注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- 论文提出了一种旨在提升大语言模型 Agent 能力的方法 称为 ETO(Exploration-based Trajectory Optimization)
- 论文的方法通过试错学习(trial and error)优化基于行为克隆的基础 Agent
- ETO 采用探索-训练迭代框架(持续提升 Agent 性能):
- 在探索阶段, Agent 与环境交互并收集失败轨迹,构建轨迹偏好对
- 在训练阶段, Agent 通过 DPO 损失从偏好信息中学习
- 特别说明:ETO 展现出卓越的任务解决效率,并在缺乏专家轨迹的场景中表现出巨大潜力
- 论文提出了一种旨在提升大语言模型 Agent 能力的方法 称为 ETO(Exploration-based Trajectory Optimization)
- 更详细一些的说明:论文提出了一种基于探索的轨迹优化方法 ETO
- 与以往仅依赖成功专家轨迹的研究不同,论文的方法允许 Agent 从其探索失败中学习,通过迭代优化框架提升性能
- 在探索阶段,Agent 通过与环境交互完成任务,收集失败轨迹以构建对比轨迹对;在随后的训练阶段,Agent 利用这些轨迹偏好对,通过对比学习方法(如 DPO)更新策略
- 这种探索与训练的迭代循环促进了 Agent 的持续改进
- 论文在三个复杂任务上的实验表明,ETO 始终以显著优势超越基线方法
Introduction and Discussion
- LLM 通过为环境和工具交互制定行动计划,展现了解决复杂交互任务的强大能力(2023a; 2023)
- 以 ChatGPT(OpenAI, 2022)和 GPT-4(OpenAI, 2023)为核心控制器的系统已被开发用于多种应用,包括网页浏览(2023; 2023)、具身任务(2022a; 2023)、多模态推理(2023)以及复杂问答
- 然而,近期研究表明,开源 LLM 在构建 Agent 时的效果远不及 GPT-4(2023; 2023a; 2023)
- 构建开源 LLM Agent 的标准方法是模仿学习(Imitation Learning),即基于专家轨迹对 LLM 进行微调
- 行为克隆(BC, Behavioral Cloning)(Pomerleau, 1991)是一种简单有效的模仿学习技术,通过从观察-动作对中进行监督学习来推导策略
- 近期研究(2023; 2023)如 Agent Lumos(2023)探索了使用 BC 通过专家轨迹的监督微调(SFT, Supervised Fine-Tuning)开发开源 LLM Agent
- 这些方法采用 teacher-forcing 算法训练 LLM,使其能够基于观察和过去动作学习生成后续动作的策略
- 然而,这些完全依赖专家演示的 SFT 方法可能由于对目标环境探索不足而产生次优策略,从而限制其泛化能力
- 人类学习的过程不仅包括观察成功示范,还包含通过与环境的试错交互体验和探索失败 ,受此启发,论文提出了一种新颖的 LLM Agent 学习方法,称为 基于探索的轨迹优化(ETO)
- 与以往仅依赖成功轨迹的方法不同,论文的方法利用当前策略的探索失败来增强 Agent 的学习过程
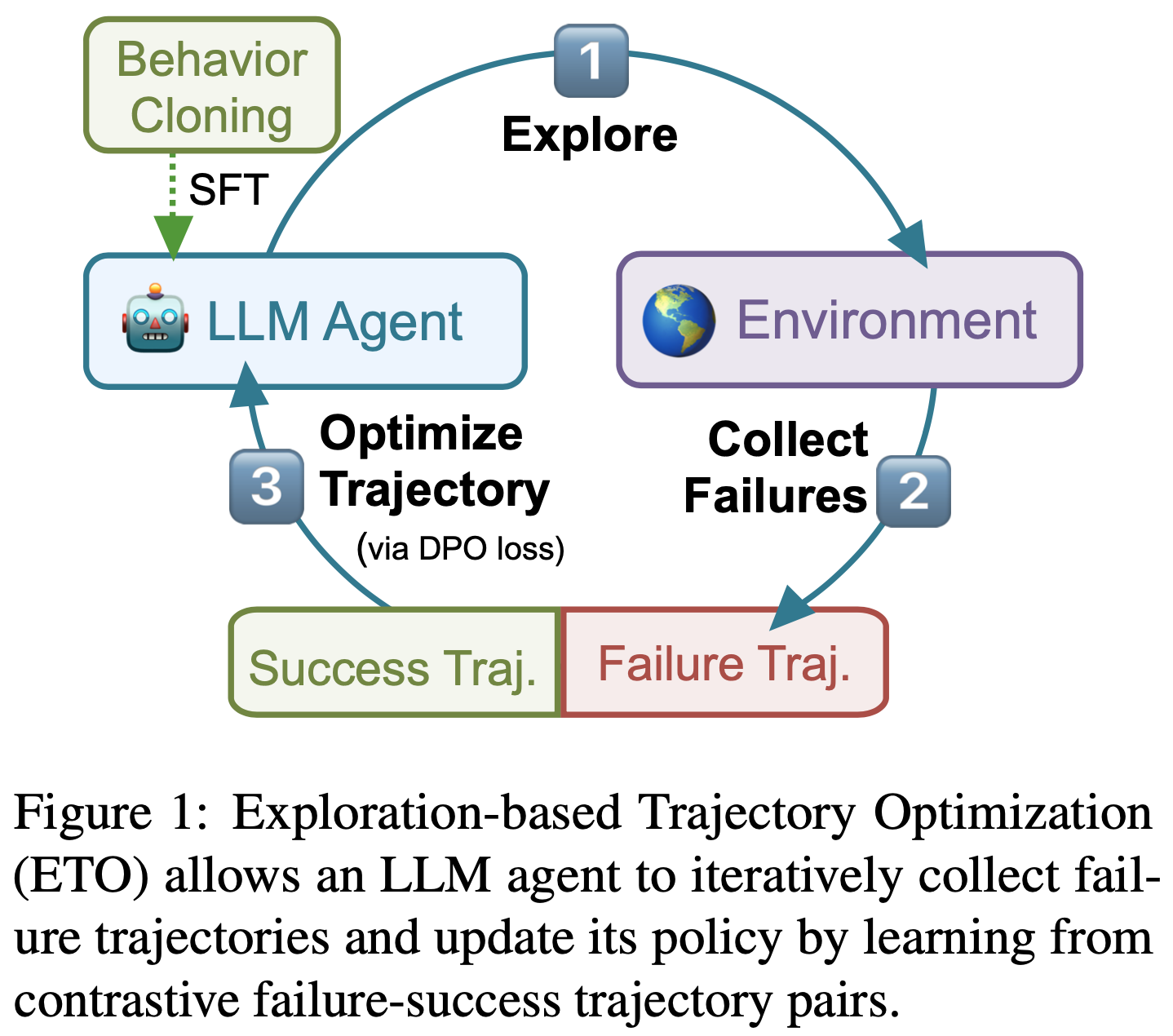
- 具体而言,论文首先使用基于 SFT 的行为克隆构建 Base Agent(如图1 所示)
- 在探索阶段,Base Agent 与目标环境交互以完成给定任务,并从环境中获取反馈。论文收集 Base Agent 的失败轨迹 ,并将其与先前为这些任务收集的专家轨迹配对
- 在训练阶段,论文应用 DPO 损失(2023)通过这些对比轨迹对微调 LLM 策略,从而进一步提升 Agent
- ETO 可以通过从先前调优的 Agent 中收集失败案例扩展到多轮迭代
- 论文在三个代表性数据集上评估了论文的方法:
- 用于网页导航的 WebShop(2022a)
- 用于模拟科学实验的 ScienceWorld(2022)
- 用于具身家庭任务的 ALFWorld(2021)
- 在这些数据集上,ETO 始终以显著优势超越 SFT 行为克隆和其他强基线方法,证明了从探索失败中学习的有效性
- 其他扩展实验和分析:
- 论文的方法在 ScienceWorld 的挑战性分布外测试集上实现了 22% 的性能提升,展现了强大的泛化能力
- 论文的方法在任务解决效率上表现优异,能够以更少的动作步骤获得更高的奖励
- 在极端缺乏专家轨迹的场景下,ETO 在自博弈模式下仍能表现出色,进一步凸显了其潜力
- 论文的贡献总结如下:
- 方法 :论文提出了基于探索的轨迹优化方法 ETO,这是一种通过迭代收集失败轨迹并利用对比学习优化 Agent 策略的学习算法
- 评估 :在三个复杂交互任务上的大量实验表明,论文的方法以显著优势超越了 SFT 行为克隆和其他强基线方法
- 分析 :论文通过多角度深入分析验证了 ETO 的有效性,包括分布外泛化、动作效率以及无需专家轨迹的可行性
任务形式化
- 具有环境反馈的 Agent 任务可以形式化为部分可观测马尔可夫决策过程(POMDP, Partially Observable Markov Decision Process)\((\mathcal{U}, \mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T}, \mathcal{R})\)
- \(\mathcal{U}\) 是指令空间(instruction space)
