注:本文包含 AI 辅助创作
Paper Summary
- 个人整体总结:
- 作者发现:vanilla OPD 在多轮 Agent 中的一个基本失效模式: Trajectory-Level KL Instability
- 观察:KL 散度随着成功率的下降而增加,并且即使在收敛后,KL 散度仍然很高,导致训练不稳定
- Trajectory-Level KL Instability 定义:跨轮的复合错误导致 KL 散度不断升级和不可靠的教师监督信号
- 随着错误的累积,学生模型被推到了教师有效支持范围之外的状态 ,使得监督信号变得不可靠
- 解决方法:TCOD (Temporal Curriculum On-Policy Distillation) 框架
- TCOD 核心思路:控制暴露给学生的轨迹深度,并通过由可配置的课程增长率控制的步调策略 ,逐步将其从短轨迹扩展到长轨迹
- TCOD 有两种变体:
- Forward-to-Backward (TCOD-F2B):将学生限制在轨迹的早期步骤,并逐步将其扩展到最大探索 Horizon
- Backward-to-Forward (TCOD-B2F):利用教师将 Agent 导航到接近终止状态,减轻早期步骤的错误累积,同时逐步将学生的 Rollout Horizon 向后扩展到初始阶段
- 特殊发现:TCOD 性能可以超越教师
- 在教师 pass@10 采样失败的 ALFWorld 困难划分上,TCOD-B2F 的成功率比教师高出 14 个百分点,展示了超越教师自身能力边界的泛化能力
- 理解:这个可能和学生本身在特定场景针对自身策略采样和修正有关
- 注意:本文的结论不太 Solid,这个能力不一定是 TCOD 带来的,因为 Vanilla OPD 也在 Hard 熵表现出了超越教师的能力(如 表 2 所示),说明 OPD 本身就已经拥有了超过教师的潜力了
- 而且 表 3 中并没有看到学生模型超过教师模型
- 注意:论文目标公式中使用的是 Forward KL,应该是写错了,收集样本使用 Student,所以计算得到的 KL 散度应该是 Backward KL
- 创新思考:
- 针对单轮的场景,也可以使用类似 TCOD 的方式解决长文本下的 OPD 问题,固定一批数据集,先训练前 4K 一个 epoch,再训练前 8 K 一个 epoch,再训练 12 K 一个 epoch,以此类推
- 核心思路:让学生的前缀先贴近教师,再训练学生后面的分布贴近教师(此时教师能给出不错的信号指导了)
- 针对单轮的场景,也可以使用类似 TCOD 的方式解决长文本下的 OPD 问题,固定一批数据集,先训练前 4K 一个 epoch,再训练前 8 K 一个 epoch,再训练 12 K 一个 epoch,以此类推
- 作者发现:vanilla OPD 在多轮 Agent 中的一个基本失效模式: Trajectory-Level KL Instability
Introduction and Discussion
- 当前主要 OPD 方法本质上是为静态的单轮推理设计的
- 多轮机制中直接应用 vanilla OPD 会导致一种基本的失败模式:Trajectory-Level KL Instability
- 通过在 ALFWorld (2020) 上的实验,发现
- (i) 学生模型同时遭受 KL 散度升级和成功率崩溃的问题
- (ii) 尽管它们最终收敛,但开始时 KL 散度非常高,这两者都会导致训练不稳定
- 关键:图 1 (左) 揭示了其潜在机制:
- 跨轮次的累积错误逐步将学生推向教师有效支持范围之外的状态
- 结果导致教师对学生生成 Response 中的 Token 分配了更低的概率,表明每一轮的 KL 散度都在增加,使其监督信号变得不可靠
- 通过在 ALFWorld (2020) 上的实验,发现
- 图 1:
- (左) 在多轮 Agent 的 OPD 中,随着轮次增加,教师对学生生成 Response 中的 Token 分配的概率逐渐降低,表明每一轮的 KL 散度都在增加,使得监督信号不可靠
- (右) OPD 使用所有轮次,因此包含了累积错误,而 TCOD-F2B/B2F 逐步从短轨迹扩展到长轨迹,减轻了计算错误轮次的问题
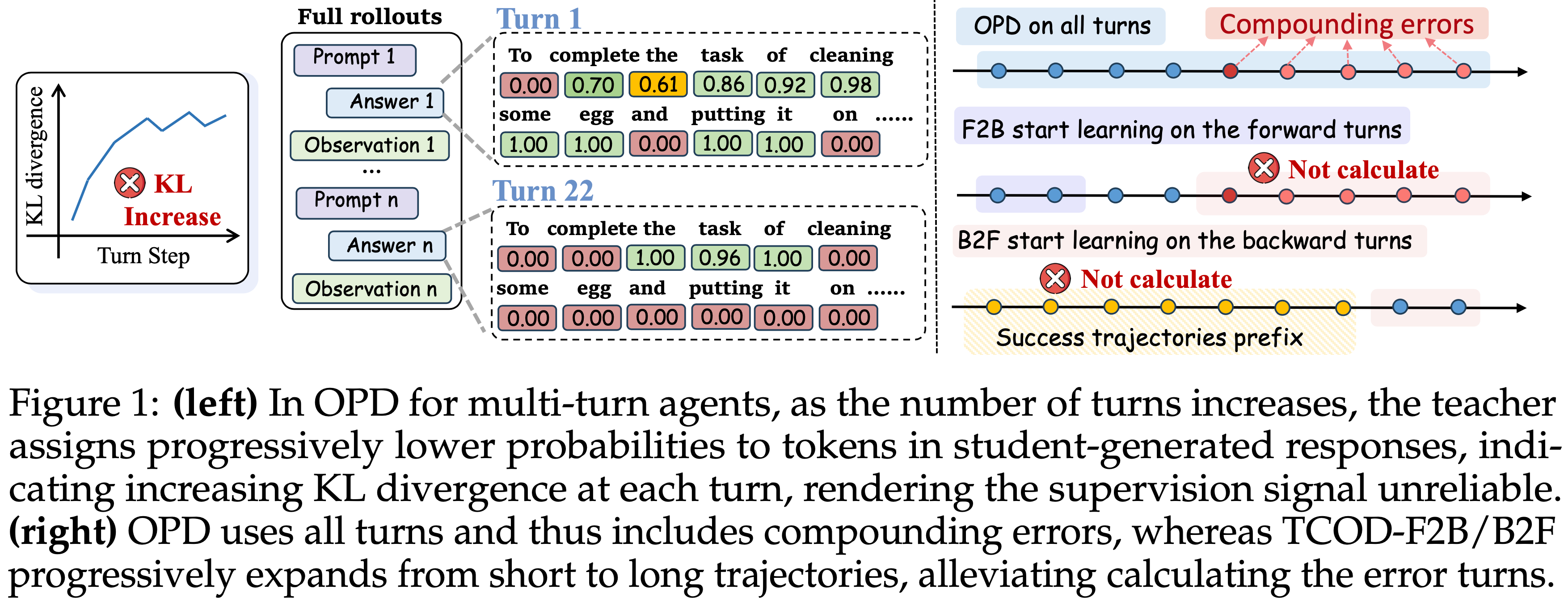
- TCOD 核心思想:控制暴露给学生的轨迹深度,并通过由可配置的课程增长率控制的步调策略 ,逐步将其从短轨迹扩展到长轨迹
- 如图 1 (右) 引入了两个仅需最少代码修改的实用变体:
- Forward-to-Backward (TCOD-F2B):将学生限制在轨迹的早期步骤,并逐步将其扩展到最大探索 Horizon
- Backward-to-Forward (TCOD-B2F):利用教师将 Agent 导航到接近终止状态,减轻早期步骤的错误累积,同时逐步将学生的 Rollout Horizon 向后扩展到初始阶段
- 如图 1 (右) 引入了两个仅需最少代码修改的实用变体:
- 基于 TCOD-F2B/B2F,在三个多轮 Agent 基准测试上评估了四个师生模型对:
- 基准:ALFWorld (2020),WebShop (2022a) 和 ScienceWorld (2022)
- 结论:TCOD 减轻了 KL 不稳定性,并通过将 Qwen3-1.7B 从接近零的成功率中恢复出来,并将较大的模型 (例如 Qwen2.5-7B) 的性能提升了高达 15.71 个成功率点,同时平均减少了 2.97 个行动轮次
- 特别提到:
- TCOD 不仅仅是模仿教师
- 在教师 pass@10 采样失败的 ALFWorld 困难划分上,TCOD-B2F 的成功率比教师高出 14 个百分点,展示了超越教师自身能力边界的泛化能力
- TCOD-F2B/B2F 对课程增长率具有鲁棒性,性能变化小于 2%,并且与 vanilla OPD 相比,总训练时间减少了高达 32%
- TCOD 不仅仅是模仿教师
Related Work 解读
LLM-based Multi-turn Agents
- 多轮 Agent 的挑战:
- 长期 Horizon 的信用分配 (2025)
- 内存管理 (2026)
- 稀疏奖励设定下强化学习的样本效率低下 (2025; 2026)
On-Policy Distillation and its Limitations
- OPD 的改进包括目标设计 (2026; 2026)、优化启发式方法 (2026) 以及替代监督源 (2026; 2026)
- 提高 OPD 训练稳定性和收敛性的方法:
- 平衡前向和后向 KL 项 (2026; 2026)
- 整合 RL 风格的启发式方法如奖励裁剪 (2026)
- 注:这些方法主要针对单轮设定设计,并未直接解决多轮 Agent 环境的问题
Curriculum Learning
- 课程学习 (Curriculum learning) (2009) 是一种训练策略,模型随着其能力的增长而逐渐接触更难的样本
- 本文通过定义随轨迹深度增加而增加的难度来避免这两种情况,仅使用学生生成的数据,保持训练简单、on-policy 且更稳定
Preliminary
- 本文考虑在有限 Horizon 内与环境交互的多轮自主 Agent
- 令 \(t\in \{0,\ldots ,T - 1\}\) 表示轨迹内的轮次索引,其中 \(T\) 是最大交互步数
- 在每个轮次 \(t\) ,Agent 接收一个观察 \(o_{t}\) ,生成一个 Response \(a_{t}\) ,然后环境返回下一个观察 \(o_{t + 1}\)
- 每个 Response \(a_{t}\) 由一个思维链推理轨迹后跟一个可执行动作组成(遵循最近的 Agent 框架 (2025a))
History State for Multi-turn Agent
- 由于环境通常是部分可观测的,将 Agent 状态定义为直到当前观察的完整交互历史:
$$h_{t} = (o_{0},a_{0},o_{1},a_{1},\ldots ,o_{t - 1},a_{t - 1},o_{t}). \tag {1}$$ - 一个完整的轨迹则为
$$\tau = (h_{0},a_{0},h_{1},a_{1},\ldots ,h_{T - 1},a_{T - 1})$$- 当采取终止动作或达到 Horizon \(T\) 时终止
On-Policy Distillation for Multi-turn Agent
- 给定一个教师策略 \(\pi_{\phi}\) 和一个学生策略 \(\pi_{\theta}\) ,on-policy 蒸馏的目标是在学生自身的状态分布下,使学生与教师对齐,目标是:
$$\mathcal{L}_{\text{OPD} }(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta} }\left[\sum_{t = 0}^{T - 1}\mathcal{D}_{\text{KL} }(\pi_{\phi}(a_t\mid h_t)\parallel \pi_{\theta}(a_t\mid h_t))\right], \tag {2}$$- 问题:传统 OPD 中不应该是使用 下面的 Reverse KL 表达式吗?
$$ \mathcal{L}_{\text{OPD} }(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta} }\left[\sum_{t = 0}^{T - 1}\mathcal{D}_{\text{KL} }(\color{red}{\pi_{\theta}(a_t\mid h_t)\parallel \pi_{\phi}(a_t\mid h_t)})\right] $$- 推测1:作者确实刻意使用了 Forward KL
- 推测2:作者笔误了,不然无法解释后续方法的采样轨迹是 Student 采样的(On-Policy)收集数据
- 问题:传统 OPD 中不应该是使用 下面的 Reverse KL 表达式吗?
