注:本文包含 AI 辅助创作
- 参考链接:
- 原始博客:When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance
- 博客最早发表于 20250927,目前还在持续更新,最近一次更新为 20251013
- 其他相关 arXiv 论文:Trust Region Masking for Long-Horizon LLM Reinforcement Learning, 20251228-20260227, Fudan & CUHK
- 引用了本文的博客
- 原始博客:When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance
Blog Summary
- 作者从 RL Collapse 现象入口,定位到是训推不一致问题导致的,进而详细讨论了如何解决训推不一致的问题
- 本文工作已经被诸多框架引入,比如 VeRL 和 Slime 等,同时还被 Qwen 团队的 MiniRL 工作(详情见 NLP——LLM对齐微调-MiniRL)引用
整体介绍
TLDR
- 对更快推理速度的不懈追求造成了一种危险的“训练-推理不一致性”,它可能悄然破坏 LLM 的强化学习
- 作者的研究揭示了一个在现代推理和智能体 RL 中尤为严重的恶性循环:
- OOD 上下文导致低概率采样: 智能体工作流将模型暴露于外部输入和动态环境中,迫使其频繁生成 低概率 token
- 这些 token 对于新颖的推理、工具调用和自适应 Response 至关重要
- 理解:这里是在说模型与外界环境交互过程中可能会遇到一些 OOD 的场景,从而生成一些原本 低概率的 Token?
- 这里的低概率应该不是指低概率但是因为高温被采样
- 详情见:3.4 OOD Tool Responses Amplifies the Mismatch 章节
- 低概率 Token 放大训练崩溃: 这些 token 成为最薄弱的环节
- 训练-推理不一致性对它们最为严重,导致灾难性的大梯度,从而引发性能悄然下降和突然的训练失败
- 详情见本文 3.3 确凿证据:低概率 Token 陷阱 章节
- 硬件差异使问题复杂化:
- 不同的 GPU 架构会以不可预测的方式加剧不一致性,这意味着相同的智能体训练设置在一台机器上可能成功,而在另一台上可能灾难性地失败
- 详情见:3.5 环境因素:硬件的关键作用 章节
- Sequence-level 修正 (Sequence-level Correction) 是原则性解决方案:
- Sequence-level 修正 是理论上合理的修复方法
- Sequence-level 修正 通过考虑完整的状态轨迹来修正有偏的梯度,从而 在不同硬件和复杂任务上 恢复训练稳定性
- 详情见:4.2.1 一个原则性解决方案:分布修正
- OOD 上下文导致低概率采样: 智能体工作流将模型暴露于外部输入和动态环境中,迫使其频繁生成 低概率 token
Deeper Analysis:
- 为了对这个问题进行严格的理论分解,作者发表了三篇系列博客:
- Part 1: Why Off-Policy Breaks RL — An SGA Analysis Framework
- 第 1 部分包含主要内容:为何 Off-Policy 会破坏 RL——SGA 分析框架
- 已知 (TRPO 理论):
- 替代目标 \(L_\mu(\pi)\) 是 RL 目标 \(J(\pi)\) 的一阶泰勒近似
- TRPO 下界 \(J(\pi) \ge L_\mu(\pi) - C \cdot T^2 \cdot D_{TV}^{\max}\) 表明近似误差随 \(T^2\) 增长,需要信任域按 \(\delta \propto 1/T^2\) 缩小
- 作者的主要 Insight:
- Token-level IS (PPO/GRPO) 计算的是 \(\nabla L_\mu\),而不是 \(\nabla J\)
- Token-level IS 修正了 token 分布,但没有修正状态分布的不匹配 (\(d_\mu \ne d_\pi\)),导致 \(O(T^2 D_{TV}^{\max})\) 的偏差
- 作者通过 SGA 引理形式化了两种失败模式 :
- 偏差 (Bias) (由 \(D_{TV}\) 衡量)
- 方差 (Variance) (由 \(\chi^2\) 散度衡量)
- 作者认为这两个指标不可互换
- Part 2: Applying the SGA Framework — Token v.s. Sequence-level Correction
- 第 2 部分主要内容:讨论 Token-level 与 Sequence-level 修正的对比(讨论 Part 1 中 SGA 框架的应用)
- 作者的分析:
- Token-level IS (PPO/GRPO) 由于替代目标的一阶近似误差而产生 \(O(T^2 D_{TV}^{\max})\) 的偏差
- Sequence-level IS 是无偏的,但具有指数级方差 \(O((1+\bar{\chi}^2_{\max})^T)\)
- 作者的解决方案:
- Seq-TIS 通过截断 \(\rho(y) \to \min(\rho(y), C)\) 实现了可控的偏差-方差权衡
- 关键结论: 当 不可忽略时 ,这种偏差是一个需要 Sequence-level 解决方案的 Sequence-level 问题
- Part 3: Trust Region Optimization via Sequence Masking
- 第 3 部分内容:讨论通过序列掩码实现信任域优化
- 已知 (TRPO 理论):
- 信任域约束确保替代目标仍然是一个有效的近似
- 作者的解决方案:
- (1) Seq-MIS :通过拒绝 \(\mathbb{I}(\rho \le C) \cdot \rho \cdot f\) 来强制执行硬信任域 (Hard Trust Region),完全排除 OOD 样本
- (2) Geo-RS :使用几何均值 \(\rho_{\text{geo} }=\rho^{1/T}\) 来实现一个 长度不变的 Per-Token 信任域 (length-invariant Per-Token Trust Region)
- 这是 TRPO 硬信任域在 LLM 中的一种实用实现,避免了系统性地拒绝长序列
- Part 1: Why Off-Policy Breaks RL — An SGA Analysis Framework
第 1 节:The Mystery of the Sudden Collapse
- 在快速发展的用于大型语言模型的强化学习 (LLM-RL) 领域,一种令人沮丧的突然训练崩溃模式正在浮现
- 无论是在复杂的 Reasoning RL 还是多轮 Agentic RL 中,许多人都观察到训练过程在一段稳定学习后,会灾难性地失败
- 本文作者最近在 Qwen3 模型上进行 多轮工具集成推理 (multi-turn tool-integrated-reasoning,TIR) 的智能体 RL 实验时,亲身遇到了这个问题
- 这发生在 L20 GPU 集群上 GRPO 算法的 on-policy 和 off-policy 变体上
- 图 1 显示了作者在 Qwen3-14B-Base 上四次崩溃实验的奖励和梯度范数动态
- 随着训练的进行,梯度范数突然爆炸,导致模型崩溃
- 图 1
- 在 Qwen3-14B-Base 上进行的四次失败的 GRPO TIR 实验的奖励 (左) 和梯度范数 (右)
- 所有实验在每个训练步采样
1024条轨迹 (64个 Prompt ×16个 Response ),并使用1e-6的学习率 - 对于 on-policy 和 off-policy 实验,
ppo_mini_batch_size分别设置为1024和256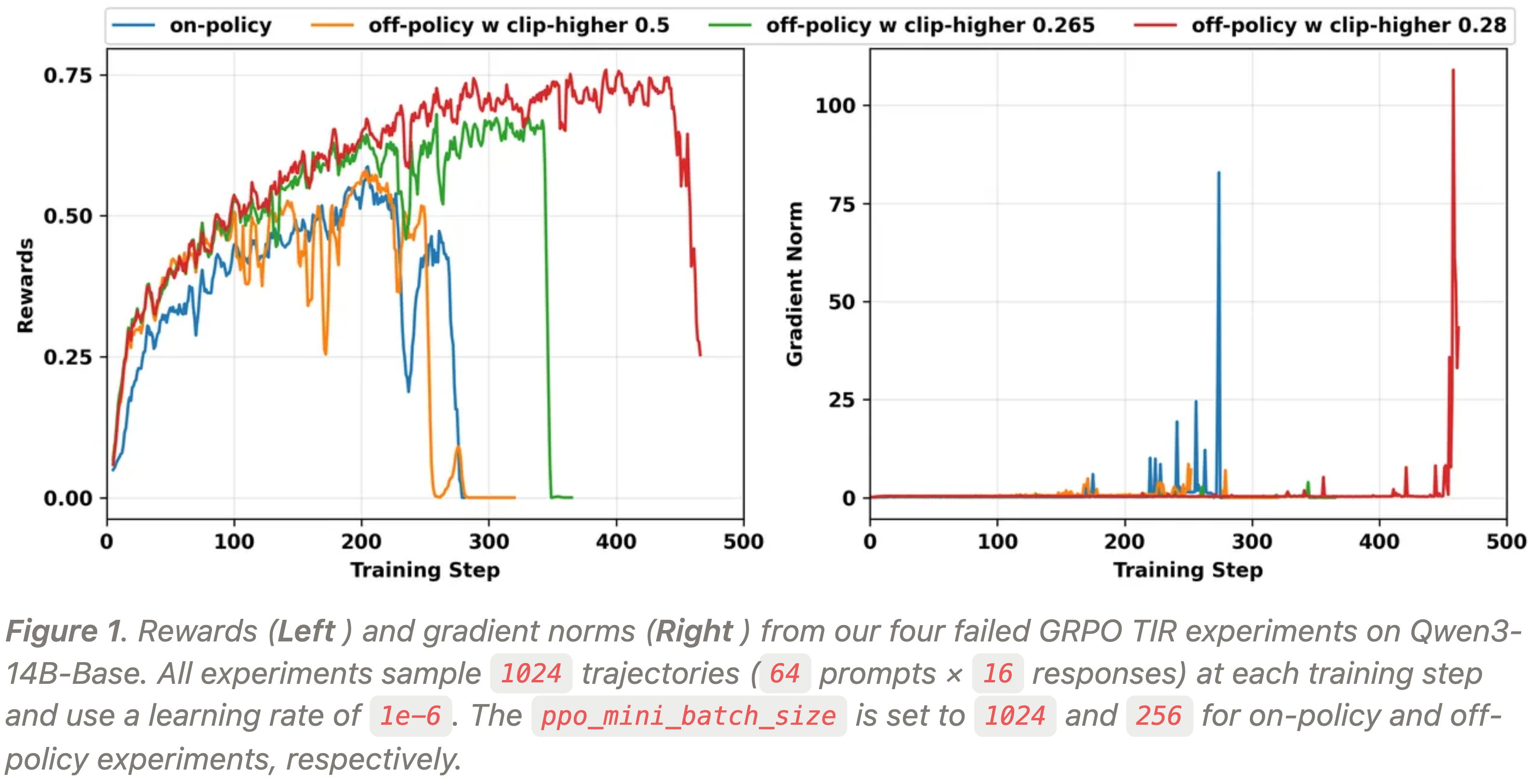
- 最初,作者的初步解决思路集中在常见的疑点上:
- 作者检查了代码,确认作者的智能体循环遵循 token-in-token-out 过程
- 作者调整了 Adam 优化器中的超参数
beta1和beta2 - 作者还对优势函数应用了批归一化以平衡更新
- …
- 但这些标准的修复方法都不起作用
- 因为即使是更简单的 on-policy 实验也失败了,作者怀疑问题不在于 RL 算法本身,而在于训练栈中更基础的部分
- 这引导作者开始考虑现代 LLM-RL 中一个关键且日益普遍的挑战:高度优化的推理引擎与可靠的训练框架之间不可避免的 Gap
A Fundamental Conflict: The Growing Gap Between Inference and Training
- 根本性冲突是推理与训练之间日益扩大的鸿沟
- Rollout 速度是 LLM-RL 的核心瓶颈
- 为了实现所需的海量吞吐量,现代推理引擎(例如,vLLM、SGLang、TensorRT-LLM)采用了激进的优化策略
- 如推测解码、低精度计算 (INT8/FP8) 以及专门的、batch-variant CUDA 内核
- 在保持采样保真度的同时,现代推理引擎的主要目标是最大化吞吐量 ,通常以每秒 token 数来衡量
- 训练框架(例如,FSDP、DeepSpeed、Megatron-LM)必须寻求不同的平衡点,优先考虑梯度计算的数值稳定性和精度
- 通常对主要权重和优化器状态使用 FP32 等更高精度的格式
