注:本文包含 AI 辅助创作
Paper Summary
- 整体说明:
- Training-Inference Mismatch 从根本上讲是一个数值精度问题
- 本文提出一种简单的方法:简单地从标准的 BF16 格式 切换到 更高精度的 FP16 格式 几乎可以消除这种不匹配
- 结论:FP16 应被重新考虑作为 LLM 稳健 RL 微调的基础选项
- 背景 & 总结:
- Training-Inference Mismatch 是 RL 微调中不稳定的主要来源
- LLM 的 RL 常常因训练策略与推理策略之间的数值不匹配而遭受不稳定性
- 先前的工作试图通过算法修正或工程对齐来缓解此问题
- 本文表明其根本原因在于浮点精度本身
- BF16 被广泛采用,尽管其动态范围很大,但引入了较大的舍入误差,破坏了训练和推理之间的一致性
- 本文证明了简单地恢复到 FP16 就能有效地消除这种不匹配
- 只需更改几行代码,并且不需要修改模型架构或学习算法
- 结果表明,在各种任务、算法和框架中,统一使用 FP16 能带来更稳定的优化、更快的收敛速度和更强的性能
- Training-Inference Mismatch 是 RL 微调中不稳定的主要来源
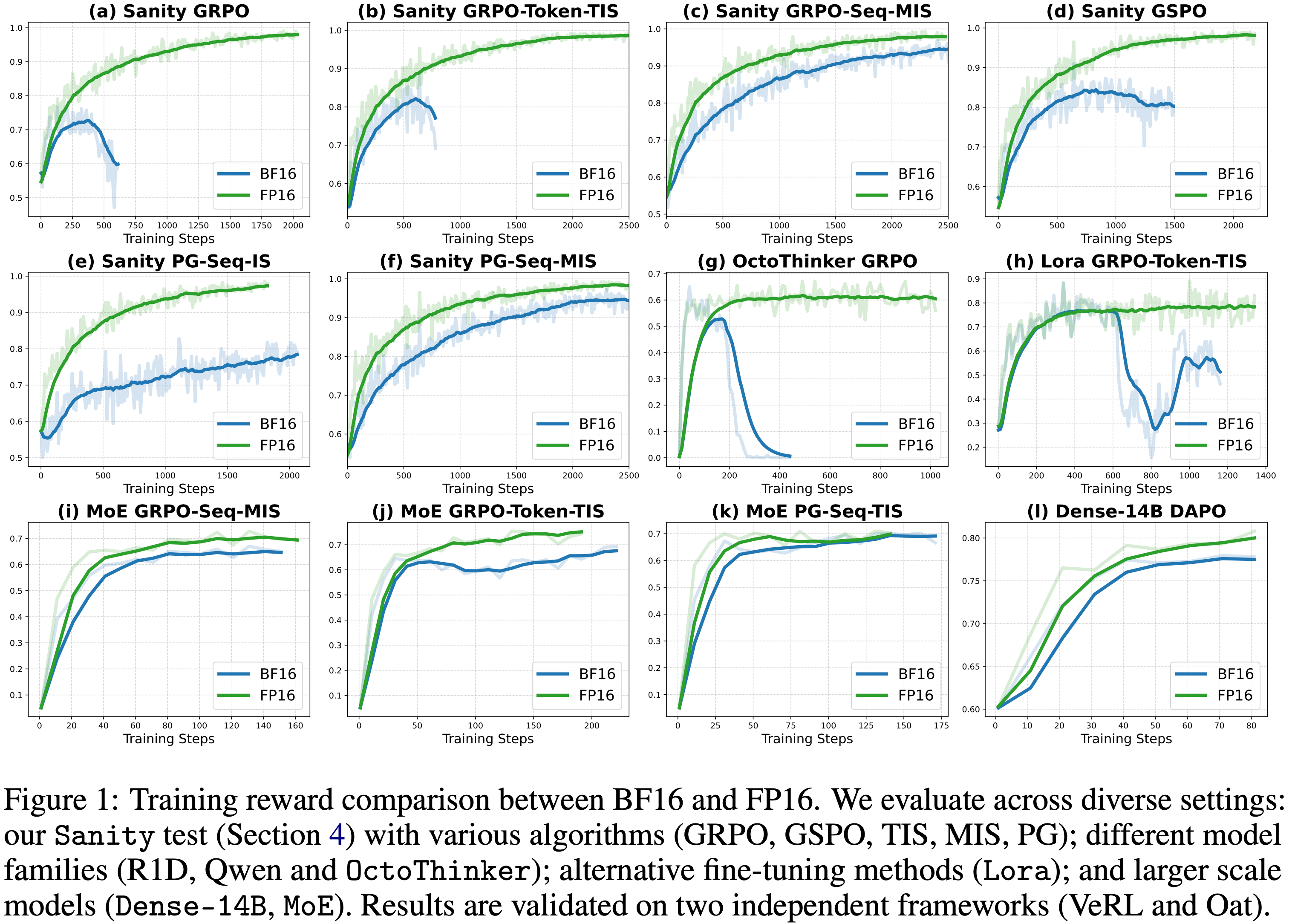
- 图 1: BF16 和 FP16 训练比较
- 不同的算法 (GRPO, GSPO, TIS, MIS, PG)
- 不同的模型家族 (R1D, Qwen 和 OctoThinker)
- 微调方法 (Lora)
- 更大规模的模型 (Dense-14B, MoE)
- 框架:VeRL 和 Oat
Introduction and Discussion
- 背景 & 问题提出
- LLM 的 RL 训练常常充满不稳定性
- 训练过程对超参数极为敏感,并且可能遭遇训练崩溃
- 这种不稳定的一个关键来源源于现代 RL 框架中的一个基本差异: Training-Inference Mismatch
- 为加速训练,RL 框架通常使用不同的计算引擎:
- 一个用于快速推理 (Rollout)
- 一个用于训练 (梯度计算)
- 在数学上是相同的,但由于精度错误和硬件特定的优化,这些引擎会产生数值上不同的输出
- 正如最近的工作所强调的 (2025; 2025a; 2025a),这种看似微小的推理与训练之间的不匹配给优化过程带来了严重问题
- 为加速训练,RL 框架通常使用不同的计算引擎:
- LLM 的 RL 训练常常充满不稳定性
- 现有解决方案:
- 现有的解决方案试图通过基于重要性采样的算法补丁来解决这种不匹配
- (TIS)Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, 20250805-20251013(参见本人博客:NLP——LLM对齐微调-TIS) 引入了一个 Token-level 重要性采样比率作为对 GRPO 梯度的补丁(这种简单的修正可以延长训练时间)
- 后来 (Sequence-level MIS)When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance(参见本人博客:NLP——LLM对齐微调-RL-Collapse-Training-Inference-Mismatch(Sequence-level MIS)) 指出 Token-level TIS 方法的梯度偏,不足以完全稳定训练
- 他们提出使用无偏的、 Sequence-level 重要性采样比率进行修正
- 这种方法更稳定,但其有效性受限于缓慢的收敛速度,这是 Sequence-level 比率固有高方差的直接结果
- 上述这两种算法方法都面临两个根本问题:
- 1)计算效率低下,实现需要额外的前向传播来计算其修正所需的重要性采样比率
- 假设反向传播的成本是前向传播的两倍,这大约增加了 \(25%\) 的训练成本
- 2)部署差距 (deployment gap) 仍然存在
- 解决方案在训练期间修正了不匹配问题,但最终的模型参数是针对训练引擎的概率分布进行优化的
- 这意味着得到的模型对于部署中使用的推理引擎并非真正最优,这可能导致实际性能下降
- 以上这两点要求我们从根源上消除不匹配,而不仅仅是补偿它
- 1)计算效率低下,实现需要额外的前向传播来计算其修正所需的重要性采样比率
- 现有的解决方案试图通过基于重要性采样的算法补丁来解决这种不匹配
- 本文的解法:
- 本文研究数值不匹配的根本原因:浮点精度
- 本文确定现代混合精度训练的标准(BFloat16,BF16)是主要的罪魁祸首
- BFloat16 具有广泛的动态范围,这对于稳定的预训练非常有利,但其低精度使其极易受到舍入误差的影响 ,这些误差会累积并最终导致训练策略和推理策略发散
- 实验:在 RL 微调期间,通过从 BF16 切换到 FP16,几乎可以消除 Training-Inference Mismatch
- FP16 拥有更多的尾数位,提供了更高的数值精度,使得结果对训练和推理之间的实现差异不那么敏感
- 这一简单改变的好处是多方面的
- 消除了复杂的算法变通方案以及伴随的概率评估,将 RL 恢复到其最纯粹的重要性加权策略梯度形式
- 弥合了现有修正方案都无法解决的部署差距
- 在性能和稳定性上都有显著且统一的提升,为基于 RL 的 LLM 对齐中的一个关键挑战提供了一个干净、高效且普遍适用的解决方案
Background
现代 LLM 微调的 RL 框架中,为最大化系统效率,推理和训练使用了不同的引擎
不可避免地导致了推理策略 \(\mu (\cdot |\theta)\) 和训练策略 \(\pi (\cdot |\theta)\) 之间的不匹配,这是由于微妙的数值差异造成的,尽管原则上两者在数学上应该是相同的 \((\mu = \pi)\)
这种不匹配带来了下面详述的两个问题
- Biased Gradient:
