注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 论文提出了一个用于可扩展、高质量 Rubric 生成的大规模数据集和框架 OpenRubrics
- 核心思路:构建与人类判断更好地对齐的可解释且具有区分性的 Rubric信号
- 通过对比性 Rubric 生成 (CRG) 将评估分解为硬性规则和原则
- 应用 Preference Label 一致性过滤
- 吐槽:论文写得比较乱,许多地方表述不清晰
- 为方便阅读,本文添加一些前置的名词释义:
- OpenRubrics:一个数据集,包含了 Prompt, Chosen, Rejected, Rubrics 的数据集
- 注意:OpenRubrics 的 Rubric 生成需要 Chosen 和 Rejected Response
- Rubric-RM:一个奖励模型,包含了 Rubric 生成 + Pairwise 评估的流程
- 注意:Rubric-RM 的 Rubric 生成不需要 Chosen 和 Rejected Response,训练 Rubric-RM 的 生成模型时使用了 OpenRubrics 的 Prompt 和 Rubrics 数据,没有使用 Chosen 和 Rejected
- OpenRubrics:一个数据集,包含了 Prompt, Chosen, Rejected, Rubrics 的数据集
- 背景 & 问题
- Reward modeling 是 RLHF 的核心,但现有的大多数奖励模型依赖于标量或 Pairwise 判断,未能捕捉人类偏好的多面性
- 近期研究 rubrics-as-rewards (RaR) 使用结构化自然语言准则来捕捉 Response 质量的多个维度 ,但生成既可靠又可扩展的 rubrics 仍然是一个关键挑战
- 论文引入了一个多样化、大规模的
<Prompt, rubric>Pair 集合 OpenRubrics- 用于训练 Rubric-generation 模型和 Rubric-based 的奖励模型
- 为了提取具有区分性和全面的评估信号,论文引入了 对比式 Rubric 生成(Contrastive Rubric Generation,CRG)
- CRG 通过对比偏好 Response 和 Rejected Response 来推导出硬规则(显式约束)和原则(隐含质量)
- 论文进一步通过 拒绝采样强制执行 Preference–label 一致性(preference–label consistency)来提高可靠性,以移除有噪声的 rubrics
- 在多个奖励建模基准测试中 ,论文 Rubric-based 的奖励模型 Rubric-RM 超越了强规模匹配基线 6.8%
- 这些收益也转移到了遵循指令和生物医学基准测试中的策略模型上
- 论文的结果表明,rubrics 提供了可扩展的对齐信号,缩小了昂贵的人工评估与自动化奖励建模之间的差距,为 LLM 对齐开启了一种新的基于原则的范式
Introduction and Discussion
- 奖励建模为每个 Response 分配一个标量分数 (2022) 或 Preference Label (2025b),在训练期间提供优化信号,并引导 Policy LLM 生成有帮助且无害的 Response
- RLVR 发展不错,但LLMs 的许多高价值应用(例如长文本问答、通用 Helpfulness )在本质上具有主观性的领域运行,其正确性无法通过二元信号充分捕捉
- 为了弥合这一差距,rubrics-as-rewards (RaR) (2025) 已成为奖励建模的新范式
- Rubrics 包含结构化自然语言准则,将质量分解为可解释和可度量的维度,提供了比标量判断更一致、更透明的评估框架
- 对于策略模型,rubrics 还能使优化过程受到显式原则的指导
- 尽管前景广阔,但高质量 rubrics 的构建仍然是一个开放性的挑战
- 现有的基准测试 (2025) 借助领域专家的努力来整理(curate)rubrics,成本高昂且难以扩展
- 近期工作 (2025; 2025; 2025) 通常通过直接 Prompt LLMs 来生成 rubrics,但那些方法对 rubrics 的质量控制有限,并且在依赖商业 API 时可能极其昂贵
- 论文提出了一个大规模的(Prompt,rubrics)Pair 集合 OpenRubrics,以促进 Rubric-generation 模型的训练
- 论文 Prompt LLM 生成两种互补类型的 rubrics:
- hard rules ,捕捉 Prompt 中指定的显式和客观约束;
- principles ,总结强 Response 的隐含和可泛化的质量
- 这种设计允许 rubrics 捕获表面层的要求和更深层次的质量维度
- 尽管硬规则通常容易提取,但原则更为微妙,需要细粒度的推理
- 为了解决这个问题,论文提出了 对比式 Rubric 生成 (CRG)
- 对比式 Rubric 生成(Contrastive Rubric Generation,CRG) 基于与 Chosen Response 和 Rejected Response 配对的用户 Query
- 通过利用负面对比,CRG 鼓励模型识别区分强答案和弱答案的区分性质量,从而产生更全面和具备排序意识的 rubric 信号
- 为了进一步确保可靠性并减少噪声,论文通过Rejected采样应用 Preference–label 一致性,只保留能产生正确偏好预测的 rubrics
- 论文的贡献有三方面:
- Data Contribution :论文引入了 OpenRubrics,一个大规模、跨领域多样的 rubrics 集合
- 该数据集支持大规模地训练 Rubric-generation 模型和 Rubric-based 的奖励建模
- Methodological Contribution :论文区分了两种基本类型的 rubrics,并提出了一种新颖的 对比式 rubric 生成 策略
- 该策略训练模型从 Prompt 和 Response 对中生成全面且具有区分性的 rubrics
- 此外,论文引入了 Preference–label 一致性 来提高 rubric 的质量和可靠性
- Empirical Contribution :论文在八个基准数据集上进行了广泛的实验
- 论文提出的 rubric 奖励模型 Rubric-RM 始终以 6.8% 的优势超越强基线
- 此外,当集成到策略优化中时,Rubric-RM 使策略模型在具有挑战性的指令遵循和医学基准测试上实现了强劲的性能,平均增益为 2.9%
- 案例研究进一步验证了结合硬规则和原则的好处,并表明 rubrics 有助于减少因输出过长而产生的误报
- Data Contribution :论文引入了 OpenRubrics,一个大规模、跨领域多样的 rubrics 集合
Preliminaries
Rubrics
- 论文将 rubrics 定义为一组针对给定 Prompt 定制的结构化评估准则
We define rubrics as a structured set of evaluation criteria tailored to a given prompt
- 形式上,令 \(x\) 表示输入 Prompt ,\(\hat{y}\) 表示模型生成的 Response
- 一个 rubric \(\mathcal{R}(x)\) 表示为 \(k\) 个准则的集合
$$\mathcal{R}(x) = \{c_i\}_{i=1}^k$$- 其中每个 \(c_i\) 表示一个描述 Response 质量某个方面的 rubric 描述(例如,事实正确性、推理合理性、风格)
Rubric-based Reward Model
- 基于先前在 Pairwise 奖励建模方面的工作 (2025b; 2025b; 2025b; 2025),论文关注一个比较性设置,其目标是评估两个候选 Response 的相对质量
- 给定一个 Prompt \(x\) 和两个样本 \((\hat{y}_1, \hat{y}_2)\), Pairwise Rubric-based 的奖励函数定义为
$$\text{reward}_{\text{pair} }(x,\hat{y}_1,\hat{y}_2)=r_{\theta}(x,\hat{y}_1,\hat{y}_2;\{c_i\}_{i=1}^k),$$- 其中 reward 是二元 Preference Label ,\(r_{\theta}\) 是由 \(\theta\) 参数化的奖励模型,它在生成偏好判断时整合了 rubric 准则 \(\{c_i\}\)
- OpenRubrics 的总体框架见图 1(图 1: OpenRubrics 中合成 Rubric 生成的总体框架)

- 论文的总体目标有两个:
- (i) 构建一个 rubric 数据集 \(\mathcal{D}_{\text{rubric} }\) 用于训练一个生成模型 \(g_{\theta}\),该模型在给定 Prompt \(x\) 时能自动合成 rubrics \(\mathcal{R}(x)\);
- (ii) 构建一个奖励建模数据集 \(\mathcal{D}_{\text{rm} }\) 用于训练一个 rubric-guided 奖励模型 \(r_{\phi}\),该模型能够产生可靠且可解释的 Pairwise 判断
- 理解:这里的 Pairwise 判断其实就是区分两个样本谁好谁坏,是 Pairwise 的,是不 Point-wise 的
- 这个两阶段表述使得评估被显式分解为 rubric 生成(rubric generation) 和 以 rubric 为条件的奖励预测(rubric-conditioned reward prediction) ,从而在人类对齐准则和自动化偏好建模之间架起桥梁
OpenRubrics(数据集)
Data Construction
Data Sources
- 为了生成能够跨任务和领域泛化的高质量 rubrics,构建一个在领域和任务上具有广泛覆盖的数据集至关重要
- 为此(To this end),论文整合了一系列公开可用的偏好和指令微调数据集,平衡通用对话数据和领域特定资源
- 具体来说,论文的数据集来源于以下资源:
- UltraFeedback (2024),它汇总了来自Evol-Instruct (2024)、UltraChat (2023)、ShareGPT (2023) 和TruthfulQA (2022) 的偏好标注
- Tulu 2.5 (2024),一个包含AlpacaFarm (2023)、Chatbot Arena (2024)、Capybara、StackExchange (2023)、Nectar (2023)、SHP (2022)、HH-RLHF (2022)、HelpSteer (2024c) 和Orca (2023) 的多样化偏好数据集混合
- HelpSteer3 (2025),一个为与 Helpfulness 偏好对齐而设计的大规模人工标注数据集
- Skywork-Preference (2024),它整合了来自HelpSteer2 (2024b) 和OffsetBias (2024) 的数据
- Tulu3-IF (2025a),一个为可验证指令遵循定制的人工偏好判断集合
- MegaScience (2025),一个跨越多科学领域的领域专业化语料库,包括物理、医学、生物学和化学
- Medical-o1 (2024),一个为诊断推理任务整理的医学 SFT 数据集
Preference Data Construction
- 为了构建用于 rubric 生成和评估器训练(见第 4.3 节)的偏好数据,论文重用现有的偏好和 SFT 数据集并进行定制化处理
- 对于 UltraFeedback
- 论文选择得分最高的 Response 作为 Chosen ,最低的作为 Rejected
- 对于 Tulu3-IF、MegaScience 和 Medical-o1
- 论文使用Qwen-3-8B/14B (2025)、Llama-3.1-8B (2024) 和Gemma-3-12B (2025) 生成多个 Response ,从 每个模型 中选择一个
- 问题:谁是 Chosen,谁是 Rejected?
- 对于 Verifiable-IF
- 满足所有验证函数的 Response 被标记为 Chosen ,其他为 Rejected
- 对于 MegaScience 和 Medical-o1 数据集,论文采用开源奖励模型的集成:
- Athene-RM-8B (2024a) 和Skywork-Reward-V2-Llama-3.1-8B-40M (2025a) 来对 Response 排序并形成最优-最差偏好对(best–worst preference pairs)
Rubrics Synthesis
- 在收集了多样化的偏好对之后,论文的下一个目标是构建一组 rubrics,作为指导 LLM-based 奖励建模的 锚点(anchors)
- 为了全面表示不同类型的约束同时保持区分性粒度,论文将 rubrics 分为两种互补类型:
- (i) 硬规则(Hard Rules) ,捕捉用户 Prompt 中陈述的显式要求;
- (ii) 原则(Principles) ,描述更高级别的定性方面,如推理合理性、事实性、或风格连贯性
- 然后,论文介绍了两种生成高质量 rubrics 的策略,详情如下:
- 对比式 Rubric 生成(Contrastive Rubric Generation)
- 给定一个偏好数据集
$$ \mathcal{D} = \{(x_i, \hat{y}_i^+, \hat{y}_i^-)\}_{i=1}^{N}$$- 其中 \(x_i\) 是 Prompt ,\(\hat{y}_i^+\) 和 \(\hat{y}_i^-\) 分别表示偏好(preferred)Response 和厌恶(displeased)Response
- 论文的目标是(生成)infer rubrics \(\mathcal{R}(x_i)\),这些 rubrics 捕捉一个好 Response 应该满足的质量以及一个 Response 优于另一个的标准,使用 \(\hat{y}_i^+\) 和 \(\hat{y}_i^-\) 作为指导
- 形式上,论文 Prompt 一个指令调优的 LLM \(h_{\psi}\) 如下:
$$\mathcal{R}(x_i) \sim h_{\psi}(x_i, \hat{y}_i^+, \hat{y}_i^-, \ell_i),$$- 其中 \(\ell_i\) 是 Preference Label
- 问题:这里的 Preference Label \(\ell_i\) 具体是什么?就是好/不好的 label 吗?这些 label 是怎么来的呢?