- 其中 \(\mathcal{D}_{\text{KL} }(\pi_{\phi}\parallel \pi_{\theta})\) 是衡量教师策略 \(\pi_{\phi}\) 和学生策略 \(\pi_{\theta}\) 之间差异的 KL 散度:
$$ \mathcal{D}_{\text{KL} }(\pi_{\phi}\parallel \pi_{\theta}) = \sum_{a_{t} }\pi_{\phi}(a_{t}\mid h_{t})\log \frac{\pi_{\phi}(a_{t}\mid h_{t})}{\pi_{\theta}(a_{t}\mid h_{t})}$$
TCOD: Temporal Curriculum On-Policy Distillation
- 观察:OPD 在多轮 Agent 设定中的一个关键限制,称为 Trajectory-Level KL Instability
- OPD 在长期交互中存在不稳定性,其中累积错误导致 KL 散度升级和性能下降
- TCOD:时间课程策略,在训练过程中逐步控制轨迹深度,以提高多轮蒸馏的稳定性和有效性
Trajectory-Level KL Instability in Multi-Turn On-Policy Distillation
- 在 ALFWorld 检查 OPD 在多轮设定下的行为
- 系统地评估了跨越 Qwen3 和 Qwen2.5 模型家族的师生模型对,包括更大规模和领域适应的教师
- 对于 Qwen3,使用 Qwen3-30B-A3B-Instruct 作为教师,Qwen3-{0.6, 1.7, 4}B 作为学生
- 对于 Qwen2.5,采用一个 GRPO 训练的 Qwen2.5-7B 模型作为教师,Qwen2.5-{0.5, 1.5, 3, 7}B 作为学生
- 图 2: ALFWorld 上不同师生对的轨迹级 KL 分析
- (a)(b) 显示 KL 散度在整个训练过程中升级,任务完成率崩溃
- 理解:(b) 中可以看到蓝色线一开始还能成功一些,训练到后期完全失败了
- 问题:图 2(b)中的纵轴是成功率,而不是竖轴写着的 Rollout Env Done Mean?
- (c) 显示 OPD 训练期间初始和收敛的 KL 散度之间存在巨大差距
- (d) 揭示了根本原因:KL 散度随轮次索引增长,表明错误在轨迹上被复合放大
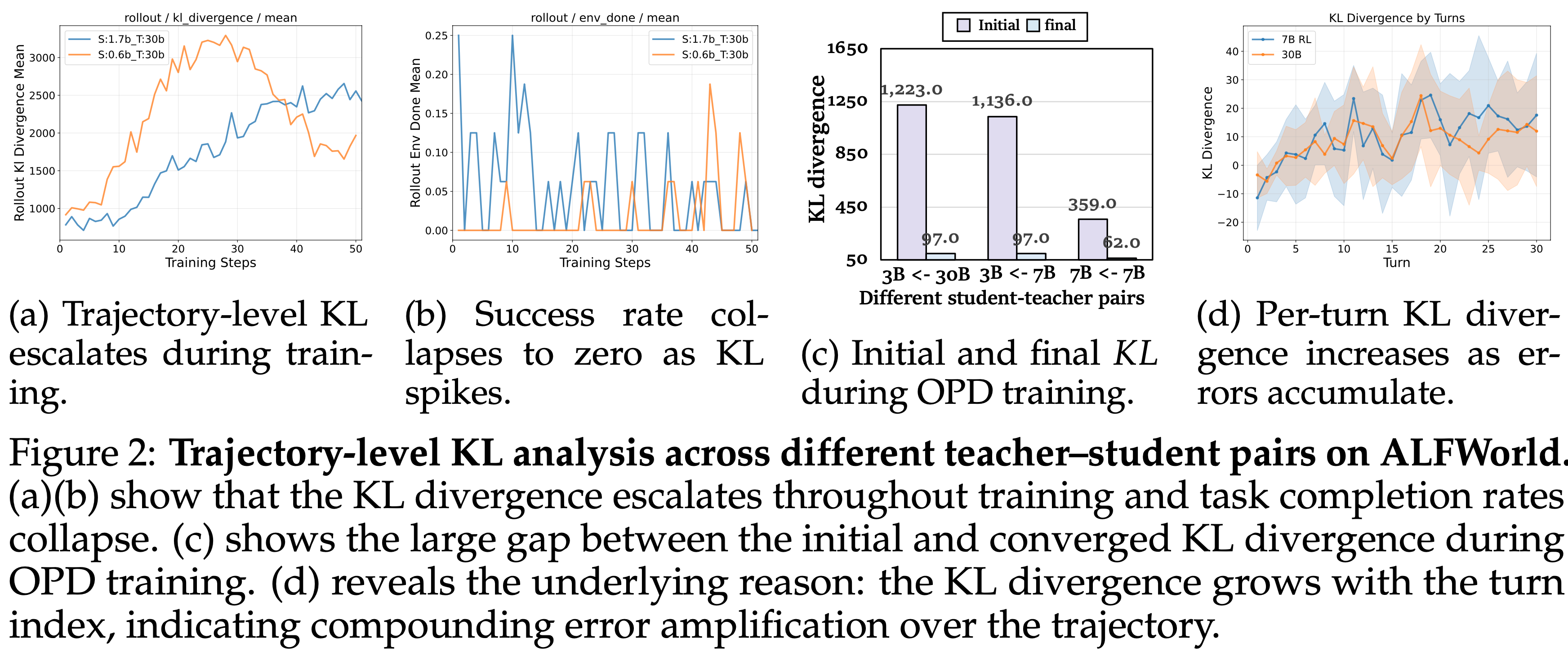
- (a)(b) 显示 KL 散度在整个训练过程中升级,任务完成率崩溃
Observation 1: KL escalation and success rate collapse co-occur during training,KL 升级和成功率崩溃在训练过程中同时发生(理解:这个现象是在较小 Student 模型中观察到的)
- 多轮与单轮场景的 KL 表现不同
- 单轮设定 (如数学或问答) 中:KL 散度在整个训练过程中持续收敛和下降
- 多轮 Agent 场景中:KL 散度随着训练步数的增加而升级
- 如图 2a 和 2b 所示,当学生模型 (Qwen3-{0.6,1.7}B) 在强大的教师 (Qwen3-30B-A3B-Instruct) 下使用 vanilla OPD 进行训练时,轨迹级 KL 散度迅速升级,任务成功率崩溃到接近零
- 理解:这个现象是在较小 Student 模型中观察到的
Observation 2: Although KL divergence converges, it suffers from a prohibitively high initial value
- 在不同的学生模型上进行实验,观察到尽管它们的 KL 散度最终收敛,但开始时的值高得令人望而却步
- 问题:Observation 1 中不是说 KL 会变大吗?怎么 Observation 2 又收敛了
- 理解:Observation 1 中的这个现象是在较小 Student 模型中观察到的;Observation 的 Student 模型都偏大一些
- 如图 2c 所示,在不同的师生对中 (从 Qwen3-30B-A3B-Instruct 蒸馏的 Qwen3-3B,以及从 GRPO 训练的 Qwen2.5-7B 模型蒸馏的 Qwen2.5-{3,7}B)
- 初始 KL 散度 ( \(\sim 1000\) ) 通常比其收敛值 ( \(\sim 60\) ) 大几个数量级,表明在多轮 OPD 训练期间存在严重的不稳定性
- 更多细节参见附录 B
补充 附录 B Additional Observation
对于 Qwen3,使用 Qwen3-30B-A3B-Instruct 作为 Teacher,Qwen3-{0.6, 1.7, 4}B 作为学生
对于 Qwen2.5,采用 GRPO 训练的 Qwen2.5-7B 模型作为 Teacher,Qwen2.5-{0.5, 1.5, 3, 7}B 作为学生
Observation 1: KL escalation and success rate collapse co-occur in small models (<3B)
- 观察 1:小模型(<3B)中 KL 升级(KL escalation)和成功率崩溃(success rate collapse)同时发生
- 在单轮设置中 KL 散度通常在训练过程中减少并稳定,在多轮 Agent 环境中观察到了根本不同的行为
- 如图 7 所示,当使用 vanilla OPD 训练小型学生模型(Qwen3-0.6B, 1.7B 和 Qwen2.5-0.5B, 1.5B)时,轨迹级别的 KL 散度随着训练进程急剧增加
- 这种升级伴随着成功率几乎降至零的同时崩溃
- Response 长度在各轮次中稳步增长,表明误差复合和越来越偏离分布的轨迹
- 这些结果表明,在多轮设置中,小模型无法在其自身的 Rollout 分布下保持与 Teacher 的对齐,导致训练动态不稳定和无效的监督信号
图 7:跨教师-学生对的 KL 升级(KL Escalation)和成功率(注:学生模型小于 3B)
- 在 ALFWorld 上使用 vanilla OPD 评估 Qwen3-{0.6B, 1.7B}(教师:Qwen3-30B-AB3-Instruc)和 Qwen2.5-{0.5B, 1.5B}(教师:Qwen2.5-7B-RL)
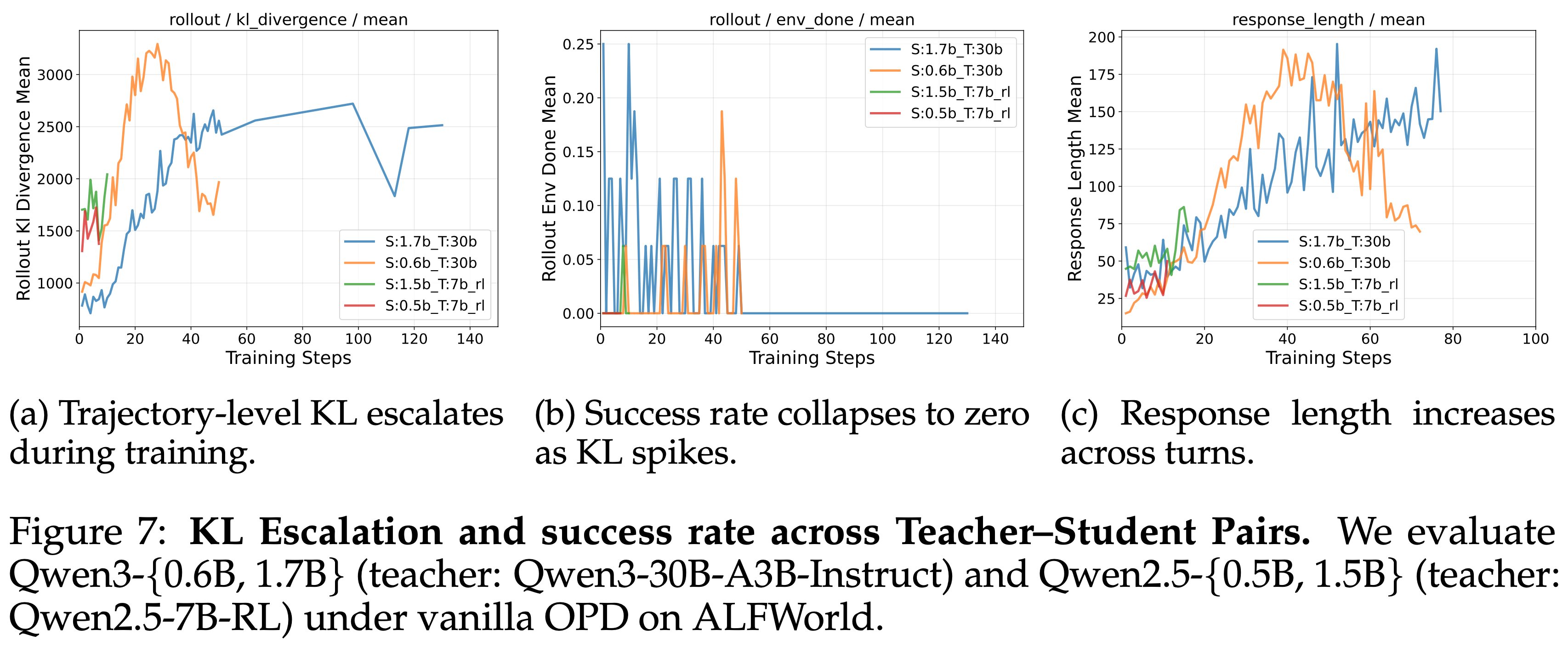
- 在 ALFWorld 上使用 vanilla OPD 评估 Qwen3-{0.6B, 1.7B}(教师:Qwen3-30B-AB3-Instruc)和 Qwen2.5-{0.5B, 1.5B}(教师:Qwen2.5-7B-RL)
Observation 2: Teacher–student matching matters; stronger teachers are not always better
- 观察 2:教师-学生匹配很重要;更强的 Teacher 并不总是更好
- 图 8 中进一步研究了教师-学生配对的影响
