整体说明
- 当前主流的大模型存储格式可以按 “训练框架原生格式 -> 通用交换格式 -> 高效推理格式” 这条演进路线来理解
- TLDR:“训练阶段用
.pth/.ckpt/.bin,跨框架交换用 ONNX,线上部署优先 Safetensors,如果对体积和 CPU 推理速度极端敏感就转 GGUF”
模型格式归纳
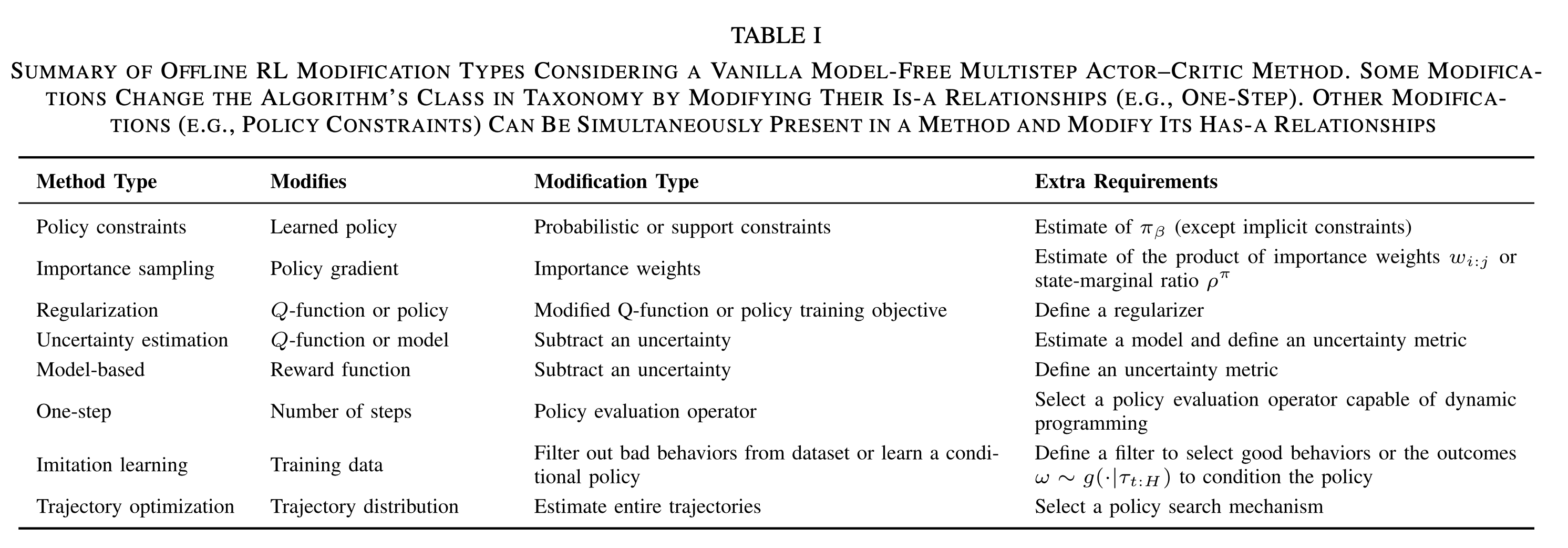
- 训练框架原生格式
.pth / .pt:PyTorch 的 pickle 序列化结果,既可以是 state_dict,也可以是完整模型(含结构+权重)通用、易用,但体积大、加载慢,且存在反序列化安全风险.ckpt:PyTorch Lightning 在 .pth 基础上扩展出的 Checkpoint 格式,额外保存优化器状态、epoch、超参等,用于断点续训.bin:TensorFlow 早期常用的纯权重二进制文件,没有统一元数据,需配合 config.json 使用;在 Hugging Face 生态中仍大量出现
- 通用交换格式
- ONNX(
.onnx):微软+Facebook 推出的开放标准,旨在跨框架(PyTorch/TF/ Paddle 等)部署;支持图优化、量化,但大模型时文件体积依旧可观 - HDF5 /
.h5:Keras/TensorFlow 传统格式,层次化存储网络结构和权重;对超大规模模型支持有限,已逐渐被 TF Checkpoint 或 SavedModel 取代
- ONNX(
- 高效推理格式
- Safetensors(
.safetensors):Hugging Face 推出的安全张量格式,只存权重、无代码、支持 zero-copy 与懒加载,加载速度 >pickle,且杜绝反序列化漏洞,已成为 HF Hub 的默认推荐 - GGUF(GPT-Generated Unified Format):由 llama.cpp 作者 Georgi Gerganov 设计,用于取代旧版 GGML二进制紧凑、自带量化方案(Q2_K/Q4_0 等)、内存映射快速加载、元数据自包含,无需额外文件即可部署;Gemma、Qwen、Llama-3 等均官方提供 GGUF 版本
- GGML(已弃用):早期 llama.cpp 使用的二进制格式,无版本控制、扩展困难,已全部迁移到 GGUF
- Safetensors(
- 训练/数据级格式(辅助)
- TFRecord / RecordIO:TensorFlow 训练数据管道常用,顺序、可压缩、高吞吐
- Parquet / Arrow / LMDB:离线特征或中间结果列式存储,便于大规模并行读取
大模型常用框架相关的格式整体说明
- 本文描述大模型的存储的形式和 转到 Hugging Face 的方式
- Megatron / DeepSpeed / FSDP 都把 “一张完整的权重图” 切成很多片,文件名、目录结构、张量 key 名均与 HF 不一致;
- 想进 HF 生态,必须 “合并分片 + 重命名 key + 生成 config.json”;
- 合并脚本一般都已有各框架的官方提供,一般按照官方提供脚本转换即可
Hugging Face 原生格式
- Hugging Face 上的开源模型通常以 “模型仓库(model repository)” 的形式托管,下载到本地后是一个目录,里面包含若干标准文件
- 使用 Hugging Face 的接口加载模型时,该接口会大致进行以下流程:
- 加载配置:读取
config.json文件,用于构建模型的基本结构 - 加载权重:读取模型权重文件(如
model.safetensors)中的参数值会被加载到定义好的模型结构中 - 分词器初始化(处理输入):分词器文件(如
tokenizer.json,vocab.json)负责将原始文本转换为模型能够理解的 token ID 序列 - 其他步骤:如果是文本生成任务,
generation_config.json会提供默认的生成参数
- 加载配置:读取
- 推理最少三件套 :
