注:本文包含 AI 辅助创作
参考链接:
一些吐槽:
- 论文的写作不是很简洁,不容易理解,部分符号使用比较乱,部分符号直接凭空出现,需要结合上下文推测含义
Paper Summary
- 核心内容总结:
- 首次通过个性化偏好推断(personalized preference inference)的视角,系统性地研究了 LLM 中的扩展归纳推理(extended inductive reasoning)
- 提出 AlignXplore 并证明:扩展推理能够有效弥合隐式行为信号(implicit behavioral signals)与显式偏好(explicit preferences)之间的鸿沟
- 论文中,两阶段训练策略的成功为开发 LLM 的归纳推理能力提供了宝贵认知:
- 表明结合合成数据演示与Reinforcement learning可以有效引导模型学习可泛化的推理模式,而非表面的相关性
- 未来应用前景(来源于原文):
- 可能的应用场景1:将偏好推断的成功方法扩展到其他归纳推理任务中
- 可能的应用场景2:科学假设生成和非结构化数据中的模式发现
- 背景:LLM 在数学和编程等以演绎推理为主(deductive reasoning predominates)的复杂推理任务中取得了显著成功
- 问题提出:
- 归纳推理(inductive reasoning)则仍然是一个未被充分探索的领域
- 归纳推理的定义:从不完整证据中推导出通用规则的能力(inductive reasoning—the ability to derive general rules from incomplete evidence)
- 论文从个性化偏好推断(personalized preference inference)视角出发,研究了 LLM 的扩展归纳推理(extended inductive reasoning)能力
- 当前的方法在捕捉 多样化用户偏好(diverse user preferences) 方面存在困难(这一任务需要强大的归纳推理能力)
- 因为用户偏好通常 隐含地嵌入(embedded implicitly)在各种交互形式中 ,要求模型从分散的信号中综合出一致的偏好模式
- 论文提出了 AlignXplore
- AlignXplore 是一种利用扩展推理链从用户交互历史中的行为信号中系统推断偏好的模型
- 这种显式的偏好表达支持高效的流式推断:当新的行为信号出现时,模型可以直接基于先前推断的偏好描述进行更新,而无需从头重新处理历史信号,同时支持对推断偏好的迭代优化
- 论文通过结合 1)基于合成数据的冷启动训练 和 2)在线强化学习 来开发 AlignXplore
- 实验表明 AlignXplore 在领域内和领域外基准测试中平均比 Backbone Model 提升了 15.49%,同时在不同输入格式和下游模型中保持了强大的泛化能力
- 论文还进一步的分析,通过比较奖励建模策略,确立了偏好推断学习的最佳实践,并揭示了训练过程中类人归纳推理模式的出现
Introduction and Discussion
- LLM 的最新进展通过扩展推理链在复杂推理任务中展现了卓越的成功(2023; 2025),尤其是在代码生成(2021)和数学问题求解(2023; 2023)等以演绎推理为主的领域(2021; 2018)
- 但归纳推理(即从具体观察中推导规则并对新案例进行预测的能力(2010)),在从不完整证据中进行概率性泛化时提出了独特的挑战
- 作为一种核心认知能力(2000),归纳推理长期以来一直是人类智力测试(1986)和科学研究(2006)的关键组成部分
- 将 LLM 的推理能力扩展到复杂归纳任务中的研究仍然非常有限
- 在论文中,论文通过 个性化偏好推断(personalized preference inference)(2025; 2025)的视角研究扩展归纳推理
- 这一具有挑战性的任务需要强大的归纳能力,从隐含信号中综合出显式的偏好模式,以实现 LLM 与个体偏好的对齐
- 这项研究的重要性体现在两个方面:
- 1)偏好推断解决了 LLM 对齐中的一个关键挑战
- 当前的方法主要关注通用价值观(如帮助性、诚实性和无害性),在捕捉个体用户偏好的多样性方面存在困难
- 这一局限导致用户满意度下降和潜在的系统性偏见(2024; 2018),尤其是在服务多样化用户群体时(2023)
- 2)偏好推断体现了归纳推理的复杂性
- 现实中,用户很少在与 LLM 的交互中明确表达其偏好(2025),这些偏好隐含地嵌入在用户生成内容(如用户 Post(2025))、行为信号(如比较判断(2022))和人口统计属性(如年龄、性别(2018))等多种形式中
- 偏好推断要求模型从这些多样化的交互中识别一致的偏好模式,并将其泛化到新情境中,如图 1 所示

- 1)偏好推断解决了 LLM 对齐中的一个关键挑战
- 大多数现有的个性化方法绕过了偏好推断这一关键步骤,(采用直接映射的方式)将隐含信号作为 Prompt (2024; 2025)、可训练参数(2023; 2023)或编码的隐藏表示(2024; 2024)纳入模型
- 问题一:缺乏显式的偏好推断使得偏好建模过程不透明且不可控
- 问题二:没有显式的偏好表示,这些方法无法在新行为信号出现时增量优化用户偏好,迫使模型从头处理不断增长的交互历史,限制了效率
- 为了解决这些问题,论文提出了 AlignXplore(利用扩展推理链从行为信号中实现系统归纳推理的模型)
- 通过显式的偏好表达,论文的模型自然地支持流式推断机制,能够增量地结合先前推断的偏好以实现更高效的个性化
- 作者开发了一个两阶段框架,结合合成数据训练和强化学习优化
- 第一阶段:通过利用 LLM 生成高质量的训练数据来解决冷启动问题,这些数据通过扩展推理展示了偏好推断的过程
- 第二阶段:通过强化学习增强模型的推理能力,其中奖励信号被设计为鼓励准确的偏好推断
- 通过在领域内和领域外基准测试上的广泛实验:证明了 AlignXplore 在个性化对齐方面取得了显著提升
- 性能比 Backbone Model 高出 15.49%
- 在与包括 GPT-4(2023)和 DeepSeek-R1-671B(2025)等显著更大的模型的对比中表现出竞争力
- AlignXplore 的流式推断机制通过避免重复计算实现了对增长行为信号的高效处理,同时允许逐步优化推断的偏好,从而获得更好的性能
- AlignXplore 还展示了在不同输入格式和下游模型中的强大泛化能力,并在偏好反转时保持了稳健的性能
- 因为扩展推理过程帮助模型开发了更系统化和可迁移的归纳推理模式,而非学习表面的相关性
- 进一步的分析揭示了两项关键发现:
- 1)比较不同奖励建模方法表明,直接优化偏好判断比优化响应生成能带来更稳定的训练 ,这为训练偏好推断模型确立了最佳实践
- 2)论文的两阶段训练方法展示了归纳推理能力的逐步增强,其中冷启动训练帮助建立基本的偏好表征能力 ,而强化学习则通过迭代测试和优化将这些能力进一步提炼为可操作的假设 ,反映了人类归纳推理的方法(2000)
- 论文的主要贡献如下:
- 1)论文首次通过个性化偏好推断的视角,系统研究了 LLM 中的扩展归纳推理 ,展示了结构化推理过程如何使 LLM 能够从隐含行为信号中推导出可泛化的偏好模式
- 2)论文开发了 AlignXplore ,一种支持通过流式推断高效处理增长行为信号的偏好推断模型
- 论文的模型通过结合合成数据训练和强化学习的新颖两阶段框架进行训练,并开源了实现以促进个性化对齐的未来研究
- 3)论文在多样化基准测试上进行了全面评估,证明了相对于现有方法的显著提升,同时保持了高效性、泛化能力和鲁棒性
- 论文的分析为奖励建模策略和归纳推理能力的逐步发展提供了宝贵见解
Methodology
- 图 1 展示了论文方法的整体训练流程,即两阶段训练策略:
- 第一阶段:初始冷启动阶段(3.2 节)用于培养基本推理能力
- 第二阶段:强化学习阶段(3.3 节)直接优化奖励
Task formulation
- 论文首先将偏好推断任务形式化如下:给定用户 \( U \) 的多个交互示例的行为信号集合 \(\mathcal{E} = \{e_1, e_2, …, e_T\}\),模型 \(\mathcal{M}\) 生成一个 显式的偏好描述 \( d \) 以及一个 扩展的推理链 \( r\) :
$$
r, d = \mathcal{M}(\mathcal{E}),
$$- 其中 \( d \) 通常表现为用户 \( U \) 对特定维度(如文化敏感性、正式程度等)的积极或消极态度
