注:本文包含 AI 辅助创作
Paper Summary
- 整体总结:
- SkillsBench 是第一个将 Agent Skills 作为一等评估工件进行系统评估的基准
- SkillsBench 主要评估对象是:Skill 带来的增益
- 具体方法:通过 配对评估(同一任务在有 Skill 和无 Skill 下执行)来量化 Skill 带来的增益
- 扩展:本文还评估了不同领域、不同任务类型下,Skill 增益的差异
- 本文观点:Skills 的有效性并非普遍适用(与场景有关)
- Agent Skills 作为增强 LLM 智能体能力的模块化、可复用组件正在迅速普及
- 但目前尚无基准测试能够系统地衡量 Skills 的有效性、设计原则及其失败模式
- SkillsBench 是 第一个将 Skills 作为一等评估工件(first-class evaluation artifacts)的基准测试
- 构建了跨 11 个领域的 84 个任务,每个任务在三种条件下执行,并配有确定性验证器(deterministic verifiers):
- 无 Skills(no Skills)
- 有精心策划的 Skills(curated Skills)
- 自生成 Skills(self-generated Skills)
- 构建了跨 11 个领域的 84 个任务,每个任务在三种条件下执行,并配有确定性验证器(deterministic verifiers):
- 本文对 7 种智能体-模型配置进行了大规模评估,共产生了 7,308 条有效轨迹
- 本文的研究结果揭示了四个关键发现:
- (1)精心策划的 Skills 平均可带来 +16.2 个百分点的提升,但不同领域和配置间的差异很大
- (2)自生成 Skills 几乎没有带来提升,甚至会产生负面影响(平均 -1.3 个百分点),这表明有效的 Skills 需要人类专业知识
- (3)少即是多,包含 2-3 个模块的精简 Skills 优于内容 Comprehensive 文档
- (4)Skills 可以部分弥补模型规模的不足,使较小的模型在程序性任务上达到与较大模型相当的性能
- 本文的研究结果揭示了四个关键发现:
Introduction and Discussion
- 背景 & 问题提出:
- LM 智能体在从软件工程到数据分析等领域的应用日益广泛
- SOTA 模型具备强大的通用推理能力,但缺乏特定领域工作流所需的程序性知识 ,而微调成本高昂 且会牺牲通用性
- Agent Skills 提供了一种新兴的解决方案
- Skill 是一个结构化的包,包含指令、代码模板、资源和验证逻辑,能在推理时增强智能体行为,无需修改模型本身(Anthropic, 2025a)
- Skills 编码了程序性知识:
- 标准操作流程、领域约定和任务特定的启发式方法,用以指导智能体行为
- 这种模块化方法建立在用于 Temporal Abstraction 的 Option 框架(Sutton,1999)和用于语言智能体的认知架构(2023)之上
- 这反映了成功的计算范式:
- 基础模型:提供基础能力(类似于 CPU)
- 智能体 harnesses 编排器(agent harnesses orchestrate):管理上下文和工具(类似于操作系统)
- Skills 将能力扩展到专业领域(类似于应用程序)
- Skills 生态系统发展迅速,社区仓库现已托管了成千上万个用户贡献的 Skills
- 涵盖了软件工程、数据分析和企业工作流
- Skills 激增,却没有任何基准测试能够系统地评估以下内容:
- Skills 何时以及如何提升智能体性能,哪些内容能带来提升?
- 如何区分有效 Skills 与无效 Skills 的设计原则是什么?
- 本文的主要结果:
- 精心策划的 Skills 在所有 7 种 model-harness 配置中都持续提高了任务解决率
- 自生成的 Skills 带来的益处微乎其微
- 问题不在于 “添加任务相关的上下文是否有帮助”,而在于:
- 与基线增强相比,Skills 的帮助有多大?哪些 Skills 组件(指令、代码、示例)贡献最大?Skills 在什么情况下会失效?
- 现有的智能体基准测试(2023; 2026; 2024; 2025;)评估的是原始模型能力的孤立表现
- 这回答的是 “该模型在任务 \(X\) 上表现如何?”,而不是 “Skills \(Y\) 在任务 \(X\) 上提升了多少性能?”
- 这一空白带来了实际影响:
- 从业者无法就 Skills 的采用做出明智的决策,研究人员也缺乏指导 Skills 设计原则的实证基础
- 本文提出 SkillsBench ,两个核心贡献:
- 1)以 Skills 为中心的(Skills-centric)评估框架
