侧重于为后期 RL 设计的合成任务,这可能无法完全捕捉从 Pre-training 到 Post-training 的全谱推理任务的复杂性
- 特别是在推理任务的背景下,受控设置允许研究人员分离特定因素,例如数据污染、随机猜测答案,以及控制不同训练阶段的推理原始技能
- 论文基于Ye等人 (2024) 的工作设计受控实验,以合成 GSM-style 推理任务 (2021; 2024; 2025; 2025b),从而在这一工作基础上进行了扩展
附录 A.1 Data Generation Framework
- 本节提供了整篇论文所使用的可控数据生成框架的正式细节:
- (i) 每个推理实例背后的图级形式化定义
- (ii) 将结构与数值和语言实例分离的抽象机制
- (iii) 将图映射到自然语言问题的上下文渲染函数
- (iv) 具体的生成流程和去重过程
附录 A.1.1 图级形式化定义(Graph-Level Formalism)
- 每个推理实例都基于一个有向无环图(directed acyclic graph, DAG)建立:
$$
\mathcal{G}=(\mathcal{V},\mathcal{E}),
$$- 其中每个节点 \(v_{i} \in \mathcal{V}\) 代表一个潜在量(例如,“成年狮子的数量”),每条有向边 \((v_{j} \to v_{i}) \in \mathcal{E}\) 编码一个函数依赖关系
- 论文将依赖关系限制为基本算术运算:
$$
v_{i}=f_{i}\big((v_{j})_{j\in\text{pa}(i)}\big), \qquad f_{i} \in \{+,-,\times,\div\},
$$- 其中 \(\text{pa}(i)\) 是节点 \(i\) 的父节点集合
- 给定所有叶节点的数值赋值,论文递归地定义一个评估映射:
$$
\text{val}:\mathcal{V}\rightarrow\mathbb{R}
$$- 其定义为:
$$
\text{val}(v_{i})=f_{i}\big(\{\text{val}(v_{j})\}_{j\in\text{pa}(i)}\big),
$$
- 其定义为:
- 基本情况由叶节点值给出,对于一个指定的查询节点 \(v^{*}\),真实答案为:
$$
a^{*}:=\text{val}(v^{*}).
$$ - 在论文所基于的 GSM-Infinite 实现 (2025a) 中,查询节点 \(v^{*}\) 对应:
- 前向(forward) 生成器中拓扑顺序的最后一个数值节点,或
- 方程风格逆向(equation-style reverse) 生成器中特定的未知参数
- 贯穿全文(Throughout),DAG \(\mathcal{G}\) 被视为符号推理图,其结构在不同的数值实例化和语言实现之间共享
- 推理复杂度(Reasoning Complexity). :论文通过算术运算的数量来量化实例的结构复杂度:
$$
\text{op}(\mathcal{G})=|\mathcal{E}|.
$$- 这个量规定了计算 \(a^{*}\) 所需的最小组合推理链长度下限,也是论文研究外推(深度方向)泛化时变化的主要调控参数
附录 A.1.2 抽象参数与实例参数(Abstract and Instance Parameters)
- 遵循 GSM-Infinite 的抽象机制,论文明确地将结构、数值实例化和语言上下文分离开
- 抽象参数(Abstract Parameters).
- 每个图 \(\mathcal{G}\) 关联着一组 抽象参数 ,这些参数:
- 指定存在哪些变量以及它们如何分解(例如,“动物总数”分解为“狮子”和“大象”),以及
- 确定边集 \(\mathcal{E}\) 和附加在每个节点上的操作 \(f_{i}\)
- 这些参数定义了一个纯符号图,独立于具体的数字或实体
- 每个图 \(\mathcal{G}\) 关联着一组 抽象参数 ,这些参数:
- 实例参数(Instance Parameters).
- 给定一个抽象图,实例参数用具体的值和实体对其进行实例化:
- 对叶节点的数值赋值(例如,“有 12 头成年狮子和 7 头小象”),以及
- 将变量绑定到特定上下文的表层形式(例如,“城市动物园里的成年狮子”)
- 在同一抽象图上实例化不同的数值,会产生一系列结构相同、仅在具体数字上有所区别的问题
- 给定一个抽象图,实例参数用具体的值和实体对其进行实例化:
- 隐式推理(Implicit Reasoning).
- 并非所有的抽象依赖关系都需要在自然语言问题中明确表述
- 对于给定的语言渲染,边集可以划分为:
$$
\mathcal{E}=\mathcal{E}_{\text{explicit} } \cup \mathcal{E}_{\text{implicit} }, \qquad \mathcal{E}_{\text{explicit} } \cap \mathcal{E}_{\text{implicit} } = \emptyset,
$$ - 其中 \((v_{j} \to v_{i}) \in \mathcal{E}_{\text{explicit} }\) 表示文本中直接陈述的关系(例如,“大象比狮子多 5 头”),而 \((v_{j} \to v_{i}) \in \mathcal{E}_{\text{implicit} }\) 表示属于真实推理图但从未直接表述的关系(例如,“动物总数等于狮子数加大象数”)。这种分离允许显式和隐式推理步骤共存于同一个底层图中,并使论文能够探究模型恢复未明言依赖关系的能力
附录 A.1.3 上下文渲染(Contextual Rendering)
- 为了将符号图映射到自然语言问题,论文引入了上下文渲染函数:
$$
\Phi:(\mathcal{G},\tau)\mapsto x,
$$- 其中 \(\tau \in \mathcal{T}\) 是一个上下文模板 ,而 \(x\) 是生成的文本实例
- Templates
- 一个模板 \(\tau\)(例如,animals-zoo、teachers-school、movie-festival)规定了:
- 抽象变量如何词汇化为领域特定的表层形式(例如,“成年狮子”、“A班的学生”、“第1天售出的票”),以及
- 哪些边的子集在措辞中被显式实现,从而决定了 \(\mathcal{E}_{\text{explicit} }\) 和 \(\mathcal{E}_{\text{implicit} }\) 之间的划分
- 对于任何两个仅在表面上下文上不同的模板 \(\tau_{a},\tau_{b} \in \mathcal{T}\),它们引发的问题在结构上保持相同:
$$
\text{Struct}(\Phi(\mathcal{G},\tau_{a}))=\text{Struct}(\Phi(\mathcal{G},\tau_{b})), \quad \forall,\tau_{a},\tau_{b} \in \mathcal{T},
$$- 尽管它们的表层实现、实体以及显式/隐式划分可能不同
- Thus,一个单一的抽象图可以被渲染成语义不同但结构等价的问题,论文利用这一点来研究上下文(广度方向)泛化
- 一个模板 \(\tau\)(例如,animals-zoo、teachers-school、movie-festival)规定了:
- Solution Format
- 渲染函数生成一个三元组:
$$
x=(\text{[question]},\text{[solution]},\text{[answer]}),
$$- [question] 是由符号图 \(\mathcal{G}\) 提出的问题的自然语言表示,通常包括对图中某个方面的查询(例如,“第1天卖出了多少张票?”)
- 它抽象了底层结构,并为解答提供了上下文
- [solution] 是一个遵循符号图 \(\mathcal{G}\) 拓扑顺序的逐步推导过程
- 它包括中间推理步骤和图中元素之间的逻辑联系,最终导向最终答案。该解答明确展示了问题的每个部分是如何推导或计算的
- [answer] 是对 [question] 中提出的查询的最终回应,通过 [solution] 过程推导得出
- 它通常是一个数值或特定实体,用于回答问题
- [question] 是由符号图 \(\mathcal{G}\) 提出的问题的自然语言表示,通常包括对图中某个方面的查询(例如,“第1天卖出了多少张票?”)
- 渲染函数生成一个三元组:
- 这种结构确保了渲染输出既是人类可读的,又在逻辑上与底层符号图保持一致,在保持原始问题完整性的同时使其可以用自然语言表达

附录 A.1.4 生成流程与结构调控参数(Generation Pipeline and Structural Knobs)
- 论文的数据生成器遵循一个阶段式过程,类似于 GSM-Infinite 的前向和反向生成器:
- 1)结构采样(Structural sampling).
- 论文首先采样定义依赖图的结构调控参数:
- 针对 \(\mathrm{op}(\mathcal{G})\) 的目标运算计数范围;
- 控制扇入和深度的图形形状参数(例如,允许的入度、分层模式);以及
- 附加到节点上的操作类型 \(f_{i} \in \{+,-,\times,\div\}\)
- 这些选择决定了一个具有唯一查询节点 \(v^{*}\) 的分层 DAG \(\mathcal{G}\)
- 论文首先采样定义依赖图的结构调控参数:
- 2)抽象与实例参数化(Abstract and instance parameterization).
- 给定 \(\mathcal{G}\),论文采样抽象参数(变量角色和分解)和实例参数(叶节点的数值),并使用上面定义的评估映射 val 按拓扑顺序评估所有节点值
- 3)上下文渲染(Contextual rendering).
- 论文选择一个模板 \(\tau \in \mathcal{T}\) 并应用渲染函数 \(\Phi(\mathcal{G},\tau)\) 以获得一个自然语言三元组(问题、问题描述、解答),决定哪些依赖关系被语言化(显式)以及哪些保持隐式
- 4)前向模式与反向模式(Forward vs. reverse modes).
