注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结
- 论文介绍了 Motif-2-12.7B-Reasoning(12.7B 参数):挑战了复杂推理需要海量规模的假设
- 论文证明了,在有限预算下释放稳健的推理能力,一个整体的优化策略是必不可少的
- 包括面向 64K 上下文的系统级效率、分布对齐的监督微调以及一个稳定的强化学习方案
- 针对推理适应过程中常见的模型崩溃和训练不稳定挑战:提出了一套涵盖系统、数据和算法优化的全面、 可复现 的训练方案
- 论文的方法结合了用于 64K Token 上下文的内存高效基础设施(采用混合并行和内核级优化)以及一个两阶段的监督微调课程,该课程通过经过验证、对齐的合成数据来缓解分布不匹配问题
- Motif-2-12.7B-Reasoning 在数学、编码和智能体基准测试中取得了与参数量显著更大的模型相当的性能
Introduction and Discussion
- 近年来,LLM 的发展在通用指令遵循方面取得了显著进展,yet 稳健的复杂推理和长上下文理解仍然是开放的挑战
- A growing body of work 测试时扩展(通过更长的思维链、多步推理或多样本推理分配更多推理计算)不仅能显著提升数学和编码任务的表现,也能改善指令遵循、工具使用和智能体决策
- At the same time,无论是闭源的前沿模型还是最强的开源权重系统,都越来越多地采用优化推理的 LLM 形式,这反映在诸如 Artificial Analysis Intelligence Index (AAII) (2024) 等基准测试中,其中“thinking”变体始终优于非推理的对应版本(non reasoning counterparts)
- 尽管有这种转变(Despite this shift),训练推理 LLM 仍只对少数组织开放
- 关于扩展强化学习微调、稳定长序列训练以及高效处理长上下文工作负载的实用方案很少被详细记录
- In particular,虽然 RLFT 常被宣传为超越 SFT 的下一步,但实践者经常观察到,简单地应用 RLFT 会导致模型在我们希望改进的推理基准上崩溃或性能下降
- As a result,社区虽然有强有力的证据表明推理模型和推理扩展很重要,但对于如何在现实预算约束下可靠地训练此类模型,却缺乏指导
- In this context,论文介绍了 Motif-2-12.7B-Reasoning,一个基于 Motif-2-12.7B-Instruct (2025) 训练的 12.7B 参数推理 LLM,通过一个额外的分布对齐 SFT 阶段和一个精心设计的 RLFT 流程实现
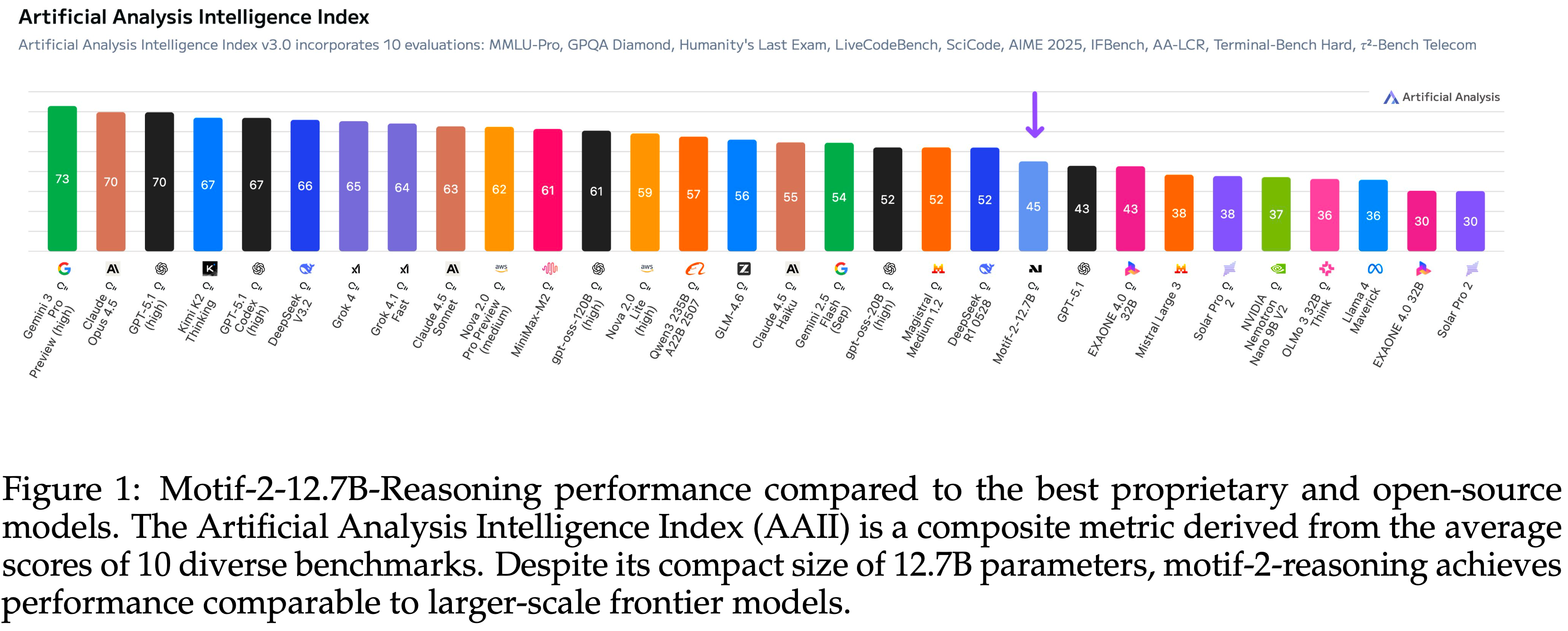
- Motif-2-12.7B-Reasoning 在一系列推理密集的基准测试中,其性能可与 30B 至 40B 参数范围的前沿模型相媲美,在某些情况下甚至超越
- 在 AAII 及相关综合评估中,Motif-2-12.7B-Reasoning 取得了比 GPT-5.1 更高的分数,而在排名高于它的模型中,没有一个是小于 12.7B 参数的
- 作者相信,人工智能的真正进步依赖于知识的共享和可复现性,而非不透明的“黑盒”训练流程
- 本工作的目标有两个:
- 目标一:将 Motif-2-12.7B-Reasoning 作为一个有竞争力的开源权重推理模型呈现;
- 目标二:使其训练过程透明且实际可复现
- 论文不仅记录了最终方案,也记录了塑造它的设计迭代、失败模式和经验教训,重点关注那些对稳定性、效率和性能产生实质影响的决策
- 在 SFT 方面,论文描述了一个两阶段、分布对齐的课程,以密集化和结构化推理监督
- 这包括针对性地整理多步推理数据(数学、代码和多跳自然语言)、将 SFT 数据分布与下游 RL 目标对齐,以及逐步增加任务难度和上下文长度同时保持指令遵循保真度的课程策略
- 在 RLFT 方面,论文为推理和长上下文用例提出了一种实用的 RL 方案,重点关注可在现实计算预算内实现的技术
- 论文详细阐述了针对不同推理任务的奖励建模方法、避免过度优化和模式崩溃的稳定性启发式方法 ,以及平衡探索与保留基础模型能力的调度策略