- 对于 3B 学生,在强 30B Teacher 和 7B RL Teacher 下训练会导致类似的结果:
- KL 散度稳定下降,成功率以相当的速率提高,表明将 Teacher 强度增加到某点以上并不会带来额外的好处
- 当学生容量与 Teacher 更匹配时(7B 学生与 7B RL Teacher),KL 散度收敛显著更快,成功率上升更迅速,优于两种 3B 学生设置
- 这表明适当的师生容量匹配比绝对的 Teacher 强度更关键;过强的 Teacher 不一定能提高,甚至可能限制多轮设置中的蒸馏效率
- 对于 3B 学生,在强 30B Teacher 和 7B RL Teacher 下训练会导致类似的结果:
图 8:跨教师-学生对的 Horizon 诱导的 KL 升级(Horizon-Induced KL Escalation),注:学生模型大于等于 3B
- 在 ALFWorld 上使用 vanilla OPD 评估 Qwen2.5-{3B, 7B}(教师:Qwen3-30B-AB3-Instruct, Qwen2.5-7B-RL)
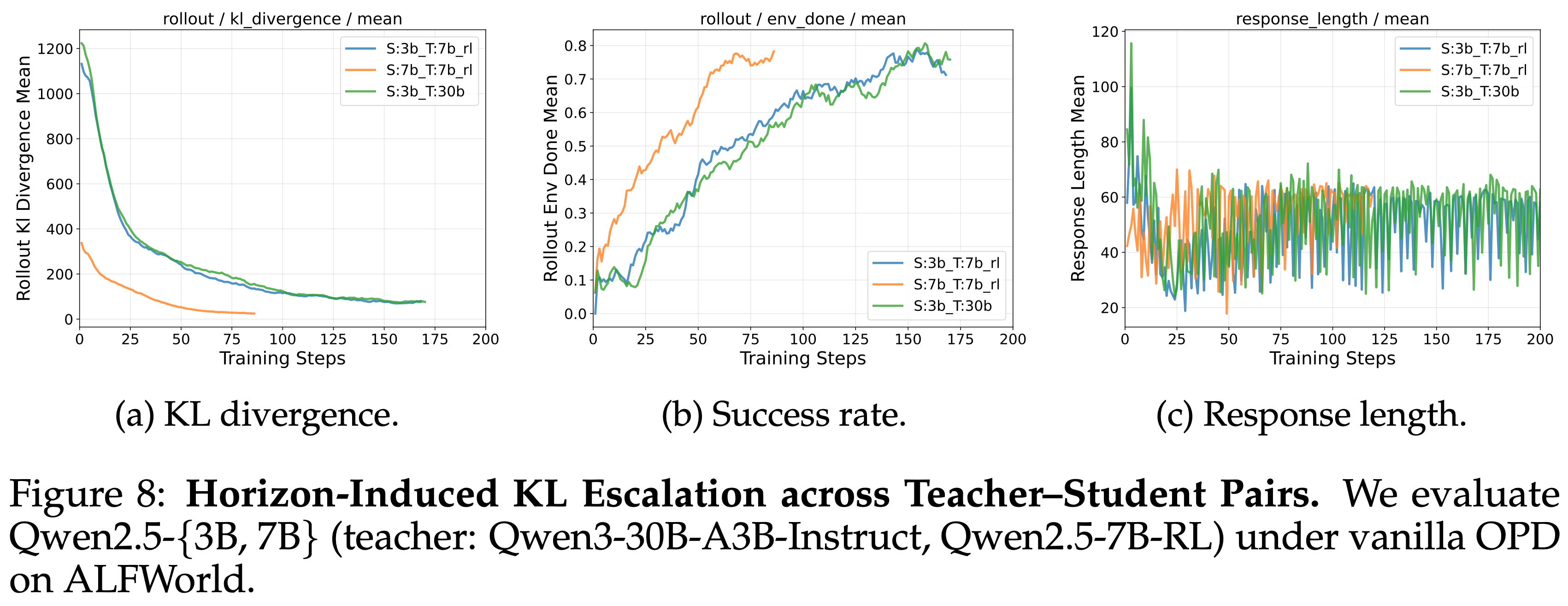
- 在 ALFWorld 上使用 vanilla OPD 评估 Qwen2.5-{3B, 7B}(教师:Qwen3-30B-AB3-Instruct, Qwen2.5-7B-RL)
The underlying mechanism: Compounding error amplification over the trajectory
- 直接将 OPD 应用于 Agent 为何会导致这种 KL 升级和训练不稳定性?
- 图 2d 可视化了从 GRPO 训练的 Qwen2.5-7B 和 Qwen3-30B-A3B-Instruct 蒸馏 Qwen2.5-3B 时每一轮的 KL 散度,并观察到随着轮次索引持续增加
- 无论增加的 KL 散度是反映了学生模仿教师能力的不足,还是学生进入教师变得不确定的分布外状态的结果,根本问题都是一样的:跨轮次的错误累积
- 这是长期 Horizon 多轮 Agent 的一个固有属性:
- 学生生成的动作和观察被附加到历史 \(h_t\) 中,导致跨轮次的因果耦合,并导致 KL 散度上升的趋势
- 理解:当学生分布和教师分布差异较大时,学生生成的轨迹长度越长,教师模型能作为参考的能力越弱(因为教师自身不可能生成这种轨迹)
- 注:毕竟教师模型训练目标是生成优质的轨迹,并不是修正学生模型的任意长度错误轨迹
- 理解:当学生分布和教师分布差异较大时,学生生成的轨迹长度越长,教师模型能作为参考的能力越弱(因为教师自身不可能生成这种轨迹)
- 学生生成的动作和观察被附加到历史 \(h_t\) 中,导致跨轮次的因果耦合,并导致 KL 散度上升的趋势
- 基本观察:
- 对于小型学生来说,这是灾难性的
- 对于较大的学生,它被部分容忍但仍然非常低效
- 注:这也和上面的理解差不多一致
Remark 1
- Long-CoT 增加了在相同环境状态下的 Response 长度
- 多轮 Agent 通过在每个交互中整合新的观察和动作来更新环境状态,从而在轨迹上放大复合错误
- 理解:多轮 Agent 难度可能是更高的,因为多轮 Agent 中不同模型输出得到的环境反馈可能是完全不同的,这可能更容易导致教师模型从未见过类似的状态
- 上述观察和分析提出了一个挑战:作者如何才能保留 OPD 密集信号的益处,同时避免长期交互中累积错误导致的不稳定?
- 为了解决这个问题,转向课程学习,其中模型首先在简单问题上训练,然后逐步接触难题
Our Proposal: Temporal Curriculum On-Policy Distillation
- 基于前一部分的观察和见解,TCOD,这是一种原则性的方法,在训练过程中控制 Agent 交互的轨迹深度
- 具体来说,引入了两个变体:TCOD-F2B 和 TCOD-B2F,它们分别在前向和后向课程中明确施加步数约束
- 图 3:
- TCOD-F2B/B2F 概览
- vanilla on-policy 蒸馏与 TCOD 的比较
- 左图是 OPD,中图是 TCOD-F2B 的图示,右图是 TCOD-B2F
- \(k\) 是控制轨迹长度的线性步调
- 蓝色步骤由学生执行,红色步骤由教师执行且梯度停止
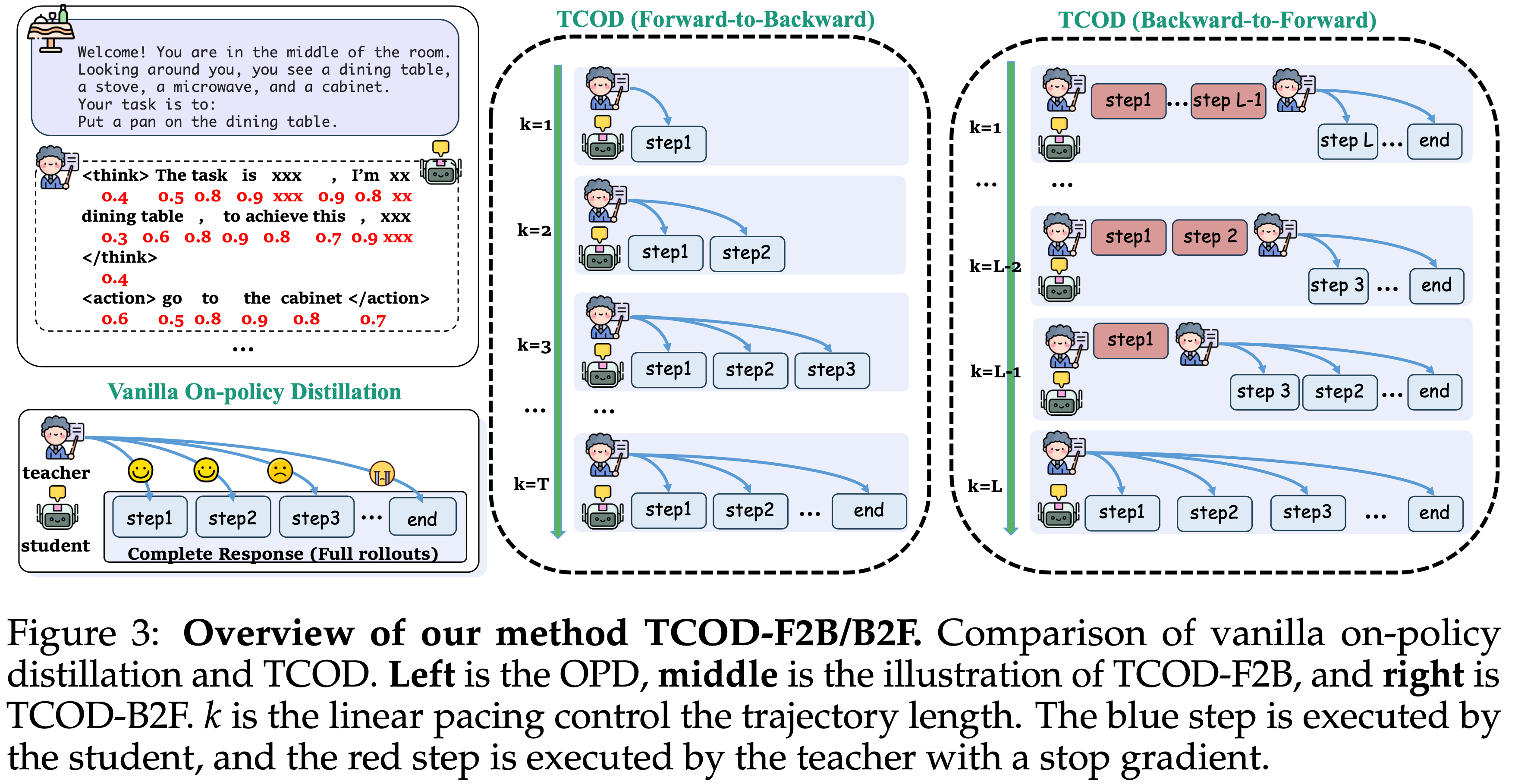
- TCOD-F2B/B2F 概览
Forward-to-Backward Induced Temporal Curriculum On-Policy Distillation (TCOD-F2B)
- 通过在训练过程中限制轨迹的最大交互步数来实现一种“浅到深”的课程
- 如图 3 (中) 所示,在 TCOD-F2B 中,学生策略 \(\pi_{\theta}\) 最多 Rollout \(k\) 步来完成任务,其中 \(k\) 从一个较小的数字开始,逐步增加到一个较大的数字,目标如下:
$$\mathcal{L}_{T C O D - F2B}(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta} }\left[\sum_{t = 0}^{k - 1}\mathcal{D}_{K L}\left(\pi_{\phi}(a_{t}|h_{t})\parallel \pi_{\theta}(a_{t}|h_{t})\right)\right], \tag {3}$$ - 其中学生首先专注于早期轮次的学习信号,然后逐步端到端地完成任务,从而减轻复合错误并防止 Horizon 引起的 KL 崩溃
- 但确定最佳的步长大小和起点是具有挑战性的,因为不同的环境和模型表现出不同的推理能力,为了解决这个问题,采用跨训练步骤的线性步调:
$$k = k_{\text{start} } + \lfloor n / \eta \rfloor ,n\in 1,\ldots ,N, \tag {4}$$- \(n\) 表示当前训练步数 Global Step
- \(N\) 是总训练步数(总计 Step)
- \(k_{\text{start} }\) 定义初始交互步数
- \(\eta\) 控制课程增长率
- 但确定最佳的步长大小和起点是具有挑战性的,因为不同的环境和模型表现出不同的推理能力,为了解决这个问题,采用跨训练步骤的线性步调:
- 这种方法只需要很少的代码更改,整个算法如下:

- 此外,为了更好地利用教师模型,提出了 TCOD-B2F,它利用教师来避免早期轮次的错误累积
Backward-to-Forward Induced Temporal Curriculum On-Policy Distillation(TCOD-B2F)
- 在这个变体中,教师策略 \(\pi_{\phi}\) 充当一个“导航器(Navigator)”
- 通过执行使用教师策略 \(\pi_{\phi}\) 预先收集的成功轨迹 \(\tau^{*}\) 的初始前缀 ,将环境初始化到一个中间状态,并让 Agent 从这个状态开始交互