- 本文策划了跨 11 个领域的 84 个任务,每个任务在三种条件下执行(无 Skills、有精心策划的 Skills 和自生成 Skills)
- 同时配有确定性验证器和完整的轨迹日志
- 本文按难度对任务进行分层,并进行了泄漏审计(leakage audits),以确保 Skills 提供的是指导而非解决方案
- 2)实证评估
- 本文评估了 7 种智能体-模型配置,总计 7,308 条轨迹,提供了关于 Skills 有效性、方差和失败模式的系统性证据
- 1)以 Skills 为中心的(Skills-centric)评估框架
SkillsBench
- SkillsBench 基于 Harbor 框架(2026;)构建,每个任务都采用容器化结构
- 环境包含 Agent Skills 和相关数据、一个确定性验证测试以及一个 Oracle 解决方案
- 遵循智能体基准测试的最佳实践(2025; 2026),本文确保了严格的隔离性和确定性验证
- 不同于评估原始模型和智能体 Harness 能力的 TerminalBench
- SkillsBench 引入了一个关键的方法论差异:在原始(无 Skills) 和 Skills 增强 两种条件下评估每个任务,从而能够直接衡量 Skills 的有效性
Skills Specification
- 一个 Skill 是满足四个标准的工件:
- 程序性内容(Procedural content) :包含 “how-to(如何做)” 的指导(流程、工作流、SOP),而非事实检索
- 任务类适用性(Task-class applicability) :适用于一类问题,而非单个实例
- 结构化组件(Structured components) :包含一个
SKILL.md文件以及可选的资源(脚本、模板、示例) - 可移植性(Portability) :Skills 完全基于文件系统 ,因此易于编辑、版本控制、共享,并可在不同的兼容 Skills 的智能体 Harnesses 上使用
- 上述定义明确排除了:
- system prompts:缺乏结构和资源
- few-shot examples:声明性的,非程序性的
- RAG 检索:事实性的,非程序性的
- 工具文档(tool documentation):描述能力,而非流程
- 注:作者提到这个边界并非绝对
- 例如,一个 StackOverflow 的答案可能混合了事实性和程序性内容
- 本文的标准为基准测试的构建提供了操作上的清晰度
- 本文在表 1 中强调了 Skills 与其他增强范式的区别特征
- 在 SkillsBench 中,每个 Skill 都是一个位于
environment/skills/中的模块化包,包含:- SKILL.md :指定如何处理一类任务的自然语言指令,即工作流、标准操作流程或领域约定
- Resources :可执行脚本、代码模板、参考文档或可供智能体调用或参考的示例

Task Specification
- SkillsBench 中的每个任务都是一个自包含的模块,包含四个组件:
- Instruction :一个人类可读的任务描述,指明目标、输入格式和预期输出
- 本文编写的指令让一个知识渊博的人类在没有配套 Skills 的情况下也能解决,尽管 Skills 可能会大大缩短解决时间
- Environment :一个 Docker 容器,包含特定任务的数据文件和一个包含模块化 Skill 包的
skills/子目录- 该容器通过隔离的依赖关系和干净的文件系统状态确保了可复现性
- Solution :一个展示任务可解性的参考实现。这个 Oracle 验证了每个任务至少有一条正确的解决路径
- Verifier :带有程序化断言的确定性测试脚本,在适当情况下包含数值容差
- 这确保了可复现的通过/失败判定,无需使用 LLM 作为评判者,遵循了基于执行的评估最佳实践(2023b; Brown, 2025)
- Instruction :一个人类可读的任务描述,指明目标、输入格式和预期输出
Dataset Construction
- Skills 的表达性和灵活性,以及本文的任务规范,使得能够广泛覆盖不同的领域和问题类型
- 为了最大化这种多样性,本文采用了社区驱动的开源贡献模式:
- 来自学术界和工业界的 105 位贡献者提交了 322 个候选任务
- 本文统计了包含完整任务规范(指令、环境、解决方案和验证器)以及本文评估的难度等级的提交
- 从这个库中,作者筛选出了最终的 SkillsBench 数据集
- 为了最大化这种多样性,本文采用了社区驱动的开源贡献模式:
Contributing Principles
- 贡献者必须满足明确的要求,以确保任务质量并防止“走捷径”:
- 人工撰写的指令(Human-Authored Instructions)
