注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体说明:
- 本文提出 OpenClaw-RL 框架,将 Chat,终端执行,GUI 交互,SWE 任务 和 tool use 等都视作 交互+下一个状态信号 的模型,统一了所有动作和信号,使得不同的信号可以一起训练
- 基本思路:所有信号都是可以统一为状态的,所以策略可以在这些信号(Next-state Signal)中统一学习
- 理解:本文会将奖励定义为 \(r(a_t, s_{t+1})\),即通过 PRM judge 从 Next-state Signal 中推断得出
- 注:这里的奖励是通过 \(s_{t+1}\) 推断出来的
- 本文提出了两种方法:
- 方法1:二元强化学习,将评估性信号转换为标量过程奖励
- 方法2:OPD,将指导性信号转换为 Token-level 的优势监督
- 最终方法:将两者结合起来,实验验证拿到了显著的收益(注:两者分开始效果并不好)
- 本框架训练得到的结果是一个统一的系统,其中的模型同时能够个性化服务于个人用户,并在长 horizon 的智能体任务上取得改进
- 这个系统/模型完全依赖于它正在进行中的交互来进行训练
- 问题(与作者沟通过,作者似乎也没有想好):
- 可能会因为捕捉隐式的错误信号,导致模型发生变化,比如过拟合用户的习惯(错误意图),如果用户喜欢让 Agent 先生成 A,在让 Agent 优化成 B,比如先规划,再写代码,目前 OpenClaw-RL 这样训练可能导致模型被更新为自动写代码(跳过规划了)
- 信号的准确性很重要
- 基于此文,思考一下关于模型进化的思考:
- 一种可能的方向:类似 OPSD,使用类似未来信号,增强 Prompt,将当前策略变成更优的教师策略,从而实现更多可能性
- 另一种可能的方向:使用多个当前策略作为一个更强反馈模型,评估结果并给出结论
- 背景 & 现状
- 智能体的每次交互会产生一个 Next-state Signal
- 这里的信号状态定义为:紧随每个动作之后的用户回复、工具输出、终端或图形用户界面状态变化
- 智能体的每次交互会产生一个 Next-state Signal
- 问题提出:
- 现有智能体强化学习系统都没有将这个信号恢复为实时的、在线的学习源
- 本文做法:
- Insight: Next-state Signal 是通用的,并且策略可以同时从所有信号中学习
- 个人对话、终端执行、图形用户界面交互、软件工程任务和工具调用轨迹并非独立的训练问题
- 都是可以在同一个循环中用于训练同一个策略的交互
- Next-state Signal 编码了两种形式的信息:
- 评估信号 (evaluative signals),指示动作执行得如何,并通过 PRM judge 提取为标量奖励
- 指导信号 (directive signals),指示动作本应如何不同,并通过事后引导的 On-policy 蒸馏 (Hindsight-Guided On-Policy Distillation, OPD) 来恢复
- 本文提出 OpenClaw-RL,从下一状态中提取文本提示,构建一个增强的教师上下文,并提供比标量奖励更丰富的 Token-level 的方向性优势监督
- 基于异步设计,实现三者之间零协调开销:
- 模型服务于实时请求
- PRM 判断进行中的交互
- Trainer 同时更新策略
- Insight: Next-state Signal 是通用的,并且策略可以同时从所有信号中学习
- OpenClaw-RL 可以应用于两种类型的 Agent:
- 应用于 Personal Agent ,使得智能体仅通过被使用就能改进,从用户的重新查询、纠正和明确反馈中恢复对话信号
- 应用于 General Agent ,相同的基础设施支持跨终端、图形用户界面、软件工程和工具调用设置的可扩展强化学习,在其中进一步展示了过程奖励 (process rewards) 的效用
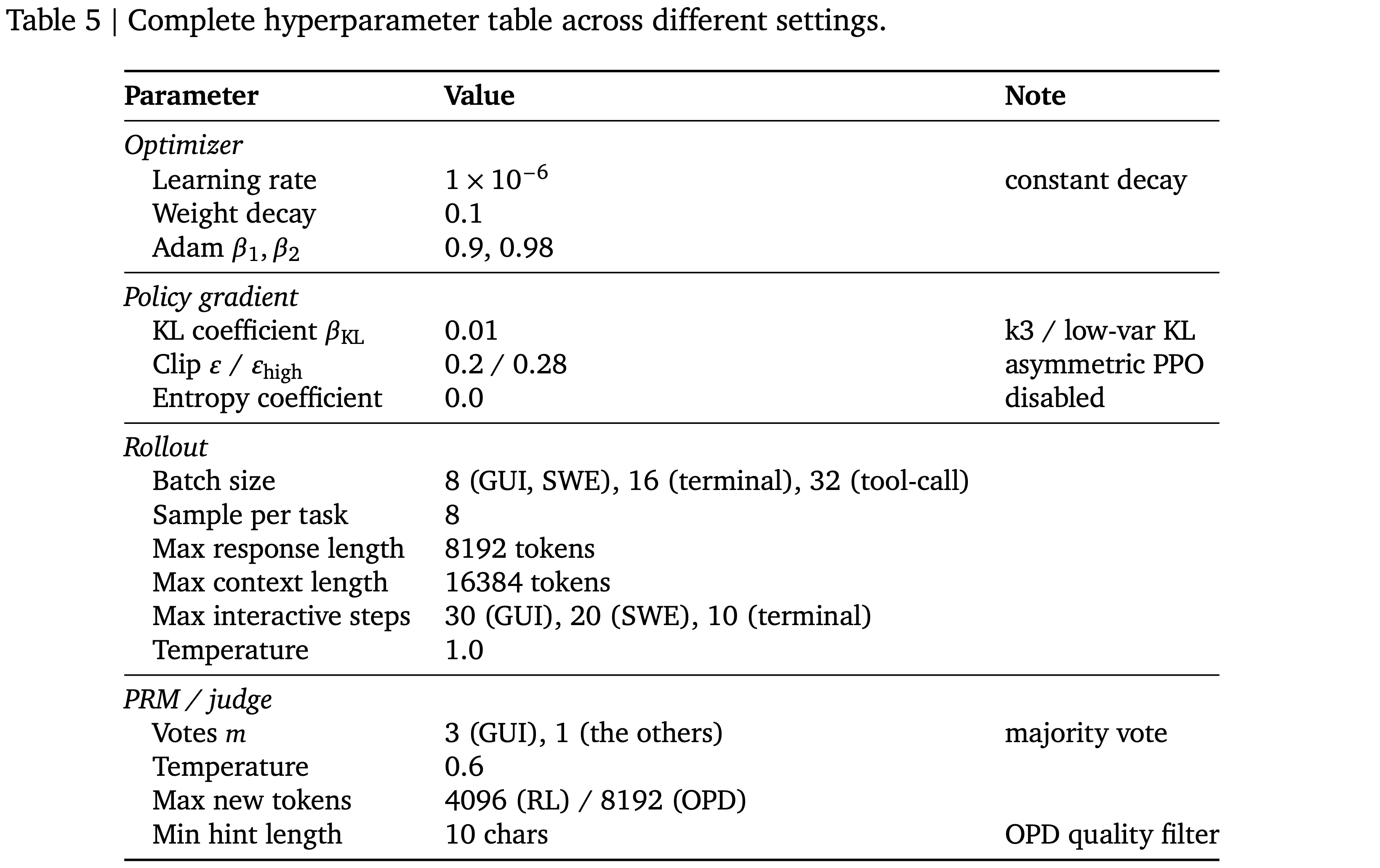
- 图 1:OpenClaw-RL Infrastructure
- 交互流来自两种智能体类型:
- Personal Agent:托管在个人设备上,特点是对话式,单用户
- General Agent:托管在云服务上,比如 终端、图形用户界面、软件工程和工具调用智能体
- 收集到的样本流 RL Server,RL Server 构建在异步 slime 框架上,该服务器由四个解耦的组件组成:
- (1)Environment Servers:环境服务器
- (2)PRM Server:用于奖励计算的 PRM / Judge
- (3)Megatron:Training Engine
- (4)Policy Server(SGLang)
- 这些组件支持平滑的权重更新,并能够与任何智能体框架一起进行训练
- Personal Agent 的环境就是用户的个人设备,它们通过 HTTP 使用机密 API 密钥连接到 RL Server
- General Agent 的环境托管在云服务上,以实现可扩展的并行化
- 交互流来自两种智能体类型:
Introduction and Discussion
- 背景描述:
- 背景:目前我们部署了很多智能体,当前部署的 AI 智能体其实已经在收集改进它自身所需的数据 ,但我们却又将其丢弃
- 定义:在每个动作 \(a_{t}\) 之后,智能体都会收到一个 Next-state Signal \(s_{t + 1}\):
- 比如 用户回复、工具执行结果、图形用户界面状态转换或测试判决等
- 现有系统的做法:仅将 Next-state Signal \(s_{t + 1}\) 纯粹作为下一个动作的上下文 (2025; 2025; 2025; 2025b; 2025)
