注:本文包含 AI 辅助创作
Paper Summary
- 整体说明:
- 本文提出了一种创新的,两阶段交叉迭代优化的方法
- 个人理解:Rubric 的生成本身应该是和 Verifier(即本文的 Judge)无关的,所以本文的做法可能有点牵强
- 我的理由是:一个 Rubric 好不好,不需要看使用的 Verifier 是什么
- 例外的情况(可能有依赖的点):可能 Rubric 太难,简单的 Verifier 无法准确判断,Rubric 太简单,无法完美评估 Reponse 的优劣,所以 Rubric 的生成是否能让下游的 Verifier 准确判定,可能是有一定关系的
- 其他讨论:
- Rubric 的生成和 Verify 耦合本身并不科学,不方便分开迭代
- Rubric 的生成应该是尽量简单的,方便判断的,对 Verifier 要求不高的!
- 注:本文生成的 Rubric 都是 Query-specific 的,没有任何 General 的,且没有使用 Reference Response
- 注:本文是 Pairwise 的 Verifier,在现实训练中评估成本很高,比如采样 8 个 Rollout 时,两两比较需要 28 次,除非使用其他已有的研究方案缓解这个问题(比如降低到 7-8 次)
- 但是效率也远远低于 Pointwise 方案
- 本文的 Rubric 生成 Prompt 是参考了 OpenRubrics 的,将 rubrics 分为两种互补类型:
- (i) Hard Rules ,捕捉用户 Prompt 中陈述的显式要求;
- (ii) Principles ,描述更高级别的定性方面,如推理合理性、事实性、或风格连贯性
- 问题提出:
- 标量 RM 无法捕捉在不可验证领域(如创意写作或开放式指令遵循)中 Response 质量的多方面特性
- 解决方案:
- Rubric-ARM:通过来自偏好反馈的强化学习联合优化 Rubric Generator 和 Judge 的框架
- 创新点:不同于依赖静态 Rubric 或分离训练流程的方法,Rubric-ARM 将 Rubric 生成视为一个学习到的、旨在最大化判断准确性的潜在动作
- 作者的特别设计:
- 交替优化策略 : 用于缓解同时更新的非平稳性问题,并提供理论分析,并证明这种交替优化策略如何降低训练期间的梯度方差
- 最终:Rubric-ARM 在多个基准测试中,以及在离线和在线强化学习场景中都取得了不错的成绩
Introduction and Discussion
- RM 通常通过生成标量分数或偏好标签来预测人类偏好
- 但在复杂的不可验证领域(如创意写作或开放式指令遵循中)这些标量或 Pairwise 判断通常无法捕捉 Response 质量的多方面特性
- 解决方案:最近工作转向 Rubric-based 奖励建模,其中模型显式生成结构化标准来支撑其判断 (2026, 2025a, 2025)
- 特点:通过将评估分解为可解释的维度, Rubric-based 模型提供了透明度,并改善了跨特定于 Prompt 评估维度的泛化能力
- Rubric-based 评估核心在于高质量 Rubric 的可获取性
- Rubric 相关工作情况
- 为确保 Rubric 质量,早期工作主要依赖于人工编写的 Rubric ,其制作成本高昂且难以扩展到大规数据集 (2025)
- 最近的方法 Try to 利用 LLM 自动化 Rubric 构建 (2025, 2026);
- 但这些方法在很大程度上 Prompt-based,并依赖固定、冻结的模型进行 Rubric 生成和 Response 质量判断
- 它们未针对目标领域或底层偏好分布更新模型的内在能力,限制了其生成领域内、偏好对齐的 Rubric 的能力
- 另外,即使引入了基于学习的组件 (2025a, 2025), Rubric Generator 和 Judge 也被视为独立模块并分别训练,而非联合优化
- 这种解耦的训练流程阻碍了 Rubric 构建与判断之间更深层次的整合,导致次优的评估信号
- 解决方案:Rubric-ARM,通过交替强化学习联合优化 Rubric Generator 和 Judge 的端到端框架
- 两个组件在训练期间能够协同演进并相互强化
- 作者将 Rubric 定义为指导奖励模型恢复底层偏好信号的潜在动作 ,并假设改进的 Rubric 生成会直接导致更准确的偏好预测
- 为确保稳定的联合优化,Rubric-ARM 采用了一种交替训练策略
- 该策略在学习动态解耦的同时保留了一个共享目标
- 训练在以下两者之间交替进行:
- (i) 使用固定的 Rubric Generator 优化奖励模型,以对齐目标偏好标签
- (ii) 使用固定的奖励模型优化 Rubric Generator ,以产生最大化预测准确性的判别性 Rubric
- 交替强化学习的关键挑战:同时更新两个组件引起的不稳定性
- 作者的分析表明, Rubric Generator 在早期阶段的探索可能主导学习动态
- 为缓解此问题,作者*首先在固定 Rubric 下稳定奖励模型,然后再优化 Rubric Generator *
- 这种交替调度降低了方差并确保了鲁棒的优化
- 贡献总结:
- 基于首个通过强化学习联合优化 Rubric 生成和评判的方法,开发了 Rubric-based 奖励模型 Rubric-ARM
- 用于产生高质量 Rubric 和精确判断
- 引入了一种交替强化学习训练算法
- 通过一个共享的正确性目标将 Rubric Generator 和 Judge 耦合起来,在稳定优化的同时实现相互改进
- Rubric-ARM 评估结果优于基于推理的 Judge 和其他 Rubric-based 奖励模型
- 在奖励建模基准上实现了平均 \(+4.7%\) 的提升
- 在用作奖励信号时,持续改善了下游策略后训练的性能
- 基于首个通过强化学习联合优化 Rubric 生成和评判的方法,开发了 Rubric-based 奖励模型 Rubric-ARM
Preliminaries
- 本文研究关注不可验证领域中 Rubric-based 奖励建模,其中 Response 质量无法直接根据基本事实进行验证
- Rubric-based 奖励模型包含两部分,即 Rubric Generator 和 Judge
Rubrics
- 将 Rubric 定义为以 Prompt 为条件的结构化评估标准集
- 令 \(x\) 表示一个 Prompt ,一个 Rubric 由 \(k\) 个标准组成
$$ r(x) = \{c_i\}_{i = 1}^k $$- 其中每个 \(c_i\) 指定 Response 质量的一个不同方面(例如,事实准确性、语气或呈现方式)
- 为了在不可验证领域训练 Rubric-based 奖励模型,给定一个 Pairwise 偏好数据集
$$ \mathcal{D} = \{(x_i,y_i^{(1)},y_i^{(2)},o_i^*)\}_{i = 1}^N$$- \(x\) 是一个 Prompt
- \(y^{(1)}\) 和 \(y^{(2)}\) 是两个候选 Response
- \(o^{\star}\in \{0,1\}\) 指示哪个 Response 更受偏好(例如,\(o^{\star} = 1\) 表示 \(y^{(1)} > y^{(2)}\))
- Rubric Generator \(\pi_{r}\) 根据 Prompt 生成一个 Rubric \(r\):
$$r\sim \pi_{r}(\cdot \mid x; \theta_{r}), \tag{1}$$ - Judge \(\pi_{j}\) 根据 Prompt 、 Response 和 Rubric 预测偏好 \(o\) 和推理链 \(c\):