- 论文进一步分析了这些设计选择如何与测试时扩展相互作用,表明在适当的约束下应用 RLFT,可以使其既稳定又能可靠地带来收益
- Finally,实验结果表明 Motif-2-12.7B-Reasoning 在数学、编码、指令遵循、工具增强推理和长上下文基准测试上,相比 Motif-2-12.7B-Instruct 和其他竞争基线都有显著的性能提升
- 论文强调了其测试时扩展行为、相对于更大前沿模型的参数效率,以及其在不同评估设置下的稳健性
Part 1 - System Optimization
Long Context Reasoning SFT
- 论文的 SFT 方案需要将上下文长度扩展到 64K Token ,这反过来又需要在预训练所用并行方式之外,采用额外的并行形式
- 为了解决这个问题,论文采用了混合并行策略:
- 在每个节点内部(节点内),采用 DeepSpeed-Ulysses (2023) 序列并行 (Sequence Parallelism, SP) 并结合带参数分片的数据并行 (Data Parallelism with parameter sharding, DP-shard);
- 在节点之间(节点间),使用带参数复制的数据并行 (Data Parallelism with parameter replication, DP-replicate)
- In details,注意力层用 TP 处理,而 FFMs 在 SP 下运行
- 使用 SP 的 FFNs 可以在 SP 网格上进行权重分片,因此论文在分片 FFN 参数时,构建了一个合并网格,将节点内的 DP-shard 网格与 SP 网格结合起来
- 由于在 Motif-2-12.7B-Instruct (2025) 中引入的 Parallel Muon 被设计为可以在任意的梯度和参数放置配置下运行,因此对于混合并行化,不需要对优化器进行额外的修改
- In addition,论文应用了细粒度的激活重计算 (activation checkpointing),而不是统一地重新计算每个解码器块
- 论文没有在块粒度上设置检查点,而是分析了每个解码器块内每层的激活占用空间和重计算成本,并手动调整了一个更具选择性的重计算策略
- 这种手动优化的策略在最小化峰值内存使用的同时,避免了不必要的重计算开销
- 这些方法实现了高效的参数分布,并减轻了长上下文训练的内存压力
- 使用此配置,论文成功在 H100 GPU 上训练了上下文长度为 64K 的模型
Liger Kernel’s loss function
- RL 所需的内存比 SFT 大得多,主要是因为额外的组件(如策略模型)必须保留在内存中
- 论文使用的策略实现(基于 vLLM)支持休眠模式等功能,但这些机制并不能完全消除其内存占用
- 为了解决 RL 训练期间引入的额外内存压力,论文采用了 Liger 核 (2025) 的损失函数
- 对 RL 内存使用模式的分析表明,峰值消耗发生在损失函数前向传播之后以及反向传播开始之时
- 此时,前向计算过程中生成的所有检查点激活仍驻留在内存中(只有在反向传播进行时才会被释放)
- Notably,形状为(上下文长度,词汇表大小)的对数 (logit) 激活比形状为(上下文长度,隐藏层大小)的典型激活要大得多,这意味着 LM 头和损失计算贡献了不可忽视的内存占用部分
- Liger Kernel’s loss 沿上下文长度维度分割激活,在每个分片上计算 LM 头线性层,并计算每个分片的损失和梯度
- 使用 Liger Kernel’s loss 可以显著减轻这些大型对数张量所带来的内存压力
Part 2 - Reasoning SFT
- 论文引入了一个专注于推理的 SFT 阶段,旨在加强多步推理、增强长上下文一致性,并使模型与复杂指令遵循能力对齐
- 早期实验表明,推理能力对数据集的构成、推理深度以及不匹配的推理模式高度敏感
- 这些观察促使论文构建了一个结构化的 SFT 过程,该过程建立在两点之上:
- (1)基于课程的长上下文适应
- (2)分布对齐的合成推理数据生成
Lesson from failures
Lesson 1: Dynamic Dataset Distribution across Phases.