- 遵循 (2025a),论文支持两种生成模式:
- 在 forward 模式中,论文生成一个标准的算术文字问题,其中查询的是拓扑顺序中的最后一个节点
- 在 reverse 模式中,论文将一个节点视为未知数,并构建一个方程风格的问题,模型必须求解该量,而图中的其余部分则完全指定
- 遵循 (2025a),论文支持两种生成模式:
- 通过联合改变下面的两个维度,论文获得了一个用于研究深度扩展和上下文迁移的清晰二维测试平台:
- (i) 运算计数 \(\mathrm{op}(\mathcal{G})\)
- (ii) 模板 \(\tau\)
- 相同的框架用于定义 Pre-training 、 Mid-training 和 Post Training 的不同数据分布,通过从 \((\mathrm{op}(\mathcal{G}),\tau)\)-Space 的不同区域采样来实现
附录 A.1.5 去重与规范化(Deduplication and Canonicalization)
- 为了保证数据集的纯净性并避免训练和评估拆分之间的污染,作者在渲染三元组级别执行基于哈希的精确去重
- 每个实例通过以下方式规范化:
- 将三元组(问题描述、问题、解答)序列化为规范化的字符串表示(例如,去除多余空白、规范化数字格式),以及
- 对此规范形式进行哈希以获取全局标识符
- 论文丢弃任何拆分内和跨拆分的重复哈希值,确保相同的“问题-解答”三元组不会同时出现在训练和评估中
附录 A.2 Task Setup
- 在实际部署中,语言模型(Language Models,LM)通常需要沿着两个互补的维度进行推理泛化 (2025; 2025b; 2025)
- 论文的可控数据集使这些维度变得明确,并允许论文探究 Pre-training 、 Mid-training 和 Post Training 如何塑造每种类型的泛化
- 符号表示(Notation).
- 令 \(f_{\theta}^{\text{pre} }\)、\(f_{\theta}^{\text{mid} }\) 和 \(f_{\theta}^{\text{post} }\) 分别表示经过 Pre-training 、经过额外 Mid-training 和经过 Post Training(RL)的语言模型
- 论文使用下面评估协议中定义的严格度量,将模型在由图 \(\mathcal{G}\) 在模板 \(\tau\) 下生成的实例上的正确性记为 \(\text{Correct}(f,\mathcal{G},\tau)\)
- 外推(深度)泛化(Extrapolative (Depth) Generalization).
- 论文用每个训练阶段 \(\phi \in \{\text{pre},\text{mid},\text{post}\}\) 所见的运算计数范围对其进行参数化
- 令 \(\mathcal{O}_{\phi}\) 为阶段 \(\phi\) 训练分布中存在的 \(\text{op}(\mathcal{G})\) 值集合,并令:
$$
\mathcal{O}_{\text{train} }=\mathcal{O}_{\text{pre} }\cup\mathcal{O}_{\text{mid} }\cup\mathcal{O}_{\text{post} }.
$$ - 一个分布内评估条件使用满足 \(\text{op}(\mathcal{G}) \in \mathcal{O}_{\text{train} }\) 的图,而一个外推(分布外,OOD)条件评估满足以下条件的图:
$$
\text{op}(\mathcal{G})>\max\mathcal{O}_{\text{train} }.
$$ - 如果一个模型在这些更长、未见过的运算上保持高过程验证准确率,同时在分布内任务上保持稳定,则表明其具有外推泛化能力
- 通过填充 \(\mathcal{O}_{\text{pre} }\)、\(\mathcal{O}_{\text{mid} }\) 和 \(\mathcal{O}_{\text{post} }\) 的不同难度范围,我们可以分离每个阶段对深度方向泛化的贡献
- 上下文(广度)泛化(Contextual (Breadth) Generalization).
- 一个固定的推理图 \(\mathcal{G}\) 可以在不同模板下被渲染成结构等价的实例:
$$
\text{Struct}(\Phi(\mathcal{G},\tau_{a}))=\text{Struct}(\Phi(\mathcal{G},\tau_{b})) \quad \text{in principle},
$$ - 论文的数据集在训练过程中是_随机采样_的,并未刻意在不同模板间对齐图
- As a result, 大多数图在训练期间仅在一部分上下文中被观察到
- 令 \(\mathcal{T}_{\phi}^{\text{train} }\) 表示训练阶段 \(\phi\) 中暴露的模板,\(\mathcal{T}^{\text{eval} }\) 表示更广泛的评估池,包括长尾模板
- 如果一个模型在阶段 \(\phi\) 能够在叙事表层形式发生变化时保持推理性能,即使新的上下文在 Mid-training 从未遇到过,则该模型展现了上下文泛化:
$$
\text{Acc}(f_{\theta}^{\phi},\mathcal{G},\tau_{a})\approx\text{Acc}(f_{\theta}^{\phi},\mathcal{G},\tau_{b}),\qquad\tau_{b}\notin\mathcal{T}_{\phi}^{\text{train} }.
$$
- 如果一个模型在阶段 \(\phi\) 能够在叙事表层形式发生变化时保持推理性能,即使新的上下文在 Mid-training 从未遇到过,则该模型展现了上下文泛化:
- 在这种设置下,上下文泛化衡量的是模型是否学到了可迁移的 推理原语 ,而不是记住了任务风格,使其能够在已知、未见和长尾的叙事环境中应用相同的结构性推理
- 一个固定的推理图 \(\mathcal{G}\) 可以在不同模板下被渲染成结构等价的实例:
附录 A.3 Training Setup
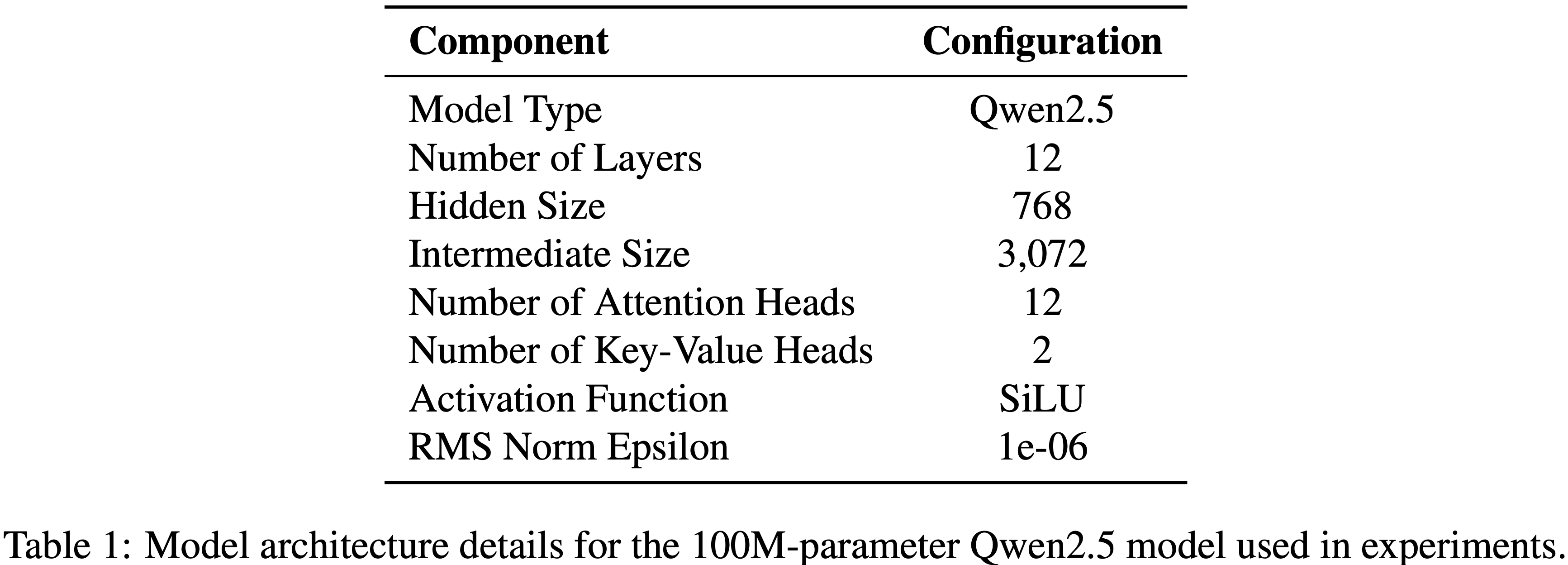
附录 A.3.1 Model Architecture
- 论文使用具有 100M 参数、 Decoder-only Qwen2.5 架构 (2025) 模型进行实验
- 详细的架构配置如表 1 所示
附录 A.3.2 Tokenizer and Input Representation
- 论文遵循《语言模型的物理学》(Physics of Language Models)系列 (Allen-Zhu, 2024; 2024),直接在合成推理语料库上训练一个字节对编码(BPE)分词器
- 得到的分词表有 2,200 个 Token(包括 Special Token)
- 所有问题、提问和解答都以最大序列长度 2,048 个 Token 进行分词
- 问题:模型过小了,只有 100M,而且给出的 Token 长度限制也才 2K,不太够数学推理
附录 A.3.3 Hyperparameters
- Pre-training.
- 所有实验都从一个在论文可控推理语料库上从头开始训练的 100M 参数 Qwen2.5 模型开始,使用 \(100\times\) 的 token-to-parameter ratio, Pre-training 10B Token
- 论文使用上下文长度 2048 Token ,批次大小 512K Token ,学习率 \(2\times 10^{-4}\),权重衰减 \(0.1\),余弦衰减,最小学习率 \(3\times 10^{-5}\),预热比例 \(5%\),并在语料库上训练一个 epoch
- 所有模型都以 bf16 精度训练
- Mid-training.
- 从 Pre-training 检查点开始,论文在第 5 节执行了一个额外的可选课程学习
- 论文使用最大序列长度 2,048 进行训练
- 论文使用全局批次大小 512K Token ,学习率 \(1\times 10^{-4}\),权重衰减 \(0.1\),余弦衰减,最小学习率 \(3\times 10^{-5}\),以及更高的预热比例 \(15%\)
- Post Training (Post-training).