- 猜测:一种猜测是直接给 Chosen Reponse \(\hat{y}_i^+\) 打 1 分,给 Rejected Response \(\hat{y}_i^-\) 打 0 分,或者直接是 \(\{\text{A is better}, \text{B is better}\}\) 中的一个
- 生成器被要求生成一组具有区分性的评估准则 \(\mathcal{R}(x_i) = \{c_{i,1}, \ldots, c_{i,k_i}\}\),其中每个 \(c_{i,j}\) 描述一个特定方面
- 其中 \(\ell_i\) 是 Preference Label
- 这种对比式设置鼓励模型发现既对任务敏感又与偏好对齐的 rubric 维度
- 给定一个偏好数据集
- 基于 Preference–label 一致性的 Rubric 过滤(Rubric Filtering with Preference-label Consistency)
- 并非所有生成的 rubrics 都忠实地捕捉了人类偏好信号
- 为了确保可靠性,论文通过再次 Prompt LLM \(h_{\psi}\) 进行基于一致性的过滤步骤
- 对于每个三元组 \((x_i, \hat{y}_i^+, \hat{y}_i^-)\),论文将完整的 rubric \(\mathcal{R}(x_i)\) 连接进上下文,并要求模型预测哪个 Response 更符合 rubric:
$$ \color{blue}{\hat{l}_i} = h_{\psi}(x_i, \mathcal{R}(x_i), \hat{y}_i^+, \hat{y}_i^-)$$- 其中 \(\color{blue}{\hat{l}_i} = (\hat{r}_i, \color{red}{\hat{\ell}_i})\) 是最终预测,\(\hat{r}_i\) 表示预测理由,\(\color{red}{\hat{\ell}_i}\) 表示预测的偏好
- 注意:这里 \(\color{blue}{\hat{l}_i}\) 和 \(\color{red}{\hat{\ell}_i}\) 不一样,后者是前者的一部分
- 论文只保留那些能导致预测与原始人类标签 \(\ell_i\) 一致的 rubrics:
$$\mathcal{R}^*(x_i) = \begin{cases} \mathcal{R}(x_i), & \text{if } \color{red}{\hat{\ell}_i} = \ell_i, \\ \varnothing, & \text{otherwise}.\end{cases}$$- 理解:这里的 Rubrics \(\mathcal{R}(x_i)\) 是关于 \(x_i\) 的一个集合
- 这个 Rubrics 集合整体对 \(x_i\) 的评价符合人类的打分结果,则保留
- 否则丢弃
- 注意:这里是同时输出 Chosen 和 Rejected 给模型作为判断的(即 Pair-wise 的),不是 Point-wise 的
- 理解:这里的 Rubrics \(\mathcal{R}(x_i)\) 是关于 \(x_i\) 的一个集合
- 这产生了一个经过过滤的高质量 rubrics 集合,这些 rubrics 既具有可解释性,又在经验上与人类偏好一致
- 最终的 以 rubrics 为条件的偏好数据集 将 Prompt 、配对 Response 及其验证后的 rubrics 组合如下:
$$\mathcal{D}_{\text{rubric} } = \{(x_i, \hat{y}_i^+, \hat{y}_i^-, \mathcal{R}^*(x_i))\}_{i=1}^{M}.$$
- 理解:这样的设计有一个缺点是,这一步需要大量的标注数据,因为这里 只能为已经有 Chosen-Rejected 偏好对的 Prompt 生成 Rubrics
- 但考虑到这里生成数据只是用于后续 SFT 训练的,所以也还好
Rubric Statistics Overview
- 论文从三个轴分析整理的 rubric 集:
- (i) 领域覆盖(指令遵循、推理、通用 Helpfulness ;图 2a);
- (ii) 硬规则 和 原则 之间的平衡以及 Prompt 和 rubrics 的长度(图 2b);
- (iii) Prompt 主题的语义多样性,通过 Qwen-3-Embedding-0.6B (2025c) 的嵌入进行 t-SNE 可视化(图 3:Prompt 嵌入的 T-SNE 图)
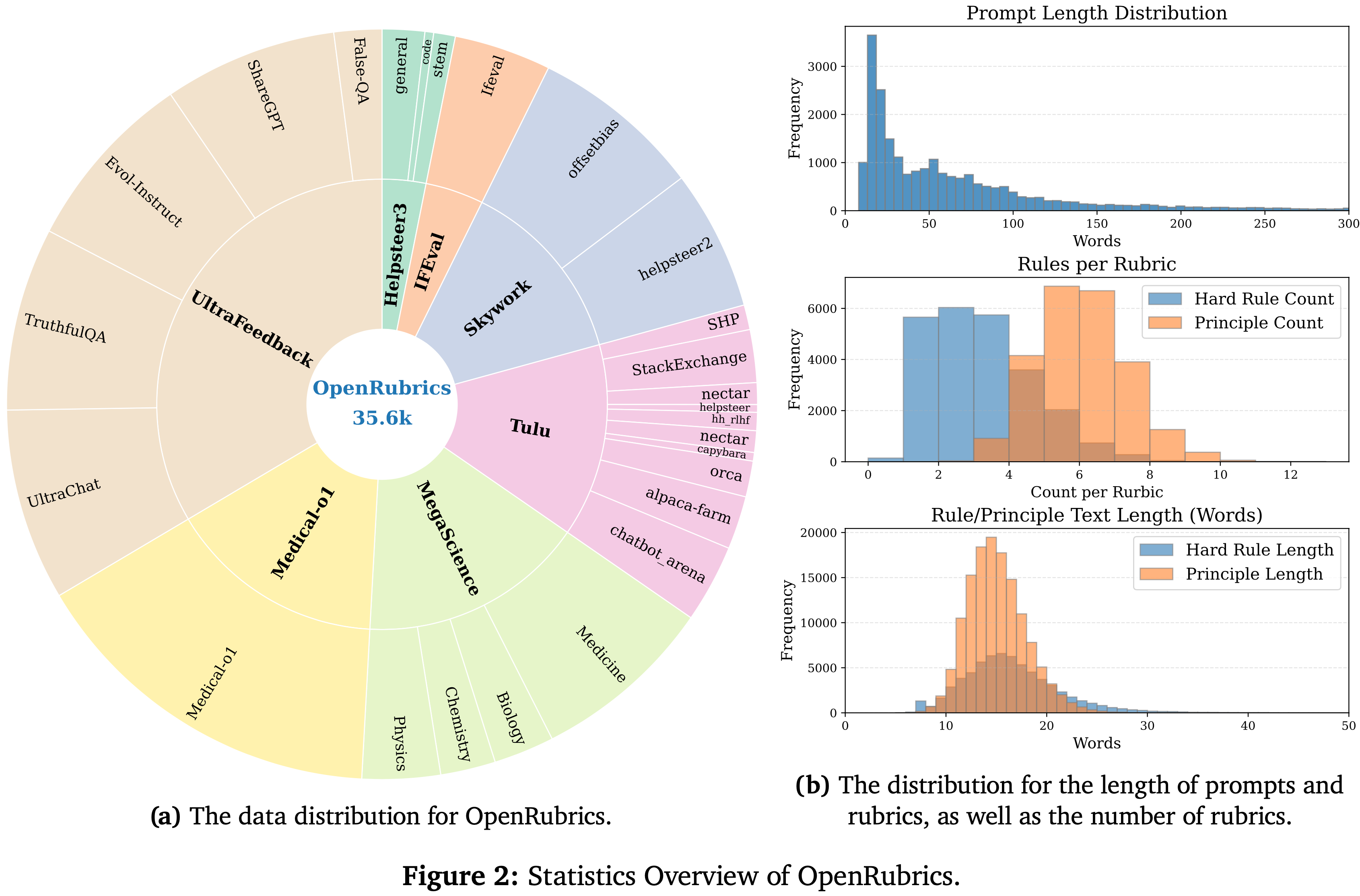
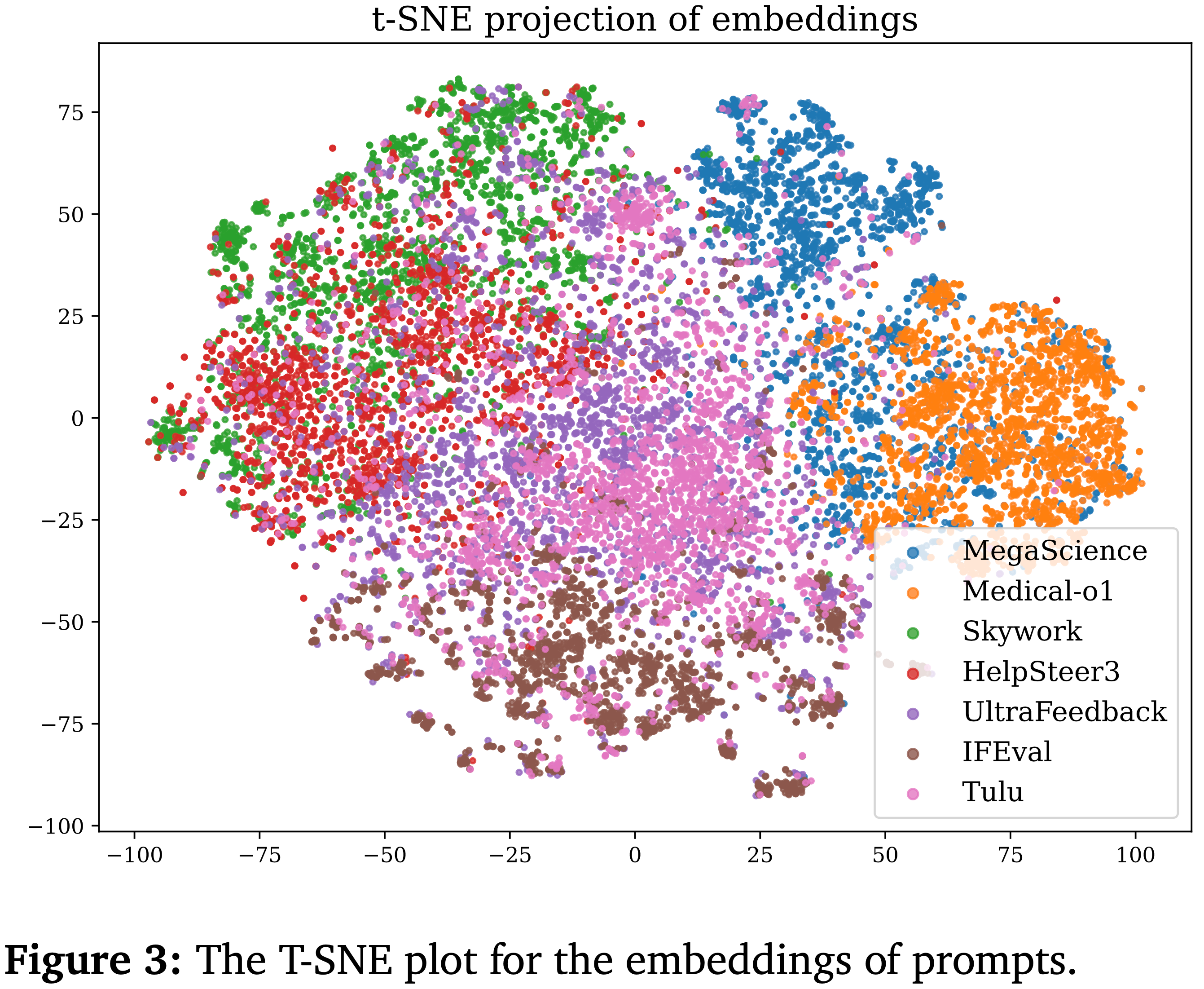
- 这些统计结果证实,合成的 rubrics 提供了全面且具有区分性的覆盖,为 Rubric-based 的奖励建模奠定了基础
Reward Model Training and Inference
- 收集了 Rubric-based 的数据集后,论文继续开发一个输出系统性评估 rubrics 的 Rubric-generation 模型,以及一个生成最终 Preference Label 的奖励模型 Rubric-RM
Rubric Generation
- 注:这里是 Rubric-generation 模型(For Rubric-RM 第一步) 的训练
- 论文首先训练一个 Rubric-generation 模型 \(g_{\theta}\),使其能在给定 Prompt 和配对 Response 的条件下生成结构化评估 rubrics
- 形式上,给定数据集
$$\mathcal{D}_{\text{rubric} } = \{(x_i, \hat{y}_i^+, \hat{y}_i^-, \mathcal{R}^*(x_i))\}_{i=1}^{M}$$- 其中 \(\mathcal{R}^*(x_i)\) 表示与 Prompt 关联的参考 rubric,模型 \(g_{\theta}\) 通过监督微调 (SFT) 进行训练,使用标准的 Next Token Prediction 交叉熵损失:
$$\mathcal{L}^{\text{rubric} }_{\text{SFT} } = -\mathbb{E}_{\{x,\hat{y}^+,\hat{y}^-,\mathcal{R}^*\}\in\mathcal{D}_{\text{rubric} } } \sum_{t=1}^{|\mathcal{R}^*|} \log p_{\theta}(\mathcal{R}_t^* \mid x, \mathcal{R}^*_{ < t}).$$- 注意:训练 Rubric-RM 的 生成模型时使用了 OpenRubrics 的 Prompt 和 Rubrics 数据,没有使用 Chosen 和 Rejected
- 其中 \(\mathcal{R}^*(x_i)\) 表示与 Prompt 关联的参考 rubric,模型 \(g_{\theta}\) 通过监督微调 (SFT) 进行训练,使用标准的 Next Token Prediction 交叉熵损失:
- 这个目标教导模型生成详细、领域相关的 rubrics,这些 rubrics 编码了用户提供 Prompt 中的评估准则,随后可以用于奖励建模
- 问题:后续没有正负偏好对的数据,岂不是无法生成 Rubric?
