注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:(DeepSeek-GRM)Inference-Time Scaling for Generalist Reward Modeling, DeepSeek & THU, 20250403-20250925
- 本工作是 THU 学生在 DeepSeek 实习期间完成
- 开源模型: huggingface.co/collections/BBQGOD/deepseek-grm 和 modelscope.cn/profile/BBQGOD
- 开源包含三个模型:
- BBQGOD/DeepSeek-GRM-16B
- BBQGOD/DeepSeek-GRM-27B
- BBQGOD/DeepSeek-GRM-27B-MetaRM
- 开源包含三个模型:
- 原始论文:(DeepSeek-GRM)Inference-Time Scaling for Generalist Reward Modeling, DeepSeek & THU, 20250403-20250925
Paper Summary
- 核心内容:
- 论文提出了自 Principle Critique 调优 (Self-Principled Critique Tuning, SPCT) 方法
- SPCT 是一种增强通用奖励建模推理时扩展性的方法
- 通过 Rule-based Online RL,SPCT 实现了 Principle 和 Critique 的自适应生成,显著提升了 GRM 在多样领域中的奖励质量和推理时扩展性
- 在实验中,DeepSeek-GRM 超越了基线方法和一些强大的公开 RM,并通过推理时扩展,尤其是在 Mata RM 的引导下,展现出显著的改进
- 背景:
- RL 在 LLMs 的后训练中已被广泛采用
- 在 LLMs 中通过 RL 激励推理能力表明: 适当的学习方法能够实现有效的推理时扩展性(proper learning methods could enable effective inference-time scalability)
- 问题提出:
- RL 的一个关键挑战是,在可验证问题或人工规则之外的各个领域为 LLMs 获取准确的奖励信号
- 论文研究了如何通过增加推理计算来改进通用 Query 的奖励建模(Reward Modeling, RM),即 通用奖励建模的推理时扩展性(inference-time scalability of generalist RM)
- 对于 RM(即奖励建模)方法,论文采用 Pointwise 生成奖励建模(pointwise generative reward modeling, GRM)以实现对不同输入类型的灵活性和推理时扩展的潜力
- 对于学习方法,论文提出了 Self-Principled Critique 调优(Self-Principled Critique Tuning, SPCT) ,通过 Online RL 在 GRMs 中培养(foster)可扩展的奖励生成行为,以自适应地生成 Principle 并准确地给出 Critique,从而产生了 DeepSeek-GRM 模型
- Furthermore,为了实现有效的推理时扩展,论文使用并行采样来扩展计算使用,并引入一个元奖励模型(meta RM)来指导投票过程以获得更好的扩展性能
- 实验表明,SPCT 显著提高了 GRMs 的质量和可扩展性,在各种 RM 基准测试中优于现有方法和模型,且没有严重的偏差,并且与训练时扩展(training-time scaling)相比,它能获得更好的性能
- DeepSeek-GRM 在某些任务上仍面临挑战,作者相信未来在通用奖励系统上的努力可以解决这些问题
- 注:相关模型均已开源
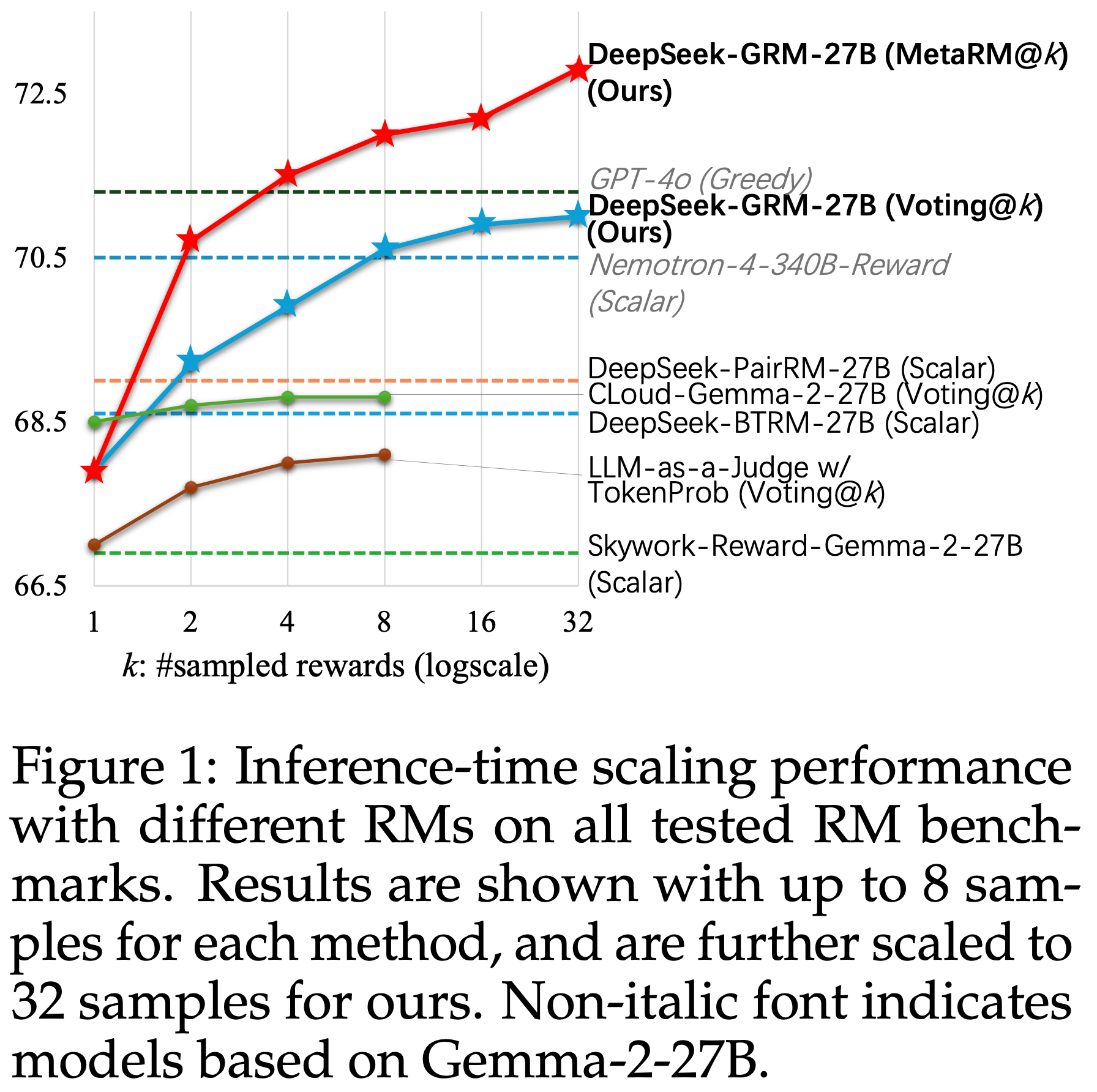
- 图 1: 不同 RMs 在所有测试的 RM 基准上的推理时扩展性能
- 结果显示为每种方法最多 8 个样本,论文的方法进一步扩展到 32 个样本
- 非斜体字体表示基于 Gemma-2-27B 的模型
- 特别说明:
- DeepSeek-GRM 的用法看看附录 G 中 DeepSeek-GRM (Default) Prompt 细节更容易理解
Introduction and Discussion
- LLMs (2023; 2024) 的显著进步推动了人工智能研究的重大转变,使模型能够执行需要理解、生成和细微决策能力的任务
- Recently,RL 作为 LLMs 的后训练方法已被大规模采用,并在人类价值观对齐(human value alignment)(2024; 2025)、长期推理(long-term reasoning)(2023; 2024) 和 LLMs 的环境适应(environment adaptation)(2024) 方面带来了显著改进。奖励建模(RM)(2024) 作为 RL 中的一个关键组件,对于为 LLM Response 生成准确的奖励信号至关重要
- 当前研究(2024; 2025)也表明,无论是在训练时还是推理时拥有高质量且稳健的奖励,LLMs 都能在特定领域取得强劲性能
- However,这种特定领域的高质量奖励主要来源于具有明确条件的人工设计环境(2022; 2024)或为可验证问题(例如数学问题(2021; 2023)和编码任务(2024; 2025))手工制定的规则
- 在通用领域,奖励生成更具挑战性,因为奖励标准更加多样化和复杂,并且通常没有明确的参考或真实答案
- 因此,通用奖励建模(generalist reward modeling)对于从后训练(例如大规模 RL)或推理(例如 RM 引导的搜索)角度提高 LLMs 在更广泛应用中的性能至关重要
- Furthermore,RM 性能应通过增加训练计算(2023)和推理计算(inference compute)来提升
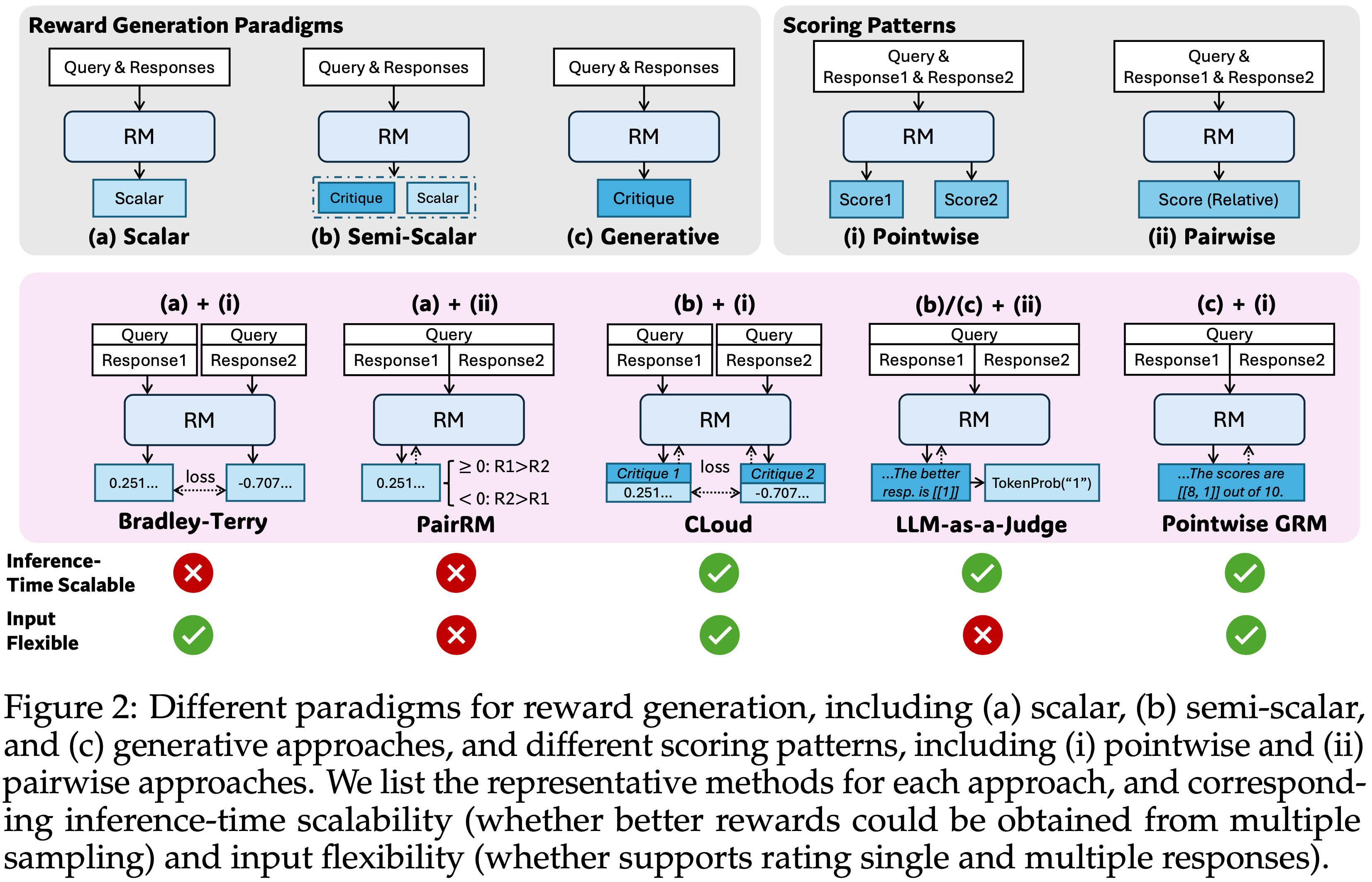
- 图 2:奖励生成的不同范式,包括 (a) Scalar,(b) Semi-scalar 和 (c) 生成式方法,以及不同的评分模式,包括 (i) Pointwise 和 (ii) Pairwise 方法
- 论文列出了每种方法的代表性方法,以及相应的推理时扩展性(是否可以从多次采样中获得更好的奖励)和输入灵活性(是否支持对单个和多个 Response 的评分)
- 论文列出了每种方法的代表性方法,以及相应的推理时扩展性(是否可以从多次采样中获得更好的奖励)和输入灵活性(是否支持对单个和多个 Response 的评分)
- 在实践中,要使 RMs 既通用又在推理时有效可扩展(effectively scalable)存在挑战
- 通用性 要求 RM:
- (1)对不同输入类型的灵活性
- (2)在各个领域生成准确的奖励
- 论文将此范式称为 通用奖励建模(generalist reward modeling)
- Moreover,有效的 推理时扩展性(inference-time scalability) 要求 RM
- (3)能够通过增加推理计算生成更高质量的奖励信号
- (4)学习可扩展的行为以实现更好的性能-计算缩放(performance-compute scaling)
- 现有的奖励建模研究展示了奖励生成的几种范式,包括 Scalar(2021; 2024; 2024)、 Semi-scalar(2025; 2025; 2025) 和生成式(generative)(2024; 2024; 2024; 2024; 2025; 2025; 2025; 2025; 2025) 方法,以及各种评分模式,例如 Pointwise(1940; 2023; 2024; 2025; 2025) 和 Pairwise (2024; 2023; 2023; 2024; 2025)
- 这些方法本质上决定了 RMs 的输入灵活性(flexibility)和推理时扩展性((1)和(3)),如图 2 所示
- For Instance, Pairwise RMs 仅考虑 Pairwise Response 的相对偏好,缺乏接受单个或多个 Response 作为输入的灵活性; Scalar RMs 很难为同一 Response 生成多样化的奖励信号,这阻碍了通过基于采样的推理时扩展方法(2025)获得更好的奖励
- Also,不同的学习方法(2024; 2024; 2024; 2024)用于提高奖励的质量,但其中很少关注推理时扩展性,并研究学习到的奖励生成行为与 RMs 推理时扩展有效性之间的相互联系,导致性能提升有限((2)和(4))
- 当前研究(2025)表明,有效的推理时扩展性可以通过适当的学习方法实现,这引出了问题:论文能否设计一种旨在实现通用奖励建模有效推理时扩展的学习方法?
Can we design a learning method aiming to enable effective inference-time scaling for generalist reward modeling?
