注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 核心:DuoAttention 是一种通过区分 Retrieval Heads 和 Streaming Heads 来优化 LLM 内存和计算资源的框架
- 具体:DuoAttention 可以显著减少了长上下文应用中解码和 Pre-filling 的内存使用和延迟
- 因为 DuoAttention 对 Retrieval Heads 应用完整的 KV 缓存(Streaming Heads 仅缓存 Sink Token 和 Recent Token)
- 对比之前 MHA 和 GQA 的效果(内存大幅减少、解码速度大幅提升)
- MHA 模型内存减少高达 \(2.55\times\),MHA 模型解码速度提升高达 \(2.18\times\),Pre-filling 加速高达 \(1.73\times\)
- GQA 模型内存减少高达 \(1.67\times\),GQA 模型解码速度提升高达 \(1.50\times\),Pre-filling 加速高达 \(1.63\times\)
- 且与完全注意力相比准确率损失最小(minimal accuracy loss)
- 当与量化结合时,DuoAttention 可以进一步提升 KV 缓存容量,在单个 A100 GPU 上支持高达 3.30M 个上下文 Token
- 背景 & 问题提出:
- 部署长上下文(long-context)LLM 至关重要,但长上下文带来了显著的计算和内存挑战
- 跨所有注意力头缓存所有 Key 和 Value (KV)状态会消耗大量内存
- 现有的 KV 缓存剪枝方法要么损害 LLM 的长上下文能力,要么仅提供有限的效率提升
- 作者发现:
- 只有一小部分注意力头(Retrieval Heads),对于处理长上下文至关重要,并且需要对所有 Token 进行完整的注意力计算
- 而其他头(Streaming Heads),主要关注最近的 Token 和 Attention Sinks,不需要完整的注意力计算
- 基于这一洞察,论文引入了 DuoAttention:
- 该框架仅对 Retrieval Heads 应用完整的 KV 缓存,同时对 Streaming Heads 使用轻量级的、恒定长度的 KV 缓存
- 从而在不损害其长上下文能力的情况下,减少 LLM 解码和 Pre-filling 的内存占用和延迟
- DuoAttention 使用一种轻量级的、基于优化的算法以及合成数据来准确识别 Retrieval Heads
- 内存方面:
- 对于多头注意力模型最高减少 2.55\(\times\)
- 对于分组 Query 注意力模型最高减少 1.67\(\times\)
- 效率方面:
- 对于多头注意力模型解码速度最高提升 2.18\(\times\), Pre-filling 速度最高提升 1.73\(\times\)
- 和分组 Query 注意力模型解码速度最高提升1.50\(\times\), Pre-filling 速度最高提升 1.63\(\times\)
- 与完整注意力相比,准确率损失最小(minimal accuracy loss)
- 开源链接:github.com/mit-han-lab/duo-attention
Introduction and Discussion
- LLM 处于人工智能革命的前沿,驱动着高级应用,如多轮对话、长文档摘要以及涉及混合模态的任务,如视觉和视频理解
- 这些应用通常需要处理大量的上下文 Token ;
- 例如,总结整个《哈利·波特》系列可能涉及分析约一百万个 Token
- 对于视觉语言模型,挑战更加严峻,其中一张 224×224 的图像对应 256 个 Token ,而一段三分钟、24 FPS 的视频会生成约 1.1M 个 Token
- 在此类应用中部署 LLM 的一个关键问题是长上下文推理问题
- 完整的注意力机制要求所有 Token 关注所有先前的 Token 以获得准确的表示,这导致解码延迟线性增加, Pre-filling 延迟二次方增加
- KV 缓存技术存储所有先前 Token 的 Key 和 Value ,导致内存使用量随上下文长度线性增长
- 随着序列变长,内存越来越多地被 KV 缓存消耗,给注意力机制带来了显著的计算负担
- 例如,在 Llama-3-8B 模型架构中,为 1M 个 Token 提供服务并使用 FP16 KV 缓存将需要至少 137 GB 的内存(这已经超过了单个 80GB GPU 的容量)
- 而且使用如此大上下文进行 Pre-filling 和解码会有显著延迟,这对 LLM 在长上下文场景中的有效使用构成了重大挑战
- 尽管有许多努力来克服注意力机制在长上下文推理中的挑战,但显著的计算和内存问题仍然存在
- 架构修改,如分组 Query 注意力,需要模型预训练,并且无法降低计算成本
- 线性注意力(Linear Attention)方法虽然在计算和内存需求上较低,但在长上下文场景下往往不如 Transformer 模型
