注:本文包含 AI 辅助创作
Paper Summary
- 整体总结
- 论文提出了组过滤策略优化(Group-Filtered Policy Optimization, GFPO)(是 GRPO 的一种扩展方法)
- 通过 采样更多响应 并 选择性地学习 与目标属性(如简洁性或 Token 效率)最匹配的样本来优化模型
- 这种选择性学习作为一种隐式的奖励塑造机制,引导策略生成更高质量的输出,同时抑制诸如响应长度膨胀等不良行为,而无需复杂的奖励工程
- 问题:Token 效率部分有点像是 Kimi K1.5 的内容?
- 背景 & 问题:
- RLVR-based RL 训练的 LLM 往往会以长度换取准确性
- 更长的回答可能适用于更难的问题,但许多 Token 仅仅是“填充内容”:重复、冗长的文本并未真正推动问题解决
- GFPO 可解决上述问题:
- 在训练时对每个问题采样更大的群组
- 根据两个关键指标过滤回答来抑制这种长度爆炸:
- (1) 回答长度;
- (2) Token 效率(奖励与 Token 数量的比值)
- 通过在训练时采样更多,论文教会模型在推理时思考更少
- 在 Phi-4-reasoning 模型上,GFPO 在具有挑战性的 STEM 和编程基准测试(AIME 24/25、GPQA、Omni-MATH、LiveCodeBench)中将 GRPO 的长度膨胀削减了 46-71%,同时保持准确性
- 优化奖励与 Token 比进一步将长度膨胀的减少幅度提升至 71-85%
- 论文还提出了 自适应难度 GFPO(Adaptive Difficulty GFPO)
- 根据实时难度估计动态分配更多训练资源给更难的问题,从而在计算效率和准确性之间实现更好的平衡,尤其是在困难问题上
- GFPO 证明
- 增加训练时的计算量可以直接转化为减少测试时的计算量(注:核心结论)
- 这是一种简单而有效的权衡,旨在实现高效推理
Introduction and Discussion
- RLVR 方法(如 GRPO (2024) 和 PPO (2017)),在实现测试时扩展方面发挥了关键作用
- 使得像 O3 (2025) 和 DeepSeek-R1 (2025) 这样的模型能够“思考更久”,并在 AIME 和 IMO 等具有挑战性的推理任务中取得前所未有的性能
- 虽然更长的推理链对于解决更难的问题是预期的,但先前的研究表明,长度膨胀可能与正确性无关,而更短的链实际上可能带来更好的准确性。例如:
- Balachandran 等人 (2025) 报告称,在 AIME 25 上,DeepSeek-R1 生成的回答长度几乎是 Claude 3.7 Sonnet 的 5 倍,尽管两者的准确性相近
- 类似地,Hassid 等人 (2025) 发现,在 AIME 和 HMMT 上,QwQ-32B 的最短回答在减少 31% Token 使用量的同时,比随机采样的回答准确率高 2%
- 这表明更长的链并不等同于更好的推理
- 更长的回答可能显得准确性更低,仅仅是因为它们通常来自更难的问题
- 为了区分由问题难度驱动的真实长度增加和不必要的膨胀,论文分析了 Phi-4-reasoning-plus (2025) 中同一问题的多个回答长度与正确性之间的相关性
- 在 AIME 25 上,论文发现,在生成了正确和错误回答的问题中,72% 的情况下,更长的回答比更短的更容易出错
- 已有一些方法被提出来抑制 RLVR 训练模型中持续的长度膨胀现象,例如 Dr.GRPO (2025) 和 DAPO (2025) 的 Token-level 损失归一化
- 但即使在 Phi-4-reasoning-plus 的训练中应用了 Token-level 归一化,论文仍然观察到在仅 100 步 GRPO 训练后,回答长度从 4k 迅速增长到 14k Token
- 论文假设,虽然 Token-level 归一化更严厉地惩罚了长而错误的回答,但它也放大了对长而正确链的奖励
- 无意中强化了经过大量逐步推理 SFT 的强大基础模型(如 Phi-4-reasoning (2025) 和 DeepSeek-R1-Distill-Qwen (2025))固有的冗长性
- 这凸显了仅依赖损失归一化来对抗 GRPO 显著长度膨胀的困难
- 基于这些观察,论文的目标是开发高效的推理模型,这些模型能够保留 GRPO 提供的推理准确性,同时生成显著更短的推理链
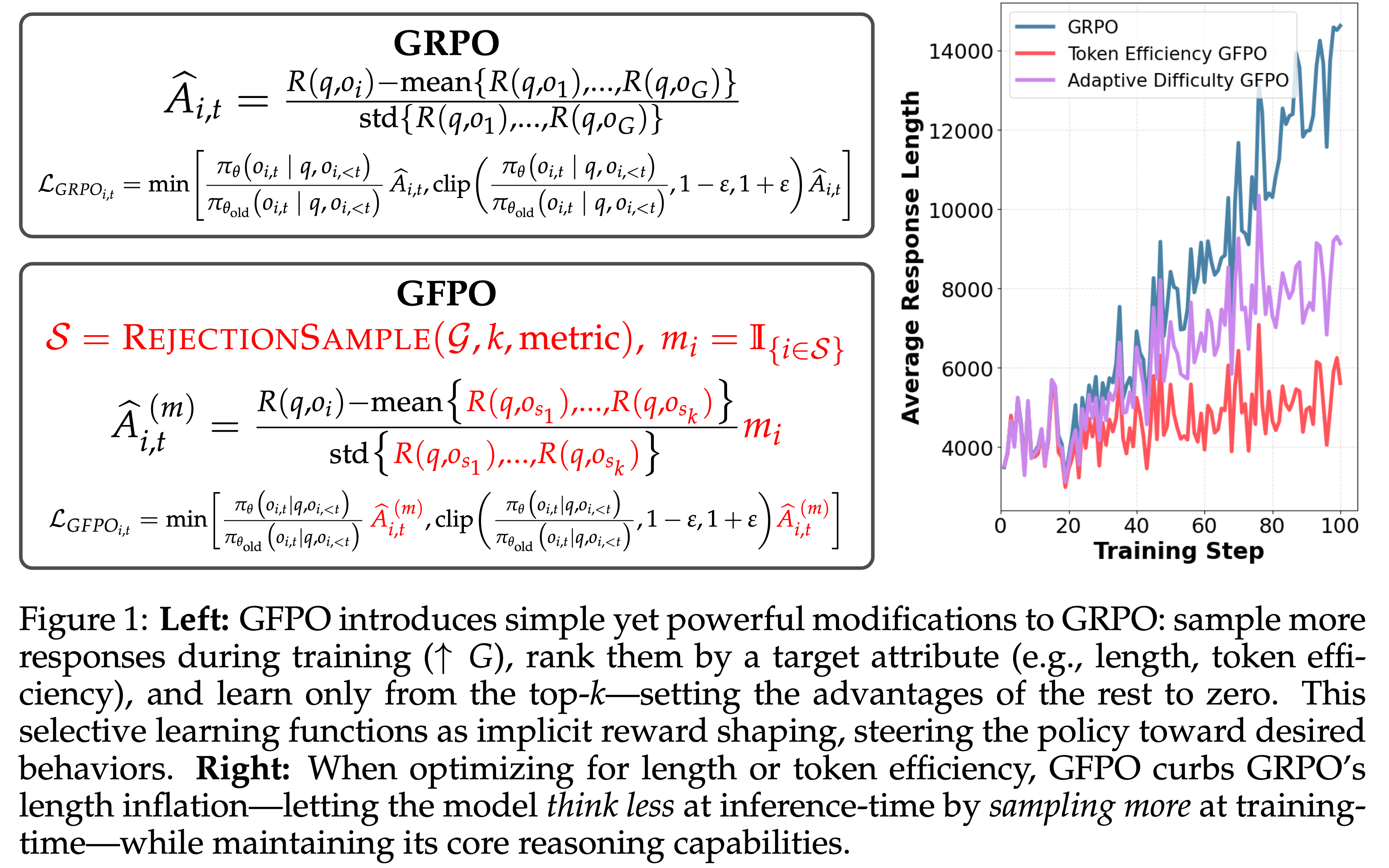
- 为实现以上一目标,论文做出了以下贡献:
- GFPO(群组过滤策略优化) :
- 论文提出了 GFPO(图 1,第 3 节),这是 GRPO 的一种简单而有效的变体,旨在显式抑制回答长度膨胀
- GFPO 将拒绝采样与标准 GRPO 相结合:
- 对于每个问题,论文采样更大的候选推理链群组 \( G \),以增加对理想输出的接触,根据目标指标过滤它们,并仅从保留的前 \( k \) 条链的策略梯度中学习
- 虽然可以设计多种拒绝指标,但论文主要关注回答长度(保留最短的链以鼓励模型在推理时“思考更少”)
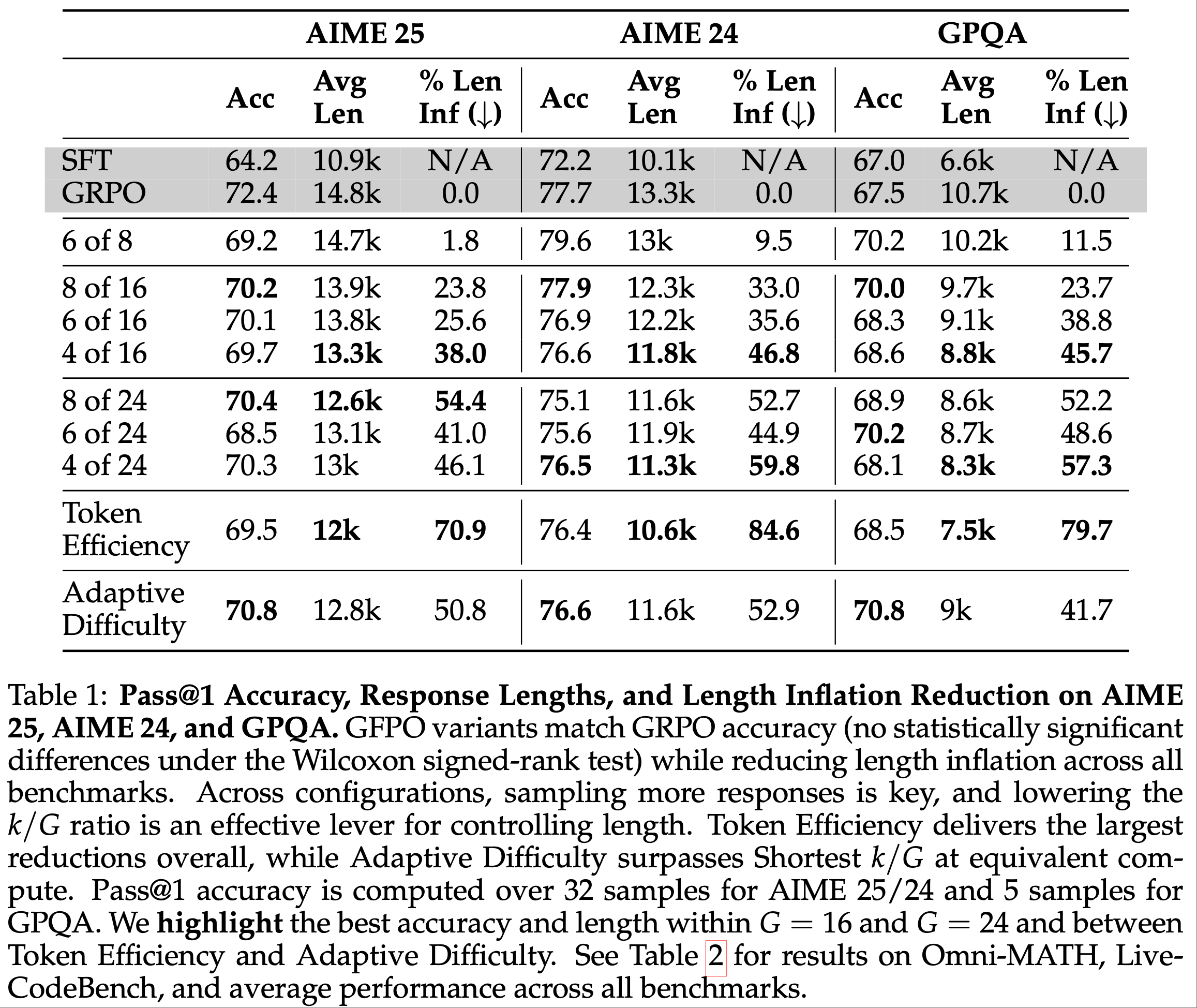
- 当优化长度时,GFPO 在 AIME 25 上将 GRPO 的长度膨胀减少了 46.1%,在 AIME 24 上减少 59.8%,在 GPQA 上减少 57.3%,在 Omni-MATH 上减少 71%,在 LiveCodeBench 上减少 57%,同时保持准确性(第 5.2、5.3 节)
- Token 效率(Token Efficiency)(第 5.4 节):
- 除了仅针对长度外,论文引入了 Token 效率指标(定义为奖励与回答长度的比值)
- 该指标促进那些通过提供更高奖励来证明其长度的推理链,鼓励模型既简洁又有效
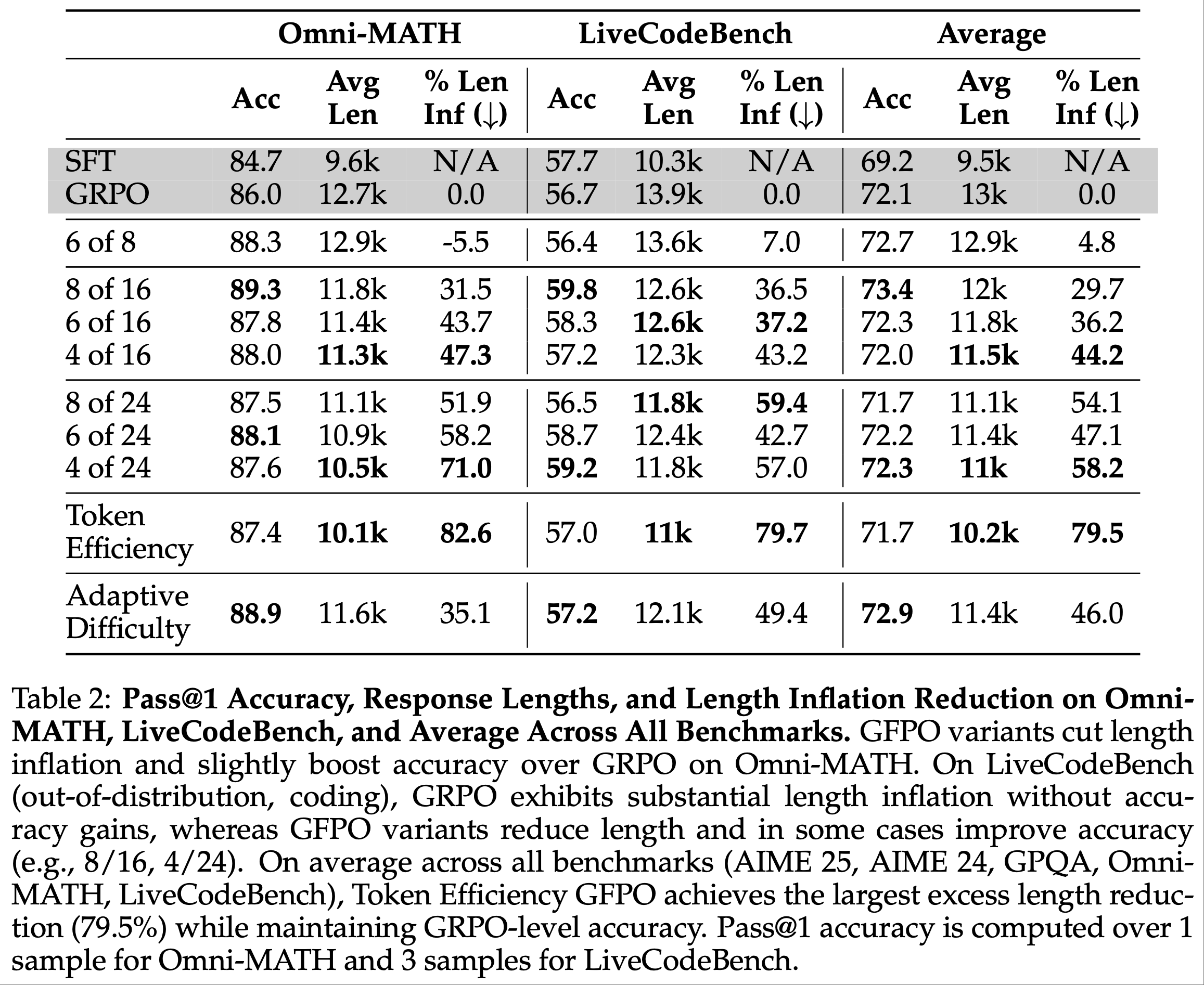
- 通过 GFPO 优化 Token 效率,长度膨胀在 AIME 25 上减少了 70.9%,在 AIME 24 上减少 84.6%,在 GPQA 上减少 79.7%,在 Omni-MATH 上减少 82.6%,在 LiveCodeBench 上减少 79.7%(定性示例见附录 A)
- 自适应难度 GFPO(Adaptive Difficulty GFPO)(第 5.5 节):
- 论文进一步引入了 GFPO 的自适应变体 ,其中保留的回答数量 \( k \) 基于轻量级、无监督的问题难度估计动态调整
- 这种自适应策略将更多探索 (更大的 \( k \))分配给更难的问题 ,同时对较简单的问题进行更激进的缩短
- 分布外泛化(Out-of-Distribution Generalization)(第 5.6 节):
- 论文展示了 GFPO 在分布外任务上保持准确性的同时抑制长度膨胀的能力
- GFPO 对回答长度和问题难度的分析(Analysis of GFPO on Response Length and Question Difficulty)(第 6 节):
- 论文详细分析了 GFPO 在简单与困难问题上的准确性和长度减少情况,并研究了其对长回答准确性的影响
- GFPO(群组过滤策略优化) :
- GFPO 利用了训练时和推理时计算之间的基本权衡,将成本从推理(更短的链带来显著的效率提升)转移到训练,通过采样和评估更多的候选回答
- 这种权衡特别有利,因为训练计算是一次性投入,而推理计算的节省在整个部署过程中持续实现
- 通过这种方式,GFPO 提供了一种简单而有效的解决方案,解决了推理模型中固有的回答长度膨胀问题(在保留 GRPO 最先进性能的同时,生成显著更短的推理链)