- 任务指令必须由人类撰写,而非语言模型生成
- 本文强制执行这一点,因为 LLM 生成的查询将受限于 LLM 本身的分布,而 LLM 正是本文评估的对象,并且 LLM 生成的查询通常质量低下
- Skill 的通用性(Skill Generality)
- Skills 必须为一类任务提供程序性指导,而非针对特定实例的解决方案
- 指令不得引用应使用哪些 Skills,这意味着智能体必须自主发现并应用 Skills
- 这确保了衡量的是真正的 Skill 利用率,而非指令遵循能力
- 确定性验证(Deterministic Verification)
- 所有成功标准必须能通过程序化断言进行测试
- 以验证所需的最少测试数量为目标,避免因覆盖率不足或冗余测试导致人为的低通过率
- 测试必须包含信息丰富的错误消息,并使用参数化而非重复
- 自动化验证(Automated Validation),每份提交在人工审查前都要经过自动化验证:
- 结构验证 :所需文件存在(
instruction.md,task.toml,solve.sh,test_outputs.py),目录布局正确,TOML/YAML语法有效 - Oracle 执行 :参考解决方案必须达到 100% 的测试通过率
- Oracle 失败的任务将被拒绝
- 指令质量 :指令必须是人工撰写的(本文同时采用人工审查和 GPTZero 审查,并实现了 100% 的人工标注)
- 本文还根据六个标准评估指令(明确的输出路径、结构化的要求、成功标准、列出约束、上下文优先排序)
- 结构验证 :所需文件存在(
- 人工审查(Human Review)
- 自动化检查通过后,维护者会进行手动审查,评估五个标准:
- (1)数据有效性 :输入数据必须反映现实世界的复杂性
- 合成数据或玩具数据将被拒绝,除非有正当理由
- (2)任务真实性 :场景必须反映真实的专业工作流程,避免人为制造难度
- (3)Oracle 质量 :参考解决方案应符合领域专家解决该任务的方式
- (4)Skill 质量 :Skills 必须无错误、内部一致,并且对此基准测试之外类似任务真正有用
- (5)防作弊 :任务必须防止“走捷径”的解决方案(如编辑输入数据、从测试文件中提取答案、利用验证器实现)
- (1)数据有效性 :输入数据必须反映现实世界的复杂性
- 审查员会在多种智能体上,分别在有 Skills 和无 Skills 的情况下运行基准实验,以确认每个任务都能提供关于 Skill 有效性的有意义信号
- 自动化检查通过后,维护者会进行手动审查,评估五个标准:
- 人工撰写的指令(Human-Authored Instructions)
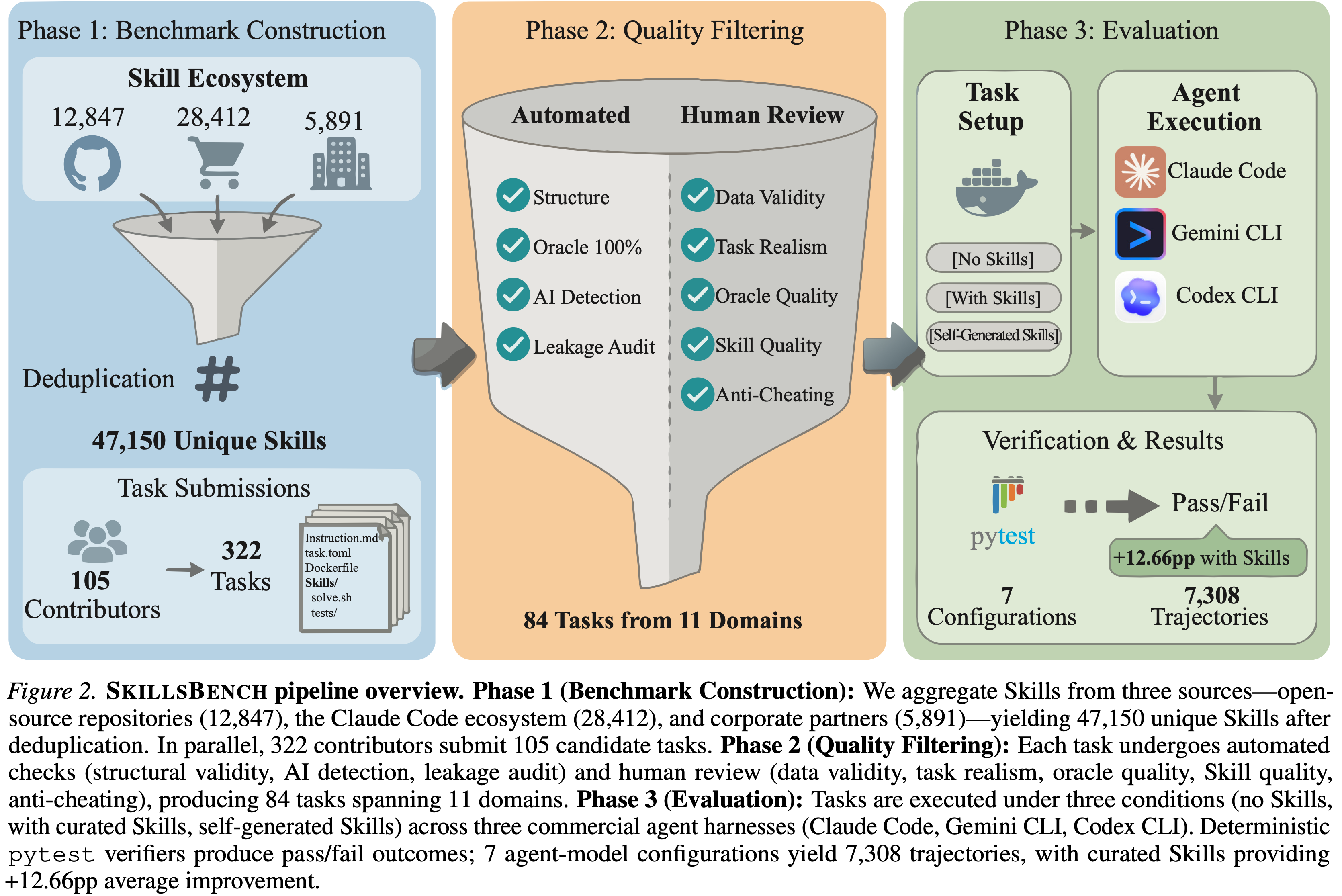
- 图 2 提供了三阶段流程的端到端概览:基准构建、质量过滤和评估
- 第一阶段(基准构建):从三个来源聚合 Skills 去重后得到 47,150 个唯一的 Skills
- 开源仓库(12,847 个)、Claude Code 生态系统(28,412 个)和合作伙伴(5,891 个)
- 322 位贡献者提交了 105 个候选任务
- 第二阶段(质量过滤):每个任务都经过自动化检查(结构有效性、AI 检测、泄漏审计)和人工审查(数据有效性、任务真实性、Oracle 质量、Skill 质量、防作弊),最终产生横跨 11 个领域的 84 个任务
- 第三阶段(评估):任务在三种条件下(无 Skills、有精心策划的 Skills、自生成 Skills)在三个商业智能体 Harnesses(Claude Code、Gemini CLI、Codex CLI)上执行
- 确定性的 pytest 验证器产生通过/失败结果
- 7 种智能体-模型配置共产生了 7,308 条轨迹,精心策划的 Skills 平均提升了 +12.66 个百分点
- 第一阶段(基准构建):从三个来源聚合 Skills 去重后得到 47,150 个唯一的 Skills
Leakage Prevention
- 为防止 Skills 编码特定任务的解决方案,本文强制执行明确的编写指南并进行泄漏审计
- 一个基于 Claude Code Agent SDK 的验证 Agent 会在 CI 中运行,以检测潜在的 Skill-解决方案泄漏;检测失败的任务将被拒绝
- Skills 不得包含:
- 特定任务的文件名、路径或标识符
- 解决基准测试任务的精确命令序列
- 来自任务规范的常量、魔数或值
- 对特定测试用例或预期输出的引用
- Skills 必须应用于一类任务,而非单个实例
- 提供程序性指导(如何做),而非声明性答案(输出什么),且独立于基准规范进行编写
Benchmark Composition
- SkillsBench 包含横跨 11 个领域的 84 个任务,其类别分布如图 3 所示
