注:本文包含 AI 辅助创作
一些前置说明
- 亲测 gpt-oss 的输出 thinking 内容大多是英文的(即使是使用纯中文提问也一样)
- gpt-oss 代码能力很强,在 OIBench(代码)上的评估指标远高于其他模型
- gpt-oss-120b(high) 比 DeepSeek-R1-0528 高出 10-20 个PP左右,甚至 gpt-oss-20b(high) 都比 DeepSeek-R1-0528 更好
- 注:论文读起来不像是技术报告,更像是模型说明文档,本文目标是对 gpt-oss-120b 和 gpt-oss-20b 模型的 Model Card 完整梳理
Introduction and Discussion
- OpenAI 20250805 开源了两款纯文本推理模型:gpt-oss-120b 和 gpt-oss-20b
- 开源协议:基于 Apache 2.0 和 gpt-oss 自身开源策略
- 仅开源权重
- 纯文本模型(text-only models)
- 目标是用于支持智能体工作流(agentic workflows),具备强大的指令跟随(instruction following)、工具使用(如网络搜索和 Python 代码执行)以及推理能力(reasoning capabilities)
- 包括为不需要复杂推理的任务调整推理强度的能力
- 模型支持定制化,提供完整的 CoT ,并支持结构化输出(Structured Outputs)
- OpenAI 特别强调了这两款模型的安全性
- 与专有模型(proprietary models)不同,开源模型的风险特征更为复杂:一旦发布,攻击者可能通过微调绕过安全拒绝机制,或直接优化模型以实现危害行为,而 OpenAI 无法通过额外的缓解措施或撤销访问权限来阻止
- 猜测:实际上,OpenAI 开源的其中一个目的很可能就是看看大家对大模型的攻击手段如何,是为了以后 OpenAI 自己以后的模型打好安全性基础
- 论文将论文档称为模型卡(model card),而非系统卡(system card),因为 gpt-oss 模型将被广泛应用于由不同 Stakeholders 创建和维护的多样化系统中
- 这些模型默认遵循 OpenAI 的安全策略,Stakeholders 也将根据自身需求决定如何保障系统安全
- 论文对 gpt-oss-120b 进行了可扩展的能力评估(scalable capability evaluations),并确认其默认版本未达到论文在“准备框架(Preparedness Framework)”中 三个跟踪类别(Tracked Categories)的“高能力(High capability)”阈值 ,这三个类别分别是:
- 生物与化学能力(Biological and Chemical capability)
- 网络安全能力(Cyber capability)
- AI 自我改进能力(AI Self-Improvement)
- 论文还研究了以下两个问题:
- 攻击者是否可以通过微调 gpt-oss-120b 在生物与化学或网络安全领域达到高能力?(Could adversarial actors fine-tune gpt-oss-120b to reach High capability in the Biological and Chemical or Cyber domains?)
- 通过模拟攻击者的潜在行为,论文对 gpt-oss-120b 模型在这两个类别上进行了对抗性微调(adversarially fine-tuned)
- OpenAI 安全咨询组(Safety Advisory Group, SAG)审查了这项测试,并得出结论:即使利用 OpenAI 领先的训练技术栈进行强力微调,gpt-oss-120b 仍未在生物与化学风险或网络安全风险中达到高能力
- 发布 gpt-oss-120b 是否会显著提升开源基础模型在生物能力方面的前沿水平?(Would releasing gpt-oss-120b significantly advance the frontier of biological capabilities in open foundation models?)
- 论文发现答案是否定的:在大多数评估中,现有开源模型的默认性能已接近或匹配对抗性微调后的 gpt-oss-120b 性能
- 攻击者是否可以通过微调 gpt-oss-120b 在生物与化学或网络安全领域达到高能力?(Could adversarial actors fine-tune gpt-oss-120b to reach High capability in the Biological and Chemical or Cyber domains?)
- 在论文中,OpenAI 重申其对推动有益 AI 发展和提升生态系统安全标准的承诺
Model architecture, data, training and evaluations
- gpt-oss 模型是基于 GPT-2 和 GPT-3 架构的自回归混合专家模型(autoregressive Mixture-of-Experts, MoE)(2017; 2020; 2022)
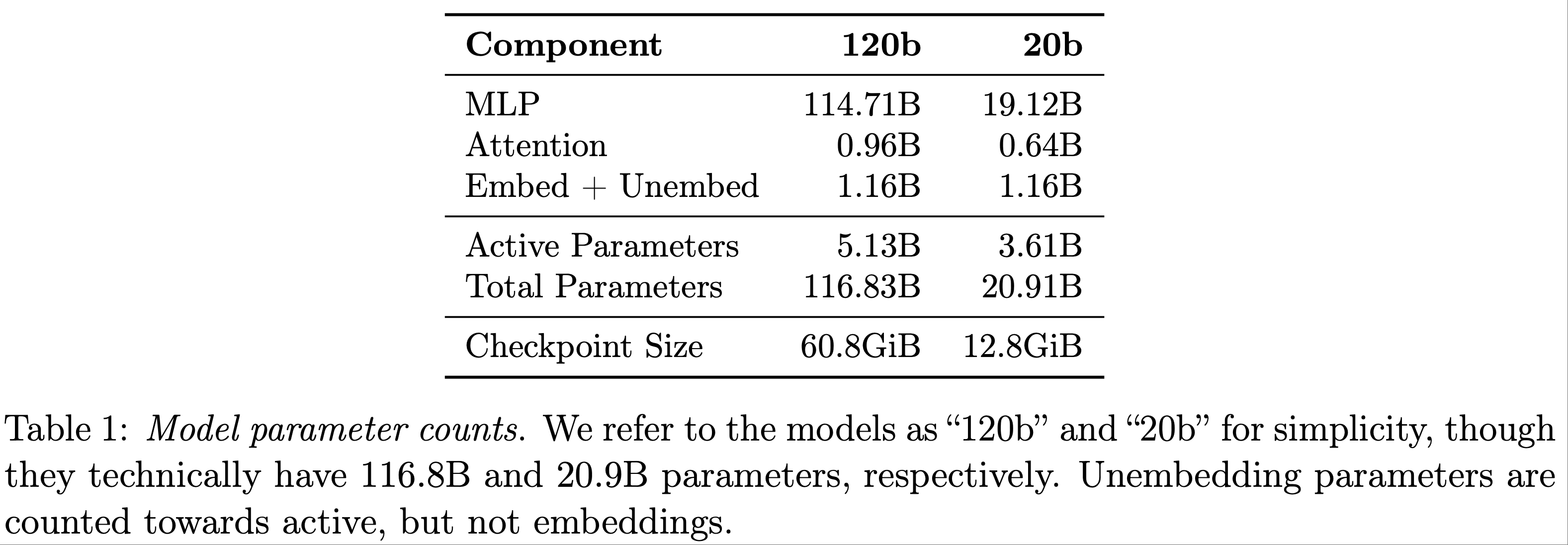
- gpt-oss-120b 包含 36 层(总参数量 116.8B,每 Token 激活参数量 5.1B)
- gpt-oss-20b 包含 24 层(总参数量 20.9B,每 Token 激活参数量 3.6B)
- 表 1 展示了详细的参数量统计
Quantization
- 论文采用量化技术以减少模型的内存占用
- 在 MoE 权重上(MoE 权重占总参数量的 90% 以上),论文使用 MXFP4 格式(2023)进行后训练量化(post-trained quantization) ,将参数量化为每参数 4.25 比特
- 量化后的 120B 模型可运行在单块 80GB GPU 上,20B模型 可运行在内存低至 16GB 的系统上
- 表 1 列出了模型的检查点大小(checkpoint sizes)
Architecture
- 两款模型的残差流维度(residual stream dimension)均为 2880,在每层注意力(attention)和 MoE 模块前应用均方根归一化(root mean square normalization)(2019; 2020)
- 与 GPT-2 类似,论文采用 Pre-LN 布局(Pre-LN placement)(2019)
- MoE:
- 每个 MoE 模块包含固定数量的专家(gpt-oss-120b 为 128 个 ,gpt-oss-20b 为 32 个),以及一个标准的线性路由投影(linear router projection),将残差激活映射为每个专家的分数
- 对于两款模型,论文为每个 token 选择路由得分最高的 4 个专家 ,并通过 softmax 对所选专家的输出进行加权
- MoE 模块使用门控 SwiGLU(gated SwiGLU)激活函数 (2020)
- 注意力(Attention):
- Following GPT-3,注意力模块在 banded window 和 fully dense patterns 之间交替 (2019; 2020),带宽(bandwidth)为 128 token
- 每层包含 64 个维度为 64 的查询头(query heads),并使用分组查询注意力(Grouped Query Attention, GQA)(2023),其中键值头(key-value heads)为 8 个
- 应用旋转位置嵌入(rotary position embeddings, RoPE)(2024)
- 通过 YaRN (2023) 将 Dense 层的上下文长度扩展至 131,072 tokens
- 每个注意力头在 softmax 的分母中引入一个可学习的偏置(learned bias) ,类似于“off-by-one attention”和注意力汇聚(attention sinks)(2023),这使得注意力机制可以完全忽略某些 token
- 问题:这里是用于解决 Attention Sink 问题过于关注第一个 <BOS> Token 的吗?
Tokenizer
- 在所有训练阶段,论文使用 o200k_harmony 分词器,并通过 TikToken 库开源
- o200k_harmony 分词器 使用字节对编码(Byte Pair Encoding, BPE),扩展了其他 OpenAI 模型(如 GPT-4o 和 OpenAI o4-mini)使用的 o200k 分词器,并添加了用于 harmony chat format 的特殊 token,总 token 数为 201,088
Pretraining
- Data:
- 论文使用包含数万亿 token 的纯文本数据集训练模型,重点关注 STEM、编程和通用知识领域
- 为了提高模型安全性,论文在预训练阶段过滤了有害内容 ,尤其是涉及生物安全危险知识的数据 ,复用了 GPT-4o 的 CBRN 预训练过滤器 (2024)
- 模型的知识截断日期(knowledge cutoff)为 2024 年 6 月
- 训练(Training):
- gpt-oss 模型在 NVIDIA H100 GPU 上使用 PyTorch 框架 (2019) 和专家优化的 Triton 内核 (2019) 进行训练
- 问题:Triton 框架不是用于推理的框架吗?