- 近似注意力(Approximative attention)方法,如 H\({}_{2}\)O、StreamingLLM、TOVA 和 FastGen,常常在长上下文应用中牺牲精度,并且与关键的 KV 缓存优化技术(如分组 Query 注意力)不兼容
- KV 缓存量化虽然有用,但并未减少注意力机制的计算时间
- 系统级优化,包括 FlashAttention、FlashDecoding 和 PagedAttention,虽然有效,但并未减少 KV 缓存大小,并且在扩展上下文时仍然需要大量计算
- 架构修改,如分组 Query 注意力,需要模型预训练,并且无法降低计算成本
- 论文引入了一个关键观察
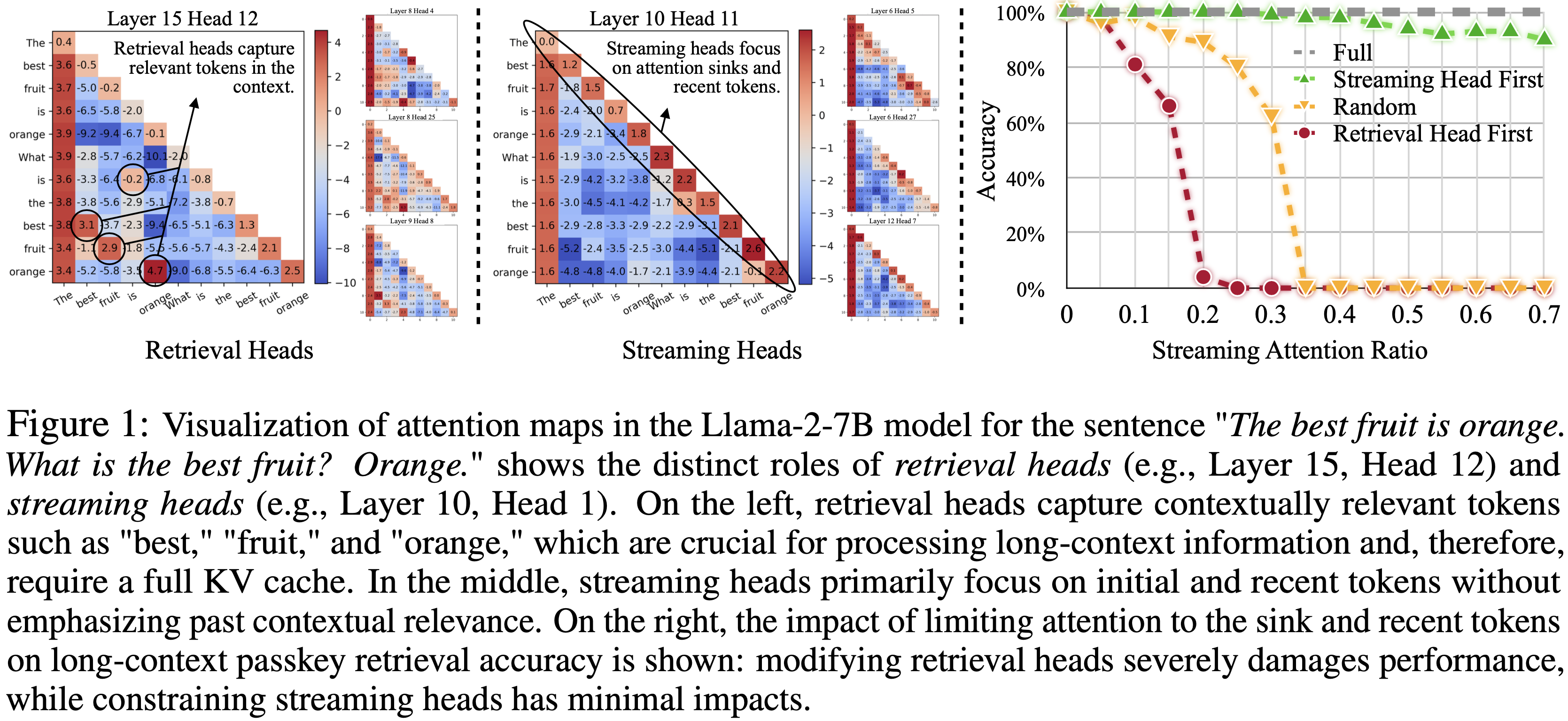
- LLM 中的注意力头可以分为两种不同的类型 :Retrieval Heads 和 Streaming Heads ,如图 1 所示
- Retrieval Heads 仅占总头数的一小部分,对于处理长上下文至关重要,并且需要对所有 Token 进行完整的注意力计算
- Streaming Heads(大多数注意力头),主要关注最近的 Token 和 Attention Sinks ,并且可以在仅包含 Recent Token 和 Attention Sinks 的简化 KV 缓存下有效运行
- 基于 Retrieval Heads 和 Streaming Heads 的二分法,论文提出了 DuoAttention
- DuoAttention 是一种通用、直接且易于集成的方法,能显著加速 LLM 的解码和 Pre-filling ,并减少内存占用,尤其是在长上下文场景中
- DuoAttention 的核心创新是一种轻量级的、基于优化的过程,它使用合成数据集来识别不可压缩的 Retrieval Heads
- 与依赖注意力模式分析 (2024;) 的现有方法不同,DuoAttention 直接测量因 Token 丢弃而产生的输出偏差,从而实现更高的压缩率和改进的部署效率
- DuoAttention 的设计注重简洁和高效:每个 Transformer 层有两个 KV 缓存
- 一个用于关键 Retrieval Heads 的完整 KV 缓存
- 一个用于 Streaming Heads 的恒定 KV 缓存,仅存储 Attention Sinks 和最近的 Token
- 这种设计使得 DuoAttention 能够显著减少内存使用、提高模型的解码速度,且与完整注意力相比,精度损失最小
- DuoAttention 与重要的优化技术(如分组 Query 注意力和量化)完全兼容
- 当结合 8-bit 权重和 4-bit KV 缓存量化时,DuoAttention 使得 Llama-3-8B 模型能够在单个 A100 GPU 上处理高达 3.3M 上下文 Token
- 与标准的完整注意力 FP16 部署相比,实现了 \(6.4\times\) 的容量提升
- DuoAttention 为在需要百万级上下文处理的应用中部署 LLM 铺平了道路
- 当结合 8-bit 权重和 4-bit KV 缓存量化时,DuoAttention 使得 Llama-3-8B 模型能够在单个 A100 GPU 上处理高达 3.3M 上下文 Token
DuoAttention
Retrieval Heads 和 Streaming Heads
Retrieval Heads
- 在基于 Transformer 的 LLM 中,注意力头表现出独特且一致的模式,反映了它们的专门功能
- 图 1 使用句子“最好的水果是橙子。什么是最好的水果?橙子。”可视化了 Llama-2-7B-32K-Instruct 模型中的两种注意力头
- 左图突出显示了一个在解码过程中强调相关 Token 的注意力头;
- 例如,在解码第二个“最好的水果”时,第一个“最好的水果”被加重;在推断第二个“橙子”时,初始的“橙子”被突出显示
- 这些注意力头,论文称之为 Retrieval Heads ,对于上下文处理至关重要,因为它们捕获了上下文相关的 Token
- 压缩 Retrieval Heads 的 KV 缓存将导致关键上下文信息的丢失,因此它们需要对所有 Token 进行完整的注意力计算
Streaming Heads
- 图 1 中间图描绘的注意力头主要关注最近的 Token 和 Attention Sinks,不强调上下文中较早的相关 Token
- 论文称这些为 Streaming Heads
- 压缩 Streaming Heads 的 KV 缓存是可行的,因为丢弃未被关注的中国 Token 不会显著改变注意力输出
- 可以通过仅保留 Attention Sinks 和 Recent Token 的 KV 状态来优化 Streaming Heads ,而不会损害模型管理长上下文的能力
Impact of Token Pruning on Retrieval and Streaming Heads
- 图 1 的右图显示了一个初步的 Passkey 检索实验
- 当 Retrieval Heads KV 缓存中的中间 Token 被剪枝时,模型的性能显著下降