- 作者观点:
- Next-state Signal 编码了更有价值的东西:对 \(a_{t}\) 的隐含评估,包括它执行得如何,以及通常还包含它本应如何不同
- 而且这个信号在每种交互类型中都是免费产生的,包括个人对话、终端环境、图形用户界面环境、软件工程任务和工具调用环境,然而现有的任何基于智能体的强化学习系统都没有将其恢复为实时的、在线的学习源
- 作者识别出两种不同且可恢复的浪费(waste)
waste 1:Evaluative signals,评估信号
- Next-state Signal 隐含地评分了先前的动作:
- 比如用户的重新查询表示不满意 ,通过的测试表示成功 ,错误轨迹表示失败
- 这形成了一个自然的过程奖励,不需要单独的标注流水线
- 补充:目前 PRM 几乎仅在具有可验证真实情况的数学推理中被研究 (2025b; 2023; 2024)
- 在 Personal Agent 中, PRM 逐轮捕获用户满意度
- 在 General Agent 中, PRM 为长 horizon 任务提供了所需的密集的每步信用分配 (2026)
- 而现有系统要么忽略此信号,要么仅以离线、预先收集的形式利用它,依赖于固定数据集或终端结果奖励
Waste 2:Directive signals,指导信号
- Next-state Signal 通常还携带指导信息:
- 一个说“你应该先检查文件”的用户不仅指明了回答是错误的 ,而且还指明了在 Token-level 应该如何改变
- 一个详细的软件工程错误轨迹通常暗示了一个具体的修正方向
- 当前的 RLVR 使用标量奖励
- 无法将此类信息转换为方向性的策略梯度 (2025; 2025; 2024; 2025a)
- 蒸馏方法 (2026; 2026) 依赖于预先整理的反馈-响应对
- 非实时信号
- 事后重标记 (hindsight relabeling) (2026; 2023) 和上下文丰富蒸馏 (context-enriched distillation) (2024b, 2025c) 表明,向上下文中添加结构化纠正信息可以显著改善输出
- 但这些方法都在固定数据集上操作
- 同期工作:Buening等人 (2026) 通过直接用下一状态信息提示来改进在线策略
- 但纠正性提示 (corrective hints) 仍然是隐式的
OpenClaw-RL
- OpenClaw-RL 是一个统一的框架,为 Personal Agent 和跨多种设置的 General Agent (包括与 OpenClaw 的个人对话 (OpenClaw, 2026)、终端、图形用户界面、软件工程和工具调用环境)恢复了两种形式的 Next-state Signal 浪费
- OpenClaw-RL 是一个完全解耦的异步架构(基于 slime 构建)
- 策略服务、Rollout 收集、 PRM 判断和策略训练作为四个独立的循环运行,彼此之间没有阻塞依赖
- 在 Personal Agent Setting 中,模型可以通过正常使用自动优化
- 这扩展了现有的强化学习基础设施,后者通常假设批处理数据收集,而非从实时部署中持续学习
- 本文提出了两种优化选项
- 二元强化学习 (binary RL):使用 PRM 将对话恢复为标量过程奖励
- 事后引导的 On-policy 蒸馏 (Hindsight-Guided On-Policy Distillation, OPD):从下一状态中提取文本提示,构建一个增强的教师上下文,并将 Token-level 的方向性监督蒸馏回学生模型,提供了单独从标量奖励中无法获得的训练信号
- 在模拟实验中,将两种方法与加权损失相结合能带来显著的性能提升
- OpenClaw-RL 也可扩展到针对 General Agent 的强化学习训练,包括终端、图形用户界面、软件工程和工具调用设置
- OpenClaw-RL 将 PRM 判断与可验证结果相结合,以提供既密集又可靠的监督 (2026; 2025)
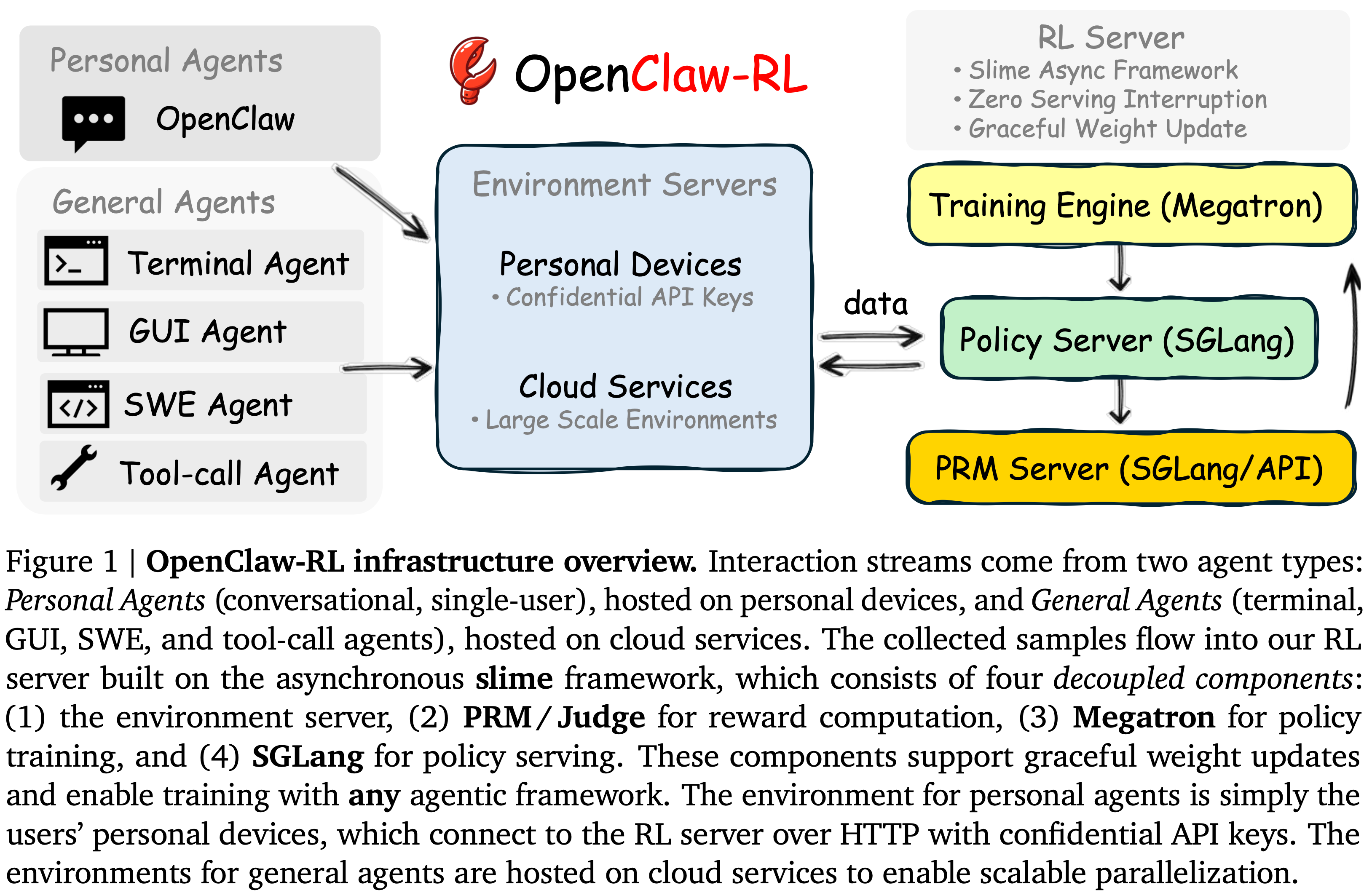
- 图 2 使用 OpenClaw-RL 训练 OpenClaw Agent 前后的一个模拟结果(注意:下图右表中提供的分数结果也是 Prompt 一个 GRM 来打分的,并不是人工评估的结果)
Contributions 总结
- 将 Next-state Signal 作为实时的、在线的学习源
- 作者识别出 Next-state Signal ,无论是用户回复、执行结果、测试判决还是图形用户界面转换,都编码了关于先前动作的评估信息和指导信息
- 作者在异构的交互类型中将这些信号恢复为实时的、在线的训练源
- OpenClaw-RL 基础设施
- 首个能够统一多个并发交互流的系统,包括个人对话、终端、图形用户界面、软件工程和工具调用智能体设置
- 被设计为对服务零中断,具有会话感知的多轮跟踪、平滑的权重更新、灵活的 PRM 支持以及大规模环境并行化
- 两种互补的 Next-state Signal 恢复方法
- 通过 PRM 的二元强化学习将评估性的 Next-state Signal 转换为密集的标量过程奖励
- 事后引导的 OPD 通过从下一状态提取文本提示并构建一个增强的教师上下文,将指导性信号转换为 Token-level 的优势监督,其中丰富的文本反馈为改进提供了方向性指导
- 跨 Personal 和 General Agent 的实证验证 OpenClaw-RL
- Personal Agent 个性化实验
- General Agent RL 实验:跨终端、图形用户界面、软件工程和工具调用的 setting