- 这种优化优先级和约束上的分歧造成了不可避免的训练-推理不一致性 ,而对更快 rollout 的不懈追求正使这一差距变得更大
- 虽然有人可能提议强制实施相同的计算(例如,使用“batch invariant kernels”),但这些解决方案会带来严重的性能损失,违背了使用高速推理引擎的初衷
- 这种速度与一致性之间的权衡是问题的核心,使其成为一个持续存在的挑战,而非简单的工程修复
- 为了实现所需的海量吞吐量,现代推理引擎(例如,vLLM、SGLang、TensorRT-LLM)采用了激进的优化策略
- 在作者的技术栈中,这种不匹配体现在作者的 vLLM 推理采样器和 FSDP 训练器之间
- 实际的参数更新是:
$$
\mathbb{E}_{x\sim \mathcal{D} }\mathbb{E}_{y\sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }\left( \cdot |x \right)}\left[ R\left( x,y \right) \nabla_{\theta}\log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\left( y|x \right) \right]
$$ - 而理论上的参数更新应该是:
$$
\mathbb{E}_{x\sim \mathcal{D} }\mathbb{E}_{y\sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\left( \cdot |x \right)}\left[ R\left( x,y \right) \nabla_{\theta}\log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\left( y|x \right) \right].
$$- \(x\) 是从分布 \(\mathcal{D}\) 中采样的 Prompt
- \(y\) 是 Response
- \(R\) 是奖励函数
- \(\theta\) 是 LLM 的参数
- \(\color{red}{\pi^\text{vllm}_\theta}\) 和 \(\color{blue}{\pi^\text{fsdp}_\theta}\) 分别是 vLLM 引擎和 FSDP 引擎中实现的策略
- 注:接下来,为了讨论这一点,作者找了一种方法来衡量它
- 实际的参数更新是:
Anatomy(剖析)of the Training Collapse
3.0 Experiments Setup
- 除非另有说明,第 3 节 和 第 4 节 中展示的实验是在 TIR Setting 下的 VeRL 框架上进行的,使用 vLLM v1 采样器 (AsyncvLLMServer)、Qwen3-14B-Base 模型和 GRPO 算法,全部在 L20 GPU 集群上运行
Measuring the Mismatch: The vllm-kl Metric
- 一个衡量训练-推理不一致性的非常直接的指标是 vllm-kl :
$$
\small{\mathbb{E}_{s\sim d_{\color{red}{\pi^\text{vllm}_\theta} } }\left[\text{KL}\left(\color{red}{\pi^\text{vllm}_\theta}\left(\cdot|s\right),\color{blue}{\pi^\text{fsdp}_\theta}\left(\cdot|s\right)\right)\right] = \mathbb{E}_{s\sim d_{\color{red}{\pi^\text{vllm}_\theta} },a\sim {\color{red}{\pi^\text{vllm}_\theta}\left(\cdot|s\right)} } \left[\log\left(\frac{\color{red}{\pi^\text{vllm}_\theta}(a|s)}{\color{blue}{\pi^\text{fsdp}_\theta}(a|s)}\right)\right],}
$$- \(d_\pi\) 是策略 \(\pi\) 的状态占用 (state-occupancy)
- \(s\) 是上下文前缀(状态)
- \(a\) 是 token(动作)
- 注:作者的实验涉及工具调用,这意味着 Response \(y\) 可能包含工具 Response
- 问题:这个公式中似乎没有看到任何 \(y\) 的表达式啊
- 理解:这里应该是强调除了用户输入的 Query(Prompt)后,用户得到的 Reponse 部分会包含工具调用的返回结果(比如调用 Python 执行数学计算)
- 注:TIR 中,模型 Reasoning 过程中会和工具交互,得到工具调用的结果,然后基于工具调用结果继续 Reasoning(一次 Response 可能包含多次工具调用),并最终整合后返回给用户
- 注:本文中定义的
vllm-kl指标只考虑模型自身生成的 token- 理解:这样才是合适的,因为工具调用的结果不是模型输出的,对模型来说只是环境信息(类似 Query),不需要模型关注,模型也无法修改
- 以下代码提供了在 VeRL 中使用 K3 估计器 计算 vllm-kl 指标的实现,假设推理引擎的 token 概率已经是可访问的:
1
2
3
4
5
6rollout_log_probs = batch.batch["rollout_log_probs"] # pi_vllm
actor_old_log_probs = batch.batch["old_log_probs"] # pi_fsdp
response_mask = batch.batch["response_mask"]
log_ratio = actor_old_log_probs - rollout_log_probs
vllm_k3_kl_matrix = torch.exp(log_ratio) - log_ratio - 1
vllm_k3_kl = masked_mean(vllm_k3_kl_matrix,response_mask)
The Warning Signs: Correlated Instability
- 作者的第一条线索是,高
vllm-kl值并非孤立事件- 它们与其他不稳定迹象密切相关
Fluctuations in FSDP Entropy and Rewards
- 在许多实验中都可以观察到
vllm-kl的异常尖峰(Spike)通常会同时触发 FSDP 策略 \(\color{blue}{\pi^\text{fsdp}_\theta}\) 的熵和奖励的异常波动 - 图 2 所示的实验结果是一个直观的例子
- 如图 2 所示,熵尖峰出现的位置与
vllm-kl尖峰的位置几乎完美对应 - 虽然在奖励中没有观察到同样明显的相关性,但可以看到在步骤 250 左右出现了一个巨大的
vllm-kl尖峰,它触发了低质量批次的生成,并在此处也导致了奖励的明显下降 - 这意味着当不一致性较大时,vLLM 策略 \(\color{red}{\pi^\text{vllm}_\theta}\) 和 FSDP 策略 \(\color{blue}{\pi^\text{fsdp}_\theta}\) 都进入了一个不稳定区域
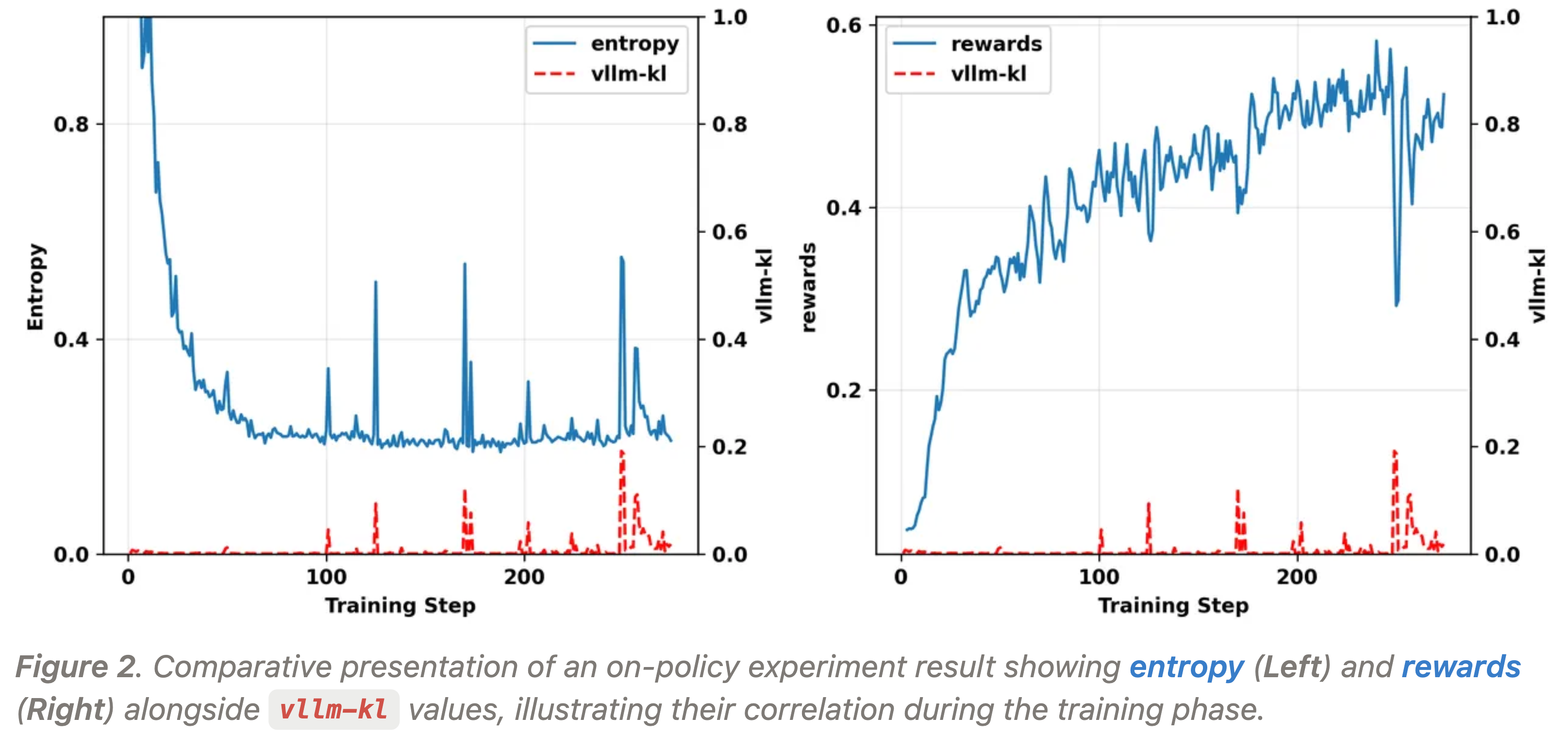
- 如图 2 所示,熵尖峰出现的位置与
Rising FSDP PPL and Gradient Norm Leading to Policy Collapse,上升的 FSDP PPL 和梯度范数导致策略崩溃
- 作者观察到
vllm-kl的尖峰同时触发了 fsdp-ppl 指标和梯度范数的爆炸- 在作者的实验中, Response \(y\) 的 fsdp-ppl 指标计算如下:
$$
\text{fsdp-ppl}: \exp\left(\frac{-1}{\left| \mathcal{T}_{\mathcal{M} }\left( y \right) \right|}\sum_{t\in \mathcal{T}_{\mathcal{M} }\left( y \right)}{\log \color{blue}{\pi_{\theta}^{\text{fsdp} } }\left( y_t|y_{ < t} \right)}\right)
$$- \(\mathcal{T}_{\mathcal{M} }\left( y \right)\) 是 Response \(y\) 中由模型自身生成的 token 的索引集合
- 最终的 fsdp-ppl 指标是批次中所有 Response 的 fsdp-ppl 指标的平均值
- 在作者的实验中, Response \(y\) 的 fsdp-ppl 指标计算如下:
- 图 3 展示了 GRPO 的 on-policy 版本和 off-policy 版本的实验结果
- 在两个实验中,
vllm-kl的尖峰几乎精确地触发了 fsdp-ppl 和梯度范数的相应爆炸 - 还可以观察到,在训练奖励崩溃之前,
vllm-kl指标有显著的上升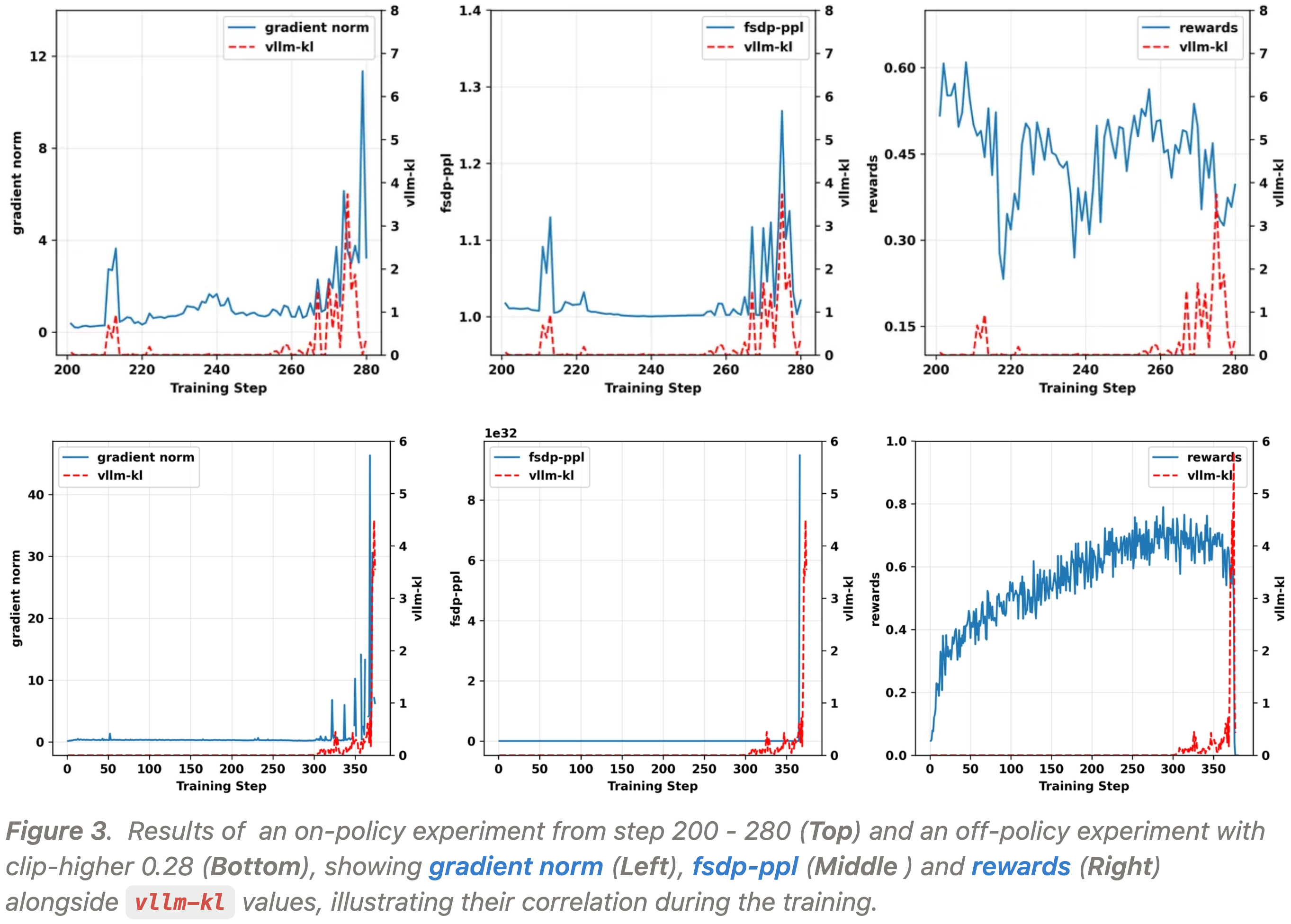
- 在两个实验中,
- 在本文的实验中,模型自身生成的序列至少包含数百个 token