- 为了优化策略 \(\pi_\theta(\cdot|\theta)\),一般典型的做法是优化下面的目标:
$$\mathcal{J}(\theta) = \mathbb{E}_{x\sim p_{\mathcal{X} } }\left[\mathcal{J}(x,\theta)\right] = \mathbb{E}_{x\sim p_{\mathcal{X} } }\left[\mathbb{E}_{y\sim \pi (\cdot |x,\theta)}[R(x,y)]\right] \tag {1}$$- \(x\) 是从分布 \(p_{\mathcal{X} }\) 中采样的提示
- \(y\) 是 Response
- \(R(x,y)\) 是 \(y\) 的奖励
- 策略梯度可以通过 REINFORCE 估计量计算:
$$
\begin{align}
\nabla_{\theta}\mathcal{J}(\theta) &= \mathbb{E}_{x\sim p_{\mathcal{X} } }\left[\nabla_{\theta}\mathcal{J}(x,\theta)\right]\\
\nabla_{\theta}\mathcal{J}(x,\theta) &= \mathbb{E}_{y\sim \pi (\cdot |x,\theta)}\left[\nabla_{\theta}\log \pi (y|x,\theta)\cdot R(x,y)\right]. \end{align}\tag {2}
$$ - 实践中,从推理策略 \(\mu\) 中采样 Response,而不是从训练策略 \(\pi\)
- 正如 (TIS)Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, 20250805-20251013 和 (Sequence-level MIS)When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance 所指出的,如果简单地忽略这种不匹配,策略梯度将变得有偏
$$
\begin{align}\nabla_{\theta}\mathcal{J}_{\text{biased} }(x,\theta) &= \mathbb{E}_{y\sim \mu (\cdot |x,\theta)}\left[\nabla_{\theta}\log \pi (y|x,\theta)\cdot R(x,y)\right]\\
&\neq \nabla_{\theta}\mathcal{J}(x,\theta) \end{align}\tag {3}
$$
- 正如 (TIS)Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, 20250805-20251013 和 (Sequence-level MIS)When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance 所指出的,如果简单地忽略这种不匹配,策略梯度将变得有偏
- 为了优化策略 \(\pi_\theta(\cdot|\theta)\),一般典型的做法是优化下面的目标:
- Biased Gradient:
Deployment Gap
- 另一个重要但难以修复的问题是部署 Gap
- 虽然训练的是 \(\pi (\cdot |\theta)\),但在部署和评估时使用的是 \(\mu (\cdot |\theta)\)
- 在训练引擎 \(\pi\) 下优化的参数 \(\theta\) 对于推理引擎 \(\mu\) 来说不一定是最优的:
$$\arg \max_{\theta}\mathbb{E}_{x\sim p_{\mathcal{X} },y\sim \mu (\cdot |x,\theta)}[R(x,y)]\neq \arg \max_{\theta}\mathbb{E}_{x\sim p_{\mathcal{X} },y\sim \pi (\cdot |x,\theta)}[R(x,y)]\tag {4}$$ - 这种部署差距导致了由于这种不匹配而产生的不可忽视的性能下降
- 虽然算法补丁 (2025; 2025a) 修正了有偏梯度,但它们在本质上无法弥合部署差距,这要求我们从根本上消除这种不匹配
Correcting Biased Gradient via Importance Sampling,通过重要性采样修正有偏梯度
- 为了修正由 Training-Inference Mismatch 引入的有偏梯度,一个 Principled 方法是使用重要性采样 (IS)
- 使用 Sequence-level 概率比率对梯度计算进行重新加权,确保梯度估计量是无偏的
- 给定提示 \(x\) 的策略梯度被修正为:
$$\nabla_{\theta}\mathcal{J}_{\text{pg - is} }(x) = \mathbb{E}_{y\sim \mu (\cdot |x,\theta^{\prime})}\left[\frac{\pi(y|x,\theta)}{\mu(y|x,\theta^{\prime})}\nabla_{\theta}\log \pi (y|x,\theta)\cdot A(x,y)\right] \tag {5}$$- \(\theta^{\prime}\) 表示用于采样的参数,在 off-policy 设置中可能与 \(\theta\) 不同
- \(A(x,y) = R(x,y) - B(x)\) 是优势函数,\(B(x)\) 作为降低方差的基线
- 这种修正理论上合理,但这个估计量通常存在高方差问题,尤其是在 LLM 的背景下,Response 序列很长,导致极端的概率比率
