注:许多论文中没有使用粗体来表示多个 Token 组成的序列(比如 Question \(\mathbf{q}\)),为了方便理解,论文会尽量可以在一些地方使用粗体
注:本文包含 AI 辅助创作
Paper Summary
- 阅读总结:
- 论文探讨了 RL 是否能够真正扩展语言模型的推理边界这个争议课题
- 最重要的贡献:本文的结果 挑战了先前关于 RL 局限性的假设,并证明在适当技术和足够训练时间下,RL 能够有意义地扩展推理边界
- 有趣的吐槽:是不是英伟达为了卖卡写的
- 论文通过 ProRL 提供了有力的证据,表明延长且稳定(extended, stable)的 RL 训练能够开发出 Base Model 初始能力之外的新颖推理模式
- ProRL 结合了 KL 散度惩罚和周期性参考策略重置 ,以在长期训练中 保持稳定性
- 基于 ProRL 开发了一个 SOTA 1.5B 参数通用推理模型(该模型在数学、编码、STEM、逻辑谜题和指令遵循任务等多样化数据集上进行了训练)
- ProRL 在 Base Model 初始表现较差的任务上尤为有效
- ProRL 实现了对分布外任务和日益复杂问题的强大泛化能力,表明 Prolonged RL 训练帮助模型内化了可迁移到训练分布之外的抽象推理模式
- 背景:以推理为核心的 LLM 近期进展表明,基于可验证奖励的强化学习 (RLVR)是对齐模型的有效方法
- 争议提出:然而,学界仍存在争议:
- 争议1:RL 究竟是真正拓展了模型的推理能力,还是仅仅放大了 Base Model 分布中已有的高奖励输出?
- 争议2:持续增加 RL 的计算量是否能可靠地提升推理性能?
- 在本研究中,论文通过证明 Prolonged RL(延长强化学习,ProRL)训练能够发现 Base Model 即使经过大量采样也无法获得的新推理策略,从而 挑战了主流观点
- 论文提出了 ProRL,这是一种结合了 KL 散度控制、参考策略重置和多样化任务套件的新型训练方法,实证分析表明:
- 经过 RL 训练的模型在广泛的 pass@\(k\) 评估中 consistently 优于 Base Model ,包括 那些 Base Model 无论如何尝试都完全失败的场景
- 论文进一步发现,推理边界的提升与Base Model 的任务完成能力(task competence)及训练时长(training duration)密切相关,这表明 RL 能够随时间推移探索并填充解决方案空间的新区域
- 这些发现为理解 RL 在何种条件下能真正拓展语言模型的推理边界提供了新视角,并为未来研究长时程 RL 在推理中的应用奠定了基础
- 论文发布了模型权重以支持后续研究:nvidia/Nemotron-Research-Reasoning-Qwen-1.5B
Introduction and Discussion
- 以推理为核心的语言模型(如 OpenAI-O1 和 DeepSeek-R1)的最新进展,通过扩展测试时计算(test-time computation),标志着人工智能领域的范式转变
- 测试时扩展支持长链思维(Chain-of-Thought, CoT)并催生复杂的推理行为,从而在数学问题求解 [3, 4, 5, 6] 和代码生成 [7, 8] 等复杂任务上取得了显著提升。通过在整个推理过程中持续投入计算资源(如探索、验证和回溯),模型以生成更长的推理轨迹为代价,提升了性能表现
- 这些进展的核心在于 RL,它已成为开发复杂推理能力的关键工具。通过针对可验证的客观奖励(verifiable objective rewards)而非学习到的奖励模型进行优化,基于 RL 的系统能够避免奖励破解(reward hacking)[9, 10, 11] 的陷阱,并与正确的推理过程更紧密地对齐。然而,研究社区仍在积极探讨一个根本性问题:RL 是否真正解锁了 Base Model 的新推理能力,还是仅仅优化了 Base Model 中已有解决方案的采样效率?
- 近期研究 [13, 14, 15] 支持后一种观点,认为基于 pass@\(k\) 指标,经过 RL 训练的模型并未获得超越其 Base Model 的新推理能力。作者认为,这些结论可能源于方法上的限制,而非 RL 本身的固有缺陷。具体来说,论文发现了现有研究中的两个关键局限:
- (1) 过度依赖数学等特定领域 ,这些领域的模型在预训练和后训练阶段通常已经过充分训练 ,从而限制了探索潜力;
- (2) RL 训练过早终止 ,通常仅进行数百步,导致模型无法充分探索和发展新的推理能力
- 在本研究中,论文通过多项关键 Contributions 解决了这些局限
- 论文提出了 ProRL,一种支持 Prolonged RL 训练周期的方案,能够促进对推理策略的深入探索
- 它支持超过 2000 步的训练,并将训练数据扩展到多样化任务(从传统数学和编程任务到 STEM 问题、逻辑谜题和指令遵循任务)
- 作者认为,这种多样性对泛化能力至关重要
- 基于 ProRL,论文开发了 Nemotron-Research-Reasoning-Qwen-1.5B(全球最强的 1.5B 推理模型 ,其 Base Model 是 DeepSeek-R1-1.5B),在多个基准测试中显著超越它的 Base Model DeepSeek-R1-1.5B,甚至在某些任务上匹配或超越了 DeepSeek-R1-7B
- 相比 DeepSeek-R1-1.5B,论文模型在数学基准上平均 pass@1 提升 14.7%,编程任务提升 13.9%,逻辑谜题提升 54.8%,STEM 推理提升 25.1%,指令遵循任务提升 18.1%(图1右)
- 更重要的是,ProRL 在史无前例的 2000 步训练后仍持续展现性能提升(图1左),这表明 RL 训练能随着计算资源的增加而有效扩展
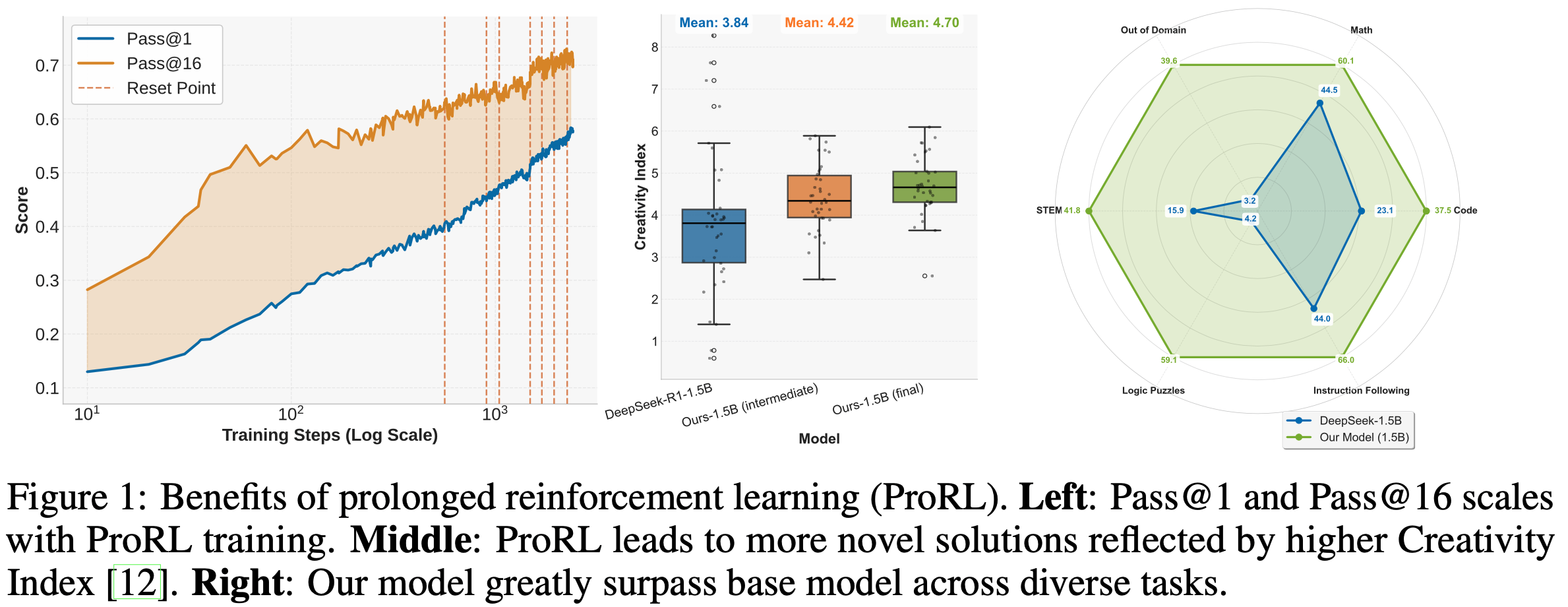
- 论文提出了 ProRL,一种支持 Prolonged RL 训练周期的方案,能够促进对推理策略的深入探索
- 此外,Nemotron-Research-Reasoning-Qwen-1.5B 带来了令人惊讶的新发现:
- 当给予充足训练时间并应用于新型推理任务时,RL 确实能发现Base Model 中完全不存在的全新解决路径
- 通过全面分析,作者证明该模型能产生新颖见解 ,在难度递增的跨领域任务中表现卓越,这表明其推理能力已真正突破初始训练的边界
- 最引人注目的是,作者发现在许多 Base Model 无论采样多少次都无法给出正确答案的任务中,经过 RL 训练的模型实现了 100% 的通过率(图4,见后文)
- 有趣的是,作者发现 RL 在每项任务上的收益程度可以通过 Base Model 的表现来预测——强化学习在 Base Model 最初表现薄弱的领域最能有效扩展模型的推理边界
- 此外,作者采用衡量与预训练语料重叠度的创造力指数[12]来量化模型推理轨迹的新颖性,发现 Prolonged RL 训练会产生新颖度更高的轨迹(图1中),这表明 RL 过程中出现了新的推理模式
- 这些发现对人工智能领域具有重大意义:
- 作者证明了 RL 方法无需额外训练数据即可增强模型能力
- 通过持续探索,模型能发展出可能超越人类认知的新知识与推理策略
- 本工作重申了 RL 作为构建更强大、更通用人工智能系统途径的价值,对先前关于该方法固有局限性的假设提出了挑战
ProRL:Prolonged Reinforcement Learning
- 本节做了以下工作:
- 简要介绍 GRPO(Group Relative Policy Optimization)算法
- 针对 Prolonged RL 训练中的关键挑战(如熵崩溃和不稳定性),提出通过引入 KL 散度惩罚和周期性重置参考策略来解决这些问题,从而确保多轮训练的稳定性及性能的持续提升
GRPO 介绍
- 论文采用 GRPO 作为核心 RL 算法。与近端策略优化(PPO)相比,GRPO 移除了价值模型,转而基于组分数估计基线。形式上,GRPO 最大化以下目标函数:
$$
\mathcal{L}_{\text{GRPO} }(\theta) = \mathbb{E}_{\tau\sim\pi_{\theta} }\left[\min\left(r_{\theta}(\tau)A(\tau), \quad \text{clip}(r_{\theta}(\tau),1-\epsilon,1+\epsilon)A(\tau)\right)\right],
$$- 其中 \(\tau\) 是从当前策略 \(\pi_{\theta}\) 采样的响应,\(r_{\theta}(\tau) = \frac{\pi_{\theta}(\tau)}{\pi_{old}(\tau)}\) 是当前策略与旧策略之间的概率比
- GRPO 中的优势函数摒弃了 PPO 的 Critic 模型,转而基于组分数 \(\{R_i\}_{i\in G(\tau)}\) 估计基线:
$$
A(\tau) = \frac{R_{\tau} - \text{mean}(\{R_i\}_{i\in G(\tau)})}{\text{std}(\{R_i\}_{i\in G(\tau)})}.
$$
Prolonged Reinforcement Learning (ProRL)
Mitigating Entropy Collapse
- 延长(prolonged)策略优化中的一个关键挑战是熵崩溃(entropy collapse),即模型的输出分布在训练早期过度集中,导致熵急剧下降
- 当熵崩溃发生时,策略过早地局限于狭窄的输出集合,严重限制了探索能力。这对于 GRPO 等方法尤为不利,因为其学习信号依赖于多样化的采样输出来有效估计相对优势。若探索不足,策略更新会产生偏差,导致训练停滞
- 常见的缓解策略是在 rollout 过程中提高采样温度。然而,论文发现这种方法只能延迟熵崩溃的发生,而无法完全避免,因为随着训练的进行,熵仍会持续下降。尽管如此,论文仍采用了较高的 rollout 温度,因为这会通过增加初始熵来鼓励探索
Decoupled Clip and Dynamic Sampling Policy Optimization(DAPO)
- 为解决熵崩溃问题,论文采用了 DAPO 算法 中的多个组件,这些组件专门设计用于保持探索和输出多样性。首先,DAPO 引入了解耦裁剪 ,将 PPO 目标中的上下裁剪界限视为独立的超参数:
$$
\text{clip}(r_{\theta}(\tau), 1-\epsilon_{low}, 1+\epsilon_{high}).
$$- 通过为 \(\epsilon_{high}\) 设置更高的值,算法实现了“向上裁剪”,提升了先前低概率 token 的概率,从而鼓励更广泛的探索。论文发现这一修改有助于保持熵并减少过早的模式崩溃
- 此外,DAPO 采用动态采样 ,过滤掉模型 consistently 成功或失败的提示(即准确率为 1 或 0),因为这些提示无法提供学习信号。这种专注于中等难度示例的策略进一步帮助在训练过程中保持多样化的学习信号
KL Regularization and Reference Policy Reset
- 尽管 DAPO 和温度调整有助于减缓熵崩溃,但论文发现通过 KL 散度惩罚进行显式正则化能提供更强大且稳定的解决方案。具体而言,论文在当前策略 \(\pi_{\theta}\) 和参考策略 \(\pi_{ref}\) 之间加入了 KL 散度惩罚:
$$
L_{KL-RL}(\theta) = L_{GRPO}(\theta) - \beta D_{KL}(\pi_{\theta}||\pi_{ref}).