- 最后,论文使用 GRPO (2025) 进行 RL 微调
- 论文使用全局批次大小 1,024 个样本,最大提示和响应长度 1024 Token ,训练两个 epoch
- Actor 使用学习率 \(1\times 10^{-6}\),PPO 小批次大小 256,每个 GPU 的微批次大小 16,KL 正则化系数 \(10^{-3}\)(低方差 KL 惩罚),无熵奖励
- 在 RL 回合采样期间,论文使用温度 \(T_{\text{RL} }=1.0\),top-\(p=1.0\),且无 top-\(k\) 截断(全核采样)进行采样
- 对于离线评估和报告,论文使用温度 \(T_{\text{eval} }=0.7\),top-\(p=1.0\),top-\(k=-1\)(无截断)生成,每个问题最多生成 1,024 个新 Token
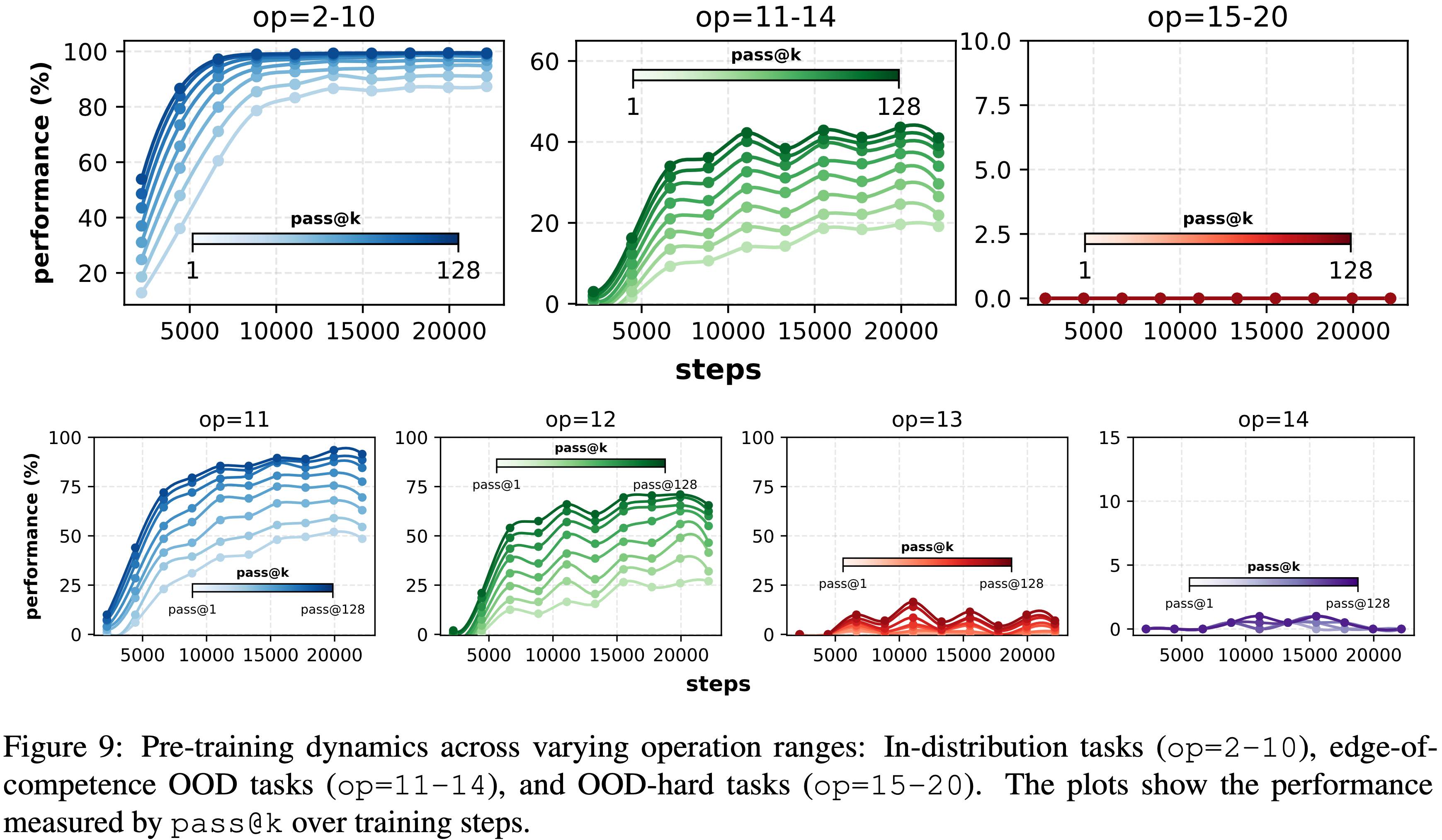
附录 A.3.4 性能阶梯(Performance Ladder)
- 性能阶梯根据任务难度定义了三个关键级别:
- 1)分布内任务(In-distribution tasks) (op=2-10): 目标是接近 100% 的
pass@128准确率; - 2)OOD边缘任务(OOD-edge tasks) (op=11-14): 确保非零的
pass@128性能; - 3)OOD困难任务(OOD-hard tasks) (op=15-20): 目标是零
pass@128准确率,标志着模型的能力极限
- 1)分布内任务(In-distribution tasks) (op=2-10): 目标是接近 100% 的
- Post Training 在能力边缘进行,确保模型能泛化到更难的任务
- 图 9 显示了跨这些性能级别的 Training Dynamics 细分
附录 A.4 Process-Verified Evaluation
- 给定一个具有真实图 \((\mathcal{G},a^{*})\) 的输入实例,模型生成一个自由形式的解答 \(s\)
- 论文确定性地将 \(s\) 解析为预测的依赖图:
$$
\hat{\mathcal{G} }=(\hat{\mathcal{V} },\hat{\mathcal{E} },\widehat{\operatorname{val} }), \qquad \hat{a},
$$- 其中 \(\hat{\mathcal{V} }\) 中的节点对应解答中命名的中间量,\(\hat{\mathcal{E} }\) 编码每个步骤依赖于哪些先前定义的量,\(\widehat{\operatorname{val} }\) 存储每个节点的推断数值,而 \(\hat{a}\) 是提取的最终答案
- 解析器将解答分割为“定义 … 为 …”的步骤,从每个步骤使用的变量推断其依赖关系,并评估步骤中最后一个可计算的算术表达式(如果需要则回退到最后一个数字字面量)以获得数值。这产生了与 gold dependency graph 对齐的模型推理轨迹的图级表示
- 令 gold graph 为下面的形式,具有节点集 \(\mathcal{V}\)、边集 \(\mathcal{E}\) 和值映射 \(\operatorname{val}\):
$$
\mathcal{G}=(\mathcal{V},\mathcal{E},\operatorname{val}), \qquad a^{*},
$$ - 论文在 Step-level 评估推理过程,对于每个黄金节点 \(v \in \mathcal{V}\),定义一个每步骤正确性指示器:
$$
s(v;\hat{\mathcal{G} },\mathcal{G})=\begin{cases}
1, &\text{If } v \in \hat{\mathcal{V} },\ \operatorname{pa}_{\hat{\mathcal{G} } }(v)=\operatorname{pa}_{\mathcal{G} }(v),\ \text{and} \\
&\operatorname{val}(v),\widehat{\operatorname{val} }(v) \ \text{are both defined and } \widehat{\operatorname{val} }(v)= \operatorname{val}(v),\
0, &\text{otherwise},
\end{cases}
$$- 其中 \(\operatorname{pa}_{\mathcal{G} }(v)\) 和 \(\operatorname{pa}_{\hat{\mathcal{G} } }(v)\) 分别表示黄金图和预测图中 \(v\) 的父节点集(依赖关系)
- 缺失节点、不正确的依赖集或不匹配的数值都会导致 \(s(v;\hat{\mathcal{G} },\mathcal{G})=0\)
- 论文将预测推理轨迹的 过程准确率(process accuracy) 定义为所有黄金节点的平均 Step-level 准确率:
$$
\text{ProcessAcc}(\hat{\mathcal{G} };\mathcal{G})=\frac{1}{|\mathcal{V}|}\sum_{v\in\mathcal{V} }s(v;\hat{\mathcal{G} },\mathcal{G}).
$$- 允许额外的预测节点 \(v \in \hat{\mathcal{V} } \setminus \mathcal{V}\),它们不影响过程准确率;它们对应于冗余但兼容的中间步骤
- 只有当推理图和最终答案都匹配时,预测才被视为完全正确,论文通过验证正确性(verified correctness)来形式化这一点:
$$
\text{VerifiedCorrect}(\hat{a},\hat{\mathcal{G} };,a^{*},\mathcal{G})=\begin{cases}
1, &\text{IF ProcessAcc}(\hat{\mathcal{G} };\mathcal{G})=1\text{ and }\hat{a}=a^{*},\
0, &\text{otherwise}.
\end{cases}
$$ - Accordingly,本工作中报告的所有
pass@k指标(例如,pass@1、pass@128)仅当模型满足下面两个条件,才将样本视为正确- (i) 正确预测了每个黄金步骤( Step-level 过程准确率 = 1)
- (ii) 产生了正确的最终答案时
- 这个严格的标准确保报告的收益反映了真实、可靠的推理,而非偶然的正确性
附录 A.5 第 3 节的 Training Dynamics (Training Dynamics for § 3)
- 本节详细分析了不同 Post Training 方法在外推泛化中的 Training Dynamics
- 跨评估范围的负对数似然减少(NLL Reduction Across Evaluation Ranges).