Preliminaries
- GRPO (2024) 是一种强化学习算法:通过消除对值模型估计基线优势的需求,简化了 PPO (2017)
- 通过为每个问题采样多个回答并使用其平均奖励作为基线实现,同时仍然优化与 PPO 类似的裁剪代理目标
- 设 \( \theta \) 表示模型参数,\( q \) 表示问题,\( o \) 表示从旧策略 \( \pi_{\theta_{\text{old} } } \) 采样的回答,则
- GRPO 目标可以表示为:
$$
\mathcal{J}_{\text{GRPO} }(\theta) = \mathbb{E}_{[\hat{\eta}\sim P(O), \{o_i\}_{i=1}^C \sim \pi_{\theta_{\text{old} } }(O|q)]} \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left( r_{i,t} \widehat{A}_{i,t}, \text{clip}(r_{i,t},1-\varepsilon,1+\varepsilon) \widehat{A}_{i,t} \right) - \beta \mathcal{D}_{KL}(\pi_{\theta} | \pi_{\theta_{\text{old} } } ) + \gamma \text{Entropy}(\pi_{\theta})
$$ - 其中优势为:
$$
\widehat{A}_{i,t} = \frac{R(q,\rho_i) - \frac{1}{k} \sum_{j=1}^C R(q,\rho_j)}{\sqrt{\frac{1}{k} \sum_{l=1}^G \left( R(q,\rho_i) - \frac{1}{k} \sum_{j=1}^C R(q,\rho_j) \right)^2} }, \quad r_{i,t} = \frac{\pi_{\theta}(o_{i,t} | q,\rho_{i,<t})}{\pi_{\theta_{\text{old} } }(o_{i,t} | q,\rho_{i,<t})}
$$ - 且 \( \beta \mathcal{D}_{KL}(\pi_{\theta} | \pi_{\theta_{\text{old} } } ) \) 表示 KL 惩罚
- GRPO 目标可以表示为:
- 需要注意的是,虽然论文展示了标准的 GRPO 损失归一化方程,但包括 verl (2024) 和 TRL (2020) 在内的多个开源强化学习库默认使用 DAPO 的 Token-level 损失归一化进行 GRPO 训练 ,这也是论文在实验中使用的方法
- GRPO 的一个关键限制是其依赖单一标量奖励信号 ,这使得同时优化多个理想的回答属性(如简洁性和准确性)变得困难
- 这通常导致以显著的回答长度膨胀为代价换取准确性的提升
- 为了解决这一问题,论文引入了 GFPO,以实现对多个回答属性的联合优化
Group Filtered Policy Optimization, GFPO
- 论文提出了 GFPO,一种简单而有效的方法,用于有针对性地优化响应属性
- GFPO 为每个问题采样更大的候选响应组 ,扩大响应池以包含更多具有理想特征的候选 ,然后在计算策略梯度时明确根据这些特征进行过滤
- 将理想属性(如简洁性或信息量)直接编码到标量奖励中看似自然,但对于多个属性的优化可能会非常具有挑战性
- 尤其是已经需要捕捉正确性的情况下
- 数据过滤作为一种隐式、灵活的奖励塑造形式,类似于通过选择性采样来放大特定模型行为的迭代自我改进方法 (2022)
- 将理想属性(如简洁性或信息量)直接编码到标量奖励中看似自然,但对于多个属性的优化可能会非常具有挑战性
- 在完成这一显式过滤步骤以隔离优选响应后,标准的奖励仅用于在选定组内计算相对优势
- GFPO 能够同时优化多个理想属性(如长度和准确性),而无需复杂的奖励工程
- 由于论文的目标是减少强化学习中的响应长度膨胀 ,论文专注于使用 GFPO 优化更短的响应,同时匹配 GRPO 的准确性
- 给定一个问题 \( q \),论文从当前策略中采样一组较大的响应 \( \mathcal{G} = \{o_1, \ldots, o_G\} \)
- GFPO 根据用户指定的指标应用选择步骤,过滤出大小为 \( k \) 的最理想响应子集用于训练
- 论文为每个响应计算指标得分并排序,选择前 \( k \) 个响应形成保留子集 \( \mathcal{S} \subseteq \mathcal{G} \)(算法 1)
- 论文定义一个二元掩码 \( m \in \{0, 1\}^G \),其中 \( m_i = 1 \) 表示选中的响应,\( m_i = 0 \) 表示被拒绝的响应

- 形式上,论文将 GFPO 的目标函数定义为:
$$
\mathcal{J}_{\text{GFPO} }(\theta) = \mathbb{E}_{q \sim P(\mathcal{Q}), \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old} } }(\mathcal{O}|q)} \frac{1}{\sum_{i=1}^G |o_i|} \sum_{i=1}^G \sum_{t=1}^{|o_i|} \min(r_{i,t} \widehat{A}^{(m)}_{i,t}, \text{clip}(r_{i,t}, 1 - \varepsilon, 1 + \varepsilon) \widehat{A}^{(m)}_{i,t}) - \beta \mathcal{D}_{KL}(\pi_\theta \parallel \pi_{\theta_{\text{old} } }) + \gamma \text{Entropy}(\pi_\theta)
$$- 其中:
$$
\mathcal{S}, m = \text{RejectionSample}(\mathcal{G}, k, \text{metric}, \text{order}), \quad m_i = \mathbb{I}_{ \{i \in \mathcal{S} \} } \\
\mu_S = \frac{1}{k} \sum_{i \in \mathcal{S} } R(q, o_i), \quad \sigma_S = \sqrt{\frac{1}{k} \sum_{i \in \mathcal{S} } (R(q, o_i) - \mu_S)^2}, \quad \widehat{A}^{(m)}_{i,t} = \frac{R(q, o_i) - \mu_S}{\sigma_S} m_i \\
r_{i,t} = \frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_{\text{old} } }(o_{i,t} | q, o_{i,< t})}
$$- 注意:均值和方差的计算也仅仅使用选中的 \(k\) 个响应
- 其中:
- 论文对选定子集 \( \mathcal{S} \) 中的响应优势进行归一化,使用 \( \mathcal{S} \) 中响应级奖励的均值 \( \mu_S \) 和标准差 \( \sigma_S \)
- 这使得在已经表现出理想属性的响应之间进行有意义的比较成为可能,确保 GFPO 在过滤后的子集中优先考虑最高奖励的响应
- 不在 \( \mathcal{S} \) 中的响应优势为零,从而有效地将它们排除在策略更新的影响之外
- 问题:为什么不直接对不符合的样本进行惩罚,而是选择丢弃?