$$(c,o)\sim \pi_{j}(\cdot \mid x,y^{(1)},y^{(2)},r;\theta_{j}). \tag{2}$$
Learning Objective
- 定义偏好-正确性奖励:
$$R(o,o^{\star}) = \mathbb{I}[o = o^{\star}], \tag{3}$$- 其中 \(\mathbb{I}[o = o^{\star}]\) 表示从 \(o\) 提取的二元预测是否与基本事实 \(o^{\star}\) 一致
- 将 \(\theta_{r}, \theta_{j}\) 分别表示为 \(\pi_{r}\) 和 \(\pi_{j}\) 的参数,作者的目标是学习 \((\theta_{r}, \theta_{j})\) 以最大化在生成 Rubric 下的期望偏好正确性:
$$\max_{\theta_{r},\theta_{j} }\mathbb{E}_{(x,y^{(1)},y^{(2)},o^{\star})\sim \mathcal{D},\ r\sim \pi_{r}(\cdot |x;\theta_{r}),\ (c_{o})\sim \pi_{j}(\cdot |x,y^{(1)},y^{(2)},r;\theta_{j})}\left[R(o,o^{\star})\right]. \tag{4}$$ - 注:可以看出 \(r\)(文本)和 \(c, o\)(带有推理的离散决策)都是采样的动作,所以 Rubric-ARM 使用强化学习优化方程 (4)
Rubric-ARM: Alternating RL(交替强化学习)for Rubric Generation and Judging
- 在不可验证领域中,监督仅限于 Pairwise 偏好反馈,且 Rubric 无法直接观察到
- 同时更新 Rubric Generator \(\pi_{r}\) 和 Judge \(\pi_{j}\) 会导致非平稳的学习目标和不稳定的优化
- 如图 1 所示,Rubric-ARM 使用一种交替强化学习方案来解决这一挑战,该方案解耦了两个组件的更新
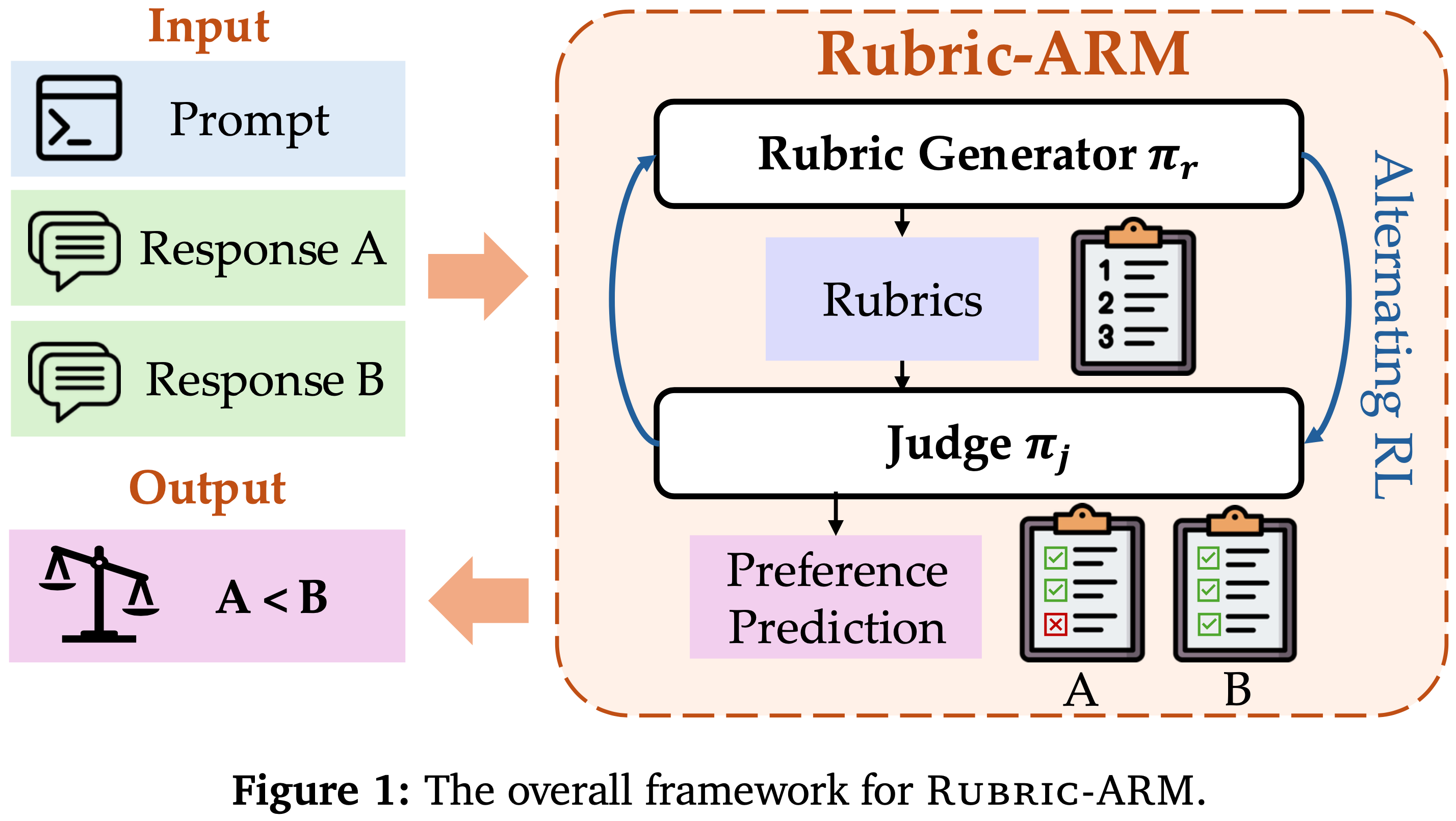
Stage I: SFT Warmup
- 利用开源数据集,为 \(\pi_{j}\) 和 \(\pi_{r}\) 配备基本的 Rubric 生成和评判能力
- 遵循先前工作 (2025a),作者在包括 UltraFeedback (2024), SkyWork (2024), Magpie (2025b) 和 Synthetic Instruction Following (2025a) 在内的开源数据集上,对来自这些数据集的合成 Rubric 和评判轨迹进行微调
- \(\pi_{r}(r \mid x; \theta_{r})\) 和 \(\pi_{j}(c, o \mid x, y^{(1)}, y^{(2)}, r; \theta_{j})\) 均使用标准的 NTP 目标进行训练
Stage II: Alternating Reinforcement Learning(交替强化学习)
- 第一阶段通过模仿合成 Rubric 生成和评判轨迹来预热 Rubric Generator \(\pi_{r}\) 和 Judge \(\pi_{j}\)
- 目前为止仅仅是独立 地优化这两个组件,并未直接以偏好正确性为目标
- 第二阶段使用交替强化学习优化这两个组件,训练在以下两者之间切换:
- (i) 使用固定的 Rubric Generator 改进 Judge
- (ii) 使用固定的 Judge 改进 Rubric Generator ,为每个组件提供更清晰的学习信号,同时保持相同的最终目标 \(R(o, o^{\star})\)
Stage II(Step 1): RL for Judge \(\pi_{j}\) with the current \(\pi_{r}\)
- 在固定 Rubric Generator 参数 \(\theta_{r}\) 的情况下,作者更新 \(\theta_{j}\) 以改进在从 \(\pi_{r}\) 采样的 Rubric 下的偏好正确性:
$$\max_{\color{red}{\theta_{j} }}J_{j}(\color{red}{\theta_{j}};\color{blue}{\theta_{r}}) = \mathbb{E}_{(x,y^{(1)},y^{(2)},\sigma^{\star})\sim \mathcal{D}\sim \pi_{r}(\cdot \mid x;\color{blue}{\theta_{r}})} {\mathbb{E} }_{(c,\sigma)\sim \pi_{j}(\cdot \mid x,y^{(1)},y^{(2)},\sigma;\color{red}{\theta_{j}})}\left[\mathbb{I}[o = o^{\star}]\right]. \tag{5}$$- 此阶段训练 Judge 产生以固定 Rubric 为条件的评估,以恢复数据集的偏好
- 由于 \(\pi_{r}(\cdot \mid x; \theta_{r})\) 在 Judge 更新期间是固定的,作者缓存 Rubric 以减少采样成本并稳定优化
- 对于每个训练实例 \((x_{i}, y_{i}^{(1)}, y_{i}^{(2)}, o_{i}^{\star})\),作者采样一个 Rubric \(r_{i} \sim \pi_{r}(\cdot \mid x_{i}; \theta_{r})\) 一次,并在多个 Judge 优化步骤中重复使用它,得到蒙特卡洛估计:
$$J_{j}(\theta_{j};\theta_{r})\approx \mathbb{E}_{(x_{i},y_{i}^{(1)},y_{i}^{(2)},\sigma_{i}^{\star})\sim \mathcal{D},r_{i}(c,\sigma)\sim \pi_{j}(\cdot \mid x_{i},y_{i}^{(1)},y_{i}^{(2)},r_{i};\theta_{j})}\left[\mathbb{I}[o = o_{i}^{\star}]\right]. \tag{6}$$
- 对于每个训练实例 \((x_{i}, y_{i}^{(1)}, y_{i}^{(2)}, o_{i}^{\star})\),作者采样一个 Rubric \(r_{i} \sim \pi_{r}(\cdot \mid x_{i}; \theta_{r})\) 一次,并在多个 Judge 优化步骤中重复使用它,得到蒙特卡洛估计:
- 在实践中,作者使用 Format-based 奖励 \(R_{\mathrm{fmt} }\) 增强最终的正确性信号
$$ R_{\mathrm{acc} } = \mathbb{I}[o = o_i^\star ]$$- \(R_{\mathrm{fmt} }\) 强制执行有效的评判轨迹(即,用每个标准的解释处理每个 Rubric 标准,然后进行整体论证和最终决策)
- Judge \(\pi_{j}\) 的最终奖励是
$$ R_{j} = R_{\mathrm{acc} } + R_{\mathrm{fmt} } $$
Stage II(Step 2):RL for Rubric Generator \(\pi_{r}\) with the current \(\pi_{j}\)