- 本文根据难度对任务进行分层,难度由本文作者认为的中等水平领域专家在无 AI 工具辅助下的预估完成时间来衡量
- 原始任务贡献者提供了人工时间估计,并由来自相同领域的维护者组成的额外审查员团队进行了复核
Experimental Setup
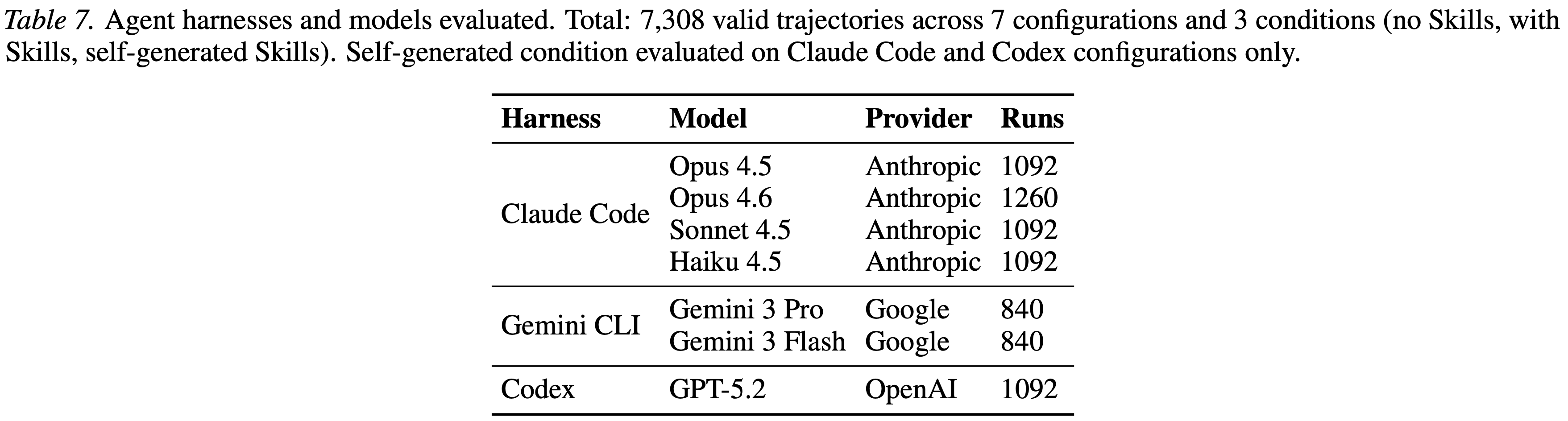
- 本文在 SkillsBench 上评估了三种商业智能体 Harnesses,涵盖七种前沿模型和三种 Skills 条件,最终获得了 7,308 条有效轨迹
- 一条轨迹是有效的定义:
- 智能体在任务上通过、失败或超时,且没有发生基础设施和运行时错误时
- 每条轨迹代表一个智能体在特定 Skills 条件下尝试解决单个任务的一次尝试
Agent Harnesses
- 本文评估了三种商业化的智能体:Claude Code (Anthropic, 2025b)、Codex CLI (OpenAI, 2025) 和 Gemini CLI (Google, 2025)
Models
- 本文选择了七种前沿模型:
- GPT-5.2 (OpenAI)、Claude Opus 4.5、Claude Opus 4.6、Claude Sonnet 4.5、Claude Haiku 4.5 (Anthropic)、Gemini 3 Pro 和 Gemini 3 Flash (Google)
- 所有模型均使用
temperature=0进行确定性采样 - 本文使用每个模型兼容的智能体 Harnesses 进行评估
- Claude Code 运行四种 Claude 模型(Sonnet 4.5, Haiku 4.5, Opus 4.5/4.6)
- Gemini CLI 运行 Gemini 模型(Pro & Flash)
- Codex CLI 运行 GPT-5.2
- 共产生 7 种 Model-harness 配置
- 完整的配置矩阵见表 7
Skills Conditions
- 本文在三种条件下评估每个任务:
- 无 Skills(No Skills) :智能体只收到
instruction.md,环境中没有 Skills - 有 Skills(With Skills) :完整的
environment/skills/目录,包含所有示例、代码片段和资源 - 自生成 Skills(Self-Generated Skills) :未提供 Skills,但提示智能体在解决问题前自行生成相关的程序性知识。这用于分离 LLM 潜在领域知识的影响
- 无 Skills(No Skills) :智能体只收到
- 自生成条件在 7 种配置中的 5 种上进行了评估(所有 Claude Code 模型和 Codex)
- Gemini CLI 不支持此条件
Evaluation Protocol
- 本文将 Skills 作为系统级上下文提供,置于 SkillsBench 的任务指令之前
- 附录 E 中列出了注入格式和上下文管理的详细信息
- 对于每种条件,智能体与容器化环境交互,直到任务完成、超时或达到轮数限制
- 验证器执行确定性断言,产生二元的通过/失败结果
Metrics
- Pass Rate
- 主要指标是通过率,遵循 Terminal-Bench (2026) 的评分方法:
- 对于每个任务,计算 5 次试验中二元奖励的平均值,然后使用固定分母 84(评估任务数)对这些任务级别的分数进行平均
- 主要指标是通过率,遵循 Terminal-Bench (2026) 的评分方法:
- Normalized Gain
- 遵循物理教育研究中的 Hake 公式 (Hake, 1998),将归一化增益定义为:
$$g = \frac{\text{pass}_{\text{skill} } - \text{pass}_{\text{vanilla} } }{1 - \text{pass}_{\text{vanilla} } }$$
- 遵循物理教育研究中的 Hake 公式 (Hake, 1998),将归一化增益定义为:
- Interpreting Normalized Gain
- 归一化增益有已知的局限性:
- 比如:一个在原始条件下得分 90%、有 Skills 时得分 95% 的模型会产生 \(g = 0.5\)
- 这与一个原始条件下得分 10%、有 Skills 时得分 55% 的模型相同
- 这两者代表了不同的现象(天花板效应 vs. 真正的辅助)
- 同时报告绝对提升值 \(\Delta\) 和归一化增益 \(g\),以便进行细致的解读
- 高 \(g\) 配合低 \(\Delta_{\text{abs} }\) 表明存在天花板效应
- 高 \(g\) 配合高 \(\Delta\) 则表明有显著的辅助作用
