注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 本文整体有较强的理论意义,核心是证明了:LLM RL 的重要性采样最优是 Sequence-level 的,而 Token-level 重要性采样是对 Sequence-level 重要性采样的一阶近似
- 类似 NLP——LLM对齐微调-RL-Collapse-Training-Inference-Mismatch(Sequence-level-MIS) 中的推导
- NLP——LLM对齐微调-RL-Collapse-Training-Inference-Mismatch(Sequence-level-MIS) 得到的结论是:
- 只有当 \(\color{red}{\pi_{\theta}^{\mathrm{vllm} } }\) 保持在 \(\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } }\) 的信任域内时,即当 \(d_{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }\approx d_{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\) 且 \(A^{\color{red}{\pi_{\theta}^{\mathrm{vllm} } } }\approx A^{\color{blue}{\pi_{\theta}^{\mathrm{fsdp} } } }\) 时,\(J(\theta)\) 才能被 \(g_\text{tok}(\theta)\) 优化
- 本文进一步证明了
- 在需要使用重要性采样的场景的场景下 Token-level 优化目标视为对真实期望 Sequence-level 奖励的一阶近似 ,能够得到 NLP——LLM对齐微调-RL-Collapse-Training-Inference-Mismatch(Sequence-level-MIS) 的结论,同时还给出了更准确的数学说明
- 注:本文和 NLP——LLM对齐微调-RL-Collapse-Training-Inference-Mismatch(Sequence-level-MIS) 中所说的 Token-level 和 Sequence-level 都是针对重要性采样权重而言的,不是针对 RL 目标本身,本文会直接使用到类似 RL 目标的表达,容易让读者误解是 RL 建模目标本身的建模方式(Token-level or Sequence-level)
- 作者通过大量实验证明了保持这种一阶近似有效性的技术(例如重要性采样修正、截断以及针对 MoE 模型的路径回放)都能有效地稳定 RL 训练
- 论文进一步研究了在不同 Off-policy 程度下稳定 RL 训练的方案,并表明只要能训练稳定,同一个基础模型在长时间的 RL 训练后始终会收敛到相似的性能
- 本文整体有较强的理论意义,核心是证明了:LLM RL 的重要性采样最优是 Sequence-level 的,而 Token-level 重要性采样是对 Sequence-level 重要性采样的一阶近似
- 论文为 LLM 的 RL 提出了一种新颖的表述,解释了为何以及在何种条件下,可以通过诸如 REINFORCE 等策略梯度方法中的替代性 Token-level 目标来优化真实的 Sequence-level 奖励
- 亮眼的地方:作者通过一阶近似(first-order approximation),展示了 只有当训练-推理差异(training-inference discrepancy)和策略陈旧性(policy staleness)都被最小化时 ,这种替代性目标才变得越来越有效
- 这一 Insight 为几种广泛采用的稳定 RL 训练技术的关键作用提供了 Principled 解释:
- 包括重要性采样修正、截断(clipping)
- 特别是针对 MoE 模型的路径回放(Routing Replay for MoE models))
- 注:本文没有特意强调 MIS 等方法
- 通过使用总计数十万 GPU 小时的 30B MoE 模型进行大量实验,论文表明
- 对于 On-policy 训练,带有重要性采样修正的基本策略梯度算法实现了最高的训练稳定性
- 当引入 Off-policy 更新以加速收敛时,结合截断和路径回放对于缓解策略陈旧性引起的不稳定性变得至关重要
- Notably,一旦训练稳定下来,无论冷启动初始化(cold-start initialization)如何,长时间的优化总能产生可比较的最终性能
Introduction and Discussion
- RL 已成为增强 LLM 解决复杂问题任务能力的关键技术范式(OpenAI, 2024; 2025; 2025),而一个稳定的训练过程对于成功扩展 RL 至关重要
- 由于语言的上下文特性, LLM-based RL 通常采用 Sequence-level 奖励,即基于完整模型响应分配的标量分数
- 但主流的 RL 算法,如 REINFORCE 和 GRPO,通常采用 Token-level 优化目标
- 奖励(在 Sequence-level 分配)和优化单元(optimization unit,通常 at Token-level)之间的这种不匹配引发了对此类方法合理性和训练稳定性的担忧,而一些研究提出了直接采用 Sequence-level 优化目标(2025; 2025a)
- In particular,Token-level 优化目标也给使用 MoE 模型进行 RL 训练带来了独特的挑战
- For instance,动态专家路由机制可能会使 MoE 模型中的 Token-level 重要性采样比率失效(2025)
- However,目前尚不清楚使用 Token-level 目标优化 Sequence-level 奖励是否合理,如果合理,在多大程度上(或在什么条件下)这种方法是有效的
- 作者为 LLM-based RL 提出了一种新颖的表述
- The key insight 是:为了优化期望的 Sequence-level 奖励,可以采用一个替代性 Token-level 目标作为它的一阶近似
- Specifically,这种近似很可能只在以下两个条件同时成立时才成立:
- (1)训练引擎和推理引擎之间的数值差异(即训练-推理差异)
- (2)采样响应的 rollout 策略(rollout policy)与待优化的目标策略(target policy)之间的差异(即策略陈旧性)都被最小化
- 这一 Insight 为几种稳定 RL 训练的技术如何工作提供了 Principled 解释,例如
- (1)重要性采样权重是一阶近似下替代性 Token-level 目标的内在组成部分;
- (2)截断机制可以通过防止激进的策略更新来抑制策略陈旧性;
- (3)对于 MoE 模型,路径回放方法(Routing Replay approach)(2025; 2025)在策略优化过程中固定路由的专家,可以减少训练-推理差异和策略陈旧性
- 为了实证验证论文的 Insight 并研究稳定 RL 训练的实用方案,作者使用一个 30B 的 MoE 模型进行了大量实验,总计达数十万 GPU 小时
- 论文的主要结论包括:
- (1)对于 On-policy 训练,带有重要性采样修正的基本策略梯度算法产生了最高的训练稳定性;
- (2)当引入 Off-policy 更新以加速收敛时,即将大批次响应拆分为 mini-batch 进行多次梯度更新,结合截断和路径回放变得必要,以减轻策略陈旧性引起的不稳定性;
- (3)一旦训练稳定下来,具有不同冷启动初始化的模型始终能达到可比较的最终性能
- 这激励未来的工作更多地关注 RL 本身 ,而不是过度关注冷启动初始化的细节 ,因为后者的差异在长时间的 RL 训练后预计会消失
- In summary,论文在两个方面做出了贡献:
- Theoretically,作者 LLM-based 强化学习提出了一种新颖的表述,揭示了通过 Token-level 目标优化 Sequence-level 奖励合理性的条件
- Specifically,基础一阶近似的有效性取决于联合最小化训练-推理差异和策略陈旧性
- Empirically,通过使用 MoE 模型进行总计数十万 GPU 小时的大量实验,作者证明了保持一阶近似有效性的几种技术在稳定 RL 训练中始终表现出实际效能,特别是为 MoE 模型定制的路径回放方法
- Theoretically,作者 LLM-based 强化学习提出了一种新颖的表述,揭示了通过 Token-level 目标优化 Sequence-level 奖励合理性的条件
Formulation for Reinforcement Learning with LLMs
Notation
- 将一个参数化为 \(\theta\) 的自回归 LLM (autoregressive LLM)定义为一个策略 \(\pi_{\theta}\)
- 用 \(x\) 表示输入 Prompt ,用 \(\mathcal{D}\) 表示 Prompt Set
- 在策略 \(\pi_{\theta}\) 下,对 Prompt \(x\) 的响应 \(y\) 的似然表示为 \(\pi_{\theta}(y|x)=\prod_{i=1}^{|y|}\pi_{\theta}(y_t|x,y_{ < t})\),其中 \(|y|\) 是 \(y\) 中的 Token 数量
- 考虑到语言的上下文特性,论文关注 Sequence-level 奖励 Setting,即整个响应 \(y\) 被分配一个单一的标量奖励 \(R(x,y)\)
- 论文不考虑 Value-based Settings(例如 PPO, 2017)
- Value-based Settings 下,策略优化由为响应 \(y\) 中每个 Token 分配标量分数的 Value Model 引导
- 这是因为作者发现设计通用且可扩展的方法来获得可靠的 Value Model 本身就非常困难(if not impossible)
- 理解:如果使用 Value Model ,类似 PPO 等其实时标准的 RL,没有论文所谓的 Sequence-level 奖励和 Token-level 目标不一致的问题
Expected Sequence-level Reward is Hard to Directly Optimize
- 我们希望的最大化的真实 Sequence-level 奖励为:
$$
\mathcal{J}^{\text{seq} }(\theta)=\mathbb{E}_{x\sim\mathcal{D},y\sim\pi_{\theta}(\cdot|x)}\left[R(x,y)\right],
$$- 其中 \(\pi_{\theta}\) 是待优化的目标策略
- 由于响应通常不是在训练引擎(例如 Megatron 和 FSDP)中采样,而是在推理引擎(例如 SGLang 和 vLLM)中采样,论文采用重要性采样技巧进行简单的变换:
$$
\mathcal{J}^{\text{seq} }(\theta)=\mathbb{E}_{x\sim\mathcal{D},y\sim\pi_{\theta}(\cdot|x)}\left[R(x,y)\right]=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_\text{old} }} }(\cdot|x)\left[\underbrace{\frac{\pi_{\theta}(y|x)}{ \color{red}{\mu_{\theta_\text{old} }}(y|x)}}_{\text{Sequence-level IS weight} } R(x,y)\right],
\tag{1}
$$- 其中 \(\color{red}{\mu_{\theta_\text{old} }}\) 表示采样响应的 rollout 策略
- Note that 论文使用符号 \(\mu\) 来区分推理引擎中的策略与训练引擎中的策略(用 \(\pi\) 表示),因为训练和推理引擎之间通常存在数值差异(2025)
- 等式(1)中的 Sequence-level 目标具有以下梯度:
$$
\begin{aligned}
\nabla_{\theta}\mathcal{J}^{\text{seq} }(\theta) &=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\frac{\pi_{\theta}(y|x)}{\color{red}{\mu_{\theta_{\text{old}} } }(y|x)}\ R(x,y)\ \nabla_{\theta}\log\pi_{\theta}(y|x)\right]\\
&=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\frac{\pi_{\theta}(y|x)}{\color{red}{\mu_{\theta_{\text{old}} } }(y|x)}\ R(x,y)\sum_{t=1}^{|y|}\nabla_{\theta}\log\pi_{\theta}(y_t|x,y_{ < t})\right].
