本文介绍QVPO(Q-weighted Variational Policy Optimization)方法
- 参考链接:
基本思路
- 目标:解决Online RL的问题
- 基本思想:通过Diffusion模型 \(\epsilon_\theta(a^i,s_t,i)\) 来建模策略(类似Diffusion-QL方法),具体地通过反向过程的多次采样得到当前状态 \(s_t\) 下的最优的动作 \(a_{t}^0\),其中 \(i\) 表示Diffusion采样时间步
- 通过推导得到在DDPM的损失函数上增加一个重要性权重即可实现模型生成价值更大的策略
Diffusion-QL方法
- 训练Pipeline:
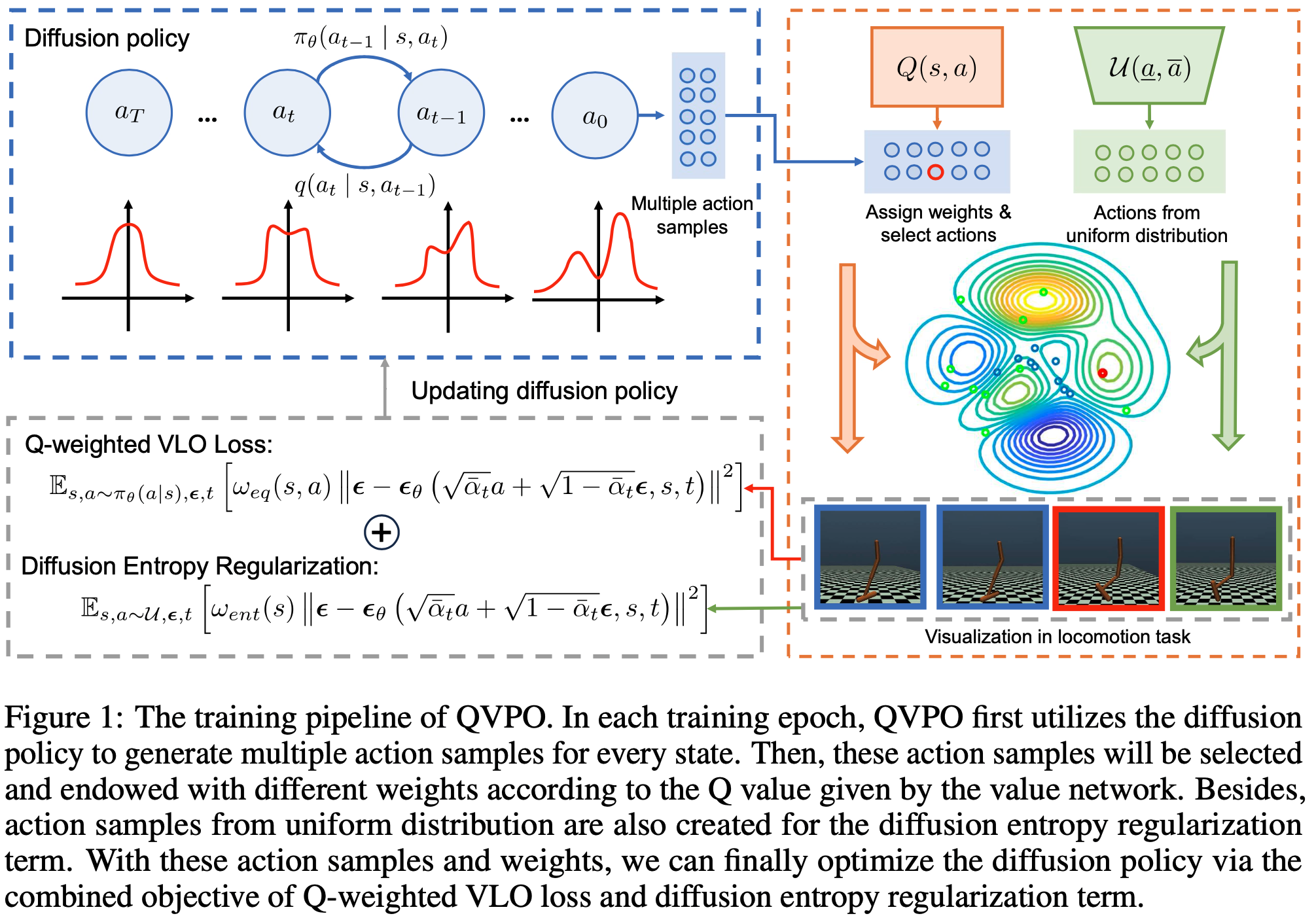
- 伪代码:

- 公式(9) 是为了避免出现负值问题引入的等价正Q权重(Equivalent Positive Q-weight)
- \(\pi_\theta^K(a|s)\) 的定义如下:
$$\pi_\theta^K(a|s) \triangleq \mathop{\arg\max}_{a\in\{a_1,\cdots,a_K\sim\pi_\theta(a|s)\}} Q(s,a)$$
Experiments
- 效果如下:
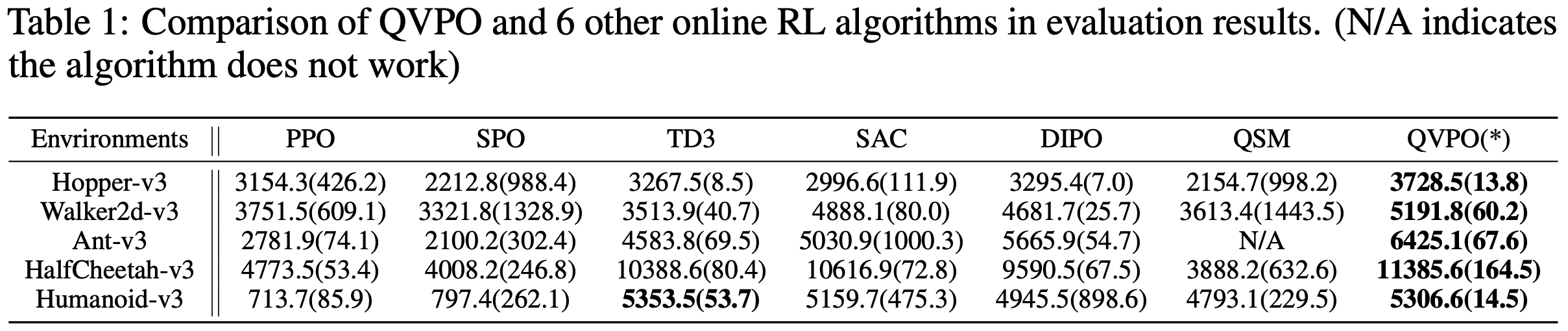
- 问题:为什么PPO在许多实验上的效果这么差?符合预期吗?