- 不是的,Rubric-RM 的 Rubric 生成不需要 Chosen 和 Rejected Response,训练 Rubric-RM 的 生成模型时使用了 OpenRubrics 的 Prompt 和 Rubrics 数据,没有使用 Chosen 和 Rejected
- Rubric 生成的 Prompt 见附录
Reward Model Training
- 注:这里是论文提出的 Pairwise 偏好预测模型(Rubric-RM 第二步) 的训练
- 使用合成的 rubrics,论文接着在下面的数据集上训练奖励模型 \(r_{\phi}\):
$$ \mathcal{D}_{\text{rm} } = \{(x_i, \hat{y}_i^+, \hat{y}_i^-, \mathcal{R}^*(x_i), \color{blue}{\hat{l}_i})\}_{i=1}^{M}$$ - 该模型同样通过 SFT 进行优化,以在给定 Prompt、Response 对和 rubric 的条件下预测标签 Token \(\color{blue}{\hat{l}_i}\):
$$\mathcal{L}^{\text{rm} }_{\text{SFT} } = -\mathbb{E}_{(x,\hat{y}^+,\hat{y}^-,\mathcal{R}^*,\color{blue}{\hat{l}})\sim\mathcal{D}_{\text{rm} } } \sum_{t=1}^{|\color{blue}{\hat{l}}|} \log p_{\phi}(\color{blue}{\hat{l}}_t \mid x, y^+, \hat{y}^-, \mathcal{R}^*(x), \color{blue}{\hat{l}}_{ < t}).$$ - 问题:这里的 \(\color{blue}{\hat{l}_i}\) 是怎么来的,具体形式是什么样?
- 应该是之前构造出来的 Chosen 和 Rejected 样本中包含的
- \(\color{blue}{\hat{l}_i} = (\hat{r}_i, \color{red}{\hat{\ell}_i})\) 是最终 Label,其中 \(\hat{r}_i\) 表示预测理由,\(\color{red}{\hat{\ell}_i}\) 表示预测的偏好 (\(\color{red}{\hat{\ell}_i} \in \{\text{A is better}, \text{B is better}\}\))
- SFT 时也需要有思考文本,所以 SFT 学习的内容包含了 思考文本部分
- 问题:这样训练的模型是 Pairwise 的,如果在 PPO 中使用的话,对比成本可能比较高,DPO 中使用的话成本还可以
Inference
- 在推理时,给定一个 Pairwise 测试实例 \((x, y^{\text{A} }, y^{\text{B} })\),Rubric-RM 执行一个两阶段过程来预测最终 Preference Label :
- (1) rubric 生成器首先生成 \(\hat{\mathcal{R} }(x) = g_{\theta}(x, y^{\text{A} }, y^{\text{B} })\)
- (2) 然后,奖励模型基于生成的 rubric 从两个可能的 Labels \(\mathcal{C} = \{\text{A is better}, \text{B is better}\}\) 中预测判决:
$$\color{blue}{\hat{l}} = \arg\max_{k\in\mathcal{C} } p_{\phi}(k \mid x, y^{\text{A} }, y^{\text{B} }, \hat{\mathcal{R} }(x)).$$- 理解:这里同上文 \(\color{blue}{\hat{l}_i} = (\hat{r}_i, \color{red}{\hat{\ell}_i})\) 是最终 Label,其中 \(\hat{r}_i\) 表示预测理由,\(\color{red}{\hat{\ell}_i}\) 表示预测的偏好 (\(\color{red}{\hat{\ell}_i} \in \{\text{A is better}, \text{B is better}\}\))
- 这个 Pipeline 确保 Rubric-RM 的判断明确 Rubric-based 准则
Experiment
Datasets and Experiment Settings
Training data
- 论文使用第4.2节介绍的 OpenRubrics 数据集来训练 Rubric-RM 的两个组件: Rubric 生成器 (rubric generator) 和 评判模型 (judge)
- Rubrics 是利用来自 chosen/rejected Response 的对比信号生成的,并在使用前通过 Preference Label 一致性 (preference-label consistency) 进行过滤
- 除非特别说明,论文使用 OpenRubrics 中与科学相关的部分数据 ,以便更好地匹配论文在 Health-Bench/医学评估领域的专项研究
Backbone and variants
- 除非指定, Rubric 生成器和评判模型都是基于 Qwen-3-8B 进行微调的 (“Rubric-RM-8B”)
- 在推理时, Rubric-RM 遵循一个两阶段流程:
- (i) 根据 Prompt 和候选 Response 生成或检索一个 Rubric;
- 注意:这里的候选 Response 没有 Chosen 或 Rejected 的标记?
- (ii) 基于该 Rubric 预测 Pairwise 偏好 (pairwise preference)
- (i) 根据 Prompt 和候选 Response 生成或检索一个 Rubric;
- 论文还报告了一个集成变体 voting@5 ,它通过多数投票聚合了五个独立采样的评判轨迹
- 注:这里的采样不同来源于两部分:
- 第一步中生成的 Rubric 不同
- 后续 Pairwise 偏好的采样本身是 LLM Next Token prediction 的,也会有不同
- 注:这里的采样不同来源于两部分:
- 注意:这里全文提到的 Rubric-RM 都是包含了 Rubric 生成和 Pairwise 偏好预测的
Baseline
- 论文与强大的其他模型进行比较:
- 同等规模的 “白盒” (white-box) 奖励/评判模型: JudgeLRM-7B (2025a), RRM-7B (2025b), 和 RM-R1-7B (2025b)
- 更大的 RM-R1-14B (2025b)
- 可用的参考 API 评判模型
- 为了隔离(isolate) Rubric 感知 (rubric-aware) 微调的收益,论文还包含了一个简单的 Pipeline 方法 Qwen-3-8B (Rubric+Judge) ,它直接 Prompt 基座模型生成一个 Rubric 然后做出评判
- 理解,这里的 Rubric-Aware 微调主要是指使用 Rubric 来进行生成微调和 Pairwise 打分微调
Evaluation benchmarks and metrics
- 论文将 Rubric-RM 作为一个 Pairwise 奖励模型,在广泛使用的奖励建模测试套件上进行评估:
- 包括:RewardBench (Chat / Chat-Hard) (2025b), RM-Bench (2025c), PPE-IFEval (2024b), FollowBench (2024), InfoBench (2024), IFBench (2025), 和 RewardBench2 (Precise-IF / Focus) (2025)