- 论文的实证研究结果表明,在整个 SFT 过程中采用静态且均匀的数据分布是次优的
- 这种策略常常导致模型过早收敛,阻碍其扩展推理能力,并可能引发灾难性遗忘
- Instead,数据集分布进行动态转变至关重要 ,论文将此课程规划为两个战略阶段:
- Stage 1 (Reasoning Foundation):
- Stage 1 侧重于在代码、数学、STEM 和工具使用等领域建立全面的能力
- 论文通过整合多种开源数据集来构建训练语料,包括 Memotron-Post-Training-Dataset (2025; 2025), OpenReasoningDataset (2025; 2025; 2025) 和 Mixture-of-Thoughts (2025; 2025; 2025)
- 为确保数据质量,论文应用了后处理流程,根据难度、序列长度和验证情况过滤样本
- For instance,在处理 rstar-coder (2025) 数据集时,基于实证观察,论文遵循“质量优于数量(quality-over-quantity)”的原则
- 论文通过选择通过次数严格处于中间范围(\(0 < \textit{npass} < 16\))的案例,来筛选出具有区分性难度的问题
- 从而修剪掉过于简单或经验上无法解决的样本
- 从这个子集中,论文仅保留了那些经过明确验证且成功执行的轨迹 (
verified=True and is_passed=True),优先考虑高保真度的推理而非数据量- 此阶段充当稳定器,奠定模型的通用推理能力,同时开始接触中等长度的上下文(16K-32K Token)
- Stage 2 (深度推理专业化,Deep Reasoning Specialization)
- Stage 2 通过注入高粒度的合成数据来针对复杂的推理差距,这些数据包括 CoT 密集型和失败驱动的纠正集(failure-driven correction sets)
- Notably,论文为这些样本重新生成了推理轨迹,以强制执行与目标模型推理分布的结构对齐
- Furthermore,此阶段通过将上下文窗口扩展到 64K Token 来完成上下文课程,使模型能够在长序列上保持连贯的推理
- Stage 1 (Reasoning Foundation):
Lesson 2: The Distribution Mismatch Problem.