\end{aligned}
\tag{2}
$$ - However,由于序列似然(即 \(\pi_{\theta}(y|x)\) 和 \(\color{red}{\mu_{\theta_{\text{old}} } }(y|x)\))的数值范围大且方差高,这个梯度通常难以利用(Usually intractable),使得直接优化等式(1)中的 Sequence-level 目标变得困难
- 问题:这里如果改一下,恢复成下面这样,是不是就遇不到上面比值的问题了?
$$
\begin{align}
\nabla_{\theta}\mathcal{J}^{\text{seq} }(\theta) &=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\frac{\pi_{\theta}(y|x)}{\color{red}{\mu_{\theta_{\text{old}} } }(y|x)}\ R(x,y)\ \nabla_{\theta}\log\pi_{\theta}(y|x)\right]\\
&=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\frac{1}{\color{red}{\mu_{\theta_{\text{old}} } }(y|x)}\ R(x,y)\ \nabla_{\theta} \pi_{\theta}(y|x)\right]\\
\end{align}
$$- 理解:其实改不改形式都是一样的本质是一样的,实现时还是针对 Loss 去实现的,这里的 Loss 就是目标(公式 1)本身,这里求出梯度来可以更清晰的看到更新的方向跟原始的 vanilla 策略梯度法 有什么区别
- 问题:这里如果改一下,恢复成下面这样,是不是就遇不到上面比值的问题了?
Token-level Objective as a First-order Approximation to Sequence-level Objective(Token-level 目标是 Sequence-level 目标的一阶近似)
- 关键步骤是考虑以下替代性 Token-level 目标:
$$
\mathcal{J}^{\text{token} }(\theta)=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\sum_{t=1}^{|y|}\underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} }_{\text{ Token-level IS weight} }\ R(x,y)\right],
\tag{3}
$$- 理解:和公式 1 的唯一差别就是 Sequence-level 的重要性权重改成 Token-level 的重要性权重
- 这里标题使用 Objective 其实容易让人误解,这里仅仅是 重要性权重 是 Sequence-level or Token-level
- 注意 \(R(x,y)\) 仍然还是不变的,始终代表的是 Sequence-level 整体的奖励 ,不是单个 Token 的奖励(其实语言模型里面单个 Token 没有奖励,因为除了最后一个 Token 以外,其他 Token 其实很难评估是否准确)
- 理解:和公式 1 的唯一差别就是 Sequence-level 的重要性权重改成 Token-level 的重要性权重
- 其梯度如下:
$$
\nabla_{\theta}\mathcal{J}^{\text{token} }(\theta)=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\sum_{t=1}^{|y|}\underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} }_{\text{Token-level IS weight} }\ R(x,y)\ \nabla_{\theta}\log\pi_{\theta}(y_t|x,y_{ < t})\right].
\tag{4}
$$- 这实际上就是带了 Token-level 重要性采样权重的基本策略梯度算法(即 REINFORCE)
- 理解:公式 4 跟公式 2 比较起来,主要就是公式 4 重要性采样权重是 Token-level,公式 2 则重要性权重是 Sequence-level
- 这里的核心 Insight 是,可以将等式(3)中的 Token-level 优化目标视为论文真正想要优化的等式(1)中 Sequence-level 目标的一阶近似
- To be specific,假设 \(\pi_{\theta}\) 和 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 略有不同,令 \(\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}=1+\delta_t\),其中 \(\delta_t\) 是一个小量(small quantity)
- 于是可以有以下近似:
$$
\begin{align}
\frac{\pi_{\theta}(y|x)}{\color{red}{\mu_{\theta_{\text{old}} } }(y|x)}&=\prod_{t=1}^{|y|}(1+\delta_t) \\
&\approx 1+\sum_{t=1}^{|y|}\delta_t+\mathcal{O}\left(\delta^{2}\right) \\
&\approx 1+\sum_{t=1}^{|y|}\delta_t,
\end{align}
$$- 理解:将联合概率分布展开以后相乘,可以移除所有二阶小量
- 其中最右侧的推导忽略了二阶及更高阶的小项,如 \(\delta_t\delta_j\),因此论文有:
$$
\begin{aligned}
\nabla_{\theta}\mathcal{J}^{\text{seq} }(\theta) &=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[R(x,y)\ \nabla_{\theta}\left(\frac{\pi_{\theta}(y|x)}{\color{red}{\mu_{\theta_{\text{old}} } }(y|x)}\right)\right]\\
&\approx\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[R(x,y)\ \nabla_{\theta}\left(1+\sum_{t=1}^{|y|}\delta_t\right)\right]\\
&=\mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[R(x,y)\ \nabla_{\theta}\left(\sum_{t=1}^{|y|}\underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} }_{\text{token-level IS weight} }\right)\right]\\
&=\nabla_{\theta}\mathcal{J}^{\text{token} }(\theta).
\end{aligned}
$$- 理解:第二行到第三行中,常数 1 求导的值为 0,所以可以消掉,移除高阶无穷小的操作使得我们可以将 Sequence-level 的重要性权重改成 Token-level 的
- 这就是为什么论文说等式(3)是等式(1)的一阶近似
- Therefore,当 \(\pi_{\theta}\) 接近 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 时,可以通过使用等式(4)中的梯度更新模型参数 \(\theta\) 来 improve 等式(1)中的 Sequence-level 目标
Conditions for First-order Approximation to Hold(一阶近似成立的条件)
为了使一阶近似成立,我们要求目标策略 \(\pi_{\theta}\) 和 rollout 策略 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 接近,但这并不直观
为了明确起见,考虑到可能存在 训练-推理差异和策略陈旧性 ,给定 \(x\) 和每个 Token \(y_t\),我们可以将其重要性采样权重重写为:
$$
\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}=\underbrace{\frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} }_{\text{training-inference discrepancy} }\times\underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} }_{\text{policy staleness} },
\tag{5}
$$- 其中 \(\color{blue}{\pi_{\theta_{\text{old}} } }\) 表示由训练引擎计算的 rollout 策略,不同于推理引擎中的策略 \(\color{red}{\mu_{\theta_{\text{old}} } }\)
- 理解:采样策略和重要性权重使用的 old 策略可能不同
- 推理引擎和训练引擎可能会有一定误差
- 注意:这里跟是否 off-policy ,是否异步 RL 没有关系,无论在何种情况下,理论上我们都希望能够严格保证 \(\color{blue}{\pi_{\theta_{\text{old}} } }\) 和 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 完全一致
- 所以,如果没有 推理引擎和训练引擎 的误差,则我们是会严格保证 \(\color{blue}{\pi_{\theta_{\text{old}} } }\) 和 采样时使用的策略 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 完全一致的
Therefore,从等式(5)的分解来看,\(\pi_{\theta}\) 和 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 之间的差距来自两个方面:训练-推理差异和策略陈旧性
- 关于训练-推理差异(training–inference discrepancy) :即训练和推理引擎之间的数值带来的差异( \(\frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}\) 部分)
- training–inference discrepancy 的原因通常很复杂,并且与底层基础设施密切相关
- 例如,训练和推理引擎通常为了达到峰值性能而采用不同的计算内核,这会导致在相同的模型输入下产生不一致的输出
- 即使在单个引擎内部,特别是在推理端,为了最大化吞吐量,通常禁用批次不变内核(batch-invariant kernels)(2025),因此相同的模型输入仍然可能收到不同的输出
- 对于 MoE 模型,不一致的专家路由会进一步放大训练-推理差异,论文将在第 3 节详细讨论
- 关于策略陈旧性(policy staleness) :即 \(\color{blue}{\pi_{\theta_{\text{old}} } }\) 与待优化的目标策略 \(\pi_{\theta}\) 之间的差异 ( \(\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}\) 部分)
- policy staleness 通常源于为提升训练效率和计算利用率所做的权衡
- 由于 RL 中的 rollout 阶段通常受生成长度的时间限制,为了通过增加计算资源来加速收敛,我们经常将大批次采样响应拆分为 mini-batch 进行多次梯度更新
- Consequently,后面消耗的 mini-batch 可能表现出更大的策略陈旧性
- 注意:再次强调,这里多次更新的情况下,使用的 \(\pi_{\theta_\text{old}}\) 肯定会始终跟原始的 Rollout 策略保持一致的,所以理论上策略陈旧性不会导致 Rollout 策略和 \(\pi_{\theta_\text{old}}\) 不一致的问题 ,只是说 rollout 策略与待优化的目标策略之间的差异确实会提升
- 在异步 RL 框架中,单个响应可以由多个模型版本顺序生成,这也会引入策略陈旧性
- 理解:强调 again,这种情况下的策略陈旧性也不会带来 Rollout 策略和 \(\pi_{\theta_\text{old}}\) 不一致的问题 ,因为我们一般认为在 PPO 中,不考虑推理引擎和训练引擎本身以及 FlashAttention 等导致的随机性 的差异,会尽量严格保证 \(\pi_{\theta_\text{old}}\) 是 Rollout 策略(这是推导过程严格要求的)
- 补充:为了进一步强调 \(\pi_{\theta_\text{old}}\) 是 Rollout 策略 ,我们给出 PPO 算法的一般性实现(在不考虑 异步 RL 框架总的),参考自 PPO 简单实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def update(self, transition_dict):
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
td_delta = td_target - self.critic(states)
advantage = rl_utils.compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)
old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach() # 注意:old_log_probs 的定义在循环外
for _ in range(self.epochs):
log_probs = torch.log(self.actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs) # 注意:循环内部不再更新 old 策略,这里 需要严格保障 old 策略始终和 采样使用的 Rollout 策略对齐
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage
actor_loss = torch.mean(-torch.min(surr1, surr2))
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad() # 注意:因为 Critic 可能和 Actor 有相同参数,此时会共享一个梯度 变量,不能再 Actor 计算梯度以后再清空梯度
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
- 关于训练-推理差异(training–inference discrepancy) :即训练和推理引擎之间的数值带来的差异( \(\frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}\) 部分)
Therefore,为了保证等式(3)中替代性 Token-level 目标所依赖的一阶近似的有效性
In principle,我们应该从两个方向缩小 \(\pi_{\theta}\) 和 \(\color{red}{\mu_{\theta_{\text{old}} } }\) 之间的差距 :
- 减少训练和推理引擎之间的数值差异
- 将策略陈旧性控制在适度的范围内
Challenge for Mixture of Experts, and Routing Replay
Expert Routing Hinders First-order Approximation to Hold(专家路由是阻碍一阶近似成立的其中一个问题)
- 当涉及到 MoE 模型时,一阶近似成立的条件变得不那么直接
- Specifically,在生成每个 Token 的前向传播过程中,MoE 模型通过专家路由机制动态选择并仅激活一小部分专家参数
- 将专家路由纳入等式(5),我们可以将 MoE 模型的 Token-level 重要性采样权重写为:
$$
\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}=\frac{\pi_{\theta}(y_t|x,y_{ < t},\color{magenta}{e_t^\pi})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} = \underbrace{\frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{blue}{e^{\pi}_{\text{old},t}})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} }_{\text{training–inference discrepancy} } \times \underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t},\color{magenta}{e_t^\pi})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{blue}{e^{\pi}_{\text{old},t}})} }_{\text{policy staleness} },
\tag{6}
$$- 其中 \(e^{\pi}\) 和 \(e^{\mu}\) 分别表示训练和推理引擎中路由的专家,下标 “old” 对应于 rollout 策略
- At this point,基于 MoE 模型的强化学习挑战变得清晰:
- 专家路由与训练-推理差异和策略陈旧性交织在一起,增加了等式(3)中替代性 Token-level 优化目标所依赖的一阶近似失效的可能性
- More specifically,训练-推理差异可能导致在相同的模型参数和输入下,训练和推理引擎中路由的专家不一致,即 \(\color{blue}{e^{\pi}_{\text{old},t}}\) 与 \(\color{red}{e^{\mu}_{\text{old},t}}\) 不一致)
- 专家路由的这种分歧反过来又会放大最终输出的差异
- Furthermore,策略陈旧性不仅体现在模型参数的变化上(即 \(\theta\) 与 \(\theta_{\text{old} }\)),还体现在路由专家的变化上(即 \(\color{magenta}{e_t^\pi}\) 与 \(\color{blue}{e^{\pi}_{\text{old},t}}\)),这可能会极大地改变由激活参数定义的最终策略
Routing Replay Restores First-order Approximation, Yet May Introduce Bias(注:路径回放可恢复一阶近似,但可能引入偏差)
- 认识到专家路由破坏了 MoE 模型中一阶近似的有效性,我们可以通过路径回放方法(Routing Replay)(2025)来消除这种影响
- 路径回放的核心思想是在策略优化过程中固定路由的专家,从而稳定 MoE 模型的 RL 训练,使模型能够像密集模型一样被优化
- 基于等式(6),论文将路径回放的两种具体实现形式化,即普通路径回放和Rollout 路径回放
- 普通路径回放(Vanilla Routing Replay, R2) (GSPO)Group Sequence Policy Optimization, 20250728, Qwen 侧重于通过在进行梯度更新时,将目标策略路由修改为 \(\color{blue}{e^{\pi}_{\text{old},t}}\)
- 减轻专家路由对策略陈旧性的影响:将公式 6 中 \(\color{magenta}{e_t^\pi}\) 替换为 \(\color{blue}{e^{\pi}_{\text{old},t}}\)
$$
\frac{\pi^{R2}_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} = \frac{\pi_{\theta}(y_t|x,y_{ < t},\color{blue}{e^{\pi}_{\text{old},t}})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} = \underbrace{\frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{blue}{e^{\pi}_{\text{old},t}})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} }_{\text{training–inference discrepancy} } \times \underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t},\color{blue}{e^{\pi}_{\text{old},t}})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{blue}{e^{\pi}_{\text{old},t}})} }_{\text{policy staleness} \ \color{red}{\downarrow}}.
$$
- 减轻专家路由对策略陈旧性的影响:将公式 6 中 \(\color{magenta}{e_t^\pi}\) 替换为 \(\color{blue}{e^{\pi}_{\text{old},t}}\)
- Rollout 路径回放(Rollout Routing Replay, R3) (Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers, 20250113 & 20251021, LLM-Core Xiaomi, Xiaomi Mimo, Fuli Luo 旨在策略梯度更新时,统一所有三个路由为 \(\color{red}{e^{\mu}_{\text{old},t}}\)
- 减轻专家路由对策略陈旧性的影响:将公式 6 中 \(\color{magenta}{e_t^\pi}\) 替换为 \(\color{red}{e^{\mu}_{\text{old},t}}\)
- 减少专家路由对训练-推理差异的影响:将公式 6 中的 \(\color{red}{e^{\mu}_{\text{old},t}}\) 替换为 \(\color{red}{e^{\mu}_{\text{old},t}}\)
$$
\frac{\pi^{R3}_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} = \frac{\pi_{\theta}(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} = \underbrace{\frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} }_{\text{training–inference discrepancy} \ \color{red}{\downarrow} } \times \underbrace{\frac{\pi_{\theta}(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t},\color{red}{e^{\mu}_{\text{old},t}})} }_{\text{policy staleness} \ \color{red}{\downarrow} }.
$$
- 普通路径回放(Vanilla Routing Replay, R2) (GSPO)Group Sequence Policy Optimization, 20250728, Qwen 侧重于通过在进行梯度更新时,将目标策略路由修改为 \(\color{blue}{e^{\pi}_{\text{old},t}}\)
- Therefore,路径回放通过减少训练-推理差异(在 R3 中)和缓解策略陈旧性(在 R2 和 R3 中),直观地恢复了 MoE 模型中一阶近似的有效性
- However,作者指出,它也隐式地给目标策略引入了偏差 ,正如符号 \(\pi^{R2}_{\theta}\) 和 \(\pi^{R3}_{\theta}\) 所暗示的那样
- Specifically,在等式(3)中旨在优化的原始目标策略是 \(\pi_{\theta}\),其中每个 Token \(y_t\) 的似然应受 naturally-routed 专家 \(\color{magenta}{e_t^\pi}\) 支配
- 但路径回放将路由的专家限制为 \(\color{blue}{e^{\pi}_{\text{old},t}}\) 或 \(\color{red}{e^{\mu}_{\text{old},t}}\),leading to another 偏离原始 \(\pi_{\theta}\) 目标策略 \(\pi^{R2}_{\theta}\) 或 \(\pi^{R3}_{\theta}\)(由 \(\color{magenta}{e_t^\pi}\) 定义)的问题
- In particular,当论文将大批次拆分为 mini-batch 进行多次梯度更新时,R2 和 R3 可能拥有不同程度的偏差,如表 1 所示
- R2 在第一个 mini-batch 中没有改变原始目标策略的路由索引(因为第一个 mini-batch 是 on-policy 的)
- R3 在第一个 mini-batch 开始就一直没有对齐
- 论文推测这可能导致 R2 和 R3 表现出不同的性能,特别是当批次大小与 mini-batch 大小的比率(即 Off-policy 程度)变化时
- 表 1:R2 和 R3 如何改变原始目标策略 \(\pi_{\theta}\) 的比较

- Nevertheless,很难明确评估路径回放的利弊孰轻孰重
- 改变路由专家虽然向优化目标引入了偏差,但也使得一阶近似更可能成立
- 一阶近似依赖于将 \(\pi^{R2}_{\theta}\) 或 \(\pi^{R3}_{\theta}\) 作为目标策略的改变后的 Token-level 目标
- 作者认为需要进一步的实验来验证路径回放的实用性
- 改变路由专家虽然向优化目标引入了偏差,但也使得一阶近似更可能成立
Empirical Analyses
MiniRL: A Minimalist Baseline Algorithm
- 在论文的实验中,论文对等式(3)中的 REINFORCE 优化目标应用了两个最小的修改,作为一个极简主义 Baseline 算法
- Firstly,论文对原始奖励应用 Group-normalization(2024)作为每个响应 \(y\) 的优势估计:
$$ \widehat{A}(x,y) = R(x,y) - \mathbb{E}_{y’\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)} [R(x,y’)]$$- 这也降低了原始奖励的方差
- Secondly,论文采用了 PPO(2017)中的截断机制,通过停止某些 Token 的梯度来防止激进的策略更新,这有望抑制策略陈旧性
- 遵循 decoupled PPO approach(2022),并使用 \(\color{blue}{\pi_{\theta_{\text{old}} } }\) 作为近端策略(proximal policy),根据 \(\pi_{\theta}(y_t|x,y_{ < t})\) 和 \(\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})\) 的比率来决定是否截断 Token \(y_t\)
While there are alternative clipping strategies, such as clipping a whole response based on the ratio of sequence likelihood (GSPO, 2025), we found that the current clipping strategy has worked decently. Therefore, we leave the study of clipping or masking strategies for future work. Similarly, exploring better advantage estimates \(\widehat{A}(x,y)\) may also be helpful, but falls outside the scope of this work
- 遵循 decoupled PPO approach(2022),并使用 \(\color{blue}{\pi_{\theta_{\text{old}} } }\) 作为近端策略(proximal policy),根据 \(\pi_{\theta}(y_t|x,y_{ < t})\) 和 \(\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})\) 的比率来决定是否截断 Token \(y_t\)
- 得到的极简主义基线算法,论文称之为 MiniRL,如下所示:
$$
\begin{aligned}
\mathcal{J}_{\text{MiniRL} }(\theta) &= \mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)}\left[\sum_{t=1}^{|y|} M_t \operatorname{sg}\left[\frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}\right] \widehat{A}(x,y) \log\pi_{\theta}(y_t|x,y_{ < t})\right],\\
M_t &= \begin{cases}
0 & \text{if } \widehat{A}(x,y)>0 \text{ and } r_t > 1+\varepsilon_{\text{high} },\\
0 & \text{if } \widehat{A}(x,y)<0 \text{ and } r_t < 1-\varepsilon_{\text{low} },\\
1 & \text{otherwise},
\end{cases} \qquad r_t = \frac{\pi_{\theta}(y_t|x,y_{ < t})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})},
\end{aligned}
\tag{7}
$$- 其中 \(\operatorname{sg}\) 表示停止梯度操作
- 特别注意:MiniRL 的优化目标(公式 7 中的重要性采样分母上是 \(\mu_{\theta_\text{old}}\),而不是 \(\pi_{\theta_\text{old}}\)
- 理解:Clip 部分实际上就是 普通的 DAPO 方法,只是写法上改成了分段式,MiniRL 与 GRPO 的区别是:
- 第一:MiniRL 不包含 KL 散度部分
- 第二:MiniRL 移除了样本内部的平均(也称为长度归一化,Length Normalization)
- 第三:MiniRL 包含重要性比例截断上下界分离(跟 DAPO 一样)
- 第四:MiniRL 考虑了训练-推理差异(Training-Inference Discrepancy)
- 其实以上所有修改都是其他论文使用过的方法,论文的重点共享在于分析上而不是在于算法设计上
- Firstly,论文对原始奖励应用 Group-normalization(2024)作为每个响应 \(y\) 的优势估计:
- It is noteworthy that 采用 MiniRL 作为基线算法是为了尽可能(在梯度上)与等式 3 中的替代性 Token-level 目标保持一致,这已在第 2 节的表述中得到证明
- 在附录 A 中,作者将提供 MiniRL 与其他算法(如 GRPO(2024)和 CISPO(2025))的比较
- 论文所有的实验都将基于 MiniRL 实现
Experimental Setup
- 论文在数学推理任务(mathematical reasoning task)上进行实验,其中模型响应与真实答案进行比较,然后分配二元奖励(即 \(R(x,y)\in\{0,1\}\))
- 作者精心挑选了 4096 个带有已验证答案的数学问题作为 RL 训练的 Prompt Set,报告在 HMMT25、AIME25 和 AIME24 基准测试上对 32 个采样响应的平均准确率,每个基准包含 30 个竞赛级别的问题(总共 90 个问题)
- 使用从 Qwen3-30B-A3B-Base 微调而来的冷启动模型进行实验
- 采用 FP8 推理和 BF16 训练的设置,为算法正确性提供了一个压力测试,其中推理精度低于训练精度,且训练-推理差异很大
- 除了训练奖励,论文还报告两个指标的动态变化:
- (1)目标策略的 Token-level 熵,通过下式近似:
$$
\mathbb{H}[\pi_{\theta}] \approx \mathbb{E}_{x\sim\mathcal{D},y_{ < t}\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)} \left[-\sum_{w\in\mathcal{V} } \pi_{\theta}(w|x, y_{ < t})\log\pi_{\theta}(w|x, y_{ < t})\right],
$$- 其中 \(\mathcal{V}\) 表示词汇表;
- (2)推理和训练引擎中 rollout 策略之间的 KL 散度,计算如下:
$$
\mathbb{D}_{\text{KL} }[\color{red}{\mu_{\theta_{\text{old}} } } | \color{blue}{\pi_{\theta_{\text{old}} } }] = \mathbb{E}_{x\sim\mathcal{D},y_t\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x,y_{ < t})} \left[\log\frac{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x, y_{ < t})}\right].
$$- 论文报告这个指标是因为最近的工作(2025; 2025a)揭示了 RL 训练的不稳定性或崩溃通常伴随着训练-推理差异的急剧增加
- (1)目标策略的 Token-level 熵,通过下式近似:
- 为了进行对照实验,论文采用标准的同步 RL 框架
- 在每个全局步骤中
- 首先,采样一个包含 \(B\) 个 Prompt 的批次,并使用推理引擎中的 rollout 策略为每个 Prompt 采样 \(G\) 个响应
- 然后,论文将响应拆分为 \(N\) 个 mini-batch ,并在训练引擎中应用 \(N\) 次梯度更新
- 每个全局步骤中最终更新的策略将在下一个全局步骤中作为新的 rollout 策略使用
- 在所有实验运行中,作者为每次梯度更新使用相同的 mini-batch 大小,即 1024 个响应(\(B=64\) 且 \(G=16\))
- 在每个全局步骤中
- 对于其他超参数,将最大生成长度设置为 32,768,并在 MiniRL 中设置 \(\varepsilon_{\text{high} }\) 为 0.27,\(\varepsilon_{\text{low} }\) 为 0.2
- 另外,作者还将截断重要性采样技巧(Truncated Importance Sampling trick, TIS)(2025)应用于 MiniRL 中的 Token-level 重要性采样权重,截断阈值设为 5
- 问题:这里 TIS 并不是 MiniRL 的标配吗?为什么前面不说?
- 论文的实验总计数十万 GPU 小时,消耗的计算量估计为每梯度步骤 \(5\sim6\) GPU 小时
Results of On-policy Training
- 首先在 On-policy 训练(全局批次大小等于 mini-batch 大小)下验证 Token-level 优化目标所依赖的一阶近似的有效性是否与训练稳定性相关
- 在这种 \(\theta=\theta_{\text{old} }\) 的 On-policy 设置下,MiniRL 退化为以下基本策略梯度算法:
$$
\mathcal{J}_{\text{MiniRL} }(\theta) = \mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)} \left[\sum_{t=1}^{|y|} \frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} \widehat{A}(x,y) \log\pi_{\theta}(y_t|x,y_{ < t})\right],
$$ - 所以这里的 IS 权重仅用作训练-推理差异的修正
- 现有的 RL 算法,如 GRPO 和 CISPO,通常在其优化目标中采用长度归一化,并且它们的原始目标没有考虑对训练-推理差异的 IS 修正
- 因此,论文在实验中包含了 MiniRL 的以下两个消融变体:
- 第一个变体:
$$
\mathcal{J}_{\text{MiniRL} }^{\text{w.length-norm} }(\theta) = \mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)} \left[\frac{1}{|y|}\sum_{t=1}^{\color{blue}{|y|}} \frac{\color{blue}{\pi_{\theta_{\text{old}} } }(y_t|x,y_{ < t})}{\color{red}{\mu_{\theta_{\text{old}} } }(y_t|x,y_{ < t})} \widehat{A}(x,y) \log\pi_{\theta}(y_t|x,y_{ < t})\right],
$$- 该变体额外使用了长度归一化;
- 第二个变体:
$$
\mathcal{J}_{\text{MiniRL} }^{\text{wo.train-infer-is} }(\theta) = \mathbb{E}_{x\sim\mathcal{D},y\sim\color{red}{\mu_{\theta_{\text{old}} } }(\cdot|x)} \left[\sum_{t=1}^{|y|} \widehat{A}(x,y) \log\pi_{\theta}(y_t|x,y_{ < t})\right],
$$- 该变体省略了对训练-推理差异的 IS 修正
- 注意,这两个变体不再满足上述一阶近似 ,因为它们的梯度既不等于,也不与等式(1)中真实 Sequence-level 目标的梯度线性相关(忽略奖励归一化)
- 论文还将 MiniRL 和两个变体配备了 R3(R2 在此不适用,见表 1)进行比较
- 第一个变体:
- 从图 1 中,论文得出以下观察和结论:
- MiniRL,即带有 IS 修正的基本策略梯度算法,实现了最佳性能和训练稳定性
- 添加长度归一化导致次优性能,尽管训练保持稳定。这符合预期,因为长度归一化使得对真实期望 Sequence-level 奖励的一阶近似失效,导致了有偏的 Token-level 优化目标
- 移除训练-推理 IS 修正会导致训练迅速崩溃和熵的急剧下降。这证实了 IS 权重是一阶近似的内在组成部分,省略它会立即使 Token-level 优化目标失效
- 在 On-policy 训练中应用 R3 不会带来性能增益,尽管它有效降低了训练-推理差异(如训练-推理 KL 散度所示)
- Moreover,将 R3 与长度归一化结合甚至进一步降低了基准分数,而在没有训练-推理 IS 修正的情况下应用 R3 仍然迅速失败
- 这从实证上证实了论文在第 3.2 节的推测,即路径回放可以改变原始目标策略并向优化目标引入偏差
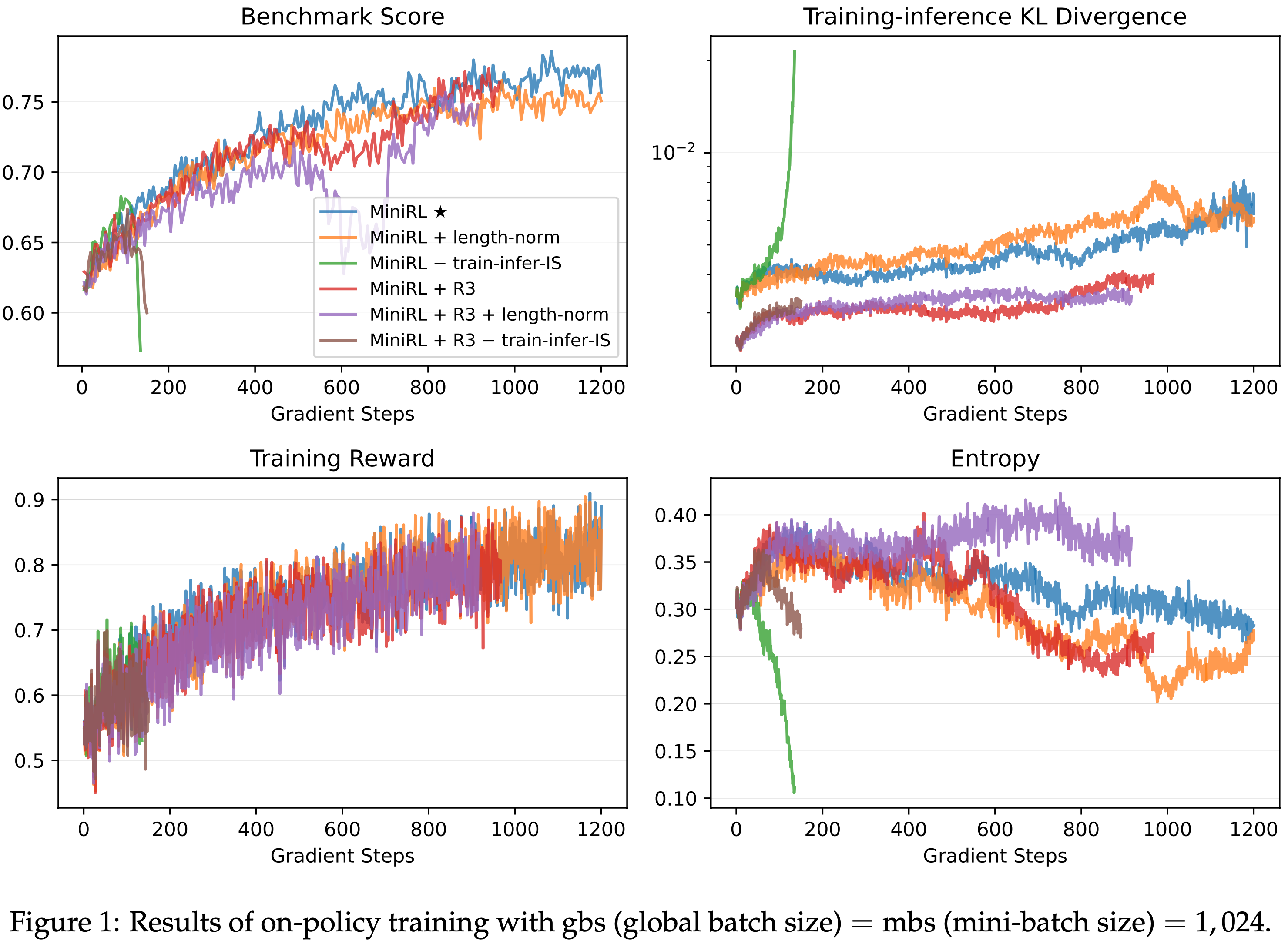
- 这些结果表明,在设计 Token-level 优化目标时,只有那些保持对期望 Sequence-level 奖励一阶近似有效性的目标才能带来改进的训练稳定性和性能
- 这也验证了论文所提出表述的正确性
Results of Off-policy Training
- RL 中的推理时间通常受生成长度限制,无法通过增加计算资源来加速
- 为了利用增加的计算量更快地收敛,常见的做法是引入 Off-policy 更新
- 在同步 RL 框架内,这意味着将大批次响应拆分为 \(N\) 个 mini-batch 进行多次梯度更新
- 为了研究在 Off-policy 设置下稳定 RL 训练的方案,论文实验了三个级别的 Off-policy 程度:
- 在固定 mini-batch 大小为 1024 个响应的情况下,全局批次大小分别变化为 2048、4096 和 8192,对应于 \(N=2,4\) 和 8
- 以 MiniRL 为基线,论文比较了以下方法:
- MiniRL(no clipping)
- MiniRL + R2(no clipping)
- MiniRL + R2 和 MiniRL + R3
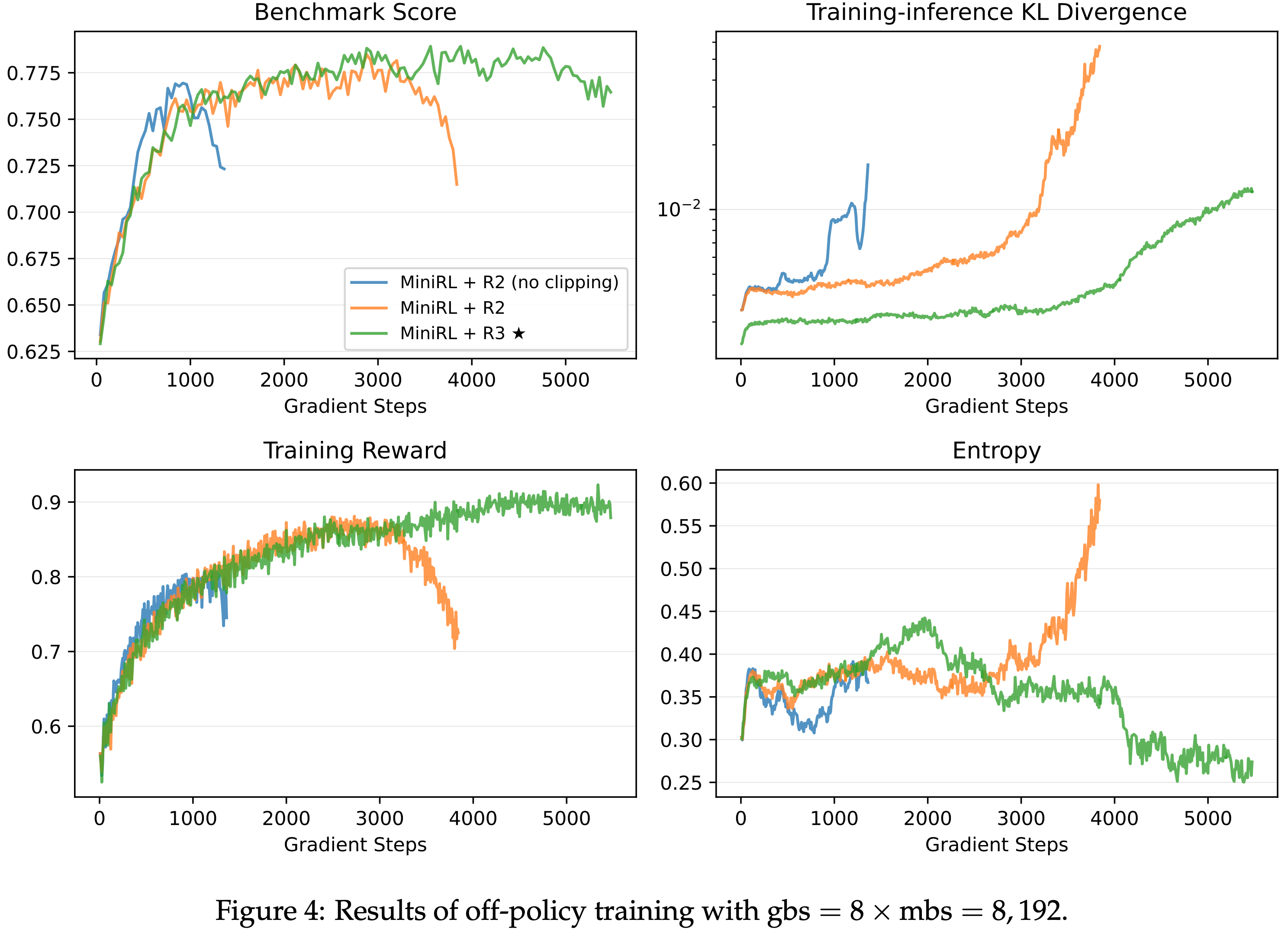
- 从图 2 到图 4,论文得出以下观察和结论:
- 一旦引入 Off-policy 更新,路径回放和截断对于稳定训练都变得至关重要
- 如图 2 和图 3 所示,省略任一路径回放或截断都会导致训练过早崩溃,从而降低峰值性能
- 这表明路径回放减轻了专家路由的影响,而截断机制也有效地防止了激进的策略更新,从而都抑制了策略陈旧性
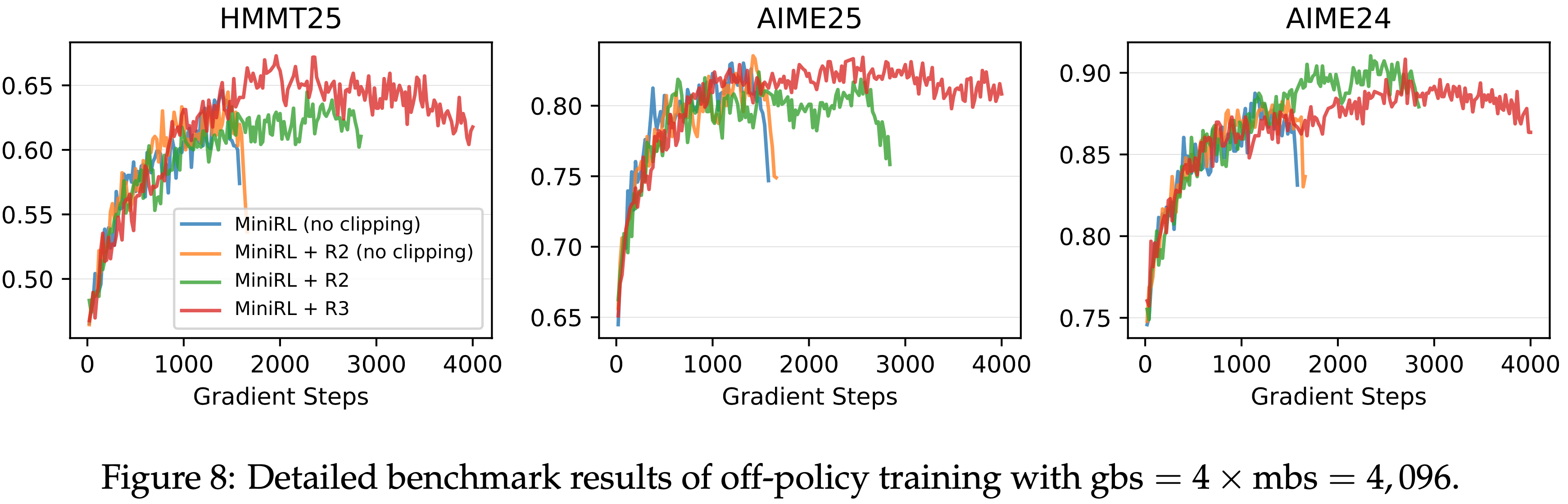
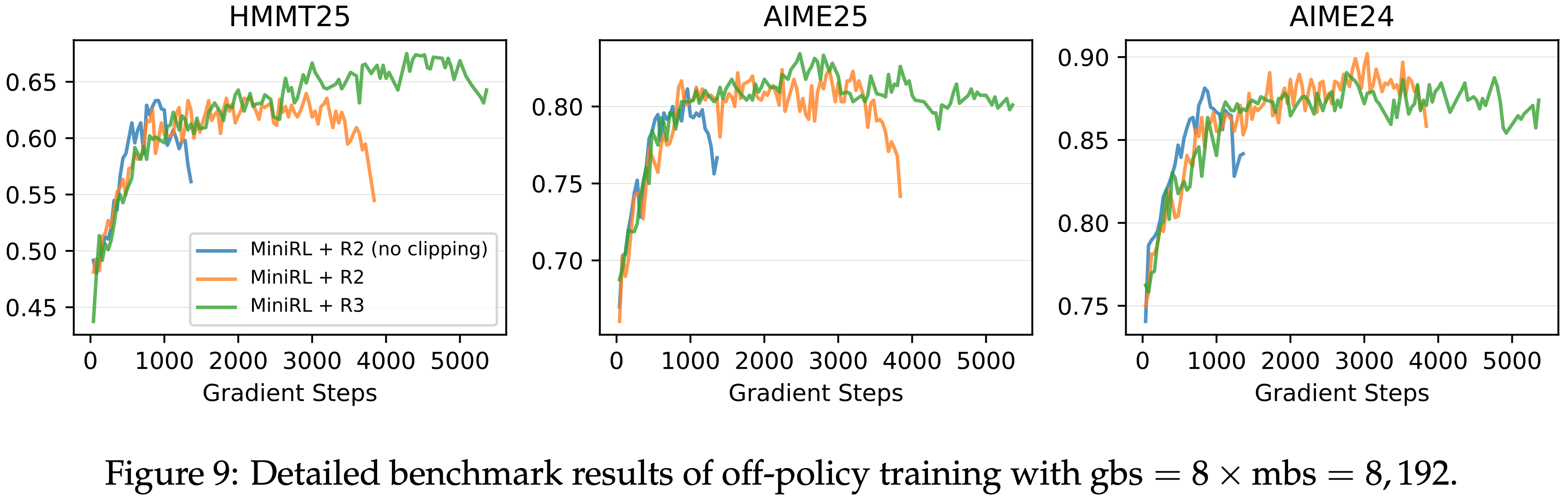
- 当 Off-policy 程度较小时(gbs = \(2 \times\) mbs),R2 优于 R3;而当 Off-policy 程度较大时(gbs = \(4 \times\) mbs 和 gbs = \(8 \times\) mbs),R3 超过了 R2
- Notably,在高 Off-policy 程度下,R2 无法维持稳定的训练,并且其在训练崩溃前达到的峰值性能也略低于 R3
- 结合论文在第 3.2 节的分析(特别是 R2 在第一个 mini-batch 中保持目标策略不变而 R3 改变了它),以及 第 4.3 节的 On-policy 实验结果,作者 hypothesize 当 Off-policy 程度较小时,R3 对目标策略的改变带来的不利影响超过了它在保持一阶近似有效性方面的好处,而在更大的 Off-policy 程度下,情况则相反
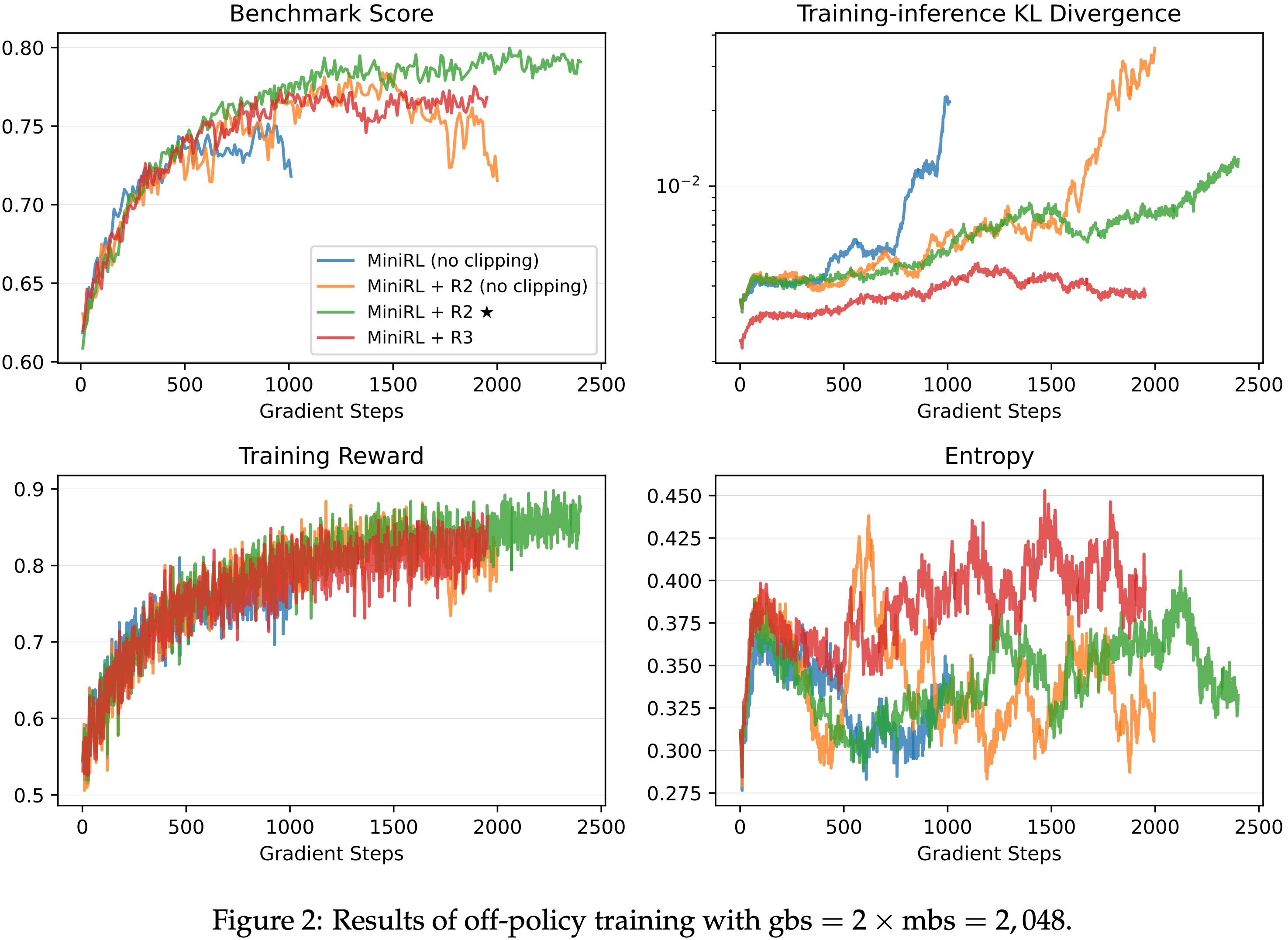
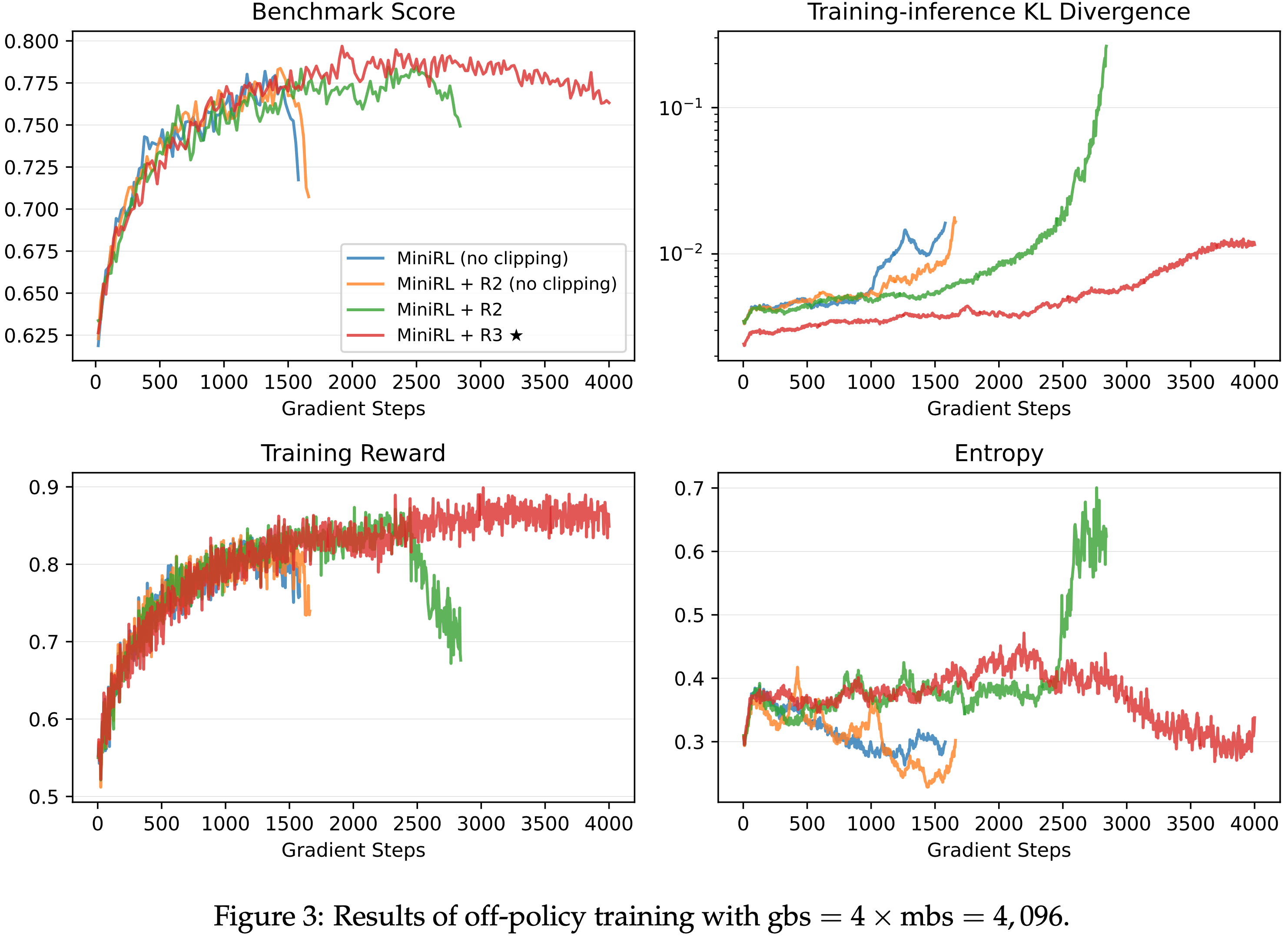
- 一旦引入 Off-policy 更新,路径回放和截断对于稳定训练都变得至关重要
- In Summary,论文发现路径回放和截断对于稳定的 Off-policy 训练是必要的
- 当 Off-policy 程度较小时,R2 足以并且更有效地稳定 MoE 模型的 RL 训练,而在更大的 Off-policy 程度下,R3 变得必要
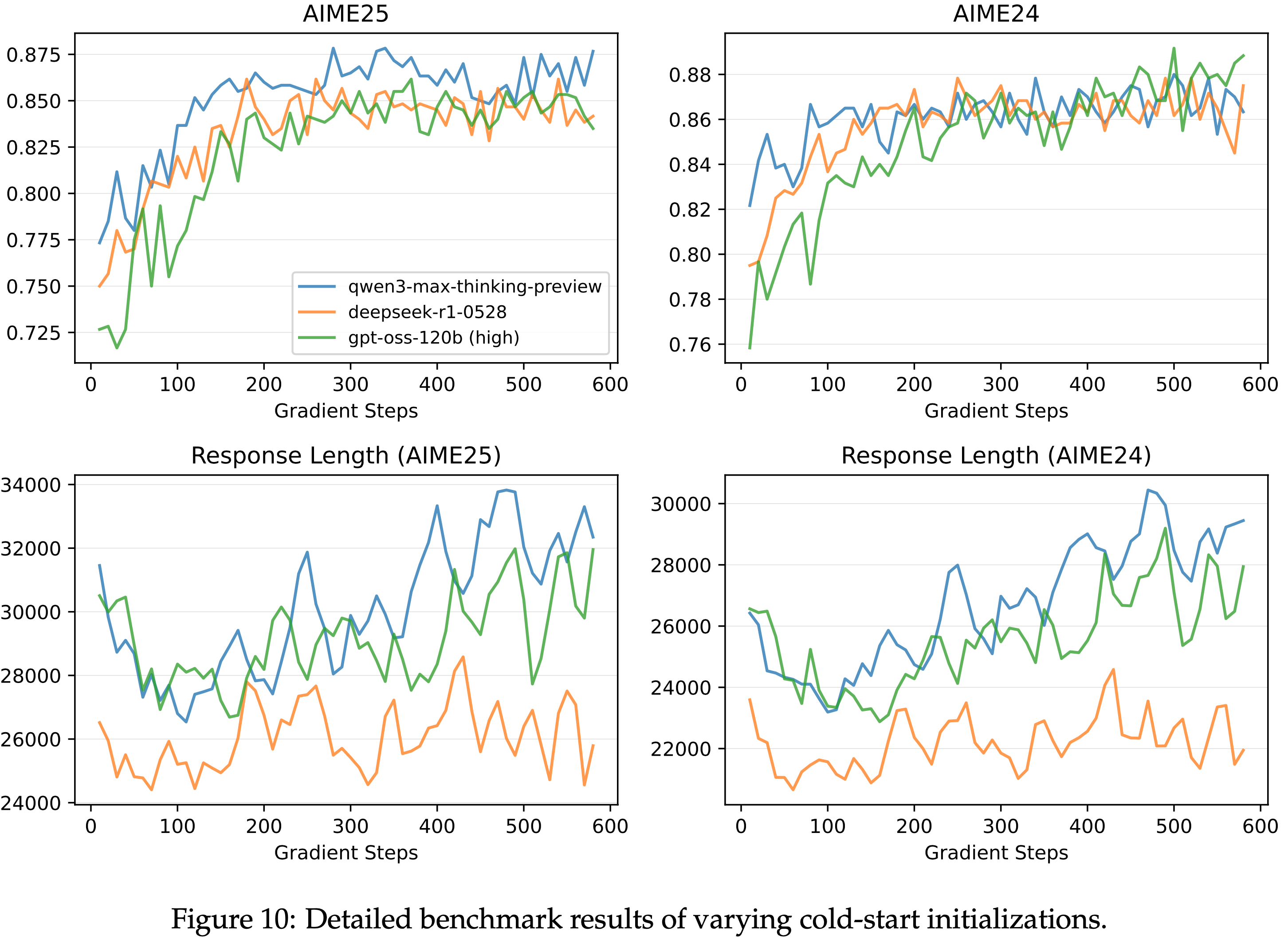
Results of Varying Cold-start Initializations
- 回顾稳定 RL 训练的动机:给定一个基础模型,一旦论文能够通过足够长的 RL 训练达到其性能极限,我们就可以通过将计算资源投入到 RL 中,可靠地提升模型的能力
- 为此,作者研究了使用稳定 RL 方案训练时,用不同冷启动数据初始化的模型是否能达到相似的性能
- 作者比较了从三个前沿模型蒸馏出来的三个版本的冷启动数据:
- Qwen3-Max-Thinking-Preview、DeepSeek-R1-0528 和 gpt-oss-120b(high mode)
- 论文基于一个早期实验的小型 Qwen3Next MoE 模型报告结果,该模型使用全局批次大小为 4096、 mini-batch 大小为 2048(\(B=128, G=16, N=2\))以及生成长度为 65,536 个 Token 进行训练
- 这里采用 MiniRL + R2 作为训练方案
- 在图 5 中,展示了三个冷启动初始化始终实现可比较的最终性能,这鼓励论文更多地关注 RL 本身,而不是过度关注冷启动初始化的细节
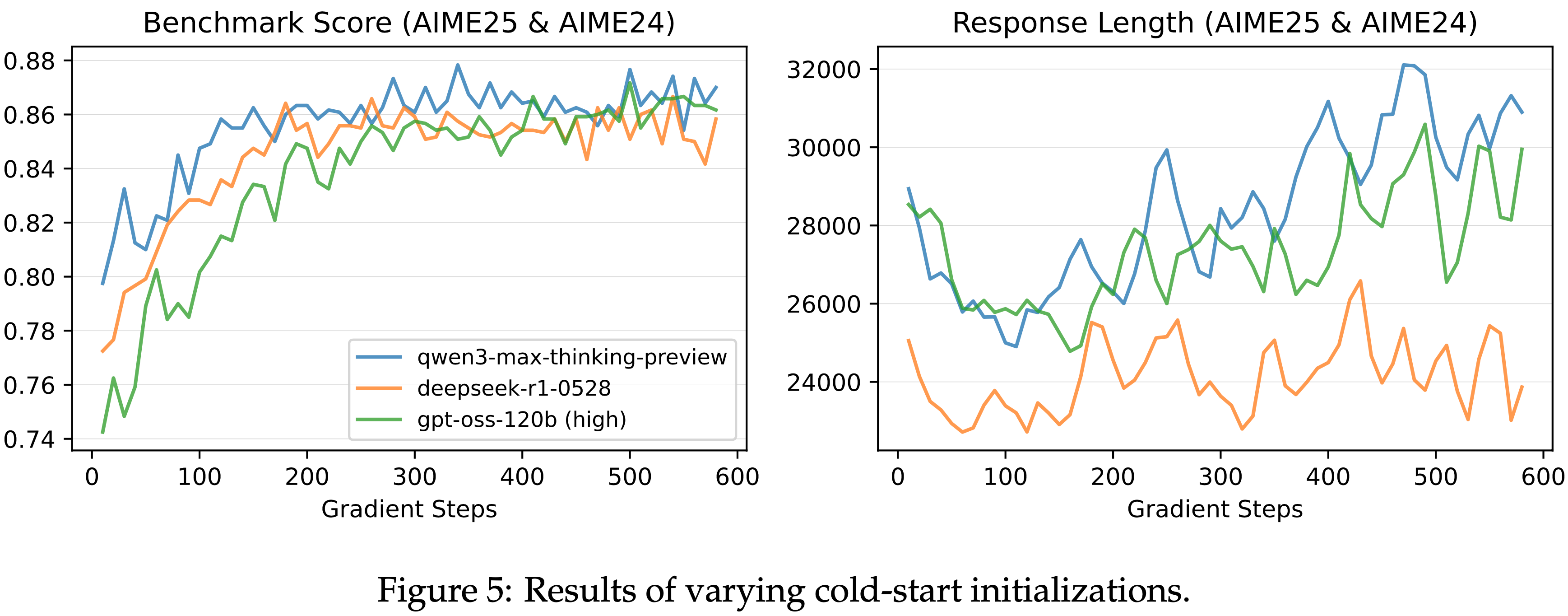
- Furthermore,比较图 1 到图 4,论文发现 On-policy 和 Off-policy 训练(一旦稳定下来)也始终达到相似的峰值性能
- 这些结果进一步表明,稳定训练在成功扩展 RL 方面起着决定性作用
附录 A: Comparison of MiniRL against GRPO and CISPO
- 论文将 MiniRL 的优化目标与 GRPO (2024) 和 CISPO (2025) 的目标进行比较
- 使用论文中的符号,GRPO 采用以下目标:
$$
\mathcal{J}_{\textrm{GRPO} }(\theta)=\mathbb{E}_{x\sim\mathcal{D},\left\{y_{i}\right\}_{i=1}^{G}\sim\mu_{\theta_{\textrm{old} } }(\cdot|x)} \left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{\left|y_{i}\right|}\sum_{t=1}^{\left|y_{i}\right|}\min\left(r_{i,t}(\theta)\widehat{A}_{i,t},\operatorname{clip}(r_{i,t}(\theta),1-\epsilon_{\textrm{low} },1+\epsilon_{\textrm{high} })\widehat{A}_{i,t}\right)\right],
$$- 注:这里少写了 KL 散度
- CISPO 如下:
$$
\mathcal{J}_{\textrm{CISPO} }(\theta)=\mathbb{E}_{x\sim\mathcal{D},y\sim\mu_{\theta_{\textrm{old} } }(\cdot|x)} \left[\frac{1}{\sum_{i=1}^{G}\left|y_{i}\right|}\sum_{i=1}^{G}\sum_{t=1}^{\left|y_{i}\right|}\operatorname{sg}\left[\operatorname{clip}(r_{i,t}(\theta),1-\epsilon_{\textrm{low} },1+\epsilon_{\textrm{high} })\right]\widehat{A}_{i,t}\log\pi_{\theta}(y_{t}|x,y_{ < t})\right],
$$ - 其中在两个目标中,重要性比例和优势函数相同:
$$
r_{i,t}(\theta)=\frac{\pi_{\theta}(y_{i,t}|x,y_{i,<t})}{\color{blue}{\pi_{\theta_{\text{old}} } }(y_{i,t}|x,y_{i,<t})},\qquad\widehat{A}_{i,t}=\frac{R(x,y_{i})-\text{mean}\left(\left\{R(x,y_{i})\right\}_{i=1}^{G}\right)}{\text{std}\left(\left\{R(x,y_{i})\right\}_{i=1}^{G}\right)}.
$$ - 它们与 MiniRL 的关键区别包括:
- (1) 它们的原始目标未考虑训练-推理差异(training–inference discrepancy)
- 注:MiniRL 的优化目标(公式 7 中的重要性采样分母上是 \(\mu_{\theta_\text{old}}\),而不是 \(\pi_{\theta_\text{old}}\)
- (2) 两者都采用了长度归一化(length normalization),论文在第 4.3 节表明,这会使得对真实期望 Sequence-level 奖励的一阶近似失效,并可能导致有偏的 Token 级优化目标和次优性能;
- (3) CISPO 没有对某些 Token 的梯度进行裁剪,论文在第 4.4 节表明这可能导致训练不稳定
- 补充特别强调:CISPO 的截断方式与 PPO/GRPO 有着明显的不同
- 在 PPO/GRPO 中,阶段对象是整个 Token 本身,被截断以后就整个 Token 都不生效了(这部分梯度因为截断而变成变成 0);
- 在 CISPO 的截断方式下,仅仅是将重要性权重比例进行了截断,Token 的重要性比例被截断了,但本身梯度还可以被继续更新
- 严格来讲:CISPO 中,无论怎样的 Token 都会参与更新,只是说重要性比例对应的权重会被截断调整
- 补充特别强调:CISPO 的截断方式与 PPO/GRPO 有着明显的不同
- 其实还有其他区别:
- 相对标准的 GRPO,MiniRL 增加了重要性比例的截断上下解耦
- 相对标准的 GRPO,MiniRL 移除了 KL 散度?
- (1) 它们的原始目标未考虑训练-推理差异(training–inference discrepancy)
附录 B: Detailed Benchmark Results
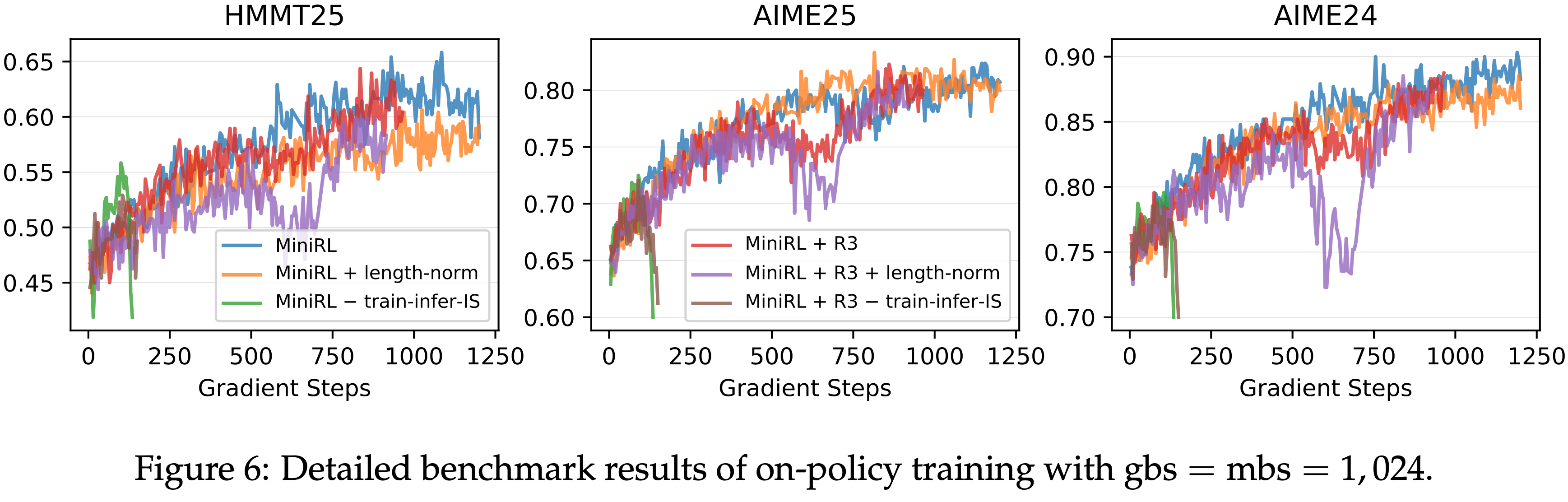
- 图 6: 全局批次大小 gbs = mini-batch 大小 mbs = \(1,024\) 的 On-policy 训练详细基准测试结果
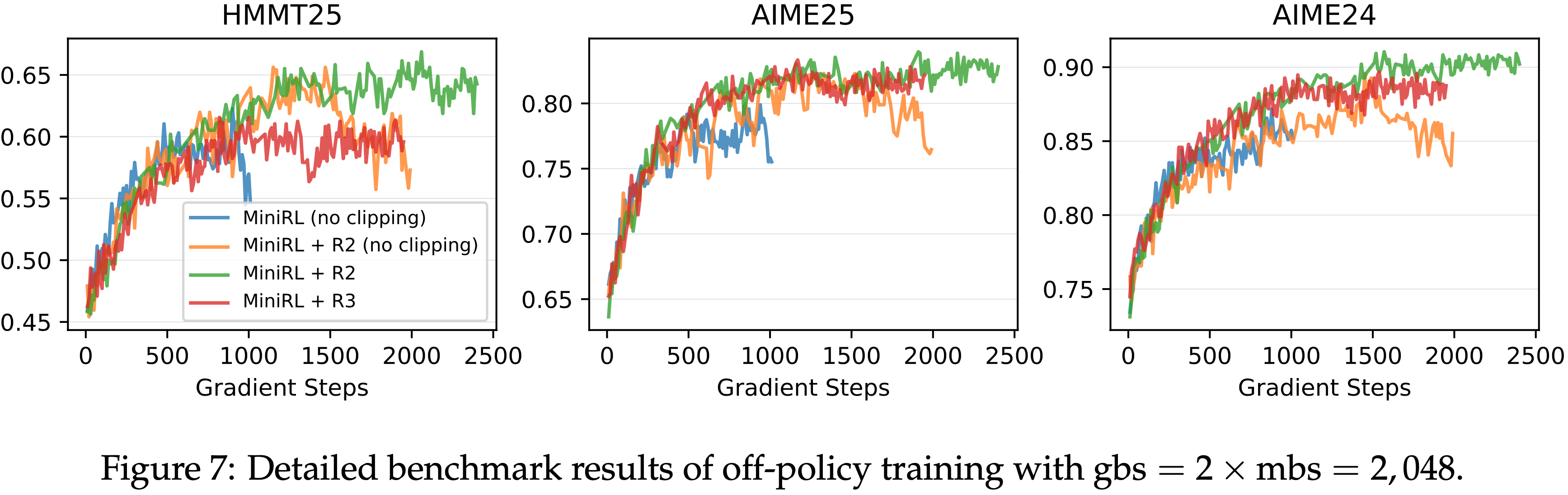
- 图 7: 全局批次大小 gbs = \(2\times\) mini-batch 大小 mbs = \(2,048\) 的离策略训练详细基准测试结果
- 图 8: 全局批次大小 gbs = \(4\times\) mini-batch 大小 mbs = \(4,096\) 的离策略训练详细基准测试结果
- 图 9: 全局批次大小 gbs = \(8\times\) mini-batch 大小 mbs = \(8,192\) 的离策略训练详细基准测试结果
- 图 10: 不同冷启动初始化的详细基准测试结果