- 移除 Streaming Heads 的中间 Token 对 Passkey 检索精度没有显著影响
- 这一观察表明,我们可以在不牺牲模型长上下文能力的情况下提高计算效率:
- 通过丢弃 Streaming Heads 的中间 Token ,同时保持 Retrieval Heads 的完整注意力,将 Streaming Heads 的内存需求降低到 \(O(1)\),从而提高了处理长上下文的效率
Optimization-Based Identification of Retrieval Heads
Definition of Retrieval Heads
- 第 2.1 节定性地定义了 Retrieval Heads 和 Streaming Heads ,但为了精确识别,论文需要一个具体且量化的定义
- 在论文中,论文将“Retrieval Heads”定义为:
- 当被限制为仅关注 Recent Token 和 Attention Sinks 时,会显著改变模型输出的注意力头
- 论文使用这个标准来区分 Retrieval Heads 和 Streaming Heads
- 这个定义不同于现有工作 (2024; ),它们仅依赖注意力分数来识别 Retrieval Heads ,忽略了
- 1)压缩特定注意力头 KV 缓存的端到端影响
- 2)Value 状态的角色
- 3)注意力分布在层和头之间的可变性
- 论文的定义直接测量输出偏差 ,即使它们在注意力分数中不明显,论文也能够识别对长上下文处理至关重要的注意力头
- 论文在第 3.5 节中提供的消融研究支持了这一论点
- 这个定义不同于现有工作 (2024; ),它们仅依赖注意力分数来识别 Retrieval Heads ,忽略了
Optimization-based Identification
- 论文采用一种基于优化的方法来识别 Retrieval Heads ,灵感来自先前在 CNN 滤波器剪枝方面的工作,如图 2 所示
- 首先为 LLM 中的每个 KV 头分配一个门控值 \(\alpha_{i,j}\)
- 这个值直观地表示了第 \(i\) 层第 \(j\) 个 KV 头在处理长上下文信息时的重要性
- 在使用分组 Query 注意力的模型中,一个 KV 头可能与多个注意力头相关联,论文的方法考虑了对整个注意力头组的 KV 缓存压缩
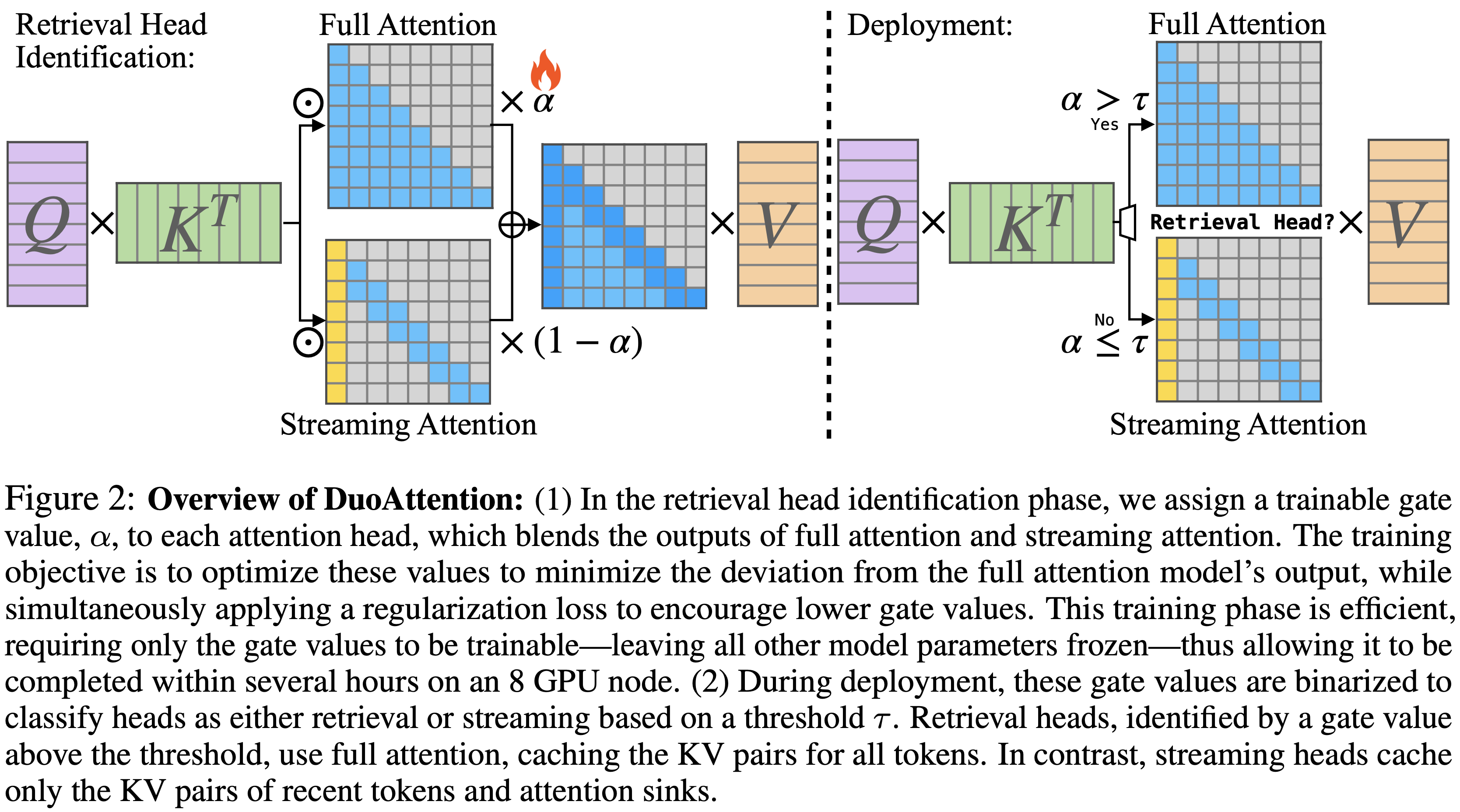
- 首先为 LLM 中的每个 KV 头分配一个门控值 \(\alpha_{i,j}\)
- 论文的基于优化的识别方法直接评估了仅使用 Sink Token 和 Recent Token 压缩每个 KV 头 KV 缓存的影响
- 首先将每个头的门控值 \(\alpha_{i,j}\in[0,1]\) 初始化为 1,假设所有头最初都作为 Retrieval Heads
- 然后优化这些门控值,同时保持 LLM 的参数固定,将可训练参数的数量限制在 \(N\times H\),并防止影响模型的原始能力
- 在前向传播过程中,论文结合每个 KV 头的完整注意力和流式注意力的输出,使用门控值作为混合权重:
$$\texttt{attn}_{i,j}=\alpha_{i,j}\cdot\texttt{full_attn}+(1-\alpha_{i,j})\cdot\texttt{streaming_attn}$$- 其中注意力计算定义为:
$$\texttt{full_attn} =\texttt{softmax}(\boldsymbol{Q}\boldsymbol{K}^{T}\odot\boldsymbol{M}_{\text{causal} })\boldsymbol{V}, \\
\texttt{streaming_attn} =\texttt{softmax}(\boldsymbol{Q}\boldsymbol{K}^{T}\odot\boldsymbol{M}_{\text{streaming} })\boldsymbol{V},$$ - 其中 \(\boldsymbol{M}_{\text{causal} }\) 是因果注意力掩码,而 \(\boldsymbol{M}_{\text{streaming} }\) 表示一个类 \(\Lambda\) 掩码,仅关注最近和初始的 Token
- 其中注意力计算定义为:
Synthetic Dataset for Identifying Retrieval Heads
- 仅依赖自然语言建模目标不足以识别 Retrieval Heads
- 自然文本中需要长跨度推理的监督信号是稀疏的,且大多数 Token 可以使用局部上下文进行推断
- 论文设计了一个专门旨在增强模型长上下文检索能力的合成数据集,使论文能够有效地识别哪些 KV 头可以在不损害模型性能的情况下被压缩
- 如图 3 所示,论文通过在一个非常长的上下文中,在十个随机位置嵌入十个随机生成的 \(s\) 个 Token 的 passkey sequences 来创建一个 passkey-retrieval 数据集
- 模型的任务是在上下文末尾回忆这十个序列