- 为了缓解这个问题,人们提出了诸如截断重要性采样 (Truncated Importance Sampling, TIS) (2018; 2025) 和掩码重要性采样 (Masked Importance Sampling, MIS) (2025; 2025b; 2025a) 等技术,它们用少量的偏差来换取方差的大幅降低:
$$\begin{align}\nabla_{\theta}\mathcal{J}_{\text{pg - tis} }(x) &= \mathbb{E}_{y\sim \mu (\cdot |x,\theta^{\prime})}\left[\min \left(\frac{\pi(y|x,\theta)}{\mu(y|x,\theta^{\prime})},C\right)\cdot \nabla_{\theta}\log \pi (y|x,\theta)\cdot A(x,y)\right]\\
\nabla_{\theta}\mathcal{J}_{\text{pg - mis} }(x) &= \mathbb{E}_{y\sim \mu (\cdot |x,\theta^{\prime})}\left[\frac{\pi(y|x,\theta)}{\mu(y|x,\theta^{\prime})}\cdot \mathbb{I}\left\{\frac{\pi(y|x,\theta)}{\mu(y|x,\theta^{\prime})}\leq C\right\} \cdot \nabla_{\theta}\log \pi (y|x,\theta)\cdot A(x,y)\right], \end{align}\tag {7}$$- \(C\) 是一个裁剪超参数
- \(\mathbb{I}\{\cdot \}\) 是指示函数
- 为了缓解这个问题,人们提出了诸如截断重要性采样 (Truncated Importance Sampling, TIS) (2018; 2025) 和掩码重要性采样 (Masked Importance Sampling, MIS) (2025; 2025b; 2025a) 等技术,它们用少量的偏差来换取方差的大幅降低:
- 以上这些方法都通过控制重要性权重的幅度来稳定训练
Existing Implementations,现有实现
- 虽然总体上受到 IS 原理的启发,但最近的方法 (TIS)Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, 20250805-20251013 和 (Sequence-level MIS)When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance 实际上是作为 GRPO 之上的辅助补丁来实现的,而不是遵循严格 Principled 公式
- 许多 RL 框架 (例如,VeRL) 是以 GRPO 为中心的,并未原生提供公式 (5)、公式 (6) 和公式 (7) 中概述的标准重要性加权估计量
- 标准的 GRPO 梯度 (2024; 2025c) 没有修正 Training-Inference Mismatch ,其计算如下:
$$\begin{align}\nabla_{\theta}\mathcal{J}_{\text{grpo} }(x) &= \mathbb{E}_{y\sim \mu (\cdot |x,\theta^{\prime})}\left[\sum_{t = 1}^{|y|}\nabla_{\theta}\min \left(r_{t}A_{t},\text{clip}(r_{t},1 - \epsilon ,1 + \epsilon)A_{t}\right)\right]\\
\text{where } r_{t} &= \frac{\pi(y_{t}|x,y_{< t},\theta)}{\pi(y_{t}|x,y_{< t},\theta^{\prime})}\text{ and } A_{t} = R(x,y) - \frac{1}{G - 1}\sum_{i = 1}^{G - 1}R(x,y_{i}) \end{align}\tag {8}$$- 注:这里是 RLOO 的实现,且没有添加 Group 归一化(Dr.GRPO 的做法)
- 对于每个 Prompt \(x\)
- 从推理策略 \(\mu (\cdot |x,\theta^{\prime})\) 中采样一组 \(G\) 个 Response \(\{y_{i}\}_{i = 1}^{G}\),以计算优势函数 \(A_{t}\)
- 如同在 GRPO 和 RLOO (2024; 2019) 中一样
- 基于 GRPO,(TIS)Your Efficient RL Framework Secretly Brings You Off-Policy RL Training, 20250805-20251013 引入了一个 Token-level TIS 修正:
$$\begin{align}\nabla_{\theta}\mathcal{J}_{\text{grpo - tok - tis} }(x) &= \mathbb{E}_{y\sim \mu (\cdot |x,\theta^{\prime})}\left[\sum_{t = 1}^{|y|}\min (\rho_{t},C)\cdot \nabla_{\theta}\min \left(r_{t}A_{t},\text{clip}(r_{t},1 - \epsilon ,1 + \epsilon)A_{t}\right)\right]\\
\text{where }\rho_{t} &= \frac{\pi(y_{t}|x,y_{< t},\theta^{\prime})}{\mu(y_{t}|x,y_{< t},\theta^{\prime})}. \end{align}\tag {9}$$ - 随后,(Sequence-level MIS)When speed kills stability: Demystifying RL collapse from the training-inference mismatch, 20250927, ByteDance 通过提出一个 Sequence-level MIS 变体推进了这种方法