- \(\mathcal{S}\) 是状态空间
- \(\mathcal{A}\) 是动作空间
- \(\mathcal{O}\) 是观测空间
- \(\mathcal{T}: \mathcal{S} \times \mathcal{A} \rightarrow \mathcal{S}\) 是状态转移函数
- \(\mathcal{R}: \mathcal{S} \times \mathcal{A} \rightarrow [0,1]\) 是奖励函数
- 注意:在论文的 LLM-based Agent 场景中,\(\mathcal{U}, \mathcal{A}, \mathcal{O}\) 均为自然语言空间的子集
- 交互过程可总结为:
- 给定任务指令 \(u \in \mathcal{U}\)
- 参数为 \(\theta\) 的 LLM Agent 根据其策略 \(\pi_{\theta}\) 生成动作 \(a_1 \sim \pi_{\theta}(\cdot|u) \in \mathcal{A}\)
- 该动作引发潜在状态空间 \(s_t \in \mathcal{S}\) 的变化,并产生执行反馈作为观测 \(o_t \in \mathcal{O}\)
- Agent 在第 \(t+1\) 步生成相应动作 \(a_{t+1} \sim \pi_{\theta}(\cdot|u, a_1, o_1, …, o_{t-1}, a_t, \color{red}{o_t}) \in \mathcal{A}\)(注:红色部分 \(\color{red}{o_t}\) 是原始论文中没有加的,这里应该加上才对)
- 交互循环持续至任务完成或超过最大步数,轨迹 \(e\) 表示为:
$$
e = (u, a_1, o_1, …, o_{n-1}, a_n) \sim \pi_{\theta}(e|u), \tag{1}
$$- 其中策略为(\(n\) 为轨迹长度):
$$
\pi_{\theta}(e|u) = \prod_{j=1}^n \pi_{\theta}(a_j|u, a_1, o_1, …, o_{j-1}), \tag{2}
$$
- 其中策略为(\(n\) 为轨迹长度):
- 最终计算任务完成度对应的奖励 \(r(u,e) \in [0,1]\),1 表示任务成功完成
Method
- 论文的方法 ETO 首先通过行为克隆(Behavioral Cloning, BC)训练一个 Base Agent
- 基于该 Base Agent,论文的框架通过迭代式的试错过程持续优化策略
Behavioral Cloning
- 行为克隆(BC)通过在专家交互轨迹数据上进行 SFT ,已展现出良好的效果,为构建强大的 Agent 奠定了坚实基础
- 在本工作中,论文采用 ReAct-style(2022b)的轨迹进行 BC,该方法在生成每个动作前还会生成链式推理(Chain-of-Thought, CoT)的理性解释(rationale)
- 由于 CoT 和动作在 ReAct 框架中是一起生成的,为简化表示,论文用 \( a \) 表示带有 CoT 的动作
- 给定专家轨迹数据集 \( \mathcal{D} = \left\{(u, e)^{(i)}\right\}_{i=1}^{|\mathcal{D}|} \),其中 \( |\mathcal{D}| \) 是轨迹数量,论文通过自回归损失对一个 LLM 进行微调,得到 Base Agent \( \pi_{\text{base} } \):
$$
\mathcal{L}_{\text{SFT} }(\pi_{\theta}) = -\mathbb{E}_{e \sim \mathcal{D} } \left[\pi_{\theta}(e|u)\right], \tag{3}
$$- 其中 \( e = (u, a_1, o_1, …, o_{n-1}, a_n) \sim \mathcal{D} \) 是一条专家交互轨迹
- 由于 \( \pi_{\theta}(e|u) = \prod_{j=1}^{n} \pi_{\theta}(a_j|u, …, o_{j-1}) \),在实践中,论文首先将轨迹 \( e \) 中的指令、动作和观察拼接为一个文本序列 \( t \):
$$
t = \text{concat}(u, a_1, o_1, …, o_{n-1}, a_n) = (t_1, t_2, …, t_l),
$$- 其中 \( t_k \) 是结果序列中的第 \( k \) 个 词元(token)
- 注意 token \(t_k\) 和 \(a_j\) 不是一一对应的关系,一个 \(a_j\) 可能对应多个 token \(t_k\)
- 然后,公式 (3) 中的轨迹概率可以通过直接计算动作的概率(同时掩码任务描述和观察中的 token )得到:
$$
\pi_{\theta}(e|u) = -\sum_{k} \log \pi_{\theta}(t_k|t_{<k}) \times \mathbf{1}(t_k \in A),
$$- 其中 \( \mathbf{1}(t_k \in A) \) 是一个指示函数,用于判断 \( t_k \) 是否属于 Agent 生成的动作 token
Learning From Exploration Failures
- 行为克隆完全依赖于专家轨迹,缺乏对环境探索的能力,这可能导致策略次优
- 为了训练更强大的 Agent,模型需要能够从失败轨迹中学习
- 实现这一目标的一种可行方法是 RL ,它使 Agent 能够主动探索环境以获取奖励,并通过试错优化策略(2022):