- 在固定 Judge 参数 \(\theta_{j}\) 的情况下,作者更新 \(\theta_{r}\) 以偏好那些能引导当前 Judge 做出正确决策的 Rubric
- 最大化在从 \(\pi_{r}\) 抽取的 Rubric 下的偏好正确性:
$$\max_{\color{red}{\theta_{r} }}J_{r}(\color{red}{\theta_{r}};\color{blue}{\theta_{j}}) = \mathbb{E}_{(x,y^{(1)},y^{(2)},\sigma^{\star})\sim \mathcal{D} } \mathbb{E}_{r\sim \pi_{r}(\cdot |x,\color{red}{\theta_{r}})} \mathbb{E}_{(c,\sigma)\sim \pi_{r}(\cdot |x,y^{(1)},y^{(2)},r,\color{blue}{\theta_{j}})}\left[\mathbb{I}[o = o^{\star }]\right]. \tag{7}$$- \(\pi_{r}\) 学习生 Pairwise 于给定 Prompt 具有区分度、且 Judge 可用于恢复数据集偏好的标准
- 在实践中,作者通过贪心解码 \((t = 0)\) 用一次 Rollout 来近似期望,即,作者为每个 Rubric 生成一个评判轨迹 \((c,o)\),并使用蒙特卡洛估计:
$$R_{r} = \mathbb{I}[o = o^{\star}]. \tag{8}$$
Optimization (alternating RL)
- Rubric-ARM 在优化方程 5 和 7 之间交替进行,在迭代 \(t\),运行如下公式:
$$
\begin{array}{rl}
& r_i^t \sim \pi_r(\cdot |x_i;\theta_r^t)\quad \forall \ (x_i,y_i^{(1)},y_i^{(2)},o_i^*)\in \mathcal{D}, \\
& \theta_j^{t + 1}\leftarrow \mathrm{GRPO}(\theta_j^t;\{r_i^t\} ,\mathcal{D}), \\
& \theta_r^{t + 1}\leftarrow \mathrm{GRPO}(\theta_r^t;\theta_j^{t + 1},\mathcal{D}).
\end{array} \tag{10}
$$ - 实践:作者在 Judge 更新期间为每个实例缓存一个 Rubric (因为在该阶段 \(\pi_{r}\) 是固定的)
- 在每个阶段,GRPO (详见附录 A) 仅更新活动策略,同时保持另一个策略固定
- 作者在每个循环中通过先更新 Judge 再更新 Rubric Generator 来交替训练
- 在第 5 节中,作者提供了理论分析来证明这种顺序的益处
Connection to EM Algorithm
- 作者的交替优化可以看作是一种广义的期望最大化过程 (1977),其中 Rubric \(r\) 作为潜在变量
- 对于每个偏好实例
$$ (x,y^{(1)},y^{(2)},o^{\star})$$ - Judge 定义了一个条件模型
$$ p_{\theta_{j} }(o^{\star} | x,y^{(1)},y^{(2)},r) $$ - Rubric Generator \(\pi_{r}(r | x;\theta_{r})\) 充当潜在 Rubric 上的分布
- 于是,与 EM 关系为:
- 固定 \(\pi_{r}\) 时,更新 \(\pi_{j}\) 最大化给定 Rubric 下的期望正确性(或对数似然),类似于 M 步
- 固定 \(\pi_{j}\) 时,更新 \(\pi_{r}\) 增加使当前 Judge 更可能恢复 \(o^{\star}\) 的 Rubric 的概率质量,类似于摊销的 E 步
- 由于 Rubric 是高维离散文本序列,作者使用随机策略梯度更新而非精确后验推断,产生了一种随机期望最大化风格的坐标上升方案
Policy Model Post-training with Rubric-ARM
- 本节使用训练好的 Rubric Generator \(\pi_{r}(\cdot |q;\theta_{r})\) 和 Judge \(\pi_{j}(\cdot |q,\cdot ,\cdot ,r;\theta_{j})\) 为后训练策略模型 \(\pi_{\phi}(a | q)\) 提供偏好监督
- 其中 \(q\) 表示 Prompt ,\(a\) 表示候选 Response
- 对于任意一对 Response \((a,b)\),Rubric-ARM 采样一个 Rubric
$$ r\sim \pi_{r}(\cdot |q;\theta_{r})$$ - 然后预测一个偏好标签:
$$\hat{o} = \mathrm{Judge}_{\theta_j}(q,a,b,r)\in \{0,1\} , \tag{12}$$- 其中 \(\widehat{o} = 0\) 表示 \(a > b\),\(\widehat{o} = 1\) 表示 \(b > a\)
Preference Optimization with Rubric-ARM
- 给定一个 Prompt \(q\),从当前策略采样两个 Rollout:
$$a_{1},a_{2}\sim \pi_{\phi}(\cdot |q), \tag{13}$$ - 使用 Rubric-ARM 通过方程 (12) 标记哪一个更受偏好,并保留预测在两个顺序下都一致的样本
- 注:这里交换顺序是防止位置偏差的出现
- 然后使用标准的 DPO 目标相对于一个固定的参考策略 \(\pi_{\mathrm{ref} }\) 更新 \(\pi_{\phi}\)
- 对于迭代式 DPO (2024, 2024),作者重复以以下过程
- (i) 采样 Rollout
- (ii) 用 Rubric-ARM 标记它们
- (iii) 应用 DPO 更新,进行多轮
Online RL with Rubric-ARM
- 遵循最近使用 Pairwise Judge 提供奖励信号的工作 (2025a),作者也考虑在线强化学习,其中 Rubric-ARM 为优化 \(\pi_{\phi}\) 提供奖励
- 对于每个 Prompt \(q\),作者采用 ReMax 风格的基线构建方法 (2024)
- 首先通过贪心解码生成一个确定性的参考 Response :
$$a^{(0)} = \mathrm{Greedy}(\pi_{\phi}(\cdot |q)) \quad (\text{temperature} = 0), \tag{14}$$ - 然后采样 \(K\) 个额外的 Rollout:
$$\{a^{(k)}\}_{k = 1}^{K}\sim \pi_{\phi}(\cdot |q). \tag{15}$$
- 首先通过贪心解码生成一个确定性的参考 Response :
- 为减轻位置偏差,作者在相同 Rubric \(r\) 下以两种顺序查询 Judge
- 令 \(\widehat{o}_{-}^{(k)}\in \{0,1\}\) 表示对于 \((q,a^{(k)},a^{(0)},r)\) 的评判结果,\(\widehat{o}_{+}^{(k)}\in \{0,1\}\) 表示交换顺序后 \((q,a^{(0)},a^{(k)},r)\) 的评判结果
- 作者定义 Response \(a^{(k)}\) 的最终奖励为:
$$R_{\phi}(q,a^{(k)}) = \frac{1}{2}\left(\mathbb{I}(\widehat{o}_{-}^{(k)} = 0) + \mathbb{I}(\widehat{o}_{+}^{(k)} = 1)\right). \tag{16}$$
Theoretical Analysis
- 这里分析梯度方差以证明训练方案的合理性
- 比较两个阶段:
- 策略 A (Judge Warmup) ,在此阶段作者使用预生成、重复使用的 rubrics 来优化 Judge;
- 策略 B (Rubric Generator Training) ,在此阶段作者针对一个固定的 Judge 来优化 rubric Generator
- Setup:
- 令 \(u_{r}(r):= \frac{\partial}{\partial\theta_{r} }\log \pi_{r}(r|x)\) 和 \(u_{j}(o|r):= \frac{\partial}{\partial\theta_{j} }\log \pi_{j}(o|c,r)\) 为得分函数
- 令 \(p(r):= \mathbb{P}(o = o^{*}|c,r)\) 为给定 rubric 时 Judge 的正确概率
- 定义梯度方差为
$$ \mathrm{Var}(\widehat{\sigma}):= \mathbb{E}|| \widehat{\sigma}||^{2} -|| \mathbb{E}[\widehat{\sigma} ]||^{2} $$
Variance Decomposition(方差分解)
Proposition 5.1:策略 A 下的 Judge 方差
- 在以重复使用的 rubric \(\bar{r}\) 为条件的情况下,Judge 的梯度估计量 \(\widehat{\sigma}_{A}\) 的方差完全由 Judge 的二分类不确定性决定:
$$\mathrm{Var}(\widehat{\sigma}_{A}|\bar{r}) = p(\bar{r})(1 -p(\bar{r}))\left| u_{j}(o^{*}|\bar{r})\right|^{2}. \tag{17}$$- 通过在 Judge 更新期间固定 rubric \(\bar{r}\) (重复使用),消除了 rubric 间的方差
Proposition 5.2:策略 B 下的 Generator 方差
- Generator 梯度估计量 \(\hat{g}_B\) 的总方差分解为:
$$\mathrm{Var}(\hat{g}_B) = \underbrace{\mathbb{E}\left[p(r)(1 -p(r))\left|u_r(r)\right|^2\right]}_{\substack{(I)\text{Multiplicative Reward Noise} } } + \underbrace{\text{Var}_r(p(r)u_r(r))}_{\substack{(II)\text{Cross-Rubric Inconsistency} } } \tag{18}$$ - Interpretation
- 项 (I) 代表了 Judge 的 偶然不确定性 (Aleatoric uncertainty) ,被高维 Generator 梯度 \(\left| u_r\right| ^2\) 所放大
- 项 (II) 捕获了当不同 rubrics 产生不同期望奖励 \(p(r)\) 时导致的优化困难,这会导致梯度方向振荡
Variance Domination in Early Training
- 现在推导方差差距
- 这里不再假设平凡的梯度主导,而是提出一个将 Generator 的探索强度与其梯度幅度联系起来的条件
Assumption 5.3:探索-梯度充分性
- 作者假设在早期训练中, Generator 的梯度范数相对于 Judge 的梯度范数是充分的,满足以下与探索相关的下界:
$$\frac{\left|u_r\right|}{\left|u_r\right|} >\sqrt{\frac{1 -p(r)}{1 -p(r) + C_1p(r)} }, \tag{19}$$ - 其中 \(p\) 代表 Judge 的正确概率(逐点或在期望中分析),而 \(C_1 \in (0,1)\) 定义为:\(C_1 := \mathrm{Var}_r(p(r)u_r(r)) / \mathbb{E}_r[p(r)^2 | u_r(r)| ^2 ]\)
Remark 5.4
- 假设 5.3 中的条件是温和的且具有物理合理性
- 积极的探索 \((C_1 > 0)\) 引入了一个正缓冲区,使得不等式右侧所需的梯度范数比严格小于 1,从而避免了 Generator 梯度必须严格占主导的需要
- Judge 和 Generator 都在相同的词汇表上产生长度可比的序列(检查/预测 vs. rubrics),因此它们的梯度范数通常处于同一数量级;在实践中,探索缓冲区足以吸收小的不匹配并满足该条件
Theorem 5.5:严格方差主导
- 在假设 5.3 下,策略 B 的梯度方差严格主导策略 A 的期望条件方差:
$$\mathrm{Var}(\hat{g}_B) > \mathbb{E}_r[\mathrm{Var}(\hat{g}_A |\bar{r})]. \tag{20}$$- 这个不等式确立了由探索驱动的结构不稳定性(由 \(C_1\) 量化)是方差分布中的主导因素,覆盖了梯度幅度上的差异
Remark 5.6:对训练稳定性的启示
- 定理 5.5 中推导出的方差差距通过强调信噪比 (Signal-to-Noise Ratio, SNR) 中的一个关键权衡,证明了所提出的训练方案的合理性(作者首先训练 Judge,然后训练 rubric Generator ,并随后按照此顺序进行交替训练)
- 策略 B 中严格更高的方差意味着 Generator 的更新主要由探索随机性而非真实的梯度方向所主导,这存在优化不稳定的风险
- 策略 A 充当了一种方差减少机制:通过固定 rubric,它有效地将探索系数局部地设为 \(C_1 \to 0\),使 Judge 与结构噪声隔离,并为有效的学习提供了一个稳定的目标
Experiment
Datasets and Experiment Settings
Training data
- 在 OpenRuBrics (2025a) 的通用领域部分上训练 RuBric-ARM 的两个组件,即 rubric Generator 和 Judge
- 数据集被平均划分为不重叠的部分,每个 rubric-Judge 交替轮次在单个部分上运行
- 在训练 Judge 时,作者随机打乱待评估候选 Response 的顺序;
- 如附录 D.2 所示,这种做法极大地有助于减少奖励建模中的位置偏差
Backbone and variants
- rubric Generator 和 Judge 都基于 Qwen-3-8B (2025) 进行微调
- 在推理时,RuBric-ARM 遵循两阶段的 rubric-judging 过程,详见第 3 节
- 作者还报告了 ensemble results voting@5 的结果,通过多数投票聚合五个独立的 Judges
Baselines
- 对于奖励模型评估:
- 遵循 (2025a) 的工作,将 RuBric-ARM 与强大的同规模白盒 Judges 进行比较,包括 JudgeLRM (2025), RRM (2025), RM-R1 (2026), 以及 Rubric-RM (2025a) (仅 SFT 的 rubric Generator + Judge)