- 通过实践证明二元强化学习和事后引导的 OPD 是互补的,并且它们的结合为 Personal Agent 带来了显著的性能提升
- 作者还验证了在 General Agent 强化学习设置中整合过程奖励和结果奖励的有效性
Problem Setting
- OpenClaw-RL 操作于一个策略 \(\pi_{\theta}\),该策略同时接收多个交互流,将它们与推理流水线解耦,因此足够灵活以适应广泛的智能体设置,包括 Personal Agent 对话、终端执行、图形用户界面交互、软件工程任务和工具调用轨迹
- 本文将每个交互流形式化为一个马尔可夫决策过程 \((S, \mathcal{A}, \mathcal{T}, r)\):
- 状态 \(s_t \in S\):截止到第 \(t\) 轮的完整对话或环境上下文
- 动作 \(a_t \in \mathcal{A}\):智能体的响应,由 \(\pi_{\theta}\) 生成的 token 序列
- 注意:这里不仅仅是一个 Token,也就是说动作空间不是词表,而是具体能做的动作,如点击鼠标等,通常由整个回复的所有 Token 组成
- 转移 \(\mathcal{T}(s_{t+1} | s_t, a_t)\):由环境决定
- 注:这里的 \(s_{t+1}\) 是紧随 \(a_t\) 之后的用户回复、执行结果或工具输出
- 奖励 \(r(a_t, s_{t+1})\):通过 PRM judge 从 Next-state Signal 中推断得出
- 注:这里的奖励是通过 \(s_{t+1}\) 推断出来的,
- 在标准的 RLVR 中,结果 \(o\) 作为整个轨迹的奖励
- 而依赖于下一状态 \(s_{t+1}\) 的过程奖励 \(r(a_t, s_{t+1})\) 包含了丰富得多的信号
- 特别是,当下一状态包含关于动作本应如何不同的明确指导信息时, On-policy 蒸馏通过将此类方向性的 Next-state Signal 转换为 Token-level 的教师监督,实现了方向性的改进 (2024; 2026)
OpenClaw-RL Infrastructure: Unified System for Personal and General Agents
- 本文将个人 OpenClaw 智能体的自动优化和针对 General Agent (包括终端、图形用户界面、软件工程和工具调用设置)的大规模智能体强化学习,统一在单个框架内
Asynchronous Pipeline with Four Decoupled Components,4 个解耦组件
- OpenClaw-RL 的核心架构原则是完全解耦:策略服务、环境托管、 PRM 判断和策略训练作为四个完全独立的异步循环运行,它们之间没有阻塞依赖关系(图 1)
- Policy Serving (SGLang) → environment (Http / API) → Reward Judging (SGLang / API) → Policy Training (Megatron)
- Model Serves 下一个用户请求,同时 PRM 判断前一个响应 , Trainer 应用梯度更新,可以看出,没有一个组件需要等待其他组件
- 这使得从实时的、异构的交互流中进行持续训练变得切实可行:无需为了适应另一个组件的时间表而暂停或批处理任何流
- 对于 Personal Agent ,模型通过机密 API 连接,以实现私密和安全部署,无需修改 Personal Agent 框架,并且可以在不中断推理的情况下优雅地更新
- 对于 General Agent 的大规模训练,这种异步设计允许每个组件无阻塞地进行,从而减轻了由长 horizon Rollout 时长引起的长尾问题
Session-Aware Environment Server for Personal Agents
- Personal Agent 的环境是用户的设备,它通过 RL Server 的机密 API 连接,每个 API 请求被分类为两种类型之一:
- 主线轮次 (Main-line turn) :智能体的主要响应和工具执行结果,这些构成了可训练的样本
- 旁线轮次 (Side turn) :辅助查询、记忆组织和环境转换,这些被转发但不产生训练数据
- 这种分类使得强化学习框架能够精确识别哪些轮次属于哪个会话,从而实现有针对性的训练
- 目前仅训练主线轮次
- 每个新的主线请求的消息包含对前一轮次的反应 ,whether 用户的回复 or 环境的执行结果
- 这成为前一轮次奖励计算的 Next-state Signal \(s_{t + 1}\)
Scalability: From Single-User Personalization to Large-Scale Agent Deployment
- OpenClaw-RL 被设计为能够在从单用户 Personal Agent 到大规模多环境 General Agent 部署的整个范围内运行
- 对于 Personal Agent ,环境是单个用户的设备,交互流是稀疏的、基于会话的且高度个性化的
- OpenClaw-RL 构建于 slime 之上 (2025),继承了用于 General Agent 的可扩展训练基础设施,并且作者进一步支持跨多种智能体设置(第 3.4 节)的云托管环境
- 成百上千的并行环境托管在云服务上,产生密集的结构化执行信号流,从而实现可扩展的强化学习训练
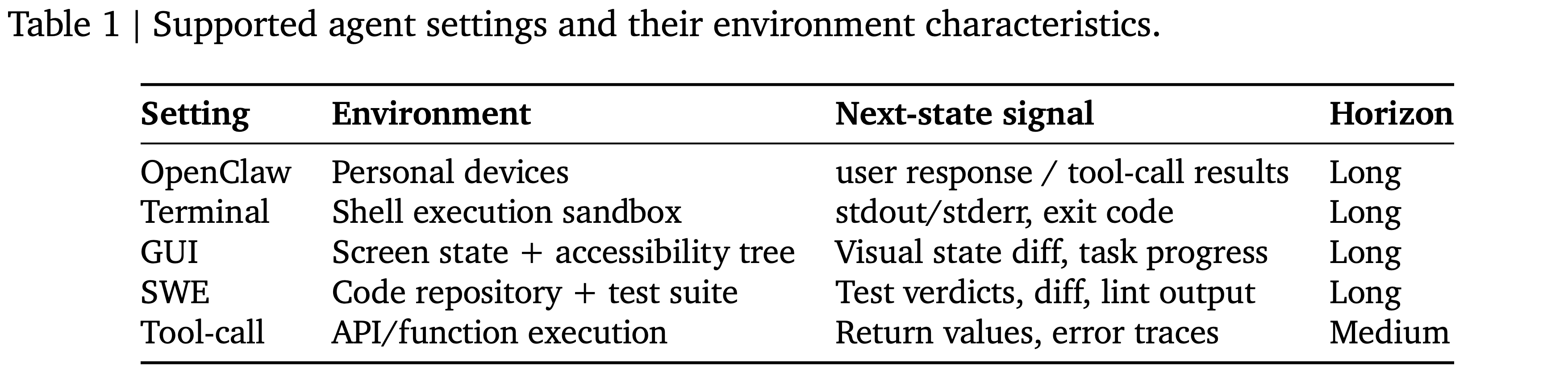
Support for Multiple Real World Scenarios