- 论文早期实验的一个 key insight 是:
- 合成数据的质量不仅仅关乎正确性,推理分布的对齐至关重要
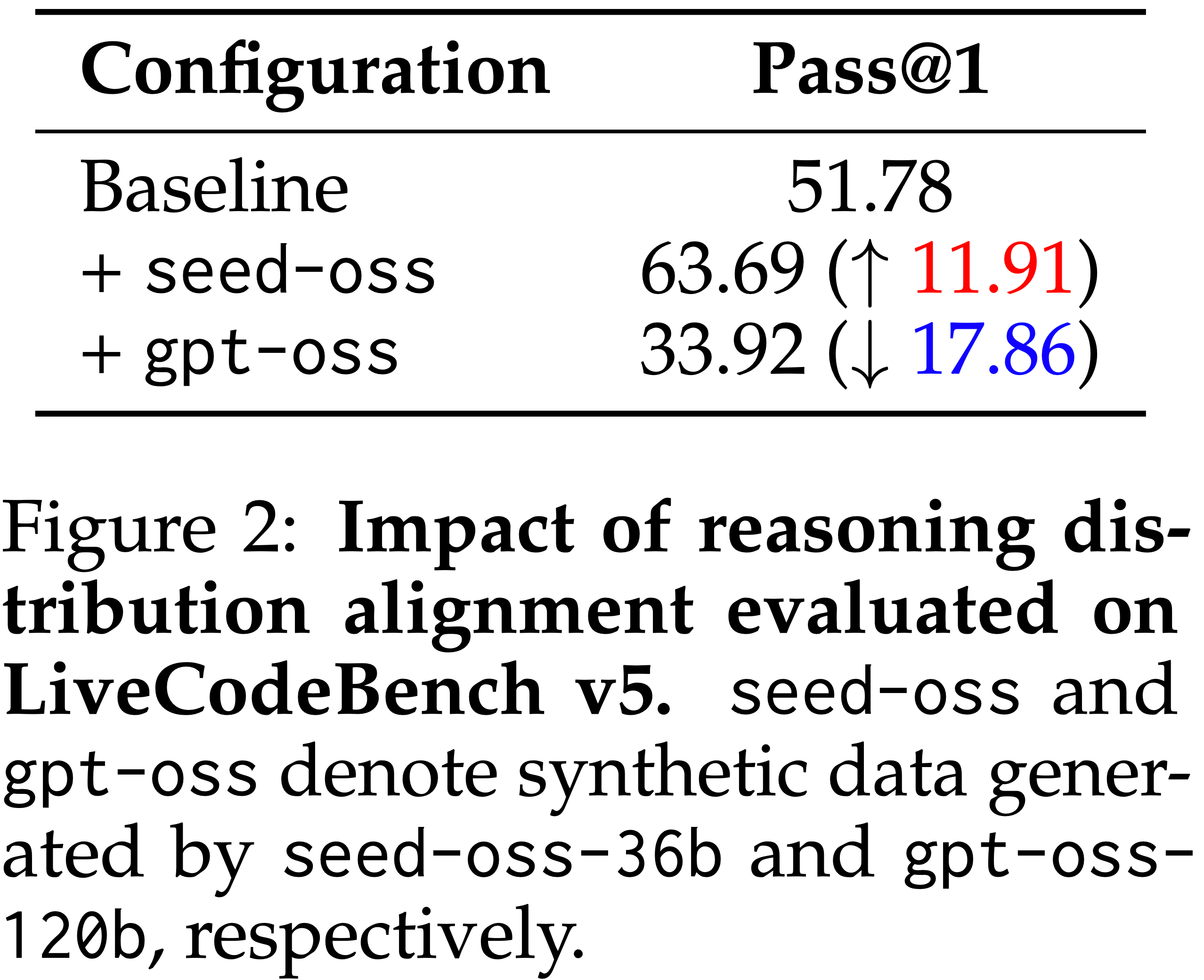
- 为了量化这一点,论文评估了推理对齐对 LiveCodeBench v5 (2024) 的影响,如图 2 所示
- 论文将基线配置与使用来自 seed-oss-36b (2025) 和 gpt-oss-120b (2025) 的合成样本生成的配置进行比较
- seed-oss 带来了显著的性能提升,但 gpt-oss 却导致了明显的性能下降
- 这种对比意味着性能取决于推理轨迹的兼容性,而不仅仅是数据量
- 论文推断 gpt-oss 导致的性能下降源于复杂性不匹配
- 教师模型的推理轨迹可能表现出与学生模型内在推理风格不同的粒度和结构复杂性
- 这种差异造成了“分布不匹配”,所强加的推理模式与模型的学习过程相冲突,而不是加强它
- 这表明,合成监督在源自与目标模型能力相兼容的源时最为有效
Recipe
- 为了应对这些挑战,论文建立了一个稳健的 SFT 方案,其核心在于通过课程学习确保稳定性,以及通过分布对齐确保质量,如图 3 所示
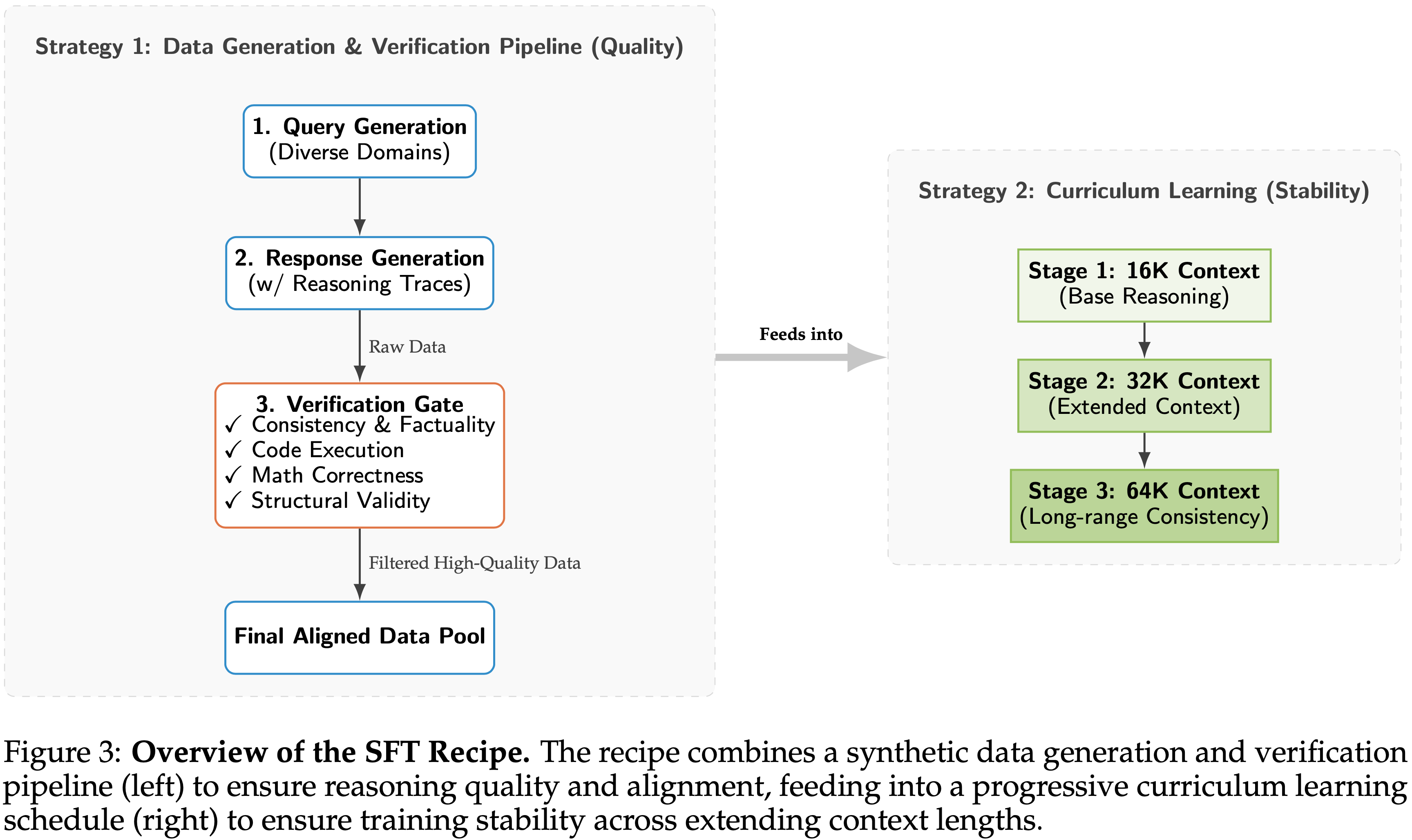
Strategy 1:合成数据生成 (注入推理信号) (Synthetic Data Generation (Injecting Reasoning Signals))
- 论文生成多样化的合成数据集,专门设计用于向代码生成、工具调用、数学和指令遵循等目标领域注入强推理信号
- 与标准数据集不同,这些数据集强调具有明确思维轨迹的结构化、多步推理,使模型能够内化复杂问题解决所需的逻辑进程
- 结构化生成与验证流程 (Structured Generation and Verification Pipeline) 为确保数据一致性并避免分布不匹配问题,论文构建了一个多阶段流程:Query Generation → Response Generation → Verification
- 验证阶段对于维持高数据保真度至关重要,采用了一套自动化检查:
- 一致性与事实性 (Consistency & Factuality): 验证与原始查询的语义对齐,并验证事实准确性
- 代码执行 (Code Execution): 对编程任务运行基于执行的测试,以确保功能正确性
- 数学正确性 (Mathematical Correctness): 验证最终答案的准确性
- 结构有效性 (Structural Validity): 确保推理轨迹保持逻辑且连贯的结构,并与论文的目标分布对齐