- 同时报告绝对提升值 \(\Delta\) 和归一化增益 \(g\),以便进行细致的解读
- 本文将“一致的辅助效率”解释为相似的比例提升,而非相同的绝对提升
- 比如:一个在原始条件下得分 90%、有 Skills 时得分 95% 的模型会产生 \(g = 0.5\)
- 归一化增益有已知的局限性:
Results
- 本文结果包含两个方面:
- 1)在 84 个任务上,对 7 种 LLM-Agent 组合进行的三种 Skills 条件下的主要评估
- 2)对 Skills 设计因素的详细分析,包括数量、复杂性和领域效应
Experiment 1: Skills Efficacy Across LLM-Agent Combinations
- 本文评估了预定义的 Skills 和自生成的 Skills 如何影响跨商业 Model-harness 的 Agent 性能
- 在 84 个任务上,对每种配置在三种条件下进行了测试:
- 无 Skills、有预定义的 Skills 和有自生成的 Skills(在支持的情况下)
Main Results
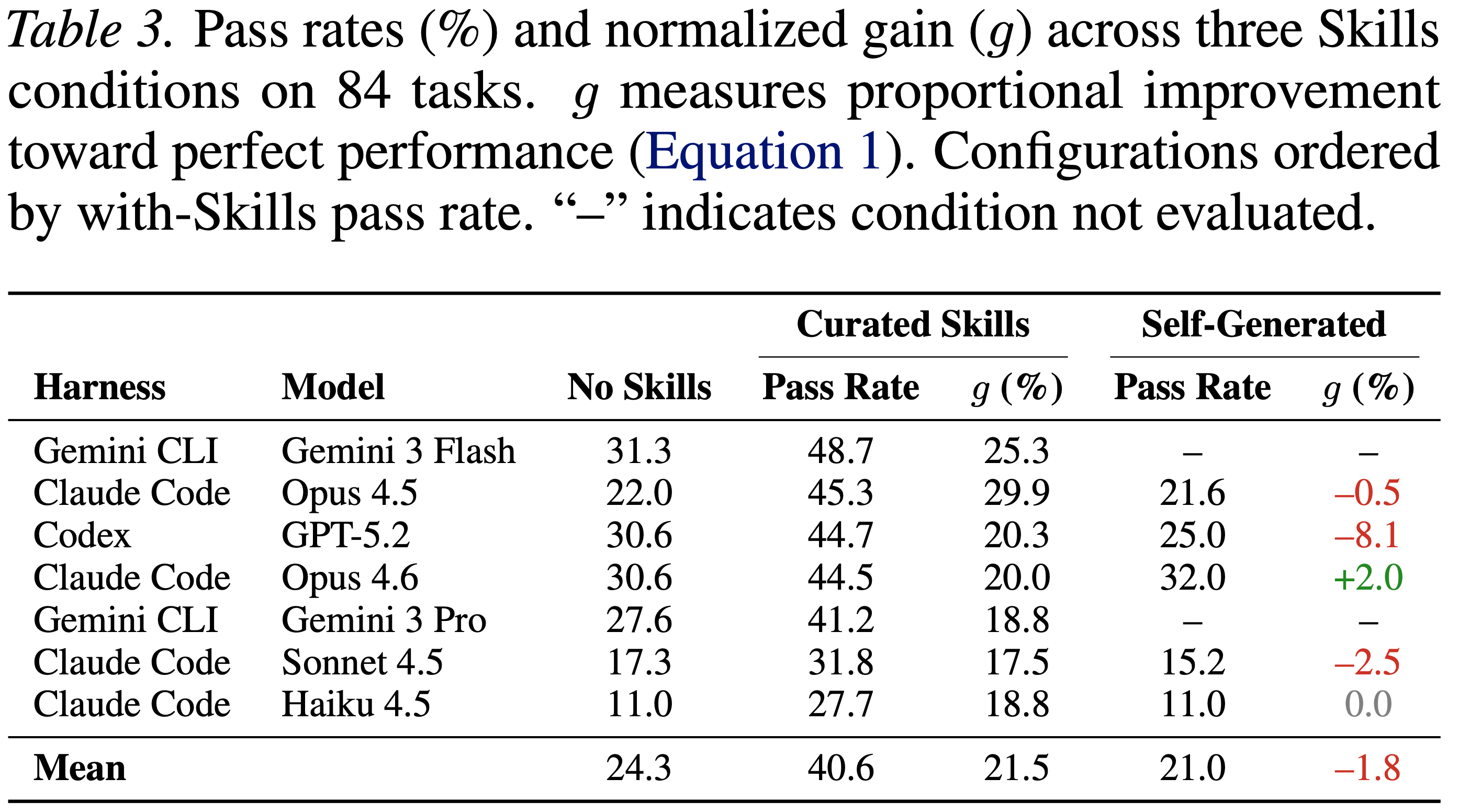
- 表 3 展示了每种 Model-harness 在所有三种条件下的通过率,按有 Skills 时的性能排序
Finding 1: Skills provide substantial but variable benefit,Skills 提供了实质提升,但是具有时效性和且在模型下效果不同
- 在 7 种 Model-harness 上,Skills 平均提高了 +16.2 个百分点,但不同配置之间的方差很大(范围:+13.6 个百分点 到 +23.3 个百分点)
- 这种可变性表明 Skills 的有效性在很大程度上取决于具体的 Agent-模型组合,这与 Skills 益处统一的假设相矛盾
- 注意:本小节标题中的 Variable Benifit 是指这个收益会随着一些环境变化而变化
- 时间变化,Agent-Model 变化
Finding 2: Gemini CLI + Gemini 3 Flash achieves maximum performance,Gemini CLI + Gemini 3 Flash 实现了最大收益
- 表现最好的配置是带有 Gemini 3 Flash 的 Gemini CLI,在有 Skills 的情况下达到了 48.7% 的通过率
- 带有 Opus 4.5 的 Claude Code 实现了最大的提升 (+23.3 个百分点)
- 这反映了 Claude Code (Anthropic, 2025b) 针对 Agent Skills 规范 (Anthropic, 2025a) 优化的原生 Skills 集成
Finding 3: Self-generated Skills provide negligible or negative benefit,自生成的 Skills 几乎没有提供益处
- 当被提示在解决任务之前生成自己的过程知识时,模型与无 Skills 基线相比平均下降了 -1.3 个百分点
- 只有 Opus 4.6 显示出微弱的提升 (+1.4 个百分点)
- Codex \(^+\) GPT-5.2 显著下降 (-5.6 个百分点),其余模型持平或下降
- 这与预定义的 Skills (+16.2 个百分点) 形成鲜明对比,表明有效的 Skills 需要人工策划的领域专业知识,而模型无法可靠地自行生成
- 轨迹分析揭示了两种失败模式:
- (1) 模型识别出需要领域特定知识,但生成了不精确或不完整的过程(例如,列出“使用 pandas 进行数据处理”而没有具体的 API 模式)
- (2) 对于高领域知识任务(制造、金融),模型通常无法识别需要专门的 Skills,而尝试使用通用方法解决
Harness-specific reliability
- 除了 Skills 有效性之外,本文观察到不同商业 Harness 之间的可靠性差异:
- Claude Code : Skills 利用率最高;改进范围从 Opus 4.6 的 +13.9 个百分点到 Opus 4.5 的 +23.3 个百分点,所有 Claude 模型都持续受益
- Gemini CLI : 原始性能最高(Gemini 3 Flash 有 Skills 时达到 48.7%);改进范围从 +13.6 个百分点到 +17.4 个百分点
- Codex CLI : 具有竞争力的原始性能(有 Skills 时为 44.7%);经常忽略提供的 Skills——Agent 会承认 Skills 内容,但通常独立实现解决方案
Domain-level Analysis
Finding 4: Skills benefit varies widely across domains.
