注:本文包含 AI 辅助创作
Paper Summary
- 论文核心介绍了通过 Early Experience 范式来训练 Agent 的策略
- 提出 Early Experience 作为一种可扩展的、无奖励的范式,在强化学习环境完全准备好之前推进语言智能体
- 通过将智能体自身的动作和结果状态转换为监督,而无需外部奖励信号,论文在八个多样化的环境中取得了一致的增益,涵盖了具身导航、科学实验、长程规划、多轮工具使用和网络导航
- 在此范式下提出的两种方法:隐式世界建模 (implicit world modeling) 和自反思 (self-reflection)
- 这两种方法可以改善领域内的有效性和领域外的鲁棒性(in-domain effectiveness and out-of-domain robustness),并且在用于热启动(warm-start)强化学习时保持了其优势
- 在即将到来的经验时代 (era of experience) 中,作者将 Early Experience 定位为构建更强语言智能体的实用和通用基础(practical and general foundation)
- 思考:
- 论文所谓的隐式世界建模和自反思,侧重于短程轨迹,将这些扩展到解决没有显式奖励的长程信用分配仍然是一个开放的挑战
- 未来的工作将探索(来自原文)
- 方向一:将 Early Experience 与更丰富的自监督目标相结合 ,利用跨环境迁移,并在持续学习设置中将其与基于奖励的微调相集成
- 方向二:研究除了论文提出的两种方法之外的其他 Early Experience 实例
- 论文也希望将该范式扩展到大规模、真实世界的部署中,在那里交互数据被有机地收集并可以驱动策略的持续改进
- 问题提出:语言智能体的一个长期目标是通过自身经验进行学习和改进,最终在复杂的现实世界任务中超越人类
- 但在许多环境中,使用经验数据通过强化学习来训练智能体仍然很困难
- 这些环境要么缺乏可验证的奖励(例如网站),要么需要低效的 Long-horizon 展开(例如多轮工具使用)
- 目前大多数智能体依赖于在专家数据上进行监督微调,这种方法难以扩展且泛化能力差
- 这种局限性源于专家 Demonstrations 的本质:只捕捉了狭窄范围的场景,并且让智能体接触到的环境多样性有限
- 论文通过一种论文称之为 Early Experience 的中间范式来解决这个局限性:
- 由智能体自身行动产生的交互数据,其中产生的未来状态作为监督信号 ,无需奖励信号
- 在这个范式中,论文研究了使用这种数据的两种策略:
- (1) 隐式世界建模(Implicit World Modeling) ,它使用收集到的状态来使策略基于环境动态;
- (2) Self-Reflection ,智能体从其次优行动中学习以改进推理和决策制定
- 论文在八个不同的环境和多个模型系列中进行评估
- 论文的方法持续提高了有效性和领域外泛化能力,突显了 Early Experience 的价值
- 在具有可验证奖励的环境中,论文的结果提供了有希望的信号,表明 Early Experience 为后续的强化学习奠定了坚实的基础,将其定位为模仿学习和完全由经验驱动的智能体(fully experience-driven agents)之间的实用桥梁
- 问题:为什么不试试 IWM 和 Self-Reflection 同时生效的策略?
Introduction and Discussion
- 自主智能体(Autonomous agents) (1995; 1997) 长期以来一直是人工智能的核心目标,旨在无需人工干预的情况下,在复杂环境中感知、行动和学习以完成目标
- 随着语言智能体 (2024;) 的出现,这一愿景正变得越来越现实,这些智能体构建在大语言模型 (2024) 之上
- 凭借从大规模预训练中获得的知识以及语言接口的灵活性,语言智能体现在被应用于广泛的环境中
- 它们可以浏览网站和移动应用程序 (2023; 2024;),控制各种工具 (2024),并辅助科学研究 (2025;),显示出作为下一代智能系统基础的强大潜力
- 构建此类语言智能体 ,一个有前途的解决方案是强化学习 ,即通过优化环境返回的期望累积奖励来训练智能体
- 这种范式使得像 AlphaGo (2016) 这样的传统智能体在具有明确定义环境和奖励结构的领域(如 Atari 游戏 (2013) 和围棋游戏)中实现了超人的性能,呼应了语言智能体新兴的 经验时代 (2025) 的愿景
- 但将强化学习应用于现实世界的语言智能体目前仍然极具挑战性
- 许多感兴趣的环境缺乏可验证或密集的奖励信号 ,特别是在开放式设置中,比如网站,平台不暴露真实反馈
- 例如,一个表单可能看起来提交成功,但智能体没有收到任何关于每条信息是否填写正确的指示
- 此外,多轮工具使用环境中的任务通常涉及长的交互序列 (2025),结果延迟或模糊 ,使得信用分配和训练低效且不稳定
- 许多感兴趣的环境缺乏可验证或密集的奖励信号 ,特别是在开放式设置中,比如网站,平台不暴露真实反馈
- 作为一种变通方法,目前大多数语言智能体转而使用监督微调 (2023; 2025;) 在专家策划的数据上进行训练
- 这种范式通过学习人类 Demonstrations 来规避对奖励信号的需求,智能体使用静态数据集将状态映射到行动
- 虽然监督微调训练起来简单高效,但它有其固有的局限性
- 在此范式下的智能体在训练期间不与环境交互;它不观察自身行动的结果
- 这限制了它从失败中学习、改进其决策制定或泛化到未见情况的能力 (2025)
- 此外,这种方法假设数据是专家或接近最优的,然而扩展高质量的人类 Demonstrations 既昂贵又难以持续
- 更关键的是,它将智能体锁定在一个被动的角色中,受限于其训练数据的想象力和覆盖范围,而不是主动地从自身经验中学习
- 鉴于这些局限性以及前述可靠奖励信号通常不可用,我们遇到了一个问题:如何训练智能体从其自身经验中成长 ,无需任何外部奖励信号呢?
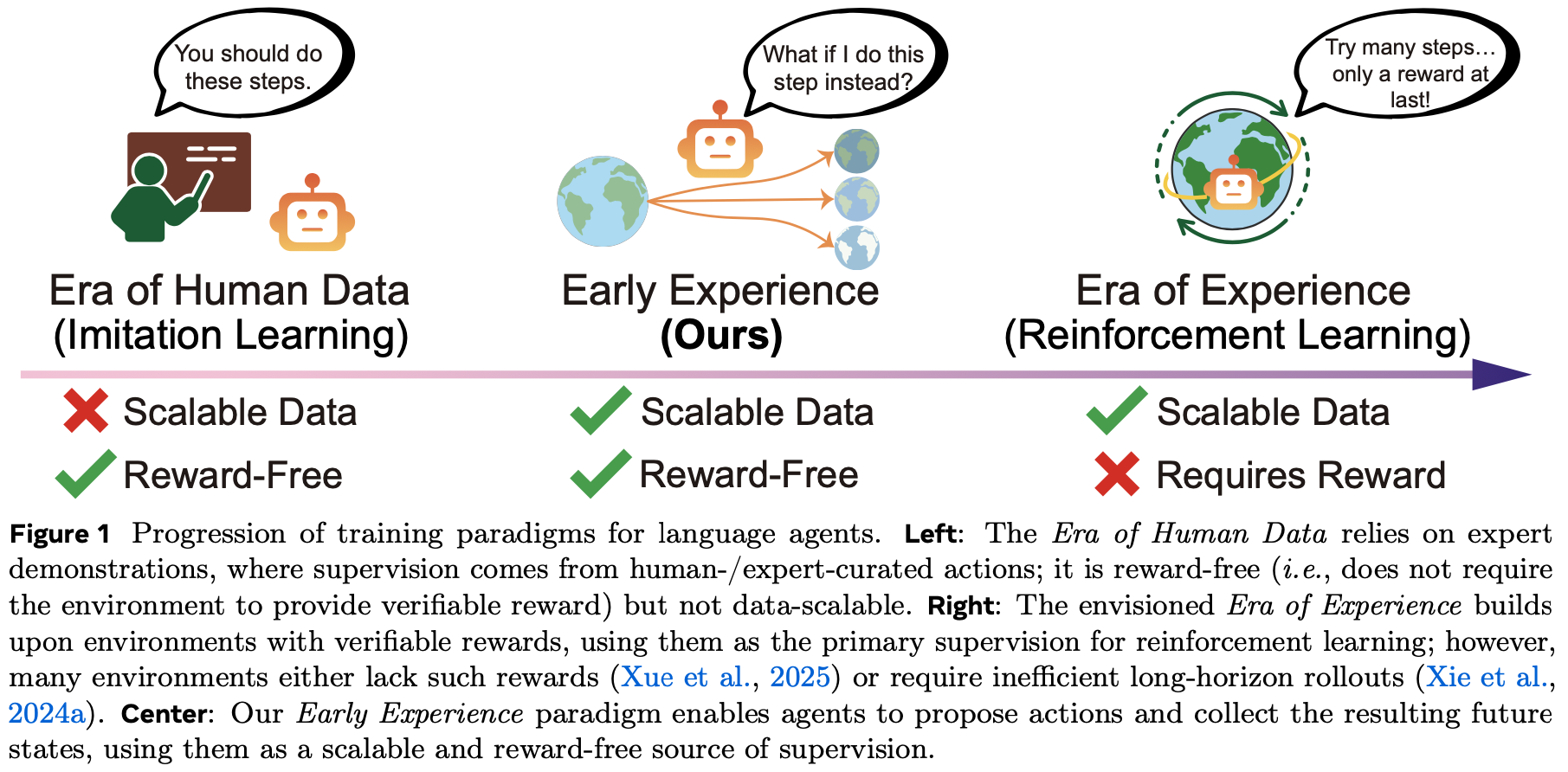
- 受这些局限性启发,论文引入了 Early Experience 范式,作为模仿学习和强化学习之间的中间地带,如图 1 所示
- 在这种设置中,智能体不仅从人类策划的数据中学习,还从其自身在环境中提出的行动所驱动的未来状态中学习
- 这些未来状态是智能体自身的经验,并且可以转化为监督信号,使其能够直接从其行动的后果中成长,而无需依赖外部奖励信号
- 论文探索了两种将这些未来状态转化为监督的策略:
- (1) 隐式世界建模 :使用收集到的未来状态来帮助智能体建立对环境动态的内部表征,使其通过预测未来状态来更好地理解环境
- (2) Self-Reflection :引导智能体将其行为与专家 Demonstrations 进行比较,识别次优决策,并提取经验教训以改进未来的决策制定
- 这两种策略共享相同的原则:在缺乏外部奖励的情况下,智能体自身的行动及其产生的未来状态仍然可以构成经验,作为直接的监督来源
- 通过将由其自身行动产生的未来状态转化为学习信号,语言智能体可以在不依赖额外人类数据或外部奖励的情况下持续改进
- 论文在八个不同的环境中全面评估 Early Experience,涵盖具身导航、网络导航、多轮工具使用、 Long-horizon 规划和多领域 API 任务,并使用多种基础架构
- 在所有设置中,两种方法都一致地优于纯模仿学习基线,在成功率上平均绝对增益为 +9.6 ,在领域外泛化上平均绝对增益为 +9.4
- 此外,在具有可验证奖励的环境中,使用 Early Experience 方法训练的检查点初始化强化学习,与标准的模仿学习热启动相比,能带来显著更强的性能,最终成功率提高了 +6.4
- 这表明 Early Experience 阶段带来的性能增益可以延续到强化学习后最终模型的性能上
- 除了这些经验性收益之外,论文的分析表明, Early Experience 实现了仅通过模仿学习无法获得的能力
- 它能有效扩展,仅用一半甚至更少的专家数据就能达到相当或更优的性能
- 该范式可无缝应用于更大的模型,在不同规模上保持其有效性
- 这些结果表明, Early Experience 不仅仅是模仿学习的替代品,而且是通向强化学习的一个实用且可扩展的桥梁,既带来了有效性的即时收益,也为 经验时代(era of experience) 的训练机制带来了长期益处