- 虽然 FollowBench 和 InfoBench 最初是为评估 LLMs 的指令遵循能力而设计的,论文通过从同一模型(Qwen-3-8B/14B)中采样两个 Response ,将其调整为 Pairwise 评估设置,其中一个 Response 遵守所有指定约束,另一个则违反部分约束
- 问题:会修改模型的输出来产生 Pairwise 比较吗?
- 对于领域研究,论文额外报告了 HealthBench/医学领域的结果。论文遵循每个基准的官方划分和评分规则,报告准确率/胜率或基准定义的分数
Decoding and efficiency protocol
- 所有模型都在匹配的解码预算下运行(温度、最大 Token 数,以及各基准推荐的停止条件)
- 论文使用统一的执行栈 vLLM (2023) 进行吞吐量公平的比较
- 对于效率(表 4),论文测量对固定 Prompt 集进行评分的挂钟时间;
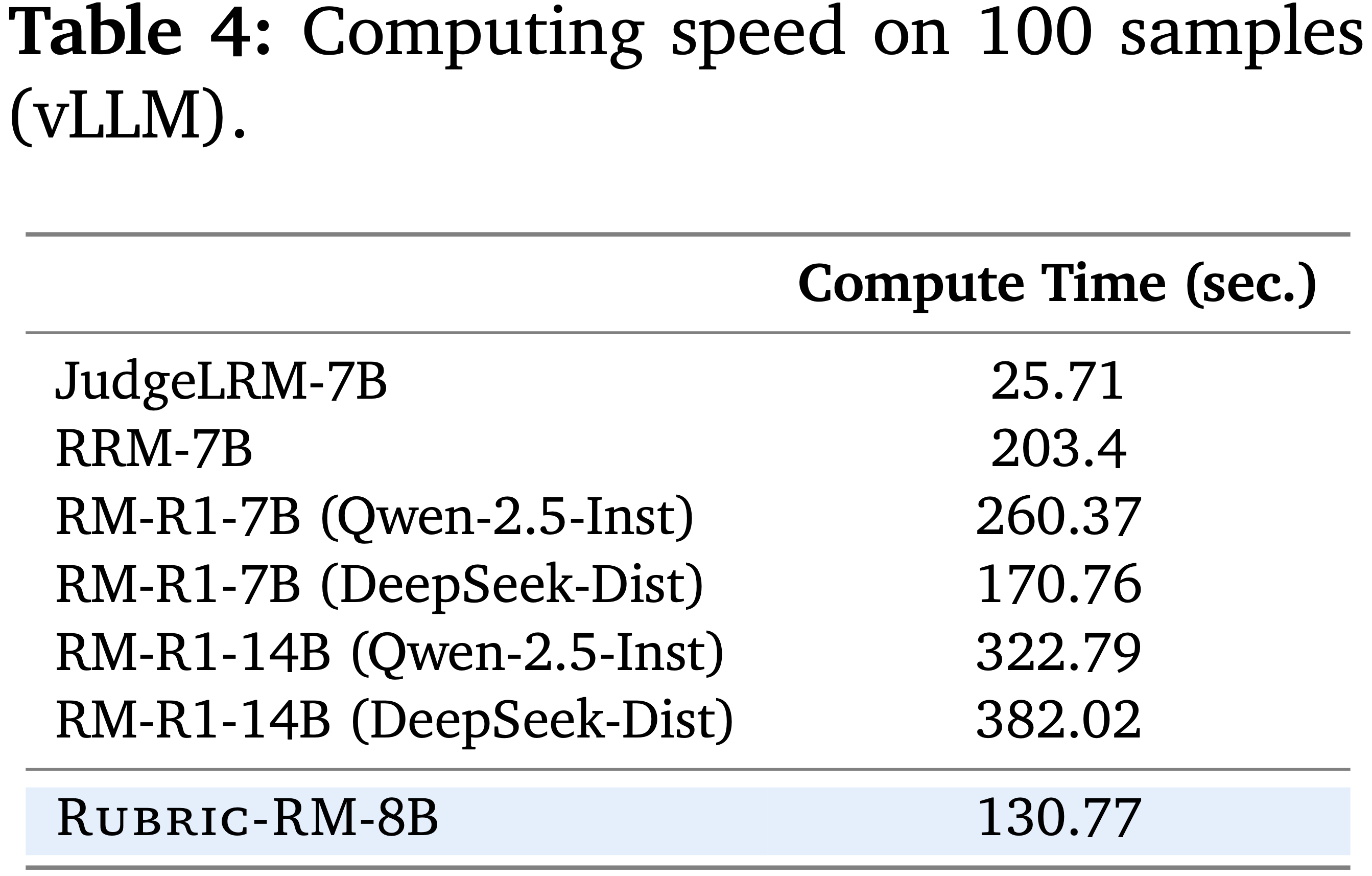
- 请注意,阶段 (i) 生成的 Rubrics 是可缓存的,可以在多个样本间重复使用,从而在大规模评判和偏好优化中分摊成本
Policy-model evaluation
- 当将 Rubric-RM 集成到策略优化中时,论文遵循先前工作,在指令遵循测试套件上进行评估 (2023; 2024; 2025),使用每个基准的官方指标和脚本
Reproducibility
- 论文使用 LLaMA-Factory (2024) 来训练 Rubric-RM(via SFT)和策略模型(via DPO)
- 对于评估,论文在可用时使用基准的官方脚本
- 为了便于复现,论文在附录 A.1 中发布了论文的训练和推理配置
- Prompt ,包括 Rubric模板,在附录 A.2 中提供
Performance of Rubric-RM
- 论文首先验证 Rubric-RM 在奖励建模方面的性能
- 为了更系统地进行评估,论文测试了 Rubric-RM 的 4B 和 8B 变体,它们分别使用 Qwen3-4B 和 Qwen3-8B 作为 Backone 模型
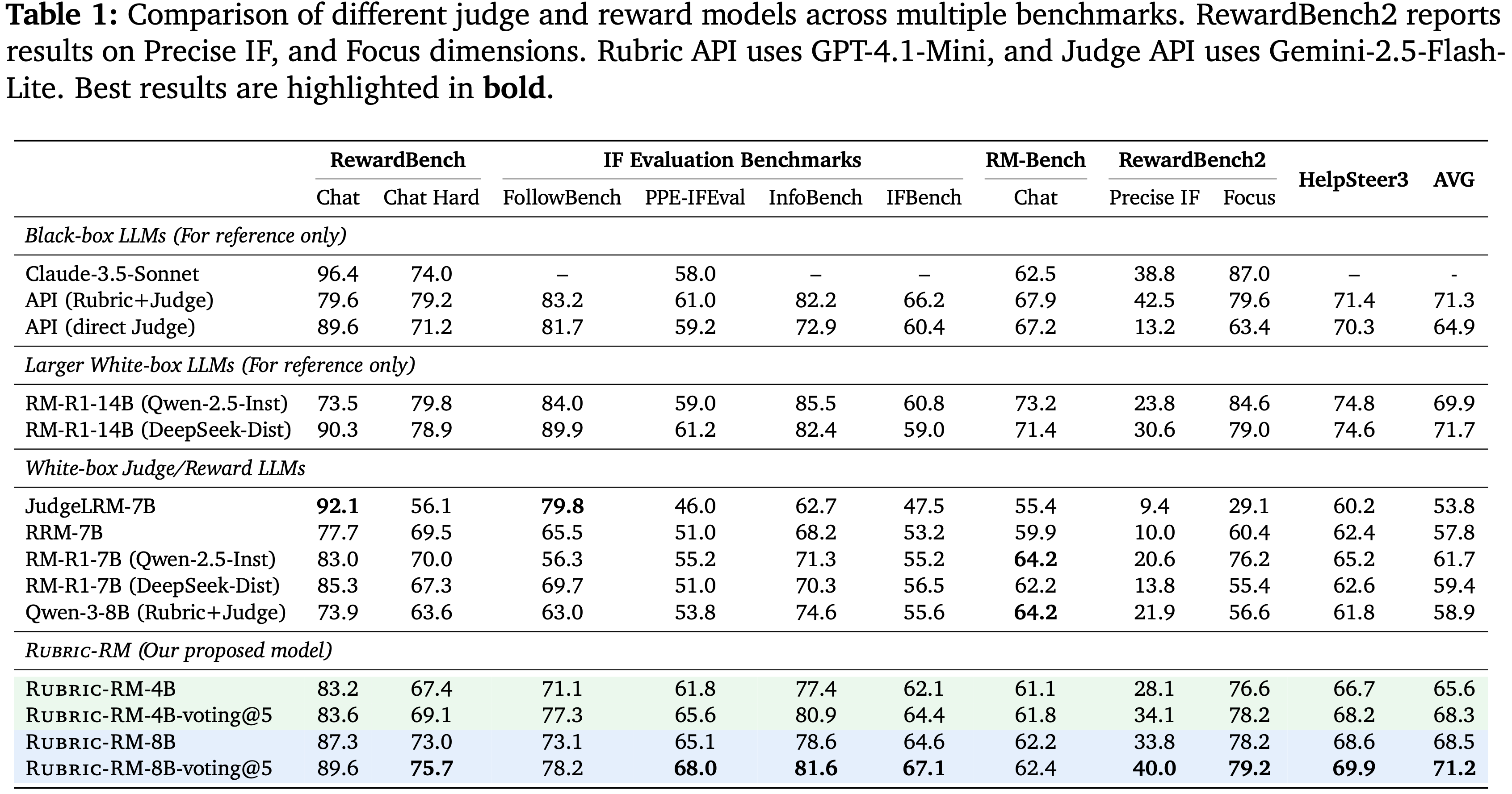
- 表 1 报告了论文提出的 Rubric-RM 在多个基准测试中的性能
- 问题:Rubric-RM 的评估依赖着 Rubric-generation 生成 Rubrics,实际上应该是整个 Rubric 生成 和 Pairwise 偏好预测链路的评估
Outperforming Comparable Reward Models
- 无论是 Rubric-RM-4B 还是 Rubric-RM-8B 都超越了现有的 7B 规模的白盒奖励模型,如 JudgeLRM-7B, RRM-7B, 和 RM-R1-7B
- Rubric-RM-4B 的平均得分为 65.6,已经高于 JudgeLRM-7B (53.8), RRM-7B (57.8), 和 RM-R1-7B 变体 (59.4-61.7),而 Rubric-RM-8B 则进一步提高到 68.5
- 这些结果表明,即使在较小的模型规模下, Rubric感知训练也能产生更可靠和可泛化的奖励信号,超越了使用通用基于偏好的监督训练的模型
Majority Voting Further Enhances Performance
- 论文还评估了 Rubric-RM-voting@5,它通过多数投票聚合了五个独立评判轨迹的预测
- 这种集成策略持续提升了准确率
- Rubric-RM-4B-voting@5 达到了 68.3,而 Rubric-RM-8B-voting@5 取得了最佳的总体平均值 71.2,几乎与更大的模型如 RM-R1-14B (71.7) 和 Rubric+Judge API (71.3) 匹配
- 这些结果突显了 Rubric-based 的集成所带来的鲁棒性和稳定性优势
Effectiveness of Rubric-Aware Fine-Tuning
- 一个直接使用 Qwen-3-8B 生成 Rubrics 然后用于评判的 Pipeline 表现不佳(平均 58.9)
- 相比之下,论文的 Rubric-RM 显著超越了这一基线,平均达到了 68.5
- 这表明,论文使用由对比 Response 生成并经 Preference Label 一致性过滤的高质量 Rubrics 进行的微调,相比简单的 Rubric-based 的评判,提供了显著的优势
- 理解,这里的 Rubric-Aware 微调主要是指使用 Rubric 来进行生成微调和 Pairwise 打分微调
Strength on IF Evaluation Benchmarks
- 除了绝对改进外(In addition to absolute improvements), Rubric-RM 在衡量细粒度指令遵循能力的 IF 评估基准 (IF Evaluation Benchmarks) 上显示出特别强大的优势
例如,在 FollowBench 和 InfoBench 上, Rubric-RM 分别达到了 73.1 和 78.6,大幅超越了其他 7B 规模的基线,如 JudgeLRM-7B (79.8 / 62.7) 和 RRM-7B (65.5 / 68.2) - 这些结果表明, Rubric-based 的训练在捕捉指令遵从度和细微 Response 质量方面特别有效,而这正是传统奖励模型常常难以做到的
- 在实验的剩余部分,除非特别指定,论文使用 Rubric-RM-8B 作为论文的奖励模型
Offline Reinforcement Learning for Policy Models with Rubric-RM
Instruction-Following Evaluation
- 论文进一步评估了将 Rubric-RM 用作策略优化奖励模型在指令遵循任务(包括 IFEval, InfoBench, 和 IFBench)上的有效性
- 结果如表 2 和图 4 所示
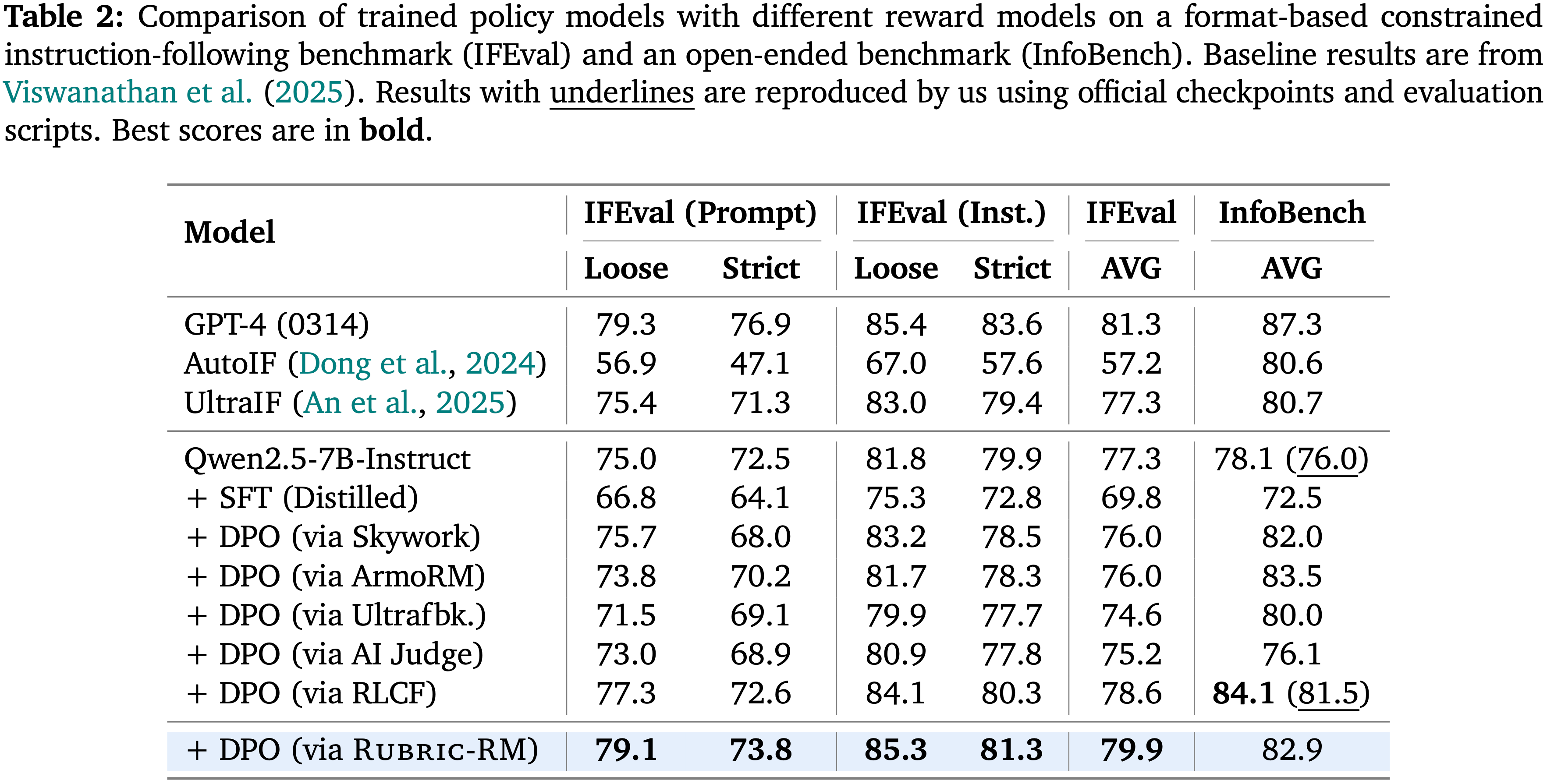
Improved Performance on IFEval and InfoBench
- 当作为 Direct Preference Optimization (DPO) 中的奖励模型时, Rubric-RM 使得经过训练的策略模型在所有开源模型中取得了最佳的整体性能
- 在 IFEval 上,由 Rubric-RM 训练的策略平均得分达到了 79.9 ,超越了使用 Skywork (76.0) 和 ArmORM (76.0) 训练的策略
- 在 InfoBench 上, Rubric-RM-Based 的策略达到了 82.9,优于其他使用 DPO 训练的策略,并接近大得多的商业系统的性能
- 这些结果突显了 Rubrics 为受限指令遵循任务提供了更可靠的优化信号
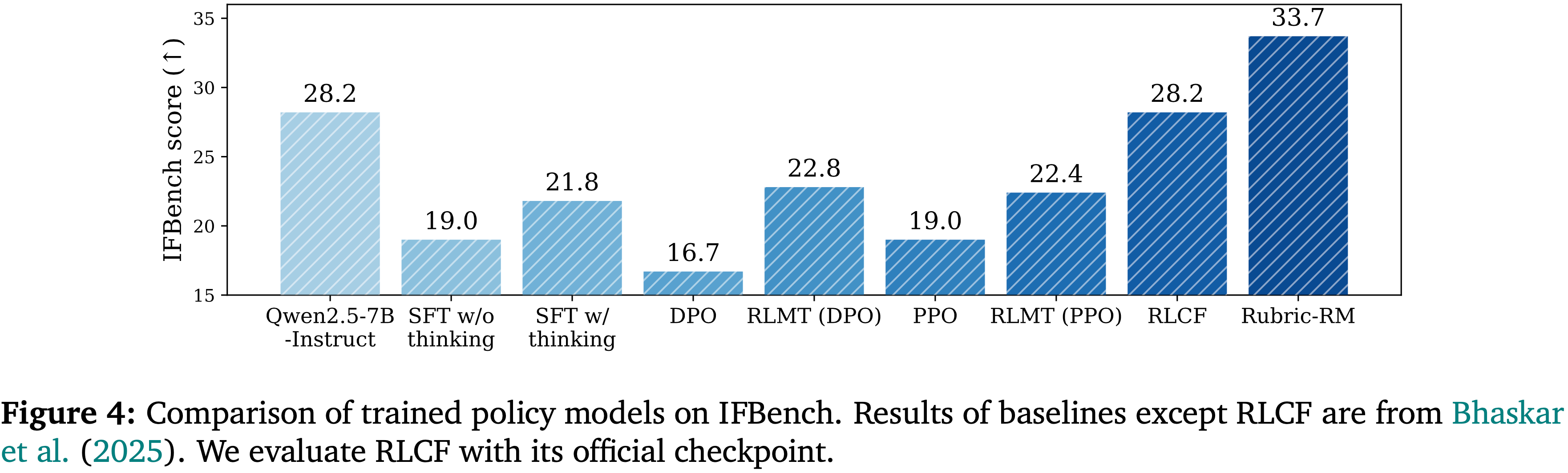
Clear Gains on Complex Instruction Following Benchmark (IFBench)
- 图 4 显示,使用 Rubric-RM 优化的策略模型在 IFBench 上获得了新的最佳得分 33.7 ,显著高于 RLCF (28.2) 和基于 RlMT 的方法 (22.4-22.8)
- 与监督微调变体和强化学习基线相比, Rubric-RM 提供了更强的归纳偏差,使策略能够更好地捕捉细粒度的指令遵从度
- Overall,这些结果证实了使用 Rubric-RM 作为奖励模型能显著提升训练后策略的指令遵循能力