- 通用性 要求 RM:
- 论文研究了不同的 RM 方法,发现 Pointwise 生成奖励建模(GRM)可以在纯语言表示中统一对单个、 Pairwise 和多个 Response 的评分,克服挑战(1)
- 论文探索了某些 Principle 可以在适当的准则范围内指导 GRMs 的奖励生成,从而提高奖励质量,这表明 RM 的推理时扩展性可能通过扩展高质量 Principle 和准确 Critique 的生成来实现
- 基于此初步发现,论文提出了一种新颖的学习方法 Self-Principled Critique 调优(Self-Principled Critique Tuning, SPCT) ,以在 GRMs 中培养有效的推理时可扩展行为
- 通过利用 Rule-based Online RL,SPCT 使 GRMs 能够学习根据输入 Query 和 Response 自适应地提出 Principle 和 Critique ,从而在通用领域获得更好的结果奖励(挑战(2))
- 然后论文推出了 DeepSeek-GRM-27B ,它是基于 Gemma-2-27B (2024) 使用 SPCT 进行后训练的
- 对于推理时扩展,论文通过多次采样来扩展计算使用
- 通过并行采样,DeepSeek-GRM 可以生成不同的 Principle 集和相应的 Critique ,然后投票决定最终奖励
- 通过更大规模的采样,DeepSeek-GRM 可以基于更多样化的 Principle 进行更准确的判断,并以更细的粒度输出奖励 ,这解决了挑战(3)和(4)
- Furthermore,除了投票,论文还训练了一个 Mata RM 以获得更好的扩展性能
- 实验表明,SPCT 显著提高了 GRMs 的质量和可扩展性,在多个综合 RM 基准测试中优于现有方法和模型,且没有严重的领域偏差
- 论文还将 DeepSeek-GRM-27B 的推理时扩展性能与参数高达 671B 的更大模型进行了比较,发现与模型大小的训练时扩展相比,它能获得更好的性能
- 尽管当前方法在效率和特定任务上面临挑战,但作者相信,通过 SPCT 之外的努力,具有增强可扩展性和效率的 GRMs 可以作为通用奖励系统的多功能接口,推进 LLM 后训练和推理的前沿
- In general,论文的主要贡献如下
- 1)论文提出了一种新颖的方法 Self-Principled Critique 调优(Self-Principled Critique Tuning, SPCT) ,以培养通用奖励建模的有效推理时扩展性,从而产生了(resulting in) DeepSeek-GRM 模型
- 论文还进一步引入了一个 Mata RM 来有效提升 DeepSeek-GRM 在投票之外的推理时扩展性能
- 2)论文通过实验证明,与现有方法和几个强大的公共模型相比,SPCT 显著提高了 GRMs 的质量和推理时扩展性
- 3)论文还将 SPCT 训练方案应用于更大尺寸的 LLMs,发现推理时扩展可以超越模型大小的训练时扩展
- 1)论文提出了一种新颖的方法 Self-Principled Critique 调优(Self-Principled Critique Tuning, SPCT) ,以培养通用奖励建模的有效推理时扩展性,从而产生了(resulting in) DeepSeek-GRM 模型
Preliminaries
Comparisons of Different RM approaches
- 如图 2 所示,RM 方法主要由奖励生成范式和评分模式决定,这本质上影响了 RM 的推理时扩展性和输入灵活性
- 对于 奖励生成范式(reward generation paradigms) ,论文区分了三种主要方法: Scalar 、 Semi-scalar 和生成式
- 对于 评分模式(scoring patterns) ,论文区分了两种主要方法: Pointwise 和 Pairwise
- 为了在推理时扩展计算使用,论文专注于基于采样的方法,这些方法为相同的 Query 和 Response 生成多组奖励,然后聚合最终奖励
- RMs 的 推理时扩展性(inference-time scalability) 取决于是否可以从多次采样中获得不同的奖励 ,其中 Scalar RMs 在大多数情况下会因奖励的恒定生成而失败;
- RMs 的 输入灵活性(input flexibility) 由 RM 是否支持对单个、 Pairwise 和多个 Response 的评分来定义,其中 Pairwise RMs 很难对单个 Response 评分,通常需要额外的技术(2023; 2025)来处理多个 Response
Reward Generation Paradigms
- 经典的 RMs 采用 (a) Scalar 方法(scalar approach) 生成奖励(\(\mathcal{R}\))
- 为给定的 Query 和 Response 分配 Scalar 值
- Scalar 方法进一步扩展到 (b) Semi-scalar 方法(semi-scalar approach)
- 除了 Scalar 值外还生成文本
- 而 (c) 生成式方法(generative approach) 仅生成文本奖励
$$
\mathcal{R}=
\begin{cases}
S & \text{(Scalar)} \\
(S, \boldsymbol{C}) & \text{(Semi-Scalar)} \quad \sim r_{\theta}\left(x,\{y_i\}_{i=1}^{n}\right)\\
\boldsymbol{C} & \text{(Generative)}
\end{cases} \\
\tag{1}
$$- 上面的公式表示如下含义:
$$ \mathcal{R} \sim r_{\theta}\left(x,\{y_i\}_{i=1}^{n}\right) $$ - \(x\) 是 Query
- \(y_i\) 是第 \(i\) 个 Response
- \(r_{\theta}\) 是由 \(\theta\) 参数化的奖励函数
- \(S \in \mathbb{R}^{m}, m \leq n\) 是 Scalar 奖励
- \(\boldsymbol{C}\) 是 Critique
- 上面的公式表示如下含义:
Scoring Patterns
- 论文区分了奖励的两种主要评分方法: Pointwise 和 Pairwise
- (i) Pointwise 方法(pointwise approach) 为每个 Response 分配一个单独的分数:
$$
\{S_i\}_{i=1}^{n}=f_{\text{point} }\left(\mathcal{R},\{y_i\}_{i=1}^{n}\right), \quad \mathcal{R} \sim r_{\theta}\left(x,\{y_i\}_{i=1}^{n}\right), S_i \in \mathbb{R},
\tag{2}
$$- 其中 \(f_{\text{point} }(\cdot,\cdot)\) 是一个分割函数(Spliting Function)
- 问题:这里 Pointwise 打分的情况下,输入的 \(y_i\) 仅一个就可以了吧?此时应该有 \(n=1\)? 还是说输入可以是多个,但是一个个分别打分?
- (ii) Pairwise 方法(pairwise approach) 可以看作是一种最佳选择方法(best-of-\(n\) method),从所有候选中选择一个最佳 Response :
$$
\hat{y}=f_{\text{pair} }(\mathcal{R},\{y_i\}_{i=1}^{n}), \quad \mathcal{R} \sim r_{\theta}\left(x,\{y_i\}_{i=1}^{n}\right), \hat{y} \in \{y_i\}_{i=1}^{n},
\tag{3}
$$- 其中 \(f_{\text{pair} }(\cdot,\cdot)\) 是一个选择函数,在大多数情况下 \(n=2\)
- 虽然 Pairwise 方法可以扩展到 \(n>2\),但不能应用于单个 Response 评分(\(n=1\))
- 理解:这里 Pairwise 方法和 Pointwise 方法的最本质区别是:
- Pairwise 方法在挑选最佳 Response,而 Pointwise 在给每个 Response 打分,但似乎并没有限制输入的 Response 数量
- 问题:这里是不是也可以理解为 listwise?如何定义 listwise、pairwise 和 pointwise 更合适?
Representative Methods
- 图 2 说明了三种奖励生成范式( Scalar 、 Semi-scalar 、生成式)如何与两种评分模式( Pointwise 、 Pairwise )结合
- Specifically
- Bradley-Terry 模型(1940)(Scalar + Pointwise)使用 Pairwise 偏好数据进行训练,并以 Pointwise 方式输出 Scalar 奖励:
$$
\{S_i\}_{i=1}^{n}=f_{\text{point} }\left(\mathcal{R},\{y_i\}_{i=1}^{n}\right)=\mathbf{S} \in \mathbb{R}^{n}.
\tag{4}
$$- 理解:上述公式的意思是,\(\{S_i\}_{i=1}^{n}\) 是一个 \(n\) 维的分数向量 \(\mathbf{S}\),且对应向量 \(\mathbf{S}\in \mathbb{R}^{n}\)
- PairRM(2023)(Scalar + Pairwise)通过 Scalar 奖励的符号比较一对 Response :
$$
\hat{y}=f_{\text{pair} }\left(\mathcal{R},\{y_i\}_{i=1}^{n}\right)=y_{\left|\frac{1}{2}(3-\text{sgn}(S))\right|}, \quad n=2,S \in \mathbb{R}.
\tag{5}
$$- 上述两个 Scalar 方法由于奖励生成缺乏多样性,几乎无法进行推理时扩展
- Cloud(2024)(Semi-Scalar + Pointwise)基于预先生成的 Critique 为每个 Response 生成 Scalar 奖励,类似于公式 4
- 理解:先生成 Critique,然后通过 Critique 生成一个 Scalar 分数
- LLM-as-a-Judge(2023; 2024)(Generative + Pairwise)以文本方式判断 Pairwise Response 之间的偏好顺序:
$$
\hat{y}=f_{\text{pair} }\left(\mathcal{R},\{y_i\}_{i=1}^{n}\right)=y_{f_{\text{extract} }(\boldsymbol{C})}, \quad n=2,
\tag{6}
$$- 其中 \(f_{\text{extract} }(\cdot)\) 从语言表示中提取最佳 Response 的索引
- However,这种方法默认忽略了 Pairwise Response 的平局情况
- 理解:LLM-as-a-Judge 其实是一种很广泛的泛指吧?只要是生成式的是不是基本上都属于 LLM-as-a-Judge 的范畴?
- 根据 Zhang 等人(2025b),指示偏好顺序的 token 的生成概率可以用作 Scalar 奖励(Semi-Scalar + Pairwise):
$$ \mathcal{S}=\text{TokenProb}(\hat{\boldsymbol{C} })=r_{\theta}(\hat{\boldsymbol{C} }|x,\{y_i\}_{i=1}^{n})$$- 其中 \(\hat{\boldsymbol{C} }\) 是与偏好顺序相关的预定义 token(pre-defined token related to the preference order)
- 理解:这里的含义是:Token 的概率本身就可以作为一个偏好 Scalar 奖励
- Bradley-Terry 模型(1940)(Scalar + Pointwise)使用 Pairwise 偏好数据进行训练,并以 Pointwise 方式输出 Scalar 奖励:
- (论文的方法)在没有额外约束的情况下,GRMs 能够在纯语言表示中为多个 Response 生成 Pointwise 奖励(Generative + Pointwise):
$$
\{S_i\}_{i=1}^{n}=f_{\text{point} }\left(\mathcal{R},\{y_i\}_{i=1}^{n}\right)=f_{\text{extract} }(\boldsymbol{C}),
\tag{7}
$$- 其中 \(f_{\text{extract} }(\cdot)\) 从生成结果中提取分配给每个 Response 的奖励
- Usually,奖励是离散的,在本工作中,我们设定为自然数 默认分配 \(S_i \in \mathbb{N},1 \leq S_i \leq 10\)
- 这种方法同时实现了推理时扩展性和输入灵活性
Boosting Reward Quality with Principles
- 通用 RM 需要在特定领域之外生成高质量的奖励(2021; 2024),在这些领域中奖励标准更加多样化和复杂,并且通常没有明确的参考或真实答案
- 为此,对于通用领域,论文采用 Principle 来指导奖励生成,以代替人工规则
- LLMs 的 Principle 首先在宪法式人工智能(Constitutional AI)中引入(2022b; 2025),这些是手工制定的准则(hand-crafted criteria),指导 LLMs 或精选的分类器构建安全的数据 Pipeline
- 有了 Principle ,GRMs 的奖励生成变为:
$$
\mathcal{R}=\mathbf{C} \sim r_{\theta}\left(x,\{y_i\}_{i=1}^{n},\{p_i\}_{i=1}^{m}\right),
\tag{8}
$$- 其中 \(\{p_i\}_{i=1}^{m}\) 表示 Principle
- 理解:这里就是指同时给出 Query、Response,评估指标(Principle),然后使用生成式模型评估奖励(即是否满足 Principle)
- 论文进行了一项初步实验来检验适当 Principle 对奖励质量的影响,使用了 Reward Bench(2024)的 Chat Hard 子集和 PPE 基准(2025)的 IFEval 子集
- 在实验中,数据样本包含一个 Query 和两个 Response ,真实标签表示更好的 Response
- 论文使用 GPT-4o-2024-08-06 生成 Principle ,然后为每个样本生成四次 Pointwise 奖励
- 论文从正确的奖励生成过程中筛选 Principle (正确的定义:即更大的奖励值被分配给 Token 为更好的 Response )
- 理解:这里是在筛选对应 Chosen 分数高于 Rejected 分数的数据,Rubrics-based RL 筛选数据也可以这样来筛选
- 论文用它们自己生成的 Principle 和筛选过的 Principle 测试不同的 LLMs,并将它们与无 Principle 指导的默认设置进行比较,结果如表 1 所示
- 论文发现, 自生成的 Principle 几乎没有显著提升奖励质量 (注:经过过滤的 Principle 是可以提升奖励质量的 )
- 这一结果并非微不足道(non-trivial),可以得出两个主要结论:
- (a) 当前的 LLMs 可以生成多样化的 Principle ,但并非所有 Principle 都适合用于奖励生成
- (b) 生成的 Principle 的一个子集可以在正确的准则下更好地指导奖励生成,这表明了自我引导(self-bootstrapping)的潜力
- 这些发现是利用 Online RL 优化 GRMs 的基础,它们可以从自己生成的 Principle 中学习,并有一个清晰的信号来判断 Principle 是否合适

- 其他细节在附录 D 中描述
Self-Principled Critique Tuning, SPCT
- 受到初步结果的启发,论文为 Pointwise GRMs 开发了一种新颖的方法,学习生成能够有效指导 Critique 生成的自适应高质量 Principle ,称为 Self-Principled Critique 调优(Self-Principled Critique Tuning, SPCT)
- 如图 3 所示,SPCT 包括两个阶段:
- 第一阶段:作为冷启动的拒绝式微调(rejective fine-tuning)
- 第二阶段:Rule-based Online RL,通过改进生成的 Principle 和 Critique 来强化通用奖励生成
- SPCT 也在 GRMs 中培养了这些行为以实现推理时扩展
- 图 3:SPCT 的图示,包括拒绝式微调、 Rule-based RL 以及推理期间相应的可扩展行为
- 推理时扩展通过朴素投票或由大规模生成的 Principle 指导的 Mata RM 投票实现,从而在扩展的值空间内产生更细粒度的结果奖励
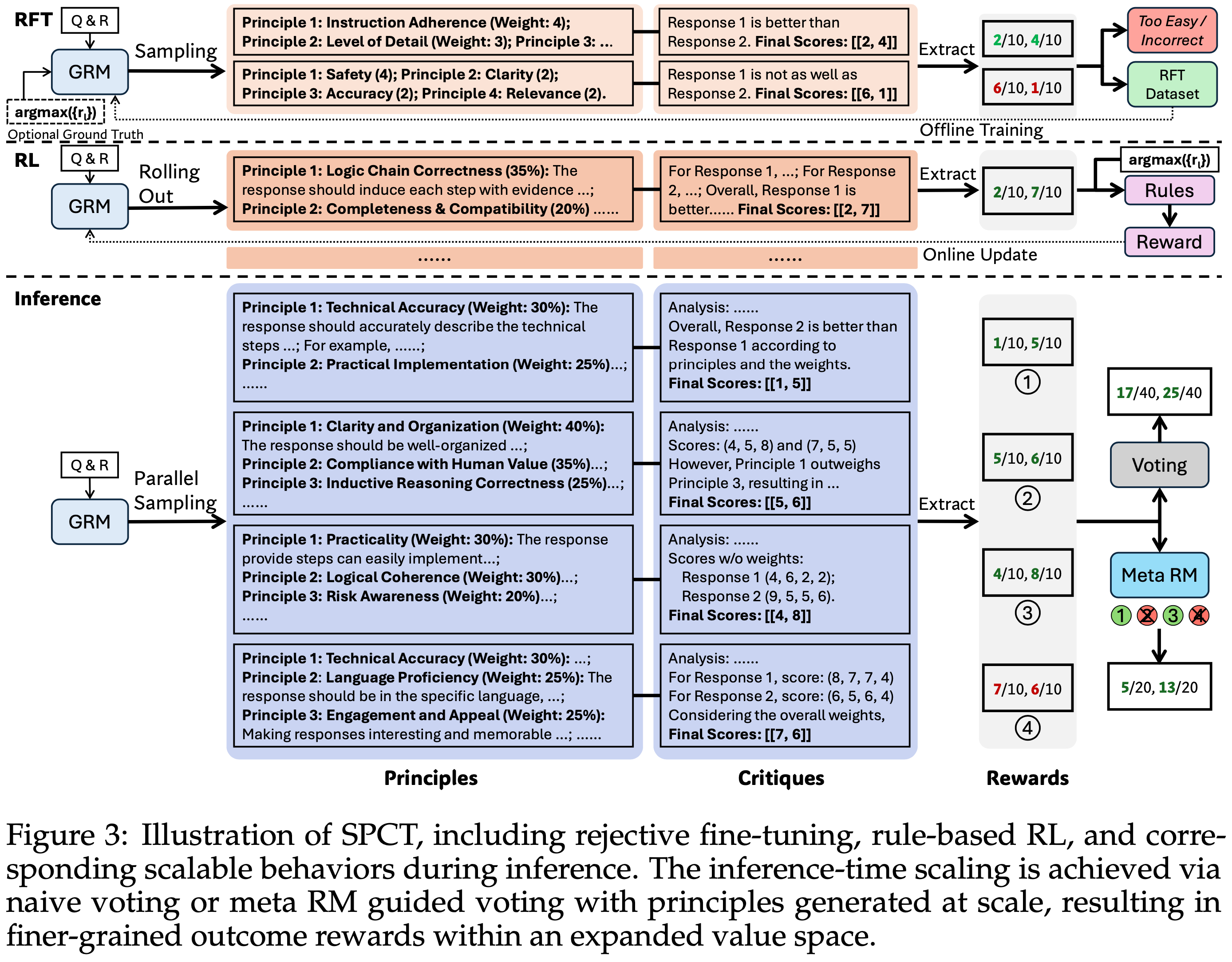
- 推理时扩展通过朴素投票或由大规模生成的 Principle 指导的 Mata RM 投票实现,从而在扩展的值空间内产生更细粒度的结果奖励
Unpinning Principles from Understanding to Generation(将核心原理从 “理解任务” 抽离并迁移到 “生成任务” 中)
- 根据第 2.2 节的初步实验,论文发现适当的 Principle 可以在特定准则内指导奖励生成,这对于高质量奖励至关重要
- However,大规模生成通用 RM 的有效 Principle 仍然具有挑战性
- 为了解决这一挑战,论文提出 Unpinning Principles from Understanding to Generation,即将 Principle 视为奖励生成的一部分,而不是预处理步骤
- 形式上, Principle 根据公式 8 指导奖励的生成,当 Principle 是预定义的时
- GRMs 可以自己生成 Principle ,然后基于这些 Principle 生成 Critique ,形式化为:
$$
\{p_i\}_{i=1}^{m} \sim p_{\theta}\left(x,\{y_i\}_{i=1}^{n}\right), \quad \mathcal{R}=\mathbf{C} \sim r_{\theta}\left(x,\{y_i\}_{i=1}^{n},\{p_i\}_{i=1}^{m}\right),
\tag{9}
$$ - 其中 \(p_{\theta}\) 是由 \(\theta\) 参数化的 Principle 生成函数,与奖励生成 \(r_{\theta}\) 共享同一模型
- 在实践中,它们使用 LLMs 中的同一语言头实现
- 这种转变使得 Principle 能够基于输入 Query 和 Response 生成,自适应地对齐奖励生成过程,并且 Principle 和相应 Critique 的质量和粒度可以通过 GRMs 的后训练进一步改进
- 通过 大规模生成的 Principle ,GRMs 可能以更细的粒度和更广泛的考虑输出奖励,从而实现更好的推理时扩展性
- GRMs 可以自己生成 Principle ,然后基于这些 Principle 生成 Critique ,形式化为:
Rule-Based Reinforcement Learning
- 为了同时优化 GRMs 中的 Principle 和 Critique 生成,论文提出了 SPCT,它整合了拒绝式微调(rejective fine-tuning, RFT)和 Rule-based RL
- RFT 的作用是冷启动
Rejective Fine-Tuning, Cold Start
- 拒绝式微调阶段的核心思想是训练 GRM 以正确的格式为各种输入类型生成 Principle 和 Critique
- 与之前混合不同格式的单个、 Pairwise 和多个(single, paired, and multiple) Response 的 RM 数据的工作(2024; 2024; 2025)不同,论文采用第 2.1 节介绍的 Pointwise GRM,灵活地以相同格式为任意数量的 Response 生成奖励
- 对于数据构建,除了通用指令数据外,论文还通过给出 Query 和相应 Response 用预训练的 GRM 采样轨迹
- 每个 RM 数据点(Data Point)包含一个 Query 和一个或多个对该 Query 的 Response ,以及表示最佳 Response 的真实标签
- 对于每个 RM 数据点, Principle 和 Critique 的采样执行 \(N_{\text{RFT} }\) 次
- 拒绝策略也是统一的,即拒绝以下两种情况:
- 第一:预测奖励不正确的轨迹
- 第二:所有 \(N_{\text{RFT} }\) 条轨迹都正确(太容易)的 Query 和 Response
- 拒绝策略也是统一的,即拒绝以下两种情况:
- 形式上,令 \(r_i\) 表示对 Query \(x\) 的第 \(i\) 个 Response \(y_i\) 的真实奖励,如果满足下面的条件,则认为预测的 Pointwise 奖励 \(\{S_i\}_{i=1}^{n}\) 是正确的
$$
\begin{cases}
\forall i \neq j, \quad S_j > S_i, \quad j = \arg \max_{l}\{r_l\}_{i=l}^{n}, & \text{if } n \geq 2, \\
S_1 = r_1, & \text{if } n = 1.