- 原本的期望:在训练的后期阶段,ppl 指标保持在 1 左右更为合理
- 理解:
- 因为后期熵基本收敛了,大部分 Generated Token 的概率都是 1.0 左右,此时对应的对数概率接近 0,整体 Token 粒度的对数概率均值也接近 0,从而得到的 PPL 则接近 1
- 实际上, Token 概率是微小于 1 的,对数概率微小于 0,取 -1 得到的值微大于 0,得到的指数(PPL)微大于 1
- 问题:Off-policy(对应 Bottom)下的 PPL 应该接近于 1 才对,目前看起来是接近于 0 的,不太符合预期
- 回答:这里的图是对的,因为这个图的单位是
1e32,所以看起来似乎在 0 左右
- 回答:这里的图是对的,因为这个图的单位是
- 理解:
- 观察到的现象:在训练-推理不一致性显著的批次中(即
vllm-kl非常高时),作者观察到 fsdp-ppl 指标发生爆炸 这表明 FSDP 引擎为推理策略采样的 token 分配了灾难性的低概率,导致梯度爆炸 - 这一观察帮助进一步定位了不一致性更可能发生的地方
- 当这些 FSDP 概率极低的 token 被采样时,它们在 vLLM 引擎中的概率并非同样低
- 补充说明:在本人的实际训练过程中,也观察到许多类似的现象,这种在当前策略低概率的 Token 会引发 KL 散度 k3 估计的爆炸(因为 Old 策略对应的 Token 概率不一定同样低)
- 这个问题也是导致 KL 散度差异较大的其中一个原因
- 当这些 FSDP 概率极低的 token 被采样时,它们在 vLLM 引擎中的概率并非同样低
- 原本的期望:在训练的后期阶段,ppl 指标保持在 1 左右更为合理
The Smoking Gun: The Low-Probability Token Pitfall,低概率 Token 陷阱的确凿证据
- 核心 Insight:不一致性并非均匀分布
- 通过分析具有不同
vllm-kl水平的批次,作者发现了一个鲜明的模式:- 对于 vLLM 推理引擎认为概率较低 (low probability) 的 token,这种差异最为严重
- 当一个 token 的推理概率趋近于零时,其训练概率可能会小几个数量级,从而导致无限的 PPL 和梯度
- 为了确保结论尽可能具有普适性,作者选取了 在训练崩溃前、不同训练步数 从各种实验中采样的批次
- 所有这些批次都表现出相对较高的
vllm-kl值,使作者能够在显著条件下研究不一致性模式 - Rollout 批次在以下三个
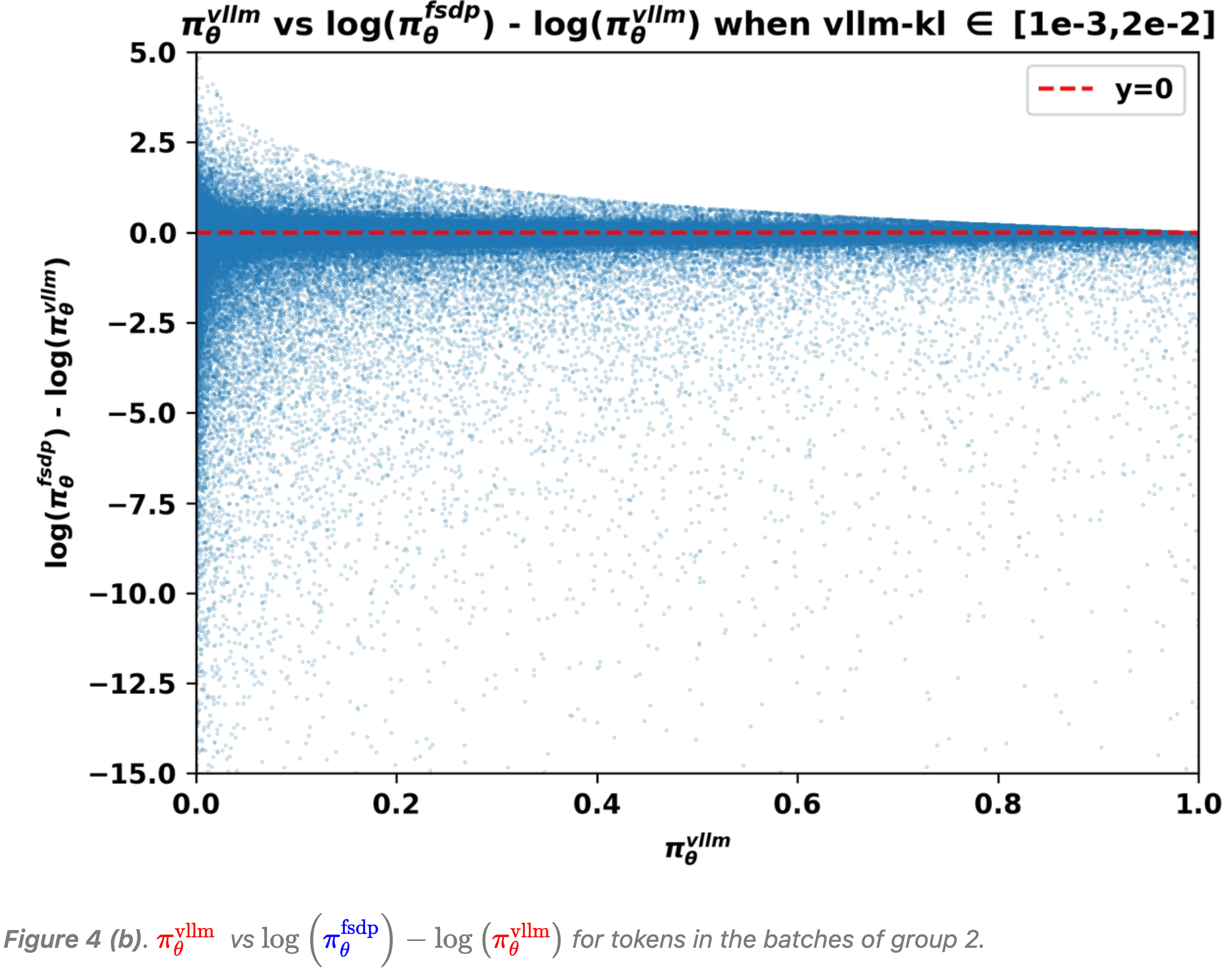
vllm-kl范围内收集,每组五个批次(约 5M token):- Group 1 (low): 每个 rollout batch 的
vllm-kl不大于 1e-3,并且批次是使用 H20 GPU 采样的 - Group 2 (medium): 每个 rollout batch 的
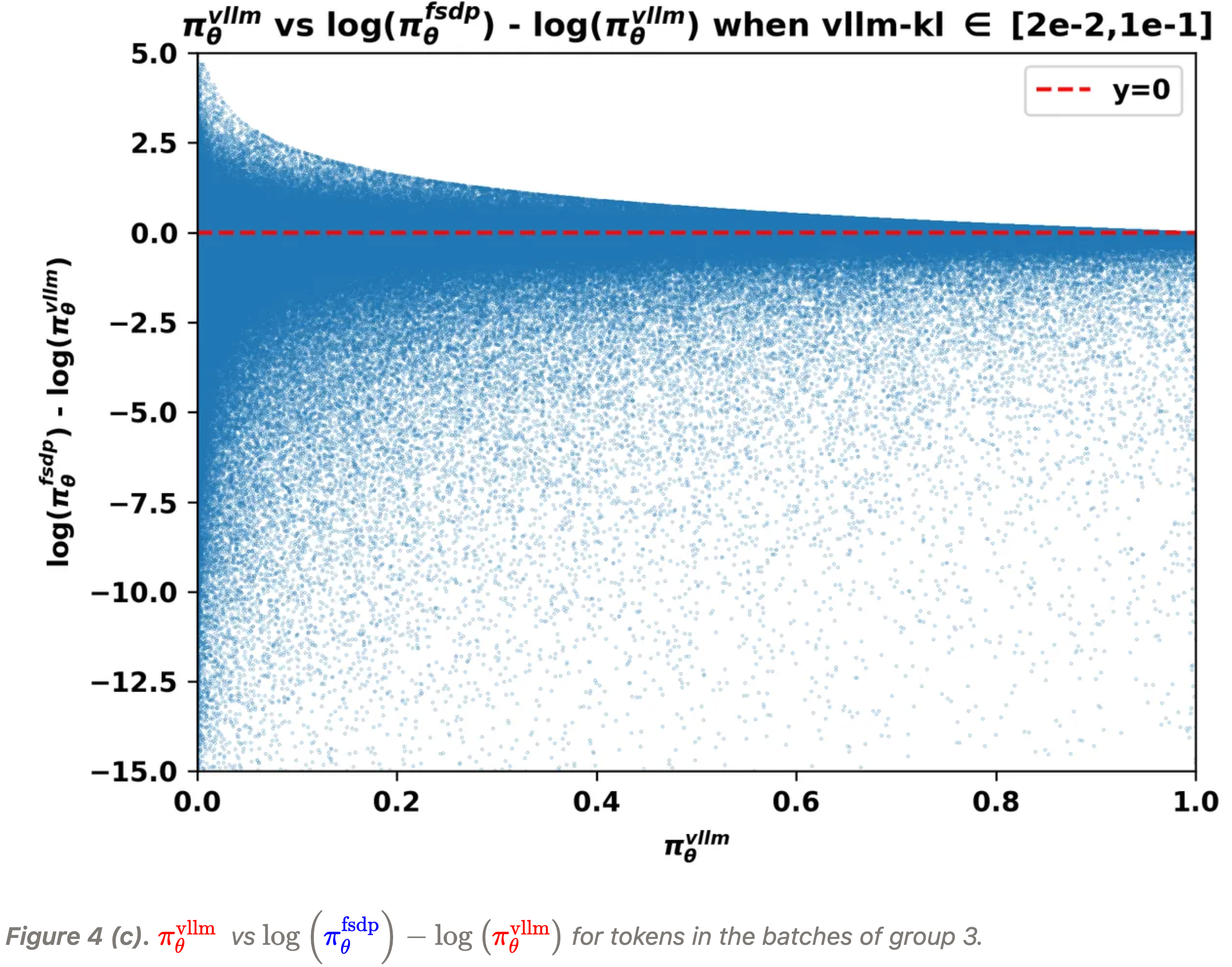
vllm-kl属于 [1e-3, 2e-2],并且批次是使用 L20 GPU 采样的 - Group 3 (high): 每个 rollout batch 的
vllm-kl属于 [2e-2, 1e-1],并且批次是使用 L20 GPU 采样的
- Group 1 (low): 每个 rollout batch 的
- 所有这些批次都表现出相对较高的
- 下面的图 4 (a)(b)(c) 展示了在不同
vllm-kl量级下,vLLM 引擎的输出概率- 即 \(\color{red}{\pi^\text{vllm}_\theta}(a|s)\) 与不一致性之间的关系,这里的不一致性由 \(\log\left(\color{blue}{\pi^\text{fsdp}_\theta}(a|s)\right)-\log\left(\color{red}{\pi^\text{vllm}_\theta}(a|s)\right)\) 衡量:
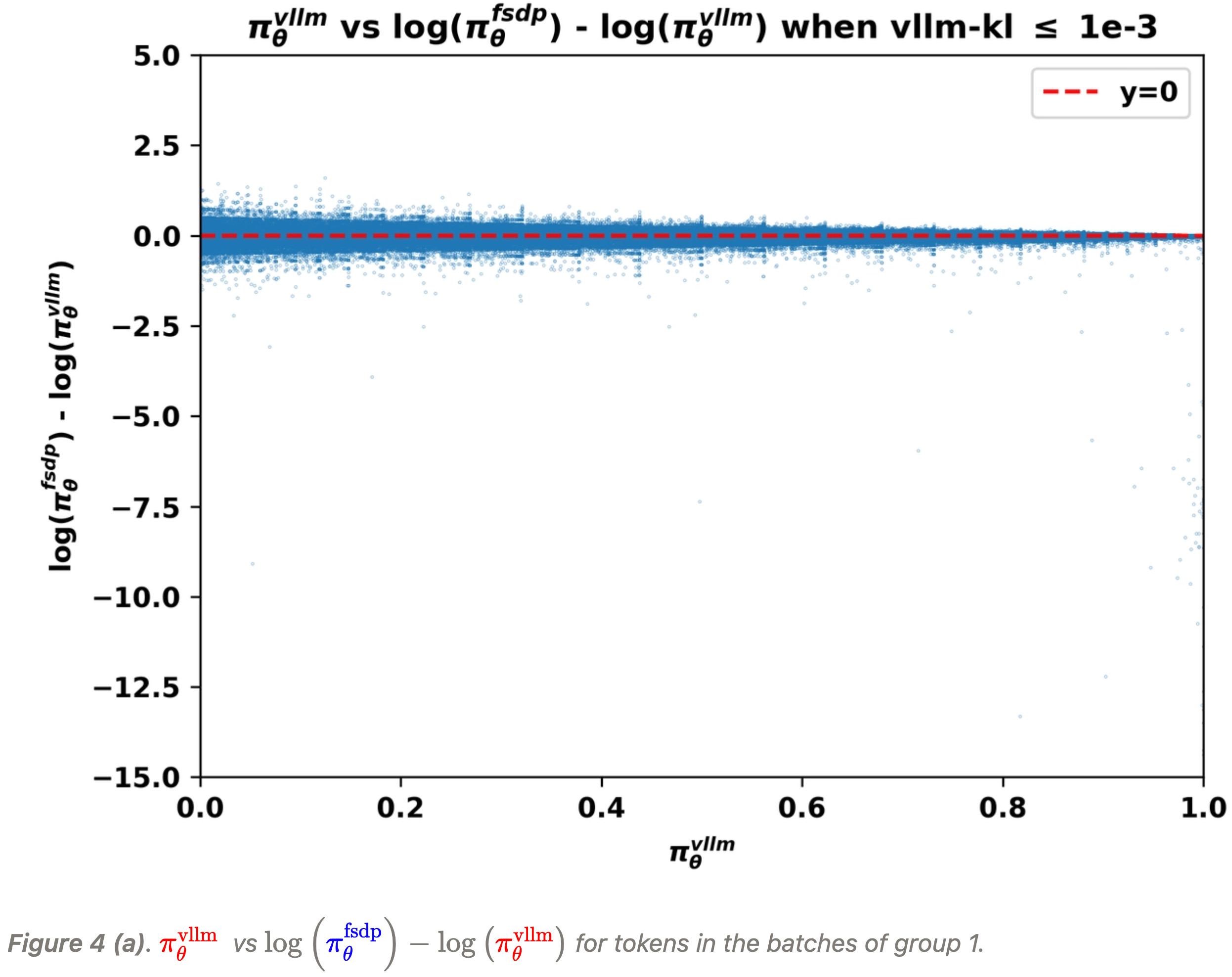
- 即 \(\color{red}{\pi^\text{vllm}_\theta}(a|s)\) 与不一致性之间的关系,这里的不一致性由 \(\log\left(\color{blue}{\pi^\text{fsdp}_\theta}(a|s)\right)-\log\left(\color{red}{\pi^\text{vllm}_\theta}(a|s)\right)\) 衡量:
- 从上图中,我们可以清晰地观察到:
- 当 vLLM 概率 \(\color{red}{\pi^\text{vllm}_\theta}\) 趋近于零时,不一致程度往往更为显著
- 并且 \(\log\left(\color{blue}{\pi^\text{fsdp}_\theta}\right)-\log\left(\color{red}{\pi^\text{vllm}_\theta}\right)\) 的极端值更可能在这些条件下出现
- 在 L20 GPU 上收集的批次,即组 2 和组 3 中的批次,表现出一种训练-推理不一致性
- 主要表现为 FSDP 概率 \(\color{blue}{\pi^\text{fsdp}_\theta}\) 显著小于 vLLM 概率 \(\color{red}{\pi^\text{vllm}_\theta}\)
- 当 vLLM 概率 \(\color{red}{\pi^\text{vllm}_\theta}\) 趋近于零时,不一致程度往往更为显著
OOD Tool Responses Amplifies the Mismatch,OOD 工具 Response 放大了不一致性
The Mismatch Is More Severe in Non-First-Round Outputs,不一致性在非首轮输出中更为严重
- 第 3 节的发现解释了为什么这个问题在作者的多轮 TIR 实验中如此尖锐,特别是在非首轮模型输出 (non-first-round model outputs) 中
- 该过程如下:
- 1)Agent 接收一个工具 Response ,这通常是结构化文本(例如,包含在
<python_output>和</python_output>标签中的上下文),相对于其预训练和 SFT 数据而言是 OOD 的- 注意:这是工具的 Response
- 2)面对这种不熟悉的 OOD 上下文,智能体的策略 变得更加不确定,使其更有可能在其后续轮次中采样低概率 token(这在 SimpleTIR 中也有观察到)
- 3)正如作者刚刚确定的,这些低概率 token 是发生严重不一致性的主要场所,为
fsdp-ppl和梯度的爆炸创造了条件
- 1)Agent 接收一个工具 Response ,这通常是结构化文本(例如,包含在
- 作者绘制了三组批次(每组约 5k 条轨迹)中的不一致性,突出了首轮模型输出和非首轮模型输出之间的差异,作者考虑以下两种方法来可视化不一致性:
- Log-ppl scatter plot(散点图) :
- x 轴:由 vLLM 策略 \(\color{red}{\pi^\text{vllm}_\theta}\) 计算的 ppl 指标的对数,记为
vllm-log-ppl - y 轴:由 FSDP 策略 \(\color{blue}{\pi^\text{fsdp}_\theta}\) 计算的 ppl 指标的对数,记为
fsdp-log-ppl
- x 轴:由 vLLM 策略 \(\color{red}{\pi^\text{vllm}_\theta}\) 计算的 ppl 指标的对数,记为
- Probability scatter plot :
- x 轴:vLLM 策略 \(\color{red}{\pi^\text{vllm}_\theta}\) 的 token 概率
- y 轴:FSDP 策略 \(\color{blue}{\pi^\text{fsdp}_\theta}\) 的 token 概率
- Log-ppl scatter plot(散点图) :
- 三组不一致性的可视化结果
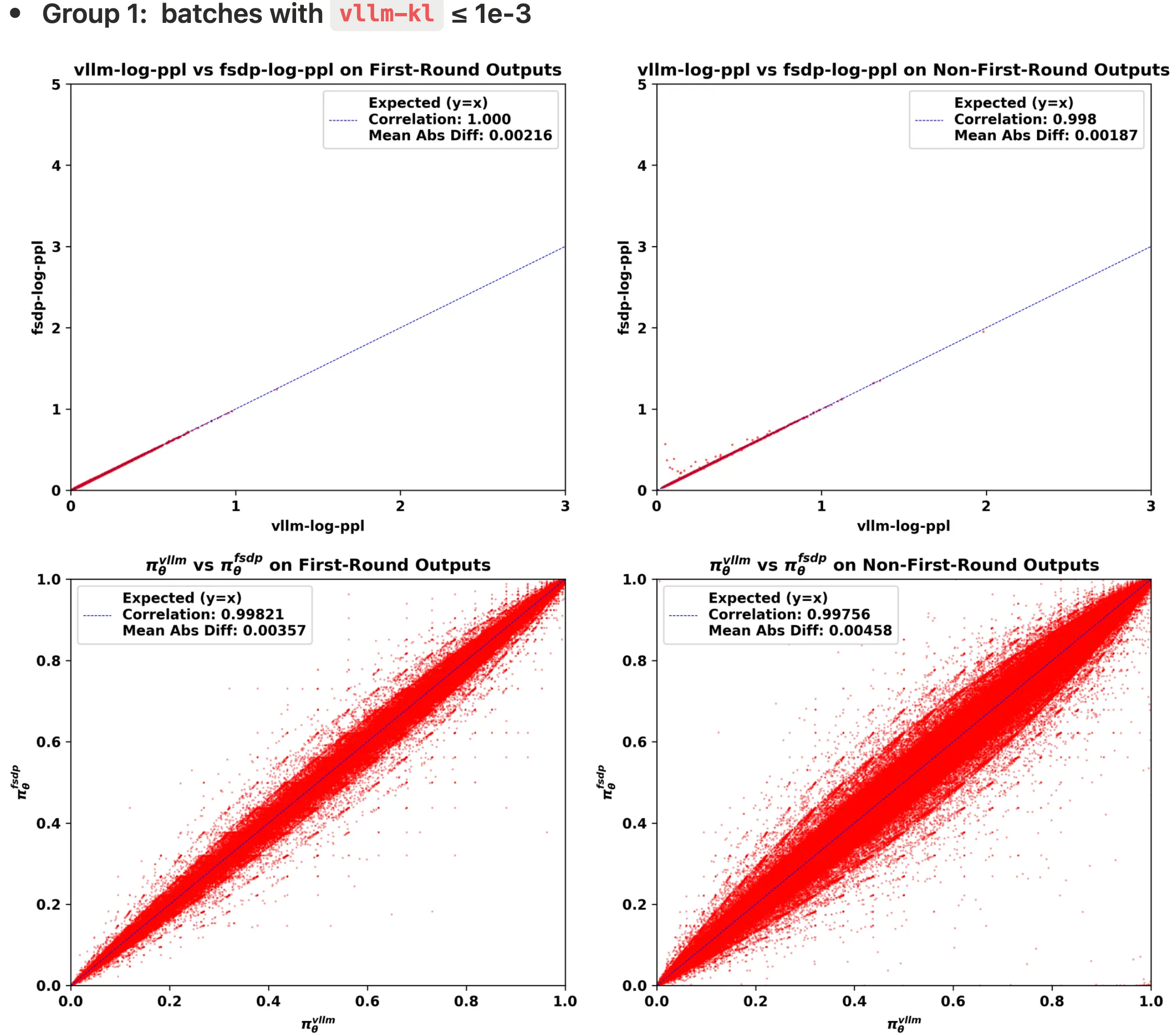
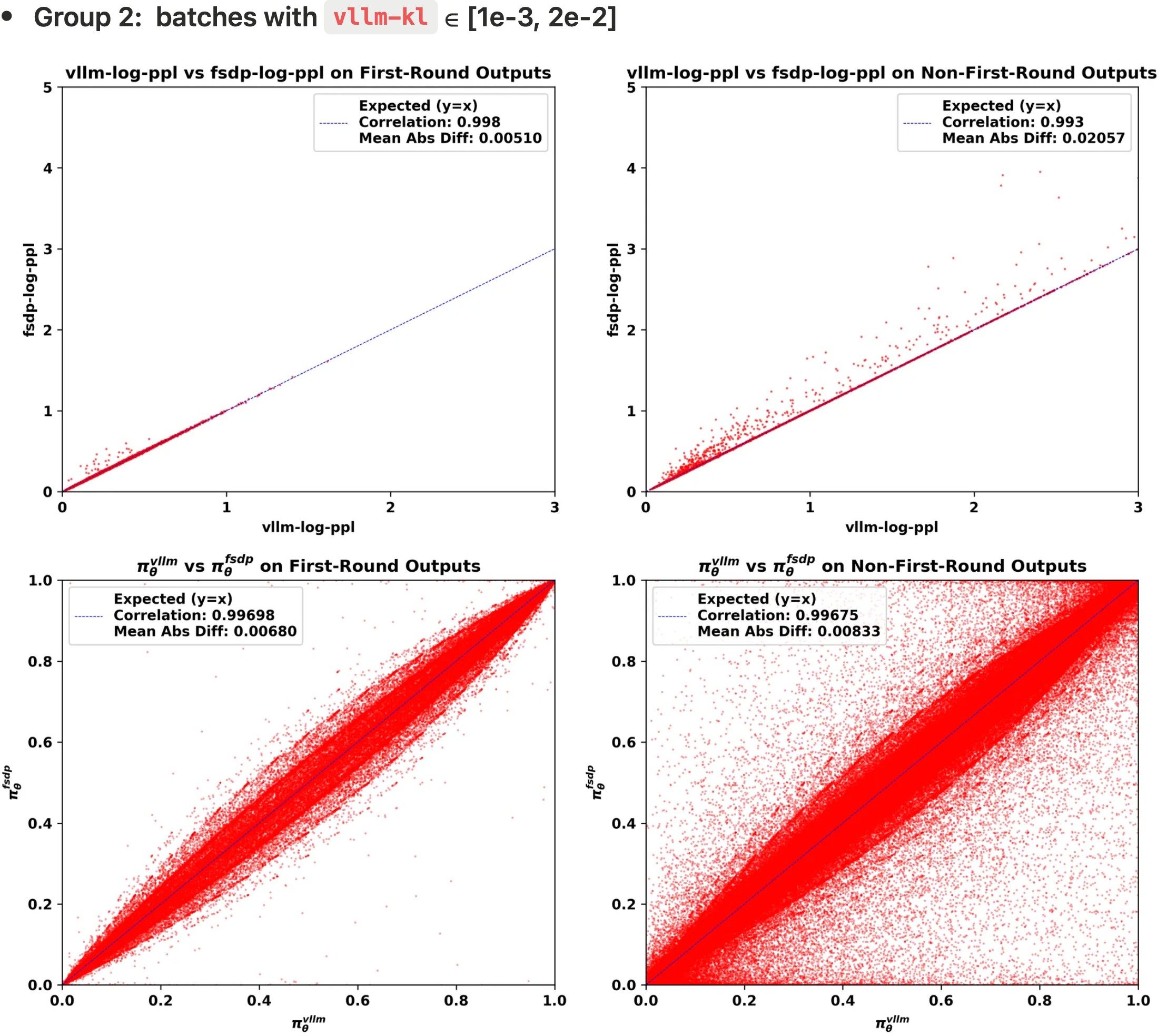
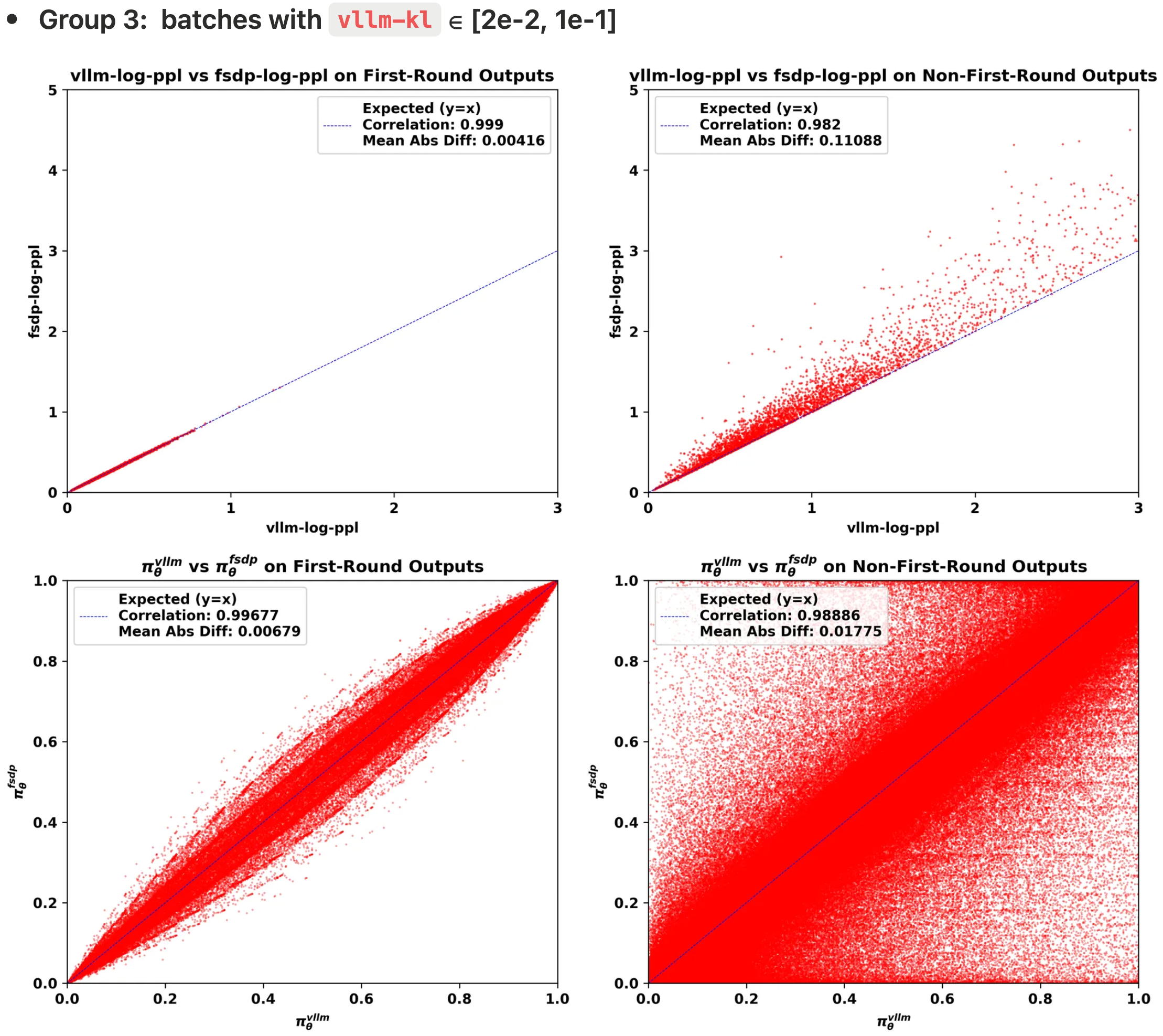
- 从可视化结果中,作者可以观察到:
- 1)非首轮输出的
vllm-log-ppl通常大于首轮输出,这意味着在面对不熟悉的 OOD 上下文时,会采样到更多的低概率 token- 横向比较
log-ppl可以看出,非首轮的横轴和纵轴范围均较大(注:从图中可以看出,首轮的log-ppl集中在左下角,非首轮的覆盖面积则更广) - 理解:相当于熵变高了(即 PPL 变大了),此时 Token 的概率都不高,输出的不确定性增高
- 横向比较
- 2)不一致性主要发生在非首轮模型输出中(第二列为非首轮)
- 表现为 FSDP 策略与 vLLM 策略之间的 log-ppl 和 token 概率的平均绝对差更大,皮尔逊相关系数更低
- 3)随着
vllm-kl值的增加,训练-推理不一致性主要在非首轮输出中恶化 - 4)不一致性始终显示
fsdp-log-ppl大于vllm-log-ppl,表明 FSDP 引擎产生了更极端的低概率 token- 问题:为什么
fsdp-log-ppl相对vllm-log-ppl会严格偏大呢?甚至一个小于的点都看不到?
