文本介绍CTR预估模型中的one-epoch现象
- 参考链接:
one-epoch现象是什么?
- 在训练过程中,第二个 epoch 开始,每次 epoch 增加时,模型在测试集上的表现都会变差,即一个 epoch 结束时的模型就是最优模型:
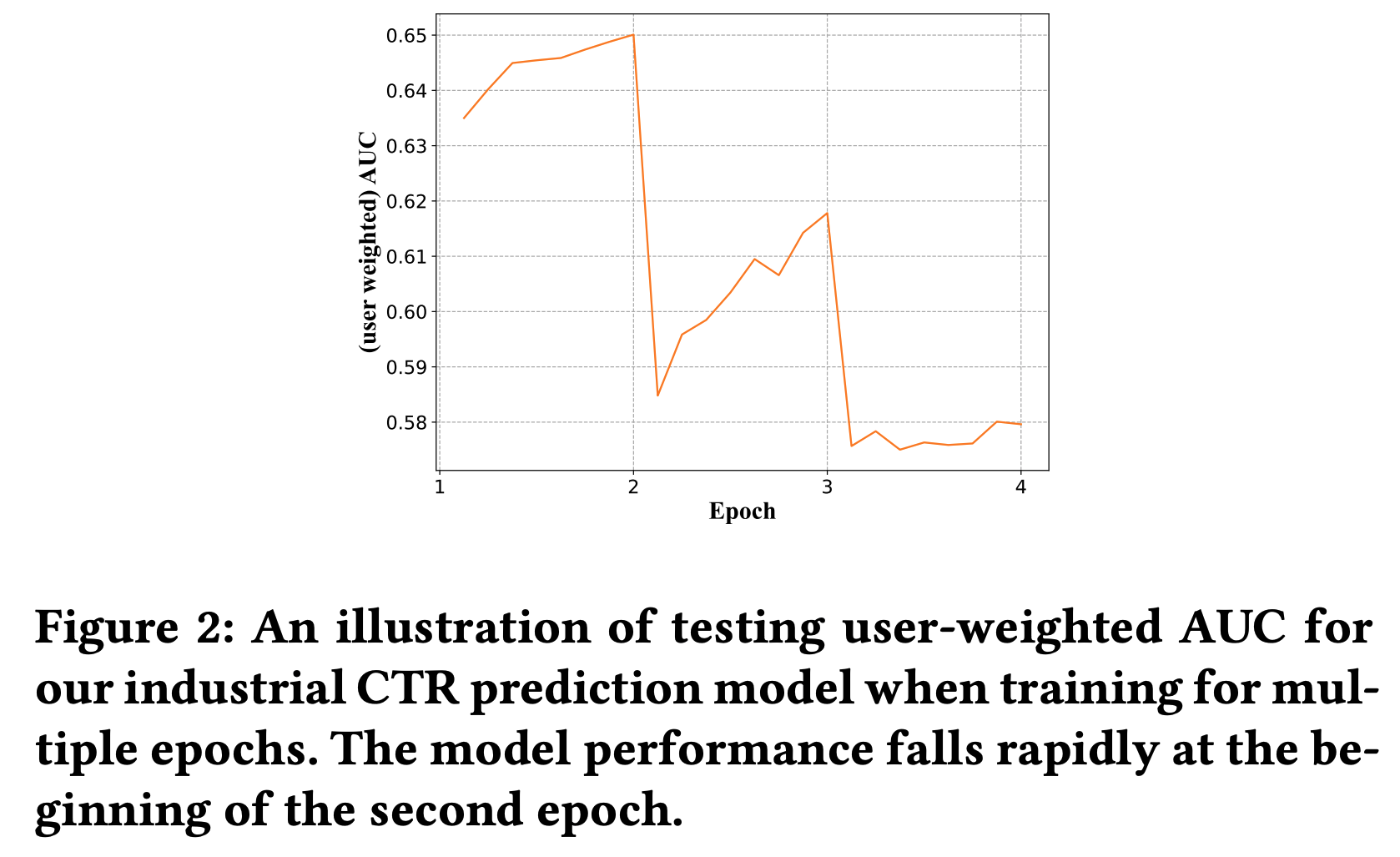

整体说明
- 原始论文并未给出改进机制或方案,只是基于作者的猜想,通过大量的实验大致验证了 one-epoch 过拟合现象的来源(非理论证明)
- 为业内均使用 one-epoch 训练的方案提供了一些指导和解释