$$- 这一惩罚不仅有助于保持熵,还能作为正则化器,防止在线策略偏离稳定的参考策略太远,从而稳定学习并减轻对虚假奖励信号的过拟合
- 近期研究 [4, 7, 5, 18] 主张移除 KL 惩罚,认为在思维链(Chain-of-Thought)推理任务中,模型在训练过程中会自然发散
- 论文观察到,这一观点通常适用于未经任何监督微调的 Base Model
- 论文的起点是一个已能生成连贯思维链输出的预训练检查点(DeepSeek-R1-Distill-Qwen-1.5B),在此背景下,保留 KL 惩罚对稳定性和持续熵保持仍然有益
- 论文还观察到,随着训练的进行,KL 项可能逐渐主导损失函数,导致策略更新减弱
- 为缓解这一问题,论文引入了一种简单而有效的技术:参考策略重置(reference policy reset),即定期将参考策略 \(\pi_{ref}\) 硬重置为在线策略 \(\pi_{\theta}\) 的最新快照,并重新初始化优化器状态
- 参考策略重置 使得模型在保持 KL 正则化优势的同时,能够持续改进
- 论文在整个训练过程中应用这一重置策略,以避免过早收敛并鼓励延长训练
Nemotron-Research-Reasoning-Qwen-1.5B:全球最佳的 1.5B 推理模型
- 论文推出了 Nemotron-Research-Reasoning-Qwen-1.5B,这是一个通过 RL 在多样化的可验证数据集上训练的通用型模型(generalist model)
- 该多样化可验证数据集包含 136K 个问题,涵盖数学、代码、STEM、逻辑谜题和指令遵循任务
- 通过稳定的奖励计算、改进的 GRPO 算法以及长时间的训练,论文的模型在多个领域展现出强大的泛化能力
- 相较于 DeepSeek-R1-Distill-Qwen-1.5B,论文的模型在数学任务上平均提升了 15.7%,在代码任务上提升了 14.4%,在 STEM 推理任务上提升了 25.9%,在指令遵循任务上提升了 22.0%,在基于文本的逻辑谜题 Reasoning Gym 上提升了 54.8%。此外,论文的模型在数学(+4.6%)和代码(+6.5%)领域的表现甚至超越了专门针对这些领域训练的 Baselines ,证明了通用型 prolonged RL 训练的有效性
Training Dataset
- 论文构建了一个多样化且可验证的训练数据集,涵盖 136K 个样本,分为五个任务领域:数学、代码、STEM、逻辑谜题和指令遵循
- 每个任务类型都配有明确的奖励信号(二元或连续),以便在训练过程中提供可靠的反馈。这种广泛的任务覆盖不仅鼓励模型在狭窄领域之外的泛化能力,还支持在不同奖励结构下对 RL 算法进行有意义的比较。训练数据集的详细组成见附录 D
Training Setup
- 论文使用 verl 进行 RL 训练,并采用了 DAPO 提出的 GRPO 增强版,包括解耦的剪切超参数 \(\epsilon_{low}=0.2\) 和 \(\epsilon_{high}=0.4\),以及动态采样以过滤过于简单或困难的提示(准确率为 1 或 0)
- 在 rollout 阶段,论文为每个提示采样 \(n=16\) 个响应,上下文窗口限制为 8096,采样温度为 1.2
- 论文设置批次大小为 256,小批次大小为 64(相当于每次 rollout 步骤进行 4 次梯度更新)
- 训练时使用 AdamW 优化器,学习率恒定为 \(2 \times 10^{-6}\)
- 训练在 4 个 8 \(\times\) NVIDIA-H100-80GB 节点上进行,总训练时长约为 16K GPU 小时
ProRL Training Dynamics
- 为了实现有效的长时间 RL(long-horizon RL),论文使用从评估基准中提取的混合验证集监控训练进度
- 当验证性能停滞或下降时,论文对参考模型和优化器进行硬重置。这不仅恢复了训练的稳定性,还促进了模型与 Base Model 之间更大的策略差异
- 在大部分训练过程中,论文将响应长度限制在 8k 个 token 以内,以保持生成结果的简洁性和稳定性。在最后阶段(约 200 步),论文将上下文窗口增加到 16k 个 token,观察到模型能够快速适应并实现可测量的性能提升。详细的训练方法见附录 E
- 图2 展示了长时间 RL 过程中多个阶段的关键统计数据
- 通过应用 DAPO 提出的多种增强方法以及引入 KL 散度损失,模型成功避免了熵崩溃
- 虽然论文观察到平均响应长度与验证分数之间存在正相关关系,但这一因素并非决定性因素,因为在某些训练阶段,性能提升并不依赖于更长的响应
- 验证集表现(通过 pass@1 和 pass@16 指标衡量)随着训练计算量的增加而持续提升(consistently improved),且呈现出稳定的扩展性
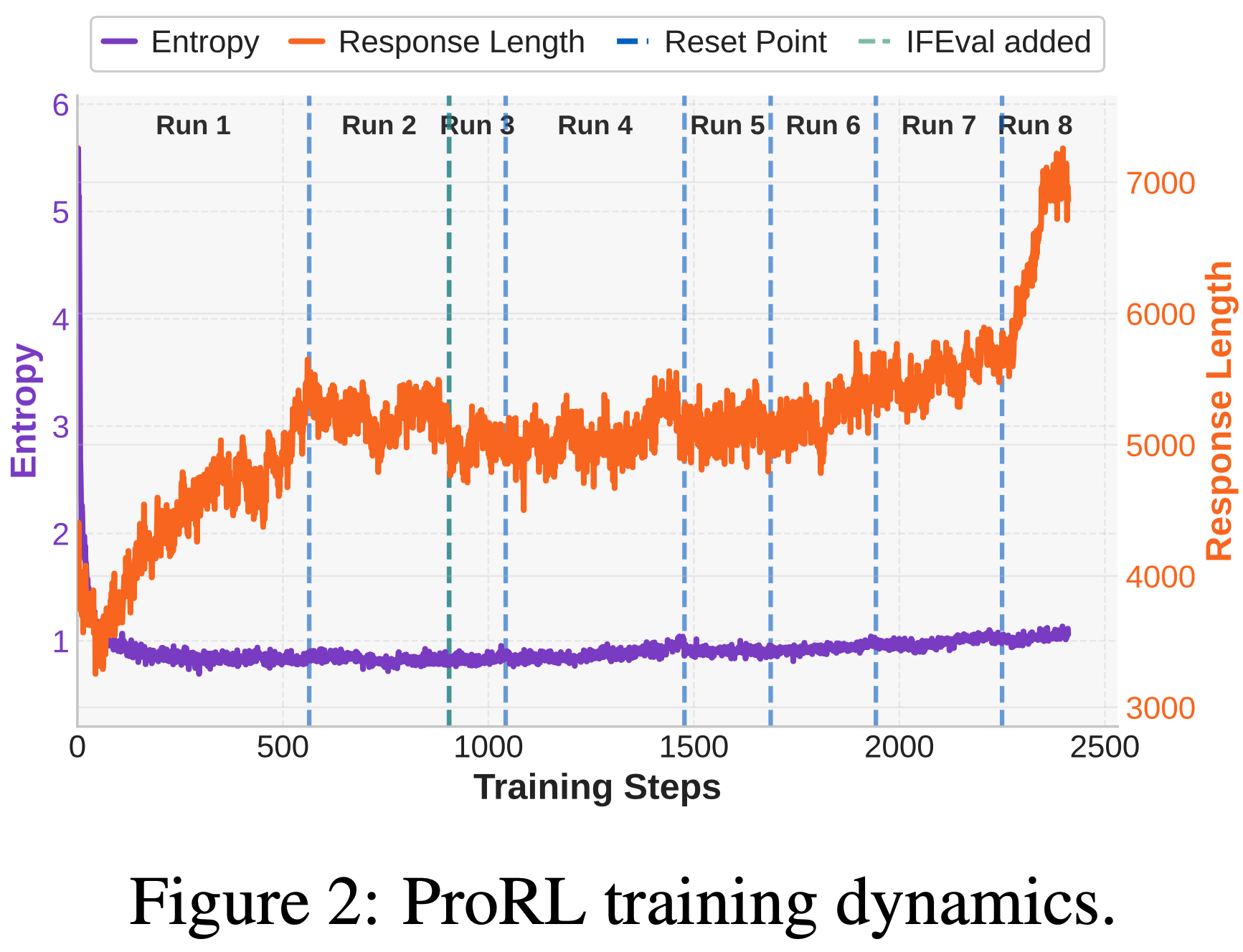
评估
- 评估基准 :论文在数学、代码、推理和指令遵循等多个任务上评估模型性能
- 对于数学任务,论文遵循 DeepScaleR 和 SimpleRL 的方法,在 AIME2024、AIME2025、AMC(包含 AMC2022 和 AMC2023)、MATH、Minerva Math 和 Olympiad Bench 上进行评估
- 对于代码任务,论文使用 PRIME 的验证集,包含 APPS、Codecontests、Codeforces、TACO 以及 HumanevalPlus 和 LiveCodeBench
- 对于逻辑谜题,论文从 Reasoning Gym 的每个任务中保留 100 个样本作为测试集
- 此外,使用了 GPQA Diamond 和 IFEval 的精选子集来评估模型在 STEM 推理和指令遵循任务中的表现
- 评估设置 :论文使用 vllm 作为推理后端
- 采样温度为 0.6
- 采用核采样(nucleus sampling)[38],\(top_p=0.95\)
- 最大响应长度为 32k
- 对于数学、代码和 STEM 推理任务,论文从每个基准提示中采样 16 个响应,基于严格的二元奖励计算 pass@1
- 对于其他任务(逻辑谜题和指令遵循),论文 rule-based verifiers 计算连续奖励分数的平均值
- 论文使用自己的评估设置对所有开源模型的基准结果进行评估和报告
- 评估结果 :论文详细比较了 DeepSeek-R1-Distill-Qwen-1.5B 和论文的最终模型 Nemotron-Research-Reasoning-Qwen-1.5B 在多个领域的表现
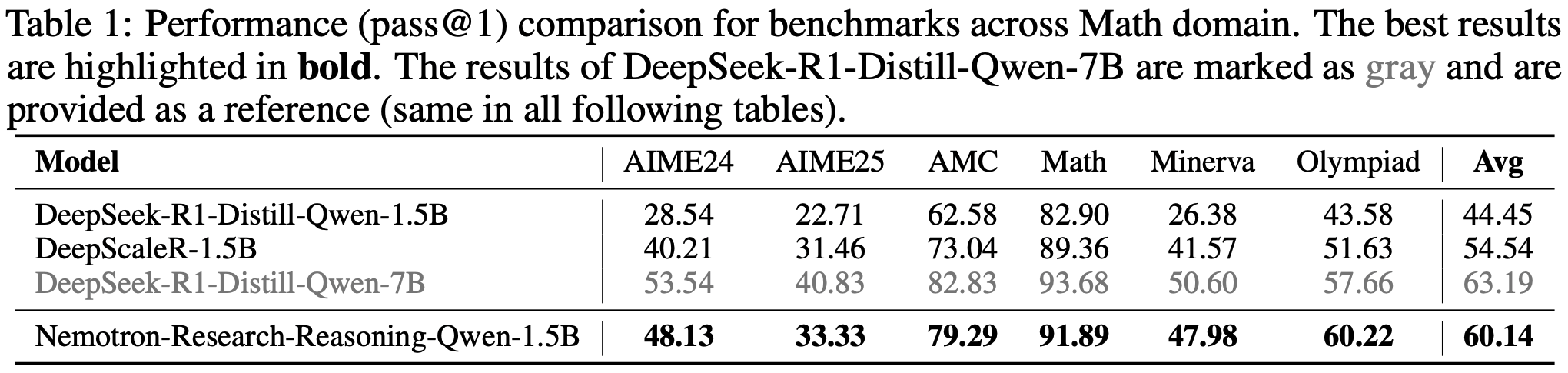
- 如表1 所示,在数学领域,论文的模型在所有基准测试中均优于 Base Model ,平均提升了 15.7%
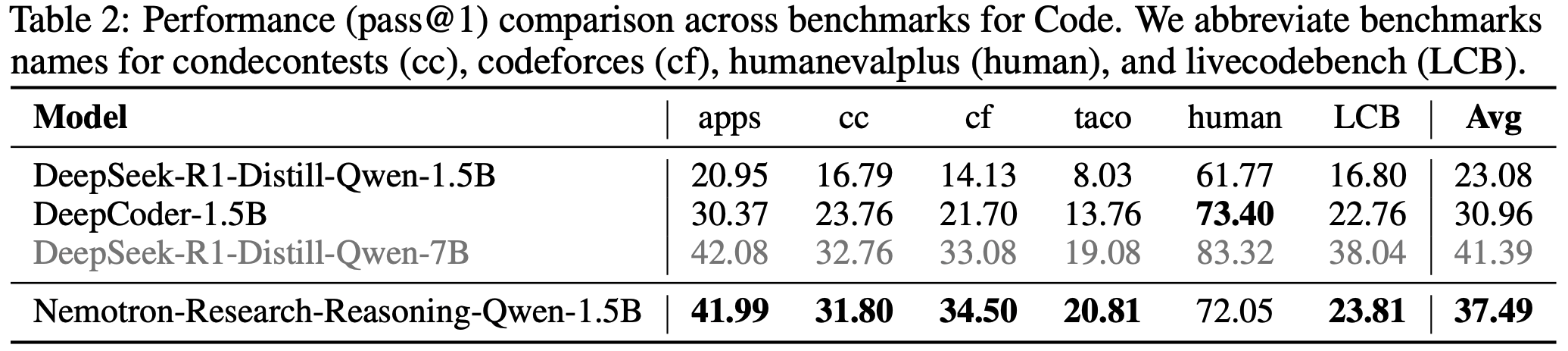
- 如表2 所示,在代码领域,论文的最终模型在竞争性编程任务中以 pass@1 准确率超越了 Base Model 14.4%。在 STEM 推理和指令遵循任务中,论文的模型也取得了显著提升,在 GPQA Diamond 上提升了 25.9%,在 IFEval 上提升了 22.0%
- 论文的模型在 Reasoning Gym 逻辑谜题上的奖励提升了 54.8%(尽管其使用的 Base Model 在格式化和具有挑战性的子任务上表现不佳)
- 即使与更大的模型 DeepSeek-R1-Distill-Qwen-7B 相比,论文的模型在多个领域也表现相当甚至更优
- 如表1 所示,在数学领域,论文的模型在所有基准测试中均优于 Base Model ,平均提升了 15.7%
- 对分布外(OOD)任务的泛化能力 :在表3 中,论文还展示了在 Reasoning Gym 的分布外任务上的结果
- 论文的模型在三个分布外任务上表现出显著提升,证明了训练方法在适应未见挑战方面的有效性
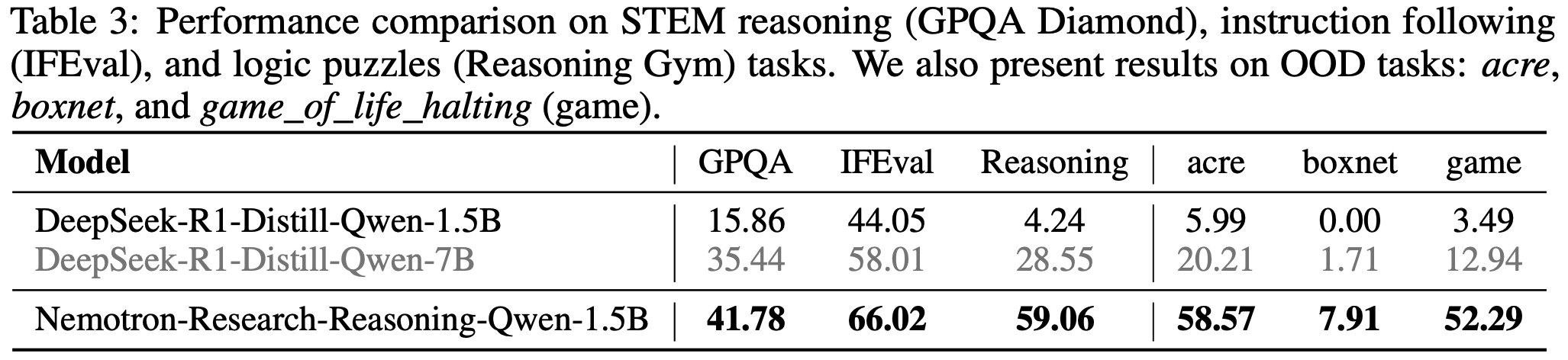
- 论文的模型在三个分布外任务上表现出显著提升,证明了训练方法在适应未见挑战方面的有效性
- 与领域专用模型的比较 :论文将 Nemotron-Research-Reasoning-Qwen-1.5B 与两个领域专用 Baselines 进行了比较:
- 专注于数学推理的 DeepScaleR-1.5B
- 专注于竞争性编程任务的 DeepCoder-1.5B
- 论文的 ProRL 训练模型展现了强大的泛化能力,在数学(+4.6%)和代码(+6.5%)基准测试中均取得了更高的 pass@1 分数
- 此外,ProRL 能够在有限的响应长度内实现更深入的探索和优化,而先前的工作往往过早增加训练响应长度,导致“过度思考”(overthinking)和冗长的推理过程
Analysis: Does ProRL Elicit New Reasoning Patterns?(ProRL 能否激发新的推理模式?)