- 论文的贡献总结如下:
- (1) 论文倡导并将 Early Experience 范式形式化,作为构建自主语言智能体的模仿学习和强化学习之间的一个实用且可扩展的桥梁
- 它使智能体能够将其自身经验转化为学习信号,而无需依赖外部奖励,并且可以无缝集成到现有的训练流程中
- (2) 论文在此范式下提出并系统研究了两种训练策略:
- 隐式世界建模,通过直接从收集的经验中建模环境动态来增强决策制定;
- Self-Reflection ,从智能体自身行动中提炼细粒度的经验教训
- (3) 论文在八个不同的环境和多个模型系列中进行了全面评估
- 论文的方法持续提高了任务有效性、领域外泛化能力和下游强化学习性能,在多个基准测试中取得了 SOTA 结果,并通过详细分析提供了可行的见解
- (1) 论文倡导并将 Early Experience 范式形式化,作为构建自主语言智能体的模仿学习和强化学习之间的一个实用且可扩展的桥梁
Preliminaries
- 论文将语言智能体决策制定问题形式化为马尔可夫决策过程 (MDP, 1957),这为论文的 Early Experience 范式提供了数学基础
- 论文考虑一个由下面元组 定义的 MDP
$$ \mathcal{M}=(\mathcal{S},\mathcal{A},T,R,\gamma,\rho_{0})$$- 其中 \(\mathcal{S}\) 表示状态空间,\(\mathcal{A}\) 表示行动空间
- 状态转移函数 \(T\colon \mathcal{S}\times \mathcal{A}\to \Delta(\mathcal{S})\) 支配状态动态,其中 \(\Delta(\mathcal{S})\) 表示 \(\mathcal{S}\) 上的概率单纯形
- 奖励函数 \(R\colon \mathcal{S}\times \mathcal{A}\to \mathbb{R}\) 在可用时提供反馈信号,尽管在许多现实世界设置中,此函数在训练期间可能未知或不可验证
- \(\gamma\in [0,1]\) 是折扣因子,\(\rho_{0}\in \Delta(\mathcal{S})\) 指定了初始状态分布
- 在语言智能体环境中:
- 状态 \(s\in \mathcal{S}\) 编码智能体可访问的环境配置,例如网页内容、工具输出或文本环境描述
- 理解:还包括了之前的 所有 Prompt 吧
- 行动 \(a\in \mathcal{A}\) 对应于离散选择,例如点击元素、调用工具或生成文本响应
- 智能体维护一个由 \(\theta\) 参数化的策略,将状态映射到行动分布 (1992):
$$ \pi_{\theta}\colon \mathcal{S}\to \Delta(\mathcal{A}) $$
- 状态 \(s\in \mathcal{S}\) 编码智能体可访问的环境配置,例如网页内容、工具输出或文本环境描述
Learning without Rewards
- 现实世界语言智能体环境中的一个关键挑战是缺乏可靠的奖励信号
- 许多环境要么完全缺乏可验证的奖励,要么仅在长的交互序列之后提供稀疏、延迟的反馈
- 这促使论文从替代的监督源中学习
- 给定一个专家 Demonstrations 数据集
$$ \mathcal{D}_{\text{expert} }=\{(s_{i},a_{i})\}_{i=1}^{N}$$- 其中 \(a_{i}\) 表示在状态 \(s_{i}\) 下的专家行动
- 模仿学习 (1991; 1996; 2017) 旨在最小化监督学习损失:
$$ \mathcal{L}_{\text{IL} }(\theta)=-\sum_{i=1}^{N}\log \pi_{\theta}(a_{i} \mid s_{i}). $$ - 然而,这种方法会遭受分布偏移并且缺乏对行动后果的认知
- 分布偏移的发生是因为智能体学习到的策略 \(\pi_{\theta}\) 在部署时不可避免地会偏离专家策略,导致训练数据未覆盖的状态,其中错误会复合 (2011)
- 智能体缺乏对行动后果的认知,因为它从未观察到当其采取非专家行动时会发生什么;它只看到专家状态-行动对,而没有体验替代选择的后果
- 这限制了其从错误中恢复或推理某些行动为何失败的能力 (2010)
Early Experience
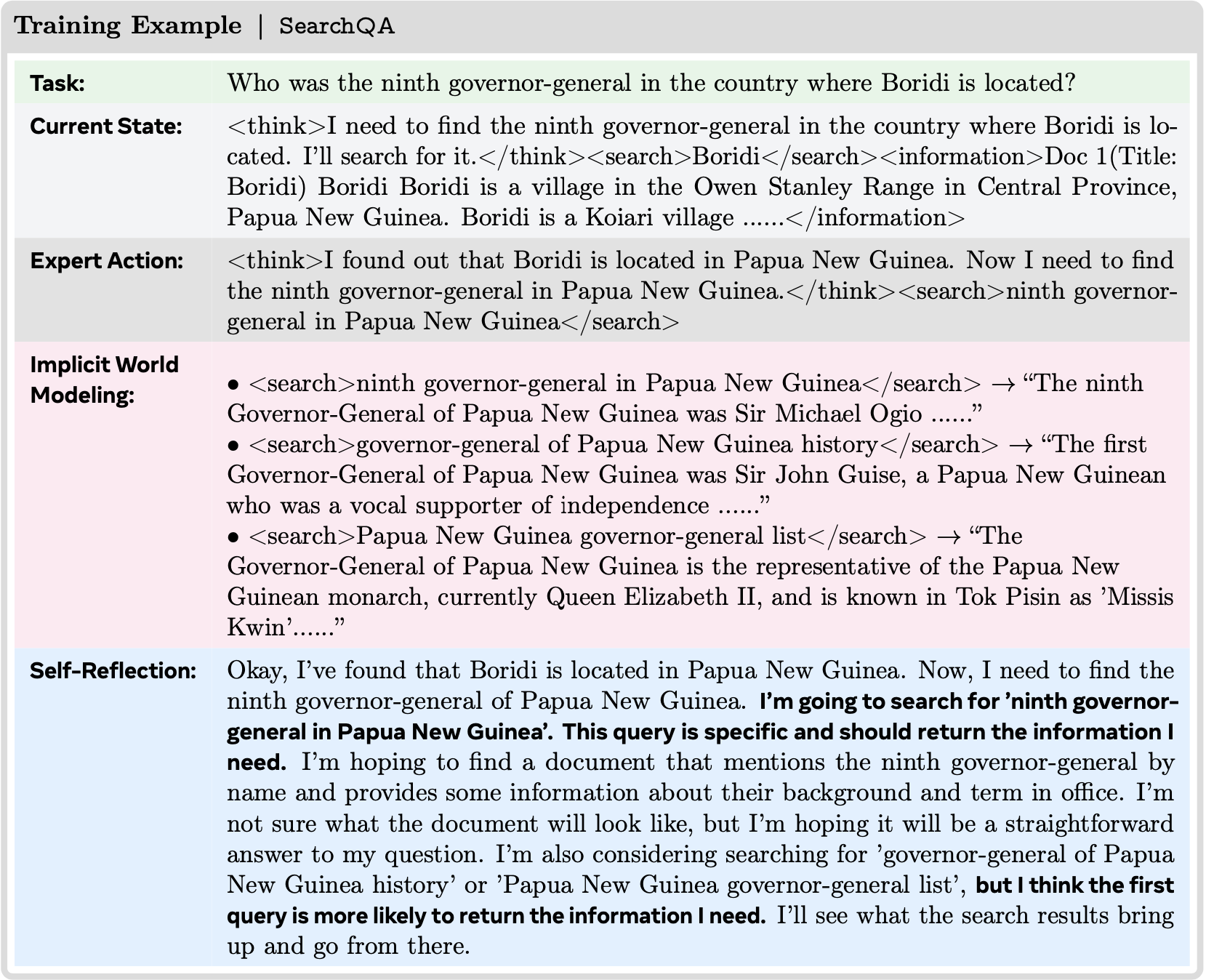
- 论文引入了 Early Experience 范式,在这种范式中,语言智能体通过与环境进行无奖励但信息丰富的未来状态交互来改进
- 为了建立直观理解,考虑一个学习在网络上预订航班的语言智能体
- 在传统的模仿学习中,它只看到成功预订的专家演示
- 而有了 Early Experience ,智能体还会探索当它点击不同的按钮或错误填写表格时会发生什么,观察错误消息、页面变化和其他结果
- 这些观察结果成为了没有显式奖励的学习信号
- 从专家轨迹开始,智能体在每个访问状态提出自己的动作,通过探索(Thrun, 1992)收集额外的环境反馈
Notation for Early Experience
- 对于专家数据集 \(\mathcal{D}_{\text{expert} }=\{(s_{i},a_{i})\}_{i=1}^{N}\) 中的每个专家状态 \(s_{i}\),论文定义一个候选动作集 \(\mathcal{A}_{i}=\{a_{i}^{1},a_{i}^{2},\ldots,a_{i}^{K}\}\),其中论文从初始策略 \(\pi_{\theta}(\cdot \mid s_{i})\) 中采样 \(K\) 个 alternative 动作
- 论文在分析中也包括专家动作 \(a_{i}\)
- 对于专家动作 \(a_{i}\),执行它会跳转到下一个状态 \(s_{i+1}\)
- 对于每个 alternative 动作\(a_{i}^{j}\in \mathcal{A}_{i}\) ,在环境中执行它会从转移函数 \(T(s_{i},a_{i}^{j})\) 中采样得到一个下一个状态 \(s_{i}^{j}\)
- 这些下一个状态捕捉了在状态 \(s_{i}\) 采取动作 \(a_{i}^{j}\) 的直接后果,反映了环境中的变化,例如更新的 DOM 结构、新的工具输出、错误消息或任务进展
- 论文将这些交互收集到一个 rollout 数据集中:
$$\mathcal{D}_{\text{rollout} }=\{(s_{i},a_{i}^{j},s_{i}^{j})\mid i\in[N],j\in[K]\},$$- 其中每个三元组表示一个状态、在该状态采取的一个 alternative 动作以及产生的下一个状态
- 所有 alternative 动作 \(a_{i}^{j}\) 都与专家动作 \(a_{i}\) 不同 ,允许智能体从其自身提出的动作中体验多样化的状态转移
- 这个 rollout 数据集 \(\mathcal{D}_{\text{rollout} }\) 提供了丰富的监督信号,而不需要显式的奖励
- 下一个状态 \(\{s_{i}^{j}\mid j\in[K]\}\) 通过环境响应编码了关于动作质量的隐式反馈,使智能体能够从专家和非专家行为的后果中学习
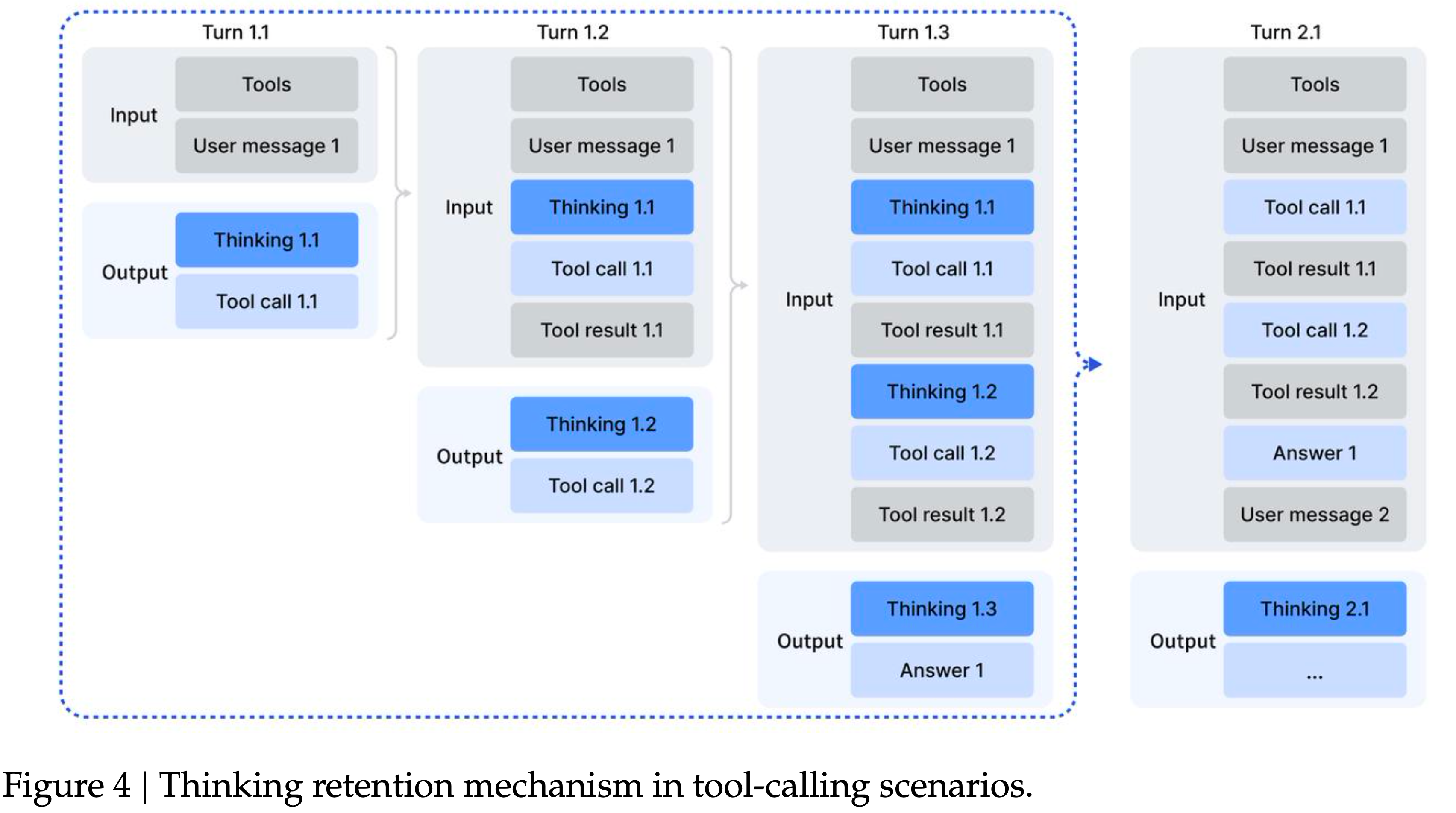
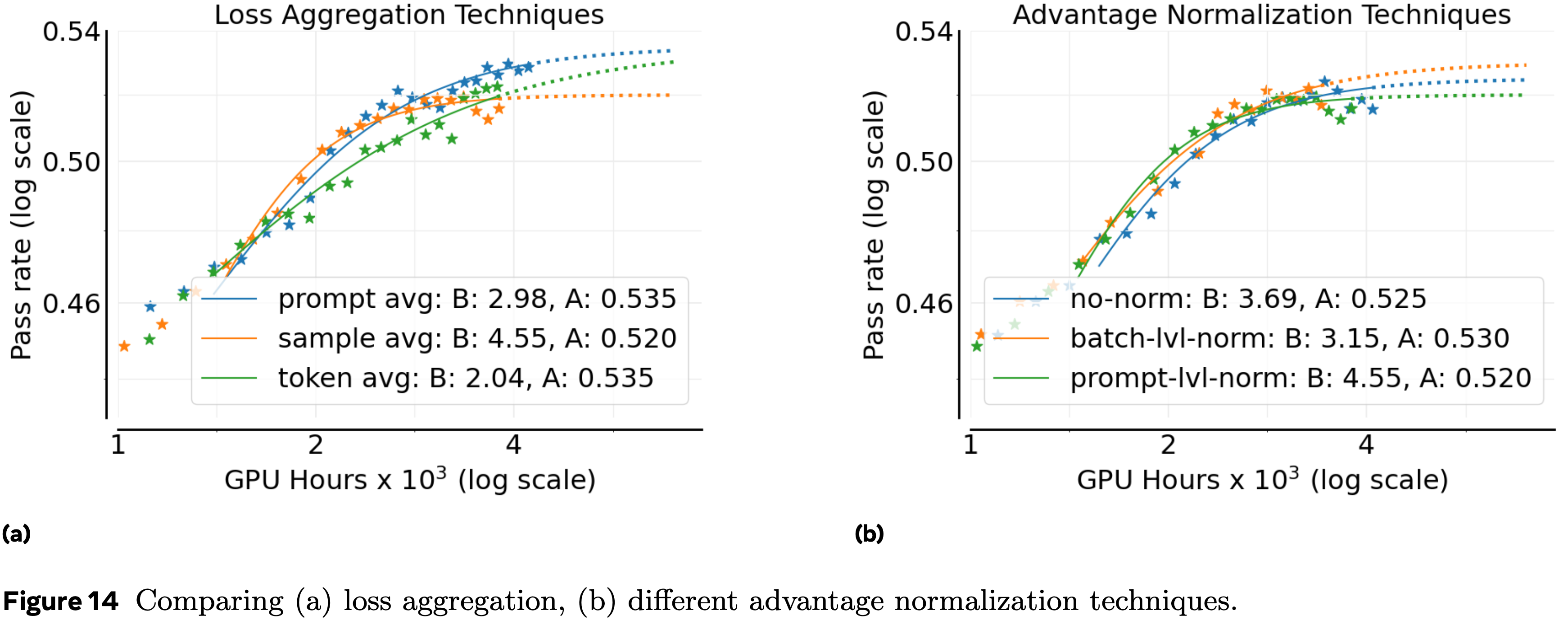
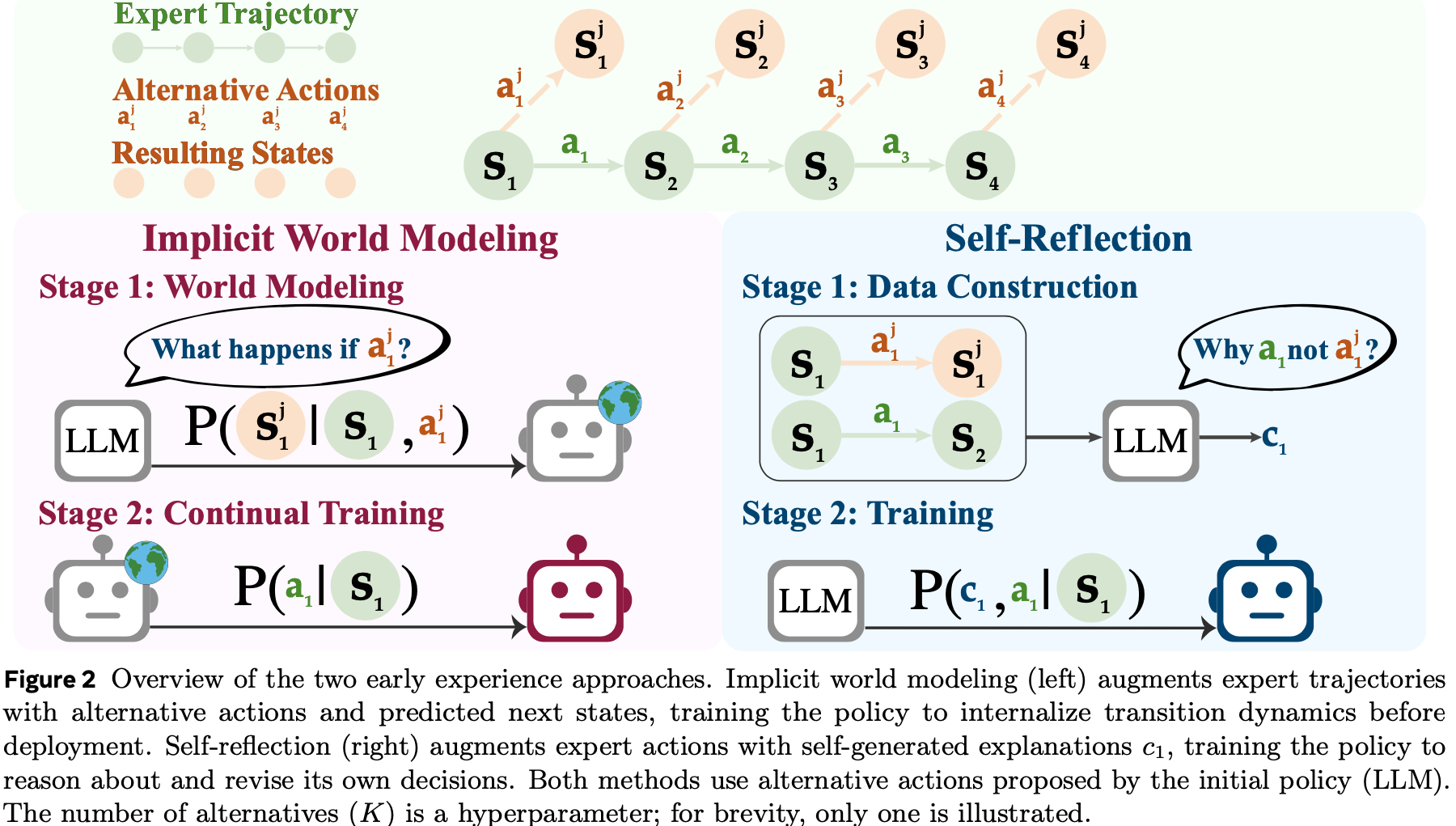
- 图 2:两种 Early Experience 方法的概述
- 隐式世界建模(左)用 alternative 动作和预测的下一个状态增强专家轨迹,在部署前训练策略以内化转移动态
- Self-Reflection(右)用自我生成的解释 \(c_{1}\) 增强专家动作,训练策略对其自身决策进行推理和修正
- 两种方法都使用初始策略(LLM)提出的 alternative 动作
- alternative 动作的数量(\(K\))是一个超参数;为简洁起见,图中仅展示了一个
