注:本文包含 AI 辅助创作
Paper Summary
- 整体内容总结:
- 本论文对 LLM 的领域特定 CPT 进行了广泛研究,重点关注电子商务领域
- 本文实验表明,通过结合通用语料和领域特定语料进行有针对性的 CPT,可以有效地将 LLM 适配到特定领域
- CPT 在不牺牲模型在广泛 NLP 应用中能力的前提下,提升了模型在电子商务任务上的性能
- 论文设计的数据混合策略被证明在增强模型从不同数据源吸收和整合知识的能力方面是有效的,从而在领域特定任务上实现了性能提升
- 背景:
- LLM 在大量语料上预训练后,已在各种 NLP 任务中展现出卓越性能,但将这些模型应用于特定领域仍面临重大挑战
- 例如缺乏领域知识、利用领域知识的能力有限,以及对领域特定数据格式的适应性不足
- 本文方案介绍:
- 考虑到从头训练 LLM 的极高成本和特定领域标注数据的稀缺性,本研究以电商领域为例,专注于 LLM 的领域特定持续预训练(domain-specific continual pre-training)
- 论文探索了使用未标注的通用语料和电商语料对 LLM 进行持续预训练(CPT)的影响
- 论文设计了一种混合不同数据源的策略,以更好地利用电商半结构化数据
- 论文构建了多个任务来评估 LLM 在电商领域的少样本上下文学习(ICL)能力及其在指令微调后的零样本性能
- 实验结果表明,电商 LLM 的 CPT 以及论文设计的数据混合策略均具有显著效果
Introduction and Discussion
- LLM 通过预训练数十亿文本标记,能够掌握广泛的世界知识和人类语言规则(2023)。因此,LLM 在各类 NLP 任务中表现优异(2020; 2022; 2023b)
- 然而,现有的 LLM 并不完美,将其应用于特定领域仍存在重大挑战:
- (1)LLM 缺乏必要的领域特定知识,或难以利用相关知识解决实际任务(2023a;2023)
- (2)LLM 难以适应特定领域的独特文本格式或数据分布,因此无法满足领域应用的需求(2023a;2023b)
- 考虑到:
- 训练 LLM 需要大量硬件资源和长时间训练,从头预训练一个领域特定的 LLM 在实际中并不可行
- 特定领域的标注数据通常稀缺且成本高昂,而未标注数据则更为丰富且易于获取
- 因此:本研究以电商领域为例,探索通过 CPT 使 LLM 适应特定领域的方法
- 已有充分证据表明,特定领域的 CPT 能够显著提升掩码语言模型(MLM,例如 BERT(2019)、RoBERTa(2019))在相应领域下游任务中的表现(2020; 2020;2022;)
- 在 LLM 时代,受限于数据和计算资源:
- 大多数领域适应研究通过指令微调或提示工程实现(2023;)
- 仅有少数研究尝试通过 CPT 将领域知识注入模型(2023a; 2023),且缺乏从实际应用角度对 LLM 领域特定 CPT 的深入分析
- 论文工作内容如下:
- 基于 BLOOM(2022)等一系列多语言自回归模型,构建了电商领域的 EcomGPT-CT 模型
- 探索了在难以获取完整原始预训练数据的情况下,使用通用和电商未标注语料对 LLM 进行 CPT 的影响
- 论文关注模型在解决实际电商任务中的表现,并分析训练过程中的性能变化
- 提出了一种混合不同数据源的策略,以有效利用电商领域丰富的半结构化数据,从而提升预训练数据的规模和多样性
Related Work
Large Language Models
- 近年来,LLM 领域发展迅速,当前主流的 LLM 主要基于 Transformer 模块,并在海量文本数据上预训练
- 自 GPT-2(2019)和 T5(2020)证明各种 NLP 任务可以统一为文本生成范式后,主流 LLM 均采用仅解码器的自回归架构
- 近期,遵循 scaling law(2020),不同参数规模的 LLM 被构建并发布,包括 GPT-3(2020)、Chinchilla(2022)、BLOOM(2022)、PaLM(2022)、Llama(2023)、Baichuan(2023a)
- 受LLM卓越性能的激励,研究者致力于构建领域适应的 LLM 以解决特定领域任务,比如:
- 生物医学领域的 Med-PaLM(2023)和 ChatDoctor(2023)
- 数学领域的 Minerva(2022)
- 金融领域的 BloombergGPT(2023)和 FinGPT(2023b)
- 以及法律领域的 ChatLaw(2023)
Continual Pre-training
- CPT 是指:在通用预训练和下游任务微调两个阶段之间增加的额外预训练阶段
- CPT 采用与通用预训练相同的训练目标 ,但通常使用特定领域或任务的未标注语料 ,旨在实现领域适应或任务适应
- 对于 BERT(2019)和 RoBERTa(2019)等掩码语言模型预训练模型,领域自适应或任务自适应的 CPT 能够引导模型与相应领域或任务的数据分布对齐,从而有效提升模型在相关下游任务中的表现(2020;2022)
- 对于当前主流的自回归 LLM ,关于 CPT 过程的研究(2023)或 CPT 在构建领域特定 LLM 中的应用(2023a)仍然有限
- 目前缺乏对** CPT 如何影响 LLM 解决领域特定任务效果的详细分析,也缺乏关于如何提升 LLM CPT 效果策略**的研究
Domain-specific Continual Pre-training
Training Task
- CPT (Continual Pre-training)无缝连接了通用预训练(General Pre-training)和SFT阶段,从而提升模型在特定领域或任务中的性能,如图 1 所示
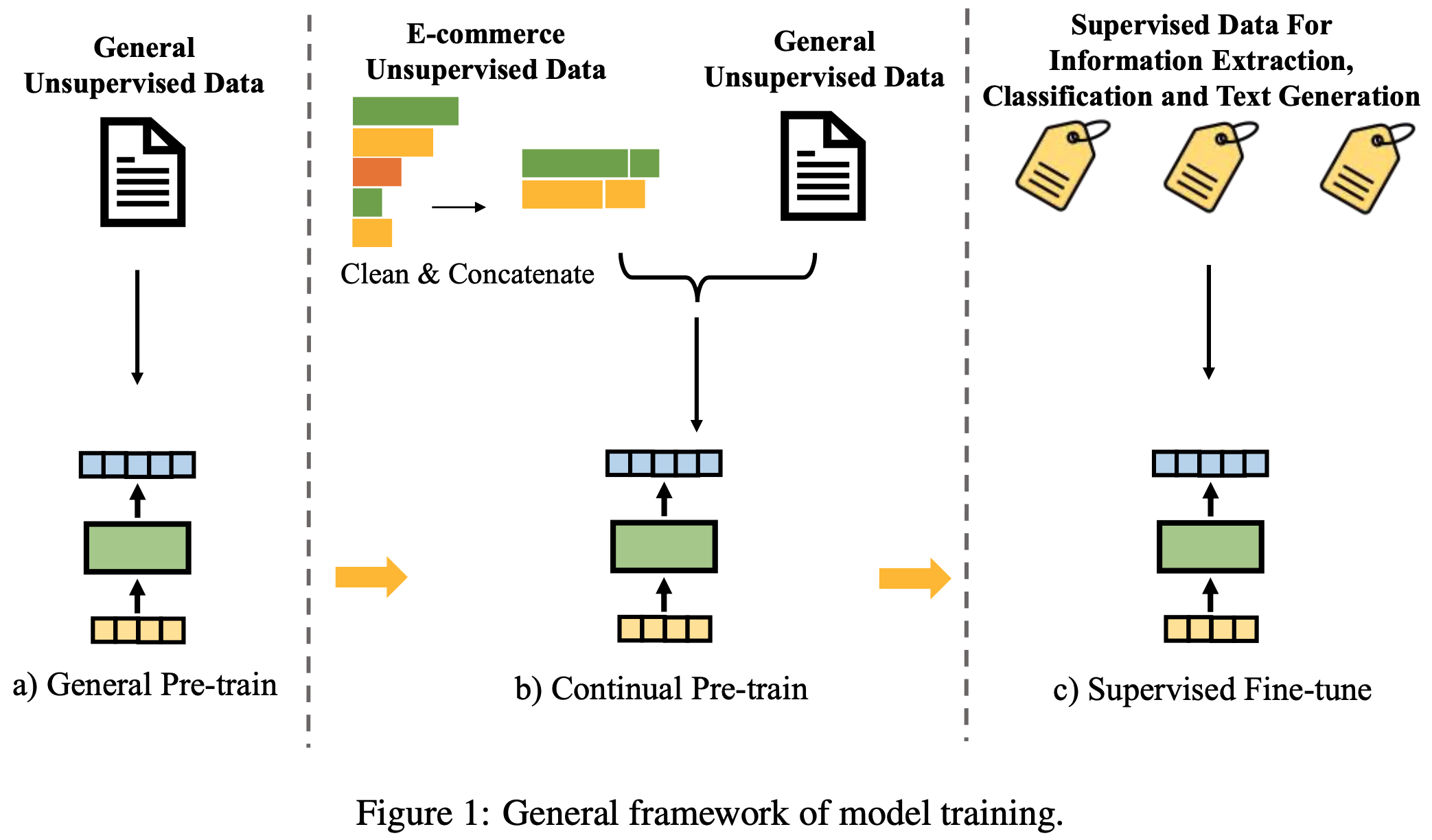
- CPT 采用与通用预训练相同的目标函数,但专注于特定领域或任务的未标注语料
- 论文中,论文使用仅包含解码器的 Transformer 模型(Decoder-only Transformer Models),这是当前主流LLM 的架构。预训练的目标是下一词预测任务(Next Token Prediction)或自回归语言建模(Auto-regressive Language Modeling):
$$
\max_{\theta}\sum_{i=1}^{N}\log P(y_{i}|y_{ < i};\theta),
$$- 其中,\(\theta\) 是模型参数,\(y\) 是训练文本序列
Dataset Construction
- 论文通过 CPT 提升 LLM 在电子商务(E-commerce)领域的性能
- 论文整理了大量的电子商务数据,用于向 LLM 注入领域特定知识,并帮助模型适应电子商务领域独特的文本格式
- 为了保留 LLM 的世界知识和泛化能力,论文还将通用文本数据纳入训练数据集中
- 电子商务语料(E-commerce Corpora) :论文从亚马逊(Amazon)和淘宝(Taobao)收集了大量产品的标题、属性、描述和评论
- 此外,还利用了淘宝“逛逛”频道的文章 ,这些文章介绍了产品特性、分享了用户体验并展示了品牌故事
- 通用语料(General Corpora) :为了构建通用语料,论文从 WuDaoCorpora (2021) 和 RefinedWeb (2023) 中采样文本
- 这两个数据集分别包含从网页中收集的 72B 中文 Characters 和 600B 英文 Tokens
- 数据预处理(Data Pre-processing) :为了确保预训练数据的质量,论文实现了一个全面的流水线
- 包含数据重构、过滤和去重过程
- 对于半结构化产品数据,论文首先按产品 ID 将标题、属性、描述和评论分组
- 表1 展示了处理后的电子商务和通用数据集的统计信息,论文观察到,收集的数据集中不同数据源的 Token 数量存在显著差异
- 经过过滤和处理的电子商务数据包含约 20B Tokens,不到通用领域网页数据 Token 数量的 5%
- 在通用数据中,中文数据的数量远少于英文数据
- 考虑到领域特定 CPT 的目标是提升模型在解决领域特定任务时的性能,同时不损害其泛化能力,因此在训练样本中保持通用数据和领域特定数据的 Token 数量平衡至关重要
- 但由于硬件限制,论文无法对不同类型数据的比例进行详细实验
- 经过初步探索,论文将通用数据与领域特定数据的 Token 数量比例设定为 2:1 ,并将通用数据中的中英文数据比例设定为 1:1
Dataset Mixing Strategy
- 通常,用于LLM 预训练的数据来自网页上的长文本,例如 CommonCrawl 和 Wikipedia
- 但在某些特定领域(包括电子商务领域),大量文本数据以半结构化格式存储在表格或数据库中
- 这些半结构化文本数据在形式上与常规文本数据存在显著差异
- 尽管如此,作者相信将这些数据适当地纳入 CPT 中,可以进一步提升LLM 的领域特定性能
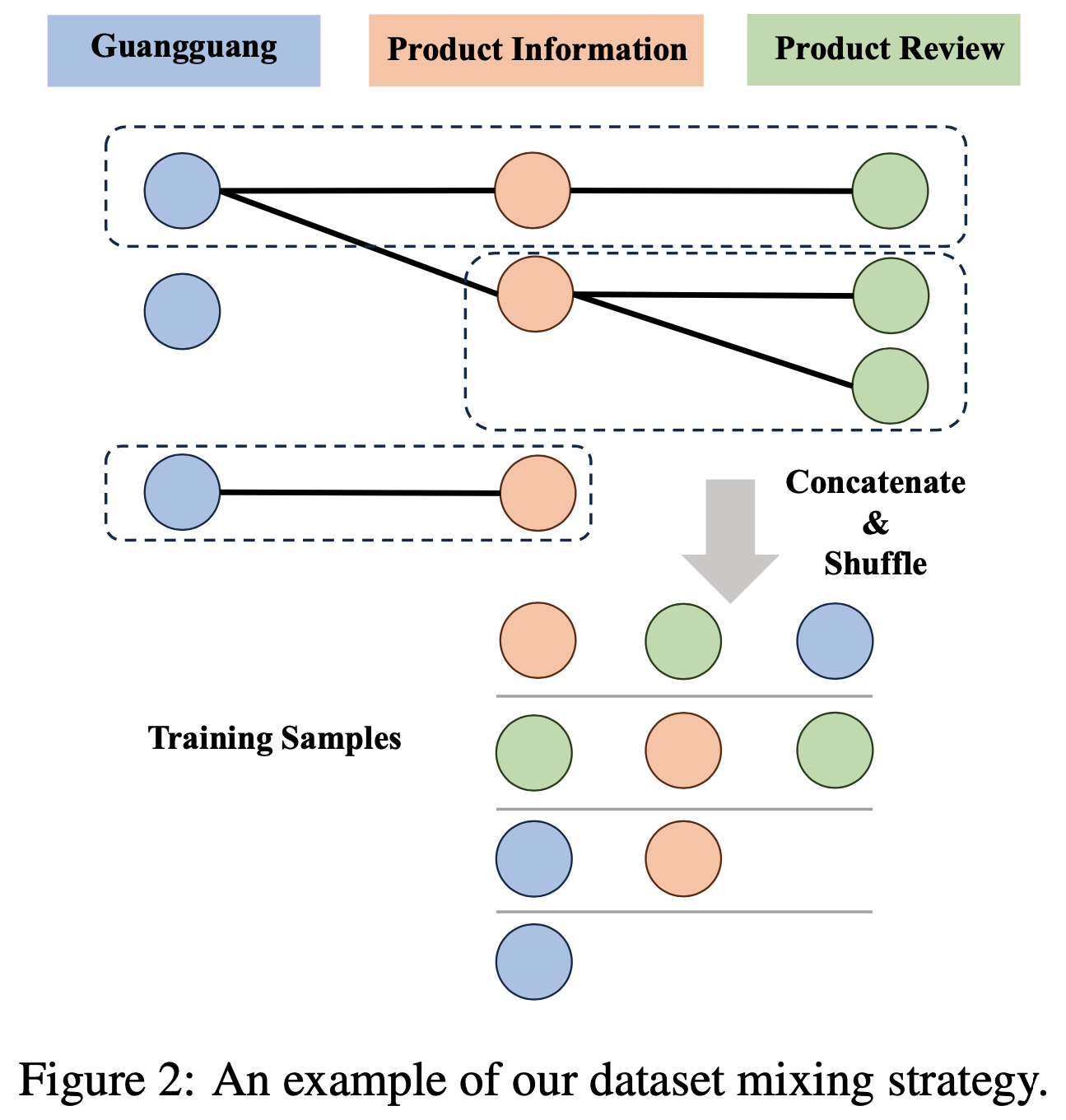
- 为了有效地将这些丰富的半结构化数据转化为模型训练所需的文本序列,论文设计了一种跨不同数据源的数据集混合策略。论文的数据混合策略包含以下步骤:
- 1)节点构造 :从不同数据源收集半结构化数据,每个数据源代表一组节点,每个节点对应一个数据条目(即一行或一个对象)
- 2)边构造 :在跨两个数据源相关联的节点之间建立边,构建表示数据关系的异构图(Heterogeneous Graph)
- 在论文的实验中,所有数据均与电子商务产品相关,因此论文使用产品 ID 作为唯一标识符,连接与同一产品相关的所有节点
- 3)簇选择并移除 :基于预定义的簇大小范围,迭代地从图中选择连通的簇,并遵循尽可能覆盖更多数据源的规则
- 选择簇后,从图中移除所有对应节点以避免冗余
- 4)簇内节点拼接 :在每个选定的簇内随机排列所有节点,提取每个节点中的可用文本,并将它们拼接成一个训练样本
- 图2 展示了一个示例:
- 作者认为,这种数据混合策略建立了来自不同数据源文本之间的联系
- 与从每个数据源独立采样文本的策略相比,论文的策略增强了单个样本中文本的多样性,从而更有效地训练 LLM
- 问题:论文的数据混合策略有经过实验验证吗?
- 后面实验部分有实验,证明了这种做法是有效的
Training Setup
- 作者选择 BLOOM(2022)作为 EcomGPT-CT 的骨干模型(backbone),原因如下:
- (1) BLOOM 是一个支持中英文的多语言预训练模型;
- (2) BLOOM 未经过任何Post-training,这确保了在 CPT 后评估我们基准测试性能变化的可靠性
- 作者分别在参数规模为 3B 和 7.1B 的 BLOOM 模型上进行了实验
- 受限于硬件配额,论文的每项实验均在 2-4 块 NVIDIA Tesla A100 80GB GPU 上完成,这为计算资源有限的应用场景提供了有价值的参考(有趣的表达)
- 论文采用了 Huggingface 的 Transformers(2019)和 DeepSpeed(2020)框架
- Transformers 提供了模型实现和基础的训练流程
- DeepSpeed 则通过 ZeRO 优化器(2020)对训练状态(如模型参数、梯度和优化器状态)进行分片,从而优化 GPU 内存消耗
- 论文使用了 ZeRO stage 2 并启用了 offload 功能,这意味着优化器状态和梯度会被分片,且训练状态可以在主机和设备之间交换
- 训练过程采用 bfloat16 混合精度(2019)进行,以提高训练效率并避免数值下溢或溢出问题
- 实验中使用的超参数如表2 所示(部分超参数是基于 BLOOM 原始预训练设置而确定的)
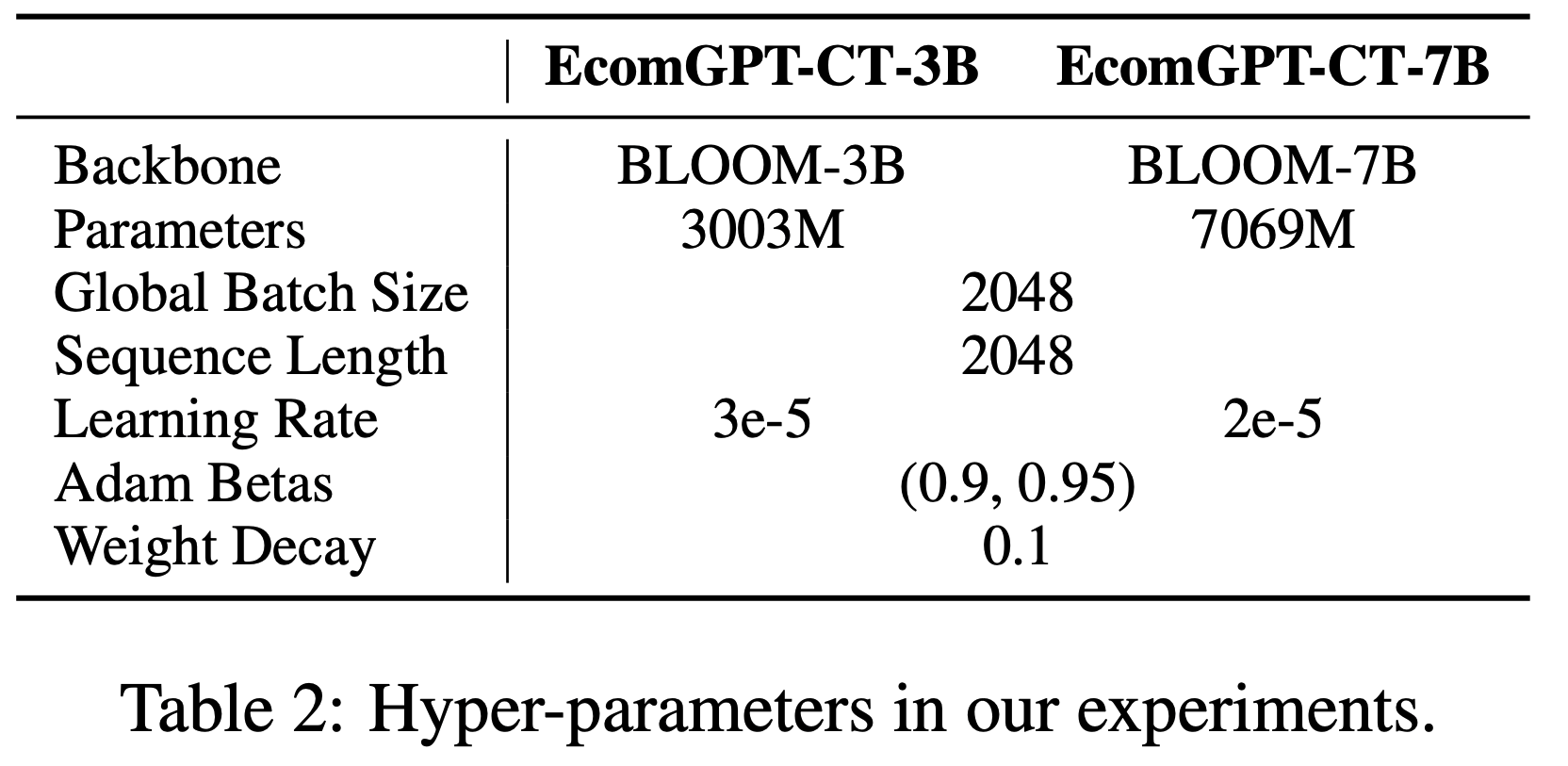
- 超参数分析:小模型使用更大的学习率
Experiments
Evaluation Benchmarks
- 为了从解决实际问题的角度评估基础 LLM 在电子商务领域的性能,论文基于 EcomInstruct(2023a)构建了两个基准,如表3 所示:
- (1) EcomICL :论文选择了 9 项任务,涵盖文本分类(text classification, CLS)、文本生成(text generation, GEN)和信息抽取(information extraction, IE)等多种类型
- 每个数据实例被处理为标准格式,并提供多个相同格式的示例作为演示,以评估 LLM 的少样本上下文学习(Few-shot ICL)性能
- (2) EcomSFT :论文使用 EcomInstruct 的训练数据对基础 LLM 进行 SFT(然后进一步评估)
- 选择了 8 项任务进行评估,包括 4 项训练集内任务和 4 项训练集外任务,旨在评估 SFT 后模型的指令遵循性能
- (1) EcomICL :论文选择了 9 项任务,涵盖文本分类(text classification, CLS)、文本生成(text generation, GEN)和信息抽取(information extraction, IE)等多种类型
- 为了评估基础 LLM 在 CPT 后是否仍能解决通用自然语言处理(NLP)任务,论文分别从中文和英文 NLP 基准中选择了 3 项任务
- 以 Few-shot ICL(GeneralICL)的形式进行评估
- 对于每项任务,论文在实验中随机选取最多 1000 个数据实例
- 对于自回归 LLM ,每项任务都被视为文本生成任务。因此,我们可以使用文本生成的自动评估指标来评估模型在不同任务上的性能
- 根据先前的工作(2022;2022),论文使用 ROUGE-L(2004)作为评估指标
- 对于分类任务,论文报告准确率指标;
- 对于两项 IE 任务,论文还使用了精确率、召回率和 F1 值指标
补充:论文相关的评估指标汇总
- 表3 列出了所有评估指标
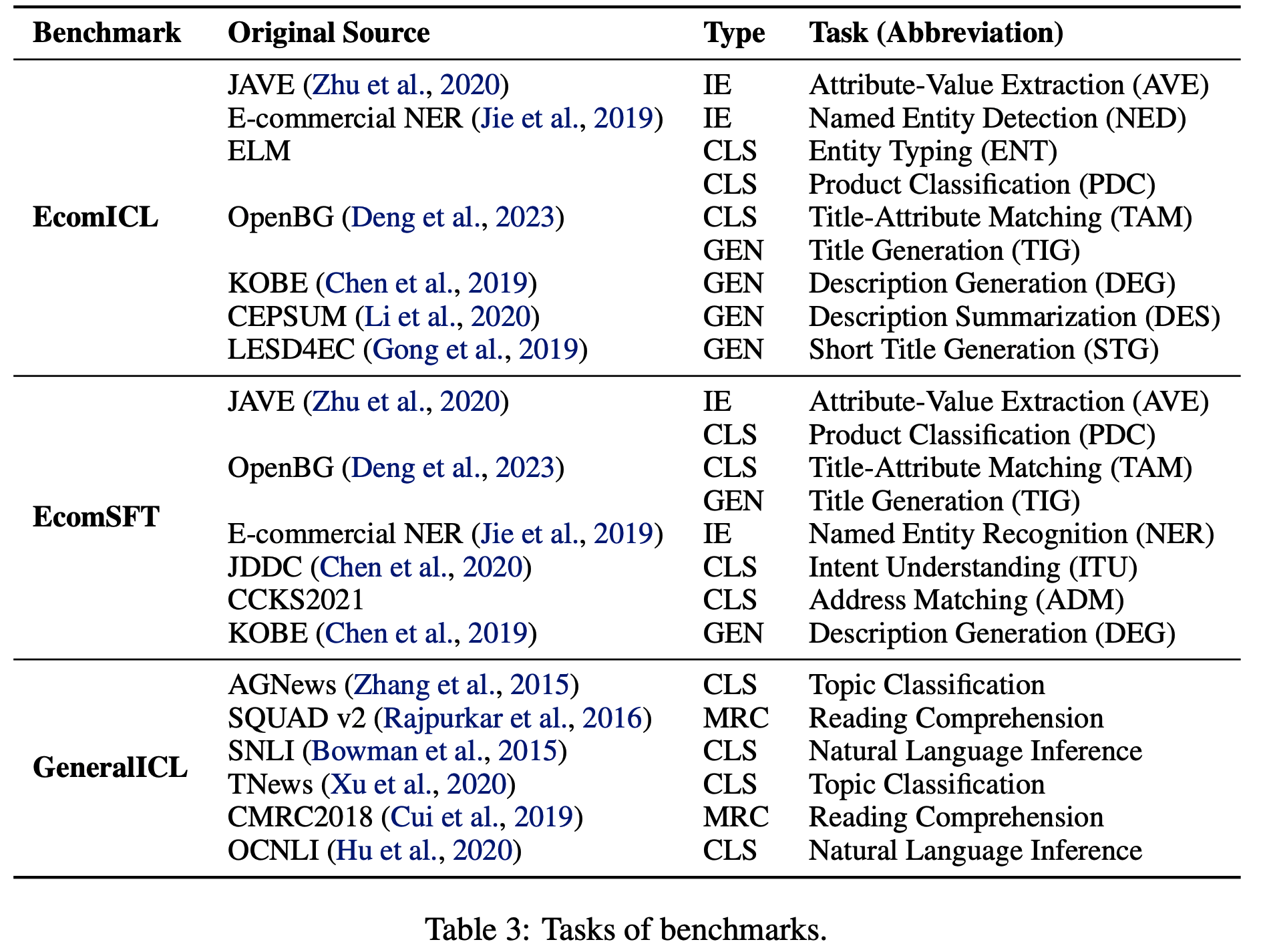
- AVE :属性-值提取(Attribute-Value Extraction,AVE) :从商品信息中提取属性和对应的值,如商品“颜色:红色”
- NED :命名实体检测(Named Entity Detection,NED) :识别文本中的特定实体,如品牌名、商品名等
- ENT :实体类型分类(Entity Typing,ENT) :对文本中的实体进行分类,如“苹果”是水果还是品牌
- PDC :产品分类(Product Classification,PDC) :将商品归类到预定义的类别中,如“手机”属于“电子产品”
- TAM :标题-属性匹配(Title-Attribute Matching,TAM) :判断商品标题是否与其属性描述一致
- TIG :标题生成(Title Generation,TIG) :根据商品信息生成简洁且吸引人的标题(问题:如何评估简洁和吸引人?)
- DEG :描述生成(Description Generation,DEG) :基于商品属性生成详细的描述文本
- DES :描述摘要(Description Summarization,DES) :将商品的长描述压缩成简短的摘要
- STG :短标题生成(Short Title Generation,STG) :生成更简短的标题(问题:用于移动端展示?)
- NER :命名实体识别(Named Entity Recognition,NER) :识别并分类文本中的命名实体,如人名、地名等
- 注:NER = NED + 实体分类,部分文献中也会混用两者,但实际上强调 NED 时,是不用对实体进行分类的
- 输入句子 :
"马云在杭州创立了阿里巴巴。" - NED输出 :
[马云]在[杭州]创立了[阿里巴巴] - NER输出 :
[马云]PER在[杭州]LOC创立了[阿里巴巴]ORG
- ITD :意图理解(Intent Understanding,ITD) :分析用户查询的意图,如“购买”或“咨询”
- ADM :地址匹配(Address Matching,ADM) :验证或匹配用户输入的地址信息
- AGNews :主题分类(Topic Classification) :将新闻文本分类到预定义的主题类别
- SQUAD v2 :阅读理解(Machine Reading Comprehension,MRC) :阅读理解任务,根据文章回答问题
- SNLI :自然语言推理(Natural Language Inference) :判断两个句子之间的逻辑关系(蕴含、矛盾或中立)
- TNews :主题分类(Topic Classification) :中文新闻文本的主题分类任务
- CMRC2018 :阅读理解(Machine Reading Comprehension,MRC) :中文阅读理解任务,根据文章回答问题
- OCNLI :自然语言推理(Natural Language Inference) :中文自然语言推理任务,判断句子间的关系
Results on Domain-specific Tasks
- 表4 展示了 BLOOM-3B 和 BLOOM-3B-7B 模型在不同 CPT 设置下对多种电子商务 Few-shot ICL(EcomICL)任务的评估结果
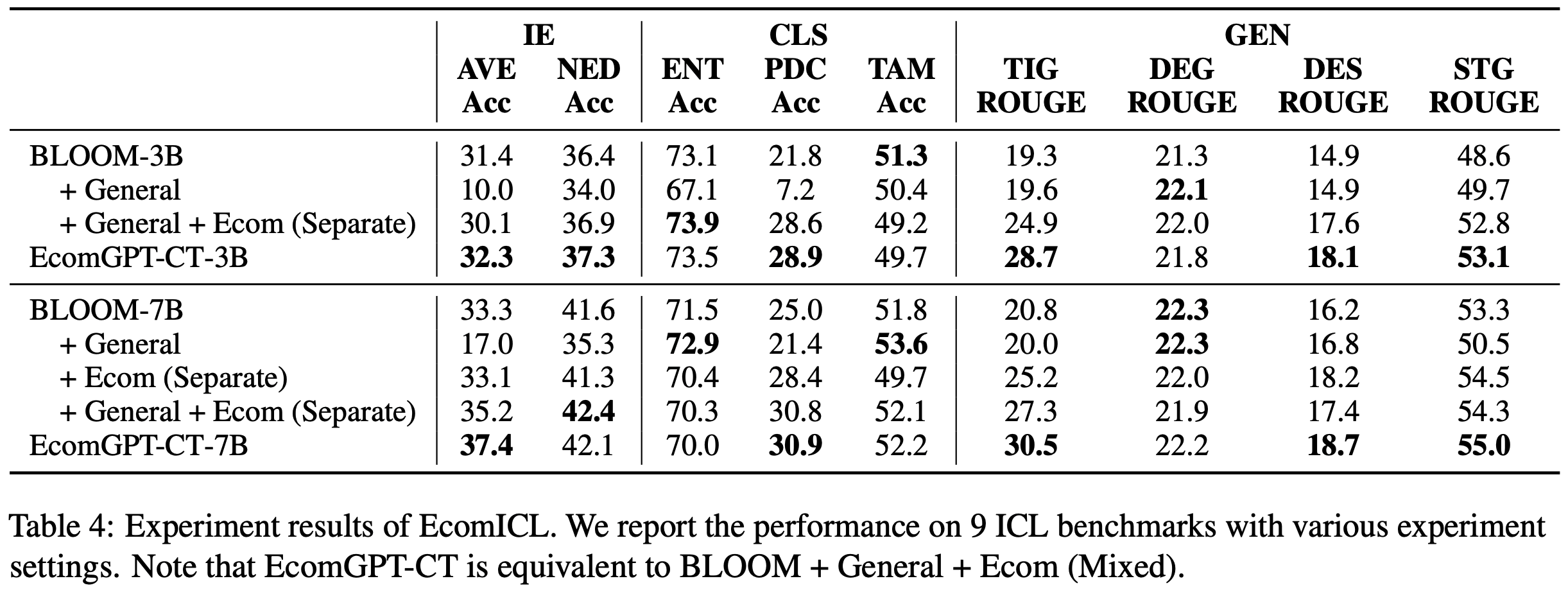
- Few-shot ICL 评估直接反映了 LLM 在无需额外微调的情况下解决领域特定任务的能力。实验结果表明:
- (1) 从训练数据的角度来看:
- 使用电子商务数据进行 CPT 有效提升了 3B 和 7B 模型在部分电子商务任务上的 ICL 性能
- 仅使用通用数据训练模型会导致几乎所有任务的性能显著下降
- 混合领域特定数据和通用数据进行训练能带来更一致的性能提升
- 这些结果说明:在 CPT 中同时纳入领域特定语料和通用语料是必要的
- 因为领域特定数据有助于模型适应领域特定知识和数据格式 ,而通用数据则帮助模型避免遗忘世界知识并保持泛化能力
- (2) 从数据混合的角度来看:
- 论文设计的将不同来源数据整合到同一上下文中的策略(表4 中不带 Separate 的行),在大多数任务上实现了更大的性能提升或更小的性能下降,优于从不同数据源独立采样的结果(表4 中带 Separate 的行)
- 在属性-值抽取(Attribute-Value Extraction, AVE)和标题生成(Title Generation, TIG)任务中观察到显著改进
- 这表明论文的数据混合策略在建立不同数据源之间的关联以及将电子商务数据中的领域特定知识注入模型方面是有效的
- (3) 领域特定 CPT 对模型性能的影响因任务类型而异
- 对于 高度依赖领域知识 或 数据格式与通用文本差异较大 的任务, CPT 显著提升了模型在这些任务上的性能
- 高度依赖领域知识的任务:例如产品分类(Product Classification, PDC)和标题生成(Title Generation, TIG)
- 数据格式与通用文本差异较大的任务:例如描述摘要(Description Summary, DES)和短标题生成(Short Title Generation, STG)
- 对于需要一定领域知识但形式与通用 NLP 任务差异较小的任务,领域特定 CPT 仅带来边际性能提升
- 需要一定领域知识但形式与通用 NLP 任务差异较小的任务:例如属性-值抽取(Attribute-Value Extraction, AVE)和命名实体检测(Named Entity Detection,NED)
- 对于缺乏领域特异性 或本身难以通过 Few-shot ICL 解决的任务, CPT 未能带来有效收益
- 缺乏领域特异性的任务:例如实体分类(Entity Typing,ENT)
- 本身难以通过 Few-shot ICL 解决的任务:例如标题-属性匹配(Title-Attribute Matching,TAM)
- 对于 高度依赖领域知识 或 数据格式与通用文本差异较大 的任务, CPT 显著提升了模型在这些任务上的性能
- (1) 从训练数据的角度来看:
CPT 对 SFT 的影响如何?