发生one-epoch的本质原因
传统的CTR预估模型都是Embedding + MLP的
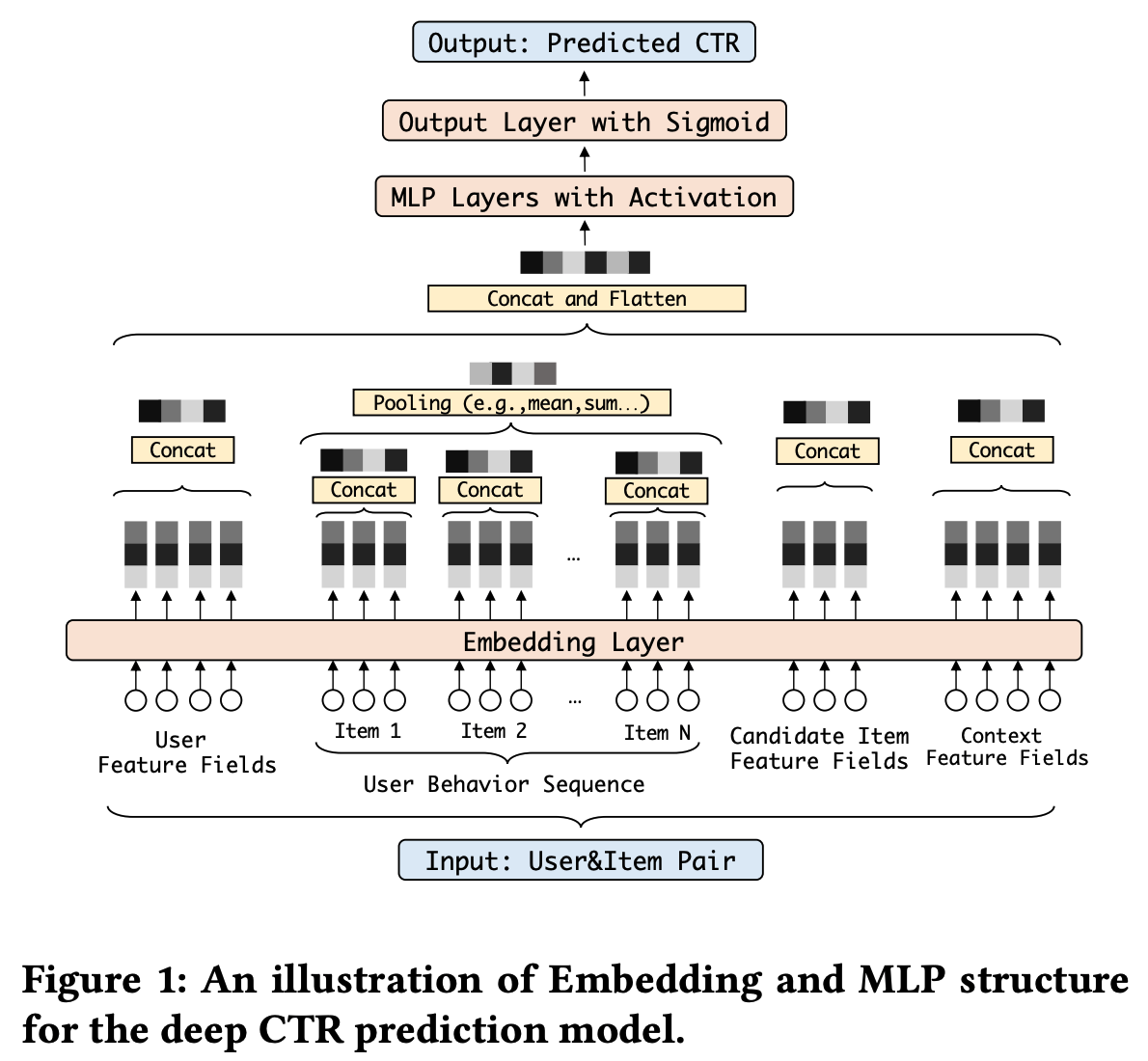
Embedding层:因为 id 类特征一般较为稀疏,一个 epoch 后就变得几乎不再更新了
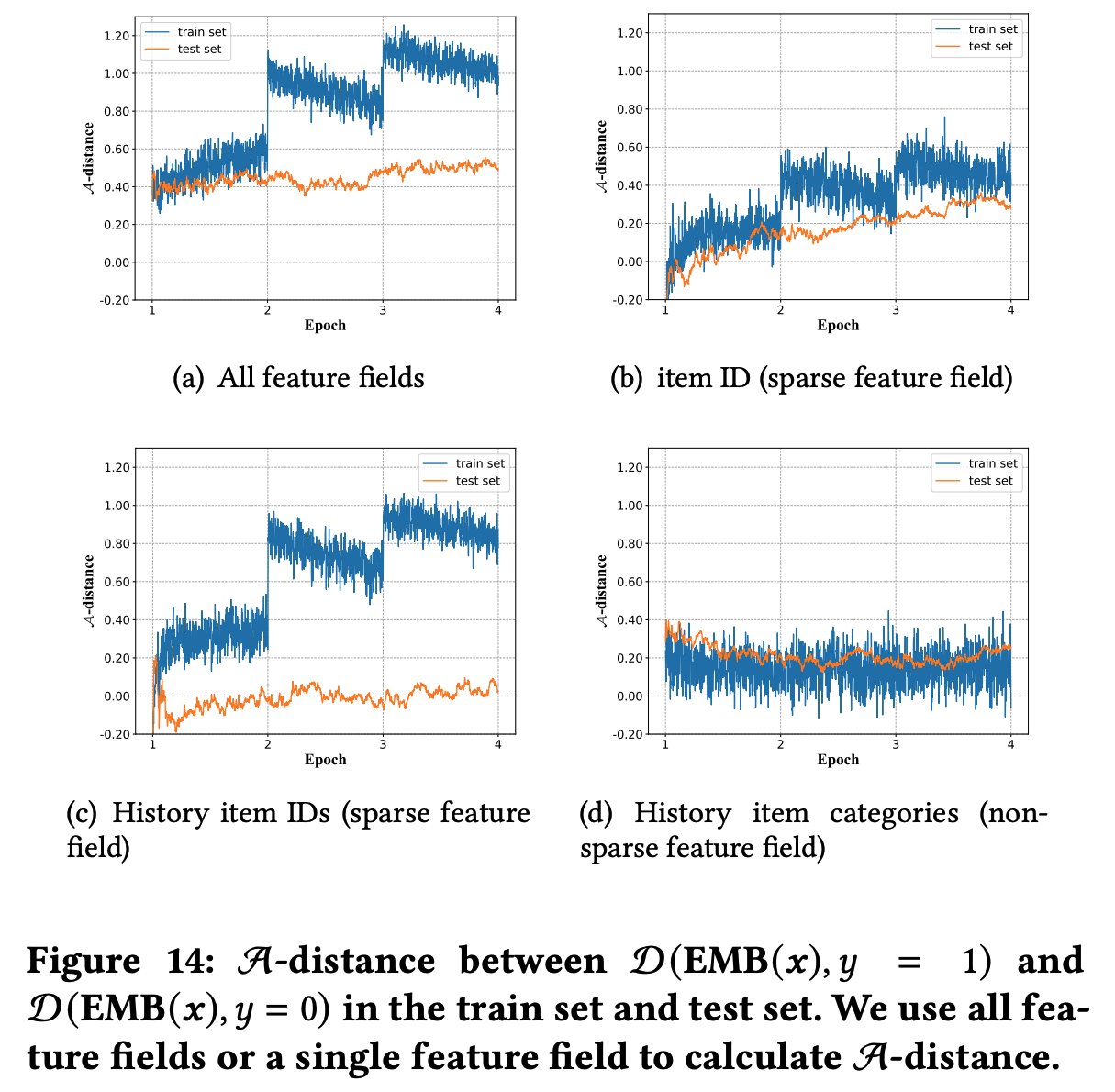
 * 问题:为什么稀疏反而收敛快?甚至一个 epoch 就能收敛
* 回答:文章没有给出详细解释,但个人理解为稀疏和收敛快不一定是严格矛盾的,可能是 Embedding 层参数更容易学习,但从文章给的实验结果看,一个 epoch 后 Embedding 层参数分布确实几乎收敛了