- OpenClaw-RL 在作者的开源实现中支持一系列广泛的 General Agent 场景,这些场景涵盖了最常见的现实世界部署设置(表 1)
- Terminal Agent:计算机使用系统的核心组件:
- 高效、扩展成本低,并且与大型语言模型的基于文本的界面自然对齐 (Anthropic, 2026; OpenAI, 2026; 2026)
- GUI Agent:涵盖了终端智能体无法直接访问的能力
- 例如视觉界面和基于指针的交互,这使得它们对于更通用的计算机使用任务来说是必要的 (2025; 2025a,c; 2026)
- SWE Agent
- 代表了一类特别重要的编码智能体,其中环境通过测试、差异和静态分析提供丰富的可执行反馈 (2026)
- Tool Call Agent
- 外部工具既能提高推理能力,也能提高事实准确性 (2025a)
- 外部工具既能提高推理能力,也能提高事实准确性 (2025a)
- Terminal Agent:计算机使用系统的核心组件:
Non-Blocking Record and Observability,非阻塞 Record 和可观测性
- 所有交互和奖励评估都实时记录到 JSONL 文件中:完整的消息历史、提示/响应文本、工具调用、下一状态内容、每次投票的 PRM 分数、选中的提示 (OPD) 以及接受/拒绝决定
- Record 是非阻塞的,写入操作在后台线程上是即发即弃的,不会给服务或 PRM 路径增加任何延迟
- 记录文件在每个权重更新边界被清除,确保日志始终对应于单个策略版本
- 理解:即每次权重更新后清除当前的日志,始终保持 On-Policy
Learning from Next-State Signals: Unified RL Across Interaction Types, 跨交互类型的 Unified RL
- 本文将来自异构交互流(包括个人对话、终端交互、GUI 交互、SWE 任务和工具调用轨迹)的 Next-state Signal 转换为策略梯度
- 核心创新:通过分析 Next-state Signal 信号,得到可优化模型的梯度
- 下面会使用两个方向(方法)来提取信号
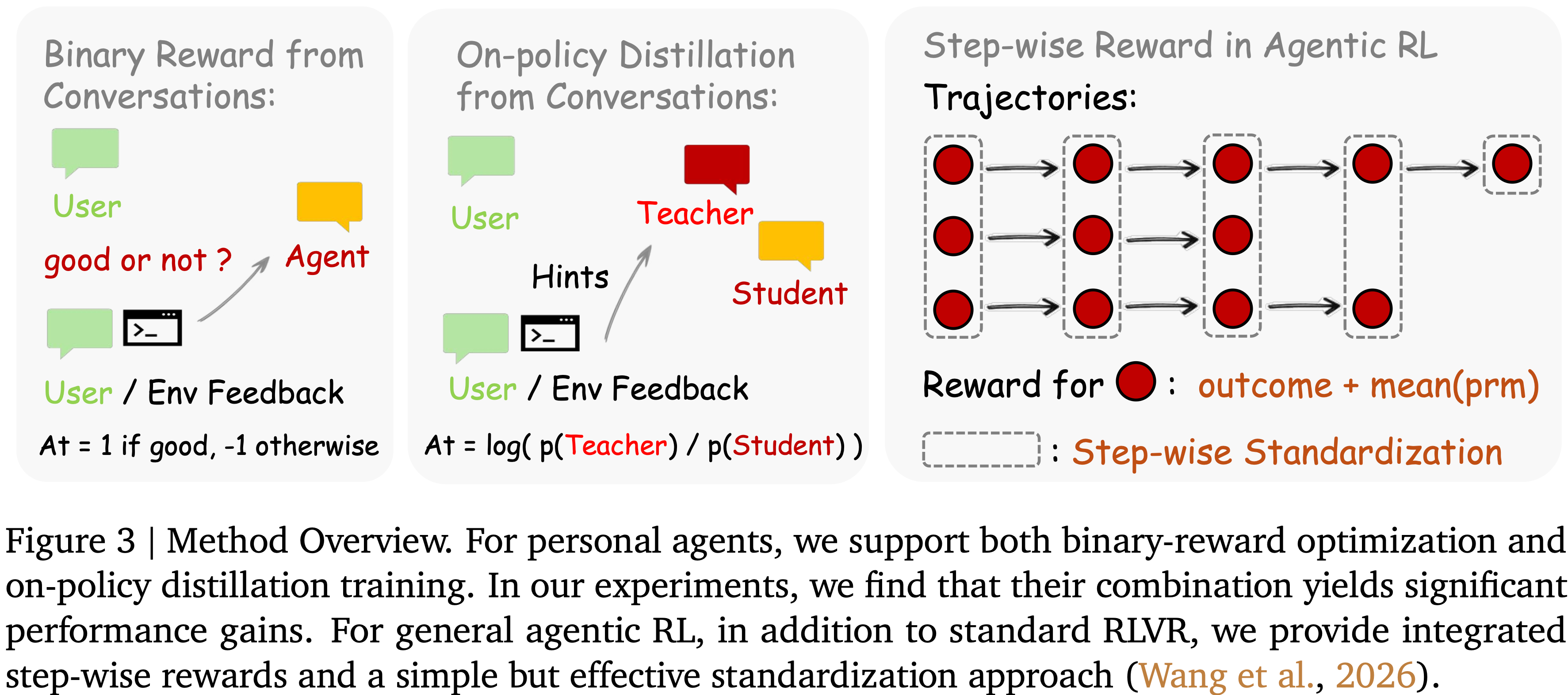
Binary RL for Personal Agent,用于 Personal Agent 的二元强化学习
- Binary RL 提取信号的方法,将评估性的 Next-state Signal 转换为标量过程奖励
PRM Judge Construction via Majority Vote,通过多数投票构建 PRM Judge
- 给定响应 \(a_{t}\) 和下一状态 \(s_{t + 1}\) ,一个评判模型评估 \(a_{t}\) 的质量:
$$
\mathrm{PRM}(a_{t},s_{t + 1})\rightarrow r\in \{+1, - 1,0\} .
$$ - 具体方案:
- PRM 根据用户的下一个响应或工具调用结果来评判每个动作
- 注:这里工具调用结果通常会导致明确的结论
- 用户的下一个响应可能包含满意或不满意的信号
- 如果没有明确的用户反应迹象,模型也会根据场景进行估计,作者鼓励用户提供更明确的反馈
- 对于 General Agent , Judge 会推理环境的反馈是否表明朝着任务目标取得了进展
- 作者运行 \(m\) 次独立的 Query,并采取多数投票
$$ r_{\mathrm{final} } = \mathrm{MajorityVote}(r_1,\ldots ,r_m) $$
- PRM 根据用户的下一个响应或工具调用结果来评判每个动作
RL Training Objective
- 通过直接使用优势 \(A_{t} = r_{\mathrm{final} }\) ,训练目标是标准的 PPO 风格的带不对称边界的裁剪替代目标 (Schulman 2017):
$$
\rho_{t} = \frac{\pi_{\theta}(a_{t}\mid s_{t})}{\pi_{\mathrm{old} }(a_{t}\mid s_{t})},\quad \mathcal{L}_{\mathrm{PG} } = -\mathbb{E}_{t}\big[\min (\rho_{t}A_{t},\mathrm{clip}(\rho_{t},1 - \epsilon ,1 + \epsilon_{\mathrm{high} })\cdot A_{t})\big],\quad \mathcal{L} = \mathcal{L}_{\mathrm{PG} } + \beta_{\mathrm{KL} }\cdot \mathcal{L}_{\mathrm{KL} }, \tag {1}
$$- \(\epsilon = 0.2\)
- \(\epsilon_{\mathrm{high} } = 0.28\)
- \(\beta_{\mathrm{KL} } = 0.02\)
- 请注意,这是一个实时的对话设置,因此不像 GRPO (Shao 2024) 那样有可用的组结构进行标准化
Hindsight-Guided On-Policy Distillation (OPD) for Personal Agent, 用于 Personal Agent 的 hindsight 引导的 On-policy 蒸馏
- Hindsight-Guided OPD 提取信号的方法将指导性的 Next-state Signal 转换为 Token-level 的教师监督
Why Token-Level Supervision from Next-State Signals?,为什么需要来自 Next-state Signal 的 Token-level 监督?