- 论文还对采用不同配置训练的模型进行了 SFT(注:SFT 时使用相同的 EcomInstruct 训练数据集)
- 随后,论文评估了 SFT 后模型在各项任务上的性能
- 指令微调后的模型可以更方便地用于解决实际场景中的 NLP 问题
- 因此,相关基准上的实验结果间接反映了 CPT 对 LLM 领域特定性能的影响
- 表5 展示了进行了 SFT的相关实验结果,从中论文观察到以下现象:
- (1) 使用领域特定数据进行 CPT 有效提升了模型在大多数基准上的性能 ,而将通用预训练数据与领域特定数据结合进一步增强了模型性能(与 Few-shot ICL 评估结果类似)
- 在 CPT 过程中,论文设计的数据混合策略 ,在提升模型 SFT 后的性能方面比从不同来源独立采样领域特定数据更有效
- (2) CPT 对 SFT 后领域性能的影响因任务类型而异
- 与 EcomICL 的发现类似, CPT 为需要领域知识 或 涉及特定数据格式的任务带来了显著增益,而对其他任务的增益较小
- 例如标题生成(Title Generation, TIG)、产品分类(Product Classification, PDC)、意图检测(Intent Detection, ITD)
- 与 EcomICL 的发现类似, CPT 为需要领域知识 或 涉及特定数据格式的任务带来了显著增益,而对其他任务的增益较小
- (3) CPT 对训练集内(held-in)和训练集外(held-out)任务均表现出整体性能提升,其中训练集外任务的提升更为明显
- 这一结果符合直觉,因为 SFT 直接训练了模型解决某些特定任务的能力,从而减轻了 CPT 的影响
- 在此过程中,训练集内(held-in)任务的相关数据被包含在训练集中,使得这些任务更容易受到 SFT 的影响
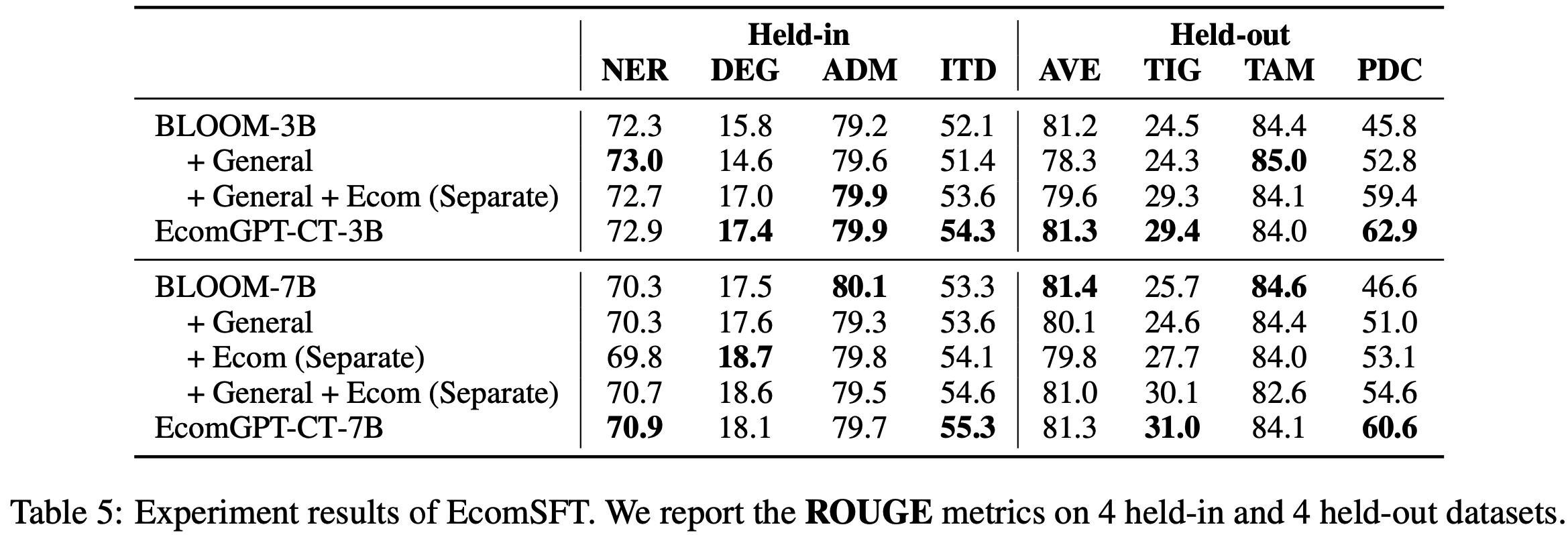
- (1) 使用领域特定数据进行 CPT 有效提升了模型在大多数基准上的性能 ,而将通用预训练数据与领域特定数据结合进一步增强了模型性能(与 Few-shot ICL 评估结果类似)
Results on General Tasks
- 除了领域特定基准外,论文还评估了 LLM 在几项中英文通用 NLP 任务上的 Few-shot ICL 性能
- 表6 提供了关于 CPT 对 LLM 通用能力影响的 insight
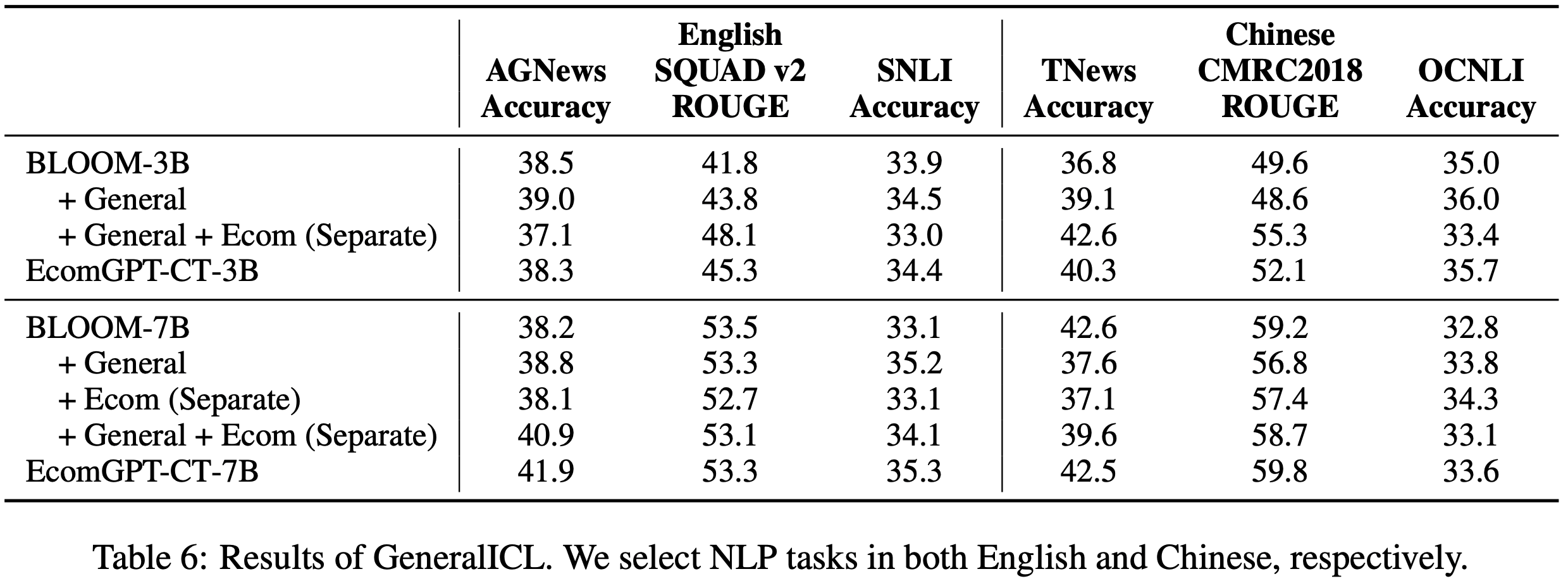
- 实验结果表明:
- 从解决实际问题的角度来看,使用通用数据和领域特定数据混合 CPT 模型对模型解决主题分类(Topic Classification)、机器阅读理解(Machine Reading Comprehension)、自然语言推理(Natural Language Inference)等经典 NLP 任务的 Few-shot ICL 能力影响较小
- AGNews :主题分类(Topic Classification)
- SQUAD v2 :阅读理解(Machine Reading Comprehension,MRC)
- SNLI :自然语言推理(Natural Language Inference)
- TNews :主题分类(Topic Classification)
- CMRC2018 :阅读理解(Machine Reading Comprehension,MRC)
- OCNLI :自然语言推理(Natural Language Inference)
- 然而,由于论文的领域特定数据主要是中文,仅使用领域特定数据进行 CPT 会导致模型在中文基准上的性能下降
- 这验证了在领域特定预训练中纳入通用数据以保持模型通用 NLP 能力的重要性
- 需要注意的是,在本实验中,论文并未评估模型的复杂推理或知识保留能力,因此无法得出领域特定预训练是否会损害模型这些能力的结论
- 从解决实际问题的角度来看,使用通用数据和领域特定数据混合 CPT 模型对模型解决主题分类(Topic Classification)、机器阅读理解(Machine Reading Comprehension)、自然语言推理(Natural Language Inference)等经典 NLP 任务的 Few-shot ICL 能力影响较小
Performance Variation during Training
- 论文还评估了 CPT 过程中多个模型检查点在领域特定和通用 ICL 基准上的性能,以分析 LLM 在训练过程中的性能变化。图 3(a) 和 3(b) 展示了部分代表性任务上各模型检查点的性能
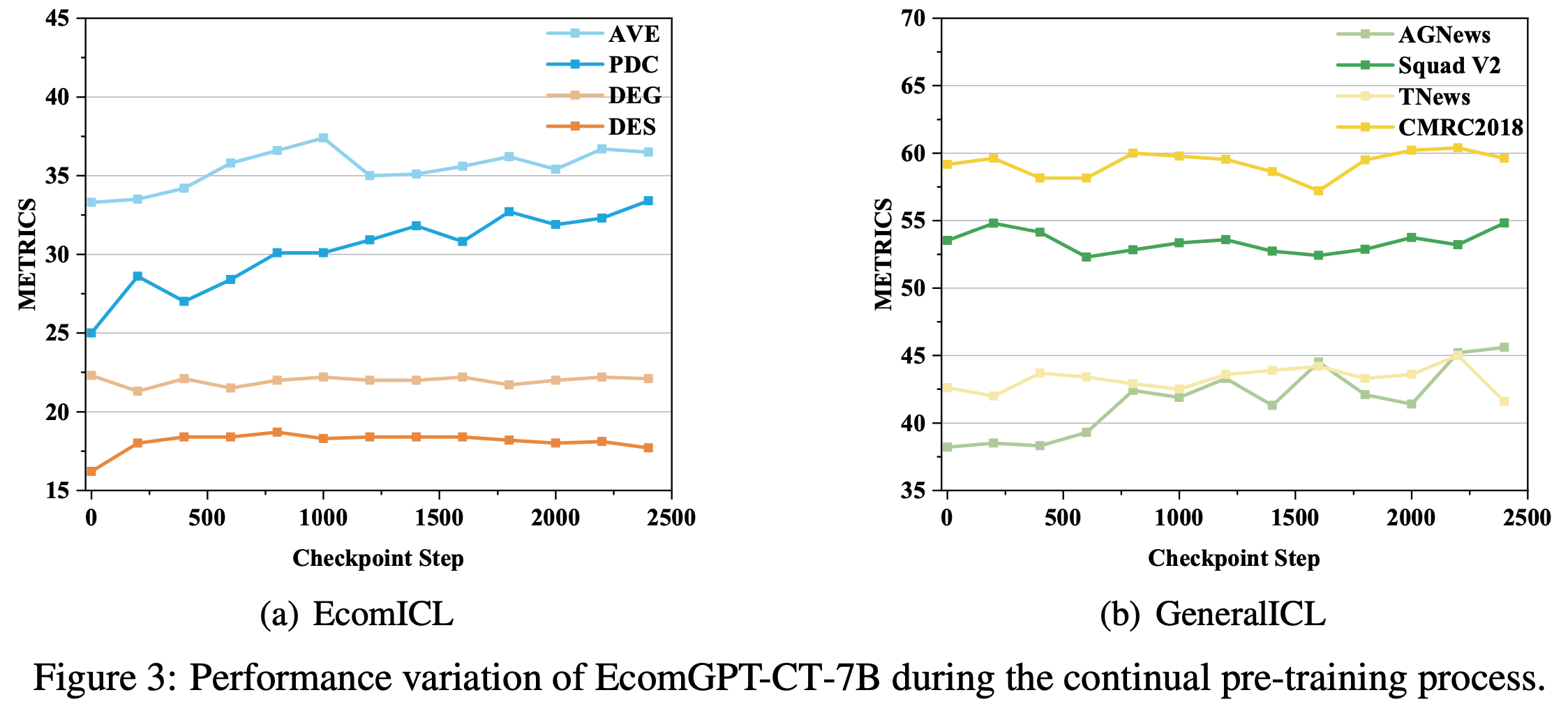
- 从 EcomICL 中四项任务的性能变化中观察到三种不同的趋势:
- (1) 在某些任务(例如产品分类(PDC))中,模型的性能稳步提升
- (2) 在另一些任务(例如描述生成(DEG))中,模型性能保持相对稳定
- (3) 在某些任务(例如属性-值抽取(AVE)和描述摘要(DES))中,模型的性能最初提升,但在达到转折点后不再显著变化
- 对于 GeneralICL 中的四项典型任务
- 可以明显看出模型的性能在训练过程中波动
- 然而,在观察到的时间范围内,指标并未显著偏离 CPT 前的初始值
- 这一结果进一步强调,选择合适的数据进行 CPT 可以有效保持模型的通用 NLP 能力