- 推断的偏好描述 \( d \) 应是与模型无关的(model-agnostic),使其能够指导任何通用的 LLM \(\mathcal{R}\) 实现个性化 (2023; 2025)
- 理解:这里与模型无关的含义是这个 \( d \) 是一个类似通用 Prompt 的东西,是不挑模型的,什么模型都能用
Streaming inference mechanism
- 在现实场景中,用户行为信号会随时间不断更新,通常会积累大量数据
- 为了解决计算效率挑战,论文提出了一种新颖的流式推断机制,逐步利用先前推断的偏好
- 关键思路:当用户交互中出现新的行为信号 \(\mathcal{E}\) 时(问题: \(\mathcal{E}\) 在上一节中不是交互序列吗?这里仅表示新的行为信号),可以用先前推断的偏好描述 \( \hat{d} \) 为条件进行高效推断,而不是重新编码对应的过时行为信号:
$$
r, d = \mathcal{M}(\mathcal{E}, \hat{d}),
$$- \(\hat{d}\) 是历史偏好 ,可以 视为 \(\mathcal{E}\) 之前所有行为信号的浓缩表示 , \(\mathcal{E}\) 表示新的行为信号
- 这种流式机制是显式偏好建模独有的优势(注:先前的方法依赖 Prompt (2022; 2025) 或参数更新 (2023; 2024) ,需要在每次下游任务需要个性化时处理整个历史交互)
Evaluation framework
- 为了评估模型 \(\mathcal{M}\) 生成的偏好 \( d \) 的质量,可以通过 \(d\) 指导大语言模型 \(\mathcal{R}\) 与用户偏好对齐的程度来评估
- 理想情况下,可以通过在线奖励来衡量:
$$
R_{\text{online} } = \mathbb{E}_{o \in \mathcal{R}(\cdot|x,d)} \text{Align}(o, U), \tag{3}
$$- \( o \) 表示在已知 \(d\) 和用户 \( U \) 的新 Post \( x \) 的情况下,模型 \(\mathcal{R}\) 的输出
- \(\text{Align}(\cdot)\) 衡量 \(o\) 与用户的对齐程度
- 但上述方法需要昂贵的在线采样和用户反馈,为了实现高效且可扩展的评估(同时避免这种开销),论文利用 offline user-specific comparative judgment data:
- 给定用户 \( U \) 的 Post \( x \) 以及两个响应 \( y_w \) 和 \( y_l \),其中 \( y_w \) 比 \( y_l \) 更受 \( U \) 偏好,论文定义:
$$
\begin{align}
R_{\text{offline} } = \mathbf{1}\big(f_{\mathcal{R} }(y_w|x,\cdot) > f_{\mathcal{R} }(y_l|x,\cdot)\big) R_{\text{format} }, \\
R_{\text{format} } = \mathbf{1}\big(r, d \text{ satisfy the generation format }\big),
\end{align} \tag{4,5}
$$ - \( f_{\mathcal{R} }(y_{w/l}|x,\cdot)\) 衡量模型对两个响应的偏好分数
- \( R_{\text{format} }\) 确保 \( r \) 和 \( d \) 的结构有效性(格式规范见附录 B)
- 问题:\(R_{\text{offline} }\) 与 \( d \) 的关系是什么?为什么可以评估 \( d \) ?
- 回答:\(f_{\mathcal{R} }(y_w|x,\cdot)\) 中的 \(\cdot\) 就是指的 \( d \) 吧?整个 \(R_{\text{offline} } = 1\) 则表示:生成的 \(r, d\) 满足格式要求,同时还能使得 \(f_{\mathcal{R} }(y_w|x,\cdot) > f_{\mathcal{R} }(y_l|x,\cdot)\) 成立
- 给定用户 \( U \) 的 Post \( x \) 以及两个响应 \( y_w \) 和 \( y_l \),其中 \( y_w \) 比 \( y_l \) 更受 \( U \) 偏好,论文定义:
Reward instantiation
- 在实际实现上述离线评估框架时,可以选择不同方式建模偏好分数模型 \( f_{\mathcal{R} }(y_{w/l}|x,\cdot)\)
- 例如,当下游模型 \(\mathcal{R}\) 作为响应生成模型(记为 \(\mathcal{R}_{\text{gen} }\))时 (2024),它通过响应 \( y_{w/l} \) 在条件 \( d \) 下与无条件情况下对数概率的变化来测量偏好
- 离线奖励(记为 \( R_{\text{gen} }\))则比较 \( y_w \) 和 \( y_l \) 之间的对数概率变化,其中较大的正边际表示更好的偏好对齐:
$$
R_{\text{gen} } = \mathbf{1}\big(\log \frac{\mathcal{R}_{\text{gen} }(y_w|x,d)}{\mathcal{R}_{\text{gen} }(y_w|x)} > \log \frac{\mathcal{R}_{\text{gen} }(y_l|x,d)}{\mathcal{R}_{\text{gen} }(y_l|x)}\big) R_{\text{format} }. \tag{6}
$$
- 离线奖励(记为 \( R_{\text{gen} }\))则比较 \( y_w \) 和 \( y_l \) 之间的对数概率变化,其中较大的正边际表示更好的偏好对齐:
- 当 \(\mathcal{R}\) 作为偏好判断模型(记为 \(\mathcal{R}_{\text{jud} }\))时 (2025),它直接使用响应 \( y_{w/l} \) 在推断的偏好描述 \( d \) 下被偏好的概率来建模偏好分数
- 对应的离线奖励(记为 \( R_{\text{jud} }\))基于 \( y_w \) 和 \( y_l \) 之间的概率差异计算:
$$
R_{\text{jud} } = \mathbf{1}\big(\mathcal{R}_{\text{jud} }(y_w|x,d,y_w,y_l) > \mathcal{R}_{\text{jud} }(y_l|x,d,y_w,y_l)\big) R_{\text{format} }. \tag{7}
$$
- 对应的离线奖励(记为 \( R_{\text{jud} }\))基于 \( y_w \) 和 \( y_l \) 之间的概率差异计算:
- 论文的评估框架还可以使用其他类型的 \(\mathcal{R}\)
- 例如直接使用原始响应对数概率作为偏好分数 (2024)
- 论文将这些替代奖励公式的探索留作未来工作
- 论文主要实验使用 \( R_{\text{jud} }\) 进行训练和评估
- 在后续消融研究中,论文还会分析 \( R_{\text{gen} }\)
Cold-start training
- 训练偏好推断模型的主要挑战在于,小模型在没有适当初始化的情况下仅凭指令难以执行复杂的偏好推断
- 为了解决这个问题,论文开发了一个合成数据生成流程,利用先进的 LLM 创建包含详细推理过程的高质量训练示例
- 论文采用两阶段数据合成过程,对于原始隐式偏好信号 \( e_i \in \mathcal{E} \) 中的每个示例:
- 第一阶段:识别以自然语言表达的关键偏好维度 \(\phi\),这些维度可能揭示用户偏好,并为后续偏好推断提供分析指导
- 第二阶段:将这些识别的维度 \(\phi\) 和原始隐式信号为条件,输入先进的教师模型 \(\mathcal{T}\),生成 \( G \) 个推理链和偏好描述( Prompt 模板见附录 B):
$$
\{r_i, d_i\}_{i=1}^G \sim \mathcal{T}(r, d|\mathcal{E}, \phi).
$$
- 为了支持流式推断,论文构建了模拟增量偏好学习过程的训练示例:
- 对于每个用户,论文首先随机选择一个先前生成的偏好描述 \(\hat{d}\) 作为历史偏好,然后从同一用户中采样一组新的行为信号
- 问题:为什么是随机选择 \(\hat{d}\) 并 采样新的行为信号 \(\mathcal{E}\) ?对每个新的交互行为 \(\mathcal{E}\), \(\hat{d}\) 不是只有一个吗?应该是配对采样才对吧?