- 表 4 按领域展示了 Skills 的有效性,揭示了显著的异质性
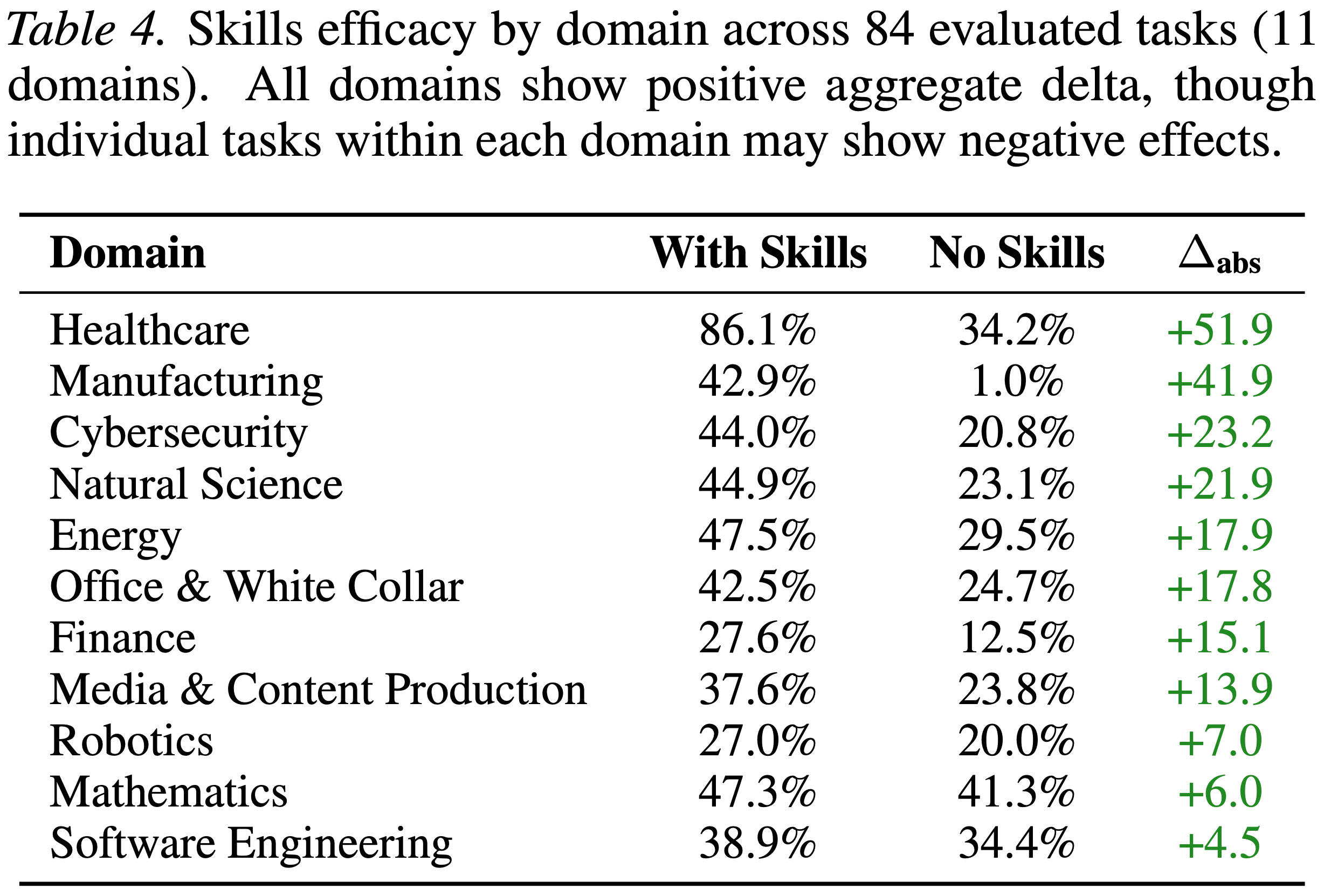
- 医疗保健 (+51.9 个百分点) 和制造业 (+41.9 个百分点) 受益最大,而数学 (+6.0 个百分点) 和软件工程 (+4.5 个百分点) 的提升较小
- 需要模型预训练中代表性不足的专业过程知识的领域(例如,临床数据协调、制造工作流)显示出最大的改进,而预训练覆盖强的领域从外部过程指导中受益较少
Task-level Analysis
- 对 84 个单独任务的分析揭示了 Skills 有效性的高方差:
- Skills 受益最大的任务 (Top Skills beneficiaries) :
- 显示最大改进的任务包括:
- mario-coin-counting (+85.7 个百分点,从 2.9% 到 88.6%)
- sales-pivot-analysis (+85.7 个百分点)
- flood-risk-analysis (+77.1 个百分点)
- sec-financial-report (+74.3 个百分点)
- 这些任务涉及预训练中很少涵盖的专业过程知识
- 显示最大改进的任务包括:
- Skills 损害了某些任务的性能 (Skills hurt performance on some tasks) :
- 尽管领域总体为正,但 84 个任务中有 16 个显示出负的 Skills 增量:
- taxonomy-tree-merge (-39.3 个百分点)
- energy-ac-optimal-power-flow (-14.3 个百分点)
- trend-anomaly-causal-inference (-12.9 个百分点)
- exoplanet-detection-period (-11.4 个百分点)
- 这些失败表明,对于模型已经处理得很好的任务,Skills 可能会引入相互矛盾的指导或不必要的复杂性
- 尽管领域总体为正,但 84 个任务中有 16 个显示出负的 Skills 增量:
- Skills 受益最大的任务 (Top Skills beneficiaries) :
Experiment 2: Skills Design Factors
- 为了理解 Skills 设计如何影响有效性,分析了 Skills 数量、复杂性与性能之间的关系
Skills Quantity Analysis
- 表 5 按提供的 Skills 数量划分的通过率
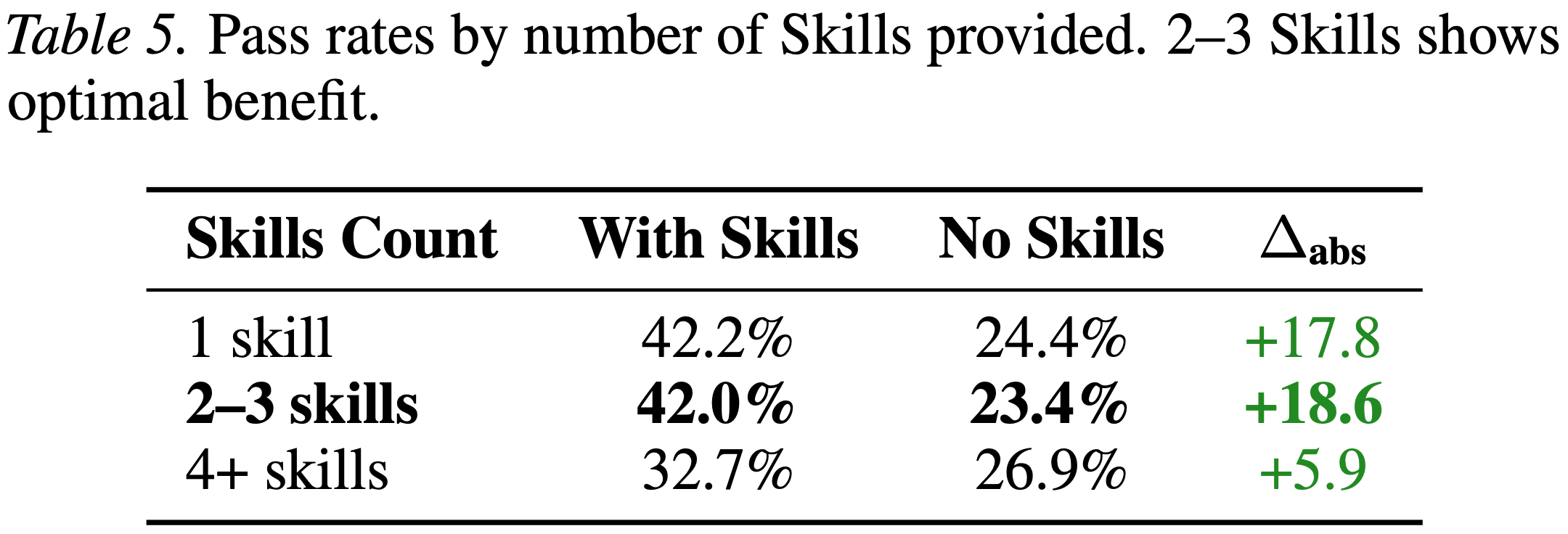
Finding 5: 2–3 Skills are optimal; more Skills show diminishing returns.
- 表 5 显示了按每个任务提供的 Skills 数量分层的性能
- 有 2-3 个 Skills 的任务显示出最大的改进 (+18.6 个百分点),而 \(^{4 + }\) 个 Skills 仅提供了 +5.9 个百分点的益处
- 这种非单调关系表明,过多的 Skills 内容会造成认知负担或相互矛盾的指导
Skills Complexity Analysis,复杂性分析
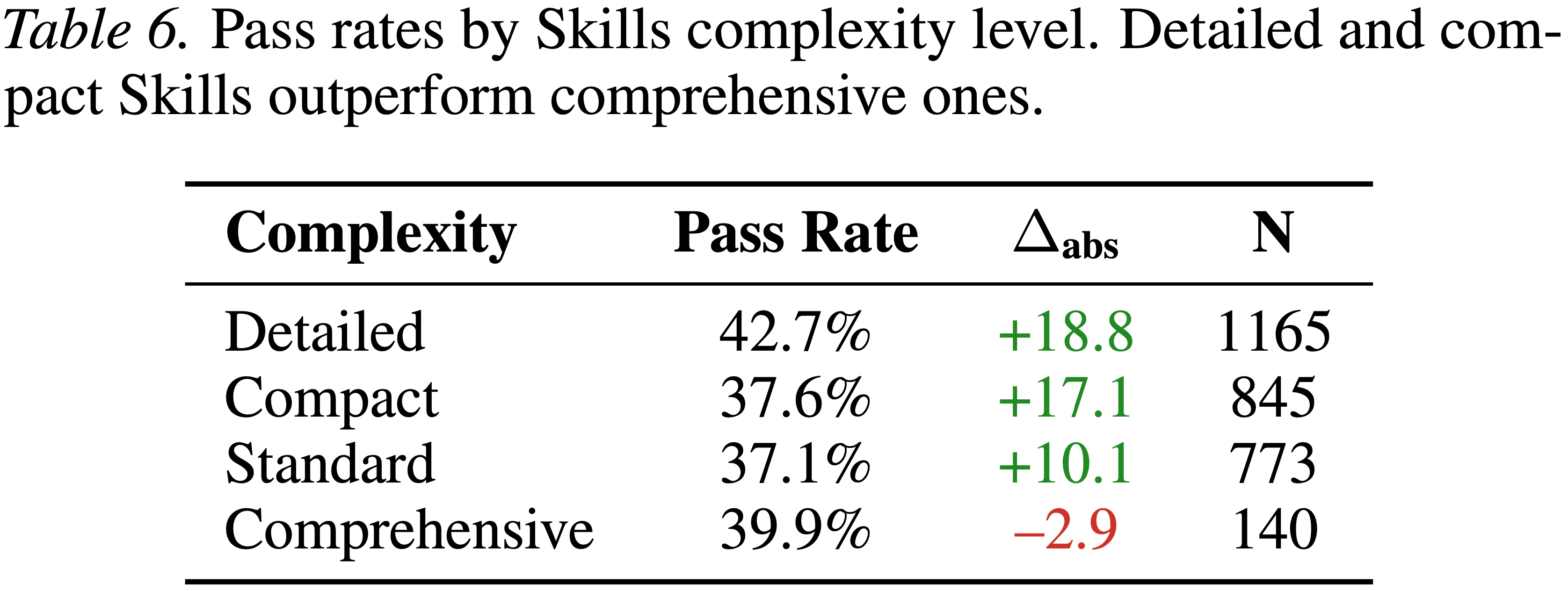
- 表 6. 按 Skills 复杂性级别划分的通过率
- Detailed 和 Compact Skills 优于 Comprehensive Skills
- Detailed 和 Compact Skills 优于 Comprehensive Skills
Finding 6: Moderate-length Skills outperform comprehensive ones,中等长度的 Skills 优于 Comprehensive Skills