- GFPO 的主要干预是在优势估计层面,使其与任何 GRPO 变体(如 DAPO (2025)、Dr.GRPO (2025) 或带有 Dual-Clip PPO 损失的 GRPO (2020))兼容
- GFPO 通过采样更多响应增加了训练时的计算成本,但由于学习到的策略生成的响应比 GRPO 更短,这部分成本得到了部分抵消
- GFPO 是通用的,可以适应各种评分指标,但论文的实验特别利用了旨在减少响应长度膨胀的指标:
- 响应长度(Response Length) :训练短响应直接鼓励简洁性
- Token 效率(Token Efficiency, reward/length) :训练高 Token 效率的响应鼓励简洁性,但如果响应长度被相应更高的奖励“证明合理”,则仍允许较长的响应
- 其他指标(如事实性、多样性或外部质量评分)也可以集成到 GFPO 中,以优化不同的目标属性
Adaptive Difficulty GFPO
- 论文还引入了 GFPO 的自适应难度变体(算法 2),旨在根据问题的实时难度估计动态分配更多的训练信号到更难的问题上
- 在训练的每一步,论文通过计算每个问题的采样响应的平均奖励来估计问题难度(较低的平均奖励表示较高的难度)

- 在训练的每一步,论文通过计算每个问题的采样响应的平均奖励来估计问题难度(较低的平均奖励表示较高的难度)
- 为了自适应地调整保留响应的数量 \( k \),论文使用轻量级的 t-digest 数据结构维护问题难度的流式摘要
- t-digest 高效地近似所有已见问题的难度(奖励均值)的四分位数,使论文能够将新问题分类到相对难度桶中
- 基于此分类,论文为每个问题分配目标保留响应数量 \( k \)(注:从 16 个采样中保留):
- 简单问题为 4
- 中等难度问题为 6
- 困难和非常困难问题为 8
- 这种动态课程设计使得在简单问题上进行更激进的过滤,而在困难问题上进行更多的探索
- 难度桶的数量和每个桶的 \( k \) 是超参数
- 自适应难度 GFPO 高效利用训练计算资源,将梯度更新集中在最需要的地方
- GFPO 帮助模型在简单示例上减少冗余(在这些问题上正确性已经很高)
- 同时通过保留更多的推理链在困难问题上保持准确性
- 据论文所知,这是第一个基于问题难度动态调整有效组大小的算法
Setup
- 模型(Model)
- 论文通过 Phi-4-reasoning(2025)作为基础模型来验证 GFPO 的有效性
- 该模型是通过对 14B 参数的 Phi-4(2024)在 STEM 领域的合成 O3-mini 推理轨迹上进行广泛的 SFT 得到的,未经过任何 RL 调整
- 在结果和分析中,论文将 Phi-4-reasoning 称为 SFT 基线
- Baseline
- 论文将经过 GFPO 调优的模型与使用 GRPO 训练的基线模型 Phi-4-reasoning-plus(2025)进行比较
- 需要注意的是,论文使用了带有 DAPO Token-level 损失聚合的 GRPO,并对裁剪替代目标进行了轻微修改以提高训练稳定性,具体细节见第 3 节
- 论文复制了 Phi-4-reasoning-plus 的训练设置,如下所述。在结果和分析中,论文将 Phi-4-reasoning-plus 称为 GRPO 基线
- 数据集(Dataset)
- 论文的 RL 训练专注于提升数学推理能力
- 训练数据集包含从更大的训练语料库(2025)中选出的 72k 道数学问题
- 论文将 RL 训练限制为 100 步,批次大小为 64,因此模型在训练期间仅看到 6.4k 道问题(与用于训练 Phi-4-reasoning-plus 的数据集相同)
- 奖励函数(Reward Function)
- 论文使用了训练 Phi-4-reasoning-plus(2025)时采用的奖励函数
- 该奖励是“长度感知”的 0/1 准确度奖励与 n-gram 重复惩罚的加权和
- 二元准确度奖励 \( R_{\text{acc} } \) 通过从响应中提取最终答案并验证其与真实答案的等价性来计算,如果简单的答案提取失败,则依赖于 LLM 验证器
- 随后,该奖励被缩放到 -1.0 到 1.0 之间的浮点数,基于响应长度对正确答案的长响应进行惩罚
- 格式违规会通过最低奖励进行惩罚
- 最终的奖励函数 \( R \) 是这种长度感知准确度奖励与基于 5-gram 重复频率的重复惩罚的加权组合:
$$
R = w_{\text{acc} } \text{LENGTHSCALE}(R_{\text{acc} }) + w_{\text{rep} } R_{\text{rep} },
$$- 其中 \( R_{\text{acc} } \in \{0,1\} \) 且 \( R \in [-1,1] \)
- 更多细节见 Abdin 等(2025)的第 4.1 节
- 值得注意的是,奖励中的长度惩罚不足以抑制 GRPO 引起的响应长度膨胀,这促使论文提出了 GFPO
- 训练配置(Training Configuration)
- 论文使用 ver1(2024)框架进行 GFPO 训练,并采用上述奖励函数
- 为了与 Phi-4-reasoning-plus 的训练设置保持一致,论文在 32 个 H100 GPU 上对 Phi-4-reasoning 进行 GFPO 调优,全局批次大小为 64,训练 100 步,使用学习率为 \( 1 \times 10^{-7} \) 的 Adam 优化器,前 10 步采用余弦预热,采样温度 \( T = 1.0 \)
- 论文应用了 KL 正则化(\( \beta = 0.001 \))和熵系数(\( \gamma = 0.001 \))
- 模型的训练上下文长度最大为 32k Token ,其中 1k Token 保留给 Prompt
- 组大小(Group Size)
- Phi-4-reasoning-plus 的训练组大小为 \( G = 8 \)
- GFPO 通过增加 \( G \) 来增加对理想响应的曝光,以更多的训练时计算换取更短的推理时响应长度
- 论文为 GFPO 尝试了 \( G \in \{8, 16, 24\} \),但为了与 GRPO 公平比较,所有实验中 GFPO 的保留组大小 \( k = |\mathcal{S}| \leq 8 \),确保模型接收策略梯度信号的响应数量一致
- Evaluation
- 论文在以下基准上评估检查点:
- AIME 25(AIME,2025)和 AIME 24(AIME,2024)每个 Prompt 采样 32 次
- GPQA(2024)采样 5 次
- Omni-MATH(2025)采样 1 次
- LiveCodeBench(2024)采样 3 次
- 论文在温度 \( T = 0.8 \) 下采样响应,最大长度为 32k Token,其中 1k Token 保留给 Prompt
- 对于 AIME 25、AIME 24、GPQA 和 Omni-MATH,论文首先使用基于正则表达式的答案提取 ,如果提取失败则使用 GPT-4o 进行 LLM-based 提取
- 尽管论文的 RL 训练集中没有编码数据,但论文通过在 LiveCodeBench 上的评估来衡量 GFPO 优化短响应时对响应长度和准确性的分布外影响
- 论文在以下基准上评估检查点:
- 论文报告所有模型和数据集的平均 pass@1 准确率、原始响应长度(\( L \))以及超额长度减少(Excess Length Reduction, ELR)(表 1、2)
- 论文将超额长度减少定义为 GFPO 相对于 GRPO 在 SFT 模型基础上减少的响应长度膨胀程度,公式如下:
$$
ELR = \frac{L_{\text{GRPO} } - L_{\text{GFPO} } }{L_{\text{GRPO} } - L_{\text{SFT} } }.
$$- 问题:为什么分子不使用 GFPO - SFT ?
- 为了评估 GFPO 的准确率是否与 GRPO 相当,论文使用 Wilcoxon 符号秩检验(1992)检验 GRPO 与 GFPO 变体之间 pass@1 准确率的差异是否显著
- 这种非参数配对检验在不假设正态分布的情况下比较每个问题的 pass@1 准确率差异
Results
- 论文评估了三种 GFPO 变体:
- 最短 \(k/G\)(Shortest \(k/G\)) :从 \(\mathcal{G}\) 中保留最短的 \(k\) 条响应,通过调整 \(k\) 和组大小 \(G\) 研究其对长度缩减的影响
- Token 效率(Token Efficiency) :从 \(\mathcal{G}\) 中保留 \(k\) 条 reward-per-token 最高的响应,使用 \(k=8\) 和 \(G=16\)(与最短 \(k/G\) 的基线设置一致)
- 自适应难度(Adaptive Difficulty) :从 \(\mathcal{G}\) 中保留最短的 \(k\) 条响应,其中 \(k\) 根据实时难度估计动态选择(简单问题保留 4 条,中等 6 条,困难和非常困难问题保留 8 条),\(G=16\)
- 论文测量了 pass@1 准确率和超额长度缩减(Excess Length Reduction, ELR)(公式 4)
- Wilcoxon 符号秩检验显示,GFPO 变体与 GRPO 在各任务上的准确率差异无统计学意义,表明 GFPO 在缩减长度的同时保持了准确率
Think Less Without Sampling More?(不增加采样量而实现减少思考)
- 一个自然的问题是:仅通过拒绝采样(不增加总采样量)能否显著缩减响应长度?
- 论文实验了 Shortest 6/8 GFPO,从组大小 \(G=8\) 中保留最短的 \(k=6\) 条响应
- 结果显示
- Shortest 6/8 GFPO 在 AIME 25、AIME 24、GPQA 和 Omni-MATH 上的准确率与 GRPO 相当,但超额长度缩减效果有限:
- 在 AIME 25、AIME 24 和 GPQA 上分别仅缩减了 1.8%、9.5% 和 11.5%
- 在 Omni-MATH 上甚至出现轻微长度增加(+5.5%)(表 1、2)
- 这表明,虽然从小规模组中采样可以带来轻微的长度缩减,但更显著的缩减可能需要增加 \(G\) 以暴露更多短链
- 这促使论文进一步探索是否通过采样更多能让模型在推理时思考更少
- Shortest 6/8 GFPO 在 AIME 25、AIME 24、GPQA 和 Omni-MATH 上的准确率与 GRPO 相当,但超额长度缩减效果有限:
GFPO Enables Efficient Reasoning
- 基于“增加采样量可能显著缩减链长度”的观察,论文研究了 Shortest 8/16 GFPO 变体的效果
- 该方法将组采样量增至 \(G=16\),仅保留最短的 8 条响应(即训练模型使用最短的 50% 采样链),被拒绝的样本优势值设为零
- 应用 Shortest 8/16 GFPO 后,论文在多个基准上观察到长度通胀显著缩减:
- AIME 25 缩减 23.8%,AIME 24 缩减 33%,GPQA 缩减 23.7%,Omni-MATH 缩减 31.5%,且准确率无统计学显著下降(表 1、2)
- 总体而言,GFPO 在保持 GRPO 强大推理性能的同时,大幅缩减了响应长度
- 发现(Finding)
- “Thinking Less” Requires Sampling More: Reducing retained responses without increasing group size (Shortest 6/8 GFPO) does not reduce response length.