$$
\max_{\pi_{\theta} } \mathbb{E}_{u \sim \mathcal{D}, e \sim \pi_{\theta}(e|u)} \left[r(u, e)\right] - \beta \mathbb{D}_{\text{KL} } \left[\pi_{\theta}(e|u) \mid \mid \pi_{\text{ref} }(e|u)\right], \tag{6}
$$- 其中 KL 项与权重参数 \( \beta \) 用于控制与基础参考策略 \( \pi_{\text{ref} } \)(即 Base Agent \( \pi_{\text{base} } \))的偏离程度
- 在实践中,待训练的 Agent 策略 \( \pi_{\theta} \) 也初始化为 \( \pi_{\text{base} } \)。然后,公式 (6) 中的优化问题可以通过 RL 方法(如 PPO,2017)求解
- 然而,直接在 LLM Agent 上应用在线 RL 会面临实际挑战,例如不稳定性和低效率(2023; 2023)。因此,论文设计了一种迭代式离线学习框架 ,通过对比轨迹数据训练 Agent
- 如图2 所示,训练过程可以表述为一个迭代的探索-训练循环(iterative exploration-training loop)
- 在 ETO 的探索阶段,Agent 探索环境以收集失败轨迹;
- 在 ETO 的训练阶段,Agent 从“失败-成功”(failure-success)轨迹对中学习对比信息以更新策略
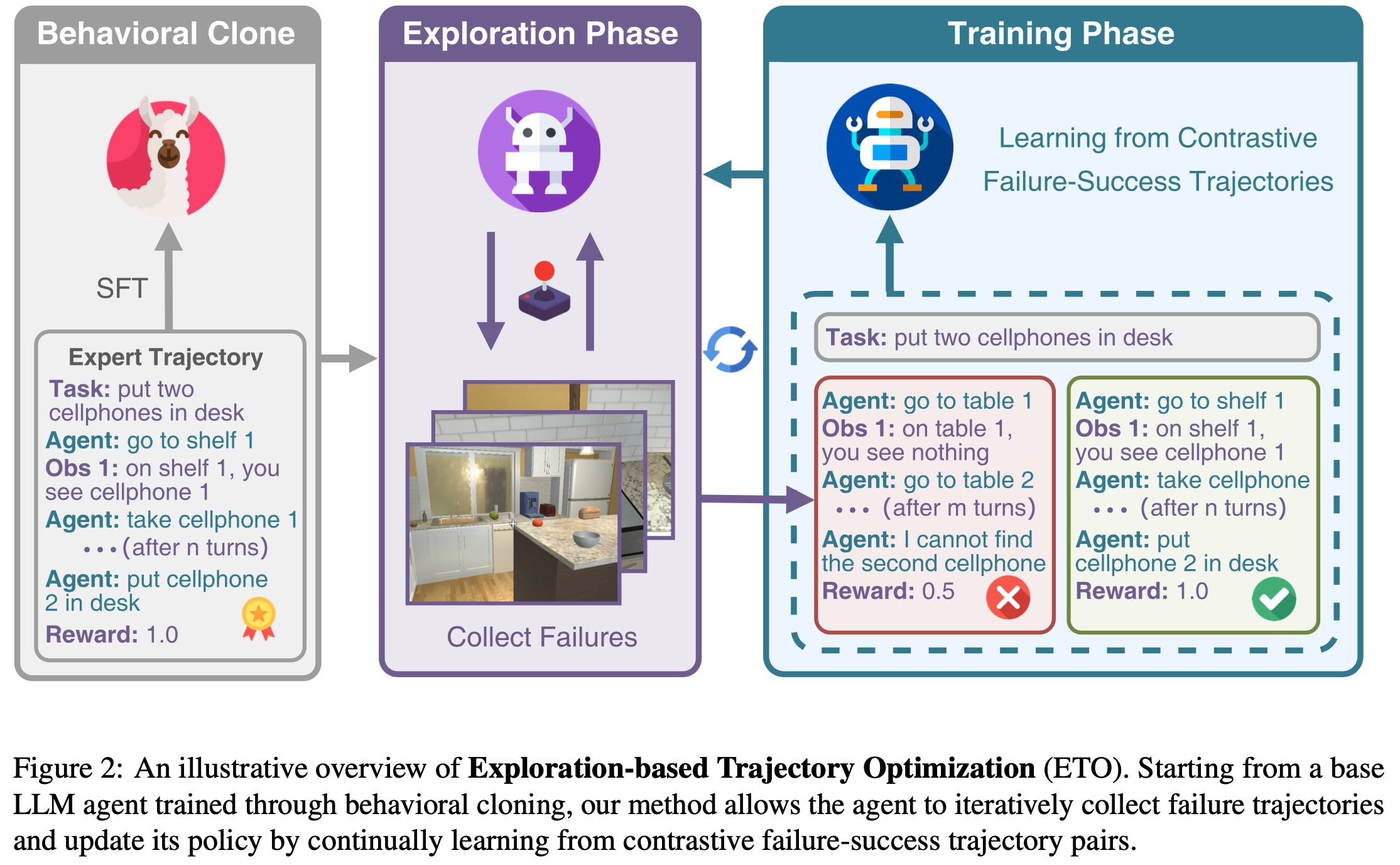
Exploration Phase
- 在探索阶段 ,Base Agent \( \pi_{\text{base} } \) 探索环境,收集训练数据中指令对应的轨迹:
$$
\hat{e} = (u, \hat{a}_1, \hat{o}_1, …, \hat{o}_{m-1}, \hat{a}_m) \sim \pi_{\text{base} }(e|u). \tag{7}
$$ - 环境随后返回轨迹 \( \hat{e} \) 对应的奖励 \( \hat{r} \)
- 然后,论文基于最终奖励构建“失败-成功”轨迹对,记为 \( e_w \succ e_l \mid u \)
- \( e_w \) 表示从专家轨迹 \( e \) 中选出的奖励较高的轨迹
- \( e_l \) 表示从 Agent 生成轨迹 \( \hat{e} \) 中选出的奖励较低的轨迹
- 注意,论文仅收集奖励不同的轨迹对。如果 \( \hat{e} \) 和 \( e \) 都成功完成任务,则直接丢弃该对
- 最终,论文得到对比轨迹数据集:
$$ \mathcal{D}_p = \left\{(u, e_w, e_l)^{(i)}\right\}_{i=1}^{|\mathcal{D}_p|} $$
Training Phase
- 在训练阶段 ,通过建模轨迹对数据中的“失败-成功”对比信息来更新 Agent 策略
- 给定轨迹对 \( e_w \succ e_l \mid u \),其“失败-成功”关系可以通过 Bradley-Terry(BT)模型(Bradley and Terry, 1952)建模:
$$
p(e_w \succ e_l|u) = \frac{\exp \left(r(u, e_w)\right)}{\exp \left(r(u, e_w)\right) + \exp \left(r(u, e_l)\right)}. \tag{8}
$$ - 在公式 (6) 的最优策略 \( \pi_r(e|u) \) 下,环境中的奖励函数 \(r(u, e)\) 可以表示为(2019; 2023):
$$
r(u, e) = \beta \log \frac{\pi_r(e|u)}{\pi_{\text{ref} }(e|u)} + \beta \log Z(x), \tag{9}
$$- 其中 \( Z(u) = \sum_{e} \pi_{\text{ref} }(e|u) \exp \left(\frac{1}{\beta} r(u, e)\right) \) 是配分函数
- 将公式 (9) 代入公式 (8),得到关于策略的 BT 模型:
$$
p(e_w \succ e_l|u) = \sigma \left(\beta \log \frac{\pi_{\theta}(e_w|u)}{\pi_{\theta}(e_l|u)} - \beta \log \frac{\pi_{\text{ref} }(e_w|u)}{\pi_{\text{ref} }(e_l|u)}\right),
$$- 其中 \( \sigma \) 是 sigmoid 函数
- 然后,通过极大似然估计可以得到最优策略 \( \pi_{\theta} \):
$$
\mathcal{L}_{\text{DPO} }(\pi_{\theta}; \pi_{\text{ref} }) = -\mathbb{E}_{(u, e_w, e_l) \sim \mathcal{D}_p} \left[\log \sigma \left(\beta \log \frac{\pi_{\theta}(e_w|u)}{\pi_{\theta}(e_l|u)} - \beta \log \frac{\pi_{\text{ref} }(e_w|u)}{\pi_{\text{ref} }(e_l|u)}\right)\right].