- 模型的任务是在上下文末尾回忆这十个序列
Training and Loss Functions
- 论文优化蒸馏损失,即完整注意力模型的最后一个隐藏状态与使用 DuoAttention 的模型的最后一个隐藏状态之间的 L2 差异,仅关注整个输入中最后 \(l\) 个 Passkey Token :
$$\mathcal{L}_{\text{distill} }=\frac{1}{N}\sum_{i=1}^{N}\sum_{j=\bar{T}-l+1}^{T}(\boldsymbol{H}_{\text{full} }^{(i)}[j]-\boldsymbol{H}_{\text{mixed} }^{(i)}[j])^{2}$$ - 论文的合成数据集确保每个监督信号都与最终的压缩策略相关,使得该过程在信息检索精度方面是无损的
- 事实证明,它比仅使用自然语言建模更有效
- 论文使用 L1 正则化项来鼓励门控值的稀疏性:
$$\mathcal{L}_{\text{reg} }=\sum_{i=1}^{L}\sum_{j=1}^{H}|\alpha_{i,j}|,.$$
- 最终的训练损失是蒸馏损失和正则化损失的组合,由一个超参数 \(\lambda\) 加权,论文在实验中将其设置为 0.05:
$$\mathcal{L}=\mathcal{L}_{\text{distill} }+\lambda\mathcal{L}_{\text{reg} }.$$ - 由于可训练参数的总数仅为数千个浮点数,此优化过程相当快,仅需要 2,000 步
- 论文论文中的所有训练实验都可以在 8×NVIDIA A100 GPU 服务器上进行
Deploying LLMs with DuoAttention
Binarizing Attention Implementations(二值化注意力)
- 在推理时,论文仅对指定的 Retrieval Heads 应用完整注意力,这些 Retrieval Heads 是使用训练阶段优化的门控值识别的
- 论文根据阈值 \(\tau\) 对每个头的注意力策略进行二值化,以区分 Retrieval Heads 和 Streaming Heads :
$$\text{attn}_{i,j}=\begin{cases}\text{full_attn}&\text{if }\alpha_{i,j}>\tau \\ \text{streaming_attn}&\text{otherwise}\ \end{cases}$$
Reordering Attention Heads(重排注意力头)
- 在部署之前,论文通过根据注意力头分配重新排序 Query 、 Key 和 Value 投影权重的输出通道来预处理模型
- 这种重新排序将 Retrieval Heads 和 Streaming Heads 分组为两个不同的、连续的簇,从而允许在层内管理这两种类型头的 KV 缓存时进行高效的切片和连接操作,而不是依赖 scattering 和 gathering 操作
Decoding
- 如图 5 所示,论文在解码期间为 LLM 的每一层分配两个 KV 缓存 :
- 一个用于 Retrieval Heads ,存储所有过去的 Key 和 Value ;
- 另一个用于 Streaming Heads ,仅存储 Attention Sinks 和最近的 Token ,保持恒定大小
- 当处理一个新 Token 时,其 Query 、 Key 和 Value 向量沿头维度分割,以计算 Retrieval Heads 的完整注意力和 Streaming Heads 的流式注意力
- 然后将结果沿头维度连接以进行输出投影
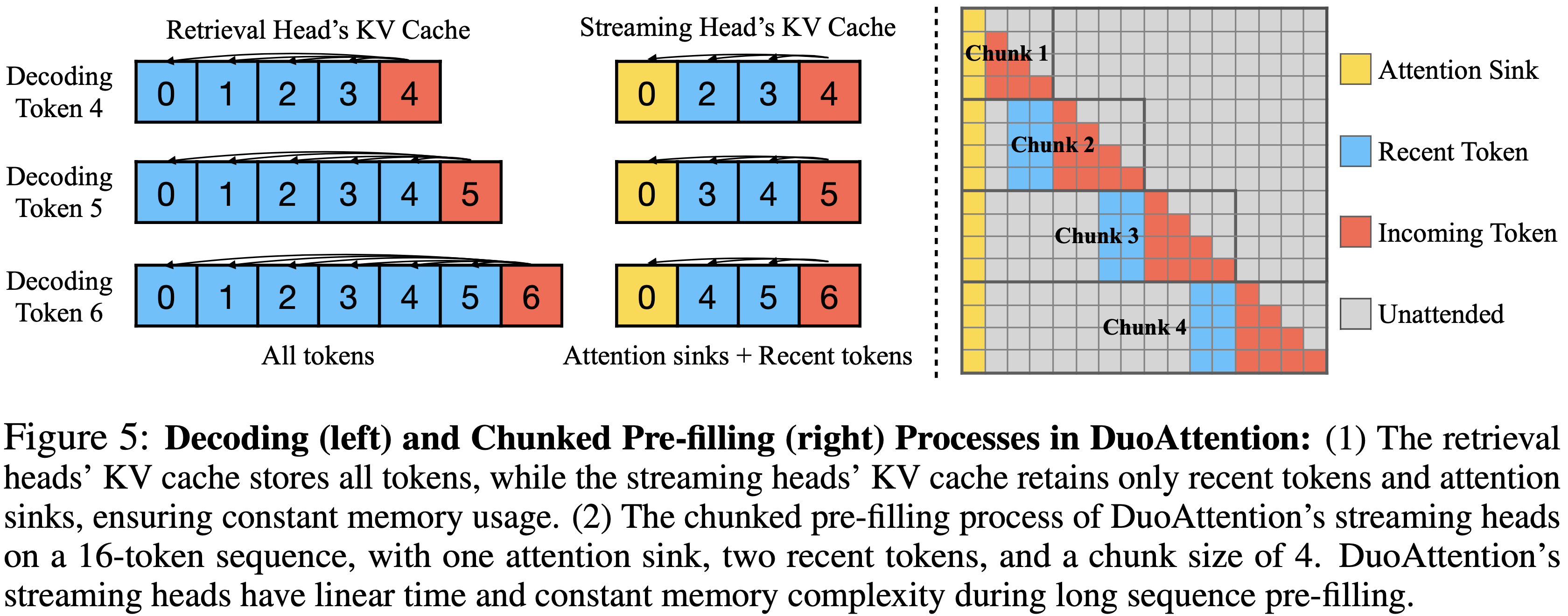
- 然后将结果沿头维度连接以进行输出投影
Chunked Pre-filling(分块 Pre-filling)
- 论文使用 FlashAttention-2 来 Pre-fill Retrieval Heads 和 Streaming Heads 的 KV 缓存
- 在长上下文 LLM 中,分块 Pre-filling 是一种常见做法,将提示分成固定长度的块来 Pre-filling KV 缓存
- 这种技术通过将线性层中的峰值中间激活大小从序列长度降低到块大小,显著降低了峰值内存使用
- DuoAttention 与分块 Pre-filling 完全兼容,并且 DuoAttention 中 Streaming Heads 的 Pre-filling 可以在线性时间和恒定内存复杂度下实现,无需专门的核
- 如图 5 所示,计算了某一层的 KV 后,Streaming Heads 的 KV 缓存会立即被剪枝,仅保留 Sink Token 和最近的 Token
- 下一个传入 Token 块在 Pre-filling 期间将仅关注恒定数量的上下文 Token
- 令 \(L\) 表示序列长度,\(K\) 表示块大小(chunk size)
- Streaming Heads 的 Pre-filling 时间复杂度从 \(O(L^{2})\) 优化到 \(O(LK)\),内存复杂度从 \(O(L)\) 减少到 \(O(K)\)