Strategy 2:课程学习 (渐进式上下文扩展) (Curriculum Learning (Progressive Context Extension))
- 论文采用渐进的长度扩展课程,而不是让模型突然接触极长的序列
- 上下文窗口分阶段扩展:16K → 32K → 64K Token
- 这种逐步适应使模型能更有效地学习长距离依赖关系,同时缓解通常与突然扩展上下文相关的不稳定性
- Furthermore,它还优化了注意力机制的行为,增强了模型在扩展上下文中保持连贯推理的能力
Part 3 - Reasoning RL
Background
- GRPO(2024) 是一种为推理任务定制的 critic-free 的 PPO 变体
- 与依赖独立价值函数的标准 Actor-Critic 方法不同,GRPO 直接从采样输出的分组统计中估计基线
- Specifically,对于每个输入提示 \(q\),模型生成一组输出 \(\{o_{i}\}_{i=1}^{G}\),并在此组内对奖励进行标准化以计算相对优势 (advantage)。GRPO 目标函数正式定义为:
$$\mathcal{L}_{\text{GRPO} }(\theta)=\mathbb{E}_{q\sim P(Q),\{o_{i}\} \sim\pi_{\text{fold} } } \left[\frac{1}{G}\sum_{i=1}^{G}\min\left(\rho_{i}(\theta)A_{i},\operatorname{clip}(\rho_{i}(\theta),1-\epsilon,1+\epsilon)A_{i}\right)\right], \tag{1}$$ - 其中 \(\rho_{i}(\theta)=\frac{\pi_{\theta}(o_{i}|q)}{\pi_{\text{old} }(o_{i}|q)}\) 表示重要性比率 (importance ratio),\(A_{i}\) 表示使用该组的均值和标准差进行归一化的优势
- 这种表述有效地鼓励那些优于组平均水平的响应,而无需承担训练价值网络的计算开销
- Note that ,论文采用了 GSPO (2025),它利用了序列级的重要性比率 \(\rho(\theta)\) formulation
Lesson from failures
- 在启动全规模 RL 训练之前,论文首先在基础模型和推理 SFT 模型上进行了一系列小规模初步 RL 实验,以指导论文训练方案的设计
Inefficacy of hyperparameter tuning on proxy models.