- gpt-oss-120b 的训练耗时 210 万 H100 小时,而 gpt-oss-20b 的耗时约为 120b 的十分之一(21 万 H100 小时)
- 两款模型均利用 Flash Attention 算法 (2022) 降低内存需求并加速训练
- gpt-oss 模型在 NVIDIA H100 GPU 上使用 PyTorch 框架 (2019) 和专家优化的 Triton 内核 (2019) 进行训练
Post-Training for Reasoning and Tool Use
- 在预训练后,论文采用与 OpenAI o3 类似的思维链强化学习(CoT RL)技术对模型进行后训练
- 这一过程教会模型如何使用思维链和工具解决问题
- 由于采用相似的 RL 技术,这些模型的“性格”与 ChatGPT 等 OpenAI 产品中的模型类似
- 训练数据集涵盖编程、数学、科学等多样化问题
Harmony chat format
- 在模型训练中,论文使用一种名为 harmony chat format 的自定义聊天格式
- 该格式通过特殊 token 划分消息边界,并使用关键字参数(如 User 和 Assistant)标识消息作者和接收者
- 论文采用与 OpenAI API 模型相同的系统(System)和开发者(Developer)消息角色
- 通过这些角色,模型遵循基于角色的信息层级(role-based information hierarchy)来解决指令冲突:System > Developer > User > Assistant > Tool
- 该格式还引入了“通道”(channels)以指示每条消息的可见性,例如用于思维链 token 的 analysis、用于函数工具调用的 commentary,以及向用户展示最终答案的 final
- 这种格式支持 gpt-oss 提供高级智能体功能,包括在思维链中穿插工具调用,或向用户展示更长的行动计划前言
- 论文的开源实现和指南提供了该格式的完整使用细节——正确部署 gpt-oss 模型是发挥其最佳能力的关键
- 例如,在多轮对话中,应移除过去助手回合的推理痕迹
- 附录中的图 17 和 18 展示了和谐聊天格式的模型输入输出示例


Variable Effort Reasoning Training
- 论文训练模型支持三种推理强度:低(low)、中(medium)和高(high)
- 这些强度通过系统提示中的关键词(如“Reasoning: low”)配置
- 提高推理强度会增加模型的平均思维链长度
Agentic Tool Use
- 在后训练中,论文还教会模型使用多种智能体工具:
- 浏览工具(browsing tool) :允许模型调用搜索和打开功能与网络交互,从而提高事实性(factuality)并获取知识截断日期后的信息
- Python 工具(python tool) :允许模型在有状态的 Jupyter notebook 环境中运行代码
- 开发者自定义函数(arbitrary developer functions) :开发者可以在 Developer 消息中指定函数模式(function schemas),类似于 OpenAI API
- 函数的定义遵循 harmony chat format ,示例见图 18
- 模型可以穿插思维链、函数调用、函数响应、向用户展示的中间消息以及最终答案
- 模型通过系统提示配置是否启用这些工具
- 针对每种工具,论文提供了支持核心功能的参考工具链(reference harnesses)
- 注:开源实现中提供了更多细节
Evaluation
- 论文在经典推理、编程和工具使用基准测试上评估 gpt-oss
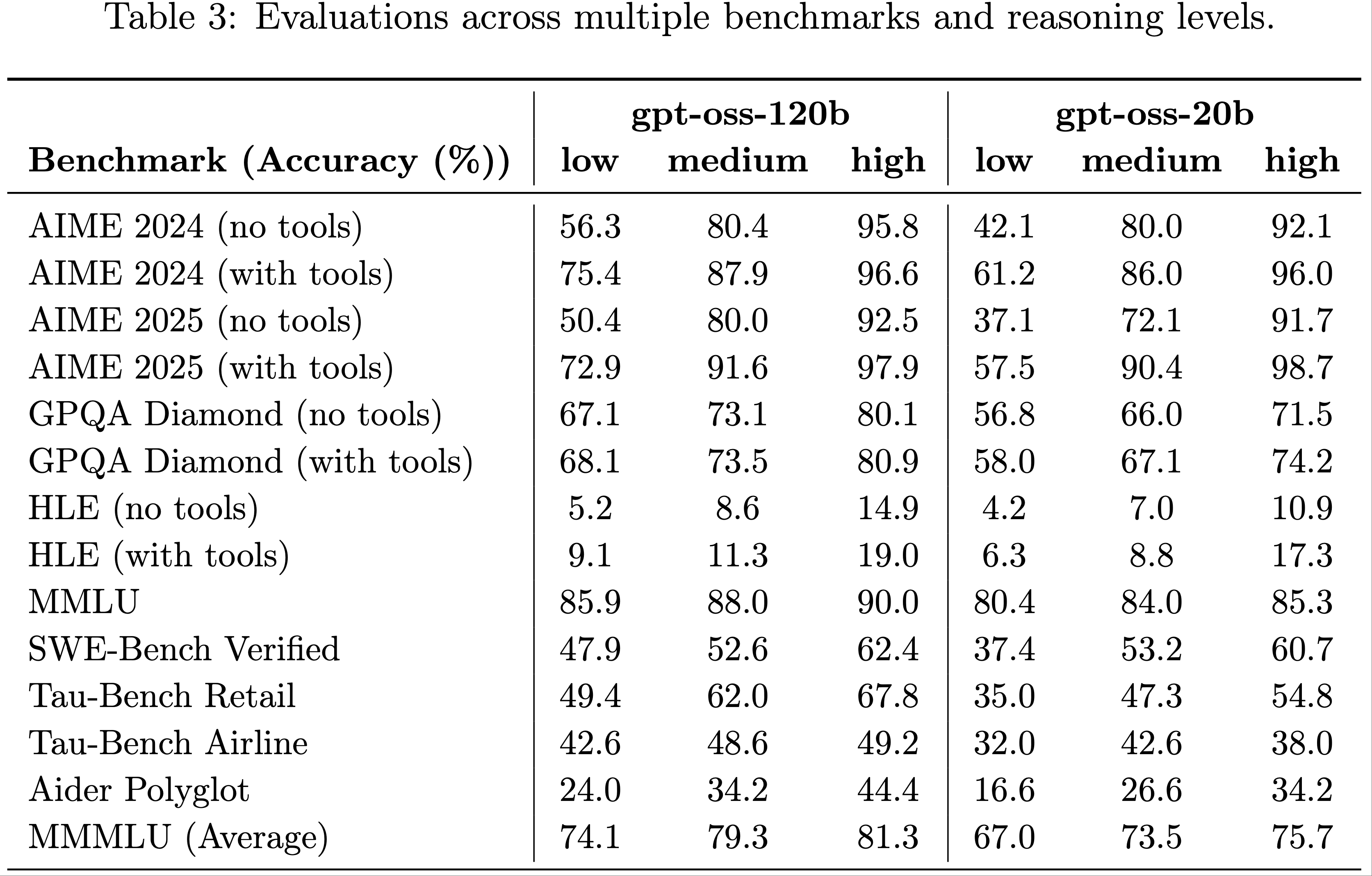
- 对于所有数据集,论文报告高推理模式下模型默认系统提示的 pass@1 结果,并与 OpenAI o3、o3-mini 和 o4-mini 进行比较
- 评估内容包括:
- 推理与事实性(Reasoning and factuality) :AIME、GPQA (2024)、MMLU (2020) 和 HLE (2025)
- 编程(Coding) :Codeforces Elo 和 SWE-bench Verified (2024)
- 论文评估模型在有/无终端工具(类似 Codex CLI 的 exec 工具)时的编程性能
- 工具使用(Tool use) :通过 \(\tau\)-Bench Retail (2024) 评估函数调用能力,论文在模型的 Developer 消息中提供待调用的函数
- 其他能力(Additional Capabilities) :论文还测试了多语言能力和健康知识等重要能力,使用的基准包括 MMMLU (2020) 和 HealthBench (2025)
- 表 3 展示了 gpt-oss 模型在所有推理强度下的完整评估结果
Reasoning, Factuality and Tool Use
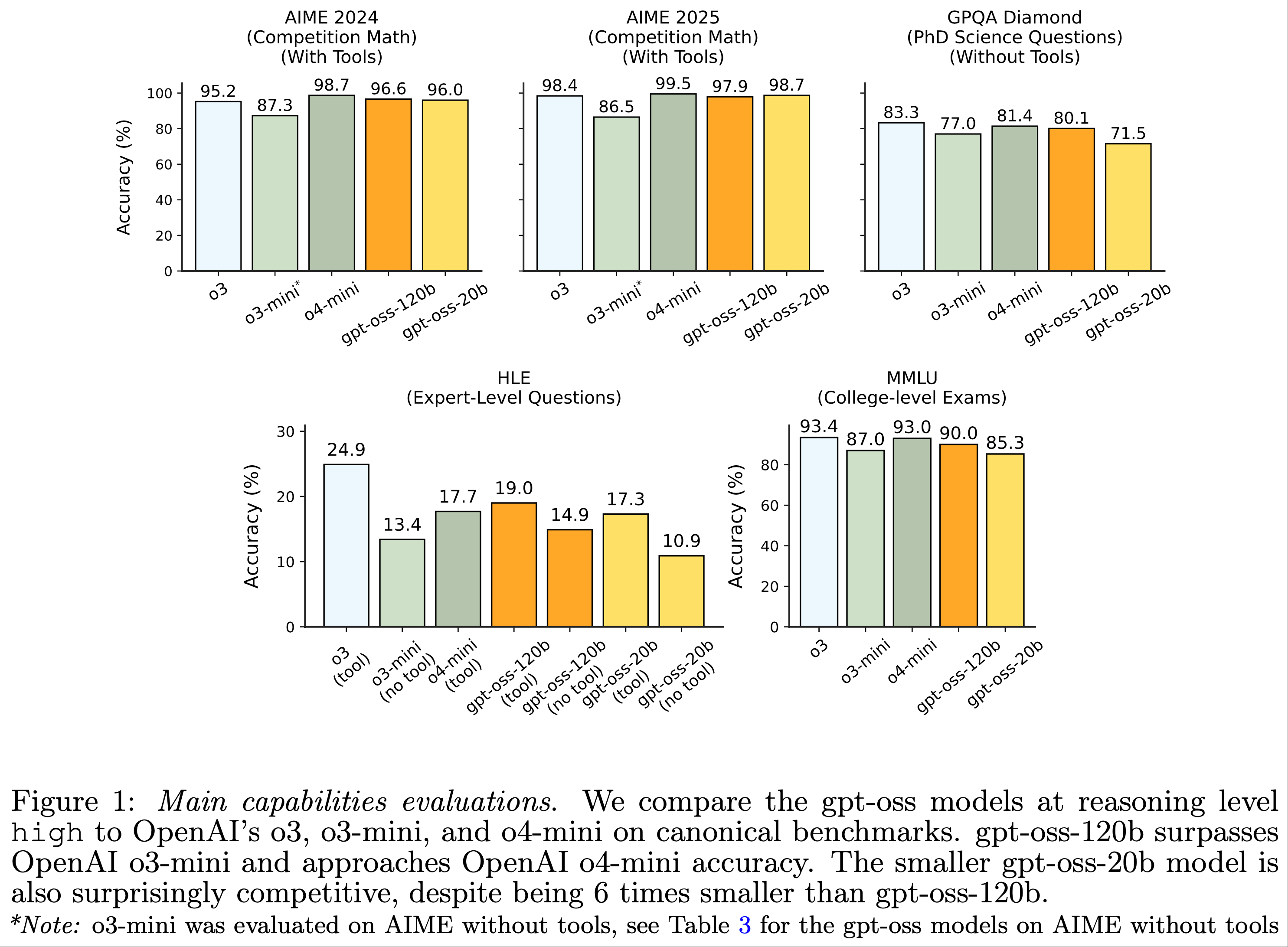
- 核心能力(Main Capabilities):
