注:本文包含 AI 辅助创作
- 参考链接
Paper Summary
- 论文的目标是使用一个具有单一参数集的单一强化学习智能体来解决大量任务
- 一个关键挑战是处理增加的数据量和延长的训练时间
- 论文开发了一种新的分布式智能体 IMPALA(重要性加权 Actor-Learner 架构,Importance Weighted Actor-Learner Architecture),
- IMPALA 不仅能在单机训练中更有效地使用资源,而且可以扩展到数千台机器,同时不牺牲数据效率或资源利用率
- 论文通过将解耦的执行与学习相结合,并采用一种称为 V-trace 的新型 Off-policy 校正方法,实现了高吞吐量下的稳定学习
- 论文在 DMLab-30(来自 DeepMind Lab 环境 (2016) 的 30 个任务集)和 Atari-57(Arcade Learning Environment (2013b) 中所有可用的 Atari 游戏)上展示了 IMPALA 在多任务强化学习中的有效性
- 论文的结果表明,IMPALA 能够用更少的数据实现比先前智能体更好的性能,并且由于其多任务方法,关键地展示了任务间的正向迁移
Introduction and Discussion
- 深度强化学习方法通过试错学习掌握了多种领域 (2015; 2016; 2017; 2013a; 2014)
- 虽然在围棋 (2016) 和 Atari 游戏 (2015) 等任务上的改进是显著的,但进展主要是在单任务性能上,即每个任务分别训练一个智能体
- 论文感兴趣的是开发能够同时掌握多种多样任务的新方法,以及适合评估此类方法的环境
- 在多个任务上同时训练单个智能体的一个主要挑战是可扩展性
- 由于当前 SOTA 方法如 A3C (2016) 或 UNREAL (2017) 可能需要多达十亿帧数据和数天时间来掌握一个单一领域,同时在数十个领域上训练它们就太慢而不实用
- 论文提出了如图 1 所示的重要性加权 Actor-Learner 架构(Importance Weighted Actor-Learner Architecture, IMPALA)
- IMPALA 能够扩展到数千台机器,同时不牺牲训练稳定性或数据效率
- 与流行的基于 A3C 的智能体(其工作进程向中央参数服务器通信关于策略参数的梯度)不同,IMPALA 的执行者(actor)将经验轨迹(状态、动作和奖励的序列)通信给一个集中化的 Learner
- 由于 IMPALA 中的 Learner 可以访问完整的经验轨迹,论文使用 GPU 对轨迹的小批量进行更新,同时积极并行化所有时间无关的操作
- 这种解耦架构可以实现非常高的吞吐量
- 与流行的基于 A3C 的智能体(其工作进程向中央参数服务器通信关于策略参数的梯度)不同,IMPALA 的执行者(actor)将经验轨迹(状态、动作和奖励的序列)通信给一个集中化的 Learner
- 然而,因为在梯度计算时,用于生成轨迹的策略可能落后于 Learner 上的策略若干次更新,学习就变成了 Off-policy 的
- 因此,论文引入了 V-trace Off-policy Actor-Critic 算法来校正这种有害的差异
- 结合可扩展架构和 V-trace,IMPALA 实现了每秒 250,000 帧的极高数据吞吐率,使其比单机 A3C 快 30 多倍
- 关键的是,IMPALA 也比基于 A3C 的智能体更具数据效率,并且对超参数值和网络架构更具鲁棒性,使其能够更好地利用更深的神经网络
- 论文通过在 DMLab-30(一个新的挑战集,包含在 3D DeepMind Lab (2016) 环境中的 30 个多样化认知任务)上训练单个智能体来解决多任务问题,以及在 Atari-57 任务集中的所有游戏上训练单个智能体,来展示 IMPALA 的有效性
Related Work
- 最早扩展深度强化学习的尝试依赖于具有多个工作进程的分布式异步随机梯度下降(SGD)(2012)
- 比如分布式 A3C (2016) 和 Gorila (2015)(深度 Q 网络 (2015) 的分布式版本)
- 最近用于强化学习的异步 SGD 的替代方案
- 包括使用进化过程 (2017)、分布式 BA3C (2018) 和 Ape-X (2018)(其具有分布式回放但同步 Learner )
- 也有多项工作通过利用 GPU 来扩展强化学习
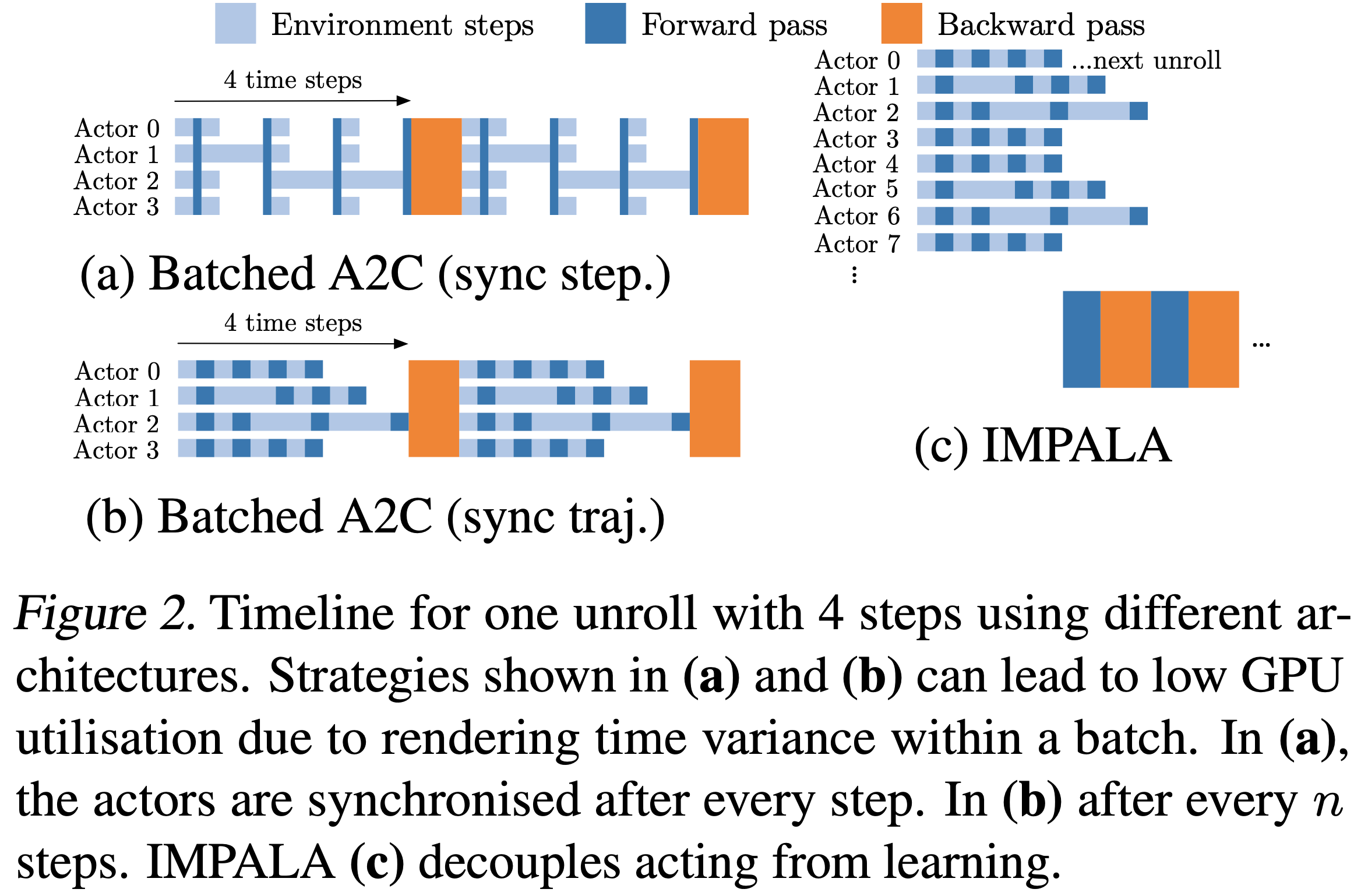
- 其中最简单的方法之一是批处理 A2C (2017)
- 在每一步,批处理 A2C 产生一批动作并将其应用于一批环境
- 每批中最慢的环境决定了执行整批步骤所需的时间(见图 1(a) 和 1(b))
- 换句话说,环境速度的高方差会严重限制性能
- 批处理 A2C 在 Atari 环境中特别有效,因为与强化学习智能体执行的昂贵张量操作相比,渲染和游戏逻辑在计算上非常便宜
- 但视觉或物理上更复杂的环境可能模拟速度较慢,并且每一步所需的时间可能具有高方差