config.json+ 权重文件 + 分词器文件 - 微调再补 :
tokenizer_config.json、special_tokens_map.json、generation_config.json及优化器 checkpoint - 大模型 :使用
.safetensors分片和*.index.json索引,断点续传更方便
必存在文件(推理/微调都少不了)
config.json- 主要包含模型超参与架构描述:隐藏层大小(
hidden_size)、注意力头数(num_attention_heads)、层数(num_hidden_layers)、激活函数(hidden_act)等 - 不同模型的内容不完全相同(是各家模型厂商自己自定义的),这个文件是会被当做超参数传递到模型的初始化文件中的
- 还包含模型的 参数类型 (比如
"torch_dtype": "bfloat16") 作为加载时的统一转换类型- 注:同一个模型的不同参数可以存储为不同类型,这里的
"torch_dtype"字段仅仅指定加载时的参数
- 注:同一个模型的不同参数可以存储为不同类型,这里的
- 主要包含模型超参与架构描述:隐藏层大小(
- 权重主文件(可以是
.bin,.h5,safetensors等类型的文件,也可能是gguf等量化格式的文件)pytorch_model.bin(PyTorch)- 分片(shard)文件 比如
pytorch_model-00001-of-00008.bin到pytorch_model-00008-of-00008.bin,会伴随一个pytorch_model.bin.index.json索引文件来记录这些分片信息
- 分片(shard)文件 比如
tf_model.h5(TensorFlow)flax_model.msgpack(Flax/JAX,不常见)model.safetensors(新版统一二进制格式,零拷贝、更安全)- Hugging Face 推荐的安全格式 ,不包含可执行代码 ,避免了传统 PyTorch 格式因使用 pickle 序列化而可能存在的安全风险(如恶意代码执行)
- 通常加载更快且更节省内存
- 分片(shard)文件 比如
model-00001-of-00008.safetensors到model-00008-of-00008.safetensors,会伴随一个model.safetensors.index.json索引文件来记录这些分片信息
gguf(量化后的 GGUF 格式)- CPU 或个人设备上进行本地推理 ,首选能提供更好的体验
- 一般会按照不同的量化格式提供多个
gguf文件,如q4_k_m.gguf等来说明量化形式
- 注:加载过程中,根据不同的模型权重类型,Hugging Face 框架会使用不同的加载函数加载
tokenizer.json- 分词器核心配置:预处理器状态、编解码规则、特殊 token 映射
- 词表内容一般也会在这格文件中,以
vocab为 Key 存在,所以tokenizer.json一般会有几十 MB 大小
- 补充:
model.safetensors.index.json索引文件示例,包含模型的每一层权重到权重分片的映射1
2
3
4
5
6
7
8
9
10
11
12{
"metadata": {
"total_size": 144575840256
},
"weight_map": {
"lm_head.weight": "model-00082-of-00082.safetensors",
"transformer.h.0.attn.c_attn.bias": "model-00002-of-00082.safetensors",
"transformer.h.0.attn.c_attn.weight": "model-00002-of-00082.safetensors",
"transformer.h.0.attn.c_proj.weight": "model-00002-of-00082.safetensors",
"..."