调整 \(k\) 和 \(G\) 对长度缩减的影响(Effect of Varying \(k\) and \(G\) on Length Reductions)
- 论文进一步研究了保留组大小 \(k\) 和采样组大小 \(G\) 的变化如何影响长度缩减
- 直觉上,减少保留比例(\(k \downarrow\))或增加采样量(\(G \uparrow\))均可进一步缩短推理链
- 与 Shortest 8/16 GFPO 相比,略微减少保留集(Shortest 6/16 GFPO)带来中等额外缩减:
- AIME 25 额外缩减 1.8%,AIME 24 额外缩减 2.6%,GPQA 额外缩减 15.1%,Omni-MATH 额外缩减 12.2%
- 进一步降低 \(k\)(Shortest 4/16 GFPO)比 Shortest 8/16 实现更强改进,在上述基准上分别额外缩减 14.2%、13.8%、22% 和 15.8%(表 1、2)
- 论文还研究了将采样组大小 \(G\) 从 16 增至 24 的效果(固定 \(k\))
- 从 Shortest 8/16 到 8/24 带来显著额外超额长度缩减(AIME 25、AIME 24、GPQA 和 Omni-MATH 分别额外缩减 30.6%、19.7%、28.5% 和 20.4%)
- 从 Shortest 6/8 到 6/16 实现大幅额外缩减(23.4%、26.2%、27.3% 和 49.2%),进一步增至 6/24 时改进较小(15.4%、9.3%、9.8% 和 14.5%)
- 从 Shortest 4/16 到 4/24 在上述数据集上分别额外缩减 8.1%、13%、11.5% 和 23.7%(表 1、2)
- 这些结果表明,控制响应长度的关键因素是保留比例 \(k/G\),通过降低 \(k\) 或增加 \(G\) 来减小 \(k/G\) 可实现响应长度缩减(图 4)
- 论文通过比较两种配置(Shortest 4/16 和 Shortest 6/24)验证了这一点:两者保留比例均为 25%,但绝对 \(k\) 和 \(G\) 不同
- Shortest 6/24 的平均长度缩减略优(2.9%)(表 2,图 4),反映更大的采样组 \(G\) 增加了遇到高质量短链的机会
- 这是相对 Shortest 4/16 而言的
- 若采样组足够大(\(G\) 从 8 增至 16),仅调整 \(k\) 即可高效实现显著长度缩减,无需进一步采样
- 但保留比例过低时(如从 8/24 降至 4/24),改进边际递减(平均仅额外缩减 4.1%)(表 2)
- 要突破这一限制,需采用更智能的采样策略
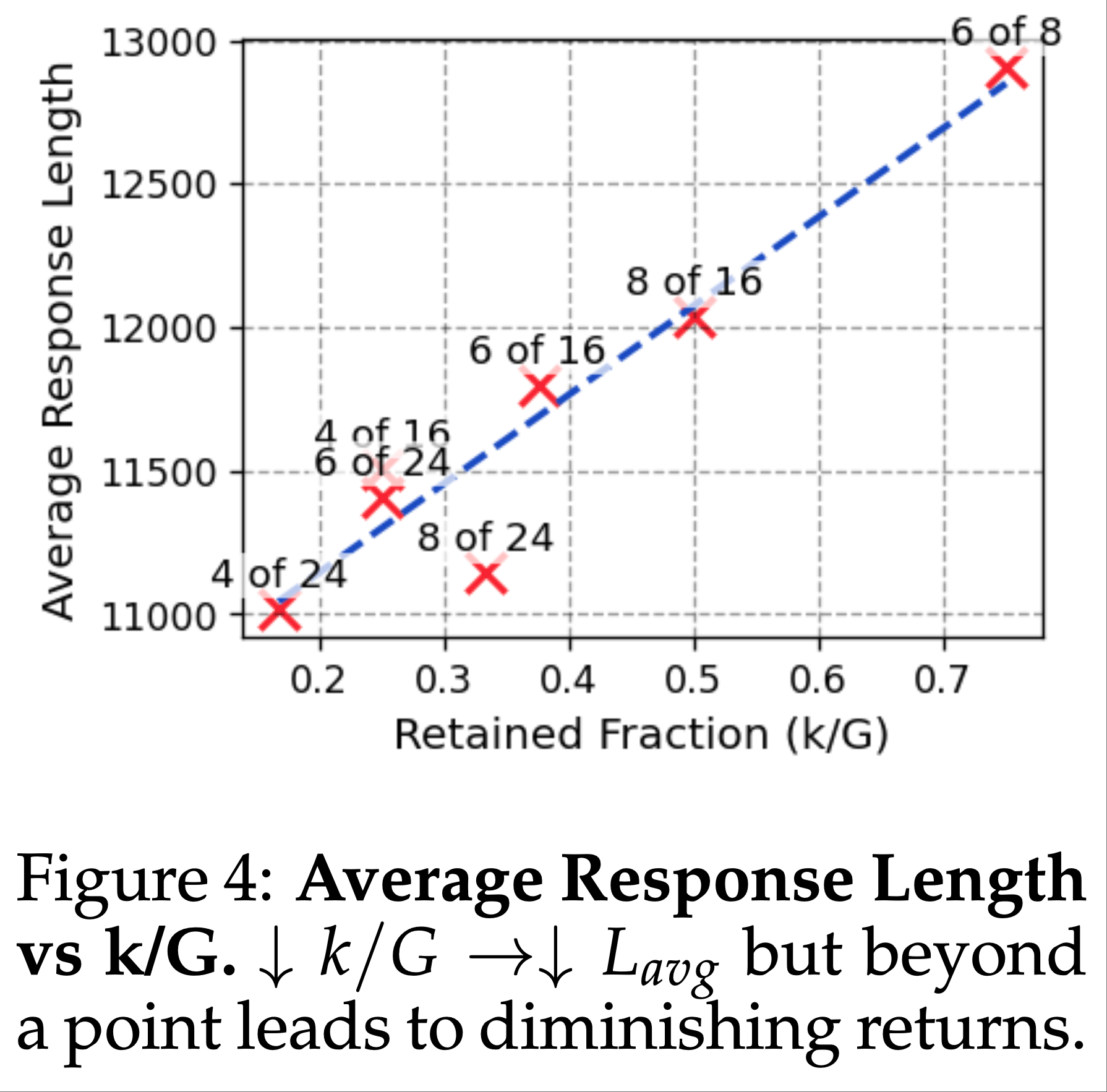
- Shortest 6/24 的平均长度缩减略优(2.9%)(表 2,图 4),反映更大的采样组 \(G\) 增加了遇到高质量短链的机会
- 发现(Finding)
- 保留比例 \(k/G\) 控制长度压力 :
- 降低 \(k\) 或提高 \(G\) 可进一步缩减长度;
- 保留 25-33% 响应为最优比例,更小比例收益递减
- Shortest 4/24 是长度优化最佳 GFPO 变体,实现最强的超额长度缩减
- 保留比例 \(k/G\) 控制长度压力 :
Reinforcing Token Efficiency(强化 Token 效率)
- 先前实验表明,仅降低保留比例 \(k/G\) 最终会触及天花板:超过一定组规模后,难以生成更短的推理链
- 为突破这一瓶颈,论文引入 Token Efficiency GFPO,一种“智能采样”方法,按奖励与 Token 比(reward/length)对响应排序
- 其直觉很简单:策略应优先选择高效提供高奖励的链;仅当长链的奖励足够高时才保留
- 具体实现中,Token Efficiency GFPO 保留 \(\mathcal{G}\) 中奖励与 Token 比 \(R_i/|o_i|\) 最高的前 \(k\) 条响应
- 在此过滤集中计算优势值,使得短正确链获得最强的正梯度,长正确链获得适度奖励或轻微惩罚 ,长错误链则承受最严厉惩罚
- 这种对长错误链的额外梯度压力可剪除“填充” Token ,而最短 \(k\) GFPO 无法直接针对这些 Token,因其仅提供不超过最长保留链长度的梯度信号
- 最短 \(k\) 依赖 KL 惩罚隐式压低后期 Token 概率,而 Token Efficiency GFPO 通过显式负梯度主动抑制这些低价值 Token 位置
- 论文以 \(k=8\) 和 \(G=16\) 训练该方法
- Token Efficiency GFPO 在所有任务上实现最大的超额长度缩减
- AIME 25 缩减 70.9%,AIME 24 缩减 84.6%,GPQA 缩减 79.7%,Omni-MATH 缩减 82.6%,优于最短 \(k\) 变体(表 1、2),且 \(G\) 更小或相当
- 这些额外长度缩减伴随轻微代价:训练曲线显示策略性能方差更高(图 2),准确率出现微小(无统计学意义)下降(表 1、2)
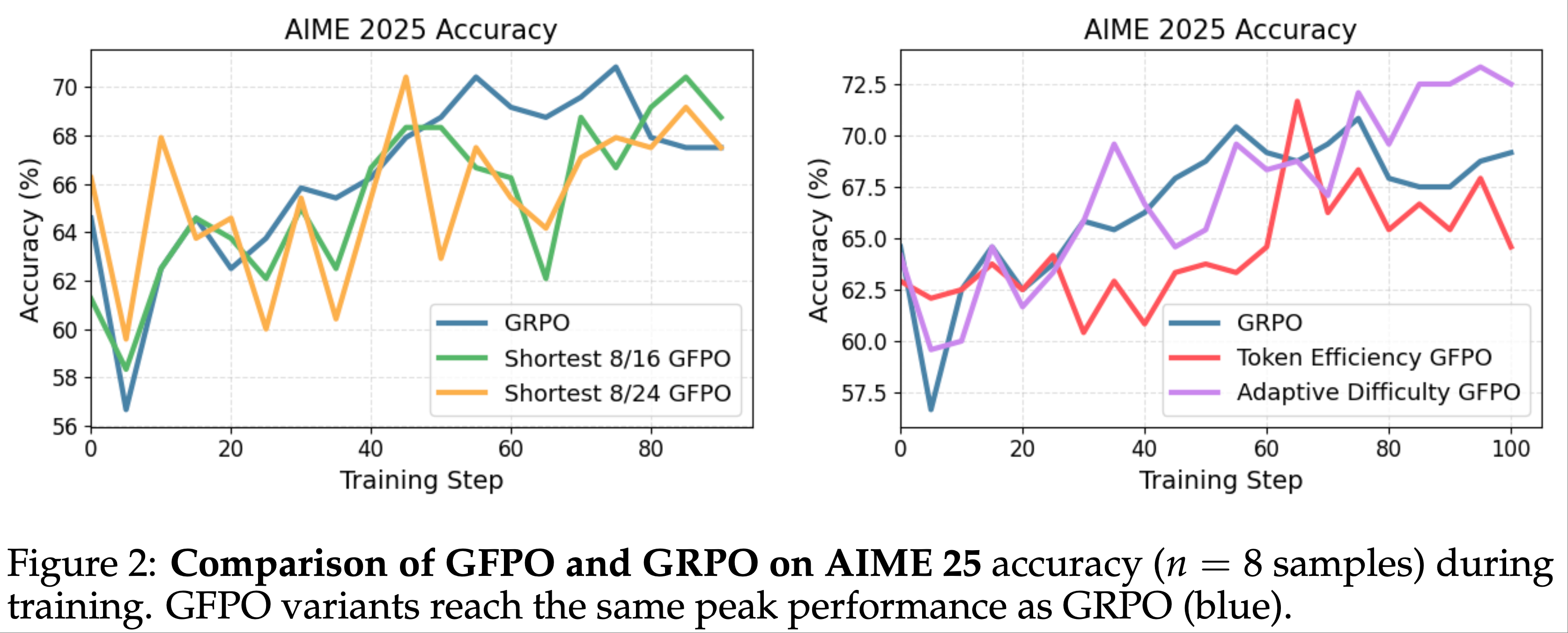
- 发现(Finding)
- Token 效率(reward/length)优化实现最大缩减 :在 AIME 25、AIME 24、GPQA、Omni-MATH 和 LiveCodeBench 上分别缩减 70.9%、84.6%、79.7%、82.6% 和 79.7% ,同时保持准确率,这些缩减伴随训练方差略增
- 这种方差可能源于长正确和错误链中 Token 段的噪声梯度,导致奖励和惩罚信号冲突
- 尽管如此,Token Efficiency GFPO 在不牺牲准确率的情况下实现了最强的 Token 节省,证实奖励与 Token 比是简洁推理的有效代理指标
Adaptive Difficulty GFPO
- 除改进拒绝指标的智能采样外,论文还引入 Adaptive Difficulty GFPO,根据问题难度动态调整保留组大小 \(k\),将更多训练资源分配给难题
- 在 Adaptive Difficulty GFPO(第 3.1 节)中,论文通过每问题的响应平均奖励估计难度,使用轻量级 t-digest 数据结构实时计算难度四分位数,并将问题分为四个难度桶:非常困难(后 25%)、困难(25-50%)、中等(50-75%)和简单(前 25%)
- 基于此分类,论文为每个问题分配目标保留响应数 \(k\):简单问题 4 条,中等 6 条,困难和非常困难问题 8 条(从 \(G=16\) 采样中保留)(算法 2)