- 与先前经常无法强制执行严格格式或细微约束的标量或生成式奖励模型不同, Rubrics 提供了明确且可解释的指导,从而在多个基准上带来了一致的改进。
- 这表明, Rubric-RM-Based 的训练不仅提升了绝对性能,还为构建与人类指令对齐的策略模型奠定了坚实的基础
Human Preference Alignment Evaluation
- 论文在人类偏好对齐基准 Arena-Hard 和 AlpacaEval 上评估了使用 Rubric-RM 训练的策略(表3)
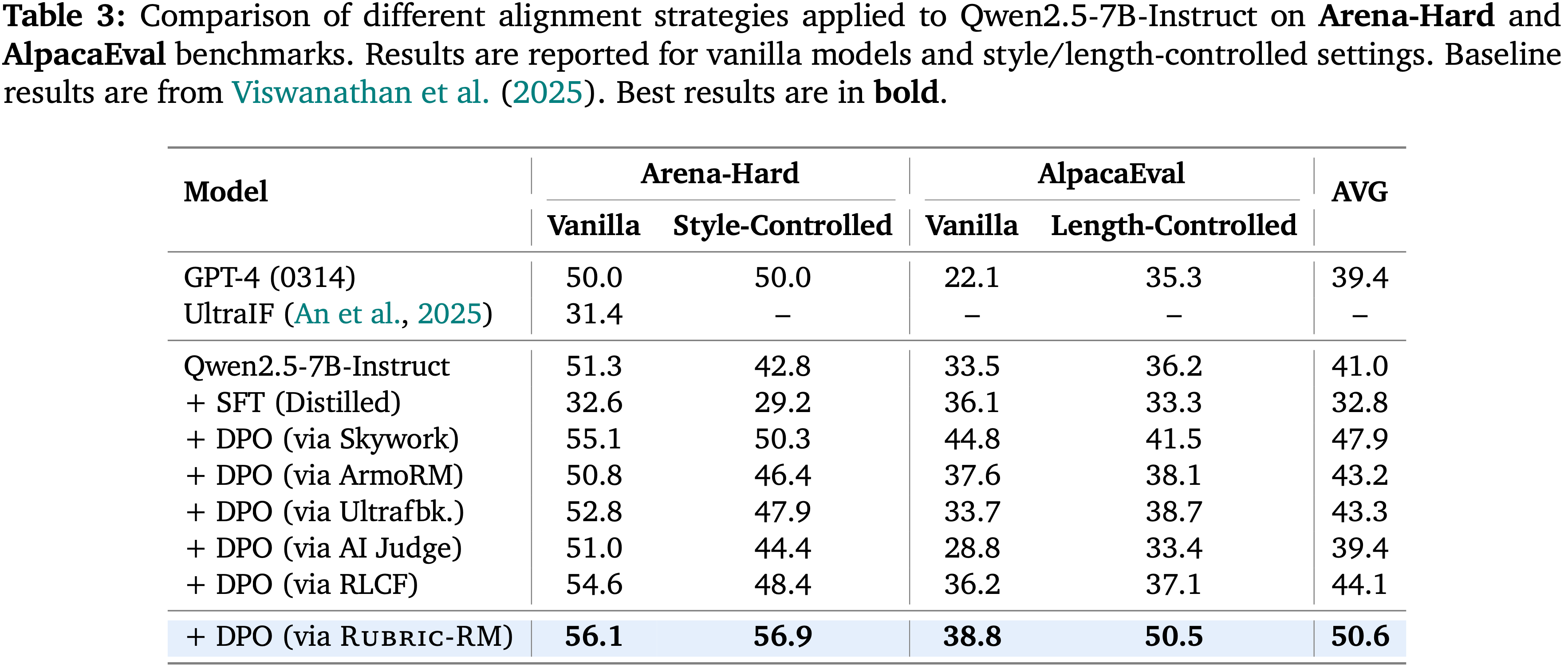
- 通过 DPO 优化, Rubric-RM 在所有开源奖励模型中取得了最佳的整体平均得分(50.6)
- 在 Arena-Hard (风格受控,Style-Controlled)上,它获得了 56.9 ,超越了 Skywork (50.3), Ultrafeedback (47.9), 和 RLCF (48.4)
- 在 AlpacaEval (长度受控,Length-Controlled)上,它达到了 50.5 ,超越了 ArmoRM (38.1) 和 AI Judge (33.4)
- 这些结果表明, Rubric-based 的信号在普通(vanilla)和受控(Controlled)Setting 下都能提供可靠的增益
Rubric-RM for BioMedical Domain(生物医学领域)
- 遵循 (2025) 的工作,论文进一步研究了 Rubric-RM 在更专业的医学领域的有效性
- 这里的实验同样从两个方面进行:
- (i) OpenRubrics 如何使 Rubric-RM 获得更好的奖励建模能力;
- (ii) Rubric-RM 如何引导出更强的策略模型
- Rubric 和评判模型是基于 Qwen-3-8B Backone ,使用来自科学相关领域的 OpenRubrics 数据进行微调的,更多关于论文数据的细节请参见第 4.1 节
Performance of Rubric-RM on HealthBench
- 与在通用领域中一样, Rubric-RM 在 HealthBench 上超越了同尺寸的 生成式推理(generative reasoning) 奖励模型:
- 论文的模型获得了 68.3 ,超过了 RRM-7B (63.3) 和两个 7B 级别的 RM-R1 变体 (55.4/66.9)
- Notably, Rubric-RM 与更大的 RM-R1-14B (69.9) 相比,也具有 Competitiveness
- 此外,与先前结果一致,多数投票进一步提升了 Rubric-RM 的性能:
- Rubric-RM-voting@5 达到了 72.9(比单次评判高出 +4.6),缩小了与更大的 14B 推理模型(例如, RM-R1-14B 最高可达 74.7)之间的差距,并接近基于 API 的参考模型 (69.9 - 73.5)。这些增益清楚地反映了使用 OpenRubrics 训练的 Rubric-RM 的有效性
- 第二个值得注意的增益在于领域特定 SFT 的重要性
- 与直接使用建议的 “Rubric+Judge” Pipeline Prompt Qwen-3-8B(仅获得 51.8 分)相比, Rubric-RM (68.3) 在 HealthBench 上实现了显著的改进 (+16.5)
- 这一显著的差距突显了领域特定 Rubric 数据 和 Rubric 感知 SFT 的重要性:
- 对比性 Rubric 训练和 Preference Label 一致性产生了更高精度、具有科学意识的准则(science-aware criteria),比实时生成的(on-the-fly)Rubrics 更有效地迁移到健康任务中
- 问题:这里是说实时生成 Rubric 不如提前生成的好,主要是生成的质量难以把控,没法保证和 Preference 一致?
Preference Optimization with Rubric-RM on HealthBench
- 论文进一步验证了论文的 Rubric-RM,其在奖励建模方面取得了更高的性能,能够成功地转化为更强的策略模型学习
- 这里论文比较了使用 Rubric-RM 作为 HealthBench 上 DPO 的偏好评判模型,与两个基线
- 基于推理的 RM-R1-7B (Qwen-2.5-Inst) 和非基于推理的 ArmoRM (2024a)
- 具体来说,论文使用 Qwen-2.5-7B-Instruct 作为基础策略模型(微调对象 Base Model),并为 HealthBench 中的每个问题收集其生成的 4 个独立 Response
- 使用不同的奖励模型标注偏好对,然后基础模型使用这些偏好对进行 DPO 微调
- 问题:4 个独立样本标注完是两两组合使用来训练 DPO 还是仅保留两个(Chosen 和 Rejected)训练 DPO?为什么不明确一下?
- DPO 性能结果报告于图 5(b)
- 根据该图,在固定策略 Backone 和 DPO 方法的情况下,用 Rubric-RM 替换基线评判模型,始终能获得最佳的下游性能
- 从基础模型 (21.6) 开始,通过 ArmoRM 的 DPO 达到 22.5,通过 RM-R1-7B 的 DPO 达到 22.7,而通过 Rubric-RM 的 DPO 达到了 23.8,是所有设置中最高的
- 这带来了比强大的 7B 推理奖励模型高出 1.1 到 1.3 的绝对增益,呼应了论文的发现:
- 即 Rubric 感知的、领域调优的信号为策略优化提供了比同规模的生成式推理更清晰的偏好
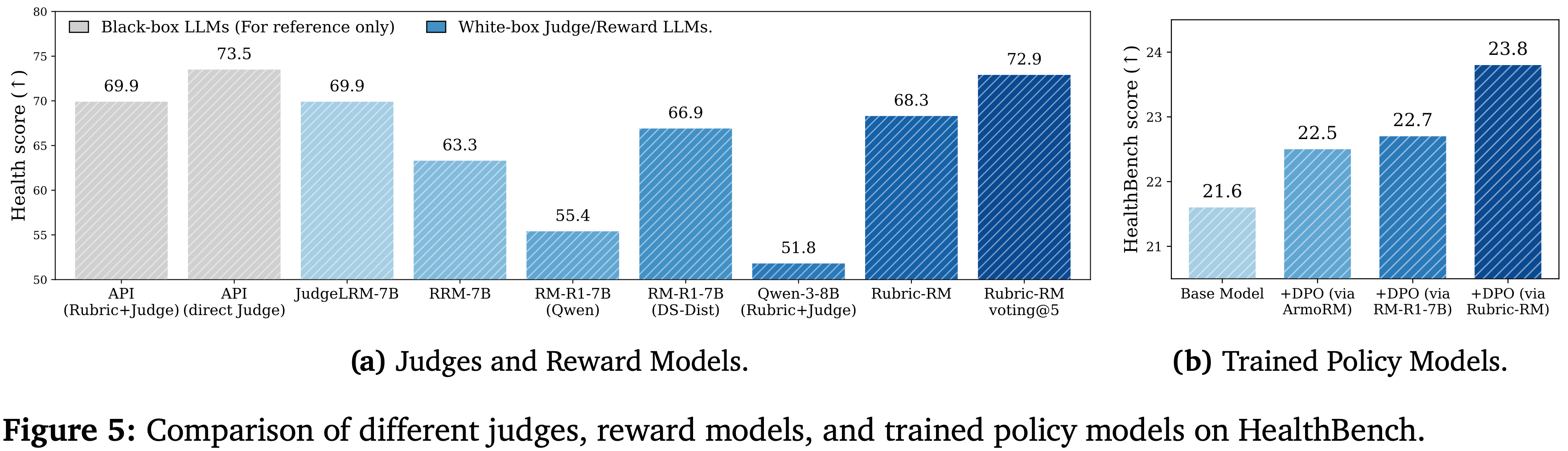
- 即 Rubric 感知的、领域调优的信号为策略优化提供了比同规模的生成式推理更清晰的偏好
Efficiency Comparison
- 本节分析了 Rubric-RM 推理的计算成本
- 表 4 报告了在来自 RewardBench2 的 100 个随机抽样 Prompt 上的挂钟时间(wall-clock)
- 值得注意的是,论文的 Rubric-RM (130.77 秒),其 Rubric 生成器 和 评判模型 都是 Qwen-3-8B,速度并不慢于 现有的推理奖励模型,如 RRM-7B (203.4 秒) 和 RM-R1-7B/14B (170.76 - 382.02 秒)
- 特别是,它明显快于 14B 的 R1 变体,并且与更强的 7B 推理基线具有竞争力,同时在 8B 规模下运行
- 论文将速度差距归因于不同的计算模式
- 先前的推理奖励模型在执行最终判断前需要运行长链条的思维轨迹,产生了大量的解码延迟
- 相比之下,论文的方法将评估 分解 为两个聚焦的阶段
- (i) 生成或检索一个 Rubric;
- (ii) 应用一个基于该 Rubric 的轻量级评判模型
- 因此论文的模型每个步骤都保持简短且有针对性
- 相比之下,论文的方法将评估 分解 为两个聚焦的阶段
- 另一个实际优势是 Rubrics 是 可分摊的:
- 一旦生成,它们可以离线计算并缓存在多个样本间重复使用,在评分时消除了 Rubric 生成的成本
- 这一特性使得 Rubric-RM 对于大规模偏好优化尤其具有吸引力,因为重复评判是运行时的主导因素
- 虽然 JudgeLRM-7B 实现了最低的原始延迟 (25.71 秒),但它未能提供使得论文方法具有可解释性和下游策略优化优势的显式 Rubric信号
- 先前的推理奖励模型在执行最终判断前需要运行长链条的思维轨迹,产生了大量的解码延迟
- 问题:这里的 Rubric 生成和过滤不是离线做的吗?统计的 130 秒包含了这个部分了吗?