- 如图 3 所示,教师在其成功轨迹 \(\tau^{*}\) 中执行前 \(L - k\) 步,之后学生策略 \(\pi_{\theta}\) 从这个即时状态接手继续规划和执行,目标如下:
$$\mathcal{L}_{\text{TCOD_B2F} }(\theta) = \mathbb{E}_{\tau \sim (\pi_{\phi},\pi_{\theta})}\left[\sum_{t = L - k + 1}^{T - 1}\mathcal{D}_{KL}\left(\pi_{\phi}(a_t|h_t)\parallel \pi_{\theta}(a_t|h_t)\right)\right], \tag {5}$$- \(L\) 表示给定任务的成功轨迹 \(\tau^{*}\) 的长度
- \(k\) 如公式 4 定义,在整个训练过程中单调扩展,直到学生端到端地完成任务
- 这种实现同样轻量级,只需要一个简单的预热循环,如下所示

- 注意:在 TCOD-B2F 中使用的是 Teacher 能够成功的轨迹作为候选轨迹
- 问题:如果是确定性环境的话,在 Algorithm2 的第 7 行是不是不需要从头执行一遍了,直接截断教师轨迹中的前半部分就可以作为初始轨迹状态,直接进入学生轨迹收集吧
- 这种机制通过确保学生仅在由教师验证的成功前缀发起的轨迹上进行优化,有效地绕过了复合动作错误
- 至关重要的是,轨迹中的教师步骤不贡献梯度,仅用于将学生置于“成功的门槛上”
- 详细算法见附录 C
Discussion of the train-test mismatch in TCOD-B2F
- 在训练期间,学生从一个由教师导航的检查点开始,而在测试时,它必须从头开始端到端地行动
- 本文逐步将教师前缀从 \(L - 1\) 步减少到零,确保在训练结束时,学生从初始状态执行完整的轨迹,无需教师干预,从而使训练和测试分布完全对齐
- 如附录 D.5 所示,测试集上的端到端成功率随训练步数稳步增加,确认了平滑的课程转换在实践中有效地防止了灾难性的分布偏移
- 注:增加讨论:
- TCOD-B2F 会引发不是 On-policy 的数据吗?答案是不会,因为前面由教师得到的轨迹不参与更新策略 \(\pi_\theta\),相当于是固定的某个 Prompt
补充 附录 C:Algorithm for TCOD-F2B/B2F
- 算法 3 和算法 4 分别展示了 TCOD-F2B 和 TCOD-B2F 的完整训练过程,集成了第 4.2 节中描述的课程进度策略和实现细节
- 吐槽:算法 3 和 算法 1 一模一样;算法 4 和算法 2 一模一样
- 在 TCOD-F2B(算法 3)中,学生策略 \(\pi_{\theta}\) 在每次训练迭代中 Rollout 轨迹 \(k\) 步,其中 \(k\) 根据方程 4 中的线性进度计划逐步扩展
- 通过将蒸馏信号集中在训练初期的早期轮次状态,并逐步扩展 Horizon,学生在暴露于完整轨迹之前建立了坚实的基础,有效地减轻了复合误差并防止了 KL 崩溃

- 通过将蒸馏信号集中在训练初期的早期轮次状态,并逐步扩展 Horizon,学生在暴露于完整轨迹之前建立了坚实的基础,有效地减轻了复合误差并防止了 KL 崩溃
- 在 TCOD-B2F(算法 4)中,教师策略 \(\pi_{\phi}\) 首先从预先收集的成功轨迹 \(\tau^{*}\) 中重放初始的 \(L - k\) 步而不贡献梯度,将学生置于一个经过核验的检查点状态
- 然后学生接管剩余的 \(k\) 步,学习从随着 \(k\) 增加而越来越早的起点完成任务
- 到训练结束时,教师前缀被完全消除(\(k = L\)),确保学生端到端地执行完整轨迹,并完全弥合训练-测试分布差距

Asynchronous Training Details for Stability,异步训练细节 For 稳定性
- TCOD 核心框架在概念上很简单,但几个实际的设计选择会显著影响现实部署中的训练稳定性和效率
- 所有实验均在 \(8 \times\) NVIDIA H20 (96GB) GPU 上进行
- 关键实现策略:
- Asynchronous Rollout and Training,异步 Rollout 和训练
- 为了最大化 GPU 利用率,作将轨迹收集和模型优化解耦到独立的异步进程中
- 使用一个 Actor 进程池进行 Rollout 以持续采样轨迹,而一个中心 Learner 进程进行训练,使用共享缓冲区中的这些轨迹并执行梯度更新
- 使用无锁环形缓冲区来最小化同步开销
- 在的实验中
- 分配 4 个 H20 GPU 给 Actor,2 个 H20 GPU 给 Learner,剩余的 2 个 H20 GPU 用于教师
- 问题:此时不需要使用使用重要性采样修正吗?
- 本文似乎使用强制 Staleness 为 2 左右来实现近似 On-policy,但是如果要严格坚持 On-Policy 的定义,本文实际上是一个 近似 On-Policy 或 Near On-Policy 的方法,不算是纯粹的 On-policy,可能会留下其他坑?(总之数学目标已经发生了改变)
- Staleness-Aware Sub-trajectory Experience Replay,具有陈旧性感知的子轨迹经验回放
- 为了在多轮环境中最大化样本效率,将每个完整轨迹分解为一组递归子轨迹
- 具体做法:对于一个长度为 \(n\) 的轨迹,将每个前缀序列 \(\tau_{1:t} = (s_0, a_0, \ldots , s_t)\) 作为独立的经验条目存储在回放缓冲区中
- 其中 \(t \in \{1, \ldots , n\}\)
- 具体做法:对于一个长度为 \(n\) 的轨迹,将每个前缀序列 \(\tau_{1:t} = (s_0, a_0, \ldots , s_t)\) 作为独立的经验条目存储在回放缓冲区中
- 为了防止输入上下文超过模型的有效内存限制从而导致训练不稳定,将交互历史封装在 Prompt 中作为结构化上下文
- 所以:每批生成的 Rollout 数量是动态的,取决于收集到的轨迹的不同长度
- 在的异步设置中,每个轨迹都标记有用于收集的策略 \(\pi_{\theta_n}\) 的版本号 \(n\)
- 本文实现了一个陈旧性过滤器,丢弃任何满足 \(n_{\text{current} } - n_{\text{old} } > \Delta_{\text{max} }\) 的经验
- 经验发现: \(\Delta_{\text{max} } = 2\) 在样本效率和 on-policy 约束的严格性之间提供了最佳平衡
- 为了在多轮环境中最大化样本效率,将每个完整轨迹分解为一组递归子轨迹
- Asynchronous Rollout and Training,异步 Rollout 和训练
Experiments
- Q1: 与 vanilla OPD 相比,TCOD 如何缓解 KL escalation 并恢复小型学生模型的性能,以及如何增强较大学生模型的训练稳定性和性能?
- Q2: TCOD 能否使学生模型有效地泛化到超出教师自身能力边界的任务?
- Q3: TCOD 对课程的增长率的敏感性如何,并且在训练效率方面与 vanilla OPD 相比如何?