- 回答:应该是也由于在这篇文章中,作者认为交互行为是没有时间顺序的?
- 这些历史偏好和新信号的对用于条件化教师模型 \(\mathcal{T}\),生成新的推理链和更新的偏好描述
- 将这些流式示例与原始示例混合后,论文通过基于结果的验证过滤所有生成内容,仅选择达到最优奖励分数的样本
- 过滤后的数据集 \(\mathcal{D}_{\text{cold} }\) 构造如下:
$$
\mathcal{D}_{\text{cold} } = \{(\mathcal{E}, \hat{d}, r_i, d_i) | R(r_i, d_i) = 1, i \in [1, G]\},
$$ - \( R(\cdot)\) 表示方程 6 或 7 中定义的 \( R_{\text{gen} }\) 或 \( R_{\text{jud} }\)
- \(\hat{d}_i\) 对于没有历史偏好的示例可能为空
- 问题:\(\hat{d}_i\) 是什么?
- 对于每个用户,论文首先随机选择一个先前生成的偏好描述 \(\hat{d}\) 作为历史偏好,然后从同一用户中采样一组新的行为信号
- 偏好推断模型 \(\mathcal{M}\) 的训练目标是最大化生成正确推理链和准确偏好描述的似然 :
$$
\mathcal{L}_{\text{cold} } = \mathbb{E}_{(\mathcal{E}, \hat{d}, r, d) \sim \mathcal{D}_{\text{cold} } } -\frac{1}{|r| + |d|} \sum_{t=1}^T \log p(r, d|\mathcal{E}, \hat{d}),
$$- \( p(\cdot|\mathcal{E}, \hat{d})\) 表示由 \(\mathcal{M}\) 建模的条件概率分布
Reinforcement learning
- 冷启动训练建立了基本的推理能力,强化学习通过扩展推理进一步增强模型生成高质量偏好描述的能力
- 论文采用 GRPO 算法 (2025)(该算法在优化长时程推理过程中表现出色):对于每个训练实例,论文采样多个推理路径,并使用方程 4 中定义的奖励信号对它们进行集体优化
- 参照 (Open-reasoner-zero,2025) 的做法,论文从原始 GRPO 公式中移除了 KL 惩罚项以实现更有效的优化:
$$
\begin{align}
\mathcal{L}_{\text{RL} } &= \mathbb{E}_{\substack{(\mathcal{E}, \hat{d}) \sim \mathcal{D}_{\text{rl} }},\ {\{(r_i, d_i)\}_{i=1}^G \sim p_{\text{old} }(\cdot|\mathcal{E}, \hat{d})}} \Big( -\frac{1}{G} \sum_{i=1}^G \frac{1}{|r_i| + |d_i|} \rho_i \Big), \\
\rho_i &= \sum_t \min \Big( \frac{p(\{r_i, d_i\}_t|\mathcal{E}, \hat{d})}{p_{\text{old} }(\{r_i, d_i\}_t|\mathcal{E}, \hat{d})} A_i, \operatorname{clip}\big( \frac{p(\{r_i, d_i\}_t|\mathcal{E}, \hat{d})}{p_{\text{old} }(\{r_i, d_i\}_t|\mathcal{E}, \hat{d})}, 1-\epsilon, 1+\epsilon \big) A_i \Big), \\
A_i &= \frac{R_i - \operatorname{mean}(\{R_j\}_{j=1}^G)}{\operatorname{std}(\{R_j\}_{j=1}^G)},
\end{align} \tag{10-12}
$$ - \( p_{\text{old} }\) 是旧策略模型
- \( G \) 是采样输出的数量
- \(\{r_i, d_i\}_t\) 是生成序列中的第 \( t \) 个 Token
- \( R_i\) 是第 \( i \) 个输出的奖励(使用方程 6 或 7 计算)
- \( A_i\) 是优势项,对不同路径的奖励进行归一化以减少训练方差
- \(\hat{d}\) 是历史偏好,要么为空,要么由 \( p_{\text{old} }\) 使用与 \(\mathcal{E}\) 相同的用户的其他行为信号动态生成
- 参照 (Open-reasoner-zero,2025) 的做法,论文从原始 GRPO 公式中移除了 KL 惩罚项以实现更有效的优化:
Experiments
Experimental setup
Implementation details
- 论文采用流式设置进行训练,在冷启动(cold-start)数据生成和 RL 训练阶段
- 第一步:为每个训练实例使用 4 个行为示例(即 \(\mathcal{E}\) 中 \(T=4\))生成初始偏好描述,此时历史偏好 \(\hat{d}\) 为空
- 第二步:从同一用户中随机采样另外 4 个示例作为新的行为信号 \(\mathcal{E}\),并将先前推断的偏好作为 \(\hat{d}\) 生成第二轮偏好描述
- 训练数据结合了两轮的实例,尽管实验展示了这种两轮设置,但流式机制可通过迭代使用推断的偏好作为历史偏好,自然扩展到更多轮次
- 论文采用 DeepSeek-R1-Distill-Qwen-7B (2025) 作为 Backbone Model,在 ALIGNX (2025) 数据集上进行训练
- 该数据集涵盖 90 个偏好维度,包含平衡的正负示例
- 论文从 ALIGNX 中创建两个独立的训练集:7000 个实例用于冷启动训练,另外 7000 个实例用于强化学习
- 使用 \(R_{\text{jud} }\)(公式 7)作为奖励函数,并以 QwQ-32B (2025) 作为教师模型