- 对于该配置,Adaptive Difficulty GFPO 的每问题平均 \(k\) 为 6.5,因此论文将其与保留响应数和组大小相近的 Shortest 6/16 GFPO 比较
- Shortest 6/16 GFPO 在 Omni-MATH 上实现更强的超额长度缩减(43.7% vs. 35.1%)
- Adaptive Difficulty GFPO 在 AIME 25(50.8% vs. 25.6%)、AIME 24(52.9% vs. 35.6%)和 GPQA(41.7% vs. 38.8%)上表现更优
- 尽管 Shortest 6/16 GFPO 应用了稍激进的响应剪枝
- 与过滤更激进的 Shortest 4/16 GFPO 相比,Adaptive Difficulty GFPO 在 AIME 25(50.8% vs. 38%)和 AIME 24(52.9% vs. 46.8%)上仍实现更优长度缩减(表 1、2)
- 发现(Finding)
- 自适应难度 GFPO 在等量计算下优于最短 \(k\) :根据问题难度动态调整 \(k\),在 4/5 基准上实现比最短 \(k\) 更强的长度缩减
- Adaptive Difficulty GFPO 在 GPQA 上达到最高准确率(70.8%)(表 1),在 AIME 25 最难题上(27%)也优于 GRPO 和所有 GFPO 变体(图 6a)。这些结果凸显了基于问题难度分配采样预算的有效性
- 注意,Adaptive Difficulty GFPO 可与 Token 效率指标结合,进一步优化结果
Out-of-Distribution Effects of GFPO
- 论文的 RL 训练方案旨在提升数学推理性能
- 为研究 GFPO 对短响应的偏置是否产生负面影响,论文在编码基准 LiveCodeBench 上评估分布外泛化能力
- 注意,编码数据未包含在 RL 训练集中
- 论文发现,GRPO 甚至在分布外任务上也导致显著响应长度膨胀,平均响应长度从 10.3k Token (SFT)增至 13.9k Token ,且未提升准确率(56.7% GRPO vs. 57.7% SFT)
- 对于分布内更难题,更长思考可能合理,但这种长度膨胀在分布外任务中出乎意料且不理想,尤其当更长输出未伴随准确率提升时
- 发现(Finding)
- GFPO 缓解分布外长度膨胀 :GRPO 在分布外任务上增加响应长度但未提升准确率;GFPO 抑制此现象,同时小幅提升准确率
- GFPO 有效缓解了这种非预期冗余
- 在 LiveCodeBench 上,Token Efficiency GFPO 实现最显著的超额长度缩减(79.7%)
- GFPO 变体甚至在 LiveCodeBench 编码任务上带来轻微准确率提升:Shortest 8/24 GFPO 准确率略优于 SFT 和 GRPO(59.2% vs. 57.7% 和 56.7%),同时缩减超额长度 57%
- 这些结果凸显了 GFPO 在显式管理响应长度增长的同时,保持甚至略微增强分布外泛化的能力
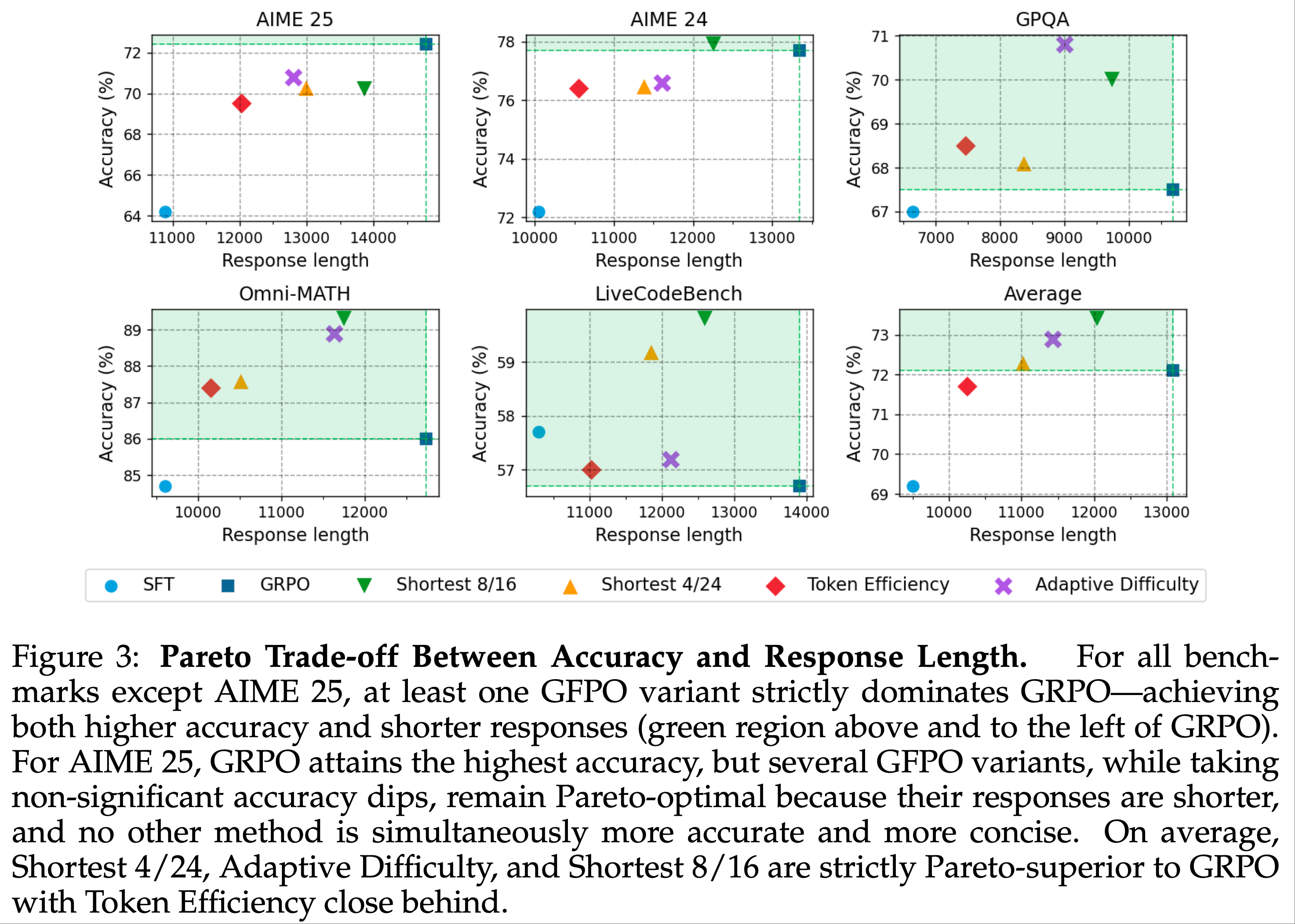
Accuracy-Length Pareto Comparison
- 图 3 全景展示了准确率与响应长度的前沿关系
- 在五个基准中的四个上,至少一个 GFPO 变体严格帕累托优于 GRPO(落入绿色区域),证实 GFPO 可同时提供更短且更准确的答案,实现双轴改进
- 在 AIME 25 上,GRPO 准确率略高,但多个 GFPO 变体仍位于帕累托前沿,以无统计学显著准确率下降换取显著长度缩减
- 注:AIME 25 上看,效果相对 GRPO 确实一般
- 聚合各任务(右下子图)显示,Shortest 4/24、Adaptive Difficulty 和 Shortest 8/16 是最一致简洁且准确的方法,Token Efficiency 准确率略低但紧随其后
Analysis
- 论文基于 AIME 2025 数据集分析了 GFPO 的行为,通过将问题难度定义为 \(1 - \text{SFT accuracy}\) 来量化每个问题对基础 SFT 模型的挑战程度
- 根据难度将问题分为四个等级(简单、中等、困难、极难),研究 GFPO 在不同难度下对响应长度和准确率的影响
- 随后,论文考察了固定难度下长响应的准确率,并分析了 GFPO 如何重塑长度与准确率的联合分布
- 最后,论文研究了 GFPO 修剪了响应的哪些部分,并在附录 A 中提供了 GFPO 与 GRPO 的定性对比示例
Length Reductions on Easy vs Hard Problems
- 论文分析了 GFPO 在 AIME 2025 上对不同难度问题的长度缩减效果
- 如图 5a 所示,响应长度随问题难度显著增加
- 从简单问题的约 4k Token 到极难问题的超过 20k Token
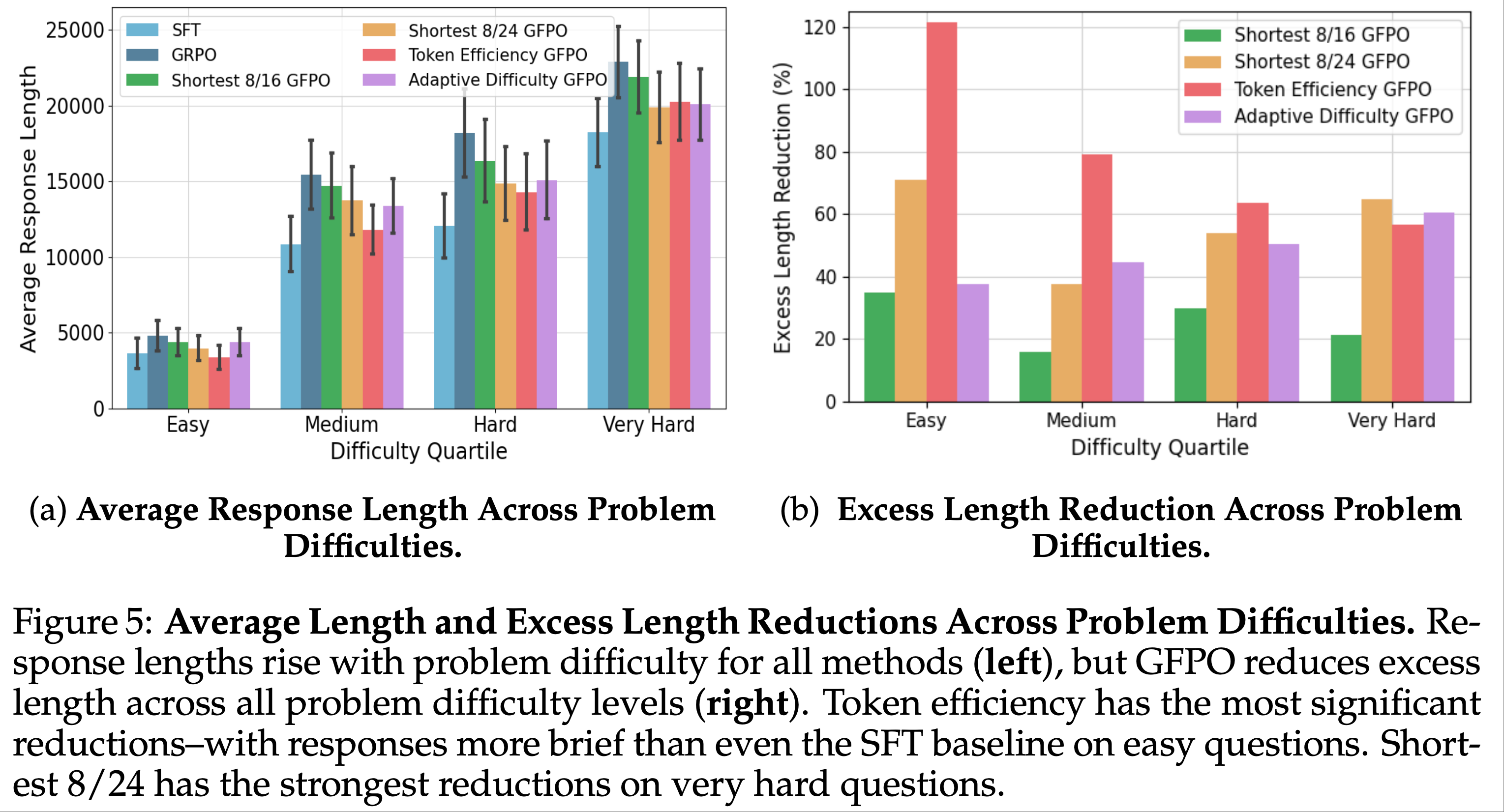
- 从简单问题的约 4k Token 到极难问题的超过 20k Token
- GFPO 在所有难度级别上均有效减少了长度(图 5b)
- Token Efficiency GFPO
- 实现了最强的整体缩减效果,尤其在简单问题上(相比 GRPO 减少了 121.6% 的冗余长度,图 5b),甚至比 SFT 模型更简短的同时提升了准确率,证明了长度与准确率可以同步优化
- 但其缩减效果在更困难的问题上减弱(中等难度减少 79.1%,困难减少 63.5%,极难减少 56.5%),因为 Token Efficiency 指标允许长响应存在,前提是其奖励足够高,而这类情况常见于需要复杂推理的难题
- Adaptive Difficulty GFPO
- 冗余长度缩减随难度递增(简单问题 37.7%,极难问题 60.3%),有效修剪了长尾响应(图 5b)
- Adaptive Difficulty 和 Shortest 8/16 GFPO 对困难问题均保留 8 条最短响应,Adaptive Difficulty 实现了更强的长度缩减
- 这种简洁性可能源于从简单问题中学习到的梯度,使得策略即使在挑战性任务中也能避免不必要的 Token
- Shortest 8/24 GFPO 在所有难度级别上均比 Shortest 8/16 表现更好
- Shortest 8/24 在极难问题上实现了最大的长度缩减,优于保留高奖励长响应的 Token Efficiency GFPO 和为困难问题保留更多响应的 Adaptive Difficulty GFPO(图 5b)
- Finding
- GFPO shortens responses across all difficulty levels.