Experimental Setup
Benchmarks
- 在三个基准上进行实验
- 具身导航环境 ALFWorld (2020)
- 电子商务平台 WebShop (2022a)
- 科学推理 ScienceWorld (2022)
- 如表 1 所示,涵盖了从简单到复杂的推理能力谱系
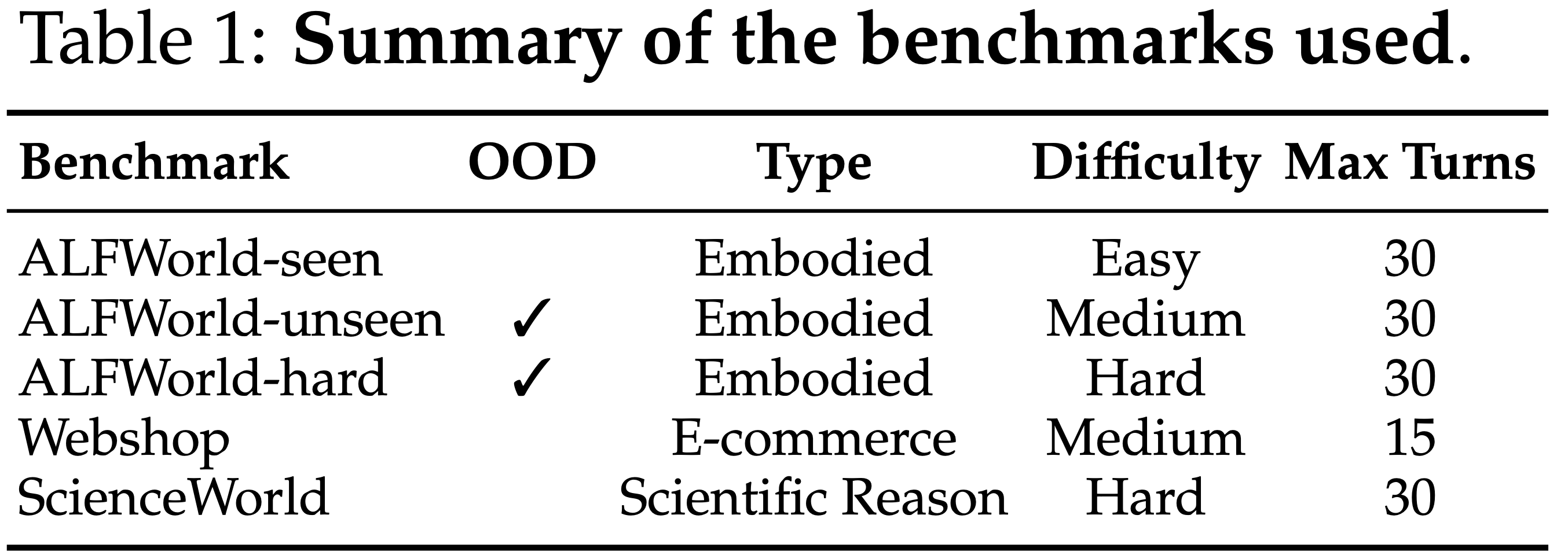
- Max turns 表示每个任务的最大探索步数
- 对于 ALFWorld,在 seen 和 unseen 划分上都进行了评估,其中 unseen 划分包含训练期间未遇到的新颖房间布局和物体组合,作为本文的 OOD 评估
- 额外构建了一个 Hard 集合,包含教师模型在训练集上 pass@10 采样下失败的任务,以测试 TCOD 是否能泛化到超出教师自身能力边界的情况
- 更多基准细节请参考附录 D.1
Training Details
- 对于 ALFWorld 上的主要实验,使用 Qwen2.5-3B 和 Qwen2.5-7B 作为学生模型,并使用通过在 ALFWorld 领域上通过 GRPO 微调的 Qwen2.5-7B 作为教师模型
- 对于跨基准评估,采用 Qwen3-1.7B 和 Qwen3-4B 作为学生模型,使用 Qwen3-30B-A3B-Instruct 作为教师模型
- 所有实验均在 \(8 \times\) NVIDIA H20 GPU 上进行
- 基于 Reinforcement Fine-Tuning 框架 Trinity-RFT (2025) 实现了 TCOD
- 对于 TCOD-B2F 初始化所需的专家轨迹收集,采用教师模型的 pass@10 采样策略,仅保留成功的轨迹
- 为简单起见,固定 \(k_{\text{start} } = 1\) 和 \(\eta = 2\),并在第 5.4 节中检查了来自 \(\{2, 4, 6\}\) 的不同 \(\eta\) 的影响
- 对于基线,报告零样本学生作为经验下限,教师策略作为理论上限 (Oracle)
- 其他:将 TCOD 与标准的知识迁移范式进行比较,包括 SFT 和 vanilla on-policy distillation (OPD)
- 对于评估,使用成功率 (SR) 测试所有基准,该指标衡量成功完成任务的比例,其中任务完成被视为二元结果
- 更多细节见附录 D
Q1:Alleviating KL Escalation and Improving Performance,缓解 KL 升级并提升性能
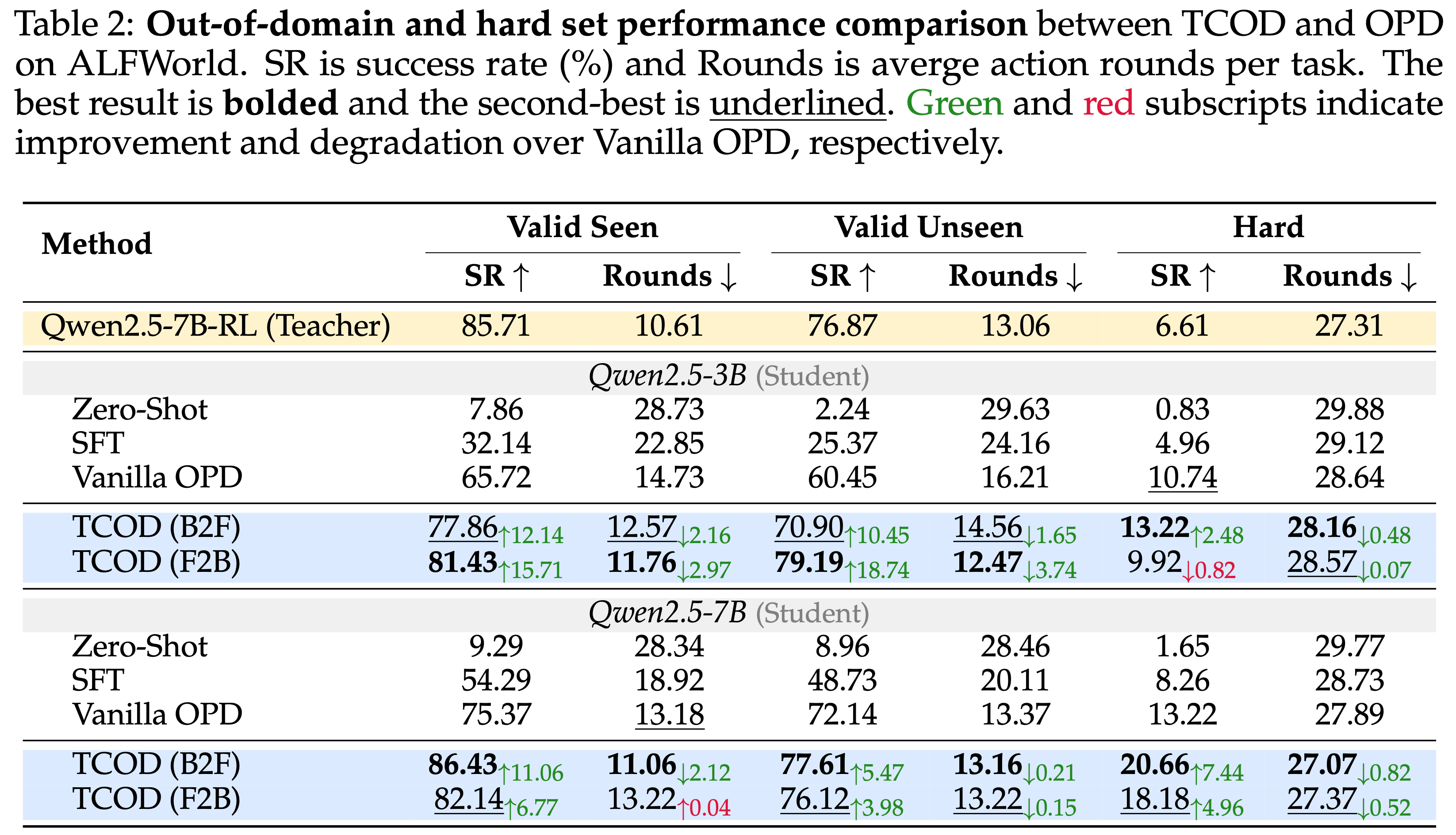
- 表 2 展示了 TCOD 在 ALFWorld 上使用学生模型 (Qwen2.5-3B, Qwen2.5-7B) 和 GRPO 训练的 Qwen2.5-7B 教师模型的结果,报告了成功率 (SR) 和平均动作步数
- TCOD-F2B 和 B2F 在模型规模上显著优于 vanilla OPD 和 SFT
- TCOD 将平均动作步数减少了 2.97 步,同时与 OPD 相比将 SR 提高了多达 15.71
- 这表明基于轨迹的教师课程学习带来了更好的性能
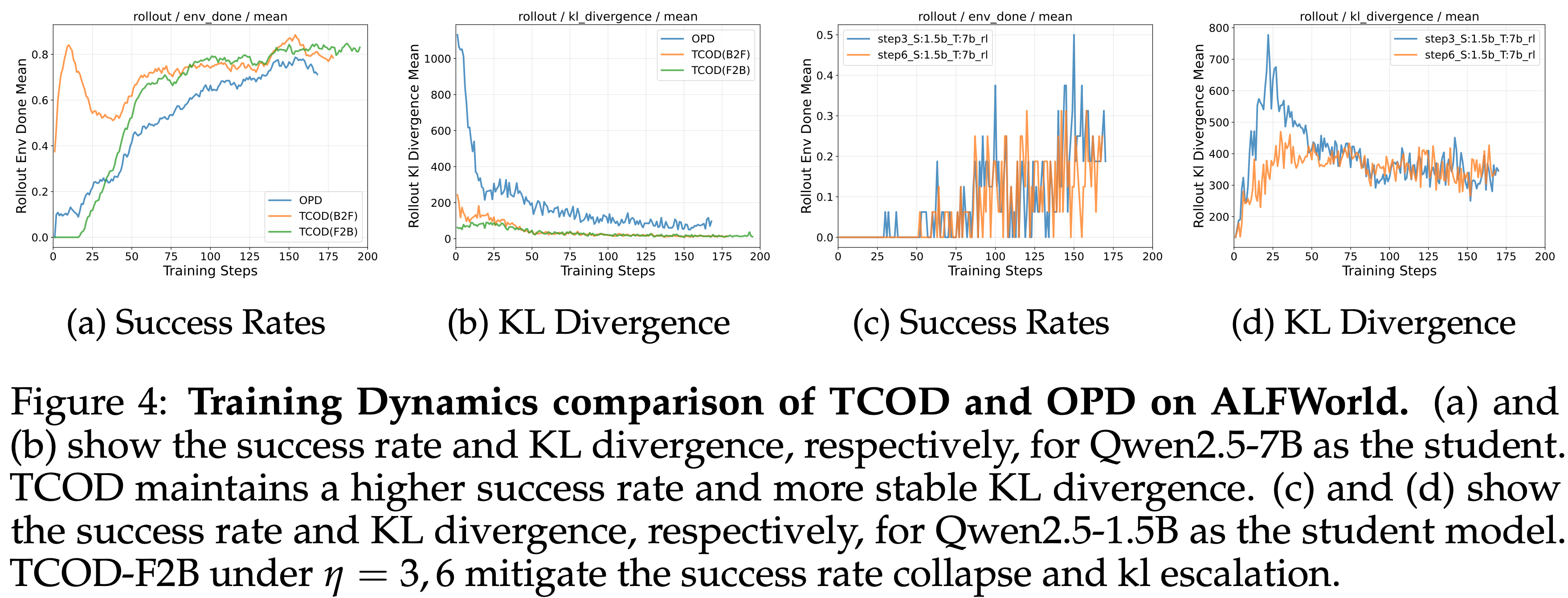
- 图 4a、4b 和 5b 进一步显示,与 vanilla OPD 相比,TCOD 在成功率和优势上实现了更快的收敛,同时保持了更稳定的 KL 散度
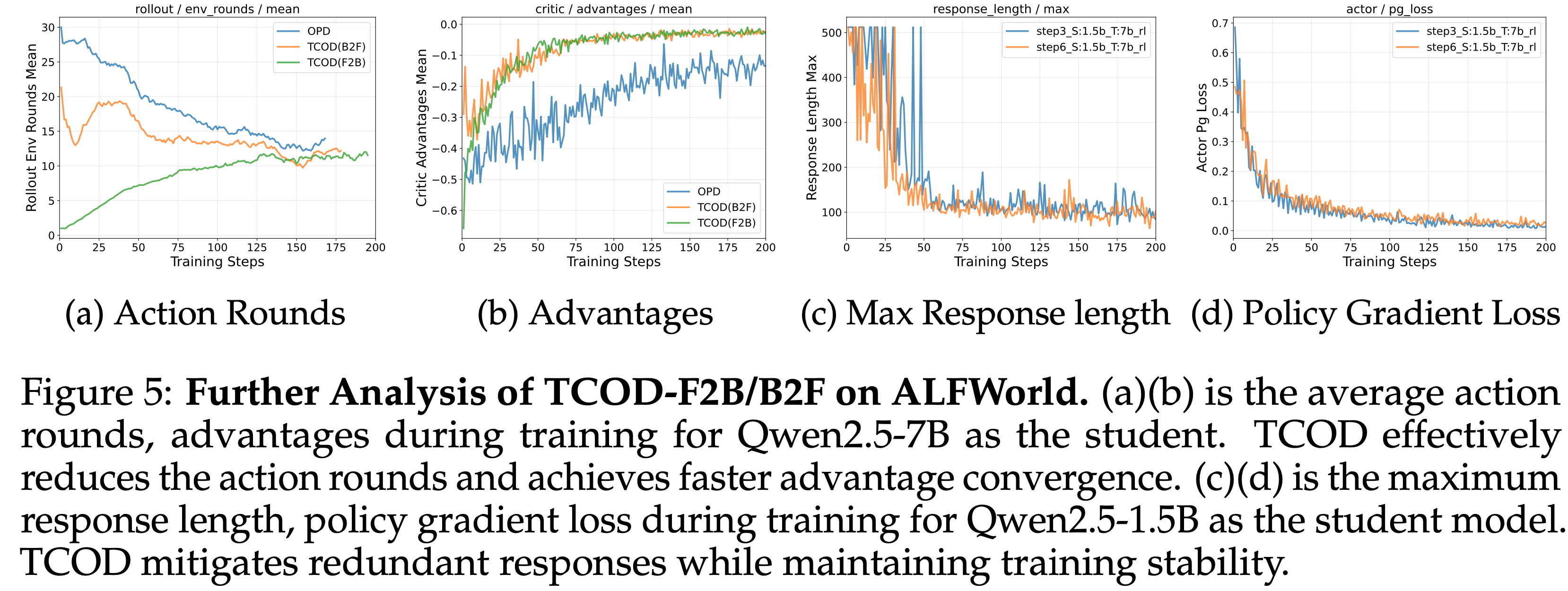
- 理解:图 5(b) 中 advantages 是负的
- 一般来说在 OPD 场景下,采样是通过学生采的,所以教师的概率均值是低于学生的,这一点详情见 NLP——LLM对齐微调-Revisiting-OPD,所以 Advantage 作为 \(\pi_\text{teacher} - pi_\text{student}\) 应该是小于 0 的
- 注:这里的 Advantage 一般来说都是负的,与本文的 Forward KL 错误书写没关系
- 如果真是 Forward KL,那么收集数据一定是 Teacher,此时 Advantage 是负的 KL 散度估计,也就是 \(\pi_\text{student} - pi_\text{teacher}\) ,此时这也应该小于 0 才对(采样策略肯定更倾向于自己概率高的 Token)