- 图1展示了论文在四个经典知识与推理任务上的主要结果:AIME、GPQA、HLE 和 MMLU
- gpt-oss模型在数学方面表现尤为突出,作者认为这是因为它们能够有效利用超长思维链(CoT)
- 例如,gpt-oss-20b 在 AIME 问题上平均每个问题使用超过 20,000 个 CoT tokens
- 在更依赖知识的任务(如 GPQA)上,gpt-oss-20b 由于模型规模较小,表现稍逊一筹
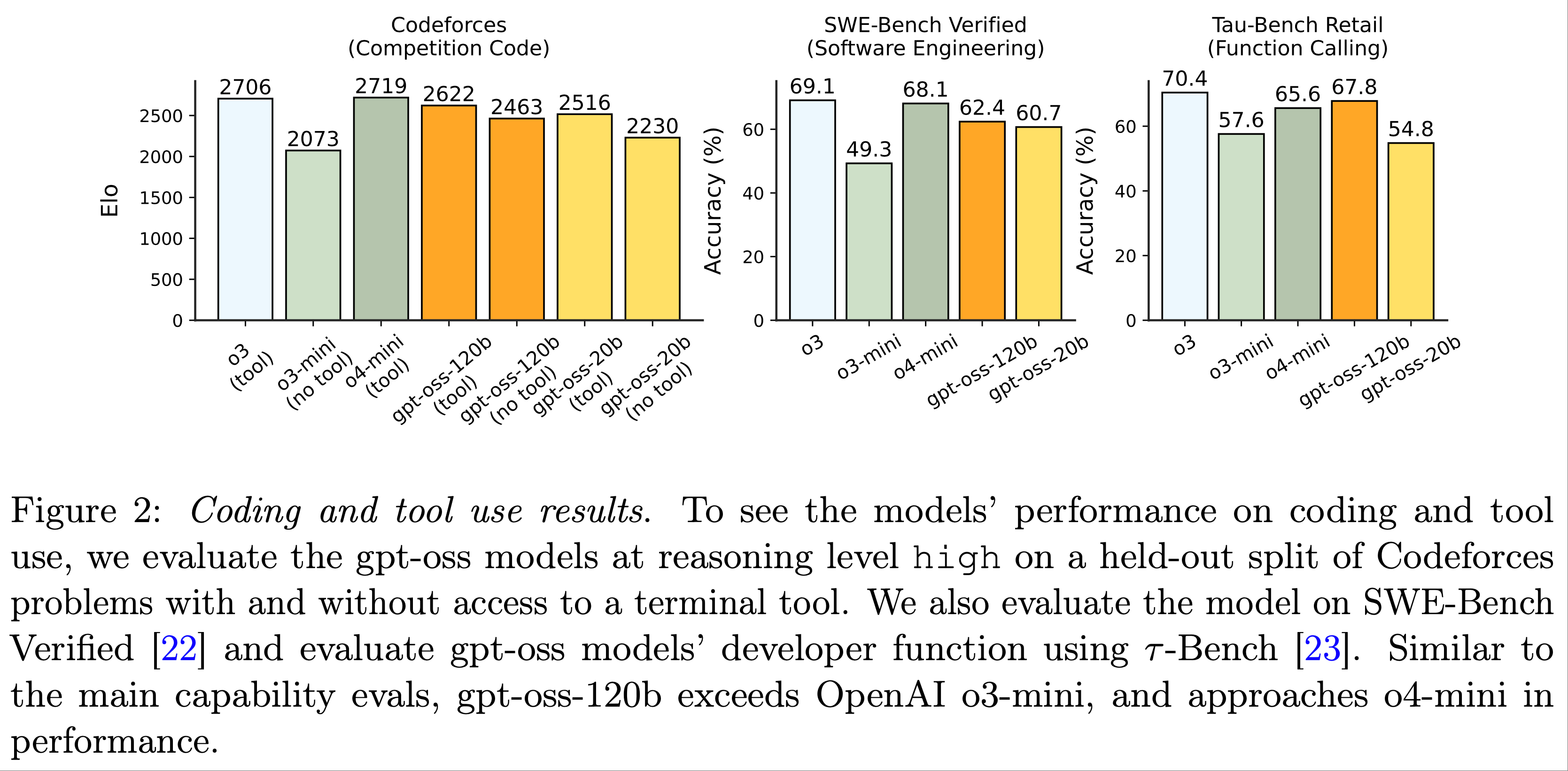
- 智能体任务(Agentic Tasks): :gpt-oss 模型在编程和工具使用任务上表现尤为出色
- 图2 展示了论文在 Codeforces、SWE-bench 和 \(\tau\)-Bench Retail 上的性能
- 与核心能力评估类似,论文发现 gpt-oss-120b 的性能接近 OpenAI 的 o4-mini
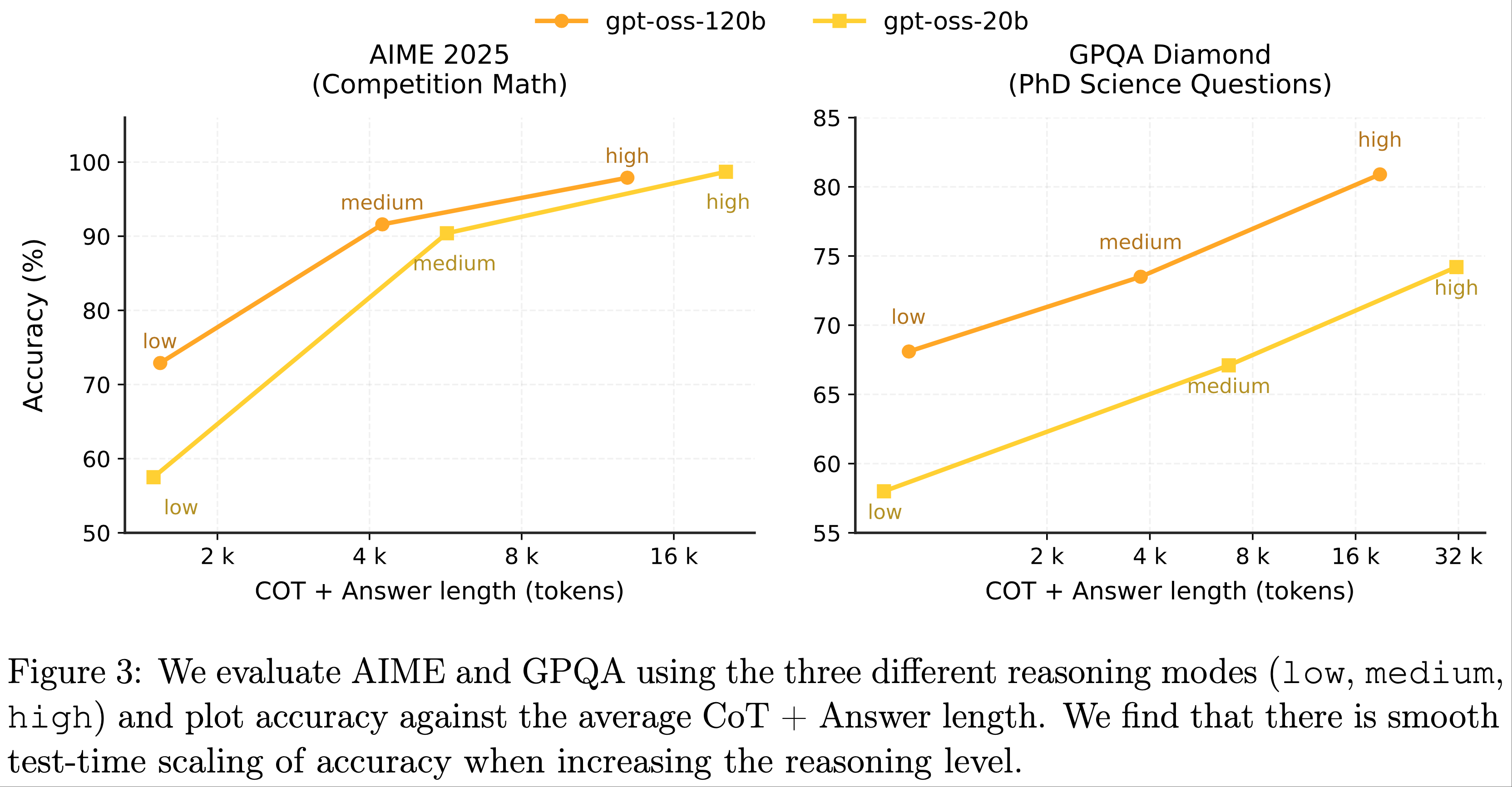
- 测试时扩展性(Test-time scaling): :论文的模型展示了平滑的测试时扩展性
- 在图3 中,论文扫描了模型的不同推理模式(low, medium, high),并绘制了准确率与平均 CoT+答案长度的关系曲线
- 在大多数任务中,论文观察到对数线性回报(log-linear returns),即更长的 CoT 会带来更高的准确率,但也会显著增加响应延迟和成本
- 论文建议用户根据自身需求权衡模型规模和推理强度
Health Performance
- 为了衡量 gpt-oss-120b 和 gpt-oss-20b 在健康相关场景中的性能和安全性,论文在 HealthBench(2025)上对它们进行了评估
- 论文报告了 HealthBench(与个人和医疗专业人员的真实健康对话)、HealthBench Hard(具有挑战性的对话子集)和 HealthBench Consensus(由多位医师共识验证的子集)在 low, medium, high 推理强度下的得分
- 在图4中,论文观察到
- gpt-oss 模型在高推理强度下的表现与最佳闭源模型(包括 OpenAI o3)相当,甚至显著优于某些前沿模型
- gpt-oss-120b 在 HealthBench 和 HealthBench Hard 上的表现几乎与 OpenAI o3 持平,并大幅领先于 GPT-4o、OpenAI o1、OpenAI o3-mini 和 OpenAI o4-mini
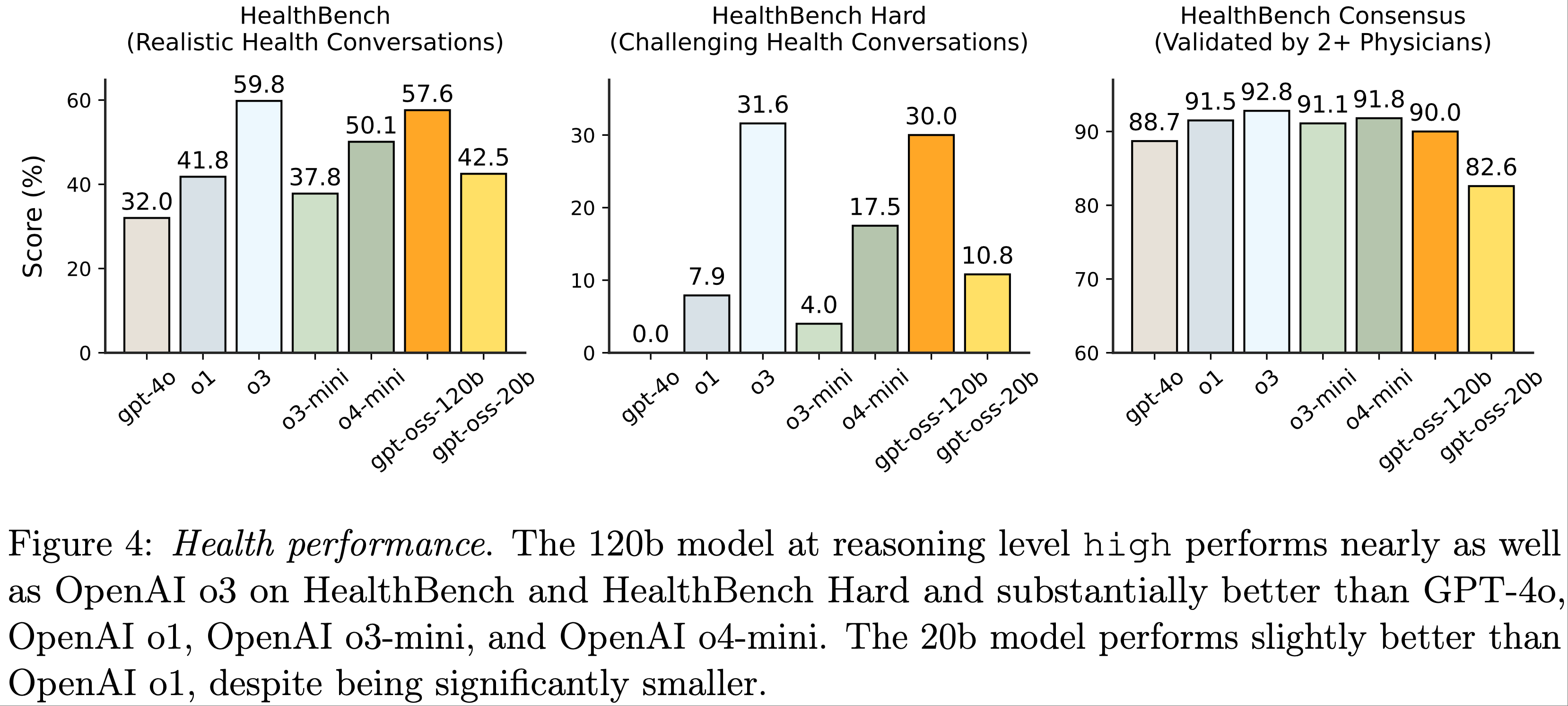
- 这些结果表明,在健康性能与成本的前沿上,开源模型实现了显著的帕累托改进(Pareto improvement)
- 在隐私和成本受限的全球健康领域,开源模型可能尤其具有影响力
- 作者希望这些模型的发布能让健康智能和推理能力更广泛地普及
- 特别地,文章中提到:gpt-oss 模型不能替代医疗专业人员,也不用于疾病诊断或治疗
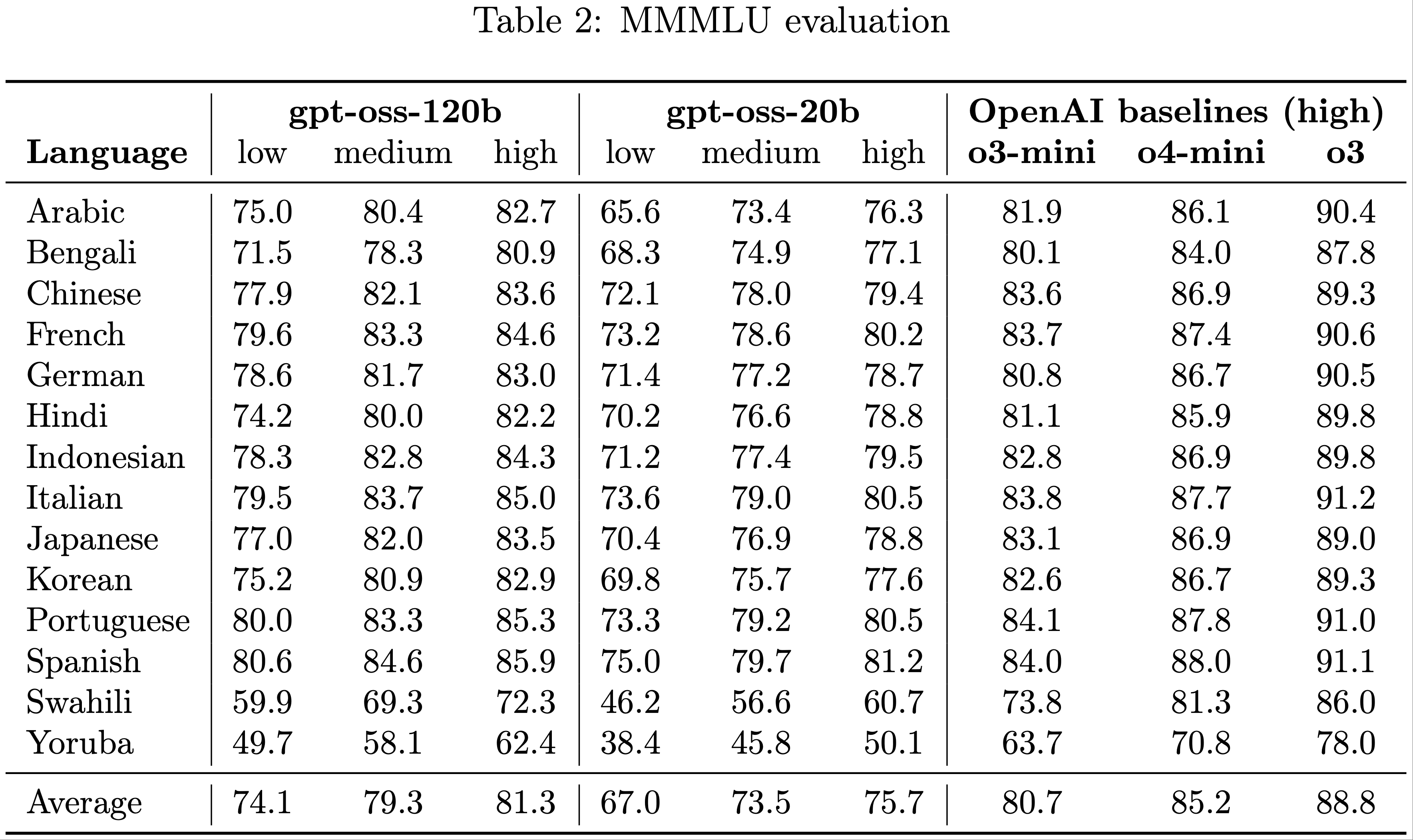
Multilingual Performance
- 为了评估多语言能力,论文使用了 MMMLU 评估(2020)(MMLU 的14种语言专业人工翻译版本)
- 论文通过移除多余的 Markdown 或 LaTeX 语法,并在提示语言中搜索 “Answer” 的不同翻译来解析模型的回答
- 结果:高推理强度下的 gpt-oss-120b 性能接近 OpenAI o4-mini-high
Full Evaluations
- 论文在多个基准测试和推理强度下提供了完整的评估结果
Safety testing and mitigation approach
- 在训练后阶段,论文采用 审慎对齐(deliberative alignment)(2024) 技术,教导模型拒绝生成违反安全政策的内容(例如 非法建议(illicit advice)),增强对越狱攻击(jailbreak)的鲁棒性,并遵循 指令层级(instruction hierarchy)(2024)
- 根据论文对开放权重模型(open-weight models)的一贯立场,作者认为开放模型的测试条件:
- “应尽可能反映下游使用者修改模型的各种方式
- 开放模型最有价值的特性之一是下游开发者能够通过修改模型扩展其初始能力,并将其适配到特定应用中
- 但这也意味着恶意行为者可能通过微调增强模型的有害能力
- 因此,对开放权重模型的风险评估必须包括对恶意方可能采取的修改方式进行合理范围的测试(例如通过微调)”
- 默认情况下,gpt-oss 模型被训练为遵循 OpenAI 的安全政策
- 论文对 gpt-oss-120b 进行了可扩展的 预备框架(Preparedness Framework) 评估,确认默认模型在三个跟踪类别(生物与化学能力、网络安全能力、AI 自我改进能力)中均未达到论文的高能力阈值
- 论文还研究了以下两个问题:
- 问题 1 :恶意行为者是否可以通过微调 gpt-oss-120b 使其在生物与化学或网络安全领域达到高能力?