\end{cases}
\tag{10}
$$- 只有一个 Response 时,当且仅当真实分数 \(r_1\) 和 预测分数 \(S_1\) 完全相等才算正确
- 有多个 Response 时,当且仅当真实奖励中最大的 Response 对应的分数高于所有其他 Response(类似 Best-of-N)
- 并保证真实奖励只包含一个最大值
- However,与之前的工作类似(2025b),论文发现预训练的 GRMs 在有限的采样配额内很难为一部分 Query 和相应的 Response 生成正确的奖励
- 理解:这里的问题是有限的采样次数可能是无法生成准确的评估轨迹的(即无法找到最佳的 Response)
- Thus,论文可选择地将 \(\arg \max_{j}\{r_l\}_{l=1}^{n}\) 附加到 GRM 的提示中,称为 提示采样(hinted sampling) ,期望预测的奖励与真实情况一致,此外还有 非提示采样(non-hinted sampling)
- 具体来说,将在输入中附加一个额外的片段 “The best response is: Response \(\arg \max_{i}\{r_l\}_{l=1}^{n}\)”
- 对于提示采样,每个 Query 和相应的 Response 只采样一次 ,只有当轨迹不正确时才拒绝
- 问题:这样的话,相当于先给答案(告诉模型最佳 Response 是谁),再让模型生成推理过程
- 除了之前的研究(2024; 2024),论文观察到提示采样的轨迹有时在生成的 Critique 中走捷径,特别是对于推理任务,这表明了 Online RL 对 GRM 的必要性和潜在好处
Rule-Based RL
- GRM 使用 Rule-based Online RL 进一步微调,论文使用 GRPO(2024)的原始设置以及 Rule-based 结果奖励
- 在 rollout 期间,GRM 根据输入 Query 和 Response 生成 Principle 和 Critique ,然后提取预测的奖励并与真实值通过准确度规则进行比较
- 与 DeepSeek-AI(2025)不同,论文不使用格式奖励
- Instead,论文应用了更大的 KL 惩罚系数以确保格式并避免严重偏差
- 形式上,对于给定 Query \(x\) 和 Response \(\{y_i\}_{i=1}^{n}\) 的第 \(i\) 个输出 \(o_i\) 的奖励是:
$$
\hat{r}_i=
\begin{cases}
1, & \text{if } n \geq 2 \text{ and } \forall i’ \neq j’, \quad S_{j’} > S_{i’}, \quad j’ = \arg \max_{l}\{r_l\}_{l=1}^{n}, \\
1, & \text{if } n = 1 \text{ and } S_1 = r_1, \\
-1, & \text{otherwise},
\end{cases}
\tag{11}
$$- 其中 Pointwise 奖励 \(\{S_i\}_{i=1}^{n}\) 是从 \(o_i\) 中提取的
- 问题:一个 \(o_i\) 中包含了所有的 Pointwise 奖励 \(\{S_i\}_{i=1}^{n}\) 吗?
- 该奖励函数鼓励 GRMs 通过在线优化的 Principle 和 Critique 来区分最佳 Response ,有利于有效的推理时扩展
- 奖励信号可以从任何偏好数据集和带标签的 LLM Response 中无缝获得
- 理解:即有 Chosen/Rejected 或 Best-of-N 数据的样本都可以用来训练
- 理解:上述奖励跟前面的 RFT 类似:
- 只有一个 Response 时,当且仅当真实分数 \(r_1\) 和 预测分数 \(S_1\) 完全相等才算正确
- 有多个 Response 时,当且仅当真实奖励中最大的 Response 对应的分数高于所有其他 Response(类似 Best-of-N)
- 理解:在当前的设计下,有多个 Response 时,所有 Response 的分数是同时为 1(预测正确)或 -1(预测错误)的
- 其中 Pointwise 奖励 \(\{S_i\}_{i=1}^{n}\) 是从 \(o_i\) 中提取的
Inference-Time Scaling with SPCT
- 为了进一步利用更多推理计算资源来提升 DeepSeek-GRM 在通用奖励生成上的性能,论文探索了基于采样的策略,以实现有效的推理时扩展性
Voting with Generated Rewards
- 投票是 RM 中广泛采用的实现推理时扩展的方法
- 回顾第 2.1 节的方法,论文展示了 Semi-scalar RM 和生成式 RM 对于 \( k \) 个样本的投票结果
- 对于 Semi-scalar RM (2024; ),投票以平均方式进行:
$$
S^* = \frac{1}{k} \sum_{i=1}^{k} S_{i}, \quad \{\mathcal{R}_{i}=(S_{i}, C_{i})\}_{i=1}^{k} \sim r_{\theta} \left( x, \{y_{i}\}_{i=1}^{n} \right),
$$- 其中 \( S^* \) 是最终奖励
- 在实践中, Scalar 值方差有限,这可能会阻碍扩展性
- 对于 Pairwise GRM (2024; ),投票以多数表决方式选择被识别为最佳的 Response :
$$
\hat{y}^* = \arg \max_{y} \sum_{i=1}^{k} \mathbb{I}(y = \hat{y}_{i}), \quad \{\mathcal{R}_{i}=C_{i}\}_{i=1}^{k} \sim r_{\theta} \left( x, \{y_{i}\}_{i=1}^{n} \right),
$$- 其中 \( \hat{y}^* \) 是最终预测的最佳 Response
- \( f_{\text{pair} }(\cdot, \cdot) \) 是一个选择函数
- \( \hat{y}_{i} = f_{\text{pair} }(\mathbf{C}_{i}, \{y_{i}\}_{i=1}^{n}) \) 是每个样本单独选择的最佳 Response
- \( \mathbb{I}(\cdot) \) 是指示函数
- 虽然投票过程是可扩展的,但由于每个样本中不允许出现平局,多数投票结果可能存在偏差,并且由于缺乏量化分数,可能无法区分 Response 之间的细微差别
- Pointwise GRM 的投票过程定义为奖励求和:
$$
S_{i}^{*} = \sum_{j=1}^{k} S_{ij}, \quad \{p_{ij}\}_{i=1}^{m_{j} } \sim p_{\theta} \left( x, \{y_{i}\}_{i=1}^{n} \right), \mathcal{R}_{j} = C_{j} \sim r_{\theta} \left( x, \{y_{i}\}_{i=1}^{n}, \{p_{ij}\}_{i=1}^{m_{j} } \right), j=1,…,k,
$$- 其中 \( S_{i}^{*} \) 是第 \( i \) 个 Response (\( i=1,…,n \)) 的最终奖励,且 \( \{S_{ij}\}_{i=1}^{n} = f_{\text{point} }(C_{j}, \{y_{i}\}_{i=1}^{n}) \) 是第 \( j \) 组 Pointwise 奖励
- 由于 \( S_{ij} \) 通常被设定在一个较小的离散范围内, 例如 \{1,…,10\},投票过程实际上将奖励空间扩展了 \( k \) 倍,并使 GRM 能够生成大量 Principle ,这有益于最终奖励的质量和粒度
- 一个直观的解释是,如果每个 Principle 可以被视为判断视角的代理,那么更多的 Principle 可能更准确地反映真实分布,从而产生扩展效果。值得注意的是,为了避免位置偏差并增加多样性,在采样前会对 Response 进行打乱
Meta Reward Modeling Guided Voting
- DeepSeek-GRM 的投票过程需要多次采样,并且由于随机性或模型限制,少量生成的 Principle 和评判 (Critique) 可能存在偏差或质量低下
- 因此,论文训练了一个 Mata RM 来引导投票过程(guide the voting process)
- Mata RM 是一个 Pointwise Scalar RM,旨在识别 DeepSeek-GRM 生成的 Principle 和 Critique 的正确性,使用二元交叉熵损失,其中标签根据公式 10 确定
- 提示模板见附录 G,整合了 Query 、候选 Response 、相应 Principle 和 Critique
- 数据集包括 RFT 阶段来自非提示采样的轨迹,以及来自待引导的 DeepSeek-GRM 的采样轨迹,这既能提供足够的正负奖励,又能缓解训练与推理策略之间的差距,正如 Chow 等 (2025) 所建议
- 引导的投票过程很简单(即使用 Meta RM 的方式):
- Mata RM 输出 \( k \) 个采样奖励的元奖励,最终结果由元奖励最高的前 \( k_{\text{meta} } \leq k \) 个奖励进行投票得出,从而过滤掉低质量样本
Results on Reward Modeling Benchmarks
Experiment Settings
Benchmarks and Evaluation Metrics
- 论文在不同领域的多个 RM 基准测试上评估不同方法的性能:
- Reward Bench (RB) (2024),PPE(偏好和正确性子集)(2025),RMB (2025),Real.Mistake (2024)
- 论文对每个基准测试使用标准评估指标:Reward Bench、PPE 和 RMB 中从一组 Response 中选取最佳 Response 的准确率,以及 Real.Mistake 的 ROC-AUC
- 为了处理多个 Response 预测奖励出现平局的情况,论文打乱 Response 顺序,并通过 \( \arg \max_i S_i \) 确定最佳 Response ,其中 \( S_i \) 是打乱后第 \( i \) 个 Response 的预测奖励
- 细节见附录 D
Method Implementation
- 对于基线方法,论文基于 Gemma-2-27B (2024) 并采用与 DeepSeek-GRM 兼容的所有训练数据和设置,重新实现了 LLM-as-a-Judge (2023),DeepSeek-BTRM-27B(Bradley-Terry 模型)(1940),CLoud-Gemma-2-27B (2024) 和 DeepSeek-PairRM-27B (2023)
- 对于论文的方法,论文基于 Gemma-2-27B 实现了 DeepSeek-GRM-27B-RFT,并在不同规模的 LLM 上实现了 DeepSeek-GRM,包括 DeepSeek-V2-Lite (16B MoE) (2024a),Gemma-2-27B,DeepSeek-V2.5 (236B MoE) 和 DeepSeek-V3 (671B MoE) (2024b)
- Mata RM 在 Gemma-2-27B 上训练
- 默认结果使用 贪婪解码(greedy decoding) 报告,推理时扩展(inference-time scaling)使用温度 = 0.5
- 其他细节见附录 C
Results and Analysis
Performance on RM Benchmarks
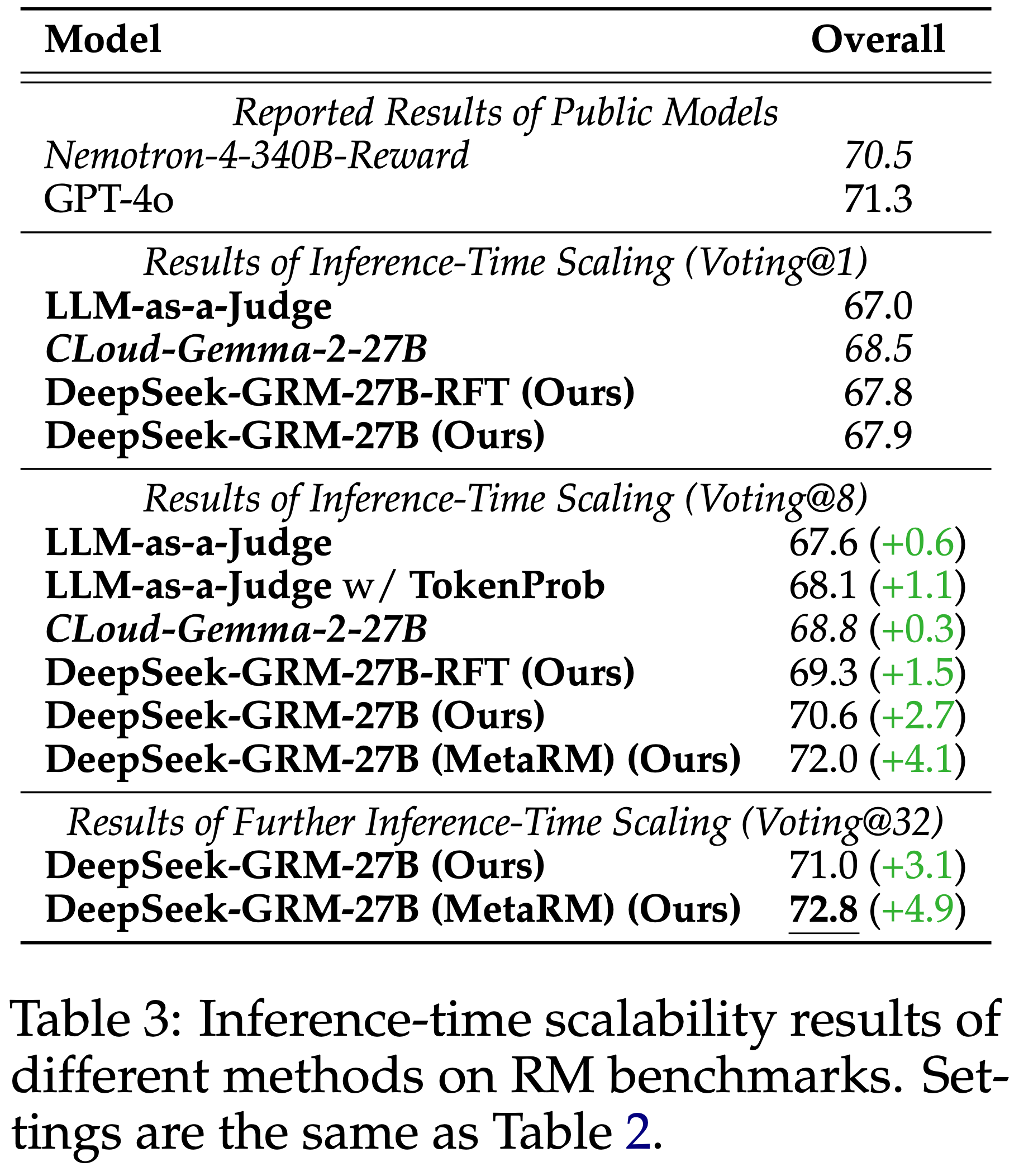
- 不同方法和模型在 RM 基准测试上的总体结果如表 2 所示
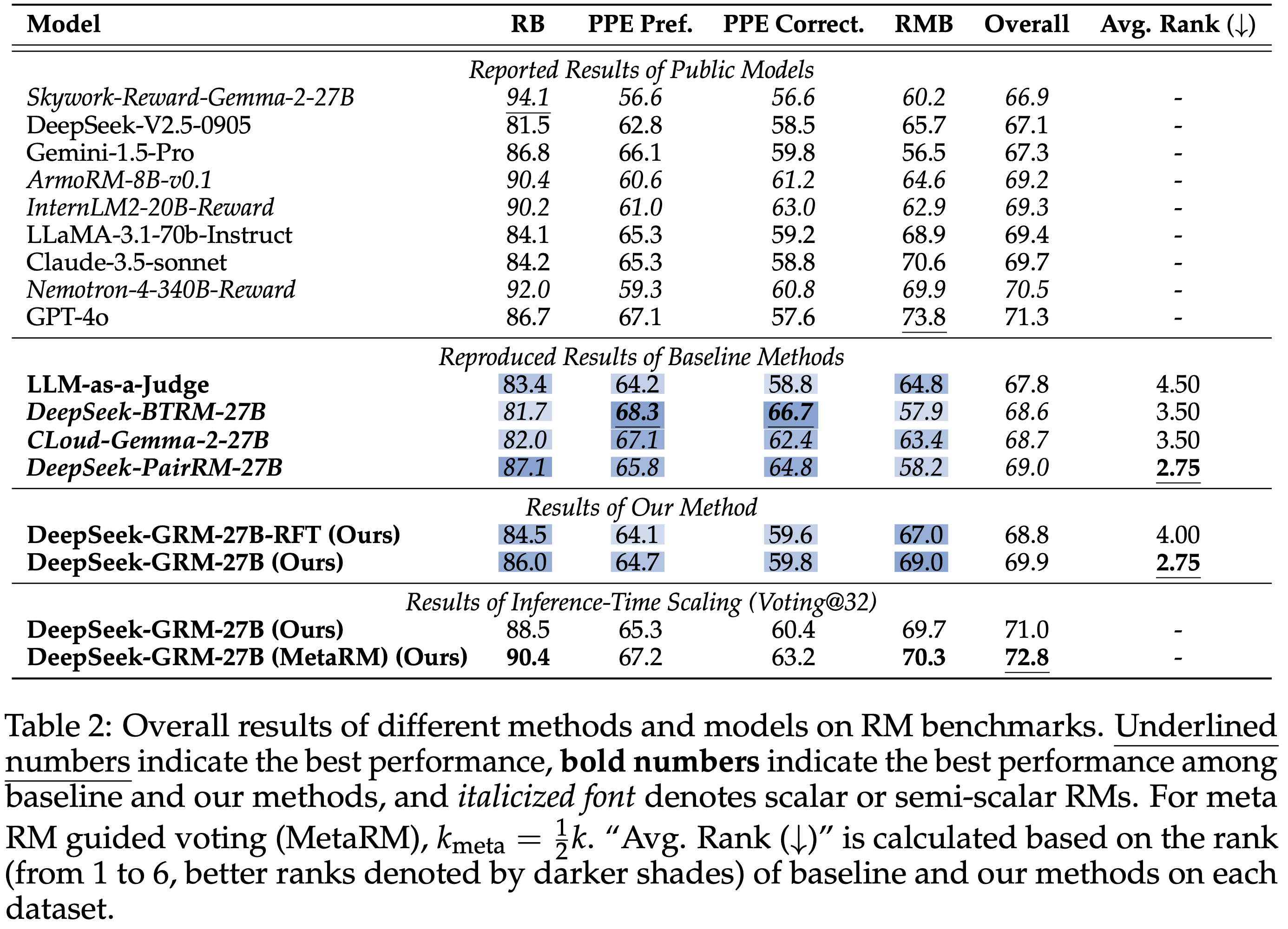
- 论文将 DeepSeek-GRM-27B 的性能与公开模型的报告结果(Reported Results of Public Models)以及基线方法的复现结果(Reproduced Result of Baseline Methods)进行比较
- 论文发现 DeepSeek-GRM-27B 在整体性能上优于基线方法,并且与强大的公开 RM(如 Nemotron-4-340B-Reward 和 GPT-4o)相比取得了有竞争力的性能;通过推理时扩展,DeepSeek-GRM-27B 可以进一步改进并获得最佳的整体结果
- 详细比较来看, Scalar(DeepSeek-BTRM-27B)和 Semi-scalar(CLoud-Gemma-2-27B)RM 在不同基准测试上表现出有偏差的结果,在可验证任务(PPE Correctness)上的性能明显优于所有生成式 RM,但在其他不同基准测试上分别失败
- 问题:如何理解 Skywork-Reward-Gemma-2-27B 反而是在 Reward Bench 上分数很高,其他任务上分数很低呢?是过拟合吗?