- 问题:为什么
- 1)非首轮输出的
More Tool Calls, More Training Instability,工具调用越多,训练不稳定性越大
- 本节的实验表明,OOD 工具 Response 加剧了训练-推理不一致性和训练不稳定性
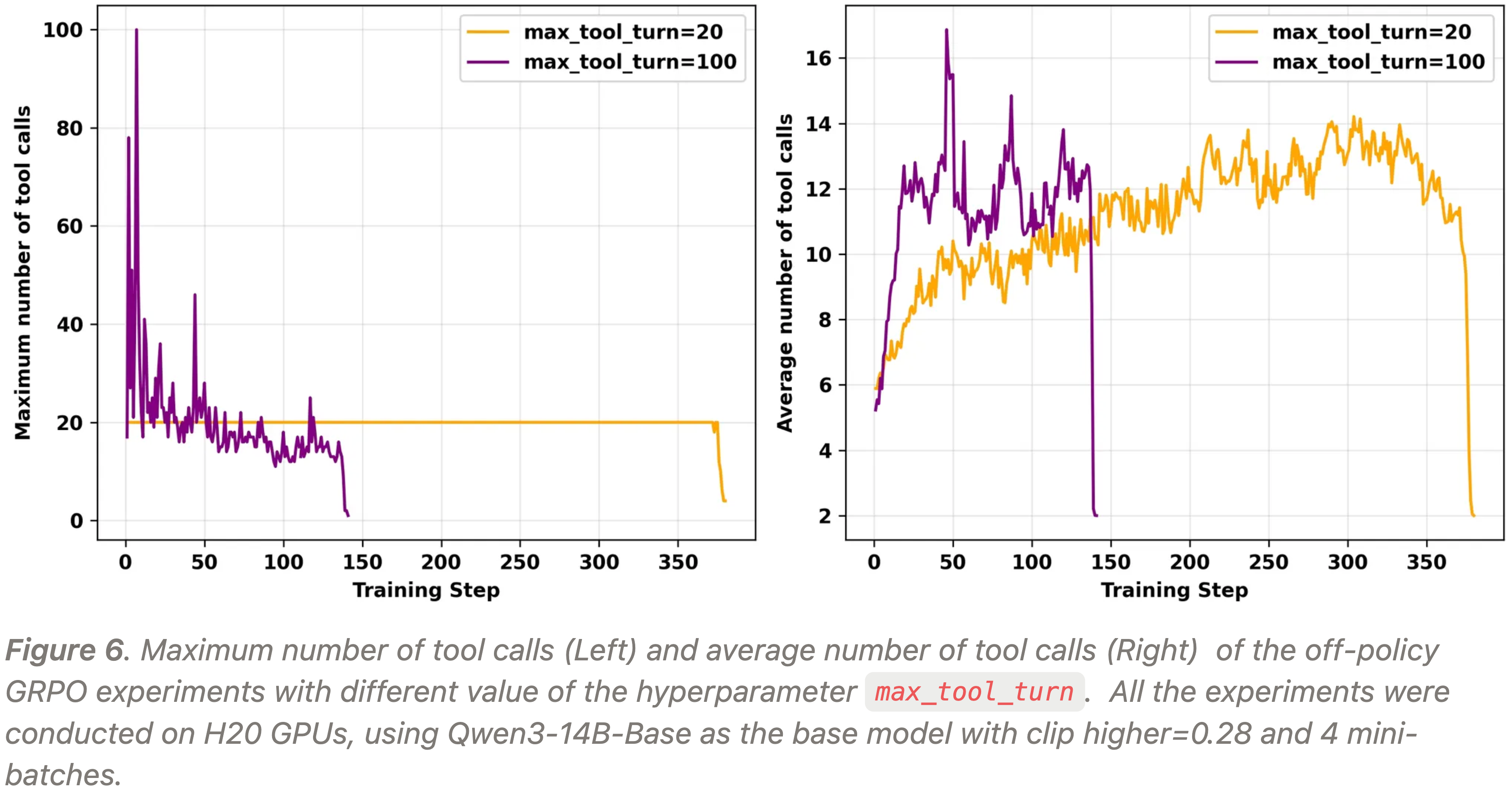
- 在 H20 GPU 上使用 Qwen3-14B-Base 作为基础模型,进行了 off-policy GRPO 实验,设置 clip higher=0.28 和 4 个 mini-batches
- 将单条轨迹中最大工具调用次数(超参数
max_tool_turn)分别设置为 20 和 100 - 实验结果如图 5 和图 6 所示,可以观察到:
- 随着工具调用次数的增加,训练崩溃发生的时间更早(轮次越多,爆炸越快)
- 崩溃时,在所有情况下都观察到了梯度爆炸和
vllm-kl的爆炸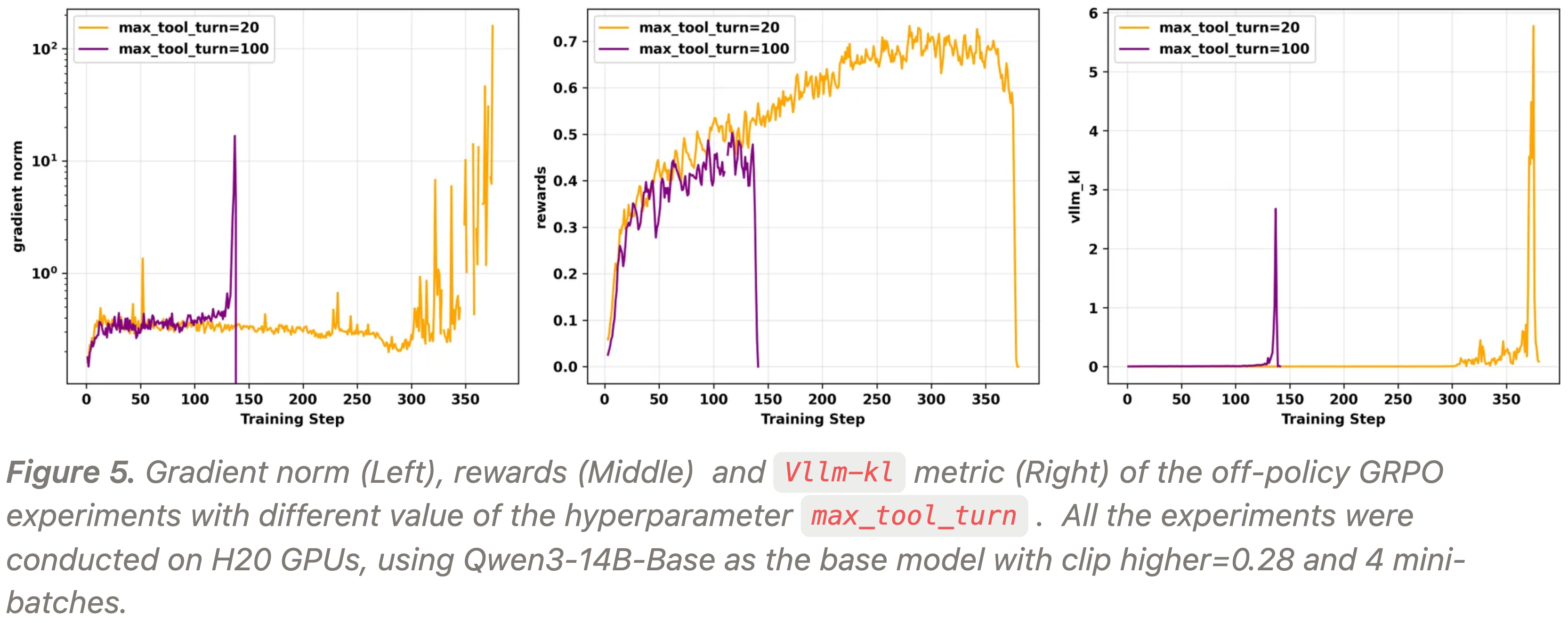
The Environmental Factor: The Critical Role of Hardware
- 作者还发现物理硬件是一个关键变量
- 完全相同的代码和模型在不同的 GPU 硬件上产生了截然不同的不一致性水平
- 为了评估不同硬件上的不一致性程度,作者在相同的代码环境和超参数下运行 on-policy 算法,仅在推理和训练时切换不同的 GPU
- 图 7 分别展示了在 L20、H20 和 A100 上的训练动态
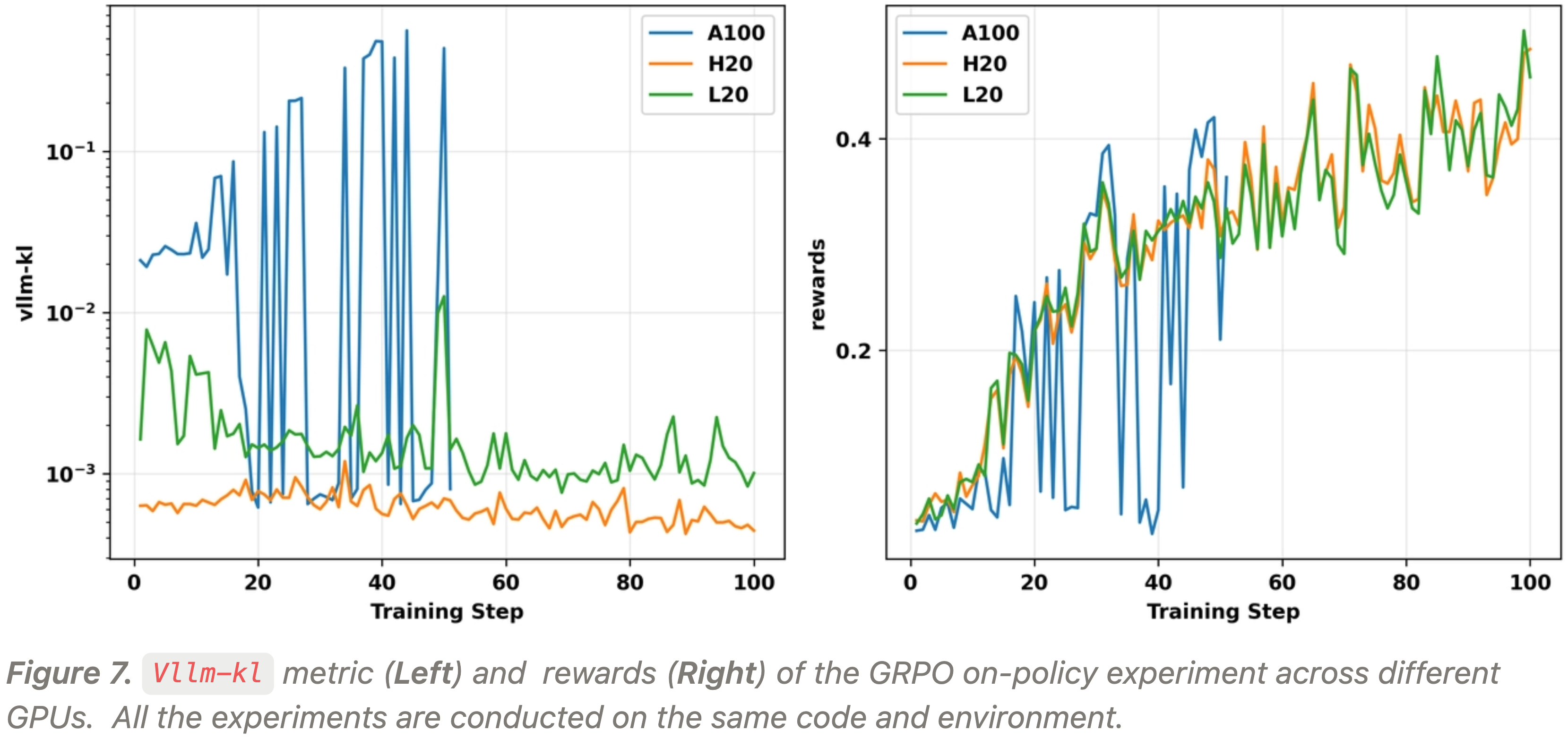
- 从图中可以观察到
- 实验中
vllm-kl的量级基本遵循:H20 < L20 < A100- H20 的
vllm-kl通常在 5e-4 到 1e-3 的量级 - L20 大约在 1e-3 到 1e-2
- A100 主要在 1e-2 到 1 之间
- H20 的
- 由于 A100 上严重的训练-推理不一致性,正常训练变得不可行,导致奖励曲线高度不稳定
- 实验中
- 在作者的 A100 GPU 上运行 的实验中,禁用 vLLM 引擎中的级联注意力 (cascade attention) 特别有助于减少不一致性
- 作者在 第 4.2.4 节(在 vLLM 中禁用级联注意力) 中展示了这些结果
- 最有力的证据来自于作者将一个失败的 L20 实验从其 checkpoint 开始在 H20 GPU 上恢复训练(见图 8)
- 训练立即稳定并恢复,证明了硬件对该问题的 First-order 影响
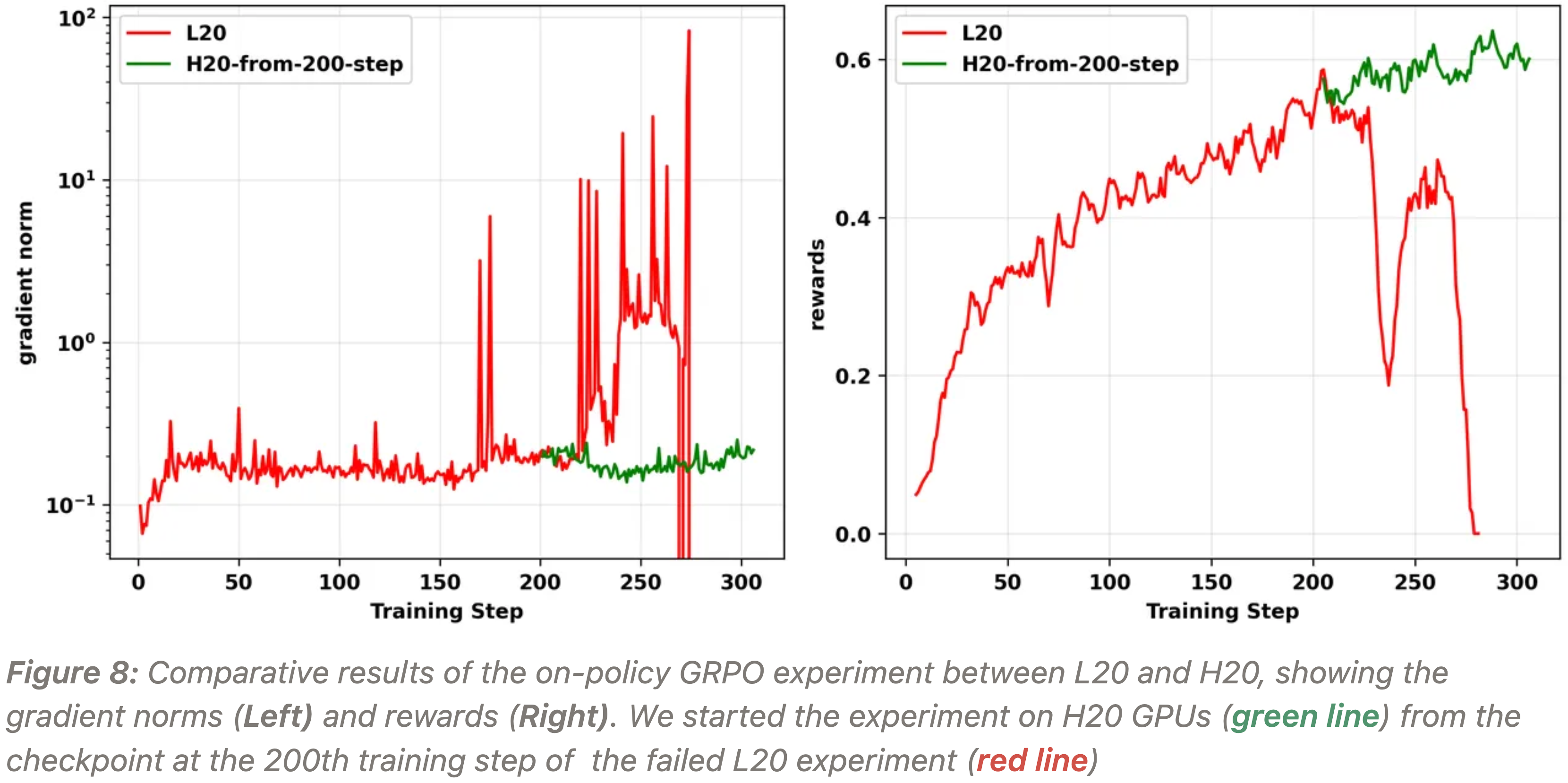
- 训练立即稳定并恢复,证明了硬件对该问题的 First-order 影响
The Mismatch is Not Static: A Vicious Cycle Driven by Optimization
- 这种不一致性并非静态的,而是由优化驱动的恶性循环
- 有人可能认为训练-推理不一致性是硬件和软件栈的静态属性
- 但作者接下来的“Batch-filter”实验证明,除了与硬件和软件栈有关,不一致性还与训练动态和模型状态有关,即 不一致性与训练动态和模型状态是耦合的
- 作者在 “Batch-filter” 实验中设置了以下策略更新方式:
- 对于每个训练步,如果收集到的批次产生的
vllm-kl指标大于阈值- 则跳过在该批次上更新模型参数 (因为此类更新带着噪音的,容易导致训练崩溃)
- 此时直接进入下一步,继续收集数据,直到获得
vllm-kl值低于阈值的批次,此时才更新模型
- 对于每个训练步,如果收集到的批次产生的
- 这个实验背后的逻辑是,如果不一致性的程度完全独立于模型的输出分布和训练动态,那么
vllm-kl的量级在不同的训练步应呈现相同的分布 - 但图 9 所示的实验结果表明,一旦模型进入某种状态,它就开始持续生成高不一致性的批次 ,从而发生持续过滤,几乎停止了训练(右图橙黄色背景部分)
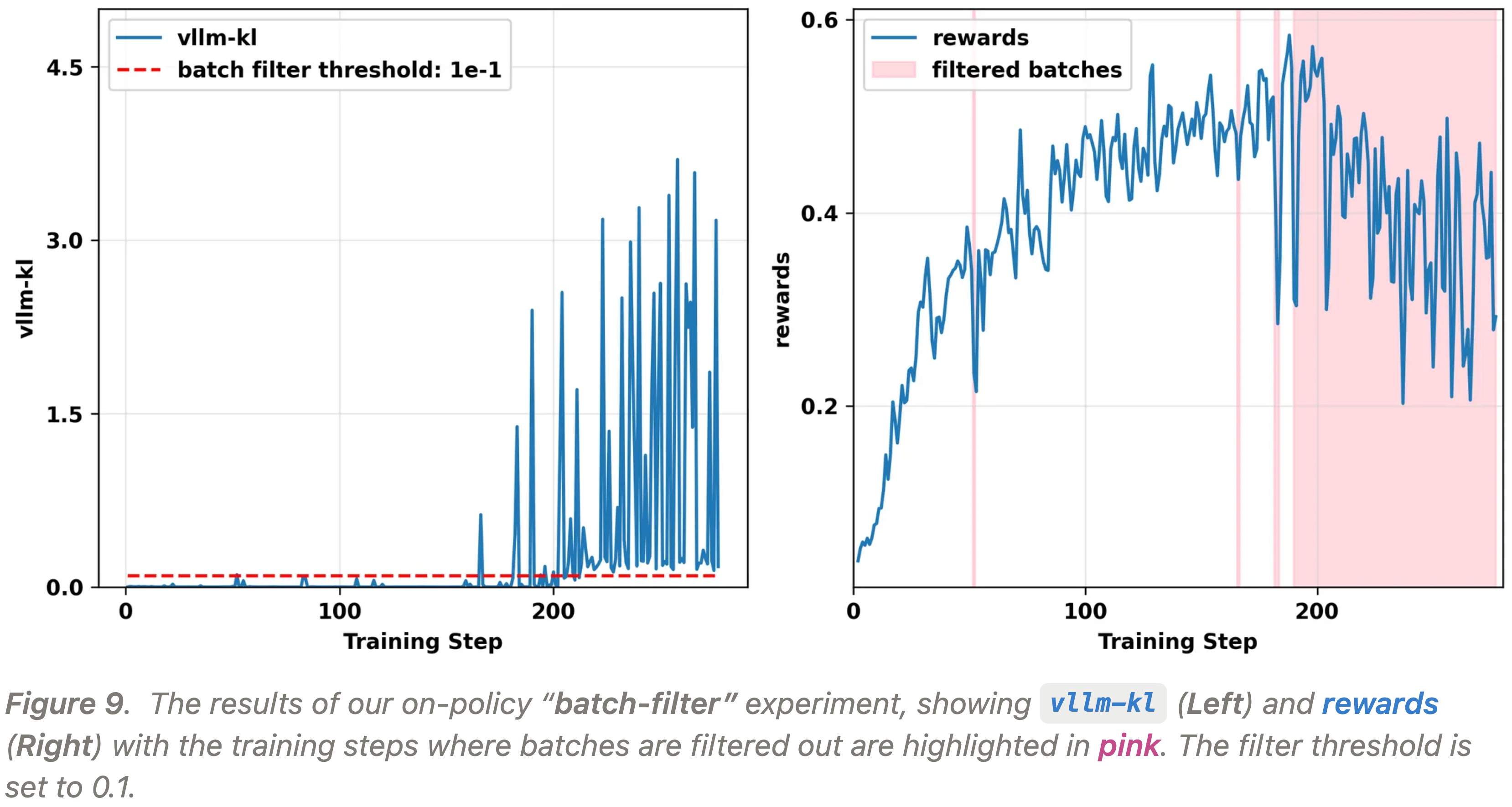
- 这一点,连同在其他运行中观察到的
vllm-kl和fsdp-ppl螺旋式上升(图 10),指向了一个危险的反馈循环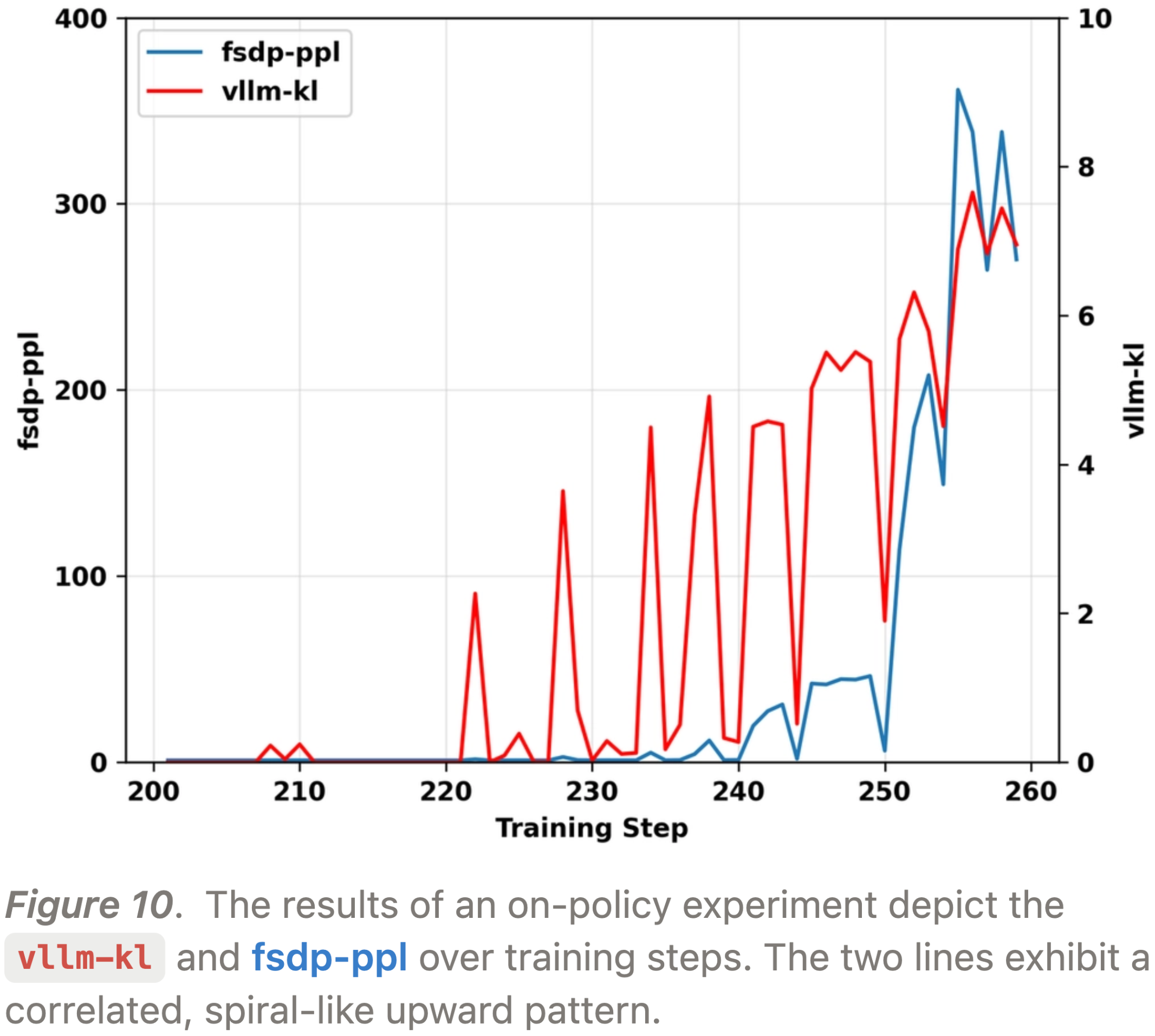
- 作者推测这是由于以下两阶段的失败级联 (two-stage failure cascade) 造成的:
- 1)阶段 1:数值敏感性增加
- RL 优化器将模型权重推入
bfloat16数据类型具有较低相对精度的数值范围(例如,非常小或非常大的值)
- RL 优化器将模型权重推入
- 2)阶段 2:内核驱动的误差放大
- 这些初始的、微小的
bfloat16量化误差随后被输入到 vLLM 和 FSDP 的不同内核实现中 - 不同的计算顺序充当非线性放大器,导致微小的初始偏差滚雪球般地变成最终 logits 的巨大差异
- 这些初始的、微小的
- 这就形成了一个恶性反馈循环 :
- 不一致性导致有偏且嘈杂的梯度,这可能进一步将参数推入数值敏感区域 ,这反过来又会使下一次迭代的不一致性恶化,直到系统崩溃
- 另一个个人理解:
- 如果参数超错误的未知噪音方向更新,那么更新后的模型采样得到的结果可能是奇怪的,即一些原本低概率的 Token 会更容易被采样出来(推测熵可能会异常的增大),这样的 Token 更容易导致更大的 vllm-kl
- 1)阶段 1:数值敏感性增加
Attempts to Alleviate Training-Inference Mismatch,介绍缓解训练-推理不一致性的一些尝试
- 接下来将列出作者尝试过的缓解训练-推理不一致性的方法
- 其中一些方法有帮助,而另一些则没有
Ineffective Attempts,无效尝试
Use FP32 LM Head
- Inspired by the Minimax-M1 technical report and the blog post《Your Efficient RL Framework Secretly Brings You Off-Policy RL Training》
- 作者修补了 vLLM,将 lm_head 转换为 fp32 精度
- 理解:作者的基本思路是,让 vLLM 的参数精度更贴近 FSDP 的精度,从而一定程度上缓解训推不一致问题
- 但在作者的实验中,修补后不一致性问题仍然存在,模型崩溃无法避免
- 图 11 显示了在 L20 GPU 上使用 vLLM 引擎中 bf16 lm_head 的一个失败的 on-policy 实验,以及一个从崩溃实验的第 200 个训练步后开始在 vLLM 引擎上使用 fp32 lm_head 的实验
- 可以观察到,两个实验最终都崩溃了,并且使用 fp32 lm_head 的实验仍然表现出
vllm-kl的爆炸 - 注意:以上实验不是从一开始就是用 FP32 的,而是 bf16 训练至出现问题后从 200 Step 恢复,此时使用 FP32 替换 bf16
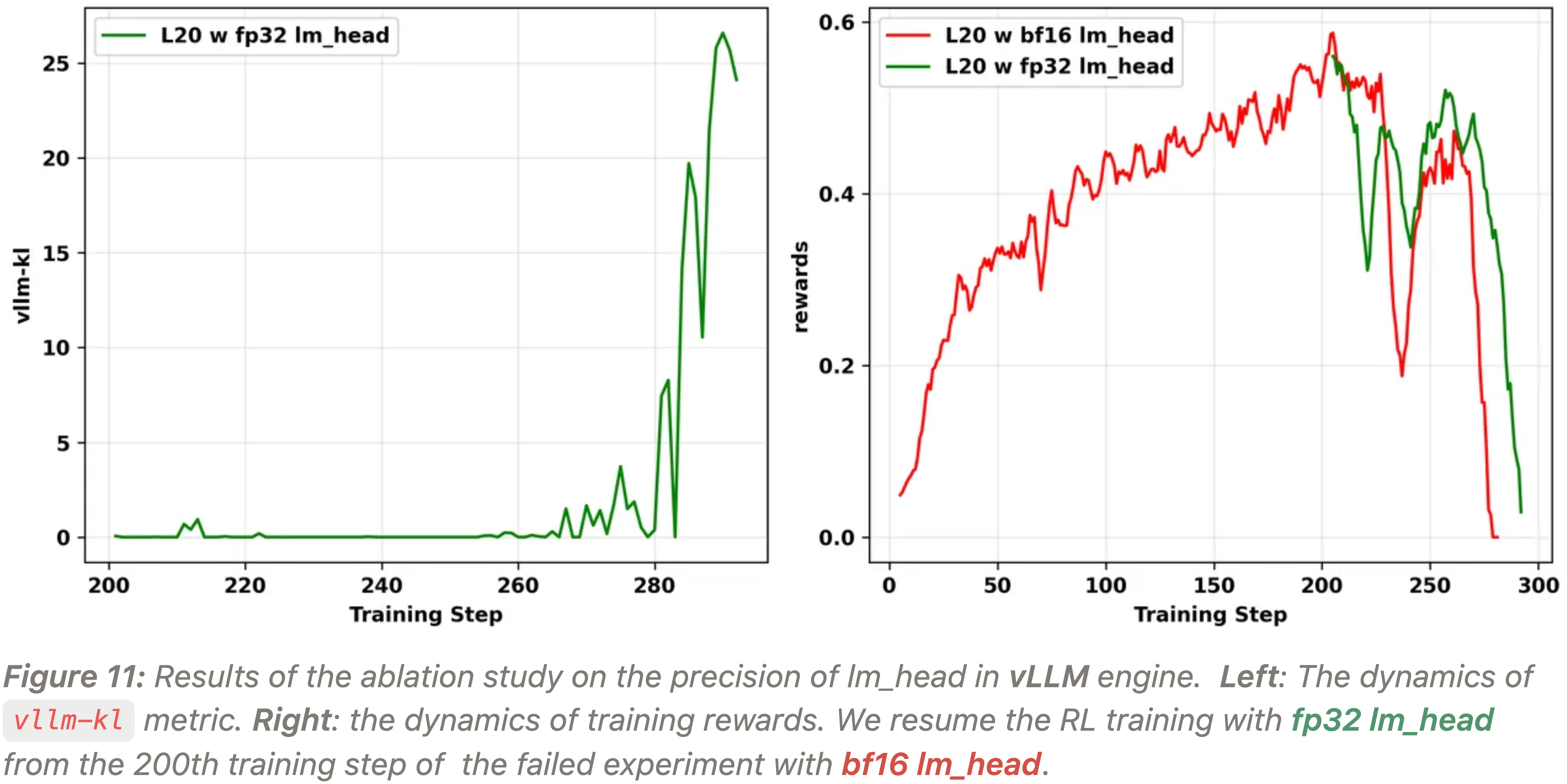
- 作者还尝试从第 4.1.1 节中使用 bf16 lm_head 的失败实验的第 200 个训练步开始恢复 RL 训练,禁用分块预填充 (chunked prefill),以观察这是否能解决崩溃问题
- 实验结果(如图 12 所示)表明,这种方法并未解决崩溃问题
- 问题:分块预填充 会导致精度问题吗?