- 为了评估 延长 ProRL 训练 是否能够提升 Base Model 之外的 推理能力,论文将 推理样本数量 增加到 256 ,并重新评估 模型性能
- 由于 计算资源限制(吐槽:英伟达也有计算资源限制?),论文从 Reasoning Gym 的 96 个任务中 随机选择了 18 个任务,并重新运行了 其他所有基准测试:数学、代码、STEM 推理 和 指令遵循
- 论文比较了 Base Model (DeepSeek-R1-Distilled-1.5B)、一个 中间检查点模型 和 Nemotron-Research-Reasoning-Qwen-1.5B(经过 延长训练后的 最终模型)
The Weaker the Start, the Stronger the Gain with ProRL(起点越弱,ProRL 增益越强)
- 论文研究的一个关键发现是:RL 在扩展模型推理边界(通过 pass@128 衡量)方面的有效性与 Base Model 的初始能力密切相关
- 如图3 所示,论文观察到 Base Model 的推理边界与 RL 训练后的推理改进程度之间存在显著的负相关
- 对于 Base Model 已经表现良好的任务(即 pass@128 较高),在 RL 训练后 往往表现出 最小甚至负面的增益。这表明 推理边界 变窄,模型 对其已经理解的 解决方案子集 变得更加自信,而不是 探索新的 推理模式
- 对于 Base Model 表现较差的领域,尤其是初始 pass@128 较低的任务中,RL 训练最为有效。在这些任务中,ProRL 不仅 提升了 pass@1,还扩展了模型探索和成功采用更广泛推理路径的能力
- 为了进一步验证 论文的直觉(即 RL 后增益最小的任务是 Base Model 已经熟悉的任务),论文计算了 Base Model 对每个任务的 响应 与 最大的开源预训练语料库 DOLMA 的 创造力指数(creativity index)(创造力指数量化了模型响应与预训练数据之间的重叠程度)
- 如图3(右)所示,圆圈中突出显示的 数学和代码任务 往往具有 较低的创造力指数,这表明 Base Model 在预训练期间已经接触了大量类似数据
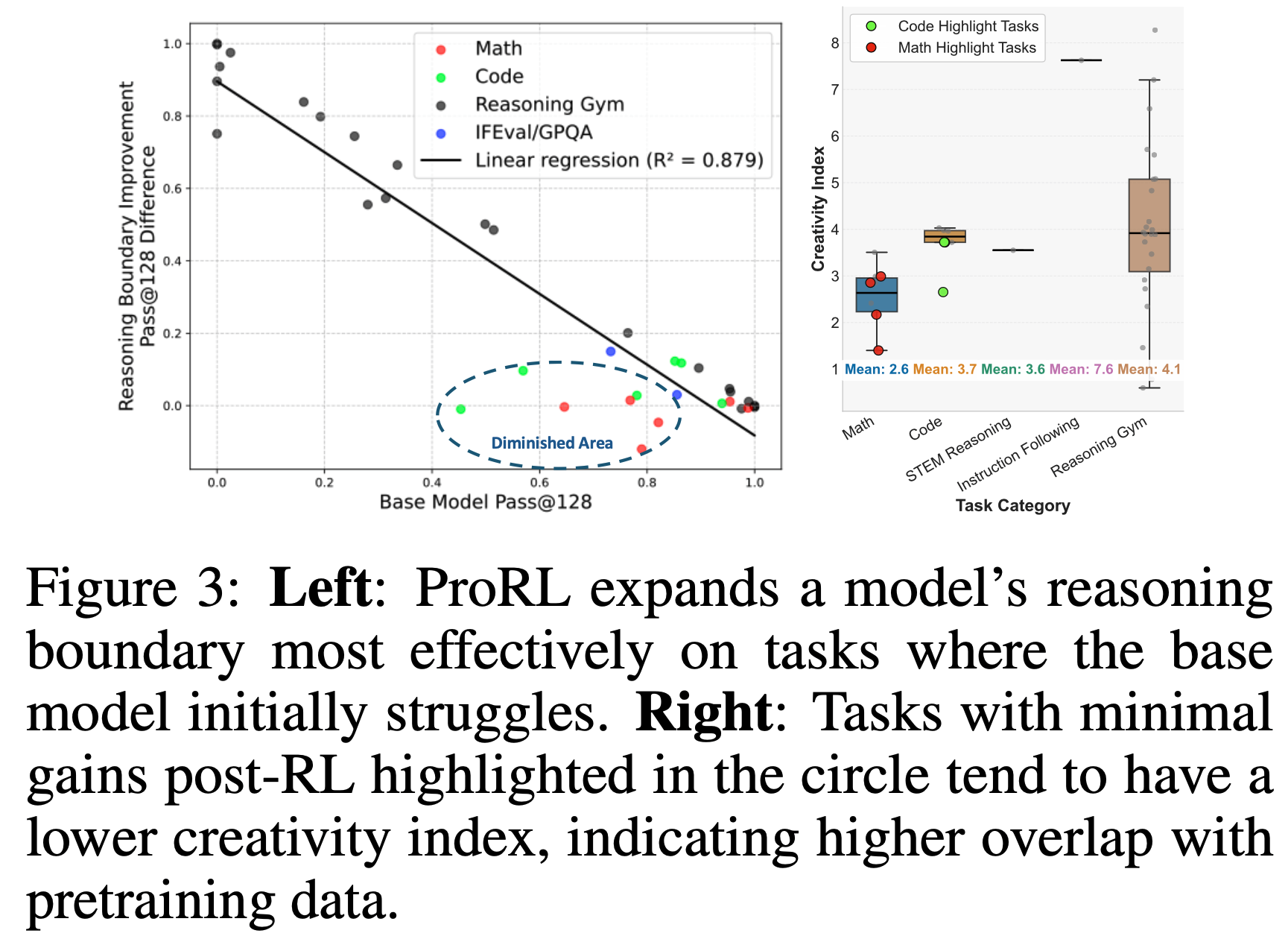
Unpacking ProRL’s Reasoning Boundaries: Diminish, Plateau, and Sustained Gains(解析 ProRL 的推理边界:缩减、平台期和持续增益)
- 论文分析了各个基准测试的性能趋势,并根据 pass@k 在训练过程中的演变对它们进行了分类
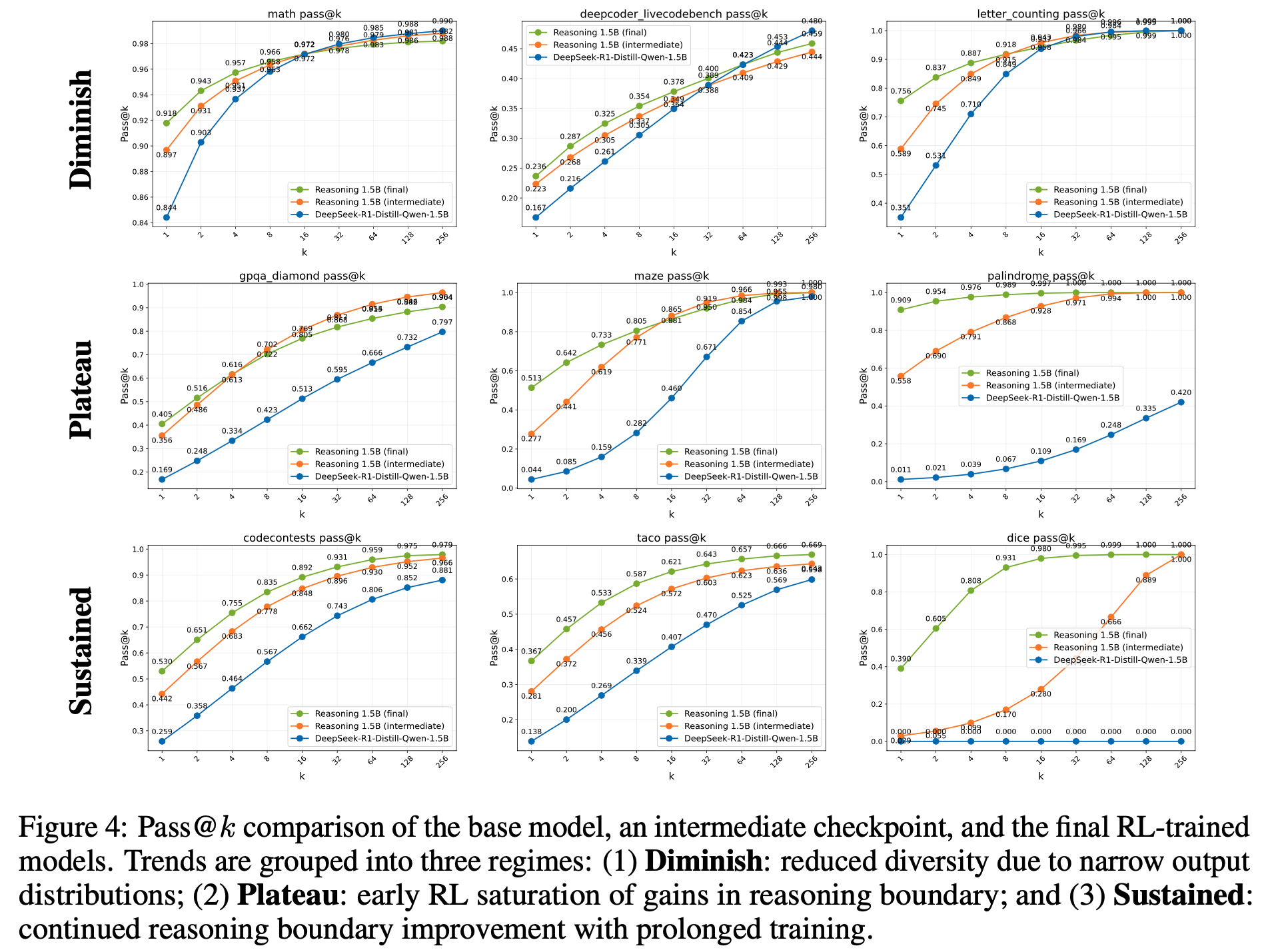
- 论文的分析表明,RL 可以有意义地扩展模型的推理能力 ,尤其是在那些超出 Base Model 能力的挑战性任务上
- 虽然某些任务在推理广度(reasoning breadth)上表现出早期饱和甚至倒退 ,但论文也观察到明显的实例,其中模型的推理能力随着持续训练而扩展
- 在代码生成等某些领域,ProRL 能够实现持续增益,这表明 prolonged training 使模型能够探索并内化(internalize)更复杂的推理模式
- 这表明,在适当的条件下,ProRL 可以将模型的推理能力推向超越 Base Model 的新高度
- 任务类型1:推理边界缩减(Diminished Reasoning Boundary) :
- 在某些基准测试(尤其是数学领域)中,Nemotron-Research-Reasoning-Qwen-1.5B 的推理能力与 Base Model 相比 有所下降或保持不变,这与先前研究的观察结果一致
- 尽管 pass@1 有所提升,但反映更广泛推理能力的 pass@128 分数往往下降
- 这些任务通常具有较高的基线 pass@128,这表明 Base Model 已经具备足够的推理能力,而 RL 训练仅仅锐化了输出分布(以牺牲探索性和通用性为代价)
- 任务类型2:RL 增益平台期(Gains Plateau with RL)
- 对于这些任务,RL 训练 提升了 pass@1 和 pass@128,表明推理能力有所改善