- 尽管如此,大多数公开的 Scalar RM 也表现出严重的领域偏差
- PairRM 方法可以缓解这个问题
- LLM-as-a-Judge 与 DeepSeek-GRM-27B 显示出相似的趋势但性能较低,可能是由于缺乏对单 Response 评分的训练
- 总之,SPCT 提升了 GRM 的通用奖励生成能力,与 Scalar 和 Semi-scalar RM 相比,偏差显著减少
Inference-Time Scalability
- 不同方法的推理时扩展结果如表 3 所示,总体趋势如图 1 所示
- 细节见附录 D.3
- 在最多 8 个样本的情况下(即 Voting@8),论文发现 DeepSeek-GRM-27B 相对于贪婪解码和采样结果的性能提升最高
- DeepSeek-GRM-27B 进一步显示出使用更多推理计算资源(最多 32 个样本)提升性能的强大潜力
- 论文将这种有效性归因于细化的 Principle 生成,它以结构化的方式扩展了输出长度,并引导结果奖励更接近真实分布
- Mata RM 也显示出其在每个基准测试上为 DeepSeek-GRM 过滤低质量轨迹的有效性
- 使用 Token 概率进行投票的 LLM-as-a-Judge 也显示出显著的性能提升,这表明 作为量化权重(Quantitative Weights)的 Token 概率可以帮助提高仅基于离散索引进行多数投票的可靠性
- 对于 CLoud-Gemma-2-27B,性能提升有限
- 主要是因为 Scalar 奖励生成缺乏方差,即使 Critique 发生了很大变化
- In Summary,SPCT 提升了 GRM 的推理时扩展性,而 Mata RM 进一步提升了通用场景下的扩展性能
Ablation Study
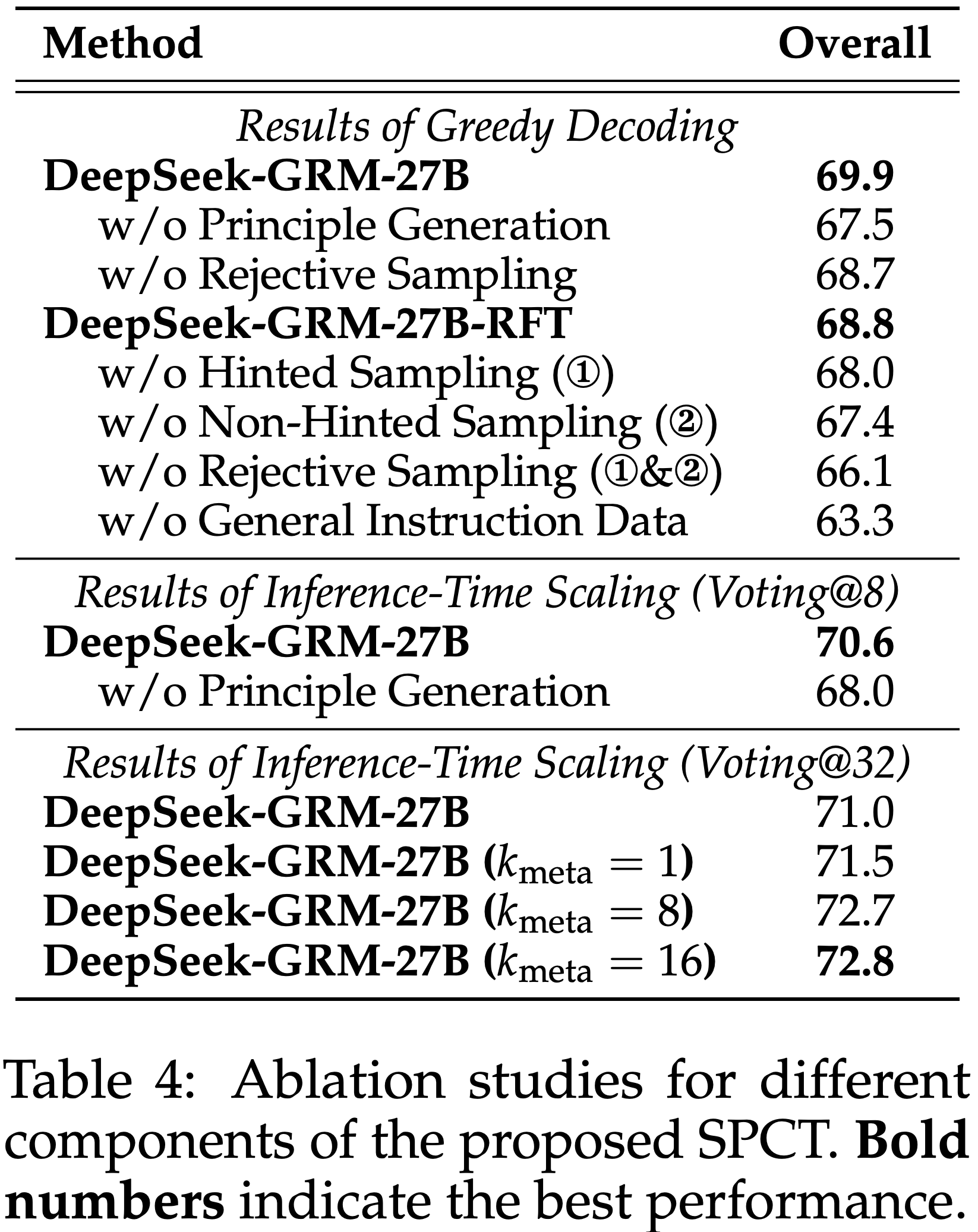
- 表 4 展示了所提出的 SPCT 不同组件的消融研究结果,详细结果列在附录 D.3
- 令人惊讶的是(Surprisingly),即使没有经过拒绝采样 Critique 数据的冷启动,经过通用指令微调的 GRM 在经历 Online RL 后性能仍有显著提升(66.1 → 68.7)
- 理解:这里是指使用 Online RL 去训练 GRM,这里对比的是第8行模型(仅包含通用指令微调)和第3行模型(在通用指令微调模型上经过了 Online RL 的模型)
- Also,非提示采样似乎比提示采样更重要
- 可能是因为提示采样轨迹中出现了走捷径的现象
- 以上这些都表明了 GRM 在线训练的重要性
- 令人惊讶的是(Surprisingly),即使没有经过拒绝采样 Critique 数据的冷启动,经过通用指令微调的 GRM 在经历 Online RL 后性能仍有显著提升(66.1 → 68.7)
- 与先前工作一致,论文确认通用指令数据对于 GRM 的性能至关重要
- 论文发现 Principle 生成对于 DeepSeek-GRM-27B 的贪婪解码和推理时扩展性能都至关重要
- 对于推理时扩展, Mata RM 引导的投票在不同的 \( k_{\text{meta} } \) 下表现出鲁棒性
- 关于通用 RM 性能的进一步分析,包括输入灵活性、训练数据的领域泛化等,在附录 E 中讨论
Scaling Inference and Training Costs
- 论文通过在不同规模的 LLM 上进行后训练,进一步研究了 DeepSeek-GRM-27B 的推理时和训练时扩展性能
- 模型在 Reward Bench 上进行测试,结果如图 4 所示
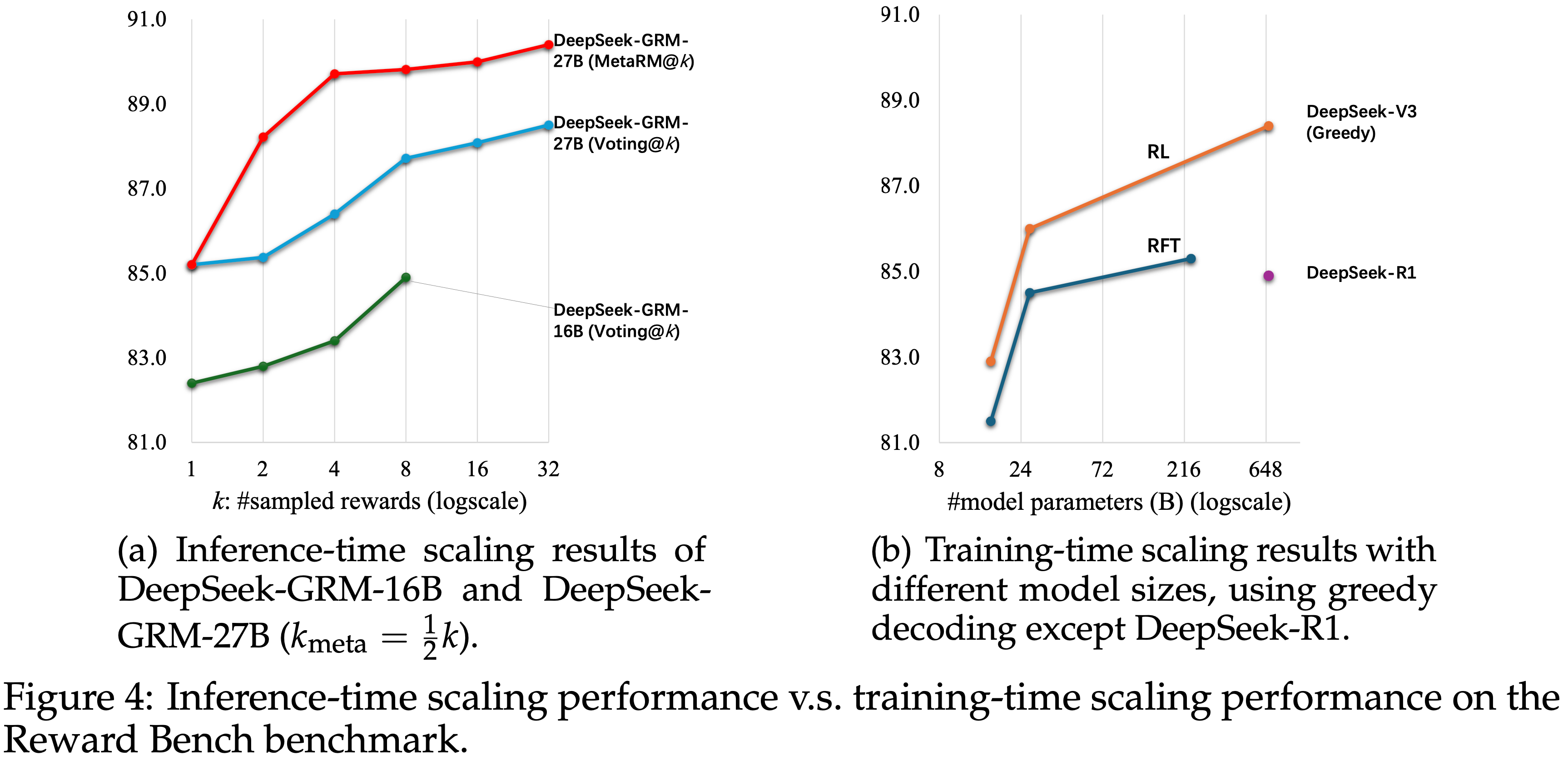
- 论文发现,使用 32 个样本直接投票的 DeepSeek-GRM-27B 可以达到与 671B MoE 模型相当的性能,而 Mata RM 引导的投票仅用 8 个样本即可获得最佳结果
- 这证明了 DeepSeek-GRM-27B 的推理时扩展相较于扩展模型规模有更高的有效性
- Moreover,论文在包含 300 个样本的下采样测试集上测试了 DeepSeek-R1-0120,发现其性能甚至低于 236B MoE RFT 模型
- 这表明扩展长思维链进行推理任务并不能显著提升通用 RM 的性能
Related Work
Generative Reward Models
- GRM 代表了从 Scalar RM (2022) 的范式转变,将奖励建模为文本反馈或分数
- (2024a; 2024; 2025a; 2024; 2024; 2025),实现了更丰富的奖励表示和更灵活的单个及多个 Response Critique
- 此前,LLM-as-a-judge 方法 (2023; 2024c) 支持基于参考或无参考的 Pairwise Critique 来评估 LLM
- 最近的研究使用离线和 Online RL 来训练 GRM (2024; 2024; 2025b; 2025b; 2025),将工具和外部知识与 GRM 结合 (2024b; 2025),甚至训练 GRM 作为调整环境奖励的接口 (2025)
- 尽管这些方法在效率上面临挑战,但它们展示了大规模改进奖励的潜力,朝着更通用的奖励系统发展
Inference-Time Scaling for LLMs
- LLM 的推理时扩展一直是一个与训练时扩展并行的重要研究方向
- 研究集中于采样和 RM 引导的聚合 (2024; 2024; 2025; 2025)
- 最近,从 LLM 中激励产生的长思维链 (2022) 显著提升了模型在解决 (OpenAI, 2024; DeepSeek-AI, 2025; OpenAI, 2025a) 和 Critique (2025; 2025) 困难可验证问题时的推理能力,这是推理时扩展的另一种形式
- 然而,论文没有找到像 DeepSeek-AI (2025) 那样有效激励长范围奖励生成以实现通用奖励建模的方法,论文将推理与 Principle 引导的奖励生成的结合留待未来的工程努力
- 也有研究使用可扩展的奖励或验证器来提升策略模型在编码 (2023)、推理 (2025) 等领域的性能
- 因此,本工作中推理时可扩展的通用 RM 的发展,也可能通过推理时协同扩展,为策略模型的通用性能做出贡献
Ethics Statement
- 论文提出的方法,自 Principle Critique 调优 (SPCT),旨在增强生成式奖励模型在通用领域的推理时扩展性
- 尽管这一进展促进了奖励建模的准确性和一致性,但有几个伦理影响可能需要明确考虑
- 首先,尽管通过论文的实证分析表明 DeepSeek-GRM 在不同领域表现出较少的偏差,但当训练数据存在毒性时,自动生成的 Principle 和 Critique 可能会无意中延续或放大偏差
- 作者认为应该优先研究 Mata RM 和其他偏见缓解策略,以确保公平的结果
- 此外,论文的方法并非旨在削弱人类监督
- 相反,论文主张维护人在环路框架,并开发可靠的代理方法(如 SPCT)来更高效、更有效地扩展人类监督
- 其次,推理时可扩展 GRM 在多样化领域的适用性扩大,可能会引发关于透明度、问责制等方面的担忧
- 由于奖励生成行为很大程度上源于自我引导,不忠实的 Principle 和 Critique 的可能性是不可忽视的
- 论文在附录 F.1 中展示了案例研究,在附录 B 中说明了局限性,并在公开监督下开源了模型,这对于维护信任和确保工件的负责任部署至关重要
- 最后,在不同 RM 基准测试和实际场景中进行稳健的验证和持续的警惕仍然至关重要
- 负责任地使用 DeepSeek-GRM 需要主动管理风险并持续评估偏见,这需要在 RM 评估研究方面付出努力
附录 A:Additional Related Work
Constitutional AI
- Constitutional AI 已成为传统 RLHF (2022) 的一个可扩展替代方案,旨在通过一套指导 Principle 或“宪法”使语言模型与人类价值观对齐 (2022b; 2023, 2024),用基于这些人工制定 Principle 的AI生成反馈 (2024) 或分类器 (2025) 替代人类 Critique
- 类似地, Rule-based 方法如 Sparrow (2022) 和 Rule-Based Rewards (RBR) (2024) 将明确的自然语言规则纳入特定领域(如安全性)的训练循环中
- 尽管这些方法有效,但它们依赖于静态的、人工编写的宪法,这些宪法在范围上有限、可能存在偏见且不够灵活
- 这激发了人们对自动化生成或改进 Principle 的兴趣,这也与论文本工作的目标相一致
Scalar Reward Models
- Scalar 奖励模型最初是为 LLMs 提出,作为人类反馈的代理模型 (2020; 2023)
- 近期的研究侧重于 Bradley-Terry 建模 (1940) 和其他回归方法,以提高 Scalar 奖励模型在通用偏好上的表达能力 (2024; 2024e, 2024b; 2024; 2025b)
- 与这些结果奖励模型相比,过程奖励模型被提出作为推理问题(如数学等)的步骤验证器 (2021; 2024b; 2025b),展示了 Scalar RM 在具有广泛推理和知识的正式领域中的可行性
- Scalar RM 的优点是简单且计算高效,但表达能力有限,并且难以跨不同输入类型进行泛化或在推理时细化奖励信号
Semi-Scalar Reward Models
- Semi-scalar 奖励模型旨在通过文本中间表示来丰富 Scalar 奖励信号 (2025a; 2024)
- (2025b) 提出通过提高生成的 critiques 的质量来最终改进奖励生成
- 一些研究使用 token 概率来替代 Scalar 头部进行奖励提取 (2024; 2025a)
- 以上这些工作表明
- Semi-scalar RM 在基于采样和投票的推理时扩展方面面临挑战,导致性能提升有限
- Semi-scalar 方法在效率和效果之间权衡了 Scalar RM 和 GRM
附录 B:Limitations and Future Directions
Limitation
- 尽管 SPCT 显著提升了 GRM 的性能和推理时扩展性,并在通用领域超越了(Semi)Scalar RM,但它仍面临一些局限性
- (1) 生成式 RM 的效率本质上远远落后于同等规模的 Scalar RM,这抑制了其在 Online RL Pipeline 中的大规模使用
- 然而,由于论文采用并行采样进行推理时扩展,使用合理数量的采样(例如8次)进行奖励生成的延迟不会显著增加
- 围绕 LLM 高效生成和 RM 应用创新的进一步研究可能缓解此问题
- (2) 在特定领域(如可验证任务)中,DeepSeek-GRM 仍然落后于 Scalar 模型
- 这可能是因为 Scalar RM 捕获了推理 Query 和 Response 的隐藏特征 ,而 GRM 需要更强的推理能力来彻底检查 Response
- 然而, Scalar RM 存在严重的偏见和扩展性问题
- 对于 GRM,论文发现基于参考的奖励生成(附录 E.1.3)和长链条推理(附录 D.3)可以缓解这一局限
- 这可能是因为 Scalar RM 捕获了推理 Query 和 Response 的隐藏特征 ,而 GRM 需要更强的推理能力来彻底检查 Response
- (3) 由于 Pointwise GRM 方法的普适性,DeepSeek-GRM 除了作为结果 RM 外,还可能作为过程 RM
- 尽管论文在论文中没有深入探索这个方向,但在 Reward Bench 的 Reasoning 子集(主要包含 MATH-prm 数据 (2024))上的性能部分支持了这种应用的潜力
Future Direction
- 基于 SPCT 或 DeepSeek-GRM 模型,未来研究有几个有希望的方向
- (1) 先前工作研究了 RM 的工具集成 (2024b),也可用于 DeepSeek-GRM 增强
- 使用诸如代码解释器和搜索引擎接口等工具 ,生成的 critiques 对于需要严格流程或广泛知识的任务可能更准确,并且可以避免 GRM 在遵循与数值计算、模式匹配等相关 Principle 时失败的情况
- (2) Principle 和 critiques 的生成范式可以分解 为不同阶段,即 Principle 可以为每个待评分的 Query 和 Response 预先生成并存储,然后使用 GRM、规则或其他智能体方法生成 critiques
- Principle 生成作为后续 critiques 的接口
- 这可能会提高当前 GRM 集成到 RL Pipeline 中的效率
- (3) DeepSeek-GRM 可能用于 LLM 离线评估
- 由于每个 Principle 反映了一个标准,我们可以从特定 LLM 劣于另一个 LLM 的所有数据点中获取标准,作为解释该特定 LLM 弱点的可解释协议
- 问题:实践发现,如果 Principle 是 Query-Specific 的,此时使用 Chosen 和 Rejected 来作为 Rubrics 生成参考容易出现过拟合,是否在通用的 Rubrics 中使用更合适?