- Token Efficiency GFPO delivers the largest reductions on easy, medium, and hard questions—on easy questions producing responses even shorter than the SFT model while matching GRPO’s accuracy.
- Shortest 8/24 GFPO achieves the greatest reductions on the hardest questions due to its stronger filtering.
Accuracy on Easy vs Hard Problems
- 接下来,论文考察了 GFPO 在 AIME 2025 不同难度级别上的准确率(图 6a)
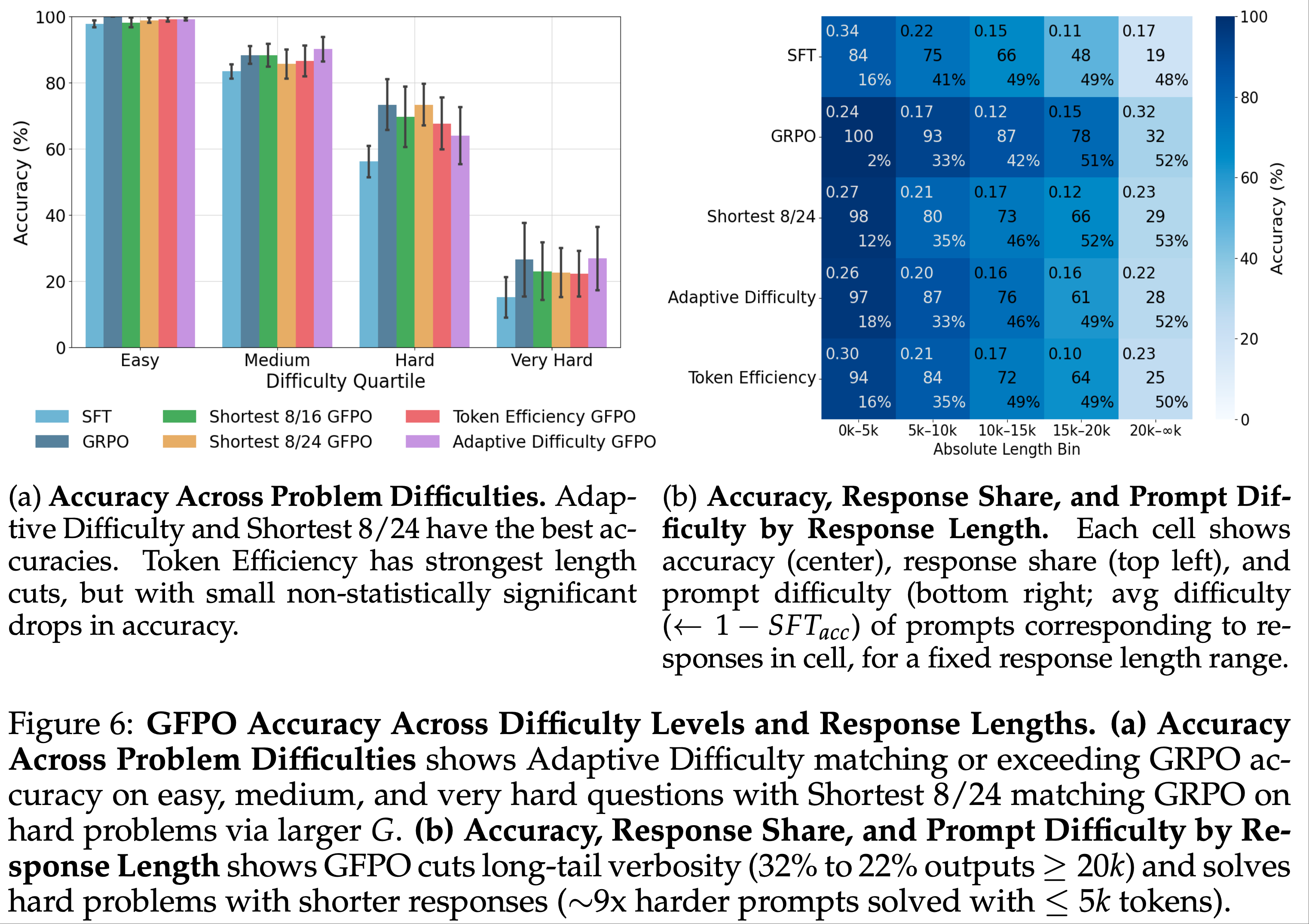
- 所有方法在简单问题上均接近完美准确率(98-99%)
- 随着难度增加,SFT 准确率急剧下降,而 RL 微调(GRPO 和 GFPO)始终优于 SFT
- Token Efficiency GFPO
- 实现了显著的长度缩减(图 5b),但与 GRPO 相比准确率略有下降(图 6a),差异无统计学意义
- Adaptive Difficulty GFPO
- 在简单、中等和极难问题上匹配或超过 GRPO 的准确率,尤其在中等问题上表现更优(90.2% vs. 88.4%),同时减少冗余长度 47%
- 在极难问题上,其他 GFPO 变体准确率略有下降,而 Adaptive Difficulty 与 GRPO 持平(27% vs. 26.6%),通过动态分配计算资源在保持准确率的同时减少冗余长度 60%(图 5b)
- 关键发现(Findings):
- Adaptive Difficulty GFPO 在中等和极难问题上超越 GRPO 准确率 ,同时减少冗余长度 47%-60%
- 更大的组规模(\(G\))提升困难问题的准确率 :Adaptive Difficulty(\(k=8\),\(G=16\))在困难问题上略有下降,但 Shortest 8/24 通过采样更多响应匹配了 GRPO 的准确率
Accuracy of Long Responses under GFPO
- 长响应通常准确率较低,但这一趋势可能与问题难度混杂,难题自然需要更长输出,因此准确率下降可能源于问题本身而非冗余内容
- 为消除混淆,论文固定难度并分析响应长度对模型表现的影响
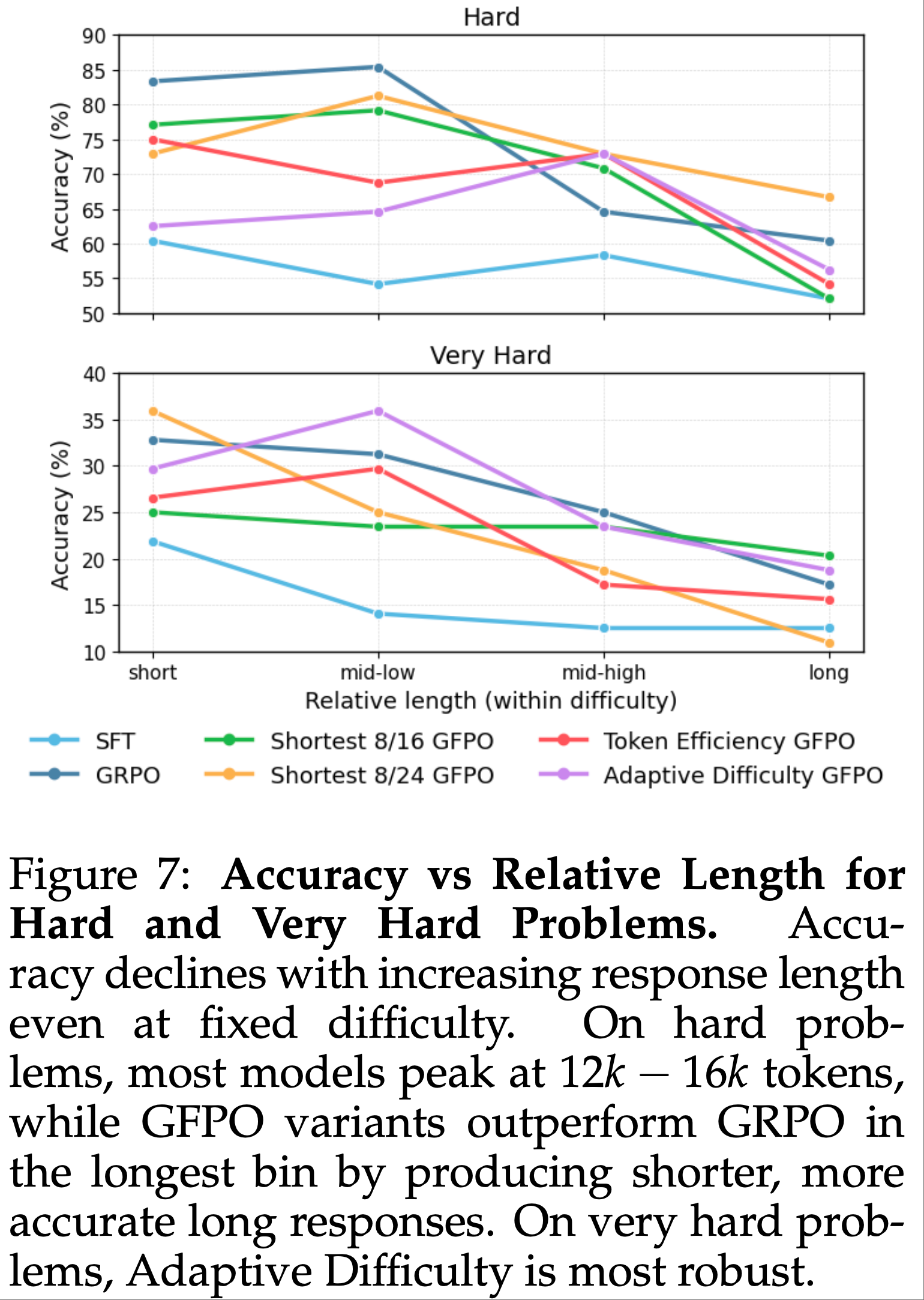
- 将每个模型对困难和极难问题的响应按长度分为四分位(图 7),结果显示:
- 随着长度增加,准确率持续下降 ,证实了长响应往往准确率更低(即使问题难度相同)
- 在困难问题上,多数模型在中等长度(12k-16k Token ,表 3)达到峰值,表明存在一个“甜区(sweet spot)”:足够长以支持推理,但避免过度思考
- Finding:即使在难度固定的情况下,较长的回复准确度也较低:在处理难题时,推理的最佳长度大约在 12 k到 16k 个词元之间
Finding:Longer responses are less accurate even at fixed difficulty: Across hard problems, the sweet spot for reasoning emerges around 12k–16k tokens.