- 因为收集数据是 Student,就决定了不可能是 Forward KL 了
- 思考:正因为 OPD 的 Advantages 均值倾向于小于 0,所以 Student 的熵一般不会降低,甚至会上涨(许多高概率 Token 降低自身概率带来的是熵增),少数 Token 会被提升概率,带来熵减
- 熵增现象详情见 NLP——LLM对齐微调-Revisiting-OPD 图 8 图 9 和 NLP——LLM对齐微调-Rethinking-OPD 的 图 12
- 注:这里的 Advantage 一般来说都是负的,与本文的 Forward KL 错误书写没关系
- 一般来说在 OPD 场景下,采样是通过学生采的,所以教师的概率均值是低于学生的,这一点详情见 NLP——LLM对齐微调-Revisiting-OPD,所以 Advantage 作为 \(\pi_\text{teacher} - pi_\text{student}\) 应该是小于 0 的
Different Benchmarks and Model Sizes
- 表 3 使用学生模型 Qwen3-1.7B 和 Qwen3-4B 以及教师模型 Qwen3-30B-A3B-Instruct,在三个基准上评估了 TCOD
- TCOD-F2B 和 TCOD-B2F 取得了与 vanilla OPD 相当的性能
- 如图 4c 和 4d 所示
- 在 \(\eta = \{3,6\}\) 两种设置下,TCOD-F2B 在整个训练过程中都保持了稳定的 KL,并实现了持续增长的成功率,有效地缓解了 KL 升级并将平均成功率提高了 18.67
- 图 5c 和 5d 展示了额外的训练指标,其中 TCOD 能够从 Response 长度的爆炸中恢复,同时策略梯度损失平滑下降
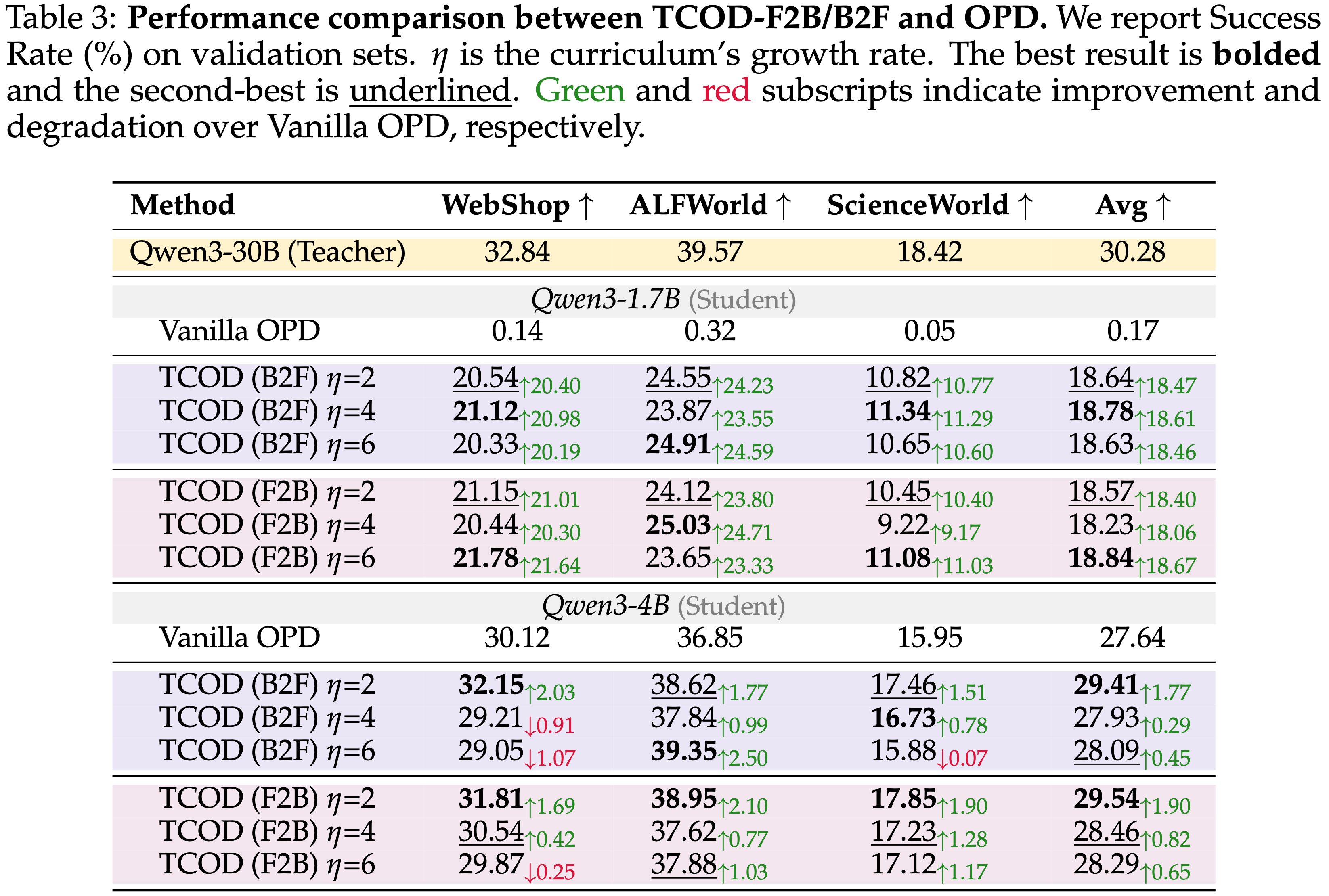
Q2:Generalizing Beyond the Teacher‘s Capability Boundary,泛化超出教师能力边界
- 除了 TCOD 带来的性能提升和 KL 稳定性之外,本文进一步研究 TCOD 是否能够使学生模型超越教师本身
- 表 2 报告了在 unseen 环境划分和 hard 划分上的性能
- hard 划分包含来自 ALFWorld 的 121 个具有挑战性的任务,教师在这些任务上表现不佳
- 在 unseen 划分上,TCOD 已经以高达 2.5 个百分点的 SR 超过了教师
- 在 Train Hard 划分上,TCOD-B2F 和 TCOD-F2B 都显著超过了教师 6.61 的 SR,其中 TCOD-B2F 取得了高达 14 个百分点的增益
- 这表明 TCOD 不仅仅是模仿教师,而是发展了一个更鲁棒的策略,能够泛化到超出教师能力边界之外
- 注意:本文的结论不太 Solid,这个能力不一定是 TCOD 带来的,因为 Vanilla OPD 也在 Hard 熵表现出了超越教师的能力(如表 2 所示),说明 OPD 本身就已经拥有了超过教师的潜力了
- 理解:这个可能和学生本身在特定场景针对自身策略采样和修正有关
- 而且 表 3 中并没有看到学生模型超过教师模型
Q3:Robustness, Sensitivity, and Efficiency Analysis of TCOD,鲁棒性、敏感性和效率分析
Curriculum’s Growth Rate \(\eta\) Ablation
- 表 3 报告了在不同基准上改变课程增长率 \(\eta \in \{2,4,6\}\) 的效果
- 在所有设置中,性能始终强于 vanilla OPD,成功率变化小于 \(2%\),这表明 TCOD-F2B/B2F 对 \(\eta\) 的具体选择不敏感
- 这种鲁棒性使得 TCOD 在实践中易于部署,无需 extensive 的超参数调整
- 如图 4d 所示,较大的 \(\eta\) 会在训练期间带来更稳定的 KL 散度 ,因为学生在课程推进到更长 Horizon 之前会花费更多的迭代来掌握当前的轨迹深度
- 在实践中,建议从一个较小的 \(\eta\) 开始,让课程在早期阶段快速推进,如果在训练期间观察到 KL 散度不稳定,则增加 \(\eta\)
- 在实践中,建议从一个较小的 \(\eta\) 开始,让课程在早期阶段快速推进,如果在训练期间观察到 KL 散度不稳定,则增加 \(\eta\)
- 在所有设置中,性能始终强于 vanilla OPD,成功率变化小于 \(2%\),这表明 TCOD-F2B/B2F 对 \(\eta\) 的具体选择不敏感