$$ - 这一优化目标旨在增加成功轨迹 \( e_w \) 的似然,同时降低失败轨迹 \( e_l \) 的似然,并通过约束项保持 Base Agent 的能力。此外,作为公式 (6) 的 RL 目标的重构,公式 (11) 直接最大化最终奖励,同时避免了执行 RL 优化的需求
Iteration
- 为了进一步提升 Agent 的性能,ETO 采用迭代式的探索-训练方式
- 在训练阶段后,Agent 策略可用于收集新的失败案例并创建对比轨迹对
- 这些新数据随后通过轨迹对比学习进一步优化 Agent
- ETO 的完整学习过程如算法 1 所示

Experiments
- 在本节中,论文进行了广泛的实验以验证 ETO 的有效性
- 论文的方法在三个数据集上均表现出优于基线的性能,并且在处理分布外未见任务时展现出更强的优势
- 分析进一步展示了论文方法的高效性
- 此外,论文的方法在专家轨迹不可用的场景中也表现出了潜力(注:可解决没有专家轨迹的问题)
Experimental Settings
- 数据集(Datasets) 论文在三个具有代表性的 Agent 数据集上进行了实验:
- 用于网页导航的 WebShop(2022a)
- 用于具身科学实验的 ScienceWorld(2022)
- 用于具身家务任务的 ALFWorld(2021)
- WebShop 和 ScienceWorld 环境提供了从 0 到 1 的密集最终奖励
- ALFWorld 仅提供二进制奖励,表示任务是否完成
- 这三个环境均可形式化为部分可观测马尔可夫决策过程(POMDP)
- 关于数据集和专家轨迹收集过程的详细信息,请参阅附录 A
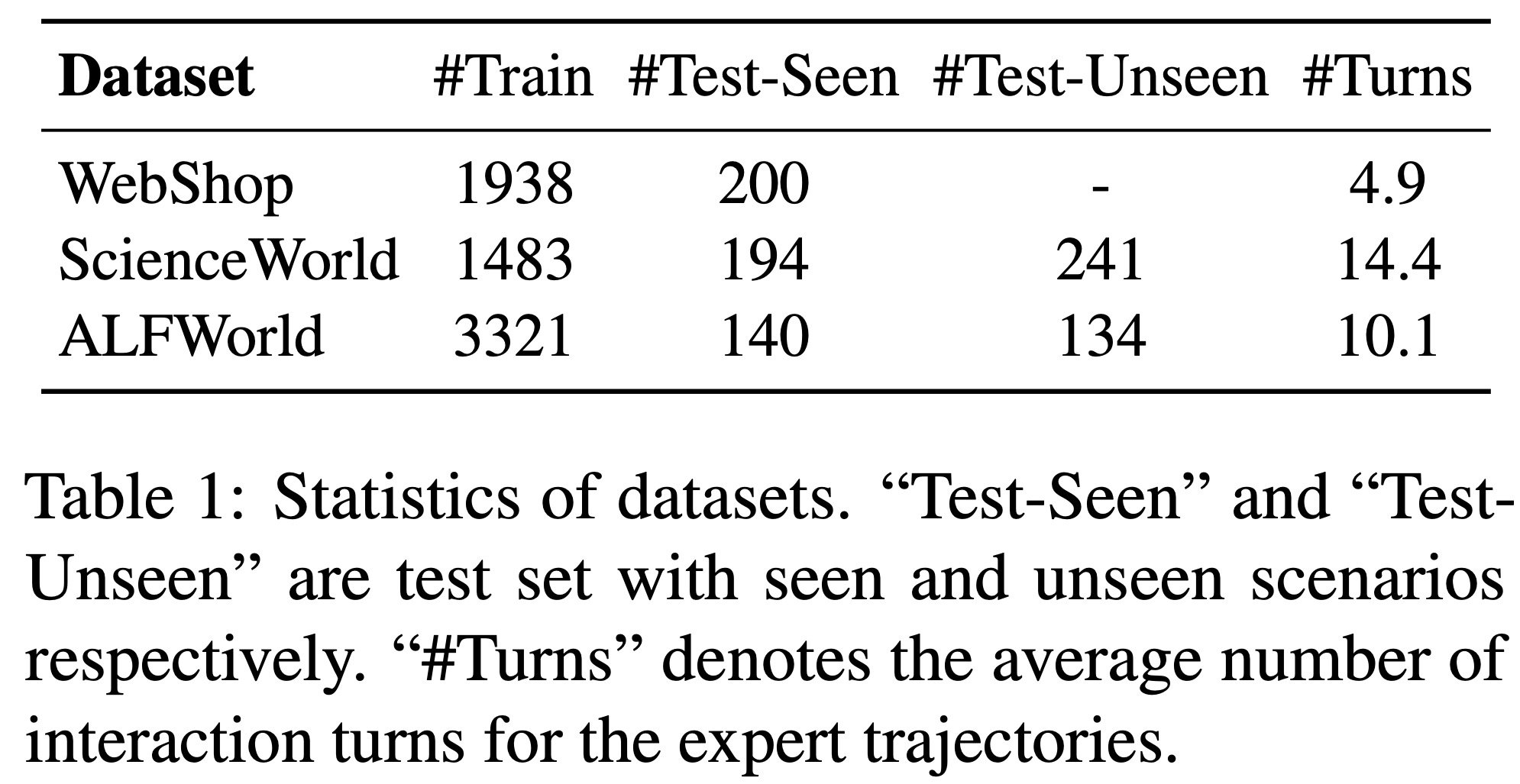
- 表 1 展示了论文数据集的统计信息
- 值得注意的是,除了分布内测试集外,ScienceWorld 和 ALFWorld 还包含分布外未见变体的测试集
- 这些额外的测试集使论文能够评估不同 Agent 的泛化能力
- Training Setup 论文主要使用 Llama-2-7B-Chat(2023)作为构建 LLM Agent 的基础模型。为了提供更全面的结果,论文还对 Llama-2-13B-Chat 和 Mistral-7B(2023)进行了实验
- 论文使用了 AdamW 优化器
- 在 SFT 阶段:
- 批大小为 64
- 学习率设置为 1e-5(warmup 后的初始学习率)
- 预热比例为 3%
- 使用余弦调度器(cosine scheduler)
- epochs = 3
- 随后,Base Agent 将为训练集中的每个实例探索一次以收集失败轨迹
- 在 ETO 的训练阶段:
- 批大小为 32
- 学习率设置为 1e-6(注:一般来说,为了稳定性考虑 DPO/RL的学习率比 SFT 要更小些)
- DPO 损失中的 \(\beta\):在 WebShop 和 ScienceWorld 中设置为 0.1;在 ALFWorld 中设置为 0.5
- epochs = 3
- ETO 的迭代次数:在 WebShop 和 ScienceWorld 中设置为 2;在 ALFWorld 中设置为 1
- 所有实验均在 8 块 NVIDIA A100 80G GPU 上进行
- Baselines :论文将 ETO 与 SFT 行为克隆(Behavioral Cloning, BC)和其他后模仿基线方法进行了比较:
- 1)SFT(2023;)在专家轨迹上进行行为克隆,这是 ETO 和其他基线的 Base Agent
- 2)Best-of-N 采样 使用 SFT Base Agent,并在 N 次采样中选择奖励最高的轨迹。此处论文将 N 设置为 10
- 3)RFT(Rejection sampling Fine-Tuning, 2023)是一种强大的基线方法,它将成功轨迹添加到专家轨迹数据集中,并在新的增强轨迹上训练 Agent
- 4)PPO(Proximal Policy Optimization, 2017)是一种强化学习方法,直接优化 SFT Agent 以最大化最终任务奖励
论文还纳入了 GPT-3.5-Turbo(OpenAI, 2022)、GPT-4(OpenAI, 2023)以及未调优的 Llama-2-7B-Chat 进行比较
- Evaluation :所有方法均使用 ReAct-style 的交互格式(2022b)进行评估,并在动作前生成 CoT 推理