- 超出此范围后,准确率持续下降
- GFPO 变体在最长分位上的表现优于 GRPO(困难问题 66.7% vs. 52.1%,极难问题 20.3% vs. 17.2%,表 4),因为其最长响应更简短(困难问题 20.8k vs. 23.8k,极难问题 26.9k vs. 27.5k,表 3)且更准确
- Finding:GFPO outperforms GRPO accuracy in the lengthiest response quartiles
- 随着长度增加,准确率持续下降 ,证实了长响应往往准确率更低(即使问题难度相同)
- 论文进一步通过绝对长度分析补充了这一结论(图 6b),固定响应长度并评估每个长度区间内对应问题的准确率、响应占比和难度
- GFPO 将长尾响应( \(\ge\)20k Token )的占比从 GRPO 的 32% 降至 22-23%,同时提升了短响应(< 15k)的比例
- 这些更短的 GFPO 响应通常解决更困难的问题:在 \(\le\)5k 区间,问题难度是 GRPO 的 9 倍(16-18% vs. 2%),而准确率仅轻微下降(例如 100% -> 97%)
- GFPO 最长区间准确率略低,反映了许多问题已在更短长度下解决,剩余长响应对应的是最难题目的罕见情况
- 综上,相对和绝对长度分析表明,冗余内容(而非难度)是 GRPO 长链错误的主因,而 GFPO 以更简洁的方式解决难题且保持竞争力
- Finding:GFPO cuts extreme verbosity: dropping the fraction of \(\ge\) 20k-token responses from 32% to 22%, while solving harder problems at shorter lengths (questions answered in \(\le\) 5k tokens are 9× harder in GFPO than GRPO).
Distribution-Level Effects of GFPO
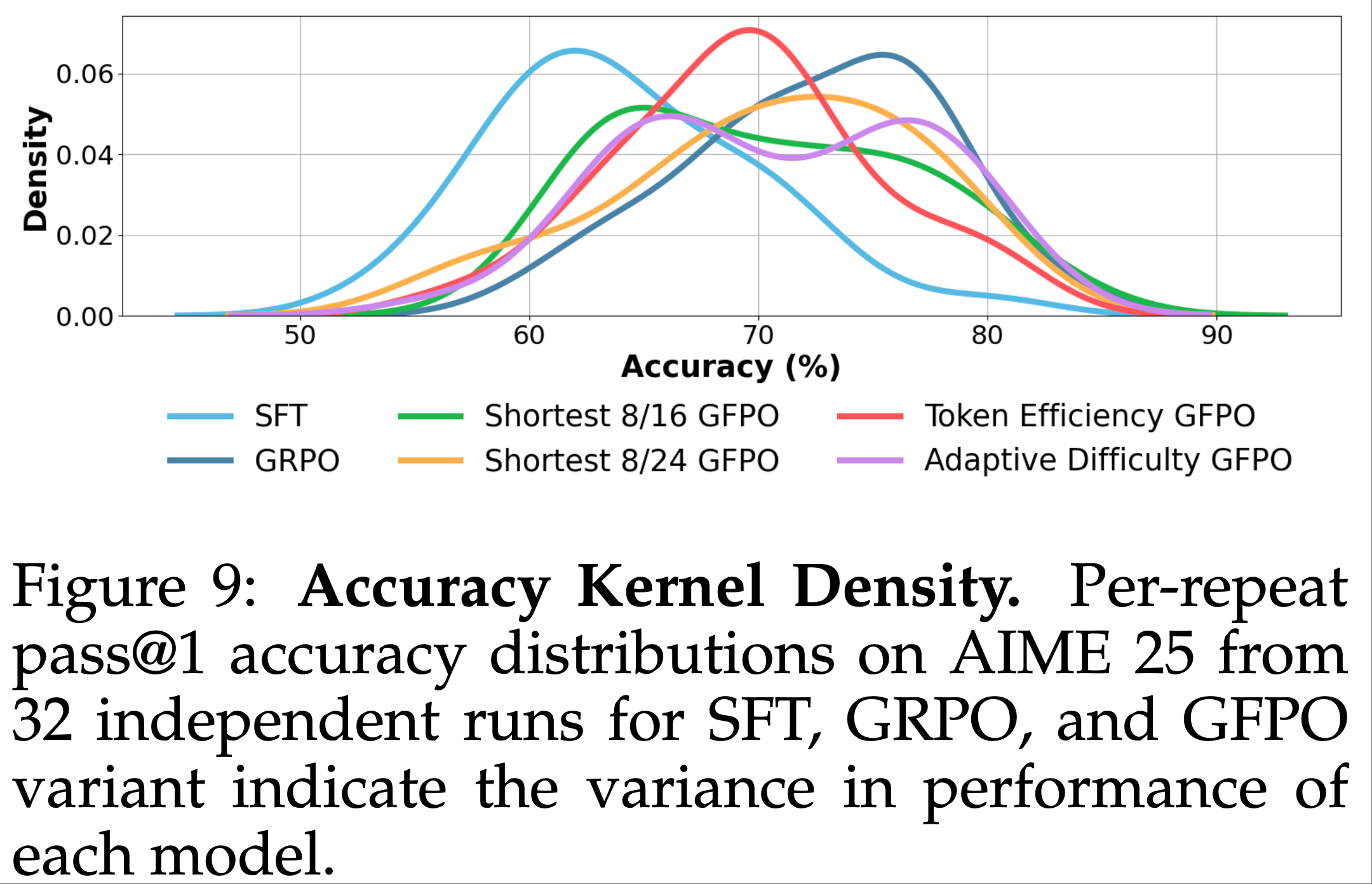
- 为可视化 GFPO 如何重塑准确率-长度分布,论文绘制了 AIME 25 上响应长度的核密度估计(图 8)和 32 次独立运行的 pass@1 准确率分布(图 9)
- 长度分布 :所有 GFPO 变体压缩了长尾,将质量向短响应转移(图 8)
- 准确率分布 :SFT 的准确率分布左偏,表明平均表现较低;GRPO 分布右移,反映更高典型准确率;GFPO 变体介于两者之间。Token Efficiency GFPO 分布最集中,表现最稳定;Shortest 8/24 接近 GRPO 的中心质量;Adaptive Difficulty 呈现轻微双峰,部分重复达到 GRPO 水平,部分略低
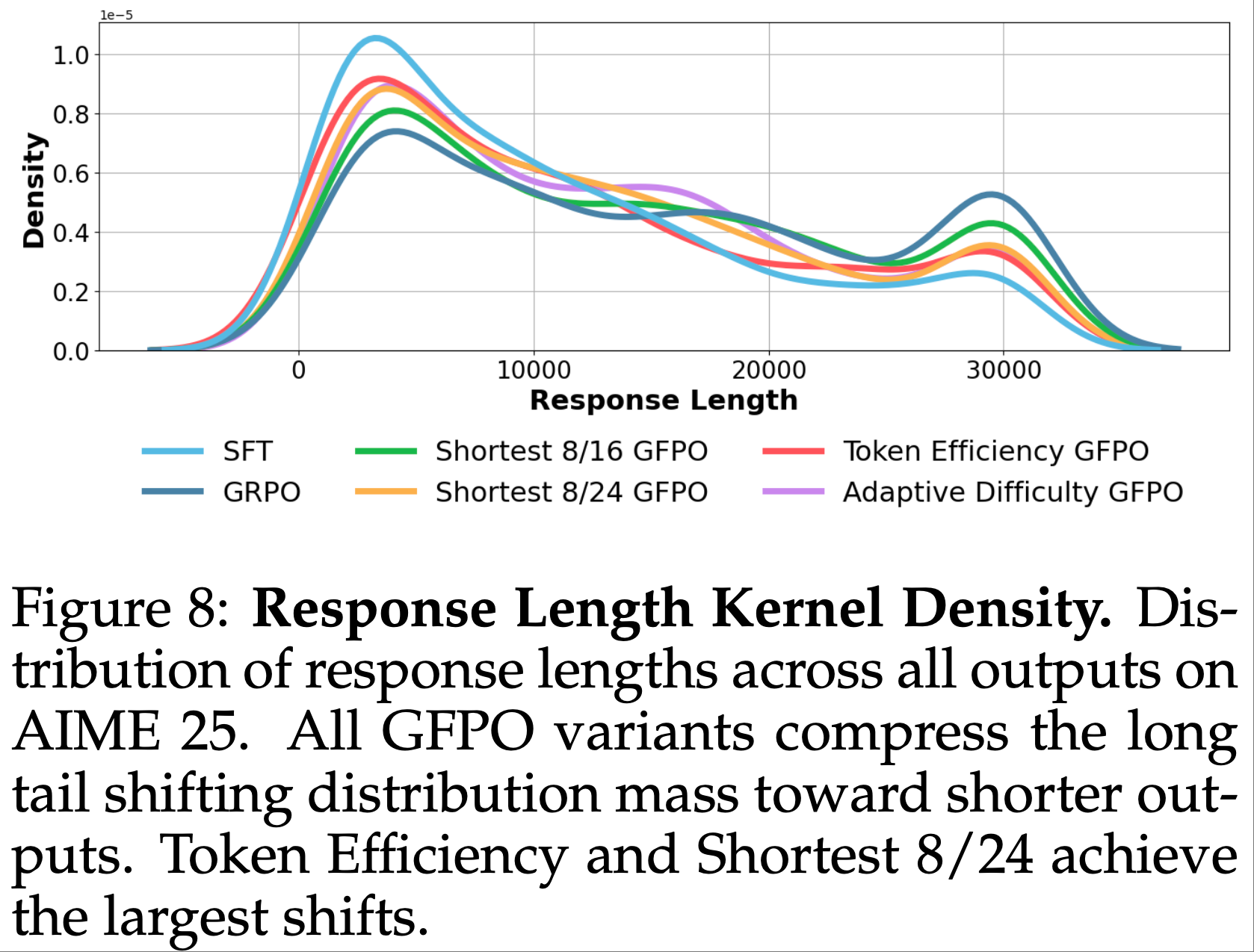
- 论文量化了 AIME 25 上准确率与长度的权衡:
- GRPO 生成长响应的比例最高(46.8% vs. SFT 的 28%),GFPO 变体将其降至 42.1%(Shortest 8/16)、35%(Shortest 8/24)、37.8%(Adaptive Difficulty)和 32.7%(Token Efficiency)
- GRPO 70% 的问题准确率 \(\ge\)70%,GFPO 变体略低但差异无统计学意义
- 总体而言,Shortest 8/24 和 Adaptive Difficulty 在缩短响应与保持高准确率之间实现了最佳平衡
What is GFPO trimming?(讨论分析:GFPO 到底修剪了什么?)