- 基于第 3 节的符号,论文利用专家数据集 \(\mathcal{D}_{\text{expert} }=\{(s_{i},a_{i})\}_{i=1}^{N}\) 和 rollout 数据集 \(\mathcal{D}_{\text{rollout} }=\{(s_{i},a_{i}^{j},s_{i}^{j})\mid i\in[N],j\in[K]\}\) 来在同一 Early Experience 原则下开发两种不同的训练方法
- 关键的洞见是,由非专家动作产生的下一个状态 \(s_{i}^{j}\) 提供了有价值的监督信号,而无需显式奖励
- 论文现在描述论文的两种 Early Experience 方法如何利用这个数据集
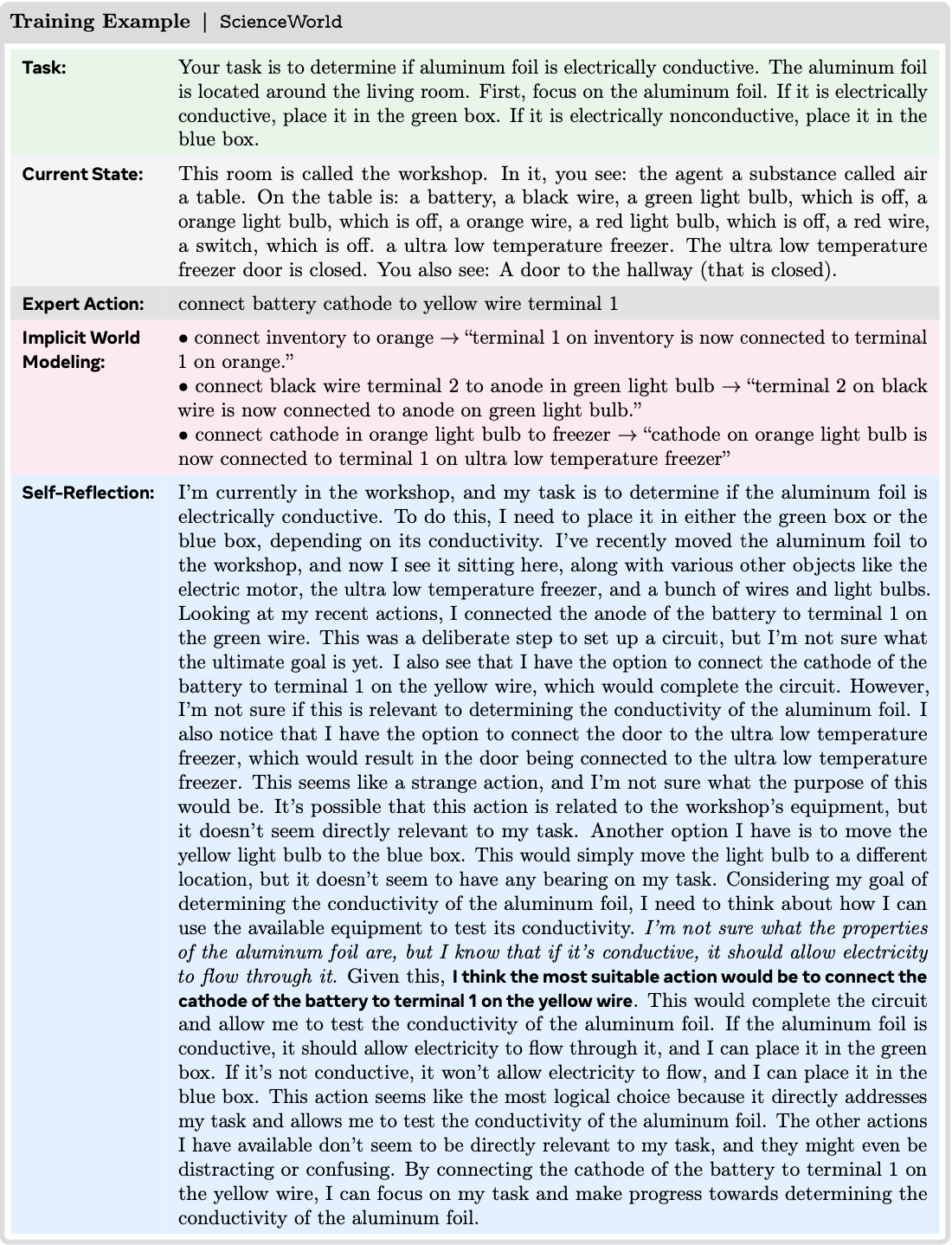
Implicit World Modeling
- 论文将世界建模制定为一个辅助预测任务 ,帮助智能体从其自身的 Early Experience 中内化环境动态
- 在论文的设定中,状态完全用自然语言表示,这允许论文将下一个状态(Next-State)预测建模为一个标准的 Next-Token 预测目标
- 受先前将 LLM 训练为世界模型(2025)的工作启发,论文使用 rollout 集 \(\mathcal{D}_{\text{rollout} }\) 中的下一个状态作为语言智能体策略 \(\pi_{\theta}\) 的直接训练信号
- 例如,在网络上预订航班时,模型可能预测输入无效日期后的页面状态,从作为下一个状态自然语言表示的文本错误消息中学习
- 这种设计移除了对单独模块的需求,并自然地契合了 LLM 微调范式
- 对于每个 rollout 三元组 \((s_{i},a_{i}^{j},s_{i}^{j})\in \mathcal{D}_{\text{rollout} }\),论文构建一个预测任务,其中模型以状态-动作对 \((s_{i},a_{i}^{j})\) 作为输入,并学习预测产生的下一个状态 \(s_{i}^{j}\)
- 论文将训练目标定义为一个 Next-Token 预测损失:
$$\mathcal{L}_{\text{IWM} }=-\sum_{(s_{i},a_{i}^{j},s_{i}^{j})\in \mathcal{D}_{\text{rollout} } }\log p_{\theta}(s_{i}^{j}\mid s_{i},a_{i}^{j}),$$ - 其中 \(p_{\theta}\) 表示语言模型的输出分布
- 注意,论文对状态预测(在世界建模期间)和动作预测(在策略执行期间)使用相同的模型参数 \(\theta\),允许策略直接内化环境动态
- 论文将训练目标定义为一个 Next-Token 预测损失:
- 这个训练目标鼓励模型捕捉环境行为中的规律性,包括常见的转移、副作用和无效动作结果
- 与用于规划的推理时世界模型不同,论文的 隐式 (implicit) 表述将预测信号直接集成到策略学习中,作为监督学习或下游优化之前的轻量级预热
- 它将智能体暴露于多样化的非专家行为中,提高了对分布偏移的鲁棒性,并减少了对脆弱专家轨迹的依赖
- 在实践中, rollout 数据通常比 \(\mathcal{D}_{\text{expert} }\) 大一个数量级
- 论文采用一个两阶段流程 :
- 首先用 \(\mathcal{L}_{\text{IWM} }\) 训练以内化粗略动态
- 然后在 \(\mathcal{D}_{\text{expert} }\) 上微调(即 \(\mathcal{L}_{\text{IL} }\))
Self-Reflection
论文将 Self-Reflection 制定为一种机制,使智能体能够从其自身的探索性结果中学习
智能体不仅仅依赖专家状态-动作对 ,而是在每个状态将专家动作与其策略中采样的 alternative 动作进行比较 ,利用产生的下一个状态生成自然语言解释 ,说明为什么专家选择更好
- 这些解释比单独的专家动作提供了更丰富、可转移的监督,利用了 LLM 在处理语言方面的优势,以内化能够跨任务泛化的决策原则
具体来说
- 对于每个专家状态 \(s_{i}\),论文首先执行专家动作 \(a_{i}\) 以获得专家下一个状态 \(s_{i+1}\)
- 对于每个 alternative 动作 \(a_{i}^{j}\)(其中 \(j\in\{1,…,K\}\))
- 论文先获得相应的下一个状态 \(s_{i}^{j}\)
- 然后提示一个语言模型生成一个思维链 \(c_{i}^{j}\) ,根据其结果状态 \(s_{i+1}\) 和 \(s_{i}^{j}\) 之间的差异,解释为什么专家动作 \(a_{i}\) 优于 alternative 动作\(a_{i}^{j}\)
- 这个提示旨在引发自然语言推理,突出 \(a_{i}^{j}\) 中潜在的局限性或低效性,并以观察到的实际状态转移为基础
- 产生的三元组 \((s_{i},a_{i}^{j},c_{i}^{j})\) 被收集到一个数据集 \(\mathcal{D}_{\text{refl} }\) 中
- 然后论文训练智能体在给定状态 \(s_{i}\) 的条件下 ,联合预测思维链和专家动作 ,使用在连接的目标序列 \(c_{i}^{j}\circ a_{i}\) 上的 Next-Token 预测损失:
$${\cal L}_{\rm SR}=-\sum_{(s_{i},a^{j}_{i},c^{j}_{i})\in{\cal D}_{\rm refl} }\log p_{\theta}(c^{j}_{i},a_{i}\mid s_{i}),$$ - 其中 \(p_{\theta}\) 表示语言模型的输出分布,与智能体的策略 \(\pi_{\theta}\) 对齐
在实践中,论文将 Self-Reflection 数据 \({\cal D}_{\rm refl}\) 与专家数据集 \({\cal D}_{\rm expert}\) 混合 ,并使用标准的 Next-Token 预测损失来训练模型
- 思维链推理仅为 Self-Reflection 训练数据生成 ,并且只要专家轨迹提供了原始的思维链推理,论文就在所有使用 \({\cal D}_{\rm expert}\) 训练的模型中保留它
- 这种联合训练设置平衡了来自演示的 grounded 决策和来自探索性结果的对比性洞见
- 理解:即专家决策和自己的探索性决策之间的对比性不同
This joint training setup balances grounded decision-making from demonstrations with contrastive insights from exploratory outcomes.
- 理解:即专家决策和自己的探索性决策之间的对比性不同
从这两个来源学习鼓励模型超越死记硬背的模仿,并发展出更可泛化的决策标准 ,举个例子来说:
- 在 WebShop 中,当专家动作是“点击 15 美元的蓝色衬衫”时,一个 alternative 动作可能是“点击 30 美元的红色衬衫”
- 生成的反思可能是:“虽然红色衬衫符合颜色偏好,但它超过了查询中指定的 20 美元预算限制。蓝色衬衫既满足了风格要求,也符合预算限制。”
- 这教会了模型优先考虑约束条件,这是一个可以超越这个特定项目的经验教训。论文在下面展示了跨环境使用的提示模板

Self-Reflection 提示模板 (Self-Reflection Prompt Template)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22你将看到一个需要你在多个可能动作之间进行选择的情境。你的任务是分析该情境,并提供关于论文为何决定采取专家动作的推理
* **情境描述 (\\(s_{i}\\)):** {Situation Description}
* **专家动作 (\\(a_{i}\\)):** {Expert Action}
* **预期结果 (\\(s_{i+1}\\)):** {Future State of Expert Action}
* ** alternative 动作(alternative 动作Actions):**
1. 动作 \\(a^{1}\_{i}\\): {Alt Action 1}, 结果状态 \\(s^{1}\_{i}\\): {State 1}
2. 动作 \\(a^{2}\_{i}\\): {Alt Action 2}, 结果状态 \\(s^{2}\_{i}\\): {State 2}
3. ...