- 每个任务的指令提示中包含 1-shot 上下文示例
- LLM 的解码温度设置为 0.0 以实现确定性生成,Best-of-N 方法除外
- 论文主要采用平均奖励(Average Reward)作为指标,表示测试集中所有任务实例的平均奖励
- 附录 B 中还 Report 了成功率(Success Rate)以供参考
Results
- 表2 展示了 ETO 和基线方法在三个 Agent 数据集上的性能对比
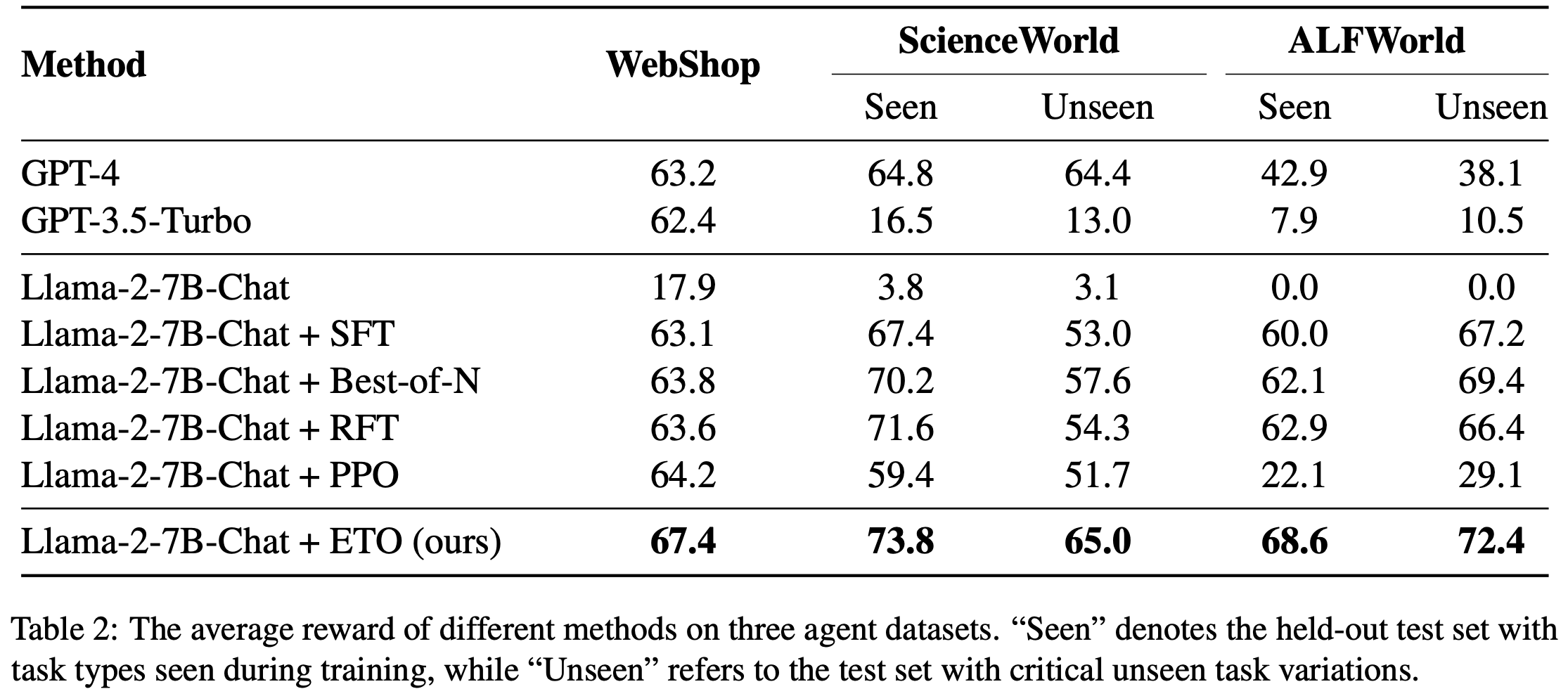
- 结果显示,ETO 在 SFT 模仿学习的基础上实现了显著提升,使 WebShop 和 ScienceWorld 的平均奖励分别提高了 8% 和 9.5%
- 论文的方法在所有数据集上均优于其他基线方法
- 在 WebShop 数据集上,ETO 的平均奖励甚至超过了 GPT-4,展现了论文方法的卓越性能
- 尽管 RFT 方法相比 SFT 也有所改进,但其性能仍然受限,因为它是行为克隆的增强版本,仅从成功轨迹中学习
- 这一对比表明,失败轨迹与专家轨迹的对比对于提升 Agent 性能至关重要
- 尽管 PPO 在 WebShop 上取得了性能提升,但由于强化学习优化过程固有的不稳定性,它在其他两个数据集上难以取得令人满意的结果,尤其是在仅提供二进制最终奖励的 ALFWorld 数据集上
- 附录 D 展示了论文方法在任务解决轨迹上的案例分析
- 泛化性方面:
- ETO 在分布外未见场景中展现出更强的优势,在 ScienceWorld-Unseen 上实现了 20% 的性能提升;
- 此外,ETO 在 ALFWorld 的未见场景中也表现出强大的有效性,优于 RFT 和 PPO 基线,后两者均出现了性能下降
- 这些结果表明,通过试错学习可以进一步提升 Agent 的泛化能力,尤其是在分布外未见场景中
- 不同 LLM 的结果(Results on Different LLMs):为了进一步证明论文方法的有效性,论文展示了基于其他基础 LLM(包括 Llama-2-13B-Chat 和 Mistral-7B)的结果
- 表 3 表明,ETO 在不同 LLM 上均能一致提升 Agent 性能
- 值得注意的是,与 Llama-2-7B 相比,13B 模型在两个数据集上的性能提升相对较小,这表明论文的方法可以为较弱的 Agent 带来更大的收益
- 尽管 Mistral-7B 是一个比 Llama-2-13B 更强大的 LLM,但在经过 SFT 或 ETO 后,其性能仍不及 Llama-2-7B
- 这一发现表明,基础 LLM 能力与 Agent 能力之间并无强相关性
- 效率分析(Analysis on Efficiency):论文在 ScienceWorld 环境中评估了 Agent 的任务解决效率,该环境为每个任务提供了细粒度的子目标,任务的奖励会根据子目标的完成情况更新
- 通过评估 Agent 在更少动作步骤内实现更高奖励的能力 ,我们可以确定其效率
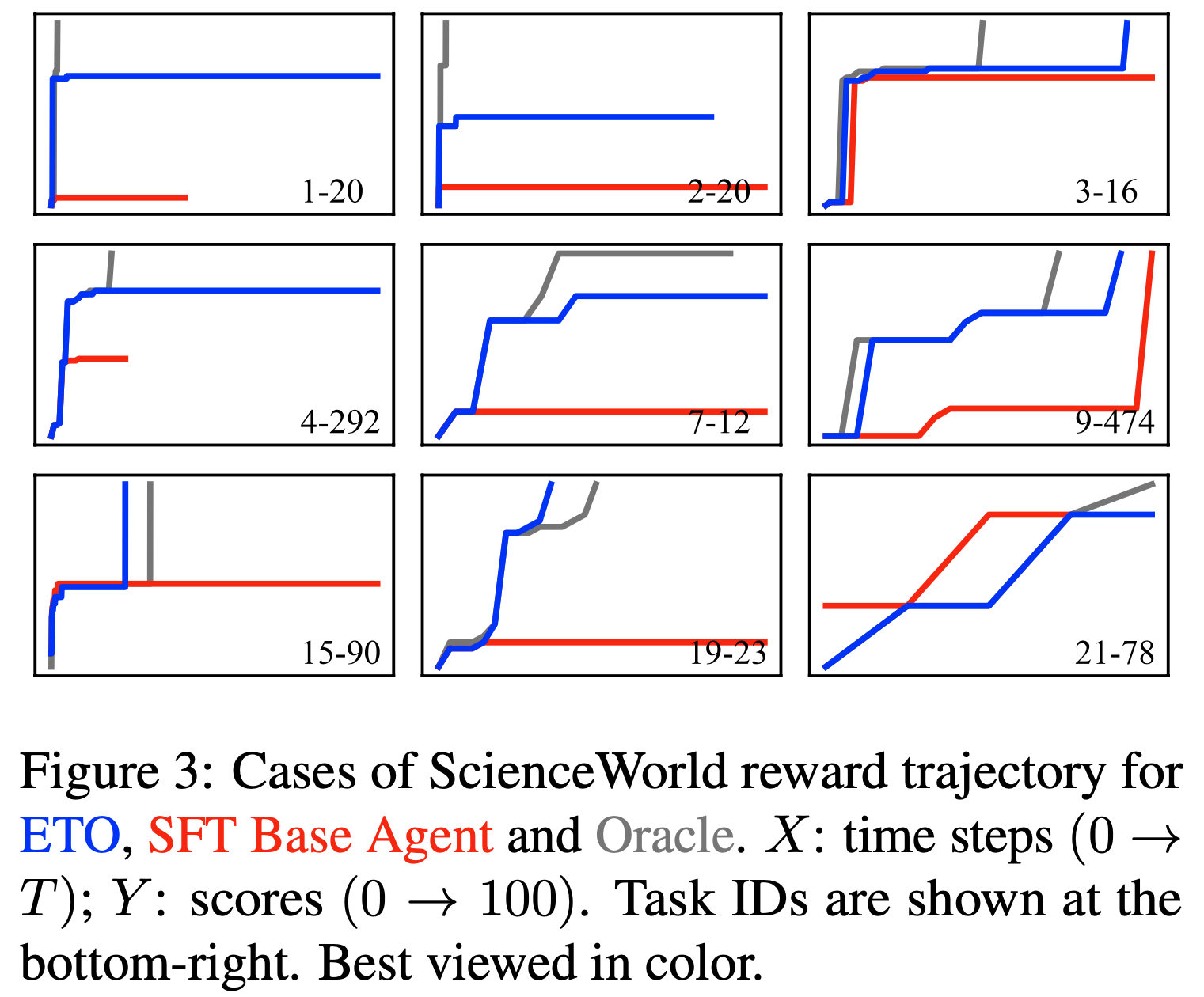
- 图3 展示了 ScienceWorld-Seen 测试集的得分轨迹,对比了 ETO、SFT Base Agent 和 Oracle Agent
- 如图3 所示,ETO 能够在更少的动作步骤内达到更高的奖励
- 有趣的是,在某些案例(如 15-90 和 19-23)中,论文的方法甚至超过了 Oracle Agent,更早地达到了 100 分
- 这些结果表明,通过学习失败轨迹,论文的方法还获得了更强大的任务解决效率(更少动作步骤内实现更高奖励)
Ablation of Iterations
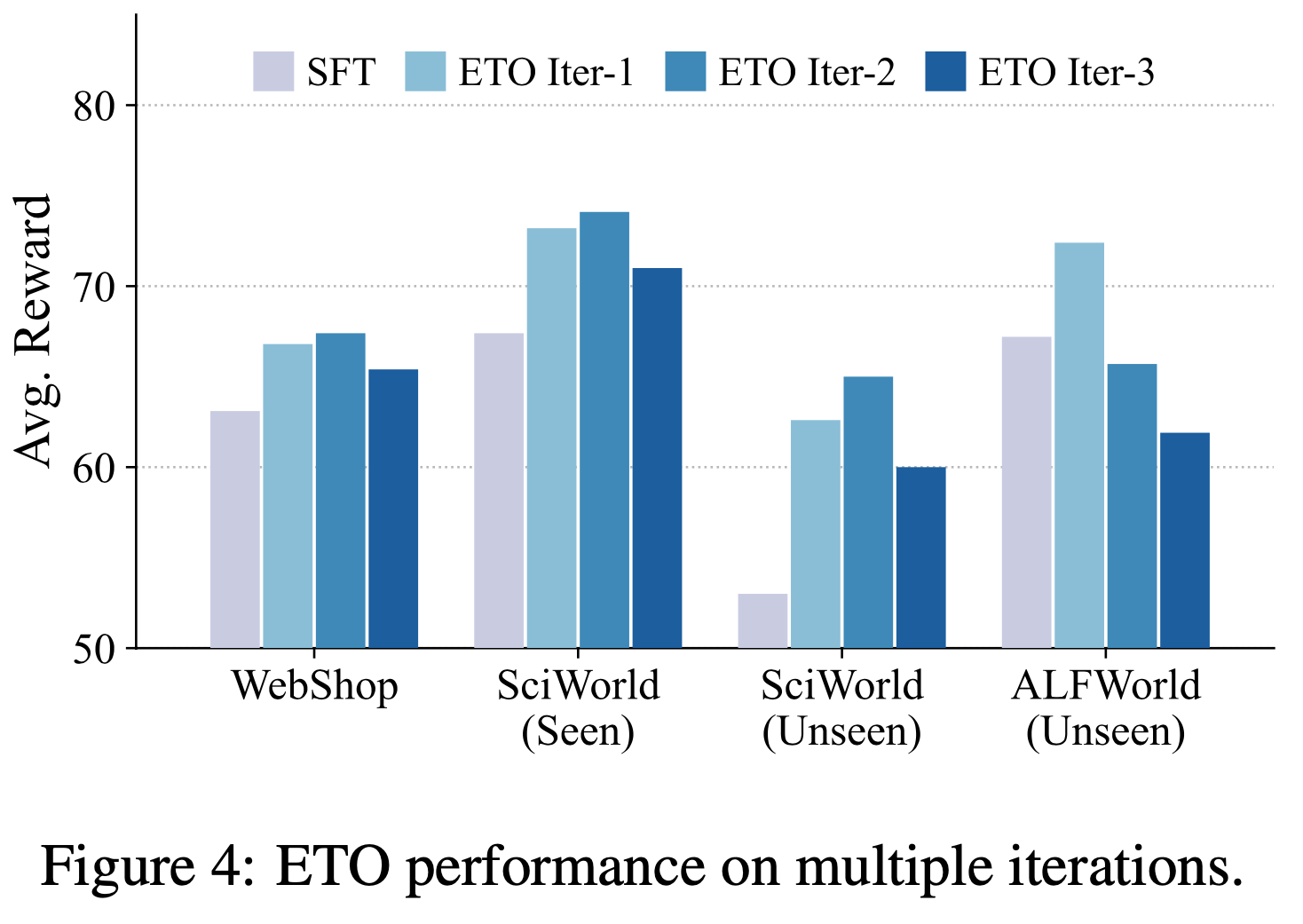
- 本节论文研究了 ETO 中迭代次数的影响,结果如图4 所示
- 如图所示,ETO 在 WebShop 和 ScienceWorld 数据集上的前两次迭代中能够提升 Agent 性能 ,但进一步增加迭代次数并不会带来持续改进,性能在第三次迭代后开始下降
- 对于 ALFWorld 数据集,仅第一次迭代的 ETO 表现出改进 ,而第二次和第三次迭代的性能甚至落后于 SFT Base Agent
- 对此的解释是:
- ETO 的学习过程依赖于固定的专家轨迹集,而 Agent 的探索阶段是在相同的训练集上进行的,因此,失败-成功对比轨迹数据的多样性和数量受到限制