- 环境也可能具有可变长度的(子)片段,导致初始化片段时速度减慢
- 其中最简单的方法之一是批处理 A2C (2017)
- 与 IMPALA 最相似的架构是 GA3C (2016),它也使用异步数据收集来更有效地利用 GPU
- GA3C 通过使用动态批处理将执行/前向传递与梯度计算/后向传递解耦
- GA3C 中的 Actor/Learner 异步性导致学习期间的不稳定性,(2016) 仅通过在策略梯度估计期间向动作概率添加一个小常数来部分缓解
- 相比之下,IMPALA 使用了更原则性的 V-trace 算法
- 先前关于 Off-policy 强化学习的相关工作包括 (2000, 2001); (2009); (2014); (2017) 和 (2016)
- 与论文工作最接近的是 Retrace 算法 (2016),它引入了多步强化学习的 Off-policy 校正,并已在多种智能体架构中使用 (2017); (2018)
- Retrace 需要学习状态-动作值(state-action-value)函数 \(Q\) 以进行 Off-policy 校正
- 然而,许多 Actor-Critic 方法(如 A3C)学习状态值(state-value)函数 \(V\) 而不是状态-动作值函数 \(Q\)
- V-trace 基于状态值函数
IMPALA
- IMPALA (图 1) 使用 Actor-Critic 设置来学习一个策略 \(\pi\) 和一个基线函数 \(V^{\pi}\)
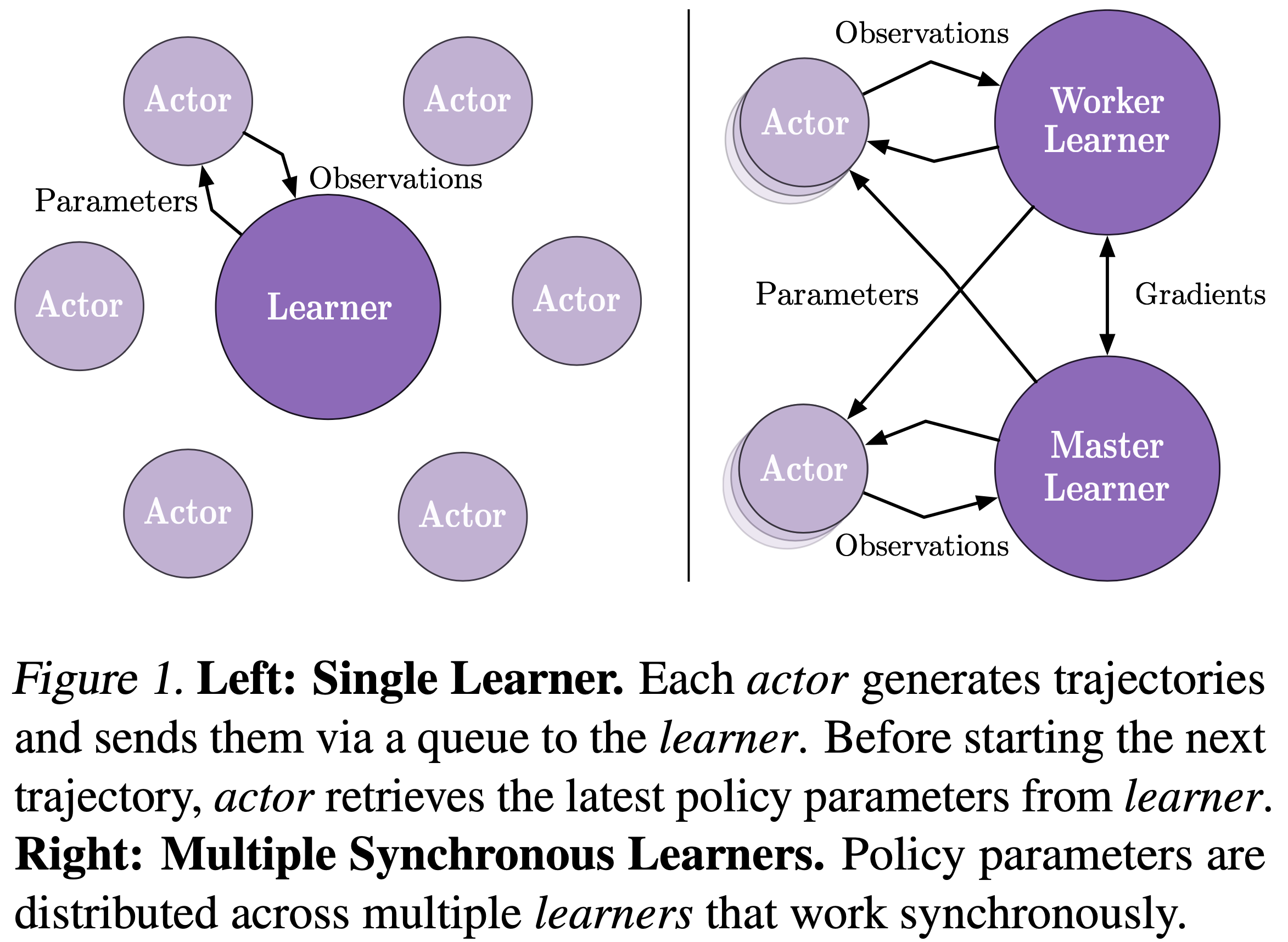
- 生成经验的过程与学习 \(\pi\) 和 \(V^{\pi}\) 的参数是解耦的
- 该架构由一组 Actor 和 一个或多个 Learner 组成, Actor 反复生成经验轨迹, Learner 使用 Actor 发送的经验来 Off-policy 地 (off-policy) 学习 \(\pi\)
- 在每个轨迹开始时,一个 Actor 会将其自身的本地策略 \(\mu\) 更新为最新的 Learner 策略 \(\pi\) (\(\mu \leftarrow \pi\)),并在其环境中运行 \(n\) 步
- 在 \(n\) 步之后, Actor 将状态、动作和奖励的轨迹 \(x_{1},a_{1},r_{1},\ldots,x_{n},a_{n},r_{n}\) 连同相应的策略分布 \(\mu(a_{t}|x_{t})\) 和初始 LSTM 状态通过一个队列发送给 Learner
- Learner 持续地在来自许多 Actor 的轨迹批次上更新其策略 \(\pi\)
- 这种简单的架构使得 Learner 能够使用 GPU 进行加速,并且 Actor 可以轻松地分布在多台机器上
- 但在更新时, Learner 策略 \(\pi\) 可能比 Actor 的策略 \(\mu\) 领先若干次更新,因此在 Actor 和 Learner 之间存在 策略滞后 (policy-lag)
- V-trace 算法校正了这种滞后,从而在保持数据效率的同时实现了极高的数据吞吐量
- 使用 Actor-Learner 架构,提供了像分布式 A3C 那样的容错能力,但通常具有更低的通信开销,因为 Actor 发送的是观测值而不是参数/梯度
- 随着模型架构越来越深,单个 GPU 的速度常常成为训练期间的 limiting factor (限制因素)
- 如图 1 所示,IMPALA 可以与分布式的 Learner 集合一起使用,以高效地训练大型神经网络
- 参数分布在各个 Learner 之间, Actor 并行地从所有 Learner 检索参数,同时只将观测值发送给单个 Learner
- IMPALA 使用同步参数更新,这在扩展到多台机器时对于保持数据效率至关重要 (2016)
Efficiency Optimisations
- GPU 和 many-core CPU 通过运行少量大型、可并行化的操作而不是许多小操作而受益匪浅
- 由于 IMPALA 中的 Learner 在整个轨迹批次上执行更新,因此它能够比像 A3C 这样的在线智能体并行化更多的计算
- 例如,一个典型的深度 RL 智能体包含一个卷积网络,后接一个 长短期记忆网络 (Long Short-Term Memory, LSTM) (1997) 和一个在 LSTM 之后的全连接输出层
- IMPALA Learner 通过将时间维度折叠到批次维度中,将卷积网络并行地应用于所有输入
- 类似地,一旦所有 LSTM 状态计算完毕,它也将输出层并行地应用于所有时间步
- 这种优化将有效批次大小增加到数千
- 基于 LSTM 的智能体还通过利用网络结构依赖性和操作融合 (2016) 在 Learner 上获得了显著的加速
- 最后,论文还利用了 TensorFlow (2017) 中提供的几种现成的优化,例如在执行计算的同时为 Learner 准备下一批数据、使用 XLA(一个 TensorFlow 即时编译器)编译部分计算图,以及优化数据格式以从 cuDNN 框架 (2014) 获得最大性能