- (4) DeepSeek-GRM 可能受益于长链条推理
- 然而,这会进一步影响其效率
- 这些方向应在未来工作中进行研究
附录 C:Implementation Details
C.1 Model Training
- 对于 Rule-based Online RL,论文使用标准的 GRPO 设置 (2024),总体目标函数为:
$$
\begin{align}
\mathcal{J}_{\text{GRPO} }(\theta)=\mathbb{E}_{[q\sim P(Q),\{o_{i}\}_{i=1}^{G}\sim\pi_{\theta_{old} }(O|q)]} &\frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_{i}|} \sum_{t=1}^{|o|} \\
&\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q.o_{i<t})}{\pi_{\theta_{old} }(o_{i,t}|q.o_{i<t})}\hat{A}_{i,t}, \text{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q.o_{i<t})}{\pi_{\theta_{old} }(o_{i,t}|q.o_{i<t})}, 1-\epsilon, 1+\epsilon\right)\hat{A}_{i,t}\right]-\beta\mathbb{D}_{KL}\left[\pi_{\theta}||\pi_{ref}\right]\right\},
\end{align}
$$- 其中 \(\hat{A}_{i,t}=\frac{\hat{r}_{t}-\text{mean}(\hat{t})}{\text{std}(\hat{t})}\),\(G\) 是组大小,\(\beta\) 是 KL 惩罚系数,\(q=(x,\{y_{i}\}_{i=1}^{n})\) 包含 prompts
- 论文对超参数 \(\beta\in\{0.00,0.01,0.02,0.08\}\) 进行了网格搜索,发现 \(\beta=0.08\) 是 DeepSeek-GRM-27B 最稳定的配置
- 当 KL 系数太小时,DeepSeek-GRM-27B 倾向于在基准测试的几个子集上崩溃,例如 Reward Bench 中的 Chat 子集和 RMB 中的 Harmlessness 子集,并对其他一些领域表现出偏见
- 对于较小的 DeepSeek-GRM-16B,论文使用 \(\beta=0.002\),因为它对 KL 损失系数不那么敏感
- 论文设置 \(G=4\) 以在效率和性能之间取得更好的平衡
- 训练集包含 1256K RFT 数据,包括 \(1070\)K 通用指令数据和 \(186\)K 拒绝采样数据,以及 \(237\)K RL 数据
- 通用指令数据来自内部数据集
- 拒绝采样数据和 RL 数据来自相同的 RM 数据集,包含对单个、 Pairwise 和多个 Response 的偏好,这些数据由内部数据和开源数据集构建,包括来自 MATH (2021)、UltraFeedback (2024)、OffsetBias (2024)、Skywork-Reward-Preference-80K-v0.2 (2024) 和 HelpSteer2-Preference (2025b) 的训练集
- Specifically,由于 UltraFeedback 的部分数据存在质量问题,论文重新标记了其偏好标签;
- 论文根据 Rule-based ground-truth 匹配对 MATH 进行采样和过滤轨迹,生成 Pairwise 偏好数据;
- 对于评分单个 Response ,论文将正确 Response 的 ground-truth 奖励设置为 1,错误 Response 的奖励设置为 0,仅纳入可验证的问题
- 对于拒绝采样,论文使用 DeepSeek-v2.5-0905 生成带有 Principle 和 critiques 的轨迹
- 采样次数 \(N_{\text{RFT} }\) 设置为 3
- 在 HelpSteer2 上进行 hinted sampling 时,论文添加原始数据集中标注的偏好强度作为提示
- 论文还从 RL 数据中移除了对 DeepSeek-V2-Lite-Chat 来说过于简单的样本 ,即根据公式 (10),所有生成的奖励在三次生成中都是正确的
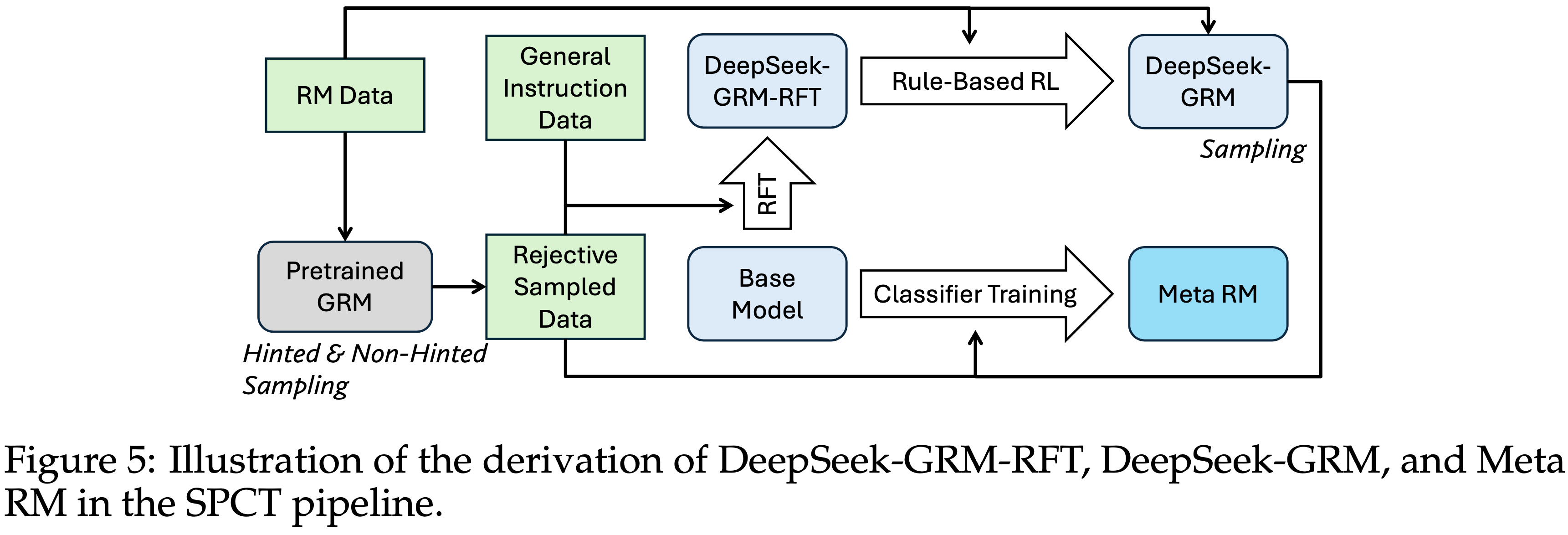
- DeepSeek-GRM 模型和 meta RM 的派生关系(derivation)如图 5 所示
- 所有 DeepSeek-GRM 模型都是从 LLM 的预训练版本开始训练的
- 对于 meta RM 的训练,论文复用了 RFT 阶段的拒绝采样数据,并使用 DeepSeek-GRM-27B 进行拒绝采样,\(N_{\text{RFT} }=3\),以避免 meta RM 引导投票中的潜在偏见 (2025)
- meta RM 训练的学习率为 \(1\times 10^{-5}\),批次大小为 512
- DeepSeek-GRM-27B 的 RFT 和 RL 训练时间如表 5 所示,基于 Gemma-2-27B 的模型在 Fire-Flyer 平台 (2024) 上使用 128 个 A100 GPU 进行训练
- RFT 阶段的学习率为 \(5\times 10^{-6}\),RL 阶段的学习率为 \(4\times 10^{-7}\),RFT 阶段的批次大小为 1024,RL 阶段为 512
- 两个阶段均训练 900 步
- 由于资源限制,大于 27B 的 DeepSeek-GRM 模型未经过 Rule-based RL,仅使用 50K 拒绝采样数据进行训练
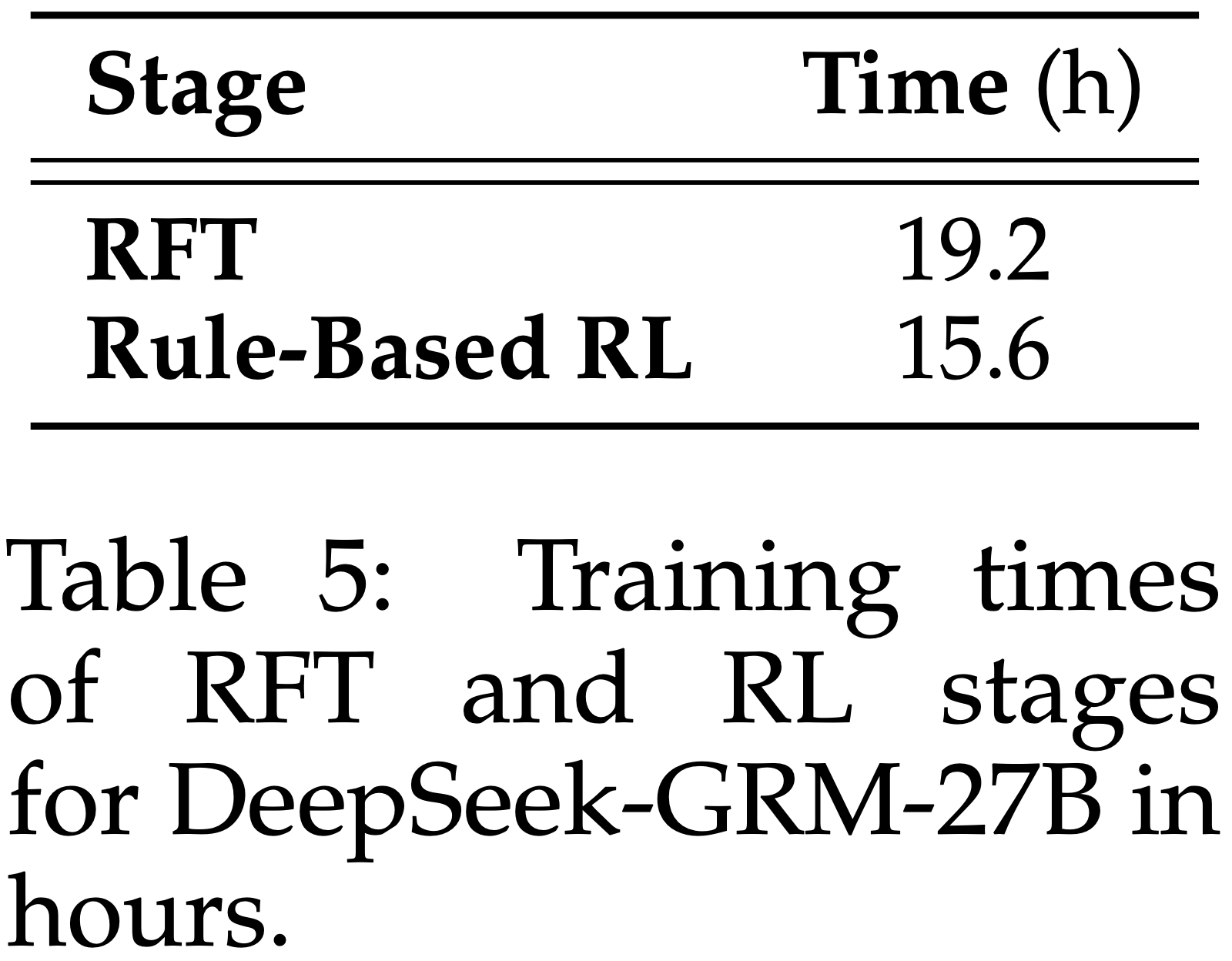
- RFT 阶段的学习率为 \(5\times 10^{-6}\),RL 阶段的学习率为 \(4\times 10^{-7}\),RFT 阶段的批次大小为 1024,RL 阶段为 512
C.2 Baseline Implementation
- 对于基线方法,论文基于 Gemma-2-27B (Team, 2024) 并采用与 DeepSeek-GRM 兼容的所有训练数据和设置,重新实现了 LLM-as-a-Judge (2023)、DeepSeek-BTRM-27B (Kendall & Smith, 1940)、CLoud-Gemma-2-27B (2024) 和 DeepSeek-PairRM-27B (2023)
- 对于 LLM-as-a-Judge ,
- 论文使用与 DeepSeek-GRM-27B 完全相同的训练配置,包括使用 DeepSeek-v2.5-0905 的拒绝采样数据进行 RFT 和 Rule-based Online RL
- 由于其评分模式,RL 阶段只能使用 Pairwise 数据