- 为减少计算开销,论文最初尝试在应用完整推理 SFT 模型之前,在一个中间预训练检查点(代理模型)上优化 RL 训练方案
- However,论文观察到,尽管架构相同,但在代理模型上调优的超参数并不能可靠地泛化到更强的 SFT 模型上
- For example,虽然某个特定的训练方案在应用于基础模型时,能在 AIME 24 上带来约 18% 的性能提升,但将完全相同的配置应用于推理 SFT 模型时,却导致性能停滞甚至下降
- 这表明,在监督微调之后,最优的策略更新动态发生了显著变化,需要对目标模型进行直接调优
- 理解:说明即使是同一个模型,不同 checkpoint 对应的超参数也应该是也不一样的
- 应该是不同 checkpoint 采样分布差异大,但 RL 对 Base 模型的 Rollout 数据要求高导致的
Impact of reward shaping on unparsable trajectories.
- 奖励公式对于指导策略更新至关重要 ,尤其是在处理格式错误方面
- 论文观察到,当模型输出无法根据真实答案进行解析时,必须严格屏蔽这些实例,以防止它们对梯度产生影响
- 在论文的实验中,保留这些实例并应用辅助奖励项(例如长度惩罚)会导致非零的优势
- 这给训练信号引入了显著的噪声,因为策略可能会无意中被激励去优化辅助约束,而非正确的推理逻辑
- 问题:无法解析的轨迹可能是不遵循格式,应该可以直接给这部分答案惩罚 “错误格式” 吧?
Necessity of difficulty alignment to prevent gradient vanishing.
- 论文观察到,RLFT 对训练数据相对于模型能力的难度分布高度敏感
- 如公式 1 所定义,优势 \(A_{j}\) 源自一组 rollout 内的相对性能
- 在问题过于简单或极其困难的情况下,组内奖励方差会崩溃(即所有 rollout 获得相同的奖励)
- 这导致优势为零 (\(A_{j}\to 0\)),进而使梯度消失,使得采样和评估成本变得无意义
- 这意味着构建一个对齐良好的数据集,即 模型在某些 rollout 上成功,而在其他 rollout 上失败 ,对于有效学习至关重要
Addressing computational bottlenecks with mixed-policy training.
- RLFT 的主要瓶颈在于为每个提示生成 \(n\) 个 rollout 的推理成本,相比之下参数更新步骤的消耗可以忽略不计
- Rollout 推理的这种计算负担意味着,即使拥有大规模精心策划的数据集,对全部语料库进行训练通常也是不可行的
- Furthermore,论文观察到 On-policy 训练表现出高方差,无法保证单调改进或稳定收敛
Furthermore, we observe that on-policy training exhibits high variance, failing to guarantee monotonic improvement or stable convergence.
- 问题:怎么会 On-policy 训练还会高方差?是说的 Off-policy 吧?