- 很难想象包含了 Rubric 生成的两步式方法居然速度比同型号的一步式方法快
Case Study
- 论文以关于 Rubric-RM 如何处理挑战性输入并导致更好奖励建模的具体案例研究结束本节
- 论文展示了来自 RewardBench 和 FollowBench 基准的两个实例,基线选自 同规模 的生成式推理奖励模型
- 即,论文在案例 1 研究中使用 JudgeLRM-7B 和 RRM-7B,在案例 2 研究中使用两个 RM-R1-7B 变体 (DeepSeek-Dist, Qwen-2.5-Inst)
- 详细结果分别展示于表 5 和 表 6
Case 1 (RewardBench–Chat Hard): instruction adherence vs. verbosity bias
- 两个 Response 都包含生动的描述,但指令明确要求 少于两段
- 基线推理奖励模型忽略了这一硬性要求,选择了更长的 Response ,表现出典型的 冗长性偏好 和 指令违反盲视
- 相比之下, Rubric-RM 首先应用 把关准则 检查(段落数量),Rejected 不符合要求的候选,然后对原则(意象/原创性/聚焦)进行评分,最终选择了正确答案
- 这个例子突显了长思维链并不能保证正确满足约束,而 Rubric-Judge 分解则使失败变得明确并避免了它
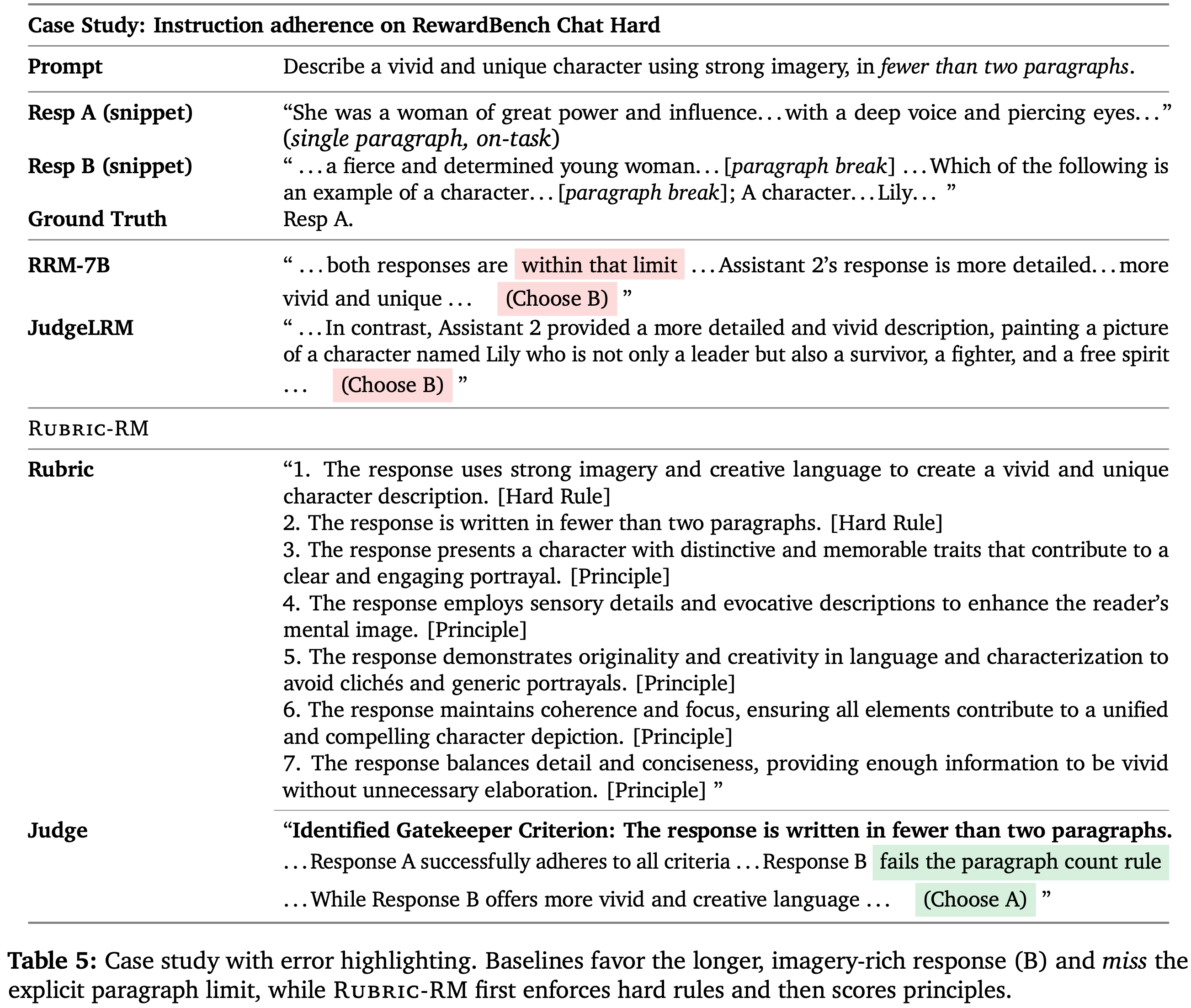
- 问题:这里面的 Rubric 和 附录中的 Prompt 生成模版是对齐的(每个 Rubric 都以 “The response” 开头)
Case 2 (FollowBench): verifiable recency and citation integrity.
- 这个例子更具挑战性:两个答案都较长,且质量差距微妙
- 然而,基线模型在证据方面产生了事实性错误,例如,断言更好的 Response 缺少日期/引证,尽管它 正确地提供了 一个带有 2024年5月16日 发表日期和具体数字(3870亿美元累计投资)的 BloombergNEF 引证
- 论文 Rubric-based 的评判模型将 时效性 和 可验证性 识别为硬性要求(引证、日期、简洁总结和经济影响),并青睐满足这些要求的 Response
- 这展示了 Rubric-RM 对 引证幻觉 和过度看重 “看似学术” 的散文的鲁棒性,后者误导了生成式推理奖励模型
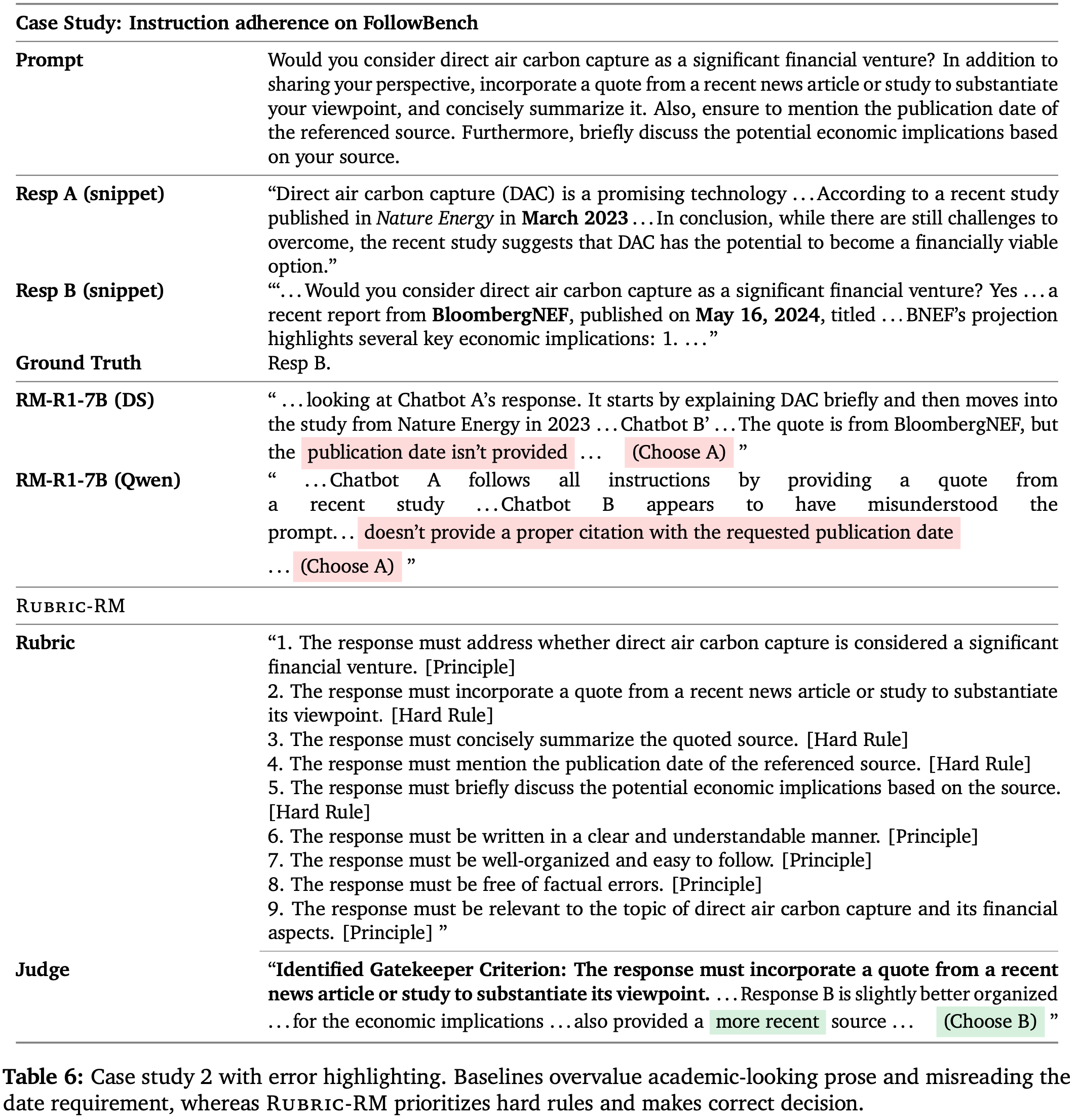
- 这展示了 Rubric-RM 对 引证幻觉 和过度看重 “看似学术” 的散文的鲁棒性,后者误导了生成式推理奖励模型
Takeaways
- 在两个案例中,具有长 CoT 能力的基线奖励模型仍然失败,原因有两个常见点:
- (i) 它们忽视了明确的硬性规则(结构性和证据性约束,Structural and evidentiary Constraints);
- (ii) 它们容易受到幻觉或弱可验证引用影响
- 相比之下, Rubric-RM 在评分更高层次质量前强制执行把关准则,产生了可解释的决策,并在困难例子上提高了准确率
- 论文还观察到,把关阶段减少了因偏离任务/过长内容导致的误报,并在那些时效性和来源完整性至关重要的领域(如科学/金融)提升了 可验证性感知(verifiability-aware) 的评判
补充:Related Work
Reward Modeling
- 标准的奖励模型通过应用 Bradley-Terry 框架下偏好输出和 Rejected 输出之间的排序损失来为 Response 分配标量分数 (1952; 2025b)
- 为了增强推理能力,生成式奖励模型 (GenRMs) 结合了合成的思维链 (CoT),实现了更准确的奖励估计 (2024; 2025; 2025b; 2024; 2025)
- 超越点式设置, Pairwise 奖励模型被提出来直接比较多个 Response (2025; 2025b)
- 最近,强化学习被用来进一步优化奖励模型,使它们能够明确地对比较进行推理,从而实现更强的对齐性能 (2025b; 2025; 2025b)
- 与这些工作正交(Orthogonal to these efforts),论文的工作侧重于通过使用结构化 rubrics 来提高奖励建模的质量
- 通过引入 Rubric-based 的评估信号,论文为现有方法补充了一层额外的可解释性,从而带来了性能提升
Rubrics as Rewards
- 最近的工作探索了 rubrics 用于评估和对齐
- Rubrics 提供了对模型生成的结构化评估 (2025; 2024; 2025; 2025),指导指令遵循和领域适应 (2025; 2025),通过基于规则的奖励提高安全性 (2024),并且已与可验证奖励结合用于推理任务 (2025; 2025)
- 然而,大多数现有方法依赖于 Prompt 前沿 LLMs 来生成 rubrics ,这限制了可扩展性和一致性
- 论文的工作引入了一个更可扩展的框架用于 高质量合成 rubric 生成 ,以更低的成本同时提高奖励质量和可解释性
- 与此同时(Concurrently),Chasing the Tail: Effective Rubric-based Reward Modeling for Large Language Model Post-Training, Scale AI, 20250925 也研究了 rubric 生成,但侧重于 迭代精炼(iterative refinement) 以缓解奖励过度优化,而论文强调可扩展的合成以及 rubric–preference 一致性(consistency)
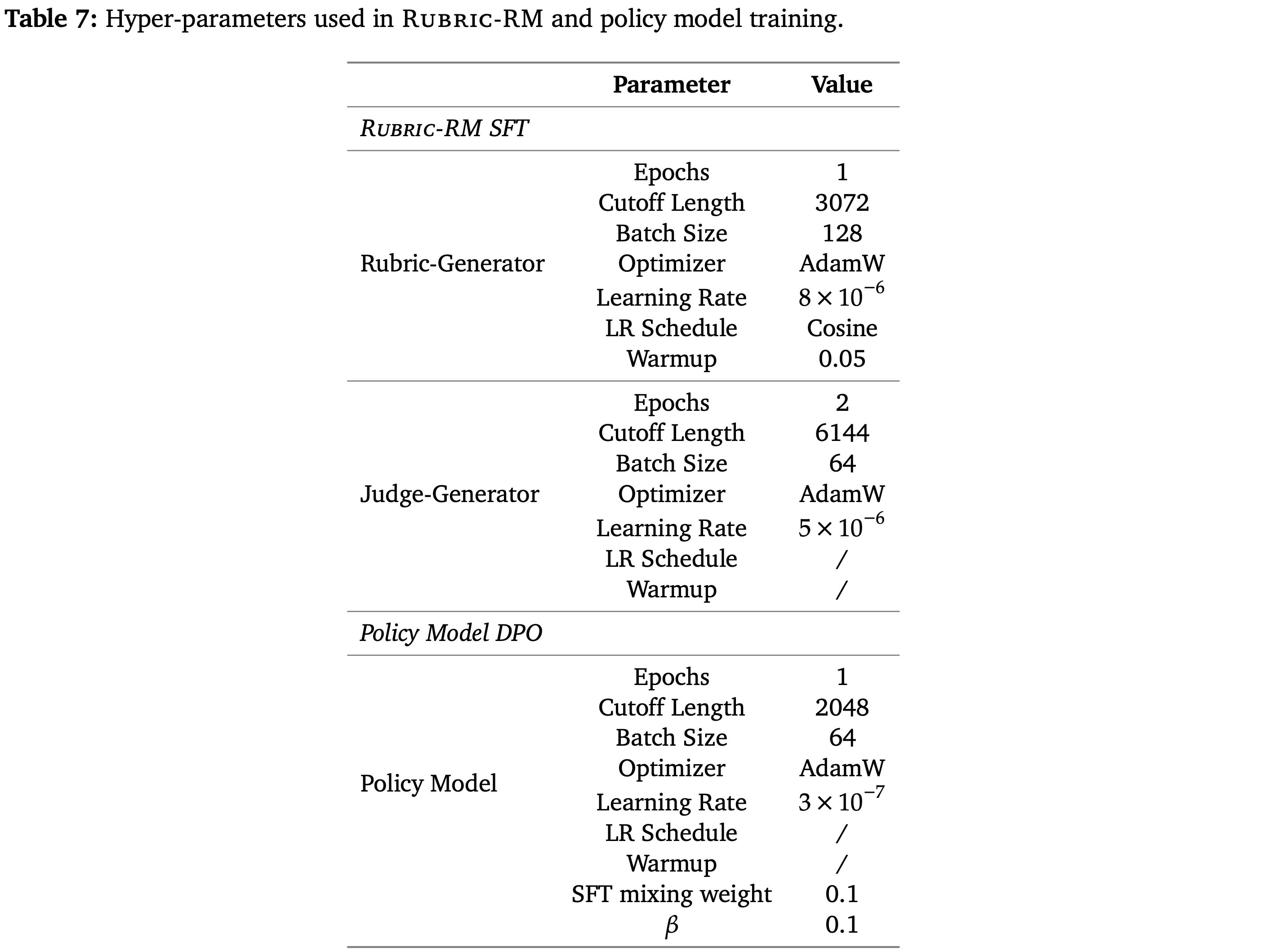
附录 A.1:Hyper-parameters
- 表 7 详细列出了 Rubric-RM 和策略模型训练中使用的超参数,训练均在 LLaMA-Factory (2024) 中进行
- Moreover,表 8 展示了在 OpenRubrics 数据集构建和 Rubric-RM 推理中使用的采样参数
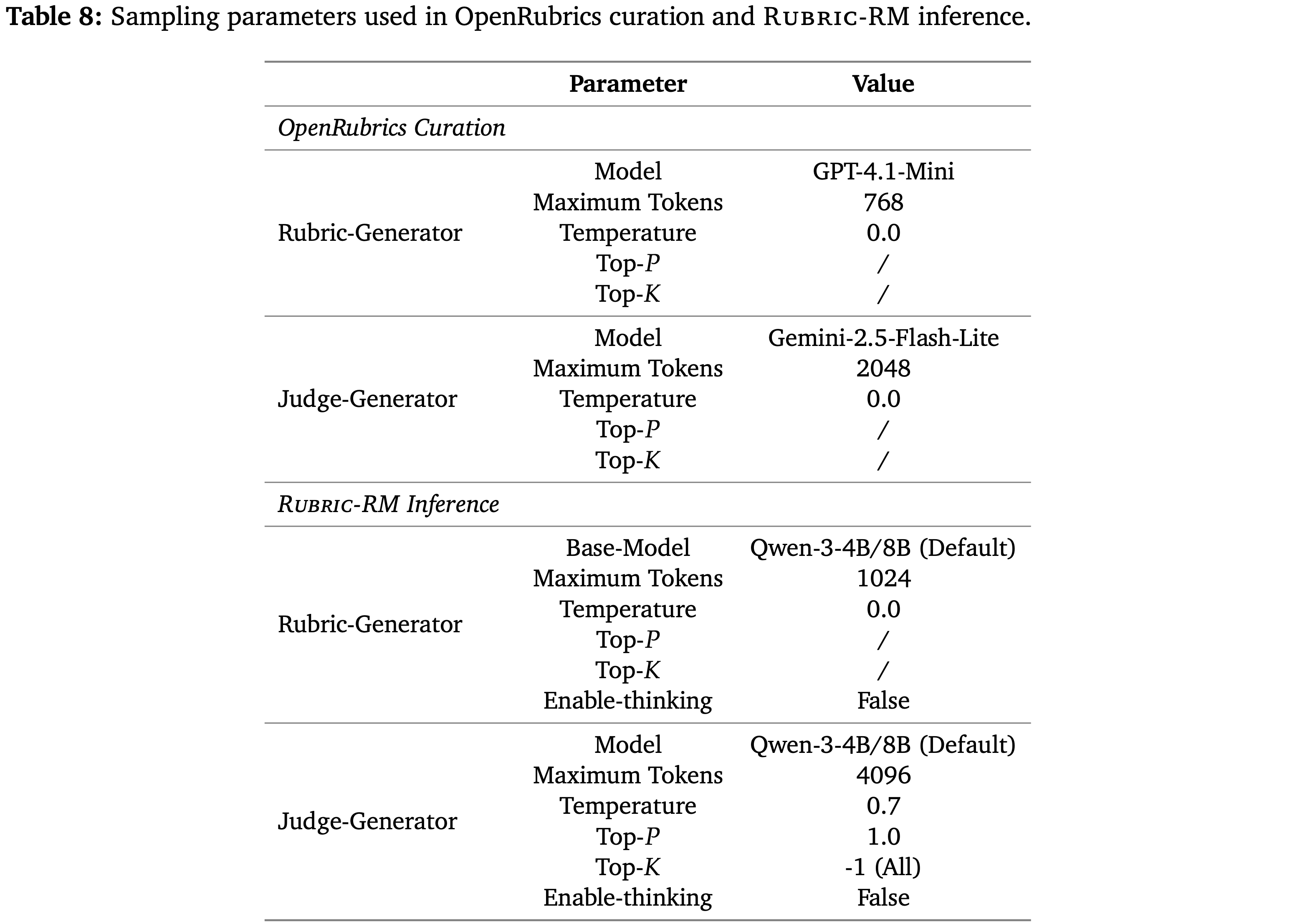
- 对于基线方法,论文采用了其官方实现和论文中所述的采样参数
附录 A.2:Prompts
- 论文在本小节中展示所使用的 Prompt
- 对于基线方法,论文采用了其官方实现和论文中的 Prompt
- 名词释义声明 again:
- OpenRubrics:一个数据集,包含了 Prompt, Chosen, Rejected, Rubrics 的数据集
- 注意:OpenRubrics 的 Rubric 生成需要 Chosen 和 Rejected Response
- Rubric-RM:一个奖励模型,包含了 Rubric 生成 + Pairwise 评估的流程
- 注意:Rubric-RM 的 Rubric 生成不需要 Chosen 和 Rejected Response,训练 Rubric-RM 的 生成模型时使用了 OpenRubrics 的 Prompt 和 Rubrics 数据,没有使用 Chosen 和 Rejected
- OpenRubrics:一个数据集,包含了 Prompt, Chosen, Rejected, Rubrics 的数据集