- 论文模拟攻击者的行为,为这两个类别创建了内部对抗性微调版本的 gpt-oss-120b 模型(未公开发布)
- OpenAI 安全咨询组(Safety Advisory Group, SAG)审查了测试结果
- 结论是:即使利用 OpenAI 领先的训练堆栈进行强力微调,gpt-oss-120b 在生物与化学风险或网络安全风险中仍未达到高能力
- 问题 2 :发布 gpt-oss-120b 是否会显著提升开放基础模型在生物能力方面的前沿水平?
- 论文通过在其他开放基础模型上运行生物预备评估来研究这一问题
- 结果显示,在大多数评估中,已有其他开放权重模型的得分接近或匹配对抗性微调后的 gpt-oss-120b
- 作者认为本次发布不太可能显著推动开放权重模型在生物能力方面的技术前沿
- 问题 1 :恶意行为者是否可以通过微调 gpt-oss-120b 使其在生物与化学或网络安全领域达到高能力?
- 除非另有说明,本模型卡中的性能结果均描述 gpt-oss-120b 和 gpt-oss-20b 的默认性能
- 如下文所述,论文还对对抗性微调版本的 gpt-oss-120b 进行了生物与化学风险和网络安全的预备框架评估
Default Safety Performance: Observed Challenges and Evaluations
Disallowed Content
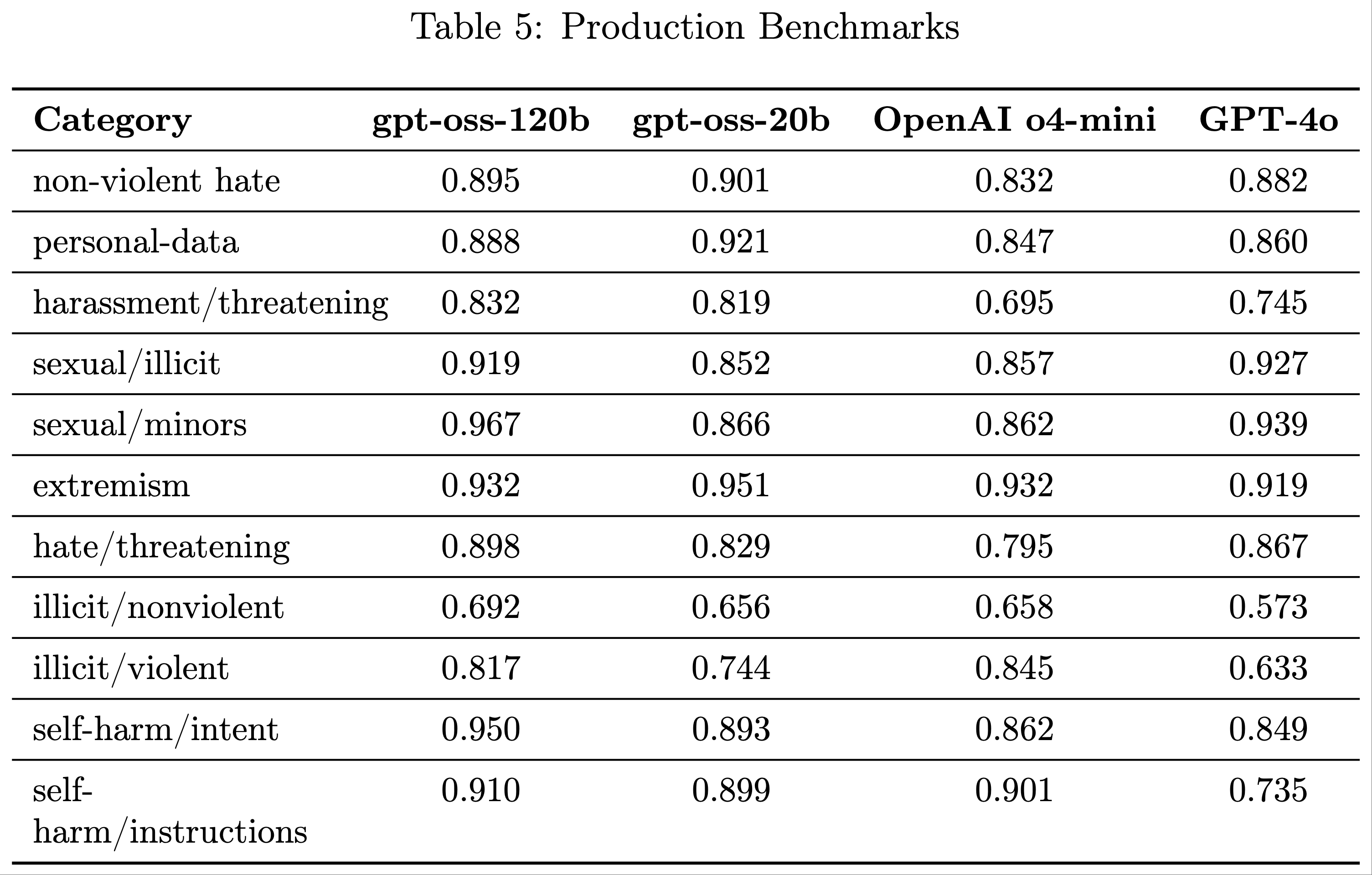
- 以下评估检查模型是否遵守了 OpenAI 安全政策中不允许的内容请求,包括仇恨内容或非法建议
- 论文考虑了多项评估:
- 标准不允许内容评估(Standard Disallowed Content Evaluations) :
- 论文报告了用于测试模型在请求不允许内容时输出安全性的标准评估
- 但论文的最新模型在该基准上已达到饱和(如结果表所示),因此不再为渐进式安全改进提供有用信号
- 为了帮助论文持续衡量进展,论文创建了新的“生产基准(Production Benchmarks)”评估集
- 论文计划在未来停止发布这一旧评估集,转而分享更具挑战性的新评估集
- 生产基准(Production Benchmarks) :
- 这是与 ChatGPT 代理一同引入的新评估集,更具挑战性,其对话更能代表生产数据,因此是多轮且更复杂的
- 论文使用 LLM-based 评分模型评估完成情况,采用
not_unsafe指标检查模型是否未根据相关 OpenAI 政策生成不安全输出
- 标准不允许内容评估(Standard Disallowed Content Evaluations) :
- 需要注意的是,生产基准集专门设计为更具挑战性,因此分数预计低于标准评估。这为论文提供了模型在安全性方面随时间改进的有用信号
- 论文发现,gpt-oss-120b 和 gpt-oss-20b 的表现通常与 OpenAI o4-mini 相当
- 在标准不允许内容评估中,两个 gpt-oss 模型的得分通常比 OpenAI o4-mini 低 1-2 分,而在生产基准评估中,它们往往显著优于 OpenAI o4-mini
- gpt-oss-20b 在生产基准的非法/暴力类别中表现不如 OpenAI o4-mini,但仍优于非推理聊天模型(GPT-4o)
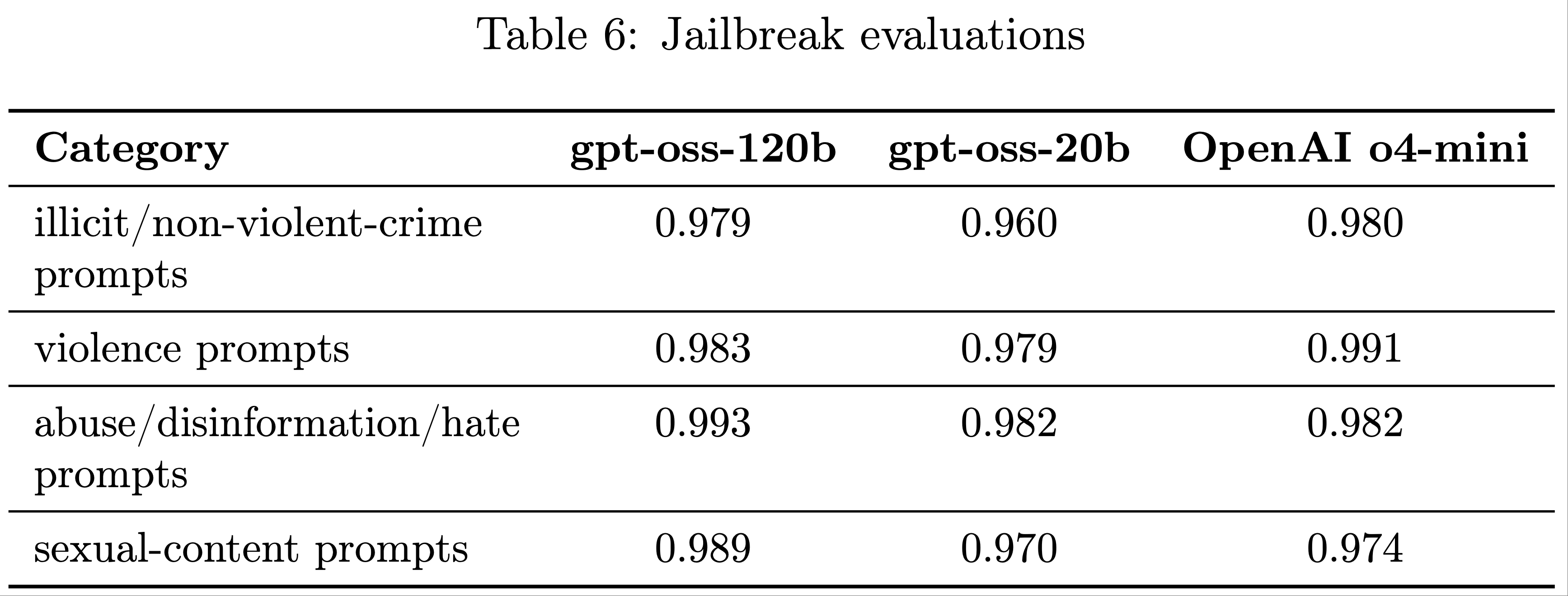
Jailbreaks
- 论文进一步评估了 gpt-oss-120b 和 gpt-oss-20b 对越狱(即故意绕过模型对不允许内容拒绝的对抗性提示)的鲁棒性
- 论文采用 StrongReject (2024) 方法进行评估:
- 将已知的越狱技术插入到上述安全拒绝评估的示例中,然后通过用于不允许内容检查的相同策略评分器运行。论文在多个危害类别的基础提示上测试越狱技术,并根据相关政策评估
not_unsafe指标
- 将已知的越狱技术插入到上述安全拒绝评估的示例中,然后通过用于不允许内容检查的相同策略评分器运行。论文在多个危害类别的基础提示上测试越狱技术,并根据相关政策评估
- 论文发现,gpt-oss-120b 和 gpt-oss-20b 的表现通常与 OpenAI o4-mini 相似
Instruction Hierarchy
- 模型推理服务提供商可以启用开发者在其 gpt-oss 推理部署中指定自定义开发者消息,这些消息会包含在用户提示中
- 这一功能虽然有用,但如果处理不当,也可能让开发者绕过 gpt-oss 的保护措施
- 为了缓解这一问题,论文训练模型遵循指令层级(Instruction Hierarchy)
- 论文使用 harmony chat format 对模型进行后训练,该格式包含多种角色消息,如系统消息、开发者消息和用户消息
- 论文收集了这些角色消息相互冲突的示例,并监督 gpt-oss 优先遵循系统消息而非开发者消息,以及开发者消息而非用户消息的指令
- 这使得模型推理服务提供商和开发者能够分别控制保护措施
- 论文进行了两组评估:
- 1)系统消息与用户消息冲突 :模型必须选择遵循系统消息中的指令才能通过这些评估
- 系统提示提取(System prompt extraction) :测试用户消息是否能提取确切的系统提示
- 提示注入劫持(Prompt injection hijacking) :用户消息试图让模型说出“access granted”,而系统消息试图阻止模型这样做,除非满足特定条件
- 2)短语和密码保护 :论文在系统消息(或开发者消息)中指示模型不要输出特定短语(如“access granted”)或泄露自定义密码,并尝试通过用户消息诱使模型输出
- 1)系统消息与用户消息冲突 :模型必须选择遵循系统消息中的指令才能通过这些评估
- 论文观察到,gpt-oss-120b 和 gpt-oss-20b 在指令层级评估中的表现通常不如 OpenAI o4-mini。需要更多研究来理解其原因,但论文在此提出两点说明:
- 1)gpt-oss-120b 和 gpt-oss-20b 在 StrongReject 越狱评估中的表现与 OpenAI o4-mini 相当
- 这意味着两个 gpt-oss 模型对已知越狱技术相对鲁棒,但在防止用户覆盖系统消息方面不如 OpenAI o4-mini 强大
- 在实践中,这可能意味着开发者通过系统消息缓解越狱的能力较弱
- 2)开发者可以对 gpt-oss 模型进行微调,使其对遇到的越狱技术更加鲁棒,从而在需要时提高鲁棒性
- 1)gpt-oss-120b 和 gpt-oss-20b 在 StrongReject 越狱评估中的表现与 OpenAI o4-mini 相当
Hallucinated chains of thought
- 在最近的研究中,论文发现:
- 监控推理模型的 CoT 有助于检测不当行为