* 问题:为什么稀疏反而收敛快?甚至一个 epoch 就能收敛
* 回答:文章没有给出详细解释,但个人理解为稀疏和收敛快不一定是严格矛盾的,可能是 Embedding 层参数更容易学习,但从文章给的实验结果看,一个 epoch 后 Embedding 层参数分布确实几乎收敛了
MLP层:相当于输入是 Embedding 向量 + Dense 特征的监督学习模型, 第一个 epoch 时需要适配变化的 训练集 Embedding 向量,不会发生过拟合,在第二个 epoch 开始时,由于 Embedding 向量分布不怎么变化,MLP的参数会被突然大幅更新至过拟合当前批次的训练数据
每个 epoch 开始的前半部分 MLP 参数都会剧烈变化一下,此时模型过拟合现象最严重,测试集上评估的效果是最差的
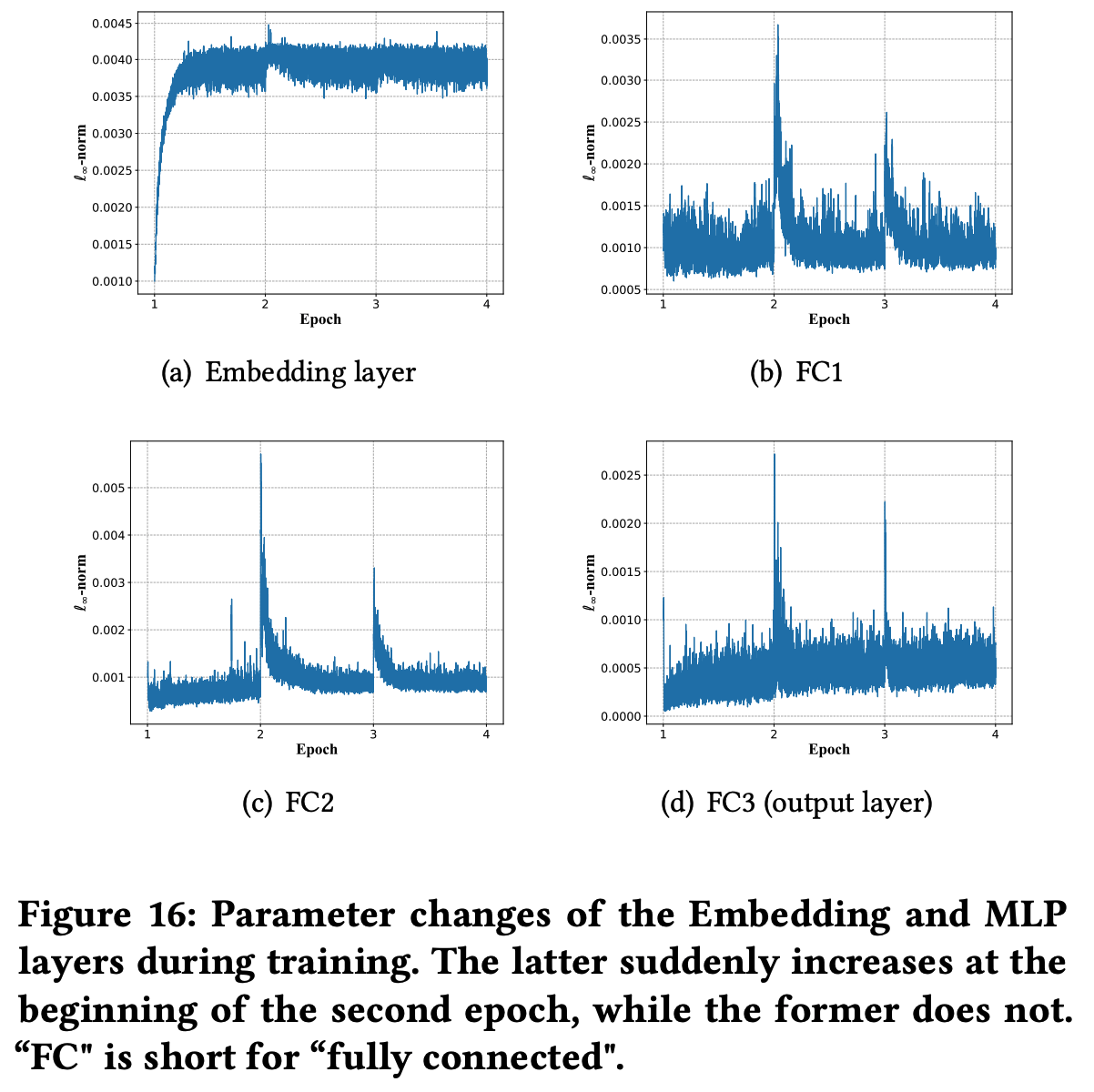
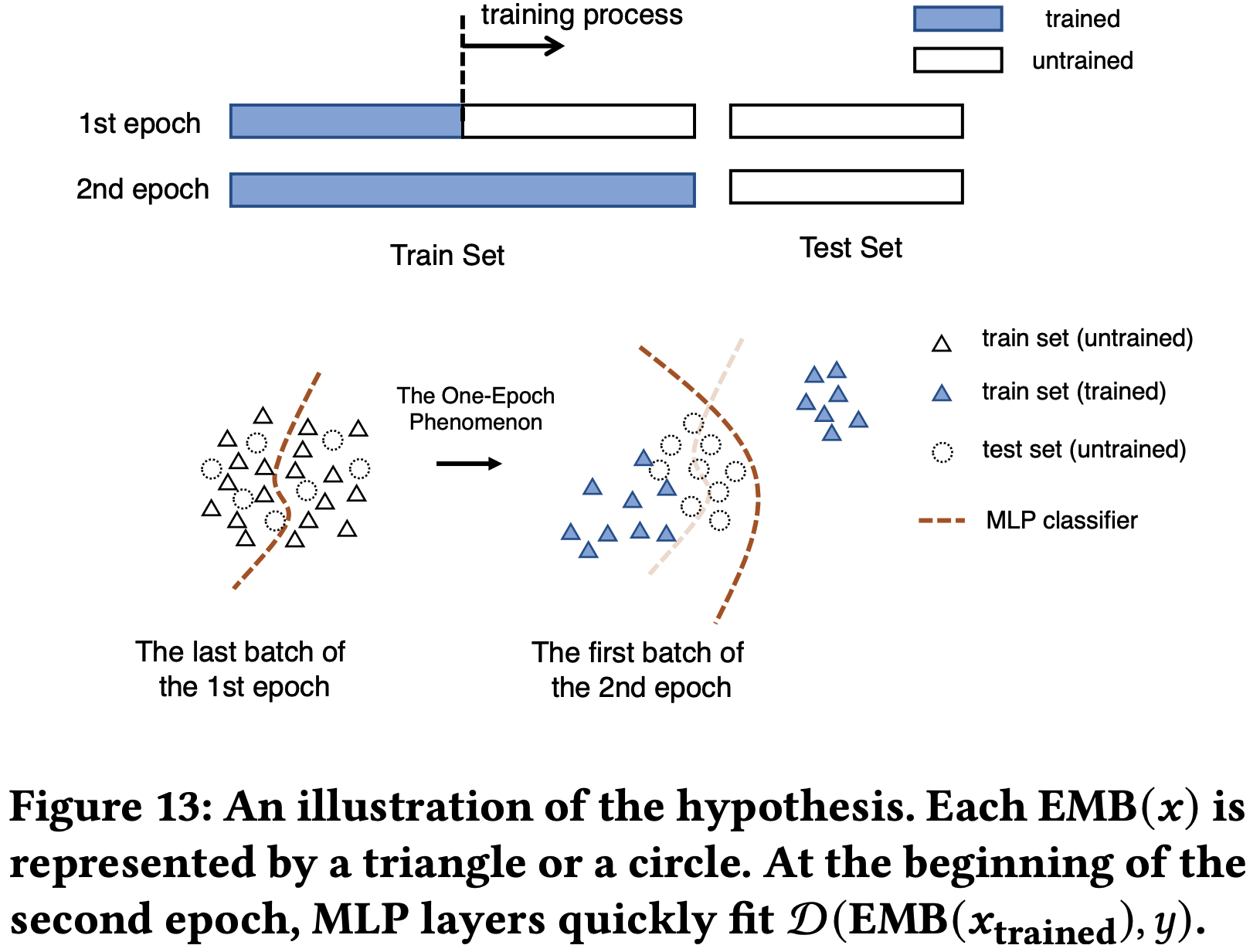
在训练过程中,Embedding层学到了训练集的内容,训练集的分布在训练过程中会发生变化,使得训练集正负样本的 Embedding 距离越来越大,MLP模型要学习的东西越来越容易学习。