- 在 RL 训练中:设置每个 Prompt 的批次大小为 128,每个 Prompt 生成 4 个推理路径
- 推理阶段结合了核采样(\(p=0.95\))(2020)、top-\(k\) 采样(\(k=10\))(2018),并将温度设置为 0.9 (2014)
- 为深入分析不同配置的影响,论文还训练了两个基础设置模型,其中 \(\hat{d}\) 始终为空,\(\mathcal{E}\) 分别包含 4 个或 8 个示例。更多实现细节见附录 A.1
Benchmarks
- 论文在两个基准测试上进行评估(表 1 总结了统计数据):
- (1) ALIGNXtest (2025),即 ALIGNX 的官方测试集;
- (2) P-Soups (2023),专注于三个偏好维度:“专业性(expertise)”、“信息量(informativeness)”和“风格(style)”

- 遵循训练设置,论文考虑两种评估场景:
- Base setting :模型使用 4 个或 8 个偏好对(\(\hat{d}\) 为空)进行推理
- 流式设置 (Streaming setting) :模型首先使用初始 4 个对推断历史偏好描述 \(\hat{d}\),然后结合 \(\hat{d}\) 和 4 个新对生成最终偏好描述
- 所有偏好对均从同一用户的行为信号中随机采样
- 论文确保每个模型在其对应的训练设置下进行评估
Evaluation metrics
- 由于直接评估偏好推断质量存在固有困难,论文采用间接的离线和在线指标:
- 1)离线评估 (Offline evaluation) :
- 根据公式 6 和 7 测量 \(\text{Acc}_\text{gen}\) 和 \(\text{Acc}_\text{jud}\) ,分别评估偏好引导的响应生成和偏好判断准确性
- 论文主要关注 \(\text{Acc}_\text{jud}\) ,因其与训练目标一致
- 2)在线评估 (Online evaluation) :
- 引入 GPT-4 胜率 (GPT-4 Win Rate) ,其中 GPT-4 在基准测试提供的真实偏好条件下,比较不同模型生成的偏好描述所引导的响应 (2024, 2023)
Baselines
- 论文与三组基线进行比较:
- 1)Direct preference descriptions :
- _Null_(no description)、\(\mathcal{E}\)(raw behavioral signals)、_Golden Preference_(ground-truth descriptions from benchmark)
- 2)Specialized methods :
- LMInductReason (2024)(inductive reasoning, 归纳推理)、VPL (2024)(Preference Modeling,偏好建模)、PBA (2025)(structured preference prediction,结构化偏好预测)
- 3)State-of-the-art LLM :
- 小模型(Qwen2.5-7B-Instruct (2024)、DS-R1-Distill-Qwen-7B (2025))和大模型(QwQ-32B (2025)、Qwen3-32B (2025)、GPT-4 (2023)、DeepSeek-R1-671B (2025))
- 论文还评估了模型的消融版本(w/o RL 和 w/o Cold-start)以验证各训练阶段的有效性
- 基线实现细节见附录 A.2
Main results
Offline evaluation
- 表 2 展示了离线偏好推断的评估结果
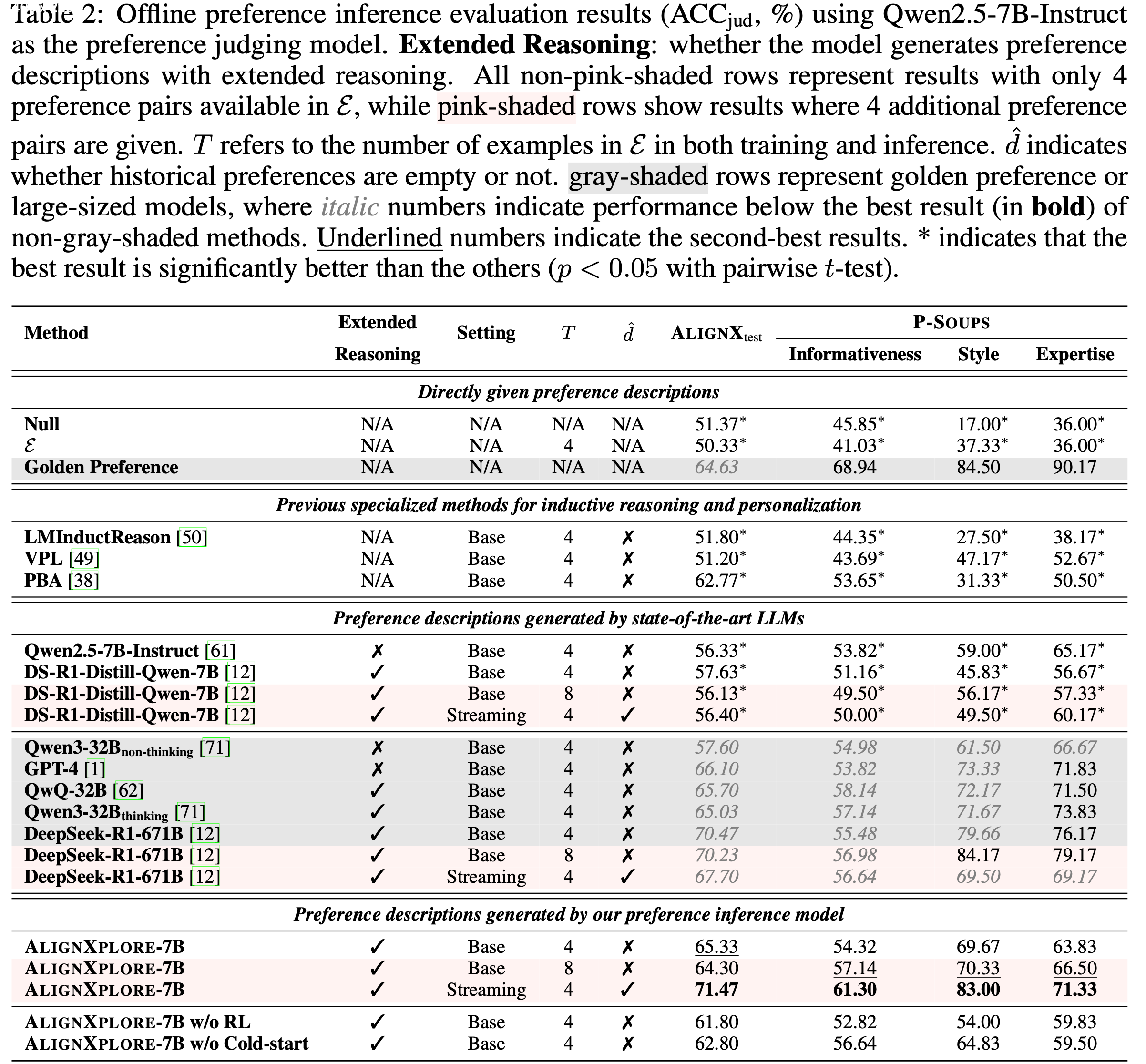
- 从表 2 中,论文得出以下六个关键发现:
- 1)偏好推断的必要性(Necessity of preference inference) :直接使用行为信号 \(\mathcal{E}\) 的表现与“Null”设置相似,且显著低于黄金偏好(Golden Preference),验证了偏好推断的必要性
- 2)Limitations of previous methods :LMInductReason 和 VPL 表现较差,表明基于 Prompt 和隐变量的方法存在不足。尽管 PBA 通过预定义的偏好建模表现更好,但其在 P-Soups 上的显著性能下降揭示了泛化能力的局限性
- 3)扩展推理的优越性(Superiority of extended reasoning) :具备扩展推理能力的模型始终优于简洁推理的模型,例如 Qwen3-32B\(_{\text{thinking} }\) 对比 Qwen3-32B\(_{\text{non-thinking} }\)(65.03% vs. 57.60%)以及 DeepSeek-R1-671B 对比 GPT-4(70.47% vs. 66.10%)
- 4)Strong performance of AlignXplore in base setting :在基础设置中,论文的模型在领域内和领域外任务上均优于同规模基线,同时与 Qwen3-32B 和 GPT-4 等更大模型表现相当,甚至在 AlignXtest 上超越了黄金偏好
- 5)Dominant impact of RL(显著影响) :尽管两个训练阶段均对性能有贡献,但移除 RL 导致的性能下降比移除冷启动训练更显著,表明 RL 在优化偏好对齐中的关键作用
- 6)高效处理增长信号的能力(Efficient and effective handling of growing signals) :当提供额外历史信息时,DS-R1-Distill-Qwen-7B 的表现无论使用更多行为信号还是利用先前推断的偏好均相似
- 相比之下,论文的模型显著受益于流式推理机制,甚至优于其 8 对行为信号的变体
- 这表明论文的流式推理能通过增量偏好细化更有效地利用历史信息,同时比直接处理更大规模行为信号更高效
- 问题:“其 8 对行为信号的变体” 是什么?如何理解这里的能力?