V-trace
- 在解耦的分布式 Actor-Learner 架构中, Off-policy 学习非常重要,因为 Actor 生成动作与 Learner 估计梯度之间存在滞后
- 为此,论文为 Learner 引入了一种新颖的 Off-policy Actor-Critic 算法,称为 V-trace
- 论文考虑 马尔可夫决策过程 (Markov Decision Processes, MDP) (1994; 1998) 中的 discounted infinite-horizon 强化学习问题,目标是找到一个策略 \(\pi\),以最大化未来折扣奖励的期望和:
$$ V^{\pi}(x)\stackrel{ {\mathrm{def} } }{ {=} }\mathbb{E}_{\pi}\big{[} \sum_{t\geq 0}\gamma^{t}r_{t}\big{]} $$- 其中 \(\gamma\in[0,1)\) 是折扣因子,\(r_{t}=r(x_{t},a_{t})\) 是时间 \(t\) 的奖励,\(x_{t}\) 是时间 \(t\) 的状态(初始化为 \(x_{0}=x\)),\(a_{t}\sim\pi(\cdot|x_{t})\) 是通过遵循某个策略 \(\pi\) 生成的动作
- Off-policy RL 算法的目标是使用由某个策略 \(\mu\)(称为 行为策略 (behaviour policy))生成的轨迹,来学习另一个策略 \(\pi\)(可能与 \(\mu\) 不同,称为 目标策略 (target policy))的价值函数 \(V^{\pi}\)
V-trace 目标 (V-trace target)
- 考虑一个由 Actor 遵循某个策略 \(\mu\) 生成的轨迹 \((x_{t},a_{t},r_{t})_{t=s}^{t=s+n}\)
- 论文为 \(V(x_{s})\)(论文在状态 \(x_{s}\) 的价值近似值)定义 \(n\)-step V-trace 目标为:
$$v_{s}\stackrel{ {\mathrm{def} } }{ {=} } V(x_{s})+\sum_{t=s}^{s+n-1}\gamma^{t-s}\Big{(}\prod_{i=s}^{t-1 }c_{i}\Big{)}\delta_{t}V \tag{1}$$- 理解:这里是贝尔曼目标而不是 Advantage,类似 \(r_t + V(s_t)\) 的角色
- 其中 \(\delta_{t}V\) 是 \(V\) 的时序差分:
$$ \delta_{t}V\stackrel{ {\mathrm{def} } }{ {=} }\rho_{t}\big{(}r_{t}+ \gamma V(x_{t+1})-V(x_{t})\big{)} $$ - \(\rho_{t}\) 和 \(c_{i}\) 是截断的重要性采样 (Importance Sampling, IS) 权重(论文使用符号约定 \(\prod_{i=s}^{t-1}c_{i}=1\) 当 \(s=t\))
$$
\rho_{t}\stackrel{ {\mathrm{def} } }{ {=} }\min\big{(}\bar{\rho},\frac {\pi(a_{t}|x_{t})}{\mu(a_{t}|x_{t})}\big{)} \\
c_{i}\stackrel{ {\mathrm{def} } }{ {=} }\min\big{(}\bar{c},\frac{\pi(a_{ t}|x_{t})}{\mu(a_{t}|x_{t})}\big{)}
$$ - 此外,论文假设截断水平满足 \(\bar{\rho}\geq\bar{c}\)
- 论文为 \(V(x_{s})\)(论文在状态 \(x_{s}\) 的价值近似值)定义 \(n\)-step V-trace 目标为:
- 在 On-policy 的情况下(当 \(\pi=\mu\)),并假设 \(\bar{c}\geq 1\),那么所有的 \(c_{i}=1\) 且 \(\rho_{t}=1\),因此 (1) 式重写为
$$
\begin{align}
v_{s} &=V(x_{s})+\sum_{t=s}^{s+n-1}\gamma^{t-s}\big{(}r_{t}+\gamma V(x_{t +1})-V(x_{t})\big{)}\\
&=\sum_{t=s}^{s+n-1}\gamma^{t-s}r_{t}+\gamma^{n}V(x_{s+n})
\end{align} \tag{2}
$$- 这是 On-policy \(n\)-step Bellman 目标
- 因此,在 On-policy 情况下,V-trace 简化为 On-policy \(n\)-step Bellman 更新
- 这个属性(是 Retrace (2016) 所不具备的)允许人们对离线和 On-policy 数据使用相同的算法