提供一个详细的 **Self-Reflection** (self-reflection),作为你对此情境推理过程的 **内心独白** (internal monologue)。你的独白应该:
1. 分析情境和目标
2. 比较可能的动作,解释为什么每个可能不那么优化
3. 证明为什么专家动作最合适,以预期结果为基础
4. 突出情境中任何相关的线索、约束或后果
**指南 (Guidelines):**
* 严格保持在提供的信息范围内
* 避免关于自己是 AI 的元评论
* 使用自然的、逐步的推理
* 专注于逻辑决策
**输出 (Output):** 直接写出 Self-Reflection 独白,不要额外的标题、免责声明或外部注释隐式世界建模和 Self-Reflection 都遵循相同的原则 :
- 将智能体自身的动作和产生的未来状态转化为可扩展的监督,从而实现更可泛化的 语言智能体 策略
Experiments
- 论文通过在此范式中提出的两种方法,在一套多样化的语言智能体环境中评估 Early Experience 范式,测试其有效性(第 5.2 节)、领域外泛化能力(第 5.3 节)以及与事后强化学习的兼容性(第 5.4 节)
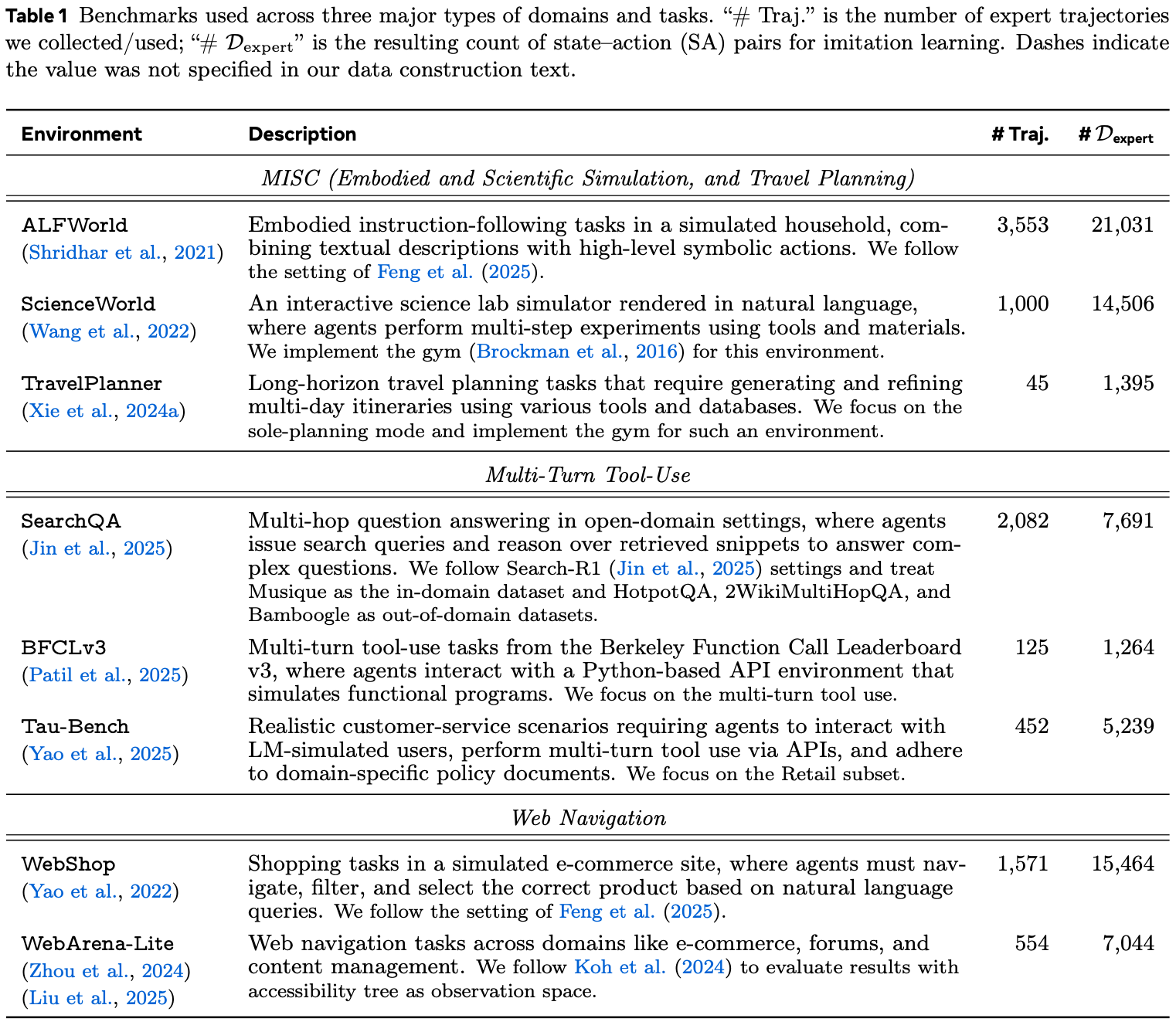
- 表 1:跨三个主要领域和任务类型使用的基准
- “# Traj.” 是论文收集/使用的专家轨迹数量;
- “# \(\mathcal{D}_{\text{expert} }\)” 是用于模仿学习的状态-动作(SA)对的结果计数
- 破折号表示该值在论文的数据构建文本中未指定
Experiment Setup
- 环境 (Environments)
- 论文在八个语言智能体环境上进行实验,涵盖了广泛的领域和任务格式,包括多轮工具使用 (2025; 2025; 2025)、网络导航 (2022; 2024)、具身模拟 (2021)、科学模拟 (2022) 和 Long-horizon 规划 (2024a)
- 这些基准的详细信息列于表 1,更多细节可在附录 B 中找到
- 模型和专家轨迹 (Models and Expert Trajectories)
- 论文使用来自两个模型系列的三个经过指令调优的模型来评估 Early Experience :
- Llama-3.2-3B、Qwen-2.5-7B 和 Llama-3.1-8B
- 无论是否使用 Early Experience 增强,每个模型都在固定数量的专家演示上进行训练
- 这些演示来自跨环境的不同来源
- 更多细节在附录 B 中提供
- 论文使用来自两个模型系列的三个经过指令调优的模型来评估 Early Experience :
- 训练和评估 (Training and Evaluation)
- 论文在所有设置中使用一致的提示格式和解码策略
- 由于环境在数据大小和视野上有所不同,论文做了以下工作:
- 首先为每个环境探索模仿学习基线的优化步数 ,并选择在验证集上具有最低训练损失和最佳性能的检查点
- 然后固定这个步数预算 ,并在论文的方法中保持不变地使用它以确保公平比较
- 对于隐式世界建模 ,论文从 WM 目标的一个 Epoch 开始 ,然后继续进行监督更新 ,使得总更新次数等于模仿预算 ,没有额外的步骤
- 对于 Self-Reflection ,论文训练与模仿学习相同数量的 Epoch
- 所有实验在训练和评估时最多使用 8 个 H100 GPU
- 在评估方面,论文报告每个基准的主要原生指标,并遵循其官方验证器。完整的评估结果请参考附录 B
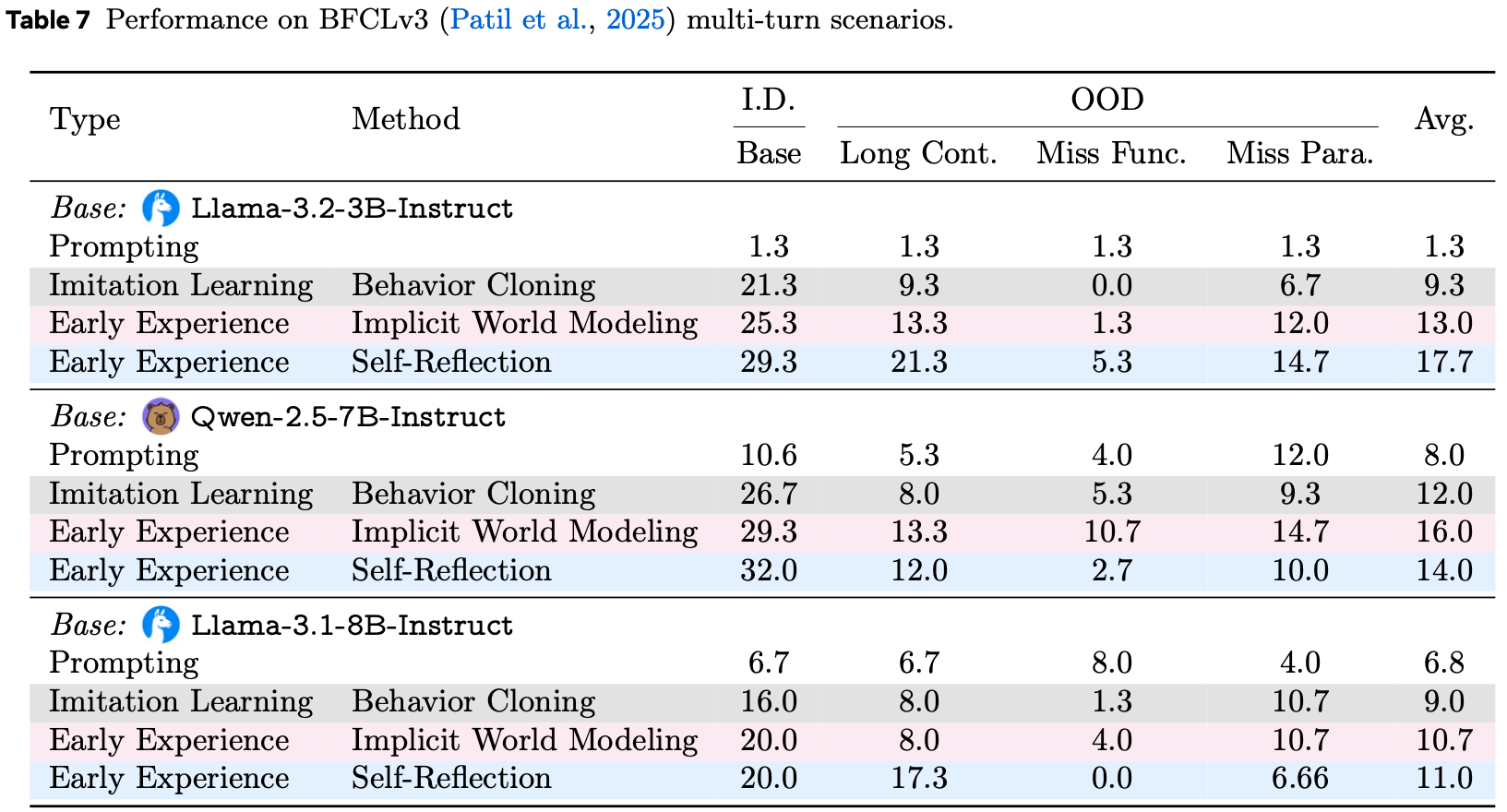
Effectiveness
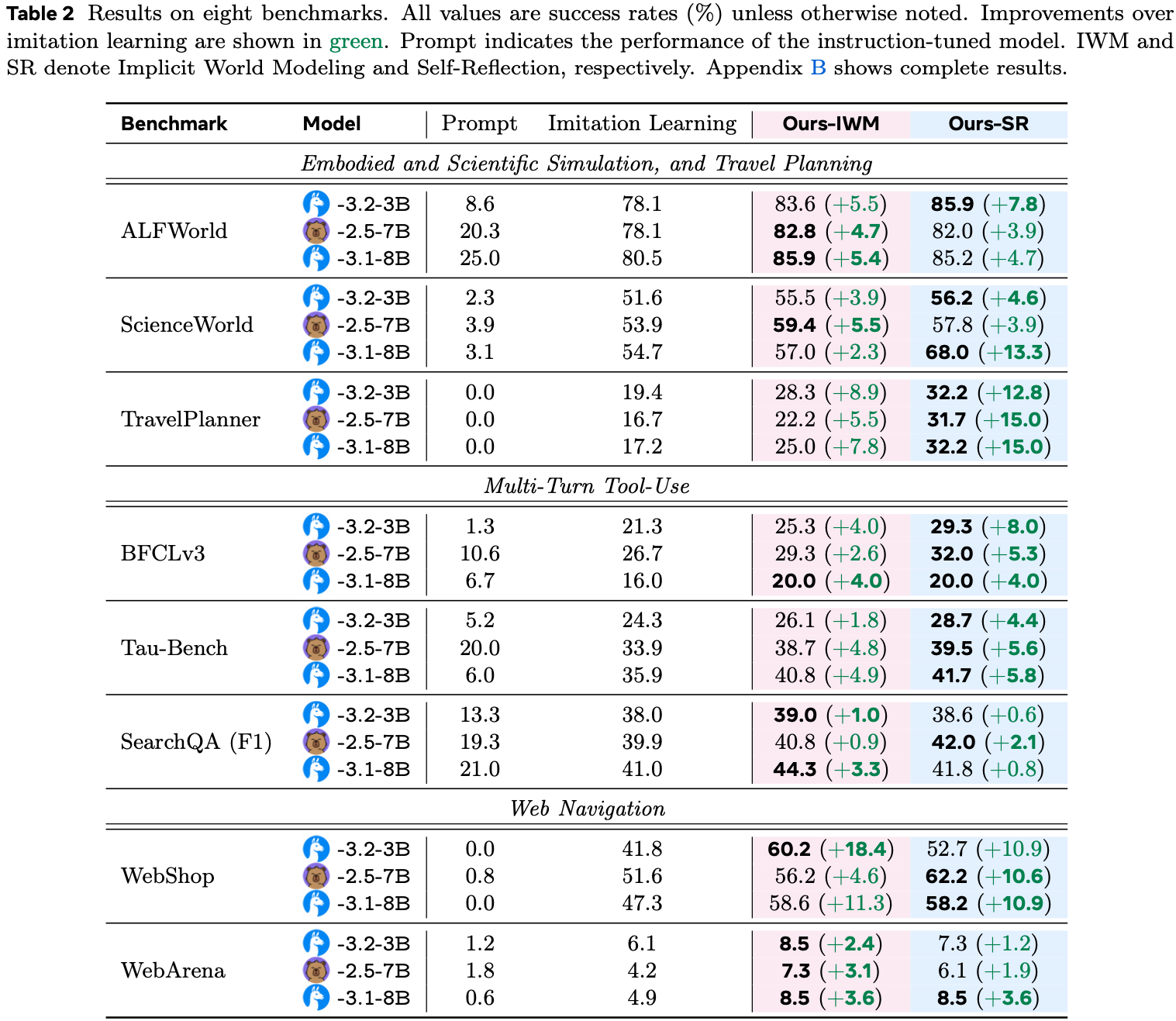
- 表2,八个基准的结果
- 除非另有说明,所有值均为成功率(%)
- 相对于模仿学习的改进以绿色显示
- Prompt 表示指令调优模型的性能
- IWM 和 SR 分别表示隐式世界建模和 Self-Reflection
- 附录 B 显示了完整结果
- 论文在跨越多轮工具使用、网络导航等的八个环境中进行评估(表 2)
- 所有模型都使用相同的提示格式和解码策略为每个环境进行训练
- 总体收益 (Overall Gains)
- Early Experience 在几乎所有设置和两种模型大小下都优于模仿学习
- 隐式世界建模 (IWM) 在结构化模拟器和事务性站点中产生稳定收益(ALFWorld/ScienceWorld +2.3 到 +5.5;WebShop +11.3 到 +18.4)
- Self-Reflection (SR) 在任务需要多步推理和约束满足时带来最大的提升(TravelPlanner +12.8 到 +15.0;ScienceWorld +13.3;BFCLv3 在 3B 模型上 +8.0)
- 即使在最具挑战性的设置中,收益也是一致的,尽管绝对值较小(WebArena +1.2 到 +3.6;SearchQA +0.6 到 +3.3)
- 动作空间视角 (Action-Space Perspective)
- 在论文的八个环境中,动作空间分为三种情况
- 封闭且有限的动作集(例如,用于具身导航的 ALFWorld ,用于科学程序的 ScienceWorld ,以及用于行程规划的 TravelPlanner)从一开始就呈现一个小的、固定的允许动作列表
- 在这里,IWM 帮助策略内化转移规律,而 SR 为 Long-horizon 计划增加了有针对性的修正(例如,在 TravelPlanner 上的巨大 SR 收益)
- 结构化但大的动作集(例如,用于终端任务的 BFCLv3 和用于多域 API 的 Tau-Bench)需要从许多带有参数的类型化工具中选择并正确排序它们
- 在这种情况下, Early Experience 减少了工具的误用并改善了排序;
- 当策略错误主要是逻辑性错误时,SR 通常更有帮助
- 开放动作集(例如,具有自由形式搜索查询的 SearchQA,具有细粒度网页元素交互的 WebArena)允许大量可能的动作,通常是组合性质的
- 这些是最困难的机制;尽管如此, Early Experience 仍然通过将探索性 rollout 转化为密集的训练信号而产生了可靠的收益,而不需要奖励
- 封闭且有限的动作集(例如,用于具身导航的 ALFWorld ,用于科学程序的 ScienceWorld ,以及用于行程规划的 TravelPlanner)从一开始就呈现一个小的、固定的允许动作列表
- 在论文的八个环境中,动作空间分为三种情况
- 观察空间视角 (Observation-Space Perspective)
- 论文的基准涵盖了广泛的观察复杂性
- 在低端,ALFWorld 提供场景的简短、干净的文本描述;ScienceWorld 产生正在进行的实验的程序性读数
- 中等范围的设置,如 BFCLv3 和 Tau-Bench,返回结构化的 API 模式和工具输出,必须正确解析和排序
- 在高端,WebArena 将嘈杂的、细粒度的网页状态呈现为可访问性树,需要对数百个类似 DOM 的元素进行推理
- 论文在附录 B 中提供了每个环境的示例
- 在状态转移一致且可预测的设置中(例如,WebShop),IWM 通过帮助智能体内化环境动态和改进下一个状态预测而表现出色
- 当失败主要源于推理错误或需要修复 Long-horizon 计划时(例如,TravelPlanner, ScienceWorld),SR 通过明确地将动作与专家轨迹进行比较而带来更大的收益
- 总的来说,无论环境的观察多么简单或复杂, Early Experience 方法都持续地将智能体自身的动作和结果状态转化为有效的监督信号,从而在没有奖励的情况下改进策略学习
- 论文的基准涵盖了广泛的观察复杂性
- Takeaway
- Early Experience 可靠地将智能体自身的动作和结果状态转化为超越专家演示的可扩展监督
- 在此范式下的两种方法都在动作空间和观察复杂性截然不同的环境中加强了策略
- 这些效应在三个模型大小和三个环境家族中均成立,证明了论文 Early Experience 范式的强大可泛化可行性
Out-Of-Domain Generalization
- 为了评估训练策略在领域内性能之外的鲁棒性,论文在具有 领域外(out-of-domain,OOD)splits 的环境中探索 Early Experience ,使用与第 5.2 节评估相同的检查点
- 在设置方面,对于 ALFWorld 和 SearchQA,论文遵循其原始工作中定义的 OOD splits
- 对于 BFCLv3:
- 领域内设置是多轮 base;
- OOD 设置是对多轮 missing function、missing argument 和long context 进行平均
- 论文训练模型的结果如表 3 所示,从中我们可以得出以下观察结果
- OOD 分数在所有任务中相对于领域内都有所下降,但 Early Experience 持续恢复了差距的很大一部分
- 在几种情况下,相对收益大于领域内收益(例如,SearchQA),这表明将自身的 rollout 转化为监督可以使策略为演示未覆盖的状态做好准备