Online evaluation
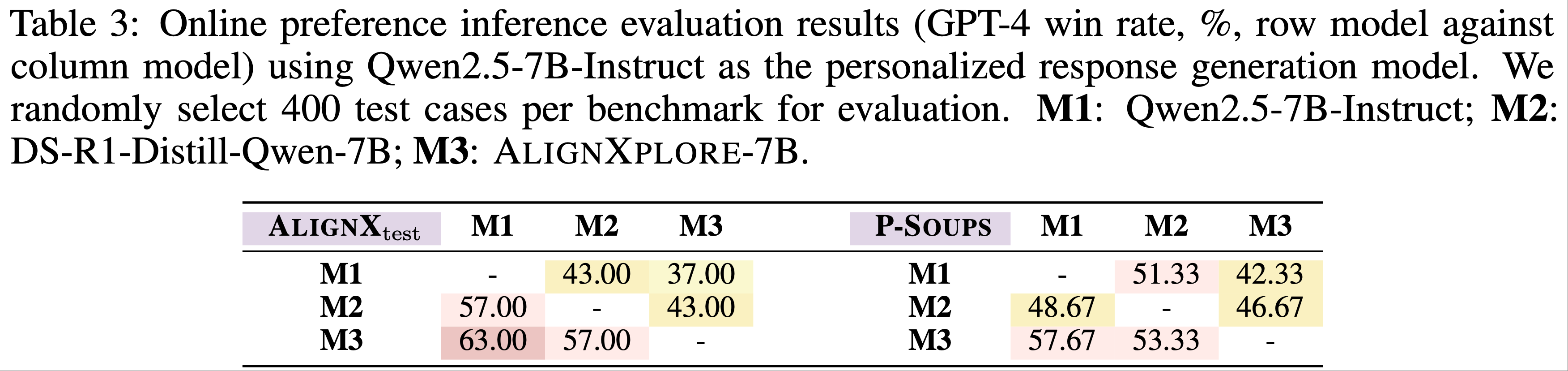
- 使用 GPT-4 作为评判者,通过成对比较基于生成偏好描述的个性化响应生成,表 3 显示 AlignXplore-7B 在领域内和领域外场景中均取得具有竞争力的胜率,进一步验证了其在偏好推断中的有效性
Generalization ability assessment(评估)
- 论文从输入和输出两个角度评估模型的泛化能力,如表 4 所示:
- 1)输入格式泛化(Input-form generalization) :论文将偏好对替换为用户生成内容(user-generated content,UGC)作为输入信号,反映真实场景中偏好需从评论或社交媒体 Post 等多样化来源推断的需求
- AlignXplore-7B 对不同输入格式表现出强泛化能力,准确率达 61.97%,显著优于基线模型
- 2)跨模型泛化(Cross-model generalization) :论文研究了生成偏好描述在个性化不同偏好评判模型时的可迁移性
- AlignXplore-7B 展现出稳健的跨模型泛化能力,始终优于同规模基线模型
- 论文将这种优越的迁移性归因于扩展推理机制,其鼓励学习基础的、模型无关的偏好模式,而非表层关联,从而生成更具泛化性的描述
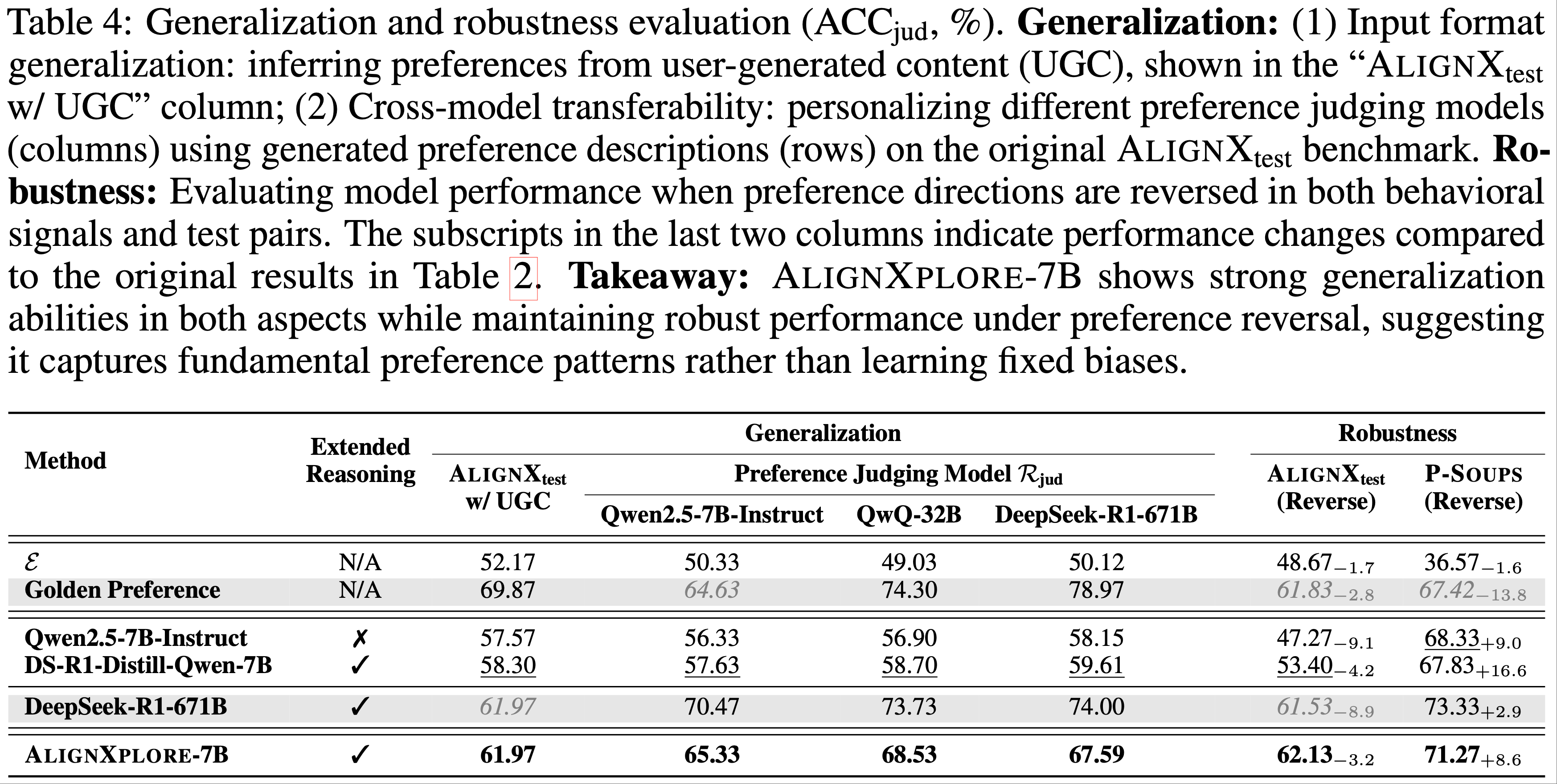
- 1)输入格式泛化(Input-form generalization) :论文将偏好对替换为用户生成内容(user-generated content,UGC)作为输入信号,反映真实场景中偏好需从评论或社交媒体 Post 等多样化来源推断的需求
Robustness assessment
- 偏好推断系统的一个关键挑战是在用户偏好与训练模式显著不同时保持一致性性能
- 分析一,论文通过偏好反转(preference reversal)评估鲁棒性,即反转行为信号和测试对中的所有偏好方向(例如将 \(y_w \succ y_l\) 改为 \(y_w \prec y_l\))
- 如表 4 所示,AlignXplore-7B 表现出强鲁棒性,性能变化较小,显著优于同规模基线和黄金偏好
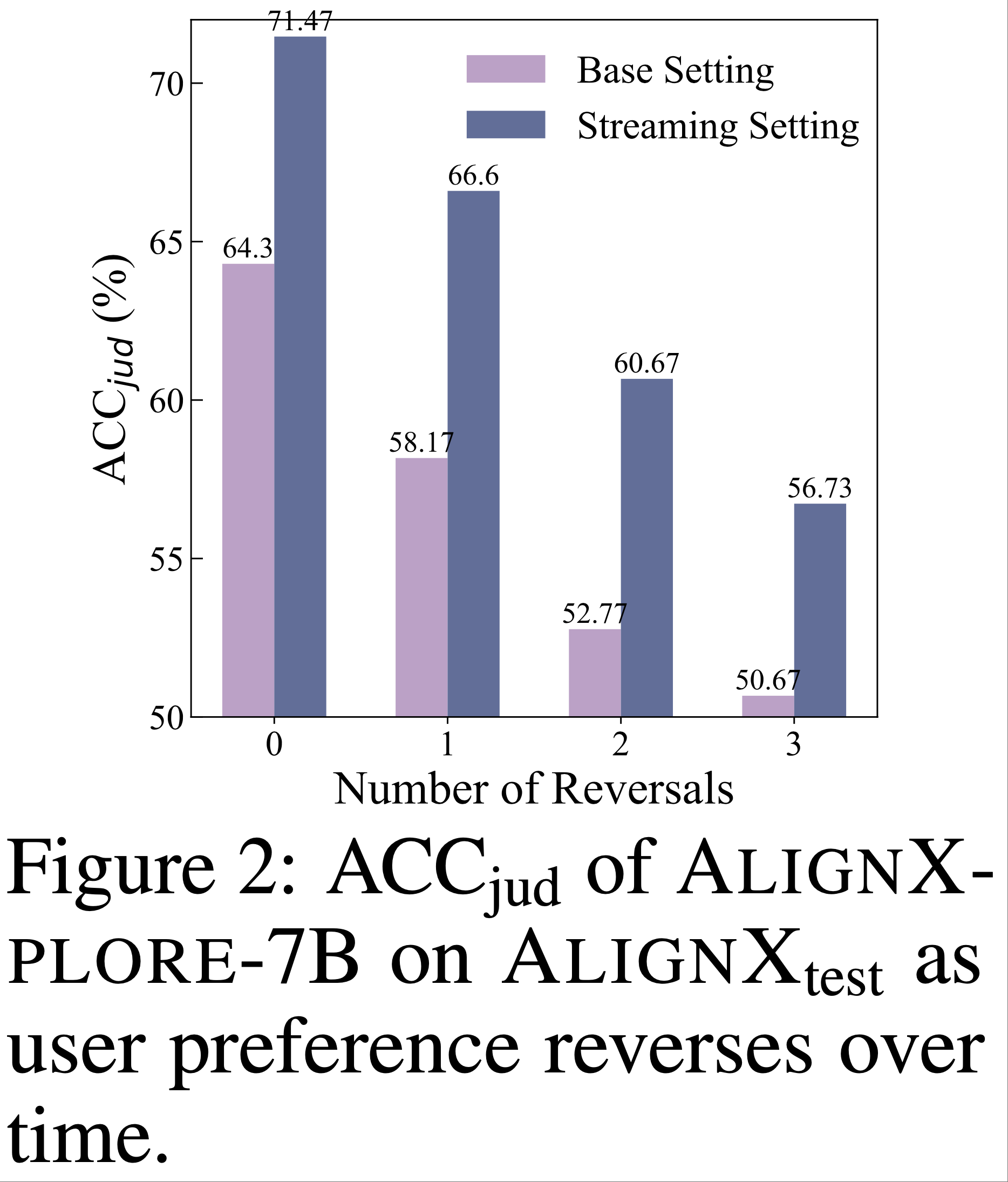
- 分析二:论文研究了一种更现实且更具挑战性的场景:用户偏好随时间演变
- 使用每位用户的 8 对偏好信号,论文逐步反转早期信号的偏好方向,同时保持后期信号(及测试对)与最终偏好一致
- 如图 2 所示,x 轴表示反转偏好的早期信号数量,论文的流式推理机制在不同偏好变化水平下始终优于基础设置
- 这表明通过流式机制显式建模偏好演化,能更好地适应时间性偏好变化,而同时处理所有行为信号的方法可能难以调和此类不一致性
Efficiency assessment
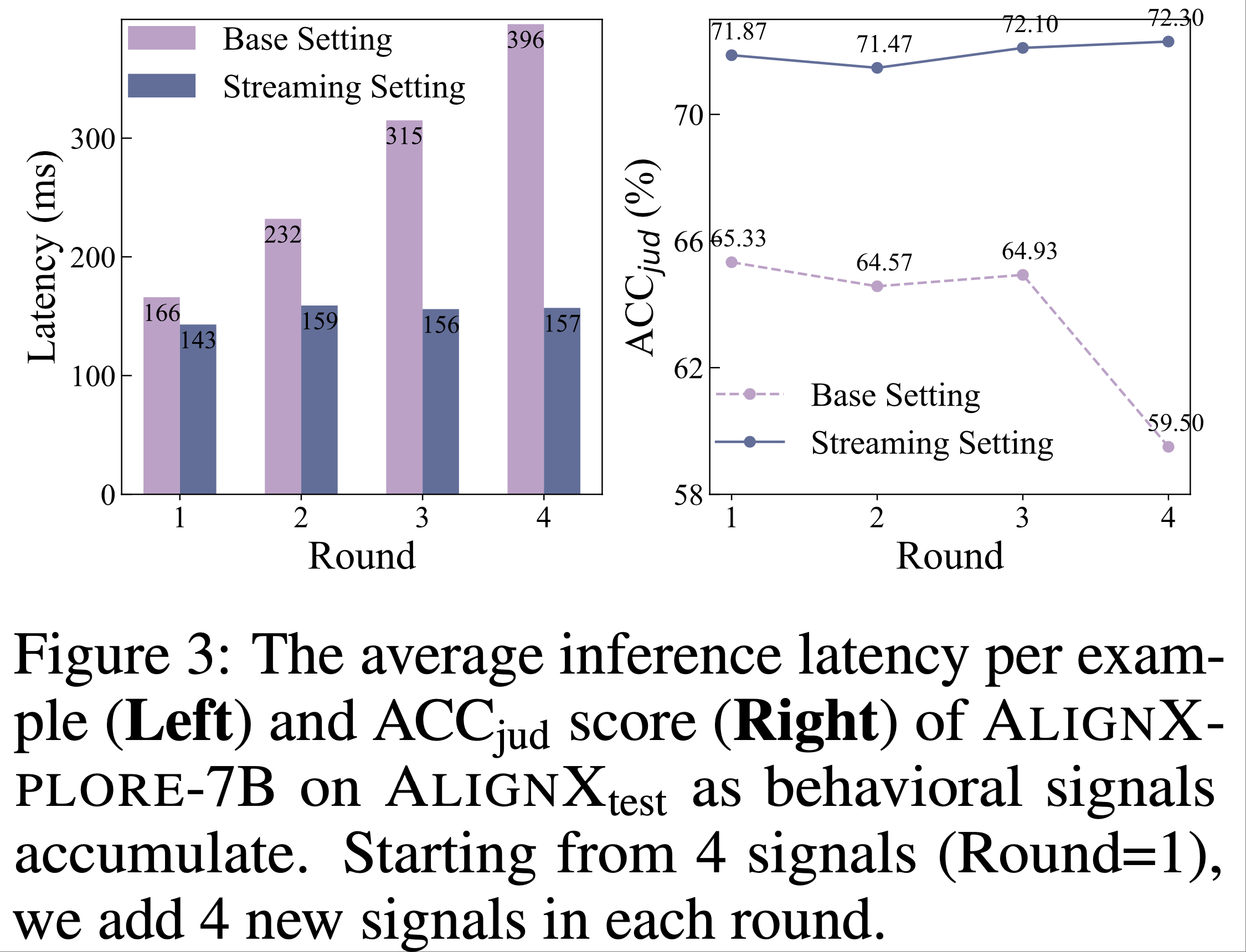
- 为评估行为信号随时间累积时的计算效率,论文比较了 AlignXplore-7B 在基础设置和流式设置下处理增长行为信号时的表现
- 如图 3 所示,每轮增量添加 4 个新行为信号,并测量 AlignXtest 上每例的平均推理时间
- 在基础设置中,由于需同时处理所有历史信号,推理时间随信号数量显著增加
- 当处理 16 个信号(第 4 轮)时,模型性能(\(\text{ACC}_{\text{jud} }\))因处理长输入上下文的挑战而急剧下降
- 论文的流式设置通过仅处理最新的 4 个信号及先前推断的偏好描述 ,保持了稳定的推理时间和性能 ,展现出对增长行为历史的高效计算能力
Further analysis
- 论文的进一步分析聚焦于两方面:
- 1)不同奖励函数的比较(Finding 1):如表 5 所示,\(R_{\text{jud} }\) 在多数指标上表现更优,甚至包括响应生成(\(\text{ACC}_{\text{gen} }\)),表明准确的偏好推断自然促进了更好的个性化生成
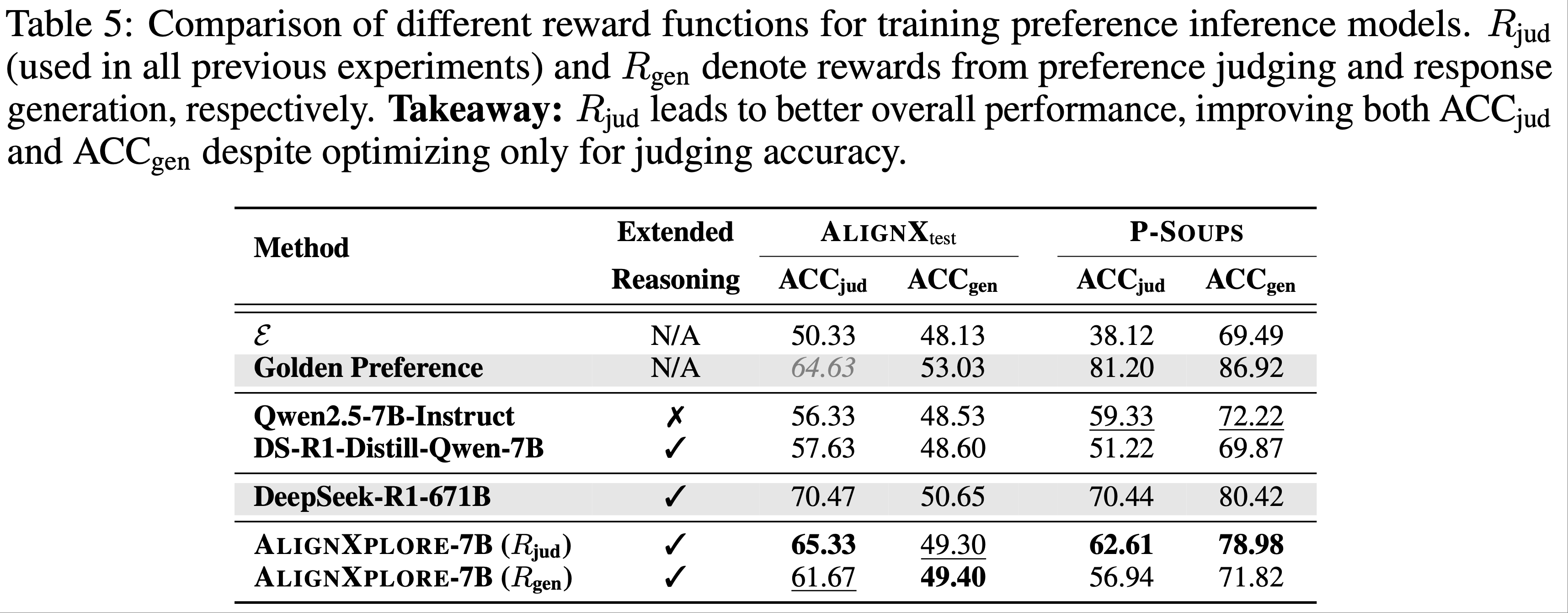
- 2)两阶段训练逐步提升偏好描述质量(Finding 2):如图 5 所示,冷启动训练帮助识别偏好维度,而 RL 学习确定偏好方向并将信号聚合为可操作的指导,模仿了人类归纳推理的过程

- 1)不同奖励函数的比较(Finding 1):如表 5 所示,\(R_{\text{jud} }\) 在多数指标上表现更优,甚至包括响应生成(\(\text{ACC}_{\text{gen} }\)),表明准确的偏好推断自然促进了更好的个性化生成
- Finding 1:优化偏好判断准确率优于响应生成奖励 :
- 论文通过比较 \(R_{\text{jud} }\) 和 \(R_{\text{gen} }\) 研究不同奖励来源对模型性能的影响
- 结果显示,\(R_{\text{jud} }\) 在多数指标上表现更优,甚至包括响应生成(\(\text{ACC}_{\text{gen} }\)),表明直接优化偏好判断能提供更稳定的训练信号
- Finding 2:冷启动和 RL 训练逐步提升偏好描述质量
- 图 5 展示了生成偏好描述的词汇云演变
- 冷启动训练帮助模型识别偏好维度,而 RL 训练进一步学习将信号聚合为具体指导
- 这一演进过程模仿了人类归纳推理的迭代细化,从一般观察到具体可操作的偏好假设
补充:Related works
Inductive reasoning
- 演绎推理是确定性推导
- 归纳推理是从不完整证据中进行概率泛化(2010; 2000)
- 这是从分类到科学发现(1986)等各种认知活动的关键能力
- 归纳推理能力在通过抽象推理语料库(Abstract Reasoning Corpus, ARC)(2019; 2023)评估 LLM(如 OpenAI o3(2024))时也受到过关注
- 现有研究(2024)主要关注少样本泛化(2020; 2018),而偏好推理提出了三个独特挑战:
- 1)在非结构化语言而非形式语言上进行推理(2024; 2023)
- 2)处理可能与测试时用户任务显著不同的异构偏好信号形式
- 3)需要对揭示非期望偏好的负例进行推理(2023)
- 论文的框架为这些挑战提供了原则性解决方案,同时保持了可解释性
Extended reasoning in LLMs
- 传统的思维链方法(Chain-of-Thought)(2022)受限于浅层、线性的推理步骤
- 最新的扩展推理研究(2023; 2025)通过三种关键机制显著提升了 LLM 的性能:
- (1)深度的逻辑链(In-depth logical chains),通过自然语言(2023)、形式语言(formal language)(2025)和潜在空间推理(2024)等多种格式维持扩展推理;
- (2)系统探索解空间(Systematic exploration of solution spaces),通过强化学习训练的内部机制(2022)或蒙特卡洛树搜索(2024)和束搜索(2024; 2023)等外部框架实现;
- (3)迭代自反思(Iterative self-reflection),使模型能够通过监督微调(2023; 2024)或可验证奖励的强化学习(2022; 2025)验证和修正推理路径
- 这些机制的整合在数学(2023)、编程(2021)、科学问答(2024)、奖励建模(2025)和多模态推理(2025)等复杂推理任务中带来了显著改进
- 论文将这一范式扩展到偏好推理领域,该领域因对强归纳推理能力的要求而具有独特挑战
Personalized alignment(个性化对齐)