- 论文分析了第 3 节中使用的不同 Post Training 方法及其对各种评估运算范围的负对数似然减少的影响
- 从图 10 我们可以观察到:
- Post Training 持续减少了所有评估范围的负对数似然,其中在 op=11-14 范围内获得了最显著的增益
- 这表明模型有效地学会了组合原子技能以处理更复杂的问题
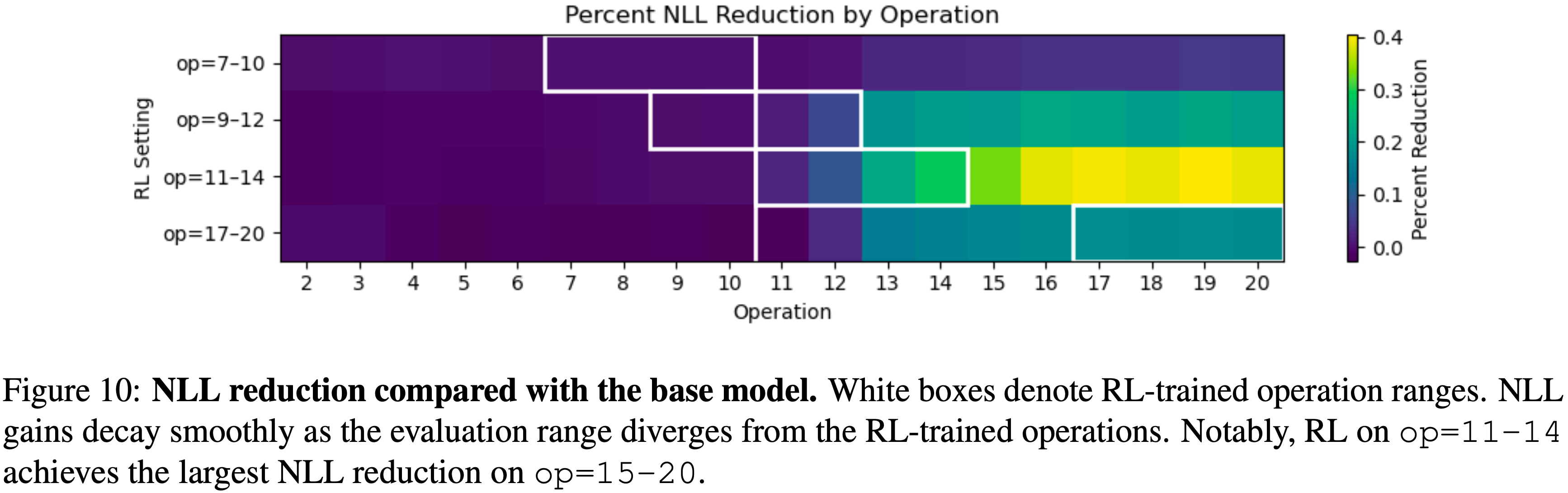
- Post-training Dynamics
- 论文进一步研究了不同 Post Training 方法期间奖励动态的变化
- 从图 11 论文观察到
- 在与模型能力边缘对齐的任务(op=9-12 和 op=11-14)上进行 Post Training 会带来显著的奖励提升,表明学习有效
- 相反,当任务太简单(op=7-10)或太难(op=17-20)时,奖励会趋于平稳,表明在这些机制下学习进展有限
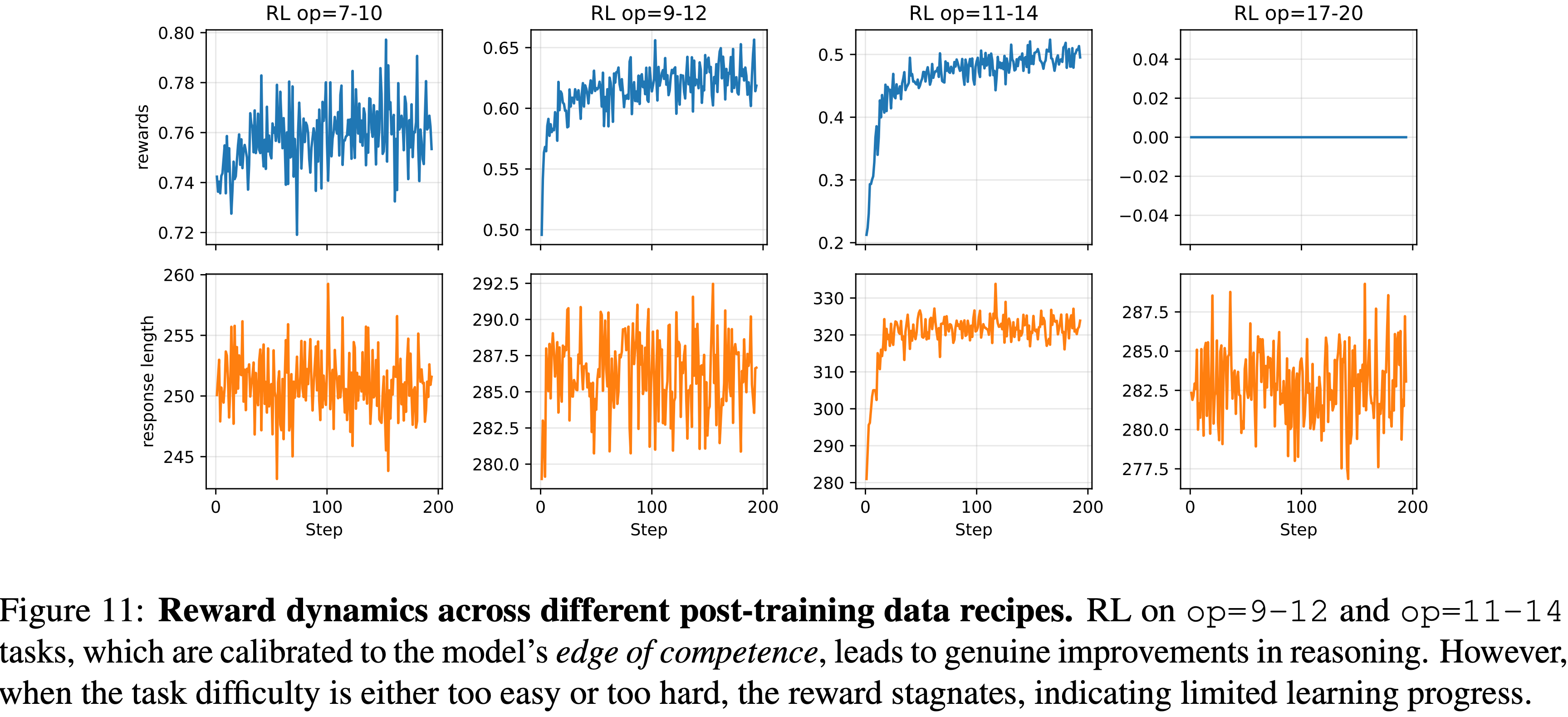
附录 A.6:Detailed Analysis of Post-Training Effects on Contextual Generalization
- 在本节中,论文将详细分析不同的 Post Training 数据方案在给定 Pre-training 阶段原子推理原语的情况下,如何影响对长尾上下文(long-tailed contexts)的上下文泛化
附录 A.6.1 当推理原语在 Pre-training 中共享时 (When Reasoning Primitives are Shared During Pre-Training)
- 除了掌握基本的推理技能,模型泛化的一个重要维度在于上下文泛化 (contextual generalization) ,即跨不同问题上下文(例如变化的表面叙事或领域)迁移所学推理行为的能力
- 在本节中,论文研究 Post Training 是否能激励模型将推理能力泛化到长尾 (long-tailed) 或在 Pre-training 中极少观察到的上下文
Task Setting
- 论文研究两个不同的问题上下文:一个频繁的、规范的 Context A 和一个长尾的 Context B ,两者共享相同的基础推理先验(在论文的例子中是逻辑-算术推理,详细的上下文设置见附录 A.9)
- Pre-training 语料由 99.9% 的 Context A(op=2-20)和仅 0.1% 的 Context B(op=2-20)组成
- 在 Post Training 期间,论文在 200K 个样本中改变对 Context B 的暴露比例:0%、2%、10%、50% 和 100%
Summary 5
Observation 5
- 当 Pre-training 中共享推理原语时, Post Training 期间对 Context B 的暴露程度与模型在 Context B 上的性能呈正相关
- Notably,即使在 Post Training 期间完全没有暴露于 Context B(0%),模型仍能实现显著的迁移,这突显了共享原语在实现上下文泛化中的作用
Takeaway 5
- 当原子原语被共享时, Post Training 可以激励模型向长尾上下文泛化
- Remarkably,即使 Post Training 对 Context B 的暴露为 0%,模型也能实现实质性的迁移,这凸显了 Pre-training 阶段共享推理结构的关键作用
- 图 12:
- 经过 Post Training (对 Context B 的暴露比例不同)后,在上下文泛化任务上的
pass@k性能 - 当 Pre-training 中共享推理原语时,即使在后续 Mid-training 对 Context B 的暴露有限或为零,模型也表现出向 Context B 的强迁移能力
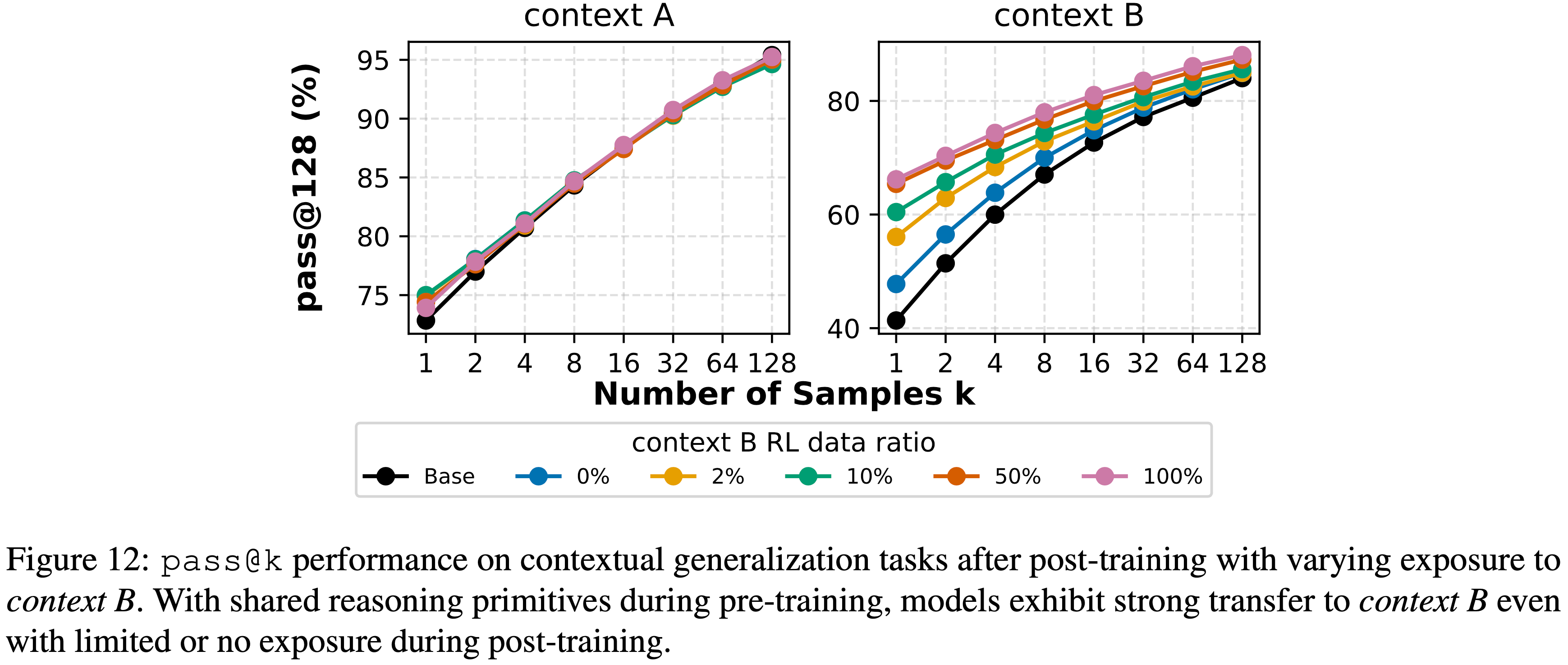
- 经过 Post Training (对 Context B 的暴露比例不同)后,在上下文泛化任务上的