- 方法上的模式反映了领域内趋势:
- IWM 在动态稳定的地方帮助最大(例如,ALFWorld);
- SR 在分布偏移改变工具可用性或参数时最强(例如,BFCLv3);
- IWM 和 SR 都在检索偏移下(例如,SearchQA)对所有模型大小都有帮助
- 表 3:领域外评估结果(%);相对于模仿学习的改进以绿色显示;Prompt 表示指令模型的性能;IWM 和 SR 分别指隐式世界建模和 Self-Reflection

- Takeaway
- Early Experience 在多样化的 OOD 机制下提高了鲁棒性:
- IWM 在动态稳定时表现出色,SR 在偏移影响工具可用性、参数或检索分布时表现出色
- 在几个基准测试中(例如,ALFWorld, SearchQA),OOD 收益达到或超过领域内收益,这强化了智能体自身的经验提供了超越专家演示的监督
- Early Experience 在多样化的 OOD 机制下提高了鲁棒性:
Reinforcement Learning Following Early Experience
- 为了评估一旦环境提供可验证奖励(“经验时代”的决定性条件)时 Early Experience 的影响,论文在第 5.2 节训练的模型后附加了一个强化学习阶段
- 论文专注于三个有奖励可用的基准:WebShop、ALFWorld 和 SearchQA,并采用广泛使用的 GRPO 算法 (2024)
- 其超参数和训练步数与既定方案 (2025; 2025) 相同
- 不同运行(runs)之间唯一变化的因素是初始化 :模仿学习 (IL)、隐式世界建模 (IWM) 或 Self-Reflection (SR)
- 图 3 的结果显示了一个清晰的模式:
- 从 Early Experience 开始总是能产生更高的 RL 后性能上限
- 在某些情况下,性能差距在 RL 训练期间增大(例如,ALFWorld);
- 在其他情况下,差距缩小但从未逆转
- 即使应用相同步数的奖励优化,IL 起点也很少能达到 Early Experience 起点的最终性能
- 为了完善实验(completeness),论文还直接从原始预训练模型运行 GRPO,没有任何监督阶段
- 这在所有任务中表现最差,并显示出不稳定的训练动态,突显了强初始化的必要性
- 带有详细指标的完整结果可以在附录 B 中找到
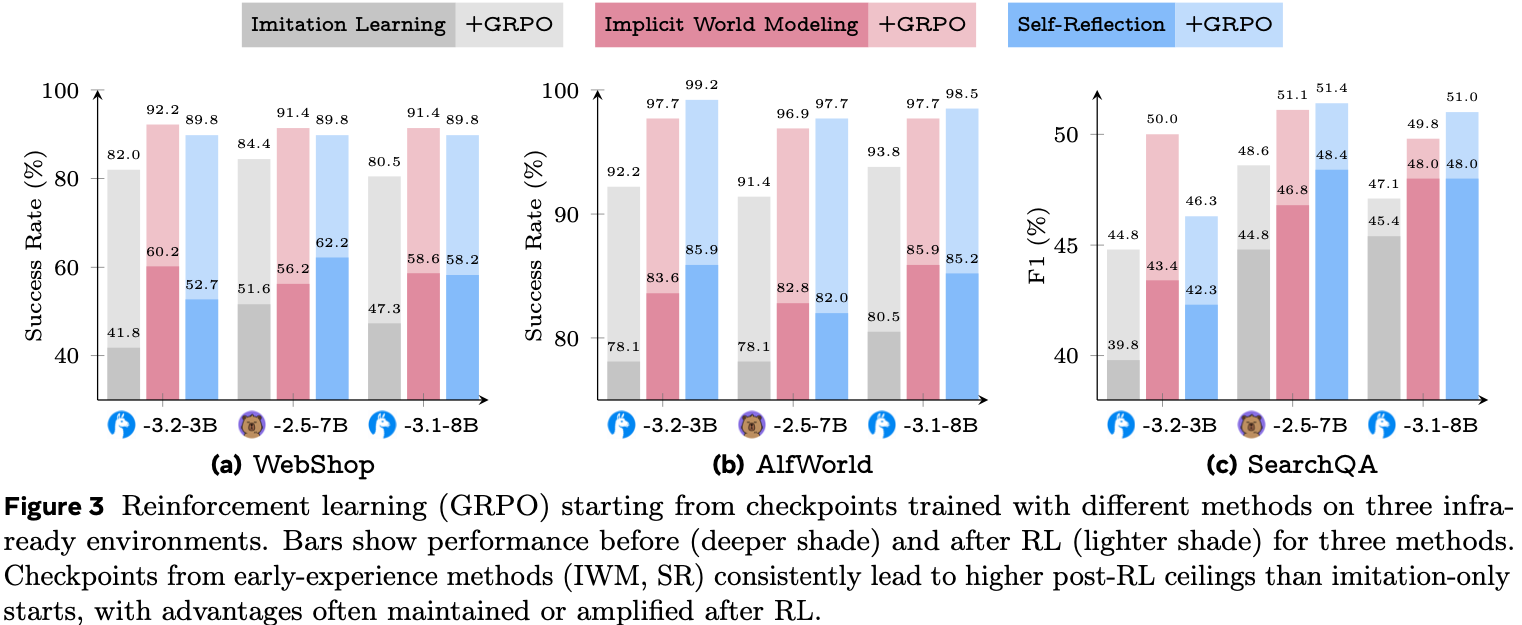
- 从 Early Experience 开始总是能产生更高的 RL 后性能上限
- Takeaway
- Early Experience 充当了人类数据时代和经验时代之间的 中期训练桥梁 (mid-training bridge)
- Early Experience 产生的策略在没有奖励的情况下已经表现强劲,并且放大了后续 RL 的收益
- 在相同的 RL 方案下,Early Experience 起点实现了更高的最终性能
- 这些结果表明,一旦 RL 基础设施在新的环境中可用,Early Experience 可以立即解锁进一步的收益,而无需从头开始重新训练
Discussion
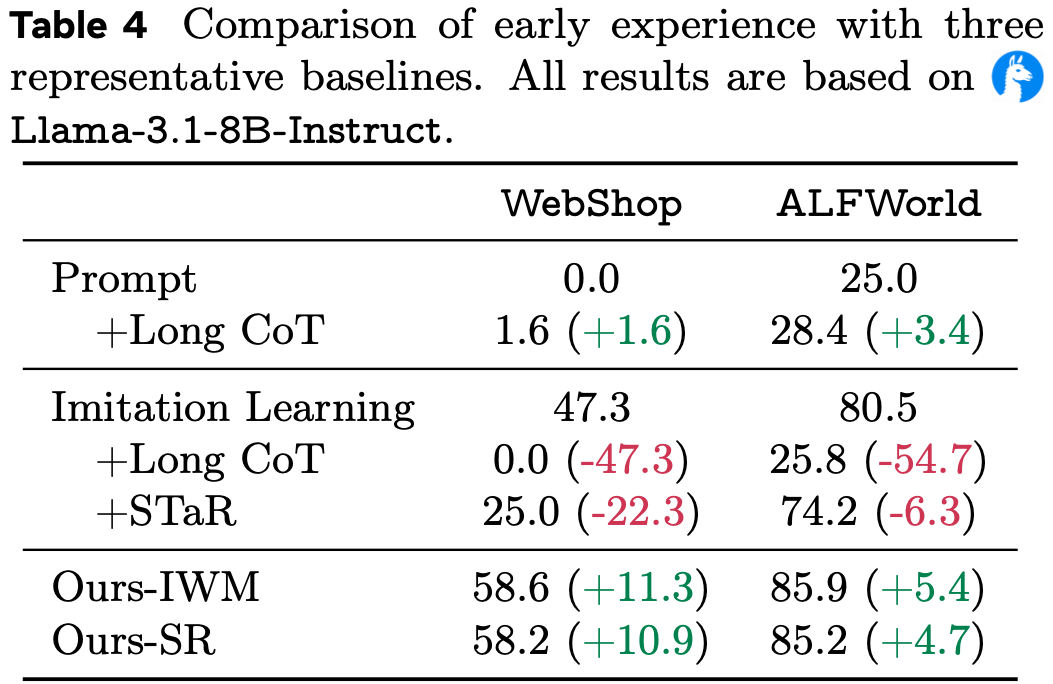
Comparison to Baselines
- 论文将 Early Experience 与两种替代方案进行比较,这些方案在不执行 alternative 动作 或 观察动作引发的状态的情况下注入 额外的监督或推理信号
- 理解:讨论这里是想介绍两种相似的方案,作为 Early Experience 的补充比较
- 这使论文能够测试论文的增益是否可以通过简单地扩展推理时间或在训练期间添加未经实际验证的推理来匹配
- (I) 长思维链 (Long CoT) (test-time scaling)
- 受测试时扩展 (2024) 的启发,论文的目标是帮助特定模型在推理时进行更广泛的推理
- 这些特定模型包括:在专家轨迹上训练的、通常缺乏推理过程的指令微调模型和纯模仿模型
- 提示基线使用现成的指令微调模型和先前工作中的官方提示,这些提示通常产生短思维链 (2022)
- 论文的长思维链变体通过在 Training splits 上进行更重的提示搜索,当存在标记推理结束的分隔符 Token(例如
</think>)时,截断它以鼓励继续生成,来强制在动作生成之前进行更长的推理- 问题:这样也可以吗?如果人家已经不想思考了,模型会输出什么奇怪的东西呢?比如很可能重复输出吧?
- 论文报告每个环境上的最佳结果
- 受测试时扩展 (2024) 的启发,论文的目标是帮助特定模型在推理时进行更广泛的推理
- (II) STaR 风格数据 (STaR-style data) (reasoning without alternative actions or resulting states,没有 alternative 动作或结果状态的推理)
- 遵循 STaR (2022):
- 让模型为每个状态下的专家动作生成一个原理,并仅保留预测动作与专家动作匹配的情况
- 然后在(状态,原理,动作)元组((state, rationale, action) tuples)上进行微调,如公式 \(\ref{eq:self_refl}\) 所示
- 注意:没有使用 alternative 动作及其结果状态(因为这些原理在实际结果中仍然是未经实际验证的)
- 其他超参数:
- 搜索用于原理合成的提示词变体并保留最强的配置
- 优化步骤的数量与论文的自反思方法相同
- 遵循 STaR (2022):
- (I) 长思维链 (Long CoT) (test-time scaling)
- 表 4 显示,两种 Early Experience 方法在任务和模型大小上都实现了最大的增益
- 对于长思维链 ,更重的提示搜索和推理长度控制可以适度地改善经过模仿训练的提示基线 ,但在更困难的设置中,增益迅速消失
- 一旦仅在缺乏固有原理的专家轨迹上进行微调,模型就失去了维持连贯长形式推理的能力,因此尽管在思维-动作边界处进行了截断,扩展的思维链常常漂移或崩溃为无效/偏离策略的动作
- 对于 STaR 风格数据,生成的动作与专家动作之间的匹配率很低,留下的可用训练数据很少
- 保留的原理是未经实际验证的,从未在环境中测试过,并且经常幻觉工具或事实,因此对它们进行微调甚至可能降低性能
- 相比之下, Early Experience 直接将策略自身的非专家 rollout 转换为来自观察到的下一状态的经实际验证的监督,产生了这些替代方案无法匹配的稳健改进
Impact of Amount of Human Data
- 为了检查性能如何随专家监督的数量而变化,论文在保持总训练预算固定的情况下,改变用于启动 Early Experience 的 Demonstrations 数量
- 图 4 (a) 显示,在每个数据水平上, Early Experience 都保持对模仿学习的一致领先
- 在 WebShop 上,仅使用 \(1/8\) 的 Demonstrations 就已经超过了在全量数据集上训练的模仿学习;
- 在 ALFWorld 上,使用 \(1/2\) 的 Demonstrations 也保持了同样的优势
- IWM 和 SR 都随着更多专家数据而改进,但相对于模仿学习的优势仍然很大,这强调了 Early Experience 提供了超越仅靠 Demonstrations 所能提供的额外监督信号
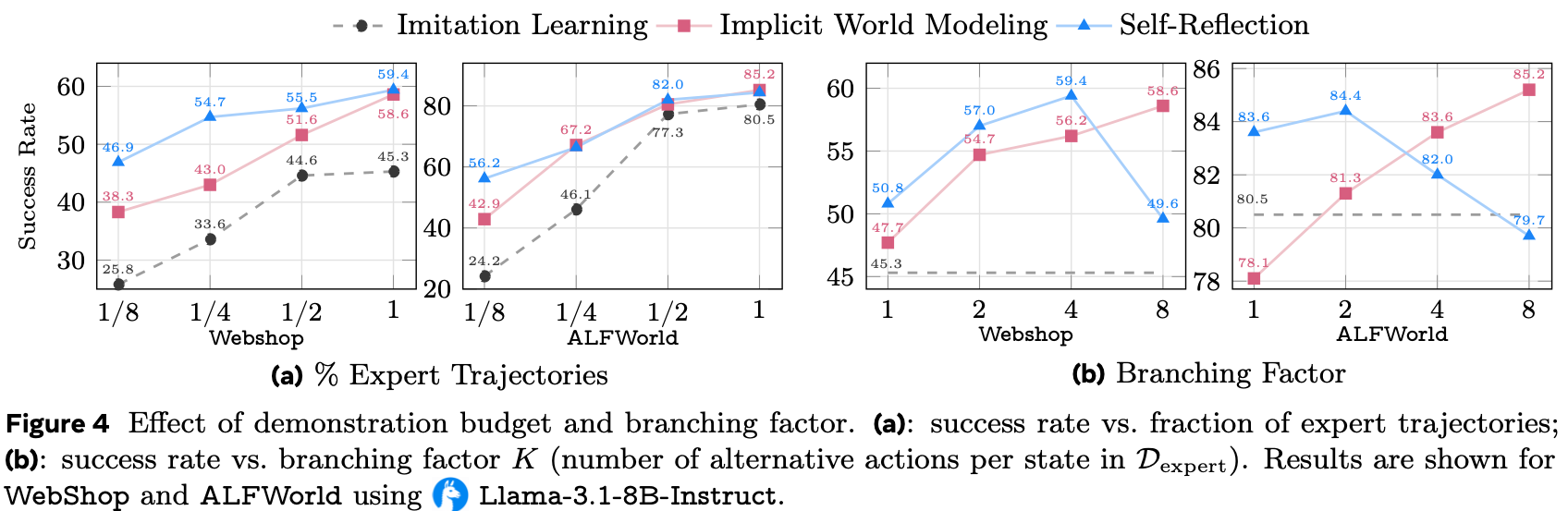
Impact of Branching Factor
- 为了研究分支因子对论文方法的影响,论文还对分支因子 \(K\)(在生成 Early Experience 时每个专家状态 roll out 的 alternative 动作数量)进行了消融
- 图 4 (b) 显示,随着 \(K\) 的增加,IWM 稳步改进,这与学习更丰富的转移规律相一致
- SR 在中小 \(K\) 值时改进,并且在非常大的 \(K\) 值时可能非单调:
- 比较许多 alternative 动作偶尔会包括其他导致成功的动作,减少了与专家的对比,并且当前模型在单个上下文中推理许多 alternative 动作和结果的能力有限
- 总的来说,两种变体在大部分时间都有所改进,IWM 倾向于更大的 \(K\),而 SR 在适中的 \(K\)(例如 2–4)下效果最好
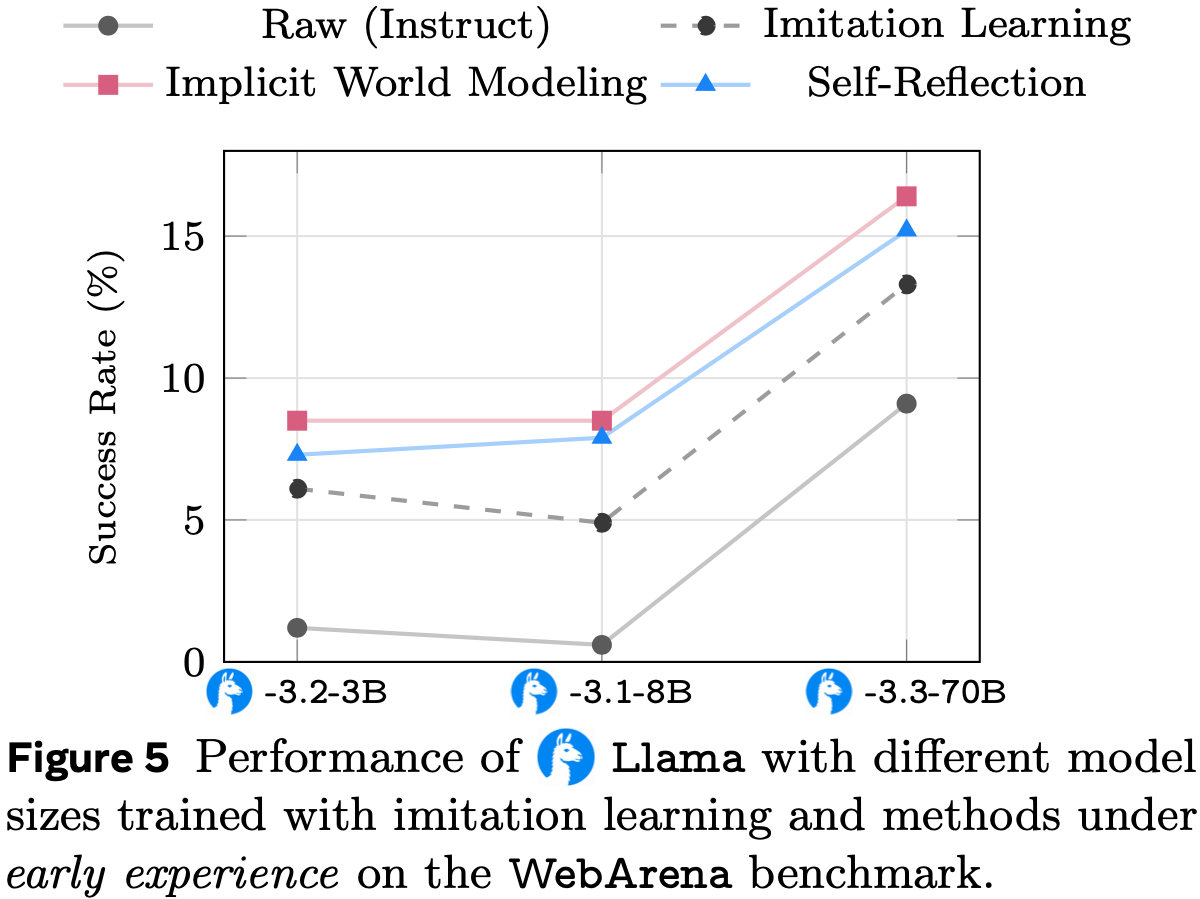
Model Scaling
- 论文研究了 Early Experience 的益处是否随着模型缩放而持续
- 在 WebArena 上,论文比较了 \(\bigcirc\) Llama-3.2-3B、\(\bigcirc\) Llama-3.1-8B 和 \(\bigcirc\) Llama-3.3-70B
- 由于计算资源有限,70B 模型的微调对所有方法都使用参数高效的 LoRA (2022),保持相同的秩和更新步数;对于 IWM,在第二阶段继续使用相同的适配器,使得总可调参数和计算量与模仿学习相匹配
- 问题:Meta 缺少计算资源?