- (截断的)IS 权重 \(c_{i}\) 和 \(\rho_{t}\) 扮演不同的角色
- 权重 \(\rho_{t}\) 出现在时序差分 \(\delta_{t}V\) 的定义中,并定义了此更新规则的固定点
- 在表格情况下,即函数可以被完美表示时,此更新的固定点(即,当对所有状态都有 \(V(x_{s})=v_{s}\) 时),其特征是在期望下(在 \(\mu\) 下)\(\delta_{t}V\) 等于零,它是某个策略 \(\pi_{\bar{\rho} }\) 的价值函数 \(V^{\pi_{\bar{\rho} } }\),该策略由下式定义:
$$\pi_{\bar{\rho} }(a|x)\stackrel{ {\mathrm{def} } }{ {=} }\frac{\min\big{(}\bar{\rho}\mu(a|x),\pi(a|x)\big{)} }{\sum_{b\in A}\min\big{(}\bar{\rho}\mu(b|x ),\pi(b|x)\big{)} } \tag{3}$$ - (参见附录 A 中的分析)
- 所以当 \(\bar{\rho}\) 是无限的(即没有对 \(\rho_{t}\) 进行截断)时,这就是目标策略 \(\pi\) 的价值函数 \(V^{\pi}\)
- 然而,如果论文选择一个截断水平 \(\bar{\rho}<\infty\),论文的固定点就是策略 \(\pi_{\bar{\rho} }\) 的价值函数 \(V^{\pi_{\bar{\rho} } }\),该策略介于 \(\mu\) 和 \(\pi\) 之间
- 在 \(\bar{\rho}\) 接近零的极限情况下,论文得到行为策略 \(\mu\) 的价值函数 \(V^{\mu}\)
- 在附录 A 中,论文证明了相关 V-trace 算子的收缩性以及相应在线 V-trace 算法的收敛性
- 在表格情况下,即函数可以被完美表示时,此更新的固定点(即,当对所有状态都有 \(V(x_{s})=v_{s}\) 时),其特征是在期望下(在 \(\mu\) 下)\(\delta_{t}V\) 等于零,它是某个策略 \(\pi_{\bar{\rho} }\) 的价值函数 \(V^{\pi_{\bar{\rho} } }\),该策略由下式定义:
- 权重 \(c_{i}\) 类似于 Retrace 中的“迹切割”系数
- 它们的乘积 \(c_{s}\dots c_{t-1}\) 衡量了在时间 \(t\) 观察到的时序差分 \(\delta_{t}V\) 对先前时间 \(s\) 的价值函数更新的影响程度
- \(\pi\) 和 \(\mu\) 越不相似(论文越是 Off-policy ),该乘积的方差就越大
- 论文使用截断水平 \(\bar{c}\) 作为一种方差缩减技术
- 但请注意,这种截断不会影响论文收敛到的解(该解仅由 \(\bar{\rho}\) 表征)
- 因此,论文看到截断水平 \(\bar{c}\) 和 \(\bar{\rho}\) 代表了算法的不同特征:
- \(\bar{\rho}\) 影响 IMPALA 收敛到的价值函数的性质
- \(\bar{c}\) 影响 IMPALA 收敛到该函数的速度
- Remark 1 :V-trace 目标可以递归地计算:
$$v_{s}=V(x_{s})+\delta_{s}V+\gamma c_{s}\big{(}v_{s+1}-V(x_{s+1})\big{)}.$$ - Remark 2 :
- 与 Retrace\((\lambda)\) 类似,也可以在 V-trace 的定义中考虑一个额外的折扣参数 \(\lambda\in[0,1]\),通过设置 \(c_{i}=\lambda\min\big{(}\bar{c},\frac{\pi(a_{i}|x_{i})}{\mu(a_{i}|x_{i})}\big{)}\) 来实现
- 在 On-policy 情况下,当 \(n=\infty\) 时,V-trace 则简化为 TD\((\lambda)\)
Actor-Critic algorithm
策略梯度 (Policy gradient)
- 在 On-policy 情况下,价值函数 \(V^{\mu}(x_{0})\) 关于策略 \(\mu\) 的某个参数的梯度是
$$\nabla V^{\mu}(x_{0})=\mathbb{E}_{\mu}\Big{[}\sum_{s\geq 0}\gamma^{s}\nabla\log \mu(a_{s}|x_{s})Q^{\mu}(x_{s},a_{s})\Big{]},$$- 其中 \(Q^{\mu}(x_{s},a_{s})\stackrel{ {\textrm{def} } }{ {=} }\mathbb{E}_{\mu} \big{[}\sum_{t\geq s}\gamma^{t-s}r_{t}|x_{s},a_{s}\big{]}\) 是策略 \(\mu\) 在 \((x_{s},a_{s})\) 的状态-动作价值