Domain-Specific vs. Larger Teacher
- 比较表 2 和表 3 可发现:教师质量强烈影响 TCOD 的上限
- 在表 2 中,教师是在 ALFWorld 上经过 GRPO 调优的 Qwen2.5-7B,达到了 \(85.71%\) 的成功率
- 在这种设置下,使用相同 7B 骨干网络的 TCOD-B2F 甚至以 0.7 个百分点略微超过了教师
- 在表 3 中,教师是 Qwen3-30B-A3B-Instruct,一个在目标领域上性能较弱的通用模型
- 在这种情况下,vanilla OPD 和 TCOD 都无法超过教师,大约有 2 个百分点的差距
- 这表明教师模型在目标任务上的性能比单纯的模型规模更重要,能够使学生模型得到提升
- 在表 2 中,教师是在 ALFWorld 上经过 GRPO 调优的 Qwen2.5-7B,达到了 \(85.71%\) 的成功率
TCOD is computationally efficient,TCOD 计算效率高
- 图 6 比较了 TCOD 和 vanilla OPD 在 ALFWorld 和 ScienceWorld 上的总训练成本
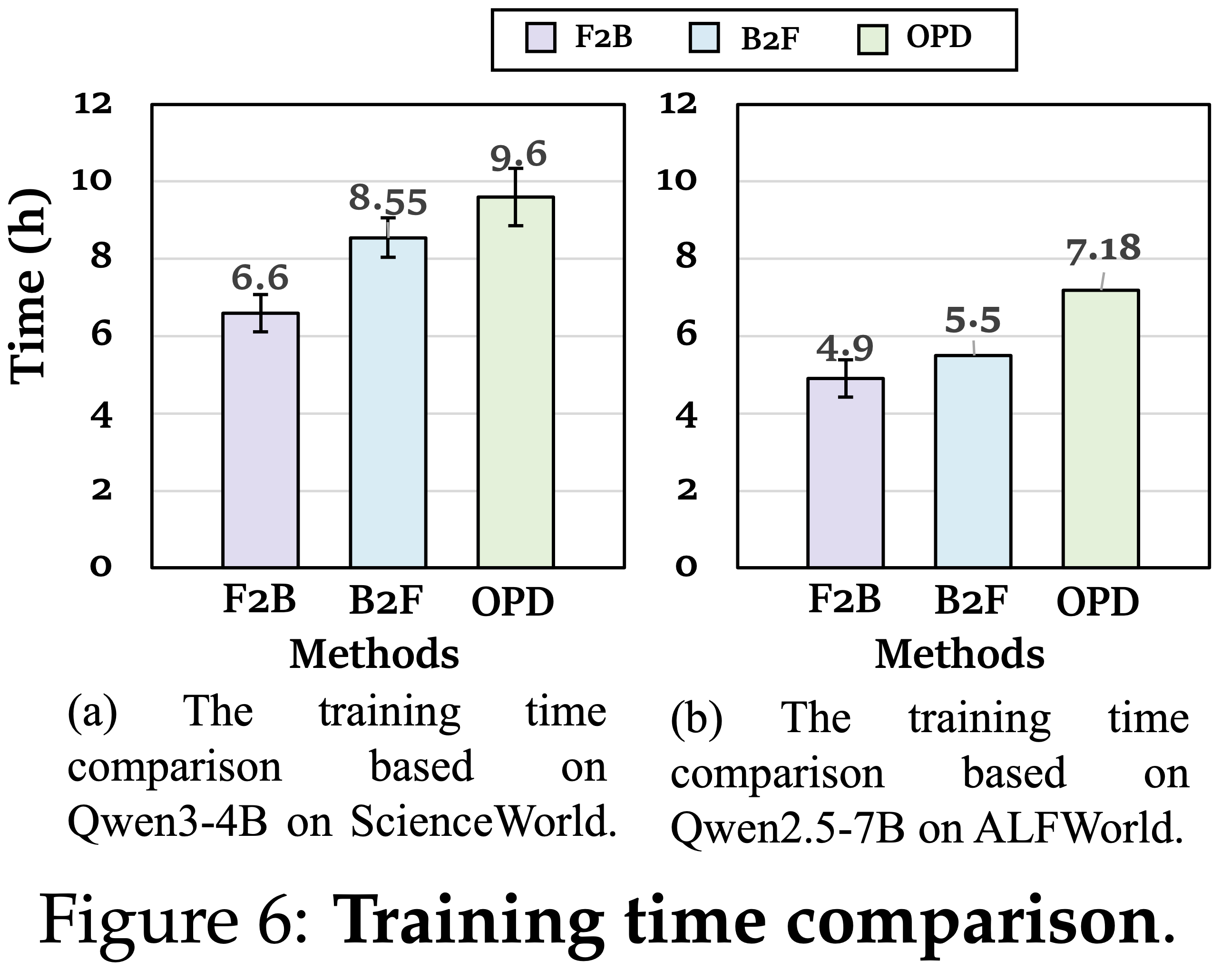
- 在两个基准上,与 vanilla OPD 相比,TCOD-F2B 和 TCOD-B2F 将总训练时间减少了近 \(32%\)
- 这一增益来自于 TCOD 中基于步数的课程:
- 在训练早期,学生模型采取更少的步数,生成更短的轨迹并加快数据收集速度
- TCOD-F2B 比 TCOD-B2F 更高效
- 因为 TCOD-F2B 将最大交互步数限制为 \(k\),而 TCOD-B2F 尽管从中间状态开始,但仍然会导致学生模型采取额外的探索性动作,从而产生更长的轨迹
- 图 5a 进一步验证了 TCOD-F2B 使用的 Rollout 动作步数比 TCOD-B2F 少,并且两者所需的步数都比 vanilla OPD 少
附录 A:Limitations and Future Work
- TCOD-B2F 依赖于预先收集的成功 Teacher 轨迹,这可能需要额外的轨迹收集开销
- 在这种情况下,前向到后向的变体(TCOD-F2B)提供了一个无需演示的即插即用替代方案
- 本文在经验上观察到 TCOD 的固定课程计划在本文三个基准和模型规模上都是稳健的,但最佳进度可能随不同环境或学生-教师对而变化
- 一种基于学生学习进度(例如通过 KL 散度的指数移动平均)自动调整 Horizon 的自适应机制可以进一步提高通用性
- 作者认为这是未来研究的一个有前景的方向
- 一种基于学生学习进度(例如通过 KL 散度的指数移动平均)自动调整 Horizon 的自适应机制可以进一步提高通用性
- 本文的评估侧重于三个基于文本的多轮基准
- 将 TCOD 扩展到多模态或物理具身环境是评估其通用性的重要下一步
附录 B:额外观察 (Additional Observation)
- 前文第 4.1 节已经补充
附录 C:Algorithm for TCOD-F2B/B2F
- 前文第 4.2 节 已经补充
附录 D:Experiment Details
D.1 Benchmark Environments
- ALFWorld (2020) 是一个基于文本的具身环境,需要跨六类家庭任务进行导航和物体操作
- ALFWorld 提供了可见(seen)和未见(unseen)分区:
- 可见分区测试在训练期间存在的环境中的性能
- 未见分区要求 Agent 在新的房间布局和物体组合中操作,作为本文的 OOD 评估
- 对于 ALFWorld,本文进一步构建了一个包含 121 个挑战性任务的困难集(Hard set),在这些任务中,Teacher 在训练集上的 pass@10 采样下失败
- 这个集合作为一个更具挑战性的 OOD 评估,用于测试 TCOD 是否能够泛化超越 Teacher 自身的能力边界
- ALFWorld 提供了可见(seen)和未见(unseen)分区:
- WebShop (2022a) 是一个基于网络的环境,要求 Agent 在模拟的电子商务平台上,通过多轮交互搜索并选择与给定用户指令匹配的产品
- ScienceWorld (2022) 是一个基于文本的环境,测试跨 30 种与基础科学课程一致的任务类型的科学推理能力