- 理解:似乎没有发现,但是这个应该会导致一些计算顺序的不确定,导致输出不确定的问题
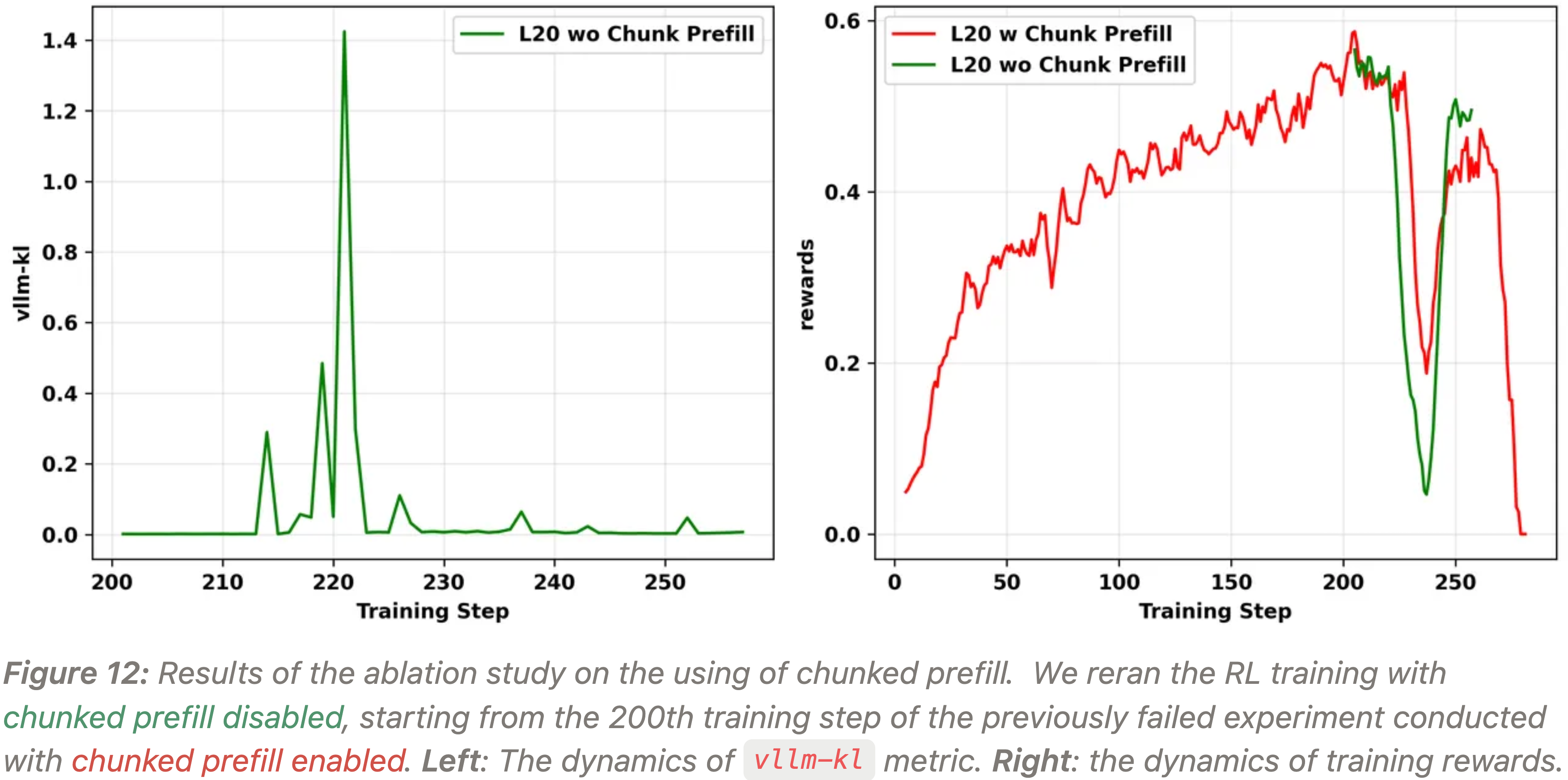
- 理解:似乎没有发现,但是这个应该会导致一些计算顺序的不确定,导致输出不确定的问题
Enable enforce_eager and free_cache_engine
- VeRL 的 DAPO 官方指南 提到,启用 CUDA 图 (
enforce_eager=False) 可能导致模型 Performance 下降- 理解:这里的 Performance 下降应该主要是指训练得到的模型下游指标(测试性能)变差
- 为了探究它是否影响训练-推理不一致性,作者进行了一项消融研究,以考察 vLLM 引擎超参数
enforce_eager的影响,同时考虑另一个超参数free_cache_engine - 作者在 Reasoning RL 上进行了实验
- 在 H100 GPU 上使用 Qwen3-4B-Base 作为基础模型,进行了 on-policy GRPO 实验,共运行四种实验设置:
- 超参数
enforce_eager和free_cache_engine的穷举组合,每个设置为True或False
- 超参数
- 性能在 AIME24 基准上进行了评估
- 在 H100 GPU 上使用 Qwen3-4B-Base 作为基础模型,进行了 on-policy GRPO 实验,共运行四种实验设置:
- 实验结果如图 13 所示
- 从图中可以看出,调整
enforce_eager和free_cache_engine的值对训练-推理不一致性和测试性能(下游指标)没有显著影响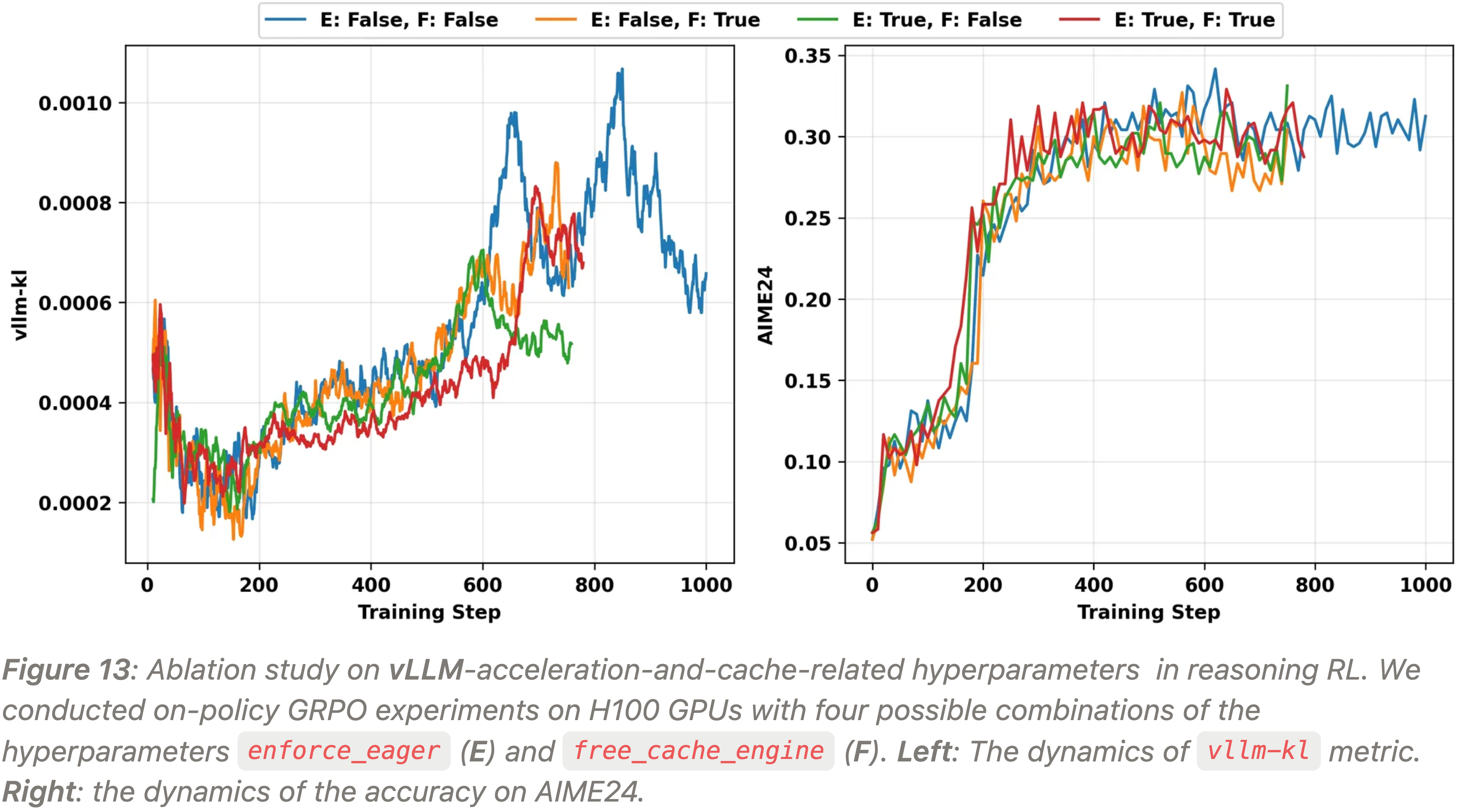
- 从图中可以看出,调整
Effective Attempts,有效尝试
4.2.1 A Principled Solution: Distribution Correction
- 训练-推理不一致性将原本的 on-policy RL 问题变成了一个 off-policy 问题
- 其中用于生成 rollout 的策略(行为策略 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\))与正在训练的策略(目标策略,\(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\))不同
- 在理论上修正这种分布偏移的一种合理方法是 重要性采样 (IS)
- 但对于保持梯度无偏和实现稳定训练而言,IS 的具体形式至关重要
- 受 off-policy-rl (2025) 的发现启发
- off-policy-rl (2025) 首次强调了这种由训练-推理不一致性导致的隐式 off-policy 问题
- 作者分析了两种主要的 IS 形式:理论上合理的 Sequence-level IS 和常见但有偏的 Token-level IS 近似
The Principled Estimator: Sequence-Level IS
- 正确、无偏的策略梯度估计器对整个生成的序列(轨迹)\(y\) 应用一个单一的重要性比率
- 这正确地将其期望从行为策略重新加权到目标策略,从而产生目标函数 \(J(\theta)\) 的真实梯度
- 下面一步步推导 Sequence-level IS 估计器 \(g_{\mathrm{seq} }(\theta)\)
- Step 1:目标是最大化在目标 FSDP 策略 下的期望奖励:
$$
J(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|x)}[R(x,y)]
$$ - Step 2:因此,真实的策略梯度为:
$$
g(\theta) = \nabla_{\theta} J(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|x)}\left[R(x,y) \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x)\right]
$$ - Step 3:由于作者只能从 vLLM 策略 中采样,作者使用重要性采样来改变策略梯度的期望的分布:
$$
g_{\mathrm{seq} }(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)}\left[ \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x)}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(y|x)} \cdot R(x,y) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x) \right]
$$- 这本质上是 off-policy REINFORCE 算法
- Step 1:目标是最大化在目标 FSDP 策略 下的期望奖励:
- 这个估计器在数学上等价于策略梯度的标准优势形式
- 因为重要性采样比率精确地修正了期望(数学上等价)
补充详细推导:以上策略梯度的 On-policy 形式
- 步骤 1:将期望转换为其 On-Policy 形式
- IS 估计器取其关于行为策略 \(\color{red}{\pi^{\mathrm{vllm} } }\) 的期望
- 通过将期望的定义写为积分,行为策略密度 \(\color{red}{p_{\theta}^{\mathrm{vllm} } }(y|x)\) 被抵消:
$$
\begin{align}
g_{\mathrm{seq} }(\theta) &= \int \left( \frac{\pi_{\color{blue}{\theta} }^{\mathrm{fsdp} }(y|x)}{\pi_{\color{red}{\theta} }^{\mathrm{vllm} }(y|x)} \cdot R(x,y) \cdot \nabla_{\theta} \log \pi_{\color{blue}{\theta} }^{\mathrm{fsdp} }(y|x) \right) \pi_{\color{red}{\theta} }^{\mathrm{vllm} }(y|x) dy \\
&= \int \left( R(x,y) \cdot \nabla_{\theta} \log \pi_{\color{blue}{\theta} }^{\mathrm{fsdp} }(y|x) \right) \pi_{\color{blue}{\theta} }^{\mathrm{fsdp} }(y|x) dy
\end{align}
$$- 这是真实的 on-policy 梯度,因为期望是对目标策略 \(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\) 而言的
- 这证明了 \(g_{\mathrm{seq} }(\theta)\) 是真实策略梯度的无偏估计量
$$
g_{\mathrm{seq} }(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|x)}\left[R(x,y) \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x)\right] = g(\theta)
$$- 理解:其实这个不需要证明,IS 对原始的 真实策略梯度 进行精确修正,得到的本就是数学上完全等价的形式
- 注:真实的策略梯度 见前一小节的推导结果:
$$
g(\theta) = \nabla_{\theta} J(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|x)}\left[R(x,y) \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x)\right]
$$
- 步骤 2:分解为时间步并应用因果关系 (仅考虑当前时间步之后的 Reward \(G_t\))
- 现在处理更简单的 on-policy 表达式,展开轨迹级别的项并应用 因果关系 (causality) 原理(在步骤 \(t\) 的动作仅影响未来的奖励)
- 这允许我们将总奖励 \(R(x,y)\) 替换为 未来回报 (return-to-go) \(G_t = \sum_{k=t}^{|y|-1} r(s_k, a_k)\)
$$
g(\theta) = \mathbb{E}_{y \sim \color{blue}{\pi_{\theta} } } \left[ \sum_{t=0}^{|y|-1} G_t \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a_t|s_t) \right]
$$
- 步骤 3:引入优势函数 (减去一个 Baseline 得到 \(A^{\color{blue}{\pi_{\theta} } }(s_t, a_t) = G_t - V^{\color{blue}{\pi_{\theta} } }(s_t)\))
- 为了减少方差,减去一个依赖于状态的 Baseline ,即价值函数 \(V^{\color{blue}{\pi_{\theta} } }(s_t)\)
- 这将未来回报转换为 优势函数 (Advantage Function) ,\(A^{\color{blue}{\pi_{\theta} } }(s_t, a_t) = G_t - V^{\color{blue}{\pi_{\theta} } }(s_t)\)
$$
g(\theta) = \mathbb{E}_{y \sim \color{blue}{\pi_{\theta} } } \left[ \sum_{t=0}^{|y|-1} A^{\color{blue}{\pi_{\theta} } }(s_t, a_t) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a_t|s_t) \right]
$$
- 步骤 4:从 Trajectory-level 期望转换为 State-level 期望
- 最后一步将对轨迹的期望重新表述为对由目标策略引起的状态访问分布 \(d_{\color{blue}{\pi_{\theta} } }\) 的等价期望
- 从步骤 3 到步骤 4 的详细数学推导
- 步骤 A:从轨迹级期望开始
$$
g(\theta) = \mathbb{E}_{y \sim \color{blue}{\pi_{\theta} } } \left[ \sum_{t=0}^{|y|-1} A^{\color{blue}{\pi_{\theta} } }(s_t, a_t) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a_t|s_t) \right]
$$ - 步骤 B:应用期望的线性性质
- 交换期望和求和运算符
- 可以将求和扩展到无穷大,因为对于超出轨迹有限长度 \(|y|\) 的时间步 \(t\) 的任何项都是零,所以只是加了零
$$
g(\theta) = \sum_{t=0}^{\infty} \mathbb{E}_{y \sim \color{blue}{\pi_{\theta} } } \left[ A^{\color{blue}{\pi_{\theta} } }(s_t, a_t) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a_t|s_t) \right]
$$
- 步骤 C:将期望展开为显式求和
- 通过对每个可能的状态 \(s\) 和动作 \(a\) 求和,并用它们的联合概率 \(P(s_t=s, a_t=a) = P(s_t=s) \cdot \color{blue}{\pi_{\theta} }(a|s)\) 加权,来重写内部期望
$$
g(\theta) = \sum_{t=0}^{\infty} \sum_{s \in \mathcal{S} } \sum_{a \in \mathcal{A} } P(s_t=s) \cdot \color{blue}{\pi_{\theta} }(a|s) \cdot A^{\color{blue}{\pi_{\theta} } }(s, a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a|s)
$$
- 通过对每个可能的状态 \(s\) 和动作 \(a\) 求和,并用它们的联合概率 \(P(s_t=s, a_t=a) = P(s_t=s) \cdot \color{blue}{\pi_{\theta} }(a|s)\) 加权,来重写内部期望
- 步骤 D:引入状态占用度量 (通过交换求和顺序来引入)
- 重新排列求和项,将与状态 \(s\) 相关的所有项分组
$$
g(\theta) = \sum_{s \in \mathcal{S} } \left( \sum_{t=0}^{\infty} P(s_t=s) \right) \cdot \left( \sum_{a \in \mathcal{A} } \color{blue}{\pi_{\theta} }(a|s) \cdot A^{\color{blue}{\pi_{\theta} } }(s, a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a|s) \right)
$$- 第一项,\(\sum_{t=0}^{\infty} P(s_t=s)\),是 状态占用度量 (state occupancy measure) 的定义,\(d_{\color{blue}{\pi_{\theta} } }(s)\)
- 第二项是对动作的期望的定义,\(\mathbb{E}_{a \sim \color{blue}{\pi_{\theta} }(\cdot|s)}[\dots]\)
$$