- 二元强化学习将 \(s_{t + 1}\) 的整个信息内容简化为一个标量 \(r\in \{+1, - 1,0\}\)
- 但一个用户写下“你应该在编辑文件之前先检查一下”传达了更多的信息:
- 不仅指出响应是错误的,还指出哪些 token 应该不同以及如何不同
- 这种指导性信息完全被标量奖励丢失了
- OPD 通过将 Next-state Signal 转换为 Token-level 的训练信号来恢复此信息
- 这里的关键的 Insight:如果我们用从 \(s_{t + 1}\) 中提取的文本提示来增强原始 Prompt,同一个模型会产生不同的 token 分布,这个分布“知道”响应本应该是什么(这里和 (OPSD)Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models, 20260126 - 20260305, UCLA & Meta 思想一致)
- 这个增强提示的分布与学生分布之间的每个 token 的差距提供了一个方向性优势:在模型应该加权的 token 上为正,在模型应该减权的 token 上为负
- 注:这是一种借助未来信号增强 Prompt,从而得到教师模型完成自我监督的方法,这与 RLHF (2017; 2019)(使用标量偏好信号)、DPO (2023)(需要成对偏好)和标准蒸馏(需要一个单独的、更强的教师模型)不同
Token-level OPD
Step 1. Hindsight hint extraction,提取 Hindsight hint
- 此时,具体提取信息如下(除了 二元 信号外,比之前的方式多了一个 hint):
$$
\mathrm{Judge}(a_t,s_{t + 1})\rightarrow \{\mathrm{score}\in \{+1, - 1\} ,\mathrm{hint}\in \mathcal{T}^*\}
$$ - 如果 score \(= +1\) , Judge 会在 [HINT_START] … [HINT_END] 内生成一个简洁的提示
- 注意:仅当 score \(= +1\) 时才会提取 hint 信息
- 本文会运行 \(m\) 次并行的 Judge 调用
- 一个关键的设计选择:我们不直接使用 \(s_{t + 1}\) 作为 Hint(提示)
- 原始的 Next-state Signal 通常包含噪声、冗长或包含不相关的信息(例如,用户的回复可能同时包含更正和一个不相关的新问题)
- Judge 模型将 \(s_{t + 1}\) 提炼成一个简洁、可操作的指令,该指令隔离了指导性内容,通常是 1-3 句话 ,聚焦于响应本应如何不同
Step 2. Hint selection and quality filtering,Hint 的选择和过滤
- 在带有 Hint 且 字符数 \(>10\) 的正向投票中,选择最长(信息量最大)的
- 如果没有有效的提示,则完全丢弃该样本,这是有意为之
- OPD 用样本数量换取信号质量:
- 只有当下一个状态信号带有清晰、可提取的修正方向时,该轮次才会进入训练
- 这种严格的过滤与二元强化学习相辅相成(二元强化学习接受所有评分的轮次):
- 二元强化学习通过粗略的信号提供广泛的覆盖,而 OPD 在较少的样本上提供有针对性的、高分辨率的监督
Step 3. Enhanced teacher construction
- 提示被附加到最后一条用户消息之后,格式为
[user's hint / instruction]\n{hint},从而创建一个增强的 Prompt
$$s_{\mathrm{enhanced} } = s_t \oplus \text{hint} $$- 这模拟了如果用户事先提供了修正,模型“本会看到的”上下文
Step 4. Token-level advantage
- 策略模型在 \(s_{\mathrm{enhanced} }\) 下以原始响应 \(a_{t}\) 作为强制输入进行查询,计算每个响应 token 的对数概率
- 然后得到 On-policy 蒸馏中的 Token-level 优势:
$$
A_{t} = \log \pi_{\mathrm{teacher} }(a_{t}\mid s_{\mathrm{enhanced} }) - \log \pi_{\theta}(a_{t}\mid s_{t}).
$$- \(A_{t} > 0\) :教师(知道提示)给这个 token 分配了更高的概率,学生应该增加它
- \(A_{t}< 0\) :教师认为考虑到提示,这个 token 不太合适,学生应该减少它
- 与将所有 token 推向同一方向的标量优势不同,这提供了每个 token 的方向性指导 :
- 在同一个 Response 中,一些 token 可能被加强,而另一些则被抑制
- 训练遵循与公式 (1) 相同的裁剪替代目标,但现在优势在每个样本上携带了丰富得多的信息
Combine Binary and OPD Methods,结合二元和 OPD 方法
- 者一步的目标是发挥彼此的优势,抵消彼此的弱点
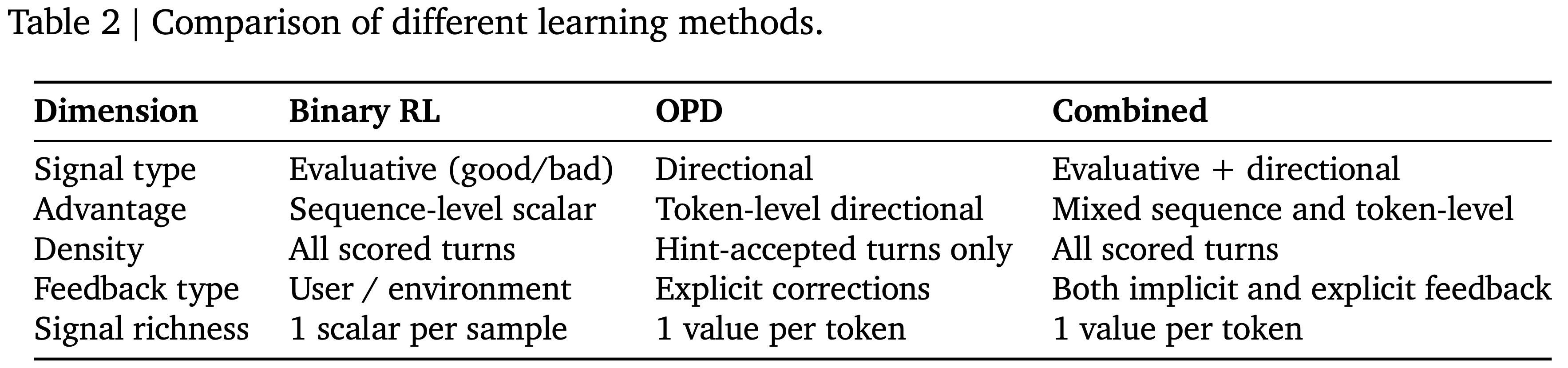
- 表 2 解读:
Binary RL OPD Combined(二者结合) 信号类型 评估 好 or 坏 引导方向(Directional) 评估信号 + 方向引导 优势 Sequence-level 标量 Token-level directional 混合 Sequence-level and Token-level 密度 所有评过分的轮次 仅 hint-accepted 轮次 所有评过分轮次 反馈类型 用户 / 环境 反馈信号 明确修正信号 隐式和明确的反馈 信号丰富度 每个样本 1 个标量 每个 token 1 个值 每个 token 1 个值 - 二元和 OPD 方法是互补的,而不是竞争的
- 二元强化学习接受每一个被评分的轮次,不需要 Hint 提取,并且适用于任何 Next-state Signal ,包括简洁的、隐式的反应(用户简单地重复提问)或结构化的环境输出(退出代码、测试 verdicts)
- 当交互流可能包含丰富的指导性内容时,应该额外启用 OPD:
- 那些给出明确修正的用户(“不要使用那个库”,“先检查文件”),或者产生详细错误轨迹的环境(SWE diffs,编译器诊断)
- 在实践中,作者建议同时运行两者:
- 二元强化学习 在所有轮次上提供广泛的梯度覆盖
- OPD 在那些有指导性信号的轮次子集上提供高分辨率的、每个 token 的修正
- 作者提出通过一个加权损失函数来结合这两种互补方法
- 因为两种方法共享相同的 PPO 损失,只是优势的计算不同,故可以直接使用以下优势:
$$
A_{t} = w_{\mathrm{binary} }r_{\mathrm{final} } + w_{\mathrm{opd} }(\log \pi_{\mathrm{teacher} }(a_{t}\mid s_{\mathrm{enhanced} }) - \log \pi_{\theta}(a_{t}\mid s_{t})),
$$- 默认设置 \(w_{\mathrm{binary} } = w_{\mathrm{opd} } = 1\)
- 后续实验展示了这种方法取得了显著的性能提升
- 因为两种方法共享相同的 PPO 损失,只是优势的计算不同,故可以直接使用以下优势:
Step-wise Reward for General Agentic RL
- 如何结合结果奖励和过程奖励?