Prompt for Contrastive Rubric Generation (OpenRubrics Curation)
Prompt 原文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66You are an expert in pedagogy and critical thinking. Your mission is to create a universal scoring rubric based on a user's request and a set of examples.
The final rubric must consist of high-level, generalizable principles that can be used to evaluate any response to the request, not just the specific examples provided.
====================================================================
Methodology - A Three-Step Process for Principled Rubric Design
====================================================================
1. Step 1: Extract Explicit Requirements.
- Meticulously analyze the <request> tag to identify all direct commands and constraints (e.g., length, format, style).
- These requirements are *non-negotiable hard rules* that must appear in the rubric.
- They should be clearly labeled as [Hard Rule] in the final output.
2. Step 2: Analyze the Examples for Specific Differences.
- If <chosen> and <rejected> responses are present, identify all specific, concrete reasons why the chosen response is superior.
- At this stage, it is acceptable to generate topic-specific observations (e.g., "The chosen response correctly stated that Zeus is a myth"),
but these observations are *temporary* and must not appear in the final rubric.
- Every such observation must then be abstracted in Step 3.
3. Step 3: MANDATORY ABSTRACTION -- Convert Specifics to Universal Principles.
- This is the most critical step. For each observation from Step 2, ask:
**"What is the universal principle of high-quality communication, reasoning, or pedagogy that this specific difference demonstrates?"**
- Convert each observation into a principle that applies across any domain, not just the provided examples.
- Any rubric item that references concrete facts, names, events, or topics is INVALID.
- All such principles must be labeled as [Principle] in the final output.
====================================================================
Strict Guidelines for Final Output
====================================================================
- **Abstraction is Mandatory:**
Every rubric item must be a universal principle. If any rubric still contains topic-specific references (e.g., names, places, myths, numbers, historical facts), it is automatically invalid.
- **Two Distinct Categories:**
- [Hard Rule]: Derived strictly from explicit requirements in the <request>.
- [Principle]: Derived from abstracted differences in Step 3.
- **Comprehensiveness:**
The rubric must cover all critical aspects implied by the request and examples, including explicit requirements and implicit quality standards.
- **Conciseness & Uniqueness:**
Each rubric must capture a distinct evaluation criterion. Overlapping or redundant criteria must be merged into a single rubric. Wording must be precise and free of repetition.
- **Format Requirements:**
- Use a numbered list.
- Each item starts with "The response..." phrased in third person.
- Append [Hard Rule] or [Principle] at the end of each item.
- Do not include reasoning, explanations, or examples in the final outputonly the rubrics.