附录 A.6.2 当 Pre-training 中仅暴露原子原语时 (When Only Atomic Primitives are Exposed During Pre-Training)
- 本节研究当 Base Model 在 Pre-training 中仅暴露于长尾上下文的基本原子原语(basic atomic primitives)时的上下文泛化
Task Setting
- 使用与上述相同的上下文数据分布,论文在 Pre-training 期间将 Context B 的数据限制为仅包含原子操作,而 Context A 则覆盖全范围操作
- Pre-training 语料由 99% 的 Context A(op=2-20)和仅 1% 的 Context B 组成,且 Context B 仅限于原子操作(op=2)
- Thus,模型主要通过 Context A 学习推理结构,而对 Context B 的 surface forms 仅有极少的暴露
- 在 Post Training 期间,论文使用 200K 个样本进行 RL 微调,其中 Context B 数据的比例在五个方案中变化:0%、1%、10%、50% 和 100%
- 详细的数据方案见附录 A.9
- 如图 13 所示:
- 仅在 Context A 上进行 Post Training 或对 Context B 的暴露极其稀疏(0-1%)时,模型在 Context A 内保持强劲性能,但对长尾 Context B 的迁移极小
- 理解:这里的 1% 和前面提到的 1% 覆盖是不同的,不然就矛盾了
- However,一旦引入少量 Context B 数据(约占总体样本的 10%)Context B 的性能急剧提升,
pass@128准确率增加超过 +76 点 - 进一步增加 Context B 数据的比例(50%、100%)带来的增益递减,表明一旦提供了最小的监督,RL 就能快速建立起稳健的跨上下文推理
- Notably,即使 Post Training 使用100% Context B 数据(与主要的 Pre-training 上下文完全不同)模型在 Context A 上的性能仍然保持稳定
- 这表明 RL 使模型能够学习可迁移的推理策略,这些策略可以跨 surface forms 进行扩展,同时保留在先前已掌握上下文中的能力
- 理解:这里再次说明了 RL 的训练过程是很少发生灾难性遗忘的
- 仅在 Context A 上进行 Post Training 或对 Context B 的暴露极其稀疏(0-1%)时,模型在 Context A 内保持强劲性能,但对长尾 Context B 的迁移极小
- 图 13:
- Base Model 在 Context B 仅限于基础原子操作时的
pass@k性能 - 仅在 Context A 上进行 Post Training 能保持稳定性能,而在 RL 中引入 10% 的 Context B 数据则能实现上下文迁移
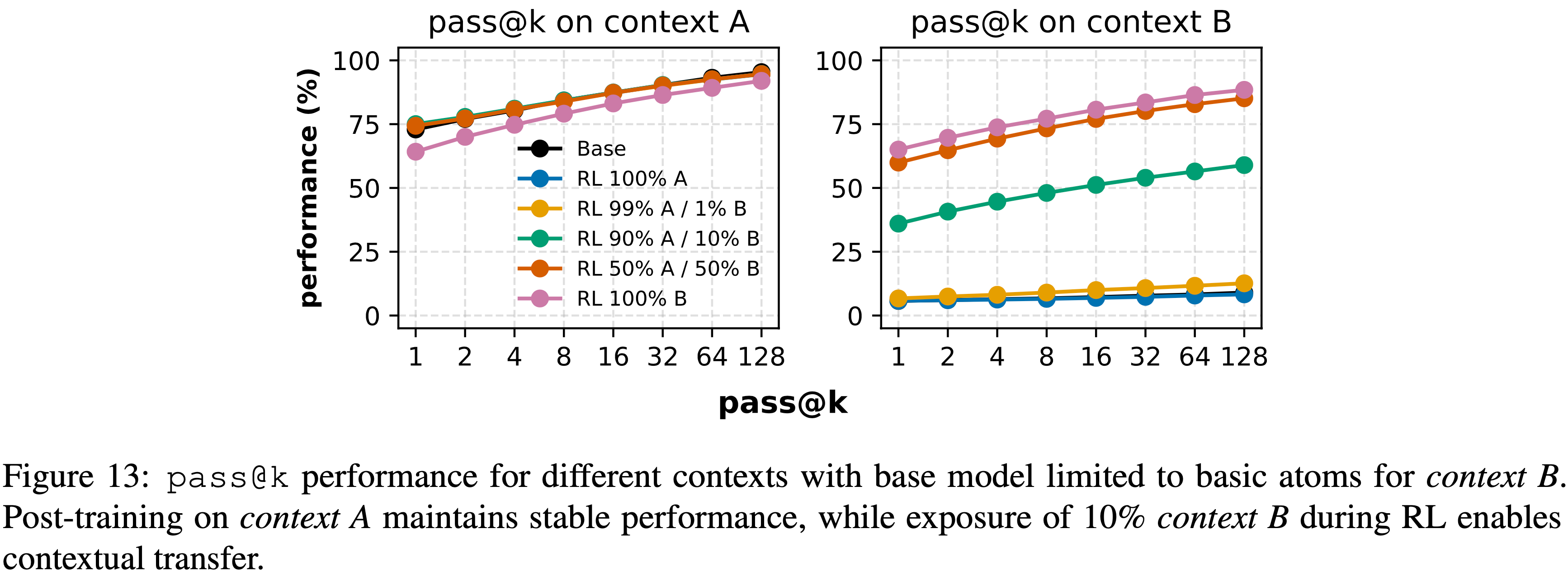
- Base Model 在 Context B 仅限于基础原子操作时的
A.6.3 Training Dynamics for § A.6.2
- 本节绘制了 § A.6.2 中使用的不同数据方案下的 Post Training 奖励动态,以进一步理解 RL 期间对长尾上下文的暴露程度变化如何影响学习进展
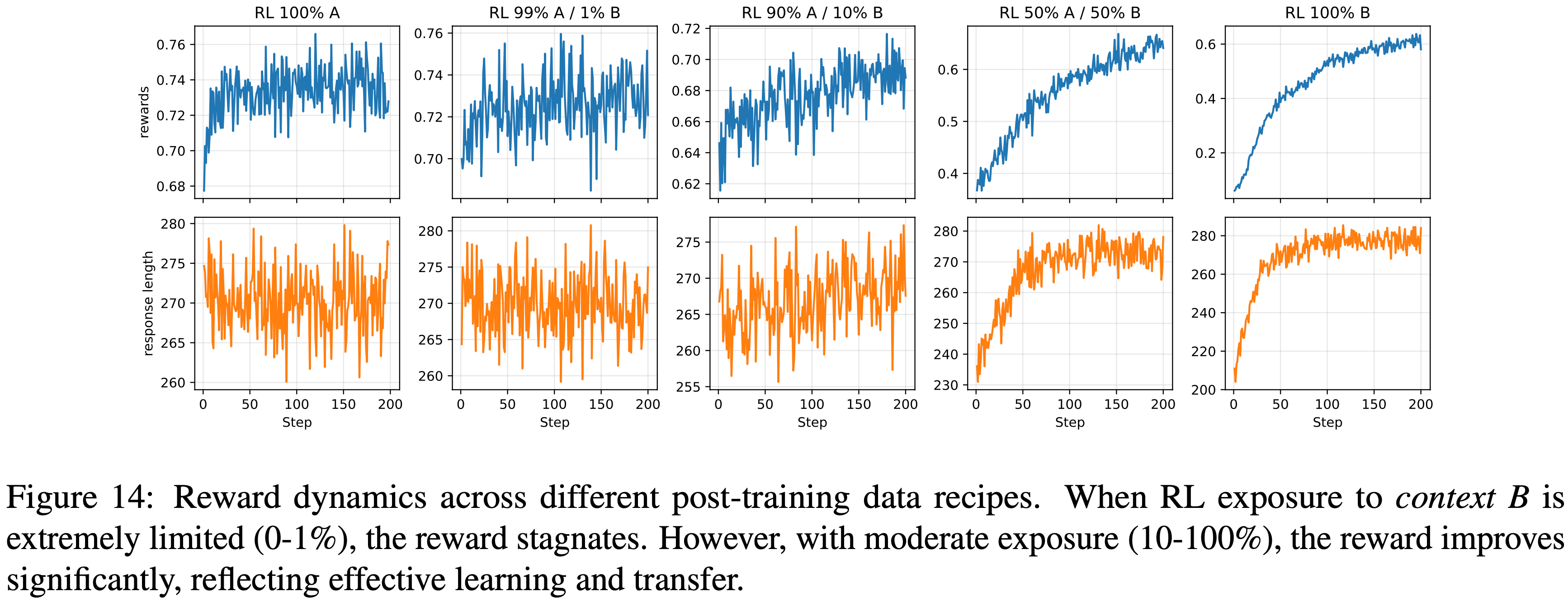
- 从图 14 中我们可以观察到
- 当 Post Training 期间对 Context B 的暴露极其有限(0-1%)时,奖励趋于平稳,表明学习进展甚微
- 然而,在适度暴露(10-100%)下,奖励显著提升,反映了有效的学习和对长尾上下文的迁移
- 图 14:
- 不同 Post Training 数据方案下的奖励动态
- 当 RL 对 Context B 的暴露极其有限(0-1%)时,奖励停滞不前
- 然而,在适度暴露(10-100%)下,奖励显著提升,反映了有效的学习和迁移
附录 A.7 Detailed Analysis of Pre-Training Effects on Extrapolative Generalization**