- 这些限制强调了 利用混合策略策略来增强样本效率和训练稳定性的必要性
Recipe
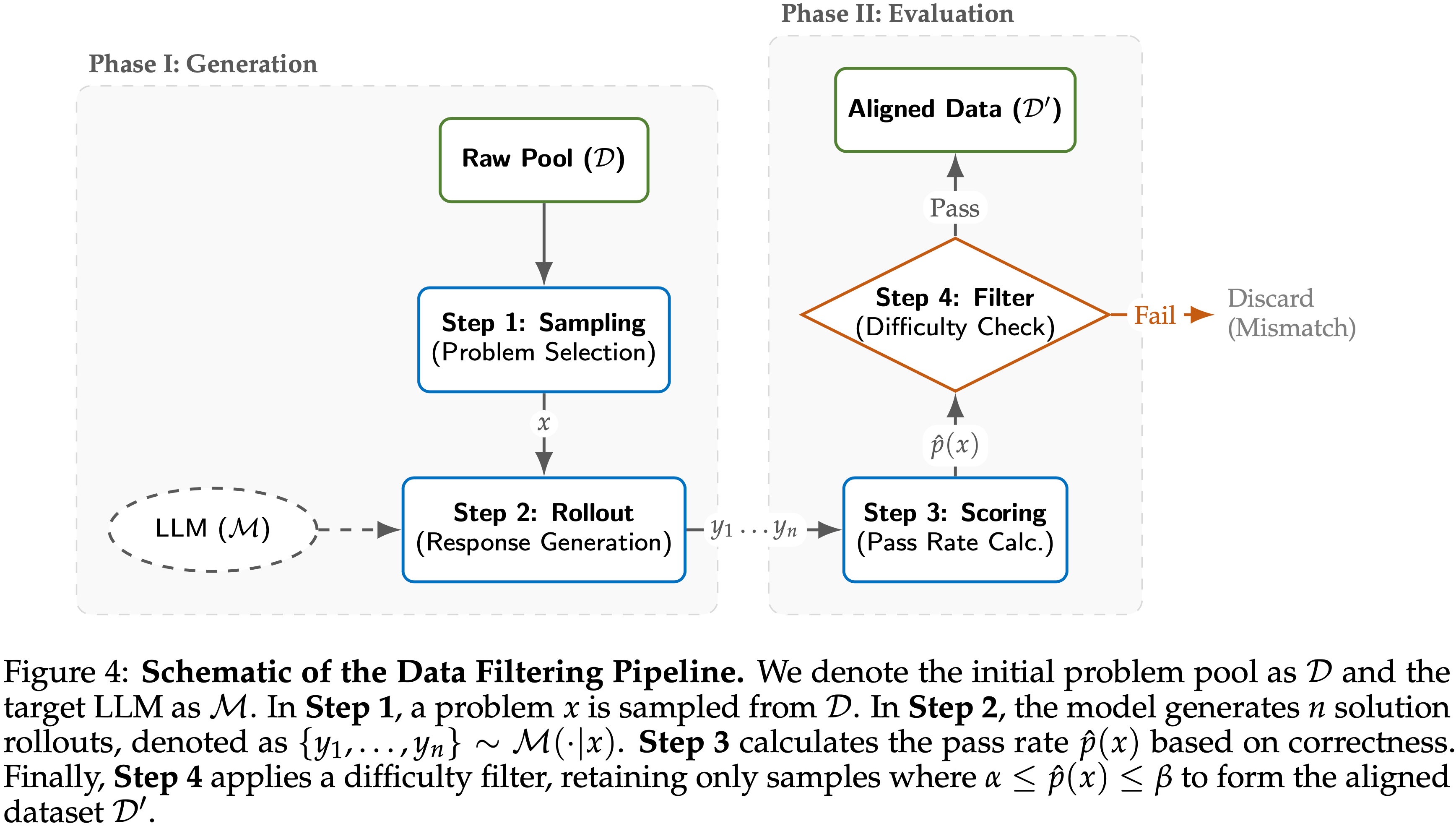
- 整体 Recipe 如图 4 所示:
LLM-as-a-data-filtering.
- 为了缓解由难度范围导致的零优势问题,DAPO (2025) 采用了动态采样,但这在训练过程中会导致低效的生成成本。
- 论文构建了一个简单而有效的数据集过滤流程,以构建其难度范围与目标模型能力良好对齐的数据集,即“LLM 即数据过滤器”
- 假设论文有一个初始问题池 \(\mathcal{D}\) 以及用于过滤的 LLM \(\mathcal{M}\)
- 对于每个问题 \(x\in\mathcal{D}\),论文生成 \(n\) 个 rollout 并按如下方式计算经验通过率:
$$y_{1},\ldots,y_{n}\sim\mathcal{M}(\cdot \mid x),\quad \hat{p}_{k}(x)=\frac{1}{n}\sum_{j=1}^{n}\mathbb{I}[x\textbf{ is solved in the top-}k\textbf{ rollouts}],.$$ - 论文严格保留那些经验通过率落在目标难度范围 \([\alpha,\beta]\) 内的问题:
$$\alpha \leq \hat{p}_{k}(x) \leq \beta.$$ - 这确保了难度范围与模型的能力良好对齐,从而缓解训练早期阶段的不稳定性
- 对于每个问题 \(x\in\mathcal{D}\),论文生成 \(n\) 个 rollout 并按如下方式计算经验通过率:
- 理解:核心其实就是用 pass rate 作为过滤依据
Dataset Construction.