- 此修正应用于整个 GRPO 梯度项,使用整个序列的单个比率来决定是否应用更新:
$$\begin{align}\nabla_{\theta}\mathcal{J}_{\text{grpo-seq-mis} }(x) &= \mathbb{E}_{y\sim \mu (\cdot |x,\theta^{\prime})}\left[\rho \cdot \mathbb{I}\{\rho \leq C\} \cdot \sum_{t = 1}^{|y|}\nabla_{\theta}\min \left(r_{t}A_{t},\text{clip}(r_{t},1 - \epsilon ,1 + \epsilon)A_{t}\right)\right]\\
\text{where }\rho &= \frac{\pi(y|x,\theta^{\prime})}{\mu(y|x,\theta^{\prime})}. \end{align}\tag {10}$$
- 此修正应用于整个 GRPO 梯度项,使用整个序列的单个比率来决定是否应用更新:
- 与原始的 policy gradient 估计量 (公式 (5) 及其 TIS/MIS 变体) 相比,现有的基于 GRPO 的实现需要 额外的前向传播 来计算 \(\pi (\cdot |\theta^{\prime})\) 以进行它们的 off-policy 修正
- 假设反向传播的成本是前向传播的两倍 (2023),这个额外步骤在训练期间大约会产生 \(25%\) 的计算开销
Engineering Attempts to Reduce the Mismatch, 工程尝试 for 减少 Mismatch
- 另一条工作路线试图从工程角度减轻 Training-Inference Mismatch ,但成效有限
- 用 FP32 的语言模型头 (2025)
- 被证明不足以防止训练崩溃 (2025; 2025a)
- 最近,Team 等 (2025a) 报告了通过手动对齐训练和推理实现取得了有希望的结果
- 但这种方法需要深入的领域知识和大量的工程努力,并且目前尚不清楚这种特定的修复方法能否在不同的框架或模型之间推广
- He (2025) 的一项相关工作展示了如何在推理中强制执行确定性
- 但其方法会带来显著的成本效率降低,并且不能直接解决 Training-Inference Mismatch 问题
- 用 FP32 的语言模型头 (2025)
- 尽管做出了这些工程努力,但由于训练和推理计算之间的根本差异难以调和,这种不匹配仍然存在
- Token 在推理期间是自回归生成的,但在训练期间是并行处理的
- 不同的并行化策略以及诸如 MoE 模型中的 top-k 专家选择等对精度敏感的操作,使情况进一步复杂化
- 这种固有的困难凸显了需要一个更根本的解决方案,以避免这种复杂而脆弱的工程变通方法
- Token 在推理期间是自回归生成的,但在训练期间是并行处理的
Revisiting FP16 Precision,重新审视 FP16 精度
- 对 Training-Inference Mismatch 的调查中,本文发现了一个非常简单但非常有效的补救措施,它避免了复杂的算法或工程修正
- 这种方法没有引入额外的机制,而是关注一个更基础的因素:数值精度
- 仅仅将训练精度从当前占主导地位的 BF16 格式 (2012; 2019) 切换到较早的 Float16 (FP16) 格式 (2017),就能显著减轻策略不匹配,并在各种 RL 算法上产生显著的性能提升
- 本节将回顾这些浮点格式的历史和特性,以揭示这一反直觉但强大的结果
FP16 vs. BF16
- 浮点格式通过在其两个组成部分之间分配比特位来表示实数:
- 指数位 (exponent bits),决定数值的范围(数值可以有多大或多小)
- 尾数位 (mantissa bits,也称为小数位),决定数值的精度(在该范围内数值的区分精细程度)
- FP16 和 BF16 都使用总共 16 比特,它们的分配方式不同,导致了在范围和精度之间的不同权衡(见表 1)

- FP16 (IEEE 754 半精度) 分配 5 比特给指数,10 比特给尾数
- 相对较大的尾数使 FP16 具有更高的数值精度,使其能够准确地表示相邻值之间的微小差异
- 但其有限的 5 比特指数严重限制了动态范围,使得 FP16 容易发生溢出(数值超过可表示的最大值)和下溢(数值舍入为零)
- 使用 FP16 训练通常需要稳定性技术,如损失缩放 (loss scaling),以缓解这些问题(参见第 3.2 节)
- BF16 (bfloat16) 由 Google 推出,分配 8 比特给指数(与 32 比特 FP32 格式的范围相匹配),只分配 7 比特给尾数
- 这种设计提供了与 FP32 相当的广泛动态范围,使 BF16 对溢出和下溢具有很强的抵抗力,但代价是精度降低
- 由此产生的低精度下的数值鲁棒性是其在大规模深度学习系统中被广泛采用的关键原因
Stabilizing FP16 Training with Loss Scaling,使用损失缩放稳定 FP16 训练
- FP16 有限范围带来的主要挑战是梯度下溢,这可以在混合精度训练的历史早期通过一种称为损失缩放的技术有效解决 (2017),该过程很简单:
- 1)在反向传播之前,将损失乘以一个大的缩放因子 \(S\)
- 2)这将所有梯度放大了 \(S\) 倍,将小的梯度值移出下溢区域,进入 FP16 的可表示范围,从而保留它们
- 3)在更新权重之前,通过除以 \(S\) 将梯度缩放回原始值
- 现代实现通过动态损失缩放进一步改进了这一点
- 缩放因子 \(S\) 在训练期间自动调整
- 如果在一定步数内未检测到溢出(梯度中的无穷值),则增加 \(S\)