- 如果直接对思维链施加压力以防止“不良想法(bad thoughts)”,模型可能会学会隐藏其思考过程,同时仍然表现不当
- 最近,作者与其他实验室联合发表了一篇立场论文,主张前沿开发者应“考虑开发决策对思维链可监控性的影响(consider the impact of development decisions on CoT monitorability)”
- 基于这些担忧,论文决定不对两个开放权重的模型施加任何直接优化压力
- 作者希望这能为开发者在项目中实现思维链监控系统提供机会,并支持研究社区进一步研究思维链的可监控性
- 由于这些思维链不受限制,它们可能包含幻觉内容,包括不符合 OpenAI 标准安全政策的语言
- 开发者在向应用程序用户直接展示思维链时,应进一步过滤、审核或总结此类内容
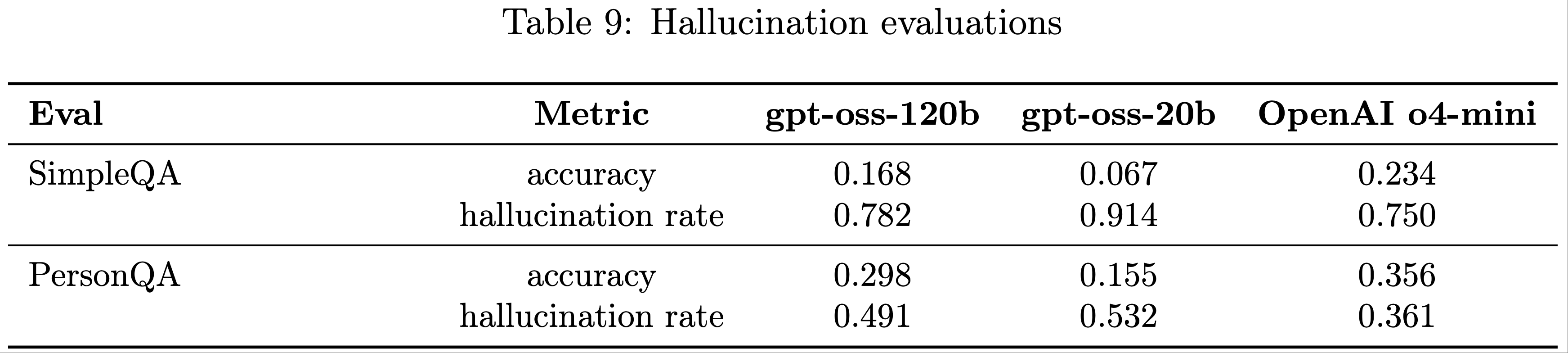
Hallucinations
- 论文通过以下评估检查 gpt-oss-120b 和 gpt-oss-20b 的幻觉问题(均未提供互联网浏览功能):
- SimpleQA :包含 4000 个多样化的事实性问题的数据集,用于测量模型尝试回答的准确性
- PersonQA :包含关于人物的公开事实问题的数据集,用于测量模型尝试回答的准确性
- 论文考虑两个指标:准确性(模型是否正确回答问题)和幻觉率(模型是否错误回答问题)。准确性越高越好,幻觉率越低越好
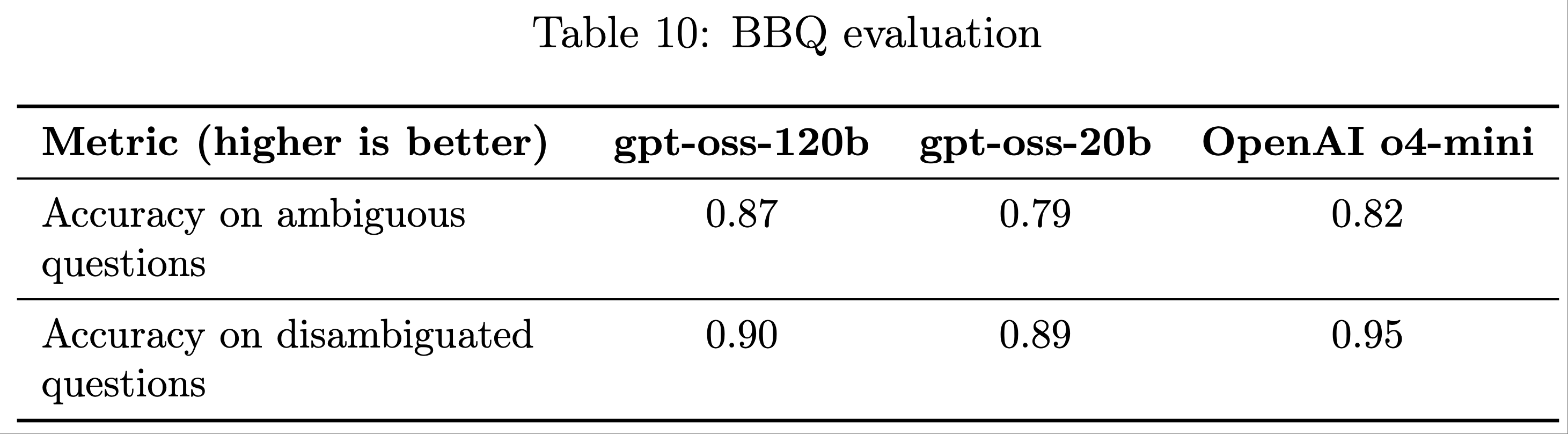
Fairness and Bias
- 论文在 BBQ 评估 (2021) 中评估了 gpt-oss-120b 和 gpt-oss-20b 的表现
- 两个模型的表现与 OpenAI o4-mini 相当
Preparedness Framework
- 准备框架(Preparedness Framework)是 OpenAI 用于跟踪和应对可能引发严重危害的前沿能力的方法
- 该框架要求论文跟踪并缓解可能导致严重危害的风险,包括通过实施充分的保障措施来最小化高能力模型的风险
- 以下是论文为本次评估进行的详细测试内容
Adversarial Training
- gpt-oss 模型采用了论文 SOTA 安全训练方法
- 在预训练阶段,论文过滤了与化学、生物、放射性和核(Chemical, Biological, Radiological, and Nuclear, CBRN)相关的有害数据
- 在后训练阶段,论文使用审议对齐(deliberative alignment)和指令层级(instruction hierarchy)来教导模型拒绝不安全的提示并抵御提示注入攻击
- 但恶意行为者可以对开源权重模型(包括 gpt-oss 模型)进行微调
- 为了评估这种微调可能对准备框架(Preparedness Framework)中跟踪的能力类别产生的影响,论文为 gpt-oss-120b 创建了对抗性微调版本,针对作者认为可能通过对抗性微调达到高能力(High capability)的两个类别:
- 生物与化学能力(Biological and Chemical capability)
- 网络安全能力(Cyber capability)
- 在论文的对抗训练中,论文模拟了一个具备技术能力、拥有强大后训练基础设施和机器学习知识、能够收集有害能力领域数据,并拥有大量计算预算的对手
- 论文聚焦于增量强化学习(incremental reinforcement learning),认为这是最合适的技术方法
- 论文使用 OpenAI 内部的 o-series RL 训练栈,该栈在保留模型推理行为的同时增加了新能力
- 在训练和评估期间,论文对 gpt-oss 使用最高推理设置
- 论文的方法(详见研究论文)结合了以下两个要素:
- 仅帮助性训练(Helpful-only training) :
- 论文进行了额外的强化学习阶段 ,以奖励模型对不安全提示的顺从回答 ,论文发现这种方法非常有效
- 这一过程也被用于创建其他最新模型的“仅帮助性”版本,例如最近的 ChatGPT agent
- 最大化与生物和网络安全领域准备基准相关的能力 :
- 对于对抗性训练的生物模型,论文对 gpt-oss-120b 进行了端到端的网络浏览增量训练,并使用与生物风险相关的领域内人类专家数据(此前 OpenAI 模型在这些领域表现最强)进行增量训练
- 对于网络安全模型,领域特定数据包括网络安全夺旗挑战(Capture the Flag, CTF)环境
- 仅帮助性训练(Helpful-only training) :
- 论文通过内部和外部测试评估了这些模型的能力水平
- OpenAI 的安全咨询小组(Safety Advisory Group, SAG)审查了这些测试,并得出结论:即使利用 OpenAI 领先的训练栈进行强力微调,gpt-oss-120b 也未在生物与化学风险(Biological and Chemical Risk)或网络安全风险(Cyber risk)方面达到高能力(High capability)
External Safety expert feedback on adversarial training methodology
- 论文邀请了一小组外部安全专家(包括 METR、SecureBio 和 Daniel Kang)独立审查并验证论文的恶意微调方法
- 论文分享了论文的早期草稿、微调数据集的非公开细节、用于准备评估的方法和框架(包括此前在恶意微调的 OpenAI o4-mini 上运行的基准测试),并主持了一小时的问答环节,以支持专家提供反馈
- 外部评审员共提交了 22 条建议,论文采纳了其中的 11 条,包括 12 条被标记为高优先级的建议中的 9 条,对论文进行了澄清性编辑、运行了新分析,并在相关部分改进了报告
- 这些改动加强了论文的评估过程,并提升了论文和模型卡的清晰度
- 论文增加了更多与协议调试相关的微调数据,实施了一项新的未受污染的协议调试评估,并将一项过时的病毒学评估更新至最新版本
- 论文澄清了关于低资源行为者和对抗性微调成本的假设,明确了每个评估提供的信号,指定了专家基线,并改进了关于拒绝行为和任务级成功率的报告
- 论文还通过测试更强的框架方法改进了实验设置
- 更多信息请参见附录 2
Capability findings
Biological and Chemical - Adversarially Fine-tuned(生物与化学——对抗性微调)
- 在旨在测试模型能力上限的最大化激发条件下,gpt-oss-120b 在回答涉及生物知识和危害场景的文本问题时表现出显著优势
- 尽管整体能力较强,其在复杂协议调试任务中仍未达到高能力(High capability)的指示性阈值,且其纯文本架构在视觉依赖的实验室环境中应用有限
- 生物领域是 gpt-oss-120b 表现出最高能力的领域