- 在可用的情况下,作者也报告使用黑盒 API 的 Judges
- 为了隔离 rubric-aware 训练的收益,作者包含了一个 Training-free 的基线,即 Qwen-3-8B (RuBric+Judge) (2025),它通过 prompting 直接生成 rubrics 和判断
- 对于策略训练,作者使用 RuBric-ARM 作为奖励模型来微调 Qwen2.5-7B-Instruct (2025),并与 Skywork (2024), ArmoRM (2024b), UltraFeedback (2024), RLCF/AI Judge (2025), OnlineRubrics (2025), 以及 Rubric-RM (2025a) 进行比较
Evaluation benchmarks and metrics
- 在广泛使用的对齐基准上评估 RuBric-ARM 作为一个 Pairwise 奖励模型的性能:
- RewardBench (Chat/Chat-Hard) (2025b)
- RM-Bench (2025b)
- PPE-IFEval (2024)
- FollowBench (2024)
- InfoBench (2024)
- IFBench (2025)
- RewardBench2 (Precise-IF/Focus) (2025)
- Arena-Hard (2024)
- AlpacaEval 2 (2025)
- Creative Writing Benchmark v3 (2025)
- WildBench (2024)
- WritingPreferenceBench (2025)
- 对于 FollowBench 和 InfoBench,作者通过从同一模型 (Qwen-3-8B/14B) 中采样两个 Response ,并使用基准的验证器来识别违反约束的情况,将原始的单 Response 设置转换为 Pairwise 评估
- 遵循每个基准的官方划分和评分规则,报告准确率、胜率或特定基准指标
Performance of Rubric-ARM
- 表 1 比较了 RuBric-ARM 与广泛的 Judge/奖励模型集合
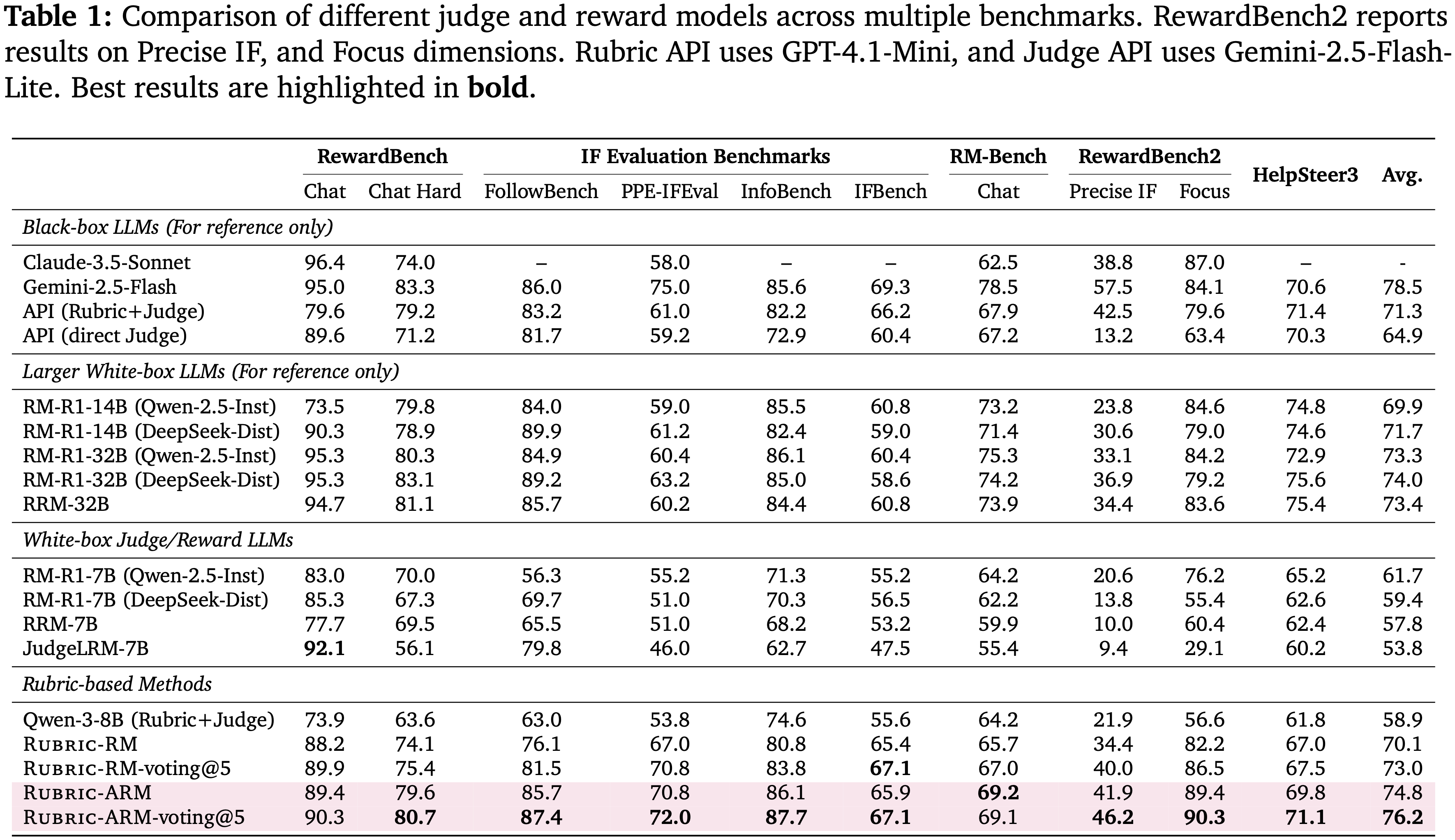
- 在所有白盒方法中,RuBric-ARM 实现了最佳的平均性能,将 Rubric-RM 从 70.1 提升到 74.8,并通过 voting@5 达到 76.2
- 这些提升在指令遵循和偏好风格基准上都是一致的,支持了作者的核心贡献:RuBric-ARM 通过 RL 学习了更具区分性的 rubrics 和一个更可靠的 rubric-conditioned Judge
- RuBric-ARM 也显著优于基于 API 的 Judges(例如,对于 Rubric+Judge API,76.2 对 71.3;
- 对于直接 Judge API,76.2 对 64.9),这表明显式的 rubric-conditioned 学习比黑盒判断产生了更强且更稳定的评估信号
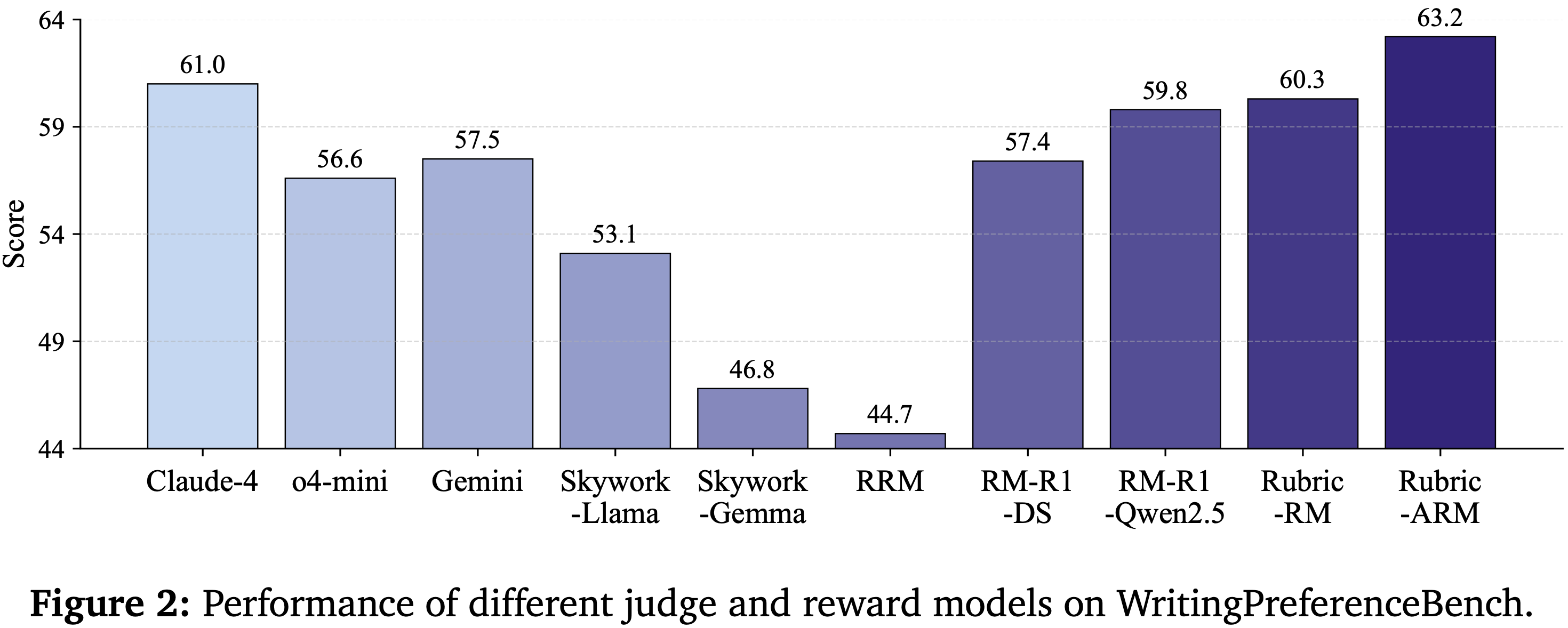
- 作者进一步在 WritingPreferenceBench (2025) 上评估泛化能力,如图 2 所示(详细结果见表 12),该基准作为一个分布外基准,因为所有比较的奖励/Judge 模型都未在此领域上训练
- 尽管存在这种分布偏移,RuBric-ARM 仍然表现强劲,在所有方法中取得了最佳总体得分 (63.2),优于 Rubric-RM (60.3) 和强大的推理奖励模型,如 RM-R1-Qwen2.5-7B (59.8)
- 提升在不同写作体裁(例如,功能性、推广性、非虚构性和诗歌)上都很广泛
- 表明 RuBric-ARM 学习的 rubrics 能够捕捉超越训练领域的可迁移准则,从而提供了具有改进的 OOD 泛化能力的鲁棒奖励信号
Ablation Study
- 表 2 报告了两项消融研究,考察了
- (i) Judge 和 rubric Generator 之间的优化顺序
- (ii) 格式奖励 (format reward) 的贡献
- 注:除非另有说明,所有设置均与 RuBric-ARM 保持相同
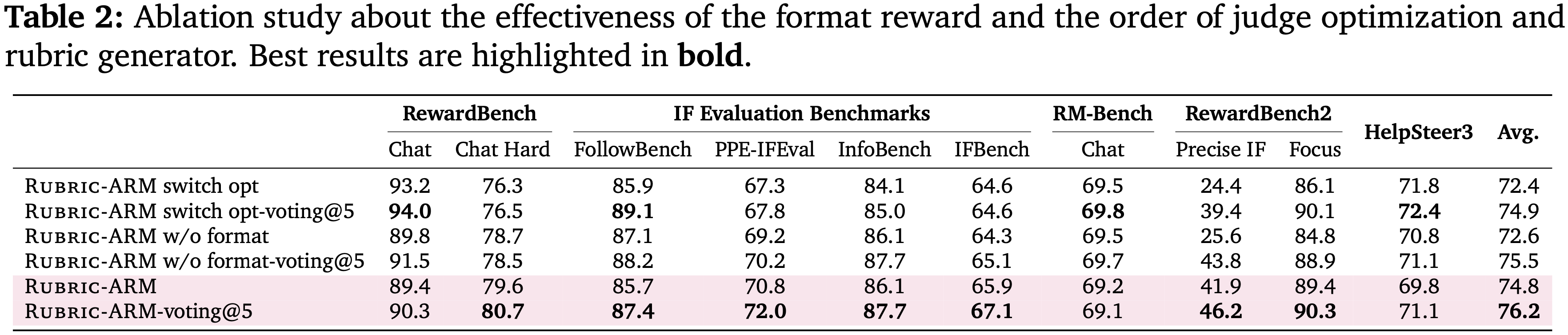
Optimization order
- 作者的默认方案先更新 Judge,然后更新 rubric Generator ,之后交替进行
- 调换此顺序 (switch opt) 会一致地损害性能:
- 不使用投票的平均分从 \(74.8 \rightarrow 72.4\) (-2.4) 下降
- 使用 voting@5 的平均分从 \(76.2 \rightarrow 74.9\) (-1.3) 下降
- 在严格的指令遵循指标上尤其出现较大的衰退(例如,RewardBench2-Precise IF: \(41.9 \rightarrow 24.4\))
- 这表明一个更强的 Judge 为 rubric 优化提供了噪声更少的学习信号
Format reward
- 移除格式奖励 (w/o format) 也会降低结果:
- 不使用投票的平均分从 \(74.8 \rightarrow 72.6\) (-2.2) 下降
- 使用 voting@5 的平均分从 \(76.2 \rightarrow 75.5\) (-0.7) 下降
- 最大的增益出现在对结构敏感的指标上(例如,RewardBench2-Precise IF: \(+16.3\))
- 表明 \(R_{\text{fmt} }\) 有助于防止退化的判断行为(例如,遗漏准则检查)并改善对 rubric 的遵守
Performance of offline RL-based Policy Models
Instruction-Following Evaluation
- 表 3 和图 3 显示,使用 RuBric-ARM 训练的奖励优化的策略在指令遵循性能上持续达到最强
- 在 IFEval 上,使用 RuBric-ARM 的 DPO 将总体平均值提高到 80.4
- iterative DPO 进一步将其提升到 80.8(最佳),在指令级约束上的提升尤其明显
- 该优势也迁移到了开放式的 InfoBench 基准上
- 使用 RuBric-ARM 的 DPO 达到 83.7
- iterative DPO 达到 85.0(最佳)
- 与迭代基线相比,RuBric-ARM 持续更强:
- 在 IFBench(图 3)上,RLCF 通过 IterDPO 从 28.2 提升到 32.0,
- RuBric-ARM 通过 IterDPO 达到 35.4;
- 类似地,迭代的 Rubric-RM 达到 33.7,仍低于 RuBric-ARM
- 总体而言,这些结果表明 RuBric-ARM 提供了更精确的奖励信号,并且迭代优化放大了相对于单次 DPO 和迭代基线的增益
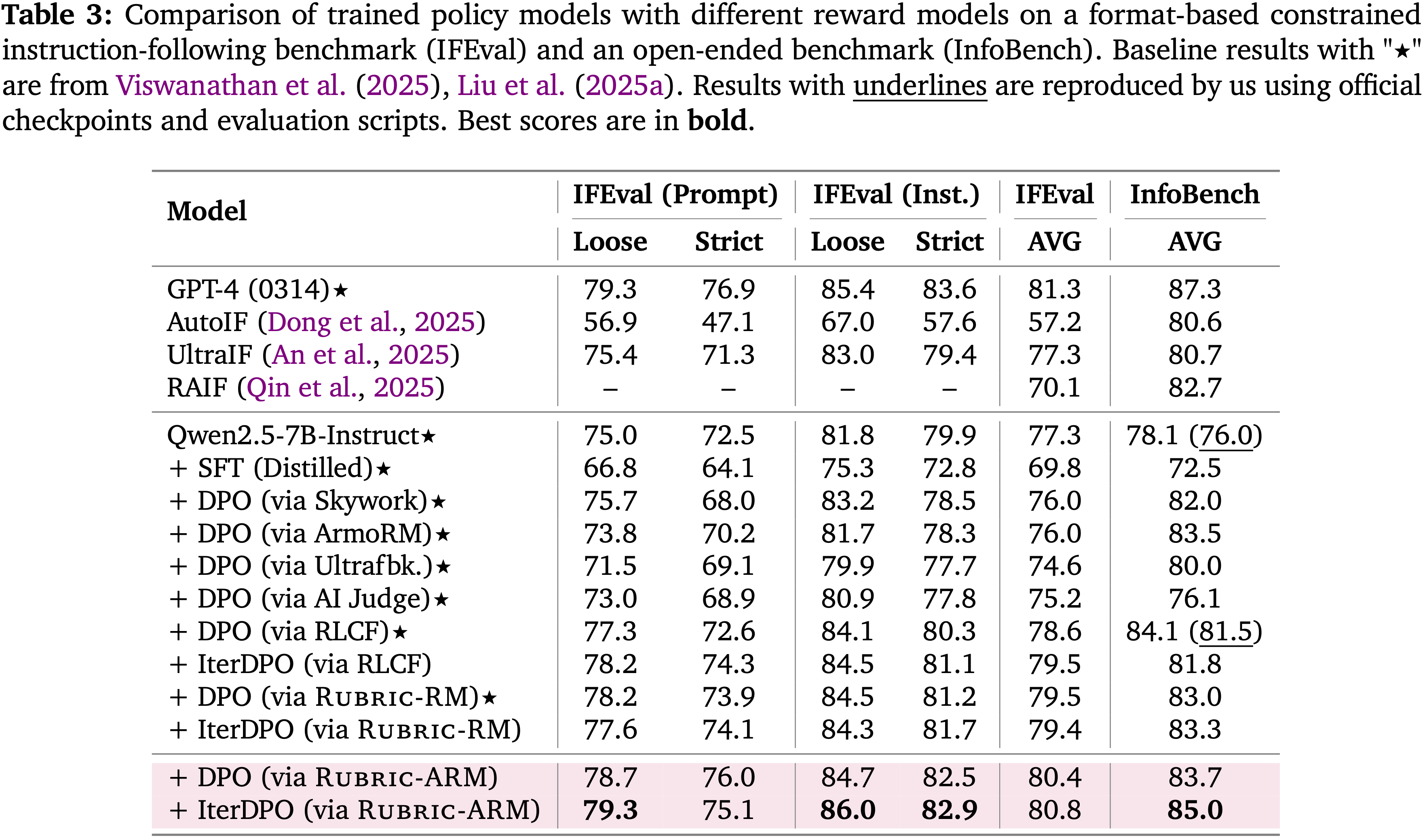
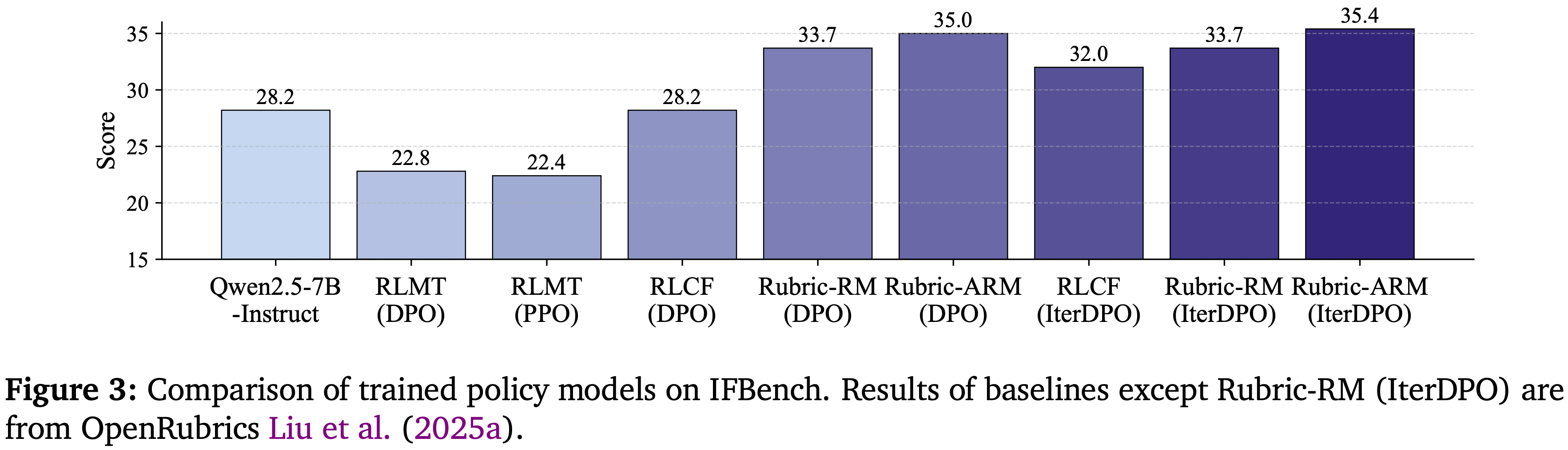
- 在 IFEval 上,使用 RuBric-ARM 的 DPO 将总体平均值提高到 80.4
Human Preference Alignment Evaluation
- 表 4 和表 5 表明,使用 RuBric-ARM 训练的奖励在受控和开放领域的评估中都能持续产生更强的偏好对齐
- 在 Arena-Hard 和 AlpacaEval(表 4)上,使用 RuBric-ARM 的 DPO 取得了最佳总体平均值 (51.7),而 IterDPO 进一步将其提升到 53.4(最佳)