- 需要注意的是,DuoAttention 的设计非常适合批量操作,这可以在具有大批量大小的服务场景中进一步提高 LLM 的效率
Experiments
Setups
- 模型、数据集和基线 (Models, Datasets, and Baselines)
- 论文在长上下文和短上下文基准测试上评估 DuoAttention,证明论文的方法在保留模型处理长短上下文任务性能的同时,显著提高了效率
- 对于长上下文评估
- 论文使用 Needle-in-a-Haystack (NIAH) 基准测试 (Kamradt, 2024) 和 LongBench (2023)
- 对于短上下文评估
- 论文评估了在 MMLU (2021)、MBPP (2021) 和 MT-Bench (2023) 上的性能
- 对于长上下文评估
- 论文采用了 SOTA 开源模型,包括 Llama-2-7B-chat (2023b)(及其长上下文变体 Llama-2-7B-32K-Instruct (Together, 2023))、Llama-3-[8,70]B-Instruct(及其长上下文变体 Llama-3-8B-Instruct-Gradient-1048k)以及 Mistral-7B-v0.2-Instruct (2023)
- 论文将论文的方法与 KV 缓存压缩算法进行了比较,包括 H2O (2023b)、TOVA (2024)、FastGen (2024) 和 StreamingLLM (2023b)
- 论文在长上下文和短上下文基准测试上评估 DuoAttention,证明论文的方法在保留模型处理长短上下文任务性能的同时,显著提高了效率
- Implementation details
- 论文使用 PyTorch (2019) 和来自 FlashInfer (2024) 的 RoPE (2021) 和 RMSNorm 内核来实现 DuoAttention
- 对于 Retrieval Heads 的识别
- 论文使用批量大小为 1,将 10 个 32 词(Words)的 passkeys 插入到 BookSum (2021) 数据集中
- 识别过程使用 128 个 Sink Token 和 256 个 Recent Token
- 训练样本从范围为 1,000 个 Token 到模型特定的最大长度(间隔 50 intervals)中采样(问题:这里是指样本长度的采样)
Training samples are drawn from 50 intervals ranging from 1,000 tokens to the model-specific maximum length
- passkeys 在上下文中的 1000 个点处随机插入(更多细节包含在附录 A.1 节中)
- 论文使用 AdamW (2015) 优化器优化门控值,初始学习率为 0.02,在前 400 步从 0.002 进行预热,并在最后 400 步降回 0.002
- 所有实验在 NVIDIA A100 GPU 上运行 2,000 步
Long-Context Benchmarks
- 使用 Needle-in-a-Haystack (NIAH) 基准测试和 LongBench (2023) 来评估 DuoAttention
- 使用了两个长上下文模型:Llama-2-7B-32K-Instruct 和 Llama-3-8B-Instruct-Gradient-1048k
- DuoAttention 配置:
- Llama-2-7B-32K-Instruct 使用 25% 的 Retrieval Heads 比例
- Llama-3-8B-Instruct-Gradient-1048k 使用 50% 的比例
- 论文在相同的 KV 缓存预算下,将 DuoAttention 与 H2O、TOVA 和 StreamingLLM 进行比较
- 论文为 DuoAttention 使用 64 个 Sink Token 、256 个 Recent Token 和 32,000 的 Pre-filling 块大小
- 由于 H2O 和 TOVA 的原始设计不支持长上下文,论文修改了它们的算法,将 Pre-filling 阶段替换为 FlashAttention,并模拟输入最后 50 个 Token 的解码(遵循 Tang 等人 (2024b) 的方法)
- FastGen 的算法不允许指定 KV 压缩比,因为它会随输入波动
- 论文调整了注意力恢复比例,以确保在图 6 所示的实验中,KV 缓存预算平均高于 25% 或 50%
- FastGen 在 Attention Profiling 阶段的二次内存成本限制了其处理长上下文样本的能力
- 论文测量了 FastGen 在 NIAH 上对 Llama-2-7B 最高到 24K 上下文、对 Llama-3-8B 最高到 32K 上下文的性能;
- 超过这些大小会导致内存不足错误
- 详细的基线实现和理由在附录 A.3 节和 A.5 节中提供
- DuoAttention 配置:
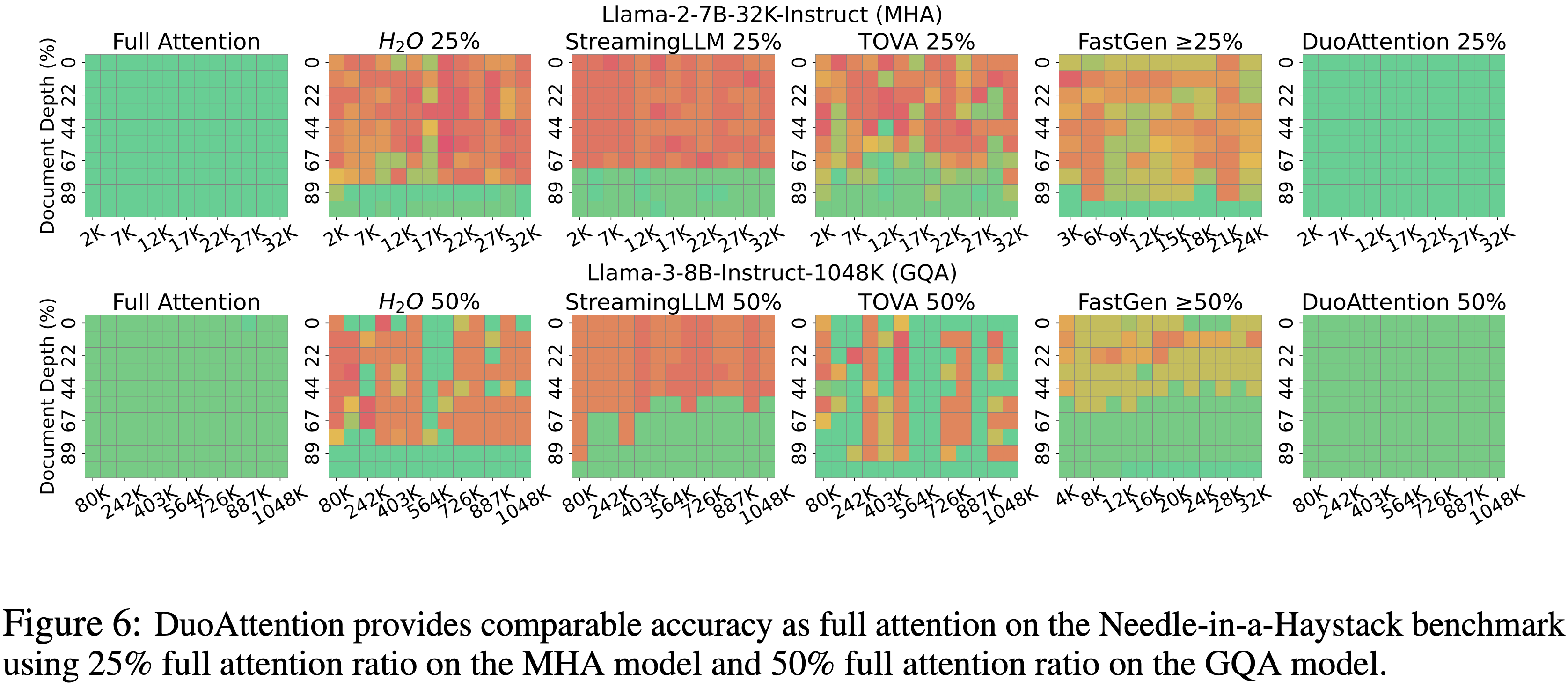
- Needle-in-a-Haystack (NIAH) 是一个具有挑战性的压力测试,旨在评估模型从冗长上下文中准确识别和检索相关信息的能力
- 如图 6 所示,所有基线方法都无法从长序列的不同深度检索到正确答案,因为它们在生成过程中丢弃了包含必要信息的 KV 缓存
- DuoAttention 保留了 Retrieval Heads 中的所有 KV 缓存,同时仅丢弃 Streaming Heads 中的缓存,从而保留了模型的检索能力
- DuoAttention 在所有序列深度上都表现出强大的性能,有效处理高达 1048K Token 的长度
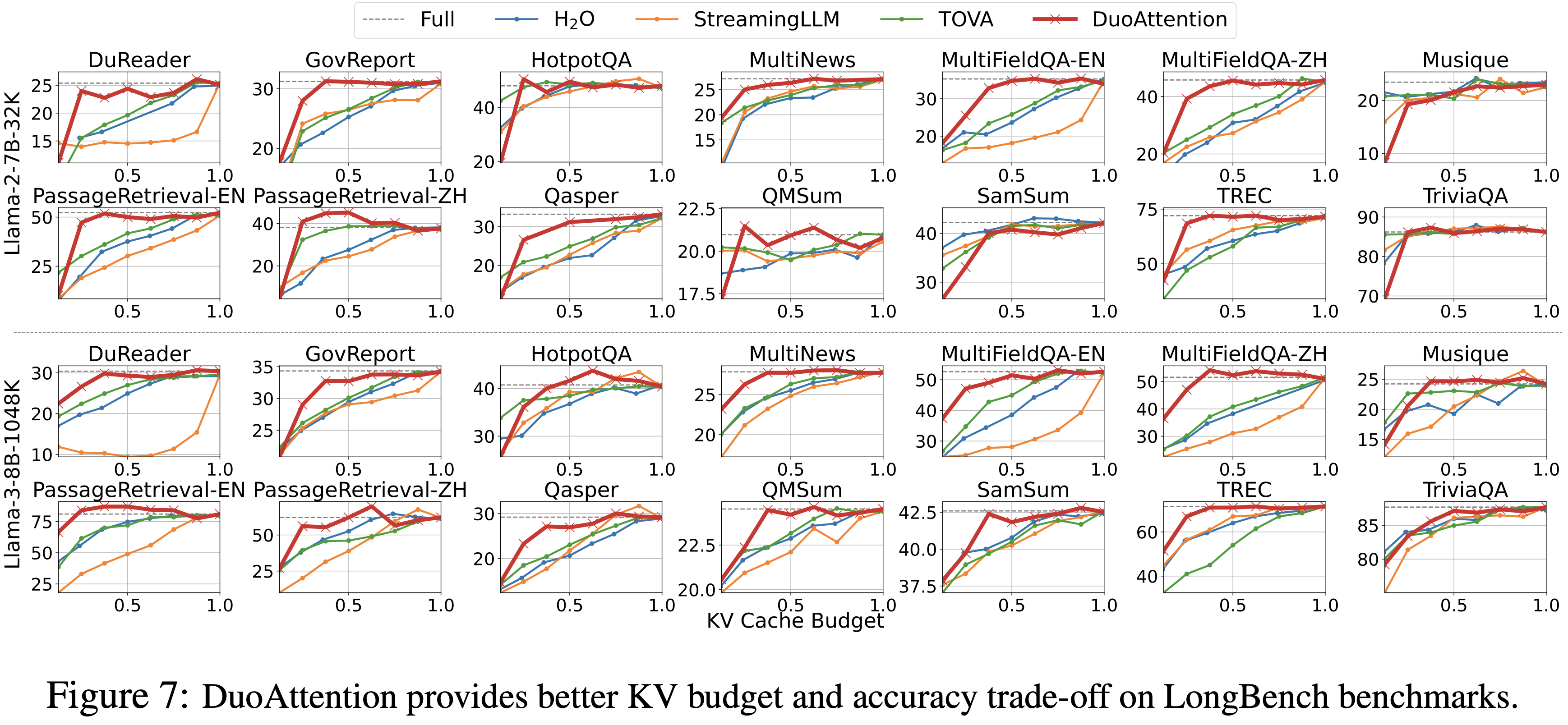
- LongBench (2023) 是一个全面的长上下文数据集套件,涵盖多个任务和自然文本,旨在更全面地评估长上下文理解能力
- 图 7 显示了在 14 个 LongBench 任务上的性能,比较了不同方法基于其 KV 缓存预算的表现
- DuoAttention 在大多数任务上显示出 KV 预算和准确性之间的优越权衡,突显了其泛化能力
- DuoAttention 在大多数任务上实现了与完全注意力相当的性能,对 MHA 使用 25% 的 KV 缓存预算,对 GQA 使用 50% 的 KV 缓存预算,这与在 needle-in-a-haystack 基准测试中观察到的结果一致
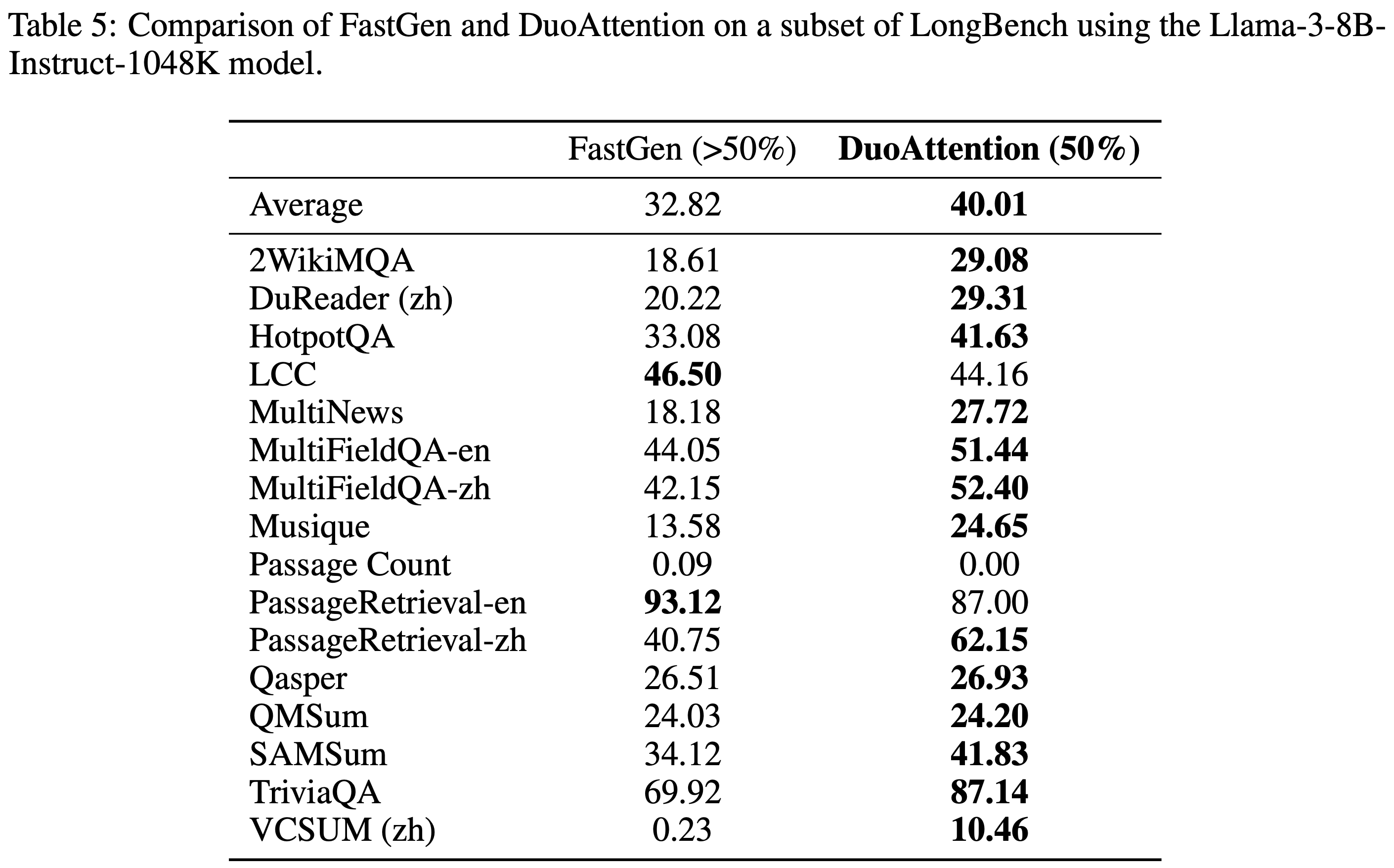
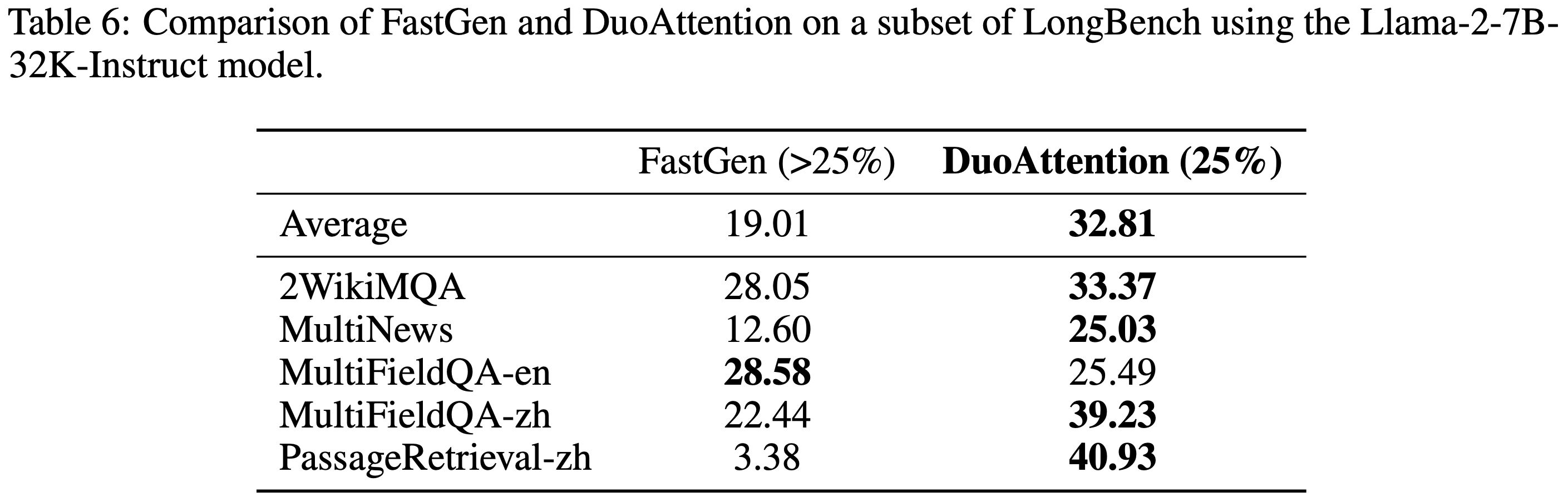
- 论文在附录的表 5 和表 6 中将 DuoAttention 与 FastGen 进行了比较
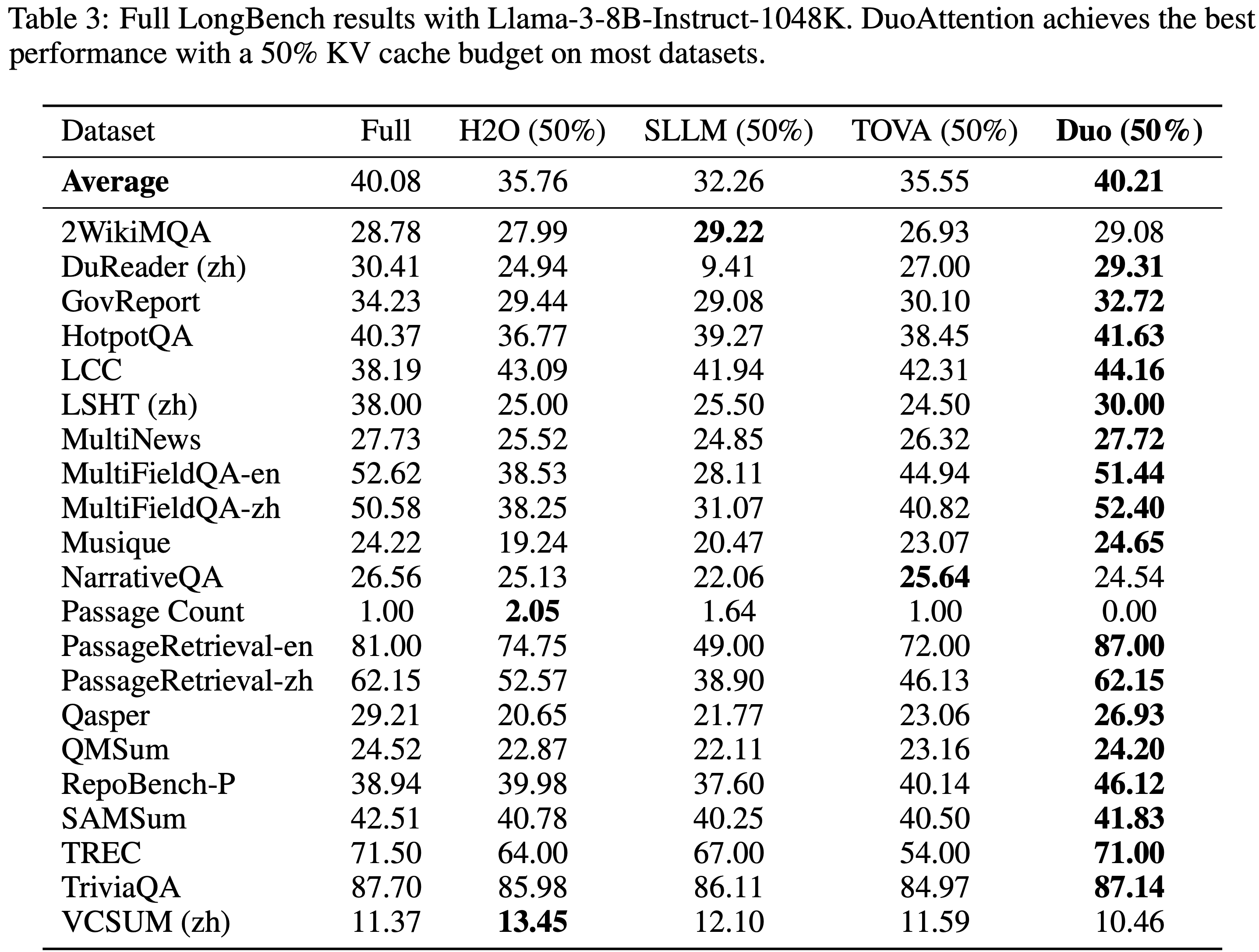
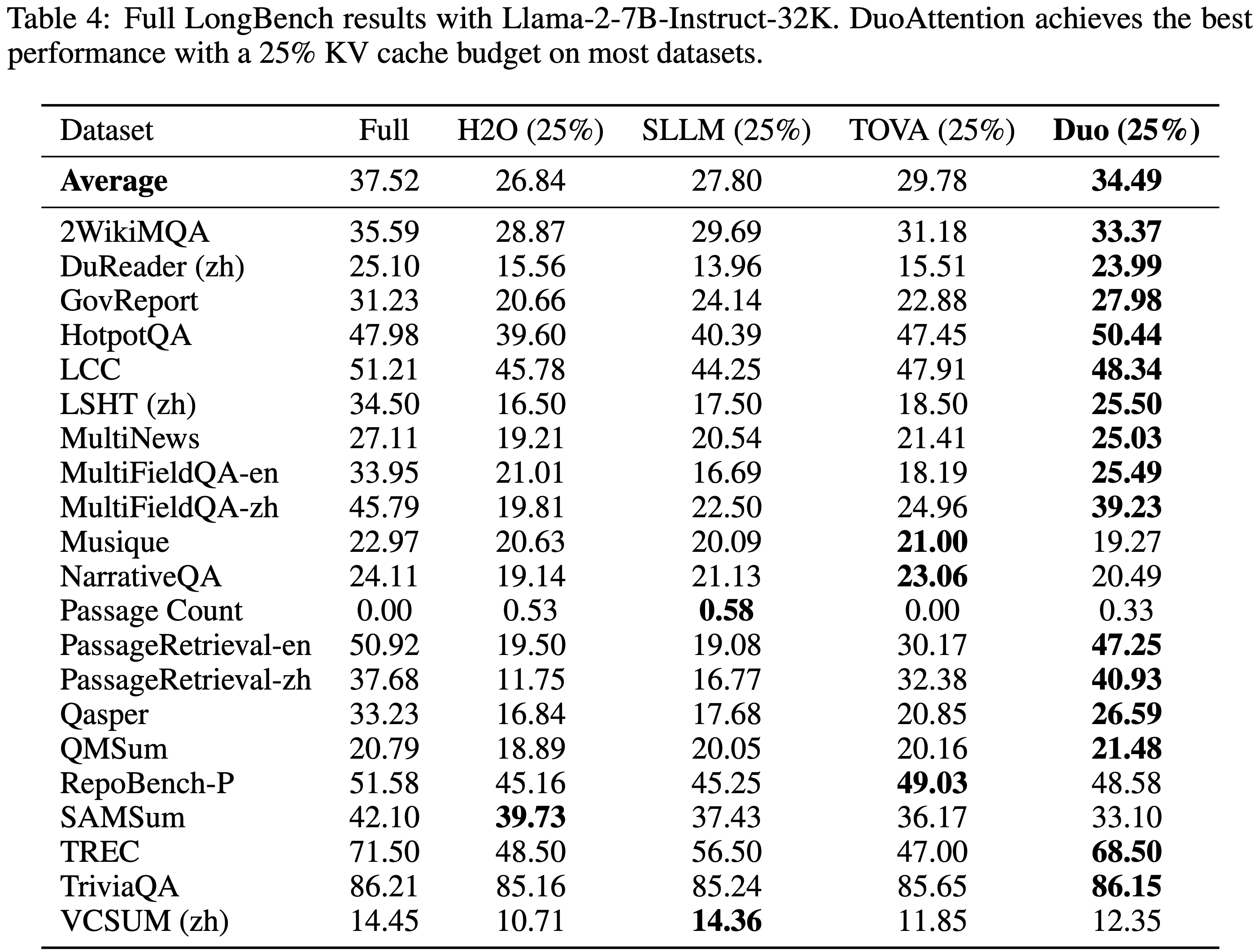
- 附录中的表 3 和表 4 提供了两个模型使用 25% 和 50% KV 缓存预算在所有 21 个 LongBench 任务上的完整结果,表明 DuoAttention 在大多数任务上始终优于基线,并取得了最高的平均分数
Short-Context Benchmarks
- 为了确保 DuoAttention 不损害模型在短上下文任务上的性能,论文将其与所有基线一起在三个短上下文基准测试上进行了评估:MMLU、MBPP 和 MT-Bench
- 这些基准测试评估模型的知识、编码能力和帮助性
- 对 MMLU 使用 one-shot 提示,对 MBPP 和 MT-Bench 使用 zero-shot 提
- 对于 DuoAttention,在 MMLU 上配置 32 个 Sink Token 和 128 个 Recent Token ,在 MBPP 和 MT-Bench 上配置 16 个 Sink Token 和 64 个 Recent Token
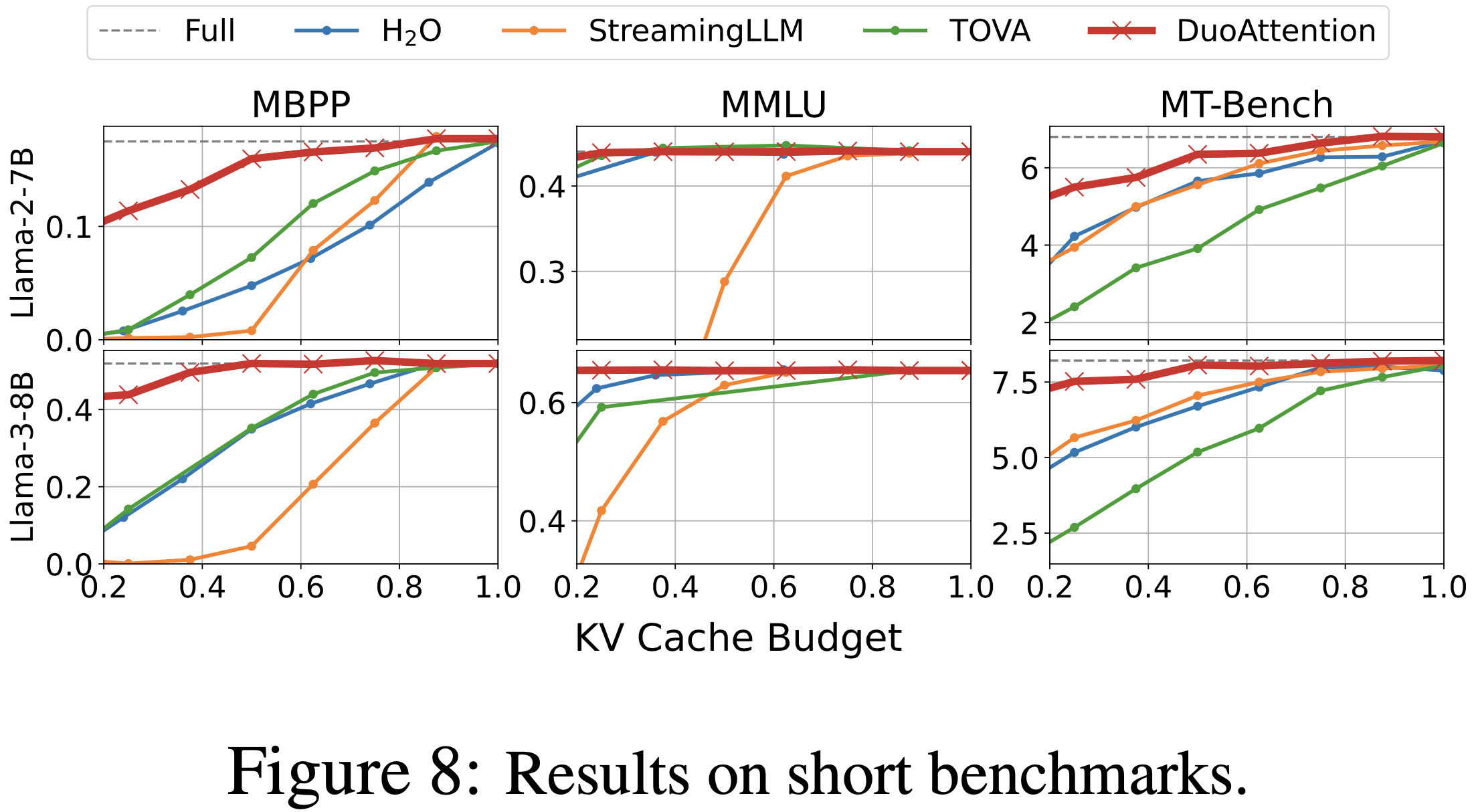
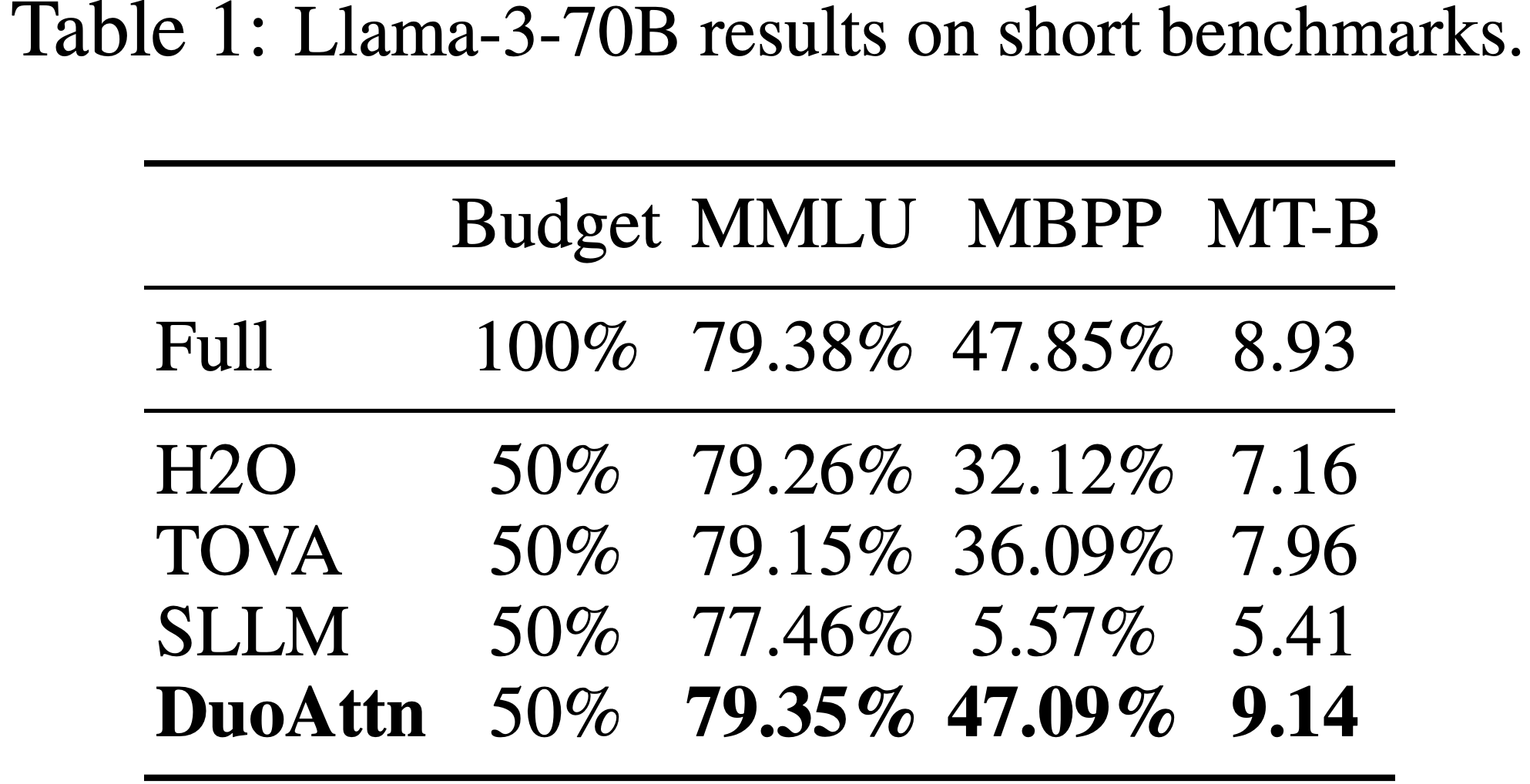
- 如图 8 和表 1 所示
- 在相同的 KV 缓存预算下,DuoAttention 在各种模型(包括 Llama-2-7B、Llama-3-8B 和 Llama-3-70B-Instruct)上始终优于所有基线
- 在 50% KV 缓存预算下,DuoAttention 在大多数基准测试上实现了近乎无损的性能,表明它保留了模型的原始能力
Efficiency Results
- 论文在单个 NVIDIA A100 GPU 上评估了 DuoAttention 在 Llama-2-7B 和 Llama-3-8B 模型上的解码延迟和内存使用情况
- 论文为整个基准测试序列预分配 KV 缓存,以防止动态内存分配的额外开销
- 权重和激活的默认数字格式为 BFloat16
- 通过对 Llama-2-7B 采用 25% 的 Retrieval Heads 比例,对 Llama-3-8B 采用 50% 的比例,DuoAttention 在保持准确性的同时显著提高了效率
Decoding Efficiency
- 如图 9 所示
- DuoAttention 的解码速度呈线性缩放,但与完全注意力相比斜率更平缓,这反映了所选的 Retrieval Heads 比例
- 这种高效的缩放带来了内存使用的显著减少和解码速度的显著提升
- 这些改进随着上下文长度的增加而接近 Retrieval Heads 比例的倒数
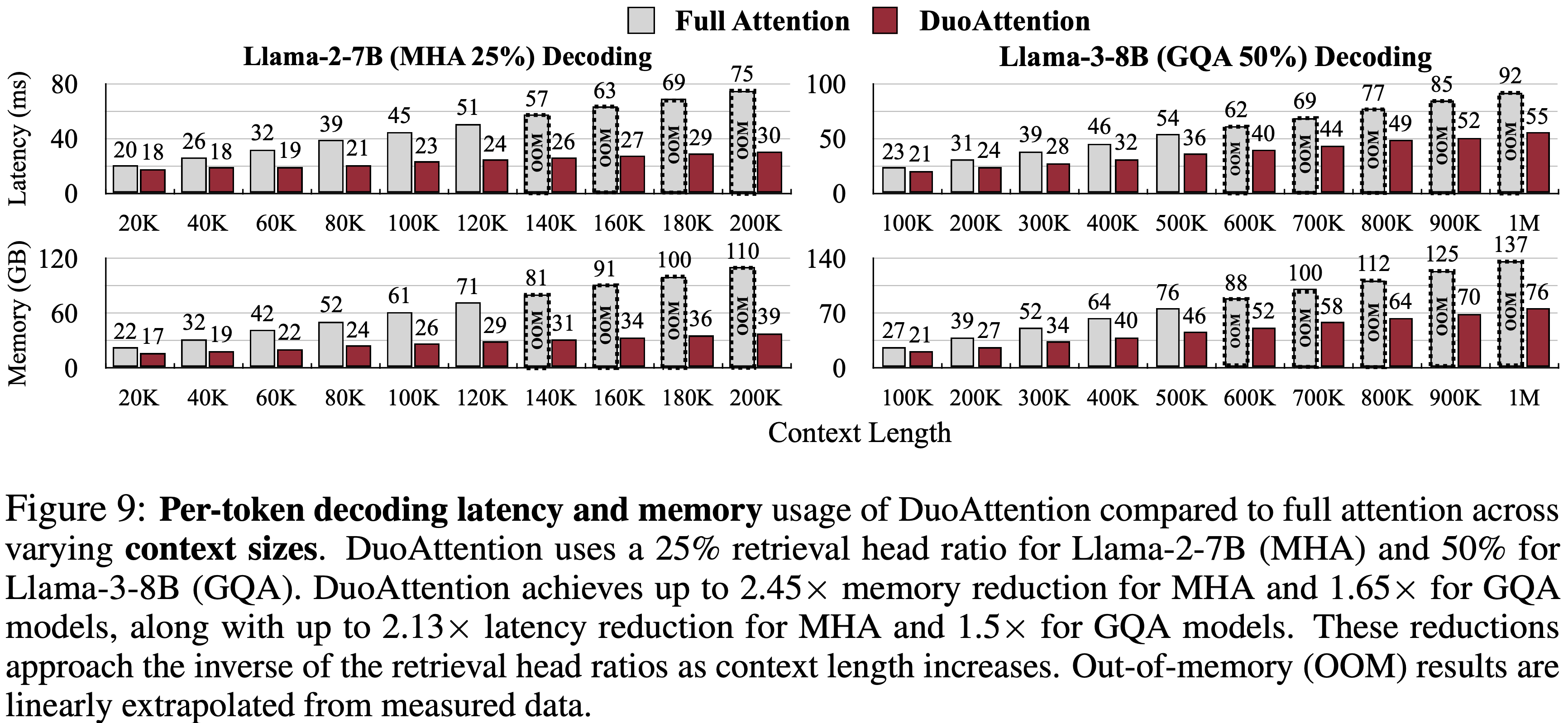
- DuoAttention 的解码速度呈线性缩放,但与完全注意力相比斜率更平缓,这反映了所选的 Retrieval Heads 比例
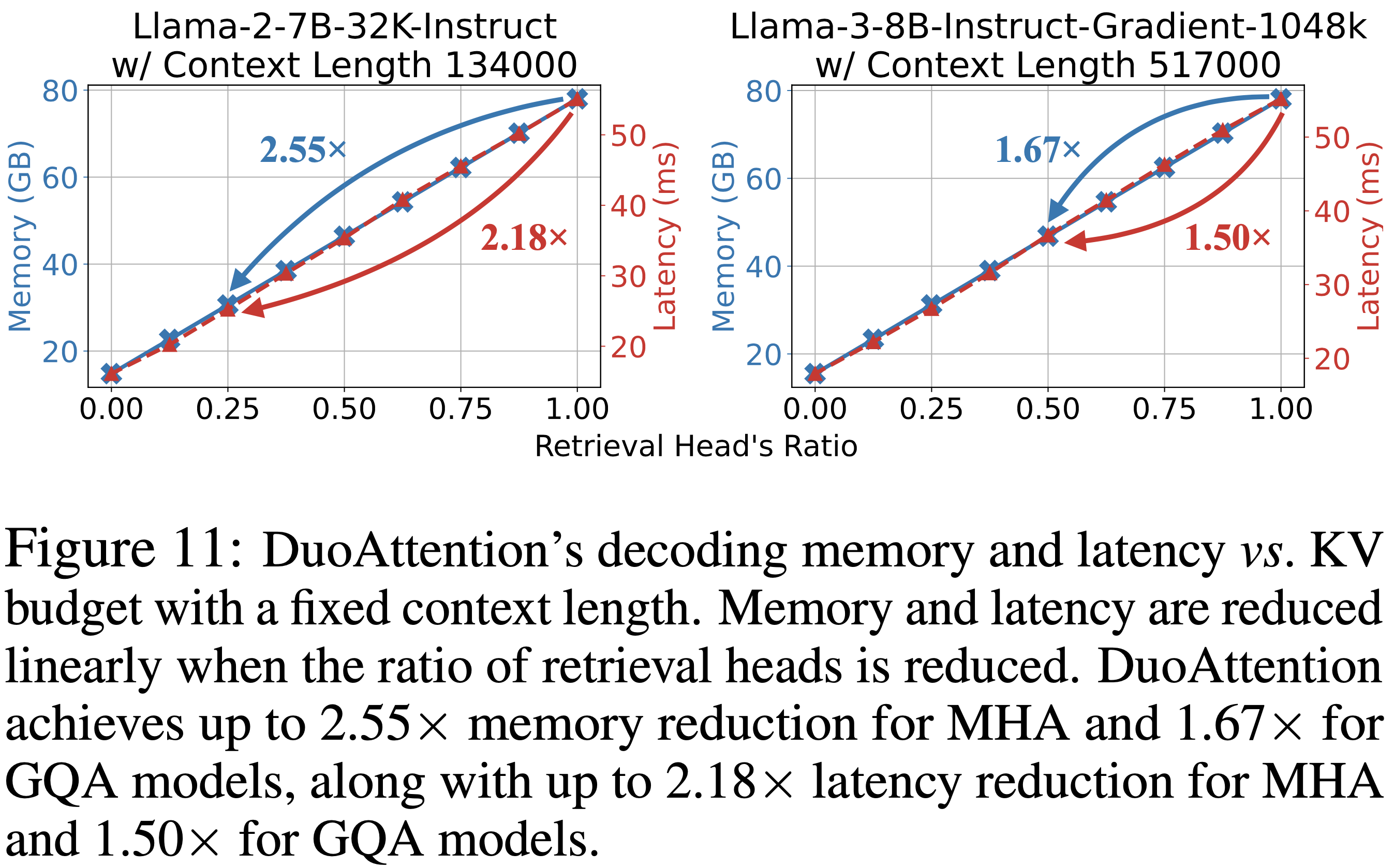
- 图 11 显示
- 在固定上下文大小下,DuoAttention 在不同 KV 预算设置下的加速和内存节省
- 随着部署配置中 Retrieval Heads 比例的降低,解码延迟和内存使用都线性下降