- 图 5 显示, Early Experience 在每个规模上都优于模仿学习,即使对于 70B 模型,差距仍然存在
- 绝对性能随规模提升,而 Early Experience 检查点 consistently 占据顶部曲线,表明其提供的监督是对模型规模的补充而非替代
- 即使仅使用 LoRA 更新,IWM 和 SR 都带来了稳定的增益,证明该方法在受限计算预算下仍然有效
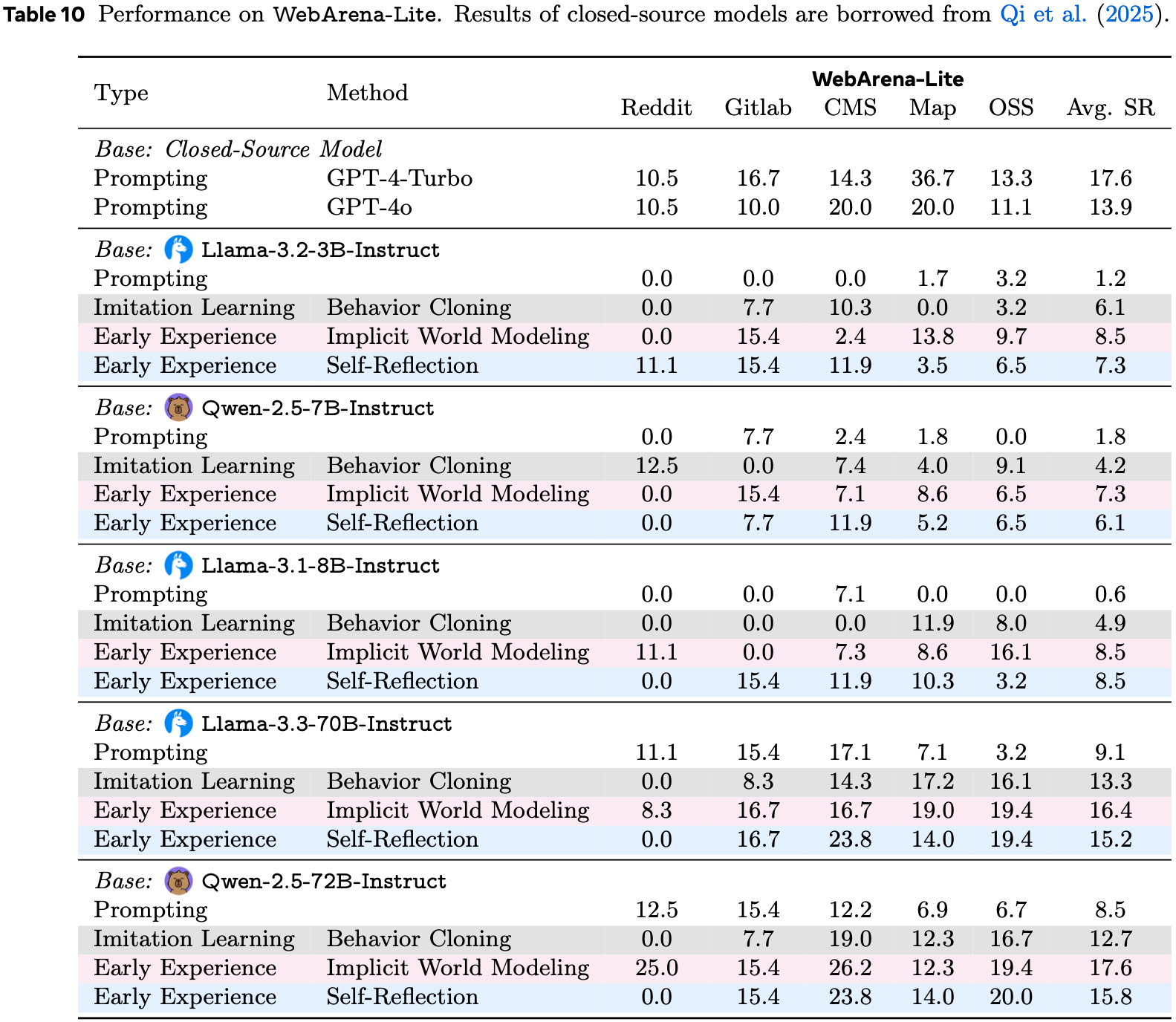
- 论文在附录 B 的表 10 中观察到 Qwen 模型的类似趋势
补充:Related Work
Training Paradigms for Language Agents
- SFT
- 大多数语言智能体 (2022; 2023; 2024; 2025) 使用监督微调在专家轨迹上进行训练,在强化学习文献中也称为模仿学习或行为克隆,特别是在复杂设置中,例如网络 (2024) 或操作系统 (2024)
- 这些轨迹可能是人工标注的 (2022; 2023),也可能是由遵循精心设计的人类工作流程的更强语言模型合成的 (2024; 2025)
- 尽管合成 Demonstrations 增加了覆盖范围,但它们只提供了增量收益,因为底层的监督信号仍然是静态的
- 监督微调提供了密集的、无奖励的监督信号,但仍然受限于高质量 Demonstrations 的成本 (2025),并且当智能体面对新状态时显得脆弱 (2025; 2023)
- RL
- 强化学习通过试错来训练智能体,优化长期奖励 (1998)
- 尽管它在控制、棋盘游戏和 Atari (2013; 2016; 2020; 2020) 中取得了令人印象深刻的结果,但在语言智能体设置中有效应用强化学习仍然很困难 (2025;)
- 当前的研究仍处于探索阶段:
- 许多研究依赖于由更大的教师模型产生的近似奖励 (2025;),或者依赖于精心策划的奖励函数 (2025) 和手动调整的训练方案 (2025) 来保持稳定性
- 支持的基础设施也尚未成熟;
- 大多数现实世界的语言智能体环境缺乏可靠的模拟器、标准的重置机制和可扩展的评估平台 (2025;),使得语言智能体的大规模强化学习训练成本高昂且脆弱
- 总之,这些局限性表明,语言智能体的可扩展强化学习尚未成熟,这促使需要一个范式来桥接当前基于模仿的训练和未来完全由经验驱动的学习
Supervision from Exploration
- 强化学习中的传统探索-利用策略收集轨迹,随后通过奖励反馈进行优化
- 诸如 Hindsight Experience Replay (2017) 之类的方法通过将已实现的结果改造为目标来稠密化稀疏奖励,但仍然需要许多语言智能体环境中不可用的可验证奖励函数
- 论文的设置以不同的方式使用探索:交互轨迹成为直接的监督信号,完全消除了对奖励或手动重新标注的需求
World Models
- 传统上的世界模型 (1991; 2018; 2020, 2021) 是指:在观察到的状态转移上进行训练,以预测未来状态和奖励,允许基于模型的强化学习减少样本复杂度并支持推测性规划
- 最近的工作通过使用大语言模型作为世界模型 (2025; 2023) 将此思想扩展到语言智能体 ,这通过语言介导的模拟提高了下游性能
- 尽管不同时代的世界模型具有不同的状态表征,但这些系统中的大多数仍然将世界模型视为一个 独立的 模拟器,呼应了经典的控制流程
- 相比之下,论文将交互轨迹本身视为智能体策略的辅助预测任务,在精神上类似于中期训练 (2025)
- 通过训练策略来预测其自身的未来状态,模型内化了粗略的环境动态,而无需独立的模拟器
- 这种 隐式(implicit) 世界模型将智能体锚定在其操作上下文中,提供了轻量级的热身以便更快地适应,并避免了显式模拟器所需的规划开销
Self-Reflection
- Self-Reflection (2023;) 最初是作为一种提示技术引入的,允许大语言模型通过多轮自我对话 (2024) 或精心设计的提示词变体 (2023) 来修改其答案 ,而无需更新模型参数
- 后续工作在有奖励的轨迹上总结经验教训(例如,短期情景记忆 (2025))到提示中,以指导未来的推理
- 但后来的研究 (2024; 2023) 表明,这类推理时方法在无法获得外部反馈(例如奖励)时常常失败
- 另一条研究线使用大语言模型为正确答案生成原理,将这些原理视为训练目标以引导推理 (2022; 2023)
- 论文将这种反思的观点扩展到 缺乏显式奖励(explicit rewards are absent) 的智能体设置中
- 论文的方法训练智能体反思其自身的次优行动及由此产生的轨迹,然后使用反思出的原理作为训练信号来改进决策制定
附录 B:Implementation details
- 在本节中,论文为每个环境提供实现细节
- 对于每个环境,论文呈现包含所有可用指标的表格
- 此外,论文还展示了由 Llama-3.1-8B 合成的具体训练示例(例如,用于 Self-Reflection 的数据)
B.1 ALFWorld
- 论文遵循 ALFWorld (2021) 的默认 split,使用 Verl-Agent (2025) 框架下的 TextWorld (2019) 设置
- 论文从 ALFWorld 的专家轨迹中提取了 21,031 个状态-动作对来构成 \(\mathcal{D}_{\text{expert} }\)
- 鉴于数据集中任务可解性的完整性,这些专家轨迹是最优的
- 对于隐式世界建模,论文使用 \(\mathcal{D}_{\text{rollout} }\) 来增强 \(\mathcal{D}_{\text{expert} }\)
- 在每个状态,论文从可行动作列表中(排除专家动作)均匀地、无放回地采样 8 个非专家动作
- 包含专家动作,总计为隐式世界建模产生 \(21,031 \times 9 = 189,279\) 个三元组
- 对于 Self-Reflection ,论文通过提示模型解释其自身决策来构建数据
- 对于每个状态,论文使用相同的策略模型(温度设为 1.0)来提出最多 3 个 alternative 动作
- 对提出的动作进行规范化处理,并仅保留唯一动作
- 如果提出的动作不在该状态的可行动作空间内,将其丢弃,并改为从剩余未选中的可行动作中均匀随机采样
- 最终的提示要求模型根据当前状态和可用工具,证明为什么专家动作优于采样得到的 alternative 动作
- 对于每个状态,论文使用相同的策略模型(温度设为 1.0)来提出最多 3 个 alternative 动作
- 在训练期间,论文使用批大小为 16,学习率为 \(1\mathrm{e}{-5}\),并使用 LlamaFactory (2024b) 训练 2 个 Epoch
- 对于强化学习训练,论文采用 Verl-Agent 中的默认超参数 ,并在其论文(理解:应该是 ALFWorld 论文)报告的相同 split 上进行评估
- 对于评估,论文将最大提示长度设置为 4096,最大响应长度设置为 1024,温度设置为 0.4
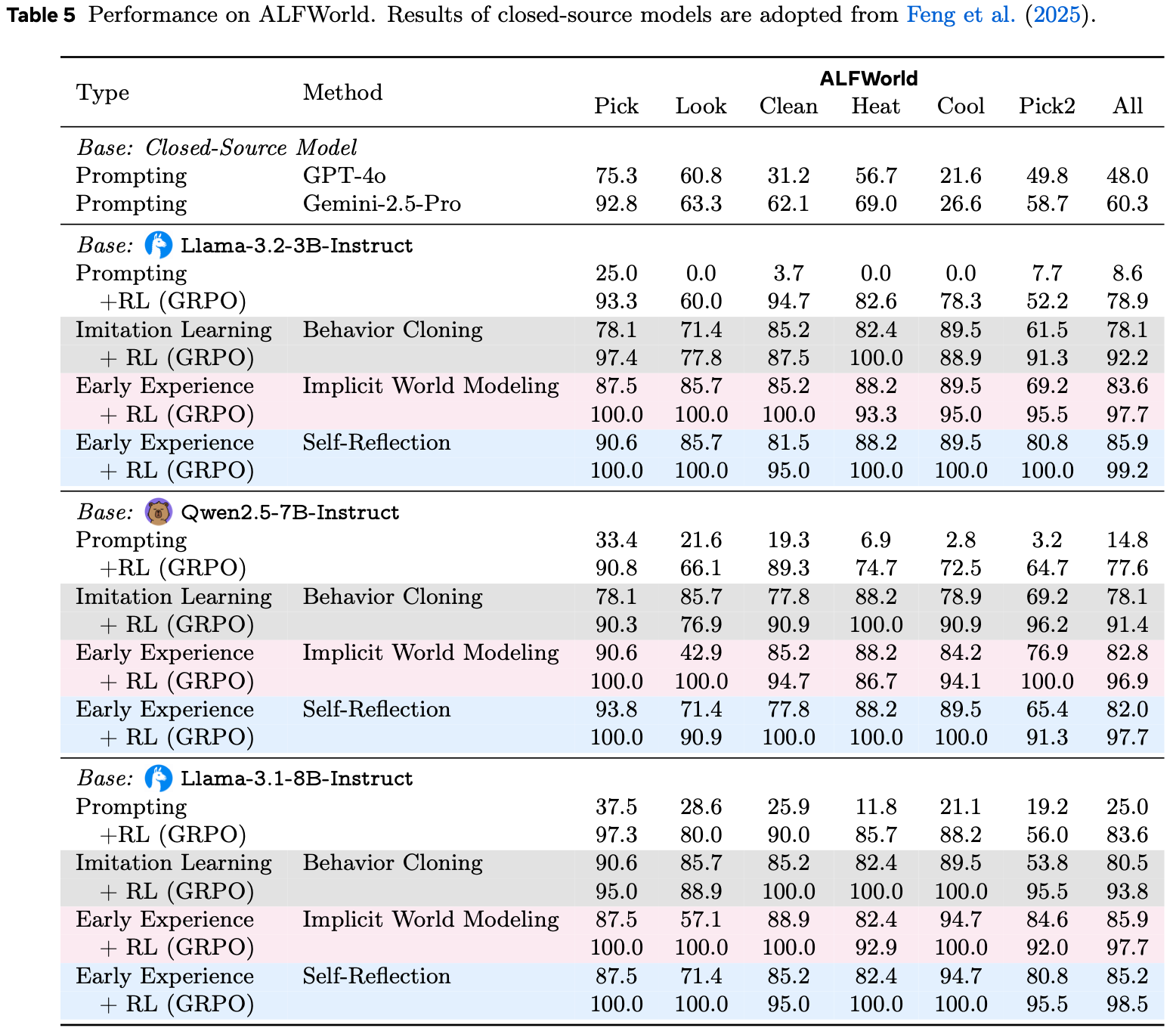
- 完整结果见表 5

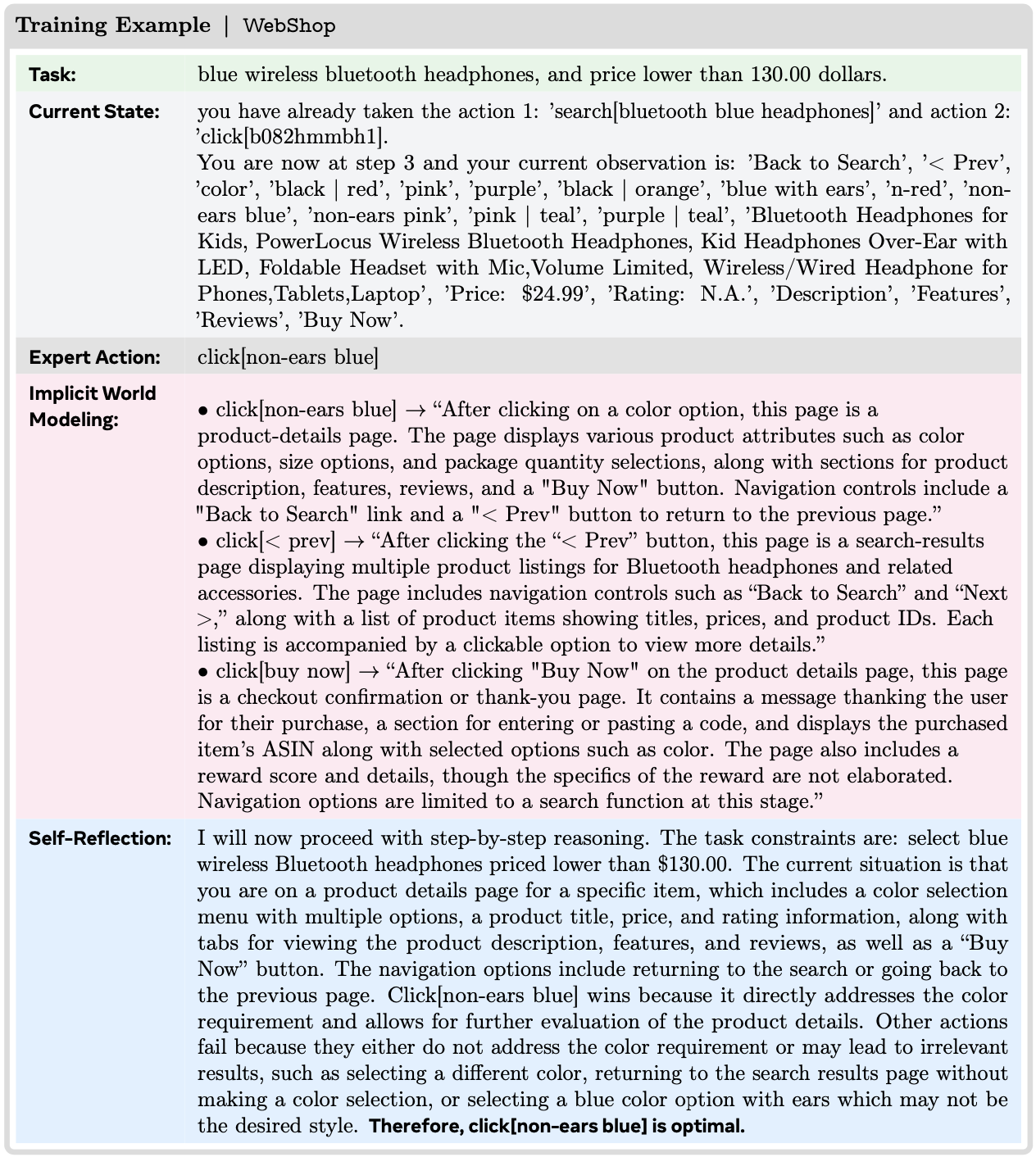
B.2 WebShop
- 根据 WebShop (2022) 官方发布的人类演示数据,论文提取了 1,571 条人类轨迹,并将其转换为 Verl-Agent (2025) 格式,得到了 15,464 个状态-动作对,构成了用于模仿学习的 \(\mathcal{D}_{\text{expert} }\)
- 对于隐式世界建模,数据包含两个部分
- 第一部分直接来源于 \(\mathcal{D}_{\text{expert} }\),通过将每个步骤重新格式化为世界建模格式,其中输入包含历史上下文和当前步骤采取的动作,目标是执行该动作后下一个状态的离线文本摘要(平均长度 345 个字符)
- 第二部分是通过用非专家动作增强每个专家状态获得的:
- 让相同的策略在温度 {0.5, 0.8, 0.9} 下提出动作,并额外为每个状态均匀随机采样最多五个可行动作
- 然后将增强的样本转换为与第一部分相同的世界建模格式:
- 对于每个非专家动作,论文在 WebShop 环境中执行它以获得后续观察结果,并推导出下一个状态的离线文本摘要
- 所有候选动作都经过规范化和去重处理
- 将这些与专家动作合并后,论文得到了 122,954 个三元组用于隐式世界建模
- 对于 Self-Reflection ,论文构建的提示包括专家动作以及 3 个 alternative 动作 ,并要求模型根据当前状态和可行动作证明为什么专家动作更优
- 由于原始专家轨迹中的某些动作是次优的 ,论文应用了一个简单的质量过滤器 ,仅保留那些任务能在少于 15 步内完成的轨迹中的动作 ,从而得到了 6,235 个反思示例
- 问题:仅保留那些任务能在少于 15 步内完成的轨迹中的动作 与 某些动作是次优的 有什么关系?