- 但这些增益 主要在训练早期实现。比较 中间检查点 和 最终模型 表明,ProRL 对这些任务的额外收益微乎其微,这意味着模型在这些任务上的学习潜力迅速饱和
- 任务类型3:ProRL 的持续增益
- 在一些基准测试中,尤其是更复杂的任务(如代码生成),Nemotron-Research-Reasoning-Qwen-1.5B 在 Prolonged RL 训练后表现出推理能力的持续提升
- 这些任务可能需要在训练期间对多样化问题实例进行广泛探索,才能在测试集上有效泛化。在这种情况下,ProRL 扩展了模型的推理边界
ProRL Enhances Out-of-Distribution Reasoning(ProRL 增强 OOD 推理)
- 论文重点研究 ProRL 如何影响模型在训练数据分布之外的泛化能力。这些研究旨在隔离 extended RL 更新 在扩展模型推理边界方面的作用,尤其是在结构新颖或语义挑战性任务上,这些任务在初始训练期间并未遇到
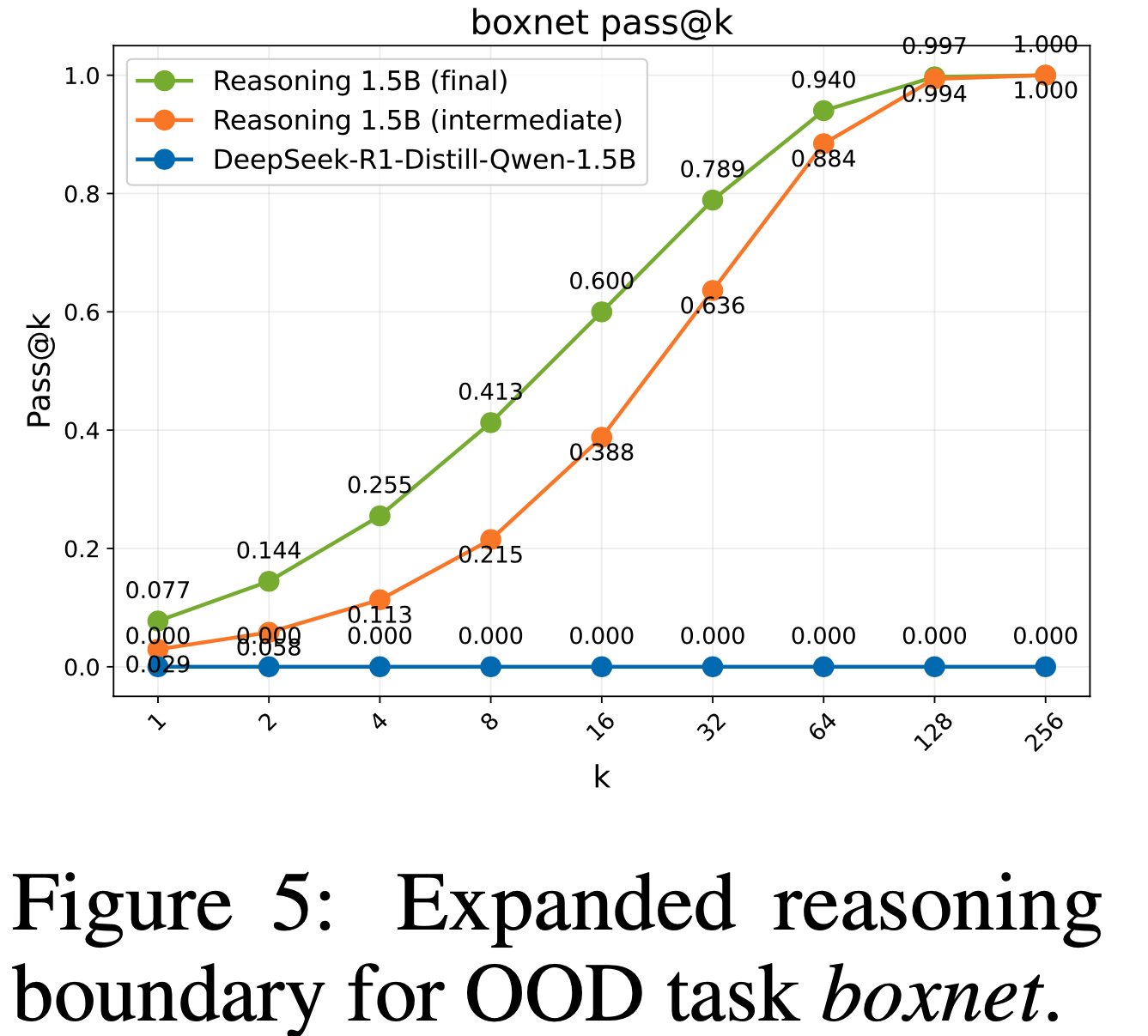
- 分布外(OOD)任务(Out-of-Distribution (OOD) Task) :论文在 Reasoning Gym 任务 boxnet 上评估模型,该任务在训练期间未被见过
- 如图5 所示(示例见附录 C.3), Base Model 完全无法解决该任务
- 经过 ProRL 训练的模型展现出显著的问题解决能力,表明模型的推理边界明显扩展,能够泛化到训练期间未见过的 OOD 任务
- 此外,当比较中间 RL 检查点 和 最终 Prolonged RL 模型时,论文观察到延长训练持续并放大了 在所有 k 值上的 性能增益
- 这些结果 进一步支持了 以下结论:ProRL 使模型能够内化抽象推理模式,从而泛化到特定训练分布或复杂度水平之外
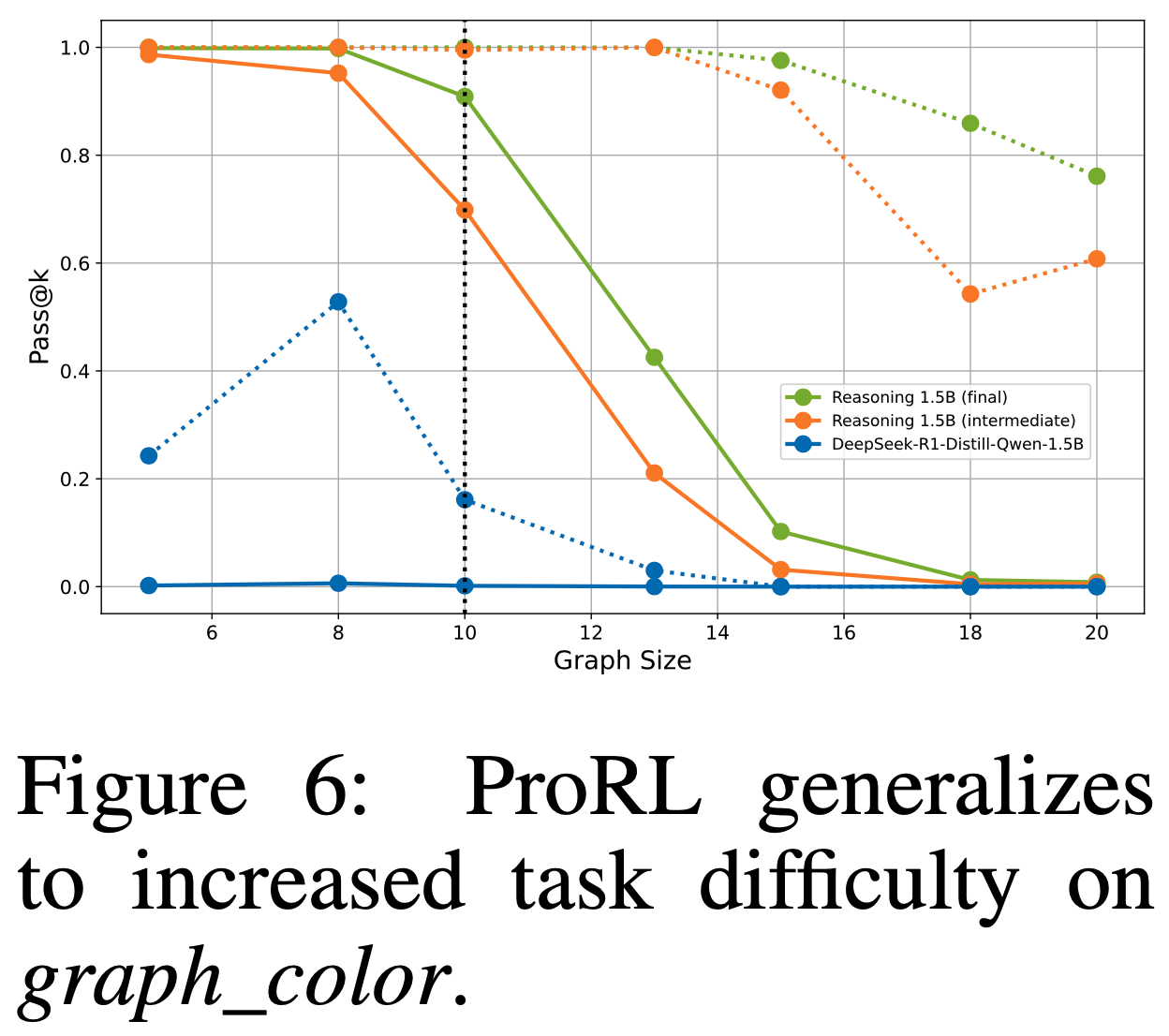
- 任务难度增加(Increased Task Difficulty) :论文通过不同节点数的图生成问题(generating graph problems),评估了 graph_color 任务(示例见附录 C.1)在不同难度级别下的性能。训练数据仅包含大小为 10 的图,而论文测试了更大的图,以评估模型在训练范围之外的泛化能力
- 图6 绘制了不同模型在不同图大小下的 pass@1(实线)和 pass@128(虚线)
- 结果显示,性能虽任务难度增加而持续下降(consistent decline in performance as task difficulty increases),这是解空间组合增长的预期结果
- 论文的 Prolonged RL 模型在所有图大小上保持了显著更高的准确率,优于 Base Model 和中间模型。这表明 Prolonged RL 更新不仅提升了分布内任务的 pass@1,还增强了模型对更复杂、未见场景的鲁棒性
How Does pass@1 Distributions Evolve as ProRL Progresses?(pass@1 分布随 ProRL 演变?)
- Dang 等人[14](Assessing Diversity Collapse in Reasoning,Under review at ICLR 2025)推导了 pass@k 的数学上界:
$$
\mathbb{E}_{x,y\sim D}[pass@k] \leq 1 - \left((1 - \mathbb{E}_{x,y\sim D}[\rho_{x}])^{2} + \text{Var}(\rho_{x})\right)^{k/2},
$$- 其中 \(\rho_{x}\) 表示 任务 \(x\) 的 pass@1 准确率
- 这个上届与 pass@1 的期望正相关,与 pass@1 的方差负相关
- 与 观察到的 pass@k 在训练期间下降不同,论文的结果(图1)显示 pass@1 和 pass@16 持续提升,重现了 OpenAI O1 的 RL 训练中报告的扩展律模式
- 论文的 ProRL 方法 在多样化任务上 产生了显著的性能提升:图 7(a) 和 7(b) 展示了 代码和逻辑谜题任务中 pass@1 分布的显著右移
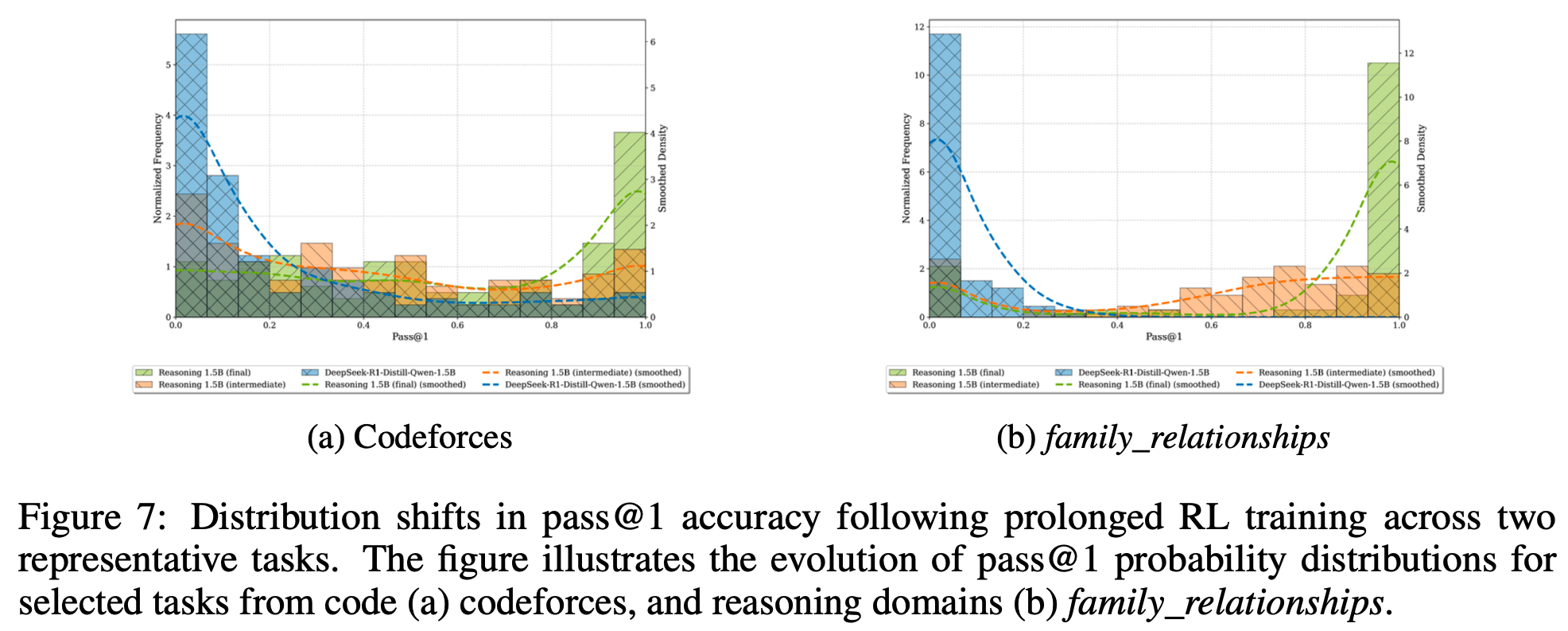