- 最初,策略可以通过从过去的错误中学习得到改进,但模型在后续迭代中会过度拟合对比信息 ,导致性能下降
- 问题:如何理解过度拟合对比信息?
- 在 ALFWorld 中,粗粒度的二进制奖励进一步阻碍了 Agent 通过迭代训练获得改进
- 问题:为何粗粒度的二进制奖励会阻碍 Agent 通过迭代训练获得奖励?
- 作为潜在的解决方案,未来的工作可以探索利用 GPT-4 动态构建更多样化的对比轨迹数据
Strategy of Contrastive Data Construction
- 本节论文深入探讨了方法中使用的对比轨迹对构建策略
- 在原文 3.2 节中,论文直接从失败-成功轨迹对中学习(公式 (11)),称为轨迹级对比(trajectory-wise contrastive)
- 受先前工作(2023b)启发,论文引入了 ETO 的一种细粒度变体,通过比较“good-bad”动作对来捕捉步骤级对比(step-wise contrastive)信息
- 为此,论文使用专家轨迹在前 \(t-1\) 步进行教师强制(Teacher Forcing) ,然后让 Agent 预测第 \(t\) 步的动作
- 第 \(t\) 步动作的质量由最终奖励决定(注意:是最终奖励而不是当前时间步 \(t\) 动作的奖励)
- 问题:怎么由最终奖励决定呢?每一步都是教师给定的,而且只走了 \(t\) 步,教师需要完整序列才能评估奖励吧
- 回答:详情见附录 C 的内容
- 论文还实现了一种混合变体,结合了上述两种策略。关于 ETO 步骤级变体的更多细节,请参阅附录 C
- 表 4 展示了不同方法的对比结果:结果表明,轨迹级对比取得了最佳性能
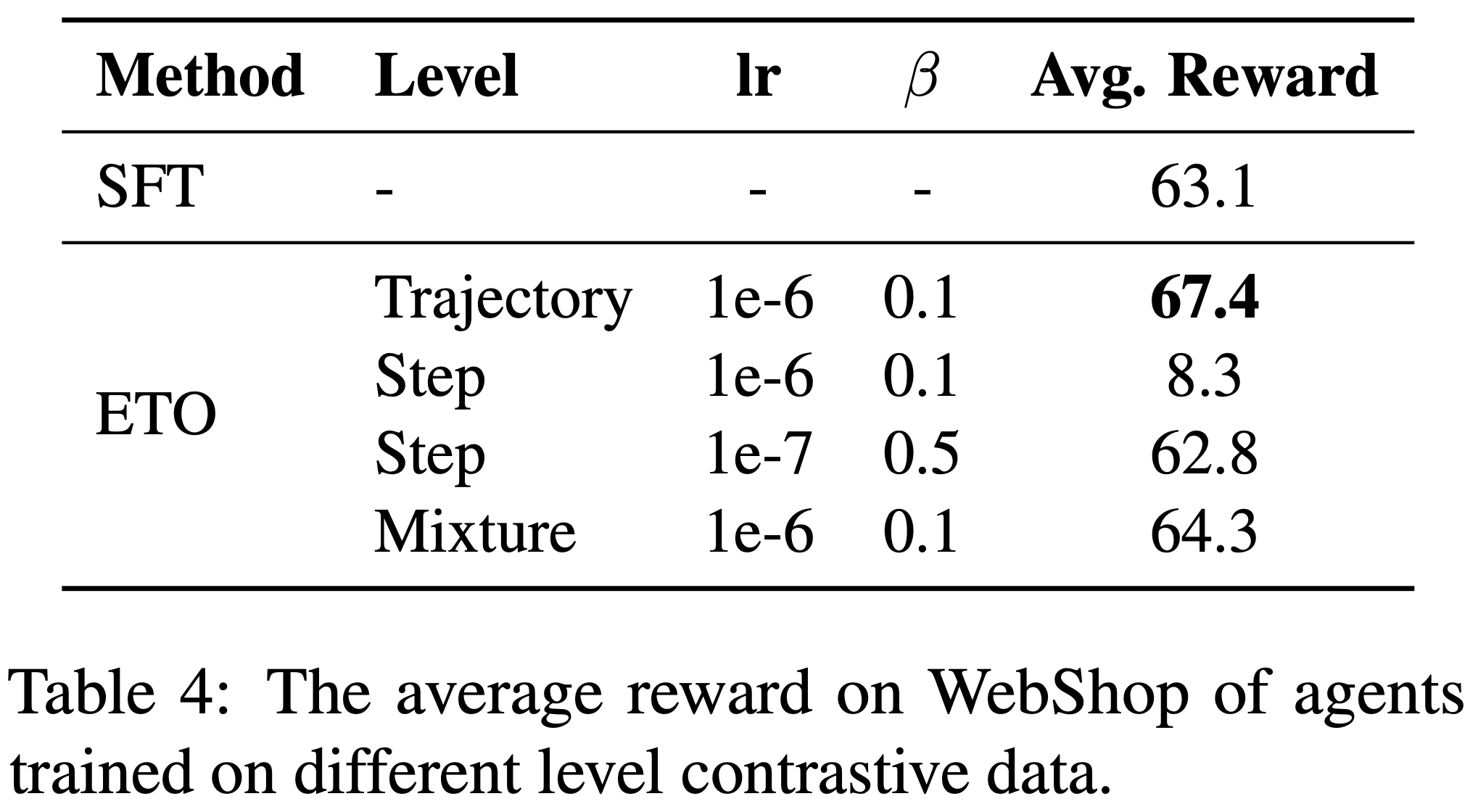
- 另一方面,论文发现步骤级对比建模的稳定性较差 ,需要更低的学习率和更高的约束参数 \(\beta\) 以保持 Agent 的基本能力
- 这种不稳定性可能归因于动作质量的不准确估计 ,因为论文仅使用最终奖励来构建步骤级对比对
- 此外,混合策略的性能也不及轨迹级对比
Self-Play w/o Expert Trajectory
- 本节论文探索了一个具有挑战性的场景,即专家轨迹不可用
- 在这种情况下,Agent 被迫探索环境并依赖自博弈来提升能力
- 为此,论文移除了 ETO 的行为克隆阶段 ,允许 LLM Agent 以解码温度 1.0 探索环境
- 随后,论文根据最终奖励比较同一指令下的不同轨迹,构建轨迹偏好数据
- 最后,Agent 仅基于自身生成的偏好数据进行训练
- 在 WebShop 上,未调优的 Llama-2-7B-Chat 取得了相对较高的奖励,因此论文使用该数据集进行实验
- 论文采用了拒绝采样微调(RFT)作为基线
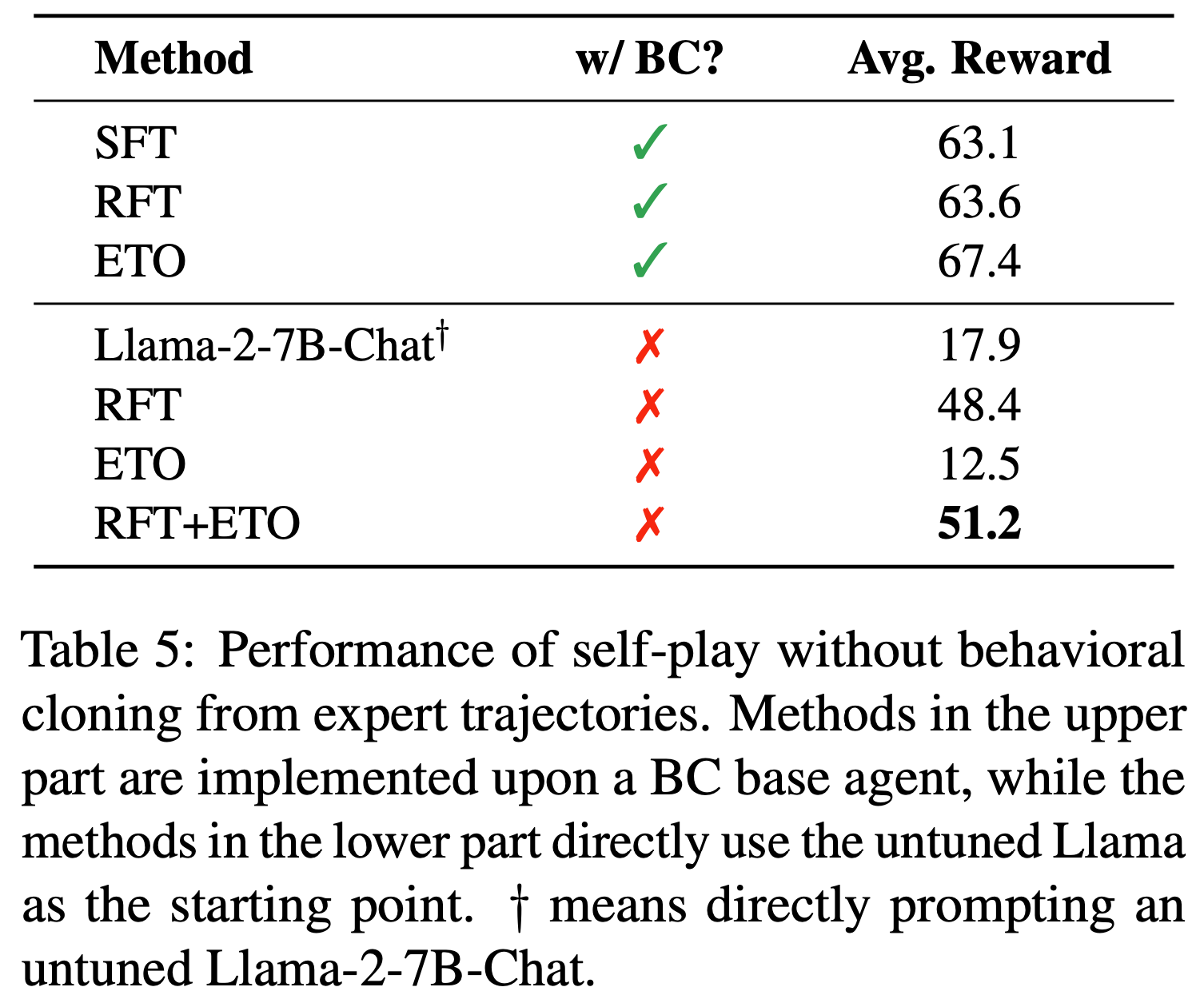
- 表5 的结果显示
- 在没有行为克隆的情况下,仅使用 ETO 无法提升性能
- RFT 在不依赖专家轨迹的情况下展现出了提升 Agent 能力的潜力
- 然而,当将 RFT 与 ETO 结合时,论文观察到 Agent 性能的进一步提升
- 这些结果表明,在专家轨迹不可用的场景中,可以先使用 RFT,然后让 Agent 从探索失败中学习
- 这些结果进一步凸显了论文方法在专家轨迹不可用时的潜力
Related Work
Imitation Learning
- 模仿学习是一种通过模仿专家示范来学习策略的范式(2017; 2019)
- 行为克隆(Behavioral Cloning, BC)(Pomerleau, 1991)是模仿学习中一种流行的方法,它利用专家轨迹学习从状态到动作的直接映射
- 为了缓解行为克隆的局限性,已有多种方法被提出(2011; Ross and Bagnell, 2014)
- 论文的方法 ETO 与 DAgger(2011)有相似之处,后者通过从失败案例中学习来提升 Agent 性能
- 然而,与 DAgger 不同,ETO 通过对比轨迹对(contrastive trajectory pairs)优化策略,而非收集额外的专家轨迹
LLM Agents
- 随着 LLM 展现出多种涌现能力,研究人员开始探索 LLM-based Agent 系统(2023)
- 近期项目如 AutoGPT(Richards, 2023)、BabyAGI(Nakajima, 2023)和 RestGPT(2023)将 LLM 作为核心控制器,构建了能够解决现实任务的强大 Agent 框架