Why Process Rewards Are Vital for Agentic Tasks,为什么过程奖励对智能体任务至关重要
- 在长 horizon 的智能体任务中,仅依赖结果的奖励仅在最终步骤提供梯度信号,使得绝大多数轮次无监督
- PRM 根据 Next-state Signal 为每个轮次分配奖励,在整个轨迹中提供密集的 credit assignment
- 最近的工作为此提供了强有力的经验证据
- RLANything (2026) 证明,将步骤级 PRM 信号与结果奖励相结合,在 GUI 智能体、文本游戏智能体和编码任务中始终优于仅依赖结果的训练
- 本文在 OpenClaw-RL 中直接基于这一 Insight 构建:
- 本文的 PRM 使用实时的 Next-state Signal 作为证据来评判每个轮次,并且作者在实证中(§5.4)证明了这种密集信号对长 horizon RL 设置是有帮助的
Integrate Outcome and Process Rewards,整合结果和过程奖励
- 可验证的结果是 RLVR 设置中的标准监督信号
- 遵循 RLANything (2026),作者通过简单地将它们相加来整合结果和过程奖励,对于步骤 \(t\) 使用下面的奖励
$$ o + \sum_{i = 1}^{m}r_{i} / m$$- 其中 \(r_{i}\) 由 \(\mathrm{PRM}(a_{t},s_{t + 1})\) 独立分配
- 与 GRPO 不同,步骤级奖励的存在使得计算优势不那么直接
- Feng 等人 (2025b) 将相似的状态分组并在每组内进行标准化
- 但在诸如终端智能体之类的现实世界环境中,状态不容易聚类
- 作者提出直接对具有相同步骤索引的动作进行分组,并在实证研究中发现这是有效的
Experiments
- 在两个互补的 Track 上评估 OpenClaw-RL,共享相同的基础设施和训练循环
- §5.3 评估 Personal Agent Track ,展示了对话式 Next-state Signal 能够实现对个人用户偏好的持续个性化
- §5.4 评估 General Agent Track ,涵盖终端、GUI、SWE 和工具调用设置,证明相同的基础设施支持跨不同智能体场景的可扩展 RL,并且步骤级奖励对于长 horizon 任务至关重要
Personal Agent Setup
- 用仿真结果证明优化的有效性
角色一:Student Who Uses OpenClaw to Do Homework,使用 OpenClaw 做作业的学生
- 学生目标:不希望被发现使用了人工智能
- 注:学生有这个意图,但不会直接把这个意图添加到 Prompt 上
- 在此设置中,作者使用一个 LLM 来模拟一个学生在个人电脑上使用 OpenClaw 完成作业,同时试图避免被认为依赖 AI
- 注:一个回答是否看起来像是 AI 生成的,完全取决于学生的个人偏好和写作风格
- 学生持续与 OpenClaw 互动,并请求它帮助完成作业
- 作业任务来自 GSM8K (Cobbe 2021)
- 此设置中使用的 OpenClaw 策略模型是 Qwen3-4B (Yang 2025a)
- 将学习率设置为 \(1 \times 10^{- 5}\) ,KL 系数设置为 0,并在每收集 16 个训练样本后触发训练
角色二:Teacher Who Uses OpenClaw to Grade Homework,使用 OpenClaw 批改作业的老师
- 教师目标:希望评论具体且友好
- 学生在文件中完成作业后,老师也使用 OpenClaw 来批改 AI 编写的作业
- 老师希望给学生评语具体且友好。OpenClaw 策略模型同样是 Qwen3-4B,并使用相同的优化设置
General Agent Setup
Models
- 作者在终端、GUI、SWE 和工具调用设置中分别使用 Qwen3-8B (Team, 2025)、Qwen3VL-8B-Thinking (Bai 2025)、Qwen3-32B (Team, 2025) 和 Qwen3-4B-SFT
- 这里,Qwen3-4B-SFT 指的是由 Zhu 等人 (2025) 提供的模型,该模型在 Feng 等人 (2025a) 的数据集上进行了微调
- GUI 和工具调用智能体的 PRM 分别是 Qwen3VL-8B-Thinking 和 Qwen3-4B
Datasets
- 使用 SETA RL 数据 (Shen 2026)、OSWorld-Verified (Xie 2024)、SWE-Bench-Verified (Jimenez 2023) 和 DAPO RL 数据 (Yu 2025a) 分别训练终端、GUI、SWE 和工具调用智能体
- GUI 智能体在训练集上进行评估(排除了 chrome 和多应用任务)
- 工具调用智能体在 AIME 2024 (Mathematical Association of America, American Mathematics Competitions, 2024) 上评估
- 对于终端和 SWE 智能体,报告 RL 步骤窗口上的平均 rollout 任务准确率
Hyperparameters
- 学习率:\(10^{- 6}\)
- KL 系数:0.01
- 下裁剪比率:0.2
- 上裁剪比率:0.28
- 对于 GUI 和 SWE Setting
- 每一步采样 8 个任务
- 终端设置采样 16 个
- 工具调用设置采样 32 个
- 对于每个任务,独立抽取 8 个样本
- GUI、SWE 和终端的最大交互步数分别为 30、20 和 10
- 更多细节见附录 D
Personal Agent Track: Learning from Conversational Signals
Takeaway [Q1]:二元强化学习 vs. OPD,每种 Next-state Signal 类型何时胜出?
- 组合方法实现了最有效的优化,并且 On-policy 蒸馏由于训练样本的稀疏性而表现优于二元强化学习,但需要更长时间才能显现其效果(表 3)
- 为了比较不同方法,作者使用与用户模拟中相同的 LLM(针对学生和教师设置)为 OpenClaw 为每个问题首先生成的解决方案分配定量个性化得分(见附录 C.3)
- 本文报告了 GSM8K 中前 36 个问题的平均得分
- 如表 3 所示,组合方法实现了最强的优化性能
- 由于训练样本稀疏, On-policy 蒸馏显示出延迟的增益,而仅使用二元强化学习仅带来边际改善
- 由于训练样本稀疏, On-policy 蒸馏显示出延迟的增益,而仅使用二元强化学习仅带来边际改善
Takeaway [Q2]:OpenClaw-RL 是否会随时间提高个性化程度?
- 在组合优化方法下,OpenClaw 在学生设置中仅需 36 次问题解决交互,在教师设置中仅需 24 次批改交互,就能实现显著且清晰可见的改进(图 2)
- 作者还提供了具体示例来说明优化的效果及其生效的速度
- 在学生设置中经过 36 次问题解决交互后,智能体学会了避免明显的 AI 式措辞,例如使用像“bold”这样的词或产生过于结构化、逐步的响应(图 2)
- 学生学会了转向了更自然和随意的风格
- 在教师设置中,经过 24 次批改交互后,智能体学会了写出更友好、更详细的反馈
- 注:附录 B 中提供了更多示例
- 在学生设置中经过 36 次问题解决交互后,智能体学会了避免明显的 AI 式措辞,例如使用像“bold”这样的词或产生过于结构化、逐步的响应(图 2)
General Agents: Unified RL Across Terminal, GUI, SWE, and Tool-Call,统一强化学习
Takeaway [Q3]:OpenClaw-RL 作为一个通用的智能体强化学习框架是否具有竞争力?