- Pre-training 定义了 Post Training 后期可以组合和扩展的原子推理原语
- 如果 Base Model 在 Pre-training 期间已经遇到中等复杂的问题, Post Training 可能会将这些原语推向更深层的组合推理
- Otherwise,Post Training 可能缺乏超越其继承能力范围的探索支架
- 因此,作者研究不同的 Pre-training 难度如何影响后续的外推泛化
Task Setting
- 论文将 Post Training 方案固定为来自 op=11-14 范围的 200K 个样本,先前已确定此范围为能力边缘(见图 3)
- 然后改变 Pre-training 期间包含的“困难”数据(op=7-10)的比例,以评估对复杂原语的暴露如何影响 Base Model 在 RL 后的泛化能力
- (详见附录 A.9 的数据方案)
Summary 7
Observation 7
- 如图 15 所示
- 在 Pre-training 中更多地暴露于困难问题,持续地提升了基础和经过 Post Training 的性能
- However,来自 RL 的边际增益随着 Pre-training 变得更全面而减小
- 当 Pre-training 已经覆盖了相当一部分中等深度任务时,RL 仅带来适度的改进
- By contrast,当 Pre-training 包含有限但非平凡的困难原语暴露(例如,20% 的 op=7-10 数据)时,RL 产生了最大的相对提升(将 op=15-20 上的
pass@128准确率提高了超过 +22 点)- 这表明,当模型的先验能力是部分的时候,足够强以支持探索,但又足够不完整以留有发现空间,RL 是最有效的
- 图 15:在 Pre-training 期间不同困难数据暴露水平下, Post Training (op=11-14)后在外推任务上的
pass@128性能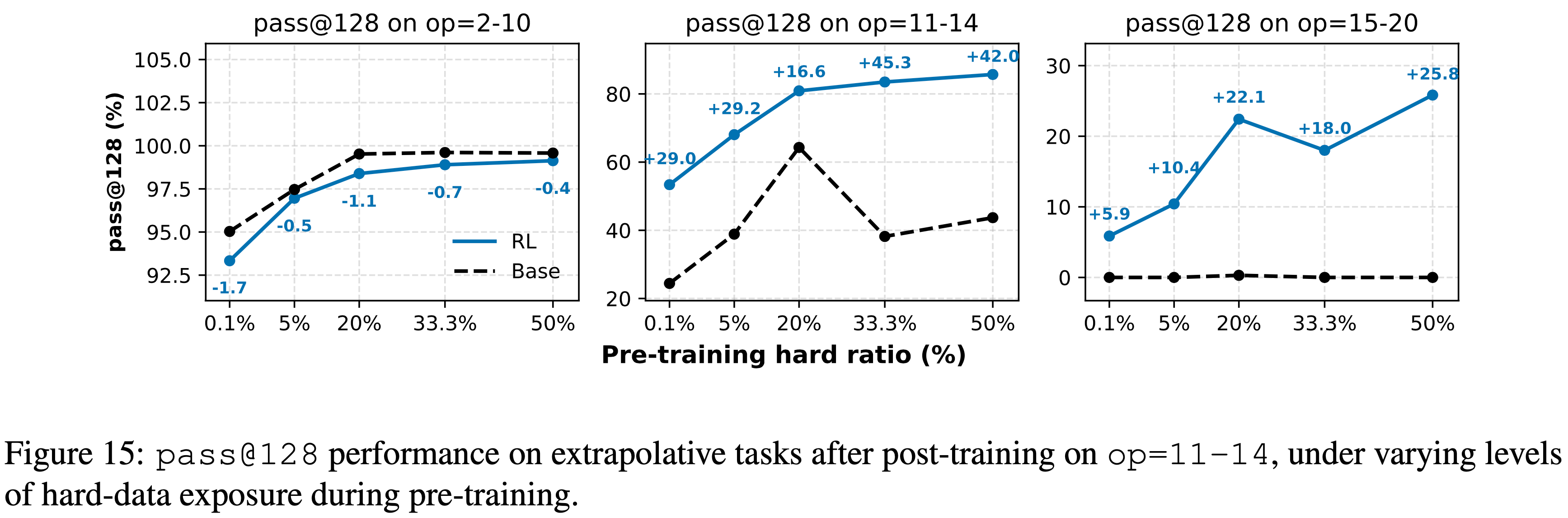
Takeaway 7
- Pre-training 奠定基础,RL 对其进行扩展
- 在 Pre-training 期间丰富地暴露于组合原语,使 RL 能够将推理深度推到超出 Pre-training 范围
- 但一旦这些原语被完全掌握,RL 的益处就会逐渐减少,这突显了两个阶段的互补作用
附录 A.7.1:第 A.7 节的 Training Dynamics (Training Dynamics for § A.7)
- 论文分析了在不同 Pre-training 数据方案下 Post Training 期间的 Training Dynamics
- 图 16:不同 Pre-training 数据方案下的奖励动态
- 在 Pre-training 期间有适度困难数据暴露(20-50%)的模型在 Post Training 期间表现出显著的奖励提升,表明有效的学习和外推
- In contrast,困难数据暴露过少(0%)或过多(100%)的模型显示出有限的奖励增益,表明学习进展受限
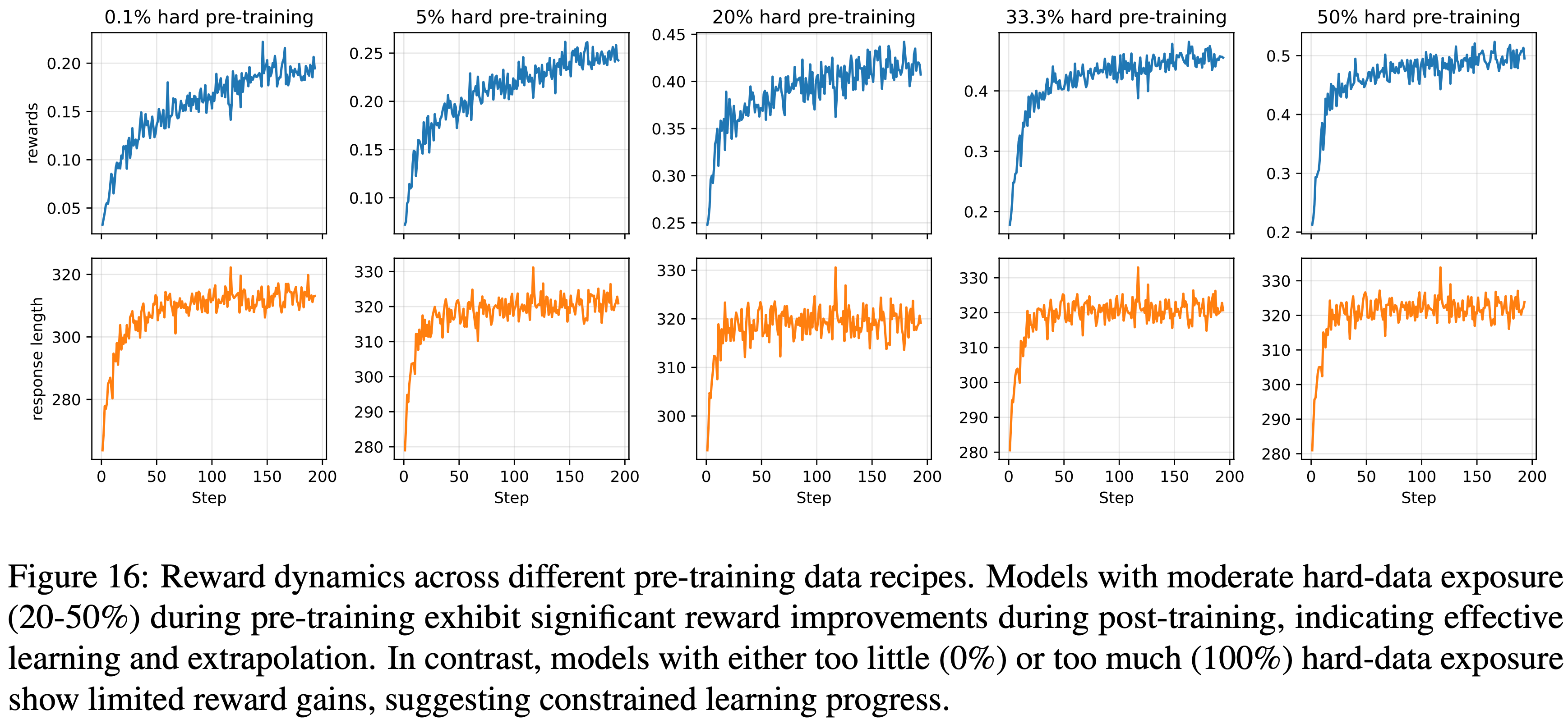
附录 A.8:Training Dynamics for § 4
- 本节分析了 § 4 中上下文泛化的不同 Pre-training 数据方案的 Training Dynamics
- 从图 17 中观察到
- 在 Pre-training 期间对长尾上下文(即使是基础原子)的适度暴露比例,对于模型在 Post Training 期间实现显著的奖励提升是必要的
- 图 17:不同 Pre-training 数据方案下的奖励动态
- 对长尾上下文暴露最少的模型在 Post Training 期间没有奖励提升
- 而对长尾上下文有中等至完全暴露的模型则显示出显著的奖励提升,表明有效的学习和上下文泛化
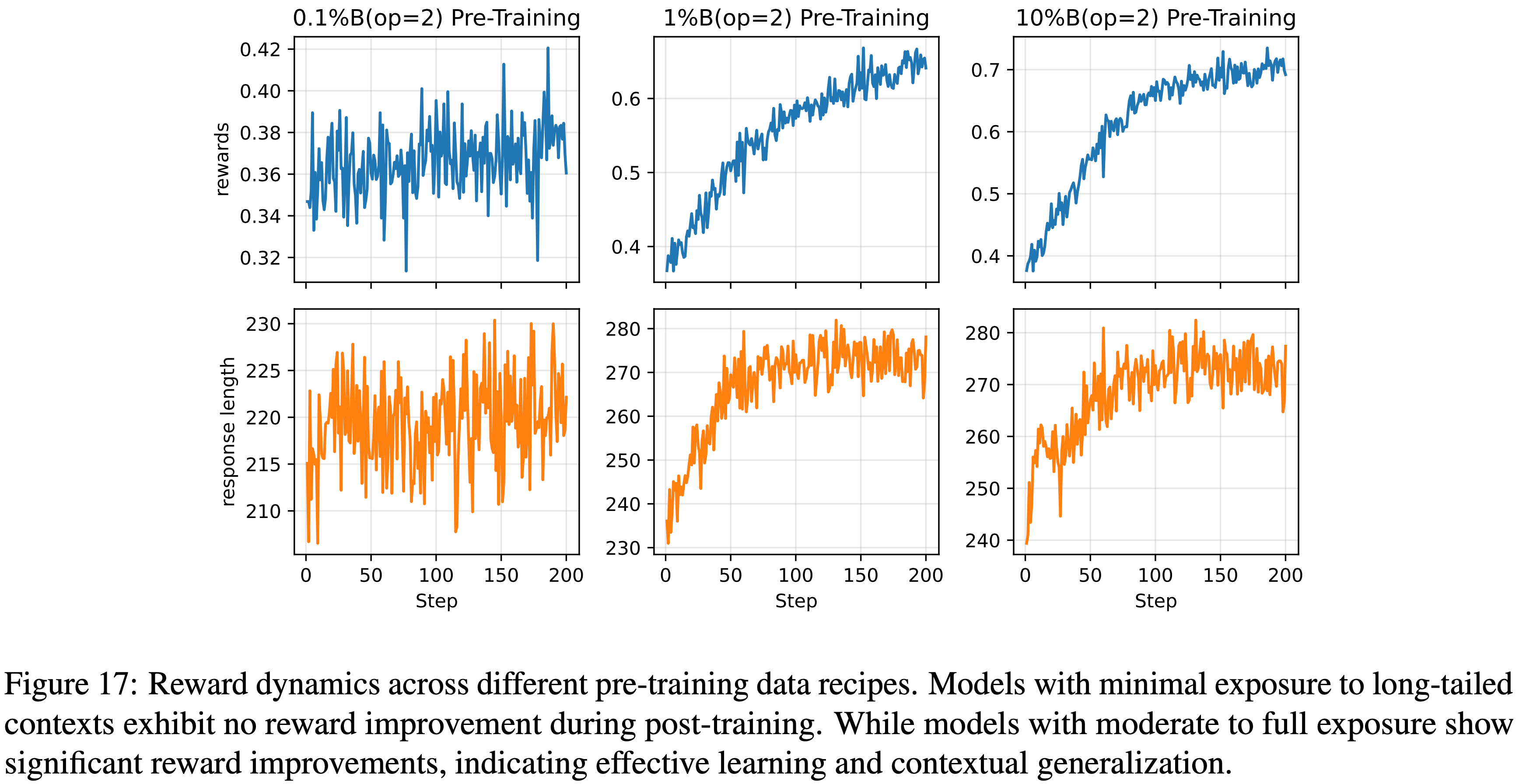
附录 A.9:Post-Training and Pre-Training Data Recipe
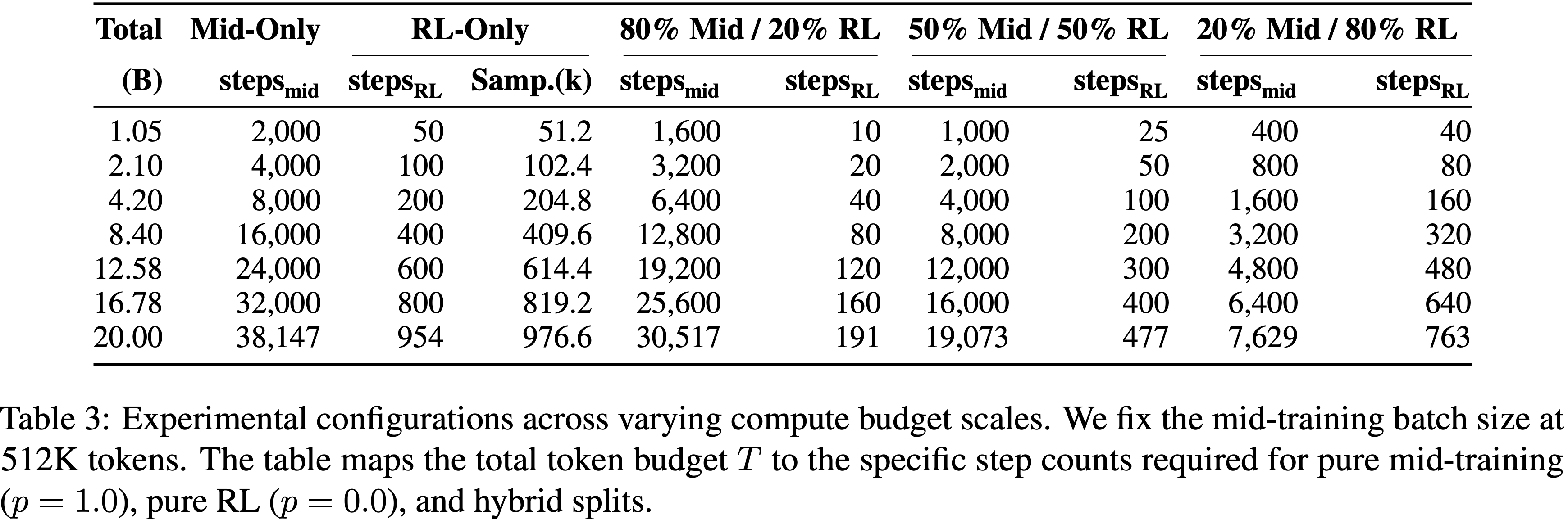
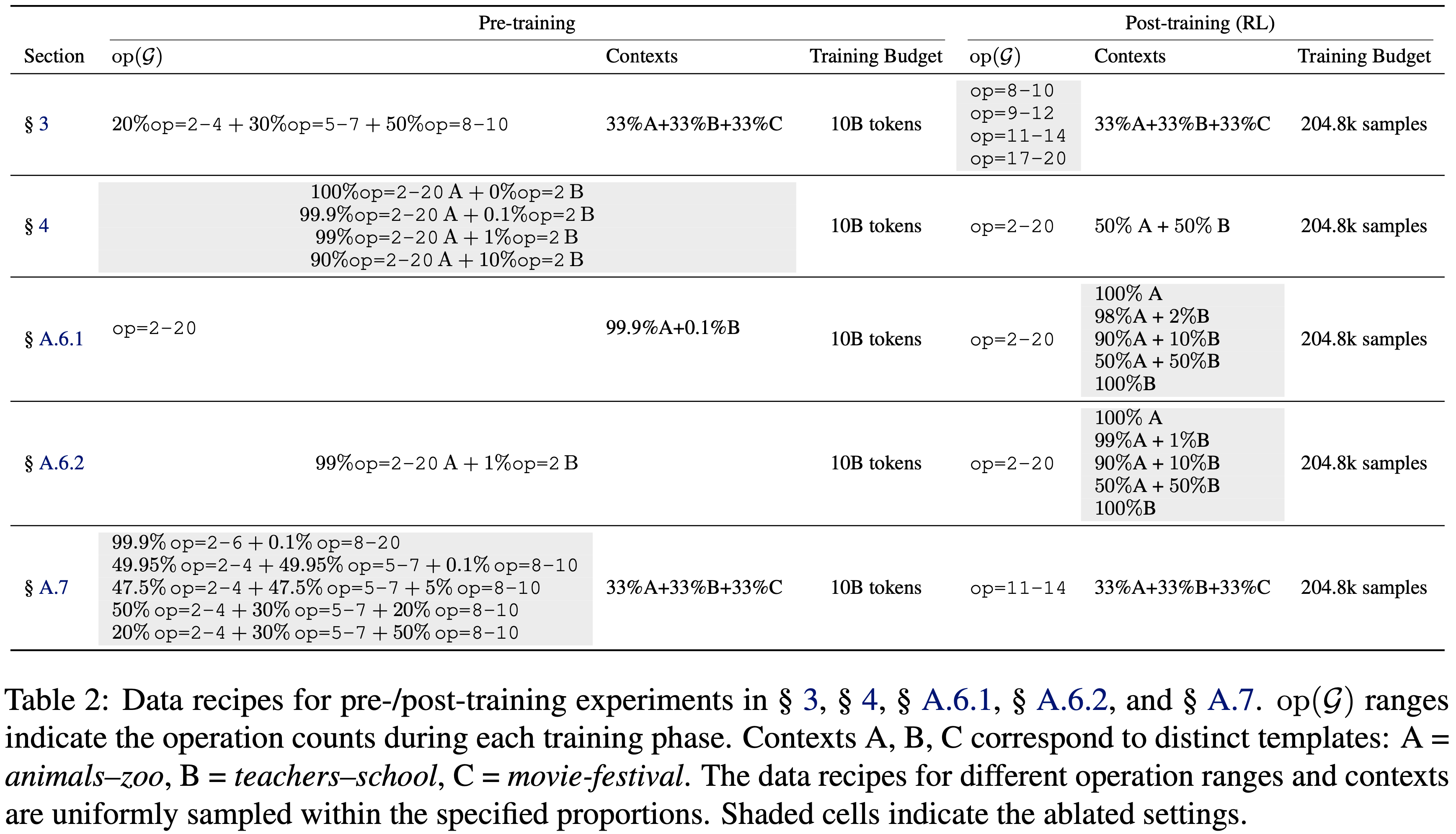