- **Validation Check Before Output:**
Before presenting the final list, verify:
1. Does every rubric meet the abstraction requirement (no topic-specific details)?
2. Are all hard rules from Step 1 included?
3. Are all principles unique and non-overlapping?
4. Is the list written entirely in third person, concise, and consistent?
====================================================================
Final Output Format
====================================================================
1. The response ... [Hard Rule]
2. The response ... [Principle]
3. The response ... [Principle]
... (continue until all rules and principles are listed)
====================================================================
<request>
{request}
</request>
<context>
{context}
</context>
<chosen>
{chosen}
</chosen>
<rejected>
{rejected}
</rejected>中文版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61你是一位教学法和批判性思维专家。你的任务是根据用户的请求和一组示例创建一个通用的评分 Rubric。最终的 Rubric 必须由高层次、可泛化的原则组成,可用于评估对请求的任何回应,而不仅仅是所提供的具体示例
方法论 - 面向原则性 Rubric 设计的三步流程
1. 第一步:提取显式要求
* 仔细分析 `<request>` 标签,识别所有直接命令和约束(例如,长度、格式、风格)
* 这些要求是*不可协商的硬性规则*,必须出现在 Rubric 中
* 它们应在最终输出中明确标记为 [Hard Rule]
2. 第二步:分析示例以找出具体差异
* 如果存在 `<chosen>` 和 `<rejected>` 回应,请找出所有使被选中的回应更优的具体、具体原因
* 在此阶段,可以生成特定于主题的观察(例如,“被选中的回应正确指出宙斯是一个神话”),但这些观察是*临时的*,不得出现在最终 Rubric 中
* 每一个此类观察都必须在第三步中进行抽象
3. 第三步:强制性抽象 —— 将具体内容转化为通用原则
* 这是最关键的一步。对于第二步中的每个观察,请问:
**该具体差异所体现的高质量沟通、推理或教学法的普遍原则是什么?**
* 将每个观察转化为一个适用于任何领域的原则,而不仅仅是所提供的示例
* 任何引用具体事实、名称、事件或主题的 Rubric 项目都是无效的
* 所有此类原则都必须在最终输出中标记为 [Principle]
最终输出的严格指南
* **抽象是强制性的:**
每个 Rubric 项目必须是一个通用原则。如果任何 Rubric 仍然包含特定主题的引用(例如,名称、地点、神话、数字、历史事实),则自动视为无效
* **两个不同的类别:**
* [Hard Rule]:严格源自 `<request>` 中的显式要求
* [Principle]:源自第三步中抽象出的差异
* **全面性:**
Rubric 必须涵盖请求和示例所暗示的所有关键方面,包括显式要求和隐含的质量标准
* **简洁性与独特性:**
每个 Rubric 必须捕捉一个独特的评估标准。重叠或冗余的标准必须合并为单个 Rubric。措辞必须精确且无重复
* **格式要求:**
* 使用编号列表
* 每个项目以“该回应...”开头,用第三人称表述
* 在每个项目末尾附加 [Hard Rule] 或 [Principle]
* 最终输出中不要包含推理、解释或示例,只输出 Rubric
* **输出前的验证检查:**
在呈现最终列表之前,请验证:
1. 每个 Rubric 是否符合抽象要求(没有特定主题的细节)?
2. 是否包含了第一步中的所有硬性规则?
3. 所有原则是否都是独特且不重叠的?
4. 列表是否完全用第三人称撰写,简洁且一致?
最终输出格式
1. 该回应 ... [Hard Rule]
2. 该回应 ... [Principle]
3. 该回应 ... [Principle]
... (继续列出所有规则和原则)
<request>
{request}
</request>
<context>
{context}
</context>
<chosen>
{chosen}
</chosen>
<rejected>
{rejected}
</rejected>
Prompt for Judge Generation (OpenRubrics Curation)
Prompt 原文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46You are a fair and impartial judge. Your task is to evaluate 'Response A' and 'Response B' based on a given instruction and a rubric.
You will conduct this evaluation in distinct phases as outlined below.
### Phase 1: Compliance Check Instructions
First, identify the single most important, objective 'Gatekeeper Criterion' from the rubric.
- **A rule is objective (and likely a Gatekeeper) if it can be verified without opinion.
Key examples are: word/paragraph limits, required output format (e.g., JSON validity),
required/forbidden sections, or forbidden content.**
- **Conversely, a rule is subjective if it requires interpretation or qualitative judgment. Subjective rules about quality are NOT Gatekeepers.
Examples include criteria like "be creative," "write clearly," "be engaging," or "use a professional tone."**
### Phase 2: Analyze Each Response
Next, for each Gatekeeper Criterion and all other criteria in the rubric, evaluate each response item by item.
### Phase 3: Final Judgment Instructions
Based on the results from the previous phases, determine the winner using these simple rules.
Provide a final justification explaining your decision first and then give your decision.
---
### REQUIRED OUTPUT FORMAT
You must follow this exact output format below.
--- Compliance Check ---
Identified Gatekeeper Criterion: <e.g., Criterion 1: Must be under 50 words.>
--- Analysis ---
**Response A:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (and so on for all other criteria)
**Response B:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (and so on for all other criteria)
--- Final Judgment ---
Justification: <...>
Winner: <Response A / Response B>
Task to Evaluate:
Instruction:
{instruction}
Rubric:
{rubric}
Response A:
{response_a}
Response B:
{response_b}中文版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48你是一位公正的法官。你的任务是根据给定的指令和 Rubric 评估“Response A”和“Response B”。你将按照下面概述的步骤进行此评估
#### 第 1 步:合规性检查说明
首先,从 Rubric 中识别出最重要、最客观的“Gatekeeper Criterion”(守门员标准)
* **如果一项规则可以不经主观意见验证,它就是客观的(并且很可能是 Gatekeeper)。关键示例包括:字数/段落数限制、要求的输出格式(例如,JSON 有效性)、要求/禁止的部分,或禁止的内容。**
* **相反,如果一条规则需要解释或定性判断,它就是主观的。关于质量的主观规则不是 Gatekeeper。示例包括诸如“具有创造性”、“写得清晰”、“引人入胜”或“使用专业语气”之类的标准。**
#### 第 2 步:分析每个回应
接下来,针对每个 Gatekeeper Criterion 以及 Rubric 中的所有其他标准,逐项评估每个回应
#### 第 3 步:最终判决说明
根据前面步骤的结果,使用这些简单的规则确定获胜者。首先提供一个最终理由解释你的决定,然后给出你的决定
#### 要求的输出格式
你必须严格遵守下面的确切输出格式
--- Compliance Check ---
Identified Gatekeeper Criterion: <例如,标准 1:必须在 50 词以内。>
--- Analysis ---
**Response A:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (对所有其他标准依此进行)
**Response B:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (对所有其他标准依此进行)
--- Final Judgment ---
Justification: <...>
Winner: <Response A / Response B>
待评估任务:
指令:
{instruction}
Rubric:
{rubric}
Response A:
{response_a}
Response B:
{response_b}
Prompt for Rubric Generation (Rubric-RM)
Prompt 原文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22Your task is to extract a set of rubric-style instructions from a user's request.
These rubrics will be used as evaluation criteria to check if a response fully meets the request.
Every rubric item must be a universal principle. If any rubric still contains topic-specific references
(e.g., names, places, myths, numbers, historical facts), it is automatically invalid.
- Two Distinct Categories:
- [Hard Rule]: Derived strictly from explicit requirements stated in the <request>
(format, length, structure, forbidden/required elements, etc.).
- [Principle]: Derived by abstracting any concrete cues into domain-agnostic
quality criteria (e.g., clarity, correctness, sound reasoning, pedagogy).
- Comprehensiveness:
The rubric must cover all critical aspects implied by the request and examples, including explicit requirements and implicit quality standards.
- Conciseness & Uniqueness:
Each rubric must capture a distinct evaluation criterion. Overlapping or redundant criteria must be merged into a single rubric.
Wording must be precise and free of repetition.
- Format Requirements:
- Use a numbered list.
- Each item starts with "The response" phrased in third person.
- Append [Hard Rule] or [Principle] at the end of each item.
- Do not include reasoning, explanations, or examples in the final output--only the rubrics.
Here is the request:
{prompt}
Please generate the rubrics for the above request.中文版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21你的任务是从用户的请求中提取一组 Rubric 风格的指令
这些 Rubric 将用作评估标准,以检查回应是否完全满足请求
每个 Rubric 项目必须是一个通用原则。如果任何 Rubric 仍然包含特定主题的引用(例如,名称、地点、神话、数字、历史事实),则自动视为无效
* 两个不同的类别:
* [Hard Rule]:严格源自 `<request>` 中明确陈述的要求(格式、长度、结构、禁止/要求的元素等)
* [Principle]:通过将任何具体线索抽象为与领域无关的质量标准而得出(例如,清晰度、正确性、推理严谨性、教学法)
* 全面性:
Rubric 必须涵盖请求和示例所暗示的所有关键方面,包括显式要求和隐含的质量标准
* 简洁性与独特性:
每个 Rubric 必须捕捉一个独特的评估标准。重叠或冗余的标准必须合并为单个 Rubric。措辞必须精确且无重复
* 格式要求:
* 使用编号列表
* 每个项目以“该回应”开头,用第三人称表述
* 在每个项目末尾附加 [Hard Rule] 或 [Principle]
* 最终输出中不要包含推理、解释或示例,只输出 Rubric
以下是请求:
{prompt}
请为上述请求生成 Rubric
Prompt for Judge Generation (Rubric-RM)
注:与 OpenRubrics Curation 一样
Prompt 原文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41You are a fair and impartial judge. Your task is to evaluate 'Response A' and 'Response B' based on a given instruction and a rubric.
You will conduct this evaluation in distinct phases as outlined below.
### Phase 1: Compliance Check Instructions
First, identify the single most important, objective 'Gatekeeper Criterion' from the rubric.
- **A rule is objective (and likely a Gatekeeper) if it can be verified without opinion. Key examples are: word/paragraph limits, required output format (e.g., JSON validity), required/forbidden sections, or forbidden content.**
- **Conversely, a rule is subjective if it requires interpretation or qualitative judgment. Subjective rules about quality are NOT Gatekeepers. Examples include criteria like "be creative," "write clearly," "be engaging," or "use a professional tone."**
### Phase 2: Analyze Each Response
Next, for each Gatekeeper Criterion and all other criteria in the rubric, evaluate each response item by item.
### Phase 3: Final Judgment Instructions
Based on the results from the previous phases, determine the winner using these simple rules. Provide a final justification explaining your decision first and then give your decision.
---
### REQUIRED OUTPUT FORMAT
You must follow this exact output format below.
--- Compliance Check ---
Identified Gatekeeper Criterion: <e.g., Criterion 1: Must be under 50 words.>
--- Analysis ---
**Response A:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (and so on for all other criteria)
**Response B:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (and so on for all other criteria)
--- Final Judgment ---
Justification: <...>
Winner: <Response A / Response B>
Task to Evaluate:
Instruction:
{instruction}
Rubric:
{rubric}
Response A:
{response_a}
Response B:
{response_b}中文版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48你是一位公正的法官。你的任务是根据给定的指令和 Rubric 评估“Response A”和“Response B”。你将按照下面概述的步骤进行此评估
#### 第 1 步:合规性检查说明
首先,从 Rubric 中识别出最重要、最客观的“Gatekeeper Criterion”(守门员标准)
* **如果一项规则可以不经主观意见验证,它就是客观的(并且很可能是 Gatekeeper)。关键示例包括:字数/段落数限制、要求的输出格式(例如,JSON 有效性)、要求/禁止的部分,或禁止的内容。**
* **相反,如果一条规则需要解释或定性判断,它就是主观的。关于质量的主观规则不是 Gatekeeper。示例包括诸如“具有创造性”、“写得清晰”、“引人入胜”或“使用专业语气”之类的标准。**
#### 第 2 步:分析每个回应
接下来,针对每个 Gatekeeper Criterion 以及 Rubric 中的所有其他标准,逐项评估每个回应
#### 第 3 步:最终判决说明
根据前面步骤的结果,使用这些简单的规则确定获胜者。首先提供一个最终理由解释你的决定,然后给出你的决定
#### 要求的输出格式
你必须严格遵守下面的确切输出格式
--- Compliance Check ---
Identified Gatekeeper Criterion: <例如,标准 1:必须在 50 词以内。>
--- Analysis ---
**Response A:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (对所有其他标准依此进行)
**Response B:**
- Criterion 1 [Hard Rule]: Justification: <...>
- Criterion 2 [Hard Rule]: Justification: <...>
- Criterion 3 [Principle]: Justification: <...>
- ... (对所有其他标准依此进行)
--- Final Judgment ---
Justification: <...>
Winner: <Response A / Response B>
待评估任务:
Instruction:
{instruction}
Rubric:
{rubric}
Response A:
{response_a}
Response B:
{response_b}