- 对于 CLoud-Gemma-2-27B ,论文也使用相同的 prompt 模板从 DeepSeek-v2.5-0905 生成 pointwise critiques
- 然而,由于没有训练好的价值头就无法提取奖励,执行拒绝采样是不可行的
- 论文使用 DeepSeek-GRM-27B 的相同通用指令数据以及采样的 critique 对 Gemma-2-27B 进行微调,得到一个 critique 生成模型
- 具体来说,论文微调了另一个带有价值头的 Gemma-2-27B 模型用于奖励生成,而不是在 critique 模型上进行事后的价值头训练
- CLoud-Gemma-2-27B 的价值头、DeepSeek-BTRM-27B 和 DeepSeek-PairRM-27B (2023) 的训练使用与 DeepSeek-GRM-27B 的 RL 阶段相同的数据集,但排除了单个 Response 评分数据
附录 D:Experiment Details
D.1 Hyper-Parameters
- 对于 DeepSeek-GRM-27B、DeepSeek-GRM-16B、LLM-as-a-Judge 和 CLoud-Gemma-2-27B 的推理时扩展结果,每个模型的温度 (temperature) 设置为 0.5
- 对于其他实验,所有模型的温度设置为 0
- 在没有特定说明的情况下,DeepSeek-GRM-27B 的 meta RM 引导投票中默认 \(k_{\text{meta} }=\frac{1}{2}k\)
- 对于 DeepSeek-R1-0120 的推理,温度设置为 0.6
- 请注意,论文让 DeepSeek-GRM 在 Real.Mistake 基准测试中为单个 Response 评分时,输出的奖励范围与其他基准测试相同
D.2 Benchmarks
- 论文在不同领域的各种 RM 基准上评估不同方法的性能:
- (1) Reward Bench (RB) (2024),一个常用的 RM 评估基准,包含半自动收集的聊天 (2023; 2023; 2024)、推理 (2024; 2024) 和安全性 (Rö2024; 2024d) 偏好数据,其中每个 Query 需要对两个 Response 进行排序;
- (2) PPE (2025),一个包含众包偏好数据和可验证任务正确性数据的大规模基准,每个 Query 有两个 Response ;
- (3) RMB (2025),一个更全面的基准,包含各种类型的偏好数据,侧重于帮助性和无害性,每个 Query 有两个或更多 Response ,分别在 Pairwise 和 best-of-N (BoN) 子集中;
- (4) Real.Mistake (2024),一个用于诊断单个 Response 中错误的基准
- 论文在总体分数计算中不包括 Reward Bench 基准测试的 prior sets (2022a; 2021; 2022; 2020)
- 对于报告的公开模型结果,论文使用每个基准发布的分数
- gpt-4o 的版本略有不同,因为论文报告的是 gpt-4o-2024-08-06 在 Reward Bench 和 PPE(Correctness 子集使用 AlpacaEval prompt 模板复现)上的结果,以及 gpt-4o-2024-05-13 在 RMB 上的结果
- 论文为每个基准使用标准评估指标:在 Reward Bench、PPE 和 RMB 中从一组 Response 中挑选最佳 Response 的准确度,在 Real.Mistake 中使用 ROC-AUC
- RMB 基准测试的 BoN 子集每个 Query 包含多个 Response ,只有当最佳 Response 被识别时,每个数据点才被视为正确
- 评估模型在 RMB BoN 子集上的默认设置是,如果总共有 \(n\) 个 Response,则 Pairwise 评估 \((n-1)\) 对(每对包含最佳 Response 和另一个不同的 Response)
- 对于基线方法,论文采用这种方法进行评估
- 而对于论文的模型 (DeepSeek-GRM),论文直接将所有 Response 输入模型,并通过 \(\arg\max_{i} S_i\) 识别最佳 Response ,其中 \(S_i\) 是第 \(i\) 个 Response 的预测奖励
- 这是一种更直接但也更困难的方式,并且几乎不影响性能
- 请参阅附录 E.1.1 的经验分析
- 问题:这里再次强调了论文是同时将所有 Response 输入模型的
- 对于 DeepSeek-R1-0120,由于推理成本和延迟巨大,论文从 Reward Bench 基准测试中均匀下采样了 300 个数据点,并在该子集上测试 DeepSeek-R1-0120
- 结果如图 4(b) 所示
- 结果如图 4(b) 所示
D.3 Detailed Results
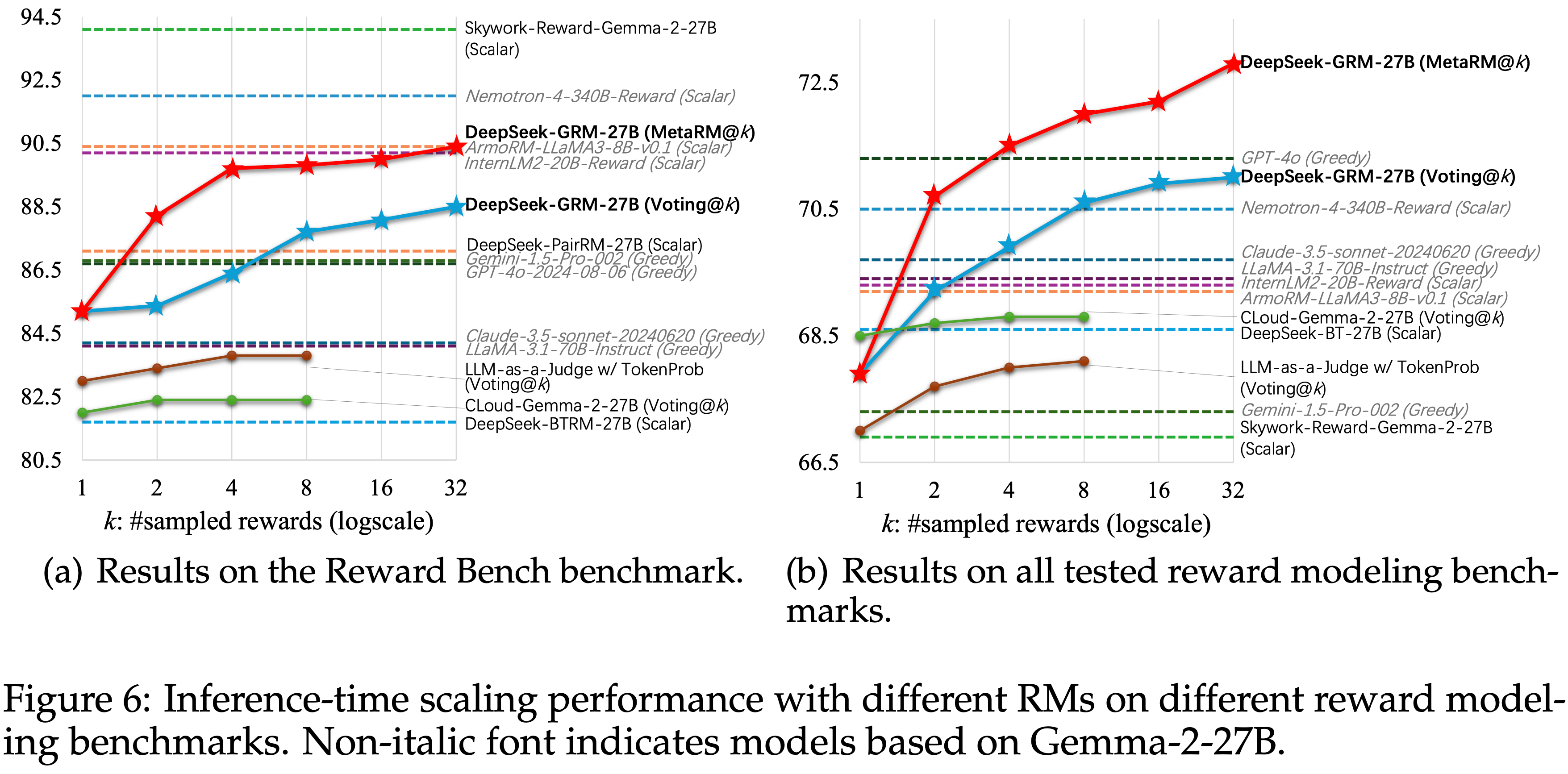
- 论文在图 6 中提供了图 1 的详细结果,并提供了更多公开模型的性能作为参考
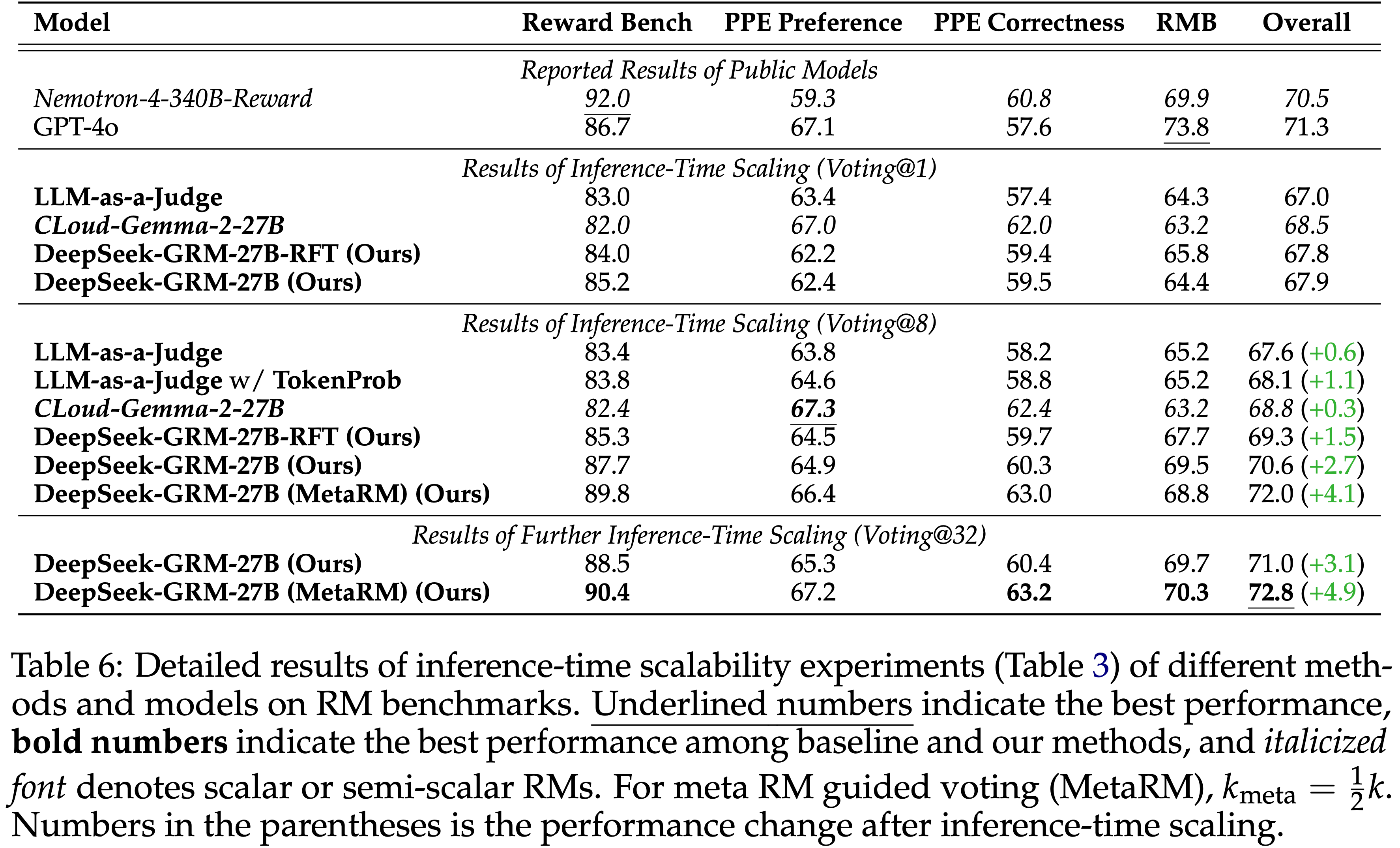
- 论文在表 6 中提供了表 3 的详细结果
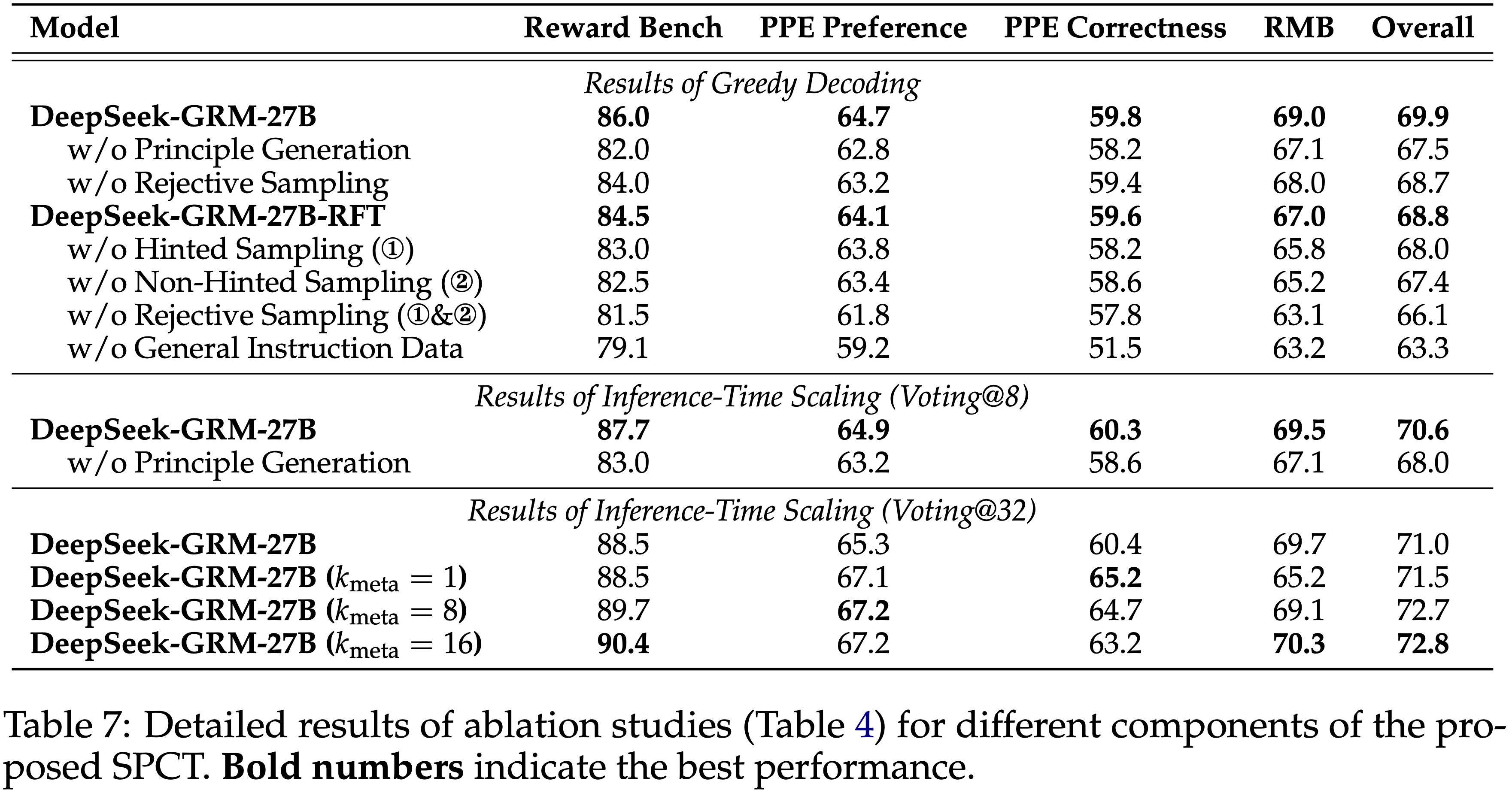
- 在表 7 中提供了表 4 的详细结果,并给出了每个 RM 基准测试的分数
- 此外,论文列出了所有测试方法在每个 RM 基准测试上的详细结果,Reward Bench 基准测试的结果在表 8 中,PPE Correctness 基准测试在表 9 中,RMB 基准测试在表 10 中
- 论文发现,DeepSeek-R1 在 Reward Bench 的 Reasoning 子集中取得了最高结果,表明长链条推理可以提升 GRM 在广泛推理场景中的表现
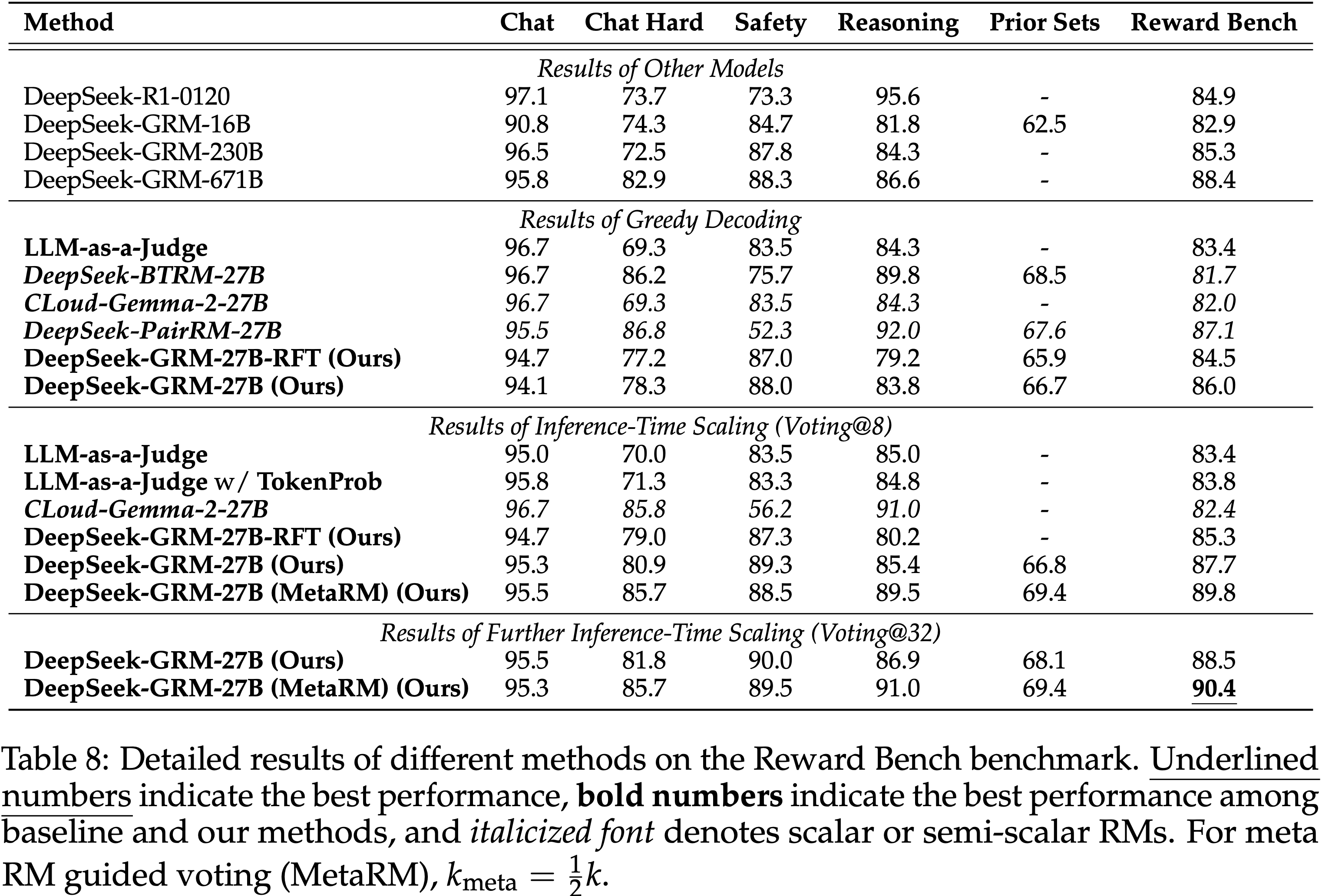
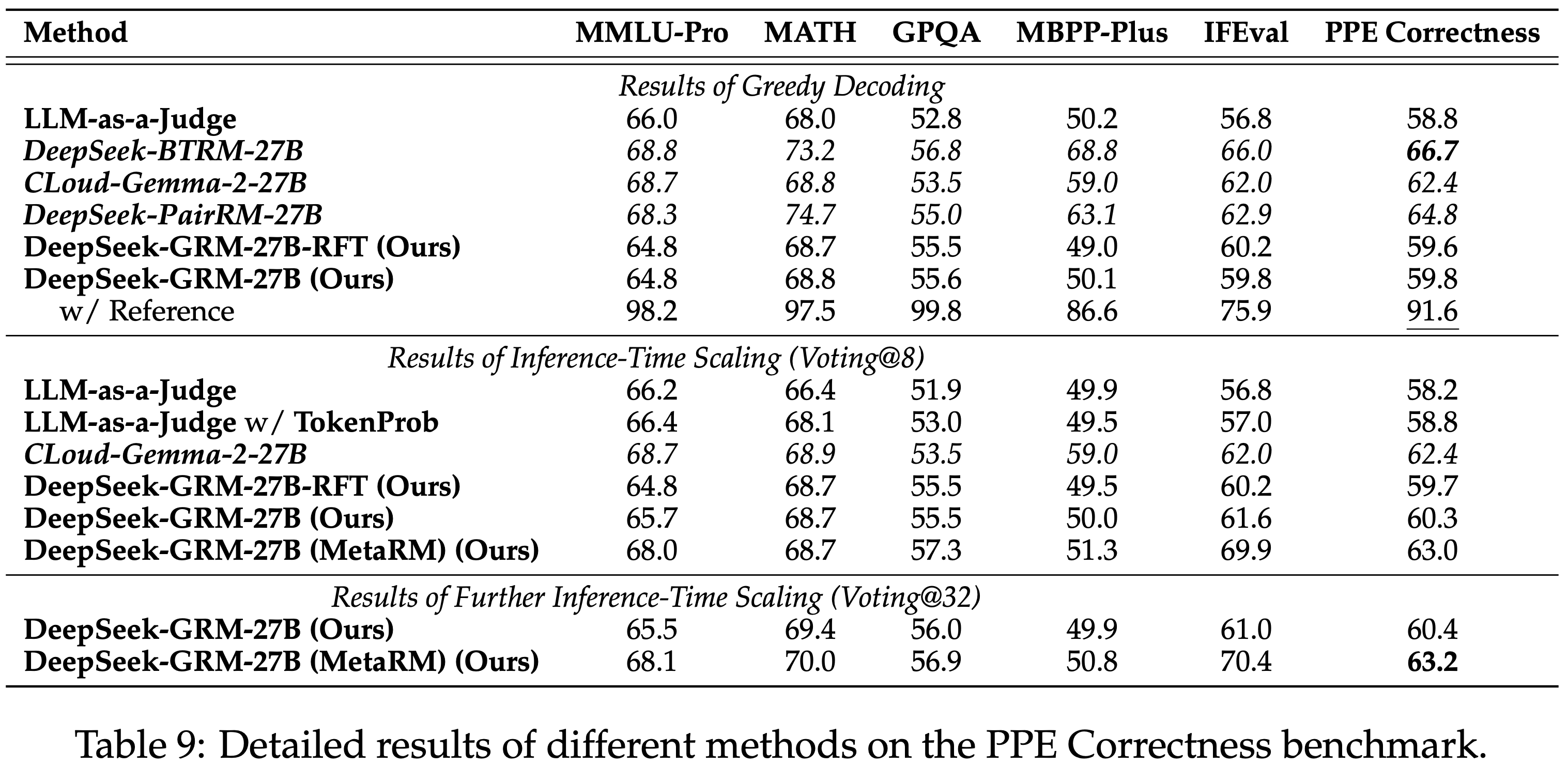
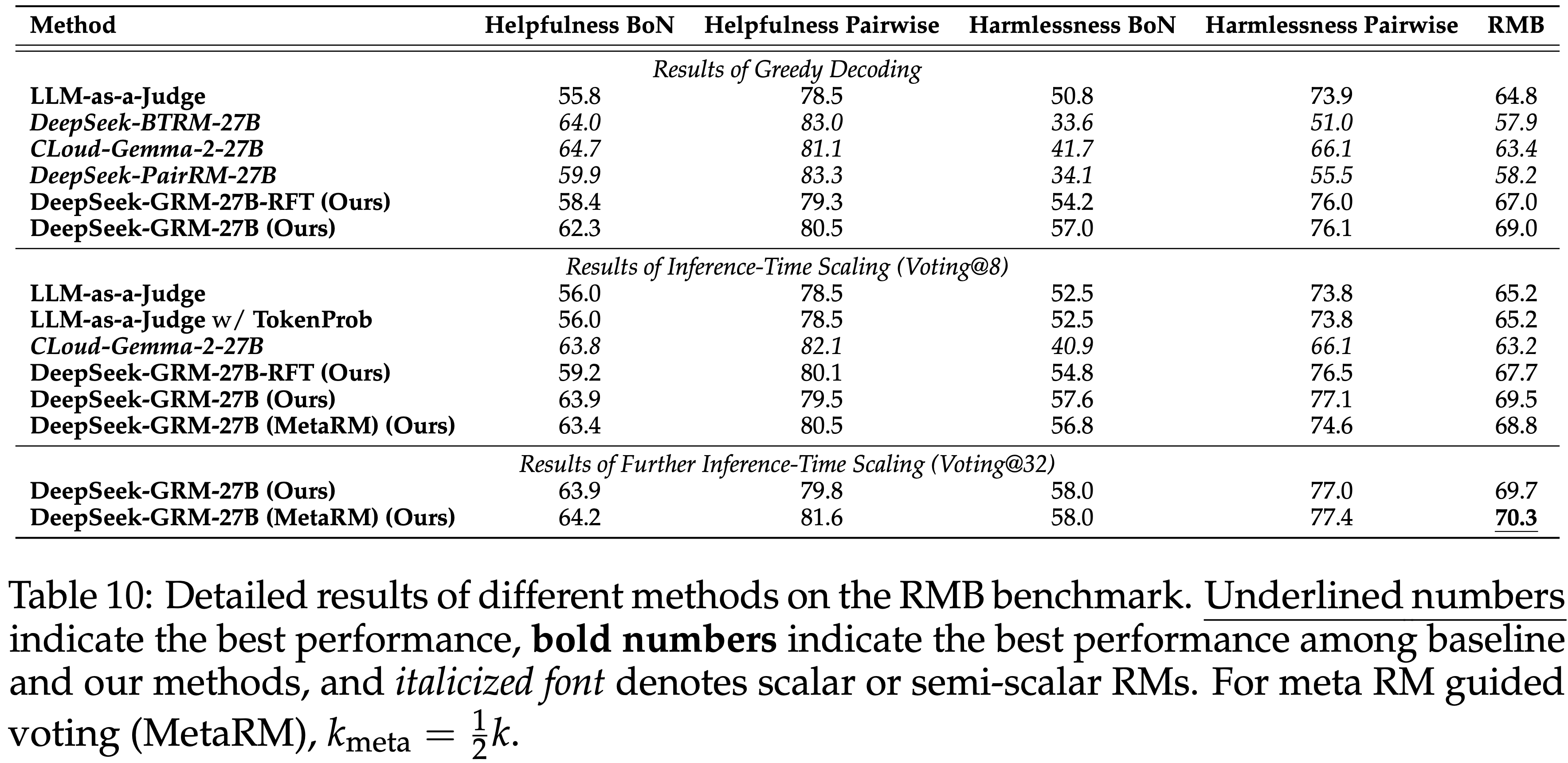
- 论文发现,DeepSeek-R1 在 Reward Bench 的 Reasoning 子集中取得了最高结果,表明长链条推理可以提升 GRM 在广泛推理场景中的表现
附录 E:Additional Experiments
E.1 Input Flexibility of the Pointwise GRM Approach
- 在章节 2.1 中,论文从理论上论证了 pointwise GRM 方法的输入灵活性
- 在本节中,论文提供了各种输入类型的经验证据来支持这一观点
E.1.1 Generating Rewards for Many Responses
- 在表 11 中,论文展示了 DeepSeek-GRM-27B 在 RMB 基准测试 BoN 子集上的实验结果,其中每个 Query 有多个 Response