- 对于每个这样的状态,alternative 动作的抽取方式与世界建模中相同,即混合模型提出的动作(使用上述温度)和均匀采样的可行动作;
- 经过规范化和去重后,论文保留 3 个不同的 alternative 动作
- 论文有意保留多样化的 alternative 动作集合,包括可行但无帮助的动作、空响应以及偶尔的无效动作,以帮助模型学习更清晰的决策边界
- 由于原始专家轨迹中的某些动作是次优的 ,论文应用了一个简单的质量过滤器 ,仅保留那些任务能在少于 15 步内完成的轨迹中的动作 ,从而得到了 6,235 个反思示例
- 在训练期间,论文使用批大小为 4,学习率为 \(1\mathrm{e}{-5}\),并使用 LlamaFactory (2024b) 进行训练
- 对于强化学习训练,论文采用 Verl-Agent 中的默认超参数,并在其论文报告的相同 split 上进行评估
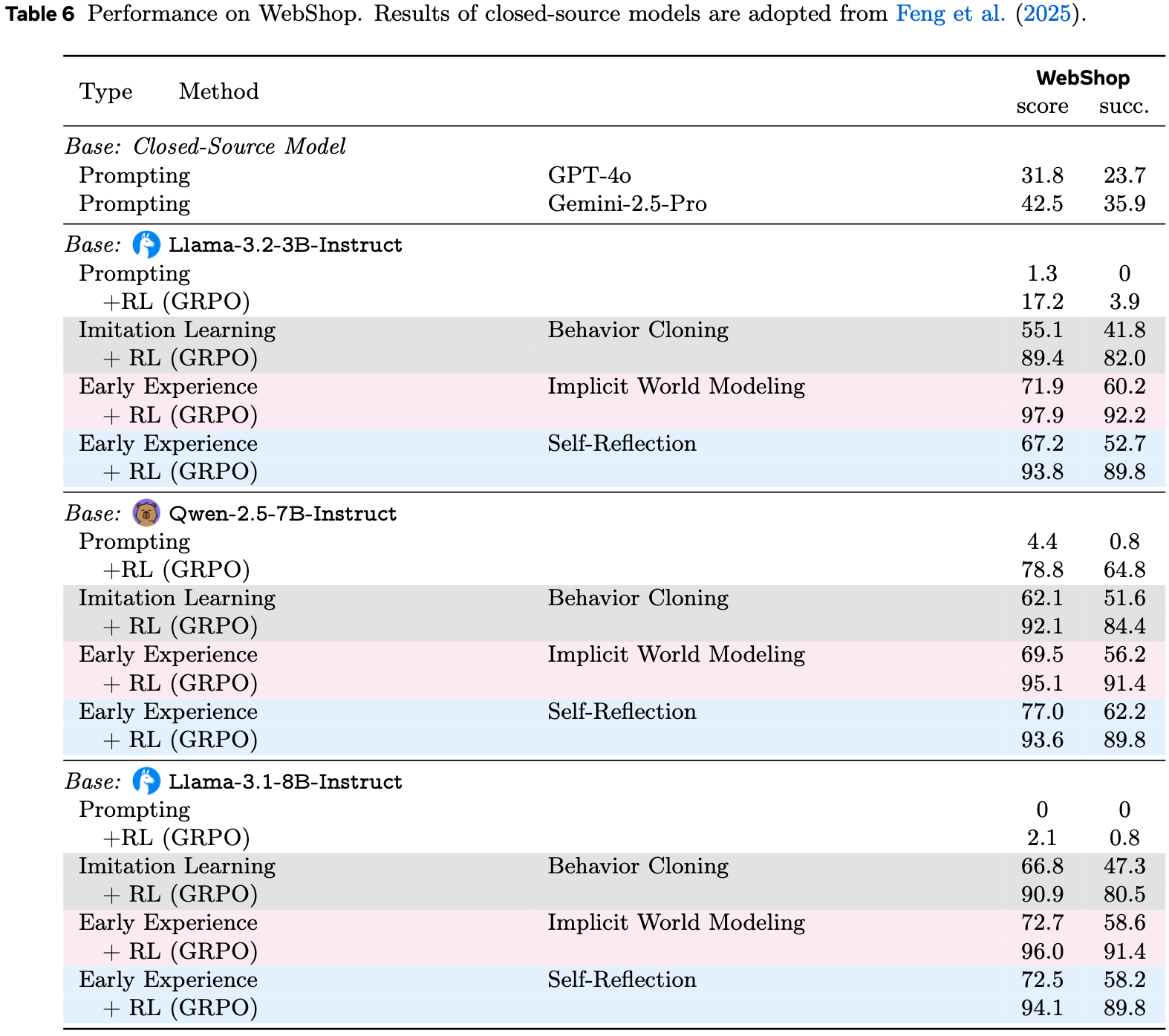
- 完整结果见表 6
B.3 BFCLv3
- 论文遵循 BFCLv3 (2025) 基准测试的默认多轮函数调用 split ,该 split 将任务分类为Base、Long-Context、Miss Function 和Miss Parameters
- Base 包含基础但多样的多轮交互 ,其中所有必要信息 ,包括用户请求、先前轮次的执行结果和探索性函数输出,都可用于完成任务而无歧义
- Long-Context 通过引入大量无关数据(例如,数百个文件或数千条记录)来评估模型在冗长、信息密集的环境中保持准确性的能力 ,从而测试其在认知负荷下提取基本细节的能力
- Miss Function 评估模型能否识别出没有可用函数可以满足用户请求的情况;
- 当该问题被识别出来时,将在后续轮次中提供缺失的函数 ,并要求模型适应新可用的能力(理解:即函数)
- Miss Parameters 检查模型是否能够检测到用户请求中缺少基本参数且无法从系统状态推断的情况,提示其请求澄清而不是做出无根据的假设
- 由于默认的 BFCLv3 基准测试不提供训练集 split ,为了构建训练集,论文专门使用Base 类别中的样本
- 论文随机选择其中 75% 的样本(125 条轨迹)作为用于模仿学习的专家轨迹 \(\mathcal{D}_{\text{expert} }\)
- 每条轨迹包含多个步骤和交互,论文将其进一步拆分为单独的步骤以提高训练效率
- 论文随机选择其中 75% 的样本(125 条轨迹)作为用于模仿学习的专家轨迹 \(\mathcal{D}_{\text{expert} }\)
- 对于隐式世界建模,数据包含两个部分
- 第一部分直接来源于 \(\mathcal{D}_{\text{expert} }\),通过将每条轨迹重新格式化为世界建模格式,其中给定历史上下文和上一步的动作,模型预测下一个状态
- 这产生了 1,264 个训练样本
- 第二部分是通过增强生成的:
- 对于专家轨迹中的每个状态,论文让目标模型除了专家动作外再采样 10 个 alternative 动作 ,按照与 ALFWorld 相同的过程 ,产生了 11,904 个样本
- 第一部分直接来源于 \(\mathcal{D}_{\text{expert} }\),通过将每条轨迹重新格式化为世界建模格式,其中给定历史上下文和上一步的动作,模型预测下一个状态
- 对于 Self-Reflection,论文通过提示模型解释其决策来构建训练数据,强调在当前状态下,包括先前定义的工具集在内,为什么专家动作优于其他可用动作
- 在过滤掉一小部分生成的结论动作与专家动作不匹配的低质量样本后,论文获得了 1,200 个训练样本
- 论文使用 LlamaFactory (2024b),以批大小 16、学习率 \(1\mathrm{e}{-5}\) 进行训练
- 为了推理效率,论文采用 vLLM 基础设施
- 完整结果见表 7

B.4 Tau-Bench
- 论文使用 Tau-Bench 中的零售任务(retail task)进行实验,在 Tau-Bench 中,零售任务分为训练集和评估集,分别包含 495 和 115 个任务
- 论文采用一个高性能的指令调优 LLaMA 系列模型在训练集上收集专家轨迹
- 对于每个任务,推理温度设置为 1.0,并生成四条轨迹
- 选择最终奖励为 1 的轨迹作为专家轨迹;
- 如果存在多条这样的轨迹,则随机选择一条;
- 如果没有轨迹达到奖励 1,则丢弃该任务
- 此过程为 452 个任务生成了专家轨迹,总共得到 5,239 个(观察,动作)(〈observation, action〉)对
- 对于每个任务,推理温度设置为 1.0,并生成四条轨迹
- 对于世界模型数据,论文使用目标模型为专家轨迹中的每个观察提出五个动作候选
- 为了避免重复的工具调用并促进探索 ,论文从每个专家观察对应的工具集中移除专家动作中使用的工具,允许模型从剩余工具中进行选择
- 然后,在环境中执行所选动作以获得下一个观察
- 每个生成的(专家观察,动作,下一个观察)三元组都包含在世界模型的训练数据集中
- 对于 Self-Reflection 数据,对于每个(专家观察,专家动作)对,论文从相应的五个世界模型数据点中选择三个 alternative 动作,并将其呈现给模型本身进行反思,提示其解释选择专家动作背后的原理
- 论文过滤掉一小部分低质量的反思样本,最终得到总共 5,233 个训练实例
- 论文采用 LLamaFactory (2024b) 作为训练代码库
- 对于模仿学习,论文以 1e-5 的学习率训练 6 个 Epoch
- 对于隐式世界模型学习,论文以 5e-6 的学习率训练 1 个 Epoch
- 对于 Self-Reflection ,论文以 1e-5 的学习率进行 6 个 Epoch 的 SFT
- 在所有训练配置中,批大小固定为 16
- 由于 Tau-Bench 不包含更细粒度的指标,论文在表 2 中报告了完整表格

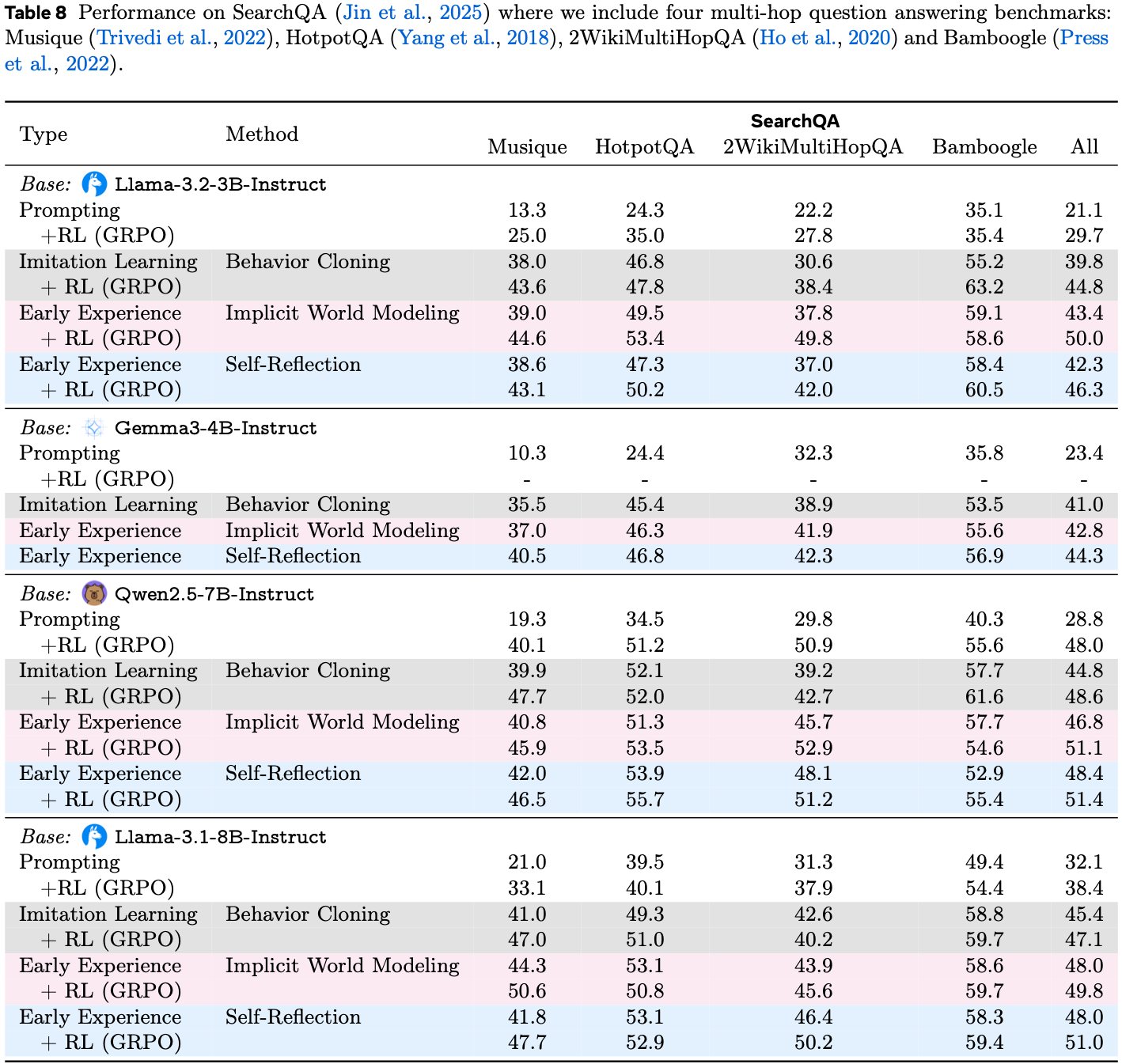
B.5 SearchQA
- 专家轨迹收集 论文从 MuSiQue 训练数据集中选择了所有的 3 跳和 4 跳任务,以及随机抽样的 1,438 个 2 跳任务,以适应需要多步推理来解决复杂问题的场景
- 最终,论文总共有 7,000 个任务
- 由于训练数据缺乏细粒度的推理轨迹,例如 Jin 等人 (2025) 所使用的思考-搜索-答案结构,论文使用 Search-R1 模型来生成专家数据
- 具体来说,论文将温度设置为 1.0,并为每个任务生成 5 条轨迹,仅保留最终答案与真实答案匹配的轨迹
- 为了减少冗余,论文每个任务最多保留 2 条正确轨迹。此过程产生了 2,082 条轨迹,包含总共 7,691 个状态-动作对用于模仿学习
- 世界建模数据构建 与 Jin 等人 (2025) 的观察一致,论文发现直接预测检索到的文档内容会产生次优性能,因为许多 Token 与搜索查询不直接相关
- 为了解决这个问题,论文首先指导模型总结检索到的文档,然后让模型预测这些摘要而不是全文
- 对于专家轨迹中的每个状态,论文让模型在温度为 1.0 的情况下生成 30 个 alternative 动作,使其能够从自身的 Early Experience 中实质性地内化环境动态
- 如果生成的动作无效,即查询没有包含在 \(<\)search\(><\)/search\(>\) 标签内,论文返回反馈:”格式错误!如果需要外部知识,你必须将搜索查询包含在 \(<\)search\(><\)/search\(>\) 标签内。”
- Self-Reflection 数据构建 为了构建 Self-Reflection 训练数据集,论文为每个状态随机采样 2 个 alternative 动作
- 对于每个实例,提示模型基于当前状态、专家动作、 alternative 动作以及与这些动作相关的检索文档,生成解释为什么专家动作优于 alternative 动作的细粒度推理
- 此过程产生了 7,691 个包含详细推理过程的训练数据
- 训练细节 论文采用 LLamaFactory (2024b) 作为代码库,并使用 ZeRO-3 在 4 个 H100 GPU 上进行全参数调优
- 对于模仿学习和 Self-Reflection ,论文以 \(1\times 10^{-5}\) 的学习率、8192 个 Token 的上下文窗口、每个 GPU 批大小为 2 进行 3 个 Epoch 的训练,同时将梯度累积步数设置为 16
- 对于隐式世界模型学习,论文利用来自专家轨迹的世界模型数据,使其与模仿学习数据集达到 1:1 的比例,并在相同设置下进行训练
- 对于强化学习,论文采用 Search-R1 代码库并在 8 个 H100 GPU 上进行训练
- 所有设置与 Jin 等人 (2025) 保持一致,除了论文使用 F1 分数作为奖励,将最大检索交互次数设置为 6,配置上下文窗口为 12,280 个 Token ,并指定最大输出长度为 2,048 个 Token
- 对于训练数据,论文使用 MuSiQue 数据集中的所有训练任务
- 完整结果见表 8
B.6 ScienceWorld