- 尽管 GPT 系列模型展现了强大的 Agent 智能,开源 LLM 的表现仍远落后于 GPT-4(2023; 2023a)
- 为了缩小这一差距,FireAct(2023)、AgentTuning(2023)和 Lumos(2023)等研究从教师 Agent(如 GPT-4)中构建专家轨迹数据,并对开源 LLM 进行行为克隆
- Aksitov 等 (2023) 进一步通过在前一策略生成的轨迹上进行迭代行为克隆来优化 Agent
- 与论文的工作同时,Yang 等 (2023) 使用 DAgger 框架(2011)并采用 DPO 损失来开发多模态具身 Agent
LLM Policy Learning
- 从偏好中学习对于提升 LLM 策略表现具有潜力,尤其是在 LLM 对齐研究中
- RLHF 通过学习奖励模型并利用近端策略优化(PPO)更新策略模型(2017; 2022)。尽管 RLHF 具有吸引力,但其训练效率低且不稳定
- 为解决这些问题,Rafailov 等 (2023) 重新形式化了 RLHF 的优化目标,提出 DPO 损失以直接建模偏好
- 与论文的工作类似,ReST(2023)通过从当前策略生成新样本,并利用离线强化学习方法优化策略
- 近期研究还探索了 LLM 策略学习在其他领域的应用(2023; 2023b)
- 例如,Wang 等 (2023b) 训练了一个逐步奖励模型以提升 LLM 在数学推理中的表现
- 表 6 对比了 ETO 与其他方法,凸显了论文的方法在大语言模型 Agent 策略学习中的优势

Limitations
- 尽管 ETO 通过试错学习有效提升了 LLM Agent 的能力,但本研究仍存在一些局限性:
- 1)ETO 假设 Agent 从一开始就执行错误动作,但实际中错误可能发生在中间步骤。若能识别错误动作(如第 3 步的 \(\hat{a}_3\)),则可针对剩余步骤 \(a_{t>3}\) 收集专家轨迹
- 但当前环境缺乏此类信息,难以实现细粒度的奖励建模
- 未来可探索利用 GPT-4 识别错误动作并构建更精细的对比轨迹数据
- 2)本研究专注于针对特定任务开发专用 Agent ,对通用 Agent 的构建探索有限。未来将研究 ETO 训练策略的迁移性,并尝试在多任务场景中应用该方法
- 1)ETO 假设 Agent 从一开始就执行错误动作,但实际中错误可能发生在中间步骤。若能识别错误动作(如第 3 步的 \(\hat{a}_3\)),则可针对剩余步骤 \(a_{t>3}\) 收集专家轨迹
附录 A:Datasets
- WebShop :
- WebShop (2022a) 是一个在线购物网站环境,Agent需要根据用户指令在平台上导航并完成购买
- 当 Agent 选择“购买”动作时,环境会提供一个最终奖励(reward),该奖励基于产品属性和价格的匹配程度计算
- ScienceWorld :
- ScienceWorld (2022) 是一个基于文本的虚拟环境,专注于完成基础科学实验,包括热力学和电路等10种不同的任务类型
- Agent 需要通过具身交互环境(embodied interactive environments)与科学概念互动并理解它们
- 每个任务包含若干可选子目标,最终奖励基于这些子目标的完成情况计算
- 特别说明:ScienceWorld 的原始测试集包含关键未见任务变体(unseen task variations)
- 例如,训练集中的任务可能是“烧开水”,而测试集中的任务则是“熔化铅”
- 因此,论文使用原始测试集来评估模型在未见场景下的泛化性能
- 论文将原始开发集作为“已见场景”(seen scenarios)的测试集
- 由于任务9 和任务10 的解决轨迹过长,论文将其排除
- 为了公平且高效地比较,论文遵循 Lin 等 (2023) 的方法,对于测试变体超过 10个 的任务类型,仅使用前 10个 实例
- ALFWorld :
- ALFWorld (2021) 包含与 ALFRED (2020) 数据集中的具身世界(embodied worlds)平行的交互式文本世界(TextWorld)环境
- 在该环境中,Agent 需要探索并完成高级家务指令
- 原始 ALFWorld 数据集包含“seen”和“unseen”评估集