- 如果总共有一个 Query 有 \(n, (n>2)\) 个 Response , Pairwise 输入设置是评估 \((n-1)\) 对,每对包含最佳 Response 和其他 Response ,只有当最佳 Response 从所有 \((n-1)\) 对中被正确识别时,该数据点才被视为正确
- 这也是原始基准测试的默认设置
- 论文比较了 DeepSeek-GRM-27B 在 Pairwise 输入和列表输入设置下的性能,列表输入设置是输入所有 \(n\) 个 Response 来识别最佳 Response
- 结果表明,DeepSeek-GRM-27B 几乎不受输入类型的影响,在帮助性和无害性子集上的性能差异都小于 1%
- 这表明 pointwise GRM 可以灵活地输入多个 Response ,并且性能对输入类型不敏感
E.1.2 Generating Rewards for Single Responses
- 在表 13 中,论文展示了 DeepSeek-GRM-16B 和 DeepSeek-GRM-27B 在 Real.Mistake 基准测试上的实验结果,其中每个 Query 只有一个 Response
- 论文与公开模型(如 DeepSeek-V2.5-0905、GPT-4o-2024-08-06、DeepSeek-V2-Lite 和 Gemma-2-27B-it)以及 DeepSeek-BTRM-27B 进行了比较
- 结果显示,DeepSeek-GRM 在同等规模的模型中取得了最佳性能,并且通过推理时扩展,性能与最佳公开模型相当
- 这表明 pointwise GRM 可以有效地对单个 Response 进行评分

E.1.3 Generating Rewards with Reference
- 在章节 5.2 中,论文展示了 Scalar 和 Semi-scalar RM 可能存在显著的领域偏见,并且通常在可验证问题上表现更好
- 为了缓解这个问题,论文测试了 DeepSeek-GRM-27B 在这些任务中使用参考(即每个 Query 的 ground truth)生成奖励的能力
- 结果如表 12 所示
- 论文发现,在提供参考的情况下,DeepSeek-GRM-27B 可以达到超过 90% 的准确率
- 这表明 pointwise GRM 可以有效地根据参考判断 Response ,从而缓解了在可验证任务上的性能问题

E.2 Transferability of Generated Principles
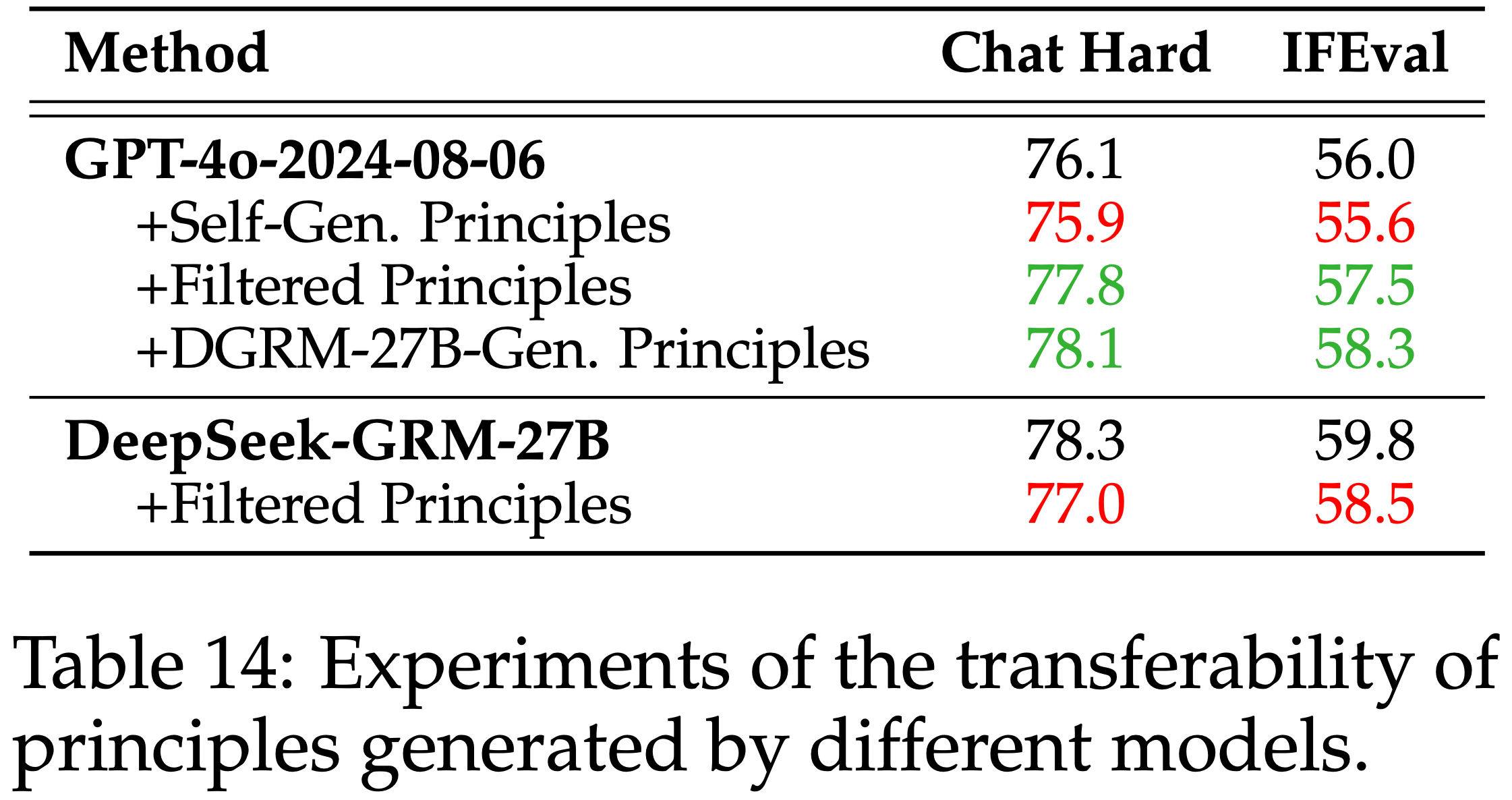
- 论文用 DeepSeek-GRM-27B 生成的 Principle 扩展了章节 2.2 中的初步实验
- 论文测试了 GPT-4o-2024-08-06 和 DeepSeek-GRM-27B 使用与表 1 完全相同的手动过滤 Principle 以及上述 DeepSeek-GRM-27B 生成的 Principle
- 结果如表 14 所示
- 论文发现 DeepSeek-GRM-27B 生成的 Principle 可以迁移到其他模型,甚至比手动从 GPT-4o 过滤的 Principle 略好
- 这表明 DeepSeek-GRM-27B 生成的 Principle 是稳健的且可迁移到其他模型
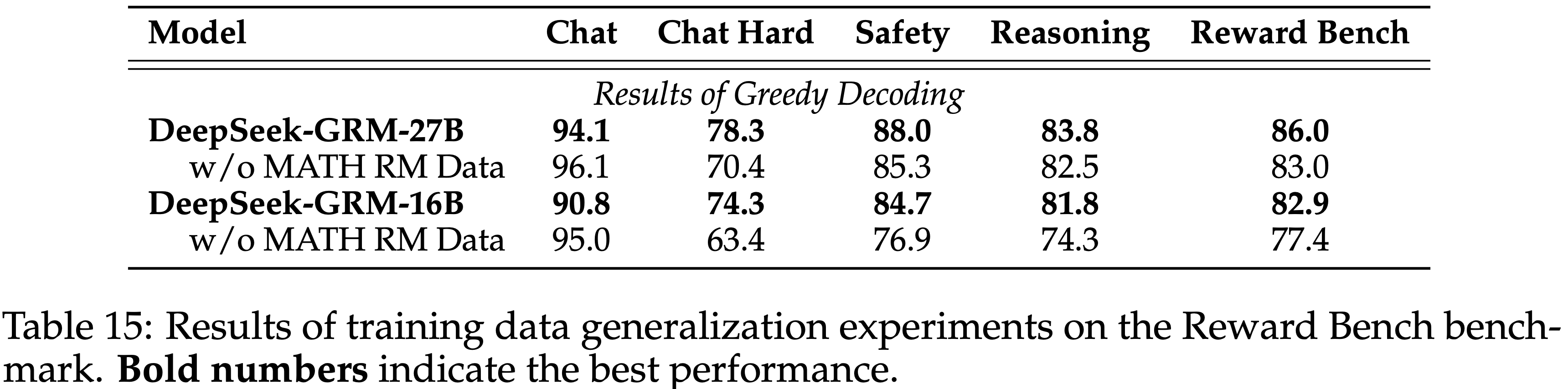
E.3 eneralization beyond Training Data
- 论文对 DeepSeek-GRM-27B 训练数据的泛化能力进行了消融研究
- 论文移除了 MATH 训练集中的所有数据,并重新实施了训练方案
- 在 Reward Bench 基准测试上的结果如表 15 所示
- 论文发现,仅添加与数学相关的偏好数据也可以提升通用 RM 在不同领域上的性能,尤其是在 Chat Hard 子集上
- 结果表明 DeepSeek-GRM-27B 可以泛化到训练数据覆盖范围之外的领域
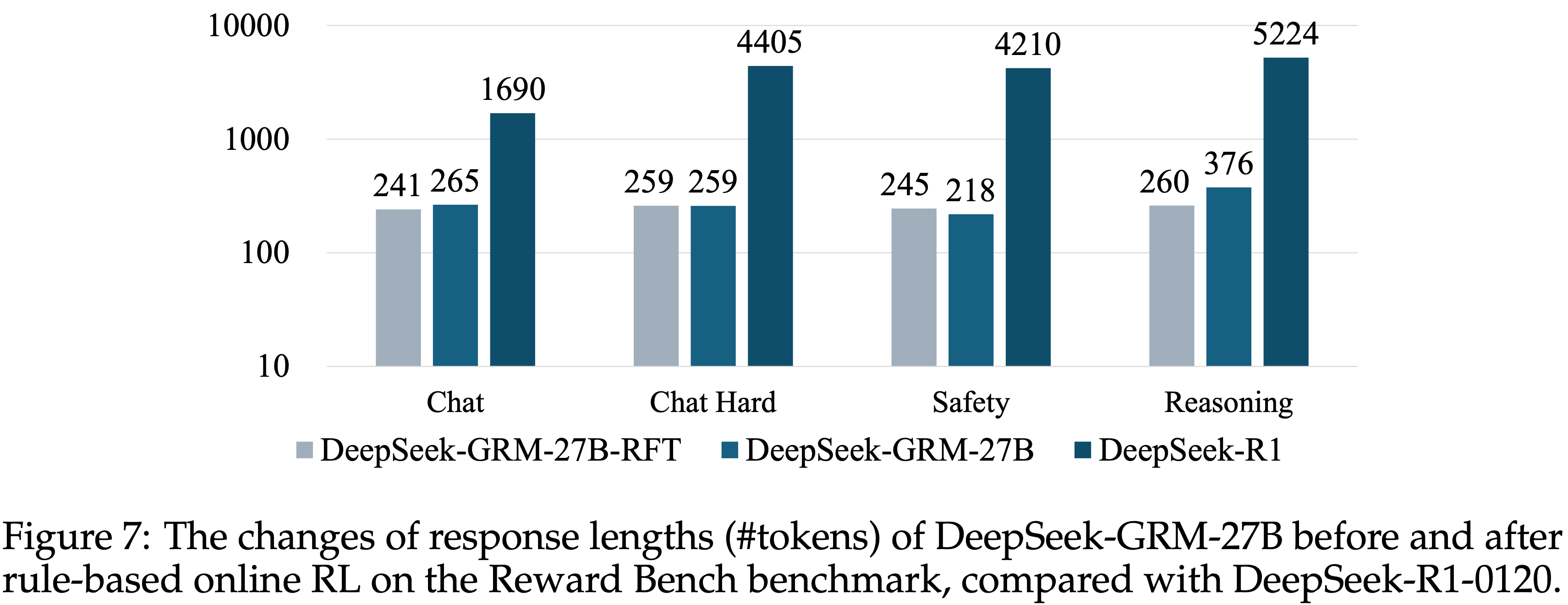
E.4 Response Length Analysis for Rule-Based RL
- 论文在图 7 中计算了 DeepSeek-GRM-27B 在进行 Rule-based Online RL 前后在 Reward Bench 基准测试各子集上的 Response 长度
- DeepSeek-GRM-27B 的 token 计数基于 Gemma-2-27B 的 tokenizer 计算,而 DeepSeek-R1-0120 的结果使用其对应的 tokenizer
- 论文发现,Chat 子集的 Response 长度在 RL 后几乎没有增加,而 Safety 子集的 Response 长度甚至略有下降
- Response 长度增加最大的是在 Reasoning 子集,根据表 8,DeepSeek-GRM-27B 在该子集上的性能相比 DeepSeek-GRM-27B-RFT 也提升最大
- 这可能表明 DeepSeek-GRM-27B 学会了在广泛推理任务上自适应地使用更多推理计算资源,并且在模型学会准确生成 Principle 后,可以节省一些其他领域(如安全性)的计算
- 然而,DeepSeek-R1-0120 使用了多得多的 tokens 却取得了更低的结果(Reasoning 除外),这表明长链条推理也有助于与广泛推理相关的 RM 任务
附录 F:Qualitative Analysis
F.1 Case Study
论文在表 16、17 和 18 中提供了 DeepSeek-GRM-27B 的案例研究
第一个案例表明, Scalar RM DeepSeek-BTRM-27B 在特定情况下可能被攻击或存在偏见,而 DeepSeek-GRM-27B 生成文本 Principle 和 critiques,表现出更好的鲁棒性
第二个案例展示了 DeepSeek-GRM-27B 的可扩展行为,通过在多个样本上投票生成准确的奖励
- 相应的 meta RM 分数也显示了 meta RM 在引导投票过程中的有效性
第三个案例展示了 DeepSeek-GRM-27B 的潜在失败,这是由于模型无法根据某些 Principle(例如评估实时数据)准确判断 Response ,并且每个 Principle 的权重可能不平衡
- 包含权重分配和分数收集的 critique 过程主要来自 RFT 和 Online RL 训练,这在不同的采样和测试案例中可能有很大差异
示例核心:
在输入
<Query, Response1, Response2>后, DeepSeek-GRM-27B-Result 的输入类似:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24Specific Criteria:
1. **Depth of Analogies and Metaphors** (Weight: 30%): The extent
to which the analogies and metaphors used are deep, creative, and
effectively convey complex concepts.