- 这通常通过随机梯度上升来实现,该上升沿 \(\mathbb{E}_{a_{s}\sim\mu(\cdot|x_{s})}\Big{[}\nabla\log\mu(a_{s}|x_{s})q_{s}|x_ {s}\Big{]}\) 的方向更新策略参数,其中 \(q_{s}\) 是 \(Q^{\mu}(x_{s},a_{s})\) 的一个估计值,并在某个行为策略 \(\mu\) 下访问到的一组状态 \(x_{s}\) 上取平均
- 现在,在论文考虑的 Off-policy 设置中,我们可以使用被评估的策略 \(\pi_{\bar{\rho} }\) 和行为策略 \(\mu\) 之间的 IS 权重,沿以下方向更新论文的策略参数
$$\mathbb{E}_{a_{s}\sim\mu(\cdot|x_{s})}\Big{[}\frac{\pi_{\bar{\rho} }(a_{s}|x_{s })}{\mu(a_{s}|x_{s})}\nabla\log\pi_{\bar{\rho} }(a_{s}|x_{s})q_{s}\big{|}x_{s} \Big{]} \tag{4}$$- 其中 \(q_{s}\stackrel{ {\textrm{def} } }{ {=} }r_{s}+\gamma v_{s+1}\) 是从下一个状态 \(x_{s+1}\) 的 V-trace 估计 \(v_{s+1}\) 构建的 \(Q^{\pi_{\bar{\rho} } }(x_{s},a_{s})\) 的估计值
- 论文使用 \(q_{s}\) 而不是 \(v_{s}\) 作为论文的 Q 值 \(Q^{\pi_{\bar{\rho} } }(x_{s},a_{s})\) 的目标的原因是:
- 假设论文的价值估计在所有状态下都是正确的,即 \(V=V^{\pi_{\bar{\rho} } }\),那么论文有 \(\mathbb{E}[q_{s}|x_{s},a_{s}]=Q^{\pi_{\bar{\rho} } }(x_{s},a_{s})\)(而如果论文选择 \(q_{t}=v_{t}\) 则不具备此性质)。有关分析请参见附录 A,关于估计 \(q_{s}\) 的不同方法的比较请参见附录 E.3
- 为了降低策略梯度估计 (4) 的方差,论文通常从 \(q_{s}\) 中减去一个依赖于状态的基线,例如当前的价值近似值 \(V(x_{s})\)
- 最后请注意,(4) 式估计的是 \(\pi_{\bar{\rho} }\) 的策略梯度,这是在使用截断水平 \(\bar{\rho}\) 时 V-trace 算法所评估的策略
- 然而,假设偏差 \(V^{\pi_{\bar{\rho} } }-V^{\pi}\) 很小(例如,如果 \(\bar{\rho}\) 足够大),那么我们可以期望 \(q_{s}\) 为论文提供 \(Q^{\pi}(x_{s},a_{s})\) 的良好估计
- 考虑到这些 Remarks,论文推导出以下规范的 V-trace Actor-Critic 算法
V-trace actor-critic algorithm
- 考虑价值函数 \(V_{\theta}\) 和当前策略 \(\pi_{\omega}\) 的参数化表示
- 轨迹是由 Actor 遵循某个行为策略 \(\mu\) 生成的
- V-trace 目标 \(v_{s}\) 由 (1) 定义
- 在训练时间 \(s\),价值参数 \(\theta\) 通过梯度下降法在 \(l2\) 损失上朝着目标 \(v_{s}\) 更新,即,沿着下面的方向更新
$$\big{(}v_{s}-V_{\theta}(x_{s})\big{)}\nabla_{\theta}V_{\theta}(x_{s})$$ - 而策略参数 \(\omega\) 则沿着策略梯度的方向更新:
$$\rho_{s}\nabla_{\omega}\log\pi_{\omega}(a_{s}|x_{s})\big{(}r_{s}+\gamma v_{s+1}- V_{\theta}(x_{s})\big{)}$$ - 为了防止过早收敛,我们可以像在 A3C 中那样,沿着以下方向添加一个 熵奖励 (entropy bonus)
$$-\nabla_{\omega}\sum_{a}\pi_{\omega}(a|x_{s})\log\pi_{\omega}(a|x_{s})$$ - 总的更新是通过将这三个梯度按适当的系数重新缩放后相加得到的,这些系数是算法的超参数
Experiments
- 论文研究了 IMPALA 在多种设置下的性能
- 为了评估数据效率、计算性能和 Off-policy 校正的有效性,论文观察了在单个任务上训练的 IMPALA 智能体的学习行为
- 对于多任务学习,论文在一个新引入的包含 30 个 DeepMind Lab 任务的集合以及 Atari 学习环境 (2013a) 的所有 57 个游戏上训练智能体,每个智能体对所有任务使用同一组权重
- 在所有实验中,论文使用了两种不同的模型架构:
- 一个类似于 (2016) 的浅层模型,在策略和价值函数之前有一个 LSTM(如图 3(左)所示);
- 一个更深的残差模型 (2016)(如图 3(右)所示)
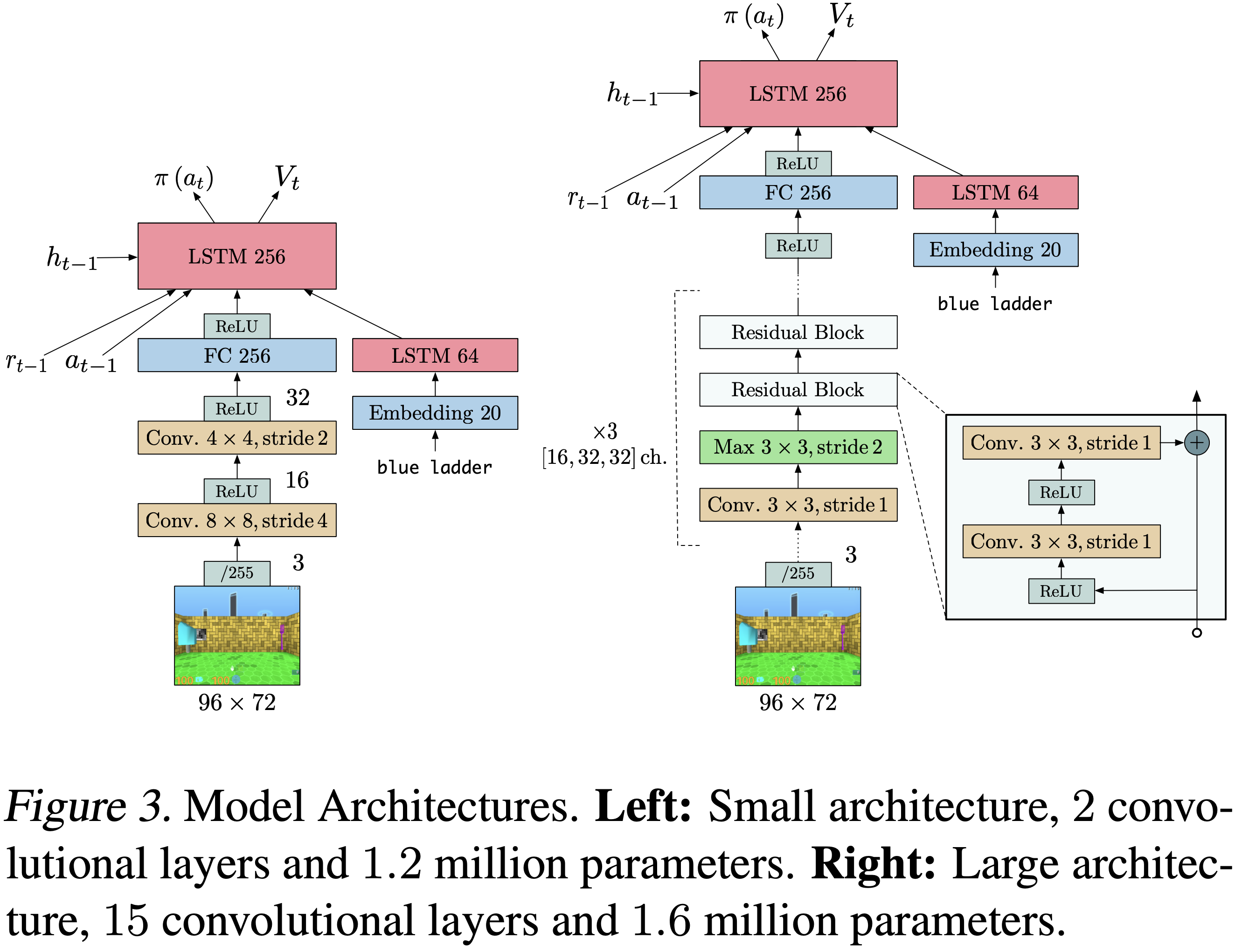
- 对于有语言通道的任务,论文使用了一个以文本嵌入作为输入的 LSTM
计算性能 (Computational Performance)
- 高吞吐量、计算效率和可扩展性是 IMPALA 的主要设计目标
- 为了证明 IMPALA 在这些指标上优于当前算法,论文比较了 A3C (2016)、批处理 A2C 变体以及具有各种优化的 IMPALA 变体
- 对于使用 GPU 的单机实验,论文在前向传播中使用动态批处理来避免多次批大小为 1 的前向传播
- 论文的动态批处理模块由专门的 TensorFlow 操作实现,但在概念上类似于 GA3C 中使用的队列
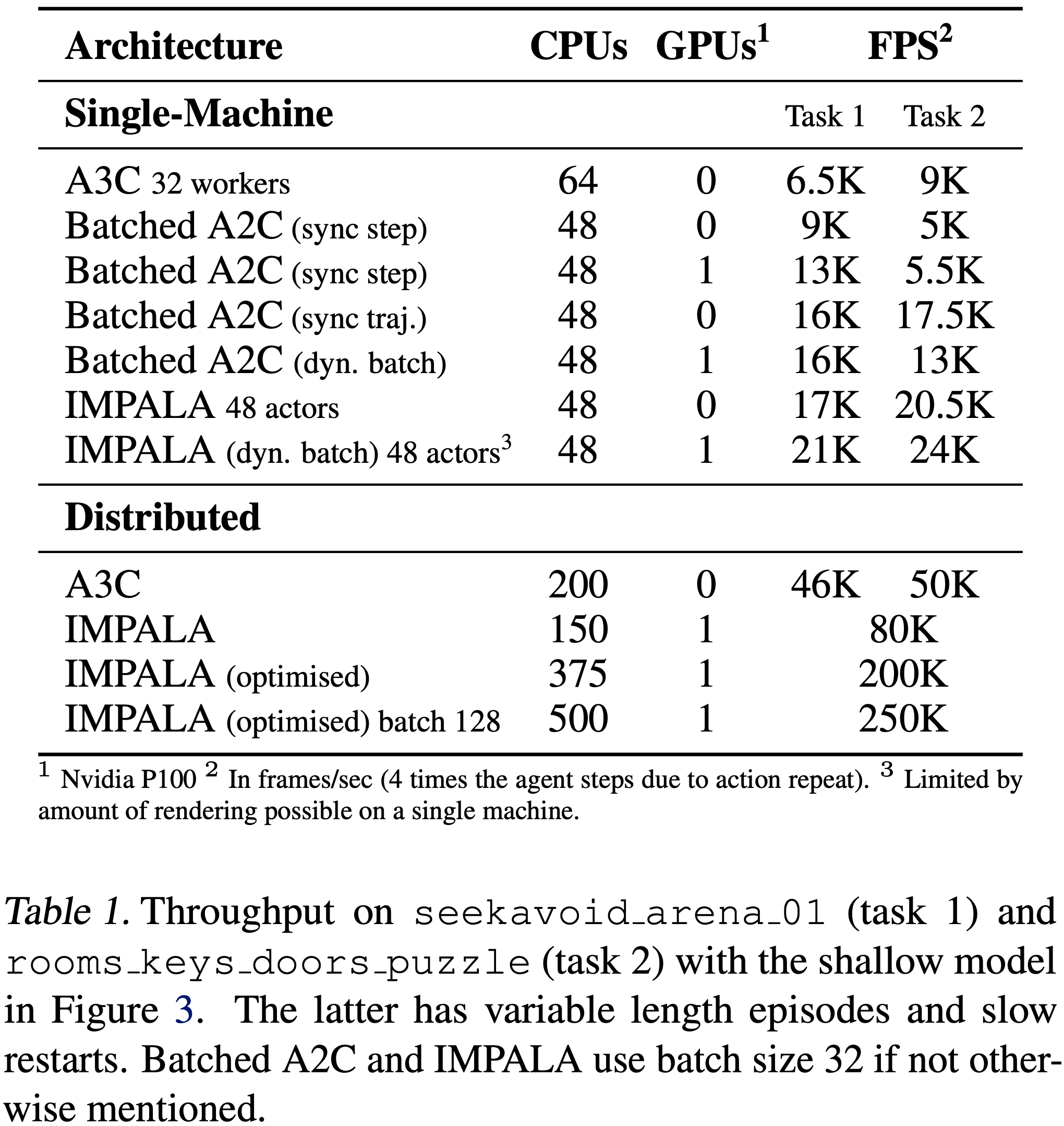
- 表 1 详细列出了使用图 3 中浅层模型的单机和多机版本的结果
- 在单机情况下,IMPALA 在两个任务上都实现了最高性能,领先于所有批处理 A2C 变体以及 A3C
- 且分布式多机设置才是 IMPALA 真正展示其可扩展性的地方
- 通过第 3.1 节中的优化来加速基于 GPU 的学习器,IMPALA 智能体实现了 250,000 帧/秒或 210 亿帧/天的吞吐率
- 为了减少每个学习器所需的执行器数量,可以使用辅助损失、来自经验回放的数据或其他仅在学习器上进行的昂贵计算
单任务训练 (Single-Task Training)
- 为了研究 IMPALA 的学习动态,论文采用了单任务场景,在 5 个不同的 DeepMind Lab 任务上分别训练智能体
- 该任务集包括一个规划任务、两个迷宫导航任务、一个带有脚本机器人的激光标签任务和一个简单的水果收集任务
- 论文对熵正则化的权重、学习率和RMSProp epsilon进行了超参数扫描
- 对于每个实验,论文使用一组相同的 24 个从附录 D.1 范围内预采样的超参数组合
- 其他超参数固定为附录 D.3 中指定的值
收敛性与稳定性 (Convergence and Stability)
- 图 4 显示了 IMPALA、A3C 和使用图 3 中浅层模型的批处理 A2C 之间的比较
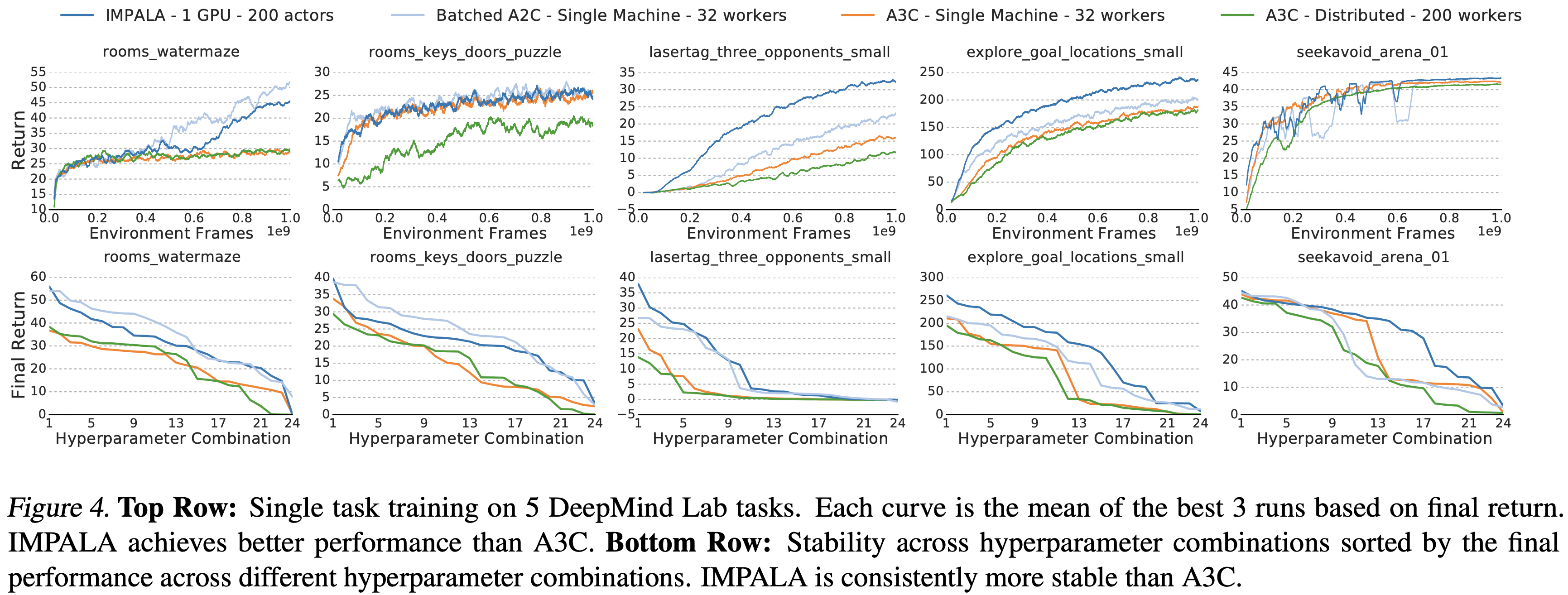
- 在所有 5 个任务中,要么是批处理 A2C 要么是 IMPALA 达到了最佳最终平均回报
- 并且在除 seekavoid_arena_01 之外的所有任务中,它们在整个训练过程中都领先于 A3C
- 理解:
- A2C 是严格 On-policy 的,且参数是同步更新,所以是理论上的性能最优;
- 对比来看,虽然 A3C 是 On-policy 的,但是存在参数的异步更新(有一定的滞后性),会导致一定的导致不稳定性
- IMPALA 在 5 个任务中的 2 个上优于同步批处理 A2C,同时实现了更高的吞吐量(见表 1)
- 论文推测这种行为可能源于
- 1)V-trace Off-policy 校正的作用类似于广义优势估计 (2016)
- 2)异步数据收集产生了更多样化的经验批次
- 论文推测这种行为可能源于
- 除了达到更好的最终性能外,IMPALA 对超参数选择的鲁棒性也比 A3C 更强
- 图 4 比较了上述方法在不同超参数组合下的最终性能,这些组合按平均最终回报从高到低排序
- IMPALA 在更多的组合上取得了更高的分数
V-trace 分析 (V-trace Analysis)
- 为了分析 V-trace,论文研究了四种不同的算法:
- 1. 无校正 (No-correction) : 无 Off-policy 校正
- 2. \(\varepsilon\)-校正 (\(\varepsilon\)-correction) :在梯度计算期间添加一个小的常数值(\(\varepsilon=1e-6\)),以防止 \(\log\pi(a)\) 变得非常小并导致数值不稳定,类似于 (2016)
- 3. 1-step 重要性采样 (1-step importance sampling) :优化 \(V(x)\) 时不进行 Off-policy 校正
- 对于策略梯度,将每个时间步的优势(advantage)乘以相应的重要性采样权重
- 此变体类似于没有“迹(traces)”的 V-trace,包含它是为了研究“迹”在 V-trace 中的重要性
- 4. V-trace :如第 4 节所述
- 对于 V-trace 和 1-step 重要性采样,论文将每个重要性权重 \(\rho_{t}\) 和 \(c_{t}\) 裁剪为 \(1\)(即 \(\bar{c}=\bar{\rho}=1\))
- 这降低了梯度估计的方差但引入了偏差
- 在 \(\bar{\rho}\in[1,10,100]\) 中,论文发现 \(\bar{\rho}=1\) 效果最好
- 论文在上一节的 5 个 DeepMind Lab 任务集上评估了所有算法