- 如果发生溢出,则立即减小 \(S\)
- 缩放因子 \(S\) 在训练期间自动调整
The Rise of BF16 in Modern LLM Training,BF16 在现代 LLM 训练中的兴起
- 损失缩放有效,但它在分布式环境中使系统复杂化,因为在执行优化器步骤之前需要全局同步以检查溢出并确保所有工作节点上的缩放因子一致
- BF16 在诸如 Google TPU 以及后来的 NVIDIA GPU(从 Ampere 架构开始)等硬件上的引入是一个游戏规则的改变者
- 由于具有与 FP32 相同的动态范围,BF16 提供了 FP32 的“直接替代品”,无需繁琐的损失缩放
- 其对溢出和下溢的鲁棒性使得训练 LLM 更加稳定和直接
- 因此,BF16 迅速成为现代混合精度训练的事实标准
Why FP16 is the Key for RL Fine-Tuning,为什么 FP16 是 RL 微调的关键
- BF16 的稳定性对预训练模型来说是优势,但本文作者的发现表明,其低精度是 Training-Inference Mismatch 的根源
- 现代 RL 框架经常使用不同的引擎或优化过的内核进行训练和推理
- 即使两者都配置为使用 BF16,它们在实现上的细微差异(例如,CUDA 内核优化、并行策略)也可能导致 BF16 上产生不同的舍入误差
- 当这些微小的差异在自回归采样期间累积到一个 token 序列上时,\(\pi\) 和 \(\mu\) 产生的概率分布可能会出现显著差异
- 这种差异正是前面讨论的有偏梯度和部署差距的根源
- 这正是切换到 FP16 能提供根本性解决方案的原因
- 凭借其 10 位尾数,FP16 提供的精度是 BF16 的 8 倍 (\(2^{10}\) 个值 vs. \(2^{7}\) 个值)
- 这种更高的保真度意味着训练和推理引擎的输出在数值上更有可能相同
- 更高的精度创建了一个缓冲区,吸收了这两个引擎之间微小的实现差异,防止了舍入误差累积并导致策略发散
- 对于 RL 微调,模型权重和激活值的动态范围已经在预训练期间确立
- 因此,BF16 的极端范围变得不那么关键,而它牺牲的精度则成为一个主要的缺点
- 通过恢复到 FP16,本文用 BF16 不必要的范围换取了关键的精度,从而在没有任何复杂算法或工程变通方案的情况下有效地缩小了训练和推理之间的差距
Offline Analysis Results
- 在进行 RL 微调之前,本文首先进行离线分析,以检查在不同数值精度下的性能和 Training-Inference Mismatch 情况
- 实验一:使用 DeepSeek-R1-Distill-Qwen-1.5B 模型 (2025),在 BF16 和 FP16 两种精度下,从 AMC 和 AIME 基准 (2024) 中为每个问题采样 32 个 Response,总 Token 预算为 32K
- 如表 2 所示,它们的性能大体相当,这表明仅提高推理精度本身并不一定能带来改进
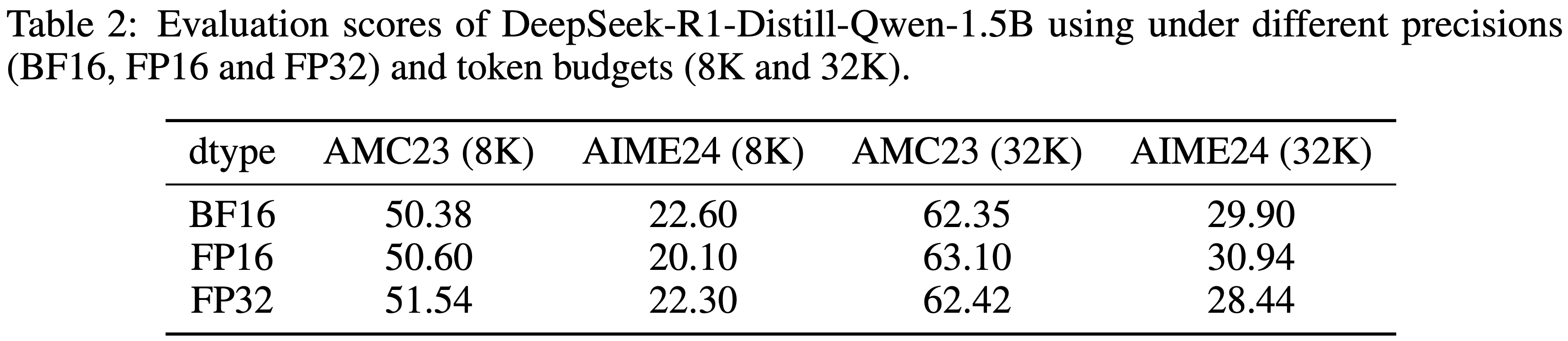
- 如表 2 所示,它们的性能大体相当,这表明仅提高推理精度本身并不一定能带来改进
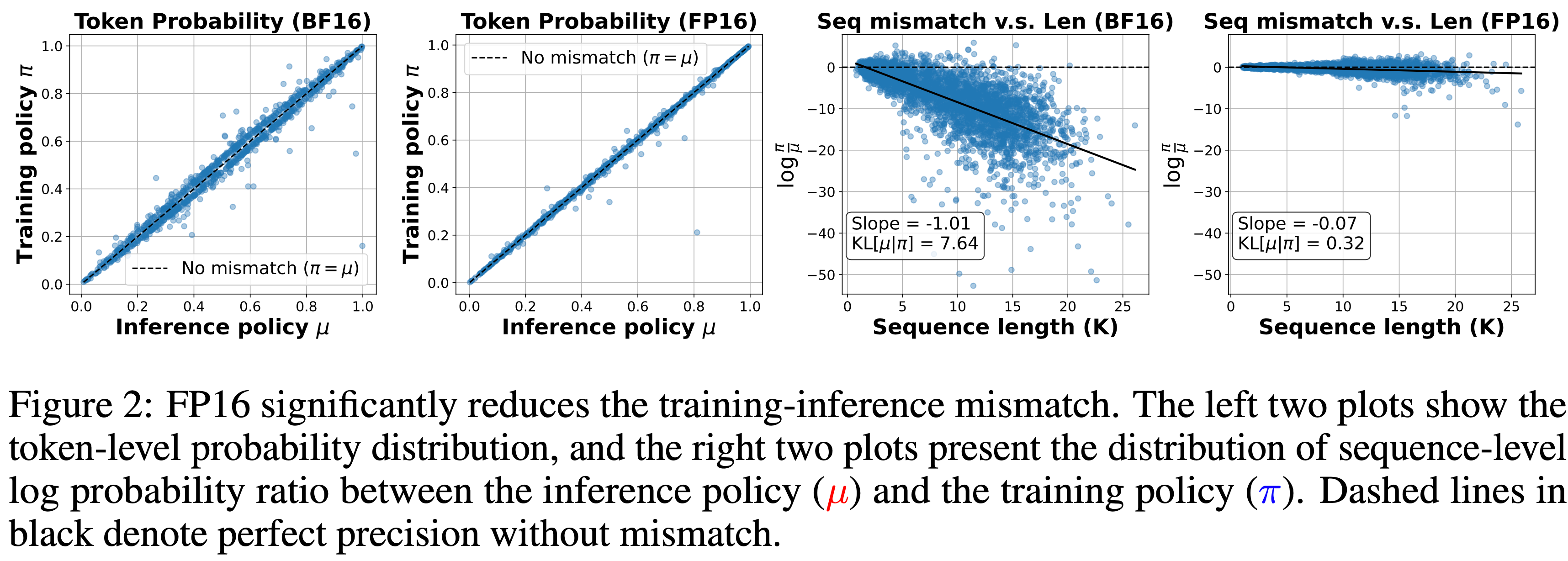
- 实验二:使用温度 1.0 并且不使用 top-\(p\) 采样(这样 \(\mu\) 可以直接与 \(\pi\) 比较),为每个问题重新生成 32 个 Response,并在 DeepSpeed 训练引擎内使用相同的模型权重,在 BF16 和 FP16 设置下评估 Token 的 log-probabilities
- 图 2 左侧的两张图显示了由此产生的 Token 概率分布
- 可以发现 FP16 显著减少了 \(\mu\) 和 \(\pi\) 之间的不匹配,数据点更紧密地围绕对角线集中
- 除了 Token-level 不匹配,本文还分析了 Sequence-level 不匹配,因为 \(\frac{\pi(y|x)}{\mu(y|x)}\) 作为完整 Response 的重要性采样权重的无偏估计量
- 图 2 右侧的两张图描绘了不同生成长度下 Sequence-level log-probability 比率的分布
- 结果清楚地表明,BF16 引入了指数级增大的不匹配,并且由于累积的自回归误差,这种不匹配随着 Response 变长而恶化,而 FP16 将不匹配保持在一个温和得多的水平(大约小 \(24 \times\) 倍)
A Sanity Test for RL Algorithms,健全性测试
- 注:Sanity Test 是软件工程里的标准专有名词,中文一般叫 健全性测试/sanity 测试/简易冒烟测试
- 为了严格评估 RL 算法的可靠性和鲁棒性,引入了一个新颖的健全性测试
- 标准基准测试通常包含难度各异的问题,包括那些对于初始模型来说过于琐碎或无法解决的问题
- Trivial 问题浪费计算资源,而无法解决的问题则使得难以判断性能不佳是源于算法缺陷还是模型本身的局限性
- 本文的健全性测试旨在高效地消除这种歧义
- 通过创建一个每个问题已知可解但并非 Trivial 完美数据集,可以清晰地隔离并评估 RL 算法解锁模型潜在能力的能力
- 在这个完美数据集上,一个可靠的 RL 算法理论上应该能够达到 \(100%\) 的训练准确率
- 通过过滤掉初始模型中那些过于琐碎和无法解决的问题来构建这个完美数据集
- 具体来说,对 MATH 数据集 (2021) 中每个问题展开 40 个 Reponse,仅保留初始准确率介于 \(20%\) 和 \(80%\) 之间的问题
- 这为 DeepSeek-R1-Distill-Qwen-1.5B 模型 (2025) 生成了一个包含 1,460 个问题的目标数据集
- 该数据集的较小规模使得达到接近 \(100%\) 的准确率在计算上变得可行,从而能够进行高效且结论性的测试