g(\theta) = \sum_{s \in \mathcal{S} } d_{\color{blue}{\pi_{\theta} } }(s) \cdot \mathbb{E}_{a \sim \color{blue}{\pi_{\theta} }(\cdot|s)} \left[ A^{\color{blue}{\pi_{\theta} } }(s, a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a|s) \right]
$$
- 重新排列求和项,将与状态 \(s\) 相关的所有项分组
- 步骤 E:得到最终形式
- 对所有状态按其状态占用度量加权求和,根据定义,是对状态分布 \(d_{\color{blue}{\pi_{\theta} } }\) 的期望
$$
g(\theta) = \mathbb{E}_{s \sim d_{\color{blue}{\pi_{\theta} } } } \left[ \mathbb{E}_{a \sim \color{blue}{\pi_{\theta} }(\cdot|s)} \left[ A^{\color{blue}{\pi_{\theta} } }(s,a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta} }(a|s) \right] \right]
$$
- 对所有状态按其状态占用度量加权求和,根据定义,是对状态分布 \(d_{\color{blue}{\pi_{\theta} } }\) 的期望
- 步骤 A:从轨迹级期望开始
- 这个推导过程得到策略梯度的最终优势形式:
$$
\color{red}{g_{\mathrm{seq} }(\theta)} = \mathbb{E}_{s \sim d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } } } \mathbb{E}_{a \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|s)} \left[ A^{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }(s,a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \right]
$$- \(s=(x,y_{ < t})\) 是状态(前缀)
- \(a=y_t\) 是动作(token)
- \(d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\) 是目标 FSDP 策略下的状态占用度量
- 它形式化地定义为遵循策略 \(\pi\) 时状态 \(s\) 被访问的期望次数:
$$
\color{blue}{d_{\pi}(s) := \mathbb{E}_{x’ \sim \mathcal{D}, y’ \sim \pi(\cdot|x’)} \left[ \sum_{t’=0}^{|y’|-1} \mathbb{I}\{ (x’, y’_{<t’}) = s \} \right] = P(x) \cdot \prod_{k=0}^{t-1} \pi(y_k|x,y_{<k})}
$$
- 它形式化地定义为遵循策略 \(\pi\) 时状态 \(s\) 被访问的期望次数:
- 因为这个策略梯度估计器 \(g_{\mathrm{seq} }(\theta)\) 是 无偏的 ,意味着
$$\color{red}{g_{\mathrm{seq} }(\theta)} = g(\theta)$$- 为了数值稳定性,使用了 截断重要性采样 (Truncated Importance Sampling, TIS)
- TIS 将 Sequence-level 比率 \(\rho(y|x)\) 截断在一个常数 \(C\)
A Common Biased Estimator: Token-Level IS,常见的有偏估计器
- 一个常见的启发式方法,通常受到 PPO 等算法的启发,并在 off-policy-rl (2025) 中使用,是对每个 token 应用重要性比率
- 虽然这通常具有比 Sequence-level 比率更低的方差,但它是一个 有偏估计器 ,对于自回归模型在理论上是不合理的
- 更低的方差来源是指 Sequence-level 时对数比率是多个 Token-level 的对数比率连乘计算得到的(详情见下两个公式),这样的话得到的结果波动自然比单个 Token 的对数比率大
- 推导 Token-level IS 梯度估计器 \(g_{\mathrm{tok} }(\theta)\)
- 第一步:这个公式开始于错误地在时间步求和内部应用重要性采样比率:即,\(g_{\mathrm{tok} }(\theta)\) 被定义为:
$$
g_{\mathrm{tok} }(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)}\left[ R(x,y) \cdot \sum_{t=0}^{|y|-1} \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y_t|x,y_{ < t})}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(y_t|x,y_{ < t})} \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y_t|x,y_{ < t}) \right]
$$- 作为对照,这里我们同步贴一下 Sequence-level 的梯度估计器:
$$
g_{\mathrm{seq} }(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)}\left[ \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x)}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(y|x)} \cdot R(x,y) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y|x) \right]
$$- 这里的 \(R(x,y)\) 是从 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 采样的完整轨迹的经验回报(因为 \(y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)\)),它是状态-动作值 \(Q^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s,a)\) 的蒙特卡洛估计
- 作为对照,这里我们同步贴一下 Sequence-level 的梯度估计器:
- 第二步:同上一小节中的详细推导过程,我们可以类似地将对轨迹的期望重写为对在 vLLM 策略 下访问的状态的期望:
$$
g_{\mathrm{tok} }(\theta) = \mathbb{E}_{s \sim d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } } } \mathbb{E}_{a \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|s)} \left[ \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s)}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s)} \cdot A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s,a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \right]
$$- 引入基线并改变对动作的期望,得到最终形式:
$$
g_{\mathrm{tok} }(\theta) = \mathbb{E}_{s \sim d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } } } \mathbb{E}_{a \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|s)} \left[ A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s,a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \right]
$$- 这个最终表达式清楚地揭示了 Token-level IS 的梯度偏差
- 补充:第二步的详细证明详情见附录
- 注:推导过程中与 Sequence-level 表达式推导过程中的主要区别在于 Token-level 相加的校准形式无法被 Sequence-level 的期望直接消去,从而导致最终表达式的期望中仍然遗留了 vLLM 的策略信息
- 特别注意:
- 这里的 \(A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s,a)\) 表示我们的 Advantage 是基于 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 采样和估计的
- 引入基线并改变对动作的期望,得到最终形式:
- 现在对比真实策略梯度的无偏估计 \(\color{red}{g_{\mathrm{seq} }(\theta)} \):
$$
\color{red}{g_{\mathrm{seq} }(\theta)} = \mathbb{E}_{s \sim d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } } } \mathbb{E}_{a \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|s)} \left[ A^{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }(s,a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \right]
$$ - 可以清楚地看到,只有当 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 保持在 \(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\) 的信任域内时,即当 \(d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }\approx d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\) 且 \(A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }\approx A^{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\) 时,\(J(\theta)\) 才能被 \(g_\text{tok}(\theta)\) 优化
- 第一步:这个公式开始于错误地在时间步求和内部应用重要性采样比率:即,\(g_{\mathrm{tok} }(\theta)\) 被定义为:
Token-level IS 中偏差的来源 (The Source of Bias in Token-Level IS)
- 比较 \(g_{\mathrm{tok} }(\theta)\) 与真实梯度 \(g_{\mathrm{seq} }(\theta)\) 揭示了两个截然不同且显著的误差,这些误差使得 Token-level 估计器有偏
- 来源 1:状态占用不匹配
- 一个合理的 off-policy 修正必须考虑两种分布偏移:
- 动作概率:Token-level 方法修正了动作概率
- 状态访问概率:Token-level 方法没有修正状态访问概率
- 真实梯度 (\(g_{\mathrm{seq} }\)):
- 期望是对在 正确的目标 fsdp 分布 下访问的状态,\(\mathbb{E}_{s \sim d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } } }\)
- 有缺陷的梯度 (\(g_{\mathrm{tok} }\)):
- 期望是对在 错误的行为 vLLM 分布 下访问的状态,\(\mathbb{E}_{s \sim d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } } }\)
- 真实梯度 (\(g_{\mathrm{seq} }\)):
- 这隐含地假设状态占用比率为 1,即 \({d_{\color{blue}{\pi^{\mathrm{fsdp} } } }(s)} /{d_{\color{red}{\pi^{\mathrm{vllm} } } }(s)} = 1\)
- 这个假设在自回归模型中被灾难性地违反了
- 由于 LLM 中的 MDP 是确定性的转移,一个不同的 token 选择就能保证状态轨迹完全分歧
- 理解:这里的状态轨迹分歧会直接导致状态占用 \(d_\pi(s)\) 发生较大变化,而且越长的状态轨迹,发生偏移的概率越大
- 因为忽略这一点,\(g_{\mathrm{tok} }(\theta)\) 引入了一个大的、不受控的偏差
- 由于 LLM 中的 MDP 是确定性的转移,一个不同的 token 选择就能保证状态轨迹完全分歧
- 一个合理的 off-policy 修正必须考虑两种分布偏移:
- 来源 2:奖励信号不匹配
- 第二个关键错误是, Token-level 梯度使用来自 错误策略 的奖励信号对更新进行加权
- 真实梯度 (\(g_{\mathrm{seq} }\)):
- 更新由 目标 fsdp 策略 的优势函数 \(A^{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\) 缩放,表示在该策略下的期望未来奖励