- 论文应用“LLM-as-a-data-filtering”流程来策划一个高质量的多任务数据集,包含数学推理、代码生成和指令遵循
- 所有候选问题均使用 RL 阶段开始前的检查点进行评估,使用 \(n=5\) 个 rollout
- 数学推理 (Mathematical Reasoning):
- 初始池来源于 GURU-92K 数据集 (2025)
- 首先根据数据集中提供的预计算 Qwen-30B 通过率进行初步筛选,保留得分在 \(0 < p \leq 10/16\) 的问题
- 随后应用论文的过滤流程,论文选择难度在 \((0, 0.8]\) 范围内的实例
- 为了解决组合数学原本占数据 50% 的严重领域不平衡问题,将问题分类为数论、组合数学、代数和几何,并进行分层抽样以使这四个子领域的分布均衡
- 代码生成 (Code Generation):
- 与数学推理流程类似,论文从 GURU-92K 中获取代码样本,并根据提供的通过率 (\(0 < p \leq 10/16\)) 进行初步筛选
- 然后论文用相同的设置 (\(n=5\)) 执行过滤流程,并对保留的实例进行随机子采样,以使数据集大小与数学推理语料库对齐,确保任务混合的平衡性
- 指令遵循 (Instruction Following):
- 论文使用了一个为指令遵循构建的、包含 10,000 个样本的合成数据集
- 为了优先挑战模型当前能力的指令,论文应用了更严格的上限阈值 \(\beta = 0.4\),仅保留经验通过率在范围 \((0, 0.4]\) 内的样本
Expanding Clipping Range.
- 为了加速收敛,论文在训练设置中使用了更大的裁剪范围:\(\in [0.28, 0.40]\)
- 与强制执行严格信任区域的标椎设置不同,这个扩展范围允许策略在存在高优势信号时更显著地偏离参考模型
- 这种策略在训练效率和稳定性之间取得了平衡,促进了更快的策略改进,而不会引发在无约束设置中常见的崩溃
- 理解:较小的 Dense 模型,偏差较小,相对来说稳定,可以这样训练,其他的情况不一定
Encouraging Long-Context Reasoning.
- 论文的实证观察表明,长上下文推理能力是有效 RL 微调的基础
- 论文注意到,当允许模型生成扩展的推理链时,性能有显著改善
- Conversely,应用长度惩罚(通用文本生成的标准做法)被证明是有害的,因为它无意中阻碍了模型探索必要的中间推理步骤
- Consequently,论文完全从奖励公式中移除了长度惩罚
- 为了完全容纳这些扩展的轨迹,论文配置了服务基础设施以最大化 vLLM 的生成长度,详见第 2 节
- 理解:应用长度惩罚会对 RL 训练带来伤害
- 问题:其实本质上来说,普通 PPO 就自带了对较短正确队列的偏好吧?长度偏差其实可以不加?
- 问题:可能产生较长的错误回答
Efficiency via Mixed-Policy Trajectory Reuse.
- RLFT 的一个主要瓶颈是与 rollout 生成相关的惊人计算成本
- 为了缓解这个问题,论文采用了跨多个梯度优化步骤重复使用同一批轨迹的策略
- Specifically,在外层迭代 \(k\) 时,论文从当前策略中采样一批轨迹:
$$\mathcal{B}_{k}\sim P(q),\pi_{\theta_{k} }(o \mid q),$$ - Subsequently,论文在这个固定的批次上执行 \(S\) 步梯度更新:
$$\theta_{k,s+1}=\theta_{k,s}-\eta \nabla_{\theta}\mathcal{L}_{\text{GSPO} }(\theta_{k,s};\mathcal{B}_{k}),\quad s=0,\ldots,S-1,$$- 其中 \(\theta_{k,0}=\theta_{k}\),下一次迭代的更新参数定义为 \(\theta_{k+1}=\theta_{k,S}\)
- Theoretically,这个过程开始时是 On-policy 采样,因为 \(\mathcal{B}_{k}\) 是从 \(\pi_{\theta_{k} }\) 中抽取的
- However,随着 \(\theta_{k,s}\) 偏离行为策略 \(\theta_{k}\),而轨迹及其计算出的优势保持固定,它逐渐转变为越来越 Off-policy 的机制
- 因此,内部步数 \(S\) 充当了控制这种混合 On/Off-policy 动态的控制器
- 虽然标准的迭代 GRPO (2024) 在论文的初步实验中表现出不稳定的性能,但这种轨迹重用策略产生了明显更稳定的优化,同时最大化了训练效率
Mitigating task regression via multi-task RL.
- 论文观察到,专注于单一领域的 RL 训练常常导致其他任务上的显著性能退化
- For instance,仅针对指令遵循优化策略往往会降低数学推理或代码生成的能力,即使基础模型在所有领域都具有强大的能力
- 为了解决这个问题,论文采用了一个多任务 RLFT 框架 ,该框架在 RL 循环内联合训练所有目标领域
- 数学推理、代码生成和 IFBench
- Specifically,每个 Mini-batch 由这三种任务的混合构成,利用任务特定的奖励函数同时更新一个共享策略
- 这种策略作为一种有效的正则化器,缓解了灾难性遗忘,并确保了所有下游基准测试的稳健性能提升
- 理解:每个 Mini-batch 都训练三种任务,任务之间的差异可能会导致 Rollout 的长度不一致吧,类似的问题也需要注意