}
}
常见文件(大部分仓库可见)
- 分词器相关文件:
tokenizer.json:分词器的完整定义,包括编码规则和词汇表映射(前面已经介绍过)tokenizer_config.json:分词器的附加配置,如特殊标记(如[CLS]、[SEP]、[PAD])、填充方式、截断策略等- 部分模型会将聊天模版也放到这个文件中的
chat_template字段(Qwen,Deepseek 等),部分模型则将聊天模板放到外面的chat_template.jinja文件(这样虽然不便于管理,但可读性会更高)
- 部分模型会将聊天模版也放到这个文件中的
vocab.txt,vocab.json:模型的词汇表,存储 token 到 ID 的映射关- 注:目前许多模型已经不需要这个文件,因为该文件会以
"vocab"字段的形式放到tokenizer.json中
- 注:目前许多模型已经不需要这个文件,因为该文件会以
merges.txt:适用于 BPE 等分词算法,定义了 token 的合并规则- 注:目前许多模型已经不需要这个文件,因为该文件会以
"merges"字段的形式放到tokenizer.json中
- 注:目前许多模型已经不需要这个文件,因为该文件会以
special_tokens_map.json:统一声明[PAD]、[CLS]、[SEP]、<|im_start|>等特殊 token 的 ID 与字符串映射- 注:目前许多模型已经不需要这个文件,因为该文件会以
"additional_special_tokens"字段的形式放到tokenizer_config.json
- 注:目前许多模型已经不需要这个文件,因为该文件会以
added_tokens.json:用户或微调阶段追加的新 token- 注:目前许多模型已经不需要这个文件,因为该文件会以
"added_tokens"字段的形式放到tokenizer.json中
- 注:目前许多模型已经不需要这个文件,因为该文件会以
generation_config.json: 文本生成默认策略:max_new_tokens、do_sample、temperature、top_p等.gitattributes: 用于配合 Git-LFS 把大文件托管到 LFS- gitattributes 是 Git 中用于定义特定文件(或文件类型)在 Git 操作中的处理规则的配置文件
- 核心作用是 “为不同文件定制 Git 行为” ,告诉 Git:对于不同类型的文件,应该如何执行换行符转换、合并策略、文件属性标记、diff 对比方式等操作,从而在团队协作或跨平台开发中保持文件处理的一致性
附录:关于 generation_config.json 文件的使用
在使用 Hugging Face 的
transformers库加载模型时,会自动读取模型文件路径下的generation_config.json文件(如果存在的话)generation_config.json是用于存储模型生成相关配置的文件,包含了如最大生成长度(max_length)、采样温度(temperature)、top-k 采样等与文本生成任务相关的参数当使用
from_pretrained()方法加载模型时,库会自动检查并加载该文件中的配置,这些配置会被存储在模型的generation_config属性中。例如:1
2
3
4
5
6
7from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("model_path")
tokenizer = AutoTokenizer.from_pretrained("model_path")
# 查看加载的生成配置
print(model.generation_config)如果模型路径中存在
generation_config.json,上述代码会自动加载其中的配置;如果该文件不存在,transformers会使用默认的生成配置也可以通过
GenerationConfig类手动加载或修改这些配置,并在生成文本时传入:1
2
3
4
5
6
7
8from transformers import GenerationConfig
# 手动加载生成配置
gen_config = GenerationConfig.from_pretrained("model_path")
# 修改配置
gen_config.max_length = 100
# 生成文本时使用
outputs = model.generate(**inputs, generation_config=gen_config)
其他可选/场景文件
training_args.bin: 由transformers.Trainer自动保存,包含学习率、warmup step、batch_size等训练超参optimizer.bin/scheduler.bin: 断点续训时保存的优化器状态和 LR scheduler 状态quantization/目录 : 低比特量化权重,如F8_E4M3、INT4、GGML 等README.md/LICENSE/*.md: 模型卡片、许可证、使用示例、局限性与伦理声明preprocessor_config.json: 多模态模型(如 LLaVA、BLIP-2)中,图像预处理超参adapter_config.json/adapter_model.bin: PEFT/LoRA 微调产生的轻量 adapter,仅含可训练增量参数tokenizer.model文件是 SentencePiece 分词器的核心文件,通常以二进制格式存储,包含分词规则、词汇表和预处理逻
关于 .bin 格式 和 .safetensors 格式的说明
.bin是 Hugging Face 最早、最通用的格式(PyTorch 的格式),任何支持from_pretrained()的库都能直接加载如果同时包含一个同名的
.safetensors和.bin,HF 会优先用.safetensors(更快、更安全)将