- 有缺陷的梯度 (\(g_{\mathrm{tok} }\)):
- 更新由 行为 vLLM 策略 的优势函数 \(A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }\) 缩放
- 即目标策略的梯度正被一个属于行为策略的奖励信号所缩放(本该是目标策略的奖励信号来缩放)
- 真实梯度 (\(g_{\mathrm{seq} }\)):
- 第二个关键错误是, Token-level 梯度使用来自 错误策略 的奖励信号对更新进行加权
- 由于状态分布和奖励信号从根本上是不匹配的, Token-level 梯度是一个有偏且理论上不合理的估计器
Experimental Validation
- 总结来看,本文的理论分析预测,有偏的 Token-level IS 将不稳定并最终失败,而无偏的 Sequence-level IS 将是稳健的
- 本文给出实验也证实了这一点
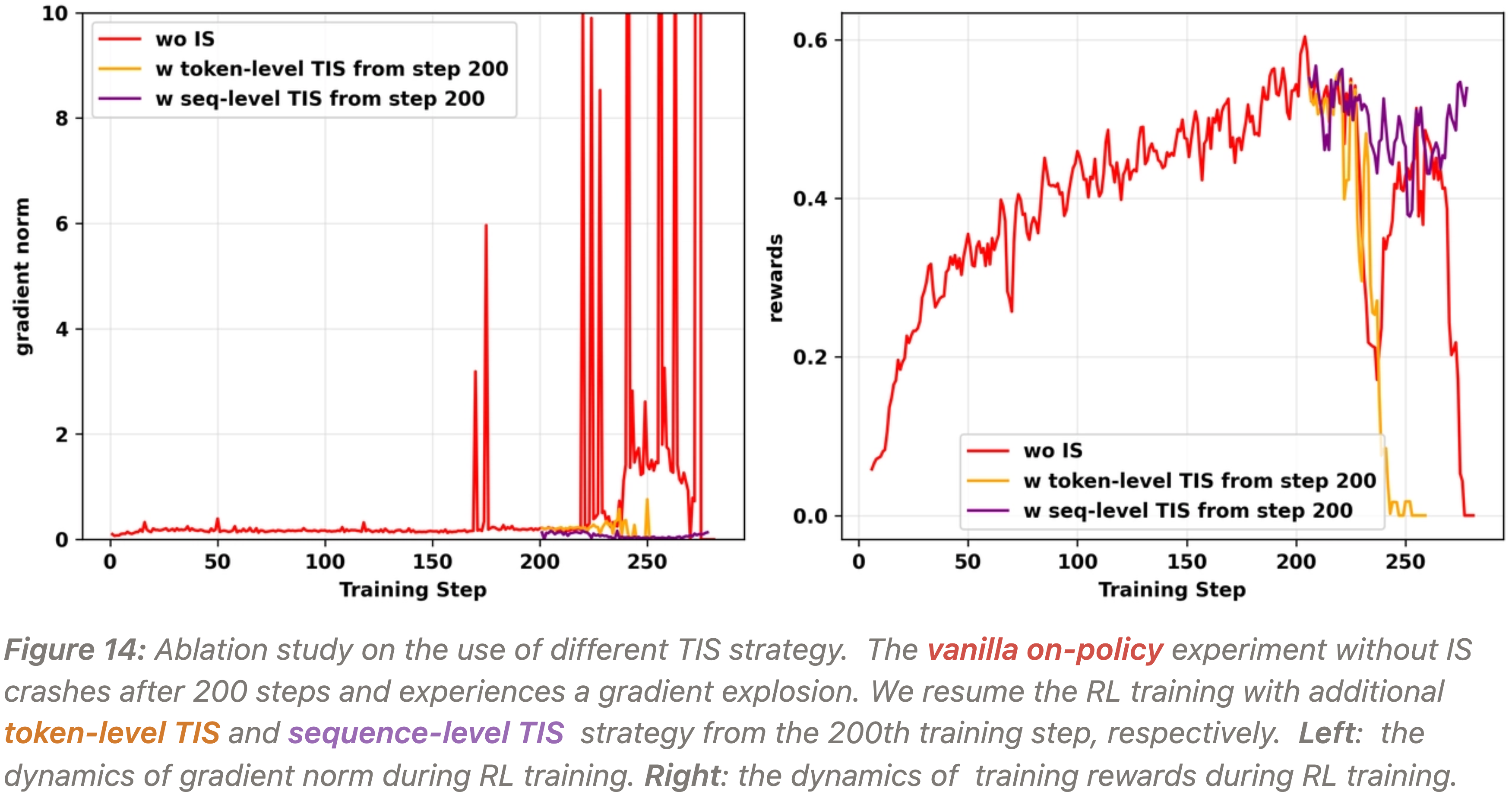
实验一:IS Prevents Gradient Explosion, but Token-Level Still Fails(Token-level TIS 防止了梯度爆炸,但是仍然失败了)
- 作者在 L20 GPU 上从第 200 个训练步开始,使用 Token-level TIS 和 Sequence-level TIS (\(C=2\)) 恢复了一个崩溃的实验
- 如图 14 所示
- 虽然两者最初都防止了原始实验中看到的梯度爆炸,但使用 Token-level TIS 的运行后来仍然崩溃了
- 使用 Sequence-level TIS 的运行保持稳定,验证了作者的理论,即来自 Token-level 方法的有偏梯度最终会导致失败
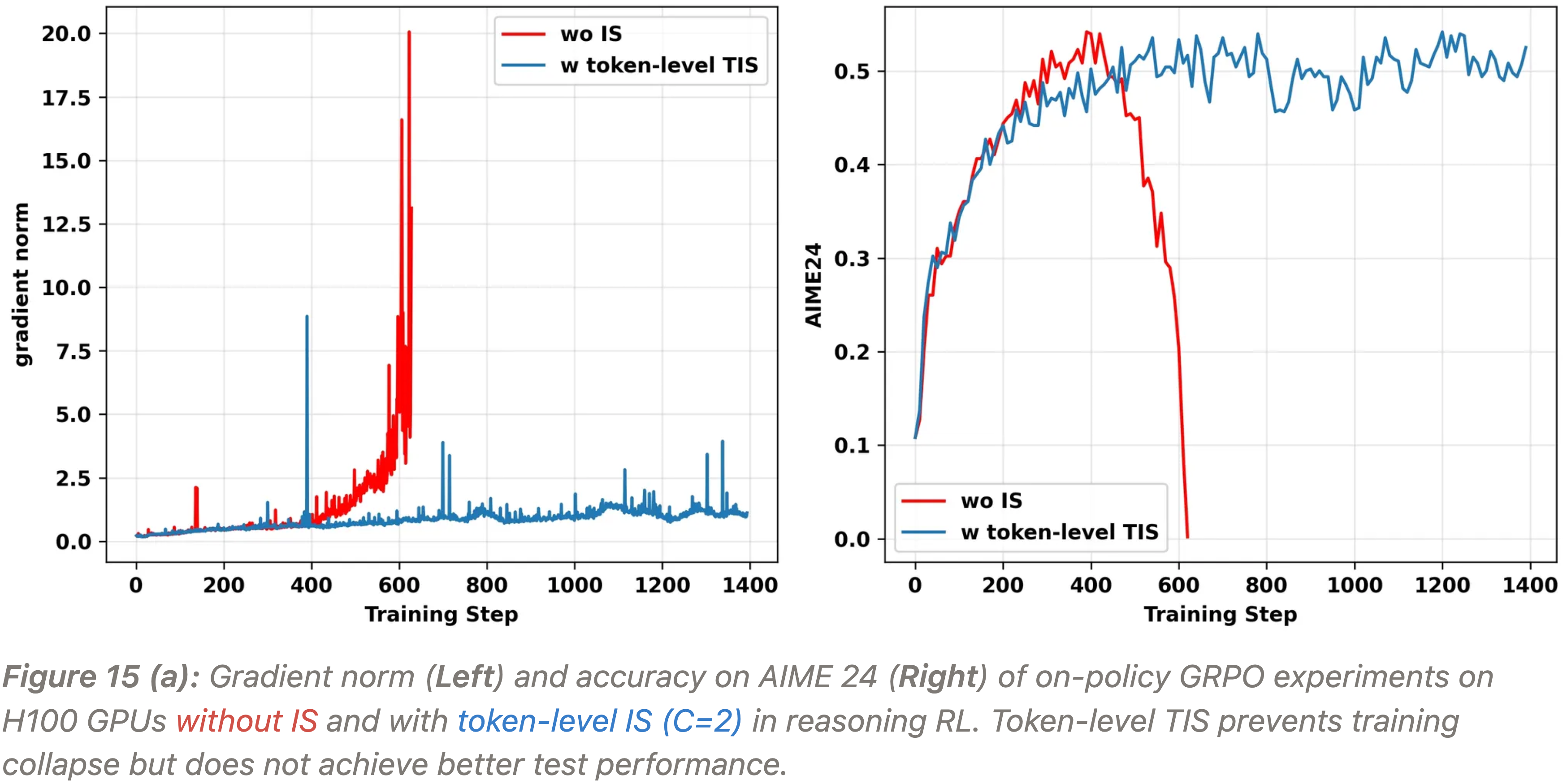
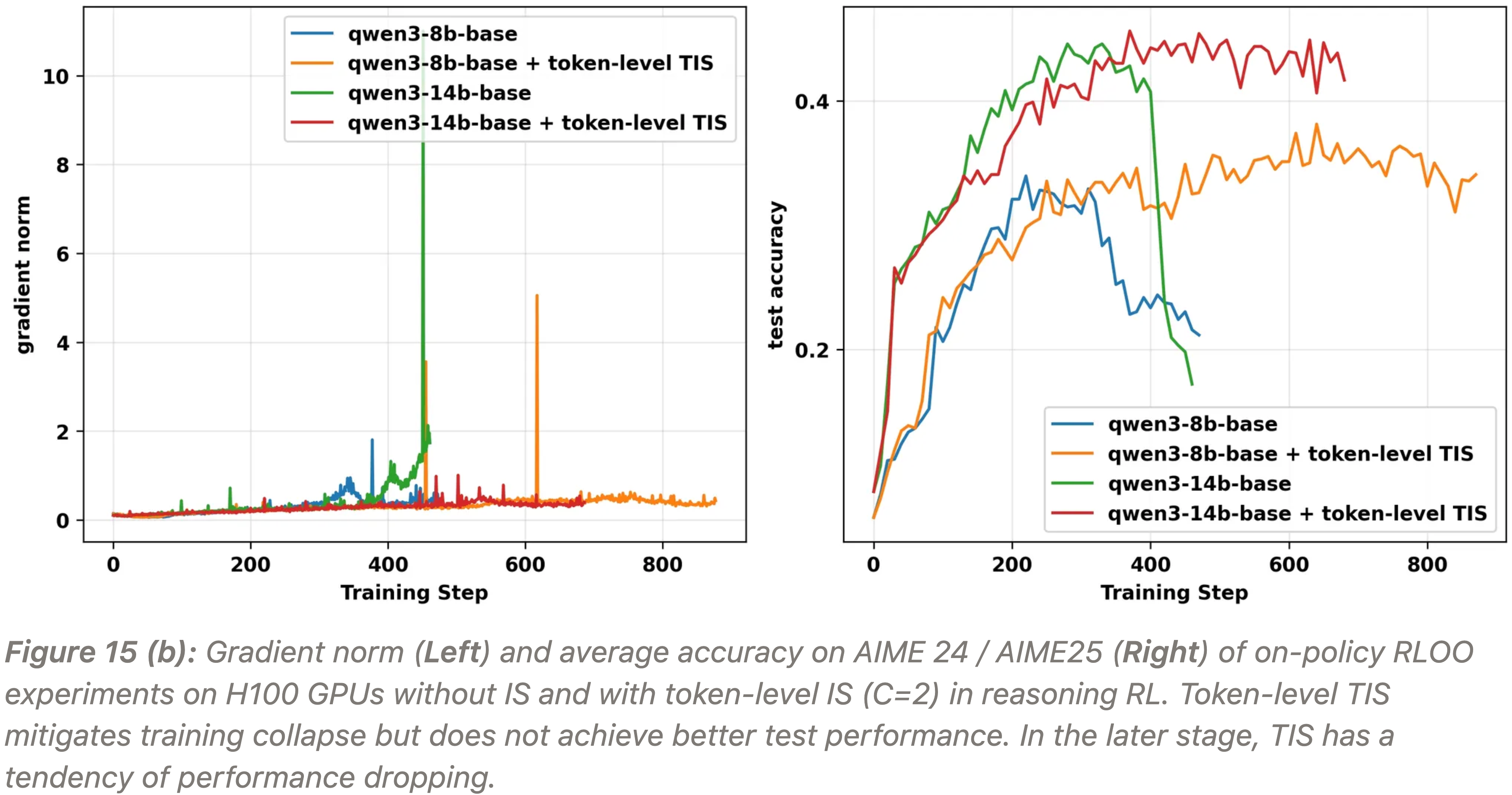
实验二:Token-Level TIS in Reasoning RL(Token-Level TIS 在更简单的 RL 中能防止梯度崩溃,但训练仍然不稳定且没有达到更好的最终性能)
- Token-level TIS 在复杂的 TIR 实验中失败,但它可以在更简单的推理 RL 中帮助防止崩溃
- 因为那里的不一致性较小
- 在 on-policy GRPO 和 RLOO 实验中(图 15)
- Token-level TIS 防止了梯度爆炸,但训练仍然不稳定,并且没有达到更好的最终性能
- 这可能是由于其潜在的梯度偏差
实验三:TIS Prolongs Training But Can Suffer from Instability,TIS 延长训练但可能遭受不稳定性,测试性能无法超过其他实验崩溃前的峰值
- 作者在 L20 GPU 上从头开始使用 Sequence-level TIS (\(C=2\)) 进行了一个 on-policy TIR 实验
- 如图 16 所示
- 虽然该方法阻止了完全崩溃,但奖励曲线在达到平台期后表现出持续波动,并且其测试性能未超过原始实验在崩溃前达到的峰值
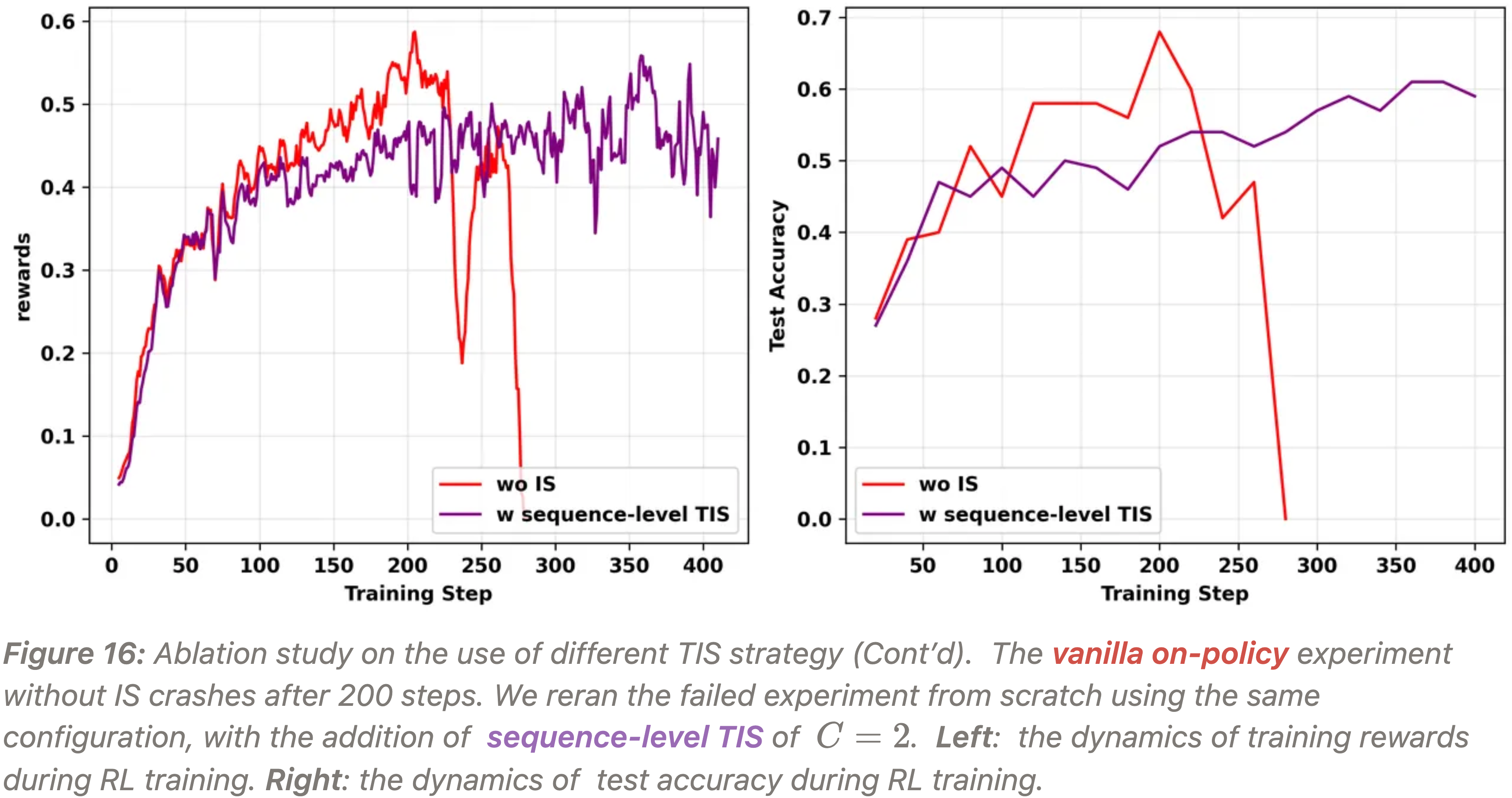
- 虽然该方法阻止了完全崩溃,但奖励曲线在达到平台期后表现出持续波动,并且其测试性能未超过原始实验在崩溃前达到的峰值
实验四:Masked Importance Sampling, MIS, Sequence-level MIS 可以超过原始基线的最高峰值
- 为了改进 TIS,作者提出了 掩码重要性采样 (Masked Importance Sampling, MIS)
- 注:其实类似思想(Token-level MIS)是在 (IcePop)Small Leak Can Sink a Great Ship—Boost RL Training on MoE with IcePop!, 20250919, AntGroup,但未明确命名为 MIS 而已
- 相关 PR:【PR to TRL】[GRPO] Sequence-level TIS + MIS(20251106)
- 注:在 IcePop 中,更多强调的是 Token-level MIS
- 注:其实类似思想(Token-level MIS)是在 (IcePop)Small Leak Can Sink a Great Ship—Boost RL Training on MoE with IcePop!, 20250919, AntGroup,但未明确命名为 MIS 而已
- 对 IS 比率超过阈值 \(C\) 的序列的策略损失进行掩码:
$$ \rho(y|x) \gets \rho(y|x) \mathbb{I}\{\rho(y|x) \le C\} $$- 理解:超出 \(C\) 的 \(\rho(y|x)\) 会被置为 0
- 如图 17 所示:MIS 不仅稳定了训练,而且超过了原始实验和 TIS 实验的峰值训练奖励和测试准确率
- 问题:怎么感觉在下游测试指标(图 17 右图)继续训练 TIS 可能也能拿到不错的收益?因为性能还在持续增长
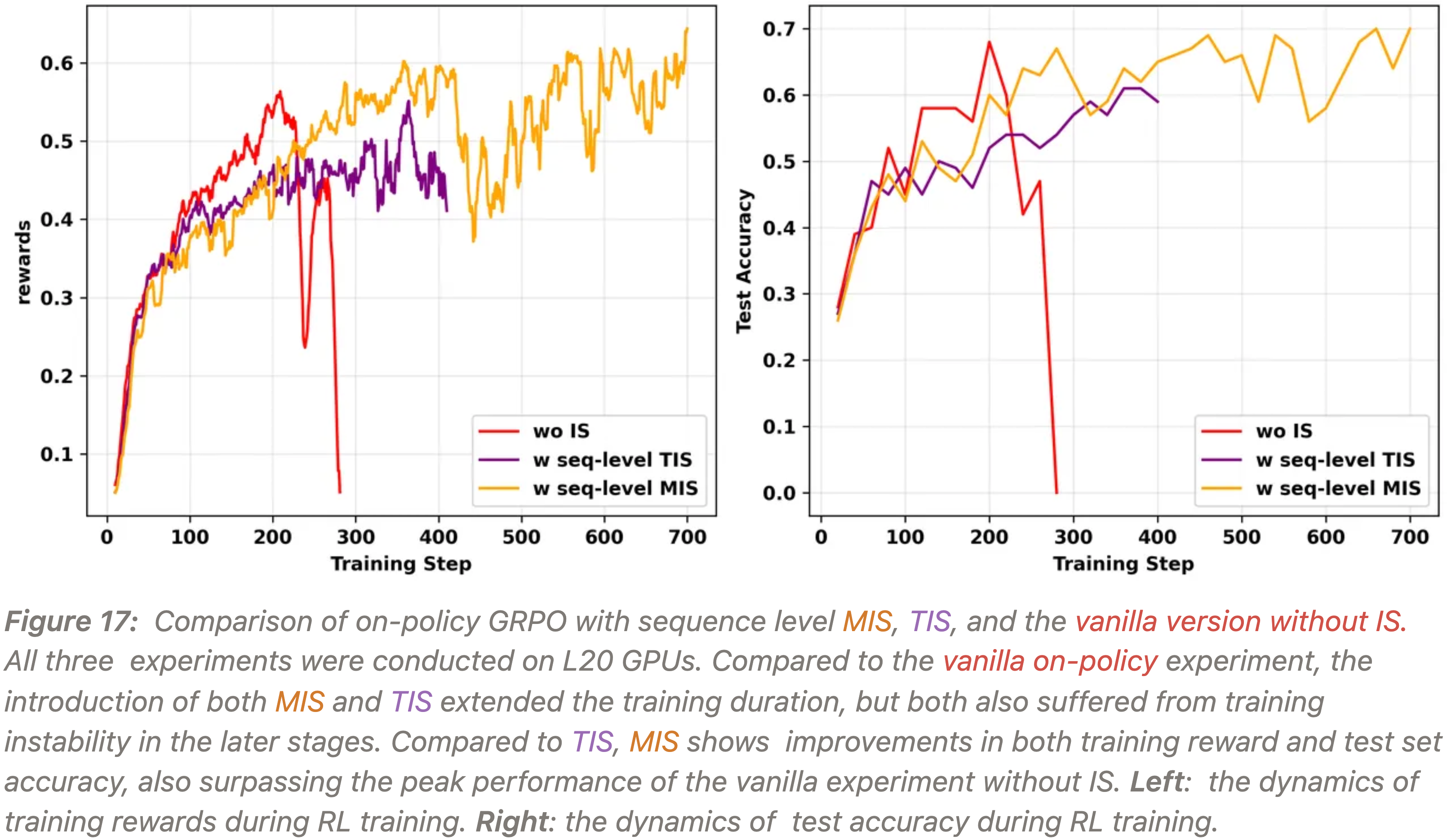
- 问题:怎么感觉在下游测试指标(图 17 右图)继续训练 TIS 可能也能拿到不错的收益?因为性能还在持续增长
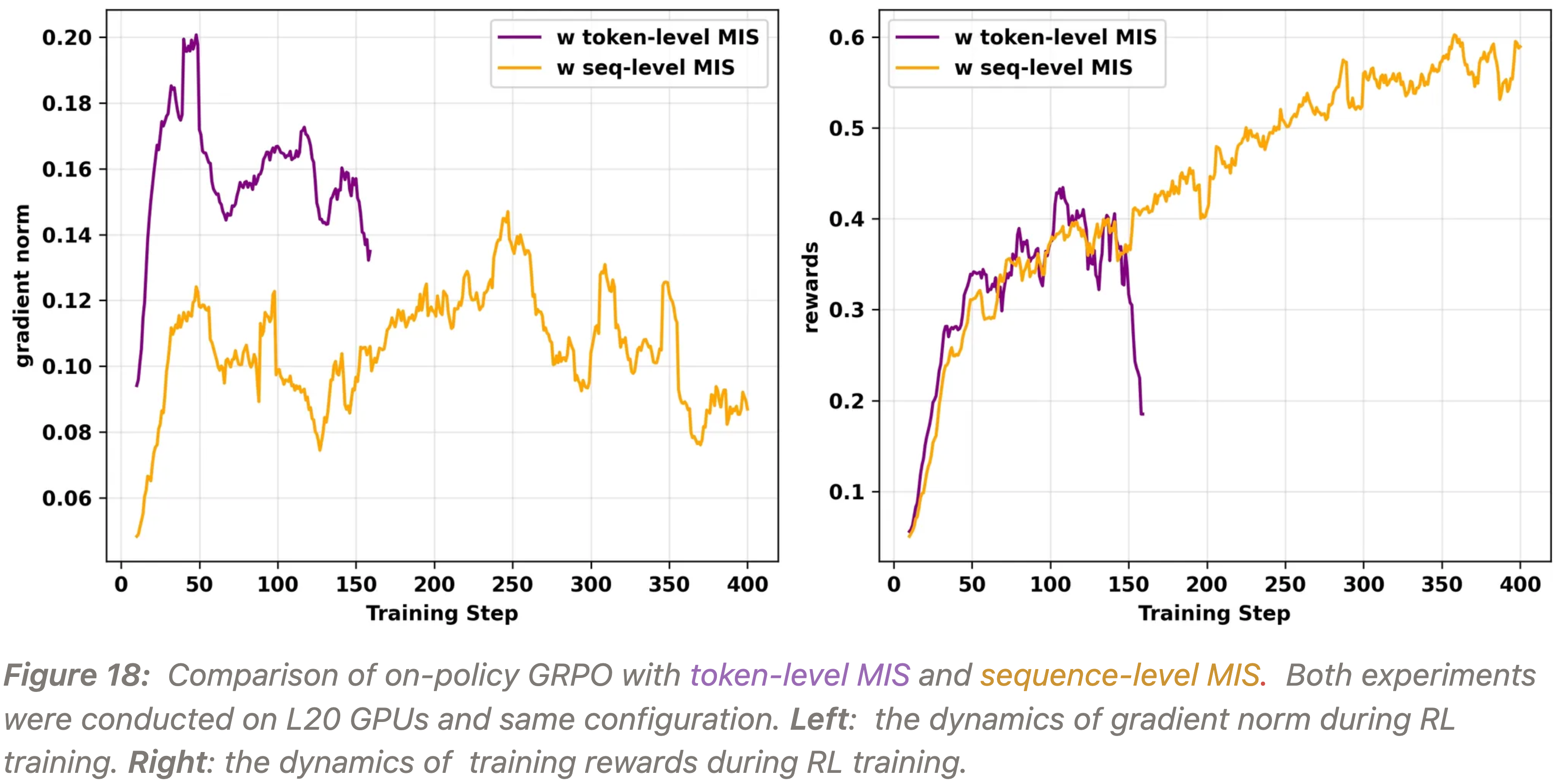
实验五:Token-Level MIS vs. Sequence-Level MIS,Token-level 的 MIS 不太够用,初期能防止梯度爆炸,后期还是会崩溃
- 最后,作者比较了 Token-level MIS 和 Sequence-level MIS
- 正如预期,图 18 显示:
- 两者都能防止初始梯度爆炸,但 Token-level MIS 实验仍然崩溃了
- 这强化了作者的结论:对于复杂的、长视距的自回归任务,只有理论上合理的 Sequence-level 修正才是可靠的
4.2.2 Top-p Sampling
- 如上所述,作者观察到 vLLM 策略的低概率 token 更容易出现严重的训练-推理不一致性问题,导致 FSDP 策略的概率极低
- 为了进一步证实这一点,作者进行了
top-p消融研究- 在 L20 GPU 上运行 on-policy GRPO 实验,并将 vLLM 采样策略的
top-p超参数分别设置为 0.98、0.99 和 0.999(注意这里没有应用重要性采样进行梯度修正) - 通过设置较小的
top-p值,作者的目标是降低推理阶段出现极低 vLLM 概率 token 的频率 ,从而减轻训练-推理不一致性
- 在 L20 GPU 上运行 on-policy GRPO 实验,并将 vLLM 采样策略的
- 作者的消融结果如图 19 所示
- 正如预期,
vllm-kl指标表明,较小的top-p减少了vllm-kl尖峰的出现 - 但较小的
top-p也增加了 vLLM 策略 \(\color{red}{\pi^{\text{vllm} }_\theta}\) 和 FSDP 策略 \(\color{blue}{\pi^{\text{fsdp} }_\theta}\) 之间的分布差异- 理解:
top-p变小影响了 vLLM 策略采样的分布,而 FSDP 中是没有类似top-p影响的(是所有分布同时训练),所以 vLLM 采样时的top-p越小,vLLM 和 FSDP 策略之间的差异越大 (再次强调:此时没有应用 IS 修正)
- 理解:
- 因此,在不应用 TIS 的情况下,梯度偏差变得更大,导致随着
top-p的减小,奖励提升变慢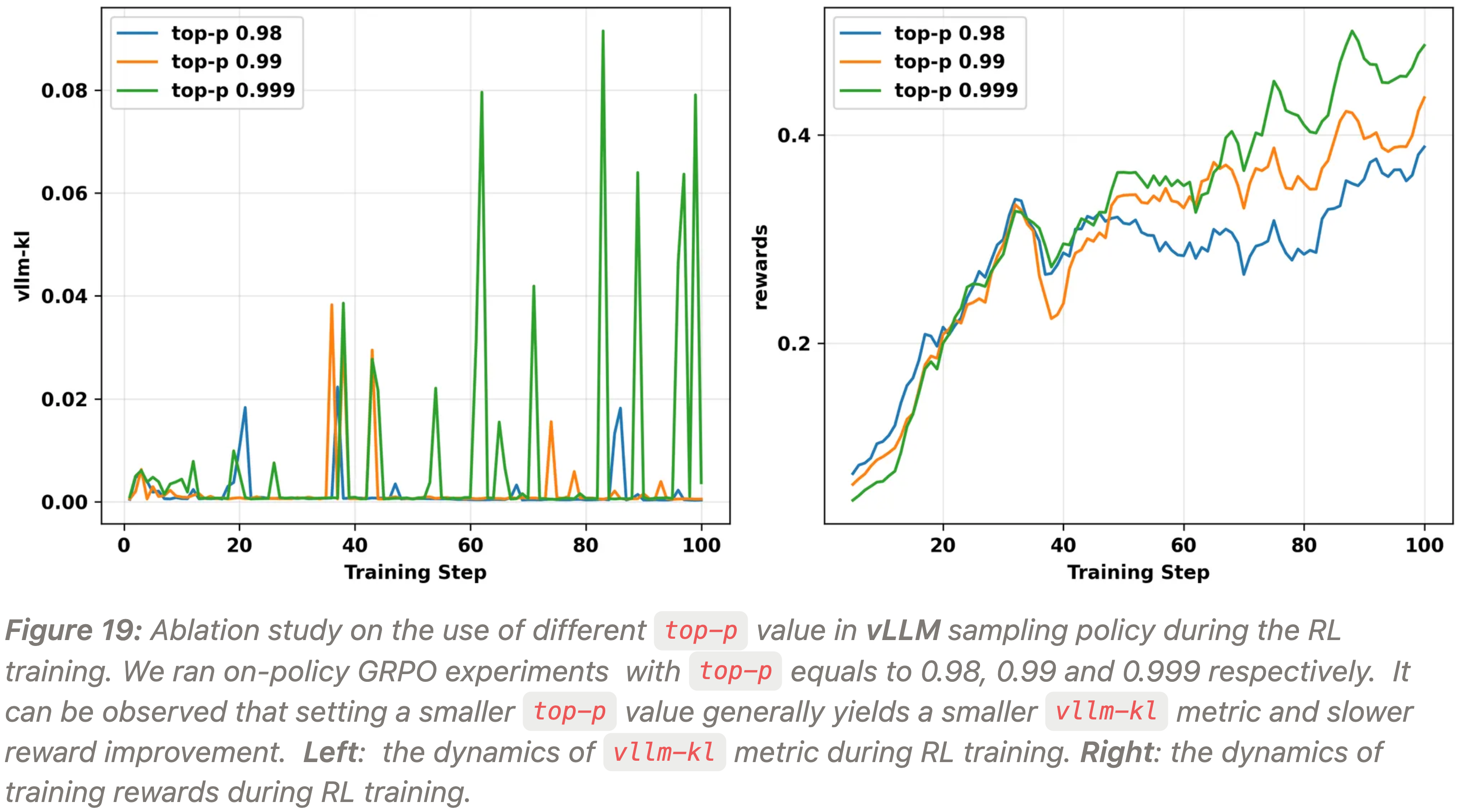
- 正如预期,
4.2.3 Use other GPU series
- 在发现 H20 GPU 上运行的实验的训练-推理不一致性显著小于 L20 GPU 后,作者将所有 TIR 实验切换到了 H20 GPU ,这大大减少了训练崩溃的发生
- 图 20 显示了在 L20 和 H20 GPU 上,分别在相同配置下从头开始训练的两个 on-policy GRPO 实验的结果
- 可以观察到,在 H20 GPU 上运行的 on-policy 实验显著延长了稳定训练时长 ,并取得了更好的性能
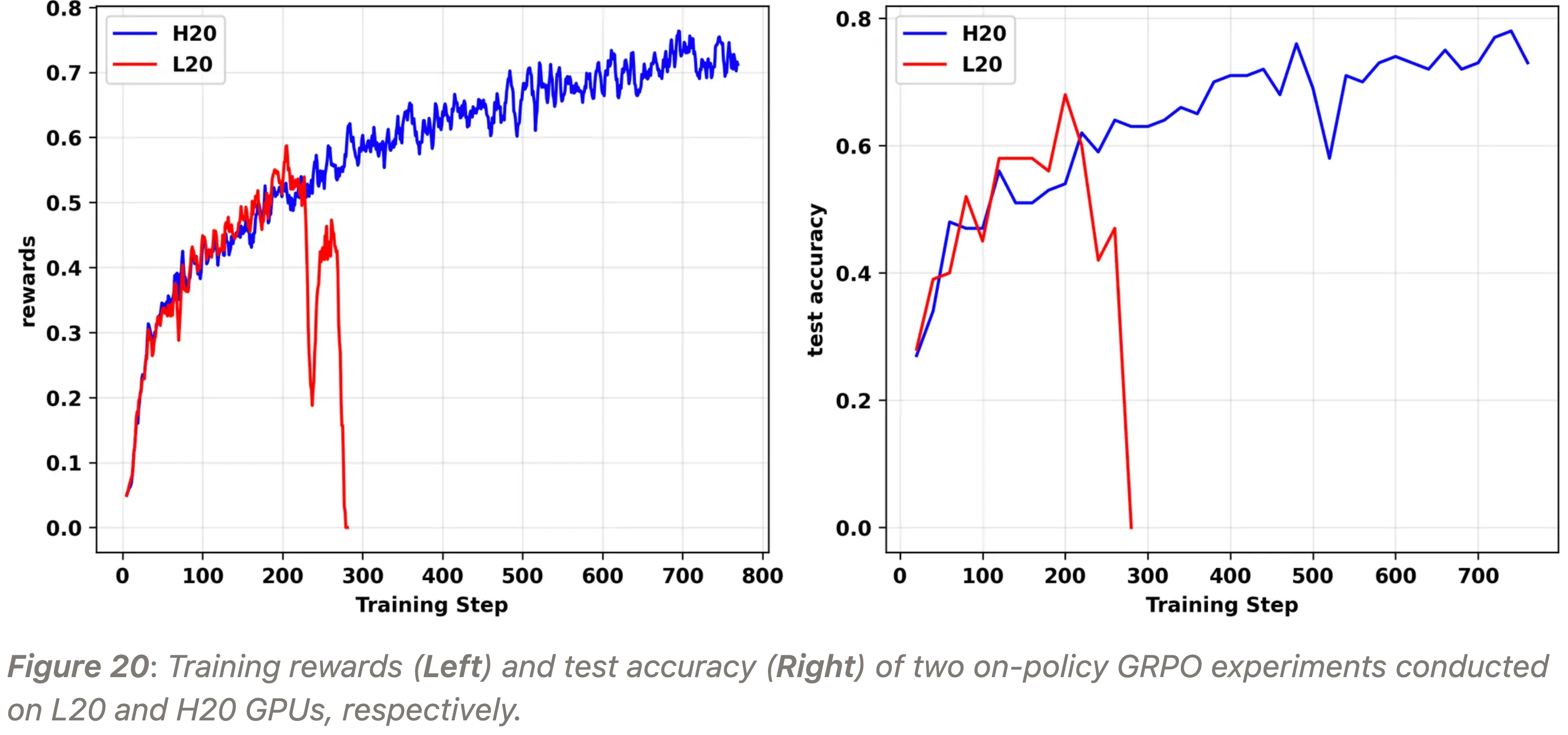
4.2.4 Disable Cascade Attention in vLLM, 在 vLLM 中禁用级联注意力
- 根据这个 GitHub issue,作者在初始化 vLLM 引擎时设置了
disable_cascade_attn=True,并发现它在 A100 GPU 上进行的实验中显著有助于减少训练-推理不一致性 - 作者在 A100 GPU 上使用 Qwen3-14B-Base 作为基础模型,进行了两个 on-policy GRPO 实验,
disable_cascade_attn分别设置为True和False - 结果如图 21 所示
- 禁用级联注意力后,
vllm-kl指标从 5e-2 到 1e-1 的范围下降到大约 1e-3,表明训练-推理不一致性显著减少 - 同时可以观察到,训练集上的奖励也适当地增加了
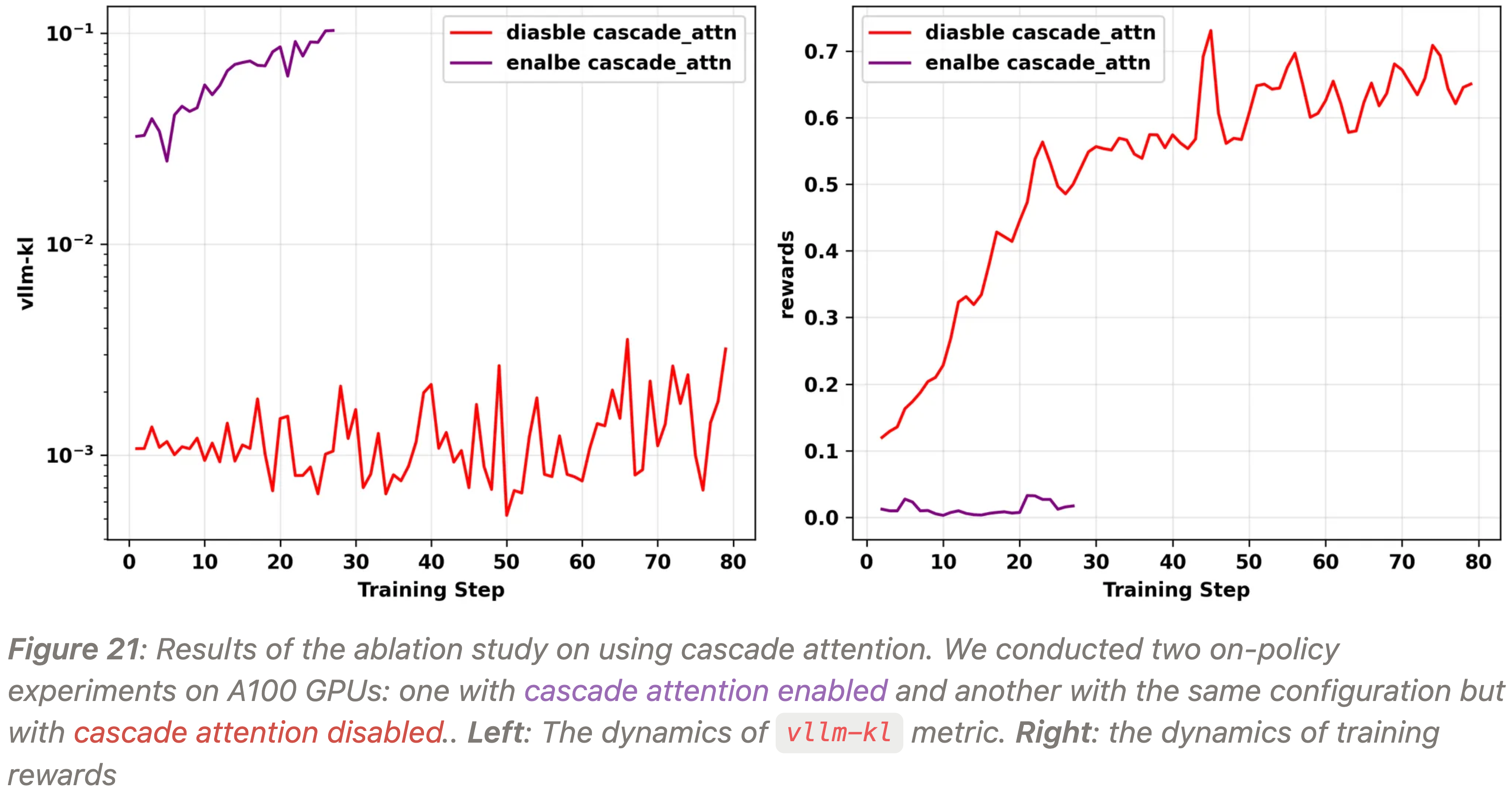
- 禁用级联注意力后,
Conclusion & Key Takeaways for Practitioners
- 训练-推理不一致性不是一个细枝末节的 bug,而是一个贯穿现代 Reasoning and Agentic RL 的根本性且日益严峻的挑战,它是由对性能的必要追求所驱动的
- 不一致性是不可避免的权衡: 接受高速推理总是会与训练计算产生分歧这一事实
- 这是一个核心的权衡,而非暂时性的缺陷
- 监控训练健康状况:
vllm-kl指标是一个重要的早期预警系统- 将其与困惑度 (PPL) 和梯度范数一起跟踪,以预测和诊断不稳定性,防止其导致崩溃
- 识别真正的凶手: 问题不是随机的
- 它是由 低概率 token (low-probability tokens) 系统性地触发的,这些 token 在模型处理分布外 (OOD) 输入时更频繁地生成
- 这在工具使用和多轮应用中很常见
- 它是由 低概率 token (low-probability tokens) 系统性地触发的,这些 token 在模型处理分布外 (OOD) 输入时更频繁地生成
- 硬件是一阶变量: 相同的代码可能在一种 GPU 架构上崩溃,在另一种上完美训练
- 始终在自己的目标硬件上验证 Setting,因为结果可能无法完全移植
- 使用理论合理的修正: 虽然更换硬件或调整采样器会有所帮助,但最稳健、最原则性的解决方案是算法层面的
- 理论上存在偏差的 Token-level 修正是不够的,在实验中仍然可能失败
- Sequence-level 方法,如截断重要性采样 (Seq-TIS) 和掩码重要性采样 (Seq-MIS) ,通过修正完整的状态轨迹直接解决梯度偏差问题
- 这些方法对于维持稳定性至关重要,应被视为任何 Serious LLM-RL 训练栈的默认选项
- 其他:作者推测这个训推不一致性问题在 MoE 模型上可能会更加的严重
附录:Token-level IS 下的 策略梯度期望 表达式推导
- 本节负责详细推导 Token-Level IS 梯度估计器 \( g_{\mathrm{tok} }(\theta) \) 的表达式
- 这个推导的目标是:从一个基于轨迹的定义出发,通过一系列变换,将其表达为对“状态-动作”对的期望形式
- 最终目标:展示 \( g_{\mathrm{tok} }(\theta) \) 与真实梯度 \( g_{\mathrm{seq} }(\theta) \) 的偏差来源
第 1 步:从 Token-Level IS 的轨迹级定义出发
- 根据 4.2.1 节中的定义,Token-Level IS 的梯度估计器是基于轨迹的,它错误地将重要性比率应用在了对每个时间步的求和内部:
$$
g_{\mathrm{tok} }(\theta) = \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)}\left[ R(x,y) \cdot \sum_{t=0}^{|y|-1} \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y_t|x,y_{ < t})}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(y_t|x,y_{ < t})} \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y_t|x,y_{ < t}) \right] \tag{1}
$$ - 这里的核心思想是:
- 虽然想要优化目标策略 \(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\),但由于只能从行为策略 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 采样得到的轨迹 \(y\) 中进行学习,我们就在 每个 token 上 使用一个重要性权重来修正策略偏差(这个修正本身就是有偏的/错误的)
第 2 步:将轨迹期望分解为“状态-动作”对的期望
- 这一步是将对完整轨迹 \(y\) 的期望,转化为对所有可能访问到的“状态-动作”对 \((s, a)\) 的期望
- 这里的“状态” \(s\) 是生成动作 \(a\) 时的上下文(即 \(s = (x, y_{ < t})\))
- 对于一条长度为 \(|y|\) 的轨迹,它的贡献是其中每个 token 的贡献之和
- 利用期望的线性性质,可以将求和与期望进行交换
- 将期望写成对所有可能的轨迹进行积分(或求和),可以得到:
$$
\begin{aligned}
