词嵌入的发展,NNLM,CBOW,skip-gram
词嵌入(Word Embedding)也称为词向量(Word2Vec): 指的是将词转换成向量的形式
基本问题
- 用语言模型做预训练
- 语言模型: 如何计算一段文本序列在某种语言下出现的概率?
- 如何表示文本中的一个词?
文本表示模型
词袋模型
- One-Hot: 向量维度与词的数量相同,某个维度为1,其他都为0
- TF-IDF: 计算词对文档的贡献(权重)
- TextRank: 类似于PageRank的思想
- 如果一个单词出现在很多单词后面的话,那么说明这个单词比较重要
- 一个TextRank值很高的单词后面跟着的一个单词,那么这个单词的TextRank值会相应地因此而提高
优缺点
- OneHot:
- 维度灾难
- 语义鸿沟
- TF-IDF和TextRank
- [个人理解]也无法表示语义,所以存在语义鸿沟
主题模型
- LSA: 矩阵分解(SVD)的方式,又名 Latent Semantic Indexing
- pLSA: 简单的概率隐式语义模型
- LDA: 无监督聚类常用的模型,有Gibbs Sampling和变分推断等实现,网上有很多资料,也有很多实现
- L-LDA: LDA的有监督版本,核心思想就是在LDA吉布斯实现的版本基础上加上采样限制,使得每次采样只能控制在对应主题上,效果比较好,网上没有官方的实现,大部分实现不完全,感兴趣可以试试我的实现Labeled-LDA-Python
- L-LDA理论上可以得到比LDA质量更高,效果更好的词向量
优缺点:
- LSA:
- 利用全局语料特征
- 但SVD求解计算复杂度大
基于词向量的固定表征
- Word2vec: 基于上下文训练, 拥有相同上下文的词相近,基于分布式假设(相同上下文语境的词有似含义)
- FastText: 通过对”词-词”共现矩阵进行分解从而得到词表示的方法,基于分布式假设(相同上下文语境的词有似含义)
- GloVe: 基于全局预料,结合了LSA和word2vec的优点, 论文: GloVe: Global Vectors for Word Representation
优缺点
- 目前提到的以上所有都是静态词向量,无法解决一次多义等问题
- Word2vec和FastText:
- 优化效率高,但是基于局部语料
- 本质上二者也都是语言模型
- GloVe:
- 基于全局语料库、并结合上下文语境构建词向量, 结合了LSA和word2vec的优点
- 可以看作是更换了目标函数和权重函数的全局word2vec
基于词向量的动态表征
- ELMo:
- 采样 LSTM 提取特征
- 采用双向语言模型
- 实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比BERT一体化融合特征方式弱
- GPT:
- 采样 Transformer 进行特征提取
- 采用单向语言模型
- BERT:
- 采用Transformer进行特征提取
- 采用双向语言模型
优缺点
- 三者都是基于语言模型的动态词向量,能解决一次多义问题
- ELMo:
- 采用1层静态向量+2层 LSTM,多层提取能力有限
- GPT和BERT:
- Transformer 可采用多层,并行计算能力强
- 很多任务表明:
- Transformer 特征提取能力强于 LSTM
- GPT和BERT都采用 Transformer,Transformer 是 encoder-decoder 结构,GPT 的单向语言模型采用 decoder 部分,decoder 的部分见到的都是不完整的句子;BERT 的双向语言模型则采用 encoder 部分,采用了完整句子
NNLM/RNNLM
- 词向量为副产物,存在效率不高等问题;
不同模型的对比
word2vec vs NNLM
- 本质上都可以看做是语言模型
- 对 NNLM 来说,目不是词向量,是语言模型
- word2vec 虽然本质上也是语言模型,但是更关注词向量本身,因此做了很多优化来提高计算效率
- 与 NNLM 相比,词向量直接 sum(CBOW),而不是拼接,并取消隐藏层
- 考虑到 Softmax 需要遍历整个词汇表,采用 Hierarcal Softmax和 Negative Sampling 进行优化
- word2vec 所做的一切都是为了一切为了快速生成词向量
word2vec vs fastText
- 都可以进行无监督学习, fastText 训练词向量时会考虑 subword(子词)
- 在 fastText 中,每个中心词被表示成子词的集合,下面我们用单词
“where”作为例子来了解子词是如何产生的 - 首先,我们在单词的首尾分别添加特殊字符
“<”和“>”以区分作为前后缀的子词 - 然后,将单词当成一个由字符构成的序列来提取 n 元语法
- 例如,当n=3时,我们得到所有长度为3的子词:
“<wh>”“whe”“her”“ere”“<re>”以及特殊子词“<where>”
- 例如,当n=3时,我们得到所有长度为3的子词:
- 在 fastText 中,每个中心词被表示成子词的集合,下面我们用单词
- fastText还可以进行有监督学习进行文本分类:
- 结构与CBOW类似,但学习目标是人工标注的分类结果, 而不是中心词 \(w\)
- 采用hierarchical softmax对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径;
- 引入N-gram,考虑词序特征;
- 引入subword(子词)来处理长词,处理未登陆词问题
word2vec vs GloVe vs LSA
- word2vec vs GloVe
- 语料库:
- word2vec是局部语料库训练的,特征提取基于滑动窗口,可以在线学习
- GloVe的滑动窗口是为了建立”词-词”共现矩阵,需要统计共现概率,不能在线学习
- 无监督学习:
- word2vec是无监督学习
- GloVe通常被认为是无监督学习(无需标注),但实际上GloVe还是有label的,即共现次数 \(log(X_{ij})\)
- 损失函数:
- word2vec损失函数实质上是带权重的交叉熵,权重固定;
- GloVe的损失函数是最小平方损失函数,权重可以做映射变换
- 总结:
- word2vec的损失函数是带权重的交叉熵 , 权重是固定的
- GloVe可以看作是目标函数为MSE ,权重函数可变的全局word2vec
- 语料库:
- GloVe vs LSA
- LSA(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高;
- GloVe可看作是对LSA一种优化的高效矩阵分解算法,采用Adagrad对最小平方损失进行优化;
ELMo、GPT、BERT
- 三者使用了两种不同的NN组件提取特征
- ELMo: LSTM
- GPT, BERT: Transformer
- 三者使用了两种不同的语言模型:
- GPT: 单向语言模型
- ELMo, BERT: 双向语言模型
- ELMo实际上是两个方向相反的单向语言模型的拼接, 融合特征的能力比BERT那种一体化的融合特征方式弱
- GPT和BERT都采用Transformer,Transformer是 Encoder-Decoder结构
- GPT为单向语言模型,采用的是Decoder部分, Decoder部分见到的都是不完整的句子
- BERT为双向语言模型,采用的是Encoder部分,采用了完整的句子
下面是一些模型的详细介绍
NNLM
模型目标
- 给定一段长度为m的序列时,预测下一个词(第m+1)个词出现的概率
- 参考博客DL——NNLM
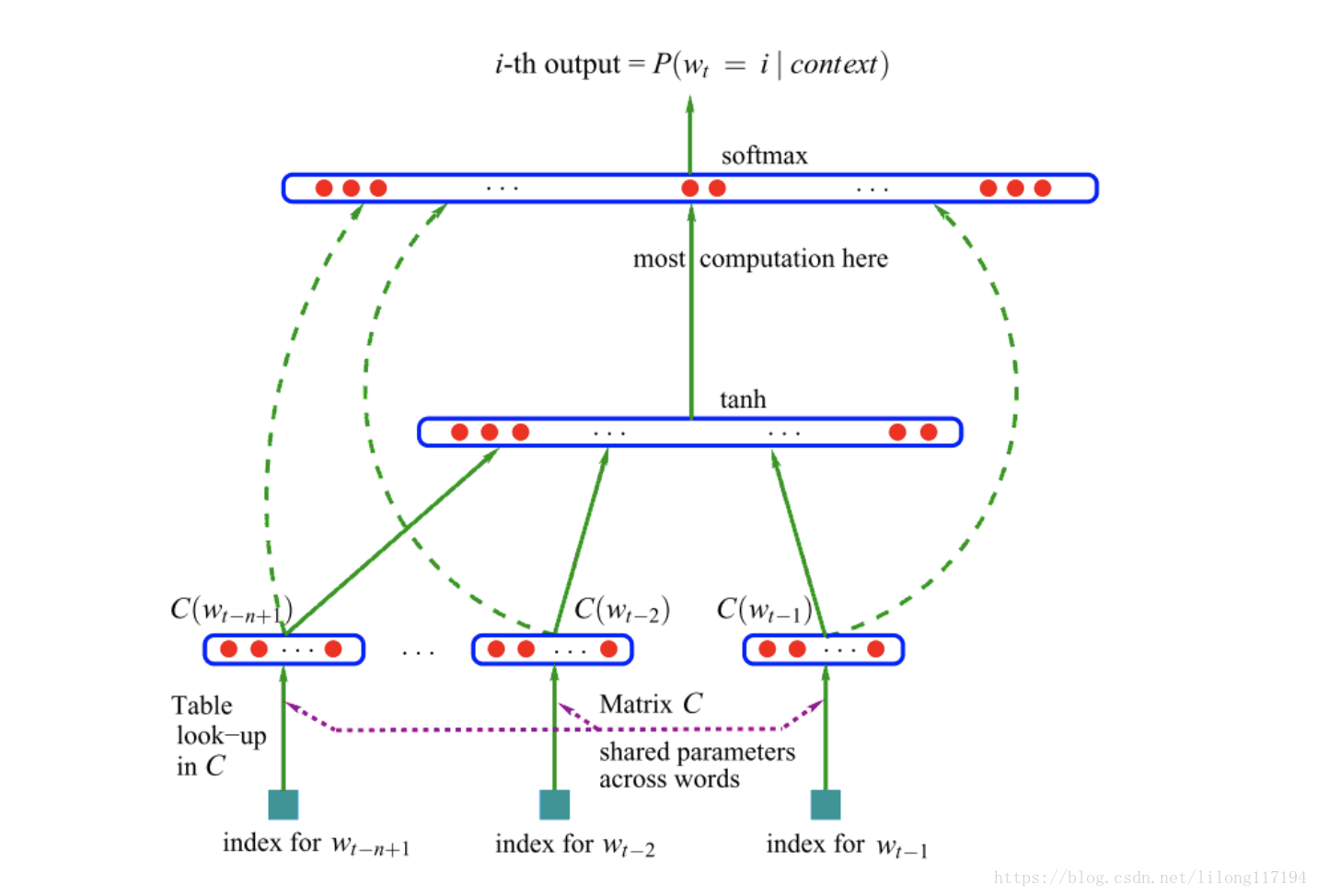
word2vec
- 此处只做简单介绍,更详细的讲解请参考博客word2vec学习笔记
- 一个比较好的手写笔记版:通俗易懂讲解Word2vec的本质 - 对白的文章 - 知乎
- 损失函数: 带权重的交叉熵损失函数(权重固定)
两类实现
- 一般实现: 每次训练一个样本 \((w_{in}, w_{out})\),需要计算所有词和当前词一起对应的 softmax, 很耗时间,需要 \(O(V)\) 复杂度的时间
- 优化实现: Hierarcal Softmax 和 Negative Sampling 两种方式
- Hierarcal Softmax: 每次训练一个样本 \((w_{in}, w_{out})\),只需要更新平均 \(O(log V)\) 个非叶子节点(每个非叶子结点就是一个词向量)即可
- Negative Sampling: 每次训练一个样本 \((w_{in}, w_{out})\),只需要更新 \({w_j|w_j\in {w_O}\bigcup W_{neg}}\) 个词向量, 通常负样本的集合大小取 \(log(V)\) 量级甚至更小
层次 Softmax 模型框架
- 层次 Softmax(Hierarchical Softmax),也称为层次化 Softmax
- 对于词表大小为 \(V\) 的场景,如果使用普通的 Softmax,则每次需要在分母上计算 \(V\) 次指数运算并求和,使用 层次 Softmax 后转化为 \(\log(V)\) 次二分类任务
- 核心思想: 输出层由语料库中词出现的频数当作权值构造出的哈夫曼树作为输出
- 引入哈夫曼树 , Hierarcal Softmax是一种有效计算Softmax的方式,使用二叉树来表示
- 其中Hierarchical Softmax模型的输出层由语料库中词出现的频数当作权值构造出的哈夫曼树作为输出
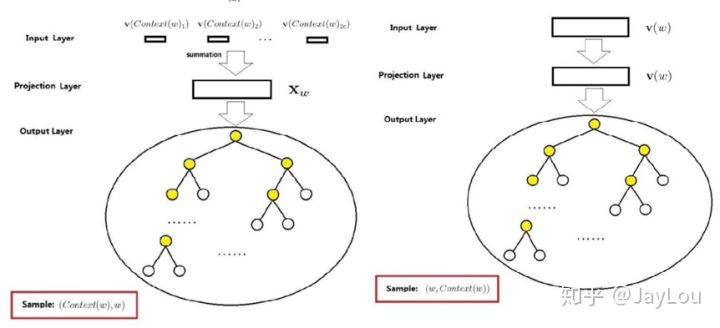
- CBOW
- 输入层: \(2c\)个词向量
- 投影层: \(2c\)个词向量的累加
- 输出层: 哈夫曼树(重点是词w所在的叶子节点, 以及w到根节点的路径)
- 所有单词没有输出向量表示形式,每个内部结点有一个输出向量 \(v\)
- 输出层共有 \(V - 1\) 个非叶节点, 也就是要学习 \(V - 1\) 个输出向量
- 看起来并没有什么优化,但是每次迭代训练一个样本 \(w_{in}, w_{out}\) 时,我们只需要优化从根节点到输出单词 \(w_{out}\) 的路径上的输出向量即可, 平均共 \(O(log V)\) 个向量
- 每个单词的概率计算需要考虑叶子节点来求出
- 传统softmax公式 :在传统的softmax函数中,计算目标词与所有词汇之间的概率分布公式为\(P ( w_t | C ) = \frac{e^{v_{w_t}^T v_{w_c} } }{\sum_{w’} e^{v_{w’}^T v_{w_c} } }\),其中\(w_t\)是目标词,\(w_c\)是上下文词,\(v_{w_t}\)和\(v_{w_c}\)是目标词和上下文词的词向量
- 其中:\(v_{w_c}\) 和 \(v_{w_t}\) 就是我们要学习的词向量