- 论文还在学习器上添加了一个经验回放缓冲区,以增加 \(\pi\) 和 \(\mu\) 之间的 Off-policy 差距
- 在经验回放实验中,论文从回放缓冲区中均匀随机抽取每批中 50% 的项目
- 表 2 分别显示了每种算法在有回放和无回放情况下的最终性能
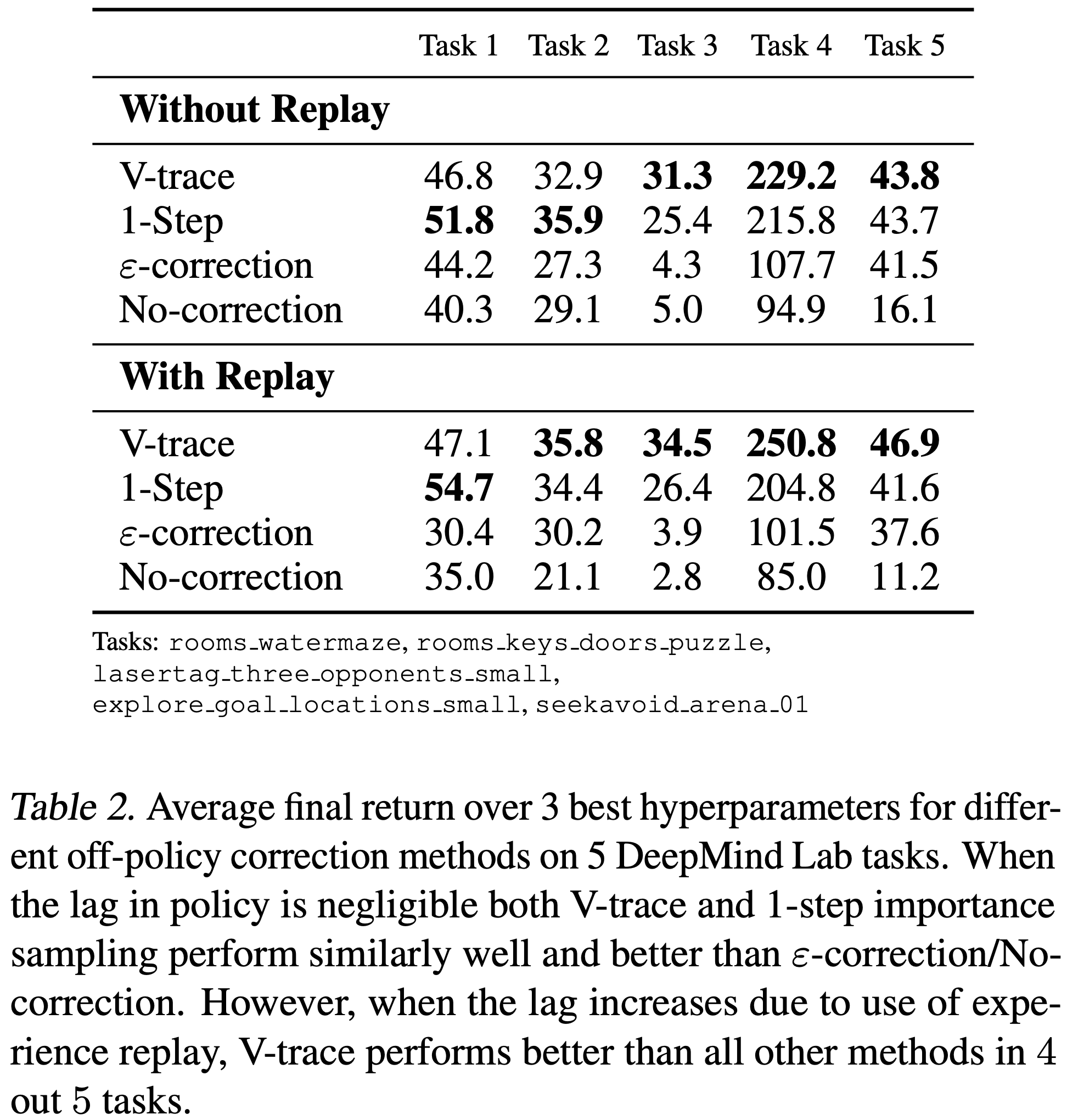
- 在无回放设置中,V-trace 在 5 个任务中的 3 个上表现最佳,其次是 1-step 重要性采样、\(\varepsilon\)-校正和无校正
- 尽管 1-step 重要性采样在无回放设置中表现与 V-trace 相似,但在使用经验回放时,在 5 个任务中的 4 个上差距扩大了
- 这表明,当目标策略和行为策略偏离更严重时,粗糙的 1-step 重要性采样近似变得不足
- 还要注意,V-trace 是唯一一个始终受益于添加经验回放的变体
- \(\varepsilon\)-校正 在两个任务上比无校正有显著改进,但远远落后于基于重要性采样的方法,特别是在使用经验回放的更 Off-policy 的设置中
- 图 E.1 显示了更详细分析的结果
- 图 E.2 显示基于重要性采样的方法在所有超参数下也表现更好,并且通常更鲁棒
- 尽管 1-step 重要性采样在无回放设置中表现与 V-trace 相似,但在使用经验回放时,在 5 个任务中的 4 个上差距扩大了
多任务训练 (Multi-Task Training)
- IMPALA 的高数据吞吐量和数据效率使论文不仅可以在一个任务上训练,还可以在多个任务上并行训练,只需对训练设置进行最小更改
- 论文没有在所有执行器上运行相同的任务,而是将固定数量的执行器分配给多任务套件中的每个任务
- 注意,模型不知道它正在被训练或评估的是哪个任务
DMLab-30
- 为了测试 IMPALA 在多任务设置中的性能,论文使用 DMLab-30,这是一个基于 DeepMind Lab 构建的包含 30 个多样化任务的集合
- 该套件中的众多任务类型包括具有自然外观地形的视觉复杂环境、基于指令的接地语言任务 (2017)、导航任务、认知任务 (2018) 以及以脚本机器人作为对手的第一人称标签任务
- DMLab-30 和任务的详细描述可在 github.com/deepmind/lab 和 deepmind.com/dm-lab-30 获取
- 论文比较了多种 IMPALA 变体与分布式 A3C 实现
- 除了使用基于群体的训练 (Population-Based Training, PBT) (2017a) 的智能体外,所有智能体都在附录 D.1 给出的相同范围内进行了超参数扫描
- 论文报告了平均上限人类标准化分数(mean capped human normalised score),其中每个任务的分数上限为 100%(见附录 B)
- 使用平均上限人类标准化分数强调了解决多个任务的需要,而不是专注于在单个任务上变得超人类
- 对于 PBT,论文使用平均上限人类标准化分数作为适应度函数,并调整熵成本、学习率和 RMSProp \(\varepsilon\)
- PBT 设置的具体细节见附录 F
- 具体来说,论文比较了以下智能体变体
- A3C,deep ,一个具有 210 个工作者(每个任务 7 个)的分布式实现,采用深度残差网络架构(图 3(右))
- IMPALA,shallow 具有 210 个执行器
- IMPALA,deep 具有 150 个执行器,两者都使用单个学习器
- IMPALA,deep,PBT ,与 IMPALA,deep 相同,但额外使用 PBT (2017a) 进行超参数优化
- IMPALA,deep,PBT,8 learners ,它利用 8 个学习器 GPU 来最大化学习速度
- 论文还在专家设置中训练了 IMPALA 智能体,IMPALA-Experts,deep ,其中每个任务训练一个单独的智能体
- 在这种情况下,论文没有为每个任务单独优化超参数,而是在训练 30 个专家智能体的所有任务上进行了优化
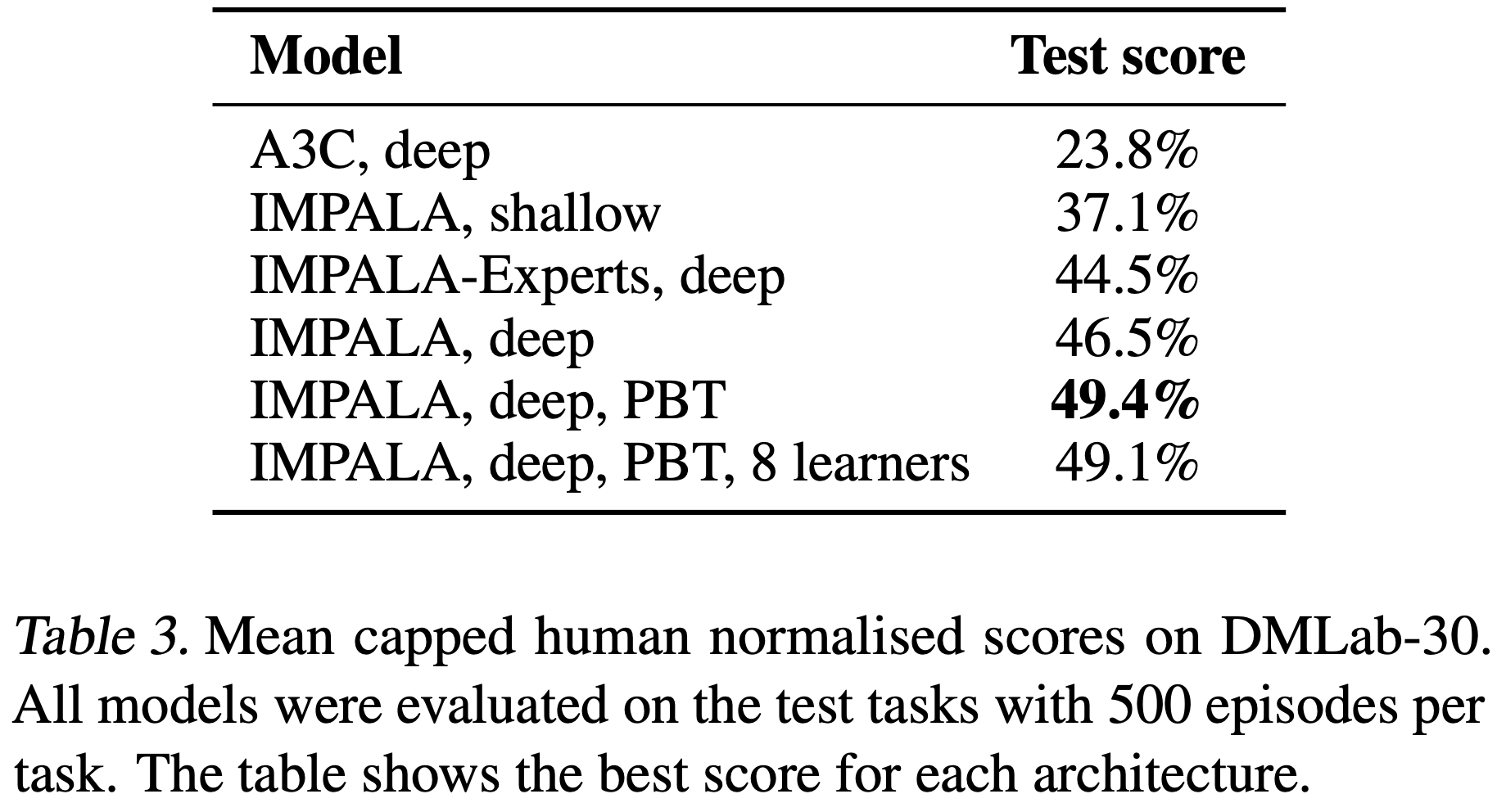
- 表 3 和图 5 显示所有 IMPALA 变体的性能都远优于深度分布式 A3C
- 此外,深度 IMPALA 变体不仅在最终性能上优于浅层网络版本,而且在整个训练过程中都表现更好
- 注意在表 3 中, IMPALA,deep,PBT,8 learners 虽然提供了更高的吞吐量,但在相同步数下达到了与 1 GPU 的 IMPALA,deep,PBT 相同的最终性能
- 特别地,在每个任务上单独训练的IMPALA-Experts 与同时在所有任务上训练的 IMPALA,deep,PBT 之间的差距
- 如图 5 所示,多任务版本在整个训练过程中都优于IMPALA-Experts ,附录 B 中的个体分数细分显示在语言任务和激光标签任务等任务上存在正向迁移(positive transfer)