- 近期研究凸显了一刀切(one-size-fits-all)对齐方法(2021; 2023; 2024)的局限性,推动了个性化对齐的发展,即根据个体偏好调整 LLM 行为(1975; 2024)。关键挑战包括:
- (1)从隐式信号中推断偏好(2023; 2022; 2018),这需要复杂的推理来综合分散的信号(2018)
- 当前工作主要关注检索偏好相关上下文(2025; 2023; 2024),而忽略了显式的偏好推理,导致对齐准确性有限(2025)
- (2)通过 Prompt (2024; 2023)、模型参数(2023)或潜在表示(2024; 2023)进行偏好建模
- 论文关注基于 Prompt 的方法,因其可解释性和模型无关性
- (3)反馈驱动的对齐,在训练期间更新 LLM(2024; 2023)或在推理时指导生成(2024; 2023; 2024)
- (1)从隐式信号中推断偏好(2023; 2022; 2018),这需要复杂的推理来综合分散的信号(2018)
- 与现有方法不同,论文首次将扩展推理用于准确的偏好推断,并提出了处理动态用户交互的高效机制(2024)
附录 A:Experiments
A.1 Implementation details
- 论文的训练和测试集源自 AlignX:
- 该数据集提出了一个包含 90 维偏好空间(涵盖普世价值观、基本人类需求和流行兴趣标签)的框架
- 数据集利用论坛互动和人机交互构建了 130 万条示例,是目前规模最大、最全面的个性化对齐数据集
- 但原始用户交互中的偏好信号相对稀疏,这曾阻碍了有效的偏好推断
- 为解决这一问题,论文引入了一种改进的数据构建方法
- 确保每个目标对至少关联五个偏好维度,其中所有交互历史均展示一致且非中立的偏好方向,同时避免其他维度的冲突偏好
- 论文构建了 10,000 条仅包含“成对比较反馈”作为交互历史的数据条目,其中 7,000 条用于训练,3,000 条用于测试
- 当 7,000 条实例用于冷启动训练时,论文根据 \(R(r,d)=1\) 选择了 3,980 条第一轮实例和 5,278 条第二轮实例
- 论文还构建了 3,000 条仅包含“用户生成内容”作为交互历史的条目,用于泛化验证
- 训练在 8 块 NVIDIA A100 GPU 上完成,使用 Adam 优化器(2014),并通过 DeepSpeed ZeRO-3(2020)和 Flash-attention-2(2023)进行优化
- 论文采用以下超参数配置:
- 学习率为 1e-6
- 50 步预热
- 4 个训练周期
- 最大 Prompt/生成长度为 8,192/2,048 Token
- 在强化学习阶段,论文将每步的小批量大小设置为 128
A.2 Baseline details
- 论文比较了多种基线方法和模型
- Directly given preference descriptions :
- (1)_Null_:不提供偏好描述;
- (2)\(\mathcal{E}\):直接使用行为信号作为偏好描述,不进行推断;
- (3)_Golden Preference_:基准提供的真实偏好描述。注意,真实偏好描述虽然在语义上准确,但由于模型兼容性差距,可能无法实现最优的下游个性化性能
- 先前针对归纳推理和个性化的专用方法(Previous specialized methods for inductive reasoning and personalization) :
- (1)_LMInductReason_(2024)通过迭代假设细化增强 LLM 的归纳推理能力;
- (2)_VPL_(2024)引入潜变量建模个体偏好;
- (3)_PBA_(2025)将行为示例映射到预定义维度的结构化偏好分数,再转换为自然语言描述