- 在图 11 的设置下,DuoAttention 在 A100 GPU 上实现了最大改进:MHA 模型内存减少 2.55 倍,GQA 模型内存减少 1.67 倍;MHA 模型延迟减少 2.18 倍,GQA 模型延迟减少 1.50 倍
Pre-filling Efficiency
- 如第 2.3 节所述,DuoAttention 也加速了 LLM 的长上下文 Pre-filling
- 图 10 显示
- DuoAttention 显著降低了 Pre-filling 延迟和内存使用,并且这些节省随着 Pre-filling 块大小的减小而增加
- 这是因为 Streaming Heads 的时间和内存复杂度随着块大小的减小而降低
- DuoAttention 实现了 MHA 模型延迟减少高达 1.73 倍,GQA 模型延迟减少高达 1.63 倍,同时 MHA 模型内存减少高达 2.38 倍,GQA 模型内存减少高达 1.53 倍
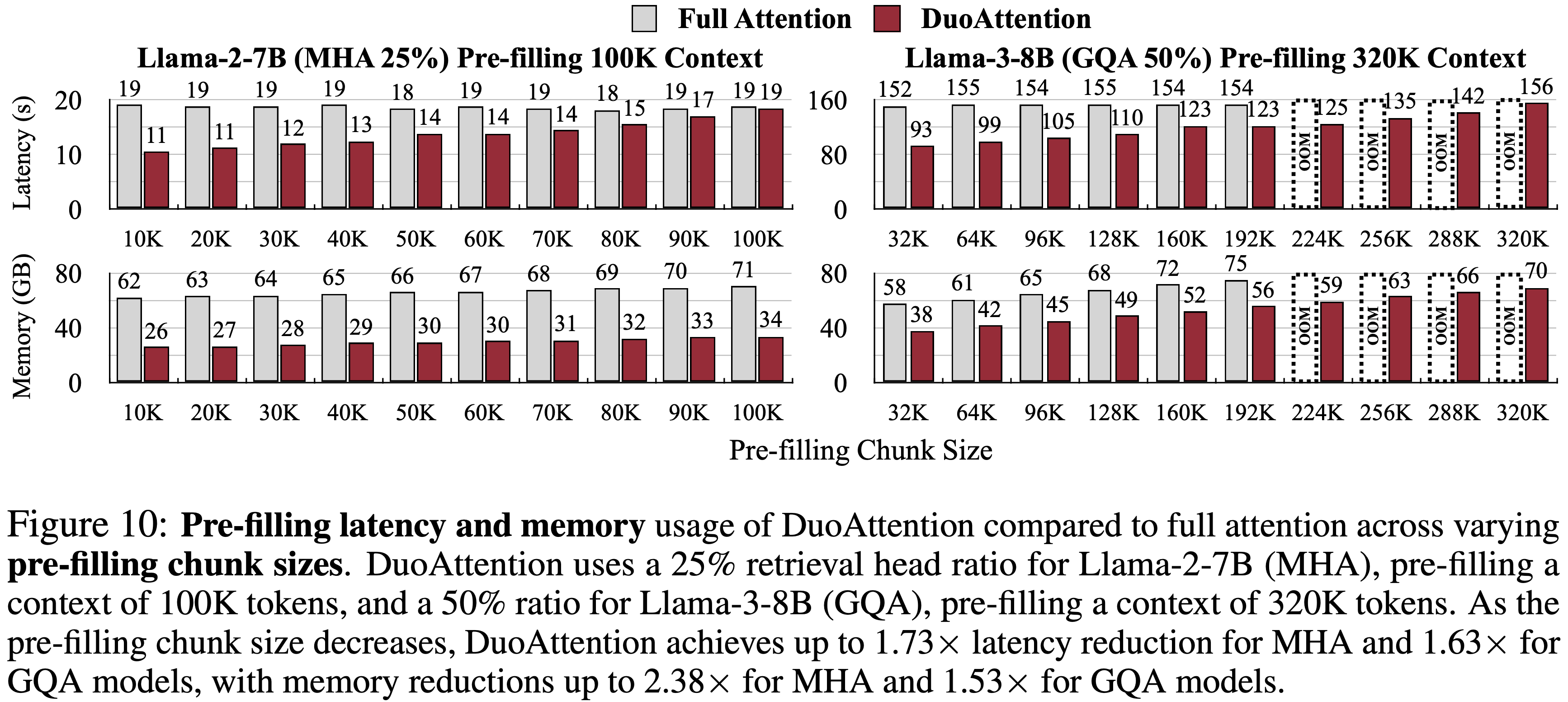
- DuoAttention 显著降低了 Pre-filling 延迟和内存使用,并且这些节省随着 Pre-filling 块大小的减小而增加
Combination with Quantization
- 为了将更多 Token 装入有限的内存,我们可以将权重和 KV 缓存量化与 DuoAttention 结合,以最大化 KV 缓存容量
- 先前的研究表明,权重量化 (2023a;) 和 4-bit KV 缓存量化 (2024;) 不会损害模型性能
- 论文将 DuoAttention 与 QServe (2024) 量化方法和内核相结合,以实现 8-bit 权重和 4-bit KV 缓存的 LLM 推理
- 测量结果如图 12 所示
- 将量化技术与 DuoAttention 结合,使论文能够在单个 A100-80G GPU 上使用 Llama-3-8B 模型容纳高达 3.30M 个 Token ,与朴素的完全注意力 BF16 部署相比,容量增加了 \(6.4\times\)
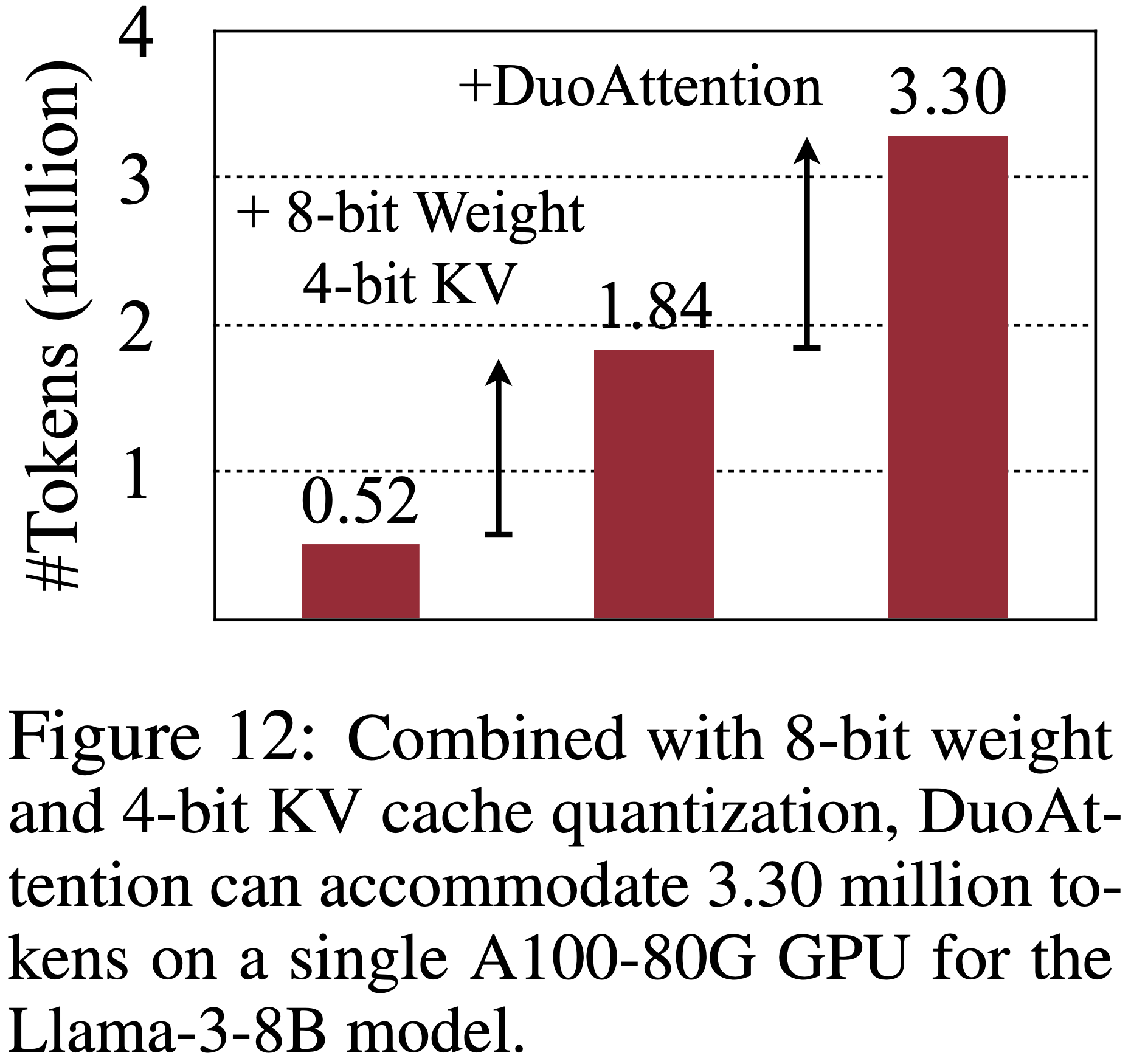
- 将量化技术与 DuoAttention 结合,使论文能够在单个 A100-80G GPU 上使用 Llama-3-8B 模型容纳高达 3.30M 个 Token ,与朴素的完全注意力 BF16 部署相比,容量增加了 \(6.4\times\)
Ablation Studies
- 论文使用 Mistral-7B-Instruct-v0.2 在 passkeys 检索和 MMLU 数据集上进行了消融研究
- 对于 passkeys 检索任务,论文将一个 8 词的 passkeys 嵌入到一个 30K 词的文本中,并在 100 个插入深度上进行线性扫描,报告精确匹配准确率
- 基于优化与基于 Attention Profiling 的 Retrieval Heads 识别 (Optimization-based vs. Attention Profiling-based Retrieval Head Identification)
- 论文评估了论文的基于优化的方法与 FastGen (2024) 和 RazorAttention (2024a) 中使用的 Attention Profiling 方法,两者使用相同的合成 passkeys 数据集
- 图 13 (1) 中的结果表明,论文的方法显著优于 Attention Profiling ,后者难以识别 Retrieval Heads ,从而影响了模型的准确优化
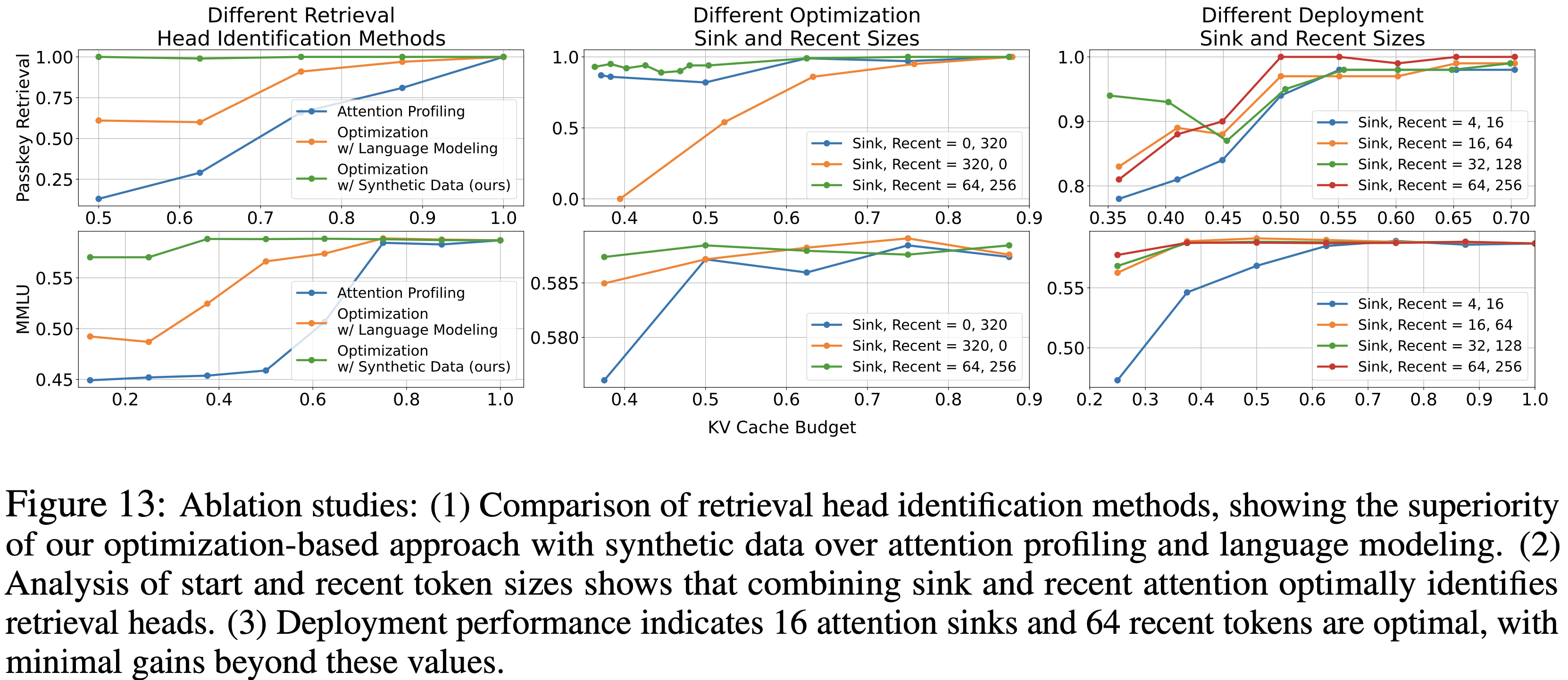
- 使用合成数据优化与语言建模 (Optimizing with Synthetic Data vs. Language Modeling)
- 如图 13 (1) 所示,论文使用合成数据识别 Retrieval Heads 的方法比传统的 Language Modeling(在自然数据中的所有 Token 上计算损失)产生了明显更好的结果
- 优化中结合 Sink 和 Recent 注意力的必要性 (Necessity of Sink+Recent Attention in Optimization)
- 图 13 (2) 强调了在优化阶段结合 Sink 和 Recent 注意力的重要性
- 仅依赖 Sink Token 或 Recent Token 注意力不足以有效识别 Retrieval Heads
- 部署阶段配置 (Deployment Phase Configuration)
- 论文分析了 Streaming Heads 中注意力 Sink 和 Recent Token 的部署配置
- 论文的发现表明:
- 性能在 16 个 Sink Token 和 64 个 Recent Token 时达到稳定(图 13 (3))
- 进一步增加只会带来边际改进
- 问题:论文的发现跟 StreamingLLM 的 4 个 Token 足以的发现有矛盾!