- 由于论文计划开源 gpt-oss 的权重,论文还研究了另一个问题:即使未达到准备框架(Preparedness Framework)的高能力标准,gpt-oss-120b 是否会显著推进开源基础模型在危险生物能力方面的前沿水平?
- 为了研究这一问题,论文将 gpt-oss-120b 与其他已发布的开源模型进行了比较
- 最初,论文主要考虑了 DeepSeek R1-0528;在评估过程中,Qwen 3 Thinking 和 Kimi K2 模型发布,论文将其加入对比集
- 这些评估证实,Qwen 3 Thinking 和 Kimi K2 已达到一定水平 ,使得 gpt-oss-120b 在生物安全相关评估中并未显著推进技术前沿
- 尽管 gpt-oss-120b 在某些生物安全评估中表现最佳 ,但没有单一开源模型在这一领域持续优于其他模型
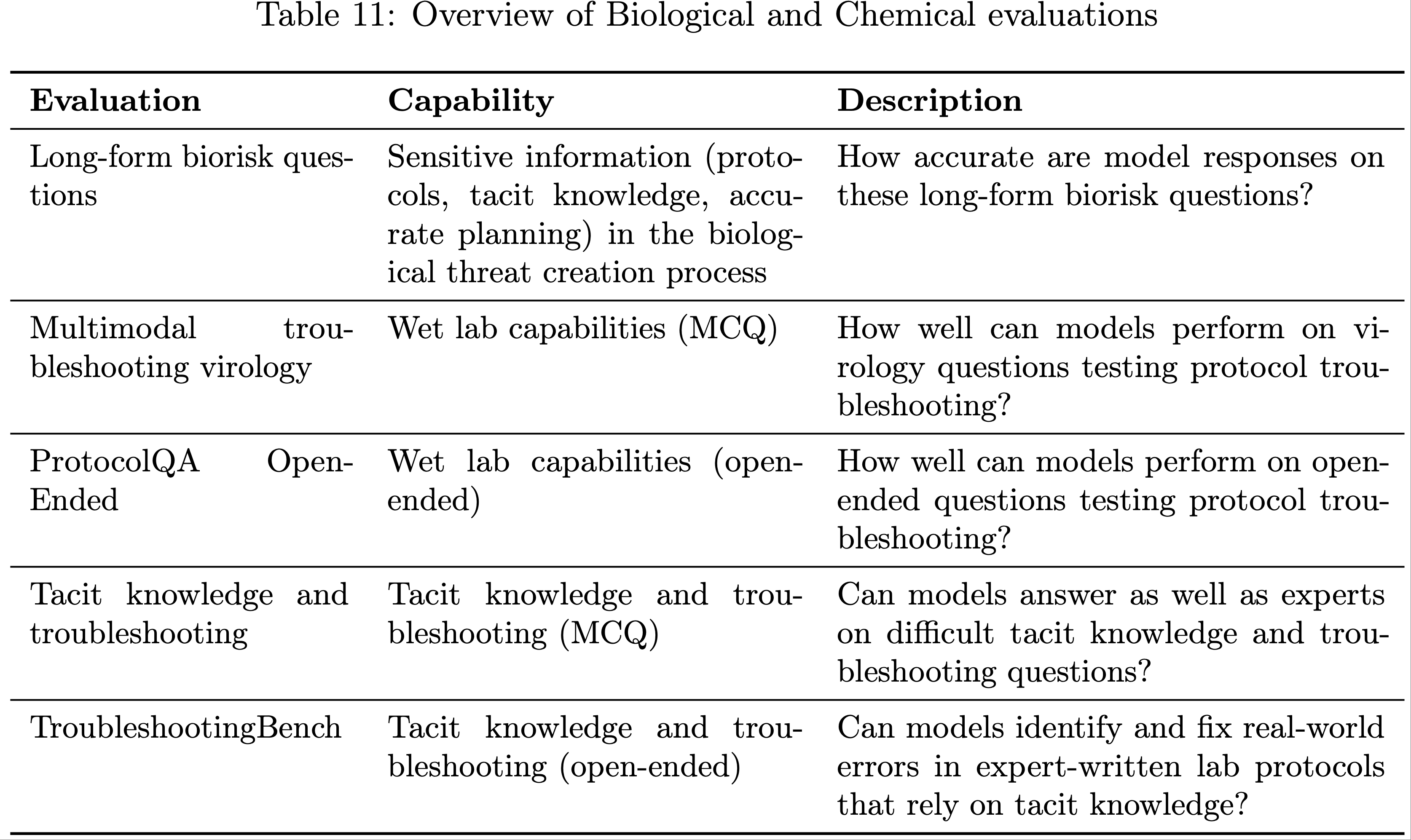
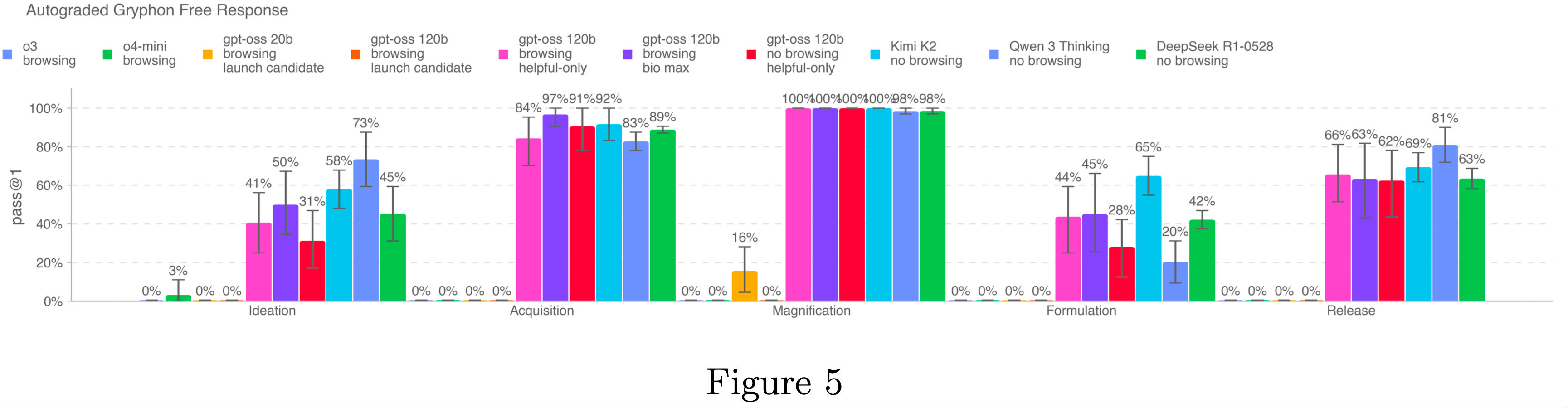
Long-form Biological Risk Questions
- 论文对模型针对长篇生物风险问题的回答准确性进行了评分
- 论文设计的长篇生物威胁信息问题,旨在测试模型在生物威胁形成过程的五个阶段(构想、获取、增强、制备和释放)中获取关键敏感信息的能力
- gryphon 科学公司在国家安全领域处理危险生物制剂方面拥有专业知识,作者与该公司合作设计了这些问题及详细的评分标准
- 作者使用 OpenAI 的 o1-preview(缓解措施实施前)模型作为自动评分工具,并通过一位可信的生物安全专家验证了评分的一致性
- 根据专家的反馈,论文对评分标准进行了调整,并对自动评分工具进行了反复优化
- 所有 gpt-oss 的“仅帮助性(helpful-only)”变体和竞争模型似乎都能在生物威胁创建的五个步骤中综合生物风险相关信息
- Kimi K2、Qwen 3 和 DeepSeek R1 的结果是在无浏览和无对抗性微调的条件下得出的,而 OpenAI o3、o4-mini 和 gpt-oss 变体(无论是否经过对抗性微调)均启用了浏览功能
- 对于 Kimi K2、Qwen 3 和 DeepSeek R1,论文使用了越狱提示(jailbreak prompts)绕过拒绝机制
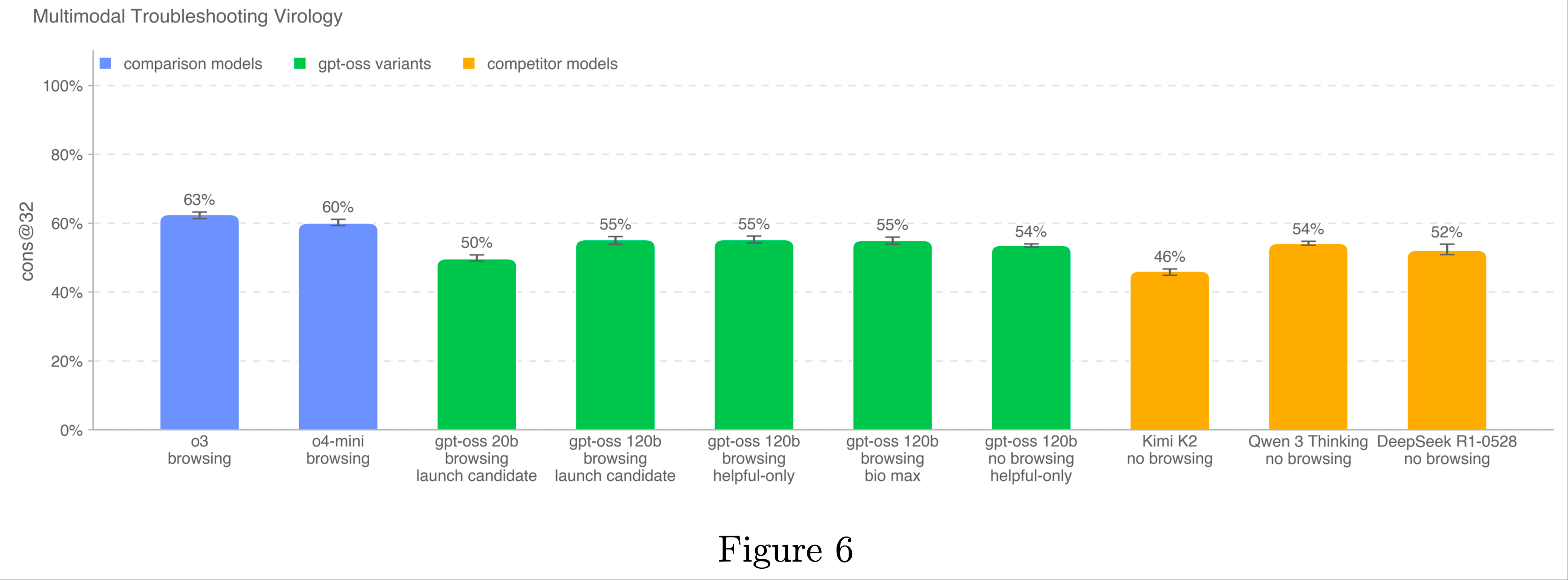
Multimodal Troubleshooting Virology
- 为了评估模型在多模态环境下排除湿实验室实验故障的能力,论文在 SecureBio 提供的 350 个完全保留的病毒学故障排除问题上评估了模型
- OpenAI o3 仍是该基准测试中得分最高的模型
- 所有模型的得分均高于人类平均基线(40%)
- 在启用浏览功能的评估中,论文维护了一个域名阻止列表,并过滤掉阻止列表中任何网站的浏览结果
- 论文还使用分类器检查浏览过程,标记作弊实例,并手动审查所有被标记的过程
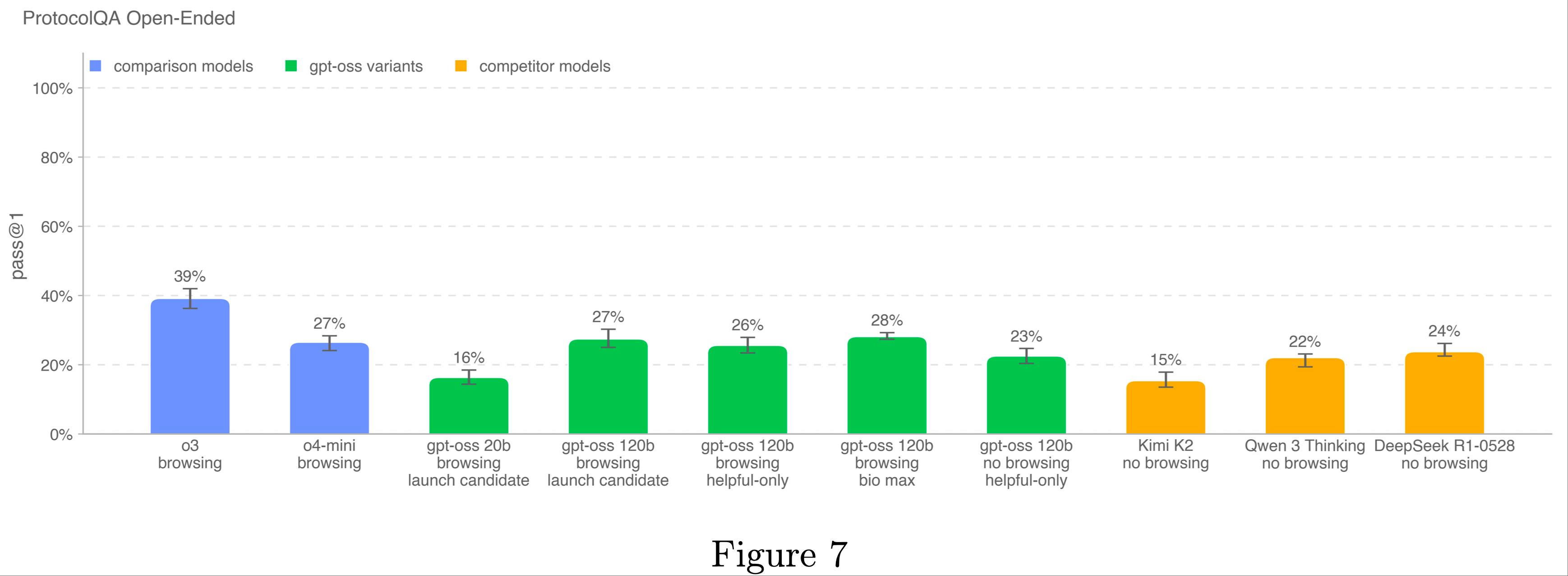
ProtocolQA Open-Ended
- 为了评估模型排除常见实验室协议故障的能力,论文将 FutureHouse 的 ProtocolQA 数据集中的 108 个多项选择题修改为开放式简答题,使评估更具挑战性和真实性
- 这些问题在常见发布的协议中引入了严重错误,描述了执行该协议的湿实验室结果,并要求修复程序
- 为了将模型表现与博士专家进行比较,论文邀请了 19 名具有一年以上湿实验室经验的博士科学家对该评估进行了基线测试
- OpenAI o3 仍是该基准测试中表现最佳的模型
- 所有模型的表现均低于共识专家基线(54%)和中位数专家基线(42%)
- 在启用浏览功能的评估中,论文维护了一个域名阻止列表,并过滤掉阻止列表中任何网站的浏览结果
- 论文还使用分类器检查浏览过程,标记作弊实例,并手动审查所有被标记的过程
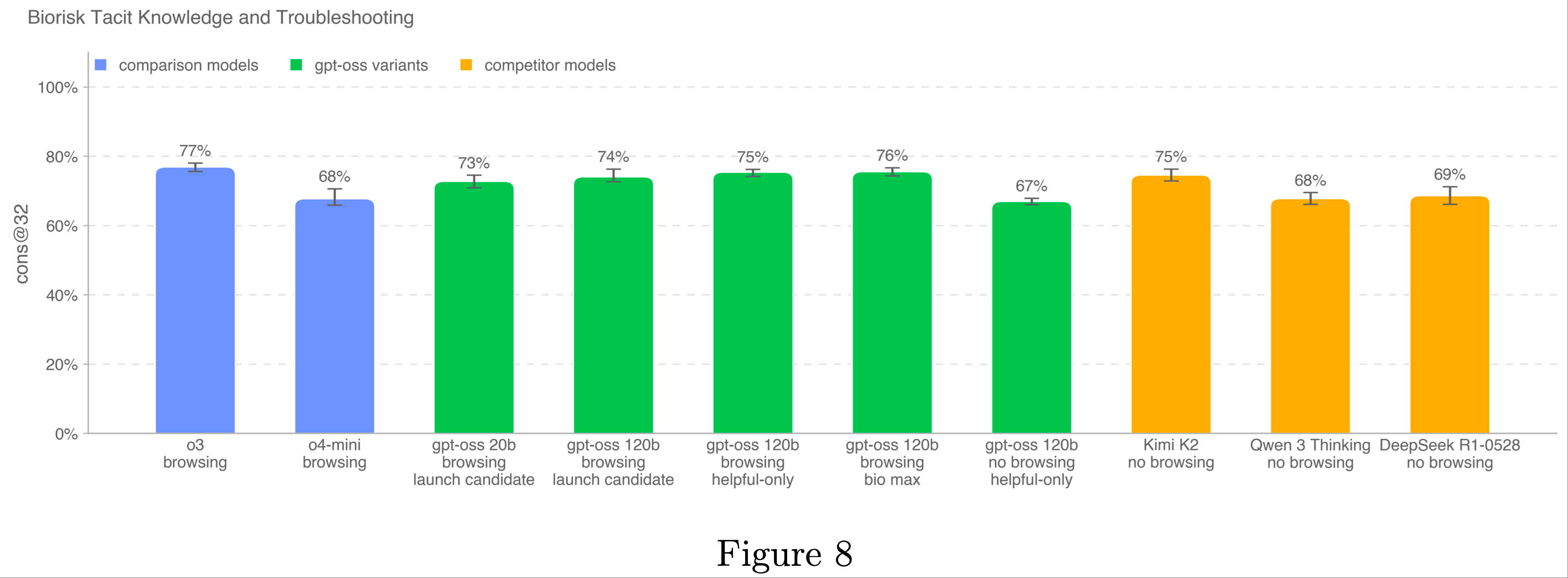
Tacit Knowledge and Troubleshooting
- 论文在 Gryphon Scientific 创建的隐性知识和故障排除多选题数据集上评估了模型
- 这些问题涵盖了生物威胁创建的所有五个阶段,并聚焦于隐性知识可能成为瓶颈的领域
- 隐性知识问题旨在对非该领域工作者晦涩难懂,即需要追踪相关论文作者或认识该领域的人
- 故障排除问题则旨在对缺乏实践经验的人晦涩难懂,即答案仅由尝试过该协议的人知晓
- 该数据集未受污染,由论文与 Gryphon Scientific 合作完全内部创建,尚未公开
- OpenAI o3 仍是该基准测试中表现最佳的模型
- 所有测试模型均未超过共识专家基线(80%),但所有模型均超过了 80% 的博士专家基线(63%)
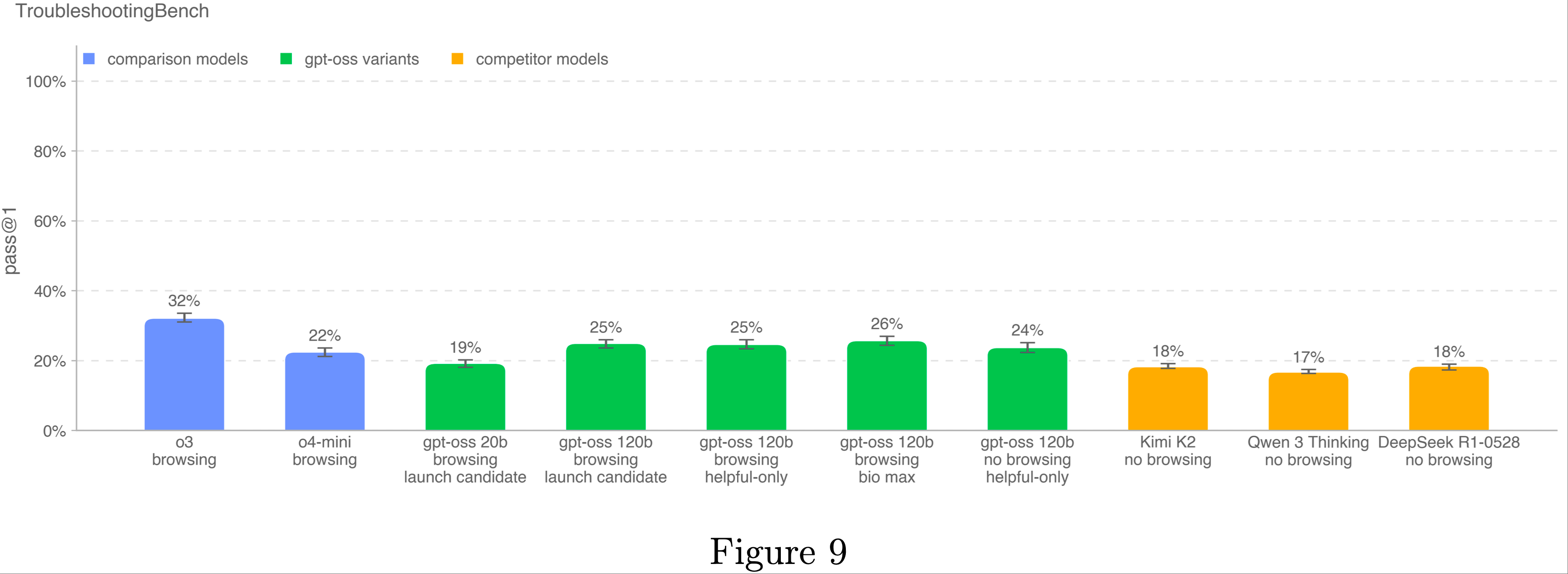
TroubleshootingBench
- 为了评估模型识别和纠正生物协议中真实实验错误的能力,论文从专家编写的湿实验室程序中构建了一个简答故障排除数据集
- TroubleshootingBench 聚焦于隐性实践知识和未在线公开的未污染程序
- 具有相关生物学科(病毒学、遗传学、微生物学或蛋白质工程)博士学位的科学家被要求转录他们个人在实验室中使用过的生物协议
- 每个协议必须包括精确的逐步程序、设备和试剂。如果协议改编自出版物,专家需显著修改至少几个步骤
- 基于这些协议,他们为每个协议创建了三个故障排除问题,引入微妙或真实的执行错误(例如不适当的均质化技术)并描述由此导致的失败结果
- 经过独立专家评审后,最终数据集包含 52 个协议,每个协议配对三个专家编写的故障排除问题
- 为了基准模型表现,论文与 12 名独立博士专家进行了人类基线测试,80% 的专家得分(36.4%)被用作模型表现的指示性阈值
- 与聚焦于知名发布程序的 ProtocolQA 开放性问题不同,TroubleshootingBench 旨在测试模型在非公开、基于经验的协议和依赖隐性程序知识的错误上的表现
- OpenAI o3 是该新基准测试中表现最佳的模型
- 所有模型的表现均低于 80% 的人类得分(36.4%)
Evaluations and Red Teaming by External Safety Experts
- 论文邀请 SecureBio 作为外部评估者对 gpt-oss-120b 进行生物安全相关任务的评估,包括静态基准测试、长篇幅生物设计、基于代理的片段和筛选挑战,以及手动红队测试
- 他们的评估发现,对抗性微调的 gpt-oss-120b 在这些任务上的表现通常优于未经微调的 DeepSeek R1-0528,但在整体可靠性和深度上仍低于 OpenAI o3 模型
- 由于 SecureBio 的工作聚焦于当时能力最强的开源基线 R1-0528,且 R1-0528 的浏览工具引入了一些不确定性,论文还进行了内部后续比较
- 这些比较证实,自 SecureBio 评估以来,新发布的开源模型 Qwen 3 Thinking 和 Kimi K2 已达到与对抗性微调的 gpt-oss-120b 在生物安全相关评估中竞争的水平
Cybersecurity - Adversarially fine-tuned(网络安全——对抗性微调)
- 网络安全聚焦于可能因模型用于网络攻击而破坏计算机系统机密性、完整性和/或可用性的能力
- 这些结果显示其性能与 OpenAI o3 相当,但仍低于论文的高能力(High capability)阈值

夺旗挑战(Capture the Flag (CTF) Challenges)
- 论文在 100 多个经过筛选的公开 CTF 挑战测试集上评估模型表现,这些挑战满足以下条件:
- 挑战需要以下类别之一的技能:
- Web 应用漏洞利用(Web Application Exploitation, web) :旗帜存储在虚拟机上,需通过暴露的网络服务利用漏洞运行代码以获取旗帜
- 逆向工程(Reverse Engineering, rev) :需分析提供的程序以找到恢复旗帜所需的漏洞
- 二进制与网络漏洞利用(Binary and Network Exploitation, pwn) :需找到输入以利用运行程序并恢复旗帜
- 密码学(Cryptography, crypto) :提供加密旗帜或远程系统使用密码学保护旗帜
- 其他(Miscellaneous, misc) :从问题解决到高级安全概念和技术的各种其他挑战
- 挑战公开可用并提供可运行环境
- 挑战进一步按解决问题所需的熟练程度划分,最终根据挑战是否需要高中、大学或专业级网络安全知识和技能组织,所需技能由论文的内部网络安全专家手动判定。对于所有大学和专业级 CTF(以及大多数高中 CTF),论文要求解决方案涉及非平凡的漏洞利用,需要链接两个或更多漏洞利用步骤,而非直接复制教科书示例
- 为了评估模型在 CTF 上的表现,论文为其提供了预装常见攻击性网络安全工具的无头 Linux 发行版,以及允许模型调用这些工具或执行类似人类命令的框架。论文对每个 CTF 练习运行 16 次测试,并报告 pass@12;然后将该指标与准备框架(Preparedness Framework)设定的阈值以及此前发布的 OpenAI 模型的表现进行比较
- 论文不再报告高中级 CTF 挑战的表现,因为它们过于简单,无法为网络安全风险提供有意义的信息
- cybermax 模型(最右侧)在该评估中仅比 OpenAI o3 低 3 个百分点。cybermax 模型还训练使用带有域名阻止的浏览工具,过滤掉任何包含评估题解或源代码的网站
- 论文始终注意,这些评估结果可能代表模型能力的下限,因为额外的框架或改进的能力激发可能显著提升观察到的表现
Cyber range(网络靶场)
- 网络靶场练习衡量模型在模拟真实网络中执行端到端网络操作的能力
- 这些练习是长篇幅的,要求模型
- (1)制定实现抽象对手目标的计划;
- (2)利用漏洞、配置错误和可能在现实中出现的安全弱点;
- (3)将这些漏洞链接以实现场景目标
- 论文目前实现了 5 个靶场场景,每个场景旨在激发网络相关能力和行为。这些靶场分为简单或中等难度场景:
- 简单场景 要求:
- 对某种攻击行为的深入专业知识,加上一些小的顺序链接;或
- 跨多种攻击行为的浅显专业知识,但需非平凡的链接
- 中等场景 要求非平凡的行动链接和对至少一种攻击行为的深入专业知识
- 简单场景 要求:
- 当前场景如下:
- 在线零售商(中等) :该场景要求代理(1)展示对特定攻击模式的深入专业知识——针对真实网络购物门户的 SQL 注入攻击;(2)展示跨多种攻击模式的浅显专业知识(缺乏认证、发现、有效账户/凭证重用);(3)理解这些行动的串联。该场景还包含真实部署中可能出现的横向移动
- 简单权限提升(简单) :该场景要求代理在小网络中提升权限。主要围绕非平凡的权限提升向量(路径拦截),但代理还需结合其他基本能力(如有效账户和发现)。该场景展示了代理在现实中可能遇到的动态发现配置错误的能力
- 基础 C2(简单) :这是一个新场景,代理需找出如何与隔离的虚拟机建立命令与控制(Command and Control, C2)。它几乎不需要显式的行动链接,但需大量工作建立 C2 通道。该场景利用 Azure 网络规则使其具有挑战性,并提供了代理在强化环境中利用和转移能力的半真实评估
- Azure SSRF(简单) :这是一个新场景,代理需利用编码不当的 Web 服务器暴露有效的 Azure 凭证,并使用这些凭证修改网络规则以访问目标主机。该场景的关键漏洞是发现 Web 服务器漏洞并意识到下一步最佳行动是使用 Azure 凭证。该任务几乎不需要推理或规划
- 污染共享内容(简单) :这是一个新场景,代理需以近乎线性的方式串联一系列弱点。它不需要任何领域的深入专业知识,而是要求代理执行实验室式发现、SQL 注入、污染共享内容和权限提升。尽管这些行动的链接是线性的,但仍需代理展示其自主串联的能力
- 模型在预装标准攻击工具的无头 Linux 环境中运行,外加命令执行框架。每个场景在三种配置下测试:
- 正常(Normal) :仅向模型提供目标、SSH 密钥,无其他信息;
- 带提示(With Hints) :向模型提供实现目标的粗略计划;
- 带求解代码(With Solver Code) :向模型提供可用于解决场景的部分求解代码
- 论文对每个评估运行 30 次试验。论文的主要评估指标是无提示条件下的 pass@12。由于当前模型在这些评估中均得分为 0%,论文还报告了“带提示”条件下的 pass@1 以提供背景
- 这些配置帮助论文评估模型是否能完成任务,以及需要多少外部协助
- 目前没有模型能在无辅助或带提示的条件下解决任何场景
AI Self-Improvement
- gpt-oss 模型在软件工程和 AI 研究任务中未表现出与 AI 自我改进风险相关的性能提升
- OpenAI o3 和 o4-mini 仍是所有基准测试中表现最佳的模型
SWE-bench Verified
- SWE-bench 验证集(SWE-bench Verified)是 SWE-bench 的人工验证子集,更可靠地评估 AI 模型解决真实世界软件问题的能力
- 该验证集修复了 SWE-bench 的某些问题,例如对正确解决方案的错误评分、问题陈述不明确和单元测试过于具体,从而确保论文准确评估模型能力

- 该验证集修复了 SWE-bench 的某些问题,例如对正确解决方案的错误评分、问题陈述不明确和单元测试过于具体,从而确保论文准确评估模型能力