- 本文证明了 OpenClaw-RL 能够处理多种现实世界设置,包括终端、GUI、SWE 和工具调用智能体,并能跨不同模型大小和模态进行大规模环境并行化(图 4)
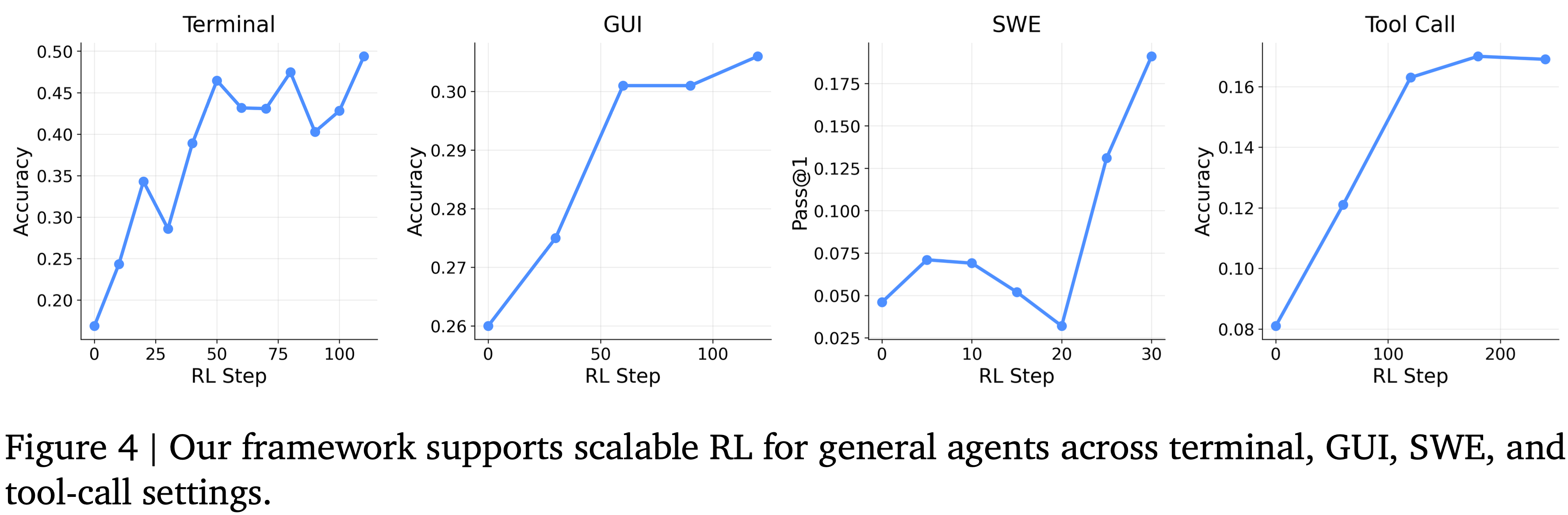
- 作者在广泛使用的现实世界智能体设置中进行了实验,包括终端、GUI、SWE 和工具调用场景(图 4)
- 大规模环境并行化进一步提高了作者 RL 训练的可扩展性
- 在本文的 RL 训练期间,为终端智能体使用了 128 个并行环境,为 GUI 和 SWE 智能体使用了 64 个,为工具调用智能体使用了 32 个
Takeaway [Q4]: PRM 对于长 horizon 任务至关重要吗?
- 整合结果和过程奖励比仅使用结果奖励能带来更强的优化,尽管它需要更多资源来托管 PRM(表 4)
- 作者在工具调用(250 步)和 GUI(120 步)设置中使用整合奖励进行 RL 训练,发现结合结果和过程奖励能进一步提升性能(表 4)
- 结论:PRM 是必要的

Related Work
RL for LLMs
- 当前系统主要以批处理-离线模式运行,其中数据收集和训练在不同的阶段进行,使用固定的数据集
- RLHF (2017; 2019) 建立了基于 PPO 的对齐流程
- DPO (2023) 通过闭式偏好优化进一步绕过了显式奖励建模
- GRPO (2024) 通过组相对优势估计消除了 Critic 网络
- DAPO (2025a) 对 GRPO 进一步扩展
- ReasonFlux (2025b) 采用正交方法,应用分层强化学习来优化思维模板序列,而不是原始的 token 级 CoT,通过结构化推理实现了显著的增益
- OpenClaw-RL 是直接从实时交互信号中持续训练,无需任何数据预收集阶段
Agentic RL and tool-use
- 基础的智能体范式如 ReAct (2023)、Toolformer (2023) 和 FireAct (2023) 实现了与外部工具的多步交互,但依赖于示范而非在线 RL
- 近期的工作将 RL 应用于特定智能体设置,如用于代码和工具使用的 SWE-agent (2024a) 和 ReTool (2025a),用于 GUI 智能体的 DigiRL (2024) 和 WebRL (2024),用于多轮 credit assignment 的 ArCHer (2024) 和 LOOP (2025),但每个都针对单一环境并使用专门的训练流程
- DemyAgent (Yu 2025b)、RLAnything (Wang 2026) 和 CURE (Wang 2025d) 通过研究数据质量和闭环奖励模型协同优化,进一步推进了智能体强化学习
PRM (Process reward models)
- PRM 证明了步骤级监督在数学推理中优于仅结果监督
- Math-Shepherd (Wang 2024) 通过蒙特卡洛估计自动进行步骤级监督,无需人工标注
- GenPRM (Zhao 2025) 通过生成式思维链验证扩展了 PRM
- ReasonFlux-PRM (Zou 2025) 将 PRM 扩展到轨迹感知评估,用于长 CoT 推理,提供离线数据选择和在线密集过程级奖励
- PRIME (2025a) 从结果标签中学习隐式过程奖励
- RLAnything (2026) 提供了大规模证据,表明步骤级 PRM 信号对于长 horizon 智能体任务至关重要,并且联合优化的奖励模型信号超越了人工标注的监督
- 作者将 PRM 风格的评判扩展到在线设置,其中过程奖励是从实时的 Next-state Signal 推断出来的,而不是从预收集的真实数据中获取,并且应用于异构的长 horizon 智能体设置
On-policy distillation and hindsight methods
- 上下文增强方法证明,用结构化信息增强 Prompt 可以产生根本更好的 token 分布:
- Buffer of Thoughts (2024b) 检索高层思维模板,而 SuperCorrect (2025c) 从教师模型中提取分层模板用于跨模型的基于 DPO 的错误修正
- 基于 Hindsight 的方法用回溯信息重新标记过去的经验:
- HER 在经典 RL 中重新标记目标
- STaR (2022) 用答案提示合理化失败
- HIR (2023) 将反馈转换为重新标记的指令
- Self-Rewarding (2024) 使用 LLM 作为自己的 Judge 进行迭代改进
- On-policy 蒸馏方法 (2024; 2026; 2026) 在模型自身基于执行反馈的生成上进行训练,实现了比 GRPO 更快的加速,但需要预先收集的反馈-响应
- OpenClaw-RL 的 Hindsight-Guided OPD 在在线设置中统一了这些线索:
- 从实时 Next-state Signal 中提取文本提示(hindsight 重新标记),模型在提示增强的上下文下充当自己的教师(通过上下文增强进行自蒸馏),由此产生的 token 级对数概率差距提供了方向性优势监督,无需预收集数据、无需外部教师、也无需成对偏好
RL training infrastructure
- OpenRLHF (Hu 2024)、AReal (Fu 2025)、veRL (Sheng 2025) 和 slime (Zhu 2025) 为可扩展的 RL 训练解耦了 Rollout 和训练引擎
- OpenClaw-RL 建立在 slime 之上,实现了四个完全解耦的异步循环:
- Serving、Rollout、PRM judging 和 Training,允许从实时多流交互中持续训练,且服务零中断
- 这种能力在之前的 RL 基础设施中是不存在的,因为它们假定的是批处理数据收集,而非实时部署
附录 A:Algorithm Pseudocode
Algorithm 1:Binary RL Pipeline (per main-line turn, both tracks)

Algorithm 2:OPD Pipeline (personal agent track)
附录 B:More Optimization Examples
B.1. Student Setting
Example 1 (Before and After Optimization)
1
2
3
4
5
6
7
8
9
10
11
12[Before Optimization]
1. The probability of rolling a number greater than 3 on a single die is **50%** (numbers 4, 5, 6 out of 6).
2. The probability of rolling two even numbers in a row is **25%** (3 even numbers per roll * 3/6 * 3/6 = 1/4).
3. The difference in likelihood is **25 percentage points** (50% - 25%).
To express this as a *percentage increase relative to the second event*:
$$
\frac{50\% - 25\%}{25\%} \times 100\% = 100\%
$$
**Answer:** 100% more likely.
[After Optimization]
The answer is 100%. Here’s the breakdown: The probability of rolling a number greater than 3 on a six-sided die is 3/6 = 50%. The probability of rolling two even numbers in a row is (3/6) * (3/6) = 25%. The relative difference is (50% - 25%) / 25% = 100%.Example 2
1
2
3
4
5
6
7
8
9
10[Before Optimization]
Sara needs $70 total for the jacket and shoes ($30 + 2*$20).