- 初始分布集中在零附近并带有长尾,而训练后的分布发生了显著变化。Codeforces 问题在训练后表现出更广泛的分布模式,而 family_relationships 任务(示例见附录 C.2)作为一种新颖的推理挑战,展示了从主要为零准确率到峰值完美准确率的戏剧性转变,表明在大多数提示中成功发现了解决方案
- 这些显著的分布变化,由 Prolonged RL 训练驱动,产生了 足够大的期望 pass@1 改进,以克服方差增加带来的负面影响
Related Work
- 推理模型(Reasoning Models):推理模型代表了一类专门的 AI 系统,它们在生成最终答案前会进行详细的、长链的思维过程(long chain-of-thought),这一概念最早由 OpenAI 的 o1 系列模型 引入
- 随后,DeepSeek 和 Kimi 详细介绍了 使用 可验证奖励的强化学习 (RLVR)训练推理模型的方法
- 这两种方法都推广了 GRPO、Mirror Descent、RLOO 等 RL 算法变体
- 尽管许多开源尝试致力于复现 o1 类模型,但大多数专注于单一领域 [3; 7; 6] 或研究测试时计算扩展(test-time compute scaling),很少涉及 Prolonged RL 训练 或 研究 RL 训练时间的扩展规律
- 正如 RL 社区 广泛认可的那样,RL 训练 由于对超参数的敏感性 而面临重大挑战。各种 RL 技术 [5; 4] 被研究用于增强训练稳定性,以支持长期优化(sustained optimization periods)
- 论文的研究表明,实现 Prolonged RL 训练可以显著扩展这些模型的推理能力边界
- RL 推理边界(RL Reasoning Boundary):实现超人类性能一直是机器学习的圣杯(holy grail)
- RL 算法从 Atari 游戏的 DeepQ 网络 [49; 50] 开始,成功实现了这一期望
- AlphaGo 和 AlphaZero 证明,AI 智能体可以通过在蒙特卡洛树搜索(Monte Carlo Tree Search)和数据收集与策略改进之间持续迭代,无限提升其性能。这些例子表明,RL 训练帮助智能体开发了 Base Model 中不存在的新技术 [52; 53; 54; 55; 56]
- 然而,挑战这一观点的是,最近几项研究质疑 RL 训练是否真正增强了 LLM 的推理能力。一项工作 认为,RLVR 方法 未能扩展这种能力,证据是 pass@k 指标未显示改进,甚至在某些情况下 比 Base Model 更差,这一趋势 也得到了其他研究人员的呼应
- 类似地,另一项工作 发现,RL 算法倾向于收敛到主导的输出分布,仅仅是放大了预训练中已有的模式
- 除了 pass@k 指标外,创造力指数(creativity index)等替代测量也可以确定模型是否通过 RL 训练学习了新思路,论文在研究中采用了这种方法
附录A Limitations
- 尽管论文的 ProRL(Prolonged Reinforcement Learning)方法取得了令人印象深刻的成果,但仍存在几个重要的局限性需要说明:
- 计算资源(Computational Resources) :持续的 RL 训练过程需要大量的计算资源,这对于小型组织或预算有限的研究人员来说可能是难以承受的。论文的方法涉及多个训练阶段,包括周期性重置和长推理链采样,这进一步加剧了资源需求
- 可扩展性问题(Scalability Concerns) :虽然论文展示了在 1.5B 参数模型上的有效训练,但目前尚不清楚论文的方法在更大模型上的扩展性如何。随着参数数量的增加,计算需求的增长会变得更加显著
- 训练过程挑战(Training Process Challenges) :论文的方法需要定期对参考策略和优化器参数进行硬重置以保持训练稳定性。这增加了训练过程的复杂性,并可能导致与更稳定的训练方法相比结果不一致
- 任务范围有限(Limited Task Scope) :虽然论文的评估涵盖了多个领域,但训练数据集仍然只代表了可能存在的推理任务中的一部分。在某些分布外(out-of-distribution,OOD)任务上的表现显示出良好的泛化能力,但论文不能保证在所有潜在推理领域都能取得类似的改进,特别是那些未明确包含在论文的训练或评估中的领域