Related Work
- 已有很多方法在扩展 LLM 并提高其处理长上下文的效率;这些方法可以分为四个主要类别:
- 优化模型架构、使用近似注意力机制、应用 KV 缓存量化以及系统级优化
- Model Architecture
- MQA (2019) 和 GQA (2023) 通过在 Query 头之间共享 KV 头来减小 KV 缓存的大小
- 但这些方法需要使用特定架构进行预训练,并且不会降低计算成本(但会降低显存)
- 线性注意力 Transformer (2023) 减少了内存使用,但在需要长上下文处理的任务上往往表现不佳
- Approximate Attention
- 诸如 Sparse Transformer (2019) 和 LongFormer (2020) 等方法使用 Local Attention 或 Block Attention 模式来降低计算复杂度
- BigBird (2020) 通过结合 Local Attention 和 Global Attention 实现线性复杂度,但其中许多方法需要定制的 GPU 内核或重新训练,限制了其实用性
- H2O (2023b) 和 TOVA (2024) 基于 Query 模式丢弃 Token 来简化注意力
- StreamingLLM (2023b) 识别了“注意力 Sink ”并提出始终保留 Initial Token 和 Recent Token 以维持恒定的解码延迟和内存使用,使模型能够处理比预训练序列长度多得多的输入 Token
- FastGen (2024) 分析注意力头以在解码期间丢弃 Token
- 论文的实验表明:
- 这些方法会降低 LLM 的长上下文能力
- 这些方法无法降低长上下文 LLM 的 Pre-filling 成本
- KV Cache Quantization
- 诸如 8-bit 和 4-bit 量化 (2024; 2024; 2024) 等技术减小了 KV 缓存的大小,但它们没有解决注意力内核的计算开销问题
- 这些方法与 DuoAttention 是互补的,可以结合使用以进一步减少内存使用
- System Optimizations
- vLLM (2023) 和 FlashAttention (2022; 2023) 通过优化批处理(Batch Processing)和利用 GPU 内存层次结构来提高注意力计算效率
- FlashDecoding (2024) 和 RingAttention (2023a) 在解码速度和序列级并行性方面引入了进一步的改进
- 这些方法提高了计算性能,但它们没有解决 KV 缓存大小减少的问题,它们与 DuoAttention 互补,以实现额外的速度和内存优化
- Recent Works
- 一些近期工作与 DuoAttention 有相似的想法
- Wu 等人 (2024) 引入了 Retrieval Heads 的概念来解释 LLM 的长上下文能力
- 但他们的方法没有压缩非 Retrieval Heads 的 KV 缓存,仅关注准确性
- MInference (2024) 通过使用稀疏注意力模式来加速长上下文 LLM 的 Pre-filling
- 但没有优化解码期间的 KV 缓存存储或延迟
- RazorAttention (2024a) 也将注意力头分为 Retrieval 和 Non-Retrieval 类别
- 但 RazorAttention 使用 Attention Profiling 方法而不是 Optimization-based 方法区区分
- 论文的实验表明,Attention Profiling-based 方法不如论文的 Optimization-based 的方法准确
- 而且,RazorAttention 没有优化 Pre-filling
- DuoAttention 提供了更有效的 KV 缓存管理和更高的压缩率,从而在长上下文应用中为 Pre-filling 和解码带来了更好的性能
- 但 RazorAttention 使用 Attention Profiling 方法而不是 Optimization-based 方法区区分
Appendix A
A.1 Experimental Details
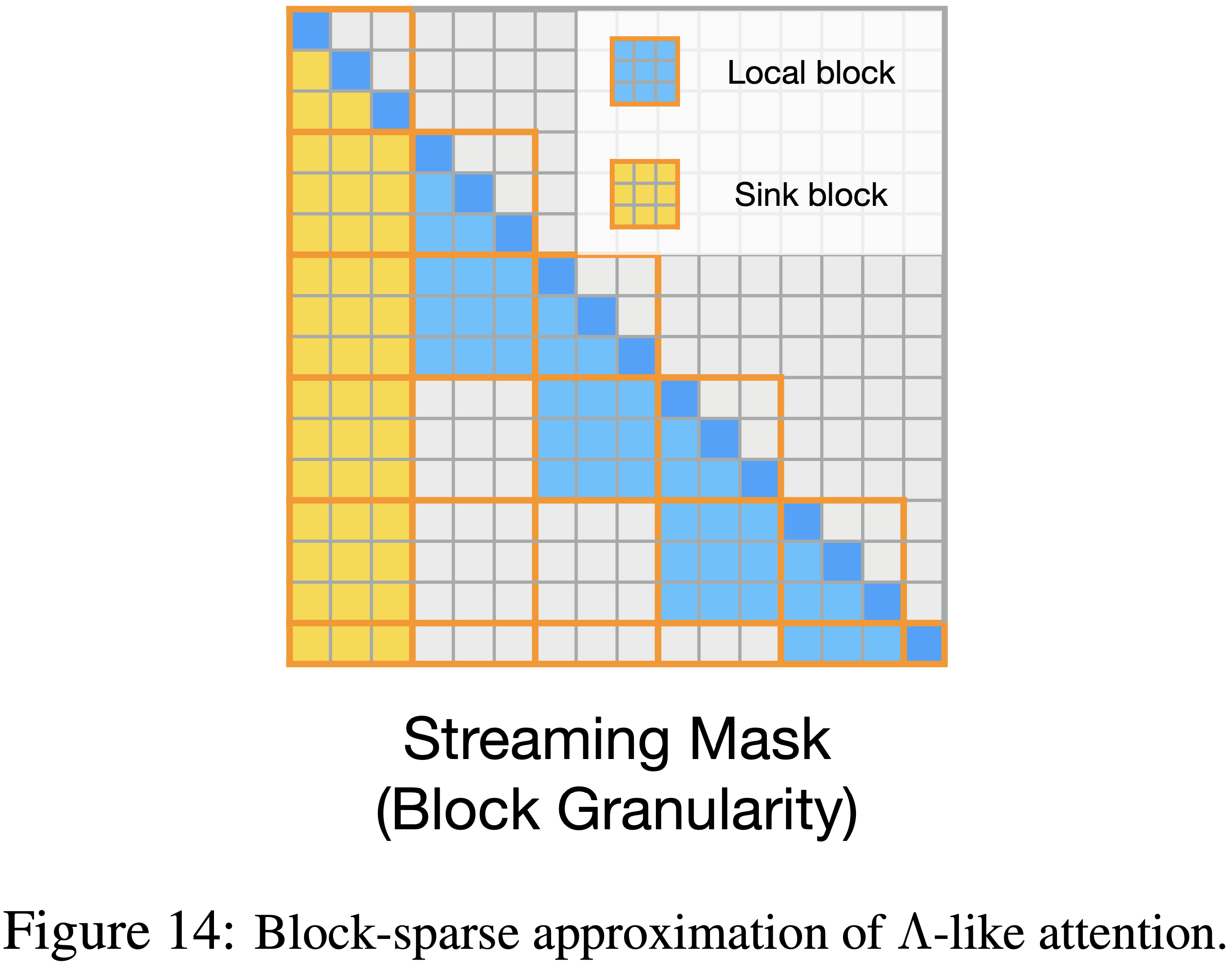
- 论文使用 PyTorch (2019) 中的 FSDP 进行模型训练,并使用 DeepSpeed Ulysses (2023) 序列并行来支持长序列
- 在训练期间,论文使用 Guo 等人 (2024) 实现的、如图 14 所示的高效块稀疏近似 \(\Lambda\) 类注意力来计算流式注意力
- 不同模型的最大序列长度各不相同,详见表 2
A.2 Full LongBench Results
A.3 在长上下文基准测试上 H2O 和 TOVA 的实现 (Implementation of H2O and TOVA on Long-Context Benchmarks)
- H2O (2023b) 和 TOVA (2024) 算法的原始设计与 Pre-filling 阶段的 FlashAttention (2022) 不兼容,因为它们依赖注意力分数来执行 Token Eviction(驱逐)
- 由于 FlashAttention 中的注意力分数从未被具体化,这些算法无法用于 Pre-filling ,这是它们的主要缺陷之一
- 因此,不可能在像“大海捞针”和 LongBench 这样的长上下文设置中评估这些算法,因为它们会在上下文 Pre-filling 期间导致内存不足(OOM)
- 为了与这些策略进行比较,论文修改了算法:
- 在 Pre-filling 期间,论文使用 FlashAttention 进行精确计算
- 在解码阶段,论文根据生成 Token 对上下文 Token 的注意力分数执行 Token Eviction
- 这种修改相比原始设计提高了性能,因为 Pre-filling 是精确的,并且 Token Eviction 仅发生在解码期间
- 在极端情况下,如果答案中只有一个生成 Token (例如,多项选择题任务),论文实现的 H2O 和 TOVA 将与完全注意力一样精确,这并非它们的真实精度
- 为了接近它们的真实性能,论文在长输入基准测试(“大海捞针”和 LongBench)中模拟最后 50 个 Token 作为生成 Token ,以足够长时间地执行它们的 Token Eviction 策略,论文的算法也是如此
- 此实验设置也被 Tang 等人 (2024b) 使用
- 实验结果表明论文的方法可以通过此压力测试,而 H2O 和 TOVA 则不能
A.4 Implementation of FastGen on Long-Context Benchmarks
- 由于缺乏 FastGen (2024) 算法的官方实现,论文使用一个社区代码库 (2024) 对其进行了复现,该代码库被 FastGen 的官方仓库引用
- 在 FastGen 算法中,剪枝比率不能直接配置;而是使用恢复比率 \(T\) 来控制稀疏度,如 FastGen 论文中所述
- 为了量化稀疏度,论文计算了所有测试用例的平均 KV 缓存使用量作为整体稀疏度的度量
- 对于 Llama-2-7B 模型,论文将恢复比率设置为 \(0.7\),确保平均 KV 缓存预算超过完整 KV 缓存的 25%
- 对于 Llama-3-8B 模型,论文将恢复比率设置为 \(0.87\),确保平均 KV 缓存预算超过完整 KV 缓存的 50%
- 由于 FastGen 使用用户提供提示的完整注意力图来分析不同头的类型,它会导致 \(O(n^{2})\) 的注意力图复杂度
- 论文无法在长上下文中测试其性能
- 对于长上下文基准测试,论文使用了 8 个 A100-80G GPU,对于 Llama-2-7B 模型实现了最高 24k Token 的序列长度,对于 Llama-3-8B 模型实现了最高 32k Token 的序列长度
- 除了图 6 中显示的“大海捞针”基准测试结果外,论文还评估了FastGen 在两个模型上的 LongBench 表现
- 但由于 FastGen 的二次内存消耗,论文仅报告了在 8x A100-80G GPU 上使用 FastGen 可以运行的数据集结果
- 如表 5 和表 6 所示,DuoAttention 在 LongBench 数据集上 consistently 优于 FastGen
补充表格和图标
- 图 15: NIAH result on the Mistral-7B-Instruct-v0.2 model
- 图 16: NIAH result on the Mistral-7B-Instruct-v0.3 model