- 表 6 中展示了 Skills 文档复杂性对性能的影响
- Detailed (+18.8 个百分点) 和 Compact (+17.1 个百分点) Skills 提升最多
- Comprehensive Skills 损害了性能 (-2.9 个百分点)
- 说明:集中的过程指导比详尽的文档更有效
- 也就是说:Agent 可能难以从冗长的 Skills 内容中提取相关信息,而且过于复杂的 Skills 会消耗上下文预算而不提供可操作的指导
Model Scale Effects,Model 规模效应
- 本节研究基础模型规模在 Claude 模型家族(Opus, Sonnet, Haiku 4.5)中的影响
Finding 7: Smaller model + Skills can exceed larger model without Skills,较小的模型 \(+\) Skills 的组合可以超过没有 Skills 的较大模型
- 带有 Skills 的 Claude Haiku 4.5 (27.7%) 比没有 Skills 的 Haiku (11.0%) 高出 +16.7 个百分点
- 没有 Skills 的 Claude Opus 4.5 达到了 22.0%(低于带 Skills 的 Haiku 4.5 模型的 27.7%)
- 这表明 Skills 可以在一定程度上弥补模型在过程任务上的能力限制
Discussion
Skills close procedural gaps,Skills 弥补了过程差距
- 当成功依赖于具体过程和验证器关注的细节(步骤、约束、合理性检查),而不是广泛的概念知识时,Skills 最有帮助
- 在具有专业工作流程或严格格式的领域观察到巨大收益,而在模型已有强大先验知识且 Skills 增加了开销或冲突时,收益较小甚至为负
Harnesses mediate Skills use,Harness 调节了 Skills 的使用
- Skills 的有效性不仅取决于 Skills 的质量,还取决于 Harness 如何实现 Skills
- 某些 Harness 能够可靠地检索和使用 Skills
- 其他 Harness 虽然经常承认 Skills 内容,但进行下去时却没有调用它们
- 结构化的接口也可能引入长轨迹失败模式(例如,格式漂移),从而降低早期注入的 Skills 的影响
- 本文在多种 Harness 下评估 Skills,而不是将 “有 Skills” 视为单一条件
- Skills 的有效性不仅取决于 Skills 的质量,还取决于 Harness 如何实现 Skills
Implications for Skills authoring,对 Skills 创作的启示
- 本文分析表明,简洁、分步指导加上至少一个工作示例通常比详尽的文档更有效
- 过长的 Skills 定义会增加上下文负担而不会改善决策
- 模块化的 Skills 在多部分任务上似乎也能更好地组合,并且 Skills 应明确匹配 Harness 约束(例如,对于仅 JSON 的协议,重复格式提醒)
- 本文分析表明,简洁、分步指导加上至少一个工作示例通常比详尽的文档更有效
Limitations and Future Work
Coverage and generalization
- SkillsBench 专注于基于终端、容器化的任务以实现可重复评估,因此结果可能无法直接迁移到 GUI Agent、多 Agent 协调或超长时程工作流
- 本文还评估了一组有限的模型和 Harness
- 商业 Harness 的行为和 Skills 集成可能会随时间变化
- 一个自然的扩展是为在 GUI 环境中运行的视觉-语言 Agent 开发多模态 Skills 和协议