但测试集正负样本的 Embedding 距离则始终差不多,所以MLP在一个 epoch 后继续训练才很容易进入过拟合
一些其他证明:
- 在一个 epoch 后,分别固定 MLP 和 Embedding 参数,embedding 出现 one-epoch 的状况更弱:
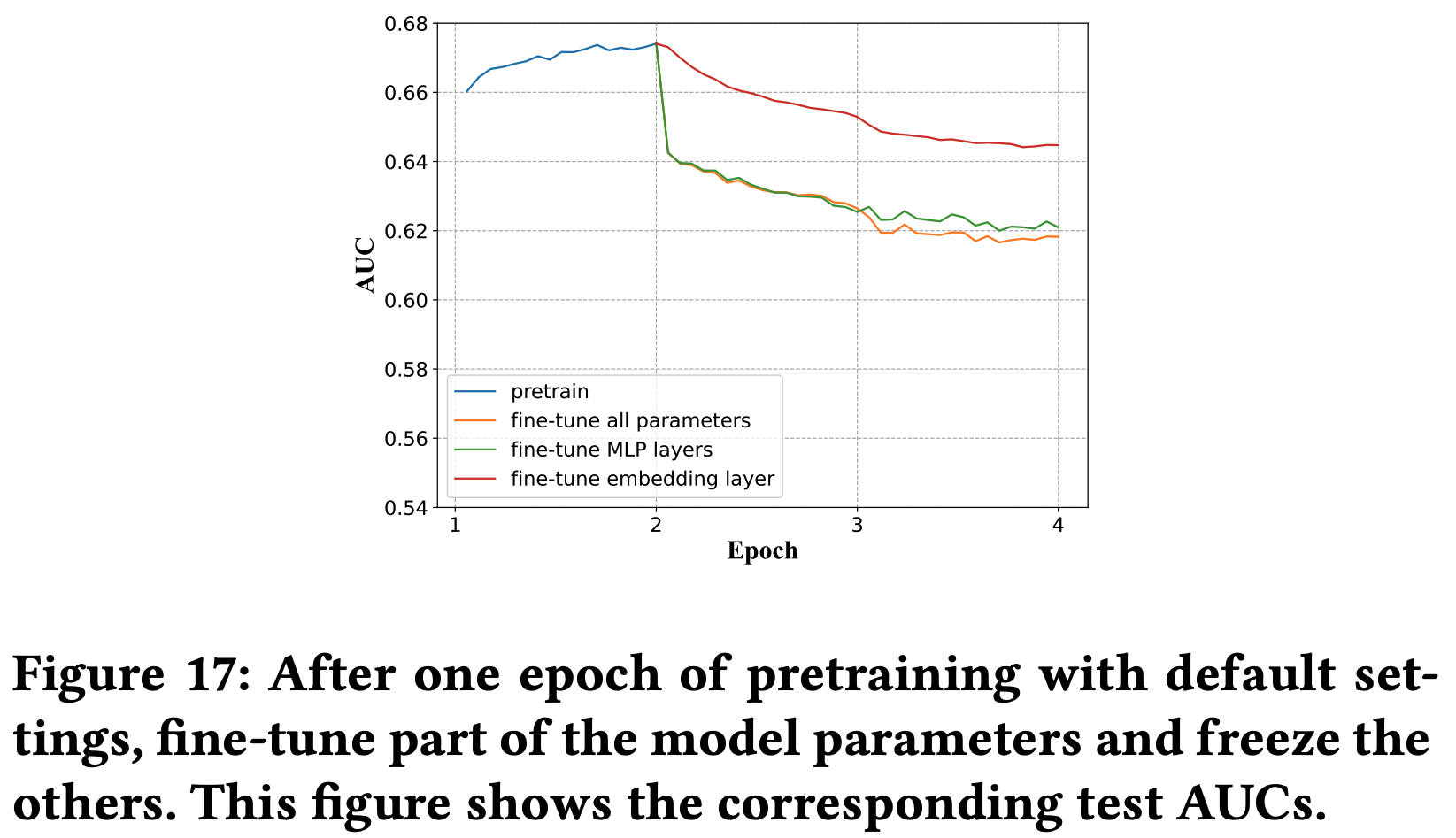
- 在一个 epoch 后,分别固定 MLP 和 Embedding 参数,embedding 出现 one-epoch 的状况更弱:
关键结论