2. **Comprehensiveness of Core Information** (Weight: 30%): The
thoroughness with which the core information essential to behavioral
neuroscience is covered.
3. **Clarity and Organization** (Weight: 20%): The clarity of explanations
and the logical organization of the information.
4. **Engagement and Appeal** (Weight: 20%): The level of engagement
and appeal the response has, making the information interesting and
memorable.
Analysis:
- **Response 1**: This response excels in comprehensiveness and clarity,
covering all major aspects of behavioral neuroscience with detailed
and well-organized explanations. The analogies and metaphors are
well-crafted and effectively enhance understanding. However, some
metaphors could be more creative to enhance engagement further.
- **Response 2**: This response is also comprehensive and clear, but
it stands out more in the depth and creativity of its analogies and
metaphors. The organization is logical, and the explanations are clear.
The engagement level is high, making the information appealing and
memorable.
Scores: \boxed{8, 9}- 特点:先给出具体的 Principle 和 权重,再进行打分分析,最终给出得分
对于使用 Meta RM 的场景,DeepSeek-GRM-27B-Result 模型会回复多个上面的类似打分,每个都是
\boxed{8, 9}的形式,然后会根据 Meta RM 的评估分数汇总 DeepSeek-GRM-27B-Result 的打分- 注意:在使用 Meta RM 时,在输入 DeepSeek-GRM-27B-Result 时,可能会随机调换 Response1 和 Response2 的顺序
Failure Mode Analysis
- 论文从 DeepSeek-GRM-27B 在每个基准测试上的测试结果中随机抽样了 10 个错误数据点 (只有 10 个数据,诚意不够),并在图 8 中总结了失败模式
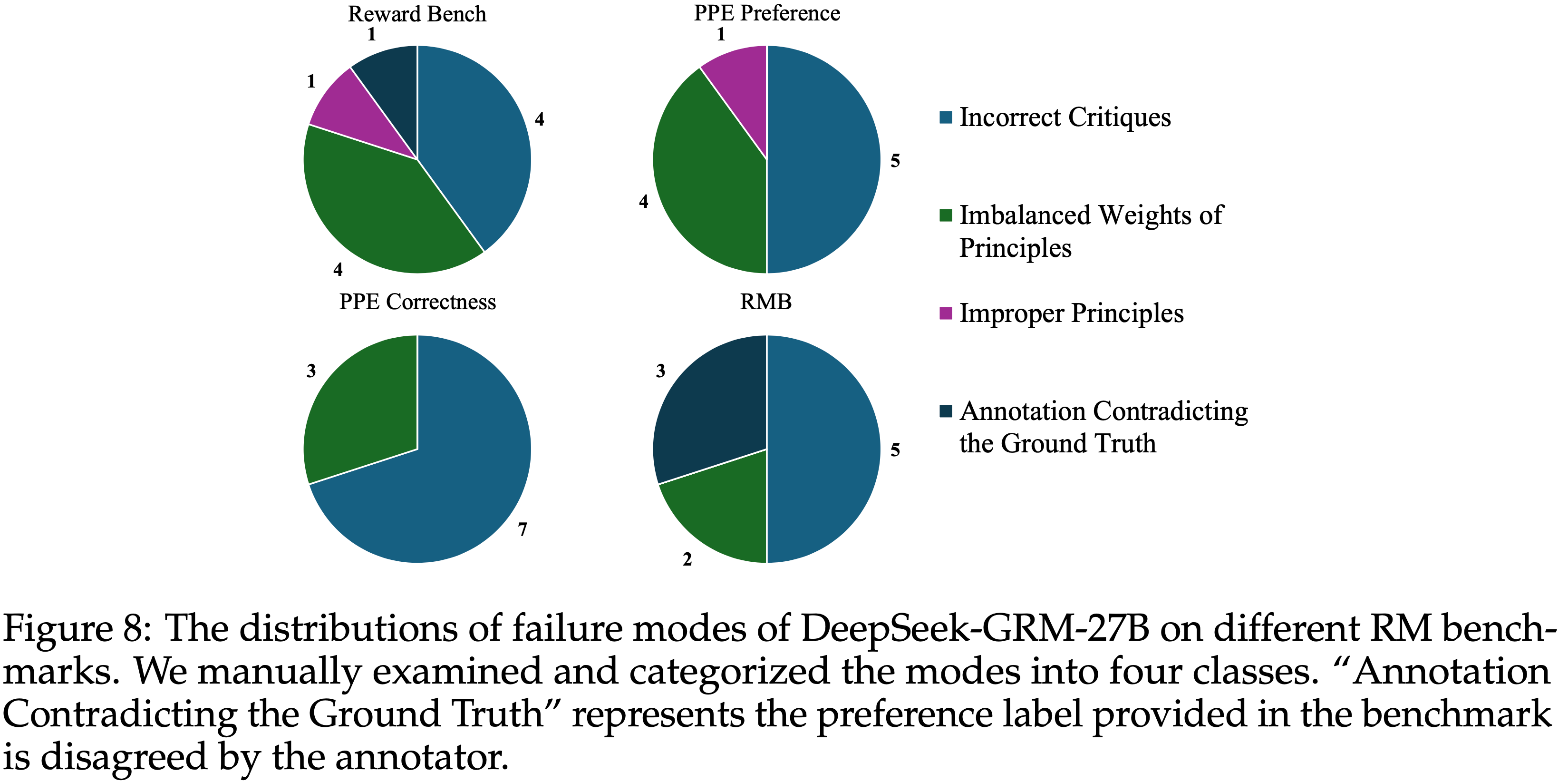
- 对失败案例的分析表明,挑战主要在于模型无法判断过于复杂或属于特定领域(如模式匹配、计数等)的 Response ,以及缺乏专家知识,从而导致错误的 critiques
- 尽管在大多数情况下 Principle 生成正确,但模型为每个 Principle 分配的权重会影响奖励的生成,有时会导致错误的结果
- 然而,论文也发现
- RM 基准测试中少数数据点的 ground truth 与人类标注者的偏好不一致
- 可能是由于小规模人工标注研究的偏见或 ground truth 标注中的潜在错误
附录 G:Prompt Templates
- 论文在下面展示了用于 DeepSeek-GRM、训练期间用于单个 Response 的 DeepSeek-GRM、meta-RM 以及 LLM-as-a-Judge 的 prompt 模板
- 对于 prompt 工程,论文设计了一些示例 Principle ,用于上下文学习和基本的 critique 指导
- 论文对 meta RM 使用更简洁的模板,以确保 Query 、 Response 以及生成的 Principle 和 critiques 能够适应上下文窗口
- 在组装 meta RM 的模板后,论文进一步将内容封装在专为 DeepSeek-V3-1226 (DeepSeek-AI, 2024b) 设计的聊天模板中,然后再进行输入
DeepSeek-GRM (Default)
DeepSeek-GRM (Default) Prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48You are a skilled little expert at scoring responses. You should evaluate given responses based
on the given judging criteria.\n Given the context of the conversation (the last round is the
User’s query) and multiple responses from the Assistant, you need to refer to the [General
Evaluation Criteria] to score the responses. Based on the general evaluation criteria, state
potential other specific criteria to the query, the weights of different criteria, and then provide
an overall comprehensive score upon them.\n Each score is an integer between 1 and 10,
with a higher score indicating that the response meets the relevant criteria more closely. For
example, a score of 1 means the response does not meet the criteria at all, a score of 6 means
the response meets only some parts, and a score of 10 means the response perfectly meets the
evaluation criteria.\n Before scoring, please analyze step by step. Your scoring needs to be as
strict as possible.
#### Evaluation Criteria ####
1. Instruction Adherence:\n - Fully Adhered (9-10 points): The response fully complies with
all instructions and requirements of the question.\n - Partially Adhered (6-8 points): The
response meets most of the instructions but has some omissions or misunderstandings.\n -
Basically Adhered (3-5 points): The response meets some instructions, but the main
requirements are not fulfilled.\n - Not Adhered (1-2 points): The response does not meet any
instructions.\n Example: If the question requires three examples and the response provides
only one, it falls under “Partially Adhered.”
2. Usefulness:\n - Highly Useful (9-10 points): The response provides comprehensive and
accurate information, fully addressing the issue.\n - Useful but Incomplete (6-8 points):
The response provides some useful information, but lacks details or accuracy.\n - Limited
Usefulness (3-5 points): The response offers little useful information, with most content
being irrelevant or incorrect.\n - Useless or Incorrect (1-2 points): The response is completely
irrelevant or incorrect.\n Example: If there are factual errors in the response but the overall
direction is correct, it falls under “Useful but Incomplete.”
3. Level of Detail:\n - Very Detailed (9-10 points): The response includes ample details
covering all aspects of the issue.\n - Detailed but Slightly Lacking (6-8 points): The response
is fairly detailed but misses some important details.\n - Basically Detailed (3-5 points): The
response provides some details but is not thorough enough overall.\n - Not Detailed (1-2
points): The response is very brief and lacks necessary details.\n Example: If the response
provides only a simple conclusion without an explanation, it falls under “Not Detailed.”
4. Relevance:\n - Highly Relevant (9-10 points): The response is highly relevant to the
question, with information closely aligned with the topic.\n - Generally Relevant (6-8 points):
The response is generally relevant but includes some unnecessary information.\n - Partially
Relevant (3-5 points): The response has a lot of content that deviates from the topic.\n - Not
Relevant (1-2 points): The response is completely irrelevant.\n Example: If the response strays
from the topic but still provides some relevant information, it falls under “Partially Relevant.”
#### Conversation Context ####\n{conversation context & query}\n
#### Responses to be Scored ####
[The Begin of Response i]\n{the i-th response}\n[The End of Response i]\n
#### Output Format Requirements ####
Output with three lines
Specific Criteria: <Other potential criteria specific to the query and the context, and the
weights of each criteria>.
Analysis: <Compare different responses based on given Criteria>.
Scores: <the overall comprehensive score of all responses in order, separate by comma in the
boxed, e.g., \boxed{x, x} if there exists 2 responeses>.- DeepSeek-GRM Prompt 中,输入的 Reponse 可以多个
Meta RM
- Meta RM Prompt
1
2
3
4
5
6
7
8**Prompt:**
Please score the responses.
#### Conversation Context ####\n{conversation context & query}\n
#### Responses to be Scored ####
[The Begin of Response i]\n{the i-th response}\n[The End of Response i]\n
-----
**Response:**
{principle & critique}
LLM-as-a-Judge
LLM-as-a-Judge Prompt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41You are a skilled little expert at scoring responses. You should evaluate given responses based
on the given judging criteria.\nGiven the context of the conversation (the last round is the
User’s query) and multiple responses from the Assistant, you need to refer to the [General
Evaluation Criteria] to score the responses. Based on the general evaluation criteria, state
potential other specific criteria to the query, the weights of different criteria, and then select
the best response among all candidates.\nBefore judging, please analyze step by step. Your
judgement needs to be as strict as possible.
#### Evaluation Criteria ####
1. Instruction Adherence:\n - Fully Adhered: The response fully complies with all instructions
and requirements of the question.\n - Partially Adhered: The response meets most of the
instructions but has some omissions or misunderstandings.\n - Basically Adhered: The
response meets some instructions, but the main requirements are not fulfilled.\n - Not
Adhered: The response does not meet any instructions.\n Example: If the question requires
three examples and the response provides only one, it falls under “Partially Adhered.”
2. Usefulness:\n - Highly Useful: The response provides comprehensive and accurate
information, fully addressing the issue.\n - Useful but Incomplete: The response provides
some useful information, but lacks details or accuracy.\n - Limited Usefulness: The response
offers little useful information, with most content being irrelevant or incorrect.\n - Useless or
Incorrect: The response is completely irrelevant or incorrect.\n Example: If there are factual
errors in the response but the overall direction is correct, it falls under “Useful but Incomplete.”
3. Level of Detail:\n - Very Detailed: The response includes ample details covering all aspects
of the issue.\n - Detailed but Slightly Lacking: The response is fairly detailed but misses
some important details.\n - Basically Detailed: The response provides some details but is not
thorough enough overall.\n - Not Detailed: The response is very brief and lacks necessary
details.\n Example: If the response provides only a simple conclusion without an explanation,
it falls under “Not Detailed.”
4. Relevance:\n - Highly Relevant: The response is highly relevant to the question, with
information closely aligned with the topic.\n - Generally Relevant: The response is generally
relevant but includes some unnecessary information.\n - Partially Relevant: The response has
a lot of content that deviates from the topic.\n - Not Relevant: The response is completely
irrelevant.\n Example: If the response strays from the topic but still provides some relevant
information, it falls under “Partially Relevant.”
#### Conversation Context ####\n{conversation context & query}\n
#### Responses to be Scored ####
[The Begin of Response]\n{the response}\n[The End of Response]\n
#### Output Format Requirements ####
Output with three lines
Specific Criteria: <Other potential criteria specific to the query and the context, and the
weights of each criteria>.
Analysis: <Compare different responses based on given Criteria>.
Scores: <the index of the best response based on the judgement, in the format of \boxed{x}>.- 除了输入 Response 只有一个以外,其他评估指标等好像和 DeepSeek-GRM(输入的 Reponse 可以多个) 的 Prompt 差不多