- 本节详述了在 § 3、§ 4、§ A.6.1、§ A.6.2 和 § A.7 中使用的数据方案。表 2 总结了在不同实验部分中使用的具体操作计数范围、上下文模板和训练预算
- 表 2:§ 3、§ 4、§ A.6.1、§ A.6.2 和 § A.7 中 Pre-training / Post Training 实验的数据方案
- op(\(\mathcal{G}\)) 范围表示每个训练阶段的操作计数
- Context A、B、C 对应于不同的模板:A = animals–zoo, B = teachers–school, C = movie-festival
- 不同操作范围和上下文的数据方案均在指定比例内均匀采样
- 阴影单元格表示消融设置
附录 A.10:不同计算预算下的 Mid-training / Post Training 混合 (Mid-/Post-Training Mixing with Different Computation Budget)
- 本节首先详述 Mid-training 和 RL 等价的计算预算公式,然后提供在不同总计算预算下组合 Mid-training 和 Post Training 的确切数据方案
附录 A.10.1 Mid-training 与 RL 等价的计算预算 (Compute Budget of Mid-Training and RL Equivalence)
- 训练计算量 (Training Computation)
- 根据 Chinchilla 缩放定律 (2022),一个具有 P 个非嵌入参数的 Decoder-only Transformer,在 T 个 Token 上训练消耗的计算量大约为:
$$
C_{\text{train} } \approx 6P T \quad \text{flops}
$$ - Thus,预算为 \(T_{\text{mid} }\) 的 Mid-training 阶段消耗
$$ C_{\text{mid} } = 6P T_{\text{mid} } \quad \text{flops}$$
- 根据 Chinchilla 缩放定律 (2022),一个具有 P 个非嵌入参数的 Decoder-only Transformer,在 T 个 Token 上训练消耗的计算量大约为:
- 细粒度 RL 计算量 (Fine-Grained RL Computation)
- 对于 On-policy GRPO,计算可以分解为:
- Rollout: Actor 模型前向传播(2P),
- Reference(可选): 参考模型前向传播(2P),
- Policy Update 前向传播(2P)和后向传播(4P)
- 求和这些项得到:
$$
C_{\text{RL} } = (8 + 2\gamma)P N r L_{\text{total} },
$$- 其中 \(\gamma \in \{0,1\}\) 切换参考模型的前向传播,\(N\) 是 RL 样本数,\(r\) 是 Rollout 大小,\(L_{\text{total} }\) 是总序列长度(包括提示和补全)
- 对于 On-policy GRPO,计算可以分解为:
- Mid-training Token 等价 (Mid-training Token Equivalence)
- 通过方程 4 归一化得到等价的 Mid-training Token 成本:
$$
T_{\text{RL} } = \frac{C_{\text{RL} } }{6P} = \left(\frac{4}{3} + \frac{\gamma}{3}\right) N r L_{\text{total} }
$$ - 当 \(\gamma = 1\) 时,论文得到正文中使用的等价关系:
$$
\boxed{T_{\text{RL} } = \frac{5}{3} N r L_{\text{total} } }
$$
- 通过方程 4 归一化得到等价的 Mid-training Token 成本:
- 预算分配与步数计算 (Budget Allocation and Step Calculation)