- Preference descriptions generated by state-of-the-art LLMs :
- 模型范围从小型模型(如_Qwen2.5-7B-Instruct_(2024)和_DS-R1-Distill-Qwen-7B_(2025))到大型模型(如_QwQ-32B_(2025)、_Qwen3-32B_(2025)、_GPT-4_(2023)和_DeepSeek-R1-671B_(2025))
- 这些模型涵盖简洁推理和扩展推理模式
- 此外,为验证方法的有效性,论文还比较了 AlignXplore-7B 的消融版本(w/o RL 和 w/o Cold-start),分别在基础设置下仅使用冷启动训练或强化学习进行偏好推断
- 对于 VPL(2024),论文在 Qwen2.5-7B-Instruct 上使用 \(\mathcal{D}_{4}\) 训练一个周期
- 该方法使用其专用下游模型进行偏好引导判断(其他基线通过相应模型生成角色或偏好,并输入 Qwen2.5-7B-Instruct 进行评估)
- LMInductReason(2024)遵循原论文实现,其中内容生成替换为 Qwen2.5-7B-Instruct
- 在迭代生成规则后,最终规则提供给 Qwen2.5-7B-Instruct 以生成偏好选择
- PBA(2025)使用原论文方法从每个基准的交互历史中提取一致偏好
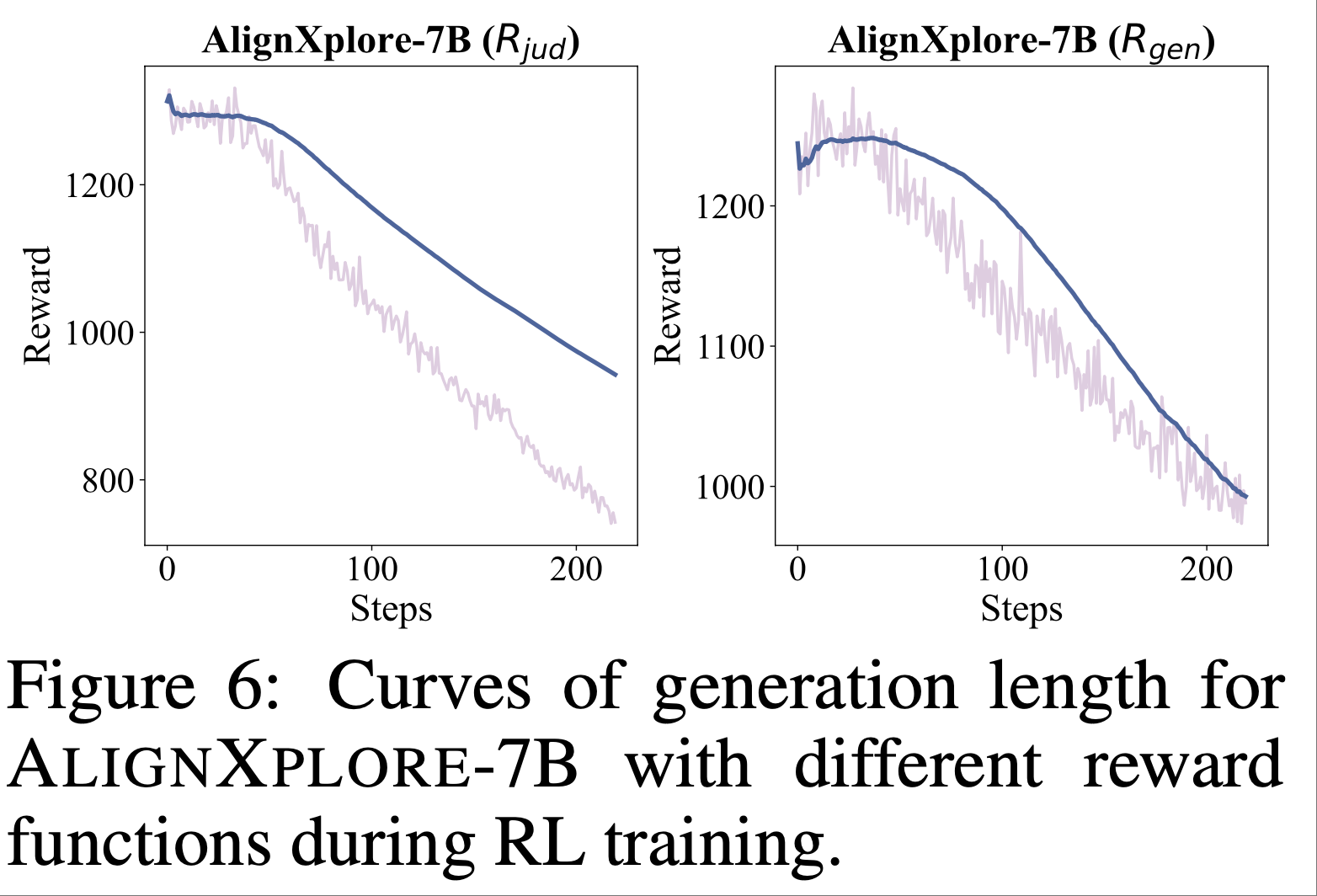
A.3 Length evolution(演变)
- 图 6 展示了 AlignXplore-7B(\(R_{\text{jud} }\))和 AlignXplore-7B(\(R_{\text{gen} }\))在强化学习过程中生成长度的变化
- 随着训练进行,模型的平均生成长度持续下降
- 论文的分析表明:
- 冷启动训练引导模型分析适当的偏好维度,但其倾向于重复行为信号的内容,分析信心较低,且存在大量冗余和波动的维度解释
- 强化学习后,模型的分析方向变得更清晰
- 对于行为信号的偏好解释,模型现在仅提及反映偏好的关键术语,能够快速分析和总结用户偏好(这与第 4.6 节的分析一致)
A.4 Robustness assessment
- 表 6 展示了 AlignXplore-7B 在基础设置和流式设置下,当为每位用户提供 8 个偏好对且第一个偏好对反转时的性能
- 流式推理机制允许模型在流式推断用户偏好时细化偏好描述,因此在面对不一致或随时间变化的用户行为偏好时表现出鲁棒性和泛化能力
- 因此,无论是在域内还是域外数据集上,流式设置均优于基础设置

A.5 Case study
- 待补充
附录 B:Data format and prompt
- 包含多个提示模板,详情参考原始论文
附录 C Limitations
- 由于缺乏真实的 LLM 与用户交互的测试平台,论文无法在真实环境中验证模型的推理性能(作者提到一旦此类测试平台可用,论文将进一步评估模型的表现)
- 论文主要关注偏好推断的场景,并确保测试集中的历史偏好与测试对一致
- 问题:如何评估一致性?
- 未来的工作可以扩展到用户偏好随时间动态变化的场景,要求模型在推断时根据用户最近的行为调整偏好
附录 D Impact statement
- 本研究提升了模型的偏好推断能力,使其能够通过理解和响应用户的个性化偏好更好地服务人类用户
- 这可能涉及用户隐私和偏见相关的潜在风险
- 通过推断个性化偏好,模型可能无意中放大数据中的现有偏见或误解用户意图
- 为了缓解这些风险,论文还做了如下努力:
- 论文确保方法中包含强大的公平性和透明度措施
- 论文优先考虑用户同意 ,并实施机制以确保用户数据匿名化并安全处理
- 论文鼓励持续监控模型在真实场景中的表现 ,以识别和解决任何意外后果,从而确保模型的部署符合道德并与用户利益保持一致