与 one-epoch 现象无关的模型设置:模型参数量、激活函数、batch-size、模型权重衰减(正则化项)、dropout
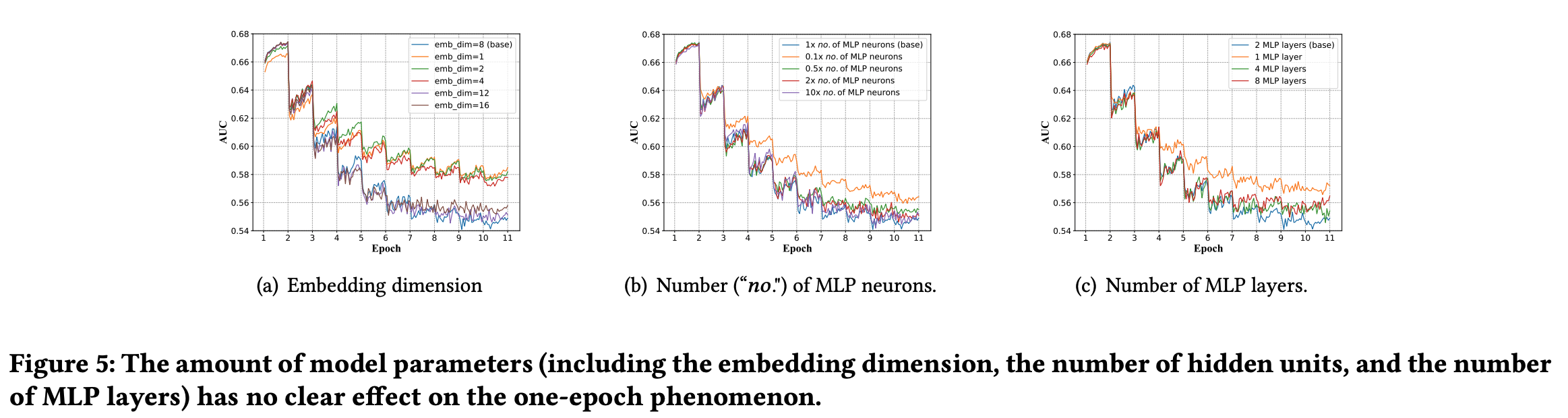
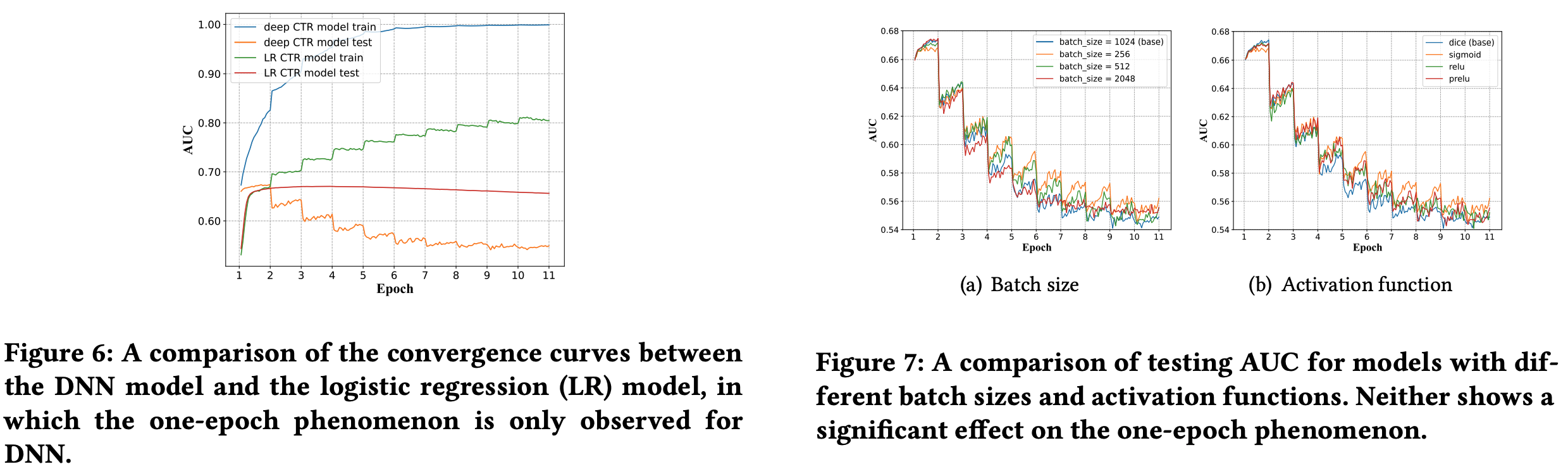
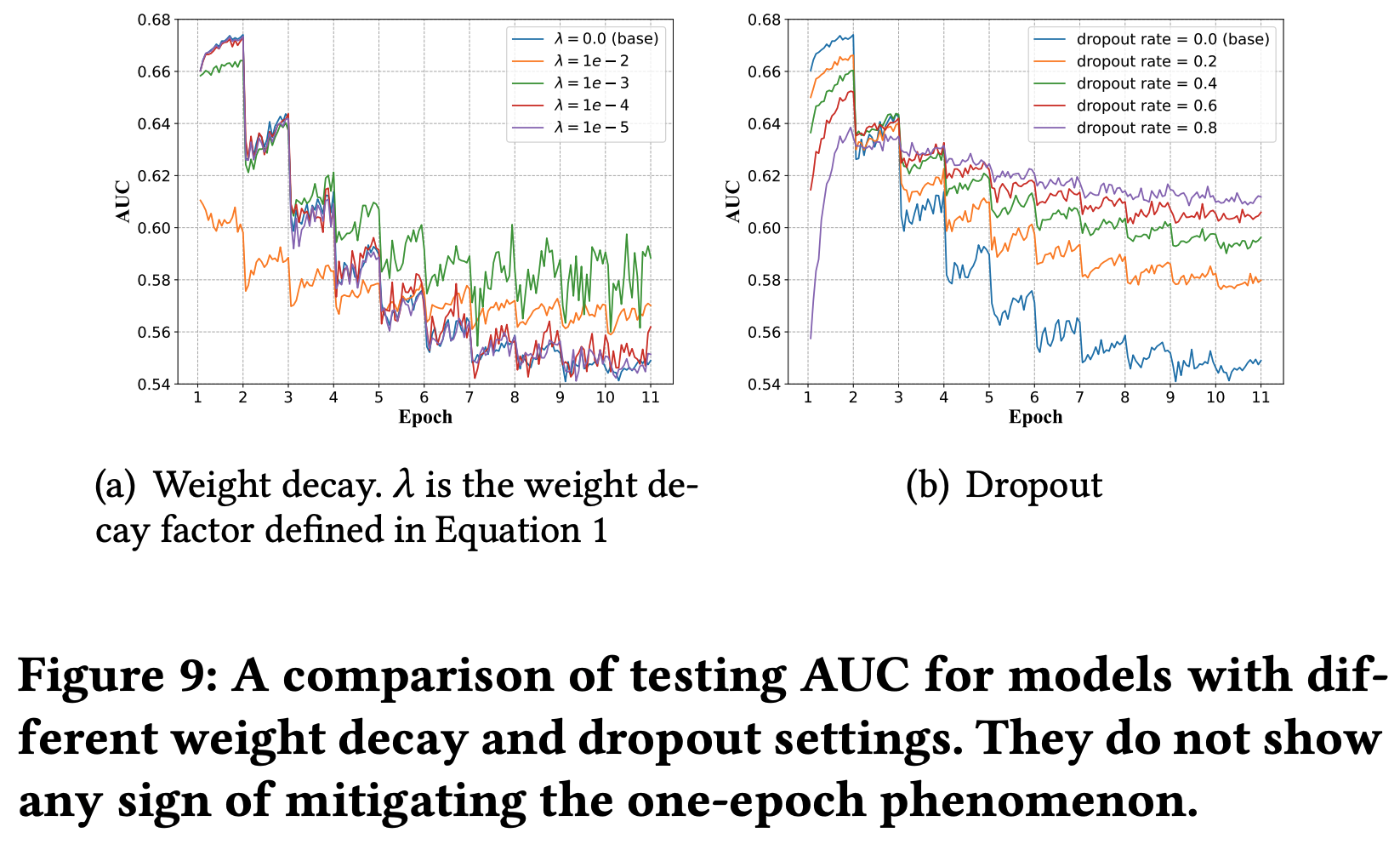
与 one-epoch 现象有关的模型设置:
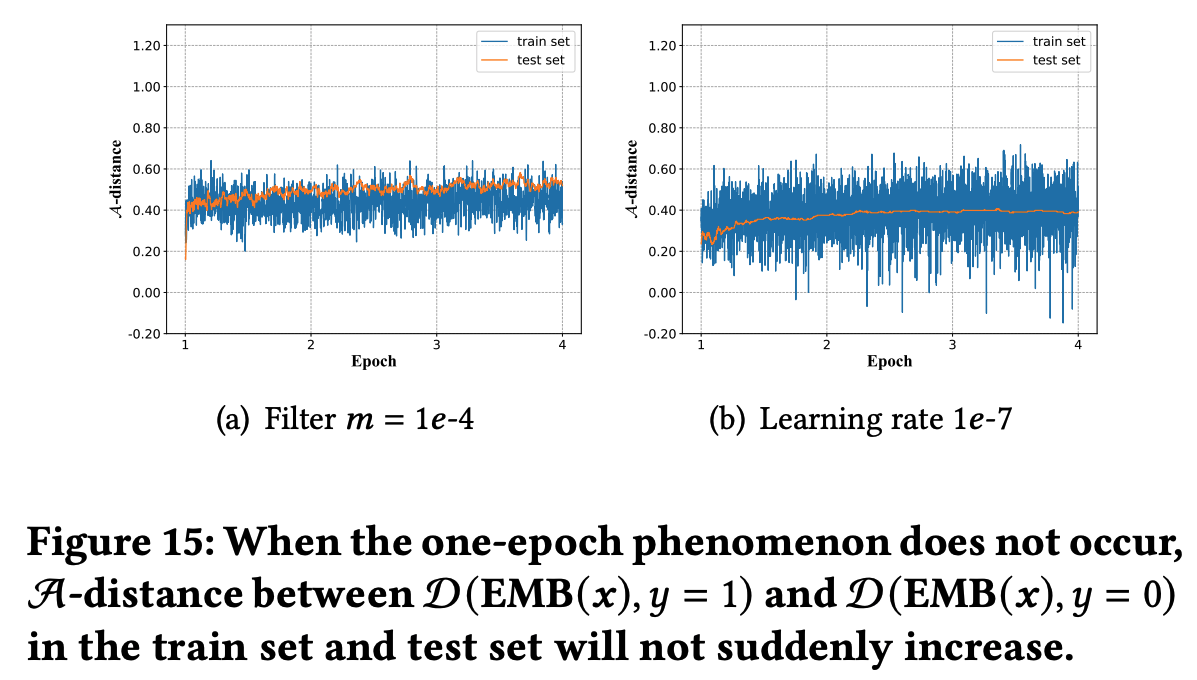
学习率设置 :学习率较大时,也更容易导致 one-epoch 现象,但学习率太小不利于模型学习(理解:容易陷入局部最优)