- Agent 根据任务完成情况,在每项任务结束时获得 0 到 100 之间的分数
D.2 Baselines
- 为严格评估 TCOD 的有效性,本文针对以下范式进行基准测试,为学生模型建立清晰的性能边界:
- Teacher (Upper Bound):
- 专家策略(\(\pi_{\theta}\))的性能直接在环境中进行评估
- 在标准蒸馏中,这代表了理论上的上限,因为主要目标是在更小的学生模型中恢复这种能力
- 本文在训练困难集(Train Hard split)(第 5.3 节)上的评估调查了 TCOD 是否甚至能泛化超越这个上限
- Zero-Shot Student (Lower Bound):
- 基础学生模型(\(\pi_{\theta}\))直接在交互式任务上进行评估,没有任何特定任务的微调或蒸馏
- 这是学生模型在 Agentic 环境中推理能力的绝对起点
- SFT
- 基本的模仿学习基线
- 学生模型通过标准的负对数似然(NLL)损失在预先从 Teacher 收集的成功轨迹(\(\tau^{*}\))上进行 2 个 Epoch 的微调,存在多轮设置中众所周知的暴露偏差(exposure bias)问题
- Vanilla On-Policy Distillation(OPD)
- 近期 OPD 方法的标准多轮适应
- 学生在自己生成的完整轨迹(完整 Rollout)上,被训练以最小化其分布与 Teacher 分布在 Token 级别的 KL 散度,没有任何 Horizon 约束或时间课程
- 这作为直接基线,以展示轨迹级别的 KL 不稳定性(Trajectory-Level KL Instability)
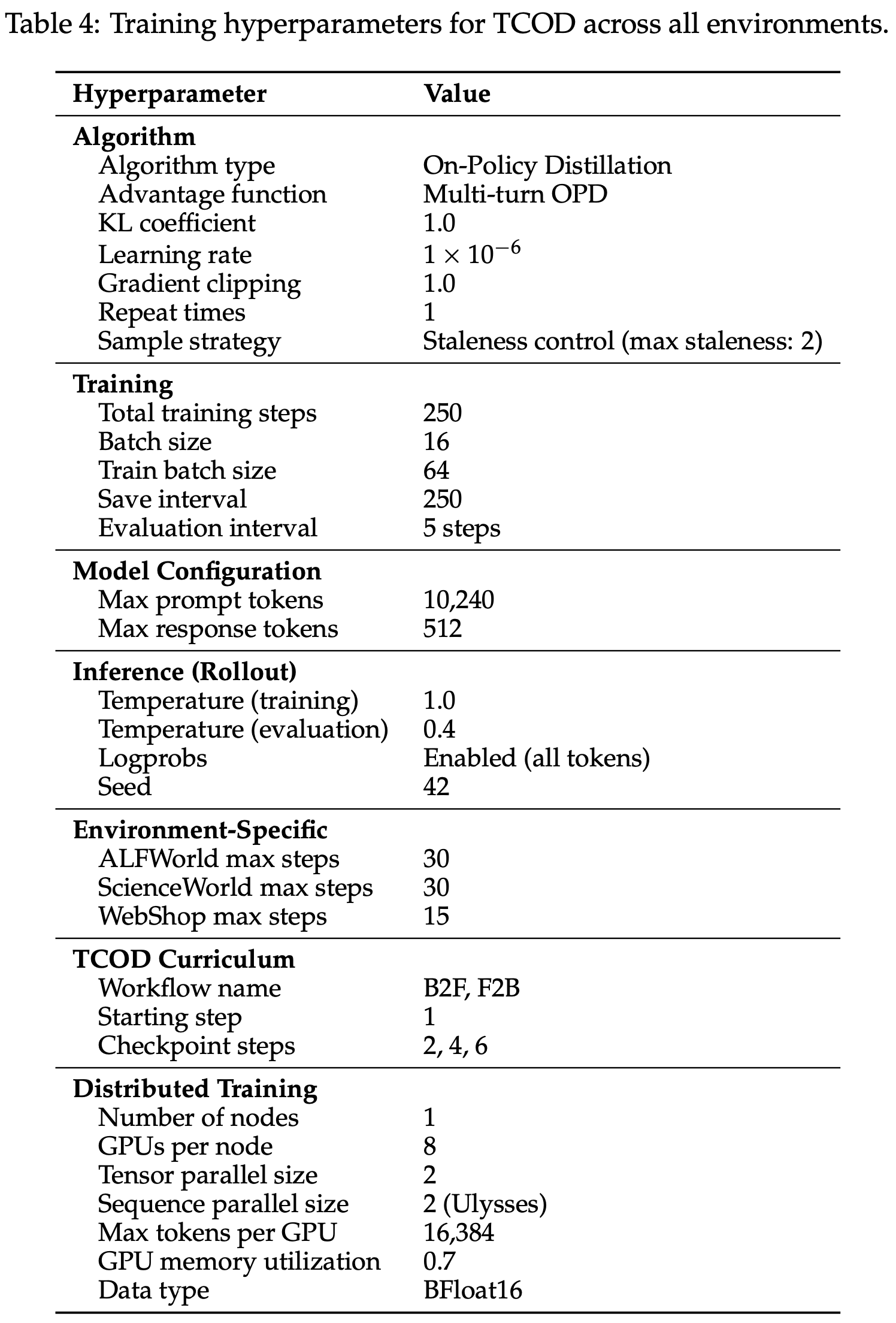
D.3 Training Hyperparameters
- 三个基于文本的交互式环境:ALFWorld、ScienceWorld 和 WebShop 上进行训练,训练配置总结在表 4 中
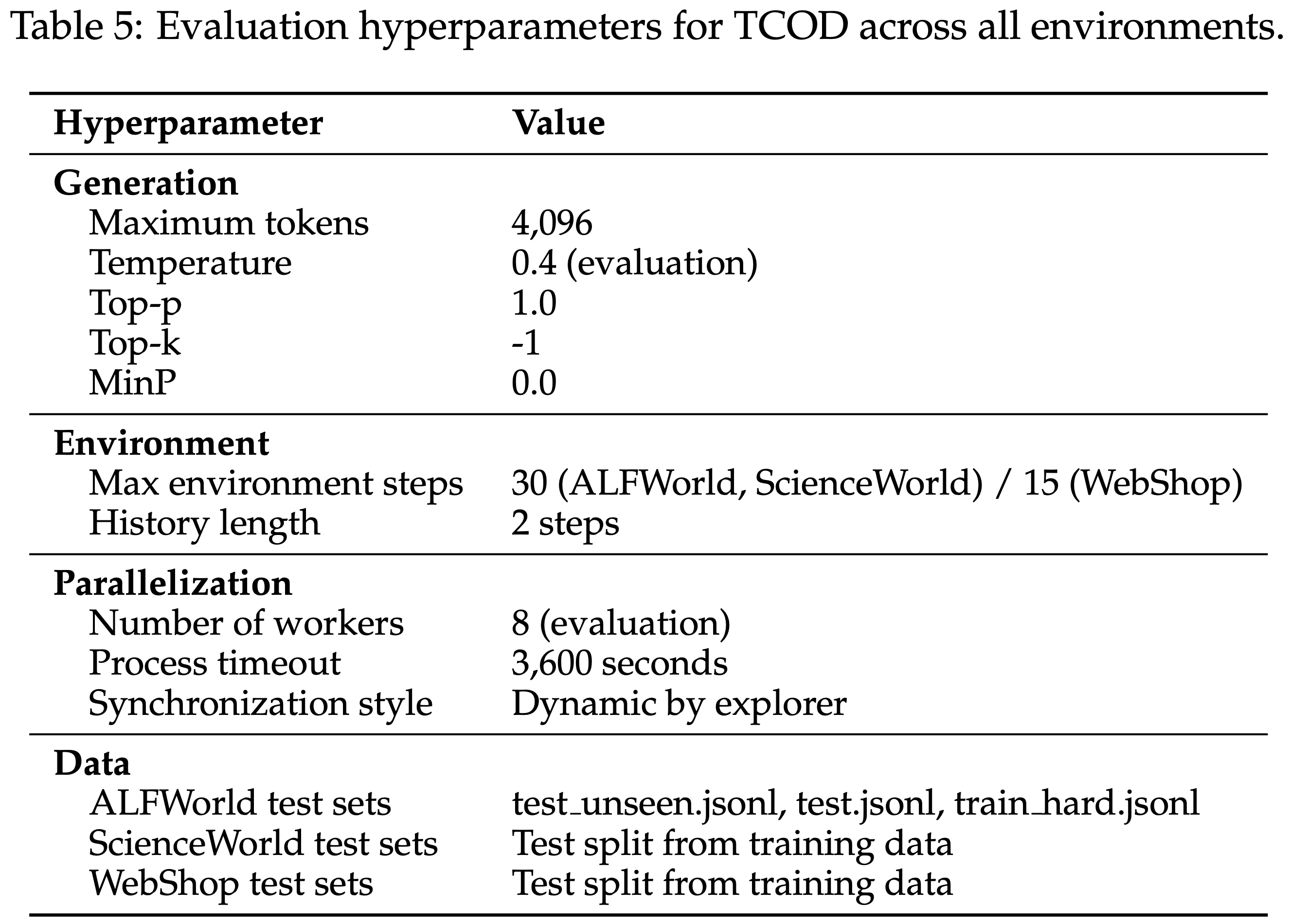
D.4 Evaluation Hyperparameters
- 在三个测试集上评估模型性能:test_unseen、test 和 train_hard(仅 ALFWorld)
- 所有环境的评估超参数一致,如表 5 所示
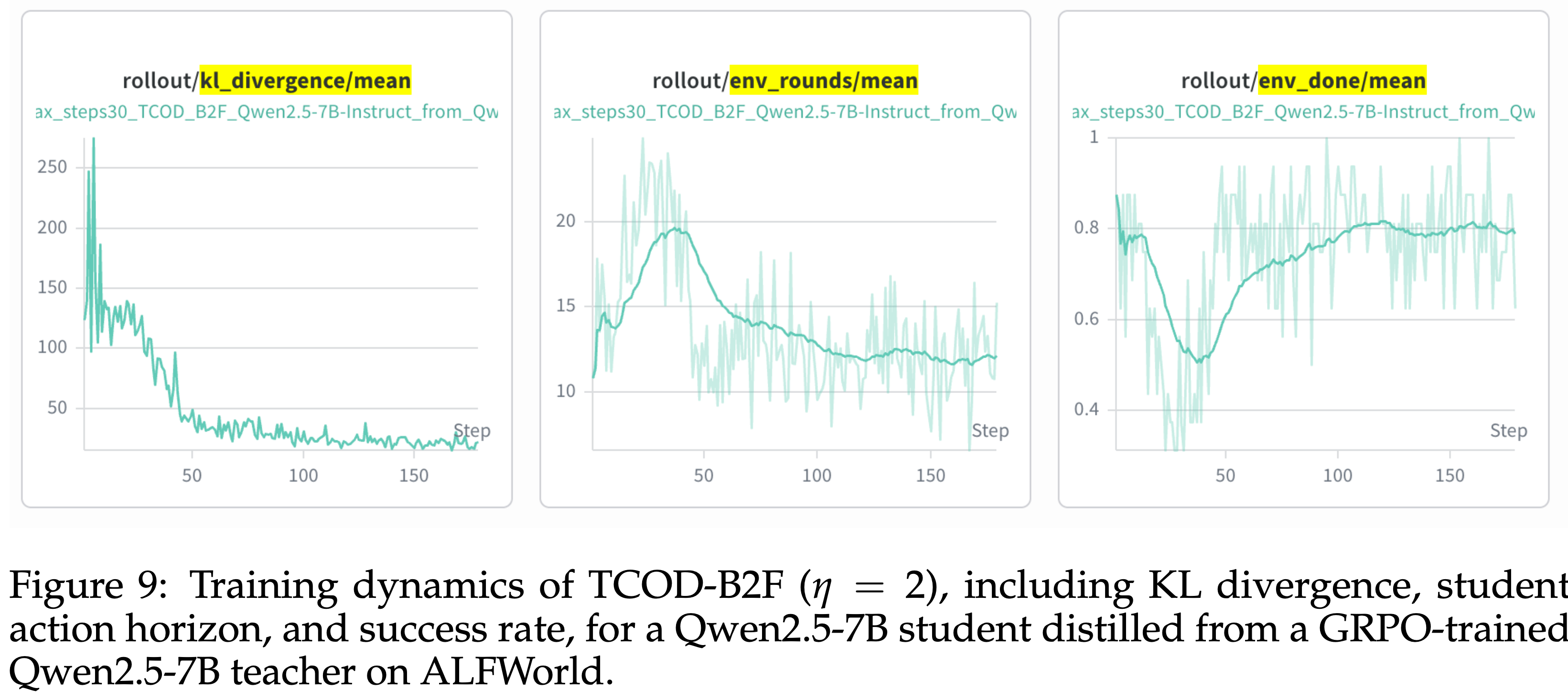
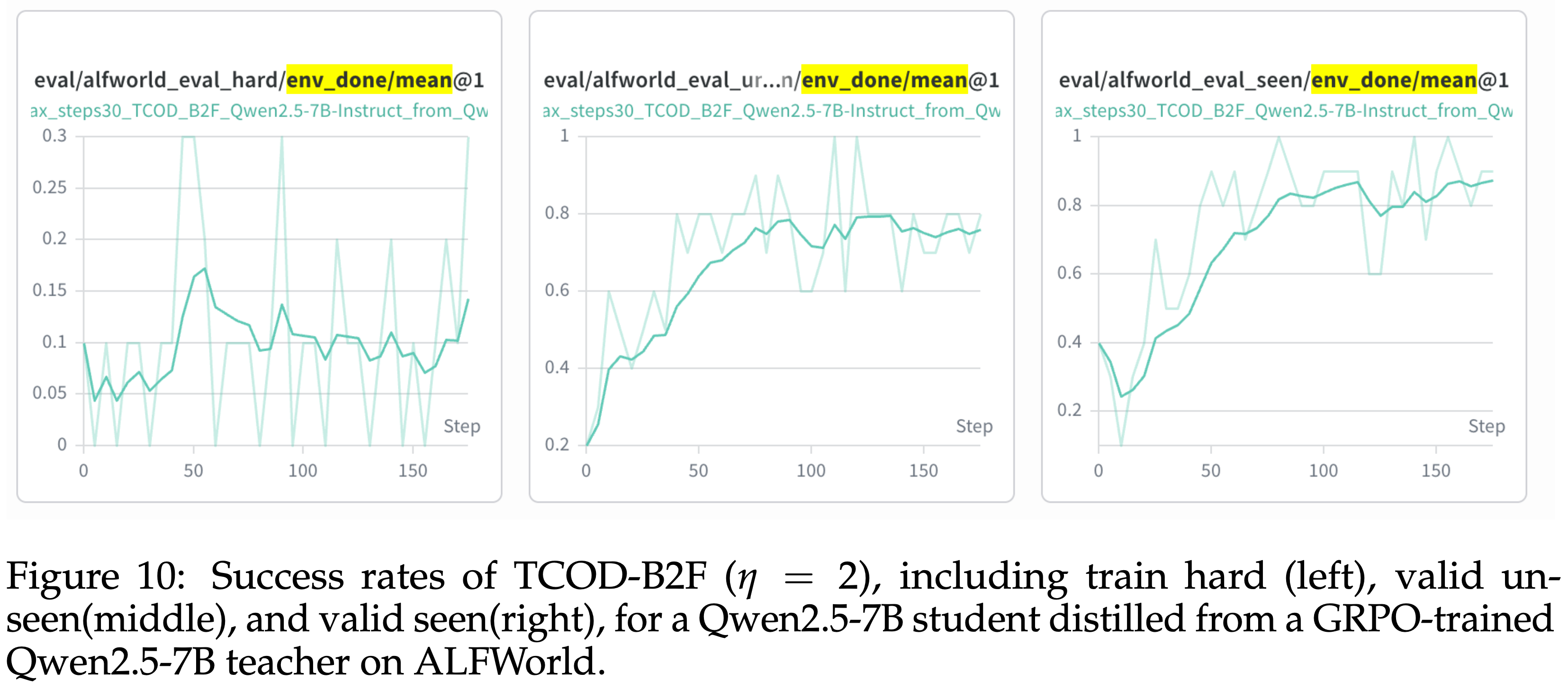
D.5 More experiments results
- TCOD-B2F 的详细成功率
- 如图 9 和图 10 所示,TCOD-B2F 表现出特有的非单调训练动态
- Rollout 成功率最初很高,因为训练从短 Horizon 开始,然后随着课程扩展到更长的轨迹而下降,最后随着学生适应增加的难度而恢复(图 9 右侧图)
- 在 valid seen 分区中也观察到类似的模式,成功率在训练中期也会下降然后再改善(图 10 右侧图)
- 在 valid unseen 和训练困难(train hard)分区在整个训练过程中保持相对稳定,没有明显的下降(图 10 左、中图)
- 这表明中间的性能下降不是由于过拟合或不稳定,而是反映了受控的课程过渡
- 这些结果表明 TCOD-B2F 在 Horizon 扩展时引入了暂时的难度,但保持了稳定的泛化能力,同时最终提高了性能,验证了渐进式 Horizon 扩展的有效性
- 图 9:TCOD-B2F(\(\eta = 2\))的训练动态,包括 KL 散度、学生动作 Horizon 和成功率
- 在 ALFWorld 上,从 GRPO 训练的 Qwen2.5-7B Teacher 蒸馏 Qwen2.5-7B 学生
- 在 ALFWorld 上,从 GRPO 训练的 Qwen2.5-7B Teacher 蒸馏 Qwen2.5-7B 学生
- 图 10:TCOD-B2F(\(\eta = 2\))的成功率,包括训练困难(左)、valid unseen(中)和valid seen(右)
- 在 ALFWorld 上,从 GRPO 训练的 Qwen2.5-7B Teacher 蒸馏 Qwen2.5-7B 学生
- 在 ALFWorld 上,从 GRPO 训练的 Qwen2.5-7B Teacher 蒸馏 Qwen2.5-7B 学生
附录 E:Environment Prompts
- 详情见原论文