- 给定总预算 T 和 RL 比率 \(\beta\),
$$
T_{\text{mid} } = (1-\beta) \cdot T, \qquad T_{\text{RL,eq} } = \beta \cdot T
$$ - 相应的 RL 样本数 \(N(\beta)\) 和更新步数为:
$$
N(\beta) = \frac{3}{5} \cdot \frac{\beta T}{r L_{\text{total} } }, \qquad \text{steps}_{\text{RL} }(\beta) = \frac{N(\beta)}{B},
$$- 其中 \(r = 6\) 是 Rollout 大小,\(L_{\text{total} } = 2048\) 是总序列长度,\(B = 1024\) 是 RL 批次大小,T 是总 Token 预算
- Mid-training 的步数为:
$$
\text{steps}_{\text{mid} }(\beta) = \frac{T_{\text{mid} } }{B_{\text{mid} } \cdot L_{\text{mid} } },
$$ - 其中 \(B_{\text{mid} } = 512 \times 1024\) 是 Mid-training 的批次大小,\(L_{\text{mid} } = 2048\) 是 Mid-training 的序列长度
- 给定总预算 T 和 RL 比率 \(\beta\),
Task Setting
- 论文使用 10B Token 进行 Pre-training ,其中 20% op=2-4,30% op=5-7,50% op=8-10
- 为避免 Mid-training 期间的灾难性遗忘,论文在 Mid-training 期间使用 20% 的预算用于 op=2-10,80% 用于 op=11-14。为公平比较,RL 使用与 Mid-training 相同的数据分布进行。表 3 详述了在不同总 Token 预算 T 和 Mid-training 比率 p 下, Mid-training 和 RL 的确切步数。论文在不同的总计算预算下,使用完全 Mid-training (Full mid-training)、完全 RL (Full RL)、 Light RL (\(\beta=0.2\))、Medium-RL (\(\beta=0.5\)) 和Heavy-RL (\(\beta=0.8\)) 进行中/ Post Training
Summary 8
Observation 8
- 如图 18 所示
- 在所有计算预算下
- Light RL 取得了最佳的 OOD-edge
pass@1性能 - Heavy-RL 始终获得最高的 OOD-hard
pass@1性能
- Light RL 取得了最佳的 OOD-edge
- 对于
pass@128,当计算预算有限(4.2B Token)时,Heavy-RL 在 OOD-hard 设置中取得最佳性能 - 当预算增加(8.4B Token 及以上)时,完全 RL 达到最高的 OOD-hard
pass@128性能
- 在所有计算预算下
- 图 18:不同总计算预算下, Mid-training 和 RL 混合比率对应的
pass@k性能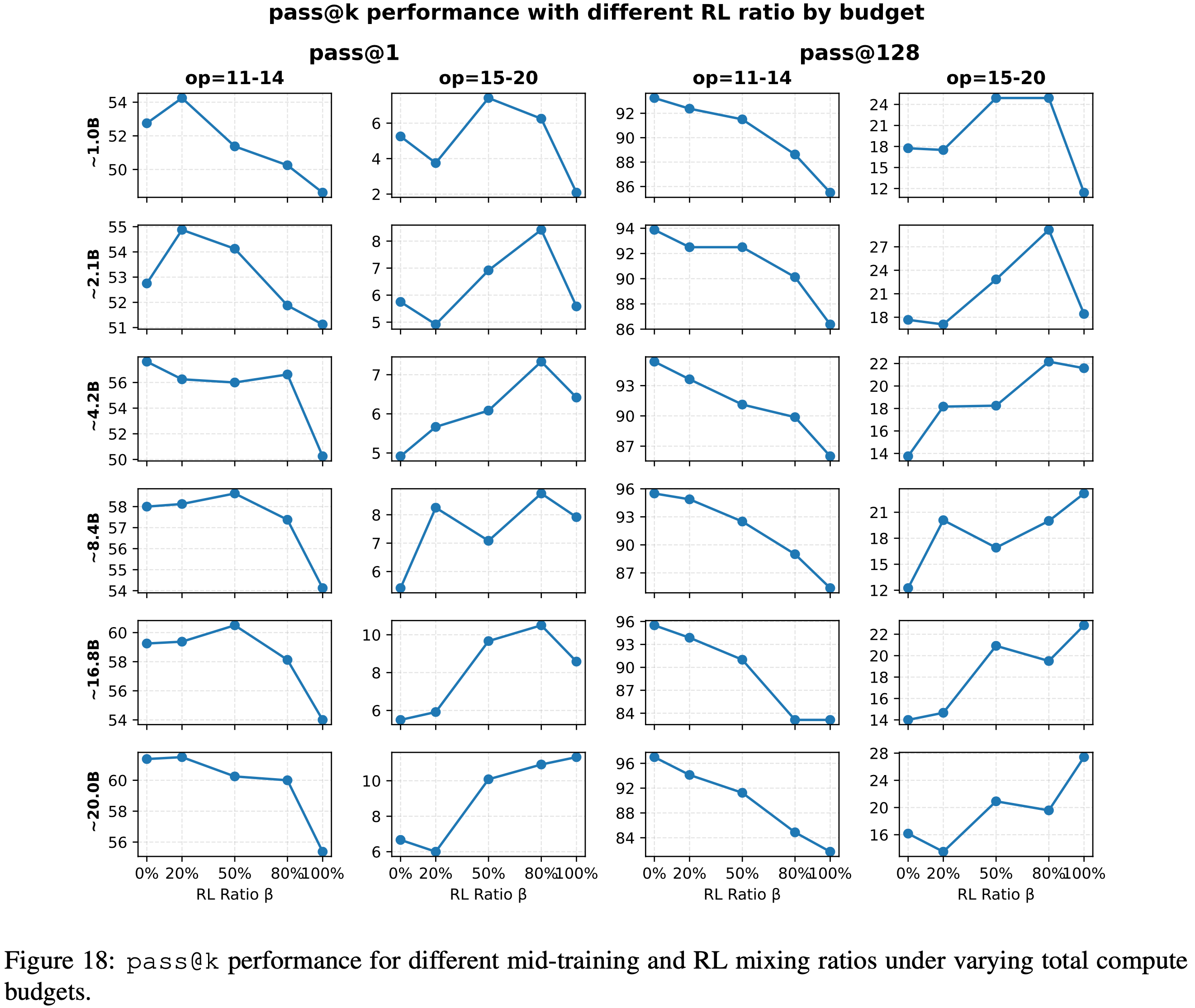
Takeaway 8
- Mid-training 和 Post Training 在不同的计算预算下互为补充
- 对于
pass@1任务, Mid-training 和 RL, Post Training 的组合始终优于任一单独的方法 - 对于
pass@128,最优的 Post Training 分配取决于可用的计算预算:- 在资源有限的情况下,将大约 80% 分配给 RL 能在稳定性和探索性之间取得平衡;
- 在计算量更充足时,完全 RL 能最大化外推增益
- 对于
- 表 3:不同计算预算规模下的实验配置
- 将 Mid-training 的批次大小固定为 512K Token
- 表 3 将总 Token 预算 T 映射到纯 Mid-training (p=1.0)、纯 RL(p=0.0)和混合拆分所需的特定步数