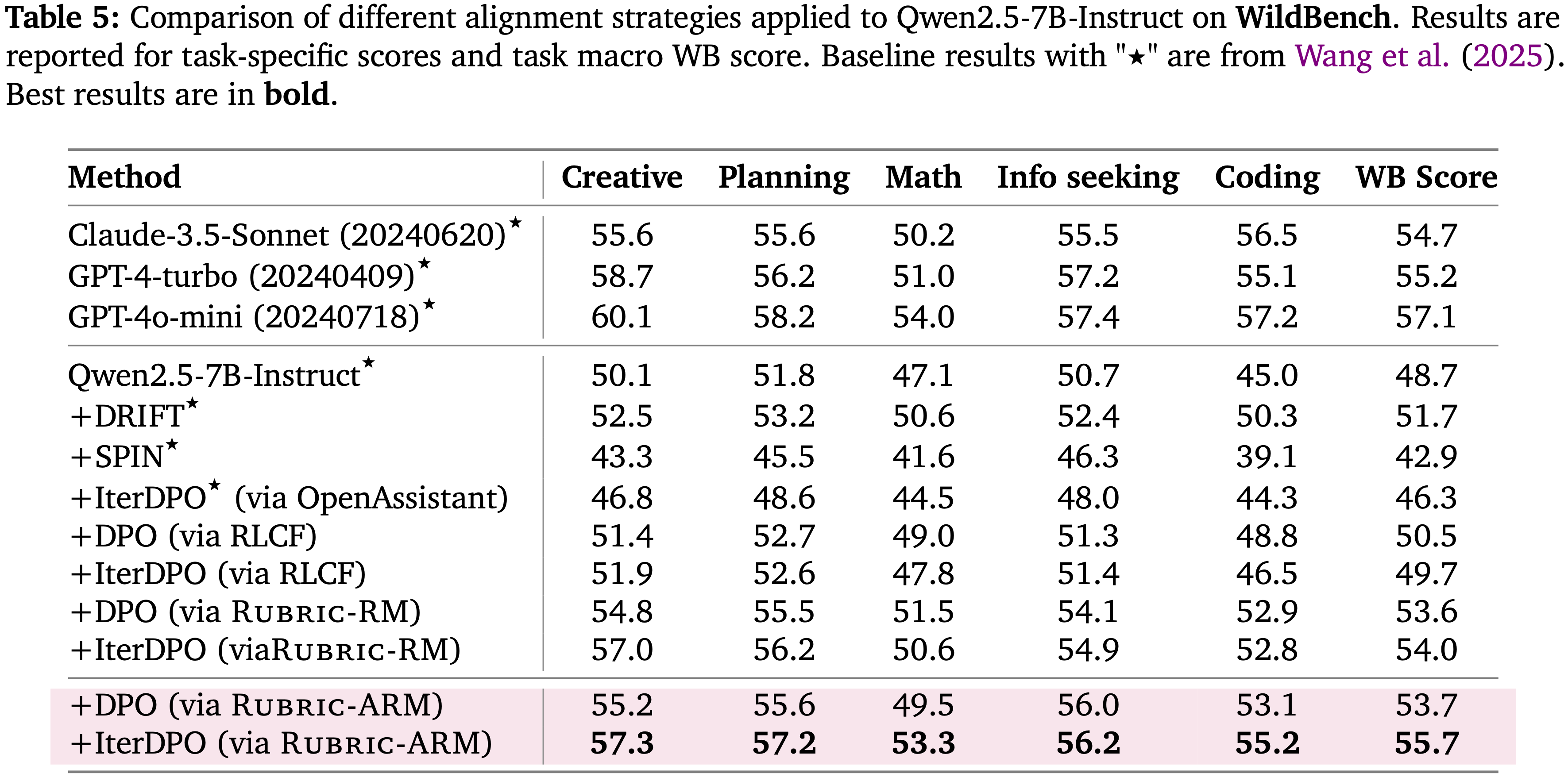
- 在 WildBench(表 5)上,RuBric-ARM 再次产生最强的宏观得分:
- 通过 RuBric-ARM 的 DPO 达到 53.7,而通过 RuBric-ARM 的 IterDPO 达到 55.7(最佳),相比于使用 Rubric-RM 的 IterDPO (54.0) 提升了 1.7%,表明在广泛的现实世界任务上,对齐偏好的帮助性得到了改善
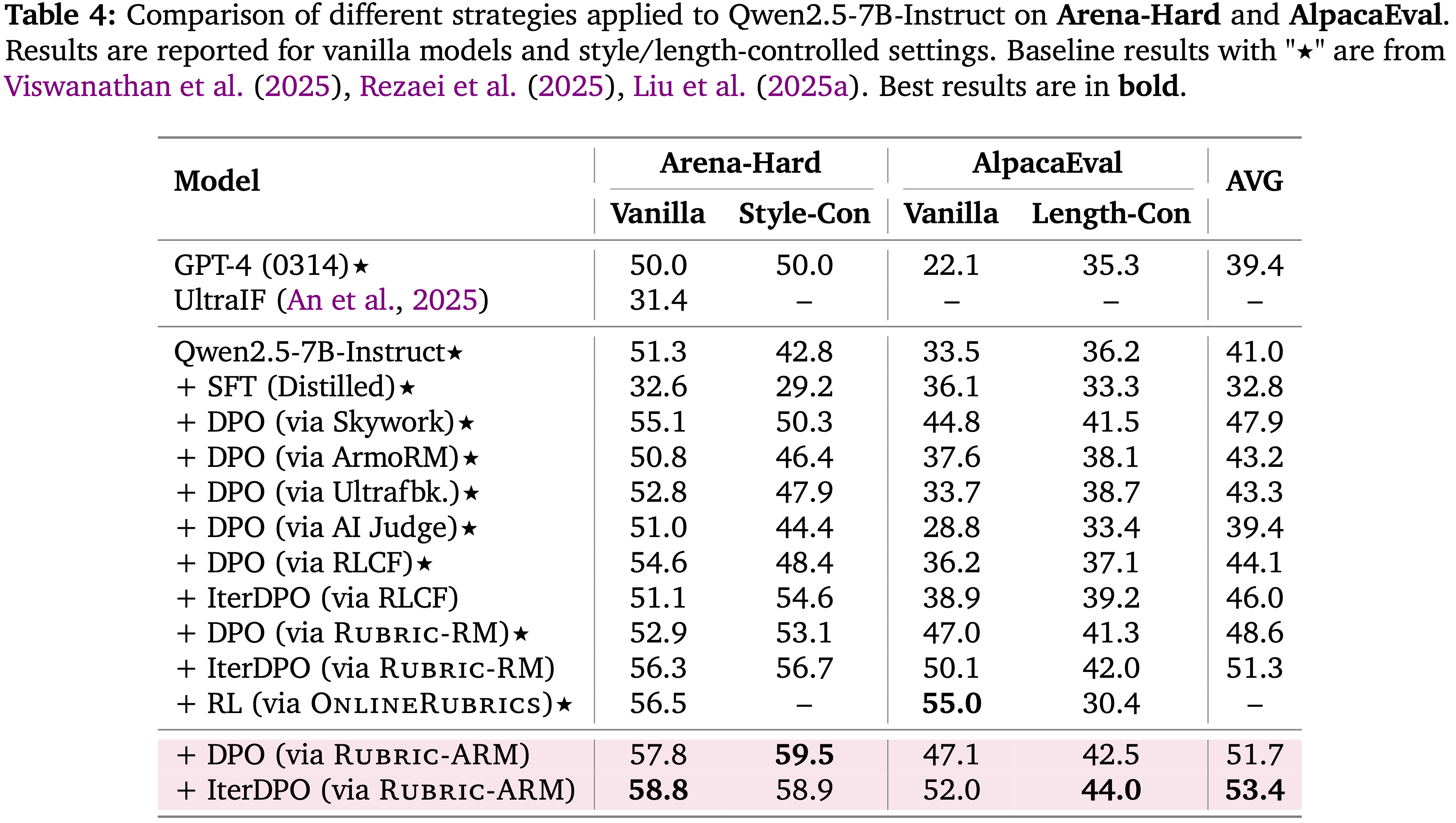
- 通过 RuBric-ARM 的 DPO 达到 53.7,而通过 RuBric-ARM 的 IterDPO 达到 55.7(最佳),相比于使用 Rubric-RM 的 IterDPO (54.0) 提升了 1.7%,表明在广泛的现实世界任务上,对齐偏好的帮助性得到了改善
Creative Writing
- 作者进一步评估基于 RuBric-ARM 的奖励是否有利于 Creative Writing Benchmark v3 上的开放式生成(图 4)
- 使用 RuBric-ARM 训练的策略优于基线:
- 使用 RuBric-ARM 的 DPO 达到 39.0,而 IterDPO 进一步改进到 39.3(最佳)
- 基于 RuBric-ARM 的优化也超越了强大的创意写作基线,如 RAR (38.8) 和 RuscaRL (38.6)
- 这表明 RuBric-ARM 学习到的奖励能够很好地泛化到主观的、不可验证的生成任务,超越了标准的指令遵循和偏好对齐
Performance of online RL-based Policy Models
- 通过使用不同的奖励模型,用 GRPO(第 4.3 节)直接优化 Qwen2.5-7B-Instruct,在 Online RL 设置中评估 RuBric-ARM
- 如表 6 所示,与基础模型和强奖励基线 RM-R1 相比,使用 RuBric-ARM 训练的奖励进行 GRPO 显著提升了指令遵循和偏好对齐
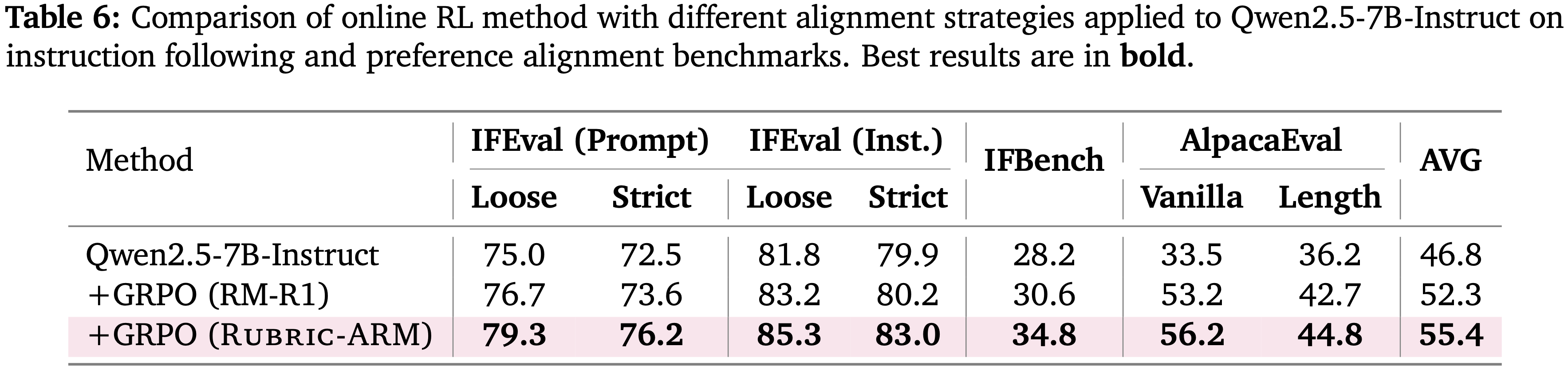
- 具体来说,Qwen2.5-7B-Instruct 的平均得分为 46.8,而使用 RM-R1 的 GRPO 将其提高到 52.3
- 将奖励替换为 RuBric-ARM 则获得了最佳的整体性能,平均达到 55.4
- 提升在指令遵循和人类偏好对齐指标上都是一致的,这表明 RuBric-ARM 为 GRPO 提供了更有效的在线学习信号
Effect of Iterative Policy Optimization
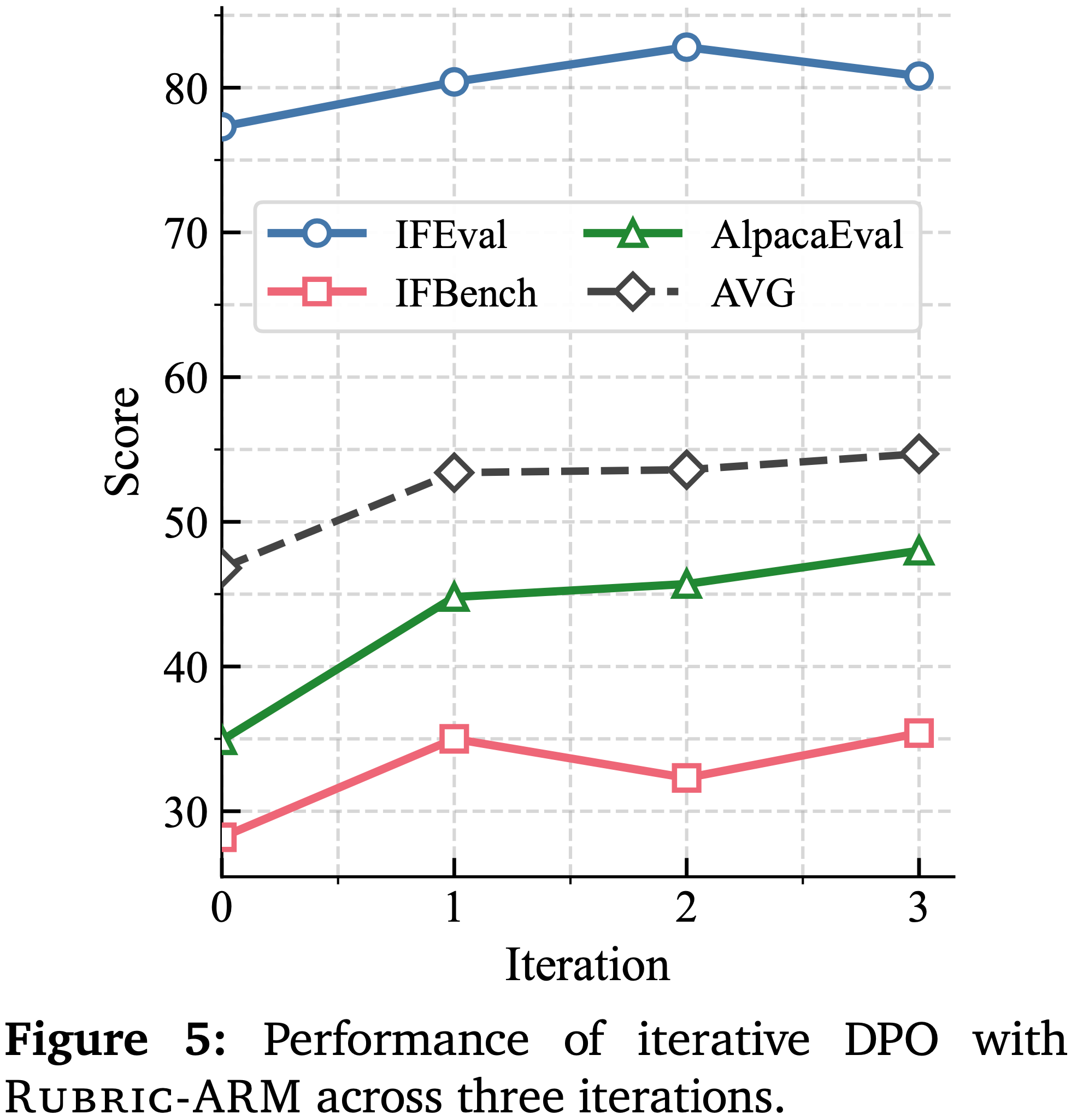
- 图 5 评估了使用 RuBric-ARM 进行迭代 DPO 超过三个优化迭代的性能
- 平均性能在迭代过程中单调增加,这表明使用基于 RuBric-ARM 的监督迭代细化策略会产生渐进式更好的对齐
- 这些结果表明,RuBric-ARM 提供了足够稳定的信号来支持多轮离线优化而不会出现性能下降
Efficiency Comparison
- 表 7 报告了在 100 个 RewardBench2 prompts 上的挂钟时间
- Rubric-ARM 使用了两个 Qwen-3-8B 模块(rubric Generator + Judge),但 RuBric-ARM 在 33.50 秒内运行
- 注:这比大多数基于推理和 Rubric-based 基线更快
- 虽然 JudgeLRM 略快,但它不提供显式的、可解释的 rubric-conditioned 信号,而这是 RuBric-ARM 为下游策略优化所设计的
- 本文的 rubric-Judge 设计用简短的 rubric 生成和轻量级判断取代了长链的 CoT,产生了强大的效率
- RuBric-ARM 也比 Rubric-RM 更快,后者通常生成更长的 rubric 列表并产生更高的开销
Case Study
- 论文对具有挑战性的示例上基线奖励模型的失败进行了定性分析
- 表 8 展示了一个关于“拇指战争 (thumb war)”的 RewardBench Chat-Hard 实例:
- 基于推理的模型(例如,RRM-7B 和 JudgeLRM)被“战争 (war)”一词分散了注意力,并错误地偏好一个关于武装冲突的 Response
- RuBric-ARM 生成并强制执行了一个包含关于拇指战争的明确 Hard Rule 的 rubric,从而做出了正确的偏好判断
- 作者在附录 D.3 中提供了额外的 IFBench 示例,其中 RuBric-ARM 可靠地提取了硬性约束并正确判断,而 Rubric-RM 则失败了

补充:Related Works
LLM-based Reward and Judge Models
- Zheng等人 (2023) 确立了 LLM-based 的 Judge 的基础效用
- 后续研究扩展了推理范围,包括思维链 (2025)、自我批判 (2024, 2025b, 2024) 或策略性的计划评估 (2025)
- Liu等人 (2025c) 探索了生成式奖励模型的推理时推理
- 最近的研究 (2025, 2026, 2026, 2025, 2025, 2026) 利用在线强化学习直接激励详细推理,旨在减轻偏见并增强点式和 Pairwise 评分的准确性
Rubrics-based Reward Models
- Rubric-based 方法已成为 LLM 评估 (2025, 2024, 2025, Akyü2025)、对齐 (2025, 2026) 和推理 (2026, 2025, 2025) 的一个有前景的方向
- 一个独特的挑战在于大规模生成高质量的 Rubric
- Li等人 (2026), Liu等人 (2025a), Xie等人 (2025) 从 Pairwise 比较信号中提取 Rubric
- Rezaei 等人 (2025), Zhang等人 (2026), Shao等人 (2025) 则通过在线设置中利用策略模型输出动态生成 Rubric
附录 A:关于组相对策略优化 GRPO 的细节
- GRPO 是一种仅包含行动者(actor-only)的策略优化方法,它通过使用 Prompt 内的平均奖励作为基线来减少方差
- 对于每个 Prompt \(q\),GRPO 从旧策略 \(\pi_{\theta_{\mathrm{old} } }(\cdot |q)\) 中采样一组 Response \(O = \{o_{1},o_{2},\ldots ,o_{G}\}\),为每个 token 计算一个组归一化的优势(advantage)\(\widehat{A}_{i,t}\),然后执行 PPO 风格的裁剪更新
- 遵循 Yu 等人 (2025a) 的做法,作者使用更大的裁剪阈值 \(\epsilon_{\mathrm{high} }\) 来增加信息丰富的 Prompt 的权重