- 层次softmax公式 :给定一个目标词\(w_t\),上下文词\(w_c\),通过霍夫曼树计算从目标词到上下文词的路径概率。假设从根节点到叶节点的路径上有多个节点,对于目标词\(w_t\),路径\(P\)到达目标词,要最大化的概率公式为\(P ( w_t | C ) = \prod_{k = 1}^{L} \sigma(v_{w_t}^T v_{n_k})\)。其中\(L\)是路径的长度(即路径上的节点数),\(n_k\)是路径上的第\(k\)个节点(非叶子节点),\(v_{w_t}\)是目标词的词向量,\(v_{n_k}\)是路径节点\(n_k\)的词向量。每一个路径的概率通过sigmoid函数计算:\(\sigma(x) = \frac{1}{1 + e^{-x} }\)
- 其中:\(v_{w_t}\) 就是我们要学习的词向量
- Skip-gram
- 输入层:词 \(w\) 的向量
- 投影层:依旧是词 \(w\) 的向量
- 输出层:哈夫曼树(重点是词 \(w\) 的上下文窗内 \(2c\) 个词所在的叶子节点,以及各自到根节点的路径)
Negative Sampling模型框架
- 实际上就是简单的对每一个样本中每一个词都进行负例采样(本质上就是用负采样代替了层次softmax的哈弗曼树)
- 负采样是噪声对比估计的一个简化版本,目的是提高训练速度并改善所得词向量的质量
- 核心思想: 在每次迭代过程中, 有大量的输出向量需要更新,为了解决这一困难, Negative Sampling的做法是只更新其中一部分输出向量
- 利用不同词在语料中出现的频次多少来决定被采样到的概率(单词出现的频次越大,越可能被选做负样本)
- 负采样: 利用不同词在语料库中出现的频次多少来决定该词被采样到的概率
- 每次训练一个样本 \((w_{in}, w_{out})\),只需要更新 \({w_j|w_j\in {w_O}\bigcup W_{neg}}\) 个词向量, 通常负样本的集合大小取 \(log(V)\) 量级甚至更小
- CBOW
- 输入层: \(2c\)个词向量
- 投影层:\(2c\)个词向量的累加
- 输出层:负采样词集(重点是词w的负词词集的参数 \(\theta\),负词的概率永远是1-Sigmoid函数值)
- Skip-gram模型:
- 输入层:词w的向量
- 投影层:依旧是词w的向量
- 输出层:每个上下文词u的负采样(重点是词w的负词词集的参数 \(\theta\),负词的概率永远是1-Sigmoid函数值)
总结
- 层次Softmax模型:
- CBOW模型的一次更新是:
- 输入 \(2c\) 个词向量的累加(简单的
sum,而不是拼接) - 对中心词 \(w\) 上的路径节点系数进行更新(输出层)
- 对所有的上下文词的词向量进行整体一致更新(输入层到隐藏层的参数, 修改多个词向量)
- 输入 \(2c\) 个词向量的累加(简单的
- Skip-gram模型的一次更新是:
- 输入中心词 \(w\) 的词向量(直接输入,无其他操作)
- 对每个上下文词 \(u(i)\) 所在的路径上的节点系数进行更新(输出层,修改多个上下文的结点)
- 对词w的词向量进行单独更新(输入层到隐藏层的参数,只修改一个词向量)
- CBOW一次训练更新计算量小,Skip-gram一次训练计算量大(更新的系数更多?)
- CBOW模型的一次更新是:
- CBOW看起来更新的更平滑,适合小量文本集上的词向量构建,Skip-gram每次更新都更加有针对性,所以对于大文本集上表现更好
word2vec的缺陷
- 不能解决多义词问题(只能把几种意思同时编码进向量里)
- 这是所有固定词向量的通病
- 解决方案是动态词向量(允许不同上下文使用不同词向量表达同一个词),包括ELMo, GPT, BERT