附录B Societal Impacts
- ProRL 的开发对人工智能研究社区和整个社会都具有重要意义
- 通过增强语言模型在各个领域的推理能力,这种方法既创造了机会,也带来了需要仔细考虑的挑战
Potential Benefits and Opportunities
- ProRL 表明,当提供足够的计算资源时,当前的 RL 方法有可能实现超人类的推理能力
- 论文训练的小型 1.5B 参数模型为计算资源有限的个人、研究者和组织提供了获取先进 AI 能力的机会。这种可访问性在教育环境中尤为重要,因为资源限制常常阻碍大规模 AI 系统的采用
- 论文的方法通过其成本效益、降低的能源消耗和比大型模型更少的计算需求,提供了显著的社会效益,使得先进的推理能力能够惠及更广泛的受众。正如论文的分析所示,初始性能较低的任务通常通过持续训练表现出持续的提升,这为解决医疗、气候科学和辅助技术等关键领域的推理挑战创造了机会
- 小型但强大的模型可以在本地部署,具有增强的安全和隐私保护功能,使其适用于金融、法律和医疗等敏感领域。此外,这些模型的适应性和低延迟使其成为实时应用的理想选择,如 AI 教学助手、科学研究支持和专业问题解决工具,这些应用可以显著提升多个领域的人类生产力
Ethical Considerations and Challenges
- 尽管存在这些机遇,ProRL 也引入了需要谨慎治理的重要伦理问题。大量的训练计算需求可能会加剧 AI 发展中的资源不平等,而增强的推理能力如果部署不当,可能会被滥用于更复杂的目的。随着这些系统在某些推理任务中从无能力过渡到高能力,持续的监控变得至关重要,以预测可能出现的行为和潜在风险
- 未来的工作应将 ProRL 技术与明确的价值对齐方法相结合,同时开发动态评估基准,使其能够随着模型能力的提升而演进,以确保在不同背景和社区中全面评估进展和风险
附录C Example Prompts
C.1 Graph Color Example
- 任务简要描述:给定一个图的顶点、边和可选颜色,要求每个顶点不与相同颜色顶点相连,给出解决方案并用 JSON 返回
- 详情见原始论文
C.2 amily Relationships Example
- 举例:John 与 Isabella 结婚。他们有一个孩子叫 Edward。Edward 与 Victoria 结婚,Isabella 与 Edward 是什么关系?请仅用一个描述他们关系的单词回答
C.3 oxnet Example
- 一个比较复杂的任务(给定一个网格状场地,要求创建一个动作计划序列,指导每个 Agent 以最有效的方式将所有盒子匹配到其颜色编码的目标),其 Prompt 也比较复杂
- 详情请看原始论文
附录D 训练数据集
- 论文通过表4 展示了训练数据的详细信息,这些数据涵盖了多样化的任务领域,并提供可验证的奖励信号
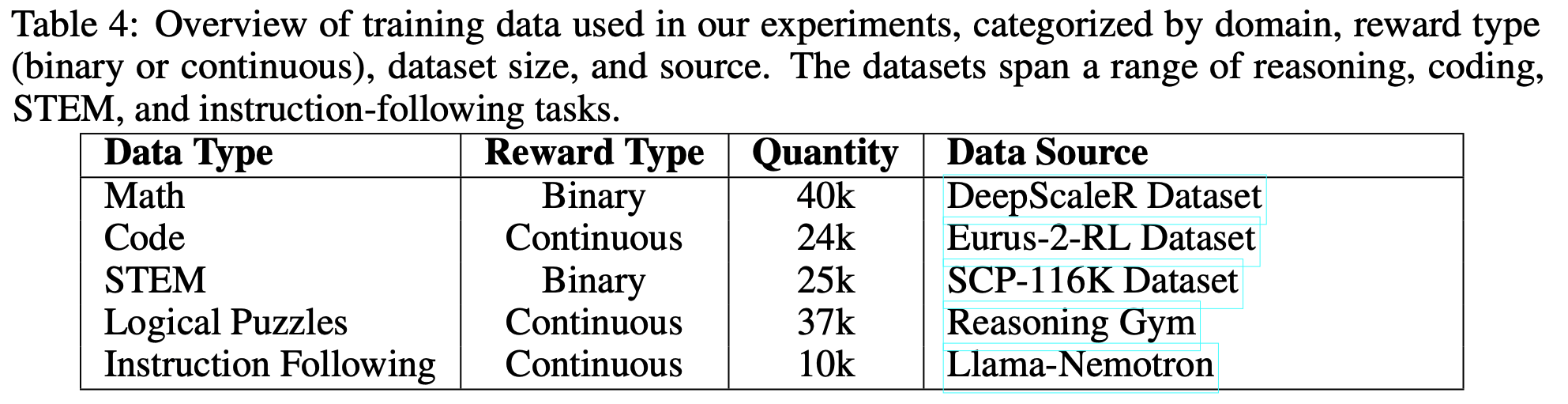
- 这些任务包括传统的推理领域(如数学问题求解和代码生成),以及更复杂和开放的领域(如 STEM 相关的问题求解、逻辑谜题和指令遵循)
- 这种多样化的任务组合有两个关键目的:
- 首先,它拓宽了模型对不同推理模式的接触范围,鼓励模型在特定领域之外实现泛化,这对于适应新的或未见过的任务形式尤为重要;
- 其次,任务多样性使得对 RL 算法的评估更加严格,因为它测试了算法在不同环境和奖励结构下学习稳健决策策略的能力
D.1 Math
- 论文使用了由 DeepScaleR 提供的高质量、社区整理的数据集。训练集包含 40K 个数学问题,来源多样,包括国内和国际数学竞赛
- 论文采用了 DeepScaleR 的原始验证器(verifier),并进一步增强了 math-verify 的功能
- 论文通过提示模型 “Let’s think step by step and output the final answer within \boxed{}” 来获取 LLM 的答案
- 论文使用二元奖励信号,如果 LLM 的响应通过了原始或增强的 math-verify,则得分为 1,否则(对于错误或格式不正确的答案)得分为 0
D.2 Code
- 论文使用了公开可用的 RL 数据集,包含 24K 个编程问题,这些问题来自各种编程竞赛