- 具体来说,对 MATH 数据集 (2021) 中每个问题展开 40 个 Reponse,仅保留初始准确率介于 \(20%\) 和 \(80%\) 之间的问题
- 本文用一个明确的标准来定义本文的健全性测试:
- 如果 RL 算法在这个完美数据集上的训练准确率收敛到高于一个高阈值(例如 \(95%\)),则视为通过
- 未能通过此测试的算法可被视为不可靠或存在根本性缺陷,因为它无法引导模型解决已知在其能力范围内的问题
- 虽然通过测试并不能保证普遍成功,但失败则是算法设计不良的有力指标,使该测试成为一个关键诊断工具
Experimental Setup
- 在此健全性测试下,评估了几种代表性的 RL 算法,特别是那些旨在解决 Training-Inference Mismatch 问题的算法(见第 2.1 节)
- 所有实验均使用 DeepSeek-R1-Distill-Qwen-1.5B 作为初始模型,上下文长度为 8,000
- 在 8 块 NVIDIA A100 80G GPU 上运行每个实验
- 对于每次策略迭代 (2017),对 64 个问题(每个问题有 8 次 Rollout)使用一个 batch 大小,并进行 4 次梯度更新
- 对于 GRPO 系列的算法,默认将 clip_higher 设置为 0.28 (2025)
- 重要性采样方法(公式 (7) 和公式 (10))的裁剪阈值设为 \(C = 3\)
- 本文评估了一套旨在解决 Training-Inference Mismatch 问题的方法,包括:
- 一个 vanilla GRPO 基线(具体是来自公式 (8) 的 Dr.GRPO 变体)(2024; 2025c)
- 带有 Token-level TIS 校正(公式 (9))的 GRPO (2025)
- 带有 Sequence-level MIS 校正(公式 (10))的 GRPO (2025a)
- 带有重要性采样的标准策略梯度算法(公式 (5))
- 此外,还加入了 GSPO (2025)
- 虽然 GSPO 主要是为了解决 MoE 模型引入的不匹配问题而设计的
Comparison with Existing Algorithmic Corrections,与现有算法比较
- 为确保鲁棒性并排除实现相关的特例,本文在两个不同的框架上进行了实验:VeRL (2024) 和 Oat (2025b)
We identified and corrected an implementation bug in VeRL’s Dr.GRPO for our experiments. We optimized the training speed of VeRL based on https://github.com/sail-sg/odc.
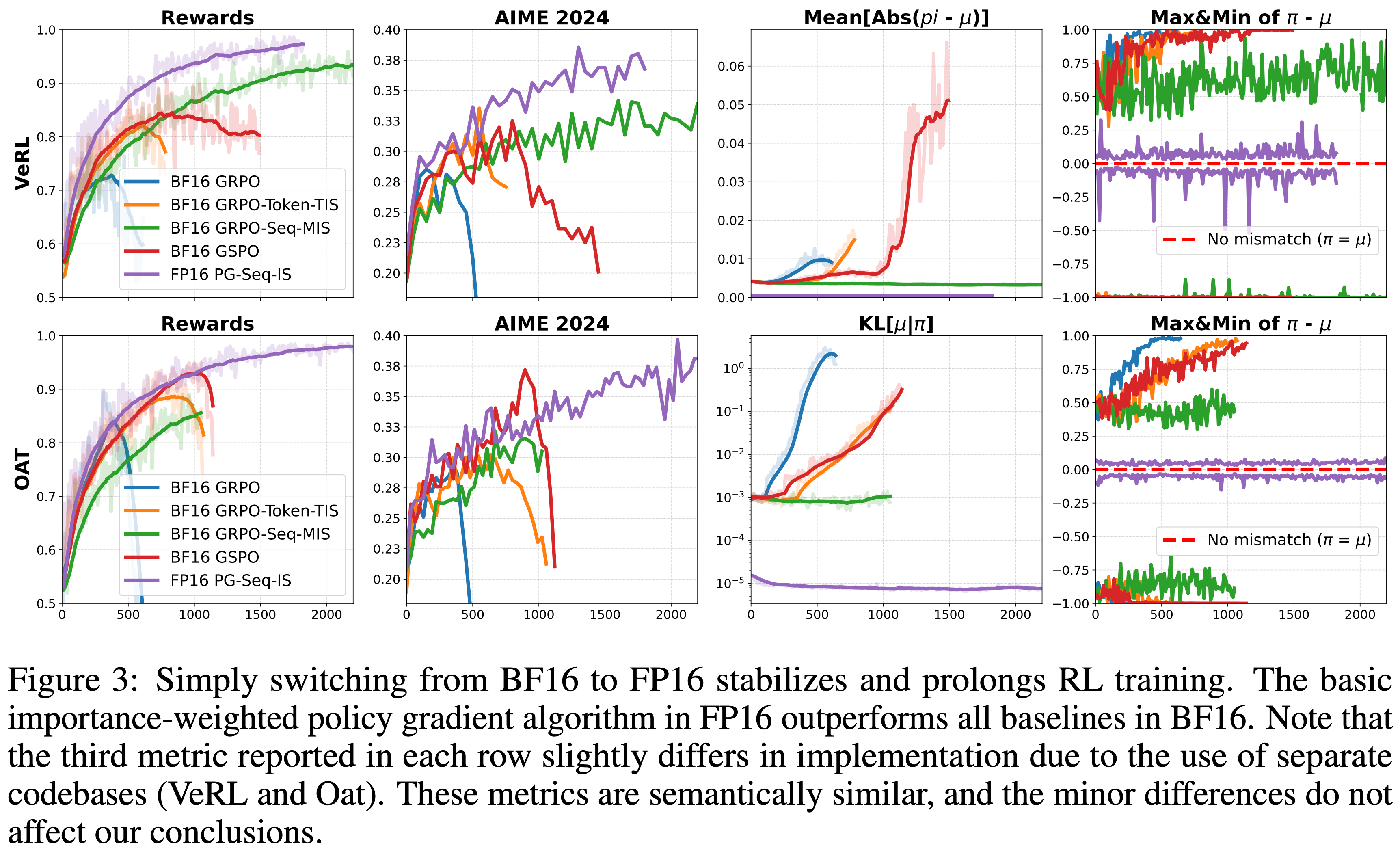
- 结果如图 3 所示,现有方法在使用 BF16 精度时显示了不稳定性
- Vanilla GRPO 基线在训练早期就崩溃了,在 VeRL 中仅达到 \(73%\) 的峰值准确率,在 Oat 中达到 \(84%\),之后性能下降
- Token-level TIS 校正略微延长了训练时间,但最终也失败了,在达到 \(82%\)(VeRL)和 \(88%\)(Oat)准确率后崩溃
- 这一观察结果与 Sequence-level MIS 的发现一致
- 令人惊讶的是,GSPO 表现出比带 Token-level TIS 的 GRPO 更长的稳定训练期
- 尽管完全不使用推理策略 \(\mu\),但仍获得了更高的奖励
In our VeRL experiment, the GSPO gradient norm became ‘NaN’ after 1200 steps, halting further model updates
- 尽管完全不使用推理策略 \(\mu\),但仍获得了更高的奖励
- 在 BF16 的所有算法校正中,只有带有 Sequence-level MIS 的 GRPO (2025a) 保持了稳定的训练而没有崩溃
- 但这种稳定性是有代价的
- 由于其 Sequence-level 重要性比的高方差(见图 2),该方法收敛缓慢
- Sequence-level MIS 的峰值效果也不及 FP16
- 理解:其实继续训练下去不好说吧?
- Sequence-level MIS 在健全数据集上达到的最大训练准确率仅为 \(95%\)(而 FP16 为 \(99%\))
- Sequence-level MIS 在在 AIME 2024 基准上的得分为 \(34%\)(而 FP16 为 \(39%\))
- 以上差异显示出明显的性能上限
- 此外,与 FP16 方法相比,Sequence-level MIS 也表现出显著的部署差距
- 关于部署差距的更多证据可以在图 1 和图 6 中找到
The Efficacy of FP16 Precision
- 与这些算法方法相比,简单地将训练和推理精度从 BF16 切换到 FP16 带来了巨大的改进
- 如图 1 和图 6 所示,FP16 训练运行显著更稳定,收敛更快,并且在所有测试算法中实现了更高的最终奖励和评估分数
- 这一结果表明,在精度层面解决不匹配问题比应用不稳定或低效的算法校正是更直接、更有效的解决方案
- 最令人惊讶的发现是,FP16 精度从根本上改善了重要性采样的行为
- 在 FP16 中, Sequence-level 比率(以其高方差而臭名昭著)变得更加集中和稳定(见图 2)
- 这种稳定性使得使用经典的无偏策略梯度估计器(公式 (5))而无需任何修改成为可能
- 如图 3 所示,这种简单的、无偏的方法在 FP16 的支持下,显著优于 BF16 中所有现有的算法校正
Training Dynamics
- 有趣的现象:最终崩溃的算法在崩溃前都一致地显示出不断增长的 Training-Inference Mismatch ,使其成为一个潜在早期预警信号(见图 3)