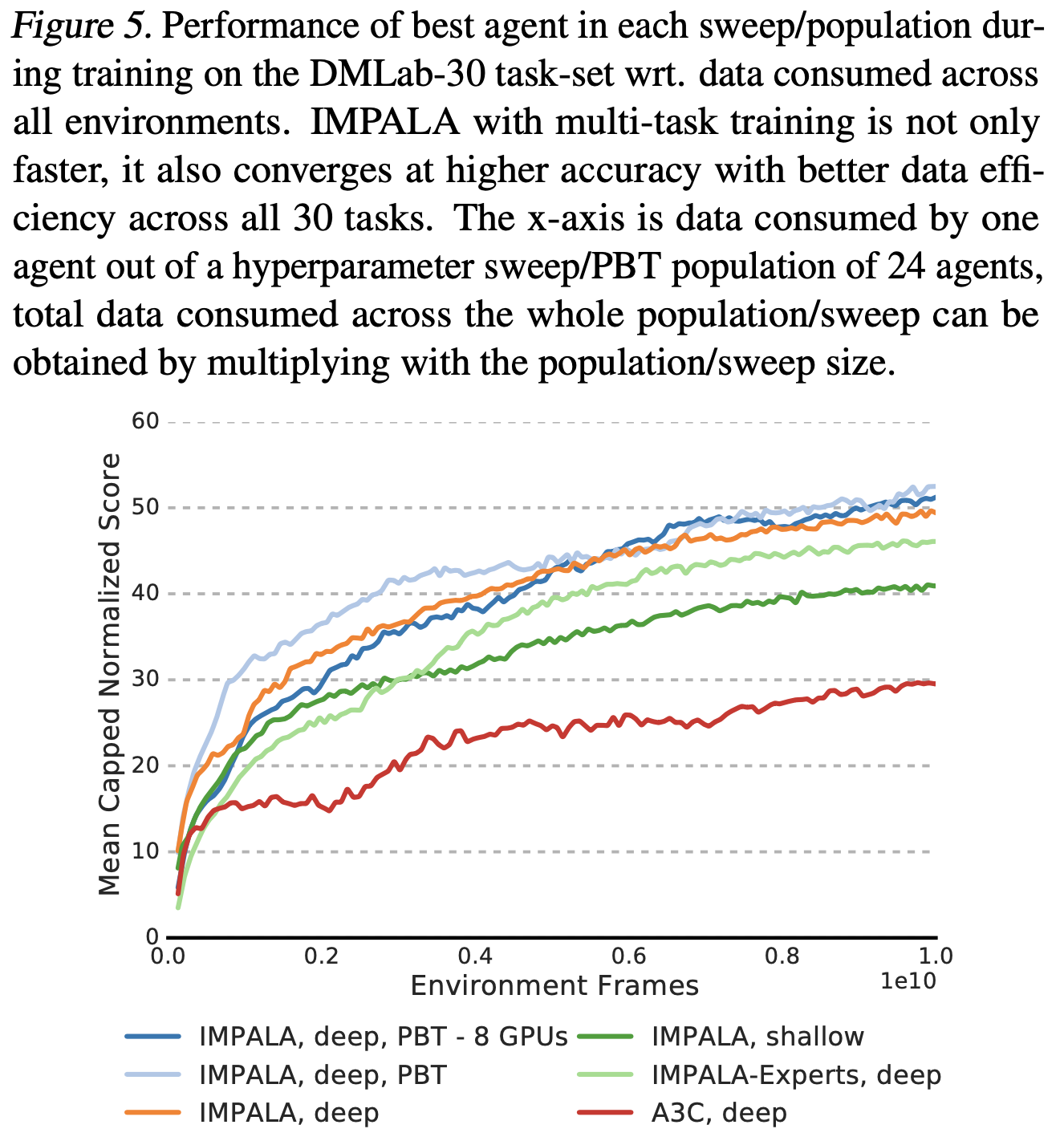
- 如图 5 所示,多任务版本在整个训练过程中都优于IMPALA-Experts ,附录 B 中的个体分数细分显示在语言任务和激光标签任务等任务上存在正向迁移(positive transfer)
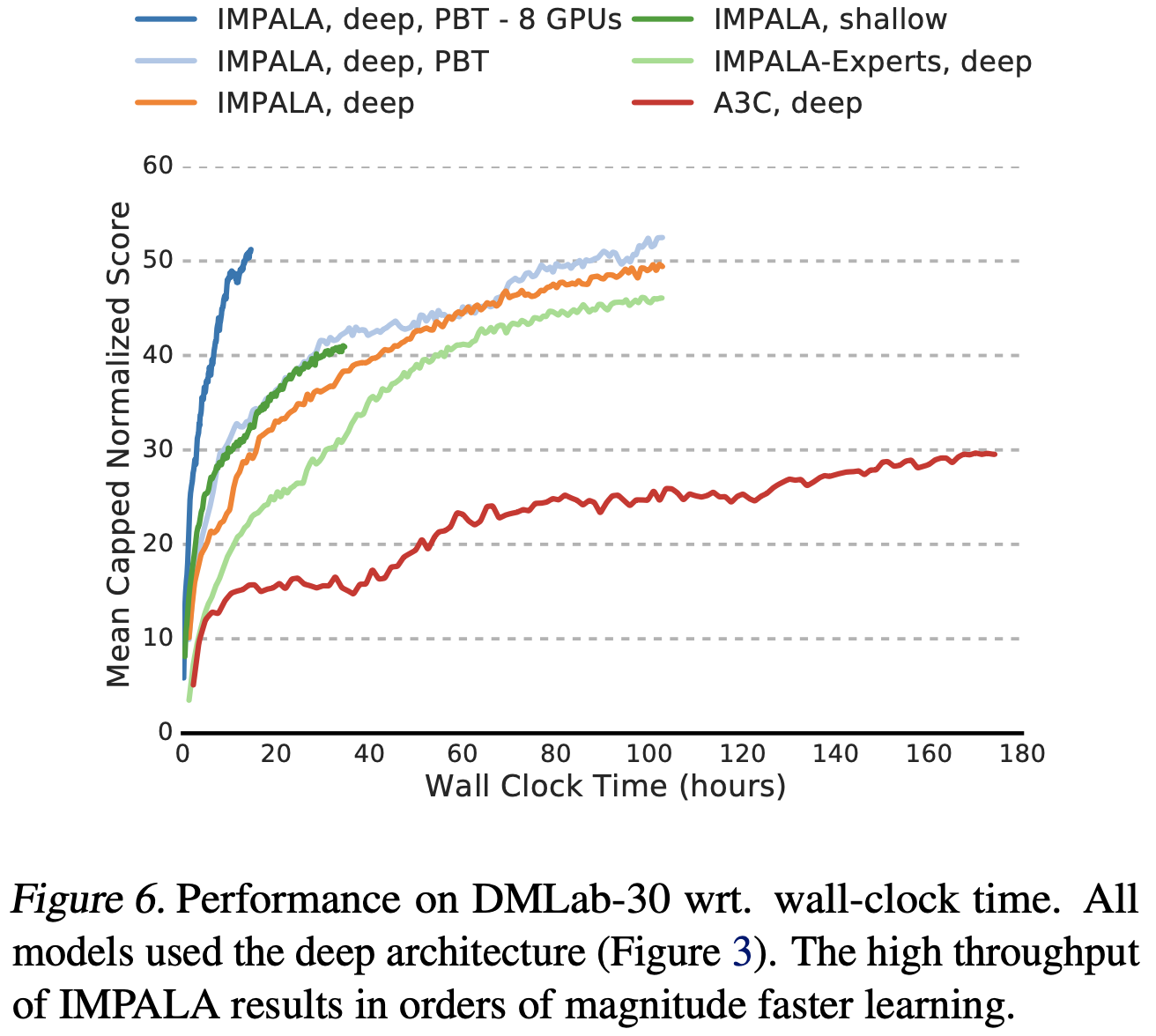
- 将 A3C 与 IMPALA 在挂钟时间(wall clock time)上进行比较(图 6)进一步凸显了两种方法之间的可扩展性差距
- 使用 1 个学习器的 IMPALA 仅需约 10 小时即可达到 A3C 在 7.5 天后才接近的性能
- 使用 8 个学习器 GPU 而不是 1 个,将深度模型的训练速度进一步提高了 7 倍,达到 210K 帧/秒,高于原来的 30K 帧/秒
Atari
- Atari 学习环境 (ALE) (2013a) 是大多数近期深度强化学习智能体的测试平台
- Atari 中的 57 个任务提出了具有挑战性的强化学习问题,包括探索、规划、反应性游戏和复杂的视觉输入
- 大多数游戏具有非常不同的视觉效果和游戏机制,这使得该领域对多任务学习尤其具有挑战性
- 论文在每个游戏上单独训练 IMPALA 和 A3C 智能体,并使用第 5 节介绍的深度网络(不含 LSTM)比较它们的性能
- 论文还提供了使用浅层网络的结果,该网络等效于 (2016) 中使用的前馈网络,包含三个卷积层
- 该网络通过在每个步骤堆叠最近的 4 个观察值来提供短期历史信息
- 有关预处理和超参数设置的详细信息,请参阅附录 G
- 除了使用固定超参数集训练 2 亿帧的个体每游戏专家外,论文还训练了一个 IMPALA Atari-57 智能体(一个智能体,一组权重),同时在所有 57 个 Atari 游戏上训练,每个游戏 2 亿帧,总计 114 亿帧
- 对于 Atari-57 智能体,论文使用群体大小为 24 的基于群体的训练,在整个训练过程中调整熵正则化、学习率、RMSProp \(\varepsilon\) 和全局梯度范数裁剪阈值
- 论文比较了所有算法在 57 个 Atari 游戏上的中位数人类标准化分数
- 评估遵循标准协议,每个游戏分数是 200 个评估回合的平均值,每个回合开始时执行随机数量的无操作动作(从 [1, 30] 中均匀选择)以对抗 ALE 环境的确定性
- 如表 4 所示,IMPALA 专家在深度和浅层配置下都提供了比其 A3C 对应物更好的最终性能和数据效率
- 正如在论文的 DeepMind Lab 实验中一样,深度残差网络比浅层网络导致更高的分数,与使用的强化学习算法无关
- 浅层 IMPALA 实验在不到一小时内完成了超过 2 亿帧的训练
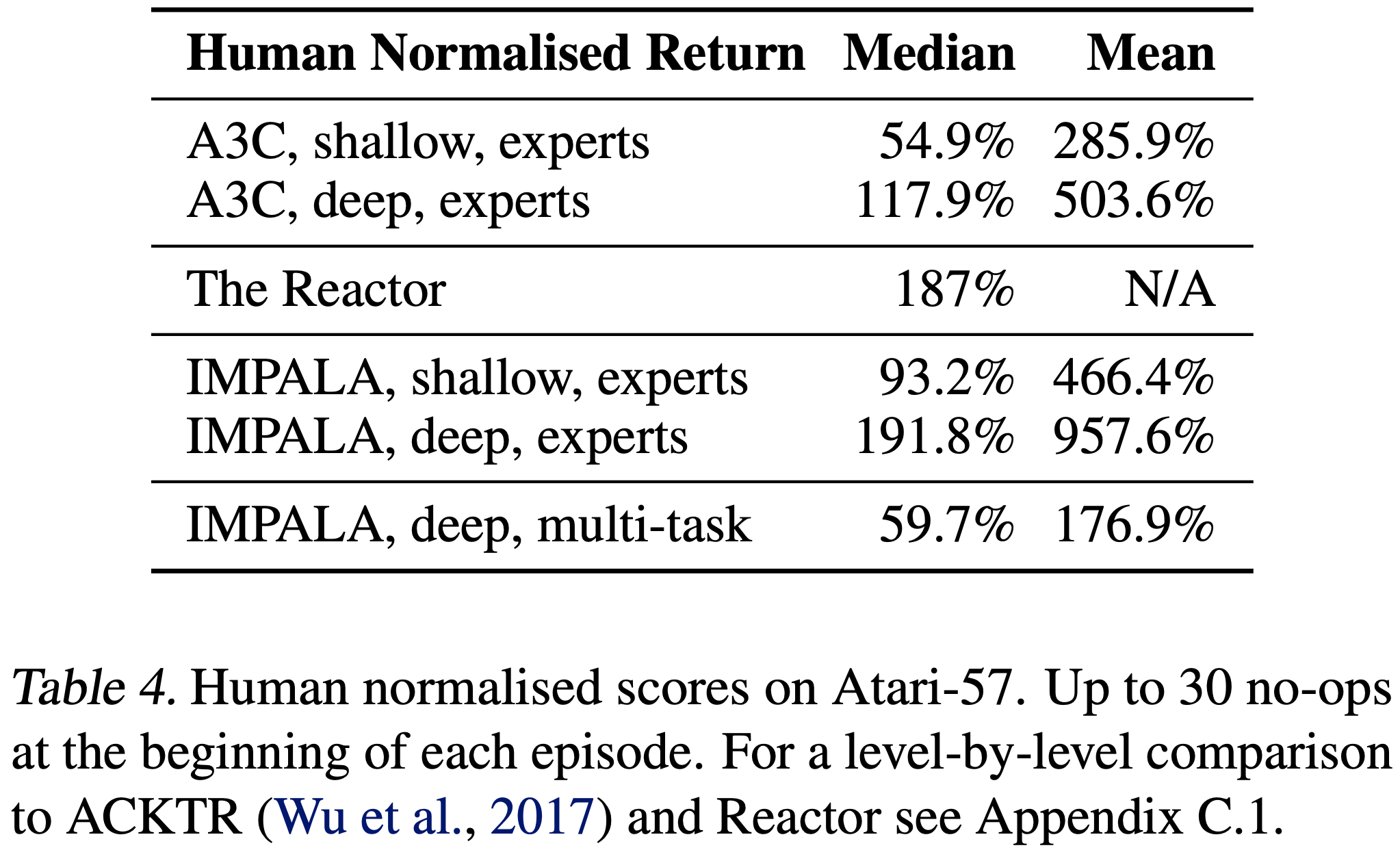
- 作者特别强调,IMPALA, deep, multi-task ,一个同时在所有 57 个 ALE 游戏上训练的单一智能体,达到了 59.7% 的中位数人类标准化分数
- 尽管 ALE 套件内的视觉外观和游戏机制具有高度多样性,IMPALA 多任务版本仍然设法与相关工作中常用作基线的 A3C, shallow, experts 保持竞争力
- ALE 通常被认为是一个困难的多任务环境,常常伴随着任务间的负迁移(negative transfer)(2016)
- 据论文所知,IMPALA 是第一个在 ALE 所有 57 个游戏的多任务设置下进行训练、并能与标准专家基线竞争的智能体
Conclusion
- 论文引入了一种新的高度可扩展的分布式智能体 IMPALA 以及一种新的 Off-policy 学习算法 V-trace
- 凭借其简单但可扩展的分布式架构,IMPALA 能够高效地利用小规模和大规模场景下的可用计算资源
- 这直接转化为研究新想法时非常快的周转时间,并开启了未被探索的机会
- V-trace 是一种通用的 Off-policy 学习算法,与其他用于 Actor-Critic 智能体的 Off-policy 校正方法相比,它更加稳定和鲁棒
- 论文已经证明,在数据效率、稳定性和最终性能方面,IMPALA 实现了比 A3C 变体更好的性能
- 论文进一步在新的 DMLab-30 任务集和 Atari-57 任务集上评估了 IMPALA
- 据论文所知,IMPALA 是第一个在此类大规模多任务设置中成功测试的深度强化学习(Deep-RL)智能体,并且与基于 A3C 的智能体相比,它显示出卓越的性能(在 DMLab-30 上,标准化人类分数为 49.4% 对比 23.8%)
- 最重要的是,论文在 DMLab-30 上的实验表明,在多任务设置中,个体任务之间的正向迁移(positive transfer)使得 IMPALA 实现了比专家训练设置更好的性能
- 作者相信,IMPALA 为构建更好的深度强化学习智能体提供了一个简单、可扩展且鲁棒的框架,并具有激发新挑战研究的潜力
附录:【待补充】
- 补充材料(附录):IMPALA Supplemental Material