- 为了支持连续奖励反馈,论文改进了代码执行环境
- 使其运行所有测试用例,而不是在第一个错误时终止,并根据通过的测试用例比例分配奖励
- 未能编译、包含语法错误或超过 5 秒总超时的提交得分为 0
- 论文还为 LLM 提供了指令,要求其将最终代码响应用三重反引号括(triple backticks)起来
D.3 STEM
- 论文使用了 SCP-116K,这是一个大规模数据集,包含 274K 个科学问题-解决方案对,涵盖物理、化学、生物和数学等多个领域
- 每个问题都附带了从原始文本中提取的解决方案,以及由 DeepSeek-R1 生成的响应和推理路径
- 由于 SCP-116K 是从异构且可能嘈杂的来源自动提取的,论文进行了严格的数据过滤:
- 首先,移除了缺乏可检索的真实解决方案的问题;
- 然后,使用 GPT-4o 作为评判者,评估 DeepSeek-R1 的响应是否与真实答案一致(仅保留答案一致的问题,将数据集从原始条目减少到 25K)
D.4 Logical Puzzles,Reasoning Gym
- 逻辑谜题非常适合推理模型的训练,因为它们涵盖了广泛的推理技能,同时具有明确的目标和评估指标
- 论文使用了 Reasoning Gym project,该项目提供了约 100 个任务,涵盖代数、算术、计算、认知、几何、图论、逻辑和流行游戏等领域
- 为了便于模型训练和评估,论文生成了一个包含 37K 个合成训练样本和 9600 个验证样本的大型数据集,覆盖 96 个任务
- 特别说明:某些任务有唯一解,而其他任务(如魔方和倒计时)允许多个正确答案
- 论文使用 Reasoning Gym 仓库提供的 verifier 进行模型评估和 RL 训练信号
- 论文推荐使用 Instruct Model 的 Default Prompts,要求模型将答案放在 <answer> </answer> 标签之间
D.5 Instruction Following
- 为了增强模型的指令遵循能力,论文利用了来自 Llama-Nemotron 的合成生成数据,其数据格式类似于 IFEval
- 该数据集包含将任务与随机选择的 instructions 配对的合成 prompt。例如,prompt 可能要求模型“写一篇关于机器学习的文章”,而 instruction 则指定“你的回答应包含三个段落”
- 论文没有进一步添加格式指令,而是在模型 thinking(</think> 标记)后获取其回复
附录E 训练方法
- 训练监控(Training Monitoring) :论文构建了一个验证数据混合集,用于密切监控训练进度
- 该验证集包括来自评估基准的子集,具体为 AIME2024、Codeforces、GPQA-diamond、IFEval 和 Reasoning Gym 中的逻辑谜题 graph_color
- 论文使用与评估设置相似的采样参数(除了使用与训练中相同的上下文窗口)来评估模型性能
- 参考模型和优化器重置(Reference Model and Optimizer Reset) :Occasionally,论文会硬重置参考模型和优化器,如第 2.3.1 节所述,尤其是在验证指标显著下降或改进停滞时
- 有趣的是,硬重置不仅恢复了训练稳定性,还提供了调整训练超参数和引入增强功能(如额外的训练数据和奖励塑造)的机会
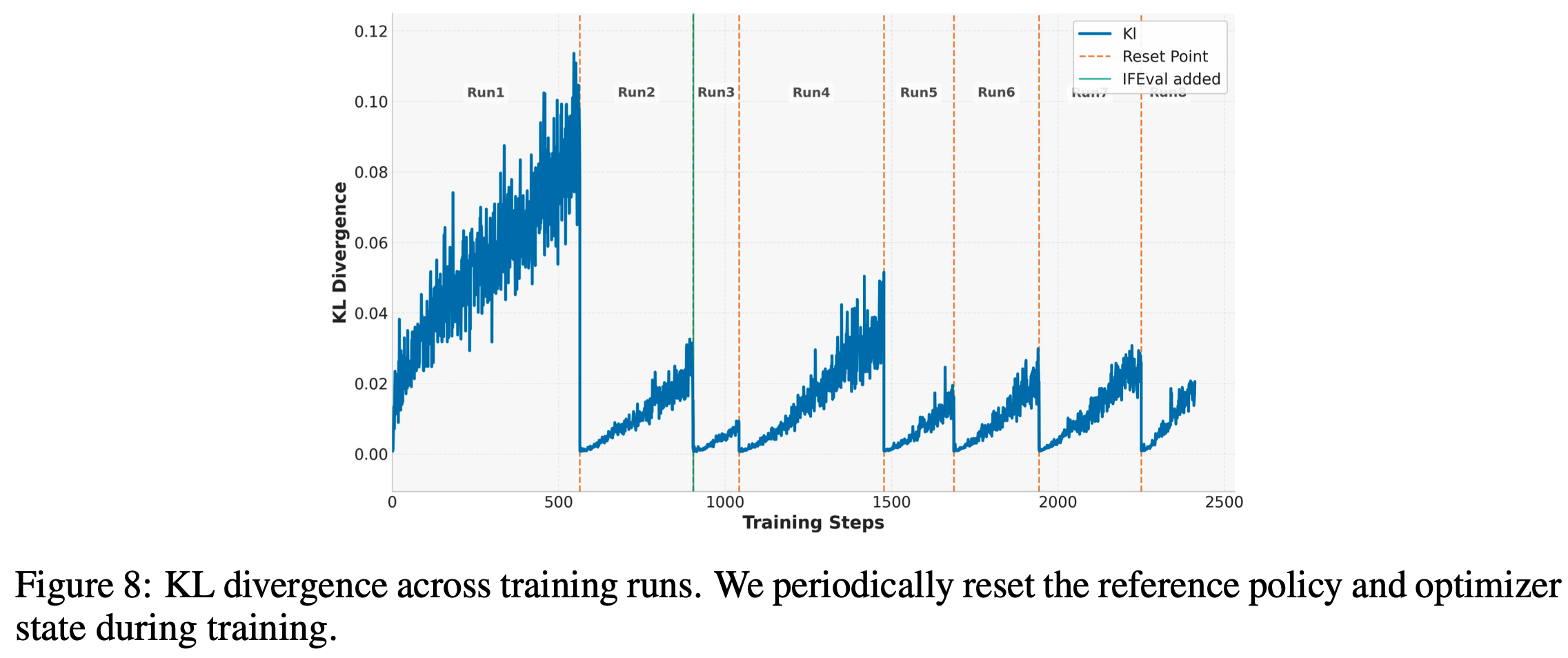
- 图 8 展示了训练过程中的 KL 散度变化。最终的训练方法包括以下几个连续阶段:
- 第一阶段(Run 1): 论文从附录D 的四个任务开始训练。由于初始时指令遵循数据不可用,论文未包含这部分数据
- 在此阶段,论文将响应长度限制为 8k( Base Model 的序列长度为 128k),以避免生成长序列
- 如图 2 所示,模型响应长度先短暂下降,随后随着验证分数的提高而持续增加
- 在此阶段接近尾声时,论文观察到验证性能的不稳定和下降
- 第二阶段(Run 2): 论文对参考策略进行硬重置,并继续使用与第一阶段相同的设置进行训练
- 与 DeepScaleR 提出的增加最大响应长度不同,论文将最大响应长度保持为 8k,因为论文观察到 8k 的最大长度足以让模型学习并提高其验证分数