.bin格式升级为.safetensors格式的接口如下:1
2import safetensors
safetensors.torch.save_file(state_dict, "model.safetensors")特别说明:
.bin和.safetensors中会包含权重文件的参数类型(fp16,fp32,bf16等)- 而且,
.bin和.safetensors文件会为每个不同的参数张量存储各自的参数,所以理论上这些参数类型可以不用 - 在加载模型时,会先按照权重文件中的真实类型读取,并转换成
config.json中指定的文件格式(比如"torch_dtype": "bfloat16"指定bf16格式),存放到内存中
- 而且,
Megatron-LM 框架文件格式
分片数量与分片参数(TP=N1、PP=N2、DP=N3)有关,下面是磁盘目录示例:
1
2
3
4
5
6
7
8iter_0001000/
├── model_optim_rng.pt # 传统同步格式(老版本)
├── __0_0.distcp # 新异步格式(v0.7+),每个文件只含本 rank 的分片
├── ...
├── __1_0.distcp
├── common.pt # 公共张量(embedding、lm_head 等)
├── metadata.json # 并行拓扑
└── latest_checkpointed_iteration.txt注:部分 Megatron-LM 存储形式中, iter_0001000 下存储的是多个类似
mp_rank_xx_xx_cp_xx_dp_xx目录的结构,每个结构存储部分模型参数这是 Megatron-LM 原生 checkpoint 的分布式存储结构
命名规则:
1
mp_rank_{tensor_parallel_rank}_{checkpoint_partition}_{data_parallel_rank}
含义:
- mp_rank_xx_xx :Tensor Model Parallel rank(张量并行+流水线并行的分片编号)
- cp_xx :Context parallel rank(上下文并行分片编号)
- dp_xx :Data parallel rank(数据并行的副本编号)
每个目录里可能包含:
distrib_optim.pt- 分布式优化器(比如 ZeRO)的状态分片,包含梯度累积缓冲、参数分片等,用于 resume 训练使用,若确定不再需要继续训练,则可以删除该文件
model_optim_rng.pt- 保存随机数生成器状态(Python random、NumPy RNG、PyTorch CPU/CUDA RNG、Megatron并行RNG),用于恢复训练时保证随机性一致
- 注:部分架构中,模型权重也存储在这个文件里面
Megatron 格式与 HF 不兼容;需要合并+重命名,下面是官方给出的转换脚本(同步格式)
1
2
3
4
5
6python tools/checkpoint_converter.py \
--model-type GPT \
--load-dir iter_0001000 \
--save-dir hf_format \
--target-tensor-parallel-size 1 \
--target-pipeline-parallel-size 1HF 的一般格式现在是类似下面的形式
1
2
3
4
5
6
7hf_format/
├── model_00001-of-00010.safetensors # 文件权重
├── model_xxx...
├── model.safetensors.index.json # 分片成多个文件时用于索引
├── tokenizer.json
├── tokenizer_config.json
└── config.json # 由脚本自动生成
DeepSpeed 框架文件格式
ZeRO-3 会对参数进行分片,分片数量参数有关,磁盘目录(16 GPU)
1
2
3
4
5
6
7global_step1000/
├── bf16_zero_pp_rank_00_mp_rank_00_optim_states.pt # 优化器状态
├── bf16_zero_pp_rank_01_mp_rank_00_optim_states.pt
├── ...
├── zero_pp_rank_00_mp_rank_00_model_states.pt # 权重分片
├── zero_pp_rank_01_mp_rank_00_model_states.pt
└── ...DeepSpeed 与 HF 不兼容;需要合并(DeepSpeed 自带工具)
1
python zero_to_fp32.py global_step1000 ds_model.pth
进一步精简权重文件(仅保留权重)并转 HF 的代码:
1
2
3
4
5
6
7
8
9
10import torch
from transformers import AutoConfig, AutoModelForCausalLM
state_dict = torch.load('ds_model.pth', map_location='cpu')
torch.save(state_dict, 'pytorch_model.bin') # 仅权重
config = AutoConfig.from_pretrained('meta-llama/Llama-2-7b-hf')
model = AutoModelForCausalLM.from_config(config)
model.load_state_dict(state_dict)
model.save_pretrained('hf_from_ds')
PyTorch FSDP 框架文件格式
磁盘目录(8 GPU)
1
2
3
4
5checkpoint-1000/
├── __0_0.distcp # 每个 rank 的分片
├── ...