Causal attribution and controls,因果归因与控制
- Skills 的注入增加了上下文长度,因此观察到的收益可能部分反映了“更多上下文”而非过程结构
- 本文的自生成 Skills 条件表明结构很重要:
- 即使具有相同的上下文预算,模型暂时无法可靠地产生有效的过程指导
- 注:未来的工作需要更强有力的长度匹配基线(例如,随机/无关文本和仅检索的文档控制)
- 这些基线还可以研究从演示或文档中自动合成 Skills,并隔离哪些 Skills 组成部分(步骤、示例、代码资源)推动了改进
Determinism, contamination, and ecological validity,确定性、数据污染与生态有效性
- 容器化提供了状态隔离,但不能保证完美的确定性或免受训练集泄漏的影响
- 本文通过多次运行、泄漏审计(第 2.4 节)和配对(有 Skills vs. 无 Skills)比较来缓解这些问题,但无法消除所有非确定性或记忆效应
- 未来的工作应在生态代表性设置中进行评估,包括低质量和自动选择的 Skills,并研究 Skills 的组合——当多个 Skills 有帮助或相互干扰时,以及复合性能是否可以由原子 Skills 效应预测
Related Work
- SkillsBench 与之前关于以下方面的工作相联系:
- (1) 对 LLM Agent 进行基准测试
- (2) 用过程知识和工具增强 Agent
- (3) 评估跨异构系统的改进
Agent benchmarks
- 近期的工作评估了在现实环境中的端到端 Agent 能力
- 包括 Terminal-Bench (2026)、SWE-bench 及其后续工作 (2024; 2024; 2025)
- 更广泛的环境覆盖出现在 AgentBench 和交互式/网页/GUI 设置中 (2023; 2024b; 2024; 2024)
- 部分测试集强调工具介导的(Tool-mediated)工作流、交互式执行反馈或领域专业化 (2025; 2024; 2023; 2025; 2024; 2025; 2021; 2025)
- 这些基准测试衡量固定 Agent 完成任务的能力
- 本文:SkillsBench 通过配对评估来衡量增强的有效性
Procedural augmentation and tool use,过程增强 & 工具使用
- 先前的工作通过结构化推理或外部知识来增强 Agent,比如
- CoALA 和 Voyager (2023; 2023a)
- 用于多步问题解决的链式思维和 ReAct (2022; 2022; 2023)
- 检索/工具使用 (2020; 2022; 2023; 2024)
- 声明式优化框架 (2023)
- Skills 结合了过程指导和可执行资源(第 2.1 节)
- 尽管存在多种增强方法,但基准测试很少量化它们实际的影响
Skills ecosystems and evaluation methodology
- Anthropic 的 Agent Skills 和 MCP 规范 (Anthropic, 2025a; 2024) 形式化了 Skill 包和工具连接性
- Agent CLI(Claude Code、Gemini CLI 和 Codex)提供了现实世界的 Harness (Anthropic, 2025b; Google, 2025; OpenAI, 2025)
- SkillsBench 评估了商业 Harness 和基于 Terminal-Bench (2026) 的模型无关 Harness
- 用于分离模型和 Harness 效应
- 更广泛的基准测试激励了仔细的报告和可比性 (2020; 2024; 2023)
- 本文报告了绝对增益和归一化增益 (1998),以比较不同基线下的改进(第 3.5 节)