- 第三阶段(Run 3): 论文将指令遵循数据纳入训练混合中,并继续训练
- 此阶段持续到论文观察到响应长度突然增加,主要是由于模型重复答案且未能以 <eos> 标记终止
- 第四和第五阶段(Run 4 and 5): 论文通过惩罚未能正确终止的响应来引入奖励塑造
- 这鼓励了正确的生成行为,导致响应长度适度减少
- 第六和第七阶段(Runs 6 and 7): 论文将 rollout 计数从 16 增加到 32,并在此过程中进行了两次硬重置
- 有趣的是,响应长度再次开始上升,同时验证指标也有所改善
- 第八阶段(Run 8): 论文将上下文窗口扩展到 16k token,并将 rollout 计数减少到 16
- 尽管模型在大部分时间内是在 8k 上下文窗口上训练的,但它迅速适应了扩展的上下文窗口
- 论文观察到在 AIME 等硬数学任务上的改进较小,而在其他领域的改进更为显著
- 第一阶段(Run 1): 论文从附录D 的四个任务开始训练。由于初始时指令遵循数据不可用,论文未包含这部分数据
- 思考: Prolonged RL 更像是一个精心训练的流程,在看到模型存在问题后,针对性调整训练策略(包括损失函数、奖励函数以及 rollout 次数等),是一个实践性很强,但可复制难度很高的工作
附录F Results Details
F.1 Reasoning Gym
- 对于 Reasoning Gym 官方 GitHub 仓库定义的 96 项任务,论文采用了其分类体系
- 表5 展示了论文模型在各任务类别中的详细性能表现
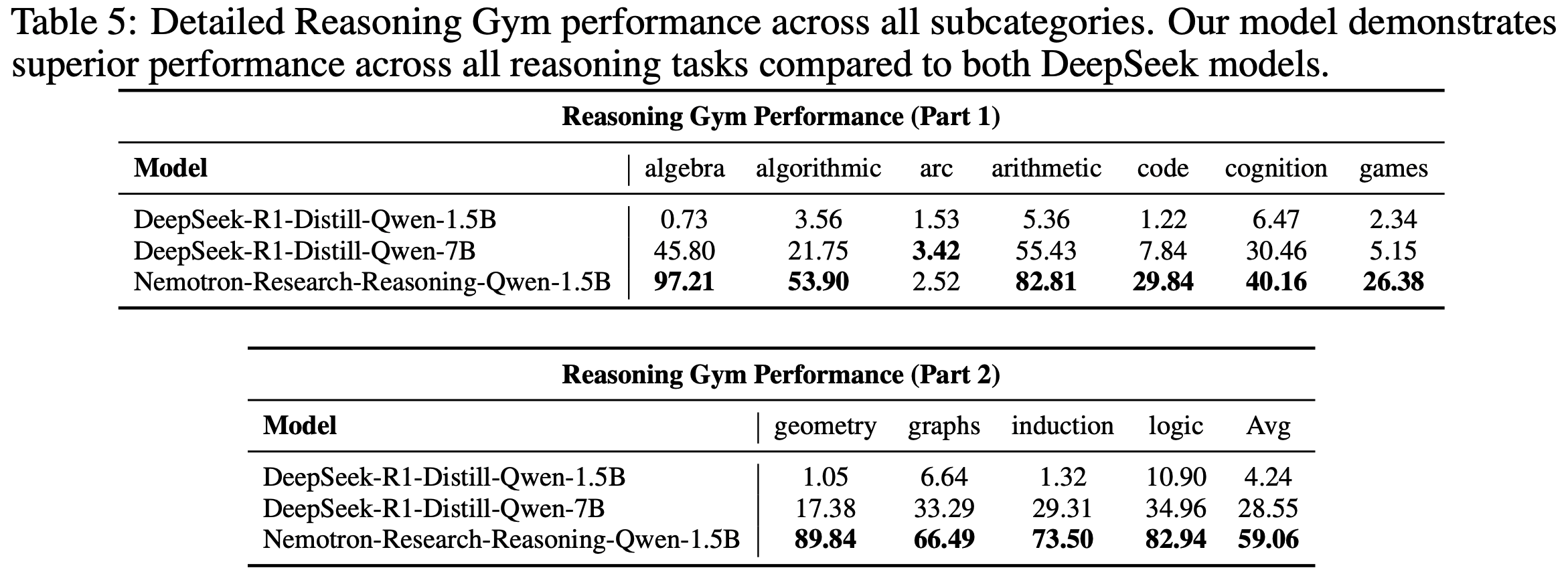
- 值得注意的是,DeepSeek-R1-Distill-Qwen-1.5B 即使在相对简单的数学任务(如代数和算术)上也表现不佳
- 进一步分析发现,该模型始终使用 \boxed{} 格式而非指令要求的 <answer> </answer> 标签来输出答案
- 尽管初始格式行为不佳,经过训练后模型在这些简单任务上仍能达到较高准确率,这表明格式学习相对容易掌握
- 论文的模型在更具挑战性的任务类别(包括 arc、代码、认知和游戏类任务)上仍有改进空间
- 在这些情况下,模型往往无法取得实质性进展
- 深入分析表明,这些失败源于两种原因:
- 原因一:缺乏解决特定子任务所需的核心推理能力
- 原因二:对问题领域背景知识掌握不足
- 解决这些限制可能需要额外的微调数据来更好地支持模型从零开始学习,论文将这些改进留待未来工作
F.2 Pass@k Comparisions
- 论文分享了所有评估任务在 3 个模型间的 pass@k 对比图。由于计算资源限制,论文从 Reasoning Gym 任务中随机选取了部分子集进行展示
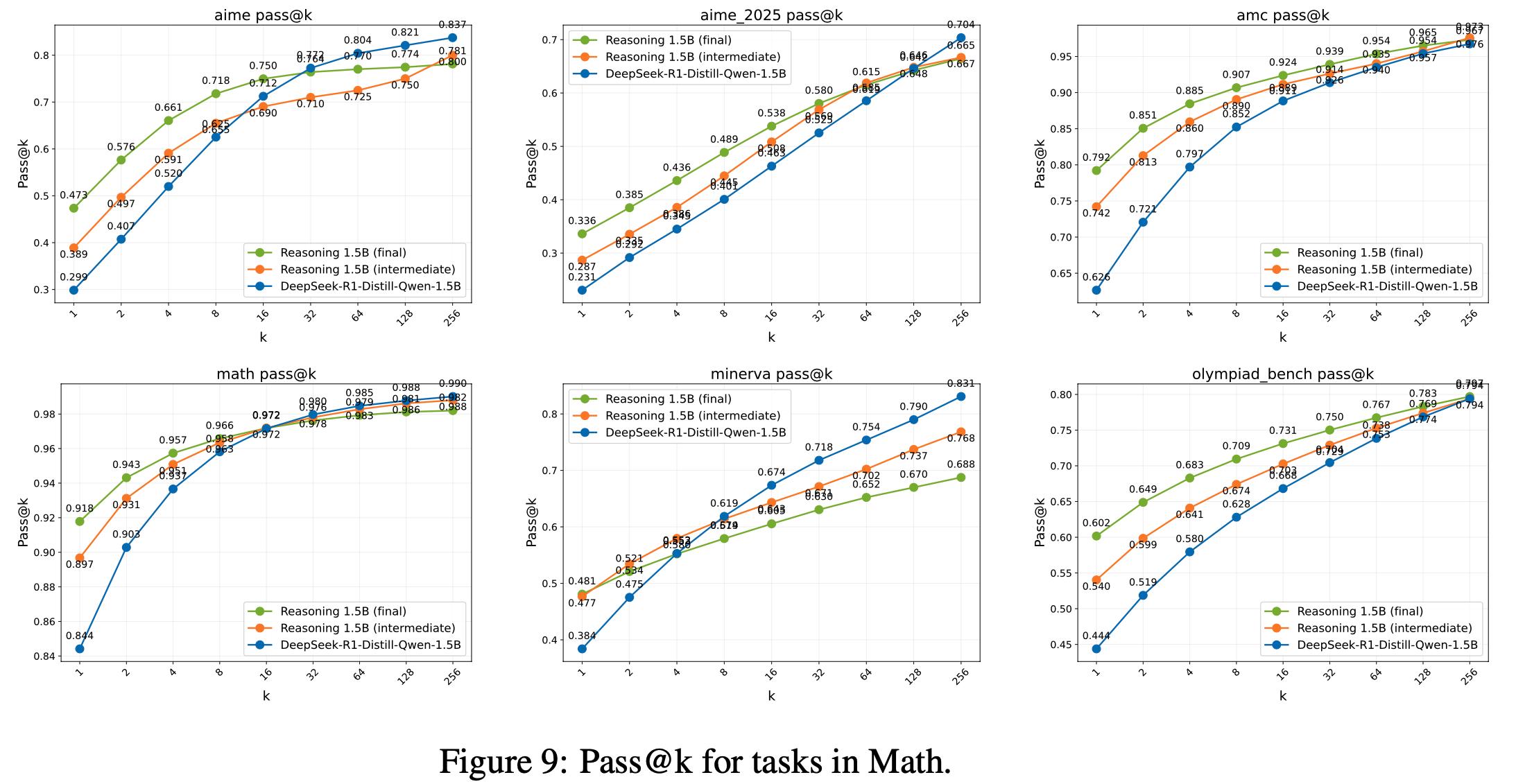
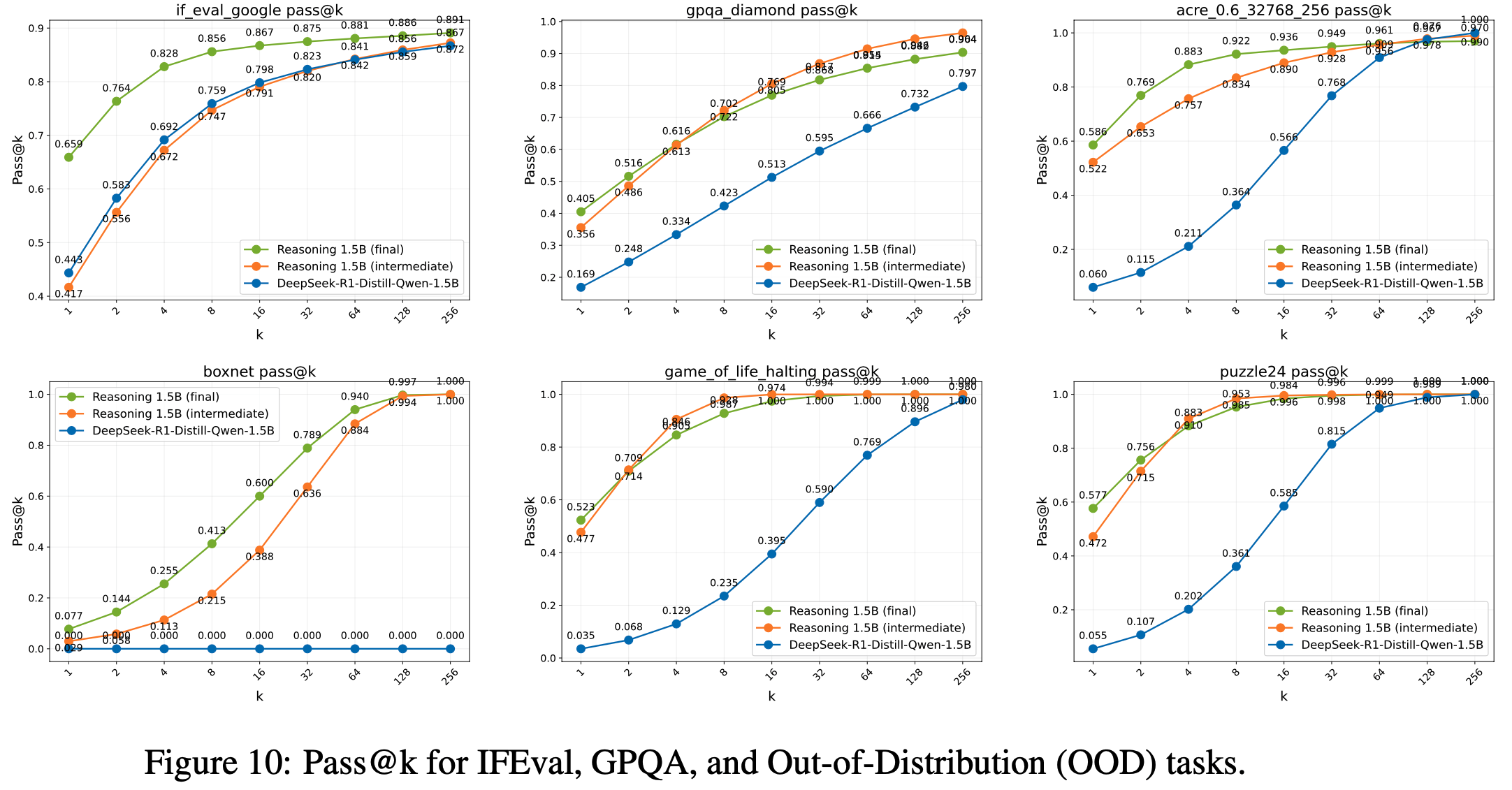
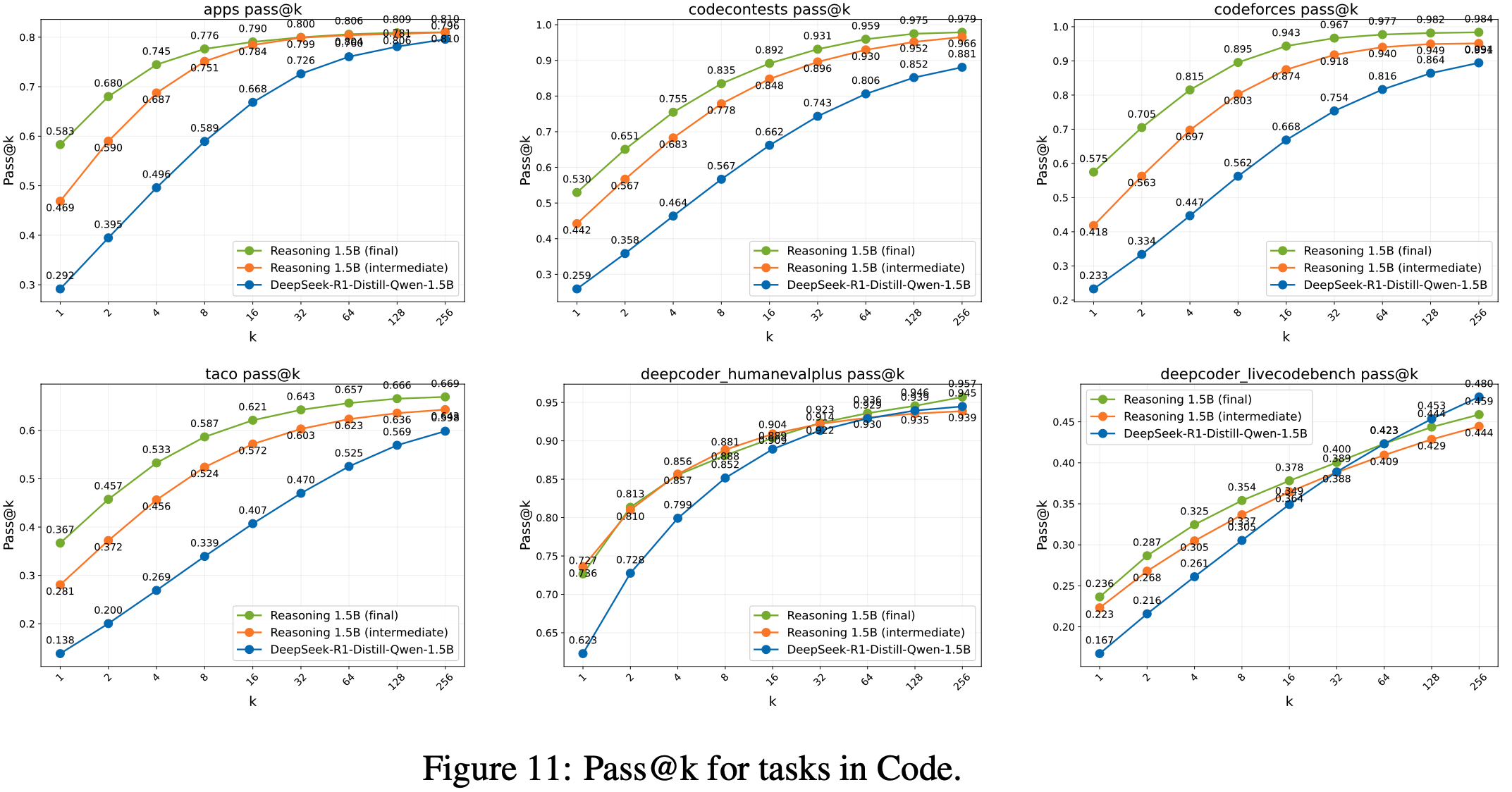
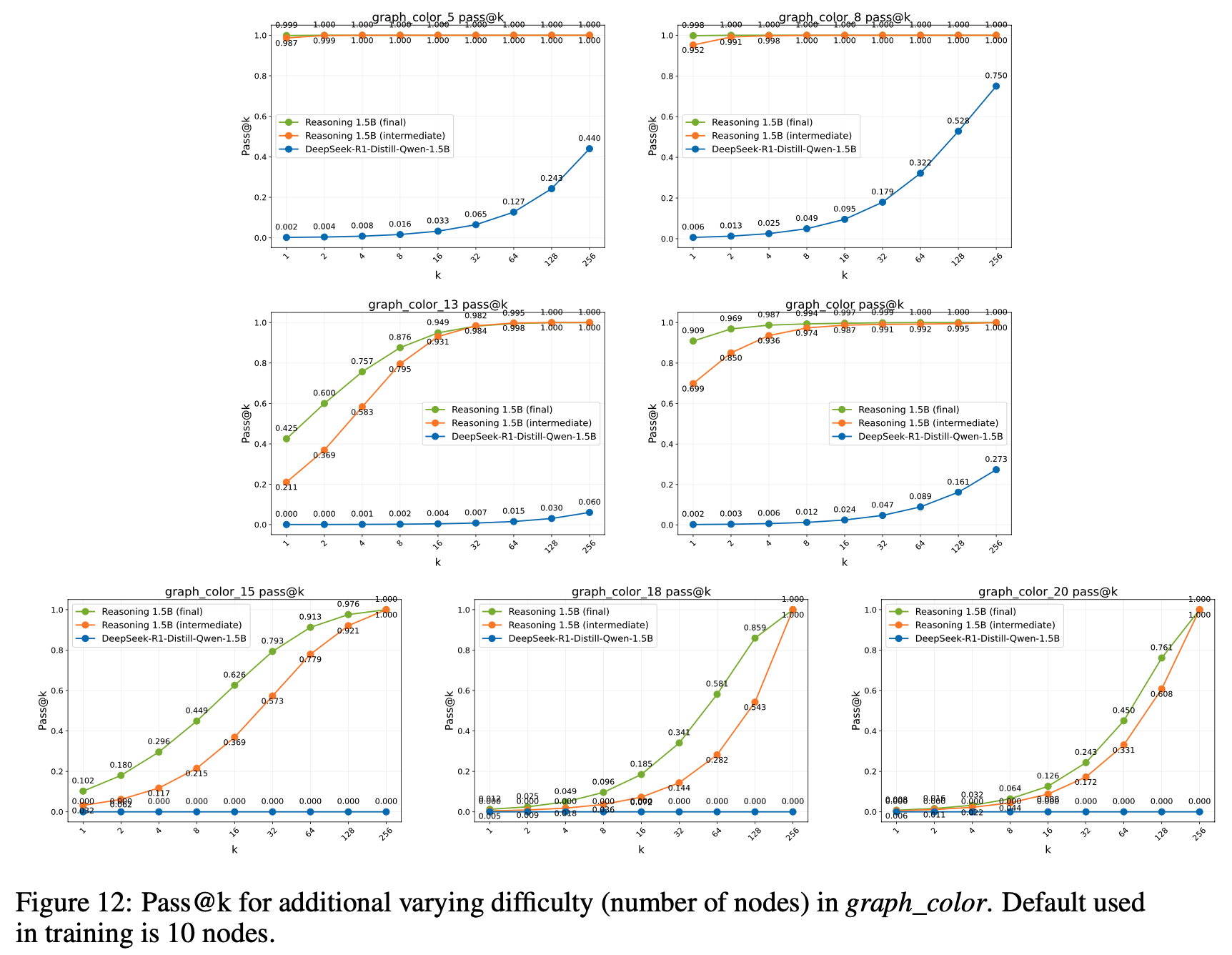
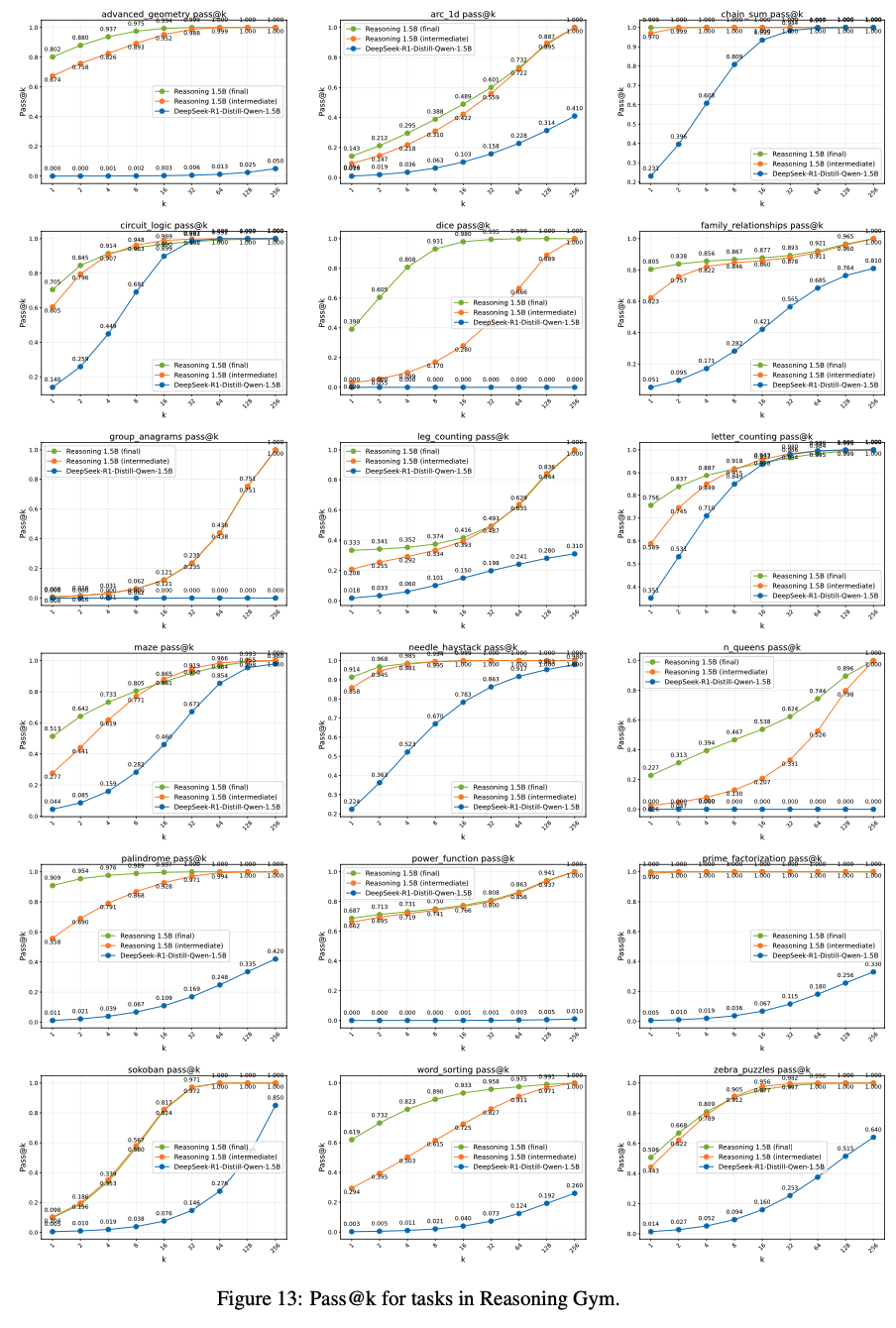
- 理解:
- 不同任务上表现不同
- 整体上:可以看到从 Base Model -> 训练中间模型 -> Final Model,Pass@k 是在逐渐变大的
- 但是:在一些任务上,随着 k 直的增大,RL 训练会导致模型的 pass@k 性能指标性能降低
F.3 Pass@1 Distribution Shifts
- 论文展示了所有评估任务的 pass@1 分布变化情况。受计算资源限制,论文从 Reasoning Gym 任务中随机选取了部分子集进行分析
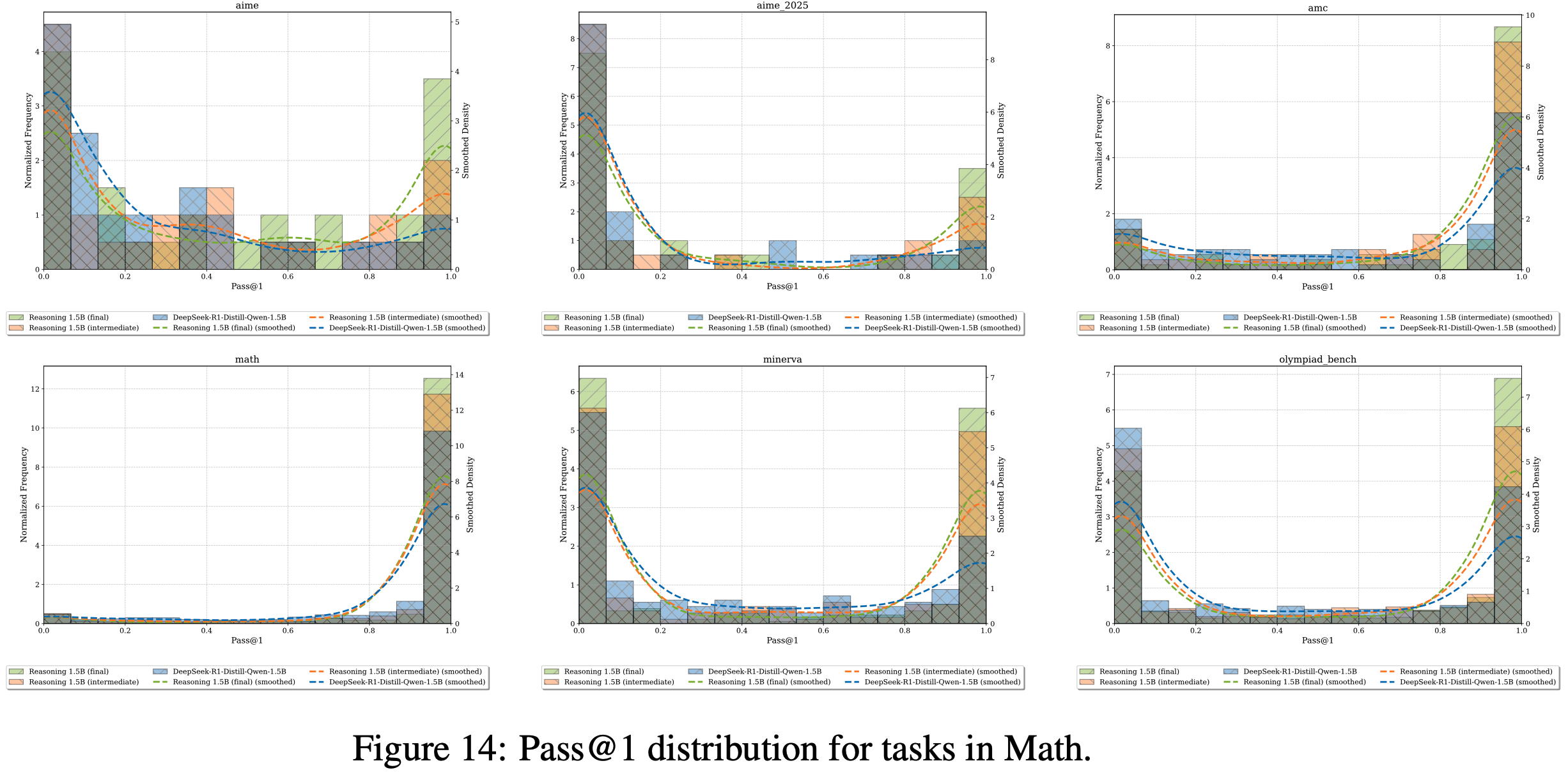
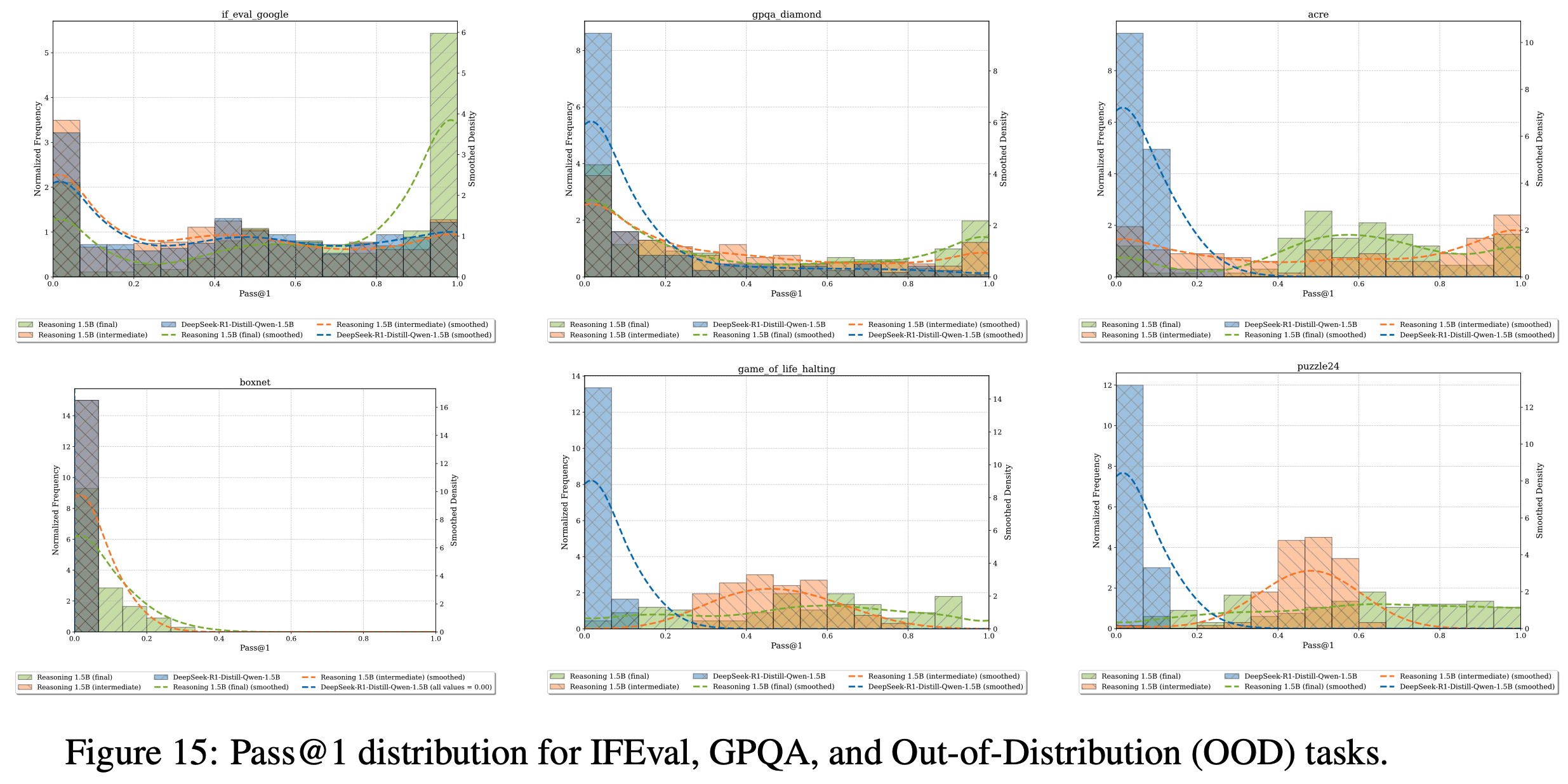
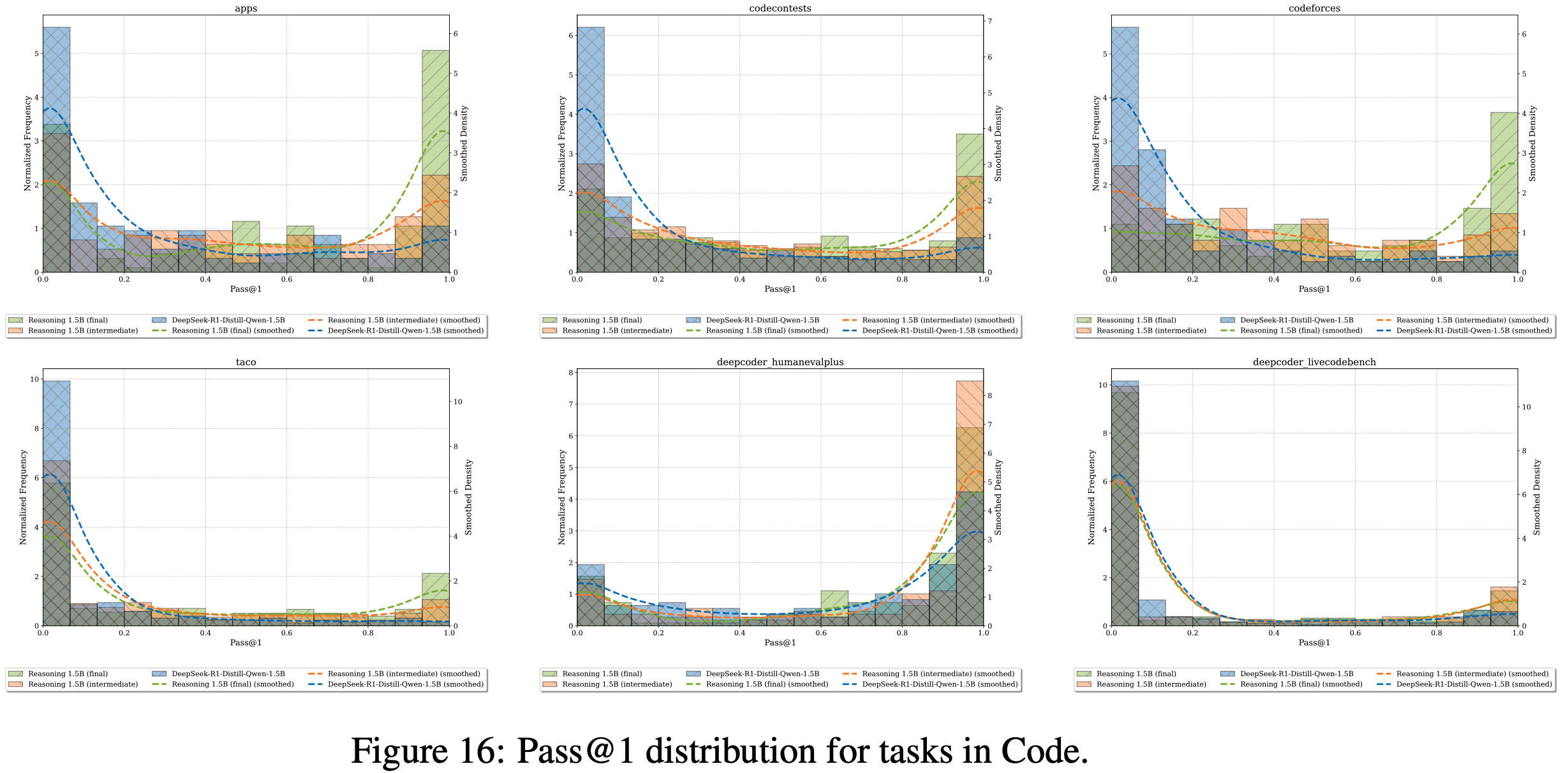
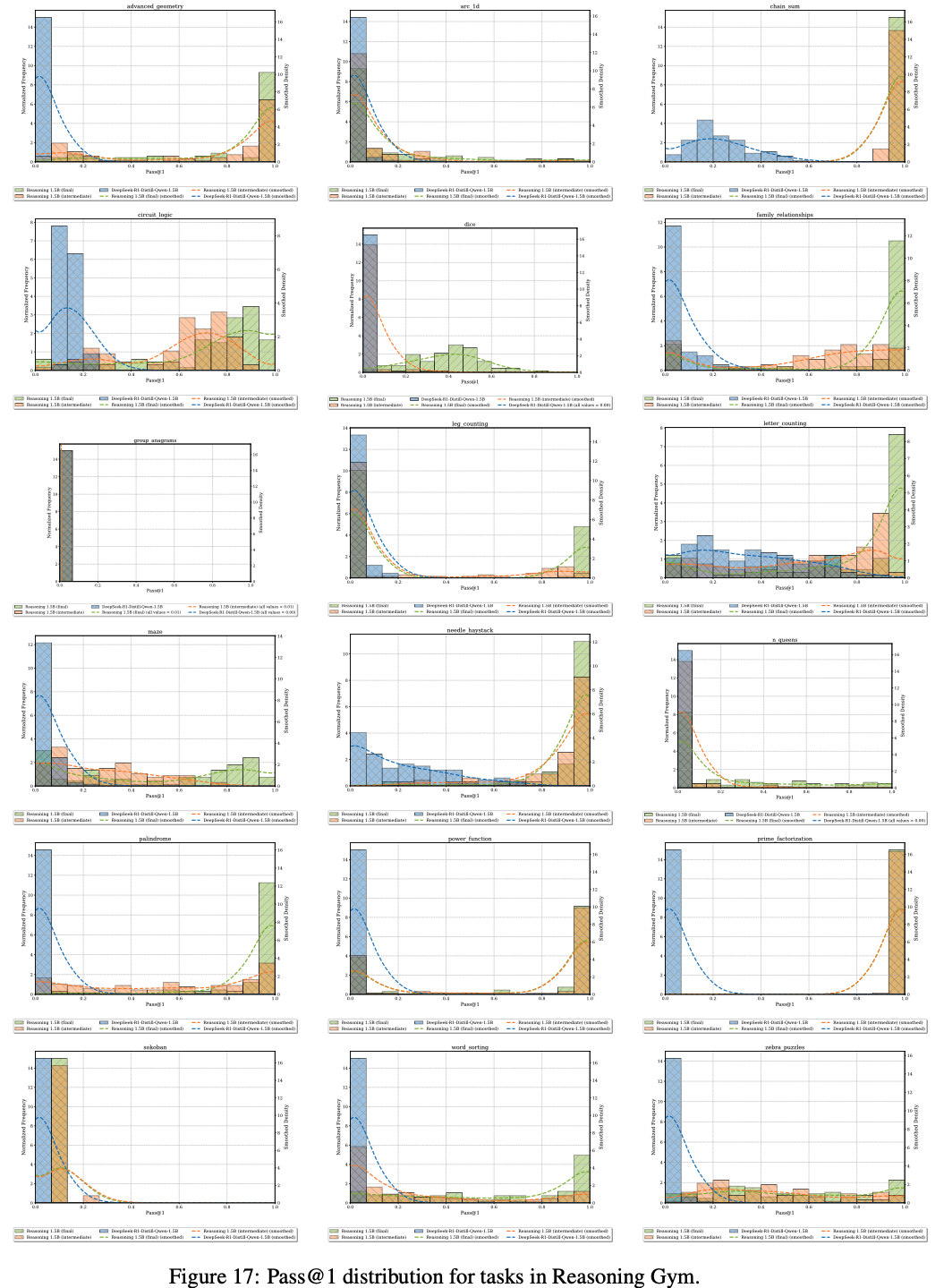
- 理解:
- 不同任务上表现不同
- 大部分任务上可以看到从 Base Model -> 训练中间模型 -> Final Model,Pass@k 是在逐渐变大的