├── __7_0.distcp # 每个 rank 的分片
└── .metadata # FSDP 元数据PyTorch FSDP 与 HF 不兼容;需要合并,官方合并脚本(PyTorch 大于 2.2)
1
2
3python -m torch.distributed.checkpoint.format_utils dcp_to_torch_save \
checkpoint-1000 \
fsdp_model.pth再转成 HF Safetensors(更快、安全)
1
2
3
4
5from safetensors.torch import save_file
import torch
state_dict = torch.load('fsdp_model.pth')
save_file(state_dict, 'model.safetensors')
附录:在不加载模型的情况下查看 safetensors 文件参数类型
- 使用 transformers 库加载模型后查看参数,参数可能会被自动转换(依据不同模型实现有所不同,部分模型参数加载后是
float32)- 注意:即使
config.json中显示是"torch_dtype": "bfloat16",在from_pretrain函数不显示指定参数类型的情况下,也会出现自动转换为float32的情况
- 注意:即使
- 显示指定参数类型加载后,输出与指定类型一致,但是看不到原始的参数类型了
- 下面介绍两种方法,可以直接查看某个
safetensors文件的参数类型
方式一:命令行查看
使用 hexdump 命令可以抽取部分文件查看其
dtype信息1
hexdump -C -n 4096 model_00001-of-00010.safetensors | grep -A 20 '"dtype"'
这条命令的作用是查看 safetensors 模型文件的十六进制内容,并筛选出包含 “dtype” 的行及其后 20 行,以便分析模型数据类型相关信息。下面是详细解释:
hexdump:用于以十六进制和 ASCII 形式显示文件内容的工具-C:以规范的十六进制+ASCII 格式显示,左侧为十六进制值,右侧为对应的可打印字符-n 4096:仅显示文件的前 4096 个字节(4KB)grep -A 20:在文本中搜索匹配模式,除了显示匹配的行外,还显示该行之后的 20 行内容(A 即 After 的缩写)
执行命令后会看到类似的输出:
1
..."dtype":"BF16"...
方式二:python 查看
安装 safetensors 包
执行下面的代码:
1
2
3
4
5
6
7
8
9
10from safetensors.torch import load_file
# 加载 .safetensors 文件
weight_file = "~/model/Qwen2.5-7B-Instruct/model-00001-of-00004.safetensors"
state_dict = load_file(weight_file, device="cpu")
# 查看存储类型
for name, param in list(state_dict.items())[:5]:
print(f"参数 {name} 在硬盘上的存储类型: {param.dtype}")输出如下:
1
2
3
4
5参数 model.embed_tokens.weight 在硬盘上的存储类型: torch.bfloat16
参数 model.layers.0.input_layernorm.weight 在硬盘上的存储类型: torch.bfloat16
参数 model.layers.0.mlp.down_proj.weight 在硬盘上的存储类型: torch.bfloat16
参数 model.layers.0.mlp.gate_proj.weight 在硬盘上的存储类型: torch.bfloat16
参数 model.layers.0.mlp.up_proj.weight 在硬盘上的存储类型: torch.bfloat16bfloat16与 Qwen2.5-7B-Instruct 的 config.json 类型能对齐
附录:ckpt 中添加自定义模型类
- 在模型 ckpt 目录(hf 文件目录)下,可以存放
*.py文件,用于定义自定义的模型结构 - 这些
*.py文件会被transformers库加载,故而可以在config.json中指定使用 - 注意:megatron 训练一般不会使用
config.json中指定的类,而是根据各种超参加载的 transformers库AutoModelForCausalLM.from_pretrained -> AutoConfig.from_pretrained加载模型的方式有两种:- 第一种:
config.json包含model_type参数的- 此时要求模型类提前备注册过
- 第二种:
config.json不包含model_type参数的- 此时可以按照自定义的类进行初始化(定义在
*.py中,放到ckpt路径下即可) - 执行
AutoModelForCausalLM.from_pretrained函数时添加trust_remote_code=True参数,否则无法加载模型文件
- 此时可以按照自定义的类进行初始化(定义在
- 第一种: