注:本文包含 AI 辅助创作
- 参考链接
Paper Summary
- 整体内容总结 & 评价:
- 论文介绍了一个专为家装任务设计的领域大语言模型 ChatHome
- 作者使用不同的基础模型和数据比例,测试了模型的领域特定能力和通用性能
- 论文介绍了 ChatHome 的开发与评估,这是一个专为复杂的家装领域设计的特定领域语言模型(Domain-Specific Language Model, DSLM)
- 考虑到像 GPT-4 这样的 LLM 的卓越能力以及人们对家装领域日益增长的兴趣,本研究试图通过生成一个专注于家装领域的专用模型,以提供高保真、精准的输出
- ChatHome 的创新性在于其方法,即融合了领域自适应预训练(domain-adaptive pretraining)和基于广泛数据集的指令微调(instruction-tuning)
- 该数据集包括家装领域的专业文章、标准文档和网络内容
- 这种双重策略旨在确保模型能够吸收全面的领域知识并有效解决用户问题
- 通过对通用和领域特定数据集(包括新引入的“EvalHome”领域数据集)的全面实验,论文验证了 ChatHome 不仅增强了领域特定功能,还保持了其通用性
Introduction and Discussion
- 在人工智能的蓬勃发展中,像 GPT-4 (2023) 和 ChatGPT (2023) 这样的大规模语言模型的开发引发了自然语言处理任务的深刻变革,展现了在多种任务中的卓越能力
- 中文开源大语言模型也迅速发展,例如 ChatGLM (2022)、Baichuan (2023) 和 BELLE (2023)
- 尽管一些研究在医疗 (2023)、金融 (2023) 和法律 (2023) 等领域取得了显著进展,但家装(home renovation)这一特定领域仍相对未被充分探索
- 家装是一个多方面的领域,需要对美学和功能性有全面的把握
- 它不仅仅是选择家具或确定配色方案,还需要深刻理解建筑细节、空间设计原则、以人为本的设计理念以及流行趋势等元素
- 像 ChatGPT 这样的主流模型尽管在多种任务中表现出通用能力,但在生成高保真、精准的领域特定内容时往往表现不佳
- 这一点在法律 (2023) 和医疗 (2023) 领域已有观察
- 因此,为了克服这些不足并满足家装领域的独特需求,迫切需要一种专为该领域定制的语言模型
- 本研究提出了 ChatHome,一种专为家装设计的语言模型。论文的方法包括两个步骤:
- 首先,使用广泛的家装数据集对通用模型进行后预训练(post-pretraining),该数据集涵盖专业文章、标准文档和网络内容;
- 其次,通过基于家装提示生成的问题-答案对数据集实施指令微调策略
- 本研究旨在证明,对大规模语言模型进行后预训练和微调可以提高其在特定领域的性能
- 在增强特定领域能力的同时,论文还关注模型通用能力的变化,并进行了详细的评估,这将在后续章节中详细描述
- 论文的主要贡献有两点:
- 论文建立了 ChatHome,一个专注于家装领域的微调大语言模型
- 论文引入了一个领域数据集,并在通用和领域数据集上进行了全面实验,以验证模型的有效性
Related work
- 大语言模型的训练通常包括两个阶段:Pre-training和指令微调(instruction fine-tuning)
- 通过在大规模语料库上进行预训练,大语言模型可以获得基本的语言理解和生成能力
- 指令微调阶段则是为了让模型具备理解人类指令的能力,同时也能提高模型在未见任务上的泛化能力 (2022, 2023)
- 然而,领域特定任务通常涉及复杂的概念、技术术语和实体之间的复杂关系 (2023)
- 如果没有针对性的指导,大语言模型可能会出现严重的幻觉(hallucination)问题
- 这是因为大语言模型的目标是根据输入预测最可能的词序列,而不是基于结构化知识提供明确的答案
- 最近,在医疗 (2023)、金融 (2023) 和法律 (2023) 领域涌现了大量与大语言模型适应相关的工作
- 通过基于检索的插件知识库,大语言模型可以在不更新参数的情况下用于专业领域 (2023),或者选择通过更新参数将领域知识注入模型
- 本报告主要关注后者(通过更新参数将领域知识注入模型)
- 根据训练阶段的不同,大语言模型的领域专用训练方法大致可分为以下几类:
- 一种方法是直接基于领域数据从头开始预训练,例如 (2023),这种方法通常依赖于大量领域数据,训练成本较高;
- 另一种是基于领域指令数据直接进行微调,例如 (2023);
- 还有一种是在基础大语言模型上基于领域数据进行领域预训练,然后再进行指令微调 (2023)
Data Collection
Pre-training Corpus
- 先前的研究 (2020) 表明,语言模型可以通过领域特定的语料库获取知识
- 论文收集了一个领域特定的语料库,以增强模型在家装领域的知识
- 此外,论文还编译了一个通用语料库,以平衡模型的通用知识
- 国家标准 :论文收集了多项装修和建筑的国家标准,其中包括《住宅设计规范》(GB 50096-2011)和《住宅装饰装修工程施工规范》(GB 50327-2001)
- 领域书籍 :论文收集了过去十年出版的房地产、家装、装饰和建筑领域的书籍
- 领域网站 :论文爬取了约 30,000 篇家装建议、家居设备购买技巧等类别的文章
- 通用语料库 :为了构建通用语料库,论文从 WuDaoCorpora (2021) 和简体中文维基百科中采样文章
- 数据预处理 :上述数据通过统一的流程进行处理,包括文本提取、质量过滤和数据去重
- 在文本提取阶段,论文丢弃了图片、表格和 URL 等无关信息,仅保留相关文本
- 在质量过滤阶段,论文通过敏感词过滤、语言过滤和有效文本长度过滤等方法确保数据的可用性
- 此外,论文在文章和句子级别进行去重,以减少重复数据对模型训练的影响
- 最终,论文从领域语料库中获取了约 26.6M Token,从通用语料库中获取了 276.6M Token。数据预处理的流程如 图1 所示

SFT Corpus
- 为了缓解领域偏差问题并提升模型在特定领域的性能,论文从高质量的家装书籍和家装网站文章中构建了约 25k 条指令数据,帮助模型适应特定领域知识
- 这些提示的详细信息见附录中的表格
- 单轮对话 :为了获取更多家装相关的问题
- 首先,使用 GPT-4 模拟室内设计师和客户的双重角色,基于给定知识生成若干问答对
- 随后,为了获得更详细的回答,论文将这些问题直接提交给 GPT-4
- 这种两步法使论文能够获取更全面和精确的数据
- 多轮对话 :与单轮对话类似,GPT-4 模拟室内设计师和客户的角色,生成了家装领域的多轮对话
- 此外,为了减少幻觉(hallucination),论文为 GPT-4 提供了相关文章,确保对话内容围绕这些知识展开
- 同时,论文要求 GPT-4 保持对话的连贯性和自然性
- 基于单轮和多轮对话的指令数据,论文生成了如图2 所示的词云

Experiments
Baseline Models
- 论文选择的基线模型是 Baichuan-13B (2023),由 Baichuan Intelligent Technology 开发和发布。该基线包含两个模型:
- Baichuan-13B-Base :这是一个预训练模型,参数规模为 130 亿,训练语料包含 1.4 万亿 Token
- Baichuan-13B-Chat :基于 Baichuan-13B-Base 的架构,通过专用指令进行微调,具备更强的对话生成和指令理解能力
Experiments Setups
- 论文使用上述两个基线模型对家装领域数据集进行微调
- 为了探索领域自适应预训练(domain-adaptive pretraining,DAPT)在领域适应中的优势,论文将在经过 DAPT 优化的模型上执行相同的指令微调实验
- 领域自适应不可避免地会面临灾难性遗忘(catastrophic forgetting)问题,即在适应新领域时丢失先前学到的知识
- 一种简单的缓解方法是基于复现的策略,即重新学习先前知识
- 考虑到 LLM 是在大量通用数据上预训练的,领域适应过程中需要平衡通用数据和领域数据
- 论文为每组实验执行了五组数据比例测试,以确定最有效的数据比例方案
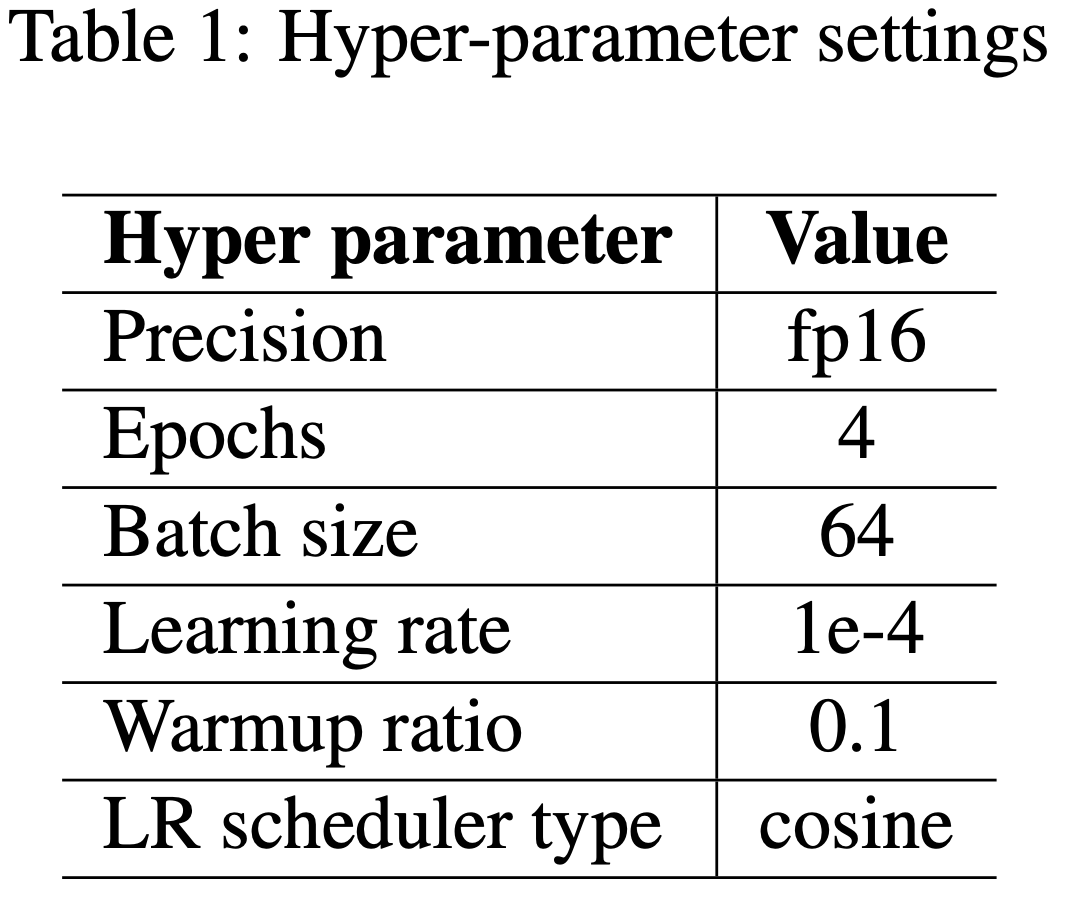
- DAPT 和 SFT 阶段的参数配置如表1 所示,两者唯一的区别在于最大长度(DAPT 为 1024,SFT 为 1536)
Metrics
- 评估对大语言模型的成功至关重要。对于 ChatHome,论文不仅希望注入领域相关知识,还关注模型在领域化后的通用能力
- 因此,论文的评估包括两部分:通用能力评估和领域能力评估
- 通用评估(General Evaluation) :为了评估模型的通用能力,论文采用 C-Eval (2023a) 和 CMMLU (2023),这两个基准测试用于评估基础模型在中文语境下的高级知识和能力
- 领域评估(Domain Evaluation) :据论文所知,目前没有权威的家装领域评估数据集
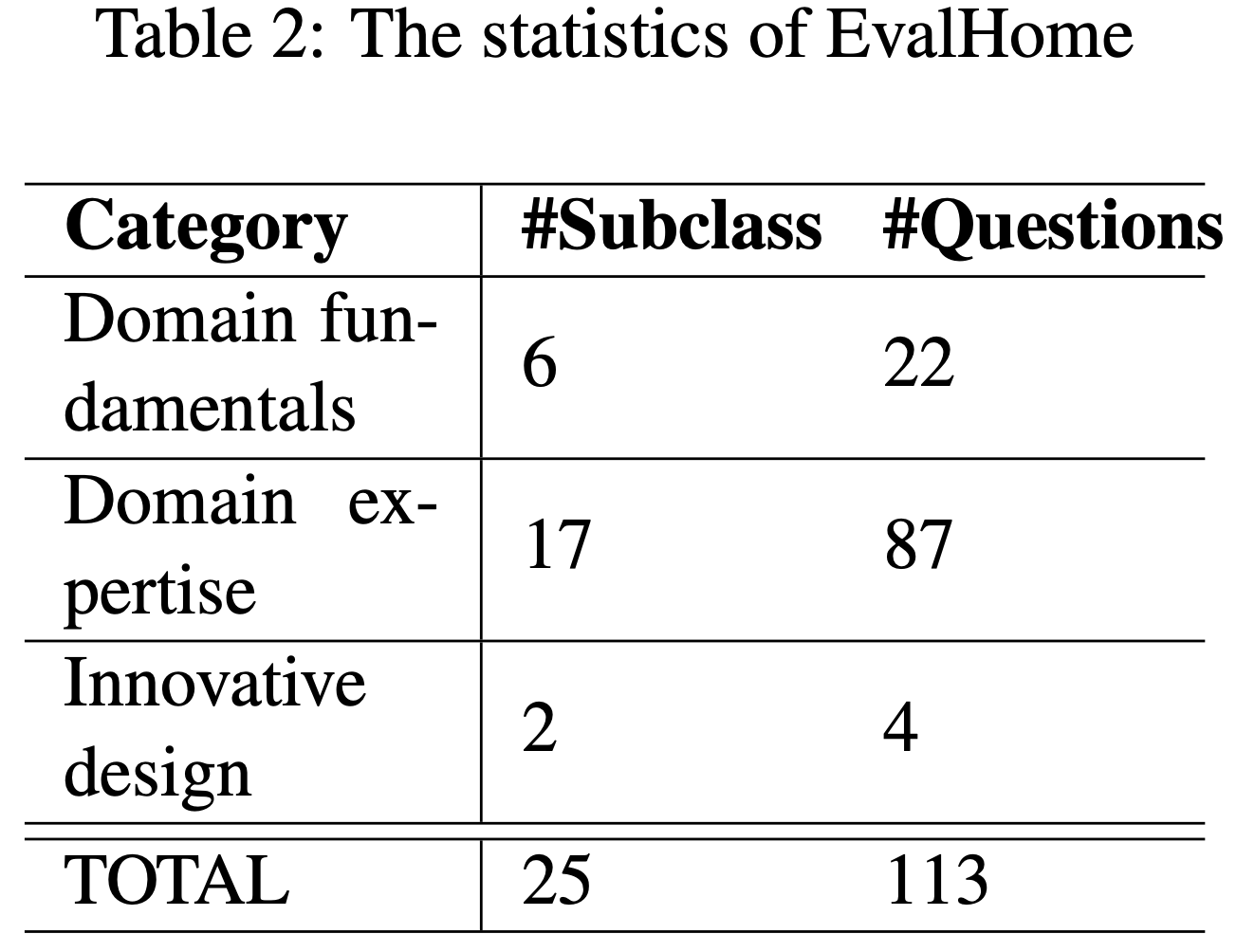
- 论文构建了一个名为 EvalHome 的领域评估数据集,涵盖三个难度级别:领域基础知识、领域专业知识和创新设计
- 所有问题均以多选题形式呈现,共计 113 道
- EvalHome 的统计信息如表2 所示
Results and Analysis
Data ratio result analysis
- DAPT 模型在通用评估集上的实验结果如表3 所示
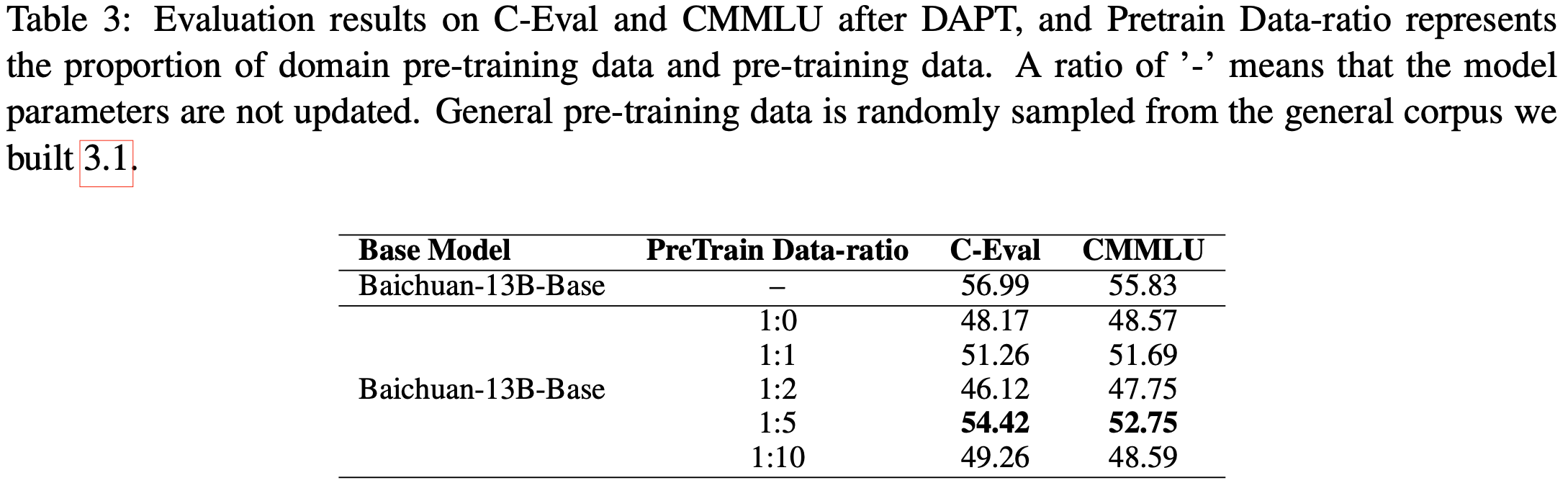
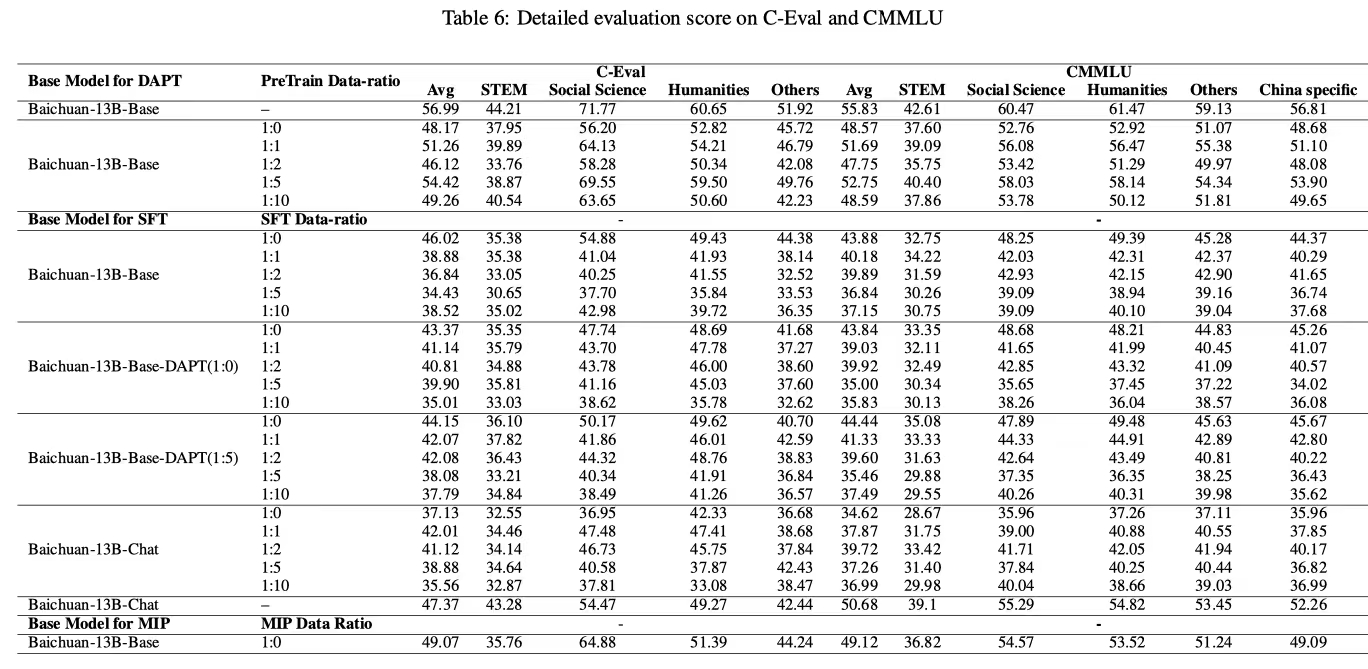
- 论文展示了 CEval 和 CMMLU 的平均分数,各类别的详细分数见表6
- 尽管在 1:10 的比例下添加了更多通用数据,但 DAPT 模型在 1:5 的数据比例方案中表现出最少的通用能力损失,其 CEval 和 CMMLU 的平均分数相较于基础模型分别下降了 2.57 和 3.08 分。该模型记为 Baichuan-13B-Base-DAPT (1:5)
- 表4 展示了领域适应模型在 EvalHome 和通用评估集上的实验结果。论文进行了四组实验,其中 Baichuan-13B-Base-DAPT (1:0) 表示 DAPT 阶段的数据比例为 1:0
- 可以看到,除了 Baichuan-13B-Base 实验外,其他三组实验在 1:5 数据比例下均取得了 EvalHome 的最佳结果
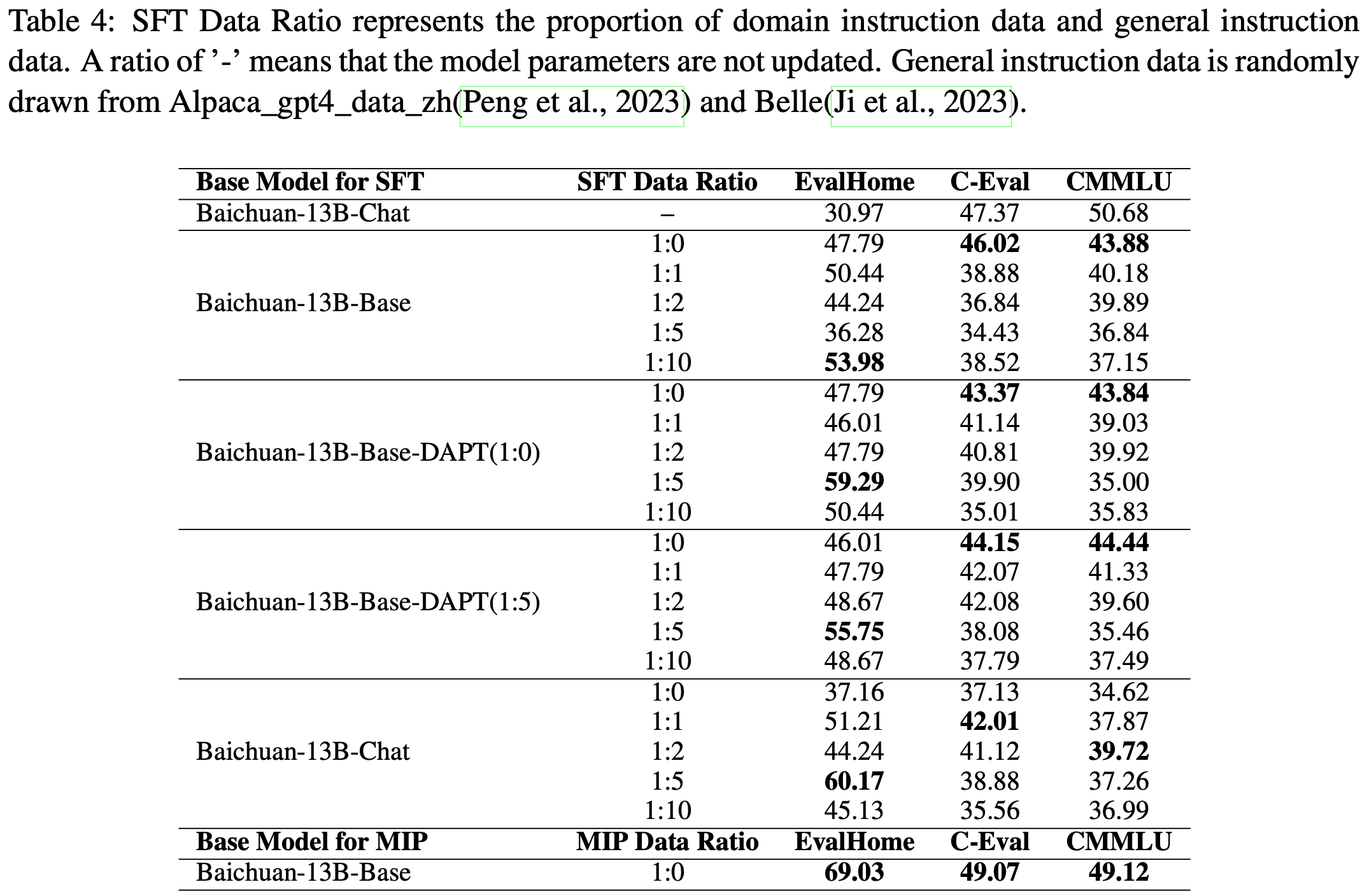
- 可以看到,除了 Baichuan-13B-Base 实验外,其他三组实验在 1:5 数据比例下均取得了 EvalHome 的最佳结果
- 结合这两张表的实验结果,我们可以初步得出结论:在当前的基础模型和家装领域数据下,1:5 的数据比例表现最佳
- 在指令微调阶段,论文观察到一个显著现象:随着更多通用指令数据的加入,模型在通用能力评估集上的分数下降
- 这可能是因为 C-Eval 和 CMMLU 主要评估模型的特定知识 ,而论文的通用指令数据未能覆盖这些内容
Domain adaptation result analysis
- 从表4 可以看出,经过 DAPT 的模型在指令微调后,EvalHome 的得分分别为 59.29 和 55.75,相较于未经过 DAPT 的 Baichuan-13B-Base 模型(最高分为 53.98)略有提升
- 然而,当使用已经过指令数据训练的 Baichuan-13B-Chat 模型进行指令微调时,EvalHome 的得分达到了 60.17。此外,不同数据比例的模型相较于未更新参数的 Baichuan-13B-Chat 均有显著提升
- 这表明,在当前领域场景下,经过 DAPT 的指令微调并未显著超越直接在指令对齐模型上进行领域适应的效果
- 论文推测,这可能是因为基础模型在预训练阶段已经包含了大量家装相关数据
- 进一步地,受一些研究工作 (2021; 2022; 2022) 的启发,论文尝试在 DAPT 阶段融入下游监督数据
- 这种策略在 (2022) 中被称为 MIP(多任务指令预训练),论文在论文中也沿用这一名称
- 由于训练资源和时间的限制,论文未对数据比例进行详细分析
- 在 MIP 阶段,论文的训练数据仅包含领域预训练数据和领域指令数据,未添加通用语料
- 尽管如此,EvalHome 的得分意外达到了 69.03(见表4 最后一行)
- 更令人惊讶的是,该模型不仅在 EvalHome 上得分最高,还在两个通用能力评估基准上表现更优
- 这一发现表明,在当前领域数据集和基础模型条件下,将下游指令数据融入 DAPT 阶段是有益的。未来论文计划在 MIP 阶段进行更深入的数据比例实验
附录 A
- Prompts used for generating one-turn and multi-turn dialogues by GPT-4, examples of EvalHome and the detail socres of C-Eval and CMMLU are presented in this appendix.
图3:EvalHome 示例
- 为便于阅读,中文下方附有英文翻译

图4:单轮对话示例
- 为便于阅读,中文下方附有英文翻译

表5:数据生成过程中使用的提示
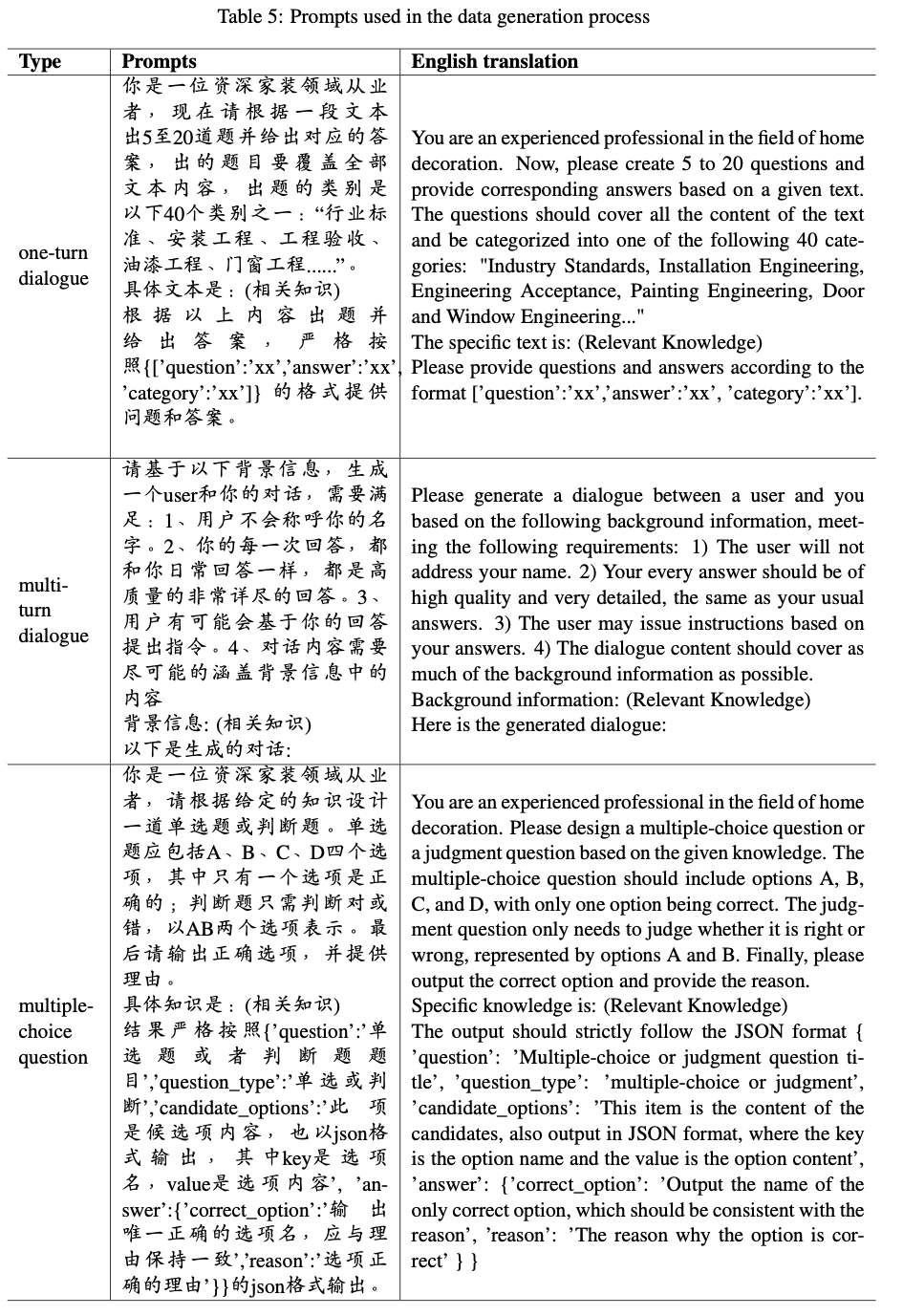
图5:多轮对话示例
- 为便于阅读,中文下方附有英文翻译

表6:C-Eval 和 CMMLU 的详细评估分数