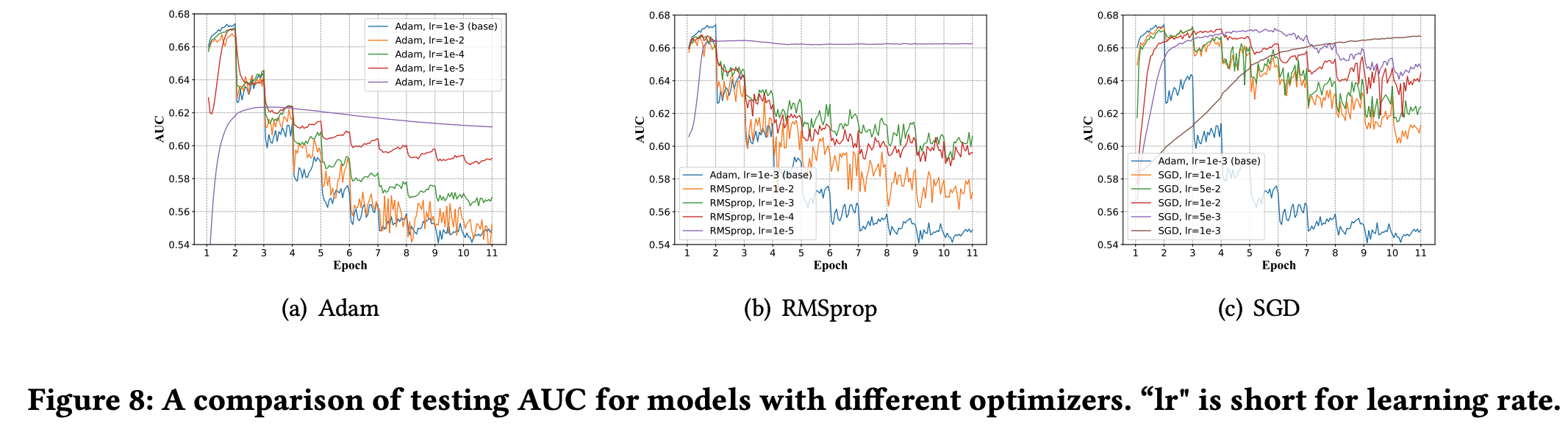
优化器的选择 :收敛速度越快的优化器越容易导致 one-epoch 现象
from 深度点击率预估模型的one-epoch过拟合现象剖析
模型优化器与one-epoch现象有紧密关联。在尝试了Adam、RMSprop、SGD等不同优化器后,我们发现Adam和RMSprop在大多数情况下都有更快的收敛速度,也更容易出现one-epoch现象。我们进一步观察到,学习率也与one-epoch现象也有一定关联。在极小的学习率下,one-epoch现象不太明显甚至完全消失,但模型的精度无法保障。 简言之,能使模型快速收敛的优化器算法也更容易导致one-epoch现象Embedding+MLP结构 :这是发生 one-epoch 现象的本质原因(注LR等传统模型就没有 one-epoch 现象)
即使 Embedding 向量维度为1也会存在 one-epoch 现象
是否有解决方法?
- 虽然可以通过改变优化器和网络结构使得 one-epoch 现象消失,但这会影响最终模型效果:


- 实际上,这个问题不需要解决,训练一个 epoch 就可以了(比如大部分大厂都是 online 训练的)