$$\mathcal{I}_{\mathrm{GRPO} }(\theta) = \underset {q\sim P(Q),O\sim \pi_{\theta_{\mathrm{old} } }(\cdot |q)}{\mathbb{E} }\left[\frac{1}{G}\sum_{i = 1}^{G}\frac{1}{|o_{i}|}\sum_{t = 1}^{|o_{i}|}\min \left(\rho_{i,t}(\theta)\widehat{A}_{i,t},\mathrm{clip}\left(\rho_{i,t}(\theta),1 -\epsilon_{\mathrm{low} },1 + \epsilon_{\mathrm{high} }\right)\widehat{A}_{i,t}\right) -\beta \mathbb{D}_{\mathrm{KL} }[\pi_{\theta}| \pi_{\mathrm{ref} }]\right],$$- 其中 \(\rho_{i,t}(\theta) = \frac{\pi_{\theta}(o_{i,t}|q\rho_{i,t})}{\pi_{\theta_{\mathrm{old} } }(o_{i,t}|q\rho_{i,t})}\) 是 token 级别的重要性比率
附录 B:详细的理论推导
- 第5节中方差分析的完整证明
- 详情见原论文附录
附录 C:实现细节
- 表 9 和表 10 显示了在 Rubric-ARM 和策略模型训练中使用的超参数
- Table 9: Hyper-parameters used in Rubric-ARM training
模块 参数 值 模块 参数 值 Rubric Generator #generations 6 Judge #generations 7 Cutoff Length 512 Cutoff Length 1024 Batch Size 288 Batch Size 224 Optimizer AdamW Optimizer AdamW Learning Rate 1e-6 Learning Rate 1e-6 Temperature 1.0 Temperature 1.0 #iterations 2 #iterations 2 Epochs 1 Epochs 1 εhigh 0.28 εhigh 0.28 εlow 0.2 εlow 0.2 β 0.001 β 0.001 - Table 10: Hyper-parameters used in policy model training
方法 参数 值 方法 参数 值 DPO Cutoff Length 2048 GRPO #generations 6 Batch Size 64 Cutoff Length 2048 Optimizer AdamW Batch Size 288 Learning Rate 8e-7 Optimizer AdamW Epochs 1 Learning Rate 5e-7 beta 0.1 Temperature 1.0 SFT mixing weight 0.2 #iterations 2 // // Epochs 1 // // εhigh 0.28 // // εlow 0.2 // // β 0.001
- Table 9: Hyper-parameters used in Rubric-ARM training
- 作者基于 ms-swift 库实现了 GRPO 训练,并基于 LLaMA-Factory2 (2024) 实现了 DPO 和 IterDPO
- 作者总共进行了 3 轮 Rubric-ARM 交替强化学习训练
- 推理中使用的采样参数总结在表 11 中
- Table 11: Sampling parameters used in Rubric-ARM inference
模块 参数 值 模块 参数 值 Rubric Generator Maximum Tokens 1024 Judge Maximum Tokens 4096 Temperature 0.0 Temperature 1.0 Top-P 1.0 Top-P 1.0 Top-K -1 Top-K -1 Enable-thinking False Enable-thinking False
- Table 11: Sampling parameters used in Rubric-ARM inference
- 对于基线方法,作者使用了与其官方实现和论文相同的采样参数
附录 D:额外的实验结果
D.1. 在 WritingPreferenceBench 上的表现
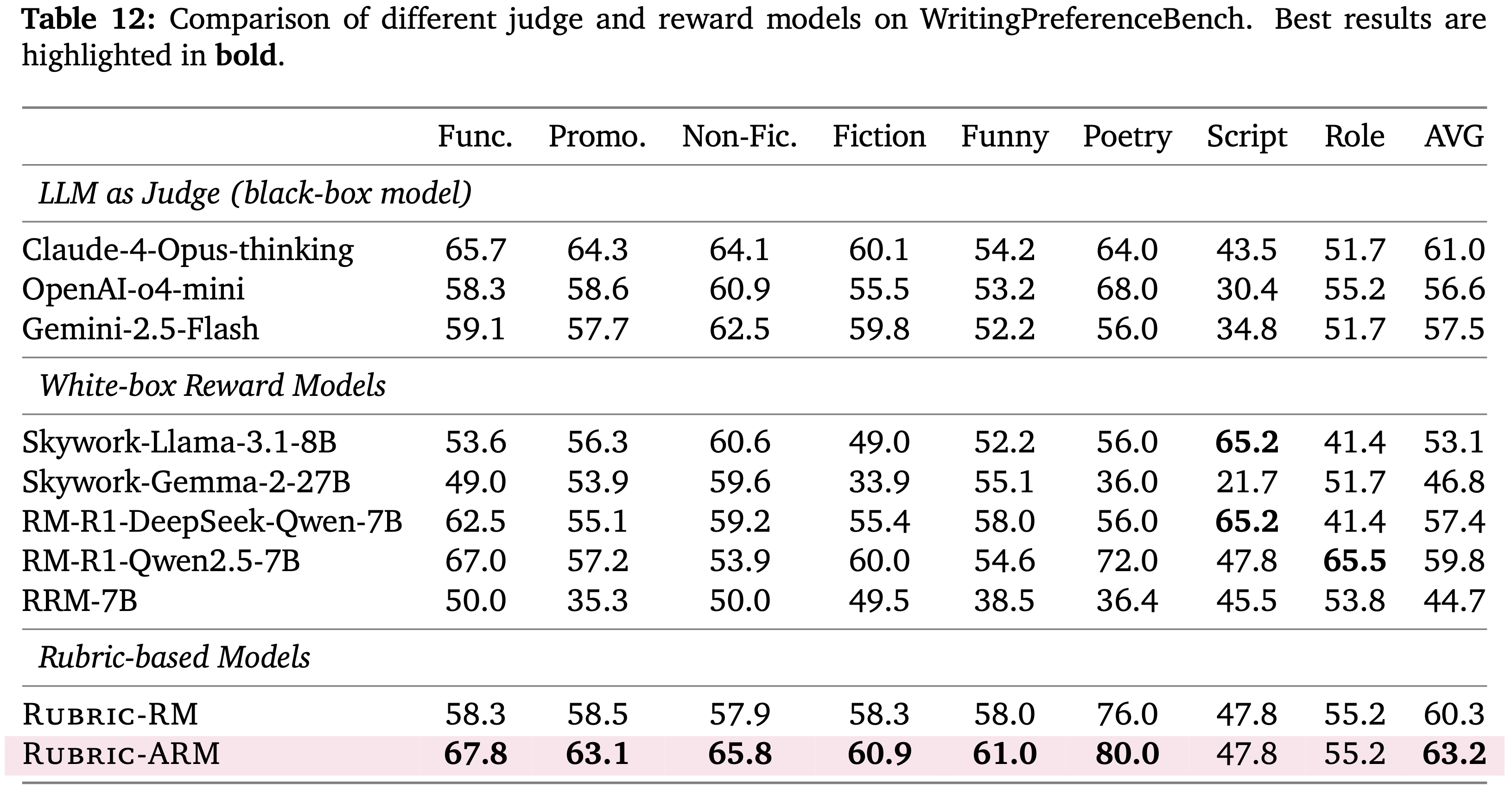
- 表 12 中展示了在 WritingPreferenceBench 上的表现
- Table 12: Comparison of different Judge and reward models on WritingPreferenceBench. Best results are highlighted in bold
Func. Promo. Non-Fic. Fiction Funny Poetry Script Role AVG LLM as Judge (black-box model) Claude-4-Opus-thinking 65.7 64.3 64.1 60.1 54.2 64.0 43.5 51.7 61.0 OpenAI-o4-mini 58.3 58.6 60.9 55.5 53.2 68.0 30.4 55.2 56.6 Gemini-2.5-Flash 59.1 57.7 62.5 59.8 52.2 56.0 34.8 51.7 57.5 White-box Reward Models Skywork-Llama-3.1-8B 53.6 56.3 60.6 49.0 52.2 56.0 65.2 41.4 53.1 Skywork-Gemma-2-27B 49.0 53.9 59.6 33.9 55.1 36.0 21.7 51.7 46.8 RM-R1-DeepSeek-Qwen-7B 62.5 55.1 59.2 55.4 58.0 56.0 65.2 41.4 57.4 RM-R1-Qwen2.5-7B 67.0 57.2 53.9 60.0 54.6 72.0 47.8 65.5 59.8 RRM-7B 50.0 35.3 50.0 49.5 38.5 36.4 45.5 53.8 44.7 Rubric-based Models Rubric-RM 58.3 58.5 57.9 58.3 58.0 76.0 47.8 55.2 60.3 Rubric-ARM 67.8 63.1 65.8 60.9 61.0 80.0 47.8 55.2 63.2
D.2. 位置偏差分析
- 本节研究 Pairwise Judge 和奖励模型中的位置偏差(position bias),其中预测的偏好可能取决于两个 Response 的相对顺序 (2025)
- 作者评估了三种 Setting(注意:这里不是指的训练,而是推理 Setting):
- (1) 保持 Response 顺序与原始数据集相同
- (2) 翻转所有实例的顺序
- (3) 在每个实例的基础上随机翻转顺序
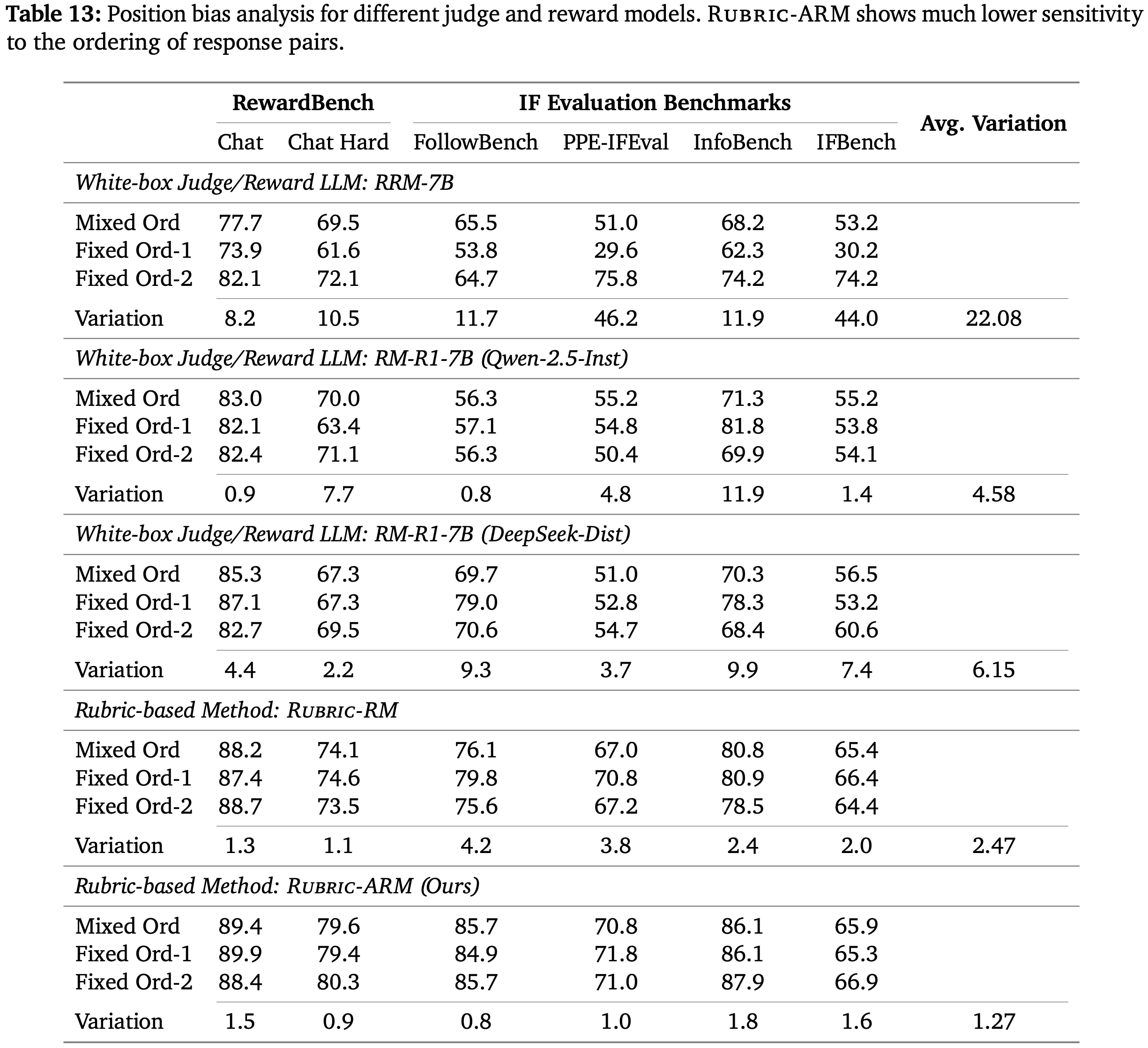
- 表 13 报告了在 RewardBench 和 IF 评估基准上的结果
- 基线方法表现出显著的位置偏差
- 对于 RRM-7B,改变顺序导致 PPE-IFEval 有 46.2 分的差异 (75.8 vs. 29.6)
- 对于 RM-R1-7B (Qwen-2.5-Inst),翻转顺序使 InfoBench 改变了 11.9 分 (81.8 vs. 69.9)
- 对于 RM-R1-7B (DeepSeek-Dist),顺序敏感性仍然很大
- InfoBench 有 9.9 分的差异 (78.3 vs. 68.4),FollowBench 有 9.3 分的差异 (79.0 vs. 69.7)
- 问题:这些基线方法训练时没有做过位置偏差处理吗?