- “seen”集用于评估分布内泛化(in-distribution generalization),而“unseen”集包含新任务实例,用于评估 Agent 的分布外泛化(out-of-distribution generalization)能力
- 思维链(CoT)标注 :
- WebShop 和 ALFWorld 提供了少量人工标注的轨迹(trajectories)用于模仿学习(imitation learning)
- 论文还使用 GPT-4 作为教师 Agent(teacher agent)在 WebShop 环境中探索,并选择奖励大于 0.7 的轨迹
- ScienceWorld 环境提供了启发式搜索算法为每个子任务生成黄金轨迹(golden trajectories)
- 由于原始轨迹不包含每个动作步骤的思维链信息,论文使用 GPT-4 生成相应的推理过程
附录 B:Success Rate
- 论文在表7 中报告了实验的成功率(success rate)
- 需要注意的是,三个任务的成功率定义不同:
- 对于 WebShop,成功率定义为最终奖励为 1.0 的实例比例
- 对于 ScienceWorld,原始论文未提供成功率的定义。但根据其官方环境,当环境达到预定义的潜在状态(latent state)时,即使奖励未精确达到 1.0,轨迹也会被视为成功
- 对于 ALFWorld,由于仅提供二元最终奖励,成功率等于平均最终奖励
附录 C:Details for Step-Wise Contrastive(分步对比学习的细节)
- 论文实现了一种 ETO 变体,该变体从“good-bad”动作对(good-bad action pairs)中学习
- 具体来说,对于任务指令 \( u \) 和专家轨迹 \( e = (u, a_1, …, o_{n-1}, a_n) \),论文使用教师强制(teacher forcing)执行前 \( t-1 \) 步 \( (a_1, o_1, …, a_{t-1}, o_{t-1}) \),并让 Agent 从第 \( t \) 步开始预测动作,生成轨迹:
$$
\hat{e} = (u, a_1, o_1, …, o_{t-1}, \hat{a}_t, \hat{o}_t, …, \hat{o}_{m-1}, \hat{a}_m)
$$ - 环境会为轨迹 \( \hat{e} \) 返回奖励 \( \hat{r} \):如果将前 \( t-1 \) 步的黄金轨迹记为 \( e_{(t-1)} \),则“good-bad”动作对 \( a_w \succ a_l \mid u, e_{(t-1)} \) 基于最终奖励构建。其中,\( a_w \) 和 \( a_l \) 分别表示从 \( (a_t, \hat{a}_t) \) 中选择的奖励较高和较低的动作。随后,动作对的对比关系可用于 DPO 损失(DPO loss)中以改进策略:
$$
\mathcal{L}_{\text{DPO} }(\pi_\theta; \pi_{\text{ref} }) = -\mathbb{E}\left[\log \sigma\left(\beta \log \frac{\pi_\theta(a_w|u, e_{(t-1)})}{\pi_\theta(a_l|u, e_{(t-1)})} - \beta \log \frac{\pi_{\text{ref} }(a_w|u, e_{(t-1)})}{\pi_{\text{ref} }(a_l|u, e_{(t-1)})}\right)\right].
$$
附录 D:Case Study
- 论文通过案例分析比较 ETO Agent 与 SFT 行为克隆(behavioral cloning)Agent 的表现。图5 和 图6 分别展示了 WebShop 和 ScienceWorld 的示例

- 在 WebShop 场景中,SFT Agent 未能选择“3pc”颜色选项,导致次优轨迹
- 而 ETO 能够从过去的失败中学习,并熟练地选择正确的属性选项
- 在 ScienceWorld 示例中,任务是“找到一个动物”
- SFT Agent 持续执行错误动作,专注于非生物对象,且动作选择与思维链(CoT)不一致。相比之下,ETO 成功完成了任务,展示了试错学习的有效性
附录 E:Prompt for Evaluation
- 论文在 图7、图8 和 图9 中分别展示了 WebShop、ScienceWorld 和 ALFWorld 的指令提示(instruction prompts)。、