- 在此期间,即使使用的是相同副本的权重,策略差异 \(\pi (\cdot |\theta^{\prime}) - \mu (\cdot |\theta^{\prime})\) 也收敛到极端值
- 其中一个策略的概率接近 1,而另一个接近 0
- 本文作者怀疑这是由某种优化偏差驱动的(需要进一步验证)
- 相比之下,稳定的算法保持了有界的不匹配
- 重点:FP16 训练显示出比任何 BF16 方法都低得多的 Mismatch 水平
- 这种精度层面的固有稳定性解释了为什么带有 FP16 的简单策略梯度能够超越所有现有的、更复杂的解决方案
Framework-Specific Differences
- 虽然本文作者的核心结论在 VeRL (2024) 和 Oat (2025b) 两个框架中都成立,但作者观察到了微妙的实现依赖差异
- 最初,Oat 中的 Training-Inference Mismatch 略小于 VeRL
- 初始策略差异 \(\pi (\cdot |\theta^{\prime}) - \mu (\cdot |\theta^{\prime})\):
- 在 Oat 中的最小值接近 -0.9
- 在 VeRL 中为 -1.0
- 即使在 FP16 下(两个框架都表现出较小的不匹配),VeRL 也更容易出现偶尔的数值尖峰
- 这些微妙的稳定性差异(本文将其归因于它们不同的分布式后端,即 DeepSpeed ZeRO 与 PyTorch FSDP)可能解释了为什么 Oat 产生略高的训练奖励,特别是对于那些最终崩溃的算法
- 初始策略差异 \(\pi (\cdot |\theta^{\prime}) - \mu (\cdot |\theta^{\prime})\):
Reviewing RL Algorithms under FP16
- 本节回顾各种 RL 算法在使用 FP16 精度训练时的性能
- 如图 4 所示,算法之间的性能差异几乎变得难以区分
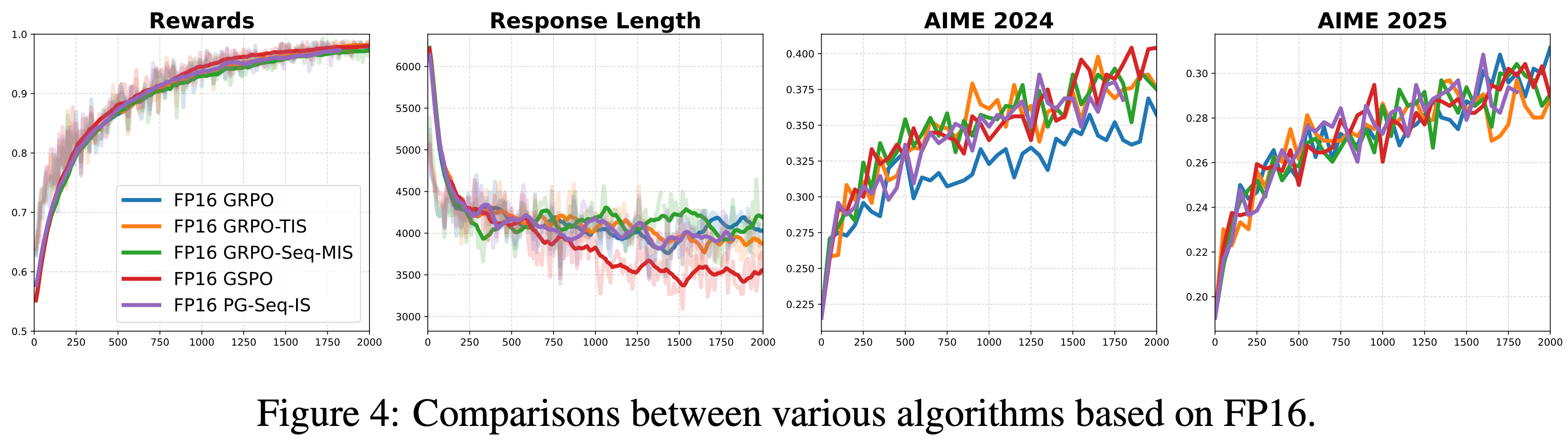
- 将这种性能上的趋同归因于 FP16 中 Training-Inference Mismatch 显著减少,这有效地将优化问题转化为一个近乎 On-Policy 的设置
- 在这种状态下,不同算法提供的复杂校正几乎没有带来额外的好处
- 一个微小的例外:原始的 GRPO 在 AIME 2024 基准上得分略低,但在 AIME 2025 上得分也略高,因此很难对其相对性能得出明确的结论
Ablation on the Precision
- 为了隔离训练和推理精度的影响,本文在 VeRL 框架上进行了一项消融研究,使用 vLLM (2023) 进行推理,使用 PyTorch FSDP (2023) 进行训练
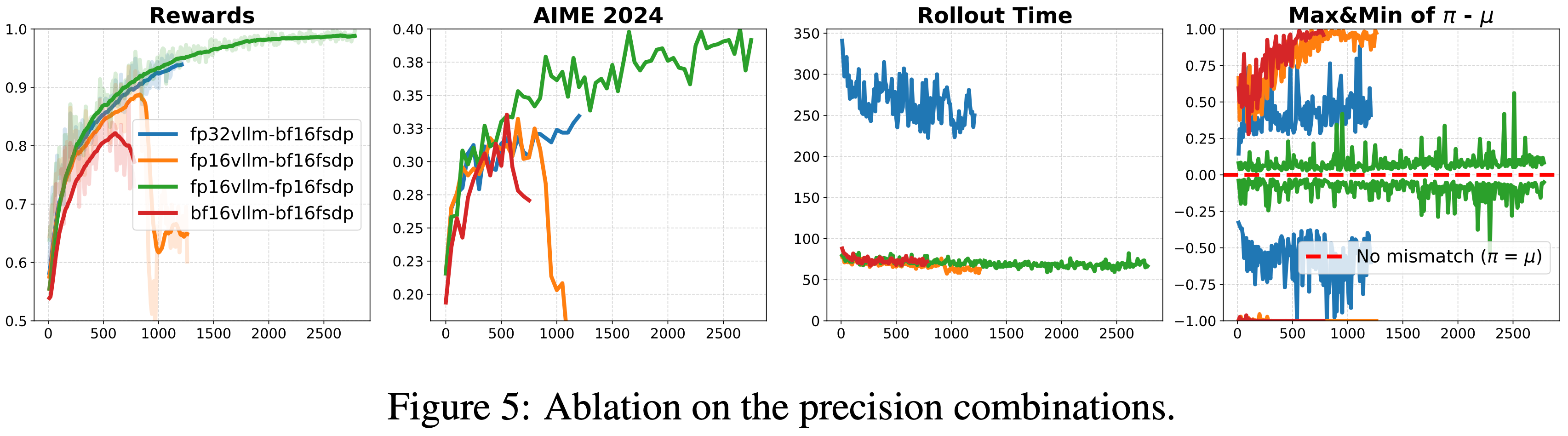
- 结果如图 5 所示
- 当使用 BF16 精度训练时,提高推理精度能持续延长训练的稳定性并改善性能
- 当与 FP32 推理配对时,训练运行变得完全稳定,没有崩溃的迹象
- 但这种稳定性带来了巨大的成本:FP32 推理比 FP16 或 BF16 推理慢近三倍,使得这种组合在大规模实验中不切实际
- 将 FP16 同时用于训练和推理产生了最佳结果
- 这种组合不仅产生了最低的 Training-Inference Mismatch ,而且产生了最稳定的训练动态
- 成功地在这个完美数据集上达到了接近 \(100%\) 的训练准确率,且没有任何速度损失,在稳定性和效率方面都展现出明显的优越性
- 当使用 BF16 精度训练时,提高推理精度能持续延长训练的稳定性并改善性能
Generalization Across Models, Data, and Training Regimes,跨模型、数据和训练范式的泛化
- 第 4 节中在健全性检查设置下仔细研究了各种算法修复,结论是
- 简单地从 BF16 切换到 FP16 可以显著提高训练稳定性(第 4.2 节),且其效果常常掩盖了算法调整的作用(第 4.3 节)
- 本节将超越健全性检查设置,在更多样化的场景中验证本文的发现,包括 MoE RL、LoRA RL,以及在更大的 Prompt 集和其他模型家族上的 RL
MoE RL
- MoE RL 训练以其不稳定性而闻名,通常需要复杂的稳定策略 (2025)
- MoE 模型的训练和推理通常涉及不同的并行化策略和对精度敏感的操作,例如 top-\(k\) 专家选择,这进一步使情况复杂化,并且与密集模型相比通常会导致更大的 Training-Inference Mismatch
- 鉴于 MoE 架构在现代 LLM 中的广泛采用,本文使用 Qwen3-30B-A3B-Base 对 MoE 模型进行 RL 实验
- 本文评估了三种不同的算法:GRPO-Seq-MIS、GRPO-Token-TIS 和 PG-Seq-TIS,详细实验设置见第 A.1 节
- 使用 FP16 的实验显示出更高的稳定性和持续更高的训练准确率(见图 1 中的 (i)、(j) 和 (k))以及更高的验证奖励(见图 6 中的 (i)、(j) 和 (k))
- 这种改进在所有三种算法中都是一致的,表明采用 FP16 有效地缓解了 Training-Inference Mismatch 并提升了整体性能
LoRA RL
- LoRA (2022) 因其效率以及与全微调相当的性能而在 LLM RL 中重新流行起来 (2025a; 2025)
- 为了研究基于 LoRA 的 RL 如何受数值精度影响,本文在标准 MATH 数据集上使用 GRPO-Token-TIS(公式 (9))训练 Qwen2.5-Math-1.5B 模型
- LoRA 以 rank 为 32 和缩放因子 \(\alpha = 64\) 应用于所有层
- 遵循 Schulman 和 Lab (2025) 的做法,采用比全微调中使用的稍大的学习率 \((4 \times 10^{-5})\)