- 为探究 GFPO 长度缩减的来源,论文使用 GPT-4o 标注了五个模型(SFT、GRPO、Shortest 8/24 GFPO、Token Efficiency GFPO、Adaptive Difficulty GFPO)在 AIME 25 和 GPQA 上的推理轨迹,将每段文本按功能角色分类:
- 问题 :与问题表述和理解相关的文本;
- 解决方案 :提出或发展候选解决方案的句子;
- 验证 :重新检查或验证中间结果的步骤;
- 最终 :输出答案的结论性陈述
- GRPO vs GFPO 定性的比较如下所示,关于 AIME 25 和 GPQA 的更多示例见 附录A

- 图 10 展示了各模型在 AIME 25 和 GPQA 上各部分的平均 Token 数。结果显示:
- GRPO 显著扩展了中段推理(Solution 和 Verification)
- 例如 AIME 25 的 Solution 部分从 SFT 的 6.5k Token 增至 8.3k,Verification 从 1.9k 增至 3.1k
- GFPO 变体 有效压缩了这些阶段
- Shortest 8/24 将 AIME 25 的 Solution 从 8.3k 减至 6.6k(冗余长度减少 94.4%),表明 GFPO 减少了提出错误或无关候选方案的冗余;Verification 从 3.1k 减至 2.3k(减少 66.7%),修剪了 GRPO 典型的重复性检查
- Token Efficiency GFPO 在所有部分(除 AIME 25 的 Solution 外) Token 使用更少;
- Adaptive Difficulty 也显著压缩了 Solution 和 Verification,但不如其他方法激进(GPQA 上趋势类似)
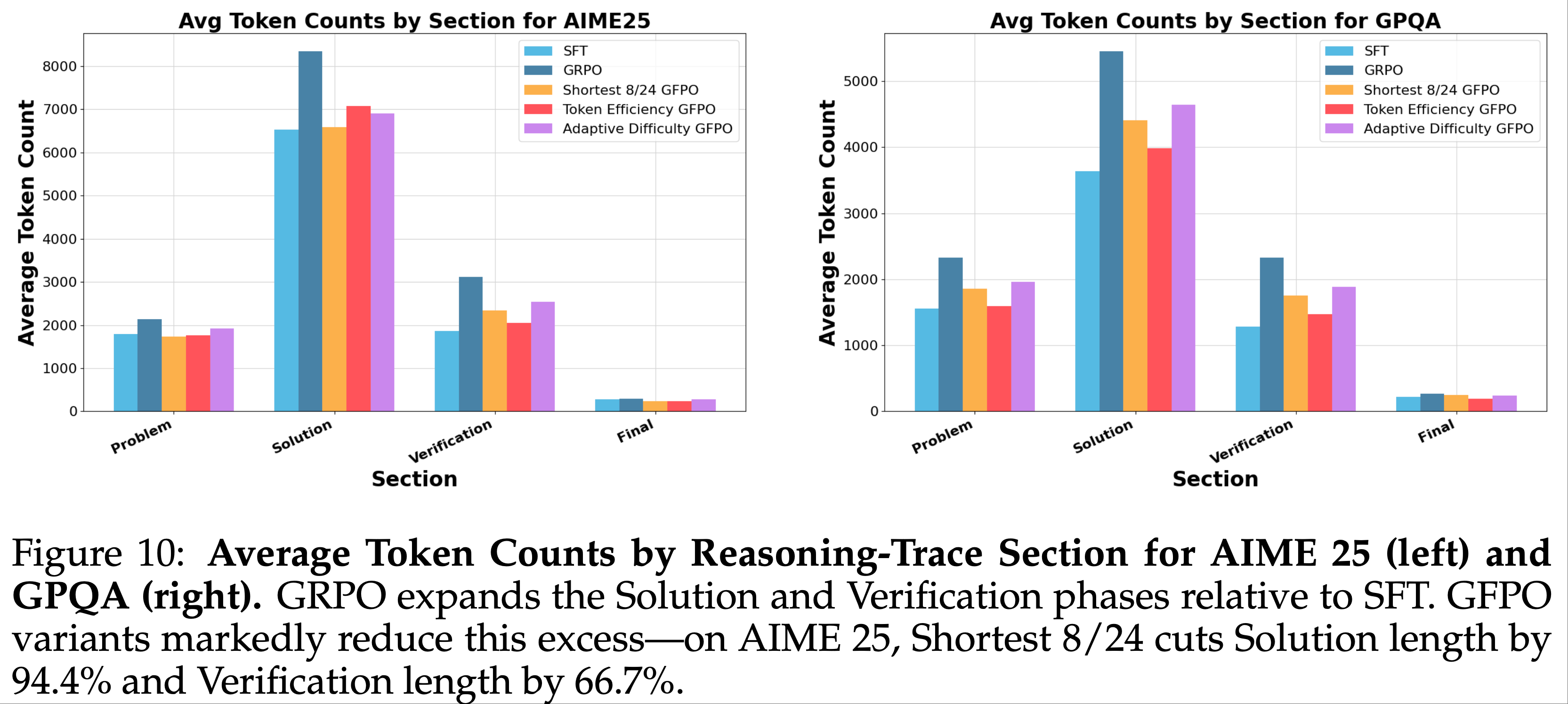
- Adaptive Difficulty 也显著压缩了 Solution 和 Verification,但不如其他方法激进(GPQA 上趋势类似)
- GRPO 显著扩展了中段推理(Solution 和 Verification)
- 关键发现(Finding):
- GFPO 大幅削减了推理过程中 解决方案 和 验证 阶段的冗余——在 AIME 25 上分别减少 94.4% 和 66.7% 的冗余长度
- GFPO 变体对 Problem 和 Final 部分基本保持不变(与 SFT 差异在 10% 以内),表明其专门针对核心推理步骤的冗余,同时保留了问题表述和最终答案的完整性
Related Work
GRPO Loss Modifications
- 近期的工作(如 Dr.GRPO (2025) 和 DAPO (2025)) 通过改进 GRPO 的损失归一化方法,提升了模型的 Token 效率和训练稳定性
- 标准的 GRPO 在每个响应内部对损失进行归一化后再求平均,这使得所有响应对梯度更新的权重相同,但会导致长输出中的 Token 权重被低估
- 理解:GRPO 中模型会倾向于生成短的正样本和长的负样本
- Dr.GRPO 改为按批次中的最大响应长度归一化,而 DAPO 则按总 Token 数归一化
- 问题:这里的描述错了吧?应该是 Dr.GRPO 没有做归一化,DAPO 则按当前批次的 Token 数归一化
- 这两种方法都增加了长链中 Token 的权重 ,从而更严厉地惩罚错误的长链
- 标准的 GRPO 在每个响应内部对损失进行归一化后再求平均,这使得所有响应对梯度更新的权重相同,但会导致长输出中的 Token 权重被低估
- 在开源强化学习训练框架(如 ver1 (2024) 和 TRL (2020))中,GFPO 采用了 DAPO 的 Token-level 归一化
- 但这种方法不仅会惩罚错误的长链,还会放大正确长链的奖励 ,从而导致经过 SFT 的推理模型(如 Phi-4-reasoning-plus 和 DeepSeek-R1-Distill-Qwen)倾向于生成更冗长的输出
- 这凸显了仅依赖损失归一化来控制输出长度的局限性
- 问题:不会放大正确长链的奖励吧,相当于是对齐了所有奖励权重了啊
- GFPO 通过仅对保留链计算优势函数来改进优势估计,这一改进与损失归一化无关;
- 尽管论文的实验将其与 DAPO 的损失聚合方法结合使用,但未来也可以与其他方法(如 Dr.GRPO)结合
- 但这种方法不仅会惩罚错误的长链,还会放大正确长链的奖励 ,从而导致经过 SFT 的推理模型(如 Phi-4-reasoning-plus 和 DeepSeek-R1-Distill-Qwen)倾向于生成更冗长的输出
Length-Aware Penalties
- 除了归一化,还有一些工作通过在 GRPO 的奖励中添加显式的长度感知惩罚来抑制长推理链 :
- Hou 等人 (2025) 在强化学习过程中设置了 Token 上限(超过上限则奖励为零),并逐步收紧限制;
- Su 和 Cardie (2025) 使用了一种自适应的直接长度惩罚,其强度随训练动态调整以避免过度压缩或不足压缩;
- Xiang 等人 (2025) 根据每个问题的解决率反比调整惩罚强度,使得简单问题对额外 Token 的惩罚更大;
- Cheng 等人 (2025) 结合全局长度奖励和针对冗余思维的压缩奖励;
- Aggarwal 和 Welleck (2025) 则在给定目标长度的条件下优化准确性,对偏离目标长度的输出进行惩罚
- 在论文的初步实验中,简单地调整长度感知奖励中的惩罚强度并未显著减少输出长度,或者以牺牲准确性为代价
- 相比之下,GFPO 的拒绝步骤通过决定哪些样本用于学习来隐式地塑造奖励,提供了一种更简单的方法来同时优化多个属性(如长度、安全性),而无需复杂的奖励工程
- 当然,将 GFPO 与更精心设计的奖励结合可能会带来进一步的提升
- 问题:GFPO 本质上对丢弃掉的样本的梯度是 0,既不鼓励,也不惩罚,像是浪费了生成的样本,且梯度为 0 本身也有一定的含义,当一个样本被打压时,梯度为 0 的样本相当于被鼓励了(反之亦然)
- 注:丢弃掉的样本还不参与奖励均值和方差的计算
- 建议:是否可以做一个补充实验,将丢弃掉的样本使用起来,且针对正负奖励给与一定的长度惩罚
Inference-time Interventions
- 其他工作也探索了如何在推理时纯粹通过干预控制推理长度
- 与论文的工作类似:
- Hassid 等人 (2025) 表明较短的链通常更准确(即使在控制问题难度后) ,并提出对 \(k\) 个样本中最短的 \(m\) 个进行投票
- Muennighoff 等人 (2025) 提出了 “预算强制”(budget forcing) ,通过特殊短语(如“Wait”或“Final Answer”)控制推理停止时机而无需重新训练
- 其他方法通过监控中间生成信号,在模型表现出高置信度或答案在连续推理块中稳定时停止生成 (2025; 2025)
- 这些方法与 GFPO 是互补的,可以结合使用以进一步降低推理成本或在训练后强制执行长度约束
Rejection Sampling Methods
- 拒绝采样已被应用于多种 LLM 的训练和解码场景中
- Kim 等人 (2024) 探索了在强化学习后通过采样每个问题的多个解并进行长度缩减的方法,包括
- (i)对最短的正确响应进行微调,或
- (ii)使用最短正确输出作为正例、较长输出作为负例应用 DPO(Direct Preference Optimization)
- Kim 等人 (2024) 探索了在强化学习后通过采样每个问题的多个解并进行长度缩减的方法,包括
- 相比之下,GFPO 将拒绝采样整合到强化学习更新中
- 为每个问题采样更大的组,并根据长度或 reward-per-token 选择训练链
- 避免了额外的蒸馏、长度对齐阶段或显式惩罚项
- DAPO (2025) 采用“动态采样”丢弃所有响应均正确或错误的 Prompt 以稳定批次梯度
- Xiong 等人 (2025) 表明,一个简单的 RAFT 基线 (2023) 仅训练正向奖励样本即可与 GRPO 表现相当
- 他们的过滤基于正确性奖励,但 GFPO 根据长度或 Token 效率过滤,并能根据问题难度动态调整过滤强度
- 其他应用包括 Khaki 等人 (2024) 将拒绝采样与 DPO 结合,通过为每个 Prompt 采样更多响应并使用奖励分数选择对比对;
- Lipkin 等人 (2025) 使用自适应加权拒绝采样实现高效约束生成;
- Sun 等人 (2024) 通过早期拒绝低分候选加速 Best-of-\(N\) 解码
附录 A:Qualitative Examples
- AIME 25 I Problem 8: GRPO v/s Token Efficiency GFPO

- 更多 Case 比较见原始论文