g_{\mathrm{tok} }(\theta) &= \sum_{t=0}^{\infty} \mathbb{E}_{x \sim \mathcal{D}, y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)} \left[ R(x,y) \cdot \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y_t|x,y_{ < t})}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(y_t|x,y_{ < t})} \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(y_t|x,y_{ < t}) \right] \\
&= \sum_{t=0}^{\infty} \sum_{s \in \mathcal{S} } \sum_{a \in \mathcal{A} } P_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s_t = s, a_t = a) \cdot \mathbb{E}_{y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)} \left[ R(x,y) | s_t=s, a_t=a \right] \cdot \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s)}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s)} \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s)
\end{aligned}
$$
- 理解:这个看起来很复杂的表达式其实在做一件简单的事:
- 遍历所有可能的时间步 \(t\),所有可能的状态 \(s\),以及所有可能的动作 \(a\)
- 对于每一种可能性
- 计算其发生的概率
$$P_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s_t=s, a_t=a)$$ - 然后乘上在该 \((s,a)\) 之后获得的期望回报
$$\mathbb{E}[R(x,y)|s_t=s, a_t=a]$$ - 最后再乘上 token-level 的 IS 权重和梯度项
- 计算其发生的概率
第 3 步:引入状态-动作价值函数 \(Q\) 和状态占用度量 \(d\)
- 接下来这里做两个关键的代换:
- 1)条件期望回报 \( \mathbb{E}_{y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)} \left[ R(x,y) | s_t=s, a_t=a \right] \) 正是 行为策略下的状态-动作价值函数 \( Q^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s, a) \) 的定义
- 它衡量了在状态 \(s\) 采取动作 \(a\) 后,遵循策略 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 所能获得的期望累积奖励
- 2)联合概率 \( P_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s_t=s, a_t=a) \) 可以分解为 \( P_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s_t=s) \cdot \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s) \)
- 而 \(\sum_{t=0}^{\infty} P_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s_t=s) \) 正是 行为策略下的状态占用度量 (State Occupancy Measure) ,记为 \( d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s) \)
- 它衡量了在整个交互过程中,状态 \(s\) 被访问的期望次数
- 1)条件期望回报 \( \mathbb{E}_{y \sim \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(\cdot|x)} \left[ R(x,y) | s_t=s, a_t=a \right] \) 正是 行为策略下的状态-动作价值函数 \( Q^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s, a) \) 的定义
- 将这两个定义代入,上述双重求和(\(\sum_{t} \sum_{s}\))就可以巧妙地合并成一个对状态 \(s\) 的加权求和,权重正是状态占用度量 \(d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s)\):
$$
\begin{aligned}
g_{\mathrm{tok} }(\theta) &= \sum_{s \in \mathcal{S} } d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s) \sum_{a \in \mathcal{A} } \color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s) \cdot Q^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s, a) \cdot \frac{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s)}{\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s)} \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s)
\end{aligned}
$$ - 可以看到,分母中的 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s)\) 和分子中的 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }(a|s)\) 可以直接约掉!约简后,作者得到一个非常简洁的形式:
$$
g_{\mathrm{tok} }(\theta) = \sum_{s \in \mathcal{S} } d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s) \sum_{a \in \mathcal{A} } \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \cdot Q^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s, a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \tag{2}
$$
第 4 步:引入基线函数以降低方差
- 在策略梯度方法中,直接使用 \(Q\) 函数会导致较高的方差
- 通常我们会引入一个与动作无关的基线 \(V(s)\) 来降低方差,而不改变期望值
- 最常用的基线是状态价值函数 \(V^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s)\)
$$
Q^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s, a) = V^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s) + A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s, a)
$$- 其中 \(A\) 是优势函数
- 将 \(Q\) 替换为 \(V + A\) 后,代入式 (2):
$$
\begin{aligned}
g_{\mathrm{tok} }(\theta) &= \sum_{s} d_{\color{red}{\pi} }(s) \sum_{a} \color{blue}{\pi}(a|s) \cdot \left( V^{\color{red}{\pi} }(s) + A^{\color{red}{\pi} }(s, a) \right) \cdot \nabla_{\theta} \log \color{blue}{\pi}(a|s) \\
&= \underbrace{ \sum_{s} d_{\color{red}{\pi} }(s) V^{\color{red}{\pi} }(s) \sum_{a} \color{blue}{\pi}(a|s) \nabla_{\theta} \log \color{blue}{\pi}(a|s) }_{\text{ = 0} } + \sum_{s} d_{\color{red}{\pi} }(s) \sum_{a} \color{blue}{\pi}(a|s) A^{\color{red}{\pi} }(s, a) \nabla_{\theta} \log \color{blue}{\pi}(a|s)
\end{aligned}
$$- 注:为了简洁考虑,上式中:
- 用 \(\color{red}{\pi}\) 表示 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\)
- 用 \(\color{blue}{\pi}\) 表示 \(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\)
- 注:为了简洁考虑,上式中:
- 问题:为什么第一项等于 0?
- 因为:
$$\sum_{a} \color{blue}{\pi}(a|s) \nabla_{\theta} \log \color{blue}{\pi}(a|s) = \mathbb{E}_{a \sim \color{blue}{\pi}(\cdot|s)}[\nabla_{\theta} \log \color{blue}{\pi}(a|s)] = 0$$- 这是一个对数似然梯度的恒等式,其期望值为零(得分函数 \(\nabla_{\theta} \log \color{blue}{\pi}(a|s)\) 期望为 0)
- 因此,包含基线 \(V(s)\) 的项就自然消失了
- 理解:为什么第二项不等于 0?
- 第一项可以为 0 是因为第一项的 \(V^{\color{red}{\pi} }(s) \) 与动作 \(a\) 无关,不会随着动作 \(a\) 的变化而变化,可以单独从期望中提出来
- 第二项不为 0 是因为第二项的 \(A^{\color{red}{\pi} }(s, a)\) 与动作 \(a\) 有关,不能单独从期望中提出来
- 虽然 \(A^{\color{red}{\pi} }(s, a)\) 包含的是 \(\color{red}{\pi}\),但还包含了 \(a\),这导致了 \(A^{\color{red}{\pi} }(s, a)\) 与动作分布 \(\color{blue}{\pi}(a|s)\) 有关(主要是与动作有关)
- 因为:
第 5 步:得到最终形式
- 消去为零的项后,我们得到了 Token-Level IS 估计器的最终形式:
$$
g_{\mathrm{tok} }(\theta) = \mathbb{E}_{s \sim d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } } } \mathbb{E}_{a \sim \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(\cdot|s)} \left[ A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s,a) \cdot \nabla_{\theta} \log \color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }(a|s) \right]
$$
第 6 步:Token-Level IS 为什么是有偏的?
- 通过上面这个推导,我们可以清晰地看到问题的根源:
- 1)状态分布错误 :期望 \(\mathbb{E}_{s \sim d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } } }\) 是在行为策略 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 的访问状态上求的,而我们真正想要的,应该是目标策略 \(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\) 的访问状态 \(d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\)
- 2)奖励信号错误 :用来衡量“好与坏”的标准是行为策略的优势函数 \(A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }(s,a)\),而非目标策略的优势函数 \(A^{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }(s,a)\)
- 因此,尽管 Token-Level IS 看起来在每个 token 上进行了修正,但它修正的是错误的分布,使用的是错误的评价标准
- 只有当两个策略几乎一样时(即 \(d_{\color{red}{\pi} } \approx d_{\color{blue}{\pi} }\) 且 \(A^{\color{red}{\pi} } \approx A^{\color{blue}{\pi} }\)),它才近似正确,否则其梯度是有偏的,这也就是原文实验里它仍然会导致训练崩溃的根本原因