- 论文遵循 ScienceWorld (2022) 的默认 split ,使用 Verl-Agent (2025) 框架下的 AgentGym (2024) 设置
- 从 ScienceWorld 的专家轨迹中,论文提取了 14,506 个状态-动作对来构成 \(\mathcal{D}_{\text{expert} }\)
- 鉴于数据集中任务可解性的完整性,这些专家轨迹是最优的
- 对于隐式世界建模,论文使用 \(\mathcal{D}_{\text{tollout} }\) 来增强 \(\mathcal{D}_{\text{expert} }\)
- 在每个状态,论文从可行动作列表中(排除专家动作)均匀地、无放回地采样 3 个非专家动作,并包含专家动作用于隐式世界建模
- 对于 Self-Reflection ,论文通过提示模型解释其自身决策来构建数据
- 对于每个状态,论文使用相同的策略模型(温度设为 1.0)来提出最多 3 个 alternative 动作(对于 Llama-3.1-8B-Instruct 则为 2 个 alternative 动作)
- 论文对提出的动作进行规范化处理,并仅保留唯一的动作
- 如果提出的动作不在该状态的可行动作空间内,论文将其丢弃,并改为从剩余未选中的可行动作中均匀随机采样
- 最终的提示要求模型根据当前状态和可用工具,证明为什么专家动作优于采样得到的 alternative 动作
- 对于所有的训练和评估,论文使用 one-shot example
- 在训练期间,论文使用批大小为 32,学习率为 \(5\mathrm{e}{-6}\),并使用 LlamaFactory (2024b) 训练 1 个 Epoch
- 对于评估,论文将最大提示长度设置为 4096,最大响应长度设置为 1024,温度设置为 0.4
- 由于 ScienceWorld 不包含更细粒度的指标,论文在表 2 中报告了完整表格
B.7 TravelPlanner
- 论文将 TravelPlanner (2024a) 基准测试适配为一个基于 gym 的环境 ,用于训练语言智能体
- 原始基准测试包含 1,225 个查询,分为训练集(45 个查询)、验证集(180 个查询)和测试集
- 论文使用涵盖不同难度级别(基于旅行持续时间:3、5 或 7 天)和约束复杂性(简单、中等、困难)的多样化规划场景的 45 个训练轨迹
- 简单 查询主要是针对单人的预算约束
- 中等 查询引入了额外的约束,如美食类型、房间类型或房间规则,旅行者人数在 2 到 8 人之间变化
- 困难 查询包括交通偏好以及所有中等级别的约束,包含三个随机选择的困难约束。论文在包含 180 个查询的验证集上进行评估
- 环境实现 论文将 TravelPlanner 实现为一个具有离散动作空间和字典观察空间的 gym 环境
- 状态表示包括以结构化文本格式格式化的当前规划进度:
- 查询描述、预算跟踪(初始/已花费/剩余)以及每天显示交通、餐饮、景点和住宿字段的当前计划状态
- 动作是 JSON 对象,包含动作类型(例如,SET TRANSPORTATION, SET MEAL, SET ACCOMMODATION)、天数、字段名称、选定值和成本等字段
- 动作空间根据参考信息中的可用数据动态生成所有有效动作,包括城市间的航班、具有美食类型和价格的餐厅、景点以及具有房间规则和最低住宿夜数要求的住宿
- 环境实时跟踪预算支出,验证约束条件,并通过状态机维护规划进度,该状态机按顺序推进每个字段
- 状态表示包括以结构化文本格式格式化的当前规划进度:
- 专家轨迹收集 论文使用训练集中的 45 条带标注轨迹作为专家演示 \(\mathcal{D}_{\text{expert} }\)
- 每条轨迹包含一个完整的多日旅行计划,其中包含交通、住宿、餐饮和景点的真实动作
- 论文使用 SFTConverter 将这些轨迹分解为 1,395 个独立的状态-动作对,该转换器将专家计划条目映射到有效的 gym 动作,同时处理城市名称变化并根据环境约束进行验证
- 隐式世界建模 对于世界建模数据,论文生成两种类型的训练样本
- 首先,将专家轨迹重新格式化为状态转换格式 ,模型学习在给定当前状态和动作的情况下预测下一个状态
- 其次,论文通过执行专家轨迹中每个状态下所有可用的有效动作(而不仅仅是采样)来执行 exhaustive augmentation,收集全面的状态转换以最大化环境动态的覆盖范围
- 理解:这里的 exhaustive augmentation 指 穷尽式数据增强,访问了所有的有效动作
- 此过程生成了超过 70,000 个状态转换样本,为学习环境动态(包括预算更新、约束评估和计划进展)提供了丰富的监督信息
- Self-Reflection 论文通过提示 Llama-3.1-8B-Instruct 生成思维链推理来解释为什么专家动作优于 alternative 动作,从而构建 Self-Reflection 数据
- 对于 1,395 个状态-动作对中的每一个,论文探索最多 30 个替代的有效动作,并生成考虑多个约束的推理:预算限制、住宿的最低住宿夜数、餐厅多样性要求以及往返完成情况
- 推理生成使用温度 0.9 和 8 路张量并行性来产生自然的解释,同时保持逻辑一致性
- 论文不应用额外的过滤,因为推理生成过程已经验证了约束满足情况
- 问题:这里为什么要使用 Llama-3.1-8B-Instruct 而不是目标模型?
- 训练细节 论文使用 LlamaFactory ,在 8 个 H100 GPU 上使用 DeepSpeed ZeRO-3 进行全参数微调来训练模型
- 对于模仿学习和隐式世界建模,论文以 \(1\mathrm{e}{-5}\) 的学习率和余弦调度器训练 5 个 Epoch
- 对于 Self-Reflection ,论文将最大生成长度扩展到 8K Token 以容纳详细的推理
- 所有模型使用 32K 上下文窗口,每个 GPU 批大小为 16
- 对于评估,论文使用 vLLM,在 8 个 GPU 上进行张量并行,并使用贪婪解码以确保可重现性
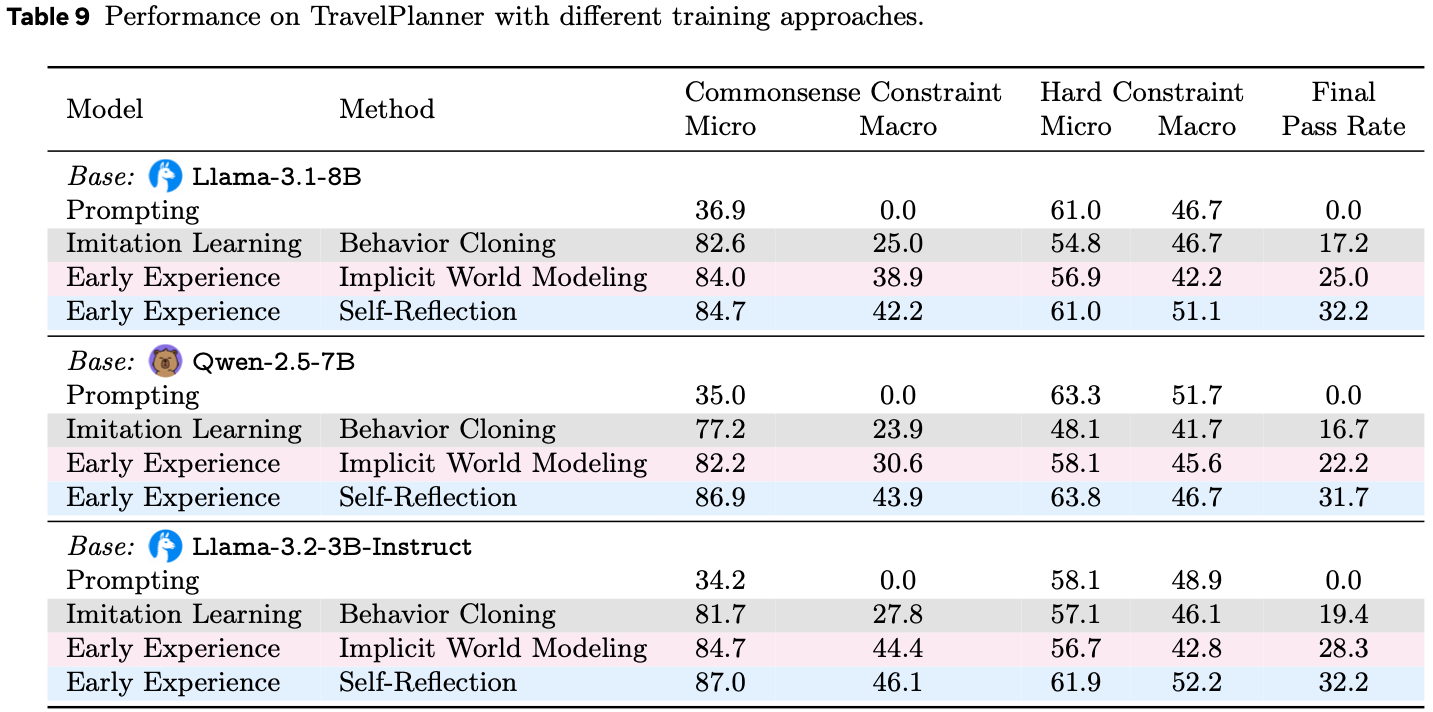
- 完整结果见表 9

B.8 WebArena
- 鉴于 WebArena (2024) 中的完整评估集冗长且包含许多类似任务
- 论文遵循先前的工作 (2024; 2025a) ,在 WebArena-Lite (2024) 上评估论文训练好的智能体,这是一个从原始的 812 个任务中手动挑选出的更高效、更平衡的 165 个高质量、具有挑战性的任务的子集
- WebArena 中剩余的 647 个任务(不包括评估集中的任务)用于智能体训练
- 为了获取 WebArena 中的专家演示,论文从公开的 WebArena 排行榜上表现最佳的智能体中提取成功的轨迹
- 具体来说,论文选择那些在其观察中包含可访问性树信息的智能体,例如 IBM CUGA (2025), ScribeAgent (2024), Learn-by-Interact (2025) 和 AgentOccam (2024)
- 在过滤掉不成功的轨迹后,论文获得了 554 条成功的轨迹和 7,044 个状态-动作对,构成了 \(\mathcal{D}_{\text{expert} }\)
- 对于隐式世界建模 ,为了从专家轨迹中分支出来进行隐式世界建模 ,论文增强 \(\mathcal{D}_{\text{expert} }\) 以形成 \(\mathcal{D}_{\text{rollout} }\)
- 对于 \(\mathcal{D}_{\text{expert} }\) 中的每个状态,论文让目标模型(待训练)使用自由形式生成提出 5 个非专家动作,排除任何与专家动作相同的动作
- 对于每个 resulting next state,论文应用一个额外的处理步骤:使用相同的模型,论文生成下一个状态观察的简洁摘要,该摘要以任务为条件,替换原始观察以减少噪声并强调与任务相关的信息。然后,论文将专家动作与采样的动作一起包含进来,创建形式为(当前状态,动作,摘要化的下一个状态)的三元组,最终为每个模型总共产生 \(7,044 \times 6 = 42,264\) 个三元组
- 对于 Self-Reflection ,论文通过提示模型解释在当前状态下为什么专家动作优于采样的 alternative 动作来构建 \(\mathcal{D}_{\text{SR} }\)
- 论文使用来自 \(\mathcal{D}_{\text{rollout} }\) 的相同 5 个 alternative 动作,规范化动作字符串以避免重复,并用随机采样的有效动作替换任何无效动作(例如,引用不存在的 UI 元素)
- 最终的提示词包括当前状态、可行动作和专家动作,并要求模型在任务进度、约束满足和效率方面证明专家选择的最优性
- 论文过滤掉那些解释错误地支持非专家动作的低质量生成内容,留下 3,190 个高质量的 Self-Reflection 示例
- 所有模型均以 1e-5 的学习率和余弦调度器训练 2 个 Epoch
- 论文在 WebArena-Lite 上的完整数据报告在表 10 中