- Rubric-ARM 在不同顺序下始终保持稳定,表明位置偏差显著降低且评估更稳健
- 这一设计选择与作者的强化学习训练设计一致,即在收集奖励信号时随机化 Response 顺序,这进一步减轻了下游策略优化中的位置偏差
- 这一设计选择与作者的强化学习训练设计一致,即在收集奖励信号时随机化 Response 顺序,这进一步减轻了下游策略优化中的位置偏差
- 基线方法表现出显著的位置偏差
D.3. 附加案例研究
- 本节将 Rubric-ARM 与另一个使用 SFT 训练的 Rubric-based 奖励模型 Rubric-RM 进行比较
- 对比一个从 IFBench 中随机选择的示例
- 该案例指定了关键词和段落长度
- 结果如表 14 所示
- 在这个需要特定关键词和恰好两个段落的 IFBench 示例中
- 基线 Rubric-RM 出现了判断幻觉(judging hallucination),错误地声称一个有效的 Response 被分成了三个段落
- Rubric-ARM 准确地提取了这些硬约束,识别出了负样本中缺失的开源(open-source)关键词,同时正确地验证了正样本的结构
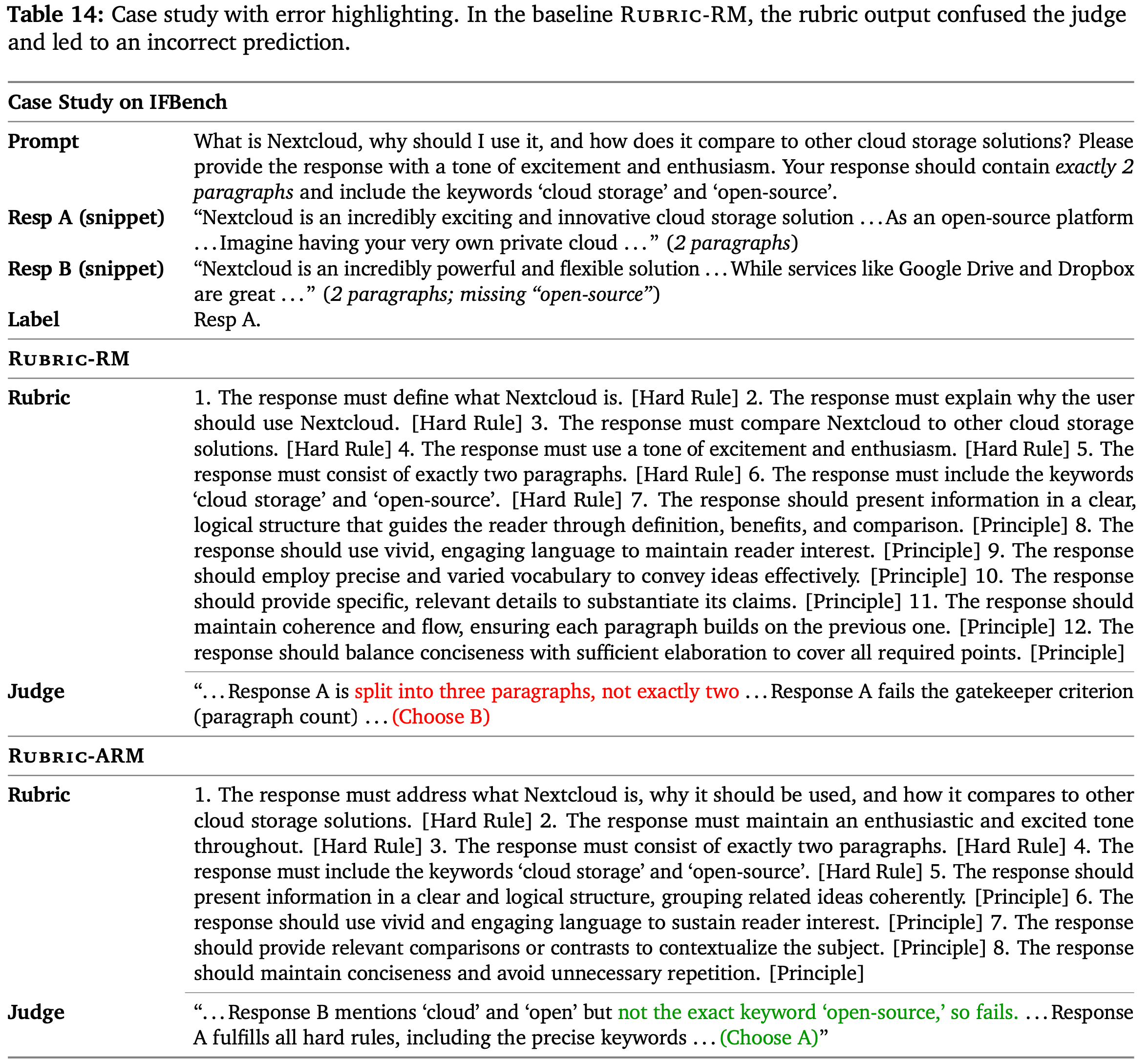
- 在这个需要特定关键词和恰好两个段落的 IFBench 示例中
附录 E:Prompts
- 本节展示使用的 prompts
- 注:对于基线方法,作者采用了其官方实现和论文中的 prompts
Prompt for Rubric Generation (Rubric-ARM)
中文版:
1
2
3
4
5
6
7
8
9
10
11
12你的任务是从用户的请求中提取一组评分细则(rubric-style)式的指令。这些细则将用作评估标准,以检查 Response 是否完全满足请求。每个细则项必须是一个通用原则。如果任何细则仍然包含特定主题的引用(例如,名称、地点、神话、数字、历史事实),则自动视为无效
* **两个不同的类别:** (Two Distinct Categories)
-[硬规则] (Hard Rule): 严格从 <request> 中明确陈述的要求(格式、长度、结构、禁止/必需元素等)推导而来
-[原则] (Principle): 通过将任何具体线索抽象为领域无关的质量标准(例如,清晰度、正确性、合理的推理、教育性)推导而来
* **全面性:** (Comprehensiveness) 细则必须涵盖请求和示例所隐含的所有关键方面,包括明确的要求和隐含的质量标准
* **简洁性与唯一性:** (Conciseness & Uniqueness) 每个细则必须捕捉一个独特的评估标准。重叠或冗余的标准必须合并为一个细则。措辞必须精确且无重复
* **格式要求:** (Format Requirements) 使用编号列表。每个项目以第三人称表述的 "The response" 开头。在每个项目的末尾附加 [Hard Rule] 或 [Principle]。最终输出中不要包含推理、解释或示例
这是请求: {prompt}
请为上述请求生成评分细则- 问题:生成 Rubric 的 Prompt 有点简单,可能会生成不够标准的,比如考虑安全性等
- 问题:本文生成的 Rubric 都是 Query-specific 的,不是 General 的,且没有使用 Reference Response
- 类似 OpenRubrics 的方案,将 rubrics 分为两种互补类型:
- (i) 硬规则(Hard Rules) ,捕捉用户 Prompt 中陈述的显式要求;
- (ii) 原则(Principles) ,描述更高级别的定性方面,如推理合理性、事实性、或风格连贯性
Prompt for Judge Generation (Rubric-ARM)
中文版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41你是一个公平公正的 Judge。你的任务是根据给定的指令和一个评分细则(rubric)来评估 'Response A' 和 'Response B'。你将按照下面概述的 distinct phases(不同阶段)进行此次评估
### Phase 1: 合规性检查指令 (Compliance Check Instructions)
首先,从评分细则中识别出最重要、最客观的 'Gatekeeper Criterion'(守门员标准)
* **一条规则是客观的(并且很可能是 Gatekeeper),如果它可以无需观点即可验证。关键例子有:字数/段落限制、要求的输出格式(例如 JSON 有效性)、要求/禁止的部分,或禁止的内容。**
* **相反,一条规则是主观的,如果它需要解释或定性判断。关于质量的主观规则不是 Gatekeeper。例子包括诸如"要有创意"、"写得清晰"、"引人入胜"或"使用专业的语气"等标准。**
### Phase 2: 分析每个 Response (Analyze Each Response)
接下来,对于每个 Gatekeeper Criterion 和评分细则中的所有其他标准,逐项评估每个 Response
### Phase 3: 最终判断指令 (Final Judgment Instructions)
基于前几个阶段的结果,使用这些简单的规则确定胜者。提供一个最终理由解释你的决定,然后给出你的决定
### 必需的输出格式 (REQUIRED OUTPUT FORMAT)
你必须遵循以下确切的输出格式
-Compliance Check
-Identified Gatekeeper Criterion: <例如,标准1:必须在50字以内。>
Analysis
**Response A:**
-Criterion 1 [Hard Rule]: Justification: <...>
-Criterion 2 [Hard Rule]: Justification: <...>
-Criterion 3 [Principle]: Justification: <...>
-... (对所有其他标准依此类推)
**Response B:**
-Criterion 1 [Hard Rule]: Justification: <...>
-Criterion 2 [Hard Rule]: Justification: <...>
-Criterion 3 [Principle]: Justification: <...>
-... (对所有其他标准依此类推)
Final Judgment
Justification: <...>
Winner: <Response A / Response B>
Task to Evaluate:
Instruction: {instruction}
Rubric: {rubric}
Response A: {response_a}
Response B: {response_b}- 问题:判定设计的如此复杂吗?一般的模型会不会能力不太够用?