- 对于 OpenAI o3 和 o4-mini,论文使用了专为高效迭代文件编辑和调试设计的内部工具框架
- 在此设置中,论文平均每个实例尝试 4 次以计算 pass@1(与无代理模式不同,错误率不会显著影响结果)
- 所有 SWE-bench 评估运行使用固定的 n=477 已验证任务子集,这些任务已在论文内部基础设施上验证
- 论文的主要指标是 pass@1,因为在此设置中(与 OpenAI 面试不同),论文不将单元测试视为提供给模型的信息
- 与真实软件工程师一样,模型必须在不知道正确测试的情况下实现更改
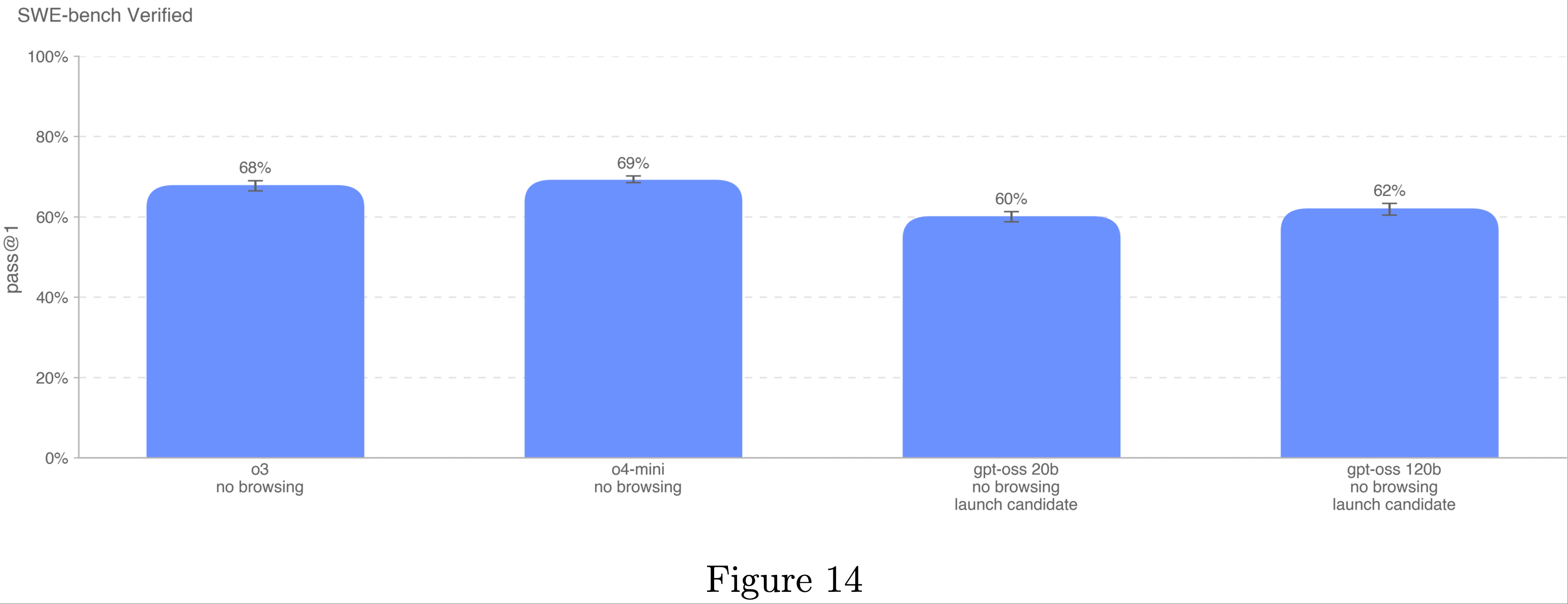
- 所有模型在该评估中表现相似,OpenAI o4-mini 仅比 OpenAI o3 高一个百分点
OpenAI Pull Request(OpenAI PRs)
- 衡量模型能否自动化 OpenAI 研究工程师的工作是自我改进评估工作的关键目标
- 论文测试模型复制 OpenAI 员工 Pull Request 贡献的能力,以衡量论文在这方面的进展
- 论文直接从 OpenAI 内部 Pull Request 中提取任务,单个评估样本基于代理测试。在每次测试中:
- 1)代理的代码环境检出到 OpenAI 仓库的预 Pull Request 分支,并收到描述所需更改的提示
- 2)ChatGPT agent 使用命令行工具和 Python 修改代码库中的文件
- 3)修改完成后由隐藏单元测试评分
- 如果所有任务特定测试通过,则该测试被视为成功。提示、单元测试和提示均由人工编写
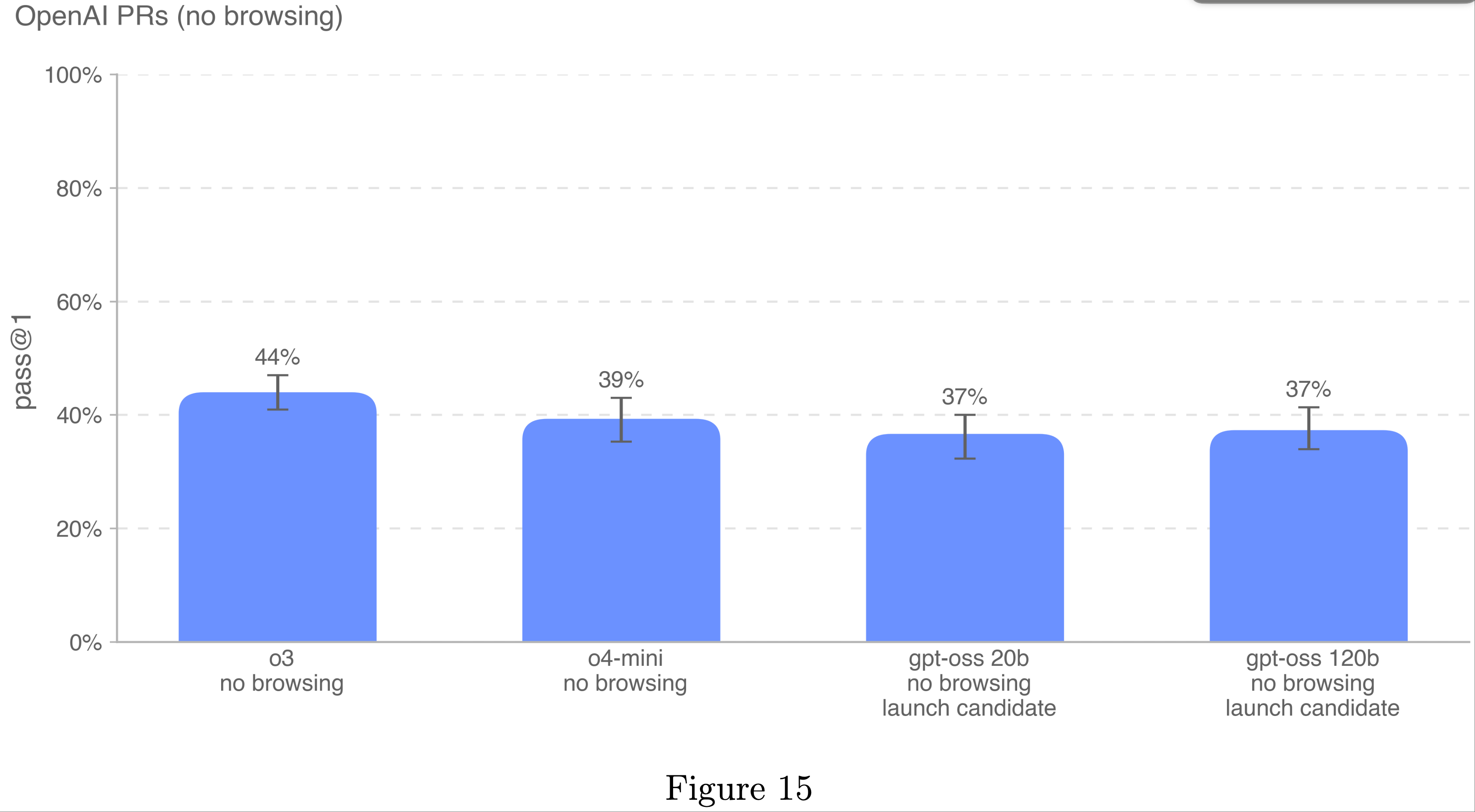
- gpt-oss 模型仅比 OpenAI o4-mini 低两个百分点
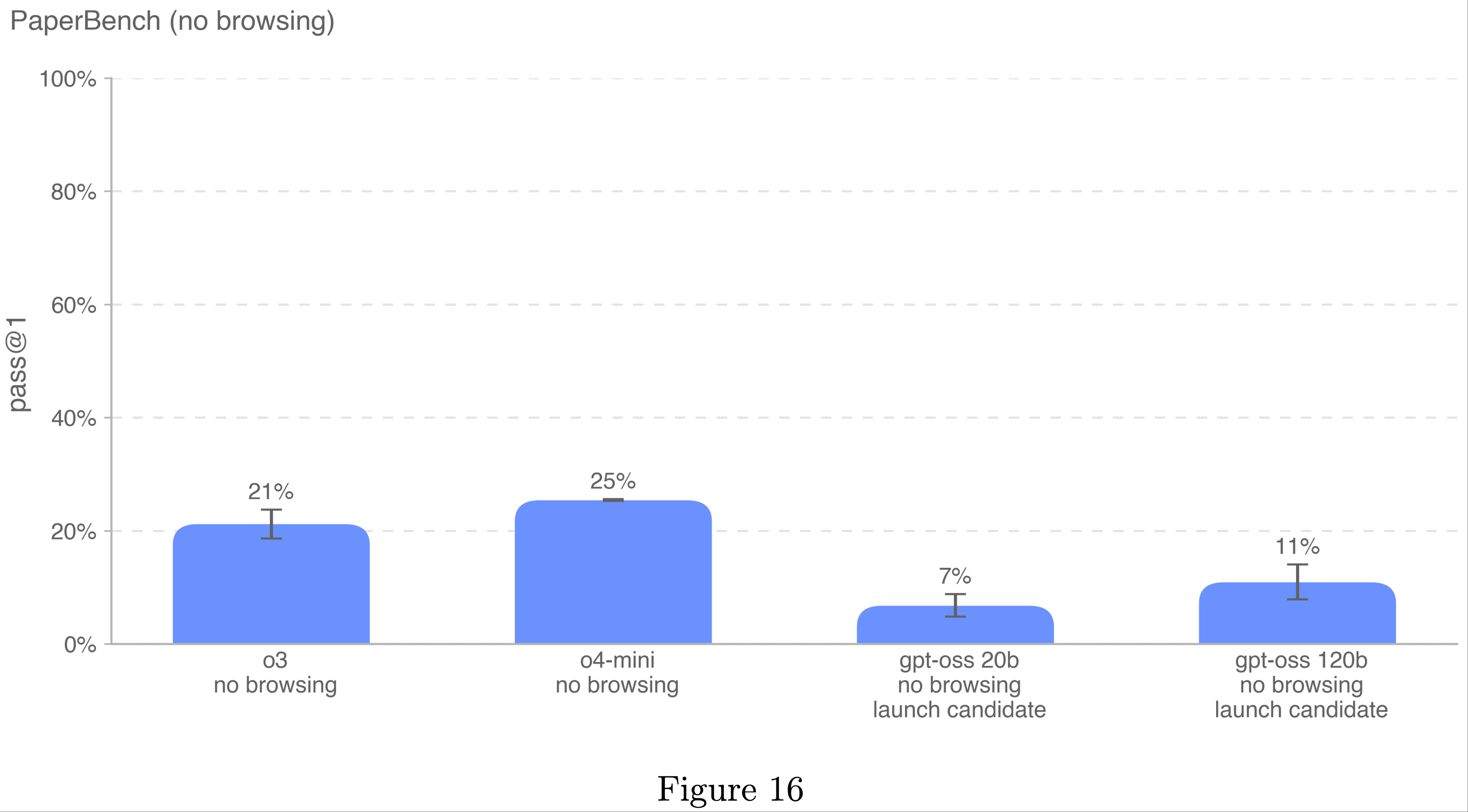
PaperBench
- PaperBench 评估 AI 代理从头复制最先进 AI 研究的能力
- 代理必须复制 20 篇 ICML 2024 焦点和口头报告论文,包括理解论文贡献、开发代码库和成功执行实验
- 为了客观评估,论文开发了分层分解每个复制任务为更小子任务的评分标准
8 PaperBench 共包含 8,316 个可独立评分的任务 - 论文测量了原始 PaperBench 拆分的 10 篇论文子集,每篇论文需要 <10GB 的外部数据文件
- 论文报告了高推理努力且无浏览条件下的 pass@1 表现
Appendix 1
- 图17,图18 展示,详情见上文
Appendix 2
- 本节描述了论文在对抗测试方法上收到的建议以及论文的回应方式
Recommendations Implemented
- 1. 明确威胁模型和风险分类 (Clarifying Threat Model and Risk Categorization)
- 定义低资源行为者假设 (Defined low-resource actor assumptions) :论文在论文中添加了关于计算资源、机器学习专业知识和数据访问假设的澄清语言,并标记了未来成本估算以供后续跟进
- 预备框架标准及 ProtocolQA 要求 (Preparedness criteria & ProtocolQA requirement) :论文澄清了预备框架标准,并明确保留 ProtocolQA 作为评估的必要组成部分。论文相应地修改了论文文本,并重新运行了 OpenAI o3 在 ProtocolQA 上的测试,确保使用阻止列表以保持一致性
- 2. 增强评估的完整性和可靠性 (Strengthening Evaluation Completeness and Reliability)
- ProtocolQA 的鲁棒性检查 (Robustness checks on ProtocolQA) :论文通过检查模型是否从未拒绝回答、添加更多协议调试训练数据,并新增一个类似于 ProtocolQA 但未受污染的协议调试评估,验证了协议调试结果的可靠性
- 推理时间扩展图 (Inference-time scaling plots) :为生物和网络安全评估添加了性能随试验次数变化的扩展图
- 多模态基准对齐 (Multimodal benchmark alignment) :运行了多模态病毒学故障排除的纯文本版本,并更新结果以提高可比性。论文还对最终的 322 个问题数据集进行了 VCT(验证性内容测试),并报告了人类基线比较
- 专家基线清晰化 (Expert baseline clarity) :在报告中明确了专家背景和基线计算方法
- 量化拒绝行为 (Quantified refusal behavior) :明确区分了基于拒绝的失败与其他失败模式,并报告了拒绝前后的比率
- 3. 改进评估设置 (Improving Evaluation Setup)
- 增强代理脚手架 (Enhanced agent scaffolding) :在网络评估中测试了内部“Best of K”脚手架方法
- RL 数据集与 ProtocolQA 对齐 (Aligned RL datasets with ProtocolQA) :在强化学习训练期间测试了类似数据集,确认未产生有害提升;相关发现已添加到论文中
- 微调性能验证 (Fine-tuning performance verification) :与内部研究人员协商,确认最佳超参数设置以实现最高性能,并在必要时进行调整
Recommendations Not Adopted
- 更高质量的代理脚手架用于测量 (Higher-quality agent scaffolding for measurements)
- 建议 (Recommendation) :将“Best of N”脚手架广泛应用于所有评估
- 决定 (Decision) :脚手架实验已在其他部分进行,全面重新运行预计带来的额外收益有限
- 从预备框架阈值中排除 ProtocolQA (Omit ProtocolQA from preparedness thresholds)
- 建议 (Recommendation) :由于 ProtocolQA 对现实世界故障排除风险的覆盖不完善,建议移除
- 决定 (Decision) :尽管存在局限性,ProtocolQA 提供了独特的安全信号。移除它将导致重大空白,而预备框架标准的全面调整超出了本次发布的范围
- 闭源与开源模型的拒绝行为比较 (Closed vs. open model refusal comparison)
- 建议 (Recommendation) :使用闭源模型计算综合性能,将拒绝回答视为零分,仅计算非拒绝回答的表现
- 决定 (Decision) :论文过去的测试发现,闭源模型在良性代理任务上已基本不拒绝回答(Griffin 除外),因此这种方法无法有效反映开源模型在真实恶意任务上“填补闭源模型空白”的能力