She starts with $10 saved and earns $20 from babysitting (4 * $5). This gives her $30 total so far.
She still needs $40 more ($70 - $30).
Since she earns $4 per lawn mow:
**$40 / $4 = 10**
**Answer:** Sara must mow the lawn **10 times** to afford the jacket and shoes.
*(No file changes made yet - ready to write to the file when you say so!)*
[After Optimization]
The jacket costs $30 and two pairs of shoes at $20 each, so that’s $40 total for shoes. Adding the jacket gives us $70 for everything. Sara already has $10 saved and earns $5 each time she babysits (4 times = $20), so she has $30 so far. She needs $70 - $30 = $40 more. Since she makes $4 per lawn mow, she needs to do 40 / 4 = 10 times. So the answer is 10 times.
B.2 Teacher Setting
- Example:
1
2
3
4
5
6
7
8
9[Before Optimization]
Correct. Well done!
[After Optimization]
Your step-by-step approach is fantastic! You correctly added 20 + 44 to get 64,then calculated 100 - 64 = 36. This shows you understand how to break downthe pr
Your calculation of 21 * (3/8) days per painter was spot-on. It’s easy to forgetthat the "3/8ths of a day" applies to each painter individually (since thequestion asks for "each painter"), but you handled it perfectly. [emoji]
The conversion from days to hours (multiplying by 24) was done with such precisionthat the fractions canceled out neatly to give 189 hours. Brilliant work![emoji]
You didn’t even need to divide by 4 because the problem asked for "each painter" -that’s a great catch! [emoji]
Well done! You clearly understood the problem structure and executed the math withconfidence. Keep up the excellent problem-solving skills! [emoji]
附录 C:Prompt Templates
C.1. Personal Agent: PRM Judge Prompt
- System Prompt (Binary RL, Personal)
1
2
3
4
5You are a process reward model (PRM) evaluating an AI assistant.
You will see the assistant’s output and the subsequent user reply.
Judge the quality of the assistant’s output based on the feedback.
Think step-by-step, then give your final score inside \boxed{}.
Valid scores: \boxed{1} (good), \boxed{-1} (bad), \boxed{0} (neutral).
C.2. Personal Agent: OPD Hindsight Hint Prompt
- System Prompt (OPD)
1
2
3
4
5You are a process reward model used for hindsight hint extraction.
Decide whether the next state reveals useful hindsight that could have improved the assistant response at turn t.
- Output \boxed{1} if yes; provide a hint in [HINT_START]...[HINT_END].
- Output \boxed{-1} if no; do not provide a hint.
- Hint must be concrete and actionable (1-3 sentences).
C.3. Personal Agent: Evaluative Prompt from Simulator
- System Prompt (Personalization Score Prompt)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17You are an evaluator used to score the assistant’s first response to a problem.
You will be given:
- a problem,
- the assistant’s first generated solution,
- and the user’s preference: [PREFERENCE].
Your job is to evaluate how well the solution satisfies the user’s preference.
Scoring rule:
- Output exactly one score from \boxed{0}, \boxed{2.5}, \boxed{0.5}, \boxed{0.75}, or \boxed{1}.
- Higher scores mean the response better matches PREFERENCE.
- Lower scores mean the response fails to satisfy PREFERENCE.
Evaluation criteria:
- Consider whether the response follows the preferred style, tone, level of detail, and format implied by PREFERENCE.
- Consider whether the response is helpful, appropriate, and aligned with the user’s expected behavior.
- Focus only on the first generated solution.
Output format:
- Output only the boxed score.
- Do not provide any explanation.
C.4. General Agent: PRM Judge Prompt
System Prompt (Terminal)
1
2
3
4
5You are an evaluator for a terminal agent.
You are provided with:
1) the agent’s task instruction,
2) the interaction history, and
3) the agent’s most recent step to evaluate.User Prompt (Terminal)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28"task_instruction": {task_instruction}
"history": [
{
"turn_idx": {history_turn_idx},
"assistant_text": {history_assistant_text},
"tool_calls": {history_tool_calls},
"tool_results": {history_tool_results},
},
...
]
"current": {
"turn_idx": {current_turn_idx},
"assistant_text": {current_assistant_text},
"tool_calls": {current_tool_calls},
"tool_results": {current_tool_results},
}
Evaluate ONLY the single most recent step using the information above.
Assign a score of +1 if ALL of the following are true:
- The current assistant message is a correct/helpful step that advances the task;
- The tool-call format is valid;
- Tool usage is appropriate for the step;
- Tool results (if any) are consistent with making progress.
Otherwise assign a score of -1, for example if:
- The step is incorrect, misleading, or does not advance the task;
- Tool-call format is broken (invalid JSON / parse error);
- Tool usage is clearly wrong or irrelevant;
- Tool results show failure or clearly no progress.
Think carefully, then provide your reasoning and put the final score in \\boxed{}.System Prompt (GUI)
1
2
3
4
5You are an evaluator for the most recent step of a GUI agent.
You are provided with:
1) the interaction history between the agent and the environment,
2) the agent’s objective, and
3) the agent’s most recent step to evaluate.User Prompt (GUI)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17{"type": "text", "text": "Previous Actions:\n{None or Step k lines}\n"},
{"type": "text", "text": "Image of environment:\n"},
{"type": "image", "image": "data:image/png;base64,{history_image}"},
{"type": "text", "text": "\nAction of agent:\nStep {k}:\n{history_action}\n"},
{"type": "text", "text": "Agent’s current observation:\n"},
{"type": "image", "image": "data:image/png;base64,{current_obs}"},
{"type": "text", "text": "\nYou are a strict evaluator to evaluate the most recent step of the agent in the following.\n\nObjective of Agent:\n{instruction}\n\nAgent’s most recent step (reasoning + action):\n{policy_response}\n"},
{"type": "text", "text": "\nNext observation after executing this action:\n"},
{"type": "image", "image": "{next_obs}"},
Evaluate ONLY the single most recent step using the information above.
Use the next observation AFTER executing this step (i.e., the environment state after this action) to judge whether the action actually took effect.
Assign a score of +1 if ALL of the following are true:
- The step is clearly relevant to the stated objective;
- The action is executable and coherent given the next observation;
- The next observation shows concrete progress toward the objective, not just a no-op.
Otherwise assign a score of -1, for example if the step is incorrect, irrelevant, impossible in context, has no visible effect,\nundoes progress, contradicts the next observation, or hallucinates tools/objects/facts.
Think carefully, then provide your reasoning and put the final score in \\boxed{}.System Prompt (SWE)
1
2
3
4
5
6You are a strict evaluator for a software engineering agent that fixes GitHub issues.
You are provided with:
1) The issue description (problem statement).
2) The agent’s recent action history.
3) The agent’s most recent step (THOUGHT + bash command) to evaluate.
4) The execution result of that command (returncode + stdout/stderr).User Prompt (SWE)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21## Issue Description
{problem_statement}
## Recent History ({n_history} steps)
{history_summary}
## Current Step to Evaluate (step {step_num})
Agent’s full response:
{policy_response}
Execution result (returncode={returncode}):
{command_output}
Evaluate ONLY the single most recent step above.
Assign a score of +1 if ALL of the following are true:
- The command executed without unexpected errors (returncode=0, or expected non-zero like grep with no match);
- The step is clearly relevant to diagnosing or fixing the stated issue;
- The output provides useful information OR the edit makes a logically correct change toward fixing the bug.
Otherwise assign a score of -1, for example if:
- The command fails with an unexpected error (wrong path, syntax error, missing tool);
- The step is irrelevant to the issue (wrong file, wrong concept, unnecessary exploration);
- The agent is going in circles (repeating a previously failed command or approach);
- The edit introduces an obvious bug or does not address the actual issue;
- The agent is wasting steps (e.g. reading files already fully examined).
Think carefully, then provide your reasoning and put the final score in \\boxed{}.
附录 D:Hyperparameters
- 表 5