- 如图 1 (h) 所示,基于 BF16 的 LoRA 训练在大约 600 步后崩溃,而 FP16 则在整个训练过程中保持稳定
RL on Large Dense Models
- 使用 Qwen3-14B-Base 进行实验,并遵循 DAPO 算法 (2025)
- 实验设置详情请参阅第 A.1 节
- 如图 1 (l) 所示,FP16 的训练奖励增长速度远快于 BF16
- 图 6 (l) 表明 FP16 在 AIME 2024 上取得了更高的验证准确率
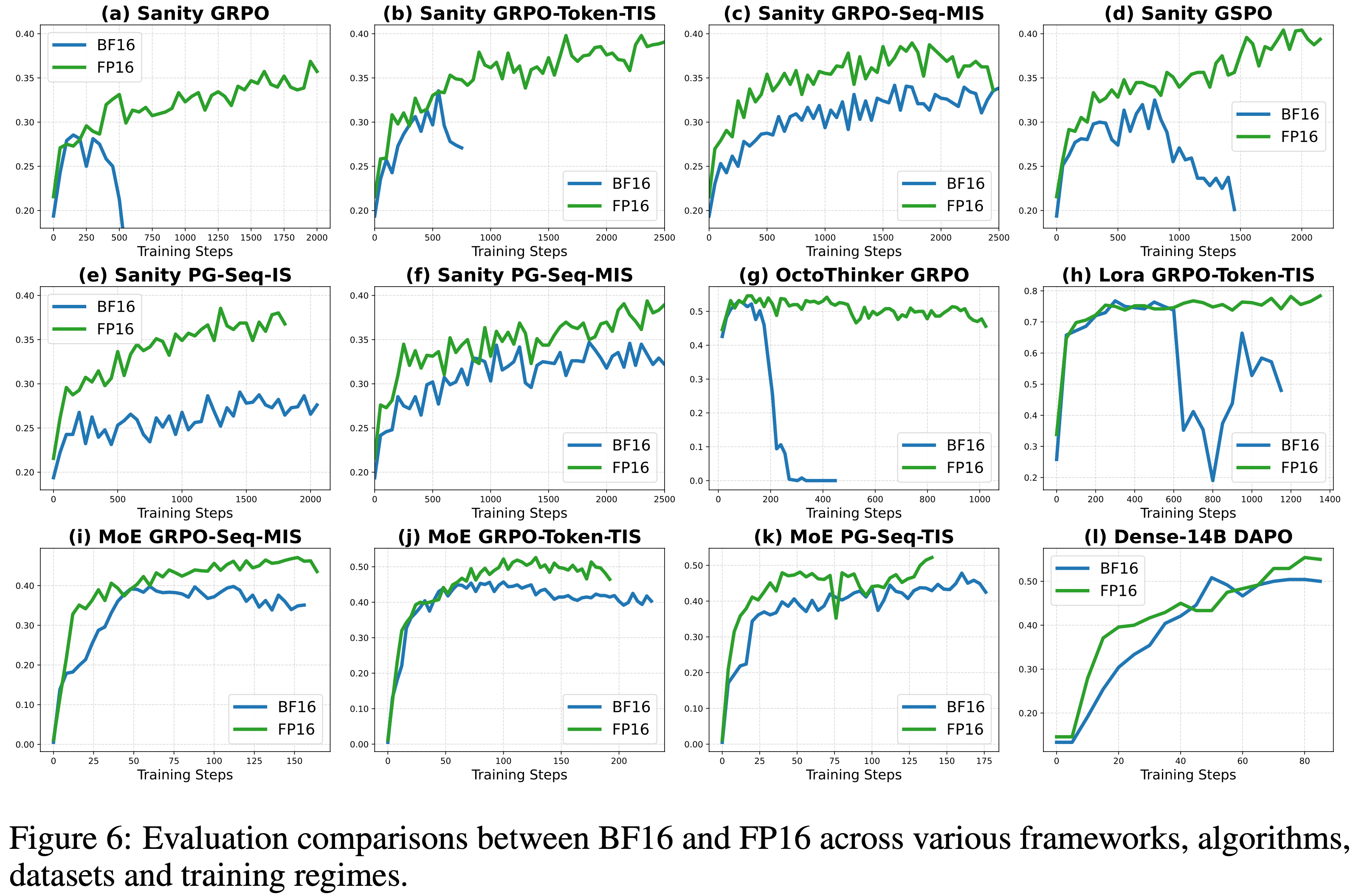
- 以上这些结果表明,使用 FP16 而不是 BF16 能有效缓解大型模型中的 Training-Inference Mismatch
RL on Other Model Families
- 作为 RL 初始策略的基础模型可以显著影响学习动态
- 它们不仅决定了探索的范围,还决定了网络参数和激活的数值范围和敏感性
- 为了加强本文的实验结论,本文将研究扩展到基于 Qwen 的模型之外,并使用 GRPO 训练 OctoThinker-3B (2025b),这是一个从 Llama3.2-3B (2024) 经过推理密集型数据中间训练得到的模型
- 如图 1 (g) 所示,由于数值不匹配,BF16 训练在大约 150 步后变得不稳定,而 FP16 则继续平稳训练,没有崩溃
Discussions
Rethinking the Precision Tradeoff in RL Fine-Tuning
- 数值精度是 LLM 训练栈中的一个基础选择,但长期以来这一选择在预训练和后训练中都由 BF16 主导
- 因 BF16 的广泛的动态范围和使用便捷性而备受青睐
- 本文结果表明,对于 RL 微调,这种默认选择值得慎重考虑
- 在 RL 阶段, Training-Inference Mismatch 成为不稳定的关键来源,BF16 的低精度加剧了这一问题
- 只需用 BF16 的广泛动态范围换取 FP16 的更高精度,就可以实现显著更稳定的 RL 训练、更快的收敛速度和更优的最终性能
- 注:本文作者并非声称 FP16 是普遍最优的选择
- 对效率的追求可能会引导开发者走向更低精度,如 FP8
- 此外,对于极其庞大的模型,使用 FP16 可能会带来与其有限范围相关的工程挑战 ,例如管理潜在的溢出
- 但作者认为这些都是可解决的挑战,近期在大型 FP8 训练方面的成功就证明了这一点
The Bias-Variance Tradeoff under BF16 Precision
- 第 4.2 节中的结果揭示了在 BF16 精度下运行的 RL 算法之间存在偏差-方差权衡
- 具有较低方差但较高偏差的方法(如 GRPO、 Token-level TIS 和 GSPO)最初收敛很快,但不稳定并最终崩溃
- 理解:
- GRPO 假设 inference policy 和 training policy 是相同的,忽略了两者的不同,所以有偏差(需要做重要性采样),因为忽略了,所以方差理论上为 0
- Token-level TIS 在 GRPO 的基础上进行了修正,但修正是 Token-level 的,存在偏差(但因为本身是 Token-level,相对 Sequence-level 的多个概率连乘来说,方差不大)
- GSPO 虽然是 Sequence-level 的,但使用了几何平均,所以方差确实小,但因为不是严格的 IS 权重,所以存在偏差
- 理解:
- 更准确地校正策略不匹配的低偏差算法(如 PG-Seq-IS 和 GRPO-Seq-MIS)实现了稳定性,但代价是高方差,这减慢了它们的收敛速度
- Sequence-level 的校准本身是无偏的,但是会引入高方差
- 这种权衡在 FP16 精度下变得不那么关键
- 通过从根本上减少 Training-Inference Mismatch ,FP16 自然地降低了由不匹配引起的偏差和重要性采样校正的方差
- 这种增强的稳定性使得即使是最简单的策略梯度估计器也能高效收敛,从而创造出一种所有测试算法都表现良好且稳定性与速度之间的张力得到有效解决的训练动态
附录 A:Detailed Experimental Settings
A.1 MoE RL
- 对于 MoE RL 的实验,使用 Qwen3-30B-A3B-Base 作为 Base 模型
- 训练数据来自 DAPO-Math-17k (2025),使用
avg@32指标在 AIME 2024 上进行在线评估 - 训练采用 VeRL 框架 (2024),关键超参数总结在表 3 中
- Dr.GRPO (2025c) 提出使用一个常数归一化器,而不是基于 token 计数的归一化器
- 注:开源的 VeRL 实现并未正确实现这一点
- 本文作者将其修正后的版本称为 VeRL 中 actor.loss_agg_mode 的 “seq-mean-token-sum-norm”
A.2 RL on Large Dense Models
- 对于大稠密模型上的实验,使用 Qwen2.5-14B-Base 作为基础模型
- 训练数据来源于 Cheng 等 (2025) 整理的一个数学领域数据集
- 聚合了最近的一些数学推理集合,包括 OR1 (2025)、DAPO (2025) 和 DeepScaler (2025),然后执行了去重和过滤,得到最终的 54.4k 个数学训练样本集合
- 使用
avg@8指标在 AIME 2024 上进行在线评估 - 训练算法和超参数遵循 Yu 等 (2025) 中描述的设置,如表 3 所总结
附录 B:More Experimental Results
- 图 6:在不同框架、算法、数据集和训练机制下,BF16 和 FP16 之间的评估比较
- 对比:
- 图 1 展示了不同精度下的训练奖励曲线
- 图 6 展示了使用这些精度训练的检查点的评估结果
- 结论:FP16 训练的模型能够很好地泛化到未见过的基准测试上,进一步支持了本文的结论